Изобретение относится к области компьютерного программирования и, в частности, к области преобразования текста программы в машинные коды (компиляции).
Заявляемый способ относится к области оптимизирующей компиляции. Компилятор преобразует программу, написанную на исходном языке (С, C++, Fortran и т.п.), в код целевой архитектуры (Intel x86, Sparc и т.д.). Оптимизирующий компилятор выполняет это преобразование так, чтобы достичь наилучшего показателя для получаемого кода по некоторому критерию. Чаще всего этим критерием является максимальная скорость исполнения программы на целевой архитектуре (платформе).
Термины
Промежуточное представление программы. Семантика программы может быть представлена в операционном виде. Элементом данного представления является операция. Операцию можно понимать как произвольное действие над окружающим контекстом. Все операции упорядочены в соответствии с семантическими зависимостями. Например, если в программе написано c=a+b, то в промежуточном представлении появляется объект 'операция', в котором указано, что выполняется сложение двух аргументов а и b и результат записывается в с.
Линейный участок. Последовательность операций, без внутренних разветвлений и схождений потока управления. Программа вида:
Граф потока управления. Граф потока управления процедуры является аналитической структурой данных, отражением результатов анализа топологии и семантики программы. Каждый узел управляющего графа соответствует некоторому линейному участку. Граф потока управления является ориентированным. Каждая дуга такого графа соответствует возможности передачи управления в программе между линейными участками. В графе выделяют узел старт и узел стоп. От этих узлов достижимы все узлы управляющего графа.
Доминирование. Для двух узлов вводится отношение доминирования. Первый узел доминирует второй, если все пути от стартового узла до второго узла проходят через первый узел. На основе этого отношения строится дерево доминаторов, узлами которого являются узлы управляющего графа, а дуги соответствуют отношению доминирования.
Дерево циклов. На основе анализа потока управления строится факторизация программы, которая называется деревом циклов. Эта факторизация нужна для выделения интересных с точки зрения оптимизации регионов программы, называемых циклами. Узлами дерева являются циклы. Дуги отображают вложенность циклов.
Граф потока данных. Граф потока данных является аналитической структурой данных, в которой узлами являются операции, а дуги отображают передачу значений между операциями. Для фрагмента программы (1) c=a+b; (2) f=d-c два узла, соответствующих операциям 1 и 2, будут связаны дугой в графе потока данных, которая соответствует передаче данных через переменную с.
Конфликт. Для двух операций доступа в память есть понятие конфликта. Конфликт означает доступ в одну и ту же область памяти.
Зависимость. Для двух операций доступа в память вводится отношение зависимости. Зависимость означает наличие конфикта и достижимость по графу потока управления.
Параллельный цикл. Параллельным является цикл, у которого нет межитерационных зависимостей.
Инвариантная переменная. Инвариантной переменной цикла является переменная, которая не изменяется в цикле.
Индуктивная переменная. Индуктивной переменной является переменная цикла, которая инкрементируется или декрементируется на константное значение на каждой итерации цикла.
Рекурентность. Рекурентностью называется последовательность операций, связанных межитерационно в графе потока данных.
Редукция. Редукцией называется переменная, которая коммутативно изменяется на каждой итерации цикла.
УРОВЕНЬ ТЕХНИКИ
Главную роль в эффективном использовании архитектур с явной параллельностью (многоядерных, кластерных и т.д.) играют системы программирования, предназначенные для создания параллельных программ. Такие системы включают в себя как языковые средства задания параллельности в программе (системы явного параллельного программирования - стандарт ОреnМР [31], платформа RapidMind [35], …), так и автоматические средства поиска параллельных вычислений (компиляторы фирм Intel [32], Portland Group [33], …) и последующего представления их с использованием существующих библиотек поддержки параллельности (MPI ([30]), libgomp ([34]), …).
Явное параллельное программирование и автоматическое программирование, взятые независимо друг от друга, обладают серьезными недостатками. Компромиссное решение, описанное в работе [29], состоит в создании системы неявного параллельного программирования. С одной стороны программист на традиционных языках программирования (С, C++, Fortran) создает программу с параллельными вычислениями. Автоматическими средствами эти параллельные вычисления должны быть распознаны. В случае проблем с анализом, программист может добавить подсказки в программу, разрешив какой либо конфликт, мешающий определению параллельности. Затем, найденные параллельные вычисления автоматически представляются в параллельных терминах конкретной архитектуры. По сути, это некоторая интерактивная среда разработки параллельных программ, в которой сбалансированы усилия человека и автоматических средств. В такой системе основную работу по анализу, оптимизациям и инструментированию параллельного кода выполняет автомат, а человек лишь точечно прагмами разрешает конфликты, с которыми статический анализатор не справляется. Невозможность автоматически разрешить конфликт возникает по двум причинам: несовершенство статического анализа и динамическая природа конфликтов. Несмотря на то что первый фактор со временем будет нивелироваться, разрешение динамических конфликтов потребует подсказок.
В работе Дроздова А.Ю. [1] был предложен компонентный подход к построению оптимизирующих компиляторов [2] и была разработана технология портировния компонент в контекст любой существующей технологии оптимизирующей компиляции. Этот способ выбран в качестве прототипа.
Технический результат, достигаемый при применении заявляемого решения, состоит в уменьшении времени обработки информации за счет увеличения числа параллельно выполняемых операций для большего числа случаев, встречающихся в практике.
Известные способы не позволяют получить заявленный технический результат.
В данной работе описан автоматический распараллеливатель программ, созданный на базе компонентного подхода, описанного в работе [1], и встроенный в технологическую цепочку GCC [34].
ОПИСАНИЕ ГРАФИЧЕСКОГО МАТЕРИАЛА
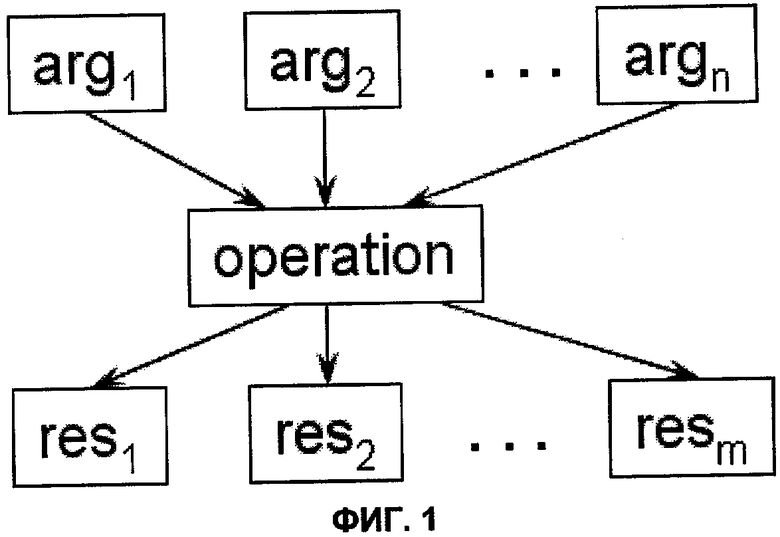
На фиг.1 показан алгоритм представления операции.
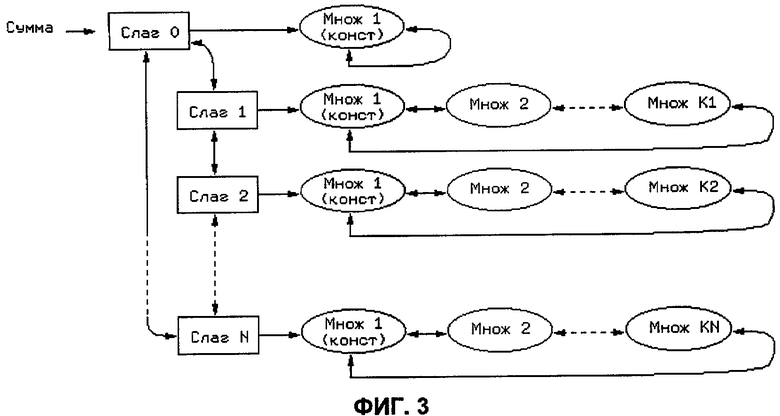
На фиг.2 показан граф потока данных в форме единственного присваивания.
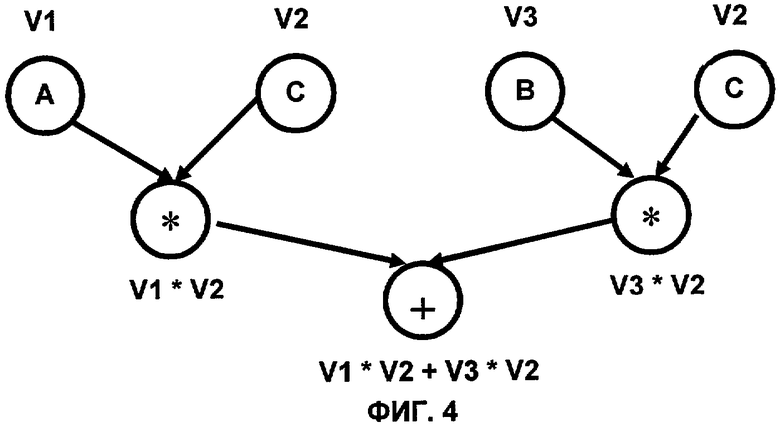
На фиг.3 приведена структура способа реализации канонической формы.
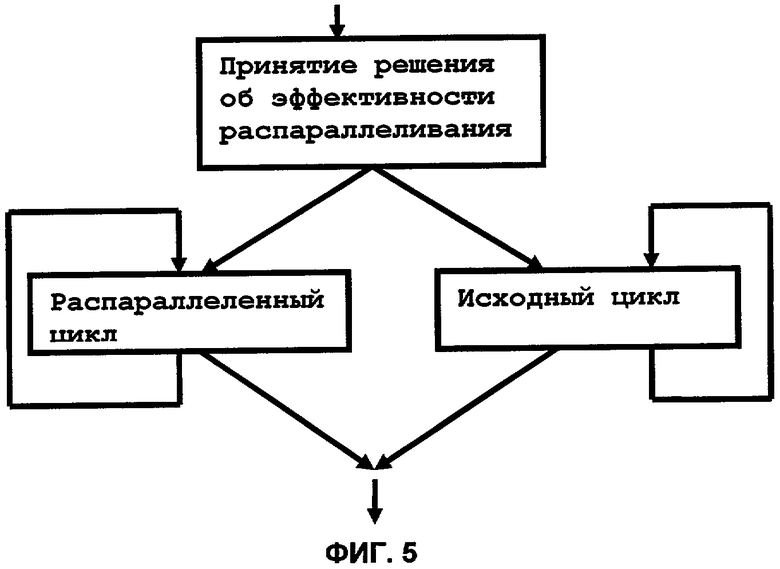
На фиг.4 приведен пример построения канонической формы для операций сложения и умножения.
На фиг.5 показан алгоритм динамической проверки эффективности распараллеливания.
ПОДРОБНОЕ ОПИСАНИЕ
Статический анализ программ
Ключевым элементом автоматического распараллеливателя (АР) является статический анализатор алгоритмической сущности (семантики) программ, реализованный на базе аналитических компонент универсальной технологии оптимизирующей компиляции [1]. Аналитическая часть содержит новые (см. далее) алгоритмы анализа потока управления, анализа потока данных, межпроцедурного анализа, анализа цикловых зависимостей и пр. Алгоритмы были опробованы в промышленных компиляторах и доказали свою высокую эффективность. В анализатор включены следующие аналитические компоненты:
- анализ потока данных методом нумераций значений;
- анализ потока управления (построение графа потока управления, построение деревьев доминаторов/постдоминаторов, построение дерева циклов, поиск итерационного фронта доминирования, определение эквивалентности по управлению);
- анализ переменных в цикле (распознавание инвариантов, индуктивностей, рекурентностей, редукций);
- анализ цикловых зависимостей;
- анализ зависимостей на ациклических участках;
- межпроцедурный анализ потока данных.
Основная задача, которую решают методы статического анализа программ в оптимизирующих компиляторах, - это определение отношения зависимости по данным и управлению между различными группами вычислений программы [1-8]. Эффективное (точное) вычисление этих отношений имеет решающую роль при проведении оптимизирующих преобразований программы.
Поэтому в современных оптимизирующих компиляторах важнейшую роль играют аналитические фазы компиляции. На фазах анализа определяют избыточные вычисления, зависимости между операциями доступа в память, зависимости по управлению, достижимость по управлению и т.п. В рамках этих фаз анализируют поток управления в программе, поток данных, решают системы линейных диофантовых уравнений и неравенств с целью определения зависимостей в цикловых регионах программы.
После анализа потоков данных и управления компилятор может использовать результаты для получения ответов на вопросы о зависимостях между любыми парами вычислений программы [2, 5, 25-28]. Под вычислениями здесь понимают такие элементы факторизации любого уровня, как операции, линейные участки, циклы, процедуры. Любой запрос на отношение зависимости имеет два измерения сложности, которые определяют структуру построения ответа. Одно из них рассматривает сложность вычислений, для которых определяют отношение зависимости, с точки зрения факторизации по управлению, а второе определяет уровень сложности объектов программы, которые участвуют в анализируемых вычислениях.
Если объекты элементарные, то для ответа достаточно результатов внутрипроцедурного потокового анализа управления и данных. По мере увеличения сложности объектов увеличивается и сложность алгоритмов анализа, результаты которых необходимы для получения наименее консервативного ответа на вопрос о зависимости. Для объектов - массивов часто бывает необходимо применить анализ зависимостей в гнездах циклов, а для объектов, на которые брался указатель, будут востребованы результаты межпроцедурного анализа потока данных.
Особенно важное значение методы статического анализа программ играют при построении анализатора и автоматического распараллеливателя, для обнаружения независимых участков программы (анализатор) и их дальнейшего оформления в виде параллельных блоков (распараллеливатель).
Подстановка промежуточного представления процедур в места их вызовов
Классическое проеобразование (inline) состоит в том, что вместо операции вызова подставляют промежуточное представление вызываемой процедуры. Благодаря этому преобразованию упрощают анализ зависимостей, так как все операции подставляемой процедуры можно явно анализировать алгоритмами анализа. При подстановке вызовов важно определить критерий, по которому это преобразование нужно применять. В настоящей работе критерий выбран таким, чтобы максимизировать количество циклов, не содержащих вызовов. Если подстановка вызова не приводит к появлению новых циклов без вызовов, то подстановку не осуществляют.
В процессе компиляции программу преобразуют из исходного представления (для языков программирования это текст программы) во внутреннее промежуточное представление компилятора. Любое промежуточное представление, используемое в компиляторах, в первую очередь сохраняет семантику исходной программы. Под семантикой программы понимают ее алгоритмическую сущность. С точки зрения фрагментации программы, написанные на наиболее распространенных языках программирования (С, C++, Fortran и т.д.), организованы в модули и процедуры. Модуль соответствует файловой организации программ. В виде процедур оформляют фрагменты программ внутри модулей. Структуры данных программ представляют объектами с фиксированными или динамически задаваемыми размерами и описанием их внутренней структуры с помощью типов. Наиболее общим способом сохранения алгоритмической составляющей программы в компиляторах является операционное представление (фиг.1).
Операционное представление является списком операций. У операции может существовать входной контекст и выходной контекст. Входной и выходной контексты задают списками аргументов и результатов. Аргументы могут быть литералами, объектами или ссылками на другие операции. Отображение связи между результатом одной операции и аргументом другой через объекты является более общим, чем представление этой связи в виде ссылки на операцию. Сама операция представляет собой набор атрибутов, определяющих семантическое действие над входным контекстом для получения выходного контекста. К такому операционному представлению может быть сведено практически любое известное промежуточное представление, начиная с синтаксических деревьев фронтендов (gcc, edg), заканчивая представлениями, наиболее приближенными к ассемблерам целевой архитектуры.
Для выполнения оптимизаций в соответствии с выбранным критерием выполняют последовательность преобразований промежуточного представления.
В приведенном алгоритме представлена последовательность шагов, которая позволяет эффективно распараллеливать циклы в программе. Алгоритм запускают на промежуточном представлении программы. В процессе работы выполняют преобразования промежуточного представления. На промежуточном представлении при применении преобразований строят (если уже построены, то используют) аналитические структуры данных: граф потока управления, дерево доминаторов, дерево циклов, граф потока данных.
Межпроцедурный анализ указателей - использовано решение, описанное в работе [22, 23, 24].
Межпроцедурный анализ указателей необходим для того, чтобы уже на стадии компиляции программы определить возможные значения указателей, содержащиеся в переменных в различных местах программы. Наличие такой информации помогает в определении того, какие группы операций могут быть выполнены параллельно, какие значения уже были вычислены и их можно повторно использовать, оптимизировать обращения к объектам в памяти, сворачивать константные вычисления. Наличие результатов такого анализа, обладающих высокой степенью детализации, позволяет эффективно применять многие оптимизирующие преобразования программы как внутри, так и межпроцедурного уровня.
На более формальном уровне задачей межпроцедурного анализа указателей является вычисление некоторой функции, которая в каждой точке программы для каждой переменной позволяет получить множество значений одного из перечисленных выше типов, которые в этой точке переменная может содержать. Задача межпроцедурного анализа может быть описана построением такого приближения семантики программы, которое отображало бы интересующее свойство поведения этой программы на стадии исполнения.
Предлагаемый здесь подход к проблеме межпроцедурного анализа потока данных описан такими характеристиками, как чувствительность к потоку управления (flow-sensitivity) и чувствительность к контексту вызова процедуры (context-sensitivity). Первое означает, что алгоритм учитывает управление внутри процедуры, что приводит к повышению его точности. Второе - что он стремится различать информацию, приходящую в процедуру по различным путям во время исполнения. Но поскольку число таких путей может быть значительным, необходимо объединять те из них, которые предположительно наиболее близки (и объединение которых внесет минимально возможный консерватизм в его результаты). Основным механизмом, который обычно используют для обеспечения свойства контекстной зависимости, является механизм частично трансферной функции (ЧТФ). Он позволяет весьма эффективно выбирать соотношение между скоростью проведения анализа и его точностью, ибо, в общем случае, межпроцедурный анализ потока данных является достаточно ресурсозатратным процессом как с точки зрения требуемой памяти, так и с точки зрения времени его проведения.
Анализ потока данных способом нумераций значений
Способ описан в диссертации [36]. Анализ потока данных в программе способом нумераций значений состоит в том, чтобы присвоить результатам операций одинаковые классы эквивалентности, если операции пишут в эти результаты эквивалентные значения. Две операции считают эквивалентными, если у них эквивалентны аргументы и операции выполняют одно и то же семантическое действие. При потоковом анализе строят граф потока данных, который связывает результаты и аргументы операций. Граф потока данных позволяет для аргументов получать операции, вырабатывающие значение аргумента. Кроме графа потока данных для анализа применяют способ, использующий форму единственного присваивания. Текст программы, переведенный в эту форму, содержит псевдооперации в точках схождения управления. В результате с учетом этих псевдоопераций, для каждого аргумента, для которого произведен перевод в форму единственного присваивания, существует единственная запись. В графе потока данных для таких аргументов будет всего одна входная дуга от единственной записи. На фиг.2 показан граф потока данных в форме единственного присваивания. В программе, приведенной для примера на фиг.2, есть две записи в переменную А и одно чтение. Запись обозначают как 'А=…', чтение обозначают как '…=А'. Прямоугольниками и связывающими их стрелками отображают поток управления в программе. Из блока BLOCK 1 возможна передача управления на блок BLOCK 2 или на блок BLOCK 3. Из блоков BLOCK 2 и BLOCK 3 управление передают в блок BLOCK 4. Черными кружками и стрелками, соединяющими их, образован граф потока данных для данного фрагмента программы. На графе потока данных каждый узел соответствует операции, и каждая дуга соответствует паре аргумент-результат. Псевдооперация, соответствующая схождению потока управления, обозначена как 'φ(А)'.
Анализ переменных цикла на инвариантность, индуктивность и редукцию
Поиск переменных цикла осуществлют по графу потока данных. Анализ состоит в поиске подграфов, удовлетворяющих свойствам инвариантности, индуктивности, редукции [2, 5, 7, 8].
Анализ операций доступа в массивы
Существенное улучшение качества потокового анализа методом нумераций значений можно получить, если использовать каноническую форму представления выражений в виде сумм произведений. Эта форма является одним из способов представления линейного выражения в виде полинома
с0+с1*x11*x12*…*x1k1+c2*x21*x22*…*x2k2+…+cn*xn1*xn2*…*xnkn,
где c0, c1, cn - некоторые константы; Xij - множители.
Эффект от использования канонической формы состоит в приведении линейных выражений к единому (каноническому) виду, что позволяет определять эквивалентные вычисления, даже если исходный вид выражений различается. В рамках приведения арифметических выражений к каноническому виду выполняют свертку констант (исполнение арифметических операций над константами), упорядочивание коммутативных операций, приведение подобных слагаемых. Например, выражение (а+b)*с и выражение а*с+b*с будут приведены к единому виду а*с+b*с и определены как эквивалентные.
На фиг.3 приведена структура способа реализации указанной канонической формы. В прямоугольниках представлены элементы, соответствующие слагаемым. В овалах представлены элементы, соответствующие множителям.
Механизм использования канонической формы во время работы алгоритма нумераций значений состоит в том, чтобы для операций сложения, вычитания и умножения строить сумму произведений по аргументам этой операции. Множителями канонической формы будут являться классы эквивалентности (напр. см. ранее «Анализ потока данных способом нумерации значений»). Хеширование операций, для которых возможно построение канонических форм, выполняют на основе этих форм.
На фиг.4 приведен пример построения канонической формы для операций сложения и умножения. Символами V1, V2 и V3 обозначены классы эквивалентностей для операций чтения из переменных А, С и В соответственно.
Способ представления адресов операций доступа в память - каноническая форма сумм произведений, множителями которой выбирают классы эквивалентности, вычисленные в результате потокового анализа методом нумераций значений. Анализ зависимостей в цикловых регионах в основном сводят к анализу конфликтов операций доступа в память. Наиболее известным способом работой с памятью является обращение к массивам по линейным индексам. Ниже приведен фрагмент программы, написанной на языке С. В строке 1 объявляют массив А размером в 10 элементов. К массиву А в строке 5 задают обращение по индексам 'i+1' и 'j-1'. Присваивают операции чтения из переменной i некоторый класс эквивалентности V. Для индекса 'i+1' строят каноническую форму 1+V. Чтению из переменной j устанавливают тот же класс эквивалентности V, так как значения переменных i и j содержат одни и те же значения. Для индекса доступа в массив 'j-1' строят каноническую форму -1+V. Для определения зависимостей решают уравнения 1+V=-1+V', где для переменных V и V' есть ограничения 0<V<10 и 0<V'<10. Переменные V и V' являются номерами итераций цикла. В результате решения системы уравнений и неравенств определяют итерации, на которых происходит обращение к одному и тому же элементу массива А.

Слияние циклов
Оптимизация по слиянию циклов (fusion) [5, 6] для увеличения количества вычислений на одной итерации цикла и уменьшения потребных ресурсов на распараллеливание. Ниже приведен пример слияния циклов. Потребные ресурсы на распараллеливание после применения преобразования сокращены вдвое, так как распараллеливают только один цикл вместо двух.

Вынос инвариантных условий
Оптимизация по выносу инвариантных условий из цикла (unswitching) [5, 6] позволяет удалять из цикла операции, исполняющиеся при этих условиях. Среди удаленных операций могут оказаться операции, препятствующие распараллеливанию. К ним относятся, в частности, операции вызова. Поэтому это преобразование увеличивает количество параллельных циклов.
Изменение порядка обхода итерационного пространства
Эти оптимизации нацелены как на повышение количества параллельных циклов, так и на повышение эффективности распараллеливания. Другое название этих трансформаций - "унимодулярные преобразования". Они подробно освещены в работах [5, 7, 8].
Анализ межитерационных зависимостей
Классический способ приведен в работах [5, 7, 8]
Задача по нахождению межитерационных зависимостей состоит в решении системы линейных диофантовых уравнений и неравенств. Уравнения составляют в результате сравнения индексов доступа в массив, а неравенства формируют из представления верхних и нижних границ переменных циклов в математической форме. Количество уравнений определяют по размерности массивов, операции обращения к которым рассматривают при постановке задачи.
После того как задача поставлена, выполняют следующую последовательность шагов.
Решают систему линейных диофантовых уравнений. Если система уравнений не имеет решения, значит зависимость не существует. Если система уравнений имеет решение, исследуют систему линейных диофантовых неравенств. Если система диофантовых неравенств имеет решение, это означает, что зависимость существует. Если не имеет решения, это означает, что зависимость не существует. Если зависимость существует, далее исследуют вектора направлений и вектора расстояний.
Классический подход к решению систем линейных диофантовых неравенств состоит в применении метода Фурье.
Анализ массивов на локальность
Если массив на каждой итерации цикла перед использованием перезаписывают новыми значениями и не используют после цикла, то для каждой итерации можно создать локальную копию таких массивов. Это преобразование называют локализацией и оно позволяет удалить межитерационные зависимости исходного массива. Таким образом, чтобы локализовать массивы нужно удостовериться, что по всем путям от начала цикла до операций чтения из массивов есть операции записи в те же элементы массива. Кроме этого, нужно проверить, что массив не используют после цикла.
Это действие позволяет устранить межитерационные зависимости в цикле, тем самым увеличивая возможности для распараллеливания.
Дублирование цикла
Для проверки эффективности от применения распараллеливания используют способ дублирования циклов. Одну копию оставляют не распараллелиной, а другую распараллеливают. Проверка перед циклами определяет целесообразность перехода на распараллелиную копию или оставление исходной версии цикла. Выполняют проверку на время исполнения итераций и сравнение этого времени с затратами ресурсов на запуск параллельного цикла.
На фиг.5 показан пример такого преобразования.
Заявляемый способ состоит в следующем.
На этапе промежуточного представлении программы строят (если уже построены, то используют) по крайней мере следующие аналитические структуры данных: граф потока управления, дерево доминаторов, дерево циклов, граф потока данных любыми известными способами.
Выполняют подстановки тел процедур в места их вызовов. В случае распараллеливания это действие направлено на то, чтобы проанализировать циклы, в которых имеются вызовы других процедур. При наличии вызовов известные способы анализа зависимостей в циклах неприменимы.
Выполняют межпроцедурный анализ потока данных. Для анализа указателей преимущественно используют способ частичных трансферных функций [22, 23, 24]. Возможно также использование различных альтернативных способов анализа [9-21].
Выполняют внутрипроцедурный анализ потока данных. Преимущественно используют известный способ нумераций значений. Цель анализа - определить эквивалентные операции. Возможно также использование классических итерационных алгоритмов распространения потоковых свойств программы [5, 6].
Выполняют анализ переменных цикла. Определяют инвариантные переменные, индуктивные переменные и редукции. Например, анализ графа потока данных с определением подграфов, соответствующих индуктивным и/или инвариантным переменным.
Выполняют анализ операций доступа в массивы. Строят индексы доступа в массивы в виде канонических форм сумм произведений.
Выполняют преобразования циклов, увеличивающие эффект от последующего распараллеливания. В их число входят преобразования по слиянию циклов, по выносу инвариантных условий, по изменению порядка обхода итерационного пространства циклов.
Выполняют анализ параллельных циклов. Дерево циклов обходят рекурсивно от корневого узла с проверкой на возможность распараллелить текущий цикл. Выполняют по крайней мере следующие виды анализа.
а. Анализ структуры цикла. Распараллеливать можно циклы с одним выходом, управление которым осуществляют индуктивной переменной с инвариантными верхней и нижней границами, а также инвариантным шагом.
b. Анализ редукций цикла. Распознанные редукции исключают при анализе межитерационных зависимостей.
с. Анализ межитерационных зависимостей в цикле. Межитерационные зависимости выявляют классическим методом с помощью решения диофантовых уравнений.
d. Анализ массивов на локальность. В случае локализации массивов межитерационные зависимости могут быть удалены.
Для параллельных циклов выполняют построение копии цикла, поскольку распараллеленный цикл не всегда работает быстрее, чем исходный цикл. При некоторых условиях потребность в дополнительных ресурсах на запуск цикла в параллель может привести к снижению производительности. Динамически осуществляют проверку на время исполнения итераций и сравнение этого времени с дополнительными ресурсами на запуск параллельного цикла.
Для параллельных циклов выполняют построение операций, которые обеспечат параллельное исполнение циклов. При параллельном исполнении производят запуск нескольких потоков, каждый из которых выполняет часть итераций цикла. Тело цикла выделяют в новую процедуру, параметрами которой являются нелокальные данные итераций цикла. Локальными структурами данных созданной процедуры назначают локальные структуры данных итераций исходного цикла.
Описанный способ был реализован на базе КТОТ [1]. Результаты, публикуемые в указанной работе, были получены за счет распараллеливания циклов.
Структура описания организована так, что сначала приводят описание некоторого уровня алгоритма на абстрактном языке, а затем приводят комментарии к каждому шагу алгоритма.
Алгоритм 1. Автоматическое распараллеливание процедуры.
На вход подают промежуточное представление программы, состоящее из набора промежуточных представлений процедур.
На выходе получают модифицированное промежуточное представление программы, в котором могут присутствовать распараллеленные циклы.
Распараллеливание_программы
1. Выполняют подстановки тел процедур в места их вызовов.
2. Выполняют межпроцедурный анализ потока данных.
3. Цикл по всем процедурам программы.
4. Распараллеливание_процедуры.
5. Конец цикла.
Распараллеливание_процедуры
1. Выполняют внутрипроцедурный анализ потока данных.
2. Выполняют анализ переменных цикла.
3. Выполняют анализ операций доступа в массивы.
4. Выполняют преобразования циклов, увеличивающие эффект от последующего распараллеливания.
5. Распараллеливание_цикла.
6. Выполняют удаление вспомогательных структур данных.
Распараллеливание_цикла
1. Выполняют проверку свойств индуктивной переменной цикла и либо переход к шагу 5, либо переход к шагу 2.
2. Выполняют анализ редукций цикла.
3. Выполняют проверку наличия межитерационных зависимостей и в случае их отсутствия переход к шагу 4.
4. В случае наличия межитерационных зависимостей выполняют попытку удалить зависимости способом локализации массивов. Если зависимости удалить не удалось, то переход на шаг 6.
5. Применение_распараллеливания_цикла. Выход из процедуры.
6. Цикл по всем вложенным циклам в дереве циклов.
7. Распараллеливание_цикла.
8. Конец цикла.
Применение_распараллеливания_цикла
1. Построение копии цикла и условия перехода на распараллеленный вариант.
2. Построение для распараллеливаемого цикла переменных, содержащих значение нижней границы, верхней границы и шага.
3. Формирование дескриптора параллельного цикла. По дескриптору в зависимости от типа среды осуществляют построение операций, которые обеспечат параллельное исполнение циклов. При параллельном исполнении производят запуск нескольких потоков, каждый из которых выполняет часть итераций цикла.
Верхний уровень алгоритма автоматического автораспараллеливания реализован в процедуре Распараллеливание_программы.
На 1-м и 2-м шагах выполняют алгоритмы межпроцедурного анализа и оптимизаций. Сначала выполняют подстановку промежуточных представлений процедур в места их вызовов, а затем выполняют межпроцедурный анализ потока данных.
На шагах 3-5 выполняют цикл по процедурам программы, в котором на шаге 4 запускают алгоритм распараллеливания процедуры Распараллеливание_процедуры.
На шагах 1-4 процедуры Распараллеливание_процедуры выполняют предварительные действия перед распараллеливанием, а именно: проводят анализ потока данных методом нумераций значений, осуществляют анализ переменных цикла, выполняют анализ операций доступа в массив, а также проводят ряд цикловых оптимизаций, направленных на увеличение количества параллельных циклов и/или усиление эффекта от распараллеливания.
На шаге 5 запускают рекурсивный алгоритм распараллеливания циклов Распараллеливание_цикла. Эта процедура рекурсивно обходит дерево циклов и пытается распараллелить текущий цикл. Стартуют процедуру от головы дерева циклов.
На шаге 6 выполняют удаление всех вспомогательных структур данных.
Следующим уровнем реализации алгоритма распараллеливания является распараллеливание цикла. Процедура Распараллеливание_цикла осуществляет проверку свойств цикла на возможное распараллеливание и в случае наличия этих свойств у цикла распараллеливает его. На шаге 1 проверяют структуру цикла. Распараллеливать можно циклы с одним выходом, управление которым осуществляет индуктивная переменная с инвариантными верхней и нижней границами, а также инвариантным шагом.
Анализ редукций цикла выполняют на шаге 2. Распознанные редукции исключают при анализе межитерационных зависимостей (зависимости между итерациями цикла) на шаге 3.
На шаге 3 проверяют наличие межитерационных зависимостей в цикле. Для этого используют анализатор. Если в цикле нет межитерационных зависимостей, то он может быть распараллелен.
В случае существования межитерационных зависимостей на шаге 4 осуществляют попытку удалить зависимости способом локализации массивов.
В случае успешного выполнения проверок на шагах 1, 3 и 4 на шаге 5 запускают процедуру Применение_распараллеливания_цикла, которая производит необходимые действия по распараллеливанию цикла.
Если решение о распараллеливании принято не было, то на шаге 7 выполняют рекурсивный вызов процедуры Распараллеливание_цикла для всех вложенных циклов текущего цикла.
Процедура Применение_распараллеливания_цикла выполняет действия по распараллеливанию цикла, для которого распараллеливание возможно. На шаге 1 выполняют построение копии цикла и условия, проверяющего эффективность распараллеливания. Дело в том, что потребные ресурсы на создание нового потока велики и если цикл недостаточно долгого исполнения, то его распараллеливание может привести к снижению производительности. Динамически осуществляют проверку на время исполнения итераций и сравнение этого времени с потребными ресурсами на запуск нового потока. Вычисление времени исполнения итераций цикла носит эвристический характер. Оценка этого времени основана на величинах счетчиков исполняемых циклов и эвристических временах исполнения отдельных команд в теле цикла. Счетчики вложенных циклов не всегда известны на уровне охватывающего цикла. В этом случае их значение выставляют эвристически. Считается, что в среднем цикл содержит 10 итераций.
На шаге 2 осуществляют инициализацию переменных значениями нижней и верхней границ, а также шагом индуктивной переменной.
На шаге 3 промежуточное представление распараллеленного цикла модифицируют. В представление встраивают операции, обеспечивающие параллельный запуск тела цикла. Тело цикла выделяют в новую процедуру. В зависимости от локальности структур данных по отношению к итерациям циклов часть из них передают параметром в новую процедуру, а часть (которые локальные) становятся структурами данных новой процедуры.
Литература
1. Дроздов А.Ю., Особенности и перспективы Универсальной технологии оптимизирующей компиляции. // Сборник научных трудов ИТМиВТ им. С.А.Лебедева РАН, Выпуск №1, Материалы Всероссийской конференции "Перспективы развития высокопроизводительных архитектур. История, современность и будущее отечественного компьютеростроения", 2008, С.62-74.
2. Alfred V. Aho, Ravi Sethi, Jeffrey D.Ullman, "Compilers: Principles, Techniques, and Tools", Addison-Wesley, Reading, 1986.
3. John R. Ellis. Bulldog: A compiler for VLIW Architectures. MIT Press, 1985.
4. Dick Grune, Henri E. Bal, Ceriel J.H. Jacobs and Koen G. Langendoen, Modern Compiler Design, by John Wiley & Sons, Ltd, 2000.
5. Randy Alien, Ken Kennedy, Optimizing Compilers for Modern Architectures. 2002 by Academic Press.
6. Steven S. Muchnick, "Advanced Compiler Design and Implementation", Morgan Kauffman, San Francisco, 1997.
7. Utpal Banerjee, Loop Transformations for Restructuring Compilers. Kluwer academic Publishers, 1993.
8. Utpal Banerjee. Dependence Analysis. Kluwer Acadmic Publishers. 1997.
9. [29] Kwangkeun Yi and Williams Ludwell Harrison III, Interprocedural Data Flow Analysis for Compile-time Memory Management. Center for Supercomputing Research and Development, University of Illinois at Urbana-Champaign.
10. Evelyn Duesterwald, Rajiv Gupta, Mary Lou Soffa, Demand-driven Computation of Interprocedural Data Flow. Department of Computer Science, University of Pittsburg, POPL'95 1/95 San Francisco, CA USA.
11. Evelyn Duesterwald, Rajiv Gupta, and Mary Lou Soffa, A Practical Framework for Demand-Driven Interprocedural Data Flow Analysis. University of Pittsburg, ASM SISPLAN-SIGACT Symposium on Principles of Programming Languages, 1995.
12. Susan Horwitz, Thomas Reps, and Mooly Sagiv, Demand Interprocedural Dataflow Analysis. University of Wisconsin, Proceedings of the Third ASM SIGSOFT Symposium on Foundations of Software Engineering, Washington DC, October 10-13, 1995.
13. В.В.Воеводин, Вл.В.Воеводин, Параллельные вычисления. Санкт-Петербург «БХВ-Петербург», 2002.
14. David R.Chase, Mark Wegman, F.Kenneth Zadeck, Analysis of Pointers and Structures. ASM SIGPLAN'90 PLDI, June 20-22, 1990.
15. Yuan-Shin Hwang, Joel Saltz, Compile-Time Analysis on Programs with Dynamic Pointer-Linked Data Structures. Depatment of Computer Science, University of Maryland, Nobember 8, 1996.
16. Rakesh Ghiya and Laurie J.Hendren, Connection Analysis: A Practical Interprocedural Heap Analysis for C. School of Computer Science, McGill University, Proceedings of the Eigth Workshop on Languages and Compilers fo rParallel Computing, Columbus, Ohio, August 10-12, 1995.
17. Xinan Tang, Rakesh Ghiya, Laurie J. Hendren, Guang R.Gao, Heap Analysis and Optimizations for Threaded Programs. School of Computing Science, McGill University, 1997.
18. Rakesh Ghiya, Practical Techniques for Interprocedural Heap Analysis. School of Computing Science, McGill University, Montreal, January 1996.
19. Keith D.Cooper, Ken Kennedy, Fast Interprocedural Alias Analysis. Rice University, 1989.
20. Bjarne Steensgaard, Points-to Analysis in Almost Linear Time, Microsoft Research, 1996.
21. Keith D.Cooper, Ken Kennedy, Interprocedural Side-Effect Analysis in Linear Time. Rice University, 1988.
22. Robert P.Wilson, Monika S.Lam. Efficient context-sensitive pointer analysis for С programs. In Proceedings of the ACM SIGPLAN'95 Conference on Programming Language and Implementation, pages 1-12, June 1995.
23. Дроздов А.Ю, Владиславлев В.Е. Межпроцедурный анализ указателей // Информационные технологии. Приложение №2, Февраль 2005 г.
24. [44] Дроздов А.Ю., Сыркин А.Г. Методы контекстного межпроцедурного распространения свойств значений переменных программы // Информационные технологии. Приложение № 2, Февраль 2005 г.
25. [46] Дроздов А.Ю., Корнев P.M., Боханко А.С. Индексный анализ зависимостей по данным // Информационные технологии и вычислительные системы, №3, 2004 г.
26. Kleanthis Psarris and Konstantinos Kyriakopoulos, Data Dependence Testing in Practice. Division of Computer Science, The University of Texas at San Antonio, San Antonio, TX 78249.
27. [48] Paul M.Petersen and David A.Padua, Experimental Evaluation of Some Data Dependence Tests (Extended Abstract), Center for Super computing Research and Development, University of Illinois at Urbana-Champaign, Urbana, Illinois, 61801.
28. [49] Paul M.Petersen, David A.Padua, Static and Dynamic Evaluation of Data Dependence Analysis. Center for Supercomputing Research and Development, University of Illinois at Urbana-Champaign.
29. [54] Wen-mei Hwu, Shane Ryoo, Sain-Zee Ueng, John H. Kelm, Isaac Gelado, Sam S. Stone, Robert E. Kidd, Sara S. Baghsorkhi, Aqeel A. Mahesri, Stephanie C. Tsao, Nacho Navarro, Steve S. Lumetta, Matthew I. Frank, and Sanjay J. Patel, Implicit Parallel Programming Models for Thousand-Core Microprocessors, Proceedings of the 44th Annual Design Automation Conference, June 2007.
30. www.mpi-forum.org [56].
31. www.openmp.org [57].
32. www.intel.com [58].
33. www.pgroup.com [59].
34. www.gnu.org [63].
35. www.rapidmind.com [64].
36. [72] Loren Taylor Simson, Value-Driven Redundancy Elimination, Thesis, Rice University, Houston, Texas, April, 1996.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ распараллеливания программ в вычислительной системе | 2018 |
|
RU2685018C1 |
| Способ распараллеливания программ в среде логического программирования в вычислительной системе | 2018 |
|
RU2691860C1 |
| Способ автоматического создания параллельной программы с временной параметризацией многопроцессорных вычислительных систем с одинаковым доступом к памяти | 2022 |
|
RU2786347C1 |
| Способ распределения данных по монофункциональным блокам процессора с управлением потоком данных | 2024 |
|
RU2818497C1 |
| Способ распределения данных по многофункциональным блокам процессора со сверхдлинной командной строкой | 2024 |
|
RU2818498C1 |
| Способ распределения данных по монофункциональным блокам процессоров вычислительной системы с управлением потоком данных | 2024 |
|
RU2820032C1 |
| Способ параллельного программирования | 2021 |
|
RU2771739C1 |
| Способ временной синхронизации работы вычислительной системы с реконфигурируемой архитектурой | 2023 |
|
RU2820034C1 |
| СПОСОБ РАСПАРАЛЛЕЛИВАНИЯ ИНТЕЛЛЕКТУАЛЬНОГО АНАЛИЗА ДАННЫХ В ВЫЧИСЛИТЕЛЬНОЙ СРЕДЕ | 2019 |
|
RU2745018C1 |
| Способ распараллеливания программ на графическом процессоре вычислительной машины | 2022 |
|
RU2803581C1 |
Изобретение относится к области оптимизирующей компиляции. Техническим результатом является уменьшение времени обработки информации за счет увеличения числа параллельно выполняемых операций. В способе автоматического распараллеливания цикловых областей в алгоритмической части программы предварительно получают граф потока управления, дерево доминаторов, дерево циклов, граф потока данных; выполняют подстановки промежуточного представления процедур в места вызовов; выполняют межпроцедурный анализ потока данных; для обнаружения эквивалентных операций выполняют анализ потока данных, предпочтительно способом нумераций значений; выполняют анализ переменных цикла на инвариантность и индуктивность; выполняют анализ операций доступа в массивы, строят индексы доступа в массивы в виде канонических форм сумм произведений; выполняют слияния циклов; выполняют вынос инвариантных условий; изменяют порядок обхода итерационного пространства циклов; выполняют анализ параллельных циклов. 5 ил.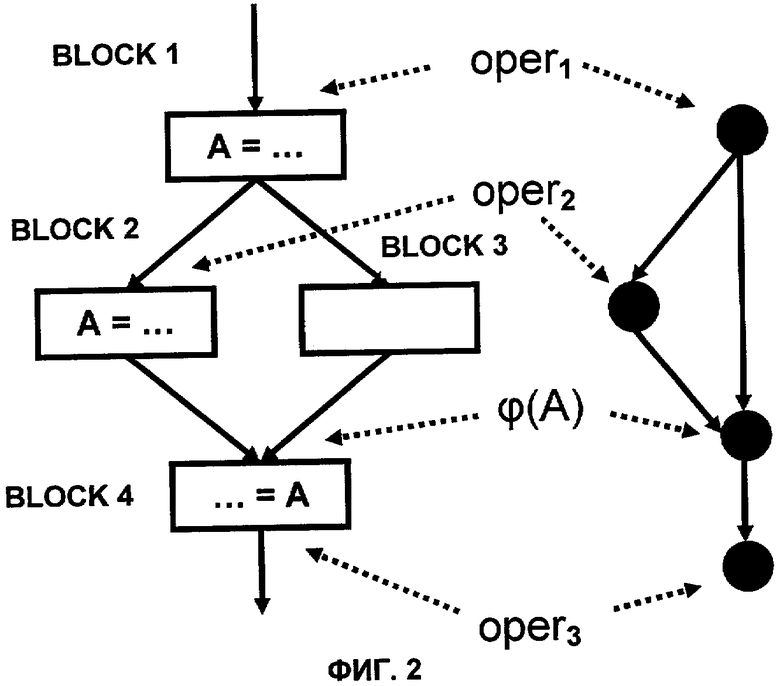
Способ автоматического распараллеливания цикловых областей в алгоритмической части программы, позволяющий максимизировать количество параллельных циклов путем применения межпроцедурных и внутрипроцедурных оптимизаций, характеризующийся встраиванием в программу динамических проверок на эффективность распараллеливания, включающий следующие шаги:
предварительно, на этапе промежуточного представления программы при выполнении преобразований строят любыми известными способами, а если уже построены, то используют по крайней мере следующие аналитические структуры данных: граф потока управления, дерево доминаторов, дерево циклов, граф потока данных;
выполняют подстановки промежуточного представления процедур в места вызовов;
выполняют межпроцедурный анализ потока данных,
для обнаружения эквивалентных операций выполняют анализ потока данных, предпочтительно способом нумераций значений;
выполняют анализ переменных цикла на инвариантность и индуктивность;
выполняют анализ операций доступа в массивы, строят индексы доступа в массивы в виде канонических форм сумм произведений;
выполняют слияния циклов;
выполняют вынос инвариантных условий;
изменяют порядок обхода итерационного пространства циклов,
выполняют анализ параллельных циклов,
причем при выполнении межпроцедурного анализа потока данных применяют метод, чувствительный к контексту и чувствительный к потоку управления,
причем подстановку осуществляют в цикловых областях для получения максимального количества циклов, не содержащих вызовы процедур,
причем способ нумераций значений дополнительно проверяют анализом, уточняющим эквивалентность для операций доступа в память,
причем при построении канонических форм используют результаты анализа потока данных методом нумераций значений,
причем при анализе параллельных циклов дерево циклов обходят рекурсивно от корневого узла с проверкой на возможность распараллеливания текущего цикла, при этом выполняют следующие виды анализа:
анализ структуры цикла на наличие единственного выхода, поскольку распараллеливать возможно только циклы с одним выходом, управление которым осуществляется индуктивной переменной с инвариантными верхней и нижней границами, а также инвариантным шагом;
анализ на наличие редукций цикла, распознанные редукции исключают при анализе межитерационных зависимостей;
анализ межитерационных зависимостей в цикле, преимущественно с помощью решения диофантовых уравнений;
анализ массивов на локальность,
причем для параллельных циклов осуществляют построение копии цикла и динамически осуществляют проверку на время исполнения итераций и сравнение этого времени с затратами ресурсов на запуск параллельного цикла,
причем для параллельных циклов выполняют построение операций, которые обеспечат параллельное исполнение циклов, при параллельном исполнении выполняют запуск нескольких потоков, каждый из которых выполняет часть итераций цикла,
причем тело параллельных циклов выделяют в новую процедуру, параметрами которой назначают нелокальные данные итераций цикла, а локальные структуры данных итераций цикла назначают локальными структурами данных созданной процедуры.
| СПОСОБ ПОЛУЧЕНИЯ ОБЪЕКТНОГО КОДА | 2000 |
|
RU2206119C2 |
| АСИНХРОННАЯ СИНЕРГИЧЕСКАЯ ВЫЧИСЛИТЕЛЬНАЯ СИСТЕМА | 2000 |
|
RU2198422C2 |
| US 6651246 B1, 18.11.2003 | |||
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |

