Настоящее изобретение относится к способам поиска данных и, в частности, к способу поиска данных в базах данных на основе графов.
Компьютерные системы часто используются для хранения больших объемов данных, отдельные записи которых должны быть извлечены в соответствии с некоторым критерием поиска. Таким образом, эффективное хранение данных для обеспечения быстрого поиска и извлечения является важнейшим вопросом.
Поиск данных неразрывно связан с понятием фильтрации данных. В целом, относительно данных, поиск означает процедуру, используемую для проверки больших объемов данных с целью найти неочевидные, скрытые или потерянные части. Поиск данных обычно ассоциируется с обработкой хранилища данных. В зависимости от характера данных для поиска данных используется большое количество поисковых алгоритмов.
Поиск данных может подразумевать поиск файлов на хранилище данных, поиск данных в файлах/документах, данных/информации в интернете, данных в базе данных и так далее. Обычно поиск данных (т.е. поиск объекта) осуществляется на основе различных параметров данных, которые отличают одни данные от других данных (т.е. поиск по параметру(ам), который однозначно характеризует искомые данные). Например, имя файла, тип файла, размер файла могут быть использованы в качестве таких отличительных характеристик; название таблицы, табличный идентификатор - для базы данных; количество символов в слове, часть речи - для слов и так далее. Для облегчения и оптимизации поиска данных могут быть использованы теги.
Обычно тег может быть назначен документу вручную во время процесса создания данных или документов, сохранения и/или добавления в базу данных. Теги характеризуют данные, так что эти теги могут быть использованы для поиска данных. Теги является неиерархическим ключевым словом или понятием, назначенным части информации (таким как интернет-закладка, цифровым изображением или компьютерным файлом). Этот вид метаданных помогает описать данные и позволяет им снова быть найденными путем поиска. Теги обычно выбираются неформально и лично создателем данных или теми, кто их просматривает в зависимости от системы, структуры данных, типа данных, содержания данных, контекста данных и так далее. Например, данные, относящиеся к компьютерным наукам, могут быть охарактеризованы по тегам "компьютер", "наука", "информация", "программное обеспечение", "оборудование" и др. Для создания тегов могут быть использованы различные алгоритмы.
Например, теги могут быть созданы на основе результатов анализа текста документа. Теги могут быть созданы автоматически (упоминаемые ниже как "автотеги") для документа и могут быть в дальнейшем ассоциированы с ним. Автотеги могут быть созданы не только для поиска данных/документа, но и для поиска Объекта, например, в базе данных (БД). Объект представляет собой сущность, например, бизнес-сущность: задача "Добавить описание для изображения животного" является Объектом, служащий "Билл" - Объект, так же как и запрос на "Постройку моста", запись в БД для пользователя, ИТ-отдел, отдел кадров или любая другая сущность. Такие сущности в области программирования называются экземплярами класса. Так, пользователь "Билл" - это экземпляр Класса "Пользователь"; ИТ-отдел, отдел кадров являются экземплярами Класса "департамент" и т.д. Такие Объекты являются искомыми данными, которые интересны пользователю, и которые должны быть найдены в базе данных.
Теги могут быть созданы для любого типа данных, хранимых в различных формах, например, в форме троек/n-tuples. Тройки, например, могут быть сохранены в различных типах баз данных, например, реляционных, иерархических, сетевых, объектно-ориентированных БД и т.д.
Как правило, тройки хранятся в хранилищах троек. Хранилище троек является специальной базой данных для хранения и получения троек. Хранилище троек - это созданная для определенных целей база данных для хранения и получения троек, тройка, являясь сущностью данных (также известная как утверждение), состоит из Подлежащего-Сказуемого-Дополнения, как "Джону есть 35 лет" или "Джон знает Хелен".
В отличие от реляционной базы данных, хранилище троек оптимизировано для хранения и получения троек. Для доступа к тройкам, хранящимся в хранилище данных, используется язык запросов. В дополнение к запросам обычно тройки могут быть импортированы/экспортированы при помощи Среды Описания Ресурса (RDF) и других форматов. Некоторые хранилища построены как СУБД с нуля, в то время как остальные построены поверх существующих коммерческих реляционных СУБД (например, основанные на SQL). Подобно ранним разработкам аналитическая обработка в реальном времени (OLAP) баз данных, этот промежуточных подход позволил создать большие и мощные СУБД с небольшими затратами на программирование на начальных фазах разработки хранилищ данных.
Однако в долгосрочной перспективе вполне вероятно, что нативные хранилища данных будут иметь преимущества в плане производительности перед. Сложность в реализацией хранилищ данных поверх SQL заключается в том, что хотя тройки могут быть сохранены, реализация эффективных запросов RDF модели на основе графов в запросы SQL - достаточно сложна.
Количество тегов растет с ростом объема данных. Сохраненные данные со временем меняются, так что старые теги удаляются или заменяются новыми тегами. Необходимо создавать новые теги. Обычно, объекты данных пересекаются друг с другом, и изменение одной части данных может повлиять на другие. Создание тегов вручную для новых данных и обновление изменившихся данных - это очень трудоемкий и дорогостоящий процесс.
Соответственно, требуется способ для автоматического создания тегов и ранжирования данных на основе весов тегов для облегчения получения данных.
Настоящее изобретение относится к способу для поиска данных в графовых базах данных, который существенно перекрывает недостатки уровня техники.
В одном аспекте изобретения предложен способ автоматического генерирования тегов и получения данных из графовой базы данных. Согласно примерному варианту реализации тройки хранятся в хранилище данных. Хранилище данных - это специальная база данных для хранения и получения троек. Хранилище троек - это специально разработанная база данных для хранения и получения троек, где тройка является сущностью данных (также известной как утверждение) состоящей из Подлежащего-Сказуемого-Дополнения.
В отличие от реляционной базы данных хранилище троек оптимизировано для хранения и получения троек. Язык запросов используется для доступа к тройкам, хранящимся в хранилище троек. В дополнение к запросам тройки, как правило, могут быть импортированы/экспортированы с помощью RDF и других форматов. Искомые Объекты необходимо пометить тегами для поиска и извлечения. Количество тегов растет с ростом объема данных. Сохраненные данные меняются со временем, так что старые теги удаляются или заменяются новыми тегами. Должны быть созданы новые теги. Теги создаются автоматически (т.е. автотеги) для обеспечения эффективного извлечения данных.
Дополнительные особенности и преимущества изобретения будут изложены в последующем описании и частично будут очевидны из описания или могут быть познаны при практическом применении изобретения. Преимущества изобретения будут реализованы и достигнуты по структуре, в частности, в указанных в письменном описании и формуле изобретении, а также на приложенных чертежах.
Следует понимать, что и вышеописанное общее описание и следующее далее подробное описание являются примерными и поясняющими и предназначены для обеспечения дальнейшего объяснения изобретения, как оно заявлено.
Сопроводительные чертежи, которые включены для обеспечения дальнейшего понимания изобретения, и которые составляют часть данного описания, иллюстрируют варианты реализации изобретения, совместно с описанием служат для объяснения принципов изобретения.
На рисунках:
ФИГ. 1 иллюстрирует пример графа, согласно примерному варианту реализации;
ФИГ. 2 иллюстрирует часть семантической сети, согласно примерному варианту реализации;
ФИГ. 3 иллюстрирует алгоритм обработки данных, согласно одному варианту реализации изобретения;
ФИГ. 4 иллюстрирует блок-схему поиска автотегов для измененного Объекта и для связанных Объектов, согласно одному варианту реализации изобретения;
ФИГ. 5 иллюстрирует пример связей данных, применимо к поиску Объектов;
ФИГ. 6 иллюстрирует процесс обработки данных при создании Объекта;
ФИГ. 7 иллюстрирует пример различных бизнес-приложений, использующихся в различных отделах компании, и обработку данных в них в примерном случае;
ФИГ. 8 иллюстрирует систему согласно примерному варианту реализации;
ФИГ. 9 иллюстрирует компьютер или сервер, который может быть использован в примерном варианте реализации.
Язык запросов используется для доступа к тройкам, хранящимся в хранилище троек. В дополнение к запросам тройки, как правило, могут быть импортированы/экспортированы с использованием RDF и других форматов. Искомые Объекты необходимо пометить тегами для поиска и извлечения. Количество тегов растет с ростом объема данных. Сохраненные данные меняются со временем, так что старые теги удаляются или заменяются новыми тегами. Должны быть созданы новые теги. Теги создаются автоматически (т.е. автотеги) для обеспечения эффективного извлечения данных.
Далее приведены два примера представления RDF-графов в XML формате (который часто является более удобным для компьютерной обработки) и в форме N-троек или N3 (который используется в существующем подходе, и который является более удобным для человеческого понимания).

Таким образом, XML синтаксис гораздо многословней, чем N3 синтаксис, но более легок для обработки компьютерами.
Тройка является базовой единицей RDF и состоит из Подлежащего, Сказуемого (Предиката) и Дополнения. Набор троек обычно связан с RDF-графом, пример которого представлен на ФИГ. 1. Направление стрелки (т.е. (110а, 110b) в любой представленной тройке (т.е. 120) указывает от Подлежащего (130) к Дополнению (140). RDF-модель данных похожа на подходы классического концептуального моделирования, такие как связь сущностей или диаграммы классов, поскольку в его основе лежит идея создания утверждений о ресурсах (в частности, веб-ресурсов) в форме выражений Подлежащее-Предикат-Дополнение.
Эти выражения рассматриваются как тройки в RDF-терминологии. Подлежащее обозначает ресурс, а предикат обозначает черты или аспекты ресурса и выражает отношение между Подлежащим и Дополнением. Коллекция RDF утверждений, по сути, представляет собой маркированный направленный мульти-граф. Как таковая, основанная на RDF модель данных более естественно подходит для некоторых видов представления графов, чем реляционная модель и другие онтологические модели.
Как было сказано выше, RDF данные часто хранятся в реляционной базе данных или нативных хранилищах троек или хранилищах четверок, если также хранится контекст (т.е. именованный граф) для каждой RDF-тройки. Именованные графы являются ключевой концепцией архитектуры Семантической Сети, в которой набор утверждения (граф) Среды описания Ресурсов (RDF) идентифицируется при помощи URI, позволяя создавать описания для данного набора утверждений, такие как контекст, информация о происхождении и другие метаданные.
Именованные графы являются простым расширением RDF-модели данных, через которые могут быть созданы графы, но, по большому счету, модель не располагает эффективными средствами различия между ними после публикации в сети. В то время как именованные графы могут появиться в Сети в качестве простых связанных документов (т.е. Связанных Данных), они также крайне полезны для управления наборами RDF-данных внутри RDF хранилища.
На ФИГ. 1 дополнения "Человек", "Менеджер" 140 и подлежащие "Джон" 130, "Майкл", "Морган", "Мона", "Алекс" RDF утверждения являются Унифицированный Идентификатор Ресурса (URI), который обозначает ресурсы. Ресурсы также могут быть показаны узлами с неизвестным потоком. Узлы с неизвестным потоком не напрямую идентифицируются из RDF утверждений. Узел с неизвестным потоком является узлом в RDF-графе, отражая ресурс, для которого не задан URI или литерал. Ресурс, представленный узлом с неизвестным потоком, также называется анонимным ресурсом. В соответствии с RDF-стандартом, узел с неизвестным потоком может быть использован только в качестве Подлежащего или Дополнения RDF-тройки. Узлы с неизвестным потоком могут быть обозначены посредством идентификаторов узлов с неизвестным потоком в следующих форматах, RDF/XML, Turtle, N3 и N-тройках. Следующий пример показывает, как это работает в RDF/XML:


Идентификаторы узла с неизвестным потоком ограничены только областью сериализации определенного RDF графа, т.е. узел "_:b" в последующем примере не представляет один и тот же узел с именем "_:b" в любом другом графе. Узлы с неизвестным потоком рассматриваются как простое свидетельство существования предмета без использования URI (Uniform Resource Identifier) для идентификации любого конкретного предмета. Это не является тем же самым, как предположение, что узел с неизвестным потоком обозначает "неизвестный" URI.
Предикат ("это" 110а, "должность" 110b) - это URI, который также обозначает ресурс, отражающий связь. Дополнение ("Менеджер", "Разработчик", "Генеральный директор" и в частных случаях "Джон", "Майкл", "Морган", "Мона", "Алекс") - это URI, узел с неизвестным потоком или строковый литерал в Юникоде. Троечный подход является тем, что используется в данном изобретении для обработки информации из различных источников.
На ФИГ. 2 показан семантический стек примерного варианта реализации. Семантический стек, используемый в примерном варианте реализации, включает URI 201. Стоит отметить, что все, что может быть идентифицировано с помощью URI, может быть описано, так что семантическая сеть может относиться к животным, людям, местам, идеям и т.д.. Семантическая разметка чаще генерируется автоматически, чем вручную. URIs могут быть классифицированы как указатели (URLs), как имена (URNs) или и тем и другим.
Единообразное Название Ресурса (URN) служит в качестве имени человека, в то время как Единый Указатель Ресурсов (URL) похож на почтовый адрес человека. URN определяет индивидуальность Объекта, в то время как URL обеспечивает метод для его поиска. CmwL (Язык Comindware) 211 описывает функцию и связь каждого из этих компонентов стека семантической сети; XML 203 обеспечивает элементарный синтаксис для структуры содержимого внутри документов, а также связывает несемантическое со значением содержимого; RDF 205 является простым языком для моделей описания данных, которые относятся к объектам ("ресурсам") и их связей. Основанная на RDF модель может быть представлена в XML- синтаксисе. RDF-схема 207 расширяет RDF и является словарем для описания свойств и классов основанных на RDF ресурсов и семантики для обобщенных иерархий таких свойств и классов.
Формально, онтология 215 представляет знание в виде набора концепций внутри домена с использованием совместного словаря для обозначения типов, свойств и взаимосвязей этих концепций. Онтологии являются структурными рамками для организации информации. Онтологии описываются (Языком Описания Онтологий) OWL или CmwL, которые позволяют описывать Классы и их связи друг с другом и другими сущностями (см. ниже). Онтологии могут расширять предопределенный словарь (например, RDF или OWL словари). Словарь представляет собой коллекцию данных/информации неких терминов, которые имеют общее значение во всех контекстах.
Онтология использует предопределенный зарезервированный словарь/глоссарий терминов для понятий и связей, определенных для конкретного домена/предметной области. Онтологии могут быть использованы для выражения семантики терминов словаря, их связей и контекста использования. Таким образом RDF-Схема является словарем для RDF. OWL или CmwL и может быть использована для записи семантики предметных областей в онтологии. По сути, любые данные, например, онтологии или таксономии, могут быть выражены в тройках. Тройка представляет собой факт.
Таксономия 209 является иерархическим способом категоризации всех объектов в данном мире: книг, продуктов, видов, понятий и т.д. В семантической сети таксономия является словарем понятий и их точных определений. Когда словарь логически упорядочен внутри иерархии, он называется таксономией. Он является общим ресурсом, собравшим все в информационную экосистему, использующимся для синхронизации смысле терминов.
Язык Comindware 211 используется вместо Языка Описания Онтологий (OWL) в семантическом стеке. Язык Comindware представляет собой ограниченную версию OWL с целью повысить производительность и избавиться от функциональности и операций, в которых нет необходимости для целей бизнес-приложений и/или для использования с онтологиями (однако используя OWL-словарь и некоторые его правила 213).
В плане хранения данных реляционная база данных является не лучшим выбором для RDF хранилища, поскольку она плохо подходит для работы со слабо структурированными данными. В реляционных базах данных MySQL-поиск информации по тегам решается путем введения промежуточной таблицы, так что может быть получена следующая структура:

Если Таблица Задач, Таблица пользователей, таблица учетных записей и другие таблицы используются в дополнение к таблице Статей, так что должны быть созданы Таблицы связей (Таблица связей 2, Таблица связей 3 и т.д.). В данном случае, если один добавляет, удаляет или редактирует какие-либо данные в одной из таблиц, связанные данные в остальных таблицах должны быть также изменены. Если нам нужно получить доступ к данным из нескольких таблиц, должен быть использован оператор SQL ОБЪЕДИНИТЬ. Оператор SQL ОБЪЕДИНИТЬ объединяет записи из двух или более таблиц в базе данных. Он создает набор, который может быть сохранен в виде таблицы или использован как есть. ОБЪЕДИНЕНИЕ - это средство для объединения полей из двух таблиц с использованием значений, общих для каждой из них (например, идентификаторы). Эта и другие связанные операции требуют большого количества времени.
Реляционные базы данных обеспечивают достаточно высокую скорость поиска только для тех данных, для которых был настроен/отрегулирован поиск. Например, поиск в SQL-базах данных использует SQL-запросы, которые необходимо переписывать каждый раз, как только в базу данных добавляются новые данные или используются новые типы данных, которые отличаются от данных, хранящихся в базе данных. Еще одним примером является добавление отдела (отделы ранее не добавлялись и такой Объект не использовался) в базу данных. В данном случае при добавлении нового отдела должны быть доступны для добавления: Информационные технологии (ИТ), Отдел управления персоналом (HR), Исследования и разработка (R&D) и другие. Так что должны быть создано несколько новых таблиц, в которых, по крайней мере, одна из них хранит данные отдела и в которых, по крайней мере, другая таблица хранит связи между другими таблицами базы данных.
Большое количество SQL-запросов (включая запросы поиска) должны быть изменены/переписаны, чтобы разрешить поиск сохраненных данных. Такое переписывание/изменения запросов является чрезвычайно дорогостоящим и ресурсоемким действием, ассоциирующимся с привлечением оператора базы данных и/или разработчика. Примерный вариант реализации обеспечивает систему, которая автоматически адаптируется к изменениям данных внутри базы данных, и которая реализует поисковые запрос(ы), которые просты для пользователя, такие как: "Что мне следует найти?" -> "Ошибки" + "Высокий приоритет" или "менеджер" + "Алекс"). Такие поисковые пользовательские запросы могут использовать текстовые поля, в которые можно вывести поисковый запрос. Также система должна обеспечивать выбор типов данных/поисковых наборов, в которых будет выполнен поиск.
Приложение для реализации примерного варианта включает Графический Интерфейс Пользователя (ГИП), текстовый интерфейс пользователя, консоль и другие элементы для взаимодействия человека с системой/приложением. ГИП может включать текстовое поле, в котором пользователь может ввести условие поиска, чтобы начать процесс поиска Объектов (иногда именуемых "объектами данных"). Стоит отметить, что ГИП может содержать более одного текстового поля. В текстовое поле пользователь может ввести часть поискового слова, и система обеспечит варианты автоматического заполнения данного слова. Например, пользователь может ввести первые символы слова (или символы из середины слова) "Морган", т.е. "Мо" в текстовое поле.
Система предоставить возможный вариант автоматического заполнения (окончания слов, т.е. слов, где будет найдена такая последовательность или где эти символы будут встречаться в любой последовательности), "Морган" и "Мона". Далее система способна обеспечить область поиска пользователю, например, с использованием ГИП. Область поиска представлена троечными предикатами, которые ассоциируются с поисковым словом. Например, для слова "Морган" система обеспечит следующим области поиска: "Создатель", "Корректор ошибок " и другие, если они были найдены в базе данных. Такие варианты областей поиска представлены предикатами автотегов для найденных автотегов для слова "Морган". Если пользователь выберет область поиска "Создатель", то результат поиска будет включать "Ошибка Номер 2121", согласно ФИГ. 1.
Здесь "Ошибка" является Классом, а "Ошибка 2121" является экземпляром этого Класса. Стоит отметить, что область поиска может быть идентифицирована/определена и еще более сужена. Примеры Классов и их экземпляров для конкретных случаев будут обсуждаться ниже. ГИП позволяет пользователю выбрать, как минимум, одну область поиска для ввода поискового слова или его части. Пользователь может пропустить выбор определенных областей поиска, например "Создатель" или "Корректор ошибок". Пользователь может отклонить выбранные/предоставленные области поиска. В этом случае такое решение равнозначно выбору всех областей поиска. Если выбрана, по крайней мере, одна область поиска, то поиск будет проведен в данной области поиска. Экземпляры Классов выступают в роли искомых Объектов (которые ассоциируются с поисковым словом). "Майкл", "Морган" (ФИГ. 1) являются еще одним примером экземпляров Класса "Человек"; "продукты:Продукт1", " продукты:Продукт2", "продукты:Продукт3" из кода ниже являются экземплярами Класса "пример:Продукт".
Как было сказано выше, система предлагает пользователю два варианта автоматического заполнения: "Морган" и "Мона" (см ФИГ. 1) после того, как пользователь ввел часть или поисковое слово, например, несколько символов "Мо" (предполагая, что пользователь имел ввиду слово "Морган"). Пользователь может выбрать, как минимум, один из них (или все), так что система запустит процесс поиска Объектов для выбранных вариантов.
Как было сказано выше, данные могут храниться в виде троек или n-кортежей. Условия поиска данных могут быть реализованы в тройках, однако для поиска должны быть известны все тройки, связанные с данными. Использование автотегов является более удобным способом поиска данных. Далее приведен пример описания/определения автотега, и пример процесса поиска значений автотегов. Также приведен пример поиска Объекта по значениям автотегов. Следующий исходный код написан на N3. N3 основывается на стандартах RDF и эквивалентен синтаксису RDF/XML, однако обладает дополнительными особенностями, такими как правилами и формулами.
Ниже приведены примеры реализации изобретения в форме исходного кода, где каждая строка начинается с символа
- @префикс cmw:<http://comindware.com/logics#>. Здесь определяется "http://comindware.com/logics#" для префикса "cmw". Указание @префикс связывает префикс с пространством имен URI. Это указывает на то, что определенное имя (qname) с этим префиксом далее будет сокращением для URI и состоит из объединения идентификатора пространства имен и части qname справа от двоеточия.
<"http://comindware.com/logics#"> является унифицированный идентификатор ресурса (URI), который представлен Единый Указатель Ресурсов URL, который ссылается на ресурс, идентифицированный как comindware.com/logics#, представление которого в форме HTML можно получить посредством Протокол Передачи Гипертекста (http) из сетевого хоста, доменное имя которого - comindware.com. Установленный единожды префикс может быть использован для остального исходного кода. Все, будь то Подлежащее, Предикат или Дополнение идентифицируется посредством URI.
- @префикс автотег: <http://comindware.com/ontology/autotag#>.
- @префикс xsd: <http://www.w3.org/2001/XMLSchema#>.
- # онтология автотега. Отсюда начинается пример онтологии для автотега.
В соответствии с синтаксисом языка, комментарии, описывающие конкретный блок документа, следуют за знаком "#". Комментарии также могут быть заключены в "##".
- автотег:Автотег a cmw:Класс;
При необходимости добавления нового словаря существует возможность определить новые классы предметов и новые свойства. Свойство, которое сообщает, что типом чего-то является rdf:тип может быть сокращено в N3 просто до "а".
Классы просто говорят о предмете, который содержится в них. Дополнение может быть представлено/описано множеством классов. Какой либо иерархической связи не требуется. Если между двумя классами существует связь, то это можно утверждать. См. свойства классов в RDF-Схеме (http://www.w3.org/TR/rdf-schema/) и OWL-словарях (http://www.w3.org/TR/owl-guide/ или http://www.w3.org/TR/owl2-overview/). Как станет понятно, изобретение может быть использовано с тройками, четверками и так далее. В качестве примера используются тройки.
-cmw:свойство автотег:имя,
Для одинаковых объектов используется сокращение: точка с запятой ";" представляет еще одно свойство того же объекта.
- автотег:предикат,
- автотег:значение.
Для одинаковых объектов используется сокращение: запятая представляет еще одно Дополнение с тем же Предикатом и Подлежащим.

Далее приведены примеры для определения автотегов:

- ## Авто-тег перечисляющего типа (enum) ##. Автотег со свойством в виде типа автотега и свойство данного автотега является списком конкретных значений (другими словами автотег для свойства, а свойство содержит список значений). Перечислитель (enum) может быть использован в качестве списка значений. Примером такого enum является ошибка или важность/приоритет задачи:


Здесь критичность ошибки является свойством. В компьютерной терминологии "критичностьОшибки" является экземпляром Класса "Свойство". Имя свойства (серьезности ошибки) - "Критичность Ошибки". Тип свойства - "свойство Enum". Свойство может иметь описание, такое как "Критичность ошибки", которое может быть использовано для отображения посредством ГИП в виде подсказки/дополнительной информации для пользователя. Данная подсказка может быть представлена в виде текста, который может быть видим, когда пользователь удерживает курсор мыши поверх какого-либо элемента ГИП, не нажимая на него. Критичность ошибки имеет значения ("вариантЗначения"). В данном случае ошибка может иметь низкую критичность, среднюю критичность и высокую критичность (которая может быть представлена как "критичностьОшибки:низкая," "критичностьОшибки:средняя" и "критичностьОшибки:высокая").
Каждое значение серьезности ошибки (низкая, средняя и высокая, представленные как критичностьОшибки:низкая, критичностьОшибки:средняя, критичностьОшибки:высокая) является экземпляром Класса "ВариантЗначения":
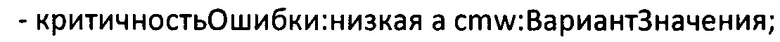
Каждое значение серьезности ошибки может иметь имя (также как и свойство из блока исходного кода, представленного выше):


Далее для серьезности ошибки будет создан автотег.
- пример: критичностьОшибкиАвтотег а автотег:Автотег;
Здесь автотег для серьезности ошибки объевлен как автотег.
- автотег:имя "Критичность";
- автотег:предикат пример:критичностьОшибки;
Теперь критичность ошибки будет использована в качестве предиката автотега.
- автотег:значение критичностьОшибки:низкая, критичностьОшибки:средняя, критичностьОшибки:высокая.
Здесь каждое значение серьезности ошибки (низкая, средняя, высокая) является значением автотега верьезности автотега.

Здесь был объявлен/создан продукт для автотега ошибки. В компьютерной терминологии данная тройка может быть интерпретирована как: продукт для ошибки является экземпляром Класса автотег.
- автотег:имя "Продукт";
- автотег:предикат пример:продукт.
Теперь продукт является предикатом автотега.
- # Первый вариант определения значений автотега для ссылок (свойств enum)
- # прямое определение
- @префикс продукты: <http://comindware.com/examples/products#>.
В следующих строках Продукт1, Продукт2 и Продукт3 будет определен как экземпляр Класса Продукт. Им также будут назначены заголовки (имена).

Значения автотега могут быть определены вручную или могут быть найдены автоматически. В приведенных выше строках Продукт1, Продукт2 и Продукт3 были определены напрямую/вручную в качестве значений автотега. Вручную созданные значения автотега должны быть созданы каждый раз, как только создается новый Объект или меняется. Также, если Объект удален по автотегу(ам), значения автотега также должны быть удалены. Правила могут быть использованы для того, чтобы избежать ручного создания/определения значений автотега.
- # второй вариант определения значений автотега для ссылок (свойства enum)
Определение посредством правил значений автотегов может быть использовано вместо прямого определения значений автотегов. Метод определения посредством правил является более приемлемым методом для определения значений автотегов.
Стоит отметить, что значение выражений, написанных на N3 в фактах и правилах может быть с легкостью понято без знания программирования. В данном описании изобретения части утверждений именованы в виде описательных названий. Так "создательАвтотег" является автотегом для автора; "пример:создательАвтотег а автотег:Автотег;" означает, что "пример:создательАвтотег" является автотегом, "cmw:создатель а cmw:Свойство;" означает, что создатель является свойством; "cmw:создатель cmw:имяСвойства "Кем создано:"; означает, что "Кем создано:" является именем свойства; "cmw:создатель cmw:типСвойства cmw:свойствоАккаунта;" является аккаунтом, который является типом свойства; пример:создательАвтотег автотег:имя "Кем создано" означает, что "Кем создано" является именем автотега и т.д. Поэтому код, описанный в данном изобретении, может быть использован в качестве описания особенностей изобретения.
Например, часть "продуктДляОшибкиАвтотег" утверждения может быть интерпретирована как "Автотег для продукта для ошибки" или как "Автотег с именем "Продукт для Ошибки". Другими словами, "Автотег, который ассоциирует Продукт с Ошибкой". Другим примером является "cmw:автрибутыСвойства", которые могут быть интерпретированы как атрибуты свойства или атрибуты свойств. Еще один пример: часть "создательАвтотег" утверждения может быть интерпретирована как Автотег с именем "Создатель" или автор, т.е. человек, который что-то создает: например, задачу или ошибку.
Как было сказано выше, N3 основана на стандартах RDF и эквивалентна синтаксису RDF/XML, однако обладает дополнительными особенностями, такими как правила и формулы. Правила могут быть записаны в N3, OWL, XNL и других.
Простое правило (N3 правило) может гласить что-то вроде: если X является частью Y, и, если Y является частью Z, значит X является частью Z, или 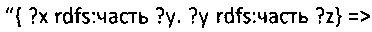
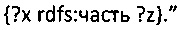
Комбинация скобок "{" и "}" и "=>" является правилом. Фигурные скобки заключают набор утверждений и представляют собой формулу. Все формулы заключены в фигурные скобки. Помимо того, что Подлежащее и Дополнение (Подлежащее в формуле представлено двумя утверждениями, а Дополнение в формуле представлено одним утверждением) тройки являются формулой, пример, показанный выше, является одиночным утверждением. Формула является частью правила и может быть представлена набором утверждений (как минимум одним утверждением), где правило также является утверждением, и где утверждение является тройкой.
В приведенном выше примере утверждения, "?х" является переменной (или неизвестной величиной, искомым значением). Стоит отметить, что "?х" не всегда представлена неизвестной величиной, напротив, известная часть утверждений (в виде URI) "?х" может быть использована для проверки подлинности факта. Как было сказано выше, любые данные, такие как сущность, событие и другие могут быть описаны тройкой. Тройка может также описывать факт, например, "Билл это Человек", "Джон это Человек", "Позиция Джона - менеджер".
Если тройка похожа на эту: "?х это Человек", значит будут найдены все предметы (которые удовлетворяют утверждению). Но, если часть утверждения, такого как "Билл" и "Джон" будут использованы в качестве входных данных для "?х", то данное утверждение может быть проверен на "истину" или "ложь", т.е. хранится ли эта тройка(тройки) среди троек. Для текущего примера после замещения "Билла" и "Джона" на "?х", следующие утверждения: "Билл это Человек" и "Джон это Человек будут правдивы, поскольку эти тройки хранятся в базе данных. Если используется утверждение "?х позиция менеджер" и "Джон" и "Билл" будут использоваться в качестве входных параметров для "?х", то только утверждение "Джон позиция менеджер" интерпретируется как правда, но утверждение "Билл позиция менеджер" является ложью, поскольку данная тройка не хранится в базе данных (и не выведена из тройки(троек)). Если ни одна из переменных "?х" не связана со значением в тройке "?х это Человек", значит данная тройка используется для поиска всего, что подходит под данную тройку, т.е. будут найдены "Билл" и "Джон".
В описанном выше примере "=>", использованный здесь в качестве специального предиката, означает "следует". Она используется для связи формул. На самом деле - это короткая запись URI лог:следует или: http://www.w3.org/2000/10/swap/log#implies. Когда две формулы связаны посредством "лог:следует", они являются правилами, как было сказано выше, все правила являются различными видами утверждений. Формула обеспечивает предметы, которые могут быть представлены с использованием текущих RDF/XML; эти правила не являются частью стандартного RDF синтаксиса.

Левая часть данного правила гласит, что все экземпляры Класса Продукт ищутся во всех сохраненных тройках. В правой части уравнения сказано, что все найденные значения в левой части формулы являются приемлемыми/возможными значениями для автотега "продуктДляОшибки Автотег".
В данном случае будут найдены следующие экземпляры: "продукты:Продукт1.", "продукты:Продукт2" и " продукты:Продукт3", т.е. экземпляры, которые были описаны тройками выше: "продукты:Продукт1 а пример:Продукт;", "продукты:Продукт2 а пример:Продукт;", "продукты:Продукт3 а пример:Продукт;".
Другими словами, это является непрямым определением значения для автотега "продуктДляОшибки Автотег."
Как было сказано выше, напрямую определенные значения для автотегов должны быть обновлены разработчиком программного обеспечения (или кем-нибудь еще с необходимыми полномочиями) каждый раз после создания или изменения объекта. Эти значения должны быть удалены после удаления соответствующих Объектов. Таким образом, если объект "Продукт4" будет добавлен (например, если создается или автоматически генерируется новая тройка "- продукты:Продукт1 а пример:Продукт;" и опционально добавляется в базу данных), то тройка "пример:пример:продуктДляОшибкиАвтотег автотег:значение продукты:Продукт1, продукты:Продукт2, продукты: Продукт3." должна быть заменена на тройку "пример:пример:продуктДляОшибкиАвтотег автотег:значение продукты: Продукт1, продукты:Продукт2, продукты:Продукт3, продукты:Продукт4." После того как будет создан новый Объект пользователем, для автотега ищутся новые значения посредством движка 305 с использованием метода "определения посредством правил" (здесь значения автотега являются результатом обработки данных/троек программным обеспечением).
Например, если создается новый продукт, то он преобразовывается движком 305 как минимум в одну тройку, например в следующую тройку: "продукты:Продукт4 а пример:Продукт;", и другие необходимые тройки, такие как "продукты:Продукт4 cmw:заголовок " Программное обеспечение для управления событиями, версия 2.5". "Фильтр-Перехватчик Событий Действий с Объектом" 310, который является частью движка 305, перехватывает все события с Объектами. "Модуль Обработки Структурированных Данных" 315, который также является частью движка 305, переводит все события с Объектами в тройки). Во время создания Объекта для автотега ищутся приемлемые/возможные значения, соответствующие добавленному Объекту.
Стоит отметить, что тройки для нового или измененного Объекта могут быть добавлены в базу данных (или в ОЗУ и/или закэшированы) во время настройки параметров Объекта, т.е., если, как минимум, один из объектов создается или изменяется, то может быть сгенерирована одна или более троек и сохранена в базу данных до сохранения Объекта. Данный набор троек описывает объект, связи объекта с другими Объектами, хранилищем данных, где хранятся тройки объектов. Стоит отметить, что эти упомянутые тройки могут быть созданы/записаны вручную разработчиком, пользователем, администратором базы данных и т.д. Также такие тройки могут быть созданы программным обеспечением.
Сохранение Объекта (хранение в ОЗУ, на жесткий диск, на Сетевое/Облачное хранилище и т.д.) может представлять собой промежуточное сохранение, например, когда параметры и атрибуты Объекта сохраняются во время настройки объекта. Также может быть выполнено полное сохранение, когда пользователь, системный администратор, разработчик, пользователь базы данных или администратор решает достаточно ли Объект модифицирован/настроен/сконфигурирован для текущих целей. Стоит отметить, что объект и его параметры могут быть изменены/переконфигурированы в будущем, например, может быть добавлена новая онтология, Объект может быть помечен как автотег и так далее.
Стоит отметить, что приемлемые/возможные значения для автотега могут быть найдены не только после создания Объекта, но и во время поискового запроса (поисковый запрос(ы) будет обсуждаться ниже) от пользователя (на самом деле, система отправляет запрос на поиск данных (преобразованный из пользовательского поискового запроса) -> для этих данных ищутся автотеги -> значения автотегов ищутся с использованием предикатов автотегов -> значения автотегов используются для поиска Объектов для формирования ответа в запрос от системы на поиск). Так что, как было описано выше, правило используется для поиска значений автотегов (так называемое вычисление автотегов), которые необходимы для поиска Объектов по поисковым словам.
Таким образом, метод определения посредством правил (метод непрямого определения) заменяет ручное добавление значений автотегов. Стоит отметить, что метод определения посредством правил не ограничивает возможность ручного добавления троек, включая части утверждений, включая свойства/атрибуты и значения. Также стоит отметить, что ручное добавление троек не ограничивает возможность автоматического добавления троек, включая части утверждений, включая свойства/атрибуты и значения.
Комбинация ручного и автоматического/программного методов добавления/создания троек может быть использована для тонкой настройки/более детального описания Объектов или системы в целом (например, такой системой может быть система отслеживания и исправления ошибок в пользовательской сервисной системе, система управления персоналом и т.д.). Также, она может быть использована для автоматизации описания/определения объекта, например, в случае дублирующихся параметров Объектов с использованием параметром похожих/связанных объектов, похожих троек, включая онтологии. Онтологии используются для описательной информации Объекта, которая может быть получена путем вычисления (из правил) и может быть прописана в коде в виде аксиом. Для Объекта возможно использовать несколько онтологий, а для нескольких Классов может быть использована одна онтология, например, для похожих Классов.
Касательно метода определения посредством правил, следует отметить, что в особом случае может быть использовано другое правило, а именно для автотега серьезности ошибки: 
 . Данное правило используется для поиска следующих значений автотега: критичностьОшибки:низкая, критичностьОшибки:средняя и критичностьОшибки:высокая для автотега серьезности ошибка.
. Данное правило используется для поиска следующих значений автотега: критичностьОшибки:низкая, критичностьОшибки:средняя и критичностьОшибки:высокая для автотега серьезности ошибка.
Далее, еще один пример автотега (для автора) включает поиск значений автотега:

В этих двух строках вводится атрибут свойства (некий вид флага) для атрибутАккаунтаТег. Каздый создатель ошибки отмечается данным флагом, т.е. у каждого создателя будет атрибут свойства атрибутАккаунтаТег.

В левой части данного правила находится формула, и формула состоит из двух утверждений. В первом утверждении выполняется поиск всех предметов с атрибутАккаунтаТег в качестве атрибута свойства. Во втором утверждении выполняется поиск всех предметов, которые связаны с предикатом имяСвойства, и эти предметы сохраняются в переменные "?свойство" и "?имя". Таким образом, все предметы, найденные и сохраненные в переменные, передаются в правую часть правила. Другими словами, будут найдены все пары для предиката имяСвойства и переданы в правую часть правила.
Первые два утверждения в правой части правила гласят, что все вещи, найденные в левой части правила, являются автотегами и предикатами автотегов. Третье утверждение состоит из использования данных, сохраненных в переменной ?имя в качестве автотегов. Четвертое утверждение объявляет Аккаунт в качестве типа автотега.
Как было сказано выше, такой метод позволяет определять/объявлять свойства, имена, типы, предикаты и т.д. автотега.
Ниже описан пример непрямого определения значений автотегов:

В первом утверждении левой части правила выполняется поиск всех предметов с автотегами типа аккаунт. Во втором утверждении правила выполняется поиск всех предметов, которые являются аккаунтами, т.е. Объектов, используемых в качестве экземпляров Класса аккаунт:Аккаунт.
Все предметы, сохраненные в "?аккаунт" в левой части правила являются значениями автотега в правой части правила.
До этого момента для автотега был описан только один предикат, однако у автотега может быть больше одного предиката, так что область поиска по автотегу может быть значительно расширена. Все предикаты автотега принадлежат одной общей группе, которая, в свою очередь, может быть разделена на нескоько групп для расширения возможностей поиска.
Пример определения нескольких предикатов для одного автотега (в данном случае для "пример:пользовательСвязанныйсОшибкойАвтотег"):

Здесь создается автотег с URI "пример:пользовательСвязанныйсОшибкойАвтотег". Этот автотег используется для установления связи(ей) между человеком и ошибкой. Такие связи могут быть представлены ошибкой и создателем ошибки (в некоторых вариантах изобретения создатель ошибки является человеком, который обнаружил ошибку и/или создал Объект Ошибка). Разработчик, корректор ошибок, пользователь, администратор БД или системный администратор, оператор и другие могут быть такими людьми. Следующие утверждения показывают, что некоторые люди могут быть связаны с ошибкой, например, создатель ошибки и разработчик/или корректор ошибок, которые исправят данную ошибку. Другими словами, в данном случае ошибка может быть связана с или назначена человеку, отвечающему за данную ошибку.

Здесь для автотега "пример:пользовательСвязанныйсОшибкойАвтотег." определены два предиката автотега "cmw:создатель" и "пример:корректорОшибок". Предикаты автотега являются характеристиками автотега. На основе предикатов можно сказать, какой области поиска принадлежит автотег. Другими словами, предикаты автотега определенного предиката принадлежат одному типу. В данном примере предикаты автотега cmw:создатель и пример:корректорОшибок, который идентифицируют лицо/человека (например, для автотега "пользовательСвязанныйсОшибкойАвтотег"). В предыдущем примере видно, что значения ?свойство были получены с использованием тройки "?свойство cmw:атрибутыСвойства автотепатрибутАккаунтаТег" и используется один тип ?свойство. Далее в примере значения ?свойство используются в качестве предикатов автотега.

Все предметы (здесь - аккаунты) ищутся в левой части правила. Все найденные предметы (которые были записаны в "Раккаунт") являются значениями автотега для автотега пример:пользовательСвязанныйсОшибкойАвтотег в правой части правила.
- # Примеры запросов. Информация, введенная пользователем (в ГИП) для поиска, будет преобразована в запрос, например, после того как пользователь щелкнет на кнопке "Поиск".
- @префикс запрос: <http://comindware.com/ontology/query#>.
- # Пример запроса для "Или" и "И"
- # Найти по Продукту1 или Продукту2 и КритичностьОшибки:Высокая//точное
Далее представлен пример поискового запроса ошибок со статусом высокой серьезности и связанных с продуктами "Продукт1" и "Продукт2".

В первом утверждении левой части правила ищутся все пары с общим предикатом "пример:продукт". Второе утверждение представляет собой сложное утверждение и написан с использованием Языка Comindware. В данном примере Язык Comindware позволяет использовать логический оператор "или" для "продукты:Продукт1" и " продукты:Продукт2" в качестве переменной "?продукт". Другими словами, первые утверждения, записанные выше, могут быть описаны как: найти все пары "?х + ?продукт" с предикатом "пример:продукт", где переменная "?продукт" может быть значением "продукты:Продукт1" или значением "продукты:Продукт2". Все предметы (в данном случае ошибки) с со статусом высокой серьезности будут найдены в третьем утверждении правила (в левой части правила).
В правой части правила все найденные предметы записываются в переменную "?х" и являются результатом запроса "запрос:42".
Здесь "запрос:42" является интерпретацией поиска пользовательским поисковым запросом. Приведенный выше пример описывает поиск всех ошибок для "Продукт1" и "Продукт2". Данный пример может рассматриваться как: пользователь вводит "высокая" в качестве поискового слова в текстовое поле ГИП; система ассоциирует введенное слово, по крайней мере, с одним элементом утверждения (в данном случае с "критичностьОшибки:высокая"), основываясь на анализе утверждения. Утверждение "критичностьОшибки:высокая cmw:имяЗначения "Высокая" может быть одним из таких проанализированных утверждений. Элемент утверждения будет связан системой с предикатом "автотег:значение" (это видно из утверждения "пример:критичностьОшибкиАвтотег автотег:значение критичностьОшибки:низкая, критичностьОшибки:средняя, критичностьОшибки:высокая.").
Далее система найдет все Объекты с помощью указанного правила, как минимум, для одного из упомянутых предикатов автотега (в данном случае предикат "пример:критичностьОшибки" из утверждения "пример:критичностьОшибкиАвтотег автотег:предикат пример:критичностьОшибки;"). Стоит отметить, что может быть использован любой тип запроса читаемого компьютером/процессором/приложением. Здесь запрос характеризует и описывает запрос от пользователя, а результат(ы) поиска автотегов сохраняются в переменную "?х".
Следующий пример является альтернативной реализацией поискового запроса для ошибок, имеющих статус высокой серьезности и относящихся к продуктам "Продукт1" и "Продукт2".

Здесь реализован метод с использованием "список:член" вместо "или". Как в приведенном выше примере, первые два утверждения могут быть описаны как: найти все пары "?х + ?продукт" с предикатом "пример:продукт", где переменная "?продукт" может иметь значения "продукты:Продукт1" или "продукты:Продукт2".
Далее следует пример поиска всех предикатов автотегов, которые связаны с поисковым словом, и всех значений автотегов, которые используются для поиска Объекта.

В данном примере строка "в ?тег, ?значения." в соответствии с используемым синтаксисом означает, что значения "?тег" и "?значения" должны быть определены до того, как будут использованы в формулах. Другими словами, в приведенном ниже примере эти переменные определяются в утверждении "(пример:критичностьОшибкиАвтотег (критичностьОшибки:высокая)) запрос: автотегЗапрос ?х.".


Второе правило схоже с приведенным выше примером запроса/поискового запроса на поиск Объекта. Сам поиск Объекта выполняется в первой формуле, в которой найденные объекты сохраняются в "?х"; и "?значения" и "?тег" из второго правила используются в качестве входных параметров. Другими словами, первое правило вызывается из второго правила с определенными параметрами - значениями "?тег" и "?значения".
В левой части первого правила: выполняется поиск пар с общим предикатом "автотег:предикат". И элементы утверждения ("пример:пример:продуктДляОшибкиАвтотег" и URI "пример:критичностьОшибкиАвтотег") используются в качестве входных параметров для ?тег. В связи с тем, что приведенный выше исходный код содержит тройку "пример:критичностьОшибкиАвтотег автотег:предикат пример:критичностьОшибки;", пара "пример:критичностьОшибкиАвтотег + пример:критичностьОшибки" будет одной из найденных пар, а пара "пример:пример:продуктДляОшибкиАвтотег + пример:продукт" будет второй найденной парой, как это можно увидеть из представленного исходного кода.
В правой части первого правила содержимое скобок (?тег ?значения) являются массивом/списком из двух элементов/переменных. Стоит отметить, что список или последовательность - являются абстрактными типами данных, которые реализуют конечный упорядоченный набор значений, где одинаковые значения могут встречаться более одного раза. Экземпляр списка является компьютерные представлением математической концепции конечной последовательности; бесконечным (потенциально) аналогом списка является стрим. Все найденные предметы (и сохраненные в переменную "?х") в левой части второго правила являются результатом поискового запроса "запрос:42".
Стоит отметить, что в первом утверждении левой части второго правила "(пример:пример:продуктДляОшибкиАвтотег (продукты:Продукт1 продукты:Продукт2))" является списком из двух элементов, где первый элемент - это "пример:пример:продуктДляОшибкиАвтотег" и второй элемент - список/массив, состоящий из элементов "продукты:Продукт1", "продукты:Продукт2".
Ниже приведен пример транзитивного автотега. Транзитивный автотег может быть использован для поиска Объекта, где Объекты связаны с другими Объектами. Например, такие автотеги могут быть использованы для поиска Объектов в группе Объектов. Группа Объектов может быть создана для нескольких Объектов с целью обеспечения связей/отношений между Объектами. В данном случае такие связанные Объекты (например, связанные, как минимум, одной группой/семейством) могут быть найдены по характеристике, которая далее может быть использована в качестве предиката автотега. В данном случае предикаты "пример:семействоПродуктов" могут быть использованы для установления принадлежности объекта, как минимум, к одной группе/семейству. Стоит отметить, что некоторые общие атрибуты/свойства Объектов могут быть описаны и использованы для всех Объектов, входящих в группу, например, для серьезности/приоритета ошибки или задачи, принадлежащих одному продукту и т.д.

В данной части кода элемент утверждения "пример:СемействоПродуктов" определен как Класс. Далее "семействаПродуктов:Семейство1" и "семействаПродуктов: Семейство1" определено как экземпляры "пример:СемействоПродуктов". Также вводится понятие семейства продуктов. Такие семейства могут быть использованы для поиска Объектов (продуктов в данном случае), которые включаются в семейство. Это может быть реализовано путем декларирования свойства элемента утверждения и использовано для поиска ошибок, которые связаны с семейством, например, продуктов, которые относятся к Корпоративным продуктам. Такие свойства могут быть использованы в качестве значений автотегов для поиска Объектов. Как было сказано выше, Объект имеет упомянутые атрибуты, такие как имя, свойства атрибутов, типы свойств и т.д. Стоит отметить, что некоторые атрибуты могут быть назначены Объекту по умолчанию, например, путем использования онтологий, которые могут содержать факты и/или правила.
Также стоит отметить, что могут быть использованы дополнительные правила (вне онтологий). Например, имя атрибута Объекта может быть назначено из системных данных, внешнего приложения/модуля, объединены из другого имени Объекта или атрибута или свойства. Например, счетчик (каждый Объект может быть пронумерован согласно счетчику) или текущая дата могут быть использованы для добавления в атрибут Объекта, например, Объект 001, Объект 002 или Ошибка_10_10_2014.

Результат данного правила будет состоять из связи ошибок "?ошибка" с продуктами (или точнее семейство продуктов "?семейство") по предикату "пример:транзитивныйОшибкаВПродуктВСемействоПредикат", и кроме этого в левой части правила выполняется поиск "?ошибка" "?семейство".
Далее приведен пример определения автотега для свойства, представленного выше.

Данное правило является еще одной демонстрацией автоматического поиска значений автотегов без необходимости определять их вручную, хотя реализация данного изобретения также позволяет использование вручную написанных автотегов и их предикатов, значений и т.д. Стоит отметить, что одна из реализаций данного изобретения позволяет комбинирование всех их. В приведенных выше примерах поиск Объектов выполняется среди всех возможных автотегов и всех автотегов, которые ассоциируются с поисковым словом. Однако, пользователь может выбрать, по крайней мере, одну из поисковых областей (ФИГ. 5), которая может быть использована для поиска Объектов. Поиск Объектов в обозначенной области поиска может быть реализован с помощью использования правил.
Согласно примерному варианту реализации имена предикатов автотегов могут быть отображены пользователю в виде областей поиска посредством ГИП. Например, введенное пользователем слово "высокая" является именем "критичностьОшибки:высокая" (как видно из утверждения "пример:критичностьОшибки cmw:вариантЗначения (критичностьОшибки:низкая критичностьОшибки:средняя критичностьОшибки:высокая)." и "критичностьОшибки:высокая cmw:вариантЗначения "Высокая"."). В свою очередь, свойство важность/критичность ошибки имеет имя "Критичность Ошибки" (см. утверждение выше: "пример:критичностьОшибки cmw:имяСвойства "Критичность Ошибки ";"). Это имя может быть использовано в качестве области поиска. Также, как видно из исходного кода, критичность ошибки является предикатом автотега (см. утверждение выше: "пример: критичностьОшибкиАвтотег автотег:предикат пример: критичностьОшибки;"), и автотег имеет имя "Критичность" (утверждение из исходного кода: "пример: критичностьОшибкиАвтотег автотег:имя "Критичность";"), которое также может быть показано пользователю в качестве области поиска.
Поиск по автотегам может быть выполнен, по крайней мере, тремя способами:
- пользователь знает свойство объекта, по которому он желает произвести поиск; напри мер, по "исполнителю" или "менеджеру". Если пользователь выбирает "менеджер", то система предложит пользователю один из автотегов, ассоциирующихся с выбранным свойством Объекта, например, "ИмяМенеджера". После того как пользователь выбирает соответствующий автотег и затем выбирает из списка имя пользователя, то систем а сохранит автотег и значение автотега (также может быть сохранен предикат автотега). Эти сохраненные данные могут быть использованы для дальнейшего поиска Объектов и/или для поиска всех объектов, связанных с текущим Объектом.
- пользователь знает точно, кого/что необходимо найти (т.е. он знает имя Объекта). Пользователь может ввести "Билл", и система предоставит ему такие автотеги, как "исполнитель", "менеджер" и другие автотеги, ассоциирующиеся с введенным поисковым словом "Билл". В данном случае известно имя объекта, и для него ищутся соответствующие автотеги. Затем процесс поиска выполняется, как было описано в предыдущем параграфе.
- Пользователь может ввести поисковое слово, но он не знает, какая область поиска ему подходит, так что он может выбрать поиск во всех автотегах, используя логический оператор "ИЛИ". В данном случае пользователю будут показаны все результаты поиска (предикаты которых связаны с поисковым словом).
Часть несколько автотегов может принадлежать набору(ам) автотегов. Другими словами, набор автотегов может быть создан/описан для серьезности ошибки, для продукта и так далее. Значения автотегов из набора автотегов будут принадлежать этому набору автотегов. В зависимости от того, осуществляется ли поиск по Объектам, принадлежащим одному или нескольким разным наборам, поиск автотегов выполняется с использованием логических операторов "И" и "ИЛИ". Оператор "ИЛИ" используется для поиска Объектов со значениями автотегов из того же набора автотегов. Например, если пользователь хочет найти ошибку с критичностью "Высокая" и "Низкая", то будет использован оператор "ИЛИ", и запрос может быть интерпретирован как "поиск по всем ошибкам, приоритет которых Высокий ИЛИ Низкий". Оператор "И" обычно используется для объединения поисковых запросов из различных наборов автотегов. В рамках данного изобретения автотег может быть определен предикатом автотега, свойством автотега, свойством Объекта.
Содержимое Объекта может быть проанализировано в процессе поиска Объекта, т.е. текст основного тела Объекта, содержимое текстовых полей Объекта, прикрепленные документы могут быть разобраны во время поиска Объекта. Разбор или синтаксический анализ является процессом анализа строки символов, либо на естественном языке, либо на компьютерных языках, в соответствии с правилами формальной грамматики. Взамен разбора может быть проведен поиск в таких элементах на этих языках. Такой поиск или разбор может быть обеспечен сторонними модулями (в дополнение к поисковой системе, которая, например, может предоставить полный поиск в Объектах). Однако для такого поиска могут быть созданы автотеги, например, для поиска данных в содержимом Объекта.
Такие автотеги могут отражать характер или эмоции данных/содержимого. Такие значения автотегов могут быть описаны на основе анализа данных объекта, например, такие данные могут содержаться в описании Объекта, во вложениях Объекта и т.д. Так что, если данные объекта или вложения содержат элементы содержимого (слов или набор слов) "А", "В", "С" и "D," то "ABCDE" можно рассматривать в качестве значения Автотега. Такое суммарное содержимое может быть ужато перед использованием в качестве значения автотега, например, оно может быть закэшировано. Такие элементы содержимого могут являться общими элементами в различных содержимых Объектов. Так что выводы могут быть сделаны на основе данных Объекта, и эти выводы могут быть использованы в качестве значений автотегов. Для анализа, описанного выше, может быть использован семантический анализ данных объектов.
Следует отметить, что описанный выше пример изобретения (когда пользователь инициирует процесс поиска Объектов) также называется поиском по требованию и налету. Стоит отметить, что ранее найденные автотеги, значений автотегов и предикаты автотегов могут быть использованы в дальнейшем поиске данных/предметов, который может быть инициирован пользователем или системой. Такие найденные автотеги, предикаты автотегов и значения автотегов могут быть использованы для поиска Объектов (которые соответствуют пользовательским поисковым словам и выбранным параметрам), которые не менялись после последнего поискового запроса.
В данном случае метод поиска по требованию обеспечивает релевантные результаты поиска, и нет необходимости запускать новый процесс поиска. Стоит отметить, что изменившиеся после последнего поиска объекты могут быть отмечены в списке изменившихся Объектов. Список изменившихся объектов может быть использован во время поиска по требованию для сигнала системе - для каких Объектов требуется найти заново значения автотегов, а для каких Объектов значения автотегов являются релевантными.
ФИГ. 3 иллюстрирует алгоритм обработки данных, согласно одному варианту реализации изобретения. Система Обработки Объекта 305 в сочетании с ГИП используется для того, чтобы позволить пользователю создавать, удалять и редактировать Объекты. Система 305 посредством использования Модуль 315 преобразует действия пользователя над Объектами в тройки и сохраняет их в Базу данных 390.
Тройки хранятся в базе(ах) данных, которая может храниться на хранилище данных, таком как локальное хранилище данных, облачное хранилище в облачных сервисах, SAN, NAS, различные веб-сервисы и другие. Также стоит отметить, что любая известная система хранения данных (например, сериализация данных может быть использована для хранения данных, например, в формате xml) может быть использована вместо Базы данных. Тройки могут быть сохранены в формате базы данных или в формате троек.
Пользователь может создать новую задачу с заголовком "Добавить новое цветное изображение с мобильным устройством в папку продукта" для сотрудника "Максим" (который является ее исполнителем) и связать данную задачу с продуктом, например, "Comindware Process,", т.е. это свяжет задачу с продуктом, которому принадлежит задача. Также пользователь может изменить статус (с "Открыта" на "Закрыта"), заголовок и другие свойства Объекта. В данном случае, Система 305 преобразует результат действий пользователя в тройки, так что, например, будет создана тройка "Задача статус Закрыта" и заменит тройку " Задача статус Открыта" в базе данных 390. Действия с объектами (например, редактирование, создание, удаление, перемещение Объекта между группами и т.д. пользователем; или системой, например, удаление Объекта после трех лет после его создания; или приложением, например, сторонним приложением/модулем, таким как "Comindware Project") отслеживаются модулем Фильтр Событий-Перехватчик Действий С Объектом 310. Одной из задач данного модуля является отслеживание необходимости маркирования/снятия маркировки с Объекта как потенциального для генерирования автотега. В качестве примера действий, инициированных системой/приложением, может быть рассмотрено автоматическое закрытие ошибки после прекращения технической поддержки продукта (для которого была создана ошибка). Еще одним примером таких действий является создание ошибки (и/или создание задачи для данной ошибки) системой/приложением после обнаружения ошибки пользователем или программным отладчиком, или посредством функции "try-catch".
Система 305 также отправляет, как минимум, один запрос к Системе Обработки Автотегов 320 для поиска Объекта, согласно поисковому слову. Запрос инициирует процесс поиска Объекта (в Системе 320) путем использования правил, упомянутых выше, для поиска значений автотегов. "Запрос" может рассматриваться в качестве примера такого запроса. Результатом работы Системы 320 является, как минимум, один найденный Объект. Стоит отметить, что "нулевой" результат может быть получен от Системы 320 в том случае, если в процессе поиска Объектов не будет найден ни один Объект.
Согласно примерному варианту реализации, автотеги, предикаты автотегов и значения автотегов могут быть сохранены в ОЗУ, включая опциональное их кэширование. Такие, сохраненные в ОЗУ данные, могут быть использованы, например, ГИП для отображения найденных Объектов и для дальнейшего поиска Объектов, который может быть инициирован пользователем посредством использования других поисковых слов и тех же или другой области(ей) поиска. Поисковые области могут быть расширены пользователем.
Модуль для Определения Связанных Объектов 330 отвечает за выявление связей Объектами друг с другом. Примером связей Объектов является "транзитивный автотег", который используется для установления прямых или непрямых связей между Объектами. Прямая связь объекта может быть представлена в виде ссылки между двумя объектами, а непрямая связь Объекта является ссылкой на другой Объект через, как минимум, один другой Объект. Связи между объектами могут быть установлены посредством использования правил и использования описания объектов, свойств Объекта и могут быть представлены в виде автотега и предикатов автотегов.
Поскольку Объект или свойства Объекта могут быть изменены в течение времени его жизни, то одни и те же значения автотегов для Объекта должны быть найдены заново. Здесь приведен пример случая, когда необходимо заново найти значения автотега: ошибка была обнаружена в Продукте 1, который является частью Семейства 1. По прошествии определенного количества времени Продукт 1 был перемещен в Семейство 2. В данном случае все найденные значения для автотегов для ошибки необходимо найти заново, поскольку его связи с Продуктом 1 и Продуктом 2 изменились. Стоит отметить, что ранее были найдены значения автотега для Объектов (Продукт 1 и Продукт 2), связанных с текущим Объектом (ошибкой в данном случае).
Поиск автотегов, предикатов автотегов и значений автотегов для связанных Объектов выполняется на базе данных, полученных из модуля 330 (и данных из ОЗУ) и из базы данных 390. Как было сказано выше, результат ранее найденных объектов и всех данных, ассоциирующихся с ними, может быть сохранен в ОЗУ. Использование данных из ОЗУ может увеличить скорость выполнения дальнейших поисковых запросов. Данные из базы данных 390 могут быть получены (и использованы Системой 305 и Системой 320) в форме троек, списка Объектов со связями и в других формах. Данные связей Объектов (и связанных с ними автотегов, значений автотегов, предикатов автотегов) опционально могут быть сохранены в базе данных 390 (или в другой базе данных, которая может быть использована для хранения троек связанных объектов) или в ОЗУ для дальнейшей обработки. Например, такие данные связей Объектов могут быть использованы для второго поискового запроса от пользователя или от системы.
Система обработки Автотегов 320 использует данные из модуля 330 и из базы данных 390 через опциональный модуль обработки троек 360. Опциональный модуль 360 отвечает за представление данных из базы данных 390 в приемлемую для системы подсчета автотегов форму, например, если такие данные были сохранены не в формате Подлежащее-Предикат-Дополнение, а в формате БД. Данные могут быть преобразованы средствами БД или модулей вместо преобразования в модуле 360. Стоит отметить, что модуль 360 отвечает за применение правил к фактам из базы данных. Модуль 360 может быть частью Семантического процессора 840 (ФИГ. 8) и исполнять все его функции или часть из них. Также, модуль 360 отвечает за представление данных из Системы Обработки Объектов 305 в формат базы данных. Если это необходимо данные из Системы Обработки Объектов 305 могут быть записаны в базу данных 390 после преобразования данных в соответствующий формат базы данных.
ФИГ. 4 иллюстрирует блок-схему части процесса поиска Объекта (406), содержащую поиск автотегов для измененных или созданных Объектов. Как упоминалось выше, автотеги и другие данные, которые необходимы для процесса поиска Объектов, могут быть найдены для связанных объектов. Вариант реализации изобретения, в котором не используется поиск по требованию автотегов, значений автотегов и предикатов автотегов изображен на ФИГ. 4. Как было сказано выше, автотеги, значения автотегов и предикаты автотегов могут быть найдены, когда пользователь просит найти предметы с использованием поисковых слов (здесь автотег и другие данные будут найдены по требованию) или когда Объект изменяется или создается новый Объект. После создания или изменения объекта (например, пользователем) в шаге 405 процесс переходит к шагу 410.
В шаге 410 процесс определяет, связан ли текущий Объект с другими Объектами. Связи устанавливаются во время создания нового Объекта и во время ассоциирования и переассоциирования Объектов друг с другом (например, задача может быть переназначена другому пользователю или связана со вторым Продуктом, или Продукт может быть перемещен в другой Проект или Семейство и т.д.). Если текущий Объект не связан с другими Объектами, то в шаге 430 процесс выполняет поиск автотега, предикатов и значений автотегов для текущих поисковых слов. Далее процесс переходит к шагу 455, в котором найденный автотег, предикаты автотегов и значения автотегов для Объекта сохраняются в ОЗУ или базу данных. Стоит отметить, что шаги 410, 430 и 440 являются шагами процесса поиска объекта. Также стоит отметить, что найденные предикаты автотегов и значения автотегов могут быть отправлены во внешнее приложение, например, если поисковый запрос был отправлен внешним приложением или результат поиска необходимо обработать внешним приложением (например, для отображения пользователям после преобразования в отображаемый формат). Также стоит отметить, что предикаты автотегов и значения автотегов могут быть преобразованы в формат внешнего приложения.
Если в шаге 410 определен хотя бы один связанный Объект, то процесс переходит в шаг 440, в котором ищутся значения и предикаты автотегов для связанных Объектов. Далее процесс переходит к шагу 430. Стоит отметить, что предварительно найденные значения и предикаты автотегов удаляются, если пользователь или система удаляет соответствующий им Объект. Если Объект изменяется, предикаты и значения автотегов должны быть найдены заново. Также, для связанных Объектов требуется найти заново предикаты и значения автотегов.
Стоит отметить, что к вышесказанной реализации поиска Объекта может быть добавлен метод пропагации автотегов с весами, т.е. предикату автотега может быть назначен вес. Данный вес используется для поиска объектов за пределами найденных предикатов автотегов посредством ранее описанного метода поиска Объектов с использованием предикатов автотегов.
Здесь описываются веса предикатов автотегов и их использование. Для описания примера использования весов предикатов автотегов используется множество предикатов. В данном примере множество предикатов описывает семейные связи внутри семьи. Например, у человека есть мать, отец, сестра, двоюродный брат и троюродный брат."связиАвтотег" создается для описания типа связи между членами семьи: "матьЧеловекаСвязь", "отецЧеловекаСвязь", "двоюродныйБратЧеловекаСвязь" "троюродныйБратЧеловекаСвязь" и "сестраЧеловекаСвязь" являются предикатами для этого автотега.
Мать, отец и сестра являются близкими родственниками, двоюродный брат является дальним родственником, а троюродный брат является самым дальним родственником. Расстояние по генеалогическому древу Объекта (человека в данном случае) может быть описано весом предикатов автотегов. Чем ближе данная связь с Объектом, тем выше вес предиката автотега. Таким образом, предикаты матьЧеловекаСвязь, отецЧеловекаСвязь и сестраЧеловекаСвязь имеют больший вес (например, вес равен 1), чем предикат двоюродныйБратЧеловекаСвязь (вес равен 0.7), но вес предиката троюродныйБратЧеловекаСвязь будет самым маленьким и будет равен 0.3. В приведенном выше примере сестра, двоюродный брат, брат являются Объектами.
Веса, описанные выше, могут быть использованы для поиска таких Объектов, т.е. возможно найти Объекты по предикатам автотегов с весами, которые больше чем 0.5. В описываемом примере поиск Объектов выполняется посредством следующих предикатов автотегов: матьЧеловекаСвязь, отецЧеловекаСвязь, сестраЧеловекаСвязь и двоюродныйБратЧеловекаСвязь, а предикат автотега троюродныйБратЧеловекаСвязь не будет участвовать в этом поиске.
Стоит отметить, что веса могут быть назначены предикатам автотегов вручную и сохранены (т.е., например, они могут быть сохранены в базу данных пользователем разработчиком, администратором базы данных и т.д.) во время процесса создания и настройки Объекта. Также веса предикатов автотегов могут быть подсчитаны и назначены/добавлены им. Подсчет весов предикатов автотегов может быть осуществлен с использованием правил и окружающего контекста, таких как онтологии, данные текущего Объекта и данные других Объектов. Например, если ошибка была создана Пятницу, то вес предиката для данной ошибки может быть выше. Подсчитанный вес может быть добавлен предикату автотега. В одном варианте реализации вычисление веса предиката автотега может привести к добавлению, увеличению, уменьшению веса предиката автотега (включая снижение веса до нуля, означающее что у предиката автотега нет веса или что вес бесконечно мал).
Имя предиката автотега может содержать вес в явном или неявном виде: вес предиката большойВесМатьЧеловекаСвязь может иметь вес равный 1 ("большойВес" в имени предиката ассоциируется с единицами веса), а среднийВесДругЧеловекаСвязь может иметь вес, равный 0.5 ("среднийВес"). Стоит отметить, что вес в имени предиката может быть определен напрямую, например, ВесОдинМатьЧеловекаСвязь, Вес1МатьЧеловекаСвязь, ВесПоловинаДругЧеловекаСвязь, Вес0Точка5ДругЧеловекаСвязь.
Также стоит отметить, что наличие определенных слов или фраз в имени предиката может влиять на вес предиката автотега. Например, такие слова как мать, отец, жена, сестра, брат, важно, интересно, ВАУ, ослепительный, великий и т.д. могут реализовывать более высокие веса для предикатов автотегов, в то время как маленький, слабый, вялый, темный, двоюродный брат могут реализовывать низкие веса. Другими словами, семантика (значение) части имен предикатов автотегов может определять вес предикатов автотегов.
Здесь приведен пример использования весов предикатов автотегов для порядка поиска Объектов. Поиск родственников Майкла (который является троюродным братом человека Вильяма) выполняется с использованием весов предикатов автотегов. Например, поиск Объектов (в данном случае Объекты являются родственниками) выполняется в порядке убывания весов предикатов автотегов. В данном случае сначала будет найден ближайший родственник (мать, отец, брат и т.д.). После этого будут найдены дальние родственники (свекровь, двоюродные братья, второй племянник дяди и т.д.). Также, как было сказано ранее, после того как будут найдены, эти найденные Объекты могут быть использованы или могут быть сохранены в виде элементов массива (ArrayList) в ОЗУ или хранилище данных.
Пропагация может быть использована для определения, по крайней мере, одного дополнительного предиката, который также вовлечен в поиск Объектов. Предикат автотега может быть использован в качестве параметра пропагации (т.е. дополнительного дескриптора). Например, предикат автотега "cmw:создатель" может быть дополнен дескриптором "пропагС", который означает, что предикат пропагируется посредством следующих предикатов "основнойПредикат пропагС цельПредикаты", через предикат "пример:корректоОшибок".
Вес для пропагации может быть настроен для избегания подсчета весов для дублирующихся связей с Объектами. Например, ошибка имеет текстовое поле "такое же_как_эта_ошибка", т.е. дублирующиеся связи существуют и хранятся в базе данных или представлены в виртуальном виде подсчитанных по требованию связей/ссылок. Виртуальные связи в данном контексте означают отношения, которые могут быть найдены с использованием правил, онтологий и т.д. Например, Билл меняет похожие/идентичные ошибки, так что Биллу (если пропагация не настроена, т.е. использована пропагация по умолчанию) могут быть назначены большие веса, поскольку каждая ошибка влияет на другую.
Для того чтобы этого избежать, дубликаты могут быть проигнорированы и не использованы при поиске Объектов. Другими словами, поисковая система может рассматривать такие ошибки-дубликаты как одну ошибку или считать эти связи между ошибками за одну связь. Стоит отметить, что в данном контексте рассматриваются веса связей, а не веса предикатов, т.е. рассматривается предполагаемый вес предиката. Также стоит отметить, что таким дубликатам также могут быть назначены маленькие веса, например, значение веса может быть равно 0.00001, так что она имеет незначительное влияние на сортировку найденных Объектов. Стоит отметить, что путем настройки значений весов можно построить гибкую систему поиска Объектов с учетом значений для веса. Такая поисковая система способна автоматически распределять веса на основании алгоритмов и/или ранее полученных данных.
Вес Объекта (и позиция в сортированном списке найденных объектов) зависит от предиката автотега, который был использован при поиске Объектов, т.е. Объекты с маленькими весами (для предикатов автотегов с маленькими весами) располагаются ближе к концу отсортированного списка Объектов, чем Объекты с большими значениями весов. Стоит отметить, что веса предикатов автотегов также используются для установления глубины поиска Объектов. Вес предикатов автотегов и параметры поиска определяют, будет ли найден конкретный Объект, или какой-либо другой Объект, или ничего не будет найдено.
В одном примерном варианте реализации могут быть использованы описанные выше пропагации для автомобиля и частей автомобиля. Автомобиль состоит из следующих частей: двери, бамперы, багажник, капот, крылья и т.д. Каждый из них является экземпляром Класса, названного по имени части Автомобиля и являются Объектами. Цвет является свойством объекта. Скажем, что Цвет пропагируется через части автомобиля. Объект Автомобиль 1 является экземпляром Класса Автомобиль. Цвет Красный может быть использован в качестве условия поиска Объектов, т.е. пользователь хочет найти Красный Автомобиль. В данном случае цветные части автомобиля могут определять цвет всего автомобиля, т.е. если одна из частей автомобиля имеет красную часть, то цвет автомобиля - красный.
В другом примере изобретения цвет может быть пропагирован, по крайней мере, через один предикат, например, предикат двери (предикат левая_передняя_дверь, предикат правая_задняя_дверь), предикат бампер, предикат багажник, предикат капот, предикат крылья и т.д. Например, бампер составляет 5 процентов от всего автомобиля, так что вес данного предиката равен 0.05. Вес предиката двери равен 0.1, вес багажника - 0.2, кузова - 0.5 и т.д. Предполагается, что в БД содержатся следующие данные для Автомобиля 1: передний и задний бамперы имеют Зеленый цвет, кузов - Зеленый, багажник - Красный и дверь - Черный.
В таком случае Автомобиль 1 имеет 60 процентов окрашенных в Зеленый цвет частей, 20 процентов окрашенных в Красный цвет частей и 10 процентов окрашенных в Черный цвет частей (передняя левая дверь была заменена и не была еще окрашена). Другой Объект, Автомобиль 2, может содержать 40 процентов окрашенных в Зеленый цвет частей (окрашенный в Зеленый Цвет багажник и две передние окрашенные в зеленый цвет двери), а также содержит 50 процентов окрашенных в Красный цвет частей (в данном случае кузов автомобиля имеет Красный цвет), и 10 процентов автомобиля составляют окрашенные в Черный цвет бамперы.
Когда пользователь инициирует процесс поиска Объектов по Цвету (например, здесь используется Зеленый цвет), БД может хранить (в форме онтологий и/или правил) тот факт, что автомобиль - Зеленый, если окрашенных в Зеленый цвет частей автомобиля более 50 процентов (т.е. общий вес предикатов автотегов больше 0.5), и автомобиль - Красный, если общий вес предикатов более 0.4, и автомобиль окрашен в Черно-Красный, если вес предикатов более чем 0.5 для Красного цвета и 0.09 для Черного цвета.
В данном случае, если процесс Поиска Объектов инициирован по Цвету (1) Зеленый цвет, (2) Красный цвет или (3) Красно-Белый цвет, то система поиска во время процесса поиска объединит предикаты автотегов частей автомобиля, так что Автомобиль 1 будет найден как окрашенный в Зеленый цвет автомобиль, а Автомобиль 2 будет найден как Красный и Красно-Черный Автомобиль. Стоит отметить, что вес предиката автотега является частью общего значения (в данном случае 0.1 - это 10% от цвета автомобиля, 0.5-50% и т.д.). Ввод и операции с весами могут меняться, поскольку вес может представлять значение определенного предиката, высокий приоритет и т.д. так что пропагация является неявной/косвенной связью между Объектами.
ФИГ. 7 иллюстрирует пример различных бизнес-приложений, используемых в различных отделах компании, и схему обработки данных в них. Данные из базы данных могут быть разделены на пользовательские данные в виде аксиом, фактов, правил и онтологий (представленных также в виде аксиом, но которые могут быть различимы по N3 синтаксису). Другими словами, онтологии содержат информацию о том, что за данные и как данные должны быть представлены конкретному пользователю в конкретном бизнес-приложении. Факты и онтологии обрабатываются Ядром, и результатом обработки являются данные в определенном контексте в соответствии с онтологиями.
Благодаря использованию RDF (Среды Описания Ресурса) можно работать с различными источниками данных (т.е. базами данных, локальными хранилищами данных, расположенными в корпоративной сети или расположенными в Интернете). Возможно использовать URI общего словаря, что позволяет интегрировать данные из различных серверов. Также, основываясь на данных и правилах, возможно обеспечить представление данных на лету (в отличие от статичных срезов (например, слепков), как это делается в OLAP кубах).
Пул информации (например, данные со всех департаментов: ИТ (705), Разработка (не показано), ЧР (701), Администрирование (не показано), Сбыт (не показано), Бухгалтерия (703) могут быть сохранены в различных базах данных или других хранилищах. Элемент 707 позволяет отображение контекстуализированной бизнес-информации для конкретного приложения. "Глобальная" является сущностью для представления данных в конкретном контексте бизнес-приложения.
Контекст может рассматриваться в качестве среды окружения конкретного события, объекта или индивида, который определяет интерпретацию данных и действий/операций над данными в конкретной ситуации. Опционально, контекст определяет метод обработки данных в конкретной ситуации. Например, чей-то адрес электронной почты может считаться информацией для входа в систему в одном контексте и в качестве контактной информации в профиле пользователя в другом контексте. Он может использоваться в качестве запрашивающей стороны в заявке в техническую поддержку в третьем контексте - все зависит от интерпретации данных.
Обмен информацией между серверами выполняется автоматически, поскольку все серверы используют общий словарь. Например:
http://<company_name>.com/tracker/ontology/global/hr, или
http://<company_name>.com/tracker/ontology/global/it или
http://<company_name>.com/tracker/ontology/global/acc, все они объединены в
http://<company_name>.com/tracker/ontology/global
Даже в случае, когда бухгалтерия при создании вручную записи о сотруднике использует свой собственный словарь, возможно написать правило 
 , тем самым обеспечив механизм перевода между словарем бухгалтерии и глобальным словарем.
, тем самым обеспечив механизм перевода между словарем бухгалтерии и глобальным словарем.
Из этого примера видно, что предлагаемая архитектура позволяет каждой отдельной группе или отделу в рамках бизнеса работать со своей собственной базой данных/хранилищем и своей собственной серверной системой, в то время как глобальный сервер с движком может представлять собой объединенное представление данных из всех отделов. Это осуществляется на лету и без дублирования данных, что особенно важно с точки зрения безопасности информации, а также с точки зрения поддержания актуальности информации (в данном случае, когда данные на одном хранилище меняются, то нет необходимости менять данные на других хранилищах).
Основанные на подсчитанных автотегах результаты представления поиска, полученные на лету, могут быть проиллюстрированы следующем примером. Рассмотрим данные онтологий (т.е. данные, которые описывают управляемые сущности) в контексте бизнес-приложений, например, управления проектами, отслеживания проблем, отслеживания ошибок, CRM и т.д. Каждый из них хранится в своей собственной базе данных (или, альтернативно, в общей базе данных), и которые объединены на более высоком уровне. При помощи логического ядра можно комбинировать различные доступные данные в различные комбинации и наборы онтологий, например, используя специальные онтологии. Разработчик может видеть контекст представления ошибки, представленный Отделу качества в виде назначенной ему задачи. Другими словами, является возможным проследить, к какой задаче относится конкретная ошибка.
Различия между представлением на лету, доступным благодаря описанному здесь подходу, и статичным представлением, предоставляемым поиском данных с использованием OLAP кубов (сетевая аналитическая обработка в реальном времени) также заслуживают рассмотрения. OLAP является общепринятой техникой для генерирования отчетов и различных статистических документов. OLAP кубы часто используются аналитиками для быстрой обработки сложных запросов к базе данных, и они особенно часто встречаются в маркетинговых отчетах, отчетам по продажам, анализе данных и так далее.
Причина, по которой OLAP кубы настолько распространены, кроется в скорости, с которой может быть выполнена обработка. Реляционные базы данных хранят информацию о различных сущностях в отдельных таблицах, которые обычно хорошо нормализованы. Эта структура удобна для большинства операционных систем баз данных, однако сложные многотабличные запросы обычно сложно быстро выполнить. Хорошей моделью для таких запросов (в отличие от изменений) является таблица, построенная с использованием фактов из OLAP кубов.
Сложность использования OLAP в качестве методологии заключается в генерировании запросов, выборе базовых данных и генерировании соответствующей схемы, которая является причиной, по которой большинство современных OLAP продуктов обычно поставляются вместе с большим количеством предопределенных запросов.
Другая проблема заключается в базовых знаниях OLAP куба, которые должны быть завершенными и непротиворечивыми. Таким образом, основной проблемой с OLAP кубами является то, что процесс анализа обычно требует пересоздания самого куба или частого генерирования срезов. В отличие от OLAP кубов предложенный подход выигрышно позволяет перегенерирование представления данных (результатов поиска) на лету без сложностей предопределения и предварительного генерирования запросов. Вкратце, процесс обсуждаемого здесь подхода может быть описан следующим образом:
- бизнес-слой запрашивает данные из ядра;
- логическое ядро собирает данные из различных источников;
- логическое ядро распознает природу данных и делит данные на аксиомы и правила. Например, для баг-трекера аксиомой может быть "решение это "нужно больше информации"", в правилом может быть 
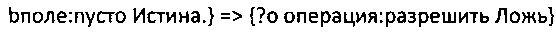 ;
;
- движок, необходимый для выполнения запроса бизнес слоя, собирает вместе скомпилированные правила (например, в С# коде, хотя изобретение не ограничено каким либо конкретным языком программирования). У движка могут быть правила, которые были собраны и скомпилированы ранее, так же как и новые правила для правил, которые еще не были обработаны. Таким образом, компилирование должно быть выполнено только для новых правил. Поэтому ядру нет необходимости постоянно работать с данными, а только лишь адресовать данные в ответ на запросы из бизнес слоя;
- движок обрабатывает аксиомы, и генерируются новые вытекающие из этого аксиомы;
- ядро возвращает запрошенные данные в бизнес слой.
Некоторые типы правил могут существовать для обработки данных. Правило типа фильтр часто используется в случаях трекера, например, получение списка тикетов службы поддержки/ошибок/задач от конкретного пользователя и для конкретного проекта с конкретными атрибутами. Поэтому, информация должна быть отфильтрована из общего пула задач/ошибок/тикетов для конкретного пользователя и проекта, и представлена в форме отдельных аксиом.
Преобразующие правила относятся к той же информации, которая может быть представлена в иной манере. Например, ИТ отдел рассматривает людей как пользователей ИТ-системы. С другой стороны, менеджер проектов может рассматривать этих же людей в виде ресурсов, работающих над конкретными задачами. В другом примере преобразующие правила могут включать следующее: на входе получаются данные (аксиомы), которые описывают конкретный тикет (т.е. запрос от конкретного конечного пользователя) и его представление данных. Следовательно движок получит на выходе аксиомы в виде определенного пользовательского интерфейса, заполненного данными.
Другим примером типов правил является генерирующее правило. Например, в конкретном проекте, в котором содержится более 50% критичных ошибок и более 50% критичных задач, система автоматически сгенерирует факт о статусе проекта (т.е. статус проекта будет отмечен как "Критический").
Пример применения правил выглядит следующим образом. Информация преобразуется из баг-трекера и исправления проектами в данные для проекта ABC. Далее фильтруются только ошибки со статусом "критичная", которые останутся, и движок подсчитает общее количество ошибок, и далее, если количество "критичных" ошибок - больше половины общего количества ошибок, то будет сгенерировано критическое состояние ошибок вы проекте:

Те же самые операции выполняются с данными (задачами) из систем управления проектами:

Далее выполняется автоматическое генерирование статуса проекта "Критичный", если в проекте есть задачи и ошибки в состояниях "Критичный":
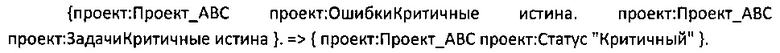
То же самое происходит со статусом, но с другим условием: автоматическое генерирование статуса "Критичный" для проекта, когда "критичных" ошибок или задач становится больше половины.
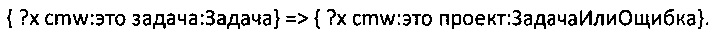


Как будет понятно специалистам в данном уровне техники, примеры из жизни обычно более сложные, чем описанные здесь, и может существовать намного больше типов правил в большинстве случаев из реальной жизни, однако, принцип остается тем же самым.
Пример конъюнкции аксиом зачастую является самым легким в понимании, например, при комбинировании информации, относящейся к требованиям проекта (аксиома "требования" - требования, определенные аналитиками), и ошибок из баг-трекера (аксиома "ошибки" - ошибки, обнаруженные тестировщиками, которые, как правило, являются специалистами по контролю качества, и заполненные формы отслеживания ошибок на основе определенных требований), результаты "результирующая аксиома", которые в сущности являются комбинацией количества ошибок связанных с одним функциональным требованием.
ФИГ. 8 иллюстрирует систему в одном варианте реализации изобретения. JSON/Ajax API 822 является модулем для реализации протокола вызовов методов API (Интерфейса Программирования Приложений) с использованием формата сообщений JSON и передачей данных посредством HTTP с использованием запросов Ajax. WCF API 824 является модулем, который реализует протокол вызова методов API с использованием формата представления XML/SOAP и передачи данных посредством HTTP.
Модуль менеджера API 826:
- ищет требуемый метод API,
- реализует сериализацию аргументов в структуры данных, использующуюся в онтологиях бизнес-логики,
- реализует вызовы метода API,
- десериализует результаты, возвращенные методом.
Модуль менеджера API 826 использует N3-файлы 830 (которые содержат тройки в формате N3) для поиска реализации метода 828, где онтология "арi:Метод" (например) содержит все методы, типы аргументов и возвращает значения. Реализация метода является программным кодом. Например, он может сохранять данные в базу данных или закрыть или открыть задачу, и другие операции.
Например, API метод "СоздатьЗадачу" используется для создания задачи. Метод принимает данные задачи в виде аргумента и возвращает идентификатор для созданной задачи. JSON-обработчик получает имя метода и аргументы (данные задачи) в JSON-формате, где метод вызывается посредством JSON-протокол. Далее аргументы преобразуются во внутреннее представление данных в памяти и передаются в API-менеджер. API-менеджер (у которого есть список методов) может найти требуемый метод "СоздатьЗадачу" по имени. Далее API-менеджер проверяет аргументы (количество и тип) и реализует метод "СоздатьЗадачу". После создания задачи методом "СоздатьЗадачу", API-менеджер возвращает результат JSON-обработчику. JSON-обработчик преобразует результат в JSON-формат и отправляет его обратно клиенту (например, в клиент MS Outlook или в приложение мобильного устройства).
API-менеджер загружает API-спецификацию и модули расширения из Базы данных во время запуска приложения (MS Outlook расширение 807). Данная спецификация может быть запрошена Outlook расширением/плагином 807 MS Outlook клиента 806 или посредством специального Ajax-запроса или в виде схемы в WSDL-формате с использованием SOAP-протокола.
Веб-клиент 802 (например, на базе JavaScript или на HTML5) или Клиент Командной Строки 804 могут быть использованы вместо MS Outlook. Консольный клиент является клиентским приложением, которое может вызывать методы API с использованием командной строки. Также может быть использовано мобильное приложение на мобильном устройстве 801.
Клиент JavaScript является клиентским приложением, которое исполняется в пользовательском веб-браузере и которое может вызывать методы API с использованием языка JavaScript.
Outlook расширение (Outlook-клиент) является клиентским приложением, которое исполняется в приложении MS-Outlook и которое может вызывать методы API с использованием WCF-протокола.
Язык Описания Веб-сервисов (WSDL) является основанным на XML языке описания интерфейсов, который используется для описания функциональности, предоставляемой веб-сервисом.
WSDL-описание веб-сервиса (также называемое WSDL-файлом) обеспечивает машиночитаемое описание того, как сервис может быть вызван, какие параметры он ожидает и какие структуры данных он ожидает. Таким образом, он служит той же цели, что, которая примерно соответствует цели сигнатуры метода в языке программирования.
Далее клиентские приложения могут осуществлять вызовы с использованием отчетности запросов Ajax в формате протокола JSON или SOAP.
Основными стадиями обработки запросов являются:
1. Входящий запрос обрабатывается HTTP-сервером (или Внешним сервером, или MS Exchange Сервером). Выполняется JSON сериализация или SOAP преобразование во внутренний формат.
2. API-менеджер 826 принимает входные данные и проверяет входные аргументы на соответствие описанию метода.
3. API-менеджер 826 загружает и подготавливает необходимую модель данных и создает слепок модели для изоляции от других запросов и операций. Транзакция записи открыта, если операция меняет данные модели.
4. Вызывается программный код (или правила с онтологиями и Язык Comindware®), который выполняет метод.
5. Транзакция закрывается, если операция является модифицирующей операцией, и выполняется проверка изменения в безопасности, определение конфликтов, обновление истории транзакций.
6. Результат сериализуется в формат, требуемый клиентом и передается в HTTP-запрос.
Бизнес логика приложения 820 реализует объектный слой поверх хранилища данных. Доступ к данным обеспечивается посредством клиентского API, который содержит методы для чтения/записи объектов (т.е. шаблоны объектов, бизнес-правила и т.д.) Вызовы клиентами методов API реализованы посредством сессий, которые создаются после авторизации клиента. Этот слой содержит несколько системных онтологий, таких как, например, "шаблон пользовательского объекта" или "бизнес-правило". Онтологии используются в API для сериализации и проверки данных.
Хранилище данных 842 обеспечивает физическое хранилище для модели данных на жестком диске. Данные оправляются в хранилище данных 842 и обратно в форме фактов (троек). Факт является тройкой, которая хранится в модели. Также, факт может быть получен путем применения правил или запросов. Хранилище данных состоит из:
- потокового хранилища троек 858 позволяет записывать и запрашивать тройки специального файлового формата. Потоковое хранение троек поддерживает несколько типов запросов по различным компонентам;
- менеджер транзакций и слепков 854 позволяет создавать:
а. транзакции. Транзакции являются объектами с интерфейсом для атомарной модификации троек хранилища. Изменение модели возможно только в рамках такой транзакции, гарантируя атомарную модификацию троек хранилища (подтверждение всех изменений, сделанных внутри транзакции, или ни одной из них);
б. слепки. Слепки представляют собой обладающие интерфейсом объекты для консистентного чтения из хранилища троек. Это гарантирует, что ни одна из транзакций (которые были подтверждены во время выполнения слепка) не повлияет на его содержимое.
- тройки, хранящиеся в репозитории, являются простыми, небольшими объектами (числами, строками, именами). Менеджер бинарных потоков 856 используется для сохранения больших значений (файлов, потоков данных) в хранилище. Поток хранится в отдельном файле, и хранится ссылка на поток сохраняется в этом файле;
- Модель хранилища данных 850 представляет набор интерфейсов для управления хранилищем данных 851. Такие интерфейсы могут включать транзакции, слепки, интерфейс для запроса фактов (троек) из слепка и интерфейс для записи фактов в транзакцию.
- Семантический процессор 840 содержит описание интерфейсов, таких как имя, факты (тройки) и правило модели.
N3-конвертер 849 позволяет генерировать модель данных на основе содержимого N3-файла 830. (Стоит отметить, что тройки могут быть сохранены в базе данных в любом формате, как говорилось выше). Объединение с хранилищем данных является еще одним методом формирования паттерна. Кроме того, могут быть сформированы объединенные модели, так что несколько моделей объединяются в одну. Запросы к таким моделям приводят к запросу фактов из каждой объединенной модели. Запись данных при этом продолжает производиться только в одну из моделей.
Обработчик бизнес-правил 844 является опциональным дополнением поверх модели данных. После подключения обработчика 844 к модели, он позволяет вычислять производные на основе существующих фактов и правил.
Интерфейс модели данных 846 является набором интерфейсов для запроса фактов из модели, для записи в модель, создания транзакция и слепков модели. Сериализатор онтологий 848 создает запросы на получение объектов из всей модели на основании онтологий (описание структуры объектов хранится в модели).
Транзакции и запросы изолированы с использованием транзакций. После открытия транзакции на запись или чтение, транзакция полностью изолирована от других транзакций. Любые изменения в модели данных, сделанные другими транзакциями, не отражаются в ней. Определение конфликтов и разрешение конфликтов выполняется при закрытии транзакции, которая была открыта на запись. Используется так называемая модель оптимистичного параллелизма. Определения конфликтов происходит на уровне отдельных семантических фактов. Конфликт возникает, когда факт был модифицирован двумя транзакциями после создания слепка модели и до закрытия транзакции. Во время определения конфликта будет сгенерировано исключение. В этом случае пользователь может попробовать обновить сохраненные изменения и попробовать еще раз подтвердить изменения.
Оптимистическое управление параллелизмом (ОСС) является методом управления параллелизмом для систем управления реляционными базами данных, который предполагает, что несколько транзакций могут быть завершены без влияния друг на друга и, следовательно, транзакции могут быть обработаны без блокировки ресурсов данных, которые они затрагивают. Перед подтверждением, каждая транзакция проверяет, что ни одна другая транзакция не изменила данные. Если проверка выявляет конфликтующие модификации, то подтверждающая транзакция откатывается.
ОСС, как правило, используется в средах с низкими конфликтами данных. Когда конфликты редки, транзакции могут быть завершены без затрат на управление блокировками и без необходимости транзакциям ожидать очистки других блокировок транзакций, что приводит к повышению пропускной способности по сравнению с другими методами управления параллелизмом. Однако, если конфликты происходят часто, то цена неоднократного перезапуска транзакций значительно влияет на производительность, и другие методы управления параллелизмом обладают большей производительностью при таких условиях.
Более конкретно, ОСС транзакции включают следующие фазы:
Начало: запись метки времени, отмечающей начало транзакции.
Модифицирование: чтение значений из базы данных и предварительная запись изменений.
Проверка: Проверка, модифицировали ли другие транзакции данные, которые используются текущей транзакцией (запись или чтение). Это включает транзакции, которые были завершены после даты начала текущей транзакции и опционально транзакции, которые еще активны на момент проверки.
Подтверждение/Откат: Если конфликта нет, сделать все изменения имеющими силу. Если конфликт существует, разрешить его, обычно путем отмены транзакции, хотя возможны другие схемы разрешения. Стоит позаботиться об избегании ошибки TOCTTOU (Time-Of-Check-To-Time-Of-Use), особенно если текущая фаза и предыдущая не выполнены в виде одной атомарной операции (см. также обсуждение механизмов разрешения конфликтов между транзакциями, т.е. транзакциями, не влияющими друг на друга, упомянутым выше.)
Со ссылкой на ФИГ. 9, типичная система для реализации изобретения включает в себя многоцелевое вычислительное устройство в виде компьютера 20 или сервера, включающего в себя процессор 21, системную память 22 и системную шину 23, которая связывает различные системные компоненты, включая системную память с процессором 21.
Системная шина 23 может быть любого из различных типов структур шин, включающих шину памяти или контроллер памяти, периферийную шину и локальную шину, использующую любую из множества архитектур шин. Системная память включает постоянное запоминающее устройство (ПЗУ) 24 и оперативное запоминающее устройство (ОЗУ) 25. В ПЗУ 24 хранится базовая система ввода/вывода 26 (БИОС), состоящая из основных подпрограмм, которые помогают обмениваться информацией между элементами внутри компьютера 20, например, в момент запуска.
Компьютер 20 также может включать в себя накопитель 27 на жестком диске для чтения с и записи на жесткий диск, не показан, накопитель 28 на магнитных дисках для чтения с или записи на съемный магнитный диск 29, и накопитель 30 на оптическом диске для чтения с или записи на съемный оптический диск 31 такой, как компакт-диск, цифровой видео-диск и другие оптические средства. Накопитель 27 на жестком диске, накопитель 28 на магнитных дисках и накопитель 30 на оптических дисках соединены с системной шиной 23 посредством, соответственно, интерфейса 32 накопителя на жестком диске, интерфейса 33 накопителя на магнитных дисках и интерфейса 34 оптического накопителя. Накопители и их соответствующие читаемые компьютером средства обеспечивают энергонезависимое хранение читаемых компьютером инструкций, структур данных, программных модулей и других данных для компьютера 20.
Хотя описанная здесь типичная конфигурация использует жесткий диск, съемный магнитный диск 29 и съемный оптический диск 31, специалист примет во внимание, что в типичной операционной среде могут также быть использованы другие типы читаемых компьютером средств, которые могут хранить данные, которые доступны с помощью компьютера, такие как магнитные кассеты, карты флеш-памяти, цифровые видеодиски, картриджи Бернулли, оперативные запоминающие устройства (ОЗУ), постоянные запоминающие устройства (ПЗУ) и т.п.
Различные программные модули, включая операционную систему 35, могут быть сохранены на жестком диске, магнитном диске 29, оптическом диске 31, ПЗУ 24 или ОЗУ 25. Компьютер 20 включает в себя файловую систему 36, связанную с операционной системой 35 или включенную в нее, одно или более программное приложение 37, другие программные модули 38 и программные данные 39. Пользователь может вводить команды и информацию в компьютер 20 при помощи устройств ввода, таких как клавиатура 40 и указательное устройство 42. Другие устройства ввода (не показаны) могут включать в себя микрофон, джойстик, геймпад, спутниковую антенну, сканер или любое другое.
Эти и другие устройства ввода соединены с процессором 21 часто посредством интерфейса 46 последовательного порта, который связан с системной шиной, но могут быть соединены посредством других интерфейсов, таких как параллельный порт, игровой порт или универсальная последовательная шина (УПШ). Монитор 47 или другой тип устройства визуального отображения также соединен с системной шиной 23 посредством интерфейса, например видеоадаптера 48. В дополнение к монитору 47, персональные компьютеры обычно включают в себя другие периферийные устройства вывода (не показано), такие как динамики и принтеры.
Компьютер 20 может работать в сетевом окружении посредством логических соединений к одному или нескольким удаленным компьютерам 49. Удаленный компьютер (или компьютеры) 49 может представлять собой другой компьютер, сервер, роутер, сетевой ПК, пиринговое устройство или другой узел единой сети, а также обычно включает в себя большинство или все элементы, описанные выше, в отношении компьютера 20, хотя показано только устройство хранения информации 50. Логические соединения включают в себя локальную сеть (ЛВС) 51 и глобальную компьютерную сеть (ГКС) 52. Такие сетевые окружения обычно распространены в учреждениях, корпоративных компьютерных сетях, Интранете и Интернете.
Компьютер 20, используемый в сетевом окружении ЛВС, соединяется с локальной сетью 51 посредством сетевого интерфейса или адаптера 53. Компьютер 20, используемый в сетевом окружении ГКС, обычно использует модем 54 или другие средства для установления связи с глобальной компьютерной сетью 52, такой как Интернет.
Модем 54, который может быть внутренним или внешним, соединен с системной шиной 23 посредством интерфейса 46 последовательного порта. В сетевом окружении программные модули или их части, описанные применительно к компьютеру 20, могут храниться на удаленном устройстве хранения информации. Надо принять во внимание, что показанные сетевые соединения являются типичными, и для установления коммуникационной связи между компьютерами могут быть использованы другие средства.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМА И СПОСОБ ОБРАБОТКИ ДАННЫХ ГРАФОВ | 2015 |
|
RU2708939C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ХРАНЕНИЯ ДАННЫХ ГРАФОВ | 2012 |
|
RU2605387C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ГЛОБАЛЬНОЙ ИДЕНТИФИКАЦИИ В КОЛЛЕКЦИИ ДОКУМЕНТОВ | 2015 |
|
RU2591175C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ХРАНЕНИЯ И ПОИСКА ИНФОРМАЦИИ, ИЗВЛЕКАЕМОЙ ИЗ ТЕКСТОВЫХ ДОКУМЕНТОВ | 2015 |
|
RU2605077C2 |
| СПОСОБ ОБРАБОТКИ ПРОЦЕССОВ МАШИНОЙ СОСТОЯНИЙ | 2012 |
|
RU2630383C2 |
| СПОСОБ УСКОРЕНИЯ ОБРАБОТКИ МНОЖЕСТВЕННЫХ ЗАПРОСОВ ТИПА SELECT К RDF БАЗЕ ДАННЫХ С ПОМОЩЬЮ ГРАФИЧЕСКОГО ПРОЦЕССОРА | 2012 |
|
RU2490702C1 |
| СПОСОБ И СИСТЕМА ДЛЯ МАШИННОГО ИЗВЛЕЧЕНИЯ И ИНТЕРПРЕТАЦИИ ТЕКСТОВОЙ ИНФОРМАЦИИ | 2015 |
|
RU2592396C1 |
| ПОИСК ИЗОБРАЖЕНИЙ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2015 |
|
RU2688271C2 |
| Способ управления требованиями | 2016 |
|
RU2632121C1 |
| СПОСОБ И СИСТЕМА СЕМАНТИЧЕСКОЙ ОБРАБОТКИ ТЕКСТОВЫХ ДОКУМЕНТОВ | 2016 |
|
RU2630427C2 |
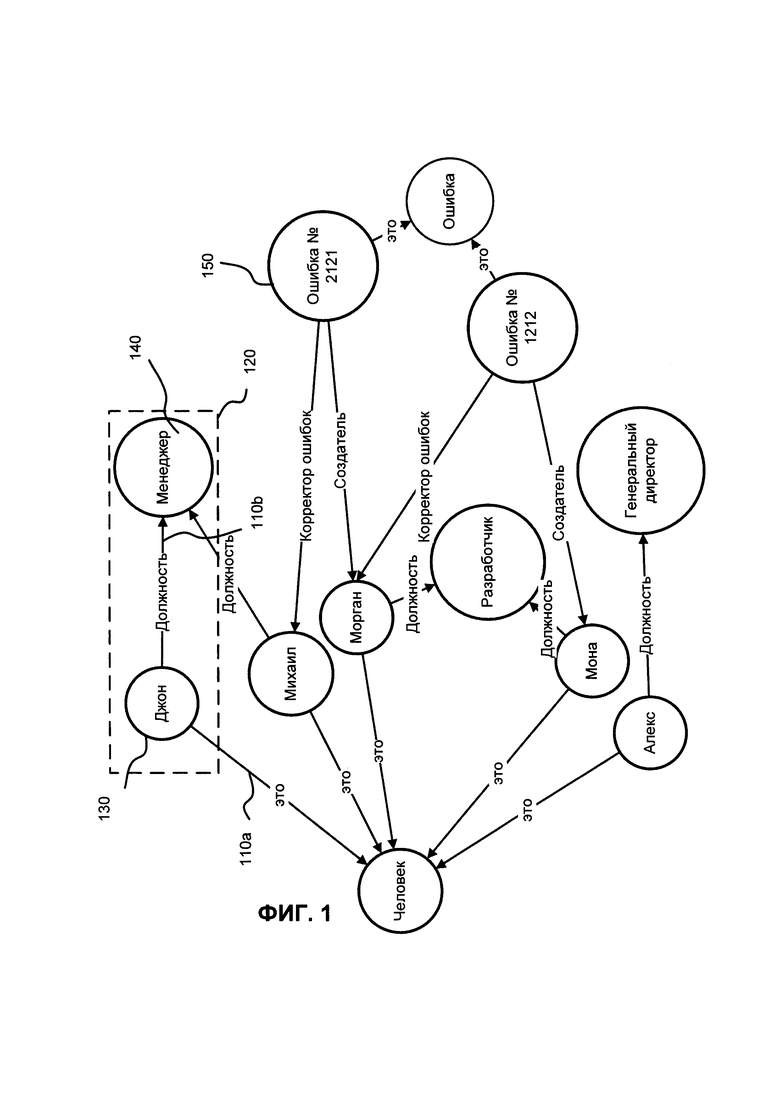
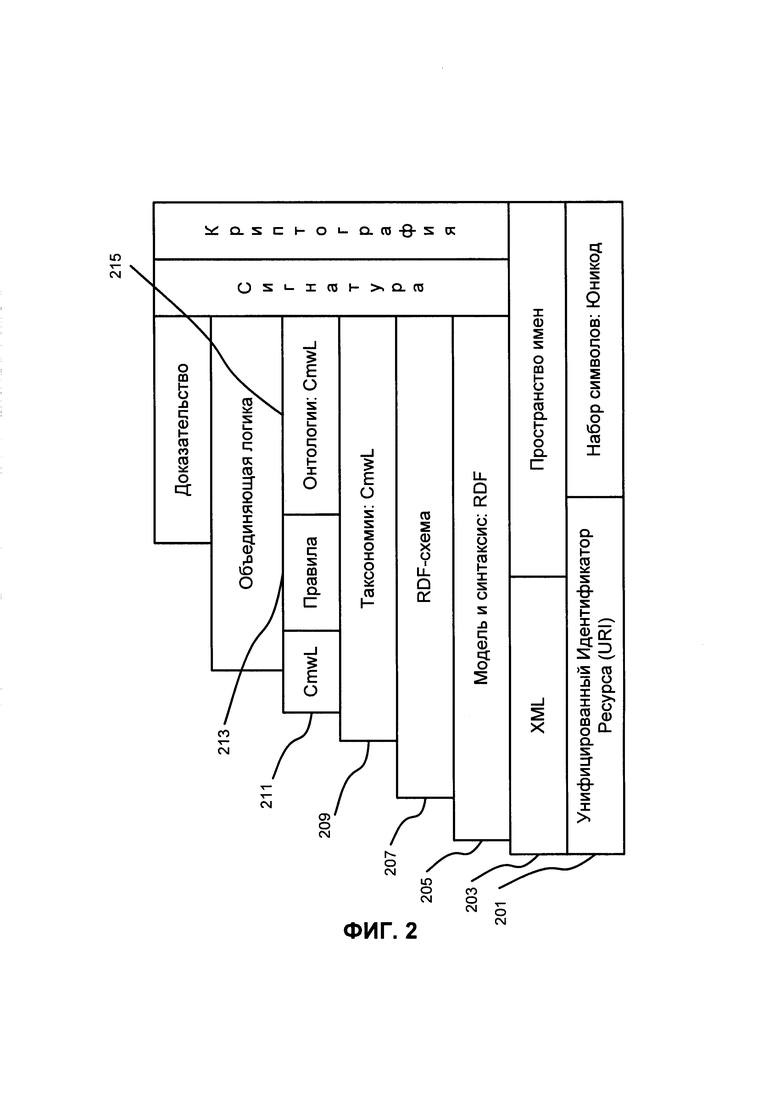
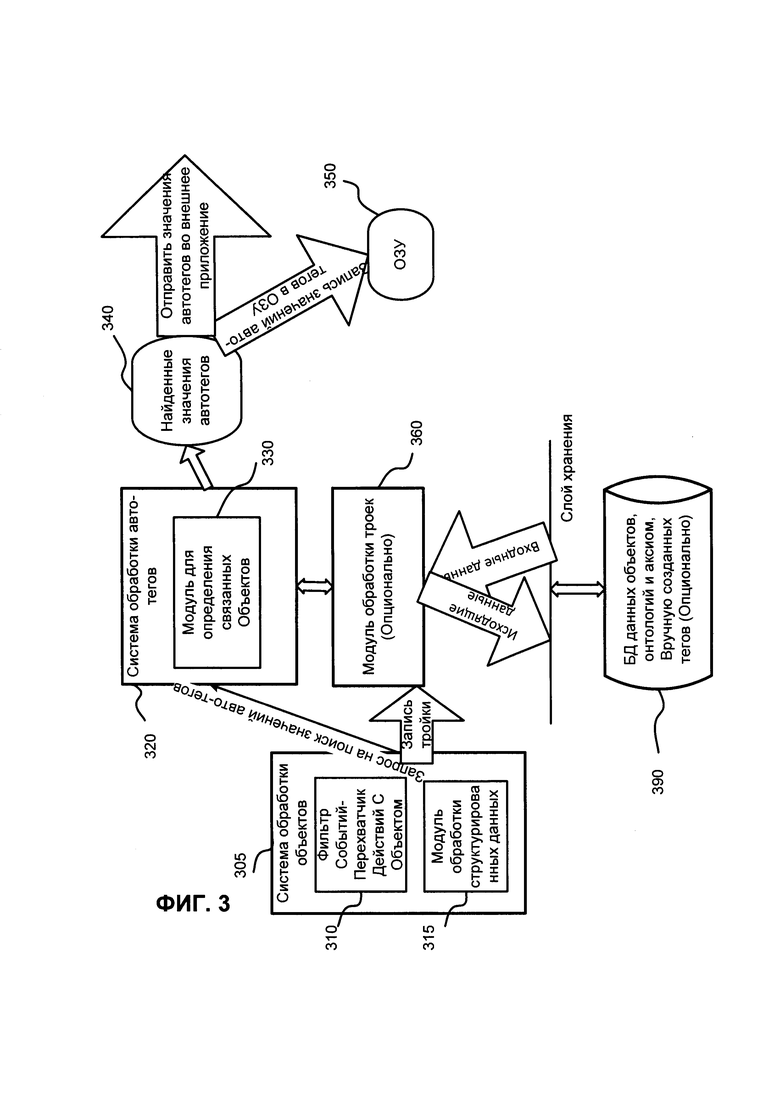
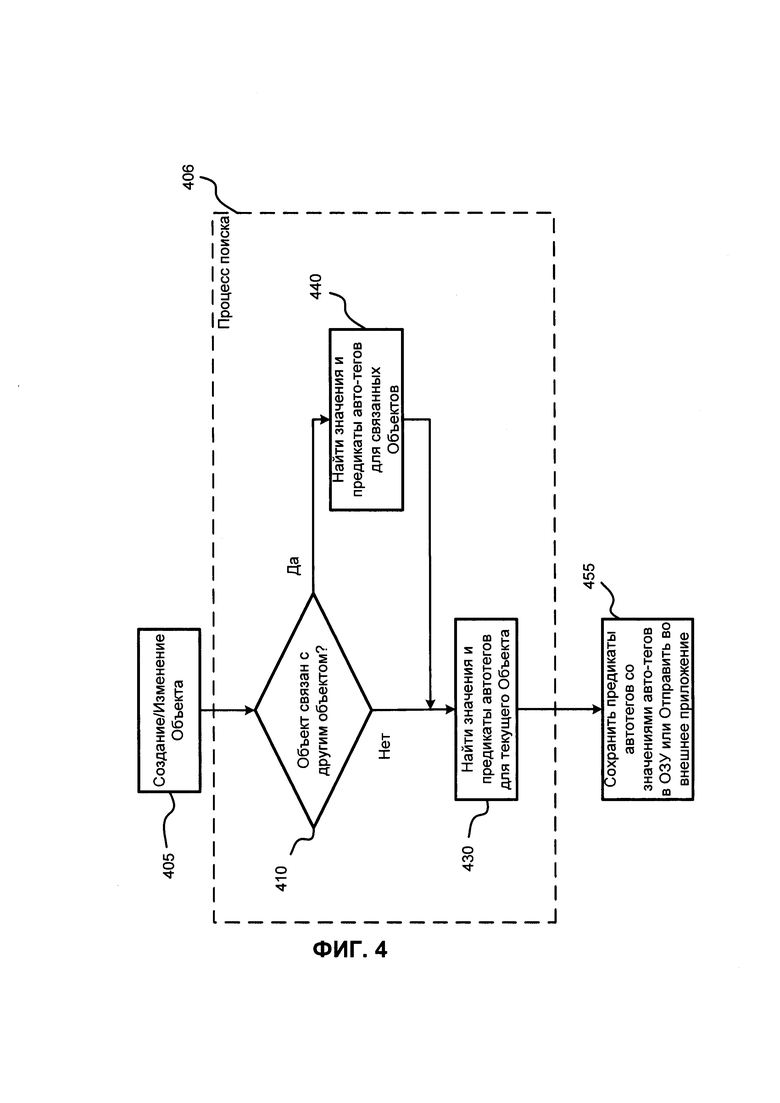
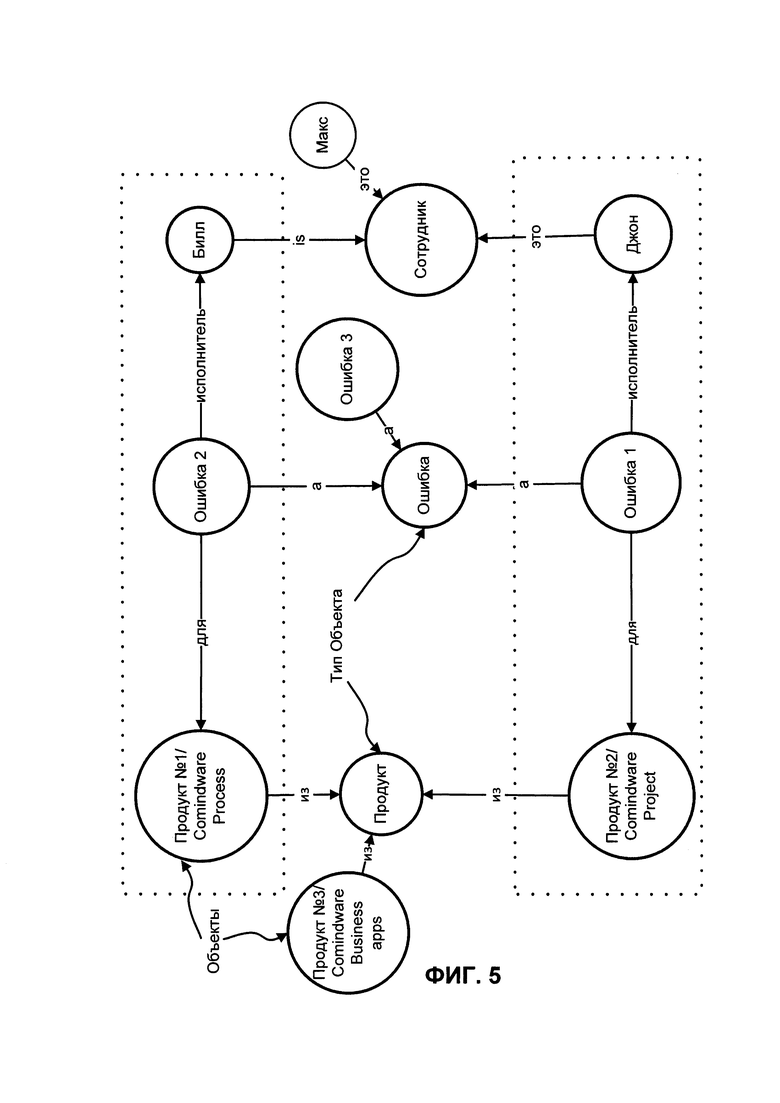
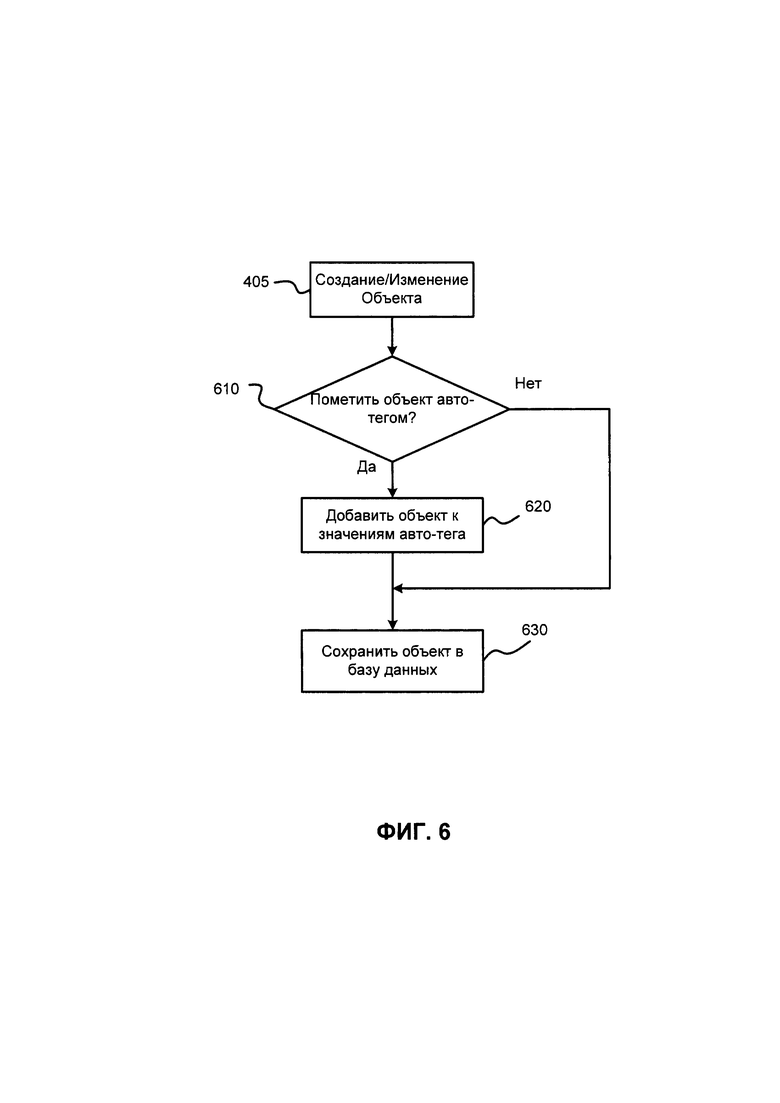
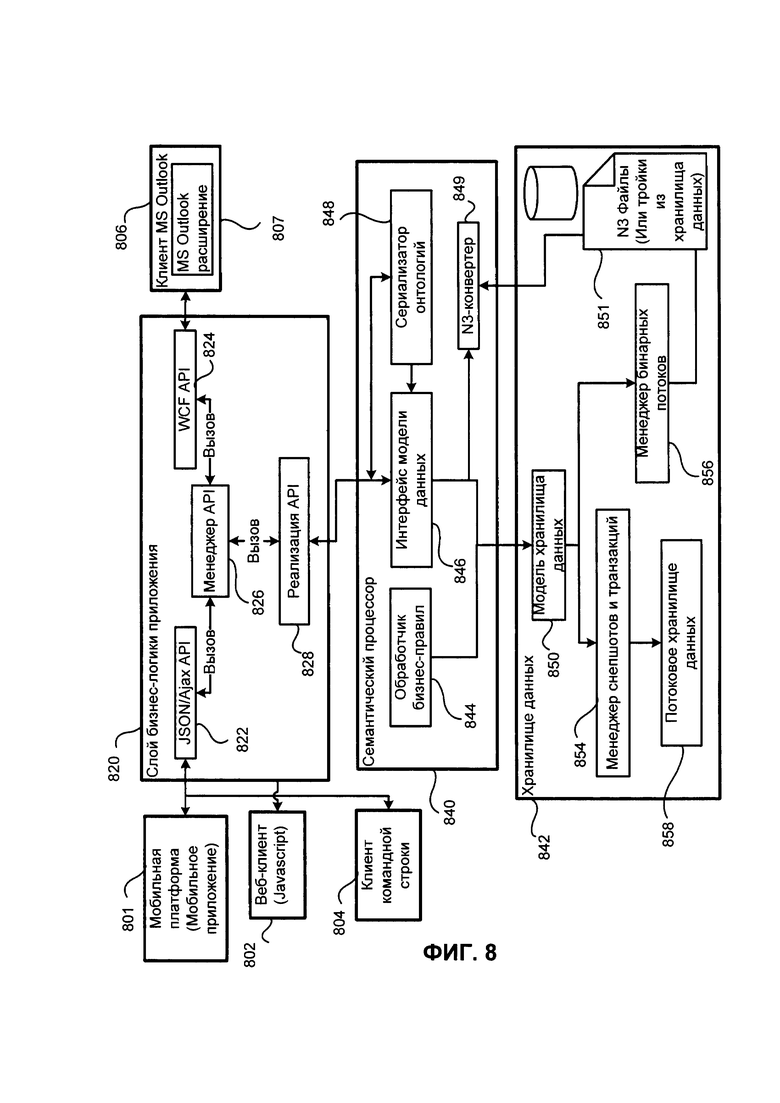
Изобретение относится к способу и системе маркирования тегами объектов для их поиска. Технический результат заключается в автоматизации поиска объектов. В способе выполняют хранение входных данных, включая аксиомы, представляющие факты, получение и преобразование входных объектов данных в формат n-кортежа на основе контекста, обработку аксиом для определения подлежащего, предиката и дополнения n-кортежа, анализ объектов данных и определение косвенных связей между объектами данных, определение атрибутов и свойств объектов данных, маркирование создаваемыми автоматически тегами (автотегами) объектов данных на основе косвенных связей между объектами данных, маркирование автотегами объектов данных на основе атрибутов и свойств данных объектов, сохранение в базе данных полученных подлежащего, предиката, дополнения и промаркированных автотегами объектов, ранжирование объектов в соответствии с автотегами, определение области поиска на основе объектов данных, где область поиска представлена n-кортежными предикатами, ассоциирующимися с объектами данных, представление вариантов областей поиска для определенных областей поиска, получение запроса на поиск объектов данных в области поиска и поиск маркированных автотегами входных объектов данных в базе данных на основе графов с использованием предикатов и значений автотегов. 2 н. и 20 з.п. ф-лы, 9 ил.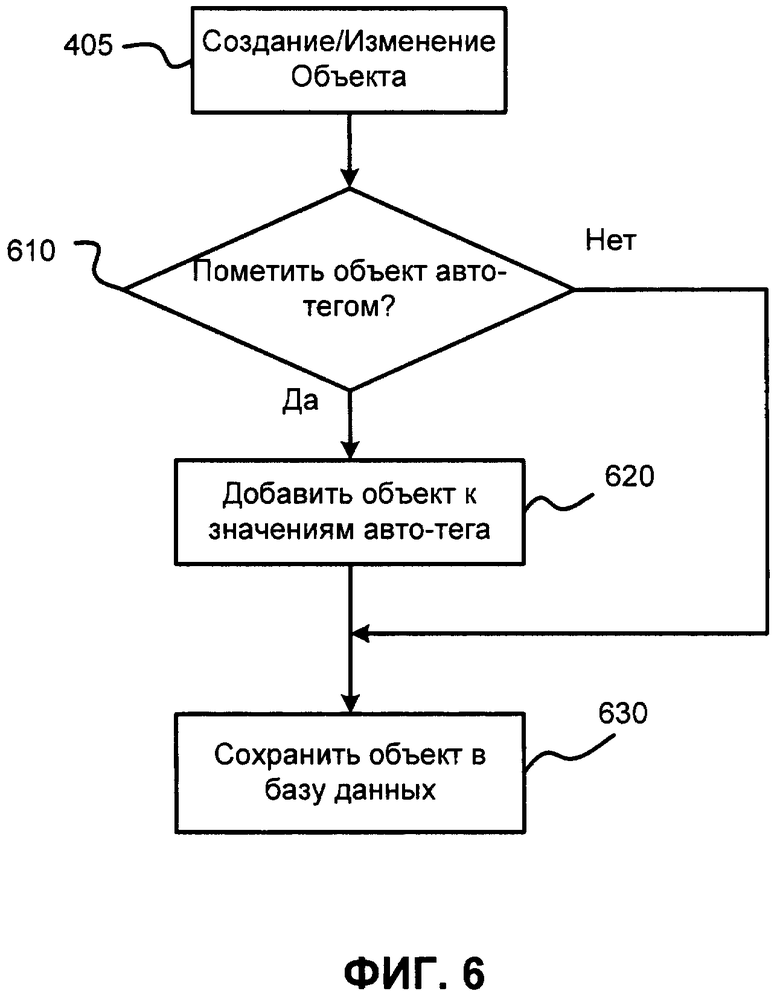
1. Внедренный в компьютер метод автоматического маркирования тегами объектов для их поиска и получения из базы данных на основе графов, включающий:
хранение входных данных, включая аксиомы, представляющие факты;
получение входных объектов данных и преобразование входных объектов данных в формат n-кортежа на основе контекста;
обработку аксиом для того, чтобы определить подлежащее, предикат и дополнение n-кортежа;
анализ объектов данных и определение косвенных связей между объектами данных; определение атрибутов и свойств объектов данных;
маркирование создаваемыми автоматически тегами (автотегами) объектов данных на основе косвенных связей между объектами данных;
маркирование автотегами объектов данных на основе атрибутов и свойств данных объектов;
сохранение в базе данных полученных подлежащего, предиката, дополнения и промаркированных автотегами объектов;
ранжирование объектов в соответствии с автотегами;
определение области поиска на основе объектов данных, где область поиска представлена n-кортежными предикатами, ассоциирующимися с объектами данных;
представление вариантов областей поиска для определенных областей поиска;
получение запроса на поиск объектов данных в области поиска; и
поиск маркированных автотегами входных объектов данных в базе данных на основе графов с использованием предикатов и значений автотегов.
2. Метод по п. 1, дополнительно включающий автоматическое маркирование объектов данных, основываясь на контексте.
3. Метод по п. 2, отличающийся тем, что контекст определяется соответствующими онтологиями и представляет собой окружающую среду объекта данных.
4. Метод по п. 3, отличающийся тем, что для одного объекта данных используется несколько онтологий.
5. Метод по п. 2, отличающийся тем, что контекст включает метод обработки аксиом на основе природы объекта данных.
6. Метод по п. 1, дополнительно включающий вычисление автотегов по требованию.
7. Метод по п. 1, отличающийся тем, что объекты данных представлены экземплярами классов.
8. Метод по п. 1, дополнительно включающий пропагацию автотегов для определения, как минимум, одного дополнительного предиката n-кортежа, который также участвует в поиске Объектов.
9. Метод по п. 8, отличающийся тем, что предикату автотега назначается вес и используется для поиска Объектов за пределами найденных предикатов автотегов.
10. Метод по п. 8, отличающийся тем, что вес описывает дерево Объектов.
11. Система для автоматического маркирования тегами объектов данных для поиска и получения из базы данных на основе графов, система, включающая:
источник данных, сконфигурированный для предоставления данных для обработки системой;
модуль обработки данных, сконфигурированный для перехвата и преобразования данных из источника данных в формат n-кортежа и обработки аксиом для того, чтобы определить подлежащее, предикат и дополнение n-кортежа; и
модуль обработки создаваемых автоматически тегов (автотегов), соединенный с модулем обработки данных и
сконфигурированный для получения запроса на обработку данных из модуля обработки данных,
а также для маркирования автотегами объектов данных на основе косвенных связей между объектами данных и на основе атрибутов и свойств данных объектов; и
модуль обработки объектов, соединенный с модулем обработки автотегов и (i) сконфигурированный для создания, удаления и редактирования Объектов, и (ii) также сконфигурированный для отправки, по крайней мере, одного запроса в модуль обработки авто-тегов для поиска объектов, и также (iii) сконфигурированный для преобразования действий с Объектами в n-кортеж;
и сохранения в базе данных полученных подлежащего, предиката, дополнения и промаркированных автотегами объектов;
где модуль обработки объектов включает фильтр событий для перехвата действий с объектами для использования в обработке автотегов; и
где данные включают аксиомы, представляющие факты; и
где:
модуль обработки данных выполняет поиск маркированных автотегами объектов данных;
и
модуль обработки данных выполняет поиск объектов данных на основе автотегов с использованием предикатов и значений автотегов.
12. Система по п. 11, отличающаяся тем, что модуль обработки автотегов сконфигурирован для выполнения любого из:
маркирование объектов данных автотегами на основе косвенных связей между объектами данных;
маркирование объектов данных автотегами на основе атрибутов и свойств объектов данных; и
ранжирование объектов данных в соответствии с автотегами.
13. Система по п. 11, отличающаяся тем, что n-кортеж является тройкой Среды Описания Ресурса (RDF).
14. Система по п. 13, отличающаяся тем, что тройка включает подлежащее, предикат и дополнение.
15. Система по п. 11, отличающаяся тем, что источник данных является RDF-графовой базой данных.
16. Система по п. 11, отличающаяся тем, что модуль обработки автотегов выполняет поиск маркированных автотегами объектов с использованием таксономии.
17. Система по п. 11, отличающаяся тем, что модуль обработки автотегов выполняет поиск маркированных автотегами объектов данных с использованием поискового запроса.
18. Система по п. 11, отличающаяся тем, что объекты данных представлены множеством экземпляров классов.
19. Система по п. 11, отличающаяся тем, что автотеги, предикаты автотегов и значения автотегов хранятся в ОЗУ.
20. Система по п. 13, отличающаяся тем, что объект данных определяется набором троек.
21. Система по п. 11, отличающаяся тем, что предикату автотега назначается вес и используется для поиска Объекта за пределами найденных предикатов автотегов.
22. Система по п. 11, отличающаяся тем, что вес описывает расстояние в дереве Объектов.
| СПОСОБ УСКОРЕНИЯ ОБРАБОТКИ МНОЖЕСТВЕННЫХ ЗАПРОСОВ ТИПА SELECT К RDF БАЗЕ ДАННЫХ С ПОМОЩЬЮ ГРАФИЧЕСКОГО ПРОЦЕССОРА | 2012 |
|
RU2490702C1 |
| US 7890518 B2, 15.02.2011 | |||
| US 8606807 B2, 10.12.2013 | |||
| US 8244772 B2, 14.08.2012. | |||

