Настоящее изобретение относится к способу и устройству для кодирования слов данных, как это необходимо, например, для передачи данных.
Простой записи данных из-за возможного возникновения ошибок при считывании или записи, как правило, недостаточно. Поэтому соответствующие данные обычно кодируются и записываются в кодированном виде. В частности, находят применение так называемые коды с коррекцией или обнаружением ошибок. При этом в кодируемом слове данных с использованием соответствующих алгоритмов определяются кодовое слово и контрольная сумма. При этом часто речь идет о данных, особенно релевантных для защиты, которые должны записываться в память с защитой.
В типичном случае применения конфиденциальное содержимое памяти электронной запоминающей среды, защищенной аппаратными средствами от несанкционированного считывания посторонними, защищается, например, с помощью кода с коррекцией ошибок от сбоев памяти, как, например, побитовые мутации (bitflips) и т.п. В качестве памяти с защитой от доступа используются, например, чип-карты или модули с защитой. При этом конфиденциальные данные, хранящиеся в памяти с защитой, интерпретируются как кодовые слова кода с коррекцией ошибок и расширяются для обнаружения или исправления ошибок на соответствующие контрольные суммы. Однако при этом по причине нехватки места в памяти необходимые контрольные суммы желательно хранить не в памяти, защищенной аппаратными средствами, а во второй, более экономичной памяти, не предоставляющей защиты от несанкционированного считывания посторонними.
Однако поскольку контрольные суммы, вычисленные для обнаружения и исправления ошибок, могут находиться в прямой связи с конфиденциальной информацией в кодовых словах, данные контрольных сумм, если никаких других защитных мер не предпринимается, допускают также выводы относительно защищаемой информации. При этом контрольные суммы, хотя они в общем случае не раскрывают информации, содержащейся в кодовых словах, полностью, с помощью частных соотношений, например линейных уравнений, все же могут позволить судить о защищаемых данных. Если в основной памяти, т.е. в памяти, защищенной от доступа, находятся данные, особенно нуждающиеся в защите, как, например, криптографические коды, и если такие данные хранятся вместе с другой известной информацией в общем кодовом слове, то в зависимости от соответствующего используемого способа исправления ошибок при известных условиях из контрольной суммы могут извлекаться также полноценные, особо защищаемые данные, как, например, полное содержимое кодов. Если контрольная сумма кодового слова состоит, например, из s байтов, то в неблагоприятном случае могут быть вычислены также s байтов кода. Поэтому для обеспечения конфиденциальности таких данных необходимы дополнительные меры.
В прошлом предлагалось, например, использование технологий кодирования. При этом семантически надежный способ кодирования имеет то свойство, что нарушитель не в состоянии различать коды блоков данных одинаковой длины, даже если он заранее выбрал кодируемые блоки данных. Поэтому коды, как правило, не дают нарушителю никакой полезной информации о кодируемых данных.
Возможность такого же обеспечения конфиденциальности контрольных сумм для обнаружения или коррекции ошибок состоит в явном кодировании вычисленных контрольных сумм и в записи в принципиально доступной памяти или в областях памяти. Это означает, что после генерирования контрольных сумм для защищаемых данных полученная контрольная сумма кодируется соответствующим криптографическим способом, а перед каждой проверкой кодового слова контрольная сумма снова декодируется.
Однако при таком подходе имеет место ряд недостатков. Дополнительные этапы кодирования при вычислении или декодирования при проверке кодовых слов требуют необходимых дополнительных вычислений, что отрицательно сказывается особенно тогда, когда контроль кодовых слов должен осуществляться с регулярными интервалами.
Кроме того, соответствующие способы кодирования и декодирования должны реализовываться таким образом, чтобы они не ухудшали обнаруживающих и корректирующих свойств используемого кода.
Способы кодирования и декодирования не должны позволять делать выводы относительно зависимостей между различными контрольными суммами. Например, при использовании побитового кодирования для кодирования контрольных сумм абсолютно необходимо пользоваться рандомизированным способом кодирования и при каждом кодировании применять новые инициализирующие векторы. Кроме того, используемые коды должны храниться в памяти с защитой, что увеличивает потребность в памяти.
В порядке альтернативы было предложено декодировать содержание данных. При таком подходе данные, защищаемые от ошибок, перед кодированием и вычислением контрольных сумм кодируются способом кодирования. При этом данные не обязательно должны записываться в кодированном виде. Может быть достаточно временно закодировать данные только для вычисления или контроля кодовых слов, в противном же случае записать их открытым текстом в памяти с защитой. Однако при этом недостаток заключается в необходимости дополнительных этапов кодирования при вычислении или по декодирования при контроле кодовых слов и дополнительных вычислений. Кроме того, используемые коды должны храниться в памяти с защитой.
Таким образом, задача изобретения состоит в создании усовершенствованного способа кодирования данных.
Эта задача решается способом согласно пункту 1 формулы изобретения.
В соответствии с этим предусмотрен способ кодирования слова данных, причем слово данных построено из заданного числа символов случайных данных и заданного числа символов полезных данных. Для слова данных вычисляется контрольная сумма с заданным числом контрольных символов. При этом число символов случайных данных соответствует числу контрольных символов контрольной суммы.
Как было показано вначале, контрольные суммы появляются, в частности, в способах обнаружения или исправления ошибок, так что согласно изобретению ни в каком явном кодировании или декодировании данных необходимости нет. Конфиденциальность данных может быть уже обеспечена использованием случайных данных и выбором числа символов случайных данных в зависимости от вычисления контрольной суммы. Под кодом или кодированием ниже понимается генерирование кодового слова и контрольной суммы на основе кодирования слова данных. В результате использования математических свойств, например соответственно реализуемого кода с обнаружением или коррекцией ошибок, достигается защита защищаемых данных в неявном виде. Благодаря введению случайных данных эти случайные символы появляются при вычислении контрольной суммы, так что даже при знании контрольной суммы, хранящейся, например, в области памяти с незащищенной записью, сделать вывод относительно содержания полезных данных невозможно. В этом смысле способ даже не представляет собой никакого кодирования, поскольку длина вычисленных контрольных сумм в большинстве случаев заметно меньше длины защищаемых полезных данных, и поэтому в общем случае никакой однозначной связи между вычисленной контрольной суммой и защищаемыми данными не существует.
Контрольная сумма предпочтительно вычисляется способом вычисления контрольных сумм кодов с коррекцией и/или с обнаружением ошибок. При этом речь идет о ряде кодов и способов кодирования, как, например, о кодах Боуза-Чаудари-Хокуенгхема (BCH - Bose-Chaudyuri-Hocquenghem), Рида-Соломона (RS), циклического избыточного контроля (CRC - Cyclic Redundancy Check) или Хемминга. Соответствующая функция вычисления контрольной суммы является предпочтительно инъективным отображением символов случайных данных на контрольных символах. В результате энтропия, обусловленная случайными данными, сохраняется и в контрольной сумме независимо от конкретного выбора символов полезных данных.
Символы случайных данных могут быть предусмотрены, например, в заданных разрядах слова данных. При этом соответствующие символы данных, как, например, биты или байты, могут быть предусмотрены во взаимосвязи или же в отдельных областях слова данных.
В одном из вариантов способа при изменении символов полезных данных заново генерируются и символы случайных данных. Таким образом, создается дополнительная надежность.
Символы полезных и случайных данных предпочтительно хранятся в области памяти, защищенной от доступа. Область памяти, защищенная от доступа, при считывании из защищенной области памяти может быть реализована с помощью чип-карты или особых механических или электронных механизмов. Контрольные символы, напротив, могут храниться в незащищенной области памяти. Поскольку при знании контрольной суммы, состоящей из контрольных символов, сделать вывод относительно полезных данных невозможно, то при хранении контрольной суммы можно сэкономить на более дорогостоящем ЗУ, например на ЗУ, оборудованном защитой от доступа.
Кроме того, символы полезных данных предпочтительно хранятся в связной области памяти, а символы случайных данных - по меньшей мере в одной прилегающей области памяти. Таким образом, для кодирования согласно изобретению могут быть использованы соседние символы случайных данных. Символы полезных данных, составляющих часть кодируемого слова данных, могут например, располагаться последовательно, так что сначала выступает определенное число кодируемых символов данных, а затем некоторое число символов случайных данных. Однако различные символы данных могут также появиться и использоваться в другой последовательности. Память таким, например, образом разделена, например, на блоки, в которые сохраняются (записываются) случайные данные, так что кодирование, а тем самым генерирование защищенной контрольной суммы может осуществляться просто.
Кроме того, изобретение предусматривает устройство для кодирования слов данных с признаками пункта 10 формулы изобретения.
Это устройство содержит блок управления, оборудованный таким образом, что для кодирования слова данных реализуется соответственно предписанный способ.
Устройство может быть реализовано, например, с помощью программного обеспечения путем соответствующего программирования микропроцессора.
Предпочтительно устройство предусмотрено с генератором случайных символов, который генерирует символы случайных данных. Кроме того, устройство может содержать вычислительный блок для контрольных сумм, вычисляющий контрольную сумму соответствующего слова данных. Кроме того, особый вариант выполнения устройства содержит запоминающее устройство, в областях памяти которого хранятся символы случайных данных, контрольные символы или символы полезных данных. При этом для символов случайных и полезных данных предпочтительно предусмотрена область памяти, защищенная от доступа.
Наконец, изобретение относится к компьютерному программному продукту, инициирующему осуществление соответствующего способа кодирования слов данных процессором с программным управлением. В качестве процессора с программным управлением может быть использован персональный компьютер, на котором установлено соответствующее программное обеспечение и который содержит интерфейсы для накопления кодированных данных и контрольных сумм. Компьютерный программный продукт может быть реализован в виде носителя данных, например USB-карты (USB-Stick), гибкого магнитного диска (Floppy-Disc), CDROM, DVD или же на сервере в виде разгружаемого программного файла.
Другие предпочтительные варианты выполнения изобретения являются предметом зависимых пунктов формулы изобретения, а также описанных ниже примеров выполнения изобретения. В дальнейшем изобретение более подробно поясняется на основе предпочтительных вариантов выполнения со ссылкой на сопровождающие чертежи, на которых:
фиг.1 изображает кодированное слово данных,
фиг.2 - кодированные слова данных согласно варианту способа кодирования,
фиг.3 - пример блок-схемы программы варианта способа кодирования слов данных,
фиг.4 - блок-схема варианта выполнения устройства для кодирования слов данных и
фиг.5 - несколько кодируемых слов данных.
На фигурах, если никаких других указаний нет, одинаковые или функционально одинаковые элементы обозначены одними и теми же позициями.
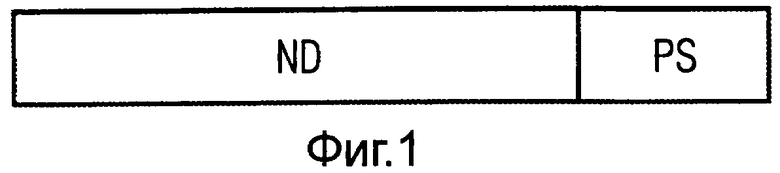
На фиг.1 изображено закодированное слово с полезными данными ND и с контрольной суммой PS. При этом полезные данные включают, например, заданное число битов или байтов данных, а контрольная сумма определена числом, например, контрольных битов. Кодовое слово, изображенное на фиг.1, могло бы быть получено с помощью кодов BCH или RS.
Ниже полагается код с параметрами (n, k, d), причем n - длина кодового слова, k - длина кодированных слов данных и d - минимальное расстояние между кодовыми словами. Через f обозначено отображение, которое слову данных w = (w0, …, wk-1) длиной k ставит в соответствие подходящую контрольную сумму s длиной n-k соответствующего кодового слова, как это схематически показано на фиг.1.
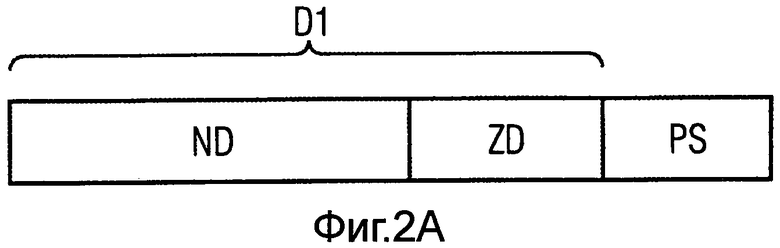
На фиг.2 для иллюстрации варианта предложенного способа кодирования слов данных показаны изображения кодируемых слов данных и кодов. На фиг.2а сначала предусмотрено слово D1 данных, содержащее заданное число символов полезных данных, как, например, битов данных ND. Кроме того, в слове D1 данных предусмотрены биты случайных данных ZD. Отправным моментом является то, что используется способ кодирования, который ставит контрольную сумму s длиной n-k символов в соответствие подходящему кодовому слову.
На фиг.2В также изображено слово D1 данных с соответствующей контрольной суммой PS или контрольными символами, причем, однако, полезные данные ND1, ND2, ND3 не взаимосвязаны, а разбиты на подобласти. Между ними расположены разряды в слове D1 данных, в которых предусмотрены биты случайных данных или символы ZD1, ZD2, ZD3 случайных данных. При этом число символов случайных данных соответствует числу символов, необходимых для контрольной суммы PS. Случайных символов может быть даже больше, чем контрольных символов.
На фиг.3 в качестве примера схематически изображена блок-схема программы для кодирования слов данных. При этом исходным является прежде всего слово данных на этапе S1.
В варианте способа кодирования для используемого кода выбираются n-k позиций символов данных 0 ≤ i1 ‹ … ‹ in-k ‹ k слова данных D и перед вычислением контрольной суммы s описываются случайными величинами, или случайными символами (этап S2). Полученное таким образом слово данных D´ записывается в защищенной памяти соответствующей запоминающей среды, а соответствующая вычисленная контрольная сумма S с соответствующими символами контрольных сумм PS записывается в незащищенной памяти.
Согласно блок-схеме на фиг.3 на этапе S3 производится вычисление контрольных сумм. При этом в качестве возможного полуэтапа S3A указывается дальнейшее кодирование уточненных с помощью символов случайных данных символов полезных данных кодируемого слова данных. Вычисление контрольных сумм происходит на этапе, обозначенном как S3B, согласно соответственно используемому способу. При этом может быть, например, применен способ с использованием кода Рида-Соломона (RS). Коды Рида-Соломона являются циклическими кодами и образуют подкласс кодов BCH. Коррекция ошибки кодов Audio происходит, например, с использованием кода Рида-Соломона. Коды RS находят также применение в цифровой мобильной радиосвязи или цифровом телерадиовещании. Затем на основе контрольной суммы могут быть, соответственно, восстановлены биты или байты, поврежденные при передаче или записи. Само собой разумеется, что использованы могут быть и другие известные способы кодирования.
На этапе записи S4 показано, что, с одной стороны, на полуэтапе S4A записывается кодовое слово, а с другой стороны, на полуэтапе S4B символы контрольных сумм записываются в качестве контрольной суммы. При этом символы контрольных сумм записываются предпочтительно в области памяти без дополнительной защиты. Однако кодовые слова, чувствительные в отношении защищенности, которые в соответствии со способом все же содержат также рандомизированные, т.е. случайные, символы, напротив, записываются в особо защищенной памяти или области памяти. Контрольная сумма может быть записана на обычной плате памяти, как, например, во флэш-памяти (Flash), а полезные и случайные данные - на специальной чип-карте.
Способ может найти, например, применение, когда в словах данных должны записываться данные, релевантные для защиты. Например, это имеет место, когда используются электронные тахографы. При этом релевантной для защиты считается, например, соответствующая информация тахоспидографа, которая не должна подвергаться манипуляциям. При этом полученные данные о водителе должны записываться на персональной карточке водителя, выполненной на чип-карте с памятью с защитой. Контрольные суммы, также полученные при записи и связанным с ней кодированием, напротив, могут записываться в менее чувствительном или в защищенном запоминающем устройстве.
В предложенном способе кодирования слов данных используется свойство функции f, определенной положенным в основу способом кодирования и генерирования контрольной суммы. Если функция f для вычисления контрольной суммы S = f(D´), в частности, имеет то свойство, что она для любых, но определенно выбранных комбинаций символов в 2k-n из i1, …, in-k различных позиций является инъективным отображением с n-k неизвестными, то вычисленная сумма S не содержит для потенциального нарушителя никакой приемлемой информации о закодированном слове D´ данных.
В результате заполнения n-k позиций i1, …, in-k слова D´ данных случайными символами энтропия источника полученных таким образом слов данных составляет n-k символов. При этом инъективность функции f с неопределенными в n-k позициях i1, …, in-k обеспечивает сохранение этой энтропии при вычислении контрольной суммы S. Это не зависит от конкретных символов в остальных 2k-n позициях. При этом вычисленная контрольная сумма S в информационно-техническом смысле не содержит никакой информации о символах в остальных позициях кодового слова D´.
Случайные символы в n-k позициях i1, …, in-k перекрывают в контрольной сумме информацию об остальных 2k-n символах данных.
Чтобы теперь обезопасить области памяти, содержащие особо защищаемые данные, как, например, криптографические коды системы, от нарушения конфиденциальности из-за откачивания контрольных сумм, в блоках длины k перед вычислением контрольных сумм соответствующие n-k позиции i1, …, in-k каждого блока резервируются и описываются случайными символами. При любом изменении информационного содержания блоков символы в этих позициях перед вычислением контрольных сумм должны снова переписываться со случайными символами.
В результате описанного подхода конфиденциальность данных гарантируется без необходимости в явном кодировании и декодировании. Обеспечение конфиденциальности защищаемых данных в неявном виде достигается лишь за счет применения определенных математических свойств используемого кода с обнаружением и коррекцией ошибок. Необходимо только выполнить обычные алгоритмические этапы для вычисления или контроля кодовых слов. Обеспечение конфиденциальности контрольных сумм достигается в неявном виде. Таким образом, описанный способ реализуется весьма эффективно.
Для достижения информационно-технической надежности способа согласно изобретению достаточно того, чтобы энтропия введенных случайных символов была больше или равна энтропии вычисленных с ними контрольных сумм. Таким образом, достигается более высокая надежность, чем при семантических способах кодирования.
Способ требует лишь, чтобы выбранные области перед вычислением контрольных сумм описывались случайными величинами. Этот этап может осуществляться, например, при инициализации прибора, реализующего способ кодирования, когда, например, пускаются в ход криптографические коды. В частности, нет необходимости ни в каких дополнительных блоках программы для функции кодирования и декодирования или дифференциации случаев обработки защищаемых данных. При этом нет нужды ни в предварительных, ни в последующих вычислительных операциях, как нет необходимости в модификации стандартных программ кодирования или декодирования.
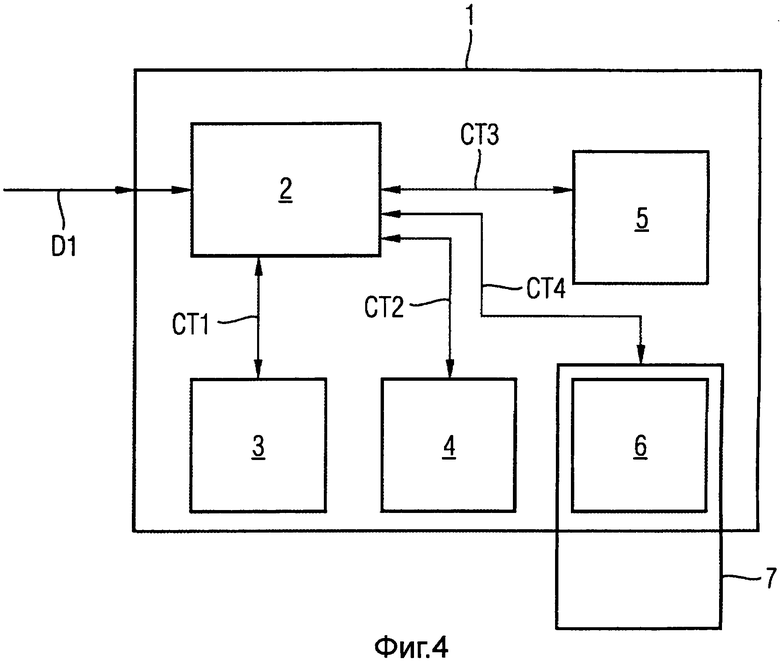
На фиг.4 показана блок-схема программы примера устройства, подходящего для осуществления способа кодирования. При этом устройство 1 содержит блок 2 управления, принимающий соответствующее слово D´ данных, например, через внешний интерфейс. Кроме того, кодирующее устройство 1 содержит генератор 3 контрольных сумм, генератор 4 случайных символов, а также запоминающие устройства 5 и 6. Блок 2 управления с помощью, например, соответствующей информационной шины соединен с генератором 3 контрольных сумм, генератором 4 случайных символов и запоминающими устройствами 5, 6.
Блок 3 управления координирует соответствующее генерирование контрольных сумм и случайных символов, а также запись в различные области памяти. При этом запоминающее устройство 5 выполнено в качестве обычной памяти без защиты от доступа. Второе запоминающее устройство 6 может быть выполнено, например, как часть чип-карты, обозначенной позицией 7. Чип-карта 7, содержащая запоминающее устройство 6 с защитой от доступа, может быть встроена, например, в сменный блок кодирующего устройства 1.
Кодирующее устройство 1 со своими соответствующими элементами 2, 3, 4, 5, 6 может быть также компьютеризировано, причем отдельные блоки 2, 3, 4, 5, 6 могут рассматриваться как соответствующие блоки программы. При работе кодирующего устройства 1 выполнение вышеописанных стадий технологического процесса координируется, например, блоком 2 управления.
В результате в запоминающих устройствах 5 и 6 хранятся закодированные данные, конфиденциальность которых может быть гарантирована.
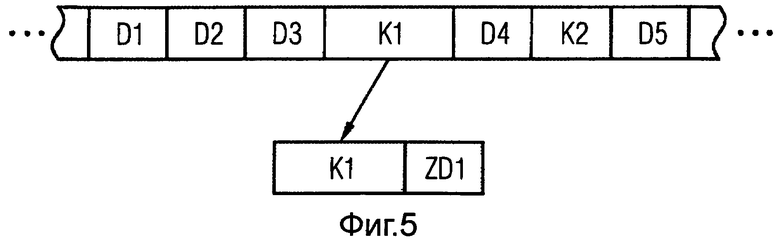
Чтобы защитить от ошибок большую область памяти соответствующая область памяти обычно разбивается на подобласти выбранной длины, и для каждой подобласти вычисляется и записывается соответствующая контрольная сумма. Если теперь подобласть включает информационное содержимое, конфиденциальность которого подлежит особой защите, как, например, криптографический код, то для осуществления способа согласно изобретению достаточно, чтобы до и/или после данных, конфиденциальность которых должна быть обеспечена, вводится область памяти со случайными данными. Это проиллюстрировано на фиг.5.
При этом изображены слова D1-D3, К1, K2 и D5 данных. Слова К1 и K2 данных имеют, например, особые релевантные для защиты криптографические коды. Слова данных, изображенные на фиг.5 в качестве примера, могут восприниматься также как области данных, в которых предусмотрены соответствующие слова данных. При этом области К1 и K2 следует рассматривать как подлежащие особой защите.
На фиг.5 в качестве примера на основе области К1, подлежащей защите, проиллюстрировано добавление случайных данных ZD1. В результате добавления символов ZD1 случайных чисел при в противном случае обычном кодировании с помощью кодов BCH, CRC или RS получаются слово кода, а также соответствующая сумма. В процессе кодирования фиксируются как кодируемое слово данных, так и символы случайных данных. На основе добавленных случайных данных или рандомизирования в областях кодируемого слова данных могут отдельно записываться контрольная сумма и получающиеся кодированные полезные данные, причем даже при знании контрольной суммы нет никакой опасности нарушения конфиденциальности закодированных данных. Само собой разумеется, что отдельные области могут быть предусмотрены с дополнительными рандомизированными данными. Для защиты области К2 она должна быть соответствующим образом расширена за счет добавления символов случайных данных.
Если особо защищаемая область перекрывает несколько кодовых слов, то во все используемые кодовые слова должны быть введены области памяти с дополнительными данными соответствующей длины.
Хотя настоящее изобретение подробно пояснялось на основе предпочтительных вариантов выполнения, оно не ограничено этим, а может быть модифицировано с разных сторон. В частности, указанные способы кодирования с генерацией контрольных сумм следует понимать лишь как пример, а не как заключение. Указанные примеры используемых защищенных и незащищенных областей памяти приведены не в качестве окончательных.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ЗАЩИТЫ ДОСТУПНОСТИ И КОНФИДЕНЦИАЛЬНОСТИ ХРАНИМЫХ ДАННЫХ И СИСТЕМА НАСТРАИВАЕМОЙ ЗАЩИТЫ ХРАНИМЫХ ДАННЫХ | 2014 |
|
RU2584755C2 |
| СПОСОБ КОНТРОЛЯ ЦЕЛОСТНОСТИ ДАННЫХ НА ОСНОВЕ НЕРАВНОМЕРНОГО КОДИРОВАНИЯ | 2023 |
|
RU2808759C1 |
| СПОСОБ И СИСТЕМА РАСПРЕДЕЛЕННОГО ХРАНЕНИЯ ВОССТАНАВЛИВАЕМЫХ ДАННЫХ С ОБЕСПЕЧЕНИЕМ ЦЕЛОСТНОСТИ И КОНФИДЕНЦИАЛЬНОСТИ ИНФОРМАЦИИ | 2017 |
|
RU2680350C2 |
| СПОСОБ КОДИРОВАНИЯ-ДЕКОДИРОВАНИЯ ИНФОРМАЦИИ В СИСТЕМАХ ПЕРЕДАЧИ ДАННЫХ | 2005 |
|
RU2310273C2 |
| СПОСОБ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ЦИФРОВОЙ ИНФОРМАЦИИ В ВИДЕ УЛЬТРАСЖАТОГО НАНОБАР-КОДА (ВАРИАНТЫ) | 2013 |
|
RU2656734C2 |
| СПОСОБ КОДИРОВАНИЯ-ДЕКОДИРОВАНИЯ КАСКАДНОЙ КОДОВОЙ КОНСТРУКЦИИ В СИСТЕМАХ ПЕРЕДАЧИ ДАННЫХ | 2009 |
|
RU2420870C1 |
| СПОСОБ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ДАННЫХ ДЛЯ СИСТЕМЫ РАДИОВЕЩАТЕЛЬНОЙ ПЕРЕДАЧИ ЦИФРОВЫХ СООБЩЕНИЙ | 1994 |
|
RU2110148C1 |
| ЗАЩИТА ОТ ПАССИВНОГО СНИФФИНГА | 2011 |
|
RU2579990C2 |
| СПОСОБ ВОССТАНОВЛЕНИЯ ЗАПИСЕЙ В ЗАПОМИНАЮЩЕМ УСТРОЙСТВЕ, СИСТЕМА ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ И МАШИНОЧИТАЕМЫЙ НОСИТЕЛЬ | 2010 |
|
RU2448361C2 |
| КОДЕК ПОМЕХОУСТОЙЧИВОГО ЦИКЛИЧЕСКОГО КОДА | 2003 |
|
RU2251210C1 |
Изобретение относится к технике связи и предназначено для кодирования слов данных. Технический результат - повышение точности кодирования. В способе кодирования слова (D1) данных с заданным числом символов случайных данных (ZD) и заданным числом символов полезных данных (ND) для слова (D1) данных вычисляется контрольная сумма с заданным числом контрольных символов (PS), а число символов случайных данных (ZD) соответствует числу контрольных символов (PS) контрольной суммы. 3 н. и 12 з.п. ф-лы, 6 ил.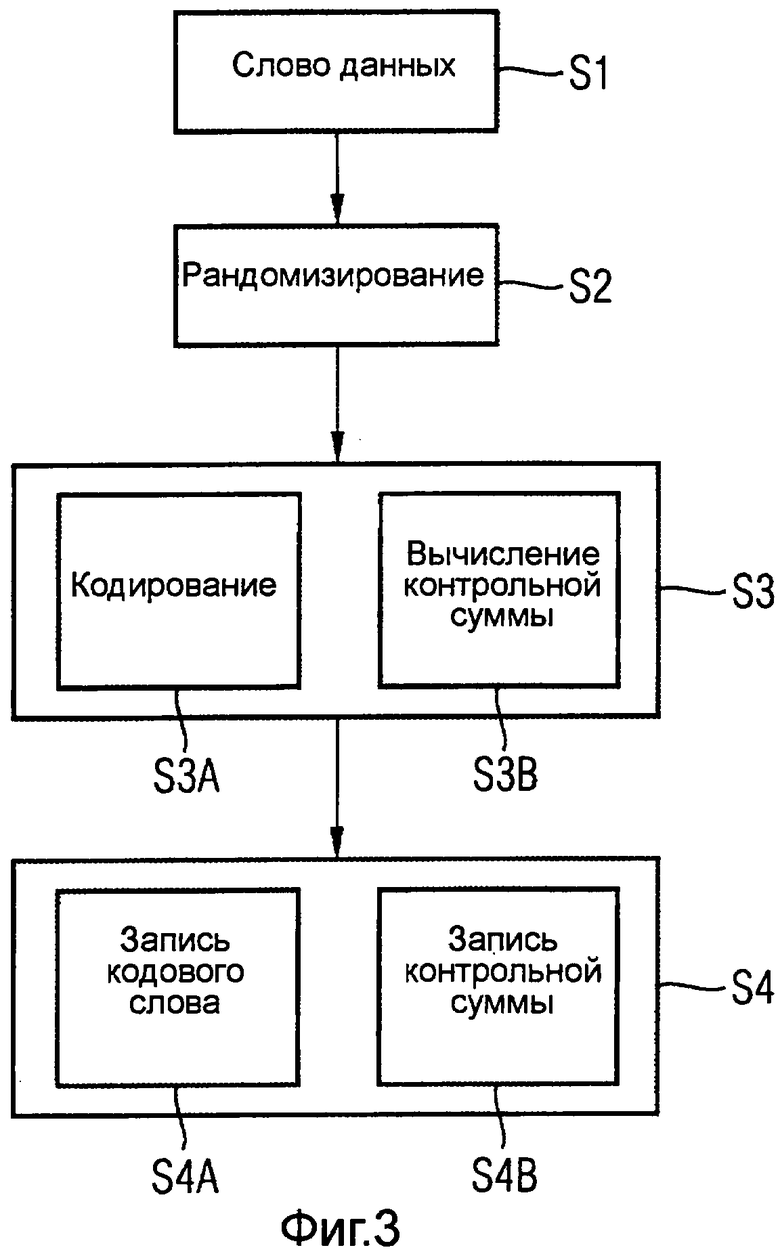
1. Способ кодирования слова (D1) данных с заданным числом символов случайных данных (ZD) и заданным числом символов полезных данных (ND), причем для слова (D1) данных вычисляется контрольная сумма с заданным числом контрольных символов (PS), а число символов случайных данных (ZD) соответствует, по меньшей мере, числу контрольных символов (PS) контрольной суммы, отличающийся тем, что функция f, используемая для вычисления контрольной суммы S=f(D'), имеет свойство, состоящее в том, что она для любых, но определенно выбранных комбинаций символов в 2k-n из i1,…, in-k различных позиций имеет инъективное отображение с n - k неизвестными в позициях i1,…, in-k.
2. Способ по п.1, в котором контрольная сумма вычисляется способом вычисления контрольных сумм кодов с коррекцией и/или обнаружением ошибок, в частности, кодов ВСН, Рида-Соломона, CRC или Хемминга.
3. Способ по п.1 или 2, в котором для вычисления контрольной суммы используется функция, которая для любой произвольно заданной интерпретации символов полезных данных (ND) является инъективным отображением символов случайных данных (ZD) на контрольных символах (PS).
4. Способ по п.1, в котором заданные разряды слова (D1) данных описаны символами случайных данных (ZD).
5. Способ по п.1, в котором при изменении символов полезных данных (ND) снова генерируются символы случайных данных (ZD).
6. Способ по п.1, в котором символы полезных данных (ND) и символы случайных данных (ZD) сохраняются в области (6) памяти с защитой от доступа.
7. Способ по п.1, в котором контрольные символы (PS) сохраняются в области (6) памяти без защиты от доступа.
8. Способ по п.1, в котором символами являются биты или байты данных.
9. Способ по п.1, в котором символы полезных данных (ND) сохраняются в ассоциированной области памяти, а символы случайных данных (ZD), по меньшей мере, в одной смежной области памяти.
10. Устройство (1) для кодирования слов (D1) данных с блоком (2) управления, выполненным с возможностью осуществления способа по одному из пп.1-9.
11. Устройство (1) по п.10, в котором предусмотрен генератор (4) случайных символов, генерирующий символы случайных данных (ZD).
12. Устройство (1) по п.10 или 11, в котором предусмотрен генератор (3) контрольных сумм, вычисляющий контрольную сумму каждого слова (D1) данных.
13. Устройство (1) по п.10, в котором предусмотрено запоминающее устройство (5, 6), сохраняющее в областях памяти символы случайных данных (ZD), контрольные символы (PS) и символы полезных данных (ND).
14. Устройство (1) по п.13, в котором для символов полезных данных (ND) и символов случайных данных (ZD) предусмотрена область памяти с защитой от доступа.
15. Машиночитаемый носитель, на котором сохранен компьютерный программный продукт, который при выполнении процессором с программным управлением побуждает процессор осуществлять способ по одному из пп.1-9.
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| СПОСОБ КОДИРОВАНИЯ МНОГОСЛОВНОЙ ИНФОРМАЦИИ ПУТЕМ ИНТЕРЛИВИНГА ПРИ СЛОВООБРАЗОВАНИИ И ЗАЩИТЫ ОТ ОШИБОК С ПОМОЩЬЮ КЛЮЧЕЙ ОПРЕДЕЛЕНИЯ МЕСТОПОЛОЖЕНИЯ, ПОЛУЧАЕМЫХ ИЗ ВЫСОКОЗАЩИЩЕННЫХ СЛОВ И УКАЗЫВАЮЩИХ НА СЛАБОЗАЩИЩЕННЫЕ СЛОВА, СПОСОБ ДЕКОДИРОВАНИЯ ТАКОЙ ИНФОРМАЦИИ, УСТРОЙСТВО ДЛЯ КОДИРОВАНИЯ И/ИЛИ ДЕКОДИРОВАНИЯ ТАКОЙ ИНФОРМАЦИИ И НОСИТЕЛЬ, СНАБЖЕННЫЙ ТАКОЙ ИНФОРМАЦИЕЙ | 1998 |
|
RU2224358C2 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| US 6671851 B1, 30.12.2003. | |||

