Предлагаемый способ относится к области оптического распознавания текста и, в частности, к анализу информации растрового изображения, полученного из оптического сканирующего устройства или иным путем.
Известные способы анализа информации включают сегментирование информации на области, сегментирование областей на более мелкие объекты - области, нетекстовые объекты (картинки), таблицы, строки, слова, символы и т.д., с последующей специальной обработкой объектов.
Известны способы предварительного анализа, состоящего в устранении искажений и помех определенных видов в растровом изображении (например, патент США №5594815 January 14, 1997). Быстродействие таких способов зависит от числа искажений и помех. Для каждой разновидности дефектов изображения предлагается единственный способ обработки.
Другая группа известных способов предлагает для анализа новые способы обработки сегментированных объектов и областей - разной степени точности, требующих разного объема вычислительных ресурсов (например, патент США №6205261, March 20, 2001).
Такие способы не всегда достаточно универсальны, они не позволяют изменять производительность обработки в зависимости от состава документа.
Существует способ, предполагающий как основной режим однократную обработку документа, использующий возможность повторной обработки как дополнительную в случае обнаружения некорректности в операциях при первом сеансе (патент США №5717794, February 10, 1998). Критерием некорректности является изменение значения длины цепочки символов, предположительно составляющих строку, после первичной обработки. При этом никакой дополнительной информации не используют, а только заново обрабатывают измененные строки теми же средствами анализа.
Технический результат состоит в увеличении производительности процесса анализа растрового изображения без снижения его качества, повышении защищенности от помех, повышении корректности анализа.
Известен способ, при котором из всего анализируемого изображения выделяют области, содержащие помехи. Затем специальными способами устраняют помехи. Такой способ реализован в патенте США №5590224 December 31, 1996. Указанный способ не подразумевает сбора и использования дополнительной информации для анализа, что значительно снижает точность и корректность способа.
Предлагаемый для достижения заданного технического результата способ анализа информации растрового изображения отличается тем, что весь имеющийся набор способов для анализа растрового изображения предварительно разделяют на две или более группы, отличающиеся точностью и достоверностью результатов. Затем выполняют по крайней мере двухэтапный анализ, состоящий из предварительного анализа объектов, с применением низкоточных способов анализа, предварительным распознаванием недостаточно надежно выявленных объектов, а также объектов с помехами и сбором дополнительной информации, и одного или нескольких этапов углубленного анализа с применением более высокоточных способов анализа с учетом накопленной на предыдущих этапах дополнительной информации, повторного распознавания недостаточно надежно выявленных объектов, а также объектов с помехами и сбора дополнительной информации по результатам анализа.
Способы, имеющие низкую точность, обычно менее громоздки в вычислениях и требуют меньших вычислительных ресурсов. Более высокоточные способы требуют более значительных вычислительных ресурсов. Использование менее громоздких, но низкоточных способов требует меньших вычислительных ресурсов и позволяет сократить длительность вычислений и анализа.
Все имеющиеся в распоряжении способы анализа изображения предварительно подразделяют на несколько групп, отличающихся точностью.
Анализ растрового изображения выполняют в два или более этапа.
На первом этапе проводят предварительный анализ изображения с использованием самых низкоточных способов анализа.
Растровое изображение сегментируют на объекты - области, таблицы, фрагменты текста, строки, слова, символы.
После этого последовательно анализируют объекты и определяют среди них объекты, выявленные недостаточно надежно, а также объекты, имеющие текст с помехами для распознавания. Проводят предварительное распознавание недостаточно надежно выявленных объектов, а также объектов с помехами. Затем определяют объекты, выявленные с недостаточно надежными значениями характеристик.
Определяют объекты с помехами, недостаточно надежно и неправильно распознанные применяемыми на первом этапе способами и требующие для распознавания более точных способов.
Причем на первом этапе для анализа применяют самые низкоточные, но требующие меньше времени и вычислительных ресурсов на выполнение способы анализа.
Одновременно выполняют сбор дополнительной информации об объектах для повышения достоверности результатов анализа и последующего распознавания текста.
На втором этапе все действия выполняют с учетом полученной на предыдущем этапе дополнительной информации. При необходимости выполняют корректировку сегментирования объектов. Выполняют повторное распознавание недостаточно надежно выявленных объектов, а также объектов с помехами. Определяют объекты, выявленные с недостаточно надежными значениями характеристик. Определяют объекты с помехами, недостаточно надежно и правильно распознанные на втором этапе и требующие для распознавания более точных способов. Продолжают сбор дополнительной информации об объектах. В зависимости от уровня надежности результатов анализа объектов и распознавания объектов с помехами принимают решение о повторении этапа углубленного анализа с учетом накопленной дополнительной информации или об окончании анализа.
Причем на каждом последующем этапе применяют более точные способы анализа и более точные способы распознавания.
Анализ заканчивают, когда все объекты выявлены с заранее заданной степенью надежности, или когда удается распознать все объекты с заранее заданной степенью надежности или, независимо от результатов распознавания, когда применены самые точные способы и более точных в распоряжении нет.
По окончании анализа проводят окончательное распознавание текста.
Помехи могут выражаться в виде написания символа курсивом, в виде инверсного написания символа, в виде посторонних точек на изображении символа, в виде недостающих точек на изображении символа, в виде наклона изображения.
Анализ дополнительно может включать по крайней мере один этап по очищению изображения от помех.
В качестве дополнительной информации могут выступать соотношения геометрических характеристик символов в пределах строки или объекта, соотношения параметров символов в пределах строки, а также соотношения параметров символов в пределах одного или нескольких объектов.
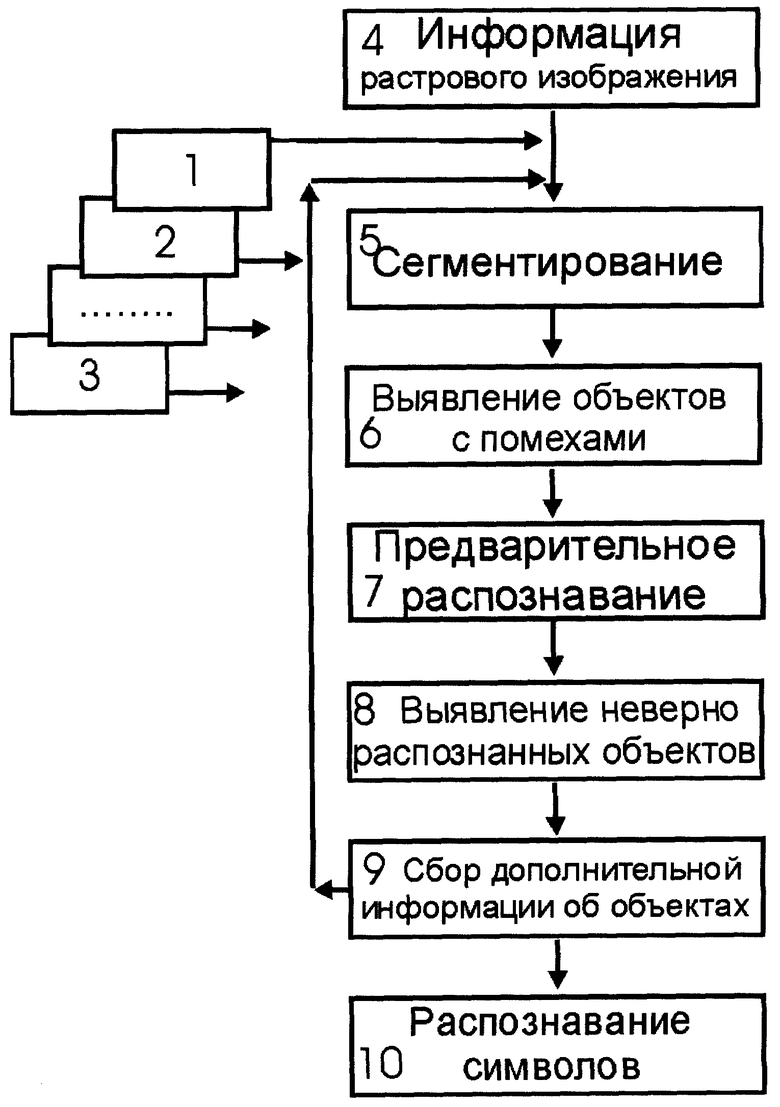
На чертеже показан перечень операций для реализации заявленного способа.
На первом этапе все имеющиеся в распоряжении способы анализа и распознавания разделяют на ряд групп (1), (2)-(3), отличающихся точностью. На чертеже набор самых низкоточных способов обозначен (1), набор самых высокоточных способов обозначен (3).
Первоначально информация растрового изображения (4) поступает на первичный анализ вместе с набором (1) низкоточных, но высокопроизводительных способов анализа и распознавания. Выполняются операции сегментирования (5) информации. Определяют недостаточно надежно выявленные объекты и объекты с помехами (6). Производят предварительное распознавание (7) недостаточно надежно выявленных объектов и объектов с помехами. Определяют объекты, выявленные с недостаточной надежностью. Определяют неверно или недостаточно достоверно распознанные объекты (8). Собирают всю появившуюся дополнительную информацию (9) о всех объектах и принимают решение о привлечении или непривлечении более точных способов для анализа и распознавания недостаточно надежно распознанных объектов и объектов с помехами.
Всю информацию направляют на повторный анализ, в котором анализируют все объекты с учетом полученной на предыдущем этапе дополнительной информации. Для анализа недостаточно надежно выявленных объектов или распознанных объектов с помехами привлекают более точные способы (2). Вновь выполняют операции сегментирования (5). Сегментирование на втором этапе анализа может не совпадать с сегментированием на первом этапе. Выявляют объекты с помехами (6). Выполняют повторное распознавание (7). Устанавливают перечень неверно выявленных или недостаточно верно распознанных объектов (8). Собирают дополнительную информацию, образовавшуюся на втором этапе (9), и принимают решение о продолжении или окончании анализа.
Анализ заканчивают, когда все объекты выявлены и распознаны с заранее установленной надежностью, или когда использованы (применены) самые точные средства анализа.
По окончании анализа переходят к окончательному распознаванию (10) всех символов и всего текста.
Изобретение относится к области оптического распознавания текста из растрового изображения. Его применение позволяет получить технический результат в виде увеличения быстродействия процесса анализа растрового изображения, защищенности от помех и корректности анализа. Этот результат достигается благодаря тому, что способ включает в себя следующие этапы: сегментирование изображения на объекты - области, фрагменты текста, изображения символов и распознавание символов. При этом предварительно весь набор применяемых средств анализа и распознавания подразделяют на группы, отличающиеся точностью результатов, затем выполняют многоэтапный анализ, состоящий по крайней мере из этапа предварительного анализа и сбора дополнительной информации и по крайней мере одного этапа углубленного анализа и сбора дополнительной информации. 11 з.п. ф-лы, 1 ил.
| СПОСОБ ИДЕНТИФИКАЦИИ ОБЪЕКТОВ | 1993 |
|
RU2037203C1 |
| US 6259812 А, 10.07.2001 | |||
| US 5761344 А, 02.06.1998 | |||
| Питательная среда для выращивания насекомых | 1974 |
|
SU513678A1 |
| Приспособление для точного наложения листов бумаги при снятии оттисков | 1922 |
|
SU6A1 |

