ОБЛАСТЬ ИЗОБРЕТЕНИЯ
[0001] Настоящее изобретение относится к области обработки изображений, а именно к обработке изображений с помощью технологии оптического распознавания символов (которое ниже именуется "OCR").
УРОВЕНЬ ТЕХНИКИ
[0002] Оптическое распознавание символов (OCR) представляет собой электронное преобразование отсканированных или сфотографированных изображений, либо машинописного или печатного текста в машиночитаемый текст в машинной кодировке. Современные технологии оптического распознавания символов активно используют обучение в качестве составной части всего процесса распознавания. Во время проведения оптического распознавания символов (OCR) создается эталон для распознавания, причем процесс обучения используется для улучшения полученного результата. Распознавание с обучением часто используется в том случае, если обрабатываемый текст содержит декоративные или специальные шрифты или специальные символы, такие как математические символы или символы редкого алфавита. Процесс обучения включает в себя создание системой пользовательских эталонов. В рамках процесса создания эталона изображения, которые должны составлять пары с символами, выявляются и предоставляются пользователю, при этом пользователю предлагается приписать соответствующие символы представленным изображениям. Такие изображения обычно получают из той части документа, которая предназначена для процесса обучения эталонов. Результаты обучения представляют собой получение множества эталонов для изображений, которые были выявлены в документе, использованном для процесса обучения. Созданное таким образом множество эталонов затем используется при распознавании основной части документа.
[0003] Также частью процесса оптического распознавания символов является верификация документа. Верификация улучшает качество распознавания символов путем исправления неточностей распознавания.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0004] Во время верификации документа пользователи часто сталкиваются с сериями однотипных ошибок, требующих внесения нескольких изменений результатов распознавания одного и того же изображения. Кроме того, при верификации с помощью специальных инструментов пользователь часто сталкивается с проблемой, когда система неоднократно запрашивает у него однотипные подтверждения символов, которые были распознаны с низкой степенью (оценкой) уверенности. Эта ситуация обычно возникает, когда в системе отсутствует эталон для данного конкретного изображения. В таких случаях пользователь вынужден вручную изменять неправильно распознанное изображение или подтверждать неуверенно распознанный символ, используя подходящий верный символ. Этот процесс может оказаться весьма продолжительным, особенно если количество распознанных страниц велико.
[0005] Как правило, отсутствие эталона, используемого для распознавания изображения, может быть компенсировано путем дополнительного обучения эталона в ходе процесса верификации. Возможность обучения эталона часто встраивается в систему распознавания (систему OCR). Однако пользователь может не знать о сущестовании возможности обучения эталона либо не знать, как использовать данную функцию. В связи с этим автоматическое оповещение пользователя о необходимости обучения эталона в процессе верификации может оказаться весьма полезным, что приводит к повышению общей точности распознавания.
[0006] Предлагаемый способ автоматизирует задачу распознавания, когда в процессе верификации необходимо организовать обучение используемого эталона. Кроме того, этот способ позволяет пользователям ознакомиться с процессом обучения эталона для распознавания документов, что повышает общую точность распознавания.
[0007] В связи с этим предлагаются способы, методы и системы для анализа выполненной пользователем верификации распознанного текста, полученного путем распознавания символов в изображении документа, для выявления однотипных изменений первого неправильного символа на первый правильный символ, и инициирования обучения эталона распознавания на основе выявленных аналогичных однотипных изменений. Подобная верификация включает замену определенного пользователем неправильного символа на определенный пользователем правильный символ, при этом эталоном распознавания является эталон, используемый для распознавания символов в изображении документа при получении распознанного текста.
[0008] В некоторых способах реализации выявление однотипных изменений включает отслеживание нескольких однотипных изменений первого неправильного символа на первый правильный символ в ходе верификации, а также определение того, что количество однотипных изменений первого неправильного символа на первый правильный символ достигло предварительно заданного порогового значения, причем инициирование обучения распознаванию эталона основано на определении того, что количество аналогичных изменений достигло предварительно заданного порогового значения. В некоторых способах реализации инициирование обучения эталона включает предоставление пользователю возможности инициировать такое обучение. В других способах реализации обучение эталона инициируется автоматически. В некоторых способах реализации система также производит повторное распознавание символов в изображении документа, или в непроверенной части данного изображения документа, на основании полученного эталона распознавания.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0009] Дополнительные цели, характеристики и преимущества настоящего изобретения будут раскрыты в приведенном ниже описании способов реализации изобретения со ссылкой на прилагаемые чертежи.
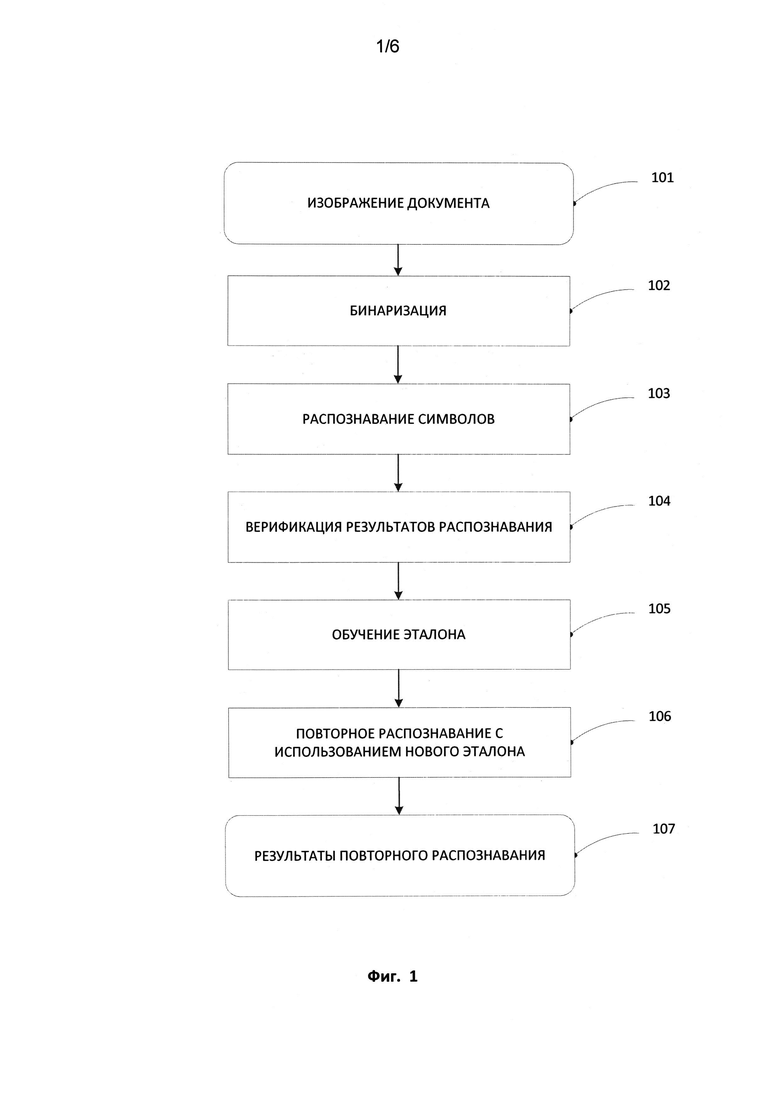
[0010] На Фиг. 1 продемонстрирована блок-схема, иллюстрирующая процесс распознавания изображения документа с процессом верификации и обучения эталона.
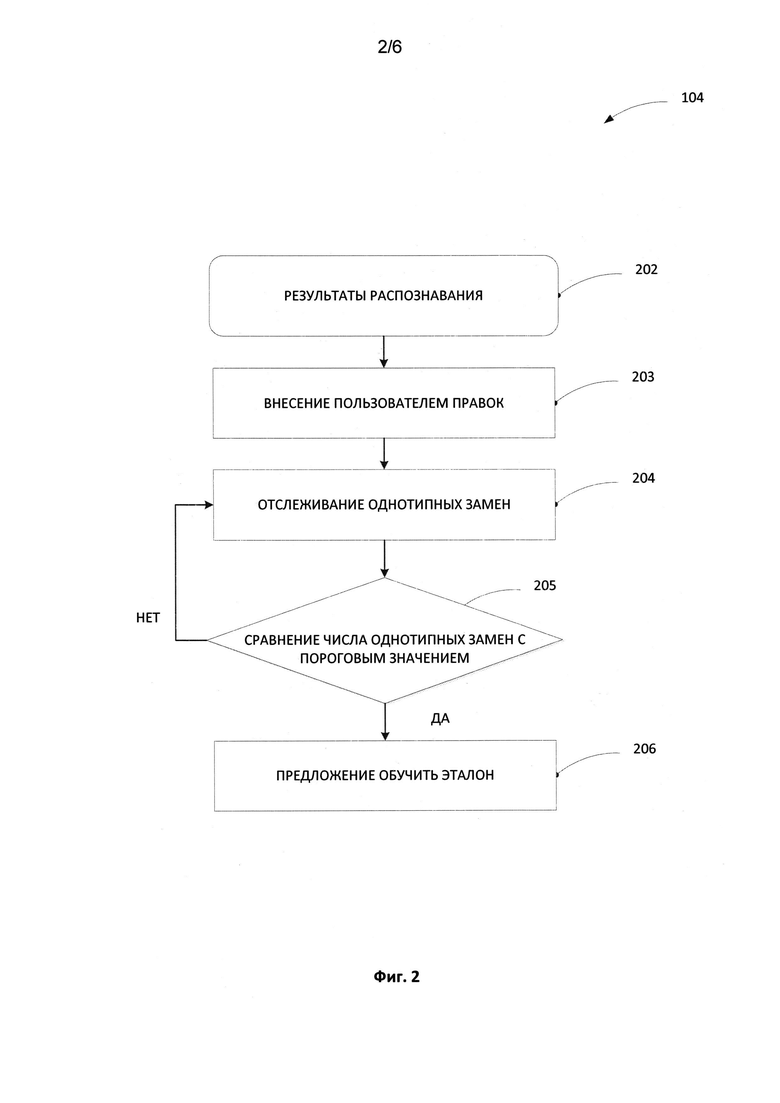
[0011] На Фиг. 2 продемонстрирована блок-схема, иллюстрирующая процесс верификации распознанного текста.
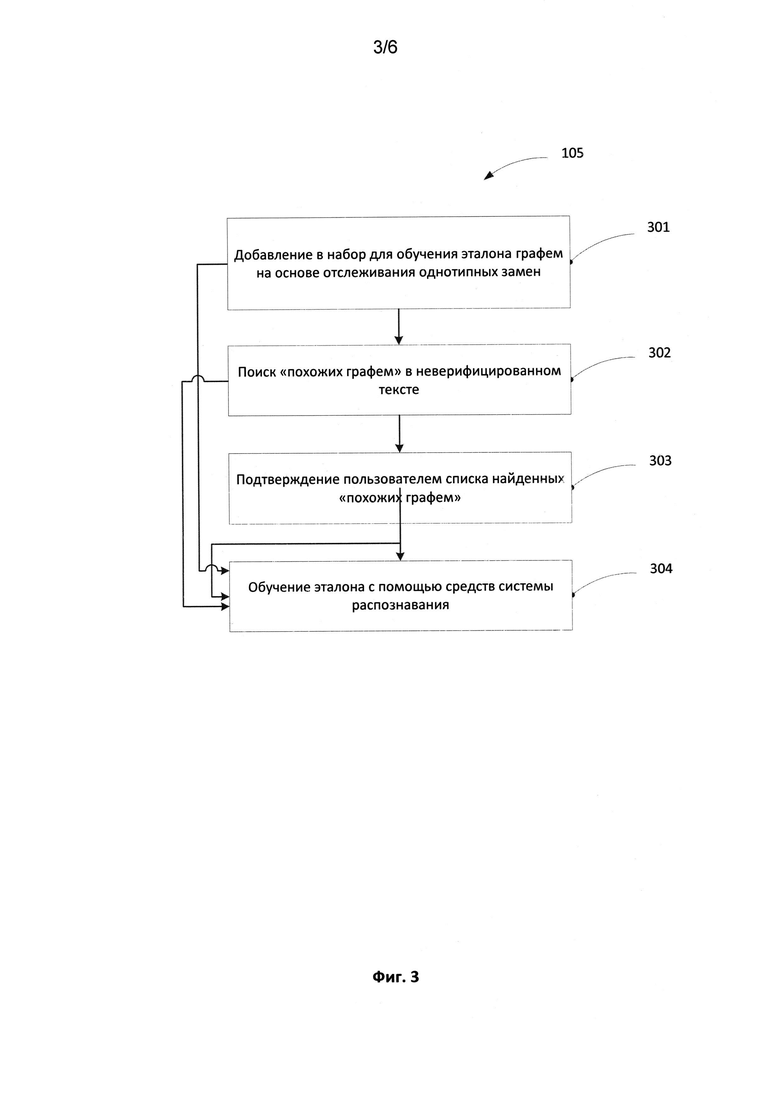
[0012] На Фиг. 3 продемонстрирована блок-схема, иллюстрирующая процесс обучения эталона.
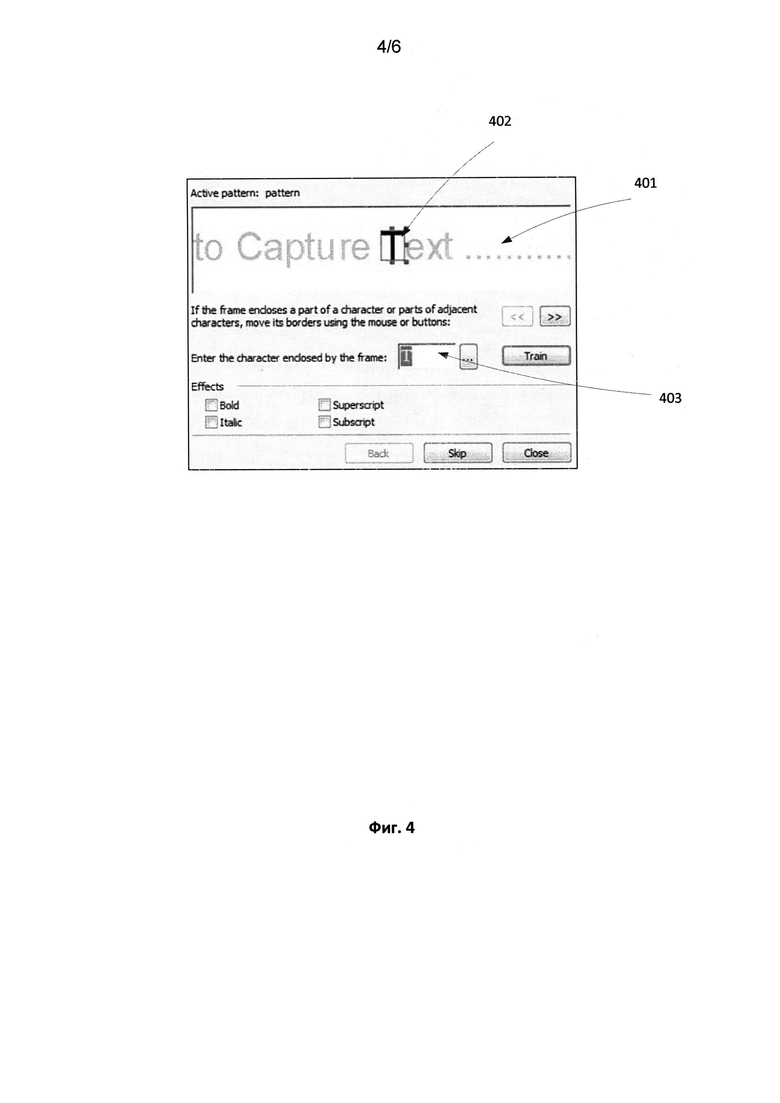
[0013] На Фиг. 4 продемонстрирован пример интерфейса, предназначенного для процесса обучения эталона.
[0014] На Фиг. 5 продемонстрирован пример интерфейса обучения эталона для китайских, японских и корейских символов (которые ниже именуются «символами CJK»).
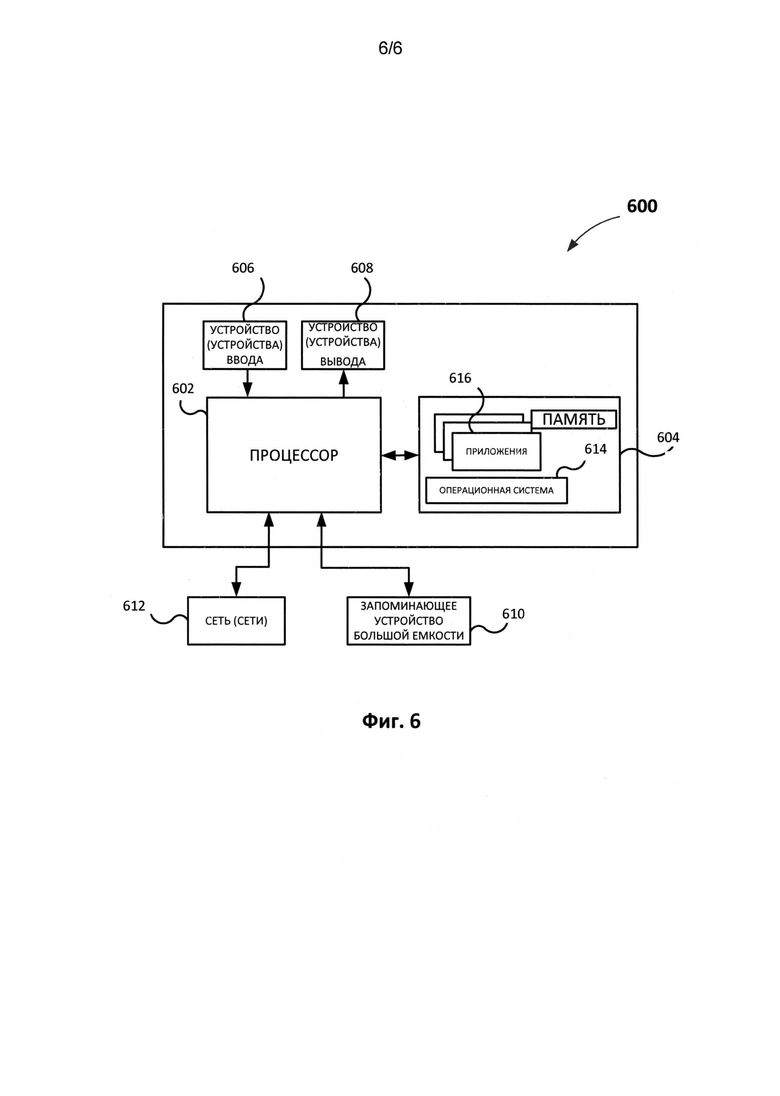
[0015] На Фиг. 6 продемонстрирован пример компьютерной системы, которая может быть использована для реализации настоящего изобретения.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ РЕАЛИЗАЦИИ
[0016] В последующем описании с целью пояснения изложены многочисленные конкретные детали для того, чтобы обеспечить исчерпывающее понимание настоящего изобретения. Однако специалистам в данной области техники будет очевидно, что это изобретение на практике может быть осуществлено без данных конкретных деталей. В других случаях структуры и устройства показаны только в виде блок-схем, чтобы не затруднять понимание сущности изобретения.
[0017] Ссылка в представленном описании на «один способ реализации» означает, что конкретный признак, структура или характеристика, описанная в связи с осуществлением изобретения, включена по меньшей мере в один из способов реализации настоящего изобретения. Неоднократное упоминание выражения «в одном из способов реализации» в различных местах описания не обязательно относятся к одному и тому же способу реализации, а отдельные или альтернативные способы реализации изобретения не являются взаимоисключающими по отношению к другим способам реализации. Кроме того, приведено описание различных признаков, которые могут использоваться в одних способах реализации изобретения, но не использоваться в других способах его реализации. Аналогично приведены описания различных требований, которые могут предъявляться к одним способам реализации этого изобретения, но не предъявляться к другим способам его реализации.
[0018] На Фиг. 1 показан способ обработки изображения в соответствии с аспектами настоящего изобретения. В некоторых способах реализации система согласно настоящему изобретению получает цифровое изображение документа 101, которое должено быть распознано, то есть преобразовано в машиночитаемый текст. Как правило, изображение документа представляет собой фотографию, сканированный документ или другой тип изображения, содержащего машинописный или печатный текст.
[0019] В некоторых способах реализации система выполняет бинаризацию 102 изображения документа 101, преобразуя его в бинаризованное изображение. Бинаризованное изображение представляет собой цифровое изображение, в котором каждый пиксель имеет только два возможных значения, например, может быть либо, черным либо белым. Другими словами, система преобразует изображение документа 101 из цветного или полутонового изображения в черно-белое представление.
[0020] В некоторых способах реализации бинаризуется полутоновое изображение документа 101. Пиксели в полутоновом изображении могут иметь различные уровни интенсивности или яркости (от черного до белого). Для того чтобы бинаризовать полутоновое изображение, система устанавливает значение порога бинаризации. Всем пикселям, имеющим значение уровня яркости выше порогового значения, присваивается белый цвет. Всем пикселям, имеющим значение уровня яркости, равное пороговому значению или меньше, присваивается черный цвет.
[0021] В некоторых способах реализации система использует метод адаптивной бинаризации для бинаризации 102 изображения документа 101. Адаптивная бинаризация позволяет системе адаптивно выбирать оптимальные параметры бинаризации для различных участков изображения документа 101, что повышает качество бинаризованного изображения. В некоторых способах реализации система использует метод бинаризации, описанный в Патенте США №8089945 «METHOD AND SYSTEM FOR BINARIZING AN IMAGE» (Способ и система для бинаризации изображения) или в Опубликованной патентной заявке США №2012-0087587 «BINARIZING AN IMAGE» (Бинаризация изображения), которые целиком включены в настоящий документ путем ссылки.
[0022] В некоторых способах реализации система производит оптическое распознавание символов (OCR) 103 изображения документа 101 после того как данное изображение было бинаризовано 102. Распознавание символов 103 может производиться с помощью одного из известных способов с использованием системы оптического распознавания символов (OCR).
[0023] Системы оптического распознавания символов (OCR) используются для преобразования изображений или представлений бумажных документов, таких как, например, документы в формате Portable Document Format (формат PDF), в машиночитаемые, редактируемые и пригодные для осуществления по ним поиска электронные файлы. Типичная система OCR включает формирователь сигналов изображения для воспроизведения цифрового изображения документа и программный компонент, который выполняется на компьютере и обрабатывает данные изображения. Как правило, такое программное обеспечение включает модуль Оптического Распознавания Символов (OCR), который распознает буквы, иероглифы, цифры и другие символы и преобразует их в машиночитаемый формат.
[0024] Иногда качество изображения документа 101 недостаточно для обеспечения уверенного распознавания символов. Например, изображение документа 101 может содержать такие дефекты или искажения, как размытие, чрезмерное зашумление, расфокусировку и т.д. Такие дефекты снижают надежность результатов распознавания. Различные способы могут быть применены к документу 101, чтобы восстановить искаженное изображение. Например, могут быть применены алгоритмы для корректировки геометрических искажений. В некоторых способах реализации изобретения к изображению документа 101 применяются способы обработки изображений, позволяющие выявить и устранить такие дефекты, как размытость, расфокусировку или чрезмерную зашумленность. Некоторые из методов устранения дефектов описаны в публикации патентной заявки США U.S. Patent Application Publication No. 2012-0243792 «Detecting and Correcting Blur and Defocusing» (Обнаружение и устранение размытия и расфокусировки), которая целиком включена в настоящий документ посредством ссылки.
[0025] После того как изображение документа 101 обработается системой с помощью OCR 103 и в результате чего будет получен распознанный текст, выполняется верификация данного распознанного текста 104. В некоторых способах реализации верификация 104 производится полуавтоматически, т.е. она выполняется с участием пользователя. В процессе верификации 104 пользователь проверяет распознанный текст на наличие в нем ошибок и вручную обрабатывает обнаруженные ошибки. В некоторых способах реализации обработка включает внесение исправлений в распознанный текст, при этом неправильно распознанный символ заменяется на «верный» символ. В некоторых способах реализации верификация 104 может быть реализована в диалоговом окне верификации. В других способах реализации верификация 104 выполняется во встроенном или интегрированном с системой OCR текстовом редакторе.
[0026] Фиг. 2 иллюстрирует способ выявления необходимости в обучении эталона в соответствии с некоторыми аспектами настоящего изобретения. Согласно одному из способов реализации изобретения, когда запускается верификация 104, система начинает отслеживать, имеется ли необходимость предоставить пользователю возможность обучения эталона.
[0027] Когда пользователь выполняет верификацию распознанного текста 202, в данный текст пользователем вносятся правки 203, например, исправляются неточности распознавания, добавляется нераспознанный текст, удаляются лишние символы, исправляется геометрическое расположение распознанных символов и т.д. В некоторых способах реализации эта часть верификации 104 выполняется с использованием специализированных инструментов верификации, а также текстового редактора, встроенного в интерфейс OCR-системы.
[0028] Во время верификации результатов распознавания система автоматически отслеживает (204) вносимые пользователем однотипные изменения. Два изменения являются однотипными, если оба они заменяют один и тот же неверно распознанный символ на один и тот же правильный символ. Другими словами, каждое однотипное изменение связано с парой символов: заменяемым неверно распознанным символом и правильным символом, на который изменяется данный неверно распознанный символ.
[0029] В некоторых способах реализации система отслеживает однотипные изменения, сохраняя их в неком банке изменений. Этот банк состоит из пар неверно распознанных символов, которые были изменены пользователем во время верификации 104 распознанного текста 202, и правильных символов. Каждая пара в этом банке, состоящая из неверно распознанного символа и правильного символа, связана со счетчиком.
[0030] Когда вносится новое исправление, система определяет неверно распознанный символ и правильный символ для нового исправления и сравнивает эту пару символов с парами символов, уже включенными в этот банк на основе ранее осуществленных исправлений распознанного текста 202. Если эта пара не совпадает ни с одной парой из данного банка, то она добавляется в банк исправлений, система создает счетчик для этой новой пары и устанавливает его значение равным 1. Если эта пара соответствует одной из существующих пар в пуле, то значение счетчика существующей пары увеличивается на 1. Помимо отслеживания однотипных изменений, система также сохраняет в памяти графемы неверно распознанных символов, которые были исправлены пользователем. Графема представляет собой образ символа в изображении документа. Сохраняемая для неверно распознанного символа графема показывает, как этот символ представлен в изображении документа 101.
[0031] В некоторых способах реализации отслеживание 204 однотипных изменений производится параллельно с процессом верификации 104. В других способах реализации такое отслеживание производится после завершения верификации распознанного текста или части распознанного текста. Такое отслеживание осуществляется путем анализа сохраненных исправлений и расчета статистики выполненных исправлений.
[0032] Каждый раз, когда пользователь вносит однотипное изменение, значение счетчика данного изменения сравнивается с пороговым значением 205. В некоторых способах реализации это пороговое значение задается предварительно. В других способах реализации это пороговое значение выбирается в ходе процесса обучения.
[0033] В некоторых способах реализации, если во время процесса верификации 104 системой определяется, что значение одного из счетчиков, связанного с парами символов для однотипных изменений, достигает порогового значения или превышает его, то система предлагает пользователю 206 обучить эталон, используемый для распознавания текста.
[0034] В других способах реализации система отслеживает количество счетчиков однотипных изменений, значения которых достигли порогового значения или превысили его, при этом предложение обучить эталон 206 запускается только в том случае, если предварительно определенное количество счетчиков достигает этого порогового значения или превышает его.
[0035] В некоторых способах реализации обучение нового эталона начинается автоматически при достижении порогового значения. В этих случаях не требуется выводить пользователю предложение начать обучение эталона 206.
[0036] В дополнение к однотипным изменениям, система также отслеживает подтверждения пользователем символов, распознанных с низкой степенью уверенности. В некоторых способах реализации символы, распознанные с низкой степенью уверенности, выделяются в тексте. Если пользователь не исправляет символ, который был распознан с низкой степенью уверенности, то система интерпретирует это как то, что пользователь соглашается с результатом распознавания. Если система регистрирует такое подтверждение пользователем результата распознавания, то оценка уверенности распознавания оставшихся неверифицированных символов становится выше. Если впоследствии оценка уверенности распознавания символа становится достаточно высокой, то дальнейшие еще не верифицированные символы более не визуализируются как символы, распознанные с низкой степенью уверенностью распознавания. При этом отпадает необходимость проверять их повторно на следующих страницах документа.
ОБУЧЕНИЕ ЭТАЛОНА
[0037] Способ обучения эталона в соответствии с некоторыми способами реализации настоящего изобретения иллюстрируется на Фиг. 3.
[0038] В некоторых способах реализации, если системой определяется, что количество однотипных изменений превысило некое пороговое значение 205, система предлагает 206 пользователю произвести обучение эталона, при этом пользователю предоставляется возможность самому инициировать процесс обучения эталона. В это время пользователю могут быть представлены правки, которые были им произведены в ходе процесса верификации распознанного документа 104, и которые могут быть подтверждены им. Например, пользователю может быть предложено подтвердить все или некоторые изменения символа «с» на символ «о», которые были им произведены.
[0039] Целью данного шага является обеспечить формирование множества графем, предназначенных для обучения эталона, только на основе представительных изображений символа, а не на основе дефектов печати, пятен, сделанных пользователем правок, или других несущественных изменений распознанного текста. Кроме того, этот шаг служит дополнительным подтверждением того, что исправленные символы были исправлены действительно правильно.
[0040] В некоторых способах реализации ожидающие подтверждения символы представлены пользователю в тексте при помощи одного из определенных средств пользовательского интерфейса, например, с помощью диалогового окна. Диалоговое окно одновременно отображает графему и распознанный символ, соответствующий данной графеме. Пользователю предоставляется возможность подтвердить то, что отображаемая графема должна быть распознана в качестве верного символа для данной графемы или отбросить предлагаемую графему и не вносить предлагаемые изменения в эталон.
[0041] В результате, в множество графем, предназначенных для обучения эталона распознавания, попадают только графемы тех символов, которые были подтверждены пользователем. После того как пользователь подтвердил графемы верифицированных символов, данные графемы добавляются в набор изображений, которые будут использоваться для обучения эталона 301.
[0042] В некоторых способах реализации пользователь может пропустить этап подтверждения графем, которые будут добавляться в множество для обучения эталонов.
[0043] В некоторых способах реализации после формирования множества графем для обучения эталона система выполняет поиск похожих графем 302 в части документа, которую пользователь еще не верифицировал. В результате поиска похожих графем 302 система выявляет изображения символов, которые, скорее всего, также будут распознаны как символы, которые недавно были исправлены пользователем. Для этого система осуществляет поиск в исходном изображении, которое соответствует неверифицированной части текста, для нахождения символов, «похожих» на графемы символов, которые были исправлены пользователем. Найденные «похожие» графемы предлагаются для обучения эталона.
[0044] В некоторых способах реализации «похожие» графемы ищутся путем сравнения множества гипотез распознавания для графемы символа, который был «исправлен» пользователем, с наборами гипотез распознавания для графемы в неверифицированной части документа. Если пересечение множества гипотез распознавания между этими наборами превышает предварительно заданный порог, то эти графемы считаются «похожими».
[0045] В других способах реализации «похожие» графемы ищутся путем сравнения эталонов, которые используются для распознания этих графем на этапе 103 (Фиг. 1). Хорошо известно, что помимо эталонов в процессе распознавания 103 используются кластеры. Кластер является некоторым признаком классификатора, используемого для распознавания 103 символа.
[0046] Например, для эталона буквы «а» существует несколько кластеров для различных наборов шрифтов, которые могут быть использованы для этого символа. В частности, имеется кластер для распознания символа «а» и имеется кластер для распознания символа «а». Если при распознавании графем (изображения символа) совпадают или почти совпадают кластеры эталона, тогда считается, что они похожи.
[0047] В некоторых способах реализации используются различные метрики для повышения надежности поиска «похожих» графем на изображении. В некоторых способах реализации эти показатели включают среднеквадратичную ошибку (Mean Squared Error или «MSE»), среднее абсолютное значение ошибки (Mean Absolute Error или «МАЕ»), метрика Хаусдорфа и так далее.
[0048] В других способах реализации корреляция между двумя изображениями, которая также называется метрикой Хаусдорфа, используется для повышения надежности поиска «похожих» графем. Настоящее изобретение не ограничивается перечисленными выше метриками.
[0049] В некоторых способах реализации как метрика Хаусдорфа, так и мера МАЕ используются для выявления «похожих» изображений на различных этапах процесса поиска. Сначала на быстром этапе для определения класса изображения вычисляется грубая оценка сходства с помощью метрики МАЕ или MSE, а затем на втором этапе члены класса определяются путем расчета метрики Хаусдорфа.
[0050] В других способах реализации кэш обучения используется для поиска в исходном изображении графем, похожих на графемы символов, которые были исправлены пользователем. Процесс обучения обрабатывает каждое новое изображение следующим образом. Во-первых, система пытается найти подходящий эталон графемы в кэше. Если эталон найден, то он дополнительно обучается на основе нового изображения. Если эталон не найден или если наложение является неполным, то на основе нового изображения создается новый эталон.
[0051] В некоторых способах реализации поиск «похожих» графем производится с помощью автоматически созданных эталонов, которые получены только на основе того участка исходного изображения, в котором символы были верифицированы пользователем. Эталон распознавания создается на основе графем правильных символов в однотипных изменениях, которые, в свою очередь, используются для поиска похожих графем в оставшейся неверифицированной части изображения документа. Другими словами, полученный эталон используется для инициирования распознавания графем в оставшейся непроверенной части изображения документа. В некоторых способах реализации результаты такого распознавания отображаются пользователю. Если пользователь удовлетворен результатами такого предварительного распознавания в целях поиска похожих графем, то графемы этих символов признаются «похожими» графемами, и вследствие чего могут быть добавлены в множество графем для обучения.
[0052] Возвращаясь к Фиг. 3, в некоторых способах реализации пользователю предоставляется возможность подтвердить список «похожих» графем 303 после того, как система провела поиск «похожих» графем в неверифицированной части текста. Пользователю предоставляется список найденных графем и предлагается выбрать из этого списка графемы, которые на самом деле соответствуют символам, исправленным пользователем. Другими словами, пользователю предлагается установить соответствие между найденными «похожими» графемами и исправленными пользователем символами. Например, пользователь может вручную указать, какой символ соответствует каждой из найденных похожих графем. В некоторых способах реализации этот шаг пропускается.
[0053] Далее на основании набора графем системой создается эталон, на основе использования инструментов распознавания 304. Множество графем, которое используется для обучения эталона, содержит одну или более графем.
[0054] В некоторых способах реализации обучение эталона включает в себя создание пользовательских графем. Эти графемы создаются в процессе обучения, если пользователь вводит комбинацию символов, которая не соответствует ни одной из стандартных графем. Пользовательская графема представляет собой растровое изображение символа, сохраняемое после завершения процесса обучения.
[0055] На Фиг. 4 проиллюстрирован интерфейс инструмента системы, используемого для создания пользовательской графемы в некоторых способах реализации настоящего изобретения. При создании пользовательской графемы отображается участок строки 401. Пользователь имеет возможность перемещать границы изображения 402 в соответствии с вариантами деления и вручную вводить соответствующий символ или лигатуру в окне символа 403.
[0056] После введения пользователем символа или лигатуры система проверяет, соответствует ли этот символ или лигатура какой-либо ранее определенной графеме. Если ранее существовавшая графема не найдена, то создается пользовательская графема.
[0057] В некоторых способах реализации, созданные пользовательские эталоны сохранятся только локально для использования при распознавании текущего документа. В других способах реализации эти эталоны сохраняются в библиотеке для последующего использования при распознавании других документов. Создание и сохранение пользовательских эталонов особенно целесообразно при распознавании документов одинаковой тематики, например, документов, содержащих математические символы и т.д.
[0058] Возвратимся к Фиг. 1; после того как система закончит обучение эталона 105, выполняется повторное распознавание изображения документа 106, на основе использования переобученного эталон с получением повторно распознанного текста 107. В некоторых способах реализации повторное распознавание производится только в той части изображения документа, которая еще не была верифицирована пользователем. В других способах реализации система также выполняет повторное распознание уже проверенной части изображения документа. Если выполняется такое повторное распознание проверенной части изображения документа, то важно не потерять правки пользователя, которые были введены им ранее в ходе верификации.
[0059] В некоторых способах реализации повторное распознавание 106 выполняется в фоновом режиме, то есть автоматически, без какой-либо явной команды пользователя. Такое фоновое распознание не блокирует средства интерфейса и может выполняться в то время, когда пользователь продолжает процесс верификации. В некоторых способах реализации повторное распознавание в фоновом режиме для пользователя выгладит как непрерывная верификация, в ходе которой периодически предлагается обучить эталон, и подтвердить группы символов, используемых для обучения нового эталона. При этом истратится время на ожидание окончания процесса распознавания. В некоторых способах реализации повторное распознавание 106 производится в явном виде, то есть с привлечением пользователя.
[0060] В некоторых способах реализации повторное распознавание 106 производится для отдельных графем, которые отвечают критериям «похожести», в других способах реализации - с использованием слов, содержащих данные символы. Повторное распознавание слов, содержащих «похожие» графемы, предоставляет возможность словарной проверки полученных результатов. Словарная проверка значительно повышает точность распознавания. Более того, в некоторых способах реализации повторное распознавание 106 выполняется для отдельных абзацев, содержащих «похожие» графемы. Это дает возможность дополнительно выполнить контекстную проверку распознанного текста, что также повышает точность распознавания.
[0061] Описанное изобретение может использоваться для обучения эталонов во время распознавания языков CJK (то есть китайского, японского и корейского языков). В таком способе реализации исходный CJK документ (документ на китайском, японском или корейском языке) распознается на этапе 103 с помощью одного из известных способов. Например, подходящий способ распознавания изображений документов на CJK языках подробно описан в публикации U.S. Patent Application Publication No. 2013-0286030 «Fast CJK Character Recognition» (Быстрое распознавание символов CJK), которая включена в настоящий документ посредством ссылки.
[0062] Во время верификации 104 результатов распознавания для CJK языков пользователю предоставляется специализированный инструмент для правки символов CJK. На Фиг. 5 показан пример интерфейса для осуществления верификации распознанного текста на CJK языках. Изображение документа на китайском языке показано в окне 500. Результаты распознавания отображаются в окне 502. Окно 504 представляет собой специализированный инструмент, который во время верификации выводит пользователю список графем, которые похожи на изображение, соответствующее выделенному символу CJK 501. Видно, что выделенный символ CJK 501 был распознан с низкой степенью уверенности. При наведении мыши на результат распознавания 503 символа CJK. 501 в окне с вариантами распознавания 504 отображается несколько вариантов распознавания данного CJK символа 501. Пользователь может вручную выбрать верный результат распознавания и вставить его в текст вместо прежнего ошибочного результата распознавания. Данный инструмент полезен в том случае, когда иероглифы вводить с клавиатуры неудобно или вовсе не представляется возможным.
[0063] В некоторых способах реализации далее эталон обучается автоматически на основе выбора пользователем требуемого результата распознавания из списка предложенных графем (в окне 505). Данное обучение осуществляется путем сохранения изображений исправленных пользователем CJK символов, например, как для символа 501, и соответствующего им указанного пользователем символа CJK (505). Точное изображение исходного символа CJK известно, так как способ деления строки на иероглифы очень надежен.
[0064] В некоторых способах реализации деление строки на символы для CJK языков выполняется путем построения Графа Линейного Деления (ГЛД) для CJK языков. Один из способов деления строки CJK символов описан в патенте США №8559718 «Defining a Layout of Text Lines of CJK and non-CJK Characters» (Определение расположения строк текста CJK и символов не-CJK), который полностью включен в настоящий документ посредством ссылки.
[0065] В одном из способов реализации, если в процессе верификации было внесено достаточно большое число поправок (превышающее предварительно определенное пороговое значение), то пользователю предлагается произвести дополнительное обучение эталона CJK символа непосредственно по изображениям, которые использовались для изменения неправильно распознанных символов CJK. Вместо того чтобы накапливать статистику по замене одного символа на другой, изображения, которым требуются исправления, объединяются в кластеры, и на основе этого объединения в кластеры принимается решение о том, проводить ли дальнейшее обучение эталона и что использовать при этом обучении.
[0066] На Фиг. 6 проиллюстрирован пример компьютерной системы 600, которая в некоторых способах реализации используется в настоящем изобретении так, как описано выше. Система 600 включает в себя один или несколько процессоров 602, соединенных с памятью 604. Процессор (процессоры) 602 могут содержать одно или более ядер процессоров, либо это может быть микросхема или другое устройство, способное выполнять вычисления (например, для оператора Лапласа можно использовать оптические устройства). Память 604 может представлять собой оперативное запоминающее устройство (ОЗУ), а также может содержать память любого другого типа или вида, в частности энергонезависимые запоминающие устройства (например, флеш-накопители) или постоянные запоминающие устройства, такие как приводы с жесткими дисками и т.д. Кроме того, можно рассматривать устройство, в котором память 604 включает удаленные носители данных, а также локальную память, такую как кэш-память процессора (процессоров) 602, используемую в качестве виртуальной памяти, и записываемую во внешнем или внутреннем постоянном запоминающем устройстве 610.
[0067] Компьютерная система 600 обычно также имеет входные и выходные порты для передачи информации и приема информации. Для взаимодействия с пользователем компьютерная система 600 может содержать одно или несколько устройств ввода 606 (например, клавиатуру, мышь, сканер или другие устройства) и устройства вывода 608 (например, дисплеи или специальные индикаторы). Компьютерная система 600 может также иметь одно или несколько постоянных устройств хранения данных 610, таких как привод оптических дисков (формата CD, DVD или другого), накопитель на жестком диске или ленточный накопитель. Кроме того, компьютерная система 600 может иметь интерфейс с одной или несколькими сетями 612, которые обеспечивают связь с другими сетями и компьютерным оборудованием. В частности, это может быть локальная сеть (LAN) или сеть Wi-Fi, она может быть подключена к сети Интернет, а может быть не подключена к ней. Разумеется, компьютерная система 600 может включать аналоговые и/или цифровые интерфейсы между процессором 602 и каждым из компонентов 604, 606, 608, 610 и 612.
[0068] Компьютерная система 600 управляется операционной системой 614, она включает различные приложения, компоненты, программы, объекты, модули и прочие составляющие, совместно обозначенные цифрой 616.
[0069] Программы, используемые для реализации способов, соответствующих данному изобретению, могут быть частью операционной системы, либо они могут представлять собой специализированное периферийное оборудование, компоненту, программу, динамически подключаемую библиотеку, модуль, сценарий или их сочетание.
[0070] Настоящее описание содержит основной изобретательский замысел, который не может быть ограничен указанным выше аппаратным обеспечением. Следует отметить, что аппаратное обеспечение предназначено в первую очередь для решения узкой проблемы. С течением времени и по мере развития технологии такая задача становится более сложной или она развивается. Возникают новые инструменты, способные удовлетворять новые требования. В этом смысле уместно рассмотреть это оборудование с точки зрения решаемого класса технических задач, а не просто как техническую реализацию в некоторой элементарной среде.
[0071] Специалистам в данной области будет понятно, что аспекты настоящего изобретения могут быть воплощены как система, способ или компьютерный программный продукт. Соответственно, аспекты настоящего изобретения могут принимать форму чисто аппаратного осуществления, полностью программного варианта (включая встроенное программное обеспечение, резидентное программное обеспечение, микрокоманды и т.д.) или осуществление, сочетающее программные и аппаратные компоненты, которое в целом может называться в этом документе «схемой», «модулем» или «системой». Кроме того, аспекты настоящего изобретения могут принимать форму компьютерного программного продукта, записанного на один машиночитаемый носитель или на несколько машиночитаемых носителей, содержащих машиночитаемый программный код.
[0072] Может использоваться любая комбинация одного машиночитаемого носителя или нескольких машиночитаемых носителей. Машиночитаемый носитель может быть содержащей сигналы машиночитаемой средой или машиночитаемым носителем данных. Например, машиночитаемый носитель данных может, помимо прочего, представлять собой электронную, магнитную, оптическую, электромагнитную, инфракрасную или полупроводниковую систему, аппарат или устройство, или любую подходящую комбинацию перечисленного выше. Более конкретные примеры машиночитаемых носителей включают следующее (неполный список): электрическое соединение, имеющее один провод или более, портативный компьютерный гибкий диск, жесткий диск, оперативное запоминающее устройство (ОЗУ), постоянное запоминающее устройство (ПЗУ), перезаписываемое программируемое постоянное запоминающее устройство (ППЗУ или флеш-память), оптическое волокно, портативный компакт-диск для однократной записи данных (CD-ROM), оптическое запоминающее устройство, магнитное запоминающее устройство или любую подходящую комбинацию перечисленного выше. В контексте этого документа машиночитаемый носитель данных может быть любым материальным носителем данных, который может содержать или хранить программу для использования выполняющей команды системой, аппаратом или устройством, либо при подключении к выполняющей команды системе, аппарату или устройству.
[0073] Записанный в машиночитаемом носителе программный код может передаваться с использованием любой подходящей среды, включая, помимо прочего, следующие среды: беспроводная среда, проводная среда, оптоволоконный кабель, радиочастотная среда и т.д. или с помощью любой подходящей комбинации перечисленных выше сред. Компьютерный программный код для выполнения операций для аспектов настоящего изобретения может быть записан в виде любой комбинации на одном или нескольких языках программирования, включая объектно-ориентированные языки программирования, такие как Java, Smalltalk, С++ и т.п., а также традиционные процедурные языки программирования, такие как язык программирования С или похожие языки программирования. Код программы может полностью выполняться на компьютере пользователя, частично на компьютере пользователя, как автономный пакет программного обеспечения, частично на компьютере пользователя и частично на удаленном компьютере или полностью на удаленном компьютере или сервере. В последнем сценарии удаленный компьютер может быть соединен с компьютером пользователя по сети любого типа, в том числе по локальной сети (LAN) или по глобальной сети (WAN), либо может быть организовано соединение с внешним компьютером (например, по сети Интернет с использованием поставщика услуг Интернета).
[0074] Аспекты настоящего изобретения были описаны выше со ссылкой на структурные схемы и/или блок-схемы способов, устройства (системы) и компьютерные программные продукты в соответствии с способами реализации изобретения. Следует понимать, что каждый блок и комбинация блоков в структурных схемах и/или блок-схемах могут быть осуществлены с помощью команд компьютерной программы. Эти команды компьютерной программы могут быть переданы в процессор универсального компьютера, специализированного компьютера или другого программируемого устройства обработки данных для получения машины, таким образом, чтобы команды, которые выполняются с помощью процессора компьютера или другого программируемого устройства обработки данных, создали средства для реализации функций или действий, указанных в блоке или блоках структурной схемы и/или блок-схемы.
[0075] Эти команды компьютерной программы также могут храниться в машиночитаемом носителе, который может заставить компьютер, другое программируемое устройство обработки данных, или другие устройства работать определенным образом так, чтобы эти команды, хранящиеся в машиночитаемом носителе, производили изделие, в том числе команды, реализующие функцию или действие, предусмотренное в блоке или блоках структурной схемы и/или блок-схемы. Команды компьютерной программы также могут быть загружены в компьютер, в другое программируемое устройство обработки данных или в другие устройства, чтобы вызвать выполнение последовательностей рабочих этапов, которые должны выполняться в компьютере, другом программируемом устройстве или в других устройствах для выполнения реализованного в компьютере процесса таким образом, чтобы команды, которые выполняются в компьютере или в другом программируемом устройстве, предоставляли процессы для выполнения функции или действия, предусмотренного в блоке или блоках структурной схемы и/или блок-схемы.
[0076] Структурные схемы или блок-схемы на приведенных выше рисунках иллюстрируют архитектуру, функциональность и работу возможных способов реализации систем, способов и компьютерных программных продуктов в соответствии с различными способами реализации настоящего изобретения. В связи с этим каждый блок в структурной схеме или блок-схеме может представлять собой модуль, часть кода или сегмент, который содержит одну или более исполняемых команд для реализации указанной логической функции (указанных логических функций). Следует также отметить, что в некоторых альтернативных реализациях отмеченные в блоке функции могут выполняться в порядке, отличном от того, который указан в иллюстрациях. Например, два блока, которые показаны как последовательные, фактически могут выполняться по существу одновременно, либо иногда блоки могут выполняться в обратном порядке, в зависимости от используемой функциональности. Кроме того, следует отметить, что каждый блок структурной схемы и/или блок-схемы и комбинации блоков в структурных схемах и/или блок-схемах могут быть реализованы с помощью специальных систем оборудования, которые выполняют заданные функции или действия, или с помощью комбинации специализированного оборудования и компьютерных команд.

Изобретение относится к области обработки изображений. Технический результат – повышение общей точности распознавания документов. Способ анализа текста включает: анализ выполняемой пользователем верификации распознанного текста, полученного в процессе распознавания изображения документа, где верификация включает в себя изменение определенного пользователем неправильного символа на определенный пользователем правильный символ; выявление однотипных изменений первого неправильного символа на первый правильный символ; и инициирование процесса обучения эталона распознавания на основе выявленных однотипных изменений, где эталон распознавания обучается для распознавания определенного символа и используется при распознавании символов в изображении документа для получения распознанного текста. 3 н. и 15 з.п. ф-лы, 6 ил.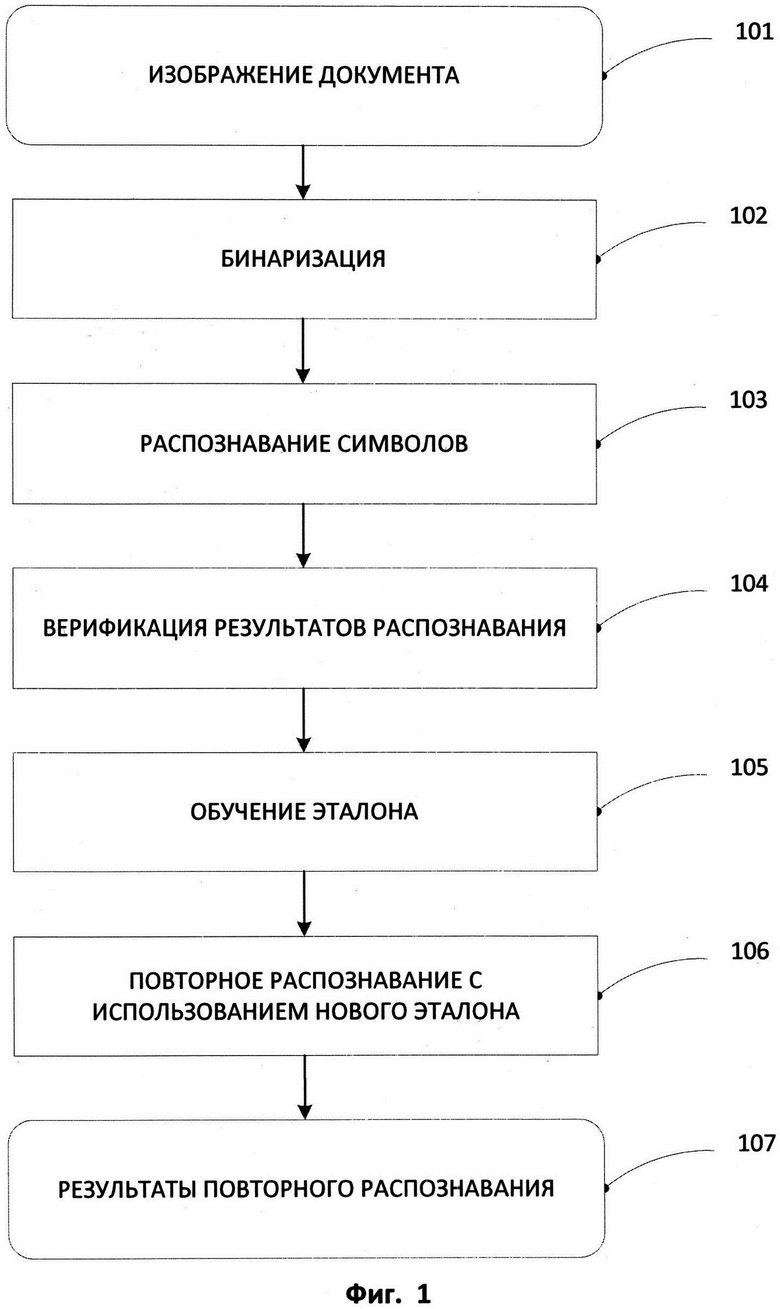
1. Реализуемый на компьютере способ анализа текста, включающий:
анализ выполняемой пользователем верификации распознанного текста, полученного в процессе распознавания изображения документа,
где верификация включает в себя изменение определенного пользователем неправильного символа на определенный пользователем правильный символ;
выявление однотипных изменений первого неправильного символа на первый правильный символ; и
инициирование процесса обучения эталона распознавания на основе выявленных однотипных изменений,
где эталон распознавания обучается для распознавания определенного символа и используется при распознавании символов в изображении документа для получения распознанного текста.
2. Реализуемый на компьютере способ по п. 1, отличающийся тем, что:
выявляемые однотипные изменения включают отслеживание количества однотипных изменений первого неправильного символа на первый правильный символ во время верификации, и
определение того, что количество однотипных изменений первого неправильного символа на первый правильный символ достигло предварительно заданного порогового значения и инициирование процесса обучения эталона распознавания, основанного на определении того, что количество однотипных изменений достигло предварительно заданного порогового значения.
3. Реализуемый на компьютере способ по п. 1, отличающийся тем, что инициировании процесса обучения эталона распознавания включает предоставление пользователю возможности инициировать данное обучение.
4. Реализуемый на компьютере способ по п. 1, отличающийся тем, что инициирование процесса обучения эталона распознавания производится автоматически.
5. Реализуемый на компьютере способ по п. 1, дополнительно включающий осуществление повторного распознавания символов в изображении документа с использованием обученного эталона распознавания.
6. Реализуемый на компьютере способ по п. 1, дополнительно включающий осуществление повторного распознавания части изображения документа, соответствующей неверифицированной части этого документа, с использованием обученного эталона распознавания.
7. Компьютерный носитель данных, закодированный с помощью одной или нескольких компьютерных программ, причем одна или несколько компьютерных программ содержат команды, которые при выполнении в устройстве обработки данных заставляют устройство обработки данных выполнять операции, включающие:
анализ выполняемой пользователем верификации распознанного текста, полученного в процессе распознавания изображения документа, где верификация включает в себя изменение определенного пользователем неправильного символа на определенный пользователем правильный символ;
выявление однотипных изменений первого неправильного символа на первый правильный символ и
инициирование процесса обучения эталона распознавания на основе выявленных однотипных изменений,
где эталон распознавания обучается для распознавания определенного символа и используется при распознавании символов в изображении документа для получения распознанного текста.
8. Компьютерный носитель данных по п. 7, отличающийся тем, что выявляемые однотипные изменения включают
отслеживание количества однотипных изменений первого неправильного символа на первый правильный символ во время верификации, и
определение того, что количество однотипных изменений первого неправильного символа на первый правильный символ достигло предварительно заданного порогового значения, и
инициирование процесса обучения эталона распознавания, основанное на определении того, что количество однотипных изменений достигло предварительно заданного порогового значения.
9. Компьютерный носитель данных по п. 7, отличающийся тем, что инициирование процесса обучения эталона распознавания предоставляет пользователю возможностью инициировать данное обучение.
10. Компьютерный носитель данных по п. 7, отличающийся тем, что инициирование процесса обучения эталона распознавания производится автоматически.
11. Компьютерный носитель данных по п. 7, дополнительно включающий:
осуществление повторного распознавания символов в изображении документа с использованием обученного эталона распознавания.
12. Компьютерный носитель данных по п. 7, дополнительно включающий:
осуществление повторного распознавания части изображения документа, соответствующей неверифицированной части этого документа, с использованием обученного эталона распознавания.
13. Система анализа текста, содержащая:
вычислительное устройство и
машиночитаемый носитель, соединенный с вычислительным устройством и имеющий записанные в нем команды, которые при выполнении вычислительным устройством заставляют вычислительное устройство выполнять операции, включающие:
анализ выполняемой пользователем верификации распознанного текста, полученного в процессе распознавания изображения документа,
где верификация включает в себя изменение определенного пользователем неправильного символа на определенный пользователем правильный символ;
выявление однотипных изменений первого неправильного символа на первый правильный символ и
инициирование процесса обучения эталона распознавания на основе выявленных однотипных изменений,
где эталон распознавания обучается для распознавания определенного символа и используется при распознавании символов в изображении документа для получения распознанного текста.
14. Система по п. 13, отличающаяся тем, что:
выявляемые однотипные изменения включают отслеживание количества однотипных изменений первого неправильного символа на первый правильный символ во время верификации, и
определение того, что количество однотипных изменений первого неправильного символа на первый правильный символ достигло предварительно заданного порога и инициирование процесса обучения эталона распознавания, основанного на определении того, что количество однотипных изменений достигло предварительно заданного порогового значения.
15. Система по п. 13, отличающаяся тем, что инициирование процесса обучения эталона распознавания включает предоставление пользователю возможности инициировать данное обучение.
16. Система по п. 13, отличающаяся тем, что инициирование процесса обучения эталона распознавания производится автоматически.
17. Система по п. 13, дополнительно включающая осуществление повторного распознавания символов в изображении документа с использованием обученного эталона распознавания.
18. Система по пункту 13, дополнительно включающая осуществление повторного распознавания части изображения документа, соответствующей неверифицированной части этого документа, с использованием обученного эталона распознавания.
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| RU 2008137125 A, 27.03.2010. | |||

