Изобретение относится к области оптического распознавания символов и, в частности, к способам распознавания печатного текста, содержащего фрагменты, написанные на разных языках, из растрового изображения, полученного любым способом.
Известны способы распознавания текстовой информации, в которых принадлежность текста единственному языку задают вручную. Это неприемлемо, когда текст включает фрагменты, написанные на разных языках.
Известные способы распознавания текста предполагают сканирование информации с бумажного или другого жесткого носителя, например микрофиш, перевод изображения в графический файл, разбивку графического файла на области (блоки), предположительно содержащие признаки изображения символов текста, с последующим сопоставлением изображения в блоках с эталонным изображением, в нескольких специальных признаковых (или растровых) классификаторах, содержащих символы одного определенного языка.
Большинство известных способов определяет язык распознаваемого текста на стадии распознавания символов с помощью одного или нескольких классификаторов. Для этого предварительно создают классификаторы с информацией о языках, которые предположительно могут встретиться в тексте. В процессе распознавания изображение символа исследуют последовательно всеми классификаторами. Вместо нескольких отдельных классификаторов иногда используют единственный, содержащий признаки символов всех языков, предположительно присутствующих в документе.
Такой способ представлен, например, в патенте США 6370269 April 9, 2002.
Недостатком описанных способов является недостаточное качество определения языка распознаваемого текста, низкая защищенность от ошибок.
Техническим результатом изобретения является повышение качества распознавания языковой принадлежности текста, большая чувствительность к ошибкам, увеличение быстродействия.
Это достигается тем, что на этапе формирования гипотезы и принятия решения о языковой принадлежности группы символов как слова выбирают перечень используемых лингвистических моделей, и проводят модельную оценку слов, вычисляют комплексную оценку группы символов как слова.
Указанная комплексная оценка в свою очередь может дополнительно учитывать следующие показатели: показатель уверенности распознавания символов, показатель соответствия слов модели, ряд специальных показателей, характеризующих согласованность символов в тексте.
Распознавание символов проводят с помощью классификатора, содержащего признаки символов всех предполагаемых языков.
Реализация этого способа позволяет существенно повысить качество распознавания языковой принадлежности текста, уменьшить чувствительность к ошибкам, увеличить быстродействие.
Известен способ автоматического определения языковой принадлежности слов и частей текста, при котором изображения символов на первом этапе анализируют одним общим или несколькими отдельными классификаторами на принадлежность к определенному языку. Затем набор возможных вариантов распознанных символов, предположительно составляющих слово, направляют в алгоритм контекстного анализа, выдвигают одну или более гипотез о языковой принадлежности набора символов как слова и выбирают один или более словарь для окончательной установки языковой принадлежности. Для повышения качества распознавания всю область текста делят на области и зоны, имеющие общую языковую принадлежность. После окончательного выбора языковой принадлежности требуется провести повторное распознавание.
Такой способ автоматического определения языковой принадлежности распознаваемого текста реализуется в патенте США № 6047251 Апрель 4, 2000.
Недостатком этого способа является низкое быстродействие, вследствие необходимости проверки слов по всем возможным для составляющих слово букв словарям, а также в связи с необходимостью выполнения разбиения распознаваемого текста на зоны и области, а также повторного распознавания, что сильно сужает область применения способа.
Указанные недостатки значительно ограничивают возможности использования известных способов для установления языковой принадлежности распознаваемой информации.
Известные способы непригодны для достижения заявленного технического результата.
Предлагаемый способ отличается тем, что на этапе формирования гипотезы о языковой принадлежности группы символов как слова выполняют следующие действия:
- выбор перечня используемых лингвистических моделей,
- модельная оценка слова.
Кроме того, на достижение технического результата влияет то, что на этапе принятия гипотезы о языковой принадлежности группы символов как слова выполняют
- вычисление комплексной оценки группы символов как слова,
- выбор одного или более словаря для окончательной проверки языковой принадлежности слова.
Указанная комплексная оценка в свою очередь может включать в том числе следующие показатели: показатель уверенности распознавания символов, модельную оценку слова вместе с показателем качества распознавания, ряд специальных показателей, характеризующих согласованность символов в тексте.
Распознавание символов проводят с помощью классификатора, содержащего признаки символов всех предполагаемых языков.
Классификатор сравнивает распознаваемое изображение с хранящимися эталонными изображениями.
Далее варианты распознанных символов объединяют в группы, предположительно составляющие слова. Группы символов и варианты распознавания направляют на проверку лингвистическими моделями разных языков и специальных форматов.
Результатом обработки лингвистическими моделями является набор слов и соответствующих им модельных оценок.
Полученные оценки соответствия языковым моделям являются частью комплексной оценки. Комплексная оценка, кроме того, может включать показатели уверенности распознавания символов, специальные показатели, характеризующие согласованность символов и/или слов в тексте, в т.ч. геометрическое согласование символов между собой в пределах слова и/или строки, языковую согласованность слова с соседними словами, словарную оценку слова, оценку правильности восстановления информации символов по растровому изображению при наличии помех.
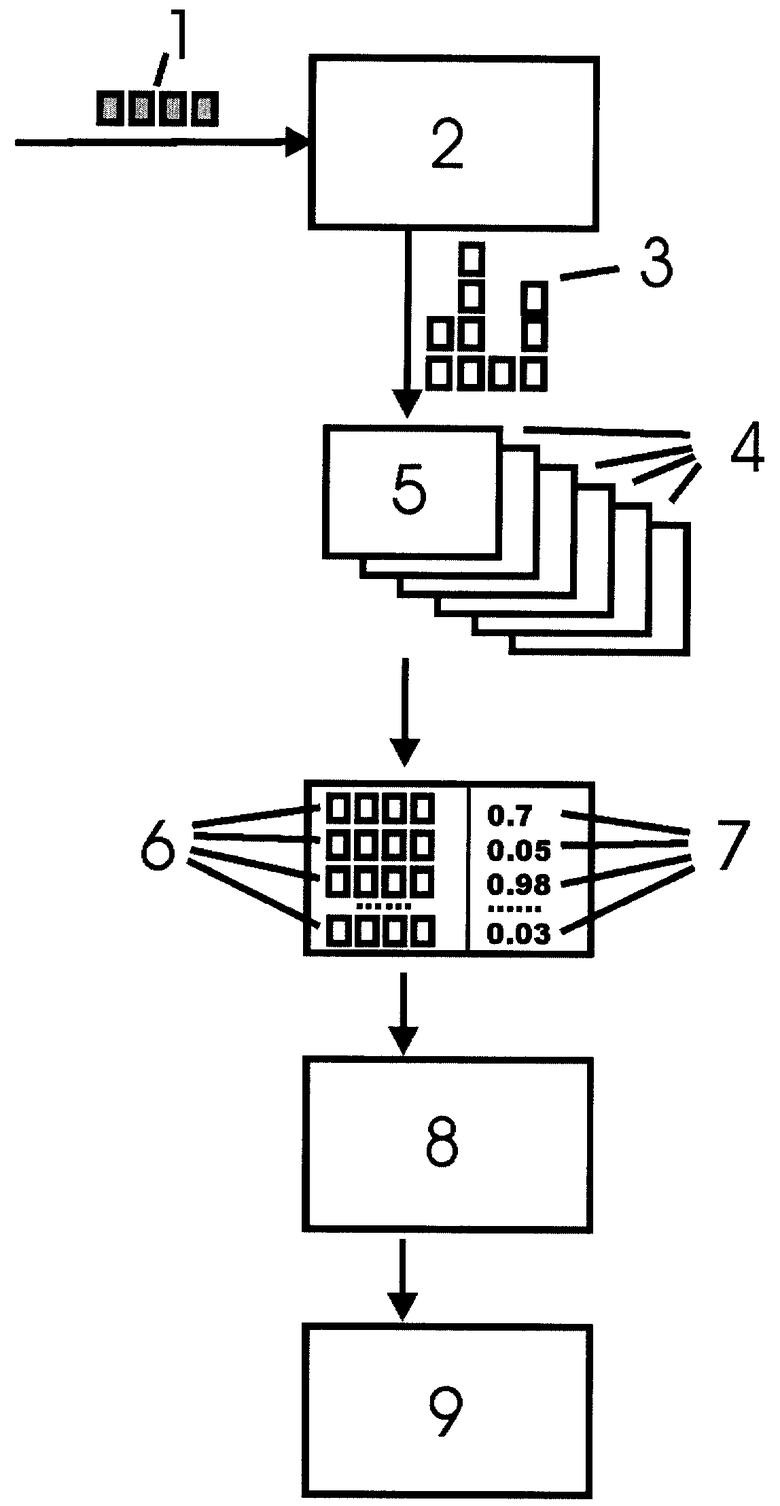
Сущность предложения иллюстрируется на чертеже.
Группа графических блоков 1 с изображениями букв, предположительно составляющих слово, направляют на распознавание в классификатор 2, содержащий признаки символов нескольких (одного или более) языков.
В результате распознавания в классификаторе 2 получают один или более возможных вариантов каждой буквы 3. Множество полученных вариантов букв далее направляют на анализ в лингвистические модели 5, в результате работы которых получают варианты возможных слов 6. Состав лингвистических моделей 4 может включать кроме моделей разных языков также и другие модели, например числовые или компьютерной адресации.
После модельной обработки варианты слов 6 вместе с коэффициентами соответствия каждой модели 7 и дополнительной информацией в виде комплексной оценки каждого слова анализируют в модуле сравнения и выбора 8.
После анализа всей информации принимают решение 9 о языковой принадлежности слова.
Изобретение относится к области оптического распознавания символов, а именно к способам распознавания текстовых документов, содержащих фрагменты, написанные на разных языках, из растрового изображения. Его применение позволяет получить технический результат в виде повышения качества распознавания языковой принадлежности текста, большая чувствительность к ошибкам, увеличение быстродействия. Этот результат достигается благодаря тому, что способ включает в себя, в частности, следующие этапы: формирование, по крайней мере, одной гипотезы о языковой принадлежности группы символов как слова, принятие или отклонение гипотезы о языковой принадлежности группы символов как слова, причем этап формирования гипотезы о языковой принадлежности группы символов как слова в свою очередь состоит, по крайней мере, из следующих действий: выбора перечня используемых лингвистических моделей, модельной оценки слова. 11 з.п. ф-лы, 1 ил.
| СПОСОБ АДАПТИВНОГО РАСПОЗНАВАНИЯ ИНФОРМАЦИОННЫХ ОБРАЗОВ И СИСТЕМА ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 1999 |
|
RU2160467C1 |
| US 5875256 A, 23.02.1999 | |||
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| Емкостный первичный преобразователь влажности сыпучих материалов | 1978 |
|
SU702289A1 |
| Походная разборная печь для варки пищи и печения хлеба | 1920 |
|
SU11A1 |

