Изобретение относится к системам классификации текстовых сообщений и может использоваться в системах обработки информации, базах данных, электронных хранилищах при наличии постоянного источника текстовой информации.
Известен способ классификации сообщений [1], заключающийся в том, что осуществляют преобразование текста сообщения из специального формата хранения в текст на естественном языке, преобразуют слова документа в базовые словоформы, осуществляют подсчет весов слов в документе в соответствии с частотами их появления; на этапе обучения по предъявленному набору классифицированных вручную документов формируют набор классификационных признаков, при необходимости классификации документа осуществляют преобразование его из специального формата хранения в текст на естественном языке, преобразуют слова документа в базовые словоформы, осуществляют подсчет весов слов в документе, на основе классификационного критерия SVM (Support Vector Machines) и классификационных признаков определяют принадлежность документа категории.
Однако указанный способ имеет существенные ограничения, заключающиеся в том, что он предназначен только для классификации сообщений в статическом режиме и не содержит средств для их потоковой обработки, таких как последовательное обучение классификатора, а также оценки информативности текстового сообщения и длительности его хранения в хранилище.
Известен также способ классификации сообщений [2], заключающийся в том, что непрерывно обрабатывают последовательность текстовых сообщений, обновляя на каждом этапе классификационные признаки по методу Видроу-Хоффа (Widrow-Hoff); это позволяет одновременно классифицировать сообщения и обучать классификатор. При этом нет необходимости предъявлять все обучающее множество документов сразу.
Однако указанный способ также имеет ограничения, связанные с тем, что он только описывает процедуру классификации сообщений и обучения классификатора и не описывает полного цикла обработки сообщения в потоковом режиме, например, начальную обработку документа и его хранение, а также не содержит механизмов оценки информативности текстового сообщения и длительности его хранения в хранилище.
Наиболее близким по технической сущности к предлагаемому является способ идентификации объектов по их описаниям [3], пригодный для решения поставленной задачи, принятый за прототип, заключающийся в том, что получают текстовые сообщения на естественных языках из информационного канала, осуществляют лингвистическую обработку слов каждого сообщения, формируют тезаурус текстового каждого сообщения, осуществляют статистическую обработку слов в тезаурусе сообщения, сохраняют текстовое сообщение и тезаурус в хранилище.
Данный способ позволяет осуществить сравнение данного текстового сообщения с множествами сообщений, поступивших за временные интервалы, и тем самым определить его тематическую близость этим интервалам как категориям. Недостатками прототипа являются невозможность задания категорий иначе как по временному признаку, а также отсутствие механизмов оценки информативности текстового сообщения и удаления его из хранилища, когда оно утрачивает свою информативность.
Технический результат, получаемый от внедрения изобретения, заключается в устранении недостатков прототипа, то есть в получении возможности произвольного задания категорий. При этом для каждого текстового сообщения определяется его информативность, которая влияет на длительность хранения данного сообщения в хранилище.
Данный технический результат получают за счет того, что получают текстовые сообщения на естественных языках из информационного канала, осуществляют лингвистическую обработку слов каждого сообщения, формируют тезаурус текстового каждого сообщения, осуществляют статистическую обработку слов в тезаурусе сообщения, сохраняют текстовое сообщение и тезаурус в хранилище. При этом автоматически определяют принадлежность текстового сообщения одной категории из заранее определенного списка категорий. Кроме того, дополнительно определяют начальную информативность текстового сообщения, сохраняют ее в хранилище вместе с текстовым сообщением; периодически проводят обновление значений информативности хранящихся в базе данных текстовых сообщений с учетом прошедшего с момента их появления времени и удаляют те текстовые сообщения, информативность которых опустилась ниже заранее установленного порога. Дополнительной особенностью данного способа является то, что при обработке каждого текстового сообщения обновляют значения классификационных признаков категорий.
Согласно данному способу, информативность текстового сообщения определяется двумя факторами:
- содержанием сообщения (словоформами, входящими в него, отклонением словарного запаса данного сообщения от встречавшихся ранее);
- временем, прошедшим с момента занесения сообщения в базу данных.
Значения классификационных признаков определяют распределением весов словоформ, наиболее часто встречающихся в сообщениях данной категории. Для каждого текстового сообщения и каждой категории определяется функция принадлежности, характеризующая меру принадлежности данного сообщения данной категории. Категория, для которой значение этой функции максимально, присваивается сообщению. При этом в случае малых значений функции принадлежности сообщения этой категории, сообщение обладает нехарактерным словарным запасом и ему в соответствии с данным способом присваивается большее значение информативности, чем у сообщений, доставляющих большие этой функции.
Непосредственно после попадания сообщения в базу данных, сообщение обладает, в соответствии с данным способом, максимальной информативностью, так как оно с большой вероятностью еще не было прочитано и оценено операторами комплекса обработки сообщений. Однако по прошествии некоторого времени, информативность сообщения снижается.
В соответствии с патентуемым способом, каждому текстовому сообщению s, попавшему в базу данных, в каждый момент времени t присваивается значение информативности по следующей формуле, согласующейся с рассуждениями, приведенными выше:
I(s)=1-(x(s),ck)-α(t-t0),
где x(s) - вектор весов словоформ тезауруса сообщения s, ck - вектор классификационных признаков категории k, которой принадлежит текстовое сообщение s, t0 - момент времени попадания сообщения s в базу данных, α - коэффициент потери информативности. Значения t и t0 могут выражаться в любых временных единицах, например в секундах. Выбор конкретных временных единиц отразится только на значении коэффициента α.
Коэффициент α отвечает за уменьшение информативности сообщения за единицу времени и подбирается с учетом требований конкретных приложений данного способа.
По мере того, как информативность сообщений опускается ниже порога информативности ε, происходит их удаление из базы данных как неинформативных.
При этом сообщения, получившие наибольшие значения информативности с самого начала, будут больше находиться в базе данных; те же из них, которые изначально были малоинформативны, будут быстрее удалены из базы данных.
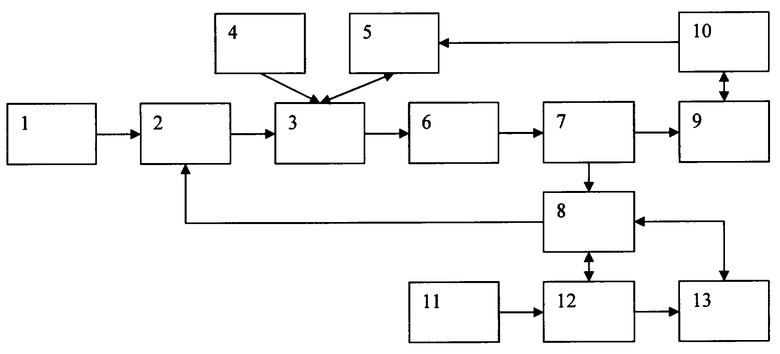
Способ может быть реализован с помощью ЭВМ или вычислительного устройства, представленного в виде блок-схемы на чертеже.
Устройство для реализации способа состоит из информационного канала 1, блока 2 формирования тезаурусов текстовых сообщений, управляющего блока 3, блока 4 обучающих данных, блока 5 классификации, блока 6 определения начальной информативности текстовых сообщений, блока 7 сохранения текстовых сообщений, хранилища 8 текстовых сообщений, блока 9 обновления классификационных признаков, хранилища 10 классификационных признаков, блока 11 генерации временных отсчетов, блока 12 пересчета информативностей текстовых сообщений, блока 13 удаления текстовых сообщений.
Согласно способу устройство работает следующим образом. При появлении в информационном канале 1 текстового сообщения оно передается в блок 2.
В блоке 2 текстовое сообщение сначала проходит предварительную обработку, заключающуюся в определении по всем его словам их базовых словоформ. Для этого может использоваться один из способов [4-7], после чего формируется тезаурус текстового сообщения. Наиболее часто для решения задач нахождения базовых словоформ используется алгоритм Портера [4], заключающийся в использовании специальных правил отсечения и замены окончаний слов.
Тезаурус сообщения состоит из всех словоформ, содержащихся в нем. При этом каждой словоформе ставится в соответствие ее нормированный вес в тексте сообщения, определяемый по формуле TD-IDF (Term Frequency -Inverted Document Frequency):
tdidf(w)=tf(w)idf(w),
где tf(w) - частота появления словоформы w в данном сообщении, то есть
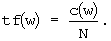
Здесь c(w) - количество раз, которое словоформа w повторяется в данном сообщении, N - общее число слов в данном сообщении. Значение инвертированной частоты документов idf(w) вычисляется по формуле:
idf(w)=log(M)-log(d(w)),
где d(w) - число документов, известных системе, в которых встречается словоформа w, М - общее число документов, известных системе. Для нормировки вектора весов используется евклидова норма:
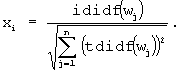
Далее сформированный тезаурус текстового сообщения направляется в управляющий блок 3, контролируемый оператором устройства. Управляющий блок 3 позволяет устройству работать в двух режимах: в режиме начального обучения и нормальном режиме. Режим начального обучения необходим для построения начальных классификационных признаков. В этом режиме управляющее устройство получает информацию о категории, которой принадлежит текстовое сообщение, из блока 4. При работе в нормальном режиме управляющий блок обращается к блоку 5 для определения категории, которой принадлежит текстовое сообщение.
При классификации текстового сообщения происходит вычисление скалярного произведения между нормированным вектором весов сообщения и векторами весов (классификационными признаками) всех категорий. Поскольку указанные вектора нормированы, то скалярное произведение этих векторов равно косинусу угла между соответствующими векторами в соответствующих многомерных пространствах. Категория, для которой это скалярное произведение будет максимальным, присваивается данному текстовому сообщению:
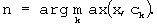
Информация о данной категории передается из блока 5 в управляющий блок 3 и далее поступает в блок определения начальной информативности текстовых сообщений.
Для определения начальной информативности текстового сообщения используется формула:
I(s)=1-(x(s),ck),
где s - текущее текстовое сообщение, x(s) - вектор весов словоформ тезауруса сообщения s, ck - вектор классификационных признаков категории k, которой принадлежит текстовое сообщение s. При этом скалярное произведение вычисляется по всем словоформам из пересечения множества словоформ данного текстового сообщения и классификационных признаков категории k, а вектора x(s) и ck имеют компоненты, отвечающие соответствующим словоформам.
Из блока 6 определения начальной информативности текстового сообщения данные о текущем текстовом сообщении, а именно само сообщение, его тезаурус и начальная информативность поступают в блок 7, который сохраняет их в хранилище 8.
Далее управление передается в блок 9. Классификационные признаки, соответствующие каждой категории, представляют собой вектора весов, соответствующие всем словоформам, встречавшимся в каком-либо текстовом сообщении из данной категории. Вектора весов нормируются в соответствии с евклидовой нормой. Определение классификационных признаков для каждой категории происходит итеративно. Для этого используется динамический алгоритм обучения линейных классификаторов Видроу-Хоффа (Widrow-Hoff). Классификационные признаки категорий извлекаются из хранилища 10 и пересчитываются по формуле:
ckj,нов=сkj,стар-2η((сk,стар,x(s))-у)хj(s),
где сkj,стар и сkj,нов - j-e компоненты соответственно старого и нового векторов классификационных признаков k-й категории, у - вектор, у которого на позиции, соответствующей номеру категории, которой принадлежит текстовое сообщение s, стоит единица, а на остальных позициях - нули, η - коэффициент скорости обучения, задаваемый оператором устройства. Затем обновленные значения классификационных признаков заносятся обратно в хранилище 10.
Блок 11 посылает сигналы в блок 12 с постоянным временным периодом, задаваемым оператором устройства. При получении сигнала блок 12 перебирает все сообщения, содержащиеся в хранилище 8, и обновляет значения их информативностей в соответствии со следующей формулой:
I(s)=I(s)-αΔt,
где α - коэффициент потери информативности, Δt - временной период между последовательными сигналами блока генерации временных отсчетов. Новые значения информативностей заносятся в хранилище 8. Коэффициент α задается оператором устройства.
В блоке 13 удаления текстовых сообщений происходит перебор всех сообщений, содержащихся в хранилище текстовых сообщений 8, и удаление из него всех сообщений, информативность которых в момент проверки ниже порога информативности ε, также задаваемого оператором устройства.
Значения коэффициентов α, η, ε могут быть различны в зависимости от специфики использования данного устройства.
Таким образом, с помощью способа происходит классификация текстовых сообщений на заранее заданном множестве категорий, а также определение информативности текстового сообщения и удаление его по мере того, как оно утрачивает информативность, чем достигается поставленный выше технический результат.
Источники информации, принятые во внимание при составлении материалов заявки:
1. Патент США 6327581, кл. G 06 F 015/18.
2. Lewis D.D., Shapire R.E., Callan J.P., Papka R. "Training algorithms for linear text classifiers", In Proceedings of SIGIR-96, 49th ACM International Conference on Research and Development in Information Retrieval, pages 294-306, Zurich, CH, 1996.
3. Патент РФ № 2167450 С2, кл. G 06 F 17/30 - прототип.
4. Porter M.F. "An algorithm for suffix stripping". Program, Vol.14, No.3, 1980, pp.130-137.
5. Патент РФ № 2096825 C1, кл. G 06 F 17/00.
6. Патент США № 6308149, кл. G 06 F 17/27.
7. Патент США № 6430557, кл. G 06 F 017/30; G 06 F 017/27; G 06 F 017/21.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ АВТОМАТИЧЕСКОЙ КЛАССИФИКАЦИИ ДОКУМЕНТОВ | 2003 |
|
RU2254610C2 |
| СПОСОБ АВТОМАТИЧЕСКОЙ КЛАССИФИКАЦИИ ФОРМАЛИЗОВАННЫХ ДОКУМЕНТОВ В СИСТЕМЕ ЭЛЕКТРОННОГО ДОКУМЕНТООБОРОТА | 2013 |
|
RU2546555C1 |
| Способ автоматической классификации конфиденциальных формализованных документов в системе электронного документооборота | 2015 |
|
RU2647640C2 |
| СПОСОБ АВТОМАТИЧЕСКОЙ КЛАССИФИКАЦИИ ФОРМАЛИЗОВАННЫХ ТЕКСТОВЫХ ДОКУМЕНТОВ И АВТОРИЗОВАННЫХ ПОЛЬЗОВАТЕЛЕЙ СИСТЕМЫ ЭЛЕКТРОННОГО ДОКУМЕНТООБОРОТА | 2017 |
|
RU2692043C2 |
| СПОСОБ АВТОМАТИЧЕСКОЙ КЛАССИФИКАЦИИ ЭЛЕКТРОННЫХ ДОКУМЕНТОВ В СИСТЕМЕ ЭЛЕКТРОННОГО ДОКУМЕНТООБОРОТА С АВТОМАТИЧЕСКИМ ФОРМИРОВАНИЕМ РЕКВИЗИТА РЕЗОЛЮЦИИ РУКОВОДИТЕЛЯ | 2018 |
|
RU2692972C1 |
| СПОСОБ АВТОМАТИЧЕСКОЙ КЛАССИФИКАЦИИ ФОРМАЛИЗОВАННЫХ ЭЛЕКТРОННЫХ ГРАФИЧЕСКИХ И ТЕКСТОВЫХ ДОКУМЕНТОВ В СИСТЕМЕ ЭЛЕКТРОННОГО ДОКУМЕНТООБОРОТА С АВТОМАТИЧЕСКИМ ФОРМИРОВАНИЕМ ЭЛЕКТРОННЫХ ДЕЛ | 2020 |
|
RU2759887C1 |
| Способ автоматической классификации электронных документов в системе электронного документооборота с автоматическим формированием электронных дел | 2019 |
|
RU2726931C1 |
| СПОСОБ КЛАССИФИКАЦИИ ДОКУМЕНТОВ ПО КАТЕГОРИЯМ | 2012 |
|
RU2491622C1 |
| СПОСОБ КЛАССИФИКАЦИИ ТЕКСТОВ, ПОЛУЧЕННЫХ В РЕЗУЛЬТАТЕ РАСПОЗНАВАНИЯ РЕЧИ | 2016 |
|
RU2628897C1 |
| КЛАССИФИКАЦИЯ ДОКУМЕНТОВ ПО УРОВНЯМ КОНФИДЕНЦИАЛЬНОСТИ | 2019 |
|
RU2732850C1 |
Изобретение относится к системам классификации текстовых сообщений. Его использование в системах обработки информации и базах данных позволяет получить технический результат в виде обеспечения возможности произвольного задания категорий и определения информативности каждого текстового сообщения. В способе получают текстовые сообщения из информационного канала, осуществляют лингвистическую обработку слов, формируют тезаурус каждого текстового сообщения, осуществляют статистическую обработку слов в тезаурусе сообщения, сохраняют текстовое сообщение и тезаурус в хранилище. Технический результат достигается благодаря тому, что автоматически определяют принадлежность текстового сообщения одной из списка категорий, определяют начальную информативность текстового сообщения, сохраняют ее в хранилище вместе с текстовым сообщением; периодически обновляют значения информативности хранящихся в базе данных текстовых сообщений с учетом прошедшего с момента их появления времени и удаляют те текстовые сообщения, информативность которых опустилась ниже заранее установленного порога; при обработке каждого текстового сообщения обновляют значения классификационных признаков категорий. 1 ил.
Способ потоковой обработки текстовых сообщений, заключающийся в том, что получают текстовые сообщения на естественных языках из информационного канала, осуществляют лингвистическую обработку слов каждого сообщения, формируют тезаурус текстового каждого сообщения, осуществляют статистическую обработку слов в тезаурусе сообщения, сохраняют текстовое сообщение и тезаурус в хранилище, отличающийся тем, что автоматически определяют принадлежность текстового сообщения одной категории из заранее определенного списка категорий, при этом определяют начальную информативность текстового сообщения, сохраняют ее в хранилище вместе с текстовым сообщением; периодически проводят обновление значений информативности, хранящихся в базе данных текстовых сообщений с учетом прошедшего с момента их появления времени, и удаляют те текстовые сообщения, информативность которых опустилась ниже заранее установленного порога; при обработке каждого текстового сообщения обновляют значения классификационных признаков категорий.
| СПОСОБ ИДЕНТИФИКАЦИИ ОБЪЕКТОВ ПО ИХ ОПИСАНИЯМ | 1999 |
|
RU2167450C2 |
| US 6553385 B1, 22.04.2003 | |||
| US 6457018 B1, 24.09.2002 | |||
| US 6311183 B1, 30.10.2001 | |||
| US 6295542 B1, 25.09.2001 | |||
| US 5500796 A, 19.03.1996 | |||
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| УСТРОЙСТВО ДЛЯ ВВОДА И ВЫВОДА ГРУЗОВЫХ ТЕЛЕЖЕК | 0 |
|
SU398477A1 |

