Изобретение относится к системам классификации документов и может использоваться в системах обработки информации, базах данных, электронных хранилищах в случаях, когда тематическая зависимость категорий друг от друга может быть представлена в виде дерева.
Известен способ автоматической классификации документов [1], заключающийся в том, что осуществляют преобразование документа из формата хранения в текст на естественном языке, преобразуют слова документа в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в документе в соответствии с частотами их появления, на этапе обучения по предъявленному набору классифицированных вручную документов формируют набор классификационных признаков, а при классификации документа осуществляют преобразование его из формата хранения в текст на естественном языке, преобразуют слова документа в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в документе, на основе простого байесовского классификационного критерия и классификационных признаков определяют принадлежность документа категории.
Отметим, что данный способ предназначен для обработки машиночитаемых текстов на естественном языке.
Данный способ простой байесовской классификации документов использует гипотезу о независимости слов документа друг от друга. При этом как документ, так и категории рассматриваются как вероятностные системы, для которых вычисляются вероятности появления словоформ как независимых событий. Для определения вероятности принадлежности документа категории вычисляется мера близости между этими двумя вероятностными системами. Способ простой байесовской классификации может использоваться как для бинарной классификации (необходимо определить, принадлежит документ категории или нет), так и для множественной (необходимо из списка категорий найти ту, которой принадлежит документ). В последнем случае документ может принадлежать лишь одной категории из списка.
В тех задачах, где документ может одновременно принадлежать нескольким категориям, используют одновременно несколько бинарных классификаторов рассмотренного типа, каждый из которых определяет, принадлежит ли текущий документ данной категории. При этом принимается гипотеза о независимости категорий друг от друга.
Однако данный способ обладает недостатком, который связан с тем, что он не позволяет классифицировать документы в случае, когда категории тематически зависимы друг от друга, например когда они иерархически подчинены друг другу.
Известен также способ автоматической классификации документов [2], заключающийся в том, что осуществляют преобразование документа из формата хранения в текст на естественном языке, преобразуют слова документа в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в документе в соответствии с частотами их появления; на этапе обучения по предъявленному набору классифицированных вручную документов формируют набор классификационных признаков, при классификации документа осуществляют преобразование его из формата хранения в текст на естественном языке, преобразуют слова документа в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в документе, на основе классификационного критерия SVM (Support Vector Machines) и классификационных признаков определяют принадлежность документа категории.
Данный способ, как и предыдущий, предназначен для обработки машиночитаемых текстов на естественном языке.
Способ, описанный в [2], основан на классификации по методу SVM, который позволяет построить в многомерном пространстве признаков гиперплоскость, отделяющую признаки документов, принадлежащих категории, от признаков документов, не принадлежащих ей. Данный способ также может использоваться в случаях, когда документ может принадлежать сразу нескольким категориям.
Однако данный способ обладает тем же недостатком, что и [1] - он не позволяет классифицировать документы в случае, когда категории тематически зависимы друг от друга.
Наиболее близким по технической сущности к предлагаемому является способ мультиклассовой классификации [3], принятый за прототип, заключающийся в том, что осуществляют преобразование документа из формата хранения в текст на естественном языке, преобразуют слова документа в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в документе в соответствии с частотами их появления и тем самым формируют вектор признаков документа, на этапе обучения по предъявленному набору классифицированных вручную документов формируют набор классификационных признаков, сохраняют классификационные признаки в базе данных, при классификации документа осуществляют преобразование его из формата хранения в текст на естественном языке, преобразуют слова документа в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в документе и формируют вектор признаков документа, после чего принимают решение о принадлежности либо не принадлежности документа каждой из категорий.
В этом способе также под текстами на естественном языке понимаются машиночитаемые тексты.
Данный способ для классификации использует слабые гипотезы о принадлежности документа множеству категорий для итеративного уточнения функции распределения категорий на множестве документов. Для получения слабых гипотез используются методы бинарной классификации документов; а при классификации используют построенное распределение для определения списка категорий, которым принадлежит документ. Данный способ проявляет хорошую работоспособность, поскольку он многократно применяет простые методы классификации, что приводит к большей точности классификации. Кроме того, в рамках указанного способа категории не считаются независимыми. Зависимость между ними задается на этапе обучения посредством представления соответствующей обучающей выборки документов. Недостатком прототипа является невозможность использования при классификации априорной информации о зависимостях категорий друг от друга.
Технический результат, получаемый от внедрения изобретения, заключается в устранении недостатков прототипа, то есть в возможности априорного задания зависимостей категорий друг от друга в виде дерева категорий.
Данный технический результат получают за счет того, что осуществляют преобразование документа из формата хранения в текст на естественном языке, преобразуют слова документа в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в документе в соответствии с частотами их появления и тем самым формируют вектор признаков документа, на этапе обучения по предъявленному набору классифицированных вручную документов формируют набор классификационных признаков, сохраняют классификационные признаки в базе данных, при классификации документа осуществляют преобразование его из формата хранения в текст на естественном языке, преобразуют слова документа в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в документе и формируют вектор признаков документа, после чего принимают решение о принадлежности либо не принадлежности документа каждой из категорий; при этом используют априорную информацию о зависимостях категорий друг от друга. Дополнительной особенностью данного способа является то, что зависимость категорий друг от друга задается деревом категорий. Кроме того, используют бинарные классификаторы для определения принадлежности документа категориям, после чего осуществляют коррекцию результатов классификации путем анализа для каждой категории принадлежностей документа категориям более высокого уровня. Отметим, что данный способ предназначен для обработки машиночитаемых текстов на естественном языке.
В способе слова документов считаются независимыми в рамках категории. Все множество категорий изначально представлено в виде дерева, отражающего тематическую зависимость одних категорий от других и их общность по отношению друг к другу. Принадлежность документа некоторой категории влечет за собой принадлежность его также и всем категориям, находящимся по иерархии выше ее. Данный способ классификации позволяет с учетом этого по входному документу определить, каким узлам дерева категорий он принадлежит, а каким нет.
Документы для классификации могут быть представлены в различных форматах, допускающих выделение из них текстового содержания. Это могут быть текстовые файлы различных форматов, графические файлы с графическим представлением некоторого текста, звуковые файлы с записью речи и другие файлы, для которых существует механизм выделения из них текста, отражающего их содержание. Каждый документ (либо обучающий, либо подвергающийся классификации) предварительно проходит стадию первичной обработки, на которой производится определение формата документа и установление того, возможно ли извлечение текста из документа данного формата. В случае положительного решения производится извлечение текста из документа. После разбиения текста на слова происходит определение для каждого слова его базовой словоформы по одному из способов [4-7]. Наиболее часто для решения подобных задач используется алгоритм Портера [4], заключающийся в использовании специальных правил отсечения и замены окончаний слов.
Согласно предлагаемому способу каждый документ Di представляется вектором признаков вида:
di=(w1,...,wn),
где значением j-го признака wj считается вес j-й словоформы в документе Di, рассчитываемый по формуле:
wj=cij/Ni.
Здесь cij - количество раз, которое j-я словоформа встречается в i-м документе, Ni - общее количество словоформ в i-м документе.
Для инициализации классификатора и построения классификационных признаков служит этап обучения классификатора. При этом должно быть задано множество обучающих документов, заранее классифицированных вручную. После извлечения из них текстового содержания происходит построение словаря документов. Словарь документов содержит базовые словоформы всех слов, встречающихся в обучающих документах.
При классификации документа в расчет берутся не все словоформы из словаря документов, а лишь те из них, которые входят в рабочий словарь классификатора данной категории. В рабочий словарь классификатора включаются наиболее информативные словоформы с точки зрения определения принадлежности документа данной категории, не попавшие в стоп-словарь. Информативность словоформы wi для классификатора по категории Cj определяется по следующей формуле [8]:

При этом устанавливается порог информативности ε; в рабочий словарь классификатора включаются все словоформы, не попавшие в стоп-словарь, информативность которых превышает этот порог. Стоп-словарь состоит из словоформ, частоты встречаемости которых во множестве обучающих документов превышают заранее установленный порог δ. При этом отсекаются слова, не несущие смысловой нагрузки, такие как предлоги, союзы, вводные слова и т.д. Значения коэффициента δ, согласно данному способу, устанавливаются в пределах от 0.05 до 0.7 в зависимости от специфики приложений способа. Значения порога информативности ε могут быть различны в различных приложениях способа.
Построение классификационных признаков включает в себя расчет априорных вероятностей категорий и построение распределения словоформ из рабочего словаря категории. Для расчета априорных вероятностей определяется доля обучающих документов от общего их числа, попавших в каждую их категорий. Для расчета распределений словоформ рабочего словаря категорий определяются частоты появления этих словоформ в категориях на множестве обучающих документов. Априорные вероятности категорий и распределения словоформ рабочего словаря данные сохраняются в базе данных классификационных признаков.
Классификация документов производится в два этапа.
На первом этапе классификации категории считаются независимыми и происходит независимое определение принадлежности документа каждой из категорий. Для этого используется неравенство
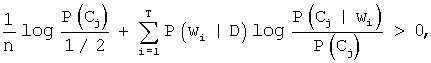
где P(Cj) - априорная вероятность текущей категории Сj, n - число слов в текущем документе D, Т - число различных словоформ в документе D, 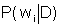 - вероятность появления i-й словоформы в документе D,
- вероятность появления i-й словоформы в документе D, 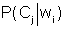 - вероятность категории Сj при условии появления i-й словоформы. Если указанное неравенство выполняется, то принимается решение о том, что документ D принадлежит категории Сj.
- вероятность категории Сj при условии появления i-й словоформы. Если указанное неравенство выполняется, то принимается решение о том, что документ D принадлежит категории Сj.
На втором этапе классификации происходит коррекция полученных на первом этапе результатов с учетом априорной информации о тематической зависимости категорий, представленной деревом категорий.
В основе коррекции лежит утверждение о том, что если документ принадлежит некоторой категории, то он также принадлежит всем категориям, лежащим выше по иерархии. Этап коррекции состоит в последовательном переборе всех вершин дерева категорий от корня (исключая сам корень, так как он не является категорией) к листьям. На каждой итерации происходит проверка, принадлежит ли данной категории текущий документ. Если принадлежит, то производится подъем по иерархии от текущей вершины до корня дерева, во время которого определяется количество вершин, которым принадлежит документ согласно решениям классификатора и количество вершин, которым он не принадлежит согласно решениям классификатора. Если число вершин, которым принадлежит документ, превышает число вершин, которым он не принадлежит, то на этапе коррекции принимается решение о том, что категории, соответствующей текущей вершине, документ принадлежит, после чего происходит корректировка решений классификатора на протяжении всего пути от текущей вершины до корня дерева с присвоением всем его промежуточным вершинам положительного решения о классификации. В случае, если число вершин, которым принадлежит документ, не превышает число вершин, которым он не принадлежит, происходит присвоение отрицательного решения о принадлежности текущего документа категории, соответствующей текущей вершине.
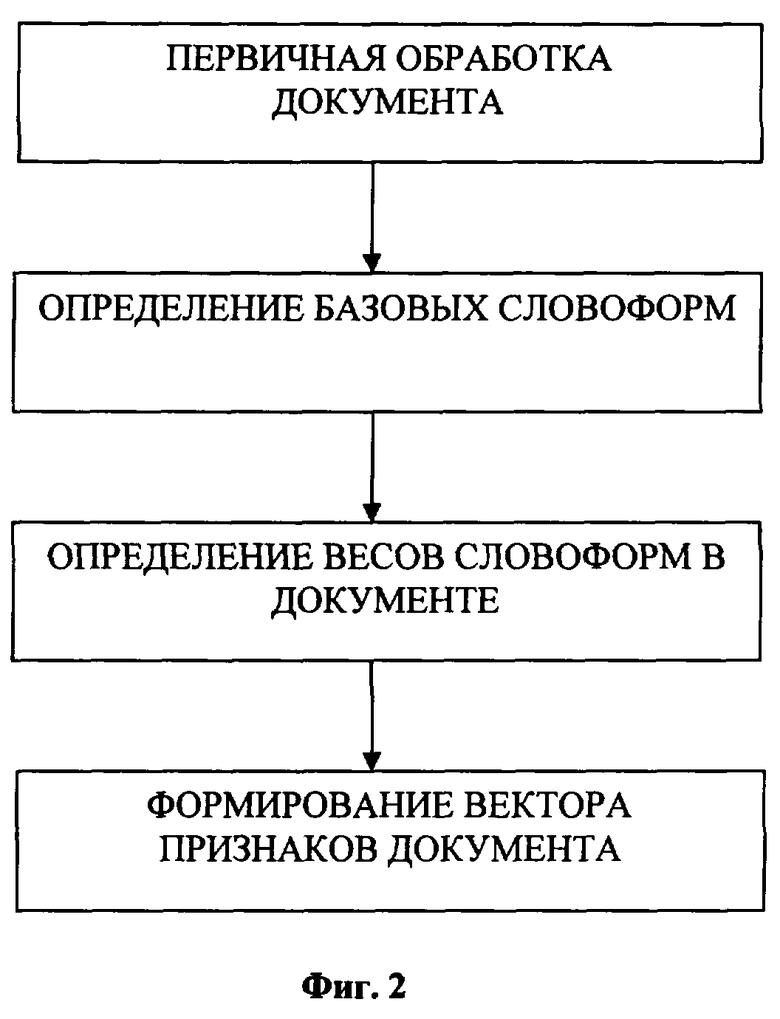
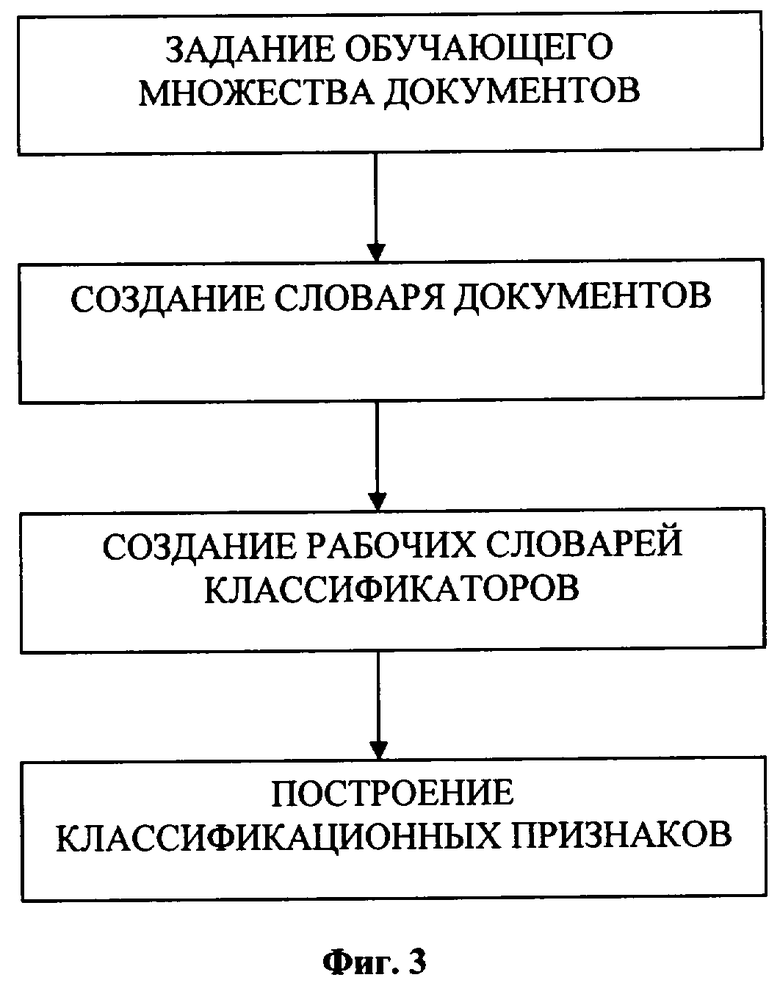
Изобретение поясняется чертежами, на фиг.1 которого представлена блок-схема вычислительного устройства для реализации способа. На фиг.2 представлен алгоритм формирования признаков документов. На фиг.3 представлен алгоритм обучения классификаторов.
Устройство для реализации способа (фиг.1) состоит из источника документов 1, блока 2 формирования признаков документа, управляющего блока 3, блока 4 обучения классификаторов, блока 5 обучающих данных, базы данных 6, блока 7 классификации, блока 8 коррекции результатов классификации, блока 9 вывода результатов классификации.
Согласно способу устройство работает следующим образом. При появлении в источнике документов 1 нового документа он поступает в блок 2, который производит обработку документа и построение по нему вектора признаков. При этом сначала происходит первичная обработка документа (фиг.2), на которой из документа извлекается текстовое содержание, затем происходит определение базовых словоформ для всех слов, содержащихся в тексте документа, после чего определяются веса словоформ в документе.
Управляющий блок 3 контролируется оператором устройства и может работать в двух режимах: в режиме обучения и в режиме классификации.
В режиме обучения признаки документа, сформированные в блоке 2, поступают далее в блок 4, в котором происходит накопление обучающих документов и формирование классификационных признаков. При этом используются обучающие данные и документы, поступающие из блока 5 и накапливаемые в базе данных 6. Блок обучающих данных предоставляет информацию и принадлежности каждого обучающего документа категориям. Эта информация вместе с признаками обучающих документов накапливается в базе данных 6. В момент завершения режима обучения непосредственно перед переключением управляющего блока в режим классификации происходит извлечение всех накопленных обучающих документов из базы данных 6 и формирование классификационных признаков (фиг.3). Для этого по накопленному множеству обучающих документов происходит создание словаря документов, который содержит все словоформы, встречающиеся в обучающих документах, после чего создаются рабочие словари классификаторов. Затем происходит построение классификационных признаков. Полученные классификационные признаки сохраняются в базе данных 6.
В режиме классификации признаки документа поступают через управляющее устройство в блок 7, где происходит классификация документа по его признакам. При этом используются поступающие из базы данных 6 классификационные признаки. Затем результаты классификации поступают в блок 8, где происходит их коррекция с учетом тематических зависимостей между категориями, после чего скорректированный список категорий, которым принадлежит документ, поступает в блок 9.
Таким образом, способ позволяет классифицировать документы с учетом априорных зависимостей между категориями, задаваемыми деревом категорий, чем достигается поставленный выше технический результат.
Источники информации
1. Li Y., Jain A. "Classification of text documents", The Computer Journal 41, 8, pp.537-546, 1998.
2. Патент США 6327581, кл. G 06 F 015/18.
3. Schapire R.E., Singer Y. "BoosTexter: A boosting-based system for text categorization". Machine Learning 39, 2/3, 2000, pp.135-168 - прототип.
4. Porter M.F. "An algorithm for suffix stripping", Program, Vol.14, No.3, 1980, pp.130-137.
5. Патент РФ №2096825 С1, кл. G 06 F 17/00.
6. Патент США 6308149, кл. G 06 F 17/27.
7. Патент США 6430557, кл. G 06 F 017/30; G 06 F 017/27; G 06 F 017/21.
8. Craven M., DiPasquo D., Freitag D. et al. "Learning to сonstruct knowledge bases from the World Wide Web", Artificial Intelligence, Vol.118(1-2), 2000, pp.69-113.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ АВТОМАТИЧЕСКОЙ КЛАССИФИКАЦИИ ФОРМАЛИЗОВАННЫХ ДОКУМЕНТОВ В СИСТЕМЕ ЭЛЕКТРОННОГО ДОКУМЕНТООБОРОТА | 2013 |
|
RU2546555C1 |
| Способ автоматической классификации конфиденциальных формализованных документов в системе электронного документооборота | 2015 |
|
RU2647640C2 |
| СПОСОБ АВТОМАТИЧЕСКОЙ КЛАССИФИКАЦИИ ФОРМАЛИЗОВАННЫХ ТЕКСТОВЫХ ДОКУМЕНТОВ И АВТОРИЗОВАННЫХ ПОЛЬЗОВАТЕЛЕЙ СИСТЕМЫ ЭЛЕКТРОННОГО ДОКУМЕНТООБОРОТА | 2017 |
|
RU2692043C2 |
| СПОСОБ АВТОМАТИЧЕСКОЙ КЛАССИФИКАЦИИ ЭЛЕКТРОННЫХ ДОКУМЕНТОВ В СИСТЕМЕ ЭЛЕКТРОННОГО ДОКУМЕНТООБОРОТА С АВТОМАТИЧЕСКИМ ФОРМИРОВАНИЕМ РЕКВИЗИТА РЕЗОЛЮЦИИ РУКОВОДИТЕЛЯ | 2018 |
|
RU2692972C1 |
| Способ автоматической классификации электронных документов в системе электронного документооборота с автоматическим формированием электронных дел | 2019 |
|
RU2726931C1 |
| СПОСОБ АВТОМАТИЧЕСКОЙ КЛАССИФИКАЦИИ ФОРМАЛИЗОВАННЫХ ЭЛЕКТРОННЫХ ГРАФИЧЕСКИХ И ТЕКСТОВЫХ ДОКУМЕНТОВ В СИСТЕМЕ ЭЛЕКТРОННОГО ДОКУМЕНТООБОРОТА С АВТОМАТИЧЕСКИМ ФОРМИРОВАНИЕМ ЭЛЕКТРОННЫХ ДЕЛ | 2020 |
|
RU2759887C1 |
| СПОСОБ ПОТОКОВОЙ ОБРАБОТКИ ТЕКСТОВЫХ СООБЩЕНИЙ | 2003 |
|
RU2251148C1 |
| Автоматическое извлечение именованных сущностей из текста | 2014 |
|
RU2665239C2 |
| Способ атрибутизации частично структурированных текстов для формирования нормативно-справочной информации | 2020 |
|
RU2750852C1 |
| СПОСОБ КЛАССИФИКАЦИИ ДОКУМЕНТОВ ПО КАТЕГОРИЯМ | 2012 |
|
RU2491622C1 |
Заявленное изобретение относится к системам классификации документов и может использоваться в системах обработки информации, базах данных, электронных хранилищах в случаях, когда тематическая зависимость категорий друг от друга может быть представлена в виде дерева. Техническим результатом является обеспечение возможности априорного задания зависимостей категорий друг от друга в виде дерева категорий. Для этого способ автоматической классификации документов основан на многократном применении простого байесовского классификатора для классификации документа и последующей коррекции результатов классификации с учетом тематических зависимостей между категориями, задаваемыми априорно. 3 ил.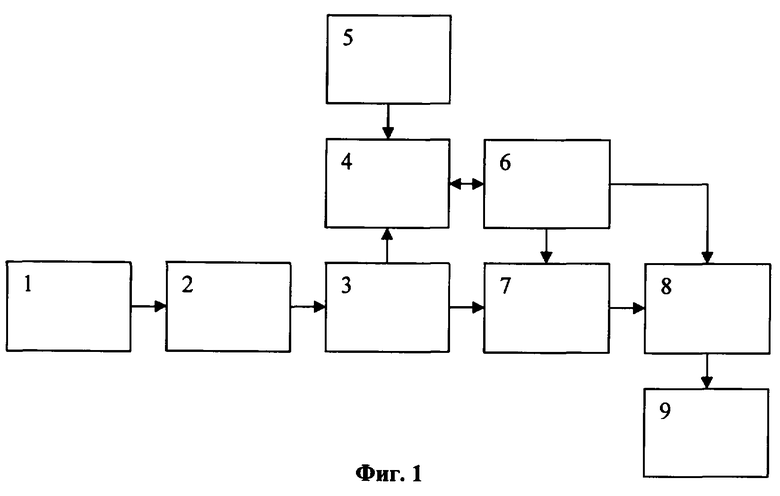
Способ автоматической классификации документов, заключающийся в том, что осуществляют преобразование документа из формата хранения в текст на естественном языке, преобразуют слова преобразованного документа в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в упомянутом документе в соответствии с частотами их появления и тем самым формируют вектор признаков документа, на этапе обучения по предъявленному набору классифицированных вручную документов формируют набор классификационных признаков, сохраняют классификационные признаки в базе данных, при классификации документа осуществляют преобразование его из формата хранения в текст на естественном языке, преобразуют слова документа в базовые словоформы, отбрасывают незначимые слова, осуществляют подсчет весов слов в документе и формируют вектор признаков документа, после чего принимают решение о принадлежности либо не принадлежности документа каждой из категорий, отличающийся тем, что на этапе определения принадлежности документа каждой из категорий используют априорную информацию о зависимостях категорий друг от друга, задаваемую деревом категорий, при этом используют бинарные классификаторы для определения принадлежности документа категориям, после чего осуществляют анализ принадлежности каждой категории документа категориям более высокого уровня, и если число вершин дерева, которым принадлежит документ, превосходит число вершин, которым он не принадлежит, то принимают решение о соответствии документа текущей вершине, после чего производят корректировку решений классификатора на протяжении всего пути от текущей вершины до корня дерева и классифицируют этот документ по всем промежуточным вершинам дерева.
| ROBERT E | |||
| SHAPIRE, YORAM SINGER, BoosTexter: A Boosting-based System for Text Categorization | |||
| ЩИТОВОЙ ДЛЯ ВОДОЕМОВ ЗАТВОР | 1922 |
|
SU2000A1 |
| Способ обделки поверхностей приборов отопления с целью увеличения теплоотдачи | 1919 |
|
SU135A1 |
| СПОСОБ УСТАНОВЛЕНИЯ В ХРАНИЛИЩЕ МЕСТОПОЛОЖЕНИЯ ОБЪЕКТА ПО ПОИСКОВОМУ ТЕМАТИЧЕСКОМУ ПРИЗНАКУ | 1994 |
|
RU2107942C1 |
| СПОСОБ ИДЕНТИФИКАЦИИ ОБЪЕКТОВ ПО ИХ ОПИСАНИЯМ | 1999 |
|
RU2167450C2 |
| УСТРОЙСТВО ОБРАБОТКИ ИНФОРМАЦИИ ДЛЯ ИНФОРМАЦИОННОГО ПОИСКА | 1996 |
|
RU2096825C1 |
| УСТРОЙСТВО ДЛЯ УПАКОВКИ ПРОДУКТОВ в ПАКЕТЫ | 0 |
|
SU304191A1 |

