Предлагаемое изобретение относится к области цифровой обработки сигналов и применяется для кодирования и декодирования речевого сигнала.
Известны способы кодирования и декодирования речевого сигнала с использованием метода линейного предсказания (см., например, Маркел Дж.Д., Грей Ф.Х., Линейное предсказание речи, М., Связь, 1980, стр.18; Рекомендация G.723.1 утверждена ITU-T в ноябре 1995 года; Рекомендация G.729a утверждена ITU-T в ноябре 1996 года; «Voice coding/decoding method and apparatus», Chan Woo Kim, US 2006/0015330 A1, Pub. Date: Jan 19, 2006). В этих способах при кодировании и декодировании речевого сигнала, аналоговый голосовой сигнал преобразуют в цифровые отсчеты (сегмент, подкадр, sample, subframe) с определенной частотой дискретизации, на участке линейного преобразования сигнала используют формулы, основанные на принципах наименьших квадратов для вычисления коэффициентов линейного предсказания следующего отсчета. Основными недостатками подобных методов является необходимость обращения матриц большой размерности при вычислении коэффициентов линейного предсказания, что требует значительных вычислительных ресурсов.
Наиболее близким по технической сути к предложенному является способ кодирования и декодирования речевого сигнала по алгоритму CELP (Code Excited Linear Prediction) с использованием метода линейного предсказания («Apparatus and method for speech coding», Kazutoshi Yasunaga, Toshiyuki Morii, US 2005/0197833 A1, Pub. Date: Sep 8, 2005), при котором аналоговый голосовой сигнал преобразуют в цифровые отсчеты с определенной частотой дискретизации, из отсчетов формируют один кадр (фрейм, блок данных, frame) голосового сигнала, для кадра вычисляют значения коэффициентов линейного предсказания (КЛП) и сигналов возбуждения (СВ), полученные данные упаковывают в битовый поток и передают через канал связи на приемную сторону, при декодировании речевого сигнала кадр восстанавливают на основе данных, полученных от передающей стороны.
Основным недостатком этого способа является вычислительная сложность, связанная с процедурами поиска оптимальных СВ по двум кодовым книгам (КК) и вычислением КЛП на основе автокорреляционных функций, приводящих к необходимости обращения матриц большой размерности.
Решаемая предлагаемым изобретением задача - повышение скорости и экономической эффективности цифровой обработки речевого сигнала.
Технический результат, который может быть достигнут при осуществлении способа, - снижение капитальных и эксплуатационных затрат на единицу обрабатываемого объема речевой информации при кодирования и декодировании сигнала без потери данных. Дополнительными техническими эффектами являются: уменьшение энтропии передаваемого сигнала за счет кодирования кадров входного потока кодом Хаффмана (либо близким к нему по эффективности), а также сжатие динамического диапазона за счет автоматической регулировки уровня сигнала.
Для решения поставленной задачи с достижением технического результата, в известном способе кодирования и декодирования речевого сигнала, при котором речевой сигнал преобразуют в цифровые отсчеты с определенной частотой дискретизации, из цифровых отсчетов формируют кадр речевого сигнала, для кадра речевого сигнала вычисляют значения КЛП и СВ, полученные данные кодируют в битовый поток и передают через канал связи на приемную сторону, на приемной стороне кадр речевого сигнала декодируют на основе информации, полученной от передающей стороны, согласно предлагаемому изобретению, преобразование осуществляют над каждым цифровым отсчетом речевого сигнала, на передающей стороне выделяют и кодируют цифровые отсчеты, соответствующие паузам в речи, при поступлении цифрового отсчета вычисляют значение СВ, для чего используют значение текущего цифрового отсчета и хранящиеся в КК предыдущие значения КЛП и цифровых отсчетов, вычисляют значения КЛП для текущего цифрового отсчета, полученные и предыдущие значения КЛП и цифровых отсчетов сохраняют в КК для вычислений со следующими отсчетами, в буфере передающей стороны накапливают определенное количество значений СВ и суммируют их с кодом паузы, формируют кадр, кадр кодируют оптимальным кодом и передают на приемную сторону, на приемной стороне кадр декодируют, восстанавливают значения СВ и выделяют код паузы, вычисляют значение цифрового отсчета на основе поступившего значения СВ и хранящихся в КК приемной стороны значений предыдущих КЛП и цифровых отсчетов, вычисляют значения КЛП для текущего цифрового отсчета, полученные и предыдущие значения КЛП и цифровых отсчетов сохраняют в КК приемной стороны для вычислений со следующими отсчетами, в соответствии с кодом паузы микшируют цифровые отсчеты с сигналом комфортного шума и восстанавливают речевой сигнал.
Возможен дополнительный вариант осуществления способа, в котором целесообразно, чтобы:
- на передающей стороне перед кодированием преобразованный речевой сигнал подвергали сжатию динамического диапазона, уменьшали по амплитуде и округляли значения цифровых отсчетов до целого, на приемной стороне восстанавливали динамический диапазон декодированного речевого сигнала.
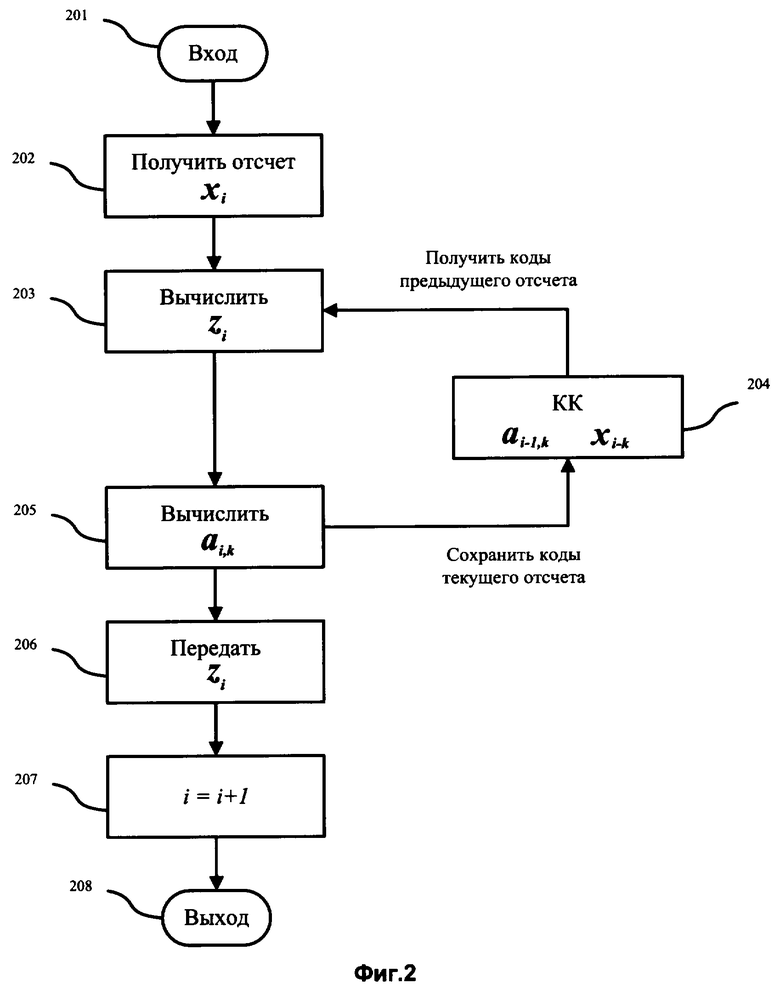
Суть предлагаемого изобретения и его дополнительных вариантов поясняется чертежами, на которых схематично представлены схемы преобразования речевого сигнала в соответствии с предложенным способом.
На фиг.1 изображена возможная схема преобразований, которым подвергается голосовой сигнал при кодировании и декодировании по предложенному способу.
На фиг.2 изображена возможная последовательность действий, выполняемых при компрессии отсчетов голосового сигнала по предложенному способу.
На фиг.1 схематично изображены: 101 - модуль ввода/вывода аналогового голосового сигнала. 102 - дифференциальная система, разделяющая приемную и передающую части голосового канала. Элементы 103 - 110 - осуществляют преобразование сигнала в процессе кодирования. 103 - 8-битное аналогово-цифровое преобразование (АЦП) с частотой дискретизации 8 кГц. 104 - выделение отсчетов, соответствующих паузам в речи. 105 - автоматическая регулировка усиления сигнала с ослаблением сильных звуков без заметного ухудшения качества речи. 106 - сжатие отсчетов речевого сигнала с вычислением КЛП. 107 - кодовая книга (КК), хранящая результаты обработки отсчетов. 108 - накопление отсчетов компрессированного сигнала с последующим формированием кадра и его кодированием. 109 - формирование из кадров сетевых пакетов. 110 - кодирование отсчетов голосового сигнала, соответствующих паузам в речи. Элементы 111-118 осуществляют преобразование сигнала в процессе декодирования. 111 - модуль преобразования принятых пакетов в последовательность байт.112 - декодирование полученных кадров с преобразованием их в отсчеты компрессированного сигнала и выделением кода паузы. 113 - декомпрессия полученных отсчетов на основе значений КЛП и предыдущих отсчетов, хранящихся в КК (114). 114 - кодовая книга (КК), хранящая результаты обработки отсчетов. 115 - автоматическая регулировка усиления сигнала. 116 - генератор сигнала комфортного шума. 117 - микширование отсчетов основного сигнала и комфортного шума. 118 - 8- битное цифроаналоговое преобразование (ЦАП) с частотой дискретизации 8 кГц. 119 - управление приемом и передачей пакетов через сеть передачи данных. 120 - сеть передачи данных.
Поясним процесс преобразований (Фиг.1) голосового сигнала при кодировании и декодировании по предложенному способу. Известно множество высокоэффективных методов сжатия голосового сигнала, приведенных в качестве аналогов и прототипа к предлагаемому изобретению и применяемых в сети передачи данных (СПД) для голосовой связи. Такие кодеры на участке компрессии сигнала 106 вычисляют КЛП. Формулы для вычисления коэффициентов получаются на основе принципа наименьших квадратов и приводят к необходимости обращения матриц большой размерности. Однако, применение принципа наименьших квадратов оправдано только для нормально распределенных величин, что не свойственно в общем виде для компонент речевого сигнала. Обращение же матриц большой размерности требует значительных вычислительных ресурсов. Предлагаемое изобретение описывает способ скоростного кодирования и декодирования речи без необходимости вычисления автокорреляционных функций высокого порядка.
Ввод аналогового голосового сигнала осуществляется АЦП 103 со скоростью 8000 отсчетов в секунду. После цифровой обработки голосовой информации, из сигнала выделяются отсчеты, соответствующие паузам в речи 104. Далее отсчеты, не несущие речевой информации, кодируются отдельно от основного сигнала 110, после чего в сеть передачи данных поступает только код наличия паузы. После выделения пауз (на пути 104-105), средняя энтропия оцифрованного сигнала при практически максимально допустимой громкости составляет около 5 бит на один отсчет. Впоследствии сигнал подвергают автоматической регулировке усиления 105 с ослаблением сильных звуков и переходом к разности соседних отсчетов. Такая обработка позволяет без заметного ухудшения качества речи снизить энтропию (на пути 105-106) до 2 бит на отсчет, а с незначительным ухудшением качества до 1,7 бит на отсчет.
Суть предлагаемого способа заключается в обработке сигнала на этапе компрессии (106, 107) и декомпрессии (113,114), при вычислении КЛП и позволяет без потери информации снизить энтропию в среднем для речи на 0,9 бита, существенно уменьшить амплитуду звуков, имеющих основную частоту и ее обертоны. После компрессии сигнал суммируется с кодом паузы, кодируется в кадры оптимальным кодом Хаффмана (108), либо близким к нему по эффективности, упаковывается в пакеты (109) и передается в СПД. Целью кодирования является преобразование входного потока в поток бит минимальной длины, что достигается уменьшением энтропии входного потока. В итоге, после кодирования результата скорость передачи информации составляет примерно 0,8 бита на отсчет (на пути 108-109), т.е. 6,4 кбит/с. Такое сжатие несколько хуже, чем в кодеках - аналогах и прототипе, однако преимущество предложенного способа в том, что алгоритм практически не требует вычислительных ресурсов процессора. Восстановление (111-118) сигнала проводится в обратном порядке.
Обозначим целочисленные значения отсчетов речевого сигнала после АРУ символом хi, где i - индекс отсчета, увеличивающийся на единицу для каждого нового отсчета. Пусть 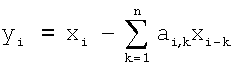 , где ai,k - КЛП, не целочисленные в общем случае величины, n - количество предыдущих отсчетов и КЛП, хранимых в КК, на основе которых выполняется линейное предсказание. Речевой сигнал xi должен хорошо удовлетворять некоторому дифференциальному уравнению, коэффициенты которого определяются состоянием речевого тракта. Потому они не могут изменяться во времени слишком быстро, а сигнал yi должен быть существенно меньше исходного сигнала, т.к. речевой тракт усиливает возбуждающий сигнал за счет резонансов на частотах, соответствующих первой, второй и следующим формантам. Таким образом, величина yi должна принимать по возможности значения, близкие к нулю, а КЛП аi,k медленно изменяться как функция i. Введем константу L, положительное целое число N и обозначим:
, где ai,k - КЛП, не целочисленные в общем случае величины, n - количество предыдущих отсчетов и КЛП, хранимых в КК, на основе которых выполняется линейное предсказание. Речевой сигнал xi должен хорошо удовлетворять некоторому дифференциальному уравнению, коэффициенты которого определяются состоянием речевого тракта. Потому они не могут изменяться во времени слишком быстро, а сигнал yi должен быть существенно меньше исходного сигнала, т.к. речевой тракт усиливает возбуждающий сигнал за счет резонансов на частотах, соответствующих первой, второй и следующим формантам. Таким образом, величина yi должна принимать по возможности значения, близкие к нулю, а КЛП аi,k медленно изменяться как функция i. Введем константу L, положительное целое число N и обозначим:
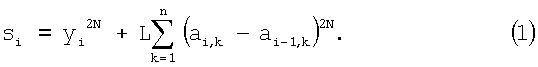
Выбирая аi,k так, чтобы минимизировать si, взяв производную si по ai,k и приравняв ее к нулю, получим уравнение:
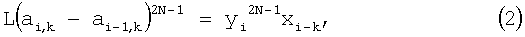
поделив уравнение (2) на L и возведя результат в степень λ=1/(2N-1), найдем для аi,k условие:
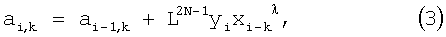
умножив (3) на хi-k и просуммировав по k, получим выражение:
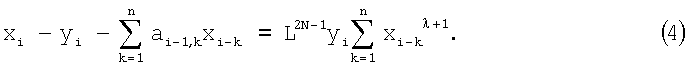
Обозначив величину сигнала возбуждения:
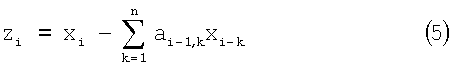
и
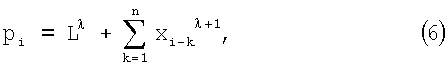
получим уравнение:

подставив (7) в (3), найдем:
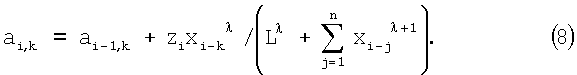
Переходя к скалярным вычислениям, будем считать N вещественным и устремим 2N к 1 с положительной стороны. Тогда формула (8) будет выглядеть так:
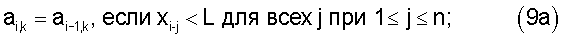
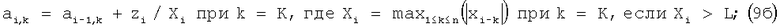
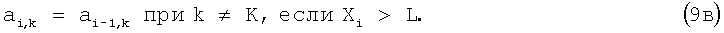
Таким образом, на каждом шаге, при увеличении i на единицу, коэффициенты аi,k либо не изменяются, либо изменяется только один из коэффициентов (по формуле 9б).
На фиг.2 схематично изображены: 201 - поступление очередного отсчета, 202 - получение значения отсчета хi и индекса i, 203 - вычисление значения СВ по формуле (5), 204 - кодовая книга, хранящая значения отсчетов и КЛП, 205 - вычисление значений КЛП по формулам (9), 206 - передача значения СВ для кодирования (Фиг.1, 108), 207 - увеличение на 1 значения индекса отсчетов, 208 - окончание процесса.
Поясним последовательность действий, изображенную на фиг.2. Кодер при получении нового отсчета хi (шаг 202) вычисляет величину zi (шаг 203) по формуле (5) и после кодирования передает ее через канал связи декодеру. При этом как кодер, так и декодер используют уже известные на предыдущем шаге и хранящиеся в КК (шаг 204) коэффициенты аi-1,k, затем по формулам (9) подсчитываются коэффициенты аi,k (шаг 205) для текущего отсчета. Полученные значения аi,k и хi сохраняются в КК для вычислений при поступлении следующего отсчета. Декодер, используя формулу (5), восстанавливает исходное значение сигнала хi. Кодирование и декодирование сигнала начинается с участка сигнала, имеющего нулевое значение, и коэффициенты аi,k, равные нулю.
Так как при изменении целочисленного значения хi на единицу zi изменяется также на единицу, то, округлив zi до целочисленного значения Zi, возможно восстановить ряд значений хi по известному ряду значений Zi, представляющему собой сжатый без потери информации речевой сигнал. Поскольку ai,k является медленно изменяющейся функцией i, то тогда zi мало отличается от yi, а потому Zi практически представляет собой малую правую часть дифференциального уравнения, которому удовлетворяет хi - речевой сигнал. При слишком больших значениях константы L коэффициенты аi,k не могут меняться слишком быстро, поэтому настройка их на конкретный сегмент речевого сигнала не будет происходить достаточно быстро и точно, а потому Zi не будет слишком малой величиной. Если же L наоборот слишком мала, то в этом случае yi может быть сделана сколь угодно малой за счет быстрой настройки аi,k, но величина zi при этом не стремится к нулю, а напротив, снова возрастет. Минимальное значение сигнал zi принимает при некоторой величине L (порядка L=30 при n=4), зависящей от неких средних параметров самого речевого сигнала. Сигнал Zi при (L около 30) на любых звуках речи меньше по абсолютной величине, чем исходный сигнал хi.
От формул (9), устремляя L к нулю и одновременно обеспечивая устойчивость решения, легко перейти к:
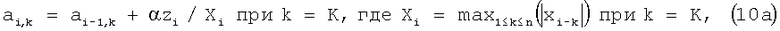
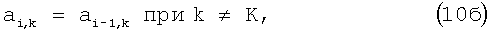
где α (0<α<1) - постоянный коэффициент.
Формулы (10) выглядят более естественно по сравнению с (9), т.к. не имеют кажущегося «искусственным» порога срабатывания.
Таким образом, преобразование хi в Zi осуществляет компрессию речевого сигнала и является взаимно однозначным. То есть для него существует обратное преобразование Zi в хi, верно восстанавливающее исходный сигнал хi. Преобразование эффективно работает как на гласных, так и на шипящих звуках и уменьшает энтропию исходного сигнала примерно на 0.9 бита без потери информации. Если исходный сигнал предварительно подвергнут сжатию динамического диапазона (АРУ), уменьшен по амплитуде и округлен до целых чисел так, что его энтропия имеет величину порядка двух бит на временной отсчет, дополнительное сжатие на 0.9 бита является существенным. Приняв в формуле (8) показатель степени N равным единице (метод наименьших квадратов), получим уменьшение энтропии только 0.5 бита на отсчет. Таким образом, в предложенном способе, полезный эффект сжатия оказывается вдвое больше, чем при использовании метода наименьших квадратов.
В отличие от способа - прототипа и аналогов, использование предложенного способа вычисления КЛП в сочетании с обращением к единственной кодовой книге при преобразовании голосового сигнала позволяет обеспечить вдвое большую эффективность использования вычислительных ресурсов без потери данных. При этом соответственно снижаются капитальные и эксплуатационные затраты на единицу обрабатываемого объема речевой информации.
Таким образом, использование предложенного способа (и его дополнительных вариантов) позволяет обеспечить решение поставленной задачи с достижением ожидаемого технического результата.
Изобретение относится к области цифровой обработки речевых сигналов. Технический результат заключается в уменьшении энтропии передаваемого сигнала за счет кодирования кадров входного потока. Для этого при кодировании и декодировании кадров входного потока, на участках компрессии и декомпрессии используют алгоритм обработки цифровых отсчетов, основанный на вычислении коэффициентов линейного предсказания с применением скалярных операций. 1 з.п. ф-лы, 2 ил.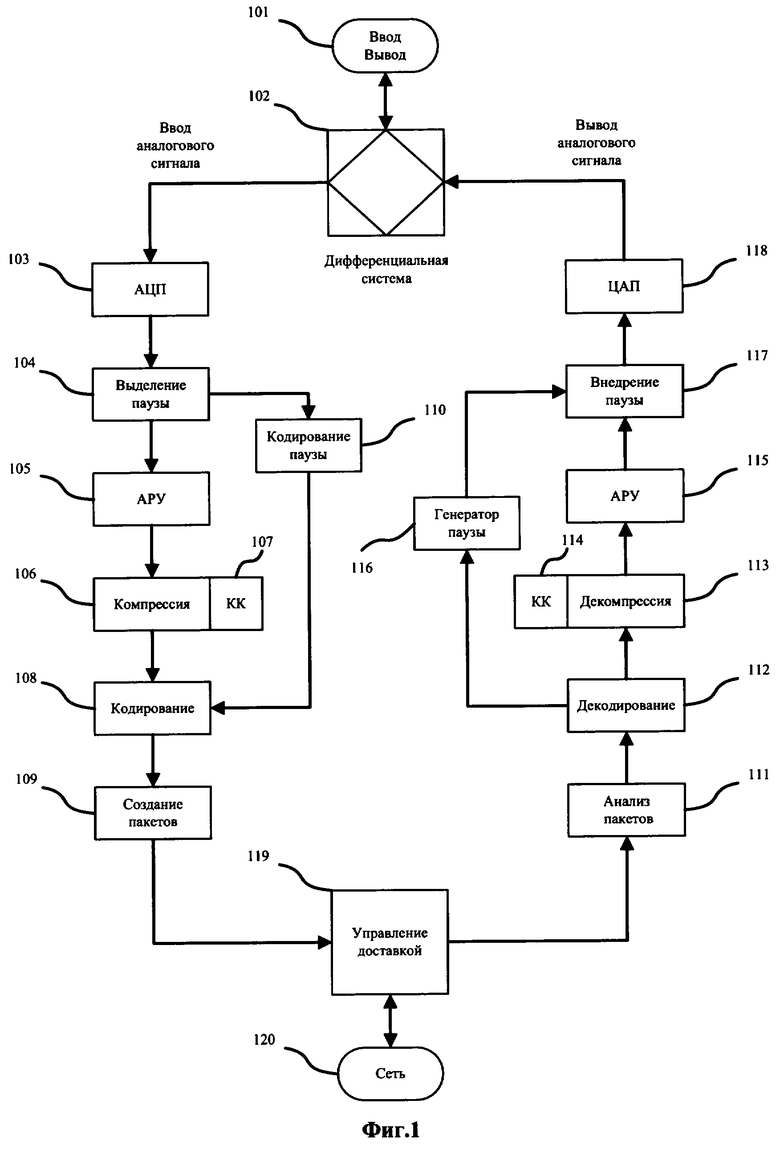
| СПОСОБ ОЦЕНКИ ПЕРИОДА "ЗАТЯГИВАНИЯ" В УСТРОЙСТВЕ ДЕКОДИРОВАНИЯ РЕЧЕВОГО СИГНАЛА ПРИ ПРЕРЫВИСТОЙ ПЕРЕДАЧЕ И УСТРОЙСТВО КОДИРОВАНИЯ РЕЧЕВОГО СИГНАЛА И ПРИЕМОПЕРЕДАТЧИК | 1996 |
|
RU2158446C2 |
| СПОСОБ СЖАТИЯ РЕЧЕВОГО СИГНАЛА ПУТЕМ КОДИРОВАНИЯ С ПЕРЕМЕННОЙ СКОРОСТЬЮ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ, КОДЕР И ДЕКОДЕР | 1993 |
|
RU2107951C1 |
| WO 9629696 A1, 26.09.1996 | |||
| Линия для укладки спичек | 1989 |
|
SU1684268A1 |
| US 2005197833, 08.09.2005 | |||
| US 2005096901 A1, 05.05.2005. | |||

