Изобретение относится к системе электросвязи, а именно к системам низкоскоростного кодирования речевого сигнала, при котором осуществляется векторное квантование с предсказанием параметров линейного предсказания (ЛП).
Системы низкоскоростного кодирования предназначены для компактного представления речевого сигнала, необходимого для передачи по каналам связи с ограниченной пропускной способностью, без значительной потери его качества. В используемом низкоскоростными системами диапазоне скоростей (<16 кбит/с) доминирующее положение среди различных методов кодирования занимает кодирование на основе метода ЛП.
Отличительным признаком метода ЛП является одношаговое приближенное представление (предсказание) текущего отсчета s(k) речевого сигнала линейной комбинацией sпр(k) конечного числа предыдущих отсчетов:

где k - номер текущего отсчета; c(k) - порождающий сигнал с единичной дисперсией; G - масштабирующий коэффициент; М - порядок предсказания; bi - коэффициенты предсказания, i=1,2,…,M.
В системах низкоскоростного кодирования, основанных на методе ЛП, порядок предсказания М, как правило, является постоянным, а значения коэффициентов bi фиксируются на коротких, примыкающих друг к другу и равных по длительности временных интервалах, называемых кадрами речевого сигнала [Быков С.Ф., Журавлев В.И., Шалимов И.А. Цифровая телефония: учеб. пособие для вузов. - М.: Радио и связь, 2003. - 144 с.: ил.]. Анализ предлагаемых алгоритмических решений низкоскоростных систем кодирования позволяет выделить доминирующие на сегодняшний день тенденции в совершенствовании липредерного метода кодирования речи:
1) преимущественное использование для описания текущего состояния голосового тракта М-мерного вектора линейных спектральных частот (ЛСЧ) Ω=(ω1,…,ωM), являющегося математическим эквивалентом множества {bi}, но обладающего лучшей устойчивостью к канальным ошибкам;
2) широкое применение разновидностей векторного квантования (ВК) для отображения кодируемых параметров речи при активном использовании внутрикадровых и межкадровых зависимостей последних с целью максимально возможного исключения избыточности.
Алгоритм определения ЛСЧ известен и представлен в [Рекомендации ITU-T G.729 «Coding of speech at 8 kbit/s using conjugate-structure algebraic-code-excited linear prediction (CS-ACELP)», Женева, 1996]. Без потери общности в дальнейшем описании под параметрами ЛП будем понимать ЛСЧ.
Известен способ векторного квантования параметров ЛП [Рекомендации ITU-T G.729 «Coding of speech at 8 kbit/s using conjugate-structure algebraic-code-excited linear prediction (CS-ACELP)», Женева, 1996], согласно которому квантование вектора параметров ЛП осуществляется в два этапа, причем вектор второго этапа разделяется на два субвектора. Недостатком данного способа является большое значение ошибки квантования, представляющей собой разницу между квантованным и исходным вектором параметров ЛП. Недостаток обусловлен малым числом бит, отводимым на квантование ЛСЧ в низкоскоростных системах кодирования речевого сигнала.
Известен способ преобразования речевого сигнала методом линейного предсказания с адаптивным распределением информационных ресурсов по патенту №2248619 от 27.08.2004, заключающийся в том, что при кодировании используют акустико-фонетическую классификацию обрабатываемых кадров речевого сигнала на четыре непересекающихся класса, классификационное решение включают в структуру кодовой комбинации, передаваемой по каналу связи, и используют для детерминирования режима функционирования классифицированного ВК, отличающихся различными объемами КК по каждому кодируемому параметру, чем обеспечивают адаптивное распределение информационных ресурсов. Недостатками данного способа являются значительная ошибка квантования параметров ЛП, увеличение числа передаваемых бит, а также артефакты звучания синтезированной речи, вызванные переключением ВК для каждого класса кадров речевого сигнала.
Наиболее близким, принятым за прототип, является способ для векторного квантования с надежным предсказанием параметров линейного предсказания в кодировании речи с переменной битовой скоростью по патенту №2326450 от 10.06.2008, заключающийся в том, что принимают входной вектор параметров линейного предсказания, классифицируют кадр речевого сигнала, соответствующий входному вектору параметров линейного предсказания, вычисляют вектор предсказания, удаляют вычисленный вектор предсказания из входного вектора параметров линейного предсказания для создания вектора ошибки предсказания, масштабируют вектор ошибки предсказания, квантуют масштабированный вектор ошибки предсказания, при этом вычисление вектора предсказания включает в себя выбор одной из множества схем предсказания в отношении классификации кадра речевого сигнала и вычисление вектора предсказания в соответствии с выбранной схемой предсказания, и масштабирование вектора ошибки предсказания включает в себя выбор по меньшей мере одной из множества схем масштабирования в отношении выбранной схемы предсказания и масштабирование вектора ошибки предсказания в соответствии с выбранной схемой масштабирования, множество схем предсказания включает в себя предсказание скользящим средним значением и предсказание авторегрессией, при этом классификация кадра речевого сигнала включает в себя определение, что кадр речевого сигнала является стационарным вокализованным кадром, выбор одной из множества схем предсказания включает в себя выбор предсказания авторегрессией, вычисление вектора предсказания включает в себя вычисление вектора ошибки предсказания посредством предсказания авторегрессией, выбор одной из множества схем масштабирования включает в себя выбор масштабного коэффициента, и масштабирование вектора ошибки предсказания включает в себя масштабирование вектора ошибки предсказания с использованием упомянутого масштабного коэффициента. Недостатками данного способа являются следующие:
1) предсказание авторегрессией, применяемое для стационарных вокализованных кадров, не является надежным в условиях потери кадров - в случае потери речевых кадров ошибка распространяется на последующие кадры;
2) для получения минимальной ошибки квантования параметров ЛП стационарных вокализованных кадров требуется затрачивать значительное число бит.
Техническим результатом, на достижение которого направлено изобретение, является снижение количества бит, выделяемых для кодирования параметров ЛП стационарных вокализованных кадров речевого сигнала, при минимальной ошибке квантования.
Для достижения такого технического результата в способе векторного квантования, заключающемся в том, что принимают входной вектор параметров линейного предсказания, классифицируют кадр речевого сигнала, соответствующий входному вектору параметров линейного предсказания, вычисляют вектор предсказания, удаляют вычисленный вектор предсказания из входного вектора параметров линейного предсказания для создания вектора ошибки предсказания, масштабируют вектор ошибки предсказания, квантуют масштабированный вектор ошибки предсказания, при этом вычисление вектора предсказания включает в себя выбор одной из множества схем предсказания в отношении классификации кадра речевого сигнала и вычисление вектора предсказания в соответствии с выбранной схемой предсказания, и масштабирование вектора ошибки предсказания включает в себя выбор по меньшей мере одной из множества схем масштабирования в отношении выбранной схемы предсказания и масштабирование вектора ошибки предсказания в соответствии с выбранной схемой масштабирования, множество схем предсказания включает в себя предсказание скользящим средним значением и предсказание авторегрессией, при этом если классификация кадра речевого сигнала включает в себя определение, что кадр речевого сигнала является стационарным вокализованным кадром, то выбор одной из множества схем предсказания включает в себя выбор предсказания авторегрессией, вычисление вектора предсказания включает в себя вычисление вектора ошибки предсказания посредством предсказания авторегрессией, выбор одной из множества схем масштабирования включает в себя выбор масштабного коэффициента и масштабирование вектора ошибки предсказания включает в себя масштабирование вектора ошибки предсказания с использованием упомянутого масштабного коэффициента, изменено множество схем предсказания. Множество схем предсказания включает в себя предсказание скользящим средним значением и предсказание с адаптацией к основному тону речи, при этом если классификация кадра звукового сигнала включает в себя определение, что кадр звукового сигнала является стационарным вокализованным кадром, то выбор одной из множества схем предсказания включает в себя выбор предсказания с адаптацией к основному тону речи, вычисление вектора предсказания включает в себя вычисление вектора ошибки предсказания посредством предсказания с адаптацией к основному тону речи, выбор одной из множества схем масштабирования включает в себя выбор масштабного коэффициента, равного одному. Далее осуществляют масштабирование вектора ошибки предсказания.
Для описания стационарных вокализованных кадров речевого сигнала модель (1) может быть преобразована к следующему виду:

где Ψ(s(k-1)) - типовое нелинейное преобразование, определяющее импульсное возбуждение линейной части уравнения [Прохоров Ю.Н. Статистические модели и рекуррентное предсказание речевых сигналов. - М.: Радио и связь, 1984. - 240 с.: ил.].
В принятой модели (2) при G=0 период основного тона речи Т0 является неслучайной величиной и может быть рассчитан по формуле Т0=(lnΔ2 - lnΔ1)/lnb1, где Δ1 и Δ2 - параметры функции Ψ(s(k-1)). Откуда зависимость параметра ЛП b1 от периода основного тона речи Т0 может быть вычислена следующим образом:

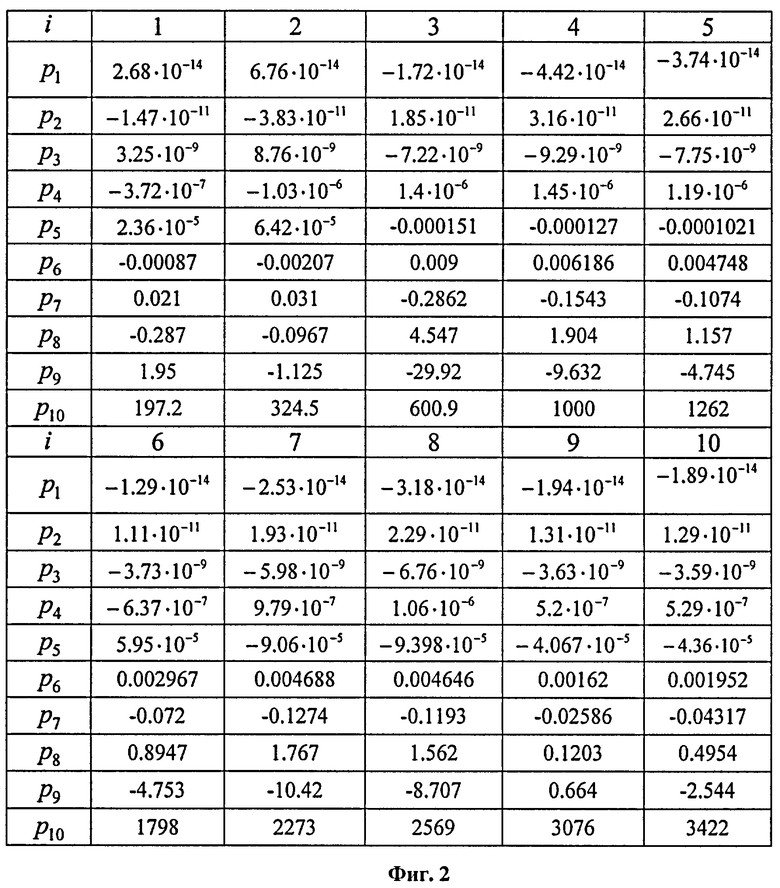
Аналогичные зависимости для линейных регрессий большего порядка (bm, m>1) в аналитическом виде получить достаточно сложно, поэтому, учитывая связь коэффициентов ЛП bi с ЛСЧ, указанные зависимости определены экспериментальным путем и представлены на фиг.1. Данные зависимости могут быть аппроксимированы полиномиальными моделями [Кобзарь А.И. Прикладная математическая статистика. Для инженеров и научных работников. - М.: ФИЗМАТЛИТ, 2006. - 816 с.] вида:

где  ;
; 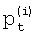 - t-й коэффициент полинома, аппроксимирующего i-ю ЛСЧ. Значения коэффициентов аппроксимирующих полиномов представлены на фиг.2.
- t-й коэффициент полинома, аппроксимирующего i-ю ЛСЧ. Значения коэффициентов аппроксимирующих полиномов представлены на фиг.2.
В низкоскоростных системах кодирования речевого сигнала значение периода (частоты, нормированного периода) основного тона подлежит передаче из кодера в декодер, поэтому реализация предсказания с адаптацией к основному тону речи в виде выражения (4) позволяет существенно уменьшить динамический диапазон ЛСЧ и, как следствие, ошибку квантования. При этом в случае потери речевых кадров ошибка не будет распространяться на последующие кадры.
Заявленное изобретение поясняется следующими чертежами:
фиг.1 - зависимости ЛСЧ ωi, i=1,2,…,М, от периода основного тона речи Т0 при М=10;
фиг.2 - коэффициенты полиномов, используемых для аппроксимации ЛСЧ;
фиг.3 - блок-схема, иллюстрирующая возможный вариант реализации векторного квантователя параметров линейного предсказания согласно изобретению;
фиг.4 - сравнительная оценка качества квантования параметров линейного предсказания стационарных вокализованных кадров речевого сигнала для разного числа бит согласно прототипу и настоящему изобретению.
Для снижения количества бит, выделяемых для кодирования параметров ЛП стационарных вокализованных кадров речевого сигнала, при минимальной ошибке квантования согласно предлагаемому способу выполняют следующие операции:
1) принимают входной вектор параметров ЛП Ω=(ω1,…,ωM);
2) классифицируют кадр речевого сигнала, соответствующий входному вектору параметров ЛП;
3) вычисляют вектор предсказания ΩПР;
4) удаляют вычисленный вектор предсказания из входного вектора параметров ЛП для создания вектора ошибки предсказания Е;
5) масштабируют вектор ошибки предсказания;
6) квантуют масштабированный вектор ошибки предсказания Е'.
При этом вычисление вектора предсказания включает в себя выбор одной из схем предсказания (предсказание скользящим средним или предсказание с адаптацией к основному тону речи) в отношении классификации кадра звукового сигнала и вычисление вектора предсказания в соответствии с выбранной схемой предсказания; масштабирование вектора ошибки предсказания включает в себя выбор по меньшей мере одной из множества схем масштабирования в отношении выбранной схемы предсказания и масштабирование вектора ошибки предсказания в соответствии с выбранной схемой масштабирования.
Если кадр речевого сигнала классифицируют как стационарный вокализованный, то в качестве схемы предсказания выбирают предсказание с адаптацией к основному тону речи и с помощью нее вычисляют вектор ошибки предсказания ΩПР = ΩОТ, где ΩОТ = (ωОТ1,…,ωОТМ); в качестве схемы масштабирования выбирают масштабный коэффициент, равный одному, что эквивалентно отсутствию операции масштабирования.
Фиг.3 иллюстрирует возможный вариант реализации ВК параметров ЛП, использующий предсказатель с адаптацией к основному тону речи.
Как изображено на фиг.3, сначала получают вектор ошибки предсказания Е посредством вычитания в блоке 301 вектора предсказания ΩПР, полученного с выхода блока 307, из входного вектора параметров ЛП Ω:

Для стационарных вокализованных кадров речевого сигнала вектор предсказания ΩПР = ΩОТ определяют в блоке 305 по полиномиальной модели (4) с коэффициентами, приведенными на фиг.2.
Для нестационарных речевых кадров вектор предсказания ΩПР = ΩСС определяют посредством предсказания скользящим средним значением [Koestoer N.Р. Robust linear prediction analysis for low bit-rate speech coding: DPh dissertation. - Brisbane: Griffith University, 2002. - 132 p.] в блоке 306.
Вектор ошибки предсказания Е масштабируют в блоке 302 соответствующим масштабным коэффициентом. При этом для схемы предсказания с адаптацией к основному тону используют масштабный коэффициент, равный 1, а для схемы предсказания скользящим средним значением - масштабный коэффициент больше 1.
Квантованное значение  масштабированного вектора ошибки предсказания Е' полученное в блоке 303, после обратного масштабирования в блоке 304 используют в блоке 306 предсказания скользящим средним значением, а его индекс в КК передают в декодер.
масштабированного вектора ошибки предсказания Е' полученное в блоке 303, после обратного масштабирования в блоке 304 используют в блоке 306 предсказания скользящим средним значением, а его индекс в КК передают в декодер.
Для проверки работоспособности рассмотренного ВК и оценки качества квантования параметров ЛП согласно предлагаемому способу было произведено имитационное моделирование.
Качество квантования параметров ЛП оценивалось с использованием спектрального искажения [Павловец А.Н., Петровский А.А. Квантование огибающей спектра в вокодере, основанное на декомпозиции речевого сигнала на периодическую и апериодическую составляющие // Цифровая обработка сигналов. - 2005. - №3. - С.13-21], определяемого следующим образом:

где Pj и  - спектры мощности речевого кадра, рассчитанные по входным и квантованным ЛСЧ соответственно. Среднее спектральное искажение оценивалось как
- спектры мощности речевого кадра, рассчитанные по входным и квантованным ЛСЧ соответственно. Среднее спектральное искажение оценивалось как

где J - число измерений (количество анализируемых кадров речевого сигнала). В [Palival K.K., Atal В.S. Efficient vector quantization of LPC parameters at 24 bits/frame // IEEE Trans. on Acoustics, Speech and Signal Processing. - 1993. - Vol.1. - №1. - P.3-14] экспериментально установлены следующие условия, приводящие к отсутствию слышимых искажений из-за спектральных несоответствий:
- среднее значение спектрального искажения SD не превышает 1 дБ;
- количество кадров, на которых sd принимает значения от 2 до 4 дБ, не превышает 2%;
- отсутствие сегментов со значением sd более 4 дБ.
Обучение КК масштабированного вектора ошибки предсказания Е' осуществлялось с помощью обобщенного алгоритма Ллойда [Макхоул Д., Рукос С., Гиш Г. Векторное квантование при кодировании речи // ТИИЭР. - 1985. - Т.73. - №11. - С.19-61]. Для обучения и тестирования КК использовалась речь различных дикторов длительностью около 125 и 15 минут соответственно. При этом речь в обучающей и тестовой выборках принадлежала различным дикторам, а общее число векторов ЛСЧ в них составило 375873 и 45318 соответственно (соотношение длительностей выборок приблизительно равно 8:1). Значение периода основного тона речи предполагалось известным. Сравнительная оценка качества квантования параметров линейного предсказания стационарных вокализованных кадров речевого сигнала для разного числа бит согласно прототипу и настоящему изобретению представлена на фиг.4.
Из фиг.4 следует, что ВК с адаптацией к основному тону речи согласно настоящему изобретению позволяет снизить количество бит, необходимых для кодирования параметров ЛП стационарных вокализованных кадров речевого сигнала, при минимальной ошибке квантования по сравнению с прототипом, использующим предсказание авторегрессией.


Изобретение относится к системе электросвязи, а именно к системам низкоскоростного кодирования речевого сигнала, при котором осуществляется векторное квантование с предсказанием параметров линейного предсказания. Техническим результатом является снижение количества бит, выделяемых для кодирования параметров линейного предсказания стационарных вокализованных кадров речевого сигнала, при минимальной ошибке квантования. Указанный технический результат достигается введением в разностный векторный квантователь параметров линейного предсказания предсказателя с адаптацией к основному тону речи: при классификации кадра речевого сигнала как стационарного вокализованного выбирают схему предсказания с адаптацией к основному тону речи, вычисление вектора предсказания включает в себя вычисление вектора ошибки предсказания посредством предсказания с адаптацией к основному тону речи, выбор одной из множества схем масштабирования включает в себя выбор масштабного коэффициента, равного одному. 4 ил.
Способ векторного квантования параметров линейного предсказания, заключающийся в том, что принимают входной вектор параметров линейного предсказания, классифицируют кадр речевого сигнала, соответствующий входному вектору параметров линейного предсказания, вычисляют вектор предсказания, удаляют вычисленный вектор предсказания из входного вектора параметров линейного предсказания для создания вектора ошибки предсказания, масштабируют вектор ошибки предсказания, квантуют масштабированный вектор ошибки предсказания, при этом вычисление вектора предсказания включает в себя выбор одной из множества схем предсказания в отношении классификации кадра речевого сигнала и вычисление вектора предсказания в соответствии с выбранной схемой предсказания, и масштабирование вектора ошибки предсказания включает в себя выбор по меньшей мере одной из множества схем масштабирования в отношении выбранной схемы предсказания и масштабирование вектора ошибки предсказания в соответствии с выбранной схемой масштабирования, множество схем предсказания включает в себя предсказание скользящим средним значением и предсказание авторегрессией, при этом если классификация кадра речевого сигнала включает в себя определение, что кадр речевого сигнала является стационарным вокализованным кадром, то выбор одной из множества схем предсказания включает в себя выбор предсказания авторегрессией, вычисление вектора предсказания включает в себя вычисление вектора ошибки предсказания посредством предсказания авторегрессией, выбор одной из множества схем масштабирования включает в себя выбор масштабного коэффициента, и масштабирование вектора ошибки предсказания включает в себя масштабирование вектора ошибки предсказания с использованием упомянутого масштабного коэффициента, отличающийся тем, что множество схем предсказания включает в себя предсказание скользящим средним значением и предсказание с адаптацией к основному тону речи, при этом если классификация кадра речевого сигнала включает в себя определение, что кадр речевого сигнала является стационарным вокализованным кадром, то выбор одной из множества схем предсказания включает в себя выбор предсказания с адаптацией к основному тону речи, вычисление вектора предсказания включает в себя вычисление вектора ошибки предсказания посредством предсказания с адаптацией к основному тону речи, выбор одной из множества схем масштабирования включает в себя выбор масштабного коэффициента, равного одному.
| СПОСОБ И УСТРОЙСТВО ДЛЯ ВЕКТОРНОГО КВАНТОВАНИЯ С НАДЕЖНЫМ ПРЕДСКАЗАНИЕМ ПАРАМЕТРОВ ЛИНЕЙНОГО ПРЕДСКАЗАНИЯ В КОДИРОВАНИИ РЕЧИ С ПЕРЕМЕННОЙ БИТОВОЙ СКОРОСТЬЮ | 2003 |
|
RU2326450C2 |
| CN 101030377 A, 05.09.2007 | |||
| Конус для классификации материала | 1937 |
|
SU60579A1 |
| EP 1202251 A2, 02.05.2002 | |||
| Огнегасительная смесь | 1958 |
|
SU122403A1 |
| US 6098037 A, 01.08.2000 | |||
| Спасательный жилет водолаза | 1976 |
|
SU573398A1 |

