Перекрестная ссылка на родственные заявки
Данная заявка заявляет преимущество Патентной заявки (Корея) №2005-65704, поданной 20 июля 2005 года в Корейское Ведомство по интеллектуальной собственности, которая полностью содержится в данном документе по ссылке.
Уровень техники
Область техники, к которой относится изобретение
Настоящая общая концепция изобретения относится к системе воспроизведения аудио и, более конкретно, к способу воспроизведения обширного монофонического звука и системе расширения монофонического звука с помощью двухканальных динамиков.
Описание предшествующего уровня техники
В общем, монофонический звук воспроизводится посредством одного канала, но в последнее время разрабатывалась технология синтезирования стереофонического звука из монофонического звука.
Технология, связанная с системой воспроизведения монофонического звука, описана в Патенте США №6590983 B1, озаглавленном "Apparatus and method for synthesizing pseudo-stereophonic outputs from a monophonic input".
Фиг.1 - это блок-схема, иллюстрирующая традиционную систему воспроизведения монофонического звука. Ссылаясь на фиг.1, сигнал M предоставляется в левый фазовый фильтр 102 и правый фазовый фильтр 104. Левый фазовый фильтр 102 - это фильтр с опережением по фазе, который генерирует опережающий сдвиг фазы в +45 градусов. Правый фазовый фильтр 104 - это фильтр с опережением по фазе, который генерирует опережающий сдвиг фазы в -45 градусов. Выход левого фазового фильтра 102 предоставляется на первый вход сумматора 120 и неинвертирующий вход сумматора 122. Выход правого фазового фильтра 104 предоставляется на второй вход сумматора 120 и инвертирующий вход сумматора 122. Выход сумматора 122 предоставляется на неинвертирующий вход сумматора 126.
Выход правого фазового фильтра 104 также предоставляется на вход перспективного фильтра 124. Выход перспективного фильтра 124 предоставляется на инвертирующий вход сумматора 126 и второй вход сумматора 128. Кроме того, выход левого фазового фильтра 102 предоставляется на неинвертирующий вход сумматора 126 и третий вход сумматора 128. Выход сумматора 128 предоставляется в фильтр 108 верхних частот и первый вход сумматора 106. Выход сумматора 126 предоставляется в фильтр 110 верхних частот и второй вход сумматора 106. Выход сумматора 106 предоставляется в фильтр 109 нижних частот.
Выход фильтра 108 верхних частот предоставляется на первый вход сумматора 112, а выход фильтра 109 нижних частот предоставляется на второй вход сумматора 112. Выход сумматора 112 предоставляется на вход выходного усилителя 116 левого канала, а выход усилителя 116 левого канала предоставляется на выход левого канала.
Выход фильтра 110 верхних частот предоставляется на первый вход сумматора 114, а выход фильтра 109 нижних частот предоставляется на второй вход сумматора 114. Выход сумматора 114 предоставляется на вход выходного усилителя 118 правого канала, а выход усилителя 118 правого канала предоставляется на выход правого канала.
Следовательно, традиционная система воспроизведения монофонического звука, проиллюстрированная на фиг.1, обрабатывает компонент разностного сигнала из левого и правого сигналов, чтобы сгенерировать стереофонический звуковой образ. Разностный сигнал обрабатывается посредством компенсации, отличающейся усилением звуковых частот нижнего диапазона и высокого диапазона. Обработанный разностный сигнал объединяется (т.е. суммируется) с левым и правым входными сигналами и суммированным сигналом, сгенерированным из исходных левого и правого сигналов.
Следовательно, в традиционной системе воспроизведения монофонического звука входной монофонический звук делится на различные полосы частот и уровни разделенных полос затем рекомбинируются. Тем не менее, вследствие того, что голова и ушная раковина слушателя, которые играют важные роли в распознавании направления источника звука, вообще не учитываются, характеристики традиционной системы воспроизведения монофонического звука очень низкие. Кроме того, поскольку традиционная система воспроизведения монофонического звука изменяет фазы при генерировании двух декоррелированных сигналов из входного монофонического звука, тембр может быть изменен.
Сущность изобретения
Настоящая общая концепция изобретения представляет способ и систему воспроизведения обширного монофонического звука, посредством которой входной монофонический звук делится на множество декоррелированных сигналов и каждый сигнал воспроизводится посредством одного из множества виртуальных динамиков с помощью различных HRTF.
Дополнительные аспекты настоящей общей концепции изобретения будут частично изложены в последующем описании и частично будут явствовать из изобретения или могут быть изучены при практическом использовании изобретения.
Вышеуказанные и/или другие аспекты настоящей общей концепции изобретения могут быть достигнуты посредством предоставления способа воспроизведения обширного монофонического звука, включающего в себя этапы, на которых разделяют входной сигнал монофонического звука на множество декоррелированных сигналов, генерируют виртуальные источники звука посредством локализации соответствующих разделенных сигналов в виртуальных размещениях, асимметричных относительно точки прослушивания, посредством применения различных функций моделирования восприятия звука (HRTF) к соответствующим разделенным сигналам и компенсируют перекрестные помехи сгенерированных виртуальных источников звука.
Вышеуказанные и/или другие аспекты настоящей общей концепции изобретения также могут быть достигнуты посредством предоставления способа воспроизведения монофонического звука, включающего в себя этапы, на которых разделяют входной сигнал монофонического звука на множество декоррелированных сигналов, выполняют операцию расширения фильтрации посредством генерирования виртуальных источников звука посредством локализации каждого из соответствующих разделенных сигналов в виртуальных местоположениях, асимметричных относительно центральной линии точки прослушивания, посредством применения различных функций моделирования восприятия звука (HRTF) к соответствующим разделенным сигналам и компенсируют перекрестные помехи разделенных сигналов, локализованных в виртуальных размещениях, и выполняют операцию прямой фильтрации, регулируя характеристики сигнала между входным монофоническим сигналом и виртуальными источниками звука с компенсированными перекрестными помехами.
Операция фильтрации расширения может быть выполнена согласно следующему уравнению
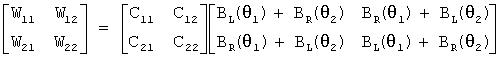 ,
,
где W11, W12, W21 и W22 представляют коэффициенты фильтра расширения, C11, C12, C21 и C22 представляют коэффициенты компенсатора перекрестных помех, BL(θ1) и BR(θ1) соответственно представляют HRTF левого уха и правого уха, измеренные с правой стороны на линии, составляющей угол θ1 от центральной линии точки прослушивания, а BL(θ2) и BR(θ2) соответственно представляют HRTF левого уха и правого уха, измеренные с правой стороны на линии, составляющей угол θ2 от центральной линии точки прослушивания.
Вышеуказанные и/или другие аспекты настоящей общей концепции изобретения также могут быть достигнуты посредством представления системы воспроизведения монофонического звука, включающей в себя блок разделения сигналов, чтобы разделять входной монофонический звуковой сигнал на множество декоррелированных сигналов, блок бинаурального синтеза, чтобы генерировать виртуальные источники звука посредством локализации каждого из разделенных сигналов в виртуальных размещениях, асимметричных относительно центральной линии точки прослушивания, посредством применения различных функций моделирования восприятия звука (HRTF) к соответствующим разделенным сигналам, блок компенсатора перекрестных помех, чтобы компенсировать перекрестные помехи между разделенными сигналами виртуальных источников звука, локализованных в виртуальных местоположениях посредством блока бинаурального синтеза на основе функции моделирования восприятия звука, блок прямой фильтрации, чтобы отрегулировать характеристики сигнала между входным монофоническим сигналом и виртуальными источниками звука с компенсированными перекрестными помехами посредством блока компенсатора перекрестных помех, и блок вывода, чтобы суммировать сигнал, выводимый из блока прямой фильтрации, с сигналом, выводимым из блока компенсатора помех, и чтобы выводить суммированные сигналы на левый и правый динамики.
Вышеуказанные и/или другие аспекты настоящей общей концепции изобретения также могут быть достигнуты посредством предоставления системы монофонического звука, включающей в себя входной одноканальный звуковой сигнал и блок генерирования виртуального источника звука, чтобы генерировать входной одноканальный звуковой сигнал, чтобы соответствовать, по меньшей мере, одному из первого и второго реальных динамиков, определять первый и второй сигналы из входного одноканального звукового сигнала и генерировать множество асимметричных виртуальных динамиков, чтобы выводить каждый из первого и второго сигналов с широким углом относительно точки прослушивания системы.
Вышеуказанные и/или другие аспекты настоящей общей концепции изобретения также могут быть достигнуты посредством предоставления системы воспроизведения одноканального звука, применяемой в электронном устройстве, включающей в себя блок генерирования виртуального звука, чтобы принимать одноканальный звуковой сигнал в качестве входа, генерировать из первой части одноканального звукового сигнала первое множество асимметричных виртуальных источников звука, генерировать из второй части одноканального звукового сигнала второе множество асимметричных виртуальных источников звука и объединять первые и вторые асимметричные виртуальные источники звука с входным одноканальным звуковым сигналом, чтобы предоставлять объединенный выходной сигнал, по меньшей мере, в один реальный динамик так, чтобы, по меньшей мере, один реальный динамик выводил объединенный выходной сигнал.
Вышеуказанные и/или другие аспекты настоящей общей концепции изобретения также могут быть достигнуты посредством предоставления системы воспроизведения звука, включающей в себя терминал ввода, чтобы принимать монофонический звуковой сигнал, блок для асимметричной локализации первого и второго компонентов монофонического звукового сигнала, фильтр, чтобы фильтровать монофонический звуковой сигнал, и терминал вывода, чтобы выводить объединенный сигнал согласно асимметрично локализованным первому и второму компонентам и отфильтрованному монофоническому звуковому сигналу.
Вышеуказанные и/или другие аспекты настоящей общей концепции изобретения также могут быть достигнуты посредством предоставления способа воспроизведения одноканального звука, применяемого в электронном устройстве, включающего в себя этапы, на которых принимают одноканальный звуковой сигнал, чтобы выводить посредством, по меньшей мере, одного реального динамика, генерируют первое множество асимметричных виртуальных источников звука из первой части одноканального звукового сигнала и генерируют второе множество асимметричных виртуальных источников звука из второй части одноканального звукового сигнала, объединяют первые и вторые асимметричные виртуальные источники звука с входным одноканальным звуковым сигналом, чтобы предоставлять объединенный выходной звуковой сигнал в, по меньшей мере, один реальный динамик.
Краткое описание чертежей
Эти и/или другие аспекты настоящей общей концепции изобретения станут очевидными и понятными из последующего описания вариантов осуществления, рассматриваемых вместе с прилагаемыми чертежами, на которых:
Фиг.1 - блок-схема, иллюстрирующая традиционную систему воспроизведения монофонического звука;
Фиг.2 - блок-схема, иллюстрирующая систему воспроизведения обширного монофонического звука согласно варианту осуществления настоящей общей концепции изобретения;
Фиг.3 - концептуальная схема, иллюстрирующая работу системы воспроизведения обширного монофонического звука по фиг.2 согласно варианту осуществления настоящей общей концепции изобретения;
Фиг.4A и 4B иллюстрируют блок разделения сигналов по фиг.2 согласно различным вариантам осуществления настоящей общей концепции изобретения;
Фиг.5 - подробная схема системы воспроизведения обширного монофонического звука по фиг.2;
Фиг.6 - упрощенная блок-схема, иллюстрирующая систему воспроизведения обширного монофонического звука по фиг.5 согласно варианту осуществления настоящей общей концепции изобретения; и
Фиг.7 - блок-схема, иллюстрирующая систему воспроизведения обширного монофонического звука, полученную посредством оптимизации системы воспроизведения обширного монофонического звука по фиг.6 согласно варианту осуществления настоящей общей концепции изобретения.
Подробное описание предпочтительных вариантов осуществления
Далее будет представлена подробная справочная информация по вариантам осуществления настоящей общей концепции изобретения, примеры которых проиллюстрированы на прилагаемых чертежах, в которых одинаковые цифры ссылок ссылаются на одинаковые элементы по всему описанию. Варианты осуществления описаны ниже, чтобы объяснить настоящую общую концепцию изобретения со ссылками на чертежи.
Система воспроизведения обширного монофонического звука согласно варианту осуществления настоящей общей концепции изобретения, проиллюстрированная на фиг.2, включает в себя блок 210 разделения сигналов, блок 220 асимметричного бинаурального синтеза, компенсатор 230 перекрестных помех и левый и правый прямые фильтры 240 и 250.
Ссылаясь на фиг.2, блок 210 разделения сигналов разделяет входной монофонический звук на множество декоррелированных сигналов посредством деления входного монофонического звука в отношении полосы частот или фазы. Например, блок 210 разделения сигналов делит входной монофонический звук на низкочастотный компонентный сигнал и высокочастотный компонентный сигнал посредством фильтрации нижних частот и фильтрации верхних частот соответственно.
Чтобы сформировать виртуальный источник звука в произвольном местоположении, блок 220 асимметричного стереофонического синтеза локализует каждый сигнал, полученный блоком 210 разделения сигналов, асимметрично относительно центра передней стороны головы слушателя (т.е. в точке прослушивания) посредством применения так называемых функций моделирования восприятия звука (HRTF от англ. Head-Related Transfer Functions) к соответствующим сигналам. Т.е. блок 220 асимметричного бинаурального синтеза размещает виртуальные динамики с помощью HRTF асимметрично относительно центра передней стороны головы слушателя. Следует понимать, что хотя варианты осуществления настоящей общей концепции изобретения описаны со ссылкой на голову слушателя, слушателя и точки прослушивания, слушатель фактически не обязательно должен находиться в точке прослушивания. Это описание не предназначено, чтобы ограничивать область применения настоящей общей концепции изобретения, и включено только для того, чтобы продемонстрировать, где типично должна находиться голова слушателя, когда используется система воспроизведения монофонического звука.
Компенсатор 230 перекрестных помех компенсирует перекрестные помехи между двумя реальными динамиками и двумя ушами слушателя в отношении виртуальных источников звука, сгенерированных в блоке 220 асимметричного бинаурального синтеза. Т.е. компенсатор 230 перекрестных помех компенсирует перекрестные помехи сигнала, воспроизводимого в левом динамике 280-1 так, чтобы сигнал левого динамика не был слышен правым ухом слушателя, компенсирует перекрестные помехи сигнала, воспроизводимого в правом динамике 280-2 так, чтобы сигнал правого динамика не был слышен левым ухом слушателя.
Левый и правый прямые фильтры 240 и 250 - это фильтры az-b, которые имеют только усиление и задержку, регулируют характеристику сигнала между входным монофоническим звуком и виртуальными источниками звука, выводимыми компенсатором 230 перекрестных помех. При этом "a" представляет уровень выходного сигнала, а "b" представляет значение задержки по времени, которая получается посредством импульсной характеристики, фазовой характеристики и экспериментов прослушивания. Т.е. левый и правый прямые фильтры 240 и 250 генерируют естественный звук посредством регулирования разности задержек по времени и уровней вывода между выходом виртуального динамика, ассоциативно связанным с источником виртуального звука, и выводом реального динамика.
Наконец, сигналы, разделенные из входного монофонического звука и отфильтрованные посредством левого и правого прямых фильтров 240 и 250, и виртуальные источники звука, выводимые компенсатором 230 перекрестных помех, объединяются соответственно для левого и правого динамиков 280-1 и 280-2.
Фиг.3 - это концептуальная схема представления, иллюстрирующая работу системы воспроизведения обширного монофонического звука по фиг.2 согласно варианту осуществления настоящей общей концепции изобретения.
Ссылаясь на фиг.3, входной монофонический звуковой сигнал (x) делится на два различных сигнала (x1, x2), декоррелированных посредством блока 210 разделения сигналов. Разделенные сигналы воспроизводятся посредством асимметрично размещенных виртуальных динамиков. Виртуальные динамики представлены пунктирными линиями. Четыре виртуальных динамика могут быть сформированы посредством отражения 4 HRTF, измеренных под различными углами (θ1, θ2) от центра напротив слушателя. Другое количество и/или варианты асимметричного размещения виртуальных динамиков также могут быть использованы. Т.е. разделенный сигнал (x1) воспроизводится посредством виртуального динамика, размещенного по линии с левой стороны, составляя первый угол (θ1) относительно центральной линии слушателя (т.е. в точке прослушивания), и виртуального динамика, размещенного по линии с правой стороны, составляя второй угол (θ2) относительно центральной линии слушателя, и разделенный сигнал (x2) воспроизводится посредством виртуального динамика, размещенного по линии с левой стороны, составляя второй угол (θ2) относительно центральной линии слушателя, и виртуального динамика, размещенного по линии с правой стороны, составляя первый угол (θ1) относительно центральной линии слушателя. Следовательно, виртуальные динамики размещены симметрично от центра передней стороны головы слушателя. Тем не менее, каждый из разделенных сигналов (x1, x2) вводится в виртуальные динамики асимметрично относительно центра передней стороны головы слушателя в точке прослушивания.
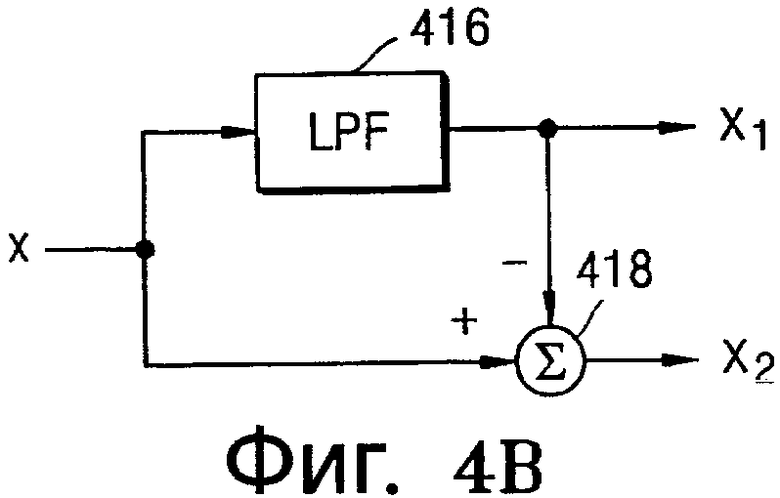
Фиг.4A и 4B иллюстрируют блок 210 разделения сигналов по фиг.2 согласно различным вариантам осуществления настоящей общей концепции изобретения.
Ссылаясь на фиг.4A, монофонический звуковой сигнал (x) разделяется на низкочастотный компонентный сигнал (x1) и высокочастотный компонентный сигнал (x2) посредством LPF 412 и HPF 414 соответственно.
Ссылаясь на фиг.4B, монофонический звуковой сигнал (x) разделяется на низкочастотный компонентный сигнал (x1) и сигнал (x2), полученный посредством суммирования исходного монофонического звукового сигнала (x) и низкочастотного компонентного сигнала (x1) с помощью LPF 416 и сумматора 418 соответственно. Любой из этих вариантов осуществления может быть использован в системе воспроизведения обширного монофонического звука.
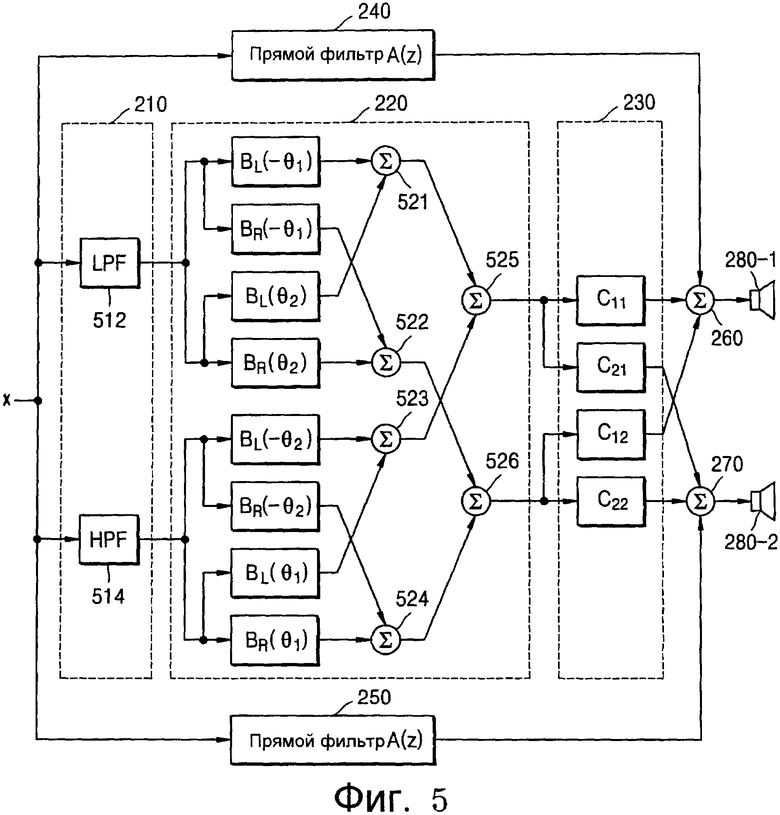
Фиг.5 - это подробная схема, иллюстрирующая систему воспроизведения обширного монофонического звука по фиг.2 согласно варианту осуществления настоящей общей концепции изобретения.
Ссылаясь на фиг.5, блок 210 разделения сигналов может использовать LPF 512 и HPF 514, чтобы делить входной монофонический сигнал (x) на полосы. Следовательно, входной монофонический сигнал (x) делится на две полосы частот посредством LPF 512 и HPF 514.
Блок 220 асимметричного бинаурального синтеза имеет функции HRTF (BL(-θ1), BR(-θ1), BL(θ2), BR(θ2), BR(-θ2), BL(-θ2), BL(θ1), Br(θ1)), которые измеряются с положений на линиях с левой стороны и правой стороны, составляя различные углы относительно центральной линии напротив слушателя. Блок 220 асимметричного бинаурального синтеза локализует каждый сигнал, разделенный посредством блока 210 разделения сигналов, в виртуальных местоположениях, асимметричных относительно центра передней стороны головы слушателя, посредством свертывания разделенных сигналов с помощью HRTF. При этом BL(-θ1) и BR(-θ1) соответственно представляют HRTF левого уха и HRTF правого уха, измеренные в положении по линии с левой стороны, составляя угол θ1 от центра слушателя. Аналогично, BL(θ2) и BR(θ2) соответственно представляют HRTF левого уха и HRTF правого уха, измеренные в положении по линии с правой стороны, составляя угол θ2 от центра слушателя.
BR(-θ2) и BL(-θ2) соответственно представляют HRTF левого уха и HRTF правого уха, измеренные в положении по линии с левой стороны, составляя угол θ2 от центра слушателя. BL(θ1) и BR(θ1) соответственно представляют HRTF левого уха и HRTF правого уха, измеренные в положении по линии с правой стороны, составляя угол θ1 от центра слушателя. Например, если источник звукового сигнала свертывается с помощью BL(-θ1) и воспроизводится посредством левого канала и свертывается с помощью BR(-θ1) и воспроизводится посредством правого канала, слушатель воспринимает, что источник виртуального звука находится на линии, составляющей угол -θ от центральной линии точки прослушивания.
Сигнал, проходящий через LPF 512, свертывается с помощью каждой из HRTF BL(-θ1), BR(-θ1), BL(θ2) и BR(θ2), а сигнал, проходящий через HPF 514, свертывается с помощью каждой из HRTF BR(-θ2), BL(-θ2), BL(θ1) и BR(θ1).
Сигнал, свертываемый с помощью BL(-θ1), добавляется к сигналу, свертываемому с помощью BL(θ2), посредством сумматора 521, а сигнал, свертываемый с помощью BR(-θ1), добавляется к сигналу, свертываемому с помощью BR(θ2), посредством сумматора 522. Кроме того, сигнал, свертываемый с помощью BL(-θ2), добавляется к сигналу, свертываемому с помощью BL(θ1), посредством сумматора 523, а сигнал, свертываемый с помощью BR(-θ2), добавляется к сигналу, свертываемому с помощью BR(θ1), посредством сумматора 524. Вывод сумматора 521 и вывод сумматора 523 суммируются посредством сумматора 525 и выводятся в левый канал. Вывод сумматора 522 и вывод сумматора 524 суммируются посредством сумматора 526 и выводятся в правый канал.
Следовательно, сигнал, проходящий через LPF 512, воспроизводится посредством виртуального динамика, расположенного на линии с левой стороны, составляя угол θ1 от центра слушателя, и виртуального динамика, расположенного на линии с правой стороны, составляя угол θ2 от центра слушателя, а сигнал, проходящий через HPF 514, воспроизводится посредством виртуального динамика, расположенного на линии с левой стороны, составляя угол θ2 от центра слушателя, и виртуального динамика, расположенного на линии с правой стороны, составляя угол θ1 от центра слушателя. Следовательно, сигналы, проходящие через HPF 514, локализуются в виртуальных местоположениях, асимметричных относительно центра передней стороны головы слушателя (т.е. в точке прослушивания).
Компенсатор 230 перекрестных помех выполняет цифровую фильтрацию двух канальных сигналов, выводимых из блока 220 асимметричного бинаурального синтеза, посредством коэффициентов пространственного фильтра (C11(Z), C21(Z), C12(Z), C22(Z)), к которым применяется алгоритм компенсации перекрестных помех.
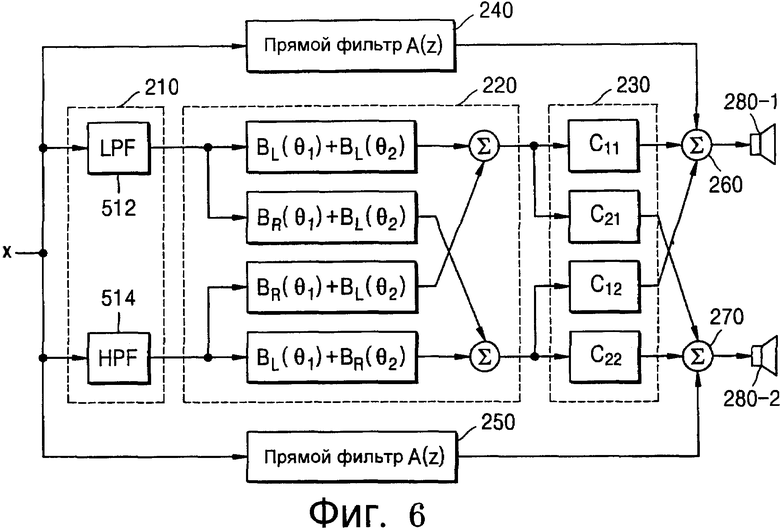
Хотя система, проиллюстрированная на фиг.5, выполняет асимметричный бинауральный синтез разделенных сигналов, виртуальные динамики в целом, как проиллюстрировано на фиг.3, имеют симметричную структуру. Другими словами, одинаковое число динамиков выводится с каждой стороны точки прослушивания в одинаковых позициях на каждой стороне. Следовательно, если используется симметрия самих HRTF, описанная ниже в уравнении 1, и HRTF, идентичные входы и выходы суммируются до того, как выполняется свертывание, структура может быть упрощена, как проиллюстрировано на фиг.6, согласно уравнению (1) ниже.
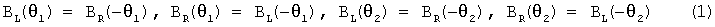
Как проиллюстрировано на фиг.6, вследствие симметричной структуры виртуальных динамиков блок 220 асимметричного бинаурального синтеза имеет симметричную структуру в целом и, как результат, можно избежать уклона звукового изображения в одну сторону. Кроме того, поскольку два канальных сигнала, входящие в блок 220 асимметричного бинаурального синтеза, являются различными сигналами (x1) и (x2), полученными из монофонического звукового сигнала, который проходит соответственно через LPF 512 и HPF 514, причем два сигнала (x1) и (x2) не генерируют ложного изображения в центре напротив слушателя.
При этом, поскольку коэффициенты блока 220 симметричного бинаурального синтеза и компенсатора 230 перекрестных помех не изменяются, они могут быть умножены друг на друга, чтобы сформировать матрицу фильтра расширения, как показано посредством следующего уравнения (2)
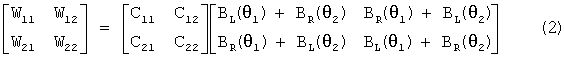 ,
,
где W11, W12, W21 и W22 представляют коэффициенты фильтра расширения, C11, C12, C21 и C22 представляют коэффициенты компенсатора перекрестных помех, BL(θ1) и BR(θ1) соответственно представляют HRTF левого уха и правого уха, измеренные по линии с правой стороны, составляя угол θ1 от центра слушателя, а BL(θ2) и BR(θ2) соответственно представляют HRTF левого и правого уха, измеренные по линии с правой стороны, составляя угол (θ2) от центра слушателя.
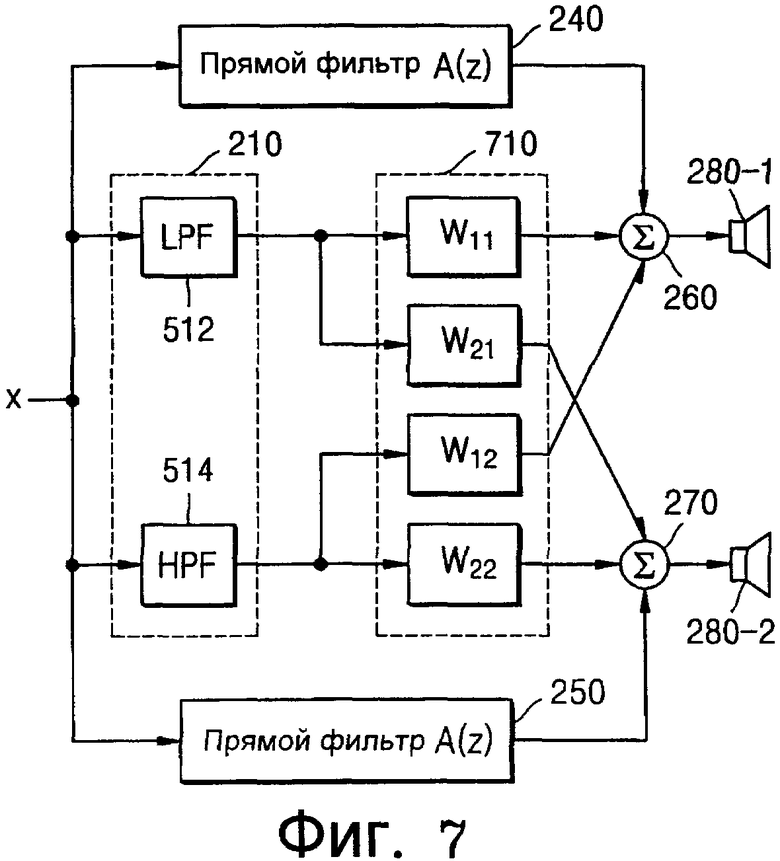
Фиг.7 - это блок-схема, иллюстрирующая систему воспроизведения обширного монофонического звука, полученного посредством оптимизации блока 220 асимметричного бинаурального синтеза и компенсатора 230 перекрестных помех по фиг.6 с помощью матрицы фильтра расширения.
Как проиллюстрировано на фиг.7, посредством объединения блока 220 асимметричного бинаурального синтеза и компенсатора 230 перекрестных помех задается блок 710 фильтра расширения. Если стереофонический звук проходит через блок 710 фильтра расширения и воспроизводится посредством двух динамиков, слушатель воспринимает, что звук исходит из виртуальных динамиков, разнесенных широко (т.е. под широким углом) напротив слушателя (к примеру, под θ1 и/или θ2). В этом случае согласно позициям и числу виртуальных динамиков воспринимается виртуальный стереофонический звук. Тем не менее, поскольку может возникнуть ощущение пустоты в центре, где не размещены виртуальные динамики, слушатель может воспринимать ощущение нестабильности и звук может быть неестественным с ухудшенным тембром. Чтобы разрешить эту проблему, звук также выводится посредством реальных левого и правого динамиков 280-1 и 280-2 посредством задания левого и правого прямых фильтров 240 и 250. Левый и правый прямые фильтры 240 и 250 регулируют амплитуды и временную задержку выходов реальных динамиков (т.е. левого и правого динамика 280-1 и 280-2) и виртуальных динамиков. Временная задержка левого и правого прямых фильтров 240 и 250 задается равной временной задержке фильтра 710 расширения, уже предоставленного, чтобы не допустить изменения тембра. Левый и правый прямые фильтры 240 и 250 также определяют соотношение уровней вывода реальных динамиков и виртуальных динамиков. Следовательно, левый и правый прямые фильтры 240 и 250 могут регулировать степень, до которой разделяется стереофонический звук. В крайнем случае, если амплитуды левого и правого прямых фильтров 240 и 250 практически равны 0, звук воспроизводится только посредством виртуальных динамиков, поэтому степень объемности стереофонического звука расширяется, и звук в центре отсутствует. Альтернативно, если амплитуды левого и правого прямых фильтров 240 и 250 очень большие, звук воспроизводится только посредством реальных динамиков (т.е. левого и правого динамиков 280-1 и 280-2) и эффект расширенного стерео исчезает.Следовательно, амплитуды левого и правого прямых фильтров 240 и 250 могут быть определены посредством экспериментов прослушивания или звуковых тестов согласно предпочтениям слушателя.
Как проиллюстрировано на фиг.7, фильтр 710 расширения выполнен для того, чтобы генерировать виртуальные источники звука из сигналов, вводимых посредством двух каналов, и выводить звук на виртуальные динамики, тогда как левый и правый прямые фильтры (A(z)) 240 и 250 выполнены для того, чтобы регулировать характеристики сигнала между двумя канальными сигналами и виртуальными источниками звука и выводить звук на реальные динамики 280-1 и 280-2.
Настоящая общая концепция изобретения также может быть реализована в качестве машиночитаемого кода на машиночитаемом носителе записи. Машиночитаемым носителем записи может быть любое устройство хранения данных, которое может сохранять данные, которые могут впоследствии быть вычислительной системой. Примеры машиночитаемого носителя записи включают в себя постоянное запоминающее устройство (ПЗУ), оперативное запоминающее устройство (ОЗУ), диски CD-ROM, магнитные ленты, гибкие диски, устройства хранения оптических данных и волновую несущую (например, передачу данных через Интернет). Машиночитаемый носитель записи также может быть распространен по соединенным по сети вычислительным системам, так что машиночитаемый код сохраняется и исполняется распределенным способом.
Согласно вариантам осуществления настоящей общей концепции изобретения, описанным выше, когда монофонический сигнал воспроизводится посредством устройства, имеющего два рядом расположенных динамика, например ПЭВМ, ТВ, портативной ЭВМ или сотового телефона, степень объемности стереофонического звука может быть расширена.
Хотя варианты настоящей общей концепции изобретения описаны со ссылкой на два реальных (фактических) динамика (к примеру, 280-1 и 280-2), следует понимать, что некоторые варианты осуществления настоящей общей концепции изобретения могут быть реализованы с помощью одного реального динамика. Например, в варианте осуществления, связанном с другой системой воспроизведения звука, такой как сотовый телефон, имеющий один передний центральный динамик, множество асимметричных виртуальных динамиков может быть размещено под широким углом относительно одного переднего динамика.
Следовательно, посредством расширения степень объемности звука с помощью HRTF в отношении входного монофонического звука может восприниматься более широкая степень объемности звука, чем посредством традиционного способа, использующего разностный сигнал левого и правого сигналов.
Кроме того, поскольку полоса частот разделения и различные HRTF передаются асимметрично, изменение тембра меньше, чем при использовании традиционного способа, который генерирует левый и правый сигналы посредством изменения фаз полос частот.
Хотя было показано и описано несколько вариантов осуществления настоящей общей концепции изобретения, специалисты в данной области техники должны принимать во внимание, что изменения могут быть выполнены в этих вариантах осуществления без отступления от принципов и духа общей концепции изобретения, рамки которой заданы в формуле изобретения и ее эквивалентах.



Изобретение предназначено для придания объема монофоническому звуку посредством использования 2 канальных динамиков. Способ включает в себя разделение входного монофонического звукового сигнала на множество декоррелированных сигналов, генерирование виртуальных источников звука посредством локализации каждого из разделенных сигналов в виртуальных местоположениях, асимметричных относительно центра передней стороны точки прослушивания, посредством применения различных функций моделирования восприятия звука к разделенным сигналам и компенсирования перекрестных помех сгенерированных виртуальных источников звука. 7 н. и 32 з.п. ф-лы, 7 ил.
разделяют входной сигнал монофонического звука на множество декоррелированных сигналов;
генерируют виртуальные источники звука при помощи локализации соответствующих разделенных сигналов в виртуальных местоположениях, асимметричных относительно точки прослушивания, посредством применения различных функций моделирования восприятия звука (HRTF) к соответствующим разделенным сигналам; и
компенсируют перекрестные помехи сгенерированных виртуальных источников звука.
локализуют разделенный сигнал в различных виртуальных местоположениях с левой стороны и с правой стороны от точки прослушивания, и
локализуют второй разделенный сигнал в различных виртуальных местоположениях с левой стороны и с правой стороны от точки прослушивания таким образом, чтобы виртуальные местоположения второго разделенного сигнала были симметричны виртуальным местоположениям, в которых локализован первый разделенный сигнал.
воспроизводят разделенный первый сигнал посредством виртуального динамика, размещенного с левой стороны по линии, составляющей первый угол с центральной линией точки прослушивания, и виртуального динамика, размещенного с правой стороны по линии, составляющей второй угол, больший первого угла, с центральной линией точки прослушивания; и
воспроизводят разделенный второй сигнал посредством виртуального динамика, размещенного с левой стороны по линии, составляющей второй угол с центральной линией точки прослушивания, и виртуального динамика, размещенного с правой стороны по линии, составляющей первый угол с центральной линией точки прослушивания.
разделяют входной сигнал монофонического звука на множество декоррелированных сигналов;
выполняют операцию расширения фильтрации посредством генерирования виртуальных источников звука при помощи локализации каждого из соответствующих разделенных сигналов в виртуальных местоположениях, асимметричных относительно центральной линии точки прослушивания, посредством применения различных функций моделирования восприятия звука (HRTF) к соответствующим разделенным сигналам, и
компенсируют перекрестные помехи разделенных сигналов, локализованных в асимметричных виртуальных местоположениях; и выполняют операцию прямой фильтрации, регулируя характеристики сигнала между входным монофоническим звуковым сигналом и виртуальными источниками звука с компенсированными перекрестными помехами.
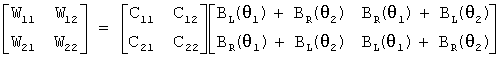 ,
,
где W11, W12, W21, W22 представляют коэффициенты фильтра расширения, С11, C12, C21, С22 представляют коэффициенты компенсатора перекрестных помех, BL(θ1 и BR(θ1), соответственно, представляют первые HRTF левого уха и правого уха, измеренные с правой стороны на линии, составляющей угол θ1 от центральной линии точки прослушивания, а BL(θ2) и BR(θ2), соответственно, представляют вторые HRTF левого уха и правого уха, измеренные с правой стороны на линии, составляющей угол θ2 от центральной линии точки прослушивания.
применяют первый набор заранее определенных функций моделирования восприятия звука (HRTF) к первому одному из множества декоррелированных сигналов, локализуя первый декоррелированный сигнал в двух или более асимметричных точках относительно точки прослушивания;
применяют второй набор заранее определенных HRTF ко второму одному из множества декоррелированных сигналов, локализуя второй декоррелированный сигнал в двух или более асимметричных точках относительно точки прослушивания;
суммируют компоненты для правого уха, выводимые из примененного первого набора заранее определенных HRTF, с компонентами для правого уха, выводимыми из примененного второго набора заранее определенных HRTF, генерируя компонентный сигнал правого уха;
суммируют компоненты для левого уха, выводимые из примененного первого набора заранее определенных HRTF, с компонентами для левого уха, выводимыми из примененного второго набора заранее определенных HRTF, генерируя компонентный сигнал левого уха; и
компенсируют перекрестные помехи между компонентными сигналами правого и левого уха с помощью заранее определенной матрицы коэффициентов компенсации перекрестных помех.
первые и вторые HRTF левого и правого уха, соответственно, локализующие часть первого декоррелированного сигнала в первом угле на первой стороне точки прослушивания; и
третьи и четвертые HRTF левого и правого уха, соответственно, локализующие другую часть первого декоррелированного сигнала во втором угле, отличном от первого угла, на второй стороне точки прослушивания.
применяют заранее определенную матрицу функций моделирования восприятия звука (HRTF), имеющую множество коэффициентов, которые соответствуют виртуальным местоположениям, позиции левого и правого уха и характеристики левого или правого уха, чтобы локализовать, по меньшей мере, первый один из множества декоррелированных сигналов в первом угле на первой стороне точки прослушивания и во втором угле, отличном от первого угла, на второй стороне точки прослушивания, чтобы определить компонентные сигналы левого уха и правого уха локализованного первого декоррелированного сигнала; и
компенсируют перекрестные помехи между компонентными сигналами правого и левого уха с помощью заранее определенной матрицы коэффициентов компенсации перекрестных помех.
блок разделения сигналов, чтобы разделять входной монофонический звуковой сигнал на множество декоррелированных сигналов;
блок бинаурального синтеза, генерирующий виртуальные источники звука при помощи локализации каждого из разделенных сигналов в виртуальных местоположениях, асимметричных относительно центральной линии точки прослушивания, посредством применения различных функций моделирования восприятия звука (HRTF) к соответствующим разделенным сигналам;
блок компенсатора перекрестных помех, чтобы компенсировать перекрестные помехи между разделенными сигналами виртуальных источников звука, локализованных в виртуальных местоположениях в блоке бинаурального синтеза на основе функции моделирования восприятия звука;
блок прямой фильтрации, чтобы регулировать характеристики сигнала между входным монофоническим сигналом и виртуальными источниками звука с компенсированными перекрестными помехами посредством блока компенсатора перекрестных помех; и
блок вывода, чтобы суммировать сигнал, выводимый из блока прямой фильтрации, с сигналом, выводимым из блока компенсатора помех, и чтобы выводить суммированные сигналы на левый и правый динамики.
фильтр верхних частот, чтобы фильтровать высокочастотный компонент входного монофонического звукового сигнала.
,
где W11, W12, W21, W22 представляют первые коэффициенты фильтра расширения, С11, С12, C21, C22 представляют первые коэффициенты компенсатора перекрестных помех, BL(θ1) и BR(θ1), соответственно, представляют первые HRTF левого уха и правого уха, измеренные с правой стороны на линии, составляющей угол θ1 от центра позиции головы слушателя, а BL(θ2) и BR(θ2), соответственно, представляют вторые HRTF левого уха и правого уха, измеренные с правой стороны на линии, составляющей угол θ2 от центра позиции головы слушателя.
по меньшей мере, первый и второй виртуальный динамики, чтобы воспроизводить первый сигнал на каждой стороне точки прослушивания таким образом, чтобы первый и второй виртуальные динамики были размещены под различными углами относительно точки прослушивания системы; и,
по меньшей мере, третий и четвертый виртуальный динамики, чтобы воспроизводить второй сигнал на каждой стороне точки прослушивания таким образом, чтобы третий и четвертый виртуальные динамики были размещены под различными углами относительно точки прослушивания системы.
терминал ввода, чтобы принимать монофонический звуковой сигнал;
блок для асимметричной локализации первого и второго компонентов монофонического звукового сигнала;
фильтр, чтобы фильтровать монофонический звуковой сигнал; и
терминал вывода, чтобы выводить объединенный сигнал согласно асимметрично локализованным первому и второму компонентам и отфильтрованному монофоническому звуковому сигналу.
блок разделения сигналов, чтобы разделять монофонический звуковой сигнал согласно характеристикам сигнала на первый и второй декоррелированный сигналы;
блок асимметричного бинаурального синтеза, чтобы генерировать компонент виртуального сигнала левого уха и компонент виртуального сигнала правого уха из первого и второго декоррелированных сигналов в соответствующих асимметричных местоположениях; и
блок компенсации перекрестных помех, чтобы компенсировать перекрестные помехи между компонентами виртуальных сигналов левого и правого уха и предоставлять компоненты виртуальных сигналов левого и правого уха с компенсированными перекрестными помехами в терминал вывода.
блок первых функций моделирования восприятия звука (HRTF), чтобы применять первый набор заранее определенных HRTF к первому декоррелированному сигналу, чтобы локализовать первый декоррелированный сигнал в двух или более асимметричных точках относительно точки прослушивания системы;
блок вторых HRTF, чтобы применять второй набор заранее определенных HRTF ко второму декоррелированному сигналу, чтобы локализовать второй декоррелированный сигнал в двух или более асимметричных точках относительно точки прослушивания системы; и
блок суммирования, чтобы суммировать компоненты для правого уха, выводимые из блока первых HRTF, с компонентами для правого уха, выводимыми из блока вторых HRTF, чтобы генерировать компонент виртуальных сигналов правого уха, суммировать компоненты для левого уха, выводимые из блока первых HRTF, с компонентами для левого уха, выводимыми из блока вторых HRTF, чтобы генерировать компонент виртуальных сигналов левого уха, и предоставлять компоненты виртуальных сигналов правого и левого уха в блок компенсации перекрестных помех.
генерируют первое множество виртуальных источников звука, асимметричных относительно точки прослушивания электронного устройства, из первой части одноканального звукового сигнала и генерируют второе множество виртуальных источников звука, асимметричных относительно точки прослушивания электронного устройства, из второй части одноканального звукового сигнала; и
объединяют первые и вторые асимметричные виртуальные источники звука с входным одноканальным звуковым сигналом, чтобы предоставлять объединенный выходной звуковой сигнал в, по меньшей мере, один реальный динамик.
| US 5301236 А, 05.04.1994 | |||
| US 6636608 B1, 21.10.2003 | |||
| Устройство для намотки | 1974 |
|
SU554031A1 |
| US 4219696 A, 26.08.1980 | |||
| СПОСОБ ФОРМИРОВАНИЯ СУБЪЕКТИВНОГО ТРЕХМЕРНОГО АКУСТИЧЕСКОГО ПРОСТРАНСТВА | 2000 |
|
RU2183355C1 |

