Настоящее изобретение относится к обработке аудиосигналов и, в частности, относится к синтезу пространственно протяженных источников звука (SESS).
В течение длительного времени исследуется воспроизведение источников звука по нескольким громкоговорителям или наушникам. Простейший способ воспроизведения источников звука в таких конфигурациях состоит в том, чтобы рендерировать их в качестве точечных источников, т.е. очень (в идеале: бесконечно) небольших источников звука. Тем не менее, эта теоретическая концепция практически не позволяет моделировать существующие физические источники звука реалистичным способом. Например, рояль имеет большую вибрирующую деревянную крышку с множеством пространственно распределенных струн внутри и в силу этого кажется гораздо большим при слуховом восприятии, чем точечный источник (в частности, когда слушатель (и микрофоны) находятся близко к роялю). Множество источников звука реального мира имеют значительный размер («пространственную протяженность»), например, музыкальные инструменты, машины, оркестр или хор либо окружающие звуки (звук водопада).
Корректное/реалистичное воспроизведение таких источников звука становится задачей множества способов воспроизведения звука, независимо от того, являются ли они бинауральными (т.е. с использованием так называемых передаточных функций восприятия звука человеком (HRTF) или бинауральных импульсных откликов в помещении (BRIR)) с использованием наушников, либо традиционными с использованием конфигураций громкоговорителей в пределах от 2 динамиков («стерео») до множества динамиков, расположенных в горизонтальной плоскости («объемный звук»), и множества динамиков, окружающих слушателя во всех трех измерениях («трехмерное аудио»).
В качестве примера, если SESS (например, фонтан) прослушивается из места, в котором часть фонтана загораживается посредством кустарников, загороженные части фонтана подвергаются процессу частотного демпфирования, т.е. ослабляются посредством определенного частотного отклика, который определяется посредством характеристик пропускания кустарника. Характеристики рендеринга таких (частично) загороженных частей SESS недоступны в первоначально описанном алгоритме рендеринга SESS. Аналогично, более удаленные части SESS могут реалистично рендерироваться с более низким уровнем с использованием настоящего изобретения.
Ширина двумерного источника
В этом разделе описаны способы, которые относятся к рендерингу протяженных источников звука на двумерной поверхности, обращенной с точки обзора слушателя, например, в определенном диапазоне изменения азимута при подъеме в нуль градусов (что имеет место в традиционном стерео-/объемном звуке), или в определенных диапазонах изменения азимута и угла места (что имеет место в трехмерном аудио или виртуальной реальности с 3 степенями свободы ["3DoF"] перемещения пользователя, т.е. вращения головы в осях наклона в продольном направлении/наклона относительно вертикальной/крена).
Увеличение кажущейся ширины аудиообъекта, который панорамируется между двумя или более громкоговорителей (формирование так называемого фантомного изображения или фантомного источника) может достигаться посредством снижения корреляции участвующих канальных сигналов. Со снижением корреляции, разброс фантомных источников увеличивается до тех пор, пока, для корреляционных значений, близких к нулю (и не слишком широких углах раскрытия), он не охватывает весь диапазон между громкоговорителями.
Декоррелированные версии сигнала источника получаются посредством извлечения и применения подходящих декорреляционных фильтров. В работе автора Lauridsen предложено суммировать/вычитать масштабированную версию с временной задержкой сигнала источника относительно себя, чтобы получать две декоррелированных версии сигнала. Более сложные подходы, например, предложены в работе автора Kendall. Он итеративно извлекает спаренные декорреляционные всечастотные фильтры на основе комбинаций последовательностей случайных чисел. Работа авторов Faller и др. предлагает подходящие декорреляционные фильтры («рассеиватели»). Также в работе Zotter и др. извлекаются пары фильтров, в которых частотно-зависимые разности фаз или амплитуд использованы для достижения расширения фантомного источника. Кроме того, предложены декорреляционные фильтры на основе бархатного шума, которые дополнительно оптимизированы.
Помимо уменьшения корреляции соответствующих канальных сигналов фантомного источника, ширина источника также может увеличиваться посредством увеличения числа фантомных источников, приписанных аудиообъекту В, ширина источника управляется посредством панорамирования одного и того же сигнала источника в (немного) различных направлениях. Первоначально предложен способ стабилизации воспринимаемого разброса фантомных источников сигналов панорамированных источников VBAP, когда они перемещаются в звуковой сцене. Это является преимущественным, поскольку в зависимости от направления источника, рендерируемый источник воспроизводится посредством двух или более динамиков, что может приводить к нежелательным изменениям воспринимаемой ширины источника.
DirAC в виртуальном мире представляет собой расширение традиционного подхода на основе направленного кодирования аудио (DirAC) для синтеза звука в виртуальных мирах. Для рендеринга пространственной протяженности, направленные звуковые компоненты источника случайно панорамируются в пределах определенного диапазона вокруг исходного направления источника, причем направления панорамирования варьируются во времени и по частоте.
Аналогичный подход задействуется в, при котором пространственная протяженность достигается посредством случайного распределения полос частот сигнала источника для различных пространственных направлений. Он представляет собой способ, направленный на формирование пространственно распределенного и огибающего звука, поступающего одинаково из всех направлений, вместо управления точной степенью протяженности.
В работе авторов Verron и др. пространственная протяженность источника достигается не посредством использования панорамированных коррелированных сигналов, а посредством синтезирования нескольких некогерентных версий сигнала источника, их равномерного распределения по окружности вокруг слушателя и смешения между собой. Число и усиление одновременно активных источников определяют интенсивность эффекта расширения. Этот способ реализован как пространственное протягивание для синтезатора для звуков окружающей среды.
Ширина трехмерного источника
В данном разделе описаны способы, которые относятся к рендерингу протяженных источников звука в трехмерном пространстве, т.е. объемным способом, что требуется для виртуальной реальности с 6 степенями свободы ("6DoF"). Это означает 6 степеней свободы перемещения пользователя, т.е. вращения головы в осях наклона в продольном направлении/наклона относительно вертикальной/крена) плюс 3 направления x/y/z поступательного перемещения в пространстве.
Работа авторов Potard и др. расширяет понятие протяженности источника в качестве одномерного параметра источника (т.е. его ширины между двумя громкоговорителями) посредством изучения восприятия форм источников. В ней формируются несколько некогерентных точечных источников посредством применения (варьирующихся во времени) технологий декорреляции к первоначальному сигналу источника и затем помещения некогерентных источников в различные пространственные местоположения и за счет этого обеспечения им трехмерной протяженности.
В усовершенствованном стандарте AudioBIFS MPEG-4 объемные объекты/формы (раковина, коробка, эллипсоид и цилиндр) могут быть заполнены несколькими одинаково распределенными и декоррелированными источниками звука, чтобы обеспечить трехмерную протяженность источника.
Чтобы увеличивать и управлять протяженностью источника с использованием амбиофонии, в работе авторов Schmele и др. предложено смешение уменьшения порядка амбиофонии входного сигнала, что внутренне увеличивает кажущуюся ширину источника и распределение декоррелированных копий сигнала источника вокруг пространства для прослушивания.
Другой подход введен в работе авторов Zotter и др., в которой приспосабливается принцип, предложенный в (т.е. извлечение пар фильтров, которые вводят частотно-зависимые разности фаз и абсолютных величин для обеспечения протяженности источника в конфигурациях для воспроизведения стереоданных) для амбиофонии.
Общий недостаток подходов на основе панорамирования (например) заключается в их зависимости от положения слушателя. Даже небольшое отклонение от зоны наилучшего восприятия приводит к тому, что пространственное изображение сворачивается до громкоговорителя, ближайшего к слушателю. Это радикально ограничивает их применение в контексте виртуальной реальности и дополненной реальности с 6 степенями свободы (6DoF), когда предполагается, что слушатель свободно перемещается. Кроме того, распределение частотно-временных элементов разрешения в подходах на основе DirAC (например) не всегда гарантирует надлежащий рендеринг пространственной протяженности фантомных источников. Кроме того, оно типично значительно ухудшает тембр сигнала источника.
Декорреляция сигналов источников обычно достигается посредством одного из следующих способов: i) извлечение пар фильтров с комплементарной абсолютной величиной (например), ii) использование всечастотных фильтров с постоянной абсолютной величиной, но (случайно) скремблированной фазой (например), или iii) пространственно случайное распределение частотно-временных элементов разрешения сигнала источника (например).
Все подходы влекут за собой свои последствия: Комплементарная фильтрация сигнала источника согласно i) типично приводит к измененному воспринимаемому тембру декоррелированных сигналов. Хотя всечастотная фильтрация, как указано в ii), сохраняет тембр сигнала источника, скремблированная фаза нарушает исходные соотношения фаз и, в частности, для переходных сигналов, вызывает серьезную временную дисперсию и артефакты размывания. Пространственное распределение частотно-временных элементов разрешения оказывается эффективным для некоторых сигналов, но также и изменяет воспринимаемый тембр сигнала. Кроме того, оно демонстрирует сильную зависимость от сигнала и вводит серьезные артефакты для импульсных сигналов.
Заполнение объемных форм несколькими декоррелированными версиями сигнала источника, предложенное в усовершенствованном AudioBIFS-стандарте, предполагает доступность большого числа фильтров, которые формируют взаимно декоррелированные выходные сигналы (типично, более десяти точечных источников в расчете на объемную форму используются). Тем не менее, нахождение таких фильтров не представляет собой тривиальную задачу и становится тем более сложным, чем больше таких фильтров требуется. Кроме того, если сигналы источников не полностью декоррелируются, и слушатель перемещается вокруг такой формы, например, в сценарии (виртуальной реальности), отдельные расстояния от источника до слушателя соответствуют различным задержкам сигналов источников, и их наложение в ушах слушателя приводит к зависимой от положения гребенчатой фильтрации, потенциально вводящей раздражающее неустановившееся окрашивание сигнала источника.
Управление шириной источника с помощью технологию на основе амбиофонии посредством понижения порядка амбиофонии демонстрирует слышимый эффект только для переходов от второго к первому или к нулевому порядку. Кроме того, эти переходы воспринимаются не только в качестве расширения источника, но также и часто в качестве перемещения фантомного источника. При том, что суммирование декоррелированных версий сигнала источника может помогать в стабилизации восприятия кажущейся ширины источника, оно также вводит эффекты гребенчатой фильтрации, которые изменяют тембр фантомного источника.
Эффективный способ бинаурального рендеринга пространственно протяженного источника звука (SESS) раскрыт в WO2021/180935 с использованием двух декоррелированных версий входной волновой формы сигнала (они могут формироваться посредством использования исходного моносигнала и декоррелятора, чтобы формировать декоррелированную версию этого моносигнала), каскада вычисления сигнальных меток, который вычисляет целевые бинауральные (и тембральные) сигнальные метки пространственно протяженного источника звука в зависимости от размера источника (например, заданного в качестве диапазона углов азимута/места в зависимости от положения и ориентации пространственно протяженного источника звука и слушателя). В предпочтительном варианте осуществления, этот каскад вычисления сигнальных меток предварительно вычисляет целевые сигнальные метки в зависимости от пространственных областей, которые должны покрываться посредством SESS, и сохраняет их в таблицу поиска, и каскад регулирования бинауральных сигнальных меток формирует подготовленный посредством бинаурального рендеринга выходной сигнал из входного сигнала, и его декоррелированная версия с использованием целевых сигнальных меток формирует каскад вычисления сигнальных меток (таблицу поиска). Каскад регулирования бинауральных сигнальных меток регулирует бинауральные сигнальные метки (межканальную когерентность (ICC), межканальную разность фаз (ICPD), межканальную разность уровней (ICLD)) входных сигналов за несколько этапов до их требуемого целевого значения, вычисленного посредством каскада вычисления сигнальных меток/таблицы поиска.
Задача настоящего изобретения состоит в создании усовершенствованной концепции для пространственно протяженных источников звука.
Данная задача решается объектами изобретения, определёнными в независимых пунктах формулы изобретения, и предпочтительные варианты осуществления определены в зависимых пунктах формулы изобретения.
Регулярный алгоритм быстрого синтеза пространственно протяженных источников звука (SESS) имитирует звуковое впечатление рассеянного поля в определенных указанных целевых пространственных областях. Это достигается посредством (виртуального) суммирования множества близкорасположенных источников звука, которые возбуждаются посредством декоррелированных версий аудиосигнала. Иногда, часть SESS загораживается посредством частично пропускающего материала (например, кустарников), приводя к частотно-избирательному ослаблению SESS в загороженной пространственной области. Этот эффект может разумно и эффективно включаться в эффективный алгоритм SESS посредством введения этапа взвешивания в вычисление между операцией табличного поиска и дополнительным вычислением требуемых бинауральных сигнальных меток. Таблица поиска сохраняет предварительно вычисленные частичные суммы членов для каждого пространственного сектора вокруг слушателя. Протягивание достигается практически без дополнительных вычислительных затрат. Варианты осуществления относятся к устройству и к способу либо к компьютерной программе для воспроизведения или синтезирования пространственно протяженного источника звука (SESS) с избирательным пространственным взвешиванием.
Преимущество настоящего изобретения заключается в том, что настоящее изобретение обеспечивает возможность обработки пространственно протяженного источника звука с возможно комплексной геометрической формой.
Дополнительное преимущество настоящего изобретения заключается в том, что варианты осуществления обеспечивают возможность усовершенствованной концепции воспроизведения пространственно протяженного источника звука и обеспечивают возможности для пространственно избирательной модификации рендеринга SESS.
Первый аспект относится к использованию элементарных пространственных секторов. Этот первый аспект относится к сохранению данных для элементарных пространственных секторов в таблице поиска, при этом элементарные пространственные секторы распределяются по сфере. Данные для элементарных пространственных секторов предпочтительно привязываются к голове пользователя, формирующей центрированную на пользователе аудиосцену, и являются одинаковыми для каждого наклона головы в одном и том же положении, а также для каждого положения головы слушателя, т.е. для каждой степени свободы из 6DOF. Тем не менее, каждое перемещение или наклон головы приводит к такой ситуации, когда звук из SESS «входит» в других одном или более элементарных пространственных секторов в голову пользователя. Модуль рендеринга определяет элементарные пространственные секторы, покрытые посредством SESS, извлекает сохраненные данные для этих конкретных секторов, при необходимости выполняет взвешивание сохраненных данных вследствие загораживающих объектов или определенных расстояний, а затем комбинирует сохраненные данные (или в случае взвешивания взвешенных сохраненных данных) и после этого использует результат комбинированной операции для рендеринга (например, сигнальные метки рендеринга вычисляются из комбинированных данных (ко)вариации, но здесь также могут использоваться другие этапы и параметры). Следовательно, этот аспект может использовать или может не использовать обращение к загораживающим объектам и может использовать или может не использовать обращение к конкретным сохраненным данным дисперсии, поскольку комбинирование (и при необходимости также взвешивание) также может осуществляться, когда сохраняются другие данные, например, (средние) HRTF (для элементарного пространственного сектора или для целой пространственной протяженности) либо даже непосредственно частотно-зависимые сигнальные метки.
Второй аспект относится к модифицирующим объектам, которые могут представлять собой загораживающие объекты или другие объекты, приводящие к модификации звука SESS на пути из положения SESS к пользователю, имеющему определенное местоположение и/или наклон. Этот второй аспект относится к обработке, например, загораживающих объектов. Воздействие загораживающего объекта представляет собой частотно-зависимое ослабление, имеющее характеристику нижних частот. Частотно-зависимое взвешивание также может применяться к процедуре из уровня техники, в которой отсутствуют элементарные пространственные секторы. На основе передаваемых данных, описывающих загораживающие объекты, следует принимать решение в отношении того, загораживается ли SESS, и затем применять функцию загораживания, например, к частотно-зависимым сохраненным сигнальным меткам, которые уже приводятся для различных частот в уровне техники. Следовательно, это представляет собой полезное применение эффекта загораживания в уровне техники без использования элементарных пространственных секторов или без использования сохраненных данных дисперсии.
Третий аспект относится к устройству хранения данных дисперсии и данных ковариации, например, для HRTF для различной пространственной протяженности или элементарных пространственных секторов. Этот третий аспект относится к устройству хранения, например, в таблице поиска, данных дисперсии и данных ковариации, например, для HRTF в положении хранения. Не имеет значения, сохраняются эти данные для определенной пространственной протяженности аналогично уровню техники или для элементарного пространственного сектора. Модуль рендеринга затем вычисляет все сигнальные метки рендеринга из сохраненных данных дисперсии на лету. В отличие от варианта применения из уровня техники, в котором сохраняется по меньшей мере IACC и вероятно другие сигнальные метки или данные HRFT, это не осуществляется в этом аспекте. Данные ковариации сохраняются, и сигнальные метки вычисляются на лету. Следовательно, этот аспект может использовать или может не использовать элементарные пространственные секторы и может использовать или может не использовать модифицирующие или загораживающие объекты.
Все аспекты могут использоваться отдельно друг от друга или вместе друг с другом, либо также только произвольно выбранные два аспекта могут комбинироваться.
Ниже описаны предпочтительные варианты осуществления настоящего изобретения с обращением к сопровождающим чертежам, на которых:
Фиг. 1 иллюстрирует устройство для синтезирования пространственно протяженного источника звука в соответствии с первым аспектом настоящего изобретения:
Фиг. 2a иллюстрирует устройство для синтезирования пространственно протяженного источника звука в соответствии со вторым аспектом изобретения;
Фиг. 2b иллюстрирует генератор аудиосцен в соответствии со вторым аспектом настоящего изобретения;
Фиг. 3 иллюстрирует предпочтительный вариант осуществления третьего аспекта настоящего изобретения;
Фиг. 4 иллюстрирует блок-схему для иллюстрации определенных частей аспектов согласно изобретению;
Фиг. 5 иллюстрирует другую блок-схему для иллюстрации нескольких частей аспектов согласно изобретению;
Фиг. 6 иллюстрирует дополнительную блок-схему для иллюстрации частей аспектов согласно изобретению;
Фиг. 7 иллюстрирует примерное разделение диапазона рендеринга на элементарные пространственные секторы;
Фиг. 8 иллюстрирует процедуру для комбинирования трех аспектов согласно изобретению для синтеза пространственно протяженных источников звука;
Фиг. 9 иллюстрирует предпочтительную реализацию блока 320 по фиг. 4, 5 и 6;
Фиг. 10 иллюстрирует реализацию второго процессора каналов;
Фиг. 11 иллюстрирует принципиальную схему, подробно показывающую признаки первого аспекта и второго аспекта изобретения;
На Фиг. 12 приведена иллюстрация для пояснения первого, второго и третьего аспектов согласно изобретению; и
Фиг. 13 иллюстрирует декоррелятор по фиг. 10, соединенный с синтезом аудиопроцессора в соответствии с дополнительным вариантом осуществления.
Фиг. 1 иллюстрирует устройство для синтезирования пространственно протяженного источника звука. Устройство содержит устройство 2000 хранения данных для сохранения элементов данных рендеринга для различных элементарных пространственных секторов, покрывающих диапазон рендеринга для слушателя. Кроме того, устройство содержит процессор 4000 идентификации секторов для идентификации, из различных элементарных пространственных секторов, набора элементарных пространственных секторов, принадлежащих конкретному пространственно протяженному источнику звука. Идентификация выполняется на основе данных слушателя и данных, связанных с пространственно протяженным источником звука (SESS). Кроме того, устройство содержит модуль 5000 вычисления целевых данных для вычисления целевых данных рендеринга из элементов данных рендеринга для набора элементарных пространственных секторов. Кроме того, устройство содержит аудиопроцессор 3000 для обработки аудиосигнала, представляющего пространственно протяженный источник звука, с использованием целевых данных рендеринга, сформированных посредством модуля 5000 вычисления целевых данных.
Фиг. 2a иллюстрирует устройство для синтезирования пространственно протяженного источника звука (SESS), содержащее входной интерфейс 4020 для приема описания аудиосцены, причем описание аудиосцены содержит данные пространственно протяженных источников звука по пространственно протяженному источнику звука и данные о модификации для потенциально модифицирующего объекта. Кроме того, входной интерфейс 4020 выполнен с возможностью приема данных слушателя.
Процессор 4000 идентификации секторов, который в общем может быть реализован как процессор 4000 идентификации секторов по фиг. 1, выполнен с возможностью идентификации ограниченного модифицированного пространственного сектора для пространственно протяженного источника звука в диапазоне рендеринга для слушателя, при этом диапазон рендеринга для слушателя больше ограниченного модифицированного пространственного сектора. Идентификация выполняется на основе данных пространственно протяженных источников звука и данных слушателя, и данных о модификации. Кроме того, устройство содержит модуль 5000 вычисления целевых данных, который, в общем, может быть реализован так же или реализован аналогично модулю 5000 вычисления целевых данных по фиг. 1. Это устройство выполнено с возможностью вычисления целевых данных рендеринга из одного или более элементов данных рендеринга, принадлежащих модифицированному ограниченному пространственному сектору, определенному посредством блока 4000 по фиг. 2a. Кроме того, устройство для синтезирования пространственно протяженного источника звука в соответствии со вторым аспектом, проиллюстрированным на фиг. 2a, содержит аудиопроцессор для обработки аудиосигнала, представляющего пространственно протяженный источник звука, с использованием целевых данных рендеринга, на которые влияют данные о модификации, т.е. данные по модифицирующему объекту, например, загораживающему объекту.
Фиг. 2b иллюстрирует, снова в соответствии со вторым аспектом, генератор аудиосцен, содержащий генератор 6010 данных пространственно протяженных источников звука, генератор 6020 данных о модификации и выходной интерфейс 6030. Генератор 6010 данных пространственно протяженных источников звука выполнен с возможностью формирования данных пространственно протяженного источника звука и передачи этих данных в выходной интерфейс. Эти данные предпочтительно содержат по меньшей мере одно из информации местоположения и информации ориентации и геометрических данных для пространственно протяженного источника звука в качестве метаданных для пространственно протяженного источника звука и, кроме того, могут содержать данные формы сигнала для SESS, такие как стереосигнал для SESS в случае, например, большого SESS, такого как рояль, либо только моносигнал для данных SESS, которые обрабатываются посредством проиллюстрированного декоррелятора, например, на фиг. 10 в элементе 310 или на фиг. 13 в элементе 3100.
Генератор 6020 данных о модификации выполнен с возможностью формирования данных о модификации, и эти данные о модификации могут содержать описание функции нижних частот или описание геометрических данных относительно потенциально модифицирующего объекта. В варианте осуществления, функция нижних частот содержит значение ослабления для более высокой частоты, причем значение ослабления для более высокой частоты, представляющее значение ослабления, является более сильным по сравнению со значением ослабления для более низкой частоты, и эти данные перенаправляются в выходной интерфейс 6030 для вставки в сформированное описание аудиосцен.
Следовательно, описание аудиосцен, проиллюстрированное на фиг. 2b, улучшается по сравнению с описанием SESS в том, что включаются не только данные SESS, но также и данные по объектам о модификации, которые, сами по себе, представляют собой не источники звука, а которые представляют собой элементы, которые модифицируют звуковое поле, сформированное посредством источника звука.
Фиг. 3 иллюстрирует предпочтительный вариант осуществления устройства для синтезирования пространственно протяженного источника звука в соответствии с третьим аспектом.
Этот элемент содержит устройство хранения данных для сохранения одного или более элементов данных рендеринга для различных ограниченных пространственных секторов, при этом различные ограниченные пространственные секторы расположены в диапазоне рендеринга для слушателя, и при этом один или более элементов данных рендеринга для ограниченного пространственного сектора содержат по меньшей мере один из левого элемента данных дисперсии, правого элемента данных дисперсии и лево-правого элемента данных ковариации.
Кроме того, устройство содержит процессор 4000 идентификации секторов для идентификации одного или более ограниченных пространственных секторов для пространственно протяженного источника звука в диапазоне рендеринга для слушателя на основе данных пространственно протяженных источников звука и предпочтительно на основе положения или ориентации слушателя.
Левые данные дисперсии, правые данные дисперсии и данные ковариации вводятся в модуль 5000 вычисления целевых данных для вычисления целевых данных рендеринга из сохраненных левых данных дисперсии, сохраненных правых данных дисперсии или сохраненных данных ковариации, соответствующих одному или более ограниченных пространственных секторов, определенных посредством процессора 4000 идентификации секторов. Целевые данные рендеринга перенаправляются в аудиопроцессор 3000 для обработки аудиосигнала, представляющего пространственно протяженный источник звука, с использованием целевых данных рендеринга. В общем, аудиопроцессор 3000 может быть реализован аналогично тому, что показано на фиг. 1 и 2b или фиг. 4, 5 и 6, либо аудиопроцессор 3000 может быть реализован по-другому.
Предпочтительно, левый элемент данных дисперсии, правый элемент данных дисперсии и/или лево-правые элементы данных ковариации представляют собой элементы данных, связанные с данными передаточной функции восприятия звука человеком или связанные с данными бинаурального импульсного отклика в помещении, или связанные с данными бинауральной передаточной функции в помещении, или связанные с данными импульсного отклика восприятия звука человеком. Кроме того, элементы данных рендеринга содержат значения элементов данных дисперсии или ковариации для различных частот таким образом, что частотно-избирательная/частотно-зависимая обработка достигается.
В частности, устройство 2000 хранения данных выполнено с возможностью сохранения, для каждого ограниченного пространственного сектора, частотно-зависимого представления левого элемента данных дисперсии, частотно-зависимого представления правого элемента данных дисперсии и частотно-зависимого представления элемента данных ковариации.
Восходящая обработка сохраненных элементов данных дисперсии/ковариации примерно иллюстрируется на нескольких чертежах из WO2021/180935, указываемых далее как фиг. 4, 5 и 6.
Фиг. 4 показывает блок-схему синтеза SESS. Фиг. 5 показывает другую блок-схему синтеза SESS, упрощенного в соответствии с вариантом 1, и фиг. 6 показывает блок-схему синтеза SESS, упрощенного в соответствии с вариантом 2.
Фиг. 4 иллюстрирует реализацию устройства для синтезирования пространственно протяженного источника звука. Устройство содержит интерфейс обработки пространственной информации, который принимает ввод информации индикатора пространственного диапазона, указывающий ограниченный пространственный диапазон для пространственно протяженного источника звука в пределах максимального пространственного диапазона. Ограниченный пространственный диапазон вводится в блок 200 обеспечения информации сигнальных меток, выполненный с возможностью обеспечения одного или более информационных элементов сигнальных меток в ответ на ограниченный пространственный диапазон, обеспеченный интерфейсом обработки пространственной информации. Информационный элемент сигнальных меток либо несколько информационных элементов сигнальных меток вводятся в аудиопроцессор 300, выполненный с возможностью обработки аудиосигнала, представляющего пространственно протяженный источник звука, с использованием одного или более информационных элементов сигнальных меток, обеспеченных блоком 200 обеспечения информации сигнальных меток. Аудиосигнал для пространственно протяженного источника звука (SESS) может представлять собой один канал или может представлять собой первый аудиоканал и второй аудиоканал, или может представлять собой более двух аудиоканалов. Тем не менее, для целей наличия низкой нагрузки по обработке, небольшое число каналов для пространственно протяженного источника звука или для аудиосигнала, представляющего пространственно протяженный источник звука, является предпочтительным.
Аудиосигнал вводится в аудиопроцессор 300, и аудиопроцессор 300 обрабатывает входной аудиосигнал, либо, когда число входных аудиоканалов меньше, чем требуется, например, составляет только один, аудиопроцессор содержит второй процессор 310 каналов, проиллюстрированный на фиг. 10, содержащий, например, декоррелятор для формирования второго аудиоканала S2, декоррелированного относительно первого аудиоканала S, который также проиллюстрирован на фиг. 10 в качестве S1. Информационные элементы сигнальных меток могут представлять собой фактические элементы сигнальных меток, такие как элементы межканальной корреляции, элементы межканальной разности фаз, элементы межканальной разности уровней и усилений, элементы G1, G2 коэффициентов усиления, совместно представляющие межканальную разность уровней и/или абсолютные уровни амплитуды или мощности, или энергии, например, либо информационные элементы сигнальных меток также могут представлять собой фактические функции фильтра, такие как передаточные функции восприятия звука человеком с числом, требуемым посредством фактического числа подлежащих синтезированию выходных каналов в синтезирующем сигнале. Таким образом, когда синтезирующий сигнал должен иметь два канала, например, два бинауральных канала или два каналов громкоговорителей, одна передаточная функция восприятия звука человеком для каждого канала требуется. Вместо передаточных функций восприятия звука человеком, необходимы функции импульсного отклика восприятия звука человеком (HRIR) или функции бинаурального или небинаурального импульсного отклика в помещении ((B)RIR). Одна такая передаточная функция требуется для каждого канала, и фиг. 4 иллюстрирует реализацию наличия двух каналов.
В варианте осуществления, блок 200 обеспечения информации сигнальных меток выполнен с возможностью обеспечения в качестве информационного элемента сигнальных меток значения межканальной корреляции. Аудиопроцессор 300 выполнен с возможностью фактического приёма через аудиосигнальный интерфейс 305 первого аудиоканала и второго аудиоканала. Тем не менее, когда аудиосигнальный интерфейс 305 принимает только один канал, при необходимости предусмотренный второй процессор каналов формирует, например, посредством процедуры на фиг. 9, второй аудиоканал. Аудиопроцессор выполняет обработку корреляции, чтобы налагать корреляцию между первым аудиоканалом и вторым аудиоканалом с использованием значения межканальной корреляции.
В качестве альтернативы или дополнения, может быть предусмотрен дополнительный информационный элемент сигнальных меток, такой как элемент межканальной разности фаз, элемент межканальной разности времен, элемент межканальной разности уровней и усилений либо информационный элемент первых коэффициентов усиления и вторых коэффициентов усиления. Элементы также могут представлять собой значения интерауральной корреляции (IACC), т.е. более конкретные значения межканальной корреляции, или элементы интерауральной разности фаз (IAPD), т.е. более конкретные значения межканальной разности фаз.
В предпочтительном варианте осуществления, корреляция налагается (320) посредством аудиопроцессора 300 в ответ на информационный элемент сигнальных меток корреляции, до того, как выполняются регулирования ICPD (330), ICTD или ICLD(340), либо до того, как выполняются HRTF или другие функциональные обработки (350) передаточного фильтра. Тем не менее, в зависимости от обстоятельств, порядок может задаваться по-другому.
В предпочтительном варианте осуществления, устройство содержит запоминающее устройство для сохранения информации касательно различных информационных элементов сигнальных меток относительно различных индикаторов пространственного диапазона. В этой ситуации блок обеспечения информации сигнальных меток дополнительно содержит выходной интерфейс для извлечения, из запоминающего устройства, одного или более информационных элементов сигнальных меток, ассоциированных с индикатором пространственного диапазона, вводимым в соответствующее запоминающее устройство. Такая таблица 210 поиска, например, иллюстрируется на фиг. 4, 5 или 6, причем таблица поиска содержит запоминающее устройство и выходной интерфейс для вывода соответствующих информационных элементов сигнальных меток. В частности, запоминающее устройство может не только сохранять значения IACC, IAPD или Gl и Gr, как проиллюстрировано на фиг. 1b, но запоминающее устройство в таблице поиска также может сохранять функции фильтра, как проиллюстрировано в блоке 220 по фиг. 5 и по фиг. 6, что указано как «выбор HRTF». В этом варианте осуществления, хотя они проиллюстрированы отдельно на фиг. 5 и на фиг. 6, блоки 210, 220 могут содержать одно и то же запоминающее устройство, причем, в ассоциации с соответствующим индикатором пространственного диапазона, указываемым в качестве углов азимута и углов места, соответствующие информационные элементы сигнальных меток, такие как IACC и, при необходимости, IAPD, и передаточные функции для фильтров, такие как HRTFl для левого выходного канала и HRTFr для правого выходного канала сохраняются, при этом левый и правый выходные каналы указываются в качестве Sl и Sr на фиг. 4 или на фиг. 5, или на фиг. 6.
Запоминающее устройство, используемое посредством таблицы 210 поиска или блока 220 выбора функции, также может использовать устройство хранения данных, в котором на основе определенных кодов секторов либо углов секторов или диапазонов углов секторов, доступны соответствующие параметры. Альтернативно, запоминающее устройство может сохранять процедуру обработки векторной таблицы кодирования или многомерной подгонки функции либо гауссову смешанную модель (GMM) или метод опорных векторов (SVM) в зависимости от обстоятельств.
Целевые сигнальные метки вычисляются так, как описано ниже по тексту. На фиг. 4, показывается общая блок-схема концепции. [Φ1, Φ2] описывает требуемую протяженность источника с точки зрения диапазона углов азимута. [θ1, θ2] является требуемой протяженностью источника с точки зрения диапазона углов места. S1(ω) и S2(ω) обозначают два декоррелированных входных сигнала, где ω описывает частотный индекс. Таким образом, для S1(ω) и S2(ω), следующее уравнение является справедливым:
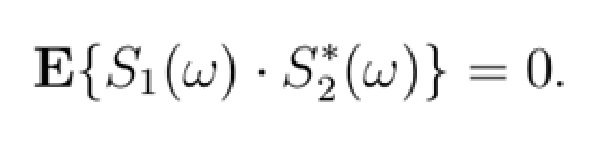 (1)
(1)
Кроме того, оба входных сигнала должны иметь равную спектральную плотность мощности. В качестве альтернативы, можно предусмотреть только один входной сигнал, S(ω). Второй входной сигнал формируется внутренне с использованием декоррелятора, как проиллюстрировано на фиг. 10. При условии Sl(ω) и Sr(ω), протяженный источник звука синтезируется посредством последовательного регулирования межканальной когерентности (ICC), межканальных разностей фаз (ICPD) и межканальных разностей уровней (ICLD) таким образом, что они совпадают с соответствующими интерауральными сигнальными метками. Величины, необходимые для этих этапов обработки, считываются из предварительно вычисленной таблицы поиска. Результирующие сигналы левого и правого канала, Sl(ω) и Sr(ω), могут воспроизводиться через наушники и напоминать SESS. Следует отметить, что регулирование ICC должно выполняться сначала; тем не менее, блоки регулирования ICPD и ICLD могут меняться местами. Вместо IAPD также могут воспроизводиться соответствующие интерауральные разности времен (IATD). Тем не менее, далее подробнее рассматривается только IAPD.
В блоке регулирования ICC, взаимная корреляция между обоими входными сигналами регулируется до требуемого значения |IACC(ω)| с использованием следующих формул [21]:
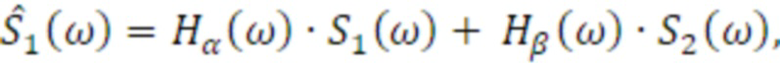 (2)
(2)
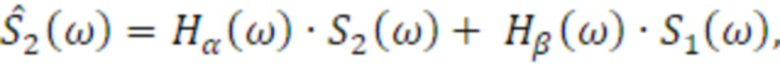 (3)
(3)
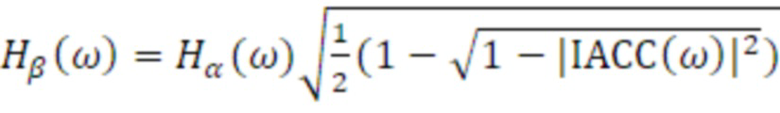 , (4)
, (4)
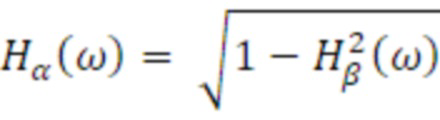 . (5)
. (5)
Применение этих формул приводит к требуемой взаимной корреляции, при условии, что входные сигналы S1(ω) и S2(ω) полностью декоррелируются. Кроме того, их спектральная плотность мощности должна быть равной. Соответствующая блок-схема показывается на фиг. 9. Четыре фильтра 321-324 и два сумматора 325, 326 обрабатывают ввод, чтобы получать вывод блока 320.
Блок 330 регулирования ICPD описан посредством следующих формул:
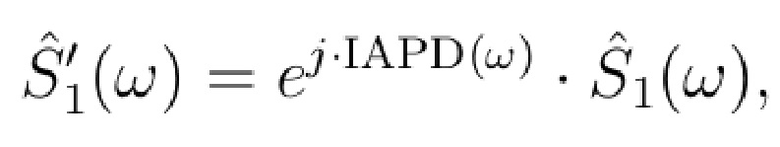 (6)
(6)
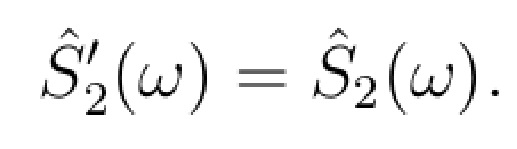 (7)
(7)
В завершение, регулирование 340 ICLD выполняется следующим образом:
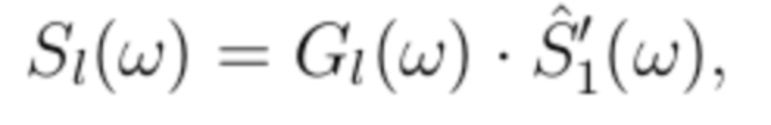 (8)
(8)
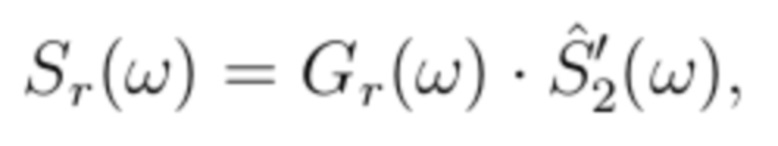 , (9)
, (9)
где Gl(ω) описывает усиление для левого уха, и Gr(ω) описывает усиление для правого уха. Это приводит к требуемой ICLD при условии, что 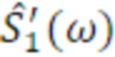 и
и 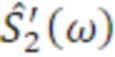 фактически имеют равную спектральную плотность мощности. Поскольку усиление для левого и правого уха используется непосредственно, монауральные спектральные сигнальные метки воспроизводятся в дополнение к IALD.
фактически имеют равную спектральную плотность мощности. Поскольку усиление для левого и правого уха используется непосредственно, монауральные спектральные сигнальные метки воспроизводятся в дополнение к IALD.
Чтобы дополнительно упростить поясняемый выше способ, описаны два варианта упрощения. Как упомянуто выше, основная интерауральная сигнальная метка, оказывающая влияние на воспринимаемую пространственную протяженность (в горизонтальной плоскости), представляет собой IACC. В силу этого должна быть возможность не использовать предварительно вычисленные IAPD и/или значения IALD, а регулировать значения IAPD и/или IALD непосредственно через HRTF. С этой целью, используется HRTF, соответствующая положению, представляющему требуемый диапазон протяженностей источников. В качестве этого положения, среднее требуемого диапазона изменения азимута/угла места выбирается здесь без потери общности. Ниже по тексту приводится описание обоих вариантов.
Первый вариант включает в себя использование предварительно вычисленных значений IACC и IAPD. Тем не менее, ICLD регулируется с использованием HRTF, соответствующей центру диапазона протяженностей источников.
Блок-схема первого варианта показывается на фиг. 5. Sl(ω) и Sr(ω) теперь вычисляются с использованием следующих формул:
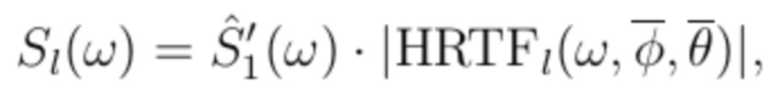 (10)
(10)
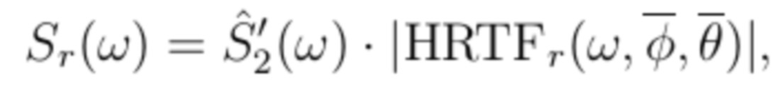 (11)
(11)
где 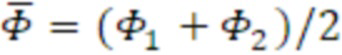 и
и 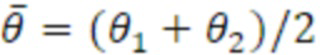 описывают местоположение HRTF, которая представляет среднее требуемого диапазона изменения азимута/угла места. Основные преимущества первого варианта включают в себя:
описывают местоположение HRTF, которая представляет среднее требуемого диапазона изменения азимута/угла места. Основные преимущества первого варианта включают в себя:
- Отсутствие формирования спектра/окрашивания, когда протяженность источника увеличивается по сравнению с точечным источником в центре диапазона протяженностей источников.
- Более низкие требования к запоминающему устройству по сравнению с полнофункциональным способом, поскольку Gl(ω) и Gr(ω) не должны обязательно сохраняться в таблице поиска.
- Большая гибкость к изменениям набора данных HRTF во время выполнения по сравнению с полнофункциональным способом, поскольку только результирующие ICC и ICPD, а не ICLD, зависят от набора данных HRTF, используемого во время предварительного вычисления.
Основной недостаток этой упрощенной версии заключается в том, что она должна сбоить каждый раз, когда радикальные изменения в IALD возникают, по сравнению с непротяженным источником. В этом случае, IALD не должна воспроизводиться с достаточной точностью. Это, например, имеет место, когда источник не центрируется вокруг азимута в 0°, и в то же время, протяженность источника в горизонтальном направлении становится слишком большой.
Второй вариант включает в себя использование только предварительно вычисленных значений IACC. ICPD и ICLD регулируются с использованием HRTF, соответствующей центру диапазона протяженностей источников.
Блок-схема второго варианта показывается на фиг. 6. Sl(ω) и Sr(ω) теперь вычисляются с использованием следующих формул:
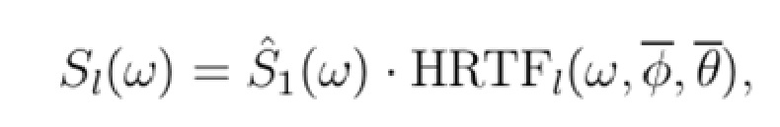 (12)
(12)
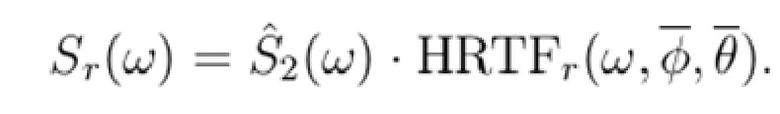 (13)
(13)
В отличие от первого варианта, фаза и абсолютная величина HRTF теперь используются вместо только абсолютной величины. Это обеспечивает возможность регулировать не только ICLD, но также и ICPD.
Во-первых, (ко)-вариационные члены вычисляются между левым и правым каналом следующим образом:
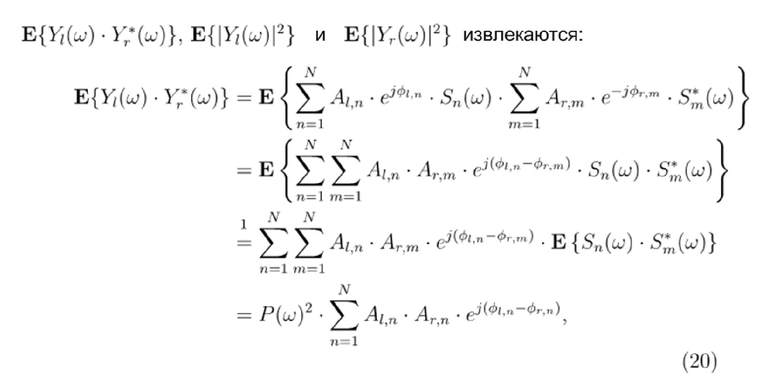
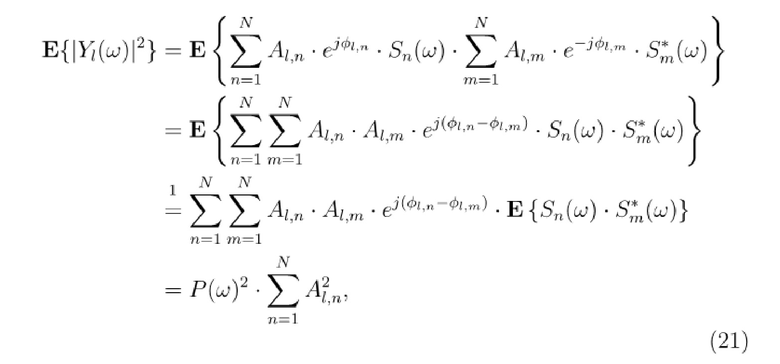
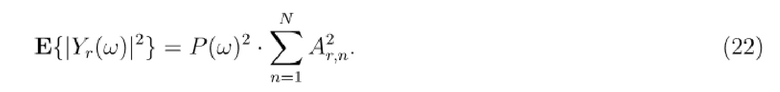
На втором этапе, целевые сигнальные метки IACC, IALD и IAPD вычисляются из дисперсионных членов следующим образом:
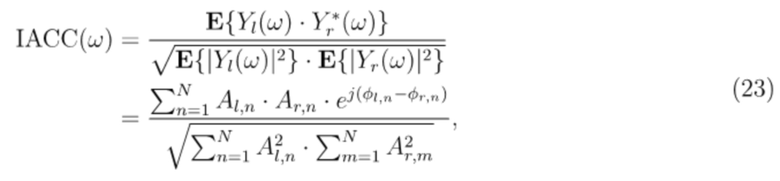
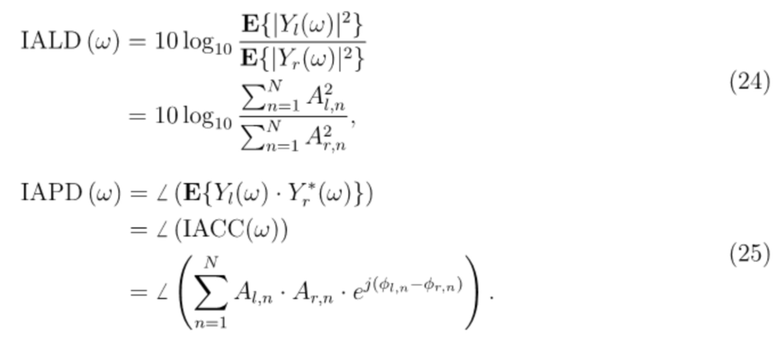 ,
,
как и усиления для левого и правого уха:
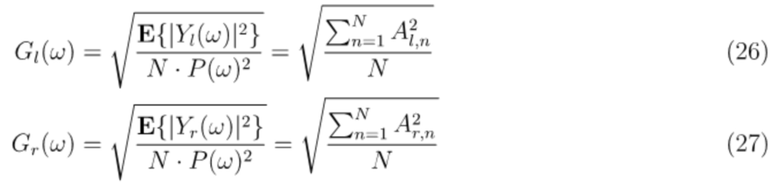
Из этих целевых сигнальных меток, конечный эффективный синтез бинаурального сигнала может выполняться посредством проектирования 4 фильтров, преобразующих входной звук в рендерируемый бинауральный вывод, как пояснено в WO2021/180935.
Первый аспект относится к использованию элементарных пространственных секторов. Этот первый аспект относится к сохранению данных для элементарных пространственных секторов в таблице поиска, при этом элементарные пространственные секторы распределяются по сфере. Данные для элементарных пространственных секторов предпочтительно привязываются к голове пользователя, формирующей центрированную на пользователе аудиосцену, и являются одинаковыми для каждого наклона головы в одном и том же положении, а также для каждого положения головы слушателя, т.е. для каждой степени свободы из 6DOF. Тем не менее, каждое перемещение или наклон головы приводит к такой ситуации, когда звук из SESS «входит» в других одном или более элементарных пространственных секторов в голову пользователя. Модуль рендеринга определяет элементарные пространственные секторы, покрытые посредством SESS, извлекает сохраненные данные для этих конкретных секторов, при необходимости выполняет взвешивание сохраненных данных вследствие загораживающих объектов или определенных расстояний, а затем комбинирует сохраненные данные (или в случае взвешивания взвешенных сохраненных данных) и после этого использует результат комбинированной операции для рендеринга (например, сигнальные метки рендеринга вычисляются из комбинированных данных (ко)вариации, но здесь также могут использоваться другие этапы и параметры). Следовательно, этот аспект может использовать или может не использовать обращение к загораживающим объектам и может использовать или может не использовать обращение к конкретным сохраненным данным дисперсии, поскольку комбинирование (и при необходимости также взвешивание) также может осуществляться, когда сохраняются другие данные, например, (средние) HRTF (для элементарного пространственного сектора или для целой пространственной протяженности) либо даже непосредственно частотно-зависимые сигнальные метки.
Второй аспект относится к модифицирующим объектам, которые могут представлять собой загораживающие объекты или другие объекты, приводящие к модификации звука SESS на пути из положения SESS к пользователю, имеющему определенное местоположение и/или наклон. Этот второй аспект относится к обработке, например, загораживающих объектов. Воздействие загораживающего объекта представляет собой частотно-зависимое ослабление, имеющее характеристику нижних частот. Частотно-зависимое взвешивание также может применяться к процедуре из уровня техники, в которой отсутствуют элементарные пространственные секторы. На основе передаваемых данных, описывающих загораживающие объекты, следует принимать решение в отношении того, загораживается ли SESS, и затем применять функцию загораживания, например, к частотно-зависимым сохраненным сигнальным меткам, которые уже приводятся для различных частот в уровне техники. Следовательно, это представляет собой полезное применение эффекта загораживания в уровне техники без использования элементарных пространственных секторов или без использования сохраненных данных дисперсии.
Третий аспект относится к устройству хранения данных дисперсии и данных ковариации, например, для HRTF для различной пространственной протяженности или элементарных пространственных секторов. Этот третий аспект относится к устройству хранения, например, в таблице поиска, данных дисперсии и данных ковариации, например, для HRTF в положении хранения. Не имеет значения, сохраняются эти данные для определенной пространственной протяженности аналогично уровню техники или для элементарного пространственного сектора. Модуль рендеринга затем вычисляет все сигнальные метки рендеринга из сохраненных данных дисперсии на лету. В отличие от варианта применения из уровня техники, в котором сохраняется по меньшей мере IACC и вероятно другие сигнальные метки или HRFT-данные, это не осуществляется в этом аспекте. Данные ковариации сохраняются, и сигнальные метки вычисляются на лету. Следовательно, этот аспект может использовать или может не использовать элементарные пространственные секторы и может использовать или может не использовать модифицирующие или загораживающие объекты.
Все аспекты могут использоваться отдельно друг от друга или вместе друг с другом, либо также только произвольно выбранные два аспекта могут комбинироваться.
Преимущество настоящего изобретения состоит в обеспечении усовершенствованного эффективного и реалистичного бинаурального рендеринга для пространственно протяженного источника звука по сравнению с WO2021/180935, например, посредством:
- организации таблицы поиска для вычисления целевых сигнальных меток конкретным способом (секторальным, с использованием (ко)-вариационных членов, частотно-зависимым); или
- выполнения (частотно-избирательного) взвешивания (ко)-вариационных членов согласно требуемому целевому частотному отклику, при необходимости для синтеза (частично или полностью) загороженных частей SESS либо для моделирования ослабления в зависимости от расстояния наверняка.
Варианты осуществления настоящего изобретения расширяют вышеописанную концепцию из WO2021/180935 для эффективного рендеринга SESS несколькими способами для повышения эффективности хранения и обеспечения характеристик рендеринга также частично загороженных частей SESS:
Раскрыт очень эффективный способ организации таблицы поиска и вычисления целевых сигнальных меток на основе таблицы поиска, который обеспечивает возможность покрывать все возможные пространственные целевые области для SESS в таблицу поиска с небольшим размером. Это достигается посредством организации таблицы поиска в качестве таблицы, которая сегментирует всю сферу вокруг головы слушателя на небольшие секторы азимута/угла места. Размер этих секторов (т.е. их размер по азимуту и углу места) предпочтительно выбирается в соответствии с разрешением человеческого восприятия азимута/угла места. Например, человеческое слуховое разрешение для азимута является самым точным (приблизительно 1 градус) впереди и снижается в направлении вбок. Кроме того, разрешение в восприятии угла места является гораздо более приблизительным, чем разрешение в азимуте вследствие того, что уши слушателя расположены слева и справа на голове. Для каждого из этих пространственных секторов, конкретные частично суммированные члены сохраняются в таблице поиска. В предпочтительном варианте осуществления, они представляют собой (ко)-вариационные члены (E{Yl•Yr*}, E{|Yl|2}, E{|Yr|2}) двух сигналов в уши, когда множество точечных источников (описанных посредством их соответствующих импульсных откликов восприятия звука человеком (HRIR) и возбужденных посредством декоррелированных версий сигнала=рассеянное поле) суммируются. Кроме того, в предпочтительном варианте осуществления, эти записи таблицы сохраняются частотно-избирательным способом (E{Yl•Yr*}, E{|Yl|2}, E{|Yr|2}).
Это также достигается отдельно или в дополнение к вышеуказанному, поскольку процесс вычисления сигнальных меток использует эти суммированные члены (E{Yl•Yr*}, E{|Yl|2}, E{|Yr|2}) из HRIR-долей, которые сохраняются для каждого пространственного сектора, так что (когда должны покрываться несколько секторов) данные (ко)вариации для этих секторов могут просто суммироваться, чтобы формировать данные (ко)вариации для всей целевой области (включающей в себя все секторы).
Кроме того, пространственное взвешивание определенных пространственных секторов (например, чтобы моделировать загораживание этой части SESS) может достигаться посредством взвешивания данных (ко)вариации, сохраненных для этих пространственных секторов, перед их использованием в последующем процессе вычисления сигнальных меток. В частности, требуемый целевой частотный отклик g(f) может налагаться посредством умножения всех (ко)-вариационных членов на соответствующий коэффициент g2(f) масштабирования энергии. В качестве примера, загораживающий кустарник должен налагать ослабление и частотный отклик нижних частот, когда звук распространяется через него. Таким образом, (ко)-вариационные члены должны ослабляться, и члены более высоких частот ослабляются больше членов низких частот. Возможны несколько зон для различных загораживаний/взвешивания. Аналогичным, также является возможным моделирование расстояния до объекта: Для больших объектов, таких как реки, части объекта могут находиться значительно дальше от слушателя, чем другие, в силу этого внося меньший уровень громкости, чем близлежащие части. Это может моделироваться и рендерироваться посредством взвешивания расстояния различных пространственных секторов. Члены в пространственных секторах взвешиваются с коэффициентом ослабления энергии в зависимости от расстояния, соответствующим (например, среднему) расстоянию объекта в этом пространственном секторе.
Ниже приведено общее представление варианта осуществления способа или устройства или компьютерной программы согласно изобретению.
В фазе инициализации/запуска модуля рендеринга, сегментация сферы вокруг головы слушателя осуществляется посредством задания пространственных секторов (например, диапазонов углов азимута и места), по которым впоследствии могут суммироваться доли HRIR. Затем, на основе этих пространственных секторов, соответствующие доли HRIR могут сохраняться в таблице поиска с использованием (ко)-вариационных членов.
Фиг. 11 иллюстрирует дополнительное общее представление настоящего изобретения (способа или устройства, или компьютерной программы), реализующее взаимодействие первого аспекта и второго аспекта. В частности, блок «выбор пространственных секторов для рендеринга SESS» соответствует процессору 4000 идентификации секторов, проиллюстрированному на фиг. 1-3. Результат выбора пространственных секторов представляет собой группу пространственных секторов, в которой могут быть предусмотрены некоторые секторы вообще без модификации, проиллюстрированной в 4010. Кроме того, из определенных секторов, могут быть предусмотрены секторы с модификацией/загораживанием в соответствии с первой характеристикой, проиллюстрированной в 4020. Кроме того, также могут быть предусмотрены секторы с другой модификацией загораживания, проиллюстрированной как «номер N». Это проиллюстрировано в 4030. Конкретное вычисление целевых данных, проиллюстрированное посредством модуля 5000 вычисления целевых данных, в частности, для второго аспекта, выполняет суммирование дисперсионных членов для левой стороны, дисперсионных членов для правой стороны и ковариационных членов для всех незагороженных секторов в случае, если предусмотрено более одного такого сектора. Кроме того, суммирование в соответствии с функцией взвешивания 1 выполняется, т.е. если предусмотрено более 1 сектора с загораживанием в соответствии с модификацией/загораживанием номер 1, они суммируются, и затем соответствующий весовой коэффициент применяется, либо операция взвешивания и операция суммирования могут меняться местами. Кроме того, в случае если предусмотрены другие секторы с модификацией/загораживанием номер N, как проиллюстрировано в 4030, такие секторы могут суммироваться с соответствующим весовым коэффициентом для конкретной функции взвешивания/модификации для этих секторов.
Естественно, может возникать такой случай, в котором только незагороженные секторы являются существующими для SESS, либо имеются только загороженные секторы в соответствии с одной функцией модификации, либо любое сочетание этих возможностей, т.е. один незагороженный сектор и один сектор с модификацией/загораживанием номер 1, но ни одного для модификации/загораживания номер N. Естественно, номер N также может быть равен 1, так что существуют только строки 4010 и 4020, но любая модификация с другой модификацией поверх модификации номер 1 не определяется посредством блока 4000.
После того, как отдельное взвешивание для отдельных модификаций/загораживаний выполнено в блоке 5020, полное суммирование сигнальных меток в блоке 5040 осуществляется, и затем входные данные для конечного вычисления 5060 целевых сигнальных меток выполняются. Эти данные целевых сигнальных меток затем вводятся в блок 3000 синтеза бинауральных сигнальных меток или аудиопроцессора по фиг. 11. Ввод в блок 3000 представляет собой входной сигнал SESS номер 1 и входной сигнал SESS номер 2, если SESS имеет волновую форму стереосигнала. Тем не менее, в случае SESS, имеющего только волновую форму моносигнала, два сигнала формируются, но с помощью декоррелятора, проиллюстрированного в 3100 на фиг. 13 либо проиллюстрированного в 3010 на фиг. 10.
Фиг. 12 иллюстрирует предпочтительную реализацию синтеза 3000 бинауральных сигнальных меток, состоящего из регулирования 3200 IACC, регулирования 3300 IAPD и регулирования 3400 IALD. Все эти блоки содержат данные из устройства хранения данных, указываемого в качестве «таблицы поиска» в блоке 2000. Тем не менее, в зависимости от реализации, соответствующие обработки для определения конечных значений для IACC, IAPD и IALD также формируются в блоке 2000 в соответствии с этапами 5020, 5040, 5060 вычисления целевых данных. Следовательно, блок с названием «таблица поиска» на фиг. 12 приведён со ссылочной позицией 2000 и со ссылочной позицией 5000. Тем не менее, ввод в этот блок обеспечивается процессором 4000 идентификации секторов любого из фиг. 1, 2a, 3, 11.
Фиг. 13 иллюстрирует, в левой стороне, декоррелятор 3100 для формирования, из одной волновой формы сигнала SESS, двух входных сигналов SESS номер 1 и номер 2 в выводе декоррелятора. Эти данные затем подвергаются четырем операциям 3210, 3220, 3230 и 3240 фильтрации, при которых соответствующие доли для левого канала суммируются через сумматор 3250, и при которых соответствующие доли правого канала суммируются через сумматор 3260 для получения левого и правого конечных выходных сигналов. Отдельные функции 3210, 3220, 3230 и 3240 фильтра либо вычисляются через модуль 5000 вычисления целевых данных, соответственно, для определенного ограниченного пространственного диапазона, как описано в WO 2021/180935, либо вычисляются в соответствии с множеством элементарных пространственных секторов, как описано относительно фиг. 7, при этом пространственно протяженный источник звука представляется посредством двух или более элементарных пространственных секторов.
Обработка для каждого аудиоблока проиллюстрирована на фиг. 11, иллюстрирующем общую блок-схему предпочтительного варианта осуществления, реализующего первый аспект, второй аспект и третий аспект вместе. Для каждого блока аудиосигналов, (изменяющиеся во времени) целевые сигнальные метки для целевой пространственной области, принадлежащей SESS, определяются и применяются к двум входным сигналам в каскаде синтеза бинауральных сигнальных меток, чтобы формировать бинауральные выходные L- и R-сигналы.
Целевые бинауральные сигнальные метки вычисляются следующим образом:
Пространственные секторы, принадлежащие SESS, вычисляются с учетом положения и ориентации слушателя и SESS, а также геометрии SESS, (например, с использованием алгоритма проецирования или анализа по трассировке лучей).
В частности, находятся пространственные секторы, принадлежащие частям SESS, которые должны взвешиваться для моделирования таких эффектов, как загораживание и/или ослабление в зависимости от расстояния и т.д. Может быть предусмотрено несколько пространственных областей, которые требуют различных характеристик ослабления/частотного отклика; соответствующие секторы обрабатываются в каждой области отдельно, принадлежащей различным так называемым «классам секторов» (например, «незагороженный», «модификация/загораживание #1»... «модификация/загораживание номер #n»).
Сохраненные (ко)-вариационные члены для секторов в каждом классе секторов суммируются. Затем суммированные данные (ко)вариации секторов различных классов секторов взвешиваются согласно требуемой функции передачи для каждого класса секторов. В частности, данные (ко)вариации этого класса секторов умножаются на (частотно-зависимую) функцию передачи энергии (квадрат коэффициента амплитудного масштабирования/амплитудно-частотного отклика), принадлежащую этому классу.
Взвешенные дисперсионные члены для всех классов секторов SESS суммируются в полные (взвешенные) (ко)-вариационные члены.
Целевые сигнальные метки с использованием модифицированных/взвешенных полных (ко)-вариационных членов вычисляются с использованием уравнений (23)-(27). Конечно, также данные (ко)вариации каждого сектора могут взвешиваться отдельно и затем суммироваться, вместо сначала выполнения частичного суммирования в классах секторов, взвешивания по одному разу для каждого класса секторов и конечного суммирования. Тем не менее, вышеописанный подход представляет собой предпочтительный вариант осуществления вследствие своей более высокой эффективности.
Преимущества вариантов осуществления изобретения по сравнению с уровнем техники обеспечивают очень эффективный и более реалистичный рендеринг размерных источников (SESS), небольшой размер таблицы поиска и/или способность включать в себя эффекты рендеринга (такие как частичное загораживание или ослабление в зависимости от расстояния), которые изменяют частотный отклик в выбранных пространственных частях размерного источника (SESS).
Предпочтительные примеры относятся к модулю рендеринга, который использует в качестве вводов один или более каналов передачи сигналов, геометрию, размер и ориентацию пространственно протяженного источника звука (SESS) и набор HRTF и оснащается возможностями бинаурального рендеринга пространственно протяженных источников звука (т.е. обеспечивает два выходных сигнала).
Дополнительно предпочтительные модули рендеринга или устройства и способы синтезирования SPESS содержат, помимо или вместо вышеуказанного, каскад вычисления целевых сигнальных меток (например, для вычисления требуемых интерауральных целевых сигнальных меток) и каскад синтеза сигнальных меток (например, для преобразования входного сигнала(ов) в подготовленные посредством бинаурального рендеринга сигналы с требуемыми целевыми сигнальными метками).
Дополнительно предпочтительные модули рендеринга или устройства и способы синтезирования SPESS содержат, помимо или вместо вышеуказанного, использование таблицы поиска, которая содержит предварительно вычисленные данные для бинаурального рендеринга SESS и обеспечивается/предварительно вычисляется для различных полос частот в зависимости от набора HRTF.
Дополнительно предпочтительные модули рендеринга или устройства и способы синтезирования SPESS содержат, помимо или вместо вышеуказанного, таблицу поиска, которая организуется с возможностью сохранения (ко)-вариационных членов для каждого пространственного сектора (например, l-(левой) дисперсии, r-(правой) дисперсии, ковариации lr).
В другом предпочтительном варианте осуществления: пространственные секторы задаются как диапазоны изменения азимута/угла места.
В других предпочтительных вариантах осуществления, размеры пространственных секторов выбираются относительно разрешения человеческих слуховых способностей к пространственной локализации (например, являются более широкими в подъемном, чем в азимутальном направлении).
В других предпочтительных вариантах осуществления, вычисление целевых сигнальных меток бинаурального рендеринга выполняется на основе суммированных дисперсионных членов пространственных секторов, принадлежащих SESS.
В других предпочтительных вариантах осуществления, модификация рендеринга различных пространственных областей SESS (например, для моделирования на основе загораживания или расстояния) достигается посредством использования модифицированных дисперсионных членов из таблицы поиска, а не первоначально сохраненного дисперсионного члена.
В других предпочтительных вариантах осуществления, модификация осуществляется посредством умножения дисперсионных членов на коэффициент ослабления энергии, принадлежащий пространственному сектору.
В других предпочтительных вариантах осуществления, этот коэффициент ослабления является частотно-зависимым (например, чтобы моделировать эффекты нижних частот вследствие частичного загораживания).
Дополнительный вариант осуществления относится к потоку битов, который включает в себя следующую информацию: размер, положение и ориентация объекта, а также форма сигнала и геометрия загораживающих объектов.
Ниже описан дополнительный предпочтительный вариант осуществления, разрабатываемый в настоящее время для MPEG I ISO 23090-4.
Этот вариант осуществления синтезирует один или более пространственно протяженных источников звука (SESS) для воспроизведения в наушниках для источников объектов, которые имеют ассоциированный флаг objectSourceHasExtent, заданный равным 1. Соответствующие параметры для источника объектов идентифицируются посредством objectSourceExtentId.
Синтез основан на описании SESS посредством (в идеале) бесконечного числа декоррелированных точечных источников, распределенных по всему пространственному диапазону протяженности источника. Посредством непрерывного проецирования геометрии SESS в направлении к текущему положению слушателя, диапазон, покрытый посредством упомянутой геометрии, может идентифицироваться каждый кадр и обновляться в реальном времени. Другими словами, геометрия проецируется на сферу, представляющую виртуальное пространство для прослушивания пользователя, каждый кадр. Кроме того, пространственные секции, занимаемые посредством проецируемой геометрии на сфере, представляют собой секции, включенные в аурализацию SESS.
SESS задается пользователем во входном формате для кодера (EIF). С учетом требуемого диапазона протяженностей источников, SESS синтезируется с использованием двух декоррелированных входных сигналов. Эти входные сигналы обрабатываются таким образом, что перцепционно важные слуховые сигнальные метки синтезируются. Это включает в себя следующие интерауральные сигнальные метки: интерауральная взаимная корреляция (IACC), интерауральные разности фаз (IAPD) и интерауральные разности уровней (IALD). Помимо этого, монауральные спектральные сигнальные метки воспроизводятся. Это проиллюстрировано на фиг. 12.
Элементы данных и переменные
itemStore - локальный указатель на объект RenderItemStore
B - размер блока
Fs - частота дискретизации
extentProcessors - преобразование из идентификатора элемента в его экземпляр extentProcessor
extentDownmixItem - RI, который сохраняет конечный вывод бинаурального сигнала всей протяженности.
Описание каскада
Чтобы сокращать вычислительные затраты в реальном времени, отдельные точки HRTF назначаются в предварительно заданные таблицы-сетки, которые разделяют виртуальную сферу прослушивания слушателя на равномерно распределенные области. Во время инициализации выполняется N-точечное DFT для получения N/2+1 частотных компонентов для каждой HRIR, где N является ее длиной. Затем три промежуточных значения для каждой сетки получаются посредством интегрирования данных всех точек HRTF, которые являются усилениями левых и правых каналов, внутри ненормализованной IACC. Помимо этого, также сохраняется число точек данных HRTF, включенных в каждую сетку,. Они используются для вычисления конечных сигнальных меток в реальном времени.
Усиления обоих каналов для каждой сетки вычисляются с помощью уравнения 28 и 29, где Al, n и Ar, n являются абсолютной величиной левой и правой HRTF, соответственно, N является числом точек HRTF, которые находятся в пределах этой сетки:
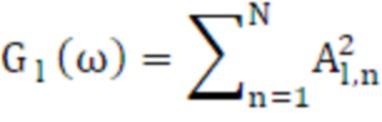 (28)
(28)
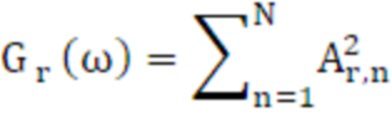 (29)
(29)
Ненормализованная IACC для каждой сетки вычисляется с помощью уравнения 30, где φ,l и φ,r является фазой левой и правой HRTF, соответственно:
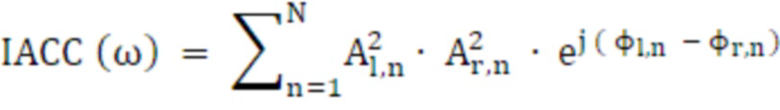 (30)
(30)
Процедуры в уравнениях 28-30 выполняются перед фактической обработкой заранее и соответствуют этапам 800, 810 по фиг. 8, и результаты этих обработок представляют собой данные, предпочтительно сохраненные в устройстве 2000 или 200 хранения данных, на соответствующих чертежах.
В ходе обработки в реальном времени, каждый уникальный протяженный источник звука формируется и управляется посредством процессора протяженности. Для каждого кадра, каждый активный процессор принимает буфер аудиовыборок и метаданных, указывающих, как следует синтезировать протяженный источник звука. Существуют две отдельных цепочки обработки: обработка метаданных в подпроцессе обновления и аудиообработка в подпроцессе аудиобоработки. Они описаны, соответственно, в следующих разделах, и их результаты комбинируются в конце второй цепочки для формирования бинаурального аудиовывода.
Вычисления, выполняемые в подпроцессе обновления
Для каждого уникального протяженного источника звука, одна или более несущих метаданных, в форме RI (элементов рендеринга), формируются посредством каскада обработки загораживания (например, соответствующего блоку 4000).
Этот каскад 4000 проходит в контуре по всем входящим RI и назначает релевантные метаданные протяженности соответствующему процессору. Если одна из пространственных секций из предварительно заданной таблицы покрывается и должна включаться для аурализации протяженности в этом кадре, то входящие метаданные должны содержать коэффициент усиления (элементы 4010, 4020, 4030 по фиг. 11) и список усилений, соответствующих некоторым предварительно заданным частотным элементам разрешения для него. Посредством выбора (например, 4000), взвешивания (например, 5020) и в конечном счете накопления (например, 5040) сохраненных промежуточных данных с усилением и EQ, достигается формирование произвольной формы протяженного источника звука с любой формой и степенью загораживания (размером/материалом).
Конечный фильтр получается посредством следующих этапов: После интегрирования (или накопления) всех точек сетки, указываемых в RI (элементе рендеринга), усиление левого и правого канала и IACC (например, данные дисперсии и ковариации) нормализуются с общим взвешенным числом точек данных HRTF:
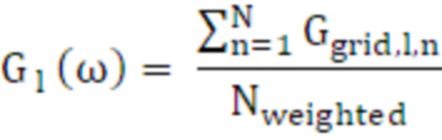 (31)
(31)
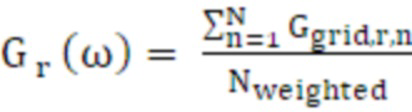 (32)
(32)
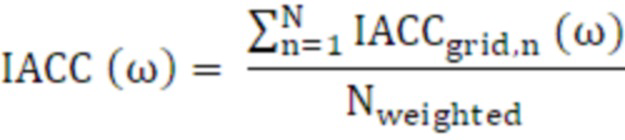 (33)
(33)
Процедуры в уравнениях 31-33 соответствуют блоку 5040.
Частотно-зависимые Hα и Hβ вычисляются с использованием нормализованной IACC:
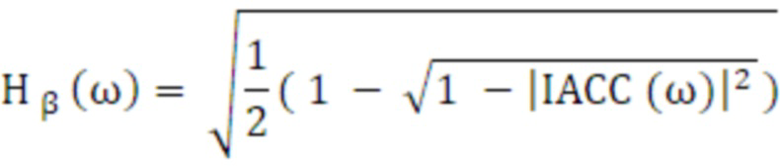 (34)
(34)
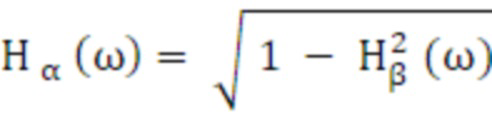 (35)
(35)
Вычисление в блоке 5060 соответствует обработке уравнений 34 и 35 в варианте осуществления.
Конечные стереофильтры 3210, 3220, 3230, 3240 получаются с использованием Hα и Hβ, усиления левого и правого каналов (Gl и Gr) и фаза, извлеченная из точки HRTF, соответствуют центру протяженности (phasel и phaser):
 (36)
(36)
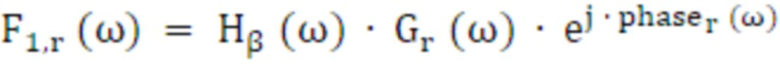 (37)
(37)
 (38)
(38)
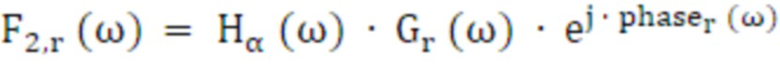 (39)
(39)
Вычисления блоков 36-39 предпочтительно также выполняются в блоке 5060.
Вычисления, выполняемые в подпроцессе аудиобоработки
Входной моносигнал сначала подается в декоррелятор 3100 для получения двух декоррелированных версий. Может использоваться декоррелятор MPEG-I или любой другой декоррелятор, например, декоррелятор, проиллюстрированный на фиг. 10.
После этого, каждый из двух декоррелированных сигналов свертывается с помощью соответствующих стереофильтров 3210, 3220, 3230, 3240, вычисленных в подпроцессе обновления, что приводит к четырем каналам вывода. Далее должно выполняться перекрестное микширование 3250, 3260, чтобы формировать конечный бинауральный вывод.
Уравнения (40) и (41) задают процесс (фильтрации и) микширования, где S1 и S2 означают два декоррелированных сигнала, и F1 и F2 представляют собой два стереофильтра (для левого и правого, соответственно), вычисленные в секции обработки метаданных. Фиг. 13 является блок-схемой последовательности сигналов для процесса. Фильтр, проиллюстрированный на фиг. 13, является аналогичным фильтру по фиг. 9.
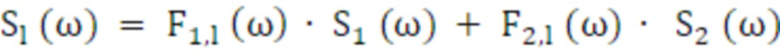 (40)
(40)
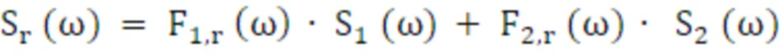 (41)
(41)
Обработка в соответствии с уравнениями 40 и 41 предпочтительно выполняется в блоке 3000 аудиопроцессора или синтеза бинауральных сигнальных меток по фиг. 11 или 300 по фиг. 4, 5, 6.
Фиг. 7 иллюстрирует схематичное представление диапазона рендеринга для слушателя. Диапазон рендеринга примерно представляет собой сферу, которая центрируется вокруг пользователя. Следовательно, пользователь или слушатель (не проиллюстрирован на фиг. 7) расположен в центре сферы, и диапазон рендеринга, соответствующий этой сфере вокруг слушателя, может считаться «привязанным» к руке пользователя. Следовательно, когда пользователь изменяет своё положение в одном из горизонтального направления, вертикального направления или направления глубины (x, y, z), сфера перемещается в соответствии с перемещением пользователя относительно пространственно протяженного источника звука, который может считаться фиксированным относительно пользователя. Кроме того, когда пользователь перемещает руку, смотря вверх, смотря вниз или смотря вбок, сфера, представляющая диапазон рендеринга для слушателя, также перемещается вверх, вниз или вбок, т.е. также выполняет «перемещение», которое пользователь применяет к своей голове без перемещения в горизонтальном направлении, вертикальном направлении или направлении глубины. Таким образом, сферический диапазон рендеринга для слушателя может считаться видом «шлема», всегда придерживающимся перемещения головы пользователя или слушателя во всех 6 степенях свободы.
Эта сфера разделяется на отдельные элементарные пространственные секторы, которые могут быть разнесены и в силу этого иметь различные размеры относительно угла азимута и угла места, чтобы отражать психоакустические выявленные сведения. В частности, диапазон рендеринга содержит сферу или часть сферы вокруг слушателя, и каждый элементарный пространственный сектор, проиллюстрированный на фиг. 7, например, имеет размер по азимуту и размер по углу места. В частности, размер по азимуту и размер по углу места элементарных пространственных секторов отличаются друг от друга, так что размер по азимуту является более точным для элементарного пространственного сектора непосредственно перед слушателем, по сравнению с размером по азимуту элементарного пространственного сектора больше вбок от слушателя, и/или размер по азимуту снижается в направлении вбок от слушателя, и/или размер по углу места элементарного пространственного сектора меньше размера по азимуту этого сектора.
Следовательно, аспекты изобретения базируются на центрированном на пользователе представлении, которое перемещается с пользователем относительно пространственно протяженного источника звука, и голова пользователя находится в центре пространства, и сфера или часть сферы является диапазоном рендеринга.
Процессор 4000 идентификации секторов теперь определяет то, какие различные элементарные пространственные секторы представляют пространственно протяженный источник звука, проиллюстрированный на фиг. 7 в 7 000. В этом примере, например, через алгоритм трассировки лучей, начинающийся с центра этой сферы и указывающий на SESS 7000, определяется, что четыре элементарных пространственных сектора (ESS), указанные как «1», «2», «3» и «4» на фиг. 7, «принадлежат» SESS 7000 в конкретной ориентации и положении пользователя относительно SESS 7000. Следовательно, предполагается, что звуковое поле, испускаемое посредством SESS 7000, которые фактически достигает ушей пользователя, проходит через эти четыре ESS. Кроме того, загораживающий объект 7010 также проиллюстрирован на фиг. 7, и для целей примера, предполагается, что элементарный пространственный сектор (ESS 1) полностью загораживается, элементарный пространственный сектор 2 (ESS2) частично загораживается, и ESS 3, 4 не загораживаются посредством загораживающего объекта.
Следовательно, обращаясь к фиг. 11, элементарные пространственные секторы 1, 2 соответствуют элементу 4010, элементарный пространственный сектор 1 соответствует элементу 4020, и элементарный пространственный сектор 2 соответствует элементу 4030 по фиг. 11. Альтернативно, может определяться то, что частично загороженный сектор также принадлежит к тому же классу, что и класс полностью загороженного сектора, либо, если сектор загорожен только с очень небольшой частью, то также можно определить, что сектор, имеющий загораживание ниже определенного порогового значения, также определяется как вообще не загороженный.
Хотя на фиг. 7 проиллюстрировано то, что элементарные пространственные секторы и при необходимости степень загораживания для характеристики загораживания или модификации секторов являются равными для обоих ушей, т.е. для левого и правого, также может возникать такой случай, в котором число и/или идентификация элементарных пространственных секторов отличаются для левого и для правого уха. Это может легко иметь место, когда SESS находится достаточно близко к пользователю, и SESS расположен больше в середине между обоими ушами, а не на одной или на другой стороне.
Кроме того, для определения проекции SESS на диапазон рендеринга для слушателя, т.е. для примерной сферы, могут выполняться процедуры, отличные от алгоритмов трассировки лучей. Кроме того, SESS 7000 не должен обязательно быть фиксированным. SESS также может быть динамическим, т.е. может перемещаться со временем. Затем положение SESS относительно пользователя должно быть задано, и, после этого, для определенной точки во времени/для определенного кадра волновой формы сигнала SESS, определяются соответствующие элементарные пространственные секторы для левой стороны и правой стороны слушателя для фактического положения головы слушателя, и далее сигнальные метки вычисляются так, как проиллюстрировано относительно блоков 5020-5060 на фиг. 11.
Кроме того, здесь следует отметить, что диапазон рендеринга не должен обязательно представлять собой полную сферу. Он может только содержать часть сферы. Кроме того, диапазон рендеринга не должен обязательно быть сферическим. Он также может быть цилиндрическим, либо он также может иметь форму многоугольника при условии, что он покрывает определенную трехмерную часть пространства вокруг слушателя.
Относительно размеров элементарных пространственных секторов, следует подчеркнуть, что элементарные пространственные секторы могут быть довольно небольшими, так что, для определения сохраненных элементов данных рендеринга, только одна HRTF, указываемая с амплитудой и фазой вместо суммирования по определенному числу (например, как проиллюстрировано в уравнении 20, уравнении 21 и уравнении 22 или в уравнении 28-30) является достаточной. Тем не менее, когда используются элементарные пространственные секторы, которые имеют определенную размерность таким образом, что размер устройства хранения данных, сохраняющего элементы данных рендеринга для каждого элементарного пространственного сектора, уменьшается, определение элементов данных рендеринга, сохраненных в устройстве хранения данных для каждого элементарного пространственного сектора, может выполняться в соответствии с уравнениями 20-22 или 28-30, при этом только HRTF, принадлежащие конкретному элементарному пространственному сектору, суммируются для получения фактических данных (ко)вариации для определенной частоты и для этого элементарного пространственного сектора.
Следует отметить, что конкретное преимущество этой процедуры состоит в том, что все эти вычисления не должны обязательно выполняться во время выполнения. Вместо этого, как только определенное разделение диапазона рендеринга на определенную сетку элементарных пространственных секторов или точек сетки определяется, затем сохраненные данные для каждого отдельного или элементарного пространственного сектора могут вычисляться и сохраняться, и для определенной инициализации с определенной сеткой, единственная процедура, осуществляемая во время выполнения, заключается в том, чтобы загружать соответствующие предварительно вычисленные данные для этой сетки в устройство хранения данных или таблицу поиска.
Единственная процедура, которая обязательно должна выполняться во время выполнения, представляет собой идентификацию элементарных пространственных секторов, принадлежащих пространственно протяженному источнику звука для конкретной ориентации/положения пользователя, и потенциально необходимое взвешивание вследствие загораживающих объектов и, после этого, конечное полное суммирование, соответствующее блоку 5040 на фиг. 11, которое затем не стоит ничего для конечного вычисления целевых сигнальных меток в блоке 5060. Следовательно, необходимые операции вычисления во время выполнения являются очень ограниченными и являются очень небольшими по сравнению с операциями вычисления, требуемыми для определения элементов данных рендеринга для элементарных пространственных секторов, т.е. для определенной сетки.
Кроме того, следует отметить, что устройство хранения данных для определенной сетки не зависит от положения/ориентации пользователя, поскольку, в случае изменения положения или характеристики SESS или в случае изменения ориентации/положения пользователя, изменяются только идентифицированные элементарные пространственные секторы, но не данные, сохраненные для элементарных пространственных секторов, которые представляют сетку. Другими словами, изменяются только идентификационные номера для элементарных пространственных секторов, но не данные для элементарного пространственного сектора, имеющего определенный идентификационный номер.
Ниже описана фиг. 8, которая иллюстрирует предпочтительную процедуру для одного или нескольких аспектов изобретения.
На этапе 800 определяется или инициализируется диапазон рендеринга, такой как сфера,. Результат, например, представляет собой сферу с определенными точками сетки или элементарными пространственными секторами. В блоке 810, элементы данных рендеринга, например, данные (ко)вариации сохраняются в устройстве хранения данных, таком как таблица поиска для всех элементарных пространственных секторов в диапазоне рендеринга.
Далее, на этапе 820, выполняется идентификация секторов, осуществляемая посредством блока 4000. Следовательно, один или более элементарных пространственных секторов, принадлежащих пространственно протяженному источнику звука, определяются на основе данных SESS и данных положения/ориентации слушателя, вводимых в блок 820. Результат блока 820 представляет собой один или более элементарных пространственных секторов.
В блоке 830, суммирование элементов данных рендеринга для множества элементарных пространственных секторов, например, с или без взвешивания выполняется, как проиллюстрировано посредством блока 5040.
В блоке 840, вычисляются целевые данные рендеринга, такие как IACC, IALD, IAPD, GL, GR, что выполняется посредством блока 5060.
В блоке 850, целевые данные рендеринга применяются к аудиосигналу пространственно протяженного источника звука, как проиллюстрировано, например, также посредством блока 3000 аудиопроцессора или блока 3000 синтеза бинауральных сигнальных меток по фиг. 11.
В соответствии с первым аспектом настоящего изобретения, сфера рендеринга реализуется так, как проиллюстрировано на фиг. 7, т.е. элементарные пространственные секторы, покрывающие диапазон рендеринга для слушателя, определяются, и процессор идентификации секторов задает набор элементарных пространственных секторов, например, два или более элементарных пространственных сектора для пространственно протяженного источника звука. Тем не менее, только в предпочтительном варианте осуществления сохраненные элементы данных рендеринга представляют собой данные дисперсии или ковариации. Вместо этого, другие элементы данных, необходимые для рендеринга, также могут сохраняться и комбинироваться посредством модуля вычисления целевых данных. Кроме того, эта процедура также не требует обязательно обработки модификации, но предпочтительно выполняет обработку модификации.
В соответствии со вторым аспектом настоящего изобретения, требуется определение потенциально модифицирующего объекта и определение ограниченного модифицированного пространственного сектора на основе идентификации потенциально модифицирующих объектов. Тем не менее, для этой процедуры, диапазон рендеринга не должен обязательно иметь такие размеры, как проиллюстрировано на фиг. 7, т.е. с отдельными элементарными пространственными секторами, имеющими отдельные сохраненные элементы данных. Вместо этого, диапазон рендеринга также может быть реализован так, как проиллюстрировано в других реализациях, например, в реализации, проиллюстрированной в WO 2021/180935. Кроме того, для определения и для учета модифицирующих объектов, не обязательно имеет место то, что сохраненные элементы данных рендеринга представляют собой данные дисперсии/ковариации. Вместо этого, также могут использоваться другие данные рендеринга, например, проиллюстрированные в качестве сохраненных данных в WO 2021/180935.
Относительно третьего аспекта, определение диапазона рендеринга, как проиллюстрировано на фиг. 7, не обязательно требуется. Вместо этого, другое определение, например, определения диапазона рендеринга, как проиллюстрировано в WO 2021/180935, может использоваться для одного или более ограниченных пространственных секторов. Тем не менее, ограниченный пространственный сектор предпочтительно реализуется в качестве элементарного пространственного сектора, показанного на фиг. 7. Кроме того, например, для целей использования данных дисперсии/ковариации в качестве сохраненных данных, конкретная обработка с модифицирующими/загораживающими объектами также не представляет собой требуемый признак, но является предпочтительной, как пояснено выше относительно блока 830 на фиг. 8.
Далее обобщаются дополнительные варианты осуществления, относящиеся к первому аспекту.
Варианты осуществления относятся к устройству для синтезирования пространственно протяженного источника звука (SESS), содержащему: устройство хранения данных для сохранения элементов данных рендеринга для различных элементарных пространственных секторов, покрывающих диапазон рендеринга для слушателя; процессор идентификации секторов для идентификации, из различных элементарных пространственных секторов, набора элементарных пространственных секторов, принадлежащих пространственно протяженному источнику звука, на основе данных слушателя и данных пространственно протяженных источников звука; модуль вычисления целевых данных для вычисления целевых данных рендеринга из элементов данных рендеринга для набора элементарных пространственных секторов; и аудиопроцессор для обработки аудиосигнала, представляющего пространственно протяженный источник звука, с использованием целевых данных рендеринга.
В дополнительных вариантах осуществления, устройство хранения данных выполнено с возможностью сохранения в качестве элементов данных рендеринга для каждого элементарного пространственного сектора по меньшей мере одного из левого элемента данных дисперсии, связанного с левыми данными передаточной функции восприятия звука человеком, правого элемента данных дисперсии, связанного с правыми данными передаточной функции восприятия звука человеком (HRTF), и элемента данных ковариации, связанного с левыми данными HRTF и правыми данными HRTF, при этом модуль вычисления целевых данных выполнен с возможностью суммирования левых элементов данных дисперсии для набора элементарных пространственных секторов или правых элементов данных дисперсии для набора элементарных пространственных секторов, или элементов данных ковариации для набора элементарных пространственных секторов, соответственно, для получения по меньшей мере одного суммированного элемента, при этом модуль вычисления целевых данных выполнен с возможностью вычисления по меньшей мере одной сигнальной метки рендеринга в качестве целевых данных рендеринга по меньшей мере из одного суммированного элемента, и при этом аудиопроцессор выполнен с возможностью обработки аудиосигнала с использованием по меньшей мере одной сигнальной метки рендеринга.
В дополнительных вариантах осуществления, процессор идентификации секторов выполнен с возможностью применения алгоритма проецирования или анализ по трассировке лучей для определения набора элементарных пространственных секторов или использования в качестве данных слушателя положения слушателя или ориентации слушателя либо использования в качестве данных пространственно протяженных источников звука (SESS) ориентации SESS, положения SESS или информации о геометрии SESS.
В дополнительных вариантах осуществления, процессор идентификации секторов выполнен с возможностью приёма из описания аудиосцены информации загораживания относительно потенциально загораживающего объекта и определения на основе информации загораживания конкретного пространственного сектора из набора элементарных пространственных секторов в качестве загораживающего сектора, и при этом модуль вычисления целевых данных выполнен с возможностью применения функции загораживания к элементам данных рендеринга, сохраненным для загораживающего сектора, таким образом, чтобы получить модифицированные данные и использовать модифицированные данные для вычисления целевых данных рендеринга.
В дополнительных вариантах осуществления, функция загораживания представляет собой функцию нижних частот, имеющую различные значения ослабления для различных частот, и при этом элементы данных рендеринга представляют собой элементы данных для различных частот, и при этом модуль вычисления целевых данных выполнен с возможностью взвешивания для нескольких частот элемента данных для определенной частоты со значением ослабления для определенной частоты для получения модифицированных данных рендеринга.
В дополнительных вариантах осуществления, процессор идентификации секторов выполнен с возможностью определения того, что другой элементарный пространственный сектор из набора элементарных пространственных секторов, определенных для загораживающего объекта, не загораживается посредством потенциального загораживающего объекта, и при этом модуль вычисления целевых данных выполнен с возможностью комбинирования модифицированных данных из загораживающего сектора и элементов данных рендеринга другого сектора без модификации с использованием функции загораживания либо с модификацией посредством другой функции модификации для получения целевых данных рендеринга.
В дополнительных вариантах осуществления процессор идентификации секторов выполнен с возможностью определения первого элементарного пространственного сектора из набора элементарных пространственных секторов как имеющего первую характеристику и определения второго элементарного пространственного сектора из набора элементарных пространственных секторов как имеющего вторую отличающуюся характеристику, и при этом модуль вычисления целевых данных выполнен с возможностью неприменения функции модификации к первому элементарному пространственному сектору и применения функции модификации к второму элементарному пространственному сектору либо применения первой функции модификации к первому элементарному пространственному сектору и применения второй функции модификации ко второму элементарному пространственному сектору, причем вторая функция модификации отличается от первой функции модификации.
В дополнительных вариантах осуществления, первая функция модификации является частотно-избирательной, и вторая функция модификации является постоянной по частоте, либо при этом первая функция модификации имеет первую частотно-избирательную характеристику, и при этом вторая функция модификации имеет вторую частотно-избирательную характеристику, отличающуюся от первой частотно-избирательной характеристики, либо при этом первая функция модификации имеет первую характеристику ослабления, и вторая функция модификации имеет вторую отличающуюся характеристику ослабления, и при этом модуль вычисления целевых данных выполнен с возможностью выбора или регулировки функции модификации из первой функции модификации и второй функции модификации на основе расстояния между первым элементарным пространственным сектором или вторым элементарным пространственным сектором и слушателем либо на основе характеристики объекта, расположенного между слушателем и соответствующим элементарным пространственным сектором.
В дополнительных вариантах осуществления, процессор идентификации секторов выполнен с возможностью классификации набора элементарных пространственных секторов на различные классы секторов на основе характеристик, ассоциированных с элементарными пространственными секторами, при этом модуль вычисления целевых данных выполнен с возможностью комбинирования элементов данных рендеринга элементарных пространственных секторов в каждом классе для получения комбинированного результата для каждого класса, если более одного элементарного пространственного сектора находится в классе, и применения конкретной функции модификации, ассоциированной по меньшей мере с одним классом, к комбинированному результату этого класса для получения модифицированного комбинированного результата для этого класса, или применения конкретной функции модификации, ассоциированной по меньшей мере с одним классом, к одному или более элементам данных одного или более элементарных пространственных секторов каждого класса для получения модифицированных элементов данных, и комбинирования модифицированных элементов данных элементарных пространственных секторов в каждом классе для получения модифицированного комбинированного результата для этого класса, комбинирования комбинированного результата, либо, при наличии, модифицированного комбинированного результата для каждого класса для получения полного комбинированного результата, и использования полного комбинированного результата в качестве целевых данных рендеринга или вычисления целевых данных рендеринга из полного комбинированного результата.
В дополнительных вариантах осуществления, характеристика для элементарного пространственного сектора определяется как представляющий собой одно из группы, содержащей загороженный элементарный пространственный сектор, включающий в себя первую характеристику загораживания, загороженный элементарный пространственный сектор, включающий в себя вторую характеристику загораживания, отличающуюся от первой характеристики загораживания, незагороженный элементарный пространственный сектор, имеющий первое расстояние до слушателя, и незагороженный элементарный пространственный сектор, имеющий второе расстояние до слушателя, при этом второе расстояние отличается от первого расстояния.
В дополнительных вариантах осуществления, модуль вычисления целевых данных выполнен с возможностью модификации или комбинирования частотно-зависимых параметров дисперсии или ковариации в качестве элементов данных рендеринга для получения в качестве полного комбинированного результата полной комбинированной дисперсии или полного комбинированного параметра ковариации, и вычисления по меньшей мере одного из сигнальной метки интерауральной когерентности, сигнальной метки интерауральной разности уровней, сигнальной метки интерауральной разности фаз, первого бокового усиления или второго бокового усиления в качестве целевых данных рендеринга.
В дополнительных вариантах осуществления, аудиопроцессор выполнен с возможностью выполнения по меньшей мере одного из регулирования межканальной когерентности, регулирования межканальной разности фаз, регулирования межканальной разности уровней с использованием соответствующих сигнальных меток в качестве целевых данных рендеринга.
В дополнительных вариантах осуществления, диапазон рендеринга содержит сферу или часть сферы вокруг слушателя, при этом диапазон рендеринга привязывается к положению слушателя или к ориентации слушателя, и при этом каждый элементарный пространственный сектор имеет размер по азимуту и размер по углу места.
В дополнительных вариантах осуществления, размер по азимуту и размер по углу места элементарных пространственных секторов отличаются друг от друга, так что размер по азимуту является более точным для элементарного пространственного сектора непосредственно перед слушателем по сравнению с размером по азимуту элементарного пространственного сектора больше вбок от слушателя, либо при этом размер по азимуту снижается в направлении вбок от слушателя, либо при этом размер по углу места элементарного пространственного сектора меньше размера по азимуту этого сектора.
Далее обобщаются дополнительные варианты осуществления, относящиеся ко второму аспекту.
Вариант осуществления для устройства для синтезирования пространственно протяженного источника звука содержит: входной интерфейс для приема описания аудиосцены, причем описание аудиосцены содержит данные пространственно протяженных источников звука по пространственно протяженному источнику звука и данные о модификации для потенциально модифицирующего объекта, и для приема данных слушателя; процессор идентификации секторов для идентификации ограниченного модифицированного пространственного сектора для пространственно протяженного источника звука в диапазоне рендеринга для слушателя, причем диапазон рендеринга для слушателя больше ограниченного модифицированного пространственного сектора, на основе данных пространственно протяженных источников звука и данных слушателя, и данных о модификации; модуль вычисления целевых данных для вычисления целевых данных рендеринга из одного или более элементов данных рендеринга, принадлежащих модифицированному ограниченному пространственному сектору; и аудиопроцессор для обработки аудиосигнала, представляющего пространственно протяженный источник звука, с использованием целевых данных рендеринга.
В дополнительных вариантах осуществления, данные о модификации представляют собой данные затемнения, и при этом потенциально модифицирующий объект представляет собой потенциально загораживающий объект.
В дополнительных вариантах осуществления, потенциально модифицирующий объект имеет ассоциированную функцию модификации, при этом один или более элементов данных рендеринга являются частотно-зависимыми, при этом функция модификации является частотно-избирательной, и при этом модуль вычисления целевых данных выполнен с возможностью применения частотно-избирательной функции модификации к одному или более частотно-зависимым элементам данных рендеринга.
В дополнительных вариантах осуществления частотно-избирательная функция модификации имеет различные значения для различных частот, и при этом частотно-зависимые один или более элементов данных рендеринга имеют различные значения для различных частот, и при этом модуль вычисления целевых данных выполнен с возможностью применения или умножения или комбинирования значения частотно-избирательной функции модификации для определенной частоты относительно значения одного или более элементов данных рендеринга для определенной частоты.
В дополнительных вариантах осуществления предложено устройство хранения данных для сохранения одного или более элементов данных рендеринга для определенного числа различных ограниченных пространственных секторов, при этом определенное число различных ограниченных пространственных секторов вместе формируют диапазон рендеринга для слушателя.
В дополнительных вариантах осуществления функция модификации представляет собой частотно-избирательную функцию нижних частот, и при этом модуль вычисления целевых данных выполнен с возможностью применения функции нижних частот таким образом, что значение одного или более элементов данных рендеринга на более высокой частоте ослабляется сильнее значения одного или более элементов данных рендеринга на более низкой частоте.
В дополнительных вариантах осуществления, процессор идентификации секторов выполнен с возможностью определения ограниченного пространственного сектора для пространственно протяженного источника звука на основе данных слушателя и данных пространственно протяженных источников звука, определения, подвергается ли по меньшей мере часть ограниченного пространственного сектора модификации посредством модифицирующего объекта, и определения ограниченного пространственного сектора в качестве модифицированного пространственного сектора, когда часть больше порогового значения, либо когда целый ограниченный пространственный сектор подвергается модификации посредством модифицирующего объекта.
В дополнительных вариантах осуществления, процессор идентификации секторов выполнен с возможностью применения алгоритма проецирования или анализа по трассировке лучей для определения ограниченного пространственного сектора или использования в качестве данных слушателя положения слушателя или ориентации слушателя либо использования в качестве данных пространственно протяженных источников звука (SESS) ориентацию SESS, положения SESS или информации о геометрии SESS.
В дополнительных вариантах осуществления, диапазон рендеринга содержит сферу или часть сферы вокруг слушателя, при этом диапазон рендеринга привязывается к положению слушателя или к ориентации слушателя, и при этом модифицированный ограниченный пространственный сектор имеет размер по азимуту и размер по углу места.
В дополнительных вариантах осуществления, размер по азимуту и размер по углу места модифицированного ограниченного пространственного сектора отличаются друг от друга, так что размер по азимуту является более точным для модифицированного ограниченного пространственного сектора непосредственно перед слушателем по сравнению с размером по азимуту модифицированного ограниченного пространственного сектора больше вбок от слушателя, либо при этом размер по азимуту уменьшается в направлении вбок от слушателя, либо при этом размер по углу места модифицированного ограниченного пространственного сектора меньше размера по азимуту модифицированного ограниченного пространственного сектора.
В дополнительных вариантах осуществления, в качестве одного или более элементов данных рендеринга, для модифицированного ограниченного пространственного сектора, используется по меньшей мере одно из левого элемента данных дисперсии, связанного с левыми данными передаточной функции восприятия звука человеком, правого элемента данных дисперсии, связанного с правыми данными передаточной функции восприятия звука человеком (HRTF), и элемента данных ковариации, связанного с левыми данными HRTF и правыми данными HRTF.
В дополнительных вариантах осуществления, процессор идентификации секторов выполнен с возможностью определения набора элементарных пространственных секторов, принадлежащих пространственно протяженному источнику звука, и определения из набора элементарных пространственных секторов одного или более элементарных пространственных секторов в качестве ограниченного модифицированного пространственного сектора, и при этом модуль вычисления целевых данных выполнен с возможностью модификации одного или более элементов данных рендеринга, ассоциированных с ограниченным модифицированным пространственным сектором, с использованием данных о модификации для получения комбинированных данных, и комбинирования комбинированных данных с элементами данных рендеринга одного или более элементарных пространственных секторов из набора элементарных пространственных секторов, отличающихся от ограниченного модифицированного пространственного сектора и не модифицируемых или модифицируемых другим способом по сравнению с модификацией для ограниченного модифицированного пространственного сектора.
В дополнительных вариантах осуществления, процессор идентификации секторов выполнен с возможностью классификации набора элементарных пространственных секторов на различные классы секторов на основе характеристик, ассоциированных с элементарными пространственными секторами, при этом модуль вычисления целевых данных выполнен с возможностью комбинирования элементов данных рендеринга элементарных пространственных секторов в каждом классе для получения комбинированного результата для каждого класса, если в классе находится более одного элементарного пространственного сектора, и применения конкретной функции модификации, ассоциированной по меньшей мере с одним классом, к комбинированному результату этого класса для получения модифицированного комбинированного результата для этого класса, или применения конкретной функции модификации, ассоциированной по меньшей мере с одним классом, к одному или более элементам данных одного или более элементарных пространственных секторов каждого класса для получения модифицированных элементов данных, и комбинирования модифицированных элементов данных элементарных пространственных секторов в каждом классе для получения модифицированного комбинированного результата для этого класса, комбинирования комбинированного результата, либо, при наличии, модифицированного комбинированного результата для каждого класса для получения полного комбинированного результата, и использования полного комбинированного результата в качестве целевых данных рендеринга или вычисления целевых данных рендеринга из полного комбинированного результата.
В дополнительных вариантах осуществления, характеристика для элементарного пространственного сектора определяется как одно из группы, содержащей загороженный элементарный пространственный сектор, включающий в себя первую характеристику загораживания, загороженный элементарный пространственный сектор, включающий в себя вторую характеристику загораживания, отличающуюся от первой характеристики загораживания, незагороженный элементарный пространственный сектор, имеющий первое расстояние до слушателя, и незагороженный элементарный пространственный сектор, имеющий второе расстояние до слушателя, при этом второе расстояние отличается от первого расстояния.
В дополнительных вариантах осуществления, модуль вычисления целевых данных выполнен с возможностью модификации или комбинирования частотно-зависимых параметров дисперсии или ковариации в качестве элементов данных рендеринга для получения в качестве полного комбинированного результата полной комбинированной дисперсии или полного комбинированного параметра ковариации, и вычисления по меньшей мере одного из сигнальной метки интерауральной или межканальной когерентности, сигнальной метки интерауральной или межканальной разности уровней, сигнальной метки интерауральной или межканальной разности фаз, первого бокового усиления или второго бокового усиления в качестве целевых данных рендеринга, и при этом аудиопроцессор выполнен с возможностью обработки аудиосигнала с использованием по меньшей мере одного из сигнальной метки интерауральной или межканальной когерентности, сигнальной метки интерауральной или межканальной разности уровней, сигнальной метки интерауральной или межканальной разности фаз, первого бокового усиления или второго бокового усиления в качестве целевых данных рендеринга.
Дополнительные варианты осуществления содержат генератор аудиосцен для формирования описания аудиосцен, содержащий: генератор данных пространственно протяженных источников звука (SESS) для формирования данных SESS пространственно протяженного источника звука; генератор данных о модификации для формирования данных о модификации для потенциально модифицирующего объекта; и выходной интерфейс для формирования описания аудиосцен, содержащего данные SESS и данные о модификации.
В дополнительных вариантах осуществления, данные о модификации содержат описание функции нижних частот или геометрических данных относительно потенциально модифицирующего объекта, при этом функция нижних частот содержит значение ослабления для более высокой частоты, причем значение ослабления для более высокой частоты, представляющее значение ослабления, является более сильным по сравнению со значением ослабления для более низкой частоты, и при этом выходной интерфейс выполнен с возможностью ввода описания функции ослабления или геометрических данных относительно потенциально модифицирующего объекта в качестве данных о модификации в описание аудиосцен.
В дополнительных вариантах осуществления, генератор -данных SESS выполнен с возможностью формирования в качестве данных SESS местоположения SESS и информации о геометрии SESS, и при этом выходной интерфейс выполнен с возможностью ввода в качестве данных SESS информации о местоположении SESS и информации о геометрии SESS.
В дополнительных вариантах осуществления, генератор данных SESS выполнен с возможностью формирования в качестве данных SESS информации о размере, относительно положения или ориентации пространственно протяженного источника звука либо данных формы сигнала для одного или более аудиосигналов, ассоциированных с пространственно протяженным источником звука, либо при этом модуль вычисления данных о модификации выполнен с возможностью вычисления в качестве данных о модификации геометрии потенциально модифицирующего объекта, например, потенциально загораживающего объекта.
Дополнительные варианты осуществления содержат описание аудиосцен, содержащее: данные пространственно протяженных источников звука и данные о модификации по одному или более потенциально модифицирующим объектам.
В дополнительных вариантах осуществления, описание аудиосцен реализуется как передаваемый или сохраненный поток битов, при этом данные пространственно протяженных источников звука представляют первый элемент потока битов, и при этом данные о модификации представляют второй элемент потока битов.
Далее обобщаются дополнительные варианты осуществления, относящиеся к третьему аспекту.
Вариант осуществления содержит устройство для синтезирования пространственно протяженного источника звука (SESS), содержащее: устройство хранения данных для сохранения одного или более элементов данных рендеринга для различных ограниченных пространственных секторов, при этом различные ограниченные пространственные секторы расположены в диапазоне рендеринга для слушателя, при этом один или более элементов данных рендеринга для ограниченного пространственного сектора содержат по меньшей мере один из левого элемента данных дисперсии, связанного с левыми данными передаточной функции восприятия звука человеком, правого элемента данных дисперсии, связанного с правыми данными передаточной функции восприятия звука человеком, и элемента данных ковариации, связанного с левыми данными передаточной функции восприятия звука человеком и правыми данными передаточной функции восприятия звука человеком; процессор идентификации секторов для идентификации одного или более ограниченных пространственных секторов для пространственно протяженного источника звука в диапазоне рендеринга для слушателя на основе данных пространственно протяженных источников звука; модуль вычисления целевых данных для вычисления целевых данных рендеринга из сохраненных левых данных дисперсии, сохраненных правых данных дисперсии или сохраненных данных ковариации; и аудиопроцессор для обработки аудиосигнала, представляющего пространственно протяженный источник звука, с использованием целевых данных рендеринга.
В дополнительных вариантах осуществления, устройство хранения данных выполнено с возможностью сохранения элементов данных дисперсии или элемента данных ковариации, связанных с данными передаточной функции восприятия звука человеком или с данными бинаурального импульсного отклика в помещении, или с данными бинауральной передаточной функции в помещении, или с данными импульсного отклика восприятия звука человеком.
В дополнительных вариантах осуществления, один или более элементов данных рендеринга содержат значения элементов данных дисперсии или ковариации для различных частот.
В дополнительных вариантах осуществления, устройство хранения данных выполнено с возможностью сохранения для каждого ограниченного пространственного сектора частотно-зависимого представления левого элемента данных дисперсии, частотно-зависимого представления правого элемента данных дисперсии и частотно-зависимого представления элемента данных ковариации.
В дополнительных вариантах осуществления, модуль вычисления целевых данных выполнен с возможностью вычисления в качестве целевых данных рендеринга по меньшей мере одного из сигнальной метки интерауральной или межканальной когерентности, сигнальной метки интерауральной или межканальной разности уровней, сигнальной метки интерауральной или межканальной разности фаз, первого бокового усиления и второго бокового усиления в качестве целевых данных рендеринга, и при этом аудиопроцессор выполнен с возможностью выполнения по меньшей мере одного из регулирования межканальной или интерауральной когерентности, регулирования интерауральной или межканальной разности фаз или регулирования интерауральной или межканальной разности уровней с использованием соответствующих сигнальных меток в качестве целевых данных рендеринга.
В дополнительных вариантах осуществления, модуль вычисления целевых данных выполнен с возможностью вычисления сигнальной метки интерауральной или межканальной когерентности на основе левого элемента данных дисперсии, правого элемента данных дисперсии и элемента данных ковариации либо вычисления сигнальной метки межканальной или интерауральной разности фаз на основе левого элемента данных дисперсии и правого элемента данных дисперсии, либо вычисления сигнальной метки межканальной или интерауральной разности фаз на основе элемента данных ковариации, либо вычисления левого или правого бокового усиления с использованием левого или правого элемента данных дисперсии и информации, связанной с мощностью сигналов аудиосигнала.
В дополнительных вариантах осуществления, модуль вычисления целевых данных выполнен с возможностью вычисления сигнальной метки интерауральной или межканальной когерентности таким образом, что значение сигнальной метки интерауральной или межканальной когерентности находится в пределах диапазона в +/-20% от значения, полученного посредством уравнения для сигнальной метки интерауральной или межканальной когерентности, поясненной в описании изобретения, либо при этом модуль вычисления целевых данных выполнен с возможностью вычисления сигнальной метки интерауральной или межканальной разности уровней таким образом, что значение сигнальной метки интерауральной или межканальной разности уровней находится в пределах диапазона в +/-20% от значения, полученного посредством уравнения для сигнальной метки интерауральной или межканальной разности уровней, поясненной в описании изобретения, либо при этом модуль вычисления целевых данных выполнен с возможностью вычисления сигнальной метки интерауральной или межканальной разности фаз таким образом, что значение сигнальной метки интерауральной или межканальной разности фаз находится в пределах диапазона в +/-20% от значения, полученного посредством уравнения для сигнальной метки интерауральной или межканальной разности фаз, поясненной в описании изобретения, либо при этом модуль вычисления целевых данных выполнен с возможностью вычисления первого или второго бокового усиления таким образом, что значение первого или второго бокового усиления находится в пределах диапазона в +/-20% от значения, полученного посредством уравнения для левого или правого бокового усиления, поясненного в описании изобретения.
В дополнительных вариантах осуществления, процессор идентификации секторов выполнен с возможностью применения алгоритма проецирования или анализа по трассировке лучей для определения одного или более ограниченных пространственных секторов в качестве набора элементарных пространственных секторов или использования в качестве данных слушателя положения слушателя или ориентации слушателя либо использования в качестве данных пространственно протяженных источников звука (SESS) ориентации SESS, положения SESS или информации о геометрии SESS.
В дополнительных вариантах осуществления, диапазон рендеринга содержит сферу или часть сферы вокруг слушателя, при этом диапазон рендеринга привязывается к положению слушателя или к ориентации слушателя, и при этом один или более ограниченных пространственных секторов имеют размер по азимуту и размер по углу места.
В дополнительных вариантах осуществления, размер по азимуту и размер по углу места различных ограниченных пространственных секторов отличаются друг от друга, так что размер по азимуту является более точным для ограниченного пространственного сектора непосредственно перед слушателем по сравнению с размером по азимуту ограниченного пространственного сектора больше вбок от слушателя, либо при этом размер по азимуту снижается в направлении вбок от слушателя, либо при этом размер по углу места ограниченного пространственного сектора меньше размера по азимуту этого сектора.
В дополнительных вариантах осуществления, процессор идентификации секторов выполнен с возможностью определения набора элементарных пространственных секторов в качестве одного или более ограниченных пространственных секторов, при этом для каждого элементарного пространственного сектора сохраняется по меньшей мере один из левого элемента данных дисперсии, правого элемента данных дисперсии и элемента данных ковариации.
В дополнительных вариантах осуществления, процессор идентификации секторов выполнен с возможностью приёма из описания аудиосцены информации загораживания относительно потенциально загораживающего объекта и определения на основе информации загораживания конкретного пространственного сектора из набора элементарных пространственных секторов в качестве загораживающего сектора, и при этом модуль вычисления целевых данных выполнен с возможностью применения функции загораживания к элементам данных рендеринга, сохраненным для загораживающего сектора таким образом, чтобы получить модифицированные данные и использовать модифицированные данные для вычисления целевых данных рендеринга.
В дополнительных вариантах осуществления, функция загораживания представляет собой функцию нижних частот, имеющую различные значения ослабления для различных частот, и при этом элементы данных рендеринга представляют собой элементы данных для различных частот, и при этом модуль вычисления целевых данных выполнен с возможностью взвешивания для нескольких частот элемента данных для определенной частоты со значением ослабления для определенной частоты для получения модифицированных данных рендеринга.
В дополнительных вариантах осуществления, процессор идентификации секторов выполнен с возможностью определения того, что другой элементарный пространственный сектор из набора элементарных пространственных секторов, определенных для загораживающего объекта, не загораживается посредством потенциального загораживающего объекта, и при этом модуль вычисления целевых данных выполнен с возможностью комбинирования модифицированных данных из загораживающего сектора и элементов данных рендеринга другого сектора без модификации с использованием функции загораживания либо с модификацией посредством другой функции модификации для получения целевых данных рендеринга.
В дополнительных вариантах осуществления, процессор идентификации секторов выполнен с возможностью определения первого элементарного пространственного сектора из набора элементарных пространственных секторов как имеющего первую характеристику и определения второго элементарного пространственного сектора из набора элементарных пространственных секторов как имеющего вторую отличающуюся характеристику, и при этом модуль вычисления целевых данных выполнен с возможностью неприменения функции модификации к первому элементарному пространственному сектору и применения функции модификации ко второму элементарному пространственному сектору либо применения первой функции модификации к первому элементарному пространственному сектору и применения вторую функцию модификации ко второму элементарному пространственному сектору, причем вторая функция модификации отличается от первой функции модификации.
В дополнительных вариантах осуществления, первая функция модификации является частотно-избирательной, и вторая функция модификации является постоянной по частоте, либо при этом первая функция модификации имеет первую частотно-избирательную характеристику, и при этом вторая функция модификации имеет вторую частотно-избирательную характеристику, отличающуюся от первой частотно-избирательной характеристики, либо при этом первая функция модификации имеет первую характеристику ослабления, и вторая функция модификации имеет вторую отличающуюся характеристику ослабления, и при этом модуль вычисления целевых данных выполнен с возможностью выбора или регулировки функции модификации из первой функции модификации и второй функции модификации на основе расстояния между первым элементарным пространственным сектором или вторым элементарным пространственным сектором и слушателем либо на основе характеристики объекта, расположенного между слушателем и соответствующим элементарным пространственным сектором.
В дополнительных вариантах осуществления, процессор идентификации секторов выполнен с возможностью классификации набора элементарных пространственных секторов на различные классы секторов на основе характеристик, ассоциированных с элементарными пространственными секторами, при этом модуль вычисления целевых данных выполнен с возможностью комбинирования элементов данных рендеринга элементарных пространственных секторов в каждом классе для получения комбинированного результата для каждого класса, если более одного элементарного пространственного сектора находится в классе, и применения конкретной функции модификации, ассоциированной по меньшей мере с одним классом, к комбинированному результату этого класса, для получения модифицированного комбинированного результата для этого класса, или применения конкретной функции модификации, ассоциированной по меньшей мере с одним классом, к одному или более элементам данных одного или более элементарных пространственных секторов каждого класса для получения модифицированных элементов данных, и комбинирования модифицированных элементов данных элементарных пространственных секторов в каждом классе для получения модифицированного комбинированного результата для этого класса, комбинирования комбинированного результата, либо, при наличии, модифицированного комбинированного результата для каждого класса, для получения полного комбинированного результат, и использования полного комбинированного результата в качестве целевых данных рендеринга или вычисления целевых данных рендеринга из полного комбинированного результата.
В дополнительных вариантах осуществления, характеристика для элементарного пространственного сектора определяется как представляющий собой одно из группы, содержащей загороженный элементарный пространственный сектор, включающий в себя первую характеристику загораживания, загороженный элементарный пространственный сектор, включающий в себя вторую характеристику загораживания, отличающуюся от первой характеристики загораживания, незагороженный элементарный пространственный сектор, имеющий первое расстояние до слушателя, и незагороженный элементарный пространственный сектор, имеющий второе расстояние до слушателя, при этом второе расстояние отличается от первого расстояния.
В дополнительных вариантах осуществления, модуль вычисления целевых данных выполнен с возможностью модификации или комбинирования частотно-зависимых параметров дисперсии или ковариации в качестве элементов данных рендеринга для получения в качестве полного комбинированного результата полной комбинированной дисперсии или полного комбинированного параметра ковариации, и вычисления по меньшей мере одного из сигнальной метки интерауральной или межканальной когерентности, сигнальной метки интерауральной или межканальной разности уровней, сигнальной метки интерауральной или межканальной разности фаз, первого бокового усиления или второго бокового усиления в качестве целевых данных рендеринга.
В дополнительных вариантах осуществления предусмотрен модуль инициализации для определения по меньшей мере одного из левого элемента данных дисперсии, правого элемента данных дисперсии и элемента данных ковариации из предварительно сохраненных данных передаточной функции восприятия звука человеком, при этом модуль инициализации выполнен с возможностью вычисления левого элемента данных дисперсии, правого элемента данных дисперсии или элемента данных ковариации из множества данных передаточной функции восприятия звука человеком для ограниченного пространственного сектора, и при этом ограниченный пространственный сектор имеет такой размер, что по меньшей мере два элемента левых данных передаточной функции восприятия звука человеком по меньшей мере два элемента правых данных передаточной функции восприятия звука человеком существуют для ограниченного пространственного диапазона.
Список литературы
Alary, B., Politis, A. и Välimäki V. 2017 г., "Velvet Noise Decorrelator".
Baumgarte, F. и Faller, C., 2003 г., "Binaural Cue Coding-Part I: Psychoacoustic Fundamentals and Design Principles", Speech and Audio Processing, IEEE Transactions on, 11(6), с. 509-519.
Blauert, J., 2001 г., Spatial hearing (3 Ausg.). Cambridge; Mass: MIT Press.
Faller, C. и Baumgarte, F., 2003 г., "Binaural Cue Coding-Part II: Schemes and Applications", Speech and Audio Processing, IEEE Transactions on, 11(6), с. 520-531.
Kendall, G. S., 1995 год, "The Decorrelation of Audio Signals and Its Impact on Spatial Imagery", Computer Music Journal, 19(4), с. 71-87.
Lauridsen, H., 1954 г., "Experiments Concerning Different Kinds of Room-Acoustics Recording", Ingenioren, 47.
Pihlajamäki T., Santala, O. и Pulkki, V., 2014 г., "Synthesis of Spatially Extended Virtual Source with Time-Frequency Decomposition of Mono Signals", Journal of the Audio Engineering Society, 62(7/8), с. 467-484.
Potard, G., 2003 г., "The study on sound source apparent shape and wideness".
Potard, G. и Burnett, I., 2004 г., "Decorrelation Techniques for the Rendering of Apparent Sound Source Width in 3D Audio Displays".
Pulkki, V., 1997 г., "Virtual Sound Source Positioning Using Vector Base Amplitude Panning", Journal of the Audio Engineering Society, 45(6), с. 456-466.
Pulkki, V., 1999 г., "Uniform spreading of amplitude panned virtual sources".
Pulkki, V., 2007 г., "Spatial Sound Reproduction with Directional Audio Coding", J. Audio Eng. Soc, 55(6), с. 503-516.
Pulkki, V., Laitinen, M.-V. и Erkut, C., 2009 г., "Efficient Spatial Sound Synthesis for Virtual Worlds".
Schlecht, S. J., Alary, B., Välimäki V. и Habets, E. A., 2018 г., "Optimized Velvet-Noise Decorrelator".
Schmele, T. и Sayin, U., 2018 г., "Controlling the Apparent Source Size in Ambisonics Unisng Decorrelation Filters".
Schmidt, J. и Schröder, E. F., 2004 г., "New and Advanced Features for Audio Presentation in the MPEG-4 Standard".
Verron, C., Aramaki, M., Kronland-Martinet, R. и Pallone, G., 2010 г., "The 3-D Immersive Synthesizer for Environmental Sounds", Audio, Speech and Language Processing, IEEE Transactions on, title="A Backward-Compatible Multichannel Audio Codec", 18(6), с. 1550-1561.
Zotter, F. и Frank, M., 2013 г., "Efficient Phantom Source Widening", Archives of Acoustics, 38(1), с. 27-37.
Zotter, F., Frank, M., Kronlachner, M. и Choi, J.-W., 2014 г., "Efficient Phantom Source Widening and Diffuseness in Ambisonics".
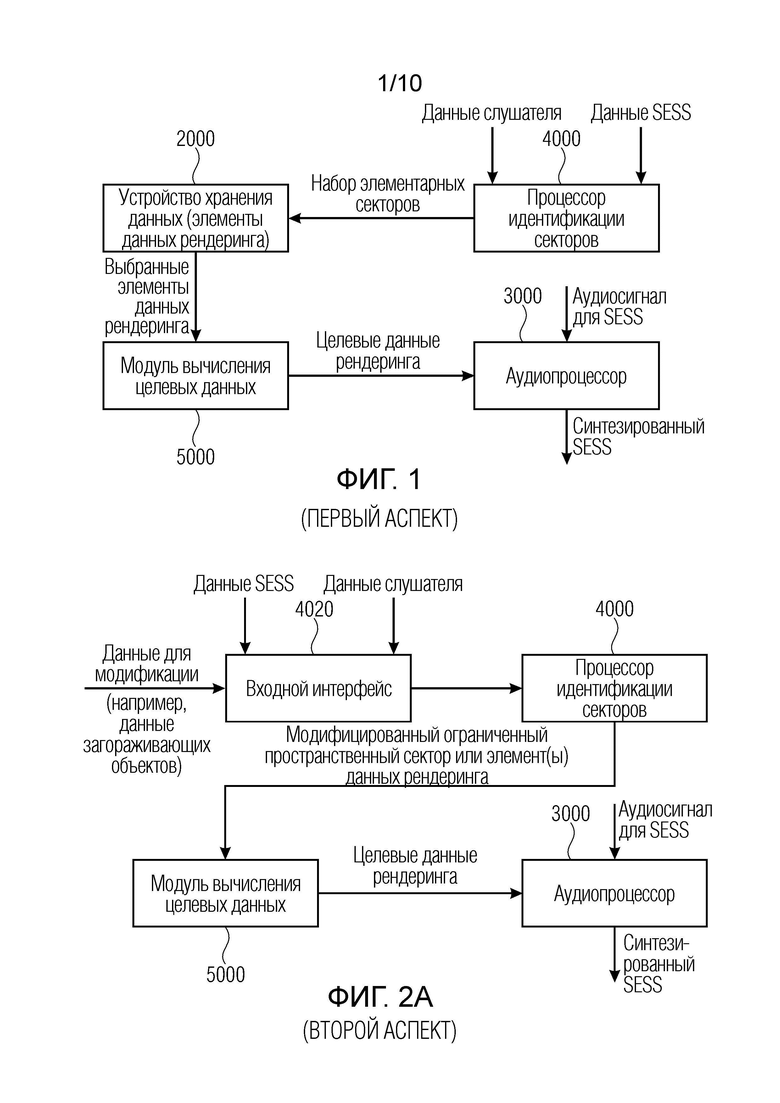
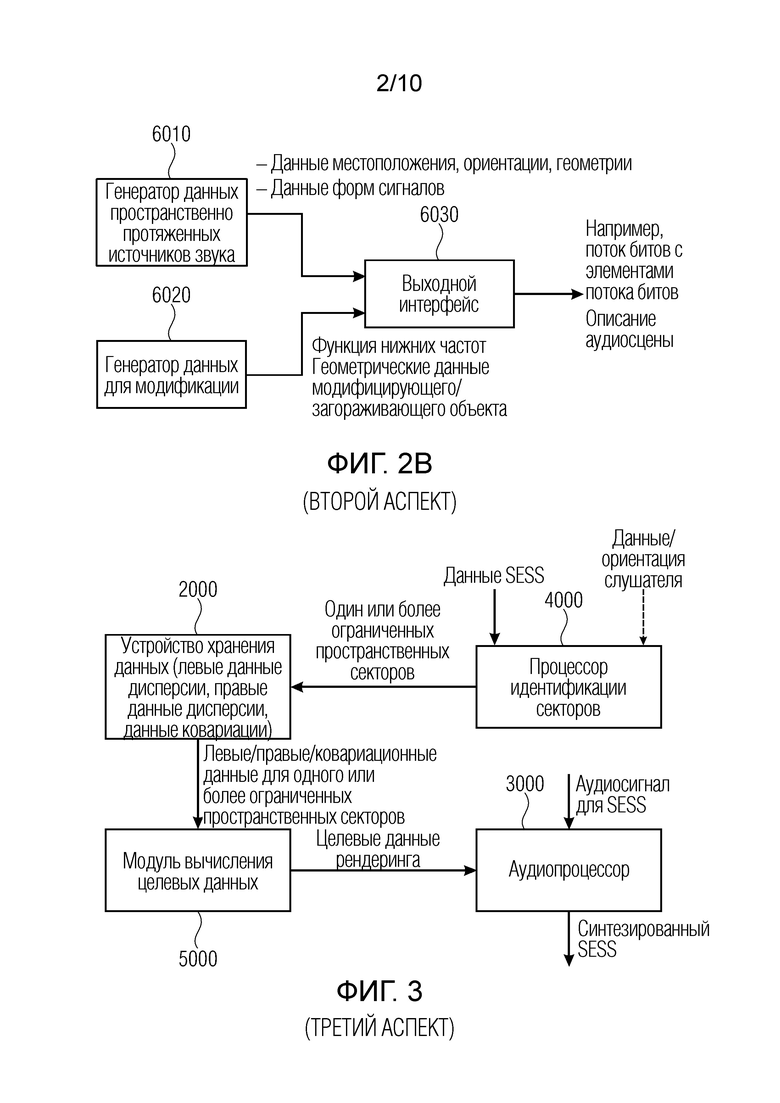
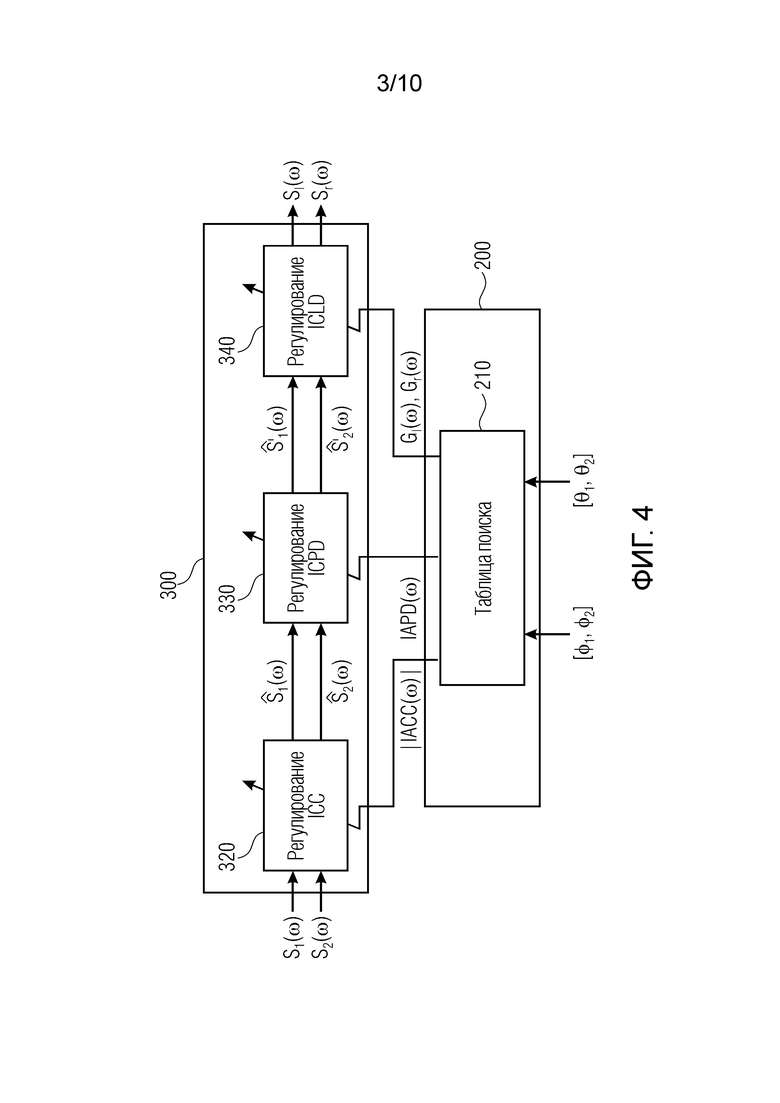
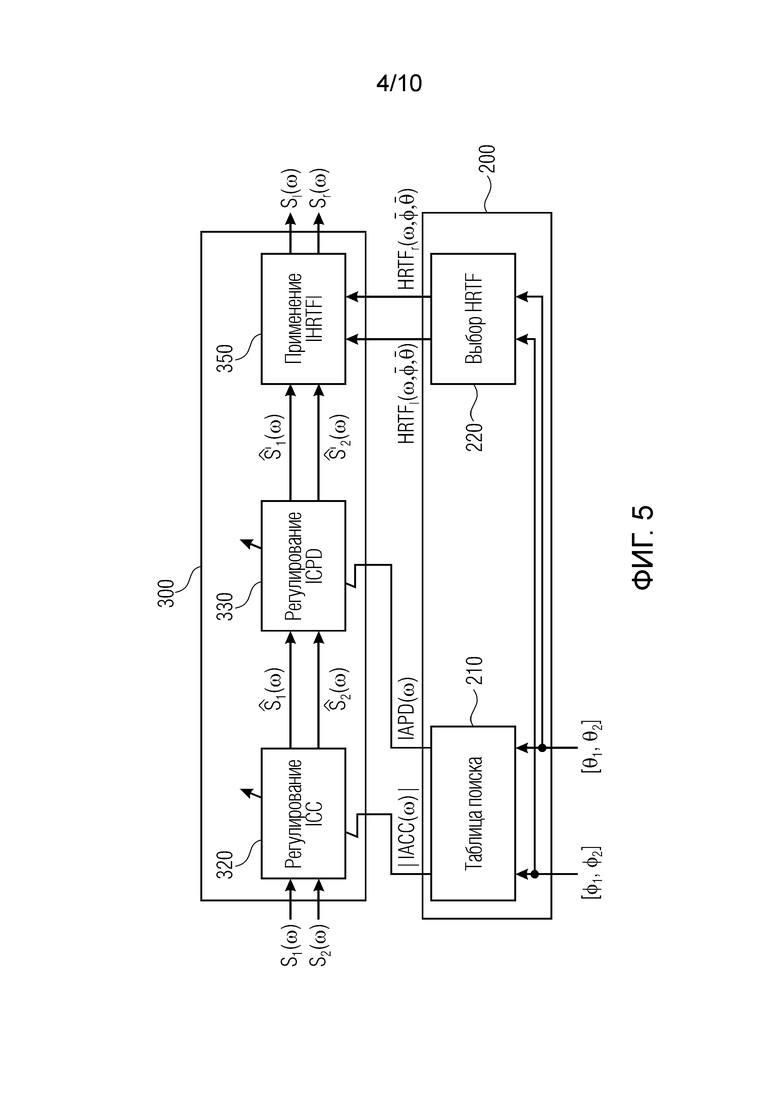
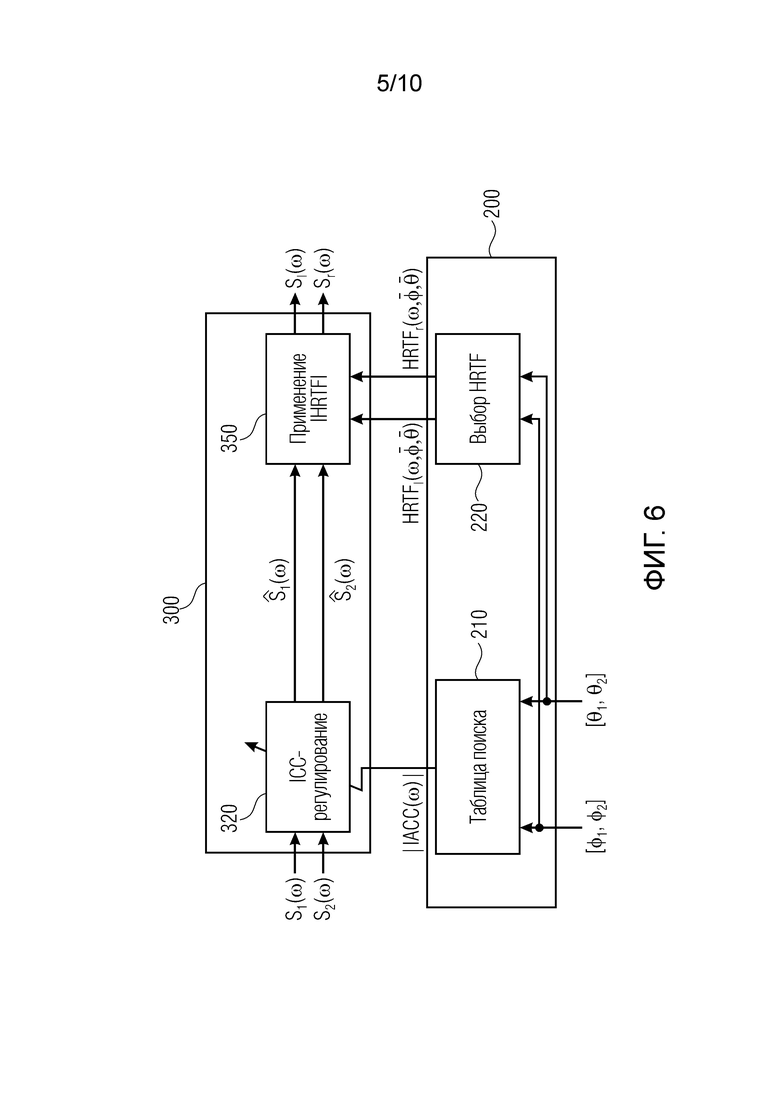
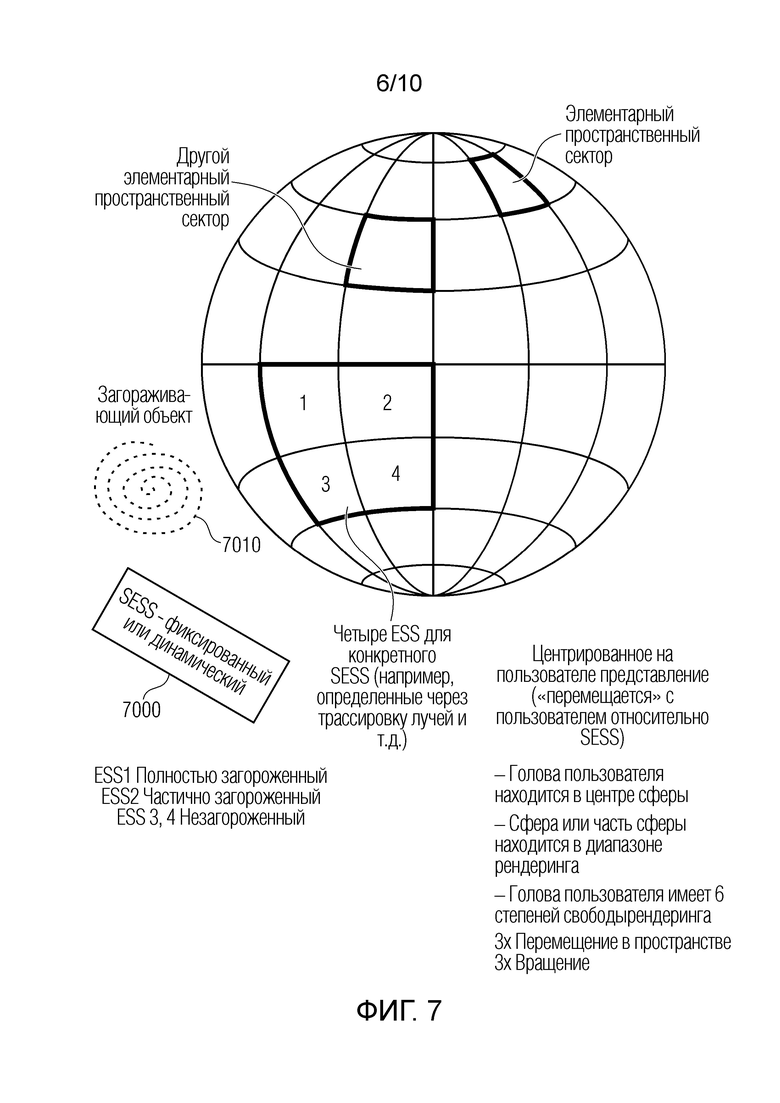
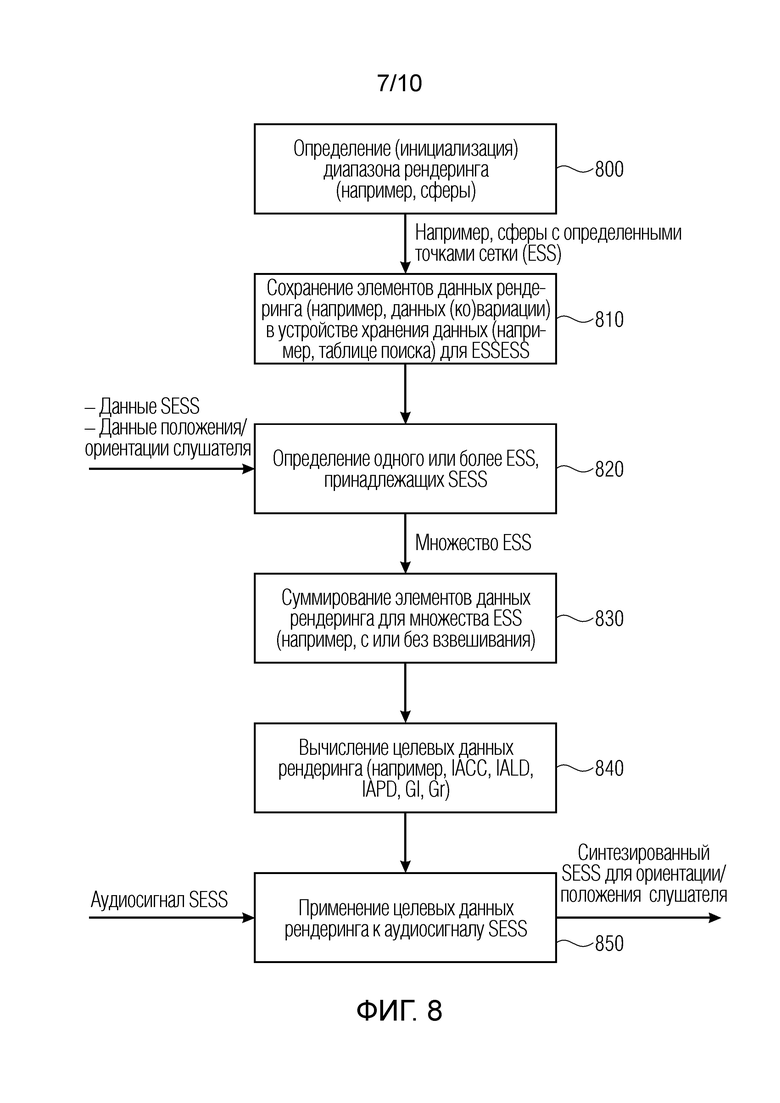
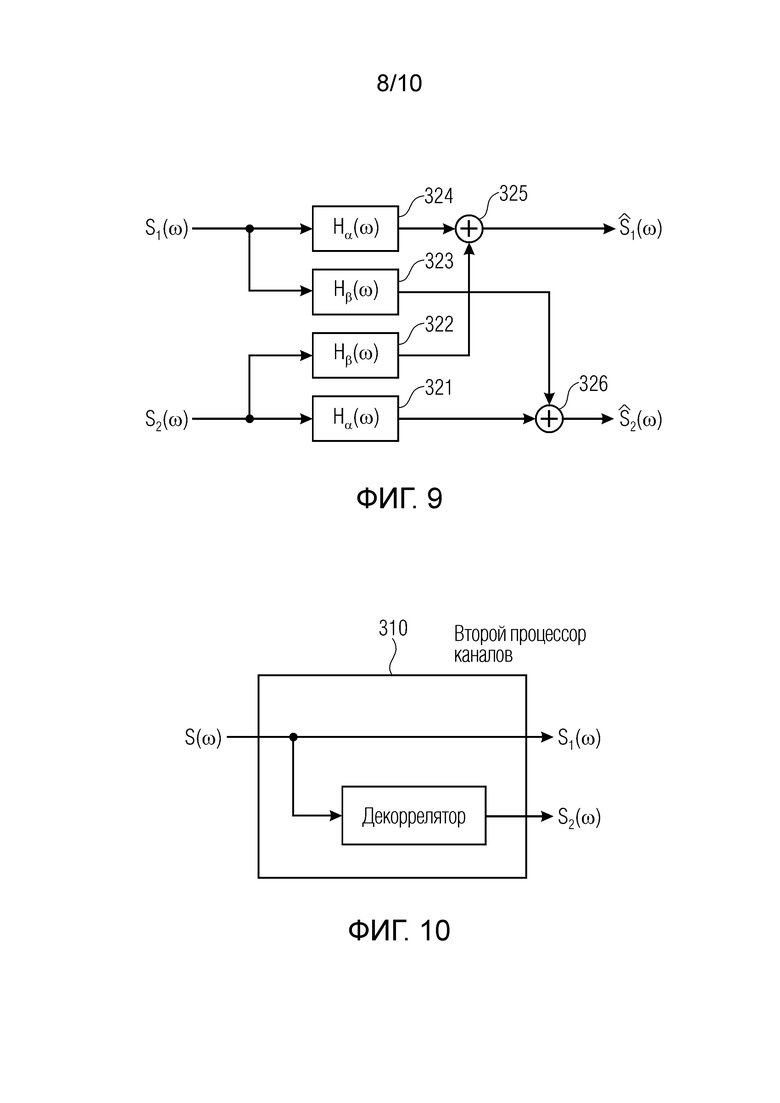
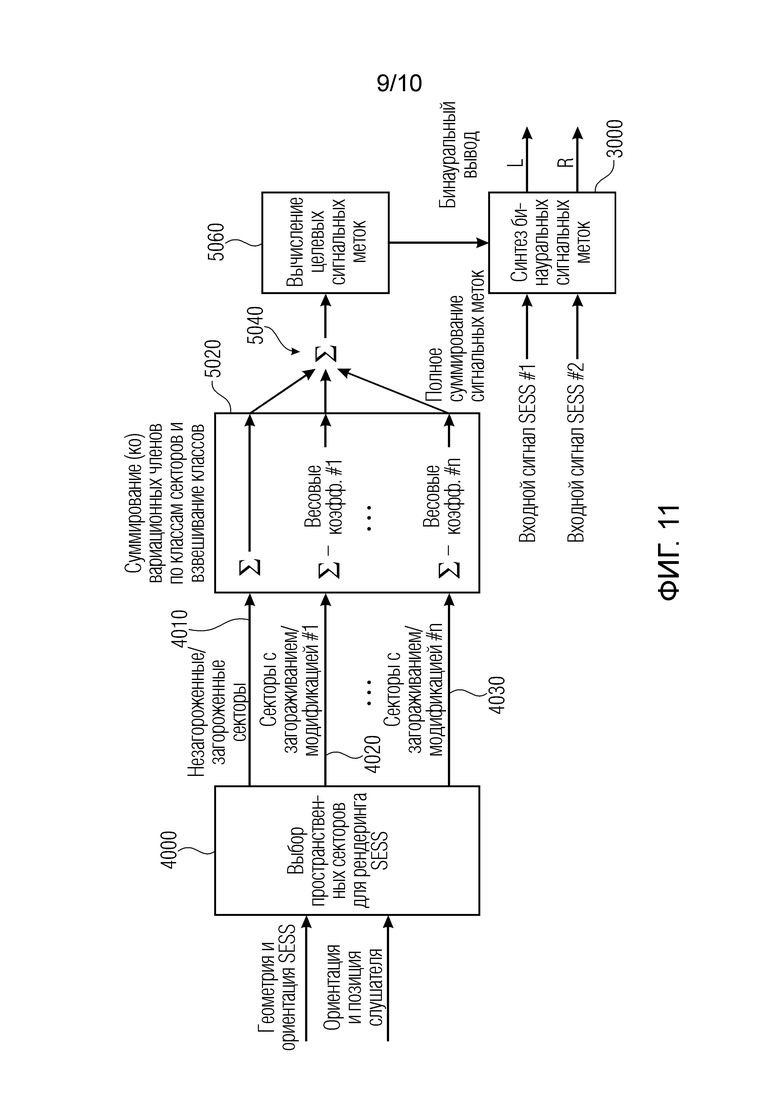
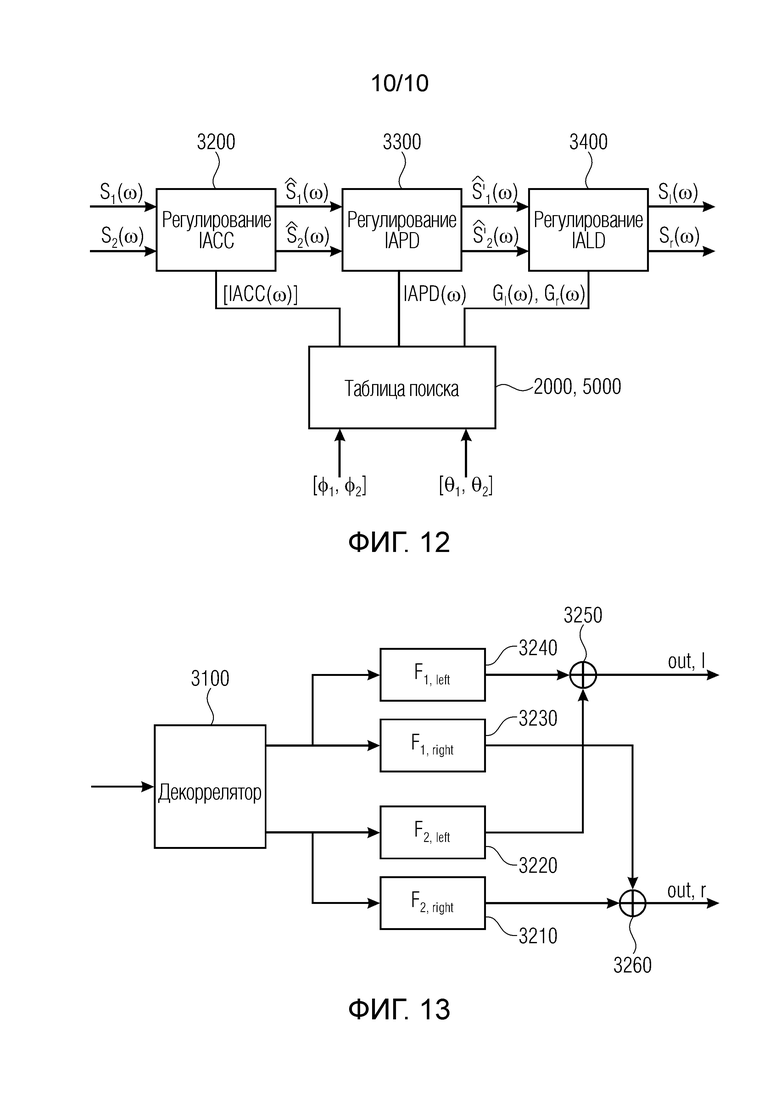
Изобретение относится к средствам для синтезирования пространственно протяженного источника звука. Технический результат заключается в повышении эффективности синтезирования пространственно протяженного источника звука. Принимают описание аудиосцены, которое содержит данные пространственно протяженных источников звука для пространственно протяженного источника звука и данные о модификации для потенциально модифицирующего объекта. Принимают данные слушателя. Идентифицируют ограниченный модифицированный пространственный сектор для пространственно протяженного источника звука в диапазоне рендеринга для слушателя, причем диапазон рендеринга для слушателя больше ограниченного модифицированного пространственного сектора, на основе данных пространственно протяженных источников звука и данных слушателя, и данных о модификации. Вычисляют целевые данные рендеринга из одного или более элементов данных рендеринга, принадлежащих модифицированному ограниченному пространственному сектору. Обрабатывают аудиосигнал, представляющий пространственно протяженный источник звука, с использованием целевых данных рендеринга. 4 н. и 18 з.п. ф-лы, 14 ил.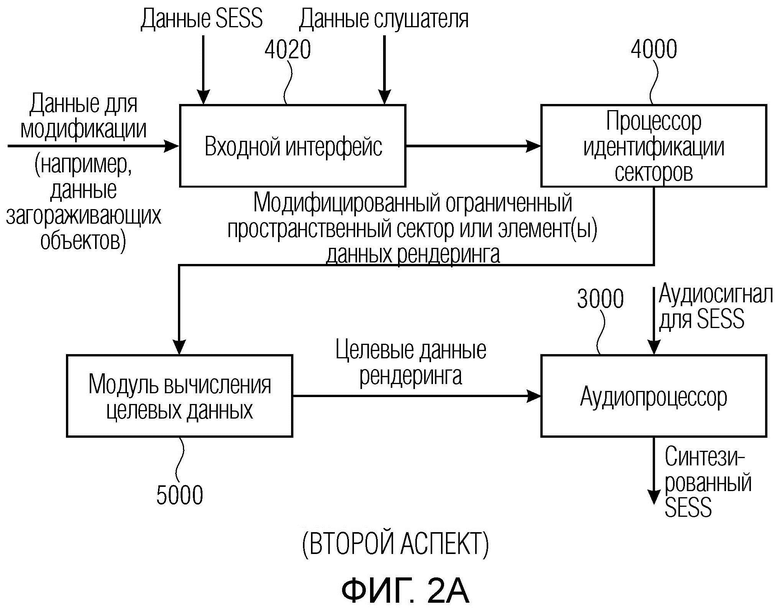
1. Устройство для синтезирования пространственно протяженного источника звука, содержащее:
- входной интерфейс (4020) для приема описания аудиосцены, причем описание аудиосцены содержит данные пространственно протяженных источников звука о пространственно протяженном источнике звука и данные о модификации о потенциально модифицирующем объекте (7010), и для приема данных слушателя;
- процессор (4000) идентификации секторов для идентификации ограниченного модифицированного пространственного сектора для пространственно протяженного источника (7000) звука в диапазоне рендеринга для слушателя, причем диапазон рендеринга для слушателя больше ограниченного модифицированного пространственного сектора, на основе данных пространственно протяженных источников звука и данных слушателя, и данных о модификации;
- модуль (5000) вычисления целевых данных для вычисления целевых данных рендеринга из одного или более элементов данных рендеринга, принадлежащих модифицированному ограниченному пространственному сектору; и
- аудиопроцессор (300, 3000) для обработки аудиосигнала, представляющего пространственно протяженный источник звука, с использованием целевых данных рендеринга.
2. Устройство по п. 1, в котором данные о модификации представляют собой данные загораживания, и при этом потенциально модифицирующий объект (7010) представляет собой потенциально загораживающий объект.
3. Устройство по одному из пп. 1 или 2, в котором потенциально модифицирующий объект (7010) имеет ассоциированную функцию модификации,
- при этом один или более элементов данных рендеринга являются частотно-зависимыми,
- при этом функция модификации является частотно-избирательной, и
- при этом модуль (5000) вычисления целевых данных выполнен с возможностью применения частотно-избирательной функции модификации к одному или более частотно-зависимым элементам данных рендеринга.
4. Устройство по п. 3, в котором частотно-избирательная функция модификации имеет различные значения для различных частот, и при этом частотно-зависимые один или более элементов данных рендеринга имеют различные значения для различных частот, и
- при этом модуль (5000) вычисления целевых данных выполнен с возможностью применения или умножения или комбинирования (5020) значения частотно-избирательной функции модификации для определенной частоты относительно значения одного или более элементов данных рендеринга для определенной частоты.
5. Устройство по одному из предшествующих пунктов, дополнительно содержащее устройство (200, 2000) хранения данных для сохранения одного или более элементов данных рендеринга для определенного числа различных ограниченных пространственных секторов, при этом определенное число различных ограниченных пространственных секторов вместе формируют диапазон рендеринга для слушателя.
6. Устройство по одному из предшествующих пунктов, в котором функция модификации представляет собой частотно-избирательную функцию нижних частот, и
- при этом модуль (5000) вычисления целевых данных выполнен с возможностью применения (5020) функции нижних частот таким образом, что значение одного или более элементов данных рендеринга на более высокой частоте ослабляется сильнее значения одного или более элементов данных рендеринга на более низкой частоте.
7. Устройство по одному из предшествующих пунктов, в котором процессор (4000) идентификации секторов выполнен с возможностью:
- определения (820) ограниченного пространственного сектора для пространственно протяженного источника звука на основе данных слушателя и данных пространственно протяженных источников звука,
- определения, подвергается ли по меньшей мере часть ограниченного пространственного сектора модификации посредством модифицирующего объекта (7010), и
- определения ограниченного пространственного сектора в качестве модифицированного пространственного сектора, когда часть больше порогового значения, либо когда целый ограниченный пространственный сектор подвергается модификации посредством модифицирующего объекта (7010).
8. Устройство по одному из предшествующих пунктов,
- в котором процессор (4000) идентификации секторов выполнен с возможностью применения алгоритма проецирования или анализа по трассировке лучей для определения ограниченного пространственного сектора, или использования в качестве данных слушателя положения слушателя или ориентации слушателя, либо использования в качестве данных пространственно протяженных источников звука (SESS) ориентации SESS, положения SESS или информации о геометрии SESS.
9. Устройство по одному из предшествующих пунктов,
- в котором диапазон рендеринга содержит сферу или часть сферы вокруг слушателя, при этом диапазон рендеринга привязан к положению слушателя или к ориентации слушателя, и при этом модифицированный ограниченный пространственный сектор имеет размер по азимуту и размер по углу места.
10. Устройство по п. 9, в котором размер по азимуту и размер по углу места модифицированного ограниченного пространственного сектора отличаются друг от друга таким образом, что размер по азимуту является более точным для модифицированного ограниченного пространственного сектора непосредственно перед слушателем по сравнению с размером по азимуту модифицированного ограниченного пространственного сектора больше вбок от слушателя, либо при этом размер по азимуту уменьшается в направлении вбок от слушателя, либо при этом размер по углу места модифицированного ограниченного пространственного сектора меньше размера по азимуту модифицированного ограниченного пространственного сектора.
11. Устройство по одному из предшествующих пунктов, в котором в качестве одного или более элементов данных рендеринга для модифицированного ограниченного пространственного сектора используется по меньшей мере одно из левого элемента данных дисперсии, связанного с левыми данными передаточной функции восприятия звука человеком, правого элемента данных дисперсии, связанного с правыми данными передаточной функции восприятия звука человеком (HRTF), и элемента данных ковариации, связанного с левыми данными HRTF и правыми данными HRTF.
12. Устройство по одному из предшествующих пунктов, в котором процессор (4000) идентификации секторов выполнен с возможностью определения набора элементарных пространственных секторов, принадлежащих пространственно протяженному источнику звука, и определения из набора элементарных пространственных секторов одного или более элементарных пространственных секторов в качестве ограниченного модифицированного пространственного сектора, и
- при этом модуль (5000) вычисления целевых данных выполнен с возможностью модификации (5020) одного или более элементов данных рендеринга, ассоциированных с ограниченным модифицированным пространственным сектором, с использованием данных о модификации для получения комбинированных данных, и комбинирования (5040) комбинированных данных с элементами данных рендеринга одного или более элементарных пространственных секторов из набора элементарных пространственных секторов, отличающихся от ограниченного модифицированного пространственного сектора и не модифицируемых либо модифицируемых другим способом по сравнению с модификацией для ограниченного модифицированного пространственного сектора.
13. Устройство по п. 12, в котором процессор (4000) идентификации секторов выполнен с возможностью классификации набора элементарных пространственных секторов на различные классы (4010, 4020, 4030) секторов на основе характеристик, ассоциированных с элементарными пространственными секторами,
- при этом модуль (5000) вычисления целевых данных выполнен с возможностью комбинирования элементов данных рендеринга элементарных пространственных секторов в каждом классе для получения комбинированного результата для каждого класса, если в классе находится более одного элементарного пространственного сектора, и применения конкретной функции модификации, ассоциированной по меньшей мере с одним классом, к комбинированному результату этого класса для получения модифицированного комбинированного результата для этого класса, или
- применения конкретной функции модификации, ассоциированной по меньшей мере с одним классом, к одному или более элементам данных одного или более элементарных пространственных секторов каждого класса для получения модифицированных элементов данных, и комбинирования модифицированных элементов данных элементарных пространственных секторов в каждом классе для получения модифицированного комбинированного результата для этого класса,
- комбинирования (5040) комбинированного результата, либо, при наличии, модифицированного комбинированного результата для каждого класса для получения полного комбинированного результата, и
- использования (5060) полного комбинированного результата в качестве целевых данных рендеринга или вычисления целевых данных рендеринга из полного комбинированного результата.
14. Устройство по п. 13,
- в котором характеристика для элементарного пространственного сектора определяется как представляющий собой одно из группы, содержащей загороженный элементарный пространственный сектор, включающий в себя первую характеристику загораживания, загороженный элементарный пространственный сектор, включающий в себя вторую характеристику загораживания, отличающуюся от первой характеристики загораживания, незагороженный элементарный пространственный сектор, имеющий первое расстояние до слушателя, и незагороженный элементарный пространственный сектор, имеющий второе расстояние до слушателя, при этом второе расстояние отличается от первого расстояния.
15. Устройство по одному из пп. 8-14, в котором модуль (5000) вычисления целевых данных выполнен с возможностью модификации или комбинирования (5040) частотно-зависимых параметров дисперсии или ковариации в качестве элементов данных рендеринга для получения в качестве полного комбинированного результата параметра полной комбинированной дисперсии или полной комбинированной ковариации, и
- вычисления (5060) по меньшей мере одного из сигнальной метки интерауральной или межканальной когерентности, сигнальной метки интерауральной или межканальной разности уровней, сигнальной метки интерауральной или межканальной разности фаз, первого бокового усиления или второго бокового усиления в качестве целевых данных рендеринга, и
- при этом аудиопроцессор (300, 3000) выполнен с возможностью обработки аудиосигнала с использованием по меньшей мере одного из сигнальной метки интерауральной или межканальной когерентности, сигнальной метки интерауральной или межканальной разности уровней, сигнальной метки интерауральной или межканальной разности фаз, первого бокового усиления или второго бокового усиления в качестве целевых данных рендеринга.
16. Способ синтезирования пространственно протяженного источника звука, содержащий этапы, на которых:
- принимают описание аудиосцены, причем описание аудиосцены содержит данные пространственно протяженных источников звука для пространственно протяженного источника звука и данные о модификации для потенциально модифицирующего объекта (7010), и принимают данные слушателя;
- идентифицируют ограниченный модифицированный пространственный сектор для пространственно протяженного источника звука в диапазоне рендеринга для слушателя, причем диапазон рендеринга для слушателя больше ограниченного модифицированного пространственного сектора, на основе данных пространственно протяженных источников звука и данных слушателя, и данных о модификации;
- вычисляют целевые данные рендеринга из одного или более элементов данных рендеринга, принадлежащих модифицированному ограниченному пространственному сектору; и
- обрабатывают аудиосигнал, представляющий пространственно протяженный источник звука, с использованием целевых данных рендеринга.
17. Генератор аудиосцен для формирования описания аудиосцен, содержащий:
- генератор (6010) данных пространственно протяженных источников звука (SESS) для формирования данных SESS для пространственно протяженного источника звука.
- генератор (6020) данных о модификации для формирования данных о модификации для потенциально модифицирующего объекта (7010); и
- выходной интерфейс (6030) для формирования описания аудиосцен, содержащего данные SESS и данные о модификации.
18. Генератор аудиосцен по п. 17, в котором данные о модификации содержат описание функции нижних частот, при этом функция нижних частот содержит значение ослабления для более высокой частоты, причем значение ослабления для более высокой частоты представляет значение ослабления, более сильное по сравнению со значением ослабления для более низкой частоты, и при этом выходной интерфейс (6030) выполнен с возможностью ввода описания функции ослабления в качестве данных о модификации в описание аудиосцен.
19. Генератор аудиосцен по п. 17 или 18, в котором данные о модификации содержат геометрические данные для потенциально модифицирующего объекта (7010), и при этом выходной интерфейс (6030) выполнен с возможностью ввода геометрических данных для потенциально модифицирующего объекта (7010) в качестве данных о модификации в описание аудиосцен.
20. Генератор аудиосцен по одному из пп. 17-19, в котором генератор (6010) данных SESS выполнен с возможностью формирования в качестве данных SESS местоположения SESS и информации о геометрии SESS, и
- при этом выходной интерфейс (6030) выполнен с возможностью ввода в качестве данных SESS информации о местоположении SESS и информации о геометрии SESS.
21. Генератор аудиосцен по одному из пп. 17-20, в котором генератор (6010) данных SESS выполнен с возможностью формирования в качестве данных SESS информации о размере, о положении или об ориентации пространственно протяженного источника звука либо данных формы сигнала для одного или более аудиосигналов, ассоциированных с пространственно протяженным источником звука, или
- при этом модуль (6020) вычисления данных о модификации выполнен с возможностью вычисления в качестве данных о модификации геометрии потенциально модифицирующего объекта (7010), например, потенциально загораживающего объекта.
22. Способ формирования описания аудиосцен, содержащий этапы, на которых:
- формируют данные пространственно протяженных источников звука (SESS) для пространственно протяженного источника звука;
- формируют данные о модификации для потенциально модифицирующего объекта (7010); и
- формируют описание аудиосцен, содержащее данные SESS и данные о модификации.
| Способ регенерирования сульфо-кислот, употребленных при гидролизе жиров | 1924 |
|
SU2021A1 |
| Способ регенерирования сульфо-кислот, употребленных при гидролизе жиров | 1924 |
|
SU2021A1 |
| Способ восстановления спиралей из вольфрамовой проволоки для электрических ламп накаливания, наполненных газом | 1924 |
|
SU2020A1 |
| Способ регенерирования сульфо-кислот, употребленных при гидролизе жиров | 1924 |
|
SU2021A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| ФОРМИРОВАНИЕ БИНАУРАЛЬНЫХ СИГНАЛОВ | 2009 |
|
RU2505941C2 |

