Настоящее изобретение относится к обработке аудиосигнала в системе декодирования 3D-аудио, такой как кодек, соответствующий стандарту MPEG-H 3D audio. Настоящее изобретение более конкретно относится к обработке монофонического сигнала, предназначенного для воспроизведения головной гарнитурой, которая, кроме того, принимает бинауральные аудиосигналы.
Термин «бинауральный» обозначает воспроизведение головной аудиогарнитурой или парой наушников аудиосигнала, который при этом включает эффекты пространственного ориентирования. Бинауральная обработка аудиосигналов, называемая далее бинаурализацией или бинаурализационной обработкой, применяет фильтры HRTF (передаточная функция с учетом положения головы) в частотной области, или фильтры HRIR, BRIR (импульсный отклик с учетом положения головы, бинауральный импульсный отклик помещения) во временной области, которые воспроизводят акустические передаточные функции между источниками звука и ушами слушателя. Эти фильтры служат цели симуляции подсказок о положении для аудитории, позволяющих слушателю определять местоположение источников звука, как это происходит в ситуациях прослушивания в реальной жизни.
Сигнал для правого уха получают путем фильтрации монофонического сигнала посредством передаточной функции (HRTF) правого уха, а сигнал для левого уха получают посредством фильтрации того же монофонического сигнала посредством передаточной функции левого уха.
В кодеках NGA (next generation audio), таких как MPEG-H 3D audio, который описан в документе со ссылкой на ISO/IEC 23008-3: «High efficiency coding and media delivery in heterogenous environments – Part 3: 3D audio», опубликованной 25/07/2014, или даже AC4, описанном в документе со ссылкой на ETSI TS 103 190: «Digital Audio Compression Standard», опубликованном в апреле 2014, сигналы, принимаемые декодером, сначала декодируют, затем подвергают бинаурализационной обработке, как описано выше, перед воспроизведением головной аудиогарнитурой. В данном документе рассматривается случай, в котором звук, воспроизводимый головной аудиогарнитурой, имеет пространственное ориентирование, т.е. такой, в котором задействован бинаурализированный сигнал.
Вышеупомянутые кодеки, таким образом, закладывают основу для возможности воспроизведения множеством виртуальных громкоговорителей бинаурализированного сигнала, прослушиваемого на головной гарнитуре, а также закладывают основу для возможности воспроизведения множеством реальных громкоговорителей пространственно ориентированного звука.
В определенных случаях с бинаурализационной обработкой связана функция, предназначенная для отслеживания головы пользователя (функция отслеживания головы), эта функция также называется динамическим воспроизведением, в противоположность статическому воспроизведению. Этот тип обработки позволяет принимать в расчет перемещение головы слушателя, с тем чтобы модифицировать звук, воспроизводимый в каждом ухе, чтобы сохранить стабильность воспроизведения аудиосцены. Другими словами, слушатель будет воспринимать источники звука как расположенные в одном и том же месте в физическом пространстве независимо от того, двигает ли он головой.
Это может быть важным при просмотре и прослушивании информационного видеоматериала с углом в 360°.
Однако обработка определенных видов информационного материала посредством этого типа обработки является нежелательной. В частности, в определенных случаях, если информационный материал был создан конкретно для бинаурального воспроизведения, например, если сигналы были записаны непосредственно с применением муляжа головы или уже были обработаны посредством бинаурализационной обработки, то они должны быть воспроизведены наушниками головной гарнитуры непосредственно. Эти сигналы не нуждаются в дополнительной бинаурализационной обработке.
Подобным образом, создатель информационного материала может пожелать, чтобы аудиосигнал воспроизводился независимо от аудиосцены, т.е. чтобы он воспринимался как звук, отдельный от аудиосцены, например, в случае с закадровым голосом.
Этот тип воспроизведения может, например, позволить обеспечивать объяснения, с воспроизведением помимо этого аудиосцены. Например, создатель информационного материала может пожелать, чтобы звук воспроизводился в одно ухо, с целью получения запланированного эффекта «головного телефона», т.е. Так, чтобы звук был слышен только в одном ухе. Также может быть желательным, чтобы этот звук никогда не был слышен в другом ухе, даже если пользователь двигает своей головой, как в случае с предыдущим примером. Создатель информационного материала может также пожелать, чтобы этот звук воспроизводился в конкретном положении в аудиопространстве относительно уха слушателя (и не только лишь внутри одного уха), даже если последний двигает своей головой.
Если такой монофонический сигнал был декодирован и подан на вход системы воспроизведения, такой как кодек MPEG-H 3D audio или AC4, он будет бинаурализирован. Звук тогда будет распределен между двумя ушами (хотя он будет более тихим в противоположном ухе), и если пользователь будет двигать головой, его ухо не будет воспринимать звук таким же образом, поскольку обработка с отслеживанием головы, при ее задействовании, заставит положение источника звука оставаться таким же, как и в начальной аудиосцене: громкость звука в каждом из двух ушей будет, таким образом, казаться переменной в зависимости от положения головы.
В одном предложенном изменении стандарта MPEG-H 3D audio, в дополнении, названном «ISO/IEC JTC1/SC29/WG11 MPEG2015/M37265» от октября 2015 предложено идентифицировать информационный материал, который не должен быть изменен посредством бинаурализации.
Таким образом, «дихотическая» идентификация связана с информационным материалом, который не должен обрабатываться посредством бинаурализации.
Тогда все аудиоэлементы будут бинаурализированы, за исключением тех, которые рассматриваются как «дихотические». Термин «дихотический» означает, что в каждое из ушей подается разный сигнал.
Таким же образом, в стандарте AC4 бит данных обозначает, что сигнал уже был виртуализирован. Этот бит позволяет деактивировать постобработку. Информационный материал, идентифицированный таким образом, представляет собой информационный материал, уже отформатированный для головной аудиогарнитуры, т.е. бинауральный информационный материал. Он содержит два канала.
Эти способы не решают проблему с монофоническим сигналом, в отношении которого создатель аудиосцены не желает выполнять бинаурализацию.
Это предотвращает воспроизведение монофонического сигнала независимо от аудиосцены в конкретном положении относительно уха слушателя, что далее будет называться режимом «головного телефона». С применением двухканальных методов из уровня техники одним способом достижения желаемого воспроизведения в одно ухо является создание двухканального информационного материала, состоящего из сигнала в одном из каналов и тишины в другом канале, или, конечно же, создание стереофонического информационного материала, принимающего в расчет желаемое пространственное положение, и идентифицирование этого информационного материала как уже имеющего пространственное ориентирование перед его передачей.
Однако, поскольку этот стереофонический информационный материал должен быть создан, этот тип обработки создает сложности и требует дополнительного диапазона частот для передачи этого стереофонического информационного материала.
Таким образом, существует потребность в обеспечении решения, которое позволяет осуществлять передачу сигнала, который будет воспроизводиться в конкретном положении относительно уха человека, носящего головную аудиогарнитуру, независимо от аудиосцены, воспроизводимой той же головной гарнитурой, с оптимизацией при этом диапазона частот, требуемого применяемым кодеком.
Настоящее изобретение предназначено для улучшения данной ситуации.
С этой целью в нем предложен способ обработки монофонического аудиосигнала в декодере 3D-аудио, включающий этап выполнения бинаурализационной обработки декодированных сигналов, предназначенных для пространственного воспроизведения головной аудиогарнитурой. Суть способа заключается в том, что
при обнаружении в потоке данных, представляющем монофонический сигнал, указания на невыполнение бинаурализационной обработки, связанного с воспроизведением информации о пространственном положении, декодированный монофонический сигнал направляется на узел стереофонического воспроизведения, который принимает в расчет информацию о положении для создания двух каналов воспроизведения, обработка которых происходит на этапе непосредственного смешивания, где эти два сигнала суммируются с бинаурализированным сигналом, полученным в результате бинаурализационной обработки, с целью воспроизведения головной аудиогарнитурой.
Таким образом, возможно указать, что монофонический информационный материал должен воспроизводиться в конкретном пространственном положении относительно уха слушателя и для этого не проходить бинаурализационной обработки, так что этот воспроизводимый сигнал может обладать эффектом «головного телефона», т.е. слышаться слушателю в определенном положении относительно одного уха, внутри его головы, таким же образом, что и стереофонический сигнал, и даже при перемещении головы слушателя.
В частности, стереофонические сигналы отличаются тем фактом, что каждый аудиоисточник присутствует в каждом из 2 (левом и правом) выходных каналов с некоторой разницей в громкости (или ILD, интерауральная разница уровней) и иногда разницей по времени (или ITD, интерауральная разница по времени) между каналами. При прослушивании стереофонического сигнала на головной гарнитуре источники воспринимаются как расположенные внутри головы слушателя, в месте между левым ухом и правым ухом, что зависит от ILD и/или ITD. Бинауральные сигналы отличаются от стереофонических сигналов тем, что в отношении источников применяется фильтр, который воспроизводит акустический путь от источника до уха слушателя. При прослушивании бинаурального сигнала на головной гарнитуре источники воспринимаются снаружи головы, в месте, расположенном на сфере, в зависимости от примененного фильтра.
Стереофонический и бинауральный сигналы похожи в том, что они состоят из 2 (левого и правого) каналов, а отличаются информационным материалом этих 2 каналов.
Воспроизводимый моносигнал (монофонический сигнал) затем накладывается на другие воспроизводимые сигналы, которые образуют трехмерную аудиосцену.
Диапазон частот, необходимый для указания этого типа информационного материала, оптимизирован, поскольку достаточно лишь закодировать указание положения в аудиосцене вдобавок к указанию на невыполнение бинаурализации, чтобы сообщить декодеру о необходимости выполнения обработки, в противоположность способу, требующему кодирования, передачи и последующего декодирования стереофонического сигнала, принимающего в расчет это пространственное положение.
Различные конкретные варианты осуществления, указанные ниже, могут быть добавлены раздельно или в сочетании друг с другом к этапам способа обработки, определенного выше.
В одном конкретном варианте осуществления информация о пространственном положении воспроизведения представляет собой двоичные данные, указывающие на один канал воспроизводящей головной аудиогарнитуры.
Эта информация требует только одного кодирующего бита, тем самым позволяя ограничить требуемый диапазон частот еще больше.
В данном варианте осуществления лишь канал воспроизведения, соответствующий каналу, указанному двоичными данными, суммируется с соответствующим каналом бинаурализированного сигнала на этапе непосредственного смешивания, при этом данное значение для другого канала воспроизведения равно нулю.
Выполняемое таким образом суммирование просто в реализации и обеспечивает достижение желаемого эффекта «головного телефона», заключающегося в наложении моносигнала на воспроизводимую аудиосцену.
В одном конкретном варианте осуществления монофонический сигнал представляет собой сигнал канального типа, который направляется на узел стереофонического воспроизведения совместно с информацией о пространственном положении воспроизведения.
Таким образом, монофонический сигнал не проходит этап, на котором выполняется бинаурализационная обработка и не обрабатывается, как сигналы канального типа, обрабатываемые обычным образом в способах из уровня техники. Этот сигнал обрабатывается узлом стереофонического воспроизведения, отличным от существующих узлов воспроизведения, используемых для сигналов канального типа. Этот узел воспроизведения дублирует монофонический сигнал в 2 каналах, но применяет коэффициенты к двум каналам в зависимости от информации о пространственном положении воспроизведения.
Этот узел стереофонического воспроизведения может, помимо этого, быть встроен в канальный узел воспроизведения, при этом обработка отличается в зависимости от обнаружения, выполненного в отношении сигнала, поступающего на вход этого узла воспроизведения, или в модуль непосредственного смешивания, который суммирует каналы, сгенерированные этим узлом стереофонического воспроизведения, с бинаурализированным сигналом, сгенерированным модулем, который выполняет бинаурализационную обработку.
В одном варианте осуществления, связанном с этим сигналом канального типа, информация о пространственном положении воспроизведения представляет собой данные ILD о интерауральной разнице уровней или в целом информацию об отношении уровней правого и левого каналов.
В другом варианте осуществления монофонический сигнал представляет собой сигнал объектного типа, связанный с набором параметров воспроизведения, содержащим указание на невыполнение бинаурализации и информацию о положении воспроизведения, при этом сигнал направляют в узел стереофонического воспроизведения совместно с информацией о пространственном положении воспроизведения.
В этом другом варианте осуществления информация о пространственном положении воспроизведения представляет собой, например, данные об азимутальном угле.
Эта информация позволяет точно определить положение воспроизведения относительно уха человека, носящего головную аудиогарнитуру, так что этот звук воспроизводится с наложением на аудиосцену.
Таким образом, монофонический сигнал не проходит этап, на котором выполняется бинаурализационная обработка и не обрабатывается, как сигналы объектного типа, обрабатываемые обычным образом в способах из уровня техники. Этот сигнал обрабатывается узлом стереофонического воспроизведения, отличным от существующих узлов воспроизведения, используемых для сигналов объектного типа. Указание на невыполнение бинаурализационной обработки и информация о положении воспроизведения содержатся в параметрах воспроизведения (метаданных), связанных с сигналом объектного типа. Этот узел воспроизведения может, помимо этого, быть встроен в объектный узел воспроизведения или в модуль непосредственного смешивания, который суммирует каналы, сгенерированные этим узлом стереофонического воспроизведения, с бинаурализированным сигналом, сгенерированным модулем, который выполняет бинаурализационную обработку.
Настоящее изобретение также относится к устройству для обработки монофонического аудиосигнала, содержащему модуль для выполнения бинаурализационной обработки декодированных сигналов, предназначенных для пространственного воспроизведения головной аудиогарнитурой. Это устройство содержит:
- модуль обнаружения, способный обнаруживать в потоке данных, представляющем монофонический сигнал, указание на невыполнение бинаурализационной обработки, связанное с информацией о пространственном положении воспроизведения;
- модуль для перенаправления, способный, в случае подтвержденного обнаружения модулем обнаружения, направлять декодированный монофонический сигнал на узел стереофонического воспроизведения;
- узел стереофонического воспроизведения, способный принимать в расчет информацию о положении для создания двух каналов воспроизведения;
- модуль непосредственного смешивания, способный непосредственно обрабатывать два канала воспроизведения посредством их суммирования с бинаурализированным сигналом, сгенерированным модулем для выполнения бинаурализационной обработки, с целью воспроизведения головной аудиогарнитурой.
Данное устройство имеет те же преимущества, что и описанный ранее способ, который оно реализует.
В одном конкретном варианте осуществления узел стереофонического воспроизведения встроен в модуль непосредственного смешивания.
Таким образом, каналы воспроизведения создаются лишь в модуле непосредственного смешивания, вследствие чего на модуль непосредственного смешивания передается лишь информация о положении совместно с моносигналом. Сигнал может быть канального типа или объектного типа.
В одном варианте осуществления монофонический сигнал представляет собой сигнал канального типа, и узел стереофонического воспроизведения встроен в канальный узел воспроизведения, который, к тому же, создает каналы воспроизведения для многоканальных сигналов.
В другом варианте осуществления монофонический сигнал представляет собой сигнал объектного типа, и узел стереофонического воспроизведения встроен в объектный узел воспроизведения, который, к тому же, создает каналы воспроизведения для монофонических сигналов, связанных с наборами параметров воспроизведения.
Настоящее изобретение относится к аудиодекодеру, содержащему устройство обработки, подобное описанному, и к компьютерной программе, содержащей команды программного кода для реализации этапов описанного способа обработки при выполнении этих команд процессором.
Наконец, изобретение относится к необязательно извлекаемому считываемому процессором информационному носителю, который может быть или не быть интегрирован в устройство обработки, и который хранит компьютерную программу, содержащую команды для выполнения способа обработки, описанного выше.
Другие признаки и преимущества настоящего изобретения станут более очевидными из прочтения нижеследующего описания, приведенного только в качестве неограничивающего примера, со ссылкой на прилагаемые графические материалы, на которых:
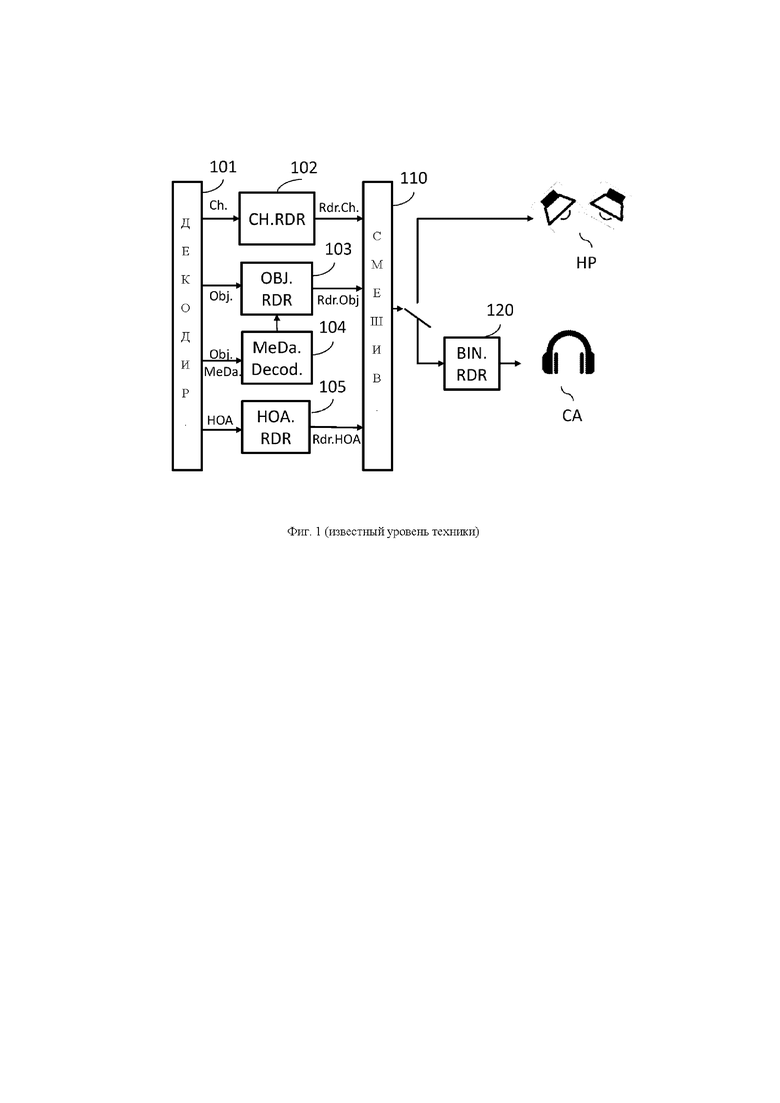
на фиг. 1 изображен декодер MPEG-H 3D audio, такой как известный из уровня техники;
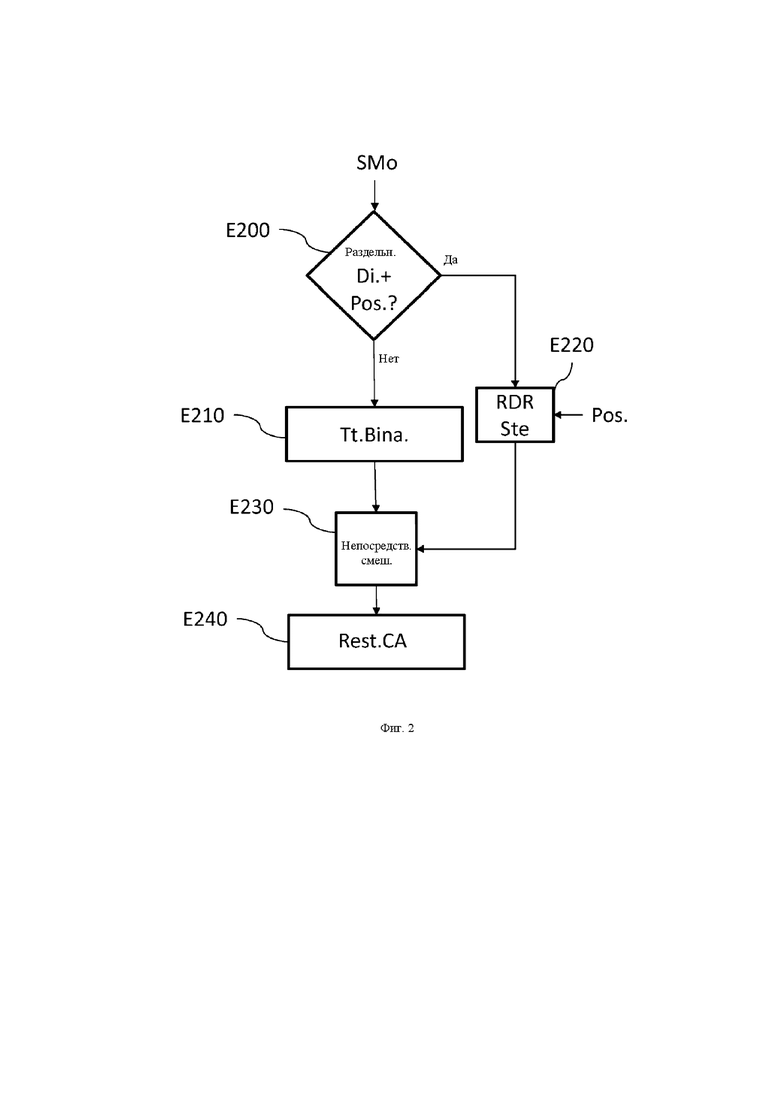
на фиг. 2 изображены этапы способа обработки в соответствии с одним вариантом осуществления настоящего изобретения;
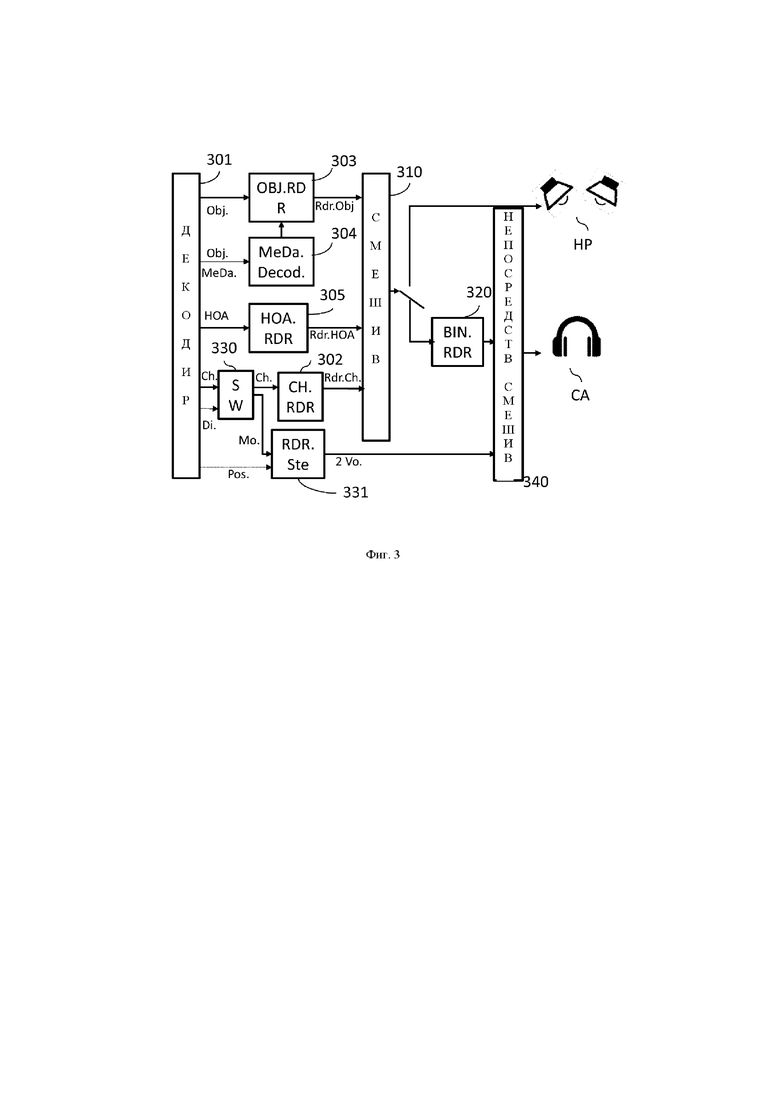
на фиг. 3 изображен декодер, содержащий устройство обработки в соответствии с первым вариантом осуществления настоящего изобретения;
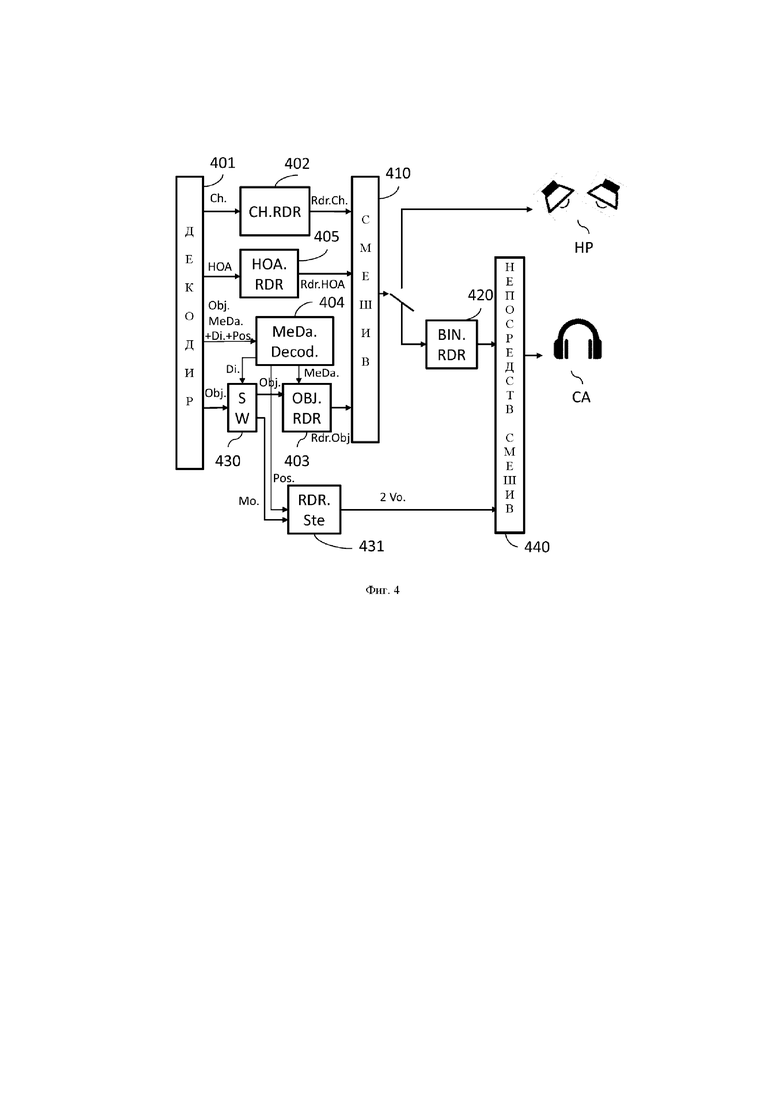
на фиг. 4 изображен декодер, содержащий устройство обработки в соответствии со вторым вариантом осуществления настоящего изобретения; и
на фиг. 5 изображено аппаратное представление устройства обработки в соответствии с одним вариантом осуществления настоящего изобретения.
На фиг. 1 схематически изображен декодер, такой как стандартизированный в стандарте MPEG-H 3D audio, обозначенном в документе, на который была дана ссылка выше. Блок 101 представляет собой модуль декодирования, который декодирует как многоканальные аудиосигналы (Ch.) «канального» типа, так и монофонические аудиосигналы (Obj.) «объектного» типа, связанные с (содержащимися в метаданных) параметрами (Obj.MeDa.) пространственного ориентирования, а также аудиосигналы в аудиоформате HOA (система Ambisonics высшего порядка).
Сигнал канального типа декодируется и обрабатывается канальным узлом 102 воспроизведения (также называемым «конвертером формата» в стандарте MPEG-H 3D audio), чтобы приспособить этот канальный сигнал к системе аудиовоспроизведения. Канальный узел воспроизведения знает характеристики системы воспроизведения и, таким образом, осуществляет передачу по одному сигналу на канал (Rdr.Ch) воспроизведения с целью приведения в действие либо реальных громкоговорителей, либо виртуальных громкоговорителей (которые затем будут бинаурализированы для воспроизведения головной гарнитурой).
Эти каналы воспроизведения смешиваются посредством модуля 110 смешивания с другими каналами воспроизведения, сгенерированными объектными и HOA-узлами 103, 105 воспроизведения, которые описаны ниже.
Сигналы (Obj.) объектного типа представляют собой монофонические сигналы, связанные с метаданными, такими как параметры пространственного ориентирования (азимутальные углы, подъем), которые позволяют расположить монофонический сигнал на аудиосцене, имеющей пространственное ориентирование, параметры приоритета или параметры громкости аудио. Эти объектные сигналы и связанные параметры декодируются модулем 101 декодирования и обрабатываются объектным узлом 103 воспроизведения, который, зная характеристики системы воспроизведения, адаптирует эти монофонические сигналы к этим характеристикам. Разные каналы (Rdr.Obj.) воспроизведения, таким образом, смешиваются с другими каналами воспроизведения, сгенерированными канальными и HOA-узлами воспроизведения, посредством модуля 110 смешивания.
Таким же образом, сигналы HOA (cистема Ambisonics высшего порядка) декодируются и декодированные компоненты системы Ambisonics подаются на вход HOA-узла 105 воспроизведения с целью адаптирования этих компонентов к системе аудиовоспроизведения.
Каналы (Rdr.HOA) воспроизведения, созданные этим HOA-узлом воспроизведения, смешиваются на этапе 110 с каналами воспроизведения, созданными другими узлами 102 и 103 воспроизведения.
Сигналы на выходе из модуля 110 смешивания могут быть воспроизведены реальными громкоговорителями HP, расположенными в комнате воспроизведения. В этом случае сигналы на выходе из модуля смешивания могут быть поданы непосредственно на эти реальные громкоговорители, при этом один канал соответствует одному громкоговорителю.
В случае, если сигналы на выходе из модуля смешивания предназначены для воспроизведения головной аудиогарнитурой CA, эти сигналы обрабатываются модулем 120 для выполнения бинаурализационной обработки с применением методик бинаурализации, таких как, например, описанных в цитируемом документе в отношении стандарта MPEG-H 3D audio.
Таким образом, все сигналы, предназначенные для воспроизведения головной аудиогарнитурой, обрабатываются модулем 120 для выполнения бинаурализационной обработки.
На фиг. 2 изображены этапы способа обработки в соответствии с одним вариантом осуществления настоящего изобретения.
Этот способ относится к обработке монофонического сигнала в 3D-аудиодекодере. На этапе E200 обнаруживают, содержит ли поток (SMo) данных, представляющем монофонический сигнал (например, поток битов на входе аудиодекодера), указание на невыполнение бинаурализации, связанное с информацией о пространственном положении воспроизведения. В противоположном случае (N на этапе E200) сигнал должен быть бинаурализирован. Он обрабатывается посредством выполнения бинаурализационной обработки на этапе E210 перед воспроизведением на этапе E240 посредством воспроизводящей головной аудиогарнитуры. Этот бинаурализированный сигнал может быть смешан с другими стереофоническими сигналами, сгенерированными на этапе E220, описанном выше.
В случае, если поток данных, представляющем монофонический сигнал, содержит как указание (Di.) на невыполнение бинаурализации, так и информацию (Pos.) о пространственном положении воспроизведения (Y на этапе E200), декодированный монофонический сигнал направляется на узел стереофонического воспроизведения для обработки на этапе E220.
Это указание на невыполнение бинаурализации может, например, как в уровне техники, представлять собой «дихотическую» идентификацию, данную монофоническому сигналу, или иную идентификацию, понимаемую как указание не обрабатывать сигнал посредством бинаурализационной обработки. Информация о пространственном положении воспроизведения может, например, представлять собой азимутальный угол, указывающий на положение воспроизведения звука относительно левого или правого уха, или даже указание на разницу уровня между левым и правым каналами, как например, информацию ILD, позволяющую распределять энергию монофонического сигнала между левым и правым каналами, или даже указание на то, что должен использоваться один канал воспроизведения, соответствующий левому или правому уху. В последнем случае эта информация представляет собой двоичную информацию, которая требует очень незначительного диапазона частот (1 единственный бит данных).
На этапе E220 информация о положении принимается в расчет для создания двух каналов воспроизведения для двух наушников головной аудиогарнитуры. Эти два канала воспроизведения, созданные таким образом, обрабатываются непосредственно на этапе Е230 непосредственного смешивания, в котором эти два стереофонических канала суммируются с двумя каналами бинаурализированного сигнала, полученными вследствие бинаурализационной обработки E210.
Каждый из стереофонических каналов воспроизведения затем суммируется с соответствующим бинаурализированным сигналом.
После этого этапа непосредственного смешивания два канала воспроизведения, сгенерированные на этапе Е230 смешивания, воспроизводятся на этапе E240 посредством головной аудиогарнитуры CA.
В варианте осуществления, где информация о пространственном положении воспроизведения представляет собой двоичные данные, указывающие на один канал воспроизводящей головной аудиогарнитуры, это означает, что монофонический сигнал должен воспроизводиться только одним наушником этой головной гарнитуры. Данные два канала воспроизведения, созданные на этапе E220 посредством узла стереофонического воспроизведения, таким образом, состоят из одного канала, содержащего монофонический сигнал, при этом второй из них равен нулю и, следовательно, может отсутствовать.
На этапе Е230 непосредственного смешивания единственный канал, таким образом, суммируется с соответствующим каналом бинаурализированного сигнала, при этом другой канал равен нулю. Этот этап смешивания, таким образом, упрощается.
Таким образом, слушатель, носящий головную аудиогарнитуру, слышит, с одной стороны, пространственно ориентированную аудиосцену, сгенерированную из бинаурализированного сигнала (в случае динамического воспроизведения физическое размещение аудиосцены, слышимой слушателем, остается тем же, даже если он двигает головой) и, с другой стороны, звук, расположенный внутри своей головы, между одним ухом и центром своей головы, независимо накладываемый на аудиосцену, т.е. если слушатель двигает своей головой, этот звук слышен в том же положении относительно одного уха.
Этот звук, таким образом, воспринимается как наложенный на другие бинаурализированные звуки аудиосцены, и будет, например, функционировать как закадровый голос в этой аудиосцене.
Таким образом достигается эффект «головного телефона».
На фиг. 3 изображен первый вариант осуществления декодера, содержащего устройство обработки, которое реализует способ обработки, описанный со ссылкой на фиг. 2. В этом примерном варианте осуществления монофонический сигнал, обрабатываемый посредством реализуемого способа, представляет собой сигнал канального типа (Ch.).
Сигналы (Obj.) объектного типа и сигналы (HOA) НОА-типа обрабатываются посредством соответствующих блоков 303, 304 и 305 таким же образом, как и в отношении блоков 103, 104 и 105, описанных со ссылкой на фиг. 1. Таким же образом, блок 310 смешивания выполняет смешивание таким же образом, как это было описано в отношении блока 110 на фиг. 1.
Блок 330, который принимает сигналы канального типа, обрабатывает монофонический сигнал, содержащий указание (Di.) на невыполнение бинаурализации, связанное с информацией (Pos.) о пространственном положении воспроизведения, отличным образом по сравнению с другим сигналом, который не содержит этих элементов информации, в частности многоканальным сигналом. Что касается этих сигналов, не содержащих этих элементов информации, они обрабатываются блоком 302 таким же образом, как и в блоке 102, описанном со ссылкой на фиг. 1.
Для монофонического сигнала, содержащего указание на невыполнение бинаурализации, связанное с информацией о пространственном положении воспроизведения, блок 330 действует как маршрутизатор или коммутатор и направляет декодированный монофонический сигнал (Mo.) на узел 331 стереофонического воспроизведения. Узел стереофонического воспроизведения, помимо прочего, принимает от модуля декодирования информацию (Pos.) о пространственном положении воспроизведения. Используя эту информацию, он создает два канала (2 Vo.) воспроизведения, соответствующие левому и правому каналам воспроизводящей головной аудиогарнитуры, так что эти каналы могут быть воспроизведены головной аудиогарнитурой CA.
В одном примерном варианте осуществления информация о пространственном положении воспроизведения представляет собой информацию о интерауральной разнице уровней между левым и правым каналами. Эта информация позволяет коэффициенту, который должен быть применен к каждому из каналов воспроизведения, обеспечить достижение этого пространственного положения воспроизведения, подлежащего определению.
Эти коэффициенты могут быть определены, как в документе со ссылкой на MPEG-2 AAC: ISO/IEC 13818-4:2004/DCOR 2, AAC в разделе 7.2, описывающем интенсивность стерео.
Перед воспроизведением головной аудиогарнитурой эти каналы воспроизведения суммируются с каналами бинаурализированного сигнала, сгенерированными модулем 320 бинаурализации, который выполняет бинаурализационную обработку таким же образом, что и блок 120 на фиг. 1.
Этот этап суммирования каналов выполняется модулем 340 непосредственного смешивания, который суммирует левый канал, сгенерированный узлом 331 стереофонического воспроизведения, с левым каналом бинаурализированного сигнала, сгенерированным модулем 320 бинаурализационной обработки, а также правый канал, сгенерированный узлом 331 стереофонического воспроизведения, с правым каналом бинаурализированного сигнала, полученным от модуля 320 бинаурализационной обработки, перед воспроизведением головной гарнитурой CA.
Таким образом, монофонический сигнал не проходит через модуль 320 бинаурализационной обработки, он передается непосредственно на узел 331 стереофонического воспроизведения перед смешиванием непосредственно с бинаурализированным сигналом.
Этот сигнал также не будет подвергаться обработке с отслеживанием головы. Воспроизводимый звук, таким образом, будет находиться в некотором положении воспроизведения относительно одного уха слушателя, и будет оставаться в этом положении, даже если слушатель двигает своей головой.
В этом варианте осуществления узел 331 стереофонического воспроизведения может быть встроен в канальный узел 302 воспроизведения. В этом случае этот канальный узел воспроизведения реализует как адаптирование традиционных сигналов канального типа, как описано со ссылкой на фиг. 1, так и создание двух каналов воспроизведения узла 331 воспроизведения, как описано выше, когда принимается информация (Pos.) о пространственном положении воспроизведения. Только два канала воспроизведения тогда перенаправляются на модуль 340 непосредственного смешивания перед воспроизведением головной аудиогарнитурой CA.
В одном иллюстративном варианте осуществления узел 331 стереофонического воспроизведения встроен в модуль 340 непосредственного смешивания. В этом случае модуль 330 маршрутизации направляет декодированный монофонический сигнал (для которого были обнаружены указание на невыполнение бинаурализации и информация о пространственном положении воспроизведения) на модуль 340 непосредственного смешивания. Кроме того, на модуль 340 непосредственного смешивания также передается декодированная информация (Pos.) о пространственном положении воспроизведения. Поскольку этот модуль непосредственного смешивания в таком случае содержит узел стереофонического воспроизведения, посредством него реализуется создание двух каналов воспроизведения, принимающих в расчет информацию о пространственном положении воспроизведения, и смешивание этих двух каналов воспроизведения с каналами воспроизведения бинаурализированного сигнала, сгенерированными модулем 320 бинаурализационной обработки.
На фиг. 4 изображен второй вариант осуществления декодера, содержащего устройство обработки, которое реализует способ обработки, описанный со ссылкой на фиг. 2. В этом примерном варианте осуществления монофонический сигнал, обрабатываемый посредством реализуемого способа, представляет собой сигнал (Obj.) объектного типа.
Сигналы (Ch.) канального типа и сигналы (HOA) НОА-типа обрабатываются посредством соответствующих блоков 402 и 405 таким же образом, как и в отношении блоков 102 и 105, описанных со ссылкой на фиг. 1. Таким же образом, блок 410 смешивания выполняет смешивание так же, как это было описано в отношении блока 110 на фиг. 1.
Блок 430, который принимает сигналы (Obj.) объектного типа, обрабатывает монофонический сигнал, для которого было обнаружено, что указание (Di.) на невыполнение бинаурализации, связанное с информацией (Pos.) о пространственном положении воспроизведения, отличается от такового для другого монофонического сигнала, для которого эти элементы информации не были обнаружены.
Что касается монофонических сигналов, для которых эти элементы информации не были обнаружены, они обрабатываются блоком 403 таким же образом, как и в блоке 103, описанном со ссылкой на фиг. 1, с применением параметров, декодированных блоком 404, который декодирует метаданные таким же образом, что и блок 104 согласно фиг. 1.
В отношении монофонического сигнала объектного типа, для которого было обнаружено указание на невыполнение бинаурализации, связанное с информацией о пространственном положении воспроизведения, блок 430 действует как маршрутизатор или коммутатор и направляет декодированный монофонический сигнал (Mo.) на узел 431 стереофонического воспроизведения.
Указание (Di.) на невыполнение бинаурализации и информация (Pos.) о пространственном положении воспроизведения декодируются блоком 404 для декодирования метаданных или параметров, связанных с сигналами объектного типа. Указание (Di.) на невыполнение бинаурализации передается на блок 430 маршрутизации, и информация о пространственном положении воспроизведения передается на узел 431 стереофонического воспроизведения.
Узел стереофонического воспроизведения, который, таким образом, принимает информацию (Pos.) о пространственном положении воспроизведения, создает два канала воспроизведения, соответствующие левому и правому каналам воспроизводящей головной аудиогарнитуры, так что эти каналы могут быть воспроизведены головной аудиогарнитурой CA.
В одном примерном варианте осуществления информация о пространственном положении воспроизведения представляет собой информацию об азимутальном угле, образующем угол между желаемым положением воспроизведения и центром головы слушателя.
Эта информация позволяет коэффициенту, который должен быть применен к каждому из каналов воспроизведения, обеспечить достижение этого пространственного положения воспроизведения, подлежащего определению.
Коэффициенты передачи для левого и правого каналов могут быть вычислены способом, представленным в документе, озаглавленном «Virtual Sound Source Positioning Using Vector Base Amplitude Panning» от Ville Pulkki в J. Audio Eng. Soc., том 45, № 6, июнь 1997.
Например, коэффициенты передачи узла стереофонического воспроизведения могут быть заданы как:
g1 = (cosO.sinH + sinO.cosH)/(2.cosH.sinH),
g2 = (cosO.sinH - sinO.cosH)/(2.cosH.sinH),
где g1 и g2 соответствуют коэффициентам для сигналов левого и правого каналов, O представляет собой угол между фронтальным направлением и объектом (называемый азимутом), и H представляет собой угол между фронтальным направлением и положением виртуального громкоговорителя (соответствующий половине угла между громкоговорителями), который задан равным, например, 45°.
Перед воспроизведением головной аудиогарнитурой эти каналы воспроизведения суммируются с каналами бинаурализированного сигнала, сгенерированными модулем 420 бинаурализации, который выполняет бинаурализационную обработку таким же образом, что и блок 120 на фиг. 1.
Этот этап суммирования каналов выполняется модулем 440 непосредственного смешивания, который суммирует левый канал, сгенерированный узлом 431 стереофонического воспроизведения, с левым каналом бинаурализированного сигнала, сгенерированным модулем 420 бинаурализационной обработки, а также правый канал, сгенерированный узлом 431 стереофонического воспроизведения, с правым каналом бинаурализированного сигнала, полученным от модуля 420 бинаурализационной обработки, перед воспроизведением головной гарнитурой CA.
Таким образом, монофонический сигнал не проходит через модуль 420 бинаурализационной обработки, он передается непосредственно на узел 431 стереофонического воспроизведения перед смешиванием непосредственно с бинаурализированным сигналом.
Этот сигнал также не будет подвергаться обработке с отслеживанием головы. Воспроизводимый звук, таким образом, будет находиться в некотором положении воспроизведения относительно одного уха слушателя, и будет оставаться в этом положении, даже если слушатель двигает своей головой.
В этом варианте осуществления узел 431 стереофонического воспроизведения может быть встроен в объектный узел 403 воспроизведения. В этом случае этот объектный узел воспроизведения реализует как адаптирование традиционных сигналов объектного типа, как описано со ссылкой на фиг. 1, так и создание двух каналов воспроизведения узла 431 воспроизведения, как описано выше, когда принимается информация (Pos.) о пространственном положении воспроизведения от модуля 404 декодирования параметров. Только два канала (2Vo.) воспроизведения тогда перенаправляются на модуль 440 непосредственного смешивания перед воспроизведением головной аудиогарнитурой CA.
В одном иллюстративном варианте осуществления узел 431 стереофонического воспроизведения встроен в модуль 440 непосредственного смешивания. В этом случае модуль 430 маршрутизации направляет декодированный монофонический сигнал (Mo.) (для которого были обнаружены указание на невыполнение бинаурализации и информация о пространственном положении воспроизведения) на модуль 440 непосредственного смешивания. Кроме того, на модуль 440 непосредственного смешивания также передается декодированная информация (Pos.) о пространственном положении воспроизведения посредством модуля 404 декодирования параметров. Поскольку этот модуль непосредственного смешивания в таком случае содержит узел стереофонического воспроизведения, посредством него реализуется создание двух каналов воспроизведения, принимающих в расчет информацию о пространственном положении воспроизведения, и смешивание этих двух каналов воспроизведения с каналами воспроизведения бинаурализированного сигнала, сгенерированными модулем 420 бинаурализационной обработки.
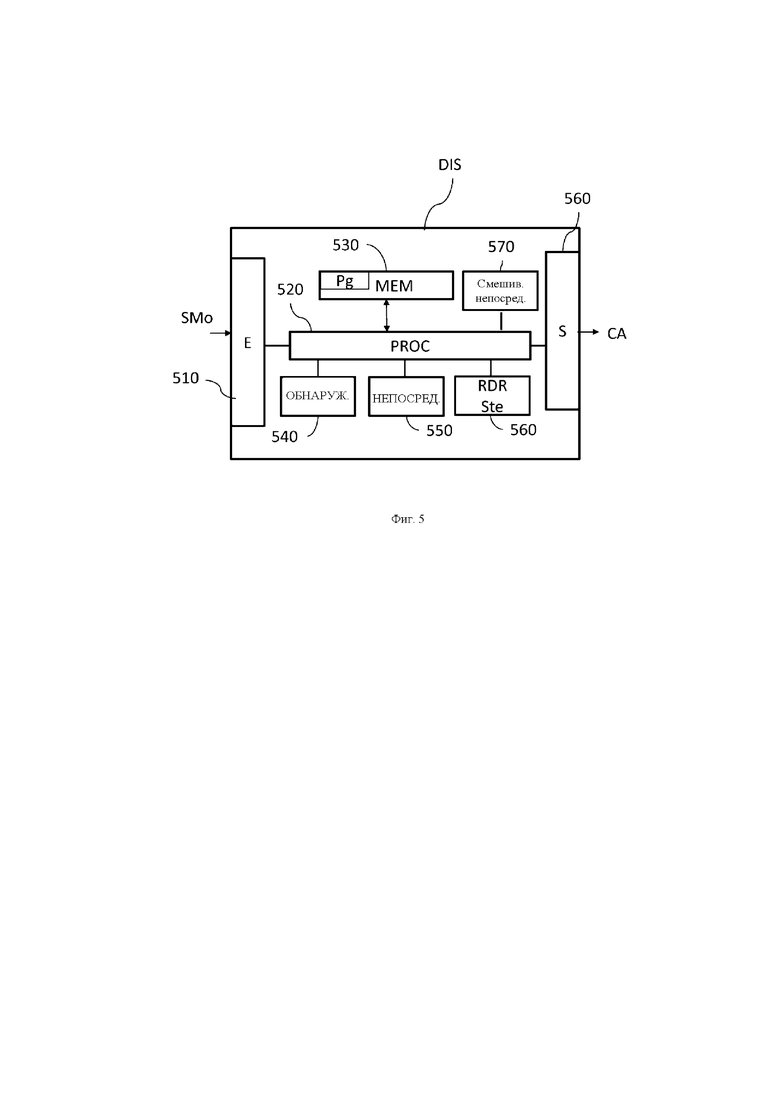
На фиг. 5 изображен пример аппаратного варианта осуществления устройства обработки, способного реализовывать способ обработки согласно настоящему изобретению.
Устройство DIS содержит некоторый объем 530 для хранения, например, запоминающее устройство MEM, и блок 520 обработки, который содержит процессор PROC, управляемый компьютерной программой Pg, хранимой в запоминающем устройстве 530, и реализующей способ обработки согласно настоящему изобретению.
Компьютерная программа Pg содержит команды программного кода для реализации этапов способа обработки согласно настоящему изобретению при выполнении этих команд процессором PROC, и, в частности, при обнаружении в потоке данных, представляющем монофонический сигнал, указания на невыполнение бинаурализационной обработки, связанного с информацией о пространственном положении воспроизведения, выполнения этапа направления декодированного монофонического сигнала на узел стереофонического воспроизведения, который принимает в расчет информацию о положении для создания двух каналов воспроизведения, непосредственная обработка которых происходит на этапе непосредственного смешивания, где эти два сигнала суммируются с бинаурализированным сигналом, полученным в результате бинаурализационной обработки, с целью воспроизведения головной аудиогарнитурой.
Как правило, описание на фиг. 2 применимо к этапам алгоритма такой компьютерной программы.
При запуске команды кода программы Pg, например, загружаются в RAM (не показано) перед их выполнением процессором PROC блока 520 обработки. Команды программы могут храниться в информационном носителе, таком как флеш-память, жесткий диск или любой другой постоянный информационный носитель.
Устройство DIS содержит приемный модуль 510, способный принимать поток данных SMo, представляющий, в частности, монофонический сигнал. Оно содержит модуль 540 обнаружения, способный обнаруживать в данном потоке данных указание на невыполнение бинаурализационной обработки, связанное с информацией о пространственном положении воспроизведения. Оно содержит модуль 550 для направления, в случае подтвержденного обнаружения модулем 540 обнаружения, декодированного монофонического сигнала на узел 560 стереофонического воспроизведения, при этом узел 560 стереофонического воспроизведения способен принимать в расчет информацию о положении для создания двух каналов воспроизведения.
Устройство DIS также содержит модуль 570 непосредственного смешивания, способный непосредственно обрабатывать два канала воспроизведения посредством суммирования их с двумя каналами бинаурализированного сигнала, сгенерированными модулем бинаурализационной обработки. Полученные таким образом каналы воспроизведения передаются на головную аудиогарнитуру CA посредством выходного модуля 560 для воспроизведения.
Варианты осуществления этих разнообразных модулей такие, как описано со ссылкой на фиг. 3 и 4.
Термин «модуль» может соответствовать либо программному компоненту, либо аппаратному компоненту, либо совокупности аппаратных и программных компонентов, при этом программный компонент как таковой соответствует одной или более компьютерным программам или подпрограммам или в более общем виде - любому элементу программы, способному реализовывать функцию или набор функций, как было описано в отношении рассматриваемых модулей. Подобным образом, аппаратный компонент соответствует любому элементу аппаратной совокупности, способной реализовывать функцию или набор функций в отношении рассматриваемого модуля (встроенная схема, печатная плата, карта памяти и т.д.).
Устройство может быть встроено в аудиодекодер, как это изображено на фиг. 3 или 4, и может, например, быть встроено в мультимедийное оборудование, такое как телевизионная приставка или устройство считывания аудио- и видеоинформационного материала. Они также могут быть встроены в оборудование связи, такое как сотовый телефон или коммуникационный шлюз.
Изобретение относится к способу обработки монофонического сигнала в декодере 3D-аудио, включающему этап обработки для бинаурализации декодированных сигналов, предназначенных для пространственного воспроизведения головной гарнитурой. Техническим результатом является обеспечение передачи сигнала для воспроизведения в конкретном положении относительно уха человека, носящего головную аудиогарнитуру, независимо от аудиосцены, воспроизводимой той же головной гарнитурой, с оптимизацией при этом диапазона частот, требуемого применяемым кодеком. Способ заключается в том, что при обнаружении (E200) в потоке данных, представляющих монофонический сигнал, указания на невыполнение бинаурализационной обработки, где указание связано с воспроизведением информации о пространственном положении, декодированный монофонический сигнал направляется (O-E200) на узел стереофонического воспроизведения, который принимает в расчет информацию о положении для создания двух каналов (E220) воспроизведения. При этом обработка каналов происходит на этапе (E230) непосредственного смешивания, где эти два сигнала суммируются с бинаурализированным сигналом, полученным в результате бинаурализационной обработки, для воспроизведения (E240) головной аудиогарнитурой. Настоящее изобретение также относится к декодирующему устройству, с помощью которого реализуется способ обработки. 4 н. и 9 з.п. ф-лы, 5 ил.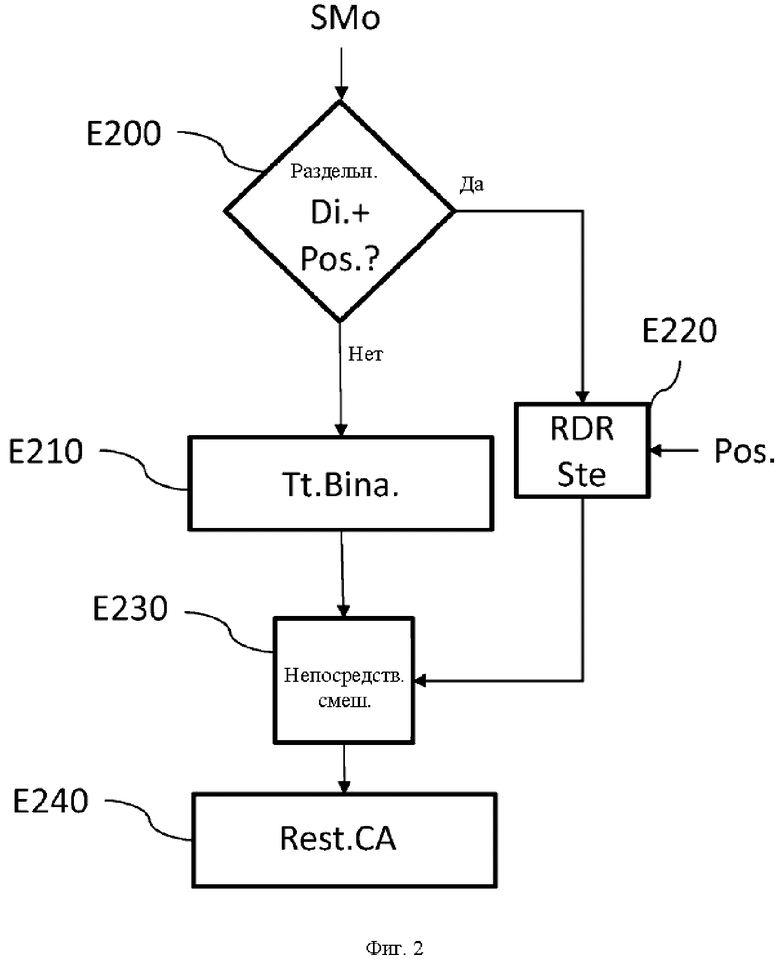
1. Способ обработки монофонического аудиосигнала в 3D-аудиодекодере, включающий этап выполнения бинаурализационной обработки декодированных сигналов, предназначенных для пространственного воспроизведения головной аудиогарнитурой, отличающийся тем, что
при обнаружении (E200) в потоке данных, представляющем монофонический сигнал, указания на невыполнение бинаурализационной обработки, связанного с информацией о пространственном положении воспроизведения, декодированный монофонический сигнал направляется (O-E200) на узел стереофонического воспроизведения и/или модуль смешивания, который принимает в расчет информацию о положении для создания двух каналов (E220) воспроизведения, непосредственная обработка которых происходит на этапе (E230) непосредственного смешивания, где эти два сигнала суммируются с бинаурализированным сигналом, полученным в результате бинаурализационной обработки, с целью воспроизведения (E240) головной аудиогарнитурой.
2. Способ по п.1, отличающийся тем, что информация о пространственном положении воспроизведения представляет собой двоичные данные, указывающие на один канал воспроизводящей головной аудиогарнитуры.
3. Способ по п.2, отличающийся тем, что лишь канал воспроизведения, соответствующий каналу, указанному двоичными данными, суммируется с соответствующим каналом бинаурализированного сигнала на этапе непосредственного смешивания, при этом данное значение для другого канала воспроизведения равно нулю.
4. Способ по п.1, отличающийся тем, что монофонический сигнал представляет собой сигнал канального типа, который направляется на узел стереофонического воспроизведения и/или модуль смешивания совместно с информацией о пространственном положении воспроизведения.
5. Способ по п.4, отличающийся тем, что информация о пространственном положении воспроизведения представляет собой данные о интерауральной разнице уровней (ILD).
6. Способ по п.1, отличающийся тем, что монофонический сигнал представляет собой сигнал объектного типа, связанный с набором параметров воспроизведения, содержащим указание на невыполнение бинаурализации и информацию о положении воспроизведения, при этом сигнал направляют в узел стереофонического воспроизведения и/или модуль смешивания совместно с информацией о положении воспроизведения.
7. Способ по п.6, отличающийся тем, что информация о пространственном положении воспроизведения представляет собой данные об азимутальном угле.
8. Устройство для обработки монофонического аудиосигнала, содержащее модуль для выполнения бинаурализационной обработки декодированных сигналов, предназначенных для пространственного воспроизведения головной аудиогарнитурой, отличающееся тем, что содержит:
- модуль (330, 430) обнаружения, способный обнаруживать в потоке данных, представляющем монофонический сигнал, указание на невыполнение бинаурализационной обработки, связанное с информацией о пространственном положении воспроизведения;
- модуль (330, 430) для перенаправления, способный, в случае подтвержденного обнаружения модулем обнаружения, направлять декодированный монофонический сигнал на узел стереофонического воспроизведения;
- узел (331, 431) стереофонического воспроизведения и/или модуль (340, 440) смешивания, способный принимать в расчет информацию о положении для создания двух каналов воспроизведения и способный непосредственно обрабатывать два канала воспроизведения посредством их суммирования с бинаурализированным сигналом, сгенерированным модулем (320, 420) для выполнения бинаурализационной обработки, с целью воспроизведения головной аудиогарнитурой.
9. Устройство обработки по п.8, отличающееся тем, что узел стереофонического воспроизведения встроен в модуль непосредственного смешивания.
10. Устройство по п.8, отличающееся тем, что монофонический сигнал представляет собой сигнал канального типа, и узел стереофонического воспроизведения встроен в канальный узел воспроизведения, который, к тому же, создает каналы воспроизведения для многоканальных сигналов.
11. Устройство по п.8, отличающееся тем, что монофонический сигнал представляет собой сигнал объектного типа, и узел стереофонического воспроизведения встроен в объектный узел воспроизведения, который, к тому же, создает каналы воспроизведения для монофонических сигналов, связанных с наборами параметров воспроизведения.
12. Аудиодекодер, содержащий устройство обработки по любому из пп.8-11.
13. Считываемый процессором информационный носитель, хранящий компьютерную программу, содержащую команды для выполнения способа обработки по любому из пп.1-7.
| US 2016266865 A1, 15.09.2016 | |||
| US 2016300577 A1, 13.10.2016 | |||
| US 2007213990 A1, 13.09.2007 | |||
| WO 2009001277 A1, 31.12.2008 | |||
| WO 2010085083 A3, 21.10.2010 | |||
| ДЕКОДЕР АУДИОСИГНАЛА, СПОСОБ ДЕКОДИРОВАНИЯ АУДИОСИГНАЛА И КОМПЬЮТЕРНАЯ ПРОГРАММА С ИСПОЛЬЗОВАНИЕМ СТУПЕНЕЙ КАСКАДНОЙ ОБРАБОТКИ АУДИООБЪЕКТОВ | 2010 |
|
RU2558612C2 |
| АУДИОКОДИРОВАНИЕ С ИСПОЛЬЗОВАНИЕМ ПОВЫШАЮЩЕГО МИКШИРОВАНИЯ | 2008 |
|
RU2474887C2 |

