Изобретение относится к области защиты конфиденциальной информации средствами цифровых водяных знаков и предназначено для обеспечения возможности установления каналов утечки конфиденциальной информации, хранящейся в текстовом виде в базах данных широкого доступа, а также выявления фактов незаконного копирования и распространения текстовой информации.
Известен способ записи дополнительной информации в текстовые данные, основанный на замене части слов исходного текста, по специальным таблицам синонимов (словарям), в соответствии с битами скрываемого сообщения. Способ, представленный в патенте RU 2257010, заключается в формировании конечного текста на основе специального шаблона-текста, в котором часть слов заменена ссылками на словоформы из соответствующих словарей. В процессе записи дополнительной информации ссылки в шаблоне-тексте последовательно заменяются определенными в них словоформами согласно битовым блокам дополнительной информации.
К недостаткам указанного способа следует отнести визуально различимое искажение текстовой информации, а также невозможность его применения к требующим однозначного толкования коротким текстовым строкам, состоящим из одного или нескольких, грамматически не связанных слов. Таким образом, известный способ не может быть применен к решению задачи внесения цифрового водяного знака в ответ базы данных, так как внесение изменений за счет замены слов в строках ответа приведет к нарушению достоверности предоставляемой информации и как следствие целостности базы данных.
Также известен способ записи дополнительной информации в текстовые данные, основанный на изменении длины пробела между словами исходного текста [J.Т.Brassil, S.Low, N.F.Maxemchuk, Copyright Protection for the Electronic Distribution of Text Documents, Invited Paper - Proceedings of the IEEE, July 1999, vol. 87, no. 7, p.1181-1196.]. Согласно данному способу запись дополнительной информации осуществляется путем выравнивания текста по ширине печатной страницы, за счет изменения длины или числа пробельных символов между отдельными словами в строке. Например, четным числом пробелов может кодироваться ноль, а нечетным единица.
Недостатком способа является возможность его применения только к достаточно длинным текстовым строкам, которые могут быть выровнены по ширине печатной страницы. Способ не может быть применен к текстовым строкам, состоящим из одного слова, а его применение к строкам, представленным в виде таблицы и состоящим из нескольких слов, будет визуально заметно.
Наиболее близким к заявленному изобретению является способ формирования текстового сообщения с цифровым водяным знаком, описанный в патенте GB 2377859. В патенте представлена система обмена короткими текстовыми сообщениями, в которой передаваемые сообщения дополняются специальной кодовой последовательностью из неотображаемых на приемном устройстве символов «пробела» и «перевода строки».
В случае баз данных, содержащих короткие текстовые строки, дописывание водяного знака в конец текстовой строки каждого поля ответа приведет к многократному увеличению длины этих строк и как следствие большим расходам машинной памяти и увеличению времени обработки. Многократное повторение символа «перевод строки» может привести к искажению представления данных в виде таблицы или при выводе на печать. Кроме того, на клиентской части СУБД (системы управления базой данных) символ «перевод строки» может быть воспринят как конец строки и следующие за ним символы будут отброшены. Дописанный в конец строки и не связанный с самой текстовой строкой цифровой водяной знак, представленный последовательностью символов «пробел» и «перевод строки», может быть достаточно легко подменен другим цифровым водяным знаком, в частности цифровым водяным знаком другого пользователя.
Задачей, на решение которой направлено это изобретение, является повышение эффективности системы контроля обработки, передачи и распространения конфиденциальной информации, хранящейся в текстовом виде в многопользовательской базе данных.
Решение задачи достигается за счет внедрения в ответ базы данных на запрос пользователя соответствующего данному пользователю уникального цифрового водяного знака. Каждому авторизованному пользователю базы данных назначают уникальный идентификатор и соответствующую ему ключевую последовательность. При обращении пользователя к базе данных вместе с запросом сообщается идентификатор пользователя. Полученный от пользователя запрос передают на обработку базе данных, а сформированный ею ответ модифицируют таким образом, чтобы осуществить его маркировку цифровым водяным знаком, соответствующим данному пользователю. Внедрение цифрового водяного знака производят путем преобразования части текстовых строк ответа, причем преобразование текстовых строк осуществляют за счет манипуляции символами разных языковых алфавитов с одинаковым начертанием, что позволяет сохранить длину строк, отведенный для их хранения объем оперативной памяти и их казуальное представление.
Формирование цифрового водяного знака для данной пары идентификатора пользователя, ответ базы данных осуществляют следующим образом. Для каждой строки ответа, содержащей символы из множества пар символов с одинаковым начертанием, осуществляют вычисление однобитовой хэш-функции, реализующей свертку исходной строки с ключевой последовательностью, соответствующей идентификатору пользователя. Если результатом вычисления однобитовой хэш-функции является значение 1, то символ, для которого осуществлялось вычисление хэш-функции, заменяют идентичным по начертанию символом из другого алфавита, если результатом вычисления является 0, то замену не осуществляют.
Для проверки цифрового водяного знака, внедренного в ответ базы данных, произвольным образом выбирают множество различных текстовых строк ответа, содержащих символы из множества пар символов с одинаковым начертанием, количество строк определяется требуемым уровнем достоверности цифрового водяного знака. Для каждой строки выбранного множества строк определяют исходную строку, из которой, для заданного пользователя, формируют проверочную строку путем внедрения в нее цифрового водяного знака выбранного пользователя. Если проверочная строка и строка из проверяемого множества строк не совпадают, то проверка цифрового водяного знака прошла с отрицательным результатом (водяной знак не принадлежит заданному пользователю). Если проверка строки прошла успешно, то процедуру проверки повторяют для оставшихся строк выбранного множества. Если для всех строк выбранного множества проверка прошла успешно, то результат проверки цифрового водяного знака считается положительным.
Техническим результатом является обеспечение возможности внедрения в ответы базы данных на запросы пользователей и проверки, уникального для каждого пользователя базы данных, цифрового водяного знака при снижении визуально заметных искажений текстовых строк ответа и сведении к минимуму необходимых дополнительных объемов памяти, выделяемых под хранение данных цифрового водяного знака. Также обеспечивается возможность проверки ЦВЗ по ограниченному числу строк, что ускоряет обработку и не накладывает ограничений на перестановку, сортировку и удаление части строк из маркированного ЦВЗ ответа базы данных. Неявная зависимость данных ЦВЗ от маркируемых текстовых строк и уникальной ключевой последовательности, поставленной в соответствие идентификатору пользователя, позволяет повысить степень защищенности ЦВЗ к модификации и подделке.
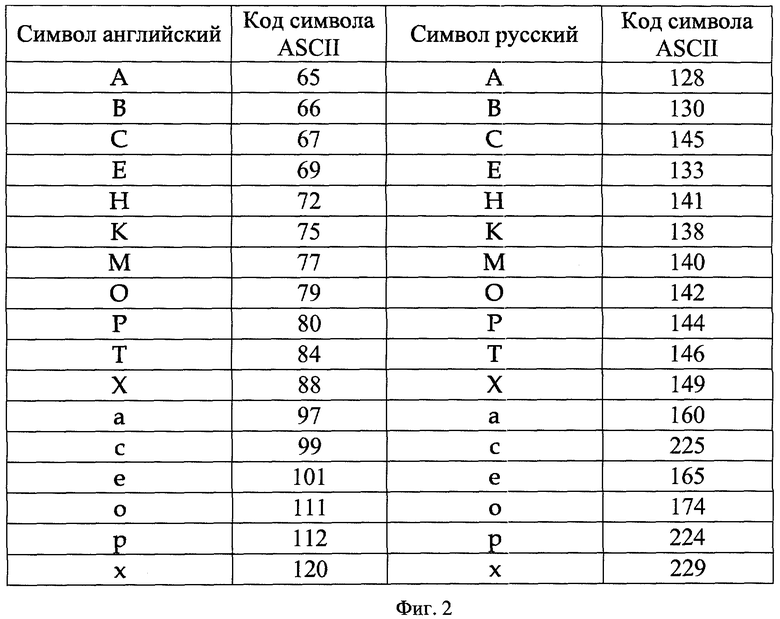
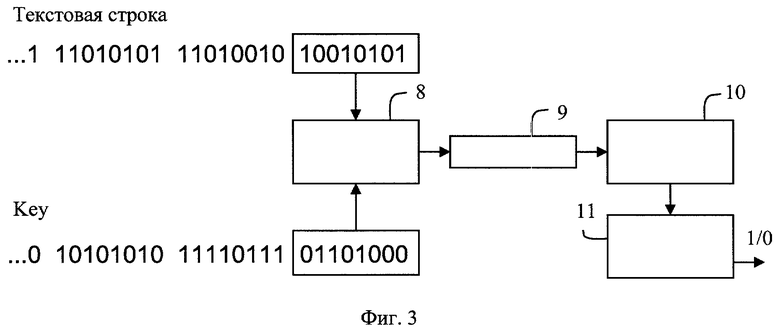
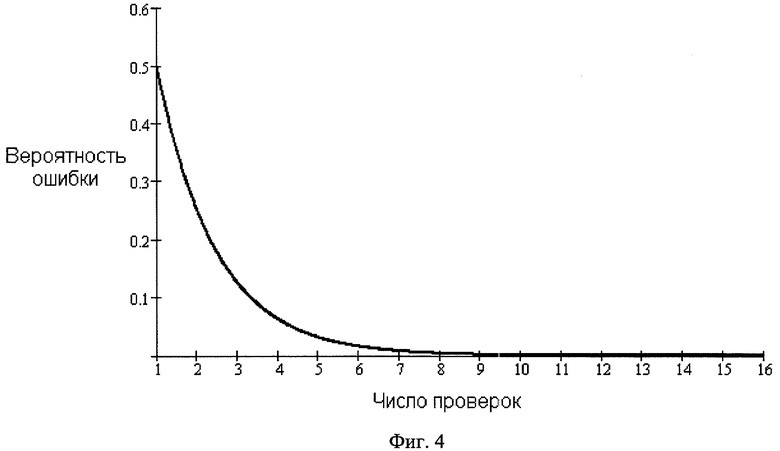
Сущность способа поясняется приведенной на фиг.1 структурной схемой взаимодействия клиентской 1 и серверной частей СУБД 3 через дополнительный блок 2, отвечающий за внедрение ЦВЗ, на фигуре также представлены блоки выработки ключевой последовательности 5 и проверки ЦВЗ 7. На фиг.2 представлена сводная таблица ASCII кодов символов с одинаковым начертанием для русского и английского алфавитов. Процесс вычисления значения однобитовой хэш-функции от выбранной текстовой строки и заданной кодовой последовательности поясняется фиг.3. На фиг.4 приведен график зависимости величины ошибки от общего числа проверок.
Структура СУБД с маркировкой ответов с использованием ЦВЗ.
В соответствии с предпочтительной реализацией настоящего изобретения в структуру используемой СУБД, согласно фиг.1 между клиентской 1 и серверной частью 3 вводят дополнительный блок маркировки 2, отвечающий за встраивание ЦВЗ в ответ серверной части СУБД, и дополнительный блок 5, отвечающий за хранение ключевых последовательностей и их предоставление, по мере необходимости блоку 2.
Каждому пользователю базы данных назначают уникальный идентификатор UID (UserID). При обращении пользователя к базе данных, посредствам клиентской части СУБД 1, блоку 2 передают сформированный пользователем запрос и идентификатор самого пользователя. Полученный блоком 2 идентификатор UID передается блоку хранения ключевых последовательностей 5, который по результатам проверки идентификатора возвращает блоку 2 соответствующую UID ключевую последовательность Key. После получения ответа от блока хранения ключевых последовательностей 5 соответствующий пользовательский запрос передают на серверную часть СУБД. В процессе проверки UID реализуют процедуру аутентификации пользователя. В настоящем изобретении используются известные способы аутентификации: Чмора А.Л. Современная прикладная криптография. 2-е изд., стер. - М.: Гелиос АРВ, 2002 г, стр.174-207.
При получении запроса серверная часть СУБД формирует ответ, содержащий записи из базы данных, и передает его блоку встраивания ЦВЗ. В блоке встраивания ЦВЗ по известным UID и Key осуществляют маркировку полученного от базы данных ответа и передают его на клиентскую часть СУБД. Клиентская часть СУБД, в свою очередь, формирует визуальное представление данных ответа 6 и предоставляет их пользователю.
Внесение ЦВЗ в ответы СУБД на запросы пользователей. Маркировка ответа серверной части СУБД осуществляется за счет замены отдельных символов в строковых полях ответа соответствующими им по начертанию символами той же кодировки, но другого алфавита. Например, в кодировке ASCII английским символам 'А', 'В', 'С' соответствуют символы русского алфавита 'А', 'В', 'С'. На фиг.2 представлена сводная таблица символов с одинаковым начертанием, но относящимся к разным алфавитам для кодировки ASCII. Из представленной таблицы видно, что русская буква «К» может быть представлена как символом с кодом 138, принадлежащим русскому алфавиту, так и символом с кодом 75, принадлежащим английскому алфавиту. Вследствие того, что символы имеют одинаковое начертание, визуальное представление строк, в которых буква «К» представлена символом 'К' с кодом 138 будет идентичным визуальному представлению аналогичных строк, в которых буква «К» представлена символом с кодом 75.
В процессе маркировки проходят по всем строкам ответа, выделяя для изменения из всего имеющегося множества текстовых строк отдельных строковых полей только строки длиной более одного текстового символа, в которых встречаются символы из таблицы символов с одинаковым начертанием. При этом стоящие на второй позиции в строке алфавитные символы (цифровые символы и специальные знаки пропускают до встречи символа однозначно относящегося к одному из алфавитов) не рассматривают, так как их используют далее для определения языка, на котором была записана исходная текстовая строка. Выбор второго символа для определения языка обусловлен большой частотой встречаемости символов с одинаковым начертанием среди заглавных символов (см. фиг.2) которые в свою очередь наиболее часто встречаются в текстовых строках на первой позиции и могут быть использованы для маркировки.
Для каждой выбранной текстовой строки, содержащей символы из множества пар символов с одинаковым начертанием, вычисляют значение однобитовой хэш-функции. Структура рекомендуемой хэш-функции представлена на фиг.3. На вход хэш-функции подают выбранную для маркировки текстовую строку и ключевую последовательность Key, соответствующую пользователю (UID пользователя), направившему запрос базе данных. Текстовая строка и ключевая последовательность подаются на вход байтового сумматора 8 хэш-функции в байтовом представлении. Байтовый сумматор может быть представлен функцией битового сложения по модулю два (операция XOR) при достаточной длине ключевой последовательности или функцией поточного шифрования текстовой строки на ключе Key. В реализации байтового сумматора с использованием функции битового сложения по модулю два, каждый бит байта текстовой последовательности складывается по модулю два с соответствующим битом ключевой последовательности. Далее, биты, полученные на выходе байтового сумматора, последовательно подают на вход регистра сдвига с линейной обратной связью 9 [Б.Шнайер, Прикладная криптография. Протоколы, алгоритмы, исходные тексты на языке Си. - М.: Издательство ТРИУМФ, 2002, стр.419-427]. Выбор конкретного примитивного многочлена для регистра сдвига зависит от особенностей реализации, в нашем случае выбран многочлен: x8+x4+x3+x2+1. Биты с выхода регистра сдвига подают во временный однобайтовый буфер 10, реализующий хранение последних 8 поступивших в него битов. По завершении циклической обработки всех битов последовательности, полученной от исходной текстовой строки с выхода сумматора 8, последние 8 битов с выхода регистра сдвига 9, оставшиеся в однобайтовом буфере 10 подают на вход блока 11, реализующего свертку 8 битного вектора. Свертка 8 битного вектора реализована функцией сложения по модулю два (операция XOR) всех битов вектора. В результате на выходе блока 11 после свертки получают один идентифицирующий бит цифровой подписи, значение которого может быть 0 или 1 и зависит от всех символов текстовой и ключевой последовательностей поданных на вход описанной хэш-функции.
По результату вычисления однобитовой хэш-функции от выбранной строки осуществляют ее преобразование согласно следующему правилу.
Если значением на выходе однобитовой хэш-функции от текстовой строки и ключевой последовательности данного пользователя является 1, произвольный символ строки, принадлежащий множеству пар символов с одинаковым начертанием и не являющийся вторым алфавитным символом в строке, заменяют символом идентичным по начертанию, но относящимся к другому алфавиту, если результатом вычисления хэш-функции является 0, то замену не осуществляют.
В случае если текстовая строка обладает достаточно большой длиной и содержит в себе большое количество алфавитных символов, принадлежащих множеству пар символов с одинаковым начертанием, то для процедуры маркировки строки может быть выбран не один, а несколько символов. В данном случае символы, подлежащие замене, обрабатывают последовательно в определенном порядке, зависящем от особенностей реализации. В частности последовательно могут быть выбраны первый, третий, пятый и так далее символы, принадлежащие множеству пар символов с одинаковым начертанием, т.е. каждый нечетный символ. В данном случае процедуру вычисления хэш-функции осуществляют для каждого символа. Для первого символа хэш-функцию вычисляют от исходной строки, а для каждого последующего от модифицированной на предыдущем шаге. Замену символов осуществляют согласно представленному выше правилу. В результате, как будет показано далее, в случае достаточно большой длины строк ответа, аутентификация пользователя, отправившего запрос базе данных, может быть проведена уже по результатам проверки всего одной строки ответа.
Проверка цифрового водяного знака
В процессе обработки пользователем ответа базы данных порядок строк в нем может быть нарушен, так же из всего ответа может быть выбрано лишь относительно небольшое число строк. В соответствии с указанными ограничениями проверка ЦВЗ должна осуществляться по ограниченному неупорядоченному произвольному набору строк ответа.
Процедуру проверки ЦВЗ осуществляют следующим образом. Сначала из множества имеющихся строк ответа случайным образом выбирают k попарно различных строк, длиннее одного символа и содержащих символы из множества пар символов с одинаковым начертанием. Количество строк k, выбранных для проверки, зависит от числа символов n≥N, относящихся к множеству символов с одинаковым начертанием, которые могли быть изменены в процессе записи данных ЦВЗ. Параметр N соответствует минимальному числу проверок и в данном случае определяется исходя из необходимого уровня достоверности D результатов проверки ЦВЗ, т.е. задается по значению максимальной допустимой ошибки. Зависимость вероятности ошибки от числа проведенных проверок представлена на фиг.4.
Из представленного графика видно, что для обеспечения достоверности результатов проверки со значением более 0.99 достаточно проведения 7-8 проверок отдельных символов. Чем заданное число проверок больше, тем больше достоверность полученных результатов. Так, по результатам 16 проверок вероятность ошибки составит менее 0.0001.
Для каждой строки из выбранного множества из k строк по второму алфавитному символу определяют алфавит исходной строки. После определения алфавита исходной строки, на основе строки ответа формируют копию исходной строки путем преобразования всех символов строки ответа к одному алфавиту, определенному по второму алфавитному символу. Далее выбирают UID пользователя, который мог отправить запрос базе данных. По заданному ключу Key, соответствующему UID, выполняют процедуру маркировки, полученной на предыдущем шаге текстовой строки. Далее осуществляют сравнение полученной проверочной строки и строки из множества выбранных для проверки текстовых строк. Сравнение строк осуществляют по символам, выбираемым в ходе маркировки строк, при этом отдельно считают количество совпавших Sc и несовпавших Sn символов. Совпавшими считаются символы, относящиеся к одному алфавиту, т.е. имеющие один и тот же двоичный код. Так, например, в строке «Иванов» (в кодах: 136162097173174162) и проверочной строке «Иванов» (в кодах: 136162097173111162) символы 'а', с кодами 097 и 097, считаются совпавшими, а символы 'о', с кодами 174 и 111, несовпавшими.
Если Sn>Sc, то результат проверки считается отрицательным, строки, выбранные для проверки, не соответствуют ответу на запрос пользователя с выбранным UID. Если Sn≤Sc, то результат проверки определяют по формуле: Dnc=1-2Sn/2Sc. Если Dnc>D (заданного уровня достоверности), то проверку считают прошедшей с положительным результатом.
Параметр Sn введен с целью противодействия возможному случайному изменению отдельных строк ответа или же намеренному их искажению пользователем. Если модификация строк невозможна, то в случае появления первого же несовпавшего символа проверка может быть остановлена с выдачей отрицательного результата.
Возможность проверки цифрового водяного знака за достаточно малое ограниченное число шагов позволяет также реализовать процедуру установления пользователя, чьи действия привели к утечке информации из базы данных. Для этого процедуру проверки последовательно повторяют для всех пользователей, имевших доступ к данной информации. Т.е. становится возможным проведение проверки не 1:1, a n:1.
Перечень чертежей
Фиг.1. Схема взаимодействия клиентской и серверной частей СУДЕ через блок внедрения ЦВЗ.
Фиг.2. Таблица ASCII кодов символов с одинаковым начертанием для английского и русского алфавитов.
Фиг.3. Вычисление однобитовой хэш-функции от заданных текстовой и ключевой строк.
Фиг.4. Зависимость вероятности ошибки при определении соответствия ответа, с внедренным ЦВЗ, запросу данного пользователя от количества независимых проверок.
Источники информации
1. Патент RU 2257010, 27.03.2002.
2. J.Т.Brassil, S.Low, N.F. Maxemchuk, Copyright Protection for the Electronic Distribution of Text Documents, Invited Paper - Proceedings of the IEEE, July 1999, vol. 87, no. 7, p.1181-1196.
3. Патент GB 2377859, 19.07.2001.
4. Чмора А.Л. Современная прикладная криптография. 2-е изд., стер. - М.: Гелиос АРВ, 2002.
5. Б. Шнайер Прикладная криптография. Протоколы, алгоритмы, исходные тексты на языке Си. - М.: Издательство ТРИУМФ, 2002. - 816 с.
| название | год | авторы | номер документа |
|---|---|---|---|
| ПОИСК ПРОИЗВОЛЬНОГО ТЕКСТА И ПОИСК ПО АТРИБУТАМ В ДАННЫХ ЭЛЕКТРОННОГО РУКОВОДСТВА ПО ПРОГРАММАМ | 2004 |
|
RU2365984C2 |
| СПОСОБ И СИСТЕМА ДЛЯ МАРКИРОВКИ ИЗДЕЛИЯ, ИЗДЕЛИЕ, ПРОМАРКИРОВАННОЕ ТАКИМ ОБРАЗОМ, И СПОСОБ И СИСТЕМА ДЛЯ АУТЕНТИФИКАЦИИ ПРОМАРКИРОВАННОГО ИЗДЕЛИЯ | 2013 |
|
RU2651167C2 |
| СПОСОБ ОБЕСПЕЧЕНИЯ РОБАСТНОСТИ ЦИФРОВОГО ВОДЯНОГО ЗНАКА, ВСТРАИВАЕМОГО В СТАТИЧЕСКОЕ ИЗОБРАЖЕНИЕ, ПЕРЕДАВАЕМОЕ ПО КАНАЛУ СВЯЗИ С ПОМЕХАМИ | 2022 |
|
RU2785832C1 |
| СПОСОБ ПРЕОБРАЗОВАНИЯ ДАННЫХ ГЕОИНФОРМАЦИОННЫХ СИСТЕМ (ГИС), СИСТЕМА ДЛЯ ЕГО РЕАЛИЗАЦИИ И СПОСОБ ПОИСКА ПО СФОРМИРОВАННОЙ ЭТИМ СПОСОБОМ БАЗЕ ДАННЫХ | 2017 |
|
RU2669143C1 |
| СПОСОБ ВЫЯВЛЕНИЯ НЕЗНАЧАЩИХ ЛЕКСИЧЕСКИХ ЕДИНИЦ В ТЕКСТОВОМ СООБЩЕНИИ И КОМПЬЮТЕР | 2014 |
|
RU2580424C1 |
| СПОСОБ ЗАЩИЩЕННОГО ДОСТУПА К БАЗЕ ДАННЫХ | 2019 |
|
RU2709288C1 |
| Система и способ идентификации криптографических кошельков на основе анализа транзакций | 2018 |
|
RU2693314C1 |
| СПОСОБ МАРКИРОВКИ ОБЪЕКТА С ЦЕЛЬЮ ЕГО ИДЕНТИФИКАЦИИ | 2011 |
|
RU2462338C1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ МАРКИРОВКИ ИЗГОТОВЛЕННЫХ ПРЕДМЕТОВ | 2011 |
|
RU2591010C2 |
| СПОСОБ АВТОМАТИЗИРОВАННОГО АНАЛИЗА ТЕКСТОВЫХ ДОКУМЕНТОВ | 2011 |
|
RU2474870C1 |
Способ относится к защите баз данных с целью от незаконного копирования и распространения информации. Техническим результатом является повышение эффективности системы контроля обработки, передачи и распространения конфиденциальной информации, хранящейся в текстовом виде в многопользовательской базе данных. Внесение данных осуществляют за счет замены символов текстовых строк идентичными по начертанию символами другого алфавита, каждому пользователю назначают уникальный идентификатор, который передается блоку маркировки при отправлении запроса системе управления базой данных. Для текстовой строки ответа с помощью однобитовой хэш-функции, по соответствующей идентификатору пользователя ключевой последовательности вычисляют значение бита подписи. Для проверки выбранной строки берут исходную строку и производят ее маркировку, результат сравнивают с проверяемой строкой, для проверки всего цифрового водяного знака достаточно осуществить проверку небольшого числа произвольно выбранных строк, что ускоряет процедуру проверки и не накладывает ограничений на порядок строк. Использование однобитовой хэш-функции и ключевых последовательностей позволяет повысить степень защищенности. 2 н.п. ф-лы, 4 ил.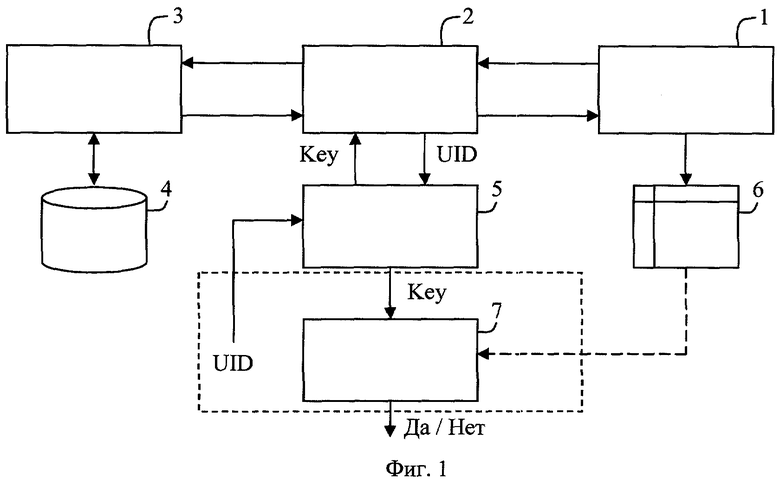
| СПОСОБ ПРОИЗВОДСТВА АРОМАТИЗИРОВАННОГО ТОПИСОЛНЕЧНО-МАНДАРИНОВОГО НАПИТКА | 2009 |
|
RU2377859C1 |
| СПОСОБ СТЕГАНОГРАФИЧЕСКОГО ПРЕОБРАЗОВАНИЯ БЛОКОВ ДВОИЧНЫХ ДАННЫХ | 2002 |
|
RU2257010C2 |
| Листовая сталь для судостроения | 1930 |
|
SU19944A1 |
| Перекатываемый затвор для водоемов | 1922 |
|
SU2001A1 |
| ВНЕДРЕНИЕ ВОДЯНОГО ЗНАКА | 2002 |
|
RU2289215C2 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| KR 20010056598, 04 | |||
| Способ восстановления хромовой кислоты, в частности для получения хромовых квасцов | 1921 |
|
SU7A1 |
| US 2006078159 A, 13.04 | |||
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| US 6351815 A1, 26.02.2002. | |||

