Данная заявка подается как заявка РСТ, поданная 17 мая 2003 г. корпорацией Майкрософт, созданной и находящейся в США, с указанием всех стран, кроме США.
Предпосылки изобретения
Современные компьютерные системы обычно хранят большой объем данных в нескольких файлах. Формат файлов может быть одним из нескольких разных форматов, совместимых с различными приложениями, например текстовыми редакторами, электронными таблицами и т.п. Часто бывает необходимо передать файл на другой компьютер, чтобы другой пользователь мог видеть данные в файле или манипулировать ими. Иногда, когда файл слишком велик, до отправки файла на другой компьютер над файлом осуществляется преобразование (например, сжатие). Благодаря сжатию файла для отправки файла на другой компьютер требуется меньшая пропускная способность. В других случаях, для защиты данных от доступа со стороны неавторизованных пользователей, можно осуществлять другое преобразование (например, шифрование).
Некоторые из этих преобразований имеют особые методы кодирования и используют отдельный файл (например, словарь) для хранения информации о конкретном методе кодирования. Этот отдельный файл должен использоваться при доступе к преобразованному файлу. В случае повреждения, потери или недоступности этого отдельного файла, преобразованный файл оказывается бесполезным. Кроме того, поскольку некоторые из этих преобразований задают свои собственные методы кодирования для перемежения кодированных данных и информации обработки, файл, подвергнутый преобразованию, не подлежит совместному использованию или общей обработке. Кроме того, до преобразования файла современные преобразования требуют, чтобы данные в файле были организованы в виде последовательных байтов. Гарантия того, что байты в файле остаются последовательными, требует больших накладных расходов и нежизнеспособно для часто редактируемых файлов. Таким образом, хотя эти преобразования весьма полезны, способ их реализации не дает пользователям большой свободы действий.
Сущность изобретения
Настоящее изобретение относится к системе и способу реализации преобразований, обеспечивающих пользователям повышенную гибкость. В целом, настоящее изобретение обеспечивает механизм сохранения информации преобразования, связанной с одним или несколькими преобразованиями в файле, состоящем из множественных частей. Файл, состоящий из множественных частей, также содержит данные, к которым применяются одно или несколько преобразований. Таким образом, настоящее изобретение обеспечивает формат файла для файла, состоящего из множественных частей, что позволяет приложениям, обращающимся к файлу, легко осуществлять доступ к преобразованным данным. Согласно изобретению, множественные преобразования данных могут образовывать цепь. Эти преобразования данных, составляющие цепь, именуются «пространствами данных». Каждое пространство данных имеет уникальный порядок и тип для преобразований, образующих цепь. Например, два пространства данных могут задавать одни и те же преобразования, но разный порядок применения преобразований. Информация преобразования содержит информацию о пространствах данных.
Согласно другому аспекту изобретения, файл, состоящий из множественных частей, содержит множество потоков. Каждый поток может быть связан с одним из пространств данных. Таким образом, согласно настоящему изобретению, некоторые потоки в файле, состоящем из множественных частей, могут преобразовываться, тогда как другие потоки могут оставаться в своем естественном формате. Эта способность преобразовывать конкретные потоки без необходимости преобразования всего файла, состоящего из множественных частей, обеспечивает пользователям большую гибкость, например позволяет пользователям шифровать только значимую информацию в файле, состоящем из множественных частей (например, при редактировании документов).
Таким образом, настоящее изобретение относится к системе и способу применения преобразований к файлам, состоящим из множественных частей. Поступает запрос на доступ к потоку данных в файле, состоящем из множественных частей. По получении запроса идентифицируется список преобразований, связанных с потоком. Список также включается в состав файла, состоящего из множественных частей. Преобразования, указанные в списке преобразований, осуществляются над данными до завершения запроса. Если это запрос на запись, то преобразования кодируют данные. Если это запрос на чтение, то преобразования декодируют данные. Список преобразований зависит от порядка. Список преобразований содержит структуру данных, имеющую первый поток, который включает в себя отображение (соответствие), сопоставляющее поток с именем списка преобразования. Второй поток, перечисляющий все преобразования для потока. Третий поток для каждого из перечисленных преобразований, который идентифицирует информацию, связанную с преобразованием.
Краткое описание чертежей
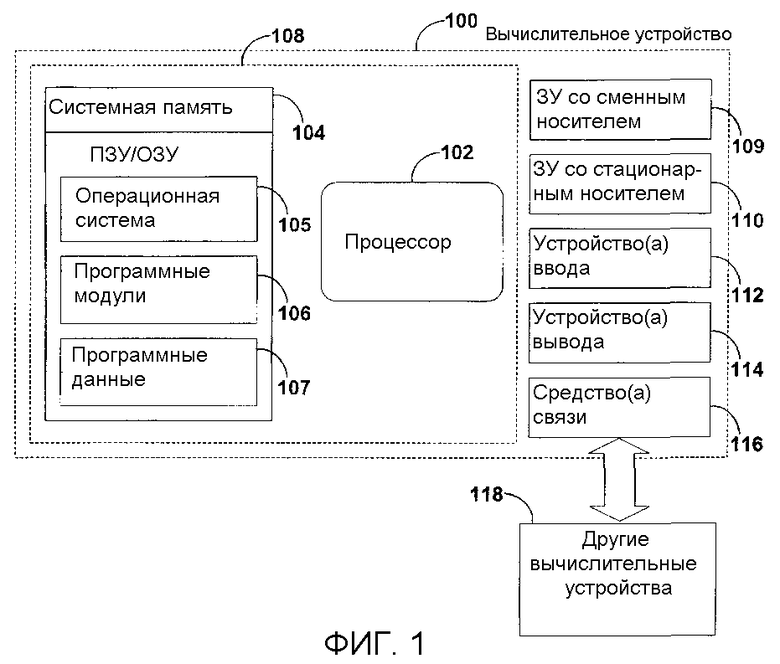
Фиг.1 - функциональная блок-схема вычислительного устройства, которое можно использовать в реализациях настоящего изобретения.
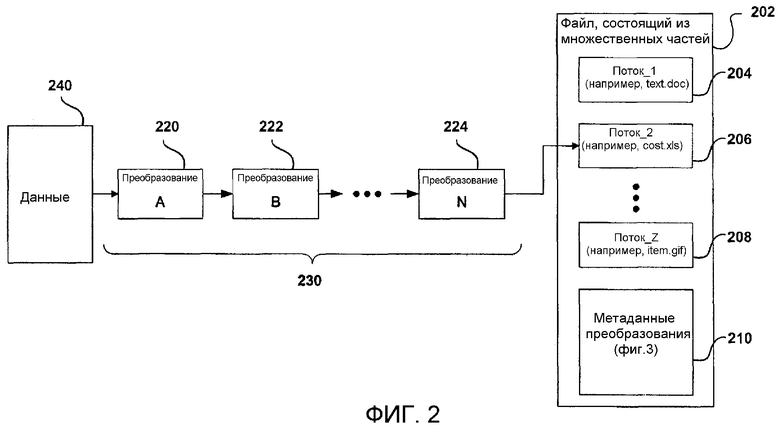
Фиг.2 - функциональная блок-схема, иллюстрирующая в общих чертах процесс преобразования согласно настоящему изобретению.
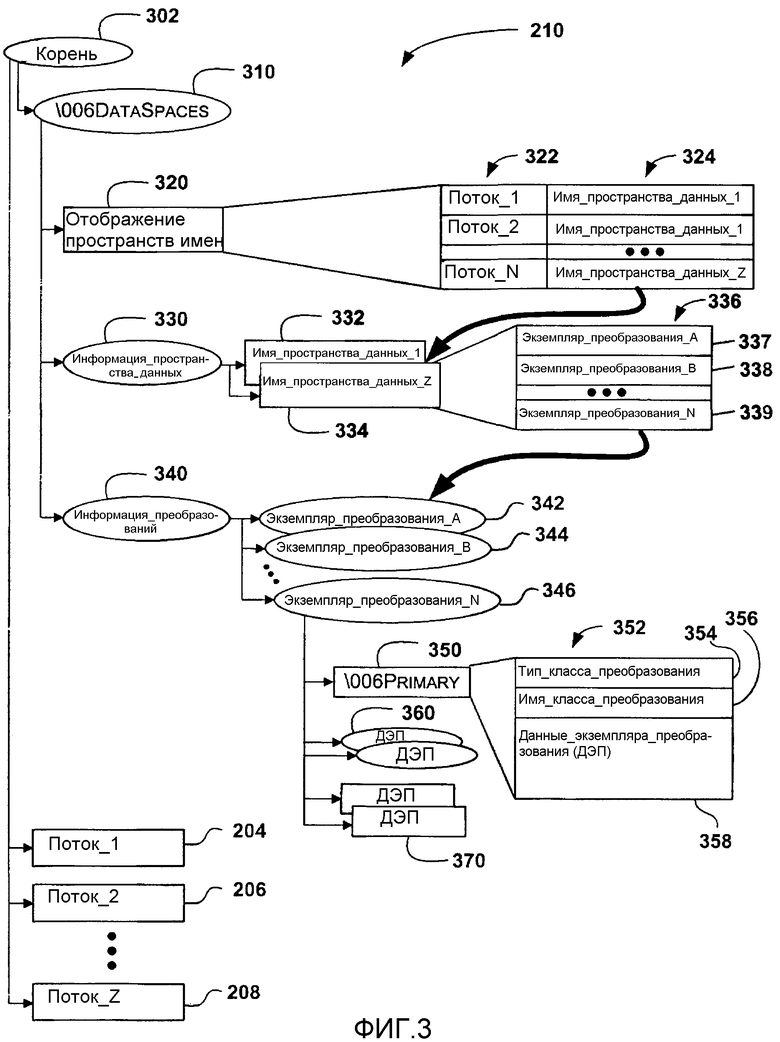
Фиг.3 - графическое представление древовидной иерархии, которая представляет метаданные преобразования, показанные на фиг.2.
Фиг.4 - схема процесса преобразования.
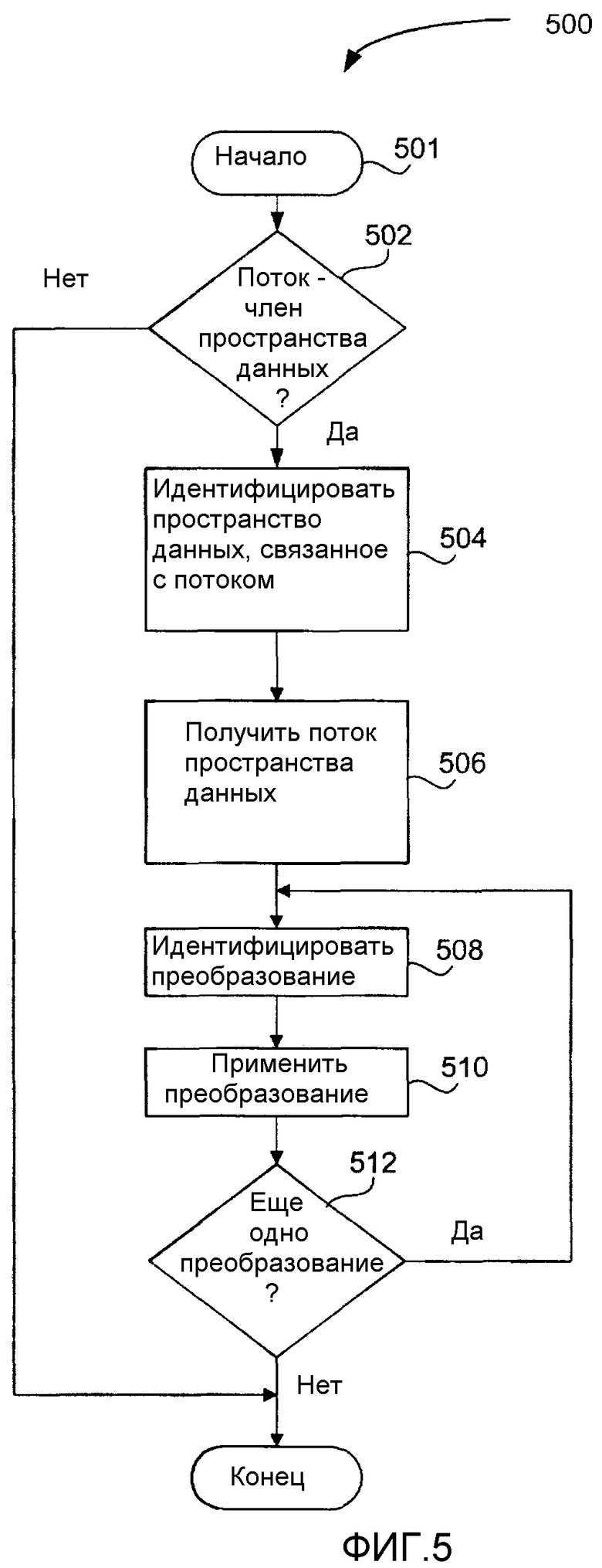
Фиг.5 - логическая последовательность операций, иллюстрирующая в общих чертах процесс доступа к преобразованным данным в файле, состоящем из множественных частей, согласно одному варианту осуществления изобретения.
Подробное описание предпочтительного варианта осуществления
Изобретение обеспечивает механизм применения преобразований к файлам, состоящим из множественных частей. Механизм предусматривает структуру для задания информации преобразования. Информация преобразования и преобразованные данные сосуществуют в одном и том же документе. Механизм, предусмотренный изобретением, предпочтительно базируется на формате файла, состоящего из множественных частей, который допускает наличие множественных типов потоков в одном документе. Изобретатели определили, что формат составного файла по стандарту связывания и встраивания объектов (OLE) особенно подходит для реализаций изобретения. Таким образом, ниже изобретение описано с использованием формата составного файла. Однако специалистам в данной области, внимательно изучившим нижеследующее описание, будет ясно, что другие форматы мультифайла могут реализовывать настоящее изобретение с различными модификациями механизма, описанными ниже, приспособленными к другим форматам мультифайла. Таким образом, очевидно, что варианты осуществления изобретения не ограничиваются описанными здесь.
Сначала опишем изобретение со ссылкой на один пример иллюстративной вычислительной среды, в которой можно реализовать варианты осуществления изобретения. Затем опишем подробный пример одной конкретной реализации изобретения. Альтернативные варианты осуществления также могут быть включены в отношении определенных деталей конкретной реализации.
Иллюстративная вычислительная среда, отвечающая изобретению
На фиг.1 показана функциональная блок-схема вычислительного устройства, которое можно использовать в реализациях настоящего изобретения. На фиг.1 показано иллюстративное вычислительное устройство, которое можно использовать в реализациях настоящего изобретения. Согласно фиг.1, в очень общей конфигурации вычислительное устройство 100 обычно содержит, по меньшей мере, один процессор 102 и системную память 104. В зависимости от конкретных конфигурации и типа вычислительного устройства 100 системная память 104 может представлять собой энергозависимое запоминающее устройство (например, ОЗУ), энергонезависимое запоминающее устройство (например, ПЗУ, флэш-память и т.д.) или какую-либо их комбинацию. В системной памяти 104 обычно размещаются операционная система 105, один или несколько программных модулей 106 и, в необязательном порядке, программные данные 107. В качестве примеров программных модулей 106 могут выступать приложение обозревателя (программы просмотра), приложение финансового управления, текстовый редактор и т.д. Эта базовая конфигурация представлена на фиг.1 компонентами, окруженными пунктирной линией 108.
Вычислительное устройство 100 может иметь дополнительные особенности или функции. Например, вычислительное устройство 100 может также включать в себя дополнительные запоминающие устройства со сменными и/или стационарными носителями, в качестве которых могут выступать магнитные диски, оптические диски или лента. Такие дополнительные запоминающие устройства представлены на фиг.1 в виде запоминающего устройства 109 со сменным носителем и запоминающего устройства 110 со стационарным носителем. Компьютерные среды хранения данных могут включать в себя энергозависимые и энергонезависимые, сменные и стационарные среды хранения, реализующие любой способ и любую технологию хранения информации, как то: считываемых компьютером команд, структур данных, программных модулей или иных данных. Системная память 104, запоминающее устройство 109 со сменным носителем и запоминающее устройство 110 со стационарным носителем - все они являются примерами компьютерных сред хранения данных. Компьютерные среды хранения данных включают в себя, но без ограничения, ОЗУ, ПЗУ, ЭСППЗУ, флэш-память или другую технологию памяти, CD-ROM, цифровые универсальные диски (DVD) или другое оптическое запоминающее устройство, магнитные кассеты, магнитную ленту, запоминающие устройства на основе магнитных дисков или других магнитных носителей, или любую другую среду, которую можно использовать для хранения полезной информации и к которой можно осуществлять доступ посредством вычислительного устройства 100. Любая такая компьютерная среда хранения данных может входить в состав устройства 100.
Вычислительное устройство 100 может также содержать устройство(а) 112 ввода, например клавиатуру, мышь, перо, устройство голосового ввода, устройство тактильного ввода и т.д. Оно также может содержать устройство(а) 114 вывода, например дисплей, громкоговорители, принтер и т.д. Эти устройства общеизвестны в технике и не нуждаются в дополнительном описании.
Вычислительное устройство 100 также может содержать средства связи 116, позволяющие устройству 100 осуществлять связь с другими вычислительными устройствами 118, например, по сети. Средства связи 116 являются примером сред связи. Среды связи обычно реализуют компьютерно-считываемые команды, структуры данных, программные модули или другие данные в модулированном сигнале данных, например несущей волне или ином транспортном механизме, и включают в себя любые среды доставки данных. Термин «модулированный сигнал данных» означает сигнал, одна или несколько характеристик которого изменяется определенным образом, что позволяет кодировать информацию в сигнале. В порядке примера, но не ограничения, среды связи включают в себя проводные среды, например проводную сеть или прямое проводное соединение, беспроводные среды, например акустические, ВЧ, инфракрасные и другие беспроводные среды. Используемый здесь термин «компьютерно-считываемые среды» подразумевает как среды хранения данных, так и среды передачи данных.
Общее рассмотрение компонентов
На фиг.2 показана функциональная блок-схема, иллюстрирующая в общих чертах компоненты среды, реализующей настоящее изобретение. Проиллюстрирован файл 202, состоящий из множественных частей, предпочтительно составной файл OLE. Модель документа OLE известна в технике и широко используется как механизм содержания многих несопоставимых типов данных в едином документе. Традиционно, составной файл OLE используется совместно с несколькими внедренными файлами или иного содержимого поддержки, связанного с единичным документом. Каждый элемент составного файла хранится так, чтобы приложение, создавшее элемент, могло манипулировать им. Каждый элемент хранится в виде потока, например потоков 204, 206 и 208, показанных на фиг.2. Согласно вышеуказанному, каждый поток может относиться к одному из нескольких типов. Например, поток 204 stream1 может представлять собой документ текстового редактора, поток 206 stream2 может представлять собой электронную таблицу, а поток 208 streamZ может быть графическим файлом.
До настоящего времени после запрашивания преобразования на файле 202, состоящем из множественных частей, требовалось, чтобы все составляющие файла 202, состоящего из множественных частей, (т.е. потоки 204-208) были непрерывными и обрабатывались совместно. Однако, согласно настоящему изобретению, потоки 204-208 не обязаны быть непрерывными. Напротив, потоки 204-208 могут быть основаны на секторах. В нижеследующем рассмотрении под секторизованными файлами будем понимать файлы, в которых сохранены множественные куски (порции) данных, представляющие целый поток. Множественные порции могут храниться последовательно, но обычно хранятся не последовательно. В одном варианте осуществления порции могут иметь фиксированный размер, например 512 байт. Альтернативно, не выходя за рамки объема настоящего изобретения, можно предусмотреть порции переменного размера. При редактировании потока новая порция данных может создаваться и сохраняться в байтах, не последовательных по отношению к другим порциям данных для потока. Таким образом, секторизованные файлы позволяют легко редактировать поток без дополнительных затрат на гарантию, что поток остается непрерывным.
Согласно подробно описанному ниже, настоящее изобретение позволяет преобразовывать конкретные порции данных 240, связанные с потоком (например, потоком 206) в файле 202, состоящем из множественных частей, без преобразования других потоков. Поскольку настоящее изобретение позволяет преобразовывать указанные потоки независимо от других потоков, изобретение обеспечивает большую гибкость для защиты данных и управления данными. Например, на фиг.2 показан поток 206 stream2, подвергнутый процессу преобразования. Поток 206 stream2 может представлять собой электронную таблицу, содержащую цены конкретных товаров. Поэтому может быть желательно защищать эту информацию цен, чтобы неавторизованные пользователи не могли видеть цены. Таким образом, данные 240, направляемые в поток 206 stream2, подвергаются цепи преобразований (т.е. преобразованиям 220-224). Специалисту в данной области очевидно, что любое количество преобразований может составлять цепь, и они могут размещаться в цепи в любом порядке. Конкретные преобразования, образующие цепь, и порядок, в котором преобразования размещены в цепи, представляют пространство 230 данных. В целом, пространство данных может задавать одно преобразование, а может задавать множественные преобразования. В вышеприведенном примере последнее преобразование (например, преобразование 224) записывает преобразованные данные в поток 206 stream2, который может размещаться на диске (не показан). Один вариант осуществления для использования механизма применения преобразований к файлам, состоящим из множественных частей, подробно описан ниже со ссылкой на фиг.4.
Рассмотрение конкретного варианта осуществления изобретения
На фиг.3 показано графическое представление одного варианта осуществления древовидной иерархии, которая представляет метаданные 210 преобразования, показанные на фиг.2. В целом, древовидную иерархию можно вводить в состав файла, состоящего из множественных частей, любым способом, совместимым с файлом, состоящим из множественных частей. Ниже описана древовидная иерархия применительно к составным файлам. В целом, составные файлы рассматриваются как «файловая система внутри файла». В составном файле имеется иерархия «хранилищ», аналогичных директориям в файловой системе, и «потоков», аналогичных файлам в файловой системе. На фиг.3 прямоугольники представляют потоки, а овалы представляют хранилища. Прежде чем перейти к описанию метаданных 210 преобразования, отвечающих настоящему изобретению, заметим, что потоки 204-208 (показанные на фиг.2) проиллюстрированы в этой иллюстративной иерархии под корнем 302. Задание потоков под корнем является обычной техникой для форматов составного файла.
Теперь рассмотрим более подробно метаданные 210 преобразования, предусмотренные настоящим изобретением. Метаданные 210 преобразования хранятся в особом хранилище, именуемом "\006DataSpaces"310 от корня 302. Хранилище 310 \006DataSpacesсодержит поток 320 DataSpaceMap, хранилище 330 DataSpaceInfo и хранилище 340 TransformInfo. Для данного варианта осуществления имя, выбранное для особого хранилища, "\006DataSpaces", написано в контексте языка программирования С. Таким образом, в данном варианте осуществления имя начинается с единичного не буквенно-цифрового маркера и значения маркера, равного 6. В целом, имя, присвоенное конкретному хранилищу, является произвольным и зависит от реализации пользователя.
Поток 320 DataSpaceMap [отображение пространств данных] отображает (преобразует) потоки (например, потоки 204-208) со связанным с ними пространством данных. В одном варианте осуществления поток 320 DataSpaceMap представляет собой таблицу, имеющую два столбца: столбец 322 ссылок на поток и столбец 324 DataSpaceName [имен пространств данных]. Содержимое столбца 322 ссылок на поток относится к одному из потоков (например, потоков 204-208), хранящихся в составном документе. Содержимое в DataSpaceName относится к конкретному пространству данных, которое задано для соответствующего потока, указанного в столбце 322 ссылки на поток. Одно пространство данных может быть связано с любым количеством потоков. Например, согласно фиг.3, пространство данных, обозначенное "DataSpaceName1", связано с потоком 204 stream1 и потоком 206 stream2. Хотя в вышеприведенном описании поток 320 DataSpaceMap представлен в виде таблицы, специалистам в данной области очевидно, что для идентификации и сопоставления потока с пространством данных можно использовать и другие форматы.
Хранилище 330 DataSpaceInfo [информация пространства данных] содержит один или несколько потоков DataSpaceName (например, потоки 332 и 334 DataSpaceName). Для описываемого варианта осуществления поток DataSpaceName назван в соответствии со стандартными соглашениями для коротких имен составных файлов. Каждый поток 332 и 334 DataSpaceName идентифицирует список 336 преобразований, связанных с соответствующим потоком 332 и 334 DataSpaceName. В одном варианте осуществления каждый из потоков 332 и 334 DataSpaceName может представлять собой список преобразований, образующих пространство данных. Потому что стек преобразований, порядок в списке 336, важен. В одном варианте осуществления первое преобразование 337 в списке 336 именуется «нижним» преобразованием, что означает, что преобразование 337 расположено ближе всех к битам в нижележащем потоке данных (например, потоке 204). Последнее преобразование 339 в списке 336 именуется «верхним» преобразованием, что означает, что преобразование 339 расположено ближе всех к потребителю/создателю данных (например, приложению). Согласно подробно описанному ниже со ссылкой на фиг.4, порядок, заданный в списке 336, определяет прохождение данных через преобразования.
Хранилище 340 TransformInfo [информация преобразований] содержит одно или несколько хранилищ TransformInstance [экземпляр преобразования] (например, хранилище 342, 344 и 346 TransformInstance). В одном варианте осуществления имена этих подхранилищ являются именами преобразований. В каждом из хранилищ 342, 344 и 346 TransformInstance имеется, по меньшей мере, один поток, названный "\006Primary"350. Поток 350 \006Primary содержит существенную информацию о конкретном преобразовании, например TransformClassType 354 [тип класса преобразования] и TransformClassName 356 [имя класса преобразования]. Тип 354 TransformClassType обозначает конкретный класс преобразования, который реализует конкретное преобразование (например, LZ-сжатие, защиту «управления правами на цифровое содержимое» (DRM) и т.п.). В одном варианте осуществления имя 356 TransformClassName задано как строка, однозначно идентифицирующая класс (т.е. тип) преобразования. Строка, идентифицирующая класс, может быть именем класса для класса, реализующего преобразование. Тип 354 TransformClassType задает идентификатор типа, который указывает, как интерпретировать строку, заданную в имени 356 TransformClassName. Поток 350 \006Primary может также содержать пространство для данных TransformInstanceData 358 [данные экземпляра преобразования]. В данных 358 TransformInstanceData хранится информация, заданная для преобразования, заданного именем 356 TransformClassName и типом 354 TransformClassType. Например, если преобразование является преобразованием сжатия, то данные 358 TransformInstanceData могут содержать размер окна и т.п.
Для некоторых преобразований данные 358 TransformInstanceData могут не обеспечивать достаточного пространства для хранения необходимой информации. Таким образом, согласно дополнительному усовершенствованию настоящее изобретение позволяет преобразованию сохранять дополнительную информацию в потоке TransformInstanceData (например, потоке 370 TransformInstanceData). Это допустимо, пока нет никаких конфликтов имен с потоком 350 \006Primary. Характер данных экземпляра преобразования изменяется в зависимости от типа преобразования.
Хотя вышеуказанная древовидная иерархия описывает один вариант осуществления формата документа для сохранения преобразованных данных совместно с их информацией преобразования, специалистам в данной области очевидно, что иерархия может изменяться, не влияя на работу настоящего изобретения. Поэтому, любая древовидная иерархия, в которой информация преобразования хранится совместно с преобразованными данными, не выходит за пределы настоящего изобретения. На фиг.4 изображена схема процесса преобразования, в котором используется механизм форматирования документов, имеющих преобразованные данные в соответствии с настоящим изобретением. В этом иллюстративном процессе преобразования приложение 400 пытается прочитать и записать файл 202, состоящий из множественных частей, описанный на фиг.2. В целом, каждый экземпляр класса преобразования берет в качестве ввода интерфейс IStream и выводит кодированные (т.е. преобразованные) данные на другой интерфейс IStream. Преобразования (например, преобразования 420 и 422) зарегистрированы, и пространство данных связано с потоком 206, которое уже задано, например, посредством программных интерфейсов приложения, обеспечиваемых составными документами OLE. Например, сначала, при создании потока 206, приложение, создавшее поток 206 в документе 202, состоящем из множественных частей, отвечает за указание, какие преобразования применять к данным. Для этого можно пользоваться списком аргументов, где каждый аргумент относится к (ссылается на) преобразованию.
Доступ для чтения и записи осуществляется через уровень ОС. До настоящего времени операция записи предусматривала обращение к потоку 206 stream2 через интерфейс 414 IStream. Однако, согласно настоящему изобретению, перед интерфейсом 414 IStream можно вставить одно или несколько преобразований. Каждое преобразование (например, преобразование 420 и 422) берет интерфейс IStream в качестве ввода (интерфейс 410 и 412 IStream, соответственно) и выводит свои кодированные (т.е. преобразованные) данные на другой интерфейс IStream (интерфейс 412 и 414 IStream, соответственно).
Аналогично, когда приложение 400 пытается читать поток 206 stream2 в файле 202, состоящем из множественных частей, можно вставить одно или несколько обратных преобразований (например, обратных преобразований 450 и 452). Количество обратных преобразований равно количеству преобразований, чтобы данные правильно декодировались и, таким образом, приложение могло понимать данные. Теперь, со ссылкой на фиг.5, опишем, как именно преобразования вставляются между приложением 400 и потоком 206.
На фиг.5 показана логическая последовательность операций, иллюстрирующая в целом процесс доступа к преобразованным данным в составном файле, согласно изобретению. Процесс 500 начинается с начального этапа 501, на котором приложение запрашивает доступ к данным в потоке файла, состоящего из множественных частей. Информация 210 преобразования для потока уже задана.
На этапе принятия решения производится определение, является ли поток членом пространства данных. Согласно фиг.3, для одного варианта осуществления, это определение производится путем поиска в отображении пространств данных ссылки 322 на поток, которая идентифицирует запрашиваемый поток. Если ссылка 322 на поток, связанная с потоком, не найдена, значит для потока не задано преобразований, и обработка заканчивается. В этом случае, приложение обращается к данным таким же образом, как это делалось до настоящего изобретения. Если же в отображении пространств данных содержится ссылка 322 на поток, то обработка переходит к этапу 504.
Этап 504 обозначает получение имени пространства данных, связанного со ссылкой 322 на поток.
На этапе 506 производится поиск в хранилище DataSpaceInfo (информации пространства данных) с использованием имени пространства данных (DataSpaceName), полученного на этапе 504, для идентификации потока DataSpaceName, связанного с именем пространства данных, указанным в отображении пространств данных (DataSpaceMap). Поток DataSpaceName содержит список преобразований, связанных с этим именем пространства данных.
На этапе 508 производится идентификация преобразования из списка. В зависимости от того, производится ли доступ для чтения или записи, преобразование может кодировать данные или декодировать данные, соответственно. В потоке DataSpaceName перечислены все преобразования в конкретном порядке. Если доступ осуществляется для записи, то порядок будет сверху вниз. Если доступ осуществляется для чтения, то порядок будет снизу вверх.
Этап 510 обозначает применение идентифицированного преобразования. При применении преобразования, для правильного преобразования данных используются данные экземпляра преобразования. Если доступ производится для записи, то применяется (кодирующее) преобразование. Если доступ производится для чтения, то применяется обратное (декодирующее) преобразование.
На этапе 512 принятия решения производится определение, содержит ли пространство данных какие-либо дополнительные преобразования, включенные в цепь. Для этого можно посмотреть, ссылается ли список 336 на какие-либо еще экземпляры преобразования. Если было применено последнее преобразование в пространстве данных, то последнее преобразование выводит данные, и процесс завершается. Если же в списке есть еще одно преобразование, то обработка возвращается к этапу 508 и продолжается, как описано выше, пока не будет применено последнее преобразование.
Кроме того, специалисту в данной области очевидно, что функции, обеспечиваемые процессом 300, могут быть реализованы разными способами. Например, может иметь место отображение непосредственно имени потока в список преобразований (с пропуском использования пространства данных). Таким образом, настоящее изобретение включает в себя этот и другие варианты осуществления для отображения потока в его информацию преобразования. Процесс 500 иллюстрирует один такой вариант осуществления.
Вышеизложенные описание изобретения, примеры и данные обеспечивают полное описание производства и использования состава изобретения. Поскольку в рамках сущности и объема изобретения возможны множественные варианты осуществления изобретения, изобретение задано нижеприведенной формулой изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМА И СПОСОБ ДЛЯ ОБЕСПЕЧЕНИЯ МНОЖЕСТВЕННЫХ ВОСПРОИЗВЕДЕНИЙ СОДЕРЖАНИЯ ДОКУМЕНТОВ | 2003 |
|
RU2322687C2 |
| СИСТЕМЫ И СПОСОБЫ СОПРЯЖЕНИЯ ПРИКЛАДНЫХ ПРОГРАММ С ПЛАТФОРМОЙ ХРАНЕНИЯ НА ОСНОВЕ СТАТЕЙ | 2003 |
|
RU2412461C2 |
| СИСТЕМЫ И СПОСОБЫ ДЛЯ ОБЕСПЕЧЕНИЯ УСЛУГ СИНХРОНИЗАЦИИ ДЛЯ БЛОКОВ ИНФОРМАЦИИ, УПРАВЛЯЕМЫХ АППАРАТНОЙ/ПРОГРАММНОЙ ИНТЕРФЕЙСНОЙ СИСТЕМОЙ | 2004 |
|
RU2377646C2 |
| СИСТЕМЫ И СПОСОБЫ РАСШИРЕНИЙ И НАСЛЕДОВАНИЯ ДЛЯ БЛОКОВ ИНФОРМАЦИИ, УПРАВЛЯЕМЫХ СИСТЕМОЙ АППАРАТНО-ПРОГРАММНОГО ИНТЕРФЕЙСА | 2004 |
|
RU2412475C2 |
| СИСТЕМЫ И СПОСОБЫ МОДЕЛИРОВАНИЯ ДАННЫХ В ОСНОВАННОЙ НА ПРЕДМЕТАХ ПЛАТФОРМЕ ХРАНЕНИЯ | 2003 |
|
RU2371757C2 |
| АРХИТЕКТУРА СИСТЕМЫ РАСПРОСТРАНЕНИЯ ОБНОВЛЕНИЙ И СПОСОБ РАСПРОСТРАНЕНИЯ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ | 2005 |
|
RU2408063C2 |
| ЗАПЕЧАТЫВАНИЕ ДАННЫХ С ПОМОЩЬЮ АНКЛАВА ЗАПЕЧАТЫВАНИЯ | 2017 |
|
RU2759329C2 |
| МЕХАНИЗМЫ ОБНАРУЖИВАЕМОСТИ И ПЕРЕЧИСЛЕНИЯ В ИЕРАРХИЧЕСКИ ЗАЩИЩЕННОЙ СИСТЕМЕ ХРАНЕНИЯ ДАННЫХ | 2006 |
|
RU2408070C2 |
| СПОСОБ И СИСТЕМА ДЛЯ СПОСОБСТВОВАНИЯ ПРОДВИЖЕНИЮ ПРОДУКТОВ И/ИЛИ УСЛУГ | 2009 |
|
RU2536382C2 |
| СИСТЕМА И СПОСОБЫ ОБЕСПЕЧЕНИЯ УЛУЧШЕННОЙ МОДЕЛИ БЕЗОПАСНОСТИ | 2004 |
|
RU2564850C2 |
Изобретение относится к системе и способу применения преобразований к файлам, состоящим из множественных частей. Техническим результатом является возможность автоматического извлечения вспомогательных объектов и решение возникающих при этом проблем за одно обращение к главному объекту. Согласно способу выполнения преобразований над данными принимают запрос доступа к потоку в файле, состоящем из множественных частей, по получении запроса идентифицируется список преобразований, связанных с потоком, при этом список также включается в файл, состоящий из множественных частей, а преобразования, указанные в списке преобразований, осуществляются над данными до выполнения запроса, причем если это запрос на запись, то кодируют данные, а если это запрос на чтение, декодируют данные. Список преобразований зависит от порядка необходимых преобразований и включает в себя структуру данных, имеющую первый поток, включающий в себя отображение, сопоставляющее поток с именем для списка преобразований, второй поток, перечисляющий каждое из преобразований для потока, третий поток для каждого из перечисленных преобразований, который идентифицирует информацию, связанную с преобразованием. 3 н. и 24 з.п. ф-лы, 5 ил.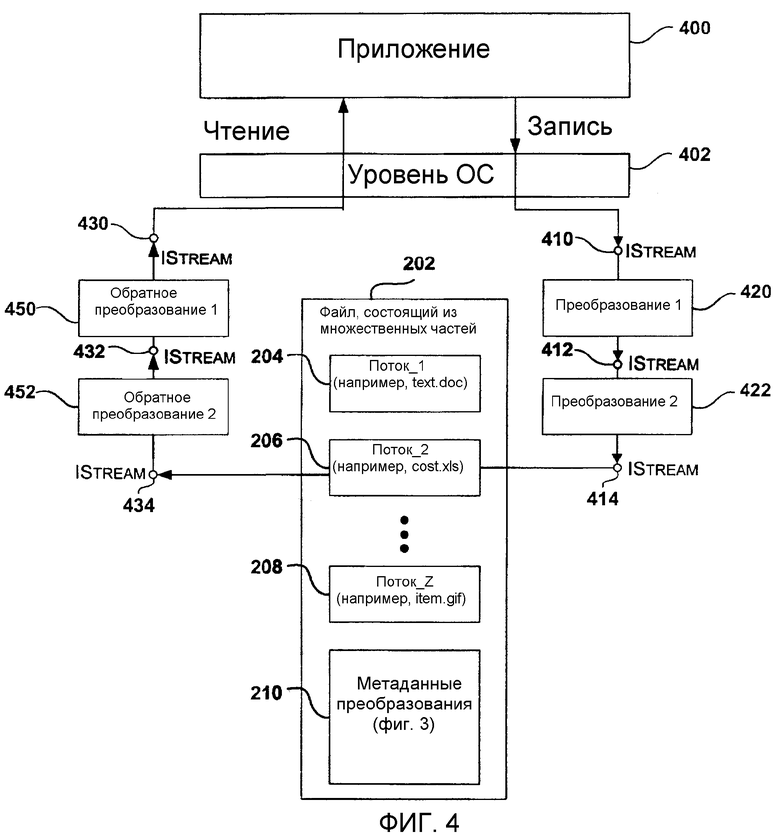
принимают запрос доступа к потоку в файле, состоящем из множественных частей, причем файл, состоящий из множественных частей, включает в себя потоки и пространства данных, при этом каждое пространство данных задает список преобразований, подлежащих применению в заданном порядке к данным внутри потока,
идентифицируют упомянутый список преобразований, связанных с потоком, причем список идентифицируют из файла, состоящего из множественных частей, и
выполняют преобразования в порядке, указанном в списке преобразований, над данными перед завершением обработки запроса.
второй поток, который перечисляет каждое из преобразований для упомянутого потока, и третий поток для каждого из преобразований, причем третий поток идентифицирует информацию, связанную с преобразованием.
| US 2001023436 A1, 20.09.2001 | |||
| СПОСОБ И УСТРОЙСТВО ДЛЯ ПЕРЕДАЧИ ИЗОБРАЖЕНИЯ | 1994 |
|
RU2139637C1 |
| US 6529948 B1, 04.03.2003 | |||
| Бесколесный шариковый ход для железнодорожных вагонов | 1917 |
|
SU97A1 |
| RU 97111724 A, 27.06.1999. | |||

