Изобретение относится к цифровой обработке изображения в процессе сканирования и копирования и особенно к области сегментации цветного и черно-белого текста, когда текст автоматически извлекается из отсканированного документа.
Основной набор процедур, которые выполняет копировальная техника, в частности Многофункциональное Цифровое Устройство (МФУ) или, иными словами, Многофункциональный Принтер (МФП), включает в себя получение отсканированных изображений от сканнера, обработку изображений и отправку их на встроенный принтер для печати. МФУ должно быть в состоянии обрабатывать различные виды оригиналов. Эти оригиналы могут иметь различное содержание, такое как текст, диаграммы, графику, фотографии; они могут быть напечатаны на различных носителях, например на бумаге различного качества; они могут быть созданы с использованием других методов, таких, например, как полутоновые или полноцветные изображения. Эти разные виды оригиналов могут при копировании подвергаться различным воздействиям в зависимости от возможностей и ограничений, имеющихся у конкретного МФУ, в частности, на копии могут появляться полосы, рассеянный свет, паразитное окрашивание, смещение объектов, изменение спектра, появления муара и т.д. При этом даже фиксированные установки параметров копирования приводят к различному качеству репродукции в зависимости от вида оригинала. Для решения этой проблемы и получения репродукций в соответствии с предпочтениями пользователя необходимо предусмотреть возможность адаптации процедур, выполняемых МФУ.
Широко распространенным подходом к решению этой проблемы является разработка алгоритмов, позволяющих управлять процедурой копирования в МФУ. Многие алгоритмы такого рода основываются на сегментации страницы и индексации каждого сегментированного участка в соответствии со специальной классификацией. Эти алгоритмы требуют одновременного доступа ко всему изображению страницы и предусматривают многократный анализ каждого пикселя. С другой стороны, любой алгоритм, применяющийся к процедуре копирования, должен быть способен обрабатывать изображение поблочно и не повторять обработку ранее обработанных блоков. Это требование практически невыполнимо на основе применения известных методов.
С другой стороны, очень важно определить цветовые параметры оригинала, поскольку, например, отнесение (классификация) изображения к черно-белым оригиналам позволило бы упростить процедуру его обработки и печати, в частности, появляется возможность использовать только картридж с черной краской и сэкономить другие краски не в ущерб качеству. Различные варианты применения классификации при обработке документов описаны в патентной литературе.
Так, патент США №6972866 [1], являющийся аналогом заявляемого изобретения, описывает способ классификации пикселей в одну из двух категорий: - к первой из которых относят монохромные пиксели, а к другой - цветные пиксели. Цвет каждого из пикселов представлен соответствующим цветовым индексом в цветовом пространстве L'a'b'. Средний цветовой индекс определяется как функция цветовых индексов пикселей в группе.
Выложенная заявка на патент США №20020081023 [2], являющаяся аналогом-прототипом заявляемого изобретения, раскрывает способ выявления цвета текста для обработки изображения в копировальном устройстве. В рамках этого способа предусмотрена поблочная обработка данных вводимого изображения путем отбора блоков вместо попиксельной обработки. Согласно этому изобретению объекты на исходном изображении выявляются путем отбора блоков и подразделяются на две категории: «текст» или «не текст». Затем для каждого текстового объекта определяют цвет переднего плана, используя данные текста переднего плана. После сбора данных о переднем плане вычисляют усредненный цвет переднего плана в некотором цветовом пространстве, например в пространстве L'a'b'. Используя информацию об усредненном цвете, определяют, является ли текстовый объект черно-белым или нет.
Общим недостатком упомянутых аналогов является то, что каждый из них решает только часть задачи, заключающейся в повышении эффективности обработки и распечатки документов со смешанным содержанием, т.е. с текстом и графикой.
Задача, на решение которой направлено заявляемое изобретение, состоит в том, чтобы разработать универсальный подход к предварительной обработке исходного документа, обеспечивающий ускоренную печать копии и экономию ресурсов МФУ.
Основной технический результат достигается за счет внедрения усовершенствованного способа сегментации текста по цветовому признаку в процессе копирования, причем заявляемый способ предусматривает выполнение следующих операций:
- исходное изображение разбивают на неперекрывающиеся блоки пикселей;
- формируют новое изображение Z, в котором каждый пиксел представляет собой соответствующий блок исходного изображения;
- последовательно выбирают в процессе сканирования блоки исходного изображения;
- выполняют классификацию для текущего блока по признаку «монохромный/цветной» в пространстве противоположных цветов;
- разбивают исходный цветной блок RGB на монохромные блоки R, G и В;
- применяют детектор краев лапласиан гауссиана с заданным порогом Т к монохромному блоку;
- вычисляют число краев для каждого пикселя в Z;
- выполняют классификацию «текстовый/нетекстовый блок» путем сопоставления числа краев с заданным порогом С;
- объединяют классифицированные каналы, используя логический оператор ИЛИ.
Для оптимального функционирования заявляемого способа важно, чтобы в процессе классификации по признаку «монохромный/цветной» выполняли следующие операции:
- преобразуют изображение из цветового пространства RGB в изображение, представленное в пространстве противоположных цветов;
- классифицируют пиксели как монохромные или цветные по признаку отдаленности от оси интенсивности в пространстве противоположных цветов;
- формируют блоки пикселей путем разбиения изображения на неперекрывающиеся квадраты;
- рассчитывают цветовую насыщенность блока пикселей как сумму расстояний для всех пикселей, принадлежащих этому блоку;
- задают порог цветовой насыщенности с учетом результатов обучения по обучающей выборке;
- классифицируют изображение как цветное, если цветовая насыщенность превышает заданный порог;
- классифицируют изображение как монохромное, если цветовая насыщенность не превышает заданный порог.
Для оптимального функционирования заявляемого способа целесообразно, чтобы сегментацию текста по признаку «монохромный/цветной» выполняли по отдельным R, G, В каналам.
Для оптимального функционирования заявляемого способа имеет смысл, чтобы сегментацию текста выполняли на произвольном цветном фоне.
Для лучшего понимания существа заявляемого изобретения далее приводится детальное описание выполняемой последовательности операций с привлечением графических материалов.
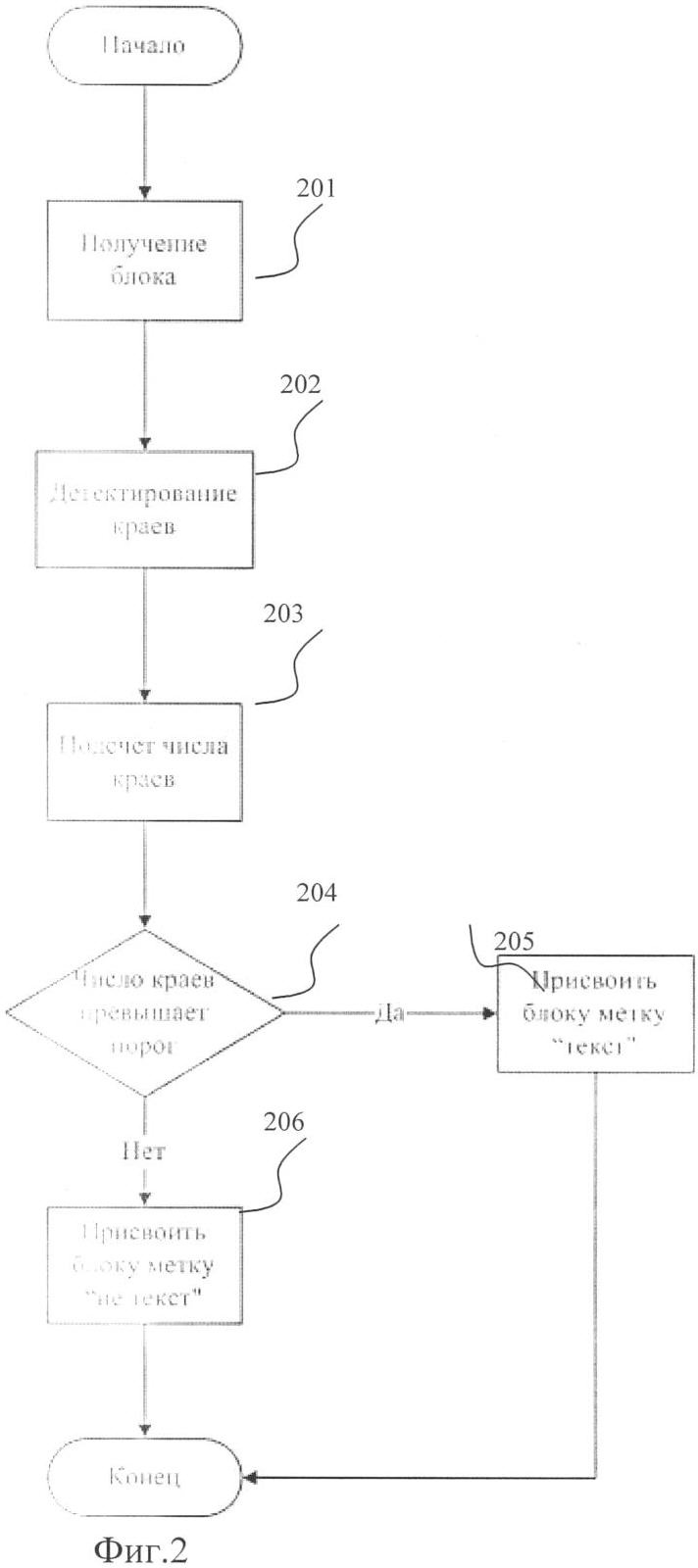
Фиг.1. Блок-схема алгоритма выполнения классификации по признаку «монохромное/цветное».
Фиг.2. Блок-схема алгоритма выполнения классификации по признаку «текст/не текст».
Фиг.3. Выявление текста на изображении документа.
Заявляемый способ реализуется путем выполнения следующих этапов:
- определение монохромности изображения выполняется в пространстве противоположных цветов L'a'b' [3], которое задается тремя каналами - интенсивности L' и цвета а' и b':
L'=(R+G+B)/3
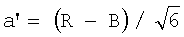
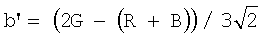
- положение точки вдоль оси L' представляет различные уровни интенсивности серого. Монохромный пиксел определяется как
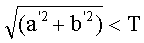
цветной пиксел определяется как
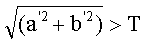
где а'2+b'2 представляет квадрат расстояния от оси L' до любой точки (а', b') вдоль оси L' и определяет расстояние или порог от оси L', выше которого пиксел рассматривается цветным. Функция T(L') представляет цилиндр. Следовательно, все точки в цветовом пространстве L'a'b' лежащие внутри этого цилиндра рассматриваются как монохромные; все точки вне цилиндра рассматриваются как цветные.
Цветовая насыщенность С(В) блока пикселей В определяется как сумма расстояний для всех пикселей, которые принадлежат блоку В. Изображение классифицируется как цветное, если С(В) больше чем порог и изображение классифицируется как монохромное в противном случае. Порог определяется из обучающей выборки.
Фиг.1 представляет блок-схему алгоритма выполнения классификации по признаку «монохромное/цветное». В 101 выполняется выбор блока в процессе сканирования документа. В 102 выполняется классификация блока по признаку «монохромное/цветное». Если изображение монохромное, в 103 блоку присваивается метка «монохромное». Если изображение монохромное, в 104 выполняется классификация блока по признаку «текст/не текст». Если изображение цветное, в 105 блоку присваивается метка «цветное». В 106 выполняется разбиение RGB на отдельные R, G и В изображения. В 107 выполняется классификация каждого R, G и В изображения по признаку «текст/не текст». В 108 выполняется объединение классифицированных R, G и В изображений, используя логическое «ИЛИ».
Фиг.2 представляет блок-схему алгоритма выполнения классификации по признаку «текст/не текст». В 201 выполняется получение выбранного блока в процессе сканирования документа. В 202 блок обрабатывается с помощью детектора краев лапласиан гауссиана. В 203 выполняется вычисление числа краев в блоке. В 204 проверяется, превышает ли число краев заданный порог С. Если да, в 205 блок классифицируется как «текст» и ему присваивается метка «текст». Если нет, в 206 блок классифицируется как «не текст» и ему присваивается метка «не текст».
Фиг.3. представляет результаты выявления текста на изображении документа. Выявленные текстовые области помечены серым цветом.
Заявляемый способ промышленно применим для цифровой обработки изображения в процессе сканирования и копирования, в частности, при сегментации цветного и черно-белого текста, когда текст автоматически извлекается из отсканированного документа, например, в многофункциональных цифровых устройствах.
Источники информации
1. Патент США №6972866.
2. Выложенная заявка на патент США №20020081023.
3. К.Dabov, A.Foi, V.Katkovnik, and К.Egiazarian, "Image denoising by sparse 3D transform-domain collaborative filtering," IEEE Trans. Image Process., vol.16, no.8, pp.2080-2095, August 2007.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА УЛУЧШЕНИЯ ТЕКСТА ПРИ ЦИФРОВОМ КОПИРОВАНИИ ПЕЧАТНЫХ ДОКУМЕНТОВ | 2012 |
|
RU2520407C1 |
| СПОСОБ И СИСТЕМА ПРЕОБРАЗОВАНИЯ МОМЕНТАЛЬНОГО СНИМКА ЭКРАНА В МЕТАФАЙЛ | 2013 |
|
RU2534005C2 |
| СПОСОБ ОБЕСПЕЧЕНИЯ КОРРЕКТНОЙ ОРИЕНТАЦИИ ДОКУМЕНТОВ ПРИ АВТОМАТИЧЕСКОЙ ПЕЧАТИ | 2011 |
|
RU2469398C1 |
| СПОСОБ АДАПТИВНОГО СГЛАЖИВАНИЯ ДЛЯ ПОДАВЛЕНИЯ РАСТРОВОЙ СТРУКТУРЫ ИЗОБРАЖЕНИЙ | 2008 |
|
RU2411584C2 |
| СПОСОБ И СИСТЕМА ГЕНЕРАЦИИ АНИМИРОВАННОГО ИЗОБРАЖЕНИЯ ДЛЯ ПРЕДВАРИТЕЛЬНОГО ПРОСМОТРА | 2009 |
|
RU2411585C1 |
| СПОСОБ ПОИСКА ЦИФРОВОГО ИЗОБРАЖЕНИЯ, СОДЕРЖАЩЕГО ЦИФРОВОЙ ВОДЯНОЙ ЗНАК | 2013 |
|
RU2559773C2 |
| РАЗДЕЛЕНИЕ ИЗОБРАЖЕНИЙ НА ОБОСОБЛЕННЫЕ ЦВЕТОВЫЕ СЛОИ | 2021 |
|
RU2792722C1 |
| СПОСОБ ПОДАВЛЕНИЯ РАСТРА | 2008 |
|
RU2405279C2 |
| СПОСОБ РАСПОЗНАВАНИЯ ТЕКСТА НА ИЗОБРАЖЕНИЯХ ДОКУМЕНТОВ | 2021 |
|
RU2768544C1 |
| СИСТЕМА И СПОСОБ СКАНИРОВАНИЯ И КОПИРОВАНИЯ | 2004 |
|
RU2368091C2 |

Изобретение относится к цифровой обработке изображения в процессе сканирования и копирования и особенно к области сегментации цветного и черно-белого текста, когда текст автоматически извлекается из отсканированного документа. Техническим результатом является универсальный подход к предварительной обработке исходного документа, обеспечивающий ускоренную печать копии и экономию ресурсов МФУ. В соответствии с настоящим изобретением способ сегментации текста по цветовому признаку заключается в выполнении следующих операций: разбивают исходное изображение на неперекрывающиеся блоки пикселей; формируют новое изображение Z, в котором каждый пиксел представляет собой соответствующий блок исходного изображения; выбирают в процессе сканирования последовательные блоки из исходного изображения; выполняют для текущего блока классификацию по признаку «монохромный/цветной» в пространстве противоположных цветов; разбивают исходный цветной блок RGB на монохромные блоки R, G и В; применяют детектор краев лапласиан гауссиана с заданным порогом Т к монохромному блоку; вычисляют число краев для каждого пикселя в Z; выполняют классификацию «текстовый/нетекстовый блок» путем сопоставления числа краев с заданным порогом С; объединяют классифицированные каналы, используя логический оператор ИЛИ. 3 з.п. ф-лы, 3 ил.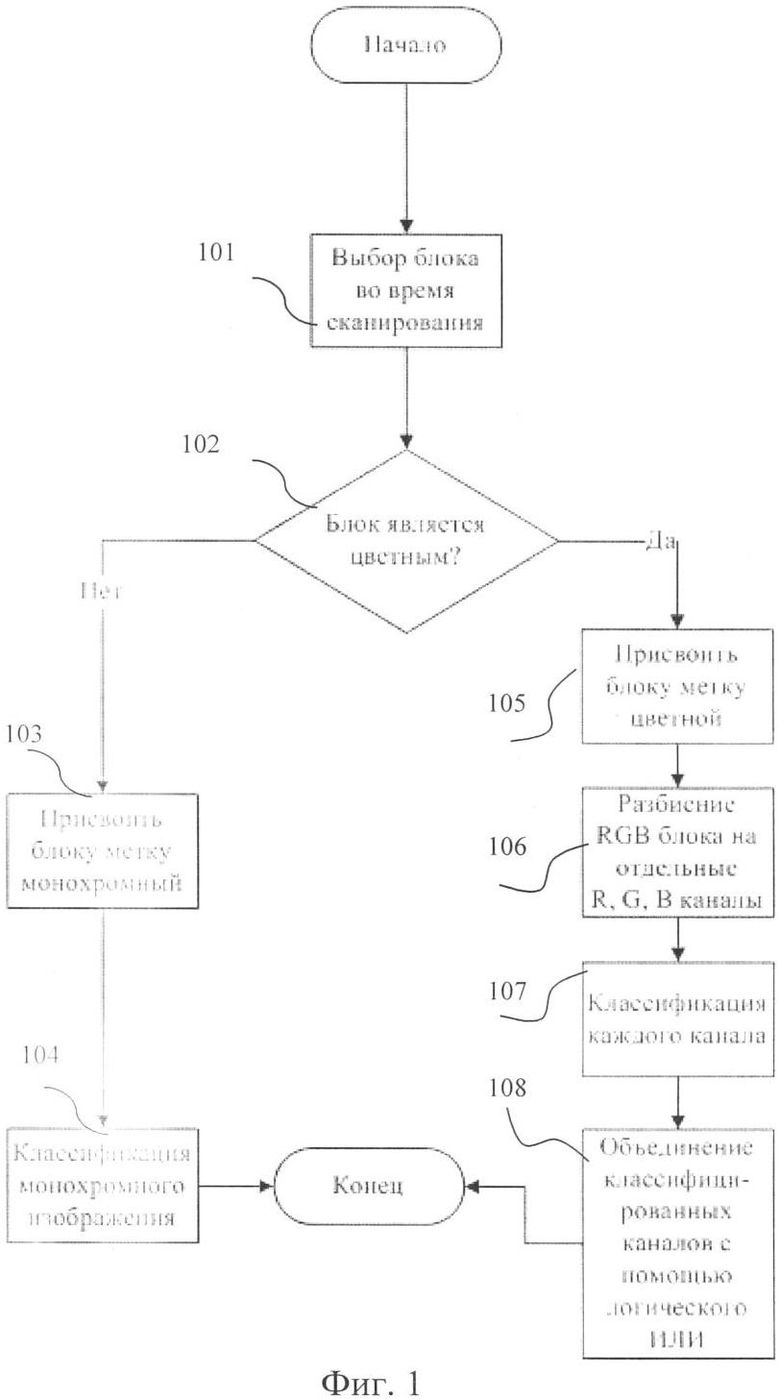
1. Способ сегментации текста по цветовому признаку, заключающийся в выполнении следующих операций:
разбивают исходное изображение на неперекрывающиеся блоки пикселей;
формируют новое изображение Z, в котором каждый пиксель представляет собой соответствующий блок исходного изображения;
выбирают в процессе сканирования последовательные блоки из исходного изображения;
выполняют для текущего блока классификацию по признаку «монохромный/цветной» в пространстве противоположных цветов;
разбивают исходный цветной блок RGB на монохромные блоки R, G и В;
примененяют детектор краев лапласиан гауссиана с заданным порогом Т к монохромному блоку;
вычисляют число краев для каждого пикселя в Z;
выполняют классификацию «текстовый/нетекстовый блок» путем сопоставления числа краев с заданным порогом С;
объединяют классифицированные каналы, используя логический оператор ИЛИ.
2. Способ по п.1, отличающийся тем, что сегментацию текста по признаку «монохромный/цветной» выполняют по отдельным R, G, В каналам.
3. Способ по п.1, отличающийся тем, что в процессе классификации по признаку «монохромный/цветной» выполняют следующие операции: преобразуют изображение из цветового пространства RGB в изображение, представленное в пространстве противоположных цветов;
классифицируют пиксели как монохромные или цветные по признаку отдаленности от оси интенсивности в пространстве противоположных цветов;
формируют блоки пикселей путем разбиения изображения на неперекрывающиеся квадраты;
рассчитывают цветовую насыщенность блока пикселей как сумму расстояний для всех пикселей, принадлежащих этому блоку;
задают порог цветовой насыщенности с учетом результатов обучения по обучающей выборке;
классифицируют изображение как цветное, если цветовая насыщенность превышает заданный порог;
классифицируют изображение как монохромное, если цветовая насыщенность не превышает заданный порог.
4. Способ по п.1, отличающийся тем, что сегментацию текста выполняют на произвольном цветном фоне.
| US 2002081023 A1, 27.06.2002 | |||
| US 6972866 В1, 06.12.2005 | |||
| СПОСОБ УПЛОТНЕНИЯ И РАСПАКОВКИ ДАННЫХ ИЗОБРАЖЕНИЯ | 2002 |
|
RU2279189C2 |
| US 5883973 A, 16.03.1999. | |||

