Область техники, к которой относится изобретение
Настоящее изобретение относится к подавлению шума. В частности, настоящее изобретение относится к устранению шумов из речевых сигналов.
Уровень техники
Общей проблемой распознавания и передачи речи является искажение речевого сигнала аддитивным шумом. В частности, является трудно обнаруживаемым и/или корректируемым искажение из-за речи, производимой другим диктором.
Согласно одному способу устранения шума делается попытка смоделировать шум с использованием набора обучающих сигналов с шумами, собираемых при различных условиях. Указанные обучающие сигналы принимаются до испытательного сигнала, который должен быть декодирован или передан, и используются, исключительно, для обучающих целей. Хотя такие системы делают попытку формирования моделей, учитывающих шум, они являются эффективными только, если шумовые условия для обучающих сигналов соответствуют шумовым условиям для испытательных сигналов. Из-за большого количества возможных шумов и, по-видимому, неограниченных комбинаций шумов, очень трудно построить модели шумов на обучающих сигналах, которые могут обрабатывать каждое проверяемое условие.
Другим способом устранения шума является оценка шума в испытательном сигнале и, затем, вычитание ее из речевого сигнала с шумами. Обычно такие системы оценивают шум из предыдущих кадров испытательного сигнала. По существу, при изменении шума во времени, оценка шума для текущего кадра будет неточной.
Одна известная система для оценки шума в речевом сигнале использует гармоники человеческой речи. Гармоники человеческой речи формируют пики в частотном спектре. Указанные системы определяют спектр шума, определяя провалы между этими пиками. Затем, для обеспечения достоверного (без шумов) речевого сигнала, этот спектр вычитается из спектра речевого сигнала с шумами.
При кодировании речи для передачи по цифровому каналу связи, гармоники речи использовались также в кодировании речи для уменьшения количества данных, которые должны быть переданы. Такие системы осуществляют попытку разделения речевого сигнала на гармоническую составляющую и случайную составляющую. Затем каждая составляющая кодируется для передачи отдельно. В частности, одна система использовала модель гармоника + шум, в которой для выполнения разложения речевого сигнала подходит модель суммы синусоид.
В кодировании речи разложение выполняется для обнаружения параметризации речевого сигнала, точно представляющей входной речевой сигнал с шумами. Разложение не обладает способностью подавления шума.
В последнее время была разработана система, которая осуществляет попытку устранения шума с использованием комбинации с альтернативным датчиком, например микрофона с костной звукопроводимостью и микрофона с воздушной звукопроводимостью. Эта система обучается с использованием трех обучающих каналов: обучающего сигнала с шумами альтернативного датчика, обучающего сигнала с шумами микрофона с воздушной звукопроводимостью и достоверного обучающего сигнала микрофона с воздушной звукопроводимостью. Каждый из сигналов преобразуется в представление в виде значений характеристик. Характеристики сигнала с шумами альтернативного датчика и сигнала с шумами микрофона с воздушной звукопроводимостью комбинируются в одиночный вектор, представляющий сигнал с шумами. Характеристики достоверного сигнала микрофона с воздушной звукопроводимостью формируют одиночный достоверный вектор. Затем эти векторы используются для подготовки (обучения) соответствия между векторами с шумами и достоверными векторами. Однажды подготовленные, соответствия применяются к вектору с шумами, сформированному из комбинации испытательного сигнала с шумами альтернативного датчика и испытательного сигнала с шумами микрофона с воздушной звукопроводимостью. Указанное соответствие формирует достоверный вектор сигнала.
Указанная система является недостаточно оптимальной, когда шумовые условия испытательных сигналов не соответствуют шумовым условиям обучающих сигналов, так как соответствия разработаны для шумовых условий обучающих сигналов.
Сущность изобретения
Заявленные способ и система используют для оценки достоверного значения речи сигнал альтернативного датчика, принятый из датчика, отличного от микрофона с воздушной звукопроводимостью. Достоверное значение речи оценивается без использования модели, обученной на обучающих данных с шумами, собранных из микрофона с воздушной звукопроводимостью. Согласно одному варианту осуществления для создания оценки достоверной речи к вектору, сформированному из сигнала альтернативного датчика, добавляются векторы поправки для формирования фильтра, применяемого к сигналу микрофона с воздушной звукопроводимостью. В других вариантах осуществления из сигнала альтернативного датчика определяется основной тон речевого сигнала, который используется для разложения сигнала микрофона с воздушной звукопроводимостью. Затем разложенный сигнал используется для определения оценки достоверного сигнала.
Краткое описание чертежей
Фиг.1 - блок-схема одной вычислительной среды, в которой может быть осуществлено практически настоящее изобретение.
Фиг.2 - блок-схема альтернативной вычислительной среды, в которой может быть осуществлено практически настоящее изобретение.
Фиг.3 - блок-схема общей системы обработки речевых сигналов, согласно настоящему изобретению.
Фиг.4 - блок-схема системы для обучения параметров подавления шума согласно одному варианту осуществления настоящего изобретения.
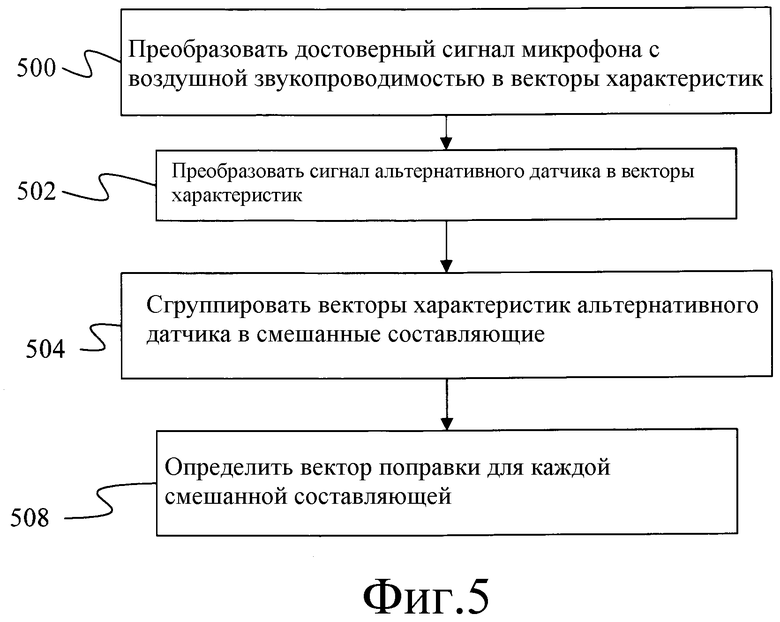
Фиг.5 - блок-схема обучения параметров подавления шума с использованием системы фиг.4.
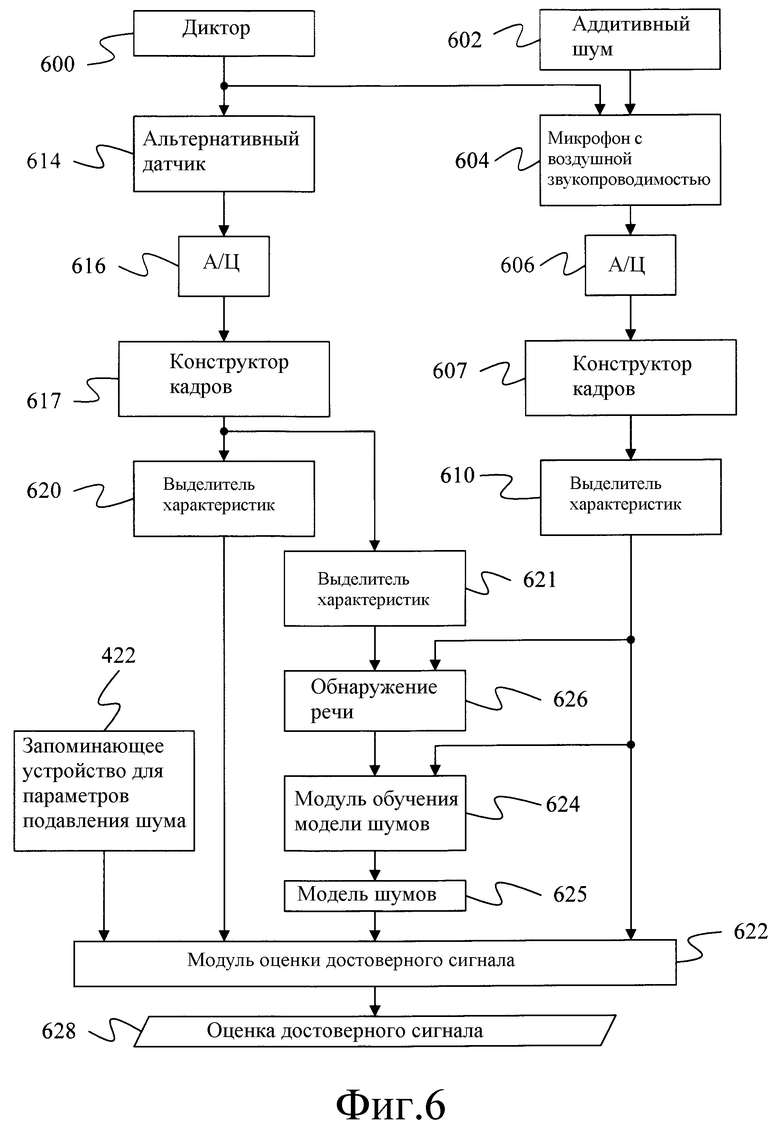
Фиг.6 - блок-схема системы для определения оценки достоверного речевого сигнала из испытательного речевого сигнала с шумами согласно одному варианту осуществления настоящего изобретения.
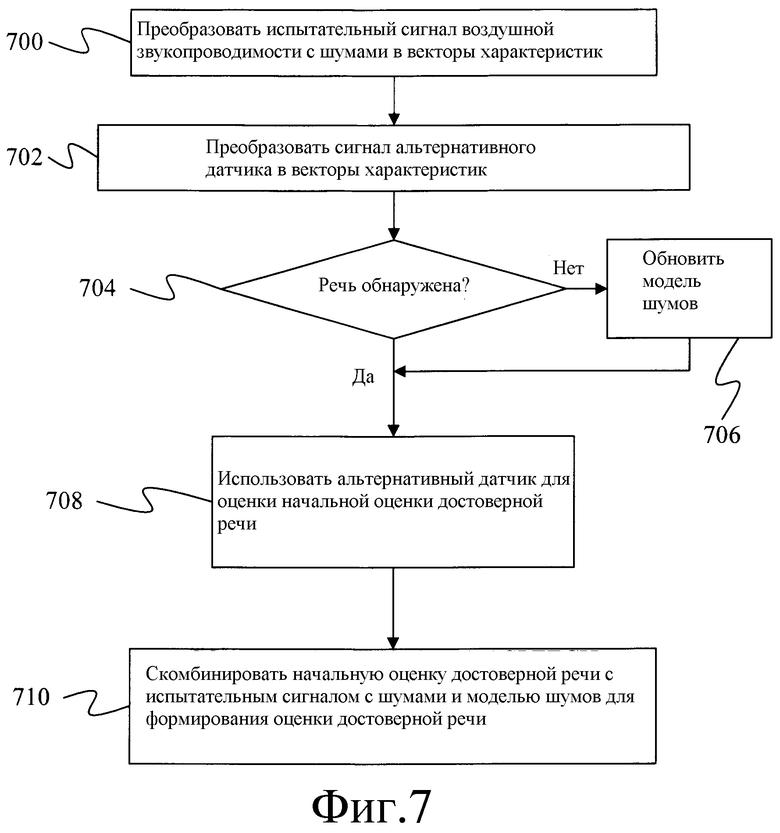
Фиг.7 - блок-схема способа определения оценки достоверного речевого сигнала с использованием системы фиг.6.
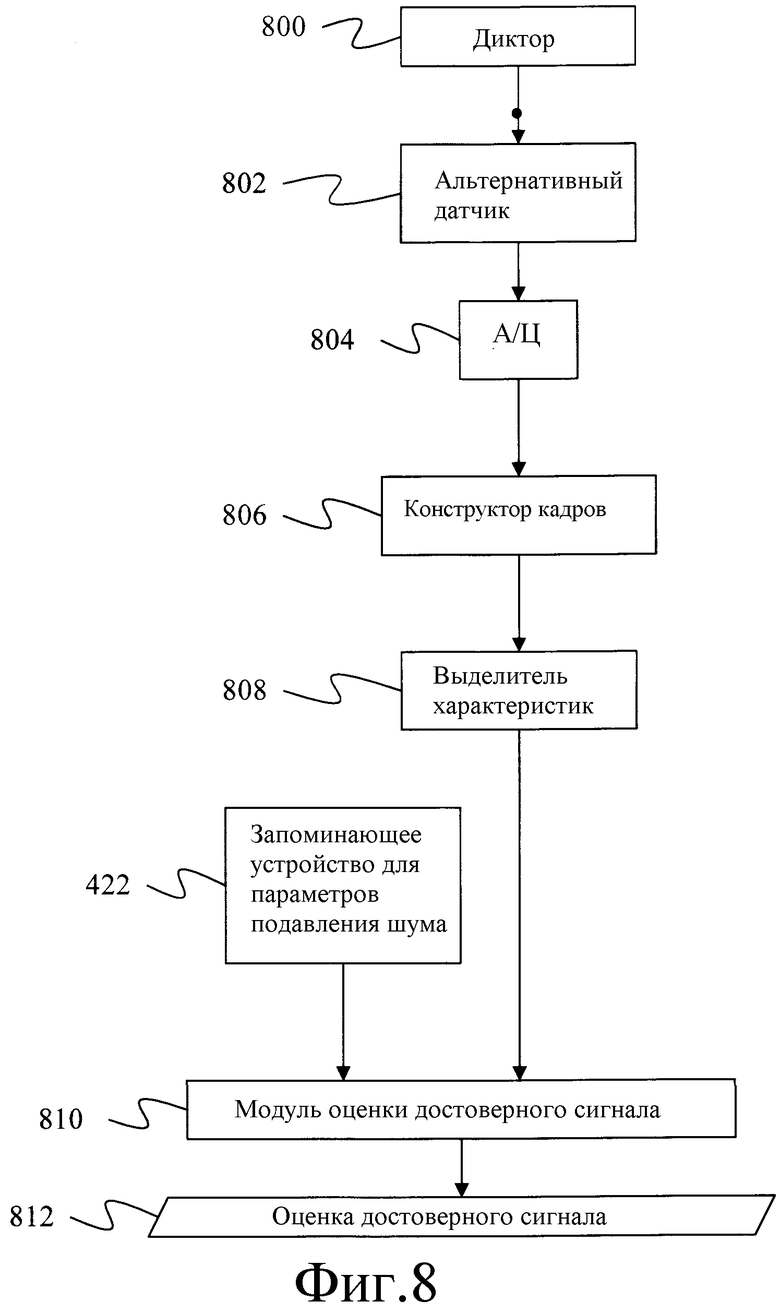
Фиг.8 - блок-схема альтернативной системы для определения оценки достоверного речевого сигнала.
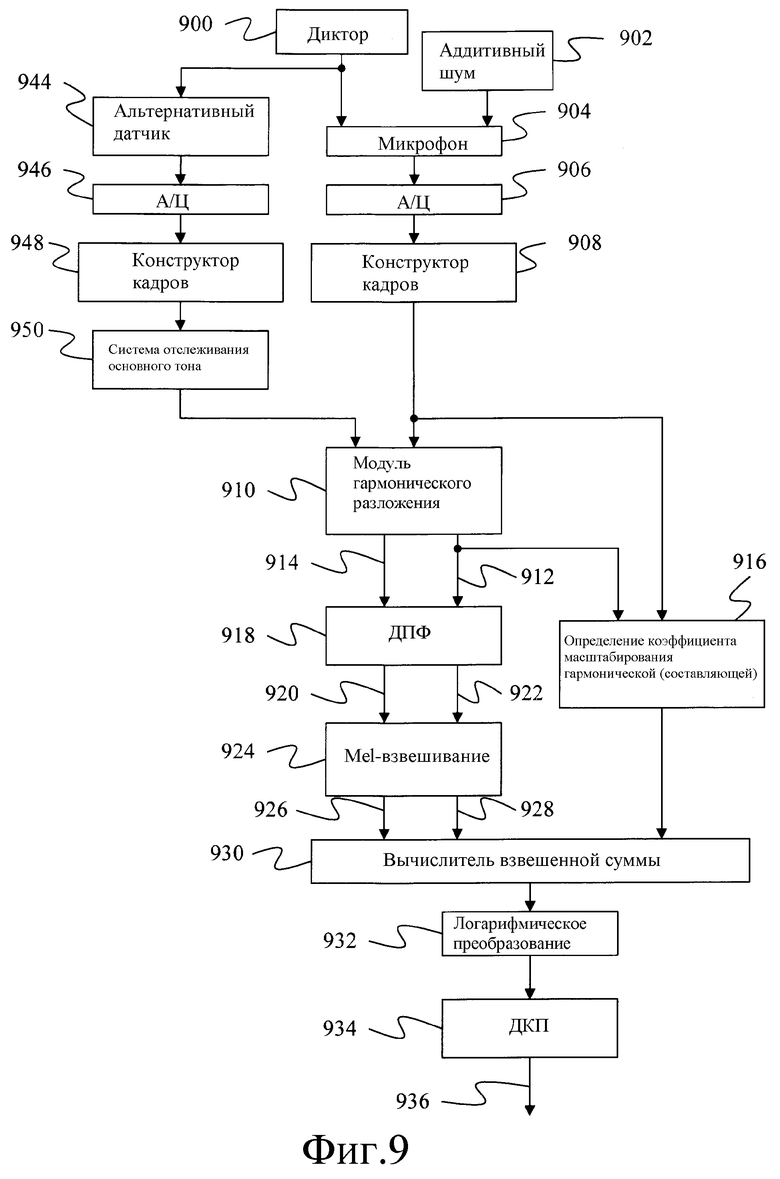
Фиг.9 - блок-схема второй альтернативной системы для определения оценки достоверного речевого сигнала.
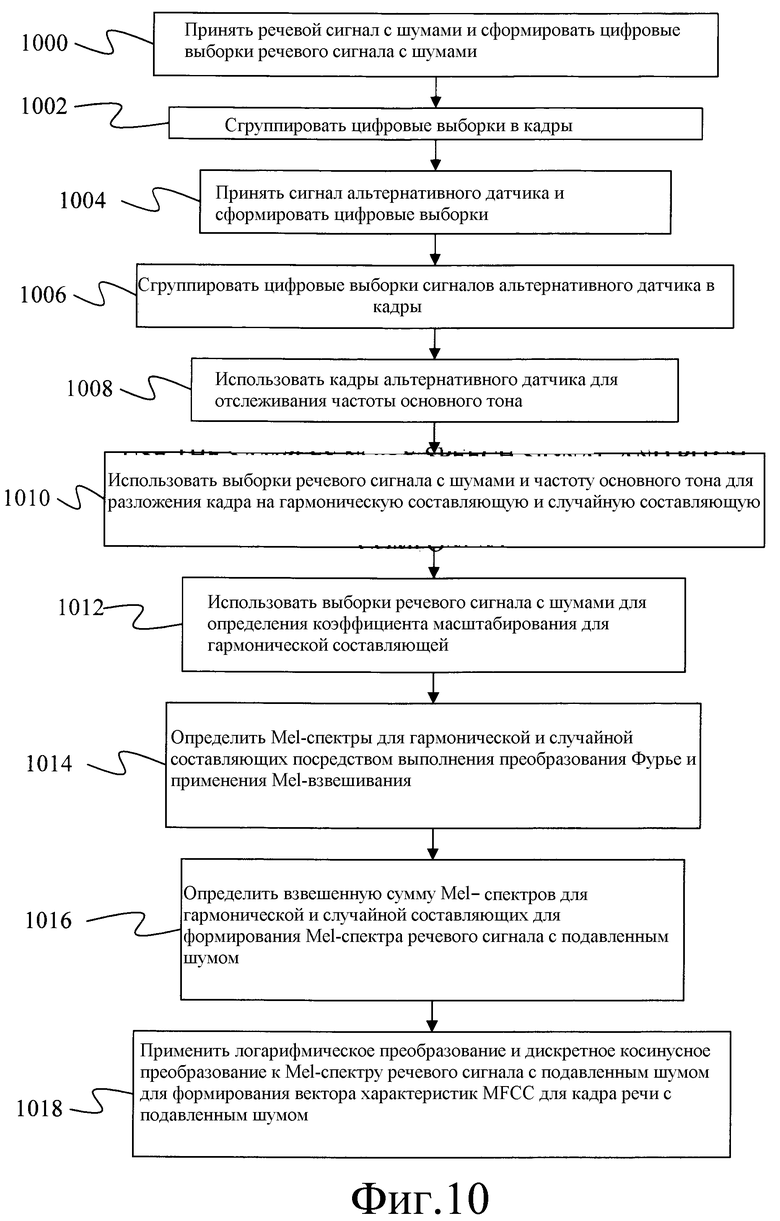
Фиг.10 - блок-схема способа определения оценки достоверного речевого сигнала с использованием системы фиг.9.
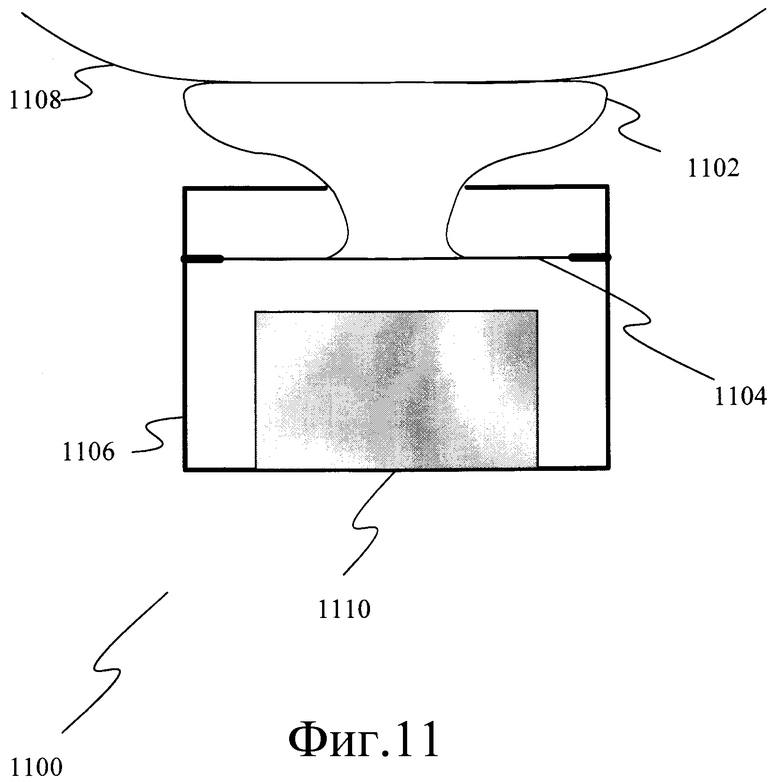
Фиг.11 - блок-схема микрофона с костной звукопроводимостью.
Подробное описание пояснительных вариантов осуществления
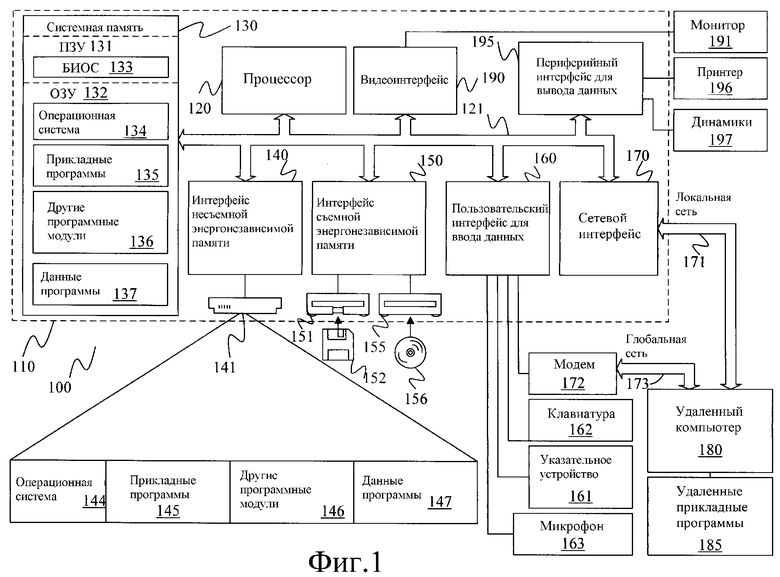
Фиг.1 иллюстрирует возможный вариант соответствующей среды 100 вычислительной системы, в которой может быть реализовано изобретение. Среда 100 вычислительной системы является только одним возможным вариантом соответствующей вычислительной среды и не предназначена для наложения какого-либо ограничения на область использования или на функциональные возможности изобретения. Также вычислительная среда 100 не должна интерпретироваться как зависимая от любого компонента или комбинации компонентов, иллюстрируемых возможной операционной средой 100, или как имеющая в них необходимость.
Изобретение может быть реализовано в отношении некоторых других конфигураций и сред универсальных и специальных вычислительных систем. Возможные варианты известных вычислительных систем, сред и/или конфигураций, которые могут быть использованы, включают в себя, например, персональные компьютеры, компьютеры-сервера, портативные или “дорожные” устройства, многопроцессорные системы, системы, основанные на микропроцессорах, компьютерные приставки к телевизору, программируемую бытовую электронику, сетевые персональные компьютеры (PC), миникомпьютеры, универсальные компьютеры, системы телефонной связи, распределенные вычислительные среды, содержащие любые из указанных систем или устройств и т.д.
Изобретение может быть описано в основном контексте команд, выполнимых компьютером, таких как программные модули, выполняемые компьютером. По существу, программные модули включают в себя процедуры, программы, объекты, компоненты, структуры данных и т.д., выполняющие конкретные задачи или реализующие определенные абстрактные типы данных. Изобретение предназначено для практического осуществления в распределенных вычислительных средах, в которых задачи выполняются удаленными устройствами обработки данных, соединенными через сеть связи. В распределенной вычислительной среде программные модули размещены на носителях информации локальных и удаленных компьютеров, включая запоминающие устройства.
Согласно фиг.1 возможная система для реализации изобретения содержит универсальное вычислительное устройство в виде компьютера 110. Компоненты компьютера 110 могут содержать, в частности, процессор 120, системную память 130 и системную шину 121, соединяющую различные компоненты системы, включая системную память, с процессором 120. Системной шиной 121 может быть любой из нескольких типов структур шины, включая шину памяти или контроллер памяти, периферийную шину и локальную шину, использующие любую из различных архитектур шины. В виде возможного варианта, такие архитектуры включают в себя шину архитектуры, соответствующую промышленному стандарту, ISA (АПС), шину микроканальной архитектуры, MCA (МКА), шину расширенной стандартной архитектуры для промышленного применения, EISA (РАПС), локальную шину Ассоциации по стандартам в области видеоэлектроники, VESA (АСВЭ), и 32-битовую системную шину PCI с возможностью расширения до 64 битов со скоростью передачи данных до 33 Мбайт/с, взаимодействие через которую происходит без участия центрального процессора (также известную, как шина Mezzanine) и т.д.
Компьютер 110, обычно, содержит несколько носителей информации, считываемых компьютером. Такой носитель информации, считываемый компьютером, может быть любым доступным носителем информации, к которому может осуществить доступ компьютер 110, и который включает в себя энергозависимый и энергонезависимый носитель информации, съемный и несъемный носитель информации. В виде возможного варианта носитель информации, считываемый компьютером, может включать в себя носитель информации компьютера и средство связи и т.д. Носитель информации компьютера включает в себя энергозависимый и энергонезависимый, съемный и несъемный носитель информации, реализованный любым способом или технологией для хранения информации, такой как команды, считываемые компьютером, структуры данных, программные модули или другие данные. Носитель информации компьютера включает в себя, например, оперативное запоминающее устройство RAM (ОЗУ), постоянное запоминающее устройство ROM (ПЗУ), электронно-перепрограммируемую постоянную память (EEPROM), флэш-память или другую технологию памяти, компакт диски CD-ROM, универсальные цифровые диски (DVD) или другой накопитель на оптических дисках, магнитные кассеты, магнитную ленту, накопитель на магнитных дисках или другие магнитные запоминающие устройства, или любой другой носитель информации, который может быть использован для хранения требуемой информации, и к которому может осуществить доступ компьютер 110. Средство связи обычно осуществляет команды, считываемые компьютером, структуры данных, программные модули или другие данные в модулированном сигнале данных, например, несущей или в другом механизме переноса информации и включает в себя любое средство доставки информации. Термин «модулированный сигнал данных» означает сигнал, который имеет одну или большее количество из набора его характеристик, или измененный таким образом, чтобы кодировать информацию в сигнале. В виде возможного варианта, средство связи включает в себя проводное средство, такое как проводная сеть или прямое кабельное соединение, и беспроводное средство, такое как акустическое, радио, инфракрасное и другое беспроводное средство и т.д. Комбинации любых упомянутых выше средств также должны быть включены в контекст носителей информации, считываемых компьютером.
Системная память 130 включает в себя носитель информации компьютера в виде энергонезависимой и/или энергозависимой памяти, такой как постоянное запоминающее устройство 131 (ПЗУ) и оперативное запоминающее устройство 132 (ОЗУ). Базовая система 133 ввода/вывода BIOS (БИОС), содержащая базовые процедуры, способствующие передаче информации между элементами внутри компьютера 110, например, используемые при запуске, в основном, хранится в ПЗУ 131. ОЗУ 132, в основном, содержит данные и/или программные модули, к которым можно осуществить доступ немедленно, и/или с которыми в текущее время оперирует процессор 120. В виде возможного варианта фиг.1, например, изображает операционную систему 134, прикладные программы 135, другие программные модули 135 и данные 137 программы.
Компьютер 110 также может содержать другие съемные/несъемные, энергозависимые/энергонезависимые носители информации компьютера. Исключительно в виде возможного варианта фиг. 1 изображает накопитель 141 на жестких дисках, который осуществляет считывание с несъемного энергонезависимого магнитного носителя информации или запись на него, накопитель 151 на магнитных дисках, который осуществляет считывание со съемного энергонезависимого магнитного диска 152 или запись на него, и накопитель 155 на оптических дисках, который осуществляет считывание со съемного энергонезависимого оптического диска 156, например, компакт-диска CD-ROM или другого оптического носителя информации, или запись на него. Другие съемные/несъемные, энергозависимые/энергонезависимые носители информации компьютера, которые могут использоваться в возможной операционной среде, включают в себя, в частности, кассеты с магнитной лентой, карты флэш-памяти, универсальные цифровые диски, цифровые видеоленты, твердотельное ОЗУ, твердотельное ПЗУ и т.д. Накопитель 141 на жестких дисках, обычно, подсоединен к системной шине 121 посредством интерфейса несъемной памяти, например интерфейса 140, а накопитель 151 на магнитных дисках и накопитель 155 на оптических дисках обычно подсоединены к системной шине 121 посредством интерфейса съемной памяти, например интерфейса 150.
Описанные выше и изображенные на фиг.1 накопители на дисках и соответствующие им носители информации компьютера обеспечивают хранение считываемых компьютером команд, структур данных, программных модулей и других данных для компьютера 110. На фиг.1, например, изображен накопитель 141 на жестких дисках, на котором хранятся операционная система 144, прикладные программы 145, другие программные модули 146 и данные 147 программы. Следует отметить, что указанные компоненты могут быть идентичны операционной системе 134, прикладным программам 135, другим программным модулям 136 и данным 137 программы, или отличны от них. Операционная система 144, прикладные программы 145, другие программные модули 146 и данные 147 программы здесь снабжены другими ссылочными позициями для пояснения того, что как минимум, они являются другими копиями.
Пользователь может осуществлять ввод команд и информации в компьютер 110 посредством устройств ввода данных, таких как клавиатура 162, микрофон 163 и указательное устройство 161, например мышь, шаровой указатель или сенсорная панель. В число других устройств ввода данных (не изображены) могут входить джойстик, игровая панель, спутниковая антенна, сканер или подобные устройства. Указанные и другие устройства ввода данных, часто, подсоединяются к процессору 120 посредством пользовательского интерфейса 160 для ввода/вывода данных, подсоединенного к системной шине, но они могут подсоединяться к процессору посредством другого интерфейса и других структур шины, таких как параллельный порт, игровой порт или универсальная последовательная шина (USB). Также к системной шине 121 посредством интерфейса, например видеоинтерфейса 190, может быть подсоединен монитор 191 или другой вид устройства отображения. В дополнение к монитору, компьютеры могут содержать также другие периферийные устройства вывода данных, такие как динамики 197 и принтер 196, которые могут быть подсоединены через интерфейс 195 периферийных устройств вывода данных.
Компьютер 110 эксплуатируется в среде с сетевой структурой с использованием логических соединений с одним или большим количеством удаленных компьютеров, например, удаленным компьютером 180. Удаленный компьютер 180 может быть персональным компьютером, переносным устройством, сервером, маршрутизатором, сетевым PC, одноранговым устройством или другим узлом общей сети и, обычно, содержит многие или все элементы, описанные выше в отношении компьютера 110. Логические соединения, изображенные на фиг.1, включают в себя локальную сеть связи LAN (ЛС) 171 и глобальную сеть связи WAN (ГС) 173. Такие сетевые среды часто используются в офисах, корпоративных вычислительных сетях, сетях интранет и в Интернете.
При использовании в сетевой среде ЛС компьютер 110 подсоединяется к ЛС 171 посредством сетевого интерфейса или адаптера 170. При использовании в сетевой среде ГС компьютер 110 обычно содержит модем 172 или другое средство для установления связи через ГС 173, такое как Интернет. Модем 172, который может быть внутренним или внешним, может подсоединяться к системной шине 121 посредством пользовательского интерфейса 160 для ввода данных или другого соответствующего механизма. В среде с сетевой структурой, программные модули, изображенные в отношении компьютера 110, или их части могут храниться в удаленных запоминающих устройствах. Например, в виде возможного варианта на фиг.1 удаленные прикладные программы 185 изображены резидентно хранящимися в удаленном компьютере 180. Ясно, что изображенные сетевые соединения являются возможными вариантами, и могут использоваться другие средства установления линии связи между компьютерами.
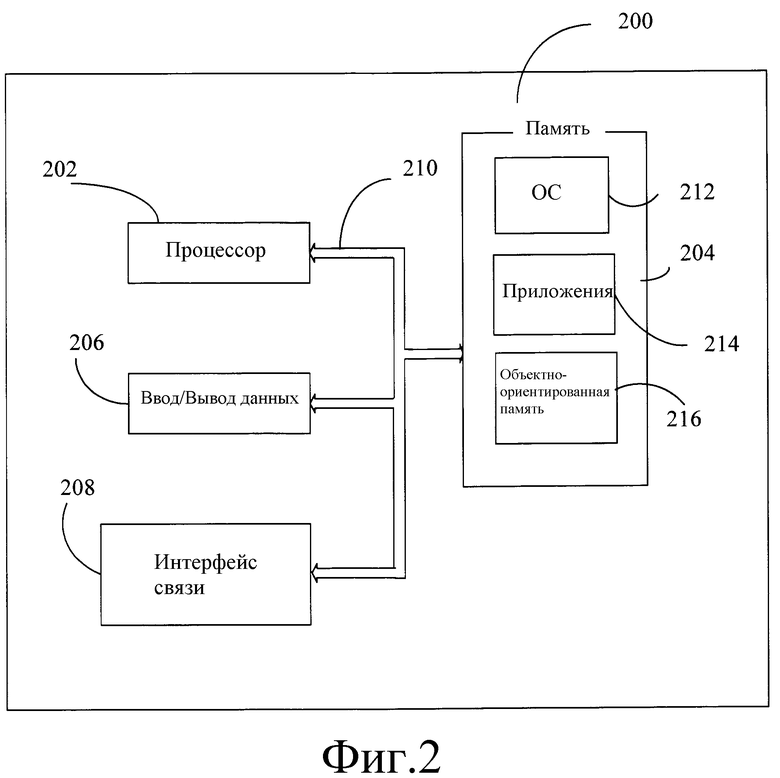
Фиг.2 - блок-схема мобильного устройства 200, которое является возможной вычислительной средой. Мобильное устройство 200 содержит микропроцессор 202, память 204, компоненты 206 ввода/вывода (I/O) данных, и интерфейс 208 связи для связи с удаленными компьютерами или другими мобильными устройствами. В одном варианте осуществления вышеупомянутые компоненты соединены для связи друг с другом через соответствующую шину 210.
Память 204 реализована в виде энергонезависимой электронной памяти, такой как оперативное запоминающее устройство (ОЗУ), с блоком батарейного питания (не изображен), чтобы при отключении общего питания мобильного устройства 200 не была потеряна информация, которая хранится в памяти 204. Часть памяти 204, предпочтительно, выделена в адресуемую память для выполнения программ, в то время как другая часть памяти 204, предпочтительно, используется для хранения, например для имитации хранения на накопителе на дисках.
Память 204 содержит операционную систему 212, прикладные программы 214, а также объектно-ориентированную память 216. При работе, предпочтительно, процессором 202 выполняется операционная система 212 из памяти 204. В одном предпочтительном варианте осуществления операционной системой 212 является операционная система марки WINDOWS® CE, серийно выпускаемая корпорацией Microsoft. Операционная система 212, предпочтительно, разработана для мобильных устройств и реализует возможности базы данных, которые могут использоваться приложениями 214 посредством набора представленных способов и интерфейсов прикладного программирования. Объекты в объектно-ориентированной памяти 216 поддерживаются приложениями 214 и операционной системой 212, по меньшей мере, в частности, в ответ на вызовы представленных способов и интерфейсов прикладного программирования.
Интерфейс 208 связи представляет многочисленные устройства и технологии, которые обеспечивают возможность передачи и приема информации мобильным устройством 200. Устройства включают в себя, в частности, проводные и беспроводные модемы, спутниковые приемники и бытовые тюнеры. Мобильное устройство 200 также может быть соединено с компьютером напрямую для обмена с ним данными. В таких случаях интерфейсом 208 связи может быть инфракрасный приемопередатчик или последовательное или параллельное соединение связи, которые все обладают способностью передачи потоковой информации.
Компоненты 206 ввода/вывода данных включают в себя разнообразные устройства ввода данных, например сенсорный экран, кнопки, ролики и микрофон, а также разнообразные устройства вывода данных, включая генератор звука, вибрационное устройство и дисплей. Перечисленные выше устройства приведены в качестве возможного варианта, и нет необходимости в наличии всех указанных устройств в мобильном устройстве 200. Дополнительно в объеме настоящего изобретения к мобильному устройству 200 могут быть присоединены или обеспечены с ним другие устройства ввода/вывода данных.
Фиг.3 обеспечивает базовую блок-схему вариантов осуществления настоящего изобретения. Согласно фиг.3 диктор (громкоговоритель) 300 формирует речевой сигнал 302, который обнаруживается микрофоном 304 с воздушной звукопроводимостью и альтернативным датчиком 306. Возможные варианты альтернативных датчиков включают в себя ларингофон, измеряющий вибрации горла пользователя, датчик с костной звукопроводимостью, размещенный на кости лица или на черепе пользователя (например, на челюстной кости) или рядом с ними, или в ухе пользователя, воспринимающий вибрации черепа и челюсти, соответствующие речи, производимой пользователем. Микрофон 304 с воздушной звукопроводимостью является видом микрофона, обычно используемым для преобразования звуковых волн в электрические сигналы.
Микрофон 304 с воздушной звукопроводимостью также принимает шум 308, производимый одним или большим количеством источников 310 шума. В зависимости от вида альтернативного датчика и уровня шума шум 308 может обнаруживаться также альтернативным датчиком 306. Однако, согласно вариантам осуществления настоящего изобретения, альтернативный датчик 306 обычно менее чувствителен к шуму окружающей среды, чем микрофон 304 с воздушной звукопроводимостью. Соответственно, сигнал 312 альтернативного датчика, сформированный альтернативным датчиком 306, в основном, содержит меньшее количество шума, чем сигнал 314 микрофона с воздушной звукопроводимостью, сформированный микрофоном 304 с воздушной звукопроводимостью.
Сигнал 312 альтернативного датчика и сигнал 314 микрофона с воздушной звукопроводимостью подаются на модуль 316 оценки достоверного сигнала, который оценивает достоверный сигнал 318. Оценка 318 достоверного сигнала подается на обработку 320 речи. Оценкой 318 достоверного сигнала может быть фильтрованный сигнал временной области (представленный временными значениями) или вектор, представленный значениями характеристик. Если оценка 318 достоверного сигнала является сигналом, представленным временными значениями, то обработка 320 речи может представлять собой слушающего абонента, систему кодирования речи или систему распознавания речи. Если оценка 318 достоверного сигнала является вектором, представленным значениями характеристик, то обработкой 320 речи, обычно, будет система распознавания речи.
Настоящее изобретение обеспечивает отдельные способы и системы для оценки достоверной речи с использованием сигнала 314 микрофона с воздушной звукопроводимостью и сигнала 312 альтернативного датчика. Одна система использует обучающие стереоданные для обучения векторов поправки для сигнала альтернативного датчика. Когда впоследствии указанные векторы поправки добавляются к испытательному вектору альтернативного датчика, они обеспечивают оценку вектора достоверного сигнала. Одно дополнительное расширение этой системы заключается сначала в отслеживании изменяющегося во времени искажения, а затем во включении этой информации в вычисление векторов поправки и в оценку достоверной речи.
Вторая система обеспечивает интерполяцию между оценкой достоверного сигнала, сформированной векторами поправки и оценкой, сформированной посредством вычитания оценки шума, имеющегося в испытательном сигнале воздушной звукопроводимости, из сигнала воздушной звукопроводимости. Третья система использует сигнал альтернативного датчика для оценки основного тона речевого сигнала и затем использует оцененный основной тон для определения оценки для достоверного сигнала. Ниже отдельно описана каждая из указанных систем.
Обучение стереовекторов поправки
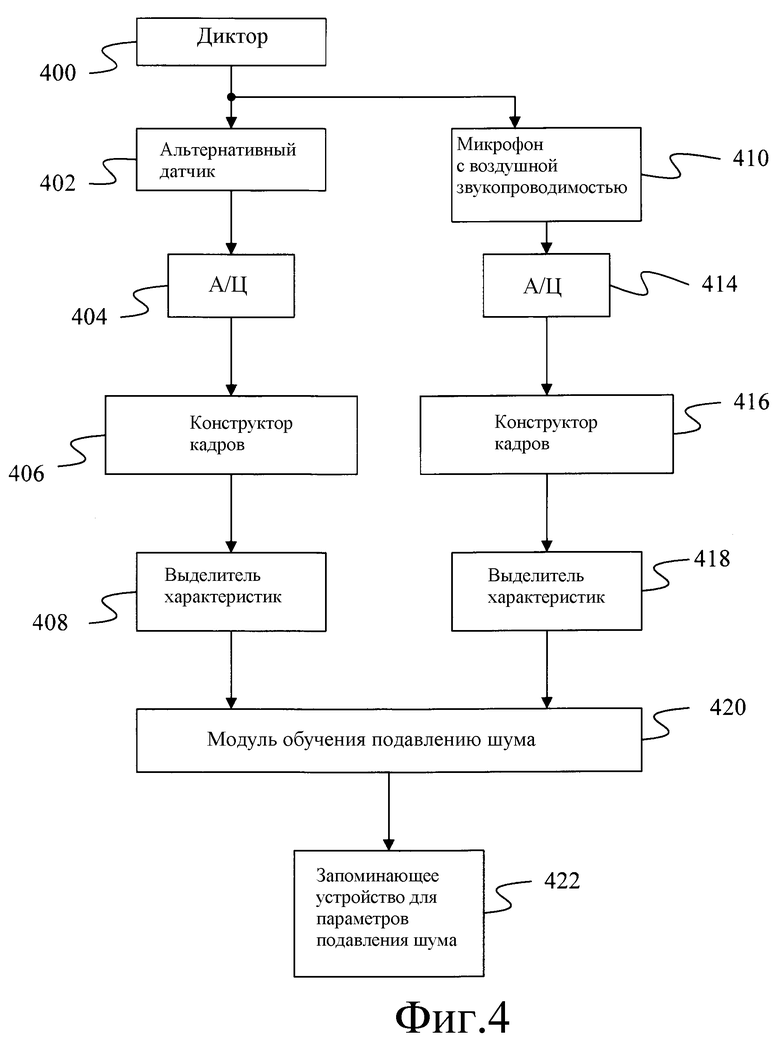
На фиг.4 и 5 изображены блок-схемы обучения стереовекторов поправки для двух вариантов осуществления настоящего изобретения, которые основаны на векторах поправки для формирования оценки достоверной речи.
Способ определения векторов поправки начинается с этапа 500 фиг.5, на котором "достоверный" сигнал микрофона с воздушной звукопроводимостью преобразуется в последовательность векторов характеристик. Для этого диктор 400 на фиг.4 говорит в микрофон 410 с воздушной звукопроводимостью, который преобразует звуковые волны в электрические сигналы. Затем электрические сигналы стробируются аналого-цифровым преобразователем 414 для формирования последовательности цифровых значений, которые группируются конструктором 416 кадров в кадры значений. В одном варианте осуществления аналого-цифровой преобразователь 414 стробирует аналоговый сигнал в 16 кГц и 16 бит на выборку, вследствие этого создавая 32 килобайта речевых данных в секунду и конструктор 416 кадров каждые 10 миллисекунд создает новый кадр, который содержит 25 миллисекунд данных.
Каждый кадр данных, обеспеченный конструктором 416 кадров, преобразуется выделителем 418 характеристик в вектор характеристик. Согласно одному варианту осуществления выделитель 418 характеристик формирует кепстральные характеристики. В возможные варианты таких характеристик входят LPC (кодирование методом линейного предсказания) - производный кепстр, и коэффициенты кепстра Mel-частоты. В другие возможные варианты возможных модулей выделения характеристик, которые могут использоваться в настоящем изобретении, входят модули для выполнения кодирования методом линейного предсказания (КЛП), LPC, перцептивного линейного предсказания (ПЛП), PLP, и выделения характеристик слуховой модели. Следует отметить, что изобретение не ограничивается указанными модулями выделения характеристик, и что в контексте настоящего изобретения могут использоваться другие модули.
На этапе 502, фиг.5, сигнал альтернативного датчика преобразуется в векторы характеристик. Хотя преобразование на этапе 502 изображено после преобразования на этапе 500, согласно настоящему изобретению указанные части преобразования могут выполняться в любом порядке, на этапе 500 или после него. Преобразование на этапе 502 выполняется посредством процесса, подобного описанному выше для этапа 500.
В варианте осуществления, изображенном на фиг.4, этот процесс начинается, когда альтернативный датчик 402 обнаруживает физическое событие, связанное с производством диктором 400 речи, таким как вибрация кости или движение лица. Как изображено на фиг.11, в одном варианте осуществления микрофона 1100 с костной звукопроводимостью, к диафрагме 1104 нормального микрофона 1106 с воздушной звукопроводимостью приклеивается гибкая высокорастяжимая перемычка 1102. Такая гибкая перемычка 1102 проводит колебания от электрода (контакта) 1108 на коже пользователя непосредственно на диафрагму 1104 микрофона 1106. Движение диафрагмы 1104 преобразуется преобразователем 1110 в микрофоне 1106 в электрический сигнал. Альтернативный датчик 402 преобразует физическое событие в аналоговый электрический сигнал, который стробируется аналого-цифровым преобразователем 404. Характеристики стробирования для аналого-цифрового преобразователя 404 идентичны характеристикам, описанным выше для аналого-цифрового преобразователя 414. Выборки, обеспеченные аналого-цифровым преобразователем 404, собираются в кадры конструктором 406 кадров, который действует подобно конструктору 416 кадров. Затем эти кадры выборок преобразуются в векторы характеристик выделителем 408 характеристик, который использует способ выделения характеристик, идентичный используемому выделителем 418 характеристик.
Затем векторы характеристик для сигнала альтернативного датчика и сигнала с воздушной звукопроводимостью подаются на модуль 420 обучения подавлению шума, изображенный на фиг.4. На этапе 504, фиг.5, модуль обучения 420 подавлению шума группирует векторы характеристик для сигнала альтернативного датчика в смешанные составляющие. Такая группировка может быть выполнена посредством совместной группировки подобных векторов характеристик с использованием способа обучения максимального правдоподобия или посредством группировки векторов характеристик, совместно представляющих временной сегмент речевого сигнала. Для специалистов в данной области техники очевидно, что для группировки векторов характеристик могут использоваться другие способы, и что два способа, приведенных выше, предложены только в качестве возможных вариантов.
Затем на этапе 508, фиг.5, модуль обучения 420 подавлению шума определяет вектор поправки, rs, для каждой смешанной составляющей, s. Согласно одному варианту осуществления вектор поправки для каждой смешанной составляющей определяется с использованием критерия максимального правдоподобия. Согласно этому способу вектор поправки вычисляется, как:
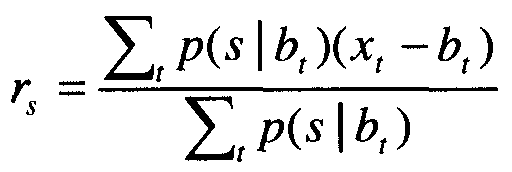
где xt является значением вектора воздушной звукопроводимости для кадра t, а bt является значением вектора альтернативного датчика для кадра t. В Уравнении 1:
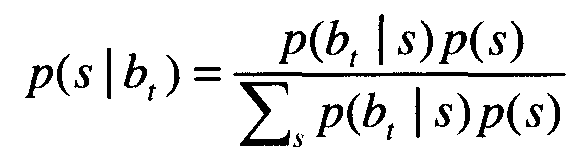
где p(s) является просто одной из некоторого количества смешанных составляющих, а p(bt|s) моделируется, как Гауссовское распределение:
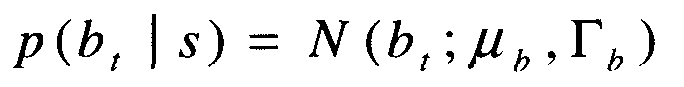
со средним μb и дисперсией Гb, подготовленных (обученных) с использованием алгоритма максимизации (математического) ожидания (EM), где каждая итерация состоит из следующих этапов:
итерация состоит из следующих этапов:
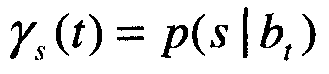
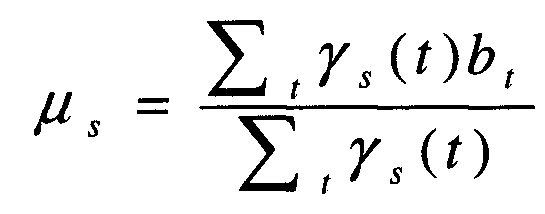
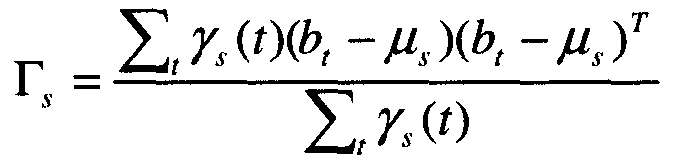
Уравнение 4 представляет E-этап в алгоритме EM, который использует предварительно оцененные параметры. Уравнение 5 и Уравнение 6 представляют M-этап, который обновляет параметры с использованием результатов E-этапа.
E-этап и M-этап алгоритма повторяются до определения устойчивого значения для параметров модели. Затем эти параметры используются для оценки уравнения 1, чтобы сформировать векторы поправки. Затем векторы поправки и параметры модели записываются в записывающее устройство 422 для параметров подавления шума.
После определения вектора поправки для каждой смешанной составляющей на этапе 508 процесс обучения системы подавления шума, предусмотренной настоящим изобретением, завершается. Когда вектор поправки определен для каждой смешанной составляющей, векторы могут использоваться в способе подавления шума, предусмотренном настоящим изобретением. Ниже описаны два отдельных способа подавления шума, которые используют векторы поправки.
Подавление шума с использованием вектора поправки и оценки шума
Систему и способ, которые подавляют шум в речевом сигнале с шумами на основе векторов поправки и оценки шума, иллюстрируют блок-схема фиг.6 и блок-схема фиг.7, соответственно.
На этапе 700 испытательный звуковой сигнал, обнаруженный микрофоном 604 с воздушной звукопроводимостью, преобразуется в векторы характеристик. Испытательный звуковой сигнал, принятый микрофоном 604, содержит речь от диктора 600 и аддитивный шум из одного или большего количества источников 602 шума. Испытательный звуковой сигнал, обнаруженный микрофоном 604, преобразуется в электрический сигнал, который подается на аналого-цифровой преобразователь 606.
Аналого-цифровой преобразователь 606 преобразует аналоговый сигнал из микрофона 604 в последовательности цифровых значений. В отдельных вариантах осуществления аналого-цифровой преобразователь 606 стробирует аналоговый сигнал в 16 кГц и 16 бит на выборку, вследствие этого создавая 32 килобайта речевых данных в секунду. Эти цифровые значения подаются на конструктор 607 кадров, который в одном варианте осуществления группирует значения в 25-миллисекундные кадры, которые запускаются с интервалом в 10 миллисекунд.
Кадры данных, созданные конструктором 607 кадров, подаются на выделитель 610 характеристик, который выделяет характеристики из каждого кадра. Согласно одному варианту осуществления указанный выделитель характеристик отличен от выделителей 408 и 418 характеристик, которые использовались для обучения векторов поправки. В частности, согласно этому варианту осуществления выделитель 610 характеристик формирует вместо кепстральных значений значения энергетического спектра. Выделенные характеристики подаются на модуль 622 оценки достоверного сигнала, модуль 626 обнаружения речи и модуль 624 обучения модели шумов.
На этапе 702 физическое событие, например вибрация кости или движение лица, связанное с производством диктором 600 речи, преобразуются в вектор характеристик. Хотя этот этап изображен на фиг.7 как отдельный этап, для специалистов в данной области техники очевидно, что, в то же время, части этого этапа могут быть выполнены на этапе 700. На этапе 702 альтернативным датчиком 614 обнаруживается физическое событие. Альтернативный датчик 614 на основе физического события формирует аналоговый электрический сигнал. Этот аналоговый сигнал преобразуется аналого-цифровым преобразователем 616 в цифровой сигнал, и результирующие цифровые выборки группируются конструктором 617 кадров в кадры. Согласно одному варианту осуществления функционирование аналого-цифрового преобразователя 616 и конструктора 617 кадров подобно функционированию аналого-цифрового преобразователя 606 и конструктора 607 кадров.
Кадры цифровых значений подаются на выделитель 620 характеристик, который использует способ выделения характеристик, идентичный используемому для обучения векторов поправки. Как упомянуто выше, в возможные варианты таких модулей выделения характеристик входят модули для выполнения кодирования методом линейного предсказания (LPC), LPC - производного кепстра, перцептивного линейного предсказания (PLP), выделения характеристик слуховой модели и выделения характеристик кепстральных коэффициентов Mel-частоты (ХККМ), MFCC. Однако во многих вариантах осуществления используются способы выделения характеристик, которые формируют кепстральные характеристики.
Модуль выделения характеристик формирует поток векторов характеристик, каждый из которых соответствует отдельному кадру речевого сигнала. Указанный поток векторов характеристик подается на модуль 622 оценки достоверного сигнала.
Кадры значений из конструктора 617 кадров также подаются на выделитель 621 характеристик, который в одном варианте осуществления выделяет энергию каждого кадра. Значение энергии для каждого кадра подается на модуль 626 обнаружения речи.
На этапе 704 модуль 626 обнаружения речи использует характеристику энергии сигнала альтернативного датчика для определения, когда вероятно наличие речи. Эта информация передается на модуль 624 обучения модели шумов, который осуществляет попытку смоделировать шум в продолжение периодов, когда на этапе 706 речь отсутствует.
Согласно одному варианту осуществления модуль 626 обнаружения речи сначала исследует последовательность значений энергии кадра для обнаружения точек максимума энергии. Затем он осуществляет поиск точки минимума после точки максимума. Энергия этой точки минимума называется разделителем d энергии. Для определения того, содержит ли кадр речь, коэффициент k энергии e кадра определяется через разделитель d энергии, как: k=e/d. Доверительность q речи для кадра определяется, как:
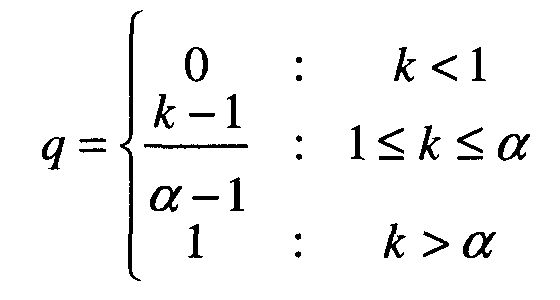
где α определяет переход между двумя состояниями, и в одной реализации установлено равным 2. В заключение, в качестве конечного значения доверительности для кадра используется среднее значение доверительности из 5 его соседних кадров (включая его самого).
Согласно одному варианту осуществления для определения наличия речи используется фиксированное пороговое значение так, что при превышении значением доверительности порогового значения кадр рассматривается как содержащий речь, а если значение доверительности не превышает пороговое значение, то кадр рассматривается как не содержащий речь. Согласно одному варианту осуществления используется пороговое значение, равное 0,1.
На этапе 706 для каждого кадра без речи, обнаруженного модулем 626 обнаружения речи, модуль 624 обучения модели шумов обновляет модель 625 шумов. Согласно одному варианту осуществления модель 625 шумов является Гауссовской моделью, которая имеет среднее μn и дисперсию Σn. Эта модель основана на скользящем окне самых последних кадров без речи. Способы определения среднего и дисперсии из кадров без речи в окне известны.
Векторы поправки и параметры модели в запоминающем устройстве 422 для параметров и модель 625 шумов подаются на модуль 622 оценки достоверного сигнала с векторами характеристик, b, для альтернативного датчика и векторами характеристик, Sy, для сигнала микрофона с воздушной звукопроводимостью с шумами. На этапе 708 модуль 622 оценки достоверного сигнала оценивает начальное значение для достоверного речевого сигнала на основе вектора характеристик альтернативного датчика, векторов поправки и параметров модели для альтернативного датчика. В частности, оценка альтернативного датчика для достоверного сигнала вычисляется как:
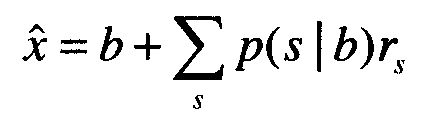
где 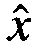 является оценкой достоверного сигнала, представленной в кепстральных значениях, b является вектором характеристик альтернативного датчика, p(s|b) определяется с использованием уравнения 2, приведенного выше, а rs является вектором поправки для смешанной составляющей s. Соответственно, оценка достоверного сигнала в Уравнении 8 формируется посредством добавления вектора характеристик альтернативного датчика к взвешенной сумме векторов поправки, где веса основаны на вероятности смешанной составляющей, заданной вектором характеристик альтернативного датчика.
является оценкой достоверного сигнала, представленной в кепстральных значениях, b является вектором характеристик альтернативного датчика, p(s|b) определяется с использованием уравнения 2, приведенного выше, а rs является вектором поправки для смешанной составляющей s. Соответственно, оценка достоверного сигнала в Уравнении 8 формируется посредством добавления вектора характеристик альтернативного датчика к взвешенной сумме векторов поправки, где веса основаны на вероятности смешанной составляющей, заданной вектором характеристик альтернативного датчика.
На этапе 710 начальная оценка достоверной речи альтернативного датчика улучшается посредством ее комбинирования с оценкой достоверной речи, сформированной из вектора микрофона с воздушной звукопроводимостью с шумами и модели шумов. Это приводит к улучшенной оценке 628 достоверной речи. Для комбинирования кепстрального значения начальной оценки достоверного сигнала с вектором характеристик энергетического спектра для микрофона с воздушной звукопроводимостью с шумами кепстральное значение преобразуется в область энергетического спектра с использованием:
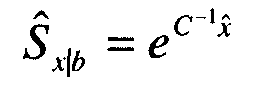
где C-1 является обратным дискретным косинусным преобразованием, а Ŝx|b является оценкой энергетического спектра достоверного сигнала на основе альтернативного датчика.
Когда начальная оценка достоверного сигнала из альтернативного датчика представлена в значениях энергетического спектра, она может быть скомбинирована с вектором микрофона с воздушной звукопроводимостью с шумами и моделью шумов следующим образом:
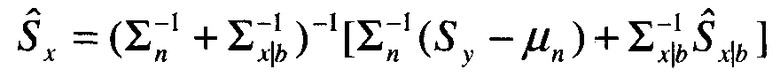
где Ŝx является улучшенной оценкой достоверного сигнала, представленной значениями энергетического спектра, Sy является вектором характеристик микрофона с воздушной звукопроводимостью с шумами, (μn, Σn) являются средним и ковариацией предыдущей модели шума (см. 624), Ŝx|b является начальной оценкой достоверного сигнала на основе альтернативного датчика, а Σx|b является матрицей ковариации распределения условной вероятности для достоверной речи, заданной измерением альтернативного датчика. Σx|b может быть вычислено следующим образом. Предполагается, что J обозначает Якобиан функции в правой части уравнения 9. Предполагается, что Σ является матрицей ковариации . Тогда ковариация Ŝx|b определяется
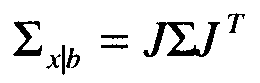
В упрощенном варианте осуществления уравнение 10 переписывается в виде следующего уравнения:
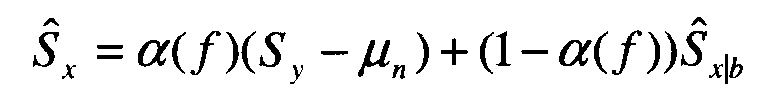
где α(f) является функцией времени и полосы частот. Так как альтернативный датчик, используемый в текущий момент, имеет ширину полосы частот до 3 кГц, то для полосы частот ниже 3 кГц выбирается α(f), равное 0. В основном, для полос низкой частоты считается правдоподобной начальная оценка достоверного сигнала из альтернативного датчика. Для полос высокой частоты начальная оценка достоверного сигнала из альтернативного датчика не столь правдоподобна. Интуитивно, когда шум является малым для полосы частот в текущем кадре, предпочтительно выбрать большую α(f), чтобы для этой полосы частот использовалось большее количество информации из микрофона с воздушной звукопроводимостью. Иначе, предпочтительно использовать большее количество информации из альтернативного датчика посредством выбора малой α(f). В одном варианте осуществления для определения уровня шума для каждой полосы частот используется энергия начальной оценки достоверного сигнала из альтернативного датчика. Предполагается, что E(f) обозначает энергию для полосы частот f. Предполагается, что M=MaxfE(f). α(f), как функция от f, определяется следующим образом:
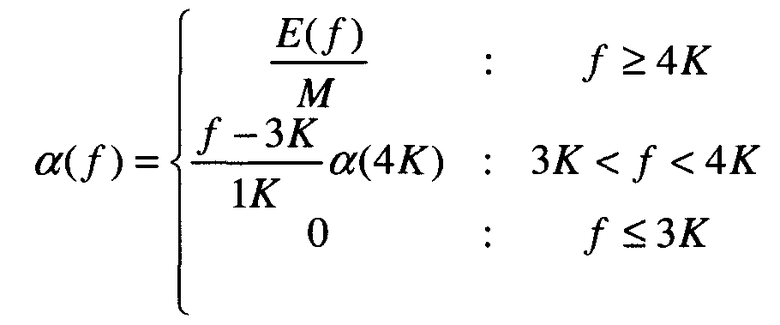
где для перехода от 3К к 4К, чтобы гарантировать гладкость α(f), используется линейная интерполяция.
Улучшенная оценка достоверного сигнала в области энергетического спектра может быть использована для формирования фильтра Винера для фильтрования сигнала микрофона с воздушной звукопроводимостью с шумами. В частности, фильтр Винера, H, устанавливается так, что:
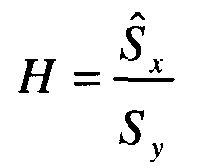
Затем этот фильтр может быть применен в отношении сигнала микрофона с воздушной звукопроводимостью с шумами, представленного временными значениями, для формирования сигнала с подавленным шумом или достоверного сигнала, представленного временными значениями. Сигнал с подавленным шумом может быть подан слушающему абоненту или на распознаватель речи.
Следует отметить, что Уравнение 12 обеспечивает улучшенную оценку достоверного сигнала, которая является взвешенной суммой двух показателей, одним из которых является оценка достоверного сигнала из альтернативного датчика. Эта взвешенная сумма может быть расширена для включения дополнительных показателей для дополнительных альтернативных датчиков. Соответственно, для формирования независимых оценок достоверного сигнала может использоваться более одного альтернативного датчика. Затем эти разные оценки могут быть скомбинированы с использованием уравнения 12.
Подавление шума с использованием вектора поправки без оценки шума.
Фиг.8 обеспечивает блок-схему альтернативной системы для оценки достоверного значения речи, согласно настоящему изобретению. Система, изображенная на фиг.8, подобна системе, изображенной на фиг.6, за исключением того, что оценка достоверного значения речи формируется без необходимости в микрофоне с воздушной звукопроводимостью или модели шумов.
На фиг.8 физическое событие, связанное с диктором 800, производящим речь, преобразуется альтернативным датчиком 802, аналого-цифровым преобразователем 804, конструктором 806 кадров и выделителем 808 характеристик в вектор характеристик способом, подобным описанному выше для альтернативного датчика 614, аналого-цифрового преобразователя 616, конструктора 617 кадров и выделителя 618 характеристик, изображенных на фиг.6. Векторы характеристик из выделителя 808 характеристик и параметры 422 подавления шума подаются на модуль 810 оценки достоверного сигнала, который определяет оценку 812 значения достоверного сигнала, Ŝx|b, с использованием уравнений 8 и 9, приведенных выше.
Оценка достоверного сигнала, Ŝx|b, представленная значениями энергетического спектра, может быть использована для создания фильтра Винера для фильтрации сигнала микрофона с воздушной звукопроводимостью с шумами. В частности, фильтр Винера, H, настроен так, что:
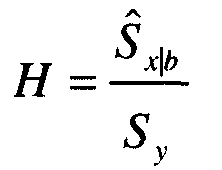
Затем для формирования сигнала с подавленным шумом или достоверного сигнала этот фильтр может быть применен к сигналу микрофона с воздушной звукопроводимостью с шумами, представленному временными значениями. Сигнал с подавленным шумом может быть подан слушающему абоненту или на распознаватель речи.
В виде другого варианта на систему распознавания речи может подаваться непосредственно оценка достоверного сигнала, представленная кепстральными значениями, , которая вычисляется в уравнении 8.
Подавление шума с использованием отслеживания основного тона
Альтернативный способ формирования оценок достоверного речевого сигнала иллюстрирует блок-схема фиг.9 и блок-схема фиг.10. В частности вариант осуществления, иллюстрируемый фиг.9 и фиг.10, определяет оценку достоверной речи посредством определения основного тона речевого сигнала с использованием альтернативного датчика и, затем для разложения, с использованием основного тона, сигнала с шумами микрофона с воздушной звукопроводимостью на гармоническую составляющую и случайную составляющую. Соответственно, сигнал с шумами представляется в виде:
где y является сигналом с шумами, yh является гармонической составляющей, а yr является случайной составляющей. Взвешенная сумма гармонической составляющей и случайной составляющей используется для формирования вектора характеристик с подавленным шумом, представляющего речевой сигнал с подавленным шумом.
Согласно одному варианту осуществления гармоническая составляющая моделируется как сумма синусоид, относящихся к гармонике, следующим образом:
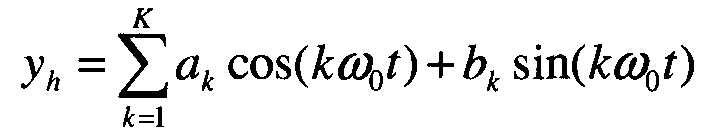
где ω0 является частотой основной гармоники или частотой основного тона, а K является полным количеством гармоник в сигнале.
Соответственно, для определения гармонической составляющей, должны быть определены оценка частоты основного тона и параметры {a1a2 … akb1b2 … bk}.
На этапе 1000 речевой сигнал с шумами собирается и преобразуется в цифровые выборки. Для этого микрофон 904 с воздушной звукопроводимостью преобразует звуковые волны от диктора 900 и из одного или большего количества источников 902 аддитивного шума в электрические сигналы. Затем электрические сигналы стробируются аналого-цифровым преобразователем 906 для формирования последовательности цифровых значений. В одном варианте осуществления аналого-цифровой преобразователь 906 стробирует аналоговый сигнал, например, в 16 кГц и 16 бит на выборку, вследствие этого создавая 32 килобайта речевых данных в секунду. На этапе 1002 цифровые выборки группируются конструктором 908 кадров в кадры. Согласно одному варианту осуществления конструктор 908 кадров каждые 10 миллисекунд создает новый кадр, который включает 25 миллисекунд данных.
На этапе 1004 альтернативным датчиком 944 обнаруживается физическое событие, связанное с формированием речи. В этом варианте осуществления для использования в качестве альтернативного датчика 944 наиболее подходит альтернативный датчик, который может обнаруживать гармонические составляющие, такой как датчик с костной звукопроводимостью. Следует отметить, что, хотя этап 1004 изображен отдельно от этапа 1000, для специалистов в данной области техники очевидно, что эти этапы могут выполняться одновременно. Аналоговый сигнал, сформированный альтернативным датчиком 944, преобразуется аналого-цифровым преобразователем 946 в цифровые выборки. Затем на этапе 1006 цифровые выборки группируются конструктором 948 кадров в кадры.
На этапе 1008 кадры сигнала альтернативного датчика используются системой 950 отслеживания основного тона для определения частоты основного тона или частоты основной гармоники речи.
Оценка частоты основного тона может быть определена с использованием любого количества доступных систем отслеживания основного тона. Многими из этих систем используются кандидаты основного тона для определения возможного интервала между центрами сегментов сигнала альтернативного датчика. Для каждого кандидата основного тона определяется корреляция между последовательными сегментами речи. В общем, частотой основного тона кадра будет кандидат основного тона, обеспечивающий наилучшую корреляцию. В некоторых системах для усовершенствования выбора основного тона используется дополнительная информация, такая как энергия сигнала и/или ожидаемые данные отслеживания основного тона.
После определения оценки основного тона из системы 950 отслеживания основного тона на этапе 1010 вектор сигнала воздушной звукопроводимости может быть разложен на гармоническую составляющую и случайную составляющую. Для этого уравнение 17 переписывается в виде:
где y является вектором из N выборок речевого сигнала с шумами, A является матрицей (порядка) Nx2K, заданной следующим образом:
с элементами
а b является вектором (порядка) 2Kx1, заданным следующим образом:
Соответственно, решением методом наименьших квадратов для амплитудных коэффициентов является:
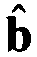 = (ATA)-1ATy
= (ATA)-1ATy
С использованием , оценка для гармонической составляющей речевого сигнала с шумами может быть определена, как:
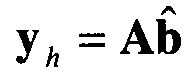
Тогда оценка случайной составляющей вычисляется как:
Соответственно, с использованием приведенных выше уравнений 18-24, модуль 910 гармонического разложения может сформировать вектор выборок 912 гармонической составляющей, yh, и вектор выборок 914 случайной составляющей yr.
После разложения выборок кадра на гармоническую и случайную выборки на этапе 1012 определяется коэффициент масштабирования или вес для гармонической составляющей. Как описано ниже, указанный коэффициент масштабирования используется как часть расчета речевого сигнала с подавленным шумом. Согласно одному варианту осуществления коэффициент масштабирования вычисляется следующим образом:
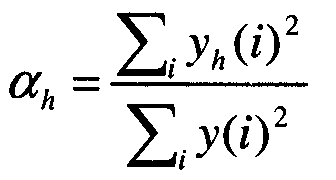
где αh является коэффициентом масштабирования, yh(i) является i-ой выборкой в векторе выборок yh гармонической составляющей, а y(i) является i-ой выборкой речевого сигнала с шумами для этого кадра. В уравнении 25 числителем является сумма энергии каждой выборки гармонической составляющей, а знаменателем является сумма энергии каждой выборки речевого сигнала с шумами. Соответственно коэффициентом масштабирования является отношение гармонической энергии кадра к полной энергии кадра.
В альтернативных вариантах осуществления коэффициент масштабирования устанавливается с использованием модуля вероятностного разделения вокализованных и невокализованных звуков. Такие модули обеспечивают вероятность того, что определенный кадр речи скорее является вокализованным, что означает, что в продолжение кадра резонируют голосовые связки, чем невокализованным. В качестве коэффициента масштабирования может использоваться непосредственно вероятность того, что кадр является кадром из вокализованной области речи.
После определения или при определении коэффициента масштабирования на этапе 1014 определяются Mel-спектры для вектора выборок гармонической составляющей и вектора выборок случайной составляющей. Это включает пропускание каждого вектора выборок через дискретное преобразование Фурье (DFT), (ДПФ), 918 для формирования вектора значений 922 частоты гармонической составляющей и вектора значений 920 частоты случайной составляющей. Затем энергетический спектр, представленный векторами значений частоты, сглаживается модулем 924 Mel-взвешивания с использованием последовательностей треугольных весовых функций, применяемых по Mel-масштабу. Это приводит к Mel-спектральному вектору 928, Yh, гармонической составляющей и Mel-спектральному вектору 926, Yr, случайной составляющей.
На этапе 1016 Mel-спектры для гармонической составляющей и случайной составляющей комбинируются в виде взвешенной суммы для формирования оценки Mel-спектра с подавленным шумом. Этот этап выполняется вычислителем 930 взвешенной суммы с использованием определенного выше коэффициента масштабирования посредством следующего уравнения:
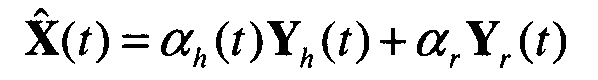
где (t) является оценкой Mel-спектра с подавленным шумом, Yh(t) является Mel-спектром гармонической составляющей, Yr(t) является Mel-спектром случайной составляющей, αh(t) является определенным выше коэффициентом масштабирования,
αr является фиксированным коэффициентом масштабирования для случайной составляющей, который в одном варианте осуществления установлен равным 0,1, и указатель времени t используется для акцентирования того, что коэффициент масштабирования для гармонической составляющей определяется для каждого кадра, в то время как коэффициент масштабирования для случайной составляющей остается фиксированным. Следует отметить, что в других вариантах осуществления коэффициент масштабирования для случайной составляющей может определяться для каждого кадра.
После вычисления Mel-спектра с подавленным шумом на этапе 1016, на этапе 1018 определяется логарифм 932 Mel-спектра и затем на этапе 1018 применяется дискретное косинусное преобразование (ДКП) 934. Посредством этого формируется вектор 936 характеристик кепстральных коэффициентов Mel-частоты (MFCC), который представляет речевой сигнал с подавленным шумом.
Для каждого кадра сигнала с шумами формируется отдельный вектор характеристик MFCC с подавленным шумом. Указанные векторы характеристик могут использоваться для любой требуемой задачи, включая повышение разборчивости речи и распознавание речи. Для повышения разборчивости речи векторы характеристик MFCC могут быть преобразованы в область энергетического спектра и могут использоваться с сигналом воздушной звукопроводимости с шумами для формирования фильтра Винера.
Хотя настоящее изобретение было описано в отношении конкретных вариантов осуществления, для специалистов в данной области техники очевидно, что, не удаляясь от сущности и объема изобретения, могут быть сделаны изменения по форме и в деталях.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И УСТРОЙСТВО ДЛЯ УЛУЧШЕНИЯ РЕЧИ С ПОМОЩЬЮ НЕСКОЛЬКИХ ДАТЧИКОВ | 2005 |
|
RU2389086C2 |
| УЛУЧШЕНИЕ РЕЧИ С ПОМОЩЬЮ НЕСКОЛЬКИХ ДАТЧИКОВ С ИСПОЛЬЗОВАНИЕМ ПРЕДШЕСТВУЮЩЕЙ ЧИСТОЙ РЕЧИ | 2006 |
|
RU2407074C2 |
| СПОСОБ МНОГОСЕНСОРНОГО УЛУЧШЕНИЯ РЕЧИ НА МОБИЛЬНОМ РУЧНОМ УСТРОЙСТВЕ И МОБИЛЬНОЕ РУЧНОЕ УСТРОЙСТВО | 2005 |
|
RU2376722C2 |
| ПОВЫШЕНИЕ КАЧЕСТВА РЕЧИ С ИСПОЛЬЗОВАНИЕМ МНОЖЕСТВА ДАТЧИКОВ С ПОМОЩЬЮ МОДЕЛИ СОСТОЯНИЙ РЕЧИ | 2006 |
|
RU2420813C2 |
| СПОСОБ, УСТРОЙСТВО И СИСТЕМА ДЛЯ ПОДАВЛЕНИЯ ШУМА | 2016 |
|
RU2685391C1 |
| СИСТЕМА ДЕТЕКТИРОВАНИЯ РЕЧИ | 2004 |
|
RU2363994C2 |
| СИСТЕМА И СПОСОБ ДЛЯ ДИАГНОСТИКИ ПРОМЫШЛЕННОГО ОБЪЕКТА НА ОСНОВЕ АНАЛИЗА АКУСТИЧЕСКИХ СИГНАЛОВ | 2020 |
|
RU2749640C1 |
| СИСТЕМЫ И СПОСОБЫ ВЫРАБОТКИ АУДИОСИГНАЛА | 2019 |
|
RU2804933C2 |
| СПОСОБ ОЦЕНКИ ШУМА С ИСПОЛЬЗОВАНИЕМ ПОШАГОВОГО БАЙЕСОВСКОГО ИЗУЧЕНИЯ | 2004 |
|
RU2370831C2 |
| ПРОЦЕССОР СИГНАЛОВ И СПОСОБ ОБЕСПЕЧЕНИЯ ОБРАБОТАННОГО АУДИОСИГНАЛА С ПОДАВЛЕННЫМ ШУМОМ И ПОДАВЛЕННОЙ РЕВЕРБЕРАЦИЕЙ | 2018 |
|
RU2768514C2 |
Изобретение относится к устранению шума из речевых сигналов. Способ и система используют для оценки достоверного значения речи сигнал альтернативного датчика, принимаемый из датчика, отличного от микрофона с воздушной звукопроводимостью. При оценке используется сигнал альтернативного датчика исключительно или совместно с сигналом микрофона с воздушной звукопроводимостью. Достоверное значение речи оценивается без использования модели, обученной на обучающих данных с шумами, собранных из микрофона с воздушной звукопроводимостью. Согласно одному варианту осуществления к вектору, сформированному из сигнала альтернативного датчика, добавляются векторы поправки для формирования фильтра, применяемого к сигналу микрофона с воздушной звукопроводимостью для создания достоверной оценки речи. В других вариантах осуществления из сигнала альтернативного датчика определяется основной тон речевого сигнала, который используется для разложения сигнала микрофона с воздушной звукопроводимостью. Затем разложенный сигнал используется для определения достоверной оценки сигнала. Технический результат - обеспечение оптимальной оценки достоверного значения речи в условиях, когда сигнал альтернативного датчика отличается от сигнала микрофона с воздушной проводимостью. 3 н. и 12 з.п. ф-лы, 11 ил.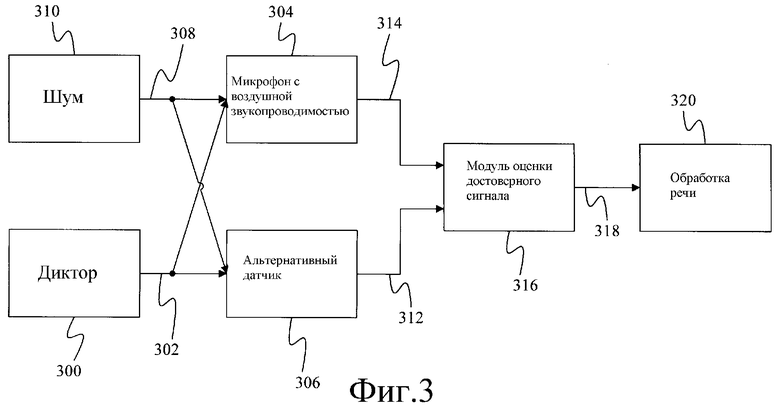
1. Способ определения оценки для достоверного значения речевого сигнала, представляющего часть достоверного речевого сигнала, заключающийся в том, что
формируют обучающий сигнал альтернативного датчика,
преобразуют обучающий сигнал альтернативного датчика в обучающий вектор альтернативного датчика,
формируют достоверный обучающий сигнал микрофона с воздушной звукопроводимостью,
преобразуют достоверный обучающий сигнал микрофона с воздушной звукопроводимостью в обучающий вектор воздушной звукопроводимости,
используют разность между обучающим вектором альтернативного датчика и обучающим вектором воздушной звукопроводимости для формирования вектора поправки,
формируют сигнал альтернативного датчика с использованием альтернативного датчика, отличного от микрофона с воздушной звукопроводимостью,
преобразуют сигнал альтернативного датчика, по меньшей мере, в один вектор альтернативного датчика,
добавляют взвешенную сумму нескольких векторов поправки к вектору альтернативного датчика для формирования оценки для достоверного значения речевого сигнала, причем каждый вес, приложенный к вектору поправки, основан на вероятности смешанной составляющей вектора поправки, заданной вектором альтернативного датчика,
формируют сигнал микрофона с воздушной звукопроводимостью,
преобразуют сигнал микрофона с воздушной звукопроводимостью в вектор воздушной звукопроводимости,
оценивают значение шума,
вычитают значение шума из вектора воздушной звукопроводимости для формирования оценки воздушной звукопроводимости, и
комбинируют оценку воздушной звукопроводимости и оценку для достоверного значения речевого сигнала для формирования уточненной оценки для достоверного значения речевого сигнала.
2. Способ по п.1, в котором при формировании сигнала альтернативного датчика используют микрофон с костной звукопроводимостью для формирования сигнала альтернативного датчика.
3. Способ по п.1, в котором при обучении вектора поправки дополнительно обучают отдельный вектор поправки для каждой из нескольких смешанных составляющих.
4. Способ по п.1, в котором при комбинировании оценки воздушной звукопроводимости и оценки для достоверного значения речевого сигнала комбинируют оценку воздушной звукопроводимости и оценку для достоверного значения речевого сигнала в области энергетического спектра.
5. Способ по п.4, в котором дополнительно используют уточненную оценку для достоверного значения речевого сигнала для формирования фильтра.
6. Способ по п.1, в котором дополнительно
формируют сигнал второго альтернативного датчика с использованием второго альтернативного датчика, отличного от микрофона с воздушной звукопроводимостью,
преобразуют сигнал второго альтернативного датчика, по меньшей мере, в один вектор второго альтернативного датчика,
добавляют вектор поправки к вектору второго альтернативного датчика для формирования второй оценки для достоверного значения речевого сигнала и
комбинируют оценку для достоверного значения речевого сигнала со второй оценкой для достоверного значения речевого сигнала для формирования уточненной оценки для достоверного значения речевого сигнала.
7. Способ определения оценки достоверного значения речи, заключающийся в том, что
принимают сигнал альтернативного датчика из датчика, отличного от микрофона с воздушной звукопроводимостью,
принимают сигнал микрофона с воздушной звукопроводимостью из микрофона с воздушной звукопроводимостью,
определяют основной тон для речевого сигнала на основе сигнала альтернативного датчика,
используют основной тон для разложения сигнала микрофона с воздушной звукопроводимостью на гармоническую составляющую и случайную составляющую и
используют взвешенную сумму гармонической составляющей и случайной составляющей для формирования вектора характеристик с подавленным шумом, представляющего речевой сигнал с подавленным шумом и предназначенного для оценки достоверного значения речи.
8. Способ по п.7, в котором при приеме сигнала альтернативного датчика принимают сигнал альтернативного датчика из микрофона с костной звукопроводимостью.
9. Носитель информации, считываемый компьютером, снабженный командами, выполнимыми компьютером, для осуществления этапов, на которых:
принимают сигнал альтернативного датчика из альтернативного датчика, который не является микрофоном с воздушной звукопроводимостью, и
используют сигнал альтернативного датчика для оценки достоверного значения речи без использования модели, обученной на обучающих данных с шумами, собранных из микрофона с воздушной звукопроводимостью, посредством этапов, на которых:
принимают испытательный сигнал с шумами от микрофона с воздушной звукопроводимостью,
формируют модель шумов из испытательного сигнала с шумами, причем модель шумов включает в себя среднее и ковариацию,
преобразуют испытательный сигнал с шумами, по меньшей мере, в один испытательный вектор с шумами,
вычитают среднее модели шумов из испытательного вектора с шумами для формирования разности,
формируют вектор альтернативного датчика из сигнала альтернативного датчика,
добавляют вектор поправки к вектору альтернативного датчика для формирования оценки альтернативного датчика для достоверного значения речи и
определяют взвешенную сумму разности и оценки альтернативного датчика для формирования оценки достоверного значения речи, причем взвешенную сумму вычисляют, используя ковариацию модели шумов для вычисления весов для взвешенной суммы.
10. Носитель информации по п.9, в котором при приеме сигнала альтернативного датчика принимают сигнал датчика из микрофона с костной звукопроводимостью.
11. Носитель информации по п.9, в котором при добавлении вектора поправки добавляют взвешенную сумму нескольких векторов поправки, причем каждый вектор поправки соответствует отдельной смешанной составляющей.
12. Носитель информации по п.11, в котором при добавлении взвешенной суммы нескольких векторов поправки используют вес, который основан на вероятности смешанной составляющей вектора поправки, заданной вектором альтернативного датчика.
13. Носитель информации по п.9, в котором оценку достоверного значения речи осуществляют в области энергетического спектра.
14. Носитель информации по п.13, в котором дополнительно используют оценку достоверного значения речи для формирования фильтра.
15. Носитель информации по п.9, в котором дополнительно принимают сигнал второго альтернативного датчика из второго
альтернативного датчика, который не является микрофоном с воздушной звукопроводимостью, и
используют сигнал второго альтернативного датчика с сигналом альтернативного датчика для оценки достоверного значения речи.
| US 2003023430 А1, 30.01.2003 | |||
| СПОСОБ И УСТРОЙСТВО ОСЛАБЛЕНИЯ ШУМА В РЕЧЕВОМ СИГНАЛЕ | 1996 |
|
RU2121719C1 |
| JP 2000250577 А, 14.09.2000 | |||
| Бесколесный шариковый ход для железнодорожных вагонов | 1917 |
|
SU97A1 |
| JP 9284877 А, 31.10.1997. | |||

