Область техники, к которой относится
Настоящее раскрытие относится, в общем, к областям обработки сигналов и, в частности, к системам и способам выработки аудиосигнала на основе аудиосигнала костной проводимости и аудиосигнала воздушной проводимости.
Уровень техники
С широким использованием электронных устройств общение между людьми становится все более и более удобным. При использовании электронного устройства для связи пользователь может полагаться на микрофон для сбора речевых сигналов в случае, когда пользователь говорит. Речевой сигнал, собранный микрофоном, может представлять собой речь пользователя. Однако иногда трудно обеспечить достаточную разборчивость речевых сигналов, собираемых микрофоном (то есть уровень качества сигналов), например, из-за характеристик самого микрофона, шумов и т.д. Особенно в общественных местах, таких как заводы, автомобили, самолеты, морские суда, торговые центры и т.д., различные фоновые шумы серьезно влияют на качество связи. Таким образом, желательно предоставить системы и способы выработки аудиосигнала с меньшим количеством шумов и/или повышенным качеством.
Раскрытие сущности изобретения
Согласно первому аспекту настоящего раскрытия предусмотрена система для выработки аудиосигнала. Система может включать в себя по меньшей мере один носитель информации и по меньшей мере один процессор, осуществляющий связь по меньшей мере с одним носителем информации. По меньшей мере один носитель информации может включать в себя набор инструкций. При исполнении набора инструкций система может быть выполнена с возможностью выполнения одной или более из следующих операций. Система может получать первые аудиоданные, собранные датчиком костной проводимости. Система может получать вторые аудиоданные, собранные датчиком воздушной проводимости. Первые аудиоданные и вторые аудиоданные могут представлять речь пользователя с различными частотными составляющими. Система может вырабатывать третьи аудиоданные на основе первых аудиоданных и вторых аудиоданных. Частотные составляющие третьих аудиоданных выше первой частотной точки могут увеличиваться по отношению к частотным составляющим первых аудиоданных выше частотной точки.
В некоторых вариантах осуществления система может выполнять первую операцию предварительной обработки первых аудиоданных для получения предварительно обработанных первых аудиоданных. Система может вырабатывать, на основе предварительно обработанных первых аудиоданных и вторых аудиоданных, третьи аудиоданные.
В некоторых вариантах осуществления первая операция предварительной обработки может включать в себя операцию нормирования.
В некоторых вариантах осуществления система может получить обученную модель машинного обучения. Система может определить, на основе первых аудиоданных, предварительно обработанные первые аудиоданные с использованием обученной модели машинного обучения. Частотные составляющие предварительно обработанных первых аудиоданных выше второй частотной точки могут увеличиваться по отношению к частотным составляющим первых аудиоданных выше второй частотной точки.
В некоторых вариантах осуществления система может получать множество групп обучающих данных. Каждая группа из множества групп обучающих данных может включать в себя аудиоданные костной проводимости и аудиоданные воздушной проводимости, представляющие выборку речевого сигнала. Система может обучать предварительную модель машинного обучения, используя множество групп обучающих данных. Аудиоданные костной проводимости в каждой группе из множества групп обучающих данных могут быть входными данными предварительной модели машинного обучения, и аудиоданные воздушной проводимости, соответствующие аудиоданным костной проводимости, могут быть требуемыми выходными данными предварительной модели машинного обучения в процессе обучения предварительной модели машинного обучения.
В некоторых вариантах осуществления область тела, где расположен конкретный датчик костной проводимости для сбора аудиоданных костной проводимости в каждой группе из множества групп обучающих данных, может быть такой же, что и область тела пользователя, где расположен датчик костной проводимости для сбора первых аудиоданных.
В некоторых вариантах осуществления предварительная модель машинного обучения может быть построена на основе модели рекуррентной нейронной сети или сети с долгой кратковременной памятью.
В некоторых вариантах осуществления система может получить фильтр, выполненный с возможностью обеспечения взаимосвязи между конкретными аудиоданными воздушной проводимости и конкретными аудиоданными костной проводимости, соответствующими конкретным аудиоданным воздушной проводимости. Система может определить предварительно обработанные первые аудиоданные с использованием фильтра для обработки первых аудиоданных.
В некоторых вариантах осуществления система может выполнять вторую операцию предварительной обработки вторых аудиоданных для получения предварительно обработанных вторых аудиоданных. Система может вырабатывать, на основе первых аудиоданных и предварительно обработанных вторых аудиоданных, третьи аудиоданные.
В некоторых вариантах осуществления вторая операция предварительной обработки может включать в себя операцию очистки от шума.
В некоторых вариантах осуществления система может определить, по меньшей мере частично на основе по меньшей мере одного из первых аудиоданных или вторых аудиоданных, один или более частотных порогов. Система может вырабатывать, на основе указанного одного или более частотных порогов, первых аудиоданных и вторых аудиоданных, третьи аудиоданные.
В некоторых вариантах осуществления система может определять уровень шума, ассоциированный со вторыми аудиоданными. Система может определять на основе уровня шума, ассоциированного со вторыми аудиоданными, по меньшей мере один из указанного одного или более частотных порогов.
В некоторых вариантах осуществления уровень шума, ассоциированный со вторыми аудиоданными, может быть указан отношением сигнал-шум (SNR) вторых аудиоданных. Система может определить SNR вторых аудиоданных посредством следующей обработки. Система может определить энергию шумов, включенных во вторые аудиоданные, с использованием датчика костной проводимости и датчика воздушной проводимости. Система может определить на основе энергии шумов, включенных во вторые аудиоданные, энергию чистых аудиоданных, включенных во вторые аудиоданные. Система может определить SNR на основе энергии шумов, включенных во вторые аудиоданные, и энергии чистых аудиоданных, включенных во вторые аудиоданные.
В некоторых вариантах осуществления, чем выше уровень шума, ассоциированный со вторыми аудиоданными, тем выше может быть по меньшей мере один из указанного одного или более частотных порогов.
В некоторых вариантах осуществления система может определить по меньшей мере один из указанного одного или более частотных порогов на основе кривой частотной характеристики, ассоциированной с первыми аудиоданными.
В некоторых вариантах осуществления система может объединять первые аудиоданные и вторые аудиоданные в частотной области в соответствии с одним или более пороговыми значениями частоты для выработки третьих аудиоданных.
В некоторых вариантах осуществления система может определить нижнюю часть первых аудиоданных, включающих в себя частотные составляющие ниже одного из указанных одного или более частотных порогов. Система может определить верхнюю часть вторых аудиоданных, включающих в себя частотные составляющие выше одного из указанных одного или более частотных порогов. Система может сшить нижнюю часть первых аудиоданных и верхнюю часть вторых аудиоданных для выработки третьих аудиоданных.
В некоторых вариантах осуществления система может определить несколько частотных диапазонов. Система может определить первый весовой коэффициент и второй весовой коэффициент для части первых аудиоданных и части вторых аудиоданных, расположенных в каждом из множества частотных диапазонов, соответственно. Система может определить третьи аудиоданные путем взвешивания указанной части первых аудиоданных и указанной части вторых аудиоданных, расположенных в каждом из множества частотных диапазонов, с использованием первого весового коэффициента и второго весового коэффициента, соответственно.
В некоторых вариантах осуществления система может определить, по меньшей мере частично на основе частотной точки, первый весовой коэффициент и второй весовой коэффициент для первой части первых аудиоданных и второй части первых аудиоданных, соответственно. Первая часть первых аудиоданных может включать в себя частотные составляющие ниже частотной точки, а вторая часть первых аудиоданных может включать в себя частотные составляющие выше частотной точки. Система может определить, по меньшей мере частично на основе частотной точки, третий весовой коэффициент и четвертый весовой коэффициент для третьей части вторых аудиоданных и четвертой части вторых аудиоданных, соответственно. Третья часть вторых аудиоданных может включать в себя частотные составляющие ниже частотной точки, а четвертая часть вторых аудиоданных может включать в себя частотные составляющие выше частотной точки. Система может определить третьи аудиоданные путем взвешивания первой части первых аудиоданных, второй части первых аудиоданных, третьей части вторых аудиоданных и четвертой части вторых аудиоданных с использованием первого весового коэффициента, второго весового коэффициента, третьего весового коэффициента и четвертого весового коэффициента, соответственно.
В некоторых вариантах осуществления система может определить, по меньшей мере частично на основе по меньшей мере одного из первых аудиоданных или вторых аудиоданных, первый весовой коэффициент, соответствующий первым аудиоданным. Система может определить, по меньшей мере частично на основе по меньшей мере одного из первых аудиоданных или вторых аудиоданных, второй весовой коэффициент, соответствующий вторым аудиоданным. Система может определить третьи аудиоданные путем взвешивания первых аудиоданных и вторых аудиоданных с использованием первого весового коэффициента и второго весового коэффициента, соответственно.
В некоторых вариантах осуществления система может выполнять операцию последующей обработки третьих аудиоданных для получения целевых аудиоданных, представляющих собой речь пользователя с более высоким качеством, чем первые аудиоданные и вторые аудиоданные.
В некоторых вариантах осуществления операция последующей обработки включает в себя операцию очистки от шума.
Согласно второму аспекту настоящего раскрытия предусмотрен способ выработки аудиосигнала. Способ может быть реализован по меньшей мере в одном вычислительном устройстве, каждое из которых может включать в себя по меньшей мере один процессор и запоминающее устройство. Способ может включать в себя одну или несколько следующих операций. Способ может включать в себя получение первых аудиоданных, собранных датчиком костной проводимости; получение вторых аудиоданных, собранных датчиком воздушной проводимости, причем первые аудиоданные и вторые аудиоданные представляют речь пользователя с отличающимися частотными составляющими; выработку, на основе первых аудиоданных и вторых аудиоданных, третьих аудиоданных, при этом частотные составляющие третьих аудиоданных выше первой частотной точки увеличиваются по отношению к частотным составляющим первых аудиоданных выше частотной точки.
Согласно третьему аспекту настоящего раскрытия предусмотрена система для выработки аудиосигнала. Система может включать в себя модуль получения, выполненный с возможностью получения первых аудиоданных, собранных датчиком костной проводимости, и вторых аудиоданных, собранных датчиком воздушной проводимости. Первые аудиоданные и вторые аудиоданные могут представлять собой речь пользователя с отличающимися частотными составляющими. Система также может включать в себя модуль выработки аудиоданных, выполненный с возможностью выработки, на основе первых аудиоданных и вторых аудиоданных, третьих аудиоданных. Частотные составляющие третьих аудиоданных выше первой частотной точки могут увеличиваться по отношению к частотным составляющим первых аудиоданных выше чем частотная точка.
Согласно четвертому аспекту настоящего раскрытия предусмотрен энергонезависимый машиночитаемый носитель информации. Энергонезависимый машиночитаемый носитель информации может включать в себя по меньшей мере один набор инструкций, которые при их исполнении по меньшей мере одним процессором предписывают по меньшей мере одному процессору выполнять способ. Указанный по меньшей мере один процессор может получать первые аудиоданные, собранные датчиком костной проводимости. Указанный по меньшей мере один процессор может получать вторые аудиоданные, собранные датчиком воздушной проводимости. Первые аудиоданные и вторые аудиоданные могут представлять речь пользователя с различными частотными составляющими. По меньшей мере один процессор может вырабатывать, на основе первых аудиоданных и вторых аудиоданных, третьи аудиоданные. Частотные составляющие третьих аудиоданных выше первой частотной точки могут увеличиваться по отношению к частотным составляющим первых аудиоданных выше чем частотная точка.
Дополнительные признаки будут частично изложены в последующем описании и частично станут очевидными для специалистов в данной области техники после прочтения последующего описания со ссылкой на сопроводительные чертежи или могут быть изучены с использованием приведенных примеров или работы с ними. Признаки настоящего раскрытия могут быть реализованы и достигнуты на практике или при использовании различных аспектов методологий, инструментальных средств и комбинаций, изложенных в подробных примерах, приведенных ниже.
Краткое описание чертежей
Настоящее раскрытие далее описывается в терминах примерных вариантов осуществления. Эти примерные варианты осуществления подробно описаны со ссылкой на чертежи. Эти варианты осуществления не являются ограничивающими иллюстративными вариантами осуществления, в которых одинаковые ссылочные позиции представляют аналогичные структуры на нескольких видах чертежей и на которых:
фиг.1 – схема, иллюстрирующая примерную систему выработки аудиосигнала согласно некоторым вариантам осуществления настоящего раскрытия;
фиг.2 – схема, иллюстрирующая примерные аппаратные и программные компоненты вычислительного устройства согласно некоторым вариантам осуществления настоящего раскрытия;
фиг.3 – схема, иллюстрирующая примерные аппаратные и/или программные компоненты мобильного устройства согласно некоторым вариантам осуществления настоящего раскрытия;
фиг.4А – блок-схема, иллюстрирующая примерное устройство обработки согласно некоторым вариантам осуществления настоящего раскрытия;
фиг.4B – блок-схема, иллюстрирующая примерный модуль выработки аудиоданных согласно некоторым вариантам осуществления настоящего раскрытия;
фиг.5 – блок-схема, иллюстрирующая примерный процесс выработки аудиосигнала согласно некоторым вариантам осуществления настоящего раскрытия;
фиг.6 – блок-схема, иллюстрирующая примерный процесс восстановления аудиоданных костной проводимости с использованием обученной модели машинного обучения согласно некоторым вариантам осуществления настоящего раскрытия;
фиг.7 – блок-схема, иллюстрирующая примерный процесс восстановления аудиоданных костной проводимости с использованием модели гармонической коррекции согласно некоторым вариантам осуществления настоящего раскрытия;
фиг.8 – блок-схема, иллюстрирующая примерный процесс восстановления аудиоданных костной проводимости с использованием метода разреженных матриц согласно некоторым вариантам осуществления настоящего раскрытия;
фиг.9 – блок-схема, иллюстрирующая примерный процесс выработки аудиоданных согласно некоторым вариантам осуществления настоящего раскрытия;
фиг.10 – блок-схема, иллюстрирующая примерный процесс выработки аудиоданных согласно некоторым вариантам осуществления настоящего раскрытия;
фиг.11 – диаграмма, иллюстрирующая частотные характеристики аудиоданных костной проводимости, соответствующие восстановленным аудиоданным костной проводимости и соответствующие аудиоданным воздушной проводимости согласно некоторым вариантам осуществления настоящего раскрытия;
фиг.12А – диаграмма, иллюстрирующая частотные характеристики аудиоданных костной проводимости, собранных датчиками костной проводимости, расположенными в различных областях тела пользователя, согласно некоторым вариантам осуществления настоящего раскрытия;
фиг.12B – диаграмма, иллюстрирующая частотные характеристики аудиоданных костной проводимости, собранных датчиками костной проводимости, расположенными в различных областях тела пользователя, согласно некоторым вариантам осуществления настоящего раскрытия;
фиг.13A – частотно-временная диаграмма, иллюстрирующая сшитые аудиоданные, выработанные путем сшивания аудиоданных костной проводимости и аудиоданных воздушной проводимости при частотном пороге 2 кГц согласно некоторым вариантам осуществления настоящего раскрытия;
фиг.13B – частотно-временная диаграмма, иллюстрирующая сшитые аудиоданные, выработанные путем сшивания аудиоданных костной проводимости и предварительно обработанных аудиоданных воздушной проводимости, очищенных от шума фильтром Винера при частотном пороге 2 кГц, согласно некоторым вариантам осуществления настоящего раскрытия;
фиг.13C – частотно-временная диаграмма, иллюстрирующая сшитые аудиоданные, выработанные путем сшивания аудиоданных костной проводимости и предварительно обработанных аудиоданных воздушной проводимости, очищенных от шума методом спектрального вычитания при частотном пороге 2 кГц согласно некоторым вариантам осуществления настоящего раскрытия;
фиг.14А – частотно-временная диаграмма, иллюстрирующая аудиоданные костной проводимости согласно некоторым вариантам осуществления настоящего раскрытия;
фиг.14B – частотно-временная диаграмма, иллюстрирующая аудиоданные воздушной проводимости согласно некоторым вариантам осуществления настоящего раскрытия;
фиг.14C – частотно-временная диаграмма, иллюстрирующая сшитые аудиоданные, выработанные путем сшивания аудиоданных костной проводимости и аудиоданных воздушной проводимости при частотном пороге 2 кГц согласно некоторым вариантам осуществления настоящего раскрытия;
фиг.14D – частотно-временная диаграмма, иллюстрирующая сшитые аудиоданные, выработанные путем сшивания аудиоданных костной проводимости и аудиоданных воздушной проводимости при частотном пороге 3 кГц согласно некоторым вариантам осуществления настоящего раскрытия; и
фиг.14E – частотно-временная диаграмма, иллюстрирующая сшитые аудиоданные, выработанные путем сшивания аудиоданных костной проводимости и аудиоданных воздушной проводимости при частотном пороге 4 кГц согласно некоторым вариантам осуществления настоящего раскрытия.
Осуществление изобретения
В нижеследующем подробном описании многочисленные конкретные детали изложены в виде примеров для того, чтобы обеспечить полное понимание соответствующего раскрытия. Однако специалистам в данной области техники должно быть очевидно, что настоящее раскрытие может применяться на практике без таких подробностей. В других случаях хорошо известные способы, процедуры, системы, компоненты и/или схемы были описаны на относительно высоком уровне без подробностей во избежание излишнего усложнения аспектов настоящего раскрытия. Специалистам в данной области техники будут очевидны различные модификации раскрытых вариантов осуществления, и определенные в данном документе общие принципы могут быть применены к другим вариантам осуществления и заявкам без отклонения от сущности и объема настоящего раскрытия. Таким образом, настоящее раскрытие не ограничивается показанными вариантами осуществления, и должно соответствовать самому широкому объему, соответствующему формуле изобретения.
Используемая в данном документе терминология предназначена только для целей описания конкретных примерных вариантов осуществления и не предназначена для ограничения. Используемые в данном документе формы единственного числа могут также включать в себя формы множественного числа, если из контекста явно не следует обратное. Кроме того, следует отметить, что термины «содержать», «содержит» и/или «содержащий», «включать в себя», «включает в себя» и/или «включающий в себя», когда они используются в данном описании, определяют наличие заявленных признаков, целые числа, этапы, операции, элементы и/или компоненты, но не исключают наличия или добавления одного или нескольких других признаков, целых чисел, этапов, операций, элементов, компонентов и/или их групп.
Следует отметить, что используемые в данном документе термины «система», «механизм», «блок», «модуль» и/или «устройство» представляют собой один из способов различения различных компонентов, элементов, частей, секций или сборок разных уровней в порядке возрастания. Однако термины могут быть заменены другими выражениями, если они служат одной и той же цели.
В общем, используемые в данном документе термины «модуль», «блок» или «устройство» относятся к логике, воплощенной в аппаратных средствах или программно-аппаратных средствах, или к набору программных инструкций. Модуль, блок или устройство, описанные в данном документе, могут быть реализованы в виде программного обеспечения и/или аппаратных средств и могут быть сохранены на любом типе энергонезависимого машиночитаемого носителя информации или другого запоминающего устройства. В некоторых вариантах осуществления программный модуль/блок/устройство может быть скомпилирован и связан с исполняемой программой. Понятно, что программные модули могут вызываться из других модулей/блоков/устройств или из самих себя и/или могут вызываться в ответ на обнаруженные события или прерывания. Программные модули/блоки/устройства, выполненные с возможностью исполнения на вычислительных устройствах, могут быть предоставлены на машиночитаемом носителе информации, таком как компакт-диск, цифровой видеодиск, флэш-накопитель, магнитный диск или любой другой материальный носитель информации, или в виде цифровой загрузки (и могут быть изначально сохранены в сжатом или устанавливаемом формате, который требует установки, распаковки или дешифровки перед исполнением). Такой программный код может быть частично или полностью сохранен на запоминающем устройстве исполняющего вычислительного устройства для исполнения вычислительным устройством. Программные инструкции могут быть встроены в программно-аппаратные средства, такие как стираемое программируемое постоянное запоминающее устройство (EPROM). Кроме того, следует отметить, что аппаратные модули/блоки/устройства могут быть включены в подсоединенные логические компоненты, такие как логические элементы и триггеры, и/или могут быть включены в программируемые блоки, такие как программируемые логические матрицы или процессоры. Модули/блоки/устройства или функциональные возможности вычислительного устройства, описанные в данном документе, могут быть реализованы как программные модули/блоки/устройства, но могут быть представлены в виде аппаратных средств или программно-аппаратных средств. В общем, модули/блоки/устройства, описанные в данном документе, относятся к логическим модулям/блокам/устройствам, которые могут быть объединены с другими модулями/ блоками/устройствами или разделены на подмодули/подблоки/подустройства, независимо от их физической организации или хранения. Описание может быть применимо к системе, механизму или их частям.
Следует отметить, что, когда блок, механизм, модуль или устройство упоминаются как «подключенные к», «подсоединенные к» или «связанные с» другим блоком, механизмом, модулем или устройством, он может быть непосредственно подсоединен или подключен к другому блоку, механизму, модулю или блоку, или могут присутствовать промежуточные блок, механизм, модуль или устройство, если из контекста явно не следует обратное. Используемый в данном документе термин «и/или» включает в себя любые и все комбинации одного или нескольких ассоциированных перечисленных элементов.
Эти и другие признаки и характеристики настоящего раскрытия, а также способы функционирования, функции соответствующих элементов структуры, комбинация частей и экономия при производстве могут стать более очевидными при рассмотрении последующего описания со ссылкой на сопроводительные чертежи, которые составляют часть настоящего раскрытия. Однако следует четко понимать, что чертежи предназначены только для целей иллюстрации и описания и не предназначены для ограничения объема настоящего раскрытия. Понятно, что чертежи выполнены не в масштабе.
Блок-схемы, используемые в настоящем раскрытии, иллюстрируют операции, которые реализуют системы согласно некоторым вариантам осуществления настоящего раскрытия. Следует четко понимать, что операции блок-схемы могут быть реализованы не по порядку. И наоборот, операции могут выполняться в обратном порядке или одновременно. Кроме того, одна или несколько других операций могут быть добавлены в блок-схемы. Одна или несколько операций могут быть удалены из блок-схем.
Настоящее раскрытие предоставляет системы и способы для выработки аудиосигнала. Системы и способы могут получать первые аудиоданные, собранные датчиком костной проводимости (также называемые аудиоданными костной проводимости). Системы и способы могут получать вторые аудиоданные, собранные датчиком воздушной проводимости (также называемые аудиоданными воздушной проводимости). Аудиоданные костной проводимости и аудиоданные воздушной проводимости могут представлять собой речь пользователя с различными частотными составляющими. Системы и способы могут вырабатывать аудиоданные на основе аудиоданных костной проводимости и аудиоданных воздушной проводимости. Частотные составляющие выработанных аудиоданных выше частотной точки могут увеличиваться по отношению к частотным составляющим аудиоданных костной проводимости выше частотной точки. В некоторых вариантах осуществления системы и способы могут определять на основе выработанных аудиоданных целевые аудиоданные, представляющие собой речь пользователя с более высоким качеством, чем аудиоданные костной проводимости и аудиоданные воздушной проводимости. Согласно настоящему раскрытию аудиоданные, выработанные на основе аудиоданных костной проводимости и аудиоданных воздушной проводимости, могут включать в себя больше высокочастотных составляющих, чем аудиоданные костной проводимости, и/или меньше шумов, чем аудиоданные воздушной проводимости, что позволяет повысить качество и разборчивость выработанных аудиоданных по отношению к аудиоданным костной проводимости и/или аудиоданным воздушной проводимости. В некоторых вариантах осуществления системы и способы могут дополнительно включать в себя восстановление аудиоданных костной проводимости для получения восстановленных аудиоданных костной проводимости, более похожих или близких к аудиоданным воздушной проводимости, путем увеличения более высокочастотных составляющих аудиоданных костной проводимости, что позволяет повысить качество восстановленных аудиоданных костной проводимости по отношению к аудиоданным костной проводимости, а также качество выработанных аудиоданных. В некоторых вариантах осуществления системы и способы могут вырабатывать, на основе аудиоданных костной проводимости и аудиоданных воздушной проводимости, аудиоданные в соответствии с одним или более частотными порогами, которые также называются частотными точками сшивания. Частотные точки сшивания могут быть определены на основе уровня шума, ассоциированного с аудиоданными воздушной проводимости, что позволяет уменьшить шумы выработанных аудиоданных и одновременно повысить точность выработанных аудиоданных.
На фиг.1 показано схематичное представление, иллюстрирующее примерную систему 100 выработки аудиосигнала согласно некоторым вариантам осуществления настоящего раскрытия. Система 100 выработки аудиосигнала может включать в себя устройство 110 сбора аудио, сервер 120, терминал 130, запоминающее устройство 140 и сеть 150.
Устройство 110 сбора аудио может получать аудиоданные (например, аудиосигнал) путем сбора звука, голоса или речи пользователя, когда пользователь говорит. Например, когда пользователь говорит, звук пользователя может вызывать вибрации воздуха вокруг рта пользователя и/или вибрации тканей тела (например, черепа) пользователя. Устройство 110 сбора аудио может принимать вибрации и преобразовывать вибрации в электрические сигналы (например, аналоговые сигналы или цифровые сигналы), также называемые аудиоданными. Аудиоданные могут передаваться в сервер 120, терминал 130 и/или запоминающее устройство 140 через сеть 150 в виде электрических сигналов. В некоторых вариантах осуществления устройство 110 для сбора аудио может включать в себя записывающее устройство, гарнитуру, такую как гарнитура Bluetooth (технология "голубой зуб"), проводную гарнитуру, слуховой аппарат и т.д.
В некоторых вариантах осуществления устройство 110 для сбора аудио может быть соединено с динамиком через беспроводное соединение (например, сеть 150) и/или проводное соединение. Аудиоданные могут быть переданы в динамик для проигрывания и/или воспроизведения речи пользователя. В некоторых вариантах осуществления динамик и устройство 110 для сбора звука могут быть интегрированы в одно устройство, такое как гарнитура. В некоторых вариантах осуществления устройство 110 для сбора звука и динамик могут быть отделены друг от друга. Например, устройство 110 сбора аудио может быть установлено в первом терминале (например, в гарнитуре), и динамик может быть установлен в другом терминале (например, в терминале 130).
В некоторых вариантах осуществления устройство 110 для сбора звука может включать в себя микрофон 112 костной проводимости и микрофон 114 воздушной проводимости. Микрофон 112 костной проводимости может включать в себя один или несколько датчиков костной проводимости для сбора аудиоданных костной проводимости. Аудиоданные костной проводимости могут вырабатываться путем сбора сигнала вибрации костей (например, черепа) пользователя, когда пользователь говорит. В некоторых вариантах осуществления один или более датчиков костной проводимости могут образовывать матрицу датчиков костной проводимости. В некоторых вариантах осуществления микрофон 112 костной проводимости может располагаться и/или контактировать с участком тела пользователя для сбора аудиоданных костной проводимости. Область тела пользователя может включать в себя лоб, шею (например, горло), лицо (например, область вокруг рта, подбородок), макушку головы, сосцевидный отросток, область вокруг уха или область внутри уха, виска и т.п. или любое их сочетание. Например, микрофон 112 костной проводимости может располагаться на экране уха, ушной раковине, внутреннем слуховом проходе, наружном слуховом проходе и т.д. и/или контактировать с ними. В некоторых вариантах осуществления одна или несколько характеристик аудиоданных костной проводимости может различаться в зависимости от области тела пользователя, где микрофон 112 костной проводимости расположен и/или с которой он соприкасается. Например, аудиоданные костной проводимости, собранные микрофоном 112 костной проводимости, расположенным в области вокруг уха, могут включать в себя большую энергию, чем данные, собранные микрофоном 112 костной проводимости, расположенным на лбу. Микрофон 114 воздушной проводимости может включать в себя один или несколько датчиков воздушной проводимости для сбора аудиоданных воздушной проводимости, передаваемых по воздуху, когда пользователь говорит. В некоторых вариантах осуществления один или более датчиков воздушной проводимости могут образовывать матрицу датчиков воздушной проводимости. В некоторых вариантах осуществления микрофон 114 воздушной проводимости может располагаться на расстоянии (например, 0 см, 1 см, 2 см, 5 см, 10 см, 20 см и т.д.) ото рта пользователя. Одна или несколько характеристик аудиоданных воздушной проводимости (например, средняя амплитуда аудиоданных воздушной проводимости) могут различаться в зависимости от различных расстояний между микрофоном 114 воздушной проводимости и ртом пользователя. Например, чем больше разное расстояние между микрофоном 114 воздушной проводимости и ртом пользователя, тем меньше может быть средняя амплитуда аудиоданных воздушной проводимости.
В некоторых вариантах осуществления сервер 120 может быть одиночным сервером или группой серверов. Группа серверов может быть централизованной (например, центр обработки данных) или распределенной (например, сервер 120 может быть распределенной системой). В некоторых вариантах сервер 120 может быть локальным или удаленным. Например, сервер 120 может получать доступ к информации и/или данным, хранящимся в терминале 130, и/или запоминающем устройстве 140 через сеть 150. В качестве другого примера, сервер 120 может быть напрямую подключен к терминалу 130 и/или запоминающему устройству 140 для доступа к сохраненной информации и/или данным. В некоторых вариантах сервер 120 может быть реализован на облачной платформе. Только в качестве примера, облачная платформа может включать в себя частное облако, общедоступное облако, гибридное облако, облако сообщества, распределенное облако, межоблачное облако, многооблачное облако и т.п. или любое их сочетание. В некоторых вариантах осуществления сервер 120 может быть реализован на вычислительном устройстве 200, имеющем один или несколько компонентов, показанных в настоящем раскрытии на фиг.2.
В некоторых вариантах осуществления сервер 120 может включать в себя устройство 122 обработки. Устройство 122 обработки может обрабатывать информацию и/или данные, относящиеся к выработке аудиосигнала, для выполнения одной или более функций, описанных в настоящем раскрытии. Например, устройство 122 обработки может получать аудиоданные костной проводимости, собранные микрофоном 112 костной проводимости, и аудиоданные воздушной проводимости, собранные микрофоном 114 воздушной проводимости, причем аудиоданные костной проводимости и аудиоданные воздушной проводимости представляют собой речь пользователя. Устройство 122 обработки может вырабатывать целевые аудиоданные на основе аудиоданных костной проводимости и аудиоданных воздушной проводимости. В качестве другого примера, устройство 122 обработки может получить обученную модель машинного обучения и/или построенный фильтр из запоминающего устройства 140 или любого другого запоминающего устройства. Устройство 122 обработки может восстановить аудиоданные кости, используя обученную модель машинного обучения и/или построенный фильтр. В качестве дополнительного примера, устройство 122 обработки может определить обученную модель машинного обучения путем обучения предварительной модели машинного обучения с использованием множества групп выборок речевого сигнала. Каждый из множества выборок речевого сигнала может включать в себя аудиоданные костной проводимости и аудиоданные воздушной проводимости, представляющие собой речь пользователя. В качестве еще одного примера, устройство 122 обработки может выполнять операцию очистки от шума над аудиоданными воздушной проводимости для получения очищенных от шума аудиоданных воздушной проводимости. Устройство 122 обработки может вырабатывать целевые аудиоданные на основе восстановленных аудиоданных костной проводимости и очищенных от шума аудиоданных воздушной проводимости. В некоторых вариантах осуществления устройство 122 обработки может включать в себя один или несколько механизмов обработки (например, одноядерный(е) механизм(ы) обработки или многоядерный(е) процессор(ы)). Только в качестве примера, устройство 122 обработки может включать в себя центральный процессор (CPU), специализированную интегральную схему (ASIC), процессор с набором команд специального назначения (ASIP), графический процессор (GPU), блок обработки физических данных (PPU), процессор цифровых сигналов (DSP), программируемая пользователем вентильная матрица (FPGA), программируемое логическое устройство (PLD), контроллер, блок микроконтроллеров, компьютер с сокращенным набором команд (RISC), микропроцессор и т.п. или любое их сочетание.
В некоторых вариантах осуществления терминал 130 может включать в себя мобильное устройство 130-1, планшетный компьютер 130-2, портативный компьютер 130-3, встроенное устройство в транспортном средстве 130-4, носимое устройство 130-5 и т.п. или любое их сочетание. В некоторых вариантах осуществления мобильное устройство 130-1 может включать в себя устройство «умный дом», интеллектуальное мобильное устройство, устройство виртуальной реальности, устройство дополненной реальности и т.п. или любое их сочетание. В некоторых вариантах осуществления устройство «умный дом» может включать в себя интеллектуальное осветительное устройство, устройство управления интеллектуальным электрическим устройством, интеллектуальное устройство мониторинга, интеллектуальный телевизор, интеллектуальную видеокамеру, переговорное устройство и т.п. или любое их сочетание. В некоторых вариантах осуществления интеллектуальное мобильное устройство может включать в себя смартфон, персональный цифровой помощник (PDA), игровое устройство, навигационное устройство, устройство в точке продаж (POS) и т.п. или любое их сочетание. В некоторых вариантах осуществления устройство виртуальной реальности и/или устройство дополненной реальности может включать в себя шлем виртуальной реальности, очки виртуальной реальности, накладку виртуальной реальности, шлем дополненной реальности, очки дополненной реальности, накладку дополненной реальности и т.п. или любое их сочетание. Например, устройство виртуальной реальности и/или устройство дополненной реальности может включать в себя очки GoogleTM, Oculus Rift, HoloLens, Gear VR и т.д. В некоторых вариантах осуществления встроенное устройство в транспортном средстве 130-4 может включать в себя бортовой компьютер, бортовой телевизор и т.д. В некоторых вариантах осуществления терминал 130 может быть устройством с технологией позиционирования для определения местоположения пассажира и/или терминала 130. В некоторых вариантах осуществления носимое устройство 130-5 может включать в себя интеллектуальный браслет, интеллектуальную обувь, интеллектуальные очки, интеллектуальный шлем, интеллектуальные часы, интеллектуальную одежду, интеллектуальный рюкзак, интеллектуальный аксессуар и т.п. или любое их сочетание. В некоторых вариантах осуществления устройство 110 для сбора звука и терминал 130 могут быть интегрированы в одно устройство.
Запоминающее устройство 140 может хранить данные и/или инструкции. Например, запоминающее устройство 140 может хранить данные множества групп выборок речи, одну или несколько моделей машинного обучения, обученную модель машинного обучения и/или построенный фильтр, аудиоданные, собранные микрофоном 112 костной проводимости и микрофоном 114 воздушной проводимости и т.д. В некоторых вариантах осуществления запоминающее устройство 140 может хранить данные, полученные из терминала 130 и/или устройства 110 для сбора звука. В некоторых вариантах осуществления запоминающее устройство 140 может хранить данные и/или инструкции, которые сервер 120 может выполнять или использовать для выполнения примерных способов, описанных в настоящем раскрытии. В некоторых вариантах осуществления запоминающее устройство 140 может включать в себя запоминающее устройство большой емкости, съемное запоминающее устройство, энергозависимую память для считывания и записи, постоянное запоминающее устройство (ROM) и т.п. или любое их сочетание. Примерное запоминающее устройство большой емкости может включать в себя магнитный диск, оптический диск, твердотельные накопители и т.д. Примерное съемное запоминающее устройство может включать в себя флэш-накопитель, дискету, оптический диск, карту памяти, zip-диск, магнитную ленту и т.д. Примерная энергозависимая память для считывания и записи может включать в себя оперативное запоминающее устройство (RAM). Примерное RAM может включать в себя динамическое RAM (DRAM), синхронное динамическое RAM с удвоенной скоростью передачи данных (DDR SDRAM), статическое RAM (SRAM), тиристорное RAM (T-RAM) и бесконденсаторное RAM (Z-RAM) и т.д. Примерное ROM может включать в себя ROM с маской (MROM), программируемое ROM (ROM), стираемое программируемое ROM (EPROM), электрически стираемое программируемое ROM (EEPROM), ROM на компакт-диске (CD-ROM) и ROM на цифровом универсальном диске и т.д. В некоторых вариантах осуществления запоминающее устройство 140 может быть реализовано на облачной платформе. Только в качестве примера облачная платформа может включать в себя частное облако, общедоступное облако, гибридное облако, облако сообщества, распределенное облако, межоблачное облако, многооблачное облако и т.п. или любое их сочетание.
В некоторых вариантах осуществления запоминающее устройство 140 может быть подключено к сети 150 для поддержания связи с одним или несколькими компонентами системы 100 выработки аудиосигнала (например, устройством 110 сбора аудио, сервером 120 и терминалом 130). Один или несколько компонентов системы 100 выработки аудиосигнала могут осуществлять доступ к данным или инструкциям, хранящимся в запоминающем устройстве 140, через сеть 150. В некоторых вариантах осуществления запоминающее устройство 140 может быть напрямую подключено к одному или несколькими компонентам системы 100 выработки аудиосигнала или может обмениваться данными с ним (например, с устройством 110 сбора аудио, сервером 120 и терминалом 130). В некоторых вариантах осуществления запоминающее устройство 140 может быть частью сервера 120.
Сеть 150 может способствовать обмену информацией и/или данными. В некоторых вариантах осуществления один или несколько компонентов (например, устройство 110 сбора аудио, сервер 120, терминал 130 и запоминающее устройство 140) системы 100 выработки аудиосигнала могут передавать информацию и/или данные в другой(ие) компонент(ы) системы 100 выработки аудиосигнала через сеть 150. Например, сервер 120 может получать аудиоданные костной проводимости и аудиоданные воздушной проводимости из терминала 130 через сеть 150. В некоторых вариантах осуществления сеть 150 может быть проводной или беспроводной сетью любого типа или их сочетанием. Только в качестве примера, сеть 150 может включать в себя кабельную сеть, проводную сеть, оптоволоконную сеть, телекоммуникационную сеть, интрасеть, Интернет, локальную вычислительную сеть (LAN), глобальную вычислительную сеть (WAN), беспроводную локальную сеть (WLAN), городскую сеть (MAN), телефонную коммутируемую сеть общего пользования (PSTN), сеть Bluetooth, сеть ZigBee, сеть ближней радиосвязи (NFC) и т.п. или любое их сочетание. В некоторых вариантах осуществления сеть 150 может включать в себя одну или несколько точек доступа к сети. Например, сеть 150 может включать в себя проводные или беспроводные точки доступа к сети, такие как базовые станции и/или точки обмена интернет-трафиком, через которые один или несколько компонентов системы 100 выработки аудиосигнала могут подключаться к сети 150 для обмена данными и/или информацией.
Специалисту в данной области техники должно быть понятно, что когда элемент (или компонент) системы 100 выработки аудиосигнала работает, этот элемент может работать посредством электрических сигналов и/или электромагнитных сигналов. Например, когда микрофон 112 костной проводимости передает аудиоданные костной проводимости на сервер 120, процессор микрофона 112 костной проводимости может выработать электрический сигнал, кодирующий аудиоданные костной проводимости. Затем процессор микрофона 112 костной проводимости может передавать электрический сигнал на выходной порт. Если микрофон 112 костной проводимости обменивается данными с сервером 120 через проводную сеть, выходной порт может быть физически соединен с кабелем, который дополнительно может передавать электрический сигнал на входной порт сервера 120. Если микрофон 112 костной проводимости осуществляет связь с сервером 120 через беспроводную сеть, выходной порт микрофона 112 костной проводимости может быть одной или несколькими антеннами, которые преобразуют электрический сигнал в электромагнитный сигнал. Аналогичным образом, микрофон 114 воздушной проводимости может передавать аудиоданные воздушной проводимости на сервер 120 посредством электрического сигнала или электромагнитных сигналов. В электронном устройстве, таком как терминал 130 и/или сервер 120, когда его процессор обрабатывает инструкцию, передает инструкцию и/или выполняет действие, инструкция и/или действие осуществляется с помощью электрических сигналов. Например, когда процессор извлекает или сохраняет данные с носителя информации, он может передавать электрические сигналы в устройство считывания/записи носителя информации, которое может считывать или записывать структурированные данные на носителе информации. Структурированные данные могут передаваться в процессор в виде электрических сигналов по шине электронного устройства. В данном документе электрический сигнал может относиться к одному электрическому сигналу, последовательности электрических сигналов и/или множеству дискретных электрических сигналов.
На фиг.2 показано схематичное представление примерного вычислительного устройства согласно некоторым вариантам осуществления настоящего раскрытия. Вычислительным устройством может быть компьютер, такой как сервер 120, показанный на фиг.1, и/или компьютер с определенными функциями, выполненный с возможностью реализации любой конкретной системы согласно некоторым вариантам осуществления настоящего раскрытия. Вычислительное устройство 200 может быть выполнено с возможностью реализации любых компонентов, которые выполняют одну или несколько функций, раскрытых в настоящем раскрытии. Например, сервер 120 может быть реализован в виде аппаратных устройств, программ программного обеспечения, программно-аппаратных средств или любого их сочетания в виде вычислительного устройства 200 компьютерного типа. Для краткости на фиг.2 показано только одно вычислительное устройство. В некоторых вариантах осуществления функции вычислительного устройства могут быть реализованы группой аналогичных платформ в распределенном режиме для рассредоточения вычислительной нагрузки системы.
Вычислительное устройство 200 может включать в себя коммуникационные порты 250, которые могут подключаться к сети, которая может осуществлять передачу данных. Вычислительное устройство 200 также может включать в себя процессор 220, который выполнен с возможностью исполнения инструкций и включает в себя один или несколько процессоров. Схематичная компьютерная платформа может включать в себя внутреннюю коммуникационную шину 210, различные типы блоков хранения программ и блоков хранения данных (например, жесткий диск 270, постоянное запоминающее устройство (ROM) 230, оперативное запоминающее устройство (RAM) 240), различные файлы данных, применяемые при компьютерной обработке и/или поддержании связи, и некоторые программные инструкции, возможно, выполняемые процессором 220. Вычислительное устройство 200 может также включать в себя устройство 260 ввода/вывода, которое может поддерживать ввод и вывод потоков данных между вычислительным устройством 200 и другими компонентами. Кроме того, вычислительное устройство 200 может принимать программы и данные через сеть связи.
На фиг.3 показана схема, иллюстрирующая примерные аппаратные и/или программные компоненты примерного мобильного устройства согласно некоторым вариантам осуществления настоящего раскрытия. Как показано на фиг.3, мобильное устройство 300 может включать в себя камеру 305, коммуникационную платформу 310, дисплей 320, графический процессор (GPU) 330, центральный процессор (CPU) 340, устройство 350 ввода-вывода, память 360, операционную систему (ОС) 370 мобильного устройства, приложение(я) и хранилище 390 данных. В некоторых вариантах осуществления любой другой подходящий компонент, включая, но без ограничений, системную шину или контроллер (не показан), может быть также включен в мобильное устройство 300.
В некоторых вариантах осуществления операционная система 370 мобильного устройства (например, iOS™, Android™, Windows Phone™ и т.д.) и одно или более приложений 380 могут быть загружены в память 360 из хранилища 390 для исполнения процессором 340. Приложения 380 могут включать в себя браузер или любое другое подходящее мобильное приложение для приема и воспроизведения информации, относящейся к обработке аудиоданных, или другой информации, полученной из системы 100 выработки аудиосигнала. Взаимодействие пользователя с информационным потоком может осуществляться через устройство 350 ввода-вывода и предоставляется базе 130 данных, серверу 105 и/или другим компонентам системы 100 выработки аудиосигнала. В некоторых вариантах осуществления мобильное устройство 300 может быть примерным вариантом осуществления, соответствующим терминалу 130.
Для реализации различных модулей, блоков и их функциональных возможностей, описанных в настоящем раскрытии, компьютерные аппаратные платформы могут использоваться в качестве аппаратных платформ для одного или нескольких элементов, описанных в данном документе. Аппаратные элементы, операционные системы и языки программирования таких компьютеров являются по своему характеру традиционными, и предполагается, что специалисты в данной области техники достаточно знакомы с ними, чтобы адаптировать эти технологии для выработки аудио и/или получения выборок речи, как описано в данном документе. Компьютер с элементами пользовательского интерфейса может использоваться для реализации персонального компьютера (PC) или других типов рабочих станций или терминальных устройств, хотя компьютер может также действовать как сервер, если он запрограммирован соответствующим образом. Считается, что специалисты в данной области техники знакомы со структурой, программированием и общими принципами работы такого компьютерного оборудования, и в результате чертежи должны быть понятными.
Специалисту в данной области техники должно быть понятно, что когда элемент системы 100 функционирует, этот элемент может функционировать посредством электрических сигналов и/или электромагнитных сигналов. Например, когда сервер 120 обрабатывает задачу, такую как определение обученной модели машинного обучения, сервер 120 может использовать логические схемы в своем процессоре для обработки такой задачи. Когда сервер 120 завершает определение обученной модели машинного обучения, процессор сервера 120 может выработать электрические сигналы, кодирующие обученную модель машинного обучения. Затем процессор сервера 120 может отправлять электрические сигналы по меньшей мере на один порт обмена данными целевой системы, взаимодействующей с сервером 120. Сервер 120 обменивается данными с целевой системой через проводную сеть, причем по меньшей мере один порт обмена данными может быть физически подключен к кабелю, который может дополнительно передавать электрические сигналы на входной порт (например, порт обмена информацией) терминала 130. Если сервер 120 обменивается данными с целевой системой через беспроводную сеть, обменный порт целевой системы может представлять собой одну или несколько антенн, которые могут преобразовывать электрические сигналы в электромагнитные сигналы. В электронном устройстве, таком как терминал 130 и/или сервер 120, когда его процессор обрабатывает инструкцию, отправляет инструкцию и/или выполняет действие, инструкция и/или действие осуществляется с помощью электрических сигналов. Например, когда процессор извлекает или сохраняет данные с носителя информации (например, запоминающего устройства 140), он может отправлять электрические сигналы в устройство для считывания/записи на носитель информации, которое может считывать или записывать структурированные данные в хранилище данных. Структурированные данные могут передаваться в процессор в виде электрических сигналов по шине электронного устройства. В данном документе электрический сигнал может быть одним электрическим сигналом, последовательностью электрических сигналов и/или множеством дискретных электрических сигналов.
На фиг.4A показана блок-схема, иллюстрирующая примерное устройство обработки согласно некоторым вариантам осуществления настоящего раскрытия. В некоторых вариантах осуществления устройство 122 обработки может быть реализовано на основе вычислительного устройства 200 (например, процессора 220), показанного на фиг.2, или CPU 340, показанного на фиг.3. Как показано на фиг.4A, устройство 122 обработки может включать в себя модуль 410 получения, модуль 420 предварительной обработки, модуль 430 выработки аудиоданных и модуль 440 хранения данных. Каждый из описанных выше модулей может представлять собой аппаратную схему, предназначенную для выполнения определенных действий, например, в соответствии с набором инструкций, хранящихся на одном или нескольких носителях информации, и/или любой комбинации аппаратной схемы и одного или нескольких носителей информации.
Модуль 410 получения может быть выполнен с возможностью получения данных для выработки аудиосигнала. Например, модуль 410 получения может получать исходные аудиоданные, одну или несколько моделей, обучающие данные для обучения модели машинного обучения и т.д. В некоторых вариантах осуществления модуль 410 получения может получать первые аудиоданные, собранные датчиком костной проводимости. Используемый в данном документе термин «датчик костной проводимости» может относиться к любому датчику (например, микрофону 112 костной проводимости), который может собирать вибрационные сигналы, проводимые через кость (например, череп) пользователя, которые вырабатываются тогда, когда пользователь говорит, как описано в другом месте настоящего раскрытия (например, в описании со ссылкой на фиг.1). В некоторых вариантах осуществления первые аудиоданные могут включать в себя аудиосигнал во временной области, аудиосигнал в частотной области и т.д. Первые аудиоданные могут включать в себя аналоговый сигнал или цифровой сигнал. Модуль 410 получения также может быть выполнен с возможностью получения вторых аудиоданных, собранных датчиком воздушной проводимости. Датчик воздушной проводимости может относиться к любому датчику (например, микрофону 114 воздушной проводимости), который может собирать вибрационные сигналы, передаваемые по воздуху тогда, когда пользователь говорит, как описано в другом месте настоящего раскрытия (например, в описании со ссылкой на фиг.1). В некоторых вариантах осуществления вторые аудиоданные могут включать в себя аудиосигнал во временной области, аудиосигнал в частотной области и т.д. Вторые аудиоданные могут включать в себя аналоговый сигнал или цифровой сигнал. В некоторых вариантах осуществления модуль 410 получения может получать обученную модель машинного обучения, построенный фильтр, модель гармонической коррекции и т.д. для восстановления первых аудиоданных и т.д. В некоторых вариантах осуществления устройство 122 обработки может получать одно или нескольких моделей, первые аудиоданные и/или вторые аудиоданные от датчика воздушной проводимости (например, микрофона 114 воздушной проводимости), терминала 130, запоминающего устройства 140 или любого другого запоминающего устройства через сеть 150 в реальном времени или периодически.
Модуль 420 предварительной обработки может быть выполнен с возможностью предварительной обработки по меньшей мере одного из: первых аудиоданных или вторых аудиоданных. Первые аудиоданные и вторые аудиоданные после предварительной обработки также могут называться предварительно обработанными первыми аудиоданными и предварительно обработанными вторыми аудиоданными, соответственно. Примерные операции предварительной обработки могут включать в себя операцию преобразования домена, операцию калибровки сигнала, операцию восстановления звука, операцию повышения качества речи и т.д. В некоторых вариантах осуществления модуль 420 предварительной обработки может выполнять операцию преобразования домена, выполняя преобразование Фурье или обратное преобразование Фурье. В некоторых вариантах осуществления модуль 420 предварительной обработки может выполнять операцию нормализации первых аудиоданных и/или вторых аудиоданных для получения нормализованных первых аудиоданных и/или нормализованных вторых аудиоданных для калибровки первых аудиоданных и/или вторых аудиоданных. В некоторых вариантах осуществления модуль 420 предварительной обработки может выполнять операцию повышения качества речи над вторыми аудиоданными (или нормализованными вторыми аудиоданными). В некоторых вариантах осуществления модуль 420 предварительной обработки может выполнять операцию очистки от шума вторых аудиоданных (или нормализованных вторых аудиоданных) для получения очищенных от шума вторых аудиоданных. В некоторых вариантах осуществления модуль 420 предварительной обработки может выполнять операцию восстановления звука над первыми аудиоданными (или нормализованными первыми аудиоданными) для выработки восстановленных первых аудиоданных с использованием обученной модели машинного обучения, построенного фильтра, модели гармонической коррекции, метода разреженных матриц и т.п. или любого их сочетания.
Модуль 430 выработки аудиоданных может быть выполнен с возможностью выработки третьих аудиоданных на основе первых аудиоданных (или предварительно обработанных первых аудиоданных) и вторых аудиоданных (или предварительно обработанных вторых аудиоданных). В некоторых вариантах осуществления уровень шума, ассоциированный с третьими аудиоданными, может быть ниже уровня шума, ассоциированного со вторыми аудиоданными (или предварительно обработанными вторыми аудиоданными). В некоторых вариантах осуществления модуль 430 выработки аудиоданных может вырабатывать третьи аудиоданные на основе первых аудиоданных (или предварительно обработанных первых аудиоданных) и вторых аудиоданных (или предварительно обработанных вторых аудиоданных) в соответствии с одним или более частотными порогами. В некоторых вариантах осуществления модуль 430 выработки аудиоданных может определить один единственный частотный порог. Модуль 430 выработки аудиоданных может объединять первые аудиоданные (или предварительно обработанные первые аудиоданные) и вторые аудиоданные (или предварительно обработанные вторые аудиоданные) в частотной области в соответствии с одним единственным частотным порогом для выработки третьих аудиоданных.
В некоторых вариантах осуществления модуль 430 выработки аудиоданных может определить, по меньшей мере частично на основе частотного порога, первый весовой коэффициент и второй весовой коэффициент для нижней части первых аудиоданных (или предварительно обработанных первых аудиоданных) и верхней части первых аудиоданных (или предварительно обработанных первых аудиоданных), соответственно. Нижняя часть первых аудиоданных проводимости (или предварительно обработанных первых аудиоданных) может включать в себя частотные составляющие первых аудиоданных проводимости (или предварительно обработанных первых аудиоданных) ниже частотного порога, и верхняя часть первых аудиоданных проводимости данные (или предварительно обработанные первые аудиоданные) может включать в себя частотные составляющие первых аудиоданных проводимости (или предварительно обработанных первых аудиоданных) выше частотного порога. В некоторых вариантах осуществления модуль 430 выработки аудиоданных может определить, по меньшей мере частично на основе частотного порога, третий весовой коэффициент и четвертый весовой коэффициент для нижней части вторых аудиоданных (или предварительно обработанных вторых аудиоданных) и верхней части вторых аудиоданных (или предварительно обработанных вторых аудиоданных), соответственно. Нижняя часть вторых аудиоданных проводимости (или предварительно обработанных вторых аудиоданных) может включать в себя частотные составляющие вторых аудиоданных проводимости (или предварительно обработанных вторых аудиоданных) ниже частотного порога, и верхняя часть вторых аудиоданных проводимости данные (или предварительно обработанные вторые аудиоданные) может включать в себя частотные составляющие вторых аудиоданных проводимости (или предварительно обработанных вторых аудиоданных) выше частотного порога. В некоторых вариантах осуществления модуль 430 выработки аудиоданных может определить третьи аудиоданные путем взвешивания нижней части первых аудиоданных (или предварительно обработанных первых аудиоданных), верхней части первых аудиоданных (или предварительно обработанных первых аудиоданных), нижней части вторых аудиоданных (или предварительно обработанных вторых аудиоданных), верхней части вторых аудиоданных (или предварительно обработанных вторых аудиоданных) с использованием первого весового коэффициента, второго весового коэффициента, третьего весового коэффициента и четвертого весового коэффициента, соответственно.
В некоторых вариантах осуществления модуль 430 выработки аудиоданных может определить весовой коэффициент, соответствующий первым аудиоданным (или предварительно обработанным первым аудиоданным), и весовой коэффициент, соответствующий вторым аудиоданным (или предварительно обработанным вторым аудиоданным), по меньшей мере частично на основе по меньшей мере одного из: первых аудиоданных (или предварительно обработанных первых аудиоданных) или вторых аудиоданных (или предварительно обработанных вторых аудиоданных). Модуль 430 выработки аудиоданных может определить третьи аудиоданные путем взвешивания первых аудиоданных (или предварительно обработанных первых аудиоданных) и вторых аудиоданных (или предварительно обработанных вторых аудиоданных), используя весовой коэффициент, соответствующий первым аудиоданным (или предварительно обработанные первые аудиоданные) и весовой коэффициент, соответствующий вторым аудиоданным (или предварительно обработанным вторым аудиоданным).
В некоторых вариантах осуществления модуль 430 выработки аудиоданных может определить, на основе третьих аудиоданных, целевые аудиоданные, представляющие собой речь пользователя с более высоким качеством, чем первые аудиоданные и вторые аудиоданные. В некоторых вариантах осуществления модуль 430 выработки аудиоданных может назначать третьи аудиоданные в качестве целевых аудиоданных. В некоторых вариантах осуществления модуль 430 выработки аудиоданных может выполнять операцию последующей обработки третьих аудиоданных для получения целевых аудиоданных. В некоторых вариантах осуществления модуль 430 выработки аудиоданных может выполнять операцию очистки от шума над третьими аудиоданными для получения целевых аудиоданных. В некоторых вариантах осуществления модуль 430 выработки аудиоданных может выполнять операцию обратного преобразования Фурье над третьими аудиоданными в частотной области для получения целевых аудиоданных во временной области. В некоторых вариантах осуществления модуль 430 выработки аудиоданных может передавать сигнал в клиентский терминал (например, терминал 130), запоминающее устройство 140 и/или любое другое запоминающее устройство (не показано в системе 100 выработки аудиосигнала) через сеть 150. Сигнал может включать в себя целевые аудиоданные. Сигнал также может быть выполнен с возможностью указания клиентскому терминалу воспроизводить целевые аудиоданные.
Модуль 440 хранения данных может быть выполнен с возможностью хранения данных и/или инструкций, ассоциированных с системой 100 выработки аудиосигнала. Например, модуль 440 хранения данных может хранить данные множества выборок речевого сигнала, одну или несколько моделей машинного обучения, обученную модель машинного обучения и/или построенный фильтр, аудиоданные, собранные микрофоном 112 костной проводимости и/или микрофоном 114 воздушной проводимости, и т.д. В некоторых вариантах осуществления модуль 440 хранения данных может иметь такую же конфигурацию, как и устройство 140 хранения.
Следует отметить, что представленное выше описание приведено исключительно в целях иллюстрации и не предназначено для ограничения объема настоящего раскрытия. Очевидно, что специалисты в данной области техники могут осуществить многочисленные изменения и модификации в соответствии с положениями настоящего раскрытия. Однако эти вариации и модификации не выходят за рамки настоящего раскрытия. Например, модуль 440 хранения данных может отсутствовать. В качестве другого примера, модуль 430 выработки аудиоданных и модуль 440 хранения данных могут быть объединены интегрированы в один модуль.
На фиг.4B показана блок-схема, иллюстрирующая примерный модуль выработки аудиоданных согласно некоторым вариантам осуществления настоящего раскрытия. Как показано на фиг.4В, модуль 430 выработки аудиоданных может включать в себя блок 432 определения частоты, блок 434 определения весового коэффициента и блок 436 объединения. Каждый из подмодулей, описанных выше, может быть аппаратной схемой, предназначенной для выполнения определенных действий, например, в соответствии с набором инструкций, хранящихся на одном или нескольких носителях информации, и/или любым сочетанием аппаратной схемы и одного или нескольких носителей информации.
Блок 432 определения частоты может быть выполнен с возможностью определения одного или более частотных порогов, по меньшей мере частично на основе по меньшей мере одного из: аудиоданных костной проводимости или аудиоданных воздушной проводимости. В некоторых вариантах осуществления частотный порог может быть частотной точкой аудиоданных костной проводимости и/или аудиоданных воздушной проводимости. В некоторых вариантах осуществления частотный порог может отличаться от частотной точки аудиоданных костной проводимости и/или аудиоданных воздушной проводимости. В некоторых вариантах осуществления блок 432 определения частоты может определить частотный порог на основе кривой частотной характеристики, ассоциированной с аудиоданными костной проводимости. Кривая частотной характеристики, ассоциированная с аудиоданными костной проводимости, может включать в себя значения частотной характеристики, изменяющиеся в зависимости от частоты. В некоторых вариантах осуществления блок 432 определения частоты может определить один или более частотных порогов на основе значений частотной характеристики кривой частотной характеристики, ассоциированной с аудиоданными костной проводимости. В некоторых вариантах осуществления модуль 432 определения частоты может определить один или более частотных порогов на основе изменения кривой частотной характеристики. В некоторых вариантах осуществления блок 432 определения частоты может определить кривую частотной характеристики, ассоциированную с восстановленными аудиоданными костной проводимости. В некоторых вариантах осуществления модуль 432 определения частоты может определить один или более частотных порогов на основе уровня шума, ассоциированного по меньшей мере с частью аудиоданных воздушной проводимости. В некоторых вариантах осуществления уровень шума может быть обозначен как отношение сигнал-шум (SNR) аудиоданных воздушной проводимости. Чем больше SNR, тем ниже может быть уровень шума. Чем больше SNR, ассоциированное с аудиоданными воздушной проводимости, тем больше может быть частотный порог.
Блок 434 определения весового коэффициента может быть выполнен с возможностью разделения аудиоданных костной проводимости и аудиоданных воздушной проводимости на множество сегментов в соответствии с одним или более частотными порогами. Каждый сегмент аудиоданных костной проводимости может соответствовать одному сегменту аудиоданных воздушной проводимости. Используемая в данном документе фраза «сегмент аудиоданных костной проводимости, соответствующих сегменту аудиоданных воздушной проводимости» может относиться к тому, что два сегмента аудиоданных костной проводимости и аудиоданных воздушной проводимости определяются с помощью одного или двух одинаковых частотных порогов. В некоторых вариантах осуществления количество или количество одного или более частотных порогов может быть равно единице, блок 434 определения весового коэффициента может разделить каждые аудиоданные костной проводимости и аудиоданные воздушной проводимости на два сегмента.
Блок 434 определения весового коэффициента также может быть выполнен с возможностью определения весового коэффициента для каждого из множества сегментов аудиоданных костной проводимости и аудиоданных воздушной проводимости. В некоторых вариантах осуществления весовой коэффициент специфического сегмента аудиоданных костной проводимости и весовой коэффициент соответствующего специфического сегмента аудиоданных воздушной проводимости могут удовлетворять критерию, в соответствии с которым сумма весового коэффициента для специфического сегмента аудиоданных костной проводимости и весового коэффициента для соответствующего специфического сегмента аудиоданных воздушной проводимости равна 1. В некоторых вариантах осуществления модуль 434 определения весового коэффициента может определить весового коэффициента для различных сегментов аудиоданных костной проводимости или аудиоданных воздушной проводимости на основе SNR аудиоданных воздушной проводимости.
Блок 436 объединения может быть выполнен с возможностью сшивания, слияния и/или объединения аудиоданных костной проводимости и аудиоданных воздушной проводимости на основе весового коэффициента для каждого из множества сегментов каждого из аудиоданных костной проводимости и аудиоданных воздушной проводимости для выработки сшитых, слитых и/или объединенных аудиоданных. В некоторых вариантах осуществления блок 436 объединения может определить нижнюю часть аудиоданных костной проводимости и верхнюю часть аудиоданных воздушной проводимости в соответствии с одним единственным частотным порогом. Блок 436 объединения может сшить и/или объединить нижнюю часть аудиоданных костной проводимости и верхнюю часть аудиоданных воздушной проводимости для выработки сшитых аудиоданных. Блок 436 объединения может определить нижнюю часть аудиоданных костной проводимости и верхнюю часть аудиоданных воздушной проводимости на основе одного или нескольких фильтров. В некоторых вариантах осуществления блок 436 объединения может определить сшитые, объединенные и/или объединенные аудиоданные путем взвешивания нижней части аудиоданных костной проводимости, верхней части аудиоданных костной проводимости, нижней части аудиоданных воздушной проводимости и верхней части аудиоданных воздушной проводимости с использованием первого весового коэффициента, второго весового коэффициента, третьего весового коэффициента и четвертого весового коэффициента, соответственно. В некоторых вариантах осуществления блок 436 объединения может определить объединенные и/или слитые аудиоданные путем взвешивания аудиоданных костной проводимости и аудиоданных воздушной проводимости с использованием весового коэффициента аудиоданных костной проводимости и весового коэффициента аудиоданных воздушной проводимости, соответственно.
Следует отметить, что представленное выше описание приведено только в целях иллюстрации и не предназначено для ограничения объема настоящего раскрытия. Очевидно, что специалисты в данной области техники могут осуществить многочисленные изменения и модификации в соответствии с положениями настоящего раскрытия. Однако эти вариации и модификации не выходят за рамки настоящего раскрытия. Например, модуль 430 выработки аудиоданных может дополнительно включать в себя подмодуль разделения аудиоданных (не показан на фиг.4B). Подмодуль разделения аудиоданных может быть выполнен с возможностью разделения аудиоданных костной проводимости и аудиоданных воздушной проводимости на множество сегментов в соответствии с одним или более частотными порогами. В качестве другого примера, блок 434 определения весового коэффициента и блок 436 объединения могут быть объединены интегрированы в один модуль.
На фиг.5 показана блок-схема, иллюстрирующая примерный процесс выработки аудиосигнала согласно некоторым вариантам осуществления настоящего раскрытия. В некоторых вариантах осуществления процесс 500 может быть реализован как набор инструкций (например, приложение), хранящихся в запоминающем устройстве 140, ROM 230, или RAM 240 или хранилище 390 данных. Устройство 122 обработки, процессор 220 и/или CPU 340 может исполнять набор инструкций, и при исполнении инструкций устройство 122 обработки, процессор 220 и/или CPU 340 могут быть выполнены с возможностью выполнения процесса 500. Операции проиллюстрированного ниже процесса предназначены для иллюстрации. В некоторых вариантах осуществления процесс 500 может выполняться с использованием одной или нескольких дополнительных операций, которые не описаны, и/или без одной или нескольких обсуждаемых операций. Кроме того, порядок, в котором операции процесса 500, показанного на фиг.5 и описанного ниже, не предназначен для ограничения.
На этапе 510 устройство 122 обработки (например, модуль 410 получения) может получить первые аудиоданные, собранные датчиком костной проводимости. Используемый в данном документе термин «датчик костной проводимости» может относиться к любому датчику (например, микрофону 112 костной проводимости), который может собирать вибрационные сигналы, проводимые через кость (например, череп) пользователя, вырабатываемые тогда, когда пользователь говорит, как описано в другом месте настоящего раскрытия (например, как описано со ссылкой на фиг.1). Вибрационные сигналы, собранные датчиком костной проводимости, могут быть преобразованы в аудиоданные (например, аудиосигналы) датчиком костной проводимости или любым другим устройством (например, усилителем, аналого-цифровым преобразователем (ADC) и т.д). Аудиоданные (например, первые аудиоданные), собранные датчиком костной проводимости, также могут называться аудиоданными костной проводимости. В некоторых вариантах осуществления первые аудиоданные могут включать в себя аудиосигнал во временной области, аудиосигнал в частотной области и т.д. Первые аудиоданные могут включать в себя аналоговый сигнал или цифровой сигнал. В некоторых вариантах осуществления устройство 122 обработки может получать первые аудиоданные от датчика костной проводимости (например, микрофона 112 костной проводимости), терминала 130, запоминающего устройства 140 или любого другого запоминающего устройства через сеть 150 в реальном времени или периодически.
Первые аудиоданные могут быть представлены суперпозицией множества волн (например, синусоидальных волн, гармонических волн и т.д.) с разными частотами и/или с разной интенсивностью (то есть с разными амплитудами). Используемая в данном документе волна с определенной частотой также может упоминаться как частотная составляющая с определенной частотой. В некоторых вариантах осуществления частотные составляющие, включенные в первые аудиоданные, собранные датчиком костной проводимости, могут находиться в диапазоне частот от 0 Гц до 20 кГц, или от 20 Гц до 10 кГц, или от 20 Гц до 4000 Гц, или от 20 Гц до 3000 Гц, или от 1000 Гц до 3500 Гц, или от 1000 Гц до 3000 Гц или от 1500 Гц до 3000 Гц и т.д. Первые аудиоданные могут собираться и/или вырабатываться датчиком костной проводимости тогда, когда пользователь говорит. Первые аудиоданные могут представлять то, что говорит пользователь, то есть речь пользователя. Например, первые аудиоданные могут включать в себя акустические характеристики и/или семантическую информацию, которые могут отражать содержание речи пользователя. Акустические характеристики первых аудиоданных могут включать в себя один или несколько признаков, ассоциированных с длительностью, один или несколько признаков, ассоциированных с энергией, один или несколько признаков, ассоциированных с основной частотой, один или несколько признаков, ассоциированных с частотным спектром, один или несколько признаков, ассоциированных с фазовым спектром и т.д. Признак, ассоциированный с длительностью, также может называться признаком длительности. Примерные признаки длительности могут включать в себя скорость речи, среднее значение за короткое время нулевого превышения и т.д. Признак, ассоциированный с энергией, также может упоминаться как признак энергии или амплитуды. Примерные признак энергии или амплитуды могут включать в себя усредненную за короткий промежуток времени энергию, усредненную за короткий промежуток времени амплитуду, кратковременный градиент энергии, скорость изменения средней амплитуды, кратковременную максимальную амплитуду и т.д. Признак, ассоциированный с основной частотой, также может называться как признак основной частоты. Примерные признаки основной частоты могут включать в себя основную частоту, шаг основной частоты, среднюю основную частоту, максимальную основную частоту, диапазон основной частоты и т.д. Примерные признаки, ассоциированные со спектром частот, могут включать в себя формантные признаки, кепстральные коэффициенты спектра линейного предсказания (LPCC), мел-частотные кепстральные коэффициенты (MFCC) и т.д. Примерные признаки, ассоциированные с фазовым спектром, могут включать в себя мгновенную фазу, начальную фазу и т.д.
В некоторых вариантах осуществления первые аудиоданные могут быть собраны и/или выработаны путем размещения датчика костной проводимости в области тела пользователя и/или приведения датчика костной проводимости в контакт с кожей пользователя. Области тела пользователя, находящиеся в контакте с датчиком костной проводимости для сбора первых аудиоданных, могут включать, но без ограничений, лоб, шею (например, горло), сосцевидный отросток, область вокруг уха или внутреннюю часть уха, висок, лицо (например, область вокруг рта, подбородок), макушку и т.д. Например, микрофон 112 костной проводимости может располагаться на ушном экране и/или контактировать с ним, в ушной раковине, во внутреннем слуховом проходе, в наружном слуховом проходе и т.д. В некоторых вариантах осуществления первые аудиоданные могут различаться в зависимости от различных областей тела пользователя, находящихся в контакте с датчиком костной проводимости. Например, различные области тела пользователя, соприкасающиеся с датчиком костной проводимости, могут вызвать изменение частотных составляющих, акустических характеристик первых аудиоданных (например, амплитуды частотной составляющей), шумов, включенных в первые аудиоданные и т.д. Например, интенсивность сигнала первых аудиоданных, собранных датчиком костной проводимости, который расположен на шее, больше, чем интенсивность сигнала первых аудиоданных, собранных датчиком костной проводимости, который расположен на козелке, и интенсивность сигнала первых аудиоданных, собранных датчиком костной проводимости, который расположен на козелке, больше, чем интенсивность сигнала первых аудиоданных, собранных датчиком костной проводимости, который расположен в слуховом проходе. В качестве дополнительного примера, аудиоданные костной проводимости, собранные первым датчиком костной проводимости, который расположен в области вокруг уха пользователя, могут включать в себя больше частотных составляющих, чем аудиоданные костной проводимости, собранные одновременно вторым датчиком костной проводимости с той же конфигурацией, но расположенным в верхней части головы пользователя. В некоторых вариантах осуществления первые аудиоданные могут собираться датчиком костной проводимости, расположенным в области тела пользователя, с определенным давлением, приложенным датчиком костной проводимости в диапазоне, например, от 0 ньютонов до 1 ньютона или от 0 ньютонов до 0,8 ньютона и т.д. Например, первые аудиоданные могут быть собраны датчиком костной проводимости, расположенным на козелке тела пользователя, с удельным давлением 0 ньютонов, или 0,2 ньютона, или 0,4 ньютона, или 0,8 ньютона и т.д., прикладываемым датчиком костной проводимости. Различные давления на одну и ту же область тела пользователя, оказываемые датчиком костной проводимости, могут вызывать изменение частотных составляющих, акустических характеристик первых аудиоданных (например, амплитуды частотного компонента), шумов, включенных в первые аудиоданные, и т.д. Например, интенсивность сигнала аудиоданных костной проводимости сначала может увеличиваться постепенно, а затем увеличение интенсивности сигнала может замедлиться до насыщения при увеличении давления от 0 Н до 0,8 Н. Дополнительное описание эффектов различных областей тела, находящихся в контакте с датчиком костной проводимости, по отношению к аудиоданным костной проводимости можно найти в другом месте настоящего раскрытия (например, в описании со ссылкой на фиг.12А). Дополнительное описание эффектов различных давлений, применяемых аудиоданными костной проводимости для аудиоданных костной проводимости, можно найти в другом месте настоящего раскрытия (например, в описании со ссылкой на фиг.12В).
На этапе 520 устройство 122 обработки (например, модуль 410 получения) может получать вторые аудиоданные, собранные датчиком воздушной проводимости. Используемый в данном документе термин «датчик воздушной проводимости» может относиться к любому датчику (например, микрофону 114 воздушной проводимости), который может собирать вибрационные сигналы, передаваемые по воздуху, тогда, когда пользователь говорит, как описано в другом месте настоящего раскрытия (например, в описании со ссылкой на фиг.1). Вибрационные сигналы, собранные датчиком воздушной проводимости, могут быть преобразованы в аудиоданные (например, аудиосигналы) датчиком воздушной проводимости или любым другим устройством (например, усилителем, аналого-цифровым преобразователем (ADC) и т.д. Аудиоданные (например, вторые аудиоданные), собранные датчиком воздушной проводимости, также могут упоминаться как аудиоданные воздушной проводимости. В некоторых вариантах осуществления вторые аудиоданные могут включать в себя аудиосигнал во временной области, аудиосигнал в частотной области и т.д. Вторые аудиоданные могут включать в себя аналоговый сигнал или цифровой сигнал. В некоторых вариантах осуществления устройство 122 обработки может получать вторые аудиоданные от датчика воздушной проводимости (например, микрофона 114 воздушной проводимости), терминала 130, запоминающего устройства 140 или любого другого запоминающего устройства через сеть 150 в реальном времени или периодически. В некоторых вариантах осуществления вторые аудиоданные могут быть собраны путем размещения датчика воздушной проводимости в пределах порогового расстояния (например, 0 см, 1 см, 2 см, 5 см, 10 см, 20 см и т.д.) от рта пользователя. В некоторых вариантах осуществления вторые аудиоданные (например, средняя амплитуда вторых аудиоданных) могут различаться в зависимости от различных расстояний между датчиком воздушной проводимости и ртом пользователя.
Вторые аудиоданные могут быть представлены суперпозицией множества волн (например, синусоидальных волн, гармонических волн и т.д.) с разными частотами и/или с разной интенсивностью (то есть с разными амплитудами). В некоторых вариантах осуществления частотные составляющие, включенные во вторые аудиоданные, собранные датчиком воздушной проводимости, могут находиться в диапазоне частот от 0 Гц до 20 кГц, или от 20 Гц до 20 кГц или от 1000 Гц до 10 кГц и т.д. Вторые аудиоданные могут быть собранные и/или выработанные аудиоданными воздушной проводимости тогда, когда пользователь говорит. Вторые аудиоданные могут представлять то, что говорит пользователь, то есть речь пользователя. Например, вторые аудиоданные могут включать в себя акустические характеристики и/или семантическую информацию, которые могут отражать содержание речи пользователя. Акустические характеристики вторых аудиоданных могут включать в себя один или несколько признаков, ассоциированных с длительностью, один или несколько признаков, ассоциированных с энергией, один или несколько признаков, ассоциированных с основной частотой, один или несколько признаков, ассоциированных с частотным спектром, один или несколько признаков, ассоциированных с фазовым спектром и т.д., как описано в операции 510.
В некоторых вариантах осуществления первые аудиоданные и вторые аудиоданные могут представлять одну и ту же речь пользователя с разными частотными составляющими. Первые аудиоданные и вторые аудиоданные, представляющие одну и ту же речь пользователя, могут относиться к тому, что первые аудиоданные и вторые аудиоданные одновременно собираются датчиком костной проводимости и датчиком воздушной проводимости, соответственно, тогда, когда пользователь произносит речь. В некоторых вариантах осуществления первые аудиоданные, собранные датчиком костной проводимости, могут включать в себя первые частотные составляющие. Вторые аудиоданные могут включать в себя компоненты второй частоты. В некоторых вариантах осуществления вторые частотные составляющие вторых аудиоданных могут включать в себя по меньшей мере часть первых частотных составляющих. Семантическая информация, включенная во вторые аудиоданные, может быть такой же или отличной от семантической информации, включенной в первые аудиоданные. Акустическая характеристика вторых аудиоданных может быть такой же, как акустическая характеристика первых аудиоданных, или отличаться от нее. Например, амплитуда специфической частотной составляющей первых аудиоданных может отличаться от амплитуды специфической частотной составляющей вторых аудиоданных. В качестве другого примера, частотные составляющие первых аудиоданных меньше частотной точки (например, 2000 Гц) или в диапазоне частот (например, от 20 Гц до 2000 Гц) могут быть больше, чем частотные составляющие вторых аудиоданных меньше частотной точки (например, 2000 Гц) или в диапазоне частот (например, от 20 Гц до 2000 Гц). Частотные составляющие первых аудиоданных, находящиеся выше частотной точки (например, 3000 Гц) или в диапазоне частот (например, от 3000 Гц до 20 кГц), могут быть меньше, чем частотные составляющие вторых аудиоданных, находящиеся выше частотной точки (например, 3000 Гц) или в диапазоне частот (например, от 3000 Гц до 20 кГц). То, что используемые в данном документе частотные составляющие первых аудиоданных меньше частотной точки (например, 2000 Гц) или в диапазоне частот (например, от 20 Гц до 2000 Гц) больше, чем частотные составляющие вторых аудиоданных меньше частотной точки (например, 2000 Гц) или в диапазоне частот (например, от 20 Гц до 2000 Гц), может означать, что количество или количество частотных составляющих первых аудиоданных меньше частотной точки (например, 2000 Гц) или в диапазоне частот (например, от 20 Гц до 2000 Гц) больше, чем количество или количество частотных составляющих вторых аудиоданных меньше частотной точки (например, 2000 Гц) или в диапазоне частот (например, от 20 Гц до 2000 Гц).
На этапе 530 устройство 122 обработки (например, модуль 420 предварительной обработки) может выполнить предварительную обработку по меньшей мере одного из: первых аудиоданных или вторых аудиоданных. Первые аудиоданные и вторые аудиоданные после предварительной обработки также могут называться предварительно обработанными первыми аудиоданными и предварительно обработанными вторыми аудиоданными, соответственно. Примерные операции предварительной обработки могут включать в себя операцию преобразования домена, операцию калибровки сигнала, операцию восстановления аудио, операцию повышения качества речи и т.д.
Операция преобразования домена может быть выполнена для преобразования первых аудиоданных и/или вторых аудиоданных из временной области в частотную область или из частотной области во временную область. В некоторых вариантах осуществления устройство 122 обработки может выполнять операцию преобразования домена путем выполнения преобразования Фурье или обратного преобразования Фурье. В некоторых вариантах осуществления для выполнения операции преобразования домена устройство 122 обработки может выполнять операцию разделения кадров, операцию оконного преобразования и т.д. над первыми аудиоданными и/или вторыми аудиоданными. Например, первые аудиоданные могут быть разделены на один или более речевых кадров. Каждый из одного или более речевых кадров может включать в себя аудиоданные в течение определенного промежутка времени (например, 5 мс, 10 мс, 15 мс, 20 мс, 25 мс и т.д.), в течение которого аудиоданные можно считать приблизительно стабильными. Для каждого из одного или более речевых кадров может выполняться операция оконного преобразования с использованием функции волновой сегментации для получения обработанного речевого кадра. Используемая в данном документе функция сегментации волны может упоминаться как оконная функция. Примерные оконные функции могут включать в себя окно Хэмминга, окно Ханна, окно Блэкмана-Харриса и т.д. Наконец, операция преобразования Фурье может использоваться для преобразования первых аудиоданных из временной области в частотную область на основе обработанного речевого кадра.
Операция калибровки сигнала может использоваться для унификации порядков величины первых аудиоданных и вторых аудиоданных (например, амплитуды), чтобы устранить разность между порядками величин первых аудиоданных и/или вторых аудиоданных, вызванную, например, разность по чувствительности датчика костной проводимости и датчика воздушной проводимости. В некоторых вариантах осуществления устройство 122 обработки может выполнять операцию нормализации первых аудиоданных и/или вторых аудиоданных для получения нормализованных первых аудиоданных и/или нормализованных вторых аудиоданных для калибровки первых аудиоданных и/или вторых аудиоданных. Например, устройство 122 обработки может определить нормализованные первые аудиоданные и/или нормализованные вторые аудиоданные в соответствии с уравнением (1) следующим образом:
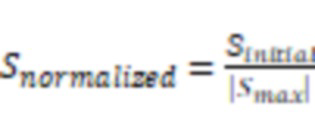 (1),
(1),
где  относится к нормализованным первым аудиоданным (или нормализованным вторым аудиоданным),
относится к нормализованным первым аудиоданным (или нормализованным вторым аудиоданным),  относится к первым аудиоданным (или вторым аудиоданным),
относится к первым аудиоданным (или вторым аудиоданным), 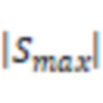 может представлять собой максимальное значение среди абсолютных значений амплитуд первых аудиоданных (или вторых аудиоданных).
может представлять собой максимальное значение среди абсолютных значений амплитуд первых аудиоданных (или вторых аудиоданных).
Операция повышения качества речи может использоваться для уменьшения шумов или другой посторонней и нежелательной информации, включенной в аудиоданные (например, первые аудиоданные и/или вторые аудиоданные). Операция повышения качества речи, выполняемая над первыми аудиоданными (или нормализованными первыми аудиоданными) и/или вторыми аудиоданными (или нормализованными вторыми аудиоданными), может включать в себя использование алгоритма повышения качества речи на основе спектрального вычитания, алгоритма повышения качества речи на основе вейвлет-анализа, алгоритма повышения качества речи на основе фильтра Калмана, алгоритма повышения качества речи на основе подпространства сигнала, алгоритма повышения качества речи на основе эффекта слуховой маскировки, алгоритма повышения качества речи на основе анализа независимых компонентов, технологии нейронной сети и т.п. или их сочетания. В некоторых вариантах осуществления операция повышения качества речи может включать в себя операцию очистки от шума. В некоторых вариантах осуществления устройство 122 обработки может выполнять операцию очистки от шума вторых аудиоданных (или нормализованных вторых аудиоданных) для получения очищенных от шума вторых аудиоданных. В некоторых вариантах осуществления нормализованные вторые аудиоданные и/или очищенные от шума вторые аудиоданные также могут упоминаться как предварительно обработанные вторые аудиоданные. В некоторых вариантах осуществления операция очистки от шума может включать в себя использование фильтра Винера, алгоритма спектрального вычитания, адаптивного алгоритма, алгоритма оценки минимальной среднеквадратичной ошибки (MMSE) и т.п. или любого их сочетания.
Операция восстановления аудио может использоваться для выделения или увеличения представляющих интерес частотных составляющих, находящихся выше частотной точки (например, 2000 Гц, 3000 Гц) или в диапазоне частот (например, от 2000 Гц до 20 кГц, от 3000 Гц до 20 кГц) исходных аудиоданных костной проводимости (например, первых аудиоданных или нормализованных первых аудиоданных), с целью получения восстановленных аудиоданных костной проводимости с повышенным качеством по сравнению с исходными аудиоданными костной проводимости (например, первыми аудиоданными или нормализованными первыми аудиоданными). Восстановленные аудиоданные костной проводимости могут быть аналогичными, близкими или идентичными аудиоданным идеальной воздушной проводимости с отсутствующим или меньшим шумом, собранным датчиком воздушной проводимости тогда, когда собираются исходные аудиоданные костной проводимости, и могут представлять ту же самую речь пользователя с исходными аудиоданными костной проводимости. Восстановленные аудиоданные костной проводимости могут быть эквивалентны аудиоданным воздушной проводимости, которые также могут называться эквивалентными аудиоданными воздушной проводимости, соответствующими исходным аудиоданным костной проводимости. Используемая в данном документе фраза «восстановленные аудиоданные, аналогичные, близкие или идентичные аудиоданным с идеальной воздушной проводимостью» может относиться к тому, что степень сходства между восстановленными аудиоданными костной проводимости и аудиоданными идеальной воздушной проводимости может превышать пороговое значение (например, 90%, 80%, 70% и др.). Дополнительное описание восстановленных аудиоданных костной проводимости, исходных аудиоданных костной проводимости и идеальных аудиоданных воздушной проводимости можно найти в другом месте настоящего раскрытия (например, в описании со ссылкой на фиг.11).
В некоторых вариантах осуществления устройство 122 обработки может выполнять операцию восстановления аудио над первыми аудиоданными (или нормализованными первыми аудиоданными) для выработки восстановленных первых аудиоданных с использованием обученной модели машинного обучения, построенного фильтра, модели гармонической коррекции, метода разреженных матриц и т.п. или любого их сочетания. В некоторых вариантах осуществления восстановленные первые аудиоданные могут быть выработаны с использованием одного из: обученной модели машинного обучения, построенного фильтра, модели гармонической коррекции, метода разреженных матриц и т.д. В некоторых вариантах осуществления восстановленные первые аудиоданные могут быть выработаны с использованием по меньшей мере двух из: обученной модели машинного обучения, построенного фильтра, модели гармонической коррекции, метода разреженных матриц и т.д. Например, устройство 122 обработки может вырабатывать промежуточные первые аудиоданные путем восстановления первых аудиоданных с использованием обученной модели машинного обучения. Устройство 122 обработки может вырабатывать восстановленные первые аудиоданные путем восстановления первых промежуточных аудиоданных с использованием одного из: построенного фильтра, модели гармонической коррекции, метода разреженных матриц и т.д. В качестве другого примера, устройство 122 обработки может вырабатывать первые промежуточные аудиоданные путем восстановления первых аудиоданных с использованием одного из: построенного фильтра, модели гармонической коррекции, метода разреженных матриц. Устройство 122 обработки может вырабатывать другие промежуточные первые аудиоданные путем восстановления первых аудиоданных с использованием другого из: построенного фильтра, модели гармонической коррекции, метода разреженных матриц и т.д. Устройство 122 обработки может вырабатывать восстановленные первые аудиоданные путем усреднения промежуточных первых аудиоданных и других промежуточных первых аудиоданных. В качестве дополнительного примера, устройство 122 обработки может вырабатывать множество промежуточных первых аудиоданных путем восстановления первых аудиоданных с использованием двух или более из: построенного фильтра, модели гармонической коррекции, метода разреженных матриц и т.д. Устройство 122 обработки может вырабатывать восстановленные первые аудиоданные путем усреднения множества промежуточных первых аудиоданных.
В некоторых вариантах осуществления устройство 122 обработки может восстанавливать первые аудиоданные (или нормализованные первые аудиоданные) для получения восстановленных первых аудиоданных с использованием обученной модели машинного обучения. Частотные составляющие, находящиеся выше частотной точки (например, 2000 Гц, 3000 Гц) или в диапазоне частот (например, от 2000 Гц до 20 кГц, от 3000 Гц до 20 кГц и т.д.) восстановленных первых аудиоданных, могут увеличиваться по отношению к частотным составляющим первых аудиоданных, находящимся выше частотной точки (например, 2000 Гц, 3000 Гц) или в диапазоне частот (например, от 2000 Гц до 20 кГц, от 3000 Гц до 20 кГц и т.д.). Обученная модель машинного обучения может быть построена на основе модели глубокого обучения, традиционной модели машинного обучения и т.п. или любого их сочетания. Примерные модели глубокого обучения могут включать в себя модель сверточной нейронной сети (CNN), модель рекуррентной нейронной сети (RNN), модель сети с долгой кратковременной памятью (LSTM) и т.д. Примерные традиционные модели машинного обучения могут включать в себя скрытую марковскую модель (HMM), модель многослойного персептрона (MLP) и др.
В некоторых вариантах осуществления обученная модель машинного обучения может быть определена путем обучения предварительной модели машинного обучения с использованием множества групп обучающих данных. Каждая группа из множества групп обучающих данных может включать в себя аудиоданные костной проводимости и аудиоданные воздушной проводимости. Группа обучающих данных также может называться выборкой речи. В процессе обучения предварительной модели машинного обучения аудиоданные костной проводимости в выборке речи могут использоваться в качестве входных данных предварительной модели машинного обучения, и аудиоданные воздушной проводимости, соответствующие аудиоданным костной проводимости в выборке речи, могут использоваться в качестве требуемых выходных данных предварительной модели машинного обучения. Аудиоданные костной проводимости и аудиоданные воздушной проводимости в выборке речи могут представлять собой одну и ту же речь и собираться, соответственно, датчиком костной проводимости и датчиком воздушной проводимости одновременно в бесшумной среде. Используемый в данном документе термин «бесшумная среда» может относиться к тому, что один или несколько параметров оценки шума (например, стандартная кривая шума, статистический уровень шума и т.д.) в среде удовлетворяют условию, например, меньше порогового значения. Обученная модель машинного обучения может быть выполнена с возможностью обеспечения соответствующего соотношения между аудиоданными костной проводимости (например, первыми аудиоданными) и восстановленными аудиоданными костной проводимости (например, эквивалентными аудиоданными воздушной проводимости). Обученная модель машинного обучения может быть выполнена с возможностью восстановления аудиоданных костной проводимости на основе соответствующего соотношения. В некоторых вариантах осуществления аудиоданные костной проводимости в каждой из множества групп обучающих данных могут быть собраны датчиком костной проводимости, расположенным в одной и той же области (например, в области вокруг уха) тела пользователя (например, испытуемого). В некоторых вариантах осуществления область тела, где расположен датчик костной проводимости для сбора аудиоданных костной проводимости, используемых для обучения обученной модели машинного обучения, может быть сходной с и/или быть такой же, как область тела, где расположен датчик костной проводимости для сбора аудиоданных костной проводимости (например, первых аудиоданных), используемых для применения обученной модели машинного обучения. Например, область тела пользователя (например, испытуемого), где расположен датчик костной проводимости для сбора аудиоданных костной проводимости в каждой группе из множества групп обучающих данных, может быть такой же, как и область тела пользователя, где расположен датчик костной проводимости для сбора первых аудиоданных. В качестве дополнительного примера, если областью тела пользователя, где расположен датчик костной проводимости для сбора первых аудиоданных, является шея, то областью тела, где расположен датчик костной проводимости для сбора аудиоданных костной проводимости, используемых в процессе обучения обученной модели машинного обучения, является шея тела. Область тела пользователя (например, испытуемого), где расположен датчик костной проводимости для сбора множества групп обучающих данных, может влиять на соответствующее соотношение между аудиоданными костной проводимости (например, первыми аудиоданными) и восстановленными аудиоданными костной проводимости (например, эквивалентными аудиоданными воздушной проводимости), тем самым влияя на восстановленные аудиоданные костной проводимости, выработанные на основе соответствующего соотношения с использованием обученной модели машинного обучения. Соответствующие соотношения между аудиоданными костной проводимости (например, первыми аудиоданными) и восстановленными аудиоданными костной проводимости (например, эквивалентными аудиоданными воздушной проводимости), когда множество групп обучающих данных, собранных датчиком костной проводимости, который расположен в разных областях, используются для обучения обученной модели машинного обучения. Например, несколько датчиков костной проводимости одной и той же конфигурации могут быть расположены в разных частях тела, таких как сосцевидный отросток, висок, макушка, наружный слуховой проход и т.д. Несколько датчиков костной проводимости могут одновременно регистрировать аудиоданные костной проводимости, когда пользователь говорит. Несколько обучающих наборов могут быть сформированы на основе аудиоданных костной проводимости, собранных множеством датчиков костной проводимости. Каждый из множества обучающих наборов может включать в себя множество групп обучающих данных, собранных одним из множества датчиков костной проводимости и датчиком воздушной проводимости. Каждая из множества групп обучающих данных может включать в себя аудиоданные костной проводимости и аудиоданные воздушной проводимости, представляющие одну и ту же речь. Каждый из множества обучающих наборов может использоваться для обучения модели машинного обучения с целью получения обученной модели машинного обучения. Несколько обученных моделей машинного обучения могут быть получены на основе нескольких обучающих наборов. Несколько обученных моделей машинного обучения могут обеспечивать различные соответствующие соотношения между специфическими аудиоданными костной проводимости и восстановленными аудиоданными костной проводимости. Например, различные восстановленные аудиоданные костной проводимости могут быть выработаны путем ввода одних и тех же аудиоданных костной проводимости в несколько обученных моделей машинного обучения, соответственно. В некоторых вариантах осуществления аудиоданные костной проводимости (например, кривые частотной характеристики), собранные различными датчиками костной проводимости в конфигурации, могут быть разными. Таким образом, датчик костной проводимости для сбора аудиоданных костной проводимости, используемый для обучения обученной модели машинного обучения, может быть сходным и/или таким же, как датчик костной проводимости для сбора аудиоданных костной проводимости (например, первых аудиоданных) используется для применения обученной модели машинного обучения в этой конфигурации. В некоторых вариантах осуществления аудиоданные костной проводимости (например, частотные характеристики), собранные датчиком костной проводимости, который расположен в области тела пользователя, с разными значениями давления в диапазоне, например, от 0 ньютонов до 1 ньютона или от 0 ньютонов до 0,8 ньютона и т.д., могут быть разными. Таким образом, давление, которое датчик костной проводимости прикладывает к области тела пользователя для сбора аудиоданных костной проводимости для обучения обученной модели машинного обучения, может быть сходным с и/или таким же, как давление, которое датчик костной проводимости прикладывает к области тела пользователя для сбора аудиоданных костной проводимости с целью применения обученной модели машинного обучения в этой конфигурации. Дополнительное описание для определения обученной модели машинного обучения и/или восстановления аудиоданных костной проводимости можно найти в описании со ссылкой на фиг.6.
В некоторых вариантах осуществления устройство 122 обработки (например, модуль 420 предварительной обработки) может восстанавливать первые аудиоданные (или нормализованные первые аудиоданные) для получения восстановленных аудиоданных костной проводимости с использованием построенного фильтра. Построенный фильтр может быть выполнен с возможностью обеспечения взаимосвязи между специфическими аудиоданными воздушной проводимости и специфическими аудиоданными костной проводимости, соответствующими специфическим аудиоданным воздушной проводимости. Используемая в данном документе фраза «соответствующие аудиоданные костной проводимости и аудиоданные воздушной проводимости» может относиться к тому, что соответствующие аудиоданные костной проводимости и аудиоданные воздушной проводимости представляют одну и ту же речь пользователя. Специфические аудиоданные воздушной проводимости также могут называться эквивалентными аудиоданными воздушной проводимости или восстановленными аудиоданными костной проводимости, соответствующими специфическим аудиоданным костной проводимости. Частотные составляющие специфических аудиоданных воздушной проводимости, находящихся выше частотной точки (например, 2000 Гц, 3000 Гц) или в диапазоне частот (например, от 2000 Гц до 20 кГц, от 3000 Гц до 20 кГц и т.д.), могут быть выше, чем частотные составляющие специфических аудиоданных воздушной проводимости, находящихся выше частотной точки (например, 2000 Гц, 3000 Гц) или в диапазоне частот (например, от 2000 Гц до 20 кГц, от 3000 Гц до 20 кГц и т.д.). Устройство 122 обработки может преобразовывать специфические аудиоданные костной проводимости в специфические аудиоданные воздушной проводимости на основе соотношения. Например, устройство 122 обработки может получить восстановленные первые аудиоданные с использованием построенного фильтра для преобразования первых аудиоданных в восстановленные первые аудиоданные. В некоторых вариантах осуществления аудиоданные костной проводимости в выборке речи могут обозначаться как  , и соответствующие данные воздушной проводимости в выборке речи могут обозначаться как
, и соответствующие данные воздушной проводимости в выборке речи могут обозначаться как  . Аудиоданные костной проводимости и соответствующие аудиоданные воздушной проводимости могут быть определены на основе исходных сигналов
. Аудиоданные костной проводимости и соответствующие аудиоданные воздушной проводимости могут быть определены на основе исходных сигналов 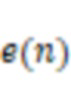 звукового возбуждения с помощью системы костной проводимости и системы воздушной проводимости соответственно, которые могут быть эквивалентны фильтру
звукового возбуждения с помощью системы костной проводимости и системы воздушной проводимости соответственно, которые могут быть эквивалентны фильтру  и фильтру
и фильтру  , соответственно. Следовательно, построенный фильтр может быть эквивалентен фильтру
, соответственно. Следовательно, построенный фильтр может быть эквивалентен фильтру  . Фильтр может быть определен согласно уравнению (2) следующим образом:
. Фильтр может быть определен согласно уравнению (2) следующим образом:
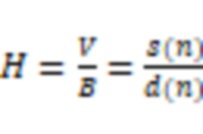 (2).
(2).
В некоторых вариантах осуществления построенный фильтр может быть определен с использованием, например, метода долговременного спектра. Например, устройство 122 обработки может определить построенный фильтр в соответствии с уравнением (3) следующим образом:
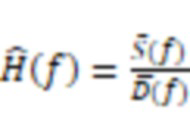 , (3)
, (3)
где 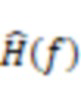 относится к построенному фильтру в частотной области,
относится к построенному фильтру в частотной области, 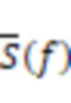 относится к выражению долговременного спектра, соответствующему аудиоданным воздушной проводимости ,
относится к выражению долговременного спектра, соответствующему аудиоданным воздушной проводимости , 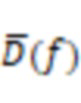 относится к выражению долговременного спектра, соответствующему аудиоданным костной проводимости. В некоторых вариантах осуществления устройство 122 обработки может получать одну или несколько групп соответствующих аудиоданных костной проводимости и аудиоданных воздушной проводимости (также называемых выборками речи), каждая из которых одновременно собирается, соответственно, датчиком костной проводимости и датчиком воздушной проводимости в бесшумной обстановке тогда, когда говорит оператор (например, испытуемый). Устройство 122 обработки может определить построенный фильтр на основе одной или более групп соответствующих аудиоданных костной проводимости и аудиоданных воздушной проводимости в соответствии с уравнением (3). Например, устройство 122 обработки может определить фильтр-кандидат, построенный на основе каждой из одной или более групп соответствующих аудиоданных костной проводимости и аудиоданных воздушной проводимости в соответствии с уравнением (3). Устройство 122 обработки может определить построенный фильтр на основе построенных фильтров-кандидатов, соответствующих одной или более группам соответствующих аудиоданных костной проводимости и аудиоданных воздушной проводимости. В некоторых вариантах осуществления устройство 122 обработки может выполнять операцию обратного преобразования Фурье (IFT) (например, быстрое IFT) над исходным фильтром для того, чтобы получить построенный фильтр во временной области.
относится к выражению долговременного спектра, соответствующему аудиоданным костной проводимости. В некоторых вариантах осуществления устройство 122 обработки может получать одну или несколько групп соответствующих аудиоданных костной проводимости и аудиоданных воздушной проводимости (также называемых выборками речи), каждая из которых одновременно собирается, соответственно, датчиком костной проводимости и датчиком воздушной проводимости в бесшумной обстановке тогда, когда говорит оператор (например, испытуемый). Устройство 122 обработки может определить построенный фильтр на основе одной или более групп соответствующих аудиоданных костной проводимости и аудиоданных воздушной проводимости в соответствии с уравнением (3). Например, устройство 122 обработки может определить фильтр-кандидат, построенный на основе каждой из одной или более групп соответствующих аудиоданных костной проводимости и аудиоданных воздушной проводимости в соответствии с уравнением (3). Устройство 122 обработки может определить построенный фильтр на основе построенных фильтров-кандидатов, соответствующих одной или более группам соответствующих аудиоданных костной проводимости и аудиоданных воздушной проводимости. В некоторых вариантах осуществления устройство 122 обработки может выполнять операцию обратного преобразования Фурье (IFT) (например, быстрое IFT) над исходным фильтром для того, чтобы получить построенный фильтр во временной области.
В некоторых вариантах осуществления область тела, где расположен датчик костной проводимости для сбора аудиоданных костной проводимости, используемых для определения построенного фильтра, может быть сходной с и/или быть такой же, как область тела, где датчик костной проводимости расположен для сбора аудиоданных костной проводимости (например, первых аудиоданных), используемых для применения построенного фильтра. Например, область тела пользователя (например, испытуемого), где расположен датчик костной проводимости для сбора аудиоданных костной проводимости в каждой группе из одной или более групп соответствующих аудиоданных костной проводимости и аудиоданных воздушной проводимости, может быть такой же, как область тела пользователя, где расположен датчик костной проводимости для сбора первых аудиоданных. В некоторых вариантах осуществления построенный фильтр может отличаться в зависимости от областей тела, где расположен датчик костной проводимости для сбора аудиоданных костной проводимости, используемых для определения построенного фильтра. Например, может быть получена одна или более первых групп соответствующих аудиоданных костной проводимости и аудиоданных воздушной проводимости, собранных первым датчиком костной проводимости, который расположен в первой области тела, и датчиком воздушной проводимости, соответственно, когда пользователь говорит. Может быть получена одна или более вторых групп соответствующих аудиоданных костной проводимости и аудиоданных воздушной проводимости, собранных вторым датчиком костной проводимости, который расположен во второй области тела, и датчиком воздушной проводимости, соответственно, когда пользователь говорит. Первый построенный фильтр может быть определен на основе одной или более первых групп соответствующих аудиоданных костной проводимости и аудиоданных воздушной проводимости. Второй построенный фильтр может быть определен на основе одной или более вторых групп соответствующих аудиоданных костной проводимости и аудиоданных воздушной проводимости. Первый построенный фильтр может отличаться от второго построенного фильтра. Восстановленные аудиоданные костной проводимости, определенные, соответственно, на основе первого построенного фильтра и второго построенного фильтра, могут отличаться при одних и тех же аудиоданных костной проводимости (например, первых аудиоданных). Соотношения между специфическими аудиоданными воздушной проводимости и специфическими аудиоданными костной проводимости, соответствующими специфическим аудиоданным воздушной проводимости, предоставленным первым построенным фильтром и вторым построенным фильтром, могут быть разными.
В некоторых вариантах осуществления устройство 122 обработки (например, модуль 420 предварительной обработки) может восстанавливать первые аудиоданные (или нормализованные первые аудиоданные) для получения восстановленных первых аудиоданных с использованием модели гармонической коррекции. Модель гармонической коррекции может быть выполнена с возможностью предоставления соотношения между амплитудным спектром специфических аудиоданных воздушной проводимости и амплитудным спектром специфических аудиоданных костной проводимости, соответствующих специфическим аудиоданным воздушной проводимости. Используемые в данном документе специфические аудиоданные воздушной проводимости могут также упоминаться как эквивалентные аудиоданные воздушной проводимости или восстановленные аудиоданные костной проводимости, соответствующие специфическим аудиоданным костной проводимости. Амплитудный спектр специфических аудиоданных воздушной проводимости могут также упоминаться как скорректированный амплитудный спектр специфических аудиоданных костной проводимости. Устройство 122 обработки может определить амплитудный спектр и фазовый спектр первых аудиоданных (или нормализованных первых аудиоданных) в частотной области. Устройство 122 обработки может корректировать амплитудный спектр первых аудиоданных (или нормализованных первых аудиоданных) с использованием модели гармонической коррекции для получения скорректированного амплитудного спектра первых аудиоданных (или нормализованных первых аудиоданных). Затем устройство 122 обработки может определить восстановленные первые аудиоданные на основе скорректированного амплитудного спектра и фазового спектра первых аудиоданных (или нормализованных первых аудиоданных). Дополнительное описание восстановления первых аудиоданных с использованием модели гармонической коррекции можно найти в другом месте настоящего раскрытия (например, в описании со ссылкой на фиг.7).
В некоторых вариантах осуществления устройство 122 обработки (например, модуль 420 предварительной обработки) может восстанавливать первые аудиоданные (или нормализованные первые аудиоданные) для получения восстановленных первых аудиоданных с использованием метода разреженных матриц. Например, устройство 122 обработки может получить первое соотношение преобразования, выполненное с возможностью преобразования словарной матрицы исходных аудиоданных костной проводимости (например, первых аудиоданных) в словарную матрицу восстановленных аудиоданных костной проводимости (например, восстановленных первых аудиоданных), соответствующих исходным аудиоданным костной проводимости. Устройство 122 обработки может получить второе соотношение преобразования, выполненное с возможностью преобразования матрицы разреженного кода исходных аудиоданных костной проводимости в матрицу разреженного кода восстановленных аудиоданных костной проводимости, соответствующих исходным аудиоданным костной проводимости. Устройство 122 обработки может определить словарную матрицу восстановленных первых аудиоданных на основе словарной матрицы первых аудиоданных с использованием первого соотношения преобразования. Устройство 122 обработки может определить матрицу разреженного кода восстановленных первых аудиоданных на основе матрицы разреженного кода первых аудиоданных с использованием второго соотношения преобразования. Устройство 122 обработки может определить восстановленные первые аудиоданные на основе определенной словарной матрицы и определенной матрицы разреженного кода восстановленных первых аудиоданных. В некоторых вариантах осуществления первое соотношение преобразования и/или второе соотношение преобразования могут представлять собой параметры настройки по умолчанию системы 100 выработки аудиосигнала. В некоторых вариантах осуществления устройство 122 обработки может определить первое соотношение преобразования и/или второе соотношение преобразования на основе одной или более групп аудиоданных костной проводимости и соответствующих аудиоданных воздушной проводимости. Дополнительное описание восстановления первых аудиоданных с использованием метода разреженных матриц можно найти в другом месте настоящего раскрытия (например, в описании со ссылкой на фиг.8).
На этапе 540 устройство 122 обработки (например, модуль 430 выработки аудиоданных) может выработать третьи аудиоданные на основе первых аудиоданных (или предварительно обработанных первых аудиоданных) и вторых аудиоданных (или предварительно обработанных вторых аудиоданных). Частотные составляющие третьих аудиоданных выше частотной точки (или порогового значения) могут увеличиваться по отношению к частотным составляющим первых аудиоданных (или предварительно обработанных первых аудиоданных) выше частотной точки (или порогового значения). Другими словами, частотные составляющие третьих аудиоданных выше частотной точки (или порогового значения) могут быть выше, чем частотные составляющие первых аудиоданных (или предварительно обработанных первых аудиоданных) выше частотной точки (или порогового значения). В некоторых вариантах осуществления уровень шума, ассоциированный с третьими аудиоданными, может быть ниже уровня шума, ассоциированного со вторыми аудиоданными (или предварительно обработанными вторыми аудиоданными). Используемая в данном документе фраза «частотные составляющие (компоненты) третьих аудиоданных выше частотной точки (или порогового значения), увеличивающиеся по отношению к частотным составляющим первых аудиоданных (или предварительно обработанных первых аудиоданных) выше частотной точки» может относиться к тому, что число отсчетов или количество волн с частотами выше частотной точки в третьих аудиоданных может быть больше, чем число отсчетов или количество волн с частотами выше частотной точки в первых аудиоданных. В некоторых вариантах осуществления частотная точка может быть постоянной в диапазоне частот от 20 Гц до 20 кГц. Например, частотная точка может быть равна 2000 Гц, 3000 Гц, 4000 Гц, 5000 Гц, 6000 Гц и т.д. В некоторых вариантах осуществления частотная точка может быть значением частоты частотных компонентов в третьих аудиоданных и/или первых аудиоданных.
В некоторых вариантах осуществления устройство 122 обработки может вырабатывать третьи аудиоданные на основе первых аудиоданных (или предварительно обработанных первых аудиоданных) и вторых аудиоданных (или предварительно обработанных вторых аудиоданных) в соответствии с одной или более частотными порогами. Например, устройство 122 обработки может определить один или более частотных порогов по меньшей мере частично на основе по меньшей мере одного из: первых аудиоданных (или предварительно обработанных первых аудиоданных) или вторых аудиоданных (или предварительно обработанных вторых аудиоданных). Устройство 122 обработки может разделить первые аудиоданные (или предварительно обработанные первые аудиоданные) и вторые аудиоданные (или предварительно обработанные вторые аудиоданные), соответственно, на множество сегментов в соответствии с одним или более частотными порогами. Устройство 122 обработки может определить весовой коэффициент для каждого из множества сегментов каждых из первых аудиоданных (или предварительно обработанных первых аудиоданных) и вторых аудиоданных (или предварительно обработанных вторых аудиоданных). Затем устройство 122 обработки может определить третьи аудиоданные на основе весового коэффициента для каждого из множества сегментов каждых из первых аудиоданных (или предварительно обработанных первых аудиоданных) и вторых аудиоданных (или предварительно обработанных вторых аудиоданных).
В некоторых вариантах осуществления устройство 122 обработки может определить один единственный частотный порог. Устройство 122 обработки может объединять первые аудиоданные (или предварительно обработанные первые аудиоданные) и вторые аудиоданные (или предварительно обработанные вторые аудиоданные) в частотной области в соответствии с одним единственным частотным порогом для выработки третьих аудиоданных. Например, устройство 122 обработки может определить нижнюю часть первых аудиоданных (или предварительно обработанных первых аудиоданных), включающую в себя частотные составляющие ниже одного единственного частотного порога, используя первый специфический фильтр. Устройство 122 обработки может определить верхнюю часть вторых аудиоданных (или предварительно обработанных вторых аудиоданных), включая частотные составляющие выше одного единственного частотного порога, используя второй специальный фильтр. Устройство 122 обработки может сшить и/или объединять нижнюю часть первых аудиоданных (или предварительно обработанных первых аудиоданных) и верхнюю часть вторых аудиоданных (или предварительно обработанных вторых аудиоданных) для выработки третьих аудиоданных. В некоторых вариантах осуществления первый специфический фильтр может быть фильтром нижних частот с одним единственным частотным порогом в качестве частоты среза, который может пропускать частотные составляющие в первых аудиоданных ниже одного единственного частотного порога. Второй специфический фильтр может быть фильтром верхних частот с одним единичным частотным порогом в качестве частоты среза, который может пропускать частотные составляющие во вторых аудиоданных выше одного единственного частотного порога. В некоторых вариантах осуществления устройство 122 обработки может определить один единственный частотный порог по меньшей мере частично на основе первых аудиоданных (или предварительно обработанных первых аудиоданных) и/или вторых аудиоданных (или предварительно обработанных вторых аудиоданных). Дополнительное описание для определения одного единственного частотного порога можно найти в описании со ссылкой на фиг.9.
В некоторых вариантах осуществления устройство 122 обработки может определить, по меньшей мере частично на основе одного единственного частотного порога, первый весовой коэффициент и второй весовой коэффициент для нижней части первых аудиоданных (или предварительно обработанных первых аудиоданных) и верхней части первых аудиоданных (или предварительно обработанных первых аудиоданных), соответственно. Устройство 122 обработки может определить, по меньшей мере частично на основе одного единственного частотного порога, третий весовой коэффициент и четвертый весовой коэффициент для нижней части вторых аудиоданных (или предварительно обработанных вторых аудиоданных) и верхней части вторых аудиоданных (или предварительно обработанные вторые аудиоданные), соответственно. В некоторых вариантах осуществления устройство 122 обработки может определить третьи аудиоданные путем взвешивания нижней части первых аудиоданных (или предварительно обработанных первых аудиоданных), верхней части первых аудиоданных (или предварительно обработанных первых аудиоданных), нижней части вторых аудиоданных (или предварительно обработанных вторых аудиоданных), верхней части вторых аудиоданных (или предварительно обработанных вторых аудиоданных) с использованием первого весового коэффициента, второго весового коэффициента, третьего весового коэффициента и четвертого весового коэффициента, соответственно. Дополнительное описание для определения третьих аудиоданных (или объединенных аудиоданных) можно найти в описании со ссылкой на фиг.9.
В некоторых вариантах осуществления устройство 122 обработки может определить весовой коэффициент, соответствующий первым аудиоданным (или предварительно обработанным первым аудиоданным), и весовой коэффициент, соответствующий вторым аудиоданным (или предварительно обработанным вторым аудиоданным), по меньшей мере частично на основе по меньшей мере одного из: первых аудиоданных (или предварительно обработанных первых аудиоданных) или вторых аудиоданных (или предварительно обработанных вторых аудиоданных). Устройство 122 обработки может определить третьи аудиоданные путем взвешивания первых аудиоданных (или предварительно обработанных первых аудиоданных) и вторых аудиоданных (или предварительно обработанных вторых аудиоданных) с использованием весового коэффициента, соответствующего первым аудиоданным (или предварительно обработанным первым аудиоданным), и весового коэффициента, соответствующего вторым аудиоданным (или предварительно обработанным вторым аудиоданным). Дополнительное описание для определения третьих аудиоданных можно найти в другом месте настоящего раскрытия (например, в описании со ссылкой на фиг.10).
На этапе 550 устройство 122 обработки (например, модуль 430 выработки аудиоданных) может определить на основе третьих аудиоданных целевые аудиоданные, представляющие собой речь пользователя с более высоким качеством, чем первые аудиоданные и вторые аудиоданные. Целевые аудиоданные могут представлять речь пользователя, которую представляют первые аудиоданные и вторые аудиоданные. Используемый в данном документе термин «точность» может использоваться для обозначения степени подобия между выходными аудиоданными (например, целевыми аудиоданными, первыми аудиоданными, вторыми аудиоданными) с исходными входными аудиоданными (например, речью пользователя). Точность может использоваться для обозначения разборчивости выходных аудиоданных (например, целевых аудиоданных, первых аудиоданных, вторых аудиоданных).
В некоторых вариантах осуществления устройство 122 обработки может назначать третьи аудиоданные в качестве целевых аудиоданных. В некоторых вариантах осуществления устройство 122 обработки может выполнять операцию последующей обработки третьих аудиоданных для получения целевых аудиоданных. В некоторых вариантах осуществления операция последующей обработки может включать в себя операцию очистки от шума, операцию преобразования домена (например, операцию преобразования Фурье (FT)) и т.п. или их сочетание. В некоторых вариантах осуществления операция очистки от шума, выполняемая над третьими аудиоданными, может включать в себя использование фильтра Винера, алгоритма спектрального вычитания, адаптивного алгоритма, алгоритма оценки минимальной среднеквадратичной ошибки (MMSE) и т.п. или любое их сочетание. В некоторых вариантах осуществления операция очистки от шума, выполняемая над третьими аудиоданными, может быть такой же или отличной от операции очистки от шума, выполняемой над вторыми аудиоданными. Например, как операция очистки от шума, выполняемая над вторыми аудиоданными, так и операция очистки от шума, выполняемая над третьими аудиоданными, могут использовать алгоритм спектрального вычитания. В качестве другого примера, операция очистки от шума, выполняемая над вторыми аудиоданными, может использовать фильтр Винера, и операция очистки от шума, выполняемая над третьими аудиоданными, может использовать алгоритм спектрального вычитания. В некоторых вариантах осуществления устройство 122 обработки может выполнять операцию IFT над третьими аудиоданными в частотной области для получения целевых аудиоданных во временной области.
В некоторых вариантах осуществления устройство 122 обработки может передавать сигнал в клиентский терминал (например, терминал 130), запоминающее устройство 140 и/или любое другое запоминающее устройство (не показано в системе 100 выработки аудиосигнала) через сеть 150. Сигнал может включать в себя целевые аудиоданные. Сигнал также может быть выполнен с возможностью указания клиентскому терминалу воспроизводить целевые аудиоданные.
Следует отметить, что представленное выше описание приведено только в целях иллюстрации и не предназначено для ограничения объема настоящего раскрытия. Для специалистов в данной области техники могут быть сделаны многочисленные изменения и модификации в соответствии с идеями настоящего раскрытия. Однако эти вариации и модификации не выходят за рамки настоящего раскрытия. Например, операция 550 может быть опущена. В качестве другого примера, операции 510 и 520 могут быть объединены в одну операцию.
На фиг.6 показана блок-схема, иллюстрирующая примерный процесс восстановления аудиоданных костной проводимости с использованием обученной модели машинного обучения согласно некоторым вариантам осуществления настоящего раскрытия. В некоторых вариантах осуществления процесс 600 может быть реализован как набор инструкций (например, приложение), хранящихся в запоминающем устройстве 140, ROM 230, или RAM 240 или хранилище 390 данных. Устройство 122 обработки, процессор 220 и/или CPU 340 могут исполнять набор инструкций, и при исполнении инструкций устройство 122 обработки, процессор 220 и/или CPU 340 могут выполнять процесс 600. Операции проиллюстрированного процесса, представленного ниже, предназначены для иллюстрации. В некоторых вариантах осуществления процесс 600 может выполняться с одной или несколькими дополнительными операциями, которые не описаны, и/или без одной или нескольких обсуждаемых операций. В дополнение к этому, порядок, в котором операции процесса 600 показаны на фиг.6 и описаны ниже, не предназначен для ограничения. В некоторых вариантах осуществления одна или несколько операций процесса 600 могут выполняться для выполнения по меньшей мере части операции 530, как описано со ссылкой на фиг.5.
На этапе 610 устройство 122 обработки (например, модуль 410 получения) может получать аудиоданные костной проводимости. В некоторых вариантах осуществления аудиоданные костной проводимости могут быть исходными аудиоданными (например, первыми аудиоданными), собранными датчиком костной проводимости тогда, когда пользователь говорит, как описано в другом месте настоящего раскрытия (например, в описании со ссылкой на фиг.1). Например, речь пользователя может собираться датчиком костной проводимости (например, микрофоном 112 костной проводимости) для выработки электрического сигнала (например, аналогового сигнала или цифрового сигнала) (то есть аудиоданных костной проводимости). Датчик костной проводимости может передавать электрический сигнал в сервер 120, терминал 130 и/или запоминающее устройство 140 через сеть 150. В некоторых вариантах осуществления аудиоданные костной проводимости могут включать в себя акустические характеристики и/или семантическую информацию, которая может отражать содержание речи пользователя. Примерные акустические характеристики могут включать в себя один или несколько признаков, ассоциированных с длительностью, один или несколько признаков, ассоциированных с энергией, один или несколько признаков, ассоциированных с основной частотой, один или несколько признаков, ассоциированных с частотным спектром, один или несколько признаков, ассоциированных с фазовым спектром, и т.д., как описано в другом месте настоящего раскрытия (например, в описании со ссылкой на фиг.5).
На этапе 620 устройство 122 обработки (например, модуль 410 получения) может получить обученную модель машинного обучения. Обученная модель машинного обучения может быть предоставлена путем обучения предварительной модели машинного обучения с использованием множества групп обучающих данных. В некоторых вариантах осуществления обученная модель машинного обучения может быть выполнена с возможностью обработки специфических аудиоданных костной проводимости для получения обработанных аудиоданных костной проводимости. Обработанные аудиоданные костной проводимости также могут называться восстановленными аудиоданными костной проводимости. Частотные составляющие обработанных аудиоданных костной проводимости выше частотного порога или частотной точки (например, 1000 Гц, 2000 Гц, 3000 Гц, 4000 Гц и т.д.) могут повышаться по отношению к частотным составляющим специфических аудиоданных костной проводимости выше частотного порога или частотной точки (например, 1000 Гц, 2000 Гц, 3000 Гц, 4000 Гц и т.д.). Обработанные аудиоданные костной проводимости могут быть идентичными, аналогичными или близкими к идеальным аудиоданным воздушной проводимости без шума или с меньшим шумом, собранным датчиком воздушной проводимости одновременно со специфическими аудиоданными костной проводимости и представляющими ту же речь со специфическими аудиоданными костной проводимости. Используемая в данном документе фраза «обработанные аудиоданные костной проводимости, идентичные, аналогичные или близкие к идеальным аудиоданным воздушной проводимости» может относиться к подобию между акустическими характеристиками обработанных аудиоданных костной проводимости и аудиоданных идеальной воздушной проводимости больше порогового значения (например, 0,9, 0,8, 0,7 и т.д.). Например, в бесшумной среде аудиоданные костной проводимости и аудиоданные воздушной проводимости могут быть получены от пользователя одновременно тогда, когда пользователь разговаривает с использованием микрофона 112 костной проводимости и микрофона 114 воздушной проводимости, соответственно. Обработанные аудиоданные костной проводимости, выработанные обученной моделью машинного обучения, обрабатывающей аудиоданные костной проводимости, могут иметь идентичные или аналогичные акустические характеристики соответствующим аудиоданным воздушной проводимости, собранным микрофоном 114 воздушной проводимости. В некоторых вариантах осуществления устройство 122 обработки может получить обученную модель машинного обучения из терминала 130, запоминающего устройства 140 или любого другого запоминающего устройства.
В некоторых вариантах осуществления предварительная модель машинного обучения может быть построена на основе модели глубокого обучения, традиционной модели машинного обучения и т.п. или любого их сочетания. Модель глубокого обучения может включать в себя модель сверточной нейронной сети (CNN), модель рекуррентной нейронной сети (RNN), модель сети с долгой кратковременной памятью (LSTM) и т.п. или любое их сочетание. Традиционная модель машинного обучения может включать в себя скрытую марковскую модель (HMM), модель многослойного персептрона (MLP) и т.п. или любое их сочетание. В некоторых вариантах осуществления предварительная модель машинного обучения может включать в себя несколько слоев, например, входной слой, несколько скрытых слоев и выходной слой. Несколько скрытых слоев могут включать в себя один или несколько сверточных слоев, один или несколько слоев объединения, один или несколько слоев пакетной нормализации, один или несколько слоев активации, один или несколько полностью ассоциированных слоев, слой функции стоимости и т.д. Каждый из множества слоев может включать в себя множество узлов. В некоторых вариантах осуществления предварительная модель машинного обучения может быть определена множеством параметров архитектуры и множеством параметров обучения, также называемых параметрами обучения. Множество параметров обучения может быть изменено во время обучения предварительной модели машинного обучения с использованием множества групп обучающих данных. Множество архитектурных параметров может быть установлено и/или отрегулировано пользователем перед обучением предварительной модели машинного обучения. Примерные параметры архитектуры модели машинного обучения могут включать в себя размер ядра слоя, общее количество (или число) слоев, количество (или число) узлов в каждом слое, скорость обучения, размер пакета, период и т.д. Например, если предварительная модель машинного обучения включает в себя модель LSTM, модель LSTM может включать в себя один единственный входной слой с 2 узлами, четыре скрытых слоя, каждый из которых включает в себя 30 узлов, и один единственный выходной слой с 2 узлами. Временные шаги модели LSTM могут составлять 65, и скорость обучения может составлять 0,003. Примерные параметры обучения модели машинного обучения могут включать в себя ассоциированный весовой коэффициент между двумя соединенными узлами, вектор смещения, относящийся к узлу, и т.д. Связанный весовой коэффициент между двумя связанными узлами может быть выполнен таким образом, чтобы представлять долю выходного значения узла в качестве входного значения другого связанного узла. Вектор смещения, относящийся к узлу, может быть выполнен с возможностью управления выходным значением узла, отклоняющимся от исходной точки.
В некоторых вариантах осуществления обученная модель машинного обучения может быть определена путем обучения предварительной модели машинного обучения с использованием множества групп обучающих данных на основе алгоритма обучения модели машинного обучения. В некоторых вариантах осуществления одна или более групп из множества групп обучающих данных могут быть получены в бесшумной среде, например, в звуконепроницаемой комнате. Группа обучающих данных может включать в себя специфические аудиоданные костной проводимости и соответствующие специфические аудиоданные воздушной проводимости. Специфические аудиоданные костной проводимости и соответствующие специфические аудиоданные воздушной проводимости в группе обучающих данных могут быть одновременно получены от конкретного пользователя датчиком костной проводимости (например, микрофоном 112 костной проводимости) и датчиком воздушной проводимости (например, микрофон воздушной проводимости 114), соответственно. В некоторых вариантах осуществления каждая группа из по меньшей мере части множества групп может включать в себя специфические аудиоданные костной проводимости и восстановленные аудиоданные костной проводимости, выработанные путем восстановления специфических аудиоданных костной проводимости с использованием одного или нескольких методов восстановления, как описано в другом месте настоящего раскрытия. Примерные алгоритмы обучения модели машинного обучения могут включать в себя алгоритм градиентного спуска, алгоритм Ньютона, квази-ньютоновский алгоритм, алгоритм Левенберга-Марквардта, алгоритм сопряженного градиента и т.п. или их сочетание. Обученная модель машинного обучения может быть выполнена с возможностью обеспечения соответствующего соотношения между аудиоданными костной проводимости (например, первыми аудиоданными) и восстановленными аудиоданными костной проводимости (например, эквивалентными аудиоданными воздушной проводимости). Обученная модель машинного обучения может быть выполнена с возможностью восстановления аудиоданных костной проводимости на основе соответствующего соотношения. В некоторых вариантах осуществления аудиоданные костной проводимости в каждой из множества групп обучающих данных могут быть собраны датчиком костной проводимости, расположенным в одной и той же области (например, в области вокруг уха) тела пользователя (например, испытуемого). В некоторых вариантах осуществления область тела, где расположен датчик костной проводимости для сбора аудиоданных костной проводимости, используемых для обучения обученной модели машинного обучения, может быть сходной с и/или быть такой же, как область тела, где расположен датчик костной проводимости для сбора аудиоданных костной проводимости (например, первых аудиоданных), используемых для применения обученной модели машинного обучения. Например, область тела пользователя (например, испытуемого), где расположен датчик костной проводимости для сбора аудиоданных костной проводимости в каждой группе из множества групп обучающих данных, может быть такой же, как и область тела пользователя, где расположен датчик костной проводимости для сбора первых аудиоданных. В качестве дополнительного примера, если областью тела пользователя, где расположен датчик костной проводимости для сбора первых аудиоданных, является шея, то областью тела, где расположен датчик костной проводимости для сбора аудиоданных костной проводимости, используемых в процессе обучения обученной модели машинного обучения, также может быть шея тела.
В некоторых вариантах осуществления область тела пользователя (например, испытуемого), где расположен датчик костной проводимости для сбора множества групп обучающих данных, может влиять на соответствующее соотношение между аудиоданными костной проводимости (например,, первые аудиоданные) и восстановленные аудиоданные костной проводимости (например, эквивалентные аудиоданные воздушной проводимости), тем самым влияя на восстановленные аудиоданные костной проводимости, выработанные на основе соответствующего соотношения с использованием обученной модели машинного обучения. Множество групп обучающих данных, собранных датчиком костной проводимости, который расположен в разных областях тела пользователя (например, испытуемого), может соответствовать различным соответствующим соотношениям между аудиоданными костной проводимости (например, первыми аудиоданными) и восстановленными аудиоданными костной проводимости (например, эквивалентными аудиоданными воздушной проводимости), когда множество групп обучающих данных, собранных датчиком костной проводимости, который расположен в разных областях, используется для обучения обученной модели машинного обучения. Например, несколько датчиков костной проводимости в одной и той же конфигурации могут быть расположены в разных частях тела, таких как сосцевидный отросток, висок, макушка, наружный слуховой проход и т.д. Несколько датчиков костной проводимости могут собирать аудиоданные костной проводимости тогда, когда пользователь говорит. Несколько обучающих наборов могут быть сформированы на основе аудиоданных костной проводимости, собранных множеством датчиков костной проводимости. Каждый набор из множества обучающих наборов может включать в себя множество групп обучающих данных, собранных одним из множества датчиков костной проводимости и датчиком воздушной проводимости. Каждый набор из множества групп обучающих данных может включать в себя аудиоданные костной проводимости и аудиоданные воздушной проводимости, представляющие одну и ту же речь. Каждый набор из множества обучающих наборов может использоваться для обучения модели машинного обучения для получения обученной модели машинного обучения. Несколько обученных моделей машинного обучения могут быть получены на основе нескольких обучающих наборов. Несколько обученных моделей машинного обучения могут обеспечивать различные соответствующие соотношения между специфическими аудиоданными костной проводимости и восстановленными аудиоданными костной проводимости. Например, различные восстановленные аудиоданные костной проводимости могут быть выработаны путем ввода одних и тех же аудиоданных костной проводимости в несколько обученных моделей машинного обучения. В некоторых вариантах осуществления аудиоданные костной проводимости (например, кривые частотной характеристики), собранные разными датчиками костной проводимости в разных конфигурациях, могут быть разными. Таким образом, датчик костной проводимости для сбора аудиоданных костной проводимости, используемый для обучения обученной модели машинного обучения, может быть сходным и/или таким же, как датчик костной проводимости для сбора аудиоданных костной проводимости (например, первых аудиоданных), используемых для применения обученной модели машинного обучения в этой конфигурации. В некоторых вариантах осуществления аудиоданные костной проводимости (например, частотные характеристики), собранные датчиком костной проводимости, который расположен в области тела пользователя, при разном давлении в диапазоне, например, от 0 ньютонов до 1 ньютона или от 0 ньютонов до 0,8 ньютона и т.д. могут быть разными. Таким образом, давление, которое датчик костной проводимости прикладывает к области тела пользователя для сбора аудиоданных костной проводимости для обучения обученной модели машинного обучения, может сходным и/или таким же, как давление, которое датчик костной проводимости прикладывает к области тела пользователя для сбора аудиоданных костной проводимости с целью применения обученной модели машинного обучения.
В некоторых вариантах осуществления обученная модель машинного обучения может быть получена путем выполнения множества итераций для обновления одного или более параметров обучения предварительной модели машинного обучения. Для каждой из множества итераций специфическую группу обучающих данных можно сначала ввести в предварительную модель машинного обучения. Например, специфические аудиоданные костной проводимости специфической группы обучающих данных могут быть введены во входной слой предварительной модели машинного обучения, и специфические аудиоданные воздушной проводимости специфической группы обучающих данных могут быть введены в выходной слой предварительной модели машинного обучения в качестве желаемого результата предварительной модели машинного обучения, соответствующего специфическим аудиоданным костной проводимости. Предварительная модель машинного обучения может извлекать одну или несколько акустических характеристик (например, признак длительности, признак амплитуды, признак основной частоты и т.д.) специфических аудиоданных костной проводимости и специфических аудиоданных воздушной проводимости, включенных в специфическую группу обучающих данных. На основе извлеченных характеристик предварительная модель машинного обучения может определить выходные данные предсказания, соответствующие специфическим данным костной проводимости. Затем предсказанный выходные данные, соответствующие специфическим данным костной проводимости, можно сравнить с входными специфическими аудиоданными воздушной проводимости (то есть с желаемыми выходными данными) в выходном слое, соответствующем специфической группе обучающих данных, на основе функции стоимости. Функция стоимости предварительной модели машинного обучения может быть выполнена с возможностью оценки разности между оценочным значением (например, предсказанными выходными данными) предварительной модели машинного обучения и фактическим значением (например, желаемыми выходными данными или специфическим входными аудиоданными воздушной проводимости). Если значение функции стоимости превышает пороговое значение в текущей итерации, параметры обучения предварительной модели машинного обучения могут быть отрегулированы и обновлены с тем, чтобы значение функции стоимости (то есть разность между предсказанными выходными данными и входными аудиоданными воздушной проводимости) было меньше порогового значения. Соответственно, в следующей итерации другая группа обучающих данных может быть введена в предварительную модель машинного обучения для обучения предварительной модели машинного обучения, как описано выше. Затем может быть выполнено множество итераций для обновления параметров обучения предварительной модели машинного обучения до тех пор, пока не будет выполнено условие завершения. Условие завершения может указывать то, достаточно ли обучена предварительная модель машинного обучения. Например, условие завершения может быть выполнено, если значение функции стоимости, ассоциированной с предварительной моделью машинного обучения, является минимальным или меньше порогового значения (например, константы). В качестве другого примера, условие завершения может быть выполнено в том случае, если сходится значение функции стоимости. Можно считать, что сходимость функции стоимости имеет место в том случае, если изменение значений функции стоимости в двух или более последовательных итерациях меньше порогового значения (например, константы). В качестве еще одного примера, условие завершения может быть выполнено тогда, когда в процессе обучения выполняется заданное количество итераций. Обученная модель машинного обучения может быть определена на основе обновленных параметров обучения. В некоторых вариантах осуществления обученная модель машинного обучения может быть передана в устройство 140 хранения, модуль 440 хранения данных или любое другое запоминающее устройство для хранения данных.
На этапе 630 устройство 122 обработки (например, модуль 420 предварительной обработки) может обрабатывать аудиоданные костной проводимости с использованием обученной модели машинного обучения для получения обработанных аудиоданных костной проводимости. В некоторых вариантах осуществления устройство 122 обработки может вводить аудиоданные костной проводимости (например, первые аудиоданные или нормализованные первые аудиоданные, как это описано со ссылкой на фиг.5) в обученную модель машинного обучения, и затем обученная модель машинного обучения может выводить обработанные аудиоданные костной проводимости (например, восстановленные первые аудиоданные, как это описано со ссылкой на фиг.5). В некоторых вариантах осуществления устройство 122 обработки может извлекать акустические характеристики аудиоданных костной проводимости (например, первые аудиоданные или нормализованные первые аудиоданные, как это описано со ссылкой на фиг.5) и вводить извлеченные акустические характеристики аудиоданных костной проводимости (например, первые аудиоданные или нормализованные первые аудиоданные, как это описано со ссылкой на фиг.5) в обученную модель машинного обучения. Обучающая модель машинного обучения может выводить обработанные аудиоданные костной проводимости. Частотные составляющие обработанных аудиоданных костной проводимости выше частотного порога (например, 1000 Гц, 2000 Гц, 3000 Гц и т.д.) могут увеличиваться по отношению к частотным составляющим аудиоданных костной проводимости выше частотного порога. В некоторых вариантах осуществления устройство 122 обработки может передавать обработанные аудиоданные костной проводимости в клиентский терминал (например, терминал 130). Клиентский терминал (например, терминал 130) может преобразовывать обработанные аудиоданные костной проводимости в голос и широковещательно передавать голос пользователю.
Следует отметить, что представленное выше описание приведено исключительно в целях иллюстрации и не предназначено для ограничения объема настоящего раскрытия. Для специалистов в данной области техники могут быть сделаны многочисленные изменения и модификации в соответствии с идеями настоящего раскрытия. Однако эти вариации и модификации не выходят за рамки настоящего раскрытия.
На фиг.7 показана блок-схема, иллюстрирующая примерный процесс восстановления аудиоданных костной проводимости с использованием модели гармонической коррекции согласно некоторым вариантам осуществления настоящего раскрытия. В некоторых вариантах осуществления процесс 700 может быть реализован как набор инструкций (например, приложение), хранящихся в запоминающем устройстве 140, ROM 230, или RAM 240 или хранилище 390 данных. Устройство 122 обработки, процессор 220 и/или CPU 340 могут исполнять набор инструкций, и при исполнении инструкций устройство 122 обработки, процессор 220 и/или CPU 340 могут выполнять процесс 700. Операции проиллюстрированного процесса, представленного ниже, предназначены для иллюстрации. В некоторых вариантах осуществления процесс 700 может быть выполнен с одной или несколькими дополнительными операциями, которые не описаны, и/или без одной или нескольких обсуждаемых операций. Кроме того, порядок, в котором операции процесса 700 показаны на фиг.7 и описаны ниже, не предназначен для ограничения. В некоторых вариантах осуществления одна или несколько операций процесса 700 могут выполняться для выполнения по меньшей мере части операции 530, как описано со ссылкой на фиг.5.
На этапе 710 устройство 122 обработки (например, модуль 410 получения) может получать аудиоданные костной проводимости. В некоторых вариантах осуществления аудиоданные костной проводимости могут быть исходными аудиоданными (например, первыми аудиоданными), собранными датчиком костной проводимости тогда, когда пользователь говорит, как описано в связи с операцией 510. Например, речь пользователя может собираться датчиком костной проводимости (например, микрофоном 112 костной проводимости) для выработки электрического сигнала (например, аналогового сигнала или цифрового сигнала) (то есть аудиоданных костной проводимости). В некоторых вариантах осуществления аудиоданные костной проводимости могут включать в себя несколько волн с разными частотами и амплитудами. Аудиоданные костной проводимости в частотной области могут быть обозначены как матрица, включающая в себя множество элементов. Каждый из множества элементов может обозначать частоту и амплитуду волны.
На этапе 720 устройство 122 обработки (например, модуль 420 предварительной обработки) может определить спектр амплитуды и спектр фазы аудиоданных костной проводимости. В некоторых вариантах осуществления устройство 122 обработки может определить амплитудный спектр и фазовый спектр аудиоданных костной проводимости путем выполнения операции преобразования Фурье (FT) над аудиоданными костной проводимости. Устройство 122 обработки может определить амплитудный спектр и фазовый спектр аудиоданных костной проводимости в частотной области. Например, устройство 122 обработки может обнаружить пиковые значения волн, включенных в аудиоданные костной проводимости, с использованием метода обнаружения пиков, такого как алгоритм вокодера оценки спектральной огибающей (SEEVOC). Устройство 122 обработки может определить амплитудный спектр и фазовый спектр аудиоданных костной проводимости на основе пиковых значений волн. Например, амплитуда волны аудиоданных костной проводимости может составлять половину расстояния между максимальным значением и минимальным значением волны.
На этапе 730 устройство 122 обработки (например, модуль 420 предварительной обработки) может получить модель гармонической коррекции. Модель гармонической коррекции может быть выполнена с возможностью предоставления соотношения между амплитудным спектром специфических аудиоданных воздушной проводимости и амплитудным спектром специфических аудиоданных костной проводимости, соответствующих специфическим аудиоданным воздушной проводимости. Амплитудный спектр специфических аудиоданных воздушной проводимости может быть определен на основе амплитудного спектра специфических аудиоданных костной проводимости, соответствующих специфическим аудиоданным воздушной проводимости, на основе соотношения. Используемый в данном документе термин «специфические аудиоданные воздушной проводимости» могут также упоминаться как эквивалентные аудиоданные воздушной проводимости или восстановленные аудиоданные костной проводимости, соответствующие специфическим аудиоданным костной проводимости.
В некоторых вариантах осуществления модель гармонической коррекции может быть настройкой по умолчанию системы 100 выработки аудиосигнала. В некоторых вариантах осуществления устройство 122 обработки может получать модель гармонической коррекции из запоминающего устройства 140, модуля 440 хранения данных или любого другого запоминающего устройства для хранения данных. В некоторых вариантах осуществления модель гармонической коррекции может быть определена на основе одной или нескольких групп аудиоданных костной проводимости и соответствующих аудиоданных воздушной проводимости. Аудиоданные костной проводимости и соответствующие аудиоданные воздушной проводимости в каждой группе могут, соответственно, собираться датчиком костной проводимости и датчиком воздушной проводимости одновременно в бесшумной среде тогда, когда говорит оператор (например, испытуемый). Датчик костной проводимости и датчик воздушной проводимости могут быть одинаковыми или отличными от датчика костной проводимости для сбора первых аудиоданных и датчика воздушной проводимости для сбора вторых аудиоданных, соответственно. В некоторых вариантах осуществления модель гармонической коррекции может быть определена на основе одной или нескольких групп аудиоданных костной проводимости и соответствующих аудиоданных воздушной проводимости в соответствии со следующими операциями с а1 по а3. В операции а1 устройство 122 обработки может определить спектр амплитуд аудиоданных костной проводимости в каждой группе и спектр амплитуд соответствующих аудиоданных воздушной проводимости в каждой группе с использованием метода обнаружения пикового значения, такого как алгоритм вокодера оценки спектральной огибающей (SEEVOC). В операции а2 устройство 122 обработки может определить матрицу коррекции-кандидат на основе амплитудных спектров аудиоданных костной проводимости и соответствующих аудиоданных воздушной проводимости в каждой группе. Например, устройство 122 обработки может определить матрицу коррекции-кандидат на основе отношения амплитудного спектра аудиоданных костной проводимости к амплитудному спектру соответствующих аудиоданных воздушной проводимости в каждой группе. В операции а3 устройство 122 обработки может определить модель гармонической коррекции на основе матрицы коррекции- кандидата, соответствующей каждой группе из одной или более групп аудиоданных костной проводимости и соответствующих аудиоданных воздушной проводимости. Например, устройство 122 обработки может определить среднее значение матриц коррекции-кандидата, соответствующих одной или более группам аудиоданных костной проводимости и соответствующих аудиоданных воздушной проводимости в качестве модели гармонической коррекции.
В некоторых вариантах осуществления область тела, где расположен датчик костной проводимости для сбора аудиоданных костной проводимости, используемых для определения модели гармонической коррекции, может быть согласована и/или совпадать с областью тела, где расположен датчик костной проводимости для сбора аудиоданных костной проводимости (например, первых аудиоданных), используемых для применения модели гармонической коррекции. Например, область тела пользователя (например, испытуемого), где расположен датчик костной проводимости для сбора аудиоданных костной проводимости в каждой группе из одной или более групп соответствующих аудиоданных костной проводимости и аудиоданных воздушной проводимости, может быть такой же, как область тела пользователя, где расположен датчик костной проводимости для сбора первых аудиоданных. В качестве другого примера, если областью тела, где расположен датчик костной проводимости для сбора аудиоданных костной проводимости (например, первые аудиоданные), является шея, то областью тела, где расположен датчик костной проводимости для сбора аудиоданных костной проводимости, используемых для определения модели гармонической коррекции, также может быть шея. В некоторых вариантах осуществления модель гармонической коррекции может отличаться в зависимости от областей тела, где расположен датчик костной проводимости для сбора аудиоданных костной проводимости, используемых для определения модели гармонической коррекции. Например, может быть получена одна или более первых групп соответствующих аудиоданных костной проводимости и аудиоданных воздушной проводимости, собранных первым датчиком костной проводимости, который расположен в первой области тела, и датчиком воздушной проводимости, соответственно, тогда, когда пользователь говорит. Может быть получена одна или более вторых групп соответствующих аудиоданных костной проводимости и аудиоданных воздушной проводимости, собранных вторым датчиком костной проводимости, который расположен во второй области тела, и датчиком воздушной проводимости, соответственно, тогда, когда пользователь говорит. Первая модель гармонической коррекции может быть определена на основе одной или более первых групп соответствующих аудиоданных костной проводимости и аудиоданных воздушной проводимости. Вторая модель гармонической коррекции может быть определена на основе одной или более вторых групп соответствующих аудиоданных костной проводимости и аудиоданных воздушной проводимости. Вторая модель гармонической коррекции может отличаться от первой модели гармонической коррекции. Соотношения между амплитудным спектром специфических аудиоданных воздушной проводимости и амплитудным спектром специфических аудиоданных костной проводимости, соответствующих специфическим аудиоданным воздушной проводимости, которые предоставляются первой моделью гармонической коррекции и второй моделью гармонической коррекции, могут быть разными. Восстановленные аудиоданные костной проводимости, определенные, соответственно, на основе первой модели гармонической коррекции и второй модели гармонической коррекции, могут отличаться при одних и тех же аудиоданных костной проводимости (например, первых аудиоданных).
На этапе 740 устройство 122 обработки (например, модуль 420 предварительной обработки) может корректировать амплитудный спектр аудиоданных костной проводимости, чтобы получить скорректированный амплитудный спектр аудиоданных костной проводимости. В некоторых вариантах осуществления модель гармонической коррекции может включать в себя матрицу коррекции, включающую в себя множество весовых коэффициентов, соответствующих каждому элементу в амплитудном спектре аудиоданных костной проводимости (например, первые аудиоданные или нормализованные первые аудиоданные, как это описано со ссылкой на фиг.5). Используемый в данном документе термин «элемент амплитудного спектра» может относиться к специфической амплитуде волны (то есть к частотной составляющей). Устройство 122 обработки может корректировать амплитудный спектр аудиоданных костной проводимости (например, первые аудиоданные или нормализованные первые аудиоданные, как это описано со ссылкой на фиг.5) путем умножения матрицы коррекции на амплитудный спектр аудиоданных костной проводимости (например, первых аудиоданных, как это описано со ссылкой на фиг.5), чтобы получить скорректированный амплитудный спектр аудиоданных костной проводимости (например, первые аудиоданные, как это описано со ссылкой на фиг.5).
На этапе 750 устройство 122 обработки (например, модуль 420 предварительной обработки) может определить восстановленные аудиоданные костной проводимости на основе скорректированного амплитудного спектра и фазового спектра аудиоданных костной проводимости. В некоторых вариантах осуществления устройство 122 обработки может выполнять обратное преобразование Фурье скорректированного амплитудного спектра и фазового спектра аудиоданных костной проводимости для получения восстановленных аудиоданных костной проводимости.
Следует отметить, что представленное выше описание приведено исключительно в целях иллюстрации и не предназначено для ограничения объема настоящего раскрытия. Для специалистов в данной области техники могут быть сделаны многочисленные изменения и модификации в соответствии с идеями настоящего раскрытия. Однако эти вариации и модификации не выходят за рамки настоящего раскрытия.
На фиг.8 показана блок-схема, иллюстрирующая примерный процесс восстановления аудиоданных костной проводимости с использованием метода разреженных матриц согласно некоторым вариантам осуществления настоящего раскрытия. В некоторых вариантах осуществления процесс 800 может быть реализован как набор инструкций (например, приложение), хранящихся в запоминающем устройстве 140, ROM 230, или RAM 240 или хранилище 390 данных. Устройство 122 обработки, процессор 220 и/или CPU 340 может исполнять набор инструкций, и при исполнении инструкций устройство 122 обработки, процессор 220 и/или CPU 340 могут выполнять процесс 800. Операции проиллюстрированного процесса, представленного ниже, предназначены для иллюстрации. В некоторых вариантах осуществления процесс 800 может выполняться с одной или несколькими дополнительными операциями, которые не описаны, и/или без одной или нескольких обсуждаемых операций. Кроме того, порядок, в котором операции процесса 800 показаны на фиг.8 и описаны ниже, не предназначен для ограничения. В некоторых вариантах осуществления одна или несколько операций процесса 800 могут быть выполнены для выполнения по меньшей мере части операции 530, как описано со ссылкой на фиг.5.
На этапе 810 устройство 122 обработки (например, модуль 410 получения) может получать аудиоданные костной проводимости. В некоторых вариантах осуществления аудиоданные костной проводимости могут быть исходными аудиоданными (например, первыми аудиоданными), собранными датчиком костной проводимости, когда пользователь говорит, как описано в связи с операцией 510. Например, речь пользователя может собираться датчиком костной проводимости (например, микрофоном 112 костной проводимости) для выработки электрического сигнала (например, аналогового сигнала или цифрового сигнала) (то есть аудиоданных костной проводимости). В некоторых вариантах осуществления аудиоданные костной проводимости могут включать в себя несколько волн с разными частотами и амплитудами. Аудиоданные костной проводимости в частотной области могут быть обозначены как матрица  . Матрица может быть определена на основе словарной матрицы
. Матрица может быть определена на основе словарной матрицы 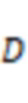 и матрицы разреженного кода
и матрицы разреженного кода  . Например, аудиоданные могут быть определены в соответствии с уравнением (4) следующим образом:
. Например, аудиоданные могут быть определены в соответствии с уравнением (4) следующим образом:
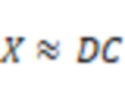 (4).
(4).
На этапе 820 устройство 122 обработки (например, модуль 420 предварительной обработки) может получить первое соотношение преобразования, выполненное с возможностью преобразования словарной матрицы аудиоданных костной проводимости в словарную матрицу восстановленных аудиоданных костной проводимости, соответствующих аудиоданные костной проводимости. В некоторых вариантах осуществления первое соотношение преобразования может быть настройкой по умолчанию системы 100 выработки аудиосигнала. В некоторых вариантах осуществления устройство 122 обработки может получать первое соотношение преобразования из запоминающего устройства 140, модуля 440 хранения данных или любого другого запоминающего устройства для хранения данных. В некоторых вариантах осуществления первое соотношение преобразования может быть определено на основе одной или нескольких групп аудиоданных костной проводимости и соответствующих аудиоданных воздушной проводимости. Аудиоданные костной проводимости и соответствующие аудиоданные воздушной проводимости в каждой группе могут, соответственно, собираться датчиком костной проводимости и датчиком воздушной проводимости одновременно в бесшумной среде тогда, когда говорит оператор (например, испытуемый). Например, устройство 122 обработки может определить словарную матрицу аудиоданных костной проводимости и словарную матрицу соответствующих аудиоданных воздушной проводимости в каждой группе из одной или более групп аудиоданных костной проводимости и соответствующих аудиоданных воздушной проводимости, как описано в операции 840. Устройство 122 обработки может разделить словарную матрицу соответствующих аудиоданных воздушной проводимости на словарную матрицу аудиоданных костной проводимости для каждой группы из одной или более групп аудиоданных костной проводимости и соответствующих аудиоданных воздушной проводимости для получения первого соотношения преобразования-кандидата. В некоторых вариантах осуществления устройство 122 обработки может определить одно или несколько возможных соотношений первого преобразования на основе одной или нескольких групп аудиоданных костной проводимости и соответствующих аудиоданных воздушной проводимости. Устройство 122 обработки может усреднять одно или более первых соотношений преобразований-кандидатов, чтобы получить первое соотношение преобразования. В некоторых вариантах осуществления устройство 122 обработки может определить одно из одного или более первых соотношений преобразований-кандидатов в качестве первого соотношения преобразования.
На этапе 830 устройство 122 обработки (например, модуль 420 предварительной обработки) может получить второе соотношение преобразования, выполненное с возможностью преобразования матрицы разреженного кода аудиоданных костной проводимости в матрицу разреженного кода восстановленных аудиоданных костной проводимости, соответствующих к аудиоданным костной проводимости. В некоторых вариантах осуществления второе соотношение преобразования может быть настройкой по умолчанию системы 100 выработки аудиосигнала. В некоторых вариантах осуществления устройство 122 обработки может получать второе соотношение преобразования из запоминающего устройства 140, модуля 440 хранения данных или любого другого запоминающего устройства для хранения данных. В некоторых вариантах осуществления второе соотношение преобразования может быть определено на основе одной или более групп аудиоданных костной проводимости и соответствующих аудиоданных воздушной проводимости. Например, устройство 122 обработки может определить матрицу разреженного кода аудиоданных костной проводимости и матрицу разреженного кода соответствующих аудиоданных воздушной проводимости в каждой группе из одной или более групп аудиоданных костной проводимости и соответствующих аудиоданных воздушной проводимости, как описано в операции 840. Устройство 122 обработки может разделить матрицу разреженного кода соответствующих аудиоданных воздушной проводимости на матрицу разреженного кода аудиоданных костной проводимости, чтобы получить второе соотношение преобразования-кандидат для каждой группы из одной или более групп аудиоданных костной проводимости и соответствующие аудиоданные воздушной проводимости. В некоторых вариантах осуществления устройство 122 обработки может определить одно или более вторых соотношений преобразований-кандидатов на основе одной или более групп аудиоданных костной проводимости и соответствующих аудиоданных воздушной проводимости. Устройство 122 обработки может усреднять одно или более вторых соотношений преобразований-кандидатов для получения второго соотношения преобразования. В некоторых вариантах осуществления устройство 122 обработки может определить одно из одного или более вторых соотношений преобразований-кандидатов в качестве второго соотношения преобразования.
В некоторых вариантах осуществления область тела, где расположен датчик костной проводимости для сбора аудиоданных костной проводимости, используемых для определения первого соотношения преобразования (и/или второго соотношения преобразования), может быть сходной с и/или быть такой же, как область тела, где расположен датчик костной проводимости для сбора аудиоданных костной проводимости (например, первых аудиоданных), используемых для применения первого соотношения преобразования (и/или второго соотношения преобразования). Например, область тела пользователя (например, испытуемого), где расположен датчик костной проводимости для сбора аудиоданных костной проводимости в каждой группе из одной или более групп соответствующих аудиоданных костной проводимости и аудиоданных воздушной проводимости, может быть такой же, как область тела пользователя, где расположен датчик костной проводимости для сбора первых аудиоданных. В качестве другого примера, если областью тела, где расположен датчик костной проводимости для сбора аудиоданных костной проводимости (например, первые аудиоданные), является шея, область тела, где расположен датчик костной проводимости для сбора аудиоданных костной проводимости, используемых для определения первого соотношения преобразования (и/или второго соотношения преобразования), также может представлять собой шею. В некоторых вариантах осуществления первое соотношение преобразования (и/или второе соотношение преобразования) может отличаться в зависимости от областей тела, где расположен датчик костной проводимости для сбора аудиоданных костной проводимости, используемых для определения первого соотношения преобразования (и/или второго соотношения преобразования). Восстановленные аудиоданные костной проводимости, определенные, соответственно, на основе различных первых соотношений преобразования (и/или вторых соотношений преобразования), могут отличаться при одних и тех же аудиоданных костной проводимости (например, первых аудиоданных).
На этапе 840 устройство 122 обработки (например, модуль 420 предварительной обработки) может определить словарную матрицу восстановленных аудиоданных костной проводимости (например, восстановленных первых аудиоданных, как это описано со ссылкой на фиг.5) на основе словарной матрицы аудиоданных костной проводимости (например, первых аудиоданных или нормализованных первых аудиоданных, как это описано со ссылкой на фиг.5) с использованием первого соотношения преобразования. Например, устройство 122 обработки может умножить первое соотношение преобразования (например, в матричной форме) на словарную матрицу аудиоданных костной проводимости (например, на первые аудиоданные или нормализованные первые аудиоданные, как это описано со ссылкой на фиг.5) для получения словарной матрицы восстановленных аудиоданных костной проводимости (например, восстановленных первых аудиоданных, как это описано со ссылкой на фиг.5). Устройство 122 обработки может определить словарную матрицу и/или матрицу разреженного кода аудиоданных (например, аудиоданных костной проводимости (например, первых аудиоданных или нормализованных первых аудиоданных, как это описано со ссылкой на фиг.5), аудиоданных костной проводимости и/или аудиоданных воздушной проводимости в группе) путем выполнения множества итераций. Перед выполнением множества итераций устройство 122 обработки может инициализировать словарную матрицу аудиоданных (например, первые аудиоданные или нормализованные первые аудиоданные, как это описано со ссылкой на фиг.5), чтобы получить исходную словарную матрицу. Например, устройство 122 обработки может установить каждый элемент в исходной словарной матрице на 0 или 1. На каждой итерации устройство 122 обработки может определить оценочную матрицу разреженного кода, используя, например, алгоритм поиска ортогонального соответствия (OMP), на основе аудиоданных (например, первых аудиоданных или нормализованных первых аудиоданных, как это описано со ссылкой на фиг.5) и исходной словарной матрицы. Устройство 122 обработки может определить оценочную словарную матрицу, используя, например, алгоритм разложения по K-сингулярному значению (K-SVD) на основе аудиоданных (например, первых аудиоданных или нормализованных первых аудиоданных, как это описано со ссылкой на фиг.5) и оценочной матрицы разреженного кода. Устройство 122 обработки может определить оценочные аудиоданные на основе оценочной словарной матрицы и оценочной матрицы разреженного кода в соответствии с уравнением (4). Устройство 122 обработки может сравнить оценочные аудиоданные с аудиоданными (например, с первыми аудиоданными или нормализованными первыми аудиоданными, как это описано со ссылкой на фиг.5). Если разность между оценочными аудиоданными, выработанными в текущей итерации, и аудиоданными превышает пороговое значение, устройство 122 обработки может обновить исходную словарную матрицу, используя оценочную словарную матрицу, выработанную в текущей итерации. Устройство 122 обработки может выполнять следующую итерацию на основе обновленной исходной словарной матрицы до тех пор, пока разность между оценочными аудиоданными, выработанными в текущей итерации, и аудиоданными не станет меньше порогового значения. Устройство 122 обработки может обозначать оценочную словарную матрицу и оценочную матрицу разреженного кода, выработанную в текущей итерации, как словарную матрицу и/или матрицу разреженного кода аудиоданных (например, первые аудиоданные или нормализованные первые аудиоданные, как это описано на фиг.5), если разность между оценочными аудиоданными, выработанными в текущей итерации, и аудиоданными меньше порогового значения.
На этапе 850 устройство 122 обработки (например, модуль 420 предварительной обработки) может определить матрицу разреженного кода восстановленных аудиоданных костной проводимости (например, восстановленных первых аудиоданных, как это описано со ссылкой на фиг.5) на основе матрицы разреженного кода аудиоданных костной проводимости (например, первых аудиоданных или нормализованных первых аудиоданных, как это описано со ссылкой на фиг.5) с использованием второго соотношения преобразования. Например, устройство 122 обработки может перемножить второе соотношение преобразования (например, матрицу) на матрицу разреженного кода аудиоданных костной проводимости (например, первые аудиоданные или нормализованные первые аудиоданные, как это описано со ссылкой на фиг.5) для получения матрицы разреженного кода восстановленных аудиоданных костной проводимости (например, восстановленных первых аудиоданных, как это описано со ссылкой на фиг.5). Матрица разреженного кода аудиоданных костной проводимости (например, первые аудиоданные или нормализованные первые аудиоданные, как это описано со ссылкой на фиг.5) может быть определена, как описано в операции 840.
На этапе 860 устройство 122 обработки (например, модуль 420 предварительной обработки) может определить восстановленные аудиоданные костной проводимости (например, восстановленные первые аудиоданные, как это описано со ссылкой на фиг.5) на основе определенной словарной матрицы и определенной матрицы разреженного кода восстановленных аудиоданных костной проводимости. Устройство 122 обработки может определить восстановленные аудиоданные костной проводимости на основе определенной словарной матрицы в операции 840 и определенной матрицы разреженного кода в операции 850 восстановленных аудиоданных костной проводимости в соответствии с уравнением (4).
Следует отметить, что представленное выше описание приведено только в целях иллюстрации и не предназначено для ограничения объема настоящего раскрытия. Для специалистов в данной области техники могут быть сделаны многочисленные изменения и модификации в соответствии с идеями настоящего раскрытия. Однако эти вариации и модификации не выходят за рамки настоящего раскрытия. Например, операции 820 и 830 могут быть объединены в одну операцию.
На фиг.9 показана блок-схема, иллюстрирующая примерный процесс выработки аудиоданных согласно некоторым вариантам осуществления настоящего раскрытия. В некоторых вариантах осуществления процесс 900 может быть реализован как набор инструкций (например, приложение), хранящихся в запоминающем устройстве 140, ROM 230, или RAM 240 или хранилище 390 данных. Устройство 122 обработки, процессор 220 и/или CPU 340 может исполнять набор инструкций, и при исполнении инструкций устройство 122 обработки, процессор 220 и/или CPU 340 могут выполнять процесс 900. Операции проиллюстрированного процесса, представленного ниже, предназначены для иллюстрации. В некоторых вариантах осуществления процесс 900 может выполняться с одной или несколькими дополнительными операциями, которые не описаны, и/или без одной или нескольких обсуждаемых операций. Кроме того, порядок, в котором операции процесса 900 показаны на фиг.9 и описаны ниже, не предназначен для ограничения. В некоторых вариантах осуществления одна или несколько операций процесса 900 могут выполняться для выполнения по меньшей мере части операции 540, как описано со ссылкой на фиг.5.
На этапе 910 устройство 122 обработки (например, модуль 430 выработки аудиоданных или блок 432 определения частоты) может определить один или более частотных порогов по меньшей мере частично на основе по меньшей мере одного из: аудиоданных костной проводимости или аудиоданных воздушной проводимости. Аудиоданные костной проводимости (например, первые аудиоданные или предварительно обработанные первые аудиоданные) и аудиоданные воздушной проводимости (например, вторые аудиоданные или предварительно обработанные вторые аудиоданные) могут быть собраны одновременно датчиком костной проводимости и датчиком воздушной проводимости, соответственно, тогда, когда пользователь говорит. Дополнительное описание аудиоданных костной проводимости и аудиоданных воздушной проводимости можно найти в другом месте настоящего раскрытия (например, в описании со ссылкой на фиг.5).
Используемый в данном документе термин «частотный порог» может относиться к частотной точке. В некоторых вариантах осуществления частотный порог может быть частотной точкой аудиоданных костной проводимости и/или аудиоданных воздушной проводимости. В некоторых вариантах осуществления частотный порог может отличаться от частотной точки аудиоданных костной проводимости и/или аудиоданных воздушной проводимости. В некоторых вариантах осуществления устройство 122 обработки может определить частотный порог на основе кривой частотной характеристики, ассоциированной с аудиоданными костной проводимости. Кривая частотной характеристики, ассоциированная с аудиоданными костной проводимости, может включать в себя значения частотной характеристики, изменяющиеся в зависимости от частоты. В некоторых вариантах осуществления устройство 122 обработки может определить один или более частотных порогов на основе значений частотной характеристики кривой частотной характеристики, ассоциированной с аудиоданными костной проводимости. Например, устройство 122 обработки может определить максимальную частоту (например, 2000 Гц кривой m частотной характеристики, которая показана на фиг.11) в качестве частотного порога среди диапазона частот (например, 0 - 2000 Гц кривой m частотной характеристики, которая показана на фиг.11), соответствующего значениям частотной характеристики меньше порогового значения (например, около 80 дБ кривой m частотной характеристики, которая показана на фиг.11). В качестве другого примера, устройство 122 обработки может определить минимальную частоту (например, 4000 Гц кривой m частотной характеристики, которая показана на фиг.11) в качестве частотного порога среди диапазона частот (например, 4000 Гц - 20 кГц) кривой m частотной характеристики, которая показана на фиг.11), соответствующего значениям частотной характеристики, превышающим пороговое значение (например, около 90 дБ кривой m частотной характеристики, которая показана на фиг.11). В качестве еще одного примера устройство 122 обработки может определить минимальную частоту и максимальную частоту как два пороговых значения частоты среди диапазона частот, соответствующих значениям частотной характеристики в диапазоне частот. В качестве дополнительного примера, как показано на фиг.11, устройство 122 обработки может определить один или более частотных порогов на основе кривой «m» частотной характеристики аудиоданных костной проводимости. Устройство 122 обработки может определить диапазон частот (0-2000 Гц), соответствующий значениям частотной характеристики меньше порогового значения (например, 70 дБ). Устройство 122 обработки может определить максимальную частоту в диапазоне частот в качестве частотного порога. В некоторых вариантах осуществления устройство 122 обработки может определить один или более частотных порогов на основе изменения кривой частотной характеристики. Например, устройство 122 обработки может определить максимальную частоту и/или минимальную частоту в качестве частотных порогов среди диапазона частот кривой частотной характеристики со стабильным изменением. В качестве другого примера, устройство 122 обработки может определить максимальную частоту и/или минимальную частоту в качестве частотных порогов среди диапазона частот резко изменяющейся кривой частотной характеристики. В качестве дополнительного примера, кривая m частотной характеристики в диапазоне частот менее 1000 Гц изменяется стабильно по отношению к диапазону частот более 1000 Гц и менее 4000 Гц. Устройство 122 обработки может определить 1000 Гц и 4000 Гц в качестве пороговых частот. В некоторых вариантах осуществления устройство 122 обработки может восстанавливать аудиоданные костной проводимости, используя одну или несколько технологий восстановления, как описано в другом месте настоящего раскрытия (например, в описании со ссылкой на фиг.5), чтобы получить восстановленные аудиоданные костной проводимости. Устройство 122 обработки может определить кривую частотной характеристики, ассоциированную с восстановленными аудиоданными костной проводимости. Устройство 122 обработки может определить один или более частотных порогов на основе кривой частотной характеристики, ассоциированной с восстановленными аудиоданными костной проводимости, аналогичными или такими же, как и на основе аудиоданных костной проводимости, как описано выше.
В некоторых вариантах осуществления устройство 122 обработки может определить один или более частотных порогов на основе уровня шума, ассоциированного по меньшей мере с частью аудиоданных воздушной проводимости. Чем выше уровень шума, тем выше может быть один (например, минимальной частотный порог) из одного или более частотных порогов. Чем ниже уровень шума, тем ниже может быть один (например, минимальной частотный порог) из одного или более частотных порогов. В некоторых вариантах осуществления уровень шума, ассоциированный с аудиоданными воздушной проводимости, может обозначаться количеством или энергией шумов, включенных в аудиоданные воздушной проводимости. Чем больше количество или энергия шумов, включенных в аудиоданные воздушной проводимости, тем выше может быть уровень шума. В некоторых вариантах осуществления уровень шума может обозначаться отношением сигнал/шум (SNR) аудиоданных воздушной проводимости. Чем больше SNR, тем ниже может быть уровень шума. Чем больше SNR, ассоциированное с аудиоданными воздушной проводимости, тем ниже может быть частотный порог. Например, если SNR равно 0 дБ, частотный порог может быть равен 2000 Гц. Если SNR составляет 20 дБ, частотный порог может составлять 4000 Гц. Например, частотный порог может быть определен на основе уравнения (5) следующим образом:
 , (5)
, (5)
где 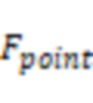 представляет собой частотный порог
представляет собой частотный порог  , и/или
, и/или 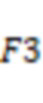 может быть значением в диапазоне частот от 0 до 20 кГц, и
может быть значением в диапазоне частот от 0 до 20 кГц, и 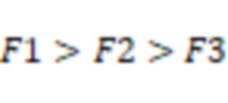 . A1 и/или A2 могут представлять собой параметры настройки по умолчанию системы 100 выработки аудиосигнала. Например, A1 и/или A2 могут быть константами, такими как 0 и/или 20, соответственно.
. A1 и/или A2 могут представлять собой параметры настройки по умолчанию системы 100 выработки аудиосигнала. Например, A1 и/или A2 могут быть константами, такими как 0 и/или 20, соответственно.
Кроме того, частотный порог может быть представлен уравнением (6) следующим образом:
 . (6)
. (6)
В некоторых вариантах осуществления устройство 122 обработки может определить SNR аудиоданных воздушной проводимости в соответствии с уравнением (7) следующим образом:
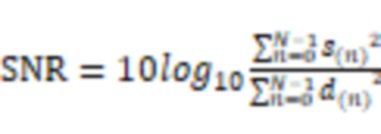 , (7)
, (7)
где n относится к n-ому речевому кадру в аудиоданных воздушной проводимости, 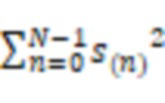 относится к энергии чистых аудиоданных, включенных в аудиоданные воздушной проводимости, и
относится к энергии чистых аудиоданных, включенных в аудиоданные воздушной проводимости, и 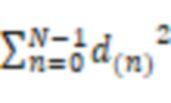 относится к энергии шумовых данных, включенных в аудиоданные воздушной проводимости. В некоторых вариантах осуществления устройство 122 обработки может определить шумовые данные, включенные в аудиоданные воздушной проводимости, с использованием алгоритма оценки шума, такого как алгоритм статистического минимума (MS), алгоритм управляемого минимумом рекурсивного усреднения (MCRA) и т.д. Устройство 122 может определить чистые аудиоданные, включенные в аудиоданные воздушной проводимости, на основе определенных шумовых данных, включенных в аудиоданные воздушной проводимости. Затем устройство 122 обработки может определить энергию чистых аудиоданных, включенных в аудиоданные воздушной проводимости, и энергию определенных шумовых данных, включенных в аудиоданные воздушной проводимости. В некоторых вариантах осуществления устройство 122 обработки может определить шумовые данные, включенные в аудиоданные воздушной проводимости, используя датчик костной проводимости и датчик воздушной проводимости. Например, устройство 122 обработки может определить опорные аудиоданные, собранные датчиком воздушной проводимости, в то время как датчик костной проводимости не собирает сигналы в определенное время или период, близкий к времени, когда аудиоданные воздушной проводимости собираются датчиком воздушной проводимости. Используемая в данном документе фраза «время или период, близкий к другому времени» может относиться к разности между временем или периодом и другим временем меньше порогового значения (например, 10 миллисекунд, 100 миллисекунд, 1 секунда, 2 секунды, 3 секунды, 4 секунды и др.). Опорные аудиоданные могут быть эквивалентны шумовым данным, включенным в аудиоданные воздушной проводимости. Затем устройство 122 обработки может определить чистые аудиоданные, включенные в аудиоданные воздушной проводимости, на основе определенных шумовых данных (то есть опорных аудиоданных), включенных в аудиоданные воздушной проводимости. Устройство 122 обработки может определить SNR, ассоциированное с аудиоданными воздушной проводимости, в соответствии с уравнением (7).
относится к энергии шумовых данных, включенных в аудиоданные воздушной проводимости. В некоторых вариантах осуществления устройство 122 обработки может определить шумовые данные, включенные в аудиоданные воздушной проводимости, с использованием алгоритма оценки шума, такого как алгоритм статистического минимума (MS), алгоритм управляемого минимумом рекурсивного усреднения (MCRA) и т.д. Устройство 122 может определить чистые аудиоданные, включенные в аудиоданные воздушной проводимости, на основе определенных шумовых данных, включенных в аудиоданные воздушной проводимости. Затем устройство 122 обработки может определить энергию чистых аудиоданных, включенных в аудиоданные воздушной проводимости, и энергию определенных шумовых данных, включенных в аудиоданные воздушной проводимости. В некоторых вариантах осуществления устройство 122 обработки может определить шумовые данные, включенные в аудиоданные воздушной проводимости, используя датчик костной проводимости и датчик воздушной проводимости. Например, устройство 122 обработки может определить опорные аудиоданные, собранные датчиком воздушной проводимости, в то время как датчик костной проводимости не собирает сигналы в определенное время или период, близкий к времени, когда аудиоданные воздушной проводимости собираются датчиком воздушной проводимости. Используемая в данном документе фраза «время или период, близкий к другому времени» может относиться к разности между временем или периодом и другим временем меньше порогового значения (например, 10 миллисекунд, 100 миллисекунд, 1 секунда, 2 секунды, 3 секунды, 4 секунды и др.). Опорные аудиоданные могут быть эквивалентны шумовым данным, включенным в аудиоданные воздушной проводимости. Затем устройство 122 обработки может определить чистые аудиоданные, включенные в аудиоданные воздушной проводимости, на основе определенных шумовых данных (то есть опорных аудиоданных), включенных в аудиоданные воздушной проводимости. Устройство 122 обработки может определить SNR, ассоциированное с аудиоданными воздушной проводимости, в соответствии с уравнением (7).
В некоторых вариантах осуществления устройство 122 обработки может извлекать энергию определенных шумовых данных, включенных в аудиоданные воздушной проводимости, и определять энергию чистых аудиоданных на основе энергии определенных шумовых данных и общей энергии аудиоданные воздушной проводимости. Например, устройство 122 обработки может вычесть энергию оценочных шумовых данных, включенных в аудиоданные воздушной проводимости, из общей энергии аудиоданных воздушной проводимости, чтобы получить энергию чистых аудиоданных, включенных в аудиоданные воздушной проводимости. Устройство 122 обработки может определить SNR на основе энергии чистых аудиоданных и энергии определенных шумовых данных в соответствии с уравнением (7).
На этапе 920 устройство 122 обработки (например, модуль 430 выработки аудиоданных или блок 434 определения весового коэффициента) может определить несколько сегментов аудиоданных костной проводимости и аудиоданных воздушной проводимости в соответствии с одним или более частотными порогами. В некоторых вариантах осуществления аудиоданные костной проводимости и аудиоданные воздушной проводимости могут находиться во временной области, и устройство 122 обработки может выполнять операцию преобразования домена (например, операцию FT) над аудиоданными костной проводимости и аудиоданными воздушной проводимости для преобразования аудиоданных костной проводимости и аудиоданных воздушной проводимости в частотную область. В некоторых вариантах осуществления аудиоданные костной проводимости и аудиоданные воздушной проводимости могут быть в частотной области. Каждые из аудиоданных костной проводимости и аудиоданных воздушной проводимости в частотной области могут включать в себя частотный спектр. Аудиоданные костной проводимости в частотной области также могут называться частотным спектром костной проводимости. Аудиоданные воздушной проводимости в частотной области также могут называться частотным спектром воздушной проводимости. Устройство 122 обработки может разделить частотный спектр костной проводимости и частотный спектр воздушной проводимости на несколько сегментов. Каждый сегмент аудиоданных костной проводимости может соответствовать одному сегменту аудиоданных воздушной проводимости. Используемая в данном документе фраза «сегмент аудиоданных костной проводимости, соответствующих сегменту аудиоданных воздушной проводимости» может относиться к тому, что два сегмента аудиоданных костной проводимости и аудиоданных воздушной проводимости определяются с помощью одного или двух одинаковых частотных порогов. Например, если специфический сегмент аудиоданных костной проводимости определяется частотными точками 2000 Гц и 4000 Гц, другими словами, специфический сегмент аудиоданных костной проводимости включает в себя частотные составляющие в диапазоне частот от 2000 Гц до 4000 Гц, сегмент аудиоданных воздушной проводимости, соответствующих специфическому сегменту аудиоданных костной проводимости, также может определяться частотными порогами 2000 Гц и 4000 Гц. Другими словами, сегмент аудиоданных воздушной проводимости, который соответствует специфическому сегменту аудиоданных костной проводимости, включая частотные составляющие в диапазоне частот от 2000 Гц до 4000 Гц, может включать в себя частотные составляющие в диапазоне частот от 2000 Гц до 4000 Гц.
В некоторых вариантах осуществления число отсчетов или количество одного или более частотных порогов может быть равно единице, устройство 122 обработки может разделить каждый частотный спектр костной проводимости и частотный спектр воздушной проводимости на два сегмента. Например, один сегмент частотного спектра костной проводимости может включать в себя часть частотного спектра костной проводимости с частотными составляющими меньше частотного порога, и другой сегмент частотного спектра костной проводимости может включать в себя остальную часть частотного спектра костной проводимости с частотные составляющие выше частотного порога.
На этапе 930 устройство 122 обработки (например, модуль 430 выработки аудиоданных или подмодуль 434 определения весового коэффициента) может определить весовой коэффициент для каждого из множества сегментов аудиоданных костной проводимости и аудиоданных воздушной проводимости. В некоторых вариантах осуществления весовой коэффициент специфического сегмента аудиоданных костной проводимости и весовой коэффициент соответствующего специфического сегмента аудиоданных воздушной проводимости могут удовлетворять критерию, в соответствии с которым сумма весового коэффициента специфического сегмента аудиоданных костной проводимости и весового коэффициента для соответствующего специфического сегмента аудиоданных воздушной проводимости равна 1. Например, если устройство 122 обработки делит аудиоданные костной проводимости и аудиоданные воздушной проводимости на два сегмента в соответствии с одним единственным частотным порогом, весовой коэффициент одного сегмента аудиоданных костной проводимости с частотными составляющими ниже одного единственного частотного порога (также называемого нижней частью аудиоданных костной проводимости) может быть равен 1, или 0,9, или 0,8 и т.д. Весовой коэффициент одного сегмента аудиоданных воздушной проводимости с частотными составляющими ниже одного единственного частотного порога (также называемого нижней частью аудиоданных воздушной проводимости) может быть равен 0, или 0,1, или 0,2 и т.д., соответствующий весовому коэффициенту одного сегмента аудиоданных костной проводимости 1, или 0,9, или 0,8 и т.д., соответственно. Весовой коэффициент еще одного сегмента аудиоданных костной проводимости с частотными составляющими выше одного единственного частотного порога (также называемый верхней частью аудиоданных костной проводимости), может быть равен 0, или 0,1, или 0,2 и т.д. Весовой коэффициент еще одного сегмента аудиоданных воздушной проводимости с частотными составляющими выше частотного порога (также называемый верхней частью аудиоданных воздушной проводимости) может быть равен 1, или 0,9, или 0,8 и т.д., что соответствует весовому коэффициенту одного сегмента аудиоданных костной проводимости 0, или 0,1 или 0,2 и т.д., соответственно.
В некоторых вариантах осуществления устройство 122 обработки может определить весового коэффициента для различных сегментов аудиоданных костной проводимости или аудиоданных воздушной проводимости на основе SNR аудиоданных воздушной проводимости. Например, чем ниже SNR аудиоданных воздушной проводимости, тем больше может быть весовой коэффициент специфического сегмента костной проводимости и тем меньше может быть весовой коэффициент соответствующего специфического сегмента воздушной костной проводимости.
На этапе 940 устройство 122 обработки (например, модуль 430 выработки аудиоданных или блок 436 объединения) может сшить аудиоданные костной проводимости и аудиоданные воздушной проводимости на основе весового коэффициента для каждого из множества сегментов каждых аудиоданных костной проводимости и аудиоданных воздушной проводимости для выработки сшитых аудиоданных. Сшитые аудиоданные могут представлять собой речь пользователя с более высоким качеством, чем аудиоданные костной проводимости и/или аудиоданные воздушной проводимости. Используемая в данном документе фраза «сшивка аудиоданных костной проводимости и аудиоданных воздушной проводимости» может относиться к выбору одной или нескольких частей частотных составляющих аудиоданных костной проводимости и одной или нескольких частей частотных составляющих данных воздушной проводимости в частотной области в соответствии с одним или более частотными порогами и позволяет вырабатывать аудиоданные на основе выбранных частей аудиоданных костной проводимости и выбранных частей аудиоданных воздушной проводимости. Частотный порог может также упоминаться как точка объединения частот. В некоторых вариантах осуществления выбранная часть аудиоданных костной проводимости и/или аудиоданных воздушной проводимости может включать в себя частотные составляющие ниже частотного порога. В некоторых вариантах осуществления выбранная часть аудиоданных костной проводимости и/или аудиоданных воздушной проводимости может включать в себя частотные составляющие ниже частотного порога и выше другого частотного порога. В некоторых вариантах осуществления выбранная часть аудиоданных костной проводимости и/или аудиоданных воздушной проводимости может включать в себя частотные составляющие, превышающие частотный порог.
В некоторых вариантах осуществления устройство 122 обработки может определить сшитые аудиоданные в соответствии с уравнением (8) следующим образом:
 , (8)
, (8)
где 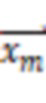 относится к аудиоданным костной проводимости,
относится к аудиоданным костной проводимости, 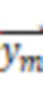 относится к аудиоданным воздушной проводимости,
относится к аудиоданным воздушной проводимости,  , включающий в себя (
, включающий в себя ( , относится к весовым коэффициентам для нескольких сегментов аудиоданных костной проводимости,
, относится к весовым коэффициентам для нескольких сегментов аудиоданных костной проводимости,  , включающий в себя (
, включающий в себя ( , относится к весовым коэффициентам для нескольких сегментов аудиоданных воздушной проводимости, (
, относится к весовым коэффициентам для нескольких сегментов аудиоданных воздушной проводимости, (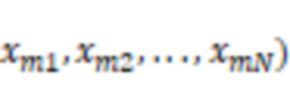 относится к нескольким сегментам аудиоданных костной проводимости, каждый из которых включает в себя частотные составляющие в частотном диапазоне, определяемом частотными порогами, и (
относится к нескольким сегментам аудиоданных костной проводимости, каждый из которых включает в себя частотные составляющие в частотном диапазоне, определяемом частотными порогами, и (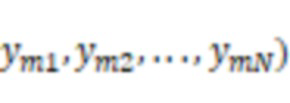 относится к множеству сегментов аудиоданных воздушной проводимости, каждый из которых включает в себя частотные составляющие в диапазоне частот , определяемом частотными порогами. Например,
относится к множеству сегментов аудиоданных воздушной проводимости, каждый из которых включает в себя частотные составляющие в диапазоне частот , определяемом частотными порогами. Например, 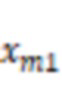 и
и 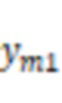 могут включать в себя частотные составляющие аудиоданных костной проводимости и аудиоданных воздушной проводимости ниже 1000 Гц, соответственно. В качестве другого примера,
могут включать в себя частотные составляющие аудиоданных костной проводимости и аудиоданных воздушной проводимости ниже 1000 Гц, соответственно. В качестве другого примера, 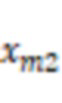 и
и 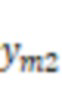 могут включать в себя частотные составляющие аудиоданных костной проводимости и аудиоданных воздушной проводимости в диапазоне частот более 1000 Гц и менее 4000 Гц, соответственно. N может быть константой, такой как 1, 2, 3 и т.д.
могут включать в себя частотные составляющие аудиоданных костной проводимости и аудиоданных воздушной проводимости в диапазоне частот более 1000 Гц и менее 4000 Гц, соответственно. N может быть константой, такой как 1, 2, 3 и т.д.  может быть константой в диапазоне от 0 до 1,
может быть константой в диапазоне от 0 до 1,  может быть константой в диапазоне от 0 до 1,
может быть константой в диапазоне от 0 до 1, 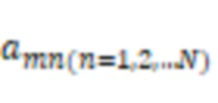 и могут удовлетворять критерию, в соответствии с которым сумма и равна 1. В некоторых вариантах осуществления N может быть равно 2. Устройство 122 обработки может определить два сегмента для каждых из аудиоданных костной проводимости и аудиоданных воздушной проводимости в соответствии с одним единственным частотным порогом. Например, устройство 122 обработки может определить нижнюю часть аудиоданных костной проводимости (или аудиоданных воздушной проводимости) и верхнюю часть аудиоданных костной проводимости (или аудиоданных воздушной проводимости) в соответствии с одним единственным частотным порогом. Нижняя часть аудиоданных костной проводимости (или аудиоданных воздушной проводимости) может включать в себя частотные составляющие аудиоданных костной проводимости (или аудиоданных воздушной проводимости) ниже одного единственного частотного порога, и верхняя часть аудиоданных костной проводимости (или аудиоданных воздушной проводимости) может включать в себя частотные составляющие аудиоданных костной проводимости (или аудиоданные воздушной проводимости) выше одного единственного частотного порога. В некоторых вариантах осуществления устройство 122 обработки может определить нижнюю часть и нижнюю часть аудиоданных костной проводимости (или аудиоданных воздушной проводимости) на основе одного или нескольких фильтров. Один или более фильтров могут включать в себя фильтр нижних частот, фильтр верхних частот, полосовой фильтр и т.п. или любое их сочетание.
и могут удовлетворять критерию, в соответствии с которым сумма и равна 1. В некоторых вариантах осуществления N может быть равно 2. Устройство 122 обработки может определить два сегмента для каждых из аудиоданных костной проводимости и аудиоданных воздушной проводимости в соответствии с одним единственным частотным порогом. Например, устройство 122 обработки может определить нижнюю часть аудиоданных костной проводимости (или аудиоданных воздушной проводимости) и верхнюю часть аудиоданных костной проводимости (или аудиоданных воздушной проводимости) в соответствии с одним единственным частотным порогом. Нижняя часть аудиоданных костной проводимости (или аудиоданных воздушной проводимости) может включать в себя частотные составляющие аудиоданных костной проводимости (или аудиоданных воздушной проводимости) ниже одного единственного частотного порога, и верхняя часть аудиоданных костной проводимости (или аудиоданных воздушной проводимости) может включать в себя частотные составляющие аудиоданных костной проводимости (или аудиоданные воздушной проводимости) выше одного единственного частотного порога. В некоторых вариантах осуществления устройство 122 обработки может определить нижнюю часть и нижнюю часть аудиоданных костной проводимости (или аудиоданных воздушной проводимости) на основе одного или нескольких фильтров. Один или более фильтров могут включать в себя фильтр нижних частот, фильтр верхних частот, полосовой фильтр и т.п. или любое их сочетание.
В некоторых вариантах осуществления устройство 122 обработки может определить, по меньшей мере частично на основе одного частотного порога, первый весовой коэффициент и второй весовой коэффициент для нижней части аудиоданных костной проводимости и верхней части аудиоданных костной проводимости, соответственно. Устройство 122 обработки может определить, по меньшей мере частично на основе порога одной частоты, третий весовой коэффициент и четвертый весовой коэффициент для нижней части аудиоданных воздушной проводимости и верхней части аудиоданных воздушной проводимости, соответственно. В некоторых вариантах осуществления первый весовой коэффициент, второй весовой коэффициент, третий весовой коэффициент и четвертый весовой коэффициент могут быть определены на основе SNR аудиоданных воздушной проводимости. Например, устройство 122 обработки может определить то, что первый весовой коэффициент меньше третьего весового коэффициента, и/или второй весовой коэффициент больше четвертого весового коэффициента, если SNR аудиоданных воздушной проводимости больше порогового значения. В качестве другого примера, устройство 122 обработки может определить множество диапазонов SNR, причем каждый из диапазонов SNR может соответствовать значениям первого весового коэффициента, второго весового коэффициента, третьего весового коэффициента и четвертого весового коэффициента, соответственно. Первый весовой коэффициент и второй весовой коэффициент могут быть одинаковыми или разными, и третий весовой коэффициент и четвертый весовой коэффициент могут быть одинаковыми или разными. Сумма первого весового коэффициента и третьего весового коэффициента может быть равна 1. Сумма второго весового коэффициента и четвертого весового коэффициента может быть равна 1. Первый весовой коэффициент, второй весовой коэффициент, третий весовой коэффициент и/или четвертый весовой коэффициент могут быть константой в диапазоне от 0 до 1, таком как 1, 0,9, 0,8, 0,7, 0,3, 0,4, 0,5, 0,6, 02, 0,1, 0 и т.д. В некоторых вариантах осуществления устройство 122 обработки может определить сшитые аудиоданные путем взвешивания нижней части аудиоданных костной проводимости, верхней части аудиоданных костной проводимости, нижней части аудиоданных воздушной проводимости и верхней части аудиоданных воздушной проводимости с использованием первого весового коэффициента, второго весового коэффициента, третьего весового коэффициента и четвертого весового коэффициента, соответственно. Например, устройство 122 обработки может определить нижнюю часть сшитых аудиоданных путем взвешивания и суммирования нижней части аудиоданных костной проводимости и нижней части аудиоданных воздушной проводимости с использованием первого весового коэффициента и третьего весового коэффициента. Устройство 122 обработки может определить верхнюю часть объединенных аудиоданных путем взвешивания и суммирования верхней части аудиоданных костной проводимости и верхней части аудиоданных воздушной проводимости с использованием второго весового коэффициента и четвертого весового коэффициента. Устройство 122 обработки может сшить нижнюю часть сшитых аудиоданных и верхнюю часть сшитых аудиоданных для получения сшитых аудиоданных.
В некоторых вариантах осуществления первый весовой коэффициент для нижней части аудиоданных костной проводимости может быть равен 1, и второй весовой коэффициент для верхней части аудиоданных костной проводимости может быть равен 0. Третий весовой коэффициент для нижней части аудиоданных воздушной проводимости может быть равен 0, и четвертый весовой коэффициент верхней части аудиоданных воздушной проводимости может быть равен 1. Сшитые аудиоданные могут быть выработаны путем сшивания нижней части аудиоданных костной проводимости и верхней части аудиоданных воздушной проводимости. В некоторых вариантах осуществления объединенные аудиоданные могут различаться в соответствии с разными пороговыми значениями одной единственной частоты. Например, что касается фиг.14А-14С, то на фиг.14A-14C показаны частотно-временные диаграммы, иллюстрирующие совмещенные аудиоданные, выработанные путем сшивания специфических аудиоданных костной проводимости и специфических аудиоданных воздушной проводимости в частотной точке 2000 Гц, 3000 Гц и 4000 Гц, соответственно, согласно некоторым вариантам осуществления настоящего раскрытия. Количество шумов в сшитых аудиоданных на фиг.14А, 14В и 14С отличаются друг от друга. Чем больше частотная точка, тем меньше количество шумов в сшиваемых аудиоданных.
Следует отметить, что представленное выше описание приведено исключительно в целях иллюстрации и не предназначено для ограничения объема настоящего раскрытия. Для специалистов в данной области техники могут быть сделаны многочисленные изменения и модификации в соответствии с идеями настоящего раскрытия. Однако эти вариации и модификации не выходят за рамки настоящего раскрытия.
На фиг.10 показана блок-схема, иллюстрирующая примерный процесс выработки аудиоданных согласно некоторым вариантам осуществления настоящего раскрытия. В некоторых вариантах осуществления процесс 1000 может быть реализован как набор инструкций (например, приложение), хранящихся в запоминающем устройстве 140, ROM 230, или RAM 240 или хранилище 390 данных. Устройство 122 обработки, процессор 220 и/или CPU 340 могут исполнять набор инструкций, и при исполнении инструкций устройство 122 обработки, процессор 220 и/или CPU 340 могут выполнять процесс 1000. Операции проиллюстрированного процесса, представленного ниже, предназначены для иллюстрации. В некоторых вариантах осуществления процесс 1000 может быть выполнен с одной или несколькими дополнительными операциями, которые не описаны, и/или без одной или нескольких обсуждаемых операций. Кроме того, порядок, в котором операции процесса 1000 показаны на фиг.10 и описанные ниже, не предназначены для ограничения. В некоторых вариантах осуществления одна или несколько операций процесса 1000 могут выполняться для выполнения по меньшей мере части операции 540, как описано со ссылкой на фиг.5.
На этапе 1010 устройство 122 обработки (например, модуль 430 выработки аудиоданных или блок 434 определения весового коэффициента) может определить, по меньшей мере частично на основе по меньшей мере одного из: аудиоданных костной проводимости или аудиоданных воздушной проводимости, весовой коэффициент, соответствующий аудиоданным костной проводимости. В некоторых вариантах осуществления аудиоданные костной проводимости и аудиоданные воздушной проводимости могут быть одновременно получены датчиком костной проводимости и датчиком воздушной проводимости, соответственно, тогда, когда пользователь говорит. Аудиоданные воздушной проводимости и аудиоданные костной проводимости могут представлять речь пользователя. Дополнительное описание аудиоданных костной проводимости и аудиоданных воздушной проводимости можно найти в описании со ссылкой на фиг.5.
В некоторых вариантах осуществления устройство 122 обработки может определить весовой коэффициент аудиоданных костной проводимости на основе SNR аудиоданных воздушной проводимости. Дополнительное описание для определения SNR аудиоданных воздушной проводимости можно найти в другом месте настоящего раскрытия (например, в описании со ссылкой на фиг.9). Чем выше SNR аудиоданных воздушной проводимости, тем ниже может быть весовой коэффициент аудиоданных костной проводимости. Например, если SNR аудиоданных воздушной проводимости больше заданного порога, весовой коэффициент аудиоданных костной проводимости может быть установлен как значение А, и если SNR аудиоданных воздушной проводимости меньше заданного порога, весовой коэффициент для аудиоданных костной проводимости может быть установлен как значение B и A<B. В качестве другого примера, устройство 122 обработки может определить весовой коэффициент аудиоданных костной проводимости в соответствии с уравнением (9) следующим образом:
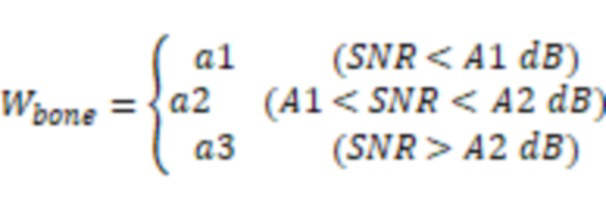 , (9)
, (9)
где 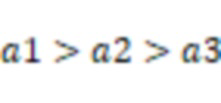 . A1 и/или A2 могут представлять собой параметры настройки по умолчанию системы 100 выработки аудиосигнала. В качестве дополнительного примера, устройство 122 обработки может определить множество диапазонов SNR, каждый из которых соответствует значению весового коэффициента для аудиоданных костной проводимости, с помощью уравнения (10):
. A1 и/или A2 могут представлять собой параметры настройки по умолчанию системы 100 выработки аудиосигнала. В качестве дополнительного примера, устройство 122 обработки может определить множество диапазонов SNR, каждый из которых соответствует значению весового коэффициента для аудиоданных костной проводимости, с помощью уравнения (10):
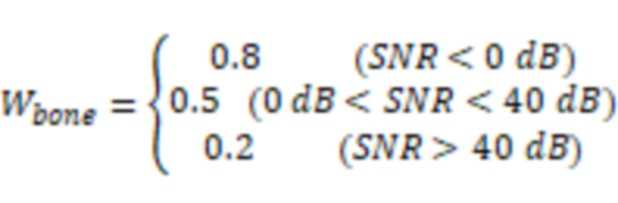 , (10)
, (10)
где 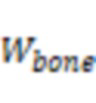 относится к весовому коэффициенту, соответствующему аудиоданным костной проводимости.
относится к весовому коэффициенту, соответствующему аудиоданным костной проводимости.
На этапе 1020 устройство 122 обработки (например, модуль 430 выработки аудиоданных или блок 434 определения весового коэффициента) может определить, по меньшей мере частично на основе по меньшей мере одного из: аудиоданных костной проводимости или аудиоданных воздушной проводимости, весовой коэффициент, соответствующий аудиоданным воздушной проводимости. Технологии, используемые для определения весового коэффициента аудиоданных воздушной проводимости, могут быть аналогичными или такими же, как и технологии, используемые для определения весового коэффициента аудиоданных костной проводимости, как описано в операции 1010. Например, устройство 122 обработки может определить весовой коэффициент аудиоданных воздушной проводимости на основе SNR аудиоданных воздушной проводимости. Дополнительное описание для определения SNR аудиоданных воздушной проводимости можно найти в другом месте настоящего раскрытия (например, в описании со ссылкой на фиг.9). Чем больше SNR аудиоданных воздушной проводимости, тем выше может быть весовой коэффициент аудиоданных воздушной проводимости. В качестве другого примера, если SNR аудиоданных воздушной проводимости больше заданного порогового значения, весовой коэффициент аудиоданных воздушной проводимости может быть установлен как значение X, и, если SNR аудиоданных воздушной проводимости меньше заданного порогового значения, весовой коэффициент для аудиоданных воздушной проводимости может быть установлен как значение Y и X>Y. Весовой коэффициент аудиоданных костной проводимости и весовой коэффициент аудиоданных воздушной проводимости могут удовлетворять критерию, в соответствии с которым сумма весовых коэффициентов аудиоданных костной проводимости и весового коэффициента аудиоданных воздушной проводимости равна 1. Устройство 122 обработки может определить весовой коэффициент аудиоданных воздушной проводимости на основе весового коэффициента аудиоданных костной проводимости. Например, устройство 122 обработки может определить весовой коэффициент аудиоданных воздушной проводимости на основе разности между значением 1 и весовым коэффициентом аудиоданных костной проводимости.
На этапе 1030 устройство 122 обработки (например, модуль 430 выработки аудиоданных или блок 436 объединения) может определить целевые аудиоданные путем взвешивания аудиоданных костной проводимости и аудиоданных воздушной проводимости с использованием весового коэффициента для аудиоданных костной проводимости и весового коэффициента для аудиоданных воздушной проводимости, соответственно. Целевые аудиоданные могут представлять собой речь пользователя как то, что представляют собой аудиоданные костной проводимости и аудиоданные воздушной проводимости. В некоторых вариантах осуществления устройство 122 обработки может определить целевые аудиоданные в соответствии с уравнением (11) следующим образом:
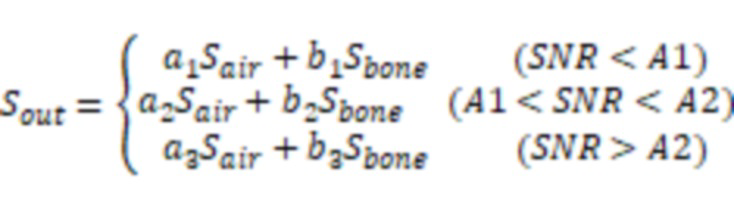 , (11)
, (11)
где 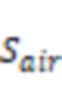 относится к аудиоданным воздушной проводимости,
относится к аудиоданным воздушной проводимости, 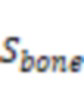 относится к аудиоданным костной проводимости,
относится к аудиоданным костной проводимости, 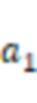 относится к весовому коэффициенту аудиоданных воздушной проводимости,
относится к весовому коэффициенту аудиоданных воздушной проводимости, 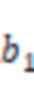 относится к весовому коэффициенту аудиоданных костной проводимости и
относится к весовому коэффициенту аудиоданных костной проводимости и  относится к целевым аудиоданным.
относится к целевым аудиоданным. 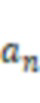 и
и 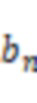 может удовлетворять критерию, в соответствии с которым сумма и равна 1. Например, целевые аудиоданные могут быть определены в соответствии с уравнением (12) следующим образом:
может удовлетворять критерию, в соответствии с которым сумма и равна 1. Например, целевые аудиоданные могут быть определены в соответствии с уравнением (12) следующим образом:
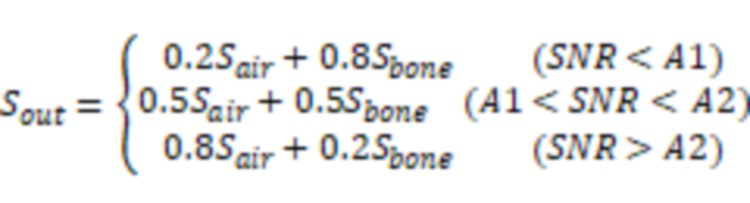 (12).
(12).
В некоторых вариантах осуществления устройство 122 обработки может передавать целевые аудиоданные в клиентский терминал (например, терминал 130), запоминающее устройство 140 и/или любое другое запоминающее устройство (не показано в системе 100 выработки аудиосигнала) через сеть 150.
ПРИМЕРЫ
Примеры представлены в иллюстративных целях и не предназначены для ограничения объема настоящего раскрытия.
Пример 1. Примерные частотные характеристики аудиоданных костной проводимости, соответствующие восстановленным аудиоданным костной проводимости и соответствующие аудиоданным воздушной проводимости
Как показано на фиг.11 кривая «m» представляет собой кривую частотной характеристики аудиоданных костной проводимости, и кривая «n» представляет собой кривую частотной характеристики аудиоданных воздушной проводимости, соответствующих аудиоданным костной проводимости. Аудиоданные костной проводимости и аудиоданные воздушной проводимости представляют одну и ту же речь пользователя. Кривая «m1» представляет собой кривую частотной характеристики восстановленных аудиоданных костной проводимости, выработанных путем восстановления аудиоданных костной проводимости с использованием обученной модели машинного обучения в соответствии с процессом 600. Как показано на фиг.11, кривая «m1» частотной характеристики больше похожа на или близка к кривой частотной характеристики «n», чем кривая «m» частотной характеристики. Другими словами, восстановленные аудиоданные костной проводимости больше похожи на или близки к аудиоданным воздушной проводимости, чем аудиоданные костной проводимости. Кроме того, часть кривой «m1» частотной характеристики восстановленных аудиоданных костной проводимости ниже частотной точки (например, 2000 Гц) аналогична или близка к части аудиоданных воздушной проводимости.
Пример 2. Примерные частотные характеристики аудиоданных костной проводимости, собранных датчиками костной проводимости, расположенными в разных частях тела пользователя
Как показано на фиг.12А, кривая «р» представляет собой частотную характеристику аудиоданных костной проводимости, собранных первым датчиком костной проводимости, который расположен на шее тела пользователя. Кривая «b» представляет собой кривую частотной характеристики аудиоданных костной проводимости, собранных вторым датчиком костной проводимости, который расположен на козелке тела пользователя. Кривая «о» представляет собой кривую частотной характеристики аудиоданных костной проводимости, собранных третьим датчиком костной проводимости, который расположен в слуховом проходе (например, наружном слуховом проходе) тела пользователя. В некоторых вариантах осуществления второй датчик костной проводимости и третий датчик костной проводимости могут быть такими же, как и первый датчик костной проводимости в этой конфигурации. Аудиоданные костной проводимости, собранные первым датчиком костной проводимости, аудиоданные костной проводимости, собранные вторым датчиком костной проводимости, и аудиоданные костной проводимости, собранные третьим датчиком костной проводимости, представляют собой одну и ту же речь пользователя, собранную одновременно первым датчиком костной проводимости, вторым датчиком костной проводимости и третьим датчиком костной проводимости, соответственно. В некоторых вариантах осуществления первый датчик костной проводимости, второй датчик костной проводимости и третий датчик костной проводимости могут отличаться друг от друга по конфигурации.
Как показано на фиг.12A, кривая «p» частотной характеристики, кривая «b» частотной характеристики и кривая «o» частотной характеристики отличаются друг от друга. Другими словами, аудиоданные костной проводимости, собранные первым датчиком костной проводимости, аудиоданные костной проводимости, собранные вторым датчиком костной проводимости, и аудиоданные костной проводимости, собранные третьим датчиком костной проводимости, различаются в зависимости от областей тела пользователя, где расположены первый датчик костной проводимости, второй датчик костной проводимости и третий датчик костной проводимости. Например, значение отклика частотной составляющей менее 1000 Гц в аудиоданных костной проводимости, собранных первым датчиком костной проводимости, который расположен на шее пользователя, больше, чем значение отклика частотной составляющей менее 1000 Гц в аудиоданных костной проводимости, собранных вторым датчиком костной проводимости, который расположен на козелке тела пользователя. Кривая частотной характеристики может отражать способность датчика костной проводимости преобразовывать энергию звука в электрические сигналы. Согласно кривым «p», «b» и «o» частотных характеристик, значения отклика, соответствующие диапазону частот от 0 до приблизительно 5000 Гц, больше, чем значения отклика, соответствующие диапазону частот более приблизительно 5000 Гц, где датчики костной проводимости расположены в разных частях тела пользователя. Значения отклика, соответствующие диапазону частот от 0 до приблизительно 2000 Гц, изменяются стабильно, чем значения отклика, соответствующие частоте, превышающей приблизительно 2000 Гц, когда датчики костной проводимости расположены в разных областях тела пользователя. Другими словами, датчик костной проводимости может регистрировать низкочастотную составляющую аудиосигнала, такую как от 0 до приблизительно 2000 Гц или от 0 до приблизительно 5000 Гц.
Таким образом, согласно фиг.12А, устройство костной проводимости для сбора и/или воспроизведения аудиосигналов может включать в себя датчик костной проводимости для сбора аудиосигналов костной проводимости, который может располагаться в области тела пользователя, определяемой на основе механической конструкции устройства костной проводимости. Область тела пользователя может быть определена на основе одной или нескольких характеристик кривой частотной характеристики, интенсивности сигнала, уровня комфорта пользователя и т.д. Например, устройство костной проводимости может включать в себя датчик костной проводимости для сбора аудиосигналов с тем, чтобы датчик костной проводимости мог располагаться на козелке пользователя и/или соприкасаться с ним тогда, когда пользователь носит устройство костной проводимости, поэтому интенсивность аудиосигналов, собранных датчиком костной проводимости, является относительно высокой.
Пример 3. Примерные частотные характеристики аудиоданных костной проводимости, собранных датчиками костной проводимости, которые расположены в одной и той же области тела пользователя при разном давлении
Как показано на фиг.12В, кривая «L1» представляет собой частотную характеристику аудиоданных костной проводимости, собранных датчиком костной проводимости, который расположен на козелке тела пользователя при давлении F1, равном 0 Н. Используемое в данном документе давление на область тела пользователя может также называться прижимным усилием, прикладываемым датчиком костной проводимости к области тела пользователя. Кривая «L2» представляет собой кривую частотной характеристики аудиоданных костной проводимости, собранных датчиком костной проводимости, который расположен на козелке тела пользователя, при давлении F2, равном 0,2 Н. Кривая «L3» представляет собой кривую частотной характеристики аудиоданных костной проводимости, собранных датчиком костной проводимости, который расположен на козелке тела пользователя, при давлении F3, равном 0,4 Н. Кривая «L4» представляет собой кривую частотной характеристики аудиоданных костной проводимости, собранных датчиком костной проводимости, который расположен на козелке тела пользователя, при давлении F4, равном 0,8 Н. Как показано на фиг.12В, кривые частотной характеристики «L1»-«L4» отличаются друг от друга. Другими словами, аудиоданные костной проводимости, собранные датчиком костной проводимости путем прикладывания различных давлений к области тела пользователя, отличаются.
Так как датчик костной проводимости оказывает разное давление на область тела пользователя, аудиоданные костной проводимости, собранные датчиком костной проводимости, могут отличаться. Интенсивность сигнала аудиоданных костной проводимости, собранных датчиком костной проводимости, может быть разной в зависимости от разных давлений. Интенсивность сигнала аудиоданных костной проводимости может сначала увеличиваться постепенно, и затем увеличение интенсивности сигнала может замедлиться до насыщения при увеличении давления от 0 Н до 0,8 Н. Однако, чем больше давление, оказываемое датчиком костной проводимости на область тела пользователя, тем в большей степени пользователь будет чувствовать себя некомфортно. Таким образом, согласно фиг.12А и 12В, устройство костной проводимости для сбора и/или воспроизведения аудиосигналов может включать в себя датчик костной проводимости для сбора аудиосигналов костной проводимости, который может располагаться в специфической области тела пользователя с прижимным усилием в определенном диапазоне на специфическую область тела пользователя и т.д. в соответствии с механической конструкцией устройства костной проводимости. Область тела пользователя и/или прижимное усилие на область тела пользователя могут быть определены на основе одной или нескольких характеристик кривой частотной характеристики, интенсивности сигнала, уровня комфорта пользователя и т.д. Например, устройство костной проводимости может включать в себя датчик костной проводимости для сбора аудиосигналов, так что датчик костной проводимости может располагаться на козелке пользователя и/или соприкасаться с ним с прижимным усилием в диапазоне от 0 до 0,8 Н, например 0,2 Н, или 0,4 Н, или 0,6 Н, или 0,8 Н и т.д. в случае, когда пользователь носит устройство костной проводимости, что позволяет обеспечить относительно высокую интенсивность сигнала аудиоданных костной проводимости, собранных датчиком костной проводимости, и одновременно пользователь может чувствовать себя комфортно при надлежащем прижимном усилии.
Пример 4. Примерные частотно-временные диаграммы объединенных аудиоданных
На фиг.13А показана частотно-временная диаграмма сшитых аудиоданных, выработанных путем сшивания аудиоданных костной проводимости и аудиоданных воздушной проводимости согласно некоторым вариантам осуществления настоящего раскрытия. Аудиоданные костной проводимости и аудиоданные воздушной проводимости представляют одну и ту же речь пользователя. Аудиоданные воздушной проводимости включают в себя шумы. На фиг.13B показана частотно-временная диаграмма сшитых аудиоданных, выработанных путем сшивания аудиоданных костной проводимости и предварительно обработанных аудиоданных воздушной проводимости согласно некоторым вариантам осуществления настоящего раскрытия. Предварительно обработанные аудиоданные воздушной проводимости были выработаны путем очистки от шума аудиоданных воздушной проводимости с использованием фильтра Винера. На фиг.13C показана частотно-временная диаграмма сшитых аудиоданных, выработанных путем сшивания аудиоданных костной проводимости и других предварительно обработанных аудиоданных воздушной проводимости согласно некоторым вариантам осуществления настоящего раскрытия. Другие предварительно обработанные аудиоданные были выработаны путем очистки от шума аудиоданных воздушной проводимости с использованием метода спектрального вычитания. Частотно-временные диаграммы объединенных аудиоданных на фиг.13A-13C были выработаны в соответствии с тем же частотным порогом 2000 Гц в соответствии с процессом 900. Как показано на фиг.13A-13C, частотные составляющие сшитых аудиоданных на фиг.13B (например, область M) и фиг.13C (например, область N) выше 2000 Гц имеют меньше шумов, чем частотные составляющие сшитых аудиоданных на фиг.13A (например, область O) выше 2000 Гц, что указывает на то, что объединенные аудиоданные, выработанные на основе очищенных от шума аудиоданных воздушной проводимости, имеют лучшую точность воспроизведения, чем сшитые аудиоданные, выработанные на основе аудиоданных воздушной проводимости, которые не были очищены от шума. Частотные составляющие сшитых аудиоданных, показанных на фиг.13B, выше 2000 Гц отличаются от частотных составляющих сшитых аудиоданных, показанных на фиг.13C, выше 2000 Гц из-за различных технологий очистки от шума, применяемых к аудиоданным воздушной проводимости. Как показано на фиг.13B и 13C, частотные составляющие сшитых аудиоданных на фиг.13B (например, область M) выше 2000 Гц имеют меньше шумов, чем частотные составляющие сшитых аудиоданных на фиг.13C (например, область N) выше 2000 Гц.
Пример 5. Примерные частотно-временные диаграммы объединенных аудиоданных, выработанных в соответствии с различными частотными порогами
На фиг.14А показана частотно-временная диаграмма аудиоданных костной проводимости. На фиг.14B показана частотно-временная диаграмма аудиоданных воздушной проводимости, соответствующих аудиоданным костной проводимости. Аудиоданные костной проводимости (например, первые аудиоданные, как это описано со ссылкой на фиг.5) и аудиоданные воздушной проводимости (например, вторые аудиоданные, как это описано со ссылкой на фиг.5) одновременно собирались датчиком костной проводимости и датчиком воздушной проводимости, соответственно, тогда, когда пользователь говорит. На фиг.14C-14E показаны частотно-временные диаграммы сшитых аудиоданных, выработанных путем сшивания аудиоданных костной проводимости и аудиоданных воздушной проводимости при частотном пороге (или частотной точке) 2000 Гц, 3000 Гц и 4000 Гц, соответственно, согласно некоторым вариантам осуществления настоящего раскрытия. Сравнивая частотно-временные диаграммы объединенных аудиоданных, показанные на фиг.14C-14E с частотно-временной диаграммой аудиоданных воздушной проводимости, показанной на фиг.14B, количество шумов в сшитых аудиоданных, показанных на фиг.14C, 14D и 14E, меньше, чем в аудиоданных воздушной проводимости. Чем выше частотный порог, тем меньше шумов в сшиваемых аудиоданных. Сравнивая частотно-временные диаграммы объединенных аудиоданных, показанные на фиг.14C-14E, с частотно-временной диаграммой аудиоданных костной проводимости, показанной на фиг.14A, частотные составляющие ниже частотных порогов 2000 Гц, 3000 Гц и 4000 Гц, соответственно, показанных на фиг.14C-14E, увеличиваются по отношению к частотным составляющим, меньшим, чем частотные пороги 2000 Гц, 3000 Гц и 4000 Гц, показанные на фиг.14А.
Следует отметить, что представленное выше описание приведено исключительно в целях иллюстрации и не предназначено для ограничения объема настоящего раскрытия. Для специалистов в данной области техники могут быть сделаны многочисленные изменения и модификации в соответствии с идеями настоящего раскрытия. Однако эти вариации и модификации не выходят за рамки настоящего раскрытия.
Таким образом, после описания основных концепций специалистам в данной области техники после прочтения этого подробного раскрытия будет очевидно, что предыдущее подробное раскрытие предназначено для представления только в качестве примера и не является ограничивающим. Возможны различные изменения, улучшения и модификации, предназначенные для специалистов в данной области техники, хотя это прямо не указано в данном документе. Предполагается, что эти изменения, улучшения и модификации предложены в настоящем раскрытии и находятся в пределах сущности и объема примерных вариантов осуществления настоящего раскрытия.
Более того, для описания вариантов осуществления настоящего раскрытия использовалась определенная терминология. Например, термины «один вариант осуществления», «вариант осуществления» и/или «некоторые варианты осуществления» означают, что конкретный признак, структура или характеристика, описанные в связи с вариантом осуществления, включены по меньшей мере в один вариант осуществления настоящего раскрытия. Таким образом, следует подчеркнуть, что две или более ссылок на «вариант осуществления», или «один вариант осуществления», или «альтернативный вариант осуществления» в различных частях настоящего описания не обязательно полностью относятся к одному и тому же варианту осуществления. Кроме того, конкретные признаки, структуры или характеристики могут быть объединены в соответствии с одним или несколькими вариантами осуществления настоящего раскрытия.
Кроме того, специалисту в данной области техники будет понятно, что аспекты настоящего раскрытия могут быть проиллюстрированы и описаны в данном документе в любом из ряда патентоспособных классов или контекстов, включая любой новый и полезный процесс, машину, изготовление или состав вещества или любое новое и полезное их улучшение. Соответственно, аспекты настоящего раскрытия могут быть реализованы полностью с помощью аппаратных средств, полностью с помощью программных средств (включая встроенное программно-аппаратные средства, резидентное программное обеспечение, микрокод и т.д.) или сочетать в себе программную и аппаратную реализацию, которые в целом могут упоминаться в данном документе как «блок», «модуль» или «система». Кроме того, аспекты настоящего раскрытия могут принимать форму компьютерного программного продукта, воплощенного на одном или нескольких машиночитаемых носителях информации, имеющих компьютерно- читаемую программу, воплощенную на них.
Невременный машиночитаемый носитель сигнала может включать в себя распространяющийся сигнал данных с воплощенным в нем машиночитаемым программным кодом, например, в основной полосе частот или как часть несущей волны. Такой распространяющийся сигнал может принимать любую из множества форм, включая электромагнитную, оптическую и т.п. или любое их подходящее сочетание. Машиночитаемый носитель сигналов может быть любым машиночитаемым носителем информации, который не является машиночитаемым носителем информации и который может передавать, распространять или транспортировать программу для использования системой, аппаратным устройством или устройством исполнения инструкций или в связи с ними. Программный код, воплощенный на машиночитаемом носителе сигнала, может быть передан с использованием любого подходящего носителя, включая беспроводную связь, проводную связь, оптоволоконный кабель, РЧ и т.п. или любого подходящего их сочетания.
Код компьютерной программы для выполнения операций для аспектов настоящего раскрытия может быть написан в любом сочетании из одного или нескольких языков программирования, включая объектно-ориентированный язык программирования, такой как Java, Scala, Smalltalk, Eiffel, JADE, Emerald, С++, С#, VB. NET, Python и т.п., традиционные процедурные языки программирования, такие как язык программирования "C", Visual Basic, Fortran, Perl, COBOL, PHP, ABAP, языки динамического программирования, такие как Python, Ruby и Groovy, или другие языки программирования. Программный код может исполняться полностью на компьютере пользователя, частично на компьютере пользователя, как отдельный программный пакет, частично на компьютере пользователя и частично на удаленном компьютере или полностью на удаленном компьютере или сервере. В последнем случае удаленный компьютер может быть подключен к компьютеру пользователя через сеть любого типа, включая локальную сеть (LAN) или глобальную сеть (WAN), или подключение может быть выполнено к внешнему компьютеру (например, через Интернет с использованием интернет-провайдера) или в среде облачных вычислений, или предлагается в виде услуги, такой как программное обеспечение как услуга (SaaS).
Кроме того, приведенный порядок элементов или последовательностей обработки или использование цифр, букв или других обозначений, таким образом, не предназначен для ограничения заявленных процессов и способов каким-либо порядком, за исключением того, который может быть указан в формуле изобретения. Хотя в приведенном выше раскрытии на различных примерах обсуждено то, что в настоящее время считается множеством полезных вариантов осуществления изобретения, следует отметить, что такие детали предназначены исключительно для этой цели и что прилагаемая формула изобретения не ограничивается раскрытыми вариантами осуществления, но, напротив, предназначены для охвата модификаций и эквивалентных компоновок, которые находятся в пределах сущности и объема раскрытых вариантов осуществления. Например, хотя реализация различных компонентов, описанных выше, может быть воплощена в аппаратном устройстве, она также может быть реализована как чисто программное решение, например, установка на существующем сервере или мобильном устройстве.
Аналогичным образом, следует отметить, что в приведенном выше описании вариантов осуществления настоящего раскрытия различные признаки иногда сгруппированы вместе в одном варианте осуществления, фигуре или ее описании, чтобы упорядочить раскрытие и помочь в понимании одного или нескольких из различных вариантов осуществления изобретения, обладающих изобретательским уровнем. Этот способ раскрытия, однако, не следует интерпретировать как отражающий намерение о том, что заявленный предмет требует большего количества признаков, чем прямо указано в каждом пункте формулы изобретения. Скорее, варианты осуществления, обладающих изобретательским уровнем, заключаются не во всех признаках одного вышеизложенного раскрытого варианта осуществления.
В некоторых вариантах осуществления числа, выражающие количество, свойства и т.д., используемые для описания и утверждения определенных вариантов осуществления настоящей заявки, следует понимать как модифицированные в некоторых случаях термином «около», «приблизительно» или «по существу». Например, «около», «приблизительно» или «по существу» может означать отклонение ±20% описываемого значения, если не указано иное. Соответственно, в некоторых вариантах осуществления числовые параметры, указанные в письменном описании и сопроводительной формуле изобретения, являются приближенными значениями, которые могут варьироваться в зависимости от желаемых свойств, которые должны быть получены в конкретном варианте осуществления. В некоторых вариантах осуществления числовые параметры следует интерпретировать с учетом количества сообщаемых значащих цифр и путем применения обычных методов округления. Несмотря на то, что числовые диапазоны и параметры, определяющие широкий объем некоторых вариантов осуществления настоящей заявки, являются приблизительными, числовые значения, указанные в конкретных примерах, представлены настолько точно, насколько это практически возможно.
Все упоминаемые здесь патенты, патентные заявки, опубликованные патентные заявки и другой материал, такой как статьи, книги, технические описания, публикации, документы, предметы и/или т.п., включены в настоящий документ полностью для всех целей посредством данной ссылки, исключая любые связанные с ними материалы делопроизводства, и любые из указанных материалов, не согласующиеся с настоящим документом или противоречащие ему, или любые из указанных материалов, которые могут ограничивать максимальный объем формулы настоящего изобретения, в настоящий момент или позже связанной с настоящим документом. Например, в случае возникновения несоответствия или конфликта между описанием, определением и/или использованием термина, связанным с любым включенным материалом, и использованием термина, связанным с настоящим документом, преимущественную силу будет иметь описание, определение и/или использование термина в настоящем документе.
В заключение следует отметить, что варианты осуществления настоящей заявки, раскрытые в данном документе, иллюстрируют принципы вариантов осуществления настоящей заявки. Другие модификации, которые могут быть использованы, могут находиться в пределах объема настоящей заявки. Таким образом, в качестве примера, но не ограничения, альтернативные конфигурации вариантов осуществления настоящей заявки могут быть использованы в соответствии с идеями, изложенными в данном документе. Соответственно, варианты осуществления настоящей заявки не ограничиваются именно тем, что показано и описано.
| название | год | авторы | номер документа |
|---|---|---|---|
| ОЧКИ | 2020 |
|
RU2809947C1 |
| НАУШНИКИ | 2021 |
|
RU2807021C1 |
| УПРАВЛЕНИЕ АКУСТИЧЕСКОЙ ЭХОКОМПЕНСАЦИЕЙ ДЛЯ РАСПРЕДЕЛЕННЫХ АУДИОУСТРОЙСТВ | 2020 |
|
RU2818982C2 |
| СПОСОБЫ ОПТИМИЗАЦИИ РАБОЧЕГО СОСТОЯНИЯ НАУШНИКОВ С КОСТНОЙ ПРОВОДИМОСТЬЮ | 2021 |
|
RU2801826C1 |
| СПОСОБ МНОГОСЕНСОРНОГО УЛУЧШЕНИЯ РЕЧИ НА МОБИЛЬНОМ РУЧНОМ УСТРОЙСТВЕ И МОБИЛЬНОЕ РУЧНОЕ УСТРОЙСТВО | 2005 |
|
RU2376722C2 |
| СИСТЕМЫ И СПОСОБЫ УПРАВЛЕНИЯ ОКОНЕЧНЫМ УСТРОЙСТВОМ | 2021 |
|
RU2806269C1 |
| СПОСОБЫ ОБУЧЕНИЯ МОДЕЛИ И КОНВЕРСИИ ГОЛОСА И УСТРОЙСТВО, ДРУГОЕ УСТРОЙСТВО И НОСИТЕЛЬ ДАННЫХ | 2022 |
|
RU2830834C2 |
| СИСТЕМЫ И СПОСОБЫ ДЛЯ ОПРЕДЕЛЕНИЯ СОСТОЯНИЯ СЛУХОВОГО УСТРОЙСТВА С КОСТНОЙ ПРОВОДИМОСТЬЮ | 2020 |
|
RU2803486C1 |
| СИСТЕМЫ, СПОСОБЫ И УСТРОЙСТВА ДЛЯ ВЫВОДА АКУСТИЧЕСКИХ СИГНАЛОВ | 2020 |
|
RU2807171C1 |
| СИСТЕМЫ И СПОСОБЫ УСТРАНЕНИЯ ШУМОВ | 2019 |
|
RU2797926C1 |
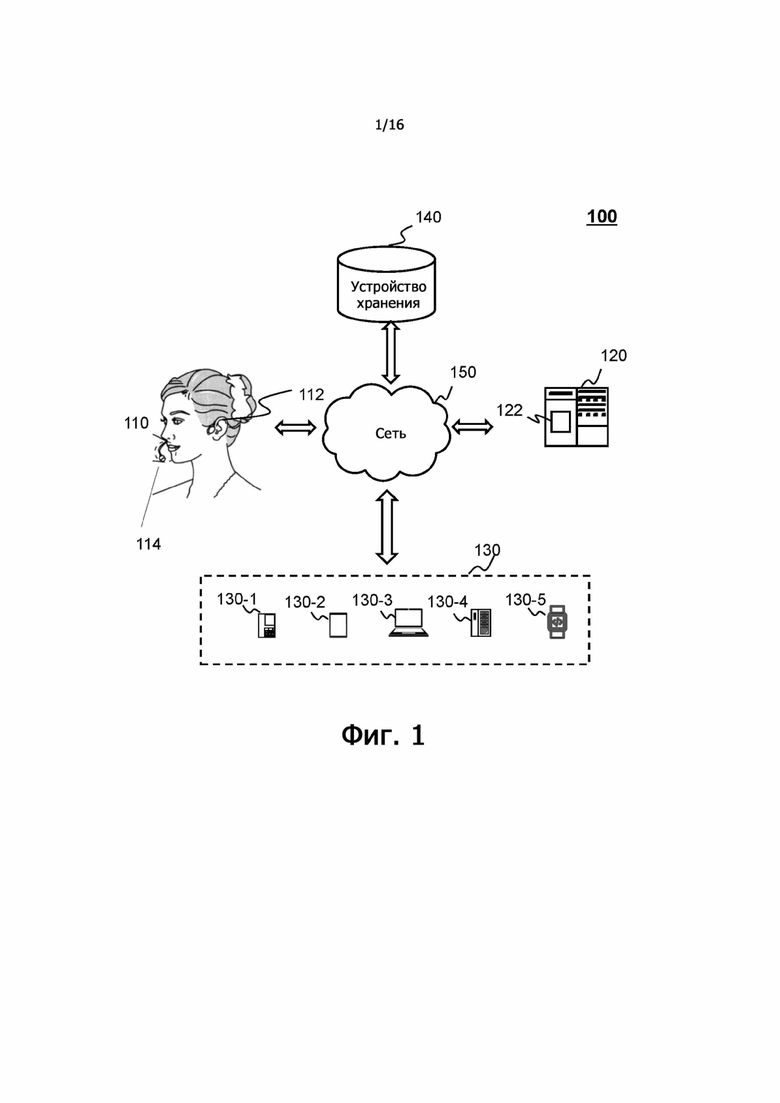
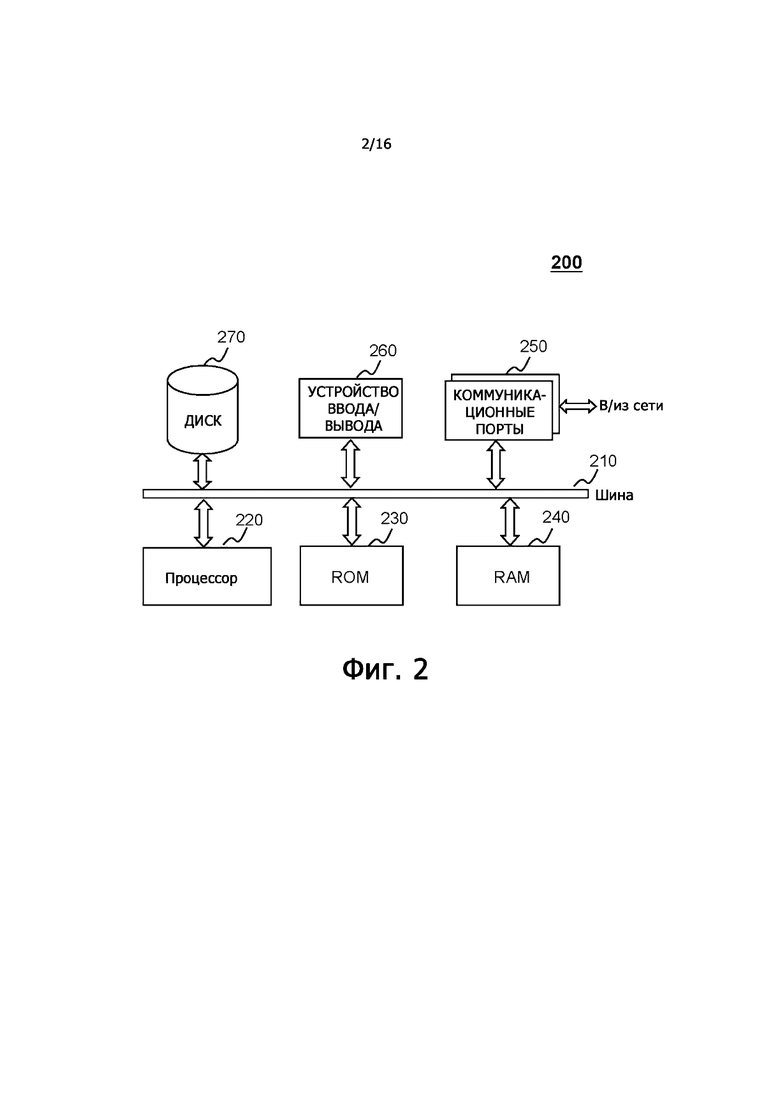
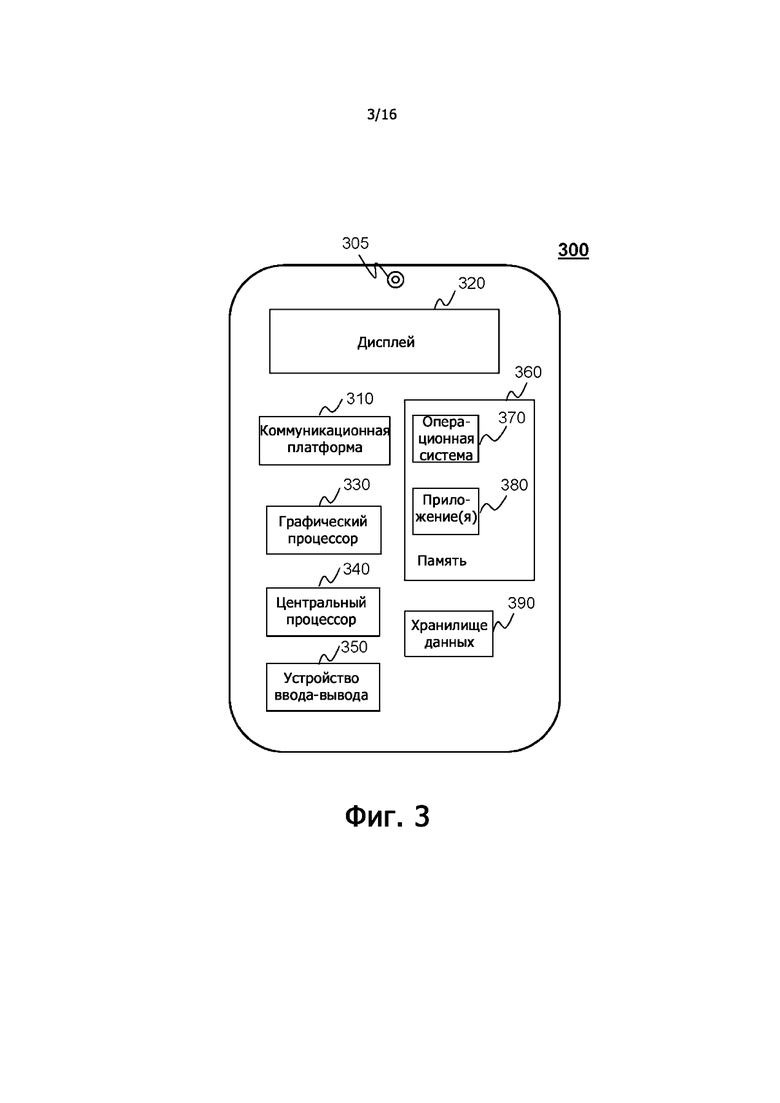
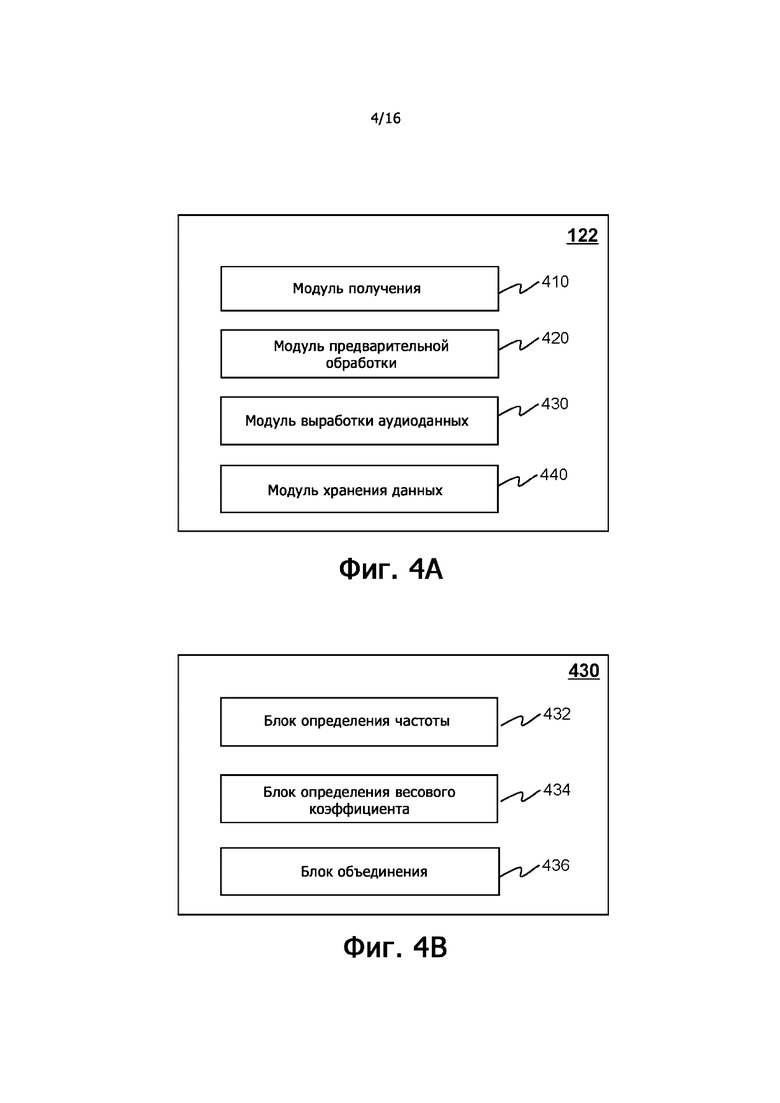
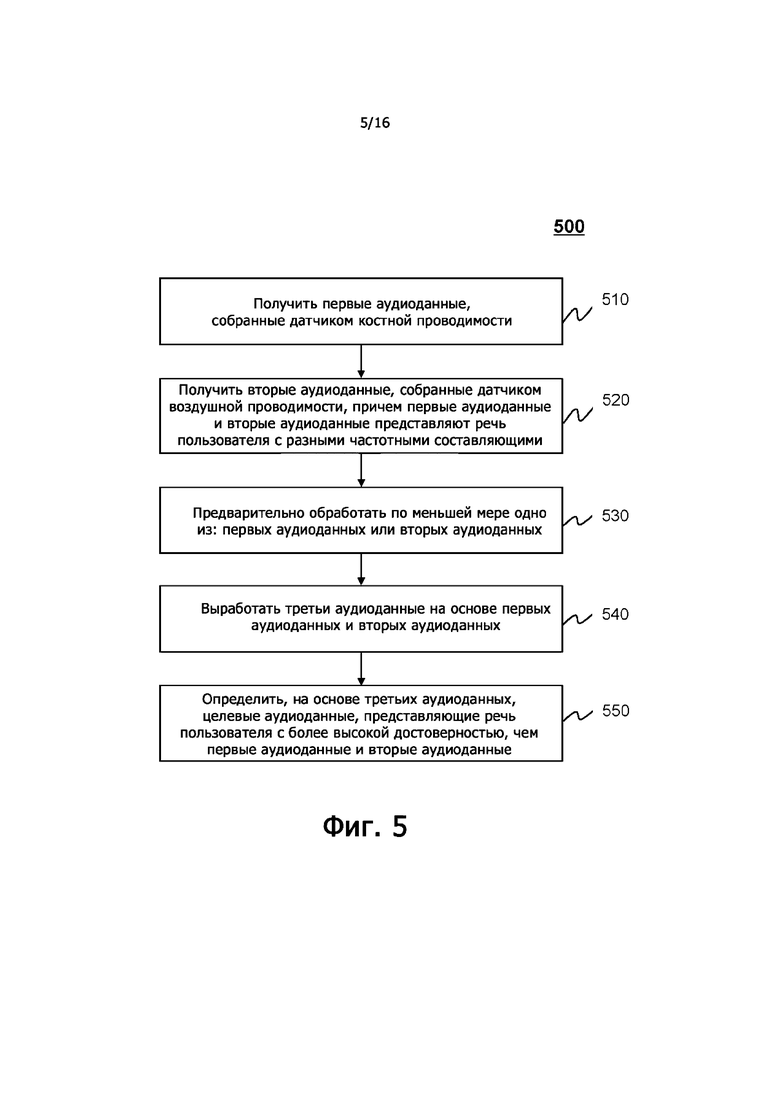
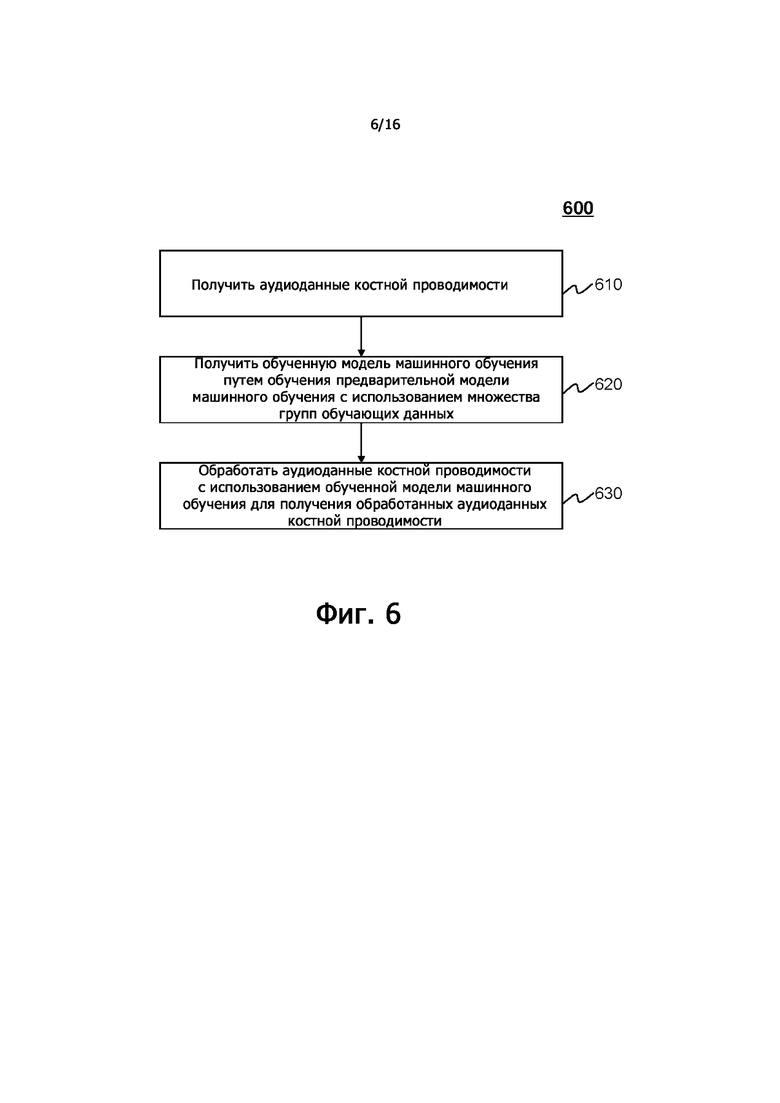
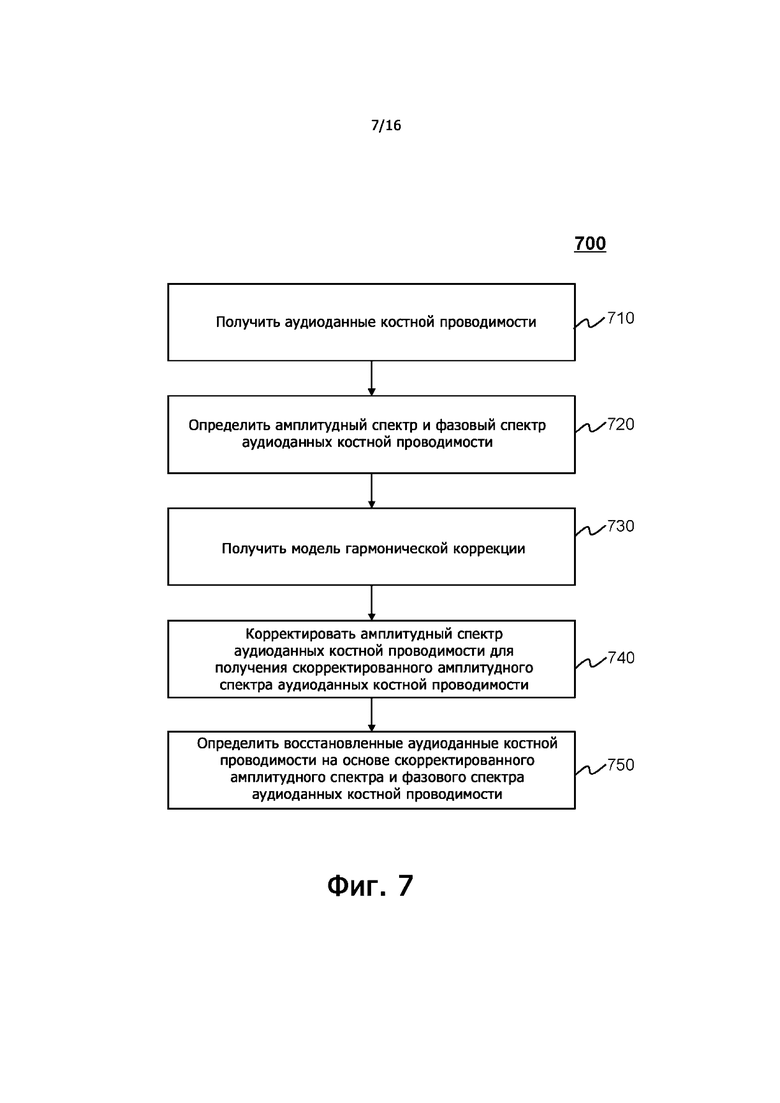
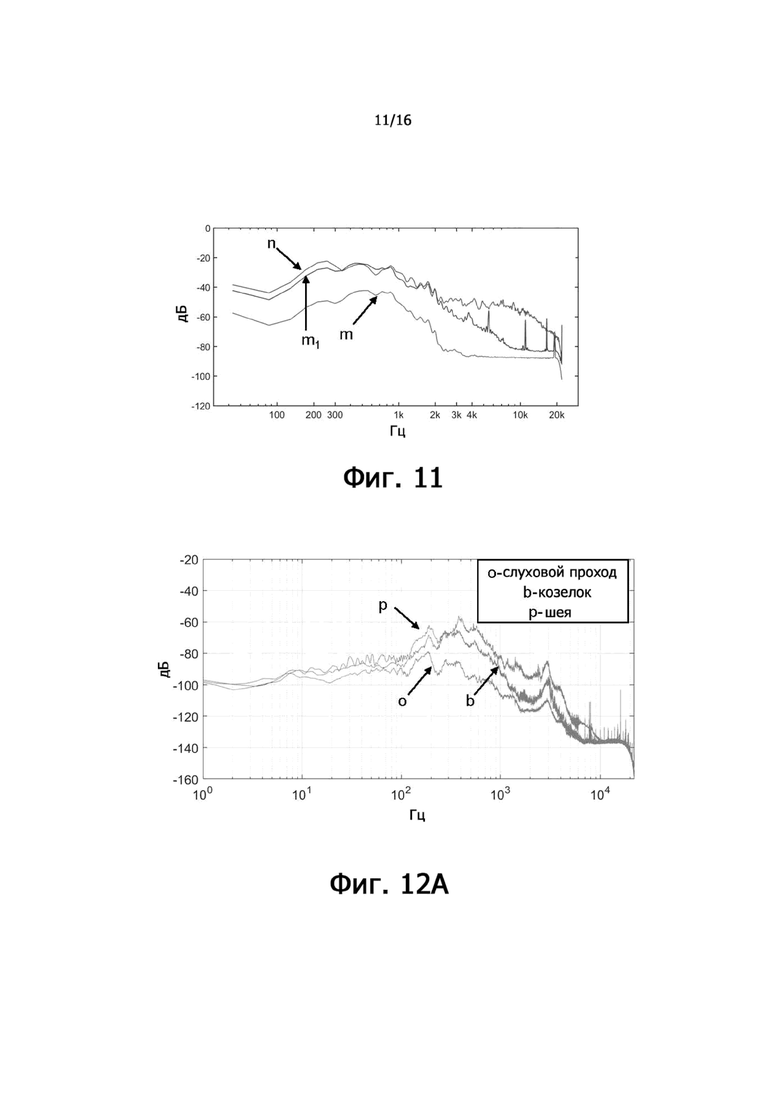
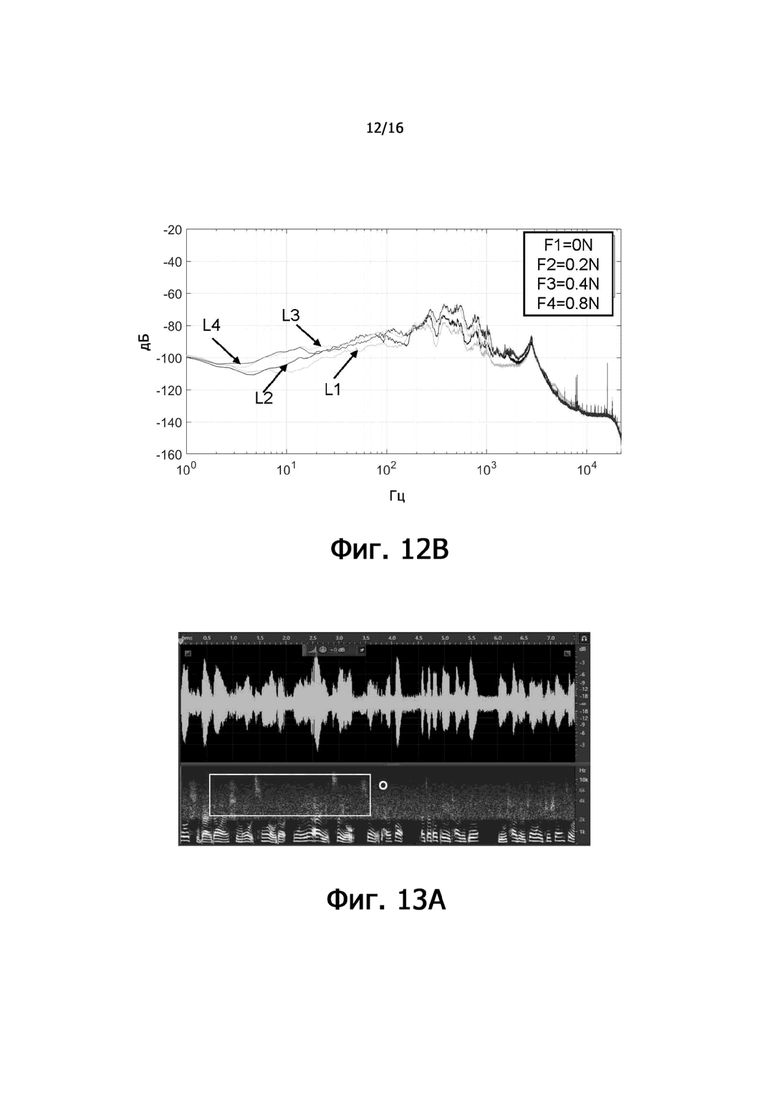
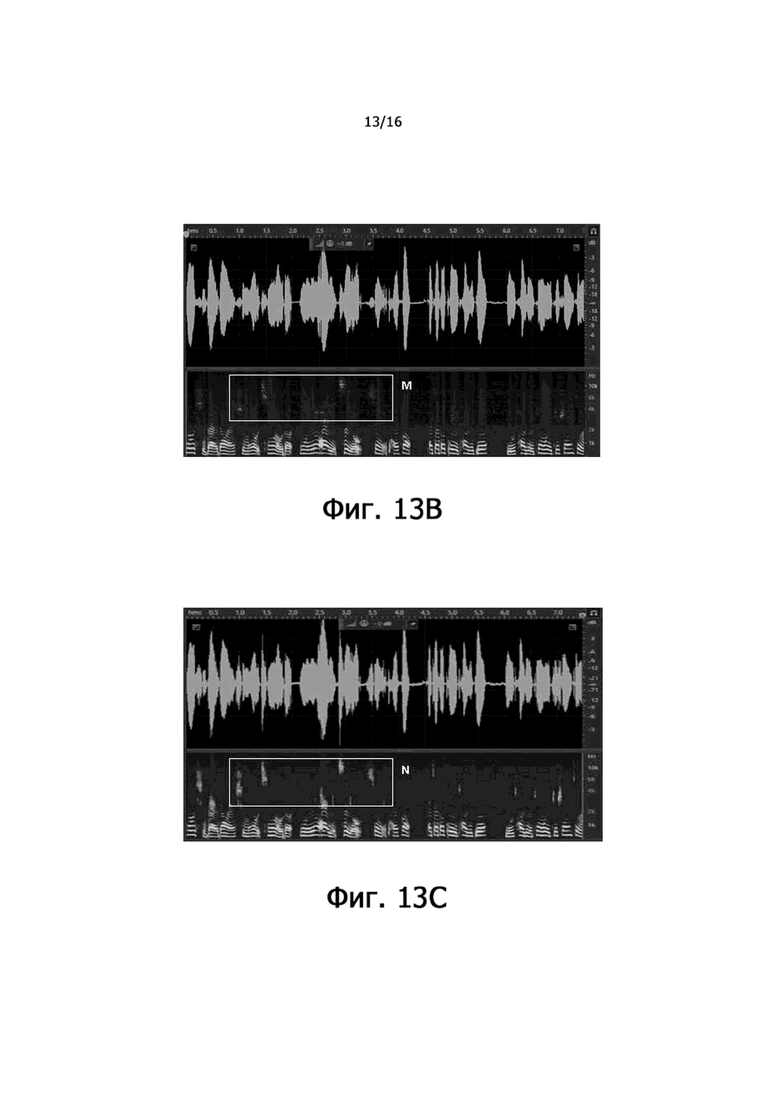

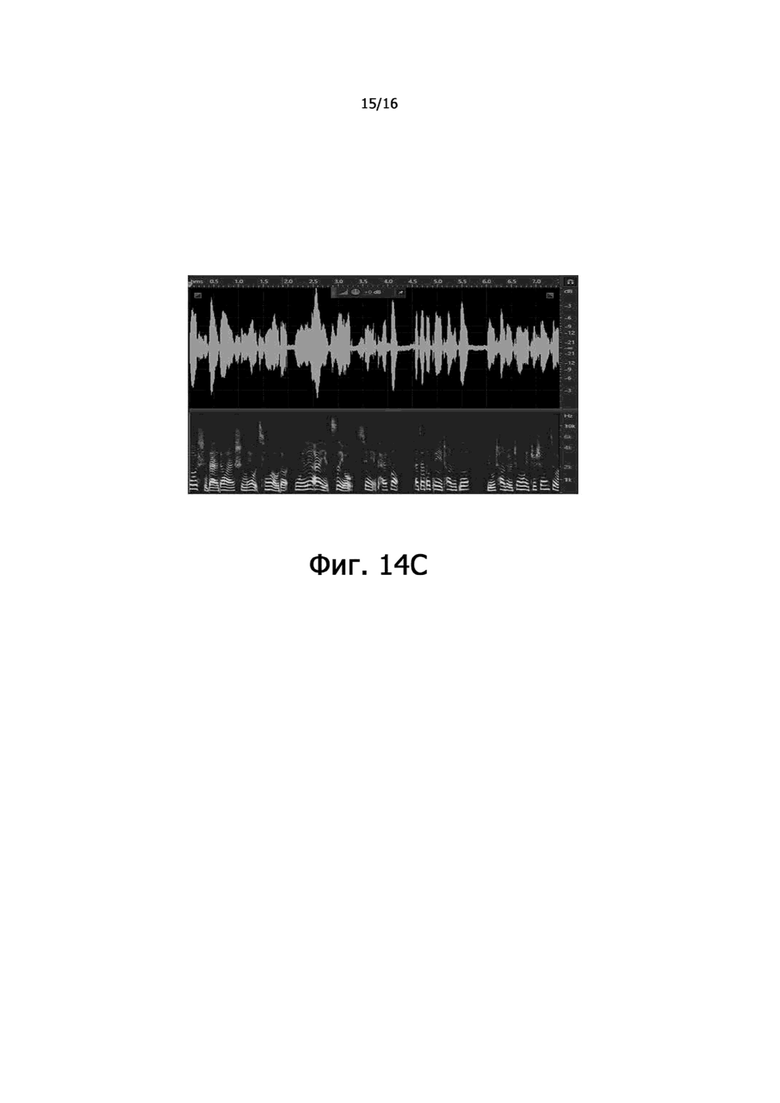
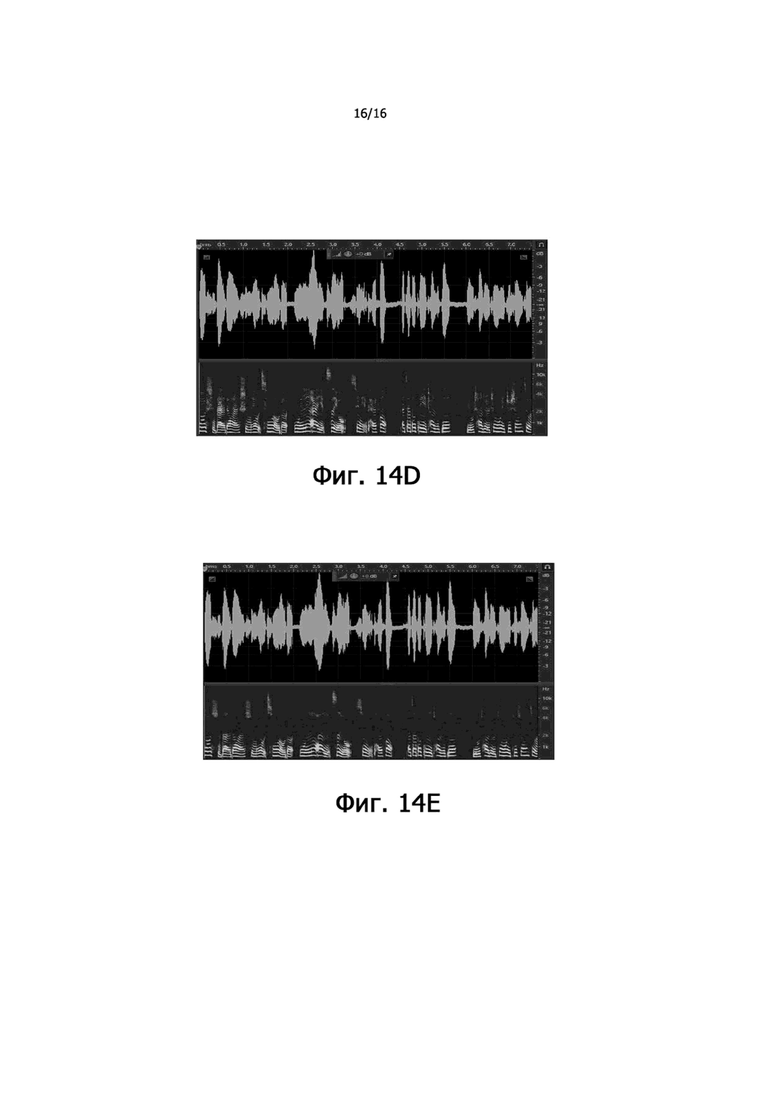
Изобретение относится к области обработки сигналов, в частности к системам и способам выработки аудиосигнала на основе аудиосигнала костной проводимости и аудиосигнала воздушной проводимости. Техническим результатом является создание систем и способов выработки аудиосигнала с меньшим количеством шумов и/или повышенным качеством. Заявленный способ включает в себя этапы, на которых получают первые аудиоданные, собранные датчиком костной проводимости, и вторые аудиоданные, собранные датчиком воздушной проводимости, причем первые аудиоданные и вторые аудиоданные представляют речь пользователя с отличающимися частотными составляющими. Далее на основе первых аудиоданных и вторых аудиоданных вырабатывают третьи аудиоданные, причем частотные составляющие третьих аудиоданных выше частотной точки увеличиваются по отношению к частотным составляющим первых аудиоданных выше первой частотной точки. Затем определяют множество частотных диапазонов согласно одному или более частотных порогов, причем указанный один или более частотных порогов определяются на основе значений частотной характеристики кривой частотной характеристики, ассоциированной с первыми аудиоданными. Определяют первый и второй весовые коэффициенты для участков первых и вторых аудиоданных, расположенных соответственно в каждом из множества частотных диапазонов, и определяют третьи аудиоданные путем взвешивания с использованием весовых коэффициентов участка первых аудиоданных и участка вторых аудиоданных. Заявлены также система выработки аудиосигнала и энергонезависимый машиночитаемый носитель информации. 3 н. и 4 з.п. ф-лы, 22 ил.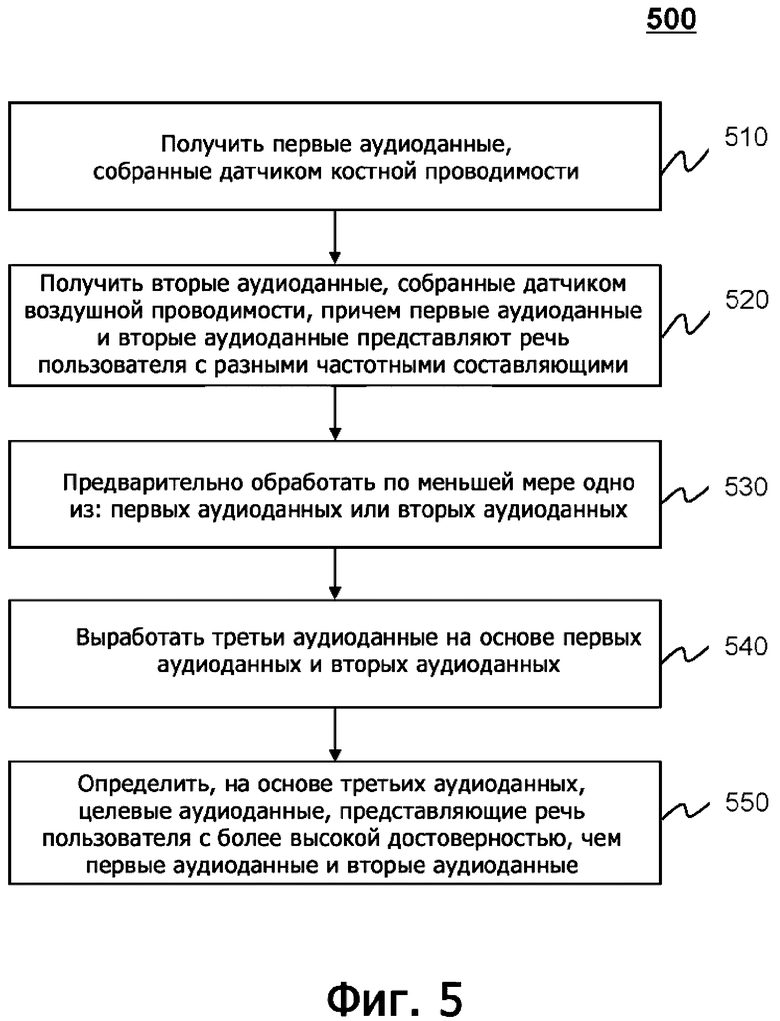
1. Способ выработки аудиосигнала, реализуемый на вычислительном устройстве, причем вычислительное устройство включает в себя по меньшей мере один процессор и по меньшей мере одно запоминающее устройство, при этом способ содержит этапы, на которых:
получают первые аудиоданные, собранные датчиком костной проводимости;
получают вторые аудиоданные, собранные датчиком воздушной проводимости, причем первые аудиоданные и вторые аудиоданные представляют речь пользователя с отличающимися частотными составляющими; и
вырабатывают, на основе первых аудиоданных и вторых аудиоданных, третьи аудиоданные, причем частотные составляющие третьих аудиоданных выше первой частотной точки увеличиваются по отношению к частотным составляющим первых аудиоданных выше первой частотной точки, при этом на этапе выработки третьих аудиоданных на основе первых аудиоданных и вторых аудиоданных:
определяют множество частотных диапазонов согласно одному или более частотных порогов, причем указанный один или более частотных порогов определяются на основе значений частотной характеристики кривой частотной характеристики, ассоциированной с первыми аудиоданными;
определяют первый весовой коэффициент и второй весовой коэффициент для участка первых аудиоданных и участка вторых аудиоданных, расположенных соответственно в каждом из множества частотных диапазонов; и
определяют третьи аудиоданные путем взвешивания участка первых аудиоданных и участка вторых аудиоданных, расположенных в каждом из множества частотных диапазонов, с использованием соответственно первого весового коэффициента и второго весового коэффициента.
2. Способ по п.1, в котором на этапе выработки третьих аудиоданных на основе первых аудиоданных и вторых аудиоданных:
выполняют первую операцию предварительной обработки первых аудиоданных для получения предварительно обработанных первых аудиоданных; и
определяют третьи аудиоданные путем взвешивания участка предварительно обработанных первых аудиоданных и участка вторых аудиоданных, расположенных в каждом из множества частотных диапазонов, с использованием соответственно первого весового коэффициента и второго весового коэффициента.
3. Способ по п.2, в котором на этапе выполнения первой операции предварительной обработки первых аудиоданных для получения предварительно обработанных первых аудиоданных:
получают обученную модель машинного обучения; и
определяют, на основе первых аудиоданных, предварительно обработанные первые аудиоданные с использованием обученной модели машинного обучения, при этом частотные составляющие предварительно обработанных первых аудиоданных выше второй частотной точки увеличиваются по отношению к частотным составляющим первых аудиоданных выше второй частотной точки,
при этом обученная модель машинного обучения предоставляется в процессе, включающем в себя этапы, на которых:
получают множество групп обучающих данных, причем каждая группа из множества групп обучающих данных включает в себя аудиоданные костной проводимости и аудиоданные воздушной проводимости, представляющие выборку речи; и
обучают предварительную модель машинного обучения с использованием множества групп обучающих данных, при этом аудиоданные костной проводимости в каждой группе из множества групп обучающих данных являются входными данными предварительной модели машинного обучения, а аудиоданные воздушной проводимости, соответствующие аудиоданным костной проводимости, являются требуемыми выходными данными предварительной модели машинного обучения в процессе обучения предварительной модели машинного обучения.
4. Способ по п.2, в котором на этапе выполнения первой операции предварительной обработки первых аудиоданных для получения предварительно обработанных первых аудиоданных:
получают фильтр, выполненный с возможностью обеспечения взаимосвязи между конкретными аудиоданными воздушной проводимости и конкретными аудиоданными костной проводимости, соответствующими конкретным аудиоданным воздушной проводимости; и
определяют предварительно обработанные первые аудиоданные с использованием фильтра для обработки первых аудиоданных.
5. Способ по п.1, в котором на этапе определения указанного одного или более частотных порогов на основе значений частотной характеристики кривой частотной характеристики, ассоциированной с первыми аудиоданными:
определяют указанный один или более частотный порог на основе изменения значений частотной характеристики кривой частотной характеристики, ассоциированной с первыми аудиоданными.
6. Система выработки аудиосигнала, содержащая:
модуль получения, выполненный с возможностью получения первых аудиоданных, собранных датчиком костной проводимости, и вторых аудиоданных, собранных датчиком воздушной проводимости, причем первые аудиоданные и вторые аудиоданные представляют речь пользователя с отличающимися частотными составляющими; и
модуль выработки аудиоданных, выполненный с возможностью выработки, на основе первых аудиоданных и вторых аудиоданных, третьих аудиоданных, причем частотные составляющие третьих аудиоданных выше первой частотной точки увеличиваются по отношению к частотным составляющим первых аудиоданных выше первой частотной точки, при этом для выработки третьих аудиоданных на основе первых аудиоданных и вторых аудиоданных модуль выработки аудиоданных выполнен с возможностью:
определения множества частотных диапазонов согласно одному или более частотных порогов, причем указанный один или более частотных порогов определяются на основе значений частотной характеристики кривой частотной характеристики, ассоциированной с первыми аудиоданными;
определения первого весового коэффициента и второго весового коэффициента для участка первых аудиоданных и участка вторых аудиоданных, расположенных соответственно в каждом из множества частотных диапазонов; и
определения третьих аудиоданных путем взвешивания участка первых аудиоданных и участка вторых аудиоданных, расположенных в каждом из множества частотных диапазонов, с использованием соответственно первого весового коэффициента и второго весового коэффициента.
7. Энергонезависимый машиночитаемый носитель информации, содержащий набор инструкций, причем при их исполнении по меньшей мере одним процессором набор инструкций вызывает выполнение указанным по меньшей мере одним процессором действий, на которых:
получают первые аудиоданные, собранные датчиком костной проводимости;
получают вторые аудиоданные, собранные датчиком воздушной проводимости, причем первые аудиоданные и вторые аудиоданные представляют речь пользователя с отличающимися частотными составляющими; и
вырабатывают, на основе первых аудиоданных и вторых аудиоданных, третьи аудиоданные, при этом частотные составляющие третьих аудиоданных выше первой частотной точки увеличиваются по отношению к частотным составляющим первых аудиоданных выше первой частотной точки, при этом на этапе выработки третьих аудиоданных на основе первых аудиоданных и вторых аудиоданных:
определяют множество частотных диапазонов согласно одному или более частотных порогов, причем указанный один или более частотных порогов определяются на основе значений частотной характеристики кривой частотной характеристики, ассоциированной с первыми аудиоданными;
определяют первый весовой коэффициент и второй весовой коэффициент для участка первых аудиоданных и участка вторых аудиоданных, расположенных соответственно в каждом из множества частотных диапазонов; и
определяют третьи аудиоданные путем взвешивания участка первых аудиоданных и участка вторых аудиоданных, расположенных в каждом из множества частотных диапазонов, с использованием соответственно первого весового коэффициента и второго весового коэффициента.
| Способ дуговой сварки стыковых вертикальных соединений | 2023 |
|
RU2811485C1 |
| JP 2007251354 A, 27.09.2007 | |||
| JP 2014096732 A, 22.05.2014 | |||
| CN 109982179 A, 05.07.2019 | |||
| US 5933506 A, 03.08.1999 | |||
| СПОСОБ МНОГОСЕНСОРНОГО УЛУЧШЕНИЯ РЕЧИ НА МОБИЛЬНОМ РУЧНОМ УСТРОЙСТВЕ И МОБИЛЬНОЕ РУЧНОЕ УСТРОЙСТВО | 2005 |
|
RU2376722C2 |
| ПОВЫШЕНИЕ КАЧЕСТВА РЕЧИ С ИСПОЛЬЗОВАНИЕМ МНОЖЕСТВА ДАТЧИКОВ С ПОМОЩЬЮ МОДЕЛИ СОСТОЯНИЙ РЕЧИ | 2006 |
|
RU2420813C2 |
