Область техники, к которой относится изобретение
Настоящее изобретение, в общем, относится к обновлению объектов данных через сети с ограниченной пропускной способностью. Более конкретно, настоящее изобретение относится к системе и способу для дифференциальной передачи данных объекта с использованием методики удаленного дифференциального сжатия (RDC). Для дополнительной минимизации нагрузки пропускной способности при передаче больших объектов может использоваться рекурсивное применение методики RDC.
Предшествующий уровень техники
Быстрый рост сетей, таких как сети интранет (корпоративные локальные сети), экстранет (объединение корпоративных сетей, взаимодействующих через Интернет) и интернет (группа связанных маршрутизаторами сетей, способная функционировать как одна большая виртуальная сеть) привело к большому росту количества пользователей, которые совместно используют информацию через широко распространенные сети. Максимальная скорость передачи данных, соответствующая каждой физической сети, основывается на пропускной способности, соответствующей среде передачи, а также других ограничениях, связанных с инфраструктурой. В результате ограниченной пропускной способности сети пользователи могут испытывать длительные задержки в извлечении и передаче через сеть больших объемов данных.
Распространенным способом передачи через сеть с ограниченной пропускной способностью больших объемов данных стали способы сжатия данных. Сжатие данных может быть охарактеризовано, в основном, как сжатие без потерь или с потерями. Сжатие без потерь включает в себя такое преобразование набора данных, чтобы при применении преобразования восстановления (сжатых данных) могло быть восстановлено точное воспроизведение набора данных. Сжатие без потерь наиболее часто используется для уплотнения данных, когда требуется точная копия.
В случае, где получатель объекта данных уже имеет предыдущую, или более раннюю, версию этого объекта, может быть использован подход сжатия без потерь, называемый удаленным дифференциальным сжатием (RDC), для определения и передачи только отличий между новой и старой версиями объекта. Так как передача RDC включает в себя только передачу отличий, наблюдаемых между новой и старой версиями, (например, в случае файлов, обновления файла или даты последнего доступа, атрибутов файла или небольших изменений содержимого файла), может быть существенно уменьшен общий объем передаваемых данных. Для дополнительного снижения сетевого трафика RDC может быть объединен с другим алгоритмом сжатия без потерь. Преимущества RDC наиболее существенны в случае, где требуется частая передача больших объектов между вычислительными устройствами в прямом и обратном направлении, и затруднительна или неосуществима поддержка старых копий этих объектов, так что локальные дифференциальные алгоритмы не могут быть использованы.
Сущность изобретения
Вкратце, настоящее изобретение относится к способу и системе для обновления объектов через сети с ограниченной пропускной способностью. Осуществляется обновление объектов между двумя или большим количеством вычислительных устройств с использованием способов удаленного дифференциального сжатия (RDC) так, чтобы были минимизированы необходимые передачи данных. Согласно одному аспекту, эффективные передачи больших объектов достигаются при рекурсивном применении алгоритма RDC к его собственным метаданным; в этом случае для уменьшения объема метаданных, передаваемых через сеть алгоритмом RDC, используется один рекурсивный этап или несколько рекурсивных этапов. Объекты и/или списки сигнатур и длин порций могут быть разделены на порции посредством размещения границ в динамически определяемых местоположениях. Математическая функция оценивает значения хеш-функции, ассоциированные в пределах окна горизонта относительно возможной границы порции. Описанные способ и система удобны в ряде приложений с сетевой структурой, таких как одноранговые репликаторы, клиенты и серверы электронной почты, системы кэширования стороны клиента, универсальные утилиты копирования, репликаторы базы данных, порталы, услуги обновления программного обеспечения, синхронизация файлов/данных и другие.
Более полное понимание настоящего изобретения и его усовершенствований может быть получено при обращении к приложенным чертежам, которые кратко описаны ниже, к последующему подробному описанию иллюстративных вариантов осуществления изобретения, и к приложенной формуле изобретения.
ПЕРЕЧЕНЬ ФИГУР ЧЕРТЕЖЕЙ
Варианты осуществления настоящего изобретения, которыми оно не исчерпывается и не ограничивается, описаны согласно следующим чертежам.
Фиг.1 - диаграмма, иллюстрирующая рабочую среду.
Фиг.2 - диаграмма, иллюстрирующая возможный вариант вычислительного устройства.
Фиг.3A и 3B - диаграммы, иллюстрирующие возможную процедуру RDC.
Фиг.4A и 4B - диаграммы, иллюстрирующие последовательности операций взаимодействия между локальным устройством и удаленным устройством в продолжение возможной процедуры RDC.
Фиг.5A и 5B - диаграммы, иллюстрирующие последовательности операций рекурсивного удаленного дифференциального сжатия списков сигнатуры и длины порции при возможном обмене информацией в продолжение процедуры RDC.
Фиг.6 - диаграмма, графически иллюстрирующая возможный вариант рекурсивного сжатия в возможной последовательности RDC.
Фиг.7 - диаграмма, иллюстрирующая взаимодействие между клиентским и серверным приложениями с использованием возможной процедуры RDC.
Фиг.8 - диаграмма, иллюстрирующая последовательность операций для возможной процедуры разделения на порции.
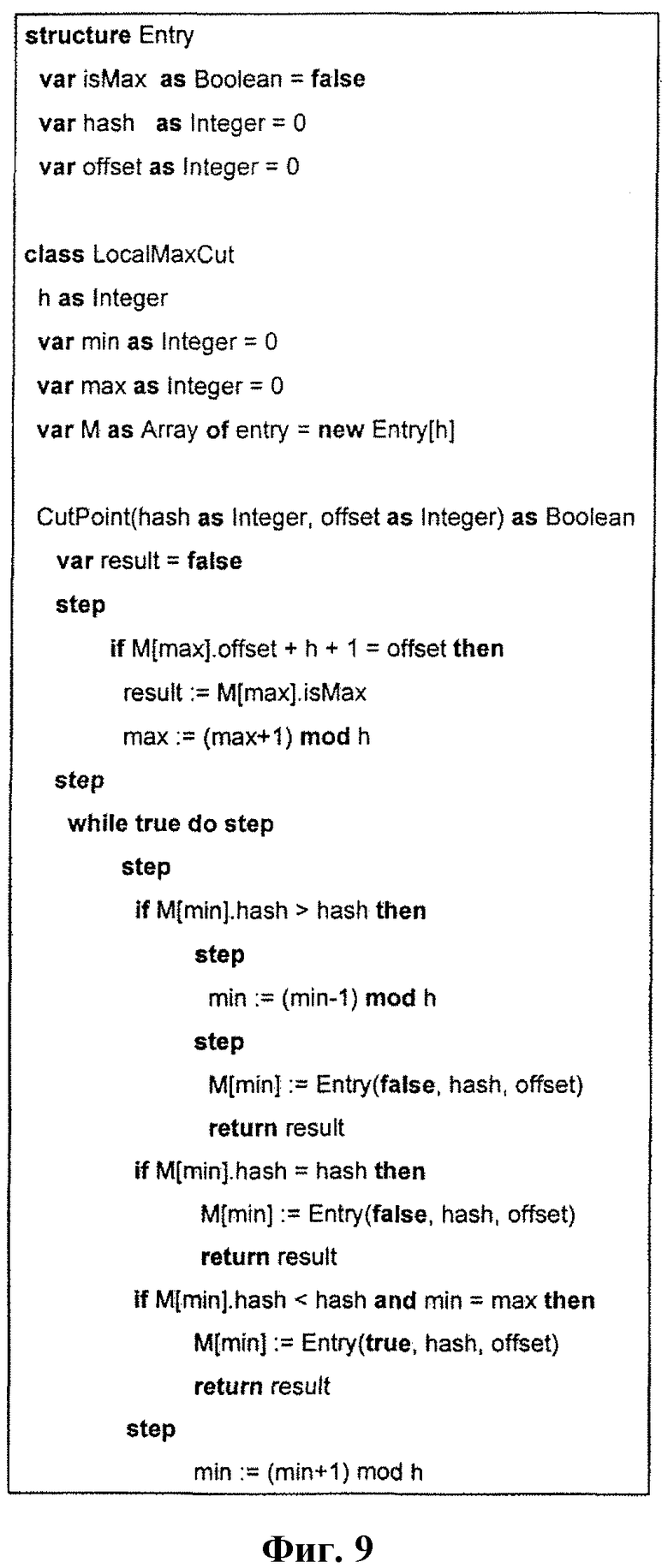
Фиг.9 - диаграмма возможного набора инструкций для возможной процедуры разделения на порции.
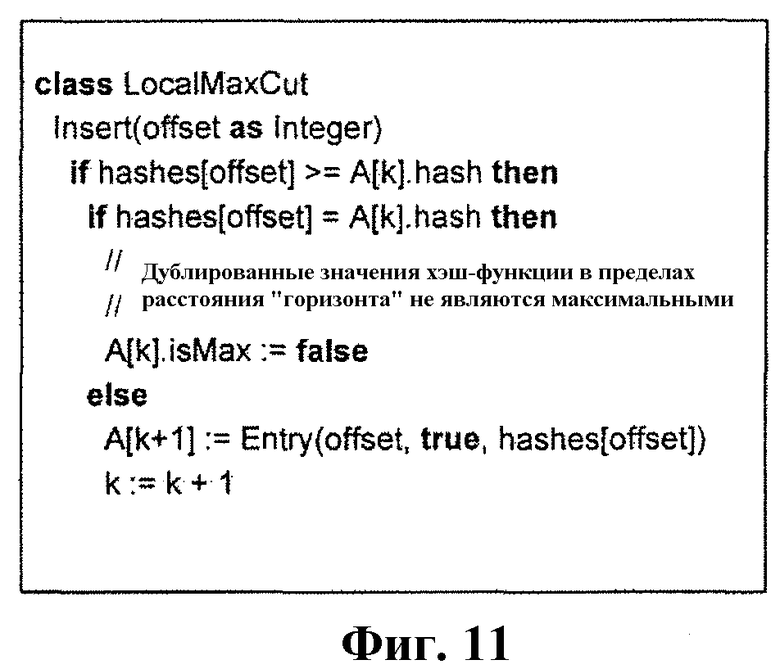
Фиг.10 и 11 - диаграммы другого возможного набора инструкций для другой возможной процедуры разделения на порции, сконфигурированного по меньшей мере согласно одному аспекту настоящего изобретения.
ПОДРОБНОЕ ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНОГО ВАРИАНТА ОСУЩЕСТВЛЕНИЯ
Различные варианты осуществления настоящего изобретения будут подробно описаны со ссылкой на чертежи, где одинаковые ссылочные позиции представляют идентичные части и совокупности в нескольких представлениях. Ссылка на различные варианты осуществления не ограничивает объем изобретения, который ограничен только рамками приложенной формулы изобретения. Дополнительно любые примеры, изложенные в этом описании, не предназначены для наложения ограничения и просто определяют некоторые из многих возможных вариантов осуществления заявленного изобретения.
Настоящее изобретение описано в контексте локальных и удаленных вычислительных устройств (или, для краткости, "устройств"), имеющих один или большее количество общеассоциированных объектов, которые на них хранятся. Термины "локальный" и "удаленный" относятся к одному варианту способа. Однако в различных вариантах одно и то же устройство может играть роль и "локального", и "удаленного". Способы удаленного дифференциального сжатия (RDC) используются для эффективного обновления общеассоциированных объектов через сеть связи с ограниченной пропускной способностью. Когда устройству, имеющему новую копию объекта, требуется обновить устройство, имеющее более старую копию этого объекта или подобного объекта, применяется способ RDC для передачи через сеть связи только отличий между объектами. Описанный возможный способ RDC использует (1) рекурсивный подход для передачи метаданных RDC для уменьшения объема метаданных, передаваемых для больших объектов, и (2) способ разделения на порции на основе локального максимума для увеличения точности, соответствующей дифференцированию объектов, чтобы минимизировать нагрузку пропускной способности. Некоторые возможные приложения, которые выигрывают от описанных способов RDC, включают в себя: одноранговые службы репликации, протоколы передачи файлов, такие как SMB (блок серверных сообщений), виртуальные серверы, передающие большие изображения, серверы электронной почты, синхронизацию сотового телефона и PDA (персонального цифрового информационного устройства), репликацию сервера базы данных и т.д.
Рабочая среда
Фиг.1 - диаграмма, иллюстрирующая возможную рабочую среду для настоящего изобретения. Как изображено на чертеже, устройства сконфигурированы для связи через сеть. Указанными устройствами могут быть универсальное вычислительное устройство, специализированное вычислительное устройство или любые другие соответствующие устройства, которые подсоединены к сети. Сеть 102 может соответствовать любой топологии связности, включая, но не в ограничительном смысле, прямое кабельное соединение (например, параллельный порт, последовательный порт, универсальную последовательную шину (USB), IEEE 1394 и т.д.), беспроводное соединение (например, инфракрасный (IR) порт, порт Bluetooth и т.д.), проводную сеть, беспроводную сеть, локальную сеть, глобальную сеть, ультра-глобальную сеть, интернет, интранет и эксранет.
При возможном взаимодействии между устройством A (100) и устройством B (101) на этих двух устройствах локально хранятся разные версии объекта: объект OA на 100 и объект OB на 101. В некоторый момент времени устройство A (100) принимает решение обновить копию объекта OA копией (объекта OB), которая хранится на устройстве B (101), и передает в устройство B (101) запрос на инициирование способа RDC. В альтернативном варианте осуществления способ RDC может быть инициирован устройством B (101).
Устройство A (100) и устройство B (101) обрабатывают объект, который хранится на них локально, и разделяют ассоциированные данные на изменяемое количество порций способом, зависящим от данных, (например, порции 1-n для объекта OB и порций 1-k для объекта OA соответственно). Обоими устройствами локально вычисляется набор сигнатур, например, значений сильных хэш-функций (SHA), для порций. Оба устройства компилируют отдельные списки сигнатур. В продолжение следующего этапа способа RDC устройство B (101) передает в устройство A (100) через сеть 102 связи вычисленный им список сигнатур и длин порций 1-n. Устройство A (100) оценивает этот список сигнатур, сравнивая каждую принятую сигнатуру со сформированным им списком сигнатур 1-k. Несоответствия в списках сигнатур указывают одно или большее количество отличий в объектах, которые требуют корректировки. Устройство A (100) передает в устройство B (101) запрос на передачу порций, которые были идентифицированы несоответствиями в списках сигнатур. Потом устройство B (101) сжимает и передает запрошенные порции, которые затем, после выполнения приема и восстановления сжатых данных, повторно собираются устройством A (100). Устройство A (100) повторно собирает принятые порции совместно с собственными соответствующими порциями для получения локальной копии объекта OB.
Возможное вычислительное устройство
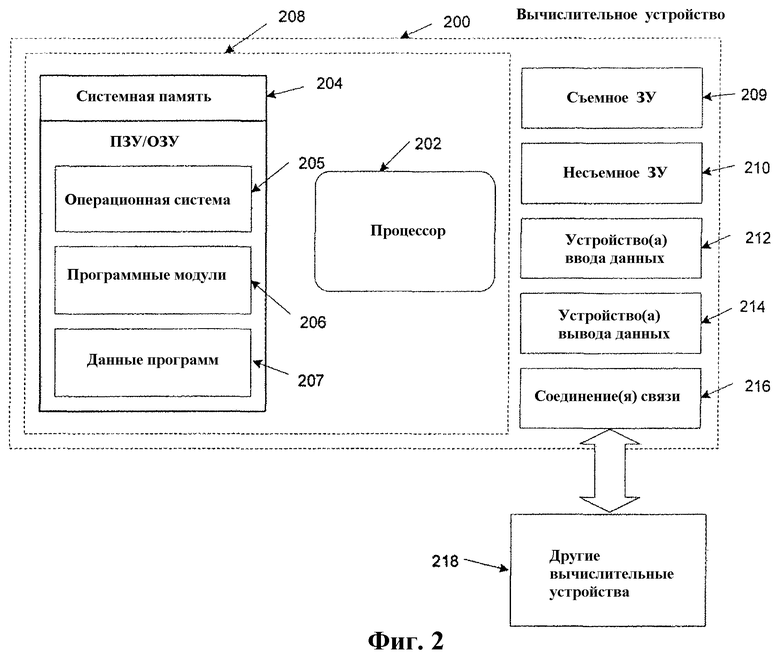
Фиг.2 - блочная диаграмма возможного вычислительного устройства, сконфигурированного в соответствии с настоящим изобретением. В базовой конфигурации вычислительное устройство 200 обычно содержит по меньшей мере один процессор (202) и системную память (204). В зависимости от точной конфигурации и вида вычислительного устройства, системная память 204 может быть энергозависимой (например, оперативным запоминающим устройством (RAM, ОЗУ)), энергонезависимой (например, постоянным запоминающим устройством (ROM, ПЗУ), флэш-памятью и т.д.) или некоторой их комбинацией. Системная память 204 обычно содержит операционную систему (205), один или большее количество программных модулей (206), и может содержать данные (207) программ. Указанная базовая конфигурация изображена на фиг.2 компонентами внутри пунктирной линии 208.
Вычислительное устройство 200 может также иметь дополнительные признаки или функциональные возможности. Например, вычислительное устройство 200 также может содержать дополнительные запоминающие устройства для хранения данных (съемные и/или несъемные), такие, например, как магнитные диски, оптические диски или ленту. Такое дополнительное запоминающее устройство иллюстрируется на фиг.2 съемным запоминающим устройством (ЗУ) 209 и несъемным запоминающим устройством 210. Компьютерные носители данных могут включать в себя энергозависимые и энергонезависимые, съемные и несъемные носители, реализованные любым способом или технологией для хранения информации, такой как машиночитаемые инструкции, структуры данных, программные модули или другие данные. Системная память 204, съемное запоминающее устройство 209 и несъемное запоминающее устройство 210, - все являются примерами компьютерных носителей данных. Компьютерные носители данных включают в себя, но не в ограничительном смысле ОЗУ, ПЗУ, электрически стираемое программируемое ПЗУ (EEPROM), флэш-память или память другой технологии, CD-ROM, цифровые универсальные диски (DVD) или другие оптические запоминающие устройства, магнитные кассеты, магнитную ленту, накопитель на магнитных дисках или другие магнитные запоминающие устройства, или любой другой носитель информации, который может использоваться для хранения требуемой информации и к которому может осуществить доступ вычислительное устройство 200. Любой такой компьютерный носитель данных может быть частью устройства 200. Вычислительное устройство 200 также может иметь устройство(а) 212 ввода данных, такое как клавиатура, мышь, перо, устройство ввода речи, сенсорное устройство ввода данных и т.д. Также может быть включено устройство(а) вывода 214 данных, такое как дисплей, динамики, принтер и т.д. Все указанные устройства известны в технике и их описание здесь не требуется.
Вычислительное устройство 200 также содержит соединение(я) 216 связи, которое обеспечивает возможность связи устройства с другими вычислительными устройствами 218, например, через сеть. Соединение(я) 216 связи является примером среды связи. Среда связи, обычно, воплощает машиночитаемые инструкции, структуры данных, программные модули или другие данные в модулированном информационном сигнале, например, несущей или другом механизме переноса информации, и включает в себя любую среду доставки информации. Термин «модулированный информационный сигнал» означает сигнал, одна или большее количество характеристик которого установлены или изменены таким образом, чтобы обеспечить кодирование информации в этом сигнале. В качестве примера, но не ограничения, среды связи включают в себя проводные среды, такие как проводная сеть или прямое кабельное соединение, и беспроводные среды, такие как акустические, радиочастотные, сверхвысокочастотные, спутниковые, инфракрасные и другие беспроводные среды. Используемый здесь термин «машиночитаемый носитель» включает в себя как носители данных, так и среды связи.
Различные процедуры и интерфейсы могут быть реализованы в одной или большем количестве прикладных программ, которые постоянно находятся в системной памяти 204. В одном возможном варианте прикладной программой является алгоритм удаленного дифференциального сжатия, который планирует синхронизацию файла между вычислительным устройством (например, клиентом) и другим удаленно размещенным вычислительным устройством (например, сервером). В другом возможном варианте прикладной программой является процедура сжатия/восстановления, которая обеспечена в системной памяти 204 для сжатия и восстановления данных. В еще одном возможном варианте прикладной программой является процедура декодирования, которая обеспечена в системной памяти 204 устройства-клиента.
Удаленное дифференциальное сжатие (RDC)
Фиг.3A и 3B - диаграммы, иллюстрирующие возможную процедуру RDC согласно по меньшей мере одному аспекту настоящего изобретения. Количество порций, в частности, может варьироваться для каждого варианта, в зависимости от фактических объектов OA и OB.
Согласно фиг.3A, между двумя вычислительными устройствами (устройством A и устройством B) выполняется согласование основного протокола RDC. Протокол RDC неявно предполагает, что устройства A и B имеют два различных варианта (или версии) одного объекта или ресурса, которые идентифицированы вариантами (или версиями) объекта OA и OB, соответственно. Для примера, иллюстрируемого этим чертежом, устройство A имеет старую версию ресурса OA, в то время как устройство B имеет версию OB с небольшим (или инкрементальным) отличием в содержимом (или данных), ассоциированном с ресурсом.
Ниже описан протокол для передачи обновленного объекта OB из устройства B в устройство A. Подобный протокол может использоваться для передачи объекта из устройства A в устройство B, и эта передача может быть инициирована по требованию любого из устройств A и B без существенного изменения протокола, описанного ниже.
1. Устройство A передает в устройство B запрос на передачу Объекта OB с использованием протокола RDC. В альтернативном варианте осуществления устройство B инициирует передачу; в этом случае протокол опускает этап 1 и начинается с этапа 2, приведенного ниже.
2. Устройство A разбивает Объект OA на порции 1-k и вычисляет сигнатуру SigAi и длину (или размер в байтах) LenAi для каждой порции 1 … k Объекта OA. Разбиение на порции будет подробно описано ниже. Устройство A сохраняет список сигнатур и длин порций ((SigA1, LenA1) … (SigAk, LenAk)).
3. Устройство B разбивает Объект OB на порции 1-n и вычисляет сигнатуру SigBi и длину LenBi для каждой порции 1 … n Объекта OB. Алгоритм разбиения, используемый на этапе 3, должен соответствовать алгоритму разбиения на этапе 2, приведенному выше.
4. Устройство B передает в устройство A список вычисленных сигнатур порций и длин порций ((SigB1, LenB1) … (SigBn, LenBn)), ассоциированных с Объектом OB. Информация длин порций может быть использована впоследствии устройством A для запроса определенного набора порций посредством их идентификации их начальным смещением и их длиной. Из-за последовательного характера списка можно вычислить начальное смещение в байтах каждой порции Bi посредством суммирования длин всех предшествующих порций в списке.
В другом варианте осуществления список сигнатур порций и длин порций, до передачи в устройство A, компактно кодируется и дополнительно сжимается с использованием алгоритма сжатия без потерь.
5. После приема упомянутых данных устройство A сравнивает принятый список сигнатур с сигнатурами SigA1 … SigAk, вычисленными для Объекта OA на этапе 2, которые ассоциированы со старой версией содержимого.
6. Устройство A передает в устройство B запрос на все порции, сигнатуры которых, принятые из устройства B на этапе 4, не соответствуют ни одной из сигнатур, вычисленных устройством A на этапе 2. Для каждой запрошенной порции Bi запрос содержит начальное смещение порции, вычисленное устройством A на этапе 4, и длину порции.
7. Устройство B передает в устройство A содержимое, ассоциированное со всеми запрошенными порциями. До передачи в устройство A содержимое, передаваемое устройством B, может быть дополнительно сжато с использованием алгоритма сжатия без потерь.
8. Устройство A воссоздает локальную копию Объекта OB с использованием порций, принятых из устройства B на этапе 7, а также собственных порций Объекта OA, соответствующих сигнатурам, переданным устройством B на этапе 4. Порядок, в котором локальные и удаленные порции повторно компонуются в устройстве A, определен списком сигнатур порций, принятых устройством A на этапе 4.
Этапы 2 и 3 разбиения могут выполняться способом, зависящим от данных, который использует функцию снятия опознавательного признака, которая вычисляется в каждой позиции байта в ассоциированном объекте (OA и OB соответственно). Для заданной позиции функция снятия опознавательного признака вычисляется с использованием малого окна данных, окружающего эту позицию в объекте; значение функции снятия опознавательного признака зависит от всех байтов объекта, включенных в упомянутое окно. Функцией снятия опознавательного признака может быть любая подходящая функция, такая, например, как хэш-функция или полином Рабина (Rabin).
Границы порции определяются в Объекте в позициях, для которых посредством функции снятия опознавательного признака вычисляется значение, удовлетворяющее выбранному условию. Сигнатуры порций могут быть вычислены с использованием криптографически защищенной хэш-функции (SHA) или некоторой другой хэш-функции, такой как хэш-функция, устойчивая к конфликтам.
Список сигнатур и длин порций, передаваемый на этапе 4, обеспечивает основу для воссоздания объекта с использованием исходных порций и идентифицированных обновленных или новых порций. Порции, запрашиваемые на этапе 6, идентифицированы их смещениями и длинами. Объект воссоздается на устройстве A с использованием локальных и удаленных порций, сигнатуры которых соответствуют сигнатурам, принятым устройством A на этапе 4, в том же порядке.
После завершения устройством A этапа воссоздания, Объект OA может быть удален и заменен копией Объекта OB, которая была воссоздана в устройстве A. В других вариантах осуществления устройство может сохранить Объект OA для возможного "повторного использования" порций в продолжение будущих передач RDC.
Для больших объектов, для варианта основного протокола RDC, иллюстрируемого фиг.3A, характерен существенный фиксированный объем дополнительной служебной информации на этапе 4, даже если Объект OA и Объект OB очень близки или идентичны. При заданном среднем размере порции, равном C, объем информации, передаваемой через сеть связи на этапе 4, пропорционален размеру Объекта OB, в частности, он пропорционален размеру Объекта OB, деленному на C, что составляет количество порций Объекта B, и соответственно пар (сигнатура порции, длина порции), передаваемых на этапе 4.
Например, согласно фиг.6, большой образ (например, виртуальный образ жесткого диска, используемый монитором виртуальных машин, таким, например, как Microsoft Virtual Server (Виртуальный сервер), может привести к Объекту (OB) размером 9,1 Гбайт. Для среднего размера C порции, равного 3 Кбайт, объект 9 Гбайт может привести к 3 миллионам порций, сформированных для Объекта OB, с 42 Мбайт ассоциированной информации сигнатур и длин порций, которую требуется передать через сеть на этапе 4. Так как 42 Мбайт информации сигнатур требуется передать через сеть связи, даже когда отличия между Объектом OA и Объектом OB (и, соответственно, объем данных, который требуется передать на этапе 7) очень малы, расходы на фиксированную дополнительную служебную информацию протокола чрезмерно высоки.
Такие расходы на фиксированную дополнительную служебную информацию могут быть существенно снижены с использованием рекурсивного применения протокола RDC вместо передачи информации сигнатур на этапе 4. Согласно фиг.3B, ниже описаны дополнительные этапы 4.2-4.8, заменяющие этап 4 основного алгоритма RDC. Этапы 4.2-4.8 соответствуют рекурсивному применению этапов 2-8 из основного протокола RDC, описанного выше. Рекурсивное применение может быть дополнительно использовано для этапа 4.4, представленного ниже, и так далее, до требуемой глубины рекурсии.
4.2. Устройство A выполняет рекурсивное разделение своего списка сигнатур и длин порций ((SigA1, LenA1) … (SigAk, LenAk)) на рекурсивные порции сигнатур, получая другой список рекурсивных сигнатур и рекурсивных длин порций ((RSigA1, RLenA1) … (RSigAs, RLenAs)), где s << k.
4.3. Устройство B рекурсивно набирает список сигнатур и длин порций ((SigB1, LenB1) … (SigBn, LenBn)) для создания списка рекурсивных сигнатур и рекурсивных длин порций ((RSigB1, RLenB1) … (RSigBr, RLenBr)), где r << n.
4.4. Устройство B передает упорядоченный список рекурсивных сигнатур и рекурсивных длин порций ((RSigB1, RLenB1) … (RSigBr, RLenBr)) в устройство A. Список рекурсивных сигнатур порций и рекурсивных длин порций, до передачи в устройство A, компактно кодируется и может быть сжат дополнительно с использованием алгоритма сжатия без потерь.
4.5. Устройство A сравнивает рекурсивные сигнатуры, принятые из устройства B, с собственным списком рекурсивных сигнатур, вычисленным на этапе 4.2.
4.6. Устройство A передает в устройство B запрос на каждую отдельную рекурсивную порцию сигнатуры (с рекурсивной сигнатурой RSigBk), для которой устройство A не имеет соответствующей рекурсивной сигнатуры в своем
наборе (RsigA1 … RSigAs).
4.7. Устройство B передает в устройство A запрошенные рекурсивные порции сигнатур. Запрошенные рекурсивные порции сигнатур, до передачи в устройство A, могут быть дополнительно сжаты с использованием алгоритма сжатия без потерь.
4.8. Устройство A воссоздает список сигнатур и информации порций ((SigB1, LenB1) … (SigBn, LenBn)) с использованием локальных соответствующих рекурсивных порций сигнатур и рекурсивных порций, принятых из устройства B на этапе 4.7.
После завершения этапа 4.8, представленного выше, выполнение продолжается на этапе 5 основного протокола RDC, описанного выше, который иллюстрируется фиг.3A.
В результате операций рекурсивного разделения на порции количество рекурсивных сигнатур, ассоциированных с объектами, уменьшается с коэффициентом, равным среднему размеру порции C, приводя к существенно меньшему количеству рекурсивных сигнатур (r << n для объекта OB и s << k для объекта OA соответственно). В одном варианте осуществления для разделения сигнатур на порции могут использоваться те же параметры разделения на порции, что для разделения на порции исходных объектов OA и OB. В альтернативном варианте осуществления для рекурсивных этапов могут использоваться другие параметры разделения на порции.
Для очень больших объектов рекурсивные этапы, упомянутые выше, могут быть применены k раз, где k ≥1. Для среднего размера порции C рекурсивное разделение на порции может уменьшить объем трафика сигнатур через сеть (этапы с 4.2 по 4.8) с коэффициентом, приблизительно соответствующим Ck. Так как C является относительно большим, то глубина рекурсии, превышающая единицу, может потребоваться только для очень больших объектов.
В одном варианте осуществления количество рекурсивных этапов может определяться динамически при рассмотрении параметров, которые включают в себя один или большее количество из следующих параметров: ожидаемый средний размер порции, размер объектов OA и/или OB, формат данных объектов OA и/или OB, задержки и характеристики пропускной способности сетевого соединения устройства A и устройства B.
Используемая на этапе 2 функция снятия опознавательного признака соответствует функции снятия опознавательного признака, используемой на этапе 3. Аналогично, функция снятия опознавательного признака, используемая на этапе 4.2, соответствует функции снятия опознавательного признака, используемой на этапе 4.3. Функция снятия опознавательного признака из этапов 2-3 может, в необязательном порядке, соответствовать функции снятия опознавательного признака из этапов 4.2-4.3.
Как описано ранее, каждая функция снятия опознавательного признака использует малое окно данных, которое окружает позицию в объекте, при этом значение, ассоциированное с функцией снятия опознавательного признака, зависит от всех байтов объекта, которые включены в пределы упомянутого окна данных. Размер окна данных может корректироваться динамически на основе одного или большего количества критериев. Кроме того, процедура разделения на порции использует значение функции снятия опознавательного признака и один или большее количество дополнительных параметров разделения на порции для определения границ порций на этапах 2-3 и 4.2-4.3, представленных выше.
При динамическом изменении размера окна и параметров разделения на порции границы порций корректируются так, чтобы любые требуемые передачи данных выполнялись с минимальной нагрузкой доступной пропускной способности.
Возможные критерии для корректировки размера окна и параметров разделения на порции включают в себя: тип данных, ассоциированный с объектом, накладываемые средой ограничения, модель использования, задержку и характеристики пропускной способности сетевого соединения устройства B и устройства A, и любую другую соответствующую модель для определения средних размеров блоков передачи данных. Возможные типы данных включают в себя файлы обработки текстов, образы базы данных, крупноформатные электронные таблицы, слайдовые презентации и графические изображения. Возможная модель использования может иметь место, где осуществляется мониторинг среднего количества байтов, требуемых при обычной передаче данных.
Изменения единичного элемента внутри прикладной программы могут привести к нескольким изменениям ассоциированного элемента данных и/или файла. Так как большинство прикладных программ имеет ассоциированный тип файла, тип файла является одним возможным критерием, который следует рассматривать при корректировке размера окна и параметров разделения на порции. В одном примере обновление одиночного символа в документе обработки текстов приводит приблизительно к 100 байтам, изменяемым в ассоциированном файле. В другом примере обновление единичного элемента в приложении базы данных приводит к 1000 байтам, изменяемым в файле индекса базы данных. Для каждого примере соответствующий размер окна и параметры разделения на порции могут быть различны, так что процедура разделения на порции имеет соответствующую глубину детализации (гранулярность), которая оптимизируется на основе конкретного приложения.
Возможная последовательность операций
Фиг.4A и 4B - диаграммы, иллюстрирующие последовательности операций для взаимодействия между локальным устройством (например, устройством A) и удаленным устройством (например, устройством B) в продолжение возможной процедуры RDC, которая сконфигурирована в соответствии по меньшей мере с одним аспектом настоящего изобретения. Левая сторона фиг.4A иллюстрирует этапы 400-413, которые выполняются на локальном устройстве A, в то время как правая сторона фиг.4A иллюстрирует этапы 450-456, которые выполняются на удаленном устройстве B.
Согласно фиг.4A, взаимодействие начинается запросом устройством A передачи объекта OB согласно RDC на этапе 400 и приемом этого запроса устройством B на этапе 450. После этого локальное устройство A и удаленное устройство B независимо вычисляют опознавательные признаки на этапах 401 и 451, разделяют свои объекты на порции на этапах 402 и 452 и вычисляют сигнатуры (например, SHA) для каждой порции на этапах 403 и 453 соответственно.
На этапе 454 устройство B передает список сигнатур и длин порций, вычисленный на этапах 452 и 453, в устройство A, которое принимает эту информацию на этапе 404.
На этапе 405 локальное устройство A инициализирует список запрошенных порций пустым списком (Empty) и инициализирует смещение (OFFSET) слежения для удаленных порций нулем (0). На этапе 406 выбирается для рассмотрения следующая пара (сигнатура, длина порции) (SigBi, LenBi) из списка, принятого на этапе 404. На этапе 407 устройство A проверяет, соответствует ли сигнатура SigBi, выбранная на этапе 406, какой-либо из сигнатур, вычисленных им в продолжение этапа 403. Если соответствует, то выполнение продолжается на этапе 409. Если не соответствует, то на этапе 408 в список запроса добавляются смещение слежения удаленной порции и длина в байтах LenBi. На этапе 409 смещение слежения увеличивается на длину текущей порции LenBi.
На этапе 410 локальное устройство A тестирует, все ли пары (сигнатура, длина порции), принятые на этапе 404, обработаны. Если нет, то выполнение продолжается на этапе 406. Иначе, на этапе 411 список запроса на порцию кодируется соответствующим образом в компактном режиме, сжимается и передается в удаленное устройство B.
Удаленное устройство B принимает сжатый список порций на этапе 455, восстанавливает его, затем сжимает и передает обратно данные порций на этапе 456.
На этапе 412 локальное устройство принимает и восстанавливает запрошенные данные порций. На этапе 413 локальные устройства, используя локальную копию объекта OA и принятые данные порций, повторно собирают локальную копию OB.
Фиг.4B подробно иллюстрирует пример этапа 413 по фиг.4A. Обработка продолжается на этапе 414, где локальное устройство A инициализирует воссозданный объект в пустой объект (Empty).
На этапе 415 выбирается для рассмотрения следующая пара (сигнатура, длина порции) (SigBi, LenBi) из списка, принятого на этапе 404. На этапе 416 устройство A проверяет, соответствует ли сигнатура SigBi, выбранная на этапе 417, какой-либо из сигнатур, вычисленных им в продолжение этапа 403.
Если соответствует, то выполнение продолжается на этапе 417, где к воссозданному объекту присоединяется соответствующая локальная порция. Если не соответствует, то на этапе 418 к воссозданному объекту присоединяется принятая и восстановленная удаленная порция.
На этапе 419 локальное устройство A тестирует, все ли пары (сигнатура, длина порции), принятые на этапе 404, обработаны. Если нет, то выполнение продолжается на этапе 415. Иначе, воссозданный объект используется на этапе 420 для замены старой копии объекта OA на устройстве A.
Возможная последовательность операций для рекурсивной передачи сигнатур.
Фиг.5A и 5B - диаграммы, иллюстрирующие последовательности операций для рекурсивной передачи списка сигнатур и длин порций в возможной процедуре RDC, которая сконфигурирована согласно по меньшей мере одному аспекту настоящего изобретения. Описанная ниже процедура может быть применена в отношении и локального, и удаленного устройства, которые осуществляют попытку обновить общеассоциированные объекты.
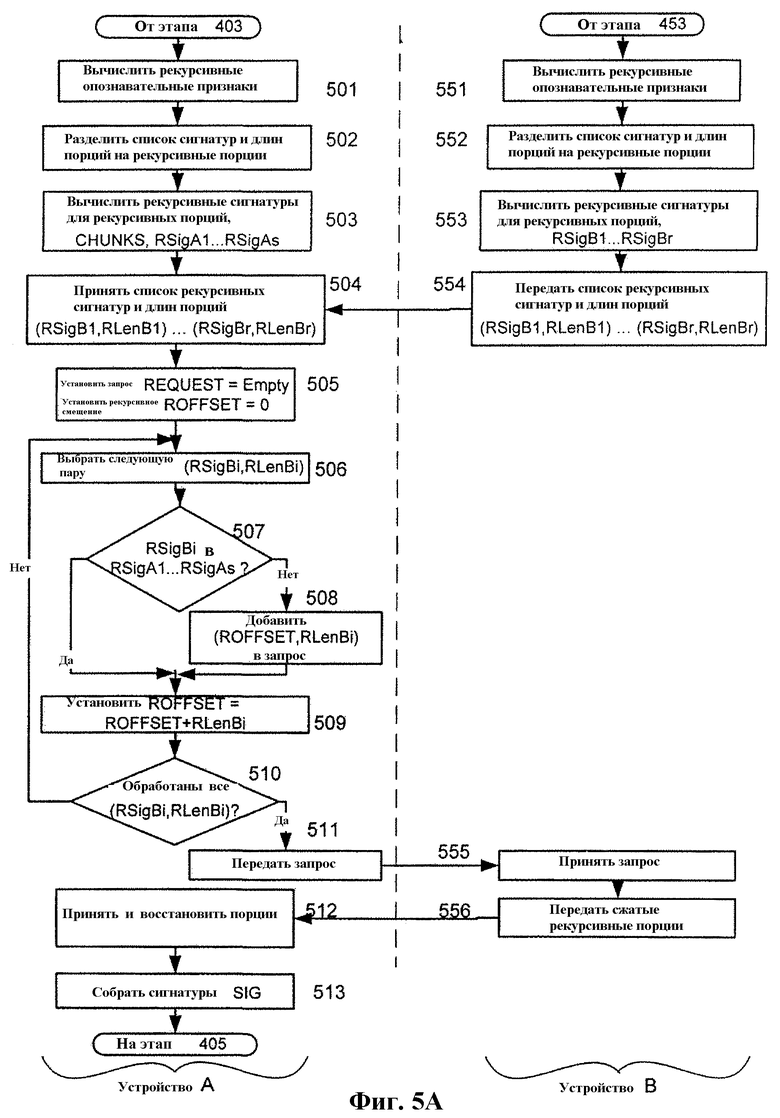
Левая сторона фиг.5A иллюстрирует этапы 501-513, которые выполняются на локальном устройстве A, в то время как правая сторона фиг.5A иллюстрирует этапы 551-556, которые выполняются на удаленном устройстве B. Этапы 501-513 заменяют этап 404 по фиг.4A, в то время как этапы 551-556 заменяют этап 454 по фиг.4A.
На этапах 501 и 551 локальное устройство A и удаленное устройство B независимо вычисляют рекурсивные опознавательные признаки своих списков сигнатур и длин порций ((SigA1, LenA1), … (SigAk, LenAk)) и ((SigB1, LenB1), … (SigBn, LenBn)), соответственно, которые были вычислены на этапах 402/403 и 452/453, соответственно. На этапах 502 и 552 устройства разделяют свои соответствующие списки сигнатур и длин порций на рекурсивные порции, и на этапах 503 и 553 вычисляют рекурсивные сигнатуры (например, SHA) для каждой рекурсивной порции, соответственно.
На этапе 554 устройство B передает рекурсивный список сигнатур и длин порций, вычисленный на этапах 552 и 553, в устройство A, которое принимает эту информацию на этапе 504.
На этапе 505 локальное устройство инициализирует список запрошенных рекурсивных порций пустым списком и инициализирует смещение слежения удаленной рекурсивной порции для удаленных рекурсивных порций в 0. На этапе 506 выбирается для рассмотрения следующая пара (рекурсивная сигнатура, рекурсивная длина порции) (RSigBi, RLenBi) из списка, принятого на этапе 504. На этапе 507 устройство A проверяет, согласуется ли рекурсивная сигнатура RSigBi, выбранная на этапе 506, с какой-либо из рекурсивных сигнатур, вычисленных им в продолжение этапа 503. Если согласуется, то выполнение продолжается на этапе 509. Если не согласуется, то на этапе 508 смещение слежения удаленной рекурсивной порции и длина в байтах RLenBi добавляются в список запроса. На этапе 509 смещение слежения удаленной рекурсивной порции увеличивается на длину текущей рекурсивной порции RLenBi.
На этапе 510 локальное устройство A тестирует, все ли пары (рекурсивная сигнатура, рекурсивная длина порции), принятые на этапе 504, обработаны. Если нет, то выполнение продолжается на этапе 506. Иначе, список запроса на рекурсивную порцию компактно кодируется, сжимается и передается в удаленное устройство B на этапе 511.
Удаленное устройство B принимает сжатый список рекурсивных порций на этапе 555, восстанавливает список, затем сжимает и передает обратно данные рекурсивных порций на этапе 556.
На этапе 512 локальное устройство принимает и восстанавливает данные запрошенной рекурсивной порции. На этапе 513 локальные устройства, используя локальную копию списка сигнатур и длин порций ((SigA1, LenA1), … (SigAk, LenAk)) и принятые данные рекурсивных порций, воссоздают локальную копию списка сигнатур и длин порций ((SigB1, LenB1), … (SigBn, LenBn)). Затем выполнение продолжается на этапе 405 по фиг.4A.
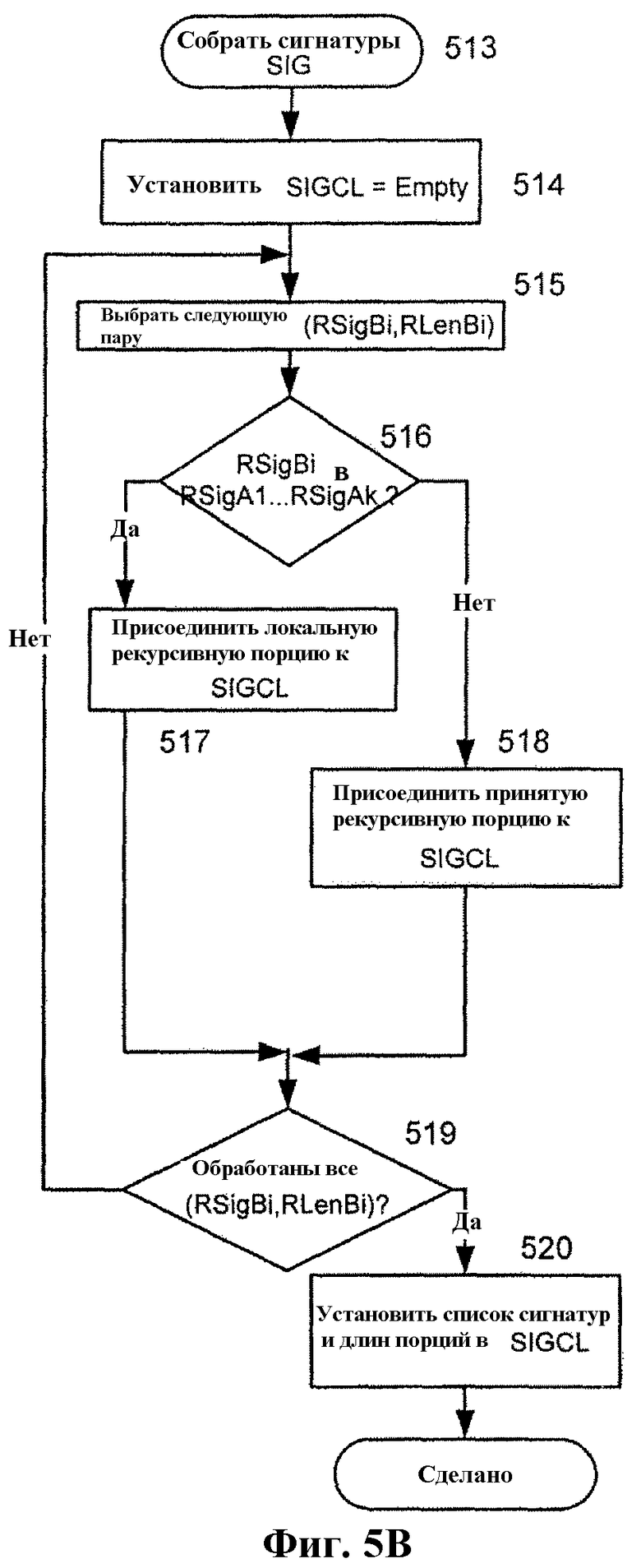
Фиг.5B подробно иллюстрирует пример для этапа 513 по фиг.5A. Обработка продолжается на этапе 514, где локальное устройство A инициализирует список удаленных сигнатур и длин порций, SIGCL, пустым списком (Empty).
На этапе 515 выбирается для рассмотрения следующая пара (рекурсивная сигнатура, рекурсивная длина порции) (SigBi, LenBi) из списка, принятого на этапе 504. На этапе 516 устройство A проверяет, соответствует ли рекурсивная сигнатура RSigBi, выбранная на этапе 515, какой-либо из рекурсивных сигнатур, вычисленных им в продолжение этапа 503.
Если соответствует, то выполнение продолжается на этапе 517, где устройство A присоединяет к SIGCL соответствующую локальную рекурсивную порцию. Если не соответствует, то на этапе 518 к SIGCL присоединяется рекурсивная порция, принятая удаленно.
На этапе 519 локальное устройство A тестирует, все ли пары (рекурсивная сигнатура, рекурсивная длина порции), принятые на этапе 504, обработаны. Если нет, то выполнение продолжается на этапе 515. Иначе, на этапе 520 локальная копия списка сигнатур и длин порций ((SigB1, LenB1), … (SigBk, LenBn)) устанавливается в значение SIGCL. Выполнение затем возвращается на этап 405 по фиг.4A.
Как описано ранее, в необязательном порядке, список рекурсивных сигнатур и длин порций может быть оценен для определения того, требуется ли дополнительное рекурсивное удаленное дифференциальное сжатие для минимизации нагрузки пропускной способности. Список рекурсивных сигнатур и длин порций может рекурсивно сжиматься с использованием описанной процедуры разделения на порции посредством замены этапов 504 и 554 другим вариантом процедуры RDC, и так далее, пока не будет достигнут требуемый уровень сжатия. После того, как список рекурсивных сигнатур достаточно сжат, список рекурсивных сигнатур возвращается для передачи между удаленным и локальным устройствами, как описано ранее.
Фиг.6 - диаграмма, иллюстрирующая графически пример рекурсивного сжатия в возможной последовательности RDC, которая сконфигурирована согласно возможному варианту осуществления. Для примера, иллюстрируемого фиг.6, исходный объект составляет 9,1 Гбайт данных. Список сигнатур и длин порций компилируется с использованием процедуры разделения на порции, при этом список сигнатур и длин порций приводит к 3 миллионам порций (или размеру 42 Мбайт). После первого рекурсивного этапа список сигнатур разделяется на 33 тысячи порций и уменьшается до списка рекурсивных сигнатур и рекурсивных длин порций размером 33 Кбайт. Следовательно, при рекурсивном сжатии списка сигнатур нагрузка пропускной способности для передачи списка сигнатур существенно снижается от 42 Мбайт до приблизительно 395 Кбайт.
Возможное обновление объекта
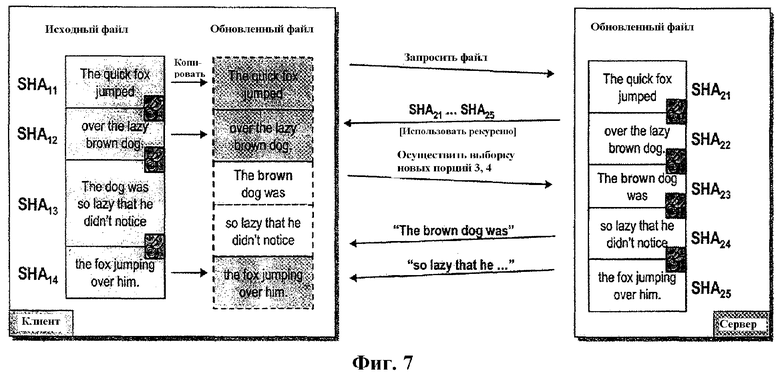
Фиг.7 - диаграмма, иллюстрирующая взаимодействие клиентского и серверного приложений с использованием возможной процедуры RDC, сконфигурированной согласно по меньшей мере одному аспекту настоящего изобретения. Исходный файл и на сервере, и на клиенте содержал текст "The quick fox jumped over the lazy brown dog. The dog was so lazy that didn't notice the fox jumping over him."
Впоследствии, файл на сервере обновляется до: "The quick fox jumped over the lazy brown dog. The brown dog was so lazy that didn't notice the fox jumping over him."
Как описано ранее, клиент периодически запрашивает файл, который должен быть обновлен. Согласно иллюстрации, как клиент, так и сервер разделяют объект (текст) на порции. На клиенте порциями являются: "The quick fox jumped", "over the lazy brown dog.", "The dog was so lazy that didn't notice" и "the fox jumping over him."; список сигнатур клиента формируется в виде: SHA11, SHA12, SHA13 и SHA14. На сервере порциями являются: "The quick fox jumped", "over the lazy brown dog.", "The brown dog was", "so lazy that didn't notice" и "the fox jumping over him."; список сигнатур сервера формируется в виде: SHA21, SHA22, SHA23, SHA24 и SHA25.
Сервер передает список сигнатур (SHA21-SHA25) с использованием способа рекурсивного сжатия сигнатур, как описано выше. Клиент распознает, что список сигнатур (SHA11-SHA14), который хранится локально, не согласуется с принятым списком сигнатур (SHA21-SHA25) и запрашивает с сервера несовпадающие порции 3 и 4. Сервер сжимает и передает порции 3 и 4 ("The brown dog was", "so lazy that didn't notice"). Клиент принимает сжатые порции, восстанавливает их и обновляет файл, как иллюстрируется фиг.7.
Анализ разделения на порции
Эффективность описанной выше основной процедуры RDC может быть повышена посредством оптимизации процедур разделения на порции, которые используются для разделения на порции данных объекта и/или разделения на порции списка сигнатур и длин порций.
Для основной процедуры RDC расходы на дополнительную служебную информацию сетевой связи определяются суммой:
(S1) |Сигнатуры и длины порций из B| = |OB| ∗ |SigLen|/C, где |OB| - размер Объекта OB в байтах, SigLen - размер пары (сигнатура, длина порции) в байтах, и C - ожидаемый средний размер порции в байтах; и
(S2) ∑ длина_порции, где (сигнатура, длина_порции) ∈ Сигнатурам из B,
и сигнатура ∉ Сигнатурам из A
Следовательно, большой средний размер порции и большое пересечение между удаленными и локальными порциями дает выигрыш в расходах на обмен данными. Выбор того, как объекты нарезаются на порции, определяет качество протокола. Локальное и удаленное устройство должны условиться, без предшествующей связи, относительно того, как нарезать объект. Далее описываются и анализируются различные способы для нахождения отрезков.
Предполагается, что следующие характеристики для алгоритма нарезки известны.
1. Резерв (slack): количество байтов, требуемых для порций для приведения в соответствие отличий между файлами. Рассматриваются последовательности s1, s2 и s3, и посредством сцепления формируются две последовательности sls3, s2s3. Для этих двух последовательностей формируются порции Chunks1 и Chunks2. Если Chunks1' и Chunks2' являются суммами длин порции из Chunks1 и Chunks2 соответственно, то до достижения первого общего суффикса резерв в байтах задается следующей формулой
slack = Chunks1' - |s1| = Chunks2' - |S2|.
2. Средний размер порции C:
Когда Объекты OA и OB имеют S сегментов, в общем, со средним размером K, количество порций, которые могут быть получены локально на клиенте, задается следующим образом:
S ∗ (K - slack)/C
и (S2), представленная выше, перезаписывается в:
|OA| - S ∗ (K - slack)/C.
Соответственно, алгоритм разделения на порции, который минимизирует резерв, будет минимизировать количество байтов, передаваемых через проводное соединение. Следовательно, предпочтительным является использование алгоритмов разделения на порции, которые минимизируют ожидаемый резерв.
Функции снятия опознавательного признака
Все алгоритмы разделения на порции используют функцию снятия опознавательного признака или хэш-функцию, которая зависит от малого окна, то есть ограниченной последовательности байтов. Время выполнения алгоритмов хэширования, используемых для разделения на порции, не зависит от размера окна хэширования, когда эти алгоритмы подвергаются оптимизации конечного дифференцирования (снижения силы алгоритма). Соответственно для окна хэширования размером k должно быть просто (требует только постоянного количества этапов) вычислить значение хэш-функции #[b1, …, bk-1, bk] с использованием только b0, bk и #[b0, b1, … bk-1]. Могут использоваться различные хеш-функции, такие как хэш-функции, использующие полиномы Рабина, а также другие хэш-функции, основанные на таблицах предварительно вычисленных случайных чисел, которые в вычислительном отношении кажутся более эффективными.
В одном примере в качестве хэш-функции для снятия опознавательных признаков может использоваться 32-битовая хэш-функция Адлера (Adler), основанная на скользящей контрольной сумме. Эта процедура обеспечивает достаточно хорошую случайную хэш-функцию посредством использования фиксированной таблицы с 256 компонентами, каждая из которых является предварительно вычисленным 16-битовым случайным числом. Таблица (table) используется для преобразования байтов, с которых снимается опознавательный признак, в случайные 16-битовые числа. 32-битовое значение хэш-функции разбивается на два 16-битовых числа sum1 и sum2, которые обновляются заданной процедурой:
sum1 += table[bk] - table[b0]
sum2 += sum1 - k∗ table[b0].
В другом примере в качестве хэш-функции для снятия опознавательных признаков может использоваться 64-битовая случайная хэш-функция с циклическим сдвигом. Период циклического сдвига ограничен размером значения хэш-функции. Соответственно использование 64- битового значения хэш-функции устанавливает период хэш-функции в 64. Процедура обновления значения хэш-функции (hash) задается в виде:
hash = hash€((table[b0] << l)| (table[b0] >> u))€table[bk];
hash = (hash << l) | (hash >> 63);
где l = k % 64 и u = 64 -l.
В еще одном примере для обеспечения снятия опознавательных признаков могут быть применены другие способы сдвига. Непосредственно прямой циклический сдвиг создает период ограниченной длины и ограничен размером значения хэш-функции. Другие перестановки имеют более длинные периоды. Например, перестановка, заданная циклами (1 2 3 0) (5 6 7 8 9 10 11 12 13 14 4) (16 17 18 19 20 21 15) (23 24 25 26 22) (28 29 27) (31 30) имеет период длиной 4·3·5·7·11 = 4620. Одиночное применение этой возможной перестановки может быть вычислено с использованием сдвига вправо, сопровождаемого операциями, которые подправляют позиции в начале каждого интервала.
Анализ предшествующего уровня техники для разделения на порции в предварительно определенных шаблонах.
Известные способы разделения на порции определяются вычислением значения хэш-функции снятия опознавательного признака с предварительно определенным размером окна k (= 48) и идентифицированием точек нарезки на основе того, соответствует ли подмножество битов значения хэш-функции предварительно определенному шаблону. При случайных значениях хэш-функции этим шаблоном также может быть 0, и релевантным подмножеством также может быть префикс хэш-функции. В основных инструкциях это переводится в предикат вида:
CutPoint(hash) ≡ 0 == (hash & ((1 << c) -1)),
где c - количество битов, относительно которых должна проводиться проверка на соответствие.
Так как вероятность соответствия, задаваемая случайной хэш-функцией, составляет 2-c, средний размер порции в результате получается равным C = 2c. Однако этой процедурой не определяются ни минимальный, ни максимальный размер порции. Если установлена минимальная длина порции m, то средний размер порции составляет
C = m + 2c.
Грубая оценка ожидаемого резерва получается при рассмотрении потоков s1s3 и s2s3. Точки нарезки в s1 и s2 могут обнаруживаться в случайных местах. Так как средняя длина порции составляет C = m + 2c, около (2c/C)2 последних точек нарезки в s1 и s2 будут вне расстояния m. Они будут добавлять в резерв около 2c. Оставшаяся часть 1 - (2c/C)2 вносит в резерв длину около C. Тогда ожидаемый резерв будет около (2c/C)3 + (1 - (2c/C)2) ∗ (C/C) = (2c/C)3 + 1 - (2c/C)2, что имеет глобальный минимум для m = 2c-1, со значением около 23/27 = 0,85. Более точный анализ дает несколько более низкую оценку для оставшейся доли 1 - (2c/C)2, но также будет требовать компенсации для отрезков в пределах расстояния m внутри s3, которые вносят более высокую оценку.
Следовательно, ожидаемый резерв для предшествующего уровня техники составляет около 0,85 · C.
Разделение на порции в фильтрах (новый уровень техники)
Разделение на порции в фильтрах основано на фиксировании фильтра, который является последовательностью шаблонов длины m, и проверку последовательности значений хэш-функции снятия опознавательного признака на соответствие относительно фильтра. Когда фильтр не обеспечивает соответствия последовательности значений хэш-функции ни с префиксом, ни с суффиксом фильтра, можно сделать вывод, что минимальное расстояние между любыми двумя соответствиями должно быть по меньшей мере m. Возможный фильтр может быть получен из предиката CutPoint, используемого в предшествующем уровне техники, при установке первых m-1 шаблонов в
0!= (hash & ((1 << c) -1))
и последнего шаблона в:
0 = (hash & ((1 << c) -1)).
Вероятность соответствия с этим фильтром задается (1 - p)m-1 p, где p составляет 2-c. Можно вычислить, что ожидаемая длина порции задается инверсией вероятности соответствия с фильтром (требуется, чтобы фильтр не обеспечивал соответствия последовательности ни с префиксом, ни с суффиксом), соответственно ожидаемая длина возможного фильтра составляет (1 - p)-m+1 p-1. Эта длина минимизируется при установке p:= 1/m, и это оказывается равным около (e ∗ m). Как может быть проверено специалистами в данной области техники, средний резерв колеблется около 0,8. Альтернативный вариант осуществления этого способа использует шаблон, который работает непосредственно с необработанными входными данными и не использует скользящие хэш-функции.
Разделение на порции в локальных максимумах (новый уровень техники)
Разделение на порции в локальных максимумах основано на выборе в качестве точек нарезки позиций, являющихся максимальными внутри ограниченного горизонта. Далее для значения горизонта используется h. Предполагается, что значение хэш-функции в позиции смещения offset является h-локальным максимумом, если значения хэш-функции при всех смещениях offset-h, … offset-1, а также offset+1, …, offset+h меньше значения хэш-функции в offset. Другими словами, все позиции, в пределах h шагов налево и h шагов направо имеют меньшие значения хэш-функции. Для специалистов в данной области техники очевидно, что локальные максимумы могут быть заменены локальными минимумами или любой другой метрикой, основанной на сравнении (такой как "ближайший к среднему значению хэш-функции").
Набор локальных максимумов для объекта размера n может быть вычислен за время, ограниченное 2 • n операциями, так что расход на вычисление набора локальных максимумов идентичен или близок к расходу на вычисление точек нарезки, основанное на независимом разделении на порции. Порции, сформированные с использованием локальных максимумов, всегда имеют минимальный размер, соответствующий h, со средним размером около 2h + 1. Процедура CutPoint иллюстрируется фиг.8 и фиг.9 и описана ниже следующим образом.
1. Выделить массив M длины h, компоненты которого инициализируются записью {isMax = false (ложь), hash = 0, offset = 0}. Первый компонент в каждом поле (isMax) указывает, может ли кандидат быть локальным максимумом. Второй компонент поля (hash) указывает значение хэш-функции, ассоциированное с этим компонентом, и инициализируется в 0 (или в альтернативном варианте, в максимальное возможное значение хэш-функции). Последнее поле (offset) в компоненте указывает абсолютное смещение в байтах для кандидата в объект, с которого снимается опознавательный признак.
2. Инициализировать минимальное (min) и максимальное (max) смещения в массиве M нулем (0). Эти переменные указывают на первый и последний элементы массива, которые используются в текущее время.
3. На этапе 800 по фиг.8 запускается CutPoint(hash, offset) и вызывается при каждом смещении объекта для обновления M и возвращения результата, указывающего, является ли конкретное смещение точкой нарезки (cutpoint).
Процедура начинается установкой result = false (результата в ложь) на этапе 801.
На этапе 803 процедура проверяет, выполняется ли условие M[max].offset + h + 1 = offset. Если это условие истинно, то выполнение продолжается на этапе 804, где выполняются следующие присвоения: результат result устанавливается в M[max].isMax, и максимум max устанавливается в max-1 % h. Затем выполнение продолжается на этапе 805. Если условие на этапе 803 ложно, то выполнение продолжается на этапе 805.
На этапе 805 процедура проверяет, выполняется ли условие M[min].hash > hash. Если условие истинно, то выполнение продолжается на этапе 806, где минимум min устанавливается в (min - 1) % h. Затем выполнение продолжается на этапе 807, где M[min] устанавливается в {isMax = false, hash = hash, offset = offset} и переходит на этап 811, где возвращается вычисленный результат.
Если условие на этапе 805 ложно, то выполнение продолжается на этапе 808, где процедура проверяет, выполняется ли условие M[min].hash = hash. Если это условие истинно, то выполнение продолжается на этапе 807.
Если условие на этапе 808 ложно, то выполнение продолжается на этапе 809, где процедура проверяет, выполняется ли условие min = max. Если это условие истинно, то выполнение продолжается на этапе 810, где M[min] устанавливается в {isMax = true (истина), hash = hash, offset = offset}. Затем выполнение продолжается на этапе 811, где возвращается вычисленный результат.
Если условие на этапе 809 ложно, то выполнение продолжается на этапе 812, где min устанавливается в (min + 1) % h. Затем выполнение возвращается на этап 805.
4. Когда CutPoint(hash, offset) возвращает истину, это означает, что смещение в позиции offset-h-1 является новой точкой нарезки.
Анализ процедуры локального максимума
Объект с n байтами обрабатывается посредством вызова CutPoint n раз, так что для заданного объекта вставляется самое большее n компонентов. Один компонент удаляется каждый раз при повторении начала цикла на этапе 805, так что существует не более n компонентов для удаления. Следовательно, вход в цикл обработки может осуществляться один раз для каждого компонента и совокупное количество повторений самое большее может составлять n. Это подразумевает, что среднее количество этапов внутри цикла при каждом вызове CutPoint немного меньше 2, и количество этапов для вычисления точек нарезки не зависит от h.
Так как значения хэш-функции от элементов формируют убывающую цепочку между минимумом min и максимумом max, можно видеть, что среднее расстояние между минимумом и максимумом (|min - max| % h) задается натуральным логарифмом h. Смещения, не включенные между двумя смежными компонентами в М, имеют значения хэш-функции, которые не превышают двух компонентов. Средняя длина таких цепочек задается рекуррентным уравнением f(n) = 1 + 1/n ∗ ∑k < nf(k). Средняя длина самой длинной убывающей цепочки на интервале длины n на 1 больше средней длины самой длинной убывающей цепочки, начинающейся с позиции наибольшего элемента, где наибольший элемент может быть обнаружен в произвольных позициях с вероятностью 1/n. Рекуррентное соотношение имеет в качестве решения соответствующее гармоническое число Hn = 1 + 1/2 + 1/3 + 1/4 + … + 1/n, которое может быть проверено подстановкой Hn в уравнение и выполнением индукции по n. Hn пропорционально натуральному логарифму n. Соответственно, хотя массив M выделен с размером h, в любой момент времени всегда используется только малая доля размера ln(h).
Вычисление минимума min и максимума max по модулю h допускает произвольный рост используемых интервалов М до тех пор, пока расстояние между числами остается в пределах h.
Выбор начальных значений для M подразумевает, что точки нарезки могут быть сформированы внутри первых h смещений. Алгоритм может быть адаптирован для исключения точек нарезки в указанных первых h смещениях.
Ожидаемый размер порций, сформированных этой процедурой, около 2h + 1. Это число получается из вероятности того, что заданная позиция является точкой нарезки.
Предполагается, что хэш-функция имеет m различных возможных значений. Тогда вероятность определяется следующим образом:
∑0 ≤ k < m 1/m(k/m)2h.
При достаточно большом m, аппроксимация с использованием интегрирования ∫0 ≤ x < m 1/m (x/m)2h dx = 1/(2h + 1) указывает вероятность.
Вероятность может быть вычислена более точно посредством первого упрощения суммы до:
(1/m)2h+1 ∑0 ≤ k < m k2h,
что с использованием чисел Бернулли Bk развертывается в:
(1/m)2h+1 1/(2h + 1) ∑0 ≤ k < 2h (2h + 1)! /k! (2h + 1 - k)! Bk m2h+1-k
Единственным нечетным числом Бернулли, отличным от нуля, является B1, которое имеет соответствующее значение, равное -1/2. Четные числа Бернулли удовлетворяют уравнению:
H∞ (2n) = (-1)n-1 22n-1 π2n B2n/(2n)!
Левая сторона представляет бесконечную сумму 1 + (1/2)2n + (1/3)2n + …, которая для умеренных четных значений n очень близка к 1.
Когда m намного больше h, все члены, кроме первого, могут игнорироваться, как наблюдалось при интегрировании. Они задаются константой между 0 и 1, умноженной на член, пропорциональный hk - 1/mk. Первый член (где B0 = 1) упрощается до 1/(2h + 1), (второй член -1/(2m), третий h/(6m2)).
Для грубой оценки ожидаемого резерва рассматриваются потоки s1s3 и s2s3. Последние точки нарезки внутри s1 и s2 могут обнаруживаться в случайных местах. Так как средняя длина порции составляет около 2h + 1, то около j-ой последних точек нарезки будет в пределах расстояния h как в s1, так и в s2. Они дополняют точки нарезки около 7/8 h. В другой 1/2 случаев одна точка нарезки будет в пределах расстояния h, другая - вне расстояния h. Они вносят точки нарезки около 3/4h. Оставшаяся 1/4-ая последних точек нарезки в s1 и s2 будет на расстоянии, превышающем h. Следовательно, ожидаемый резерв будет около 1/4 · 7/8 + 1/2 · 3/4 + 1/4 · 1/4 = 0,66.
Соответственно, ожидаемый резерв для нашего подхода независимого разделения на порции составляет 0,66 · C, что является усовершенствованием относительно предшествующего уровня техники (0,85 · C).
Существует альтернативный способ идентифицирования точек нарезки, который в среднем требует выполнения меньшего количества инструкций при использовании расстояния, по большей части, пропорционального h, или в среднем lnh. Процедура, описанная выше, вставляет компоненты для каждой позиции 0.. n-1 в поток длины n. Основная идея альтернативной процедуры состоит в обновлении только тогда, когда встречаются элементы возрастающей цепочки в пределах интервалов длины h. Наблюдалось, что в среднем имеет место только lnh таких обновлений на интервал. Кроме того, сравнивая локальные максимумы в двух последовательных интервалах длины h, можно определить, может ли каждый из двух локальных максимумов также быть h-локальным максимумом. У альтернативной процедуры имеется одна особенность; требуется вычисление возрастающих цепочек посредством обхода потока блоками размера h, причем обход каждого блока осуществляется в обратном направлении.
В альтернативной процедуре (см. фиг.10 и 11) для простоты предполагается, что поток значений хэш-функции задан в виде последовательности. Процедура CutPoint вызывается для каждой подпоследовательности длиной h (на чертежах развертывается в "horizon" (горизонт)). Она возвращает смещений, которые определены являющимися точками нарезки, или одно такое смещение. Первый тест проходят только ln(h) вызовов Insert (Вставки).
Вставка в A достигается посредством тестирования значения хэш-функции в смещении относительно наибольшего компонента в A до текущего времени.
Цикл, который обновляет и A[k], и B[k].isMax, может быть оптимизирован, чтобы в среднем в теле цикла выполнялся только один тест. Случай B[1].hash <= A[k].hash и B[1].isMax обрабатывается в двух циклах, первый проверяет значение хэш-функции относительно B[1].hash до тех пор, пока оно не становится меньшим, второй обновляет A[k]. Другой случай может быть обработан с использованием цикла, который обновляет A[k] только с последующим обновлением B[1].isMax.
Каждый вызов CutPoint в среднем требует ln h операций записи в память для A, и с циклом, реализующим h + ln h сравнений, относящихся к обнаружению максимумов. Последнее обновление A[k].isMax может быть выполнено посредством двоичного поиска или посредством обхода B, начиная с индекса 0, в среднем максимум за lnh этапов. Каждый вызов CutPoint также требует повторного вычисления значения скользящей хэш-функции в последней позиции last в обновляемом окне. Для этого требуется количество этапов, соответствующее размеру окна скользящей хэш-функции.
Наблюдаемые преимущества усовершенствованных алгоритмов разделения на порции
В обоих способах, описанных выше, способе фильтра и локальных максимумов создается минимальный размер порции. Стандартные реализации требуют, чтобы минимальный размер порции обеспечивался независимо дополнительным параметром.
Способы, основанные на локальном максимуме (или математические), создают измеряемую более хорошую оценку резерва, которая претворяется в дополнительном сжатии через сеть. Способ фильтра также создает более хорошие характеристики резерва, чем стандартные способы.
Оба новых способа имеют свойство определения местоположения точек нарезки. Все точки нарезки внутри s3, которые находятся вне горизонта, будут точками нарезки для обоих потоков s1s3 и s2s3 (другими словами, рассматривается поток s1s3, если p является позицией ≥ |s1| + horizon, и p является точкой нарезки в s1s3, то она также является точкой нарезки в s2s3. То же свойство выполняется для другого направления (симметрично), если p является точкой нарезки в s2s3, то она также является точкой нарезки в s1s3). Это не так для стандартных способов, где требование, чтобы отрезки находились вне некоторого минимального размера порции, может повлиять неблагоприятным образом.
Альтернативные математические функции
Хотя описанные выше процедуры разделения на порции описывают использующий вычисление локальных максимумов способ определения местоположения точек нарезки, настоящее изобретение не ограничено только им. Для исследования потенциальных точек нарезки может быть применена любая математическая функция. Каждая потенциальная точка нарезки оценивается посредством оценки значений хэш-функции, которые размещены внутри окна горизонта, относительно рассматриваемой точки нарезки. Оценка значений хэш-функции выполняется математической функцией, которая может включать в себя по меньшей мере одно из определения местоположения максимального значения внутри горизонта, определения местоположения минимальных значений внутри горизонта, оценки разности между значениями хэш-функции, оценки разности значений хэш-функции и сравнения результата относительно случайной константы, а также некоторой другой математической или статистической функцией.
Определенной математической функцией, описанной ранее для локальных максимумов, является двуместный предикат "_ > _". Для случая, где p является смещением в объекте, p выбирается в качестве точки нарезки, если hashp > hashk для всех k, где p-horizon ≤ k < p, или p < k ≤ p + horizon. Однако, не отступая от сущности изобретения, двуместный предикат "_ > _" можно заменить на любую другую математическую функцию.
Описание, приведенное выше, примеры и данные обеспечивают полное описание изготовления и использования состава изобретения. Так как не отступая от сути и не выходя за рамки объема изобретения, могут быть созданы многие варианты осуществления изобретения, объем изобретения определяется приложенной формулой изобретения.







Изобретение относится к способу и системе обновления объектов через сети с ограниченной пропускной способностью. Техническим результатом является расширение функциональных возможностей. Осуществляется обновление объектов между двумя или большим количеством вычислительных устройств, с использованием способов удаленного дифференциального сжатия (RDC). Эффективные передачи больших объектов достигаются при рекурсивном применении алгоритма RDC к его собственным метаданным, в этом случае для уменьшения объема метаданных, передаваемых через сеть связи алгоритмом RDC, используется один рекурсивный этап или несколько рекурсивных этапов. Объекты и/или списки длин порций и сигнатур могут быть разделены на порции посредством размещения границ в динамически определенных местоположениях. Математическая функция оценивает значения хеш-функции, ассоциированные в пределах окна горизонта, относительно потенциальной границы порции. Способ и система наиболее применимы в ряде приложений с сетевой структурой, таких как: одноранговые репликаторы, клиенты и серверы электронной почты, системы кэширования стороны клиента, универсальные утилиты копирования, репликаторы базы данных, порталы, услуги обновления программного обеспечения, синхронизация файлов/данных и другие. 42 з.п. ф-лы, 14 ил.
1. Система для обновления объектов через сеть связи между локальным устройством и удаленным устройством, содержащая
удаленное устройство, которое выполнено с возможностью обеспечения обновления объектов через сеть, причем удаленное устройство содержит:
первое устройство соединения с сетью, которое выполнено с возможностью обеспечения связи через сеть,
первое хранилище данных, которое выполнено с возможностью хранения первого объекта, и
первый процессор, который подключен к первому хранилищу данных и первому устройству соединения с сетью и выполнен с возможностью
вычисления первой функции снятия опознавательного признака в каждом байтовом смещении первого объекта на удаленном устройстве,
разделения первого объекта на порции на удаленном устройстве на основе первой функции снятия опознавательного признака,
вычисления удаленной сигнатуры для каждой порции, ассоциированной с первым объектом, на удаленном устройстве,
формирования списка удаленных сигнатур и длин порций на удаленном устройстве, причем список удаленных сигнатур и длин порций ассоциирован с первым объектом,
передачи списка удаленных сигнатур и длин порций с удаленного устройства в сеть,
приема на удаленном устройстве запроса из сети на передачу по меньшей мере одной обновленной порции объекта и
передачи упомянутой по меньшей мере одной обновленной порции объекта через сеть; и
локальное устройство, которое осуществляет оперативную связь с удаленным устройством для обеспечения обновления объектов через сеть, причем локальное устройство содержит:
второе устройство соединения с сетью, которое выполнено с возможностью обеспечения связи через сеть,
второе хранилище данных, которое выполнено с возможностью хранения второго объекта, и
второй процессор, который подключен ко второму хранилищу данных и второму устройству соединения с сетью и выполнен с возможностью
вычисления второй функции снятия опознавательного признака в каждом байтовом смещении второго объекта на локальном устройстве, где первый и второй объекты ассоциированы друг с другом, и где первая функция снятия опознавательного признака соответствует второй функции снятия опознавательного признака,
разделения второго объекта на порции на основе второй функции снятия опознавательного признака на локальном устройстве, причем разделение первого объекта на порции на удаленном устройстве соответствует разделению второго объекта на порции на локальном устройстве,
вычисления локальной сигнатуры для каждой порции, ассоциированной со вторым объектом, на локальном устройстве, причем вычисление локальной сигнатуры соответствует вычислению удаленной сигнатуры,
формирования списка локальных сигнатур и длин порций на локальном устройстве, причем список локальных сигнатур и длин порций ассоциирован со вторым объектом,
согласования разделенной на порции передачи списка удаленных сигнатур и длин порций из удаленного устройства в локальное устройство через сеть таким образом, чтобы была минимизирована нагрузка пропускной способности для передачи списка удаленных сигнатур и длин порций в локальное устройство,
идентификации отличий между первым объектом и вторым объектом на локальном устройстве посредством сравнения списка локальных сигнатур и длин порций со списком удаленных сигнатур и длин порций,
запрашивания передачи по меньшей мере одной обновленной порции объекта из удаленного устройства, когда локальным устройством идентифицированы отличия между первым объектом и вторым объектом,
приема упомянутой по меньшей мере одной обновленной порции объекта из удаленного устройства, и
сборки копии первого объекта с по меньшей мере одной обновленной порцией объекта на локальном устройстве.
2. Система по п.1, в которой второй процессор дополнительно сконфигурирован для запрашивания обновления первого объекта из удаленного устройства.
3. Система по п.1, в которой первый процессор дополнительно сконфигурирован для запрашивания обновления первого объекта из локального устройства.
4. Система по п.1, в которой передача списка удаленных сигнатур и длин порций содержит передачу по меньшей мере части списка удаленных сигнатур и длин порций из удаленного устройства в локальное устройство.
5. Система по п.1, в которой одно из локального устройства и удаленного устройства является клиентом, а другое из локального устройства и удаленного устройства является сервером.
6. Система по п.1, в которой сеть является по меньшей мере одним из: прямого кабельного соединения, параллельного порта, последовательного порта, порта универсальной последовательной шины (USB), порта IEEE 1394 (стандарт Института инженеров по электротехнике и электронике), беспроводного соединения, инфракрасного порта, порта Bluetooth, проводной сети, беспроводной сети, локальной сети, глобальной сети, ультраглобальной сети, Интернет, Интранет и Экстранет.
7. Система по п.1, в которой вычисление локальной сигнатуры для каждой порции, ассоциированной со вторым объектом, на локальном устройстве содержит применение сильной хеш-функции к порциям на локальном устройстве.
8. Система по п.1, в которой идентификация отличий между первым объектом и вторым объектом на локальном устройстве содержит
сравнение списка удаленных сигнатур и длин порций со списком локальных сигнатур и длин порций,
идентификацию по меньшей мере одного отличия между списком удаленных сигнатур и длин порций и списком локальных сигнатур и длин порций,
отображение упомянутого по меньшей мере одного отличия на список удаленных сигнатур и длин порций, и
идентификацию упомянутой по меньшей мере одной обновленной порции объекта на основе отображения между упомянутым по меньшей мере одним отличием и списком удаленных сигнатур и длин порций.
9. Система по п.1, в которой вычисление первой функции снятия опознавательного признака в каждом байтовом смещении первого объекта на удаленном устройстве содержит
обеспечение малого окна, которое является опорным, вокруг каждой позиции байта, ассоциированной с первым объектом, и
формирование опознавательного признака с использованием малого окна в каждой позиции байта.
10. Система по п.9, в которой первый процессор дополнительно сконфигурирован для корректировки размера окна, ассоциированного с малым окном, на основе по меньшей мере одного из: типа данных, ассоциированного с первым объектом, типа данных, ассоциированного со вторым объектом, накладываемого средой ограничения, ассоциированного с удаленным устройством, и накладываемого средой ограничения, ассоциированного с локальным устройством, характеристик сети, модели использования, ассоциированной с первым объектом, и модели использования, ассоциированной со вторым объектом.
11. Система по п.1, в которой первая функция снятия опознавательного признака содержит по меньшей мере одну из: хэш-функции, использующей полином Рабина, хэш-функции с циклическим сдвигом, 32-битовой хэш-функции Адлера.
12. Система по п.1, в которой разделение первого объекта на порции на удаленном устройстве содержит определение по меньшей мере одного параметра разделения на порции.
13. Система по п.12, в которой разделение первого объекта на порции на удаленном устройстве дополнительно содержит
определение промежутка разделения на порции на основе упомянутого по меньшей мере одного параметра разделения на порции,
вычисление значений хэш-функции в каждой позиции внутри первого объекта,
применение математической функции к значениям хэш-функции, расположенным в пределах промежутка разделения на порции вокруг каждой позиции внутри первого объекта, при этом математической функцией является двухместный предикат, который отображает значения хэш-функции в булево значение,
обозначение по меньшей мере одного из точек нарезки и границ разделения на порции, когда математическая функция удовлетворена, и
разделение первого объекта на порции согласно обозначенным точкам нарезки.
14. Система по п.13, в которой упомянутый двухместный предикат является следующим для случая, когда р является смещением в первом объекте:
р выбирается в качестве точки нарезки, если hashp>hashk для всех k, где р - horizon≤k<p, или р<k≤р+horizon, a horizon представляет собой упомянутый промежуток.
15. Система по п.12, в которой второй процессор дополнительно сконфигурирован для корректировки упомянутого по меньшей мере одного параметра разделения на порции на основе по меньшей мере одного из: типа данных, ассоциированного с первым объектом, типа данных, ассоциированного со вторым объектом, накладываемого средой ограничения, ассоциированного с удаленным устройством, и накладываемого средой ограничения, ассоциированного с локальным устройством, характеристик сети, модели использования, ассоциированной с первым объектом, и модели использования, ассоциированной со вторым объектом.
16. Система по п.1, в которой первый процессор дополнительно сконфигурирован для извлечения упомянутой по меньшей мере одной обновленной порции объекта из второго объекта на удаленном устройстве в ответ на принятый запрос на передачу упомянутой по меньшей мере одной обновленной порции объекта.
17. Система по п.1, в которой второй процессор дополнительно сконфигурирован для сборки обновленного первого объекта с упомянутой по меньшей мере одной обновленной порцией объекта на локальном устройстве.
18. Система по п.17, в которой сборка обновленного первого объекта дополнительно приспособлена так, чтобы обновленный первый объект включал в себя по меньшей мере одну неизмененную порцию из первого объекта.
19. Система по п.1, в которой первый процессор дополнительно сконфигурирован для:
разделения на порции списка удаленных сигнатур и длин порций для обеспечения разделенного на порции списка удаленных сигнатур и длин порций,
вычисления рекурсивной удаленной сигнатуры для каждой порции, ассоциированной с разделенным на порции списком удаленных сигнатур и длин порций,
формирования списка рекурсивных удаленных сигнатур и длин порций с помощью рекурсивных удаленных сигнатур,
разделения на порции списка локальных сигнатур и длин порций на локальном устройстве, причем разделение на порции списка локальных сигнатур и длин порций соответствует разделению на порции списка удаленных сигнатур и длин порций, и
при этом второй процессор дополнительно сконфигурирован для:
вычисления рекурсивной локальной сигнатуры для каждой порции, ассоциированной с разделенным на порции списком локальных сигнатур и длин порций, причем вычисление рекурсивной локальной сигнатуры соответствует вычислению рекурсивной удаленной сигнатуры,
формирования списка рекурсивных локальных сигнатур и длин порций на локальном устройстве с помощью рекурсивных локальных сигнатур и разделенного на порции списка локальных сигнатур и длин порций, причем формирование списка рекурсивных локальных сигнатур и длин порций соответствует формированию списка рекурсивных удаленных сигнатур и длин порций,
согласования передачи списка рекурсивных удаленных сигнатур и длин порций из удаленного устройства в локальное устройство через сеть так, чтобы была минимизирована нагрузка пропускной способности для передачи в локальное устройство списка рекурсивных удаленных сигнатур и длин порций,
идентификации отличий между списком рекурсивных удаленных сигнатур и длин порций и списком рекурсивных локальных сигнатур и длин порций на локальном устройстве,
запрашивания передачи по меньшей мере одной обновленной порции сигнатуры из удаленного устройства, когда локальным устройством идентифицированы отличия между списком рекурсивных удаленных сигнатур и длин порций и списком рекурсивных локальных сигнатур и длин порций.
20. Система по п.19, в которой согласование передачи списка рекурсивных удаленных сигнатур и длин порций из удаленного устройства в локальное устройство содержит передачу по меньшей мере части списка рекурсивных удаленных сигнатур и длин порций из удаленного устройства в локальное устройство через сеть.
21. Система по п.19, в которой разделение на порции списка удаленных сигнатур и длин порций на удаленном устройстве содержит
вычисление третьей функции снятия опознавательного признака в каждом байтовом смещении списка удаленных сигнатур и длин порций на удаленном устройстве и
разделение на порции списка удаленных сигнатур и длин порций на удаленном устройстве на основе третьей функции снятия опознавательного признака для обеспечения разделенного на порции списка удаленных сигнатур и длин порций.
22. Система по п.21, в которой разделение на порции списка локальных сигнатур и длин порций на локальном устройстве содержит
вычисление четвертой функции снятия опознавательного признака в каждом байтовом смещении списка локальных сигнатур и длин порций на локальном устройстве, причем четвертая функция снятия опознавательного признака соответствует третьей функции снятия опознавательного признака, и
разделение на порции списка локальных сигнатур и длин порций на локальном устройстве на основе четвертой функции снятия опознавательного признака для обеспечения разделенного на порции списка локальных сигнатур и длин порций, причем разделение на порции списка локальных сигнатур и длин порций на локальном устройстве соответствует разделению на порции списка удаленных сигнатур и длин порций на удаленном устройстве.
23. Система по п.22, в которой при вычислении третьей функции снятия опознавательного признака и разделении на порции списка удаленных сигнатур и длин порций на удаленном устройстве применяется методика, отличная от вычисления первой функции снятия опознавательного признака и разделения первого объекта на порции на удаленном устройстве.
24. Система по п.21, в которой при вычислении третьей функции снятия опознавательного признака и разделении на порции списка удаленных сигнатур и длин порций на удаленном устройстве применяется методика, идентичная вычислению первой функции снятия опознавательного признака и разделению на порции первого объекта на удаленном устройстве.
25. Система по п.21, в которой вычисление третьей функции снятия опознавательного признака в каждом байтовом смещении списка удаленных сигнатур и длин порций на удаленном устройстве содержит
обеспечение малого окна, которое является опорным, вокруг каждой позиции байта, ассоциированной со списком удаленных сигнатур и длин порций, и
формирование опознавательного признака с использованием малого окна в каждой позиции байта.
26. Система по п.25, в которой первый процессор дополнительно сконфигурирован для корректировки размера окна, ассоциированного с малым окном, на основе по меньшей мере одного из: типа данных, ассоциированного с первым объектом, типа данных, ассоциированного со вторым объектом, накладываемого средой ограничения, ассоциированного с удаленным устройством, и накладываемого средой ограничения, ассоциированного с локальным устройством, характеристик сети, модели использования, ассоциированной с первым объектом, и модели использования, ассоциированной со вторым объектом.
27. Система по п.21, в которой третья функция снятия опознавательного признака содержит по меньшей мере одну из: хэш-функции, использующей полином Рабина, хэш-функции с циклическим сдвигом, 32-битовой хэш-функции Адлера и 64-битовой случайной хэш-функции с циклическим сдвигом.
28. Система по п.19, в которой разделение на порции списка удаленных сигнатур и длин порций на удаленном устройстве содержит определение по меньшей мере одного рекурсивного параметра разделения на порции.
29. Система по п.28, в которой разделение на порции списка удаленных сигнатур и длин порций на удаленном устройстве дополнительно содержит
определение рекурсивного промежутка разделения на порции на основе упомянутого по меньшей мере одного рекурсивного параметра разделения на порции,
вычисление значений хэш-функции в каждой позиции внутри списка удаленных сигнатур и длин порций,
применение математической функции к значениям хэш-функции, расположенным в пределах рекурсивного промежутка разделения на порции вокруг каждой позиции внутри списка удаленных сигнатур и длин порций, при этом математической функцией является двухместный предикат, который отображает значения хэш-функции в булево значение,
обозначение точек нарезки в границах разделения на порции, когда математическая функция удовлетворена, и
разделение на порции списка удаленных сигнатур и длин порций с помощью обозначенных точек нарезки.
30. Система по п.29, в которой упомянутый двухместный предикат является следующим для случая, когда р является смещением в первом объекте:
р выбирается в качестве точки нарезки, если hashp>hashk для всех k, где р - horizon≤k<р, или р<k≤р+horizon, a horizon представляет собой упомянутый промежуток.
31. Система по п.29, в которой первый процессор дополнительно сконфигурирован для корректировки упомянутого по меньшей мере одного рекурсивного параметра разделения на порции на основе по меньшей мере одного из: типа данных, ассоциированного с первым объектом, типа данных, ассоциированного со вторым объектом, накладываемого средой ограничения, ассоциированного с удаленным устройством, и накладываемого средой ограничения, ассоциированного с локальным устройством, характеристик сети, модели использования, ассоциированной с первым объектом, и модели использования, ассоциированной со вторым объектом.
32. Система по п.26, в которой вычисление рекурсивной удаленной сигнатуры для каждой порции сигнатуры, ассоциированной с разделенным на порции списком удаленных сигнатур и длин порций, на удаленном устройстве дополнительно содержит применение сильной хеш-функции к порциям сигнатуры на удаленном устройстве.
33. Система по п.19, в которой первый процессор дополнительно сконфигурирован для извлечения упомянутой по меньшей мере одной обновленной порции сигнатуры из списка удаленных сигнатур и длин порций на удаленном устройстве в ответ на принятый запрос на передачу упомянутой по меньшей мере одной обновленной порции сигнатуры.
34. Система по п.33, в которой сборка списка локальных сигнатур и длин порций дополнительно содержит обеспечение новой копии списка удаленных сигнатур и длин порций на локальном устройстве, причем эта новая копия списка удаленных сигнатур и длин порций включает в себя упомянутую по меньшей мере одну обновленную порцию сигнатуры.
35. Система по п.19, в которой второй процессор дополнительно сконфигурирован для
приема из сети упомянутой по меньшей мере одной обновленной порции сигнатуры локальным устройством и
сборки копии списка удаленных сигнатур и длин порций на локальном устройстве с упомянутой по меньшей мере одной обновленной порцией сигнатуры.
36. Система по п.33, в которой список удаленных сигнатур и длин порций включает в себя по меньшей мере одну неизмененную порцию из списка локальных сигнатур и длин порций.
37. Система по п.19, в которой идентификация отличий между списком рекурсивных удаленных сигнатур и длин порций и списком рекурсивных локальных сигнатур и длин порций на локальном устройстве дополнительно содержит
сравнение списка рекурсивных удаленных сигнатур и длин порций со списком рекурсивных локальных сигнатур и длин порций,
идентификацию по меньшей мере одной порции сигнатуры, ассоциированной с отличием между списком рекурсивных удаленных сигнатур и длин порций и списком рекурсивных локальных сигнатур и длин порций,
отображение упомянутой по меньшей мере одной порции сигнатуры на список удаленных сигнатур и длин порций и
идентификацию упомянутой по меньшей мере одной обновленной порции сигнатуры на основе отображения между упомянутой по меньшей мере одной порцией сигнатуры и списком удаленных сигнатур и длин порций.
38. Система по п.1, в которой согласование разделенной на порции передачи списка удаленных сигнатур и длин порций из удаленного устройства в локальное устройство через сеть дополнительно содержит определение количества итераций для рекурсивной обработки на основе по меньшей мере одного из: размера данных, ассоциированного с первым объектом, размера данных, ассоциированных со вторым объектом, накладываемого средой ограничения, ассоциированного с удаленным устройством, и накладываемого средой ограничения, ассоциированного с локальным устройством, характеристик сети, модели использования, ассоциированной с первым объектом, и модели использования, ассоциированной со вторым объектом, количества сигнатур порций, ассоциированных с первым объектом, и количества сигнатур порций, ассоциированных с разделенным на порции списком удаленных сигнатур и длин порций.
39. Система по п.38, в которой первый процессор и второй процессор дополнительно сконфигурированы для выполнения рекурсивной процедуры обработки списка сигнатур и длин порций, содержащей
разделение на порции списка сигнатур и длин порций для обеспечения разделенного на порции списка сигнатур и длин порций,
вычисление рекурсивной сигнатуры для каждой порции, ассоциированной с разделенным на порции списком сигнатур и длин порций,
формирование списка рекурсивных сигнатур и длин порций с помощью рекурсивных сигнатур и разделенного на порции списка сигнатур и длин порций,
инициализацию списка сигнатур и длин порций списком рекурсивных сигнатур и длин порций, когда для рекурсивной обработки требуются дополнительные итерации, и
возврат списка рекурсивных сигнатур и длин порций, когда рекурсивная процедура выполнила упомянутое количество итераций,
при этом первый процессор дополнительно сконфигурирован для обработки списка удаленных сигнатур и длин порций с помощью рекурсивной процедуры на удаленном устройстве посредством передачи списка удаленных сигнатур и длин порций в рекурсивную процедуру в качестве списка сигнатур и списка длин порций и посредством возврата из рекурсивной процедуры списка рекурсивных удаленных сигнатур и длин порций,
при этом второй процессор дополнительно сконфигурирован для обработки списка локальных сигнатур и длин порций с помощью рекурсивной процедуры на локальном устройстве посредством передачи списка локальных сигнатур и длин порций в рекурсивную процедуру в качестве списка сигнатур и длин порций и возврата из рекурсивной процедуры списка рекурсивных локальных сигнатур и длин порций.
40. Система по п.1, в которой формирование списка удаленных сигнатур и длин порций на удаленном устройстве дополнительно содержит компактное кодирование списка удаленных сигнатур и длин порций.
41. Система по п.1, в которой формирование списка локальных сигнатур и длин порций на локальном устройстве дополнительно содержит компактное кодирование списка локальных сигнатур и длин порций.
42. Система по п.19, в которой формирование списка рекурсивных удаленных сигнатур и длин порций на удаленном устройстве дополнительно содержит компактное кодирование списка рекурсивных удаленных сигнатур и длин порций.
43. Система по п.19, в которой формирование списка рекурсивных локальных сигнатур и длин порций на локальном устройстве дополнительно содержит компактное кодирование списка рекурсивных локальных сигнатур и длин порций.
| Дорожная спиртовая кухня | 1918 |
|
SU98A1 |
| ИСПОЛНИТЕЛЬНАЯ ПРОГРАММА РЕГЕНЕРАЦИИ ДЛЯ ВСПОМОГАТЕЛЬНОЙ ПРОГРАММЫ РЕЗЕРВНОГО КОПИРОВАНИЯ | 1997 |
|
RU2192039C2 |
| Походная разборная печь для варки пищи и печения хлеба | 1920 |
|
SU11A1 |
| US 6505228 B1, 07.01.2003. | |||

