Изобретение относится к техническим средствам информатики и вычислительной техники и может быть использовано для решения задач символьной обработки текстовой информации и предварительной обработки текстовых данных для информационного поиска.
Известно устройство для информационного поиска (патент RU 2039376, МПК G06F 17/30), содержащее блок сопряжения с памятью, память исходного массива, блок ввода-вывода, наборное поле, блок отображения, буферную память ввода-вывода, блок управления, буферную память, магистральную шину, включающую шины адресную, информационную и управляющую.
Недостатком известного устройства является то, что исходный массив текстовой информации для обработки необходимо преобразовывать к специальному виду, используемому в устройстве, результат обработки информации не дает возможности оценить содержание текста и не может быть использован в качестве аннотации к обработанному тексту, устройство не обеспечивает возможность выборки данных.
Наиболее близким по своей сущности к заявляемому изобретению является устройство обработки информации для информационного поиска (патент RU 2096825, МПК G06F 17/00, 17/30), которое содержит блок сопряжения с памятью, память исходного массива, блок ввода-вывода, наборное поле, блок отображения, буферную память ввода-вывода, блок управления, буферную память, блок синтеза текстовых фрагментов, блок структурного анализа текстового фрагмента, блок символьной обработки текстового фрагмента, блок корректировки словаря словосочетаний, блок синтеза первичного словаря, блок фильтрации первичного словаря, блок синтеза вторичных словарей, блок анализа вторичных словарей, блок синтеза архивной карточки, блок архивации текстовых фрагментов, блок корректировки системных словарей, память архивной карточки, магистральную шину, включающую шины адресную, информационную и управляющую.
В устройстве, соответствующем прототипу, процесс обработки информации и формирования архивной карточки разбит на два этапа.
На первом этапе устройство функционирует под управлением оператора. Итогом первого этапа работы является очередной текстовый фрагмент, который имеет тривиальный смысл: отдельная глава документа, отдельный абзац, отдельная статья сборника статей и т.п.
На втором этапе устройство работает в автоматическом режиме следующим образом.
Оператор устройства формирует в наборном поле команду активизации устройства. С наборного поля на вход блока ввода-вывода поступает сигнал начала работы устройства в автоматическом режиме. С выхода блока ввода-вывода по магистральной шине сигнал передается на вход блока управления, где он преобразуется в последовательность команд управления устройством. Блок управления последовательно активизирует блоки структурного анализа текстового фрагмента, символьной обработки текстового фрагмента, корректировки словаря словосочетаний, синтеза первичного словаря, фильтрации первичного словаря, синтеза вторичных словарей, анализа вторичных словарей, синтеза архивной карточки, архивации текстовых фрагментов, корректировки системных словарей путем подачи команд управления на входы указанных блоков. Сигнал результата работы устройства (архивная карточка текстового фрагмента) подается на вход памяти архивных карточек, где он записывается для дальнейшего использования.
Принцип функционирования всех перечисленных блоков одинаков. На вход блока № k по магистральной шине последовательно поступают сигналы из информационного массива буферной памяти, сформированного блоком № (k-1). С выхода блока № k сигналы последовательно подаются в информационный массив буферной памяти, а с него - на блок № (k+1).
Блок структурного анализа текстового фрагмента выделяет информационные сигналы о наличии во входных данных строк с определенным процентным содержанием цифровых символов, а также сигналы символьного информационного массива заданной длины. Сигнал структуры указанных выходных данных запоминается в блоке структурного анализа текстового фрагмента при настройке устройства. Настройка устройства осуществляется до начала его работы.
В блоке символьной обработки текстового фрагмента проводится обработка входных сигналов, соответствующая декомпозиции исходной информации на отдельные слова и словосочетания (совокупность слов, ограниченных в информации исходного текста кавычками). С выхода блока символьной обработки текстового фрагмента на буферной памяти поступает сигнал информационного массива, структура которого позволяет считывать из буферной памяти отдельное слово или словосочетание, а также различать при поиске слова и словосочетания, при этом в буферную память записываются сигналы данных о количестве строк и слов обработанной информации текстового фрагмента.
В блоке корректировки словаря словосочетаний проводится сравнение сигналов количества символов в считанной из блока информации с эталонным сигналом. При превышении количества символов эталонного значения сигнал, считанный из буферной памяти, подвергается в блоке корректировки словаря словосочетаний обработке, соответствующей декомпозиции словосочетаний на отдельные слова. Результаты обработки информационных сигналов в блоке 1 корректировки словаря словосочетаний запоминаются в его информационном массиве, структура которого позволяет проводить поиск нужного слова и хранить кроме символьной информации также числовую, привязанную с помощью адресации данных к конкретному слову.
Блок синтеза первичного словаря формирует сигнал нового информационного массива той же структуры, но не содержащий одинаковых слов и словосочетаний. Сигналы числовых данных, привязанных к каждому слову указанного информационного массива, содержат информацию о количестве таких слов в сигнале входной информации блока синтеза первичного словаря.
Блок фильтрации первичного словаря предназначен для формирования сигнала нового информационного массива той же структуры. В блоке фильтрации первичного словаря формируется сигнал, соответствующий результату операции удаления из входного информационного массива информации о тех словах, которые совпадают со словами информационного массива той же структуры, записываемого в память блока фильтрации первичного словаря при настройке устройства. Если сигнал слова из входной информации блока фильтрации первичного словаря удовлетворяет условиям сравнения со словами внутренней памяти блока, данные о нем не попадают в выходной информационный массив. Операция сравнения проводится в два этапа. На первом этапе сигналы слов сравниваются по схеме полного совпадения, на втором этапе сигналы слов из входной информации оцениваются на предмет совпадения символьной структуры слов (например, последовательности символов "работали" и "работ." совпадают по символьной структуре).
В блоке синтеза вторичных словарей проводится обработка входного информационного сигнала, соответствующая разделению данных входного информационного массива на четыре независимых информационных массива той же структуры. Сигнал каждого слова из входной информации проходит в блоке синтеза вторичных словарей посимвольную обработку на предмет выяснения вида каждого символа ("строчной", "прописной", "цифровой", "алфавитный", "специальный", "значимый", "пробел"). Сигналы слов, состоящих только из цифровых и специальных символов, исключаются из дальнейшей обработки. Сигналы оставшихся слов (и данные им соответствующие) суммируются с сигналами одного из выходных информационных массивов: "имена собственные", "аббревиатуры", "кавычки", "рядовые слова".
Блок анализа вторичных словарей анализирует сигнал идентификационного кода информационного массива, который считывается с выхода буферной памяти, и выполняет в зависимости от значения идентификационного кода один из трех вариантов обработки входного информационного сигнала. Первый вариант обработки заключается в считывании входного сигнала и записи его в один из выходных информационных массивов, два остальных варианта основаны на выделении из сигнала слова последовательности символов основы слова путем удаления символов суффиксов и окончаний и проведения оценки совпадения символьной структуры полученной последовательности символов с сигналами оставшихся слов текущего информационного массива.
Блок синтеза архивной карточки формирует выходной сигнал, адреса для хранения в памяти архивной карточки новой архивной карточки, проводит адресацию входной информации для информационного поиска, формирует выходной информационный сигнал новой архивной карточки.
Блок архивации текстовых фрагментов проводит обработку входных сигналов, соответствующую операциям определения адреса архивной области буферной памяти для хранения фрагмента, проверки ее существования и при необходимости ее создания и идентификации, сжатия исходной информации.
В блоке корректировки системных словарей определяется адрес доступа к последней архивной карточке, притом выходной сигнал адреса с выхода блока корректировки системных словарей поступает на вход блока управления. Блок управления формирует команду чтения архивной карточки и вместе с сигналом адреса доступа к карточке направляет ее на вход памяти архивной карточки. Параллельно блок управления подает на вход буферной памяти управляющий сигнал подготовки для записи области системных словарей.
С выхода памяти архивных карточек снимаются сигналы шести информационных массивов, записанных в память архивных карточек с выхода блока синтеза архивной карточки. Информационные сигналы с выхода памяти архивных карточек подаются на вход блока корректировки системных словарей.
Блок корректировки системных словарей выполняет операции обработки входных информационных сигналов, соответствующие преобразованию входной информации к виду списка слов без какой-либо дополнительной числовой информации, и сформированный информационный сигнал с его выхода поступает на вход буферной памяти. После выполнения этой операции блок корректировки системных словарей подает на вход блока управления команду завершения работы устройства.
Блок управления формирует последовательность команд управления, соответствующих очистке буферной памяти, за исключением областей памяти системных словарей и архивных областей хранения сигналов сжатой информации текстовых фрагментов, и после выполнения указанной последовательности команд завершает работу устройства.
Недостатком прототипа является схематичность и условность отображения содержания текстового документа, задействование человека-оператора при предварительной обработке информации,
Целью изобретения является расширение области применения и функциональных возможностей устройства за счет обеспечения возможности обработки и поиска текстовой информации различной тематической и смысловой направленности, а также автоматической адаптации устройства к изменению предметной области обрабатываемой информации на основе полного исключения человека из процесса анализа, чтения, аннотирования и каталогизации текстов.
Цель достигается тем, что в известное устройство обработки информации для информационного поиска, содержащее последовательно соединенные наборное поле, блок отображения, который является выходом устройства в целом, блок ввода-вывода, магистральную шину, к которой подключены входы и выходы блока управления и памяти архивных карточек, второй выход которой через блок ввода-вывода подключен ко второму входу блока отображения, а вход памяти архивных карточек соединен с выходом блока синтеза архивной карточки, память исходного массива, первый выход которой через блок символьной обработки текста подключен ко входу блока структурного анализа текста, буферную память ввода-вывода, вход которой является входом устройства в целом, согласно изобретению введены долговременная память, блок выделения служебной информации, блок хранения и корректировки стоп-словаря, блок квазиморфологического анализа, блок формирования инвертированного индекса основ слов, блок формирования связанных основ слов, блок формирования признаков отбора предложений для архивной карточки, блок отбора предложений для архивной карточки и счетчик знаков в аннотации текста, причем выход буферной памяти ввода-вывода через долговременную память, которая подключена к магистральной шине, соединен со входом памяти исходного массива, второй выход которой через блок выделения служебной информации соединен с первым входом блока синтеза архивной карточки, а через последовательно соединенные блок отбора предложений для архивной карточки и счетчик знаков в аннотации текста подключен ко второму входу блока синтеза архивной карточки, к третьему входу которого подключены последовательно соединенные блок хранения и корректировки стоп-словаря, блок квазиморфологического анализа, блок формирования инвертированного индекса основ слов, при этом выход блока структурного анализа текста через блок квазиморфологического анализа и последовательно соединенные блок формирования связанных основ слов и блок формирования признаков отбора предложений для архивной карточки соединен со вторым входом блока отбора предложений для архивной карточки.
Сопоставительный анализ технического решения с устройством, выбранным в качестве прототипа, показывает, что новизна технического решения заключается в ведении в заявленное устройство новых схемных элементов: долговременной памяти, блока выделения служебной информации, блока хранения и корректировки стоп-словаря, блока квазиморфологического анализа, блока формирования инвертированного индекса основ слов, блока формирования связанных основ слов, блока формирования признаков отбора предложений для архивной карточки, блока отбора предложений для архивной карточки и счетчика знаков в аннотации текста, с соответствующими связями.
Таким образом, заявляемое техническое решение соответствует критерию изобретения «новизна».
Анализ известных технических решений в исследуемой и смежных областях позволяет сделать вывод о том, что введенные функциональные узлы известны. Однако введение их в известное устройство с указанными связями придает этому устройству новые свойства. Введенные функциональные узлы взаимодействуют таким образом, что позволяют расширить область применения и функциональные возможности устройства обработки, автоматически адаптировать устройства к изменению предметной области обрабатываемой информации, исключить человека из процесса анализа, чтения, аннотирования и каталогизации текстов.
Таким образом, техническое решение соответствует критерию "изобретательский уровень", так как оно для специалиста явным образом не следует из уровня техники.
Изобретение может быть использовано для решения задач символьной обработки текстовой информации и предварительной обработки текстовых данных для информационного поиска.
Таким образом, изобретение соответствует критерию "промышленная применимость".
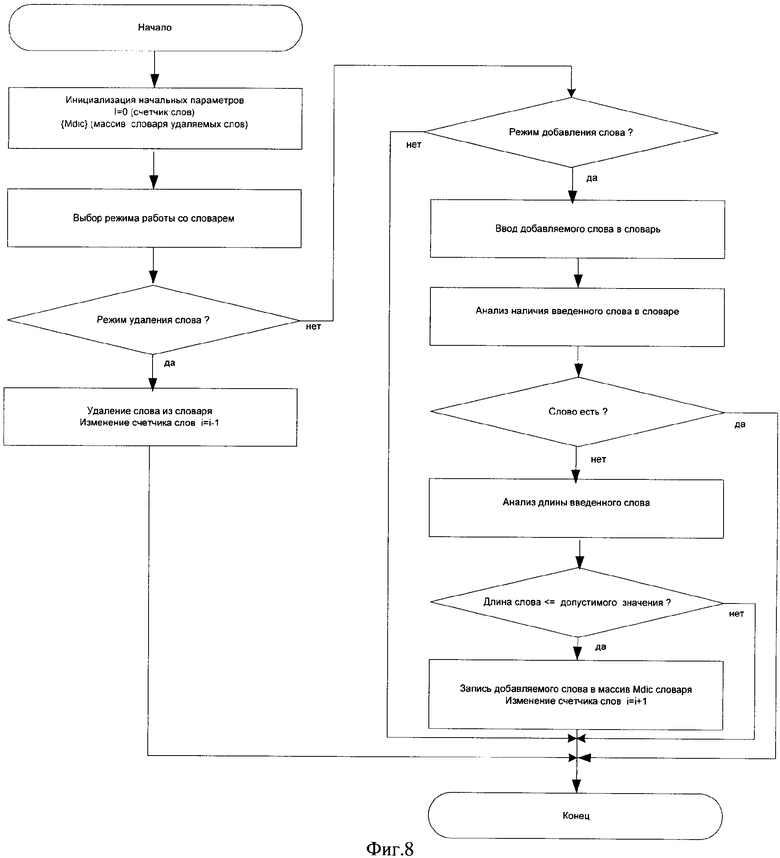
На фиг.1 представлена блок-схема устройства обработки информации для информационного поиска, на фиг.2 - блок-схема алгоритма функционирования блока квазиморфологического анализа, на фиг.3 - блок-схема алгоритма функционирования блока формирования связанных пар основ слов, на фиг.4 - блок-схема алгоритма функционирования блока формирования признаков отбора предложений, на фиг.5 - блок-схема алгоритма функционирования блока отбора предложений, на фиг.6 - блок-схема алгоритма функционирования блока формирования инвертированного индекса, на фиг.7 - блок-схема алгоритма функционирования блока выделения служебной информации, на фиг.8 - блок-схема алгоритма функционирования блока хранения и корректировки стоп-словаря.
Фиг.1:
1 - память исходного массива;
2 - блок символьной обработки текста;
3 - наборное поле;
4 - блок отображения;
5 - блок ввода-вывода;
6 - буферная память ввода-вывода;
7 - долговременная память;
8 - блок структурного анализа текста;
9 - блок выделения служебной информации;
10 - блок хранения и корректировки стоп-словаря;
11 - блок квазиморфологического анализа;
12 - блок формирования инвертированного индекса основ слов;
13 - блок управления;
14 - блок синтеза архивной карточки;
15 - память архивных карточек;
16 - блок формирования связанных основ слов;
17 - блок формирования признаков отбора предложений для архивной карточки;
18 - блок отбора предложений для архивной карточки;
19 - счетчик знаков в аннотации текста;
20 - магистральная шина,
причем вход буферной памяти 6 ввода-вывода является входом устройства в целом, а блок 4 отображения является выходом устройства в целом, при этом выход буферной памяти 6 ввода-вывода через долговременную память 7, которая подключена к магистральной шине 20, соединен со входом памяти 1 исходного массива, первый выход которой через блок 2 символьной обработки текста подключен ко входу блока 8 структурного анализа текста, а второй выход которой через блок 9 выделения служебной информации соединен с первым входом блока 14 синтеза архивной карточки, а через последовательно соединенные блок 18 отбора предложений для архивной карточки и счетчик 19 знаков в аннотации текста подключен ко второму входу блок 14 синтеза архивной карточки, к третьему входу которого подключены последовательно соединенные блок 10 хранения и корректировки стоп-словаря, блок 11 квазиморфологического анализа, блок 12 формирования инвертированного индекса основ слов, при этом выход блока 8 структурного анализа текста через блок 11 квазиморфологического анализа и последовательно соединенные блок 16 формирования связанных основ слов и блок 17 формирования признаков отбора предложений для архивной карточки соединен со вторым входом блока 18 отбора предложений для архивной карточки, при этом к магистральной шине 20 подключены входы и выходы блока 13 управления и памяти 15 архивных карточек, второй выход которой через блок 5 ввода-вывода подключен ко второму входу блока 4 отображения, а вход памяти 15 архивных карточек соединен с выходом блока 14 синтеза архивной карточки,
Работа указанного устройства состоит в следующем.
С выхода устройства преобразования исходного файла к формату. t×t текстовые файлы через буферную память 6 ввода-вывода записываются в долговременную память 7, а атрибуты этих файлов из долговременной памяти 7 через магистральную шину 20, блок 5 ввода-вывода поступают на блок 4 отображения, по данным которого оператор с помощью наборного поля 3 выбирает файл, подлежащий обработке. Управляющие сигналы с наборного поля 3 через блок 4 отображения, блок 5 ввода-вывода и магистральную шину 20 поступают на блок 13 управления, откуда на долговременную память 7 подается сигнал на считывание соответствующего файла в память 1 исходного массива. Из памяти 1 исходного массива текстовый файл поступает на блок 9 выделения служебной информации, блок 18 отбора предложений для архивной карточки и через блок 2 символьной обработки текста на блок 8 структурного анализа текста
Работа памяти 1 исходного массива, блока 2 символьной обработки текста, наборного поля 3, блока 4 отображения, блока 5 ввода-вывода, буферной памяти 6 ввода-вывода, блока 8 структурного анализа текста, блока 13 управления полностью аналогична прототипу.
С блока 8 структурного анализа текста на блок 11 квазиморфологического анализа поступает текстовый файл, в котором удалены все служебные символы и выделены отдельные слова. Блок 11 квазиморфологического анализа функционирует в соответствии с алгоритмом, представленным на фиг.2, по которому из текстового файла удаляются слова, содержащие менее трех символов, удаляются незначащие слова, находящихся в блоке 10 хранения и корректировки стоп-словаря, из оставшихся слов текстового файла формируются основы слов путем отсечения окончаний, затем удаляются полученные основы, содержащие менее трех символов.
В качестве примера может быть использовано преобразование первого предложения описания данного устройства.
Исходное предложение: «Изобретение относится к техническим средствам информатики и вычислительной техники и может быть использовано для решения задач символьной обработки текстовой информации и предварительной обработки текстовых данных для информационного поиска»
Предложение после квазиморфологической обработки:
«изобретен относит техническ средств информатик вычислител техник использован решен задач символ обработк текстов информац предварител обработк текстов данн информационн поиск»
С блока 11 квазиморфологического анализа основы значащих слов длиной три и более символов поступают на блок 16 формирования связанных основ слов и блок 12 формирования инвертированного индекса основ слов. Блок 16 формирования связанных основ слов функционирует в соответствии с алгоритмом, представленным на фиг.3, по которому из последовательности отдельных основ значащих слов формируются двухосновные сочетания. Пример результатов такого преобразования приведен в табл.1.
С блока 16 формирования связанных основ слов двухосновные сочетания в виде, аналогичном представленному в табл.1, поступают на блок 17 формирования признаков отбора предложений для архивной карточки. Блок 17 формирования признаков отбора предложений для архивной карточки функционирует в соответствии с алгоритмом, представленным на фиг.4, по которому вычисляется количество появлений двухосновных сочетаний из табл.1, и двухосновные сочетания сортируются в порядке убывания количеств их появления в текстовом файле. Затем двухосновные сочетания, имеющие максимальное количество появлений, определяются как признаки отбора предложений для аннотации, включаемой в архивную карточку. В данном примере это двухосновное сочетание «обработк текстов», которое появляется в тексте два раза (табл.2).
Признаки отбора из блока 17 формирования признаков отбора предложений для архивной карточки, в данном случае - это двухосновное сочетание «обработк текстов», передаются в блок 18 отбора предложений для архивной карточки, на второй вход которого из памяти 1 исходного массива поступает исходный текст для обработки. Блок 18 отбора предложений для архивной карточки функционирует в соответствии с алгоритмом, представленным на фиг.5, по которому для архивной карточки отбираются предложения, содержащие двухсловные сочетания, являющиеся признаками отбора. Отобранные предложения из блока 18 отбора предложений для архивной карточки через счетчик 19 знаков в аннотации, который ограничивает объем каждого отобранного предложения шестью первыми словами в этом предложении и ограничивает общий объем архивной карточки, в соответствии с ГОСТ 7.9-95 СИБИД «Реферат и аннотация. Общие требования», 500 символами, поступают на блок 14 синтеза архивной карточки, на второй вход которого поступает служебная информация из блока 9 выделения служебной информации и ключевые слова из блока 12 формирования инвертированного индекса основ слов.
Ключевые слова формируются следующим образом. Из блока 11 квазиморфологического анализа основы значащих слов длиной три и более символов поступают на блок 12 формирования инвертированного индекса основ слов, где указанные основы слов упорядочиваются в порядке убывания частоты их появления в анализируемом тексте, чем формируется инвертированный индекс анализируемого текста. Считается, что слова, чаще встречающиеся в тексте, в целом полнее отражают его содержание, нежели слова, редко встречающиеся в тексте. Шесть основ слов, имеющих максимальную частоту появления в анализируемом тексте, из блока 12 формирования инвертированного индекса основ слов в качестве «ключевых слов» поступают на третий вход блока 14 синтеза архивной карточки.
Работа блока 14 синтеза архивной карточки полностью аналогична прототипу. Блок 9 выделения служебной информации функционирует в соответствии с алгоритмом, представленным на фиг.7. Блок 12 формирования инвертированного индекса основ слов функционирует в соответствии с алгоритмом, представленным на фиг.6.
Сформированные в блоке 14 синтеза архивной карточки архивные карточки накапливаются в памяти 15 архивных карточек. Накопленные в памяти 15 архивных карточек архивные карточки используются при составлении тематических указателей текстов, каталогизации текстов и при информационном поиске по ключевым словам и атрибутам.
Таким образом, положительный эффект по сравнению с прототипом заключается в расширении области применения и функциональных возможностей устройства обработки информации различной тематической и смысловой направленности, а также автоматической адаптации устройства к изменению предметной области обрабатываемой информации на основе полного исключения человека из процесса анализа, чтения, аннотирования и каталогизации текстов.
Устройство обработки информации для информационного поиска реализовано на базе входных формирователей сигнала 74LCX16 245; перепрограммируемой логической интегральной схемы (ППЛИС) VirtexII FG676 и модуля оперативной памяти 7С1380 (ОЗУ1); ППЛИС XC9572XL-VQ6, линейки индикаторов КРС3216, генератора 50 МГц; процессора цифровой обработки сигналов (ЦОС) TMS320C6416, постоянного запоминающего устройства 93LC66B и трех модулей оперативной памяти 7С1380 (ОЗУ2-ОЗУ4). Устройство устанавливается в стандартную шину PCI персонального компьютера, с которого и производится загрузка рабочих конфигураций ППЛИС и процессора ЦОС. Сигналы текстовых сообщений поступают на вход устройства через формирователи на ППЛИС.
| название | год | авторы | номер документа |
|---|---|---|---|
| УСТРОЙСТВО ОБРАБОТКИ ИНФОРМАЦИИ ДЛЯ ИНФОРМАЦИОННОГО ПОИСКА | 1996 |
|
RU2096825C1 |
| СИСТЕМА ПОИСКА РАЗНОРОДНОЙ ИНФОРМАЦИИ В ЛОКАЛЬНОЙ КОМПЬЮТЕРНОЙ СЕТИ | 2013 |
|
RU2540832C1 |
| СПОСОБ РАБОТЫ ПОЛЬЗОВАТЕЛЬСКОГО ЛИНГВИСТИЧЕСКОГО ИНТЕРФЕЙСА | 2010 |
|
RU2479867C2 |
| ВОССТАНОВЛЕНИЕ ТЕКСТОВЫХ АННОТАЦИЙ, СВЯЗАННЫХ С ИНФОРМАЦИОННЫМИ ОБЪЕКТАМИ | 2017 |
|
RU2665261C1 |
| СПОСОБ ОБУЧЕНИЯ И УСВОЕНИЯ ИНФОРМАЦИИ, СОДЕРЖАЩЕЙСЯ В УЧЕБНОМ МАТЕРИАЛЕ ИЛИ ЛЮБОМ ТЕКСТЕ | 2008 |
|
RU2396605C2 |
| СПОСОБ РАСПРОСТРАНЕНИЯ ИНФОРМАЦИИ В МНОГОАБОНЕНТНОЙ СИСТЕМЕ И СИСТЕМА ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 1997 |
|
RU2155451C2 |
| СПОСОБ АВТОМАТИЗИРОВАННОГО ФОРМИРОВАНИЯ ИНСТРУКЦИЙ ПО ЛИКВИДАЦИИ ИНЦИДЕНТОВ ИНФОРМАЦИОННОЙ БЕЗОПАСНОСТИ И ФОРМИРОВАНИЯ НА ИХ ОСНОВЕ МАШИННЫХ СЦЕНАРИЕВ НАСТРОЙКИ СИСТЕМЫ ЗАЩИТЫ ИНФОРМАЦИИ | 2023 |
|
RU2832692C1 |
| КОМПЬЮТЕРНОЕ УСТРОЙСТВО ДЛЯ ЧТЕНИЯ ПЛОСКОПЕЧАТНОГО ТЕКСТА | 1996 |
|
RU2113726C1 |
| СПОСОБ И СИСТЕМА СИНТЕЗА ТЕКСТА НА ОСНОВЕ ИЗВЛЕЧЕННОЙ ИНФОРМАЦИИ В ВИДЕ RDF-ГРАФА С ИСПОЛЬЗОВАНИЕМ ШАБЛОНОВ | 2015 |
|
RU2610241C2 |
| СПОСОБ ПОИСКА ИНФОРМАЦИИ | 2006 |
|
RU2320005C1 |






Изобретение относится к техническим средствам информатики и вычислительной техники и может быть использовано для решения задач символьной обработки текстовой информации и предварительной обработки текстовых данных для информационного поиска. Технический результат заключается в расширении области применения и функциональных возможностей устройства обработки информации за счет обеспечения возможности обработки и поиска текстовой информации различной тематической и смысловой направленности, а также автоматической адаптации устройства к изменению предметной области обрабатываемой информации на основе полного исключения человека из процесса анализа, чтения, аннотирования и каталогизации текстов. Устройство содержит память (1) исходного массива, блок (2) символьной обработки текста, наборное поле (3), блок (4) отображения, блок (5) ввода-вывода, буферную память (6) ввода-вывода, блок (8) структурного анализа текста, блок (13) управления, блок (14) синтеза архивной карточки, память (15) архивных карточек, магистральную шину (20). Технический результат достигается за счет введения долговременной памяти (7), блока (9) выделения служебной информации, блока (10) хранения и корректировки стоп-словаря, блока (11) квазиморфологического анализа, блока (12) формирования инвертированного индекса основ слов, блока (16) формирования связанных основ слов, блока (17) формирования признаков отбора предложений для архивной карточки, блока (18) отбора предложений для архивной карточки и счетчика (19) знаков в аннотации текста с соответствующими связями. 8 ил., 2 табл.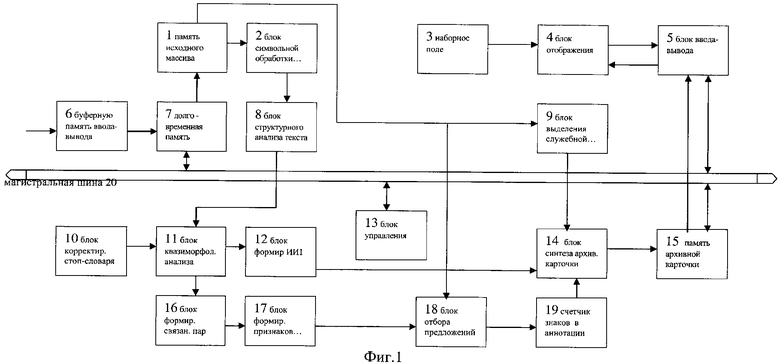
Устройство обработки информации для информационного поиска, содержащее последовательно соединенные наборное поле, блок отображения, который является выходом устройства в целом, блок ввода-вывода, магистральную шину, к которой подключены входы и выходы блока управления и памяти архивных карточек, второй выход которой через блок ввода-вывода подключен ко второму входу блока отображения, а вход памяти архивных карточек соединен с выходом блока синтеза архивной карточки, память исходного массива, первый выход которой через блок символьной обработки текста подключен ко входу блока структурного анализа текста, буферную память ввода-вывода, вход которой является входом устройства в целом, отличающееся тем, что в него введены долговременная память, блок выделения служебной информации, блок хранения и корректировки стоп-словаря, блок квазиморфологического анализа, блок формирования инвертированного индекса основ слов, блок формирования связанных основ слов, блок формирования признаков отбора предложений для архивной карточки, блок отбора предложений для архивной карточки и счетчик знаков в аннотации текста, причем выход буферной памяти ввода-вывода через долговременную память, которая подключена к магистральной шине, соединен со входом памяти исходного массива, второй выход которой через блок выделения служебной информации соединен с первым входом блока синтеза архивной карточки, а через последовательно соединенные блок отбора предложений для архивной карточки и счетчик знаков в аннотации текста подключен ко второму входу блока синтеза архивной карточки, к третьему входу которого подключены последовательно соединенные блок хранения и корректировки стоп-словаря, блок квазиморфологического анализа, блок формирования инвертированного индекса основ слов, при этом выход блока структурного анализа текста через блок квазиморфологического анализа и последовательно соединенные блок формирования связанных основ слов и блок формирования признаков отбора предложений для архивной карточки соединен со вторым входом блока отбора предложений для архивной карточки.
| УСТРОЙСТВО ОБРАБОТКИ ИНФОРМАЦИИ ДЛЯ ИНФОРМАЦИОННОГО ПОИСКА | 1996 |
|
RU2096825C1 |
| СПОСОБ СИНТЕЗА САМООБУЧАЮЩЕЙСЯ СИСТЕМЫ ИЗВЛЕЧЕНИЯ ЗНАНИЙ ИЗ ТЕКСТОВЫХ ДОКУМЕНТОВ ДЛЯ ПОИСКОВЫХ СИСТЕМ | 2002 |
|
RU2273879C2 |
| СПОСОБ ПОИСКА ИНФОРМАЦИИ | 2006 |
|
RU2320005C1 |
| Преобразователь "угол-фаза | 1978 |
|
SU752676A1 |
| JP 2004192344 (A), 08.07.2004. | |||

