Изобретение относится к области цифровой связи и может быть использовано в системах телеинформационных коммуникаций для эффективного кодирования речевых сигналов.
Основной проблемой цифрового представления речевого сигнала является задача качественного и компактного кодирования данных для их передачи по цифровым каналам связи. Решение этой проблемы позволит в условиях заданного критерия качества связи увеличить пропускную способность линейных трактов и каналов передачи. Часто в некоторых задачах кодирования речевого сигнала предполагается снизить скорость передачи при сохранении качественных показателей ее восприятия.
Среди многообразия методов кодирования речевых сигналов одним из наиболее эффективных является метод линейного предсказания. Метод линейного предсказания речи принадлежит к классу методов, использующих модель речевого сигнала в виде отклика линейной системы с переменными параметрами (голосового тракта) на соответствующий сигнал возбуждения (порождающий сигнал). Анализатор речепреобразующего устройства выделяет из короткого сегмента речевого сигнала параметры состояния линейной системы и сигнала возбуждения, позволяющие синтезатору восстановить исходный сигнал с требуемой степенью верности.
Известны способы синтеза сигналов возбуждения в вокодерах с линейным предсказанием, основанные на анализе остатка линейного предсказания (О.И.Шелухин, Н.Ф.Лукьянцев. Цифровая обработка и передача речи. М., Радио и Связь, 2000 г. - С.102-166; Рабинер Л.Р., Шафер Р.В. Цифровая обработка речевых сигналов. - М.: Радио и связь, 1981. - С.365-428).
В устройствах, реализующих данные способы, осуществляется анализ остатка линейного предсказания с целью синтеза сигналов возбуждения на приеме. При этом по каналу связи передается информация о коэффициентах формирующей модели, параметрах, характеризующих сигнал возбуждения и кодируемый речевой сигнал.
Для эффективного представления сигнала возбуждения в таких устройствах используются различные способы снижения информативной избыточности данных последовательностей (патенты US №7289952 от 30.10.2007, US №7233896 от 10.07.2007, US №7133823 от 7.11.2006, US №5963897 от 5.10.1999, US №6757650 от 29.06.2004, RU №2163399 от 22.10.1997, RU №97117357 от 20.02.2001).
Недостатком данных способов является значительное расходование информационного ресурса на представление сигнала возбуждения при его передаче по каналу связи, и, следовательно, относительно высокая скорость передачи данных по каналам связи при эффективном кодировании речи.
Техническим результатом предлагаемого способа является уменьшение скорости передачи данных по каналам связи при эффективном кодировании речевых сигналов на основе линейного предсказания.
Для достижения данного технического результата в вокодере с линейным предсказанием предлагается исключить передачу по каналу связи информации о сигнале возбуждения. Формирование сигнала возбуждения можно реализовать непосредственно на приеме по данным о синтезирующей модели. При этом по каналу связи передается информация только о параметрах формирующей модели, коэффициенте усиления и параметрах, характеризующих кодируемый речевой сигнал, которые должны быть рассчитаны на каждом квазистационарном сегменте анализа речевого сигнала.
Экспериментальные исследования модели линейного предсказания речи показали, что если подвергнуть анализу остаток линейного предсказания, то ясно прослеживается практически незначительно искаженный речевой сигнал. Данный факт указывает на схожесть нормированных спектральных плотностей мощности реального речевого сигнала и остатка линейного предсказания, и дальнейшие исследования подтвердили данное предположение. В качестве синтезирующего фильтра при линейном предсказании используют рекурсивный фильтр, при этом его полюсы отражают максимумы формируемой амплитудно-частотной характеристики (АЧХ), которые соответствуют максимумам спектральной плотности мощности анализируемого сегмента речевого сигнала на участке квазистационарности. Параметры синтезирующей системы при линейном предсказании отражают формантную структуру речи на участке квазистационарности. В качестве таких параметров используют линейные спектральные частоты. При этом достаточно передавать и принимать данные о значениях линейных спектральных частот и их амплитудах. Сигнал возбуждения в таком вокодере с линейным предсказанием формируется как суперпозиция формантных частот спектральной плотности мощности речевого сигнала на участке квазистационарности. При этом начальные фазы соответствующих частот рассчитывают в предположении о равномерном распределении. В литературе, посвященной анализу и восприятию речевого сигнала, указывается на тот факт, что информация о фазовом спектре речевого сигнала является несущественной для его разборчивости и на ухудшение его восприятия влияет незначительно (Маркел Дж.Д., А.Х.Грэй. Линейное предсказание речи. - М.: Связь, 1980. - С.166-196).
Сущность предлагаемого способа заключается в следующем. Для формирования сигнала возбуждения в вокодере на основе линейного предсказания на приеме из кадра передачи выделяют параметры синтезирующего фильтра, содержащие информацию о коэффициентах предсказания или линейных спектральных частотах, а также значение коэффициента усиления сигнала возбуждения. По данным параметрам рассчитывают АЧХ синтезирующего фильтра на фазовых углах его полюсов и формируют спектр амплитуд и фаз сигнала возбуждения. Затем формируют сигнал возбуждения на основе данных о коэффициенте усиления и спектрах его амплитуд и фаз, который используют в синтезирующем фильтре липредера для формирования цифрового речевого сигнала на участке квазистационарности.
Алгоритм функционирования предложенной системы, реализующей способ формирования сигнала возбуждения в низкоскоростных вокодерах с линейным предсказанием, представлен на фиг.1.
Проведенный анализ уровня техники позволил установить, что аналоги, характеризующиеся совокупностью признаков, тождественных всем признакам заявленного технического решения, отсутствуют, что указывает на соответствие заявленного способа условию патентоспособности "новизна".
Благодаря новой совокупности существенных признаков системы, обеспечивающих исключение информации о сигнале возбуждения из формата кадра передачи и его формирование на приеме по значениям параметров синтезирующей модели, достигается значительное снижение скорости передачи данных в канале связи.
Анализ существующих технических решений в данной области показал, что введенные отличительные признаки в них отсутствуют и не следуют явным образом из уровня техники. Следовательно, заявленное техническое решение удовлетворяет критерию "изобретательский уровень".
Промышленная применимость введенных элементов обусловлена наличием элементной базы, на основе которой они могут быть выполнены.
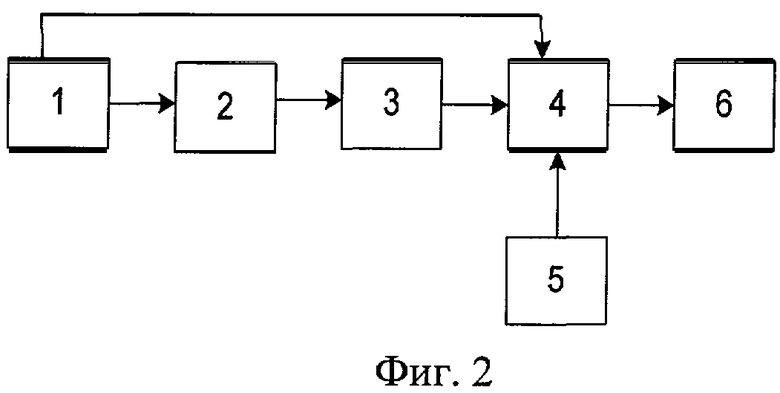
Заявленное техническое решение поясняется чертежом (фиг.2), на котором показана функциональная схема устройства, реализующего способ формирования сигнала возбуждения в низкоскоростных вокодерах с линейным предсказанием посредством использования информации о параметрах синтезирующей модели.
Устройство, реализующее данный способ, состоит из блока приема кадра передачи вокодера с линейным предсказанием 1, на который непосредственно поступает информационная последовательность кадра передачи. Он соединен с блоком выделения параметров синтезирующего фильтра 2, в котором происходит формирование совокупности параметров, описывающих данный фильтр. Сформированные параметры подаются на блок расчета значений АЧХ синтезирующего фильтра на фазовых углах его полюсов 3. Данный блок соединен с блоком формирования сигнала возбуждения 4. На другие входы блока 4 подается сигнал с блока формирования начальных фаз спектральных составляющих сигнала возбуждения 5, а также поступает сигнал от блока 1, в котором содержится дополнительная информация для формирования сигнала возбуждения, например значение коэффициента усиления. Сформированный сигнал возбуждения подается на блок 6 - получатель сигнала возбуждения низкоскоростного вокодера с линейным предсказанием, где используется для возбуждения синтезирующего фильтра приемной части вокодера с линейным предсказанием.
Устройство, реализующее заявленный способ, работает следующим образом. Кадр передачи вокодера с линейным предсказанием, сформированный на участке квазистационарности речевого сигнала, поступает на блок 1, в котором происходит его анализ и выделение информационной составляющей, описывающей формирующий фильтр. Данный сигнал поступает на блок 2, в котором вычисляются значения полюсов передаточной функции синтезирующего фильтра, по которым в блоке 3 рассчитывается значения его АЧХ на соответствующих фазовых углах. В блоке 4 происходит формирование сигнала возбуждения синтезирующего фильтра по данным о его спектре амплитуд, полученным с блока 3, спектре фаз и коэффициенте усиления, полученных с блоков 5 и 1 соответственно. Данный сигнал возбуждения далее подается в блок 6, где используется для возбуждения синтезирующего фильтра приемной части вокодера с линейным предсказанием.
К достоинствам способа следует отнести тот факт, что устранение из кадра передачи информации о сигнале возбуждения позволяет значительно снизить скорость передачи данных в канале связи, а также уменьшить вычислительную сложность алгоритма кодирования речевого сигнала на передающей стороне. Использование предлагаемого технического решения для формирования сигнала возбуждения в вокодерах с линейным предсказанием позволит понизить скорость передачи данных в канале связи на 40-50% от известных решений, либо перераспределить информационный ресурс, предоставляемый каналом связи, на формирование дополнительных сервисов абонентского обслуживания.
Приведенные технические решения показывают, что устройство, воплощающее изобретение при его осуществлении, способно обеспечить более низкую скорость передачи данных за счет устранения из кадра передачи информации о сигнале возбуждения и формировании его на приеме по параметрам, описывающим модель голосового тракта.
Изобретение относится к области цифровой связи и может быть использовано в системах телеинформационных коммуникаций для эффективного кодирования речевых сигналов. Техническим результатом является уменьшение скорости передачи данных по каналам связи за счет эффективного кодирования речевых сигналов на основе линейного предсказания. Указанный технический результат достигается посредством отказа от передачи по каналу связи информации о сигнале возбуждения, который синтезируют непосредственно на приеме по данным о параметрах синтезирующей модели. По каналу связи передают информацию о параметрах синтезирующего фильтра, содержащих информацию о коэффициентах предсказания или линейных спектральных частотах, а также значение коэффициента усиления сигнала возбуждения. На приеме по данным параметрам рассчитывают амплитудно-частотную характеристику синтезирующего фильтра на фазовых углах его полюсов и формируют спектр амплитуд и фаз сигнала возбуждения. Сигнал возбуждения формируют на основе данных о спектрах его амплитуд и фаз и коэффициенте усиления. 2 ил.
Способ синтеза сигналов возбуждения в вокодерах с линейным предсказанием, основанный на формировании сигнала возбуждения путем использования параметров синтезирующего фильтра, отличающийся тем, что для формирования сигнала возбуждения в вокодере на основе линейного предсказания на приеме из кадра передачи выделяют параметры синтезирующего фильтра, содержащие информацию о коэффициентах предсказания или линейных спектральных частотах, а также значение коэффициента усиления сигнала возбуждения, по данным параметрам рассчитывают амплитудно-частотную характеристику синтезирующего фильтра на фазовых углах его полюсов и формируют спектр амплитуд и фаз сигнала возбуждения, затем формируют сигнал возбуждения на основе данных о коэффициенте усиления и спектрах его амплитуд и фаз, который используют в синтезирующем фильтре вокодера с линейным предсказанием для формирования сегмента речевого сигнала на участке квазистационарности.
| РЕЧЕВОЙ КОДЕР С ЛИНЕЙНЫМ ПРЕДСКАЗАНИЕМ И ИСПОЛЬЗОВАНИЕМ АНАЛИЗА ЧЕРЕЗ СИНТЕЗ | 1996 |
|
RU2163399C2 |
| Устройство для взвешивания пастообразных материалов в таре | 1960 |
|
SU138073A1 |
| US 2004024597 A1, 05.02.2004 | |||
| US 2001034600 A1, 25.10.2001 | |||
| KR 20080095514 A, 29.10.2008 | |||
| US 3975587 A, 17.08.1976 | |||
| РАБИНЕР Л.Р., ШАФЕР Р.В | |||
| Цифровая обработка речевых сигналов | |||
| - М.: Радио и связь, 1981, с.420-423. | |||

