Изобретение относится к области цифровой связи, а именно к методам кодирования и обработки речевых сигналов. Предлагаемый способ может быть использован для эффективного кодирования речевых сигналов в системах телеинформационных коммуникаций с переменной скоростью передачи.
Одной из основных задач цифрового представления речевого сигнала является задача качественного и компактного кодирования данных для их передачи по цифровым каналам связи. Решение этой задачи позволит в условиях заданного критерия качества связи увеличить пропускную способность линейных трактов и каналов передачи. Широкое распространение в инфокоммуникациях в настоящее время получили методы кодирования речевых данных с переменной скоростью передачи при заданном качестве связи и асинхронным вводом в канал связи.
Среди множества методов кодирования речевых сигналов одним из наиболее эффективных является метод линейного предсказания. Метод линейного предсказания речи принадлежит к классу методов, использующих модель речевого сигнала в виде отклика линейной системы с переменными параметрами (голосового тракта) на соответствующий сигнал возбуждения (порождающий сигнал). Анализатор речепреобразующего устройства выделяет из короткого сегмента речевого сигнала параметры состояния линейной системы и сигнала возбуждения, позволяющие синтезатору восстановить исходный сигнал с требуемой степенью верности.
Для получения информации о параметрах формирующей модели речеобразования применяют ряд методов (Рабинер Л.Р., Шафер Р.В. Цифровая обработка речевых сигналов. - М.: Радио и связь, 1981. - С.366-390).
В устройствах, реализующих данные способы, осуществляют анализ речевого сигнала на участке квазистационарности, который по разным оценкам составляет 2,5-30 мс.(О.И.Шелухин, Н.Ф.Лукьянцев. Цифровая обработка и передача речи. - М., Радио и Связь, 2000 г. - С.51). По каналу связи при этом передается информация о коэффициентах формирующей модели, параметрах, характеризующих сигнал возбуждения и кодируемый речевой сигнал на участке квазистационарности.
Для эффективного представления информационных параметров, необходимых для синтеза речевого сигнала на приеме, в устройствах, реализующих известные способы, основанные на методе линейного предсказания, используют различные способы снижения их информативной избыточности (О.И.Шелухин, Н.Ф.Лукьянцев. Цифровая обработка и передача речи. - М., Радио и Связь, 2000 г. - С.102-112, С.123-146, патенты RU №02163399 от 20.02.2001, US №7233896 от 10.07.2007).
Недостатком перечисленных выше аналогов является достаточно высокая скорость передачи при заданном качестве синтеза речевого сигнала, а также наличие фиксированного сегмента квазистационарности при описании речи линейной моделью, что не всегда соотносится с природой формирования речевого сигнала.
Наиболее близким по технической сущности является патент RU №02107951 от 27.03.1998 г, заключающийся в том, что выходные данные с кодера на основе метода линейного предсказания с кодовым возбуждением формируют с переменной скоростью передачи, как результат анализа активности речевого сигнала. Особенностью данного метода является то, что параметры корректируют менее часто или с меньшей точностью в течение пауз речи или незначительной активности. При этом такая процедура позволяет достичь существенно большего уменьшения информации, предназначенной для передачи. Свойством, которое используется для уменьшения скорости передачи данных, является коэффициент активности голоса, под которым подразумевают среднее время в процентах фактически занимаемое словами, произносимыми говорящим во время разговора. Во время речевых пауз в вокодере кодируют только окружающий шум. В эти моменты нет необходимости передавать часть параметров, относящихся к модели человеческого голосового тракта.
Недостатком этого способа-прототипа является значительное расходование информационного ресурса на представление параметров, описывающих передаточную функцию голосового тракта, это объясняется тем, что выделение и кодирование этих параметров осуществляют на каждом интервале квазистационарности, что определяет относительно высокую скорость передачи данных по каналам связи при эффективном кодировании речи.
Техническим результатом предлагаемого способа является снижение требуемой пропускной способности каналов связи для вокодеров с линейным предсказанием в классе систем с переменной скоростью передачи.
Для достижения такого технического результата выходные данные с кодера на основе метода линейного предсказания с кодовым возбуждением формируют с переменной скоростью передачи, как результат анализа активности речевого сигнала, однако при кодировании следующих друг за другом вокализованных сегментов исключают постоянную передачу информации о параметрах формирующей модели вокодера с линейным предсказанием. Информацию о параметрах формирующей модели передают только для первого из последовательности вокализованных сегментов, а для остальных сохраняют неизменной, число таких сегментов не должно превышать четырех, для пятого подряд следующего вокализованного сегмента параметры формирующей модели рассчитывают заново. Формируют кадр передачи, для этого используют рассчитанные параметры формирующей модели, совместно с вычисленными сигналом возбуждения и коэффициентом усиления, который несет в себе информацию о синтезе первого сегмента из последовательности. В кадрах передачи, несущих информацию о последующих вокализованных сегментах из анализируемой последовательности, информацию о параметрах формирующей модели заменяют информацией о принадлежности данного сегмента к такой последовательности, при этом параметры синтезирующей системы оставляют неизменными, как для первого сегмента из последовательности, число таких сегментов не должно превышать четырех, для пятого подряд следующего вокализованного сегмента параметры формирующей системы рассчитывают и передают заново. При кодировании шумоподобных и переходных сегментов вычисление параметров синтезирующей системы осуществляют на каждом сегменте квазистационарности речевого сигнала. Это объясняется тем, что параметры синтезирующей системы при линейном предсказании отражают формантную и фонемную структуру речи на участке квазистационарности. При этом в слитной речи длительность фонемы на полностью вокализованном участке значительно превышает длительность установленного сегмента квазистационарности речевого сигнала (Рабинер Л.Р., Шафер Р.В. Цифровая обработка речевых сигналов. - М: Радио и связь, 1981 - С.42-59). Классификацию речевых сегментов на участке квазистационарности на вокализованные, шумоподобные, переходные и паузы можно осуществлять на основе выделения и анализа параметров речевого сигнала (О.И.Шелухин, Н.Ф.Лукьянцев. Цифровая обработка и передача речи. - М., Радио и Связь, 2000 г. - С.51-66).
Формирование сигнала возбуждения можно реализовать стандартными известными методами на основе процедуры анализа через синтез (Быков С.Ф., Журавлев В.И., Шалимов И.А. Цифровая телефония. Учебное пособие для ВУЗов. - М.: Радио и связь, 2003. - с.63-74).
Таким образом, при установившемся режиме следования вокализованных сегментов квазистационарности речевого сигнала по каналу связи передают информационный сигнал, состоящий из подтверждения о принадлежности сегмента к вокализованному типу, параметры, описывающие сигнал возбуждения, и коэффициент его усиления, управляющий мощностью речевого сигнала на выходе синтезирующей системы. Заявленный способ поясняется чертежами:
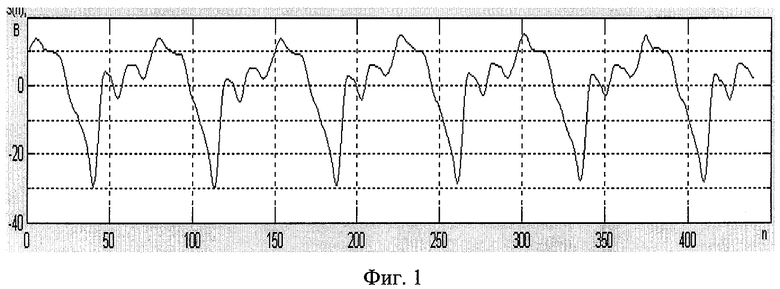
- Фиг.1. Временное представление установившегося режима следования вокализованных сегментов квазистационарности речевого сигнала.
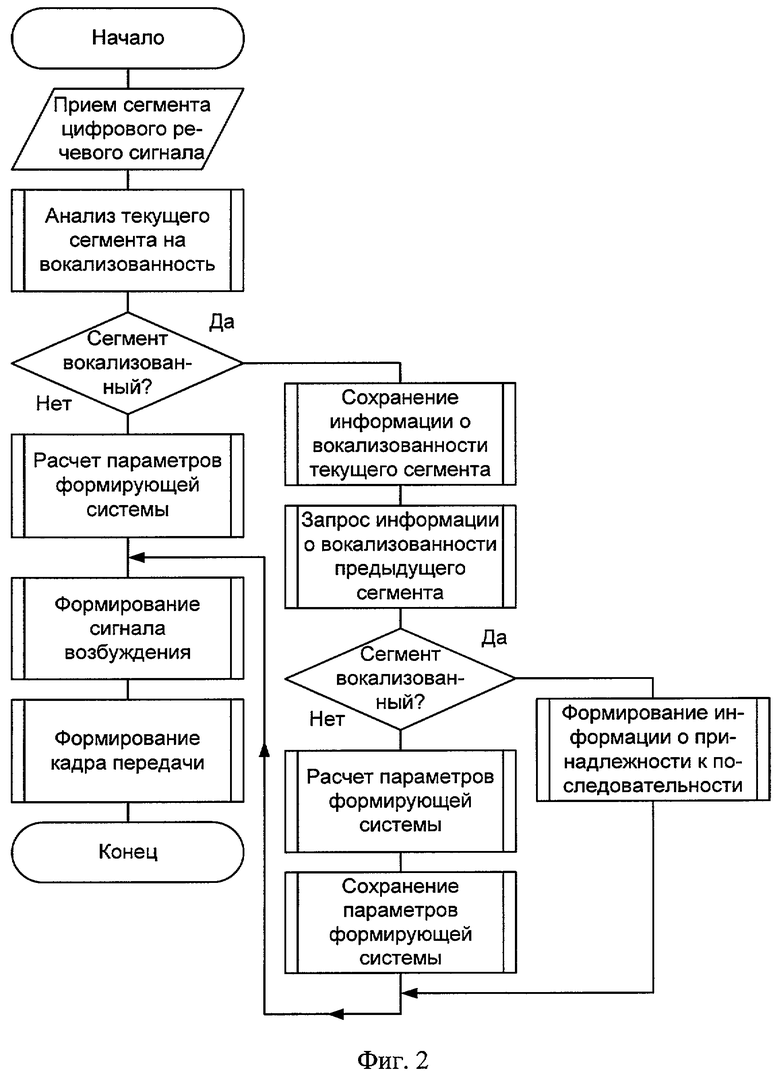
- Фиг.2. Алгоритм функционирования системы, реализующий предлагаемый способ, на передаче.
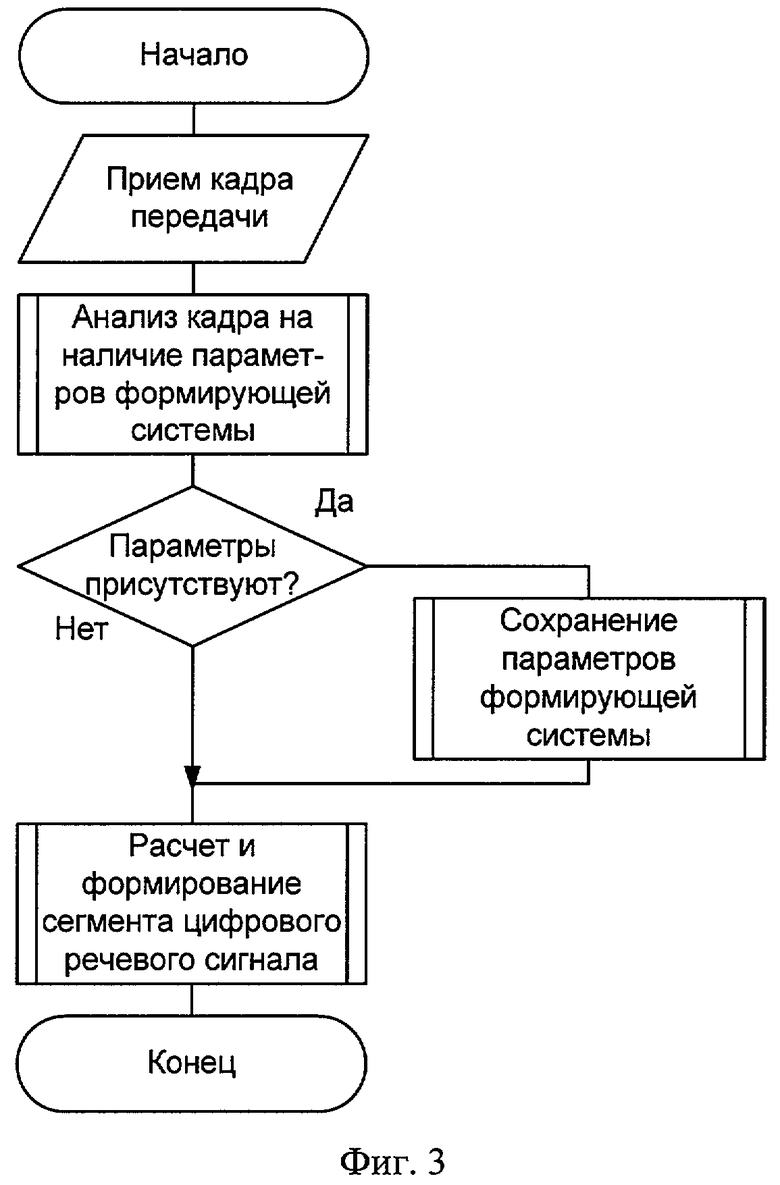
- Фиг.3. Алгоритм функционирования системы, реализующий предлагаемый способ, на приеме.
- Фиг.4. Функциональная схема устройства, реализующего предлагаемый способ.
Сущность предлагаемого способа заключается в следующем. При кодировании следующих друг за другом вокализованных сегментов исключают постоянную передачу информации о параметрах формирующей модели вокодера с линейным предсказанием. Информацию о параметрах формирующей модели передают только для первого из последовательности вокализованных сегментов, а для остальных сохраняют неизменной, число таких сегментов не должно превышать четырех, для пятого подряд следующего вокализованного сегмента параметры формирующей модели рассчитывают заново. Формируют кадр передачи, для этого используют рассчитанные параметры формирующей модели, совместно с вычисленными сигналом возбуждения и коэффициентом усиления, который несет в себе информацию о синтезе первого сегмента из последовательности. В кадрах передачи, несущих информацию о последующих вокализованных сегментах из анализируемой последовательности, информацию о параметрах формирующей модели заменяют информацией о принадлежности данного сегмента к такой последовательности, при этом параметры синтезирующей системы оставляют неизменными, как для первого сегмента из последовательности, число таких сегментов не должно превышать четырех, для пятого подряд следующего вокализованного сегмента параметры формирующей системы рассчитывают и передают заново. При кодировании шумоподобных и переходных сегментов вычисление параметров синтезирующей системы осуществляют на каждом сегменте квазистационарности речевого сигнала.
Такой подход позволяет значительно снизить требуемую пропускную способность каналов связи для функционирования вокодеров с линейным предсказанием в классе систем с переменной скоростью передачи, при этом качественные показатели синтезированного сигнала остаются на достаточно высоком уровне.
Проведенный анализ уровня техники позволил установить, что аналоги, характеризующиеся совокупностью признаков, тождественных всем признакам заявленного технического решения, отсутствуют, что указывает на соответствие заявленного способа условию патентоспособности “новизна”.
Благодаря новой совокупности существенных признаков системы, обеспечивающих исключение информации о параметрах синтезирующего фильтра из кадра передачи при кодировании подряд следующих вокализованных сегментов, кроме первого, достигается значительное снижение скорости передачи данных в канале связи.
Анализ существующих технических решений в данной области показал, что введенные отличительные признаки в них отсутствуют и не следуют явным образом из уровня техники. Следовательно, заявленное техническое решение удовлетворяет критерию “изобретательский уровень”.
Для проверки работоспособности предлагаемого способа были проведены теоретические исследования и компьютерное моделирование.
Экспериментальные исследования модели линейного предсказания речи показали, что в установившемся режиме следования вокализованных сегментов квазистационарности речевого сигнала, при их кодировании по данному методу, параметры, описывающие передаточную функцию голосового тракта, изменяются незначительно, что свидетельствует о линейном характере формирования речевого сигнала на интервалах превышающих установленные сегменты квазистационарности в существующих кодеках на основе линейного предсказания, что показано на фиг.1. Данный факт дает возможность в условиях установившегося режима следования вокализованных сегментов квазистационарности речевого сигнала подстраивать лишь сигнал возбуждения под параметры формирующей модели, выбранные для первого из последовательности вокализованных сегментов, а для остальных сохранять неизменной, число таких сегментов не должно превышать четырех, для пятого подряд следующего вокализованного сегмента параметры формирующей системы рассчитываются заново.
Алгоритм функционирования системы, реализующий предлагаемый способ, представлен на фиг.2 и фиг.3 соответственно.
Заявленное техническое решение поясняется чертежом (см. фиг.4). Устройство, реализующее данный способ, состоит из блока приема сегмента цифрового речевого сигнала 1, на который непосредственно поступает сегмент цифрового речевого сигнала. Он соединен с блоком классификации текущего речевого сегмента 2, который соединен с блоком расчета параметров формирующей системы 3 и блоком хранения информации на передающей стороне 5, на другой вход блока 5 поступает сигнал с блока 3, который соединен с блоком формирования сигнала возбуждения 4, на другой вход блока 4 поступает сигнал с блока 5, который также соединен с блоком формирования информации о принадлежности к последовательности вокализованных сегментов 7, который соединен с блоком формирования кадра передачи 6, на другие входы которого поступают сигналы с блоков 3 и 4. Сформированный кадр передачи передается в канал связи 8 и поступает на блок приема кадра передачи 9, который связан с блоком анализа кадра передачи на наличие параметров формирующей системы 10 и блоком синтеза сегмента цифрового речевого сигнала 12, на другие входы которого поступают сигналы с блока 9 и блока хранения текущей информации кадра передачи 11, на вход которого поступает сигнал с блока 10.
Устройство, реализующее заявленный способ, работает следующим образом. На блок 1 поступает сегмент цифрового речевого сигнала. Блок 1 соединен с блоком 2, в котором происходит анализ поступившего на блок 1 сегмента на вокализованность. Блок 3 рассчитывает параметры формирующей системы методом анализа через синтез в случае если сегмент не вокализованный или же вокализованный, но является одиночным или первым в последовательности вокализованных сегментов и сохраняет их в блоке 5. Если до принятого вокализованного сегмента был принят также вокализованный сегмент, то расчет параметров формирующей системы не производится, информация о принадлежности сегмента к последовательности вокализованных сегментов сохраняется в блоке 5, а блок 4 использует параметры формирующей системы, сохраненные в блоке 5. Блок формирует сигнал возбуждения. Блок 7 формирует информацию о принадлежности сегмента к последовательности вокализованных сегментов. На блок 6 поступает информация с блоков 3, 4, 5, а также блока 7. Данный блок формирует кадр передачи. Сформированный кадр передачи направляется в канал связи 8 и далее поступает на блок 9. Далее блок 10 анализирует принятый кадр на наличие параметров формирующей системы и сохраняет их при обнаружении в блоке 11. Блок 12 рассчитывает и формирует сегмент цифрового речевого сигнала на основе параметров формирующей системы и сигнала возбуждения, поступающих из блоков 9, 10 и 11.
Промышленная применимость введенных элементов обусловлена наличием элементной базы, на основе которой они могут быть выполнены.
К достоинствам способа следует отнести тот факт, что использование информации о параметрах синтезирующего фильтра, вычисленных на первом сегменте квазистационарности вокализованного участка речевого сигнала для кодирования последующих сегментов квазистационарности этого вокализованного участка, позволит снизить скорость передачи данных в канале связи, а также уменьшить вычислительную сложность алгоритма кодирования речевого сигнала на передающей стороне.
Анализ возможности использования предлагаемого технического решения для понижения требуемого информационного ресурса канала связи для функционирования вокодера с линейным предсказанием показывает, что средняя скорость передачи данных в канале связи уменьшается в среднем на 10-15% от известных решений, при этом существует возможность перераспределить информационного ресурса, предоставляемого каналом связи, на формирование дополнительных сервисов абонентского обслуживания.
Приведенные технические решения показывают, что устройство, воплощающее изобретение при его осуществлении, способно обеспечить более низкую скорость передачи данных за счет устранения из кадра передачи информации о параметрах синтезирующей системы при кодировании подряд следующих вокализованных сегментов речевого сигнала, при этом информация о параметрах синтезирующей системы предается в кадре передачи первого сегмента вокализованного участка речевых данных.
Изобретение относится к области цифровой связи и может быть использовано в системах телеинформационных коммуникаций для эффективного кодирования речевых сигналов. Техническим результатом является снижение требуемой пропускной способности каналов связи для вокодеров с линейным предсказанием в классе систем с переменной скоростью передачи. Указанный технический результат достигается исключением из кадра передачи информации о параметрах формирующей модели вокодера с линейным предсказанием при кодировании следующих друг за другом вокализованных сегментов. Информацию о данных параметрах передают только для первого из последовательности вокализованных сегментов, а для остальных сохраняют неизменной, число таких сегментов не должно превышать четырех, для пятого подряд следующего вокализованного сегмента параметры формирующей модели рассчитывают заново. При кодировании шумоподобных и переходных сегментов вычисление параметров синтезирующей системы осуществляют на каждом сегменте квазистационарности речевого сигнала. В установившемся режиме следования вокализованных сегментов квазистационарности речевого сигнала при кодировании по каналу связи передают информационный сигнал подтверждения о принадлежности сегмента к вокализованному типу, сигнал возбуждения, вычисленный на основе процедуры анализа через синтез, и коэффициент его усиления, управляющий мощностью речевого сигнала на выходе синтезирующего фильтра. 4 ил.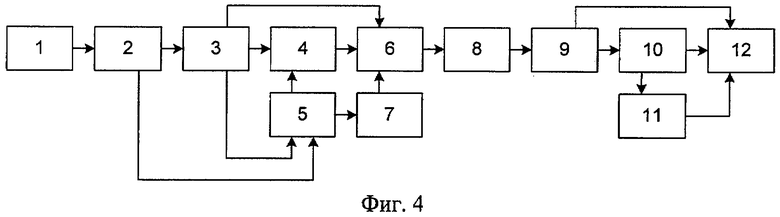
Способ сжатия и восстановления речевых сигналов для систем кодирования с переменной скоростью передачи, заключающийся в том, что выходные данные с кодера на основе метода линейного предсказания с кодовым возбуждением формируют с переменной скоростью передачи как результат анализа активности речевого сигнала, отличающийся тем, что при кодировании следующих друг за другом вокализованных сегментов информацию о параметрах формирующей модели передают только для первого из последовательности вокализованных сегментов, а для остальных сохраняют неизменной, число таких сегментов не должно превышать четырех, для пятого подряд следующего вокализованного сегмента параметры формирующей модели рассчитывают заново, формируют кадр передачи, для этого используют рассчитанные параметры формирующей модели совместно с вычисленными сигналом возбуждения и коэффициентом усиления, который несет в себе информацию о синтезе первого сегмента из последовательности, в кадрах передачи, несущих информацию о последующих вокализованных сегментах из анализируемой последовательности, информацию о параметрах формирующей модели заменяют информацией о принадлежности данного сегмента к такой последовательности, при этом параметры синтезирующей системы оставляют неизменными, как для первого сегмента из последовательности, число таких сегментов не должно превышать четырех, для пятого подряд следующего вокализованного сегмента параметры формирующей системы рассчитывают и передают заново, а при кодировании шумоподобных и переходных сегментов вычисление параметров синтезирующей системы осуществляют на каждом сегменте квазистационарности речевого сигнала.
| СПОСОБ СЖАТИЯ РЕЧЕВОГО СИГНАЛА ПУТЕМ КОДИРОВАНИЯ С ПЕРЕМЕННОЙ СКОРОСТЬЮ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ, КОДЕР И ДЕКОДЕР | 1993 |
|
RU2107951C1 |
| СПОСОБ И УСТРОЙСТВО ВОКОДИРОВАНИЯ ПЕРЕМЕННОЙ СКОРОСТИ ПРИ ПОНИЖЕННОЙ СКОРОСТИ КОДИРОВАНИЯ | 1995 |
|
RU2146394C1 |
| CN 101388214 A, 18.03.2009 | |||
| US 4701955 A, 20.10.1987 | |||
| РАБИНЕР Л.Р., ШАФЕР Р.В | |||
| Цифровая обработка речевых сигналов | |||
| - М.: Радио и связь, 1981, с.319-323. | |||

