Изобретение относится к области цифровой связи, а именно к методам кодирования и обработки речевых сигналов. Предлагаемый способ может быть использован для эффективного кодирования речевых сигналов в системах телеинформационных коммуникаций с переменной скоростью передачи.
Основной проблемой цифрового представления речевого сигнала является задача качественного и компактного кодирования данных для их передачи по цифровым каналам связи. Решение этой проблемы позволит в условиях заданного критерия качества связи увеличить пропускную способность линейных трактов и каналов передачи. Часто в некоторых задачах кодирования речевого сигнала предполагается снизить скорость передачи при сохранении качественных показателей ее восприятия. Широкое распространение в инфокоммуникациях в настоящее время получили методы кодирования речевых данных с переменной скоростью передачи и асинхронным вводом в канал связи.
Среди многообразия методов кодирования речевых сигналов одним из наиболее эффективных является метод линейного предсказания. Метод линейного предсказания речи принадлежит к классу методов, использующих модель речевого сигнала в виде отклика линейной системы с переменными параметрами (голосового тракта) на соответствующий сигнал возбуждения (порождающий сигнал). Анализатор речепреобразующего устройства выделяет из короткого сегмента речевого сигнала параметры состояния линейной системы и сигнала возбуждения, позволяющие синтезатору восстановить исходный сигнал с требуемой степенью верности.
Известны и описаны различные способы линейного предсказания, отличающиеся видом сигнала возбуждения и параметрами, описывающими состояния линейной формирующей системы (О.И.Шелухин, Н.Ф.Лукьянцев. Цифровая обработка и передача речи. - М.: Радио и связь, 2000. - С.102-112, с.123-146, патенты RU №2233010 от 27.01.1999, US №6385577 от 07.05.2002).
Недостатками аналогов является относительно высокая скорость передачи при заданном качестве синтеза речевого сигнала, а также значительное расходование информационного ресурса на представление параметров, описывающих передаточную функцию голосового тракта, что объясняется тем, что выделение и кодирование этих параметров осуществляют на каждом фиксированном интервале квазистационарности.
В устройствах, реализующих данные методы, осуществляется анализ речевого сигнала на участке квазистационарности, который по разным оценкам составляет 2,5-30 мс. (О.И.Шелухин, Н.Ф.Лукьянцев. Цифровая обработка и передача речи. - М.: Радио и связь, 2000. - С.51), при этом по каналу связи передается информация о коэффициентах формирующей модели, параметрах, характеризующих сигнал возбуждения и кодируемый речевой сигнал. На данном участке сигнал принято считать близким к стационарному, вследствие чего он получил название квазистационарный.
Наиболее близким по технической сущности является патент US №6073092 от 06.06.2000 г., заключающийся в том, что используют фиксированные сегменты речевого сигнала, на основании которых рассчитывают параметры состояния линейной системы и сигнала возбуждения, позволяющие синтезатору восстановить исходный сигнал с требуемой степенью верности, при этом входные отсчеты речевого сигнала разделяются на сегменты фиксированной длины (80, 160 или 320 отсчетов), для каждого из сегментов рассчитывают коэффициенты формирующей модели, а затем кодируют с использованием алгоритма линейного предсказания с возбуждением от кода. Недостатком прототипа является использование фиксированной длительности сегмента квазистационарности при использовании кодирования на основе линейного предсказания с возбуждением от кода, что не всегда соотносится с природой формирования речевого сигнала.
Выбор длины данного сегмента является весьма важной задачей. Его увеличение приводит к уменьшению скорости передачи в канале связи, а сокращение - к повышению качественных характеристик синтезируемого сигнала, так как сигнал становится близким к стационарному, и уменьшению времени задержки сигнала на обработку. Анализ речевого сигнала на фиксированно выбранном сегменте квазистационарности является достаточно грубым допущением, так как за пределами сегмента сигнал представляется равным нулю, что не соответствует действительности и приводит к появлению искажений на стыках сегментов при их анализе и кодировании, а также искажений в восприятии синтезированного речевого сигнала на приеме, при этом на вокализованных участках речи длина сегмента стационарности может быть увеличена, что связано с линейным характером образования речевого сигнала на этом участке, а на шумоподобных участках желательно ее уменьшать, так как речевой сигнал в данном случае имеет нестационарные свойства. Деление речевого сигнала на вокализованные и шумоподобные (невокализованные) сегменты достаточно широко используется в технике эффективного речевого кодирования (Рабинер Л.Р., Шафер Р.В. Цифровая обработка речевых сигналов. - М.: Радио и связь, 1981. - С.110-128).
Техническим результатом применения предлагаемого изобретения является снижение требуемой скорости передачи при сохранении качественных показателей синтезированного речевого сигнала.
Для достижения этого выполняют анализ на основе линейного предсказания поступающего на вход вокодера речевого сигнала, деля его на сегменты по 20 миллисекунд, если принимают решение о том, что сигнал является активной речью. Выделяют переход огибающей сигнала через нулевое значение и от положения отсчета со значением, наиболее близким нулю, выбирают длину сегмента соответствующую 20 миллисекундам, и рассчитывают значение частоты основного тона и сигнала тон-шум, если принимают решение о вокализованности анализируемого сигнала, то увеличивают длительность сегмента квазистационарности на количество отсчетов, кратное периоду основного тона, но не более чем на 60 миллисекунд, с обязательной проверкой на вокализованность следующих сегментов по 20 миллисекунд. Если принимают решение о шумоподобности следующего сегмента, то границу сегмента анализа выбирают кратной количеству отсчетов на периоде основного тона, но не более половины следующего сегмента длительностью 20 миллисекунд. Если принимают решение о шумоподобности анализируемого сегмента, то длину сегмента анализа уменьшают, при этом границу сегмента формируют на значении, близком нулю и кратном вычисленному периоду основного тона.
При таком подходе с высокой вероятностью можно утверждать, что начальный и конечный отсчеты во вновь сформированном сегменте будут иметь значения, близкие нулю, что значительно уменьшит возможные искажения на стыках сегментов.
В большинстве вокодеров с линейным предсказанием в качестве одного из параметров, входящих в кадр передачи, является частота основного тона говорящего, таким образом, использование данного параметра в качестве одного из критериев формирования границ сегмента квазистационарности речевого сигнала не приведет к повышению скорости передачи в таких вокодерах, а существенно сократит ее, при этом повышается качество синтезированной речи на выходе вокодера с линейным предсказанием, так как отсчеты на стыках сегментов квазистационарности имеют практически нулевую энергию. В некоторых методах линейного предсказания частота основного тона говорящего не передается в кадре передачи, для таких методов данный параметр будет дополнительным, что снизит эффект от внедрения изобретения, однако общий выигрыш от ее использования будет достаточно велик. Методы выделения частоты основного тона речевого сигнала хорошо известны и нашли широкое распространение в речевом кодировании (Рабинер Л.Р., Шафер Р.В. Цифровая обработка речевых сигналов. - М.: Радио и связь, 1981. - С.128-150).
Использование данного способа для выделения сегментов квазистационарности при анализе речевого сигнала в вокодерах с линейным предсказанием будет рационально для класса систем кодирования речевого сигнала с переменной скоростью передачи.
Сущность предлагаемого способа заключается в следующем. Предполагается выполнение анализа на основе линейного предсказания поступающего на вход вокодера речевого сигнала посредством его деления на сегменты по 20 миллисекунд, если сигнал является активной речью. Выделяется переход огибающей сигнала через нулевое значение и от положения отсчета со значением, наиболее близким нулю, выбирается сегмент длительностью 20 миллисекунд. Рассчитывается значение частоты основного тона и сигнала тон-шум для текущего сегмента, если принимается решение о его вокализованности, то оно служит сигналом для увеличения длительности сегмента квазистационарности (текущего сегмента) на количество отсчетов, кратное периоду основного тона, но не более чем на 60 миллисекунд, с обязательной проверкой на вокализованность следующих сегментов по 20 миллисекунд. Если принимается решение о шумоподобности следующего сегмента, то длительность текущего сегмента увеличивается на количество отсчетов, кратное количеству отсчетов на периоде основного тона, но не более половины следующего сегмента длительностью 20 миллисекунд. При анализе текущего сегмента может быть принято решение о его шумоподобности. В этом случае длина текущего сегмента уменьшается, причем граница сегмента формируется на значении, близком нулю и кратном вычисленному периоду основного тона.
Такой подход позволяет значительно снизить требуемую пропускную способность каналов связи для функционирования вокодеров с линейным предсказанием, при этом качественные показатели синтезированного сигнала значительно повышаются.
Заявленный способ поясняется чертежами.
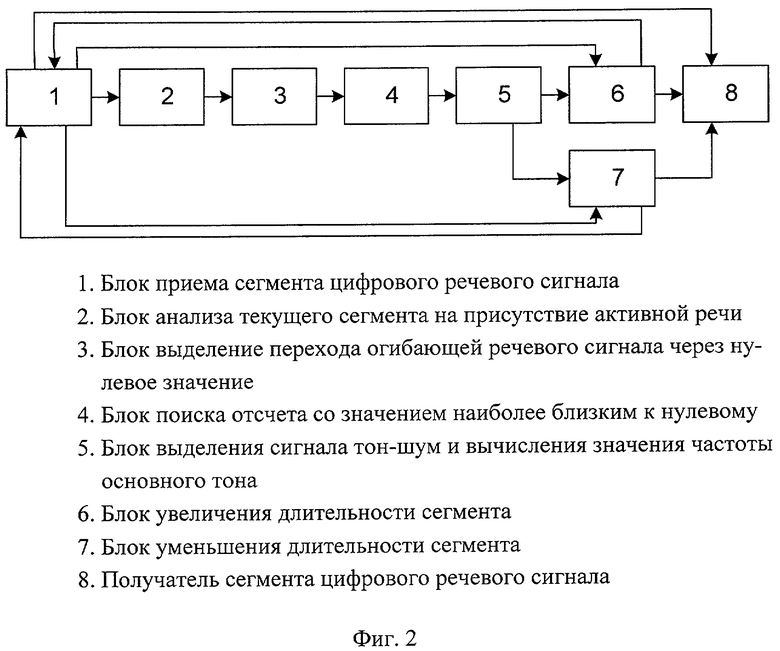
- Фиг.1. Алгоритм функционирования способа выделения сегментов квазистационарности при анализе речевого сигнала в вокодерах с линейным предсказанием.
- Фиг. 2. Функциональная схема устройства, реализующего способ выделения сегментов квазистационарности при анализе речевого сигнала в вокодерах с линейным предсказанием.
Проведенный анализ уровня техники позволил установить, что аналоги, характеризующиеся совокупностью признаков, тождественных всем признакам заявленного технического решения, отсутствуют, что указывает на соответствие заявленного способа условию патентоспособности "новизна".
Анализ существующих технических решений в данной области показал, что введенные отличительные признаки в них отсутствуют и не следуют явным образом из уровня техники. Следовательно, заявленное техническое решение удовлетворяет критерию "изобретательский уровень".
Для проверки работоспособности предлагаемого способа были проведены теоретические исследования и компьютерное моделирование.
Благодаря новой совокупности существенных признаков системы, обеспечивающих увеличение длительности вокализованного сегмента квазистационарности речевого сигнала и уменьшение - шумоподобного, а также выбор отсчетов на границах сегмента с энергией, приблизительно равной нулю, достигается значительное снижение скорости передачи данных в канале связи и повышение качественных показателей синтезированного речевого сигнала.
Промышленная применимость введенных элементов обусловлена наличием элементной базы, на основе которой они могут быть выполнены.
Заявленное техническое решение поясняется чертежом (фиг.2). Оно состоит из блока приема сегмента цифрового речевого сигнала 1, который связан с блоком увеличения длительности сегмента 6, блоком уменьшения длительности сегмента 7, получателем сегмента цифрового речевого сигнала 8, а также с блоком анализа текущего сегмента на присутствие активной речи 2, который связан с блоком выделения перехода огибающей речевого сигнала через нулевое значение 3, информация с которого подается на блок поиска отсчета со значением, наиболее близким к нулевому, 4, который связан с блоком выделения сигнала тон-шум и вычисления значения частоты основного тона, который связан с блоком 6 и блоком 7, которые связаны с блоком 8, а также блоком 1.
Устройство функционирует следующим образом. На блок 1 поступает сегмент цифрового речевого сигнала длительностью 20 мс. Блок 2 анализирует сигнал на присутствие активной речи. Если он принимает решение "пауза", то длительность сегмента остается неизменной, и он передается в блок 8, иначе блок 3 производит выделение перехода огибающей речевого сигнала через нулевое значение и затем блок 4 осуществляет поиск отсчета со значением, наиболее близким к нулевому. Далее сигнал поступает в блок 5, который выделяется сигнал тон-шум и вычисляет частоту основного тона. Если в блоке 5 принято решение, что сегмент вокализованный, то вычисляется частота основного тона и в соответствии с информационными параметрами, получаемыми с блока 5, блок 6 увеличивает длительность сегмента квазистационарности на количество отсчетов, кратное периоду основного тона, но не более чем на 60 миллисекунд, с обязательной проверкой на вокализованность следующих сегментов по 20 миллисекунд, если следующий сегмент является шумоподобным, то граница сегмента анализа выбирается кратной количеству отсчетов на периоде основного тона, но не более половины следующего сегмента длительностью 20 миллисекунд. Блок 6 напрямую взаимодействует с блоком 1 и получает от него необходимое количество отсчетов для увеличения длительности сегмента, который затем направляется в блок 8. Если в блоке 5 принято решение о том, что сегмент шумоподобный, то блок 7 уменьшает длину сегмента анализа. При этом последний отсчет сегмента формируется на значении, близком к нулю, а длина сегмента выбирается кратной периоду основного тона. Оставшееся количество отсчетов направляется в блок 1, с которым блок 7 связан напрямую. Измененный сегмент направляется в блок 8.
К достоинствам использования предлагаемого способа следует отнести тот факт, что изменение длительности сегментов квазистационарности при анализе речевого сигнала в вокодерах с линейным предсказанием дает возможность уменьшить среднюю скорость передачи в вокодерах с линейным предсказанием, функционирующих с переменной скоростью передачи.
Использование предлагаемого технического решения дает возможность понизить среднюю скорость передачи данных в канале связи по сравнению с известными решениями, в которых применяется фиксированный сегмент квазистационарности речевого сигнала.
Приведенные технические решения показывают, что устройство, воплощающее заявленный способ при его осуществлении, способно обеспечить более низкую среднюю скорость передачи данных.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ СЖАТИЯ И ВОССТАНОВЛЕНИЯ РЕЧЕВЫХ СИГНАЛОВ ДЛЯ СИСТЕМ КОДИРОВАНИЯ С ПЕРЕМЕННОЙ СКОРОСТЬЮ ПЕРЕДАЧИ | 2009 |
|
RU2394284C1 |
| СПОСОБ КОМПРЕССИИ РЕЧЕВОГО СИГНАЛА | 2007 |
|
RU2380765C2 |
| ПОМЕХОУСТОЙЧИВАЯ КЛАССИФИКАЦИЯ РЕЖИМОВ КОДИРОВАНИЯ РЕЧИ | 2012 |
|
RU2584461C2 |
| ТРАНСФОРМАЦИЯ ШКАЛЫ ВРЕМЕНИ КАДРОВ В ШИРОКОПОЛОСНОМ ВОКОДЕРЕ | 2007 |
|
RU2414010C2 |
| ГЕНЕРАЦИЯ ВЫСОКОПОЛОСНОГО СИГНАЛА ВОЗБУЖДЕНИЯ | 2015 |
|
RU2683632C2 |
| СПОСОБ УЛУЧШЕНИЯ ВОСПРИЯТИЯ СИНТЕЗИРОВАННОЙ РЕЧИ ПРИ РЕАЛИЗАЦИИ ПРОЦЕДУРЫ АНАЛИЗА ЧЕРЕЗ СИНТЕЗ В ВОКОДЕРАХ С ЛИНЕЙНЫМ ПРЕДСКАЗАНИЕМ | 2010 |
|
RU2445719C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ УЛУЧШЕНИЯ РЕЧЕВОГО СИГНАЛА В ПРИСУТСТВИИ ФОНОВОГО ШУМА | 2004 |
|
RU2329550C2 |
| СПОСОБ ВЫДЕЛЕНИЯ СЕГМЕНТОВ ОБРАБОТКИ РЕЧИ НА ОСНОВЕ АНАЛИЗА КОРРЕЛЯЦИОННЫХ ЗАВИСИМОСТЕЙ В РЕЧЕВОМ СИГНАЛЕ | 2010 |
|
RU2445718C1 |
| СПОСОБ АНАЛИЗА И СИНТЕЗА РЕЧИ | 2005 |
|
RU2296377C2 |
| РЕШЕНИЕ ОТНОСИТЕЛЬНО НАЛИЧИЯ/ОТСУТСТВИЯ ВОКАЛИЗАЦИИ ДЛЯ ОБРАБОТКИ РЕЧИ | 2014 |
|
RU2636685C2 |
Изобретение относится к области цифровой связи и может быть использовано в системах телеинформационных коммуникаций для выделения сегментов квазистационарности при анализе речевого сигнала. Технический результат - повышение точности кодирования и снижение требуемой скорости передачи. Для этого выделение сегментов квазистационарности при анализе речевого сигнала в вокодерах с линейным предсказанием основано на изменении их длительности в соответствии с классификацией речевых сегментов и вычислении частоты основного тона. 2 ил.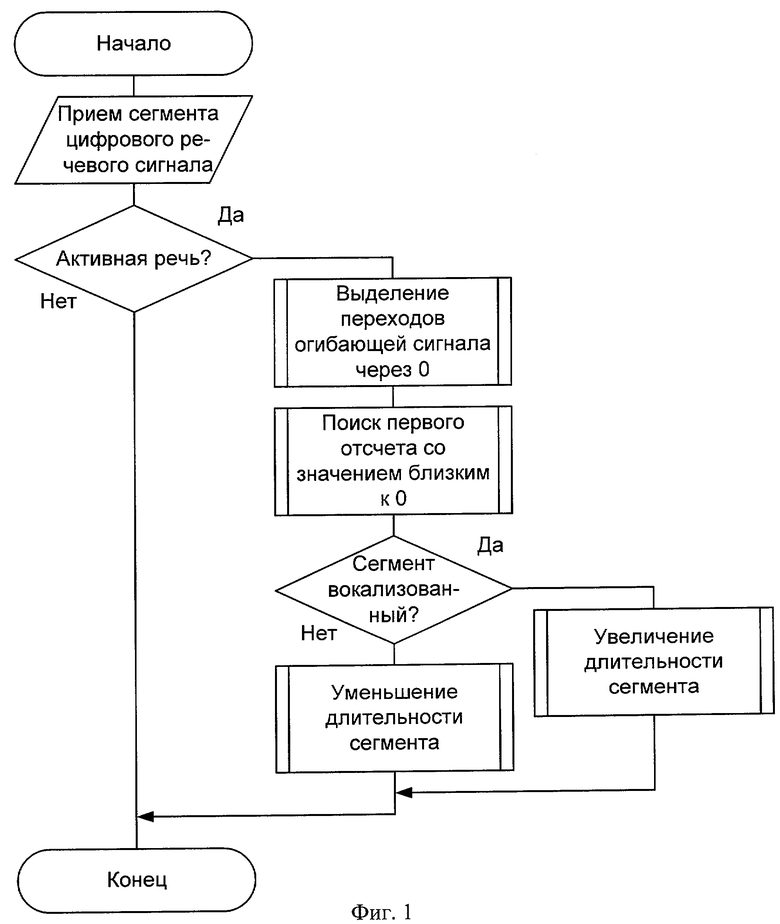
Способ выделения сегментов квазистационарности при анализе речевого сигнала в вокодерах с линейным предсказанием, заключающийся в том, что используют фиксированные сегменты речевого сигнала, на основании которых рассчитывают параметры состояния линейной системы и сигнала возбуждения, позволяющие синтезатору восстановить исходный сигнал с требуемой степенью верности, отличающийся тем, что выполняют анализ на основе линейного предсказания поступающего на вход вокодера речевого сигнала, деля его на сегменты по 20 мс, если принимают решение о том, что сигнал является активной речью, то выделяют переход огибающей сигнала через нулевое значение и от положения отсчета со значением, наиболее близким к нулю, выбирают длину сегмента соответствующую 20 мс и рассчитывают значение частоты основного тона и сигнала тон-шум, если принимают решение о вокализованности анализируемого сигнала, то увеличивают длительность сегмента квазистационарности на количество отсчетов, кратное периоду основного тона, но не более чем на 60 мс с обязательной проверкой на вокализованность следующих сегментов по 20 мс, если принимают решение о шумоподобности следующего сегмента, то границу сегмента анализа выбирают кратной количеству отсчетов на периоде основного тона, но не более половины следующего сегмента длительностью 20 мс, если принимают решение о шумоподобности анализируемого сегмента, то длину сегмента анализа уменьшают, при этом границу сегмента формируют на значении, близком к нулю и кратном вычисленному периоду основного тона.
| US 6073092 А, 06.06.2000 | |||
| СПОСОБЫ И УСТРОЙСТВА ДЛЯ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ РЕЧЕВЫХ СИГНАЛОВ | 1996 |
|
RU2233010C2 |
| СПОСОБ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ РЕЧЕВОГО СИГНАЛА МЕТОДОМ ЛИНЕЙНОГО ПРЕДСКАЗАНИЯ | 2006 |
|
RU2319222C1 |
| СПОСОБ И УСТРОЙСТВО ВОКОДИРОВАНИЯ ПЕРЕМЕННОЙ СКОРОСТИ ПРИ ПОНИЖЕННОЙ СКОРОСТИ КОДИРОВАНИЯ | 1995 |
|
RU2146394C1 |
| US 6385577 В2, 07.05.2002 | |||
| US 6223152 В1, 24.04.2001 | |||
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| ДРИЛЬБОР | 2002 |
|
RU2269967C2 |
| Способ монтажа башни | 1983 |
|
SU1173028A1 |

