ОБЛАСТЬ ТЕХНИКИ
[001] Данное техническое решение в общем относится к компьютерным системам хранения данных и, в частности, к системе распределенного хранения восстанавливаемых данных и способу восстановления данных после отказа узла хранения данных в системе или диска в одном из узлов.
УРОВЕНЬ ТЕХНИКИ
[002] В настоящее время большой объем компьютерных данных обычно хранится в распределенной системе хранения. Распределенные системы хранения предлагают несколько преимуществ, таких как возможность увеличения емкости хранения по мере роста требований пользователей, надежность данных на основе избыточности данных и гибкость в обслуживании и замене вышедших из строя компонентов. Распределенные системы хранения были реализованы в различных формах, например, таких как системы с избыточными массивами независимых дисков (RAID), которые широко известны в уровне техники.
[003] Например, в статье «Параллельная RAID-архитектура TickerTAIP» (автор Цао и др.) описывают систему дискового массива (RAID), которая включает в себя ряд рабочих узлов и исходных узлов. Каждый рабочий узел имеет несколько дисков, подключенных через шину. Исходные узлы обеспечивают подключения к компьютерам-клиентам. Когда диск или узел выходит из строя, система восстанавливает потерянные данные, используя частичное резервирование, предусмотренное в системе. Описанный метод применим только к системам хранения RAID. Кроме того, этот метод не решает проблему распределенной системы хранения, состоящей из очень большого количества независимых массивов хранения.
[004] Также из уровня техники известен патент США US 6438661 «Method, system, and program for managing meta data in a storage system and rebuilding lost meta data in cache» (правообладатель: International Business Machines Corp), который описывает способ и систему для восстановления потерянных метаданных в кэш-памяти. Метаданные предоставляют информацию о пользовательских данных, хранящихся на устройстве хранения. Метод определяет, были ли изменены дорожки метаданных в кэше, указывает в энергонезависимой памяти, что дорожки метаданных были изменены, и восстанавливает дорожки метаданных. Восстановление данных включает в себя доступ к дорожкам данных, ассоциированным с дорожками метаданных, размещение дорожек данных, к которым осуществляется доступ, в кэш и обработку дорожек данных для восстановления дорожек метаданных. Описанный метод не восстанавливает данные, утерянные из-за отказа узла в распределенной системе хранения.
[005] Заявка на патент US20020062422A1 «Method for rebuilding meta-data in a data storage system and a data storage system» (правообладатель: International Business Machines Corp) описывает другой способ восстановления метаданных в системе хранения, в которой потоки данных записываются в систему как сегменты. Метод сканирует метаданные в каждом сегменте, чтобы определить последний сегмент, записанный из каждого потока. Затем он восстанавливает метаданные, используя метаданные в сегментах, за исключением метаданных для идентифицированных последних сегментов. Описанный метод неприменим к распределенной многоузловой системе хранения и не решает проблему восстановления данных после сбоя узла.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[006] Технической проблемой или технической задачей, решаемой в данном техническом решении, является осуществление способа и системы распределенного хранения восстанавливаемых данных с обеспечением целостности и конфиденциальности информации.
[007] Техническим результатом, достигаемым при решении вышеуказанной технической проблемы, является повышение надежности восстановления данных.
[008] Указанный технический результат достигается за счет осуществления способа распределенного хранения восстанавливаемых данных с обеспечением целостности и конфиденциальности информации, который выполняется по меньшей мере одной системой, которая содержит множество узлов хранения, связанных сетью и хранящих данные в виде экстентов, агентов службы данных (DS) для управления экстентами, агентов службы метаданных (MDS) для управления метаданными, относящимися к узлам и экстентам, и агентов диспетчеров кластеров (CM), причем способ состоит из следующих этапов: обнаружение сбоя диска в системе одним из агентов CM; уведомление агентов DS или MDS о сбое; формирование независимо уведомленными агентами DS или MDS плана восстановления экстентов данных, затронутых сбоем; и коллективное восстановление затронутых экстентов на основе сгенерированного плана на предыдущем шаге, причем каждый узел включает в себя множество дисков; и отказ диска обнаруживается агентом DS на основании частоты ошибок дисков.
[009] Также указанный технический результат достигается благодаря осуществлению системы распределенного хранения восстанавливаемых данных с обеспечением целостности и конфиденциальности информации, которая содержит множество узлов хранения, соединенных сетью, причем каждый узел хранит данные в виде экстентов; агент службы данных (DS) в каждом узле для управления экстентами в узле; множество агентов службы метаданных (MDS) для управления метаданными, относящимися к узлам и экстентам, причем агенты MDS работают в подмножестве узлов; агент диспетчера кластеров (CM) в каждом узле для обнаружения сбоя в системе и уведомления подмножества агентов DS или MDS о сбое,при этом после уведомления об отказе подмножество агентов DS или MDS независимо генерирует план для восстановления экстентов, затронутых отказом, и коллективного восстановления затронутых экстентов на основе плана; и постоянная карта, которая коррелирует экстенты данных с узлами, при этом каждый агент MDS управляет подмножеством карты.
[0010] В некоторых вариантах реализации технического решения система дополнительно содержит интерфейс, позволяющий приложению получать доступ к данным, хранящимся в системе.
[0011] В некоторых вариантах реализации технического решения система дополнительно содержит средство для определения подмножества узлов, в которых работают агенты MDS.
[0012] В некоторых вариантах реализации технического решения каждый агент CM поддерживает упорядоченный список узлов, которые в настоящее время работают в системе.
[0013] В некоторых вариантах реализации технического решения каждый агент CM включает в себя средство для обнаружения отказа узла.
[0014] В некоторых вариантах реализации технического решения каждый агент CM включает в себя средство для обнаружения нового узла в системе.
[0015] В некоторых вариантах реализации технического решения упомянутое средство для обнаружения нового узла включает в себя средство для мониторинга сетевых сообщений от нового узла.
[0016] В некоторых вариантах реализации технического решения каждый агент DS распространяет обновления до экстентов в ассоциированном узле другим агентам DS в системе.
[0017] В некоторых вариантах реализации технического решения каждый агент DS управляет кэшированием данных в ассоциированном узле.
[0018] В некоторых вариантах реализации технического решения каждый узел содержит множество дисков с данными, и каждый агент DS включает в себя средство для обнаружения отказа дисков в ассоциированном узле.
[0019] В некоторых вариантах реализации технического решения средство для обнаружения отказа диска основано на частоте ошибок дисков.
[0020] В некоторых вариантах реализации технического решения план восстановления включает в себя список экстентов, которые должны быть восстановлены для восстановления избыточности данных в системе.
[0021] В некоторых вариантах реализации технического решения восстанавливаемые экстенты совместно восстанавливаются агентами DS.
[0022] В некоторых вариантах реализации технического решения пространство выделяется в узлах, которые все еще работают, для замены экстентов, затронутых отказом.
[0023] В некоторых вариантах реализации технического решения данные в затронутых экстентах определяются и переносятся в выделенное пространство.
[0024] В некоторых вариантах реализации технического решения агенты DS уведомлены об отказе и уведомленные агенты DS определяют те экстенты, которые имеют данные на отказавшем узле.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
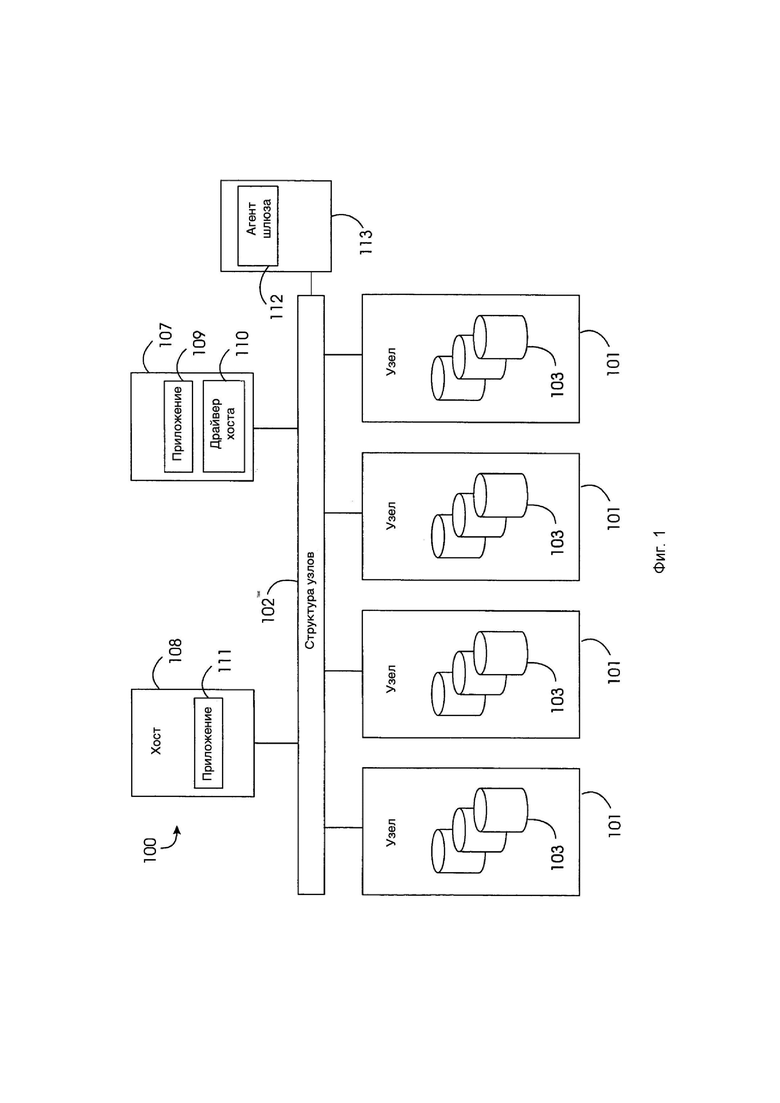
[0025] Фиг. 1 иллюстрирует блок-схему, показывающую типичную конфигурацию системы коллективного хранения согласно изобретению.
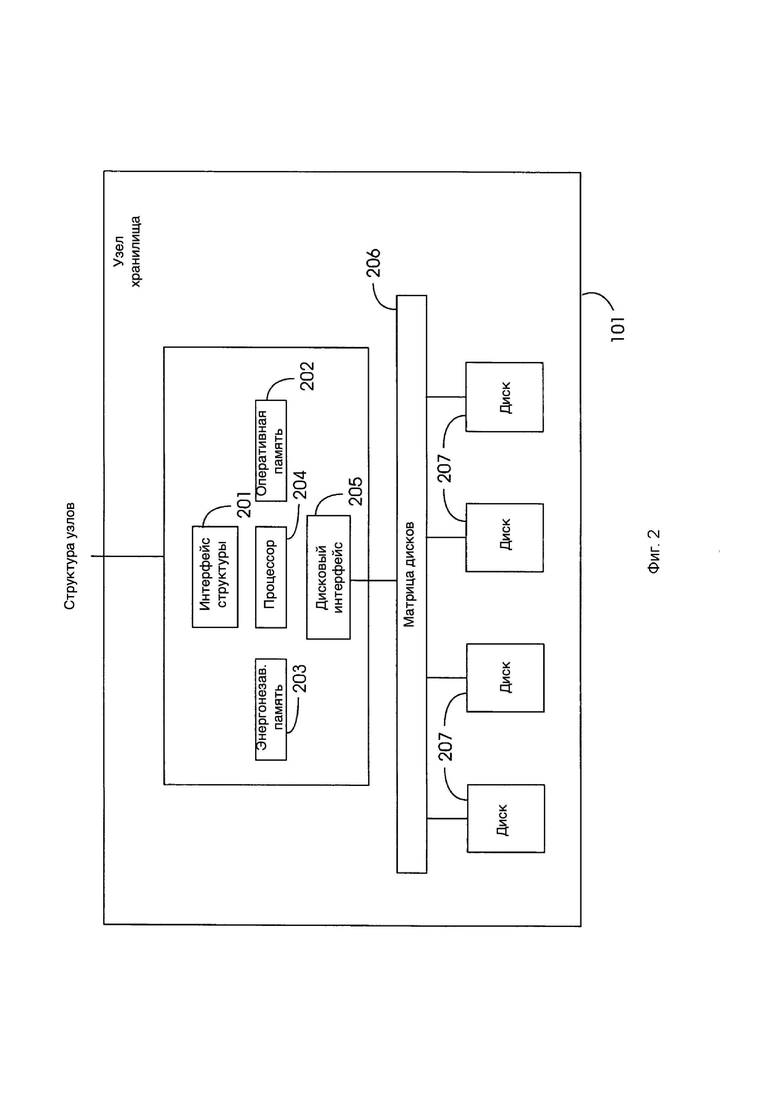
[0026] Фиг. 2 иллюстрирует блок-схему, показывающую типичную физическую конфигурацию узла хранения коллективной системы хранения.
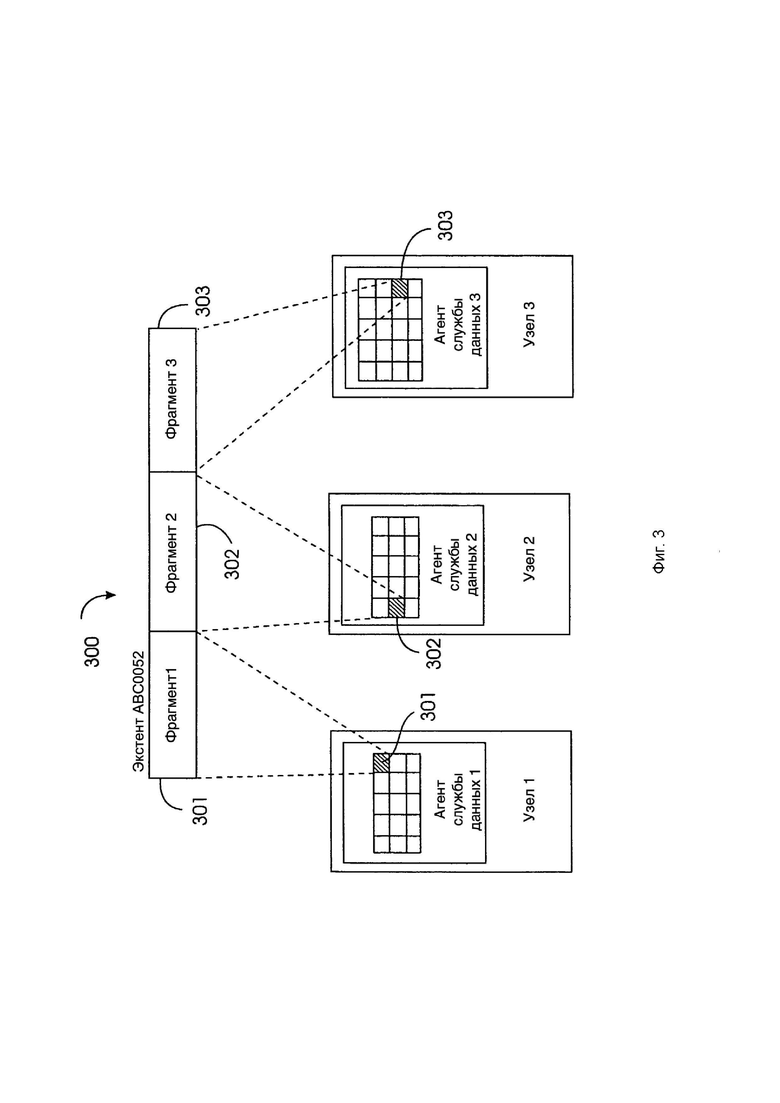
[0027] Фиг. 3 иллюстрирует пример экстента данных и его фрагментов, которые находятся на разных узлах хранения.
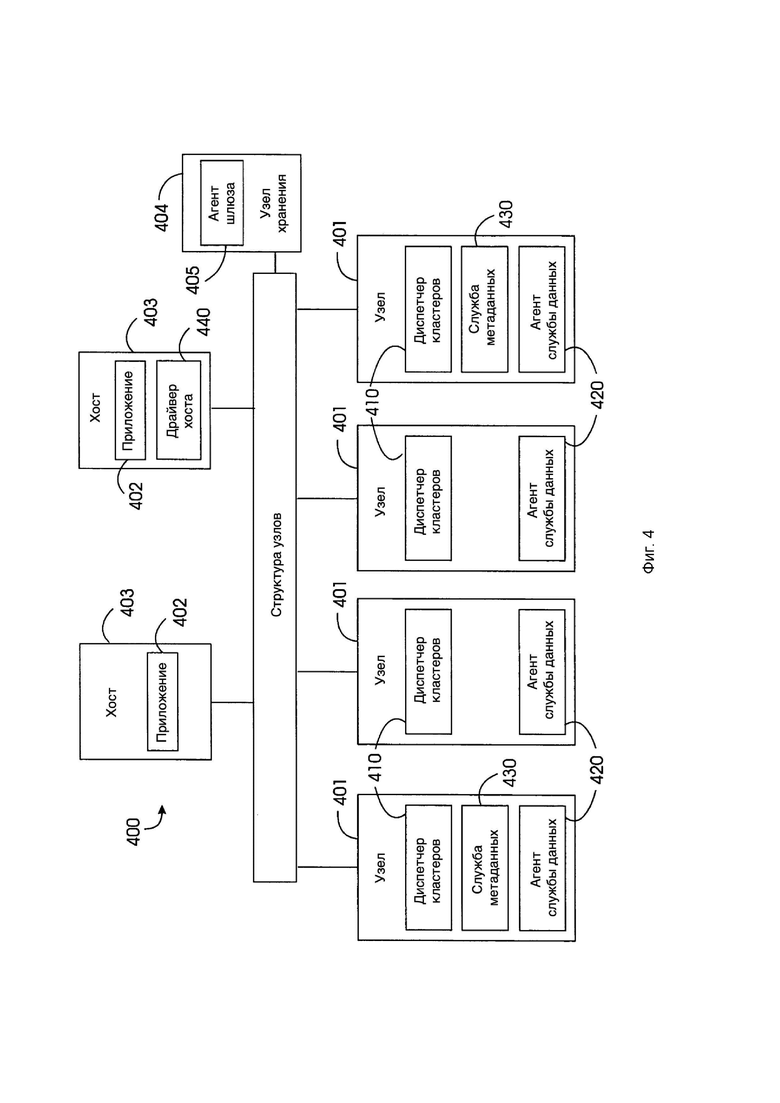
[0028] Фиг. 4 иллюстрирует блок-схему, типичную конфигурацию системы коллективного хранения с агентами для поддержки операций восстановления данных в соответствии с изобретением.
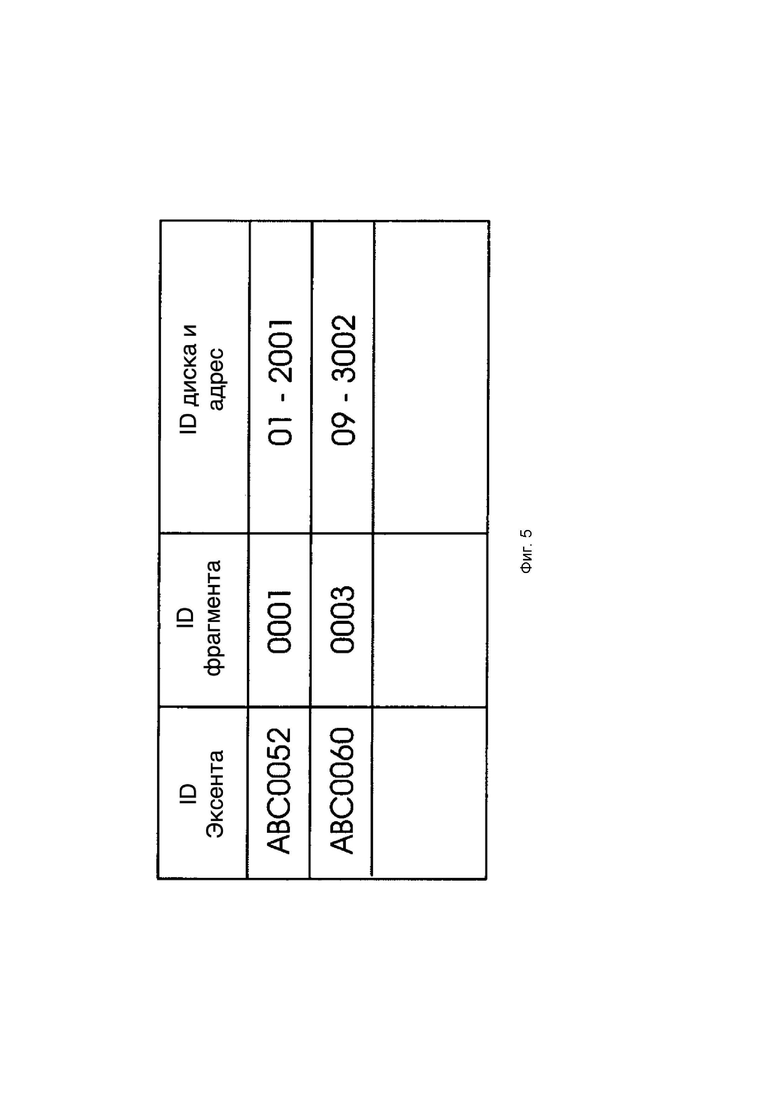
[0029] Фиг. 5 иллюстрирует пример карты Fragment_To_Disk в соответствии с изобретением.
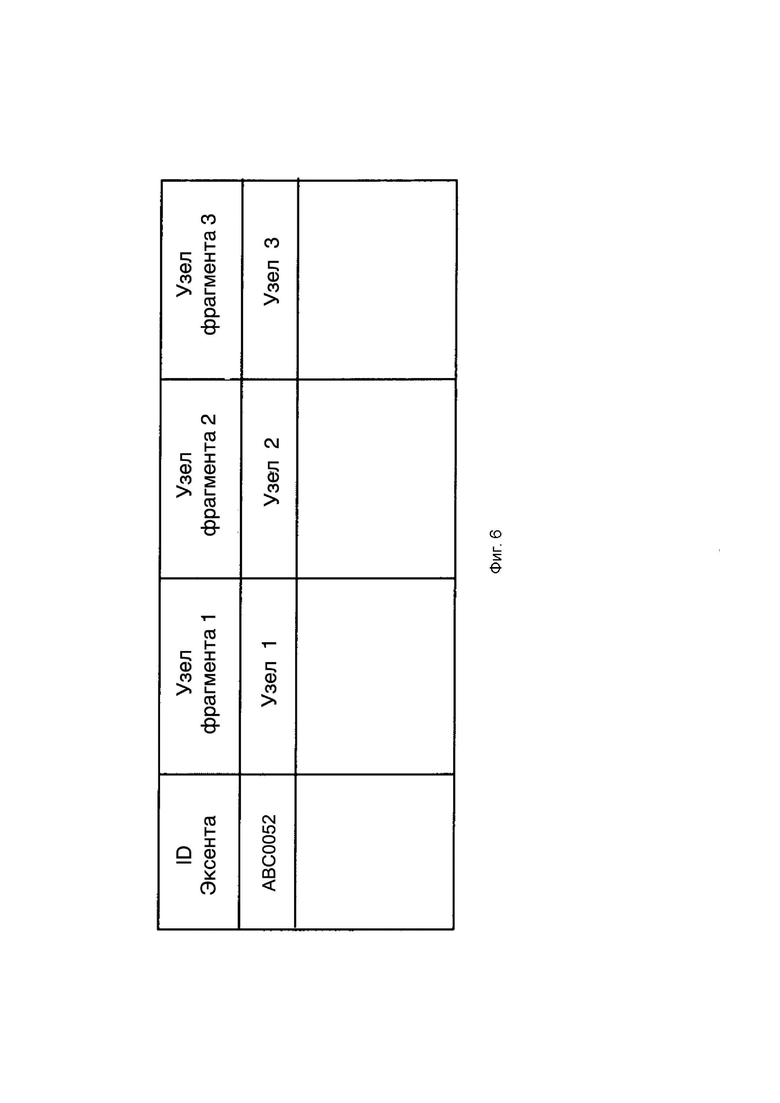
[0030] Фиг. 6 иллюстрирует пример карты Extent_To_Node в соответствии с изобретением.
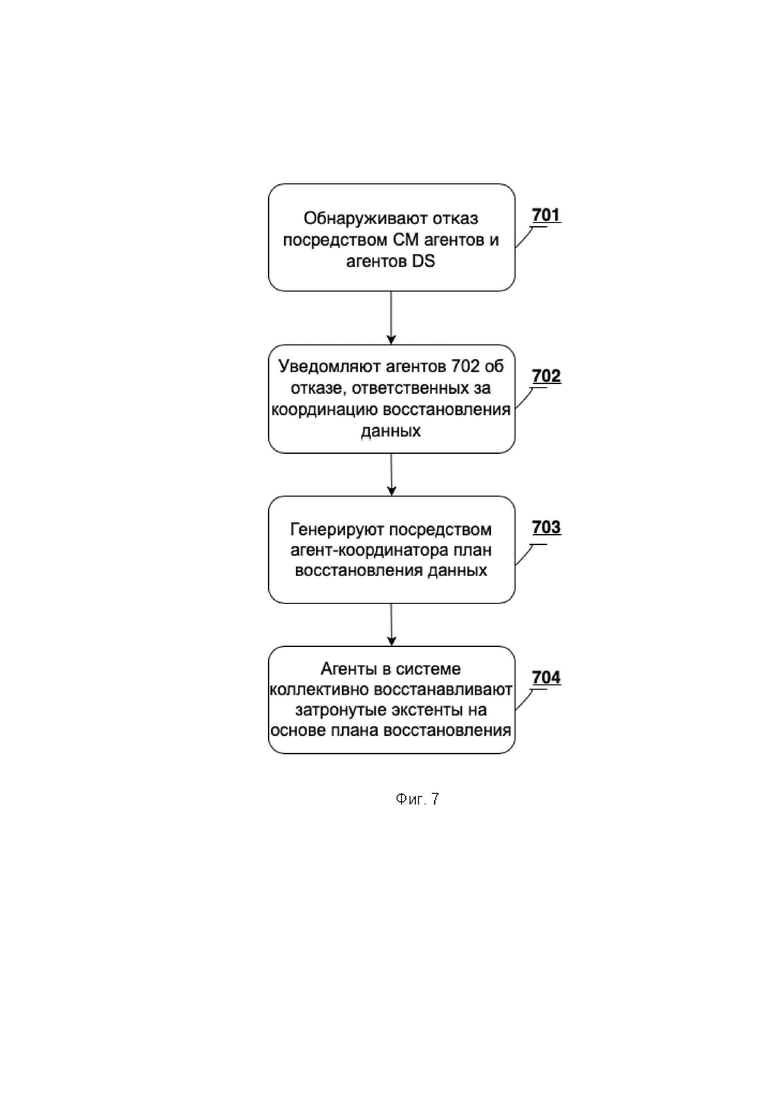
[0031] Фиг. 7 иллюстрирует блок-схему, показывающую общий процесс восстановления данных после отказа узла или отказа диска в коллективной системе хранения.
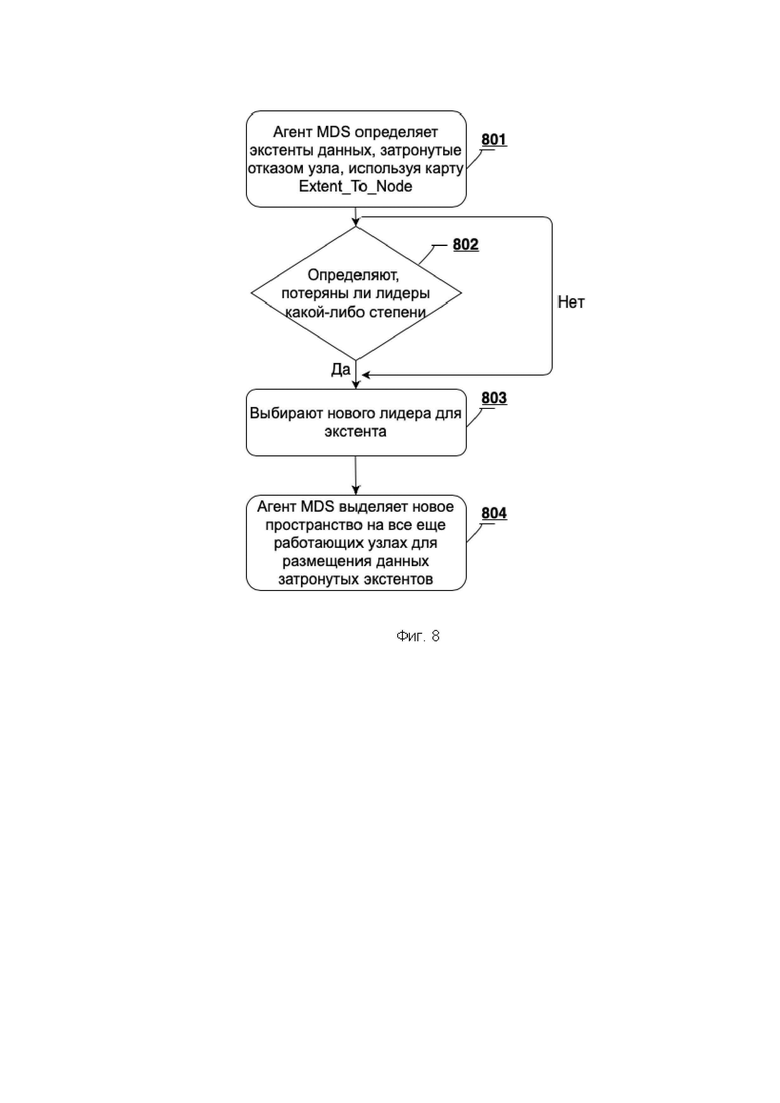
[0032] Фиг. 8 иллюстрирует блок-схему, показывающую предпочтительный процесс создания плана восстановления данных после отказа узла.
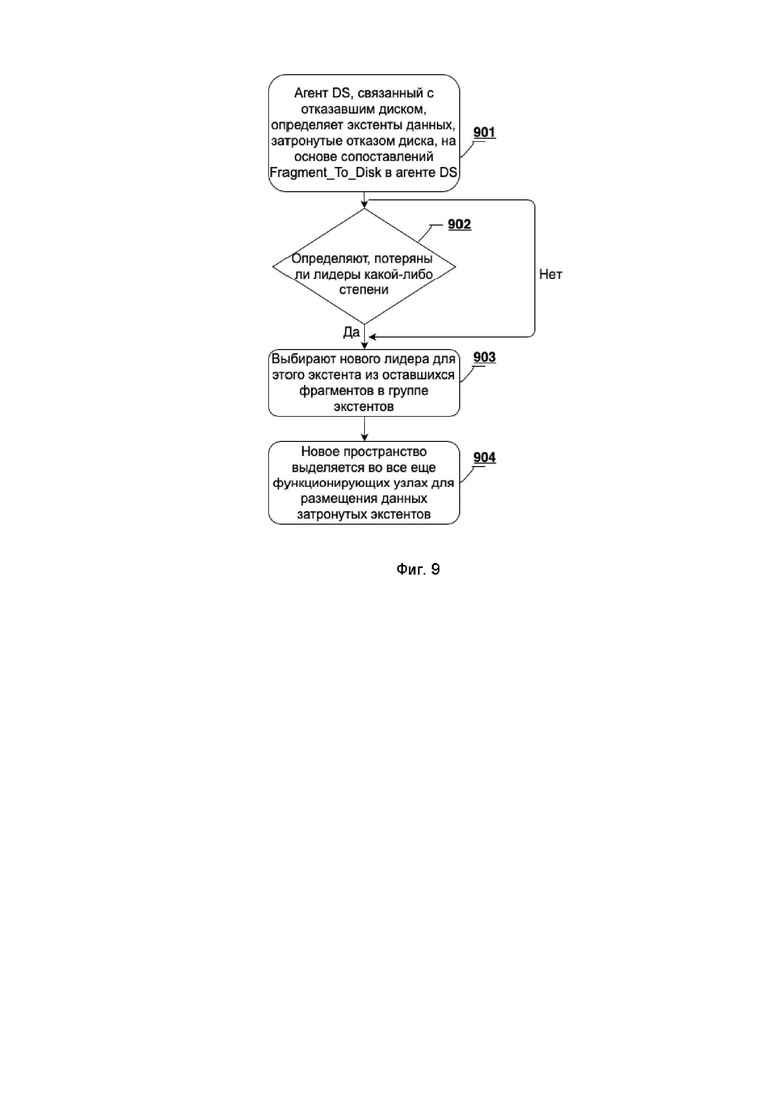
[0033] Фиг. 9 иллюстрирует блок-схему, показывающую предпочтительный процесс создания плана восстановления данных после сбоя диска.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
[0034] Ниже будут подробно рассмотрены термины и их определения, используемые в описании технического решения.
[0035] В данном изобретении под системой подразумевается компьютерная система, ЭВМ (электронно-вычислительная машина), ЧПУ (числовое программное управление), ПЛК (программируемый логический контроллер), компьютеризированные системы управления и любые другие устройства, способные выполнять заданную, четко определенную последовательность операций (действий, инструкций), централизованные и распределенные базы данных, смарт-контракты.
[0036] Под устройством обработки команд подразумевается электронный блок либо интегральная схема (микропроцессор), исполняющая машинные инструкции (программы), смарт-контракт, виртуальная машина Ethereum (EVM) или подобное. Устройство обработки команд считывает и выполняет машинные инструкции (программы) с одного или более устройства хранения данных. В роли устройства хранения данных могут выступать, но, не ограничиваясь, жесткие диски (HDD), флеш-память, ПЗУ (постоянное запоминающее устройство), твердотельные накопители (SSD), оптические приводы.
[0037] Программа - последовательность инструкций, предназначенных для исполнения устройством управления вычислительной машины или устройством обработки команд.
[0038] Диспетчер кластеров обычно является серверной частью графическим пользовательским интерфейсом (GUI) или программным обеспечением командной строки, который работает на одном или всех узлах кластера (в некоторых случаях он работает на другом сервере или кластере серверов управления). Диспетчер кластера работает вместе с агентом управления кластером. Эти агенты работают на каждом узле кластера для управления и настройки служб, набора служб или для управления и настройки всего самого сервера cluster (см. суперкомпьютеры) В некоторых случаях диспетчер кластера в основном используется для диспетчеризации работы, которую должен выполнять кластер (или облако). В последнем случае подмножество диспетчера кластера может быть приложением удаленного рабочего стола, которое используется не для настройки, а просто для отправки работы и получения результатов работы из кластера. В других случаях кластер больше связан с доступностью и балансировкой нагрузки, чем с вычислительными или конкретными сервисными кластерами.
[0039] Изобретение будет описано в первую очередь как система распределенного хранения восстанавливаемых данных с обеспечением целостности и конфиденциальности информации. Однако специалисты в данной области техники поймут, что система, в качестве которой может быть средство обработки данных, включая центральный процессор, память, блок ввода / вывода, хранилище программ, соединительную шину и другие соответствующие компоненты, может быть запрограммировано или иным образом спроектировано для облегчения осуществления изобретения. Такая система должна включать соответствующие программные средства для выполнения операций изобретения.
[0040] Кроме того, техническое решение, такое как предварительно записанный диск или другой подобный компьютерный программный продукт, для использования с системой обработки данных, может включать в себя носитель данных и записанные на нем программные средства для управления системой обработки данных, чтобы облегчить осуществление изобретения. Такие устройства и технические решения также подпадают под сущность и объем изобретения.
[0041] Фиг. 1 представляет собой высокоуровневую блок-схему системы 100 распределенного хранения восстанавливаемых данных с обеспечением целостности и конфиденциальности информации согласно изобретению. Система 100 включает в себя большое количество узлов 101 хранения, которые обычно подключены к структуре 102 узлов. Каждый узел 101 включает в себя один или несколько подключенных в частном порядке дисков 103, которые содержат данные клиентов. Структура 102 узлов предпочтительно представляет собой сеть Fibre Channel (сверхвысокоскоростная (до 1 Гбит/с и выше) схема полнодуплексной передачи данных), сеть iSCSI или сеть другого типа. Более подробно узлы 101 хранения описаны ниже со ссылкой на Фиг. 2–6. Целостность данных, хранящихся в запоминающих устройствах, зависит от физического состояния этих устройств, а именно, от того, функционируют ли они надлежащим образом или, например, по меньшей мере до некоторой степени неисправны.
[0042] Клиенты данных, поддерживаемые коллективной системой 100 хранения, называются хостами. Хосты могут быть подключены к системе 100 хранения с использованием двух типов интерфейсов: драйвера хоста или шлюза. На Фиг. 1 изображены два хоста 107 и 108. В случае хоста 107 его приложение 109 обращается к данным в узлах хранения 101, используя драйвер 110 хоста. В случае хоста 108 его приложение 111 обращается к данным клиента с помощью агента 112 шлюза, который находится в узле 113 шлюза. Более подробная информация о функциях драйвера 110 хоста и агента 112 шлюза описана ниже с другими агентами в системе 100. Обычно приложения 109 и 111 являются файловыми системами или системами баз данных.
[0043] Фиг. 2 иллюстрирует предпочтительный вариант осуществления узла 101 хранения с точки зрения его физических компонентов. Узел 101 имеет интерфейс 201 структуры для подключения к структуре 102 узлов, RAM 202 и NVRAM 203 для хранения данных во время обработки данных узлом, процессором 204 для управления и обработки данных и дисковый интерфейс 205. Узел 101 дополнительно включает в себя набор дисков 207 для хранения данных клиентов, которые подключены к интерфейсу 205 диска через матрицу 206 дисков.
[0044] Узлы 101 хранения в системе 100 коллективного хранения не являются избыточными, то есть компоненты оборудования в узлах, такие как процессор 204, память 202-203 и диски 207, не являются избыточными. Таким образом, отказ одного или нескольких компонентов в узле 101 хранения может вывести из строя весь этот узел и предотвратить доступ к дискам 207 на этом узле. Это отсутствие избыточности в сочетании с более высокой частотой отказов, возникающей из-за большого количества дисков 207 и узлов 101, означает, что программное обеспечение в системе 100 должно обрабатывать отказы и делать данные клиентов достаточно избыточными, чтобы обеспечить доступ к данным, несмотря на отказы.
[0045] В системе 100 коллективного хранения доступность данных клиента может быть обеспечена с использованием методики, основанной на избыточности, такой как разделение данных RAID, простая репликация. В каждом из этих методов данные о клиентах хранятся в наборе блоков или фрагментов физической памяти, где каждый блок данных находится на отдельном узле.
[0046] Распределение данных клиента по узлам 101 и дискам 103 выполняется процессом распределения для достижения одной или нескольких системных целей. Желаемый процесс распределения данных должен преследовать две ключевые цели: доступность и балансировка нагрузки. Что касается доступности, при выходе из строя узла 101 или диска 103 все фрагменты хранения на этом узле 101 или диске 103 могут быть потеряны. Следовательно, на других узлах должно быть достаточно избыточных данных для восстановления потерянных фрагментов данных. Что касается балансировки нагрузки, нагрузка чтения / записи данных должна распределяться по узлам 101, чтобы избежать узких мест.
[0047] Организация данных осуществления следующим образом как раскрыто ниже.
[0048] Данные клиента в системе 100 организованы в виде блоков фиксированного размера, которые линейно адресуются в логических устройствах SCSI (то есть дисках). У каждого логического устройства есть номер, который называется LUN (или номер логического устройства). Система выглядит как блочное устройство SCSI на одной шине с множеством логических модулей (хотя это является гибким для операционных систем хоста, которые имеют ограниченные возможности LUN). Внутренне логическая единица отображается на контейнер. Контейнер - это набор объектов, называемых экстентами. Атрибуты контейнера включают в себя идентификатор (ID контейнера), который однозначно идентифицирует контейнер в системе 100 хранения. Отображение LUN хоста или функция отображения между LUN и ID контейнера явно хранится и управляется системой 100.
[0049] Экстент — в файловых системах, непрерывная область носителя информации. Как правило, в файловых системах с поддержкой экстентов большие файлы состоят из нескольких экстентов, не связанных друг с другом напрямую. Экстент хранится как группа фрагментов, где каждый фрагмент находится на другом узле. Фрагмент однозначно идентифицируется по идентификатору экстента и идентификатору фрагмента. Группа фрагментов, составляющая экстент, называется группой экстентов (или группой отношений фрагментов). Фиг. 3 иллюстрирует экстент 300, который содержит три фрагмента 301, 302 и 303. Фрагменты 301, 302 и 303 находятся соответственно на узле 1, узле 2 и узле 3.
[0050] Экстент относится к ряду примыкающих друг к другу блоков на носителях информации и может различаться в зависимости от приложения. Например, одно приложение может разделить диск на экстенты, имеющие один размер, в то время как другое приложение может разделить диск на экстенты, имеющие другой размер.
[0051] Если некоторый блок на диске изменяется после создания «теневой» копии, то, прежде чем блок будет изменен, экстент, содержащий этот блок копируется в место на запоминающем устройстве, расположенное в дифференциальной области. Для конкретной «теневой» копии экстент копируется только первый раз, когда изменяется какой-либо блок внутри экстента. Когда принят запрос на информацию, содержащуюся в «теневой» копии, сначала проводится проверка, имеющая целью определить, изменился ли этот блок в оригинальном томе (например, посредством проверки того, имеется ли экстент, содержащий этот блок, в дифференциальной области). Если блок не изменился, то извлекаются и возвращаются данные из оригинального тома. Если блок изменился, то извлекаются и возвращаются данные из дифференциальной области. Следует отметить, что если блок перезаписан теми же данными, то экстент, содержащий этот блок, не записывается в дифференциальную область.
[0052] Атрибуты экстента включают в себя его идентификатор (ID экстента), уровень избыточности и список узлов 101, которые имеют зависимости данных (реплики, код стирания и т.д.) от данных клиента, хранящихся в этом экстенте. Идентификатор экстента уникален внутри контейнера. Надежность и доступность экстента 300 достигаются путем распределения его фрагментов 301–303 на отдельные узлы 101.
[0053] В некоторых вариантах реализации системы могут быть выполнены различные криптографические функции для обеспечения целостности данных, такие как SFLA-1 (алгоритм безопасного хеширования), MD5 и RSA, и предусматривается несколько возможностей шифрования, включая DES, 3DES и AES. В некоторых вариантов технического решения циклический избыточный код (англ. «Cyclic redundancy check», сокр. CRC) - один из алгоритмов нахождения контрольной суммы, предназначенный для проверки целостности данных. В соответствии с не имеющими ограничительного характера вариантами воплощения настоящей технологии циклический избыточный код может быть реализован с помощью операции деления полиномов над конечным полем.
[0054] В некоторых вариантах реализации для контроля целостности для каждого экстента определяют его контрольную сумму. После подсчета контрольной суммы от каждого экстента, например по алгоритму MD5, получают набор значений: 1bc29b36f623ba82aaf6724fd3bl6718,…, 026f8e459c8f89ef75fa7a78265a0025. Контрольная сумма - некоторое значение, рассчитанное по набору данных путем применения вычислительного алгоритма и используемое для проверки целостности данных при их передаче или хранении.
[0055] В предпочтительном варианте осуществления способа разбивают узел данных на три области, при этом разбивают каждую из трех областей на подобласть замены и подобласть данных, при этом разбивают подобласти на блоки фиксированной длины, каждый из которых защищают контрольной суммой алгоритма CRC (cyclic redundancy check - циклический избыточный код) для проверки целостности данных в блоке, причем, в случае обнаружения некорректной контрольной суммы в блоке из подобласти данных, используют вместо данного блока из подобласти данных соответствующий ему блок из подобласти замены.
[0056] При восстановлении данных в узлах данных используют контрольные суммы экстентов при проверке целостности.
[0057] Конфиденциальность данных в текущей системе решается посредством применения дополнительного шифрования данных. Шифрование является традиционным способом обеспечения конфиденциальности данных при их хранении. В данном решении используется алгоритм шифрования, основанный на применении блочных шифров. Такие шифры оперируют фрагментами данных фиксированной длины - блоками, и сочетают в себе стойкость и высокую скорость работы.
[0058] Тенденция на увеличение объемов хранимой информации и скорости передаваемых данных требует от используемых блочных шифров высокой производительности. Эффективным методом увеличения быстродействия алгоритма шифрования является использование параллельных вычислений. Одним из способов организации параллельных вычислений в случае программной реализации алгоритма является использование SIMD-технологий, в основе которых лежит применение одной инструкции процессора для одновременной обработки нескольких фрагментов данных, предварительно размещенных на одном регистре. SIMD-технологии получили широкое распространение и поддерживаются на большинстве современных вычислительных платформ, в том числе на процессорах общего назначения Intel и AMD. В данном решении может использоваться несколько типовых наборов SIMD-инструкций, каждый из которых предназначен для работы с регистрами определенной длины, широко известных из уровня техники.
[0059] В данном техническом решении в алгоритмах блочного шифрования, SIMD-технологии используются для эффективной обработки сразу нескольких блоков данных. С помощью SIMD-технологий алгоритм шифрования, предназначенный для обработки одного блока, выполняют одновременно для нескольких блоков. Эффективность такого подхода напрямую зависит от возможности параллельного выполнения использующихся в алгоритме шифрования преобразований и операций, которая, в свою очередь, определяется наличием в вычислительной платформе соответствующих им SIMD-инструкций. В случае возможности распараллеливания каждой из операций такой подход позволяет выполнять обработку нескольких блоков данных за время, необходимое для обработки одного блока данных, то есть производительность алгоритма растет пропорциональному количеству одновременно обрабатываемых блоков. Поскольку число одновременно обрабатываемых блоков определяется длиной используемых регистров, производительность в этом случае растет пропорционально увеличению длины используемых регистров. В данном техническом решении может использоваться алгоритм шифрования «Кузнечик». «Кузнечик» (англ. Kuznyechik или англ. Kuznechik) — симметричный алгоритм блочного шифрования с размером блока 128 бит и длиной ключа 256 бит, использующий для генерации раундовых ключей SP-сеть.
[0060] Конфигурация системы подробно раскрывается ниже.
[0061] Фиг. 4 представляет собой блок-схему, показывающую типичную конфигурацию системы 400 коллективного хранения с необходимыми агентами для поддержки операций восстановления данных. Каждый узел 401 коллективной системы 400 хранения одновременно выполняет один или несколько программных агентов, также называемых модулями. В системе 400 коллективного хранения есть четыре типа агентов: агенты 410 диспетчера кластеров (CM), агенты 420 сервера данных (DS), агенты 430 сервера метаданных (MDS) и агент 440 драйвера хоста (HD). Не все четыре типа агента работают на каждом узле 401 хранения. Кроме того, в предпочтительных вариантах осуществления изобретения на узле 401 может работать не более одного экземпляра типа агента.
[0062] Агент диспетчера кластеров (CM) работает следующим образом.
[0063] Агент 410 диспетчера кластера (CM) отвечает за ведение упорядоченного списка узлов 401, которые в настоящее время работают в коллективной системе 400 хранения, обнаружение отказов узлов и обнаружение новых узлов в системе 400. В предпочтительных вариантах осуществления изобретения только один агент 410 CM работает на каждом узле 401. Каждый агент 410 CM в системе 400 имеет уникальное имя, которое предпочтительно является уникальным идентификатором соответствующего узла. Упорядоченные списки текущих функциональных узлов 401, поддерживаемые агентами 410 CM в системе 400, идентичны друг другу. Таким образом, все узлы 401 в системе 400 имеют одинаковую информацию о том, какие узлы 401 в настоящее время работают в системе, то есть идентичный вид системы.
[0064] Агент 410 диспетчера кластеров обнаруживает отказ узла, когда он не получает ожидаемого отклика в пределах интервала обнаружения отказа от отказавшего узла. Обнаружение сбоев широко известно из текущего уровня техники.
[0065] Когда несколько узлов 401 пытаются одновременно присоединиться к системе 400 коллективного хранения или покинуть ее, каждый агент 410 CM гарантирует, что уведомления о присоединении и выходе доставляются последовательно в одном и том же порядке всем узлам 401 в системе 400.
[0066] Агент службы данных (DS) работает следующим образом.
[0067] Агент 420 службы данных (DS) отвечает за управление необработанными данными в узле 401 хранения в форме фрагментов данных, находящихся на этом узле. Это включает в себя кэширование данных и избыточность данных. Кэширование данных связано с кэшированием записи или упреждающим чтением. Чтобы обеспечить избыточность данных для экстента, обновление любого, если его фрагменты данных, распространяется на узлы, которые содержат связанные фрагменты в той же группе экстентов. Кроме того, агент 420 DS поддерживает постоянную карту, называемую картой Fragment_To_Disk. Карта Fragment_To_Disk содержит информацию, которая коррелирует фрагменты данных в узле 101, на котором агент DS работает, с адресами логических блоков на дисках 103 в этом узле. На Фиг. 5 показан пример карты 400 Fragment_To_Disk, которая указывает, что фрагмент 0001 экстента ABC0052 находится на диске 01 по адресу диска 1001.
[0068] Агент 420 DS также управляет локальной копией второй постоянной карты, называемой картой Extent_To_Node. Эта карта включает информацию, которая коррелирует экстент с рабочими узлами, которые содержат фрагменты, составляющие этот экстент. Агент 420 DS, который содержит первый фрагмент в группе экстентов, называется лидером для этого экстента. Агенты 420 DS, содержащие оставшиеся фрагменты этого размера, называются последователями. Лидер группы экстентов отвечает за восстановление, восстановление и обновление данных для последователей. Лидерство передается при отказе диска или узла, что приводит к потере лидера. Механизм контроля согласованности для чтения / записи в сопоставление фрагментов в той же степени управляется лидером. То есть все операции ввода-вывода отправляются лидеру группы экстентов, и лидер действует как точка сериализации для чтения / записи в этом объеме.
[0069] Лидеры групп экстентов в системе 400 распределяются между узлами 401 с помощью алгоритма распределения, чтобы гарантировать, что ни один узел не станет узким местом для того, чтобы быть лидером. Можно ослабить требование, чтобы все считывания данных проходили через лидера. Также можно ослабить потребность в том, чтобы все записи передавались лидеру, за счет тщательно синхронизированных часов для узлов и использования временных меток. На Фиг. 6 показан пример карты Extent_To_Node для экстента ABC0052.
[0070] Все агенты 420 DS в системе 400 хранения коллективно управляют группами экстентов в системе во время чтения и записи данных клиента, восстановления после сбоя диска или узла, реорганизации и операций моментального снимка.
[0071] В предпочтительных вариантах осуществления изобретения существует один экземпляр агента DS, работающего на каждом узле в системе 400 коллективного хранения. Экстенты данных полностью размещены на диске, то есть экстент не распространяется на несколько дисков. Следовательно, что касается экстентов, отказ диска, содержащего фрагмент экстента, сродни отказу узла 401, содержащего тот же самый фрагмент.
[0072] Агент 420 службы данных обнаруживает отказ диска, используя регулярные тайм-ауты запроса проверки связи. Например, когда диск не используется, агент 420 DS опрашивает диск через регулярные промежутки времени, чтобы определить состояние диска. В случае тайм-аутов запроса агент 420 DS может периодически проверять частоту ошибок диска, чтобы определить свой статус.
[0073] Агент службы метаданных (MDS) подробно раскрыт ниже.
[0074] Агент 430 службы метаданных (MDS) отвечает за управление картой Extent_To_Node, постоянной картой, коррелирующей все экстенты данных в системе с узлами, которые содержат фрагменты, составляющие экстенты. Каждый агент 420 DS (описанный выше) имеет карту Extent_To_Node, которая содержит записи только для тех экстентов, фрагментами которых он управляет. С другой стороны, агент 430 MDS имеет карту Extent_To_Node для всех экстентов в системе 400 хранения. Карта MDS индексируется с идентификатором экстента в качестве первичного ключа. Также поддерживается вторичный индекс на узлах, который полезен при создании плана ремонта в ответ на отказ узла. Кроме того, в отличие от агента 420 DS, агент 430 MDS не запускается на каждом узле 401. Вместо этого используется адаптивный метод для определения набора узлов 401, которые будут запускать агенты 430 MDS. Агент 430 MDS также сохраняет и управляет метаданными экстентов и выполняет создание и удаление экстентов.
[0075] Преобразование экстента в контейнере в его группу экстентов выполняется агентом 430 MDS. Кроме того, распределение экстентов обеспечивается агентом 430 MDS, который формирует группу экстентов для нового экстента. Агент 430 MDS дополнительно управляет списком сконфигурированных контейнеров и их атрибутов.
[0076] Агент хост-драйвера (HD) раскрывается ниже.
[0077] Агент 440 хост-драйвера (HD) — это интерфейс, через который клиентское приложение 402 может получать доступ к данным в коллективной системе 400 хранения. Агент 440 HD обменивается данными с приложением 402 в терминах логических модулей (LUN) и с остальными система хранения 400 с точки зрения контейнеров и экстентов данных. Агент 440 HD обычно находится в хосте 403, где выполняется приложение 402. Однако его интерфейсные функции могут быть обеспечены в узле 404 хранения в форме агента 405 шлюза. Затем хост-приложение получает доступ к данным в системе 400 хранения через агента 405 шлюза, который находится в узле 404 шлюза.
[0078] Чтобы получить доступ к данным клиента в системе 400, агент 440 HD или агент 405 шлюза определяет экстент и лидера для этого экстента. Агент 440 HD или агент 405 шлюза затем обращается к данным из узла хранения, который содержит лидер экстента. Чтобы получить доступ к экстенту данных, клиент должен сначала получить местоположение экстента. Эта функция обеспечивается агентом 430 MDS. По заданному идентификатору экстента агент 430 MDS возвращает список узлов, где можно найти фрагменты этого экстента.
[0079] Восстановление данных раскрывается подробно ниже.
[0080] Теперь описывается процесс восстановления данных в коллективной системе 400 хранения после отказа узла или отказа диска. Восстановление — это процесс воссоздания потерянных данных из-за неисправного диска или узла на новых узлах или дисках, чтобы застраховаться от потери данных в результате последующих сбоев. Желаемый процесс восстановления должен иметь следующие свойства:
[0081] а) надежность: все затронутые данные клиентов в конечном итоге восстанавливаются.
[0082] б) отказоустойчивость: если во время восстановления данных происходит второй сбой, то свойство (а) сохраняется.
[0083] c) эффективность: процесс восстановления требует как можно меньше обменов сообщениями и перемещений данных между узлами.
[0084] d) сбалансированность: работа по восстановлению данных распределяется по узлам, чтобы минимизировать влияние на одновременный доступ к данным клиентов.
[0085] e) масштабируемость: время, необходимое для восстановления с отказавшего диска или узла, должно обратно пропорционально масштабироваться с размером системы, то есть чем больше система, тем короче время восстановления. Это важно, поскольку системе приходится иметь дело с более высокой интенсивностью отказов по мере роста системы.
[0086] Фиг. 7 представляет собой блок-схему, показывающую общий процесс восстановления потерянных данных после отказа узла или отказа диска в системе 400 коллективного хранения. На этапе 701 отказ обнаруживается агентом в системе 400. Как описано выше для CM и агенты DS, отказ узла обнаруживается агентом CM, а отказ диска обнаруживается агентом DS. На этапе 702 агенты в системе 400, ответственные за координацию восстановления данных, уведомляются об отказе. В одном предпочтительном варианте осуществления в соответствии с изобретением восстановление координируется одним из агентов MDS в системе. В другом варианте осуществления изобретения восстановление координируется одним из агентов DS в системе. На этапе 703 агент-координатор генерирует план восстановления данных, как описано ниже со ссылкой на Фиг. 8–9. План определяет экстенты данных в системе, на которые повлиял сбой. На этапе 704 агенты в системе коллективно восстанавливают затронутые экстенты на основе плана восстановления.
[0087] На Фиг. 8 показана блок-схема, показывающая предпочтительный процесс создания плана восстановления данных после отказа узла в соответствии с изобретением. На этапе 801 агент MDS определяет экстенты данных, затронутые отказом узла, используя карту Extent_To_Node. Записи на этой карте соотносят экстенты в системе хранения с узлами системы. При сканировании этой карты на основе идентификации отказавшего узла идентифицируются затронутые экстенты. На этапе 802 способ определяет, потеряны ли лидеры какой-либо степени. Если лидер потерян из-за сбоя, то новый лидер для этого экстента выбирается из оставшихся фрагментов в группе экстентов на этапе 803. Простой выбор здесь - сделать так, чтобы агент DS удерживал первый из оставшихся фрагментов в экстенте как нового лидера, если бы это не был предыдущий лидер. Затем на этапе 804 агент MDS выделяет новое пространство на все еще работающих узлах для размещения данных затронутых экстентов.
[0088] Фиг. 9 иллюстрирует блок-схему, показывающую предпочтительный процесс создания плана восстановления данных после сбоя диска в соответствии с изобретением. На этапе 901 агент DS, связанный с отказавшим диском, определяет экстенты данных, затронутые отказом диска, на основе сопоставлений Fragment_To_Disk в агенте DS. Эта карта указывает идентификаторы фрагментов для фрагментов на каждом диске. Используя идентификатор отказавшего диска, фрагменты на отказавшем диске могут быть определены путем сканирования карты. На этапе 902 способ определяет, потеряны ли лидеры какой-либо степени. Если лидер потерян из-за сбоя, то новый лидер для этого экстента выбирается из оставшихся фрагментов в группе экстентов на этапе 903. Простой выбор здесь - сделать так, чтобы агент DS удерживал первый из оставшихся фрагментов в экстенте как новый лидер, если бы это не был предыдущий лидер. На этапе 904 новое пространство выделяется во все еще функционирующих узлах для размещения данных затронутых экстентов. В одном предпочтительном варианте осуществления изобретения агенты DS запускают задачу восстановления и, таким образом, выделяют новое пространство. В другом предпочтительном варианте осуществления изобретения агент MDS отвечает за координацию работы по восстановлению и обрабатывает задачу распределения.
[0089] Приведенный пример показал, что заявляемый(ая) способ и система распределенного хранения восстанавливаемых данных с обеспечением целостности и конфиденциальности информации функционирует корректно, технически реализуем (а) и позволяет решить поставленную задачу.
[0090] Элементы заявляемого технического решения находятся в функциональной взаимосвязи, а их совместное использование приводит к созданию нового и уникального технического решения. Таким образом, все блоки функционально связаны.
[0091] Все блоки, используемые в системе, могут быть реализованы с помощью электронных компонент, используемых для создания цифровых интегральных схем, что очевидно для специалиста в данном уровне техники. Не ограничиваюсь, могут использоваться микросхемы, логика работы которых определяется при изготовлении, или программируемые логические интегральные схемы (ПЛИС), логика работы которых задаётся посредством программирования. Для программирования используются программаторы и отладочные среды, позволяющие задать желаемую структуру цифрового устройства в виде принципиальной электрической схемы или программы на специальных языках описания аппаратуры: Verilog, VHDL, AHDL и др. Альтернативой ПЛИС могут быть программируемые логические контроллеры (ПЛК), базовые матричные кристаллы (БМК), требующие заводского производственного процесса для программирования; ASIC - специализированные заказные большие интегральные схемы (БИС), которые при мелкосерийном и единичном производстве существенно дороже.
[0092] Обычно, сама микросхема ПЛИС состоит из следующих компонент:
• конфигурируемых логических блоков, реализующих требуемую логическую функцию;
• программируемых электронных связей между конфигурируемыми логическими блоками;
• программируемых блоков ввода/вывода, обеспечивающих связь внешнего вывода микросхемы с внутренней логикой.
[0093] Также блоки могут быть реализованы с помощью постоянных запоминающих устройств.
[0094] Таким образом, реализация всех используемых блоков достигается стандартными средствами, базирующимися на классических принципах реализации основ вычислительной техники.
[0095] Как будет понятно специалисту в данной области техники, аспекты настоящего технического решения могут быть выполнены в виде системы, способа или компьютерного программного продукта. Соответственно, различные аспекты настоящего технического решения могут быть реализованы исключительно как аппаратное обеспечение, как программное обеспечение (включая прикладное программное обеспечение и так далее) или как вариант осуществления, сочетающий в себе программные и аппаратные аспекты, которые в общем случае могут упоминаться как «модуль», «система» или «архитектура». Кроме того, аспекты настоящего технического решения могут принимать форму компьютерного программного продукта, реализованного на одном или нескольких машиночитаемых носителях, имеющих машиночитаемый программный код, который на них реализован.
[0096] Также может быть использована любая комбинация одного или нескольких машиночитаемых носителей. Машиночитаемый носитель хранилища может представлять собой, без ограничений, электронную, магнитную, оптическую, электромагнитную, инфракрасную или полупроводниковую систему, аппарат, устройство или любую подходящую их комбинацию. Конкретнее, примеры (неисчерпывающий список) машиночитаемого носителя хранилища включают в себя: электрическое соединение с помощью одного или нескольких проводов, портативную компьютерную дискету; жесткий диск, оперативную память (ОЗУ), постоянную память (ПЗУ), стираемую программируемую постоянную память (EPROM или Flash-память), оптоволоконное соединение, постоянную память на компакт-диске (CD-ROM), оптическое устройство хранения, магнитное устройство хранения или любую комбинацию вышеперечисленного. В контексте настоящего описания, машиночитаемый носитель хранилища может представлять собой любой гибкий носитель данных, который может содержать или хранить программу для использования самой системой, устройством, аппаратом или в соединении с ними.
[0097] Программный код, встроенный в машиночитаемый носитель, может быть передан с помощью любого носителя, включая, без ограничений, беспроводную, проводную, оптоволоконную, инфракрасную и любую другую подходящую сеть или комбинацию вышеперечисленного.
[0098] Компьютерный программный код для выполнения операций для шагов настоящего технического решения может быть написан на любом языке программирования или комбинаций языков программирования, включая объектно-ориентированный язык программирования, например Python, R, Java, Smalltalk, С++ и так далее, и обычные процедурные языки программирования, например язык программирования «С» или аналогичные языки программирования. Программный код может выполняться на компьютере пользователя полностью, частично, или же как отдельный пакет программного обеспечения, частично на компьютере пользователя и частично на удаленном компьютере, или же полностью на удаленном компьютере. В последнем случае, удаленный компьютер может быть соединен с компьютером пользователя через сеть любого типа, включая локальную сеть (LAN), глобальную сеть (WAN) или соединение с внешним компьютером (например, через Интернет с помощью Интернет-провайдеров).
[0099] Аспекты настоящего технического решения были описаны подробно со ссылкой на блок-схемы, принципиальные схемы и/или диаграммы способов, устройств (систем) и компьютерных программных продуктов в соответствии с вариантами осуществления настоящего технического решения. Следует иметь в виду, что каждый блок из блок-схемы и/или диаграмм, а также комбинации блоков из блок-схемы и/или диаграмм, могут быть реализованы компьютерными программными инструкциями. Эти компьютерные программные инструкции могут быть предоставлены процессору компьютера общего назначения, компьютера специального назначения или другому устройству обработки данных для создания процедуры, таким образом, чтобы инструкции, выполняемые процессором компьютера или другим программируемым устройством обработки данных, создавали средства для реализации функций/действий, указанных в блоке или блоках блок-схемы и/или диаграммы.
[00100] Эти компьютерные программные инструкции также могут храниться на машиночитаемом носителе, который может управлять компьютером, отличным от программируемого устройства обработки данных или отличным от устройств, которые функционируют конкретным образом, таким образом, что инструкции, хранящиеся на машиночитаемом носителе, создают устройство, включающее инструкции, которые осуществляют функции/действия, указанные в блоке блок-схемы и/или диаграммы.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА УПРАВЛЕНИЯ МЕТАДАННЫМИ В ВЫСОКОНАГРУЖЕННЫХ ОБЛАЧНЫХ СРЕДАХ | 2024 |
|
RU2829567C1 |
| СПОСОБ КОДИРОВАНИЯ ДАННЫХ И СИСТЕМА ХРАНЕНИЯ ДАННЫХ | 2023 |
|
RU2819584C1 |
| Интегрированный программно-аппаратный комплекс | 2016 |
|
RU2646312C1 |
| СИСТЕМА ХРАНЕНИЯ ДАННЫХ | 2023 |
|
RU2824327C1 |
| ВЫСОКОСКОРОСТНОЕ УПРАВЛЕНИЕ БЛОКИРОВКАМИ ДЛЯ МГНОВЕННОГО КОПИРОВАНИЯ В СИСТЕМАХ ХРАНЕНИЯ ДАННЫХ С СОВМЕСТНЫМ ИСПОЛЬЗОВАНИЕМ ПАМЯТИ N УЗЛАМИ | 2003 |
|
RU2297662C2 |
| ПРОЗРАЧНОЕ ВОССТАНОВЛЕНИЕ ПОСЛЕ ОТКАЗА | 2012 |
|
RU2595903C2 |
| СИСТЕМА УПРАВЛЕНИЯ И ДИСПЕТЧЕРИЗАЦИИ КОНТЕЙНЕРОВ | 2019 |
|
RU2751576C2 |
| Способ централизованного реагирования на отказ сети или отказ сервера в кластере высокой доступности и восстановления виртуальной машины в кластере высокой доступности и система, реализующая данный способ | 2022 |
|
RU2788309C1 |
| СИСТЕМА УПРАВЛЕНИЯ И ДИСПЕТЧЕРИЗАЦИИ КОНТЕЙНЕРОВ | 2015 |
|
RU2666475C1 |
| СИСТЕМА УПРАВЛЕНИЯ И ДИСПЕТЧЕРИЗАЦИИ КОНТЕЙНЕРОВ | 2015 |
|
RU2704734C2 |
Изобретение относится к системе распределенного хранения восстанавливаемых данных и способу распределенного хранения восстанавливаемых данных. Техническим результатом является повышение надежности восстановления данных. Способ распределенного хранения восстанавливаемых данных с обеспечением целостности информации выполняется по меньшей мере одной системой, которая содержит множество узлов хранения, связанных сетью и хранящих данные в виде экстентов, агентов службы данных (DS) для управления экстентами, агентов службы метаданных (MDS) для управления метаданными, относящимися к узлам и экстентам, и агентов диспетчеров кластеров (CM). Способ состоит из следующих этапов: формирование контрольной суммы для каждого экстента данных; обнаружение сбоя узла в системе одним из агентов CM или диска в системе агентом DS; уведомление агентов DS или MDS о сбое; формирование независимо уведомленными агентами DS или MDS плана восстановления экстентов данных, затронутых сбоем; и коллективное восстановление затронутых экстентов на основе сгенерированного плана на предыдущем шаге с использованием контрольных сумм, причем каждый узел включает в себя множество дисков; и сбой диска обнаруживается агентом DS на основании частоты ошибок дисков. 2 н. и 15 з.п. ф-лы, 9 ил.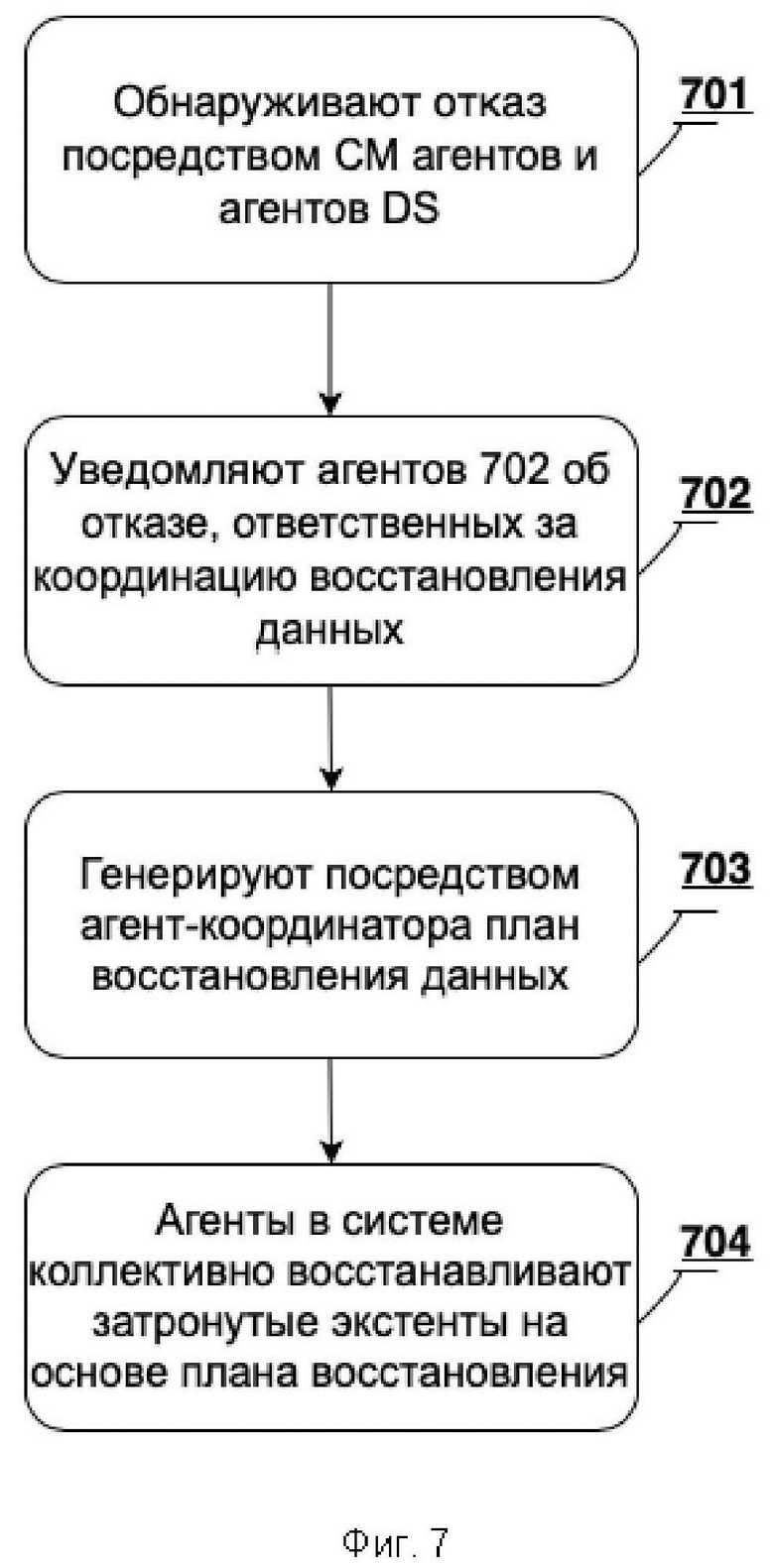
1. Способ распределенного хранения восстанавливаемых данных с обеспечением целостности информации, выполняемый по меньшей мере одной системой, которая содержит множество узлов хранения, связанных сетью и хранящих данные в виде экстентов, агентов службы данных (DS) для управления экстентами, агентов службы метаданных (MDS) для управления метаданными, относящимися к узлам и экстентам, и агентов диспетчеров кластеров (CM), причем способ состоит из следующих этапов:
• формирование контрольной суммы для каждого экстента данных;
• обнаружение сбоя узла в системе одним из агентов CM или диска в системе агентом DS;
• уведомление агентов DS или MDS о сбое;
• формирование независимо уведомленными агентами DS или MDS плана восстановления экстентов данных, затронутых сбоем; и
• коллективное восстановление затронутых экстентов на основе сгенерированного плана на предыдущем шаге с использованием контрольных сумм, причем каждый узел включает в себя множество дисков; и сбой диска обнаруживается агентом DS на основании частоты ошибок дисков.
2. Система распределенного хранения восстанавливаемых данных с обеспечением целостности информации, содержащая
• множество узлов хранения, соединенных сетью, причем каждый узел хранит данные в виде экстентов, по которым рассчитаны контрольные суммы;
• агент службы данных (DS) в каждом узле для управления экстентами в узле;
• множество агентов службы метаданных (MDS) для управления метаданными, относящимися к узлам и экстентам, причем агенты MDS работают в подмножестве узлов;
• агент диспетчера кластеров (CM) в каждом узле для обнаружения сбоя узла в системе,
• при этом после уведомления о сбое подмножество агентов DS или MDS независимо генерирует план для восстановления экстентов с использованием контрольных сумм, затронутых сбоем, и коллективного восстановления затронутых экстентов на основе плана; и
• постоянная карта, которая коррелирует экстенты данных с узлами, при этом каждый агент MDS управляет подмножеством карты.
3. Система хранения по п.2, дополнительно содержащая интерфейс, позволяющий приложению получать доступ к данным, хранящимся в системе.
4. Система хранения по п.2, дополнительно содержащая средство для определения подмножества узлов, в которых работают агенты MDS.
5. Система хранения по п.2, в которой каждый агент CM поддерживает упорядоченный список узлов, которые в настоящее время работают в системе.
6. Система хранения по п.2, в которой каждый агент CM включает в себя средство для обнаружения сбоя узла.
7. Система хранения по п.2, в которой каждый агент CM включает в себя средство для обнаружения нового узла в системе.
8. Система хранения по п.7, в которой упомянутое средство для обнаружения нового узла включает в себя средство для мониторинга сетевых сообщений от нового узла.
9. Система хранения по п.2, в которой каждый агент DS распространяет обновления до экстентов в ассоциированном узле другим агентам DS в системе.
10. Система хранения по п.2, в которой каждый агент DS управляет кэшированием данных в ассоциированном узле.
11. Система хранения по п.2, в которой каждый узел содержит множество дисков с данными, и каждый агент DS включает в себя средство для обнаружения сбоя дисков в ассоциированном узле.
12. Система хранения по п.11, в которой упомянутое средство для обнаружения сбоя диска основано на частоте ошибок дисков.
13. Система хранения по п.2, в которой план восстановления включает в себя список экстентов, которые должны быть восстановлены для восстановления избыточности данных в системе.
14. Система хранения по п.13, в которой восстанавливаемые экстенты совместно восстанавливаются агентами DS.
15. Система хранения по п.13, в которой пространство выделяется в узлах, которые все еще работают, для замены экстентов, затронутых сбоем.
16. Система хранения по п.15, в которой данные в затронутых экстентах определяются и переносятся в выделенное пространство.
17. Система хранения по п.2, в которой агенты DS уведомлены о сбое, и уведомленные агенты DS определяют те экстенты, которые имеют данные на отказавшем узле.
| СПОСОБ И СИСТЕМА РАСПРЕДЕЛЕННОГО ХРАНЕНИЯ ВОССТАНАВЛИВАЕМЫХ ДАННЫХ С ОБЕСПЕЧЕНИЕМ ЦЕЛОСТНОСТИ И КОНФИДЕНЦИАЛЬНОСТИ ИНФОРМАЦИИ | 2017 |
|
RU2680350C2 |
| Способ хранения данных в избыточном массиве независимых дисков с повышенной отказоустойчивостью | 2020 |
|
RU2750645C1 |
| RU 2017110458 A, 04.10.2018 | |||
| US 20080126842 A1, 29.05.2008 | |||
| US 10019323 B1, 10.07.2018. | |||

