ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
[01] Изобретение в основном относится к декодированию сжатой цифровой информации. В частности, по меньшей мере несколько вариантов осуществления этого изобретения относятся к декодированию битовых потоков, отражающих контент, который сжат с применением одного или более методов, использующих кодирование с долговременным предсказанием.
ПРЕДПОСЫЛКИ СОЗДАНИЯ ИЗОБРЕТЕНИЯ
[02] Для того чтобы минимизировать количество данных, которые должны быть сохранены и/или переданы через канал связи, контент (например, аудио и/или видеоинформация) часто уплотняется в поток данных, содержащий меньшее число битов, чем это потребовалось бы в противном случае. Разработаны многочисленные способы такого сжатия. Некоторые из этих способов используют методы кодирования с предсказанием. Например, формат усовершенствованного звукового кодирования (Advanced Audio Coding, AAC), определяемый различными стандартами экспертной группы по кинематографии (Motion Picture Experts Group, MPEG), включает несколько наборов средств кодирования (и последующего декодирования) аудиоконтента (например, музыки). Эти средства, или профили, включают профили: основной (Main), с низкой сложностью (Low Complexity, LC), с масштабируемой частотой дискретизации (Scalable Sampling Rate, SSR) и с долговременным предсказанием (Long-Term Prediction, LTP). Кодирование LTP может обеспечивать более высокое качество звука для конечного пользователя, но за счет повышения требований к вычислениям. В результате это может привести к необходимости использования дополнительной памяти и аппаратных средств обработки в таком устройстве, как мобильный телефон или цифровой музыкальный плеер. Кроме того, коммерческая необходимость может требовать, чтобы устройства, предназначенные для декодирования и воспроизведения аудиоданных ААС, имели возможность работы с несколькими профилями. Например, пользователям часто требуется загружать музыку из разнообразных источников. Некоторые из этих источников могут кодировать музыку с использованием профиля AAC-LC, тогда как другие источники могут кодировать музыку с помощью профиля AAC-LTP.
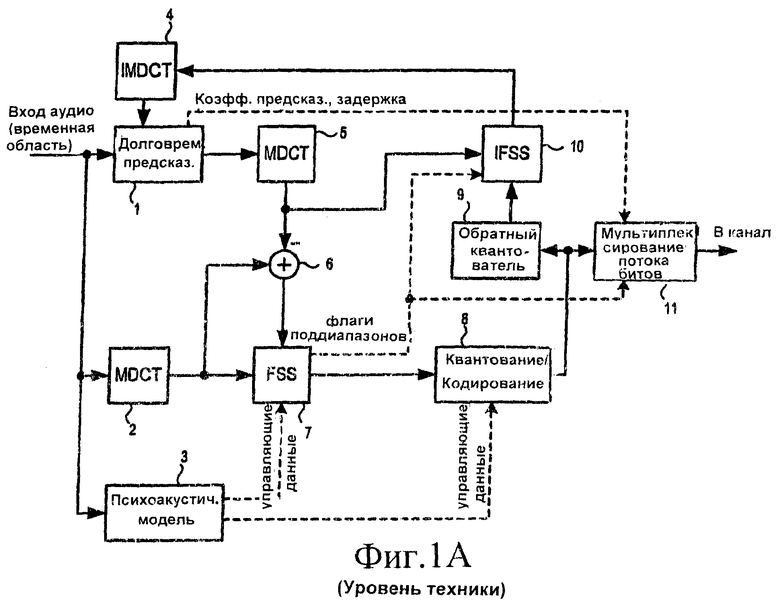
[03] На фиг.1А приведена блок-схема, показывающая общую структуру кодирующего устройства AAC-LTP. Хотя функционирование таких кодеров (и некоторых соответствующих декодеров) является общеизвестным, ниже приводится его обзор, чтобы обеспечить основу для последующего описания. Поступающий аудиосигнал во временной области (в виде функции от времени) принимается устройством 1 долговременного предсказания, модифицированным дискретным косинусным преобразованием (MDCT) 2 и психоакустической моделью 3. Устройство 1 долговременного предсказания формирует данные (коэффициенты предсказания и задержку, соответствующую периоду основного тона), которые могут использоваться для предсказания текущего входного сигнала во временной области на основе сигналов во временной области для предыдущих частей аудиопотока. Версии этих предыдущих частей во временной области принимаются в качестве входных сигналов из обратного модифицированного дискретного косинусного преобразования (IMDCT) 4 и из банка фильтров синтеза (не показан) и сохраняются устройством долговременного предсказания в буфере (также не показан на фиг.1А). Коэффициенты предсказания и задержка, соответствующая периоду основного тона, подаются устройством 1 долговременного предсказания в мультиплексор 11 потока битов. Предсказанный звук (т.е. аудиосигнал во временной области, который будет результатом применения вычисленных коэффициентов предсказания и задержки) преобразуется в частотную область устройством MDCT 5.
[04] Поступающий аудиосигнал во временной области подается также в отдельное устройство MDCT 2. В отличие от устройства MDCT 5, которое преобразует только предсказанную версию аудиосигнала, устройство MDCT 2 преобразует в частотную область исходный поступающий аудиосигнал. Выходной сигнал из MDCT 2 подается в частотно-избирательный коммутатор (FSS) 7 (рассматривается ниже) и в сумматор 6. Сумматор 6 вычисляет разность между выходным сигналом MDCT 5 (версией предсказанного аудиосигнала в частотной области) и выходным сигналом MDCT 2 (версией исходного аудиосигнала в частотной области). Фактически, выходной сигнал сумматора 6 (или ошибка предсказания) является разностью между фактическим аудиосигналом и предсказанной версией того же самого сигнала. Выход ошибки предсказания из сумматора 6 подается на коммутатор FSS 7.
[05] Коммутатор FSS 7 принимает управляющие входные сигналы от психоакустической модели 3. Психоакустическая модель 3 содержит полученные экспериментальным образом перцепционные данные, относящиеся к частотным диапазонам, которые воспринимаются слушателями. Психоакустическая модель 3 также содержит данные относительно определенных типов акустических шаблонов, которые плохо моделируются с использованием долговременного предсказания. Например, сегменты с быстрым изменением или кратковременным сигналом могут быть затруднительными для моделирования путем предсказания. Психоакустическая модель 3 исследует поступающий аудиосигнал во временной области и определяет, какие поддиапазоны должны представляться посредством ошибки предсказания (из сумматора 6), коэффициентов предсказания (из устройства 1 предсказания) и задержки (также из устройства 1 предсказания), а какие поддиапазоны следует представить коэффициентами MDCT исходного аудиосигнала (из модуля преобразования MDCT 2). На основе данных из психоакустической модели 3 коммутатор FSS 7 выбирает данные, пересылаемые в блок 8 для квантования и кодирования. Для поддиапазонов, для которых должно использоваться предсказание, коэффициенты ошибки предсказания из сумматора 6 пересылаются в квантователь/кодер 8. Для других поддиапазонов в квантователь/кодер 8 пересылается выходной сигнал MDCT 2. Выходной управляющий сигнал коммутатора FSS 7 содержит флаг для каждого поддиапазона, указывающий, возможно ли долговременное предсказание для этого поддиапазона.
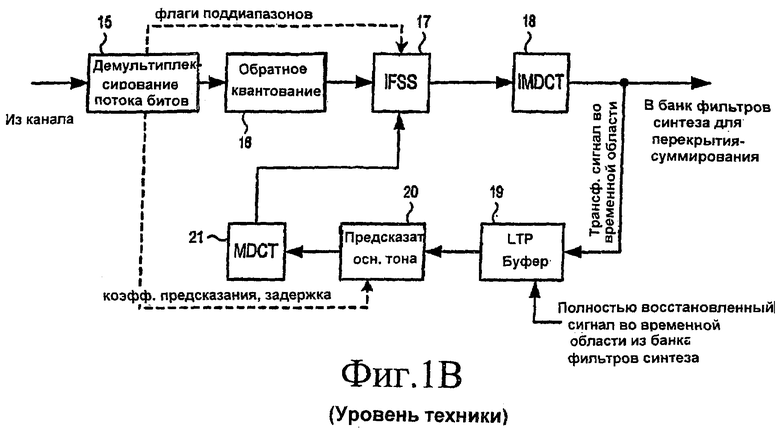
[06] Сигнал из FSS 7 затем дискретизируется в квантователе/кодере 8 (например, с использованием кодирования по методу Хаффмана). Перцепционные данные из психоакустической модели 3 также используются квантователем/кодером 8. Затем выходной сигнал квантователя/кодера 8 мультиплексируется в блоке 11 с управляющими данными из устройства 1 долговременного предсказания (например, коэффициентами предсказания и задержкой) и коммутатора FSS 7 (флаги поддиапазонов). Из блока 11 мультиплексированные данные затем подаются в канал связи (например, для передачи по радио или Интернету) или в среду для хранения. Выходной сигнал квантователя/кодера 8 также подается в обратный квантователь 9. Выходной сигнал обратного квантователя 9 пересылается в обратный частотно-избирательный коммутатор (IFSS) 10 аналогично выходному сигналу MDCT 5 и управляющим сигналам (флагам поддиапазонов) из FSS 7. Затем коммутатор IFSS 10 для каждого поддиапазона, для которого квантованные коэффициенты ошибок предсказания переданы в поток битов, выдает сумму деквантованных коэффициентов ошибок предсказания и выходного сигнала MDCT 5. Для каждого поддиапазона, для которого квантованный выходной сигнал MDCT 2 передается в поток битов, коммутатор IFSS предоставляет деквантованный выходной сигнал MDCT 2. Выходной сигнал IFSS затем преобразуется обратно во временную область преобразователем IMDCT 4. Выходной сигнал во временной области из IMDCT 4 затем подается в устройство 1 долговременного предсказания. Часть выходного сигнала IMDCT 4 сохраняется непосредственно в буфере предсказания, описанном выше; другие части этого буфера хранят полностью восстановленные кадры аудиоданных (во временной области), сформированные методом "перекрытия-суммирования" (overlap-add) (в банке фильтров синтеза) из выходного сигнала IMDCT 4.
[07] На фиг.1В приведена блок-схема, отражающая общую структуру декодера AAC-LTP. Поступающий поток битов демультиплексируется в блоке 15. Флаги поддиапазонов из FSS 7 (фиг.1А) подаются в коммутатор IFSS 17. Коэффициенты предсказания и задержка, соответствующая периоду основного тона, из устройства 1 долговременного предсказания на фиг.1А подаются в предсказатель 20 основного тона. Квантованные данные из FSS 7 на фиг.1А деквантуются в обратном квантователе 16, а затем подаются в коммутатор IFSS 17. На основе соответствующих значений флагов поддиапазонов коммутатор IFSS 17 определяет, возможно ли долговременное предсказание для различных поддиапазонов. Для поддиапазонов, для которых предсказание оказалось невозможным, коммутатор IFSS 17 просто пересылает выходные данные обратного квантователя 16 в IMDCT 18. Для поддиапазонов, для которых имелась возможность предсказания, IFSS 17 добавляет выходные данные обратного квантователя 16 (то есть деквантованные коэффициенты ошибок предсказания) к выходному сигналу MDCT 21 (рассмотренному выше) и пересылает результат в IMDCT 18. Преобразователь IMDCT 18 затем преобразует выходной IFSS 17 обратно во временную область. Выходной сигнал преобразователя IMDCT 18 используется затем для перекрытия-суммирования в банке фильтров синтеза (не показан), чтобы выдать полностью восстановленный сигнал во временной области, который является близкой копией исходного входного аудиосигнала на фиг.1А. Этот полностью восстановленный сигнал во временной области может затем обрабатываться посредством цифроаналогового преобразователя (не показан на фиг.1В) для воспроизведения, например, с помощью одного или более громкоговорителей.
[08] Последние части выходного сигнала во временной области из IMDCT 18 и полностью восстановленный сигнал во временной области из банка фильтров синтеза сохраняются также в буфере 19 долговременного предсказания (LTP). Буфер 19 LTP имеет такие же размеры, как буфер в устройстве 1 долговременного предсказания на фиг.1А, и предназначается для дублирования его содержимого. Данные из буфера 19 LTP используются предсказателем 20 основного тона (совместно со значениями коэффициентов предсказания и задержки), чтобы предсказывать поступающий аудиосигнал во временной области. Выходной сигнал предсказателя 20 основного тона соответствует выходному сигналу устройства 1 долговременного предсказания, подаваемому в MDCT 5 на фиг.1А. Затем выходной сигнал предсказателя 20 основного тона преобразуется в частотную область в MDCT 21, и выходной сигнал MDCT 21 подается в IFSS 17.
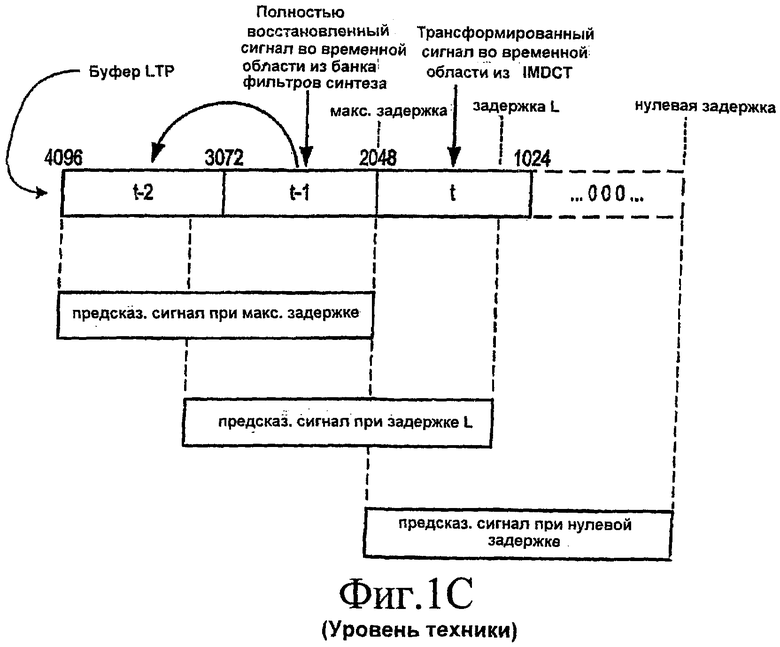
[09] Обычная структура буфера 19 LTP (как это устанавливается соответствующими стандартами MPEG-4) показана на фиг.1C. Кадр t-1 является самым последним полностью восстановленным сигналом во временной области, сформированным посредством перекрытия-суммирования сигналов во временной области в банке фильтров синтеза (не показан) в декодере. Кадр t - это выходной сигнал во временной области из IMDCT 18, и он является трансформированным сигналом во временной области, используемым для перекрытия-суммирования в следующем кадре, который будет выдан банком фильтров синтеза. Кадр t-2 - это полностью восстановленный кадр из предыдущего временного периода. Размер (или длина) N каждого кадра равна 1024 отсчетам. Блок с пунктирной линией в правой части буфера LTP представляет собой кадр, содержащий 1024 отсчета с нулевой амплитудой. Этот блок, содержащий все нули, фактически не является частью буфера 19 LTP. Он используется, чтобы концептуально указать местоположение нулевой точки задержки фильтра долговременного предсказания. В частности, когда значение задержки, соответствующей периоду основного тона, имеет максимальную величину, тогда 2048 отсчетов во временной области прогнозируются на основе 2048 отсчетов в кадрах t-1 и t-2. Когда задержка находится между минимальным и максимальным значениями (например, в точке, обозначенной как "задержка L"), тогда для предсказания 2048 Отсчетов используются 2048 отсчетов перед местоположением значения задержки (т.е. справа от точки L на фиг.1C). Когда задержка меньше 1024, тогда для отсчетов с номером 1023 и ниже используются нули из буфера LTP. Например, когда задержка имеет минимальное значение (нулевая задержка), 1024 отсчета из кадра t и 1024 отсчета с нулевой амплитудой используются для предсказания 2048 отсчетов. Хотя использование амплитуд, содержащих одни нули, приводит к снижению точности воспроизведения звука, это уменьшает потребность в памяти для буфера LTP. Так как нулевые или очень низкие значения задержки встречаются относительно редко, это не оказывает существенного влияния на качество звука.
[10] Декодер, аналогичный показанному на фиг.1В, и соответствующий буфер LTP, показанный на фиг.1C, часто используются в мобильном устройстве, таком как портативный музыкальный плеер или мобильный терминал. Такие устройства часто имеют ограниченные вычислительные ресурсы и память. Добавление дополнительной памяти и возможностей обработки часто является дорогостоящим, повышающим тем самым общую стоимость устройства. Так как декодер и буфер используют достаточно большое количество этих ресурсов, они могут иметь ограниченные возможности для размещения дополнительных функций. Например, для устройств воспроизведения звука часто желательно иметь возможность быстрого перемещения вперед. Если производительность аудиоплеера повышается, различные операции декодирования могут выполняться с еще большей скоростью. В качестве другого примера, для устройства, которое декодирует и воспроизводит аудиопоток, может потребоваться быстрое выполнение какой-либо другой задачи (например, возможность ответа на поступающий телефонный вызов или другое сообщение). Если возможности обработки и емкость памяти не увеличены или не могут быть уменьшены ресурсы на обработку и память, необходимые для декодирования аудиосигнала и воспроизведения, возможно, что устройство не сможет одновременно выполнять несколько задач.
КРАТКОЕ ИЗЛОЖЕНИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
[11] Здесь представлены в упрощенном виде концепции, которые ниже будут рассмотрены подробно. Этот обзор не предназначается для определения ключевых или важнейших признаков заявленного изобретения, а предназначается для помощи в определении объема заявленного изобретения.
[12] По меньшей мере некоторые варианты осуществления изобретения включают способ обработки кодированных данных с использованием методов предсказания, базирующихся на предыдущих данных в буфере кодирования с предсказанием, имеющем известные размеры. После кодирования и передачи (и/или сохранения) декодер принимает поток, содержащий кодированные данные и информацию предсказания, которая формируется при кодировании с предсказанием. Кроме того, декодер принимает коэффициент, указывающий, должны ли (и на какую величину) кодированные данные подвергаться повышающей или понижающей дискретизации во время процесса декодирования. При декодировании кодированных данных части декодированных данных сохраняются в буфере для их использования при декодировании последующих кодированных данных на основе последующей информации предсказания. Буфер, в который помещаются декодированные данные, имеет размеры, отличные от размеров буфера, используемого во время операций предсказания, выполняемых кодером. Часть данных в буфере декодера идентифицируется и затем модифицируется, для того чтобы соответствовать размерам буфера кодирования с предсказанием. В некоторых вариантах осуществления изобретения такое модифицирование включает вставку нулевых значений между элементами идентифицированных данных.
[13] В определенных вариантах осуществления изобретения кодированные данные представлены в частотной области, и декодирование включает их преобразование во временную область. В некоторых таких вариантах осуществления изобретения модифицированные данные из буфера декодера сначала преобразуют в частотную область. Такие преобразованные и модифицированные данные затем масштабируют и добавляют к коэффициентам ошибок предсказания в частотной области, а результирующие значения затем преобразуют во временную область.
[14] По меньшей мере в некоторых вариантах осуществления изобретения декодер обеспечивает повышающую дискретизацию во время декодирования кодированных данных. При декодировании кодированных данных только выбранные отсчеты из кадра полностью восстановленных отсчетов во временной области сохраняют в кадре буфера, соответствующем текущим данным.
[14а] В одном из вариантов осуществления изобретения устройство для декодирования кодированных с предсказанием данных содержит декодер, включающий средство для преобразования отсчетов в частотной области, кодирующих N отсчетов во временной области, в N*F отсчетов во временной области, где F - коэффициент повышающей или понижающей дискретизации, средство предсказания и средство для адаптации выходного сигнала указанного средства преобразования для использования в средстве предсказания. При этом, если F - коэффициент повышающей дискретизации, то средство для адаптации конфигурируется так, чтобы обновлять кадр буфера долговременного предсказания с использованием каждого F-го отсчета из полностью восстановленного выходного кадра во временной области. Если же F - коэффициент понижающей дискретизации, то средство для адаптации конфигурируется так, чтобы расширять 2N*F отсчетов во временной области в части долговременного буфера до 2N отсчетов во временной области.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[15] Предшествующий обзор изобретения, а также последующее подробное описание иллюстративных вариантов его осуществления будут более понятны при рассмотрении вместе с сопроводительными чертежами, которые даны в качестве примера, а не с целью ограничения заявленного изобретения.
[16] На фиг.1А приведена блок-схема, показывающая общую структуру стандартного кодера AAC-LTP.
[17] На фиг.1В приведена блок-схема, показывающая общую структуру стандартного декодера AAC-LTP.
[18] На фиг.1C приведена блок-схема стандартного буфера LTP в декодере, показанном на фиг.1В.
[19] На фиг.2 представлена блок-схема одного из примеров системы, в которой могут использоваться варианты осуществления изобретения.
[20] На фиг.3 представлена блок-схема одного из примеров мобильного устройства, сконфигурированного для приема и декодирования аудиосигналов в соответствии по меньшей мере с некоторыми вариантами осуществления изобретения.
[21] На фиг.4 представлена блок-схема декодера в соответствии по меньшей мере с некоторыми вариантами осуществления изобретения, адаптированными для обеспечения понижающей дискретизации.
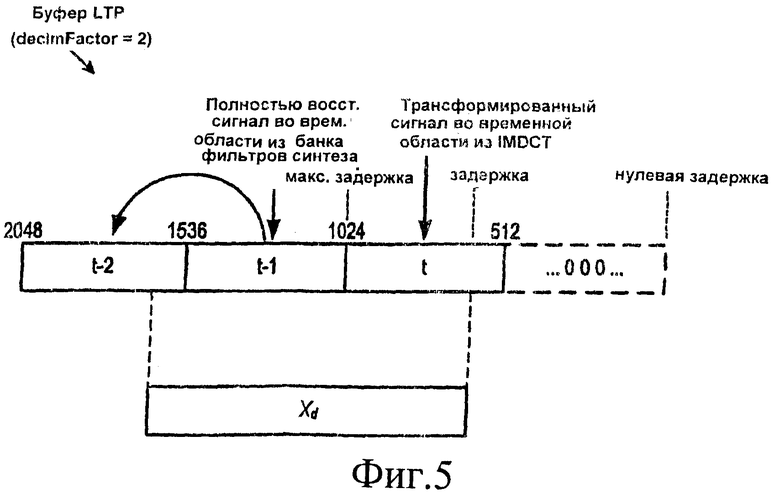
[22] На фиг.5 показан буфер LTP из декодера на фиг.4 в том случае, когда коэффициент прореживания равен 2.
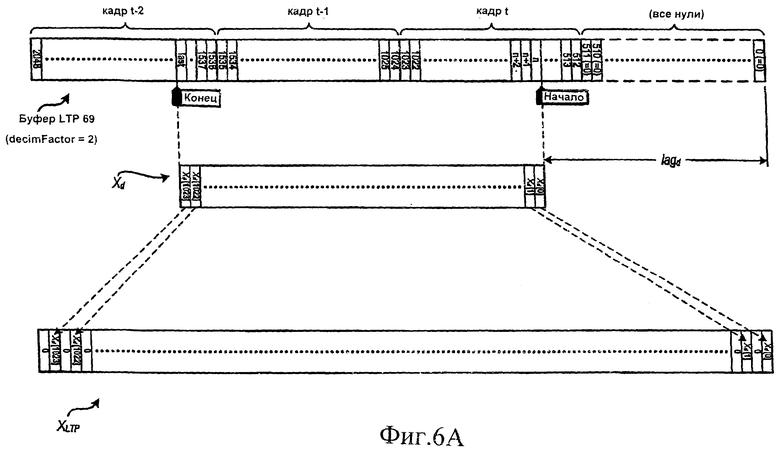
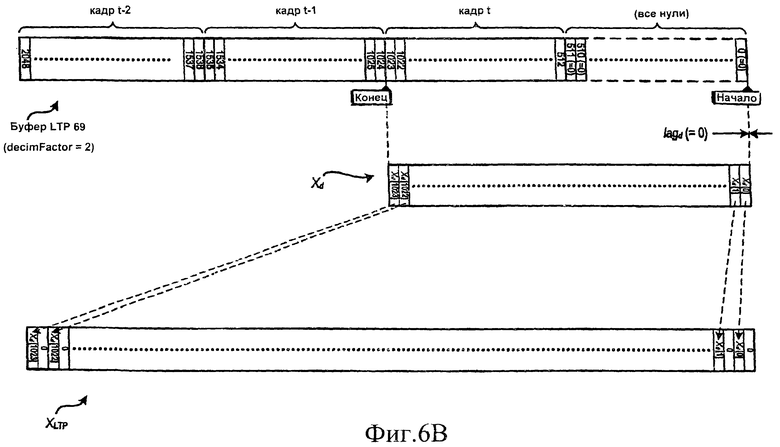
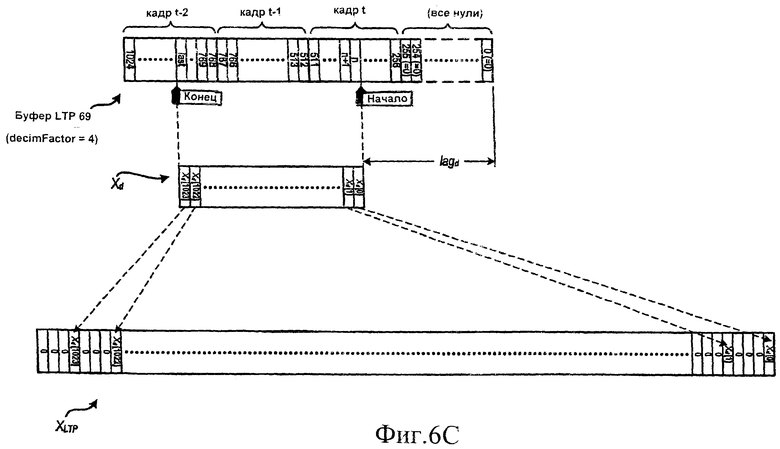
[23] На фиг.6A-6D демонстрируется вычисление массива XLTP [] из буфера LTP на фиг.5 при различных обстоятельствах.
[24] На фиг.7А и 7В приведены блок-схемы, показывающие операции декодера на фиг.4 в соответствии по меньшей мере с некоторыми вариантами осуществления изобретения.
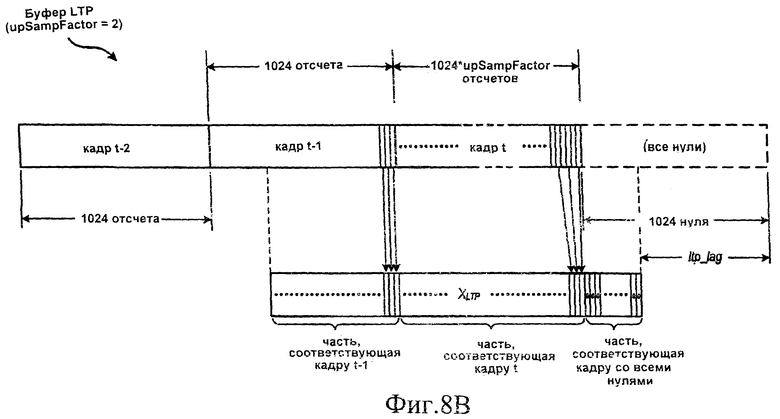
[25] На фиг.8А и 8В показано, как адаптируется буфер LTP, чтобы настроить его для повышающей дискретизации по меньшей мере в некоторых вариантах осуществления изобретения.
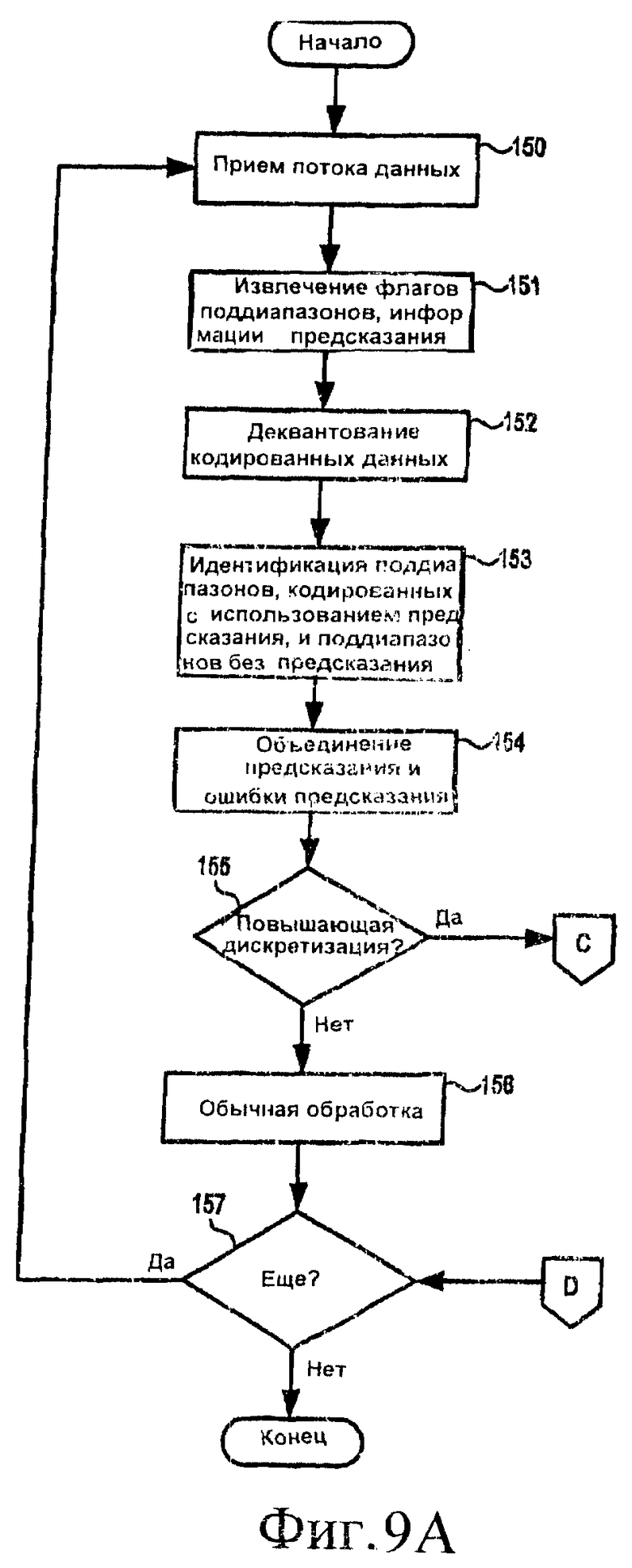
[26] На фиг.9А и 9В приведены блок-схемы, демонстрирующие работу декодера по меньшей мере в некоторых вариантах осуществления изобретения, когда осуществляется повышающая дискретизация.
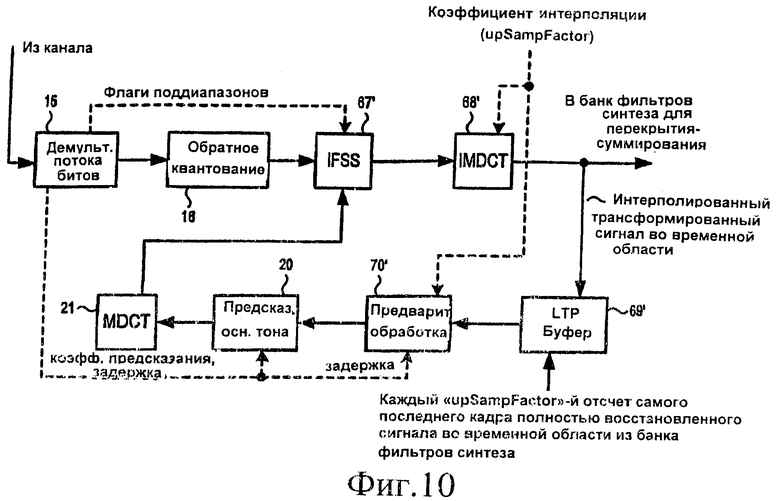
[27] На фиг.10 представлена блок-схема декодера в соответствии по меньшей мере с некоторыми вариантами осуществления изобретения, адаптированными для обеспечения повышающей дискретизации.
[28] На фиг.11 представлена блок-схема декодера в соответствии по меньшей мере с некоторыми вариантами осуществления изобретения, адаптированными для обеспечения как повышающей, так и понижающей дискретизации.
ПОДРОБНОЕ ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
[29] Хотя варианты осуществления изобретения будут рассмотрены здесь на примере связи в соответствии с форматом усовершенствованного звукового кодирования (Advanced Audio Coding, AAC) и профиля долговременного предсказания (Long-Term Prediction, LTP), как это определено стандартом MPEG-4 экспертной группы по кинематографии (Motion Picture Experts Group) (ISO-14496), изобретение этим не ограничивается. В частности, изобретение также применимо для других схем кодирования, в которых кодированный поток данных создается с использованием способов кодирования с предсказанием.
[30] На фиг.2 представлена блок-схема одного из примеров системы, в которой могут использоваться варианты осуществления изобретения. Источник 30 выдает сжатые аудиосигналы AAC-LTP для передачи удаленным пользователям. Источник 30 может производить этот вывод AAC-LTP путем обработки в реальном времени входного аудиосигнала (не показано) или посредством организации доступа к предварительно сжатому аудиосигналу, который сохранен в базе 31 данных. Источник 30 производит беспроводную передачу аудиосигнала AAC-LTP в мобильные устройства 32 (например, мобильные телефоны, сконфигурированные для приема и декодирования сжатых аудиосигналов от источника 30). Мобильные устройства 32 могут взаимодействовать с широкомасштабной беспроводной сетью (например, с мобильной телефонной сетью, сетью 3GPP и т.д.), могут взаимодействовать с небольшими беспроводными сетями (например, с сетью BLUETOOTH), могут взаимодействовать через беспроводные линии Интернета, могут принимать широковещательные передачи (например, спутниковые радиопередачи) и т.д. Источник 30 также обеспечивает передачу сжатых сигналов AAC-LTP через проводную сеть (например, проводные подключения к Интернету) для их загрузки посредством таких устройств, как персональный компьютер 34.
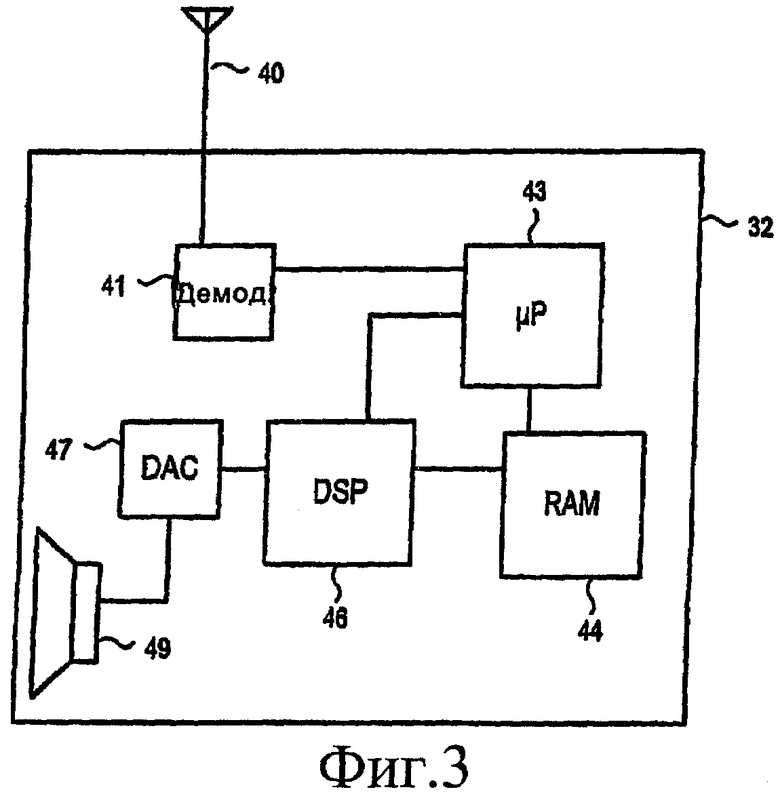
[31] На фиг.3 представлена блок-схема одного из примеров мобильного устройства 32, сконфигурированного для приема и декодирования аудиосигналов AAC-LTP в соответствии по меньшей мере с некоторыми вариантами осуществления изобретения. Беспроводные передачи от источника 30 принимаются через антенну 40. Поступающий радиосигнал демодулируется или же обрабатывается в блоке 41, для того чтобы восстановить переданный цифровой поток битов данных. Контроллер 43 (например, микропроцессор (µР)) принимает восстановленный цифровой сигнал из блока 41. Контроллер 43 выделяет управляющие сигналы (например, коэффициенты предсказания и задержку, флаги поддиапазонов) из квантованных компонентов в частотной области, соответствующих выходному сигналу коммутатора FSS в источнике 30, аналогично FSS 7 на фиг.1А. Контроллер 43 выполняет деквантование этих компонентов в частотной области и предоставляет эти компоненты (с управляющими сигналами) в цифровой сигнальный процессор (DSP) 46.
Процессор DSP 46 затем использует эти данные так, как это описано ниже, для формирования сигнала во временной области. Сигнал во временной области из DSP 46 подается в цифроаналоговый преобразователь (DAC) 47 и выводится через громкоговоритель 49. Оперативная память 44 используется, чтобы сохранить инструкции для функционирования контроллера 43 и процессора 46, а также для буферизации данных (например, для использования в качестве буфера LTP). Постоянная память (ROM) может также использоваться, чтобы хранить программные инструкции для контроллера 43 и/или DSP 46.
[32] Конфигурация на фиг.3 является только одним из примеров. В других вариантах осуществления изобретения может отсутствовать отдельный процессор DSP, а вся обработка выполняется в единственном процессоре. Может быть также опущена отдельная оперативная память - вместо этого используется контроллер и/или процессор DSP, имеющие внутреннюю оперативную память. Контроллер 43, DSP 46 и RAM 44 обычно представлены в виде одной или более встроенных схем (микросхем или набора микросхем).
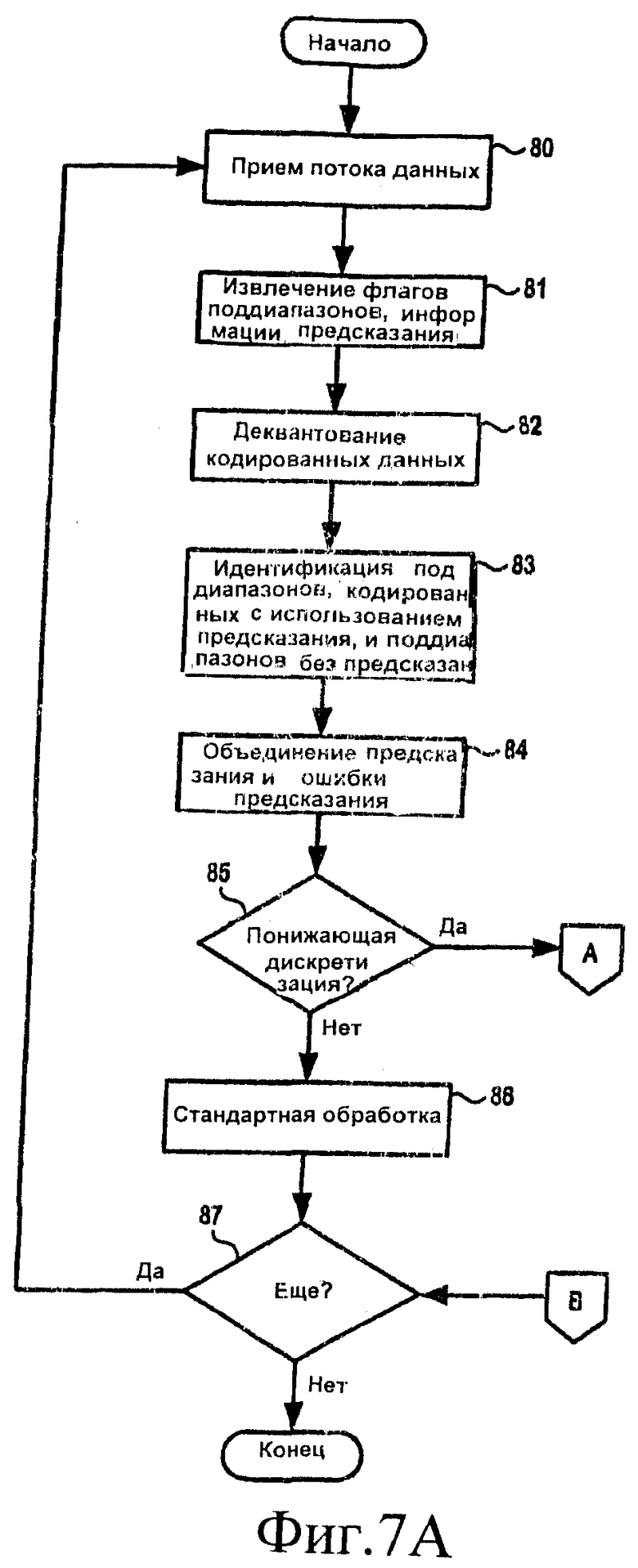
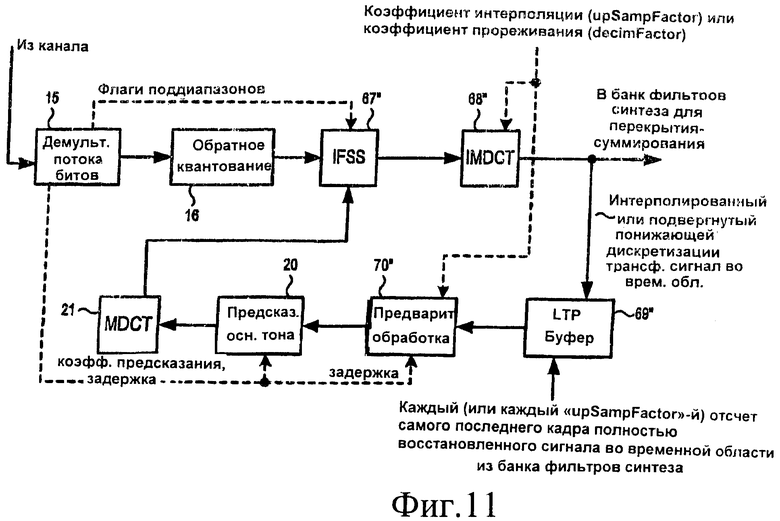
[33] На фиг.4 представлена блок-схема декодера в соответствии по меньшей мере с некоторыми из вариантов осуществления изобретения. Это устройство декодирует сигнал обычного кодера, такого как представленный на фиг.1А. В некоторых вариантах осуществления изобретения операции, представленные блоками 67, 68, 70, 20 и 21 на фиг.4 (а также банк фильтров синтеза и другие элементы, не показанные на фиг.4), осуществляются посредством выполнения программных инструкций процессором DSP 46 вместе с блоком 69 (буфером LTP), реализованным в отдельной оперативной памяти RAM 44. Однако, как указано выше, один или несколько из блоков 67, 68, 70, 20 и 21 (и/или других элементов) может, в качестве альтернативы, реализовываться путем исполнения программных инструкций в контроллере 43. Аналогично, оперативная память RAM 69 может входить в состав процессора DSP 46 и/или контроллера 43 вместо использования отдельной памяти RAM 44.
[34] Демультиплексор 15 потока битов, обратный квантователь 16, предсказатель 20 основного тона и преобразователь MDCT 21 работают аналогично компонентам на фиг.1В, имеющим такую же нумерацию. Коммутатор IFSS 67 может выполнять функции устройства IFSS 17, показанного на фиг.1В, но, кроме того, он может выполнять и дополнительные операции, как это описано ниже. Преобразователь IMDCT 68 может функционировать аналогично устройству IMDCT 18 на фиг.1В. Однако IMDCT 68 также конфигурирован для выполнения понижающей дискретизации в отношении выходного аудиосигнала в ответ на входной коэффициент прореживания (decimFactor). В частности, IMDCT 68 уменьшает с коэффициентом decimFactor число коэффициентов MDCT, которые обрабатываются при преобразовании сигнала из частотной области обратно во временную область. Когда выполняется понижающая дискретизация, это влияет также на количество отсчетов в кадрах, хранимых в буфере LTP 69. Например, когда decimFactor = 2, каждый кадр в буфере LTP 69 содержит только 512 отсчетов (по сравнению с 1024 отсчетами в стандартных буферах LTP). Хотя понижающая дискретизация уменьшает объем вычислений, выполняемых в IMDCT 68, и снижает требования к объему памяти, необходимому для буфера LTP, это приводит к особой проблеме. В частности, буфер LTP для понижающей дискретизации не будет соответствовать буферу устройства долговременного предсказания в кодере AAC-LTP, который изначально создал кодированный сигнал. Если не выполнить дополнительные шаги, то субкомпонент аудиосигнала, основанный на содержимом буфера LTP 69, не будет согласован с соответствующим субкомпонентом, предсказанным в кодере.
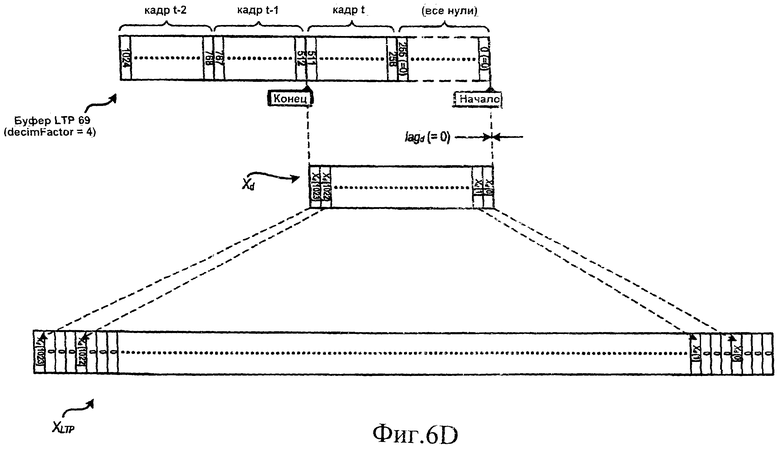
[35] На фиг.5 показан буфер LTP 69 в том случае, когда decimFactor = 2. Аналогично стандартному буферу LTP, показанному на фиг.1C, кадр t заполняется выходными данными трансформированного сигнала во временной области из IMDCT 68, а кадр t-1 заполняется самым последним полностью восстановленным кадром во временной области, выдаваемым банком фильтров синтеза. В связи с понижающей дискретизацией, как это указано выше, кадры буфера LTP 69 короче, чем кадры буфера LTP кодера. Для того чтобы адаптироваться к этому несоответствию, по меньшей мере в некоторых вариантах осуществления изобретения сначала идентифицируется часть Xd буфера LTP 69. В частности, вычисляется значение смещения (lagd) на основе значения задержки переданного из кодера, и затем Xd заполняется содержимым буфера LTP 69, начиная со значения lagd и в направлении, обратном времени (влево на фиг.5), для двух длин кадров текущего буфера LTP 69 (1024 отсчета в примере на фиг.5). Отсчеты Xd затем расширяются препроцессором 70 так, как это описано ниже, для того чтобы более точно соответствовать буферу LTP в кодере.
[36] На фиг.6А более подробно показан буфер LTP 69 и массив данных Xd. Начальная точка для Xd идентифицируется с помощью lagd; конечная точка для Xd идентифицируется на основе текущего коэффициента прореживания (decimFactor). Ниже приводится описание процедуры вычисления значения lagd. По меньшей мере в некоторых вариантах осуществления изобретения Xd реализуется как массив, имеющий 1024/decimFactor элементов (т.е. Xd [0,1,2,… (1024/decimfactor-1)]). Элемент массива Xd [0] заполняется отсчетом из буфера LTP 69 после начальной точки (отсчет n на фиг.6А), элемент Xd [1] заполняется следующим отсчетом (n+1) и т.д.; а элемент Xd [1023] заполняется «последним» отсчетом. Затем Xd [] расширяется в массив XLTP [], который имеет такое же количество отсчетов, какое используется устройством долговременного предсказания в кодере (например, 1024 отсчета). Для того чтобы массив XLTP [] имел более полное сходство с отсчетами, использованными для предсказания устройством долговременного предсказания в кодере, содержимое Xd [] равномерно распределяется по длине XLTP [] с использованием нулевых значений, вставленных для промежуточных интервалов отсчетов в XLTP []. Как показано на фиг.6А, результатом этого является: XLTP [0] = Xd [0], XLTP [1] = 0, XLTP [2] = Xd [1],… XLTP [1023]=0.
[37] По меньшей мере в некоторых вариантах осуществления изобретения, как это показано на фиг.6В, массив XLTP [] заполняется несколько отличным способом, когда значение параметра lagOffset = 0 (вычисление lagOffset описывается ниже). В таком случае порядок нулей и элементов массива Xd [] меняется на обратный. Это делается для того, чтобы выдать полностью совмещенный по времени предсказанный сигнал во временной области, который получился бы, если параметр decimFactor был бы равен 1. Фиг.6С и 6D аналогичны фиг.6А и 6В, но на этих фигурах показано формирование массива XLTP [], когда decimFactor = 4.
[38] Отсчеты массива XLTP [] используются предсказателем 20 основного тона, чтобы сформировать предсказание для исходного аудиосигнала во временной области. Это предсказание будет аппроксимировать предсказание, которое формируется на выходе устройства долговременного предсказания в кодере (например, сигнал, переданный из устройства 1 долговременного предсказания в MDCT 5 на фиг.1А). Затем выходной сигнал предсказателя 20 основного тона подается в MDCT 21 для преобразования в частотную область. По меньшей мере в некоторых вариантах осуществления изобретения это приводит к формированию массива XMDCT [], содержащего коэффициенты MDCT. Как понятно специалистам в этой области техники, массив XMDCT [] не обязательно будет иметь такое же количество элементов, как массив XLTP []. Коэффициенты MDCT в массиве XMDCT [] затем подаются в IFSS 67. Затем коммутатор IFSS 67 добавляет коэффициенты XMDCT [] к деквантованным коэффициентам предсказания ошибок (например, выходной сигнал сумматора 6 на фиг.1А) с использованием описанного ниже способа.
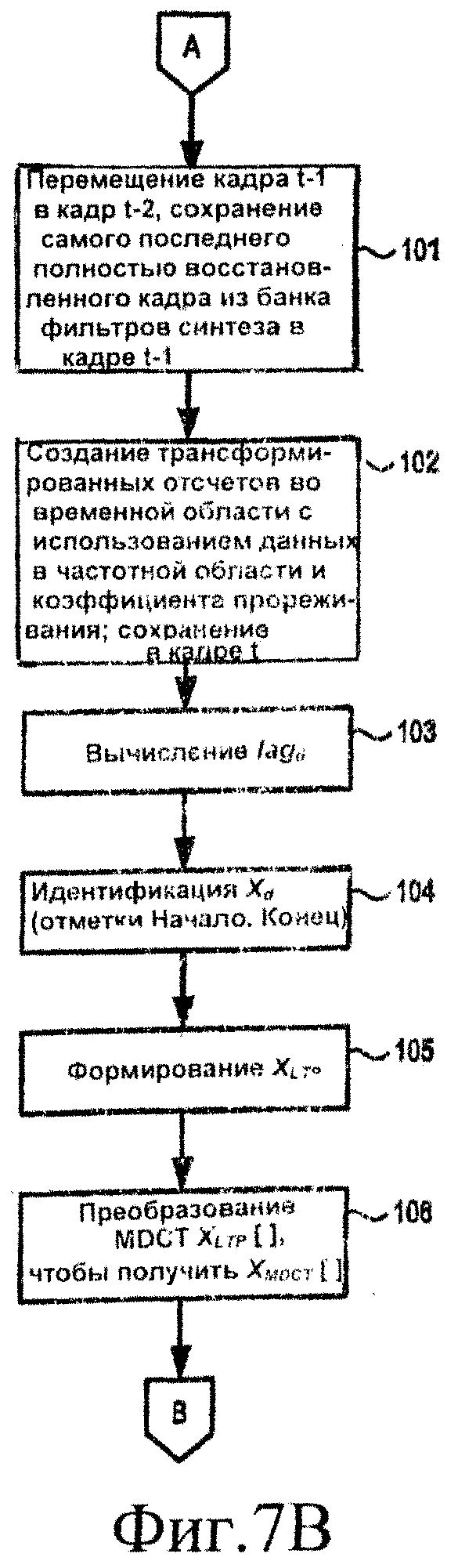
[39] На фиг.7А и 7В приведены блок-схемы, демонстрирующие функционирование декодера AAC-LTP в соответствии по меньшей мере с некоторыми вариантами осуществления изобретения, как это описано выше в отношении фиг.4-6D. Описание работы декодера начинается, как показано на фиг.7А, и продолжается в блоке 80, в котором осуществляется прием поступающего потока данных (например, демультиплексором 15 потока битов). Поступающий поток данных содержит флаги поддиапазонов и информацию предсказания (например, коэффициенты предсказания и задержку, соответствующую периоду основного тона, с выхода устройства 1 предсказания на фиг.1А), а также квантованные данные в частотной области. Для некоторых поддиапазонов данные в частотной области являются результатом преобразования MDCT исходного входного аудиосигнала (например, выходной сигнал MDCT 2 на фиг.1А). Для других поддиапазонов данные в частотной области являются значениями ошибок предсказания (например, в виде выходного сигнала сумматора 6 на фиг.1А).
[40] Декодер переходит к блоку 81, где флаги поддиапазонов и информация предсказания извлекается из принятого потока данных. Флаги поддиапазонов пересылаются в IFSS 67 (фиг.4), а информация предсказания пересылается в предсказатель 20 основного тона. Задержка, соответствующая периоду основного тона, также пересылается в препроцессор 70. Возвращаясь к фиг.7А, декодер затем переходит к блоку 82, где квантованные данные в частотной области деквантуются и пересылаются в IFSS 67. Обработка продолжается в блоке 83, где декодер идентифицирует (используя флаги поддиапазонов и IFSS 67) поддиапазоны, которые требуется воспроизвести, используя данные предсказания, и поддиапазоны, которые требуется воспроизвести из коэффициентов MDCT исходного входного аудиосигнала.
[41] В блоке 84 для поддиапазонов, которые будут воспроизводиться с использованием данных предсказания, декодер объединяет деквантованные значения ошибки предсказания (выходной сигнал сумматора 6 на фиг.1А) с предсказаниями в частотной области, базирующимися на содержимом буфера LTP 69 (XMDCT [], как это описано выше). В частности, отсчеты в частотной области из MDCT 21 (XMDCT []) масштабируются и добавляются к значениям ошибок предсказания (представленным для удобства как массив Xq []). Когда не производится понижающая дискретизация, значения в XMDCT [] масштабируются с коэффициентом (cLTP), переданным в декодер в потоке данных. Когда производится понижающая дискретизация, декодер добавляет XMDCT [] к Xq [] в IFSS 67 в соответствии со следующим псевдокодом (соблюдается синтаксис языка программирования С).

[42] В приведенном выше коде «ltp_bands» - это ограничение частотных диапазонов, для которых могут передаваться сигналы ошибки предсказания. Для вариантов осуществления изобретения, реализованных с использованием кодирования AAC-LTP, это значение задается соответствующим стандартом MPEG-4. Другими словами, псевдоакустическая модель будет обычно задавать поддиапазоны поступающих аудиосигналов, которые требуется воспроизвести посредством коэффициентов MDCT (выход MDCT 2 на фиг.1А) или посредством коэффициентов предсказания ошибок (выход сумматора 6 на фиг.1А). Если каждый из этих поддиапазонов нумеруется как 0, 1, 2,… k, то значение «ltp_bands» - это самый большой из этих номеров, соответствующий поддиапазону, в котором используется долговременное предсказание. Значение «ltp_used [sfb]» указывает, возможно ли долговременное предсказание для поддиапазона «sfb». Иначе говоря, «ltp_used []» - это массив флагов поддиапазонов, подаваемый на вход IFSS 67 на фиг.4.
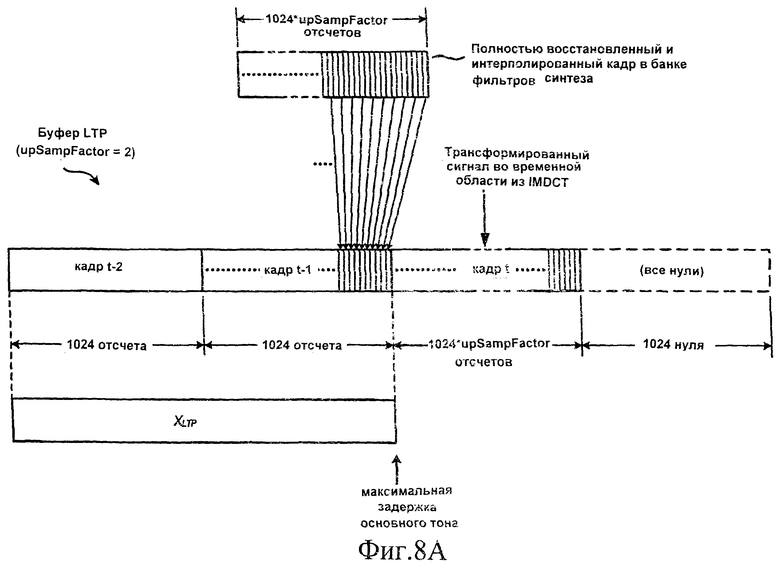
Массивы «startBinOffset []» и «endBinOffset []» содержат соответственно начальные и конечные индексы для каждого поддиапазона. В частности, «startBinOffset [sfb]» и «endBinOffset [sfb]» - это соответственно начальный и конечный индекс для поддиапазона «sfb». Начальные и конечные индексы для всех поддиапазонов задаются также соответствующими стандартами MPEG-4. Переменная «scale» равна cLTP или адаптивному поправочному коэффициенту, полученному из коэффициента LTP и из свойств квантованного спектра, как показано в уравнении 1.
Уравнение 1:

где
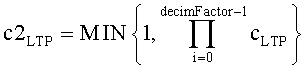
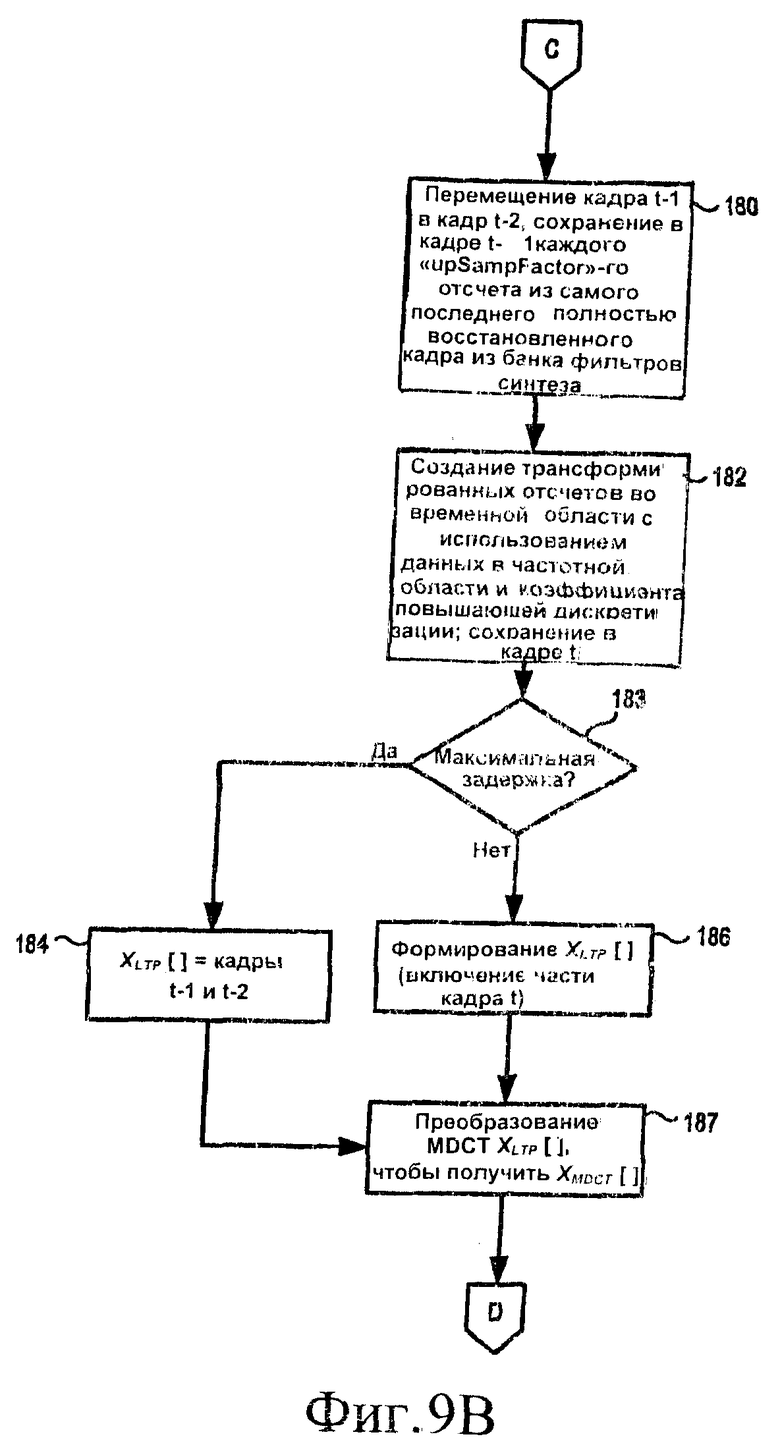
если квантованные значения для диапазона «sfb» равны нулю, или в ином случае
c2LTP =cLTP.
[43] Как понятно специалистам в этой области техники, возможно отсутствие предсказанных значений (XMDCT []) во время одного или нескольких начальных проходов цикла алгоритма, показанного на фиг.7А. В таких случаях массив XMDCT [] может быть сначала заполнен нулями.
[44] Из блока 84 декодер переходит в блок 85 и определяет (например, на основе принятого коэффициента прореживания), требуется ли выполнять понижающую дискретизацию. Если это не требуется, декодер переходит по ветви «Нет» к блоку 86 и обрабатывает обычным способом данные в частотной области из IFSS 67. Препроцессор 70 (фиг.4) бездействует, когда не используется понижающая дискретизация, и массив XLTP [] получается из буфера LTP 69 традиционным образом. Из блока 86 декодер переходит к блоку 87 (описанному ниже). Если в блоке 85 декодер определяет, что необходимо выполнять понижающую дискретизацию, он продолжает работу, переходя (через межстраничный соединитель А) к фиг.7В.
[45] В блоке 101 на фиг.7В декодер перемещает содержимое кадра t-1 буфера LTP 69 в кадр t-2 и сохраняет отсчеты из самого последнего полностью восстановленного кадра во временной области (выданного банком фильтров синтеза) в кадре t-1. В блоке 102 декодер, используя IMDCT 68, создает трансформированные отсчеты данных во временной области, используя данные в частотной области из IFSS 67 и коэффициент прореживания, и сохраняет эти трансформированные отсчеты в кадре t буфера LTP 69. В блоке 103 декодер вычисляет значение lagd, используя уравнения 2 и 3.
Уравнение 2:
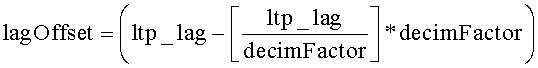
Уравнение 3:
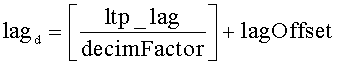
Величина «ltp_lag» в уравнениях 2 и 3 - это переданное кодером значение задержки LTP, соответствующей периоду основного тона; это значение предполагает, что буфер LTP имеет стандартный размер. Обозначение «» представляет функцию floor, которая возвращает значение, представляющее самое большое целое число, меньшее или равное аргументу этой функции.
[46] Затем декодер переходит к блоку 104, отмечает точки «START» (Начало) и «END» (Конец) в буфере LTP и создает массив Xd []. Затем декодер переходит к блоку 105 и формирует массив XLPT [] из массива Xd []. Ниже приводится псевдокод, имеющий синтаксис языка программирования С, для формирования массива XLPT [] в соответствии по меньшей мере с некоторыми вариантами осуществления изобретения.

В приведенном выше коде переменная «N» - это размер каждого кадра буфера LTP 69 при наличии понижающей дискретизации. На примерах, приведенных на фиг.6А-6D, значение N равно 1024/decimFactor. Хотя обычными значениями для параметра decimFactor являются 2 и 4, могут также использоваться и другие значения. Аналогично, изобретение не ограничивается его использованием в отношении систем, использующих размер кадра буфера LTP, равный 1024 отсчетам при отсутствии понижающей дискретизации. Операторы «--» и «++» указывают соответственно на уменьшение и приращение во время каждого прохода цикла.
[47] Декодер затем переходит к блоку 106 и выполняет преобразование MDCT над массивом XLTP [], чтобы получить массив коэффициентов в частотной области XMDCT []. Заново вычисленные значения XMDCT [] пересылаются в IFSS 67 для их объединения со значениями ошибок предсказания (Xq []), принимаемыми в следующей части потока данных. Из блока 106 декодер возвращается (через межстраничный соединитель В) в блок 87 на фиг.7А. В блоке 87 декодер определяет, имеются ли дополнительные аудиоданные для обработки. Если данные имеются, декодер возвращается в блок 80 по ветви «Да». В противном случае алгоритм завершается.
[48] По меньшей мере в некоторых вариантах осуществления изобретения декодер имеет также возможность выполнять повышающую дискретизацию. Другими словами, иногда желательно увеличить (путем интерполяции коэффициентов MDCT, принятых из кодера) число коэффициентов MDCT, которые используются для создания выходного сигнала во временной области. Это может выполняться, например, чтобы сформировать сигнал, совместимый с другими устройствами. Однако повышающая дискретизация может привести к несоответствию между буфером LTP в кодере и буфером LTP в декодере. Например, когда производится декодирование стандартного аудиосигнала AAC-LTP, коэффициент повышающей дискретизации (или интерполяции), равный 2, приведет к кадрам буфера LTP, содержащим 2048 отсчетов, если не выполнить дополнительные шаги.
[49] На фиг.8А и 8В иллюстрируется, как адаптируется буфер LTP по меньшей мере в некоторых вариантах осуществления изобретения, чтобы приспособить его для повышающей дискретизации. На фиг.8А и 8В предполагается, что коэффициент повышающей дискретизации (или интерполяции) «upSampFactor» равен 2, хотя могут также использоваться и другие значения. Как показано на фиг.8А, только каждый «upSampFactor»-й отсчет из выходного полностью восстановленного кадра банка фильтров синтеза перемещается в кадр t-1 буфера LTP вместе с перемещением кадра t-1 в кадр t-2 во время последующего временного периода. Кадр t хранит самый последний трансформированный и интерполированный выходной сигнал преобразователя IMDCT. Как показано на фиг.8А, кадр t имеет размер, равный 1024*upSampFactor. По меньшей мере в некоторых вариантах осуществления изобретения кадр t не является частью буфера LTP. Вместо этого трансформированный выходной сигнал IMDCT буферируется где-то в другом месте внутри декодера. В таких вариантах осуществления изобретения доступ к данным, представленным кадром t, достигается посредством указателей адресов ячеек памяти, используемых для буферизации трансформированного и интерполированного выходного сигнала IMDCT во время перекрытия-суммирования. Аналогичное размещение точек может осуществляться для кадра t в вариантах осуществления изобретения на фиг.4-7В.
[50] Когда параметр задержки, соответствующей периоду основного тона, имеет максимальное значение, как показано на фиг.8А, массив XLTP [] получается непосредственно из кадров t-1 и t-2. Когда параметр задержки, соответствующей периоду основного тона, имеет значение меньше максимального, как показано на фиг.8В, часть массива XLTP [], находящаяся за пределами кадра t, заполняется непосредственно из кадра t-1 и (в некоторых случаях) из кадра t-2. Часть XLTP [], соответствующая «кадру» со всеми нулями, заполняется нулями. Часть XLTP [], соответствующая кадру t, заполняется посредством выборки каждого «upSampFactor»-го отсчета из кадра t. Для упрощения передача отсчетов в кадр t и t-1 на фиг.8В не показана.
[51] На фиг.9А и 9В приведены блок-схемы, демонстрирующие работу декодера AAC-LTP в соответствии по меньшей мере с некоторыми вариантами осуществления изобретения, когда осуществляется повышающая дискретизация. Операции, соответствующие блокам 150-153, 156 и 157, в общем аналогичны соответствующим операциям в блоках 80-83, 86 и 87, описанным в связи с фиг.7А, и, таким образом, не рассматриваются в дальнейшем. Операции, соответствующие блоку 154, аналогичны операциям в блоке 84, за исключением масштабирования значений XMDCT [], когда производится повышающая дискретизация. В коммутаторе IFSS 67' (см. фиг.10, описываемую ниже) декодер добавляет XMDCT [] к Xq [] в соответствии с тем же самым псевдокодом, который рассматривался выше для блока 84 на фиг.7А. Однако в алгоритме, приведенном на фиг.9А, для переменной «scale» устанавливается значение, равное cLTP*upSampFactor. Блок 155 также аналогичен блоку 85 на фиг.7А, за исключением того, что декодер определяет в блоке 155 (например, на основе принятого коэффициента повышающей дискретизации или интерполяции), требуется ли выполнение повышающей дискретизации. Если это необходимо, декодер продолжает обработку, переходя через межстраничный соединитель С на фиг.9В.
[52] В блоке 180 на фиг.9В декодер сдвигает содержимое кадра t-1 буфера LTP 69' (фиг.10) в кадр t-2. Декодер также сохраняет каждый «upSampFactor»-й отсчет из самых последних полностью восстановленных отсчетов во временной области (из банка фильтров синтеза) в кадре t-1. В блоке 182 декодер создает интерполированные и трансформированные отсчеты данных во временной области из IFSS 67' и коэффициента повышающей дискретизации и сохраняет эти трансформированные отсчеты в кадре t. В блоке 183 декодер определяет, имеет ли задержка, соответствующая периоду основного тона (ltp_lag), максимальное значение. Если это так, декодер переходит по ветви «Да» в блок 184, где массив XLTP [] заполняется из кадров буфера t-1 и t-2. Из блока 184 декодер затем переходит к блоку 187 (описанному ниже).
[53] Если задержка, соответствующая периоду основного тона, меньше своего максимального значения, декодер переходит по ветви «Нет» из блока 183 в блок 186. В блоке 186 формируется массив XLTP [] с использованием значения ltp_lag, переданного из декодера. Для частей массива XLTP [], соответствующих кадру t, только каждый «upSampFactor»-й отсчет копируется в массив XLTP []. Из блока 186 декодер переходит к блоку 187 и выполняет преобразование MDCT над массивом XLTP [], чтобы получить массив коэффициентов в частотной области XMDCT []. Из блока 187 декодер возвращается в блок 157 (фиг.9А) через межстраничный соединитель D.
[54] На фиг.10 представлена блок-схема декодера в соответствии по меньшей мере с некоторыми вариантами осуществления изобретения, сконфигурированного для выполнения операций, показанных на фиг.9А и 9В. Компоненты 15, 16, 20 и 21 аналогичны компонентам с такими же номерами, которые описаны в отношении фиг.1В и 4. Компоненты 67', 68', 69' и 70' аналогичны компонентам 67, 68, 69 и 70 на фиг.4, но они сконфигурированы для выполнения повышающей дискретизации способом, описанным выше в отношении фиг.8А-9В. На фиг.11 представлена блок-схема декодера, в соответствии по меньшей мере с некоторыми дополнительными вариантами осуществления, сконфигурированного для выполнения повышающей и понижающей дискретизации. Компоненты 15, 16, 20 и 21 аналогичны компонентам с такими же номерами, которые описаны в отношении фиг.1В, 4 и 10. Компоненты 67", 68", 69" и 70" аналогичны компонентам 67, 68, 69 и 70 на фиг.4, но они также сконфигурированы для выполнения повышающей дискретизации способом, описанным выше при рассмотрении фиг.8А-9В.
[55] Хотя были описаны конкретные примеры осуществления изобретения, специалисты в этой области техники поймут, что возможны различные варианты и изменения описанных выше систем и способов, которые соответствуют объему и сущности изобретения, определенному в прилагаемых пунктах формулы. Например, изобретение может также реализовываться в виде машиночитаемого носителя (например, оперативной памяти, постоянной памяти, отдельной флэш-памяти и т.д.), имеющего машинно-исполняемые инструкции, хранящиеся на носителе, так что при чтении и исполнении инструкций соответствующим устройством (или устройствами) выполняются шаги способа в соответствии с изобретением. В качестве еще одного примера, декодеры, такие как описанные выше, могут также реализовываться в других типах различных устройств (например, в портативных музыкальных плеерах и других типах пользовательских электронных устройств). Эти и другие модификации находятся в рамках изобретения, определенных в прилагаемых пунктах формулы. В формуле различные части снабжены для удобства буквенными или цифровыми ссылками. Однако использование таких ссылок не подразумевает временной взаимосвязи, если этого не следует из других признаков формулы.
| название | год | авторы | номер документа |
|---|---|---|---|
| КОДЕР И ДЕКОДЕР АУДИОСИГНАЛА, ИСПОЛЬЗУЮЩИЕ ПРОЦЕССОР ЧАСТОТНОЙ ОБЛАСТИ, ПРОЦЕССОР ВРЕМЕННОЙ ОБЛАСТИ И КРОССПРОЦЕССОР ДЛЯ НЕПРЕРЫВНОЙ ИНИЦИАЛИЗАЦИИ | 2015 |
|
RU2668397C2 |
| СПОСОБ ГИБРИДНОГО МАСКИРОВАНИЯ: КОМБИНИРОВАННОЕ МАСКИРОВАНИЕ ПОТЕРИ ПАКЕТОВ В ЧАСТОТНОЙ И ВРЕМЕННОЙ ОБЛАСТИ В АУДИОКОДЕКАХ | 2016 |
|
RU2714365C1 |
| КОДЕР И ДЕКОДЕР АУДИОСИГНАЛА, ИСПОЛЬЗУЮЩИЕ ПРОЦЕССОР ЧАСТОТНОЙ ОБЛАСТИ С ЗАПОЛНЕНИЕМ ПРОМЕЖУТКА В ПОЛНОЙ ПОЛОСЕ И ПРОЦЕССОР ВРЕМЕННОЙ ОБЛАСТИ | 2015 |
|
RU2671997C2 |
| ПРОЦЕССОР ДЛЯ ФОРМИРОВАНИЯ СПЕКТРА ПРОГНОЗИРОВАНИЯ НА ОСНОВЕ ДОЛГОСРОЧНОГО ПРОГНОЗИРОВАНИЯ И/ИЛИ ГАРМОНИЧЕСКОЙ ПОСТФИЛЬТРАЦИИ | 2022 |
|
RU2826967C2 |
| КОДЕР, ДЕКОДЕР, СПОСОБ КОДИРОВАНИЯ И СПОСОБ ДЕКОДИРОВАНИЯ ДЛЯ ДОЛГОВРЕМЕННОГО ПРЕДСКАЗАНИЯ В ЧАСТОТНОЙ ОБЛАСТИ ТОНАЛЬНЫХ СИГНАЛОВ ДЛЯ КОДИРОВКИ АУДИО | 2019 |
|
RU2806121C1 |
| АУДИОКОДЕР И ДЕКОДЕР | 2008 |
|
RU2456682C2 |
| АУДИОКОДЕР И ДЕКОДЕР | 2015 |
|
RU2696292C2 |
| УСТРОЙСТВО И СПОСОБ, РЕАЛИЗУЮЩИЕ УЛУЧШЕННЫЕ КОНЦЕПЦИИ ДЛЯ TCX LTP | 2014 |
|
RU2665279C2 |
| АУДИОКОДЕР И ДЕКОДЕР | 2019 |
|
RU2793725C2 |
| АУДИОКОДЕР И ДЕКОДЕР | 2008 |
|
RU2562375C2 |
3Изобретение относится к декодированию сжатой цифровой информации, в частности к декодированию битовых потоков, отражающих контент, который сжат с применением методов кодирования с долговременным предсказанием. Декодер (например, декодер AAC-LTP) принимает поток, содержащий кодированные аудиоданные и данные предсказания. Кодированные данные во время декодирования подвергают повышающей или понижающей дискретизации. Части декодированных данных хранят в буфере для их использования при декодировании последующих кодированных данных. Буфер, в который помещают декодированные данные, имеет размеры, отличные от размеров буфера, используемого в кодере при создании кодированных данных. Часть данных в буфере декодера идентифицируют и модифицируют с использованием перемежающихся нулевых значений, чтобы обеспечить соответствие размерам буфера кодирования с предсказанием в кодере. Технический результат - повышение качества звука при декодировании. 6 н. и 13 з.п. ф-лы, 11 ил.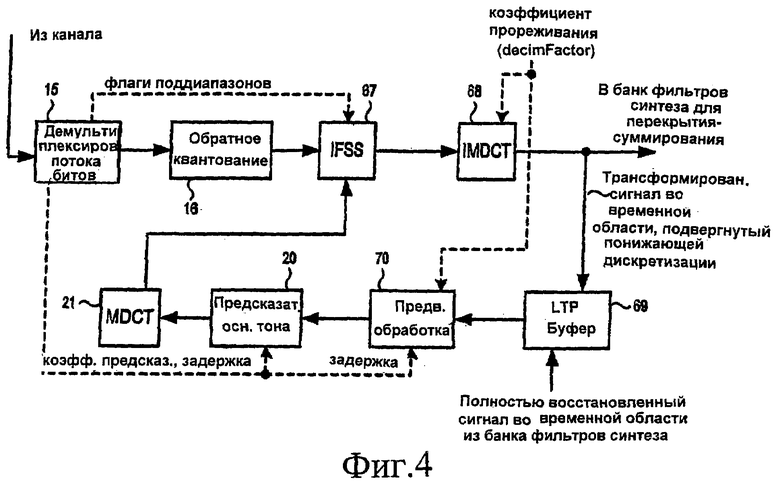
1. Способ декодирования кодированных с предсказанием данных, включающий:
прием потока, содержащего кодированные данные, включающие множество коэффициентов модифицированного дискретного косинусного преобразования, представляющих сигнал в частотной области, связанный с аудиосигналом, а также включающие информацию предсказания, содержащую значение задержки, соответствующей периоду основного тона, и множество коэффициентов ошибок предсказания, связанных с кодированными данными, при этом информация предсказания создана на основе данных в буфере кодирования с предсказанием;
прием коэффициента прореживания, указывающего величину уменьшения числа коэффициентов модифицированного дискретного косинусного преобразования, содержащихся в кодированных данных, при понижающей дискретизации в качестве части процесса декодирования кодированных данных;
формирование декодированных данных из кодированных данных с использованием принятых коэффициента прореживания и информации предсказания, включающее выполнение модифицированного дискретного косинусного преобразования над начальными данными или модифицированными идентифицированными данными, при этом начальные данные используют только при первом выполнении цикла способа, масштабирование данных, являющихся результатом указанного выполнения модифицированного дискретного косинусного преобразования, и добавление масштабированных данных после указанного масштабирования данных к множеству коэффициентов ошибок предсказания;
буферизацию по меньшей мере части декодированных данных в одном или более буферах долговременного предсказания, при этом по меньшей мере один из одного или более буферов долговременного предсказания имеет, по меньшей мере, один размер, отличный от соответствующего размера буфера кодирования с предсказанием;
идентификацию части в буферизованных декодированных данных для использования при декодировании последующих кодированных данных, при этом границы этой части определены значением смещения, вычисленным на основе значения задержки, соответствующей периоду основного тона, и двумя длинами кадра; и
модифицирование идентифицированных данных путем вставки равномерно распределенных нулевых значений между элементами идентифицированных данных для обеспечения соответствия указанному, по меньшей мере, одному размеру буфера кодирования с предсказанием с получением новых модифицированных идентифицированных данных.
2. Способ по п.1, в котором
кодированные данные включают данные в частотной области, созданные путем использования одного или более модифицированного дискретного косинусного преобразования, и
указанное формирование декодированных данных включает создание данных во временной области из данных в частотной области с использованием одного или более обратного модифицированного косинусного преобразования.
3. Способ по п.2, в котором
указанный шаг идентификации, по меньшей мере, части данных включает вычисление модифицированного значения задержки, соответствующей периоду основного тона.
4. Способ по п.3, в котором
указанная идентификация, по меньшей мере, части данных включает вычисление модифицированного значения задержки, соответствующей периоду основного тона, на основе выражений
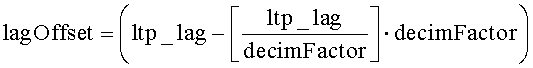
и
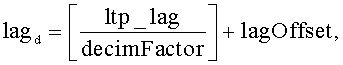
где lagd - модифицированное значение задержки, соответствующей периоду основного тона, ltp_lag - значение задержки, соответствующей периоду основного тона, включенное в принятую информацию предсказания, a decimFactor - коэффициент прореживания.
5. Способ по п.1, в котором кодированные данные включают частотные поддиапазоны, при этом указанное масштабирование данных включает, в отношении каждого поддиапазона, масштабирование данных, полученных в результате указанного выполнения модифицированного дискретного косинусного преобразования, в соответствии с выражением

где scale - коэффициент масштабирования, применяемый к элементам данных после упомянутого выполнения модифицированного дискретного косинусного преобразования,
decimFactor - коэффициент, принятый на указанном шаге приема коэффициента прореживания и указывающий на понижающую дискретизацию,
CLTP - коэффициент LTP, включенный в поток, принятый на указанном шаге приема потока,
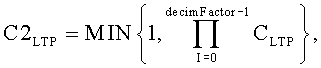 если квантованные значения для поддиапазона равны нулю, или в противном случае
если квантованные значения для поддиапазона равны нулю, или в противном случае
C2LTP=CLTP.
6. Устройство для декодирования кодированных с предсказанием данных, содержащее:
один или более процессоров, сконфигурированных для выполнения способа обработки данных, включающего:
прием потока, содержащего кодированные данные, включающие множество коэффициентов модифицированного дискретного косинусного преобразования, представляющих сигнал в частотной области, связанный с аудиосигналом, а также включающие информацию предсказания, содержащую значение задержки, соответствующей периоду основного тона, и множество коэффициентов ошибок предсказания, связанных с кодированными данными, при этом информация предсказания создана на основе данных в буфере кодирования с предсказанием;
прием коэффициента прореживания, указывающего величину уменьшения числа коэффициентов модифицированного дискретного косинусного преобразования, содержащихся в кодированных данных, при понижающей дискретизации в качестве части процесса декодирования кодированных данных;
формирование декодированных данных из кодированных данных с использованием принятых коэффициента прореживания и информации предсказания, включающее выполнение модифицированного дискретного косинусного преобразования над начальными данными или модифицированными идентифицированными данными, при этом начальные данные используют только при первом выполнении цикла способа, масштабирование данных, являющихся результатом указанного выполнения модифицированного дискретного косинусного преобразования, и добавление масштабированных данных после указанного масштабирования данных к множеству коэффициентов ошибок предсказания;
буферизацию по меньшей мере части декодированных данных в одном или более буферах долговременного предсказания, при этом, по меньшей мере, один из одного или более буферов долговременного предсказания имеет, по меньшей мере, один размер, отличный от соответствующего размера буфера кодирования с предсказанием;
идентификацию части в буферизованных декодированных данных для использования при декодировании последующих кодированных данных, при этом границы этой части определены значением смещения, вычисленным на основе значения задержки, соответствующей периоду основного тона, и двумя длинами кадра; и
модифицирование идентифицированных данных путем вставки равномерно распределенных нулевых значений между элементами идентифицированных данных для обеспечения соответствия указанному, по меньшей мере, одному размеру буфера кодирования с предсказанием с получением новых модифицированных идентифицированных данных.
7. Устройство по п.6, в котором
кодированные данные включают данные в частотной области, созданные путем использования одного или более модифицированного дискретного косинусного преобразования, и
указанное формирование декодированных данных включает создание данных во временной области из данных в частотной области с использованием одного или более обратного модифицированного косинусного преобразования.
8. Устройство по п.7, в котором
указанный шаг идентификации по меньшей мере части данных включает вычисление модифицированного значения задержки, соответствующей периоду основного тона.
9. Устройство по п.8, в котором
указанная идентификация, по меньшей мере, части данных включает вычисление модифицированного значения задержки, соответствующей периоду основного тона, на основе выражений
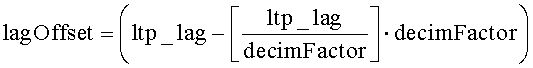
и
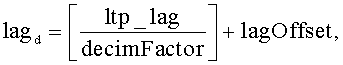
где lagd - модифицированное значение задержки, соответствующей периоду основного тона, ltp_lag - значение задержки, соответствующей периоду основного тона, включенное в принятую информацию предсказания, a decimFactor - коэффициент прореживания.
10. Устройство по п.9, в котором кодированные данные включают частотные поддиапазоны, при этом указанное масштабирование данных включает, в отношении каждого поддиапазона, масштабирование данных, полученных в результате указанного выполнения модифицированного дискретного косинусного преобразования, в соответствии с выражением

где scale - коэффициент масштабирования, применяемый к элементам данных после упомянутого выполнения модифицированного дискретного косинусного преобразования,
decimFactor - коэффициент, принятый на указанном шаге приема коэффициента прореживания и указывающий на понижающую дискретизацию,
CLTP - коэффициент LTP, включенный в поток, принятый на указанном шаге приема потока,
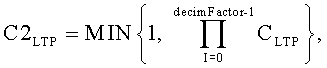
если квантованные значения для поддиапазона равны нулю, или в противном случае
C2LTP=CLTP.
11. Устройство по п.6, которое является устройством мобильной связи.
12. Устройство по п.6, которое является компьютером.
13. Устройство по п.6, которое является портативным музыкальным плеером.
14. Способ декодирования кодированных с предсказанием данных, содержащий:
прием потока, содержащего кодированные данные, включающие множество коэффициентов модифицированного дискретного косинусного преобразования, представляющих сигнал в частотной области, связанный с аудиосигналом, а также включающие информацию предсказания, содержащую значение задержки, соответствующей периоду основного тона, и множество коэффициентов ошибок предсказания, связанных с кодированными данными, где
информация предсказания создана на основе данных в буфере кодирования с предсказанием и включает значение задержки, соответствующей периоду основного тона, и
кодированные данные включают данные в частотной области, сформированные с использованием одного или более модифицированного дискретного косинусного преобразования (MDCT), и кодированные данные также включают коэффициенты ошибок предсказания;
прием коэффициента прореживания, указывающего величину понижающей дискретизации, которой требуется подвергнуть кодированные данные в качестве части процесса декодирования кодированных данных;
формирование декодированных данных из кодированных данных с использованием принятых коэффициента прореживания и информации предсказания, причем указанное формирование включает создание данных во временной области из данных в частотной области с использованием одного или более обратного модифицированного дискретного косинусного преобразования;
буферизацию, по меньшей мере, части декодированных данных в буфере долговременного предсказания, имеющем, по меньшей мере, один размер, отличный от соответствующего размера буфера кодирования с предсказанием;
идентификацию части в буферизованных декодированных данных для использования при декодировании последующих кодированных данных, причем указанная идентификация включает вычисление модифицированного значения задержки, соответствующей периоду основного тона, на основе выражений
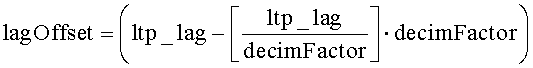
и
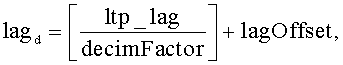
где lagd - модифицированное значение задержки, соответствующей периоду основного тона, ltp_lag - значение задержки, соответствующей периоду основного тона, включенное в принятую информацию предсказания, a decimFactor - коэффициент прореживания, принятый на указанном шаге приема коэффициента прореживания;
модифицирование идентифицированных данных для обеспечения их соответствия указанному, по меньшей мере, одному размеру буфера кодирования с предсказанием, причем указанное модифицирование включает вставку нулевых значений между элементами идентифицированных данных, кодированные данные включают частотные поддиапазоны, и указанное формирование декодированных данных включает
выполнение модифицированного дискретного косинусного преобразования над модифицированными идентифицированными данными после указанного модифицирования идентифицированных данных,
масштабирование данных, являющихся результатом указанного выполнения модифицированного дискретного косинусного преобразования, в соответствии с выражением

где scale - коэффициент масштабирования, применяемый к элементам данных после упомянутого выполнения модифицированного дискретного косинусного преобразования,
CLTP - коэффициент LTP, включенный в поток, принятый на указанном шаге приема потока,
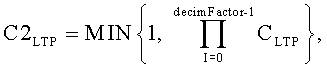
если квантованные значения для поддиапазона равны нулю, или в противном случае
C2LTP=CLTP, и
добавление масштабированных данных после указанного масштабирования данных к коэффициентам ошибок предсказания.
15. Устройство для декодирования кодированных с предсказанием данных, содержащее:
одну или более интегральных схем, сконфигурированных для выполнения способа, включающего
прием потока, содержащего кодированные данные, включающие множество коэффициентов модифицированного дискретного косинусного преобразования, представляющих сигнал в частотной области, связанный с аудиосигналом, а также включающие информацию предсказания, содержащую множество коэффициентов ошибок предсказания, связанных с кодированными данными, при этом информация предсказания создана на основе данных в буфере кодирования с предсказанием, и значение задержки, соответствующей периоду основного тона;
прием коэффициента прореживания, указывающего величину уменьшения числа коэффициентов модифицированного дискретного косинусного преобразования, содержащихся в кодированных данных, при понижающей дискретизации в качестве части процесса декодирования кодированных данных;
формирование декодированных данных из кодированных данных с использованием принятых коэффициента прореживания и информации предсказания, включающее выполнение модифицированного дискретного косинусного преобразования над начальными данными или модифицированными идентифицированными данными, при этом начальные данные используют только при первом выполнении цикла способа, масштабирование данных, являющихся результатом указанного выполнения модифицированного дискретного косинусного преобразования, и добавление масштабированных данных после указанного масштабирования данных к множеству коэффициентов ошибок предсказания;
буферизацию, по меньшей мере, части декодированных данных в одном или более буферов долговременного предсказания, при этом, по меньшей мере, один из одного или более буферов долговременного предсказания имеет по меньшей мере один размер, отличный от соответствующего размера буфера кодирования с предсказанием;
идентификацию части в буферизованных декодированных данных для использования при декодировании последующих кодированных данных, при этом границы этой части определены значением смещения, вычисленным на основе значения задержки, соответствующей периоду основного тона, и двумя длинами кадра; и
модифицирование идентифицированных данных путем вставки равномерно распределенных нулевых значений между элементами идентифицированных данных для обеспечения соответствия указанному, по меньшей мере, одному размеру буфера кодирования с предсказанием с получением новых модифицированных идентифицированных данных.
16. Машиночитаемый носитель, содержащий инструкции, которые при исполнении их компьютером обеспечивают выполнение компьютером способа по любому из пп.1-5.
17. Устройство для декодирования кодированных с предсказанием данных, содержащее:
декодер, включающий
средство для преобразования отсчетов в частотной области, кодирующих N отсчетов во временной области, в N·F отсчетов во временной области, где F - коэффициент повышающей или понижающей дискретизации,
средство предсказания и
средство для адаптации выходного сигнала указанного средства преобразования для использования в средстве предсказания.
18. Устройство по п.16, в котором
F - коэффициент повышающей дискретизации, и
средство для адаптации конфигурировано так, чтобы обновлять кадр буфера долговременного предсказания с использованием каждого F-го отсчета из полностью восстановленного выходного кадра во временной области.
19. Устройство по п.16, в котором
F - коэффициент понижающей дискретизации, и
средство для адаптации конфигурировано так, чтобы расширять 2N·F отсчетов во временной области в части долговременного буфера до 2N отсчетов во временной области.
| WO 2006049179 A1, 11.05.2006 | |||
| RU 2005123381 A, 20.01.2006 | |||
| US 2005025361 A1, 03.02.2005 | |||
| РЕЧЕВОЙ КОДЕР С ЛИНЕЙНЫМ ПРЕДСКАЗАНИЕМ И ИСПОЛЬЗОВАНИЕМ АНАЛИЗА ЧЕРЕЗ СИНТЕЗ | 1996 |
|
RU2163399C2 |
| JP 2003323199 A, 14.11.2003 | |||
| US 6384759 B2, 07.05.2002. | |||

