Изобретение относится к способу управления системой реляционной базы данных путем запроса в реляционную базу данных, содержащему в качестве соответствующей структуры данных множество таблиц данных, связанных между собой отношениями, с использованием языка базы данных, причем имеется таблица отношений и причем генерируется подлежащая выполнению команда базы данных, не содержащая операций, связанных с отношениями, и конкретно определяется тракт доступа, задающий последовательность доступа в базу данных.
Концепция реляционной базы данных отличается от других баз данных повышенной ориентацией на пользователя, разделением программ и данных, структурой таблиц и целостностью данных за счет сокращения избыточной информации.
Предпринималось несколько попыток создания языков запроса в базу данных, базирующихся на модели реляционной базы данных, из которых самым удобным для использования оказался язык SQL. Все другие подходы, как-то: OLAP, OQL и TSQL с течением времени были интегрированы в стандартный язык SQL.
Из US 2005/0076045 A1 известен способ структурирования данных в реляционной базе данных, с помощью которого совершенствуются возможности использования многомерной системы в виде базы данных, в которой предоставляется возможность комбинации нескольких элементов (VALUE HOLDING ITEMS и STRUKTURE ITEMS) одной размерности в один новый элемент (STRUKTURE ITEM) размерности, и одновременно применяется способ генерирования оптимизированных обобщенных команд на языке SQL путем промежуточного запоминания данных, с тем чтобы скомпенсировать большие потери в скорости, обычно вызываемые для тех же запросов другими командами на языке SQL. Указывается путь иерархического сведения различных элементов одной размерности, для комбинации которых в используемой таблице данных агрегат отсутствует. Элементы (STRUKTURE ITEMS), существующие без агрегатов, в соответствии со способом, описанным в этой публикации, в отличие от элементов (VALUE HOLDING ITEMS), существующих с агрегатами, являются произвольно выбираемыми и в любое время изменяемыми и расширяемыми.
US 6 732 091 В1 описывает способ обработки запросов в базу данных, например, на языке SQL, причем выбирается наилучший план доступа из множества всех возможных планов доступа к конкретной структуре данных, дающих по данной команде (Statement) одинаковый результат. Основой для этого является ограниченная форма таблицы отношений, причем допускаются только соединения NATURAL-JOIN.
На практике недостаток выразился в том, что запросы относятся лишь к одной конкретной структуре данных используемой базы данных в сиюминутном состоянии. Изменение в структуре данных сразу же влечет за собой изменения в запросе. Поэтому один и тот же запрос в отношении конкретной структуры данных для другой структуры данных иногда выглядит совсем иначе.
Основной элемент запроса на языке SQL во многих случаях формируется операциями, ориентированными на отношения, как-то: проекция, соединение (Join) или селекция, или операции, ориентированные на количество, как-то: объединение, отсечение, разность множеств. При этом практически всегда с помощью указания отношений используется по меньшей мере получение Декартова произведения таблиц данных или ограничений.
В нижеприведенном примере 1 иллюстрируется влияние структуры данных на формулирование запроса.
Пример 1:
Перечень всех венских фирм, рассортированных по названиям фирм, их отделов и контактным лицам
Структура 1 данных:
Отношения: Фирмы <-> Отделы <-> Контактные лица
Структура 2 данных:
Отношения: Фирмы <-> Сфера деятельности <-> Отделы <-> Контактные лица
Как видно, в зависимости от структуры данных существуют соответствующие отношения, которые для каждого оператора (Statement) базы данных должны указываться заново, благодаря чему возникает зависимость от структуры данных.
Целью изобретения является создание способа, с помощью которого устраняется зависимость команды базы данных от структуры данных и достигается упрощение пользования.
Другая цель заключается в укорочении формы представления записей, благодаря чему существенно улучшается наглядность запросов.
Еще одна цель изобретения состоит в представлении вышеупомянутого способа, с помощью которого можно одновременно обращаться к различным структурам, имеющимся в наличии, а именно, операторами (Statements), написанными для некоторой структуры.
Согласно изобретению это достигается тем, что
- созданная команда базы данных содержит лишь функции обработки, таблицы данных и их столбцы, к которым должны быть применены функции обработки, и последовательность, а также иерархический уровень, с которого должно осуществляться выполнение, причем последовательность и иерархические уровни используемых таблиц данных представляются в виде упорядоченного дерева, а корень упорядоченного дерева содержит все названия таблиц данных только главного запроса, в то время как вспомогательные запросы, подчиненные корню, заносятся в древовидную структуру в качестве узлов, содержащих названия таблиц данных, присвоенные вспомогательным запросам,
- в таблице отношений последние самим по себе известным способом указываются в виде связей между двумя соответствующими таблицами данных с помощью по меньшей мере одного поля ключа,
- определяется путь доступа, для чего сначала с помощью таблицы отношений между каждыми двумя последовательно расположенными выбранными таблицами данных на основе отношений, существующих между двумя последовательно расположенными таблицами данных, вычисляется частичный путь доступа, а затем из всех рассчитанных частичных путей доступа составляется путь доступа,
- операции, ориентированные на отношения, на основе пути доступа, определенного с помощью таблицы отношений, вводятся в указанную команду базы данных, в результате чего появляется SQL-оператор (Statement), который может обрабатываться любой системой в виде базы данных, использующей стандартный язык SQL.
В результате исключения операций, связанных с отношениями, с одной стороны, команда базы данных укорачивается и становится наглядной для пользователя, а, с другой, представляется в форме, независимой от структуры данных, положенной в основу, что обеспечивает преимущества в скорости при формулировании и выполнении команд. При помощи таблицы отношений, известной для любой структуры данных, вычисляется путь доступа, определяющий последовательность доступа к банку данных и который может использоваться как для генерирования SQL-оператора, так и для его непосредственного выполнения.
В таблице отношений содержатся все отношения, соответствующие структуре данных, назначенные запрашиваемой базе данных, и, кроме того, могут содержаться произвольно генерируемые отношения.
Возможная форма осуществления способа согласно изобретению может состоять в том, что для определения частичных путей доступа таблица отношений считывается в граф, основывающийся на теории графов, а частичные пути доступа вычисляются с помощью полученного графа. Таким образом, определение пути доступа согласно изобретению может осуществляться простым использованием самого по себе известного метода.
Другой вариант осуществления изобретения может заключаться в том, что в команду базы данных включаются операции, ориентированные на отношения на основе пути доступа. При этом включенные операции, ориентированные на отношения, могут обладать такими свойствами, что в результате команда базы данных согласно изобретению с помощью программы будет преобразовываться в достоверный SQL-оператор, благодаря чему пользователю, особенно при неясных запросах, не придется самому формулировать и представлять всю команду базы данных на языке SQL.
Согласно одному из альтернативных вариантов осуществления способа согласно изобретению определенный путь доступа, который поэтапно содержит ссылки на таблицы данных, в команде базы данных может указываться отдельно, а для доступа в базу данных необходимо поэтапно следовать этим ссылкам на таблицы данных. При этом выполняемая команда базы данных и определенный путь доступа для запроса используются непосредственно.
Если наличествуют различные структуры данных, то согласно одному из вариантов выполнения изобретения преобразование команды базы данных, достоверной для одной структуры данных, в достоверную для другой структуры данных происходит за счет того, что
- из команды базы данных для первой базы данных с первой назначенной структурой данных удаляются соответствующие первые операции, ориентированные на отношения,
- в команду базы данных, освобожденную от первых отношений, вставляются вторые операции, ориентированные на отношения, причем эти вторые операции соответствуют второй структуре данных, назначенной второй базе данных,
- осуществление запроса производится на основе команды базы данных, включающей вторые операции, ориентированные на отношения, в ходе которого с использованием соответствующей таблицы вторых отношений определяются частичные пути доступа, составляемые в один путь доступа.
В частности, у крупных пользователей таким образом может быть проведено экономически эффективное объединение уже существующих операторов (Statements) запроса к некоторой структуре данных с операторами (Statements) для другой структуры данных.
Все вышеупомянутые варианты осуществления способа согласно изобретению в равной степени пригодны для программно-технической реализации системы в виде реляционной базы данных, содержащей вычислительную систему с реляционной базой данных, устройство обработки данных и запоминающее устройство, причем устройство для обработки данных работает в соответствии со способом согласно изобретению.
При этом такая компьютерная программа может выступать в любом виде, а в частности, и в качестве компьютерного программного продукта на носителе, доступном компьютеру, например, на дискете, CD или DVD, причем он содержит средство кодирования компьютерной программы, при котором компьютерная программа после загрузки побуждает компьютер к осуществлению способа создания носителя данных согласно изобретению или электронного несущего сигнала. Однако она может выступать и как компьютерный программный продукт, содержащий компьютерную программу в виде электронного несущего сигнала, при котором компьютерная программа после загрузки, соответственно, побуждает компьютер к осуществлению способа согласно изобретению.
Таким образом, задача согласно изобретению решается также с помощью носителя данных или равным образом с помощью электронного несущего сигнала для считывания в систему реляционной базы данных, в которой команда базы данных, записанная на носителе данных, сформулирована без операций, связанных с отношениями, для чего указаны только функции обработки, таблицы данных и их столбцы, к которым должны быть применены функции обработки, и последовательность, а также иерархический уровень, с которого должно осуществляться выполнение, причем последовательность и иерархические уровни используемых таблиц данных представляются в виде упорядоченного дерева, а корень упорядоченного дерева содержит все названия таблиц данных только главного запроса, в то время как вспомогательные запросы относительно корня, заносятся в древовидную структуру в качестве узлов, содержащих названия таблиц данных, присвоенные вспомогательным запросам, что в таблице отношений последние самим по себе известным способом указываются в виде связей между двумя соответствующими таблицами данных с помощью по меньшей мере одного поля ключа, и что на носителе данных имеется путь доступа, для определения которого сначала с помощью таблицы отношений между каждыми двумя последовательно расположенными выбранными таблицами данных на основе отношений, существующих между двумя последовательно расположенными таблицами данных, вычисляется частичный путь доступа, а затем из всех вычисленных частичных путей доступа составляется путь доступа, причем операции, ориентированные на отношения, на основе пути доступа, определенного с помощью таблицы отношений, вводятся в указанную команду базы данных, в результате чего появляется SQL-оператор, который может обрабатываться любой системой базы данных, использующей стандартный язык SQL.
Другая форма выполнения носителя данных согласно изобретению, содержащего команды базы данных, может заключаться в том, что в команды базы данных введен путь доступа, определенный в соответствии со способом согласно изобретению и используемый для управления системой базы данных с помощью команды базы данных для доступа к реляционной базе данных.
В порядке альтернативы носитель данных для считывания в систему реляционной базы данных согласно изобретению должен обладать такими свойствами, чтобы путь доступа, используемый для управления системой базы данных посредством команды базы данных для доступа к реляционной базе данных, указывался на носителе данных отдельно, а путь для доступа поэтапно содержал ссылки на таблицы данных, в то время как для доступа к базе данных необходимо поэтапно следовать этим ссылкам на таблицы данных.
Кроме того, изобретение относится к компьютерной программе, содержащей команды, сформированные для осуществления способа согласно изобретению.
Изобретение относится также к компьютерному программному продукту, содержащему носитель со средствами компьютерного программного кода, доступный компьютеру, который каждый раз после его загрузки побуждает компьютер к осуществлению способа согласно изобретению.
Изобретение относится, наконец, и к компьютерному программному продукту, содержащему компьютерную программу в электронном несущем сигнале, которая каждый раз после ее загрузки побуждает компьютер к осуществлению способа согласно изобретению.
Ниже изобретение более подробно поясняется на примерах осуществления, представленных на чертежах.
Фиг.1 изображает схематически упорядоченное дерево для осуществления способа согласно изобретению в применении к примеру запроса (пример 1);
фиг.2 - схематически упорядоченное дерево для определения пути доступа с помощью способа согласно изобретению в другом примере запроса (пример 2);
фиг.3 - графическое представление в качестве примера таблицы отношений для первой структуры данных;
фиг.4 - графическое представление в качестве примера таблицы отношений для второй структуры данных и
фиг.5 - расширенная таблица отношений для другого примера применения способа согласно изобретению.
Основными задачами системы базы данных являются хранение данных и управление ими, а также предоставление данных по запросам в базу данных. При этом изобретение относится к системам баз данных, которые с использованием языка базы данных обеспечивают доступ к данным, хранящимся в базе данных. В приведенных примерах выполнения используется широко распространенный язык SQL базы данных, однако изобретение не ограничивается использованием последнего.
В любой реляционной базе существует соответствующая структура данных в виде множества таблиц данных, связанных друг с другом отношениями. Под таблицами понимаются данные, размещенные в столбцах и строках, как это показано в качестве примера в таблицах 1-10.
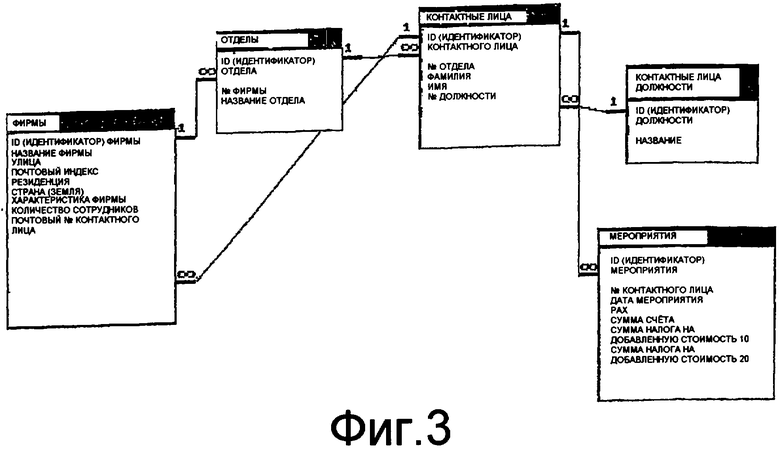
В рамках описания под понятием «строчное отношение» подразумеваются соответствующие строки таблицы, т.е. в таблице 1, например, «фирмы» («ID (идентификатор) фирмы»; «название», «улица», «почтовый индекс», «резиденция», «количество сотрудников»), а в таблице 2 «отделы («ID (идентификатор) отдела», «№ фирмы», «название отдела»). В отличие от этого в качестве «отношений» с помощью по меньшей мере одного соответствующего поля ключа указываются связи между двумя соответствующими таблицами, т.е., например, 1:n; фирмы (ID (идентификатор) фирмы <-> отделы (№ фирмы). Столбец «ID (идентификатор) фирмы» в таблице «фирмы» (таблица 1) является первичным ключом, для которого в таблице «отделы» (таблица 2) в столбце «№ фирмы» могут стоять несколько значений.
Для каждой структуры данных имеется таблица отношений, в которой содержатся все отношения, соответствующие структуре данных, назначенной (присвоенной) запрашиваемой базе данных, а также отношения, произвольно генерируемые в случае необходимости.
В вышеупомянутой структуре данных таблиц данных 1-10 (таблицы 1-10) можно сформулировать, например, следующую задачу, из которой видно, какие комплексы постановок вопроса могут быть разрешены. В нижеприведенном примере делается ссылка на эту структуру данных.
Пример 2
Все фирмы и их общий оборот за этот год свидетельствуют, но только для тех, с кем по найму было осуществлено по меньшей мере десять контактов, а в маркетинговых отделах было проведено по счетам бухгалтерского учета по найму минимум три мероприятия с оборотом по блюдам и напиткам свыше 50 Евро.
Согласно способу согласно изобретению, в основном, выполняются следующие шаги.
1) Указание одной выполняемой команды базы данных, без операций, связанных с отношениями.
2) Определение пути доступа.
Это происходит, в частности, следующим образом:
На 1) Указать функции обработки и таблицы данных, а также их столбцы, к которым должны быть применены функции обработки, последовательность, а также иерархический уровень, с которого должно осуществляться выполнение.
SELECT …………Функция обработки.
Фирмы ……………таблица данных, к которым должна быть применена функция обработки.
Все столбцы (.*) … столбцы, к которым должна быть применена функция обработки.
Указать столбцы таблицы «Фирмы».
Для каждой выбранной фирмы определить сумму всех сумм позиции из соответствующего столбца таблицы «позиции счетов» с оговоркой относительно года мероприятия (аренда).
Поэтому формирование команды базы данных согласно изобретению дает:
SELECT Фирмы.*
(SELECT SUM (Позиции счетов. Сумма позиции)
WHERE (Мероприятия. VA дата= Дата. Год (date. year))
WHERE (SELECT COUNT (Контакты.*)
WHERE (Контакты. Дата контакта= Дата. Год (date. year))
)> = 10
AND (SELECT COUNT (Мероприятия.*)
WHERE (Отделы. Название отдела=“Marketing“)
AND (SELECT SUM (Позиции счетов. Сумма позиции)
WHERE (Наименования позиций дополнительных счетов.
Наименование позиции.
IN («Блюда», «Напитки»))
)> 50
AND (Мероприятия. VA-дата= Дата. Год (date. year))
)>=3
[При этом «Date.year» (Дата. Год) означает промежуток времени между (BETWEEN) 01.01. и (AND) 31.12.текущего года].
В этом запросе содержатся только таблицы без отношений, к которым должны быть применены функции обработки. Таким образом, имеет место независимость любой структуры данных и одновременно происходит укорочение представления и тем самым повышение наглядности. Так, например, отпадают обычно принятые Декартовы произведения, ограничиваемые отношениями, поскольку в команде содержится вся информация, которая в комбинации с таблицей отношений может быть использована для определения пути доступа к любой структуре данных, так что, с одной стороны, имеет место независимость от конкретной структуры данных, а с другой, укорачивается ввод запроса для пользователя, сводясь лишь к существенному, что, в свою очередь, повышает наглядность.
На 2) Исходя из постановки вопроса в запросе (Statement), обусловленном подлежащими выполнению вспомогательными запросами (SUBSELECT), создаются естественная последовательность используемых таблиц, а также иерархические уровни, по которым с помощью таблицы отношений (Таблица 11) определяются частичные пути доступа для генерирования обобщенной команды (Statement) на языке SQL для соответствующей структуры данных.
Вышеупомянутая последовательность и иерархические уровни используемых таблиц данных представляются, предпочтительно, в виде упорядоченного дерева 7 (фиг.1), содержащего корень 10 и узлы 11, 12, 13 и 14, причем узел 14 является подузлом узла 13.
Корень 10 упорядоченного дерева 7 содержит в качестве информационного поля 21 все названия таблиц данных только главного запроса, например, в виде списка или массива (Array), а именно, практически в последовательности, указанной в операторе (Statement), при желании без двойного названия таблицы. Для корней 10 информационное поле 21 содержит таблицу данных «Фирмы» (FIRMEN) (Таблица 1). Корню 10 подчинены вспомогательные запросы (SUBSELECT) и их подчиненные вспомогательные запросы (SUBSELECT im SUBSELECT), введенные в древовидную структуру в качестве узлов 11, 12, 13, 14. Информационные поля 22, 23, 24, 25 корней 11, 12, 13, 14 содержат названия таблиц данных, подчиненные вспомогательным запросам и указываемые в соответствующем вспомогательном запросе (SUBSELECT), а также, например, в виде списка или массива (Array). Для узла 13 - это таблицы данных «Мероприятия» (Таблица 5), «Отделы» (Таблица 2) и «Мероприятия» (Таблица 5) в информационном поле 24. Вспомогательный запрос (SUBSELECT) согласно постановке вопроса содержит следующий вспомогательный запрос (SUBSELECT) со стороны узла 14, который, в свою очередь, содержит в своем информационном поле таблицы данных «Позиции счетов» (Таблица 9) и «Наименования позиций дополнительных счетов» (Таблица 10).
Это дерево 7 прогоняют, используя прямой обход: узел 10, узел 11, узел 12, узел 13 и узел 14.
В качестве иерархических уровней можно представить нижеприведенные.
Уровень 1
 Фирмы
Фирмы
Корень 10, главный запрос
Уровень 1.1
Позиции счетов, мероприятия
Узел 11, вспомогательный запрос в разделе SELECT главного запроса
Уровень 1.2
Контакты, контакты
Узел 12, вспомогательный запрос в разделе WHERE главного запроса
Уровень 1.3
Мероприятия, отделы, мероприятия
Узел 13, вспомогательный запрос, раздел AND главного запроса
Уровень 1.3.1
Позиции счетов, Наименования позиций дополнительных счетов
Узел 14, вспомогательный запрос во вспомогательном запросе AND
Затем следует определение пути доступа, конкретно задающего последовательность доступа к базе данных, для чего с помощью таблицы отношений между каждыми двумя последовательными выбранными таблицами данных на основе отношений, существующих между последовательными таблицами данных, вычисляется частичный путь доступа, а из всех вычисленных частичных путей доступа составляется путь доступа.
При этом следует учесть, что из-за отсутствия каких-либо описаний произведений в операторе (Statement) (раздел FROM) указанная последовательность таблиц данных с функциями обработки может приводить к двойному или многократному проходам частичных путей доступа, в результате чего при получении Декартовых произведений одинаковые таблицы данных ошибочно использовались бы многократно, что могло бы привести к ложному результату запроса.
После этого на основе пути доступа, определенного с помощью вышеприведенной таблицы отношений (Табл. 11), в команду базы данных, сформированную согласно изобретению (Пример 2), могут быть введены операции, ориентированные на отношения, в результате чего получается следующий оператор (Statement) на языке SQL (введенные операции обозначены курсивом), который может быть обработан любой системой базы данных, использующей стандартный язык SQL. Ниже поясняется возможная форма расчета.
SELECT Фирмы.*,
(SELECT SUM (Позиции счетов. Сумма позиции)
FROM Отделы, контактные лица, мероприятия, счета, позиции счетов
WHERE (Фирмы.ID (идентификатор) фирмы=Отделы.№ фирмы)
AND (Отделы.ID (идентификатор) отдела=контактные лица.№ отдела)
AND (Контактные лица.ID (идентификатор) контактного лица=Мероприятия,№ контактного лица)
AND (Мероприятия. ID (идентификатор) мероприятия=Счета.№ мероприятия)
AND (Счета. ID (идентификатор) счета=Позиции счета.№ счета)
AND (Мероприятия.VА дата = Дата. Год (date. year))
)
FROM Фирмы
WHERE (SELECT Count(Контакты.*)
FROM Отделы, контактные лица, контакты
WHERE (Фирмы.ID (идентификатор) фирмы=Отделы.№ фирмы)
AND (Отделы.ID (идентификатор) отдела=Контактные лица.
№ отдела)
AND (Контактные лица.ID (идентификатор)
контактного лица=Контакты.№ контакта)
AND (Контакты. Дата контакта = Дата. Год (Date. Year)
)> = 10
AND (SELECT Count(Мероприятия.*)
FROM Отделы, контактные лица, мероприятия
WHERE (Фирмы, ID (идентификатор) фирмы=Отделы.№ фирмы)
AND (Отделы. ID (идентификатор) отдела=контактные лица. № отдела)
AND (Контактные лица. ID (идентификатор) контактного лица=Мероприятия.№ контактного лица)
AND (Отделы. Название отдела=«Маркетинг»)
AND (SELECT sum(Позиции счетов. Сумма позиции)
FROM Счета, позиции счетов, Наименования позиций дополнительных счетов
WHERE (Мероприятия. ID (идентификатор) мероприятия = Счета.№ мероприятия)
AND (Счета. ID (идентификатор) счета = позиции счетов. № счета
AND (Позиции счетов. № позиции = Наименования позиций дополнительных счетов. ID (идентификатор) позиции)
AND (Наименования позиций дополнительных счетов. Наименование позиции
IN («Блюда», «Напитки»
)> 50)
AND (Мероприятия.VА дата = Дата. Год (date. year)
)> = 3
По длине оператора (обобщенной команды) (Statement), полученного таким путем, из сравнения с шагом 1) ясно видно, какие преимущества могут быть достигнуты в отношении краткости и наглядности, а особенно независимости от структуры данных.
Если оператор (Statement) формулируется как запрос, то приняты могут быть способ записи согласно изобретению и генерируемый способ записи, а новые вычисления опускаются. Последнее производится лишь при изменениях структуры данных или самого оператора (Statement). В результате очень небольшой промежуток времени для преобразования исчезает в SQL-оператор. Другие действия по оптимизации находятся в области специальных знаний.
Другая возможность может заключаться в том, чтобы в команде базы данных определенный путь доступа, который поэтапно содержит ссылки на таблицы данных, указывался отдельно, а для доступа к базе данных может быть необходимо поэтапно следовать этим ссылкам на таблицы данных. Таким образом, получается, например,
WAY Фирмы
-> Отделы WHERE (Фирмы.ID (идентификатор)фирмы=Отделы.
№ фирмы)
-> Контактные лица WHERE (Отделы.ID (идентификатор)отдела = Контактные лица. № отдела)
-> Мероприятия
WHERE (Контактные лица. ID (идентификатор)контактного лица = Мероприятия. № контактного лица)
-> Счета WHERE (Мероприятия.ID (идентификатор)мероприятия = Счета. № мероприятия)
-> Позиции счетов
-> WHERE (Счета. ID (идентификатор)счета = Позиции счетов. № счета)
-> Наименования позиций дополнительных счетов
-> WHERE (Позиции счетов. № позиции = Наименования позиций дополнительных счетов. ID позиции)
Контактные лица → контакты
WHERE (Контактные лица. ID (идентификатор)контактного лица = Контакты. № контактного лица)
SELECT Фирмы.*
(SELECT SUM (Позиции счетов. Сумма позиции)
WHERE (Мероприятия. VА дата = Дата. Год (date. year))
WHERE (SELECT COUNT(Контакты.*)
WHERE (Контакты. Дата контакта = Дата. Год
(date. year)
)> = 10
AND (SELECT COUNT (Мероприятия.*)
WHERE (Отделы. Название отдела = «Маркетинг»)
AND (SELECT SUM (Позиции счетов. Сумма счета)
WHERE (Наименования позиций дополнительных счетов. Наименование позиции
IN («Блюда»,«Напитки»))
)> 50
AND (Мероприятия. VА дата = Дата. Год (date. year)
)> = 3
В результате отпадает включение в оператор объединения, путь доступа поэтапно ссылается на таблицы данных. Для доступа к базе данных необходимо поэтапно следовать этим ссылкам.
Возможный алгоритм для определения пути доступа с помощью упорядоченного дерева, как он показан на фиг.1, для облегчения понимания и сосредоточения внимания на названиях таблиц и т.п. представлен ниже с упрощенной структурой данных. При этом следует подчеркнуть, что этот представленный алгоритм является лишь одним из многих, какие могут быть использованы для вычисления.
В общем случае частичные пути, указанные при определении общего пути доступа дважды, исключаются.
Например, таблицами данных являются A, B, C, D, E, F, G, H.
Информационное поле корня упорядоченного дерева содержит, например, таблицы: F, C, F, B. Таким образом, в качестве частичных путей выступают
Частичный путь AC: A B C
Частичный путь CF: C D E F
Частичный путь FB: F E D C B
Поэтому неотработанным общим путем является путь: A B C D E F E D C B.
Как видно, путь E D C B указан дважды и поэтому должен быть исключен.
Таким образом, правильным общим путем является: A B C D E F.
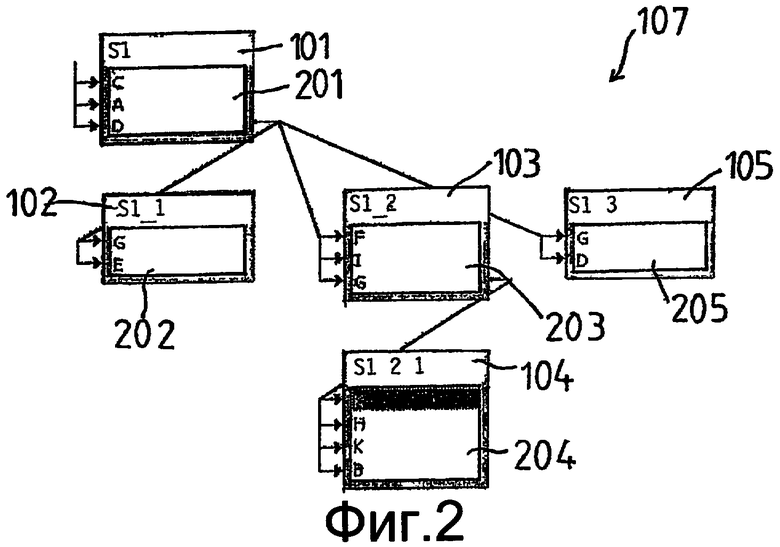
Если исходить из наличия конкретного дерева, каким оно представлено на фиг. 2, то показана одна из многих возможностей вычисления пути доступа в соответствии со способом согласно изобретению и перевода в SQL-оператор с помощью следующих шагов.
Имеются таблицы данных A, B, C, D, E, … с некоторой структурой данных.
Из запроса, лежащего в основе изображения на фиг.2, который для большей наглядности не показан, получается следующая структура дерева.
Корень (узел) 101 с информационным полем 201, содержащим таблицы C, A, D.
Корень 102 с информационным полем 202, содержащим таблицы G, E.
Корень 103 с информационным полем 203, содержащим таблицы F, I, G.
Корень 104 с информационным полем 204, содержащим таблицы K, H, K, B.
Корень 105 с информационным полем 205, содержащим таблицы G, D.
При этом таблица отношений, соответствующая выбранной структуре, для упрощения изображения связывает соответствующие таблицы данных, последовательно расположенные в алфавитном порядке, с помощью соответствующего общего поля отношений в упрощенном виде, т.е., A<->B, B<->C, C<->D,… Принимаются, как это следует из таблицы 12 (таблицы отношений), следующие поля отношений.
Таблица А Столбцы a, z1
Таблица B Столбцы b, a1
Таблица C Столбцы c, b1
Таблица D Столбцы d, c1
…
Упорядоченное дерево, сформированное под некоторый запрос, прогоняется в, так называемой, последовательности с прямым обходом, для чего, начиная с первого узла корня 101 упорядоченного дерева 107, в соответствии с иерархическими уровнями прогоняются все остальные узлы 102, 103, 104, 105.
Как упоминалось, на фиг.2 изображено дерево запроса без подробностей. Корень 101 (самый верхний корень) содержит в информационном поле 201 список или массив или что-либо подобное всех названий таблиц данных, содержащихся на иерархическом уровне 1 запроса верхнего уровня, причем в неуказанном запросе, как описано выше, названы только таблицы данных, к которым применяются функции обработки. При этом последовательностью указанных таблиц данных является последовательность C, A, D.
На следующем иерархическом уровне 1.1 каждому вспомогательному запросу запроса верхнего уровня придается соответствующий узел 102, 103, 105, содержащий в качестве информационного поля 202, 203, 205 названия таблиц данных, используемые в этом вспомогательном запросе, в виде списка, массива и т.п. Последовательностью для узла 102 является, например, последовательность G, E, для узла 103, например, последовательность E, I, G и т.д.
Иерархический уровень 1.2.1 представляет собой вспомогательный запрос к вспомогательному запросу 1.2 (Узел 103), который, в свою очередь, содержит в качестве информационного поля 204 используемые для этой цели названия таблиц K, H, K, B данных.
Внутри узла, таким образом начиная с узла 101, следует прогнать (пройти) соответствующий список таблиц данных, например, в информационном поле 201 таблицы C, A, D данных, и для каждых двух таблиц данных, последовательно расположенных в списке, вычисляются частичные пути доступа, причем, как уже было описано выше, многократные прогоны во избежание получения излишних произведений, приводящих к получению ложного произведения, исключаются.
При этом следует учесть: узел, расположенный непосредственно под другим узлом, называется (прямым) преемником этого узла. И, наоборот, этот другой узел называется прямым предшественником.
Если список информационного поля какого-либо узла пройден полностью, в последовательности с прямым ходом отыскивается следующий узел. Между первой таблицей данных списка информационного поля этого следующего узла и последней таблицей данных списка информационного поля его прямого предшественника определяется частичный путь доступа, после чего список этого следующего узла проходится вплоть до последней таблицы данных, как это было описано выше, например,
Узел 104:
Проход (обход) списка таблиц данных в информационном поле 204:
K, H, K, B.
Следующим узлом последовательности с прямым обходом является узел 105, прямым предшественником которого, однако, является узел 101, поэтому отыскивается связь между таблицами G (Узел 105) и D (Узел 101) данных, и вычисляется частичный путь доступа. После этого осуществляется проход таблиц G, D данных в информационном поле 205 в узле 105 дерева 107.
После или во время прохода (обхода) каждого узла, как уже упоминалось, сдвоенные частичные пути доступа удаляются, причем все дублированные или многократные названия таблиц данных и реляционные данные о соответствующем узле или одном из его предшественников вплоть до корня, включительно, отвергаются.
Для вычисления каждого отдельного частичного пути доступа поступают, например, следующим образом.
Сначала считывается таблица отношений (Таблица 12), например, в один граф, причем ребра графа содержат также соответствующие условия отношений для определения через отношения с помощью теории графов связей между двумя соответствующими таблицами данных.
Поэтому для этапа 1 при первом шаге С -> А в качестве пути между С и А как результат вычисления, например, кратчайшего пути, получается следующий список:
Таким образом, осуществлен проход списка информационного поля 201 первого узла 101, после чего происходит исправление равнозначных строк, результат преобразуется в последовательность, и SQL-оператор вставляется в нужное место (после SELECT и перед WHERE).
Для этапа 1 получается следующая последовательность:
FROM A, B, C, D
WHERE (A.a = B.a1)AND (B.b = C.b1)AND (C.c = D.c1)
Таким образом доходят до конца списка текущего узла, в данном случае до корня. В качестве следующего шага устанавливается, есть ли предшествующие узлы. В случае корня этого не делается по определению.
Информационное поле 201 узла 101
С -> А
А -> D
Отсюда: FROM A,B,C,D
WHERE(A.a = B.a1)AND(B.b = C.b1)AND(C.c = D.c1)
Первый текущий узел таблицы данных и последние предшествующие узлы таблицы данных
D -> G
Обход списка
G -> E
Отсюда: FROM E,F,G
WHERE(D.d = E.d1)AND(E.e = F.e1)AND(F.f = G.f1)
Первый текущий узел таблицы данных и последние предшествующие узлы таблицы данных
D -> F
Обход списка
F -> I
I -> G
Отсюда:FROM E,F,G,H,I
WHERE(D.d=E.d1)AND(E.e=F.e1)AND(F.f=G.f1)AND(G.g=H.g1)
Первый текущий узел таблицы данных и последние предшествующие узлы таблицы данных
G -> K
Обход списка
K -> H
H -> K
K -> B
Отсюда: FROM J,K
WHERE (I.i = J.i1)AND(J.j = K.j1)
Первый текущий узел таблицы данных и последние предшествующие узлы таблицы данных
D -> G
Обход списка
G -> E
Отсюда: FROM E,F,G
WHERE(D.d = E.d1)AND(E.e = F.e1)AND(F.f = G.f1)
Одно из применений способа согласно изобретению может заключаться в том, что для одной существующей структуры данных могут быть различные операторы, которые к другой структуре данных не применимы, поскольку между таблицами данных имеют место другие отношения. На практике эта проблема часто возникает, например, при слиянии фирм или при перекодировке данных в связи с изменением изготовителя программ, или при изменениях структуры данных, проводимых из-за потерь в скорости.
Поскольку изобретение дает возможность сформировать команду базы данных безотносительно к структуре данных, можно поступить следующим образом.
В команде базы данных для первой базы данных с первой назначенной структурой данных первые соответствующие операции, ориентированные на отношения, удаляются.
В команду базы данных, освобожденную от первых операций, ориентированных на отношения, вставляются вторые операции, ориентированные на отношения, соответствующие второй структуре данных, назначенной второй базе данных.
После этого на основе команды базы данных, снабженной вторыми операциями, ориентированными на отношения, может осуществляться запрос, для чего с использованием соответствующей таблицы вторых отношений определяются частичные пути доступа и сводятся в один путь доступа.
SELECT A.*
FROM A
WHERE ( (SELECT Count(C.*)
FROM B,C
WHERE (A.a = B.a1)
AND (B.b = C.b1)
AND (C.Feld1 = 100)
) > 20)
AND (A.Feld1 = 40)
Удаляется: FROM A
Удаляется: FROM B, C
И поэтому удаляются все отношения A - B и B - C и A - C, найденные в таблице отношений
т.е., A.a = B.b1 B.b = C.b1
Остается как обобщенная команда (Statement) согласно изобретению:
SELECT A.*
WHERE((SELECT Count(C.*)
WHERE (C.Feld1 = 100)
) > 20)
AND (A.Feld1 = 40)
К этой обобщенной команде можно применить способ согласно изобретению с новой таблицей отношений.
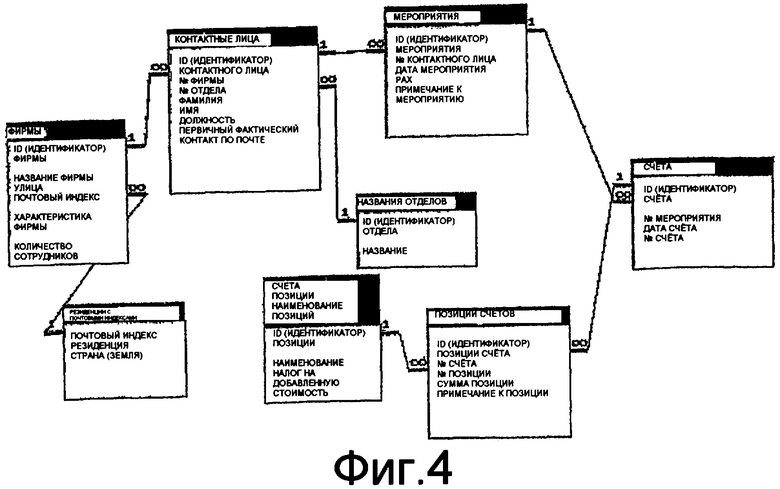
Для иллюстрации влияния структуры данных на команду базы данных на фиг.3 и 4 еще раз в виде схемы графически изображены две различные таблицы отношений для структур 3 и 4 данных, для которых должен быть выполнен тот же самый запрос.
На фиг.5 приведена таблица отношений для структуры 4 данных согласно фиг.4 в расширенной форме. В дополнение к обычным отношениям между таблицами данных в правом столбце приведены произвольно присваиваемые имена или макрокоды, которые устанавливаются или выполняются по вызову вместо таблиц данных, приведенных в левом столбце. В связи с принципом изобретения благодаря этому достигается еще большая независимость от структуры данных, поскольку названия (имена) и поля таблиц могут вычисляться или переименовываться.
Расширенная таблица отношений для структуры 4 данных на фиг.5:
Здесь представлены имена тех же таблиц и полей, а также информация, относящаяся к делению таблиц, например, «фирмы», «резиденция».
Пример 3:
Все фирмы по меньшей мере с 3 контактными лицами в отделе маркетинга.
Согласно изобретению для использования в качестве примера сначала указываются в соответствии с запросом необходимые таблицы данных и функции обработки.
SELECT Фирмы.*
WHERE (
(SELECT Count(Контактные лица.*)
WHERE (Отделы. Название =«Маркетинг»))
> = 3)
Для структур данных 3 и 4 при осуществлении способа согласно изобретению, соответственно, получаются разные SQL-операторы.
Со структурой 3 данных:
SELECT Фирмы.*
FROM Фирмы
WHERE (
(SELECT Count(*)
FROM Отделы, контактные лица
WHERE (Фирмы, ID (индикатор) фирмы=Отделы.№ фирмы)
AND (Отделы. ID (индикатор) отдела=Контактные лица.
№ отдела)
AND (Отделы. Название =«Маркетинг»)
)
> = 3)
Со структурой 4 данных:
SELECT Фирмы.*
FROM Фирмы
WHERE (
(SELECT Count(*)
FROM Контактные лица, названия отделов
WHERE (Фирмы, ID (идентификатор)фирмы=Контактные лица.
№ фирмы)
AND (Контактные лица. № отдела=Названия отделов.ID (идентификатор)отдела)
AND (Названия отделов. Обозначение=«Маркетинг»)
)
> = 3)
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ УПРАВЛЕНИЯ РЕЛЯЦИОННОЙ СИСТЕМОЙ БАЗЫ ДАННЫХ | 2006 |
|
RU2419862C2 |
| АРХИТЕКТУРА ОТОБРАЖЕНИЯ С ПОДДЕРЖАНИЕМ ИНКРЕМЕНТНОГО ПРЕДСТАВЛЕНИЯ | 2007 |
|
RU2441273C2 |
| РАСШИРЯЕМЫЙ ЯЗЫК ЗАПРОСОВ С ПОДДЕРЖКОЙ ДЛЯ РАСШИРЕНИЯ ТИПОВ ДАННЫХ | 2007 |
|
RU2434276C2 |
| Способ для разграничения доступа к данным в базе данных | 2018 |
|
RU2682010C1 |
| Способ обработки поисковых запросов для нескольких реляционных баз данных произвольной структуры | 2019 |
|
RU2730241C1 |
| СПОСОБЫ И СИСТЕМЫ ЗАГРУЗКИ ДАННЫХ В ХРАНИЛИЩА ВРЕМЕННЫХ ДАННЫХ | 2012 |
|
RU2599538C2 |
| СИСТЕМЫ И СПОСОБЫ СОПРЯЖЕНИЯ ПРИКЛАДНЫХ ПРОГРАММ С ПЛАТФОРМОЙ ХРАНЕНИЯ НА ОСНОВЕ СТАТЕЙ | 2003 |
|
RU2412461C2 |
| СПОСОБ ФОРМИРОВАНИЯ РЕЛЯЦИОННОГО ОПИСАНИЯ СИНТАКСИСА КОМАНДЫ | 2013 |
|
RU2546058C1 |
| ОБЪЕДИНЕНИЕ МНОГОМЕРНЫХ ВЫРАЖЕНИЙ И РАСШИРЕНИЙ ГЛУБИННОГО АНАЛИЗА ДАННЫХ ДЛЯ ИЗВЛЕЧЕНИЯ ИНФОРМАЦИИ ИЗ КУБОВ OLAP | 2005 |
|
RU2398273C2 |
| СИСТЕМЫ И СПОСОБЫ МОДЕЛИРОВАНИЯ ДАННЫХ В ОСНОВАННОЙ НА ПРЕДМЕТАХ ПЛАТФОРМЕ ХРАНЕНИЯ | 2003 |
|
RU2371757C2 |

Изобретение относится к способу управления системой реляционной базы данных путем запроса в реляционную базу данных, содержащему в качестве соответствующей структуры данных множество таблиц данных, связанных между собой отношениями, с использованием языка базы данных. Техническим результатом является повышение быстродействия при работе с базой данных. В способе генерируется подлежащая выполнению команда базы данных, не содержащая операций, связанных с отношениями, указанными в таблице отношений, для чего указываются те таблицы данных, к которым должны быть применены функции обработки, и последовательность выбранных таблиц данных, согласно которой должно осуществляться выполнение. Кроме того, определяется путь доступа, конкретно задающий последовательность доступа к базе данных, для этого сначала с помощью таблицы отношений между каждыми двумя последовательно расположенными выбранными таблицами данных на основе отношений, существующих между последовательно расположенными таблицами данных, вычисляется частичный путь доступа, а затем из всех вычисленных частичных путей доступа составляется путь доступа. 4 н. и 12 з.п. ф-лы, 5 ил., 12 табл.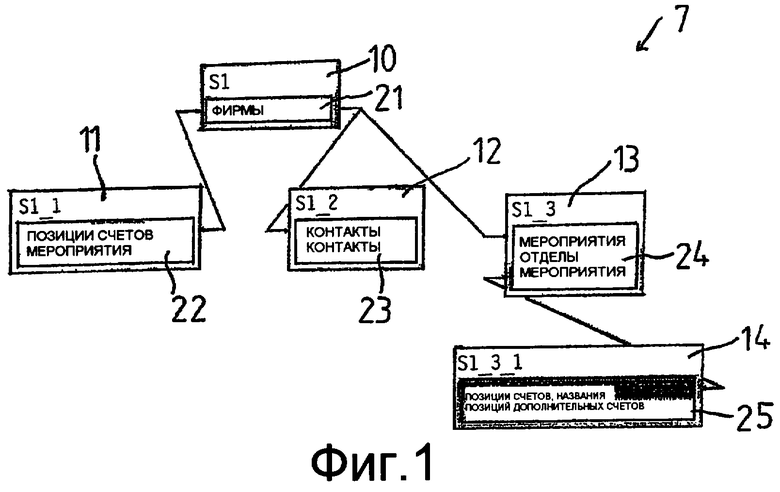
1. Способ управления системой реляционной базы данных путем запроса в реляционную базу данных, содержащий в качестве соответствующей структуры данных множество таблиц данных, связанных между собой отношениями, с использованием языка базы данных, причем имеется таблица отношений и причем генерируется подлежащая выполнению команда базы данных и конкретно определяется путь доступа, задающий последовательность доступа в базу данных, отличающийся тем, что
сформированная команда базы данных не содержит операций, связанных с отношениями, а содержит лишь функции обработки, ссылки на таблицы данных и их столбцы, к которым должны быть применены функции обработки, и последовательность используемых таблиц данных, а также иерархический уровень, с которого должно осуществляться выполнение, причем последовательность и иерархические уровни используемых таблиц данных представляются в виде упорядоченного дерева, а корень упорядоченного дерева содержит все названия таблиц данных только главного запроса, в то время как вспомогательные запросы, подчиненные корню, заносятся в древовидную структуру в качестве узлов, содержащих названия таблиц данных, назначенные вспомогательным запросам,
в таблице отношений последние любым известным способом указываются в виде связей между двумя соответствующими таблицами данных с помощью по меньшей мере одного поля ключа,
определяется путь доступа, для чего сначала с помощью таблицы отношений между каждыми двумя последовательно расположенными выбранными таблицами данных на основе отношений, существующих между двумя последовательно расположенными таблицами данных, вычисляется частичный путь доступа, а затем из всех вычисленных частичных путей доступа составляется путь доступа,
операции, ориентированные на отношения, на основе пути доступа, определенного с помощью таблицы отношений, вводятся в указанную команду базы данных, в результате чего получают SQL-команду, которая может обрабатываться любой системой базы данных, использующей стандартный язык SQL.
2. Способ по п.1, отличающийся тем, что в таблице отношений содержатся все отношения, соответствующие структуре данных, назначенной запрашиваемой базе данных, а также при необходимости произвольно генерируемые отношения.
3. Способ по п.1 или 2, отличающийся тем, что для определения частичных путей доступа таблица отношений считывается в граф, основывающийся на теории графов, а частичные пути доступа вычисляются с помощью полученного графа.
4. Способ по п.1 или 2, отличающийся тем, что в команду базы данных включаются операции, ориентированные на отношения на основе пути доступа.
5. Способ по п.3, отличающийся тем, что в команду базы данных включаются операции, ориентированные на отношения на основе пути доступа.
6. Способ по п.1 или 2, отличающийся тем, что определенный путь доступа, который поэтапно содержит ссылки на таблицы данных, в команде базы данных может указываться отдельно, а для доступа в базу данных необходимо поэтапно следовать этим ссылкам на таблицы данных.
7. Способ по п.3, отличающийся тем, что определенный путь доступа, который поэтапно содержит ссылки на таблицы данных, в команде базы данных может указываться отдельно, а для доступа в базу данных необходимо поэтапно следовать этим ссылкам на таблицы данных.
8. Способ по любому одному из пп.1, 2, 5, 7, отличающийся тем, что
из команды базы данных для первой базы данных с первой назначенной структурой данных удаляются соответствующие первые операции, ориентированные на отношения,
в команду базы данных, освобожденную от первых отношений, вставляются вторые операции, ориентированные на отношения, причем эти вторые операции соответствуют второй структуре данных, назначенной второму базе данных,
осуществление запроса производится на основе команды базы данных, включающей вторые операции, ориентированные на отношения, в ходе которого с использованием соответствующей таблицы вторых отношений определяются частичные пути доступа, составляемые в один путь доступа.
9. Способ по п.3, отличающийся тем, что
из команды базы данных для первой базы данных с первой назначенной структурой данных удаляются соответствующие первые операции, ориентированные на отношения,
в команду базы данных, освобожденную от первых отношений, вставляются вторые операции, ориентированные на отношения, причем эти вторые операции соответствуют второй структуре данных, назначенной второму базе данных,
осуществление запроса производится на основе команды базы данных, включающей вторые операции, ориентированные на отношения, в ходе которого с использованием соответствующей таблицы вторых отношений определяются частичные пути доступа, составляемые в один путь доступа.
10. Способ по п.4, отличающийся тем, что
из команды базы данных для первой базы данных с первой назначенной структурой данных удаляются соответствующие первые операции, ориентированные на отношения,
в команду базы данных, освобожденную от первых отношений, вставляются вторые операции, ориентированные на отношения, причем эти вторые операции соответствуют второй структуре данных, назначенной второму базе данных,
осуществление запроса производится на основе команды базы данных, включающей вторые операции, ориентированные на отношения, в ходе которого с использованием соответствующей таблицы вторых отношений определяются частичные пути доступа, составляемые в один путь доступа.
11. Способ по п.6, отличающийся тем, что
из команды базы данных для первой базы данных с первой назначенной структурой данных удаляются соответствующие первые операции, ориентированные на отношения,
в команду базы данных, освобожденную от первых отношений, вставляются вторые операции, ориентированные на отношения, причем эти вторые операции соответствуют второй структуре данных, назначенной второму базе данных,
осуществление запроса производится на основе команды базы данных, включающей вторые операции, ориентированные на отношения, в ходе которого с использованием соответствующей таблицы вторых отношений определяются частичные пути доступа, составляемые в один путь доступа.
12. Система реляционной базы данных, содержащая вычислительную систему с реляционной базой данных, устройство обработки данных и запоминающее устройство, причем устройство для обработки данных работает в соответствии со способом согласно одному из пп.1-11.
13. Носитель данных с командой базы данных, представленной на языке базы данных, для управления и для считывания в систему реляционной базы данных по п.12, отличающийся тем, что команда базы данных, записанная на носителе данных, сформулирована без операций, связанных с отношениями, для чего указаны только функции обработки, таблицы данных и их столбцы, к которым должны быть применены функции обработки, и последовательность используемых таблиц данных, а также иерархический уровень, с которого должно осуществляться выполнение, причем последовательность и иерархические уровни используемых таблиц данных представляются в виде упорядоченного дерева, а корень упорядоченного дерева содержит все названия таблиц данных только главного запроса, в то время как вспомогательные запросы относительно корня заносятся в древовидную структуру в качестве узлов, содержащих названия таблиц данных, присвоенные вспомогательным запросам, что в таблице отношений последние известным способом указываются в виде связей между двумя соответствующими таблицами данных с помощью по меньшей мере одного поля ключа, и что на носителе данных имеется путь доступа, для определения которого сначала с помощью таблицы отношений между каждыми двумя последовательно расположенными выбранными таблицами данных на основе отношений, существующих между двумя последовательно расположенными таблицами данных, вычисляется частичный путь доступа, а затем из всех вычисленных частичных путей доступа составляется путь доступа, причем операции, ориентированные на отношения, на основе пути доступа, определенного с помощью таблицы отношений, вводятся в указанную команду базы данных, в результате чего появляется SQL-команда, которая может обрабатываться любой системой базы данных, использующей стандартный язык SQL.
14. Носитель данных по п.13 и для считывания в систему реляционной базы данных по п.12, отличающийся тем, что носитель данных содержит команды базы данных, в которые введен путь доступа, определенный в соответствии со способом согласно пп.1-11 и используемый для управления системой в виде базы данных с помощью команды базы данных для доступа к реляционной базе данных.
15. Носитель данных по п.13 для считывания в систему реляционной базы данных по п.12, отличающийся тем, что путь доступа, используемый для управления системой базы данных с помощью команды базы данных для доступа к реляционной базе данных, указывается на носителе данных отдельно, а путь для доступа поэтапно содержит ссылки на таблицы данных, в то время как для доступа к базе данных необходимо поэтапно следовать этим ссылкам на таблицы данных.
16. Носитель данных, содержащий сохраненные на нем инструкции, которые при выполнении компьютером побуждают компьютер к осуществлению способа по пп.1-11.
| US 2005076045 A1 (PAL STANSLET AT AL), 07.04.2005 | |||
| US 6732091 B1 (MORTEN MIDDELFART), 04.05.2004 | |||
| US 6834287 B1 (FOLK-WILLIAMS BEN ET AL), 21.12.2004 | |||
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| СИСТЕМА И УСТРОЙСТВО ПЕРСОНАЛИЗАЦИИ ИНТЕЛЛЕКТУАЛЬНЫХ КАРТОЧЕК | 1997 |
|
RU2260849C2 |
| ОБЪЕКТНО-ОРИЕНТИРОВАННАЯ СИСТЕМА УПРАВЛЕНИЯ РЕЛЯЦИОННЫМИ БАЗАМИ ДАННЫХ | 2003 |
|
RU2253894C1 |

