Область техники, к которой относится изобретение
Настоящая технология относится к алгоритмам машинного обучения и, в частности, к способам и системам для оценки обучающих объектов, включая признаки и обучающие образцы, посредством алгоритма машинного обучения.
Уровень техники
Совершенствование компьютерных аппаратных средств и технологий в сочетании с увеличением количества подключенных электронных устройств вызвало резкий рост заинтересованности в разработке решений для автоматизации решения задач, предсказания итогов, классификации информации и обучения на опыте, что привело к возникновению машинного обучения. Машинное обучение, тесно связанное с глубинным анализом данных, вычислительной статистикой и оптимизацией, имеет дело с изучением и созданием алгоритмов, способных обучаться и выполнять прогнозирование на основе данных.
В течение последнего десятилетия область машинного обучения значительно расширилась, что обеспечило заметные успехи в создании самоуправляемых автомобилей, в распознавании речи и образов, в персонализации и в понимании генома человека. Кроме того, машинное обучение позволяет усовершенствовать различные операции извлечения информации, такие как поиск документов, совместная фильтрация, смысловой анализ и т.д.
Алгоритмы машинного обучения (MLA) можно разделить на широкие категории, такие как обучение с учителем, обучение без учителя и обучение с подкреплением. В случае обучения с учителем алгоритм машинного обучения анализирует обучающие данные, состоящие из входной информации и выходной информации, размеченной экспертами, при этом цель обучения заключается в определении алгоритмом машинного обучения общего правила для выявления соответствия между входной информацией и выходной информацией. В случае обучения без учителя алгоритм машинного обучения анализирует неразмеченные данные, при этом цель заключается в поиске алгоритмом машинного обучения структуры или скрытых закономерностей в данных. В случае обучения с подкреплением алгоритм развивается в меняющихся условиях без использования размеченных данных или исправления ошибок.
Одна из проблем, связанных с алгоритмами машинного обучения при построении гибких и надежных прогнозирующих моделей, описывающих реальные данные, заключается в выборе надлежащих признаков для использования в прогнозирующей модели и надлежащих наборов обучающих данных для обучения прогнозирующей модели. Построение прогнозирующей модели может оказаться трудоемкой и дорогостоящей в вычислительном отношении задачей, поэтому часто требуется находить компромисс между использованием вычислительных ресурсов и точностью прогнозирующей модели.
В отношении построенной прогнозирующей модели возникает риск «сверхподгонки», когда модель может хорошо работать на наборе обучающих данных, но не обеспечивать точных прогнозов на новых данных.
В патентной заявке США №2014/0172753 (Resource allocation for machine learning, Nowozin et al.) описано распределение ресурсов для машинного обучения с целью выбора из большого количества возможных вариантов, например, чтобы в процессе эффективного обучения случайного дерева решений выбрать семейство, наилучшим образом описывающее данные, из множества семейств моделей или чтобы выбрать признак, обеспечивающий наилучшую классификацию элементов, из множества признаков. В различных примерах образцы информации о неопределенных вариантах используются для оценки этих вариантов. В различных примерах доверительные интервалы рассчитываются для оценок и используются для выбора одного или несколько вариантов. В примерах эти оценки могут ограничиваться статистическими показателями различий, которые мало изменяются при игнорировании любого образца при расчете оценки. В одном примере обучение методом случайного дерева решений выполняется более эффективно при сохранении точности для приложений, которые не ограничиваются определением положения человеческого тела по изображениям, содержащим информацию о глубине.
В патентной заявке США №2015/0095272 (Estimation of predictive accuracy gains from added features, Bilenko et al.) описана оценка повышения точности прогноза в результате добавления возможного признака в набор признаков, причем имеющийся предиктор обучается на наборе признаков. Выходные данные имеющегося предиктора для элементов набора данных могут быть получены из запоминающего устройства. Кроме того, оценка повышения точности прогноза в результате добавления возможного признака в набор признаков может измеряться в зависимости от выходных данных имеющегося предиктора для элементов набора данных. Оценка повышения точности прогноза может измеряться без обучения обновленного предиктора на наборе признаков, дополненном возможным признаком.
В патентной заявке США №2016/0042292 A1 (Automated methodology for inductive bias selection and adaptive ensemble choice to optimize predictive power, Caplan et al.) описан реализованный посредством компьютера способ автоматизированного выбора индуктивного смещения, включая получение посредством компьютера множества примеров, каждый из которых содержит множество пар признак-значение. Компьютер формирует набор данных индуктивных смещений, связывающий каждый соответствующий пример из множества примеров с числовыми показателями качества обучения. Числовые показатели качества обучения для каждого соответствующего примера формируются путем создания множества моделей, каждая из которых соответствует определенному набору индуктивных смещений. Качество обучения для каждой соответствующей модели оценивается в ходе применения к соответствующему примеру. Набор данных индуктивных смещений используется компьютером для выбора множества индуктивных смещений для применения к одному или нескольким новым наборам данных.
Раскрытие изобретения
Разработанные варианты осуществления настоящей технологии основываются на понимании разработчиками, по меньшей мере, одной технической проблемы, связанной с известными решениями.
Разработанные варианты осуществления настоящей технологии основываются понимании разработчиками того, что, несмотря на наличие известных решений в уровне техники для оценки новых признаков и/или новых обучающих данных, «сверхподгонка» (переобучение) и шум иногда приводят к ненадежным результатам.
Кроме того, оценка прогнозирующей способности или качества прогнозирующей модели, обученной на новом признаке или новом обучающем образце в одной точке «сверхподгонки», не обязательно указывает на общую прогнозирующую способность прогнозирующей модели в отношении нового признака или обучающего образца в силу различных факторов, таких как ошибки прогнозирования, шум, ошибки разметки и т.д.
Поэтому разработчики изобрели способы и системы для оценки обучающих объектов посредством алгоритма машинного обучения.
Настоящая технология позволяет оценить влияние нового признака или новых обучающих образцов с большей чувствительностью и/или с использованием меньших вычислительных ресурсов, и благодаря этому повышает эффективность алгоритма машинного обучения при экономии вычислительных ресурсов.
В соответствии с первым общим аспектом настоящей технологии разработан реализованный посредством компьютера способ обучения для алгоритма машинного обучения (MLA), выполняемый сервером и включающий в себя следующие действия:
получают посредством алгоритма MLA первый набор обучающих образцов, содержащий множество признаков;
итеративно обучают посредством алгоритма MLA первую прогнозирующую модель на основе, по меньшей мере, части из множества признаков, при этом обучение на каждой первой обучающей итерации включает в себя формирование соответствующего первого показателя ошибки прогнозирования, по меньшей мере, частично указывающего на связанную с первой прогнозирующей моделью ошибку прогнозирования на соответствующей первой обучающей итерации;
анализируют посредством алгоритма MLA соответствующий первый показатель ошибки прогнозирования на каждой первой обучающей итерации для определения точки «сверхподгонки», соответствующей данной первой обучающей итерации, после которой тенденция для первого показателя ошибки прогнозирования изменяется с общего уменьшения на общее увеличение;
определяют посредством алгоритма MLA, по меньшей мере, одну начальную точку оценивания, расположенную за несколько итераций до точки «сверхподгонки»;
получают посредством алгоритма MLA данные нового набора обучающих объектов;
итеративно переобучают посредством алгоритма MLA первую прогнозирующую модель, находящуюся в соответствующем обученном состоянии, связанном с указанной, по меньшей мере, одной начальной точкой оценивания, с использованием, по меньшей мере, одного обучающего объекта из нового набора обучающих объектов для получения множества переобученных первых прогнозирующих моделей;
формируют соответствующий показатель ошибки прогнозирования для каждой модели из множества переобученных первых прогнозирующих моделей после переобучения на, по меньшей мере, одной итерации переобучения, соответствующей, по меньшей мере, одной первой обучающей итерации, причем соответствующий показатель ошибки прогнозирования после переобучения, по меньшей мере, частично указывает на ошибку прогнозирования, связанную с переобученной первой прогнозирующей моделью;
выбирают посредством алгоритма MLA один из первых наборов обучающих образцов и, по меньшей мере, один обучающий объект из нового набора обучающих объектов на основе множества показателей ошибки прогнозирования после переобучения, связанных с множеством переобученных первых прогнозирующих моделей, и на основе множества соответствующих первых показателей ошибки прогнозирования.
В некоторых вариантах осуществления новый набор обучающих объектов представляет собой новый набор признаков или новый набор обучающих образцов.
В некоторых вариантах осуществления обучение и переобучение первой прогнозирующей модели осуществляется с применением метода градиентного бустинга.
В некоторых вариантах осуществления выбор посредством алгоритма MLA, по меньшей мере, одного обучающего объекта из нового набора обучающих объектов включает в себя сравнение множества показателей ошибки прогнозирования для переобученной первой прогнозирующей модели с множеством соответствующих первых показателей ошибки прогнозирования посредством проверки статистической гипотезы.
В некоторых вариантах осуществления первый показатель ошибки прогнозирования и соответствующий показатель ошибки прогнозирования переобученной первой прогнозирующей модели представляет собой среднеквадратическую ошибку (MSE) или среднюю абсолютную ошибку (МАЕ).
В некоторых вариантах осуществления проверка статистической гипотезы выполняется с использованием критерия знаковых рангов Уилкоксона.
В некоторых вариантах осуществления указанная, по меньшей мере, одна начальная точка оценивания представляет собой множество начальных точек оценивания.
В некоторых вариантах осуществления каждая из множества начальных точек оценивания связана с соответствующим множеством переобученных первых прогнозирующих моделей.
В соответствии со вторым общим аспектом настоящей технологии разработана система обучения для алгоритма машинного обучения (MLA), содержащая: процессор и машиночитаемый физический носитель информации, содержащий команды, при выполнении которых процессор осуществляет следующие действия:
получение посредством алгоритма MLA первого набора обучающих образцов, содержащего множество признаков;
итеративное обучение посредством алгоритма MLA первой прогнозирующей модели на основе, по меньшей мере, части из множества признаков, при этом обучение на каждой первой обучающей итерации включает в себя формирование соответствующего первого показателя ошибки прогнозирования, по меньшей мере, частично указывающего на связанную с первой прогнозирующей моделью ошибку прогнозирования на соответствующей первой обучающей итерации;
анализ посредством алгоритма MLA соответствующего первого показателя ошибки прогнозирования на каждой первой обучающей итерации для определения точки «сверхподгонки», соответствующей данной первой обучающей итерации, после которой тенденция для первого показателя ошибки прогнозирования изменяется с общего уменьшения на общее увеличение;
определение посредством алгоритма MLA, по меньшей мере, одной начальной точки оценивания, расположенной за несколько итераций до точки «сверхподгонки»;
получение посредством алгоритма MLA данных нового набора обучающих объектов;
итеративное переобучение посредством алгоритма MLA первой прогнозирующей модели, находящейся в соответствующем обученном состоянии, связанном с, по меньшей мере, одной начальной точкой оценивания, с использованием, по меньшей мере, одного обучающего объекта из нового набора обучающих объектов, для получения множества переобученных первых прогнозирующих моделей;
формирование соответствующего показателя ошибки прогнозирования для каждой модели из множества переобученных первых прогнозирующих моделей после переобучения на, по меньшей мере, одной итерации переобучения, соответствующей, по меньшей мере, одной первой обучающей итерации, причем соответствующий показатель ошибки прогнозирования после переобучения, по меньшей мере, частично указывает на ошибку прогнозирования, связанную с переобученной первой прогнозирующей моделью;
выбор посредством алгоритма MLA одного из первых наборов обучающих образцов и, по меньшей мере, одного обучающего объекта из нового набора обучающих объектов на основе множества показателей ошибки прогнозирования после переобучения, связанных с множеством переобученных первых прогнозирующих моделей, и на основе множества соответствующих первых показателей ошибки прогнозирования.
В некоторых вариантах осуществления новый набор обучающих объектов представляет собой новый набор признаков или новый набор обучающих образцов.
В некоторых вариантах осуществления обучение и переобучение первой прогнозирующей модели осуществляется с применением метода градиентного бустинга.
В некоторых вариантах осуществления выбор посредством алгоритма MLA, по меньшей мере, одного обучающего объекта из нового набора обучающих объектов включает в себя сравнение множества показателей ошибки прогнозирования для переобученной первой прогнозирующей модели с множеством соответствующих первых показателей ошибки прогнозирования посредством проверки статистической гипотезы.
В некоторых вариантах осуществления первый показатель ошибки прогнозирования и соответствующий показатель ошибки прогнозирования переобученной первой прогнозирующей модели представляют собой среднеквадратическую ошибку (MSE) или среднюю абсолютную ошибку (МАЕ).
В некоторых вариантах осуществления проверка статистической гипотезы представляет собой проверку с использованием критерия знаковых рангов Уилкоксона.
В некоторых вариантах осуществления, по меньшей мере, одна начальная точка оценивания представляет собой множество начальных точек оценивания.
В некоторых вариантах осуществления каждая из множества начальных точек оценивания связана с соответствующим множеством переобученных первых прогнозирующих моделей.
В контексте настоящего описания модель или прогнозирующая модель может соответствовать сформированной алгоритмом машинного обучения математической модели, способной выполнять прогнозы на основе свойств набора обучающих данных.
В контексте настоящего описания обучающий объект может соответствовать признаку или обучающему образцу, используемому алгоритмом машинного обучения. Признак, также известный как переменная или атрибут, может соответствовать отдельному доступному для измерения свойству результата наблюдений. Признаки могут быть представлены посредством векторов признаков, при этом вектор признаков содержит множество признаков, описывающих результат наблюдений. Обучающий образец может соответствовать размеченным данным, которые используются, чтобы выявить потенциально прогнозируемые взаимосвязи. В общем случае, обучающий образец может быть представлен как вектор признаков, содержащий множество признаков и метку.
В контексте настоящего описания, если явно не указано иное, под электронным устройством, пользовательским устройством, сервером и компьютерной системой понимаются любые аппаратные и/или программные средства, подходящие для решения поставленной задачи. Таким образом, некоторые не имеющие ограничительного характера примеры аппаратных и/или программных средств включают в себя компьютеры (серверы, настольные компьютеры, ноутбуки, нетбуки и т.п.), смартфоны, планшеты, сетевое оборудование (маршрутизаторы, коммутаторы, шлюзы и т.п.) и/или их сочетания.
В контексте настоящего описания, если явно не указано иное, выражения «машиночитаемый носитель» и «запоминающее устройство» означают носители любого типа и вида, не имеющие ограничительного характера примеры которых включают в себя оперативное запоминающее устройство (ОЗУ), постоянное запоминающее устройство (ПЗУ), диски (CD-ROM, DVD, гибкие диски, жесткие диски и т.д.), USB-накопители, карты флэш-памяти, твердотельные накопители и накопители на магнитных лентах.
В контексте настоящего описания, если явно не указано иное, числительные «первый», «второй», «третий» и т.д. используются только для указания различия между существительными, к которым они относятся, но не для описания каких-либо определенных взаимосвязей между этими существительными. Например, должно быть понятно, что использование терминов «первый сервер» и «третий сервер» не подразумевает какого-либо определенного порядка, типа, хронологии, иерархии или ранжирования, в данном случае, серверов, и что их использование (само по себе) не подразумевает обязательного наличия «второго сервера» в любой ситуации. Кроме того, как встречается в настоящем описании в другом контексте, ссылка на «первый» элемент и «второй» элемент не исключает того, что эти два элемента могут быть одним и тем же реальным элементом. Таким образом, например, в некоторых случаях «первый» сервер и «второй» сервер могут представлять собой одно и то же программное и/или аппаратное средство, а в других случаях - различные программные и/или аппаратные средства. Краткое описание чертежей
Дальнейшее описание приведено для лучшего понимания настоящей технологии, а также других аспектов и их признаков, и должно использоваться совместно с приложенными чертежами.
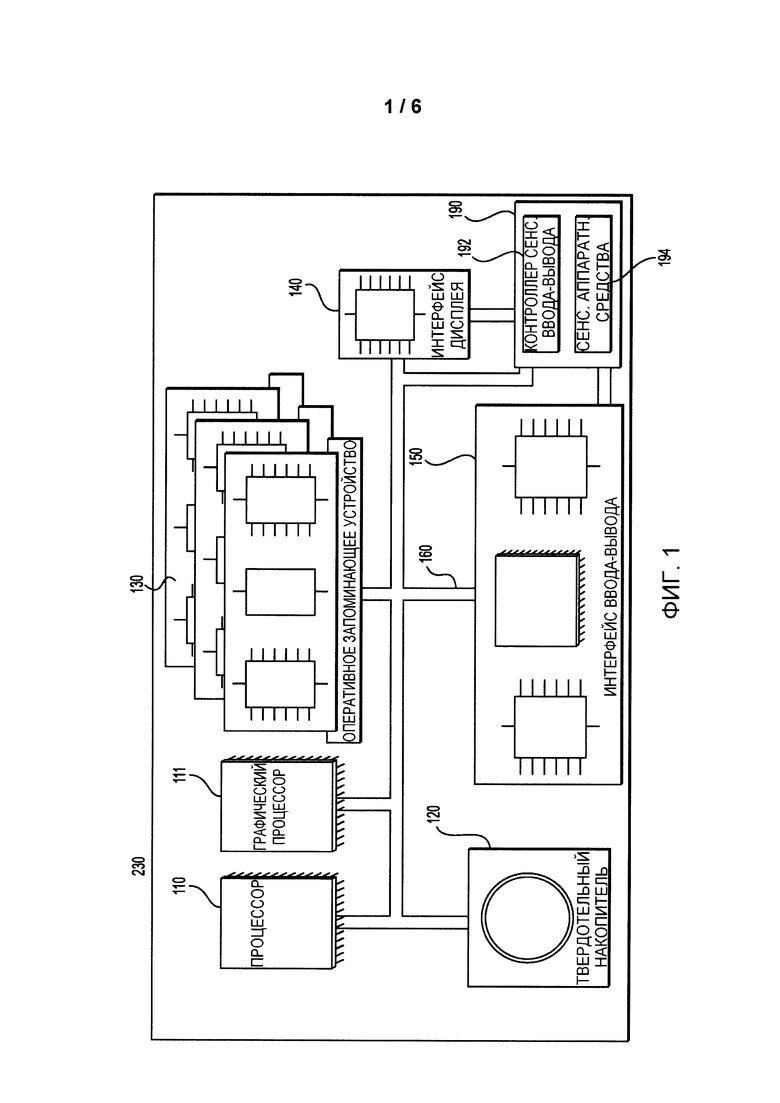
На фиг. 1 представлена схема не имеющего ограничительного характера варианта осуществления обучающего сервера согласно не имеющим ограничительного характера вариантам осуществления настоящей технологии.
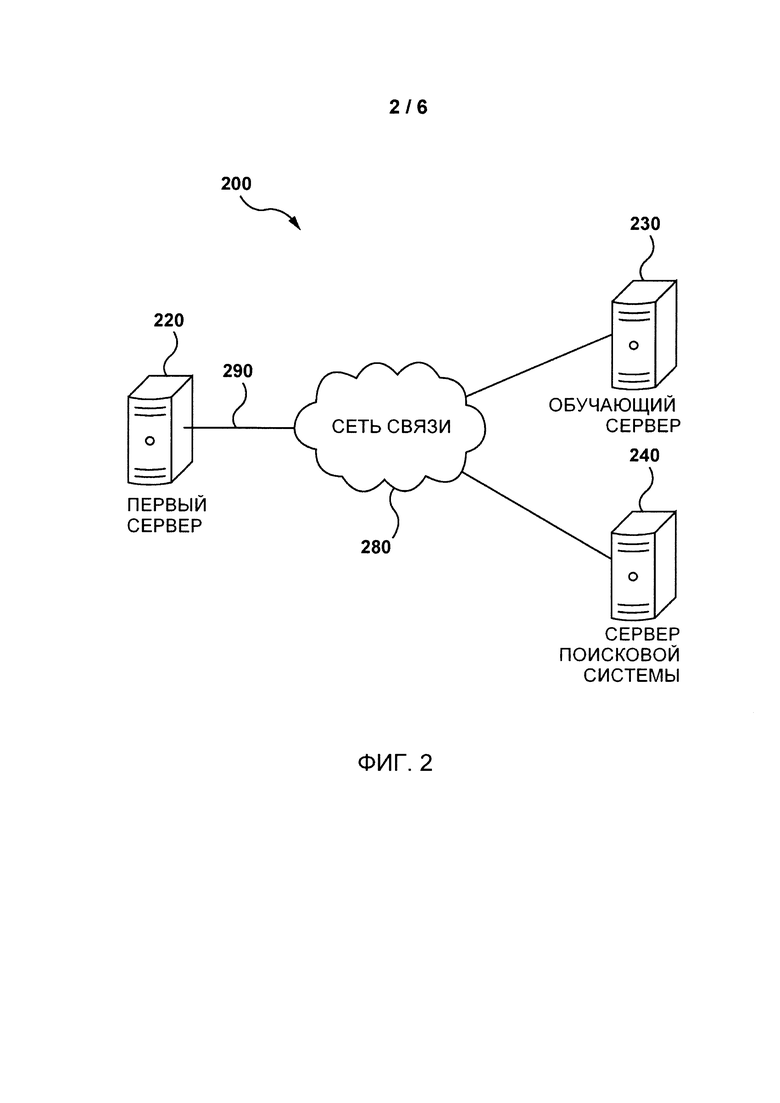
На фиг. 2 представлена схема не имеющего ограничительного характера варианта осуществления системы связи согласно настоящей технологии.
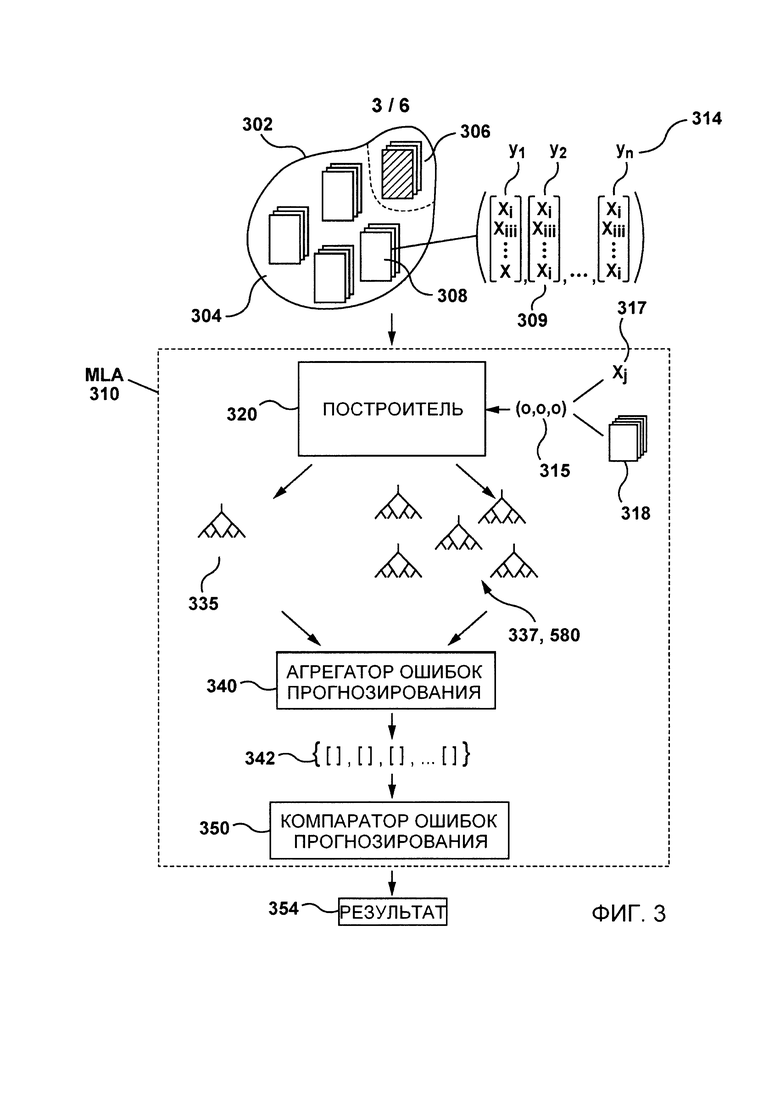
На фиг. 3 представлена система машинного обучения согласно не имеющим ограничительного характера вариантам осуществления настоящей технологии.
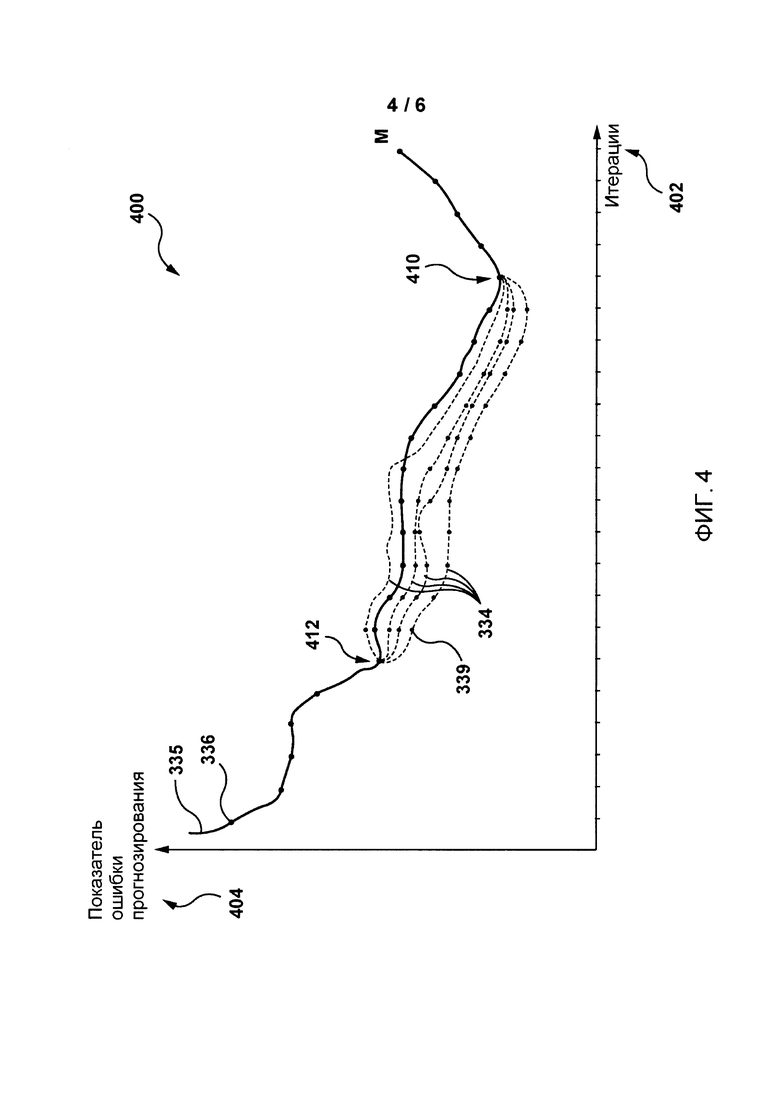
На фиг. 4 представлена первая процедура обучения согласно не имеющим ограничительного характера вариантам осуществления настоящей технологии.
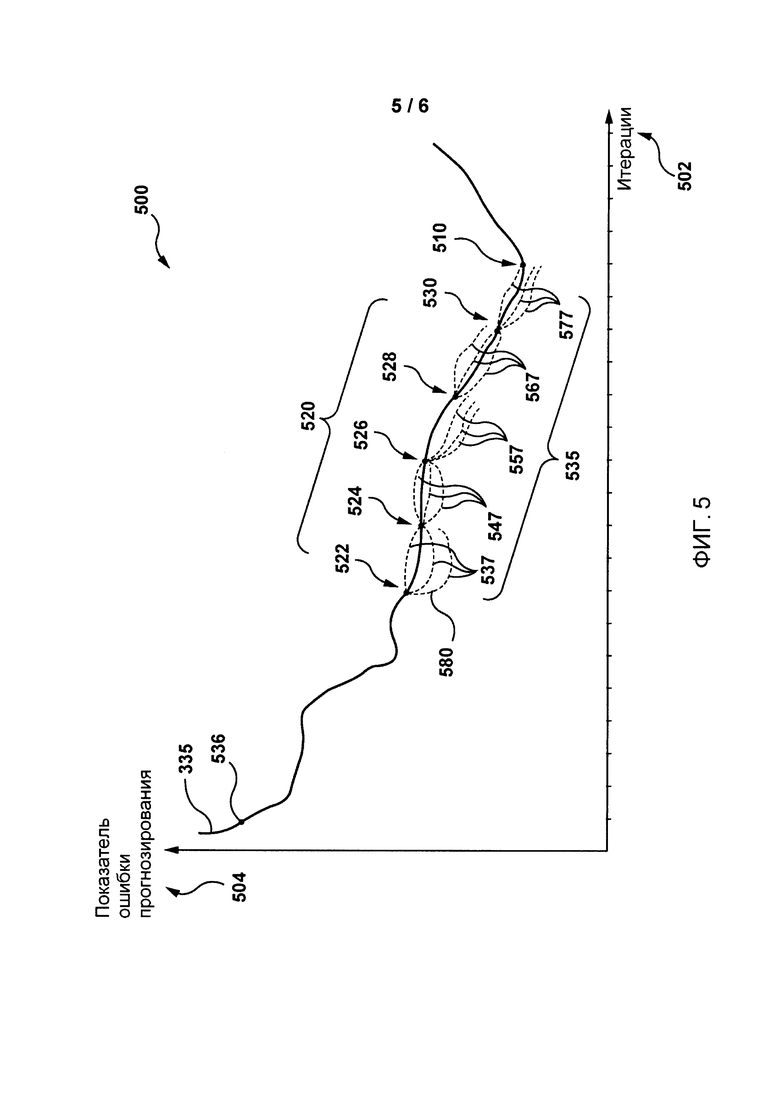
На фиг. 5 представлена вторая процедура обучения согласно не имеющим ограничительного характера вариантам осуществления настоящей технологии.
На фиг. 6 представлена блок-схема, иллюстрирующая не имеющий ограничительного характера вариант осуществления способа оценки нового обучающего объекта согласно не имеющим ограничительного характера вариантам осуществления настоящей технологии.
Осуществление изобретения
Дальнейшее подробное описание представляет собой лишь описание примеров, иллюстрирующих настоящую технологию. Это описание не предназначено для определения объема или задания границ настоящей технологии. В некоторых случаях приводятся полезные примеры модификаций, которые способствуют пониманию, но не определяют объем и не задают границы настоящей технологии. Эти модификации не составляют исчерпывающего списка, возможны и другие модификации. Кроме того, если в некоторых случаях примеры модификаций не описаны, это не означает, что модификации невозможны и/или описание содержит единственный вариант осуществления определенного аспекта настоящей технологии. Кроме того, следует понимать, что настоящее подробное описание в некоторых случаях касается упрощенных вариантов осуществления настоящей технологии, и что такие варианты представлены для того, чтобы способствовать лучшему ее пониманию. Различные варианты осуществления настоящей технологии могут быть значительно сложнее.
Учитывая вышеизложенные принципы, далее рассмотрены некоторые не имеющие ограничительного характера примеры, иллюстрирующие различные варианты осуществления аспектов настоящей технологии.
На фиг. 1 показан обучающий сервер 230, пригодный для использования в некоторых вариантах осуществления настоящей технологии и содержащий различные аппаратные компоненты, включая один или несколько одно- или многоядерных процессоров, которые коллективно представлены процессором 110, графический процессор (GPU) 111, твердотельный накопитель 120, ОЗУ 130, интерфейс 140 дисплея и интерфейс 150 ввода-вывода.
Связь между различными частями обучающего сервера 230 может осуществляться через одну или несколько внутренних и/или внешних шин 160 (таких как шина PCI, шина USB, шина Fire Wire стандарта IEEE 1394, шина SCSI, шина Serial-ATA и т.д.), с которыми различные аппаратные части соединены электронными средствами.
Интерфейс 150 ввода-вывода может соединяться с сенсорным экраном 190 и/или с одной или несколькими внутренними и/или внешними шинами 160. Сенсорный экран 190 может быть частью дисплея. В некоторых вариантах осуществления сенсорный экран 190 представляет собой дисплей. Сенсорный экран 190 может также называться экраном 190. В варианте осуществления, представленном на фиг. 1, сенсорный экран 190 содержит сенсорные аппаратные средства 194 (например, чувствительные к нажатию ячейки в слое дисплея, позволяющие обнаруживать физическое взаимодействие между пользователем и дисплеем) и контроллер 192 ввода-вывода для сенсорных устройств, обеспечивающий связь с интерфейсом 140 дисплея и/или с одной или несколькими внутренними и/или внешними шинами 160. В некоторых вариантах осуществления интерфейс 150 ввода-вывода может соединяться с клавиатурой (не показана), манипулятором «мышь» (не показан) или сенсорной площадкой (не показана), которые обеспечивают взаимодействие пользователя с обучающим сервером 230 в дополнение к сенсорному экрану 190 или вместо него.
Согласно вариантам осуществления настоящей технологии, твердотельный накопитель 120 хранит программные команды, пригодные для загрузки в ОЗУ 130 и для выполнения процессором 110 и/или графическим процессором 111. Программные команды могут, например, представлять собой часть библиотеки или приложения.
Обучающий сервер 230 может представлять собой сервер, настольный компьютер, ноутбук, планшет, смартфон, электронный персональный помощник или любое устройство, пригодное для осуществления настоящей технологии, как должно быть понятно специалисту в данной области.
На фиг. 2 представлена система 200 связи, соответствующая варианту осуществления настоящей технологии. Система связи 200 содержит первый сервер 220, обучающий сервер 230, сервер 240 поисковой системы, сеть 280 связи и линию 290 связи.
В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии в качестве сети 280 связи может использоваться сеть Интернет. В других вариантах осуществления настоящей технологии сеть 280 связи может быть реализована иначе, например, в виде произвольной глобальной сети связи, локальной сети связи, личной сети связи и т.д.
На реализацию линии 290 связи не накладывается каких-либо особых ограничений, она зависит от реализации первого сервера 220, обучающего сервера 230 и сервера 240 поисковой системы.
Первый сервер 220, обучающий сервер 230 и сервер 240 поисковой системы соединяются с сетью 280 связи посредством соответствующих линий 290 связи. Первый сервер 220, обучающий сервер 230 и сервер 240 поисковой системы могут реализовываться как традиционные компьютерные серверы. В примере осуществления настоящей технологии первый сервер 220, обучающий сервер 230 и сервер 240 поисковой системы могут быть реализованы как сервер Dell™ PowerEdge™, работающий под управлением операционной системы Microsoft™ Windows Server™. Очевидно, что первый сервер 220, обучающий сервер 230 и сервер 240 поисковой системы могут быть реализованы с использованием любых других подходящих аппаратных средств и/или программного обеспечения, и/или встроенного программного обеспечения, либо их сочетания.
Первый сервер 220 может быть реализован как репозиторий обучающих данных для машинного обучения, в котором размеченные обучающие данные могут накапливаться с течением времени и сохраняться для обучения и переобучения с использованием алгоритмов машинного обучения. Например, первый сервер 220 может принимать или получать обучающие данные непосредственно из сервера 240 поисковой системы. В других вариантах осуществления первый сервер 220 может представлять собой общедоступный репозиторий обучающих данных, куда пользователи могут загружать размеченные обучающие данные. В не имеющем ограничительного характера примере первый сервер 220 может хранить обучающие образцы, которые могут быть предварительно размечены экспертами.
Обучающий сервер 230 может использоваться для обучения одного или нескольких алгоритмов машинного обучения, связанных с сервером 240 поисковой системы. Например, сформированная алгоритмом машинного обучения прогнозирующая модель может приниматься через заранее заданные интервалы времени из сервера 240 поисковой системы, а затем переобучаться и проверяться с использованием новых обучающих данных перед отправкой обратно на сервер 240 поисковой системы.
Сервер 240 поисковой системы может быть реализован как традиционный сервер поисковой системы, использующий алгоритм машинного обучения, например, предоставляемый GOOGLE™, MICROSOFT™, YAHOO™ или YANDEX™. Сервер 240 поисковой системы может выполнять алгоритм машинного обучения, чтобы ранжировать результаты поиска по запросам пользователей. Алгоритм машинного обучения может непрерывно обучаться и обновляться посредством обучающего сервера 230 с использованием обучающих данных с первого сервера 220.
Очевидно, что варианты реализации первого сервера 220, обучающего сервера 230 и сервера 240 поисковой системы приводятся только для иллюстрации. Специалисту в данной области ясны и другие конкретные детали реализации первого сервера 220, обучающего сервера 230, сервера 240 поисковой системы, лини 290 связи и сети 280 связи. Представленные выше примеры никоим образом не ограничивают объем настоящей технологии.
На фиг. 3 представлена система 300 машинного обучения для оценки обучающих объектов согласно не имеющим ограничительного характера вариантам осуществления настоящей технологии.
Система 300 машинного обучения содержит алгоритм MLA 310, включающий в себя построитель модели (далее - построитель) 320, агрегатор 340 ошибок прогнозирования и компаратор 350 ошибок прогнозирования.
Система 300 машинного обучения может быть реализована на обучающем сервере 230. В некоторых вариантах осуществления система 300 машинного обучения может быть распределена между несколькими серверами, такими как первый сервер 220 и сервер 240 поисковой системы.
Алгоритм MLA 310 может принимать первый набор 302 обучающих образцов в качестве входных данных для построителя 320.
Первый набор 302 обучающих образцов может быть получен из первого сервера 220 и/или из сервера 240 поисковой системы через сеть 280 связи. В других вариантах осуществления первый набор 302 обучающих образцов может быть получен из запоминающего устройства (не показано) обучающего сервера 230.
Первый набор 302 обучающих образцов может содержать множество обучающих образцов 308. В общем случае, часть 304 первого набора 302 обучающих образцов может использоваться для обучения прогнозирующей модели, а другая часть 306 первого набора 302 обучающих образцов может использоваться для проверки прогнозирующей модели посредством тестирования ее прогнозирующей способности. На способ выбора части 304 и другой части 306 первого набора 302 обучающих образцов не накладывается каких-либо ограничений. Часть 304 и другая часть 306 для обучения и проверки могут выбираться динамически. Кроме того, как объясняется ниже, на первом наборе 302 обучающих образцов может выполняться операция перекрестной проверки, позволяющая разделить первый набор 302 обучающих образцов на множество частей (не показаны) и использовать каждую часть для проверки и для тестирования.
Обучающий образец 308 может представлять собой любой электронный файл или документ, который может храниться на машиночитаемом носителе, включая твердотельный накопитель 120, но не ограничиваясь им. На реализацию обучающего образца 308 из первого набора 302 обучающих образцов не накладывается каких-либо ограничений. Обучающий образец 308 может включать в себя информацию или данные любого типа и может представлять собой текстовый файл, страницу HTML, документ в формате PDF, информацию о форматировании, метаданные, аудиозапись, изображение или видеозапись.
Первый набор 302 обучающих образцов может содержать множество связанных с ним признаков 309, причем каждый обучающий образец 308 может быть представлен вектором признаков 309 (формируется на основе множества признаков 309) и соответствующей меткой 314. Вектор признаков 309 может представлять собой список признаков, каждый из которых представляет собой доступное для измерения свойство обучающего образца 308. Метка 314 может соответствовать выходным данных обучающего образца 308, т.е. классу или тегу, который желательно знать.
В не имеющем ограничительного характера примере в контексте серверов поисковых систем (таких как сервер 240 поисковой системы), использующих алгоритмы машинного обучения, векторы признаков могут, в общем случае, быть не зависящими от запроса (т.е. содержать статические признаки), зависящими от запроса (т.е. содержать динамические признаки) и признаками уровня запроса. Примеры признаков включают в себя суммы TF, TF-IDF, ВМ25, IDF и длины зон документа, ранги PageRank и HITS документа или другие варианты.
В не имеющем ограничительного характера примере признаки из векторов признаков могут включать в себя популярность документа, «свежесть» документа, количество исходящих ссылок, количество входящих ссылок и длину документа. Каждый элемент вектора признаков может иметь вещественную величину, представляющую признак. Как должно быть понятно, размерность вектора признаков не ограничивается и может зависеть от реализации сервера 240 поисковой системы. В не имеющем ограничительного характера примере вектор признаков для каждого документа, связанного с запросом, может представлять собой 136-элементный вектор, включающий в себя следующие сведения для тела документа, его анкера, заголовка и URL-адреса, а также для всего документа: количество терминов из запроса в документе, доля покрытия терминов из запроса в документе, длина потока, обратная частота документа (IDF), сумма частотностей терминов, максимальная частотность термина, минимальная частотность термина, средняя частотность термина и т.д.
Построитель 320 способен принимать первый набор 302 обучающих образцов в качестве входных данных, чтобы выдавать одну или несколько прогнозирующих моделей на основе каждого вектора признаков 309 и метки 314 каждого обучающего образца 308 из первого набора 302 обучающих образцов.
Построитель 320 может выдавать прогнозирующую модель с использованием метода градиентного бустинга. Метод градиентного бустинга хорошо известен в данной области техники. Вкратце, градиентный бустинг, также известный под названием машины градиентного бустинга (GBM), представляет собой семейство методов машинного обучения для задач регрессии и классификации, когда прогнозирующая модель создается в виде ансамбля слабых прогнозирующих моделей, включая деревья решений, но не ограничиваясь ими.
Основная идея метода градиентного бустинга заключается в последовательном добавлении новых моделей в ансамбль, причем новая слабая прогнозирующая модель базового построителя обучается на каждой итерации с учетом ошибки всего обученного ансамбля. Иными словами, цель заключается в получении новых базовых построителей, которые максимально соответствуют антиградиенту функции потерь, связанной с ансамблем. В общем случае, метод градиентного бустинга предполагает использование вещественной обучающей метки и выполняет поиск приближения в форме взвешенной суммы слабых прогнозирующих моделей. Примеры функций потерь включают в себя функции потерь по Гауссу, Лапласу, Губеру и квантильную функцию потерь для непрерывных переменных, биномиальную функцию и функцию Adaboost для градационных переменных отклика, а также другие специфические функции потерь для моделей выживаемости и дискретных данных.
Не имеющие ограничительного характера примеры параметров для градиентного бустинга включают в себя параметры, характерные для дерева (влияющие на каждое отдельное дерево в прогнозирующей модели), параметры бустинга (влияющие на операцию бустинга в прогнозирующей модели) и прочие параметры (влияющие на общее функционирование). В не имеющем ограничительного характера примере могут быть заданы четыре параметра: количество деревьев, показатель обучения, максимальная глубина дерева и минимальное количество образцов на лист. В общем случае, может быть задано как можно большее количество деревьев (>1000). Показатель обучения, который масштабирует влияние каждого дерева на общий прогноз, может быть выбран небольшим (<0,01). В общем случае, максимальная глубина дерева может быть в диапазоне от 1 до 10, а минимальное количество образцов на лист может зависеть от размера первого набора 302 обучающих образцов.
Не имеющие ограничительного характера примеры алгоритмов градиентного бустинга включают в себя бустинг на основе деревьев, стохастический градиентный бустинг, бустинг на основе правдоподобия, GBoost, AdaBoost, Gentle Boost и т.д.
В представленном здесь не имеющем ограничительного характера примере на основе, по меньшей мере, части вектора признаков 309 и метки 314 каждого обучающего образца 308 из первого набора 302 обучающих образцов, построитель 320 может формировать и выдавать первую прогнозирующую модель 335, обеспечивающую приблизительное соответствие каждого вектора признаков 309 обучающей метке 314. Первая прогнозирующая модель 335 может представлять собой функцию, оценивающую зависимость между вектором признаков 309 и обучающей меткой 314 каждого обучающего образца 308 с целью минимизации функции потерь. В целом, функция потерь указывает, насколько хорошо прогнозирующая модель соответствует обучающим данным, и, в общем случае, может зависеть от реализации построителя 320 и вида решаемой проблемы. В не имеющем ограничительного характера примере в качестве функции потерь может использоваться среднеквадратическая ошибка (MSE), средняя абсолютная ошибка (МАЕ) или функция потерь по Губеру.
Для получения на выходе первой прогнозирующей модели 335 общая процедура градиентного бустинга в построителе 320 может выполняться для М итераций, количество которых соответствует количеству деревьев в первой прогнозирующей модели 335.
В общем случае, первая прогнозирующая модель 335 может итеративно обучаться на части 304 первого набора 302 обучающих образцов на этапе обучения и проверяться на другой части 306 первого набора 302 обучающих образцов на этапе проверки.
На фиг. 4 и фиг. 5 представлены описания двух различных процедур обучения для оценки нового обучающего объекта 315.
Сначала следует одновременно рассмотреть фиг. 3 и фиг. 4, на которой в форме графика представлена первая процедура 400 обучения, реализованная посредством алгоритма MLA 310 в построителе 320, согласно не имеющим ограничительного характера вариантам осуществления настоящего изобретения.
График первой процедуры 400 обучения может содержать множество итераций 402 на независимой оси и показатель 404 ошибки прогнозирования на зависимой оси для первой прогнозирующей модели 335 и множества переобученных прогнозирующих моделей 334.
Первый показатель 336 ошибки прогнозирования, представляющий собой результат функции потерь на данной итерации, может быть сформирован построителем 320 на этапе обучения и/или на этапе проверки и, по меньшей мере, частично указывает на связанную с первой прогнозирующей моделью 335 ошибку прогнозирования на данной итерации. Реализация первого показателя 336 ошибки прогнозирования, на которую не накладывается каких-либо ограничений, зависит от реализации алгоритма градиентного спуска в построителе 320. В общем случае, показатель 336 ошибки прогнозирования на данной итерации может, по меньшей мере, частично основываться на различии прогнозируемого выходного значения первой прогнозирующей модели 335 и метки 314 каждого вектора признаков 309 каждого обучающего образца 308. В качестве не имеющего ограничительного характера примера может использоваться ошибка MSE.
В общем случае, на этапе обучения и/или проверки построитель 320 может сохранять состояние первой прогнозирующей модели 335 на каждой итерации (например, в запоминающем устройстве или в памяти обучающего сервера 230), чтобы иметь возможность вернуться к определенной итерации этапа обучения и/или проверки, на которой первая прогнозирующая модель 335 находится в определенном состоянии. В других вариантах осуществления построитель 320 может сохранять состояние первой прогнозирующей модели 335 только через заранее заданные интервалы (например, через каждые две или три итерации).
Как указано выше, построитель 320 может прекратить обучение первой прогнозирующей модели 335 после М итераций. Построитель 320 может анализировать каждый первый показатель 336 ошибки прогнозирования на соответствующей итерации для обнаружения точки 410 «сверхподгонки», которая соответствует данной итерации, после которой тенденция для первого показателя 336 ошибки прогнозирования изменяется с общего уменьшения на общее увеличение. Точка 410 «сверхподгонки» может указывать на то, что после соответствующей итерации первый показатель 336 ошибки прогнозирования (соответствующий ошибке MSE) первой прогнозирующей модели 335 может начать увеличиваться и что обучение первой прогнозирующей модели 335 следует прекратить.
После обнаружения точки 410 «сверхподгонки» на основе первого показателя 336 ошибки прогнозирования на данной итерации построитель 320 может вернуться назад на несколько итераций, чтобы определить начальную точку 412 оценивания, которая соответствует предыдущему состоянию первой прогнозирующей модели 335. Способ определения начальной точки 412 оценивания, на который не накладывается каких-либо ограничений, может зависеть от реализации построителя 320, метода градиентного бустинга и первой прогнозирующей модели 335. В общем случае, местоположение начальной точки 412 оценивания может определяться эмпирически оператором алгоритма MLA 310 согласно настоящей технологии. Тем не менее, в других вариантах осуществления местоположение начальной точки 412 оценивания может определяться в зависимости от общего количества итераций М, от первого показателя 336 ошибки прогнозирования или может определяться любым другим подходящим способом.
Затем построителем 320 могут быть приняты или получены данные нового набора обучающих объектов 315. Данные нового набора обучающих объектов 315 могут быть данными, инициирующими использование построителем 320, по меньшей мере, одного нового обручающего объекта из нового набора обучающих объектов 315 во время обучения первой прогнозирующей модели 335. Как указано выше, данные нового обучающего объекта 315 могут представлять собой новый признак 317 или новый набор обучающих образцов 318.
В вариантах осуществления, где данные обучающего объекта 315 из нового набора представляют собой данные, по меньшей мере, одного нового признака 317, этот, по меньшей мере, один новый признак может уже присутствовать в списке признаков каждого вектора признаков 309, но может не учитываться построителем 320 при обучении первой прогнозирующей модели 335. В других вариантах осуществления новый признак 317 может быть не включен во множество признаков каждого вектора признаков 309, и может потребоваться его получение или извлечение построителем 320 путем выполнения операции извлечения признака (не показана). Затем новый признак 317 может быть добавлен в каждый вектор признаков 309. В общем случае, в первую прогнозирующую модель 335 может быть добавлен отдельный признак, тем не менее, в других вариантах осуществления в первую прогнозирующую модель 335 может быть добавлено множество признаков.
Новый обучающий объект 315 (т.е., по меньшей мере, один новый признак 317 или новый набор обучающих образцов 318) может использоваться для переобучения первой прогнозирующей модели 335, начиная с начальной точки 412 оценивания, где первая прогнозирующая модель 335 находится в определенном состоянии. В других вариантах осуществления новый обучающий объект 315 может добавляться в первую прогнозирующую модель 335, начиная с первой итерации. Далее цель может заключаться в сравнении первой прогнозирующей модели 335 с переобученной на новом обучающем объекте 315 первой прогнозирующей моделью (в виде множества переобученных прогнозирующих моделей 334), чтобы посредством соответствующих показателей ошибки прогнозирования определить, улучшает ли добавление нового обучающего объекта 315 прогнозирующую способность первой прогнозирующей модели 335.
Начиная с начальной точки 412 оценивания, где первая прогнозирующая модель 335 находится в определенном состоянии, построитель 320 может переобучать первую прогнозирующую модель 335 с использованием нового обучающего объекта 315, чтобы получить множество переобученных первых прогнозирующих моделей 334, начиная с первой прогнозирующей модели 335, которые находятся в том же состоянии. Количество переобученных первых прогнозирующих моделей 334 может определяться эмпирически, чтобы их количество было статистически значимым, а результаты, получаемые переобученными первыми прогнозирующими моделями 334, не зависели от шума или других флуктуаций. Построитель 320 может итеративно вновь обучать переобученную первую прогнозирующую модель 334, чтобы получить множество переобученных первых прогнозирующих моделей 334, начиная с начальной точки 412 оценивания и заканчивая точкой 410 «сверхподгонки».
Построитель 320 может формировать соответствующий показатель 339 ошибки прогнозирования после переобучения для каждой из множества переобученных первых прогнозирующих моделей 334 на каждой итерации (соответствующих итерациям первой прогнозирующей модели 335), начиная с начальной точки 412 оценивания и заканчивая точкой 410 «сверхподгонки», при этом соответствующий показатель 339 ошибки прогнозирования после переобучения определяется так же, как и первый показатель 336 ошибки прогнозирования, причем соответствующий показатель 339 ошибки прогнозирования после «сверхподгонки», по меньшей мере, частично указывает на ошибку прогнозирования, связанную с соответствующей переобученной первой прогнозирующей моделью из множества переобученных первых прогнозирующих моделей 334. В общем случае, каждый соответствующий показатель 339 ошибки прогнозирования после переобучения может соответствовать соответствующему первому показателю 336 ошибки прогнозирования для данной итерации.
Далее следует одновременно рассмотреть фиг. 3 и фиг. 5, на которой в форме графика представлена вторая процедура 500 обучения, реализованная согласно не имеющим ограничительного характера вариантам осуществления настоящего изобретения.
Как и в случае первой процедуры 400 обучения, график второй процедуры 500 обучения может содержать множество итераций 502 на независимой оси и показатель 504 ошибки прогнозирования на зависимой оси для первой прогнозирующей модели 335 и множества переобученных прогнозирующих моделей 535.
Вторая процедура 500 обучения может отличаться от первой процедуры 400 обучения тем, что вместо лишь одной начальной точки оценивания, такой как начальная точка 412, на фиг. 5 имеется множество 520 начальных точек оценивания, включая первую начальную точку 522 оценивания, вторую начальную точку 524 оценивания, третью начальную точку 526 оценивания, четвертую начальную точку 528 оценивания и пятую начальную точку 530 оценивания.
В зависимости от варианта осуществления настоящей технологии, количество точек в множестве 520 начальных точек оценивания может различаться. Как и в случае начальной точки 412, построитель 320 может вернуться назад на несколько итераций к первой начальной точке 522 оценивания и разделить интервал на несколько равных подинтервалов, каждый из которых начинается на соответствующей итерации, связанной с соответствующей начальной точкой оценивания и с соответствующим состоянием первой прогнозирующей модели 335, таким как вторая начальная точка 524 оценивания, третья начальная точка 526 оценивания, четвертая начальная точка 528 оценивания и пятая начальная точка 530 оценивания. В других вариантах осуществления начальная точка оценивания может быть предусмотрена на каждой итерации, начиная с первой начальной точки 522 оценивания и заканчивая точкой 510 «сверхподгонки» (точки переобучения).
В любой из начальных точек оценивания, такой как первая начальная точка 522 оценивания, вторая начальная точка 524 оценивания, третья начальная точка 526 оценивания, четвертая начальная точка 528 оценивания и пятая начальная точка 530 оценивания, соответствующей определенному состоянию обучения первой прогнозирующей модели 335, построитель 320 может переобучать первую прогнозирующую модель 335 с использованием нового обучающего объекта 315 с тем, чтобы получить множество 535 переобученных первых прогнозирующих моделей.
Множество 535 переобученных первых прогнозирующих моделей содержит первое множество переобученных первых прогнозирующих моделей 537, второе множество переобученных первых прогнозирующих моделей 547, третье множество переобученных первых прогнозирующих моделей 557, четвертое множество переобученных первых прогнозирующих моделей 567 и пятое множество переобученных первых прогнозирующих моделей 577, начиная, соответственно, с первой начальной точки 522 оценивания, второй начальной точки 524 оценивания, третьей начальной точки 526 оценивания, четвертой начальной точки 528 оценивания и пятой начальной точки 530 оценивания.
Количество моделей для каждой начальной точки оценивания во множестве 535 переобученных прогнозирующих моделей может определяться так, чтобы их количество было статистически значимым и позволяло сравнивать первую прогнозирующую модель 335 с множеством переобученных первых прогнозирующих моделей 535.
Построитель 320 может формировать показатель 580 ошибки прогнозирования переобученной первой прогнозирующей модели для каждой модели из множества переобученных первых прогнозирующих моделей 535 на каждой итерации (соответствующих итерациям первой прогнозирующей модели 335), начиная с первой начальной точки 522 оценивания и заканчивая точкой 510 «сверхподгонки».
Первая процедура 400 обучения и вторая процедура 500 обучения могут также выполняться с использованием операции перекрестной проверки (не показана).
В целом, перекрестная проверка, также известная как скользящий контроль, представляет собой метод проверки модели, используемый для оценки адекватности прогнозирующей модели. В общем случае, цель перекрестной проверки заключается в оценке точности прогнозирующей модели путем обучения прогнозирующей модели на наборе обучающих данных и проверки модели на наборе проверочных данных, чтобы получить точную прогнозирующую модель и ограничить проблемы, в частности, «сверхподгонку». Не имеющие ограничительного характера примеры методов перекрестной проверки включают в себя перекрестную проверку с исключением по р объектов (LpOCV), перекрестную проверку с исключением по одному объекту (LOOCV), k-кратную перекрестную проверку, метод контрольной выборки, перекрестную поверку методом Монте-Карло и т.д.
Перекрестная проверка включает в себя разделение набора данных на несколько подмножеств, обучение модели на части подмножеств (обучающие наборы) и проверку модели на другой части подмножеств (проверочные или тестовые наборы). Чтобы уменьшить изменчивость, выполняется несколько циклов перекрестной проверки с использованием различных разделений и результаты проверки обычно усредняются по циклам.
Далее вновь следует обратиться к фиг. 3. После формирования множества переобученных первых прогнозирующих моделей 334 (или множества переобученных первых прогнозирующих моделей 537), начиная с начальной точки 412 оценивания (или множества 520 начальных точек оценивания) и заканчивая точкой 410 «сверхподгонки» (или точкой 510 «сверхподгонки»), соответствующий первый показатель 336 ошибки прогнозирования и соответствующий показатель 339 ошибки прогнозирования после переобучения (или соответствующий показатель 580 ошибки прогнозирования после переобучения) для каждой итерации принимаются в качестве входных данных агрегатором 340 ошибок прогнозирования.
Агрегатор 340 ошибок прогнозирования обрабатывает показатели ошибки прогнозирования для сравнения в ходе первой процедуры 400 обучения (или второй процедуры 500 обучения) или после нее. В не имеющем ограничительного характера примере соответствующие показатели 339 ошибок прогнозирования после переобучения (или соответствующий показатель 536 ошибки прогнозирования после переобучения) могут усредняться для каждой итерации на множестве переобученных первых прогнозирующих моделей 334 (или множестве переобученных первых прогнозирующих моделей 535), а агрегатор 340 ошибок прогнозирования может затем формировать вектор для каждой итерации, каждая строка которого может соответствовать разности соответствующего среднего показателя ошибки прогнозирования после переобучения (не показан) и соответствующего первого показателя 336 ошибки прогнозирования. Агрегатор 340 ошибок прогнозирования может выдавать набор объединенных показателей 342 ошибки прогнозирования. В другом не имеющем ограничительного характера примере агрегатор 340 ошибок прогнозирования может создавать пары для каждой итерации, каждая из которых содержит соответствующий первый показатель 336 ошибки прогнозирования и среднее значение соответствующего показателя 339 ошибки прогнозирования после переобучения для данной итерации (или среднее значение соответствующего показателя 580 ошибки прогнозирования после переобучения). В еще одном не имеющем ограничительного характера примере агрегатор 340 ошибок прогнозирования может вычитать каждый соответствующий показатель 339 ошибки прогнозирования после переобучения (или соответствующий показатель 580 ошибки прогнозирования после переобучения) из соответствующего первого показателя 336 ошибки прогнозирования для каждой итерации, чтобы выдавать набор объединенных показателей 342 ошибки прогнозирования.
Затем набор объединенных показателей 342 ошибки прогнозирования обрабатывается компаратором 350 ошибок прогнозирования, чтобы сравнить эффективность первой прогнозирующей модели 335 и эффективность множества переобученных первых прогнозирующих моделей 334 (или множества переобученных первых прогнозирующих моделей 535) с использованием соответствующего первого показателя 336 ошибки прогнозирования (или первого показателя 580 ошибки прогнозирования) и соответствующего показателя 339 ошибки прогнозирования после переобучения (или соответствующего показателя 580 ошибки прогнозирования после переобучения), представленных набором объединенных показателей 342 ошибки прогнозирования.
Алгоритм MLA 310 может использовать компаратор 350 ошибок прогнозирования для того, чтобы оценить, улучшает ли новый обучающий объект 315 прогнозирующую способность первой прогнозирующей модели 335.
На способ сравнения набора объединенных показателей 342 ошибок прогнозирования посредством компаратора 350 ошибок прогнозирования не накладывается каких-либо ограничений. Статистический критерий может применяться для набора объединенных показателей 342 ошибки прогнозирования, чтобы сравнить первую прогнозирующую модель 335 и переобученную первую прогнозирующую модель. В не имеющем ограничительного характера примере критерий знаковых рангов Уилкоксона, критерий Манна-Уитни-Уилкоксона или знаковый критерий могут использоваться для объединенных показателей 342 ошибки прогнозирования, чтобы сравнить прогнозирующую способность первых прогнозирующих моделей, переобученных с использованием нового обучающего объекта 315, и прогнозирующую способность первой прогнозирующей модели 335.
Затем компаратор 350 ошибок прогнозирования может выдать результат 354 сравнения и, таким образом, оценить, улучшает ли добавление нового обучающего объекта 315 эффективность или прогнозирующую способность первой прогнозирующей модели 335. Если множество переобученных первых прогнозирующих моделей 334 или 535 статистически достоверно превосходит первую прогнозирующую модель 335, сервер 240 поисковой системы может быть обновлен путем включения переобученной первой прогнозирующей модели. Как должно быть понятно специалисту в данной области, эта процедура может выполняться параллельно для множества признаков или множества обучающих образцов из набора новых обучающих объектов 315.
На фиг. 6 представлена блок-схема способа 600 оценки нового обучающего объекта согласно не имеющим ограничительного характера вариантам осуществления настоящей технологии.
Способ 600 может начинаться с шага 602.
Шаг 602: получение посредством алгоритма MLA первого набора обучающих образцов, содержащего множество признаков.
На шаге 602 алгоритм MLA 310 обучающего сервера 230 может получать из первого сервера 220 набор 302 обучающих образцов, содержащий множество признаков, причем каждый обучающий образец 308 из набора 302 обучающих образцов содержит вектор признаков 309 и метку 314.
Далее способ 600 может продолжаться на шаге 604.
Шаг 604: итеративное обучение посредством алгоритма MLA первой прогнозирующей модели на основе, по меньшей мере, части из множества признаков, причем обучение для каждой первой обучающей итерации включает в себя формирование соответствующего первого показателя ошибки прогнозирования, который, по меньшей мере, частично указывает на связанную с первой прогнозирующей моделью ошибку прогнозирования на соответствующей первой обучающей итерации.
На шаге 604 алгоритм MLA 310 обучающего сервера 230 может посредством построителя 320 итеративно обучать первую прогнозирующую модель 335 на основе, по меньшей мере, части из множества признаков из набора 302 обучающих образцов, причем обучение для каждой обучающей итерации включает в себя формирование соответствующего первого показателя 336 ошибки прогнозирования, который, по меньшей мере, частично указывает на связанную с первой прогнозирующей моделью 335 ошибку прогнозирования на соответствующей первой обучающей итерации. Первая прогнозирующая модель 335 может формироваться с использованием метода градиентного бустинга для М итераций, для каждой из которых имеется соответствующий первый показатель 336 ошибки прогнозирования.
Далее способ 600 может продолжаться на шаге 606.
Шаг 606: анализ посредством алгоритма MLA соответствующего первого показателя ошибки прогнозирования для каждой первой обучающей итерации, чтобы определить соответствующую данной первой обучающей итерации точку «сверхподгонки», после которой тенденция для первого показателя ошибки прогнозирования изменяется с общего уменьшения на общее увеличение.
На шаге 606 алгоритм MLA 310 обучающего сервера 230 может посредством построителя 320 анализировать соответствующий первый показатель 336 ошибки прогнозирования для каждой первой обучающей итерации, чтобы определить соответствующую данной первой обучающей итерации точку 410 «сверхподгонки», после которой тенденция для первого показателя 336 ошибки прогнозирования изменяется с общего уменьшения на общее увеличение.
Далее способ 600 может продолжаться на шаге 608.
Шаг 608: определение посредством алгоритма MLA, по меньшей мере, одной начальной точки оценивания, которая расположена за несколько итераций до точки «сверхподгонки».
На шаге 608 алгоритм MLA 310 обучающего сервера 230 может посредством построителя 320 определить, по меньшей мере, одну начальную точку 412 оценивания, которая расположена за несколько итераций до точки «сверхподгонки». В некоторых вариантах осуществления алгоритм MLA 310 может посредством построителя 320 определить множество 520 начальных точек оценивания, включая первую начальную точку 522 оценивания, вторую начальную точку 524 оценивания, третью начальную точку 526 оценивания, четвертую начальную точку 528 оценивания и пятую начальную точку 530 оценивания.
Далее способ 600 может продолжаться на шаге 610.
Шаг 610: получение посредством алгоритма MLA данных нового набора обучающих объектов.
На шаге 610 алгоритм MLA 310 обучающего сервера 230 может получить или принять данные нового набора обучающих объектов 315. Данные нового набора обучающих объектов 315 могут быть данными, инициирующими использование алгоритмом MLA 310, по меньшей мере, одного нового обручающего объекта из нового набора обучающих объектов 315 во время обучения и переобучения первой прогнозирующей модели 335. Новый обучающий объект 315 может представлять собой, по меньшей мере, один новый признак 317 или новый набор обучающих образцов 318.
Далее способ 600 может продолжаться на шаге 612.
Шаг 612: итеративное переобучение посредством алгоритма MLA первой прогнозирующей модели, находящейся в обученном состоянии, связанном с, по меньшей мере, одной начальной точкой оценивания, с использованием, по меньшей мере, одного обучающего объекта из нового набора обучающих объектов, чтобы получить множество переобученных первых прогнозирующих моделей.
На шаге 612 алгоритм MLA 310 обучающего сервера 230 может итеративно переобучать первую прогнозирующую модель 335, начиная с начальной точки 412 оценивания (или с каждой начальной точки оценивания, такой как первая начальная точка 522 оценивания, вторая начальная точка 524 оценивания, третья начальная точка 526 оценивания, четвертая начальная точка 528 оценивания и пятая начальная точка 530 оценивания), путем добавления нового признака 317 или нового набора обучающих образцов 318. При этом может быть сформировано множество переобученных первых прогнозирующих моделей 334 или 535.
Далее способ 600 может продолжаться на шаге 614.
Шаг 614: формирование соответствующего показателя ошибки прогнозирования для каждой модели из множества переобученных первых прогнозирующих моделей после переобучения на, по меньшей мере, одной итерации переобучения, соответствующей, по меньшей мере, одной первой обучающей итерации, причем соответствующий показатель ошибки прогнозирования после переобучения, по меньшей мере, частично указывает на ошибку прогнозирования, связанную с переобученной первой прогнозирующей моделью.
На шаге 614 алгоритм MLA 310 обучающего сервера 230 может формировать соответствующий показатель 339 или 580 ошибки прогнозирования для каждой модели из множества переобученных первых прогнозирующих моделей 334 или 535 после переобучения для, по меньшей мере, одной итерации переобучения, соответствующей, по меньшей мере, одной первой обучающей итерации, причем соответствующий показатель 339 или 580 ошибки прогнозирования после переобучения, по меньшей мере, частично указывает на ошибку прогнозирования, связанную с переобученной первой прогнозирующей моделью.
Далее способ 600 может продолжаться на шаге 616.
Шаг 616: выбор посредством алгоритма MLA одного из первых наборов обучающих образцов и, по меньшей мере, одного обучающего объекта из нового набора обучающих объектов, осуществляемый на основе множества показателей ошибки прогнозирования после переобучения, связанных с множеством переобученных первых прогнозирующих моделей, и на основе множества соответствующих первых показателей ошибки прогнозирования.
На шаге 616 выбор посредством алгоритма MLA одного из первых наборов обучающих образцов и, по меньшей мере, одного обучающего объекта из нового набора обучающих объектов осуществляется на основе множества показателей ошибки прогнозирования после переобучения, связанных с множеством переобученных первых прогнозирующих моделей и на основе множества соответствующих первых показателей ошибки прогнозирования.
На этом способ 600 может быть завершен.
Настоящая технология позволяет оценить новый обучающий объект, такой как новый признак или новый набор обучающих образцов, предназначенный для добавления в прогнозирующую модель, сформированную алгоритмом машинного обучения. Как ясно из представленного выше описания, сравнение множества переобученных прогнозирующих моделей, начиная с, по меньшей мере, одной начальной точки оценивания, расположенной до точки «сверхподгонки» и связанной с соответствующим обученным состоянием, позволяет оценить вклад нового обучающего объекта в прогнозирующую модель. Посредством выбора, по меньшей мере, одного интервала оценивания, начинающегося в начальной точке оценивания, настоящая технология обеспечивает баланс между оценкой нового обучающего объекта только в точке «сверхподгонки» и оценкой на всем наборе итераций. В результате можно точно определить вклад нового обучающего объекта в прогнозирующую способность прогнозирующей модели и оптимизировать время вычислений и вычислительные ресурсы, необходимые для выполнения такой оценки.
Несмотря на то, что описанные выше варианты осуществления приведены со ссылкой на конкретные шаги, выполняемые в определенном порядке, должно быть понятно, что эти шаги могут быть объединены, разделены или их порядок может быть изменен без отклонения от настоящей технологии. Соответственно, порядок и группировка шагов не носят ограничительного характера для настоящей технологии.
Очевидно, что не все упомянутые в данном описании технические эффекты должны присутствовать в каждом варианте осуществления настоящей технологии. Например, возможны варианты осуществления настоящей технологии, когда пользователь не получает некоторые из этих технических эффектов, или другие варианты осуществления, когда пользователь получает другие технические эффекты либо технический эффект отсутствует.
Некоторые из этих шагов и передаваемых и/или принимаемых сигналов хорошо известны в данной области техники и по этой причине опущены в некоторых частях данного описания для упрощения. Сигналы могут передаваться и/или приниматься с использованием оптических средств (например, использующих волоконно-оптическое соединение), электронных средств (например, использующих проводное или беспроводное соединение) и механических средств (например, основанных на давлении, температуре или любом другом подходящем физическом параметре).
Изменения и усовершенствования описанных выше вариантов осуществления настоящей технологии очевидны для специалиста в данной области. Предшествующее описание приведено в качестве примера, а не для ограничения объема изобретения. Объем охраны настоящей технологии определяется исключительно объемом приложенной формулы изобретения.

Группа изобретений относится к области машинного обучения и может быть использована для оценки обучающих объектов. Техническим результатом является повышение эффективности алгоритма машинного обучения при экономии вычислительных ресурсов. Способ содержит получение первого набора обучающих образцов, содержащего множество признаков, итеративное обучение первой прогнозирующей модели на основе множества признаков и формирование соответствующего первого показателя ошибки прогнозирования; анализ соответствующего первого показателя ошибки прогнозирования для каждой итерации, чтобы определить точку «сверхподгонки», и определение по меньшей мере одной начальной точки оценивания; получение данных нового набора обучающих объектов и итеративное переобучение с использованием по меньшей мере одного обучающего объекта первой прогнозирующей модели, начиная с по меньшей мере одной начальной точки оценивания, для получения множества переобученных первых прогнозирующих моделей, и формирование соответствующего показателя ошибки прогнозирования после переобучения. На основе множества показателей ошибки прогнозирования после переобучения и множества соответствующих первых показателей ошибки прогнозирования выполняется выбор одного из первых наборов обучающих образцов и по меньшей мере одного обучающего объекта. 2 н. и 14 з.п. ф-лы, 6 ил.
1. Реализованный посредством компьютера способ обучения для алгоритма машинного обучения (MLA), выполняемый сервером и включающий в себя следующие действия:
получают посредством алгоритма MLA первый набор обучающих образцов, содержащий множество признаков;
итеративно обучают посредством алгоритма MLA первую прогнозирующую модель на основе, по меньшей мере, части из множества признаков, при этом обучение на каждой первой обучающей итерации включает в себя формирование соответствующего первого показателя ошибки прогнозирования, по меньшей мере, частично указывающего на связанную с первой прогнозирующей моделью ошибку прогнозирования на соответствующей первой обучающей итерации;
анализируют посредством алгоритма MLA соответствующий первый показатель ошибки прогнозирования на каждой первой обучающей итерации для определения точки «сверхподгонки», соответствующей данной первой обучающей итерации, после которой тенденция для первого показателя ошибки прогнозирования изменяется с общего уменьшения на общее увеличение;
определяют посредством алгоритма MLA по меньшей мере одну начальную точку оценивания, расположенную за несколько итераций до точки «сверхподгонки»;
получают посредством алгоритма MLA данные нового набора обучающих объектов;
итеративно переобучают посредством алгоритма MLA первую прогнозирующую модель, находящуюся в соответствующем обученном состоянии, связанном с указанной по меньшей мере одной начальной точкой оценивания, с использованием по меньшей мере одного обучающего объекта из нового набора обучающих объектов для получения множества переобученных первых прогнозирующих моделей;
формируют соответствующий показатель ошибки прогнозирования для каждой модели из множества переобученных первых прогнозирующих моделей после переобучения на по меньшей мере одной итерации переобучения, соответствующей по меньшей мере одной первой обучающей итерации, причем соответствующий показатель ошибки прогнозирования после переобучения, по меньшей мере, частично указывает на ошибку прогнозирования, связанную с переобученной первой прогнозирующей моделью;
выбирают посредством алгоритма MLA один из первых наборов обучающих образцов и по меньшей мере один обучающий объект из нового набора обучающих объектов на основе множества показателей ошибки прогнозирования после переобучения, связанных с множеством переобученных первых прогнозирующих моделей, и на основе множества соответствующих первых показателей ошибки прогнозирования.
2. Способ по п. 1, отличающийся тем, что новый набор обучающих объектов представляет собой новый набор признаков или новый набор обучающих образцов.
3. Способ по п. 2, отличающийся тем, что обучение и переобучение первой прогнозирующей модели осуществляют с применением метода градиентного бустинга.
4. Способ по п. 3, отличающийся тем, что выбор посредством алгоритма MLA по меньшей мере одного обучающего объекта из нового набора обучающих объектов включает в себя сравнение множества показателей ошибки прогнозирования после переобучения с множеством соответствующих первых показателей ошибки прогнозирования посредством проверки статистической гипотезы.
5. Способ по п. 4, отличающийся тем, что первый показатель ошибки прогнозирования и соответствующий показатель ошибки прогнозирования переобученной первой прогнозирующей модели представляют собой среднеквадратическую ошибку (MSE) или среднюю абсолютную ошибку (МАЕ).
6. Способ по п. 5, отличающийся тем, что проверку статистической гипотезы выполняют с использованием критерия знаковых рангов Уилкоксона.
7. Способ по п. 6, отличающийся тем, что указанная по меньшей мере одна начальная точка оценивания представляет собой множество начальных точек оценивания.
8. Способ по п. 7, отличающийся тем, что каждая из множества начальных точек оценивания связана с соответствующим множеством переобученных первых прогнозирующих моделей.
9. Система обучения для алгоритма машинного обучения (MLA), содержащая:
процессор;
машиночитаемый физический носитель информации, содержащий команды, причем процессор выполнен с возможностью при выполнении команд осуществлять следующие действия:
получение посредством алгоритма MLA первого набора обучающих образцов, содержащего множество признаков;
итеративное обучение посредством алгоритма MLA первой прогнозирующей модели на основе, по меньшей мере, части из множества признаков, при этом обучение на каждой первой обучающей итерации включает в себя формирование соответствующего первого показателя ошибки прогнозирования, по меньшей мере, частично указывающего на связанную с первой прогнозирующей моделью ошибку прогнозирования на соответствующей первой обучающей итерации;
анализ посредством алгоритма MLA соответствующего первого показателя ошибки прогнозирования на каждой первой обучающей итерации для определения точки «сверхподгонки», соответствующей данной первой обучающей итерации, после которой тенденция для первого показателя ошибки прогнозирования изменяется с общего уменьшения на общее увеличение;
определение посредством алгоритма MLA по меньшей мере одной начальной точки оценивания, расположенной за несколько итераций до точки «сверхподгонки»;
получение посредством алгоритма MLA данных нового набора обучающих объектов;
итеративное переобучение посредством алгоритма MLA первой прогнозирующей модели, находящейся в соответствующем обученном состоянии, связанном с по меньшей мере одной начальной точкой оценивания, с использованием по меньшей мере одного обучающего объекта из нового набора обучающих объектов, для получения множества переобученных первых прогнозирующих моделей;
формирование соответствующего показателя ошибки прогнозирования для каждой модели из множества переобученных первых прогнозирующих моделей после переобучения на по меньшей мере одной итерации переобучения, соответствующей по меньшей мере одной первой обучающей итерации, причем соответствующий показатель ошибки прогнозирования после переобучения, по меньшей мере, частично указывает на ошибку прогнозирования, связанную с переобученной первой прогнозирующей моделью;
выбор посредством алгоритма MLA одного из первых наборов обучающих образцов и по меньшей мере одного обучающего объекта из нового набора обучающих объектов на основе множества показателей ошибки прогнозирования после переобучения, связанных с множеством переобученных первых прогнозирующих моделей, и на основе множества соответствующих первых показателей ошибки прогнозирования.
10. Система по п. 9, отличающаяся тем, что новый набор обучающих объектов представляет собой новый набор признаков или новый набор обучающих образцов.
11. Система по п. 10, отличающаяся тем, что процессор выполнен с возможностью применения метода градиентного бустинга для обучения и переобучения первой прогнозирующей модели.
12. Система по п. 11, отличающаяся тем, что процессор выполнен с возможностью сравнения множества показателей ошибки прогнозирования после переобучения с множеством соответствующих первых показателей ошибки прогнозирования посредством проверки статистической гипотезы с целью выбора посредством алгоритма MLA по меньшей мере одного обучающего объекта из нового набора обучающих объектов.
13. Система по п. 12, отличающаяся тем, что первый показатель ошибки прогнозирования и соответствующий показатель ошибки прогнозирования после переобучения представляют собой среднеквадратическую ошибку (MSE) или среднюю абсолютную ошибку (МАЕ).
14. Система по п. 13, отличающаяся тем, что проверка статистической гипотезы проводится с использованием критерия знаковых рангов Уилкоксона.
15. Система по п. 14, отличающаяся тем, что по меньшей мере одна начальная точка оценивания представляет собой множество начальных точек оценивания.
16. Система по п. 15, отличающаяся тем, что каждая из множества начальных точек оценивания связана с соответствующим множеством переобученных первых прогнозирующих моделей.

