Притязание на приоритет
[0001] По данной заявке испрашивается приоритет на основании предварительной заявки на патент США № 62/902,074, поданной 18 сентября 2019 г. и озаглавленной "COMPUTER-BASED SYSTEMS, COMPUTING COMPONENTS AND COMPUTING OBJECTS CONFIGURED TO IMPLEMENT DYNAMIC OUTLIER BIAS REDUCTION IN MACHINE LEARNING MODELS", которая полностью включена в данный документ путём ссылки.
Уведомление об авторском праве
[0002] Часть описания данного патентного документа содержит материалы, на которые распространяется охрана авторским правом. Обладатель авторского права не имеет возражений против факсимильного воспроизведения кем-либо патентного документа или описания патента в том виде, в котором он содержится в патентном фонде или базе Бюро по патентам и товарным знакам, но в иных случаях сохраняет за собой любые авторские права. Нижеследующее уведомление относится к программному обеспечению и данным, описанным ниже и на чертежах, которые составляют часть данного документа: авторское право, Hartford Steam Boiler Inspection and Insurance Company, все права защищены.
Область техники, к которой относится изобретение
[0003] Настоящее изобретение относится в общем к усовершенствованным компьютерным системам, вычислительным компонентам и вычислительным объектам, выполненным с возможностью реализации уменьшения отклонения в моделях машинного обучения.
Уровень техники
[0004] Модель машинного обучения может включать в себя один или более компьютеров или обрабатывающих устройств для формирования прогнозов или определений на основе тенденций и выводов, изученных из данных выборки/обучающих данных. Отклонение в выборе данных выборки/обучающих данных может распространяться на прогнозирования и определения на основе модели машинного обучения.
Раскрытие изобретения
[0005] Варианты осуществления настоящего изобретения включают в себя способы для моделей машинного обучения с уменьшенным динамическим отклонением, обусловленным выбросовыми значениями. Способы включают в себя прием посредством по меньшей мере одного процессора набора обучающих данных целевых переменных, представляющих по меньшей мере один связанный с активностью атрибут по меньшей мере для одной пользовательской активности; прием посредством по меньшей мере одного процессора по меньшей мере одного критерия отклонения, используемого для определения одного или более выбросовых значений; определение посредством по меньшей мере одного процессора набора параметров модели для модели машинного обучения, что включает в себя: (1) применение посредством по меньшей мере одного процессора, модели машинного обучения, имеющей набор начальных параметров модели, к набору обучающих данных для того, чтобы определять набор прогнозируемых значений модели; (2) формирование посредством по меньшей мере одного процессора набора ошибок для ошибок в элементах данных посредством сравнения набора прогнозируемых значений модели с соответствующими фактическими значениями набора обучающих данных; (3) формирование посредством по меньшей мере одного процессора вектора выбора данных для того, чтобы идентифицировать невыбросовые целевые переменные по меньшей мере частично на основе набора ошибок для ошибок в элементах данных и по меньшей мере одного критерия отклонения; (4) использование посредством по меньшей мере одного процессора вектора выбора данных для набора обучающих данных для того, чтобы формировать набор невыбросовых данных; (5) определение посредством по меньшей мере одного процессора набора обновленных параметров модели для модели машинного обучения на основе набора невыбросовых данных; и (6) повторение посредством по меньшей мере одного процессора этапов (1)-(5) в качестве итерации до тех пор, пока не будет удовлетворен по меньшей мере один критерий завершения выполнения цензурирования, таким образом, чтобы получить набор параметров модели для модели машинного обучения в качестве обновленных параметров модели, за счет чего каждая итерация повторно формирует набор прогнозируемых значений, набор ошибок, вектор выбора данных и набор невыбросовых данных с использованием набора обновленных параметров модели в качестве набора начальных параметров модели; обучение посредством по меньшей мере одного процессора по меньшей мере частично на основе набора обучающих данных и вектора выбора данных, набора параметров классификационной модели для модели машинного обучения классификаторов выбросовых значений для того, чтобы получать обученную модель машинного обучения классификаторов выбросовых значений, которая выполнена с возможностью идентификации по меньшей мере одного выбросового элемента данных; применение посредством по меньшей мере одного процессора обученной модели машинного обучения классификаторов выбросовых значений к набору данных для связанных с активностью данных по меньшей мере для одной пользовательской активности, чтобы определять: i) набор выбросовых связанных с активностью данных в наборе данных для связанных с активностью данных и ii) набор невыбросовых связанных с активностью данных в наборе данных для связанных с активностью данных; и применение посредством по меньшей мере одного процессора модели машинного обучения к набору элементов невыбросовых связанных с активностью данных для того, чтобы прогнозировать будущий связанный с активностью атрибут, связанный по меньшей мере с одной пользовательской активностью.
[0006] Варианты осуществления настоящего изобретения включают в себя системы для моделей машинного обучения с уменьшенным динамическим отклонением, обусловленным выбросовыми значениями. Системы включают в себя по меньшей мере один процессор, осуществляющий связь с постоянным машиночитаемым носителем данных, на котором сохранены программные инструкции, причем программные инструкции при выполнении предписывают по меньшей мере одному процессору выполнять этапы для: приёма набора обучающих данных целевых переменных, представляющих по меньшей мере один связанный с активностью атрибут по меньшей мере для одной пользовательской активности; приёма по меньшей мере одного критерия отклонения, используемого для определения одного или более выбросовых значений; определения набора параметров модели для модели машинного обучения, что включает в себя: (1) применение модели машинного обучения, имеющей набор начальных параметров модели, к набору обучающих данных для определения набора прогнозируемых значений модели; (2) формирование набора ошибок для ошибок в элементах данных посредством сравнения набора прогнозируемых значений модели с соответствующими фактическими значениями набора обучающих данных; (3) формирование вектора выбора данных для идентификации невыбросовых целевых переменных по меньшей мере частично на основе набора ошибок для ошибок в элементах данных и по меньшей мере одного критерия отклонения; (4) использование вектора выбора данных для набора обучающих данных для формирования набора невыбросовых данных; (5) определение набора обновленных параметров модели для модели машинного обучения на основе набора невыбросовых данных; и (6) повторение этапов (1)-(5) в качестве итерации до тех пор, пока не будет удовлетворён по меньшей мере один критерий завершения выполнения цензурирования, таким образом, чтобы получить набор параметров модели для модели машинного обучения в качестве обновленных параметров модели, за счет чего каждая итерация повторно формирует набор прогнозируемых значений, набор ошибок, вектор выбора данных и набор невыбросовых данных с использованием набора обновленных параметров модели в качестве набора начальных параметров модели; обучения по меньшей мере частично на основе набора обучающих данных и вектора выбора данных, набора параметров классификационной модели для модели машинного обучения классификаторов выбросовых значений для получения обученной модели машинного обучения классификаторов выбросовых значений, которая выполнена с возможностью идентификации по меньшей мере одного выбросового элемента данных; применения обученной модели машинного обучения классификаторов выбросовых значений к набору данных для связанных с активностью данных по меньшей мере для одной пользовательской активности для определения: i) набора выбросовых связанных с активностью данных в наборе данных для связанных с активностью данных и ii) набора невыбросовых связанных с активностью данных в наборе данных для связанных с активностью данных; и применения модели машинного обучения к набору элементов невыбросовых связанных с активностью данных для прогнозирования будущего связанного с активностью атрибута, связанного по меньшей мере с одной пользовательской активностью.
[0007] Системы и способы вариантов осуществления настоящего изобретения, дополнительно включающие в себя: применение посредством по меньшей мере одного процессора вектора выбора данных к набору обучающих данных для определения набора выбросовых обучающих данных; обучение посредством по меньшей мере одного процессора с использованием набора выбросовых обучающих данных по меньшей мере одного параметра относящейся к выбросовым значениям модели для по меньшей мере одной относящейся к выбросовым значениям модели машинного обучения для прогнозирования выбросовых значений данных; и использование посредством по меньшей мере одного процессора относящейся к выбросовым значениям модели машинного обучения для прогнозирования выбросовых значений связанных с активностью данных для набора выбросовых связанных с активностью данных.
[0008] Системы и способы вариантов осуществления настоящего изобретения, дополнительно включающие в себя: обучение посредством по меньшей мере одного процессора с использованием набора обучающих данных, обобщенных параметров модели для обобщенной модели машинного обучения для прогнозирования значений данных; использование посредством по меньшей мере одного процессора обобщенной модели машинного обучения для прогнозирования выбросовых значений связанных с активностью данных для набора выбросовых связанных с активностью данных; и использование посредством по меньшей мере одного процессора обобщенной модели машинного обучения для прогнозирования значений связанных с активностью данных.
[0009] Системы и способы вариантов осуществления настоящего изобретения, дополнительно включающие в себя: применение посредством по меньшей мере одного процессора вектора выбора данных к набору обучающих данных для определения набора выбросовых обучающих данных; обучение посредством по меньшей мере одного процессора с использованием набора выбросовых обучающих данных, параметров относящейся к выбросовым значениям модели для относящейся к выбросовым значениям модели машинного обучения для прогнозирования выбросовых значений данных; обучение посредством по меньшей мере одного процессора, с использованием набора обучающих данных, обобщенных параметров модели для обобщенной модели машинного обучения для прогнозирования значений данных; использование посредством по меньшей мере одного процессора, относящейся к выбросовым значениям модели машинного обучения для прогнозирования выбросовых значений связанных с активностью данных для набора выбросовых связанных с активностью данных; и использование посредством по меньшей мере одного процессора относящейся к выбросовым значениям модели машинного обучения для прогнозирования значений связанных с активностью данных.
[0010] Системы и способы вариантов осуществления настоящего изобретения, дополнительно включающие в себя: обучение посредством по меньшей мере одного процессора с использованием набора обучающих данных, обобщенных параметров модели для обобщенной модели машинного обучения для прогнозирования значений данных; использование посредством по меньшей мере одного процессора обобщенной модели машинного обучения для прогнозирования значений связанных с активностью данных для набора связанных с активностью данных; использование посредством по меньшей мере одного процессора модели машинного обучения классификаторов выбросовых значений для идентификации выбросовых значений связанных с активностью данных из значений связанных с активностью данных; и удаление посредством по меньшей мере одного процессора выбросовых значений связанных с активностью данных.
[0011] Системы и способы вариантов осуществления настоящего изобретения, в которых набор обучающих данных включает в себя по меньшей мере один связанный с активностью атрибут прочности на сжатие бетона в качестве функции от состава бетона и отверждающего возедйствия на бетон.
[0012] Системы и способы вариантов осуществления настоящего изобретения, в которых набор обучающих данных включает в себя по меньшей мере один связанный с активностью атрибут данных использования энергии в качестве функции от бытовых окружающих условий и условий освещения.
[0013] Системы и способы вариантов осуществления настоящего изобретения, дополнительно включающие в себя: прием посредством по меньшей мере одного процессора запроса интерфейса прикладного программирования (API), чтобы формировать прогнозирование по меньшей мере с одним элементом данных; и создание посредством по меньшей мере одного процессора экземпляра по меньшей мере одного облачного вычислительного ресурса для планирования выполнения модели машинного обучения; использование посредством по меньшей мере одного процессора согласно планированию для выполнения модели машинного обучения для прогнозирования по меньшей мере одного значения элемента связанных с активностью данных по меньшей мере для одного элемента данных; и возврат посредством по меньшей мере одного процессора по меньшей мере одного значения элемента связанных с активностью данных в вычислительное устройство, ассоциированное с запросом API.
[0014] Системы и способы вариантов осуществления настоящего изобретения, в которых набор обучающих данных включает в себя по меньшей мере один связанный с активностью атрибут формирования трехмерных изображений пациентов набора медицинских данных; и в которых модель машинного обучения выполнена с возможностью прогнозирования значений связанных с активностью данных, включающих в себя два или более параметров физического рендеринга на основе набора медицинских данных.
[0015] Системы и способы вариантов осуществления настоящего изобретения, в которых набор обучающих данных включает в себя по меньшей мере один связанный с активностью атрибут результатов моделированного управления для электронных машинных команд; и в которых модель машинного обучения выполнена с возможностью прогнозирования значений связанных с активностью данных, включающих в себя команды управления для электронной машины.
[0016] Системы и способы вариантов осуществления настоящего изобретения, дополнительно включающие в себя: разбиение посредством по меньшей мере одного процессора набора связанных с активностью данных на множество поднаборов связанных с активностью данных; определение посредством по меньшей мере одного процессора модели из ансамбля для каждого поднабора связанных с активностью данных из множества поднаборов связанных с активностью данных; причем модель машинного обучения включает в себя ансамбль моделей; причем каждая модель из ансамбля включает в себя случайное сочетание моделей из ансамбля моделей; использование посредством по меньшей мере одного процессора каждой модели из ансамбля по отдельности для прогнозирования относящихся к ансамблю значений связанных с активностью данных; определение посредством по меньшей мере одного процессора ошибки для каждой модели из ансамбля на основе относящихся к ансамблю значений связанных с активностью данных и известных значений; и выбор посредством по меньшей мере одного процессора модели из ансамбля с наилучшими функциональными параметрами на основе наименьшей ошибки.
Краткое описание чертежей
[0017] Различные варианты осуществления настоящего изобретения дополнительно могут поясняться со ссылкой на прилагаемые чертежи, на которых аналогичные структуры указаны аналогичными позициями на нескольких видах. Показанные чертежи не обязательно выполнены в масштабе, вместо этого акцент делается в общем на иллюстрации принципов настоящего изобретения. Следовательно, конкретные структурные и функциональные подробности, раскрытые в данном документе, должны интерпретироваться не в качестве ограничения, а просто в качестве характерной основы для обучения специалистов в данной области техники на предмет различного использования одного или более иллюстративных вариантов осуществления.
[0018] Фиг. 1-14B показывают одну или более принципиальных блок-схем, определенных компьютерных архитектур и/или снимков экрана различных специализированных графических пользовательских интерфейсов, которые иллюстрируют некоторые примерные аспекты по меньшей мере некоторых вариантов осуществления настоящего изобретения.
Осуществление изобретения
[0019] В данном документе раскрыты различные подробные варианты осуществления настоящего изобретения, рассматриваемые в сочетании с сопровождающими чертежами; однако следует понимать, что раскрытые варианты осуществления являются лишь иллюстративными. Кроме того, каждый из примеров, приведенных в связи с различными вариантами осуществления настоящего изобретения, подразумевается иллюстративным, а не ограничивающим.
[0020] Во всем подробном описании следующие термины принимают смысловые значения, явным образом присвоенные им в данном документе, если контекст явно не предписывает иное. Словосочетания «в одном варианте осуществления» и «в некоторых вариантах осуществления» при использовании в данном документе не обязательно означают одни и те же вариант(ы) осуществления, хотя и могут означать. Кроме того, словосочетания «в другом варианте осуществления» и «в некоторых других вариантах осуществления» при использовании в данном документе не обязательно означают другой вариант осуществления, хотя и могут означать. Таким образом, как описано ниже, различные варианты осуществления могут легко объединяться без отступления от объема или сущности настоящего изобретения.
[0021] Помимо этого, термин «на основе» не является исключающим и позволяет основываться на дополнительных, не описанных факторах, если контекст явно не предписывает иное. Помимо этого, во всем подробном описании, смысловое значение терминов в единственном числе включает в себя указания на множественное число. Значение «в» включает в себя «в» и «на».
[0022] Следует понимать, что по меньшей мере один аспект/функциональность различных вариантов осуществления, описанных в данном документе, может выполняться в реальном времени и/или динамически. При использовании в данном документе термин «реальное время» направлен на событие/действие, которое может происходить мгновенно или почти мгновенно со временем, когда произошло другое событие. Например, «обработка в реальном времени», «вычисление в реальном времени» и «выполнение в реальном времени» относятся к выполнению вычисления в течение фактического времени, когда происходит соответствующий физический процесс (например, взаимодействие пользователя с приложением на мобильном устройстве), так что результаты вычисления могут использоваться при управлении физическим процессом.
[0023] При использовании в данном документе термин «динамически» и термин «автоматически» и их логические и/или лингвистические родственные понятия и/или производные понятия означают, что определенные события и/или действия могут инициироваться и/или происходить вообще без вмешательства человека. В некоторых вариантах осуществления, события и/или действия в соответствии с настоящим изобретением могут осуществляться в реальном времени и/или на основе предварительно определенной периодичности как по меньшей мере одно из: наносекунды, нескольких наносекунд, миллисекунды, нескольких миллисекунд, секунды, нескольких секунд, минуты, нескольких минут, ежечасно, нескольких часов, ежедневно, нескольких дней, еженедельно, ежемесячно и т.д.
[0024] В некоторых вариантах осуществления, примерные специально программируемые вычислительные системы согласно изобретению с ассоциированными устройствами выполнены с возможностью работы в распределенном сетевом окружении, с обменом данными между собой по одной или более подходящих сетей передачи данных (например, Интернет, спутниковых и т.д.) и использованием одного или более подходящих протоколов/режимов обмена данными, таких как, не ограничиваясь, IPX/SPX, X.25, AX.25, AppleTalk(TM), TCP/IP (например, HTTP), беспроводная связь ближнего действия (NFC), RFID, узкополосный Интернет вещей (NBIoT), 3G, 4G, 5G, GSM, GPRS, Wi-Fi, WiMAX, CDMA, спутниковая связь, ZigBee и другие подходящие режимы связи. В некоторых вариантах осуществления, NFC может представлять технологию ближней беспроводной связи, в которой устройства с поддержкой NFC «проводятся», «соприкасаются», «быстро прикасаются» или иным образом перемещаются в непосредственной близости для обмена данными.
[0025] Материал, раскрытый в данном документе, может быть реализован в программном обеспечении или микропрограммном обеспечении либо в их сочетании, или в виде инструкций, сохраненных на машиночитаемом носителе, которые могут считываться и выполняться посредством одного или более процессоров. Машиночитаемый носитель может включать в себя любой носитель и/или механизм для сохранения или передачи информации в машиночитаемой форме (например, вычислительного устройства). Например, машиночитаемый носитель может включать в себя постоянное запоминающее устройство (ROM); оперативное запоминающее устройство (RAM); носители хранения данных на магнитных дисках; оптические носители хранения данных; устройства флэш-памяти; электрические, оптические, акустические или другие формы распространяемых сигналов (например, несущие волны, инфракрасные сигналы, цифровые сигналы и т.д.) и другие.
[0026] При использовании в данном документе, термины «компьютерный механизм» и «механизм» идентифицируют по меньшей мере один программный компонент и/либо сочетание по меньшей мере одного программного компонента и по меньшей мере одного аппаратного компонента, которые проектируются/программируются/конфигурируются с возможностью регулирования/управления другими программными и/или аппаратными компонентами (такими как библиотеки, комплекты разработки программного обеспечения (SDK), объекты и т.д.).
[0027] Примеры аппаратных элементов могут включать в себя процессоры, микропроцессоры, схемы, схемные элементы (такие как транзисторы, резисторы, конденсаторы, индукторы и т.п.), интегральные схемы, специализированные интегральные схемы (ASIC), программируемые логические устройства (PLD), процессоры цифровых сигналов (DSP), программируемую пользователем вентильную матрицу (FPGA), логические вентили, регистры, полупроводниковые устройства, микросхемы, небольшие микросхемы, наборы микросхем и т.п. В некоторых вариантах осуществления, один или более процессоров могут реализовываться как процессоры на базе архитектуры компьютера со сложным набором команд (CISC) или компьютера с сокращенным набором команд (RISC); совместимые с x86-набором команд процессоры, многоядерный или любой другой микропроцессор или центральный процессор (CPU). В различных реализациях, один или более процессоров могут представлять собой двухъядерный процессор(ы), двухъядерный мобильный процессор(ы) и т.д.
[0028] Примеры программного обеспечения могут включать в себя программные компоненты, программы, приложения, компьютерные программы, прикладные программы, системные программы, машинные программы, программное обеспечение операционной системы, промежуточное программное обеспечение, микропрограммное обеспечение, программные модули, стандартные программы, подпрограммы, функции, методы, процедуры, программные интерфейсы, интерфейсы прикладного программирования (API), наборы инструкций, вычислительный код, компьютерный код, сегменты кода, сегменты компьютерного кода, слова, значения, символы либо любое их сочетание. Определение того, реализуется ли вариант осуществления с использованием аппаратных элементов и/или программных элементов, может варьироваться в соответствии с любым числом факторов, таких как требуемая скорость вычислений, уровни мощности, теплостойкость, бюджет цикла обработки, скорости передачи входных данных, скорости передачи выходных данных, ресурсы запоминающего устройства, скорости шин данных и другие проектные ограничения или ограничения по производительности.
[0029] Один или более аспектов по меньшей мере одного варианта осуществления могут реализовываться посредством характерных инструкций, сохраненных на машиночитаемом носителе, которые представляют различную логику в процессоре, которые, при считывании посредством машины, предписывают машине создавать логику, чтобы выполнять технологии, описанные в данном документе. Такие представления, известные как «IP-ядра», могут сохраняться на материальном машиночитаемом носителе и передаваться различным клиентам или на различные заводы для загрузки в производственное оборудование, которое создает логику или процессор. Следует отметить, что различные варианты осуществления, описанные в данном документе, конечно, могут реализовываться с использованием любых соответствующих аппаратных средств и/или языков для создания вычислительного программного обеспечения (например, C++, Objective C, Swift, Java, JavaScript, Python, Perl, QT и т.д.).
[0030] В некоторых вариантах осуществления, одно или более примерных компьютерных устройств согласно изобретению по настоящему изобретению могут включать в себя или включаться, частично или полностью по меньшей мере в один персональный компьютер (PC), переносной компьютер, ультрапереносной компьютер, планшетный компьютер, сенсорную панель, портативный компьютер, карманный компьютер, карманный компьютер, карманный персональный компьютер (PDA), сотовый телефон, комбинированный сотовый телефон/PDA, телевизионный приемник, интеллектуальное устройство (например, смартфон, интеллектуальный планшетный компьютер или интеллектуальный телевизионный приемник), мобильное Интернет-устройство (MID), устройство для обмена сообщениями, устройство обмена данными и т.д.
[0031] При использовании в данном документе следует понимать, что термин «сервер» означает точку оказания услуг, которая обеспечивает средства обработки, управления базами данных и связи. В качестве примера, а не ограничения, термин «сервер» может означать один физический процессор с ассоциированными средствами связи и хранения данных и управления базами данных, либо он может означать сетевой или кластеризованный комплекс процессоров и ассоциированных сетевых устройств и устройств хранения данных, а также системного программного обеспечения и одной или более систем баз данных и прикладного программного обеспечения, которые поддерживают услуги, оказываемые посредством сервера. Облачные серверы представляют собой примеры.
[0032] В некоторых вариантах осуществления, как подробно описано в данном документе, одна или более примерных компьютерных систем согласно изобретению по настоящему изобретению могут получать, обрабатывать, передавать, сохранять, преобразовывать, формировать и/или выводить любой цифровой объект и/или единицу данных (например, изнутри и/или за пределами конкретного варианта применения), которая может иметь любую подходящую форму, к примеру, без ограничения, файла, контакта, задачи, почтового сообщения, твита, карты, целого приложения (например, калькулятора) и т.д. В некоторых вариантах осуществления, как подробно описано в данном документе, одна или более примерных компьютерных систем согласно изобретению по настоящему изобретению могут быть реализованы через одну или более различных компьютерных платформ, таких как, не ограничиваясь: (1) AmigaOS, AmigaOS 4, (2) FreeBSD, NetBSD, OpenBSD, (3) Linux, (4) Microsoft Windows, (5) OpenVMS, (6) OS X (Mac OS), (7) OS/2, (8) Solaris, (9) Tru64 UNIX, (10) VM, (11) Android, (12) Bada, (13) BlackBerry OS, (14) Firefox OS, (15) iOS, (16) Embedded Linux, (17) Palm OS, (18) Symbian, (19) Tizen, (20) WebOS, (21) Windows Mobile, (22) Windows Phone, (23) Adobe AIR, (24) Adobe Flash, (25) Adobe Shockwave, (26) Binary Runtime Environment for Wireless (BREW), (27) Cocoa (API), (28) Cocoa Touch, (29) Java Platforms, (30) JavaFX, (31) JavaFX Mobile, (32) Microsoft XNA, (33) Mono, (34) Mozilla Prism, XUL and XULRunner, (35).NET Framework, (36) Silverlight, (37) Open Web Platform, (38) Oracle Database, (39) Qt, (40) SAP NetWeaver, (41) Smartface, (42) Vexi и (43) Windows Runtime.
[0033] В некоторых вариантах осуществления, примерные компьютерные системы согласно изобретению и/или примерные компьютерные устройства согласно изобретению по настоящему изобретению могут быть выполнены с возможностью использования аппаратно реализованной схемы, которая может использоваться вместо или в сочетании с программными инструкциями для реализации признаков в соответствии с принципами изобретения. Таким образом, реализации, согласованные с принципами изобретения, не ограничены каким-либо конкретным сочетанием аппаратной схемы и программного обеспечения. Например, различные варианты осуществления могут осуществляться множеством различных способов в качестве программного компонента, к примеру, без ограничения, автономного программного пакета, сочетания программных пакетов, либо они могут представлять собой программный пакет, включенный в качестве «инструментального средства» в больший программный продукт.
[0034] Например, примерное программное обеспечение, специально программируемое в соответствии с одним или более принципов настоящего изобретения, может быть загружаемым из сети, например, из веб-узла, в качестве автономного продукта или в качестве надстраиваемого пакета для установки в существующем программном приложении. Например, примерное программное обеспечение, специально программируемое в соответствии с одним или более принципов настоящего изобретения, также может быть доступным в качестве клиент-серверного программного приложения или в качестве программного веб-приложения. Например, примерное программное обеспечение, специально программируемое в соответствии с одним или более принципов настоящего изобретения, также может осуществляться в качестве программного пакета, установленного на аппаратном устройстве.
[0035] В некоторых вариантах осуществления, примерные компьютерные системы/платформы согласно изобретению, примерные компьютерные устройства согласно изобретению и/или примерные компьютерные компоненты согласно изобретению по настоящему изобретению могут быть выполнены с возможностью обработки множества параллельных пользователей, которые могут составлять, не ограничиваясь, по меньшей мере 100 (например, не ограничиваясь, 100-999) по меньшей мере 1000 (например, не ограничиваясь, 1000-9999) по меньшей мере 10000 (например, не ограничиваясь, 10000-99999) по меньшей мере 100000 (например, не ограничиваясь, 100000-999999) по меньшей мере 1000000 (например, не ограничиваясь, 1000000-9999999) по меньшей мере 10000000 (например, не ограничиваясь, 10000000-99999999) по меньшей мере 100000000 (например, не ограничиваясь, 100000000-999999999) по меньшей мере 1000000000 (например, не ограничиваясь, 1000000000-10000000000).
[0036] В некоторых вариантах осуществления, примерные компьютерные системы согласно изобретению и/или примерные компьютерные устройства согласно изобретению по настоящему изобретению могут быть выполнены с возможностью вывода в отдельные реализации специально программируемого графического пользовательского интерфейса настоящего изобретения (например, в настольное приложение, веб-приложение и т.д.). В различных реализациях настоящего изобретения, конечный вывод может отображаться на отображающем экране, который, без ограничения, может представлять собой экран компьютера, экран мобильного устройства и т.п. В различных реализациях, дисплей может представлять собой голографический дисплей. В различных реализациях, дисплей может представлять собой прозрачную поверхность, которая может принимать визуальную проекцию. Такие проекции могут передавать различные формы информации, изображений и/или объектов. Например, такие проекции могут представлять собой визуальное наложение для приложения в стиле мобильной дополненной реальности (MAR).
[0037] При использовании в данном документе, термины «облако», «Интернет-облако», «облачные вычисления», «облачная архитектура» и аналогичные термины соответствуют по меньшей мере одному из следующего: (1) большое число компьютеров, соединенных через сеть связи в реальном времени (например, Интернет); (2) обеспечение возможности одновременного выполнения программы или приложения на множестве соединенных компьютеров (например, физических машин, виртуальных машин (VM)); (3) сетевые услуги, которые очевидно оказываются посредством реальных серверных аппаратных средств и фактически обслуживаются посредством виртуальных аппаратных средств (например, виртуальных серверов), моделированных посредством программного обеспечения, выполняющегося на одной или более реальных машин (например, с обеспечением возможности перемещения и увеличения (или уменьшения)непосредственного масштабирования без влияния на конечного пользователя).
[0038] В некоторых вариантах осуществления, примерные компьютерные системы согласно изобретению и/или примерные компьютерные устройства согласно изобретению по настоящему изобретению могут быть выполнены с возможностью защищенного сохранения и/или передачи данных посредством использования одной или более технологий шифрования (например, технологии на основе пары закрытого/открытого ключа, стандарта тройного шифрования данных (3DES), алгоритмов блочного шифрования (например, IDEA, RC2, RC5, CAST и Skipjack), криптографических хэш-алгоритмов (например, MD5, RIPEMD-160, RTR0, SHA-1, SHA-2, Tiger (TTH),WHIRLPOOL, RNG).
[0039] Вышеуказанные примеры, конечно, являются иллюстративными, а не ограничивающими.
[0040] При использовании в данном документе, термин «пользователь» должен иметь смысловое значение по меньшей мере одного пользователя. В некоторых вариантах осуществления, следует понимать, что термины «пользователь», «абонент», «потребитель» или «клиент» означают пользователя приложения или приложений, как описано в данном документе, и/или потребителя данных, обеспечиваемые поставщиком данных. В качестве примера, а не ограничения, термины «пользователь» или «абонент» могут означать пользователя, который принимает данные, обеспечиваемые поставщиком данных или услуг по Интернету в сеансе браузера, либо могут означать автоматизированное программное приложение, которое принимает данные и сохраняет или обрабатывает данные.
[0041] Фиг. 1 иллюстрирует блок-схему примерной компьютерной системы 100 для уменьшения отклонения в машинном обучении в соответствии с одним или более вариантов осуществления настоящего изобретения. Тем не менее, не все эти компоненты могут требоваться для осуществления на практике одного или более вариантов осуществления, и варьирования в компоновку и тип компонентов могут вноситься без отступления от сущности или объема различных вариантов осуществления настоящего изобретения. В некоторых вариантах осуществления, примерные вычислительные устройства согласно изобретению и/или примерные вычислительные компоненты согласно изобретению в примерной компьютерной системе 100 могут быть выполнены с возможностью управления большим числом членов и/или параллельных транзакций, как подробно описано в данном документе. В некоторых вариантах осуществления, примерная компьютерная система/платформа 100 может быть основана на масштабируемой компьютерной и/или сетевой архитектуре, которая включает варьирующиеся стратегии для оценки данных, кэширования, выполнения поиска и/или объединения в пул соединений с базой данных, включающие в себя уменьшение динамического отклонения, обусловленного выбросовыми значениями (DOBR), как описано в вариантах осуществления в данном документе. Пример масштабируемой архитектуры представляет собой архитектуру, которая допускает работу нескольких серверов.
[0042] В некоторых вариантах осуществления, обращаясь к фиг. 1, члены 102-104 (например, клиенты) примерной компьютерной системы 100 могут включать в себя фактически любое вычислительное устройство, допускающее прием и отправку сообщения по сети (например, по облачной сети), к примеру, сети 105, в/из другого вычислительного устройства, к примеру, серверов 106 и 107, между собой и т.п. В некоторых вариантах осуществления, устройства-члены 102-104 могут представлять собой персональные компьютеры, многопроцессорные системы, микропроцессорные или программируемые бытовые электронные приборы, сетевые PC и т.п. В некоторых вариантах осуществления, одно или более устройств-членов в устройствах-членах 102-104 могут включать в себя вычислительные устройства, которые типично соединяются с использованием беспроводной среды связи, такие как сотовые телефоны, смартфоны, устройства поискового вызова, рации, радиочастотные (RF) устройства, инфракрасные (IR) устройства, CB, интегрированные устройства, комбинирующие одно или более предыдущих устройств, либо фактически любое мобильное вычислительное устройство и т.п. В некоторых вариантах осуществления, одно или более устройств-членов в устройствах-членах 102-104 могут представлять собой устройства, которые допускают соединение с использованием носителя проводной или беспроводной связи, такие как PDA, карманный компьютер, носимый компьютер, переносной компьютер, планшетный компьютер, настольный компьютер, нетбук, устройство для видеоигр, устройство поискового вызова, смартфон, ультрамобильный персональный компьютер (UMPC) и/или любое другое устройство, которое оснащается возможностями обмениваться данными по проводной и/или беспроводной среде связи (например, NFC, RFID, NBIoT, 3G, 4G, 5G, GSM, GPRS, Wi-Fi, WiMAX, CDMA, спутниковая связь, ZigBee и т.д.). В некоторых вариантах осуществления, одно или более устройств-членов в устройствах-членах 102-104 могут включать в себя, могут выполнять одно или более приложений, таких как Интернет-браузеры, мобильные приложения, голосовые вызовы, видеоигры, видеоконференц-связь и электронная почта, в числе других. В некоторых вариантах осуществления, одно или более устройств-членов в устройствах-членах 102-104 могут быть выполнены с возможностью приёма и отправки веб-страниц и т.п. В некоторых вариантах осуществления, примерное специально программируемое приложение браузера настоящего изобретения может быть выполнено с возможностью приёма и отображения графики, текста, мультимедиа и т.п. с использованием фактически любого веб-языка, включающего в себя, но не только, стандартный обобщенный язык разметки (SMGL), такой как язык разметки гипертекста (HTML), прикладной протокол беспроводной связи (WAP), язык разметки для карманных устройств (HDML), такой как язык разметки для беспроводной связи (WML), WMLScript, XML, JavaScript и т.п. В некоторых вариантах осуществления, устройство-член в устройствах-членах 102-104 может специально программироваться посредством Java.NET, QT, C, C++ и/или другого подходящего языка программирования. В некоторых вариантах осуществления, одно или более устройств-членов в устройствах-членах 102-104 могут специально программироваться таким образом, что они включают в себя или выполняют приложение для выполнения множества возможных задач, таких как, без ограничения, функциональность обмена сообщениями, просмотр, выполнение поиска, воспроизведение, потоковая передача или отображение различных форм контента, включающих в себя локально сохраненные или выгруженные сообщения, изображения и/или видео и/или игры.
[0043] В некоторых вариантах осуществления, примерная сеть 105 может обеспечивать сетевой доступ, транспортировку данных и/или другие услуги в любое вычислительное устройство, соединенное с ней. В некоторых вариантах осуществления, примерная сеть 105 может включать в себя и реализовывать по меньшей мере одну специализированную сетевую архитектуру, которая может быть основана по меньшей мере частично на одном или более стандартов, заданных, например, посредством, без ограничения, ассоциации по разработке стандартов глобальной системы мобильной связи (GSM), инженерной группы по развитию Интернета (IETF) и форума по разработке стандартов общемировой совместимости широкополосного беспроводного доступа (WiMax). В некоторых вариантах осуществления, примерная сеть 105 может реализовывать одно или более из архитектуры GSM, архитектуры на основе стандарта общей службы пакетной радиопередачи (GPRS), архитектуры на основе стандарта универсальной системы мобильной связи (UMTS) и развития архитектуры UMTS, называемого «стандартом долгосрочного развития (LTE)». В некоторых вариантах осуществления, примерная сеть 105 может включать в себя и реализовывать, в качестве альтернативы или в сочетании с одним или более из вышеуказанного, WiMAX-архитектуру, заданную посредством WiMAX-форума. В некоторых вариантах осуществления и, при необходимости, в сочетании любых вариантов осуществления, описанных выше или ниже, примерная сеть 105 также может включать в себя, например по меньшей мере одно из локальной вычислительной сети (LAN), глобальной вычислительной сети (WAN), Интернета, виртуальной LAN (VLAN), корпоративной LAN, виртуальной частной сети (VPN) уровня 3, корпоративной IP-сети либо любого их сочетания. В некоторых вариантах осуществления и, при необходимости, в сочетании любых вариантов осуществления, описанных выше или ниже по меньшей мере одна компьютерная сетевая связь по примерной сети 105 может передаваться по меньшей мере частично на основе одного из более режимов связи, таких как, но не только: NFC, RFID, узкополосный Интернет вещей (NBIoT), ZigBee, 3G, 4G, 5G, GSM, GPRS, Wi-Fi, WiMAX, CDMA, спутниковая связь и любое их сочетание. В некоторых вариантах осуществления, примерная сеть 105 также может включать в себя систему хранения данных большой емкости, такое как система хранения данных с подключением по сети (NAS), сеть хранения данных (SAN), сеть доставки контента (CDN) или другие формы компьютерных или машиночитаемых носителей.
[0044] В некоторых вариантах осуществления, примерный сервер 106 или примерный сервер 107 может представлять собой веб-сервер (или набор серверов), работающим под управлением сетевой операционной системы, примеры которого могут включать в себя, но не только, Microsoft Windows Server, Novell NetWare или Linux. В некоторых вариантах осуществления, примерный сервер 106 или примерный сервер 107 может использоваться для и/или обеспечивать облачные и/или сетевые вычисления. Хотя не показано на фиг. 1, в некоторых вариантах осуществления, примерный сервер 106 или примерный сервер 107 может иметь соединения с внешними системами, такими как электронная почта, обмен SMS-сообщениями, обмен текстовыми сообщениями, поставщики рекламного контента и т.д. Любой из признаков примерного сервера 106 также может реализовываться в примерном сервере 107, и наоборот.
[0045] В некоторых вариантах осуществления, один или более примерных серверов 106 и 107 могут специально программироваться с возможностью работы, в неограничивающем примере, в качестве серверов аутентификации, поисковых серверов, почтовых серверов, серверов обеспечения услуг общения в социальных сетях, серверов SMS, серверов IM, серверов MMS, обменных серверов, серверов оказания услуг обмена фотографиями, серверов оказания рекламных услуг, серверов оказания финансовых/банковских услуг, серверов оказания туристических услуг либо любых аналогично подходящих серверов оказания услуг для пользователей вычислительных устройств-членов 101-104.
[0046] В некоторых вариантах осуществления и, при необходимости, в сочетании любых вариантов осуществления, описанных выше или ниже, например, одно или более примерных вычислительных устройств-членов 102-104, примерный сервер 106 и/или примерный сервер 107 могут включать в себя специально программируемый программный модуль, который может быть выполнен с возможностью отправки, обработки и приёма информации с использованием языка подготовки сценариев, удаленного вызова процедур, электронной почты, твита, службы коротких сообщений (SMS), службы мультимедийных сообщений (MMS), мгновенного обмена сообщениями (IM), ретранслируемого Интернет-чата (IRC), mIRC, Jabber, интерфейса прикладного программирования, способов взаимодействия на основе простого протокола доступа к объектам (SOAP), общей архитектуры посредника запросов к объектам (CORBA), HTTP (протокола передачи гипертекста), REST (передачи репрезентативного состояния) либо любого их сочетания.
[0047] Фиг. 2 иллюстрирует блок-схему другой примерной компьютерной системы/платформы 200 в соответствии с одним или более вариантов осуществления настоящего изобретения. Тем не менее, не все эти компоненты могут требоваться для осуществления на практике одного или более вариантов осуществления, и изменения конфигурации и типа компонентов могут вноситься без отступления от сущности или объема различных вариантов осуществления настоящего изобретения. В некоторых вариантах осуществления, показанные вычислительные устройства-члены 202a, 202b-202n включают в себя по меньшей мере машиночитаемый носитель, такой как оперативное запоминающее устройство 208 (RAM), соединенное с процессором 210, или флэш-память. В некоторых вариантах осуществления, процессор 210 может выполнять машиноисполняемые программные инструкции, сохраненные в запоминающем устройстве 208. В некоторых вариантах осуществления, процессор 210 может включать в себя микропроцессор, ASIC и/или машину состояний. В некоторых вариантах осуществления, процессор 210 может включать в себя или может поддерживать связь с носителями, например, с машиночитаемыми носителями, которые сохраняют инструкции, которые, при выполнении посредством процессора 210, могут предписывать процессору 210 выполнять один или более этапов, описанных в данном документе. В некоторых вариантах осуществления, примеры машиночитаемых носителей могут включать в себя, но не только, электронное, оптическое, магнитное или другое устройство хранения или передачи данных, допускающее передачу в процессор, к примеру, в процессор 210 клиента 202a, машиночитаемых инструкций. В некоторых вариантах осуществления, другие примеры подходящих носителей могут включать в себя, но не только, гибкий диск, CD-ROM, DVD, магнитный диск, микросхему запоминающего устройства, ROM, RAM, ASIC, сконфигурированный процессор, все оптические носители, все магнитные ленты или другие магнитные носители либо любой другой носитель, с которого компьютерный процессор может считывать инструкции. Также различные другие формы машиночитаемых носителей могут передавать или переносить инструкции в компьютер, включающие в себя маршрутизатор, частную сеть или сеть общего пользования либо другое устройство или канал передачи, как проводной, так и беспроводной. В некоторых вариантах осуществления, инструкции могут содержать код из любого машинного языка программирования, включающего в себя, например, C, C++, Visual Basic, Java, Python, Perl, JavaScript и т.д.
[0048] В некоторых вариантах осуществления, вычислительные устройства-члены 202a-202n также могут содержать определенное число внешних или внутренних устройств, таких как мышь, CD-ROM, DVD, физическая или виртуальная клавиатура, дисплей либо другие устройства ввода или вывода. В некоторых вариантах осуществления, примеры вычислительных устройств-членов 202a-202n (например, клиентов) могут представлять собой любой тип процессорных платформ, которые соединяются с сетью 206, таких как, без ограничения, персональные компьютеры, цифровые помощники, персональные цифровые устройства, смартфоны, устройства поискового вызова, цифровые планшетные компьютеры, переносные компьютеры, приборы с подключением к Интернету и другие процессорные устройства. В некоторых вариантах осуществления, вычислительные устройства-члены 202a-202n могут специально программироваться с одной или более прикладных программ в соответствии с одними или более принципов/технологий, подробно описанных в данном документе. В некоторых вариантах осуществления, вычислительные устройства-члены 202a-202n могут работать в любой операционной системе, допускающей поддержку браузера или приложения с возможностями браузера, такого как Microsoft™, Windows™ и/или Linux. В некоторых вариантах осуществления, показанные вычислительные устройства-члены 202a-202n могут включать в себя, например, персональные компьютеры, выполняющие прикладную программу браузера, такую как Internet Explorer™ компании Microsoft Corporation, Safari™ компании Apple Computer, Inc., Mozilla Firefox и/или Opera. В некоторых вариантах осуществления, через вычислительные клиентские устройства-члены 202a-202n, пользователи, 212a-212n, могут обмениваться данными по примерной сети 206 друг с другом и/или с другими системами и/или устройствами, соединенными с сетью 206. Как показано на фиг. 2, примерные серверные устройства 204 и 213 также могут соединяться с сетью 206. В некоторых вариантах осуществления, одно или более вычислительных устройств-членов 202a-202n могут представлять собой мобильные клиенты.
[0049] В некоторых вариантах осуществления по меньшей мере одна база данных из примерных баз 207 и 215 данных может представлять собой любой тип базы данных, включающий в себя базу данных, управляемую посредством системы управления базами данных (DBMS). В некоторых вариантах осуществления, примерная DBMS-управляемая база данных может специально программироваться в качестве механизма, который управляет организацией, хранением, управлением и/или извлечением данных в соответствующей базе данных. В некоторых вариантах осуществления, примерная DBMS-управляемая база данных может специально программироваться с обеспечения возможности выполнения запроса, резервирования и репликации, принудительной активации правил, обеспечения безопасности, вычисления, выполнения регистрации изменений и доступа и/или автоматизации оптимизации. В некоторых вариантах осуществления, примерная DBMS-управляемая база данных может выбираться из базы данных Oracle, IBM DB2, Adaptive Server Enterprise, FileMaker, Microsoft Access, Microsoft SQL Server, MySQL-, PostgreSQL- и NoSQL-реализации. В некоторых вариантах осуществления, примерная DBMS-управляемая база данных может специально программироваться с возможностью задания каждой соответствующей схемы каждой базы данных в примерной DBMS, согласно конкретной модели баз данных настоящего изобретения, которая может включать в себя иерархическую модель, сетевую модель, реляционную модель, объектную модель или некоторую другую подходящую организацию, которая может приводить к одной или более применимых структур данных, которые могут включать в себя поля, записи, файлы и/или объекты. В некоторых вариантах осуществления, примерная DBMS-управляемая база данных может специально программироваться с возможностью включения метаданных, относящихся к сохраняемым данным.
[0050] В некоторых вариантах осуществления, примерные компьютерные системы/платформы согласно изобретению, примерные компьютерные устройства согласно изобретению и/или примерные компьютерные компоненты согласно изобретению по настоящему изобретению, в частности, могут быть выполнены с возможностью работы в облачной вычислительной архитектуре, такой как, но не только: инфраструктура как услуга (IaaS), платформа как услуга (PaaS) и/или программное обеспечение как услуга (SaaS). Фиг. 3 и 4 иллюстрируют схематические виды примерных реализаций облачной вычислительной архитектуры, в которой примерные компьютерные системы/платформы согласно изобретению, примерные компьютерные устройства согласно изобретению и/или примерные компьютерные компоненты согласно изобретению по настоящему изобретению, в частности, могут быть выполнены с возможностью работы.
[0051] В вариантах осуществления примерных компьютерных систем и/или устройств согласно изобретению, уменьшение динамического отклонения, обусловленного выбросовыми значениями (DOBR) может использоваться для повышения точности и понимания обобщенных линейных моделей специально для исследований на основе сравнительного тестирования. Тем не менее, оно представляет собой способ, который может применяться к широкому спектру аналитических моделей, в которых имеются одна или более независимых переменных и одна зависимая переменная. Настоящее изобретение и его варианты осуществления иллюстрируют применение DOBR согласно изобретению для повышения точности прогнозирований на основе модели машинного обучения.
[0052] В вариантах осуществления, DOBR не представляет собой прогнозирующую модель. Вместо этого, в вариантах осуществления, оно представляет собой надстраиваемый способ для прогнозирующих или интерпретирующих моделей, который позволяет повышать точность прогнозирований на основе модели. В вариантах осуществления, идентифицированные DOBR выбросовые значения основаны на разности между целевой переменной на основе обеспечиваемых данных и вычисленным с помощью модели значением. По мере того, как выбросовые значения идентифицируются, через предварительно определенный критерий выбора, зависимые от выбросовых значений записи данных и сформированные посредством модели зависимые переменные удаляются из анализа. Дополнительный анализ может продолжаться с этими записями, постоянно удаленными. Тем не менее, в других вариантах осуществления примерной системы и способов согласно изобретению, на каждой модельной итерации, процесс идентификации выбросовых данных включает в себя весь набор данных таким образом, что все записи подвергаются тщательному исследованию выбросовых значений с использованием прогнозирующей модели последней итерации, заданной посредством параметров вычисления. Соответственно, примерные варианты осуществления настоящего изобретения уменьшают отклонение в модели машинного обучения, например, посредством включения всего набора данных на каждой итерации, чтобы уменьшать распространение отклонения выбора обучающих данных. Таким образом, модели машинного обучения могут обучаться и реализовываться более точно и более эффективно для улучшения работы систем машинного обучения.
[0053] Фиг. 5 иллюстрирует блок-схему примерной системы уменьшения отклонения в машинном обучении согласно изобретению в соответствии с одним или более вариантов осуществления настоящего изобретения.
[0054] В некоторых вариантах осуществления, система 300 уменьшения отклонения может включать в себя компонент для уменьшения динамического отклонения, обусловленного выбросовыми значениями (DOBR) в наборах данных при анализе, например, посредством механизмов машинного обучения. В некоторых вариантах осуществления, DOBR обеспечивает итеративный процесс для удаления выбросовых записей согласно предварительно заданному критерию. Это условие представляет собой определяемое пользователем значение приемлемости ошибки, выражаемое как процентная доля. Это означает то, какую часть ошибки пользователь имеет намерение считать приемлемой в модели потенциально на основе своего понимания и других результатов анализа, которые описываются ниже в этом пояснении. Значение в 100% обозначает то, что ошибка считается полностью приемлемой, и записи не должны удаляться в процессе DOBR. Если выбирается 0%, то все записи удаляются. В общем, значения приемлемости ошибки в диапазоне 80-95% наблюдаются для промышленных вариантов применения.
[0055] В некоторых вариантах осуществления, пользователь может взаимодействовать с системой 300 уменьшения отклонения, чтобы администрировать значение приемлемости ошибки через устройство 308 пользовательского ввода и просматривать результаты через устройство 312 отображения, в числе других поведений пользовательского взаимодействия с использованием устройства 312 отображения и устройства 308 пользовательского ввода. На основе значения приемлемости ошибки, система 300 уменьшения отклонения может анализировать набор 311 данных, принимаемый в базе 310 данных или в другом устройстве хранения данных, поддерживающем связь с системой 300 уменьшения отклонения. Система 300 уменьшения отклонения может принимать набор 311 данных через базу 310 данных или другое устройство хранения данных и выполнять прогнозирования с использованием одной или более моделей машинного обучения с уменьшением динамического отклонения, обусловленного выбросовыми значениями, для повышенной точности и эффективности.
[0056] В некоторых вариантах осуществления, система 300 уменьшения отклонения включает в себя сочетание аппаратных и программных компонентов, включающих в себя, например, устройства хранения данных и запоминающие устройства, кэш, буферы, шину, интерфейсы ввода-вывода, процессоры, контроллеры, сетевые устройства и устройства связи, операционную систему, ядро, драйверы устройств, в числе других компонентов. В некоторых вариантах осуществления, процессор 307 поддерживает связь с несколькими другими компонентами, чтобы реализовывать функции других компонентов. В некоторых вариантах осуществления, каждый компонент имеет время, планируемое в процессоре 307 для выполнения компонентных функций; тем не менее, в некоторых вариантах осуществления, каждый компонент планируется в один или более процессоров в системе обработки процессора 307. В других вариантах осуществления, каждый компонент имеет включенный собственный процессор.
[0057] В некоторых вариантах осуществления, компоненты системы 300 уменьшения отклонения могут включать в себя, например, механизм 301 DOBR, поддерживающий связь с индексом 302 модели и библиотекой 303 моделей, библиотеку 305 регрессионных параметров, библиотеку 304 классификационных параметров и фильтр 306 DOBR, в числе других возможных компонентов. Каждый компонент может включать в себя сочетание аппаратных средств и программного обеспечения, чтобы реализовывать компонентные функции, таких как, например, запоминающие устройства и устройства хранения данных, обрабатывающие устройства, устройства связи, интерфейсы ввода-вывода, контроллеры, сетевые устройства и устройства связи, операционная система, ядро, драйверы устройств, набор инструкций, в числе других компонентов.
[0058] В некоторых вариантах осуществления, механизм 301 DOBR включает в себя модельный механизм для создания экземпляра и выполнения моделей машинного обучения. Механизм 301 DOBR может осуществлять доступ к моделям для создания экземпляра в библиотеке 303 моделей с помощью индекса 302 модели. Например, библиотека 303 моделей может включать в себя библиотеку моделей машинного обучения, которые могут быть избирательно доступными и подвергаться созданию экземпляра для использования посредством механизма, такого как механизм 301 DOBR. В некоторых вариантах осуществления, библиотека 303 моделей может включать в себя модели машинного обучения, такие как, например, метод опорных векторов (SVM), линейный регрессор, модель LASSO, регрессоры на основе дерева решений, классификаторы на основе дерева решений, регрессоры на основе случайного леса, классификаторы на основе случайного леса, регрессоры на основе принципа K соседних узлов, классификаторы на основе принципа K соседних узлов, регрессоры на основе градиентного бустинга, классификаторы на основе градиентного бустинга, в числе других возможных классификаторов и регрессоров. Например, библиотека 303 моделей может импортировать модели согласно нижеприведенному примерному псевдокоду 1:
Псевдокод 1
import sys
sys.path.append("analytics-lanxess-logic")
import numpy as np
import pandas as pd
import random, time
import xgboost as xgb
from xgboost import XGBClassifier, XGBRegressor
from scipy import stats
from scipy.stats import mannwhitneyu, wilcoxon
from sklearn.metrics import mean_squared_error, roc_auc_score, classification_report, confusion_matrix
from sklearn import svm
from sklearn.svm import SVR, SVC
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression, Lasso
from sklearn.tree import DecisionTreeRegressor, DecisionTreeClassifier
from sklearn.ensemble import RandomForestRegressor, RandomForestClassifier, BaggingClassifier,BaggingRegressor
from sklearn.neighbors import KNeighborsRegressor , KNeighborsClassifier
from sklearn.ensemble import GradientBoostingRegressor, GradientBoostingClassifier
from optimizers.hyperparameters.hyperband_optimizer import Hyperband, HyperparameterOptimizer
from optimizers.hyperparameters.base_optimizer import HyperparameterOptimizer
import warnings
from warnings import simplefilter
simplefilter(action='ignore', category=FutureWarning)
simplefilter(action='ignore', category=DeprecationWarning)
warnings.filterwarnings(module='numpy*' , action='ignore', category=DeprecationWarning)
warnings.filterwarnings(module='numpy*' , action='ignore', category=FutureWarning)
warnings.filterwarnings(module='scipy*' , action='ignore', category=FutureWarning)
warnings.filterwarnings(module='scipy*' , action='ignore', category=DeprecationWarning)
warnings.filterwarnings(module='sklearn*', action='ignore', category=DeprecationWarning)
[0059] Тем не менее, в некоторых вариантах осуществления, чтобы упрощать доступ к библиотеке моделей машинного обучения в библиотеке 303 моделей, механизм 301 DOBR может использовать индекс 302 модели, который индексирует каждую модель согласно идентификатору модели, который следует использовать в качестве функции посредством механизма 301 DOBR. Например, модели, включающие в себя, например, линейную регрессию, регрессию XGBoost, регрессию на основе метода опорных векторов, регрессию LASSO, регрессию на основе принципа K соседних узлов, регрессию на основе принципа улучшения агрегации, регрессию на основе градиентного бустинга, регрессию на основе случайного леса, регрессия на основе дерева решений, в числе других регрессионных моделей и моделей классификации, могут индексироваться посредством числового идентификатора и помечаться с помощью названия. Например, нижеприведенный псевдокод 2 иллюстрирует пример индексного кода модели для использования посредством индекса 302 модели.
Псевдокод 2
model0=LinearRegression()
model1=xgb.XGBRegressor()
model2=SVR()
model3=Lasso()
model4=KNeighborsRegressor()
model5=BaggingRegressor()
model6=GradientBoostingRegressor()
model7=RandomForestRegressor()
model8=DecisionTreeRegressor()
#
ModelName0=" Linear Regression"
ModelName1="XGBoost Regression"
ModelName2="Support Vector Regression"
ModelName3=" Lasso"
ModelName4="K Neighbors Regression"
ModelName5="Bagging Regression"
ModelName6="Gradient Boosting Regression"
ModelName7="Random Forest Regression"
ModelName8="Decision Tree Regression"
[0060] Другие варианты осуществления псевдокода для библиотеки 303 моделей и индекса 302 модели предполагаются. В некоторых вариантах осуществления, программные инструкции сохраняются в запоминающем устройстве соответствующей библиотеки 303 моделей или индекса 302 модели и буферизуются в кэше для передачи в процессор 307. В некоторых вариантах осуществления, механизм 301 DOBR может использовать индекс 302 модели посредством осуществления доступа или вызова индекса через связь и/или устройства ввода-вывода, использовать индекс для вызова моделей в качестве функций из библиотеки 303 моделей через устройства связи и/или ввода-вывода.
[0061] В некоторых вариантах осуществления, чтобы упрощать оптимизацию и индивидуальную настройку моделей, вызываемых посредством механизма 301 DOBR, система 300 уменьшения отклонения может записывать параметры модели, например, в запоминающее устройство или устройство хранения данных, такое как, например, жесткие диски, полупроводниковые накопители, оперативное запоминающее устройство (RAM), флэш-память, в числе других устройств хранения данных и запоминающих устройств. Например, регрессионные параметры могут регистрироваться и регулироваться в библиотеке 305 регрессионных параметров. Таким образом, библиотека 305 регрессионных параметров может включать в себя аппаратные средства хранения данных и связи, сконфигурированные с достаточным объемом запоминающего устройства и полосой пропускания, чтобы сохранять, регулировать и передавать множество параметров для нескольких регрессоров, например, в реальном времени. Например, для каждой регрессионной модели машинного обучения, подвергающейся созданию экземпляра посредством механизма 301 DOBR, соответствующие параметры могут инициализироваться и обновляться в библиотеке 305 регрессионных параметров. В некоторых вариантах осуществления, пользователь, через устройство 308 пользовательского ввода, может устанавливать начальный набор параметров. Тем не менее, в некоторых вариантах осуществления, начальный набор параметров может предварительно определяться или случайно формироваться. После создания экземпляра регрессионной модели машинного обучения, механизм 301 DOBR может коррелировать модель, идентифицированную в индексе 302 модели, с набором параметров в библиотеке 305 регрессионных параметров. Например, механизм 301 DOBR может вызывать набор параметров, например, согласно идентификационному номеру, ассоциированному с данной регрессионной моделью. Например, библиотека 305 регрессионных параметров может идентифицировать параметры для каждой регрессионной модели, аналогично нижеприведенному псевдокоду 3:
Псевдокод 3
#from utilities.defaults import DefaultParameters
#print(DefaultParameters(ctr=0).__dict__)
#!conda install -y -c conda-forge xgboost
def gen_params(id):
# XGBoost
if id==1:
""" default parameters - best achieved in prototyping XGBOOST """
HYPERPARAMETERS={"objective": "reg:linear",
"tree_method": "exact",
"eval_metric": "rmse",
"eta": 1,
"gamma": 5,
"max_depth": 2,
"colsample_bytree": .5,
"colsample_bylevel": .5,
"min_child_weight": 1,
"subsample": 1,
"reg_lambda": 1,
"reg_alpha": 0,
"silent": 1}
""" fixed parameters which will not change in optimisation """
FIXED={"objective": "reg:linear",
"tree_method": "exact",
"eval_metric": "rmse"}
""" boundaries & types of optimisable parameters """
BOUNDARIES={"eta": (0, 1, np.float64),
"gamma": (0, 100, np.float64),
"max_depth": (1, 30, np.int32),
"colsample_bytree": (0, 1, np.float64),
"colsample_bylevel": (0, 1, np.float64),
"min_child_weight": (0, 100, np.int32),
"subsample": (0, 1, np.float64),
"reg_lambda": (0, 1, np.float64),
"reg_alpha": (0, 1, np.float64)}
elif id==2:
# SVR
""" default parameters - """
HYPERPARAMETERS={"kernel": "rbf",
"cache_size": 100000,
"C": 0.5,
"gamma": 0.023 }
""" fixed parameters which will not change in optimisation """
FIXED={"kernel": "rbf",
"cache_size": 100000,
"tol": 0.00001 }
""" boundaries & types of optimisable parameters """
BOUNDARIES={ "C": (0.01 , 1000, np.float64),
"gamma": (0.001, 100, np.float64)}
# "epsilon": (0.001, 100, np.float64)
elif id==3:
# LASSO
""" default parameters - """
HYPERPARAMETERS={"fit_intercept": "False",
"max_iter": 100000,
"tol": 0.0001,
"alpha": 25}
""" fixed parameters which will not change in optimisation """
FIXED={"fit_intercept": "False",
"max_iter": 100000,
"tol": 0.0001 }
""" boundaries & types of optimisable parameters """
BOUNDARIES={"alpha": (0.1, 100, np.float64) }
elif id==4:
# KNN PARAMETERS
""" default parameters - """
HYPERPARAMETERS={ "algorithm": "auto",
"n_neighbors": 7,
"leaf_size": 30}
""" fixed parameters which will not change in optimisation """
FIXED={"algorithm": "auto"}
""" boundaries & types of optimisable parameters """
BOUNDARIES={"n_neighbors": (3 , 51, np.int32),
"leaf_size": (2 , 500, np.int32)}
elif id==5:
# Bagging Regression
HYPERPARAMETERS={ "bootstrap_features": "False",
"bootstrap": "True",
"n_estimators": 21,
"max_samples": 23}
""" fixed parameters which will not change in optimisation """
FIXED={ "bootstrap_features": "False",
"bootstrap": "True"}
""" boundaries & types of optimisable parameters """
BOUNDARIES={"n_estimators": (1 , 50, np.int32),
"max_samples": (1 , 50, np.int32)}
elif id==6:
# GRADIENT BOOSTING PARAMETERS
""" default parameters - """
HYPERPARAMETERS={"criterion": "friedman_mse",
"min_impurity_split": 1.0e-07,
"max_features": "auto",
"learning_rate": 0.2,
"n_estimators": 100,
"max_depth": 10}
""" fixed parameters which will not change in optimisation """
FIXED={"criterion": "friedman_mse",
"min_impurity_split": 1.0e-07,
"max_features": "auto"}
""" boundaries & types of optimisable parameters """
BOUNDARIES={"learning_rate": (0.01, 1, np.float64),
"n_estimators": (50, 500, np.int32),
"max_depth": (1, 50, np.int32)}
elif id==7:
# RANDOM FOREST PARAMETERS
""" default parameters - """
HYPERPARAMETERS={"bootstrap": "True",
"criterion": "mse",
"n_estimators": 100,
"max_features": 'auto',
"max_depth": 50,
"min_samples_leaf": 1,
"min_samples_split": 2}
""" fixed parameters which will not change in optimisation """
FIXED={"bootstrap": "True",
"criterion": "mse",
"max_features": 'auto' }
""" boundaries & types of optimisable parameters """
BOUNDARIES={"n_estimators": (1 , 1000, np.int32),
"max_depth": (1 , 500, np.int32),
"min_samples_leaf": (1 , 50, np.int32),
"min_samples_split": (2 , 50, np.int32)}
else:
# DECISION TREE PARAMETERS
""" default parameters - """
HYPERPARAMETERS={"criterion": "mse",
"max_features": "auto",
"max_depth": 2,
"min_samples_leaf": 0.25,
"min_samples_split": 2 }
""" fixed parameters which will not change in optimisation """
FIXED={"criterion": "mse",
"max_features": "auto"}
""" boundaries & types of optimisable parameters """
BOUNDARIES={ "max_depth": (1 , 500, np.int32),
"min_samples_leaf": (1 , 50, np.int32),
"min_samples_split": (2 , 50, np.int32)}
return HYPERPARAMETERS, FIXED,BOUNDARIES
[0062] Аналогично, в некоторых вариантах осуществления, классификационные параметры могут регистрироваться и регулироваться в библиотеке 304 классификационных параметров. Таким образом, библиотека 304 классификационных параметров может включать в себя аппаратные средства хранения данных и связи, сконфигурированные с достаточным объемом запоминающего устройства и полосой пропускания, чтобы сохранять, регулировать и передавать множество параметров для нескольких регрессоров, например, в реальном времени. Например, для каждой классификационной модели машинного обучения, подвергающейся созданию экземпляра посредством механизма 301 DOBR, соответствующие параметры могут инициализироваться и обновляться в библиотеке 305 регрессионных параметров. В некоторых вариантах осуществления, пользователь, через устройство 308 пользовательского ввода, может устанавливать начальный набор параметров. Тем не менее, в некоторых вариантах осуществления, начальный набор параметров может быть предварительно определен. После создания экземпляра регрессионной модели машинного обучения, механизм 301 DOBR может коррелировать модель, идентифицированную в индексе 302 модели, с набором параметров в библиотеке 305 регрессионных параметров. Например, механизм 301 DOBR может вызывать набор параметров, например, согласно идентификационному номеру, ассоциированному с данной регрессионной моделью. Например, библиотека 305 регрессионных параметров может идентифицировать параметры для каждой регрессионной модели, аналогично нижеприведенному псевдокоду 4:
Псевдокод 4
def gen_paramsClass(II):
# XGBoost CLASSIFER PARAMETERS
if II==0:
""" default parameters - best achieved in prototyping """
HYPERPARAMETERS={"objective": "binary:hinge",
"tree_method": "exact",
"eval_metric": "error",
"n_estimators": 5,
"eta": 0.3,
"gamma": 0.1,
"max_depth": 5,
"min_child_weight": 5,
"subsample": 0.5,
"scale_pos_weight": 1,
"silent": 1}
""" fixed parameters which will not change in optimization """
FIXED={ "objective": "binary:hinge",
"tree_method": "exact",
"eval_metric": "error"}
""" boundaries & types of optimisable parameters """
BOUNDARIES={ "eta": (0, 10, np.float64),
"gamma": (0, 10, np.float64),
"min_child_weight": (0, 50, np.float64),
"subsample": (0, 1, np.float64),
"n_estimators": (1,1000, np.int32),
"max_depth": (1, 1000, np.int32),
"scale_pos_weight": (0, 1, np.float64) }
else:
# RANDOM FOREST CLASSIFIER PARAMETERS
""" default parameters - """
HYPERPARAMETERS={"bootstrap": "True",
"n_estimators": 500,
"max_features": 'auto',
"max_depth": 200,
"min_samples_leaf": 1,
"min_samples_split": 2 }
""" fixed parameters which will not change in optimisation """
FIXED={"bootstrap": "True",
"max_features": "auto" }
""" boundaries & types of optimisable parameters """
BOUNDARIES={"n_estimators": (10 , 1000, np.int32),
"max_depth": (10 , 50, np.int32),
"min_samples_leaf": (1 , 40, np.int32),
"min_samples_split": (2 , 40, np.int32)}#
return HYPERPARAMETERS, FIXED,BOUNDARIES
[0063] В некоторых вариантах осуществления, посредством вызова и приема набора моделей из библиотеки 303 моделей через индекс 302 модели и соответствующих параметров из библиотеки 305 регрессионных параметров и/или библиотеки 304 классификационных параметров, механизм 301 DOBR может загружать одну или более подвергающихся созданию экземпляра и инициализированных моделей, например, в кэш или буфер механизма 301 DOBR. В некоторых вариантах осуществления, набор 311 данных затем может загружаться из базы 310 данных, например, в идентичный или различный кэш или буфер либо в другое устройство хранения данных механизма 301 DOBR. Процессор 307 или процессор в механизме 301 DOBR затем может выполнять каждую модель, чтобы преобразовывать набор 311 данных, например, в соответствующее прогнозирование значений связанных с активностью данных, которые характеризуют результаты или параметры активности на основе определенных входных атрибутов, связанных с активностью. Например, использование энергии приборов в домашних и/или коммерческих окружениях, прочность на сжатие бетона во множестве вариантов применения и формулирований, распознавание объектов или изображений, распознавание речи или другие варианты применения на основе машинного обучения. Например, механизм 301 DOBR может моделировать использование энергии приборов на основе набора 311 данных статистического использования энергии, времени года, времени суток, местоположения, в числе прочих факторов. Механизм 301 DOBR может вызывать набор регрессоров из библиотеки 303 моделей через индекс 302 модели, соединенный с шиной механизма 301 DOBR. Механизм 301 DOBR затем может вызывать файл или журнал регистрации параметров, ассоциированный с регрессорами для оценки использования энергии приборов в библиотеке 305 регрессионных параметров, соединенной с шиной механизма 301 DOBR. -Затем механизм 301 DOBR может использовать процессор 307 для прогнозирования будущего энергопотребления на основе моделей и параметров модели, времени и даты, местоположения или другого фактора и их сочетаний.
[0064] Аналогично, например, механизм 301 DOBR может моделировать прочность на сжатие бетона на основе набора 311 данных материалов бетона, времени года, времени суток, местоположения, влажности, времени отверждения, возраста, в числе прочих факторов. Механизм 301 DOBR может вызывать набор регрессоров из библиотеки 303 моделей через индекс 302 модели, соединенный с шиной механизма 301 DOBR. Механизм 301 DOBR затем может вызывать файл или журнал регистрации параметров, ассоциированный с регрессорами для оценки прочности на сжатие бетона в библиотеке 305 регрессионных параметров, соединенной с шиной механизма 301 DOBR. Затем механизм 301 DOBR может использовать процессор 307 для прогнозирования будущей прочности на сжатие бетона на основе моделей и параметров модели для конкретного состава бетона, времени и даты, местоположения или другого фактора и их сочетаний.
[0065] В качестве другого примера, механизм 301 DOBR может выполнять распознавание речи на основе набора 311 данных речевых фрагментов и транскрипций экспериментально полученных проверочных данных, в числе прочих факторов. Механизм 301 DOBR может вызывать набор классификаторов из библиотеки 303 моделей через индекс 302 модели, соединенный с шиной механизма 301 DOBR. Затем механизм 301 DOBR может вызывать файл или журнал регистрации параметров, ассоциированный с классификаторами для распознавания речи в библиотеке 304 классификационных параметров, соединенной с шиной механизма 301 DOBR. Затем механизм 301 DOBR может использовать процессор 307 для прогнозирования транскрипции записанных речевых данных на основе моделей и параметров модели для набора из одного или более речевых фрагментов.
[0066] В качестве другого примера, механизм 301 DOBR может автоматически прогнозировать настройки рендеринга для формирования медицинских изображений на основе набора 311 данных настроек для нескольких параметров рендеринга через формирование изображений и/или визуализации, в числе прочих факторов, как описано в патенте США № 10339695. Механизм 301 DOBR может вызывать набор классификаторов из библиотеки 303 моделей через индекс 302 модели, соединенный с шиной механизма 301 DOBR. Затем механизм 301 DOBR может вызывать файл или журнал регистрации параметров, ассоциированный с классификаторами для рендеринга настроек в библиотеке 304 классификационных параметров, соединенной с шиной механизма 301 DOBR. Затем механизм 301 DOBR может использовать процессор 307 для прогнозирования данных настроек рендеринга на основе моделей и параметров модели для набора из одного или более наборов медицинских данных.
[0067] В качестве другого примера, механизм 301 DOBR может выполнять роботизированное управление машинным оборудованием на основе набора 311 данных результатов выполнения машинных команд управления и моделированных результатов машинных команд управления, в числе прочих факторов, как описано в патенте США № 10317854. Механизм 301 DOBR может вызывать набор регрессионных моделей из библиотеки 303 моделей через индекс 302 модели, соединенный с шиной механизма 301 DOBR. Затем механизм 301 DOBR может вызывать файл или журнал регистрации параметров, ассоциированный с регрессионной моделью для роботизированного управления в библиотеке 305 регрессионных параметров, соединенной с шиной механизма 301 DOBR. Затем механизм 301 DOBR может использовать процессор 307 для прогнозирования успешности или сбоя конкретных команд управления на основе моделей и параметров модели для набора команд управления, информации окружающей среды, данных датчиков и/или моделирований команд.
[0068] В некоторых вариантах осуществления, система 300 уменьшения отклонения может реализовывать модели машинного обучения в облачном окружении, например, в качестве облачной услуги для удаленных пользователей. Такая облачная услуга может проектироваться с возможностью поддержки больших чисел пользователей и широкого спектра алгоритмов и размеров задач, включающих в себя алгоритмы и размеры задач, описанные выше, а также другие потенциальные модели, наборы данных и настройки параметров, относящиеся к варианту использования пользователя, как описано в патенте США № 10452992. В одном варианте осуществления, число программируемых интерфейсов (к примеру, интерфейсов прикладного программирования (API)) может задаваться посредством услуги, в которой реализуется система 300 уменьшения отклонения, которые направляют неопытных пользователей с возможностью начала использования принципа «наиболее успешной практики» для машинного обучения относительно быстро, без необходимости для пользователей тратить много времени и усилий при настройке моделей или при обучении усовершенствованных статистических технологий или технологий искусственного интеллекта. Интерфейсы, например, могут обеспечивать возможность неспециалистам базироваться на настройках или параметрах по умолчанию для различных аспектов процедур, используемых для компоновки, обучения и использования моделей машинного обучения, в которых значения по умолчанию извлекаются из одного или более наборов параметров в библиотеке 304 классификационных параметров и/или библиотеке 305 регрессионных параметров для аналогичных моделей для отдельного пользователя. Настройки или параметры по умолчанию могут использоваться в качестве начальной точки, чтобы индивидуально настраивать модель машинного обучения пользователя с использованием обучения с помощью наборов данных пользователя через механизм 301 DOBR и оптимизатор 306. Одновременно, пользователи могут индивидуально настраивать параметры или настройки, которые они хотят использовать для различных типов задач машинного обучения, таких как обработка входных записей, обработка признаков, компоновка, выполнение и оценка моделей. По меньшей мере, в некоторых вариантах осуществления, помимо или вместо использования предварительно заданных библиотек, реализующих различные типы задач машинного обучения, дополнительно, система 300 уменьшения отклонения облачной услуги может иметь расширяемые встроенные возможности услуги, например, посредством регистрирования индивидуально настраиваемых функций в услуге. В зависимости от бизнес-потребностей или целей клиентов, которые реализуют такие индивидуально настраиваемые модули или функции, модули в некоторых случаях могут совместно использоваться с другими пользователями услуги, в то время как в других случаях использование индивидуально настраиваемых модулей может ограничиваться их разработчиками/владельцами.
[0069] В некоторых вариантах осуществления, независимо от того, реализуются они в качестве облачной услуги, локальной или удаленной системы либо в любой другой архитектуре системы, система 300 уменьшения отклонения может включать в себя модели в библиотеке 303 моделей, которые обеспечивают подход на основе ансамблирования к обучению и реализации моделей машинного обучения, как описано в патенте США № 9646262. Такой подход может быть полезным для применения к средствам анализа данных с использованием электронных наборов данных электронных данных активности. В некоторых вариантах осуществления, база 310 данных может включать в себя один или более структурированных или неструктурированных источников данных. Модуль неконтролируемого обучения, в конкретных вариантах осуществления, выполнен с возможностью сбора неструктурированного набора данных в организованный набор данных с использованием множества технологий неконтролируемого обучения, например, в ансамбле моделей из библиотеки 303 моделей. Например, модуль неконтролируемого обучения выполнен с возможностью сбора неструктурированного набора данных в несколько версий организованного набора данных, в то время как модуль контролируемого обучения, в конкретных вариантах осуществления, выполнен с возможностью формирования одного или более ансамблей машинного обучения на основе каждой версии из нескольких версий организованного набора данных и определять то, какой ансамбль машинного обучения демонстрирует наибольшую производительность прогнозирования, например, согласно ошибке модели после обучения каждой модели в каждом ансамбле с использованием механизма 301 DOBR и оптимизатора 306.
[0070] Пример инструкций механизма 301 DOBR для управления аппаратными средствами, чтобы выполнять прогнозирования на основе набора 311 данных проиллюстрирован в нижеприведенном псевдокоде 5:
Псевдокод 5
filename='energydataBase'
filename='Concrete_Data'
path='.'
filetype='.csv'
path1=filename+filetype
data=pd.read_csv(path1).values
YLength=len(data)
X_Data=data[:, 1:]
y_Data=data[:,0]
#
# ***** Set Run Parameters *****
#
ErrCrit=0.005
trials=2
list_model=[ model0, model1, model2, model3, model4 ]
list_modelname=[ ModelName0, ModelName1, ModelName2, ModelName3, ModelName4]
Acceptance=[87.5, 87.5, 87.5, 87.5, 87.5]
#
mcnt=-1
for model in list_model:
f=open("DOBR04trainvaltestRF"+".txt","a")
mcnt += 1
print("-------------running----------------", mcnt, list_modelname[mcnt])
timemodelstart=time.time()
Error00=[0]*trials
PIM=[0]*trials
modelfrac=[0]*trials
DOBRFULL0,DOBRFULL0a, DOBRFULL0e=([0] * trials for i in range(3))
DOBRFULL1,DOBRFULL1a, DOBRFULL1e=([0] * trials for i in range(3))
DOBRFULL2,DOBRFULL2a, DOBRFULL2e=([0] * trials for i in range(3))
#
# Bootstrappng Loop starts here
#
X_train, X_temp, y_train, y_temp=train_test_split(X_Data, y_Data, test_size=0.60)
if mcnt > 0:
new_paramset=gen_params(mcnt)
hyperband=Hyperband(X_train, y_train, new_paramset[0], new_paramset[1], new_paramset[2])
hyperband.optimize(model)
# print("Best parameters", hyperband.best_parameters)
RefModel=model.set_params(**hyperband.best_parameters)
else:
RefModel=model
print(RefModel, file=f)
#
for mc in range(0,trials):
x_val, x_test, y_val, y_test=train_test_split(X_temp, y_temp, test_size=0.20)
timemodelstart1=time.time()
len_yval=len(y_val)
len_ytest=len(y_test)
Errmin=999
Errvalue=999
cnt=0
#
BaseModel=RefModel.fit(x_val, y_val).predict(x_test)
Error00[mc]=(mean_squared_error(BaseModel, y_test))**0.5
#
DOBRModel=RefModel.fit(x_val, y_val).predict(x_val)
Errorval=(mean_squared_error(DOBRModel, y_val))**0.5
print("Train Error ", Error00[mc],"Test Error ",Errorval," Ratio: ",Error00[mc]/Errorval,"mc=",mc)
# Data_xin0_values=x_val
# Data_yin0_values=y_val
# XinBest=x_val
# YinBest=y_val
#
rmsrbf1=Error00[mc]
while Errvalue > ErrCrit:
cnt += 1
timemodelstart1=time.time()
if cnt > 500:
print("Max iter. cnt for Error Acceptance: ",Errvalue, Acceptance[mcnt])
break
#
# Absolute Errors & DOBR Filter
#
AError=RMS(DOBRModel, y_val)
inout1=DOBR(AError, Acceptance[mcnt])
#
Data_yin_scrub, dumb1=scrub1(inout1, y_val)
Data_xin_scrub, dumb2=scrub2(inout1, x_val)
DOBR_yin_scrub, dumb3=scrub1(inout1, DOBRModel)
rmsrbf2=(mean_squared_error(DOBR_yin_scrub, Data_yin_scrub) )**0.5
#
if rmsrbf2 < Errmin:
# XinBest=Data_xin0_values
# YinBest=Data_yin0_values
Errmin=rmsrbf2
Errvalue=abs(rmsrbf2 - rmsrbf1)/rmsrbf2
# print(cnt, Errvalue," ",rmsrbf2,rmsrbf1,sum(inout1)/len_yval)
rmsrbf1=rmsrbf2
DOBRModel=RefModel.fit(Data_xin_scrub, Data_yin_scrub).predict(x_val)#<----------------
# Data_xin0_values=Data_xin_scrub
# Data_yin0_values=Data_yin_scrub
#
# DOBRModel=RefModel.fit(Data_xin_scrub, Data_yin_scrub).predict(x_val)
# AError=RMS(DOBRModel, y_val)
# inout1=DOBR(AError, Acceptance[mcnt])
print( " Convergence in ",cnt," iterations with Error Value=",Errvalue)
#
#+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
if mc == mc:
timemodelstart2=time.time()
new_paramset=gen_paramsClass(1)
hyperband=Hyperband(np.array(x_val), np.array(inout1), new_paramset[0], new_paramset[1], new_paramset[2])
modelClass=RandomForestClassifier() #xgb.XGBClassifier()
hyperband.optimize(modelClass, True)
Classmodel=modelClass.set_params(**hyperband.best_parameters)
print(hyperband.best_parameters, file=f)
print(hyperband.best_parameters)
#
inout2=Classmodel.fit(x_val, inout1).predict(x_test)
modelfrac[mc]=sum(inout1)/len_yval
PIM[mc]=sum(inout2)/len_ytest
#
# MODEL DOBR CENSORED DATASETS
#
Data_yin_scrub, Data_yout_scrub=scrub1 (inout1, y_val)
Data_xin_scrub, Data_xout_scrub=scrub2 (inout1, x_val)
#
# TEST DOBR CENSORED DATASET
Data_xtestin_scrub, Data_xtestout_scrub=scrub2 (inout2, x_test)
y_testin_scrub, y_testout_scrub=scrub1 (inout2, y_test)
y_test_scrub=[*y_testin_scrub, *y_testout_scrub]
#
# DOBR INFORMATION APPLIED BASE MODEL PREDICTOR DATASET
BaseModel_yin_scrub, BaseModel_yout_scrub=scrub1(inout2, BaseModel)
#
DOBR_Model_testin=model.fit(Data_xin_scrub, Data_yin_scrub ).predict(Data_xtestin_scrub )
if len(y_test) == sum(inout2):
DOBR_Model0=DOBR_Model_testin
DOBR_Model1=DOBR_Model_testin
DOBR_Model2=BaseModel_yin_scrub
print("inout2:",sum(inout2),"len=",len(y_test))
else:
DOBR_Model_testout=model.fit(Data_xout_scrub, Data_yout_scrub).predict(Data_xtestout_scrub)
DOBR_Model0=[*DOBR_Model_testin, *DOBR_Model_testout ]
DOBR_Model1=[*DOBR_Model_testin , *BaseModel_yout_scrub]
DOBR_Model2=[*BaseModel_yin_scrub, *DOBR_Model_testout ]
#
DOBRFULL0[mc]=(mean_squared_error(DOBR_Model0, y_test_scrub))**0.5
DOBRFULL1[mc]=(mean_squared_error(DOBR_Model1, y_test_scrub))**0.5
DOBRFULL2[mc]=(mean_squared_error(DOBR_Model2, y_test_scrub))**0.5
#
ModelFrac=np.mean(modelfrac, axis=0)
Error00a=np.mean(Error00,axis=0)
DOBRFULL0a=np.mean(DOBRFULL0,axis=0)
DOBRFULL1a=np.mean(DOBRFULL1,axis=0)
DOBRFULL2a=np.mean(DOBRFULL2, axis=0)
Error00e=1.96 * stats.sem(Error00,axis=0)
DOBRFULL0e=1.96 * stats.sem(DOBRFULL0,axis=0)
DOBRFULL1e=1.96 * stats.sem(DOBRFULL1,axis=0)
DOBRFULL2e=1.96 * stats.sem(DOBRFULL2,axis=0)
#
PIM_Mean=np.mean(PIM)
PIM_CL=1.96 * stats.sem(PIM)
#
print(" "+ list_modelname[mcnt], " # of Trials =",trials, file=f)
print(Classmodel, file=f)
print(" Test Dataset Results for {0:3.0%} of Data Included in DOBR Model {1:3.0%} ± {2:4.1%} "
.format(ModelFrac, PIM_Mean, PIM_CL),file=f)
print(" Base Model={0:5.2f} ± {1:5.2f} DOBR_Model #1={2:5.2f} ± {3:5.2f}"
.format(Error00a, Error00e, DOBRFULL0a, DOBRFULL0e),file=f)
print(" DOBR_Model #2={0:5.2f} ± {1:5.2f}".format(DOBRFULL1a, DOBRFULL1e),file=f)
print(" DOBR_Model #3={0:5.2f} ± {1:5.2f}".format(DOBRFULL2a, DOBRFULL2e),file=f)
print(" "+ list_modelname[mcnt], " # of Trials =",trials)
print(Classmodel, file=f)
print(" Test Dataset Results for {0:3.0%} of Data Included in DOBR Model {1:3.0%} ± {2:4.1%} "
.format(ModelFrac, PIM_Mean, PIM_CL))
print(" Base Model={0:5.2f} ± {1:5.2f} DOBR_Model #1={2:5.2f} ± {3:5.2f}"
.format(Error00a, Error00e, DOBRFULL0a, DOBRFULL0e))
print(" DOBR_Model #2={0:5.2f} ± {1:5.2f}".format(DOBRFULL1a, DOBRFULL1e))
print(" DOBR_Model #3={0:5.2f} ± {1:5.2f}".format(DOBRFULL2a, DOBRFULL2e))
print("+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++")
#
f.close()
modeltime=(time.time() - timemodelstart) / 60
print("Total Run Time for {0:3} iterations={1:5.1f} min".format(trials, modeltime))
[0071] Тем не менее, в некоторых вариантах осуществления, выбросовые значения в наборе 311 данных могут уменьшать точность реализованных моделей, за счет этого увеличивая число обучающих итераций, чтобы достигать точного набора параметров для данной модели в данном варианте применения. Чтобы повышать точность и эффективность, механизм 301 DOBR может включать в себя фильтр 301b DOBR, с тем чтобы динамически тестировать ошибки точек данных в наборе данных для определения выбросовых значений. Таким образом, выбросовые значения могут удаляться для обеспечения более точного или характерного набора 311 данных. В некоторых вариантах осуществления, фильтр 301b DOBR может обеспечивать итеративный механизм для удаления выбросовых точек данных согласно предварительно заданному критерию, например, определяемому пользователем значению приемлемости ошибки, описанному выше и обеспечиваемому, например, пользователем через устройство 308 пользовательского ввода. В некоторых вариантах осуществления, определяемое пользователем значение приемлемости ошибки выражается как процентная доля, при этом, например, значение в 100% обозначает то, что ошибка считается полностью приемлемой, и точки данных не должны удаляться посредством фильтра 301b, тогда как значение, например, в 0% приводит к удалению всех точек данных. В некоторых вариантах осуществления, фильтр 301b может быть сконфигурирован со значением приемлемости ошибки, например, в диапазоне между приблизительно 80% и приблизительно 95%. Например, фильтр 301b может быть выполнен с возможностью выполнения функций, проиллюстрированных в нижеприведенном псевдокоде 6:
Псевдокод 6
# Absolute Errors & DOBR Filter
#
AError=RMS(DOBRModel, y_val)
inout1=DOBR(AError, Acceptance[mcnt])
#
Data_yin_scrub, dumb1=scrub1(inout1, y_val)
Data_xin_scrub, dumb2=scrub2(inout1, x_val)
DOBR_yin_scrub, dumb3=scrub1(inout1, DOBRModel)
rmsrbf2=(mean_squared_error(DOBR_yin_scrub, Data_yin_scrub) )**0.5
#
if rmsrbf2 < Errmin:
# XinBest=Data_xin0_values
# YinBest=Data_yin0_values
Errmin=rmsrbf2
Errvalue=abs(rmsrbf2 - rmsrbf1)/rmsrbf2
# print(cnt, Errvalue," ",rmsrbf2,rmsrbf1,sum(inout1)/len_yval)
rmsrbf1=rmsrbf2
DOBRModel=RefModel.fit(Data_xin_scrub, Data_yin_scrub).predict(x_val)#<----------------
# Data_xin0_values=Data_xin_scrub
# Data_yin0_values=Data_yin_scrub
#
# DOBRModel=RefModel.fit(Data_xin_scrub, Data_yin_scrub).predict(x_val)
# AError=RMS(DOBRModel, y_val)
# inout1=DOBR(AError, Acceptance[mcnt])
print( " Convergence in ",cnt," iterations with Error Value=",Errvalue)
#
[0072] В некоторых вариантах осуществления, фильтр 301b DOBR работает в сочетании с оптимизатором 306, который выполнен с возможностью определения ошибки и оптимизации параметров для каждой модели в библиотеке 305 регрессионных параметров и в библиотеке 304 классификационных параметров. Таким образом, в некоторых вариантах осуществления, оптимизатор 306 может определять модель и передавать ошибку в фильтр 301b механизма 301 DOBR. Таким образом, в некоторых вариантах осуществления, оптимизатор 306 может включать в себя, например, устройства хранения данных и/или запоминающие устройства и устройства связи с достаточной емкостью запоминающего устройства и полосой пропускания, чтобы принимать набор 311 данных и прогнозирования на основе модели и определять, например, выбросовые значения, сходимость, ошибку, ошибку абсолютного значения, в числе других показателей ошибки. Например, оптимизатор 306 может быть выполнен с возможностью выполнения функций, проиллюстрированных в нижеприведенном псевдокоде 7:
Псевдокод 7
def DOBR(AErrors, Accept):
length=len(AErrors)
Inout=[1]*length
AThres=stats.scoreatpercentile(AErrors, Accept)
for i in range(0,length):
if AErrors[i] > AThres:
Inout[i]=0
return Inout
def RMS(Array1,Array2):
length=len(Array1)
Array3=[0 for m in range(0,length)]
for i in range(0,length):
Array3[i]=(Array1[i] - Array2[i])**2
return Array3
def scrub1(IO, ydata):
lendata=len(ydata)
outlen=sum(IO)
Yin=[]*outlen
Yout=[]*(lendata - outlen)
for i in range(0,lendata):
if IO[i] > 0:
Yin.append(ydata[i])
else:
Yout.append(ydata[i])
return Yin, Yout
def scrub2(IO, Xdata):
lendata=len(Xdata)
inlen=sum(IO)
outlen=len(IO) - inlen
cols=len(Xdata[0])
Xin=[[0 for k in range(cols)] for m in range(inlen )]
Xout=[[0 for k in range(cols)] for m in range(outlen)]
irow=-1
jrow=-1
for i in range(0,lendata):
if IO[i] > 0:
irow += 1
for j in range(0,cols):
Xin[irow][j]=Xdata[i][j]
else:
jrow += 1
for k in range(0,cols):
Xout[jrow][k]=Xdata[i][k]
return Xin, Xout
[0073] В некоторых вариантах осуществления, система 300 уменьшения отклонения затем может возвращать пользователю, например, через дисплей 312, прогнозирования на основе модели машинного обучения, анализ выбросовых значений, сходимость прогнозирований, в числе других данных, сформированных посредством механизма 301 DOBR, более точным и эффективным способом вследствие уменьшения выбросовых значений, которые в противном случае должны смещать прогнозирования.
[0074] Фиг. 6 иллюстрирует блок-схему последовательности операций способа примерной технологии согласно изобретению в соответствии с одним или более вариантов осуществления настоящего изобретения.
[0075] DOBR, к примеру, механизм 301 DOBR и фильтр 301b, описанные выше, обеспечивает итеративный процесс для удаления выбросовых записей согласно предварительно заданному критерию. Это условие представляет собой определяемое пользователем значение приемлемости ошибки, выражаемое как процентная доля. Это означает то, какую часть ошибки пользователь имеет намерение считать приемлемой в модели потенциально на основе своего понимания и других результатов анализа, которые описываются ниже в этом пояснении. Значение в 100% обозначает то, что ошибка считается полностью приемлемой, и записи не должны удаляться в процессе DOBR. Если выбирается 0%, то все записи удаляются. В общем, значения приемлемости ошибки в диапазоне 80-95% наблюдаются для промышленных вариантов применения.
[0076] Тем не менее, в некоторых вариантах осуществления, также следует отметить, что если набор данных не содержит выбросовых значений, то DOBR не обеспечивает значения. Но в практических ситуациях, аналитик редко имеет эти знания до начала работы с набором данных. Как продемонстрировано далее в этом пояснении, варианты осуществления технологии DOBR также могут определять процентную долю от набора данных, которая представляет выбросовые значения модели. Этот этап предварительного анализа может помогать в задании надлежащего значения приемлемости ошибки либо того, присутствуют вообще или нет выбросовые значения.
[0077] Следующие этапы приводят фундаментальный способ DOBR, который применяется к полному набору данных.
[0078] Предварительный анализ: в варианте осуществления, сначала выбирается критерий приемлемости ошибки, скажем, выбирается ∞=80%. (То, каким образом можно определить это значение из данных, будет показано после пояснения способа DOBR). После этого, задается критерий приемлемости ошибки, C(∞), например, согласно нижеприведенному уравнению 1:
уравнение 1 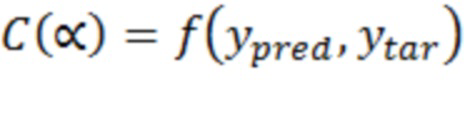 ,
,
[0079] - где ∞ является критерием приемлемости ошибки, C является функцией критерия приемлемости ошибки, f является сравнительной функцией, y является значением записи данных, ypred является прогнозируемым значением, и ytar является целевым значением.
[0080] Другие функциональные взаимосвязи могут использоваться для задания C(α), но процентильная функция представляет собой интуитивные руководящие принципы в понимании того, почему модель включает в себя или исключает определенные записи данных, к примеру, согласно нижеприведенному уравнению 2:
уравнение 2 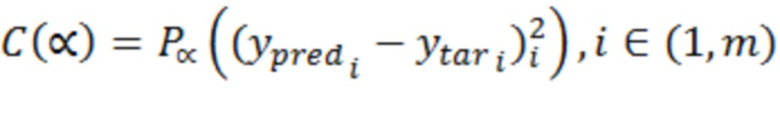 ,
,
[0081] - где P∞ является процентильной функцией, i является индексом вхождения записи, и m является числом вхождений записей.
[0082] Поскольку процедура DOBR является итеративной, в варианте осуществления, также задается критерий сходимости, который в этом пояснении задается равным 0,5%.
[0083] В варианте осуществления, с учетом набора 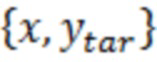 404 данных, модели M 408 принятия решений и критерия ∞ 424 приемлемости ошибки, DOBR может реализовываться с возможностью уменьшения отклонения в обучении модели M 408. В некоторых вариантах осуществления, модель M 408 принятия решений реализуется посредством модельного механизма, включающего в себя, например, обрабатывающее устройство и запоминающее устройство и/или устройство хранения данных. Согласно варианту осуществления, примерная технология вычисляет коэффициенты модели, M(c) 402, и оценки
404 данных, модели M 408 принятия решений и критерия ∞ 424 приемлемости ошибки, DOBR может реализовываться с возможностью уменьшения отклонения в обучении модели M 408. В некоторых вариантах осуществления, модель M 408 принятия решений реализуется посредством модельного механизма, включающего в себя, например, обрабатывающее устройство и запоминающее устройство и/или устройство хранения данных. Согласно варианту осуществления, примерная технология вычисляет коэффициенты модели, M(c) 402, и оценки 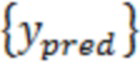 410 модели для всех записей, применяющих модель принятия решений, M 408, к полному входному набору 404 данных, например, согласно нижеприведенному уравнению 3:
410 модели для всех записей, применяющих модель принятия решений, M 408, к полному входному набору 404 данных, например, согласно нижеприведенному уравнению 3:
уравнение 3 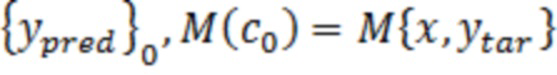 ,
,
[0084] - где 0 указывает начальное состояние, и x означает входную запись.
[0085] Затем, согласно иллюстративному варианту осуществления, функция 418 полных ошибок вычисляет начальную полную ошибку e0 модели, например, согласно нижеприведенному уравнению 4:
уравнение 4 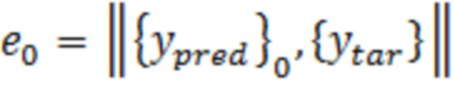 ,
,
[0086] - где e0 является начальной полной ошибкой модели, и 0 обозначает начальное значение.
[0087] Затем, согласно иллюстративному варианту осуществления, функция 412 ошибок вычисляет ошибки модели, например, согласно нижеприведенному уравнению 5:
уравнение 5 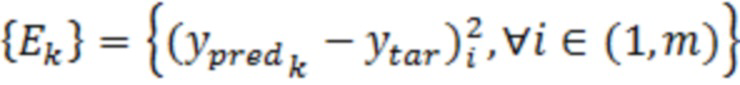 ,
,
[0088] - где E являются прогнозируемыми ошибками записи, и k обозначает итерацию выбора записей.
[0089] Затем, согласно иллюстративному варианту осуществления, функция 412 ошибок вычисляет новый вектор 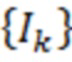 выбора записей данных, например, согласно нижеприведенному уравнению 6:
выбора записей данных, например, согласно нижеприведенному уравнению 6:
уравнение 6 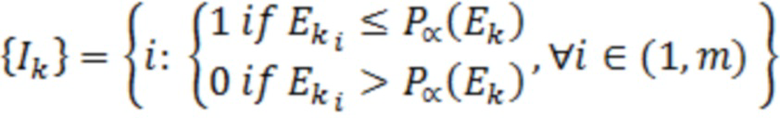 ,
,
[0090] - где I является вектором выбора записей.
[0091] После этого, согласно иллюстративному варианту осуществления, блок 414 выбора записей данных вычисляет невыбросовые записи данных, которые должны включаться в вычисление с использованием модели, посредством выбора только записей, в которых вектор выбора записей равен 1, например, согласно нижеприведенному уравнению 7:
уравнение 7 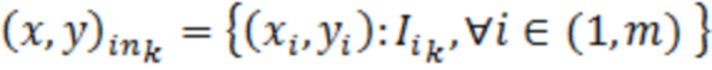 ,
,
[0092] - где  является индексом, указывающим на набор включенных в DOBR записей в качестве невыбросовых значений.
является индексом, указывающим на набор включенных в DOBR записей в качестве невыбросовых значений.
[0093] Затем, согласно иллюстративному варианту осуществления, модель 408 с последними коэффициентами 402 вычисляет новые прогнозируемые значения 420 и коэффициенты 402 модели из выбранных DOBR записей 416 данных, например, согласно нижеприведенному уравнению 8:
уравнение 8 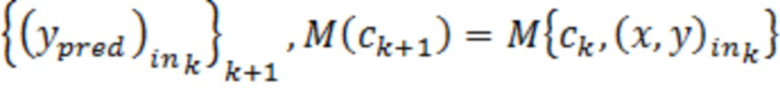 .
.
[0094] Затем, согласно иллюстративному варианту осуществления, модель 408 с использованием новых коэффициентов модели вычисляет новые прогнозные значения 420 для полного набора данных. Этот этап воспроизводит вычисление прогнозируемых значений 420 для выбранных DOBR записей на формальных этапах, но на практике новая модель может применяться только к удаленным DOBR записям, например, согласно нижеприведенному уравнению 9:
уравнение 9 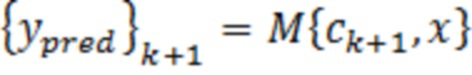 .
.
[0095] Затем, согласно иллюстративному варианту осуществления, функция 418 полных ошибок вычисляет полную ошибку модели, например, согласно нижеприведенному уравнению 10:
уравнение 10 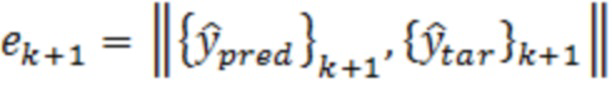 ,
,
[0096] - где 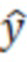 является целевым выводом.
является целевым выводом.
[0097] Затем, согласно иллюстративному варианту осуществления, тест 424 сходимости тестирует сходимость модели, например, согласно нижеприведенному уравнению 11:
уравнение 11 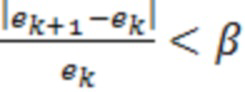 ,
,
[0098] - где β является критериями 422 сходимости, такими как, например, 0,5%.
[0099] В некоторых вариантах осуществления, тест 424 сходимости может завершать итеративный процесс, если, например, процентная ошибка меньше, например, 0,5%. В противном случае, процесс может возвращаться к начальному набору 404 данных. Каждый из вышеприведенных этапов затем может выполняться, и критерии 422 сходимости могут повторно тестироваться. Процесс повторяется до тех пор, пока тест 424 сходимости не ниже критериев 424 сходимости.
[0100] Фиг. 7 является графиком, иллюстрирующим пример взаимосвязи между ошибкой модели и критерием приемлемости ошибки другой примерной компьютерной модели машинного обучения с уменьшенным отклонением в соответствии с одним или более вариантов осуществления настоящего изобретения.
[0101] Поскольку ∞ является входным параметром в DOBR, и результаты расчетов по модели могут варьироваться на основе выбранного значения, в варианте осуществления, важно документировать процедуру на основе данных для объяснения того, какое значение используется. В практических вариантах применения, в которых DOBR разрабатывается и применяется, (еще) отсутствует теоретическая основа для его выбора. Тем не менее, на практике, график ошибки модели в зависимости от ∞ может вызывать изменение уклона, при котором очевидные эффекты выбросовых значений уменьшаются. Фиг. 1 показывает этот график для вычисления нелинейной регрессии 402, связанного со сравнительным тестированием на предмет выработки мощности согласно варианту осуществления настоящего изобретения.
[0102] В варианте осуществления, общая форма этой кривой является предварительно определенной в том, она всегда должна начинаться с наибольшей ошибки в ∞=100%, и ошибка модели равна нулю, когда ∞=0%. На фиг. 7, следует отметить, что уклон кривой изменяется около ∞=85%. Кроме того, для всех меньших значений ∞, уклон является почти постоянным. Изменение уклона в этой точке обеспечивает то, вариабельность модели не изменяется относительно удаления записей данных, либо другими словами, выбросовые значения не присутствуют при этих уровнях приемлемости ошибки. Выше ∞=85%, предусмотрено по меньшей мере два очевидных изменения наклона, что обеспечивает то, что определенные доли набора данных содержат поведения или явления, которые не учитываются в модели. Этот визуальный тест может помогать задавать соответствующий уровень приемлемости ошибки, а также определять то, требуется или нет DOBR вообще. Если уклон линии на фиг. 7 не изменяется, то модель считается удовлетворительной для наблюдаемой вариабельности в данных. Отсутствуют выбросовые значения модели, и DOBR не должно обязательно применяться.
[0103] В исследованиях с помощью моделирования, в которых конкретные процентные доли от дополнительной вариабельности добавлены в набор данных, кривые, такие как фиг. 6, показывают начальную линию крутого уклона, которая пересекает уклон с меньшим значением приблизительно при значении приемлемости ошибки, программируемом согласно моделированию. Тем не менее, на практике, когда выбросовые значения наблюдаются, переход к постоянному уклону, в общем, возникает постепенно, обеспечивая то, что имеется более одного типа вариабельности, которая не учитывается в модели.
[0104] Вычисление соответствующего значения приемлемости ошибки является необходимой частью использования DOBR, и оно также визуально показывает величину и серьезность выбросовых влияний на результаты расчетов по модели. Этот этап документирует выбор ∞ и может оправдывать неиспользование DOBR, если выбросовое влияние определяется как минимальное по сравнению со значением прогнозирований на основе модели из выбросовых данных.
[0105] В некоторых вариантах осуществления, ∞ и значение ошибки модели в зависимости от ∞ могут использоваться в качестве показателя для идентификации модели с наилучшими функциональными параметрами или ансамбля моделей для конкретного сценария. Поскольку различные наборы данных могут варьироваться по степени линейности, точное значение ∞ для данных и для модели может изменять производительность модели. Таким образом, ошибка модели в качестве функции от уровня приемлемости ошибки может использоваться для определения степени, в которой данная модель может учитывать вариабельность в данных, за счет наличия ошибки модели, которая указывает больший или меньший допуск в отношении вариабельности данных для формирования точных прогнозирований. Например, точность и точность в прогнозированиях на основе модели могут быть настроены посредством выбора параметров модели и/или параметров модели, которые демонстрируют, например, низкую ошибку модели для высокого значения приемлемости ошибки, чтобы выбирать для модели, которая является более толерантной к выбросовым данным.
[0106] В некоторых вариантах осуществления, выбор модели может быть автоматизирован посредством использования, например, программирования моделей машинного обучения на основе правил и/или для идентификации модели с наилучшими функциональными параметрами для набора данных согласно балансу ошибки модели и критериев приемлемости ошибки. Таким образом, может автоматически выбираться модель, которая оптимально учитывает выбросовые значения в наборе данных. Например, ошибка модели может сравниваться по моделям для одного или более значений приемлемости ошибки, причем модель, имеющая наименьшую ошибку модели, автоматически выбирается для формирования прогнозирований.
[0107] Как результат, технологии машинного обучения DOBR согласно аспектам настоящего изобретения обеспечивают более эффективное обучение модели, а также улучшенную видимость для данных и моделируют поведения для отдельного набора данных. Как результат, в таких областях техники, как искусственный интеллект, средства анализа данных, бизнес-аналитика, а также другие области, модели машинного обучения могут более рационально и эффективно испытываться для различных типов данных. Производительность модели затем может более эффективно оцениваться, чтобы определять то, что она представляет собой оптимальную модель для варианта применения и для типа данных. Например, приложения на основе искусственного интеллекта могут улучшаться с помощью моделей, выбранных и обученных с использованием DOBR для формируемого типа интеллектуальности. Аналогично, бизнес-аналитика и средства анализа данных, а также другие варианты применения, такие как физическое прогнозирование поведения, рекомендация контента, прогнозирования использования ресурсов, обработка естественного языка и другие приложения на основе машинного обучения, могут улучшаться посредством использования DOBR, чтобы как настраивать параметры модели, так и выбирать модели на основе выбросовых характеристик и ошибки модели в ответ на выбросовые значения.
[0108] Фиг. 8 является графиком, иллюстрирующим пример взаимосвязи между ошибкой модели и критерием приемлемости ошибки другой примерной компьютерной модели машинного обучения с уменьшенным отклонением в соответствии с одним или более вариантов осуществления настоящего изобретения.
[0109] В качестве примера варианта осуществления DOBR для набора данных, используется набор 504 данных прочности на сжатие бетона, загружаемый из репозитория данных машинного обучения Калифорнийского университета в Ирвайне. Этот набор данных содержит 1030 наблюдений, записей или экземпляров с 8 независимыми переменными. Первые семь описывают состав бетона, при этом возраст задается в днях: количество цемента, суперпластификатор, доменный шлак, крупный заполнитель, зольная пыль, мелкий заполнитель, вода и возраст.
[0110] Выходная переменная представляет собой прочность на сжатие бетона, измеренную в мегапаскалях (МПа). Для сравнения, 1 МПа ≈ 145 фунтов на квадратный дюйм. Линейная регрессионная модель конструируется, например, согласно нижеприведенному уравнению 12:
уравнение 12 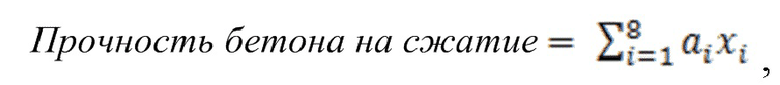
[0111] - где ai является коэффициентом, вычисленным посредством линейной регрессионной модели, xi является наблюдениями этих 8 переменных, и i является переменным индексом.
[0112] Фиг. 8 конструируется посредством выполнения линейной регрессионной модели 504 в качестве функции от процентной доли приемлемости ошибки DOBR, ∞, от 100 до 60%. От ∞=100% приблизительно до ∞=95%, возникает быстрое понижение ошибки модели, как показано посредством регрессии 506, затем уменьшение ошибки в качестве функции α снижается на немного меньшей скорости до ∞=85%. С этой точки, ∞ снижается с постоянной скоростью, как показано посредством регрессии 508. Точка, в которой ошибка начинает снижаться с постоянной скоростью, представляет собой точку, в которой влияние выбросовых значений модели опускается из вычисления с использованием модели. В этом случае, точка выбора представляет собой ∞=85%.
[0113] В варианте осуществления, DOBR в таком случае представляет собой модифицированную линейную регрессионную модель, повторно выполняется для ∞=92,5%, чтобы определять наилучшую модель, которая подгоняется под невыбросовые данные. Фиг. 9 и фиг. 10 отображают результаты этих вычислений с использованием полного набора 512 данных (фиг. 9) и версии DOBR (фиг. 10) с выбросовыми значениями, идентифицированными и удаленными из вычисления. Выбросовые значения 516, помечаемые как красные кресты, вычисляются из невыбросовой модели. Оба этих графика показывают сравниваемые фактические и прогнозируемые целевые значения с диагональной линией 510 и 514, соответственно, для фиг. 9 и фиг. 10, иллюстрирующей равенство. Вычисление полного набора данных (фиг. 9) показывает то, как выбросовые значения могут смещать результаты. Модифицированный DOBR график (фиг. 10) показывает удаленное отклонение, с диагональной линией 514, делящей пополам невыбросовые значения 518, а также очевидными группами выбросовых точек 516 данных, которые могут гарантировать дополнительное исследование.
[0114] Фиг. 9 является графиком, иллюстрирующим пример взаимосвязи между прочностью на сжатие и прогнозируемой прочностью на сжатие базовой компьютерной модели машинного обучения без уменьшенного отклонения в соответствии с одним или более вариантов осуществления настоящего изобретения.
[0115] Фиг. 10 является графиком, иллюстрирующим пример взаимосвязи между прочностью на сжатие и прогнозируемой прочностью на сжатие другой примерной компьютерной модели машинного обучения с уменьшенным отклонением в соответствии с одним или более вариантов осуществления настоящего изобретения
[0116] Идентификация выбросовых значений и тенденций, которые они иногда формируют, на вышеуказанном типе графиков является полезной для дополнительных выгод способа DOBR в промышленных вариантах применения. Выбросовые значения могут формировать шаблоны или группы, которые просто не наблюдаются посредством других способов. Эта информация создается посредством просто использования DOBR с обеспечиваемой аналитиками моделью. Дополнительная информация или предположения не требуются. На практике, набор задаваемых DOBR выбросовых значений может обеспечивать полезную информацию для улучшения, обеспечения понимания или проверки достоверности базовой модели.
[0117] Фиг. 11 является блок-схемой другой примерной компьютерной системы для прогнозирований машинного обучения с DOBR в соответствии с одним или более вариантов осуществления настоящего изобретения.
[0118] В варианте осуществления настоящего изобретения, процедура машинного обучения начинается с набора данных,  , состоящего из n независимых переменных и m записей по длине, и массива (mx1) целевых переменных,
, состоящего из n независимых переменных и m записей по длине, и массива (mx1) целевых переменных,  . В варианте осуществления, чтобы обучать модель машинного обучения, набор данных
. В варианте осуществления, чтобы обучать модель машинного обучения, набор данных  разделяется на два случайно выбранных поднабора предварительно определенного размера: один для обучения модели и другой для проверки точности ее прогнозирования, например, согласно нижеприведенному уравнению 13:
разделяется на два случайно выбранных поднабора предварительно определенного размера: один для обучения модели и другой для проверки точности ее прогнозирования, например, согласно нижеприведенному уравнению 13:
уравнение 13 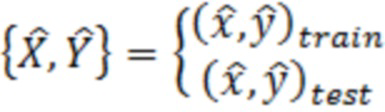 ,
,
[0119] - где 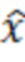 является поднабором независимых переменных набора данных, и является поднабором независимых переменных набора данных.
является поднабором независимых переменных набора данных, и является поднабором независимых переменных набора данных.
[0120] Для этого пояснения, разбиение 70%/30% для используется для обучения (n записей) и тестирования (j записей) (например, 70% записей являются обучающими, и 30% являются тестовыми); тем не менее, может использоваться любое подходящее разбиение, такое как, например, 50%/50%, 60%/40%, 80%/20%, 90%/10%, 95%/5% или другое подходящее разбиение обучения/тестирования. Модель машинного обучения, L, обученная с использованием 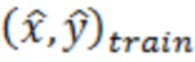 , тестируется посредством вычисления набора прогнозируемых целевых переменных, , выражаемых так, как, например, указано в нижеприведенном уравнении 14:
, тестируется посредством вычисления набора прогнозируемых целевых переменных, , выражаемых так, как, например, указано в нижеприведенном уравнении 14:
уравнение 14 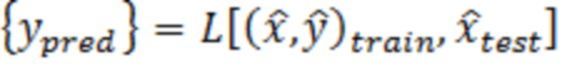 .
.
[0121] В иллюстративном варианте осуществления, точность модели затем измеряется в качестве нормы, 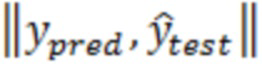 , которая может иметь, например, следующую форму:
, которая может иметь, например, следующую форму:
уравнение 15 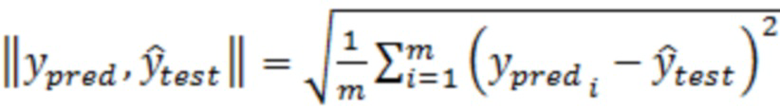 .
.
[0122] В иллюстративном варианте осуществления, в обучающих и тестовых окружениях, можно непосредственно измерять выбросовые значения, поскольку имеются входные и выходные переменные. В общем, выбросовые значения в прогнозированиях на основе модели, , к примеру, с большими отклонениями от фактических значений целевой переменной, обусловлены неспособностью модели L преобразовывать конкретные входные значения в прогнозные значения около известной целевой переменной. Входные данные для этих записей содержат эффекты факторов и/или явлений, которые модель не может увязывать реальностью, представленной посредством целевых переменных. Хранение этих записей в наборе данных может смещать результаты, поскольку коэффициенты модели вычисляются при таком допущении, что все записи данных являются одинаково допустимыми.
[0123] В некоторых вариантах осуществления, процесс DOBR, описанный выше, например, с обращением к вышеприведенной фиг. 6, работает для данного набора данных, в котором аналитик хочет наилучшей модели, которая подгоняется под данные, за счет удаления выбросовых значений, которые негативно смещают результаты. Это увеличивает точность прогнозирования модели посредством ограничения решения с использованием модели поднабором начального набора данных, который имеет удаленные выбросовые значения. В иллюстративном варианте осуществления, упрощаемое DOBR решение имеет два результата вывода:
a) Набор значений x, параметров модели и решений с использованием модели, для которых модель описывает данные, и
b) Набор значений x, параметров модели и решений с использованием модели, для которых модель не описывает данные.
[0124] Следовательно, в дополнение к вычислению более точной модели для ограниченного набора данных, в вариантах осуществления, DOBR также обеспечивает выбросовый набор данных, который дополнительно может изучаться относительно данной модели, чтобы понимать причину или причины высокой ошибки прогнозирования на основе модели.
[0125] В иллюстративном варианте осуществления инфраструктуры машинного обучения, как показано выше в этом разделе, прогнозирующая модель вычисляется из обучающих данных, и только эта модель используется в фазе тестирования. Поскольку, согласно расчетам, фаза тестирования может не использовать целевые значения, чтобы определять выбросовые значения, технология DOBR, описанная выше с обращением к фиг. 6, может не применяться. Тем не менее, имеется примерный аспект технологии DOBR, который, возможно не использован выше: потенциал классификации выбросовых значений/невыбросовых значений, обеспечиваемый посредством результатов вывода DOBR, упомянутых ранее.
[0126] В качестве описания DOBR в приложении на основе машинного обучения варианта осуществления настоящего изобретения, набор данных может разделяться на две случайно выбранных части: одну для обучения и одну для тестирования. В фазе обучения, сохраняются независимые и целевые переменные, но в тестировании, целевые переменные маскируются, а независимые переменные используются для прогнозирования целевой переменной. Известные значения целевых переменных используются только для измерения ошибки прогнозирования модели.
[0127] В варианте осуществления, с учетом набора 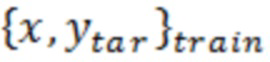 604 обучающих данных с n записей, модели L 608 машинного обучения и критерия ∞ 622 приемлемости ошибки, DOBR может быть реализована с возможностью уменьшения отклонения в обучении модели L 608 машинного обучения. В некоторых вариантах осуществления, модель L 608 машинного обучения реализуется посредством модельного механизма, включающего в себя, например, обрабатывающее устройство и запоминающее устройство и/или устройство хранения данных. Согласно варианту осуществления, примерные оценки технологической модели,
604 обучающих данных с n записей, модели L 608 машинного обучения и критерия ∞ 622 приемлемости ошибки, DOBR может быть реализована с возможностью уменьшения отклонения в обучении модели L 608 машинного обучения. В некоторых вариантах осуществления, модель L 608 машинного обучения реализуется посредством модельного механизма, включающего в себя, например, обрабатывающее устройство и запоминающее устройство и/или устройство хранения данных. Согласно варианту осуществления, примерные оценки технологической модели, 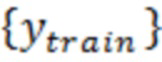 606, для всех записей, применяющих модель L 608 машинного обучения, к полному входному набору 604 данных, например, согласно нижеприведенному уравнению 16:
606, для всех записей, применяющих модель L 608 машинного обучения, к полному входному набору 604 данных, например, согласно нижеприведенному уравнению 16:
уравнение 16 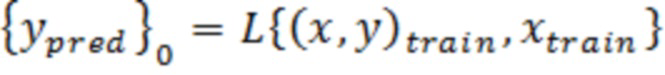 ,
,
[0128] - где 0 указывает начальное состояние, и x означает входную запись.
[0129] Затем, согласно иллюстративному варианту осуществления, функция 618 полных ошибок вычисляет начальную полную ошибку e0 модели, например, согласно нижеприведенному уравнению 17:
уравнение 17 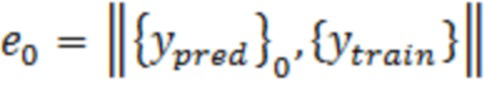 ,
,
[0130] - где e0 является начальной полной ошибкой модели.
[0131] Затем, согласно иллюстративному варианту осуществления, функция 612 ошибок вычисляет ошибки модели, например, согласно нижеприведенному уравнению 18:
уравнение 18 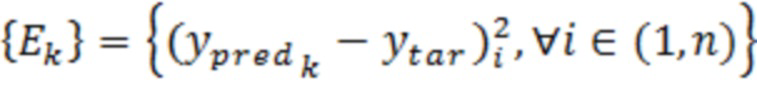 ,
,
[0132] - где E является прогнозируемой ошибкой записи, и k обозначает итерацию.
[0133] Затем, согласно иллюстративному варианту осуществления, функция 612 ошибок вычисляет новый вектор выбора записей данных, например, согласно нижеприведенному уравнению 19:
уравнение 19 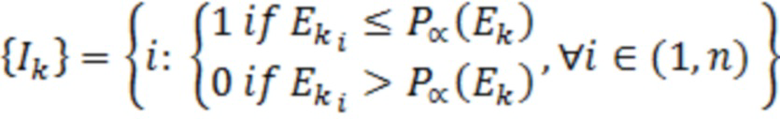 ,
,
[0134] - где I является вектором выбора записей.
[0135] После этого, согласно иллюстративному варианту осуществления, блок 614 выбора записей данных вычисляет невыбросовые записи данных, которые должны включаться в вычисление с использованием модели, посредством выбора только записей, в которых вектор выбора записей равен 1, например, согласно нижеприведенному уравнению 20:
уравнение 20 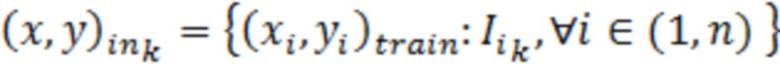 ,
,
[0136] - где является индексом, указывающим на набор включенных DOBR записей в качестве невыбросовых значений.
[0137] Затем, согласно иллюстративному варианту осуществления, модуль машинного обучения 608 с последними коэффициентами 602 вычисляет новые прогнозируемые значения 620 для полного обучающего набора 604 с использованием выбранных DOBR записей данных, например, согласно нижеприведенному уравнению 21:
уравнение 21 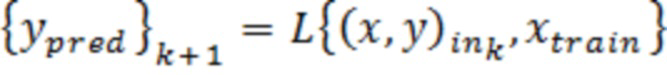 .
.
[0138] Затем, согласно иллюстративному варианту осуществления, функция 618 полных ошибок вычисляет полную ошибку модели, например, согласно нижеприведенному уравнению 22:
уравнение 22 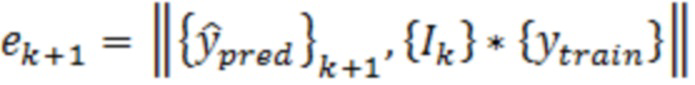 ,
,
[0139] Затем, согласно иллюстративному варианту осуществления, тест 624 сходимости тестирует сходимость модели, например, согласно нижеприведенному уравнению 23:
уравнение 23 ,
[0140] - где β является критериями 622 сходимости, такими как, например, 0,5%.
[0141] В некоторых вариантах осуществления, тест 624 сходимости может завершать итеративный процесс, если, например, процентная ошибка меньше, например, 0,5%. В противном случае, процесс может возвращаться к набору 604 обучающих данных.
[0142] В некоторых вариантах осуществления, итеративная процедура DOBR измеряет то, насколько хорошо модель может прогнозировать себя, вместо измерения ее точности относительно набора тестовых данных. Цель здесь состоит в том, чтобы тестировать возможности модели прогнозировать целевую переменную, и записи с большими отклонениями систематически удаляются, чтобы повышать способность модели фокусироваться на подавляющем большинстве данных, в которых прогнозирования данных являются относительно хорошими. Этот процесс должен осуществляться с идентичным набором данных. Нецелесообразно удалять записи из обучающего набора, если выбросовые значения идентифицируются в тестовом наборе. Этот процесс является фундаментальным для способа DOBR в том, что записи, которые удаляются на предыдущей итерации, повторно вводятся после того, как новая модель (параметры новой модели) вычислена. Этот процесс требует того, что должен использоваться идентичный набор данных.
[0143] В варианте осуществления, эта итеративная процедура выполняется после того, как обучающая модель задается. На основе проблемы, которая должна разрешаться в варианте осуществления, пользователь выбирает алгоритм машинного обучения и затем определяет конкретные гиперпараметры, которые «настраивают» или конфигурируют модель. Эти параметры могут выбираться с использованием стандартных технологий, таких как перекрестная проверка достоверности либо просто посредством иллюстрации на графике ошибки тестирования в качестве функции от конкретных обеспечиваемых пользователем диапазонов параметров. Используемые конкретные значения могут оптимизировать точность прогнозирования в зависимости от времени вычислений при обеспечении того, что модель не подгоняется ни недостаточно, ни избыточно. Предусмотрено несколько надежных инструментальных средств, чтобы помогать в этом процессе, но опыт и интуиция пользователей также представляют собой ценные преимущества в выборе наилучших гиперпараметров модели. Конкретные модели и ассоциированные гиперпараметры используются в примерах, поясненных ниже.
[0144] График зависимости приемлемости ошибки от ошибки модели вычисляется из этого этапа посредством применения последовательности значений приемлемости ошибки и сведения в таблицу или иллюстрации на графике результатов. Эти графики идентифицируют долю набора данных, которые представляют собой выбросовые значения, в том смысле, что их доля ошибки незначительно больше доли ошибки записей данных, которые подгоняются под модель. Также на практике, эти графики могут показывать более одного типа варьирования, не поясненных посредством модели. Уклон может варьироваться по мере того, как он сходится к уклону модели. Эти варьирования могут помогать в исследовании природы кодированного из дополнительных данных поведения, которое не объясняется посредством модели. Записи, которые занимают различные наклонные интервалы, могут идентифицироваться, и их дополнительное исследование может обеспечивать понимание, которое может помогать в конструировании еще более надежной модели.
[0145] В варианте осуществления, после обучения, как описано выше, вычисляются две модели:
Модель 1
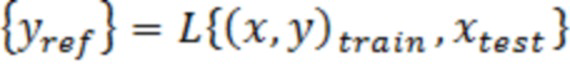 ,
,
[0146] - где 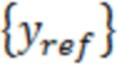 является опорной моделью, которая используется в качестве основы для измерения повышения точности; и
является опорной моделью, которая используется в качестве основы для измерения повышения точности; и
Модель 2
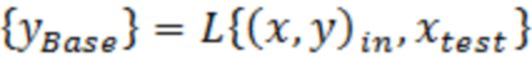 ,
,
[0147] - где 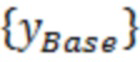 является базовой моделью DOBR, компонуемой из сходящихся выбросовых цензурированных записей и обученной на невыбросовых данных
является базовой моделью DOBR, компонуемой из сходящихся выбросовых цензурированных записей и обученной на невыбросовых данных 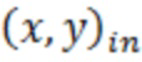 .
.
[0148] В вариантах осуществления, ошибки, ассоциированные с моделью 1 и моделью 2, например, представляют собой 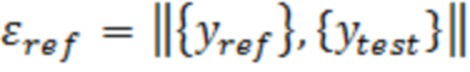 и
и 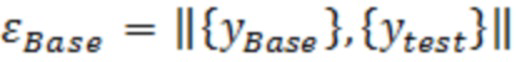 , соответственно.
, соответственно.
[0149] Таким образом, в вариантах осуществления, базовая модель предлагает то, что она может представлять собой лучший предиктор для невыбросовых записей. Тем не менее, набор тестовых данных является нецензурированным, так что он содержит как невыбросовые значения, так и выбросовые значения. Следовательно, непонятно, если применение невыбросовой индивидуально настраиваемой модели к нецензурированным тестовым данным должно формировать лучшую прогнозирующую модель по сравнению с . Тем не менее, во многих случаях, 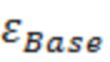 может наблюдаться как статистически равное или большее
может наблюдаться как статистически равное или большее 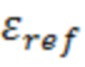 .
.
[0150] В вариантах применения не на основе машинного обучения, в которых цель состоит в том, чтобы вычислять наилучшую прогнозирующую модель для данного набора данных, модель DOBR, вычисленная из выбранных (невыбросовых) записей, всегда формирует более низкую ошибку модели, поскольку опускаются идентифицированные выбросовые записи. В ограничивающем случае отсутствия выбросовых значений, ошибка модели DOBR равна полной ошибке модели, поскольку наборы данных являются идентичными.
[0151] Тем не менее, в приложениях на основе машинного обучения, цель может состоять в том, чтобы разрабатывать модель с использованием поднабора доступных данных (обучение) и затем измерять ее точность прогнозирования на другом поднаборе (тестирование). Но, в некоторых вариантах осуществления, технология DOBR удаляет выбросовые значения модели на каждой итерации перед вычислением параметров модели. При разработке моделей машинного обучения, это может осуществляться в фазе обучения, но по определению, целевые значения в тестировании могут использоваться только для измерения точности прогнозирования модели без расширенных знаний выбросовых значений. Это наблюдение означает, что стандартная технология DOBR может обобщаться с использованием большего объема информации модели DOBR, вычисленной в фазе обучения.
[0152] Фиг. 11 является блок-схемой другой примерной компьютерной системы для машинного обучения с уменьшенным отклонением в соответствии с одним или более вариантов осуществления настоящего изобретения.
[0153] В вариантах осуществления, после обучения, как описано выше, формируется следующая информация: выбранные DOBR значения набора обучающих данных для невыбросовых значений, вектор 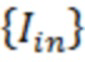 выбора обучающих данных DOBR для невыбросовых значений, выбранные DOBR значения
выбора обучающих данных DOBR для невыбросовых значений, выбранные DOBR значения 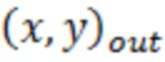 набора обучающих данных для выбросовых значений и вектор
набора обучающих данных для выбросовых значений и вектор 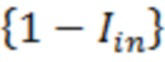 выбора обучающих данных DOBR для выбросовых значений.
выбора обучающих данных DOBR для выбросовых значений.
[0154] В вариантах осуществления, DOBR классифицирует обучающие данные на два взаимоисключающих поднабора. Помимо этого, также имеются соответствующие векторы выбора, которые обеспечивают двоичный результат: (невыбросовое или выбросовое) классификационное значение для каждой записи в наборе обучающих данных, например, согласно нижеприведенному уравнению 24:
уравнение 24 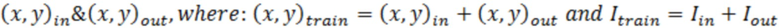 .
.
[0155] В вариантах осуществления, полный набор атрибутов обучающих данных,  , и сформированных DOBR классификаций,
, и сформированных DOBR классификаций, 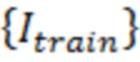 , используется для построения/обучения классификационной модели машинного обучения, C, например, сохраненную в библиотеке 303 моделей. Эта модель применяется к набору тестовых данных, xtest, для классификации записей тестовых данных в качестве выбросовых значений или невыбросовых значений на основе устанавливаемого DOBR знания набора обучающих данных. Например, классификационная модель машинного обучения C реализуется согласно нижеприведенному уравнению 25:
, используется для построения/обучения классификационной модели машинного обучения, C, например, сохраненную в библиотеке 303 моделей. Эта модель применяется к набору тестовых данных, xtest, для классификации записей тестовых данных в качестве выбросовых значений или невыбросовых значений на основе устанавливаемого DOBR знания набора обучающих данных. Например, классификационная модель машинного обучения C реализуется согласно нижеприведенному уравнению 25:
уравнение 25 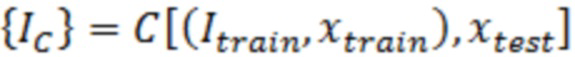 .
.
[0156] Таким образом, в варианте осуществления, 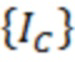 формирует два тестовых набора данных прогнозирования;
формирует два тестовых набора данных прогнозирования;  и
и  , где
, где 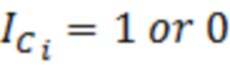 , соответственно. Вышеприведенная информация создает несколько возможных прогнозирующих моделей «полных наборов данных» для анализа набора тестовых данных. В некоторых вариантах осуществления, три модели, которые показывают наибольшие улучшения прогнозирования для всего набора данных, представляют собой:
, соответственно. Вышеприведенная информация создает несколько возможных прогнозирующих моделей «полных наборов данных» для анализа набора тестовых данных. В некоторых вариантах осуществления, три модели, которые показывают наибольшие улучшения прогнозирования для всего набора данных, представляют собой:
Модель 3
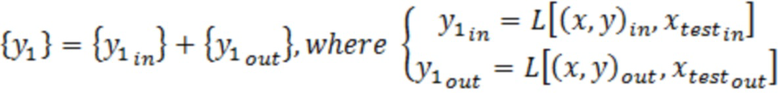 ,
,
Модель 4
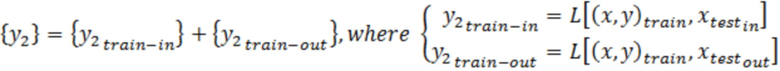 ,
,
Модель 5
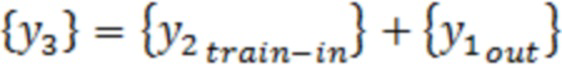 .
.
[0157] В некоторых вариантах осуществления, для 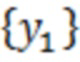 , модель L 608 машинного обучения задается посредством невыбросовых данных, , и применяется к тестовым классифицированным DOBR данным для прогнозирования невыбросовых тестовых значений. Идентичная процедура осуществляется для выбросовых данных. В вариантах осуществления, цель данного сочетания состоит в использовании самой точной прогнозирующей модели с соответствующим набором данных. Другими словами, эта модель тестирует полную точность прогнозирования невыбросовых и выбросовых моделей, применяемых по отдельности к соответствующим наборам данных, которые заданы с помощью классификации DOBR.
, модель L 608 машинного обучения задается посредством невыбросовых данных, , и применяется к тестовым классифицированным DOBR данным для прогнозирования невыбросовых тестовых значений. Идентичная процедура осуществляется для выбросовых данных. В вариантах осуществления, цель данного сочетания состоит в использовании самой точной прогнозирующей модели с соответствующим набором данных. Другими словами, эта модель тестирует полную точность прогнозирования невыбросовых и выбросовых моделей, применяемых по отдельности к соответствующим наборам данных, которые заданы с помощью классификации DOBR.
[0158] В некоторых вариантах осуществления, для 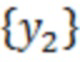 , модель L 608 машинного обучения задается посредством обучающих данных,
, модель L 608 машинного обучения задается посредством обучающих данных, 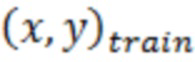 , и также применяется к тестовым классифицированным DOBR данным . Эта модель использует широкие знания
, и также применяется к тестовым классифицированным DOBR данным . Эта модель использует широкие знания 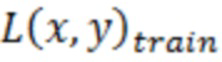 для прогнозирования целевых значений задаваемых DOBR выбросовых и невыбросовых значений x. Назначение этой модели заключается в тестировании точности прогнозирования полной модели обучения, применяемой по отдельности к классифицированным DOBR невыбросовым и выбросовым наборам данных.
для прогнозирования целевых значений задаваемых DOBR выбросовых и невыбросовых значений x. Назначение этой модели заключается в тестировании точности прогнозирования полной модели обучения, применяемой по отдельности к классифицированным DOBR невыбросовым и выбросовым наборам данных.
[0159] В некоторых вариантах осуществления, третья модель 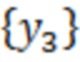 представляет собой гибридную схему, которая объединяет характеристики прогнозирования предыдущих двух подходов. Эта модель тестирует преимущество в прогнозировании, если имеется, объединения , модели 608, обученной на полном обучении, с
представляет собой гибридную схему, которая объединяет характеристики прогнозирования предыдущих двух подходов. Эта модель тестирует преимущество в прогнозировании, если имеется, объединения , модели 608, обученной на полном обучении, с 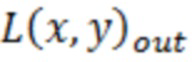 , конкретной моделью, обученной на классифицированных DOBR выбросовых значениях в обучающем наборе, применяемом к соответствующим классифицированным наборам данных. Возникают дополнительные гибридные модели, которые могут изучаться в дальнейшем исследовании.
, конкретной моделью, обученной на классифицированных DOBR выбросовых значениях в обучающем наборе, применяемом к соответствующим классифицированным наборам данных. Возникают дополнительные гибридные модели, которые могут изучаться в дальнейшем исследовании.
[0160] В каждой из этих трех моделей и других вариантов осуществления, полный набор тестовых данных прогнозируется с использованием классифицированных DOBR невыбросовых и выбросовых записей. Способность способа DOBR повышать полную точность прогнозирования модели машинного обучения тестируется с помощью этих моделей. Но основное преимущество DOBR состоит в идентификации выбросовых значений модели, удалять их и вычислять наилучший предиктор модели из оставшихся невыбросовых значений. Кроме того, по определению, задаваемые DOBR выбросовые значения представляют собой записи, которые содержат варьирование, не описанное надлежащим образом в текущих переменных (или признаках), с учетом используемой модели машинного обучения.
[0161] В некоторых вариантах осуществления, при вычисленных наборах выбросовых и невыбросовых данных, аналитик имеет три варианта. В варианте осуществления, первый вариант заключается в том, чтобы применять базовую модель, , и не применять DOBR. Означенное представляет собой управляемую данными стратегию, когда кривая зависимости приемлемости риска от ошибки модели находится близко к линейной взаимосвязи. В варианте осуществления, второй вариант заключается в том, чтобы применять одну или более моделей: , или , и комбинировать, например, усреднять результаты. В варианте осуществления, третий вариант заключается в том, чтобы разрабатывать прогнозирования только для невыбросовых записей и дополнительно исследовать выбросовые данные для разработки стратегии моделирования для этого специализированного нового набора данных, например, изменения модели машинного обучения или добавлять переменные, чтобы учитывать необъясненное варьирование, и т.д.
[0162] Относительно варианта 3, предусмотрено несколько способов вычислять набор невыбросовых данных, и здесь упоминаются два возможных варианта выбора. Одна причина относительно большого числа возможностей может быть обусловлена нелинейностью многих применяемых моделей машинного обучения. В общем, 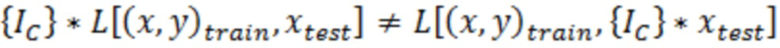 . Это неравенство может быть обусловлено сложностью многих моделей машинного обучения. Равенство является применимым для линейной регрессии, например, но не в качестве общего правила для моделей машинного обучения.
. Это неравенство может быть обусловлено сложностью многих моделей машинного обучения. Равенство является применимым для линейной регрессии, например, но не в качестве общего правила для моделей машинного обучения.
[0163] В вариантах осуществления, относительно невыбросовых прогнозирований, способ DOBR первоначально не проектируется с возможностью улучшения прогнозирования полного набора данных. Согласно расчетам, способ сходится к наилучшему набору выбросовых значений на основе обеспеченной модели и набора данных. Оставшиеся данные и вычисления с использованием модели обеспечивают повышенную точность, но отсутствуют методологические принципы в отношении того, как выполнять прогнозирования для выбросовых значений. Неявное решение состоит в том, чтобы применять различную модель к выбросовому набору данных, которая отражает уникальные варьирования данных, которые не присутствуют в невыбросовой модели.
[0164] В вариантах осуществления, задаются две модели для проверки невыбросовой точности прогнозирования с удалением выбросовых значений из анализа. Первый вариант для выбора набора невыбросовых данных применяет классификационный вектор DOBR, , к опорной модели, , например, согласно нижеприведенной модели 6:
Модель 6
 .
.
[0165] В вариантах осуществления, опорная модель использует полную заданную на основе обучающих данных модель, чтобы выполнять прогнозирования из набора данных, xtest. Классификационный вектор затем применяется, чтобы удалять прогнозируемые выбросовые значения на основе знаний способа DOBR, полученных из набора обучающих данных. Эта модель применяет DOBR к модели самой общей или широкой предметной области.
[0166] В вариантах осуществления, вторая модель применяет DOBR самым узким или «точным» способом посредством использования модели DOBR, созданной из стадии обучения, из невыбросовых обучающих данных, только к записям, выбранным посредством модели классификации, , например, согласно нижеприведенной модели 7:
Модель 7
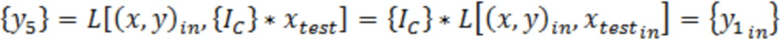 .
.
[0167] Предусмотрены другие модели, которые могут формироваться из аналитических формулирований, разработанных в этом исследовании, и в зависимости от проблемы, они могут иметь значительный потенциал улучшения прогнозируемости. Тем не менее, модели, используемые здесь, 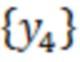 и
и 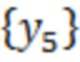 , ограничивают случаи, представляющие самые широкие и самые узкие версии, с точки зрения эффективности использования обучающей предметной области и определения моделей.
, ограничивают случаи, представляющие самые широкие и самые узкие версии, с точки зрения эффективности использования обучающей предметной области и определения моделей.
[0168] В вариантах осуществления, чтобы тестировать точность прогнозирования разработанных DOBR моделей, заданных выше, таких как, например, модели 3-7, используется в качестве основы сравнения для моделей , и (моделей 3, 4 и 5, соответственно). Для и (моделей 6 и 7, соответственно), прогнозирования на основе модели для набора невыбросовых данных, основа сравнения представляет собой 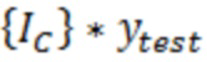 . Таким образом, в вариантах осуществления, ошибка может определяться, например, согласно нижеприведенным уравнениям 26, 27 и 28:
. Таким образом, в вариантах осуществления, ошибка может определяться, например, согласно нижеприведенным уравнениям 26, 27 и 28:
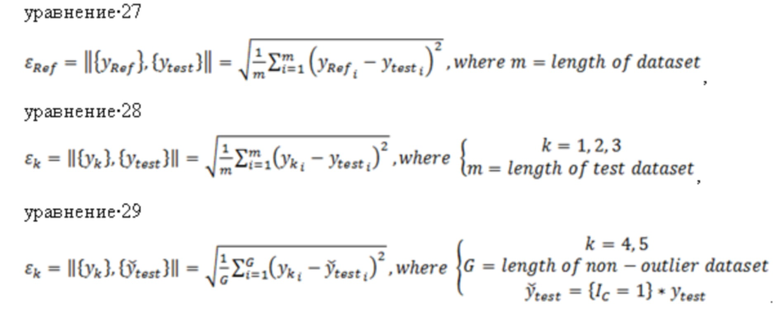
[0169] В нижеприведенных примерах иллюстративных вариантов осуществления, показатель точности прогнозирования DOBR измеряется за счет того, насколько (если вообще) 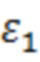 ,
, 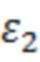 и/или
и/или 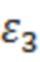 меньше
меньше 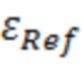 . Для ошибок набора невыбросовых данных,
. Для ошибок набора невыбросовых данных, 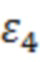 и
и 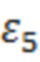 , показатель улучшения представляет собой снижение ошибки относительно выбросовой отрегулированной базовой ошибки . Регулирование описывается ниже относительно примерных результатов.
, показатель улучшения представляет собой снижение ошибки относительно выбросовой отрегулированной базовой ошибки . Регулирование описывается ниже относительно примерных результатов.
[0170] В некоторых вариантах осуществления для примеров машинного обучения примерных улучшений DOBR согласно изобретению, точность ранее заданных пяти моделей может тестироваться с помощью семи регрессионных моделей машинного обучения: линейная регрессия, k ближайших соседних узлов, LASSO-регрессия, метод опорных векторов, дерево решений, улучшение агрегации и случайный лес. Эти регрессионные модели машинного обучения представляют собой примеры широкого спектра модельных конструкций. Также предполагаются дополнительные или альтернативные модели, такие как нейронные сети, кластеризация, модели из ансамбля, в числе других, и их сочетание.
[0171] Линейная регрессия представляет собой способ, который дает понимание аналитикам относительно процесса, в котором коэффициенты (или параметры модели) могут иметь связанное с техническим процессом смысловое значение. Модель процесса, представленная посредством уравнения, должна обеспечиваться аналитиком, и коэффициенты определяются посредством минимизации ошибки между прогнозируемыми целевыми значениями и целевыми значениями на основе обеспечиваемых данных.
[0172] LASSO-регрессия, сокращение для «оператора сжатия и выбора коэффициентов по наименьшим абсолютным отклонениям», представляет собой связанную с регрессией технологию, в которой дополнительный член добавляется в целевую функцию. Этот член представляет собой сумму абсолютных значений коэффициентов регрессии, и он минимизируется согласно обеспечиваемому пользователем параметру. Цель этого дополнительного члена состоит в добавлении штрафа за увеличение значения коэффициентов переменных (или признаков). Минимизация только сохраняет доминирующие коэффициенты и может помогать в уменьшении сложных в интерпретации эффектов ковариации или коллинеарности переменных (или признаков).
[0173] Регрессия на основе дерева решений может имитировать человеческое мышление и является интуитивной и простой в интерпретации. Модель выбирает конструкцию дерева решений, которая логически показывает то, как значения x формируют целевую переменную. Конкретные параметры, такие как максимальная глубина и минимальное число выборок в расчете на лист, задаются аналитиком в обучающем/тестовом упражнении на основе машинного обучения.
[0174] Регрессия на основе случайного леса основывается на способе на основе дерева решений. Точно так же, как леса создаются с помощью деревьев, регрессионная модель на основе случайного леса создается с помощью групп деревьев решений. Аналитик задает лесную структуру посредством обеспечения модулей оценки (числа деревьев в лесу), некоторых параметров, аналогичных максимальной глубине деревьев решений деревьев, характеристик листьев и технических параметров, связанных с тем, как ошибка модели вычисляется и применяется.
[0175] k-NN означает способы на основе принципа k ближайших соседних узлов, в которых прогнозируемое значение вычисляется из k ближайших соседних узлов в области x (или признаков). Выбор показателя для измерения расстояния и конкретное число ближайших соседних узлов, которые следует использовать, представляет собой главные параметры, задаваемые аналитиком в настройке модели для прогнозирований относительно данного набора данных. Именно простой способ может хорошо работать для регрессионных и классификационных прогнозирований.
[0176] Регрессия на основе метода опорных векторов представляет собой универсальный способ на основе машинного обучения, который имеет несколько варьирований. Регрессия означает подгонку модели под данные, и оптимизация обычно представляет собой минимизацию ошибки между прогнозируемыми и целевыми переменными. При использовании регрессии на основе метода опорных векторов, критерий ошибки обобщается, чтобы указывать то, что если ошибка меньше некоторого значения "ε", то указывается то, что они «являются достаточно хорошими», и только ошибки, большие "ε", измеряются и оптимизируются. В дополнение к этому атрибуту, способ обеспечивает возможность преобразования данных в нелинейные области с помощью стандартных или, в некоторых случаях, определяемых пользователем функций или ядер преобразования. Используется многомерная структура данных, в которой цель состоит в том, чтобы вычислять надежные прогнозирования, а не в том, чтобы не моделировать данные согласно традиционной сущности регрессии.
[0177] Регрессия на основе принципа улучшения агрегации вычисляет прогнозные оценки из взятия случайных поднаборов с заменой. Каждая случайная выборка вычисляет прогнозирование на основе дерева решений (по умолчанию) целевой переменной. Конечное прогнозное значение ансамбля может вычисляться несколькими способами: среднее значение представляет собой один пример. Первичные переменные машинного обучения представляют собой число модулей оценки в каждом ансамбле, число переменных (или признаков) и выборок для взятия, чтобы обучать каждый модуль оценки, и инструкции по выбору/замене. Способ может уменьшать дисперсию по сравнению с другими способами, такими как регрессия на основе дерева решений.
[0178] Классификационная модель, 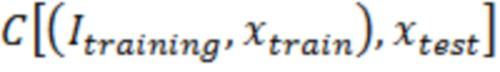 , представляет собой иллюстративный пример, поскольку она применяется к классификациям DOBR невыбросовых значений/выбросовых значений и значений x обучающего набора, чтобы задавать невыбросовое значение и выбросовые значения в наборе тестовых данных. Она представляет собой критический этап в варианте применения на основе машинного обучения DOBR, поскольку она передает знания выбросовых значений из обучающего набора в набор тестовых или производственных данных. Если возникают неподходящие классификации, полезность технологии DOBR для повышения точности прогнозирований машинного обучения, не реализуется.
, представляет собой иллюстративный пример, поскольку она применяется к классификациям DOBR невыбросовых значений/выбросовых значений и значений x обучающего набора, чтобы задавать невыбросовое значение и выбросовые значения в наборе тестовых данных. Она представляет собой критический этап в варианте применения на основе машинного обучения DOBR, поскольку она передает знания выбросовых значений из обучающего набора в набор тестовых или производственных данных. Если возникают неподходящие классификации, полезность технологии DOBR для повышения точности прогнозирований машинного обучения, не реализуется.
[0179] Классификационные модели на основе дерева решений, на основе принципа k-NN, на основе случайного леса и на основе принципа улучшения агрегации тестируются на предмет своей точности классификации. Модели на основе принципа улучшения агрегации и на основе случайного леса выбирается, и обе модели настраиваются с возможностью формирования корректной доли приемлемости ошибки для невыбросовых значений. Более подробный классификационный анализ может предлагать другие модели. Обширный классификационный анализ, даже если точность классификации является главной, находится за рамками объема этого начального пояснения.
[0180] Фиг. 12 является графиком, иллюстрирующим пример взаимосвязи между ошибкой модели и критерием приемлемости ошибки некоторых примерных компьютерных моделей машинного обучения с уменьшенным отклонением для прогнозирования прочности бетона в соответствии с одним или более вариантов осуществления настоящего изобретения.
[0181] Первый пример использует идентичный набор данных с тем, что описано выше в отношении прочности на сжатие бетона, причем DOBR применяется к полному набору данных. В качестве краткого обзора, этот набор данных содержит прочность на сжатие бетона в качестве функции от его состава и воздействия на него, заданной посредством 8 количественных входных переменных. Набор данных имеет 1030 записей или экземпляров и содержится в архиве репозитория данных машинного обучения Калифорнийского университета в Ирвайне.
[0182] Учебное упражнение на основе машинного обучения разделяет этот набор данных согласно разбиению 70%:30% с настройкой модели, выполняемой для набора обучающих данных (70%), и результатами прогнозирования, измеренными с тестовым (30%-м) набором данных.
[0183] Результаты настройки модели для семи моделей машинного обучения при прогнозировании прочности на сжатие бетона приводятся в нижеуказанной таблице 1.
[0184] Параметры модели по умолчанию (например, для Python 3,6) не показаны, поскольку они не добавляют информацию в результаты. В вариантах осуществления, процесс настройки представляет собой упражнение в выборе параметров, которые минимизируют ошибки в наборе обучающих и тестовых данных с использованием среднеквадратической ошибки в качестве индикатора. Более сложные алгоритмы могут применяться, но простой подход использован лишь для обеспечения того, что результаты ни недостаточно, ни избыточно не подгоняются под ошибку в наборе данных.
[0185] В варианте осуществления, чтобы применять DOBR, выполняется определение процентной доли от данных, если таковые имеются, в которых ошибка является чрезмерно большой. В вариантах осуществления, модели машинного обучения, которые применяются для последовательности долей приемлемости ошибки, записывают соответствующие ошибки модели. Это осуществляется только для набора обучающих данных, поскольку набор тестовых данных используется только для измерения точности прогнозирования модели машинного обучения. Процентная доля данных, включенных в модель, «приемлемость ошибки», означает величину полной ошибки модели, которую пользователь имеет намерение считать приемлемой, а также указывает долю данных, которые адекватно описывает модель.
[0186] В вариантах осуществления, последовательность процентных долей приемлемости ошибки колеблется от 100% до 60% с приращениями в 2.
[0187] Фиг. 13 является графиком, иллюстрирующим пример взаимосвязи между ошибкой модели и критерием приемлемости ошибки некоторых примерных компьютерных моделей машинного обучения с уменьшенным отклонением для прогнозирования использования энергии в соответствии с одним или более вариантов осуществления настоящего изобретения.
[0188] Второй пример содержит данные использования энергии приборов вместе с бытовыми окружающими условиями и условиями освещения с дискретизацией каждые 10 минут в течение 4½ месяцев. Они состоят из 29 атрибутов: 28 входных переменных и 1 выходной (целевой переменной) и 19735 записей. Набор данных и документация содержатся в архиве репозитория данных машинного обучения Калифорнийского университета в Ирвайне.
[0189] Аналогично вышеуказанному, в вариантах осуществления, результаты настройки модели для семи моделей машинного обучения при прогнозировании использования энергии приборов приводятся в нижеприведенной таблице 2.
[0190] В вариантах осуществления, параметры модели по умолчанию (например, для Python 3,6) не показаны, поскольку они не добавляют информацию в результаты. Процесс настройки представляет собой упражнение в выборе параметров, которые минимизируют ошибки в наборе обучающих и тестовых данных с использованием среднеквадратической ошибки в качестве индикатора. Более сложные алгоритмы могут применяться, но простой подход использован лишь для обеспечения того, что результаты ни недостаточно, ни избыточно не подгоняются под ошибку в наборе данных.
[0191] В варианте осуществления, чтобы применять DOBR, выполняется определение процентной доли от данных, если таковые имеются, в которых ошибка является чрезмерно большой. В вариантах осуществления, модели машинного обучения, которые применяются для последовательности долей приемлемости ошибки, записывают соответствующие ошибки модели. Это осуществляется только для набора обучающих данных, поскольку набор тестовых данных используется только для измерения точности прогнозирования модели машинного обучения. Процентная доля данных, включенных в модель, «приемлемость ошибки», означает величину полной ошибки модели, которую пользователь имеет намерение считать приемлемой, а также указывает долю данных, которые адекватно описывает модель.
[0192] В вариантах осуществления, последовательность процентных долей приемлемости ошибки колеблется от 100% до 60% с приращениями в 2.
[0193] Фиг. 12 и фиг. 13 показывают, частично, возможности моделей машинного обучения адаптироваться к сильноварьирующимся данным. Чем ближе линии к линейным (чем в большей степени являются прямыми), тем больше способность модели адекватно описывать данные, которые транслируются в меньше число, если такие имеются, выбросовых значений. Линейное поведение для нескольких моделей, применяемых к данным по бетону, показывает то, они могут почти полностью адекватно описывать весь набор обучающих данных. Нелинейность результатов для набора данных по энергопотреблению предлагает то, что имеется значительная процентная доля от записей данных, в которых модели формируют неточные прогнозирования или выбросовые значения.
[0194] Для каждой кривой на вышеуказанном графике данных по бетону, включающем в себя, например, линейную регрессию 530, LASSO-регрессию 540, регрессию 522 на основе дерева решений, регрессию 528 на основе случайного леса, регрессию 524 на основе принципа k соседних узлов, регрессию 520 на основе метода опорных векторов (SVR) и регрессию 526 на основе принципа улучшения агрегации, и на вышеуказанном графике данных использования энергии, включающем в себя, например, линейную регрессию 730, LASSO-регрессию 740, регрессию 722 на основе дерева решений, регрессию 728 на основе случайного леса, регрессию 724 на основе принципа k соседних узлов, регрессию 720 на основе метода опорных векторов (SVR) и регрессию 726 на основе принципа улучшения агрегации, прямая линия, заданная посредством низких процентных долей приемлемости ошибки, может экстраполироваться, чтобы определять значение приемлемости ошибки, при котором доля выбросовых значений начинается, согласно варианту осуществления настоящего изобретения. Этот процесс может быть автоматизирован, но на практике, он может выполняться вручную, чтобы обеспечивать то, что выбранное значение приемлемости ошибки отражает суждение аналитика.
[0195] Упражнение на основе экстраполяции и выбор процентных долей приемлемости ошибки представляют собой относительно простой процесс, но он имеет очень важные последствия. Он указывает то, насколько хорошо предложенная модель подгоняется под данные. Дополнение значения приемлемости ошибки представляет собой процентную долю набора данных, которые представляют собой выбросовые значения, т.е. процентную долю от записей, в которых модель не может осуществлять относительно точные прогнозирования. Оно представляет собой важную информацию в выборе машинного обучения (или любой модели) для данного набора данных и практического варианта применения. Таблица 3 представляет значения приемлемости ошибки, выбранные для каждого режима для двух примерных наборов данных.
[0196] В вариантах осуществления, точность прогнозирования просто выбранных DOBR значений сравнивается с опорной моделью. Это представляет собой базовую полезность DOBR, поскольку способ отдельно не обеспечивает конкретной информации относительно повышения точности прогнозирования для полного набора данных. Следовательно, анализ DOBR представляет аналитику потенциальный компромисс: иметь лучшую силу прогнозирования для части набора данных, но без информации, обеспечиваемой для выбросовых записей. Вопрос, рассматриваемый в этом разделе, заключается в том, насколько, если вообще, выбранные DOBR результаты являются более точными по сравнению с соответствующими прогнозированиями на основе тестовых данных опорной модели.
[0197] Опорная ошибка вычисляется для полного набора данных. Значения отрегулированной опорной ошибки для сравнения с наборами невыбросовых данных вычисляются посредством умножения полной опорной ошибки на значение приемлемости ошибки. Например, если опорная ошибка составляет 10,0, и значение приемлемости ошибки составляет 80%, то отрегулированная опорная ошибка составляет 10×80%, или 8,0. Интерпретация использует определение «приемлемости ошибки». Если невыбросовые данные вычисляются для 80% данных, например, то 80% от полной ошибки должны по-прежнему оставаться в невыбросовых данных. Означенное представляет собой определение приемлемости ошибки.
[0198] Результаты, измеряющие производительность в виде точности прогнозирования выбранных DOBR невыбросовых значений, представляются в нижеприведенных таблице 4 и таблице 5, соответствующих, например, набору данных прочности бетона и набору данных по энергопотреблению, соответственно. Опорная ошибка вычисляется посредством умножения фактических процентных долей приемлемости ошибки на точечные оценки 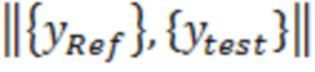 . Классификатор на основе случайного леса не применяется к набору данных по бетону, поскольку он определен как не подлежащий изменению заключения относительно повышения точности прогнозирования DOBR.
. Классификатор на основе случайного леса не применяется к набору данных по бетону, поскольку он определен как не подлежащий изменению заключения относительно повышения точности прогнозирования DOBR.
[0199] Для всех последующих статистических данных, результаты показывают средний ±95%-й доверительный интервал из 100 вариантов выбора случайного испытания поднаборов обучающих и тестовых данных. В некоторых примерах в следующих таблицах, результаты выполнения метода опорных векторов вычислены из меньшего числа итераций (5 или 10) для управления проблемами, связанными с временем вычисления.
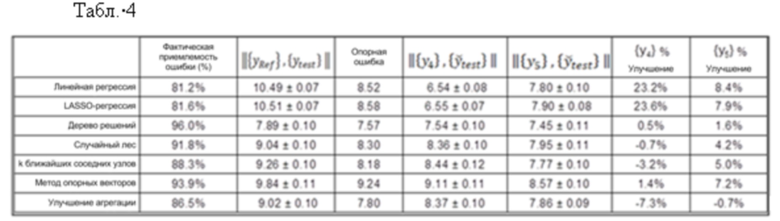
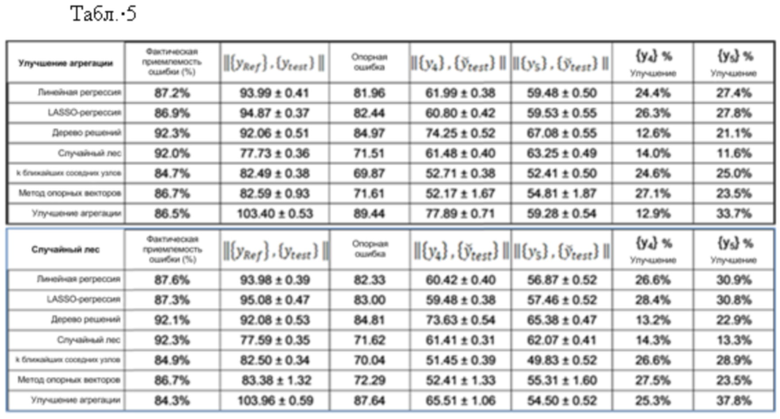
[0200] Таблица 4 показывает то, что практически не возникает улучшение прогнозирования с использованием выбранных DOBR записей. Этот результат не является неожиданным и фактически ожидается на основе формы кривой зависимости приемлемости ошибки от ошибки модели, показанной на фиг. 12.
[0201] Кроме того, как и следовало ожидать, на основе фиг. 13, таблица 5 указывает то, что возникает значительное улучшение выбранных DOBR прогнозирований из значений опорной модели для классификаторов на основе принципа улучшения агрегации и на основе случайного леса, см., соответственно, нижеприведенные фиг. 14A и для фиг. 14B. Модель DOBR 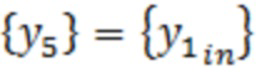 показывает, что наибольшее улучшение, обеспечивающее удаление выбросовых значений до обучения на основе моделей, вместе с классификацией DOBR, обеспечивает лучшие результаты, чем при использовании только классификации DOBR для полной (не DOBR) модели. Различие в результатах улучшения между моделями показывает то, что выбор модели является важным. Даже если это решение принимается аналитиком, интересно сравнивать точность прогнозирования посредством модели. Время работы модели и несколько других факторов также являются важными, и это исследование не проектируется с возможностью обеспечения жизнеспособности одной модели по сравнению с другой или не предназначено для этого.
показывает, что наибольшее улучшение, обеспечивающее удаление выбросовых значений до обучения на основе моделей, вместе с классификацией DOBR, обеспечивает лучшие результаты, чем при использовании только классификации DOBR для полной (не DOBR) модели. Различие в результатах улучшения между моделями показывает то, что выбор модели является важным. Даже если это решение принимается аналитиком, интересно сравнивать точность прогнозирования посредством модели. Время работы модели и несколько других факторов также являются важными, и это исследование не проектируется с возможностью обеспечения жизнеспособности одной модели по сравнению с другой или не предназначено для этого.
[0202] Заключение из таблицы 5 является ясным и статистически значимым. С учетом потенциала для отклонения выбросовых значений, как указано на графике, аналогичном фиг. 13, модель машинного обучения с технологией DOBR может обеспечивать лучшую точность прогнозирования для невыбросовых записей, чем посредством использования модели машинного обучения без DOBR. Таким образом, примерная вычислительная система согласно изобретению, включающая в себя модель машинного обучения с помощью DOBR, имеет повышенную точность и сниженную ошибку при выполнении прогнозирований, за счет этого повышая производительность и эффективность реализации модели. Но улучшение может достигаться за счет следующего: не предусмотрено значений прогнозирования или учета идентифицированных выбросовых значений. В вариантах осуществления, то, каким образом моделируются выбросовые записи, может варьироваться на основе варианта применения.
[0203] Таблица 6 показывает результаты точности прогнозирования для обучающих/тестовых дискретизаций набора данных прочности на сжатие бетона с классификатором на основе принципа улучшения агрегации. Классификатор на основе случайного леса не применяется к этому набору данных. Таблица показывает среднеквадратическую ошибку (см., уравнение 15) при 95%-м доверительном уровне между тестовыми данными и каждой из моделей для 100 случайных вариантов выбора наборов обучающих и тестовых данных.
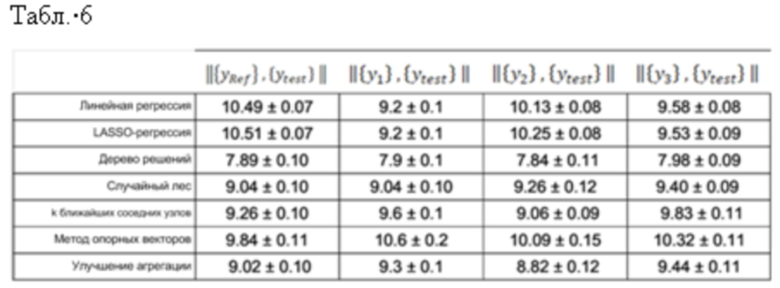
[0204] Линейная регрессия и LASSO-регрессия формируют наибольшие ошибки базовой или опорной модели. Тем не менее, моделей дают в результате точности прогнозирования, статистически идентичные точностям прогнозирования всех других моделей, за исключением дерева решений. В этом случае, модель в виде дерева решений формирует наилучшую точность прогнозирования, и все модели, за исключением линейной регрессии и LASSO-регрессии, очевидно, не улучшаются с добавлением DOBR.
[0205] Таблица 7 показывает увеличение (+) или снижение (-) точности прогнозирования моделей DOBR относительно опорной модели в каждом случае, например, для производительности точности прогнозирования прочности на сжатие бетона моделей DOBR: классификатор на основе принципа улучшения агрегации.
[0206] Эти результаты не являются неожиданными, поскольку кривые зависимости ошибки модели от приемлемости ошибки для линейной регрессии и LASSO-регрессии представляют собой графики с наибольшей нелинейностью, а другие представляют собой почти прямые линии, что предположительно показывает то, что модели адекватно прогнозируют целевую переменную, и анализ выбросовых значений не требуется. Кроме того, означенное представляет собой сообщение, передаваемое в таблице 7. Выводы модели относительно прогнозируемой прочности на сжатие бетона представляются в Приложении A, прилагаемом к данному документу.
[0207] Далее, если рассматривать результаты по ошибкам прогнозирования энергопотребления в таблице 8, существует другая ситуация, предусматривающая, например, ошибки прогнозирования энергопотребления приборов для классификаторов на основе принципа улучшения агрегации и на основе случайного леса. Модели на основе принципа улучшения агрегации, линейные регрессионные модели и LASSO-модели имеют наибольшие опорные ошибки прогнозирования, и модель на основе случайного леса имеет наименьшие опорные ошибки прогнозирования. Ошибки модели DOBR в трех правых столбцах показывают то, что во многих случаях, модели DOBR дают в результате более высокую точность прогнозирования, чем опорные модели.
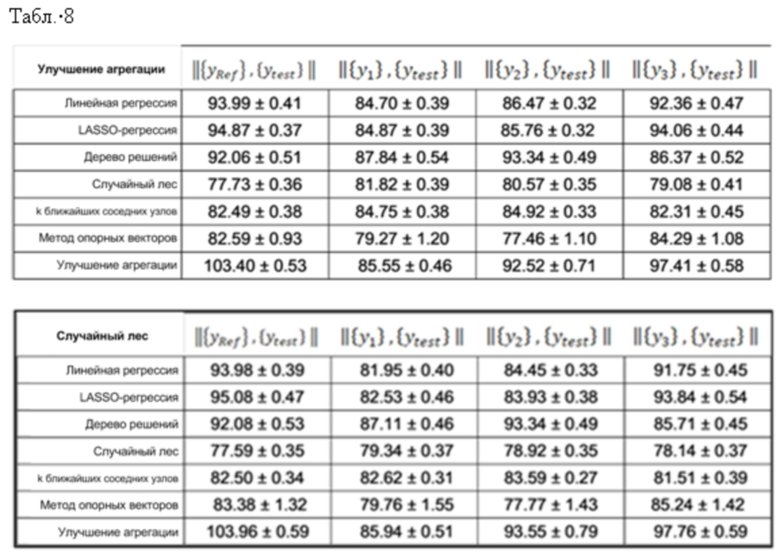
[0208] Интересно отметить, что опорная модель на основе принципа улучшения агрегации имеет наибольшие опорные значения ошибки, но ее результаты дополненной DOBR модели, в общем, находятся в идентичных статистических диапазонах с другими моделями. Также, по практическим причинам, модель на основе метода опорных векторов выполнена только для 10 итераций. Это поясняет увеличение неопределенности для результатов расчетов по модели.
[0209] Подробные результаты улучшения показаны в таблице 9, связанные, например, с производительностью в виде точности прогнозирования энергопотребления приборов моделей DOBR. Следует отметить, что по меньшей мере одна из моделей DOBR создает некоторое повышение точности прогнозирования для большинства моделей машинного обучения. Тем не менее, также возникают относительно большие различия, так что отсутствуют окончательные результаты относительно сформированного DOBR улучшения прогнозируемости. Из кривых зависимости ошибки модели от приемлемости ошибки для данных по энергопотреблению, все графики показывают нелинейное поведение, с моделями на основе случайного леса и в виде дерева решений, имеющими наименьшую величину искривления. Кроме того, очевидно, что модели, в частности, случайный лес, могут адекватно моделировать это варьирование на основе результатов, показанных здесь. Выводы модели относительно прогнозируемого использования энергии представляются в Приложении B, прилагаемом к данному документу.
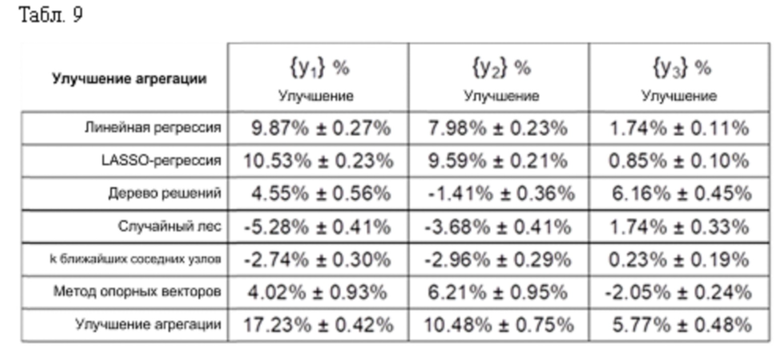
[0210] Фиг. 14A и фиг. 14B иллюстрируют графики распределений невыбросовых и выбросовых значений в классификационных моделях согласно примерному варианту осуществления примерной компьютерной системы согласно изобретению с классификатором DOBR в соответствии с одним или более вариантов осуществления настоящего изобретения.
[0211] Набор данных по бетону является относительно небольшим, так что графики данных могут обеспечивать визуальное понимание, но поскольку DOBR имеет небольшое значение, в этом случае, изображение этого набора данных в виде графика не улучшает понимание касательно того, как работает DOBR. Тем не менее, для прогнозирований набора данных по энергопотреблению, DOBR формирует некоторые значительные улучшения прогнозирования. Но относительно большой размер означенного (13814 обучающих записей, 5921 тестовых записей) приводит к затруднению интерпретации прямых визуализаций графика рассеяния. Графики рассеяния, такие как на фиг. 9 и фиг. 10, с большим числом точек могут стирать все подробности. Результаты улучшения по ошибкам, представленные в таблице 3, представляют собой суммирования по наборам невыбросовых данных, но остается вопрос в отношении того, как способ DOBR и модель классификации приводят к этим результатам.
[0212] В вариантах осуществления, чтобы рассматривать этот вопрос, могут анализироваться распределения ошибок для двух представлений модели: , классификатор на основе случайного леса (фиг. 14A), и , классификатор на основе принципа улучшения агрегации (фиг. 14B) наборов выбросовых и невыбросовых данных. В варианте осуществления, невыбросовые ошибки должны быть меньше выбросовых ошибок, согласно расчетам, но примерная модель DOBR согласно изобретению и процесс классификации конструируются исключительно из обучающих данных, так что набор тестовых данных может содержать информацию, ранее не наблюдаемую. Следовательно, модель и классификационные вычисления могут не быть точными, и степень ошибок классификации может визуализироваться на этих графиках. Эта работа выполняется для линейных регрессионных моделей и регрессионных моделей на основе принципа улучшения агрегации, поскольку этих два подхода имеют наибольшие и наименьшие преимущества в виде улучшения, соответственно, представленные в таблицах 5.
[0213] Для пояснения, опорное значение ошибки выделяется на обоих графиках по фиг. 14A и фиг. 14B. Верхний набор стрелок показывает то, что 80% невыбросовых значений ошибки меньше 1000, что указывает то, что 20% значений ошибки > 1000. Этот нижний набор стрелок также показывает то, что для распределений выбросовых значений, приблизительно 20% выбросовых значений имеют ошибку < 1000, или 80% имеют ошибки > 1000, что должно представлять выбросовые ошибки. Без заблаговременного знания процентных значений приемлемости ошибки, невозможно точно вычислять точность процесса классификации, но вышеуказанные графики обеспечивают то, что даже если неправильная классификация возникает, большинство значений классифицируются надлежащим образом.
[0214] Фиг. 15 иллюстрирует графики ошибки модели в качестве функции от значений приемлемости ошибки для примерного случая использования примерного варианта осуществления примерной компьютерной системы согласно изобретению с обученной DOBR моделью машинного обучения для прогнозирования времени простоя при бурении скважин в соответствии с одним или более вариантов осуществления настоящего изобретения.
[0215] Операции бурения прибрежных скважин содержат уникальные сложные задачи для нефтегазовых отраслей. В дополнение к наблюдаемым логистическим и экологическим рискам в силу погоды и океанских глубин, имеются скрытые риски забоя скважин в виде работы в окружениях с высокой температурой, давлением и вибрацией. Времена бурения придерживаются плотных графиков, и задержки вследствие отказов внутрискважинного оборудования (время простоя, или NPT) могут представлять значительные штрафы в виде снижения дохода.
[0216] Чтобы помогать при управлении NPT, модель машинного обучения конструируется с возможностью помощи в прогнозировании будущих событий времени простоя для целей включения этих оцененных задержек в положения контракта, которые задают цели по бурению. Основные статистические события включают в себя: пробуренное расстояние [футы], диаметр ствола скважины [дюймы], размер инструмента [дюймы], степень воздействия давления на площадке, максимальный излом ствола [градусы/100 футов], категория по степени воздействия вибрации, категория по искривлению и NPT (часы).
[0217] Линейные регрессионные модели, регрессионные XGBoost-модели, регрессионные модели на основе градиентного бустинга и регрессионные модели на основе случайного леса применяются к данным отказов внутрискважинного оборудования с обучающим/тестовым разбиением в 80/20, чтобы измерять точность прогнозирования модели. Гиперполоса частот использована для настройки моделей и применимых значений параметров, показанных в нижеприведенной таблице 10:
[0218] Классификационная функция, которая передает информацию вычисленных DOBR выбросовых значений в набор тестовых данных, может выбираться в качестве модели на основе случайного леса с числом модулей оценки, равных, например, 5. Эта активность настройки также выполняется в обучающей части анализа. Показатель для выбора параметров заключается в том, чтобы вычислять процентную долю от корректно классифицированных элементов обучающего набора и сравнивать ее со значением приемлемости ошибки модели.
[0219] Линейная регрессия включается в этот анализ, поскольку она представляет собой единственную модель, в которой коэффициенты могут обеспечивать техническое понимание, с тем чтобы помогать идентифицировать дополнительные детализации по принципу «наиболее успешной практики». Другие модели являются более надежными с точки зрения прогнозирования, но практически не обеспечивают понимание.
[0220] Как пояснено в этом подробном описании, предусмотрено несколько связанных с DOBR моделей, которые могут представлять собой сконструированный базовый процесс DOBR. В этом примере, представляются три модели: M представляет данную гипернастроенную модель.
[0221] С использованием выбранных DOBR безвыбросовых значений и выбросовых значений наборов обучающих и тестовых данных:
Псевдокод 8
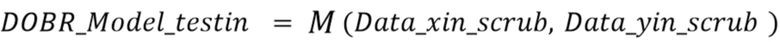
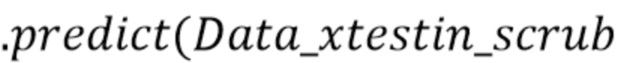
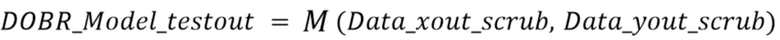
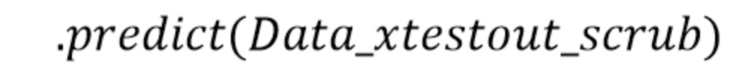
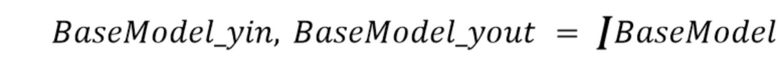
[0222] - где 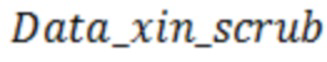 и
и 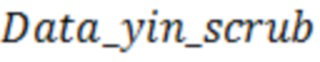 являются вычисленными DOBR безвыбросовыми значениями из обучающего набора,
являются вычисленными DOBR безвыбросовыми значениями из обучающего набора,  и
и  являются вычисленными DOBR выбросовыми значениями из обучающего набора,
являются вычисленными DOBR выбросовыми значениями из обучающего набора,  и
и  являются безвыбросовыми и выбросовыми значениями набора тестовых данных, соответственно, вычисленными из классификационной модели DOBR,
являются безвыбросовыми и выбросовыми значениями набора тестовых данных, соответственно, вычисленными из классификационной модели DOBR, 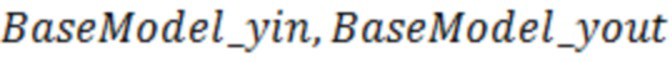 являются не вычисленными DOBR результатами расчетов по модели, классифицируемыми на безвыбросовые значения и выбросовые значения с использованием классификационной модели DOBR, и
являются не вычисленными DOBR результатами расчетов по модели, классифицируемыми на безвыбросовые значения и выбросовые значения с использованием классификационной модели DOBR, и  назначает значения
назначает значения 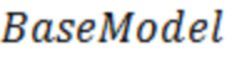 для
для 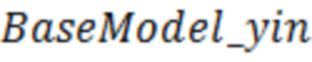 для задаваемых DOBR безвыбросовых значений и для для задаваемых DOBR выбросовых значений.
для задаваемых DOBR безвыбросовых значений и для для задаваемых DOBR выбросовых значений.
[0223] Из этих поднаборов, три модели DOBR представляют собой:
a. 
b. 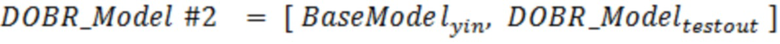
c. 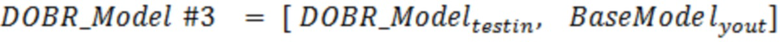
[0224] Прохождение по кривым зависимости процентной доли приемлемости ошибки от ошибки модели для вышеуказанных гипернастроенных моделей формирует кривые, как показано на фиг. 15. Важное свойство этих кривых представляет собой их искривление, а не непосредственно значения ошибки. В общем, чем более линейным является уклон данной кривой по области (0,100%), тем меньшим является влияние выбросовых значений. Для данных отказов прибрежного внутрискважинного оборудования, кривые выглядят линейными приблизительно вплоть до приемлемости ошибки 80%, и после этого возникают различные нелинейные уклоны. При анализе уклона в качестве функции от значений приемлемости ошибки, следующая таблица (таблица 11) показывает определенные пороговые значения приемлемости ошибки для анализа DOBR.
[0225] Модели выполняются с вычисленными гиперпараметрами и назначенными значениями приемлемости ошибки. Выводы модели относительно прогнозируемого NPT представляются в Приложении C, прилагаемом к данному документу, и в результатах по ошибкам, приведенных в нижеприведенной таблице 12:
[0226] Теперь, когда имеется модель не DOBR вместе с тремя моделями DOBR, имеется возможность выбирать то, какую модель следует использовать при производстве для будущего прогнозирования. В целом, линейная модель предлагает наименьшую точность прогнозирования, и модели DOBR #1 или #2 предлагают наилучшую точность прогнозирования. В этот момент, аналитик может балансировать эти показатели точности с другими практическими соображениями, например, временем вычислений, чтобы выбирать модель, которую следует применять к будущему прогнозированию.
[0227] Хотя результаты служат для использования DOBR для обучения и реализации моделей машинного обучения для применения при прогнозировании механического напряжения при сжатии бетона и при прогнозировании энергии, также предполагаются другие варианты применения.
[0228] Например, рендеринг изображений и визуализация могут использовать модели машинного обучения для автоматического прогнозирования и реализации параметров рендеринга, например, на основе медицинских данных, как описано в патенте США № 10339695. DOBR может использоваться для обучения и реализации моделей машинного обучения для рендеринга на основе контента. Набор медицинских данных, представляющий трехмерную область пациента, может использоваться в качестве входных данных. С использованием DOBR, выбросовые значения из набора обучающих медицинских данных могут удаляться таким образом, что модель машинного обучения может обучаться на невыбросовых данных согласно технологиям DOBR, описанным выше. Машина обученная модель обучается с помощью глубокого обучения невыбросовых данных из набора обучающих медицинских данных для извлечения признаков из набора медицинских данных и выводить значения для двух или более параметров физического рендеринга на основе ввода набора медицинских данных. В некоторых вариантах осуществления, параметры физического рендеринга представляют собой средства управления для согласованной обработки данных, проектного решения по освещению, проектного решения по просмотру, обоснованности использования материалов или внутреннего свойства модуля рендеринга. Модуль физического рендеринга подготавливает посредством рендеринга фотореалистическое изображение трехмерной области пациента с использованием выходных значений, получающихся в результате применения.
[0229] В другом примерном варианте применения DOBR для обучения и реализации моделей машинного обучения, модель машинного обучения может обучаться с помощью технологий DOBR, описанных выше, таким образом, чтобы формировать команду управления для машины, чтобы выводить команду управления, как описано в патенте США № 10317854. В таком примере, модуль моделирования может выполнять моделирование рабочей операции машины на основе команды управления. Модуль моделирования может формировать полный набор данных для обучения модели машинного обучения посредством моделирования физических действий машины на основе команды управления. Такой набор данных может обрабатываться с использованием итераций DOBR, чтобы обеспечивать то, что все выбросовые моделирования удаляются, когда параметры обучения модели, включающие в себя данные рабочих операций, данные команд управления и машинные данные, используются в качестве ввода для каждого моделирования.
[0230] В некоторых вариантах осуществления и, при необходимости, в сочетании любых вариантов осуществления, описанных выше или ниже, примерная модель DOBR машинного обучения может быть основана по меньшей мере частично на методе Монте-Карло вычислительных алгоритмов (например, алгоритмов Соловея-Штрассена, алгоритмов БПСВ, алгоритмов Миллера-Рабина и/или алгоритмов Шрайера-Симса), которые могут учитывать статистические данные по качеству для требуемых невыбросовых данных. В некоторых вариантах осуществления и, при необходимости, в сочетании любых вариантов осуществления, описанных выше или ниже, примерная модель DOBR машинного обучения может непрерывно обучаться, например, посредством, без ограничения, применения по меньшей мере одной технологии машинного обучения (такой как, но не только, деревья решений, бустинг, методы опорных векторов, нейронные сети, алгоритмы на основе принципа ближайших соседних узлов, наивный байесовский подход, улучшение агрегации, случайные леса и т.д.) к собранным и/или скомпилированным данным датчиков (например, к различному типу визуальных данных относительно окружающей среды и/или физического/внешнего вида груза). В некоторых вариантах осуществления и, при необходимости, в сочетании любых вариантов осуществления, описанных выше или ниже, примерная нейронная сетевая технология может представлять собой одно из, без ограничения, нейронной сети с прямой связью, радиально-базисной функциональной сети, рекуррентной нейронной сети, сверточной сети (например, U-сети) или другой подходящей сети. В некоторых вариантах осуществления и, при необходимости, в сочетании любых вариантов осуществления, описанных выше или ниже, примерная реализация нейронной сети может выполняться следующим образом:
i) задание нейронной сетевой архитектуры/модели,
ii) передача входных данных в примерную нейронную сетевую модель,
iii) инкрементное обучение примерной модели,
iv) определение точности для конкретного числа временных шагов,
v) применение примерной обученной модели, чтобы обрабатывать новые принимаемые входные данные,
vi) при необходимости и параллельно, продолжение обучения примерной обученной модели с предварительно определенной периодичностью.
[0231] В некоторых вариантах осуществления и, при необходимости, в сочетании любых вариантов осуществления, описанных выше или ниже, примерная обученная нейронная сетевая модель может указывать нейронную сеть посредством по меньшей мере нейронной сетевой топологии, последовательности активирующих функций и соединительных весовых коэффициентов. Например, топология нейронной сети может включать в себя конфигурацию узлов нейронной сети и соединений между такими узлами. В некоторых вариантах осуществления и, при необходимости, в сочетании любых вариантов осуществления, описанных выше или ниже, примерная обученная нейронная сетевая модель также может указываться как включающая в себя другие параметры, в том числе, но не только, значения/функции отклонения и/или агрегирующие функции. Например, активирующая функция узла может представлять собой ступенчатую функцию, синусоидальную функцию, непрерывную или кусочно-линейную функцию, сигмоидальную функцию, гиперболическую функцию тангенса или другой тип математической функции, которая представляет пороговое значение, при котором активируется узел. В некоторых вариантах осуществления и, при необходимости, в сочетании любых вариантов осуществления, описанных выше или ниже, примерная агрегирующая функция может представлять собой математическую функцию, которая комбинирует (например, сумма, произведение и т.д.) входные сигналы в узел. В некоторых вариантах осуществления и, при необходимости, в сочетании любых вариантов осуществления, описанных выше или ниже, вывод примерной агрегирующей функции может использоваться в качестве ввода в примерную активирующую функцию. В некоторых вариантах осуществления и, при необходимости, в сочетании любых вариантов осуществления, описанных выше или ниже, отклонение может представлять собой постоянное значение или функцию, которая может использоваться посредством агрегирующей функции и/или активирующей функции для обеспечения большей или меньшей вероятности активации узла.
[0232] В некоторых вариантах осуществления и, при необходимости, в сочетании любых вариантов осуществления, описанных выше или ниже, примерные данные по соединению для каждого соединения в примерной нейронной сети могут включать в себя по меньшей мере одно из пары узлов или соединительного весового коэффициента. Например, если примерная нейронная сеть включает в себя соединение от узла N1 к узлу N2, то примерные данные по соединению для этого соединения могут включать в себя пару узлов <N1, N2>. В некоторых вариантах осуществления и, при необходимости, в сочетании любых вариантов осуществления, описанных выше или ниже, соединительный весовой коэффициент может быть численной величиной, которая оказывает влияние на то, модифицируется либо нет, и/или на то, как вывод N1 модифицируется до ввода в N2. В примере рекуррентной сети, узел может иметь соединение с собой (например, данные по соединению могут включать в себя пару узлов <N1, N1>).
[0233] В некоторых вариантах осуществления и, при необходимости, в сочетании любых вариантов осуществления, описанных выше или ниже, примерная обученная нейронная сетевая модель также может включать в себя идентификатор вида и данные подгонки. Например, идентификатор каждого вида может указывать, в каком из множества видов (например, категорий потерь груза) классифицируется модель. Например, данные подгонки могут указывать то, насколько хорошо примерная обученная нейронная сетевая модель моделирует входной набор сенсорных данных. Например, данные подгонки могут включать в себя значение подгонки, которое определяется на основе оценки функции подгонки относительно модели. Например, примерная функция подгонки может представлять собой целевую функцию, которая основана на частоте и/или абсолютной величине ошибок, сформированных посредством тестирования примерной обученной нейронной сетевой модели на входном наборе сенсорных данных. В качестве простого примера, предположим, что входной набор сенсорных данных включает в себя десять строк, что входной набор сенсорных данных включает в себя два столбца, обозначаемые A и B, и что примерная обученная нейронная сетевая модель выводит прогнозируемое значение B, с учетом входного значения A. В этом примере, тестирование примерной обученной нейронной сетевой модели может включать в себя ввод каждого из десяти значений A из входного набора данных датчиков, сравнение прогнозируемых значений B с соответствующими фактическими значениями B из входного набора данных датчиков и определение того, отличаются или нет, и/или того, насколько отличаются два прогнозируемых и фактических значения B. В качестве иллюстрации, если конкретная нейронная сеть корректно прогнозирует значение B для девяти из десяти строк, то примерная функция подгонки может назначать для соответствующей модели значение подгонки в 9/10=0,9. Следует понимать, что предыдущий пример служит только для иллюстрации и не должен считаться ограничением. В некоторых вариантах осуществления, примерная функция подгонки может быть основана на факторах, не связанных с частотой повторения ошибок или частотой ошибок, таких как число входных узлов, узловых слоев, скрытых слоев, соединений, вычислительная сложность и т.д.
[0234] В некоторых вариантах осуществления и, при необходимости, в сочетании любых вариантов осуществления, описанных выше или ниже, настоящее изобретение может использовать несколько аспектов по меньшей мере одного из следующего:
Патент США № 8195484, озаглавленный "Insurance product, rating system and method";
Патент США № 8548833, озаглавленный "Insurance product, rating system and method";
Патент США № 8554588, озаглавленный "Insurance product, rating system and method";
Патент США № 8554589, озаглавленный "Insurance product, rating system and method";
Патент США № 8595036, озаглавленный "Insurance product, rating system and method";
Патент США № 8676610, озаглавленный "Insurance product, rating system and method";
Патент США № 8719059, озаглавленный "Insurance product, rating system and method";
Патент США № 8812331, озаглавленный "Insurance product, rating and credit enhancement system and method for insuring project savings".
[0235] Ниже описаны по меньшей мере некоторые аспекты настоящего изобретения с обращением к следующим пронумерованным пунктам:
Пункт 1. Способ, содержащий:
- прием посредством по меньшей мере одного процессора набора обучающих данных целевых переменных, представляющих по меньшей мере один связанный с активностью атрибут по меньшей мере для одной пользовательской активности;
- прием посредством по меньшей мере одного процессора по меньшей мере одного критерия отклонения, используемого для определения одного или более выбросовых значений;
- определение посредством по меньшей мере одного процессора набора параметров модели для модели машинного обучения, что содержит:
(1) применение посредством по меньшей мере одного процессора модели машинного обучения, имеющей набор начальных параметров модели, к набору обучающих данных для определения набора прогнозируемых значений модели;
(2) формирование посредством по меньшей мере одного процессора набора ошибок для ошибок в элементах данных посредством сравнения набора прогнозируемых значений модели с соответствующими фактическими значениями набора обучающих данных;
(3) формирование посредством по меньшей мере одного процессора вектора выбора данных для идентификации невыбросовых целевых переменных по меньшей мере частично на основе набора ошибок для ошибок в элементах данных и по меньшей мере одного критерия отклонения;
(4) использование посредством по меньшей мере одного процессора вектора выбора данных для набора обучающих данных для формирования набора невыбросовых данных;
(5) определение посредством по меньшей мере одного процессора набора обновленных параметров модели для модели машинного обучения на основе набора невыбросовых данных; и
(6) повторение посредством по меньшей мере одного процессора этапов (1)-(5) в качестве итерации до тех пор, пока не будет удовлетворён по меньшей мере один критерий завершения выполнения цензурирования, таким образом, чтобы получить набор параметров модели для модели машинного обучения в качестве обновленных параметров модели, за счет чего каждая итерация повторно формирует набор прогнозируемых значений, набор ошибок, вектор выбора данных и набор невыбросовых данных с использованием набора обновленных параметров модели в качестве набора начальных параметров модели;
- обучение посредством по меньшей мере одного процессора по меньшей мере частично на основе набора обучающих данных и вектора выбора данных, набора параметров классификационной модели для модели машинного обучения классификаторов выбросовых значений для получения обученной модели машинного обучения классификаторов выбросовых значений, которая выполнена с возможностью идентификации по меньшей мере одного выбросового элемента данных;
- применение посредством по меньшей мере одного процессора обученной модели машинного обучения классификаторов выбросовых значений к набору данных для связанных с активностью данных по меньшей мере для одной пользовательской активности, чтобы определять:
i) набор выбросовых связанных с активностью данных в наборе данных для связанных с активностью данных, и
ii) набор невыбросовых связанных с активностью данных в наборе данных для связанных с активностью данных; и
- применение посредством по меньшей мере одного процессора модели машинного обучения к набору элементов невыбросовых связанных с активностью данных для прогнозирования будущего связанного с активностью атрибута, связанного по меньшей мере с одной пользовательской активностью.
Пункт 2. Система, содержащая:
- по меньшей мере, один процессор, осуществляющий связь с постоянным машиночитаемым носителем данных, на котором сохранены программные инструкции, при этом программные инструкции при выполнении предписывают по меньшей мере одному процессору выполнять этапы для:
- приёма набора обучающих данных целевых переменных, представляющих по меньшей мере один связанный с активностью атрибут по меньшей мере для одной пользовательской активности;
- приёма по меньшей мере одного критерия отклонения, используемого для определения одного или более выбросовых значений;
- определения набора параметров модели для модели машинного обучения, что содержит:
(1) применение модели машинного обучения, имеющей набор начальных параметров модели, к набору обучающих данных для определения набора прогнозируемых значений модели;
(2) формирование набора ошибок для ошибок в элементах данных посредством сравнения набора прогнозируемых значений модели с соответствующими фактическими значениями набора обучающих данных;
(3) формирование вектора выбора данных для идентификации невыбросовых целевых переменных по меньшей мере частично на основе набора ошибок для ошибок в элементах данных и по меньшей мере одного критерия отклонения;
(4) использование вектора выбора данных для набора обучающих данных для формирования набора невыбросовых данных;
(5) определение набора обновленных параметров модели для модели машинного обучения на основе набора невыбросовых данных; и
(6) повторение этапов (1)-(5) в качестве итерации до тех пор, пока не будет удовлетворён по меньшей мере один критерий завершения выполнения цензурирования, таким образом, чтобы получить набор параметров модели для модели машинного обучения в качестве обновленных параметров модели, за счет чего каждая итерация повторно формирует набор прогнозируемых значений, набор ошибок, вектор выбора данных и набор невыбросовых данных с использованием набора обновленных параметров модели в качестве набора начальных параметров модели;
- обучения по меньшей мере частично на основе набора обучающих данных и вектора выбора данных набора параметров классификационной модели для модели машинного обучения классификаторов выбросовых значений для получения обученной модели машинного обучения классификаторов выбросовых значений, которая выполнена с возможностью идентификации по меньшей мере одного выбросового элемента данных;
- применения обученной модели машинного обучения классификаторов выбросовых значений к набору данных для связанных с активностью данных по меньшей мере для одной пользовательской активности, для определения:
i) набора выбросовых связанных с активностью данных в наборе данных для связанных с активностью данных, и
ii) набора невыбросовых связанных с активностью данных в наборе данных для связанных с активностью данных; и
- применения модели машинного обучения к набору элементов невыбросовых связанных с активностью данных для прогнозирования будущего связанного с активностью атрибута, связанного по меньшей мере с одной пользовательской активностью.
Пункт 3. Системы и способы по пунктам 1 и/или 2, дополнительно содержащие:
- применение посредством по меньшей мере одного процессора вектора выбора данных к набору обучающих данных для определения набора выбросовых обучающих данных;
- обучение посредством по меньшей мере одного процессора с использованием набора выбросовых обучающих данных по меньшей мере одного параметра относящейся к выбросовым значениям модели для по меньшей мере одной относящейся к выбросовым значениям модели машинного обучения для прогнозирования выбросовых значений данных; и
- использование посредством по меньшей мере одного процессора относящейся к выбросовым значениям модели машинного обучения для прогнозирования выбросовых значений связанных с активностью данных для набора выбросовых связанных с активностью данных.
Пункт 4. Системы и способы по пунктам 1 и/или 2, дополнительно содержащие:
- обучение посредством по меньшей мере одного процессора с использованием набора обучающих данных, обобщенных параметров модели для обобщенной модели машинного обучения для прогнозирования значений данных;
- использование посредством по меньшей мере одного процессора обобщенной модели машинного обучения для прогнозирования выбросовых значений связанных с активностью данных для набора выбросовых связанных с активностью данных; и
- использование посредством по меньшей мере одного процессора обобщенной модели машинного обучения для прогнозирования значений связанных с активностью данных.
Пункт 5. Системы и способы по пунктам 1 и/или 2, дополнительно содержащие:
- применение посредством по меньшей мере одного процессора вектора выбора данных к набору обучающих данных для определения набора выбросовых обучающих данных;
- обучение посредством по меньшей мере одного процессора с использованием набора выбросовых обучающих данных, параметров относящейся к выбросовым значениям модели для относящейся к выбросовым значениям модели машинного обучения для прогнозирования выбросовых значений данных;
- обучение посредством по меньшей мере одного процессора с использованием набора обучающих данных, обобщенных параметров модели для обобщенной модели машинного обучения для прогнозирования значений данных;
- использование посредством по меньшей мере одного процессора относящейся к выбросовым значениям модели машинного обучения для прогнозирования выбросовых значений связанных с активностью данных для набора выбросовых связанных с активностью данных; и
- использование посредством по меньшей мере одного процессора относящейся к выбросовым значениям модели машинного обучения для прогнозирования значений связанных с активностью данных.
Пункт 6. Системы и способы по пунктам 1 и/или 2, дополнительно содержащие:
- обучение посредством по меньшей мере одного процессора с использованием набора обучающих данных, обобщенных параметров модели для обобщенной модели машинного обучения для прогнозирования значений данных;
- использование посредством по меньшей мере одного процессора обобщенной модели машинного обучения для прогнозирования значений связанных с активностью данных для набора связанных с активностью данных;
- использование посредством по меньшей мере одного процессора модели машинного обучения классификаторов выбросовых значений для идентификации выбросовых значений связанных с активностью данных из значений связанных с активностью данных; и
- удаление посредством по меньшей мере одного процессора выбросовых значений связанных с активностью данных.
Пункт 7. Системы и способы по пунктам 1 и/или 2, в которых набор обучающих данных содержит по меньшей мере один связанный с активностью атрибут прочности на сжатие бетона в качестве функции от состава бетона и отверждающего воздействия на бетон.
Пункт 8. Системы и способы по пунктам 1 и/или 2, в которых набор обучающих данных содержит по меньшей мере один связанный с активностью атрибут данных использования энергии в качестве функции от бытовых окружающих условий и условий освещения.
Пункт 9. Системы и способы по пунктам 1 и/или 2 формулы изобретения, дополнительно содержащие:
- прием посредством по меньшей мере одного процессора запроса интерфейса прикладного программирования (API), чтобы формировать прогнозирование по меньшей мере с одним элементом данных; и
- создание посредством по меньшей мере одного процессора экземпляра по меньшей мере одного облачного вычислительного ресурса для планирования выполнения модели машинного обучения;
- использование посредством по меньшей мере одного процессора согласно планированию для выполнения модели машинного обучения для прогнозирования по меньшей мере одного значения элемента связанных с активностью данных по меньшей мере для одного элемента данных; и
- возврат посредством по меньшей мере одного процессора по меньшей мере одного значения элемента связанных с активностью данных в вычислительное устройство, ассоциированное с запросом API.
Пункт 10. Системы и способы по пунктам 1 и/или 2 формулы изобретения, в которых набор обучающих данных содержит по меньшей мере один связанный с активностью атрибут формирования трехмерных изображений пациентов набора медицинских данных; и
- при этом модель машинного обучения выполнена с возможностью прогнозирования значений связанных с активностью данных, содержащих два или более параметров физического рендеринга на основе набора медицинских данных.
Пункт 11. Системы и способы по пунктам 1 и/или 2, в которых набор обучающих данных содержит по меньшей мере один связанный с активностью атрибут результатов моделированного управления для электронных машинных команд; и
- при этом модель машинного обучения выполнена с возможностью прогнозирования значений связанных с активностью данных, содержащих команды управления для электронной машины.
Пункт 12. Системы и способы по пунктам 1 и/или 2, дополнительно содержащие:
- разбиение посредством по меньшей мере одного процессора набора связанных с активностью данных на множество поднаборов связанных с активностью данных;
- определение посредством по меньшей мере одного процессора модели из ансамбля для каждого поднабора связанных с активностью данных из множества поднаборов связанных с активностью данных;
- при этом модель машинного обучения содержит ансамбль моделей;
- при этом каждая модель из ансамбля содержит случайное сочетание моделей из ансамбля моделей;
- использование посредством по меньшей мере одного процессора каждой модели из ансамбля по отдельности для прогнозирования относящихся к ансамблю значений связанных с активностью данных;
- определение посредством по меньшей мере одного процессора ошибки для каждой модели из ансамбля на основе относящихся к ансамблю значений связанных с активностью данных и известных значений; и
- выбор посредством по меньшей мере одного процессора модели из ансамбля с наилучшими функциональными параметрами на основе наименьшей ошибки.
[0236] Хотя описаны один или более вариантов осуществления настоящего изобретения, следует понимать, что эти варианты осуществления являются только иллюстративными, а не ограничивающими, и что специалистам в данной области техники может стать очевидным множество модификаций, в том числе то, что различные варианты осуществления технологий согласно изобретению, систем/платформ согласно изобретению и устройств согласно изобретению, описанных в данном документе, могут использоваться в любом сочетании друг с другом. Кроме того, различные этапы могут выполняться в любом необходимом порядке (и могут быть добавлены любые необходимые этапы, и/или могут быть исключены любые необходимые этапы).
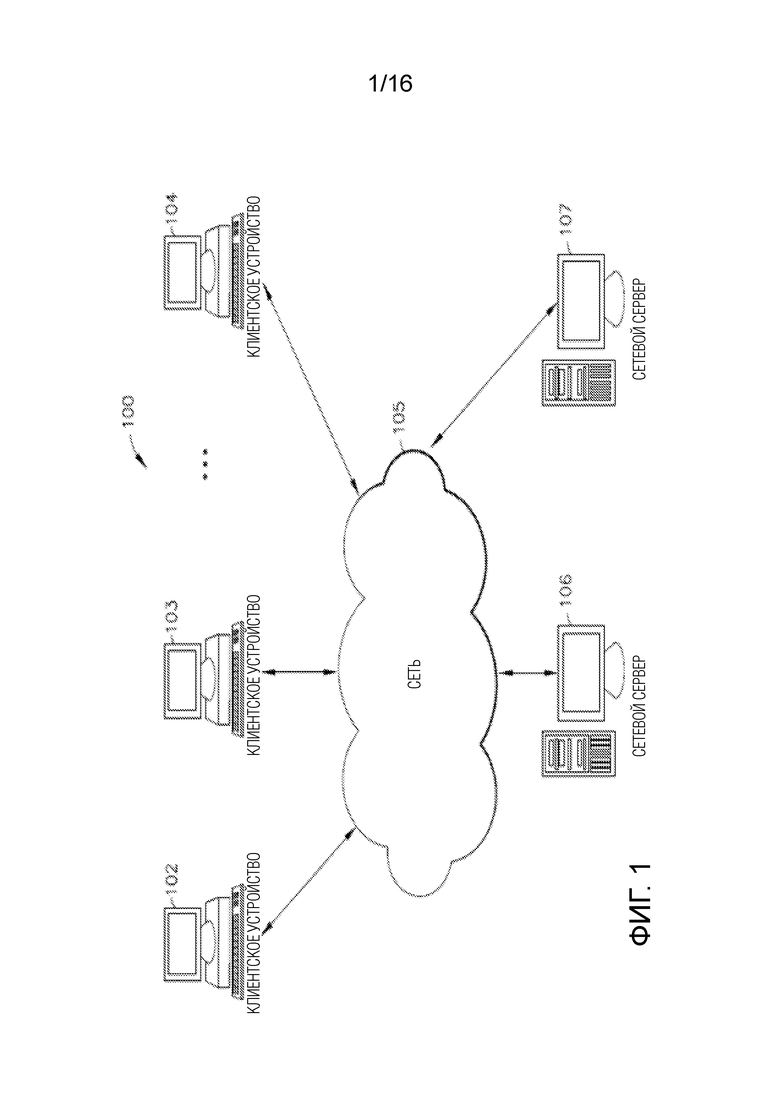
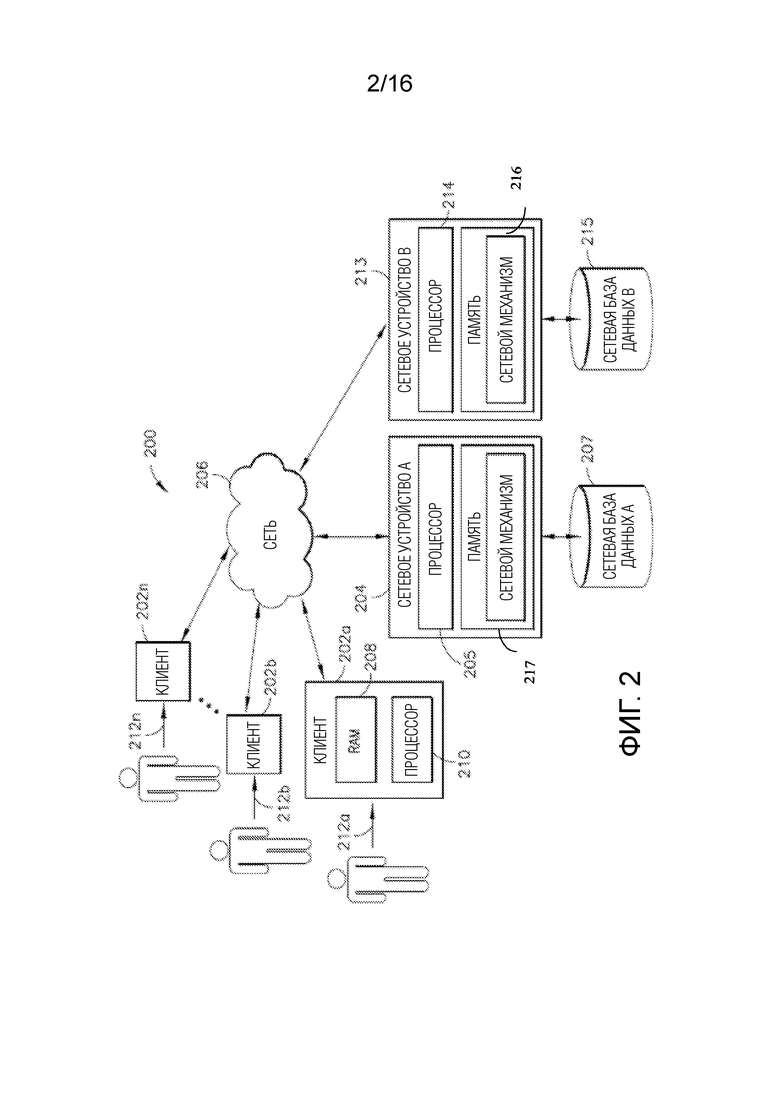
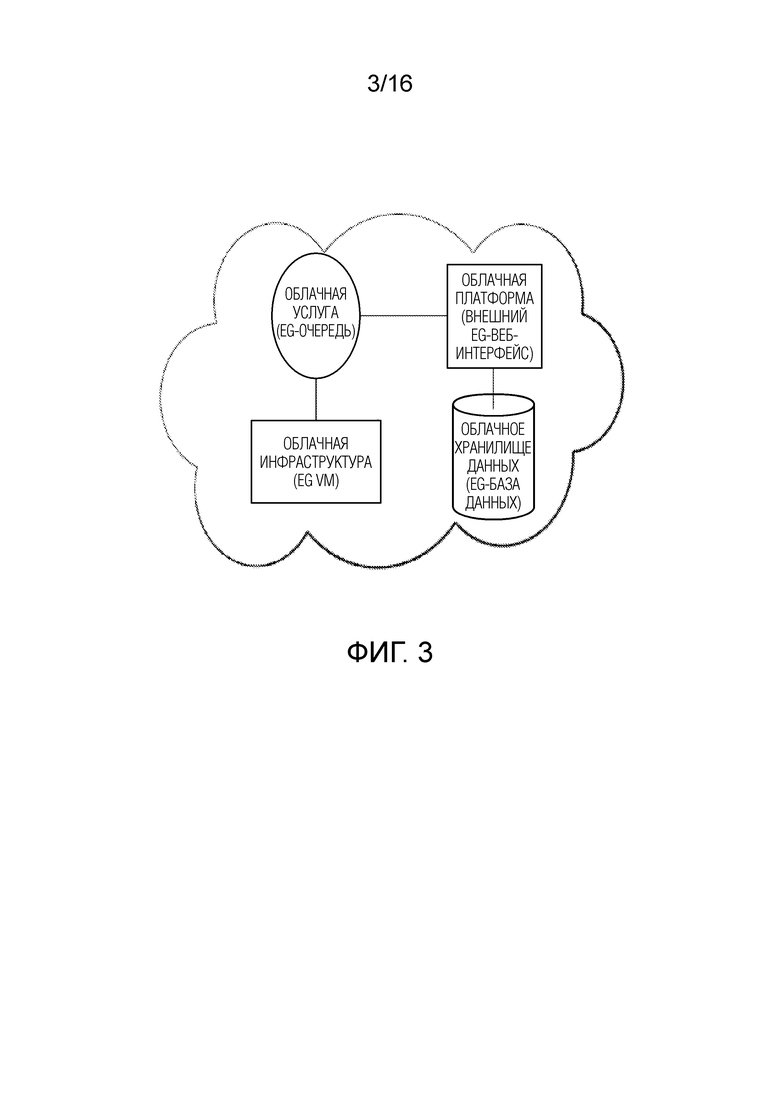
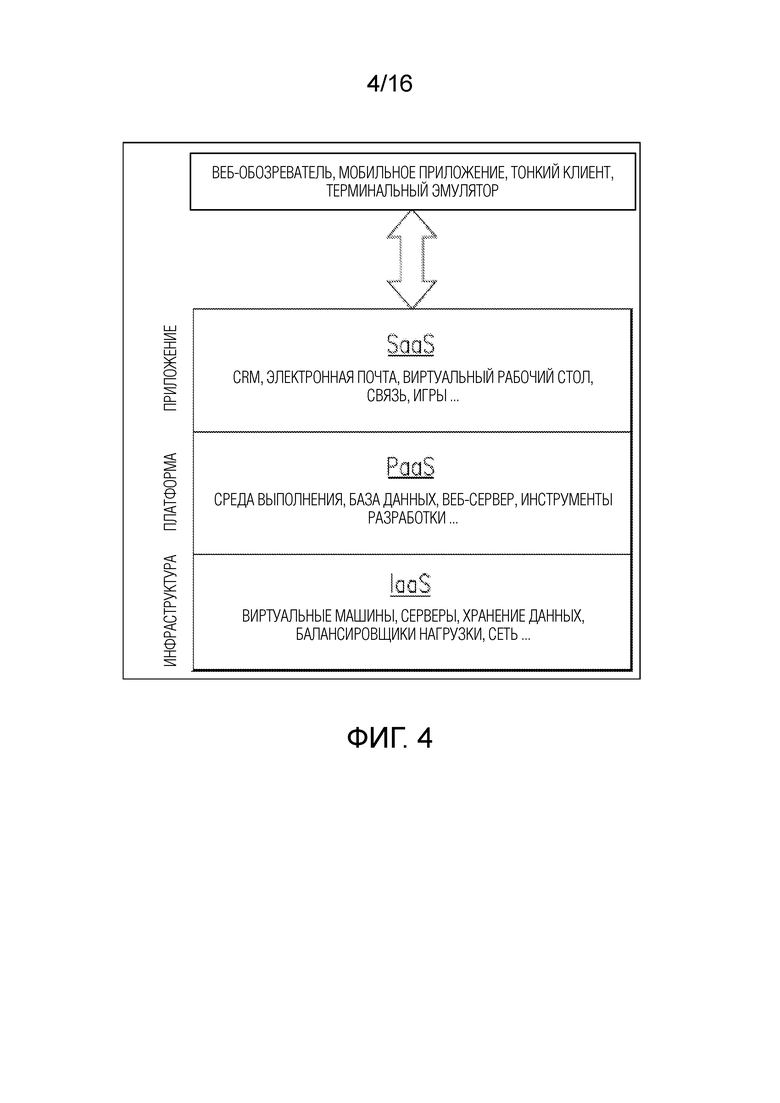
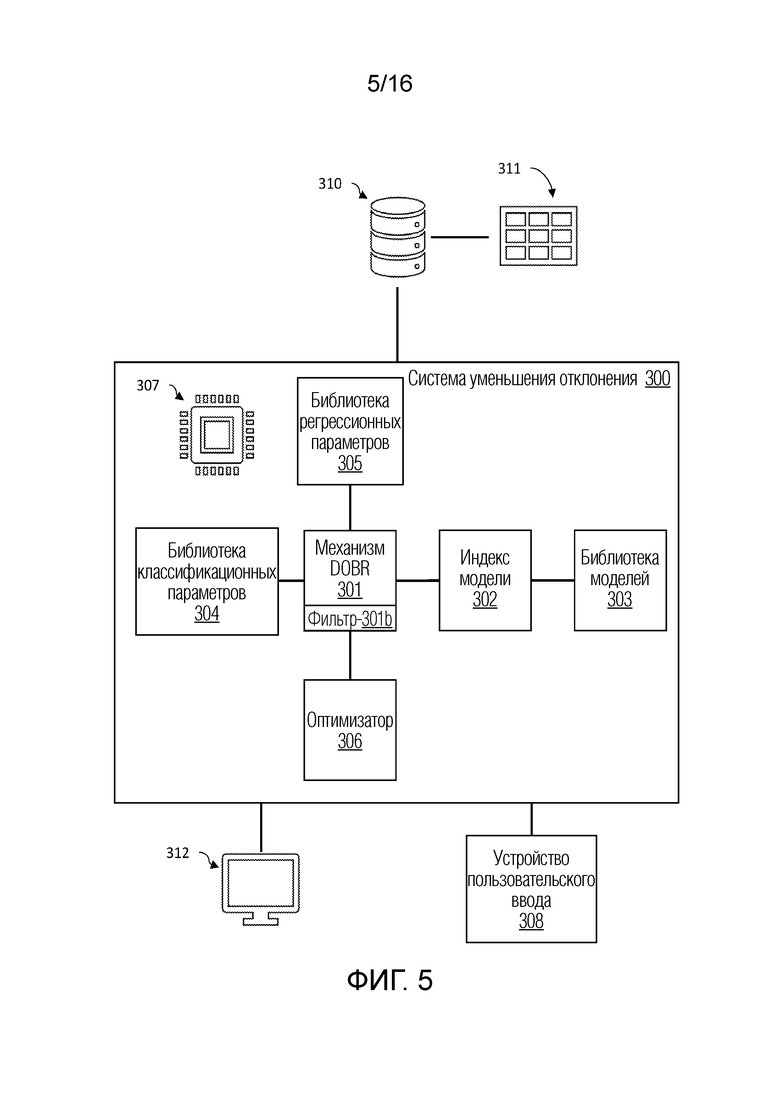
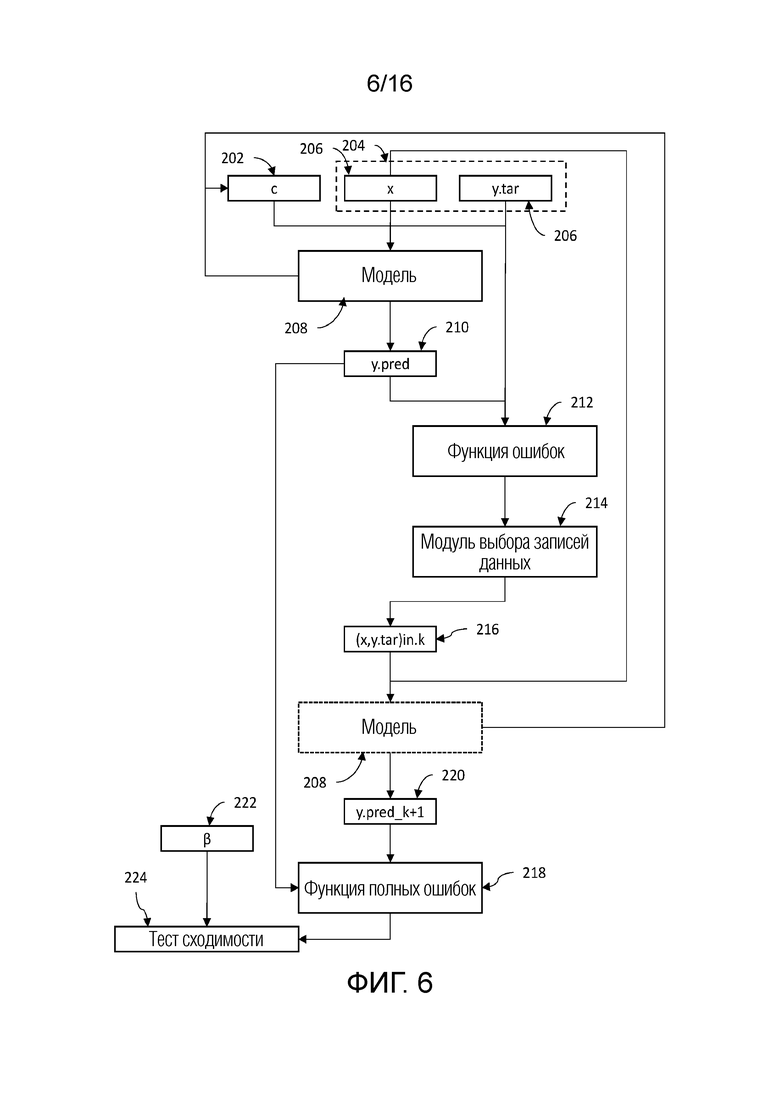
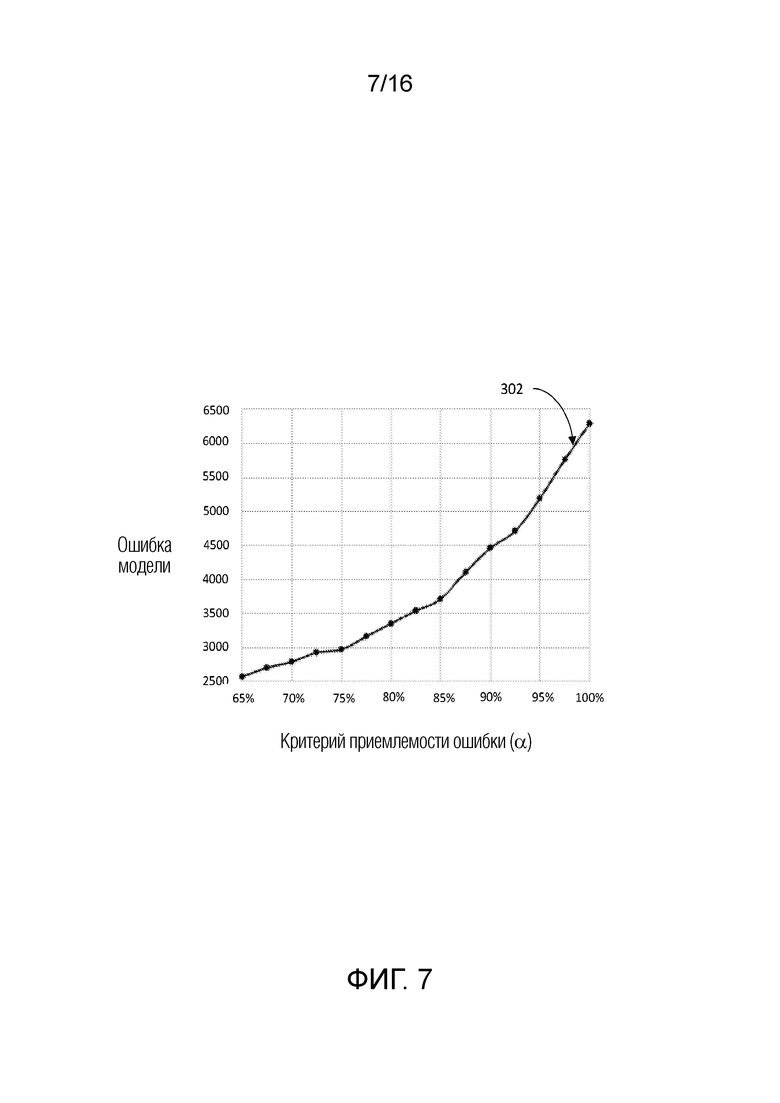
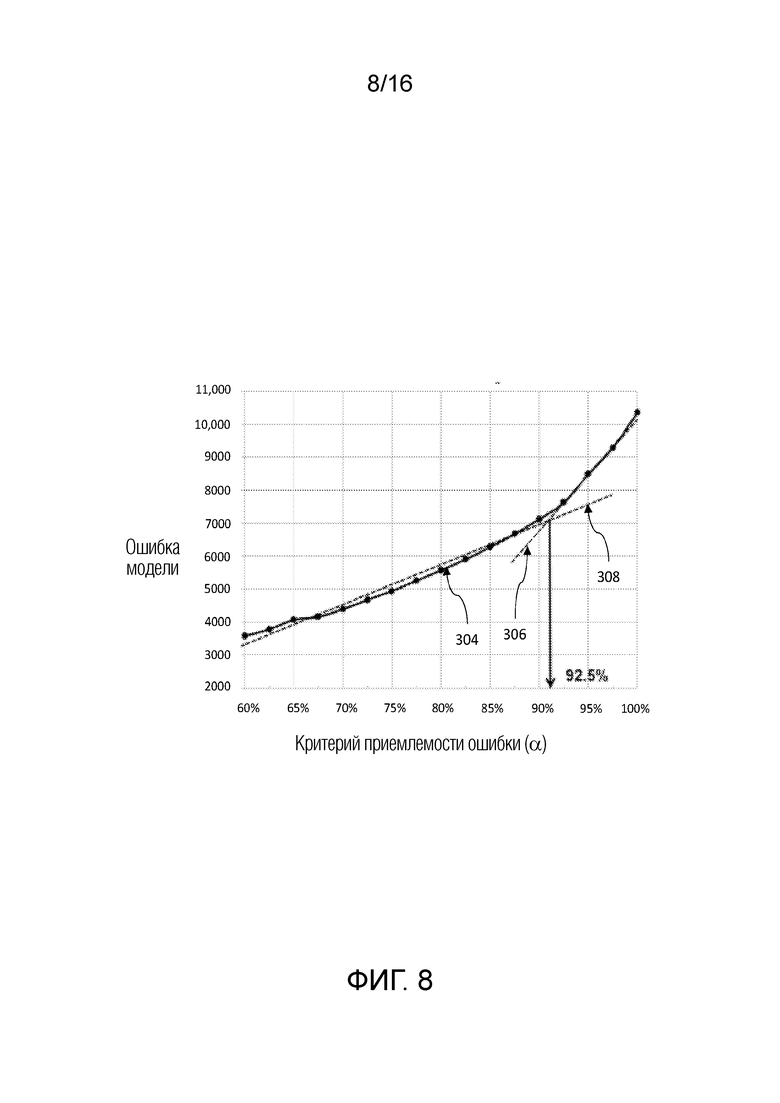
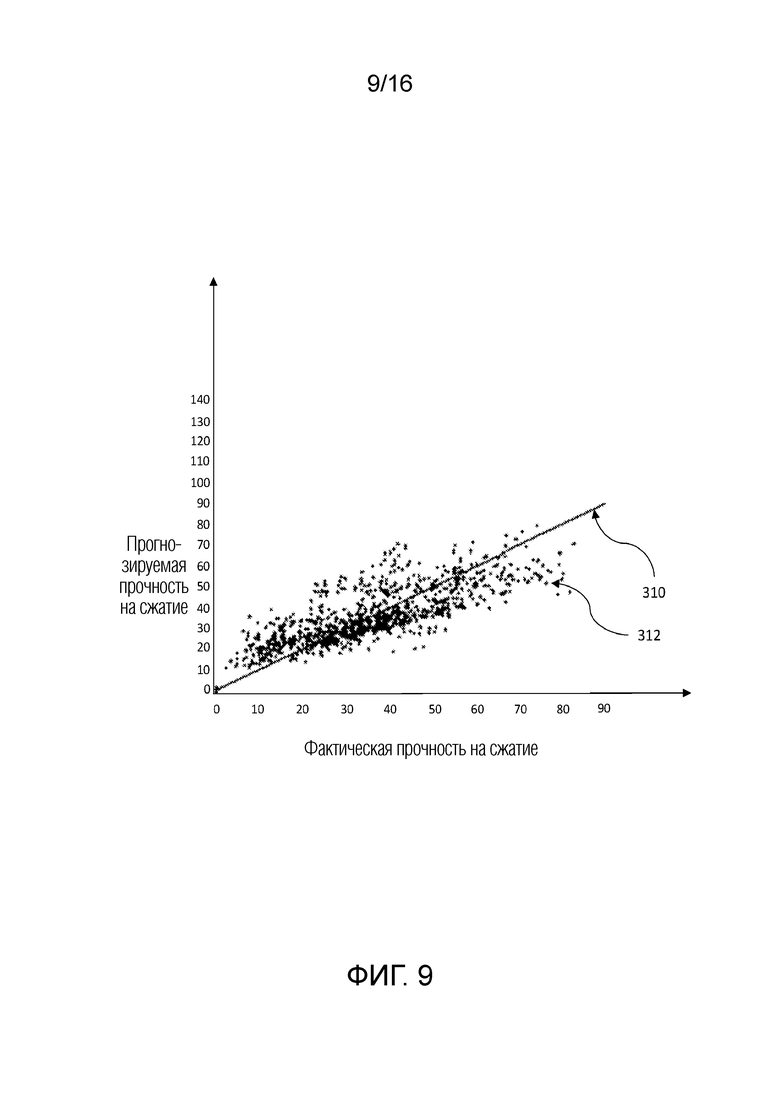
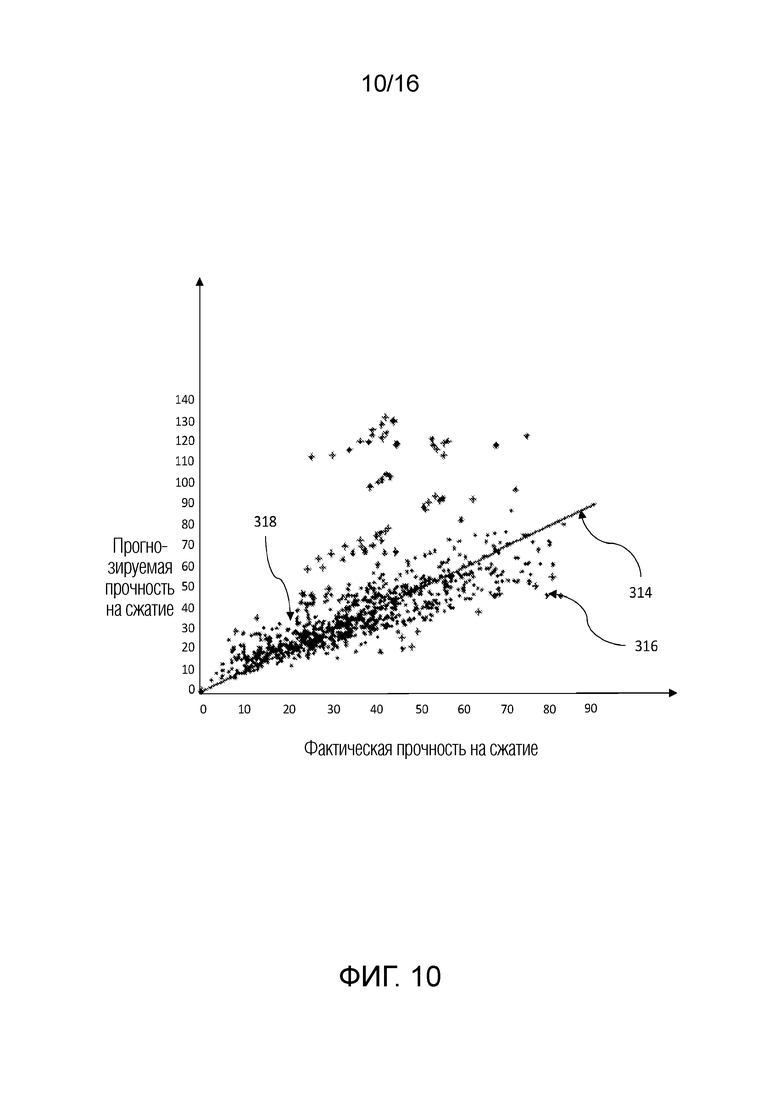
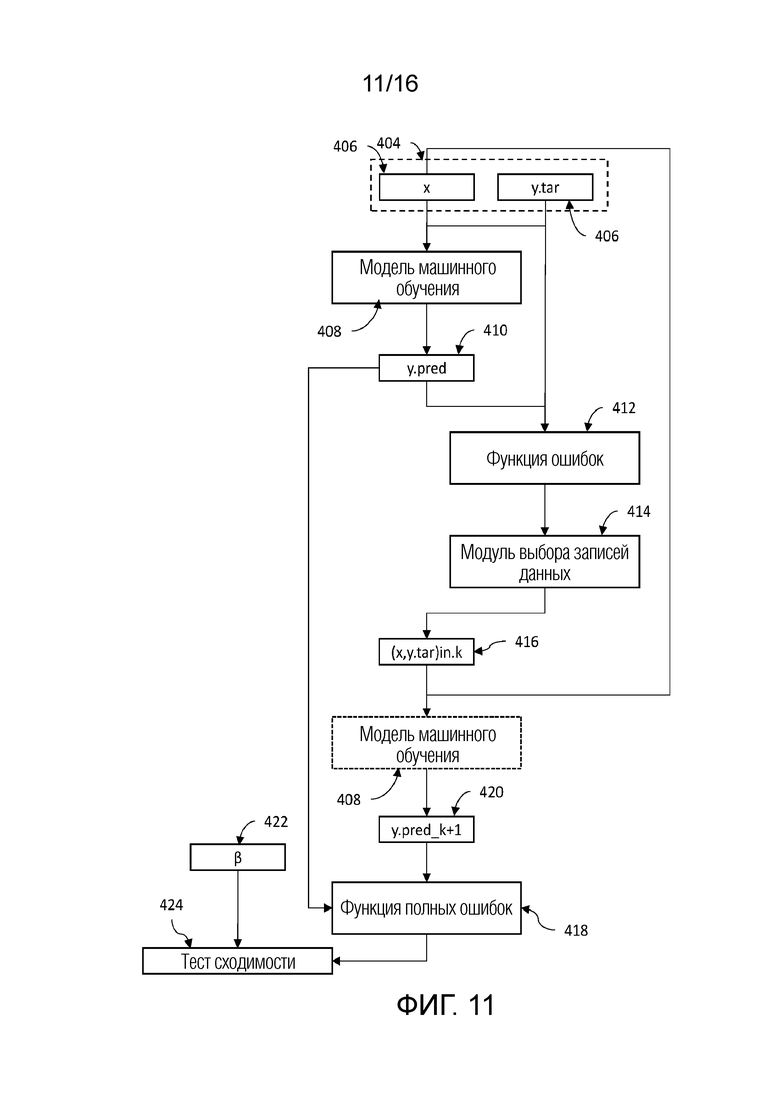
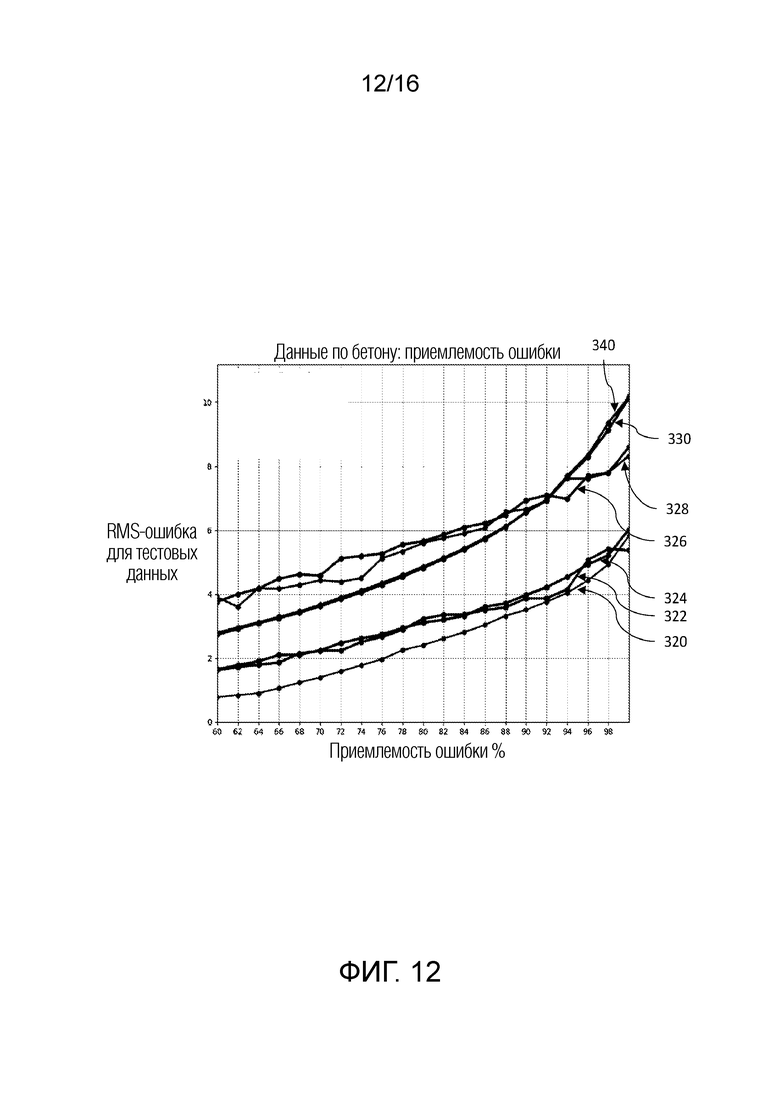
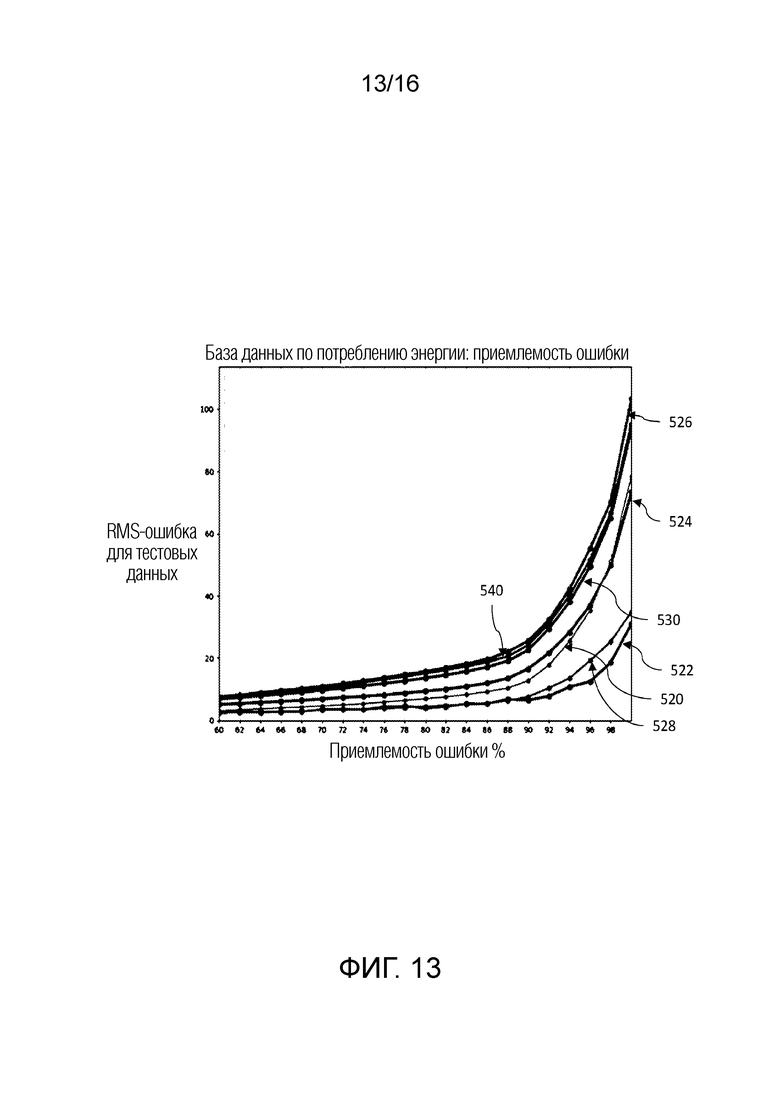
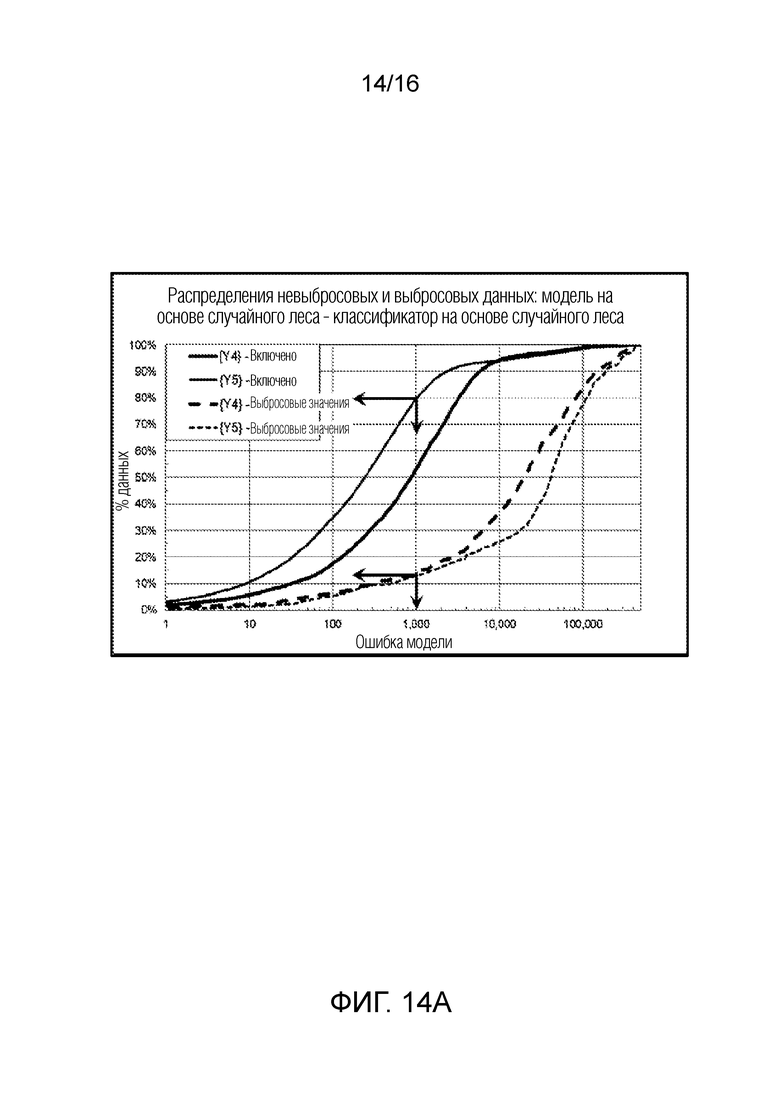
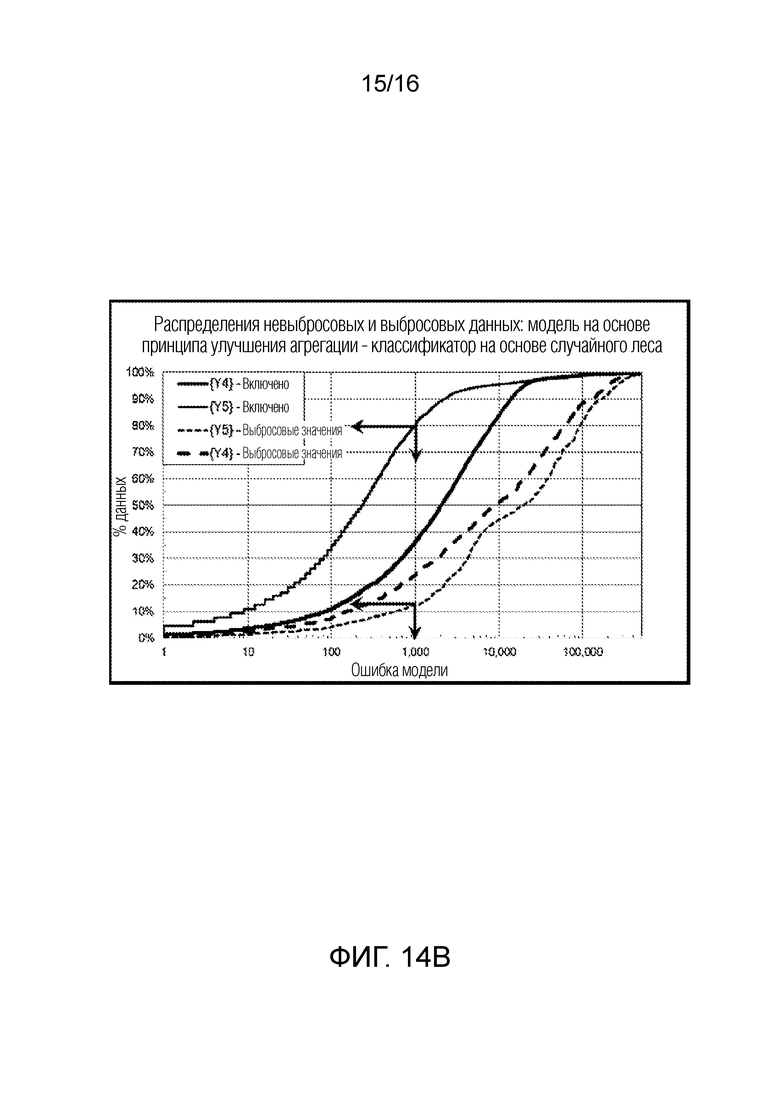
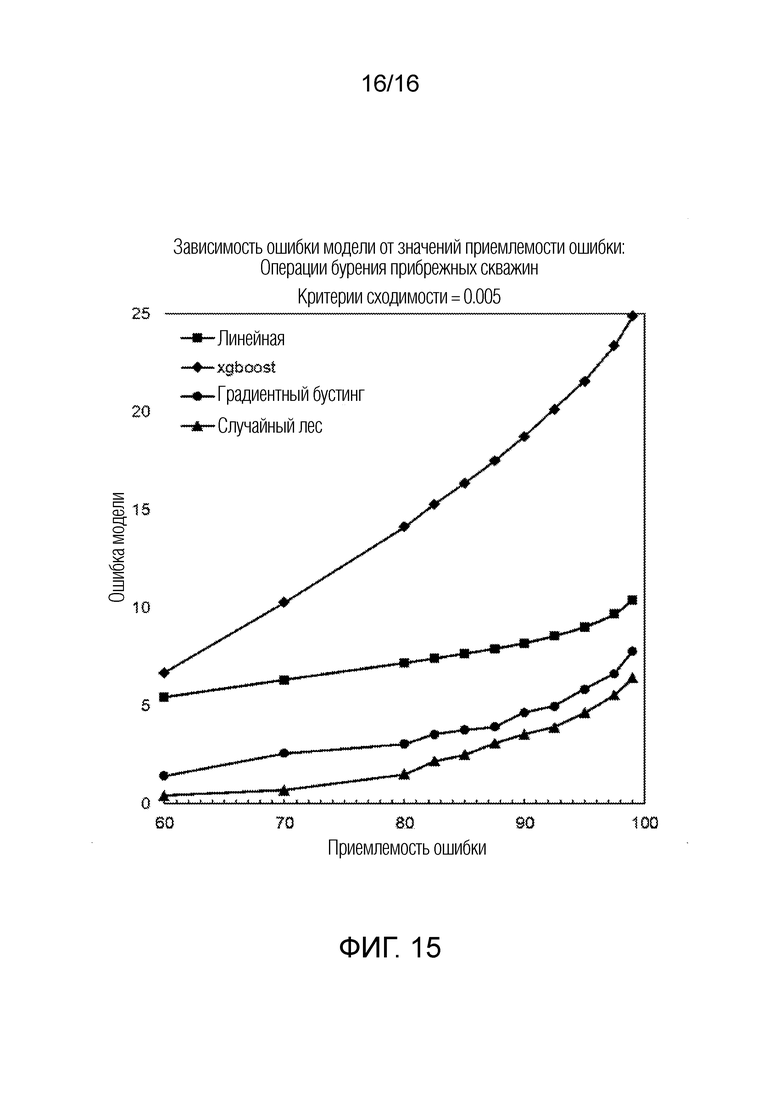
Изобретение относится к способу и системе управления электронным устройством посредством использования модели машинного обучения. Технический результат заключается в повышении точности прогнозирования атрибутов пользовательской активности для формирования машинной команды управления электронным устройством. Система включает в себя процессор для приема обучающих данных для пользовательской активности; приема критериев отклонения; определения набора параметров модели для модели машинного обучения, что включает в себя: (1) применение модели машинного обучения к обучающим данным; (2) формирование ошибок прогнозирования на основе модели; (3) формирование вектора выбора данных для идентификации невыбросовых целевых переменных на основе ошибок прогнозирования на основе модели; (4) использование вектора выбора данных для формирования набора невыбросовых данных; (5) определение обновленных параметров модели на основе набора невыбросовых данных; и (6) повторение этапов (1)-(5) до тех пор, пока не будет удовлетворён критерий завершения выполнения цензурирования; обучение параметров классификационной модели для модели машинного обучения классификаторов выбросовых значений; применение модели машинного обучения классификаторов выбросовых значений к связанным с активностью данным для определения невыбросовых связанных с активностью данных; применение модели машинного обучения к невыбросовым связанным с активностью данным для прогнозирования будущих связанных с активностью атрибутов для пользовательской активности; и формирование машинной команды управления на основании применения модели машинного обучения и прогнозирования будущего связанного с активностью атрибута, связанного с пользовательской активностью. 2 н. и 18 з.п. ф-лы, 16 ил., 12 табл.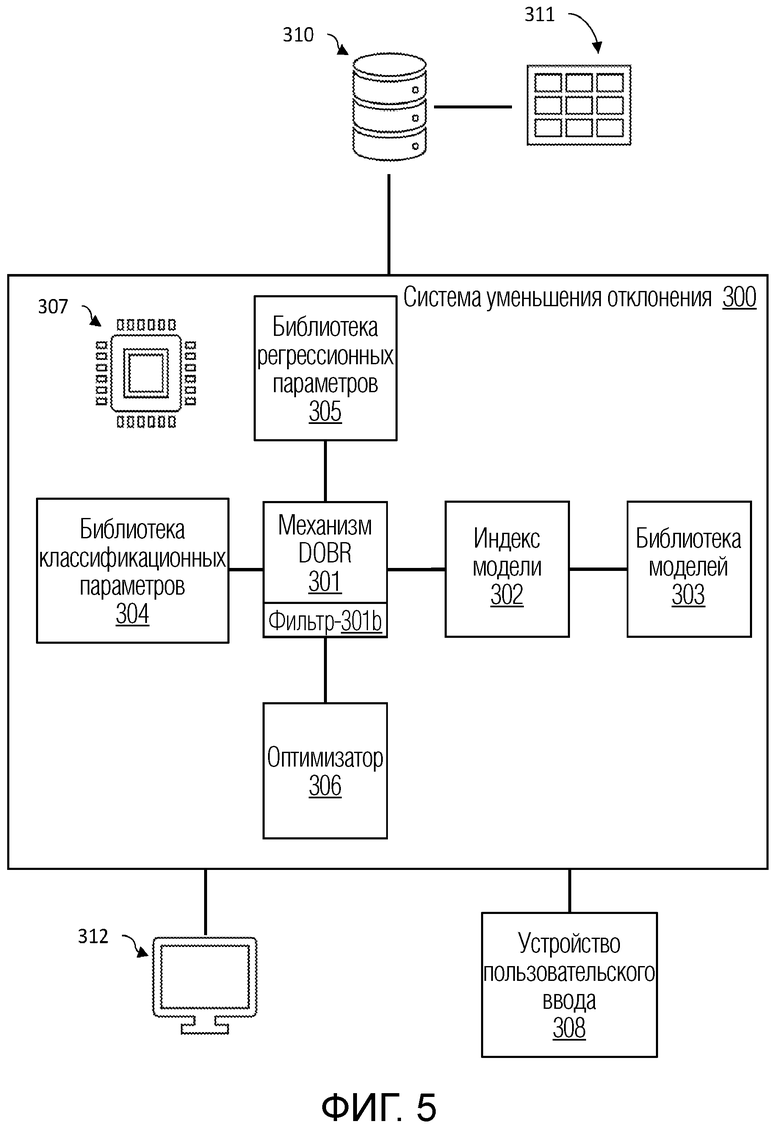
1. Способ управления электронным устройством посредством использования модели машинного обучения, обученной на невыбросовых данных, содержащий этапы, на которых:
- принимают посредством по меньшей мере одного процессора набор обучающих данных целевых переменных, представляющих по меньшей мере один связанный с активностью атрибут по меньшей мере для одной пользовательской активности,
причём набор обучающих данных целевых переменных содержит множество переменных, связанных с использованием энергии, для упомянутого по меньшей мере одного устройства;
- принимают посредством по меньшей мере одного процессора по меньшей мере один критерий отклонения, используемый для определения одного или более выбросовых значений;
- определяют посредством по меньшей мере одного процессора набор параметров модели для упомянутой модели машинного обучения, что содержит этапы, на которых:
(1) применяют посредством по меньшей мере одного процессора модель машинного обучения, имеющую набор начальных параметров модели, к набору обучающих данных для определения набора прогнозируемых значений модели;
(2) формируют посредством по меньшей мере одного процессора набор ошибок для ошибок в элементах данных посредством сравнения набора прогнозируемых значений модели с соответствующими фактическими значениями набора обучающих данных;
(3) формируют посредством по меньшей мере одного процессора, вектор выбора данных для идентификации невыбросовых целевых переменных по меньшей мере частично на основании набора ошибок для ошибок в элементах данных и по меньшей мере одного критерия отклонения;
(4) используют посредством по меньшей мере одного процессора вектор выбора данных для набора обучающих данных для формирования набора невыбросовых данных;
(5) определяют посредством по меньшей мере одного процессора набор обновленных параметров модели для модели машинного обучения на основании набора невыбросовых данных; и
(6) повторяют посредством по меньшей мере одного процессора этапы (1)-(5) в качестве итерации до тех пор, пока не будет удовлетворен по меньшей мере один критерий завершения выполнения цензурирования, таким образом, чтобы получить набор параметров модели для модели машинного обучения в качестве обновленных параметров модели, за счет чего каждая итерация повторно формирует набор прогнозируемых значений, набор ошибок, вектор выбора данных и набор невыбросовых данных с использованием набора обновленных параметров модели в качестве набора начальных параметров модели;
- обучают посредством по меньшей мере одного процессора по меньшей мере частично на основе набора обучающих данных и вектора выбора данных набор параметров классификационной модели для модели машинного обучения классификаторов выбросовых значений для получения обученной модели машинного обучения классификаторов выбросовых значений, которая выполнена с возможностью идентификации по меньшей мере одного выбросового элемента данных;
- применяют посредством по меньшей мере одного процессора обученную модель машинного обучения классификаторов выбросовых значений к набору данных для связанных с активностью данных по меньшей мере для одной пользовательской активности для определения:
i) набора выбросовых связанных с активностью данных в наборе данных для связанных с активностью данных и
ii) набора невыбросовых связанных с активностью данных в наборе данных для связанных с активностью данных;
- применяют посредством по меньшей мере одного процессора упомянутую модель машинного обучения к набору элементов невыбросовых связанных с активностью данных для прогнозирования будущего связанного с активностью атрибута, связанного по меньшей мере с одной пользовательской активностью; и
- автоматически формируют посредством по меньшей мере одного процессора по меньшей мере одну машинную команду управления на основании применения модели машинного обучения и прогнозирования будущего связанного с активностью атрибута, связанного по меньшей мере с одной пользовательской активностью.
2. Способ по п. 1, дополнительно содержащий этапы, на которых:
- применяют посредством по меньшей мере одного процессора вектор выбора данных к набору обучающих данных для определения набора выбросовых обучающих данных;
- обучают посредством по меньшей мере одного процессора с использованием набора выбросовых обучающих данных по меньшей мере один параметр относящейся к выбросовым значениям модели для по меньшей мере одной относящейся к выбросовым значениям модели машинного обучения для прогнозирования выбросовых значений данных; и
- используют посредством по меньшей мере одного процессора относящуюся к выбросовым значениям модель машинного обучения для прогнозирования выбросовых значений связанных с активностью данных для набора выбросовых связанных с активностью данных.
3. Способ по п. 1, дополнительно содержащий этапы, на которых:
- обучают посредством по меньшей мере одного процессора с использованием набора обучающих данных обобщенные параметры модели для обобщенной модели машинного обучения для прогнозирования значений данных;
- используют посредством по меньшей мере одного процессора обобщенную модель машинного обучения для прогнозирования выбросовых значений связанных с активностью данных для набора выбросовых связанных с активностью данных; и
- используют посредством по меньшей мере одного процессора обобщенную модель машинного обучения для прогнозирования значений связанных с активностью данных.
4. Способ по п. 1, дополнительно содержащий этапы, на которых:
- применяют посредством по меньшей мере одного процессора вектор выбора данных к набору обучающих данных для определения набора выбросовых обучающих данных;
- обучают посредством по меньшей мере одного процессора с использованием набора выбросовых обучающих данных параметры относящейся к выбросовым значениям модели для относящейся к выбросовым значениям модели машинного обучения для прогнозирования выбросовых значений данных;
- обучают посредством по меньшей мере одного процессора с использованием набора обучающих данных обобщенные параметры модели для обобщенной модели машинного обучения для прогнозирования значений данных;
- используют посредством по меньшей мере одного процессора относящуюся к выбросовым значениям модель машинного обучения для прогнозирования выбросовых значений связанных с активностью данных для набора выбросовых связанных с активностью данных; и
- используют посредством по меньшей мере одного процессора относящуюся к выбросовым значениям модель машинного обучения для прогнозирования значений связанных с активностью данных.
5. Способ по п. 1, дополнительно содержащий этапы, на которых:
- обучают посредством по меньшей мере одного процессора с использованием набора обучающих данных обобщенные параметры модели для обобщенной модели машинного обучения для прогнозирования значений данных;
- используют посредством по меньшей мере одного процессора обобщенную модель машинного обучения для прогнозирования значений связанных с активностью данных для набора связанных с активностью данных;
- используют посредством по меньшей мере одного процессора модель машинного обучения классификаторов выбросовых значений для идентификации выбросовых значений связанных с активностью данных из значений связанных с активностью данных; и
- удаляют посредством по меньшей мере одного процессора выбросовые значения связанных с активностью данных.
6. Способ по п. 1, в котором набор обучающих данных содержит по меньшей мере один связанный с активностью атрибут прочности на сжатие бетона в качестве функции от состава бетона и отверждающего воздействия на бетон.
7. Способ по п. 1, в котором набор обучающих данных содержит по меньшей мере один связанный с активностью атрибут данных использования энергии в качестве функции от бытовых окружающих условий и условий освещения.
8. Способ по п. 1, дополнительно содержащий этапы, на которых:
- принимают посредством по меньшей мере одного процессора запрос интерфейса прикладного программирования (API) для формирования прогнозирования по меньшей мере с одним элементом данных; и
- создают посредством по меньшей мере одного процессора экземпляр по меньшей мере одного облачного вычислительного ресурса для планирования выполнения модели машинного обучения;
- используют посредством по меньшей мере одного процессора модель машинного обучения согласно планированию для выполнения для прогнозирования по меньшей мере одного значения элемента связанных с активностью данных по меньшей мере для одного элемента данных; и
- возвращают посредством по меньшей мере одного процессора по меньшей мере одно значение элемента связанных с активностью данных в вычислительное устройство, ассоциированное с запросом API.
9. Способ по п. 1, в котором набор обучающих данных содержит по меньшей мере один связанный с активностью атрибут формирования трехмерных изображений пациентов для набора медицинских данных; и
при этом модель машинного обучения выполнена с возможностью прогнозирования значений связанных с активностью данных, содержащих два или более параметра физического рендеринга, на основе набора медицинских данных.
10. Способ по п. 1, в котором набор обучающих данных содержит по меньшей мере один связанный с активностью атрибут результатов моделируемого управления для электронных машинных команд; и
при этом модель машинного обучения выполнена с возможностью прогнозирования значений связанных с активностью данных, содержащих команды управления для электронной машины.
11. Способ по п. 1, дополнительно содержащий этапы, на которых:
- разбивают посредством по меньшей мере одного процессора набор связанных с активностью данных на множество поднаборов связанных с активностью данных;
- определяют посредством по меньшей мере одного процессора модель из ансамбля для каждого поднабора связанных с активностью данных из множества поднаборов связанных с активностью данных;
при этом модель машинного обучения содержит ансамбль моделей;
при этом каждая модель из ансамбля содержит случайное сочетание моделей из ансамбля моделей;
- используют посредством по меньшей мере одного процессора каждую модель из ансамбля по отдельности для прогнозирования относящихся к ансамблю значений связанных с активностью данных;
- определяют посредством по меньшей мере одного процессора ошибку для каждой модели из ансамбля на основе относящихся к ансамблю значений связанных с активностью данных и известных значений; и
- выбирают посредством по меньшей мере одного процессора модель из ансамбля с наилучшими функциональными параметрами на основе наименьшей ошибки.
12. Система управления электронным устройством посредством использования модели машинного обучения, обученной на невыбросовых данных, содержащая
по меньшей мере один процессор, осуществляющий связь с постоянным машиночитаемым носителем данных, на котором сохранены программные инструкции, при этом программные инструкции при выполнении предписывают по меньшей мере одному процессору выполнять этапы для:
- приёма набора обучающих данных целевых переменных, представляющих по меньшей мере один связанный с активностью атрибут по меньшей мере для одной пользовательской активности,
причём набор обучающих данных целевых переменных содержит множество переменных, связанных с использованием энергии, для упомянутого по меньшей мере одного устройства;
- приёма по меньшей мере одного критерия отклонения, используемого для определения одного или более выбросовых значений;
- определения набора параметров модели для упомянутой модели машинного обучения, что содержит:
(1) применение модели машинного обучения, имеющей набор начальных параметров модели, к набору обучающих данных для определения набора прогнозируемых значений модели;
(2) формирование набора ошибок для ошибок в элементах данных посредством сравнения набора прогнозируемых значений модели с соответствующими фактическими значениями набора обучающих данных;
(3) формирование вектора выбора данных для идентификации невыбросовых целевых переменных по меньшей мере частично на основе набора ошибок для ошибок в элементах данных и по меньшей мере одного критерия отклонения;
(4) использование вектора выбора данных для набора обучающих данных для формирования набора невыбросовых данных;
(5) определение набора обновленных параметров модели для модели машинного обучения на основе набора невыбросовых данных; и
(6) повторение этапов (1)-(5) в качестве итерации до тех пор, пока не будет удовлетворён по меньшей мере один критерий завершения выполнения цензурирования, таким образом, чтобы получить набор параметров модели для модели машинного обучения в качестве обновленных параметров модели, за счет чего каждая итерация повторно формирует набор прогнозируемых значений, набор ошибок, вектор выбора данных и набор невыбросовых данных с использованием набора обновленных параметров модели в качестве набора начальных параметров модели;
- обучения по меньшей мере частично на основе набора обучающих данных и вектора выбора данных набора параметров классификационной модели для модели машинного обучения классификаторов выбросовых значений для получения обученной модели машинного обучения классификаторов выбросовых значений, которая выполнена с возможностью идентификации по меньшей мере одного выбросового элемента данных;
- применения обученной модели машинного обучения классификаторов выбросовых значений к набору данных для связанных с активностью данных по меньшей мере для одной пользовательской активности для определения:
i) набора выбросовых связанных с активностью данных в наборе данных для связанных с активностью данных и
ii) набора невыбросовых связанных с активностью данных в наборе данных для связанных с активностью данных;
- применения модели машинного обучения к набору элементов невыбросовых связанных с активностью данных для прогнозирования будущего связанного с активностью атрибута, связанного по меньшей мере с одной пользовательской активностью; и
- автоматического формирования посредством упомянутого по меньшей мере одного электронного устройства по меньшей мере одной машинной команды управления на основании применения модели машинного обучения и прогнозирования будущего связанного с активностью атрибута, связанного по меньшей мере с одной пользовательской активностью.
13. Система по п. 12, в которой программные инструкции при выполнении дополнительно предписывают по меньшей мере одному процессору выполнять этапы для:
- применения вектора выбора данных к набору обучающих данных для определения набора выбросовых обучающих данных;
- обучения с использованием набора выбросовых обучающих данных по меньшей мере одного параметра относящейся к выбросовым значениям модели по меньшей мере одной относящейся к выбросовым значениям модели машинного обучения для прогнозирования выбросовых значений данных; и
- использования относящейся к выбросовым значениям модели машинного обучения для прогнозирования выбросовых значений связанных с активностью данных для набора выбросовых связанных с активностью данных.
14. Система по п. 12, в которой программные инструкции при выполнении дополнительно предписывают по меньшей мере одному процессору выполнять этапы для:
- обучения с использованием набора обучающих данных обобщенных параметров модели для обобщенной модели машинного обучения для прогнозирования значений данных;
- использования обобщенной модели машинного обучения для прогнозирования выбросовых значений связанных с активностью данных для набора выбросовых связанных с активностью данных; и
- использования обобщенной модели машинного обучения для прогнозирования значений связанных с активностью данных.
15. Система по п. 12, в которой программные инструкции при выполнении дополнительно предписывают по меньшей мере одному процессору выполнять этапы для:
- применения вектора выбора данных к набору обучающих данных для определения набора выбросовых обучающих данных;
- обучения с использованием набора выбросовых обучающих данных параметров относящейся к выбросовым значениям модели для относящейся к выбросовым значениям модели машинного обучения для прогнозирования выбросовых значений данных;
- обучения с использованием набора обучающих данных обобщенных параметров модели для обобщенной модели машинного обучения для прогнозирования значений данных;
- использования относящейся к выбросовым значениям модели машинного обучения для прогнозирования выбросовых значений связанных с активностью данных для набора выбросовых связанных с активностью данных; и
- использования относящейся к выбросовым значениям модели машинного обучения для прогнозирования значений связанных с активностью данных.
16. Система по п. 12, в которой программные инструкции при выполнении дополнительно предписывают по меньшей мере одному процессору выполнять этапы для:
- обучения с использованием набора обучающих данных обобщенных параметров модели для обобщенной модели машинного обучения для прогнозирования значений данных;
- использования обобщенной модели машинного обучения для прогнозирования значений связанных с активностью данных для набора связанных с активностью данных;
- использования модели машинного обучения классификаторов выбросовых значений для идентификации выбросовых значений связанных с активностью данных из значений связанных с активностью данных; и
- удаления выбросовых значений связанных с активностью данных.
17. Система по п. 12, в которой набор обучающих данных содержит по меньшей мере один связанный с активностью атрибут прочности на сжатие бетона в качестве функции от состава бетона и отверждающего воздействия на бетон.
18. Система по п. 12, в которой набор обучающих данных содержит по меньшей мере один связанный с активностью атрибут данных использования энергии в качестве функции от бытовых окружающих условий и условий освещения.
19. Система по п. 12, в которой программные инструкции при выполнении дополнительно предписывают по меньшей мере одному процессору выполнять этапы для:
- приёма запроса интерфейса прикладного программирования (API) для формирования прогнозирования по меньшей мере с одним элементом данных; и
- создания экземпляра по меньшей мере одного облачного вычислительного ресурса для планирования выполнения модели машинного обучения;
- использования согласно планированию для выполнения модели машинного обучения для прогнозирования по меньшей мере одного значения элемента связанных с активностью данных по меньшей мере для одного элемента данных; и
- возвращения по меньшей мере одного значения элемента связанных с активностью данных в вычислительное устройство, ассоциированное с запросом API.
20. Система по п. 12, в которой программные инструкции при выполнении дополнительно предписывают по меньшей мере одному процессору выполнять этапы для:
- разбиения набора связанных с активностью данных на множество поднаборов связанных с активностью данных;
- определения модели из ансамбля для каждого поднабора связанных с активностью данных из множества поднаборов связанных с активностью данных;
при этом модель машинного обучения содержит ансамбль моделей;
при этом каждая модель из ансамбля содержит случайное сочетание моделей из ансамбля моделей;
- использования каждой модели из ансамбля по отдельности для прогнозирования относящихся к ансамблю значений связанных с активностью данных;
- определения ошибки для каждой модели из ансамбля на основе относящихся к ансамблю значений связанных с активностью данных и известных значений; и
- выбора модели из ансамбля с наилучшими функциональными параметрами на основе наименьшей ошибки.
| СПОСОБЫ И СИСТЕМЫ ДЛЯ ОЦЕНКИ ОБУЧАЮЩИХ ОБЪЕКТОВ ПОСРЕДСТВОМ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2017 |
|
RU2672394C1 |
| Способ и система создания параметра качества прогноза для прогностической модели, выполняемой в алгоритме машинного обучения | 2017 |
|
RU2694001C2 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| US 9111212 B2, 18.08.2015 | |||
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| US 10317854 B2, 11.06.2019 | |||
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |
| CN 109495327 A, 19.03.2019 | |||
| US 10389828 B2, 20.08.2019. | |||

