Уровень техники
Управление параллельным выполнением в системах, которые позволяют множеству пользователей одновременно обращаться к совместно используемым объектам, записям данных и т.д., представляет собой важное свойство любого продукта, построенного на основе сервера, для управления совместно используемыми элементами данных. В частности, в системах планирования ресурсов предприятия часто существует потребность поддерживать непоследовательное взаимодействие между пользователями, имеющими долговременные транзакции с данными.
Обычно пессимистичное управление параллельным выполнением не блокирует операции чтения других использований. Например, многократное считывание обеспечивает то, что считываемая строка (строки) не будет обновляться, не будет обновляться в течение транзакции с данными. Однако при операциях считывания с целью обновления считываемой строки пессимистичное управление параллельным выполнением помещает исключительное блокирование или блокирование обновления на элемент данных в течение длительности транзакции с данными, не позволяя, таким образом, другим пользователям считывать элемент данных с целью обновления. В результате, другие пользователи должны ждать пока блокирование не будет устранено, прежде, чем они смогут считать элемент данных с целью обновления, что влияет на параллельное выполнение и масштабируемость системы. В некоторых случаях охват блокированием применяют ко всей базе данных, всей таблице в пределах базы данных или к нескольким строкам в таблице вместо только одной строки, содержащей считываемый или обновляемый элемент данных. В результате, охват блокирования не позволяет множеству пользователей одновременно считывать или обновлять элементы данных, находящиеся в других строках и/или таблицах. Кроме того, в пределах сбалансированных древовидных структур данных, запросы, например запросы SQL (ЯСЗ, язык структурированных запросов), не могут начать сканирование в точном месте расположения. Как часть выполнения запроса строки сканируют, и фильтры применяют во время оценки запроса. В результате, одновременно выполняющие считывание пользователи не позволяют друг другу считывать элементы данных, даже когда их конечные результаты запросов не пересекаются. Хотя приложение может выбирать строки и применять фильтры для отброса выбранных строк на основе критериев фильтра, блокирование, которое применяют в выбранных строках, продолжает действовать в течение длительности транзакции с данными. Таким образом, параллельные задачи могут стать последовательными в течение долговременных транзакций с данными, которые включают совместно используемые таблицы, даже когда не существует пересечения в пределах конечного множества, получаемого в результате выполнения запроса.
Оптимистичное управление параллельным выполнением позволяет пользователю считывать, обновлять и удалять элемент данных, не мешая другим пользователям делать то же самое. Оптимистичное управление параллельным выполнением предполагает, что вероятность обновления или удаления одного и того же элемента данных в течение операции записи мала, и операции считывания не ограничены. Однако в случае, когда множество транзакций с данными обновляют один и тот же элемент данных в течение операции записи, обновления могут быть потеряны, и только последнее обновление будет поддерживаться между параллельными пользователями, тем самым вызывая несовместимость данных. Другими словами, первый пользователь может в конечном итоге обновить элемент данных в строке таблицы на основе первоначально полученных значений, которые впоследствии были изменены параллельным пользователем. В результате, обновление будет основано на устаревших данных.
Сущность изобретения
Управление параллельным выполнением между множеством транзакций с данными, включающих в себя одни и те же данные, обеспечивает способ, в котором исключение, генерируемое в результате управления параллельным выполнением, обрабатывается в пределах транзакции с данными, вместо немедленного прерывания транзакции с данными. Исключения могут обрабатываться путем повторного считывания и повторной попытки обновления данных, в результате чего происходит задержка прерывания транзакции с данными. Управление параллельным выполнением дополнительно обеспечивает вариант выбора между оптимистичным управлением параллельным выполнением и пессимистичным управлением параллельным выполнением, с учетом относительных обновлений и нестабильных зависимостей. В широком смысле, во время транзакции с данными, которая включает в себя запрос записи от приложения, идентификация версии, которая уникально идентифицирует версию данных, предназначенных для обновления, сравнивают с идентификацией версии, которая идентифицирует версию данных, когда данные были ранее считаны во время такой же транзакции с данными. Если идентификации версий не совпадают, исключение отбрасывают и обрабатывают в пределах транзакции с данными. При этом ожидается, что использование методик управления параллельным выполнением приведет к непоследовательным транзакциям с данными, обеспечит совместимость данных и высокую масштабируемость, даже если транзакции с данными являются долговременными.
Краткое описание чертежей
На фиг.1 показана упрощенная и представительная блок-схема компьютерной сети;
на фиг.2 показана блок-схема компьютера, который может быть подключен к сети по фиг.1;
на фиг.3 показана представительная блок-схема системы для администрирования управления параллельным выполнением;
на фиг.4 показана блок-схема, представляющая подпрограмму оптимистичного управления параллельным выполнением;
на фиг.5 показана блок-схема, представляющая подпрограмму обнаружения конфликтов обновления в подпрограмме оптимистичного управления параллельным выполнением по фиг.4;
на фиг.6 показана блок-схема, представляющая подпрограмму структурированного исключения, отброшенного во время выполнения подпрограммы обнаружения конфликтов обновления по фиг.5;
на фиг.7 показана блок-схема, представляющая подпрограмму обработки исключения во время транзакции с данными, если исключение будет отброшено во время выполнения подпрограммы обнаружения конфликтов обновления по фиг.5;
на фиг.8 показана блок-схема, представляющая подпрограмму проведения относительного обновления данных; и
на фиг.9 показана блок-схема, представляющая подпрограмму обновления данных, зависящих от данных в других таблицах.
Подробное описание изобретения
Хотя в следующем тексте представлено подробное описание нескольких различных вариантов осуществления изобретения, следует понимать, что правовой объем описания определен содержанием формулы изобретения, представленной в конце данного раскрытия. Подробное описание изобретения следует рассматривать только как пример, и оно не описывает каждый возможный вариант осуществления, поскольку описание каждого возможного варианта осуществления было бы непрактичным, или даже невозможным. Несколько различных альтернативных вариантов осуществления могут быть выполнены с использованием либо современной технологии или технологии, которая будет разработана после даты подачи данного патента, которые, тем не менее, все еще будут находиться в пределах объема формулы изобретения.
Следует также понимать, что, если термин не будет явно определен в этом патенте с использованием предложения "используемый здесь термин '_______' определен так, что он означает..." или аналогичного предложения, не предполагается ограничивать значение этого термина ни явно, ни посредством подразумеваемого значения за пределами его ясного или обычного значения, и такой термин не следует интерпретировать как ограниченный по объему на основе любого выражения, представленного в любой части данного патента (кроме формулировки формулы изобретения). В тех случаях, когда любой термин, представленный в формуле изобретения в конце настоящего патента, рассматривается в данном патенте таким образом, что он соответствует единственному значению, это выполнено с целью ясности только для того, чтобы не запутать читателя, при этом считается, что такой термин будет ограничен подразумеваемым значением или другим образом ограничен этим единственным значением. Наконец, пока элемент пункта формулы изобретения не будет определен с помощью слов "средство" и функции без подробного описания какой-либо структуры, не предполагается, что объем любого элемента пункта формулы изобретения следует интерпретировать на основе применения 35 U.S.C. § 112, шестой абзац.
Большая часть функциональности изобретения и множество принципов изобретения лучше всего могут быть реализованы с помощью программных средств или инструкций и интегральных микросхем (IC), например, специализированных IC. При этом предполагается, что специалист в данной области техники, несмотря на возможно значительные усилия и множество вариантов конструктивного выбора, мотивируемые, например, доступным временем, современной технологией и экономическими соображениями, будучи направленным концепцией и раскрытыми здесь принципами, сможет легко сгенерировать такие программные инструкции и программы, и IC при минимальном объеме экспериментов. Поэтому в интересах краткости и минимизации любого риска неясности изложения принципов и концепций в соответствии с настоящим изобретением, дополнительное описание таких программных средств и IC, если такое вообще имеется, будет ограничено необходимыми моментами в отношении принципов и концепций предпочтительных вариантов осуществления.
На фиг.1 и 2 представлена структурная основа сети и вычислительных платформ, относящихся к настоящему раскрытию.
На фиг.1 представлена сеть 10. Сеть 10 может представлять собой сеть Интернет, виртуальную частную сеть (VPN), или любую другую сеть, которая позволяет один или больше компьютеров, устройств передачи данных, баз данных и т.д. соединять с возможностью осуществления связи друг с другом. Сеть 10 может быть подключена к персональному компьютеру 12 и компьютерному терминалу 14 посредством Ethernet 16 и маршрутизатора 18, и наземной линии 20 связи. Ethernet 16 может представлять собой подсеть более крупной сети, в которой используется протокол Internet. Другие сетевые ресурсы, например проекторы или принтеры (не показаны), также могут поддерживаться через Ethernet 16 или другую сеть передачи данных. С другой стороны, сеть 10 может быть соединена беспроводным способом с переносным компьютером 22 и персональным карманным компьютером 24 посредством беспроводной станции 26 связи и беспроводного подключения 28. Аналогично, сервер 30 может быть подключен к сети 10, используя подключение 32 связи, и мэйнфрейм 34 может быть подключен к сети 10, используя другое подключение 36 связи. Сеть 10 можно использовать для поддержки сетевого трафика между равнозначными узлами.
На фиг.2 иллюстрируется вычислительное устройство в форме компьютера 110. Компоненты компьютера 110 могут включать в себя, но не ограничиваются этим, блок 120 обработки, системную память 130 и системную шину 121, которая соединяет различные компоненты системы, включая системную память с блоком 120 обработки. Системная шина 121 может представлять собой любую из нескольких типов структур шин, включающих в себя шину памяти или контроллер памяти, периферийную шину и локальную шину, с использованием любой из различных архитектур шины. В качестве примера, а не ограничения, такие архитектуры включают в себя шину архитектуры шины промышленного стандарта (ISA), шину микроканальной архитектуры (MCA), расширенную шину ISA (EISA), локальную шину Ассоциации по стандартизации видеоэлектроники (VESA), и шину межсоединения периферийных компонентов (PCI), также известную как мезанинная шина.
Компьютер 110 обычно включает в себя различные машиночитаемые носители. Машиночитаемые носители могут представлять собой любые доступные носители, к которым может обращаться компьютер 110, и включают в себя как энергозависимые, так и энергонезависимые носители, съемные и несъемные носители. В качестве примера, а не ограничения, машиночитаемые носители могут содержать компьютерные устройства хранения и среды связи. Компьютерные устройства хранения включают в себя энергозависимые и энергонезависимые, съемные и несъемные носители, реализованные с использованием любого способа или технологии для хранения информации, такой как машиночитаемые инструкции, структуры данных, программные модули или другие данные. Компьютерные устройства хранения включают в себя, но без ограничений, RAM, ROM, EEPROM, флэш-память или другие технологии памяти, CD-ROM, цифровые универсальные диски (DVD) или другие оптические накопители, магнитные кассеты, магнитную ленту, накопители на магнитных дисках или другие магнитные устройства хранения, или любой другой носитель, который можно использовать для хранения требуемой информации и к которому может обращаться компьютер 110. Среды связи обычно воплощают считываемые компьютером инструкции, структуры данных, программные модули или другие данные в виде модулированного сигнала данных, такого как, несущая волна или другой механизм транспортирования, и включают себя любые среды доставки информации. Термин "модулированный сигнал данных" означает сигнал, одна или больше характеристик которого установлена или изменена таким образом, чтобы кодировать информацию в сигнале. В качестве примера, а не ограничения, среды связи включают в себя кабельную среду, такую как кабельная сеть или прямое кабельное соединение, и беспроводные среды, такие как акустическая, радиочастотная, инфракрасная и другие беспроводные среды. Комбинации любых из описанных выше устройств также следует включить в пределы объема машиночитаемых носителей.
Системная память 130 включает в себя компьютерные устройства хранения в форме энергозависимой и/или энергонезависимой памяти, такие как постоянное запоминающее устройство (ROM) 131 и оперативное запоминающее устройство (RAM) 132. Базовая система 133 ввода-вывода (BIOS), содержащая основные подпрограммы, которые помогают передавать информацию между элементами внутри компьютера 110, например, во время запуска, обычно хранится в ROM 131. RAM 132 обычно содержит данные и/или программные модули, к которым можно немедленно обращаться и/или которыми в данный момент времени оперирует блок 120 обработки. В качестве примера, а не ограничения, на фиг.2 иллюстрируется операционная система 134, прикладные программы 135, другие программные модули 136 и программные данные 137.
Компьютер 110 также может включать в себя другие съемные/несъемные, энергозависимые/энергонезависимые компьютерные устройства хранения. Только в качестве примера, на фиг.2 иллюстрируется накопитель 141 на жестких дисках, который считывает данные с или записывает их на несъемный, энергонезависимый магнитный носитель, накопитель 151 на магнитных дисках, который считывает данные с или записывает их на съемный, энергонезависимый магнитный диск 152, и накопитель 155 на оптических дисках, который считывает данные с или записывает их на съемный, энергонезависимый оптический диск 156, такой как CD-ROM или другие оптические носители. Другие съемные/несъемные, энергозависимые/энергонезависимые компьютерные устройства хранения, которые можно использовать в примерной операционной среде, включают в себя, но без ограничений, кассеты с магнитной лентой, карты флэш-памяти, цифровые универсальные диски, цифровую видеоленту, твердотельное RAM, твердотельное ROM и т.п. Накопитель 141 на жестких дисках обычно соединен в системной шиной 121 через интерфейс несъемной памяти, такой как интерфейс 140, и накопитель 151 на магнитных дисках и накопитель 155 на оптических дисках обычно соединены с системной шиной 121 с помощью интерфейса съемной памяти, такого как интерфейс 150.
Накопители и ассоциированные с ними компьютерные накопители, описанные выше и представленные на фиг.2, предоставляют хранение машиночитаемых инструкций, структур данных, программных модулей и других данных для компьютера 110. На фиг.2, например, накопитель 141 на жестких дисках представлен как содержащий операционную систему 144, прикладные программы 145, другие программные модули 146 и программные данные 147. Следует отметить, что эти компоненты могут быть либо такими же, или могут отличаться от операционной системы 134, прикладных программ 135, других программных модулей 136 и программных данных 137. Операционная система 144, прикладные программы 145, другие программные модули 146 и программные данные 147 обозначены здесь разными номерами ссылочных позиций для того, чтобы иллюстрировать тот факт, что, как минимум, они представляют собой разные копии. Пользователь может вводить команды и информацию в компьютер 110, через устройства ввода, такие как клавиатура 162 и устройство 161 управления курсором, обычно называемое мышью, шаровым указателем или сенсорной панелью. Камера 163, такая как сетевая web-камера, может захватывать и вводить изображения среды, связанной с компьютером 110, например, предоставляя изображения пользователей. Сетевая камера 163 может захватывать изображения по желанию, например, когда поступает инструкция от пользователя, или может снимать изображения периодически под управления компьютера 110. Другие устройства ввода (не показаны) могут включать в себя микрофон, джойстик, игровую панель, спутниковую тарелку, сканер или тому подобное. Эти и другие устройства ввода часто соединяют с блоком 120 обработки через интерфейс 160 ввода, который соединен с системной шиной, но могут быть соединены с помощью другого интерфейса и структур шины, таких как параллельный порт, игровой порт или универсальная последовательная шина USB. Монитор 191 или устройство отображения другого типа также соединен с системной шиной 121 через интерфейс, такой как графический контроллер 190. В дополнение к монитору компьютеры также могут включать в себя другие периферийные устройства вывода, такие как громкоговорители 197 и принтер 196, которые могут быть соединены через периферийный интерфейс 195 вывода.
Компьютер 110 может работать в сетевой среде, используя логические соединения с одним или больше удаленными компьютерами, такими как удаленный компьютер 180. Удаленный компьютер 180 может представлять собой персональный компьютер, сервер, маршрутизатор, сетевой PC, одноранговое сетевое устройство или другой обычный сетевой узел, и обычно включает в себя множество или все элементы, описанные выше в отношении компьютера 110, хотя только устройство 181 хранения представлено на фиг.2. Логические соединения, показанные на фиг.2, включают в себя локальную вычислительную сеть (LAN) 171 и глобальную вычислительную сеть (WAN) 173, но также могут включать в себя другие сети. Такие сетевые среды часто присутствуют в офисах, в компьютерных сетях предприятия, в интранет и в Интернет.
При использовании в сетевом окружении LAN компьютер 110 соединен с LAN 171 через сетевой интерфейс или адаптер 170. При использовании в сетевом окружении WAN компьютер 110 обычно включает в себя модем 172 или другое средство установления связи через WAN 173, такое как сеть Интернет. Модем 172, который может быть внутренним или внешним, может быть подключен к системной шине 121 через интерфейс 160 ввода или другой соответствующий механизм. В сетевой среде программные модули, представленные в отношении компьютера 110, или их части, могут быть сохранены в удаленном устройстве хранения. В качестве примера, а не ограничения, на фиг.2 показаны удаленные прикладные программы 185, как находящиеся в устройстве 181 хранения.
Соединения 170, 172 связи позволяют устройству связываться с другими устройствами. Соединения 170, 172 связи представляют собой пример среды связи. Среда связи обычно воплощает считываемые компьютером инструкции, структуры данных, программные модули или другие данные в модулированном сигнале данных, таком как несущая волна или другой механизм транспортирования, и включают в себя любую среду доставки информации. "Модулированный сигнал данных" может представлять собой сигнал, одна или больше характеристик которого установлена или изменена таким образом, чтобы кодировать информацию в сигнале. В качестве примера, а не ограничения, среда связи включает в себя кабельную среду, такую как кабельная сеть или прямое кабельное соединение, и беспроводные среды, такие как акустические, RF, инфракрасные и другие беспроводные среды. Машиночитаемые носители могут включать в себя как устройства хранения, так и среды связи.
На фиг.3 представлена примерная сеть 200 клиент - сервер, такая как система планирования ресурсов предприятия, которая может быть аналогичной сети 10 по фиг.1 или может быть соединена с ней. Сеть 200 клиент - сервер может включать в себя отдельные системы 202, 204, 206, 208, соединенные сетями 210 212 214. Сети 210, 212, 214 могут быть кабельными или беспроводными и могут поддерживать версию 6 Протокола Интернет (IPv6) и безопасный протокол связи, например, такой как уровень защищенных сокетов (SSL). В одном примере сеть Интернет можно использовать как сети 210, 212, 214. Система 202 представляет собой серверную систему, которая может включать в себя один сервер 216 или множество серверов. Серверная система 202 может представлять собой серверную бизнес-систему предприятия, или сервер управления базой данных SQL или другой базой данных, серверную систему сообщений и совместной работы, хотя могут быть включены другие серверные типы или использования.
Системы 204, 206 представляют собой клиентские системы, каждая из которых включает в себя устройство 218, 220 обмена данными с сетью, включающее в себя, но без ограничений, персональный компьютер, телефон, персональный карманный компьютер, телевизионную приставку, телевизионный приемник и систему развлечения и т.п. Система 208 включает в себя базу 222 данных, функционально соединенную с серверной системой 202, и в которой содержатся элементы данных. В одном примере в базе 222 данных могут храниться элементы данных в строках таблицы, и база 222 данных может содержать множество таблиц для хранения данных. Система 202 сервера может управлять элементами данных, которые содержатся в различных таблицах, имеющих одну или больше строк, соответствующих разным элементам данных. В одном примере сетевые устройства 218, 220 передачи данных могут относиться к разным пользователям, которые могут задействовать операции считывания и/или записи с сервера 216, для доступа и/или модификации элемента данных, хранящегося в базе 222 данных. Обычно серверная система 202 позволяет множеству пользователей 204, 206 одновременно считывать или обновлять элементы данных в базе 222 данных, элементы данных в одной и той же таблице или один и тот же элемент данных, используя описанные здесь технологии управления параллельным выполнением. В дополнительном примере, используя описанную выше систему 200, сервер 216 может позволять множеству клиентов 204, 206 возможность запускать серверное приложение, управляемое серверной системой 202. В качестве альтернативы, клиенты 204, 206, могут выполнять приложения локально. Приложение может включать в себя код приложения, который включает в себя операторы считывания и/или обновления для предоставления запросов считывания и/или записи. Используемый здесь термин "обновлять" тем самым определен как означающий любую модификацию элемента данных, включая, но без ограничений, модификацию данных, запись новых данных или удаление данных.
Хотя показано, что каждая из клиентских систем 204, 206 включает в себя одно сетевое устройство 218, 220 связи, следует понимать, что можно использовать разное количество сетевых устройств связи. Аналогично, серверная система 202 может включать в себя другое количество серверов, и система 208 базы данных может включать в себя разное количество баз данных. Кроме того, хотя каждый из сервера 216, сетевых устройств 218, 220 связи и базы 222 данных показаны так, что они предусмотрены в своих собственных системах 202, 204, 206, 208, следует понимать, что сервер 216, сетевые устройства 218, 220 связи и база 222 данных могут быть предусмотрены в одной и той же системе. Следует также понимать, что может быть предусмотрено множество систем, включающих в себя сотни или тысячи клиентских систем и систем баз данных. Хотя в следующем описании, в общем, описывается множество транзакций с данными, выполняющих параллельные операции записи для одного и того же элемента данных, которые могут включать в себя взаимодействие между одним сервером 216 и множеством одновременных пользователей или приложений, следует понимать, что один или больше серверов могут работать одновременно, каждый с одним или больше параллельными пользователями или приложениями, выполняющими транзакции с данными для выполнения операции записи для одного или больше элементов данных. Кроме того, хотя в следующем раскрытии, в общем, описываются технологии управления параллельным выполнением, которые воплощены на уровне доступа к данным ядра операционной системы, следует понимать, что можно использовать различные другие варианты воплощения технологий управления параллельным выполнением. Различные примеры компьютерного кода предусмотрены ниже, некоторые из которых написаны с использованием языка программирования X++, который представляет собой простой объектно-ориентированный язык, или кода программирования C++, хотя могут быть использованы различные другие языки программирования, включающие в себя другие объектно-ориентированные языки.
Обычно, во время транзакции с данными, включающей в себя операции считывания, серверная система 202 принимает запрос на считывание из приложения, такого как бизнес-процесс, выполняемый пользователем. Используя описанные здесь технологии управления параллельным выполнением, серверная система 202 может обеспечивать возможность неограниченных операций считывания элементов данных параллельными пользователями, поскольку простое считывание элемента данных не приводит к потере целостности. При этом приложению разрешено считывать строки и соответствующие элементы данных без установки ограничивающих блокировок для операций считывания, в результате чего обеспечивается возможность максимального параллельного выполнения в серверной системе 202. Кроме того, операции считывания с целью обновления данных также могут выполняться без установки исключающих блокировок, в результате чего операция считывания открывается для считывания свободных от каких-либо запретов данных. Как описано далее ниже, целостность данных может поддерживаться путем сравнения идентификации версии данных, подверженных воздействию во время обновления.
С другой стороны, во время транзакций с данными, которые включают в себя операцию записи, серверная система 202 может обеспечивать совместимость данных для исключения потери обновлений. Операции с данными могут обрабатываться на трех фазах: фаза считывания, фаза удостоверения и фаза записи, которая фактически выполняет операцию записи. В одном примере серверная система 202 может обрабатывать фазу считывания, и база 222 данных может обрабатывать фазы удостоверения и записи. Каждому запросу на запись предшествует запрос на считывание. Запросы на запись могут обрабатываться путем приема исходного запроса на считывание, выбора элемента данных и предоставления результата в приложение, когда данные выбирают из базы данных для последующего обновления. Приложение затем модифицирует элемент данных и предоставляет обновление в серверную систему 202 или в базу 222 данных. Блокировка обновления может быть инициирована по строке, соответствующей элементу данных, элемент данных может быть выбран, и обновленный элемент данных может быть удостоверен. Во время удостоверения может быть инициирован алгоритм проверки совместимости, который определяет, был ли элемент данных обновлен во время другой транзакции с данными, путем сравнения идентификации версий, также называемых здесь "RecVersion", элемента данных в том виде, как он был первоначально считан, и обновляемого элемента данных. Другими словами, может быть определено, является ли версия обновляемого элемента данных той же, что и версия элемента данных, который был первоначально считан. Если версии одинаковы, выполнение обновления разрешают, изменения передают в базу 222 данных, и строку, соответствующую этим данным, разблокируют, после того, как транзакция данных будет зафиксирована. Если версии отличаются, серверная система 202 обнаруживает конфликт и вызывает исключение конфликта обновления, и приложению предоставляется возможность обработать конфликт в попытке компенсации конфликта обновления во время транзакции с данными, без автоматического возвращения или прерывания транзакции с данными. Если приложение неспособно компенсировать конфликт обновления, серверная система 202 откатывает транзакцию с данными. Приложение может иметь информацию об исключении и может откатить код приложения к месту, где приложение может попытаться записать операцию позже. Серверная система 202, таким образом, обеспечивает управление параллельным выполнением во время операции записи, без блокирования строки, соответствующей элементу данных, когда элемент данных выбирают из базы данных для последующего обновления. Вместо этого, блокирование на уровне строки используют во время фактического обновления, позволяя, таким образом, другим транзакциям с данными считывать элемент данных или обновлять любой другой элемент данных в таблице данных и/или в базе 222 данных. Если элемент данных модифицируется другой транзакцией данных между выборкой и обновлением, эту модификацию обнаруживают, и генерируют исключение, которое обрабатывают и которое может быть отброшено с уровня доступа к данным ядра до кода приложения.
Оптимистичное и пессимистичное управление параллельным выполнением
В дополнение к предоставлению оптимистичного управления параллельным выполнением серверная система 202 может дополнительно поддерживать вариант пессимистичного управления параллельным выполнением. В соответствии с этим в серверной системе 202 могут быть предусмотрены различные варианты управления параллельным выполнением, включающие в себя, но без ограничений, глобальное разрешение оптимистичного управления параллельным выполнением, глобальный запрет оптимистичного управления параллельным выполнением и разрешение оптимистичного управления параллельным выполнением для каждой таблицы. Глобальное разрешение оптимистичного управления параллельным выполнением позволяет ядру выполнять транзакции с данными в условиях оптимистичного управления параллельным выполнением для всех таблиц в пределах базы 222 данных. Глобальный запрет на оптимистичное управление параллельным выполнением инструктирует ядро выполнять транзакции с данными в условиях пессимистичного управления параллельным выполнением для всех таблиц в базе 222 данных. При обеспечении возможности оптимистичного управления параллельным выполнением для каждой таблицы отдельные таблицы в базе 222 данных конфигурируют так, что они могут работать с использованием специфичного способа управления параллельным выполнением. Например, все таблицы могут быть первоначально установлены так, что в них будет разрешено оптимистичное управление параллельным выполнением, и пользователи могут менять это значение от таблицы к таблице соответствующим образом.
Может быть предусмотрен переключатель глобального оптимистичного управления параллельным выполнением, который переключается между разрешением и запретом глобального оптимистичного управления параллельным выполнением и разрешением или запретом оптимистичного управления параллельным выполнением для каждой таблицы. Переключатель глобального оптимистичного управления параллельным выполнением может быть предусмотрен как флаг установки, сохраненный в базе 222 данных, который переключают между различными вариантами для поддержки управления параллельным выполнением. Серверная система 202 может проверять состояние глобального переключателя оптимистичного управления параллельным выполнением, когда серверную систему 202 активируют, и глобальные установки выбирают и сохраняют в памяти. Когда клиент активируют, вызов сеанса передает обратно значения переключателя в устройство - клиент, которое устанавливает эти значения локально. Для каждой таблицы оптимистичное управление параллельным выполнением добавляют к свойству таблицы, установленному во время работы, и предоставляемому в свойство дерева объекта приложения для таблиц. Для оптимистичного управления параллельным выполнением для каждой таблицы можно использовать неиспользуемый бит флага в хранилище метаданных, можно определять принятое по умолчанию значение в виде бита, равного "0", и в этом случае свойство оптимистичного управления параллельным выполнением для таблицы будет установлено как значение "true".
В некоторых случаях приложению может потребоваться исключение из описанных выше конфигураций. Например, может потребоваться запретить оптимистичное управление параллельным выполнением на уровне оператора для отдельных приложений, даже если для определенной таблицы будет установлено разрешение оптимистичного управления параллельным выполнением для большинства других приложений. Таким образом, ядро может вводить ключевые слова, такие как "pessimisticlock" и "optimisticlock", описанные ниже, в языке программирования для отмены ключей управления отдельной таблицы и глобального оптимистичного управления параллельным выполнением. Следующий пример воплощения в псевдокомпьютерном коде иллюстрирует пример администрирования пессимистичным управлением параллельным выполнением на уровне оператора, в случае, когда оптимистичное управление параллельным выполнением глобально разрешено (или разрешено на уровне таблицы), но для конкретного приложения требуется пессимистичная блокировка:

Ключевое слово "pessimisticlock" позволяет ядру не выполнять поиск идентификации версии "RecVersion", которая идентифицирует версию обновляемого элемента данных, отменяя, таким образом, оптимистичное управление параллельным выполнением и позволяя считывать элемент данных с необходимыми блокировками обновления, помещенными на место, в соответствии с пессимистичным управлением параллельным выполнением.
Следующий пример реализации в виде псевдокомпьютерного кода иллюстрирует альтернативный пример администрирования оптимистичным управлением параллельным выполнением на уровне операторов, когда оптимистичное управление параллельным выполнением глобально запрещено (или запрещено на уровне таблицы), но для конкретного приложения требуется оптимистичная блокировка:

Идентификация версии
Как отмечено выше, каждый элемент данных ассоциирован с идентификацией ("RecVersion") версии. Каждая таблица в базе 222 данных, в которой используется оптимистичное управление параллельным выполнением, включает в себя столбец, относящийся к идентификации версии. Когда формируют таблицу в базе 222 данных, уровень доступа к данным ядра добавляет столбец идентификации версии к определению таблицы. В случае, когда таблицы уже существуют в базе 222 данных без столбца идентификации версии, столбец идентификации версии может быть добавлен к существующим таблицам, и серверная система 202 автоматически генерирует значения идентификации версии для всех строк в таблице. Когда запись вставляют в таблицу, имеющую столбец идентификации версии, серверная система 202 автоматически генерирует новое значение идентификации версии для новой записи. Для всех операций записи, в которых используется оптимистичное управление параллельным выполнением, уровень доступа к данным ядра считывает значения идентификации версии для всех строк, выборку из которых производят, и размещает значения идентификации версии для последующей проверки совместимости элементов данных, для обнаружения конфликтов обновления. При обновлении элемента данных в пределах строки уровень доступа к данным ядра получает значение идентификации версии для этой строки во время первоначальной выборки из базы 222 данных и добавляет его к предикату оператора обновления. Если предикат оператора обновления не находит соответствие значения идентификации версии, обнаруживается конфликт обновления, и исключение конфликта обновления накладывают на приложение, которое пытается обработать этот конфликт. Если операция записи подразумевает удаление записи, которая была ранее считана, уровень доступа к данным ядра добавляет значение идентификации версии к предикатам оператора для определения, была ли ранее модифицирована удаляемая запись.
Новые значения идентификации версии, генерируемые для обновляемых данных, могут содержаться в доступе к данным ядра для поддержания семантики транзакции среди множества операций с данными. В результате новые значения идентификации версии могут генерироваться в серверной системе 202, а не в базе 222 данных.
В одном примере идентификация версии может представлять собой временную отметку сервера, которая уникально идентифицирует элемент данных. В другом примере идентификация версии может просто представлять собой последовательно увеличивающееся целое число. Однако, при преобразовании последовательной формы транзакций с данными в параллельную, для обеспечения максимального количества параллельных транзакций с данными, которые могут происходить, можно использовать не связанные с чтением уровни изоляции, которые позволяют выбирать и обновлять элементы данных при транзакциях с данными как в пределах, так и за пределами других транзакций с данными. Обычно уровень изоляции относится к степени, в которой транзакция должна быть изолирована от других транзакций. Однако для увеличения степени параллельного чтения используют не связанные уровни изоляции для получения преимущества, связанного с возможностью того, что не все транзакции с данными всегда будут требовать полной изоляции. В результате, может быть нарушена корректность данных без соответствующей идентификации версии. В любом из приведенных выше примеров идентификации данных существует вероятность того, что обновление в ходе предыдущей транзакции с данными может быть не правильно обнаружено, в результате чего происходит перезапись, как иллюстрируется в приведенной ниже таблице:
Как показано выше, первая транзакция с данными может считывать исходное значение V идентификации версии и обновлять элемент данных, в результате чего происходит обновление значения идентификации версии на V+1. Перед фиксацией операции записи первая транзакция с данными может отменить операцию записи, и значение идентификации версии будет повторно установлено равным V. Однако вторая транзакция с данными начинается с операции записи до отмены и считывает значение V+1 идентификации версии. Третья транзакция с данными начинается с операции записи после отмены, сохраняет значение V идентификации версии в памяти и фиксирует операцию записи перед тем, как вторая транзакция с данными фиксирует свою операцию записи. Следовательно, третья транзакция с данными также обновляет значение идентификации версии как V+1, поскольку значение V идентификации версии, сохраненное в памяти, соответствует значению V идентификации версии обновляемого элемента данных. Когда вторая транзакция с данными фиксирует свою операцию записи, значение V+1 идентификации версии, сохраненное в памяти, соответствует значению V+1 идентификации версии обновляемого элемента данных. В соответствии с этим, во второй транзакции с данными предполагают, что в ней выполняют обновление элемента данных на основе прерванного обновления первой транзакции с данными, и эффективно перезаписывают обновление с помощью третьей транзакции с данными.
Для получения этой возможности может быть предусмотрена идентификация версии как случайное число, которое уникально идентифицирует элемент данных для всех размещений сервера. В одном примере начальное число для случайного числа может быть основано на содержании самого элемента данных, что, таким образом, обеспечивает уникальность случайного числа для элемента данных с течением времени, пользователей и серверной системы 202, и каждая версия элемента данных после обновления будет иметь уникальное значение идентификации версии, ассоциированное с ним. В другом примере начальное число для случайного числа представляет собой случайное начальное число, используемое для генерирования случайного числа в алгоритме генерирования случайного числа.
При генерировании случайного числа можно использовать криптографический программный интерфейс приложения CryptGenRandom. Функция CryptGenRandom заполняет буфер криптографически случайными байтами, которые являются в большей степени случайными, чем обычные случайные классы. Мера неопределенности (то есть энтропия) может быть сгенерирована для функции CryptGenRandom из одного или больше следующих источников: поток в переключателях ядра, идентификатор текущего процесса, количество импульсов после начальной загрузки, текущее время, информации в памяти и статистика сохранения объекта. Функция CryptGenRandom может быть инициирована один раз, используя статический способ. Пример инициирования функции CryptGenRandom показан ниже. Используются CRYPT_NEWKEYSET|CRYPT_MACHINE_KEYSET, что позволяет обратиться к ключам для услуг. Хотя используется стиль комментариев C++ для описания инициирования, инициирование не ограничивается этим.


Кроме того, может быть добавлен способ использования CryptGenRandom для генерирования следующего значения идентификации версии RecVersion, для обеспечения генерирования функцией положительной идентификации версии. Новое значение идентификации версии может быть сгенерировано для каждого успешного обновления элемента данных, где транзакция с данными была фиксирована. Пример этой функции показан ниже.

Отмена пессимистичного блокирования
Как отмечено выше, может быть предусмотрен вариант между пессимистичным управлением параллельным выполнением и оптимистичным управлением параллельным выполнением, например, посредством переключателей глобального оптимистичного управления параллельным выполнением. Однако при обновлении элемента данных код приложения для приложения может включать триггеры, которые обновляют операторы, которые автоматически разрешают пессимистичное блокирование по умолчанию. Например, в программном коде X++ пессимистичное блокирование может быть инициировано с помощью подсказки forupdate в операторах SELECT и WHILE SELECT, и приложения, использующие подсказку forupdate, могут работать с предположением, что платформа серверной системы 202 поддерживает пессимистичное блокирование.
Для отмены пессимистичного блокирования, но с поддержанием обратной совместимости с приложениями, которые предполагают пессимистичное блокирование, оптимистичное управление параллельным выполнением может удалять, игнорировать или повторно интерпретировать триггер в операторах обновления для отмены пессимистичного блокирования во время оптимистичного управления параллельным выполнением. Например, триггер может быть повторно интерпретирован в контексте каждого оператора, каждой таблицы и глобальных переключателей оптимистичного управления параллельным выполнением. Более конкретно, триггер может не приводить к сохранению блокировки обновления в базе данных. Вместо этого триггер может устанавливать намерение приложения. Например, триггер может устанавливать, представляет ли собой намерение просто операцию считывания, или состоит ли намерение в использовании операции считывания для обновления в будущем. На основе переключателей уровень доступа к данным ядра может определять, следует ли поддержать (пессимистичное) блокирование обновления, или следует ли выполнить (оптимистичную) выборку идентификации версии для строки. В другом примере, при программировании X++, база данных вырабатывает подсказку для получения удаления блокировки обновления базы данных из операторов SELECT и WHILE SELECT, не изменяя код приложения для пессимистичного блокирования. Пример отключения пессимистичного блокирования показан ниже, путем удаления подсказки базы данных из операторов SELECT и WHILE SELECT:


На фиг.4 показан пример подпрограммы оптимистичного управления параллельным выполнением 300, которая может выполняться в серверной системе 202 и, в частности, на уровне доступа к данным ядра для ядра серверной системы 202, для отмены пессимистичного блокирования во время операции записи, для обновления элемента данных в таблице, когда оптимистичное управление параллельным выполнением было разрешено для таблицы (глобально или для отдельной таблицы). Как отмечено выше, каждому запросу на запись предшествует запрос на считывание. Независимо от того, какие бы элементы данных не были считаны в режиме оптимистичного управления параллельным выполнением, уровень доступа к данным ядра считывает значения идентификации версии для всех соответствующих рядов, из которых он делает выборки, и сохраняет их для будущего использования, такого как, когда выполняют обновление для элементов данных строк, из которых были сделаны выборки. После запроса на считывание блокировки не поддерживают до тех пор, пока не поступит запрос на запись для обновления элемента данных. В описанных здесь технологиях оптимистичного управления параллельным выполнением при обновлении элемента данных (то есть строки таблицы), уровень доступа к данным ядра получает значение идентификации версии для соответствующей строки, из которой была выполнена выборка для базы данных во время операции считывания, и добавляется значение идентификации версии к предикатам оператора обновления для того, чтобы посмотреть, был ли модифицирован элемент данных. Если обновление подразумевает в себя удаление элемента данных, который был считан ранее, уровень доступа к данным ядра добавляет значение идентификации версии к предикатам оператора обновления с тем, чтобы можно было видеть, был ли модифицирован удаляемый элемент данных. Уровень доступа к данным ядра запрашивает базу 222 данных, чтобы выяснить, изменили ли какие-либо другие транзакции с данными обновляемый элемент данных после его считывания. Если обнаруживается конфликт обновления, отбрасывают исключение UpdateConflict. Как будет описано дополнительно ниже, вместо немедленного прерывания транзакции с данными, когда отбрасывают исключение UpdateConflict, исключение может быть обработано в пределах транзакции с данными.
Как показано на фиг.4, начинаясь в блоке 302, подпрограмма 300 оптимистичного управления параллельным выполнением принимает запрос на считывание из приложения во время транзакции с данными. Если запрос на считывание не относится к операции считывания с намерением обновления строки, такой как "forupdate", "pessimisticlock", или "optimistic lock", как определено в блоке 304, любые последующие запросы обновления, принятые в блоке 306, могут не быть разрешены в блоке 308, и транзакция может быть прекращена. Если запрос на считывание относится к операции считывания, которая имеет намерение обновить строку, подпрограмма 300 может определять, следует ли применять оптимистичное управление параллельным выполнением, например, путем определения, было ли разрешено оптимистичное управление параллельным выполнением для таблицы, в блоке 310. Подпрограмма 300 дополнительно определяет, в блоке 310, будет ли возвращена идентификация версии, и будет ли она использоваться для обновления.
Для определения, требуется ли оптимистичное управление параллельным выполнением, как определяется в блоке 310, в уровне доступа к данным ядра может быть предусмотрено централизованное хранилище для расчетов определения, следует ли применять оптимистичное управление параллельным выполнением, и следует ли получить идентификацию версии. Такие расчеты могут быть выполнены только один раз для объекта данных, например элемента данных, строки, таблицы или т.п. В одном примере такое определение может быть выполнено с помощью схемы, которая проверяет, требуется ли проверять идентификацию версии для строки, используя RecVersion, для обновления и удаления. Проверка идентификации версии может не потребоваться или может не использоваться в одной или больше следующих ситуациях: когда RecVersion не считывают для операции установки строки, если таблица или строка специально помечены как требующие сравнения столбца, которое будет дополнительно описано ниже, или если обновление представляет собой относительное обновление, которое также дополнительно описано ниже. Ниже показан пример такой схемы, SqlStmt::IsRecVersionCheckNeededForupdate, которая определяет, следует ли использовать проверку RecVersion для обновления, и которая дополнительно требует, чтобы оптимистичное управление параллельным выполнением было разрешено для таблицы. Значение "TRUE" возвращают, если проверка RecVersion должна использоваться.


В качестве альтернативы, или совместно со схемой SqlStmt::IsRecVersionCheckNeededForupdate, определение в блоке 312 может быть дополнительно выполнено с помощью схемы, которая проверяет, следует ли использовать какую-либо форму обнаружения конфликта обновления. Например, обнаружение конфликта обновления используют, если идентификация версии необходима для обновления или если указано повторное считывание для обновления. Флаг повторного считывания означает, что данные были первоначально выбраны по формам, и оптимистичное управление параллельным выполнением следует использовать независимо от других установок. Если оптимистичное управление параллельным выполнением запрещено, тогда можно использовать обнаружение конфликта обновления только для форм. В формах, и также в отчетах используются запросы на выборку данных, где источник данных закреплен на объекте запроса, и свойство обновления определяет, разрешен ли запрос для обновления элементов данных в базе данных. С другой стороны, если разрешено оптимистичное управление параллельным выполнением, тогда обнаружение конфликта обновления может использовать идентификацию версии или сравнение столбца. Ниже показан пример такой схемы, SqlStmt:: IsUpdateConflictDetectionNeededForupdate, который проверяет, следует ли использовать для обновления какую-нибудь форму обнаружения конфликта обновления, например, проверку RecVersion или сравнение столбца. Значение "TRUE" возвращают, если должна использоваться какая-нибудь форма обнаружения конфликта обновления.


Рассмотрим снова блок 310 по фиг.4, если оптимистичное управление параллельным выполнением не будет использоваться во время обновления, что может быть определено, используя схему примера, предусмотренную выше, идентификацию версии не получают, и блокировку обновления содержат в базе данных для строки, обновляемой в блоке 312. В блоке 314 может быть получен запрос на обновление, и в блоке 316 выполняют фактическую запись и/или обновление элемента данных, которое может включать себя запись новых данных в строку, удаление элемента данных или т.п. Транзакцию с данными фиксируют в блоке 318, и блокировку обновления высвобождают в блоке 320. Если оптимистичное управление параллельным выполнением будет включено для таблицы и его требуется использовать во время обновления, как определено в блоке 310, идентификацию версии получают из базы данных в блоке 322, запрос на обновление принимают в блоке 324 и идентификацию версии используют для обнаружения конфликта обновления с использованием процедуры 326 обнаружения обновления конфликтов. Следует отметить, что блокировка обновления не реализуется и не содержится для базы данных в блоке 322.
Обнаружение конфликтов обновления
На фиг.5 показан пример подпрограммы 326 обнаружения обновления конфликтов, которая может выполняться серверной системой 202, и, в частности, уровнем доступа к данным ядра серверной системы 202 для обнаружения, возникли ли какие-либо конфликты при обновлении элемента данных. Другими словами, подпрограмма 326 обнаружения обновления конфликтов может определять, изменился ли элемент данных в результате другой транзакции с данными между первоначальной выборкой элемента данных и обновлением. Подпрограмма 326 обнаружения конфликтов обновления может обнаружить любые такие изменения и отбрасывать исключение из уровня доступа к данным ядра для кода приложения.
Начинаясь в блоке 402, подпрограмма обнаружения конфликтов обновления 326 первоначально может проверить, имеется ли потребность выполнить проверку идентификации версии (проверка RecVersion) или сравнение столбца. Например, сравнение столбца можно использовать, если приложение просто модифицирует существующий элемент данных. Сравнение столбца можно использовать для обратной совместимости, или если этого требует логика приложения. С другой стороны, проверка идентификации версии может использоваться для всех форм обновления, например модификации данных или удаления элемента данных. Ниже приведен пример схемы, SqlStmt:: AddOccExpressionNodes, которая вначале проверяет, требуется ли проверка идентификации версии или сравнение столбца (например, если строка была заблокирована после чтения, не требуется ни того, ни другого), и затем переключается на использование либо идентификации версии, или сравнения столбца, если это необходимо. Полученные в результате узлы выражения BuildUpdateConflictDetectionExpressionNode для выполнения сравнения столбца и BuildRecVersonExpressionNode для выполнения проверки идентификации версии возвращают, если следует использовать какую-либо форму обнаружения конфликта обновления.


Возвращаясь снова к фиг.5, если требуется выполнить сравнение столбца, как определено в блоке 402, подпрограмма 326 может перейти к сравнению столбцов в блоке 404. В частности, серверная система 202 может запросить базу данных выполнить сравнение. В одном примере оператор обновления, использующий сравнение столбца, может выглядеть следующим образом:
Update table 1 set fieldl = new fieldl Value where RecID = myRecID and fieldl = fieldl OldValue
Ниже приведен пример схемы, SqlStmt::BuildUpdateConflictDetectionExpressionNode, который строит и возвращает уведомление выражения для обнаружения конфликта обновления, используя сравнение столбца. В частности, следует отметить, что в этом конкретном примере обнаружения конфликта обновления идентификация версии не используется.


Если подпрограмма 326 определяет, что требуется выполнить проверку идентификации версии, идентификацию версии добавляют к предикату оператора обновления в блоке 406 для определения, был ли модифицирован элемент данных между выборкой и обновлением. В блоке 408 идентификацию версии выбранного элемента данных получают и сравнивают с идентификацией версии обновляемого элемента данных. Следует отметить, что если сравнение идентификации версии требуется выполнить с помощью базы 222 данных, серверной системе 222 не требуется делать выборку идентификации версии от имени базы 222 данных. Поскольку идентификации версии являются уникальными для версии элемента данных, любое различие между идентификацией версии выбранного элемента данных и идентификацией версии обновляемого элемента данных, обнаруживаемое в блоке 410, приводит к отбрасыванию исключения в блоке 412. В одном примере исключение может быть отброшено из уровня доступа к данным ядра в код приложения, который генерировал оператор обновления. В блоке 412 структурированная подпрограмма исключения может быть выполнена как дополнительно описано ниже, и исключение конфликта обновления может быть обработано с помощью подпрограммы в блоке 414.
С другой стороны, если отсутствует различие в идентификациях версии, как определено в блоке 410, фактическое обновление элемента данных выполняют в блоке 416, который может включать в себя запись новых данных в элемент данных, удаление элемента данных или т.п. После обновления данных в блоке 416 поддерживают блокировку записи (также называемую исключительной блокировкой). В блоке 418 транзакцию с данными фиксируют, и блокировку записи отключают в блоке 420.
Структурированные исключения
На фиг.6 показан пример подпрограммы 500 структурированного исключения, которая может выполняться в блоке 322 всякий раз, когда происходит отброс исключения конфликта обновления. В частности, подпрограмма 500 структурированного исключения демонстрирует пример поддержки во время работы обработки структурированного исключения. Как обозначено выше, во время работы обнаруживают ошибку конфликта обновления с помощью уровня доступа к данным ядра, и выполняют отброс исключения конфликта обновления. Логическая структура обработки и структурированного исключения может захватывать конфликт обновления, в котором выполняют блокировку захвата только, когда происходит конфликт обновления, по таблице, указанной в логической структуре. В качестве сравнения, в логической структуре обработки не структурированного исключения блок захвата может исполняться всякий раз, когда происходит исключение конфликта обновления внутри блока попытки.
Начинаясь в блоке 502, ядро доступа к данным может отслеживать элемент таблицы, в котором произошло исключение конфликта обновления. Ядро может поддерживать представление ядра для элемента таблицы, в котором произошел конфликт обновления. В языке программирования C++ представление может быть названо как cqlCursor. В языке программирования X++ в качестве представления может использоваться любая переменная, которая представляет таблицу. В частности, ядро может установить представление ядра, cqlCursor, в свойстве таблицы, которое может называться свойством LastUpdateConflictingTable, таким образом, что ядро имеет информацию, в какой таблице возникло исключение конфликта обновления. В одном примере эта функция может выполняться со следующей схемой, cqlDatasourceSql:: RaiseUpdateConflitError, пример которой приведен ниже, в результате которой возникает специфичное обозначение ошибки конфликта обновления, и возвращает целое число, обозначающее код ошибки, определяющий исключение конфликта обновления.


В блоке 504 подпрограмма 500 информирует пользователя или клиента об исключении конфликта обновления. В частности, подпрограмма 500 устанавливает свойство таблицы LastUpdateConflictingTable через вызов сервера/клиента для правильной установки свойства таблицы на стороне клиента, всякий раз, когда осуществляют вызов через границу сервер/клиент. Клиент поддерживает свойство локальной таблицы. При этом любая таблица, в отношении которой возникло исключение UpdateConflict, должна иметь локальную ссылку на сторону клиента для таблицы. Таким образом, всякий раз, когда серверная система 202 собирается возвратить вызов клиенту, он проверяет, существует ли исключение UpdateConflict, и передает ссылку обратно клиенту. Клиент видит, что существует исключение UpdateConflict, считывает ссылку, проверяет эту ссылку локально и интерпретирует эту ссылку. В частности, клиент может проверить тип исключения и локальную ссылку, прекратить ссылаться на нее и установить ссылку по свойству таблицы.
В блоке 506 подпрограмма 500 структурированного исключения представляет экземпляр таблицы, который привел к исключению UpdateConflict. Например, свойство LastUpdateConflictingTable может быть предоставлено в код приложения по классу приложения. В блоке 508 выполняемая во время работы функция позволяет выполнять обработку структурированного исключения. Например, байтовый код можно использовать как индекс для таблицы указателя функции. Функция может быть добавлена к классу пояснений и отображается на байтовый код для обработки структурированного исключения для конфликта обновления. Во время работы функцию вызывают и проверяют как тип исключения, так и таблицу, в которой возник конфликт обновления. Функция затем устанавливает следующую инструкцию для блока захвата только, когда они оба соответствуют друг другу. Управление затем может быть передано подпрограмме 414 обработки конфликтов обновления.
Обработка исключений конфликта обновления
На фиг.7 показан пример подпрограммы 414 обработки конфликтов обновления, схематично показанной на фиг.5 и 6, которая может выполняться для обработки любых исключений конфликта обновления, UpdateConflict, который может возникнуть во время подпрограммы 322 обнаружения конфликта обновления. В частности, и как обозначено выше, обработка исключений конфликта обновления, UpdateConflict, может выполняться во время транзакции с данными, а не автоматически с прекращением транзакции с данными, когда возникает исключение. Подпрограмма 600 обработки конфликтов обновления позволяет коду приложения повторно считать данные, повторно использовать логику обновления и снова попытаться выполнить обновление. Хотя подпрограмма 414 обработки конфликтов обновления, описанная ниже, представляет собой примерное представление компенсации исключения UpdateConflict, следует понимать, что можно использовать разные формы логики компенсации.
Обычно оператор обновления поддерживают в пределах блоков "попытки" таким образом, что любое исключение, которое возникает в блоке попытки, захватывают в блоке "захвата". В некоторых случаях блоки попытки вложены в другие блоки попытки, в результате чего формируется множество уровней блоков попытки. Подпрограмма 414 обработки конфликтов обновления обеспечивает возможность обработки исключения UpdateConflict внутри транзакции с данными и задерживает прерывание транзакции с данными путем попытки повторного считывания и повторной попытки транзакции с данными в пределах блока захвата каждого уровня блока попытки, перед переводом выполнения обработки обратно к следующему уровню блока попытки, и повторного захвата исключения UpdateConflict в пределах другого блока захвата. Код приложения может выполнять это всякий раз, когда выполняют захват и обработку исключения конфликта. Более конкретно, приложение может удостоверяться, что данные в базе данных и состояние объектов в памяти находятся в связном состоянии. Транзакция данных может быть прервана только при достижении самого внешнего уровня блока попытки и после выполнения соответствующего блока захвата, или когда уровень транзакций достигает "0".
Для реализации подпрограммы 414 уровень блока попытки можно отслеживать путем последовательного приращения и последовательного уменьшения величины подсчета уровня попытки, tryLevelCount, по мере того, как транзакция входит в каждый блок попытки и выходит из него. Величина подсчета уровня попытки может использоваться серверной системой 202 совместно с клиентом. Пример реализации в псевдокомпьютерном коде отслеживания уровня блока попытки по мере того, как транзакция данных входит в блок попытки и выходит из него, может быть представлен в следующем виде:
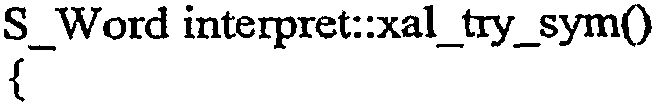

Кроме того, для вложенных блоков уровней попытки в некоторых случаях код приложения может быть завернут в другой код приложения. В результате, транзакция данных может быть вложена в другие транзакции с данными. Для изящной обработки логики компенсации или для обработки подпрограммы 414 конфликтов обновления исключение UpdateConfiict может быть просто отброшено на самую внешнюю транзакцию с данными, поскольку вся транзакция данных была возвращена назад. Пример реализации с использованием псевдокомпьютерного кода для обеспечения исключения возможности обработки самой внешней транзакции UpdateConfiict может быть представлен следующим образом:

Как видно из приведенного выше примера, обеспечивается поддержка вложенных блоков попытки. Вместо прекращения транзакции с данными, когда возник конфликт обновления, вложенный блок ttsbegin и блок ttscommit могут привести к увеличению уровня вложения без начала или фиксации новых транзакций с данными. Скорее, он включен как часть внешней транзакции. Транзакции начинают и фиксируют с помощью самого внешнего уровня вложения, но могут быть прекращены в любом месте во вложении. Если конфликт обновления возникает внутри блока попытки, обращаются к уровню вложения транзакции, когда код вошел в блок попытки. Транзакцию прекращают, если этот уровень равен 0. Может возникнуть конфликт обновления, который можно захватить, используя логическую структуру обработки структурированного исключения, когда блок захвата выполняют только, когда конфликт происходит в указанной таблице, или можно захватить, используя логическую структуру обработки неструктурированного исключения, когда блок захвата выполняют всякий раз, когда конфликт возникает внутри блока попытки. Это механизм, который может использовать код приложения для того, чтобы определить, какая таблица стала источником конфликта.
Рассмотрим снова фиг.7, начало в блоке 602, после того, как только было отброшено исключение UpdateConflict, транзакция данных входит в блок захвата. В блоке 604 подпрограмма 414 обработки обновления конфликтов определяет, находится ли транзакция данных в пределах блока попытки путем проверки величины подсчета уровня попытки. Например, если величина подсчета уровня попытки имеет нулевое значение, транзакция данных больше не находится в пределах блока попытки и может быть прекращена в блоке 606. Если транзакция данных находится в пределах блока попытки, код приложения может попытаться повторно считать и попытаться повторно выполнить транзакции с данными. В частности, блок захвата может сделать попытку заданного количества повторных считываний и повторных попыток прежде, чем исключение будет отброшено обратно на следующий уровень блока попытки. Таким образом, в блоке 608 подпрограмма 414 обработки конфликтов обновления определяет, превысило ли количество повторных попыток заданный предел. Если это так, подпрограмма 414 отбрасывает исключение обратно на следующий уровень блока попытки, в блоке 610.
С другой стороны, если количество повторных попыток не превысило заданный уровень, подпрограмма 414 может повторно считать строку и повторно попытаться выполнить транзакцию с данными в блоке захвата в блоке 612, без возвращения назад или немедленного прерывания транзакции с данными. Если исключение UpdateConflict успешно обрабатывается, как определено в блоке 614, соответствующая регистрационная запись информации в отношении исключения UpdateConflict может быть отброшена в блоке 616, и транзакция данных может быть зафиксирована. Исключение UpdateConflict может успешно обрабатываться, например, путем повторного считывания данных из базы данных и повторной попытки обновления. В таком случае блокировку обновления не содержат в базе данных, но приложение может выбрать переключение на пессимистичную блокировку в коде обработки, и в этом случае блокировка обновления поддерживается через считывание и обновление исключительной блокировки после обновления. Если исключение UpdateConflict не было успешно обработано, величина подсчета повторных попыток может быть увеличена на единицу, и управление может быть передано обратно в блок 608.
Пример реализации с использованием псевдокомпьютерного кода обработки исключения UpdateConflict может быть представлен в следующем виде. В следующем примере уровень захвата попытки представляет собой единицу, и разрешено не более чем пять повторных попыток.

Пример реализации с использованием псевдокомпьютерного кода обработки исключения UpdateConflict с множеством обновлений может быть представлен в следующем виде. Как демонстрируется псевдокомпьютерным кодом, конфликт обновления, с которым столкнулось первое приложение, приводит к прекращению транзакций с данными, что диктуется кодом приложения. С другой стороны, конфликт обновления, с которым столкнулось второе приложение, приводит к повторной попытке.

В примере псевдокомпьютерного кода, представленном выше для обработки исключения UpdateConflict с множеством обновлений, используют механизм обработки структурированного исключения. В качестве альтернативы, ниже приведен псевдокомпьютерный код для неструктурированной обработки исключения UpdateConflict с множеством обновлений. И снова, первое приложение приводит к прерыванию транзакции с данными, тогда как второе приложение пытается повторно выполнить транзакцию с данными.


Относительное обновление
Как отмечено выше, в некоторых случаях обновление может относиться к относительному обновлению, и в этом случае не используют проверку идентификации версии. Тем не менее, относительные обновления могут использоваться для уменьшения конфликтов обновления и могут быть особенно полезными для вещественных и целочисленных типов полей. Если обновление элемента данных является относительным, в отличие от абсолютного, это обновление выполняют в следующей форме: таблица 1 обновления устанавливает field1=field1+изменение, тогда как абсолютное обновление может быть выполнено следующим образом: таблица 1 обновления устанавливает field1=finalValue. Например, две одновременные транзакции с данными каждая может пытаться уменьшить значение поля на "два", где поле имеет исходное значение "восемь", в отличие от указания нового значения для поля. Уменьшение при относительном обновлении приводит к уменьшению исходного значения на два в ответ на первую транзакцию с данными и уменьшает новое значение на два снова в ответ на вторую транзакцию с данными с получением конечного значения "четыре". Преимущество относительного обновления состоит в том, что относительное обновление не переписывает другое изменение пользователя, даже если изменение происходит между считанным и обновленным значением, поскольку свойство формата относительного обновления делает его устойчивым к другому изменению пользователя. В соответствии с этим, если все поля обновляют, используя относительное обновление, может быть исключена проверка идентификации версии. Для реализации относительных обновлений поля обновления могут быть помечены как использующие относительное обновление.
На фиг.8 показан пример подпрограммы 700 относительного обновления, которую можно использовать для выполнения относительных обновлений элемента данных. Начинаясь в блоке 702, подпрограмма 700 относительного обновления определяет, вызывает ли обновление относительное обновление, и/или помечено ли обновляемое поле, как использующее относительное обновление. Если обновление не является относительным обновлением, управление может снова обратиться к подпрограмме 300 оптимистичного управления параллельным выполнением. Пример псевдокомпьютерного кода представлен ниже для определения, можно ли использовать относительное обновление. Как упомянуто выше, поскольку идентификация версии не используется, поля, ассоциированные с идентификацией версии, игнорируют.

Семантику транзакции следует поддерживать, когда можно поддерживать потенциальное множество ссылок на одну и ту же строку в таблице, и множество операций могут быть выполнены по множеству ссылок. Когда выполняют обновление, идентификацию версии по переменным, содержащим ссылки на одну и ту же обновляемую строку, обновляют, как если бы они были считаны в одной транзакции. В дополнение к столбцу RecVersion могут быть добавлены два других столбца: TransactionRecVersiona и OriginalRecVersion, где уникальный TransactionRecVersion генерируют для каждой новой транзакции, и когда первое обновление внутри этой транзакции касается строки, TransactionRecVersion обновляют, используя новую, только что сгенерированную TransactionRecVersion и старую TransactionRecVersion назначают OrignalRecVersion. Обновление разрешается выполнять, если TransactionRecVersion соответствует текущей транзакции и OrignalRecVersion соответствует RecVersion, содержащейся в памяти (что означает, что эта строка принадлежит транзакции), или если RecVersion соответствует RecVersion, содержащейся в памяти. Всякий раз, когда выполняют обновление, RecVersion может быть обновлена.
Как и при любом обновлении, подпрограмма 700 может обновлять идентификацию значения для обновленного поля. Однако поскольку подпрограмма 700 относительного обновления не проверяет идентификацию значения, существует возможность того, что обновление может заместить другое обновление транзакции с данными, если идентификация значения обновляется с новым значением, используя технологии, описанные выше, как представлено в приведенной ниже таблице:
Как представлено выше, первая транзакция с данными может считывать исходное значение V идентификации версии и обновлять элемент данных, обеспечивая, таким образом, обновление значения идентификации версии в V1. Однако вторая транзакция с данными начинает операцию записи перед обновлением и выполняет два обновления, при этом первое обновление представляет собой относительное обновление, и последующее второе обновление представляет собой абсолютное обновление. Первое обновление второй транзакции с данными не проверяет значение V1 идентификации версии, поскольку это обновление представляет собой относительное обновление. Тем не менее, первое обновление предусматривает новое значение V2 идентификации версии. Второе обновление во второй транзакции с данными получает значение V2 идентификации версии во время считывания, использует значение V2 идентификации версии после обновления, обновляет элемент данных и успешно фиксирует транзакцию с данными, поскольку значение V2 идентификации версии во время обновления соответствует значению V2 идентификации версии, первоначально считанному перед вторым обновлением. В результате, вторая транзакция с данными может перезаписывать изменения, выполненные первой транзакцией с данными.
Для обеспечения такой возможности новую идентификацию версии рассчитывают как относительную идентификацию версии, когда обновление выполняют как относительное обновление. В частности, подпрограмма 700 рассчитывает новое значение для идентификации версии в том виде, как предоставлено выше в блоке 704. В блоке 706 подпрограмма 700 относительного обновления рассчитывает разность между новой идентификацией версии и старой идентификацией версии и вырабатывает обновление для установки идентификации версии для обновленного элемента данных как значение идентификации версии плюс разность, которое может быть выражено, как " Update... set RecVersion = RecVersion + delta", в блоке 708. Это обновление выполняют в блоке 710. Таким образом, для всех ссылок на одну и ту же строку, которая была считана внутри одной и той же транзакции, идентификацию версии обновляют, используя также разность. Если никакая другая транзакция не обновляет строку, значение идентификации версии в базе данных соответствует значению идентификации версии всех ссылок в памяти, которые были считаны в одной и той же транзакции с одинаковым исходным значением идентификации версии, и будущее обновление продолжают для этих строк. С другой стороны, если бы строка была обновлена некоторой другой транзакцией перед тем, как было выполнено относительное обновление, то идентификации версии не соответствовали бы друг другу, и любые будущие обновления привели бы к исключению UpdateConflict.
Зависимости между таблицами
В некоторых случаях значения в некоторых столбцах в пределах таблицы (например, таблицы A) могут быть рассчитаны на основе значений в некоторых столбцах другой таблицы (например, в таблице B). Например, обновление до элемента данных в таблице A может первоначально считывать значение из таблицы B, но перед обновлением элемента данных в таблице А другой пользователь обновляет значение таблицы B. В результате, последующее обновление до элемента данных в таблице A будет основано на устаревшем значении из таблицы B.
Для обеспечения такой совместимости значений, по причине зависимости между таблицами, уровень доступа к данным ядра может передавать повторяемую подсказку на считывание для кода приложения. Повторяемую подсказку на считывание переводят в повторяемую подсказку блокирования считывания RepeatableRead для серверной системы 202, которая поддерживает совместное использование блокирования в отношении выбираемых данных пока не закончатся транзакции с данными. Повторяемую подсказку блокирования считывания применяют только к определенному оператору считывания, а не ко всей транзакции с данными. В отсутствие повторяемой подсказки блокирования считывания совместное использование блокирования высвобождают сразу после операции считывания. Это может предотвратить обновление строки другими пользователями до тех пор, пока транзакция с данными не будет зафиксирована. Совместно используемые блокирования являются совместимыми друг с другом таким образом, что множество пользователей, у которых работает тот же сценарий, не будут блокированы друг от друга.
На фиг.9 показан пример подпрограммы 800 зависимости между таблицами, которую можно использовать для обновленного элемента данных, зависимого от значения из другой таблицы. В блоке 802 подпрограмма 800 может принимать повторяемую подсказку на считывания из кода приложения, которую переводят в повторяемую подсказку блокирования считывания в серверную систему 202. В отсутствие повторяемой подсказки на считывание совместное использование блокирования высвобождают непосредственно после операции считывания в блоке 804, и транзакцию фиксируют. Если повторяемая подсказка на считывание предусмотрена, совместно используемое блокирование как для таблицы A, так и для таблицы B, для выбираемых данных предусмотрено в блоке 806 в течение длительности транзакции с данными для предотвращения обновления элемента данных другими пользователями до тех пор, пока транзакция не будет зафиксирована. Элемент данных выбирают из таблицы B в блоке 808. В блоке 810 элемент данных для таблицы A рассчитывают на основе обновленного элемента данных из таблицы B и обновляют в блоке 812. В блоке 814 совместное использование блокирования высвобождают, и транзакцию с данными фиксируют.
Хотя в приведенном выше тексте представлено подробное описание множества разных вариантов осуществления изобретения, следует понимать, что объем изобретения определен формулой изобретения, представленной в конце настоящего патента. Подробное описание изобретения следует рассматривать только как пример, а не как описание каждого возможного варианта осуществления изобретения, поскольку описание каждого возможного варианта осуществления было бы непрактичным, если вообще невозможным. Различные альтернативные варианты осуществления могут быть реализованы, используя либо современную технологию, либо технологию, которая будет разработана после даты подачи данного патента, которая все еще будет находиться в пределах объема формулы изобретения, определяющей изобретение.
Таким образом, множество модификаций и вариантов могут быть выполнены для технологий и структур, описанных и иллюстрируемых здесь, без выхода за пределы сущности и объема настоящего изобретения. В соответствии с этим следует понимать, что описанные здесь способы и устройство представляют собой только иллюстрацию и не ограничивают объем изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИНХРОНИЗАЦИЯ СТРУКТУРИРОВАННОГО СОДЕРЖИМОГО ВЕБ-УЗЛОВ | 2007 |
|
RU2432608C2 |
| РАСШИРЕНИЕ СОГЛАСУЮЩЕГО ПРОТОКОЛА ДЛЯ ИНДИКАЦИИ СОСТОЯНИЯ ТРАНЗАКЦИИ | 2015 |
|
RU2665306C2 |
| ФАЙЛОВАЯ СЛУЖБА, ИСПОЛЬЗУЮЩАЯ ИНТЕРФЕЙС СОВМЕСТНОГО ФАЙЛОВОГО ДОСТУПА И ПЕРЕДАЧИ СОСТОЯНИЯ ПРЕДСТАВЛЕНИЯ | 2015 |
|
RU2686594C2 |
| СПОСОБ И СИСТЕМА ДЛЯ УПРАВЛЕНИЯ ВЫПОЛНЕНИЕМ ВНУТРИ ВЫЧИСЛИТЕЛЬНОЙ СРЕДЫ | 2012 |
|
RU2577487C2 |
| ФИЛЬТРАЦИЯ ПРОГРАММНОГО ПРЕРЫВАНИЯ В ТРАНЗАКЦИОННОМ ВЫПОЛНЕНИИ | 2012 |
|
RU2568923C2 |
| МЕХАНИЗМ ЗАПРОСА ПОЗДНЕЙ БЛОКИРОВКИ ДЛЯ ПРОПУСКА АППАРАТНОЙ БЛОКИРОВКИ (HLE) | 2008 |
|
RU2501071C2 |
| КЛОНИРОВАНИЕ И УПРАВЛЕНИЕ ФРАГМЕНТАМИ БАЗЫ ДАННЫХ | 2006 |
|
RU2417426C2 |
| АРХИТЕКТУРА ОТОБРАЖЕНИЯ С ПОДДЕРЖАНИЕМ ИНКРЕМЕНТНОГО ПРЕДСТАВЛЕНИЯ | 2007 |
|
RU2441273C2 |
| БЛОК ДИАГНОСТИКИ ТРАНЗАКЦИЙ | 2012 |
|
RU2571397C2 |
| СОХРАНЕНИЕ/ВОССТАНОВЛЕНИЕ ВЫБРАННЫХ РЕГИСТРОВ ПРИ ТРАНЗАКЦИОННОЙ ОБРАБОТКЕ | 2012 |
|
RU2562424C2 |
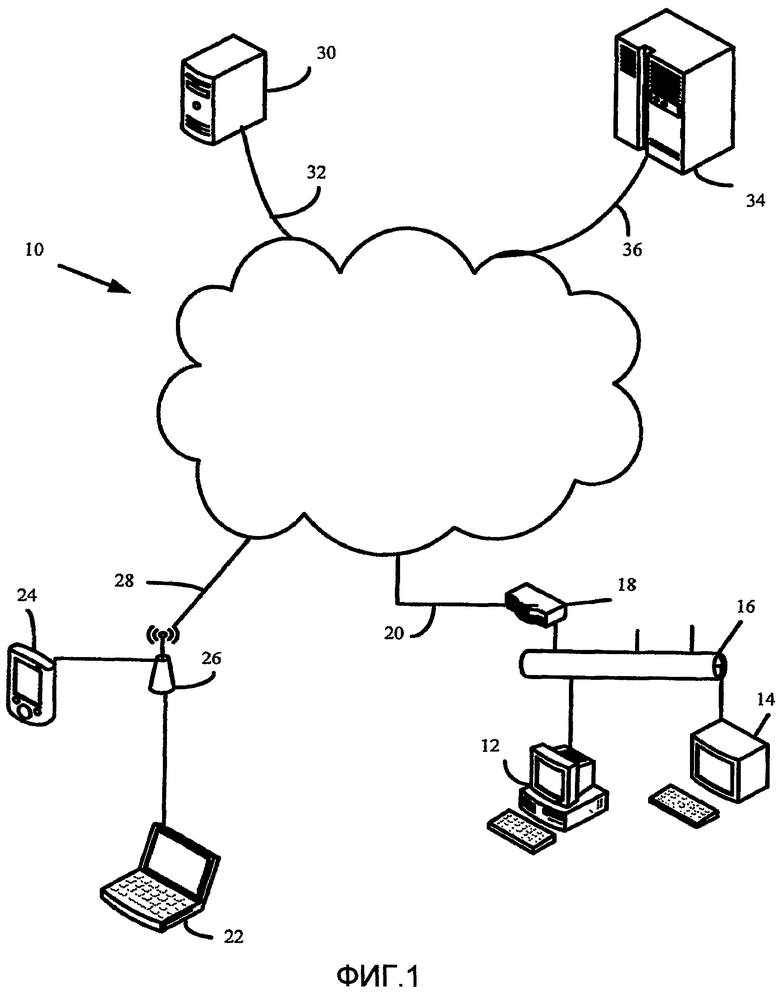
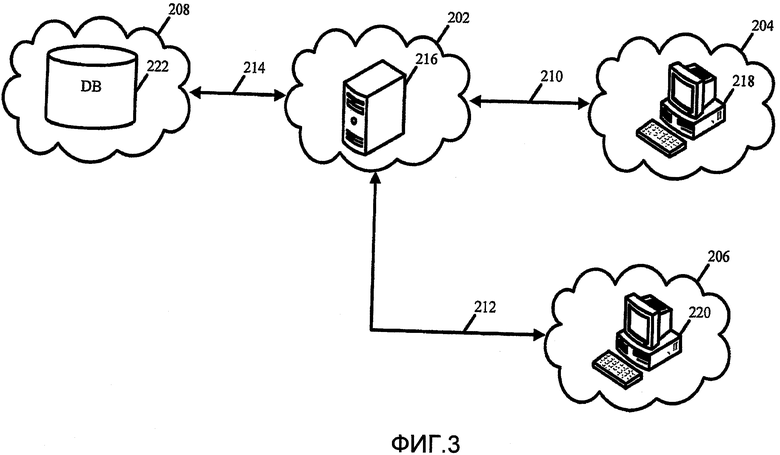
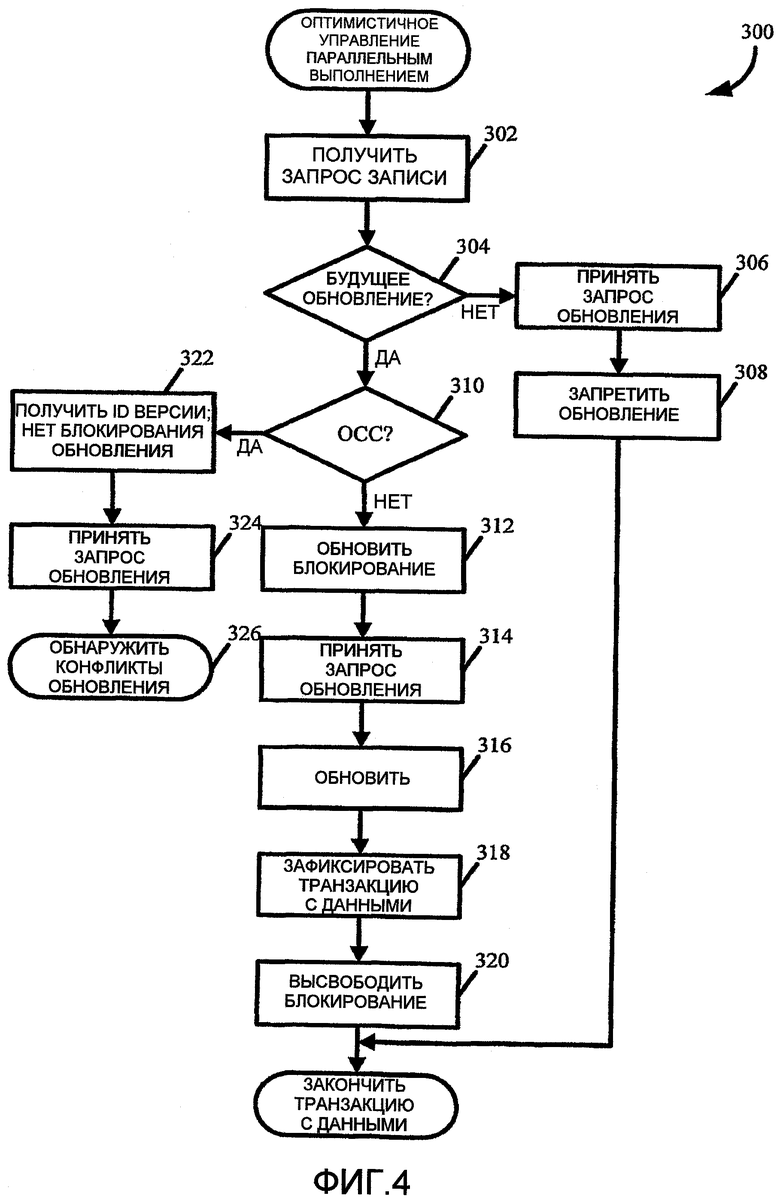
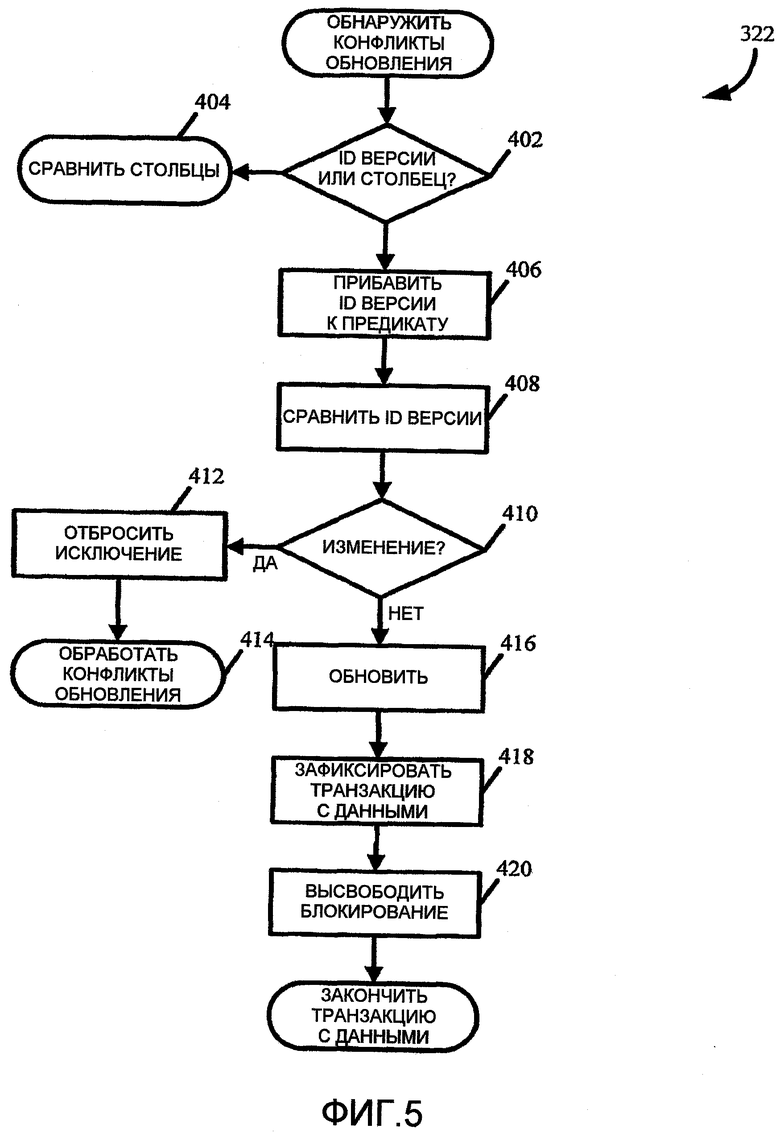
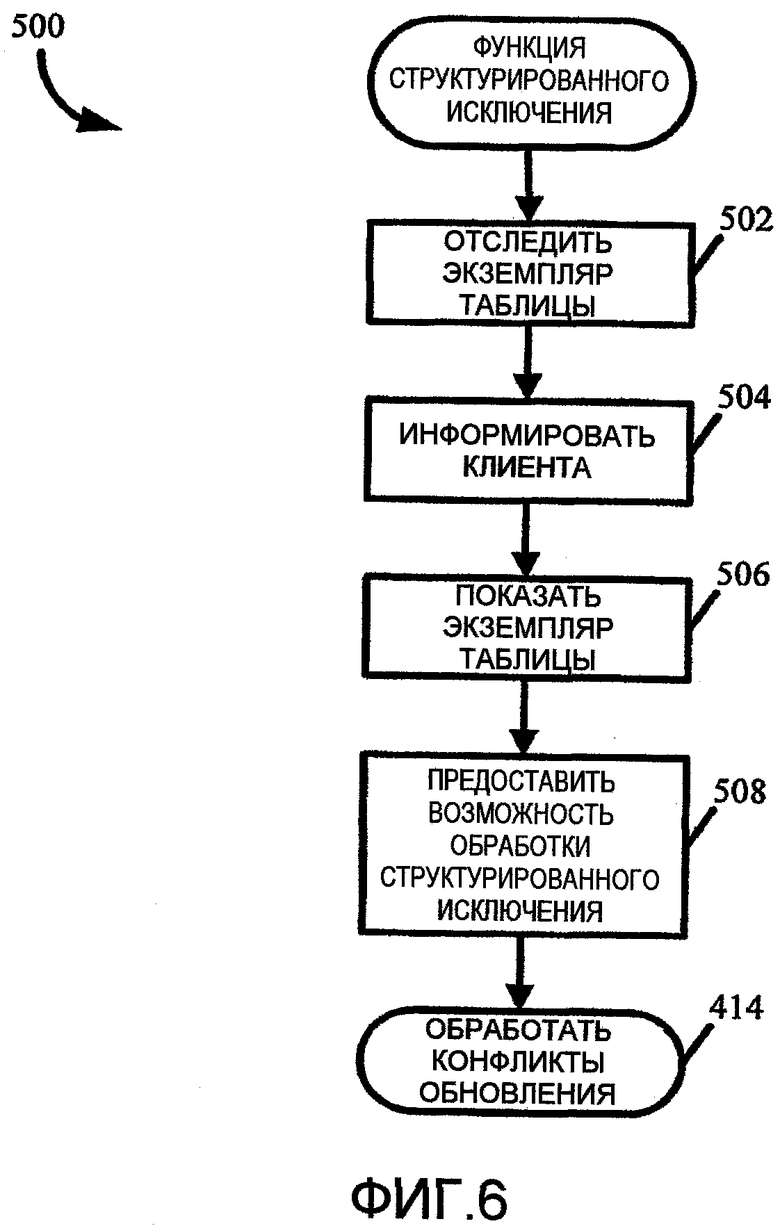
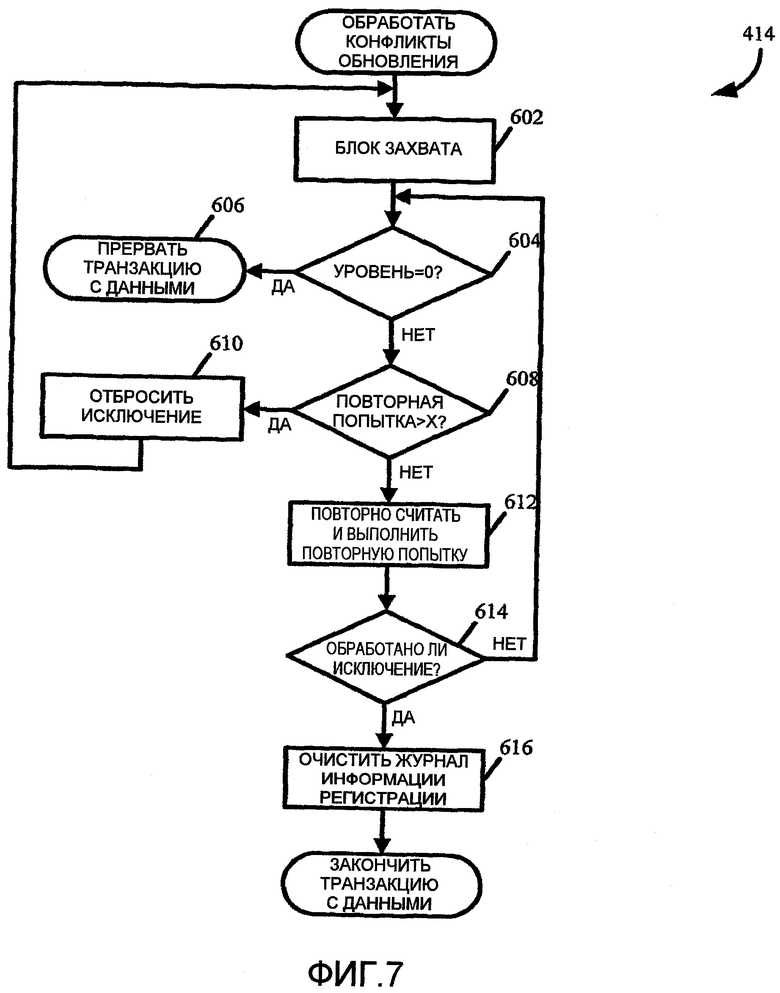

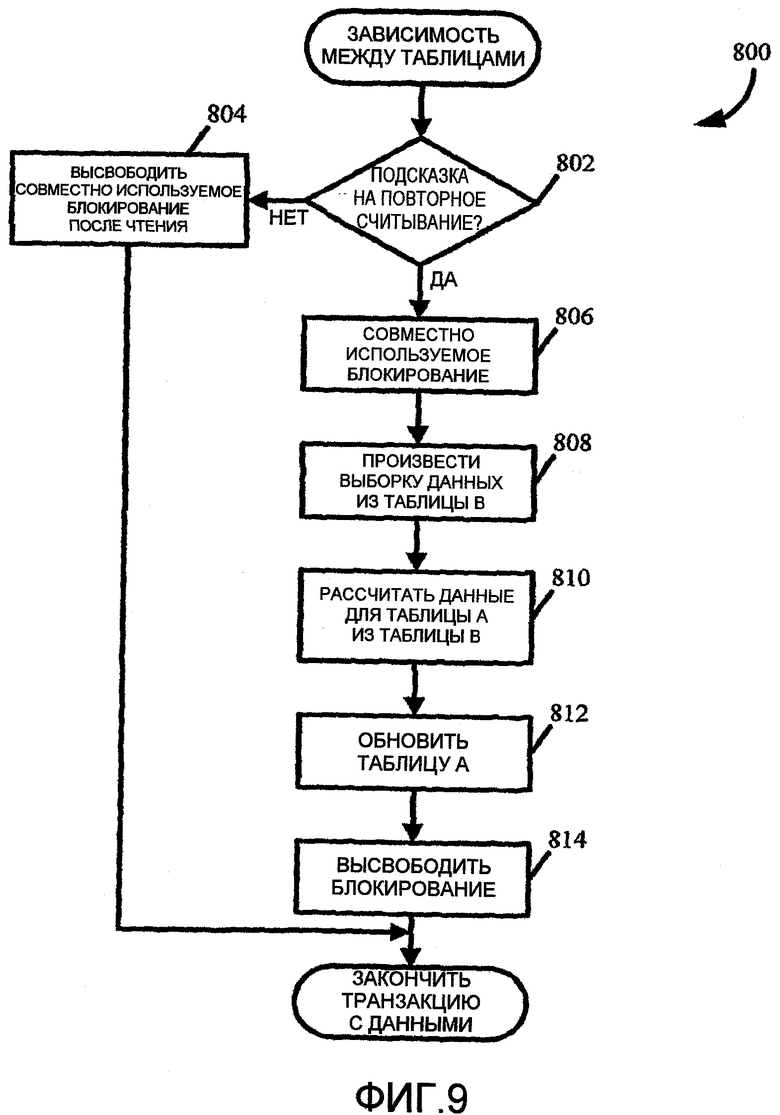
Изобретение относится к системам обработки данных в системе планирования ресурсов предприятия. Техническим результатом является повышение достоверности обработки данных при параллельной обработке данных. Управление параллельным выполнением между множеством транзакций с данными с вовлечением одинаковых данных включает в себя этапы, на которых: сравнивают идентификации версий, которые уникально идентифицируют версии данных, во время запроса чтения и во время запроса записи транзакции с данными. Исключение отбрасывают, если идентификация версии не соответствует, и исключение обрабатывают в пределах транзакции с данными. 3 н. и 17 з.п. ф-лы, 9 ил., 1 табл.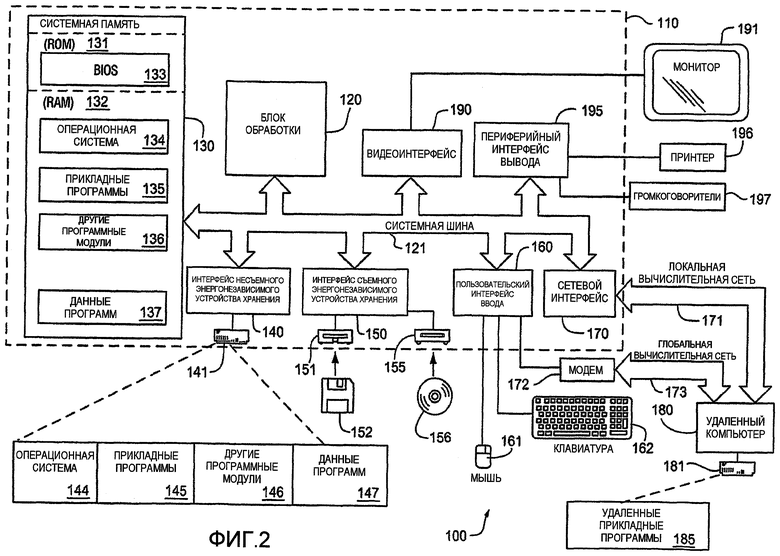
1. Способ управления параллельным выполнением в системе планирования ресурсов предприятия, содержащей базу данных, выполненную с возможностью содержания данных в таблице, имеющей множество строк, способ, содержащий этапы, на которых:
принимают запрос записи из запрашивающего приложения для обновления данных в пределах строки первой таблицы во время первой транзакции с данными, в которой строка содержит первую идентификацию версии, уникально идентифицирующую версию обновляемых данных (302);
сравнивают первую идентификацию версии обновляемых данных со второй идентификацией версии, уникально идентифицирующей версию данных в пределах строки, когда данные выбирают в ответ на предыдущий запрос чтения во время первой транзакции с данными (408); и выполняют отброс исключения, если первая идентификация версии не соответствует второй идентификации версии (412).
2. Способ по п,1, дополнительно содержащий этапы, на которых:
блокируют данные из запроса записи второй транзакции с данными для предотвращения обновления второй транзакции с данными в пределах строки, если первая идентификация версии соответствует второй идентификации версии (416);
обновляют данные в пределах строки (416);
фиксируют первую транзакцию с данными (418);
убирают блокирование данных (420); и
генерируют третью идентификацию версии, которая уникально идентифицирует версию обновленных данных.
3. Способ по п.2, дополнительно содержащий этап, на котором: разрешают чтение данных в пределах строки первой таблицы в ответ на запрос чтения из запрашивающего приложения во время второй транзакции с данными, в то время как данные заблокированы для запроса записи.
4. Способ по п.1, дополнительно содержащий этапы, на которых:
производят выборку данных в ответ на запрос чтения из запрашивающего приложения для данных в течение первой транзакции с данными;
сохраняют идентификацию первой версии, которая уникально идентифицирует выбранные данные;
разрешают вторую транзакцию с данными для обновления данных; и
генерируют идентификацию второй версии, которая уникально идентифицирует обновленные данные второй транзакции с данными, причем обновленные данные второй транзакции с данными содержат данные, обновленные во время первой транзакции с данными.
5. Способ по п.1, в котором отбрасывание исключения содержит этап, на котором: отбрасывают исключение в код приложения запрашивающего приложения (412).
6. Способ по п.1, в котором запрос на запись генерируют из оператора обновления запрашивающего приложения, заключенного в пределах первого блока попытки, и в котором обработка исключения в пределах первой транзакции с данными содержит этапы, на которых:
захватывают исключение в пределах блока захвата блока попытки (602);
повторно считывают идентификацию второй версии из строки (612); и
повторно пытаются сравнить идентификацию первой версии с идентификацией второй версии (612).
7. Способ по п.6, в котором первый блок попытки вложен во второй блок попытки, причем способ дополнительно содержит обработку исключения в пределах первой транзакции с данными, содержащую этапы, на которых:
перемещают исполнение обработки обратно во второй блок попытки, если повторная попытка сравнения идентификации первой версии с идентификацией второй версии в пределах блока захвата первого блока попытки приводит к отбросу исключения (614); и
пытаются обработать исключение в пределах второго блока попытки (612).
8. Способ по п.6, в котором обработка первой транзакции с данными содержит этап, на котором: прекращают первую транзакцию с данными, если повторная попытка сравнения идентификации первой версии с идентификацией второй версии в пределах блока захвата первого блока попытки приводит к отбросу исключения, и если первый блок попытки не вложен во второй блок попытки (604), (606).
9. Способ по п.1, в котором первая транзакция с данными вложена во вторую транзакцию с данными, в которой обработка исключения в первой транзакции с данными содержит: перемещают исполнение обработки обратно во вторую транзакцию с данными (608), (610).
10. Способ по п.1, в котором идентификация первой версии содержит одно из следующего: случайное число, основанное на обновленных данных, или случайное число, основанное на первом случайном исходном числе, и в котором номер идентификации второй версии содержит одно из следующего: случайное число, основанное на данных, когда данные выбирают в ответ на предыдущий запрос чтения в течение первой транзакции с данными, или случайное число основано на втором случайном исходном числе.
11. Способ по п.1, в котором данные в пределах строки второй таблицы зависят от обновляемых данных, причем способ дополнительно содержит этапы, на которых:
блокируют данные в пределах строки первой таблицы из запроса записи второй транзакции с данными для предотвращения обновления данных в строке первой таблицы со стороны второй транзакции с данными, если данные, находящиеся в строке второй таблицы данных рассчитывают из данных в пределах строки первой таблицы (806);
блокируют данные в пределах строки второй таблицы из запроса на запись второй транзакции с данными для предотвращения обновления данных в строке второй таблицы со стороны второй транзакции с данными (806);
производят выборку данных в пределах строки первой таблицы (808);
обновляют данные в пределах строки первой таблицы (808);
определяют данные в пределах строки второй таблицы на основе, по меньшей мере, части обновленных данных в пределах строки первой таблицы (810);
обновляют данные в пределах строки второй таблицы (812);
фиксируют первую транзакцию с данными (814); и
высвобождают блокировки для данных в пределах строк первой и второй таблиц (814).
12. Способ по п.1, дополнительно содержащий этапы, на которых:
обновляют данные без сравнения идентификации первой и второй версии, если запрос записи содержит обновление для предоставления нового значения для данных в пределах строки первой таблицы, соответственно, зависящей от существующего значения данных в пределах строки первой таблицы (710);
генерируют идентификацию третьей версии (704);
определяют разность между идентификацией второй версии и идентификацией третьей версии (706); и
вырабатывают обновление для установки идентификации версии, которая уникально идентифицирует версию обновленных данных как значение идентификации второй версии плюс разность (708).
13. Машиночитаемый носитель, имеющий машиноисполняемые инструкции, для реализации способа управления параллельным выполнением между множеством транзакций с данными для данных в пределах первой строки первой таблицы, причем машиноисполняемые инструкции содержат инструкции для:
сравнения первой версии значения идентификации и второй версии значения идентификации, в котором значение идентификации первой версии уникально идентифицирует версию данных из первой строки во время запроса на считывание первой транзакции с данными, и в котором вторая идентификация версии уникально идентифицирует версию данных из первой строки во время запроса записи первой транзакции с данными (410);
отбрасывания исключения, если первая идентификация версии не соответствует второй идентификации версии (412); и
обработки исключения в пределах первой транзакции с данными, если первая таблица разрешена для оптимистичного управления параллельным выполнением (414).
14. Машиночитаемый носитель, имеющий машиноисполняемые инструкции по п.13, в котором запрос записи генерируют из оператора обновления запрашивающего приложения, и в котором оператор обновления содержит перезапись оптимистичного управления параллельным выполнением, если первая таблица будет установлена для оптимистичного управления параллельным выполнением, причем машиноисполняемые инструкции дополнительно содержат инструкции для блокирования первой строки первой таблицы от каких-либо запросов чтения операции записи или запросов записи из запрашивающего приложения во время второй транзакции с данными, в которой блокировку удерживают в течение длительности первой транзакции с данными (312).
15. Машиночитаемый носитель, содержащий машиноисполняемые инструкции по п.13, в котором запрос записи генерируют из оператора обновления запрашивающего приложения, и в котором оператор обновления содержит подсказку на обновление для обеспечения возможности пессимистичного блокирования, причем выполняемые компьютером инструкции дополнительно содержат инструкции, которые запрещают подсказку на обновление для обеспечения возможности пессимистичного блокирования, если разрешено оптимистичное управление параллельным выполнением для первой таблицы (310).
16. Машиночитаемый носитель, имеющий машиноисполняемые инструкции по п.13, дополнительно содержащий этап, на котором:
выполняют пессимистичное блокирование элемента данных в течение длительности транзакции с данными, если оптимистичное управление параллельным выполнением не разрешено для первой таблицы (312), в котором пессимистичное блокирование содержит этапы, на которых:
блокируют первую строку для каких-либо запросов чтения и запросов записи из запрашивающего приложения во время второй транзакции с данными (312); и
обновляют первую строку без сравнения идентификации первой версии с идентификацией второй версии (316).
17. Машиночитаемый носитель, имеющий машиноисполняемые инструкции по п.13, в котором запрос записи генерируют из оператора на обновление запрашивающего приложения, заключенного в первый блок попытки, и в котором обработка исключения в пределах первой транзакции с данными содержит этапы, на которых:
захватывают исключение в пределах блока захвата блока попытки (602);
повторно считывают идентификацию второй версии из строки (612); и
выполняют повторную попытку сравнения идентификации первой версии с идентификацией второй версии (612).
18. Компьютер, выполненный с возможностью участия в сети планирования ресурсов предприятия, содержащий:
сетевое устройство (170), (172) связи, предназначенное для приема данных через сеть;
память (130), (140), (150), в которой содержатся машиночитаемые инструкции; и
процессор (120), предназначенный для исполнения машиночитаемых инструкций, выполняющих способ, содержащий этапы, на которых:
принимают запрос чтения из запрашивающего приложения для чтения первой строки первой таблицы, содержащейся в базе данных, в течение первой транзакции с данными (302);
сохраняют первую идентификацию версии, которая уникально идентифицирует версию данных, считанных из первой строки (302);
принимают запрос записи из запрашивающего приложения для обновления первой строки во время первой транзакции с данными (302);
сравнивают идентификацию первой версии с идентификацией второй версии, которая уникально идентифицирует версию данных из первой строки, когда принимают первый запрос записи (410);
отбрасывают исключения в запрашивающее приложение, если идентификация первой версии не соответствует идентификации второй версии (412); и
обрабатывают исключения в пределах первой транзакции с данными (414).
19. Компьютер по п.18, в котором инструкции для обработки исключения в пределах первой транзакции с данными содержат инструкции для:
повторного считывания идентификации второй версии из строки (612); и выполнения повторной попытки сравнения идентификации первой версии с идентификацией второй версии (612).
20. Компьютер по п.18, в котором запрос записи генерируют из оператора обновления запрашивающего приложения, включенного в пределы первого блока попытки, и в котором инструкции на обработку исключения в пределах первой транзакции с данными содержат инструкции для:
перемещения исключения обработки назад ко второму блоку попытки и обработки исключения в пределах второго блока попытки, если первый блок попытки заключен во второй блок попытки, и если обработка исключения в пределах первого блока попытки приводит к отбрасыванию исключения (608), (610), (612), (614); и
прекращают первую транзакцию с данными, если первый блок попытки не заключен во второй блок попытки, и если обработка исключения в пределах первого блока попытки приводит к отбрасыванию исключения (604), (606).
| WO 2004099940 A2, 18.11.2004 | |||
| US 20030212699 A1, 13.11.2003 | |||
| WO 03083690 A1, 09.10.2003 | |||
| RU 2004104442 A, 27.07.2005 | |||
| RU 2004104444 A, 27.07.2005. |

