ОБЛАСТЬ ТЕХНИКИ
[1] Настоящее изобретение, в общем, находится в области кодирования сигналов. В частности, настоящее изобретение находится в области улучшения классификации между кодированием во временной области и кодированием в частотной области.
Уровень техники
[2] Кодирование речи относится к процессу, который сокращает скорость передачи битов файла речи. Кодирование речи является применением сжатия данных цифровых аудиосигналов, содержащих речь. Кодирование речи использует оценку специфических для речи параметров с использованием технологий обработки аудиосигналов для моделирования сигнала речи, в сочетании с типовыми алгоритмами сжатия данных для представления, получившихся в результате смоделированных параметров в компактном битовом потоке. Целью кодирования речи является достижение сэкономленных ресурсов в требуемом месте запоминающего устройства, ширине полосы пропускания передачи и мощности передачи посредством сокращения числа битов на выборку, так чтобы декодированная (декомпрессированная) речь была перцепционно неотличима от исходной речи.
[3] Однако кодеры речи являются кодерами с потерями, то есть декодированный сигнал отличается от исходного. Поэтому одна из целей в кодировании речи заключается в том, чтобы минимизировать искажение (или воспринимаемую потерю) при данной скорости передачи битов, или минимизировать скорость передачи битов для достижения данного искажения.
[4] Кодирование речи отличается от других форм аудиокодирования тем, что речь является намного более простым сигналом, чем большинство других аудиосигналов, и намного больше статистической информации доступно о свойствах речи. В качестве результата, некоторая слуховая информация, которая является значимой в аудиокодировании, может быть ненужной в контексте кодирования речи. В кодировании речи, самым важным критерием является сохранение разборчивости и "приятности" речи с ограниченным объемом передаваемых данных.
[5] Разборчивость речи включает в себя, помимо фактического дословного содержания, также индивидуальность говорящего, эмоции, интонация, тембр и так далее, все то, что является важным для идеальной разборчивости. Более абстрактной концепцией приятности ухудшенной речи является отличное свойство, чем разборчивость, поскольку возможно, что ухудшенная речь является полностью разборчивой, но субъективно раздражающей для слушателя.
[6] Традиционно, все параметрические способы кодирования речи используют избыточность, свойственную для сигнала речи, для сокращения объема информации, которая должна быть отправлена, и для оценки параметров выборок речи сигнала на коротких интервалах. Эта избыточность в основном возникает из повторения очертаний волн речи при квазипериодической скорости, и медленно изменяющейся спектральной огибающей сигнала речи.
[7] Избыточность форм волн речи может рассматриваться в отношении нескольких различных типов сигнала речи, таких как сигналы вокализованной и невокализованной речи. Вокализованные звуки, например, "а", "б" происходят по существу вследствие колебаний голосовых связок и являются колебательными. Поэтому через короткие периоды времени они хорошо моделируются посредством сумм периодических сигналов, таких как синусоиды. Другими словами, для вокализованной речи сигнал речи по существу является периодическим. Однако эта периодичность может быть изменчивой в течение продолжительности сегмента речи, и очертание периодической волны обычно изменяется постепенно от сегмента к сегменту. Кодирование речи низкой скорости передачи битов может сильно выигрывать от выявления такой периодичности. Кодирование речи во временной области может сильно выигрывать от выявления такой периодичности. Период вокализованной речи также называется основным тоном, и предсказание основного тона часто называют долгосрочным предсказанием (LTP). В противоположность, невокализованные звуки, такие как "с", "ш", являются более шумоподобными. Это вызвано тем, что сигнал невокализованной речи больше похож на случайный шум и имеет меньшую степень предсказуемости.
[8] В любом случае, параметрическое кодирование может быть использовано для сокращения избыточности сегментов речи посредством отделения компонента возбуждения сигнала речи от компонента спектральной огибающей, который меняется при более медленной скорости. Медленно изменяющийся компонент спектральной огибающей может быть представлен кодированием линейного предсказания (LPC), также называемым краткосрочным предсказанием (STP). Кодирование речи низкой скорости передачи битов также может сильно выигрывать от выявления такого краткосрочного предсказания. Преимущество кодирования возрастает от медленной скорости, при которой изменяются параметры. При этом это является редким для параметров быть значительно отличными от значений, поддерживаемых в пределах нескольких миллисекунд.
[9] В более поздних хорошо известных стандартах, таких как G.723.1, G.729, G.718, были адаптированы система улучшенного скоростного кодирования речи (EFR), вокодер с выбираемым режимом (SMV), адаптивная мультискоростная система (AMR), многорежимная широкополосная система с переменной скоростью (VMR-WB) или адаптивная мультискоростная широкополосная система (AMR-WB), технология линейного предсказания с кодовым возбуждением ("CELP"). CELP обычно понимается как техническая комбинация кодового возбуждения, долгосрочного предсказания и краткосрочного предсказания. CELP в основном используется для кодирования сигнала речи, выигрывая от специфических характеристик человеческого голоса или вокальной модели воспроизведения голоса человека. Кодирование речи CELP является очень популярным принципом алгоритма в области сжатия речи, хотя детали CELP для различных кодеков могут быть значительно отличающимися. Вследствие его популярности алгоритм CELP использовался в различных стандартах ITU-T, MPEG, 3GPP и 3GPP2. Варианты CELP включают в себя алгебраическое CELP, ослабленное CELP, CELP с малой задержкой и линейное предсказание с возбуждением суммы векторов и другие. CELP является общим термином для класса алгоритмов и не для конкретного кодека.
[10] Алгоритм CELP основан на четырех главных идеях. Первая, используется модель фильтра-источника речеобразования посредством линейного предсказания (LP). Модель фильтра-источника речеобразования моделирует речь в качестве комбинации источника звука, такого как голосовые связки, и линейного акустического фильтра, голосового тракта (и характеристики излучения). В реализации модели фильтра-источника речеобразования источник звука или сигнал возбуждения часто моделируется в качестве периодической импульсной последовательности для вокализованной речи или в качестве белого шума для невокализованной речи. Вторая, адаптивная и фиксированная кодовая книга используется в качестве входа (возбуждения) модели LP. Третья, поиск выполняется в замкнутом цикле в "перцепционно взвешенной области". Четвертая, применяется квантование векторов (VQ).
Сущность изобретения
[11] В соответствии с вариантом осуществления настоящего изобретения, способ для обработки сигналов речи до кодирования цифрового сигнала, содержащего аудиоданные, включает в себя выбор кодирования в частотной области или кодирования во временной области на основе скорости передачи битов кодирования, которая должна быть использована для кодирования цифрового сигнала, и обнаружения короткого запаздывания основного тона цифрового сигнала.
[12] В соответствии с альтернативным вариантом осуществления настоящего изобретения, способ для обработки сигналов речи до кодирования цифрового сигнала, содержащего аудиоданные, содержит выбор кодирования в частотной области для кодирования цифрового сигнала, когда скорость передачи битов кодирования выше, чем верхнее ограничение скорости передачи битов. В качестве альтернативы, способ выбирает кодирование во временной области для кодирования цифрового сигнала, когда скорость передачи битов кодирования ниже, чем нижнее ограничение скорости передачи битов. Цифровой сигнал содержит сигнал короткого основного тона, для которого запаздывание основного тона короче, чем ограничение запаздывания основного тона.
[13] В соответствии с альтернативным вариантом осуществления настоящего изобретения, способ для обработки сигналов речи до кодирования содержит выбор кодирования во временной области для кодирования цифрового сигнала, содержащего аудиоданные, когда цифровой сигнал не содержит сигнал короткого основного тона и цифровой сигнал классифицируется как невокализованная речь или нормальная речь. Способ дополнительно содержит выбор кодирования в частотной области для кодирования цифрового сигнала, когда скорость передачи битов кодирования является промежуточной между нижним ограничением скорости передачи битов и верхним ограничением скорости передачи битов. Цифровой сигнал содержит сигнал короткого основного тона, и периодичность голоса является низкой. Способ дополнительно включает в себя выбор кодирования во временной области для кодирования цифрового сигнала, когда скорость передачи битов кодирования является промежуточной и цифровой сигнал содержит сигнал короткого основного тона и периодичность голоса является очень сильной.
[14] В соответствии с альтернативным вариантом осуществления настоящего изобретения, аппарат для обработки сигналов речи до кодирования цифрового сигнала, содержащего аудиоданные, содержит селектор кодирования, сконфигурированный с возможностью выбора кодирования в частотной области или кодирования во временной области на основе скорости передачи битов кодирования, которая должна быть использована для кодирования цифрового сигнала, и обнаружения короткого запаздывания основного тона цифрового сигнала.
Краткое описание чертежей
[15] Для более полного понимания настоящего изобретения и его преимуществ в данный момент ссылка дается на следующие описания, рассматриваемые вместе с сопроводительными чертежами, на которых:
[16] Фигура 1 иллюстрирует операции, выполняемые во время кодирования исходной речи с использованием традиционного кодера CELP;
[17] Фигура 2 иллюстрирует операции, выполняемые во время декодирования исходной речи с использованием декодера CELP;
[18] Фигура 3 иллюстрирует традиционный кодер CELP;
[19] Фигура 4 иллюстрирует базовый декодер CELP, соответствующий кодеру на фигуре 3;
[20] Фигуры 5 и 6 иллюстрируют примеры схематических сигналов речи и их отношение к размеру кадра и размеру подкадра во временной области;
[21] Фигура 7 иллюстрирует пример исходного вокализованного широкополосного спектра;
[22] Фигура 8 иллюстрирует кодированный вокализованный широкополосный спектр исходного вокализованного широкополосного спектра, проиллюстрированного на фигуре 7, с использованием кодирования запаздывания основного тона с удвоением;
[23] Фигуры 9A и 9B иллюстрируют схематическое изображение типичного перцепционного кодека частотной области, при этом фигура 9A иллюстрирует кодер частотной области, тогда как фигура 9B иллюстрирует декодер частотной области;
[24] Фигура 10 иллюстрирует схематическое изображение операций на кодере до кодирования сигнала речи, содержащего аудиоданные, в соответствии с вариантами осуществления настоящего изобретения;
[25] Фигура 11 иллюстрирует систему 10 связи согласно варианту осуществления настоящего изобретения;
[26] Фигура 12 иллюстрирует блок-схему системы обработки, которая может быть использована для реализации устройств и способов, раскрытых в этом документе;
[27] Фигура 13 иллюстрирует блок-схему аппарата для обработки сигналов речи до кодирования цифрового сигнала; и
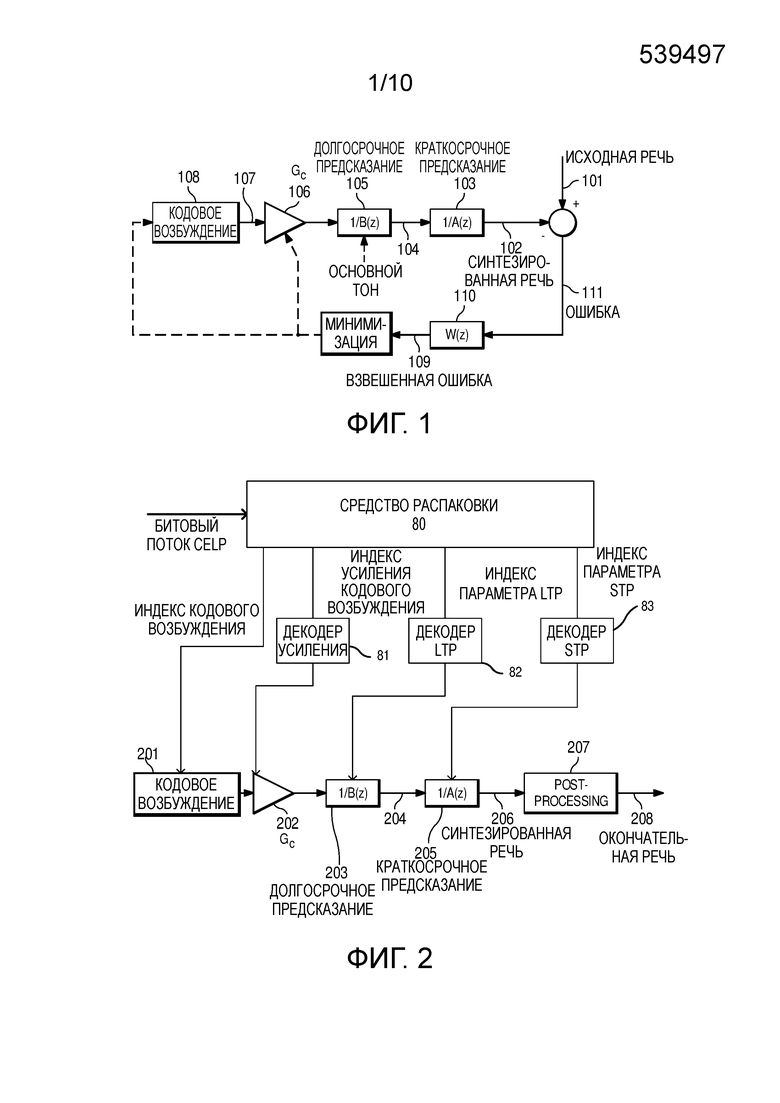
[28] Фигура 14 иллюстрирует блок-схему другого аппарата для обработки сигналов речи до кодирования цифрового сигнала.
Подробное описание иллюстративных вариантов осуществления
[29] В современной системе связи цифровых сигналов аудио/речи цифровой сигнал сжимается на кодере, и сжатая информация или битовый поток может пакетироваться и отправляться декодеру по кадрам через канал связи. Декодер принимает и декодирует сжатую информацию для получения цифрового сигнала аудио/речи.
[30] В современной системе связи цифровых сигналов аудио/речи цифровой сигнал сжимается на кодере, и сжатая информация или битовый поток может пакетироваться и отправляться декодеру по кадрам через канал связи. Система и кодера, и декодера вместе называется кодек. Сжатие речи/аудио может быть использовано для сокращения числа битов, которые представляют сигнал речи/аудио, посредством этого сокращая ширину полосы пропускания и/или скорость передачи битов, необходимую для передачи. В общем, более высокая скорость передачи битов даст в результате более высокое качество аудио, в то время как более низкая скорость передачи битов даст в результате более низкое качество аудио.
[31] Фигура 1 иллюстрирует операции, выполняемые во время кодирования исходной речи с использованием традиционного кодера CELP.
[32] Фигура 1 иллюстрирует традиционный изначальный кодер CELP, где взвешенная ошибка 109 между синтезированной речью 102 и исходной речью 101 часто минимизируется посредством использования подхода анализа через синтез, который означает, что кодирование (анализ) выполняется посредством перцепционной оптимизации декодированного (синтез) сигнала в замкнутом цикле.
[33] Основным принципом, которым пользуются все кодеры речи, является факт, что сигналы речи представляют собой высоко коррелированные формы волн. В качестве иллюстрации, речь может быть представлена с использованием авторегрессивной (AR) модели как в уравнении (1) ниже по тексту.
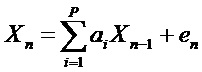
[34] В уравнении (11), каждая выборка представлена как линейная комбинация из предыдущих P выборок плюс белый шум. Коэффициенты взвешивания a1, a2,... aP, называются коэффициентами линейного предсказания (LPC). Для каждого кадра коэффициенты взвешивания a1, a2,... aP, выбираются так, что спектр из {X1, X2,..., XN}, сгенерированный с использованием вышеуказанной модели, близко согласуется со спектром входного кадра речи.
[35] В качестве альтернативы, сигналы речи также могут быть представлены комбинацией из гармонической модели и модели шума. Гармоническая часть модели является эффективным представлением в виде ряда Фурье периодической составляющей сигнала. В общем, для вокализованных сигналов, модель гармоники и шума в речи состоит из смешения и гармоник и шума. Соотношение гармоники и шума в вокализованной речи зависит от количества факторов, включающих в себя характеристики говорящего (например, до какой степени голос говорящего является нормальным или хриплым); характер сегмента речи (например, до какой степени сегмент речи является периодическим), и от частоты. Более высокие частоты вокализованной речи имеют более высокое соотношение шумоподобных компонентов.
[36] Модель линейного предсказания и модель гармоники-шума являются двумя основными способами для моделирования и кодирования сигналов речи. Модель линейного предсказания в частности является хорошей при моделировании спектральной огибающей речи, тогда как модель гармоники-шума является хорошей при моделировании тонкой структуры речи. Два способа могут быть объединены для использования их относительных сильных сторон.
[37] Как указано ранее, до кодирования CELP, входной сигнал в микрофон телефонного аппарата фильтруется и подвергается выборке, например, при скорости 8000 выборок в секунду. Каждая выборка затем квантуется, например, со скоростью 13 бит на выборку. Подвергнутая выборке речь сегментируется в сегменты или кадры из 20 мс (например, в этом случае 160 выборок).
[38] Сигнал речи анализируется, и извлекаются его модель LP, сигналы возбуждения и основной тон. Модель LP представляет спектральную огибающую речи. Она преобразуется в набор из коэффициентов частот спектральных линий (LSF), который является альтернативным представлением параметров линейного предсказания, поскольку коэффициенты LSF имеют хорошие свойства квантования. Коэффициенты LSF могут быть подвергнуты скалярному квантованию, или более эффективно они могут быть подвергнуты векторному квантованию с использованием ранее подготовленных векторных кодовых книг LSF.
[39] Кодовое возбуждение включает в себя кодовую книгу, содержащую кодовые векторы, которые имеют компоненты, которые все являются независимо выбранными так, что каждый кодовый вектор может иметь приблизительно "белый" спектр. Для каждого подкадра входной речи, каждый из кодовых векторов фильтруется посредством фильтра 103 краткосрочного линейного предсказания и фильтра 105 долгосрочного предсказания, и выход сравнивается с выборками речи. На каждом подкадре, кодовый вектор, чей выход согласуется наилучшим образом с входной речью (минимизированная ошибка), выбирается для представления этого подкадра.
[40] Кодовое возбуждение 108 обычно содержит импульсовидный сигнал или шумоподобный сигнал, которые математически создаются или сохраняются в кодовой книге. Кодовая книга является доступной и для кодера, и для принимающего декодера. Кодовое возбуждение 108, которое может быть стохастической или фиксированной кодовой книгой, может быть словарем квантования векторов, который (неявно или явно) жестко закодирован в кодеке. Такая фиксированная кодовая книга может быть алгебраическим линейным предсказанием с кодовым возбуждением или может быть явно сохранена.
[41] Кодовый вектор из кодовой книги масштабируется надлежащим усилением, чтобы сделать энергию равной энергии входной речи. Соответственно, выход кодового возбуждения 108 масштабируется усилением Gc 107 до прохождения через линейные фильтры.
[42] Фильтр 103 краткосрочного линейного предсказания формирует "белый" спектр кодового вектора, чтобы он имел сходство со спектром входной речи. Эквивалентно, во временной области, фильтр 103 краткосрочного линейного предсказания включает краткосрочные корреляции (корреляцию с предыдущими выборками) в белой последовательности. Фильтр, который формирует возбуждение, имеет полюсную модель формы 1/A(z) (фильтр 103 краткосрочного линейного предсказания), где A(z) называют фильтром предсказания и он может быть получен с использованием линейного предсказания (например, алгоритма Левинсона-Дарбина). В одном или более вариантах осуществления может быть использован полюсный фильтр, поскольку он является хорошим представлением речевого тракта человека и поскольку его легко вычислить.
[43] Фильтр 103 краткосрочного линейного предсказания получается посредством анализа исходного сигнала 101 и представляется посредством набора коэффициентов:
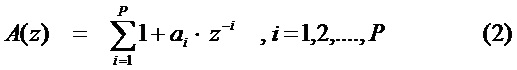
[44] Как описано ранее, зоны вокализованной речи проявляют долгосрочную периодичность. Этот период, известный как основной тон, вводится в синтезированный спектр фильтром 1/(B(z)) основного тона. Выход фильтра 105 долгосрочного предсказания зависит от основного тона и усиления основного тона. В одном или более вариантах осуществления, основной тон может быть оценен из исходного сигнала, остаточного сигнала или взвешенного исходного сигнала. В одном варианте осуществления, функция (B(z)) долгосрочного предсказания может быть выражена с использованием уравнения (3) следующим образом.
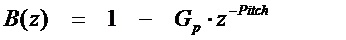
[45] Фильтр 110 взвешивания относится к вышеуказанному фильтру краткосрочного предсказания. Один из типичных фильтров взвешивания может быть представлен, как описано в уравнении (4).
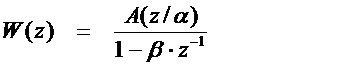
где 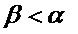
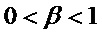
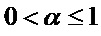
[46] В другом варианте осуществления, фильтр W(z) взвешивания может быть выведен из фильтра LPC посредством использования расширения полосы частот, как проиллюстрировано в одном варианте осуществления в уравнении (5) ниже по тексту.
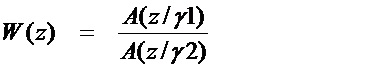
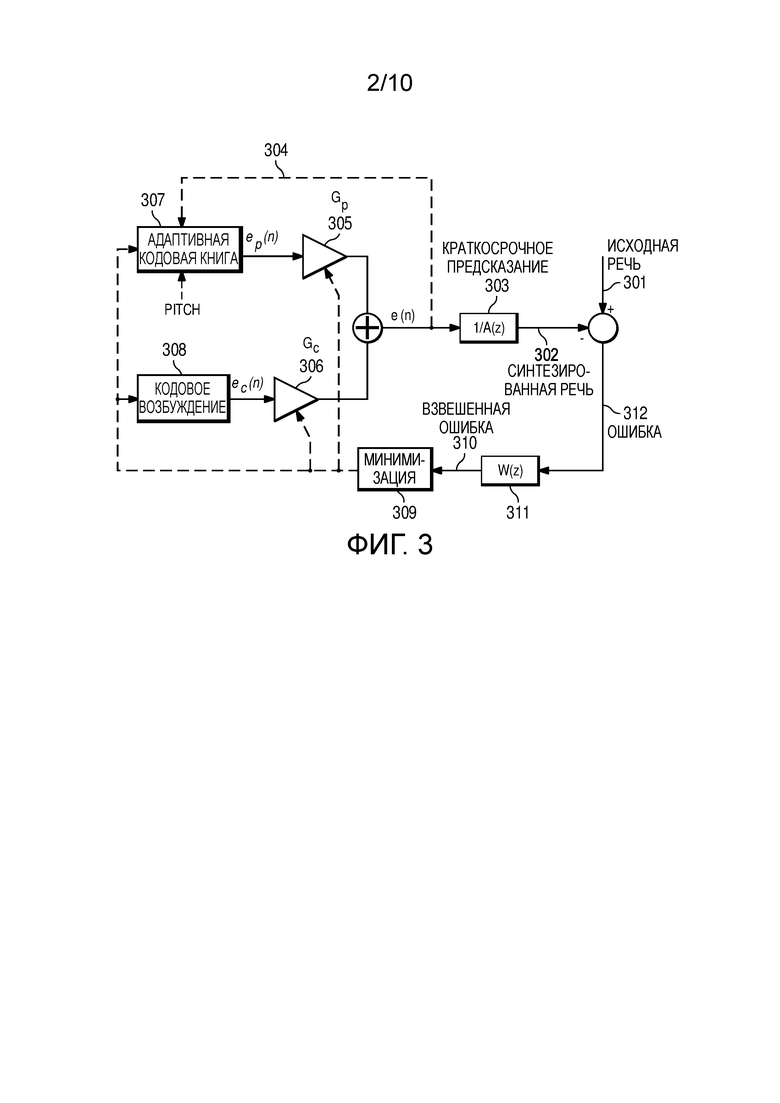
В уравнении (5), γ1 > γ2, которые являются множителями, с которыми полюса перемещаются в направлении к началу координат.
[47] Соответственно, для каждого кадра речи вычисляются LPC и основной тон и обновляются фильтры. Для каждого подкадра речи, кодовый вектор, который производит "лучший" фильтрованный выход, выбирается для представления подкадра. Соответствующее квантованное значение усиления должно быть передано декодеру для правильного декодирования. Значения основного тона и LPC также должны быть квантованы и отправлены каждому кадру для восстановления фильтров на декодере. Соответственно, индекс кодового возбуждения, индекс квантованного усиления, индекс квантованного параметра долгосрочного предсказания и индекс квантованного параметра краткосрочного предсказания передаются декодеру.
[48] Фигура 2 иллюстрирует операции, выполняемые во время декодирования исходной речи с использованием декодера CELP.
[49] Сигнал речи восстанавливается на декодере посредством прохождения принятых кодовых векторов через соответствующие фильтры. Следовательно, каждый блок, за исключением последующей обработки, имеет одно и то же определение, как описано в кодере с фигуры 1.
[50] Кодовый битовый поток CELP принимается и распаковывается 80 на устройстве приема. Для каждого принятого подкадра, принятый индекс кодового возбуждения, индекс квантованного усиления, индекс квантованного параметра долгосрочного предсказания и индекс квантованного параметра краткосрочного предсказания используются для поиска соответствующих параметров с использованием соответствующих декодеров, например, декодера 81 усиления, декодера 82 долгосрочного предсказания и декодера 83 краткосрочного предсказания. Например, позиции и знаки амплитуды импульсов возбуждения и алгебраический кодовый вектор кодового возбуждения 402 могут быть определены из принятого индекса кодового возбуждения.
[51] Ссылаясь на фигуру 2, декодер является комбинацией из нескольких блоков, которые включают в себя кодовое возбуждение 201, долгосрочное предсказание 203, краткосрочное предсказание 205. Изначальный декодер дополнительно включает в себя блок 207 последующей обработки после синтезированной речи 206. Последующая обработка может дополнительно содержать краткосрочную последующую обработку и долгосрочную последующую обработку.
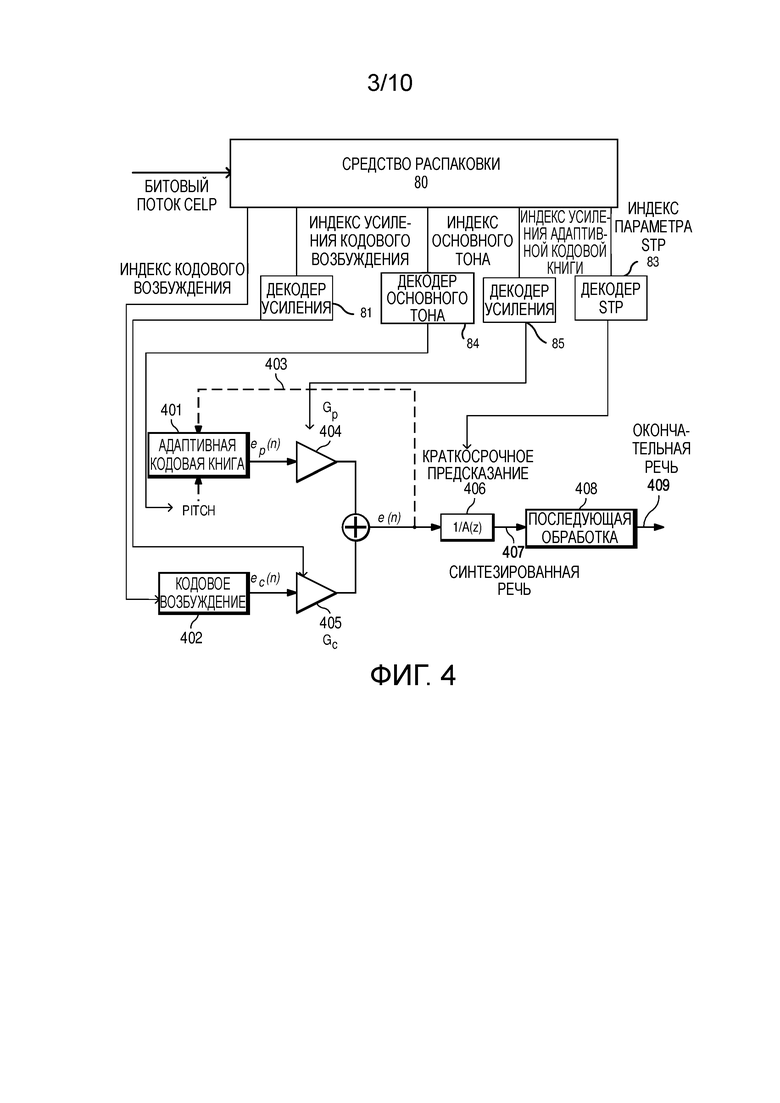
[52] Фигура 3 иллюстрирует традиционный кодер CELP.
[53] Фигура 3 иллюстрирует базовый кодер CELP с использованием дополнительной адаптивной кодовой книги для улучшения долгосрочного линейного предсказания. Возбуждение производится посредством суммирования вкладов из адаптивной кодовой книги 307 и кодового возбуждения 308, которое может быть стохастической или фиксированной кодовой книгой, как описано ранее. Записи в адаптивной кодовой книге содержат отложенные версии возбуждения. Это позволяет эффективно кодировать периодические сигналы, такие как вокализованные звуки.
[54] Ссылаясь на фигуру 3, адаптивная кодовая книга 307 содержит прошедшее синтезированное возбуждение 304 или повторяющийся цикл основного тона прошедшего возбуждения в период основного тона. Запаздывание основного тона может быть кодировано в целом значении, когда оно большое или долгое. Запаздывание основного тона часто кодируется в более точной дробной величине, когда оно маленькое или короткое. Периодическая информация основного тона используется для генерирования адаптивного компонента возбуждения. Этот компонент возбуждения затем масштабируется усилением Gp 305 (также называемым усиление основного тона).
[55] Долгосрочное предсказание играет очень важную роль для кодирования вокализованной речи, поскольку вокализованная речь имеет сильную периодичность. Соседние циклы основного тона вокализованной речи являются аналогичными друг другу, что математически означает, что усиление Gp основного тона в следующем выражении возбуждения является высоким или близким к 1. Получившееся в результате возбуждение может быть выражено в уравнении (6) в качестве комбинации индивидуальных возбуждений.
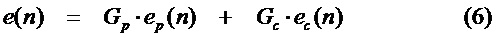
где ep(n) является одним подкадром ряда выборок, индексированного посредством n, исходящим из адаптивной кодовой книги 307, которая содержит прошедшее возбуждение 304, через цепь обратной связи (фигура 3). ep(n) может быть адаптивно пропущен через фильтр нижних частот, так как область низкой частоты является часто более периодической или более гармонической, чем область высокой частоты. ec(n), который исходит из кодовой книги 308 кодового возбуждения (также называемой фиксированной кодовой книгой), является текущим вкладом возбуждения. Дополнительно, ec(n) также может быть улучшен, например посредством использования улучшения фильтра верхних частот, улучшения основного тона, улучшения дисперсии, улучшения форманта и другого.
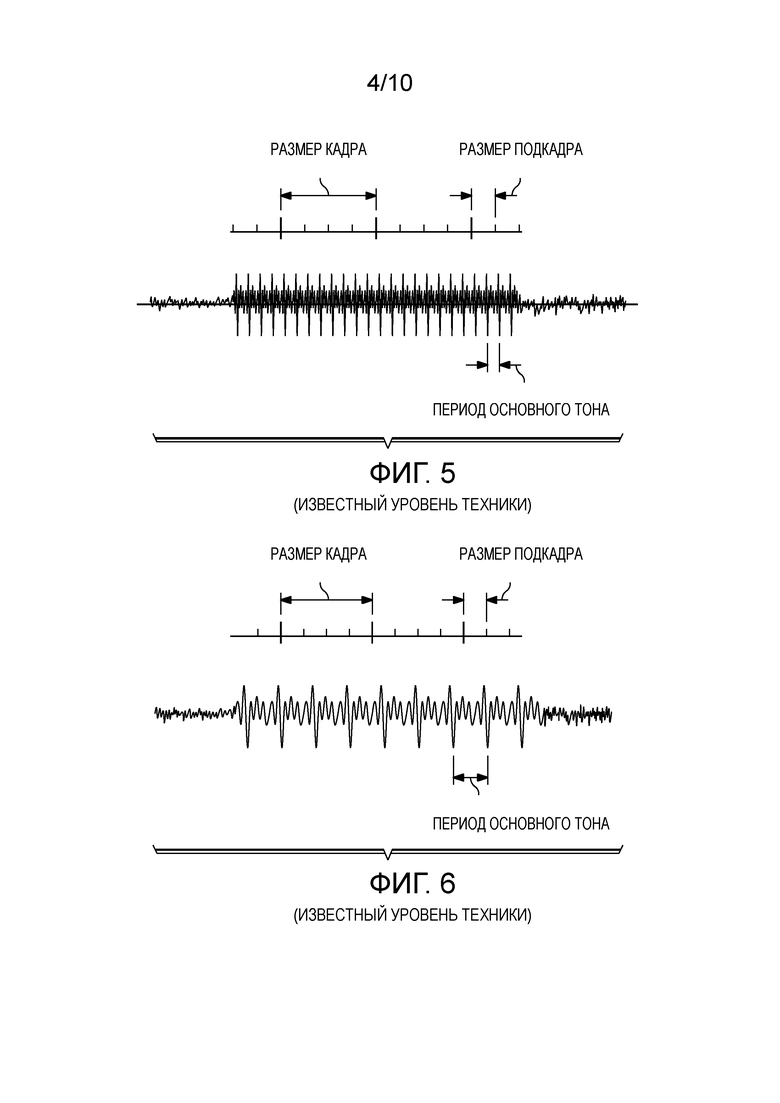
[56] Для вокализованной речи, вклад ep(n) из адаптивной кодовой книги 307 может быть преобладающим и усиление Gp 305 основного тона примерно равно значению 1. Возбуждение обычно обновляется для каждого подкадра. Типичный размер кадра равен 20 миллисекундам и типичный размер подкадра равен 5 миллисекундам.
[57] Как описано на фигуре 1, фиксированное кодовое возбуждение 308 масштабируется усилением Gc 306 до прохождения через линейные фильтры. Два масштабированных компонента возбуждения из фиксированного кодового возбуждения 108 и адаптивной кодовой книги 307 добавляются вместе до фильтрации через фильтр 303 краткосрочного линейного предсказания. Два усиления (Gp и Gc) квантуются и передаются декодеру. Соответственно, индекс кодового возбуждения, индекс адаптивной кодовой книги, индексы квантованных усилений и индекс квантованного параметра краткосрочного предсказания передаются принимающему аудиоустройству.
[58] Битовый поток CELP, кодированный с использованием устройства, проиллюстрированного на фигуре 3, принимается на устройстве приема. Фигура 4 иллюстрирует соответствующий декодер устройства приема.
[59] Фигура 4 иллюстрирует базовый декодер CELP, соответствующий кодеру на фигуре 3. Фигура 4 включает в себя блок 408 последующей обработки, принимающий синтезированную речь 407 от главного декодера. Этот декодер является аналогичным фигуре 3, за исключением адаптивной кодовой книги 307.
[60] Для каждого принятого подкадра, принятый индекс кодового возбуждения, индекс квантованного усиления кодового возбуждения, индекс квантованного основного тона, индекс квантованного усиления адаптивной кодовой книги и индекс квантованного параметра краткосрочного предсказания используются для поиска соответствующих параметров с использованием соответствующих декодеров, например, декодера 81 усиления, декодера 84 основного тона, декодера 85 усиления адаптивной кодовой книги и декодера 83 краткосрочного предсказания.
[61] В различных вариантах осуществления, декодер CELP является комбинацией из нескольких блоков и содержит кодовое возбуждение 402, адаптивную кодовую книгу 401, краткосрочное предсказание 406 и последующую обработку 408. Каждый блок, за исключением последующей обработки, имеет одно и то же определение, как описано в кодере с фигуры 3. Последующая обработка может дополнительно включать в себя краткосрочную последующую обработку и долгосрочную последующую обработку.
[62] Блок с кодовым возбуждением (упоминаемый с меткой 308 на фигуре 3 и 402 на фигуре 4) иллюстрирует местоположение фиксированной кодовой книги (FCB) для общего кодирования CELP. Выбранный кодовый вектор из FCB масштабируется усилением, часто отмеченным как Gc 306.
[63] Фигуры 5 и 6 иллюстрируют примеры схематических сигналов речи и их отношение к размеру кадра и размеру подкадра во временной области. Фигуры 5 и 6 иллюстрируют кадр, включающий в себя множество подкадров.
[64] Выборки входной речи разделяются на блоки выборок, каждый из которых называется кадрами, например, 80-240 выборок или кадров. Каждый кадр разделяется на более маленькие блоки выборок, каждый из которых называется подкадрами. При частоте выборки 8 кГц, 12,8 кГц или 16 кГц алгоритм кодирования речи является таким, что номинальная продолжительность кадра находится в диапазоне от десяти до тридцати миллисекунд, и типично двадцати миллисекунд. На проиллюстрированной фигуре 5, кадр имеет размер 1 кадра и размер 2 кадра, в котором каждый кадр разделяется на 4 подкадра.
[65] Ссылаясь на нижнюю или крайнюю части с фигур 5 и 6, вокализованные зоны в речи похожи на почти периодический сигнал в представлении временной области. Периодическое открытие и закрытие голосовых складок говорящего приводит в результате к гармонической структуре в сигналах вокализованной речи. Поэтому за короткие периоды времени вокализованные сегменты речи могут рассматриваться как периодические для всего практического анализа и обработки. Периодичность, ассоциированная с такими сегментами, задается как "Период основного тона" или просто "Основной тон" во временной области и "Частота основного тона или основная частота f0" в частотной области. Инверсия периода основного тона является основной частотой речи. Термины основной тон и основная частота речи часто используются взаимозаменяемо.
[66] Для большей части вокализованной речи, один кадр содержит более, чем два цикла основного тона. Фигура 5 дополнительно иллюстрирует пример, что период 3 основного тона меньше, чем размер 2 подкадра. В отличие от этого, фигура 6 иллюстрирует пример, в котором период 4 основного тона больше, чем размер 2 подкадра и меньше, чем половинный размер кадра.
[67] Для того, чтобы более эффективно кодировать сигнал речи, сигнал речи может быть классифицирован на различные классы и каждый класс кодируется различным способом. Например, в некоторых стандартах, таких как G.718, VMR-WB или AMR-WB, сигнал речи классифицируется на невокализованный, переходный, типичный, вокализованный и шумовой.
[68] Для каждого класса фильтр STP или LPC всегда используется для представления спектральной огибающей. Однако возбуждение для фильтра LPC может быть различным. Невокализованный и шумовой классы могут быть кодированы с улучшением некоторого возбуждения и возбуждения шума. Переходный класс может быть кодирован с улучшением некоторого возбуждения и возбуждения импульса без использования адаптивной кодовой книги или LTP.
[69] Типичный может быть кодирован традиционным подходом CELP, таким как алгебраическое CELP, используемое в G.729 или AMR-WB, в котором один 20 мс кадр содержит четыре 5 мс подкадра. И компонент возбуждения адаптивной кодовой книги, и компонент возбуждения фиксированной кодовой книги производятся с некоторым улучшением возбуждения для каждого подкадра. Запаздывания основного тона для адаптивной кодовой книги в первом и третьем подкадрах кодируются в полном диапазоне от минимального ограничения основного тона PIT_MIN до максимального ограничения основного тона PIT_MAX. Запаздывания основного тона для адаптивной кодовой книги во втором и четвертом подкадрах кодируются по-разному от предыдущего кодированного запаздывания основного тона.
[70] Вокализованные классы могут быть кодированы таким путем, что они будут являться немного отличающимися от параметризованного класса. Например, запаздывание основного тона в первом подкадре может быть кодировано в полном диапазоне от минимального ограничения основного тона PIT_MIN до максимального ограничения основного тона PIT_MAX. Запаздывания основного тона в других подкадрах могут быть кодированы по-разному от предыдущего кодированного запаздывания основного тона. В качестве иллюстрации, предположим, что частота выборки возбуждения равна 12,8 кГц, тогда примерное значение PIT_MIN может быть 34 и PIT_MAX может быть 231.
[71] Сейчас будут описаны варианты осуществления настоящего изобретения для улучшения классификации кодирования во временной области и кодирования в частотной области.
[72] В сущности, лучше использовать кодирование во временной области для сигнала речи и кодирование в частотной области для музыкального сигнала для того, чтобы достигать лучшего качества при довольно высокой скорости передачи битов (например, 24 кбит/с <= скорость передачи битов <= 64 кбит/с). Однако, для некоторого специфического сигнала речи, такого как сигнал короткого основного тона, речевой сигнал пения или очень шумный сигнал речи, может быть лучше использовать кодирование в частотной области. Для некоторых специфических музыкальных сигналов, таких как очень периодический сигнал, может быть лучше использовать кодирование во временной области, извлекая выгоду из очень высокого усиления LTP. Скорость передачи битов является важным параметром для классификации. Обычно кодирование во временной области поддерживает низкую скорость передачи битов, и кодирование в частотной области поддерживает высокую скорость передачи битов. Лучшая классификация или выбор между кодированием во временной области и кодированием в частотной области должен быть определен осторожно, также принимая во внимание диапазон скорости передачи битов и характеристику алгоритмов кодирования.
[73] В следующих разделах будет описано обнаружение нормальной речи и сигнала короткого основного тона.
[74] Нормальная речь является сигналом речи, который исключает речевой сигнал пения, речевой сигнал короткого основного тона или смешанный сигнал речи/музыки. Нормальная речь также может быть быстро изменяющимся сигналом речи, спектр и/или энергия которого меняется быстрее, чем большинство музыкальных сигналов. Обычно, алгоритм кодирования во временной области лучше, чем алгоритм кодирования в частотной области для кодирования сигнала нормальной речи. Нижеследующее является примерным алгоритмом для обнаружения сигнала нормальной речи.
[75] Для варианта P основного тона, корреляция нормализованного основного тона часто задана в математической форме как в уравнении (8).
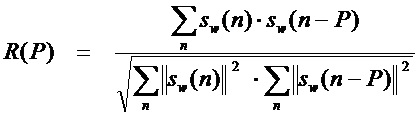
[76] В уравнении (8), sw(n) является взвешенным сигналом речи, числитель является корреляцией, и знаменатель является множителем нормализации энергии. Предположим, что Voicing отмечает среднее значение корреляции нормализованного основного тона четырех подкадров в текущем кадре речи, Voicing может быть вычислено, как в уравнении (9) ниже по тексту.
Voicing=[ R1(P1)+R2(P2)+R3(P3)+R4(P4) ]/4 (9)
[77] R1(P1), R2(P2), R3(P3) и R4(P4) представляют собой четыре корреляции нормализованного основного тона, вычисленные для каждого подкадра; P1, P2, P3, и P4 для каждого подкадра являются лучшими вариантами основного тона, найденными в диапазоне основного тона от P=PIT_MIN до P=PIT_MAX. Сглаженная корреляция основного тона от предыдущего кадра до текущего кадра может быть вычислена, как в уравнении (10).
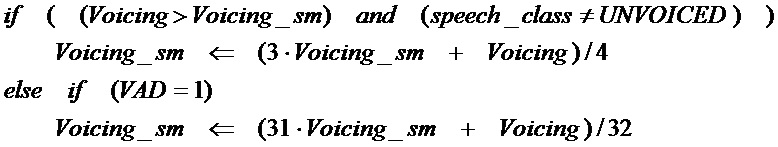
[78] В уравнении (10), VAD является обнаружением голосовой активности и VAD=1 обозначает, что сигнал речи существует. Предположим, что Fs является частотой выборки, максимальной энергией в зоне очень низкой частоты [0, FMIN=Fs/PIT_MIN] (Гц) является Energy0 (дБ), максимальной энергией в зоне низкой частоты [FMIN, 900] (Гц) является Energy1 (дБ), и максимальной энергией в зоне высокой частоты [5000, 5800] (Гц) является Energy3 (дБ), параметр Tilt наклона спектра задан следующим образом.
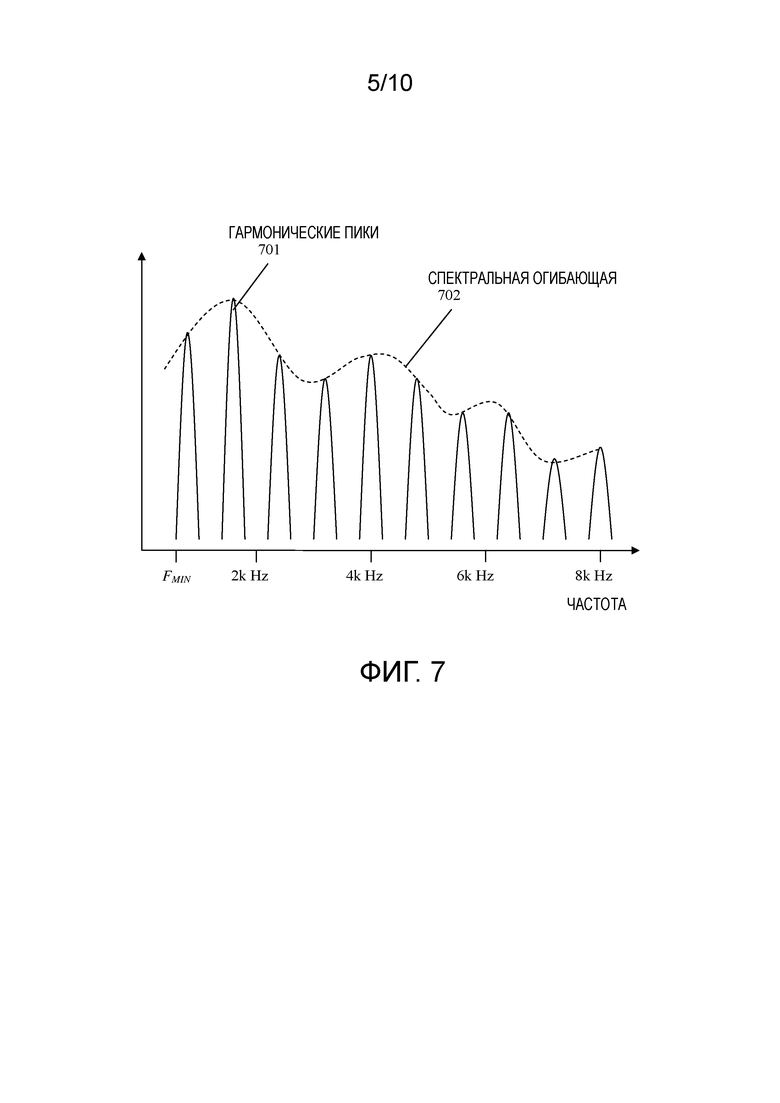
Tilt=energy3 - max{energy0,energy1} (11)
[79] Сглаженный параметр наклона спектра отмечен как в уравнении (12).
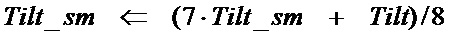
[80] Разностный наклон спектра текущего кадра и предыдущего кадра может быть дан в уравнении (13).
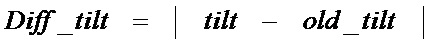
[81] Сглаженный разностный наклон спектра дается в уравнении (14).

[82] Разностная энергия низкой частоты текущего кадра и предыдущего кадра представляет собой
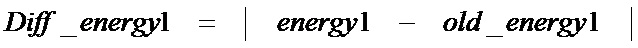
[83] Сглаженная разностная энергия дается посредством уравнения (16).
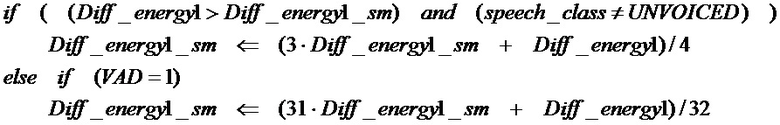
[84] Дополнительно, флаг нормальной речи, обозначенный как Speech_flag, определяется и изменяется во время вокализованной области, учитывая изменение Diff_energy1_sm энергии, изменение Voicing_sm голоса и изменение Diff_tilt_sm наклона спектра, которые обеспечены в уравнении (17).

[85] Будут описаны варианты осуществления настоящего изобретения для обнаружения сигнала короткого основного тона.
[86] Большинство кодеков CELP хорошо работают для нормальных сигналов речи. Однако, кодеки CELP низкой скорости передачи битов часто терпят неудачу с музыкальными сигналами и/или голосовыми сигналами пения. Если диапазон кодирования основного тона находится от PIT_MIN до PIT_MAX и реальное запаздывание основного тона меньше, чем PIT_MIN, выполнение кодирования CELP может быть перцепционного плохим вследствие двойного основного тона или тройного основного тона. Например, диапазон основного тона от PIT_MIN=34 до PIT_MAX =231 для частоты выборки Fs=12,8 кГц адаптирует большинство человеческих голосов. Однако реальное запаздывание основного тона обычной музыки или голосового сигнала пения может быть гораздо короче, чем минимальное ограничение PIT_MIN=34, заданное в вышеуказанном примерном алгоритме CELP.
[87] Когда реальное запаздывание основного тона равно P, соответствующая нормализованная основная частота (или первая гармоника) равна f0=Fs/P, где Fs является частотой выборки и f0 является местоположением первого гармонического пика в спектре. Значит, для данной частоты выборки, минимальное ограничение PIT_MIN основного тона фактически задает максимальное ограничение FM=Fs/PIT_MIN основной гармонической частоты для алгоритма CELP.
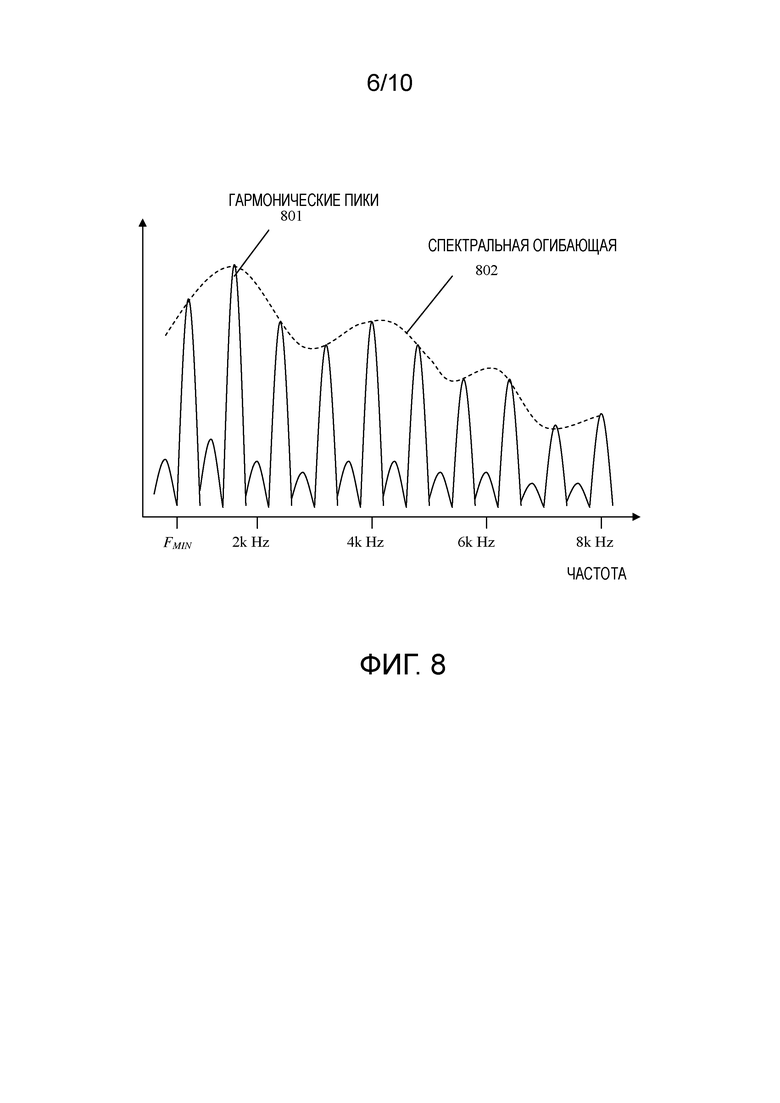
[88] Фигура 7 иллюстрирует пример исходного вокализованного широкополосного спектра. Фигура 8 иллюстрирует кодированный вокализованный широкополосный спектр исходного вокализованного широкополосного спектра, проиллюстрированного на фигуре 7, с использованием кодирования запаздывания основного тона с удвоением. Другим словами, фигура 7 иллюстрирует спектр до кодирования и фигура 8 иллюстрирует спектр после кодирования.
[89] В примере, показанном на фигуре 7, спектр формируется гармоническими пиками 701 и спектральной огибающей 702. Реальная основная гармоническая частота (местоположение первого гармонического пика) уже находится за пределами ограничения FM максимальной основной гармонической частоты, так что переданное запаздывание основного тона для алгоритма CELP не может быть равным реальному запаздыванию основного тона, и оно может быть двойным или кратным реальному запаздыванию основного тона.
[90] Неправильное запаздывание основного тона, переданное с числом, кратным реальному запаздыванию основного тона, может вызывать явное ухудшение качества. Другими словами, когда реальное запаздывание основного тона для сигнала гармонической музыки или голосового сигнала пения меньше, чем минимальное ограничение PIT_MIN запаздывания, заданное в алгоритме CELP, переданное запаздывание может быть двойным, тройным или кратным реальному запаздыванию основного тона.
[91] В качестве результата, спектр кодированного сигнала с переданным запаздыванием основного тона мог быть таким, как показано на фигуре 8. Как проиллюстрировано на фигуре 8, помимо включения гармонических пиков 8011 и спектральной огибающей 802, могут быть видны нежелательные небольшие пики 803 между реальными гармоническими пиками, в то время как правильный спектр должен быть похожим на спектр с фигуры 7. Эти маленькие пики спектра на фигуре 8 могут вызывать неудобное перцепционное искажение.
[92] В соответствии с вариантами осуществления настоящего изобретения, одно решение для разрешения этой проблемы, когда CELP терпит неудачу с некоторыми специфическими сигналами, заключается в том, что кодирование в частотной области используется вместо кодирования во временной области.
[93] Обычно музыкальные гармонические сигналы или голосовые сигналы пения являются более постоянными, чем нормальные сигналы речи. Запаздывание основного тона (или основная частота) нормального сигнала речи продолжает изменяться все время. Однако, запаздывание основного тона (или основная частота) музыкального сигнала или голосового сигнала пения часто поддерживает относительно медленное изменение на довольно длительный период времени. Диапазон очень короткого основного тона задается от PIT_MIN0 до PIT_MIN. При частоте выборки Fs=12,8 кГц, примерное определение диапазона очень короткого основного тона может быть от PIT_MIN0<=17 до PIT_MIN=34. Так как вариант основного тона является слишком коротким, энергия от 0 Гц до FMIN=Fs/PIT_MIN Гц должна быть достаточно относительно низкой. Другие условия, такие как обнаружение голосовой активности и вокализованная классификация, могут быть добавлены во время обнаружения существования сигнала короткого основного тона.
[94] Следующие два параметра могут помочь обнаружить возможное существование сигнала очень короткого основного тона. Один является характерной чертой "Отсутствия энергии очень низкой частоты" и другой является характерной чертой "Спектральной резкости". Как уже упомянуто выше по тексту, предположим, что максимальная энергия в зоне частоты [0, FMIN] (Гц) является Energy0 (дБ), максимальная энергия в зоне частоты [FMIN, 900] (Гц) является Energy1 (дБ), относительное соотношение энергии между Energy0 и Energy1 обеспечено в уравнении (18) ниже по тексту.
Ratio=Energy1 - Energy0 (18)
[95] Это соотношение энергии может быть взвешено посредством умножения среднего значения Voicing корреляции нормализованного основного тона, которое показано ниже по тексту в уравнении (19).
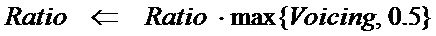
[96] Причина, чтобы делать взвешивание в уравнении (19) посредством использования множителя Voicing заключается в том, что обнаружение короткого основного тона является важным для вокализованной речи или гармонической музыки, и не является важным для невокализованной речи или негармонической музыки. До использования параметра Ratio для обнаружения отсутствия энергии низкой частоты, лучше осуществить сглаживание для того, чтобы сократить погрешность, как в уравнении (20).

[97] Если LF_lack_flag=1 означает, что обнаружено отсутствие энергии низкой частоты (иначе LF_lack_flag=0 ), LF_lack_flag может быть определен следующей процедурой.
if ( (LF_EnergyRatio_sm>30) or (Ratio>48) or
(LF_EnergyRatio_sm>22 and Ratio>38) ) {
LF_lack_flag=1 ;
}
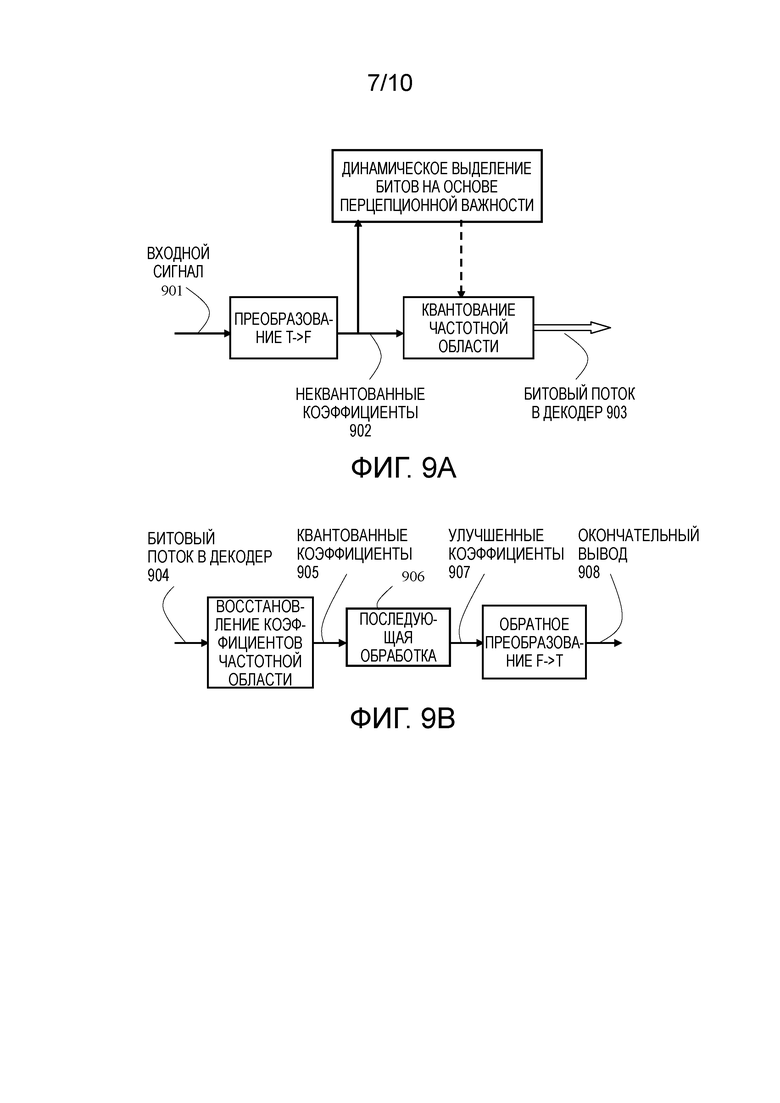
else if (LF_EnergyRatio_sm <13) {
LF_lack_flag=0 ;
}
else {
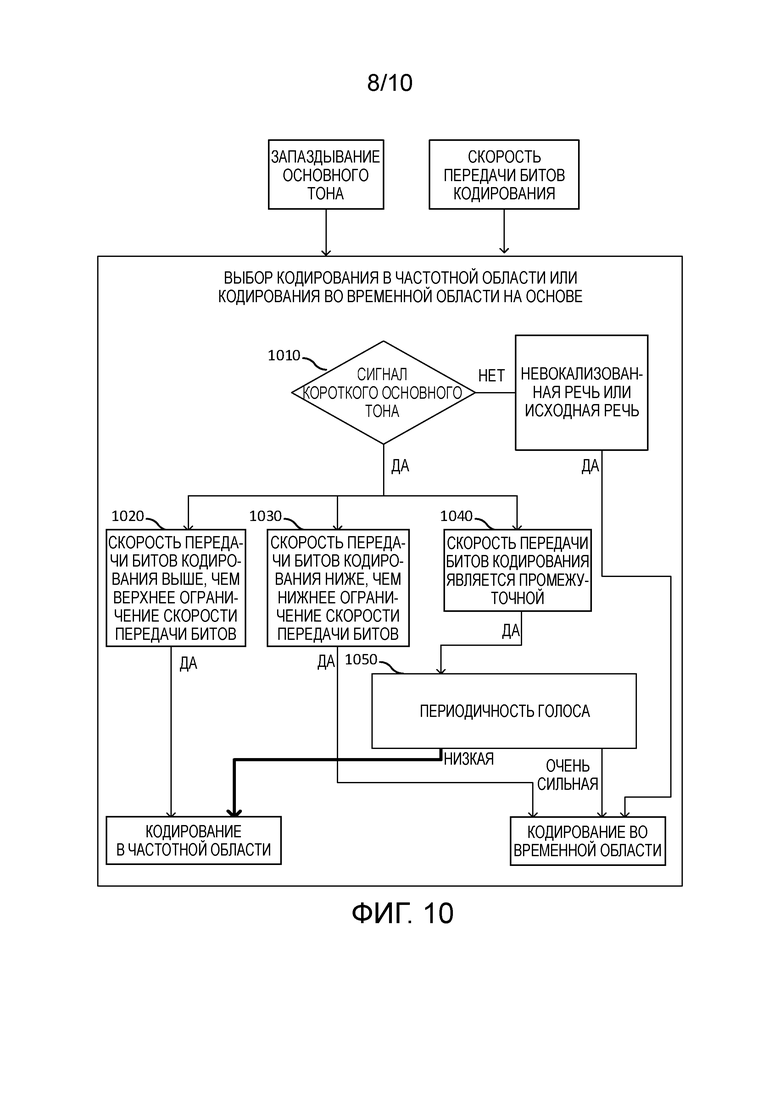
LF_lack_flag остается неизменным.
}
[98] Параметры, связанные со спектральной резкостью, определяются следующим образом. Предположим, что Energy1 (дБ) является максимальной энергией в зоне низкой частоты [FMIN, 900] (Гц), i_peak является местоположением гармонического пика максимальной энергии в зоне частоты [FMIN,900] (Гц) и Energy2 (дБ) является средней энергией в зоне частоты 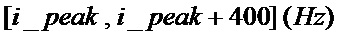
SpecSharp=max{Energy1-Energy2, 0 } (21)
[99] Сглаженный параметр спектральной резкости дается следующим образом.
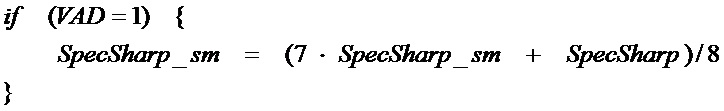
[100] Один флаг спектральной резкости, указывающий возможное существование сигнала короткого основного тона, оценивается следующим образом.
if ( SpecSharp_sm>50 or SpecSharp>80 ) {
SpecSharp_flag=1; // возможный короткий основной тон или тона
}
if ( SpecSharp_sm<8 ) {
SpecSharp_flag=0;
}
если ни одно из вышеуказанных условий не удовлетворено, SpecSharp_flag остается неизменным.
[101] В различных вариантах осуществления, вышеуказанные оцененные параметры могут быть использованы для улучшения классификации или выбора из кодирования во временной области и кодирования в частотной области. Предположим, что Sp_Aud_Deci=1 обозначает, что выбрано кодирование в частотной области и Sp_Aud_Deci=0 обозначает, что выбрано кодирование во временной области. Следующая процедура дает примерный алгоритм для улучшения классификации кодирования во временной области и кодирования в частотной области для различных скоростей передачи битов кодирования.
[102] Варианты осуществления настоящего изобретения могут быть использованы для улучшения высоких скоростей передачи битов, например, скорость передачи битов кодирования больше, чем или равна 46200 бит в секунду. Когда скорость передачи битов кодирования является очень высокой и сигнал короткого основного тона возможно существует, выбирается кодирование в частотной области, поскольку кодирование в частотной области может доставлять надежное и безотказное качество, в то время как кодирование во временной области рискует плохим влиянием от неправильного обнаружения основного тона. В отличие от этого, когда сигнал короткого основного тона не существует и сигнал является невокализованной речью или нормальной речью, выбирается кодирование во временной области, поскольку кодирование во временной области может доставлять лучшее качество, чем кодирование в частотной области для сигнала нормальной речи.
/* для возможного сигнала короткого основного тона, выбор кодирования в частотной области */
if (LF_lack_flag=1 or SpecSharp_flag=1) {
Sp_Aud_Deci=1; // выбор кодирования в частотной области
}
/* для невокализованной речи или исходной речи, выбор кодирования во временной области */
if (LF_lack_flag=0 and SpecSharp_flag=0) {
if ( (Tilt>40) and (Voicing<0.5) and (speech_class=UNVOICED) and
(VAD=1) ) {
Sp_Aud_Deci=0; // выбор кодирования во временной области
}
if (Speech_flag=1) {
Sp_Aud_Deci=0; // выбор кодирования во временной области
}
}
[103] Варианты осуществления настоящего изобретения могут быть использованы для улучшения промежуточного кодирования скорости передачи битов, например, когда скорость передачи битов кодирования находится между 24,4 кбит/с и 46200 бит/с. Когда сигнал короткого основного тона возможно существует и периодичность голоса является низкой, выбирается кодирование в частотной области, поскольку кодирование в частотной области может доставлять надежное и безотказное качество, в то время как кодирование во временной области рискует плохим влиянием от низкой периодичности голоса. Когда сигнал короткого основного тона не существует и сигнал является невокализованной речью или нормальной речью, выбирается кодирование во временной области, поскольку кодирование во временной области может доставлять лучшее качество, чем кодирование в частотной области для сигнала нормальной речи. Когда периодичность голоса является очень сильной, выбирается кодирование во временной области, поскольку кодирование во временной области может во много извлекать пользу из высокого усиления LTP с очень сильной периодичностью голоса.
[104] Варианты осуществления настоящего изобретения также могут быть использованы для улучшения высоких скоростей передачи битов, например, скорость передачи битов кодирования меньше, чем 24,4 кбит/с. Когда сигнал короткого основного тона существует и периодичность голоса не является низкой с правильным обнаружением короткого запаздывания основного тона, кодирование в частотной области не выбирается, поскольку кодирование в частотной области не может доставлять надежное и безотказное качество при низкой скорости, в то время как кодирование во временной области может хорошо извлекать пользу из функции LTP.
[105] Следующий алгоритм иллюстрирует специфический вариант осуществления вышеуказанных вариантов осуществления в качестве иллюстрации. Все параметры могут быть вычислены как описано ранее в одном или более вариантах осуществления.
/* подготовка параметров или пороговых значений */
if (предыдущий кадр является кодированием во временной области) {
DPIT=0.4;
TH1=0.92;
TH2=0.8;
}
else {
DPIT=0.9;
TH1=0.9;
TH2=0.7;
}
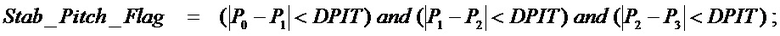
High_Voicing=(Voicing_sm>TH1) and (Voicing>TH2) ;
/* для возможного сигнала короткого основного тона с низкой периодичностью (низким голосом), выбор кодирования частотной области */
if ( (LF_lack_flag=1) or (SpecSharp_flag=1) ) {
if ( ( (Stab_Pitch_Flag=0 or High_Voicing=0) and ( Tilt_sm<=-50) )
or (Tilt_sm<=-60) )
{
Sp_Aud_Deci=1; // выбор кодирования частотной области
}
}
/* для невокализованного сигнала или сигнала исходной речи, выбор кодирования во временной области */
if ( LF_lack_flag=0 and SpecSharp_flag=0 )
{
if ( Tilt>40 and Voicing<0.5 and speech_class=UNVOICED and Vad=1)
{
Sp_Aud_Deci=0; // выбор кодирования во временной области
}
if ( Speech_flag=1)
{
Sp_Aud_Deci=0; // выбор кодирования во временной области
}
}
/* для сигнала сильного голоса, выбор кодирования во временной области */
if ( Ttilt_sm>-60 and ( speech_class is not UNVOICED ) )
{
if ( High_Voicing=1 and
(Stab_Pitch_Flag=1 or (LF_lack_flag=0 and SpecSharp_flag=0) ) )
{
Sp_Aud_Deci=0; // выбор кодирования во временной области
}
}
[106] В различных вариантах осуществления, классификация или выбор из кодирования во временной области и кодирования в частотной области может быть использован, чтобы значительно улучшить перцепционное качество некоторых специфических сигналов речи или музыкального сигнала.
[107] Аудио-кодирование на основе технологии набора фильтров широко используется в кодировании в частотной области. В обработке сигналов, набор фильтров является массивом полосовых фильтров, которые разделяют входной сигнал на несколько компонентов, каждый из которых переносит один частотный поддиапазон исходного входного сигнала. Процесс разложения, выполняемый набором фильтров, называют анализом, и вывод анализа набора фильтров упоминается как сигнал поддиапазона, имеющий столько же поддиапазонов, сколько имеется фильтров в наборе фильтров. Процесс восстановления называют синтезом набора фильтров. В обработке цифровых сигналов, термин набор фильтров также обычно применяется к набору приемников, которые также могут преобразовывать с понижением поддиапазоны в низкую центральную частоту, которая может быть подвергнута повторной выборке при сокращенной скорости. Один и тот же синтезированный результат иногда также может быть достигнут посредством субдискретизации поддиапазонов полосы пропускания. Вывод анализа набора фильтров может быть в форме сложных коэффициентов. Каждый сложный коэффициент, имеющий реальный элемент и мнимый элемент, соответственно представляют член, содержащий косинус, и член, содержащий синус, для каждого поддиапазона набора фильтров.
[108] Анализ набора фильтров и синтез набора фильтров является одним видом пары преобразований, которая преобразует сигнал временной области в коэффициенты частотной области и обратно - преобразует коэффициенты частотной области назад в сигнал временной области. Другие популярные пары преобразований, такие как (FFT и iFFT), (DFT и iDFT), и (MDCT и iMDCT), также могут быть использованы в кодировании речи/аудио.
[109] В применении наборов фильтров для сжатия сигналов, некоторые частоты являются перцепционно более важными, чем другие. После разложения, перцепционно значимые частоты могут быть кодированы с высоким разрешением, так как небольшие различия на этих частотах являются перцепционно заметными, чтобы гарантировать использование схемы кодирования, которая сохраняет эти различия. С другой стороны, менее перцепционно значимые частоты не повторяются так точно. Поэтому, может быть использована грубая схема кодирования, даже несмотря на то, что некоторые из более мелких деталей будут потеряны в кодировании. Типичная грубая схема кодирования может быть использована на основе концепции расширения полосы пропускания (BWE), также известной как расширение верхнего диапазона (HBE). Один популярный в последнее время специфический подход HBE или BWE известен как реплика поддиапазона (SBR) или повторение диапазона спектра (SBR). Эти технологии являются аналогичными в том, что они кодируют и декодируют некоторые частотные поддиапазоны (обычно высокие диапазоны) с небольшим или без запаса скорости передачи битов, посредством этого приводя к значительно более низкой скорости передачи битов, чем обычный подход кодирования/декодирования. С технологией SBR, спектральная тонкая структура в высокочастотном диапазоне копируется из диапазона низкой частоты, и может быть добавлен случайный шум. Далее, спектральная огибающая высокочастотного диапазона принимает форму посредством использования дополнительной информации, переданной от кодера декодеру.
[110] Имеет смысл использовать психоакустический принцип или эффект перцепционной маскировки для разработки сжатия аудио. Оборудование аудио/речи или связь предназначена для взаимодействия с людьми, со всеми способностями и ограничениями восприятия людей. Традиционное аудиооборудование пытается воспроизвести сигналы с предельной точностью с оригиналом. Более направленная подходящим образом и часто более эффективная цель состоит в том, чтобы достигнуть точности, заметной людьми. Это является целью перцепционных кодеров.
[111] Хотя одной главной целью цифровых аудио перцепционных кодеров является сокращение объема данных, перцепционное кодирование также может быть использовано для улучшения представления цифрового аудио посредством усовершенствованного выделения битов. Одним из примеров перцепционных кодеров могут быть многополосные системы, разделяющие спектр некоторым образом, который имитирует критические полосы психоакустики. Посредством моделирования человеческого восприятия, перцепционные кодеры могут обрабатывать сигналы наиболее близко к тому, как это делают люди, и пользоваться эффектами, такими как маскировка. В то время как это является их целью, процесс зависит от точного алгоритма. Вследствие того факта, что это сложно иметь очень точную перцепционную модель, которая касается общего человеческого поведения слушания, точность какого-либо математического выражения перцепционной модели все еще ограничена. Однако с ограниченной точностью перцепционная концепция помогла в разработке аудиокодеков. Многочисленные схемы аудиокодирования MPEG извлекли выгоду из исследования перцепционного эффекта маскировки. Несколько кодеков стандарта ITU также используют перцепционную концепцию. Например, ITU G.729.1 выполняет так называемое динамическое выделение битов на основе перцепционной концепции маскировки. Концепция динамического выделения битов на основе перцепционной важности также используется в последнем кодеке 3GPP EVS.
[112] Фигуры 9A и 9B иллюстрируют схематическое изображение типичного перцепционного кодека частотной области. Фигура 9A иллюстрирует кодер частотной области, тогда как фигура 9B иллюстрирует декодер частотной области.
[113] Сначала, исходный сигнал 901 преобразуется в частотную область, чтобы получить неквантованные коэффициенты 902 частотной области. До квантования коэффициентов, функция маскировки (перцепционная значимость) разделяет частотный спектр на множество поддиапазонов (часто равномерно распределенных для простоты). Каждый поддиапазон динамически выделяет необходимое количество битов, в то время как поддержание общего количества битов, распределяемых всем поддиапазонам, не находится за пределами верхнего ограничения. Некоторым поддиапазонам может быть выделено 0 битов, если оценивается, что они находятся под порогом маскировки. Как только определение сделано относительно того, от чего можно отказаться, оставшейся части выделяется доступное количество битов. Поскольку биты не потрачены на замаскированный спектр, они могут быть распределены в большем количестве остальной части сигнала.
[114] Согласно выделенным битам, коэффициенты квантуются, и битовый поток 703 отправляется декодеру. Хотя перцепционная концепция маскировки во многом помогла во время разработки кодека, она все еще не является совершенной вследствие различных причин и ограничений.
[115] Ссылаясь на фигуру 9B, последующая обработка стороны декодера может дополнительно улучшать перцепционное качество декодированного сигнала, произведенного с ограниченными скоростями передачи битов. Сначала, декодер использует принятые биты 904 для восстановления квантованных коэффициентов 905. Затем, они подвергаются последующей обработке надлежаще разработанным модулем 906 для получения улучшенных коэффициентов 907. Обратное преобразование выполняется в отношении улучшенных коэффициентов, чтобы иметь окончательный вывод 908 временной области.
[116] Фигура 10 иллюстрирует схематическое изображение операций на кодере до кодирования сигнала речи, содержащего аудиоданные, в соответствии с вариантами осуществления настоящего изобретения.
[117] Ссылаясь на фигуру 10, способ содержит выбор кодирования в частотной области или кодирования во временной области (блок 1000) на основе скорости передачи битов кодирования, которая должна быть использована для кодирования цифрового сигнала, и запаздывания основного тона цифрового сигнала.
[118] Выбор кодирования в частотной области или кодирования во временной области содержит этап, на котором определяют, содержит ли цифровой сигнал, сигнал короткого основного тона, для которого запаздывание основного тона короче, чем ограничение запаздывания основного тона (блок 1010). Дополнительно, определяется, является ли скорость передачи битов кодирования выше, чем верхнее ограничение скорости передачи битов (блок 1020). Если цифровой сигнал содержит сигнал короткого основного тона, и скорость передачи битов кодирования выше, чем верхнее ограничение скорости передачи битов, кодирование в частотной области выбирается для кодирования цифрового сигнала.
[119] В противном случае, определяется, является ли скорость передачи битов кодирования ниже, чем нижнее ограничение скорости передачи битов (блок 1030). Если цифровой сигнал содержит сигнал короткого основного тона, и скорость передачи битов кодирования ниже, чем нижнее ограничение скорости передачи битов, кодирование во временной области выбирается для кодирования цифрового сигнала.
[120] В противном случае, определяется, является ли скорость передачи битов кодирования промежуточной между нижним ограничением скорости передачи битов и верхним ограничением скорости передачи битов (блок 1040). Затем определяется периодичность голоса (блок 1050). Если цифровой сигнал содержит сигнал короткого основного тона, и скорость передачи битов кодирования является промежуточной и периодичность голоса является низкой, кодирование в частотной области выбирается для кодирования цифрового сигнала. В качестве альтернативы, если цифровой сигнал содержит сигнал короткого основного тона, и скорость передачи битов кодирования является промежуточной и периодичность голоса является очень сильной, кодирование во временной области выбирается для кодирования цифрового сигнала.
[121] В качестве альтернативы, ссылаясь на блок 1010, цифровой сигнал не содержит сигнал короткого основного тона, для которого запаздывание основного тона короче, чем ограничение запаздывания основного тона. Определяется, классифицируется ли цифровой сигнал как невокализованная речь или нормальная речь (блок 1070). Если цифровой сигнал не содержит сигнал короткого основного тона, и если цифровой сигнал классифицируется как невокализованная речь или нормальная речь, кодирование во временной области выбирается для кодирования цифрового сигнала.
[122] Соответственно, в различных вариантах осуществления способ для обработки сигналов речи до кодирования цифрового сигнала, содержащего аудиоданные, включает в себя выбор кодирования в частотной области или кодирования во временной области на основе скорости передачи битов кодирования, которая должна быть использована для кодирования цифрового сигнала, и обнаружения короткого запаздывания основного тона цифрового сигнала. Цифровой сигнал содержит сигнал короткого основного тона, для которого запаздывание основного тона короче, чем ограничение запаздывания основного тона. В различных вариантах осуществления способ выбора кодирования в частотной области или кодирования во временной области содержит выбор кодирования в частотной области для кодирования цифрового сигнала, когда скорость передачи битов кодирования выше, чем верхнее ограничение скорости передачи битов, и выбор кодирования во временной области для кодирования цифрового сигнала, когда скорость передачи битов кодирования ниже, чем нижнее ограничение скорости передачи битов. Скорость передачи битов кодирования выше, чем верхнее ограничение скорости передачи битов, когда скорость передачи битов кодирования больше, чем или равна 46200 бит/с. Скорость передачи битов кодирования ниже, чем нижнее ограничение скорости передачи битов, когда скорость передачи битов кодирования меньше, чем 24,4 кбит/с.
[123] Аналогичным образом, в другом варианте осуществления способ для обработки сигналов речи до кодирования цифрового сигнала, содержащего аудиоданные, содержит выбор кодирования в частотной области для кодирования цифрового сигнала, когда скорость передачи битов кодирования выше, чем верхнее ограничение скорости передачи битов. В качестве альтернативы, способ выбирает кодирование во временной области для кодирования цифрового сигнала, когда скорость передачи битов кодирования ниже, чем нижнее ограничение скорости передачи битов. Цифровой сигнал содержит сигнал короткого основного тона, для которого запаздывание основного тона короче, чем ограничение запаздывания основного тона. Скорость передачи битов кодирования выше, чем верхнее ограничение скорости передачи битов, когда скорость передачи битов кодирования больше чем или равна 46200 бит/с. Скорость передачи битов кодирования ниже, чем нижнее ограничение скорости передачи битов, когда скорость передачи битов кодирования меньше чем 24,4 кбит/с.
[124] Аналогичным образом, в другом варианте осуществления способ для обработки сигналов речи до кодирования содержит выбор кодирования во временной области для кодирования цифрового сигнала, содержащего аудиоданные, когда цифровой сигнал не содержит сигнал короткого основного тона и цифровой сигнал классифицируется как невокализованная речь или нормальная речь. Способ дополнительно содержит выбор кодирования в частотной области для кодирования цифрового сигнала, когда скорость передачи битов кодирования является промежуточной между нижним ограничением скорости передачи битов и верхним ограничением скорости передачи битов. Цифровой сигнал содержит сигнал короткого основного тона, и периодичность голоса является низкой. Способ дополнительно включает в себя выбор кодирования во временной области для кодирования цифрового сигнала, когда скорость передачи битов кодирования является промежуточной и цифровой сигнал содержит сигнал короткого основного тона и периодичность голоса является очень сильной. Нижнее ограничение скорости передачи битов равно 24,4 кбит/с и верхнее ограничение скорости передачи битов равно 46,2 кбит/с.
[125] Фигура 11 иллюстрирует систему 10 связи согласно варианту осуществления настоящего изобретения.
[126] Система 10 связи имеет устройства 7 и 8 доступа к аудио, соединенные с сетью 36 по линиям 38 и 40 связи. В одном варианте осуществления, устройство 7 и 8 доступа к аудио являются устройствами системы телефонии по протоколу передачи данных в Интернет (VOIP) и сеть 36 является глобальной сетью (WAN), коммутируемой телефонной сетью общего пользования (PTSN) и/или Интернет. В другом варианте осуществления, линии 38 и 40 связи являются проводными и/или беспроводными широкополосными соединениями. В альтернативном варианте осуществления, устройства 7 и 8 доступа к аудио являются сотовым или мобильным телефонами, линии 38 и 40 являются беспроводными мобильными телефонными каналами и сеть 36 представляет мобильную телефонную сеть.
[127] Устройство 7 доступа к аудио использует микрофон 12 для преобразования звука, такого как музыка или голос человека в аналоговый аудио входной сигнал 28. Микрофонный интерфейс 16 преобразует аналоговый аудио входной сигнал 28 в цифровой аудиосигнал 33 для ввода в кодер 22 кодека 20. Кодер 22 производит кодированный аудиосигнал TX для передачи сети 26 по сетевому интерфейсу 26 согласно вариантам осуществления настоящего изобретения. Декодер 24 в пределах кодека 20 принимает кодированный аудиосигнал RX из сети 36 по сетевому интерфейсу 26 и преобразует кодированный аудиосигнал RX в цифровой аудиосигнал 34. Интерфейс 18 динамика преобразует цифровой аудиосигнал 34 в аудиосигнал 30, подходящий для запуска громкоговорителя 14.
[128] В вариантах осуществления настоящего изобретения, где устройство 7 доступа к аудио является устройством VOIP, некоторые или все из компонентов в пределах устройства 7 доступа к аудио реализованы в пределах телефонного аппарата. Однако в некоторых вариантах осуществления микрофон 12 и громкоговоритель 14 являются отдельными блоками, и микрофонный интерфейс 16, интерфейс 18 динамика, кодек 20 и сетевой интерфейс 26 реализованы в пределах персонального компьютера. Кодек 20 может быть реализован, или в программном обеспечении, работающем на компьютере или предназначенном процессоре, или посредством предназначенного аппаратного обеспечения, например, на специализированной интегральной схеме (ASIC). Микрофонный интерфейс 16 реализован аналого-цифровым (A/D) преобразователем, а также другой схемой интерфейса, расположенной в пределах телефонного аппарата и/или в пределах компьютера. Аналогичным образом, интерфейс 18 динамика реализован цифроаналоговым преобразователем и другой схемой интерфейса, расположенной в пределах телефонного аппарата и/или в пределах компьютера. В дополнительных вариантах осуществления, устройство 7 доступа к аудио может быть реализовано и разделено другими способами, известными в области техники.
[129] В вариантах осуществления настоящего изобретения, где устройство 7 доступа к аудио является сотовым или мобильным телефоном, элементы в пределах устройства 7 доступа к аудио реализованы в пределах сотового телефонного аппарата. Кодек 20 реализован программным обеспечением, работающим на процессоре в пределах телефонного аппарата или посредством предназначенного аппаратного обеспечения. В дополнительных вариантах осуществления настоящего изобретения, устройство доступа к аудио может быть реализовано в других устройствах, таких как пиринговые проводные и беспроводные цифровые системы связи, например, переговорные устройства и ручные радиостанции. В прикладной области, такой как аудиоустройства потребителя, устройство доступа к аудио может содержать кодек только с кодером 22 или декодером 24, например, в цифровой микрофонной системе или устройстве воспроизведения музыки. В других вариантах осуществления настоящего изобретения, кодек 20 может быть использован без микрофона 12 и динамика 14, например, в сотовых базовых станциях, которые осуществляют доступ к PTSN.
[130] Обработка речи для улучшения невокализованной/вокализованной классификации, описанной в различных вариантах осуществления настоящего изобретения, например, может быть реализована в кодере 22 или декодере 24. Обработка речи для улучшения невокализованной/вокализованной классификации может быть реализована в аппаратном обеспечении или программном обеспечении в различных вариантах осуществления. Например, кодер 22 или декодер 24 может быть частью кристалла цифровой обработки сигналов (DSP).
[131] Фигура 12 иллюстрирует блок-схему системы обработки, которая может быть использована для реализации устройств и способов, раскрытых в этом документе. Специфические устройства могут использовать все из показанных компонентов, или только поднабор из компонентов, и уровни интеграции могут меняться от устройства к устройству. Кроме того, устройство может содержать несколько примеров компонента, например, несколько блоков обработки, процессоров, запоминающих устройств, передатчиков, приемников и так далее. Система обработки может содержать блок обработки, оборудованный одним или более устройствами ввода/вывода, такими как динамик, микрофон, мышь, воспринимающий касание экран, клавишная панель, клавиатура, принтер устройство отображения и подобное. Блок обработки может включать в себя центральный блок обработки (CPU), память, массовое устройство хранения, видеоадаптер и интерфейс I/O, соединенный с шиной.
[132] Шина может быть одной или более из какого-либо типа нескольких архитектур шин, включающих в себя шину памяти или контроллер памяти, периферийную шину, шину видеосигналов или подобное. CPU может содержать какой-либо тип электронного процессора данных. Память может содержать какой-либо тип системной памяти, например, статическое запоминающее устройство с произвольной выборкой (SRAM), динамическое запоминающее устройство с произвольной выборкой (DRAM), синхронное DRAM (SDRAM), постоянное запоминающее устройство (ROM), их комбинацию или подобное. В варианте осуществления, память может включать в себя ROM для использования во время загрузки, и DRAM, чтобы использовать хранение данных и программ при исполнении программ.
[133] Массовое устройство хранения может содержать какой-либо тип устройства хранения, сконфигурированного с возможностью хранения данных, программ и другой информации, и с возможностью делать данные, программы и другую информацию доступной через шину. Массовое устройство хранения может содержать, например, один или более из твердотельного накопителя, накопителя на жестком диске, накопителя на магнитных дисках, накопителя на оптических дисках или подобного.
[134] Видеоадаптер и интерфейс I/O обеспечивают интерфейсы для соединения внешних устройств ввода и вывода с блоком обработки. Как проиллюстрировано, примеры устройств ввода и вывода включают в себя устройство отображения, соединенное с видеоадаптер, и мышь/клавиатуру/принтер, соединенный с интерфейсом I/O. Другие устройства могут быть соединены с блоком обработки, и дополнительные или меньшее количество интерфейсных плат может быть использовано. Например, последовательный интерфейс, такой как универсальная последовательная шина (USB) (не показан), может быть использован для обеспечения интерфейса для принтера.
[135] Блок обработки также включает в себя один или более сетевых интерфейсов, которые могут содержать проводные линии связи, такие как Ethernet-кабель или подобное, и/или беспроводные линии связи для осуществления доступа к узлам или различным сетям. Сетевой интерфейс позволяет блоку обработки осуществлять связь с удаленными блоками по сетям. Например, сетевой интерфейс может обеспечивать беспроводную связь через одну или более антенн передатчиков/передачи и одну или более антенн приемников/приема. В варианте осуществления, блок обработки соединен с локальной сетью или глобальной сетью для обработки данных и связи с удаленными устройствами, такими как другие блоки обработки, Интернет, удаленные блоки памяти или подобное.
[136] В то время как это изобретение было описано со ссылкой на иллюстративные варианты осуществления, это описание не следует истолковывать в ограничительном смысле. Различные модификации и комбинации иллюстративных вариантов осуществления, а также другие варианты осуществления изобретения будут очевидны специалистам в данной области техники после ссылки на описание. Например, различные варианты осуществления, описанные выше по тексту, могут быть объединены друг с другом.
[137] Ссылаясь на Фигуру 13, описывается вариант осуществления аппарата 130 для обработки сигналов речи до кодирования цифрового сигнала. Аппарат включает в себя:
[138] селектор 131 кодирования, сконфигурированный с возможностью выбора кодирования в частотной области или кодирования во временной области на основе скорости передачи битов кодирования, которая должна быть использована для кодирования цифрового сигнала, и обнаружения короткого запаздывания основного тона цифрового сигнала.
[139] При этом когда цифровой сигнал включает в себя сигнал короткого основного тона, для которого запаздывание основного тона короче, чем ограничение запаздывания основного тона, селектор кодирования сконфигурирован с возможностью
[140] выбора кодирования в частотной области для кодирования цифрового сигнала, когда скорость передачи битов кодирования выше, чем верхнее ограничение скорости передачи битов, и
[141] выбора кодирования во временной области для кодирования цифрового сигнала, когда скорость передачи битов кодирования ниже, чем нижнее ограничение скорости передачи битов.
[142] При этом когда цифровой сигнал включает в себя сигнал короткого основного тона, для которого запаздывание основного тона короче, чем ограничение запаздывания основного тона, селектор кодирования сконфигурирован с возможностью выбора кодирования в частотной области для кодирования цифрового сигнала, когда скорость передачи битов кодирования является промежуточной между нижним ограничением скорости передачи битов и верхним ограничением скорости передачи битов, и при этом периодичность голоса является низкой.
[143] При этом когда цифровой сигнал не включает в себя сигнал короткого основного тона, для которого запаздывание основного тона короче, чем ограничение запаздывания основного тона, селектор кодирования сконфигурирован с возможностью выбора кодирования во временной области для кодирования цифрового сигнала, когда цифровой сигнал классифицируется как невокализованная речь или нормальная речь.
[144] При этом когда цифровой сигнал включает в себя сигнал короткого основного тона, для которого запаздывание основного тона короче, чем ограничение запаздывания основного тона, селектор кодирования сконфигурирован с возможностью выбора кодирования во временной области для кодирования цифрового сигнала, когда скорость передачи битов кодирования является промежуточной между нижним ограничением скорости передачи битов и верхним ограничением скорости передачи битов, и периодичность голоса является очень сильной.
[145] Аппарат дополнительно включает в себя блок 132 кодирования, причем блок кодирования сконфигурирован с возможностью кодирования цифрового сигнала с использованием кодирования в частотной области, выбранного селектором 131, или кодирования во временной области, выбранного селектором 131.
[146] Селектор кодирования и блок кодирования могут быть реализованы посредством CPU или некоторыми схемами аппаратного обеспечения, такими как FPGA, ASIC.
[147] Ссылаясь на Фигуру 14, описывается вариант осуществления аппарата 140 для обработки сигналов речи до кодирования цифрового сигнала. Аппарат включает в себя:
[148] блок 141 выбора кодирования, блок выбора кодирования сконфигурирован с возможностью
выбора кодирования во временной области для кодирования цифрового сигнала, содержащего аудиоданные, когда цифровой сигнал не включает в себя сигнал короткого основного тона и цифровой сигнал классифицируется как невокализованная речь или нормальная речь;
[149] выбора кодирования в частотной области для кодирования цифрового сигнала, когда скорость передачи битов кодирования является промежуточной между нижним ограничением скорости передачи битов и верхним ограничением скорости передачи битов, и цифровой сигнал включает в себя сигнал короткого основного тона и периодичность голоса является низкой; и
[150] выбора кодирования во временной области для кодирования цифрового сигнала, когда скорость передачи битов кодирования является промежуточной и цифровой сигнал включает в себя сигнал короткого основного тона и периодичность голоса является очень сильной.
[151] Аппарат дополнительно включает в себя второй блок 142 кодирования, причем второй блок кодирования сконфигурирован с возможностью кодирования цифрового сигнала с использованием кодирования в частотной области, выбранного блоком 141 выбора кодирования, или кодирования во временной области, выбранного блоком 141 выбора кодирования.
[152] Блок выбора кодирования и блок кодирования могут быть реализованы посредством CPU или некоторыми схемами аппаратного обеспечения, такими как FPGA, ASIC.
[153] Хотя настоящее изобретение и его преимущества были описаны подробно, следует понимать, что различные изменения, замены и исправления могут быть сделаны в этом документе без отклонения от сущности и объема изобретения, как задано прилагаемой формулой изобретения. Например, многие из признаков и функций, рассматриваемых выше по тексту, могут быть реализованы в программном обеспечении, аппаратном обеспечении или программно-аппаратном обеспечении, или в их комбинации. Более того, объем настоящей заявки не предназначен для ограничения конкретными вариантами осуществления процесса, механизма, изготовления, композиции, средств, способов и этапов, описанных в описании. Как должно быть понятно обычному специалисту в данной области техники из раскрытия настоящего изобретения, процессы, механизмы, изготовление, композиции, средства, способы или этапы, в настоящий момент существующие или разрабатываемые в будущем, которые выполняют по существу одну и ту же функцию или достигают по существу одного и того же результата как соответствующие варианты осуществления, описанные в этом документе, могут быть использованы согласно настоящему изобретению. Соответственно, прилагаемая формула изобретения предназначена, чтобы включать в свой объем такие процессы, механизмы, изготовление, композиции, средства, способы или этапы.

Изобретение относится к средствам для кодирования сигналов. Технический результат заключается в повышении эффективности классификации между кодированием во временной области и кодированием в частотной области. Выбирают кодирование в частотной области или кодирование во временной области на основе скорости передачи битов кодирования, которая должна быть использована для кодирования цифрового сигнала, и обнаружения короткого запаздывания основного тона цифрового сигнала. Обнаружение короткого запаздывания основного тона содержит обнаружение того, содержит ли цифровой сигнал, сигнал короткого основного тона, для которого запаздывание основного тона короче, чем ограничение запаздывания основного тона, при этом ограничение запаздывания основного тона является минимальным допустимым основным тоном для алгоритма линейного предсказания с кодовым возбуждением (CELP) для кодирования цифрового сигнала. 2 н. и 12 з.п. ф-лы, 15 ил.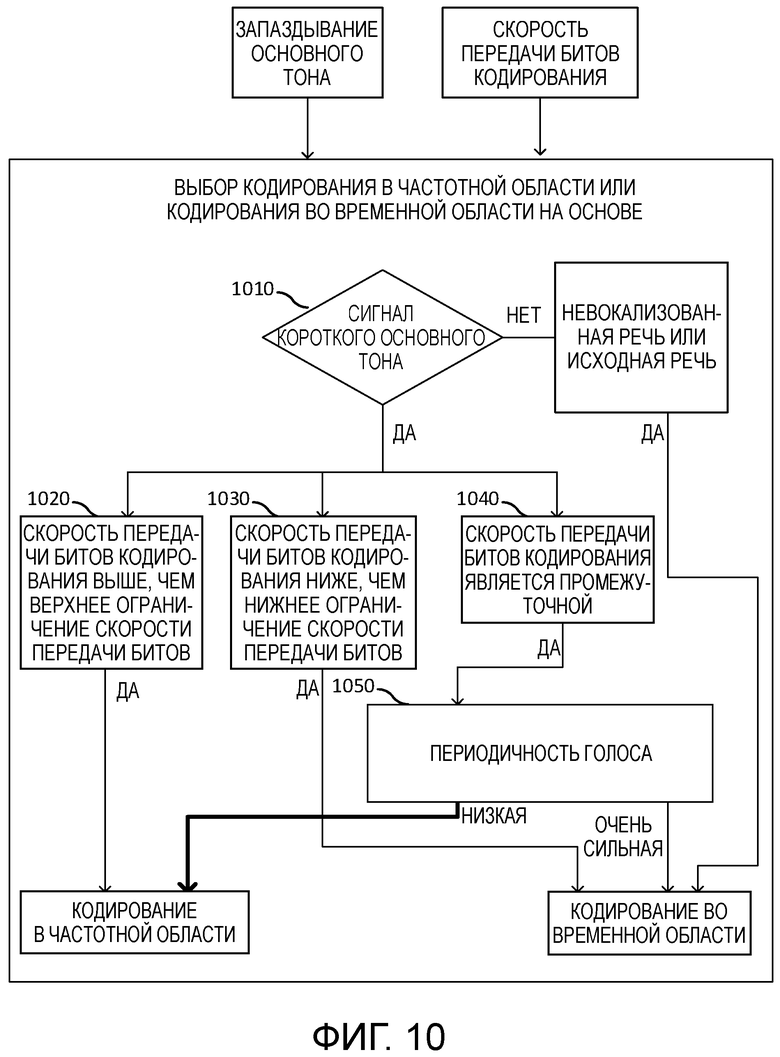
1. Способ для обработки сигналов речи до кодирования цифрового сигнала, содержащего аудиоданные, причем способ содержит этапы, на которых:
выбирают кодирование в частотной области или кодирование во временной области на основе
скорости передачи битов кодирования, которая должна быть использована для кодирования цифрового сигнала, и
обнаружения короткого запаздывания основного тона цифрового сигнала;
при этом обнаружение короткого запаздывания основного тона содержит обнаружение того, содержит ли цифровой сигнал, сигнал короткого основного тона, для которого запаздывание основного тона короче, чем ограничение запаздывания основного тона, при этом ограничение запаздывания основного тона является минимальным допустимым основным тоном для алгоритма линейного предсказания с кодовым возбуждением (CELP) для кодирования цифрового сигнала.
2. Способ по п. 1, при этом цифровой сигнал содержит сигнал короткого основного тона, для которого запаздывание основного тона короче, чем ограничение запаздывания основного тона, и при этом выбор кодирования в частотной области или кодирования во временной области содержит этап, на котором:
выбирают кодирование во временной области для кодирования цифрового сигнала, когда скорость передачи битов кодирования ниже, чем нижнее ограничение скорости передачи битов.
3. Способ по п. 2, при этом скорость передачи битов кодирования ниже, чем нижнее ограничение скорости передачи битов, когда скорость передачи битов кодирования меньше, чем 24,4 кбит/c.
4. Способ по п. 1, при этом цифровой сигнал содержит сигнал короткого основного тона, для которого запаздывание основного тона короче, чем ограничение запаздывания основного тона, и при этом выбор кодирования в частотной области или кодирования во временной области содержит этап, на котором:
выбирают кодирование в частотной области для кодирования цифрового сигнала, когда скорость передачи битов кодирования выше, чем верхнее ограничение скорости передачи битов.
5. Способ по п. 4, при этом скорость передачи битов кодирования выше, чем верхнее ограничение скорости передачи битов, когда скорость передачи битов кодирования больше, чем или равна 46200 бит/с.
6. Способ по п. 1, при этом цифровой сигнал не содержит сигнал короткого основного тона, для которого запаздывание основного тона короче, чем ограничение запаздывания основного тона, и при этом выбор кодирования в частотной области или кодирования во временной области содержит этап, на котором:
выбирают кодирование во временной области для кодирования цифрового сигнала, когда цифровой сигнал классифицируется как невокализованная речь или нормальная речь.
7. Способ по п. 1, дополнительно содержащий этап, на котором осуществляют кодирование цифрового сигнала с использованием выбранного кодирования в частотной области или выбранного кодирования во временной области.
8. Аппарат для обработки сигналов речи до кодирования цифрового сигнала, содержащего аудиоданные, причем аппарат содержит селектор кодирования, сконфигурированный с возможностью выбора кодирования в частотной области или кодирования во временной области на основе скорости прохождения битов кодирования, которая должна быть использована для кодирования цифрового сигнала, и обнаружения короткого запаздывания основного тона цифрового сигнала, при этом обнаружение короткого запаздывания основного тона содержит обнаружение, содержит ли цифровой сигнал, сигнал короткого основного тона, для которого запаздывание основного тона короче, чем ограничение запаздывания основного тона, при этом ограничение запаздывания основного тона является минимальным допустимым основным тоном для алгоритма линейного предсказания с кодовым возбуждением (CELP) для кодирования цифрового сигнала.
9. Аппарат по п. 8, при этом когда цифровой сигнал содержит сигнал короткого основного тона, для которого запаздывание основного тона короче, чем ограничение запаздывания основного тона, селектор кодирования сконфигурирован с возможностью
выбора кодирования во временной области для кодирования цифрового сигнала, когда скорость передачи битов кодирования ниже, чем нижнее ограничение скорости передачи битов.
10. Аппарат по п. 9, при этом скорость передачи битов кодирования ниже, чем нижнее ограничение скорости передачи битов, когда скорость передачи битов кодирования меньше, чем 24,4 кбит/с.
11. Аппарат по п. 8, при этом, когда цифровой сигнал содержит сигнал короткого основного тона, для которого запаздывание основного тона короче, чем ограничение запаздывания основного тона, селектор кодирования сконфигурирован с возможностью:
выбора кодирования в частотной области для кодирования цифрового сигнала, когда скорость передачи битов кодирования выше, чем верхнее ограничение скорости передачи битов.
12. Аппарат по п. 11, при этом скорость передачи битов кодирования выше, чем верхнее ограничение скорости передачи битов, когда скорость передачи битов кодирования больше, чем или равна 46200 бит/с.
13. Аппарат по п. 8, при этом когда цифровой сигнал не содержит сигнал короткого основного тона, для которого запаздывание основного тона короче, чем ограничение запаздывания основного тона, селектор кодирования сконфигурирован с возможностью:
выбора кодирования во временной области для кодирования цифрового сигнала, когда цифровой сигнал классифицируется как невокализованная речь или нормальная речь.
14. Аппарат по п. 8, при этом аппарат дополнительно содержит блок кодирования, который сконфигурирован с возможностью кодирования цифрового сигнала с использованием кодирования в частотной области, выбранного селектором, или кодирования во временной области, выбранного селектором.
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| CN 103915100 A, 09.07.2014 | |||
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| CN 101283255 B, 04.12.2013 | |||
| УСТРОЙСТВО И СПОСОБ ДЕКОДИРОВАНИЯ КОДИРОВАННОГО ЗВУКОВОГО СИГНАЛА | 2009 |
|
RU2483366C2 |

