Область техники
Изобретение относится к системам и методам создания описания и сравнения функционала исполняемых файлов и более конкретно к определению их принадлежности к известным коллекциям.
Уровень техники
В настоящее время наблюдается значительный рост количества вредоносных программ. Каждый день появляется несколько десятков тысяч новых вариантов вредоносного программного обеспечения, из-за чего антивирусным компаниям все сложнее и сложнее предоставлять пользователю достойный уровень защиты. Одна из причин тому - появление полиморфных и метаморфных вредоносных программ. Полиморфизм заключается в формировании уникального кода программы непосредственно во время исполнения, при этом сама процедура, формирующая код, также является уникальной при каждом новом заражении. Метаморфизм заключается в шифровании или искажении некоторых частей программы, делая ее «неузнаваемой». «Новый вариант» не означает полностью отличную от других новую вредоносную программу, но в большинстве своем, новыми они являются только для существующей в данный момент одной из основных технологий детектирования - сигнатурной.
Растущая угроза со стороны полиморфных и метаморфных вирусов заставила антивирусных разработчиков дополнить сигнатурный анализ другими методами, которые включали технологии редуцированной маски, криптографического и статистического анализа, а также эмуляции кода.
Технология редуцированной маски заключается в применении к зашифрованному телу вируса некоторого преобразования, которое на выходе выдает уникальную комбинацию, идентифицирующую вирус вне зависимости от выбора ключа шифрования.
Эмуляция кода также использовалась для более эффективного эвристического обнаружения, поскольку она делала возможным динамический анализ кода. Однако базовый метод сигнатурного детектирования практически не улучшался.
Альтернативным решением проблемы резкого увеличения числа угроз стал поведенческий анализ. В то время как традиционные антивирусные сканеры хранили сигнатуры вредоносных программ в базах данных и при сканировании сверяли код с имеющимися в базах сигнатурами, поведенческий блокиратор определял, является ли программа вредоносной, исходя из ее поведения в системе. Если программа выполняла действия, не разрешенные правилами, определенными заранее, то выполнение этой программы блокировалось.
Основным преимуществом поведенческого блокиратора является его способность отличать «хорошие» программы от «плохих» без помощи профессионального вирусного аналитика. Поскольку нет необходимости анализировать каждую новую угрозу, регулярное обновление баз сигнатур становится ненужным, а пользователи тем временем надежно защищены от новых угроз.
Проблема в том, что существует некая промежуточная зона между явно вредоносными и допустимыми действиями. Кроме того, одни и те же действия могут быть вредоносными в программе, предназначенной для нанесения ущерба, и полезными в легитимном программном обеспечении. Например, низкоуровневая запись данных, используемая вредоносной программой для того, чтобы стереть информацию с жесткого диска, совершенно легитимно применяется операционной системой. Кроме того, поведенческому блокиратору, установленному на файловом сервере, сложно определить, законно пользователь изменяет или удаляет документ, или это результат действии вредоносной программы.
В связи с этим основная масса антивирусов по-прежнему ориентирована на обнаружение известных вредоносных программ, используя метод сигнатур. Тем не менее, поведенческий анализ получил свое дальнейшее развитие: в некоторых современных решениях по защите от информационных угроз он используется в сочетании с другими методами поиска, обезвреживания и удаления вредоносного кода.
Большой процент ложных срабатываний и невысокий уровень детектирования вредоносного программного обеспечения посредством новых технологий не позволяет отказаться от сигнатурного метода детектирования и ставит вопрос его усовершенствования.
Существует другой метод описания функциональности исполняемых файлов, описанный, например, в патенте US 5752039, в котором раскрывается идея сравнения исполняемых файлов, обновление одного исполняемого файла до функционала другого исполняемого файла, а также описывается система структуризации исполняемых файлов с помощью создания логических блоков, аналогичная описанной в изобретении.
Однако в патенте не описываются логические объединения элементов исполняемых файлов, присутствующих в данном изобретении.
Существуют другие методы выделения в коде исполняемого файла бесполезной для проведения сравнения информации, описанные, например, в заявке US 20050028149 A1, в которой раскрывается идея создания схемы, которая распознает циклический код, или патенте US 7349931, в котором раскрывается идея сканирования компьютерной системы в поисках файлов с добавленным кодом, работающих с потенциально вредоносными процессами.
Однако в реализации данных методов ничего не сказано об избавлении от шумящего кода от компилятора.
Также существуют методы сравнения неизвестных исполняемых файлов с коллекцией известных файлов, а также составления коллекций, описанные, например, в заявке US 20080195587 A1, где описываются метод и система, которые определяют похожести моделей множеств, или в патенте US 7103913, в котором раскрывается идея метода сравнения проверяемых записей с уже хранящимися записями в системе, или в патенте US 7447703, где раскрывается идея создания коллекций информации, которые улучшают продуктивность работы сотрудников.
Однако в представленном изобретении используются различные виды составления коллекций вредоносных файлов - список более широкий, чем в представленных выше патентах. Метод сравнения файлов, аналогичный данному изобретению, используется в представленном патенте, однако существуют различия в его реализации.
Анализ предшествующего уровня техники и возможностей, которые появляются при комбинировании их в одной системе, позволяют получить новый результат. Соответственно, техническим результатом заявленного изобретения является предоставление системы, способа и машиночитаемого носителя, которые повышают надежность и точность детектирования вредоносного программного обеспечения за счет сравнения исполняемых файлов посредством шаблонов функциональности.
Раскрытие изобретения
Настоящее изобретение предназначено для описания и сравнения функционала исполняемых файлов с целью определения их принадлежности к коллекциям известных файлов.
Технический результат настоящего изобретения заключается в повышении надежности и точности детектирования вредоносного программного обеспечения и достигается за счет сравнения исполняемых файлов посредством шаблонов функциональности.
Согласно способу определения принадлежности файлов к коллекциям известных файлов на основе сравнения файлов с помощью шаблонов функциональности, содержащий этапы, на которых: (а) формируют шаблоны функциональности на основе информации об исполняемом файле; (б) удаляют выделенную шумовую информацию из шаблонов функциональности исполняемого файла; (в) приводят блоки шаблонов функциональности исполняемого файла к нормализованному виду для последующего сравнения; (г) сравнивают нормализованные блоки шаблонов функциональности исполняемого файла с блоками шаблонов функциональности известных файлов и по результатам сравнения принимают решение о принадлежности нормализованного блока шаблонов функциональности к одному из шаблонов функциональности известных файлов.
В частном варианте осуществления информация об исполняемом файле может быть собрана посредством таких инструментов сбора информации, как модуль, эмулирующий исполнение программы; модуль виртуализации программ; модуль контроля приложений; модуль, который дизассемблирует программу и позволяет облегчить дальнейшее выстраивание между определенными функциями связей.
В другом частном варианте осуществления формирование шаблонов функциональности исполняемого файла осуществляется в два этапа: динамический и статический. Динамический этап подразумевает сбор информации об исполняемом файле при помощи инструментов сбора информации; и результатом работы динамического этапа при формировании шаблонов функциональности исполняемого файла являются дамп памяти и журнал событий. Статический этап подразумевает непосредственную трассировку дампа памяти и формирование шаблонов функциональности исполняемого файла.
В другом частном варианте осуществления шаблоны функциональности исполняемого файла бывают двух типов: шаблон функциональности, который основан на последовательности блоков; и шаблон функциональности, который основан на последовательности ребер. Блоками называются совокупности элементов, такие как API-функции, ссылки на строки кода и ссылки на другие логические блоки. Ребрами называются участки между вызовами одного блока другим.
В другом частном варианте осуществления выделенная шумовая информация включает в себя базовые библиотеки компилятора и статически слинкованные функции стандартных библиотек.
В другом частном варианте осуществления сравнение шаблонов функциональности исполняемого файла с шаблонами из коллекций известных файлов осуществляется по различным для каждого типа шаблонов функциональности математическим алгоритмам, таким как расстояние Хемминга; расстояние Левенштейна; алгоритм вычисления весов; алгоритм выделения характеристической информации.
Система определения принадлежности файлов к коллекциям известных файлов на основе сравнения файлов с помощью шаблонов функциональности, содержащая: средство эмуляции, которое осуществляет сбор информации об исполняемом файле; средство создания шаблонов функциональности исполняемого файла, которое на основе информации, собранной средством эмуляции, формирует блоки и составляет из них шаблоны функциональности исполняемого файла; средство обработки шаблонов функциональности исполняемых файлов, которое удаляет выделенную из шаблонов функциональности шумовую информацию и приводит блоки шаблонов функциональности к нормализованному виду; средство хранения коллекций шаблонов функциональности известных файлов; средство сравнения шаблонов функциональности исполняемых файлов, которое осуществляет сравнение нормализованных блоков шаблонов функциональности, полученных от средства обработки шаблонов функциональности, с шаблонами функциональности известных файлов из упомянутого средства хранения коллекции в соответствии с классификацией шаблонов функциональности исполняемых файлов.
В частном варианте осуществления средство эмуляции включает в себя такие инструменты сбора информации, как модуль, эмулирующий исполнение программы; модуль виртуализации программ; модуль контроля приложений; модуль, который дизассемблирует программу и позволяет облегчить дальнейшее выстраивание между определенными функциями связей.
Машиночитаемый носитель определения принадлежности файлов к коллекциям известных файлов на основе сравнения файлов с помощью шаблонов функциональности, на котором сохранена компьютерная программа, при исполнении которой на компьютере выполняются следующие этапы: (а) формируют шаблоны функциональности на основе информации об исполняемом файле; (б) удаляют выделенную шумовую информацию из шаблонов функциональности исполняемого файла; (в) приводят блоки шаблонов функциональности исполняемого файла к нормализованному виду для последующего сравнения; (г) сравнивают нормализованные блоки шаблонов функциональности исполняемого файла с блоками шаблонов функциональности известных файлов и по результатам сравнения принимают решение о принадлежности нормализованного блока шаблонов функциональности к одному из шаблонов функциональности известных файлов.
Дополнительные признаки и преимущества изобретения будут установлены из описания, которое прилагается, и частично будут очевидны из описания или могут быть получены при использовании изобретения. Преимущества изобретения будут реализовываться и достигаться посредством структуры, конкретно подчеркнутой в написанном описании и формулах, а также прилагаемых чертежах.
Понятно, что предшествующее общее описание и последующее подробное описание являются примерными и объясняющими и предназначены для обеспечения дополнительного объяснения заявленного изобретения.
Краткое описание чертежей
Дополнительные цели, признаки и преимущества настоящего изобретения будут очевидными из прочтения последующего описания осуществления изобретения со ссылкой на прилагаемые чертежи, на которых:
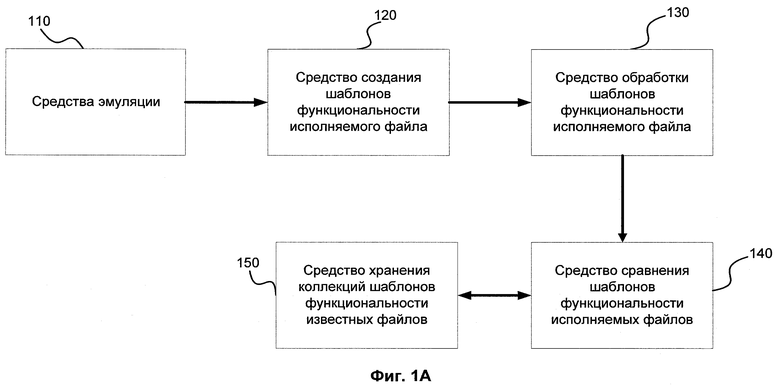
Фиг.1А показывает схему взаимодействия средств данного изобретения.
Фиг.1Б - способ работы данного изобретения.
Фиг.2 показывает пример логического блока, сформированного в результате работы настоящего изобретения.
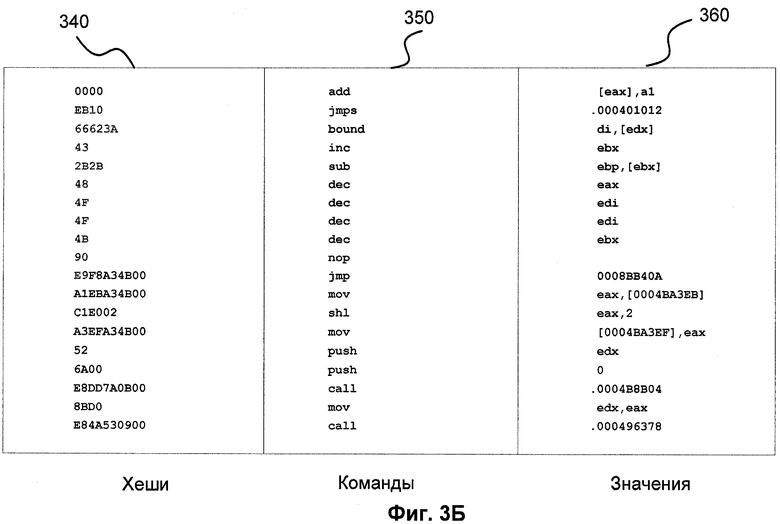
Фиг.3А и 3Б показывают примеры сигнатур различных компиляторов.
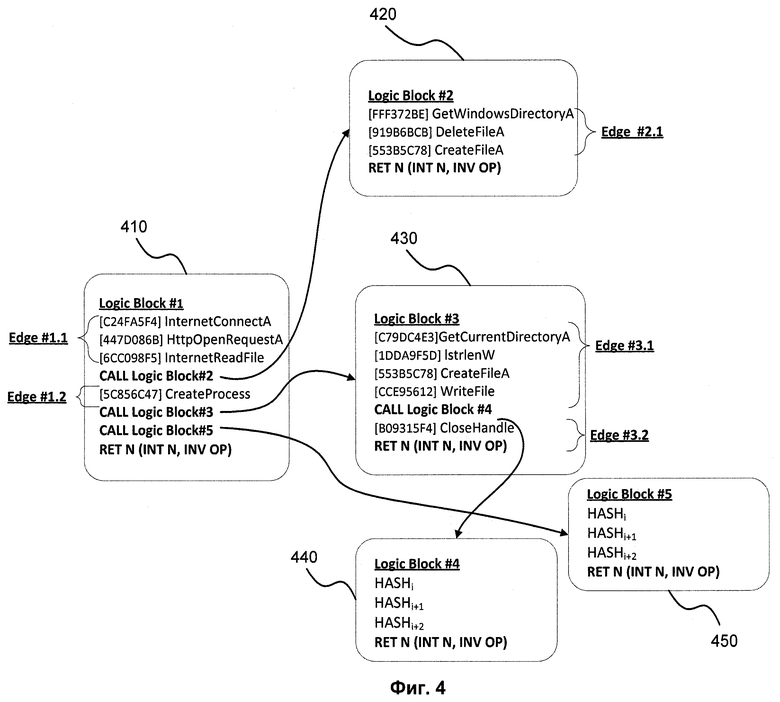
Фиг.4 показывает схематичное представление структуры функционального шаблона.
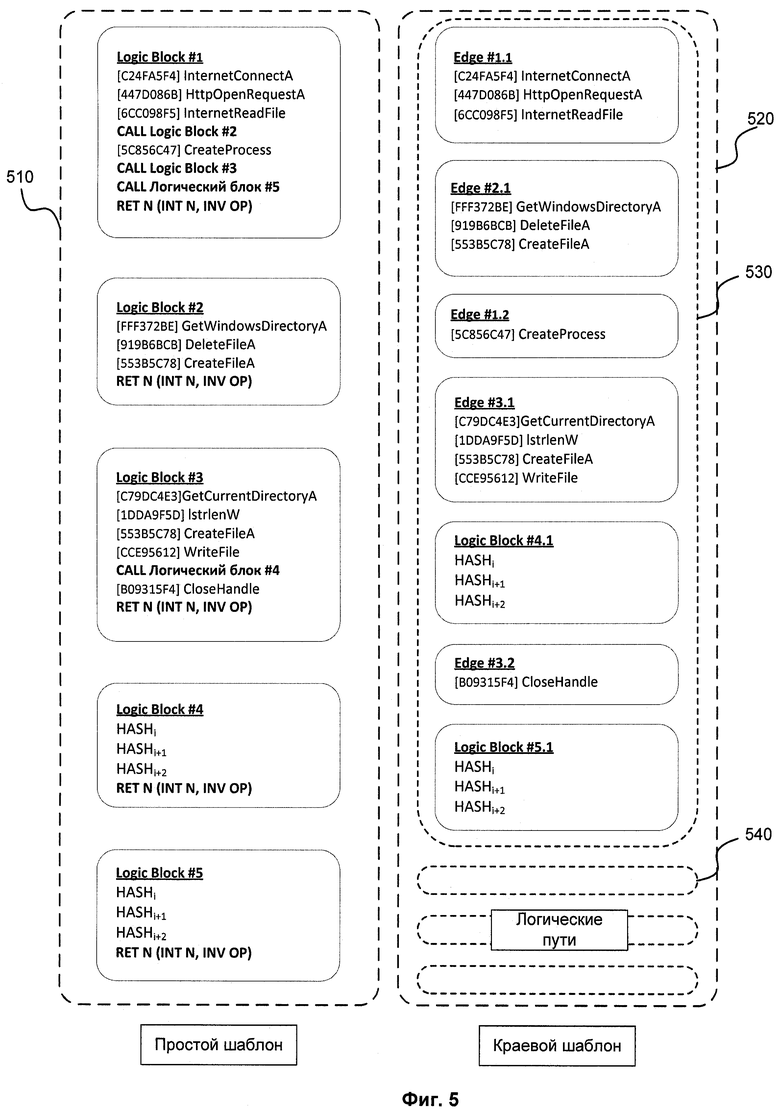
Фиг.5 показывает структуру данных функционального шаблона.
Фиг.6 показывает схематичное представление наборов файлов для алгоритма выделения стандартных логических блоков по «значению информативности».
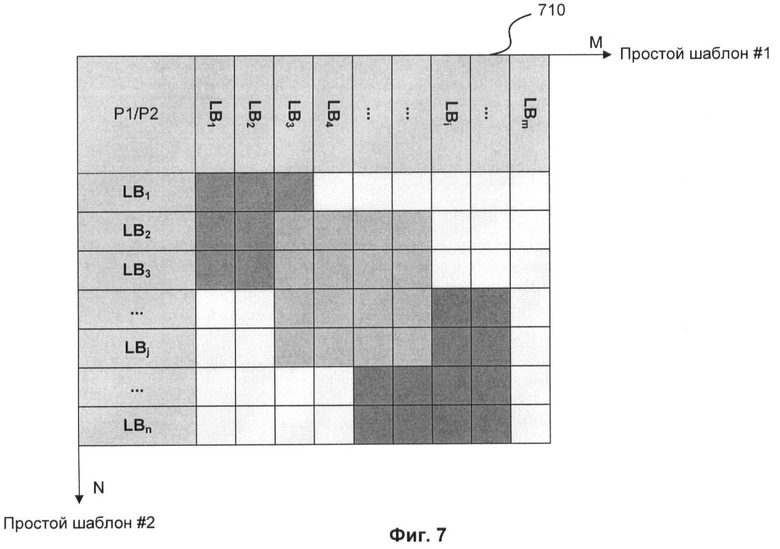
Фиг.7 показывает схему сравнения логических блоков двух функциональных шаблонов.
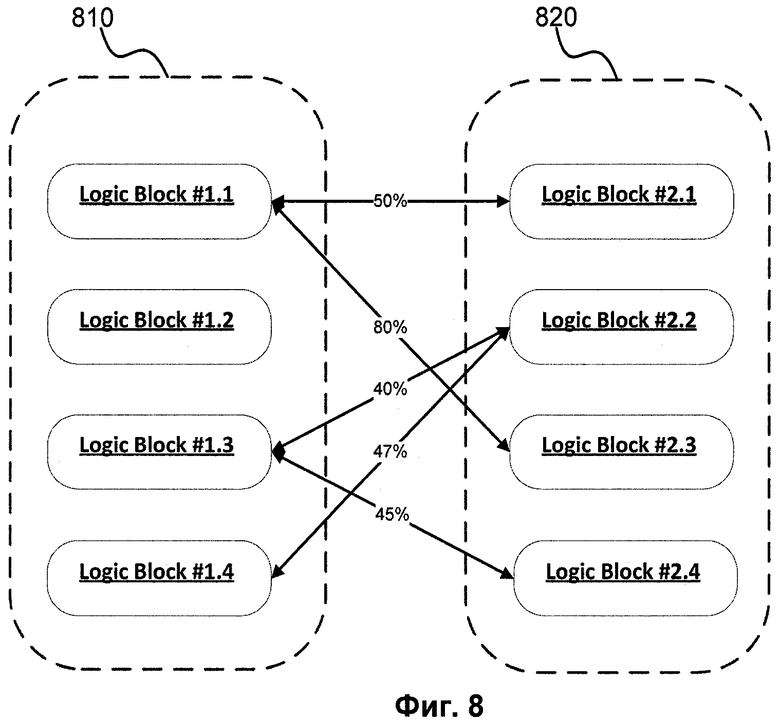
Фиг.8 показывает взаимно-однозначное соответствие со значением похожести между логическими блоками двух функциональных шаблонов.
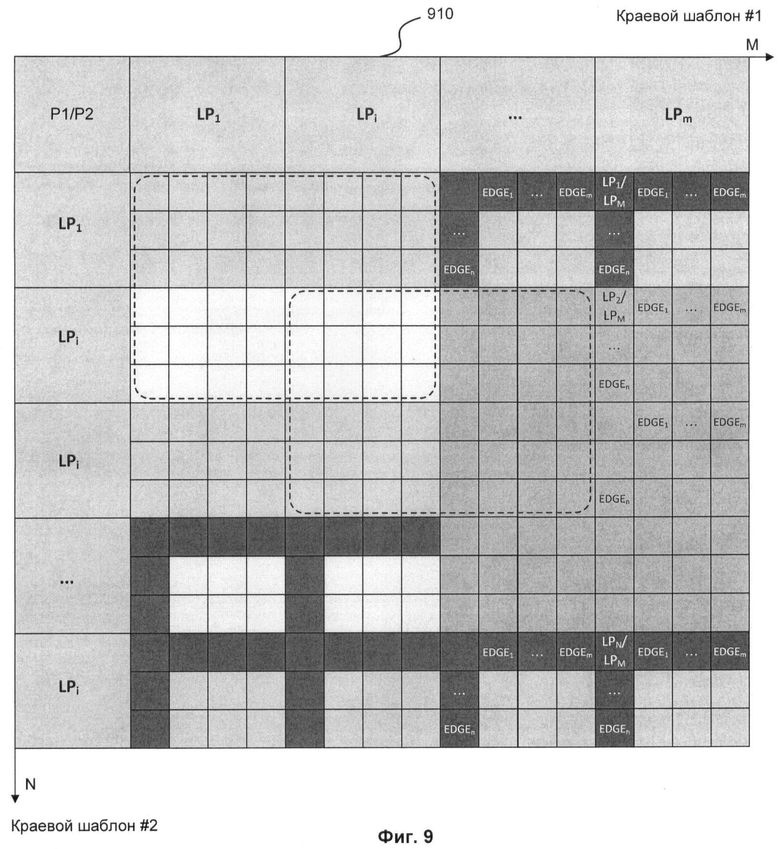
Фиг.9 показывает таблицу сравнения логических путей двух информационных шаблонов.
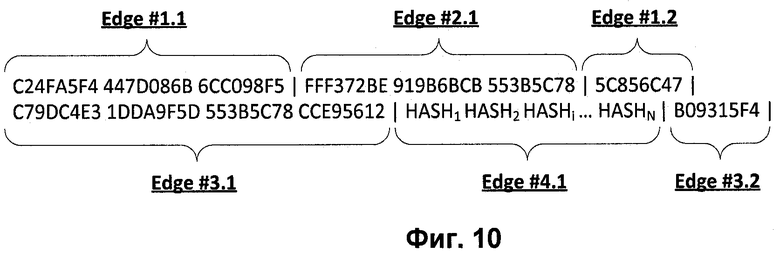
Фиг.10 показывает бинарное представление логических путей функционального шаблона в виде последовательности хеш-функции, взятых от имен событий/элементов блока.
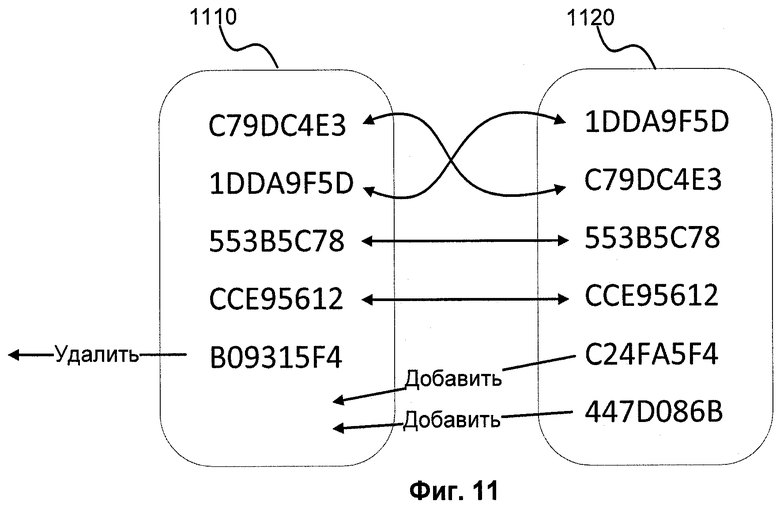
Фиг.11 показывает пример сравнения блоков по алгоритму измерения расстояния Левенштейна.
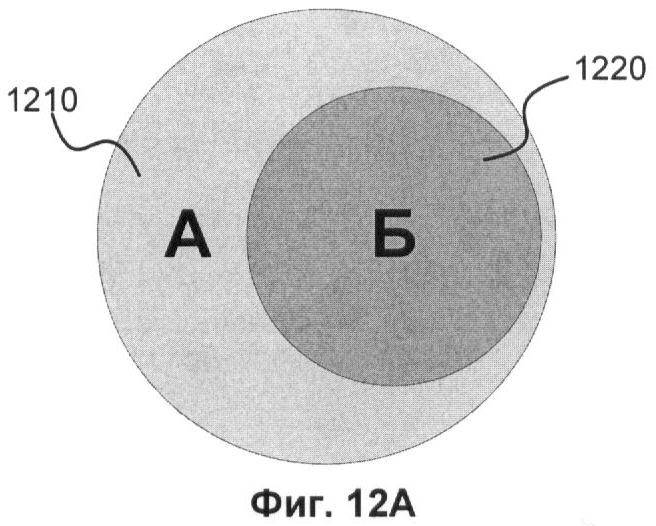
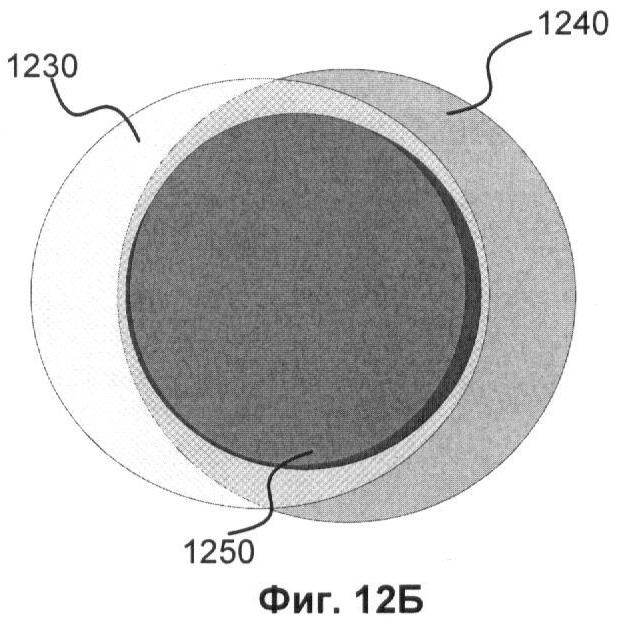
Фиг.12А и 12Б показывает выделение информации из функциональных шаблонов для алгоритма детектирования, основывающегося на выделении характеристической информации.
Фиг.13 показывает пример функционального шаблона для алгоритма детектирования, основывающегося на выделении характеристической информации.
Описание вариантов осуществления изобретения
Объекты и признаки настоящего изобретения, способы для достижения этих объектов и признаков станут очевидными посредством отсылки к примерным вариантам осуществления. Однако настоящее изобретение не ограничивается примерными вариантами осуществления, раскрытыми ниже, оно может воплощаться в различных видах. Сущность, приведенная в описании, является ничем иным, как конкретными деталями, обеспеченными для помощи специалисту в области техники в исчерпывающем понимании изобретения, и настоящее изобретение определяется только в объеме приложенной формулы.
Данное изобретение позволяет описывать и сравнивать функционал исполняемых файлов, собирая и структурируя его в шаблоны функциональности. При этом сбор информации производится как статическими, так и динамическими системами, что позволяет собрать максимум информации о действиях программы.
В отличие от эвристического детектирования, изобретение позволяет построить полные структурированные описания исполняемых файлов, а не выделять конкретный «вредоносный» функционал. Метод основан на сборе и сравнении именно функционала исполняемого файла, поэтому изменение двоичного представления исполняемого файла никак не влияет на описание программы, а следовательно, и на результаты сравнения.
Такие мощные инструменты сбора информации об исполняемом файле, как Эмулятор - инструмент моделирования состояния имитируемой системы, для выполнения оригинального машинного кода; «Песочница» - инструмент виртуализации, контролирующий взаимодействие между операционной системой и программой; HIPS - инструмент контроля приложений и Трейсер (Tracer) - модуль, который дизассемблирует программу и позволяет облегчить дальнейшее выстраивание между определенными функциями логических связей - позволяют собирать большое количество информации о поступившем на проверку исполняемом файле. Сама по себе собранная с разных источников информация в чистом виде не поддается анализу и сравнению. Для проведения качественного сравнения ее нужно нормализовать и структурировать. Одним из вариантов представления собранной информации является шаблон функциональности.
Шаблон функциональности представляет собой набор собранной и объединенной в логические блоки информации, а также связей между ними. Логический блок (Logic Block) - это совокупность элементов, таких как API-функций, ссылки на строки кода, ссылки на другие логические блоки и др. Пример логического блока изображен на Фиг.2. Объединение собранной информации в шаблоны функциональности дает ряд преимуществ:
создание шаблонов функциональности проходит по четко заданным логическим правилам, описанным далее, поэтому внутри одного семейства вредоносных программ, видоизменение шаблонов функциональности, их описывающих, будет очень ограниченным;
локальность: элементы, отвечающие за выполнение определенного действия, будь то получение привилегий или выполнение запросов на сервер, обычно расположены либо в одном логическом блоке, либо в наборе связанных между собой блоков;
так как шаблон функциональности обладает четкой структурой, то он поддается сравнению различными математическими алгоритмами, описанными далее;
структура шаблона функциональности не зависит от инструментов сбора информации, поэтому для разных задач и ограничений инструменты сбора могут комбинироваться;
количество уникальных шаблонов функциональности на порядки меньше, чем количество уникальных вредоносных файлов, т.к. большинство файлов могут быть похожими по функциональности и одновременно отличаться друг от друга бинарно. Уникальный шаблон функциональности можно составить для каждой программы (исполняемого файла) и для каждого семейства (коллекции) - он характеризует функционал программы или семейства программ в целом.
Создавая шаблоны функциональности по уже известным вредоносным программам, можно:
сравнивать с ними вновь прибывшие файлы и добавлять в базы автоматические записи при условии похожести;
выделять из коллекций вредоносных программ характеристические логические блоки и создавать по этим блокам правила-эвристики;
генерировать автоматические описания.
Так же появляется возможность проводить кластеризацию неизвестных объектов, а также объектов вообще, что способствует ускорению их дальнейшей обработки.
Схема взаимодействия средств данного изобретения приведена на Фиг.1А. Процесс создания шаблонов функциональности исполняемых файлов состоит из двух этапов. На первом этапе средства эмуляции 110 осуществляют динамический сбор информации об исполняемом файле в процессе его исполнения. Средство эмуляции 110 может включать в себя различные инструменты сбора информации, такие как модуль, эмулирующий исполнение программы; модуль виртуализации программ - «песочница»; модуль контроля приложений; или модуль, который дизассемблирует программу и производит некоторые действия, которые позволяют затем выстраивать между определенными функциями логическую связь. На втором этапе с помощью средства создания шаблонов функциональности исполняемых файлов 120 на основе накопленной информации по логическим правилам формируются шаблоны функциональности. Далее средство обработки шаблонов функциональности исполняемых файлов 130 разделяет шаблоны функциональности исполняемых файлов по типам, основываясь на логических связях между последовательностями логических элементов, а также выделяет из шаблонов функциональности шумовую информацию и приводит внутренние структурные элементы шаблонов функциональности к нормализованному виду. Подготовленный к дальнейшему анализу шаблон функциональности передается средству сравнения шаблонов функциональности исполняемых файлов 140, которое осуществляет сравнение внутренних структурных элементов шаблонов функциональности с шаблонами функциональности известных файлов из средства хранения коллекций шаблонов функциональности известных файлов 150, используя математические алгоритмы, в соответствии с классификацией шаблонов функциональности исполняемых файлов. В результате сравнения, относящийся к шаблону функциональности исполняемый файл относится к соответствующей коллекции файлов.
На фиг.1Б приведен способ работы данного изобретения. По этому способу на этапе 170 при помощи инструментов сбора информации накапливаются данные об исполняемом файле 160. Эти данные главным образом состоят из дампа памяти 171 и журнала событий 172. Далее на основании полученных данных на этапе 180 формируются шаблоны функциональности исполняемого файла, которые бывают двух типов: шаблоны функциональности, которые основаны на последовательности блоков 181; и шаблоны функциональности, которые основаны на последовательности ребер 182. Сформированные шаблоны функциональности исполняемого файла подвергаются дополнительной обработке на этапе 190, в ходе которой из них выделяется шумовая информация. После этого на этапе 191 блоки шаблонов функциональности исполняемого файла приводятся к нормализованному виду для последующего сравнения. На этапе 192 происходит сравнение нормализованных блоков шаблонов функциональности исполняемого файла с блоками шаблонов функциональности известных файлов и по результатам сравнения на этапе 193 принимается решение о принадлежности нормализованного блока шаблонов функциональности к одному из шаблонов функциональности известных файлов.
Далее будут подробно рассмотрены все этапы функционирования данного изобретения.
Создание шаблона функциональности исполняемого файла при помощи средства создания шаблонов функциональности 120 осуществляется в два основных этапа.
Динамический этап:
предварительная обработка исполняемого файла динамической системой сбора информации, функционирующей в рамках средств эмуляции 110. Например, может использоваться эмулятор, хотя, как говорилось ранее, идеология шаблонов функциональности не ограничивает в использовании других средств, таких как SandBox, HIPS и др., а также объединения этих инструментов. На выходе с этого этапа должно быть два основных компонента дальнейшего анализа:
отпечаток памяти (дамп);
журнал событий.
Основная информация из журнала событий, которая потребуется, - это набор следующих пар: {VA1 - HASH1, VA2 - HASH2,…, VAn - HASHn}, где VAi - виртуальный адрес данного элемента-события, HASH; 210 на Фиг.2 - хеш-функция (например, CRC32), взятая от имени события, 220. Событием может являться вызов API функции, чтение памяти системных dll и т.п.
Статический этап:
на этом этапе происходит непосредственно трассировка отпечатка памяти и формирование шаблона функциональности исполняемого файла на основе всей собранной информации. Для поиска первичных точек входа в отпечатке памяти используются сигнатуры компилятора.
На Фиг.3А изображен пример сигнатуры компилятора Microsoft Visual C++6.×l (MSVCRT):
558BEC6AFF68::::::::68::::::::64A100000000506489250000000083::::5356 578965E833DB895DFC6A::FF15::::::::59830D::::::::FF830D::::::::FFFF15::::::::8 BOD, где:: (два двоеточия) обозначает любой байт. Хеш сигнатуры выделен цветом в столбце Хеши 310. В столбцах 320 и 330 приведены соответствующие команды и значения.
Пример сигнатуры компилятора Borland C++представлен на Фиг.3Б:
EB1066623A432B2B484F4F4B90E9. Хеш сигнатуры выделен цветом в столбце Хеши 340. В столбцах 350 и 360 приведены соответствующие команды и значения.
Для формирования логических блоков имеем следующие правила:
логический блок начинается с «точки входа» трассировки;
команда call, не вызывающая API функцию и ведущая в выделенную область памяти, является вызовом следующего или существующего логического блока;
трассировка происходит до появления команды ret (ret N), int N, jmp N или до любого из исключений invalid opcode. После чего проверяется наличие перехода за данную команду. Если перехода нет, логический блок заканчивается. Если есть, то производится попытка трассировки за данной командой;
любая встреченная ссылка на код кладется в список «точек входа», т.е. мест в коде, с которых программа может начать исполнение;
при нахождении вызова API функции, ссылки на строку или соответствия трассируемого адреса логу динамической системы в логический блок добавляется новый соответствующий элемент.
Схематично структура шаблона функциональности изображена на Фиг.4. HASHi, HASHi+1 в блоках 440 и 450 - хеши от функций (включая их аргументы), например, от функции «WriteFile», хеш которой равен ССЕ95612 в блоке 430. При этом выделяется 2 типа последовательностей элементов, связанных между собой:
непосредственно логические блоки и
участки между вызовами одного логического блока другим, названные ребрами (Edge). Например, Edge #1.1 и Edge #1.2 блока 410.
Как говорилось ранее, логический блок - это совокупность элементов, таких как API-функций, ссылки на строки, ссылки на другие логические блоки и др. На чертеже логическими блоками являются Logic Block #1 410, Logic Block #2 420, Logic Block #3 430, Logic Block #4 440 и Logic Block #5 450.
Логический блок, состоящий только из вызовов API-функций, не содержащий переходов, является простейшим логическим блоком и целиком является ребром. При возникновении в логическом блоке вызова на другой логический блок, первый логический блок будет делиться на два ребра: от его начала до вызова второго логического блока и от начала вызова второго логического блока до конца первого логического блока. Соответственно, если логический блок ссылается на n других логических блоков, то он будет состоять из n+1 ребер. Например, в логическом блоке Logic Block #1 410 существуют ребра Edge #1.1, Edge #1.2 и т.д., где CALL Logic Block #2, CALL Logic Block #3 - вызовы логических блоков Logic Block #2 220 и Logic Block #3 430, соответственно.
Основываясь на логических связях между последовательностями элементов, было создано два типа шаблонов функциональности исполняемых файлов:
упорядоченный набор логических блоков, далее будем использовать термин простой шаблон - шаблон функциональности, в котором основополагающим фактором являются зависимости элементов внутри логических блоков;
набор взаимосвязанных ребер, далее будем использовать термин краевой шаблон - шаблон функциональности, в котором основополагающим фактором являются зависимости между ребрами.
За разделение шаблонов по типам отвечает средство обработки шаблонов функциональности 130 данного изобретения, изображенное на Фиг.1.
На представленном примере, Фиг.4, структура данных шаблонов функциональности будет выглядеть следующим способом, изображенным на Фиг.5: упорядоченный набор логических блоков 510 - список логических блоков (возможна сортировка по размеру для оптимизации процесса).
Для составления набора взаимосвязанных ребер 520 выстраивается взаимосвязь ребер по тому порядку, по которому они и вызываются в коде программы. Каждое ребро встречается в наборе 520 только один раз для избегания дублирования и циклизации информации.
Логический путь (Logic Path), например, логический путь 530 или 540 - это путь от «точки входа» в программу, т.е. от места в коде, с которого программа может начать исполнение. Соответственно, путей столько, сколько существует «точек входа» в программе. В список «точек входа», как уже говорилось, на статическом этапе помещаются любые встреченные ссылки на код.
Среди всей информации, описывающей файл и собранной в шаблоне функциональности, может присутствовать «шумовая» информация, такая как базовые библиотеки компилятора, статически слинкованные функции стандартных библиотек и т.д. Если не убрать шумовую информацию, то вполне возможна ситуация, что чистая программа и вредоносная будут схожи более чем на 90%, из чего можно сделать вывод, что они являются похожими. Понятно, что без выделения, оценки и предобработки такой информации сравнивать шаблоны функциональности опасно, т.к. в определенных условиях велика вероятность ложного срабатывания. Логические блоки, содержащие такую «шумовую информацию», в дальнейшем будем называть стандартными логическими блоками. В данном изобретении выделение логических блоков, содержащих шумовую информацию, из шаблонов функциональности выполняется средством обработки шаблонов функциональности 130, изображенным на Фиг.1.
Одним из алгоритмов выделения стандартных логических блоков является выделение по «значению информативности», т.е. по величине, которая характеризует уровень неинформативных блоков с точки зрения нашего метода (объяснено ниже). Возьмем два набора файлов: Х - вредоносные программы, Y - чистые программы, изображенные на Фиг.6. Причем набор будет характеризоваться признаками:
одинаковый компилятор для всех файлов в наборах;
схожие используемые системные библиотеки (± несколько библиотек);
схожее общее количество логических блоков (±15-20%) в паттерне;
схожее общее количество хешей в каждом паттерне (±15-20%).
Выбраны именно эти признаки, т.к. в большинстве своем шумом является базовый код библиотек компилятора или стандартные библиотеки компилятора. Чтобы автоматически найти шумовые блоки для компилятора Visual C++, нужно взять набор файлов, скомпилированных этим компилятором.
Общее количество логических блоков и количество хешей в шаблоне функциональности - это наиболее общие параметры похожести. Т.е. если один шаблон функциональности состоит из одного хеша в одном логическом блоке, а другой - из сотни хешей в сотне логических блоков. Вероятность появления в таких файлах схожих (шумящих) участков мала. Как уже упоминалось, хеш - это хеш-функция, взятая от имени события.
Выделим все уникальные логические блоки на таком наборе, т.е. уникальный набор хешей. Для каждого уникального блока определим количество файлов на каждом наборе, в которых он присутствует. Для каждого блока получим 4 значения:
Х - общее количество вредоносных паттернов 610;
Y - общее количество чистых паттернов 620;
х - количество вредоносных паттернов 630, содержащих логический блок;
у - количество чистых паттернов 640, содержащих логический блок.
Таким образом, для каждого блока можно вычислить значение информативности iGain(X,Y,x,y), которое будет показывать, насколько значим данный логический блок для разделения множества {X+Y} на два подмножества Х и Y, то есть насколько этот логический блок определяет принадлежность шаблона функциональности к той или иной коллекции. Следует заметить, что действительно вредоносный блок не будет встречаться на множестве чистых шаблонов функциональности 620, а если же это блок компилятора (одна и та же MD5-сумма), то он будет встречаться и в чистых, и во вредоносных файлах, то есть у него будет очень низкая информативность. При низкой информативности существует возможность принадлежности блока к шумовой информации. Впоследствии данный неинформативный блок удаляется из базы данных. При удалении элемента все логические связи необходимо сохранить для сохранения путей. Интересны такие блоки, которые присутствуют во множестве {X+Y} более чем в половине файлов и при этом будут иметь достаточно низкую информативность:
{x+y}≥{X+Y}/2;
iGain≤ε, где ε - заданный достаточно малый порог информативности.
После выделения стандартных логических блоков переходим к алгоритмам сравнения информационных паттернов.
Например, есть логический блок, состоящий из следующих функций (runtime компилятора Visual C++):
_except_handler3
_set_app_type
_р_fmode
_р_commode
_adjust_fdiv_XREFF
_setusermatherr
_initterm
_getmainargs
_initterm
_acmdln_XREFF
GetStartupInfoA
GetModuleHandleA
exit
_XcptFilter
В коллекции существуют:
вредоносные паттерны Х=67;
чистые паттерны Y=84.
При этом в чистых паттернах такой блок встретился у=71 раз, а во вредоносных х=62 раза. Получается, что iGain(P,N,p,n)=1134·10-6.
Рассмотрим другой логический блок, состоящий из таких функций (получение API функций для поднятия привилегий):
"ADVAPIXX.DLL"
GetModuleHandleA
"ADJUSTTOKENPRIVILEGES"
GetProcAddress
"LOOKUPPRIVILEGEVALUEA"
GetProcAddress
"OPENPROCESSTOKEN"
GetProcAddress
GetCurrentProcess
CloseHandle
Для тех же подмножеств чистых и вредоносных паттернов такой блок среди чистых паттернов встретился у=2 раза, а среди вредоносных х=65 раз. Получается, что iGain(P,N,p,n)=81461·10-6.
Между значениями iGain для этих логических блоков видна количественная разница.
Первый логический блок встречается достаточно большое количество раз, как в чистых файлах, так и во вредоносных, поэтому он имеет низкую информативность для разделения множества М=Х+Y на 2 подмножества Х и Y. Т.е. он не информативен и не будет использоваться при создании шаблона функциональности.
Второй логический блок часто встречается во вредоносных файлах, но редко в чистых, поэтому имеет высокое значение информативности для разделения множества на подмножества, поэтому он может быть использован при сравнении.
Сравнение шаблонов функциональности между собой осуществляется средством сравнения шаблонов функциональности 140, изображенным на Фиг.1, и заключается в сравнении между собой логических блоков (или ребер, в зависимости от типа шаблона функциональности). Так как прямого соответствия между блоками в шаблонах функциональности нет, то встает задача эвристическим путем отобрать только те блоки, которые потенциально могут быть похожими. При этом для разных типов паттернов эвристика отбора разная. В результате сравнения шаблона функциональности с шаблонами функциональности из коллекций известных файлов 150, изображенных на Фиг.1, относящийся к шаблону функциональности исполняемый файл будет помещен в соответствующую коллекцию файлов.
Сравнение простых шаблонов:
Схема сравнения представлена на Фиг.7. Логические блоки в простых шаблонах сортируются по количеству элементов в блоке и сравниваются между собой только те блоки, в которых количество элементов примерно равное (отклонение задается параметром). Так же ограничивающим фактором является количество вызовов внутри логического блока других блоков. Получаем матрицу 710 M×N, где М и N - количество логических блоков в простом шаблоне, а в каждой ячейке лежит значение похожести между соответствующими логическими блоками.
После сравнения логических блоков друг с другом происходит поиск наилучшего варианта сочетания похожих блоков. Наилучшим считается тот вариант, при котором, сопоставив «похожие» логические блоки двух простых шаблонов между собой, получается наилучший общий процент похожести паттернов. При этом, для ускорения сравнения, поиск наилучшего варианта происходит только по тем логическим блокам, которые могут быть потенциально похожи. Если искать наилучший вариант без ускорения по всем ячейкам таблицы, то сложность алгоритма была бы К!, где К=Max(M,N), т.к. каждый из логических блоков сравнивается со всеми блоками другого простого шаблона.
На Фиг.8 изображен аналогичный пример сравнения простых шаблонов, где 810 - это логические блоки первого шаблона функциональности, 820 - логические блоки второго шаблона функциональности. Поставив им взаимно-однозначное соответствие со значением похожести между блоками обоих файлов, необходимо найти самую оптимальную комбинацию похожестей. Например, для Фиг.8 самым оптимальным соответствием будет 1.1-2.3, 1.3-2.4, 1.4-2.2.
Сравнение краевых шаблонов:
На Фиг.9 изображена таблица сравнения 910 логических путей (LPx). Размер данной задачи увеличивается, т.к. на Фиг.8 было сравнение логических блоков, а на Фиг.9 изображено сравнение логических путей. Так как в структуре данных краевых шаблонов присутствует уже не один тип элементов, а два (ребра и логические пути), соответственно и сравнение проводится чуть сложнее. Сравнение происходит в два этапа. Сначала происходит сортировка логических путей по количеству в них ребер и элементов. После чего, выбираются только потенциально похожие пути и в сравнении и в поиске наилучшего варианта участвуют только они. Вторым этапом является сравнение непосредственно двух путей между собой, которое происходит таким же образом, как сравнение упорядоченных наборов логических блоков, только вместо логических блоков сравниваются ребра. Логический путь в данной ситуации становится эквивалентен упорядоченному набору логических блоков.
«Нижним» элементом сравнения (самым элементарным элементом сравнения) является логический блок или ребро в зависимости от типа шаблона функциональности соответственно. Логические блоки/ребра представляют собой последовательность элементов (событий) и могут сравниваться различными алгоритмами. Но для того чтобы сравнивать блоки между собой, нужно привести их к определенному нормализованному виду, готовому для сравнения. Приведение к нормализованному виду выполняется средством обработки шаблонов функциональности 130, изображенным на Фиг.1.
Одним из вариантов нормализованного вида является представление логических блоков в виде бинарных строк. Алфавитом для строк будут являться хеш-функции от имен событий/элементов. В таком виде работа с элементами представляется наиболее удобной и логически понятной.
Вызовы логических блоков, для наглядности, будут обозначаться как 00000000+номер логического блока, что будет показано далее на примере упорядоченных наборов логических блоков в виде 00000002 или 00000005.
Выполнив преобразования на приведенном выше примере логических блоков/ ребер, имеем:
упорядоченный набор логических блоков, изображенный на Фиг.5:
Logic Block #1:
C24FA5F4 447D086B 6CC098F5 00000002 5C856C47 00000003 00000005, где 00000002, 00000003, 00000005 - это переходы между хешами. Одним из вариантов использования этих значений может быть восстановление логических путей. Возможна реализация хранения этих значений внутри упорядоченного набора логических блоков.
Logic Block #2:
FFF372BE 919 В6 ВСВ 553 В5С78
Logic Block #3:
C79DC4E3 1DDA9F5D 553 В5С78 CCE95612 00000004 B09315F4
Logic Block #4:
HASH1, HASH2, HASH3, HASHi,…, HASHN
наборов взаимосвязанных ребер:
Logic Path #1 представляется в виде последовательности, изображенной на Фиг.10.
В таком виде шаблоны функциональности с легкостью можно подвергать различным математическим преобразованиям и сравнениям.
Далее будут рассмотрены алгоритмы сравнения логических блоков/ ребер, которые уже были использованы для сравнения и при работе с которыми были получены положительные результаты.
Расстояние Хемминга - это мера различия между кодовыми комбинациями (двоичными векторами) в векторном пространстве кодовых последовательностей. В этом случае расстоянием Хэмминга между двумя двоичными последовательностями (векторами) Х и Y длины n называется число позиций, в которых они различны. В нашем случае вектора Х и Y определяются уникальными элементами в данных логических блоках;
расстояние Левенштейна - это мера разницы двух последовательностей символов (строк) относительно минимального количества операций вставки, удаления и замены, необходимых для перевода одной строки в другую. В нашем случае строками являются логические блоки/ребра. Каждый элемент (HASH) внутри логического блока/ребра является одной буквой. Элементы не имеют веса, т.е. равнозначны. На Фиг.11 изображен процесс вычисления расстояния Левенштейна при сравнении двух блоков 1110 и 1120. Исходя из определения данного алгоритма, видно, что в данном случае расстояние Левенштейна равно 5.
Алгоритм вычисления весов (iGain):
каждому элементу присваивается сгенерированный вес. Веса генерируются по множеству {X+Y}, где Х - общее количество вредоносных шаблонов функциональности, Y - общее количество чистых шаблонов функциональности;
Х и Y выбираются либо сторонним алгоритмом, либо по косвенным признакам.
В итоге каждый ID получает вес wid, показывающий, насколько он характеризует шаблон функциональности на Х подмножестве. Далее логические блоки/ребра сравниваются друг с другом и находится наилучший вариант. Шаблон функциональности/путь имеет общий вес W=W1+W2+…+Wn, где Wi - вес i-го логического блока/ребра.
Wi=Wid1+Wid2+…+Widm - суммы весов всех элементов логического блока/ребра.
Когда происходит сравнение двух блоков, элементы делятся на 2 группы:
элементы есть в обоих логических блоках (причем с учетом количества). Их вес W+;
элементов нет в обоих логических блоках. Их вес W-.
Wcpi - вес сравнения. Wcp=W+-W-. Если Wcpi≤0, то Wcpi=0 и логические блоки считаются совершенно не похожими. Если Wcpi>0, то Wcpi/Wi·100 - процент похожести логических блоков. Wcpi/W·100 - процент похожести внутри шаблона функциональности/логического пути.
Итоговая величина, представляющая интерес:
Umax=(Wcp1+Wcp2+…+Wcpn)·100/W.
Например, для семейства Trojan Downloader существуют функции, которые он часто использует (CreateProcess, UrIDownload и т.д.). Также для этого семейства существует набор функций, которые никогда не используются или случайно используются. Берется набор похожих программ Trojan Downloader различных версий (X). Для этих программ выделяем логические блоки, идентификаторы, используемые библиотеки. В качестве Y-множества берутся похожие по первичным характеристикам чистые программы или программы, которые не принадлежат данному семейству. Далее для каждого хеша вычисляются значения х и у (сколько раз он встречался среди вредоносных шаблонов функциональности и среди чистых шаблонов функциональности соответственно). Затем для каждого хеша вычисляется вес iGain. Т.к. набор семейства вредоносных программ был изначально точным, то iGain будет большим у тех функций, которые определяют это семейство. Для каждого логического блока высчитывается вес, как сумма весов хешей внутри логического блока. Затем для проверяемых хешей составляется сумма его вхождений в логические блоки программ из множеств Х и Y. Если вес положителен, то это значение - это процент от общего веса;
алгоритм выделения характеристической информации:
алгоритм детектирования основывается на выделении из шаблона функциональности только семейств поведенческо-определяющей информации в виде Логического блока или Логического пути. Т.е. выделяется семейство похожих шаблонов функциональности. Далее анализируется, какая информация является определяющей (характеризующей), какие логические блоки (Логические пути) встречаются постоянно и характерны для семейства, а какие видоизменяются или являются неинформативными (например, выполняющими какие-либо вспомогательные - не вредоносные действия, которые встречаются и в чистых программах). Анализ может проходить как автоматически (статистика частоты встречаемости), так и проводится аналитиком (или совместно, аналитику предоставляется статистическая информация, и он по ней генерирует запись).
Схематично выделение информации представлено на Фиг.12А и 12Б. Где А 1210 - вся информация из шаблона функциональности, Б 1220 - характеристическая информация, определяющая семейство, или набор вредоносных действий, информация.
Для двух шаблонов функциональности из семейства имеем возможность игнорировать неинтересную (не попадающую в объединение) информацию и проводить поиск только характеристической информации 1250 на Фиг.12. На основе этой характеристической информации 1320 на Фиг.13 могут составляться коллекции известных файлов 150, изображенных на Фиг.1.
В заключение следует отметить, что приведенные в описании сведения являются только примерами, которые не ограничивают объем настоящего изобретения, определенного формулой. Специалисту в данной области становится понятным, что могут существовать и другие варианты осуществления настоящего изобретения, согласующиеся с сущностью и объемом настоящего изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| МЕТОД ОТНЕСЕНИЯ РАНЕЕ НЕИЗВЕСТНОГО ФАЙЛА К КОЛЛЕКЦИИ ФАЙЛОВ В ЗАВИСИМОСТИ ОТ СТЕПЕНИ СХОЖЕСТИ | 2009 |
|
RU2420791C1 |
| СИСТЕМА И СПОСОБ ПОВЫШЕНИЯ ЭФФЕКТИВНОСТИ ОБНАРУЖЕНИЯ НЕИЗВЕСТНЫХ ВРЕДОНОСНЫХ ОБЪЕКТОВ | 2010 |
|
RU2454714C1 |
| Системы и способы защиты от вредоносного программного обеспечения на основе нечеткого вайтлистинга | 2012 |
|
RU2607231C2 |
| Система и способ обнаружения вредоносных файлов на мобильных устройствах | 2015 |
|
RU2614557C2 |
| Способ выявления вредоносных файлов с использованием графа связей | 2023 |
|
RU2823749C1 |
| СИСТЕМА И СПОСОБ СОЗДАНИЯ ПРАВИЛ ФИЛЬТРАЦИИ НЕЗНАЧИТЕЛЬНЫХ СОБЫТИЙ ДЛЯ АНАЛИЗА ПРОТОКОЛОВ СОБЫТИЙ | 2012 |
|
RU2514139C1 |
| Способ обнаружения вредоносных сборок | 2015 |
|
RU2628920C2 |
| Способ определения похожести составных файлов | 2016 |
|
RU2628922C1 |
| Система и способ определения похожих файлов | 2015 |
|
RU2614561C1 |
| СИСТЕМА И СПОСОБ СОЗДАНИЯ ГИБКОЙ СВЕРТКИ ДЛЯ ОБНАРУЖЕНИЯ ВРЕДОНОСНЫХ ПРОГРАММ | 2013 |
|
RU2580036C2 |




Изобретение относится к системам и методам создания описания и сравнения функционала исполняемых файлов и предназначено для определения принадлежности исполняемых файлов к известным коллекциям файлов. Технический результат, заключающийся в повышении надежности и точности детектирования вредоносного программного обеспечения, достигается за счет сравнения исполняемых файлов посредством шаблонов функциональности. Способ определения принадлежности файлов к коллекциям известных файлов на основе сравнения файлов с помощью шаблонов функциональности содержит этапы, на которых формируют шаблоны функциональности на основе информации об исполняемом файле. Далее удаляют выделенную шумовую информацию из шаблонов функциональности исполняемого файла. Приводят блоки шаблонов функциональности исполняемого файла к нормализованному виду. Затем сравнивают данные блоки с блоками шаблонов функциональности известных файлов и по результатам сравнения принимают решение о принадлежности блока к одному из шаблонов функциональности известных файлов. Создавая шаблоны функциональности по уже известным вредоносным программам, можно сравнивать с ними вновь прибывшие файлы и добавлять в базы автоматические записи при условии похожести; выделять из коллекций вредоносных программ характеристические логические блоки и создавать по этим блокам правила-эвристики; генерировать автоматические описания. Так же появляется возможность проводить кластеризацию объектов, что способствует ускорению их дальнейшей обработки. 3 н. и 11 з.п. ф-лы, 16 ил.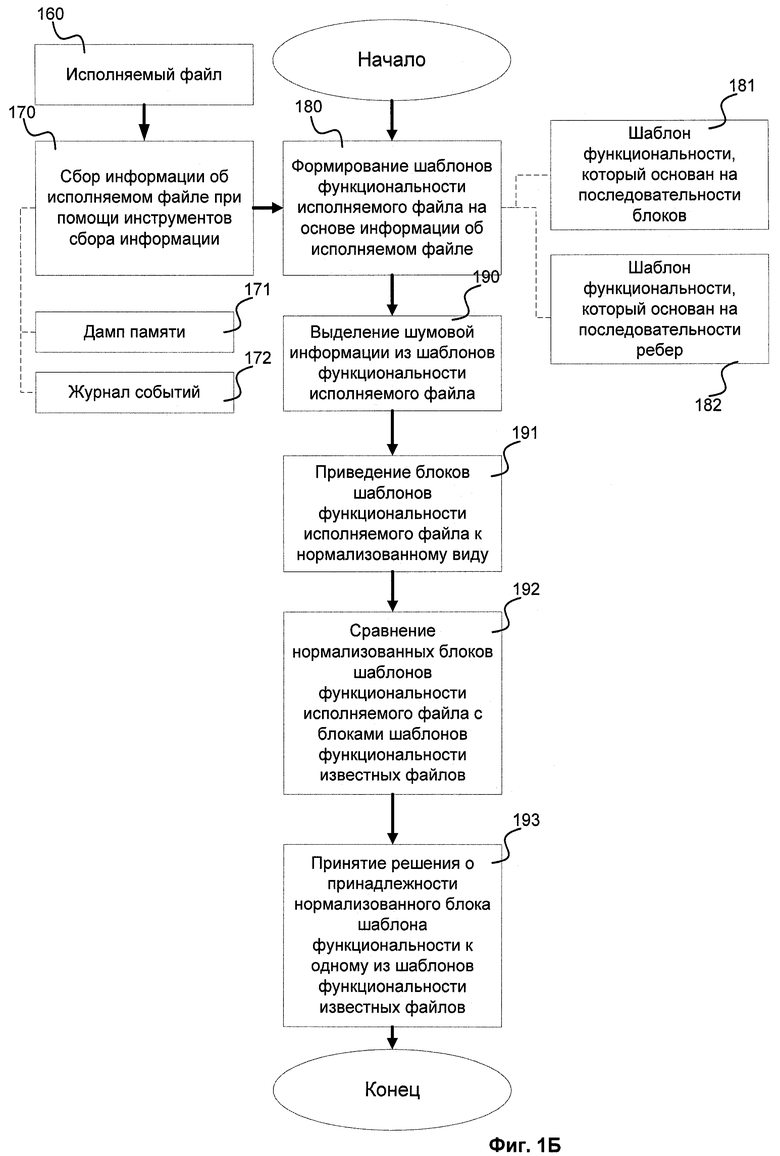
1. Способ определения принадлежности файлов к коллекциям известных файлов на основе сравнения файлов с помощью шаблонов функциональности, содержащий этапы, на которых
(а) формируют шаблоны функциональности на основе информации об исполняемом файле;
(б) удаляют выделенную шумовую информацию из шаблонов функциональности исполняемого файла;
(в) приводят блоки шаблонов функциональности исполняемого файла к нормализованному виду для последующего сравнения;
(г) сравнивают нормализованные блоки шаблонов функциональности исполняемого файла с блоками шаблонов функциональности известных файлов и по результатам сравнения принимают решение о принадлежности нормализованного блока шаблонов функциональности к одному из шаблонов функциональности известных файлов.
2. Способ по п.1, в котором информация об исполняемом файле может быть собрана посредством таких инструментов сбора информации, как модуль, эмулирующий исполнение программы; модуль виртуализации программ; модуль контроля приложений; модуль, который дизассемблирует программу и позволяет облегчить дальнейшее выстраивание между определенными функциями связей.
3. Способ по п.1, в котором формирование шаблонов функциональности исполняемого файла осуществляется в два этапа: динамический и статический.
4. Способ по п.3, в котором динамический этап подразумевает сбор информации об исполняемом файле при помощи инструментов сбора информации и результатом работы динамического этапа при формировании шаблонов функциональности исполняемого файла являются дамп памяти и журнал событий.
5. Способ по п.3, в котором статический этап подразумевает непосредственную трассировку дампа памяти и формирование шаблонов функциональности исполняемого файла.
6. Способ по п.1, в котором шаблоны функциональности исполняемого файла бывают двух типов:
шаблон функциональности, который основан на последовательности блоков и
шаблон функциональности, который основан на последовательности ребер.
7. Способ по п.6, в котором блоками называются совокупности элементов, такие как API-функции, ссылки на строки кода и ссылки на другие логические блоки.
8. Способ по п.6, в котором ребрами называются участки между вызовами одного блока другим.
9. Способ по п.1, в котором выделенная шумовая информация включает в себя базовые библиотеки компилятора и статически слинкованные функции стандартных библиотек.
10. Способ по п.1, в котором сравнение шаблонов функциональности исполняемого файла с шаблонами из коллекций известных файлов осуществляется по различным для каждого типа шаблонов функциональности математическим алгоритмам, таким как расстояние Хемминга; расстояние Левенштейна; алгоритм вычисления весов; алгоритм выделения характеристической информации.
11. Система определения принадлежности файлов к коллекциям известных файлов на основе сравнения файлов с помощью шаблонов функциональности, содержащая
средство эмуляции, которое осуществляет сбор информации об исполняемом файле;
средство создания шаблонов функциональности исполняемого файла, которое на основе информации, собранной средством эмуляции, формирует блоки и составляет из них шаблоны функциональности исполняемого файла;
средство обработки шаблонов функциональности исполняемых файлов, которое удаляет выделенную из шаблонов функциональности шумовую информацию и приводит блоки шаблонов функциональности к нормализованному виду;
средство хранения коллекций шаблонов функциональности известных файлов;
средство сравнения шаблонов функциональности исполняемых файлов, которое осуществляет сравнение нормализованных блоков шаблонов функциональности, полученных от средства обработки шаблонов функциональности, с шаблонами функциональности известных файлов из упомянутого средства хранения коллекции в соответствии с классификацией шаблонов функциональности исполняемых файлов.
12. Система по п.11, в которой средство эмуляции включает в себя такие инструменты сбора информации, как модуль, эмулирующий исполнение программы; модуль виртуализации программ; модуль контроля приложений; модуль, который дизассемблирует программу и позволяет облегчить дальнейшее выстраивание между определенными функциями связей.
13. Машиночитаемый носитель определения принадлежности файлов к коллекциям известных файлов на основе сравнения файлов с помощью шаблонов функциональности, на котором сохранена компьютерная программа, при исполнении которой на компьютере выполняются следующие этапы:
(а) формируют шаблоны функциональности на основе информации об исполняемом файле;
(б) удаляют выделенную шумовую информацию из шаблонов функциональности исполняемого файла;
(в) приводят блоки шаблонов функциональности исполняемого файла к нормализованному виду для последующего сравнения;
(г) сравнивают нормализованные блоки шаблонов функциональности исполняемого файла с блоками шаблонов функциональности известных файлов и по результатам сравнения принимают решение о принадлежности нормализованного блока шаблонов функциональности к одному из шаблонов функциональности известных файлов.
| АВТОМАТИЧЕСКОЕ ОБНАРУЖЕНИЕ УЯЗВИМЫХ ФАЙЛОВ И УСТАНОВКА ЗАПЛАТОК НА НИХ | 2004 |
|
RU2358313C2 |
| RU 2005135472 A, 27.05.2007 | |||
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |

