Изобретение относится к компьютерным средствам высокопроизводительной обработки информации и предназначено для разработки наноразмерных систем.
Известен нанотехнологический комплекс по патенту РФ №2308782, кл. G12В 21/01 с приоритетом 2006.05.06, в котором реализован замкнутный цикл производства изделий наноэлектроники. К недостаткам этого комплекса относятся ограниченность области применения и отсутствие используемых методов анализа и моделирования наносистем. Известны также патенты US №4677296, G01N 23/00, 1987, US №6057546, Н01J 37/26, 1991, US №5508527, G01J 1/00, 1996, US №5804027, H01J 37/32, 1998, GB №2316222, H02N 2/04, 1998, RU №2220429, G02В 21/00, 2000, RU 2237022 C2, кл. 7 C02F 1/28, C02F 1/50, C02F 103:04 от 2000.95.19, RU №2186663 С2, кл. 7 В23Н 7/22 с приоритетом 2002.08.10, RU №2227363, H02N 2/00, 2004, RU №2254640, Н01L 41/00, 2004, RU 2254640, H02N 2/001, 2005, в которых рассмотрены отдельные вопросы производства наносистем, однако их реализация ориентирована на достаточно простые архитектуры ЭВМ и осуществляется без использования современных суперкомпьютерных средств высокопроизводительных вычислений и интеллектуальных технологий обработки информации, что затрудняет выполнение сложных логических и математических операций при разработке наносистем новых поколений.
Наиболее близким аналогом по рассматриваемому комплексу является проблемно-ориентированная компьютерная среда PSE (Problem Solving Environment), [S.Gallopoulos, E.Housts, J.Rice. IEEE Computational Science and Engineering. Summer, 1994], позволяющая формализовать логику изучения сложного явления средствами компьютерного моделирования, обеспечивающая выполнение вычислений на основе заданных алгоритмов и программ, построение и реализацию различных сценариев разработки систем, подготовку данных, анализ и обобщение полученных результатов с использованием современных средств человеко-компьютерного взаимодействия, включая научную визуализацию, когнитивную графику и виртуальную реальность.
Недостаток этой среды связан с отсутствием единых подходов к унификации математических моделей, алгоритмов и программ, представлению данных и знаний применительно к задачам выполнения сложных расчетов и моделирования в рамках приоритетных направлений в области нанотехнологий. Кроме того, недостаточная проработанность алгоритмической базы нановычислений, ориентированной на достаточно простые параллельные архитектуры, не позволяет эффективно использовать ресурсы современных суперкомпьютерных комплексов при объединении программных решений в интегрированную вычислительную систему, а отсутствие методов искусственного интеллекта при информационной поддержке пользователей значительно осложняет выполнение параллельных вычислений в распределенной иерархической среде.
Технический результат изобретения связан с реализацией интеллектуальных технологий интерпретации информации в мультипроцессорной вычислительной среде и увеличением производительности обработки данных при создании наносистем новых поколений. Технический результат достигается путем построения интеллектуальной проблемно-ориентированной интегрированной динамической вычислительной среды, модифицированной на основе PSE, и реализующей принципы высокопроизводительной обработки информации в рамках нечеткого логического базиса и конкурирующих вычислительных технологий, основанных на методах классической математики, нечетких и нейросетевых алгоритмах, что снимает многие допущения, упрощающие предположения и ограничения, связанные со сложностью задачи, неопределенностью среды ее реализации и трудностями формализации в рамках стандартных расчетных схем, а также при метаописании предметной области, онтологии данных, знаний и вычислительных процедур, унификации перспективных математических моделей, вычислительных методов, параллельных алгоритмов и программных решений.
Указанный технический результат достигается путем построения суперкомпьютерного комплекса интеллектуальной поддержки процесса разработки наносистем на основе формализованной логики изучения физических закономерностей и построения сценариев, реализующих всю технологическую цепочку анализа и синтеза наносистем: динамической базы знаний экспертной системы, обеспечивающей функционирование суперкомпьютерного комплекса в заданной вычислительной среде, адаптивной компоненты, реализующей процедуры адаптивного обучения, перестройки логических моделей и извлечения «скрытых» знаний и закономерностей в моделях наносистем, хранилища данных, представляющего собой предметно-ориентированную среду, поддерживающую работу суперкомпьютерного комплекса, интеллектуального тренажера для обучения пользователей выполнению последовательности логических и математических операций при изучении сложных явлений наносистем, интеллектуального интерфейса, представляющего собой программно-аналитическую среду, обеспечивающую «прозрачность» смысла доступа к информации при поддержании взаимодействия пользователя с суперкомпьютерным комплексом.
Функциональная схема суперкомпьютерного комплекса, обеспечивающего разработку наносистем, представлена на фиг.1.
Комплекс состоит из 5 основных блоков: блок интеллектуальной поддержки вычислений, моделирования и разработки наносистем 1, блок программного управления 2, блок человеко-компьютерного взаимодействия 3, репозиторий вычислительных и прикладных сервисов 4, блок системных библиотек 5.
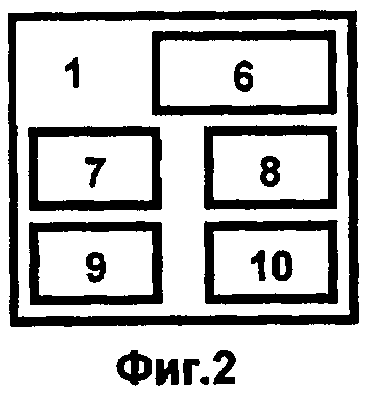
Блок интеллектуальной поддержки вычислений, моделирования и разработки наносистем 1 (фиг.2) является основным функциональным элементом интеллектуального комплекса и включает экспертную систему 6, блок доступа к знаниям и данным 7, содержащий менеджер данных 8, менеджер знаний 9 и блок адаптации 10.
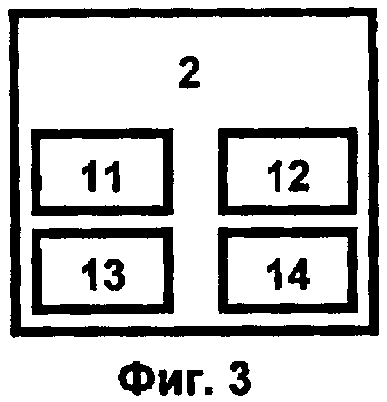
Блок программного управления 2 (фиг.3) с помощью экспертной системы 6 реализует функции интеллектуальной поддержки принятия решений. На основе поступившего запроса блок 2 определяет архитектуру расчетного приложения (блок 11) с точки зрения оптимизации системы функционалов (производительности, точности, надежности и др.), интерпретирует задание и формирует набор активных фактов предметной области (блок 12), определяет набор активных вычислительных сервисов и сценариев их взаимодействия (блок 13), строит последовательность конкурирующих оптимальных расписаний их параллельного выполнения на основе текущего состояния системы (блок 14). Результатом работы блока 2 является определение оптимальной архитектуры вычислительного комплекса, генерация описания задания, автоматическая генерация и компиляция кода с подключением соответствующих системных библиотек 5.
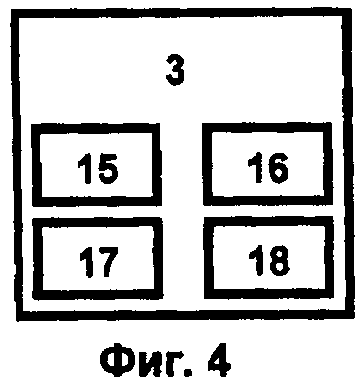
Блок человеко-компьютерного взаимодействия 3 (фиг.4) обеспечивает ввод и вывод информации при функционировании суперкомпьютерного программного комплекса, реализуемого на основе интеллектуальных технологий обработки информации в мультипроцессорной вычислительной среде для разработки наносистем и содержит четыре базовые компоненты:
интеллектуальный интерфейс 15, осуществляющий разработку и запуск задания, блок визуализации 16, интеллектуальный тренажер 17 для обучения работе с интегрированной средой, хранилище данных 18 для представления и хранения информации.
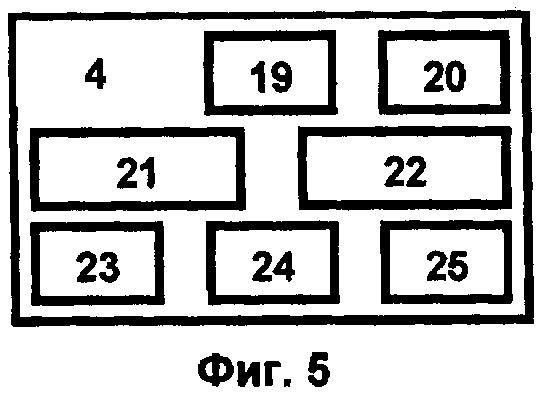
Репозиторий вычислительных и прикладных сервисов 4 (фиг.5) определяет содержательную часть комплекса для выполнения расчетов, моделирования и разработки наносистем и содержит следующие сервисы: сервис высокоточных расчетов (блок 19), сервис моделирования и разработки атомно-молекулярных и мезосистем (блок 20), сервис термодинамических расчетов и разработки тонких пленок (блок 21), сервис электронных и фононных свойств твердотельных наноструктур (квантовых точек) и тонких пленок (блок 22), сервис вычислений электронной структуры наносистем (блок 23), сервис расчета линейных и оптических свойств ансамблей наночастиц (блок 24), сервисы моделирования процессов наногидродинамики и формирования наноструктур (течение, структуры), формирование наночастиц, нанопластин и нанотрубок и др. (блок 25).
Блок системных библиотек 5 (фиг.6) реализует базовые компоненты для выполнения параллельных вычислений, моделирования и разработки наносистем (блок 26) и визуализацию результатов (блок 27) при работе с блоком 16.
Экспертная система предметных областей 6 (фиг.7) обеспечивает функционирование суперкомпьютерного комплекса в заданной вычислительной среде и включает базу знаний 28, механизм логического вывода 29, систему объяснений 30, базу данных 31, обеспечивающую выполнение операций логического вывода 29 и поддержку системы объяснений 30 с использованием прикладных компьютерных программ расчета и моделирования наносистем 4. База знаний 28 экспертной системы 6 содержит набор понятий предметной области в виде фреймово-продукционных моделей, причем модель представления предметных знаний реализуется с использованием онтологии в виде семантической сети, множество узлов которой соответствует фактам, а множество дуг отражает логические связи между ними.
Менеджер данных 7 (фиг.8) содержит базу описательной информации 32, базу данных вычислений 33 и базу данных констант 34.
Менеджер знаний 8 (фиг.9) определяет сценарии моделирования 35, онтологии предметной области 36 и характеристики производительности сервисов 37.
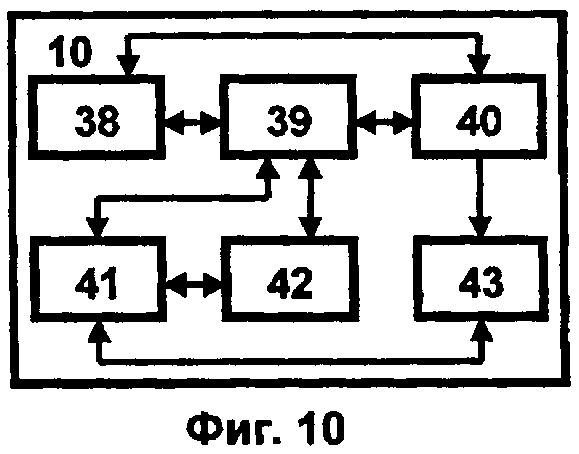
Блок адаптации 10 (фиг.10) реализует процедуры адаптивного обучения 38 и перестройки логических моделей 39 за счет возможности прогноза и управления вычислительным процессом с динамически меняющейся информацией 40. При этом обеспечивается взаимодействие с базой данных 31 экспертной системой 6 и репозиторием прикладных сервисов 4, содержащим оперативную информацию для обеспечения работы базы знаний 28 с помощью прикладных компьютерных программ расчета, моделирования и разработки наносистем 4. Помимо этого блок адаптации 10 осуществляет поддержку процесса поиска и извлечения «скрытых» знаний и закономерностей (процедуры интеллектуального анализа данных - Data Mining) 41, отбор и визуализацию информации 42, реализацию процессов интеграции знаний 43 в условиях неопределенности и неполноты исходной информации.
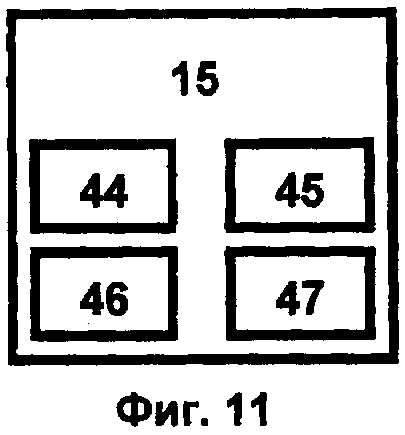
Блок интеллектуального интерфейса 15 (фиг.11) представляет собой программно-аналитический комплекс, обеспечивающий «прозрачность» смысла доступа к информации при поддержании взаимодействия пользователя с суперкомпьютерным комплексом. Интеллектуальный интерфейс 15 ориентирован на формализацию понятий предметной области и включает четыре основных модуля: синтаксический анализатор 44, выполняющий процедуры морфологического и синтаксического анализа входных данных, семантический анализатор 45, использующий результаты синтаксического анализа для формализации информационного содержания входных данных, процессор понятийного словаря 46, представляющий собой библиотеку функций, обеспечивающих вычисление характеристик, представленных в словаре понятий, и полного набора отношений между ними, а также фиксированного набора ассоциативных отношений, процессор справочника баз данных 47, который характеризует модели предметных областей, определяющих функционирование интегрированного компьютерного комплекса с помощью средств адаптации 10 и блока программного управления 2. В сложных ситуациях с помощью интеллектуального интерфейса 15 реализуется взаимосвязь блока адаптации 10 с блоками интеллектуальной поддержки вычислений и моделирования наносистем 1, блоком человеко-компьютерного взаимодействия 3, репозитарием вычислительных сервисов 4 и блоком системных библиотек 5, обеспечивающих интеллектуальные возможности системы.
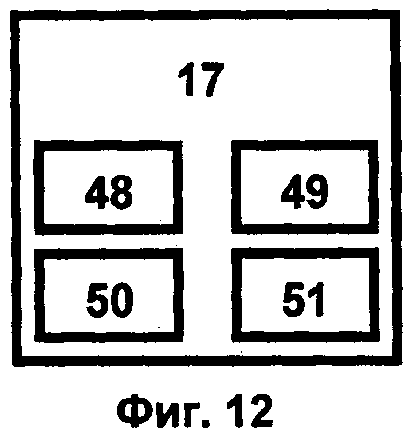
Интеллектуальный тренажер 17 (фиг.12) обеспечивает функционирование компоненты обучения пользователей работе с суперкомпьютерным комплексом. Компонентами интеллектуального тренажера являются блок руководителя обучения 48, блок оценки действий обучаемого 49, средства виртуальной реальности 50, блок модели обучаемого 51. Интеллектуальный тренажер поддерживает взаимодействие пользователя суперкомпьютерного комплекса и руководителя обучения с другими блоками интеллектуального тренажера и работает совместно с блоком программного управления 2 и экспертной системой 6.
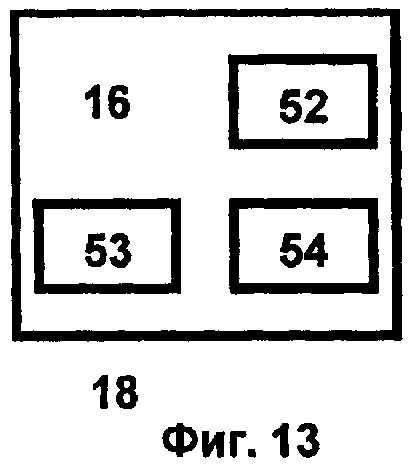
Хранилище данных 18 для представления и хранения информации (фиг.13) состоит из трех блоков, первый из которых 52 обеспечивает визуализацию данных расчетов, моделирования и разработки наносистем в блоках 16, 27 и работает совместно с блоком доступа к знаниям и данным 7, содержащим менеджер данных 8 и менеджер знаний 9. Второй блок 53 выполняет функции хранения данных, а третий блок 54 - репозитория метаданных. Блок 53 представляет собой предметно-ориентированную среду, содержащую данные из различных источников, описания которых помещены в репозитории метаданных 54. Пользователь, применяя различные инструменты, включая механизмы обработки данных в блоках 12, 13, 14, 41, средства визуализации 52 и содержимое репозитория 54, анализирует данные в хранилище 53. Результатом анализа является информация в виде «скрытых» знаний и закономерностей, их интеграция с имеющимися данными.
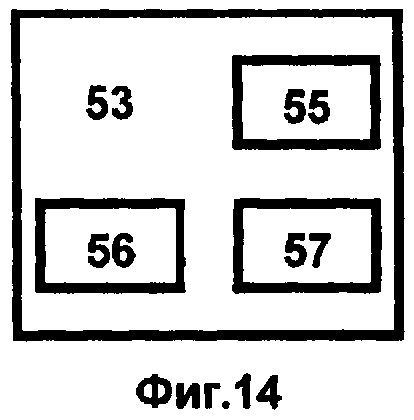
Структура хранилища данных 53 представляется в рамках трехуровневой архитектуры (фиг.14). На первом уровне 55 расположены внешние и внутренние источники данных. Второй уровень 56 содержит центральное хранилище, куда стекается интегрированная информация от всех источников первого уровня. Этот уровень предоставляет аналитическую информацию для оперативного управления суперкомпьютерным комплексом и подготовки данных для последующей загрузки в центральное хранилище. Третий уровень 57 содержит собой набор предметно-ориентированных витрин данных для конкретных приложений при выполнении расчетов и моделирования наносистем, источником информации для которых является центральное хранилище данных 56. Именно с витринами данных 57 оперативно работает большинство пользователей суперкомпьютерного комплекса.
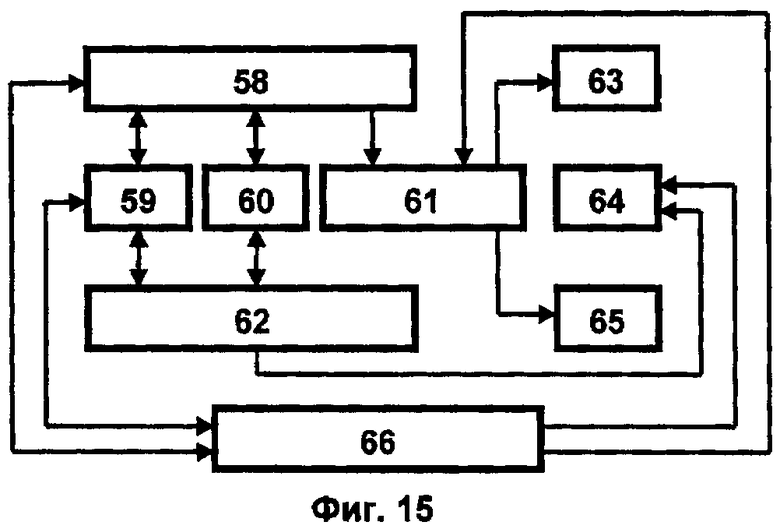
Блок 29 реализует механизм логического вывода, в том числе и вывода по прецеденту (фиг.15), позволяющего обеспечить усиление процедуры вывода в сложных ситуациях за счет приобретения новых знаний в процессе функционирования суперкомпьютерного комплекса. Модель вывода по прецеденту строится путем интеграции механизма вывода по аналогии с использованием базового решателя задач 58, взаимосвязанного с экспертной системой 6 и осуществляющего поиск 59, выполнение 60 и генерацию 61 прецедентов на основе фреймово-продукционного представления базы знаний 28 предметной области. Такая интеграция позволяет осуществлять формирование базы знаний прецедентов 62, задаваемых в форме результатов и трасс генерации решений. Обучение модели происходит путем накопления и повторного использования прецедентов, а также настройки структур базы прецедентов 62 в виде определения релевантных атрибутов 63, индексирования прецедентов 64 и определения независимых фрагментов 65 для эффективного поиска релевантных случаев. Формирование решений осуществляется как в автоматизированном режиме, когда пользователь 66 выбирает на каждой фазе функционирования модели один из предлагаемых вариантов решений или вводит свой вариант с необходимыми пояснениями, так и в полностью автоматическом режиме. Если для решения представляется новая задача, в базе прецедентов 62 устанавливаются структуры, которые наиболее полно соответствуют новой задаче. Вариант решения формируется за счет выполнения или модификации процесса решения задачи, заданного в прецедентах, для новой ситуации.
Модульный принцип построения суперкомпьютерного комплекса для разработки наносистем реализуется на автономных носителях информации с применением самостоятельно функционирующих блоков: блока интеллектуальной поддержки вычислений, моделирования и разработки наносистем 1, блока программного управления 2, блока человеко-компьютерного взаимодействия 3, репозитория вычислительных сервисов 4 и блока системных библиотек 5.
Инструментальная оболочка как проблемно-ориентированная программно-аппаратная среда суперкомпьютерного комплекса для разработки наносистем обеспечивает формализацию знаний по проведению расчетов, моделирования и построения наносистем с применением текстово-графических процедур при интеллектуальной поддержке пользователей (блоки 1, 4.5) в рассматриваемой предметной области.
Реализация суперкомпьютерного комплекса осуществляется на базе суперЭВМ с иерархической параллельной архитектурой, включающей не менее 96 узлов, соединенных высокоскоростными средствами связи, с производительностью от 0,5 до 50 Терафлопс. Комплекс реализуется с использованием языков программирования Fortran 90 / C++/ Java / С#, функционирует в операционных системах Linux (на ядре версии не ниже 2.6) и Windows Compute Cluster Server (версия не ниже 2003). При этом обеспечена совместимость с СУБД Postgre SQL, My SQL, MS SQL Server, Oracle, а также совместимость с внешними приложениями, в том числе GAMESS v. April 11, 2008, ORCA v. 2.6, Dalton v. 2.0.
Основным программным средством суперкомпьютерного комплекса при работе с хранилищем данных является DataStage продуктов компании Ascential Software. Ядро DataStage использует многопроцессорную среду для автоматического распределения потока независимых заданий на несколько процессоров, что гарантирует эффективное использование доступных ресурсов и увеличивает скорость обработки данных. В системе реализована поддержка технологии высокоскоростной загрузки данных. Для перемещения файлов между компьютерами используется протокол FTP, который поддерживается программами-оболочками. Обработка изменений в данных существенно влияет на производительность приложения по извлечению и преобразованию данных. Поддержка в DataStage захвата изменений данных (Change Data Capture) уменьшает время загрузки, требуемое для обновления витрин 57 в хранилище данных 53, описывает методологии и инструменты для поддержки сбора, модификации и перемещения введенных ранее или обновленных данных и предоставляет стратегию, помогающую разработчикам наносистем сформировать эффективное решение. Компонент Change Data Capture обеспечивает возможность проверки временных отметок (timestamp) и кодов, указывающих тип транзакции (вставка, изменение, удаление).
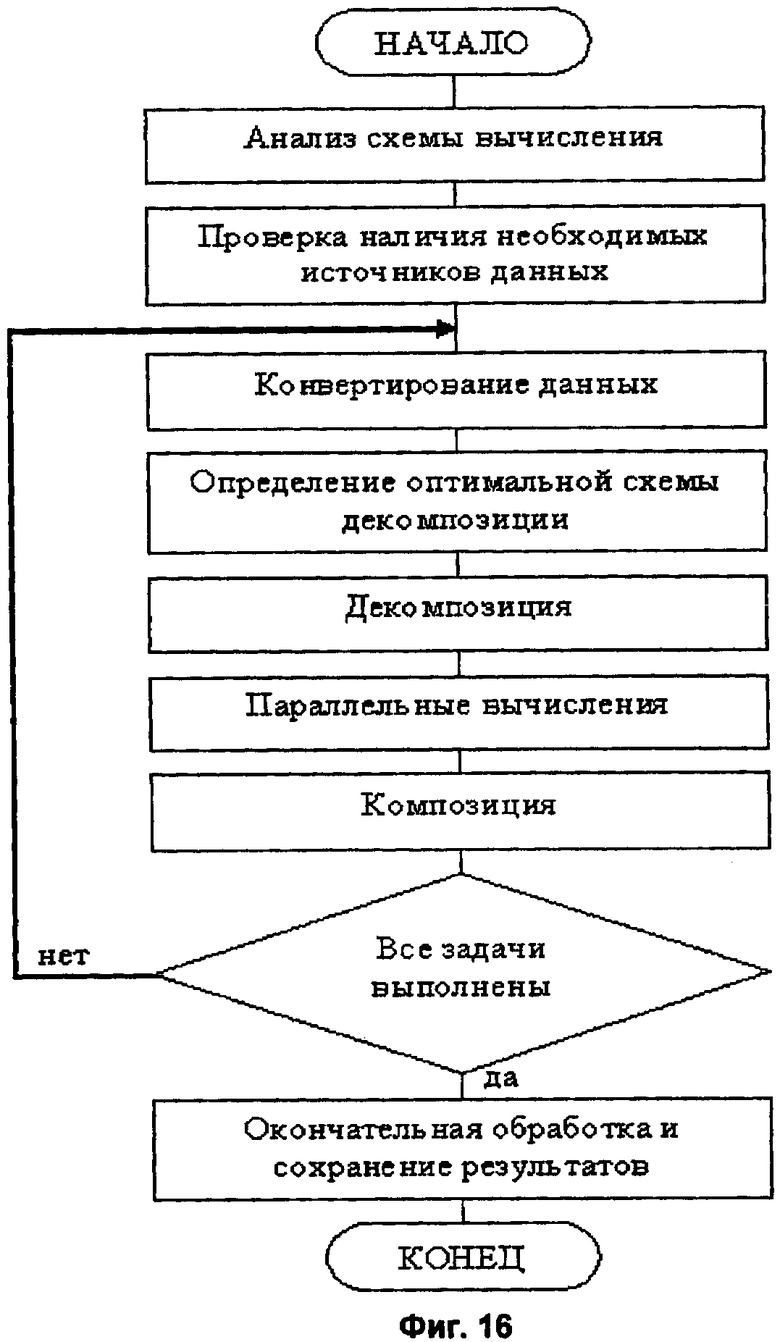
Функционирование суперкомпьютерного комплекса определяется совместной работой блоков программного управления 2 с блоками вычислений, моделирования и разработки наносистем 1, репозиторием вычислительных и прикладных сервисов 4 и системных библиотек 5. Взаимодействие указанных блоков осуществляется в зависимости от особенностей рассматриваемой задачи, алгоритмов выполнения расчетов, моделирования и разработки наносистем. Последовательность операций описана на основе алгоритма, представленного на фиг.16.
После включения комплекса начинается выполнение циклов параллельных вычислений, определяющих процессы функционирования суперкомпьютерного комплекса при выполнении расчетов, моделирования и разработки наносистем. Процесс вычисления разбивается на ряд шагов, на каждом из которых производится решение поставленной задачи путем запуска в параллельном режиме соответствующих вычислительных модулей (блоки 1, 4, 5). При этом на каждом шаге выбирается оптимальная схема распараллеливания исходя из текущего состояния системы и параметров рассматриваемого алгоритма.
Шаг 1. Анализ схемы вычисления (блоки 2, 6, 15). На этом шаге рассматриваются особенности работы программного комплекса с большими объемами информации (блоки 11-14, 28). Для решения поставленной задачи применяется технология REST, ориентированная на обеспечение эффективного представления ресурсов.
Шаг 2. Проверка наличия необходимых источников данных (блок 6). Доступ к ресурсам (блок 7) обладает фиксированным интерфейсом, что обеспечивает унификацию ресурсов и упрощает взаимодействие с пользователем. Совместное использование технологий SOA и REST позволяет добиться организации унифицированного доступа к различным данным 19-25 и 32-34, 37, 55-57, используемым суперкомпьютерным комплексом.
Шаг 3. Конвертирование данных (блок 15). Процедура конвертирования осуществляется перед запуском каждой из задач 7-9 выполняемой последовательности 11-14. При большом количестве вычислительных модулей используется формат с возможностью конвертирования каждого из используемых форматов, что снижает объем потенциально требующихся форматов с ~N2 до ~2N.
Шаг 4. Определение оптимальной схемы декомпозиции (блоки 2, 26). Декомпозиция массивов входных данных (полей) является одним из самых востребованных вариантов декомпозиции при работе большинства используемых в комплексе вычислительных модулей. Наиболее распространенным вариантом является декомпозиция файлов, содержащих последовательность матриц. Такой тип декомпозиции осуществляется разделением массива входных полей на последовательные подмассивы, каждый из которых представляет собой входные данные для одного из параллельно работающих вычислительных модулей. В процессе декомпозиции учитывается опциональное наличие заголовочной информации, как у файла, так и у каждого из наборов данных.
Шаг 5. Декомпозиция (блоки 11, 12, 13, 14). Общая схема декомпозиции входных данных выполняется в форме файла, существенно уменьшает вероятность ошибки при передаче параметров в экземпляр класса унифицированной декомпозиции входных файлов.
Шаг 6. Параллельные вычисления (блоки 2, 14, 26). Блок программного управления параллельными вычислениями 2 является центральным управляющим сервисом суперкомпьютерной системы, ответственным за организацию, подбор оптимальной схемы распараллеливания, осуществление декомпозиции и композиции, контроль параллельных вычислений. Организация многоуровневых, или иерархических, параллельных вычислений предусматривает различные программно-аппаратные средства реализации параллельной работы суперкомпьютерного комплекса: аппаратный уровень, при котором взаимодействие происходит в рамках системы, состоящей из ряда соединенных коммуникационной средой вычислительных узлов, на каждом из которых установлен один или более процессоров (ядер), имеющих доступ к общей для них памяти. Системный уровень взаимодействия оперирует объектами операционной системы, процессами, потоками, нитями в рамках одного вычислительного узла и взаимодействиями на уровне сетевых коммуникаций при синхронизации различных узлов. Программный уровень (блок 5) предполагает использование библиотечных средств, предназначенных для коммуникации, синхронизации, балансировки и других задач организации параллельных вычислений, средствами реализации которых являются МР1 для систем с разделенной памятью и OpenMP - для систем с общей памятью. Логический уровень (блок 6) представляет собой вычислительный алгоритм, который выполняется с использованием средств нижних уровней, обеспечивая оптимальную загрузку вычислительных ресурсов системы. При изучении производительности вычислительной системы учитываются средства обеспечения параллельной работы всех уровней, их вертикальная и горизонтальная взаимосвязь, зависимость от программно-аппаратной среды исполнения и другие условия работы.
Шаг 7. Композиция (блоки 2, 28). Этот шаг осуществляется по завершении процесса обработки всех данных, полученных в результате декомпозиции и выполнения параллельных вычислительных модулей 14, 26. Результаты композиции используются в качестве входных данных для следующего вычислительного модуля.
Шаг 8. Проверка условия выполнения задач (блок 18). Если нет, то возврат на шаг 3, если да, то переход к шагу 9. Для оценки эффективности выполнения шагов 4-7 с учетом использования принятого средства параллельной обработки информации применяются соответствующие модели оценки производительности 37.
Шаг 9. Окончательная обработка и сохранение результатов (блоки 18, 53). Этот этап связан с запуском вычислительного сервиса и реализуется после выполнения шагов 1-8 для окончательной обработки информации при решении поставленной задачи в соответствии с последовательностью параллельных реализаций. В процессе работы контролируется время выполнения каждого из вычислительных модулей и параллельной схемы в целом, загруженность вычислительных узлов, стабильность работы и т.п. Эти характеристики получаются монитором выполнения приложений и служат входными данными для этапа адаптации 10, связанного с приобретением дополнительных знаний при анализе и усвоении результатов мониторинга. На основании истории запусков вычислительных модулей производится обновление и уточнение базы знаний 39. Процесс управления вычислениями осуществляется сервисом, оперирующим базой знаний о производительности вычислительных модулей 37 при оптимальной схеме распараллеливания и соответствующими вычислительными модулями. Располагая информацией о каждом из вычислительных и прикладных сервисов 4, блок программного управления 2 организует их вызов, координацию, связывание потоков данных, управление работой, контроль параллельных вычислений, выступая в роли шины, связывающей сервисы и организующей их взаимодействие. Результаты решения задачи заносятся в блок документирования 18, а их сохранение осуществляется в хранилище данных 53.
В качестве примера практического использования разработанной интеллектуальной технологии ниже рассмотрена одна из типичных задач в области приоритетных направлений наносистем (контроль свойств наноструктур, вычисление электронной структуры наноматериалов и тонких пленок и др.), связанная с реализацией технологии моделирования мезосистем, содержащих сотни и тысячи атомов, на основе квантового метода Монте-Карло [см. Замалин В.М., Норман Г.Э., Филинов B.C. Метод Монте-Карло в статистической термодинамике. - М.: Наука, 1977]. Этот метод содержит достаточно сложные вычислительные процедуры. требующие распараллеливания, и позволяет рассчитывать термодинамические свойства квантовых систем при ненулевых температурах без привлечения каких-либо упрощающих предположений. Реализация вычислительных процедур моделирования мезосистем 20 позволяет генерировать набор конфигураций координат частиц и вычисления средних значений. При моделировании учитывается начальный участок, на котором система приходит в равновесное состояние, и равновесный участок, где осуществляется усреднение термодинамических функций. При формализации алгоритма Монте-Карло выделяются следующие этапы его выполнения.
Этап 1. Инициализация исходных данных (блоки 7, 12). В качестве входных данных для моделирования используются размерность задачи, число частиц, число вершин ломаных, температура и размер ячейки Монте-Карло. По умолчанию принимается потенциал для любых видов частиц, однако можно задавать и другие потенциалы. Для ускорения выхода системы на равновесный участок начальная конфигурация использует расположение частиц из предыдущего расчета. В качестве выходных данных рассматриваются значения термодинамических функций, а также их последовательность в зависимости от номера конфигурации и парные корреляционные функции для различных пар частиц.
Этап 2. Оценка ресурсоемкости вычислительной среды (блок 2). Алгоритм оценки ресурсоемкости включает в себя этапы, связанные с заданием и анализом начальных данных 12, генерацией последовательности конфигураций на начальном и равновесном участках моделирования 14, вычисление средних значений и корреляционных функций.
Этап 3. Организация параллельных вычислений (блоки 12-14). Распараллеливание вычислительного алгоритма производится посредством независимой генерации последовательности конфигураций на равновесном участке в каждом параллельном процессе, что обеспечивает высокую эффективность и простоту реализации.
Детализированный параллельный алгоритм выполняется в виде следующих шагов.
Шаг 1. Задание и анализ начальных данных 12, задание размерности задачи, числа вершин ломаных, числа частиц, температуры и размера ячейки Монте-Карло, потенциалов взаимодействия, генерация начальной конфигурации, инициализация датчика случайных чисел 20.
Шаг 2. Генерация последовательности конфигураций на начальном участке моделирования 14; генерирование новой конфигурации посредством изменения координат одной из случайно выбранных вершин ломаной; вычисление вероятности принятия новой конфигурации, принятие новой или оставление старой конфигурации, повторение этой процедуры заданное число раз 20.
Шаг 3. Генерация последовательности конфигураций на равновесном участке моделирования 14 и вычисление средних и корреляционных функций; генерирование новой конфигурации из старой посредством изменения координат одной из случайно выбранных вершин ломаной; вычисление вероятности принятия новой конфигурации, принятие новой или оставление старой конфигурации; вычисление средних значений термодинамических функций и корреляционных функций, повторение указанных процедур заданное число раз 20.
Выполнение приведенных этапов моделирования мезосистем позволяет получить данные для разработки наносистем, которые представляются в виде таблиц и графиков термодинамических свойств и корреляционных функций. Анимация результатов сводится к последовательности равновесных конфигураций в ячейке Монте-Карло для визуального анализа связанных состояний или структуры системы частиц 16, 52.
В результате использования предлагаемого изобретения на базе суперкомпьютерного комплекса формируется гибкое информационное пространство, включающее методы вычислений, моделирования и разработки наносистем, настраиваемые адаптивные автоматизированные циклы параллельного выполнения аналитических и графических операций с учетом особенностей решаемой проблемы и изменения используемых моделей путем выявления «скрытых» знаний и закономерностей вычислительной среды в процессе решения сложных задач вычисления, моделирования и разработки наносистем.
Реализация стратегии вычислений, моделирования и разработки наносистем на основе предлагаемой интеллектуальной технологии позволяет пользователю самостоятельно формировать понятия и взаимосвязи предметной области, а также взаимодействовать с суперкомпьютерным комплексом на творческом уровне при выполнении квантово-механических расчетов и компьютерного моделирования наноразмерных атомно-молекулярных систем, наноструктур и наноматериалов на основе комплексного подхода к анализу и синтезу наносистем с использованием суперЭВМ с иерархической параллельной архитектурой.
Таким образом, суперкомпьютерный комплекс предоставляет пользователю инструментальную среду, при помощи которой выполняются сложные расчеты, моделирование, разработка и исследование физических закономерностей наносистем в заданной предметной области. Пользователю предлагается интеллектуальная поддержка в виде соответствующего математического аппарата, средств научной визуализации, когнитивной графики и виртуальной реальности, после чего формируется модель созданного пользователем когнитивного пространства вычислительной технологии. Полученные результаты сравнивается с имеющимися данными эталонных моделей до тех пор, пока не будет достигнута идентичность когнитивных моделей разработчика и интеллектуальной системы. Только после завершения этой процедуры разработчик может перейти к проверке полученных результатов на основе тестирования и их использованию при практической реализации наносистем.
| название | год | авторы | номер документа |
|---|---|---|---|
| ИНТЕЛЛЕКТУАЛЬНАЯ ГРИД-СИСТЕМА ДЛЯ ВЫСОКОПРОИЗВОДИТЕЛЬНОЙ ОБРАБОТКИ ДАННЫХ | 2009 |
|
RU2411574C2 |
| СПОСОБ ПРОЕКТИРОВАНИЯ МНОГОРЕЖИМНОЙ ИНТЕЛЛЕКТУАЛЬНОЙ СИСТЕМЫ УПРАВЛЕНИЯ РАСПРЕДЕЛЕННОЙ СРЕДОЙ МЯГКИХ ВЫЧИСЛЕНИЙ | 2014 |
|
RU2596992C2 |
| СПОСОБ АВТОМАТИЗИРОВАННОГО УПРАВЛЕНИЯ ПРОЕКТИРОВАНИЕМ БОРТОВЫХ ИНТЕЛЛЕКТУАЛЬНЫХ СИСТЕМ | 2012 |
|
RU2502131C1 |
| ИНФОРМАЦИОННО-АНАЛИТИЧЕСКАЯ СИСТЕМА В ОБЛАСТИ ТЕЛЕМЕДИЦИНЫ | 2003 |
|
RU2251965C2 |
| СПОСОБ КОНТРОЛЯ ЧРЕЗВЫЧАЙНЫХ СИТУАЦИЙ НА ОСНОВЕ ИНТЕГРАЦИИ ВЫЧИСЛИТЕЛЬНЫХ И ИНФОРМАЦИОННЫХ КОМПОНЕНТ ГРИД-СИСТЕМЫ | 2014 |
|
RU2569568C1 |
| ИНТЕЛЛЕКТУАЛЬНАЯ ОБУЧАЮЩАЯ СИСТЕМА | 2006 |
|
RU2310237C1 |
| СПОСОБ ОПЕРАТИВНОГО КОНТРОЛЯ ОСТОЙЧИВОСТИ СУДНА В ЧРЕЗВЫЧАЙНЫХ СИТУАЦИЯХ | 2015 |
|
RU2631127C2 |
| МОРСКОЙ ИНТЕЛЛЕКТУАЛЬНЫЙ ТРЕНАЖЕР | 2003 |
|
RU2251157C2 |
| СПОСОБ ТЕХНИЧЕСКОГО КОНТРОЛЯ И ДИАГНОСТИРОВАНИЯ БОРТОВЫХ СИСТЕМ БЕСПИЛОТНОГО ЛЕТАТЕЛЬНОГО АППАРАТА С ПОДДЕРЖКОЙ ПРИНЯТИЯ РЕШЕНИЙ И КОМПЛЕКС КОНТРОЛЬНО-ПРОВЕРОЧНОЙ АППАРАТУРЫ С ИНТЕЛЛЕКТУАЛЬНОЙ СИСТЕМОЙ ПОДДЕРЖКИ ПРИНЯТИЯ РЕШЕНИЙ ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2014 |
|
RU2557771C1 |
| СПОСОБ АВТОМАТИЗИРОВАННОГО ПРОЕКТИРОВАНИЯ СИСТЕМЫ УПРАВЛЕНИЯ МНОГОПАРАМЕТРИЧЕСКИМ ОБЪЕКТОМ И ПРОГРАММНО-АППАРАТНЫЙ КОМПЛЕКС ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2019 |
|
RU2730387C2 |
Изобретение относится к области компьютерных средств высокопроизводительной обработки информации для разработки наноразмерных систем. Техническим результатом является увеличение производительности обработки данных при создании наносистем новых поколений. Суперкомпьютерный комплекс для разработки наносистем содержит блок интеллектуальной поддержки вычислений, моделирования и разработки наносистем, включающий экспертную систему, блок доступа к знаниям и данным, менеджер данных, менеджер заданий и блок адаптации, блок программного управления, включающий компоненты, формирующие архитектуру расчетного приложения и соответствующую интерпретацию задания в рамках принципа конкуренции, генерацию и компиляцию кода с помощью экспертной системы с динамической базой знаний, выполняющей функции анализа альтернатив и интеллектуальной поддержки принятия решений в режиме реального времени, блок человеко-компьютерного взаимодействия, интеллектуальный интерфейс, интеллектуальный тренажер, хранилище данных, репозиторий вычислительных и прикладных сервисов, блок системных библиотек. 16 ил.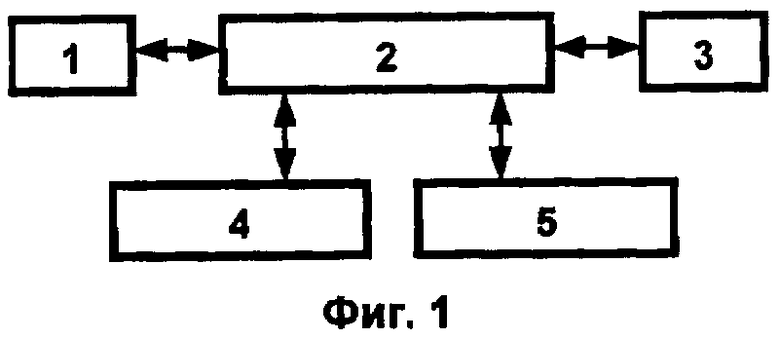
Суперкомпьютерный комплекс для разработки наносистем, реализуемый на основе принципов обработки информации в мультипроцессорной вычислительной среде, интегрированной в проблемно-ориентированную компьютерную среду PSE (Problem Solving Environment), содержащей формализованную логику изучения сложных явлений средствами расчетов, моделирования и построения наносистем, обеспечивающий обработку информации на основе заданных алгоритмов и программ, построение и реализацию различных сценариев всей технологической цепочки исследований, связанной с подготовкой данных, анализом и обобщением полученных результатов с использованием современных средств человеко-компьютерного взаимодействия, включая научную визуализацию, когнитивную графику и виртуальную реальность, отличающийся тем, что реализация высокопроизводительных вычислений в интегрированном комплексе обеспечивается на основе принципов обработки информации в мультипроцессорной вычислительной среде: принципа конкуренции, обеспечивающего выбор предпочтительной вычислительной технологии путем анализа альтернативных решений, и принципа формализации нечеткой информации при реализации управления и принятия решений, что достигается за счет введения в систему параллельно функционирующих дополнительных блоков, разработанных с использованием интеллектуальных технологий высокопроизводительных вычислений: блока интеллектуальной поддержки вычислений, моделирования и разработки наносистем, включающего экспертную систему, блок доступа к знаниям и данным, менеджер данных, менеджер заданий и блок адаптации, блок программного управления, включающего компоненты, формирующие архитектуру расчетного приложения и соответствующую интерпретацию задания в рамках принципа конкуренции, генерацию и компиляцию кода с помощью экспертной системы с динамической базой знаний, выполняющей функции анализа альтернатив и интеллектуальной поддержки принятия решений в режиме реального времени, блок человеко-компьютерного взаимодействия, реализующий функции ввода и вывода информации, интеллектуальный интерфейс, обеспечивающий разработку и запуск задания, представление информации, ее визуализацию и документирование, интеллектуальный тренажер для обеспечения процедуры обучения пользователя при работе с интегрированной программно-аппаратной средой, хранилище данных, выполняющее основные функции хранения и оперативного представления информации, причем функционирование указанных интеллектуальных средств поддерживается с помощью репозитория вычислительных и прикладных сервисов, определяющего содержательную часть задания и включающего сервисы расчетов и проектирования, атомно-молекулярных систем, моделирования мезосистем, термодинамических расчетов, вычисления электронных и фононных свойств трердотельных наноструктур, электронной структуры наносистем, оптических свойств ансамблей наночастиц, моделирования процессов наногидродинамики и формирования наночастиц, нанопластин и нанотрубок, блок системных библиотек, содержащий базовые компоненты параллельных вычислений и визуализации с учетом достижений современной когнитивной графики.
| СПОСОБ АНАЛИЗА И ПРОГНОЗИРОВАНИЯ РАЗВИТИЯ ДИНАМИЧЕСКОЙ СИСТЕМЫ И ЕЕ ОТДЕЛЬНЫХ ЭЛЕМЕНТОВ | 2000 |
|
RU2236700C2 |
| СПОСОБ АВТОМАТИЗИРОВАННОГО МИКРОСКОПИЧЕСКОГО ИССЛЕДОВАНИЯ ОБРАЗЦА | 2007 |
|
RU2330265C1 |
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |

