Область техники
Настоящее изобретение относится к способу генерации предсказанной опорной информации и к соответствующему устройству, которые применяются, когда (i) обрабатывают видеоизображение путем разделения изображения на отдельные области; применяют к каждой области разделенного изображения кодирование с временным или пространственным межкадровым предсказанием; и генерируют предсказанное изображение обрабатываемой целевой области на основании опорного кадра обрабатываемой целевой области и опорную информацию, которая указывает предсказанное целевое положение обрабатываемой целевой области в опорном кадре; и (ii) генерируют предсказанную опорную информацию в качестве предсказанной информации соответствующей опорной информации. Настоящее изобретение также относится к способу кодирования видео с использованием способа генерации предсказанной опорной информации и соответствующего устройства; устройству декодирования видео для декодирования кодированных данных, сгенерированных посредством способа кодирования видео и соответствующего устройства; программе генерации предсказанной опорной информации для реализации способа генерации предсказанной опорной информации и компьютерно-читаемому носителю, который хранит эту программу; программе кодирования для реализации способа кодирования видео и компьютерно-читаемому носителю, который хранит эту программу; и к программе декодирования видео для реализации способа декодирования видео и компьютерно-читаемому носителю, который хранит эту программу.
Настоящая заявка притязает на приоритет японской патентной заявки № 2006-293929, поданной 30 октября 2006 г., содержимое которой включено в настоящий документ посредством ссылки.
Уровень техники
Многоперспективные видеоизображения представляют собой множество видеоизображений, которые получают путем снятия одного и того же объекта и его фона посредством множества камер. В настоящем документе видеоизображение, полученное посредством одной камеры, обозначается термином "двумерное видеоизображение", а набор из множества двумерных видеоизображений, полученных путем снятия одного и того же объекта и его фона, обозначается термином "многоперспективное видеоизображение".
Существует строгая временная корреляция между двумерными видеоизображениями каждой камеры, которые включаются в состав многоперспективного видеоизображения. В добавление, когда камеры синхронизированы друг с другом, изображения (снимаемые камерами), соответствующие одному и тому же моменту времени, захватывают объект и его фон как одно целое с различных позиций, так что между камерами есть строгая корреляция. Посредством этой корреляции эффективность кодирования видео может быть повышена.
Ниже следует иллюстрация обычных способов кодирования двумерных видеоизображений.
Во многих способах кодирования двумерных видеоизображений, таких как MPEG-2 и H.264 (которые являются международными стандартами кодирования видео) и т.п., высокая эффективность кодирования достигается посредством кодирования с межкадровым предсказанием, в котором используется временная корреляция.
Кодирование с межкадровым предсказанием, выполняемое для кодирования двумерных видеоизображений, использует временную вариацию видеоизображения, то есть движение. Соответственно, способ, используемый в кодировании с межкадровым предсказанием, обычно называют "компенсацией движения". Так, кодирование с межкадровым предсказанием вдоль временной оси называется "компенсация движения". В добавление, "кадр" представляет собой изображение, которое образует часть видеоизображения и получается в определенный момент времени.
Обычно, кодирование двумерного видеоизображения имеет два режима кодирования для каждого кадра: "I-кадр" кодируется без использования межкадровой корреляции, "P-кадр" кодируется с выполнением компенсации движения на основе одного уже кодированного кадра, а "B-кадр" кодируется с выполнением компенсации движения на основе двух уже кодированных кадров.
Для дополнительного улучшения эффективности предсказания в стандартах H.263 и H.264 декодированные изображения множества кадров (то есть двух или более кадров) сохраняются в памяти опорных изображений, и для выполнения предсказания из этой памяти выбирается одно опорное изображение.
Опорное изображение может быть выбрано для каждого блока, и информация описания опорного изображения, описывающая это опорное изображение, может быть закодирована для выполнения соответствующего декодирования.
При компенсации движения, в добавление к информации описания опорного изображения, также кодируется вектор для индикации позиции в опорном изображении, причем целевой блок кодируется, используя эту позицию, и вектор называется "вектором движения".
При кодировании вектора движения в стандарте MPEG-4 или H.264 генерируется предсказанный вектор, используя вектор движения блока, смежного с кодируемым целевым блоком, и при компенсации движения, прилагаемой к целевому блоку, используется только дифференциальный вектор между предсказанным вектором и вектором движения. Согласно этому способу, когда между соответствующими смежными блоками присутствует непрерывность движения, вектор движения может быть закодирован с высокой степенью эффективности кодирования.
В непатентном документе 1 раскрыт подробный процесс генерации предсказанного вектора согласно стандарту H.264. Ниже представлено обобщенное описание этого процесса.
Как показано на Фиг.20A, в стандарте H.264 на основании векторов (mv_a, mv_b и mv_c) движения, используемых в левом блоке (см. "a" на Фиг.20A), верхнем блоке (см. "b" на Фиг.20A) и правом верхнем блоке (см. "c" на Фиг.20A) относительно целевого блока, горизонтальные и вертикальные компоненты получаются путем вычисления медианы для каждого направления.
Поскольку в стандарте H.264 применяется компенсация движения с переменным размером блока, размер блока для компенсации движения может быть разным для кодируемого целевого блока и блоков, расположенных по его периферии. В таком случае, как показано на Фиг.20B, в качестве блока "a" выбирается самый верхний блок из блоков, примыкающих к целевому блоку с левой стороны, в качестве блока "b" устанавливается самый левый блок из блоков, примыкающих к целевому блоку с верхней стороны, а в качестве блока "c" выбирается самый ближний верхний левый блок.
Как исключение, если размер целевого блока составляет 8×16 пикселей, как показано на Фиг.20C, то вместо медианы для выполнения предсказания используется блок "a" и блок "c" соответственно для левой стороны и правой стороны. Аналогично, если размер целевого блока составляет 16×8 пикселей, как показано на Фиг.20D, то вместо медианы для выполнения предсказания используется блок "a" и блок "b" соответственно для нижней стороны и верхней стороны.
Как описано выше, в стандарте H.264 для каждого блока опорный кадр выбирается из множества уже кодированных кадров и используется для компенсации движения.
Обычно, движение объекта изображения неравномерно и зависит от опорного кадра. Следовательно, по сравнению с вектором движения в компенсации движения с использованием опорного кадра, отличного от опорного кадра кодируемого целевого блока, вектор движения в компенсации движения с использованием опорного кадра, совпадающего с опорным кадром целевого блока, должен быть ближе к вектору движения, используемому для целевого блока.
Следовательно, согласно стандарту H.264, если присутствует только один блок (из блоков a, b и c), опорный кадр которого совпадает с опорным кадром кодируемого целевого блока, то вместо медианы в качестве предсказанного вектора используется вектор движения соответствующего блока, чтобы генерировать предсказанный вектор с относительно более высоким уровнем надежности.
Для случая когда во множестве кадров присутствует непрерывность движения, например, когда объект выполняет равномерное линейное движение, известен способ кодирования вектора движения с высокой эффективностью, в котором вектор движения непосредственно предшествующего кадра в порядке кодирования накапливается, и информация вектора движения подвергается масштабированию согласно соответствующему временному интервалу, чтобы вычислить вектор движения.
Для детектирования временного интервала в качестве информации используется время выхода каждого кадра.
Обычно, подобная информация времени кодируется для каждого кадра, поскольку информация времени необходима, когда, например, порядок ввода и порядок кодирования заданных изображений отличаются друг от друга, и изображения декодируются в порядке времени формирования изображений. То есть на стороне кодера каждый кадр кодируется, устанавливая информацию времени, назначенную каждому введенному изображению, согласно порядку ввода, а на стороне декодера декодированное изображение каждого кадра выводится в порядке согласно установленной информации времени.
Согласно стандарту H.264 так называемый "временной прямой режим" представляет собой способ кодирования вектора движения с высоким уровнем эффективности кодирования, используя непрерывность движения по множеству кадров.
Например, для кадров A, B и C, показанных на Фиг.21, предполагается, что кадры A, C и B последовательно кодируются в этом порядке и кадр C кодируется с использованием кадра A в качестве опорного кадра, чтобы выполнить компенсацию движения. В таком состоянии во временном прямом режиме вычисляется вектор движения блока в кадре B, как описано ниже.
Сначала детектируется вектор mv движения, который используется на блоке, принадлежащем кадру C, и который находится в той же позиции, что и кодируемый целевой блок.
Далее, согласно нижеприведенным формулам вычисляется вектор fmv движения, когда в качестве опорного рассматривается кадр A, а также вектор bmv движения, когда в качестве опорного рассматривается кадр C.
fmv = (mv×TAB)/TAC,
bmv = (mv×TBC)/TBC,
где TAB, TBC и TAC представляют собой соответственно временной интервал между кадрами A и B, временной интервал между кадрами B и C и временной интервал между кадрами A и C.
Согласно стандарту H.264 временной прямой режим может использоваться только для "B-кадра" (кадра с предсказанием в двух направлениях), который использует два опорных кадра для каждого блока.
В непатентном документе 2 описано применение вышеупомянутого режима таким образом, что эффективное кодирование вектора движения может быть реализовано также в P-кадре, который использует только один опорный кадр для каждого блока.
Кроме того, в непатентном документе 3 раскрыт способ эффективного кодирования вектора движения при условии непрерывности движения между смежными блоками и непрерывности движения по множеству кадров.
Фиг.22A-22D иллюстрируют общую концепцию этого способа. В этом способе, подобно стандартам H.264 и MPEG-4, предсказанный вектор генерируется, используя вектор движения периферийного блока, расположенного рядом с кодируемым целевым блоком, и кодируется только дифференциальный вектор между предсказанным вектором и вектором движения, который используется в фактической компенсации движения (см. Фиг.22A).
В отличие от стандарта H.264 и т.п. вектор движения периферийного блока не используется напрямую, а вместо этого он используется после масштабирования согласно соответствующему временному интервалу посредством следующей формулы.
mv_k' = mv_k × Tct/Tck,
где mv_k представляет собой исходный вектор движения, mv_k' представляет собой вектор движения после масштабирования, Tct - это временной интервал между кодируемым целевым кадром и кадром, на который должен ссылаться кодируемый целевой блок, а Tck - это временной интервал между кодируемым целевым кадром и кадром, на который ссылается периферийный блок целевого блока (см. Фиг.22B-22D).
Ниже описаны обычные способы кодирования многоперспективных видеоизображений.
Обычно, при кодировании многоперспективного видео используется корреляция между камерами, и высокий уровень эффективности кодирования обеспечивается путем использования "компенсации расхождения", при которой компенсация движения применяется к кадрам, которые сняты в одно время посредством разных камер.
Например, подобный способ используется в профиле MPEG-2 Multiview, а также в непатентном документе 4.
В способе, раскрытом в непатентном документе 4, для каждого блока выбирается какой-либо один тип компенсации - либо компенсация движения, либо компенсация расхождения. То есть для каждого блока выбирается компенсация с более высокой эффективностью кодирования, чтобы можно было использовать как временную корреляцию, так и корреляцию между камерами. По сравнению со случаем применения только одного типа корреляции, в этом случае обеспечивается более высокая эффективность кодирования.
В компенсации расхождения в добавление к остатку предсказания также кодируется вектор расхождения. Вектор расхождения соответствует вектору движения для индикации временной вариации между кадрами, и он указывает разность между позициями на плоскостях изображения, которые получаются камерами, установленными в разных позициях, и на которые проектируется одно положение снимаемого объекта.
Фиг.23 представляет собой схематический вид, иллюстрирующий расхождение, генерируемое между такими камерами. В схематическом виде с Фиг.23 плоскости изображения камер, оптические оси которых параллельны друг другу, показаны сверху.
При кодировании вектора расхождения, подобно кодированию вектора движения, представляется возможным, что предсказанный вектор генерируется с использованием вектора расхождения блока, расположенного рядом с кодируемым целевым блоком, и кодируется только дифференциальный вектор между предсказанным вектором и вектором расхождения, используемый в компенсации расхождения, которое применяется к целевому блоку. Согласно такому способу, когда между соответствующими смежными блоками присутствует непрерывность расхождения, вектор расхождения может быть кодирован с высокой степенью эффективности кодирования.
Непатентный документ 1: ITU-T Rec.H.264/ISO/IEC 11496-10, "Editor's Proposed Draft Text Modifications for Joint Video Specification (ITU-T Rec. H.264/ISO/IEC 14496-10 AVC), Draft 7", Final Committee Draft, Document JVT-E022, p. 63-64 and 117-121, September, 2002.
Непатентный документ 2: Alexis Michael Tourapis, "Direct Prediction for Predictive (P) and Bidirectionally Predictive (B) frames in Video Coding," JVT-C128, Joint Video Team (JVT) of ISO/IEC MPEG&ITU-T VCEG Meeting, p. 1-11, May, 2002.
Непатентный документ 3: Sadaatsu Kato and Choong Seng Boon, "Motion Vector Prediction for Multiple Reference Frame Video Coding Using Temporal Motion Vector Normalization", PCSJ2004, Proceedings of the 19th Picture Coding Symposium of Japan, P-2.18, Nov., 2004.
Непатентный документ 4: Hideaki Kimata and Masaki Kitahara, "Preliminary results on multiple view video coding (3DAV)", document M10976 MPEG Redmond Meeting, July, 2004.
Раскрытие изобретения
Проблемы, решаемые с помощью изобретения
Обычные способы, в которых вектор движения или вектор расхождения, по существу, используемый при кодировании целевого блока, кодируется, используя различие от предсказанного вектора, сгенерированного посредством вектора движения или вектора расхождения, используемого в смежном блоке, основаны на том факте, что снятое изображение непрерывно в вещественном пространстве и что есть высокая вероятность того, что само движение снятого объекта значительно не меняется. Следовательно, вектор движения или вектор расхождения, используемые в целевом блоке, могут быть кодированы посредством меньшего объема кода.
Тем не менее, если опорный кадр, который является наиболее подходящим для предсказания изображения целевого блока, не используется в соответствующем смежном блоке, разность между предсказанным вектором и фактически использованным вектором движения увеличивается, и объем кода невозможно значительно уменьшить.
В частности, при выполнении кодирования путем адаптивного выбора компенсации движения или компенсации расхождения для каждого блока невозможно сгенерировать предсказанный вектор вектора расхождения из вектора движения, или сгенерировать предсказанный вектор вектора движения из вектора расхождения, поскольку вектор движения и вектор расхождения имеют значительно отличающиеся характеристики. Следовательно, представляется невозможным эффективно кодировать информацию для межкадрового предсказания.
Для вектора движения, даже когда опорный вектор не используется в смежном блоке на момент, который является наиболее подходящим для предсказания изображения кодируемого целевого блока, эффективный вектор движения может быть сгенерирован путем использования временного прямого режима, раскрытого в непатентном документе 1, либо способа, раскрытого в непатентном документе 2 или непатентном документе 3.
Тем не менее, в таких способах предполагается наличие непрерывности движения по кадрам. Следовательно, если снятый объект не демонстрирует движения, близкого по форме к линейному равномерному движению по нескольким кадрам, будет невозможно сгенерировать эффективный предсказанный вектор.
Кроме того, для вектора расхождения, если опорный кадр, снятый камерой, которая является наиболее подходящей для предсказания изображения кодируемого целевого блока, не используется для смежного блока, эффективный вектор расхождения может быть сгенерирован по способу, который может быть легко выведен по аналогии и в котором вектор расхождения, используемый в смежном блоке, подвергается масштабированию, используя интервал между соответствующими камерами вместо временного интервала.
В таком способе, хотя подходящий предсказанный вектор может быть сгенерирован, когда направления камер параллельны (то есть имеют параллельные оптические оси), в иных условиях генерация подходящего предсказанного вектора будет невозможна.
Само собой разумеется, что даже когда применяется такой способ, в котором используется уже кодированный вектор движения или вектор расхождения, полученный путем масштабирования с помощью временного интервала или интервала между камерами, представляется сложным генерировать подходящий предсказанный вектор, если для каждого блока адаптивно выбирается либо компенсация движения, либо компенсация расхождения. Соответственно, эффективное кодирование невозможно реализовать.
В свете вышеизложенных обстоятельств целью настоящего изобретения является предоставление нового способа для генерации предсказанного вектора или предсказанной информации расхождения, которая значительно не отличается от предсказанного вектора или информации расхождения, использованной при предсказании изображения во время кодирования, даже когда фактическое или видимое движение снятого объекта или камеры не является линейным равномерным движением по множеству кадров.
Средство для решения проблемы
(1) Устройство генерации предсказанной опорной информации настоящего изобретения
Для достижения вышеупомянутой цели устройство генерации предсказанной опорной информации согласно настоящему изобретению обрабатывает видеоизображение путем разделения изображения на области; применения к каждой области разделенного изображения кодирования с временным или пространственным межкадровым предсказанием; и генерации предсказанного изображения обрабатываемой целевой области на основании опорного кадра обрабатываемой целевой области и опорной информации, которая указывает предсказанное целевое положение обрабатываемой целевой области в опорном кадре; и генерирует предсказанную опорную информацию в качестве предсказанной информации соответствующей опорной информации. Устройство генерации предсказанной опорной информации включает в себя:
(a) блок установки данных предсказания предсказанной опорной информации для установки опорной информации, которая была использована при обработке области, смежной с обрабатываемой целевой областью, в качестве данных предсказания предсказанной опорной информации, используемых для предсказания опорной информации обрабатываемой целевой области;
(b) блок генерации опорной информации опорной области для генерации опорной информации опорной области на основании одного или более кусков опорной информации, использованной при обработке опорной области, указанной данными предсказания предсказанной опорной информации;
(c) блок обновления данных предсказания предсказанной опорной информации для обновления данных предсказания предсказанной опорной информации путем использования сгенерированной опорной информации опорной области; и
(d) блок генерации предсказанной опорной информации для генерации предсказанной опорной информации путем использования одного или более кусков данных предсказания обновленной предсказанной опорной информации.
Вышеупомянутые блоки также могут быть реализованы посредством компьютерной программы. Такая компьютерная программа может быть предоставлена путем ее сохранения на подходящем компьютерно-читаемом носителе, либо посредством сети, и она может быть инсталлирована и приведена в действие на устройстве управления, таком как CPU, чтобы реализовать настоящее изобретение.
В устройстве генерации предсказанной опорной информации с вышеупомянутой структурой сначала опорная информация, которая была использована при обработке области, смежной с обрабатываемой целевой областью, устанавливается в качестве данных предсказания предсказанной опорной информации, используемых для предсказания опорной информации обрабатываемой целевой области.
Далее, опорная информация опорной области генерируется на основании одного или более кусков опорной информации, использованной при обработке опорной области, указанной данными предсказания предсказанной опорной информации, и установленные данные предсказания предсказанной опорной информации обновляются путем использования сгенерированной опорной информации опорной области.
Далее, предсказанная опорная информация генерируется как предсказанная информация опорной информации для обрабатываемой целевой области путем использования одного или более кусков обновленных данных предсказания предсказанной информации.
Следовательно, в устройстве генерации предсказанной опорной информации согласно настоящему изобретению предсказанная опорная информация как предсказанная информация опорной информации для обрабатываемой целевой области не генерируется путем прямого применения опорной информации, использованной, когда была обработана смежная область обрабатываемой целевой области. Вместо этого, принимая во внимание нелинейное движение снятого объекта или неравномерное движение камеры, соответствующая обработка включает в себя установку опорной информации, использованной, когда была обработана смежная область обрабатываемой целевой области; генерацию опорной информации опорной области на основании одного или более кусков опорной информации, использованной при обработке опорной области, указанной данными предсказания предсказанной опорной информации; обновление данных предсказания предсказанной опорной информации путем использования сгенерированной опорной информации опорной области; и генерацию предсказанной опорной информации в качестве предсказанной информации опорной информации для обрабатываемой целевой области путем использования данных предсказания обновленной предсказанной опорной информации.
В упомянутой обработке процесс обновления данных предсказания предсказанной опорной информации может повторяться с использованием данных предсказания обновленной предсказанной опорной информации. В таком случае соответствующий процесс может повторяться до тех пор, пока не будет получен опорный кадр обрабатываемого целевого кадра.
В устройстве генерации предсказанной опорной информации согласно настоящему изобретению, даже когда нет какой-либо временной непрерывности вариации видеоизображения по множеству кадров или когда многоперспективное изображение кодируется или декодируется с выбором компенсации движения либо компенсации расхождения для каждой обрабатываемой целевой области, разность между предсказанной опорной информацией и опорной информацией, использованной при кодировании или декодировании обрабатываемой целевой области может быть уменьшена, таким образом, обеспечивая эффективное кодирование или декодирование вектора движения или информации расхождения, используемой при кодировании с межкадровым предсказанием.
(2) Способ кодирования видео настоящего изобретения
Способ генерации предсказанной опорной информации настоящего изобретения, который может быть реализован посредством вышеупомянутого устройства генерации предсказанной опорной информации настоящего изобретения, может быть применен к способу кодирования видео.
Следовательно, способ кодирования видео согласно настоящему изобретению используется для кодирования видеоизображения путем разделения всего изображения на области; выбора, для каждой области разделенного изображения, из множества уже кодированных кадров одного опорного кадра кодируемой целевой области, который используется в качестве опорного кадра при предсказании информации изображения этой области; генерации предсказанного изображения путем использования опорного кадра кодируемой целевой области и опорной информации (например, вектор движения или вектор расхождения), которая указывает предсказанную целевую позицию кодируемой целевой области в опорном кадре кодируемой целевой области; и кодирования информации разности между предсказанным изображением и изображением кодируемой целевой области. Способ кодирования видео включает в себя:
(a) этап установки данных предсказания предсказанной опорной информации, на котором устанавливают опорную информацию, которая была использована при кодировании области, смежной с кодируемой целевой областью, в качестве данных предсказания предсказанной опорной информации, используемых для предсказания опорной информации кодируемой целевой области;
(b) этап генерации опорной информации опорной области, на котором генерируют опорную информацию опорной области на основании одного или более кусков опорной информации, использованной при кодировании опорной области, указанной данными предсказания предсказанной опорной информации;
(c) этап обновления данных предсказания предсказанной опорной информации, на котором обновляют данные предсказания предсказанной опорной информации путем использования сгенерированной опорной информации опорной области;
(d) этап генерации предсказанной опорной информации, на котором генерируют предсказанную опорную информацию, которая исполняет роль предсказанной информации опорной информации кодируемой целевой области, путем использования одного или более кусков данных предсказания обновленной предсказанной опорной информации, и
(e) этап кодирования дифференциальной опорной информации, на котором кодируют информацию разности между предсказанной опорной информацией и опорной информацией, использованной при генерации предсказанного изображения кодируемой целевой области.
В типовом примере на этапе обновления данных предсказания предсказанной опорной информации данные предсказания предсказанной опорной информации обновляются путем замены информации корреспондирующих точек, указанной данными предсказания предсказанной опорной информации, на сумму информации корреспондирующих точек, указанной данными предсказания предсказанной опорной информации, и информации корреспондирующих точек, указанной опорной информацией опорной области.
В еще одном типовом примере на этапе обновления данных предсказания предсказанной опорной информации данные предсказания предсказанной опорной информации обновляются путем замены информации корреспондирующих точек, указанной данными предсказания предсказанной опорной информации, на информацию корреспондирующих точек, указанную опорной информацией опорной области.
Предпочтительно, на этапе обновления данных предсказания предсказанной опорной информации данные предсказания предсказанной опорной информации обновляются путем замены информации корреспондирующих точек, указанной данными предсказания предсказанной опорной информации, либо на сумму информации корреспондирующих точек, указанной данными предсказания предсказанной опорной информации, и информации корреспондирующих точек, указанной опорной информацией опорной области, либо на информацию корреспондирующих точек опорной информации опорной области.
В этом случае представляется возможным, что на этапе обновления данных предсказания предсказанной опорной информации определяется, была ли заменена информация корреспондирующих точек данных предсказания предсказанной опорной информации на сумму информации корреспондирующих точек данных предсказания предсказанной опорной информации и информации корреспондирующих точек опорной информации опорной точки или на информацию корреспондирующих точек опорной информации опорной области, на основании информации времени и информации точки обзора опорного кадра кодируемой целевой области, информации времени и информации точки обзора кадра, который включает в себя опорную область, информации времени и информации точки обзора опорного кадра опорной области, который представляет собой опорный кадр, используемый при кодировании опорной области, и информации времени и информации точки обзора кодируемого целевого кадра.
Предпочтительный пример дополнительно включает в себя этап геометрического преобразования предсказанной опорной информации, на котором применяют геометрическое преобразование к информации корреспондирующих точек, указанной данными предсказания предсказанной опорной информации, путем использования параметра камеры на точке обзора кодируемого целевого кадра, параметра камеры на точке обзора опорного кадра кодируемой целевой области и параметра камеры на точке обзора кадра, указанного данными предсказания предсказанной опорной информации.
Еще один предпочтительный пример дополнительно включает в себя этап геометрического преобразования предсказанной опорной информации, на котором применяют геометрическое преобразование к информации корреспондирующих точек, указанной опорной информацией опорной области, путем использования параметра камеры на точке обзора кодируемого целевого кадра, параметра камеры на точке обзора опорного кадра кодируемой целевой области, параметра камеры на точке обзора кадра, указанного данными предсказания предсказанной опорной информации, и параметра камеры на точке обзора кадра, указанного опорной информацией опорной области, соответствующей данным предсказания предсказанной опорной информации.
Еще один предпочтительный пример дополнительно включает в себя этап поиска данных предсказания предсказанной опорной информации, на котором выполняют поиск цели, которая представляет собой область в опорном кадре кодируемой целевой области, для области, соответствующей опорной области, указанной данными предсказания предсказанной опорной информации, и заменяют данные предсказания предсказанной опорной информации на соответствующую информацию результата поиска.
На этапе поиска данных предсказания предсказанной опорной информации может быть выполнен поиск, в котором центр поиска устанавливается на область, указанную вышеупомянутой соответствующей информацией для данных предсказания предсказанной опорной информации, и данные предсказания предсказанной опорной информации могут быть заменены на информацию согласно результату поиска.
Еще один предпочтительный пример дополнительно включает в себя этап поиска данных предсказания предсказанной опорной информации, на котором выполняют поиск цели, которая представляет собой область в опорном кадре кодируемой целевой области, для области, соответствующей области, которая является смежной относительно кодируемой целевой области, и заменяют данные предсказания предсказанной опорной информации на соответствующую информацию результата поиска.
На этапе поиска данных предсказания предсказанной опорной информации может быть выполнен поиск, при котором центр поиска устанавливается на область, указанную вышеупомянутой соответствующей информацией для данных предсказания предсказанной опорной информации, и данные предсказания предсказанной опорной информации могут быть заменены на информацию согласно результату поиска.
(3) Способ декодирования видео согласно настоящему изобретению
Способ генерации предсказанной опорной информации настоящего изобретения, который может быть реализован посредством вышеупомянутого устройства генерации предсказанной опорной информации настоящего изобретения, может быть применен к способу декодирования видео.
Ниже описан способ декодирования видео, реализуемой посредством способа генерации предсказанной опорной информации согласно настоящему изобретению.
Так, способ декодирования видео согласно настоящему изобретению используется для декодирования изображения путем разделения всего изображения на области и генерации предсказанного изображения путем использования множества уже декодированных кадров, причем видеоизображение декодируется путем декодирования, для каждой области разделенного изображения, информации для указания опорного кадра декодируемой целевой области, который представляет собой уже декодированный кадр, использованный для генерации предсказанного изображения; опорной информации для указания предсказанной целевой позиции декодируемой целевой области в опорном кадре декодируемой целевой области; и информации разности между предсказанным изображением и изображением декодируемой целевой области. Способ декодирования видео включает в себя:
(a) этап установки данных предсказания предсказанной опорной информации, на котором устанавливают опорную информацию, которая была использована при декодировании области, смежной с декодируемой целевой областью, в качестве данных предсказания предсказанной опорной информации, используемых для предсказания опорной информации декодируемой целевой области;
(b) этап генерации опорной информации опорной области, на котором генерируют опорную информацию опорной области на основании одного или более кусков опорной информации, использованной при декодировании опорной области, указанной данными предсказания предсказанной опорной информации;
(c) этап обновления данных предсказания предсказанной опорной информации, на котором обновляют данные предсказания предсказанной опорной информации путем использования сгенерированной опорной информации опорной области;
(d) этап генерации предсказанной опорной информации, на котором генерируют предсказанную опорную информацию, которая исполняет роль предсказанной информации опорной информации декодируемой целевой области, путем использования одного или более кусков данных предсказания обновленной предсказанной опорной информации, и
(e) этап декодирования дифференциальной опорной информации, на котором из кодированных данных декодируют информацию разности между предсказанной опорной информацией и опорной информацией, использованной при генерации предсказанного изображения декодируемой целевой области.
В типовом примере на этапе обновления данных предсказания предсказанной опорной информации данные предсказания предсказанной опорной информации обновляются путем замены информации корреспондирующих точек, указанной данными предсказания предсказанной опорной информации, на сумму информации корреспондирующих точек, указанной данными предсказания предсказанной опорной информации, и информации корреспондирующих точек, указанной опорной информацией опорной области.
В еще одном типовом примере на этапе обновления данных предсказания предсказанной опорной информации данные предсказания предсказанной опорной информации обновляются путем замены информации корреспондирующих точек, указанной данными предсказания предсказанной опорной информации, на информацию корреспондирующих точек, указанную опорной информацией опорной области.
Предпочтительно, на этапе обновления данных предсказания предсказанной опорной информации данные предсказания предсказанной опорной информации обновляются путем замены информации корреспондирующих точек, указанной данными предсказания предсказанной опорной информации, либо на сумму информации корреспондирующих точек, указанной данными предсказания предсказанной опорной информации, и информации корреспондирующих точек, указанной опорной информацией опорной области, либо на информацию корреспондирующих точек, указанную опорной информацией опорной области.
В этом случае представляется возможным, что на этапе обновления данных предсказания предсказанной опорной информации определяется, была ли заменена информация корреспондирующих точек данных предсказания предсказанной опорной информации на сумму информации корреспондирующих точек данных предсказания предсказанной опорной информации и информации корреспондирующих точек опорной информации опорной точки или на информацию корреспондирующих точек опорной информации опорной области, на основании информации времени и информации точки обзора опорного кадра декодируемой целевой области, информации времени и информации точки обзора кадра, который включает в себя опорную область, информации времени и информации точки обзора опорного кадра опорной области, который представляет собой опорный кадр, используемый при декодировании опорной области, и информации времени и информации точки обзора декодируемого целевого кадра.
Предпочтительный пример дополнительно включает в себя этап геометрического преобразования предсказанной опорной информации, на котором применяют геометрическое преобразование к информации корреспондирующих точек, указанной данными предсказания предсказанной опорной информации, путем использования параметра камеры на точке обзора декодируемого целевого кадра, параметра камеры на точке обзора опорного кадра декодируемой целевой области и параметра камеры на точке обзора кадра, указанного данными предсказания предсказанной опорной информации.
Еще один предпочтительный пример дополнительно включает в себя этап геометрического преобразования предсказанной опорной информации, на котором применяют геометрическое преобразование к информации корреспондирующих точек, указанной опорной информацией опорной области, путем использования параметра камеры на точке обзора декодируемого целевого кадра, параметра камеры на точке обзора опорного кадра декодируемой целевой области, параметра камеры на точке обзора кадра, указанного данными предсказания предсказанной опорной информации, и параметра камеры на точке обзора кадра, указанного опорной информацией опорной области, соответствующей данным предсказания предсказанной опорной информации.
Еще один предпочтительный пример дополнительно включает в себя этап поиска данных предсказания предсказанной опорной информации, на котором выполняют поиск цели, которая представляет собой область в опорном кадре декодируемой целевой области, для области, соответствующей опорной области, указанной данными предсказания предсказанной опорной информации, и заменяют данные предсказания предсказанной опорной информации на соответствующую информацию результата поиска.
На этапе поиска данных предсказания предсказанной опорной информации может быть выполнен поиск, при котором центр поиска устанавливается на область, указанную вышеупомянутой соответствующей информацией для данных предсказания предсказанной опорной информации, и данные предсказания предсказанной опорной информации могут быть заменены на информацию согласно результату поиска.
Еще один предпочтительный пример дополнительно включает в себя этап поиска данных предсказания предсказанной опорной информации, на котором выполняют поиск цели, которая представляет собой область в опорном кадре декодируемой целевой области, для области, соответствующей области, которая является смежной относительно декодируемой целевой области, и заменяют данные предсказания предсказанной опорной информации на соответствующую информацию результата поиска.
На этапе поиска данных предсказания предсказанной опорной информации может быть выполнен поиск, при котором центр поиска устанавливается на область, указанную вышеупомянутой соответствующей информацией для данных предсказания предсказанной опорной информации, и данные предсказания предсказанной опорной информации могут быть заменены на информацию согласно результату поиска.
Полезный эффект изобретения
Согласно настоящему изобретению опорная информация, которая использовалась при кодировании области, смежной с кодируемой целевой областью, преобразовывается посредством кодированных данных, которые были использованы при кодировании соответствующей опорной области, в опорную информацию, подходящую для отношений по времени и точке обзора между кодируемым целевым кадром и кодируемым целевым опорным кадром, и далее генерируется предсказанная опорная информация. Соответственно, даже когда отсутствует временная непрерывность вариации видеоизображения по множеству кадров или когда многоперспективное изображение кодируется с выбором компенсации движения либо компенсации расхождения для каждой кодируемой единичной области, то не добавляется какой-либо дополнительной информации, которая указывает соответствующий способ преобразования, и разность между предсказанной опорной информацией и опорной информацией, использованной при кодировании кодируемой целевой области, может быть уменьшена, благодаря чему эффективно кодируется вектор движения или информация расхождения, используемая при кодировании с межкадровым предсказанием.
Краткое описание чертежей
Фиг.1 - схема, иллюстрирующая пример обработки для замены данных предсказания предсказанной опорной информации на сумму данных предсказания предсказанной опорной информации и опорной информации опорной области согласно настоящему изобретению;
Фиг.2 - схема, иллюстрирующая пример обработки для замены данных предсказания предсказанной опорной информации на опорную информацию опорной области согласно настоящему изобретению;
Фиг.3 - иллюстрация одного варианта осуществления устройства кодирования видео согласно настоящему изобретению;
Фиг.4 - пример схемы последовательности операций процесса кодирования видео, выполняемого устройством кодирования видео этого варианта осуществления;
Фиг.5 - пример схемы последовательности операций процесса обновления данных предсказания предсказанной опорной информации, когда при кодировании настоящего варианта осуществления возможно только временное предсказание видео;
Фиг.6 - пример схемы последовательности операций процесса обновления данных предсказания предсказанной опорной информации, когда при кодировании настоящего варианта осуществления возможно либо временное предсказание видео, либо предсказание видео на основе отношения между камерами;
Фиг.7 - пример схемы последовательности операций в виде части схемы последовательности операций с Фиг.6, когда кодируемый целевой блок подвергается предсказанию изменения видео между камерами;
Фиг.8 - пример схемы последовательности операций в виде части схемы последовательности операций с Фиг.6, когда кодируемый целевой блок подвергается предсказанию временного изменения видео;
Фиг.9 - пример схемы последовательности операций процесса обновления данных предсказания предсказанной опорной информации, когда при кодировании настоящего варианта осуществления для каждого кодируемого целевого блока возможно любое предсказание видео;
Фиг.10 - пример схемы последовательности операций в виде части схемы последовательности операций с Фиг.9, когда кодируемый целевой блок подвергается предсказанию изменения видео между камерами;
Фиг.11 - пример схемы последовательности операций в виде части схемы последовательности операций с Фиг.9, когда кодируемый целевой блок подвергается предсказанию временного изменения видео;
Фиг.12 - пример схемы последовательности операций в виде части схемы последовательности операций с Фиг.9, когда кодируемый целевой блок подвергается предсказанию изменения видео, которое включает в себя как временное изменение видео, так и изменение видео между камерами;
Фиг.13 - схема, разъясняющая процесс обновления данных предсказания предсказанной опорной информации, выполняемый на этапе S310 с Фиг.7;
Фиг.14 - схема, разъясняющая процесс обновления данных предсказания предсказанной опорной информации, выполняемый на этапе S318 с Фиг.7;
Фиг.15 - схема, разъясняющая процесс обновления данных предсказания предсказанной опорной информации, выполняемый на этапе S415 с Фиг.10;
Фиг.16 - схема, разъясняющая процесс обновления данных предсказания предсказанной опорной информации, выполняемый на этапе S433 с Фиг.11;
Фиг.17 - схема, разъясняющая процесс обновления данных предсказания предсказанной опорной информации, выполняемый на этапе S444 с Фиг.12;
Фиг.18 - иллюстрация одного варианта осуществления устройства декодирования видео согласно настоящему изобретению;
Фиг.19 - пример схемы последовательности операций процесса декодирования видео, выполняемого устройством кодирования видео этого варианта осуществления;
Фиг.20A - схема, разъясняющая предсказание вектора движения согласно стандарту H.264;
Фиг.20B - еще одна схема, разъясняющая предсказание вектора движения согласно стандарту H.264;
Фиг.20C - еще одна схема, разъясняющая предсказание вектора движения согласно стандарту H.264;
Фиг.20D - еще одна схема, разъясняющая предсказание вектора движения согласно стандарту H.264;
Фиг.21 - схема, разъясняющая генерацию вектора движения в прямом режиме;
Фиг.22A - схема, разъясняющая способ генерации предсказанного вектора путем использования векторов движения периферийных блоков, расположенных вокруг кодируемого целевого блока;
Фиг.22B - схема, разъясняющая предсказание вектора движения, к которому применяется масштабирование с использованием информации времени;
Фиг.22C - еще одна схема, разъясняющая предсказание вектора движения, к которому применяется масштабирование с использованием информации времени;
Фиг.22D - еще одна схема, разъясняющая предсказание вектора движения, к которому применяется масштабирование с использованием информации времени;
Фиг.23 - схема, иллюстрирующая расхождение, генерируемое между камерами.
Ссылочные обозначения
100 - устройство кодирования видео
101 - блок ввода изображения
102 - блок реализации сопоставления блоков
103 - генератор предсказанного изображения
104 - кодер дифференциального изображения
105 - декодер дифференциального изображения
106 - память опорных кадров
107 - память накопления опорной информации
108 - память данных предсказания предсказанной опорной информации
109 - генератор предсказанной опорной информации
110 - кодер дифференциальной опорной информации
111 - обновитель опорной информации
112 - память накопления информации описания опорного кадра
113 - селектор опорного кадра
114 - кодер информации описания опорного кадра
Лучший вариант осуществления изобретения
Согласно способу кодирования видео или способу декодирования видео настоящего изобретения при предсказании опорной информации, используемой для кодирования или декодирования кодируемой целевой области или декодируемой целевой области путем использования опорной информации области, которая является смежной относительно кодируемой целевой области или декодируемой целевой области, опорная информация смежной области корректируется посредством опорной информации, которая была использована при кодировании или декодировании опорной области, на которую ссылались при кодировании или декодировании смежной области, так что, даже когда непрерывность в изменении видео между множеством кадров отсутствует, может быть сгенерирована точно предсказанная опорная информация.
Поскольку согласно обычному способу, проиллюстрированному пунктирной линией на Фиг.1, опорная информация просто корректируется (то есть из опорной информации генерируется предсказанная опорная информация) на основе предположения, что по множеству кадров есть непрерывность изменения видео, то когда непрерывность изменения видео по множеству кадров отсутствует, выполняются неправильные преобразования.
В отличие от этого согласно настоящему изобретению изменение с опорного кадра смежной области на другой кадр может быть получено из опорной информации, когда опорная информация смежной области кодировалась или декодировалась, посредством чего опорная информация смежной области может быть откорректирована без предположения, что по множеству кадров присутствует непрерывность изменения видео.
В настоящем изобретении опорная информация смежной области, то есть опорная информация, полученная при кодировании или декодировании области, указанной "данными предсказания предсказанной опорной информации", обозначается термином "опорная информация опорной области".
Эта опорная информация опорной области фактически использовалась при кодировании или декодировании опорной области, и она рассматривается как надежно выражающая изменение видеоизображения благодаря своей более высокой эффективности кодирования. Информация, откорректированная посредством такой информации, также рассматривается как надежно выражающая изменение видео.
В способе коррекции опорной информации, как показано на Фиг.1, опорная информация опорной области может быть добавлена к опорной информации, относящейся к смежной области (то есть реализуется способ синтеза вектора).
В этом способе изменение видео с опорного кадра опорной области смежной области к опорному кадру смежной области добавляется к изменению видео с опорного кадра смежной области к кодируемому или декодируемому целевому кадру, посредством чего определяется изменение видео с опорного кадра опорной области смежной области к кодируемому или декодируемому целевому кадру.
На основании того что изменение видео, которое уже было кодировано или декодировано, не меняется, этот способ обеспечивает преобразование опорной информации с высокой надежностью.
Также предполагается возможность случая, когда опорная область смежной области не является единичной областью процесса кодирования или декодирования, и она содержит множество кусков опорной информации. Если указанное справедливо, то может быть использован один из следующих способов.
(i) Опорная информация, использованная в единичной области процесса кодирования или декодирования, которая содержит большую долю опорной области, устанавливается как опорная информация опорной области.
(ii) Усредненная опорная информация, которая определяется путем назначения весовых коэффициентов опорной информации единичных областей процесса кодирования или декодирования согласно коэффициенту включения в нее опорной области, устанавливается как опорная информация опорной области.
(iii) Все пиксели в единичной области процесса кодирования или декодирования сохраняют опорную информацию, которая должна быть кодирована или декодирована, и опорная информация, которая появляется чаще всего во множестве опорных областей, устанавливается в качестве опорной информации опорной области.
Эта коррекция может быть выполнена не только единожды, а многократно, например, путем повторной корректировки опорной информации, которая ранее была откорректирована.
Путем добавления повторных коррекций, когда опорный кадр опорной области смежной области находится недостаточно близко к опорному кадру кодируемой или декодируемой целевой области, предоставляется возможность получения данных предсказания предсказанной опорной информации, которые ближе к изменению видео с опорного кадра кодируемой или декодируемой целевой области.
Что касается способа коррекции опорной информации, то, как показано на Фиг.2, опорная информация для смежной области может быть заменена на опорную информацию опорной области.
В этом способе изменение видео с опорного кадра кодируемой или декодируемой целевой области на кодируемый или декодируемый целевой кадр определяется путем обработки изменения видео с опорного кадра смежной области на кодируемый или декодируемый целевой кадр как равного изменению видео с опорного кадра смежной области на опорный кадр кодируемой или декодируемой целевой области.
В этом способе используются два факта.
Первый факт заключается в том, что существуют физические ограничения на изменение снятого объекта. Физическое ограничение изменения снятого объекта указывает высокую временную корреляцию расхождения.
То есть расхождение в областях с заданным отношением соответствия в разных кадрах во времени, то есть в смежной области и опорной области этой смежной области, имеет высокое сходство.
Следовательно, если временная опорная информация смежной области заменяется опорной информацией отношения между камерами в опорной области смежной области, преобразование опорной информации отношения между камерами в смежной области может быть обеспечено с высокой точностью.
Второй факт заключается в том, что снятый объект в действительности имеет одно движение. Тот факт, что снятый объект имеет только одно движение, указывает на то, что движение, снятое всеми камерами, является одним и тем же и что движение снятого объекта имеет высокую корреляцию между камерами.
То есть движение в областях с заданным отношением соответствия в кадрах, которые сняты в одно и то же время с разных камер, то есть движения в смежной области и опорной области этой смежной области, имеют высокое сходство.
Следовательно, если опорная информация отношения между камерами смежной области заменяется временной опорной информацией в опорной области этой смежной области, преобразование временной опорной информации в смежной области может быть обеспечено с высокой точностью.
Так, даже если опорная цель отличается в направлении времени и направлении камеры в кодируемой целевой области и ее смежных областях, опорная информация может быть точно предсказана.
В этом способе, чем больше подобие отношения времени и отношения точки обзора между опорной областью этой смежной области и ее опорном кадром на отношение времени и отношение точки обзора между кодируемым или декодируемым целевым кадром и опорным кадром декодируемой целевой области, тем точнее будет предсказание, достигаемое при преобразовании.
Для корректировки опорной информации в каждой кодируемой или декодируемой целевой области как подходящий способ может быть выбран один из описанных способов.
Поскольку характеристика изображения, используемого в каждом способе, различается, то выбор подходящего способа будет варьирован в зависимости от обстоятельств.
Следовательно, смена способа для каждой кодируемой или декодируемой целевой области обеспечивает возможность добавления коррекции, подходящей для этой области, а также возможность генерации предсказанной опорной информации, которая выражает изменение видео более точно.
Так, поскольку первый способ накапливает временное изменение в видеоизображении между кадрами, он подходит для предсказания изменения видео в направлении времени, тогда как последний способ подходит для преобразования изменения видео между камерами и по времени, и определение предпочтительности того или иного способа может быть реализовано на основе предсказания изображения, используемого в кодируемой или декодируемой целевой области, или на основе размера изменения видео, указанного данными предсказания предсказанной опорной информации и опорной информацией опорной области.
То есть подходящий способ может быть точно определен посредством информации времени и информации точки обзора опорного кадра кодируемой или декодируемой целевой области, информации времени и информации точки обзора кадра, который содержит соответствующую опорную область, информации времени и информации точки обзора опорного кадра опорной области, который представляет собой опорный кадр, используемый при кодировании или декодировании опорной области, и информации времени и информации точки обзора кодируемого или декодируемого целевого кадра.
Опорная информация может быть скорректирована путем геометрического преобразования опорной информации согласно параметрам точки обзора камеры для кодируемого или декодируемого целевого кадра, параметрам точки обзора камеры для опорного кадра кодируемой или декодируемой целевой области и параметрам точки обзора для кадра, который содержит опорную область.
Этот способ преобразования может быть реализован относительно данных предсказания предсказанной опорной информации и опорной информации опорной области.
Согласно этим способам изменение видео по кадрам, снятым двумя камерами, может быть преобразовано в изменение видео по кадрам, снятым другой комбинацией двух камер.
В отличие от временного изменения видеоизображения, изменение отношения между камерами возникает из положения камер и положения снятого объекта. Следовательно, когда изображения снимаются с двух разных положений в одно и то же время и параметры камеры, указывающие позиционное отношение камер и т.п., известны заранее, предоставляется возможность точно предсказывать изображение, снятое с еще одного, другого положения.
Поскольку это отношение соответствия не может быть получено путем простого выполнения масштабирования согласно интервалу камеры, преобразование, которое обеспечивает точное предсказание, не может быть достигнуто путем простого расширения обычного способа масштабирования согласно временному интервалу.
В качестве способа коррекции опорной информации область опорного кадра кодируемой или декодируемой области может рассматриваться как цель поиска, выполняется поиск области, которая устроена в соответствии с опорной областью, специфицированной данными предсказания предсказанной опорной информации, и данные предсказания предсказанной опорной информации заменяются на соответствующую информацию результата поиска.
В еще одном способе коррекции опорной информации область на опорном кадре кодируемой целевой области устанавливается как цель поиска, выполняется поиск области, которая расположена в соответствии со смежной областью кодируемой целевой области, и тогда данные предсказания предсказанной опорной информации могут быть заменены на соответствующую информацию результата поиска.
Несмотря на то что эти способы требуют значительного объема арифметических операций как при кодировании, так и при декодировании, они могут обеспечить более точное определение точки соответствия на опорном кадре кодируемой или декодируемой целевой области данной смежной области, а также генерацию предсказанной опорной информации, которая более точно выражает изменение видео, тем самым, эффективно кодируя опорную информацию.
То, насколько точно эти способы могут определить точку соответствия, в большой степени зависит от способа поиска и диапазона поиска, выполняемого в соответствующей области, то есть от арифметической стоимости.
Тем не менее, когда опорный кадр данных предсказания предсказанной опорной информации расположен ближе к опорному кадру кодируемой или декодируемой целевой области, чем к кодируемому или декодируемому целевому кадру, поскольку опорная информация данных предсказания предсказанной опорной информации выражает движение в находящуюся посередине точку, то этого будет достаточно для поиска изменения после этой точки, и стоимость арифметических вычислений может быть уменьшена.
Ниже настоящее изобретение подробно описано на примере вариантов осуществления.
Фиг.3 представляет собой иллюстрацию одного варианта осуществления устройства 100 кодирования видео согласно настоящему изобретению.
Устройство 101 кодирования видео включает в себя блок 101 ввода изображения, в который изображение вводится как цель кодирования, блок 102 выполнения сопоставления блоков, который выполняет сопоставление блоков, чтобы определить соответствующую область в опорном кадре, который уже был кодирован, в каждой области разделенного кодируемого целевого изображения, генератор 103 предсказанного изображения, который генерирует предсказанное изображение изображения в кодируемой целевой области посредством результата сопоставления блоков и опорного кадра, кодер 104 дифференциального изображения, который кодирует дифференциальное изображение между изображением в кодируемой целевой области и предсказанным изображением, декодер 105 дифференциального изображения, который декодирует кодированные данные дифференциального изображения, память 106 опорного кадра, которая накапливает декодированное изображение изображения в кодируемой целевой области, сгенерированное путем суммирования декодированного дифференциального изображения и предсказанного изображения в качестве опорного кадра, память 107 накопления опорной информации, которая накапливает опорную информацию, относящуюся к результату сопоставления блоков, используемому при генерации предсказанного изображения, память 108 данных предсказания предсказанной опорной информации, которая накапливает опорную информацию, которая становится кандидатом для предсказанной опорной информации, используемой при кодировании опорной информации, относящейся к результату сопоставления блоков, который используется при генерации предсказанного изображения, генератор 109 предсказанной опорной информации, который генерирует предсказанную опорную информацию из данных предсказания предсказанной опорной информации, кодер 110 дифференциальной опорной информации, который кодирует разность между опорной информацией, относящейся к результату сопоставления блоков, используемому при генерации предсказанного изображения, и предсказанной опорной информацией, обновитель 111 опорной информации, который корректирует данные предсказания предсказанной опорной информации в памяти 108 данных предсказания предсказанной опорной информации, память 112 накопления информации описания опорного кадра, которая накапливает информацию о кадре, на который ссылается каждая уже кодированная область, селектор 113 опорного кадра, который выбирает опорный кадр, который должен быть использован при кодировании изображения в кодируемой целевой области, и кодер 114 информации описания опорного кадра, который кодирует информацию для описания опорного кадра, используемого при кодировании кодируемой целевой области.
Фиг.4 представляет собой схему последовательности операций, выполняемых устройством 100 кодирования видео с вышеописанной структурой.
Процессы, выполняемые устройством 100 кодирования видео с этой конфигурацией, подробно описаны ниже на основании этой схемы последовательности операций.
В этом примере изображения множества кадров уже кодированы, и результаты накоплены в памяти 106 опорного кадра, памяти 107 накопления опорной информации и памяти 112 накопления информации описания опорного кадра.
Сначала, через блок 101 ввода изображения вводится изображение, которое станет целью кодирования (S101).
Введенное кодируемое целевое изображение целиком разделяется на области, и каждая область кодируется (S102-S121).
В данной схеме последовательности операций blk обозначает индекс блока (области), а MaxBlk обозначает общее количество блоков для одного изображения.
Изначально индексу blk присваивается значение 1 (S102), после чего последующие процессы (S103-S119) выполняются по циклу, приращивая blk на 1(S121) до тех пор, пока он не достигнет значения MaxBlk (S120).
В процессе, выполняемом для каждого блока, определяются опорный кадр best_ref, опорная информация best_mv и предсказанная опорная информация best_pmv, которые должны быть использованы для кодирования этого блока (S103~S117), и эта информация для предсказания видео и информация блока blk, кодированного посредством той информации, кодируются и выводятся (S188). Для выполнения последующих процессов кодирования кодированные данные декодируются, и информация декодированного изображения, а также best_ref и best_mv сохраняются в памяти 106 опорного кадра, памяти 112 накопления информации описания опорного кадра и памяти 107 накопления опорной информации соответственно (S119).
В процессе кодирования (S118) информация, указывающая best_ref, кодируется посредством кодера 114 информации описания опорного кадра, тогда как разность между best_mv и best_pmv кодируется посредством кодера 110 дифференциальной опорной информации, а кодер 104 дифференциального изображения кодирует изображение разности между введенным изображением и предсказанным изображением, сгенерированным генератором 103 предсказанного изображения с помощью этой информации.
В процессе декодирования (S119) декодер 105 дифференциального изображения декодирует кодированные данные, относящиеся к дифференциальному изображению, и информация декодированного изображения блока blk получается путем определения суммы декодированного результата и предсказанного изображения, сгенерированного генератором 103 предсказанного изображения.
Информация для предсказания видео, используемая при кодировании, определяется путем многократного выполнения следующих процессов (S104-S115) относительно всех используемых опорных кадров.
Сначала индексу ref опорного кадра присваивается значение 1, и минимальной стоимости bestCost несоответствия скорости присваивается абсолютно недостижимая максимальная величина MaxCost (S103), после чего процессы генерации предсказанной опорной информации (S104-S107) и процессы определения опорной информации, при которых минимизируется стоимость несоответствия скорости (S108-S115), многократно повторяются с приращением ref на 1 (S117) до тех пор, пока не будет достигнуто общее количество NumOfRef используемых опорных кадров (S116).
В течение процесса генерации предсказанной опорной информации после инициализации памяти 108 данных предсказания предсказанной опорной информации (S104), для множества блоков, смежных с блоком blk, комбинация номера REF опорного кадра, используемого при кодировании этого блока, опорной информации MV и информации POS, указывающей положение этого блока (REF, MV, POS), сохраняется в памяти 108 данных предсказания предсказанной опорной информации (S105).
Предполагается, что MV и REF накапливаются соответственно в памяти 107 накопления опорной информации и памяти 112 накопления информации описания опорного кадра согласно индексу блока или положению в изображении.
Например, когда области разделенного изображения кодируются в последовательности растрового сканирования, множество блоков, смежных с блоком blk, может включать в себя блоки на верхней, левой и верхней правой сторонах.
В этом варианте осуществления опорная информация соответствующих трех смежных блоков устанавливается в качестве данных предсказания предсказанной опорной информации. Блоки, расположенные вне экрана, исключаются из списка кандидатов.
Впоследствии данные предсказания предсказанной опорной информации извлекаются из памяти 108 данных предсказания предсказанной опорной информации, обновляются посредством обновителя 111 опорной информации и снова накапливаются в памяти 108 данных предсказания предсказанной опорной информации (S106). Ниже этот процесс описан подробным образом.
Предсказанная опорная информация pmv генерируется из множества кусков опорной информации, накопленной в памяти 108 данных предсказания предсказанной опорной информации (S107). В частности, предсказанная опорная информация pmv генерируется путем определения промежуточной величины данных предсказания предсказанной опорной информации для каждого компонента опорной информации.
То есть, когда опорная информация выражается как двумерный вектор по линии X-Y, для каждого компонента промежуточная величина определяется для соответствующих компонентов, принадлежащих множеству данных предсказания предсказанной опорной информации, и pmv для соответствующего компонента присваивается эта величина.
Вместо промежуточной величины может использоваться другая величина, такая как средняя величина, максимальная величина, минимальная величина и т.п. Тем не менее, используемая величина должна быть той же, что и величина, которая используется декодирующим устройством.
Используя определенную таким образом pmv, выполняется процесс, чтобы определить опорную информацию, которая минимизирует стоимость несоответствия скорости.
Сначала индексу mv_idx опорной информации присваивается значение 1 (S108), после чего следующие процессы (S110-S113) повторяются с приращением mv_idx на 1 (S115) до тех пор, пока он не совпадет с количеством кандидатов NumOfListMv для опорной информации, которая может быть использована для кодирования блока blk (S114).
Сначала получают опорную информацию, соответствующую mv_idx (S109). В этом примере опорная информация, соответствующая mv_idx, уже накоплена в памяти cand_mv.
Используя эту mv и опорный кадр, генерируется предсказанное изображение Pre для блока blk (S110).
В частности, предполагается, что предсказанное изображение представляет собой информацию изображения для области в опорном кадре ref, где область указывается вектором mv из позиции блока blk.
Далее, посредством следующей формулы вычисляется стоимость cost несоответствия скорости, используя сгенерированное предсказанное изображение Pre, информацию Org изображения блока blk, а также pmv, mv и ref (S111).
[Формула 1]

где λ представляет собой неопределенный множитель Лагранжа, который является предопределенной величиной. Кроме того, выражение bit() представляет функцию, которая возвращает объем кода, который необходим для кодирования прилагаемой информации.
Несмотря на то что величина D представляет сумму абсолютных разностей двух кусков информации изображения, она также может являться суммой квадратов разностей, или индикатором, известным как Сумма Абсолютных Преобразованных Разностей (Sum of Absolute Transformed Differences, SATD), где сумма определяется после преобразования дифференциальной информации в частотный диапазон.
В способе точного определения стоимости несоответствия скорости, который сам по себе дополнительно увеличивает арифметическую стоимость процесса кодирования, используется объем BITS кода, когда фактически кодируется дифференциальное изображение Diff (=Org-Pre) между изображением кодируемой целевой области и предсказанным изображением и декодируемое дифференциальное изображение DecDiff, полученное путем декодирования кодированных данных этого дифференциального изображения, согласно следующей формуле.
[Формула 2]

Выполняется сравнение стоимости и полученной указанным образом величины bestCost (S112), и если стоимость меньше, то bestCost заменяется на cost, best_ref заменяется на ref, best_mv заменяется на mv, а best_pmv заменяется на pmv (S113), и, таким образом, получается информация для кодирования, которая обеспечивает наименьшую стоимость несоответствия скорости.
Процесс S106, выполняемый посредством обновителя 111 опорной информации, описан ниже со ссылкой на Фиг.5-12.
В процессе S106, переменные FIN, которые назначаются всем данным предсказания предсказанной опорной информации, накопленным в памяти 108 данных предсказания предсказанной опорной информации, изначально устанавливаются в нулевое значение, и процессы с Фиг.5-12 повторяются до тех пор, пока все FIN не достигнут значения 1.
Фиг.5 представляет собой схему последовательности операций, где все входные кадры и опорные кадры представляют собой кадры, которые были сняты одной и той же камерой.
Фиг.6-8 представляют собой схемы последовательности операций для случая, когда вводится многоперспективное изображение, и опорный кадр либо имеет то же время отображения (время снятия), что и введенный кадр, либо он снят посредством той же камеры.
Фиг.9-12 представляют собой схемы последовательности операций для случая, когда вводится многоперспективное изображение, и любой кадр, который уже был кодирован, может быть использован в качестве опорного кадра.
Ниже описана схема последовательности операций для случая с Фиг.5, где все введенные кадры и опорные кадры представляют собой кадры, которые были сняты одной и той же камерой.
Сначала данные предсказания предсказанной опорной информации, которые еще не были обновлены, то есть для которых FIN равен 0, извлекаются из памяти 108 данных предсказания предсказанной опорной информации и устанавливаются как p_can (S201).
Как описано для процесса S105, поскольку информация в памяти данных предсказания предсказанной опорной информации включает в себя опорный кадр, использованный при кодировании множества блоков, смежных с блоком blk, который является кодируемым целевым блоком, опорную информацию и информацию, указывающую положение этих блоков, p_can представляет собой информацию, которая включает в себя количество опорных кадров смежных блоков, опорную информацию смежных блоков и информацию, указывающую позицию смежных блоков.
Соответственно, номер p_can опорного кадра устанавливается как ref_can, а опорная информация p_can устанавливается как mv_can (S202).
Так, если ref_can равен номеру ref опорного кадра, который должен быть использован при кодировании блока blk (S203), FIN меняется на 1 (S204), а p_can сохраняется в неизменном виде в памяти 108 данных предсказания предсказанной опорной информации (S211).
То есть, когда опорный кадр ref_can соответствующего смежного блока совпадает с опорным кадром ref кодируемого целевого блока, при генерации предсказанной опорной информации pmv лучше использовать неизмененные данные предсказания предсказанной опорной информации, извлеченные из памяти 108 данных предсказания предсказанной опорной информации. По этой причине p_can сохраняется в неизменном виде в памяти 108 данных предсказания предсказанной опорной информации.
С другой стороны, если ref_can не равен номеру ref опорного кадра, который должен быть использован для кодирования блока blk, то в кадре ref_can опорный кадр, который используется большинством пикселей при кодировании области (опорной области), полученной путем сдвига p_can (смежной области) на mv_can, устанавливается как ref_tel, а опорная информация, опорным кадром которой является ref_tel и которая используется в большинстве пикселей в этой области, устанавливается как mv_tel (S205), после чего процесс выполняется согласно следующей условной формуле.
[Формула 3]

где TIME () представляет собой функцию, которая возвращает время отображения (время формирования изображения) кадра, соответствующего заданному номеру опорного кадра.
Эта условная формула определяет, находится ли опорный кадр ref_tel ближе во времени к опорному кадру ref кодируемого целевого блока blk, чем опорный кадр ref_can.
Когда условие этой формулы удовлетворяется, ref_can перезаписывается как ref_tel, а mv_tel добавляется к mv_can (S207).
Если условие этой формулы не удовлетворяется, то, используя информацию изображения кодируемого целевого кадра в положении p_can, при поиске соответствующей области в опорном кадре ref опорный кадр ref кодируемого целевого блока blk используется как цель поиска, и центр поиска устанавливается в mv_can, смещение от центра поиска (соответствующая информация) устанавливается равным mv_canBM (S208), ref_can перезаписывается как ref, а mv_canBM прибавляется к mv_can (S209).
В любом случае, после обновления ref_can и mv_can, ref_can и mv_can устанавливаются как номер опорного кадра и опорная информация p_can (S210), и p_can сохраняется в памяти 108 данных предсказания предсказанной опорной информации (S211), после чего процесс завершается.
Несмотря на то что процедура схемы последовательности операций с Фиг.5 повторяется до тех пор, пока FIN всех данных предсказания предсказанной опорной информации не примет значение 1, то есть до тех пор, пока не будет достигнут опорный кадр ref кодируемого целевого блока blk, причем количество повторений может быть, например, фиксировано согласно определенным условиям (если это применимо).
Сверх того, наряду с тем что в схеме последовательности операций с Фиг.5 в процессе S208 сопоставления блоков выполняется поиск области, которая совпадает с опорной областью для смежной области кодируемого целевого блока blk, используя опорный кадр ref кодируемого целевого блока blk в качестве цели поиска, также представляется возможным выполнять поиск области, которая совпадает со смежной областью кодируемого целевого блока blk.
Кроме того, несмотря на то что в схеме последовательности операций с Фиг.5 в процессе S206 определяется, выполнять ли процесс S207 либо процессы S208 и S209, процесс S207 может выполняться безоговорочно.
Так, обновитель 111 опорной информации реализует схему последовательности операций с Фиг.5, посредством чего данные предсказания предсказанной опорной информации, сохраненные в памяти 108 данных предсказания предсказанной опорной информации, обновляются, как показано на Фиг.1.
Далее следует описание схем последовательности операций с Фиг.6-8, где вводится многоперспективное изображение, и опорный кадр либо имеет то же время отображения (время формирования изображения), что и введенный кадр, либо он снят посредством той же камеры.
Предполагается, что схемы последовательности операций с Фиг.6-8 многократно выполняются до тех пор, пока значения FIN для всех данных предсказания предсказанной опорной информации не будут установлены в значение 1, однако повторения могут выполняться, например, предопределенное количество раз (если это приемлемо).
Сначала данные предсказания предсказанной опорной информации, для которых FIN равен 0, извлекаются и устанавливаются как p_can (S301). Далее, номер p_can опорного кадра устанавливается равным ref_can, а опорная информация p_can устанавливается как mv_can (S302).
Так, если ref_can равен номеру ref опорного кадра, который должен быть использован при кодировании блока blk (S303), FIN меняется на 1 (S304), а p_can сохраняется в неизменном виде в памяти 108 данных предсказания предсказанной опорной информации (S336 и S337).
В противном случае, опорный кадр, который используется большинством пикселей при кодировании области (опорной области), указанной посредством mv_can кадра ref-can, устанавливается как ref_tel, и опорная информация, опорным кадром которой является ref_tel и которая используется в большинстве пикселей этой области, устанавливается равной mv_tel (S305), и, далее, выполняются следующие процессы (S306-S335), после чего p_can сохраняется в памяти 108 данных предсказания предсказанной опорной информации (S306 и S337).
В процессах S306-S335, если ref_tel равна ref (S306), ref_can перезаписывается как ref, а mv_tel прибавляется к mv_can (S307).
В противном случае, время отображения кодируемого целевого кадра cur сравнивается со временем отображения опорного кадра ref кодируемого целевого блока (S308), и если они одинаковы, то выполняются процессы, когда предсказывают изменение видео между камерами с блоком blk (Фиг.7: S309-S320), а если они различаются, то выполняются процессы, когда предсказывают временное изменение видео в блоке blk (Фиг.8: S321-S335).
Если выполняются процессы, когда предсказывают изменение видео между камерами с блоком blk (Фиг.7: S309-S320), то определяется, являются ли одинаковыми точки обзора (камеры), которые сняли изображения кадра cur и кадра ref_cur (S309).
Так, в схеме последовательности операций с Фиг.7 VIEW() представляет собой функцию, которая возвращает индекс точки обзора (камеры), которая сняла изображение кадра, соответствующего заданному номеру кадра.
Если кадры cur и ref_cur были сняты разными камерами (S309), то расхождение mv_can от области (смежной области) в позиции p_can в кадре cur к кадру ref_can геометрически преобразуется в расхождение mv_trans1 смежной области относительно кадра ref путем использования параметров камеры кадра cur, кадра ref_can и кадра ref (S310), причем ref_can перезаписывается как ref, а mv_can перезаписывается как mv_trans1 (S311).
Геометрическое преобразование, выполняемое в процессе S310, реализуется в следующей последовательности.
1. Определяют центральную позицию pos_cur области, выраженной посредством p_can (области, смежной с кодируемой или декодируемой целевой областью).
2. Определяют центральную позицию pos_can области (опорной области), которая отклонена от позиции, выраженной посредством p_can, ровно на mv_can.
3. Используя x как переменную, определяют Trans(cur, ref_can, pos_cur, x) (это отображается как знак "~" сверху p (который представляет собой соответствующий пиксель, как описано ниже)).
Trans(src, dst, pix, d) может быть задан следующей формулой, где d представляет собой расстояние от пикселя в позиции pix на изображении с точки обзора src до снятого объекта, причем данная формула выражает однородные координаты соответствующего пикселя pix на изображении с точки обзора dst.
[Формула 4]

где A, R и t являются параметрами камеры, которые соответственно представляют внутренние параметры, параметры вращения и параметры трансляции. Внутренние параметры и параметры вращения представляют собой матрицы 3×3, тогда как t является трехмерным вектором.
Координаты со знаком "~" представляют однородные координаты. В частности, однородные координаты, третий компонент которых равен 1, выражаются путем добавления знака "^".
Существует множество различных способов выражения параметров камеры, однако в этом варианте осуществления используются параметры камеры, которые обеспечивают возможность вычисления корреспондирующих точек между камерами с помощью вышеизложенной формулы.
4. Определяют значение x, которое минимизирует эвклидово расстояние между ^p (однородной координатой p, где третий компонент равен 1) и pos_can, и обозначают результат как dcur.
5. Определяют mv_trans1 согласно следующей формуле.
[Формула 5]
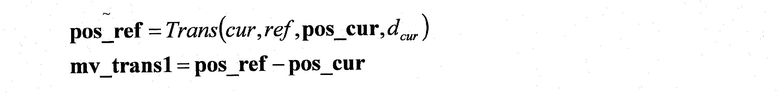
Эти формулы описывают случай, где каждому куску позиционной информации задаются двухмерные координаты, и опорная информация выражается посредством двумерного вектора.
Фиг.13 иллюстрирует пример геометрического преобразования, выполняемого в процессе S310. Для ясности mv_can и mv_trans1 смещены в вертикальном направлении.
Как показано на Фиг.13, на этапе S310, при выполнении условия "TIME(cur) = TIME(ref) = TIME(ref_can)", mv_can геометрически преобразуется в mv_trans1, а на этапе S311 mv_can перезаписывается как mv_trans1.
С другой стороны, если кадр cur и кадр ref_can были сняты одной и той же камерой (ветвь ДА в S309), то определяют, были ли сняты кадр ref_can и кадр ref_tel одной и той же камерой (S312).
Если они были сняты одной и той же камерой, то определяют, меньше ли временной интервал между кадром ref_cur и кадром ref_tel, чем предопределенное пороговое значение TH1 (S313). Если этот временной интервал меньше пороговой величины TH1, то ref_can перезаписывается как ref_tel, а mv_tel прибавляется к mv_can (S314).
С другой стороны, если временной интервал равен или больше порогового значения TH1, то в опорном кадре ref определяется соответствующая область, используя информацию декодированного изображения кодируемого целевого кадра в позиции p_can, смещение от позиции p-can (соответствующая информация) устанавливается как mv_BM (S315), ref_can перезаписывается как ref, а mv_can перезаписывается как mv_BM (S316).
Если в процессе S312 определения определяется, что кадр ref_can и ref_tel были сняты разными камерами, то определяют, были ли сняты кадр ref и кадр ref_tel одной и той же камерой (S317).
Если они не были сняты одной и той же камерой, то выполняется геометрическое преобразование с использованием параметров камеры VIEW(ref_can), VIEW(ref_tel) и VIEW(ref) (S318), так что расхождение mv_tel области (эталонной области) (в изображении, снятом посредством VIEW(ref_can)) в позиции, которая получается, когда p_can (позиция смежного блока) отклоняется на величину mv_can, к изображению, снятому посредством VIEW(ref_tel), преобразуется в расхождение mv_trans2 соответствующей опорной области к изображению, снятому посредством VIEW(ref), ref_can перезаписывается как ref, а mv_can перезаписывается как mv_trans2 (S319).
Геометрическое преобразование, выполняемое в процессе S318, реализуется в следующей последовательности.
1. Определяют центральную позицию pos_can области в позиции, которая отклонена от p_can ровно на величину mv_can.
2. Определяют центральную позицию pos_tel области в позиции, которая отклонена от p_can ровно на величину mv_can + mv_tel.
3. Используя x как переменную, определяют Trans(ref_can, ref_tel, pos_can, x) (это отображается как знак "~" сверху p).
4. Определяют значение x, при котором минимизируется эвклидово расстояние между ^p и pos_tel, и обозначают результат как dcan.
5. Определяют mv_trans2 согласно следующей формуле.
[Формула 6]
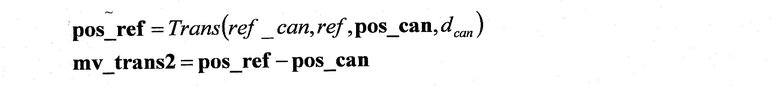
Фиг.14 иллюстрирует пример геометрического преобразования, выполняемого в процессе S318.
Как показано на Фиг.14, на этапе S318, при условии, что "TIME(cur) = TIME(ref), VIEW(cur) = VIEW(ref_can), TIME(ref_can) = TIME(ref_tel), VIEW(ref) ≠ VIEW(ref_tel)", mv_tel геометрически преобразуется в mv_trans2, а на этапе S319 mv_can перезаписывается как mv_trans2 (пунктирная линия на Фиг.14 представляет результат этого процесса).
Если в процессе S317 определения определяется, что кадр ref и кадр ref_tel были сняты одной и той же камерой, то ref_can перезаписывается как ref, а mv_can перезаписывается как mv_tel (S320).
С другой стороны, в процессах предсказания временного изменения в блоке blk (Фиг.8: S321-S335) сначала определяется, что кадр cur и кадр ref_can были сняты одной и той же камерой (S321).
Если определяется, что они были сняты одной и той же камерой, то далее определяется, были ли сняты кадр ref_can и кадр ref_tel одной и той же камерой (S322).
Если определяется, то эти кадры также были сняты одной и той же камерой, то определяется, который из них расположен ближе во времени к кадру ref (S323).
Если определяется, что кадр ref_tel ближе по времени к кадру ref, ref_can перезаписывается как ref_tel, а mv_tel прибавляется к mv_can (S324).
Если в процессе S322 определения определяется, что кадр ref_can и кадр ref_tel были сняты разными камерами, или если в процессе S323 определения определяется, что кадр ref_can расположен ближе во времени к кадру ref, то, используя информацию декодированного изображения кодируемого целевого кадра в положении p_can, определяется соответствующая область опорного кадра ref путем установки центра поиска в mv_can, смещение от центра поиска (соответствующая информация) устанавливается как mv_canBM (S325), ref_can перезаписывается как ref, а mv_canBM прибавляется к mv_can (S326).
С другой стороны, если в процессе S321 определения определяется, что кадр ref_cur и кадр ref_can были сняты разными камерами, то определяют, были ли сняты кадр ref_can и кадр ref_tel одной и той же камерой (S327).
Если определяется, что они были сняты одной и той же камерой, то определяют, совпадает ли время отображения кадра ref с временем отображения (временем формирования изображения) кадра ref_tel (S328).
Если определяется, что они имеют одинаковое время отображения, то ref_can перезаписывается как ref, а mv_can перезаписывается как mv_tel (S329).
Если в процессе S328 определения определяется, что времена отображения различаются, то путем использования информации декодированного изображения кодируемого целевого кадра в положении p_can центр поиска устанавливается на mv_tel при определении соответствующей области в опорном кадре ref, смещение от центра поиска (соответствующая информация) устанавливается как mv_telBM (S330), ref_can перезаписывается как ref, а mv_can перезаписывается как сумма mv_tel и mv_telBM (S331).
Если в процессе S327 определения определяется, что кадр ref_can и кадр ref_tel были сняты разными камерами, то определяют, больше ли коэффициент совпадения между снятыми областями VIEW(cur) и VIEW(ref_tel), чем предопределенное пороговое значение TH2 (S332).
В этой схеме последовательности операций Diff(cam1, cam2) выражает степень совпадения между снятыми областями и выдает в качестве результата отношение области, которая могла быть снята обеими камерами, к области, которая могла быть снята одной камерой (что определяется заранее, и для этого выбирается подходящее пороговое значение TH2). Цель с камер ограничивается фактическим пространством, насколько это может быть обеспечено отдельно предоставленным расстоянием. Пороговое значение TH2 больше, чем наименьшая величина Diff во всех комбинациях камер.
Если в процессе S332 определения выявляется, что отношение совпадения между снятыми областями VIEW(cur) и VIEW(ref_tel) больше, чем пороговое значение TH2, то ref_can перезаписывается как ref_tel, а mv_tel прибавляется к mv_can (S333).
С другой стороны, если в процессе S332 определения выявляется, что отношение совпадений между снятыми областями VIEW(cur) и VIEW(ref_tel) равно или меньше, чем пороговое значение TH2, то соответствующая область в опорном кадре ref определяется, используя информацию декодированного изображения кодируемого целевого кадра в позиции p_can, смещение от позиции p_can (соответствующая информация) устанавливается как mv_BM (S334), ref_can перезаписывается как ref, а mv_can перезаписывается как mv_BM (S335).
Ниже описаны схемы последовательности операций с Фиг.9-12, где вводится многоперспективное изображение и кадр, который уже был кодирован, используется в качестве опорного кадра.
Предполагается, что процедуры схем последовательности операций с Фиг.9-12 многократно выполняются до тех пор, пока значения FIN для всех данных предсказания предсказанной опорной информации не будут установлены в значение 1, однако повторения могут выполняться, например, предопределенное количество раз (если это приемлемо).
Сначала данные предсказания предсказанной опорной информации, для которых FIN равен 0, извлекаются и устанавливаются как p_can (S401). Номер p_can опорного кадра устанавливается равным ref_can, а опорная информация p_can устанавливается как mv_can (S402).
Так, если ref_can равен номеру ref опорного кадра, который должен быть использован при кодировании блока blk (S403), FIN меняется на 1 (S404), а p_can сохраняется в неизменном виде в памяти 108 данных предсказания предсказанной опорной информации (S452 и S453).
В противном случае, опорный кадр, который используется большинством пикселей при кодировании области (опорной области) в кадре ref_can, получаемом путем смещения p_can (смежной области) на mv_can, устанавливается как ref_tel, и опорная информация, опорным кадром которой является ref_tel и которая используется в большинстве пикселей этой области, устанавливается равной mv_tel (S405), и, далее, выполняются следующие процессы (S406-S451), после чего p_can сохраняется в памяти 108 данных предсказания предсказанной опорной информации (S452 и S453).
В процессах S406-S451, если ref_tel равна ref (S406), то ref_can перезаписывается как ref, а mv_tel прибавляется к mv_can (S407).
В противном случае, время отображения кодируемого целевого кадра cur сравнивается со временем отображения опорного кадра ref кодируемого целевого блока (S408), и если они одинаковы, то выполняются процессы, когда предсказывают изменение видео между камерами в блоке blk (Фиг.10: S409-S420), если же они различаются, то определяют, были ли кадр cur и кадр ref сняты одной и той же камерой (S421).
Если они одинаковы, то выполняются процессы, когда предсказывают временное изменение видео в блоке blk (Фиг.11: S422-S441), если же они различаются, то выполняются процессы, когда предсказывают комбинацию временного изменения видео и изменения видео между камерами (Фиг.12: S422-S451).
В процессах, когда предсказывают изменение видео между камерами в блоке blk (Фиг.10: S409-S420), сначала определяют, совпадает ли время отображения кадра cur со временем отображения кадра ref_can (S409).
Если определяется, что они совпадают, то, используя тот же способ, что и в процессе S310, расхождение mv_can области (смежной области) в позиции p_can в кадре cur к кадру ref_can геометрически преобразуется в расхождение mv_trans1 соответствующей смежной области относительно кадра ref, путем использования параметров камеры для кадра cur, кадра ref_can и кадра ref (S410), причем ref_can перезаписывается как ref, а mv_can перезаписывается как mv_trans1 (S411).
Геометрическое преобразование, выполняемое на этапе S410, совпадает с описанным для этапа S310.
С другой стороны, если в процессе S409 определяется, что времена отображения кадра cur и кадра ref_can отличаются, то определяется, совпадает ли время отображения кадра ref_can со временем отображения кадра ref_tel (S412).
Если определяется, что они одинаковы, то определяется, являются ли одинаковыми камера, которая сняла кадр ref_tel, и камера, которая сняла кадр ref, и являются ли одинаковыми камера, которая сняла кадр ref_can, и камера, которая сняла кадр cur (S413).
Если определяется, что две пары камер одинаковы, то ref_can перезаписывается как ref, а mv_can перезаписывается как mv_tel (S414).
Если в процессе S413 определения определяется, что одна или обе из двух пар камер не являются одинаковыми, то геометрическое преобразование выполняется посредством параметров камер VIEW(cur), VIEW(ref_can), VIEW(ref_tel) и VIEW(ref) (S415), так что расхождение mv_tel области (опорной области) (в изображении, снятом с VIEW(ref_can)) в позиции, которая получается, когда p_can (позиция смежного блока) отклонена ровно на mv_can, к изображению, снятому с VIEW(ref_tel), преобразуется в расхождение mv_trans3 области (смежной области) в позиции p_can в изображении, снятом с VIEW(cur), к изображению, снятому с VIEW(ref), ref_can перезаписывается как ref, а mv_can перезаписывается как mv_trans3 (S416).
Геометрическое преобразование, выполняемое в процессе S415, реализуется в следующей последовательности.
1. Определяют центральную позицию pos_can области в позиции, которая отклонена от p_can ровно на величину mv_can.
2. Определяют центральную позицию pos_tel области в позиции, которая отклонена от p_can ровно на величину mv_can + mv_tel.
3. Используя x как переменную, определяют Trans(ref_can, ref_tel, pos_can, x) (это отображается как знак "~" сверху p).
4. Определяют значение x, при котором минимизируется эвклидово расстояние между ~p и pos_tel, и обозначают результат как dcan.
5. Определяют mv_trans3 согласно следующей формуле.
[Формула 7]

Фиг.15 иллюстрирует один пример геометрического преобразования, выполняемого в процессе S415. Для ясности mv_can и mv_trans3 смещены в вертикальном направлении.
Как показано на Фиг.15, при условии, что "TIME(cur) = TIME(ref) ≠ TIME(ref_can) = TIME(ref_tel)" и "VIEW(ref) ≠ VIEW(ref_tel) или VIEW(cur) ≠ VIEW(ref_can)", на этапе S415 mv_tel геометрически преобразуется в mv_trans3, а на этапе S416 mv_can перезаписывается как mv_trans3 (пунктирная линия на Фиг.15 представляет обработанный результат).
Если в процессе S412 определения определяется, что времена отображения кадра ref_can и кадра ref_tel отличаются, то определяется, меньше ли временной интервал между кадром cur и кадром ref_tel, чем предопределенное пороговое значение TH1 (S417).
Если этот временной интервал меньше пороговой величины TH1, то ref_can перезаписывается как ref_tel, а mv_tel прибавляется к mv_can (S418).
Если же временной интервал равен или больше порогового значения TH1, то в опорном кадре ref определяется соответствующая область, используя информацию декодированного изображения кодируемого целевого кадра в позиции p_can, смещение от позиции p-can (соответствующая информация) устанавливается как mv_BM (S419), ref_can перезаписывается как ref, а mv_can перезаписывается как mv_BM (S420).
В процессах, когда предсказывается временное изменение видео с блоком blk (Фиг.11: S422-S441), определяется, одинаковы ли камера, которая сняла кадр cur, и камера, которая сняла кадр ref_can (S422).
Если они одинаковы, то дополнительно определяется, одинаковы ли камера, которая сняла кадр ref_can, и камера, которая сняла кадр ref_tel (S423).
Если последние также совпадают, то выполняется определение согласно Формуле 3, описанной выше (S424).
Если Формула 3 удовлетворяется, то ref_can перезаписывается как ref_tel, а mv_tel добавляется к mv_can (S425).
С другой стороны, если Формула 3 не удовлетворяется, то, используя информацию декодированного изображения кодируемого целевого кадра в позиции p_can, центр поиска устанавливается на mv_can при определении соответствующей области в опорном кадре ref, смещение от центра поиска (соответствующая информация) устанавливается как mv_canBM (S426), ref_can перезаписывается как ref, а mv_canBM прибавляется к mv_can (S427).
Если в процессе S423 определения определяется, что камера, которая сняла кадр ref_can, и камера, которая сняла кадр ref_tel, различаются, то далее определяется, одинаковы ли камера, которая сняла кадр ref, и камера, которая сняла кадр ref_tel (S428).
Если они одинаковые, то, используя информацию декодированного изображения кодируемого целевого кадра в позиции p_can, центр поиска устанавливается как mv_can + mv_tel при определении соответствующей области в опорном кадре ref, смещение от центра поиска (соответствующая информация) устанавливается как mv_epiBM1 (S429), ref_can перезаписывается как ref, а mv_tel и mv_ epiBM1 прибавляются к mv_can (S430).
В поиске на этапе S429 ограничения между камерами могут использоваться для поиска только тех случаев, где центр соответствующей области становится периметром вокруг прямой линии, полученной согласно следующей последовательности.
1. Определяют центральную позицию pos_tel области в позиции, которая отклонена от p_can ровно на величину mv_can + mv_tel.
2. Используя x как переменную, определяют Trans(ref_tel, ref, pos_tel, x) (это отображается как знак "~" сверху p).
3. Определяют прямую линию на кадре ref, за которой следует p, когда x меняется.
Несмотря на то что максимальная и минимальная величины переменной x в этом случае не определяются, они могут быть установлены заранее.
Если в процессе S428 определения определяется, что камера, которая сняла кадр ref, и камера, которая сняла кадр ref_tel, различаются, то выполняются процессы S426 и S427.
С другой стороны, если в первом определении на этапе S422 определяется, что камера, которая сняла кадр cur, и камера, которая сняла кадр ref_can, являются разными, то определяют, одинаковы ли время отображения кадра ref и время отображения кадра ref_tel (S431).
Если они одинаковы, то дополнительно определяется, являются ли одинаковыми время отображения кадра ref и время отображения кадра ref_can (S432).
Если последние также одинаковы, то выполняется геометрическое преобразование (S433), при котором применяется тот же способ, что и в процессе S318, используя параметры камеры VIEW(ref_can), VIEW(ref_tel) и VIEW(ref) таким образом, что расхождение mv_tel области (опорной области) (в изображении, снятом с VIEW(ref_tel)) в позиции, которая получается, когда p_can (позиция смежного блока) отклонена ровно на mv_can, относительно изображения, снятого с VIEW(ref_tel), преобразуется в расхождение mv_trans2 соответствующей опорной области относительно изображения, снятого с VIEW(ref), ref_can перезаписывается как ref, а mv_trans2 прибавляется как mv_can (S434).
Фиг.16 иллюстрирует один пример геометрического преобразования, выполняемого в процессе S433.
Как показано на Фиг.16, при условии, что "VIEW(cur) = VIEW(ref), VIEW(cur) ≠ VIEW(ref_can) и TIME(ref) = TIME(ref_can) = TIME(ref_tel)", на этапе S433 mv_tel геометрически преобразуется в mv_trans2, а на этапе S434 mv_trans2 прибавляется к mv_can (пунктирная линия с Фиг.16 представляет обработанный результат).
Если в процессе S432 определения определяется, что время отображения кадра ref и время отображения кадра ref_can различаются, то выполняются процессы S429 и S430.
Если в процессе S431 определения определяется, что время отображения кадра ref и время отображения кадра ref_tel различаются, то определяется, являются ли одинаковыми время отображения кадра ref и время отображения кадра ref_can (S435).
Если определяется, что они одинаковы, то, используя информацию декодированного изображения кодируемого целевого кадра в позиции p_can, центр поиска устанавливается на mv_can при определении соответствующей области в опорном кадре ref, смещение от центра поиска (соответствующая информация) устанавливается как mv_epiBM2 (S436), ref_can перезаписывается как ref, а mv_epiBM2 прибавляется к mv_can (S437).
В поиске на этапе S436 ограничения между камерами могут использоваться для поиска только тех случаев, где центр соответствующей области становится периметром вокруг прямой линии, полученной согласно следующей последовательности.
1. Определяют центральную позицию pos_can области в позиции, которая отклонена от p_can ровно на величину mv_can.
2. Используя x как переменную, определяют Trans(ref_can, ref, pos_can, x) (это отображается как знак "~" сверху p).
3. Определяют прямую линию на кадре ref, за которой следует p, когда x меняется.
Несмотря на то что максимальная и минимальная величины переменной x не определяются в этом случае, они могут быть установлены заранее.
Если в процессе S435 определения определяется, что время отображения кадра ref и время отображения кадра ref_can различаются, то выполняется определение согласно следующим двум условным формулам (S438).
[Формула 8]
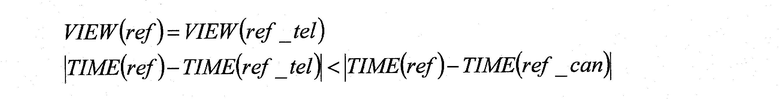
Если какая-либо из этих формул удовлетворяется, то ref_can перезаписывается как ref_tel, а mv_tel добавляется к mv_can (S439).
Если ни одна из них не удовлетворяется, то, используя информацию декодированного изображения кодируемого целевого кадра в позиции p_can, определяется соответствующая область в опорном кадре ref, смещение от p_can (соответствующая информация) устанавливается как mv_BM (S440), ref_can перезаписывается как ref, а mv_can перезаписывается как mv_BM (S441).
В процессах, выполняемых при предсказании комбинации временного изменения видео и изменения видео между камерами с блоком blk (Фиг.12: S442-S451), сначала определяется, являются ли одинаковыми время отображения кадра ref_can и время отображения кадра ref (S422).
Если они одинаковы, то дополнительно определяется, являются ли одинаковыми время отображения кадра ref_tel и время отображения кадра ref (S443).
Если последние также одинаковы, то выполняется геометрическое преобразование, при котором применяется тот же способ, что и в процессе S318, используя параметры камеры VIEW(ref_can), VIEW(ref_tel) и VIEW(ref) таким образом, что расхождение mv_tel области (опорной области) (в изображении, снятом с VIEW(ref_can)) в позиции, которая получается, когда p_can (позиция смежного блока) отклонена ровно на mv_can, относительно изображения, снятого с VIEW(ref_tel), преобразуется в расхождение mv_trans2 опорной области относительно изображения, снятого с VIEW(ref) (S444), ref_can перезаписывается как ref, а mv_trans2 прибавляется к mv_can (S445).
Фиг.17 иллюстрирует пример геометрического преобразования, выполняемого в процессе S444. Для ясности mv_tel и mv_trans2 смещены в вертикальном направлении.
Как показано на Фиг.17, при условии, что "TIME(cur)≠TIME(ref), VIEW(cur)≠VIEW(ref) и TIME(ref)=TIME(ref_can)=TIME(ref_tel)", на этапе S444 mv_tel геометрически преобразуется в mv_trans2, а на этапе S445 mv_trans2 прибавляется к mv_can (пунктирная линия на Фиг.17 представляет результат процесса).
Если в процессе S443 определения определяется, что время отображения кадра ref_tel и время отображения кадра ref различаются, то, используя информацию декодированного изображения кодируемого целевого кадра в позиции p_can, центр поиска устанавливается на mv_can при определении соответствующей области в опорном кадре ref, смещение от центра поиска (соответствующая информация) устанавливается как mv_epiBM2 (S446), ref_can перезаписывается как ref, а mv_epiBM2 прибавляется к mv_can (S447).
В поиске на этапе S446 ограничения между камерами могут использоваться для поиска только тех случаев, где центр соответствующей области становится периметром вокруг прямой линии, полученной посредством той же последовательности, что и для процесса S336, описанного выше.
С другой стороны, если в процессе S442, выполненном в первую очередь, определяется, что время отображения кадра ref_can и время отображения кадра ref различаются, то выполняется определение по Формуле 3 (S448).
Если Формула 3 удовлетворяется, то ref_can перезаписывается как ref_tel, а mv_tel прибавляется к mv_can (S449).
Если же Формула 3 не удовлетворяется, то в опорном кадре ref определяется соответствующая область, используя информацию декодированного изображения кодируемого целевого кадра в позиции p_can, смещение от позиции p-can (соответствующая информация) устанавливается как mv_BM (S450), ref_can перезаписывается как ref, а mv_can перезаписывается как mv_BM (S451).
Таким образом, путем выполнения процедур схемы последовательности операций с Фиг.6-12, обновитель 111 опорной информации обновляет данные предсказания предсказанной опорной информации, хранимые в памяти 108 данных предсказания предсказанной опорной информации, как показано на Фиг.1 и 2.
Ниже описано устройство декодирования видео согласно настоящему изобретению.
Фиг.18 представляет собой иллюстрацию одного варианта осуществления устройства 200 декодирования видео согласно настоящему изобретению.
Устройство 200 декодирования видео включает в себя декодер 201 дифференциального изображения, который декодирует кодированные данные декодированного изображения относительно предсказанного изображения, которое становится целью декодирования, декодер 202 дифференциальной опорной информации, который декодирует кодированные данные дифференциальной опорной информации относительно предсказанной опорной информации, когда генерируется предсказанное изображение, декодер 203 информации описания опорного кадра, который декодирует кодированные данные информации описания опорного кадра, когда генерируется предсказанное изображение, генератор 204 предсказанного изображения, который генерирует предсказанное изображение декодируемого целевого кадра, используя уже декодированный опорный кадр, информацию описания опорного кадра и опорную информацию, память 205 опорных кадров, которая накапливает декодированное изображение, определенное из суммы предсказанного изображения и декодированного дифференциального изображения, генератор 206 предсказанной опорной информации, который генерирует предсказанную опорную информацию из данных предсказания предсказанной опорной информации (то есть из опорной информации, которая становится кандидатом для предсказанной опорной информации), память 207 данных предсказания предсказанной опорной информации, которая накапливает данные предсказания предсказанной опорной информации, память 208 накопления опорной информации, которая накапливает опорную информацию, использованную ранее при декодировании изображения, обновитель 209 опорной информации, который корректирует данные предсказания предсказанной опорной информации в памяти 207 данных предсказания предсказанной опорной информации, и память 210 накопления информации описания опорного кадра, которая накапливает информацию описания опорного кадра, использованную ранее при декодировании изображения.
Фиг.19 представляет собой схему последовательности операций, выполняемых устройством 200 декодирования видео с вышеописанной структурой.
Процессы, выполняемые устройством 200 декодирования видео с этой конфигурацией, подробно описаны ниже на основании этой схемы последовательности операций. Здесь предполагается, что изображения множества кадров уже декодированы, и соответствующие результаты накоплены в памяти 205 опорных кадров, памяти 208 накопления опорной информации и памяти 210 накопления информации описания опорного кадра.
Сначала кодированные данные дифференциального изображения, кодированные данные дифференциальной опорной информации и кодированные данные информации описания опорного кадра вводятся в устройство 200 декодирования видео и передаются соответственно в декодер 201 дифференциального изображения, декодер 202 дифференциальной опорной информации и декодер 203 информации описания опорного кадра (S501).
Декодируемое целевое изображение целиком разделяется на области, и каждая область декодируется (S502-S515). В данной схеме последовательности операций blk обозначает индекс блока (области), а MaxBlk обозначает общее количество блоков в одном изображении.
Изначально индексу blk присваивается значение 1 (S502), после чего последующие процессы (S503-S513) выполняются по циклу, приращивая blk на 1 (S515) до тех пор, пока не будет достигнуто значение MaxBlk (S514).
В процессе, выполняемом в каждом блоке, декодируются кодированные данные информации описания опорного кадра, извлекается информация ref описания опорного кадра (S503) и генерируется предсказанная опорная информация pmv для предсказания опорной информации для опорного кадра ref (S504-S507). Далее, декодируются кодированные данные дифференциальной опорной информации, получается дифференциальная опорная информация mvd (S508), и генерируется опорная информация mv, сформированная из суммы pmv и mvd (S509).
Далее, используя опорный кадр ref и опорную информацию mv, генерируется предсказанное изображение Pre (S510), кодированные данные дифференциального изображения декодируются, чтобы извлечь дифференциальное изображение Sub (S511), и декодированное изображение Dec генерируется путем вычисления суммы Pre и Sub для каждого пикселя (S512).
Декодированное изображение Dec, опорная информация mv, которая была использована при декодировании блока blk, и информация ref описания опорного кадра соответственно сохраняются в памяти 205 опорных кадров, памяти 208 накопления опорной информации и памяти 210 накопления информации описания опорного кадра (S513).
Для каждого кадра, после завершения процесса декодирования всех блоков в этом кадре и после того, как все кадры, время отображения которых раньше, чем этот кадр был выведен, декодированный кадр выводится из устройства 200 декодирования видео.
В процессах генерации предсказанной опорной информации pmv (S504-S507), после инициализации памяти 207 данных предсказания предсказанной опорной информации (S504), относительно множества блоков, смежных с блоком blk, номер REF опорного кадра и информация MV опорного кадра, использованные при декодировании соответствующего блока, а также информация POS, указывающая позицию этого блока, сохраняются в комбинации (REF, MV и POS) в памяти 207 данных предсказания предсказанной опорной информации (S505).
В это время MV и REF накапливаются в памяти 208 накопления опорной информации и памяти 110 накопления информации описания опорного кадра согласно индексу блока или позиции в изображении.
Например, когда области разделенного изображения кодируются в последовательности растрового сканирования, множество блоков, смежных с блоком blk, может включать в себя блоки на верхней, левой и верхней правой сторонах.
В этом варианте осуществления опорная информация соответствующих смежных блоков устанавливается в качестве данных предсказания предсказанной опорной информации. Блоки, расположенные вне экрана, исключаются из списка кандидатов.
Впоследствии, данные предсказания предсказанной опорной информации извлекаются из памяти 207 данных предсказания предсказанной опорной информации, обновляются посредством обновителя 209 опорной информации и снова накапливаются в памяти 207 данных предсказания предсказанной опорной информации (S506). Ниже этот процесс описан подробным образом.
Предсказанная опорная информация pmv генерируется из множества кусков опорной информации, накопленной в памяти 207 данных предсказания предсказанной опорной информации (S507). В частности, предсказанная опорная информация pmv генерируется путем определения промежуточной величины данных предсказания предсказанной опорной информации для каждого компонента опорной информации.
То есть, когда опорная информация выражается как двумерный вектор по линии X-Y, для каждого компонента промежуточная величина определяется для соответствующих компонентов, принадлежащих множеству данных предсказания предсказанной опорной информации, и pmv для соответствующего компонента присваивается эта величина.
Вместо промежуточной величины может использоваться другая величина, такая как средняя величина, максимальная величина, минимальная величина и т.п. Тем не менее, используемая величина должна быть той же, что и величина, которая используется кодирующим устройством.
Процесс, выполняемый обновителем 209 опорной информации на этапе S506, схож с процессом S106, показанным на Фиг.4, который выполняется посредством обновителя 111 опорной информации в устройстве 100 кодирования видео.
Так, переменные FIN, которые назначаются всем данным предсказания предсказанной опорной информации, накопленным в памяти 207 данных предсказания предсказанной опорной информации, изначально устанавливаются в нулевое значение, и процессы с Фиг.5-12 повторяются до тех пор, пока все FIN не достигнут значения 1.
Фиг.5 представляет собой схему последовательности операций, где все входные кадры и опорные кадры представляют собой кадры, которые были сняты одной и той же камерой.
Фиг.6~8 представляют собой схемы последовательности операций для случая, когда вводится многоперспективное изображение, и опорный кадр либо имеет то же время отображения (время снятия), что и введенный кадр, либо он снят посредством той же камеры.
Фиг.9~12 представляют собой схемы последовательности операций для случая, когда вводится многоперспективное изображение, и любой кадр, который уже был кодирован, может быть использован в качестве опорного кадра. Для декодирующего устройства это может рассматриваться как схема последовательности операций, где каждый кадр, который уже был декодирован, может быть использован в качестве опорного кадра.
Несмотря на то что изобретение было описано со ссылкой на конкретные варианты осуществления, настоящее изобретение не ограничивается этими вариантами осуществления.
Например, в способе генерации mv_tel вместо использования наиболее часто применяемой величины, как описано выше, может быть использована промежуточная величина или средняя величина каждого компонента.
Тем не менее, на стороне устройства кодирования видео и на стороне устройства декодирования видео должен использоваться один и тот же способ.
Сверх того, несмотря на то что в вышеописанных вариантах осуществления не упоминается кодирование с межкадровым предсказанием, оно может быть легко добавлено как способ создания предсказанного изображения посредством, например, назначения другого номера в качестве информации описания опорного кадра.
Так, когда смежный блок является кодированным с межкадровым предсказанием, то может быть определено, что данные предсказания предсказанной опорной информации генерируются посредством MV (опорной информации), установленной в нулевое значение, а функции TIME() и VIEW() настраиваются так, чтобы возвращать большие абсолютные величины, которые они определенно не возвращают в других случаях (то есть, когда он не является кодированным с межкадровым предсказанием). Соответственно, даже если смежный блок является кодированным с межкадровым предсказанием, согласно вышеописанным схемам последовательности операций может быть выполнена подходящая обработка. Сверх того, устройство кодирования видео и устройство декодирования видео, которые не используют информацию описания опорного кадра и реализованы путем подготовки отдельных режимов кодирования, как в стандарте H.264, могут быть легко выведены из настоящего изобретения.
Описанные выше процессы кодирования и декодирования видео также могут быть реализованы посредством компьютерной программы. Подобная компьютерная программа может быть предоставлена путем ее сохранения на подходящем компьютерно-читаемом носителе или посредством сети.
Несмотря на то что устройства кодирования и декодирования видео были, главным образом, разъяснены в вышеописанных вариантах осуществления, способы кодирования и декодирования видео настоящего изобретения могут быть реализованы, используя этапы, соответствующие работе каждого блока, входящего в состав устройств кодирования и декодирования видео.
Несмотря на то что варианты осуществления настоящего изобретения были описаны со ссылкой на чертежи, следует понимать, что они являются иллюстративными вариантами осуществления настоящего изобретения и не должны рассматриваться как ограничивающие. В рамках сущности и объема настоящего изобретения могут быть выполнены различные дополнения, исключения или замены структурных элементов или другие модификации вышеописанных вариантов осуществления.
Промышленная применимость
Согласно настоящему изобретению опорная информация, которая использовалась при кодировании области, смежной с кодируемой целевой областью, преобразовывается посредством кодированных данных, которые были использованы при кодировании соответствующей опорной области, в опорную информацию, подходящую для отношений по времени и точке обзора между кодируемым целевым кадром и кодируемым целевым опорным кадром, и далее генерируется предсказанная опорная информация. Соответственно, даже когда отсутствует временная непрерывность вариации видеоизображения по множеству кадров или когда многоперспективное изображение кодируется с выбором компенсации движения либо компенсации расхождения для каждой кодируемой единичной области, то не добавляется какой-либо дополнительной информации, которая указывает соответствующий способ преобразования, и разность между предсказанной опорной информацией и опорной информацией, использованной при кодировании кодируемой целевой области, может быть уменьшена, благодаря чему эффективно кодируется вектор движения или информация расхождения, используемая при кодировании с межкадровым предсказанием.







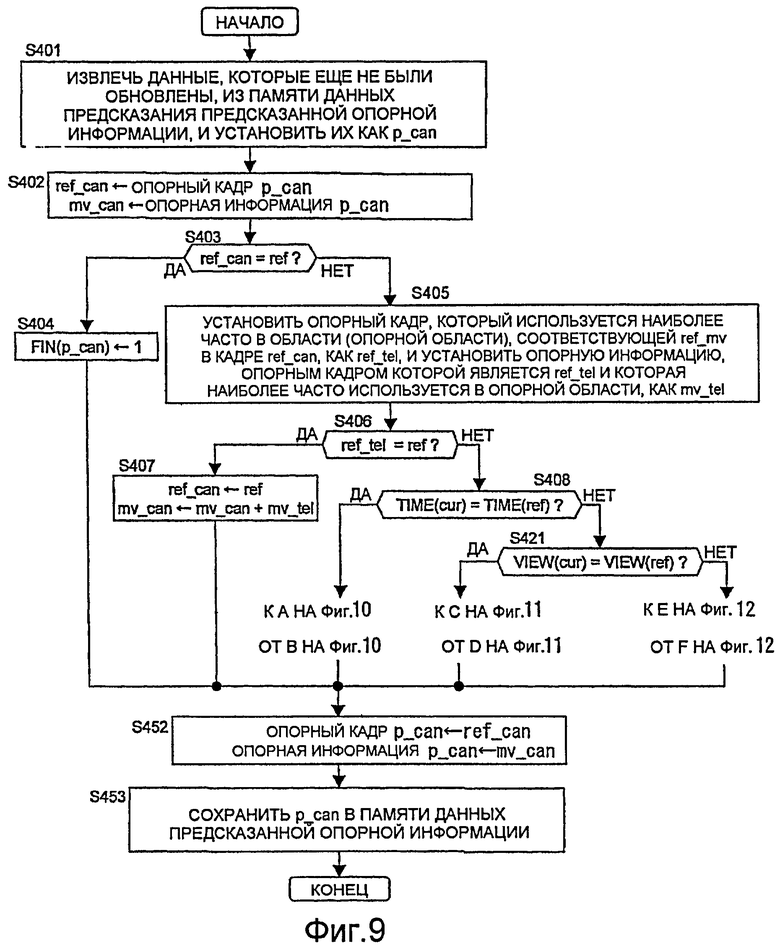



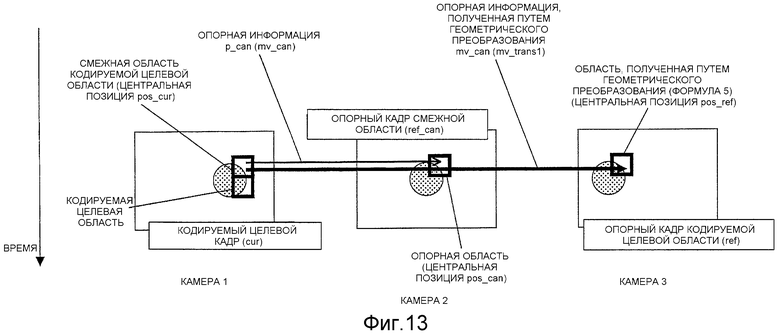

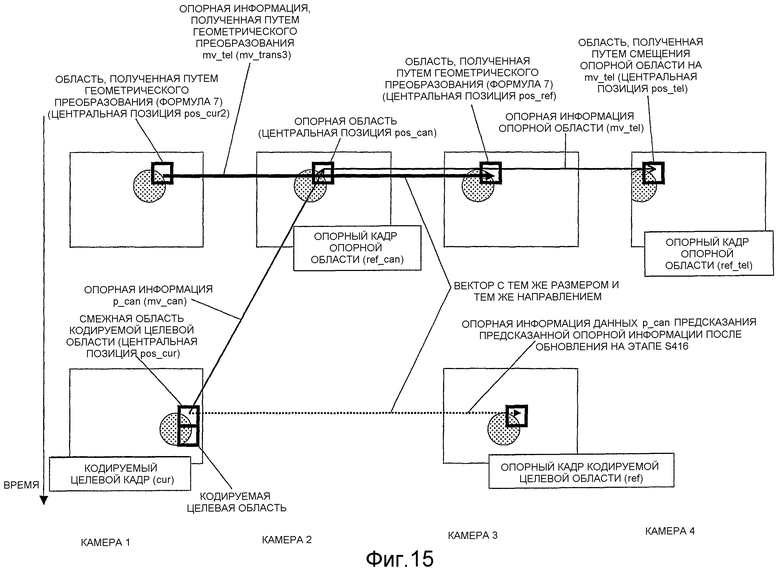





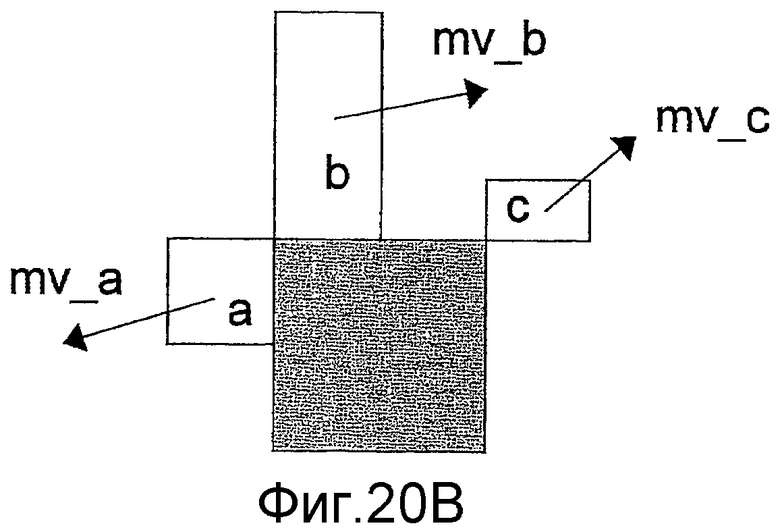








Изобретение относится к способу кодирования многовидового видео с использованием способа генерации предсказанной опорной информации. Техническим результатом является повышение эффективности кодирования информации для межкадрового предсказания. Предложено видеоизображения обрабатывать путем применения к каждой разделенной области операций кодирования с межкадровым предсказанием по времени или по пространству и генерации предсказанного изображения обрабатываемой целевой области на основании опорного кадра обрабатываемой целевой области и опорной информации, которая указывает предсказанную целевую позицию обрабатываемой целевой области в опорном кадре, предсказанная опорная информация генерируется как предсказанная информация опорной информации. Опорная информация, использованная при обработке целевой области, смежной с обрабатываемой целевой областью, определяется как данные предсказания предсказанной опорной информации, используемые при предсказании опорной информации обрабатываемой целевой области. Опорная информация опорной области генерируется, используя один или более частей опорной информации, использованной при обработке опорной области, указанной данными предсказания. Данные предсказания предсказанной опорной информации обновляются, используя опорную информацию опорной области. Предсказанная опорная информация генерируется, используя один или более частей данных предсказания обновленной предсказанной опорной информации. 9 н. и 16 з.п. ф-лы, 29 ил.
1. Способ генерации предсказанной опорной информации, используемый, когда:
обрабатывают видеоизображение путем разделения изображения на области; применяют к каждой области разделенного изображения кодирование с межкадровым предсказанием по времени или пространству и генерируют предсказанное изображение обрабатываемой целевой области на основании опорного кадра обрабатываемой целевой области и опорной информации, которая включает в себя предсказанную целевую позицию обрабатываемой целевой области в опорном кадре, и
генерируют предсказанную опорную информацию в качестве предсказанной информации соответствующей опорной информации,
причем способ генерации предсказанной опорной информации содержит:
этап установки данных предсказания предсказанной опорной информации, на котором устанавливают опорную информацию, которая была использована при обработке области, смежной с обрабатываемой целевой областью, в качестве данных предсказания предсказанной опорной информации, используемых для предсказания опорной информации обрабатываемой целевой области;
этап генерации опорной информации опорной области, на котором генерируют опорную информацию опорной области на основании одной или более частей опорной информации, использованной при обработке опорной области, указанной данными предсказания предсказанной опорной информации;
этап обновления данных предсказания предсказанной опорной информации, на котором обновляют данные предсказания предсказанной опорной информации путем использования сгенерированной опорной информации опорной области; и
этап генерации предсказанной опорной информации, на котором генерируют предсказанную опорную информацию путем использования одной или более частей данных предсказания обновленной предсказанной опорной информации.
2. Способ кодирования видео для кодирования видеоизображения путем разделения всего изображения на области; выбора для каждой области разделенного изображения из множества уже кодированных кадров опорного кадра кодируемой целевой области, который используется в качестве опорного кадра при предсказании информации изображения этой области; генерации предсказанного изображения путем использования опорного кадра кодируемой целевой области и опорной информации, которая указывает предсказанную целевую позицию кодируемой целевой области в опорном кадре кодируемой целевой области; и кодирования информации разности между предсказанным изображением и изображением кодируемой целевой области,
причем способ содержит:
этап установки данных предсказания предсказанной опорной информации, на котором устанавливают опорную информацию, которая была использована при кодировании области, смежной с кодируемой целевой областью, в качестве данных предсказания предсказанной опорной информации, используемых для предсказания опорной информации кодируемой целевой области;
этап генерации опорной информации опорной области, на котором генерируют опорную информацию опорной области на основании одной или более частей опорной информации, использованной при кодировании опорной области, указанной данными предсказания предсказанной опорной информации;
этап обновления данных предсказания предсказанной опорной информации, на котором обновляют данные предсказания предсказанной опорной информации путем использования сгенерированной опорной информации опорной области;
этап генерации предсказанной опорной информации, на котором генерируют предсказанную опорную информацию, которая исполняет роль предсказанной информации опорной информации кодируемой целевой области, путем использования одной или более частей данных предсказания обновленной предсказанной опорной информации; и
этап кодирования дифференциальной опорной информации, на котором кодируют информацию разности между предсказанной опорной информацией и опорной информацией, использованной при генерации предсказанного изображения кодируемой целевой области.
3. Способ кодирования видео по п.2, в котором на этапе обновления данных предсказания предсказанной опорной информации данные предсказания предсказанной опорной информации обновляются путем замены информации корреспондирующих точек, указанной данными предсказания предсказанной опорной информации, на сумму информации корреспондирующих точек, указанной данными предсказания предсказанной опорной информации, и информации корреспондирующих точек, указанной опорной информацией опорной области.
4. Способ кодирования видео по п.2, в котором на этапе обновления данных предсказания предсказанной опорной информации данные предсказания предсказанной опорной информации обновляются путем замены информации корреспондирующих точек, указанной данными предсказания предсказанной опорной информации, на информацию корреспондирующих точек, указанную опорной информацией опорной области.
5. Способ кодирования видео по п.2, в котором на этапе обновления данных предсказания предсказанной опорной информации данные предсказания предсказанной опорной информации обновляются путем замены информации корреспондирующих точек, указанной данными предсказания предсказанной опорной информации, либо на сумму информации корреспондирующих точек, указанной данными предсказания предсказанной опорной информации, и информации корреспондирующих точек, указанной опорной информацией опорной области, либо на информацию корреспондирующих точек опорной информации опорной области.
6. Способ кодирования видео по п.5, в котором: на этапе обновления данных предсказания предсказанной опорной информации определяют, была ли заменена информация корреспондирующих точек данных предсказания предсказанной опорной информации на сумму информации корреспондирующих точек данных предсказания предсказанной опорной информации и информации корреспондирующих точек опорной информации опорной точки или на информацию корреспондирующих точек опорной информации опорной области на основании информации времени и информации точки обзора опорного кадра кодируемой целевой области, информации времени и информации точки обзора кадра, который включает в себя опорную область, информации времени и информации точки обзора опорного кадра опорной области, который представляет собой опорный кадр, используемый при кодировании опорной области, и информации времени и информации точки обзора кодируемого целевого кадра.
7. Способ кодирования видео по п.2, дополнительно содержащий этап геометрического преобразования предсказанной опорной информации, на котором применяют геометрическое преобразование к информации корреспондирующих точек, указанной данными предсказания предсказанной опорной информации, путем использования параметра камеры на точке обзора кодируемого целевого кадра, параметра камеры на точке обзора опорного кадра кодируемой целевой области и параметра камеры на точке обзора кадра, указанного данными предсказания предсказанной опорной информации.
8. Способ кодирования видео по п.2, дополнительно содержащий этап геометрического преобразования предсказанной опорной информации, на котором применяют геометрическое преобразование к информации корреспондирующих точек, указанной опорной информацией опорной области путем использования параметра камеры на точке обзора кодируемого целевого кадра, параметра камеры на точке обзора опорного кадра кодируемой целевой области, параметра камеры на точке обзора кадра, указанного данными предсказания предсказанной опорной информации, и параметра камеры на точке обзора кадра, указанного опорной информацией опорной области, соответствующей данным предсказания предсказанной опорной информации.
9. Способ кодирования видео по п.2, дополнительно содержащий этап поиска данных предсказания предсказанной опорной информации, на котором выполняют поиск цели, которая представляет собой область в опорном кадре кодируемой целевой области, для области, соответствующей опорной области, указанной данными предсказания предсказанной опорной информации, и заменяют данные предсказания предсказанной опорной информации на соответствующую информацию результата поиска.
10. Способ кодирования видео по п.2, дополнительно содержащий этап поиска данных предсказания предсказанной опорной информации, на котором выполняют поиск цели, которая представляет собой область в опорном кадре кодируемой целевой области, для области, соответствующей области, которая является смежной относительно кодируемой целевой области, и заменяют данные предсказания предсказанной опорной информации на соответствующую информацию результата поиска.
11. Способ декодирования видео для декодирования изображения путем разделения всего изображения на области и генерации предсказанного изображения путем использования множества уже декодированных кадров, причем видеоизображение декодируется путем декодирования для каждой области разделенного изображения информации для указания опорного кадра декодируемой целевой области, который представляет собой уже декодированный кадр, использованный для генерации предсказанного изображения; опорной информации для указания предсказанной целевой позиции декодируемой целевой области в опорном кадре декодируемой целевой области и информации разности между предсказанным изображением и изображением декодируемой целевой области, причем способ декодирования видео содержит:
этап установки данных предсказания предсказанной опорной информации, на котором устанавливают опорную информацию, которая была использована при декодировании области, смежной с декодируемой целевой областью, в качестве данных предсказания предсказанной опорной информации, используемых для предсказания опорной информации декодируемой целевой области;
этап генерации опорной информации опорной области, на котором генерируют опорную информацию опорной области на основании одной или более частей опорной информации, использованной при декодировании опорной области, указанной данными предсказания предсказанной опорной информации;
этап обновления данных предсказания предсказанной опорной информации, на котором обновляют данные предсказания предсказанной опорной информации путем использования сгенерированной опорной информации опорной области;
этап генерации предсказанной опорной информации, на котором генерируют предсказанную опорную информацию, которая исполняет роль предсказанной информации опорной информации декодируемой целевой области, путем использования одной или более частей данных предсказания обновленной предсказанной опорной информации; и
этап декодирования дифференциальной опорной информации, на котором из кодированных данных декодируют информацию разности между предсказанной опорной информацией и опорной информацией, использованной при генерации предсказанного изображения декодируемой целевой области.
12. Способ декодирования видео по п.11, в котором на этапе обновления данных предсказания предсказанной опорной информации данные предсказания предсказанной опорной информации обновляются путем замены информации корреспондирующих точек, указанной данными предсказания предсказанной опорной информации, на сумму информации корреспондирующих точек, указанной данными предсказания предсказанной опорной информации, и информации корреспондирующих точек, указанной опорной информацией опорной области.
13. Способ декодирования видео по п.11, в котором на этапе обновления данных предсказания предсказанной опорной информации данные предсказания предсказанной опорной информации обновляются путем замены информации корреспондирующих точек, указанной данными предсказания предсказанной опорной информации, на информацию корреспондирующих точек, указанную опорной информацией опорной области.
14. Способ декодирования видео по п.11, в котором на этапе обновления данных предсказания предсказанной опорной информации данные предсказания предсказанной опорной информации обновляются путем замены информации корреспондирующих точек, указанной данными предсказания предсказанной опорной информации, либо на сумму информации корреспондирующих точек, указанной данными предсказания предсказанной опорной информации, и информации корреспондирующих точек, указанной опорной информацией опорной области, либо на информацию корреспондирующих точек, указанную опорной информацией опорной области.
15. Способ декодирования видео по п.14, в котором на этапе обновления данных предсказания предсказанной опорной информации определяют, была ли заменена информация корреспондирующих точек данных предсказания предсказанной опорной информации на сумму информации корреспондирующих точек данных предсказания предсказанной опорной информации и информации корреспондирующих точек опорной информации опорной точки или на информацию корреспондирующих точек опорной информации опорной области на основании информации времени и информации точки обзора опорного кадра декодируемой целевой области, информации времени и информации точки обзора кадра, который включает в себя опорную область, информации времени и информации точки обзора опорного кадра опорной области, который представляет собой опорный кадр, используемый при декодировании опорной области, и информации времени и информации точки обзора декодируемого целевого кадра.
16. Способ декодирования видео по п.11, дополнительно содержащий этап геометрического преобразования предсказанной опорной информации, на котором применяют геометрическое преобразование к информации корреспондирующих точек, указанной данными предсказания предсказанной опорной информации, путем использования параметра камеры на точке обзора декодируемого целевого кадра, параметра камеры на точке обзора опорного кадра декодируемой целевой области и параметра кадра на точке обзора кадра, указанного данными предсказания предсказанной опорной информации.
17. Способ декодирования видео по п.11, дополнительно содержащий этап геометрического преобразования предсказанной опорной информации, на котором применяют геометрическое преобразование к информации корреспондирующих точек, указанной опорной информацией опорной области путем использования параметра камеры на точке обзора декодируемого целевого кадра, параметра камеры на точке обзора опорного кадра декодируемой целевой области, параметра камеры на точке обзора кадра, указанного данными предсказания предсказанной опорной информации, и параметра камеры на точке обзора кадра, указанного опорной информацией опорной области, соответствующей данным предсказания предсказанной опорной информации.
18. Способ декодирования видео по п.11, дополнительно содержащий этап поиска данных предсказания предсказанной опорной информации, на котором выполняют поиск цели, которая представляет собой область в опорном кадре декодируемой целевой области, для области, соответствующей опорной области, указанной данными предсказания предсказанной опорной информации, и заменяют данные предсказания предсказанной опорной информации на соответствующую информацию результата поиска.
19. Способ декодирования видео по п.11, дополнительно содержащий этап поиска данных предсказания предсказанной опорной информации, на котором выполняют поиск цели, которая представляет собой область в опорном кадре декодируемой целевой области, для области, соответствующей области, которая является смежной относительно декодируемой целевой области, и заменяют данные предсказания предсказанной опорной информации на соответствующую информацию результата поиска.
20. Устройство генерации предсказанной опорной информации, содержащее блоки для выполнения этапов способа генерации предсказанной опорной информации по п.1.
21. Компьютерно-читаемый носитель, который хранит в себе программу генерации предсказанной опорной информации, посредством которой компьютер выполняет этапы способа генерации предсказанной опорной информации по п.1.
22. Устройство кодирования видео, содержащее блоки для выполнения этапов способа кодирования видео по п.2.
23. Компьютерно-читаемый носитель, который хранит в себе программу кодирования видео, посредством которой компьютер выполняет этапы способа кодирования видео по п.2.
24. Устройство декодирования видео, содержащее блоки для выполнения этапов способа декодировании явидео по п.11.
25. Компьютерно-читаемый носитель, который хранит в себе программу декодирования видео, посредством которой компьютер выполняет этапы способа декодирования видео по п.11.
| US 2003190079 А1, 2003.10.09 | |||
| US 6430224 В1, 2002.08.06 | |||
| WO 2006073116 A1, 2006.07.13 | |||
| US 2005031035 A1, 2005.02.10 | |||
| JP 10136374 A, 1998.05.22 | |||
| JP 2004056823 A, 2004.02.19 | |||
| US 2004223548 A1, 2004.11.11 | |||
| JP 2003009179 A, 2003.01.10 | |||
| EP 1596609 A2, 2005.11.16 | |||
| СПОСОБ И УСТРОЙСТВО СЖАТИЯ ВИДЕОИНФОРМАЦИИ | 1997 |
|
RU2209527C2 |
| MERKLE P | |||
| et al | |||
| EFFICIENT COMPRESSION OF MULTI-VIEW VIDEO | |||

