Область техники, к которой относится изобретение
Настоящее изобретение относится к методикам кодирования и декодирования для видеоизображений с множеством точек обзора.
Приоритет заявлен по патентной заявке Японии №2006-353628, поданной 28 декабря 2006 г., содержание которой включено в настоящий документ посредством ссылки.
Уровень техники
Видеоизображения с множеством точек обзора являются множеством видеоизображений, полученных с помощью фотографирования одного и того же объекта и его фона с использованием множества камер. Ниже, видеоизображение, полученное с помощью одной камеры, называют "двумерным видеоизображением", а набор множества двумерных видеоизображений, полученных с помощью фотографирования одного и того же объекта и его фона, называют "видеоизображением с множеством точек обзора".
Имеется сильная временная корреляция в двумерном видеоизображении каждой камеры, которая включена в видеоизображение с множеством точек обзора. Кроме того, когда камеры синхронизированы друг с другом, изображения (снятые с помощью камер) в один и тот же момент времени фиксируют объект и его фон совершенно в одном и том же состоянии с разных позиций таким образом, что имеется сильная корреляция между камерами.
Эффективность видеокодирования может быть улучшена с использованием этой корреляции.
Во-первых, будут показаны традиционные методики, относящиеся к кодированию двумерных видеоизображений.
Во многих известных способах кодирования двумерных видеоизображений, таких как H.264, MPEG-2, MPEG-4 (которые являются международными стандартами кодирования) и тому подобных, высокоэффективное кодирование выполняют посредством компенсации движения, ортогонального преобразования, квантования, статистического кодирования или тому подобного. Например, в Н.264 можно выполнять кодирование с использованием временной корреляции между настоящим кадром, прошлым или будущим кадрами.
Непатентный документ 1 раскрывает подробные методики компенсации движения, используемые в Н.264. Далее последуют общие объяснения этих методик.
В соответствии с компенсацией движения в Н.264 целевой кадр кодирования разделяют на блоки любого размера, и каждый блок может иметь индивидуальный вектор движения, таким образом, достигая высокого уровня эффективности кодирования, даже для локального изменения в видеоизображении.
Кроме того, так как кандидаты для опорного изображения, прошлые и будущие кадры (относительно настоящего кадра), которые уже закодированы, могут быть подготовлены таким образом, что каждый блок может иметь индивидуальный опорный кадр, тем самым осуществляя высокий уровень эффективности кодирования даже для видеоизображения, в котором происходит перекрытие вследствие временного изменения.
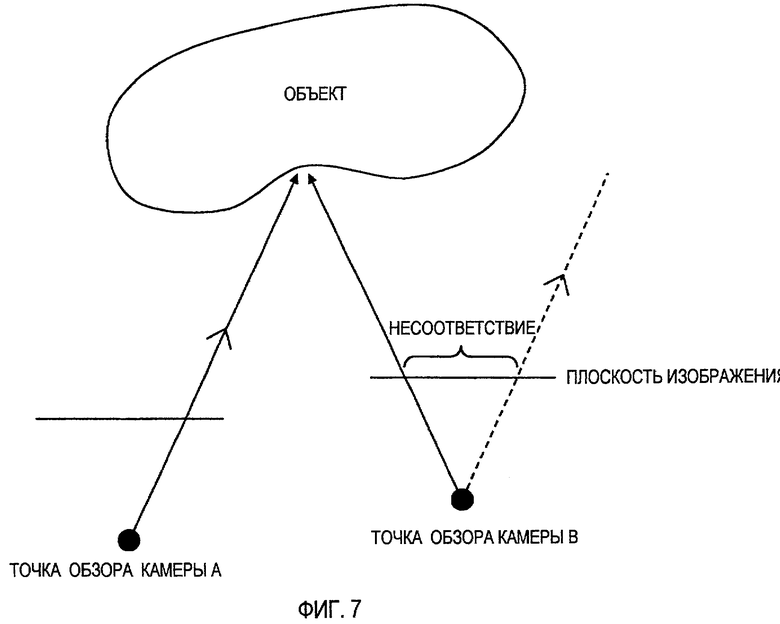
Далее будет объяснен традиционный способ кодирования видеоизображений с множеством точек обзора. Так как кодирование видеоизображений с множеством точек обзора использует корреляцию между камерами, видеоизображения с множеством точек обзора высокоэффективно кодируют известным способом, который использует “компенсацию несоответствия”, в котором компенсацию движения применяют к изображениям, полученным с помощью разных камер в один и тот же момент времени. В настоящем описании несоответствие является разностью между позициями, в которые проецируют одну и ту же точку на отображенном объекте, на плоскостях изображения камер, которые расположены в разных позициях.
Фиг. 7 является схематическим изображением, иллюстрирующим концепцию несоответствия, сформированную между такими камерами. То есть, Фиг. 7 изображает состояние, в котором наблюдатель смотрит вниз на плоскости изображения камер А и В, оптические оси которых параллельны друг другу, с верхнего края плоскостей. В общем, такие точки, в которые проецируют одну и ту же точку на отображенном объекте, на плоскостях изображения разных камер называют “соответствующими точками”. При кодировании, основанном на компенсации несоответствия, на основе вышеупомянутой взаимосвязи, каждое значение пикселя целевого кадра кодирования предсказывают с использованием опорного кадра и кодируют соответственную разность предсказания и информацию о несоответствии, которая обозначает зависимость подобия.
Для каждого кадра в видеоизображении с множеством точек обзора временная избыточность и межкадровая избыточность присутствуют одновременно. Каждый из непатентного документа 2 и патентного документа 1 (раскрывающего устройство кодирования изображения с множеством точек обзора) раскрывает способ для одновременного удаления обеих избыточностей.
В данных способах выполняется временное предсказание разностного изображения между исходным изображением и изображением с компенсированным несоответствием и кодирование разности компенсации движения в разностном изображении.
В соответствии с такими способами временная избыточность, которая не может быть удалена с помощью компенсации несоответствия для удаления избыточности между камерами, может быть удалена с использованием компенсации движения. Вследствие этого разность предсказания, которую, в конце концов, кодируют, уменьшается таким образом, что может быть достигнут высокий уровень эффективности кодирования.
Непатентный документ 1: ITU-T Rec.H.264/ISO/IEC 11496-10, "Editor's Proposed Draft Text Modifications for Joint Video Specification (ITU-T Rec.H.264/ISO/IEC 11496-10 AVC), Draft 7", Final Committee Draft, Document JVT-E022, стр.10-13 и 62-68, сентябрь 2002.
Непатентный документ 2: Shinya SHIMIZU, Masaki KITAHARA, Kazuto KAMIKURA and Yoshiyuki YASHIMA, "Multi-view Video Coding based on 3-D Warping with Depth Map", In Proceedings of Picture Coding Symposium 2006, SS3-6, Апрель 2006.
Патентный документ 1: Непроанализированная патентная заявка Японии, первая публикация №Н10-191393.
Раскрытие изобретения
Проблемы, решаемые с помощью изобретения
В соответствии с традиционным способом кодирования видео с множеством точек обзора, применяющим компенсацию движения к разностному изображению, разность предсказания в части, имеющей как временную избыточность, так и избыточность между камерами, может быть уменьшена таким образом, что кодирование может быть выполнено эффективно.
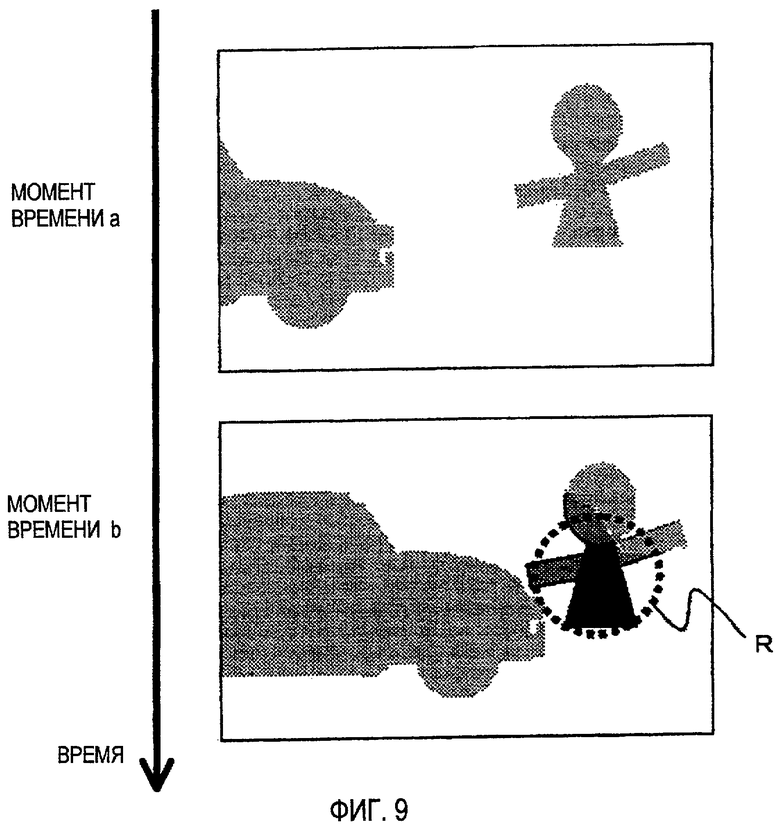
Однако если между отображенными объектами происходит перекрытие, как изображено на Фиг. 8, тогда наличие/отсутствие избыточности между камерами для одного объекта может изменяться в зависимости от времени.
Фиг. 8 иллюстрирует пример перекрытия между объектами в изображениях, которые получены с помощью камер А и В в каждый из моментов времени а и b.
Фиг. 9 иллюстрирует пример разностного изображения компенсации несоответствия, когда имеется перекрытие.
В соответствии со способом, раскрытым в непатентном документе 2, в каждый пиксель опорного кадра, используемого в компенсации несоответствия, предоставляют информацию, которая обозначает соответствующую точку в другом кадре. Вследствие этого, если изображение камеры В компенсировано относительно несоответствия из изображения камеры А (см. Фиг. 8), получают разностное изображение, как изображено на Фиг. 9.
На Фиг. 9 глубина цвета обозначает величину разностного сигнала таким образом, что чем ближе к белому цвету, тем меньше соответствующая разность.
В настоящей заявке используют информацию о несоответствии, которая обозначает, какой части в изображении камеры В соответствует каждый пиксель в опорном кадре (т.е. изображении камеры А). Вследствие этого не выполняют никакой компенсации несоответствия в каждой части, которая присутствует в изображении камеры В, но не присутствует в изображении камеры А. Соответственно, цвет каждой части (в соответствующем изображении), для которого может быть получена соответствующая точка, становится близким к белому. Наоборот, в части R (внутри пунктирной окружности на Фиг. 9), для которой не может быть получена соответствующая точка, исходное изображение остается неизмененным, как разностный сигнал.
Однако вследствие разности в чувствительности между камерами или влиянии отражения разностный сигнал не полностью становится нулем, даже в каждой части, для которой может быть получена соответствующая точка. В области, такой как R на Фиг. 9, очевидно, что разность предсказания не может быть уменьшена даже с помощью компенсации движения, выполненной из разностного изображения в другой момент времени, такой как момент времени а на Фиг. 9.
В простом способе решения вышеупомянутой проблемы каждый блок относится к разному кадру. Поэтому в качестве опорного кадра может быть использовано не только декодированное изображение разностного изображения, но также декодированное изображение конечного изображения камеры, полученное с помощью прибавления изображения с компенсированным несоответствием к разностному изображению, и в каждом блоке можно обращаться с возможностью переключения к одному из двух декодированных изображений.
Таким образом, даже в области R на Фиг. 9, где остается исходное изображение камеры, разность предсказания может быть уменьшена с помощью выполнения компенсации движения из декодированного изображения камеры.
Однако в таком способе необходимо кодировать информацию, предназначенную для указания опорного кадра каждого блока, что вызывает увеличение объема кода.
Кроме того, вышеупомянутый способ является неэффективным, если часть, имеющая перекрытие, и часть, не имеющая перекрытия, одновременно присутствуют в блоке.
С другой стороны, в способе, раскрытом в непатентном документе 1, при кодировании целевого кадра кодирования вместо кодирования всего кадра с помощью подвергания разностного изображения компенсации движения можно выбирать для каждого блока: (i) подвергать ли разностное изображение компенсации движения, (ii) выполнять ли только компенсацию несоответствия, или (iii) выполнять ли только компенсацию движения.
Соответственно, даже в части, в которой происходит перекрытие между камерами, разность предсказания может быть эффективно уменьшена, если имеется временная избыточность.
Однако в вышеупомянутом способе необходимо кодировать информацию, предназначенную для указания, какой способ предсказания был использован в каждом блоке, то есть кодировать большой объем дополнительной информации, несмотря на то, что разность предсказания может быть уменьшена. Вследствие этого невозможно достичь высокого уровня эффективности кодирования.
Кроме того, так как в каждом блоке может быть выбран только один способ предсказания, соответствующий способ является неэффективным, если наличие/отсутствие перекрытия не является фиксированным в каждой части блока.
В свете вышеупомянутых обстоятельств задачей настоящего изобретения является предоставление новых способов кодирования и декодирования видео для достижения высокого уровня эффективности кодирования с помощью осуществления соответственного предсказания без увеличения объема кода, требуемого для предсказания.
Средство для решения проблемы
Для того чтобы решить вышеупомянутые проблемы, настоящее изобретение предоставляет способ видеокодирования для формирования на основании информации о несоответствии между уже закодированным опорным изображением камеры и кодирующимся целевым изображением камеры, соответствующим опорному изображению камеры, изображения с несоответствием, скомпенсированным посредством предсказания изображения между камерами; и для кодирования разностного изображения между кодирующимся целевым изображением камеры и изображением с компенсированным несоответствием. Способ имеет этап выбора для каждой предварительно определенной единицы секции (например, каждого пикселя) в разностном изображении одной из следующих двух групп изображений в качестве опорной цели с помощью определения, имеется ли или нет изображение с компенсированным несоответствием в соответствующей позиции, иначе говоря, имеет ли или нет соответствующий пиксель в изображении с компенсированным несоответствием эффективную величину:
(i) группы декодированного разностного изображения, которую получают с помощью декодирования разностного изображения между уже закодированным изображением камеры и изображением с компенсированным несоответствием (т.е. набора декодированных разностных изображений, которые включают в себя декодированное разностное изображение, которое было получено в другой момент времени и уже закодировано, или декодированное разностное изображение уже закодированной части разностного изображения для кодирующегося целевого изображения камеры), и
(ii) группы декодированного изображения камеры, которую получают с помощью декодирования уже закодированного изображения камеры (набора декодированных изображений камеры, каждое из которых представлено с помощью суммы каждого декодированного разностного изображения (которое может быть декодированным разностным изображением в другой момент времени) и соответствующего изображения с компенсированным несоответствием).
В соответствии с вышеупомянутым способом кодирование с предсказанием, использующее подходящее опорное изображение для каждого желаемого блока секции, может быть выполнено без добавления новой дополнительной информации о выборе для способа опорного изображения. То есть, можно уменьшить разностный элемент, подлежащий кодированию без увеличения объема кода, требуемого для дополнительной информации, тем самым осуществляя высокий уровень эффективности кодирования.
В вышеупомянутом способе информация о несоответствии может быть предоставлена как вектор несоответствия или представлена как геометрическая информация, такая как расстояние от камеры до изображенного объекта, то есть она может быть предоставлена в любом формате, с помощью которого могут быть получены соответствующие зависимости между соответствующими изображениями.
При кодировании разностного изображения с использованием обозначенной опорной цели кодирование может быть выполнено с использованием способа предсказания сигнала в одном блоке обработки кодирования.
В обычном кодировании с предсказанием разные контрольные цели, вероятно, имеют разные оптимальные способы предсказания. Вследствие этого, если один блок обработки кодирования включает в себя пиксели или области, которые имеют разные контрольные цели, способ предсказания выбирают для каждой опорной цели и кодируют дополнительную информацию, которая обозначает множество способов предсказания.
Однако, если кодирование выполняют с использованием одного способа предсказания в одном блоке обработки кодирования, как описано выше, информация, которая обозначает только один способ предсказания, должна быть закодирована для каждого блока обработки кодирования, в связи с этим уменьшают объем кода, требуемого для всего кодирования. В этом случае для ожидаемого ухудшения эффективности предсказания эффективность предсказания не должна быть существенно ухудшена, принимая во внимание случай, который изображен на Фиг. 9, то есть при выполнении предсказания видео с помощью применения одного способа (т.е. компенсации движения с использованием одного вектора движения) даже к части границы.
Кроме того, принимая во внимание баланс между эффективностью предсказания и объемом кода, требуемого для дополнительной информации, можно выбрать, использовать ли один способ предсказания в каждом блоке или назначать отдельный способ предсказания для каждой опорной цели. С учетом такого баланса между эффективностью предсказания и объемом кода, требуемого для дополнительной информации, можно осуществлять более гибкое кодирование, имеющее более высокий уровень эффективности кодирования.
В этом случае декодирующая сторона может определить из закодированных данных, переключен ли или нет способ предсказания, таким образом, что сторона декодирования может соответствующим образом декодировать релевантное изображение.
Преимущество изобретения
В соответствии с настоящим изобретением при подвергании разностного изображения, полученного с помощью компенсации несоответствия, кодированию с предсказанием не используют никакую новую дополнительную информацию и подходящее опорное изображение используют посредством операции переключения для каждого пикселя. Вследствие этого разность для цели кодирования может быть уменьшена без увеличения объема кода, требуемого для дополнительной информации, таким образом, осуществляют эффективное видеокодирование всего видеоизображения с множеством точек обзора.
Краткое описание чертежей
Фиг. 1 - схема, изображающая устройство видеокодирования в качестве варианта осуществления настоящего изобретения.
Фиг. 2 - блок-схема последовательности этапов видеокодирования, выполняемых в варианте осуществления.
Фиг. 3 - подробная блок-схема последовательности этапов для определения режима предсказания в варианте осуществления.
Фиг. 4 - схема, изображающая устройство видеокодирования в качестве варианта осуществления настоящего изобретения.
Фиг. 5 - блок-схема последовательности этапов видеокодирования, выполняемых в варианте осуществления.
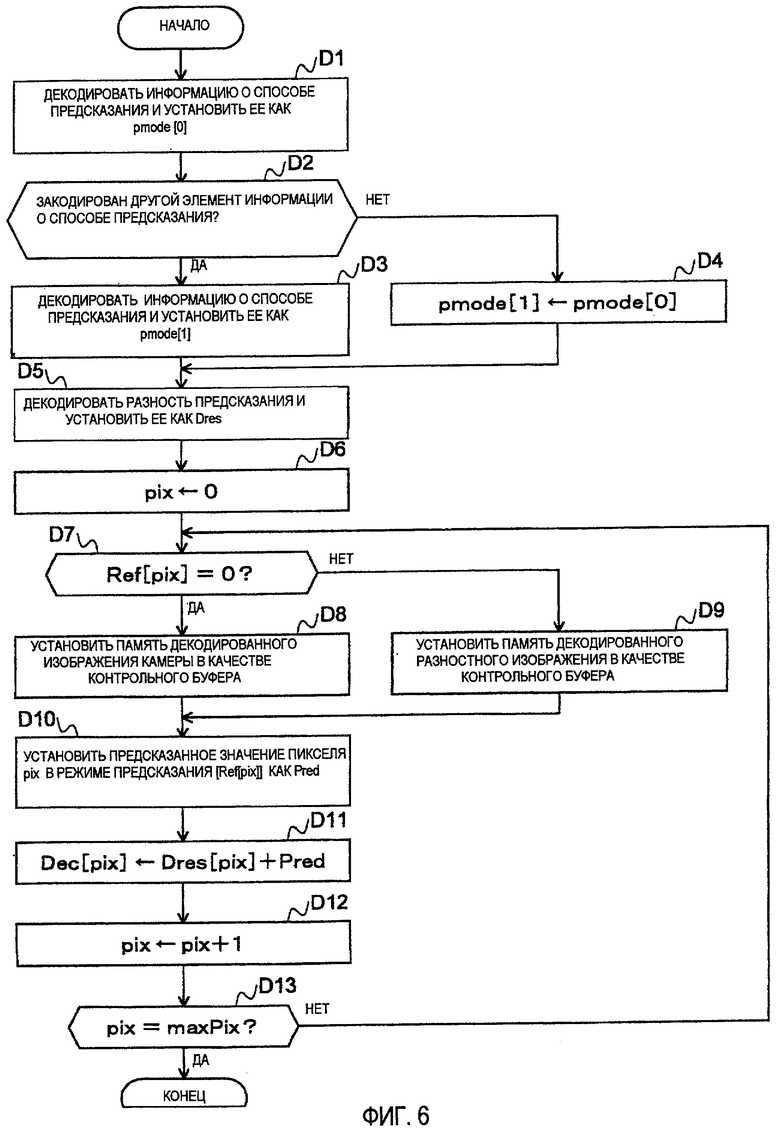
Фиг. 6 - подробная блок-схема последовательности этапов декодирования закодированных данных для разностного изображения в варианте осуществления.
Фиг. 7 - схематичное изображение, иллюстрирующее концепцию несоответствия, сформированную между камерами.
Фиг. 8 - схема, изображающая пример, в котором происходит перекрытие между изображенными объектами.
Фиг. 9 - схема, изображающая пример разностного изображения компенсации несоответствия, когда имеется перекрытие.
Обозначение позиций
100 - устройство видеокодирования
101 - блок ввода видео
102 - блок ввода опорного изображения
103 - блок ввода информации о несоответствии
104 - генератор изображения с компенсированным несоответствием
105 - кодер с предсказанием разностного изображения
106 - блок установки опорного изображения
107 - память декодированного изображения камеры
108 - память декодированного разностного изображения
109 - опорный переключатель
110 - декодер разностного изображения
200 - устройство декодирования видео
201 - блок ввода закодированных данных
202 - блок ввода опорного изображения
203 - блок ввода информации о несоответствии
204 - генератор изображения с компенсированным несоответствием
205 - блок установки опорного изображения
206 - память декодированного изображения камеры
207 - память декодированного разностного изображения
208 - опорный переключатель
209 - декодер разностного изображения
Осуществление изобретения
До объяснения вариантов осуществления настоящего изобретения будет описана сущность настоящего изобретения.
В традиционных способах, предназначенных для кодирования с множеством точек обзора, необходимо кодировать и передавать информацию, которая обозначает выбранное изображение. В противоположность, настоящее изобретение характеризуется тем, что информация, которая обозначает выбранное изображение, может быть декодирована с использованием другой информации. Таким образом, когда настоящее изобретение имеет тот же самый объем кода, что и традиционные способы, настоящее изобретение имеет лучшее качество по сравнению с традиционными способами.
Для того чтобы кодировать видеоизображение с множеством точек обзора, если получают разность между видеоизображением, полученным с помощью камеры, и соответствующим изображением, сформированным посредством компенсации несоответствия из другой камеры, и кодирование выполняют с учетом временной корреляции относительно разностного видеоизображения, тогда в традиционных способах часть перекрытия, такая как R на Фиг. 9, не может быть эффективно закодирована.
В противоположность, в настоящем изобретении, часть перекрытия, такая как R на Фиг. 9, может быть эффективно закодирована с помощью подвергания релевантной части кодированию с предсказанием, которое использует не разностное видеоизображение из изображения, сформированного с помощью компенсации несоответствия, а декодированное изображение исходного видеоизображения.
Кроме того, в легко предвосхищаемом способе решения проблемы, такой, что часть перекрытия не может быть эффективно закодирована, используют способ обращения к множеству кадров, использованный в Н.264, таким образом, что кодирование выполняют с помощью назначения отдельного опорного изображения в каждый блок.
Однако в таком случае (i) кодируют информацию для обозначения опорного изображения для каждого блока, что вызывает увеличение объема кода, а (ii) переключение опорного изображения может быть выполнено только с помощью единицы секции. Вследствие этого релевантный способ является неэффективным, когда блок имеет как часть перекрытия, так и часть не перекрытия.
В противоположность, в настоящем изобретении переключение опорного изображения выполняют с использованием информации, полученной формированием изображения с помощью компенсации несоответствия. Вследствие этого не нужно кодировать новую информацию. Кроме того, в соответствии с использованной информацией для каждого пикселя может быть определено наличие/отсутствие перекрытия. Вследствие этого переключение опорного изображения может быть выполнено с помощью единицы пикселя.
Для того чтобы осуществить вышеупомянутые функции, в настоящем изобретении формируют информацию Ref, которая обозначает, может ли или нет быть сформировано изображение с компенсированным несоответствием Syn цели кодирования с использованием изображения, полученного с помощью другой камеры, и переключение опорного изображения выполняют с использованием информации Ref.
Результат определения того, что изображение с компенсированным несоответствием Syn может быть сформировано, означает, что один и тот же объект появляется в изображении другой камеры и, следовательно, не произошло никакое перекрытие.
В противоположность, результат определения того, что изображение с компенсированным несоответствием Syn не может быть сформировано, означает, что один и тот же объект не появляется в изображении другой камеры и, следовательно, появилось перекрытие.
То есть, переключение опорного изображения выполняют с использованием информации, которая обозначает, может ли или нет быть сформировано изображение с компенсированным несоответствием Syn, таким образом, что можно решить проблему, что соответственное предсказание может быть выполнено в части перекрытия R на Фиг. 9.
Способ обращения к множеству кадров, использованный в Н.264, также известен как способ, предназначенный для выбора опорного изображения, используемого для кодирования из множества кандидатов опорных изображений. В этом известном способе необходимо кодировать и передавать информацию, которая обозначает, какое изображение было выбрано.
В противоположность, в настоящем изобретении информацию, используемую для выбора опорного изображения, формируют с использованием информации, которую используют для формирования изображения с компенсированным несоответствием и которая также должна быть передана при использовании вышеупомянутого известного способа. Вследствие этого не нужно передавать дополнительную информацию, используемую для переключения опорного изображения, тем самым уменьшая объем кода.
В вариантах осуществления, изображенных далее, информацию, которую используют для выбора опорного изображения и формируют на основании информации, используемой для формирования изображения с компенсированным несоответствием, представляют как информацию Ref, и та же самая информация может быть использована на кодирующей и декодирующей сторонах (например, информацию на кодирующей стороне формируют на этапе А6 на Фиг. 2, а информацию на декодирующей стороне формируют на этапе С4 на Фиг. 5).
Кроме того, если опорное изображение выбирают для каждого пикселя известным способом, таким как способ обращения к множеству кадров в Н.264, или тому подобным, объем кода, требуемого для кодируемого сигнала ошибки предсказания, может быть уменьшен. Однако в таком случае необходимо кодировать информацию, используемую для переключения опорного изображения для каждого пикселя, что вызывает увеличение объема кода. То есть, в этом случае опорное изображение может быть переключено только с помощью единицы секции таким образом, чтобы уменьшить полный объем кода.
В противоположность, в настоящем изобретении информация, предназначенная для переключения опорного изображения, не является информацией, дополнительно передаваемой, как описано выше. Вследствие этого при формировании такой информации в соответствии с каждым пикселем переключение опорного изображения для каждого пикселя может быть выполнено без увеличения объема кода, таким образом, уменьшают объем кода, требуемого для сигнала ошибки предсказания.
Далее настоящее изобретение будет объяснено более подробно в соответствии с вариантами осуществления.
В вариантах осуществления допускают, что видеоизображение с множеством точек обзора, полученное с использованием двух камер, кодируют, где изображение камеры В кодируют с использованием изображения камеры А в качестве опорного изображения.
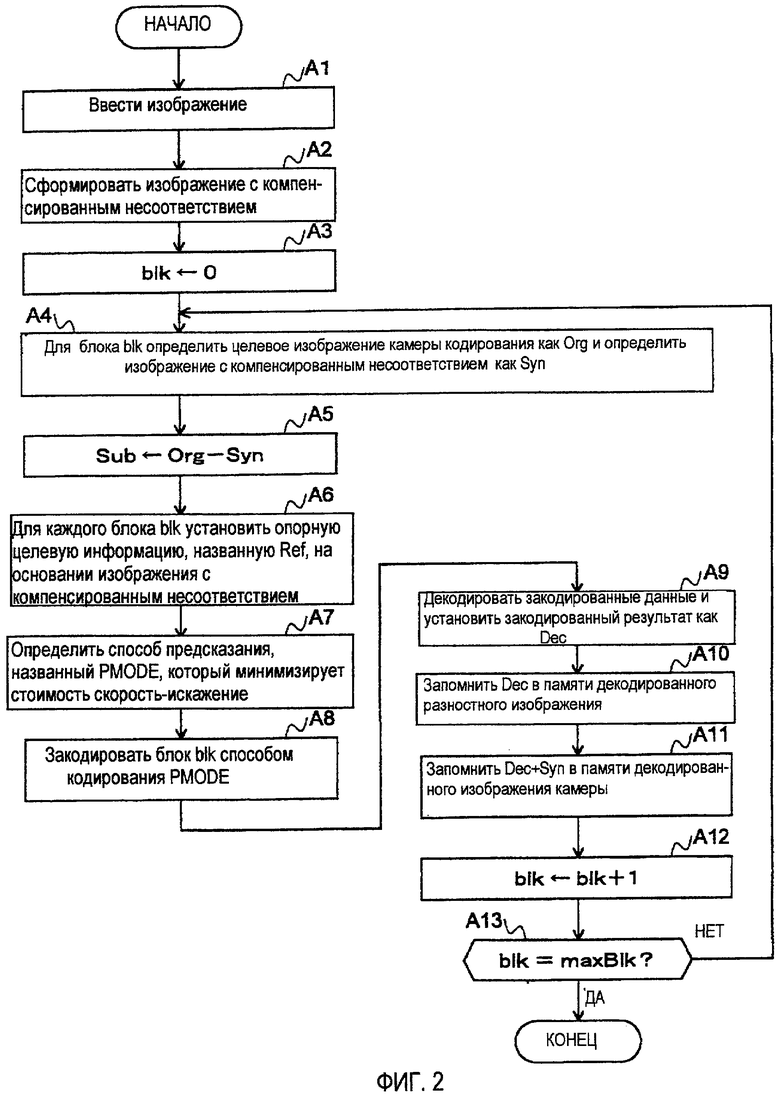
Фиг. 1 изображает устройство 100 видеокодирования в качестве варианта осуществления настоящего изобретения.
Устройство 100 видеокодирования включает в себя блок 101, блок 101 ввода изображения, предназначенный для ввода изображения (в качестве целевого изображения кодирования), полученного с помощью камеры В, в устройство, блок 102 ввода опорного изображения, предназначенный для ввода декодированного изображения (в качестве опорного изображения) камеры А в устройство, блок 103 ввода информации о несоответствии, предназначенный для ввода информации о несоответствии, которая обозначает, какой позиции в целевом изображении кодирования соответствует каждый пиксель в опорном изображении, в устройство, генератор 104 изображения с компенсированным несоответствием, предназначенный для формирования изображения с компенсированным несоответствием в позиции камеры В с помощью использования опорного изображения и информации о несоответствии, кодер 105 с предсказанием разностного изображения, предназначенный для подвергания кодированию с предсказанием разностного изображения между целевым изображением кодирования и изображением с компенсированным несоответствием, блок 106 установки опорного изображения, предназначенный для назначения группы опорного изображения каждому пикселю на основании состояния изображения с компенсированным несоответствием, память 107 декодированного изображения камеры, предназначенную для сохранения декодированных изображений (в качестве группы опорного изображения) изображений, полученных с помощью камеры В, память 108 декодированного разностного изображения, предназначенную для сохранения декодированных изображений (в качестве другой группы опорного изображения) закодированных разностных изображений, опорный переключатель 109, предназначенный для переключения памяти опорного изображения на основании информации установки о группе опорного изображения, и декодер 110 разностного изображения, предназначенный для декодирования каждого закодированного разностного изображения.
Фиг. 2 и Фиг. 3 являются блок-схемами последовательности этапов, выполняемых с помощью устройства 100 видеокодирования, имеющего вышеописанную структуру. Ссылаясь на блок-схемы последовательности этапов, операция, выполняемая с помощью устройства 100 видеокодирования, будет описана более подробно.
Как изображено в потоке операций на Фиг. 2, которая изображает общую операцию кодирования, изображение камеры В вводят с помощью блока 101 ввода изображения в устройство 100 видеокодирования (см. этап А1).
Здесь декодированное изображение камеры А, которое имеет то же самое время отображения (то есть то же самое время изображения), что и входное изображение камеры В, вводят с помощью блока 102 ввода опорного изображения, а информацию о несоответствии между изображениями вводят в соответствующий момент времени с помощью блока 103 ввода информации о несоответствии.
Ниже входное изображение камеры В называют “целевое изображение камеры кодирования”, а декодированное изображение камеры А называют “опорное изображение камеры”.
На основании опорного изображения камеры, введенного с помощью блока 102 ввода опорного изображения, и информации о несоответствии, введенной с помощью блока 103 ввода информации о несоответствии, формируют изображение с компенсированным несоответствием с помощью генератора 104 изображения с компенсированным несоответствием (см. этап А2).
Формирование изображения с компенсированным несоответствием выполняют способом, таким, что величину пикселя каждого пикселя в опорном изображении камеры используют в качестве величины пикселя соответствующего пикселя в изображении с компенсированным несоответствием.
В этом процессе, если множество точек в опорном изображении камеры соответствует той же самой точке в изображении с компенсированным несоответствием, тогда определяют прямые зависимости между изображенными объектами и используют значение пикселя точки в изображенном объекте, ближайшей к камере. Например, если камеры имеют параллельные оптические оси, можно определить, что чем больше несоответствие, тем ближе релевантная точка к камере.
Кроме того, так как информация о несоответствии обозначает подобную точку в кодирующемся целевом изображении камеры в каждом пикселе опорного изображения камеры, нет изображения с компенсированным несоответствием для части, которая отсутствует в опорном изображении камеры.
С помощью использования изображения с компенсированным несоответствием, полученного выше, целевое изображение камеры кодирования кодируют для каждого блока обработки кодирования (см. этапы А3 по А13).
В текущем потоке “blk” является индексом для каждого блока, а maxBlk обозначает полное число блоков в изображении. То есть, после того как blk инициализируют в ноль (см. этап А3), итеративно выполняют следующий процесс (см. А4 по А11), в то время как blk увеличивают на 1 (см. этап А 12) до тех пор, пока blk не достигнет полного числа maxBlk (см. этап А13).
Во-первых, определяют для блока blk, что Org обозначает целевое изображение камеры кодирования, а Syn обозначает изображение с компенсированным несоответствием (см. этап А4). Вычисляют разность Org-Syn для каждого пикселя, принадлежащего блоку blk, таким образом, что формируют разностное изображение Sub (см. этап А5).
Для каждой части пикселей, не имеющей изображения с компенсированным несоответствием, величину пикселя Syn устанавливают в 0 при вычислении разностного изображения.
Затем блок 106 установки опорного изображения устанавливает информацию Ref, которая обозначает ссылку, используемую при подвергании разностного изображения каждого пикселя в блоке blk кодированию с предсказанием, как изображено ниже (см. этап А6).
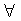 pix
pix
 {0,1,…,maxPix-1}
{0,1,…,maxPix-1}
Ref[pix]=0, когда изображение с компенсированным несоответствием не сохранено в Syn[pix]
Ref[pix]=1, когда изображение с компенсированным несоответствием сохранено в Syn[pix],
где pix - индекс, указывающий каждый пиксель в блоке blk, maxPix обозначает полное число пикселей в блоке blk. Кроме того, информация о единице секции, к которой добавлен “[pix]”, обозначает информацию пикселя в позиции индекса пикселя pix.
Кроме того, несмотря на то что любой способ может быть использован для определения, установлено ли изображение с компенсированным несоответствием как Syn, таким образом, чтобы сформировать Ref, пример этого способа будет изображен ниже.
До формирования изображения с компенсированным несоответствием Syn величину пикселя каждого пикселя инициализируют в абсолютно недостижимую величину (например, -1). Формируют изображения с компенсированным несоответствием Syn с помощью обновления величины пикселя способом, таким, что величину пикселя каждого пикселя в опорном изображении камеры определяют как величину пикселя в соответствующей позиции в изображении с компенсированным несоответствием. Затем формируют Ref способом, таким, что, если Syn, назначенное каждому пикселя, равен -1, Ref устанавливают в 0, и что, если Syn имеет значение, отличное от -1, Ref устанавливают в 1. Таким образом, целевое Ref может быть сформировано при взаимно однозначном соответствии с Syn.
В вышеописанном способе при вычислении разностного изображения Sub на вышеупомянутом этапе А5 в каждой части, в которой Syn равно -1, величину пикселя считают как 0, а Sub устанавливают в значении Org.
В другом способе до вычисления разностного изображения Sub формируют Ref в соответствии с вышеописанным способом или тому подобным, в каждой части, в которой Syn равно -1, Syn переписывают как 0, а затем вычисляют разностное изображение Sub с помощью вычисления Org-Syn.
В настоящем примере для удобства объяснений полное Syn, которое также включает в себя каждую часть, в которой не присутствует изображение с компенсированным несоответствием, и величину пикселя считают равной 0, называют изображением с компенсированным несоответствием.
Затем получают способ предсказания, который обеспечивает минимальную стоимость скорость-искажение при подвергании разностного изображения Sub кодированию с предсказанием с помощью использования вышеупомянутого Ref, и устанавливают как PMODE (см. этап А7).
Когда “sad” является суммой абсолютных значений ошибок предсказания в способе предсказания, а “bin” является предсказанным значением объема кода, требуемого для кодирования информации, которая обозначает способ предсказания, вычисляют стоимость скорость-искажение, называемую “cost” с помощью следующей формулы, где λ - неопределенный множитель Лагранжа и равен предварительно определенной величине.
cost=sad+λ∙bin
С помощью использования вышеопределенного PMODE разностное изображение Sub блока blk фактически подвергают кодированию с предсказанием (см. этап А8).
Определение способа предсказания и фактическое кодирование выполняют в кодере 105 с предсказанием разностного изображения. Результат кодирования включает в себя не только закодированные данные соответственного изображения, но также закодированные данные информации (например, PMODE), требуемой для кодирования.
Результат кодирования выводят из устройства 100 видеокодирования, а также декодируют в декодере 110 разностного изображения (см. этап А9).
В данном описании Dec обозначает декодированное изображение разностного изображения Sub блока blk, и его сохраняют в памяти 108 декодированного разностного изображения таким образом, чтобы использовать в предсказании внутри кадра, выполняемом при кодировании другого блока, или предсказании между кадрами, выполняемом при кодировании кадра в другой момент времени (см. этап А10).
Кроме того, формируют декодированное изображение камеры блока blk с помощью вычисления суммы Dec и Syn и сохраняют в памяти 107 декодированного изображения камеры (см. этап А11).
Вышеописанную операцию применяют к каждому блоку.
Фиг. 3 изображает подробный поток операций процесса определения способа предсказания (этап А7), выполняемого в кодере 105 с предсказанием разностного изображения.
В потоке операций вычисляют стоимость скорость-искажение, называемую “cost”, указанную с помощью следующей формулы, для каждого способа предсказания и определяют способ предсказания, который обеспечивает минимальное значение
cost=SAD+λ∙code(pmode),
где SAD - сумма абсолютных разностей для каждого пикселя между предсказанным изображением и исходным изображением, pmode обозначает индекс способа предсказания, а code( ) является функцией, которая возвращает предсказанное значение объема кода, требуемого для представления информации о предоставленном способе предсказания.
Как изображено в потоке операций, после того, как индекс способа предсказания pmode инициализируют в ноль (см. этап В1), итеративно выполняют следующий процесс (этапы В2 по В16), в то же время увеличивают pmode на 1 (см. этап В17) до тех пор, пока pmode не достигнет числа “maxPmode” способа предсказания (см. этап В18), таким образом определяют способ предсказания, который минимизирует “cost”.
В следующем процессе каждый способ предсказания оценивают с использованием стоимости скорость-искажение, где maxCost определяют как максимальное значение, которое является недостижимым в качестве оцененного значения. Кроме того, для того чтобы выполнить повторную оценку, наилучшие оцененные значения при отдельных условиях, объясненных ниже, соответственно указаны с помощью minCost, minCost1 и minCost2, а индексы способа предсказания, назначенные этим способам, соответственно указаны с помощью best_mode, best_mode1 и best_mode2.
Переменные minCost и best_mode представляют наилучшее оцененное значение и соответствующий индекс способа предсказания при предсказании всех пикселей в соответственном блоке, переменные minCost1 и best_mode1 представляют наилучшее оцененное значение и соответствующий индекс способа предсказания при предсказании только пикселей, соответствующее Ref которых имеет значение 0, и переменные minCost2 и best_mode2 представляют наилучшее оцененное значение и соответствующий индекс способа предсказания при предсказании только пикселей, соответствующее Ref которых имеет значение 1.
После инициализации каждого из minCost, minCost1 и minCost2 в maxCost (см. этап В1) формируют предсказанное изображение для способа предсказания pmode для каждого пикселя (см. этапы В2 по В8).
При формировании предсказанного изображения после того, как индекс пикселя “pix” инициализируют в ноль (этап В2), итеративно выполняют следующий процесс (этапы В3 по В6), в то время как pix увеличивают на 1 (см. этап В7), до тех пор, пока pix не достигнет числа “maxPix” пикселей в блоке (см. этап В8), таким образом, определяют способ предсказания, который минимизирует “cost”.
Во-первых, в соответствии с Ref[pix] определяют, имеется или нет изображение с компенсированным несоответствием в соответствующем пикселе (см. этап В3).
Если изображение с компенсированным несоответствием не присутствует, контрольным переключателем 109 управляют таким образом, что кодер 105 с предсказанием разностного изображения обращается к памяти 107 декодированного изображения камеры (см. этап В4). В противоположность, если имеется изображение с компенсированным несоответствием, контрольным переключателем 109 управляют таким образом, что кодер 105 с предсказанием разностного изображения обращается к памяти 108 декодированного разностного изображения (см. этап В5).
Затем с помощью использования установленного разностного изображения вычисляют предсказанное значение Pred[pix] для соответственного пикселя способом предсказания pmode (см. этап В6).
После того как формирование предсказанного изображения закончено для всех пикселей в блоке, вычисляют три типа суммы абсолютных разностей между предсказанным изображением и исходным изображением с помощью следующих формул.
SAD1=∑ |Sub[pix]-Pred[pix]|∙(1-Ref[pix])
SAD2=∑ |Sub[pix]-Pred[pix]|∙Ref[pix]
SAD=SAD1+SAD2,
где SAD1 обозначает сумму абсолютных разностей для пикселей, каждый из которых не имеет изображения с компенсированным несоответствием, SAD2 обозначает сумму абсолютных разностей для пикселей, каждый из которых имеет изображения с компенсированным несоответствием, и SAD обозначает сумму абсолютных разностей для всех пикселей в блоке. Кроме того, обозначает вычисление полной суммы для pix=0 до maxPix-1. Несмотря на то что приведенные выше формулы используют операции умножения, вычисление суммы абсолютных разностей может быть осуществлено с использованием простого ветвления по условию, поскольку пиксели для вычисления SAD1 и SAD2 являются исключающими друг для друга.
С помощью использования SAD, SAD1, SAD2 и pmode вычисляют стоимости скорость-искажение, названные cost1 и cost2, в соответствии с вышеописанной формулой (см. этап В10).
Вычисленные результаты соответственно сравнивают с наилучшими затратами скорость-искажение, которые уже вычислены (см. этапы В11, В13 и В15). Для каждого случая, если способ предсказания pmode может реализовать меньшие затраты, обновляют переменную, которая обозначает наилучший способ предсказания и наилучшее значение стоимости (см. этапы В12, В14 и В16).
После того как оценка всех способов предсказания закончена, определяют, назначены ли разные способы предсказания каждому пикселю, имеющему изображение с компенсированным несоответствием, и каждому пикселю, не имеющему компенсации несоответствия, или один и тот же способ предсказания назначен всем пикселям (см. этапы В19 по В21).
Во-первых, определяют, являются ли или нет все best_mode, best_mode1 и best_mode2 одинаковыми (см. этап В19).
Если все из вышеупомянутых элементов являются одинаковыми, это обозначает, что в блоке может быть использован один способ, и, следовательно, best_mode сохраняют в качестве способа предсказания PMODE, используемого в кодировании с предсказанием (см. этап В22). Затем операцию заканчивают.
Если, по меньшей мере, один из трех обозначает другой способ, тогда сумму minCost1, minCost2 и OHCost сравнивают с minCost (см. этап В20).
В данном описании первое (сумма) обозначает стоимость, требуемую, когда в соответственном блоке используют разные способы, а OHCost представляет стоимость непроизводительных затрат, учитывая, что кодируют два способа предсказания.
Если первое обеспечивает лучшую стоимость, множество из best_mode1 и best_mode2 сохраняют в качестве PMODE (см. этап В21). Затем операцию заканчивают.
Если последнее обеспечивает лучшую стоимость, best_mode сохраняют в качестве PMODE (см. этап В22) и операцию заканчивают.
В настоящем варианте осуществления выбирают, использовать ли один способ предсказания или использовать ли два способа предсказания в блоке.
Однако всегда может быть использован один способ предсказания. В таком случае на этапе В10 вычисляют только “cost”, этапы В13 по В16 и В19 по В22 пропускают, и PMODE может быть использован вместо best_mode.
С другой стороны, всегда могут быть использованы два способа предсказания. В таком случае вычисление SAD на этапе В9, вычисление Cost на этапе В10 и этапы В11 по В12, В19 по В20 являются ненужными, и, если результатом определения на этапе В18 является ДА, операция переходит на этап В21.
Способ предсказания в настоящем варианте осуществления означает, как предсказать величину пикселя.
В качестве способа предсказания имеется предсказание внутри кадра для предсказания величины пикселя с использованием периферийного блока, который принадлежит тому же кадру, что и настоящий блок, и уже закодирован и декодирован, и предсказание между кадрами для предсказания величины пикселя с использованием другого кадра, который уже закодирован и декодирован, и вышеописанные способы предсказания включают в себя оба способа. Вектор движения, требуемый в предсказании между кадрами, также действует в качестве способа предсказания. Кроме того, любой способ, который может предсказывать величину пикселя с использованием данных, которые уже закодированы и декодированы, может действовать в качестве способа предсказания.
Фиг. 4 изображает устройство 200 декодирования видео в качестве варианта осуществления настоящего изобретения.
Устройство 200 декодирования видео включает в себя блок 201 ввода закодированных данных, предназначенный для ввода закодированных данных в устройство, блок 202 ввода опорного изображения, предназначенный для ввода декодированного изображения камеры А в устройство, блок 203 ввода информации о несоответствии, предназначенный для ввода информации о несоответствии, которая обозначает, какой позиции в изображении в качестве цели декодирования соответствует каждый пиксель в декодированном изображении камеры А, в устройство, генератор 204 изображения с компенсированным несоответствием, предназначенный для формирования изображения с компенсированным несоответствием в позиции камеры В, блок 205 установки опорного изображения, предназначенный для назначения группы опорного изображения каждому пикселю на основании состояния изображения с компенсированным несоответствием, память 206 декодированного изображения камеры, предназначенную для сохранения декодированных изображений (в качестве группы опорного изображения) изображений, полученных с помощью камеры В, память 207 декодированного разностного изображения, предназначенную для сохранения декодированных изображений (в качестве другой группы опорного изображения) разностных изображений, опорный переключатель 208, предназначенный для переключения памяти опорного изображения на основании информации установки о группе опорного изображения, и декодер 209 разностного изображения, предназначенный для декодирования входных закодированных данных.
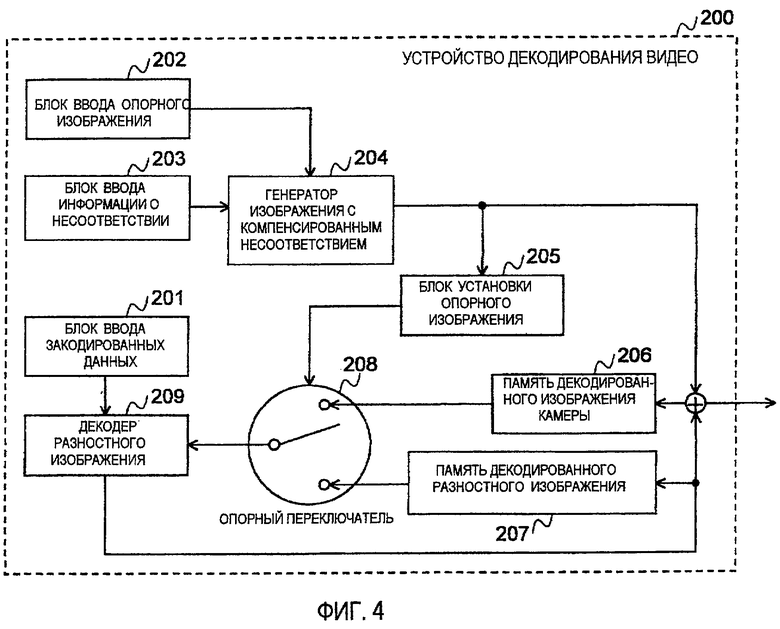
Фиг. 5 и Фиг. 6 являются блок-схемами последовательности этапов, выполняемых с помощью устройства 200 декодирования видео, имеющего вышеописанную структуру, и изображают поток операций, предназначенный для декодирования одного кадра закодированных данных камеры В. Поток операций будет подробно объяснен ниже.
В настоящем описании допускают, что кадр камеры А уже декодирован в тот же момент времени, что и целевой кадр декодирования, и соответственная информация о несоответствии уже получена.
Во-первых, закодированные данные камеры В вводят в блок 201 ввода закодированных данных (см. этап С1). В настоящем варианте осуществления закодированное изображение камеры А, которое имеет такое же время отображения, что и входное изображение камеры В, вводят с помощью блока 202 ввода опорного изображения.
Затем формируют изображение с компенсированным несоответствием в генераторе 204 на основании декодированного изображения камеры В и информации о несоответствии (см. этап С2). Процесс на этом этапе соответствует процессу, который выполняют на объясненном выше этапе А2 на Фиг. 2.
Закодированные данные, введенные для каждого блока, декодируют с использованием изображения с компенсированным несоответствием, таким образом, что получают декодированное изображение камеры В (см. этапы С3 по С9).
В этом процессе “blk” является индексом для каждого блока, а maxBlk обозначает полное число блоков в изображении. После того как blk инициализируют в ноль (см. этап С3), итеративно выполняют следующий процесс (см. С4 по С7), в то время как blk увеличивают на 1 (см. этап С8), до тех пор, пока blk не достигнет полного числа maxBlk блоков (см. этап С9).
Во-первых, блок 205 установки опорного изображения формирует информацию Ref для каждого пикселя в блоке blk в соответствии со способом, подобным способу на вышеописанном этапе А6, где Ref обозначает ссылку, используемую, когда опорное изображение было подвергнуто кодированию с предсказанием (см. этап С4).
Входные закодированные данные декодируют в декодере 209 разностного изображения с помощью использования вышеупомянутой информации таким образом, что получают декодированное значение Dec разностного изображения (см. этап С5).
Декодированное значение Dec непосредственно используют для декодирования кадра в другой момент времени или в другом блоке и, следовательно, сохраняют в памяти 207 декодированного разностного изображения (см. этап С6).
Кроме того, получают декодированное изображение изображения, полученного с помощью камеры В, с помощью вычисления суммы Dec и изображения с компенсированным несоответствием Syn для каждого пикселя в блоке blk.
Полученное декодированное изображение выводят из устройства 200 декодирования видео и одновременно сохраняют в памяти 206 декодированного изображения камеры (см. этап С7).
Фиг. 6 изображает подробный поток операций процесса (на этапе С5) декодирования разностного изображения для каждого блока, который выполняют в декодере 209 разностного изображения.
Во-первых, декодируют информацию о способе предсказания из закодированных данных и устанавливают как pmode[0] (см. этап D1). В этом процессе, если в закодированные данные включен другой элемент информации о способе предсказания (см. этап D2), элемент также декодируют и устанавливают как pmode[1] (см. этап D3). Если другой элемент информации о способе предсказания не включен (см. этап D2), pmode[1] устанавливают в то же значение, что и pmode[0] (см. этап D4).
Затем декодируют разность предсказания для каждого пикселя, которая включена в закодированные данные, и устанавливают как Dres (см. этап D5).
Операцию после D5 выполняют для каждого пикселя в блоке. То есть, после того как индекс пикселя “pix” инициализируют в ноль (см. этап D6), итеративно выполняют следующий процесс (этапы D7 по D11), в то время как pix увеличивают на 1 (см. этап D12), до тех пор, пока pix не достигнет числа “maxPix” пикселей в блоке (см. этап D13).
В операции, применяемой к каждому пикселю, во-первых, контрольным переключателем 208 управляют в соответствии со значением Ref[pix] (см. этап D7) таким образом, что буфер ссылки устанавливают в память 206 декодированного изображения камеры (см. этап D8) или память 207 декодированного разностного изображения (см. этап D9).
Затем предсказывают значение Pred пикселя pix способом предсказания pmode[Ref[pix]] (см. этап D10).
Затем получают декодированное значение Dec[pix] разностного изображения с помощью суммирования Dres[pix] и Pred (см. этап D11).
В настоящем варианте осуществления информацию о несоответствии, которая обозначает, какой позиции в изображении камеры В соответствует каждый пиксель в опорном изображении камеры, получают вне устройства 100 видеокодирования или устройства 200 декодирования видео и информацию кодируют, передают и декодируют.
Однако информация о несоответствии может быть получена и закодирована в устройстве 100 видеокодирования, и закодированная информация может быть выведена вместе с закодированными данными разностного изображения. Подобным образом информация о несоответствии может быть принята в устройстве 200 декодирования видео, и принятая информация может быть декодирована и использована.
Кроме того, информация, которая непосредственно не обозначает, какой позиции в изображении камеры В соответствует каждый пиксель в опорном изображении камеры, но предоставляет вышеописанную соответствующую зависимость вследствие преобразования, примененного к информации, может быть введена и преобразована в информацию о несоответствии (которая обозначает соответствующую зависимость) в устройстве 100 видеокодирования и устройстве 200 декодирования видео.
В качестве примера такой информации имеется информация, состоящая из трехмерной информации изображенного объекта и параметров камеры. Трехмерная информация может быть трехмерными координатами каждой части изображенного объекта или может указывать расстояние от изображенного объекта до соответственной камеры.
Кроме того, в данных вариантах осуществления переключение группы опорного изображения в качестве опорной цели может быть выполнено для каждого пикселя в кодирующемся целевом изображении камеры. Однако переключение может быть выполнено для конкретной единицы секции, которая включает в себя множество пикселей. Например, когда переключение может быть выполнено для каждого блока, имеющего конкретный размер, может быть выбрана опорная цель, подходящая для некоторого числа пикселей в блоке, или может быть выбрана группа декодированного изображения камеры, если блок включает в себя, по меньшей мере, один пиксель, величина изображения с компенсированным несоответствием которого является бесполезной. Выбор, основанный на соответственной единице секции, может уменьшить время обработки.
Процессы кодирования и декодирования видео, которые описаны выше, могут быть осуществлены с использованием ресурсов аппаратного обеспечения или программно-аппаратного обеспечения, а также могут быть осуществлены с использованием компьютерной программы и программы программного обеспечения. Компьютерная программа может быть обеспечена с помощью сохранения ее в среде памяти, доступной для чтения с помощью компьютера, или посредством сети.
Промышленная применимость
В соответствии с настоящим изобретением при подвергании разностного изображения, полученного с помощью компенсации несоответствия, кодированию с предсказанием не используют никакую новую дополнительную информацию и соответствующее опорное изображение используют посредством операции переключения для каждого пикселя. Вследствие этого разность для цели кодирования может быть уменьшена без увеличения объема кода, требуемого для дополнительной информации, таким образом, осуществляют эффективное видеокодирование всего видеоизображения с множеством точек обзора.


Изобретение относится к способам кодирования и декодирования для видеоизображений с множеством точек обзора. Техническим результатом является повышение эффективности кодирования видео с множеством точек обзора, применяющего компенсацию движения к разностному изображению, уменьшение разности предсказания в части, имеющей как временную избыточность, так и избыточность между камерами. Указанный технический результат достигается тем, что предложен способ видеокодирования для формирования на основании информации о несоответствии между уже закодированным опорным изображением камеры и кодирующимся целевым изображением камеры, включающий в себя этап, на котором выбирают для каждой предварительно определенной единицы секции в разностном изображении одной из следующих групп: группы декодированного разностного изображения, полученного с помощью декодированного разностного изображения между уже закодированным изображением камеры и изображением с компенсированным несоответствием, и группы декодированного изображения камеры, полученного с помощью декодирования уже закодированного изображения камеры, с помощью определения, имеется ли или нет изображение с компенсированным несоответствием в соответствующей позиции, то есть имеет ли или нет соответствующий пиксель в изображении с компенсированным несоответствием эффективную величину. 6 н. и 8 з.п. ф-лы, 9 ил.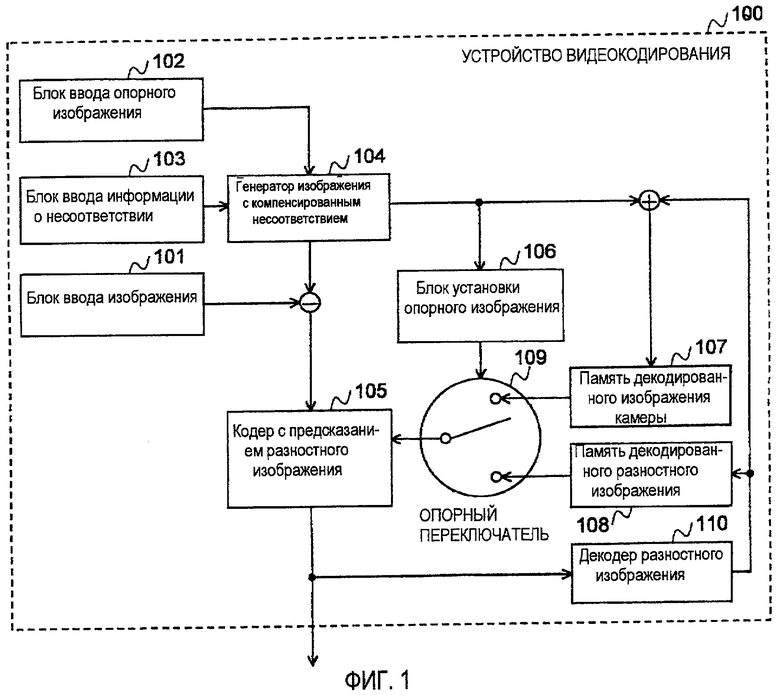
1. Способ кодирования видео для кодирования изображения с множеством точек обзора посредством использования компенсации несоответствия, содержащий этапы, на которых:
формируют на основании информации о несоответствии между опорным изображением камеры, которое получают с помощью декодирования уже закодированного изображения камеры, и кодируемым целевым изображением камеры, соответствующим опорному изображению камеры, изображение с компенсированным несоответствием для кодируемого целевого изображения камеры;
устанавливают опорную целевую информацию, которая обозначает группу опорного изображения в качестве опорной цели, для каждой предварительно определенной единицы секции в кодируемом целевом изображении камеры в соответствии с состоянием изображения с компенсированным несоответствием;
выбирают для каждой предварительно определенной единицы секции в кодируемом целевом изображении камеры одну из следующих групп: группу декодированного разностного изображения, которую получают с помощью декодирования разностного изображения между уже закодированным изображением камеры и изображением с компенсированным несоответствием, и группу декодированного изображения камеры, которую получают с помощью декодирования уже закодированного изображения камеры, в качестве опорной цели на основании установленной опорной целевой информации,
кодируют с предсказанием разностное изображение между кодируемым целевым изображением камеры и изображением с компенсированным несоответствием с помощью обращения к опорному изображению, включенному в группу изображения, выбранную в качестве опорной цели;
сохраняют декодированное разностное изображение, которое получают с помощью декодирования закодированного разностного изображения, в качестве составляющей группы декодированного разностного изображения; и
сохраняют декодированное изображение камеры, которое получают с помощью декодирования уже закодированного изображения камеры на основании декодированного разностного изображения, в качестве составляющей группы декодированного изображения камеры.
2. Способ кодирования видео по п.1, в котором этап, на котором кодируют с предсказанием разностное изображение, включает в себя вычисление затрат кодирования, возникающих, когда каждый из предварительно определенных способов предсказания применяется к каждому блоку обработки кодирования, который принадлежит к разностному изображению и состоит из множества пикселей, где предсказание видео для одного блока обработки кодирования выполняют с использованием одного способа предсказания, который обеспечивает минимальные затраты кодирования.
3. Способ кодирования видео по п.1, в котором этап, на котором кодируют с предсказанием разностное изображение, включает в себя вычисление затрат кодирования, возникающих, когда каждый из предварительно определенных способов предсказания применяется к каждой группе пикселей в каждом блоке обработки кодирования, который относится к разностному изображению и состоит из множества пикселей, где каждая группа пикселей имеет отдельное опорное изображение, и кодирование выполняют при выборе, следует ли выполнять предсказание видео для одного блока обработки кодирования с использованием одного способа предсказания или множества способов предсказания, в соответствии с вычисленными затратами.
4. Способ кодирования видео по п.1, в котором предварительно определенная единица секции является пикселем.
5. Способ декодирования видео для декодирования видеоизображения с множеством точек обзора посредством использования компенсации несоответствия, содержащий этапы, на которых:
формируют на основании информации о несоответствии между уже декодированным опорным изображением камеры и декодируемым целевым изображением камеры, соответствующим опорному изображению камеры, изображение с компенсированным несоответствием для декодируемого целевого изображения камеры;
устанавливают опорную целевую информацию, которая обозначает группу опорного изображения в качестве опорной цели, для каждой предварительно определенной единицы секции в декодируемом целевом изображении камеры в соответствии с состоянием изображения с компенсированным несоответствием;
выбирают для каждой предварительно определенной единицы секции в декодируемом целевом изображении камеры одну из следующих групп: группу декодированного разностного изображения, имеющую разностное изображение между уже декодированным изображением камеры и изображением с компенсированным несоответствием, и группу декодированного изображения камеры, имеющую уже декодированное изображение камеры, в качестве опорной цели на основании установленной опорной целевой информации;
декодируют разностное изображение между декодируемым целевым изображением камеры и изображением с компенсированным несоответствием посредством обращения к опорному изображению, включенному в группу изображения, выбранную в качестве опорной цели, на основании разности предсказания каждого пикселя, которую получают с помощью декодирования входных закодированных данных;
сохраняют декодированное разностное изображение в качестве составляющей группы декодированного разностного изображения; и
добавляют декодированное разностное изображение к изображению с компенсированным несоответствием, выводят их сумму в качестве декодированного изображения камеры для видеоизображения с множеством точек обзора и сохраняют декодированное изображение камеры в качестве составляющей группы декодированного изображения камеры.
6. Способ декодирования видео по п.5, в котором этап, на котором декодируют разностное изображение, включает в себя декодирование разностного изображения таким образом, что один назначенный способ предсказания применяется к каждому блоку обработки декодирования, который относится к декодируемому целевому изображению камеры и состоит из множества пикселей.
7. Способ декодирования видео по п.5, в котором этап, на котором декодируют разностное изображение, включает в себя декодирование разностного изображения при выборе для каждого блока обработки декодирования, который относится к декодируемому целевому изображению камеры и состоит из множества пикселей, следует ли использовать один назначенный способ предсказания или множество назначенных способов предсказания.
8. Способ декодирования видео по п.5, в котором предварительно определенная единица секции является пикселем.
9. Устройство кодирования видео для кодирования видеоизображения с множеством точек обзора посредством использования компенсации несоответствия, содержащее:
устройство для формирования на основании информации о несоответствии между опорным изображением камеры, которое получено с помощью декодирования уже закодированного изображения камеры, и кодируемым целевым изображением камеры, соответствующим опорному изображению камеры, изображения с компенсированным несоответствием для кодируемого целевого изображения камеры;
устройство для установки опорной целевой информации, которая обозначает группу опорного изображения в качестве опорной цели, для каждой предварительно определенной единицы секции в кодируемом целевом изображении камеры в соответствии с состоянием изображения с компенсированным несоответствием;
устройство для выбора для каждой предварительно определенной единицы секции в кодируемом целевом изображении камеры одной из следующих групп: группы декодированного разностного изображения, которое получено с помощью декодирования разностного изображения между уже закодированным изображением камеры и изображением с компенсированным несоответствием, и группы декодированного изображения камеры, которое получено с помощью декодирования уже закодированного изображения камеры, в качестве опорной цели на основании установленной опорной целевой информации;
устройство для кодирования с предсказанием разностного изображения между кодируемым целевым изображением камеры и изображением с компенсированным несоответствием посредством обращения к опорному изображению, включенному в группу изображения, выбранную в качестве опорной цели;
устройство для сохранения декодированного разностного изображения, которое получено с помощью декодирования закодированного разностного изображения, в качестве составляющей группы декодированного разностного изображения; и
устройство для сохранения декодированного изображения камеры, которое получено с помощью декодирования уже закодированного изображения камеры на основании декодированного разностного изображения, в качестве составляющей группы декодированного изображения камеры.
10. Устройство кодирования видео по п.9, в котором предварительно определенная единица секции является пикселем.
11. Устройство декодирования видео для декодирования видеоизображения с множеством точек обзора с использованием компенсации несоответствия, содержащее:
устройство для формирования на основании информации о несоответствии между уже декодированным опорным изображением камеры и декодируемым целевым изображением камеры, соответствующим опорному изображению камеры, изображения с компенсированным несоответствием для декодируемого целевого изображения камеры;
устройство для установки опорной целевой информации, которая обозначает группу опорного изображения в качестве опорной цели, для каждой предварительно определенной единицы секции в декодируемом целевом изображении камеры в соответствии с состоянием изображения с компенсированным несоответствием;
устройство для выбора для каждой предварительно определенной единицы секции в декодируемом целевом изображении камеры одной из следующих групп: группы декодированного разностного изображения, имеющей разностное изображение между уже декодированным изображением камеры и изображением с компенсированным несоответствием, и группы декодированного изображения камеры, имеющей уже декодированное изображение камеры, в качестве опорной цели на основании набора установленной опорной целевой информации;
устройство для декодирования разностного изображения между декодируемым целевым изображением камеры и изображением с компенсированным несоответствием посредством обращения к опорному изображению, включенному в группу изображения, выбранную в качестве опорной цели, на основании разности предсказания каждого пикселя, которая получена с помощью декодирования входных закодированных данных;
устройство для сохранения декодированного разностного изображения в качестве составляющей группы декодированного разностного изображения; и
устройство для добавления декодированного разностного изображения к изображению с компенсированным несоответствием, вывода их суммы в качестве декодированного изображения камеры для видеоизображения с множеством точек обзора и сохранения декодированного изображения камеры в качестве составляющей группы декодированного изображения камеры.
12. Устройство декодирования видео по п.11, в котором предварительно определенная единица секции является пикселем.
13. Машиночитаемый носитель, который хранит программу кодирования видео, с помощью которой компьютер выполняет процесс для осуществления способа кодирования видео по п.1.
14. Машиночитаемый носитель, который хранит программу декодирования видео, с помощью которой компьютер выполняет процесс, предназначенный для осуществления способа декодирования видео по п.5.
| JP 10191393 A, 1998.07.21 | |||
| WO 2006073116 A1, 2006.07.13 | |||
| JP 10191394 A, 1998.07.21 | |||
| JP 9275578 A, 1997.10.21 | |||
| WO 2005018217 A2, 2005.02.24 | |||
| WO 9821690 A1, 1998.05.22 | |||
| JP 2003009179 A, 2003.01.10 | |||
| УСТРОЙСТВО И СПОСОБ ПРЕДСТАВЛЕНИЯ ТРЕХМЕРНОГО ОБЪЕКТА НА ОСНОВЕ ИЗОБРАЖЕНИЙ С ГЛУБИНОЙ | 2002 |
|
RU2237283C2 |
| ВИЗУАЛЬНОЕ УСТРОЙСТВО ОТОБРАЖЕНИЯ И СПОСОБ ФОРМИРОВАНИЯ ТРЕХМЕРНОГО ИЗОБРАЖЕНИЯ | 1995 |
|
RU2168192C2 |
| Survey of Algorithms used for Multi-view Video Coding (MVC), ISO/IEC JTC1/SC29/WG11, MPEG2005/N6909, | |||

