Область техники, к которой относится изобретение
Настоящее изобретение относится к способу кодирования видео для кодирования видеоизображения с помощью способа межкадрового прогнозирующего кодирования и соответствующего устройства; способу декодирования видео для декодирования закодированных данных, сформированных посредством способа кодирования видео и соответствующего устройства; программе кодирования видео для реализации способа кодирования видео и машиночитаемому носителю хранения данных, который сохраняет программу; и программе декодирования видео для реализации способа декодирования видео и машиночитаемому носителю хранения данных, который сохраняет программу.
Данная заявка притязает на приоритет Патентной заявки Японии № 2006-293901, зарегистрированной 30 октября 2006 года, содержание которой включено в настоящий документ посредством ссылки.
Уровень техники
Видеоизображения с несколькими точками обзора - это множество видеоизображений, полученных посредством съемки одного объекта и его фона с помощью множества камер. Ниже, видеоизображение, полученное посредством одной камеры, называется "двумерным видеоизображением", а набор из нескольких двумерных видеоизображений, полученных посредством съемки одного объекта и его фона, называется "видеоизображением с несколькими точками обзора".
Имеется сильная временная корреляция в двумерном видеоизображении каждой камеры, которое включено в видеоизображение с несколькими точками обзора. Помимо этого, когда камеры синхронизированы друг с другом, изображения (снятые камерами), соответствующие одному и тому же времени, фиксируют объект и их фон полностью в одном и том же состоянии с различных позиций, так что есть сильная корреляция между камерами. Эффективность кодирования видео может быть повышена с помощью этой корреляции.
Сначала показываются традиционные методы, касающиеся кодирования двумерных видеоизображений.
Во многих известных способах кодирования двумерных видеоизображений, таких как MPEG-2 и H.264 (которые являются международными стандартами кодирования видео) и т.п., высокая эффективность кодирования получается посредством межкадрового прогнозирующего кодирования, которое использует временную корреляцию.
Межкадровое прогнозирующее кодирование, выполняемое для кодирования двумерных видеоизображений, использует временную вариацию в видеоизображении, т.е. движение. Следовательно, способ, используемый в межкадровом прогнозирующем кодировании, в общем, называется "компенсацией движения". Соответственно, межкадровое прогнозирующее кодирование вдоль временной оси ниже называется "компенсацией движения". Помимо этого, "кадр" - это изображение, которое является составляющей частью видеоизображения и получается в конкретное время.
В общем, двумерное кодирование видео имеет следующие режимы кодирования для каждого кадра: I-кадр, кодируемый без использования межкадровой корреляции, P-кадр, кодируемый при выполнении компенсации движения на основе одного уже кодированного кадра, и B-кадр, кодируемый при выполнении компенсации движения на основе двух уже кодированных кадров.
Чтобы дополнительно повысить эффективность прогнозирования видеоизображений, в H.263 и H.264 декодированные изображения множества кадров (т.е. двух кадров или более) сохраняются в запоминающем устройстве опорных изображений, и опорное изображение выбирается из изображений запоминающего устройства, чтобы выполнять прогнозирование.
Опорное изображение может быть выбрано для каждого блока, и информация обозначения опорного изображения для обозначения опорного изображения может быть кодирована, чтобы выполнять соответствующее декодирование.
Для P-кадра одна часть информации обозначения опорного изображения кодируется для каждого блока. Для B-кадра две части элементов информации обозначения опорного изображения кодируются для каждого блока.
В компенсации движения, в дополнение к информации обозначения опорного изображения, кодируется вектор для указания позиции в опорном изображении, при этом целевой блок кодируется с помощью этой позиции, и вектор называется "вектором движения". Аналогично информации обозначения опорного изображения, один вектор движения кодируется для P-кадра, и два вектора движения кодируются для B-кадра.
При кодировании вектора движения в MPEG-4 или H.264, спрогнозированный вектор формируется с помощью вектора движения блока, смежного с целевым блоком кодирования, и только разностного вектора между прогнозированным вектором и вектором движения, используемым в компенсации движения, применяемой к целевому блоку. В соответствии с этим способом, когда непрерывность движения присутствует между релевантными смежными блоками, вектор движения может быть кодирован с высоким уровнем эффективности кодирования.
Непатентный документ 1 раскрывает процесс формирования прогнозированного вектора в H.264, и общее пояснение этого представляется ниже.
В H.264, как показано на фиг. 13A, на основе векторов движения (mv_a, mv_b и mv_c), используемых в блоке слева (см. "a" на фиг. 13A), блоке вверху (см. "b" на фиг. 13A) и блоке вверху справа (см. "c" на фиг. 13A) целевого блока кодирования, горизонтальные и вертикальные компоненты получаются посредством вычисления медианы для каждого направления.
Поскольку H.264 использует компенсацию движения с переменным размером блока, размер блока для компенсации движения может не быть одинаковым между целевым блоком и его периферийными блоками. В таком случае, как показано на фиг. 13B, блок "a" задается как самый верхний блок среди блоков слева, смежных с целевым блоком, блок "b" задается как крайний левый блок среди блоков сверху, смежных с целевым блоком, а блок "c" задается как самый близкий верхний левый блок.
Как исключение, если размер целевого блока составляет 8x16 пикселов, как показано на фиг. 13C, вместо медианы блок "a" и блок "c", соответственно, используются для прогнозирования левых и правых блоков. Как исключение, если размер целевого блока составляет 8x16 пикселов, как показано на фиг. 13C, вместо медианы блок "a" и блок "c", соответственно, используются для прогнозирования левых и правых блоков.
Как описано выше, в H.264 опорный кадр выбирается для каждого блока из множества уже кодированных кадров и используется для компенсации движения.
В общем, движение визуализируемого объекта не универсально и зависит от опорного кадра. Следовательно, по сравнению с вектором движения в компенсации движения, выполненной с помощью опорного кадра, отличного от опорного кадра для целевого блока, вектор движения в компенсации движения, выполненной с помощью того же опорного кадра, что и для целевого блока, должен быть близким к вектору движения, используемому для целевого блока.
Следовательно, в H.264, если есть только один блок (из блоков a, b и c), опорный кадр которого является таким же, что и опорный кадр целевого блока кодирования, то вместо медианы, вектор движения релевантного блока используется в качестве прогнозированного вектора для того, чтобы формировать прогнозированный вектор, имеющий относительно более высокий уровень надежности.
Далее поясняются традиционные способы кодирования для видеоизображений с несколькими точками обзора.
В общем, кодирование видео с несколькими точками обзора использует корреляцию между камерами, и высокий уровень эффективности кодирования получается за счет использования "компенсации диспаратности (различия)", в которой компенсация движения применяется к кадрам, которые получаются одновременно посредством использования различных камер.
Например, MPEG-2 Multiview profile или Непатентный документ 2 использует такой способ.
В способе, раскрытом в Непатентном документе 2, любая из компенсации движения и компенсации диспаратности выбирается для каждого блока. Таким образом, одна из них, имеющая более высокую эффективность кодирования, выбирается для каждого блока, так чтобы и временная корреляция, и корреляция между камерами могли использоваться. По сравнению со случаем использования только одного типа корреляции, получается более высокая эффективность кодирования.
В компенсации диспаратности, в дополнение к остатку прогнозирования, также кодируется вектор диспаратности. Вектор диспаратности соответствует вектору движения для указания временной вариации между кадрами и указывает разность между позициями на плоскостях изображения, которые получаются посредством камер, размещенных в различных позициях, и на которые проецируется одна позиция в визуализируемом объекте.
Фиг. 14 - это схематичное представление, показывающее идею диспаратности, формируемой между такими камерами. В схематичном представлении по фиг. 14, плоскости изображения камер, оптические оси которых параллельны друг другу, наблюдаются вертикально от верхней стороны.
При кодировании вектора диспаратности, аналогичном кодированию вектора движения, возможно то, что прогнозированный вектор формируется с помощью вектора диспаратности блока, смежного с целевым блоком кодирования, и кодируется только разностный вектор между прогнозированным вектором и вектором диспаратности, используемым в компенсации диспаратности, применяемой к целевому блоку. В соответствии с таким способом, когда есть непрерывность диспаратности между релевантными смежными блоками, вектор диспаратности может быть кодирован с высоким уровнем эффективности кодирования.
Для каждого кадра в видеоизображениях с несколькими точками обзора временная избыточность и избыточность между камерами присутствуют одновременно. Непатентный документ 3 раскрывает способ для одновременного удаления обеих избыточностей.
В релевантном способе выполняется временное прогнозирование разностного изображения между исходным изображением и компенсированным по диспаратности изображением, чтобы выполнять релевантное кодирование. Таким образом, после компенсации диспаратности кодируется остаток компенсации движения в разностном изображении.
В соответствии с вышеупомянутым способом, временная избыточность, которая не может быть удалена посредством компенсации диспаратности для удаления избыточности между камерами, может быть удалена с помощью компенсации движения. Следовательно, остаток прогнозирования, который в итоге кодируется, уменьшается, так что может достигаться высокий уровень эффективности кодирования.
Непатентный документ 1: ITU-T Rec.H.264/ISO/IEC 11496-10, "Editor's Proposed Draft Text Modifications for Joint Video Specification (ITU-T Rec. H.264/ISO/IEC 14496-10 AVC), Draft 7", Final Committee Draft, Document JVT-E022, стр. 63-64, сентябрь 2002 г.
Непатентный документ 2: Hideaki Kimata and Masaki Kitahara, "Preliminary results on multiple view video coding(3DAV)", document M10976 MPEG Redmond Meeting, июль 2004 года.
Непатентный документ 3: Shinya Shimizu, Masaki Kitahara, Kazuto Kamikura and Yoshiyuki Yashima, "Multi-view Video Coding based on 3-D Warping with Depth Map", In Proceedings of Picture Coding Symposium 2006, SS3-6, апрель 2006 года.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Проблема, которая должна быть решена изобретением
Традиционные способы, в которых вектор движения или вектор диспаратности, который фактически используется в целевом блоке кодирования, кодируются с помощью разности от прогнозированного вектора, сформированного с помощью вектора движения или вектора диспаратности, используемого в смежном блоке, основаны на том факте, что визуализируемый объект имеет непрерывность в реальном пространстве, и высока вероятность того, что движение самого визуализируемого объекта изменяется незначительно. Следовательно, вектор движения или вектор диспаратности, используемый в целевом блоке, могут быть кодированы с меньшим объемом кода.
Тем не менее, если опорный кадр, который является самым подходящим для прогнозирования изображения целевого блока, не используется в релевантном смежном блоке, разность между прогнозированным вектором и фактически используемым вектором движения возрастает, и объем кода не может быть уменьшен в достаточной степени.
В частности, при выполнении кодирования посредством адаптивного выбора компенсации движения или компенсации диспаратности для каждого блока невозможно сформировать прогнозированный вектор для вектора диспаратности из вектора движения или сформировать прогнозированный вектор для вектора движения из вектора диспаратности, поскольку вектор движения и вектор диспаратности имеют существенно отличающиеся характеристики. Следовательно, невозможно эффективно кодировать вектор движения или вектор диспаратности.
С другой стороны, в способах, применяемых к B-кадру или раскрытых в Непатентном документе 3, прогнозирование видео выполняется более точно, и размер остаточного сигнала, который в итоге кодируется, уменьшается так, чтобы видеоизображение могло быть кодировано с меньшим объемом кода.
Тем не менее, для B-кадра две части информации обозначения опорного изображения и две части векторной информации должны быть кодированы, и таким образом объем кода такой дополнительной информации, используемой для формирования прогнозированного изображения, увеличивается.
Также в способе по Непатентному документу 3, информация "глубины" для формирования компенсированного по диспарантности изображения и вектор движения для выполнения компенсации движения на разностном изображении для компенсации диспаратности должны быть кодированы, что увеличивает объем информации, используемый для прогнозирования видео.
В свете вышеописанного, цель настоящего изобретения, касающаяся кодирования видео, заключается в том, чтобы предоставить новый способ для эффективного кодирования векторной информации (как цели кодирования), используемой для межкадрового прогнозирующего кодирования, даже когда опорный кадр, используемый в межкадровом прогнозирующем кодировании, отличается между целевой областью кодирования и ее смежной областью.
Средство решения проблемы
Чтобы достичь вышеупомянутой цели, настоящее изобретение предоставляет способ кодирования видео для кодирования видеоизображения посредством деления всего изображения на области, формирования прогнозированного изображения для каждой области разделенного изображения на основе информации изображений множества уже кодированных кадров и кодирования разностной информации между изображением целевой области кодирования в целевом кадре кодирования и прогнозированным изображением, при этом способ кодирования видео содержит:
- этап выбора целевого кадра опорного вектора для выбора целевого кадра опорного вектора из числа уже кодированных кадров;
- этап кодирования информации обозначения целевого кадра опорного вектора для кодирования информации, которая обозначает целевой кадр опорного вектора;
- этап задания опорного вектора для задания опорного вектора, который указывает область, которая принадлежит целевому кадру опорного вектора и соответствует целевой области кодирования;
- этап кодирования опорного вектора для кодирования опорного вектора;
- этап выбора опорного кадра для выбора опорного кадра из числа уже кодированных кадров;
- этап кодирования информации обозначения опорного кадра для кодирования информации, которая обозначает опорный кадр;
- этап задания области опорного кадра для поиска соответствующей области посредством использования опорного кадра и информации изображений целевой области опорного вектора, которая принадлежит целевому кадру опорного вектора и указывается посредством опорного вектора; и задания опорной области в опорном кадре на основе результата поиска;
- этап формирования прогнозированного изображения для формирования прогнозированного изображения с помощью информации изображений опорного кадра, который соответствует опорной области; и
- этап кодирования разностной информации для кодирования разностной информации между информацией изображений целевой области кодирования и сформированного прогнозированного изображения.
В типичном примере, на этапе формирования прогнозированного изображения, прогнозированное изображение формируется с помощью информации изображений опорной области и информации изображений целевой области опорного вектора.
В другом типичном примере, на этапе формирования прогнозированного изображения выбирается то, формируется ли прогнозированное изображение с помощью информации изображений опорной области или с помощью информации изображений опорной области и информации изображений целевой области опорного вектора, и прогнозированное изображение формируется посредством выбранного способа формирования; и
- способ кодирования видео дополнительно содержит:
- этап кодирования информации обозначения способа формирования прогнозированных изображений для кодирования информации, которая обозначает выбранный способ формирования.
В другом типичном примере, если опорный кадр, выбранный на этапе выбора опорного кадра, является опорным кадром, который использовался при кодировании целевой области опорного вектора, то опорная область, заданная на этапе задания области опорного кадра, - это опорная область, которая использовалась при кодировании целевой области опорного вектора.
В другом типичном примере, если опорный кадр, выбранный на этапе выбора опорного кадра, является целевым кадром опорного вектора, который использовался при кодировании целевой области опорного вектора, то опорная область, заданная на этапе задания области опорного кадра, - это целевая область опорного вектора, которая использовалась при кодировании целевой области опорного вектора.
В другом типичном примере, если опорный кадр, выбранный на этапе выбора опорного кадра, является уже кодированным кадром, где зависимости информации по времени и точкам обзора между этим уже кодированным кадром и целевым кадром кодирования совпадают с зависимостями между целевым кадром опорного вектора, который использовался при кодировании целевой области опорного вектора, и целевым кадром опорного вектора, заданным для целевой области кодирования, то опорная область, заданная на этапе задания области опорного кадра, - это область, которая принадлежит выбранному опорному кадру и указывается посредством вектора, начальная точка которого задается в целевой области кодирования и который имеет такое же направление и размер, как и опорный вектор, который использовался при кодировании целевой области опорного вектора.
В другом типичном примере, если опорный кадр, выбранный на этапе выбора опорного кадра, является уже кодированным кадром, где зависимости информации по времени и точкам обзора между этим уже кодированным кадром и целевым кадром кодирования совпадают с зависимостями между опорным кадром, который использовался при кодировании целевой области опорного вектора, и целевым кадром опорного вектора, заданным для целевой области кодирования, то опорная область, заданная на этапе задания области опорного кадра, - это область, которая принадлежит выбранному опорному кадру и указывается посредством вектора, начальная точка которого задается в целевой области кодирования и который имеет такое же направление и размер, как и вектор, который указывает соответствующую зависимость между целевой областью опорного вектора и опорной областью, которая использовалась при кодировании целевой области опорного вектора.
В предпочтительном примере способ кодирования видео дополнительно содержит:
- этап задания промежуточного кадра для задания промежуточного кадра, который отличается от каждого из целевого кадра опорного вектора и опорного кадра и является уже закодированным, при этом:
- на этапе задания области опорного кадра, промежуточная область в промежуточном кадре задается с помощью информации целевой области опорного вектора, а опорная область задается с помощью информации промежуточной области или набора информации промежуточной области и информации целевой области опорного вектора.
В вышеупомянутом случае возможно то, что:
- промежуточный кадр, заданный на этапе задания промежуточного кадра, - это уже кодированный кадр, при этом зависимости информации по времени и точкам обзора между этим уже кодированным кадром и целевым кадром опорного вектора совпадают с такими зависимостями между целевым кадром кодирования и опорным кадром; и
- на этапе формирования прогнозированного изображения, прогнозированное изображение формируется с помощью информации изображений опорной области, информации изображений промежуточной области и информации изображений целевой области опорного вектора.
Также в вышеупомянутом случае возможно то, что:
- промежуточный кадр, заданный на этапе задания промежуточного кадра, - это уже кодированный кадр, при этом зависимости информации по времени и точкам обзора между этим уже кодированным кадром и целевым кадром опорного вектора совпадают с такими зависимостями между целевым кадром кодирования и опорным кадром;
- на этапе формирования прогнозированного изображения выбирается то, формируется ли прогнозированное изображение с помощью информации изображений опорной области, с помощью информации изображений опорной области и информации изображений целевой области опорного вектора или с помощью информации изображений опорной области, информации изображений промежуточной области и информации изображений целевой области опорного вектора, и прогнозированное изображение формируется посредством выбранного способа формирования; и
- способ кодирования видео дополнительно содержит:
- этап кодирования информации обозначения способа формирования прогнозированных изображений для кодирования информации, которая обозначает выбранный способ формирования.
Когда предусмотрен этап кодирования информации обозначения способа формирования прогнозированных изображений, возможно то, что:
- на этапе кодирования информации обозначения опорного кадра, таблица кодовых слов, используемая для кодирования информации, которая обозначает опорный кадр, переключается на основе кодированных данных целевой области опорного вектора; и
- на этапе кодирования информации обозначения способа формирования прогнозированных изображений, таблица кодовых слов, используемая для кодирования информации, которая обозначает выбранный способ формирования, переключается на основе, по меньшей мере, одного из кодированных данных целевой области опорного вектора, опорного кадра и целевого кадра опорного вектора.
Настоящее изобретение также предоставляет способ декодирования видео для декодирования видеоизображения посредством деления всего изображения на области, формирования прогнозированного изображения для каждой области разделенного изображения на основе информации изображений множества уже декодированных кадров и декодирования разностной информации между прогнозированным изображением и изображением целевой области декодирования в целевом кадре декодирования, при этом способ декодирования видео содержит:
- этап декодирования информации обозначения целевого кадра опорного вектора для декодирования, из кодированных данных, информации, которая обозначает целевой кадр опорного вектора, выбранный из числа уже декодированных кадров;
- этап декодирования опорного вектора для декодирования, из кодированных данных, опорного вектора, который указывает область, которая принадлежит целевому кадру опорного вектора и задается в соответствии с целевой областью декодирования;
- этап декодирования информации обозначения опорного кадра для декодирования, из кодированных данных, информации, которая обозначает опорный кадр, выбранный из числа уже декодированных кадров;
- этап задания области опорного кадра для поиска соответствующей области посредством использования опорного кадра и информации изображений целевой области опорного вектора, которая принадлежит целевому кадру опорного вектора и указывается посредством опорного вектора; и задания опорной области в опорном кадре на основе результата поиска; и
- этап формирования прогнозированного изображения для формирования прогнозированного изображения с помощью информации изображений опорного кадра, который соответствует опорной области.
В типичном примере, на этапе формирования прогнозированного изображения, прогнозированное изображение формируется с помощью информации изображений опорной области и информации изображений целевой области опорного вектора.
В другом типичном примере, этап декодирования информации обозначения способа формирования прогнозированных изображений для декодирования, из кодированных данных, информации, которая обозначает то, формируется ли прогнозированное изображение с помощью информации изображений опорной области или с помощью информации изображений опорной области и информации изображений целевой области опорного вектора, при этом:
- на этапе формирования прогнозированного изображения, прогнозированное изображение формируется посредством способа формирования, обозначенного посредством декодированной информации.
В другом типичном примере, если кадр, указанный посредством информации обозначения опорного кадра, которая декодирована при декодировании целевой области опорного вектора, совпадает с опорным кадром, то на этапе задания области опорного кадра, опорная область, которая использовалась при декодировании целевой области опорного вектора, задается в качестве опорной области.
В другом типичном примере, если кадр, указанный посредством информации обозначения целевого кадра опорного вектора, которая декодирована при декодировании целевой области опорного вектора, совпадает с опорным кадром, то на этапе задания области опорного кадра, целевая область опорного вектора, которая использовалась при декодировании вышеупомянутой целевой области опорного вектора, задается в качестве опорной области.
В другом типичном примере, если зависимости информации по времени и точкам обзора между целевым кадром опорного вектора и кадром, указанным посредством информации обозначения целевого кадра опорного вектора, которая декодирована при декодировании целевой области опорного вектора, совпадают с зависимостями между целевым кадром декодирования и опорным кадром, то на этапе задания области опорного кадра, область, которая принадлежит опорному кадру и указывается посредством вектора, начальная точка которого задается в целевой области декодирования и который имеет такое же направление и размер, как и опорный вектор, который использовался при декодировании целевой области опорного вектора, задается в качестве опорной области.
В другом типичном примере, если зависимости информации по времени и точкам обзора между целевым кадром опорного вектора и кадром, указанным посредством информации обозначения опорного кадра, которая декодирована при декодировании целевой области опорного вектора, совпадают с зависимостями между целевым кадром декодирования и опорным кадром, то на этапе задания области опорного кадра, область, которая принадлежит опорному кадру и указывается посредством вектора, начальная точка которого задается в целевой области декодирования и который имеет такое же направление и размер, как и вектор, который указывает соответствующую зависимость между целевой областью опорного вектора и опорной областью, которая использовалась при декодировании целевой области опорного вектора, задается в качестве опорной области.
В предпочтительном примере способ декодирования видео дополнительно содержит:
- этап задания промежуточного кадра для задания промежуточного кадра, который отличается от каждого из целевого кадра опорного вектора и опорного кадра и уже декодирован, при этом:
- на этапе задания области опорного кадра, промежуточная область в промежуточном кадре задается с помощью информации целевой области опорного вектора, а опорная область задается с помощью информации промежуточной области или набора информации промежуточной области и информации целевой области опорного вектора.
В вышеупомянутом случае возможно то, что:
- промежуточный кадр, заданный на этапе задания промежуточного кадра, - это уже декодированный кадр, при этом зависимости информации по времени и точкам обзора между этим уже декодированным кадром и целевым кадром опорного вектора совпадают с зависимостями между целевым кадром декодирования и опорным кадром; и
- на этапе формирования прогнозированного изображения, прогнозированное изображение формируется с помощью информации изображений опорной области, информации изображений промежуточной области и информации изображений целевой области опорного вектора.
Также в вышеупомянутом случае возможно то, что:
- промежуточный кадр, заданный на этапе задания промежуточного кадра, - это уже декодированный кадр, при этом зависимости информации по времени и точкам обзора между этим уже декодированным кадром и целевым кадром опорного вектора совпадают с зависимостями между целевым кадром декодирования и опорным кадром;
- способ декодирования видео дополнительно содержит:
- этап декодирования информации обозначения способа формирования прогнозированных изображений для декодирования, из кодированных данных, информации, которая обозначает то, формируется ли прогнозированное изображение с помощью информации изображений опорной области, с помощью информации изображений опорной области и информации изображений целевой области опорного вектора или с помощью информации изображений опорной области, информации изображений промежуточной области и информации изображений целевой области опорного вектора; и
- на этапе формирования прогнозированного изображения, прогнозированное изображение формируется с помощью способа формирования, обозначенного посредством декодированной информации.
Когда предусмотрен этап декодирования информации обозначения способа формирования прогнозированных изображений, возможно то, что:
- на этапе декодирования информации обозначения опорного кадра, таблица кодовых слов, используемая для декодирования информации, которая обозначает опорный кадр, переключается на основе кодированных данных целевой области опорного вектора; и
- на этапе декодирования информации обозначения способа формирования прогнозированных изображений, таблица кодовых слов, используемая для декодирования информации, которая обозначает выбранный способ формирования, переключается на основе, по меньшей мере, одного из декодированных данных целевой области опорного вектора, опорного кадра и целевого кадра опорного вектора.
Настоящее изобретение также предоставляет устройство кодирования видео, имеющее устройства для выполнения этапов в вышеописанном способе кодирования видео; программу кодирования видео, посредством которой компьютер выполняет соответствующие этапы; и машиночитаемый носитель хранения данных, который сохраняет программу.
Настоящее изобретение также предоставляет устройство декодирования видео, имеющее устройства для выполнения этапов в вышеописанном способе декодирования видео; программу декодирования видео, посредством которой компьютер выполняет соответствующие этапы; и машиночитаемый носитель хранения данных, который сохраняет программу.
Преимущество изобретения
В соответствии с настоящим изобретением, даже когда опорный кадр, используемый для формирования прогнозированного изображения, отличается между смежными областями, используется один и тот же целевой кадр опорного вектора, так что основной фактор (время или диспаратность), который вызывает изменение изображения и должен быть представлен вектором, является унифицированным, и прогнозированный вектор, близкий вектору, который должен быть кодирован, может быть сформирован с помощью уже кодированного вектора в смежной области. Следовательно, векторная информация для межкадрового прогнозирующего кодирования может быть кодирована с меньшим объемом кода.
Краткое описание чертежей
Фиг. 1 - схематичное представление, показывающее пример способа определения опорной области с помощью опорного кадра, когда целевая область опорного вектора была кодирована.
Фиг. 2 - схематичное представление, показывающее пример способа определения опорной области с помощью целевого кадра опорного вектора, когда целевая область опорного вектора была кодирована.
Фиг. 3 - схематичное представление, показывающее пример способа определения опорной области с помощью опорного вектора, когда целевая область опорного вектора была кодирована.
Фиг. 4 - схематичное представление, показывающее пример способа определения опорной области с помощью вектора, когда целевая область опорного вектора была кодирована.
Фиг. 5 - схематичное представление, показывающее пример способа определения опорной области с помощью опорного вектора, когда целевая область опорного вектора была кодирована.
Фиг. 6 показывает вариант осуществления устройства кодирования видео по настоящему изобретению.
Фиг. 7 - пример блок-схемы процесса кодирования видео, выполняемого посредством устройства кодирования видео по варианту осуществления.
Фиг. 8 - пример блок-схемы процесса определения опорной области, когда промежуточный кадр не используется, в варианте осуществления.
Фиг. 9 - пример блок-схемы процесса определения опорной области, когда промежуточный кадр используется, в варианте осуществления.
Фиг. 10 - пример блок-схемы процесса поиска соответствующей области в варианте осуществления.
Фиг. 11 показывает вариант осуществления устройства декодирования видео по настоящему изобретению.
Фиг. 12 - пример блок-схемы процесса декодирования видео, выполняемого посредством устройства декодирования видео по варианту осуществления.
Фиг. 13A - схематичное представление, поясняющее прогнозирование вектора движения в H.264.
Фиг. 13B - также схематичное представление, поясняющее прогнозирование вектора движения в H.264.
Фиг. 13C - также схематичное представление, поясняющее прогнозирование вектора движения в H.264.
Фиг. 13-D - также схематичное представление, поясняющее прогнозирование вектора движения в H.264.
Фиг. 14 - схематичное представление, показывающее диспаратность, формируемую между камерами.
Номера ссылок
100 - устройство кодирования видео
101 - модуль ввода изображений
102 - формирователь прогнозированных изображений
103 - кодер разностных изображений
104 - декодер разностных изображений
105 - запоминающее устройство опорных кадров
106 - модуль задания опорных кадров
107 - модуль задания целевых кадров опорного вектора
108 - модуль задания способа формирования прогнозированных изображений
109 - кодер дополнительной информации
110 - модуль поиска целевых областей опорного вектора
111 - модуль поиска опорных областей
112 - запоминающее устройство накопления информации о соответствующих зависимостях
113 - формирователь прогнозированных опорных векторов
114 - кодер разностных опорных векторов
Оптимальный режим осуществления изобретения
В настоящем изобретении, при задании векторной информации, используемой для межкадрового прогнозирующего кодирования, которое выполняется при кодировании информации изображений целевой области кодирования, задается не вектор, который указывает область в опорном кадре для формирования прогнозированного изображения, а целевой кадр опорного вектора, который является кадром, используемым для указания вектора. Получается и кодируется опорный вектор, который указывает область в целевом кадре опорного вектора, и выполняется поиск соответствующих точек, такой как поблочное сравнение, с помощью опорного кадра и информации изображений целевой области опорного вектора в целевом кадре опорного вектора, где область указана посредством опорного вектора. Прогнозированное изображение формируется с помощью информации изображений опорной области в опорном кадре, который получается в соответствии с поиском соответствующих точек.
Соответственно, даже когда опорный кадр отличается между смежными областями, векторная информация для межкадрового прогнозирующего кодирования может быть эффективно закодирована.
В традиционных способах векторная информация, которая закодирована для каждой целевой области кодирования (т.е. единичной области кодирования) и используется для межкадрового прогнозирующего кодирования, представляется посредством вектора, который указывает изменение изображения от опорного кадра, который задан для каждой целевой области кодирования, к целевому кадру кодирования.
Следовательно, в традиционных способах, когда опорный кадр отличается между смежными областями, основной фактор (время или камера, или продолжительное время или короткое время), который вызывает изменение изображения, указанное посредством релевантного вектора, также отличается, и изменение изображения, представленное посредством прогнозированного вектора, может отличаться от изменения изображения, представленного посредством целевого вектора, который должен быть кодирован.
В таком случае, целевой вектор, который должен быть кодирован, не может быть точно спрогнозирован посредством сформированного прогнозированного вектора. Кроме того, объем кода, требуемый для кодирования разностного вектора между целевым вектором и прогнозированным вектором, может быть большим, чем объем кода, требуемый для кодирования непосредственно целевого вектора.
Напротив, в соответствии с настоящим изобретением, даже когда опорный кадр, используемый для формирования прогнозированного изображения, отличается между смежными областями, используется тот же самый целевой кадр опорного вектора, так что основной фактор, чтобы вызвать изменение изображения, указанное посредством релевантного вектора, унифицируется, и может быть сформирован прогнозированный вектор, близкий к вектору, который должен кодироваться. Следовательно, векторная информация для межкадрового прогнозирующего кодирования может быть кодирована с меньшим объемом кода.
Дополнительно, информация обозначения целевого кадра опорного вектора для обозначения целевого кадра опорного вектора и информация обозначения опорного кадра для обозначения опорного кадра может быть кодирована по отдельности или закодирована совместно как информация, которая может обозначать целевой кадр опорного вектора и опорный кадр.
Таким образом, когда есть два уже кодированных кадра, (i), если информация обозначения целевого кадра опорного вектора и информация обозначения опорного кадра кодируются по отдельности, значение (0 или 1) может быть кодировано для каждой из них, и (i), если информация, которая может обозначить целевой кадр опорного вектора и опорный кадр, кодируется, то информация, которая указывает любое из (0, 0), (0, 1), (1, 0) и (1, 1), может быть кодирована.
Дополнительно, в настоящем изобретении, поскольку один опорный вектор кодируется для целевой области кодирования, две соответствующие области получаются, соответственно, в целевом кадре опорного вектора и опорном кадре. Следовательно, аналогично B-кадру, прогнозированное изображение может быть сформировано с помощью информации изображений этих двух областей.
Когда такие две соответствующие области получаются, кодирование может быть выполнено посредством выбора того, формируется ли прогнозированное изображение с помощью информации изображений обеих соответствующих областей или с помощью информации изображений только соответствующей области (т.е. опорной области) в опорном кадре.
Тем не менее, в таком случае, должна быть закодирована информация, которая указывает то, посредством какого способа сформировано прогнозированное изображение.
В качестве критерия для выбора способа формирования прогнозированных изображений может использоваться (i) функция затрат на искажение в зависимости от скорости передачи, вычисленная при кодировании релевантной области посредством использования прогнозированного изображения, (ii) сумма абсолютных значений разностей между входным изображением и прогнозированным изображением, или (iii) дисперсия значений пикселов прогнозированного остаточного изображения, сформированного посредством разностей между входным изображением и прогнозированным изображением, и любой критерий может применяться.
При кодировании информации, которая обозначает способ формирования прогнозированных изображений, информация может быть кодирована непосредственно или кодирована вместе с другой информацией, которая также должна быть кодирована. Например, она может быть кодирована вместе с информацией обозначения целевого кадра опорного вектора или информацией обозначения опорного кадра.
Таким образом, (i) "0 или 1" может быть кодировано в качестве информации обозначения опорного кадра, и "0 или 1" может быть кодировано в качестве информации обозначения способа формирования прогнозированных изображений, или (ii) информация, которая указывает любое из (0, 0), (0, 1), (1, 0) и (1, 1), может быть кодирована для комбинации информации обозначения опорного кадра и информации обозначения способа формирования прогнозированных изображений.
В качестве опорного кадра может быть выбран опорный кадр, используемый, когда кодировалась целевая область опорного вектора, или может быть выбран целевой кадр опорного вектора, используемый, когда кодировалась целевая область опорного вектора.
В таких случаях, в качестве опорной области в опорном кадре в каждом случае, область, используемая в качестве опорной области при кодировании целевой области опорного вектора, или область, используемая в качестве целевой области опорного вектора при кодировании целевой области опорного вектора, может быть задана надлежащим образом.
Фиг. 1 и 2 показывают пример опорной области, заданной такими способами.
Фиг. 1 показывает пример процесса, выполняемого, когда опорный кадр, используемый, когда целевая область опорного вектора кодируется, выбирается в качестве текущего опорного кадра, и область, которая использовалась в качестве опорной области при кодировании целевой области опорного вектора, выбирается в качестве опорной области в текущем опорном кадре.
Фиг. 2 показывает пример процесса, выполняемого, когда целевой кадр опорного вектора, используемый, когда целевая область опорного вектора кодировалась, выбирается в качестве текущего опорного кадра, и область, которая использовалась в качестве целевой области опорного вектора при кодировании текущей целевой области опорного вектора, выбирается в качестве опорной области в текущем опорном кадре.
Область, которая выбрана в качестве целевой области опорного вектора или опорной области при кодировании текущей целевой области опорного вектора, использовалась для прогнозирования информации изображений текущей целевой области опорного вектора, и таким образом имеет информацию изображений, близкую к информации изображений текущей целевой области опорного вектора. В частности, такая область принадлежит целевому кадру опорного вектора или опорному кадру, который использовался при кодировании текущей целевой области опорного вектора.
Таким образом, при получении области в опорном кадре, который соответствует целевой области опорного вектора, если этот опорный кадр совпадает с релевантным кадром (т.е. целевым кадром опорного вектора или опорным кадром), используемым в каждом из вышеописанных случаев, то область, которая выбрана в качестве целевой области опорного вектора или опорной области при кодировании вышеупомянутой целевой области опорного вектора, выбирается.
Соответственно, поскольку опорная область в опорном кадре определяется на основе информации кодирования целевой области опорного вектора, возможно сократить количество раз выполнения поиска соответствующих областей, который должен быть выполнен при кодировании и декодировании, при этом сохраняя требуемое качество прогнозированного изображения.
В качестве опорного кадра:
(i) может быть выбран уже кодированный кадр, где зависимости, которые равны зависимостям информации по времени и точкам обзора между целевым кадром опорного вектора, используемым при кодировании целевой области опорного вектора, и целевым кадром опорного вектора, заданным для целевой области кодирования, могут быть установлены между уже кодированным кадром и целевым кадром кодирования, или
(ii) может быть выбран уже кодированный кадр, где зависимости, которые равны зависимостям информации по времени и точкам обзора между опорным кадром, используемым при кодировании целевой области опорного вектора, и целевым кадром опорного вектора, заданным для целевой области кодирования, могут быть установлены между уже кодированным кадром и целевым кадром кодирования.
Для каждого случая, в качестве опорной области:
(i) может быть задана область в (выбранном) опорном кадре, при этом область указывается посредством вектора, который начинается с целевой области кодирования и имеет то же самое направление и размер, как и опорный вектор, используемый при кодировании целевой области опорного вектора, или
(ii) может быть задана область в (выбранном) опорном кадре, при этом область указывается посредством вектора, который начинается с целевой области кодирования и имеет то же самое направление и размер, как и вектор, который указывает соответствующую зависимость между целевой областью опорного вектора и опорной областью, используемой при кодировании целевой области опорного вектора.
Фиг. 3-5 показывают примеры опорной области, заданной посредством вышеописанных способов.
В соответствии со способами, уникальная опорная область может быть назначена целевой области кодирования в случае (i), когда соответствующие области имеют одинаковую камеру или время, как показано на фиг. 3 или 4, или (ii) когда соответствующие области имеют различные камеры и различные времена, как показано на фиг. 5.
В способах, когда соответствующие области имеют одинаковую камеру или время, как показано на фиг. 3 или 4, предполагается, что расстояние (которое вызывает диспаратность) от каждой камеры до визуализируемого объекта значительно не изменяется независимо от времени, и обозначается опорная область, подходящая для соответствующей области.
В случае по фиг. 5, в дополнение к этому также предполагается, что движение визуализируемого объекта продолжается между релевантными временами, чтобы обозначить опорную область, подходящую для соответствующей области.
Первое предположение фактически эффективно в большинстве случаев, поскольку видеоизображение, которое зачастую видимо, такое как видеоизображение с несколькими точками обзора, фотографирующее целевой объект или сцену, находится в предполагаемом состоянии.
Второе предположение, в общем, не является эффективным. Тем не менее, когда интервал между кадрами является коротким, можно предположить, что каждый объект, в общем, выполняет линейное равномерное движение, и таким образом второе предположение может также быть эффективным в большинстве случаев.
Тем не менее, последнее предположение может быть неэффективным, когда интервал между кадрами является длительным, и таким образом этот способ может быть применен только в том случае, когда соответствующие области имеют одинаковую камеру или время, как показано на фиг. 3 или 4, или применение этого способа может быть прервано, когда интервал между кадрами в релевантной соответствующей зависимости становится длинным.
В вышеописанных способах кодирования и декодирования видео, опорная область задается с помощью информации при кодировании целевой области опорного вектора, чтобы сократить количество раз выполнения поиска соответствующих областей.
Тем не менее, вследствие влияния оптимизации искажения в зависимости от скорости передачи или если предположенное условие неэффективно, опорная область, заданная таким способом, может не быть наиболее подходящей для формирования прогнозированного изображения целевой области кодирования.
Следовательно, с учетом такой характеристики, что даже если опорная область отклоняется от оптимальной области, отклонение не является настолько большим, опорная область, заданная релевантным способом, может рассматриваться как временная опорная область, и только ее периферийная область может быть подвергнута поиску соответствующих областей, чтобы улучшить возможность обеспечения оптимального условия для формирования прогнозированного изображения.
В релевантных способах, при меньших вычислительных затратах, чем требуется для простого поиска соответствующих областей, может быть найдена соответствующая точка, имеющая почти равное качество.
Дополнительно, вместо непосредственного задания опорной области в опорном кадре посредством использования информации изображений или информации кодирования целевой области опорного вектора, возможно то, что уже кодированный кадр, отличный от целевого кадра опорного вектора или опорного кадра, задается в качестве промежуточного кадра; промежуточная область, которая является соответствующей областью в промежуточном кадре, задается с помощью информации изображений или информации кодирования целевой области опорного вектора; и затем соответствующая область в опорном кадре задается с помощью информации изображений или информации кодирования промежуточной области, чтобы использовать заданную область в качестве опорной области.
В общем, чтобы обнаружить соответствующую область, связанную с изменением, обусловленным диспаратностью между изображениями различных кадров, требуется более узкий диапазон поиска, чем требуемый для обнаружения соответствующей области, относящейся к временному изменению. Это вызвано тем, что такое изменение изображения, обусловленное диспаратностью, которая вызывается посредством расположения камер, появляется в одном направлении, и объем изменений находится в пределах определенного ограниченного диапазона.
В частности, когда параметры камер для получения изображений известны, эпиполярное геометрическое ограничение является эффективным, так что область в изображении, полученном посредством одной из камер, присутствует вдоль прямой линии в изображении, полученном посредством другой одной из камер. Следовательно, достаточно искать только на периферийной области прямой линии с учетом ошибок в параметрах камеры.
Тем не менее, если и диспаратность, и изменения во времени присутствуют между релевантными кадрами, вышеописанная характеристика является неэффективной, и поиск должен быть выполнен в большем диапазоне, чем требуемый для обнаружения только изменения во времени.
Тем не менее, в вышеописанном способе промежуточного кадра, заданная промежуточная область позволяет выполнять поиск соответствующей области, относящейся к изменению изображения, обусловленному одним из факторов времени и размещения между камерами в каждом из первых и вторых этапов поиска. Соответственно, надлежащая область может быть обнаружена за меньшее число раз вычисления по сравнению с прямым обнаружением опорной области.
Дополнительно, промежуточный кадр может быть целевым кадром опорного вектора, используемым при кодировании целевой области опорного вектора, или опорным кадром, используемым при кодировании целевой области опорного вектора. Для каждого случая промежуточная область может быть целевой областью опорного вектора, используемой при кодировании текущей целевой области опорного вектора, или опорной областью, используемой при кодировании целевой области опорного вектора.
В вышеупомянутом процессе, если промежуточный кадр ближе к опорному кадру по сравнению с целевым кадром опорного вектора, поиск для определения опорной области с помощью промежуточной области может выполняться проще, чем поиск для определения опорной области с помощью целевой области опорного вектора, тем самым сокращая объем вычислений.
При задании опорной области с помощью промежуточной области, могут использоваться не только информация изображений и информация кодирования промежуточной области, но также информация изображений и информация кодирования целевой области опорного вектора.
Если заданный промежуточный кадр - это уже кодированный кадр, при этом зависимости информации по времени и точкам обзора между уже кодированным кадром и целевым кадром опорного вектора равны зависимостям между целевым кадром кодирования и опорным кадром, то прогнозированное изображение может быть сформировано с помощью информации изображений трех соответствующих областей, назначенных целевой области кодирования, т.е. информации изображений целевой области опорного вектора, информации изображений промежуточной области и информации изображений опорной области.
Чтобы сформировать прогнозированное изображение с помощью информации изображений трех соответствующих областей, может использоваться способ вычисления среднего или срединного значения для каждого пиксела.
Дополнительно, поскольку опорный кадр и целевой кадр кодирования имеют зависимость, равную зависимости между промежуточным кадром и целевым кадром опорного вектора, можно предположить, что изменение между промежуточной областью и целевой областью опорного вектора также возникает между опорной областью и целевой областью кодирования, так чтобы сформировать прогнозированное изображение в соответствии со следующей формулой.
[Формула 1]
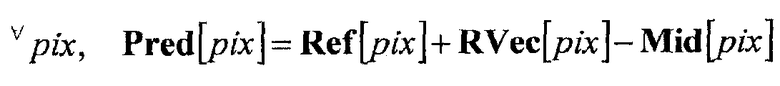
В вышеупомянутой формуле pix указывает позицию пиксела в релевантной области, Pred указывает прогнозированное изображение, Ref указывает информацию изображений опорной области, RVec указывает информацию изображений целевой области опорного вектора, а Mid указывает информацию изображений промежуточной области.
В вышеупомянутых способах информация большего числа соответствующих областей используется без увеличения объема информации, который должен быть кодирован, и используется для формирования прогнозированного изображения. Следовательно, возможно сформировать прогнозированное изображение близко к информации изображений целевой области кодирования.
Хотя прогнозированное изображение может быть сформировано любым способом, один и тот же способ формирования должен использоваться сторонами кодера и декодера.
Также возможно выполнять кодирование при выборе того, формируется ли прогнозированное изображение с помощью информации изображений опорной области, информации изображений опорной области и целевой области опорного вектора или информации изображений опорной области, целевой области опорного вектора и промежуточной области.
В таком случае необходимо кодировать информацию, которая указывает то, что информация изображения этой области использовалась для формирования прогнозированного изображения.
Дополнительно, информация может также быть назначена способу формирования прогнозированного изображения посредством использования другой комбинации областей или к каждому из способов формирования прогнозированных изображений с помощью вышеописанных трех областей, чтобы выбрать способ формирования прогнозированных изображений.
При кодировании информации, которая указывает способ формирования прогнозированных изображений, только эта информация может кодироваться или эта информация может кодироваться с другой информацией (к примеру, информацией обозначения опорного кадра), которая также должна кодироваться.
Таким образом, 0 или 1 может кодироваться в качестве информации обозначения опорного кадра, и 0, 1 или 2 может кодироваться в качестве информации для обозначения способа формирования прогнозированных изображений; или информация, которая указывает любое из (0, 0), (0, 1), (0, 2), (1, 0), (1, 1) и (1, 2), может кодироваться для комбинации обоих информационных элементов.
Когда целевая область опорного вектора закодирована без выполнения межкадрового прогнозирования видео, она представляет то, что никакой уже кодированный кадр и никакая область в нем, подходящая для прогнозирования информации изображений целевой области опорного вектора, не могут быть найдены.
Следовательно, также в целевой области кодирования, соответствующей такой целевой области опорного вектора, вероятность того, что область в кадре, отличном от целевого кадра опорного вектора, выбирается в качестве области, используемой для формирования прогнозированного изображения, должна быть малой.
Следовательно, при кодировании информации обозначения опорного кадра, код, соответствующий информации для обозначения того же кадра в качестве целевого кадра опорного вектора, может быть коротким, чтобы уменьшить объем кода, требуемый для кодирования информации обозначения опорного кадра.
Помимо этого, код, соответствующий информации для обозначения кадра, который соответствует опорному кадру или целевому кадру опорного вектора, используемому при кодировании целевой области опорного вектора, которой была назначена соответствующая зависимость, может также быть коротким, чтобы дополнительно уменьшить объем кода, требуемый для кодирования информации обозначения опорного кадра.
Таким образом, таблица кодовых слов, используемая при кодировании информации обозначения опорного кадра, может быть переключена с помощью информации кодирования целевой области опорного вектора, чтобы кодировать информацию обозначения опорного кадра с меньшим объемом кода.
Аналогично, также при кодировании информации обозначения способа формирования прогнозированных изображений, релевантная таблица кодовых слов может быть переключена с помощью информации кодирования целевой области опорного вектора.
Ниже, настоящее изобретение поясняется подробнее в соответствии с вариантами осуществления.
Фиг. 6 показывает устройство 100 кодирования видео в качестве варианта осуществления настоящего изобретения.
Устройство 100 кодирования видео включает в себя модуль 101 ввода изображений, в который вводится изображение в качестве цели кодирования, формирователь 102 прогнозированных изображений, который формирует прогнозированное изображение с помощью уже кодированного изображения для каждой области разделенного целевого изображения кодирования, кодер 103 разностных изображений, который кодирует разностное изображение между входным изображением и прогнозированным изображением, декодер 104 разностных изображений, который декодирует кодированные данные разностного изображения, запоминающее устройство 105 опорных кадров, которое накапливает декодированное изображение целевой области кодирования, сформированное посредством суммы декодированного разностного изображения и прогнозированного изображения, модуль 106 задания опорных кадров для выбора опорного кадра для формирования прогнозированного изображения из запоминающего устройства 105 опорных кадров, модуль 107 задания целевых кадров опорного вектора для выбора целевого кадра опорного вектора в качестве опорного целевого (кадра) векторной информации, которая должна быть закодирована, из запоминающего устройства 105 опорных кадров, модуль 108 задания способа формирования прогнозированных изображений для задания способа формирования прогнозированных изображений, назначенного полученной соответствующей области, кодер 109 дополнительной информации для кодирования дополнительной информации, которая состоит из информации обозначения опорного кадра, информации обозначения целевого кадра опорного вектора и информации обозначения способа формирования прогнозированных изображений, модуль 110 поиска целевых областей опорного вектора для получения опорного вектора с помощью входного изображения и целевого кадра опорного вектора, модуль 111 поиска опорных областей для поиска опорной области посредством использования информации изображений целевой области опорного вектора и опорного кадра, запоминающее устройство 112 накопления информации о соответствующих зависимостях, которое сохраняет набор из опорного вектора, опорной области, целевого кадра опорного вектора и опорного кадра, который использовался для релевантного кодирования, в ассоциативной связи с целевым кадром кодирования и целевой областью кодирования, формирователь 113 прогнозированных опорных векторов для формирования прогнозированного опорного вектора, соответствующего опорному вектору целевой области кодирования, используя опорный вектор, который использовался при кодировании смежной области с целевой областью кодирования, и кодер 114 разностных опорных векторов для кодирования разностного опорного вектора, который является разностью между опорным вектором и прогнозированным опорным вектором.
Фиг. 7 показывает блок-схему процесса кодирования видео, выполняемого устройством 100 кодирования видео, имеющего вышеописанную структуру.
В каждой блок-схеме способа, поясненной ниже, блок или кадр, которому назначается индекс, представляет блок или кадр, указанный посредством индекса.
В соответствии с релевантной блок-схемой способа, процесс кодирования видео, выполняемый посредством сконфигурированного выше устройства 100 кодирования видео, подробнее поясняется, при этом предполагается, что изображения множества кадров уже кодированы, и результаты этого сохранены в запоминающем устройстве 105 опорных кадров и запоминающем устройстве 112 накопления информации о соответствующих зависимостях.
Сначала, изображение, которое должно стать целью кодирования, вводится через модуль 101 ввода изображений (S101).
Входное целевое изображение кодирования полностью делится на области, и каждая область кодируется (S102-S131).
На этой блок-схеме способа blk указывает индекс блока (области), а MaxBlk указывает общее количество блоков для одного изображения.
После инициализации индекса blk равным 1 (S102), следующие процессы (S103-S129) выполняются многократно при увеличении blk на 1 (S131), пока оно не достигает MaxBlk (S130).
В процессе, выполняемом для каждого блока, целевой кадр опорного вектора best_ref_vec, опорный кадр best_ref и опорный вектор best_mv_ref для кодирования блока; вектор best_mv, который указывает опорную область в опорном кадре; способ формирования прогнозированных изображений best_pmode; и прогнозированный опорный вектор best_pmv определяются (S113-S126), и прогнозированное изображение для информации изображений целевой области кодирования формируется с помощью вышеупомянутой информации (S127). Затем дополнительная информация, состоящая из best_ref_vec, best_ref и best_pmode, кодируется в кодере 109 дополнительной информации, best_mv_ref-best_pmv кодируются посредством кодера 114 разностных опорных векторов, разностное изображение между входным изображением и прогнозированным изображением кодируется посредством кодера 103 разностных изображений, и релевантные кодированные данные выводятся (S128).
Для следующего выполнения процесса кодирования кодированные данные декодируются, и декодированное изображение сохраняется в запоминающем устройстве 105 опорных кадров. Информация, касающаяся соответствующих областей (т.е. двух областей, таких как целевая область опорного вектора, указанная посредством best_mv_ref, и опорная область, указанная посредством best_mv), используемых для формирования прогнозированного изображения, сохраняется в запоминающем устройстве 112 накопления информации о соответствующих зависимостях в ассоциативной связи с номером целевого кадра кодирования и позицией блока blk в релевантном изображении (S129).
Таким образом, когда cur указывает индексное значение для указания целевого кадра кодирования, а pos указывает позицию блока blk в релевантном изображении, набор из "cur, pos, best_ref, best_ref_vec, best_mv_ref, и best_mv" сохраняется в запоминающем устройстве 112 накопления информации о соответствующих зависимостях.
Процесс формирования прогнозированного изображения на S127 и процесс кодирования дополнительной информации на S128 подробнее поясняются далее.
Дополнительно, информация, используемая для формирования прогнозированного изображения для кодирования, получается посредством многократного выполнения следующих процессов (S104-S124) для всех уже кодированных кадров в запоминающем устройстве 105 опорных кадров, которые могут использоваться в качестве целевого кадра опорного вектора.
В частности, после инициализации индекса целевого кадра опорного вектора ref_vec равным 1 (S102), также инициализации минимальной функции затрат на искажение в зависимости от скорости передачи bestCost для блока blk равным абсолютно недостижимому максимальному значению MaxCost и задания pos равным позиции в изображении блока blk (S103), следующие процессы выполняются многократно при увеличении ref_vec на 1 (S126) до тех пор, пока оно не достигает числа NumOfRef кадров, которые сохраняются в запоминающем устройстве 105 опорных кадров и могут использоваться (S125). В повторных процессах прогнозированный опорный вектор pmv формируется с помощью опорного вектора в уже кодированном блоке, смежном с блоком blk (S104), и определяется комбинация опорного вектора, опорного кадра, опорной области и способа формирования прогнозированных изображений, которая минимизирует функцию затрат на искажение в зависимости от скорости передачи, когда кадр, указанный посредством ref_vec, является целевым кадром опорного вектора (S105-S124).
В этом процессе следующие этапы (S106-S122) многократно выполняются для всех уже кодированных кадров, которые сохранены в запоминающем устройстве 105 опорных кадров и могут использоваться в качестве опорного кадра.
В частности, после инициализации индекса опорного кадра ref равным в 1 (S105) следующие процессы выполняются многократно при увеличении ref на 1 (S124) до тех пор, пока оно не достигает NumOfRef (S123), при этом в повторных процессах определяется то, что ref_vec совпадает с ref (S106), и если определяется то, что они совпадают друг с другом, т.е. если фактически нет целевого кадра опорного вектора (соответствующего традиционному состоянию), то процесс определения опорного вектора, который предоставляет минимальную функцию затрат на искажение в зависимости от скорости передачи (S107-S114), многократно выполняется, пока опорный кадр и целевой кадр опорного вектора указываются посредством ref.
В релевантном процессе, после инициализации индекса вариантов опорного вектора mv_ref_idx равным 1 (S107) следующие процессы (S108-S112) выполняются многократно при увеличении mv_ref_idx на 1 (S114) до тех пор, пока оно не достигает предварительно определенного числа NumOfListMvRef вариантов для опорного вектора (S113). В повторных процессах опорный вектор, соответствующий mv_ref_idx, задается как mv_ref (S108), информация изображений области в позиции pos+mv_ref в кадре ref задается как прогнозированное изображение Pred[] (S109), функция затрат на искажение в зависимости от скорости передачи, называемая просто cost, вычисляется (S110), и определяется то, меньше ли cost, чем bestCost (S111).
Когда определяется то, что cost меньше, чем bestCost, bestCost перезаписывается как cost, best_ref перезаписывается как ref, best_ref_vec перезаписывается как ref, best_ref_mid перезаписывается как ref, best_mv перезаписывается как 0 (нулевой вектор), best_mv_ref перезаписывается как mv_ref, best_pmode перезаписывается как 1, и best_pmv перезаписывается как pmv (S112).
Функция затрат на искажение в зависимости от скорости передачи, вычисленная на S110, может быть получена посредством фактического кодирования разностного изображения, разностного опорного вектора mv_ref-pmv и дополнительной информации, чтобы вычислить объем кода, и посредством декодирования кодированных данных, чтобы вычислить ухудшение качества, тем самым выполняя вычисление на основе следующей формулы 2. В другом способе упрощенная функция затрат на искажение в зависимости от скорости передачи может быть вычислена как функция затрат на искажение в зависимости от скорости передачи на основе следующей формулы 3.
Тем не менее, одна формула должна использоваться в процессе кодирования одного блока blk.
[Формула 2]
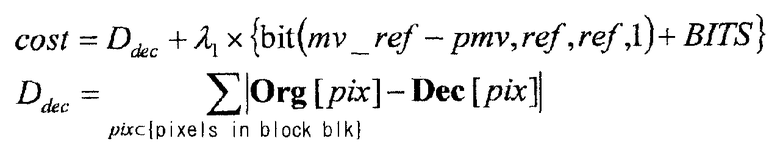
В вышеупомянутой формуле, λ1 - неопределенный множитель Лагранжа, являющийся предварительно определенным значением. Помимо этого, pix указывает позицию пиксела, Org[] указывает информацию изображений целевой области кодирования во входном изображении, а Dec[] указывает информацию изображений декодированного изображения. Дополнительно, bit(vector, ref1, ref2, mode) является функцией, которая возвращает объем кода, сформированный, когда vector кодируется как разностный опорный вектор, ref1 кодируется как информация обозначения целевого кадра опорного вектора, ref2 кодируется как информация обозначения опорного кадра, а mode кодируется как информация обозначения способа формирования прогнозированных изображений. BITS указывает объем кода, требуемый при кодировании разностного изображения Res[] (= Org[]-Pred[]).
[Формула 3]
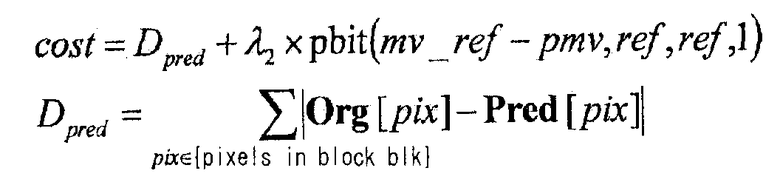
В вышеупомянутой формуле, λ2 - неопределенный множитель Лагранжа, являющийся предварительно определенным значением. Помимо этого, pbit(vector, ref1, ref2, mode) является функцией, которая возвращает объем кода, сформированный, когда vector кодируется как разностный опорный вектор, ref1 кодируется как информация обозначения целевого кадра опорного вектора, ref2 кодируется как информация обозначения опорного кадра, а mode кодируется как информация обозначения способа формирования прогнозированных изображений.
Если при определении на этапе S106 определено, что ref_vec не совпадает с ref (т.е. целевой кадр опорного вектора не совпадает с опорным кадром), то определяются опорный вектор b_mv_ref, вектор b_mv, который указывает опорную область, и индекс b_pmode способа формирования прогнозированных изображений, которые предоставляют минимальную функцию затрат на искажение в зависимости от скорости передачи, называемую mcost, когда кадр, указанный посредством ref, является опорным кадром, а кадр, указанный посредством ref_vec, является целевым кадром опорного вектора (S117).
Процесс S117 подробнее поясняется далее.
Далее определяется то, меньше ли mcost, чем bestCost (S118). Когда mcost меньше, чем bestCost, bestCost перезаписывается как mcost, best_ref перезаписывается как ref, best_ref_vec перезаписывается как ref_vec, best_mv перезаписывается как b_mv, best_mv_ref перезаписывается как b_mv_ref, best_pmode перезаписывается как b_pmode, и best_pmv перезаписывается как pmv (S119).
В отличие от этого, если mcost больше, чем bestCost, процесс на этапе S119 опускается.
Затем, уже кодированный кадр (промежуточный кадр) обнаруживается, где зависимости времени и точки обзора между уже кодированным кадром и кадром, указанным посредством ref_vec, совпадают с зависимостями между целевым кадром кодирования и кадром, указанным посредством ref, и индекс, который указывает уже кодированный кадр, задается как ref_mid (S115).
Если уже кодированный кадр, который удовлетворяет вышеупомянутому условию, отсутствует в запоминающем устройстве 105 опорных кадров, ref_mid задается как ref.
Затем определяется то, совпадает ли ref_mid с ref или ref_vec (S116).
При определении на этапе S116, если определено то, что ref_mid не совпадает ни с одним из ref и ref_vec, то определяются опорный вектор b_mv_ref, вектор b_mv_mid, который указывает промежуточную область, вектор b_mv, который указывает опорную область, и индекс b_pmode способа формирования прогнозированных изображений, которые предоставляют минимальную функцию затрат на искажение в зависимости от скорости передачи mcost, когда кадр, указанный посредством ref, является опорным кадром, кадр, указанный посредством ref_vec, является целевым кадром опорного вектора, а кадр, указанный посредством ref_mid, является промежуточным кадром (S120).
Процесс S120 подробнее поясняется далее.
Далее определяется то, меньше ли mcost, чем bestCost (S121). Когда mcost меньше, чем bestCost, bestCost перезаписывается как mcost, best_ref перезаписывается как ref, best_ref_vec перезаписывается как ref_vec, best_ref_mid перезаписывается как ref_mid, best_mv перезаписывается как b_mv, best_mv_ref перезаписывается как b_mv_ref, best_mv_mid перезаписывается как b_mv_mid, best_pmode перезаписывается как b_pmode, и best_pmv перезаписывается как pmv (S122).
В отличие от этого, если mcost больше, чем bestCost, процесс на S122 опускается.
При определении на S116, если ref_mid совпадает с ref или ref_vec, процессы от S120 до вышеупомянутого S122 также опускаются.
Причина, по которой S120 выполняется после S117, заключается в том, что функция затрат на искажение в зависимости от скорости передачи может быть уменьшена при формировании промежуточного кадра.
Затем, процесс на S117 подробно поясняется со ссылкой на блок-схему способа, показанную на фиг. 8.
В этом процессе, хотя опорный вектор варьируется, опорная область назначается заданному в настоящий момент опорному вектору, и вычисляется способ формирования прогнозированных изображений для предоставления функции затрат на искажение в зависимости от скорости передачи, наиболее подходящей для него.
В частности, после инициализации индекса вариантов опорного вектора mv_ref_idx равным 1, а также инициализации минимальной функции затрат на искажение в зависимости от скорости передачи mcost равной абсолютно недостижимому максимальному значению MaxCost (S201), следующие процессы (S202-S211) выполняются многократно с приращением mv_ref_idx на 1 (S213) до тех пор, пока оно не достигает назначенного числа NumOfListMvRef вариантов опорного вектора (S212).
В повторных процессах (S202-S211), сначала получается опорный вектор, которому назначен mv_ref_idx, и задается как mv_ref (S202).
Затем, степень разности между информацией изображений блока blk во входном изображении и информацией изображений области в позиции pos+mv_ref в кадре ref_vec вычисляется, и определяется то, меньше ли степень, чем предварительно определенное пороговое значение TH (S203).
Степень разности между двумя элементами информации изображений может быть вычислена любым способом, например, посредством вычисления суммы абсолютных разностей, суммы квадратов разностей или дисперсии разностей на основе значений соответствующих пикселов между релевантными двумя областями, где пороговое значение TH должно быть назначено используемому способу вычислений.
Когда степень разности больше или равна пороговому значению, это указывает то, что информация изображений целевой области опорного вектора, указанной посредством mv_ref, значительно отличается от информации изображений целевой области кодирования, и таким образом целевая область опорного вектора не соответствует целевой области кодирования. Следовательно, операция, применяемая к текущему mv_ref_idx, заканчивается.
Если при определении на этапе S203 определено, что степень разности меньше, чем пороговое значение, то область, которая принадлежит кадру ref и соответствует области в позиции pos+mv_ref в кадре ref_vec, вычисляется, и mv вычисляется для задания позиции вычисленной области как pos+mv_ref+mv (S204). Процесс S204 подробнее поясняется далее.
Затем, определяется то, может ли прогнозированное изображение для предоставления минимальной функции затрат на искажение в зависимости от скорости передачи быть сформировано с помощью информации изображений RVec[] области в позиции pos+mv_ref в кадре ref_vec и информации изображений Ref[] области в позиции pos+mv_ref+mv в кадре ref (S205-S211).
В частности, после инициализации индекса способа формирования прогнозированных изображений pmode равным 1 (S205), следующие процессы (S206-S209) выполняются многократно при увеличении pmode на 1 (S211) до тех пор, пока оно не достигает 2 (S210). В повторных процессах прогнозированное изображение формируется с помощью способа формирования прогнозированных изображений, соответствующего pmode (S206), соответствующая функция затрат на искажение в зависимости от скорости передачи cost вычисляется (S207), и определяется то, меньше ли cost, чем mcost (S208). Если определено то, что cost меньше, mcost перезаписывается как cost, b_mv_ref перезаписывается как mv_ref, b_mv перезаписывается как mv, и b_pmode перезаписывается как pmode (S209).
Вычисление функции затрат на искажение в зависимости от скорости передачи на S207 выполняется с помощью способа, аналогичного используемому на вышеописанном этапе S110.
В вышеупомянутом процессе максимальное значение pmode задано как 2. Это вызвано тем, что в качестве способа формирования прогнозированных изображений, который может использоваться, когда получаются два элемента информации изображений (информация изображений целевого кадра опорного вектора и информация изображений опорного кадра), только два способа рассматриваются в качестве кандидатов, т.е. способ формирования прогнозированного изображения с помощью только информации изображений опорного кадра и способ формирования прогнозированного изображения посредством вычисления среднего двух значений информации изображений для каждой пары соответствующих пикселов.
Тем не менее, максимальное значение pmode может быть увеличено, чтобы также использовать другой способ, например, для вычисления суммы взвешенных значений для двух элементов информации изображений.
Таким образом, хотя здесь определены способы формирования прогнозированных изображений (pmode=1, 2) (см. формулу 4) для удобства пояснения, может быть использован или добавлен другой способ формирования прогнозированных изображений.
[Формула 4]
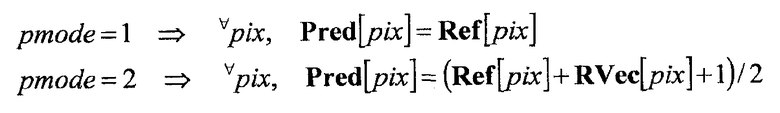
В настоящем варианте осуществления способ формирования прогнозированного изображения посредством использования только информации изображений целевого кадра опорного вектора не используется в качестве кандидата. Это обусловлено тем, что такой способ соответствует способу формирования прогнозированных изображений, когда целевой кадр опорного вектора равен опорному кадру.
Далее, процесс на этапе S117 подробно поясняется со ссылкой на блок-схему способа, показанную на фиг. 9.
В этом процессе, хотя опорный вектор варьируется, опорная область и промежуточная область назначаются в настоящий момент заданному опорному вектору, и вычисляется способ формирования прогнозированных изображений для предоставления функции затрат на искажение в зависимости от скорости передачи, наиболее подходящей для него.
В частности, после инициализации индекса вариантов опорного вектора mv_ref_idx равным 1, а также инициализации минимальной функции затрат на искажение в зависимости от скорости передачи mcost равной абсолютно недостижимому максимальному значению MaxCost (S301), следующие процессы (S202-S211) выполняются многократно при увеличении mv_ref_idx на 1 (S314) до тех пор, пока оно не достигает назначенного числа NumOfListMvRef вариантов опорного вектора (S313).
В повторных процессах (S302-S312), сначала получается опорный вектор, которому назначен mv_ref_idx, и задается как mv_ref (S302).
Затем, степень разности между информацией изображений блока blk во входном изображении и информацией изображений области в позиции pos+mv_ref в кадре ref_vec вычисляется, и определяется то, меньше ли степень, чем предварительно определенное пороговое значение TH (S303).
Релевантный процесс аналогичен процессу на S203, и степень разности может быть вычислена так, как вычисляется на S203.
Когда степень разности больше или равна пороговому значению, это указывает то, что информация изображений целевой области опорного вектора, указанной посредством mv_ref, значительно отличается от информации изображений целевой области кодирования, и таким образом целевая область опорного вектора не соответствует целевой области кодирования. Следовательно, операция, применяемая к текущему mv_ref_idx, заканчивается.
Если определено при определении на S303 то, что степень разности меньше, чем пороговое значение, то область, которая принадлежит кадру ref_mid и соответствует области в позиции pos+mv_ref в кадре ref_vec, вычисляется, и mv_mid вычисляется для задания позиции вычисленной области как pos+mv_ref+mv_mid (S304).
Затем область, которая принадлежит кадру ref и соответствует области в позиции pos+mv_ref+mv_mid в кадре ref_mid, вычисляется, и mv вычисляется для задания позиции вычисленной области как pos+mv_ref+mv (S305). Процессы S304 и S305 подробно поясняются далее.
В процессе на S305, при определении области в кадре ref, вместо области в позиции pos+mv_ref+mv_mid в кадре ref_mid, область в позиции pos+mv_ref в кадре ref_vec может использоваться в качестве соответствующей базовой области.
В таком случае, информация изображений, используемая в качестве шаблона, не изменяется, и таким образом можно не допустить накопления ошибки, обусловленного вычислением соответствующей области, которое может предоставить соответствующую область, имеющую информацию изображений, которая не находится близко к информации изображений целевой области кодирования.
Затем, определяется то, может ли прогнозированное изображение для предоставления минимальной функции затрат на искажение в зависимости от скорости передачи быть сформировано с помощью информации изображений RVec[] области в позиции pos+mv_ref в кадре ref_vec, информации изображений Mid[] области в позиции pos+mv_ref+mv_mid в кадре ref_mid и информации изображений Ref[] области в позиции pos+mv_ref+mv в кадре ref (S306-S312).
В частности, после инициализации индекса способа формирования прогнозированных изображений pmode равным 1 (S306), следующие процессы (S307-S310) выполняются многократно при увеличении pmode на 1 (S211) до тех пор, пока оно не достигает числа MaxMode способов формирования прогнозированных изображений (S311). В повторных процессах прогнозированное изображение формируется с помощью способа формирования прогнозированных изображений, соответствующего pmode (S307), соответствующая функция затрат на искажение в зависимости от скорости передачи cost вычисляется (S308), и определяется то, меньше ли cost, чем mcost (S309). Если определено то, что cost меньше, чем mcost, mcost перезаписывается как cost, b_mv_ref перезаписывается как mv_ref, b_mv_mid перезаписывается как mv_mid, b_mv перезаписывается как mv, и b_pmode перезаписывается как pmode (S310).
Вычисление функции затрат на искажение в зависимости от скорости передачи на S308 выполняется с помощью способа, аналогичного используемому на вышеописанном этапе S110.
В вышеупомянутом процессе, в качестве способа формирования прогнозированных изображений, который может использоваться, когда получаются три элемента информации изображений (информация изображений целевого кадра опорного вектора, информация изображений опорного кадра и информация изображений промежуточного кадра), в дополнение к способам, представленным посредством формулы 4, доступны другие три способа, т.е. способ формирования прогнозированного изображения посредством вычисления среднего трех значений информации изображений для каждого набора соответствующих пикселов, способ формирования прогнозированного изображения посредством вычисления срединного значения трех значений информации изображений для каждого набора соответствующих пикселов и способ формирования прогнозированного изображения при допущении, что изменение между промежуточной областью и целевой областью опорного вектора также происходит между опорной областью и целевой областью кодирования.
Эти три способа формирования прогнозированных изображений могут быть представлены посредством формулы 5 ниже. Для удобства пояснения эти три способа соответствуют pmode=3, 4, 5. Тем не менее, другое значение pmode может быть назначено другому способу, или порядок назначения значения pmode может быть изменен.
[Формула 5]
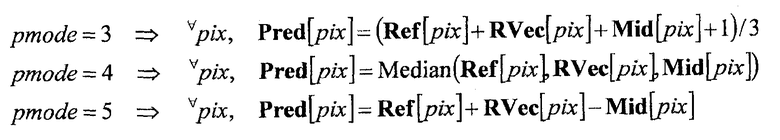
Для прогнозирования pmode=5 более высокая точность прогнозирования может быть получена, когда процесс S305 выполняется точно так же, как записано в блок-схеме, поскольку предположенное состояние чаще реализуется.
Напротив, для прогнозирования pmode=4 более высокая точность прогнозирования может быть получена, когда процесс S305 не выполняется точно так же, как записано, а выполняется посредством определения области в кадре ref с помощью, как описано выше, области (в качестве соответствующей базовой области) в позиции pos+mv_ref в кадре ref_vec, вместо области в позиции pos+mv_ref+mv_mid в кадре ref_mid, чтобы уменьшить накопление ошибки.
Следовательно, этап S305 релевантной блок-схемы может использовать способ выбора того, используется ли область в позиции pos+mv_ref+mv_mid в кадре ref_mid или область в позиции pos+mv_ref в кадре ref_vec, в соответствии с pmode.
Далее со ссылками на блок-схему, показанную на фиг. 10, подробно поясняются процессы на вышеописанных этапах S204, S304 и S305.
На этой блок-схеме процессы на этапах S204, S304 и S305 обобщаются, и процесс вычисления области Y, которая принадлежит кадру B и соответствует области в позиции X в кадре A, показан.
Здесь, для mv или mv_mid, определенных на этапах S204, S304 и S305, требуемое значение вычисляется с помощью позиции Y в каждом случае. Ниже, область в позиции X в кадре A называется просто "областью AX".
Сначала, индекс целевого кадра опорного вектора, используемого, когда область кодирования AX извлекается из запоминающего устройства 112 накопления информации о соответствующих зависимостях, и задается как ref_vec_t (S401).
В этом процессе, один целевой кадр опорного вектора используется, когда область кодирования AX не может быть определена, если, например, область AX не совпадает с единичным блоком для кодирования.
В таком случае, среди множества целевых кадров опорного вектора, индекс целевого кадра опорного вектора, который используется наибольшей частью в рамках области AX, задается как ref_vec_t.
Помимо этого, если целевой кадр опорного вектора отсутствует, ref_vec_t задается равным абсолютно недостижимому значению.
Затем определяется то, совпадает ли полученный ref_vec_t с B (S402).
Если определено то, что они совпадают друг с другом, получается опорный вектор mv_vec_t, используемый при кодировании области AX, (S403).
В этом процессе используется один опорный вектор, когда область кодирования AX не может быть задана, если, например, область AX не совпадает с единичным блоком для кодирования.
В таком случае, среди опорных векторов областей в целевом кадре опорного вектора, указанном посредством ref_vec_t, опорный вектор, который используется посредством наибольшей области, задается как mv_vec_t.
Здесь, вместо простого выбора опорного вектора, используемого посредством наибольшей области, вектор может быть выбран с помощью среднего или срединного значения, вычисленного посредством взвешивания в соответствии с размером каждой области, или среднего или срединного значения, вычисленного без такого взвешивания.
После того как mv_vec_t вычислен, область Y, имеющая информацию изображений, близкую к информации области AX, обнаруживается вокруг позиции X+mv_vec_t в кадре B (S404).
Чтобы уменьшить объем вычислений при поиске, позиция X+mv_vec_" может быть заменена на Y. Это обусловлено тем, что область, указанная посредством X+mv_vec_t, упоминалась при области кодирования AX, и таким образом имеет информацию изображений, возможно близкую к информации области AX. В таком случае, приемлемость релевантной соответствующей зависимости не ухудшается существенно.
Напротив, если определено при определении на S402 то, что ref_vec_t и B не совпадают друг с другом, индекс опорного кадра, используемый при кодировании области AX, извлекается из запоминающего устройства 112 накопления информации о соответствующих зависимостях и задается как ref_t (S405).
В этом процессе, аналогичном процессу S401, может быть получено множество опорных кадров. В таком случае, один ref_t определяется с помощью способа, аналогичного поясненному на вышеописанном этапе S401.
Затем, определяется то, совпадают ли ref_t и B друг с другом (S406).
Если определено, что они совпадают друг с другом, то вектор mv_t, заданный от позиции X к опорной области, которая использовалась при кодировании области AX, извлекается из запоминающего устройства 112 накопления информации о соответствующих зависимостях (S407).
Если множество векторов mv_t получается для области AX, один mv_t определяется в соответствии со способом, как пояснено на вышеописанном этапе S403.
После того как mv_t получен, область Y, имеющая информацию изображений, близкую к информации из области, AX обнаруживается вокруг позиции X+mv_t в кадре B (S408).
Как описано на вышеописанном этапе S404, позиция X+mv_t может быть заменена на Y, чтобы уменьшить объем вычислений при поиске.
Напротив, если определено при определении на этапе S406 то, что ref_t не совпадает с B, то область Y, которая принадлежит кадру B и имеет информацию изображений, близкую к информации области AX, получается посредством обычного способа поиска, такого как поблочное сравнение (S409).
Далее подробно поясняется процесс формирования прогнозированного изображения на этапе S127.
Прогнозированное изображение формируется посредством следующей процедуры 1 в соответствии с pos, best_ref, best_ref_vec, best_ref_mid, best_mv, best_mv_ref, best_mv_mid и best_pmode, которые получены через процессы до S127.
Процедура 1
1. Информация изображений RVec[] области в позиции pos+best_mv_ref в кадре best_ref_vec извлекается из запоминающего устройства 105 опорных кадров.
2. Если best_ref совпадает с best_ref_vec, управление переходит к 6.
3. Информация изображений Ref[] области в позиции pos+best_mv_ref+best_mv в кадре best_ref извлекается из запоминающего устройства 105 опорных кадров.
4. Если best_ref_mid совпадает с best_ref, управление переходит к 6.
5. Информация изображений Mid[] области в позиции pos+best_mv_ref+best_mv_mid в кадре best_ref_mid извлекается из запоминающего устройства 105 опорных кадров.
6. Прогнозированное изображение Pred[] формируется с помощью формулы 4 или 5 в соответствии со значением pmode.
Помимо этого, другой способ формирования прогнозированных изображений может быть назначен pmode и использован.
Далее подробно поясняется процесс формирования прогнозированного изображения на S127.
Здесь, дополнительная информация соответствует best_ref, best_ref_vec и best_pmode. Перед кодированием дополнительной информации, разностный опорный вектор кодируется.
Сначала, кодируется целевой кадр опорного вектора best_ref_vec.
Весьма вероятно, что выбранный best_ref_vec - это кадр, который кодирован как best_ref_vec в смежной области блока blk, или соответствует кадру, смежному с целевым кадром кодирования. Следовательно, таблица кодовых слов переключается так, чтобы индексы таких кадров могли быть кодированы с меньшим объемом кода по сравнению с кодированием индексов кадров, назначенных другим кадрам.
Соответственно, кодирование может быть выполнено с меньшим объемом кода по сравнению со случаем, в котором каждый кадр требует одинакового объема кода.
Затем кодируется опорный кадр best_ref.
Здесь таблица кодовых слов переключается с помощью уже кодированного best_ref_vec и опорный вектор, который может быть сформирован с помощью разностного опорного вектора, который также кодирован отдельно.
Таким образом, используя информацию кодирования целевой области опорного вектора, которая принадлежит целевому кадру опорного вектора best_ref_vec и указывается посредством опорного вектора, таблица кодовых слов переключается так, чтобы короткое кодовое слово было назначено индексу кадра, который должен появляться очень часто.
Например, если внутреннее кодирование является наиболее часто используемым в целевой области опорного вектора, хотя целевым кадром опорного вектора best_ref_vec не является I-кадр, это представляет то, что в другом кадре нет области, которая имеет информацию изображений, близкую к информации из целевой области опорного вектора. Следовательно, высока вероятность того, что best_ref становится равным best_ref_vec. В таком случае, короткое кодовое слово назначается тому же индексу кадра, что и best_ref_vec.
Аналогично, для кадра, используемого в качестве опорного кадра или целевого кадра опорного вектора при кодировании целевой области опорного вектора, чем более широкой является используемая часть релевантного кадра, тем выше вероятность того, что релевантный кадр выбирается как best_ref. Следовательно, кодовое слово назначается кадру в соответствии с рангом вероятности.
Соответственно, кодирование может быть выполнено с меньшим объемом кода по сравнению со случаем, когда кодовое слово, имеющее одну и ту же длину, назначается каждому индексу.
В завершение, best_pmode кодируется. Таблица кодовых слов переключается с помощью уже кодированного best_ref_vec и best_ref и информации о кадре в запоминающем устройстве 105 опорных кадров.
Например, если best_ref_vec и best_ref совпадают друг с другом, это представляет то, что только одна соответствующая область может быть получена для блока blk, и таким образом значение pmode, отличное от 1, не имеет смысла. В таком случае, объем кода может быть уменьшен посредством задания таблицы кодовых слов для опускания кодирования самого pmode.
Напротив, если best_ref_vec и best_ref не совпадают друг с другом, возможность того, что 1 выбрано как pmode, должна быть очень низкой. Следовательно, таблица кодовых слов переключается так, чтобы короткое кодовое слово назначалось но каждому значению pmode, отличному от 1, тем самым выполняя кодирование с меньшим объемом кода по сравнению со случаем, когда кодовое слово, имеющее одну и ту же длину, назначается каждому способу формирования прогнозированных изображений.
Дополнительно, если только два кадра сохранены в запоминающем устройстве опорных кадров или если соответствующий промежуточный кадр для комбинации best_ref_vec и best_ref не сохранен в запоминающем устройстве 105 опорных кадров, то способ формирования прогнозированных изображений, который требует трех соответствующих областей, не может использоваться. Следовательно, таблица кодовых слов может быть переключена так, чтобы короткое кодовое слово назначалось другим способам формирования прогнозированных изображений, тем самым выполняя кодирование с меньшим объемом кода по сравнению со случаем, когда кодовое слово, имеющее одну длину, назначается каждому способу формирования прогнозированных изображений.
Как описано выше, элементы дополнительной информации могут быть кодированы по отдельности, или число может быть назначено каждой их комбинации, с тем чтобы кодировать число.
Следовательно, если два изображения (индексы которых 1 и 2) сохранены в запоминающем устройстве опорных кадров, и пять типов способа формирования прогнозированных изображений являются подходящими для использования, то набор {best_ref, best_ref_vec, best_pmode} имеет 20 комбинаций значений, такие как {1, 1, 1}, {1, 1, 2}, {1, 1, 3}, {1, 1, 4}, {1, 1, 5}, {1, 2, 1}, {1, 2, 2}, {1, 2, 3}, {1, 2, 4}, {1, 2, 5}, {2, 1, 1}, {2, 1, 2}, {2, 1, 3}, {2, 1, 4}, {2, 1, 5}, {2, 2, 1}, {2, 2, 2}, {2, 2, 3}, {2, 2, 4} и {2, 2, 5}.
Этим 20 комбинациям номера 1-20 могут быть назначены и кодированы.
Тем не менее, некоторые из комбинаций фактически не имеют смысла.
Например, когда best_ref и best_ref_vec имеют одинаковое значение, только одна соответствующая область может быть получена для целевой области кодирования, и таким образом pmode=2-5 невозможно.
Следовательно, только 12 комбинаций, такие как {1, 1, 1}, {1, 2, 1}, {1, 2, 2}, {1, 2, 3}, {1, 2, 4}, {1, 2, 5}, {2, 1, 1}, {2, 1, 2}, {2, 1, 3}, {2, 1, 4}, {2, 1, 5} и {2, 2, 1}, являются действующими, и один из номеров 1-12 должен быть кодирован.
Дополнительно, если запоминающее устройство опорных кадров включает в себя только два изображения, ни один кадр не может быть выбран в качестве промежуточного кадра, и таким образом каждое значение pmode, которое требует трех соответствующих областей, не имеет смысла. Следовательно, действующие комбинации дополнительно уменьшаются, и только 6 комбинаций, такие как {1, 1, 1}, {1, 2, 1}, {1, 2, 2}, {2, 1, 1}, {2, 1, 2} и {2, 2, 1}, являются действующими. В таком случае, один из номеров 1-6 должен быть кодирован.
Даже когда три или более изображений сохранены в запоминающем устройстве опорных кадров, в настоящем варианте осуществления, соответствующий промежуточный кадр не может присутствовать в зависимости от комбинации best_ref и best_ref_vec, и может оказаться невозможным выполнять способ формирования прогнозированных изображений, который требует трех соответствующих областей. Даже в таком случае может использоваться способ без назначения кода каждой недействующей комбинации.
Дополнительно, вместо кодирования всех трех информационных элементов, конкретные два из них могут быть комбинированы и кодированы.
Например, best_ref_vec может быть кодирован по отдельности, тогда как best_ref и pmode могут быть комбинированы с тем, чтобы кодировать их с помощью одного кодового слова. В таком случае, может быть легко выведен способ кодирования посредством переключения таблицы кодовых слов для {best_ref, pmode} в соответствии с кодированными данными целевой области опорного вектора (которые получены с помощью best_ref_vec и опорного вектора, который отдельно кодирован).
Фиг. 11 показывает устройство 200 декодирования видео в качестве варианта осуществления настоящего изобретения.
Устройство 200 декодирования видео включает в себя декодер 201 разностных изображений, который декодирует кодированные данные разностного изображения относительно прогнозированного изображения, которое становится целевым объектом декодирования, декодер 202 разностных опорных векторов, который декодирует кодированные данные разностного опорного вектора как разность между опорным вектором, который необходим для формирования прогнозированного изображения, и прогнозированным опорным вектором, декодер 203 дополнительной информации, который декодирует кодированные данные дополнительной информации, состоящей из информации обозначения целевого кадра опорного вектора, информации обозначения опорного кадра и информации обозначения способа формирования прогнозированных изображений, которые необходимы для формирования прогнозированного изображения, формирователь 204 прогнозированных изображений, который формирует прогнозированное изображение целевой области декодирования в соответствии с предоставленной информацией, запоминающее устройство 205 опорных кадров, которое накапливает декодированное изображение, определенное из суммы прогнозированного изображения и декодированного разностного изображения, формирователь 206 прогнозированных опорных векторов, который формирует прогнозированный опорный вектор как прогнозированный вектор опорного вектора, используемого в целевой области декодирования на основе векторной информации, которая использовалась в области, смежной с целевой областью декодирования, запоминающее устройство 207 накопления информации о соответствующих зависимостях, которое сохраняет набор из опорного вектора, опорной области, целевого кадра опорного вектора и опорного кадра, который использовался для релевантного декодирования, в ассоциативной связи с целевым кадром декодирования и целевой областью декодирования, модуль 208 задания целевой области опорного вектора для задания целевой области опорного вектора, которая принадлежит целевому кадру опорного вектора и указывается посредством опорного вектора, определенного посредством суммы прогнозированного опорного вектора и декодированного разностного опорного вектора, и модуль 209 поиска опорных областей для поиска опорной области с помощью информации изображений целевой области опорного вектора и опорного кадра.
Фиг. 12 показывает блок-схему процесса декодирования видео, выполняемого посредством устройства 200 декодирования видео, имеющего вышеописанную структуру.
В соответствии с релевантной блок-схемой способа, процесс декодирования видео, выполняемый посредством сконфигурированного выше устройства 200 декодирования видео, подробнее поясняется, при этом предполагается, что изображения множества кадров уже кодированы, и результаты этого сохранены в запоминающем устройстве 205 опорных кадров и запоминающем устройстве 207 накопления информации о соответствующих зависимостях.
Сначала, кодированные данные разностного изображения, кодированные данные разностного опорного вектора и закодированные данные дополнительной информации вводятся в устройство 200 декодирования видео и отправляются, соответственно, в декодер 201 разностных изображений, декодер 202 разностных опорных векторов и декодер 203 дополнительной информации (S501).
Целевое изображение декодирования полностью делится на области, и каждая область декодируется (S502-S517).
На этой блок-схеме последовательности операций способа blk указывает индекс блока (области), а MaxBlk указывает общее количество блоков в одном изображении. В частности, после инициализации индекса blk равным 1 (S502), следующие процессы (S503-S515) многократно выполняются при увеличении blk на 1 (S517) до тех пор, пока оно не достигает MaxBlk (S516), чтобы декодировать релевантное изображение.
В процессе, выполняемом в каждом блоке, позиция блока blk сохраняется как pos (S503), и прогнозированный опорный вектор pmv формируется с помощью, например, опорного вектора, который сохраняется в запоминающем устройстве 207 накопления информации о соответствующих зависимостях и используется в периферийном блоке вокруг блока blk (S504).
Затем, из кодированных данных, индекс целевого кадра опорного вектора dec_ref_vec, индекс опорного кадра dec_ref, индекс способа формирования прогнозированных изображений dec_pmode, разностный опорный вектор dec_sub_mv_ref и информация изображений Res[] прогнозированного остаточного изображения для блока blk декодируются; опорный вектор dec_mv_ref получается посредством вычисления pmv+dec_sub_mv_ref; и mv инициализируется как нулевой вектор (S505).
Затем определяется nj, совпадает ли dec_ref с dec_ref_vec (S506). Если определено, что они совпадают друг с другом, прогнозированное изображение Pred[] формируется (S512).
Процесс формирования прогнозированного изображения, выполняемый здесь, выполняется в соответствии с вышеописанной процедурой 1, при этом best_ref рассматривается как dec_ref, best_ref_vec рассматривается как dec_ref_vec, best_mv_ref рассматривается как dec_mv_ref, best_pmode рассматривается как dec_pmode, best_ref_mid рассматривается как ref_mid, best_mv_mid рассматривается как mv_mid, и best_mv рассматривается как mv в процедуре 1.
Напротив, если при определении на этапе S506 определено, что dec_ref не совпадает с dec_ref_vec, то затем обнаруживается уже декодированный кадр, где зависимости времени и точек обзора между уже декодированным кадром и кадром, указанным посредством dec_ref_vec, совпадают с зависимостями между целевым кадром декодирования и кадром, указанным посредством dec_ref, и индекс, который указывает уже декодированный кадр, задается как ref_mid (S507).
Если уже декодированный кадр, который удовлетворяет вышеупомянутому условию, отсутствует в запоминающем устройстве 205 опорных кадров, ref_mid задается как dec_ref.
Затем определяется, совпадает ли ref_mid с dec_ref или dec_ref_vec (S508).
Если определено, что они совпадают друг с другом, то вычисляется область, которая принадлежит кадру dec_ref и соответствует области в позиции pos+dec_mv_ref в кадре dec_ref_vec, и mv вычисляется для задания позиции вычисленной области как pos+dec_mv_ref+mv (S509).
Этот процесс тождественен выполняемому на вышеописанном этапе S204 за исключением того, что имена некоторых переменных различаются между этапами.
Напротив, если при определении на этапе S508 определено, что ref_mid не совпадает с dec_ref или с dec_ref_vec, то сначала вычисляется область, которая принадлежит кадру ref_mid и соответствует области в позиции pos+dec_mv_ref в кадре dec_ref_vec, и mv_mid вычисляется для задания позиции вычисленной области как pos+dec_mv_ref+mv_mid (S510).
Во-вторых, вычисляется область, которая принадлежит кадру dec_ref и соответствует области в позиции pos+dec_mv_ref+mv_mid в кадре ref_mid, и mv вычисляется для задания позиции вычисленной области как pos+dec_mv_ref+mv (S3511).
Вышеуказанный процесс тождественен выполняемому на вышеописанных этапах S304 и S305 за исключением того, что имена некоторых переменных различаются между соответствующими этапами.
После того как процесс S509 или S511 завершен, прогнозированное изображение Pred[] формируется с помощью полученной информации (S512).
Как описано выше, выполняемый здесь процесс формирования прогнозированного изображения выполняется в соответствии с вышеописанной процедурой 1, при этом best_ref рассматривается как dec_ref, best_ref_vec рассматривается как dec_ref_vec, best_mv_ref рассматривается как dec_mv_ref, best_pmode рассматривается как dec_pmode, best_ref_mid рассматривается как ref_mid, best_mv_mid рассматривается как mv_mid, и best_mv рассматривается как mv в процедуре 1.
После того как прогнозированное изображение Pred[] сформировано, значения пикселов Pred[] и Res[] добавляются друг к другу для каждого пиксела, так что формируется декодированное изображение Dec[] (S513). Сформированное Dec[] выводится и одновременно сохраняется в запоминающем устройстве 205 опорных кадров (S514).
Помимо этого, dec_ref_vec, dec_ref, dec_mv_ref, dec_pmode и mv, которые использовались для декодирования, сохраняются в запоминающем устройстве 207 накопления информации о соответствующих зависимостях в ассоциативной связи с индексом целевого кадра декодирования и pos (или blk) (S515).
При декодировании кодированных данных дополнительной информации на S505 декодирование выполняется при переключении таблицы кодовых слов, аналогично вышеописанным способам для кодирования.
Здесь, перед декодированием кодированных данных дополнительной информации, кодированные данные разностного опорного вектора декодируются, и таким образом получается опорный вектор, используемый в блоке blk.
Сначала декодируется dec_ref_vec.
Весьма вероятно то, что кадр, указанный посредством dec_ref_vec, является кадром, который использовался как целевой кадр опорного вектора в смежной области блока blk, или соответствует кадру, смежному с целевым кадром кодирования. Следовательно, также высока вероятность того, что индексы кадров, соответствующие таким кадрам, кодированы, и таблица кодовых слов переключается так, чтобы более короткие кодовые слова назначались релевантным индексам кадра по сравнению с назначаемыми индексами кадра, соответствующими другим кадрам.
Затем, кодируется dec_ref. Здесь, таблица кодовых слов переключается с помощью уже декодированного dec_ref_vec и опорного вектора.
Таким образом, используя информацию кодирования целевой области опорного вектора, которая принадлежит кадру dec_ref_vec и указывается посредством опорного вектора, таблица кодовых слов переключается так, чтобы короткое кодовое слово назначалось индексу кадра, который должен часто появляться.
Например, если внутреннее кодирование является наиболее часто используемым в целевой области опорного вектора, хотя кадр dec_ref_vec не является I-кадром, это представляет то, что нет области в другом кадре, которая имеет информацию изображений, близко к информации целевой области опорного вектора. Следовательно, высока вероятность того, что dec_ref становится равным dec_ref_vec. В таком случае, используется таблица кодовых слов, в которой короткое кодовое слово назначается тому же индексу кадра, как и dec_ref_vec.
Аналогично, для кадра, используемого в качестве опорного кадра или целевого кадра опорного вектора при декодировании целевой области опорного вектора, чем более широкой является используемая часть релевантного кадра, тем выше вероятность того, что релевантный кадр выбирается как dec_ref. Следовательно, используется таблица кодовых слов, в которой кодовое слово назначается кадру в соответствии с релевантной вероятностью.
В завершение, декодируется dec_pmode. Таблица кодовых слов переключается с помощью уже декодированного dec_ref_vec и dec_ref и информации о кадре в запоминающем устройстве 205 опорных кадров.
Например, если dec_ref_vec и dec_ref совпадают друг с другом, это представляет то, что только одна соответствующая область может быть получена для блока blk, и таким образом значение dec_pmode, отличное от 1, не имеет смысла. Следовательно, определяется то, что dec_pmode не включается в кодированные данные, и декодированное значение задается как 1.
Напротив, если dec_ref_vec и dec_ref не совпадают друг с другом, возможность того, что 1 выбрано как dec_pmode, должна быть очень низкой. Следовательно, таблица кодовых слов, в которой короткое кодовое слово назначается каждому значению dec_pmode, отличному от 1, используется.
Дополнительно, если только два кадра сохранены в запоминающем устройстве опорных кадров или если соответствующий промежуточный кадр для комбинации dec_ref_vec и dec_ref не сохранены в запоминающем устройстве 205 опорных кадров, то способ формирования прогнозированных изображений, который требует трех соответствующих областей, не может использоваться. Следовательно, таблица кодовых слов переключается так, чтобы короткое кодовое слово назначалось другим способам формирования прогнозированных изображений.
Тем не менее, таблица кодовых слов и критерий для переключения таблицы, используемой здесь, должны соответствовать применяемым в соответствующем кодировании.
Дополнительно, как пояснено в варианте осуществления устройства 100 кодирования видео, вместо кодирования по отдельности элементов дополнительной информации, число может быть назначено каждой комбинации вышеозначенного, чтобы кодировать число. В таком случае, декодирование также выполняется с учетом того, что число назначено каждой комбинации.
Хотя настоящее изобретение пояснено в соответствии с вариантами осуществления, настоящее изобретение не ограничивается вариантами осуществления.
Например, в вариантах осуществления, промежуточный кадр всегда является кадром, который удовлетворяет тому, что зависимости времени и точек обзора между этим кадром и целевым кадром опорного вектора совпадают с зависимостями между целевым кадром кодирования или декодирования и опорным кадром.
Тем не менее, кадр, заданный посредством другого условия, может использоваться, хотя стороны кодирования и декодирования должны иметь одинаковое условие.
Например, промежуточный кадр может быть задан равным одному из (i) кадра, имеющего время отображения, равное времени целевого кадра опорного вектора, и информацию о точке обзора, равную информации опорного кадра, и (ii) кадра, имеющего время отображения, равное времени из опорного кадра, и информацию о точке обзора, равную информации целевого кадра опорного вектора, при этом между двумя кадрами выбирается одно из наличия времени отображения и информации о точке обзора ближе к таковым из целевого кадра кодирования или декодирования.
При использовании промежуточного кадра, выбранного выше, изменение изображения от целевого кадра опорного вектора на промежуточный кадр и изменение изображения от промежуточного кадра на опорный кадр вызываются посредством любого из временного фактора или фактора камеры, так чтобы объем вычислений, требуемый для поиска соответствующей области, мог быть уменьшен.
Также при использовании промежуточного кадра, выбранного выше, вероятность того, что информация изображения, сформированного посредством способа формирования прогнозированных изображений, когда pmode=5, является близкой к информации изображений целевой области кодирования (или декодирования), уменьшается. Это обусловлено тем, что допущение, предоставляемое посредством релевантного способа формирования прогнозированных изображений, не удовлетворено.
В таком случае, (i) другое условие может быть применено так, что релевантный способ формирования прогнозированных изображений может быть выбран только при удовлетворении условию, допускаемому посредством способа формирования прогнозированных изображений так, что зависимость между опорным кадром и целевым кадром кодирования совпадает с зависимостью между промежуточным кадром (выбранным посредством релевантного способа) и целевым кадром опорного вектора, или (ii), таблица кодовых слов может быть переключена в зависимости от того, удовлетворяется ли это допустимое условие, чтобы назначить более короткое кодовое слово способу формирования прогнозированных изображений, который выбирается чаще, чем другие способы.
Кроме того, хотя варианты осуществления не упоминают внутрикадровое кодирование, оно может легко быть добавлено в качестве способа формирования прогнозированного изображения, например, посредством выделения другого числа в качестве способа формирования прогнозированных изображений.
Помимо этого, устройство кодирования видео или устройство декодирования видео, реализованное посредством отдельного предоставления режимов кодирования (как в H.264) вместо предоставления способов формирования прогнозированных изображений, также может быть легко выведено из настоящего изобретения.
Процессы кодирования и декодирования видео, описанные выше, также могут быть реализованы посредством компьютерной программы. Такая компьютерная программа может быть предоставлена посредством сохранения на соответствующем машиночитаемом носителе хранения данных или посредством сети.
Хотя устройства кодирования и декодирования видео главным образом поясняются в вышеописанных вариантах осуществления, способы кодирования и декодирования видео настоящего изобретения могут быть реализованы с помощью этапов, соответствующих работе каждого модуля, включенного устройства кодирования и декодирования видео.
Хотя варианты осуществления настоящего изобретения описаны со ссылкой на чертежи, следует понимать, что они являются примерными вариантами осуществления изобретения и не должны рассматриваться как ограничивающие.
Следовательно, добавления, исключения или замены структурных элементов, а также другие модификации для вышеописанных вариантов осуществления могут быть сделаны без отступления от сущности и объема настоящего изобретения.
Промышленная применимость
В соответствии с настоящим изобретением, даже когда опорный кадр, используемый для формирования прогнозированного изображения, отличается между смежными областями, используется один и тот же целевой кадр опорного вектора, так что основной фактор (время или диспаратность), который вызывает изменение изображения и должен быть представлен вектором, унифицируется, и прогнозированный вектор рядом с вектором, который должен быть кодирован, может быть сформирован с помощью уже кодированного вектора в смежной области. Следовательно, векторная информация для межкадрового прогнозирующего кодирования может быть кодирована с меньшим объемом кода.
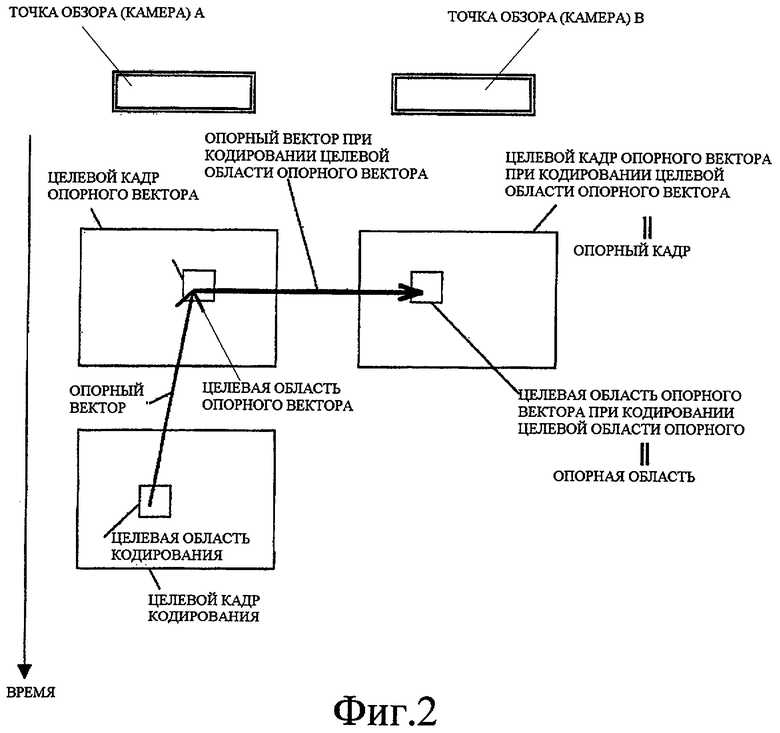
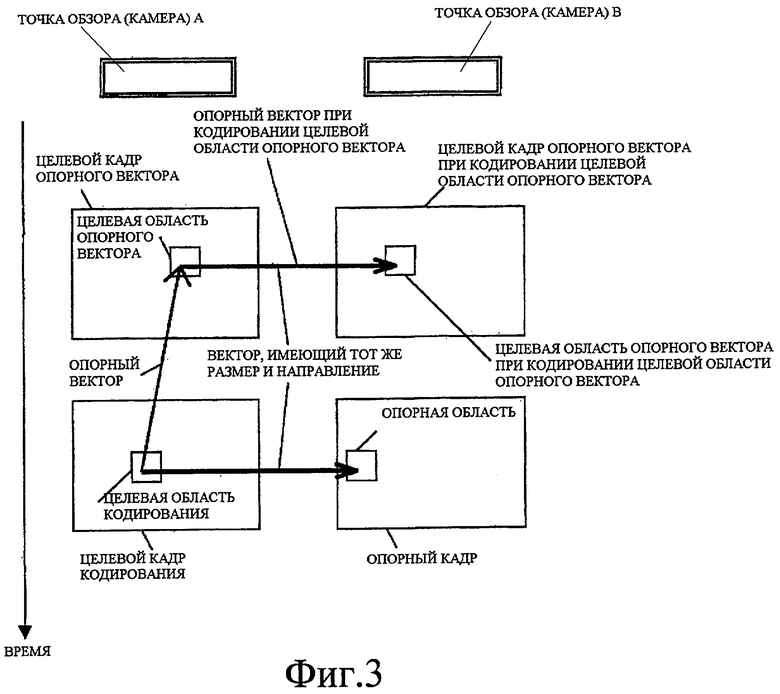
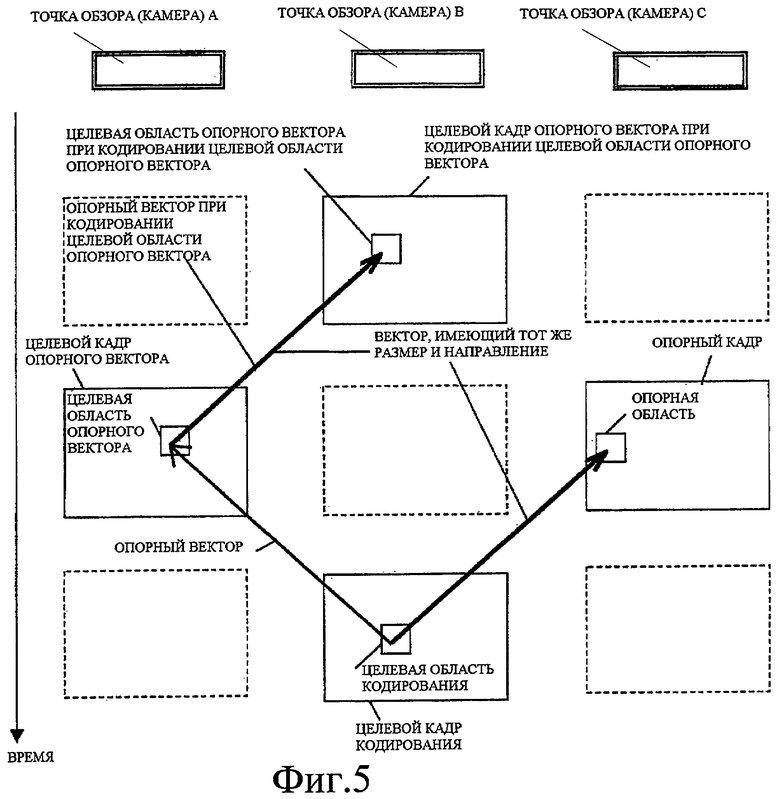
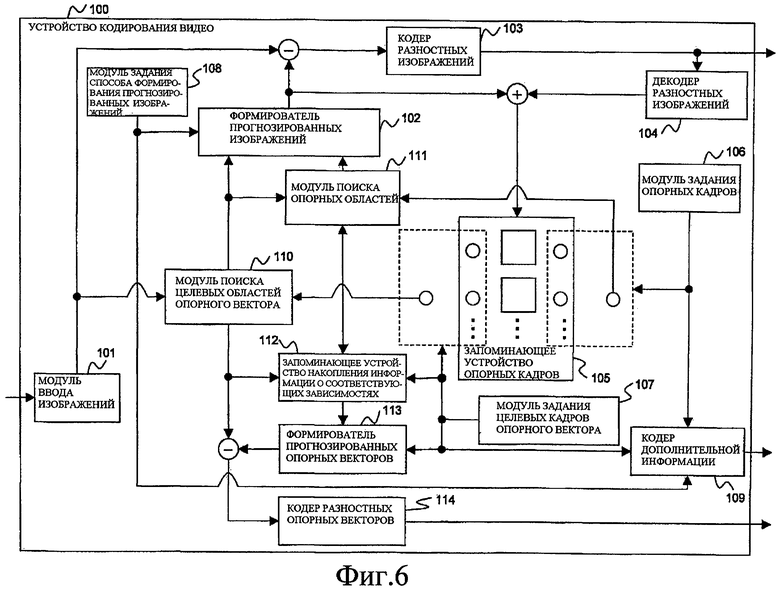
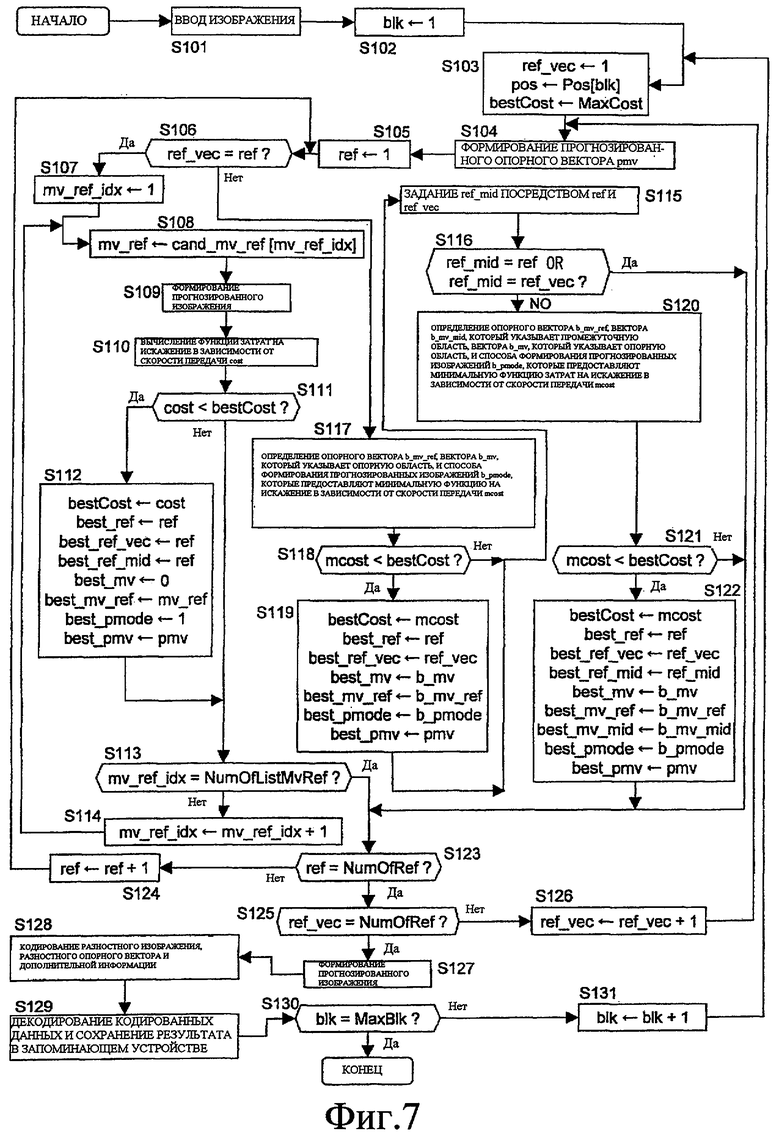
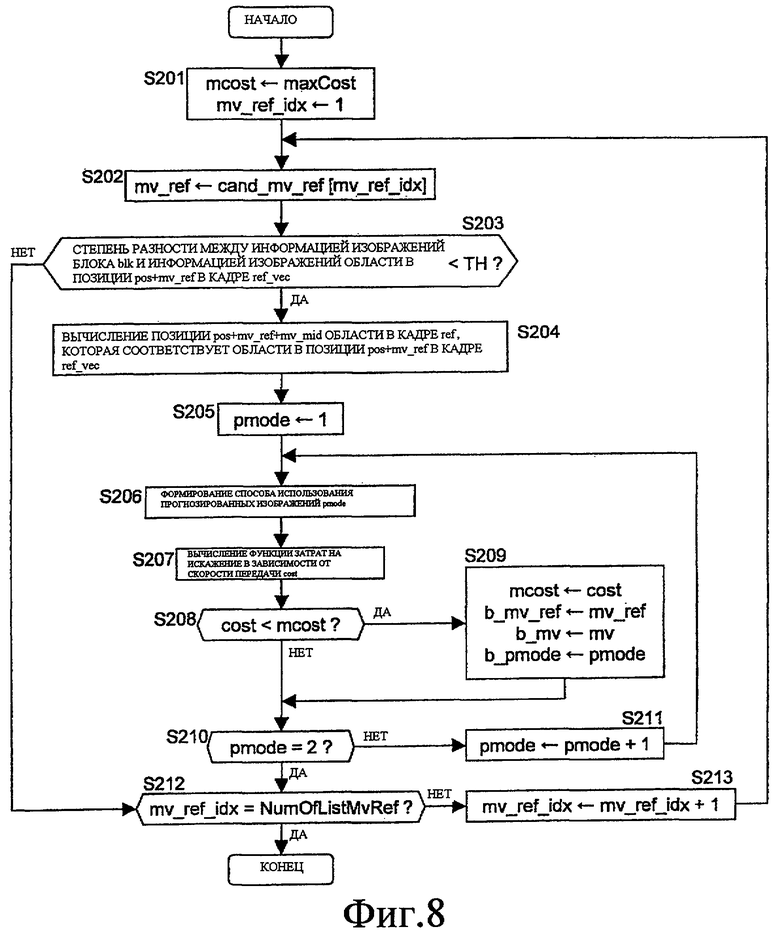
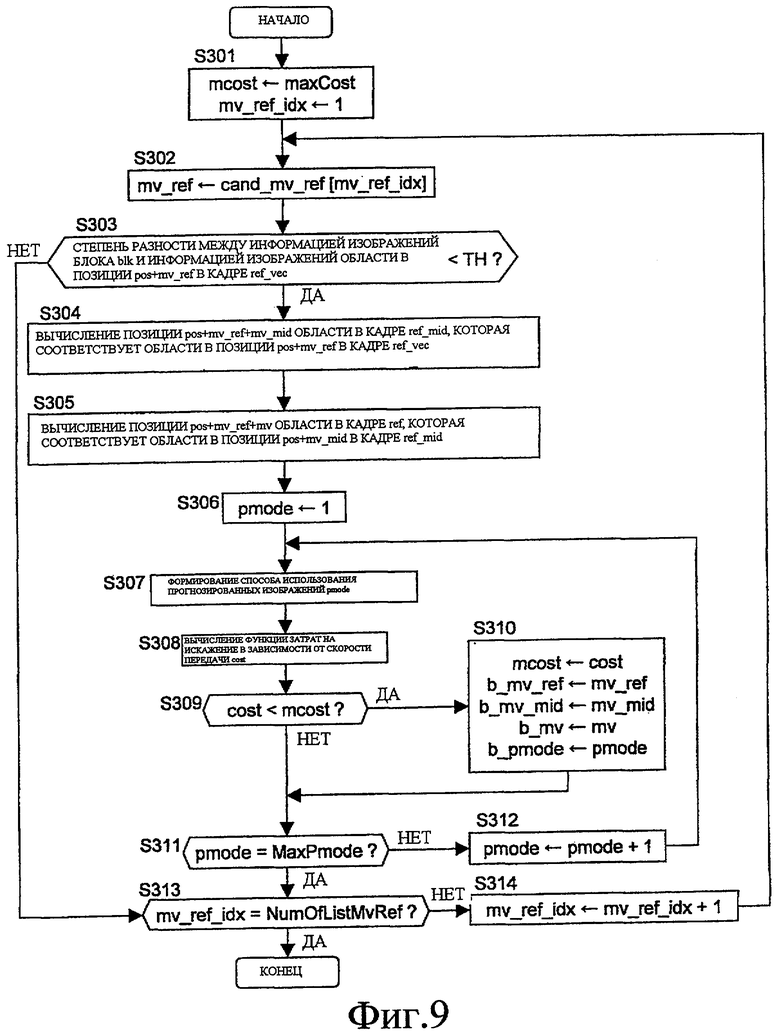
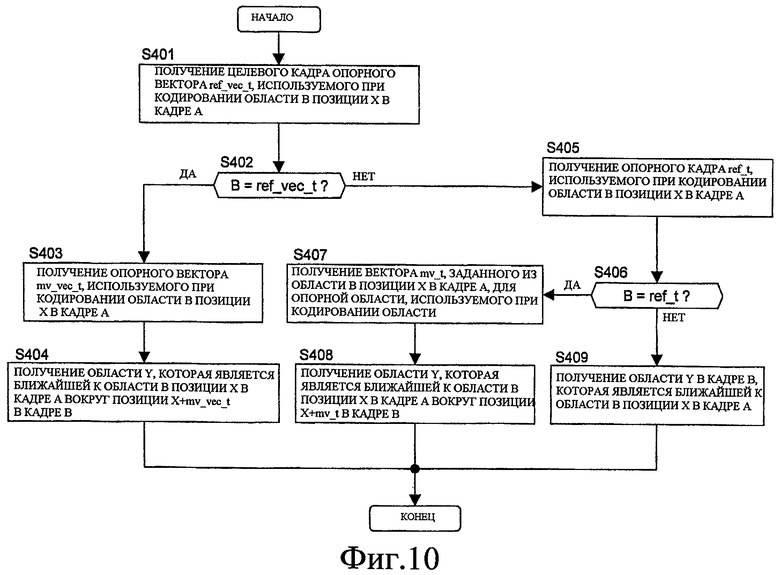
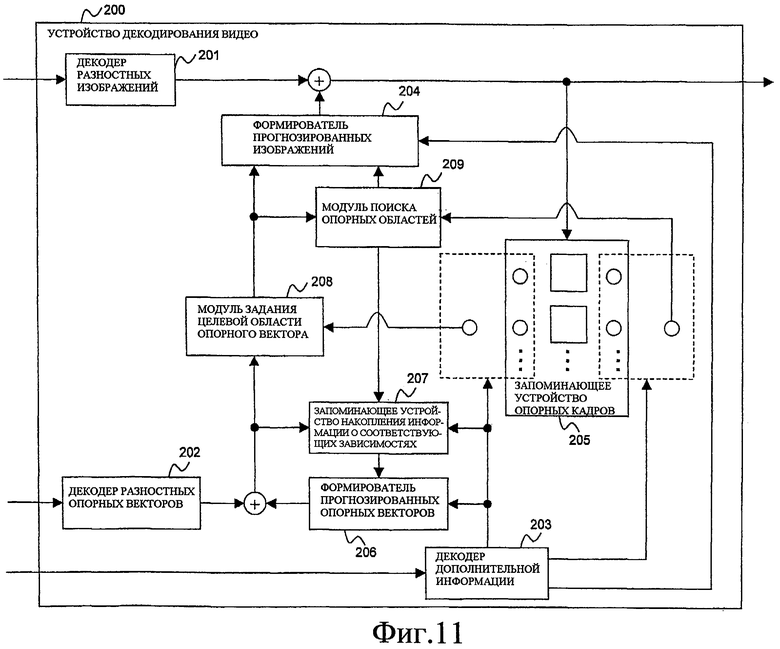
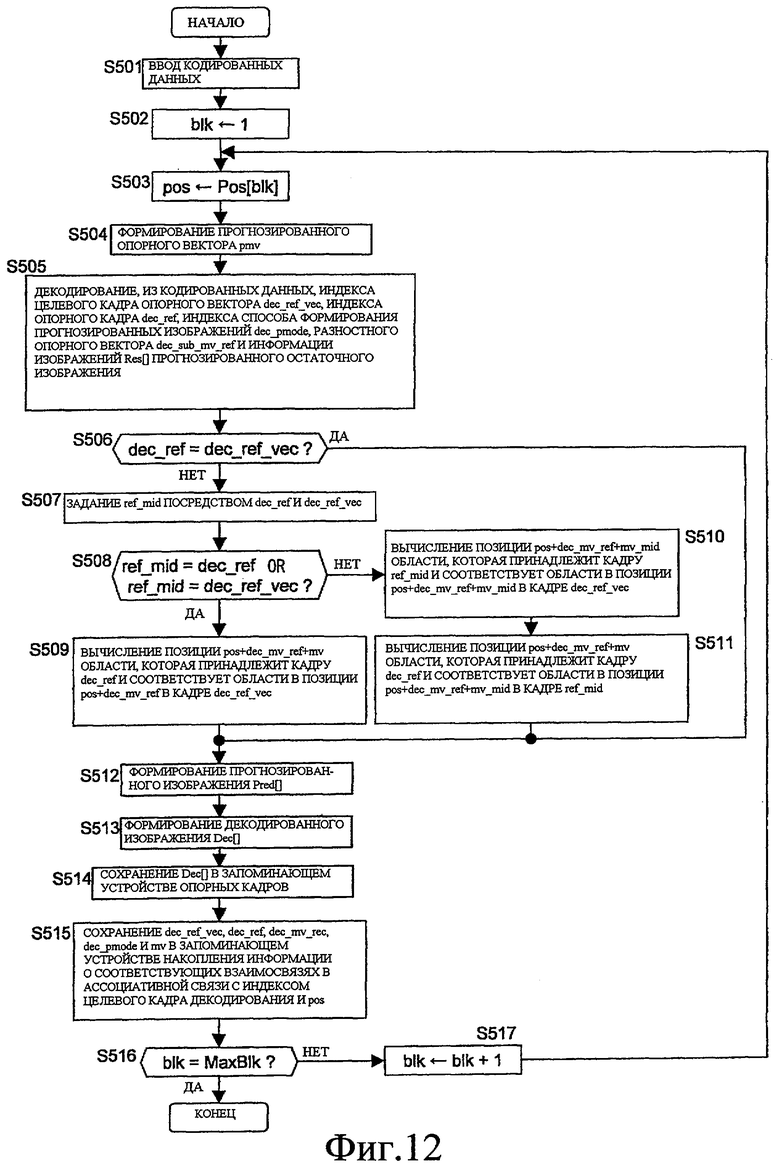
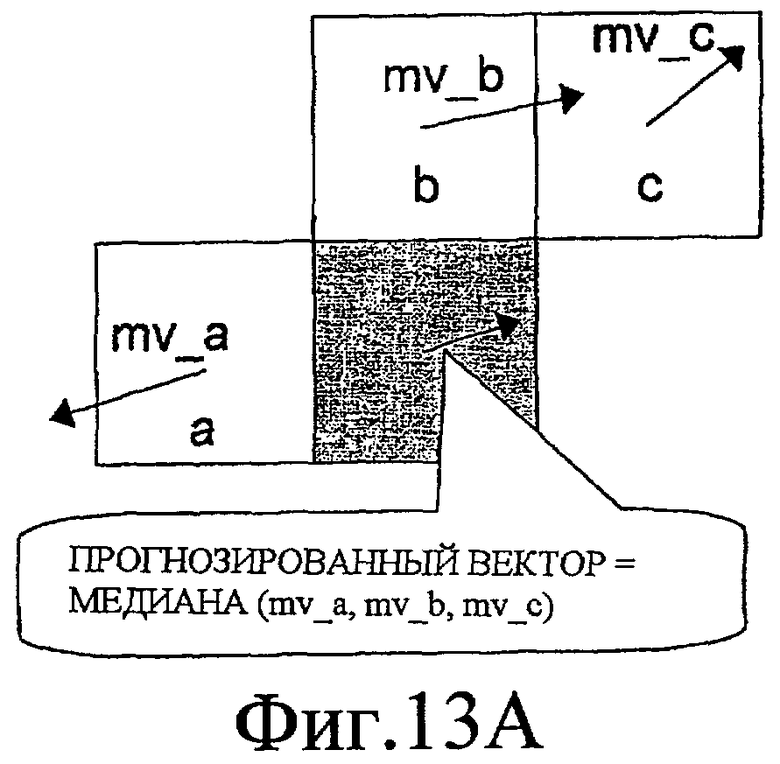
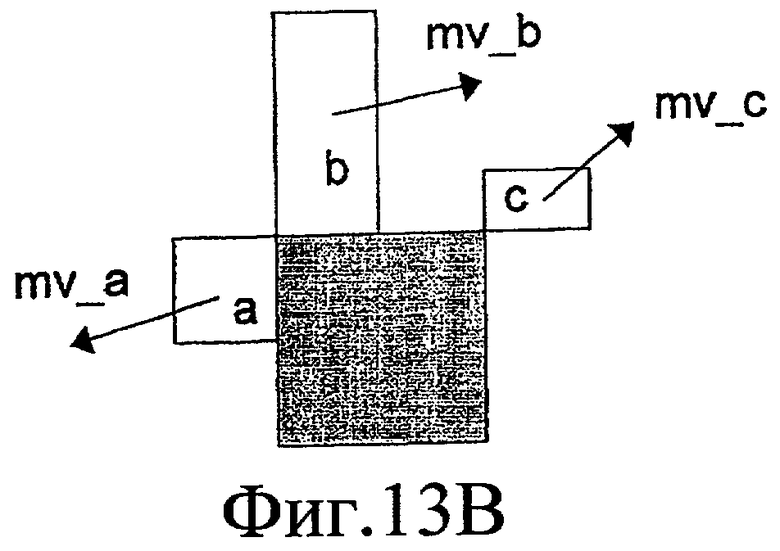
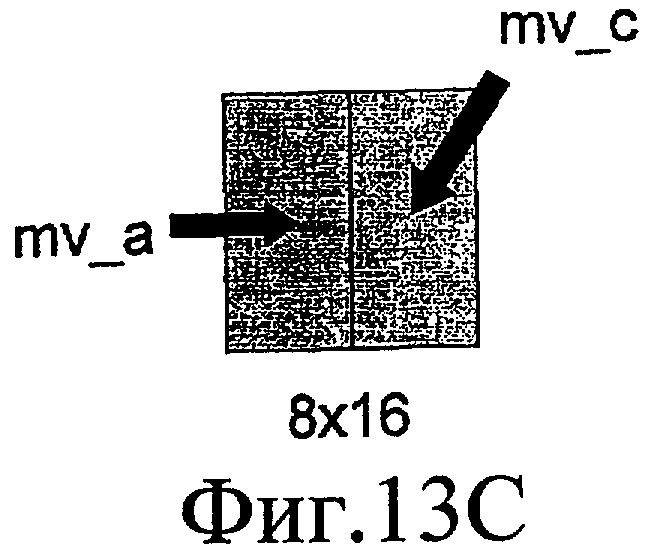
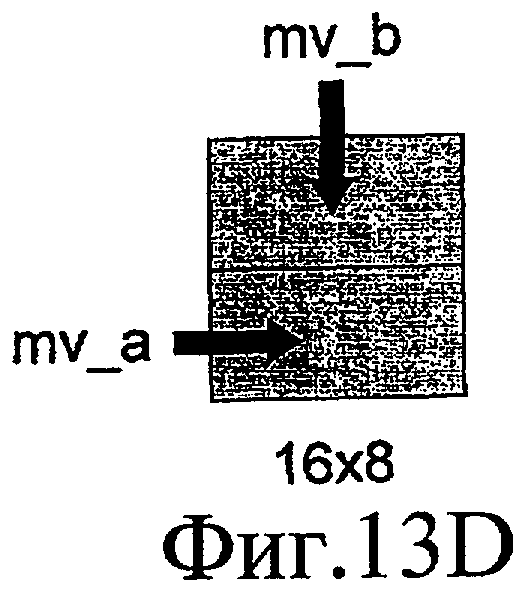
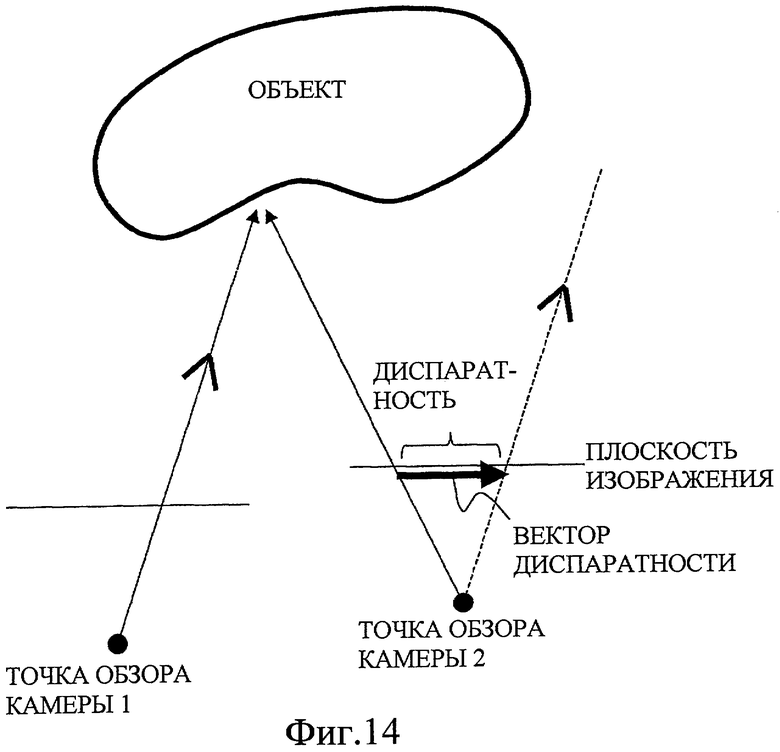
Изобретение относится к кодированию/декодированию видео с несколькими точками обзора с помощью способа межкадрового прогнозирующего кодирования. Техническим результатом является обеспечение эффективного кодирования векторной информации, используемой для межкадрового прогнозирующего кодирования, даже когда опорный кадр, используемый в межкадровом прогнозирующем кодировании, отличается между целевой областью кодирования и ее смежной областью. Указанный технический результат достигается тем, что осуществляют выбор целевого кадра опорного вектора и опорного кадра из числа уже кодированных кадров; кодирование информации для обозначения каждого кадра; задание опорного вектора для указания области в целевом кадре опорного вектора относительно целевой области кодирования; кодирование опорного вектора; выполнение поиска соответствующих областей с помощью информации изображений целевой области опорного вектора, которая принадлежит целевому кадру опорного вектора и указывается посредством опорного вектора и опорного кадра; определение опорной области в опорном кадре на основе результата поиска; формирование прогнозированного изображения с помощью информации изображений опорного кадра, который соответствует опорной области; и кодирование разностной информации между информацией изображений целевой области кодирования и прогнозированным изображением. 6 н. и 18 з.п. ф-лы, 14 ил.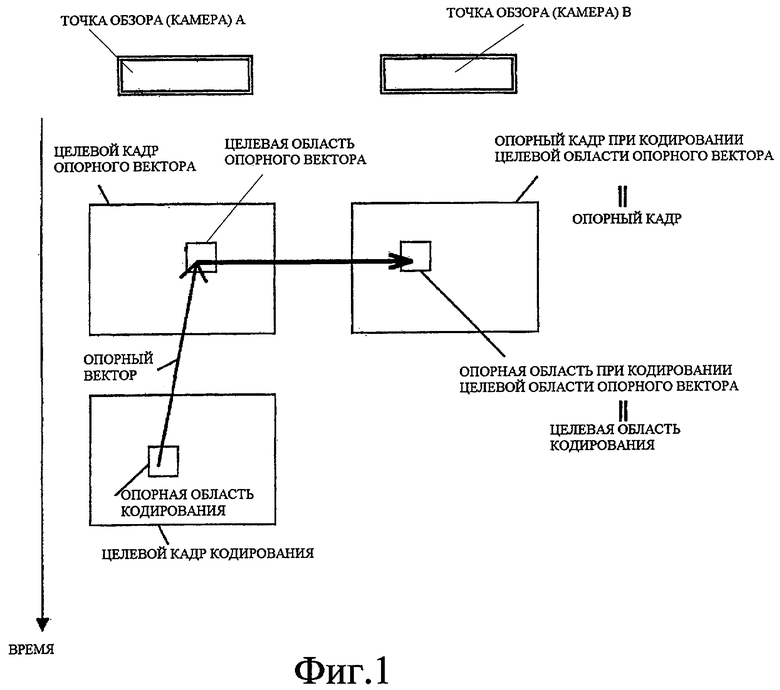
1. Способ кодирования видео для кодирования видеоизображения посредством деления всего изображения на области, формирования прогнозированного изображения для каждой области разделенного изображения на основе информации изображений множества уже кодированных кадров и кодирования разностной информации между изображением целевой области кодирования в целевом кадре кодирования и прогнозированным изображением, при этом способ кодирования видео содержит:
этап (S103 - S126) выбора целевого кадра опорного вектора, на котором выбирают целевой кадр опорного вектора, указанный опорным вектором целевой области кодирования, из числа уже кодированных кадров;
этап (S105 - S124) сопоставления, на котором выбирают опорный кадр из уже кодированных кадров и устанавливают целевую область опорного вектора, которая принадлежит целевому кадру опорного вектора и имеет тот же размер, что и целевая область кодирования, таким образом, что ошибка в совпадении между информацией изображения целевой области кодирования и информацией изображения опорной области в опорном кадре минимизируется, где информация изображения опорной области соответствует информации изображения целевой области опорного вектора ввиду поблочного сопоставления;
этап (S107) формирования прогнозированного опорного вектора, на котором формируют прогнозированный опорный вектор как прогнозированный вектор опорного вектора целевой области кодирования, с использованием целевого кадра опорного вектора целевой области кодирования и опорного вектора и целевого кадра опорного вектора, которые используются при кодировании смежной области целевой области кодирования;
этап (S128) кодирования информации обозначения целевого кадра опорного вектора, на котором кодируют информацию, которая обозначает целевой кадр опорного вектора целевой области кодирования;
этап (S128) кодирования разностного опорного вектора, на котором кодируют разностный вектор между опорным вектором и прогнозированным опорным вектором кодированной целевой области;
этап (S128) кодирования информации обозначения опорного кадра, на котором кодируют информацию, которая обозначает опорный кадр;
этап (S127) формирования прогнозированного изображения, на котором формируют прогнозированное изображение с помощью информации изображения опорной области в опорном кадре; и
этап (S128) кодирования разностной информации, на котором кодируют разностную информацию между информацией изображения целевой области кодирования и сформированного прогнозированного изображения.
2. Способ кодирования видео по п.1, в котором:
на этапе формирования прогнозированного изображения прогнозированное изображение формируется с помощью информации изображения опорной области и информации изображения целевой области опорного вектора.
3. Способ кодирования видео по п.1, в котором:
на этапе формирования прогнозированного изображения выбирают, формируется ли прогнозированное изображение с помощью информации изображения опорной области или с помощью информации изображения опорной области и информации изображения целевой области опорного вектора, и прогнозированное изображение формируют посредством выбранного способа формирования; и
способ кодирования видео дополнительно содержит:
этап кодирования информации обозначения способа формирования прогнозированного изображения, на котором кодируют информацию, которая обозначает выбранный способ формирования.
4. Способ кодирования видео по п.1, в котором:
если опорный кадр, выбранный на этапе сопоставления, является опорным кадром, который использовался при кодировании целевой области опорного вектора, то опорная область опорного кадра является опорной областью, которая использовалась при кодировании целевой области опорного вектора.
5. Способ кодирования видео по п.1, в котором:
если опорный кадр, выбранный на этапе сопоставления, является целевым кадром опорного вектора, который использовался при кодировании целевой области опорного вектора, то опорная область опорного кадра является целевой областью опорного вектора, которая использовалась при кодировании целевой области опорного вектора.
6. Способ кодирования видео по п.1, в котором:
если опорный кадр, выбранный на этапе сопоставления, является уже кодированным кадром, где зависимости информации по времени и точкам обзора между этим уже кодированным кадром и целевым кадром кодирования совпадают с зависимостями между целевым кадром опорного вектора, который использовался при кодировании целевой области опорного вектора, и целевым кадром опорного вектора, установленным для целевой области кодирования, то опорная область опорного кадра является областью, которая принадлежит выбранному опорному кадру и указывается вектором, начальная точка которого установлена в целевой области кодирования и который имеет такие же направление и размер, как и опорный вектор, который использовался при кодировании целевой области опорного вектора.
7. Способ кодирования видео по п.1, в котором:
если опорный кадр, выбранный на этапе сопоставления, является уже кодированным кадром, где зависимости информации по времени и точкам обзора между этим уже кодированным кадром и целевым кадром кодирования совпадают с зависимостями между опорным кадром, который использовался при кодировании целевой области опорного вектора, и целевым кадром опорного вектора, установленным для целевой области кодирования, то опорная область опорного кадра является областью, которая принадлежит выбранному опорному кадру и указывается вектором, начальная точка которого установлена в целевой области кодирования и который имеет такие же направление и размер, как и вектор, который указывает соответствующую зависимость между целевой областью опорного вектора и опорной областью, которая использовалась при кодировании целевой области опорного вектора.
8. Способ кодирования видео по п.1, в котором видеоизображение является видеоизображением с несколькими точками обзора, полученным посредством множества камер, причем способ кодирования видео дополнительно содержит:
этап (S115) установки промежуточного кадра, на котором устанавливают промежуточный кадр, который имеет то же положение, что и целевой кадр опорного вектора для одного из факторов времени и размещения между камерами, и имеет то же положение, что и опорный кадр для другого из факторов времени и положения между камерами, и уже закодирован, при этом:
на этапе сопоставления опорный кадр выбирают и целевую область опорного вектора устанавливают таким образом, что ошибка в совпадении между информацией изображения целевой области кодирования и информацией изображения опорной области в опорном кадре минимизируется, где информация изображения опорной области соответствует информации изображения промежуточной области в промежуточном кадре ввиду поблочного сопоставления и информация области в промежуточном кадре соответствует информации изображения целевой области опорного вектора ввиду поблочного сопоставления.
9. Способ кодирования видео по п.8, в котором:
на этапе формирования прогнозированного изображения выбирают, формируется ли прогнозированное изображение с помощью информации изображения опорной области, с помощью информации изображения опорной области и информации изображения целевой области опорного вектора или с помощью информации изображения опорной области, информации изображения промежуточной области и информации изображения целевой области опорного вектора, и прогнозированное изображение формируют посредством выбранного способа формирования; и
способ кодирования видео дополнительно содержит:
этап кодирования информации обозначения способа формирования прогнозированного изображения, на котором кодируют информацию, которая обозначает выбранный способ формирования.
10. Способ кодирования видео по п.3 или 9, в котором:
на этапе кодирования информации обозначения опорного кадра таблица кодовых слов, используемая для кодирования информации, которая обозначает опорный кадр, переключается на основе кодированных данных целевой области опорного вектора; и
на этапе кодирования информации обозначения способа формирования прогнозированного изображения таблица кодовых слов, используемая для кодирования информации, которая обозначает выбранный способ формирования, переключается на основе по меньшей мере одного из кодированных данных целевой области опорного вектора, опорного кадра и целевого кадра опорного вектора.
11. Способ декодирования видео для декодирования видеоизображения посредством деления всего изображения на области, формирования прогнозированного изображения для каждой области разделенного изображения на основе информации изображений множества уже декодированных кадров и декодирования разностной информации между прогнозированным изображением и изображением целевой области декодирования в целевом кадре декодирования, при этом способ декодирования видео содержит:
этап (S505) декодирования информации обозначения целевого кадра опорного вектора, на котором декодируют, из кодированных данных, информацию, которая обозначает целевой кадр опорного вектора, который выбран из числа уже декодированных кадров и указан опорным вектором целевой области декодирования;
этап (S504) формирования прогнозированного опорного вектора, на котором формируют прогнозированный опорный вектор как прогнозированный вектор опорного вектора целевой области декодирования с использованием целевого кадра опорного вектора целевой области декодирования и опорного вектора и целевого кадра опорного вектора, которые использованы при декодировании смежной области целевой области декодирования;
этап (S505) декодирования разностного опорного вектора, на котором декодируют, из кодированных данных, разностный вектор, соответствующий разности между опорным вектором и прогнозированным опорным вектором декодированной целевой области;
этап (S505) формирования опорного вектора, на котором формируют опорный вектор целевой области декодирования с использованием прогнозированного опорного вектора и разностного вектора;
этап декодирования информации обозначения опорного кадра, на котором декодируют, из кодированных данных, информацию, которая обозначает опорный кадр, выбранный из числа уже декодированных кадров;
этап (S509 или S511) установки области опорного кадра, на котором устанавливают опорную область в опорном кадре таким образом, что ошибка в поблочном сопоставлении между информацией изображения опорной области и информацией изображения целевой области опорного вектора, которая принадлежит целевому кадру опорного вектора целевой области декодирования и указана опорным вектором целевой области декодирования, минимизирована; и
этап формирования прогнозированного изображения, на котором формируют прогнозированное изображение с помощью информации изображения опорного кадра, которая соответствует опорной области.
12. Способ декодирования видео по п.11, в котором:
на этапе формирования прогнозированного изображения прогнозированное изображение формируют с помощью информации изображения опорной области и информации изображения целевой области опорного вектора.
13. Способ декодирования видео по п.11, дополнительно содержащий:
этап декодирования информации обозначения способа формирования прогнозированного изображения, на котором декодируют, из кодированных данных, информацию, которая обозначает, формируется ли прогнозированное изображение с помощью информации изображения опорной области или с помощью информации изображения опорной области и информации изображения целевой области опорного вектора, при этом:
на этапе формирования прогнозированного изображения прогнозированное изображение формируют посредством способа формирования, обозначенного посредством декодированной информации.
14. Способ декодирования видео по п.11, в котором:
если кадр, указанный посредством информации обозначения опорного кадра, которая была декодирована при декодировании целевой области опорного вектора, совпадает с опорным кадром, то на этапе установки области опорного кадра опорная область, которая использовалась при декодировании целевой области опорного вектора, устанавливается в качестве опорной области.
15. Способ декодирования видео по п.11, в котором:
если кадр, указанный посредством информации обозначения целевого кадра опорного вектора, которая была декодирована при декодировании целевой области опорного вектора, совпадает с опорным кадром, то на этапе установки области опорного кадра целевая область опорного вектора, которая использовалась при декодировании вышеупомянутой целевой области опорного вектора, устанавливается в качестве опорной области.
16. Способ декодирования видео по п.11, в котором:
если зависимости информации по времени и точкам обзора между целевым кадром опорного вектора и кадром, указанным посредством информации обозначения целевого кадра опорного вектора, которая была декодирована при декодировании целевой области опорного вектора, совпадают с зависимостями между целевым кадром декодирования и опорным кадром, то на этапе установки области опорного кадра область, которая принадлежит опорному кадру и указывается вектором, начальная точка которого установлена в целевой области декодирования и который имеет такие же направление и размер, как и опорный вектор, который использовался при декодировании целевой области опорного вектора, устанавливается в качестве опорной области.
17. Способ декодирования видео по п.11, в котором:
если зависимости информации по времени и точкам обзора между целевым кадром опорного вектора и кадром, указанным посредством информации обозначения опорного кадра, которая была декодирована при декодировании целевой области опорного вектора, совпадают с зависимостями между целевым кадром декодирования и опорным кадром, то на этапе установки области опорного кадра область, которая принадлежит опорному кадру и указывается вектором, начальная точка которого установлена в целевой области декодирования и который имеет такие же направление и размер, как и вектор, который указывает соответствующую зависимость между целевой областью опорного вектора и опорной областью, которая использовалась при декодировании целевой области опорного вектора, устанавливается в качестве опорной области.
18. Способ декодирования видео по п.11, в котором видеоизображение является видеоизображением с несколькими точками обзора, полученным посредством множества камер, причем способ декодирования видео дополнительно содержит:
этап установки промежуточного кадра, на котором устанавливают промежуточный кадр, который имеет то же положение, что и целевой кадр опорного вектора, для одного из факторов времени и размещения между камерами и имеет то же положение, что и опорный кадр, для другого из факторов времени и размещения между камерами, и уже декодирован, при этом:
на этапе установки области опорного кадра опорную область устанавливают таким образом, что ошибка в поблочном сопоставлении между информацией изображения опорной области и информацией изображения промежуточной области в промежуточном кадре минимизируется, причем информация изображения промежуточной области соответствует информации изображения целевой области опорного вектора ввиду поблочного сопоставления.
19. Способ декодирования видео по п.18, в котором:
способ декодирования видео дополнительно содержит:
этап декодирования информации обозначения способа формирования прогнозированного изображения, на котором декодируют, из кодированных данных, информацию, которая обозначает, формируется ли прогнозированное изображение с помощью информации изображения опорной области, с помощью информации изображения опорной области и информации изображения целевой области опорного вектора или с помощью информации изображения опорной области, информации изображения промежуточной области и информации изображения целевой области опорного вектора; и
на этапе формирования прогнозированного изображения прогнозированное изображение формируют с помощью способа формирования, обозначенного посредством декодированной информации.
20. Способ декодирования видео по п.13 или 19, в котором:
на этапе декодирования информации обозначения опорного кадра таблица кодовых слов, используемая для декодирования информации, которая обозначает опорный кадр, переключается на основе декодированных данных целевой области опорного вектора и
на этапе декодирования информации обозначения способа формирования прогнозированного изображения таблица кодовых слов, используемая для декодирования информации, которая обозначает способ формирования прогнозированного изображения, переключается на основе по меньшей мере одного из декодированных данных целевой области опорного вектора, опорного кадра и целевого кадра опорного вектора.
21. Устройство (100) кодирования видео, имеющее устройства для выполнения этапов в способе кодирования видео по п.1.
22. Машиночитаемый носитель хранения данных, который сохраняет программу кодирования видео, посредством которой компьютер выполняет этапы в способе кодирования видео по п.1.
23. Устройство (200) декодирования видео, имеющее устройства для выполнения этапов в способе декодирования видео по п.11.
24. Машиночитаемый носитель хранения данных, который сохраняет программу декодирования видео, посредством которой компьютер выполняет этапы в способе декодирования видео по п.11.
| S-H LEE et al | |||
| Disparity vector prediction methods in MVC, ITU STUDY GROUP 16 -VIDEO CODING EXPERTS GROUP - ISO/IEC MPEG & ITU-T VCEG, JVT-U040, 21st Meeting: Hangzhou, China, 20-27 October 2006 | |||
| WO 2006016418 A1, 2006.02.16 | |||
| WO 2006001653 A1, 2006.01.05 | |||
| US 2005031035 A1, 2005.02.10 | |||
| WO 2006073116 A1, 2006.07.13 | |||
| УСТРОЙСТВО И СПОСОБ ПРЕДСТАВЛЕНИЯ ТРЕХМЕРНОГО ОБЪЕКТА НА ОСНОВЕ ИЗОБРАЖЕНИЙ С ГЛУБИНОЙ | 2002 |
|
RU2237283C2 |
| RU | |||

