ОБЛАСТЬ ТЕХНИКИ
Настоящий документ относится к вычислительным системам, а именно к системам и способам верификации результатов оптического распознавания символов.
УРОВЕНЬ ТЕХНИКИ
Оптическое распознавание символов (OCR) представляет собой реализованное вычислительными средствами преобразование изображений текстов (включая типографский, рукописный или печатный текст) в машиночитаемые электронные документы.
КРАТКОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Одним из вариантов реализации изобретения является способ, включающий: оптическое распознавание символов на одном или более исходных изображениях документа с целью получения исходных результатов оптического распознавания символов и демонстрации исходных результатов оптического распознавания символов документа пользователю; получение от пользователя отклика, содержащего местоположение ошибки в исходных результатах оптического распознавания символов, при этом местоположение ошибки представляет собой положение последовательности неверно распознанных символов в исходных результатах оптического распознавания символов; получение дополнительного изображения документа, при этом дополнительное изображение содержит часть документа, которая соответствует местоположению ошибки, и выполнение оптического распознавания символов дополнительного изображения для получения дополнительных результатов оптического распознавания символов; выявление кластера символьных последовательностей, которые соответствуют местоположению ошибки, с использованием исходных результатов оптического распознавания символов и дополнительных результатов оптического распознавания символов; выявление порядка символьных последовательностей в кластере символьных последовательностей на основе соответствующих им значений вероятности; и демонстрации пользователю измененного результата оптического распознавания символов, который содержит в местоположении ошибки исправленную символьную последовательность, но в остальном идентичен исходному результату оптического распознавания символов, причем исправленная символьная последовательность представляет собой символьную последовательность с максимальным значением вероятности среди символьных последовательностей кластера, отличающихся от искаженной символьной последовательности.
Другим вариантом осуществления изобретения является система, включающая: (а) память; (b) дисплей; (с) обрабатывающее устройство, соединенное с памятью и дисплеем, причем обрабатывающее устройство позволяет: выполнять оптическое распознавание символов на одном или более исходных изображениях документа с целью получения исходных результатов оптического распознавания символов и демонстрировать пользователю исходные результаты оптического распознавания символов документа; получать от пользователя отклик, содержащий местоположение ошибки в исходных результатах оптического распознавания символов, при этом местоположение ошибки представляет собой положение последовательности неверно распознанных символов в исходных результатах оптического распознавания символов; получать дополнительное изображение документа, при этом дополнительное изображение содержит часть документа, которая соответствует местоположению ошибки, и выполнять оптическое распознавание символов дополнительного изображения для получения дополнительных результатов оптического распознавания символов; определять кластер символьных последовательностей, которые соответствуют местоположению ошибки, используя исходные результаты оптического распознавания символов и дополнительные результаты оптического распознавания символов для; определять порядок символьных последовательностей в кластере символьных последовательностей на основе соответствующих им значений вероятности; и демонстрировать пользователю измененный результат оптического распознавания символов, который содержит в местоположении ошибки исправленную символьную последовательность, но в остальном идентичен исходному результату оптического распознавания символов, причем исправленная символьная последовательность представляет собой символьную последовательность с максимальным значением вероятности среди символьных последовательностей кластера, отличающихся от искаженной символьной последовательности.
Еще одним из вариантов осуществления изобретения является машиночитаемый постоянный носитель данных, содержащий исполняемые команды, которые при выполнении в обрабатывающем устройстве заставляют это обрабатывающее устройство выполнять операции, включающие: оптическое распознавание символов на одном или более исходных изображениях документа с целью получения исходных результатов оптического распознавания символов и демонстрацию пользователю исходных результатов оптического распознавания символов документа; получение от пользователя обратной связи, содержащей местоположение ошибки в исходных результатах оптического распознавания символов, при этом местоположение ошибки представляет собой положение последовательности неверно распознанных символов в исходных результатах оптического распознавания символов; получение дополнительного изображения документа, при этом дополнительное изображение содержит часть документа, которая соответствует местоположению ошибки, и выполнение оптического распознавания символов дополнительного изображения для получения дополнительных результатов оптического распознавания символов; определение кластера символьных последовательностей, которые соответствуют местоположению ошибки, с использованием исходных результатов оптического распознавания символов и дополнительных результатов оптического распознавания символов; определение порядка символьных последовательностей в кластере символьных последовательностей на основе соответствующих им значений вероятности; и демонстрации пользователю измененного результата оптического распознавания символов, который содержит в местоположении ошибки исправленную символьную последовательность, но в остальном идентичен исходному результату оптического распознавания символов, причем исправленная символьная последовательность представляет собой символьную последовательность с максимальным значением вероятности среди символьных последовательностей кластера, отличающихся от искаженной символьной последовательности.
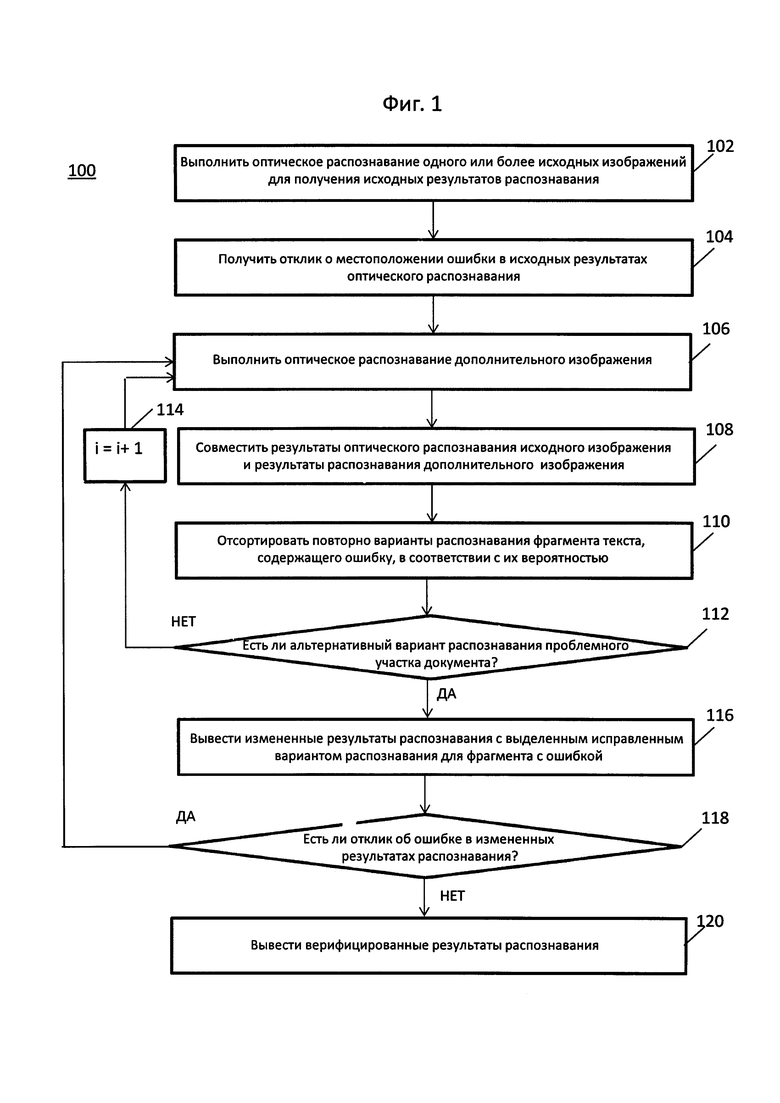
На Фиг. 1 показана блок-схема примера осуществления способа верификации результатов оптического распознавания символов.
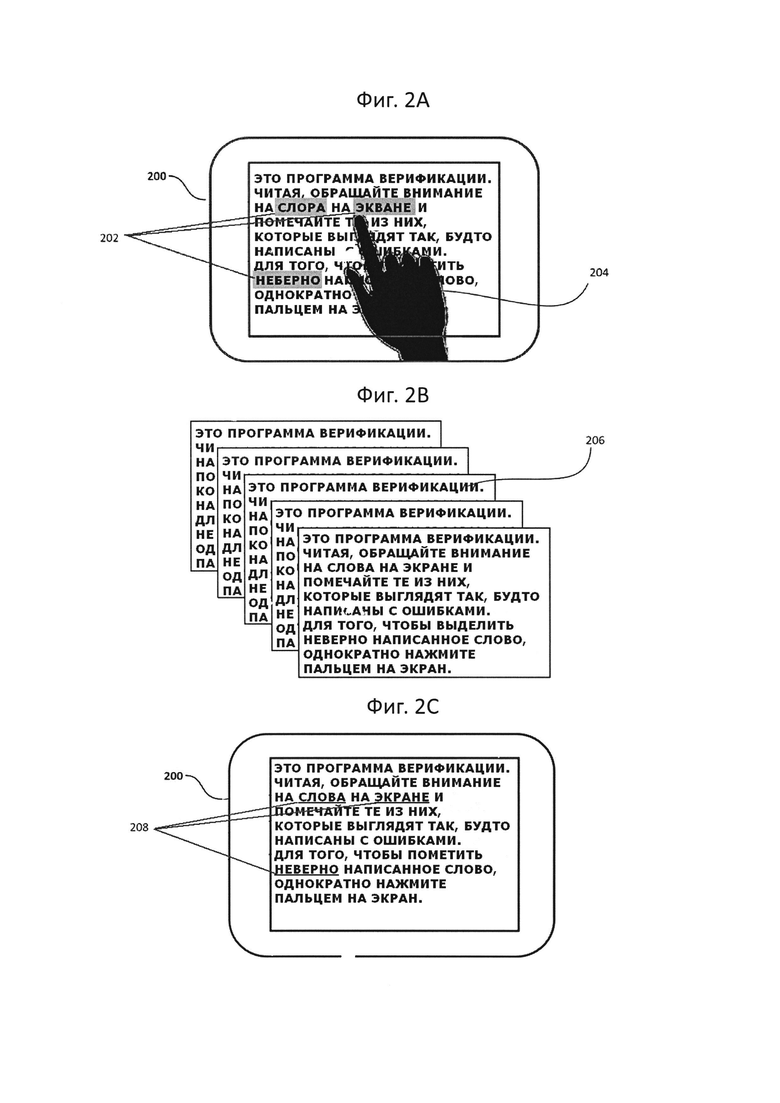
На Фиг. 2А-2С показано, как результаты оптического распознавания символов демонстрируются пользователю для проведения верификации
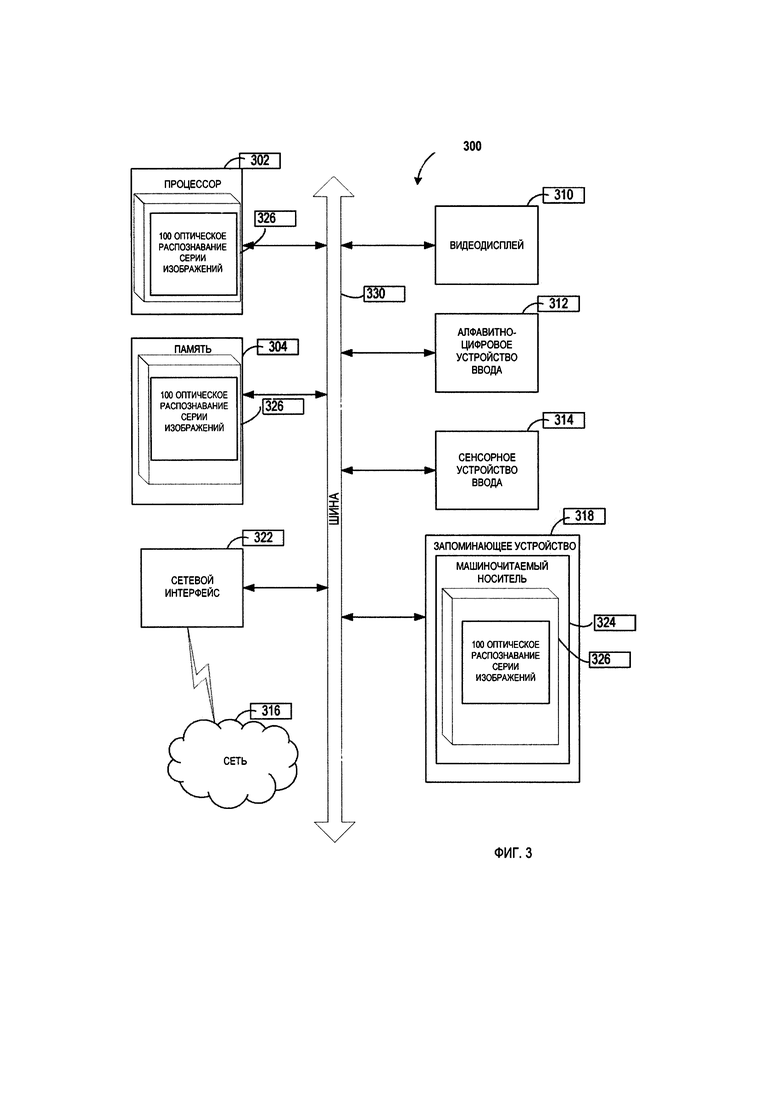
На Фиг. 3 схематически изображен пример вычислительной системы, которая может использоваться для реализации способов, раскрываемых в настоящем изобретении.
ПОДРОБНОЕ ОПИСАНИЕ
Сопутствующие документы
Следующие документы, полностью включенные в данный документ посредством ссылок, могут быть полезны для понимания раскрытия настоящего изобретения: а) Патентная заявка США №15/168 548, подана 31 мая 2016 г.; и b) Патентная заявка США №15/195 603, подана 28 июня 2016 г.
Раскрытие изобретения
Слова, употребленные в единственном числе, обозначают один или более объектов, если не указано другое.
В данном разделе описаны способы и системы для осуществления оптического распознавания символов (OCR) серии изображений, содержащих символы определенной системы письменности. Системы письменности, символы которых могут быть обработаны с помощью систем и способов, описанных в настоящем документе, включают алфавиты с отдельными символами или глифами, соответствующим отдельным звукам, а также иероглифические системы письменности с отдельными символами, соответствующими более крупным блокам, таким как слоги или слова. Верификация результатов OCR на мобильных устройствах, таких как мобильный телефон или планшет, может производиться вручную, например, путем ручного ввода исправленного текста с помощью клавиатуры, например, виртуальной клавиатуры на сенсорном экране устройства. Однако подобная верификация результатов OCR вручную может быть неудобна для пользователя. Способы в соответствии с настоящим изобретением могут заменить ручной ввод текста с помощью клавиатуры в процессе верификации результатов OCR.
Хотя отдельные ошибки в результатах OCR могут быть потенциально исправлены путем повторного выполнения процесса OCR исходного изображения, то есть изображения всего документа, из которого были получены исходные результаты OCR, такой подход может привести к появлению новых ошибок в новых местах документа. Поэтому желательно иметь возможность определить в исходных результатах OCR конкретное место, которое содержит ошибку. В раскрываемых в настоящем документе способах пользователь может определить в исходных результатах OCR обрабатываемого документа конкретное место, которое содержит ошибку, такую как неправильно распознанную или искаженную символьную последовательность, например, неправильно распознанное или искаженное слово; в ответ программа может рекомендовать исправление этой ошибки. Рекомендуемое исправление может быть следующей наиболее вероятной символьной последовательностью (отличающейся от последовательности в выведенных исходных результатах OCR), например, словом или последовательностью слов для определенного местоположения искаженной последовательности символов. Искаженная последовательность символов, например, искаженное слово, может означать, что последовательность символов, присутствующая в результатах OCR, отличается от соответствующей исходной последовательности символов в исходном документе. Искаженная последовательность символов может отличаться от соответствующей исходной последовательности символов, например, одним или более символами и (или) порядком символов и (или) шрифтом символов.
В рамках способов раскрытия настоящего изобретения исходные результаты OCR одного или более исходных изображений документа вместе с откликом пользователя о расместоположении ошибки в исходных результатах OCR могут использоваться для получения одного или более дополнительных изображений части документа, которые содержат место ошибки. Дополнительные изображения могут иметь более высокое качество, чем исходные изображения, за счет, например, изменения одного или нескольких следующих параметров: шум изображения, масштаб изображения, угол съемки, яркость изображения, выдержка, диафрагма и наличие бликов. Дополнительные качественные изображения могут использоваться вместе с исходными результатами OCR для получения измененных результатов OCR, которые будут иметь более высокое качество, чем исходные результаты OCR. В измененных результатах OCR ошибка, обнаруженная в исходных результатах OCR, может быть исправлена автоматически. Лучше, чтобы эти исправления не затрагивали части исходного результата OCR, которые не содержат ошибок и (или) не требуют исправления. В некоторых вариантах осуществления изобретения исходные изображения и (или) дополнительные изображения могут быть получены в непрерывном режиме. В качестве непрерывного режима может использоваться, например, режим предварительного просмотра камеры, в котором получаемые изображения не сохраняются в памяти вычислительной системы после оптического распознавания символов, или режим видеозаписи, в котором получаемые изображения могут сохраняться в памяти вычислительной системы.
Способы раскрытия настоящего изобретения могут использоваться для верификации результатов оптического распознавания символов на изображении исходного документа. Исходный документ представляет собой документ в форме изображения документа, которое могло быть получено с помощью камеры. Например, во многих вариантах реализации изобретения исходный документ может быть представлен физическим объектом с напечатанным текстом, машинописным текстом и (или) рукописным текстом. В некоторых других вариантах осуществления изобретения исходный документ может быть изображением, которое выведено, например, на экран или дисплей. В некоторых вариантах осуществления изобретения предлагаемые способы могут использоваться при преобразовании изображения, содержащего текст, в машиночитаемый электронный документ с текстовым слоем. Изображение, содержащее текст, может быть изображением, содержащим один или более фрагментов печатного текста, машинописного текста или рукописного текста. В некоторых вариантах осуществления изобретения предлагаемые способы могут использоваться для извлечения информации из информационных полей документа, созданного по образцу, который также содержит статические элементы. Оптическое распознавание символов в документах, созданных по образцу, раскрыто в патентной заявке США №15/195 603.
Термин «электронный документ» здесь относится к файлу, содержащему один или более элементов цифрового содержимого, которые могут быть использованы для создания визуального представления электронного документа (например, на дисплее или на печатном носителе). Электронный документ можно получить путем сканирования или получения изображения бумажного документа иным образом, а также выполнения оптического распознавания символов (OCR) для получения текстового слоя, связанного с документом. В различных иллюстративных примерах электронные документы могут соответствовать определенным форматам файлов, таким как PDF, PDF/A, DjVu, EPub, JPEG, JPEG 2000, JBIG2, BMP и другие. Электронный документ может содержать любое количество пикселей.
Термин «текстовый слой» здесь означает набор кодированных текстовых символов. Одним из наиболее часто используемых стандартов для кодирования текстовых символов является стандарт Юникод. В стандарте Юникод обычно применяются 8-битные байты для кодирования символов, входящих в кодировочную таблицу American Standard Code for Information Exchange («ASCII») и 16-битные машинные слова для кодирования символов множества языков. Электронный документ может изначально содержать текстовый слой. Или же текстовый слой может быть сформирован путем оптического распознавания символов (OCR).
Хотя представленные способы не имеют конкретных ограничений по размеру документа, они могут быть особенно полезны для верификации результатов оптического распознавания символов относительно небольших исходных документов, например, абзаца текста или визитной карточки, с помощью мобильного устройства, оборудованного камерой. Например, камера мобильного устройства может быть направлена пользователем на интересующий его документ на физическом носителе для получения одного или более исходных изображений документа, которые могут быть сделаны, например, в непрерывном режиме, таком как режим предварительного просмотра камеры или режим видеозаписи. После обработки одного или более исходных изображений с помощью технологий OCR мобильное устройство может вывести исходные результаты OCR на свой экран. Затем мобильное устройство может получить отклик от пользователя, указывающий на одно или более мест, которые содержат ошибки в исходных результатах OCR. В мобильных устройствах с сенсорным дисплеем пользователь может осуществить отклик путем указания места с ошибкой, нажав или коснувшись места на сенсорном дисплее, на котором выводится ошибка. В некоторых вариантах реализации изобретения пользователь может указать одновременно несколько мест с ошибками в исходных результатах OCR. В других вариантах реализации изобретения пользователь может указать только одно место с ошибками в исходных результатах OCR. Затем пользователь может направить камеру мобильного устройства на местоположение одной из ошибок, чтобы получить одно или более дополнительных изображений. В рамках способов настоящего изобретения после выполнения OCR одного или более дополнительных изображений процессор мобильного устройства может анализировать результаты OCR одного или более дополнительных изображений вместе с исходными результатами OCR. На основе результатов OCR одного или более дополнительных изображений и исходных результатов OCR процессор может выбрать дополнительные варианты распознавания для места ошибки и вариант исправления, который является наиболее вероятным вариантом, не совпадающим с одним или более результатами OCR для места ошибки. После этого мобильное устройство может вывести измененные результаты OCR с вариантом исправления для местоположения ошибки, в остальном идентичные исходным результатам OCR. Вариант исправления может быть выделен так, чтобы пользователь мог легко увидеть это исправление. В некоторых вариантах реализации изобретения может быть выделена вся символьная последовательность с исправлениями. Кроме того, в некоторых вариантах реализации изобретения могут быть выделены отдельные символы, например, буквы или цифры, которые отличают исправленную символьную последовательность от исходной искаженной символьной последовательности (например, символьной последовательности для местоположения ошибки в исходных результатах OCR). В определенных вариантах реализации весь исправленный вариант символьной последовательности может быть выделен одним цветом, а отдельные символы, которыми исправленная символьная последовательность отличается от исходной искаженной символьной последовательности, могут быть выделены другим цветом.
Предлагаемые способы могут применяться как к серии изображений, которые могут быть получены в непрерывном режиме, например, в режиме предварительного просмотра камеры или в режиме видеозаписи, так и к отдельным дискретным изображениям, которые могут быть получены в режиме фотосъемки. Для изображений, полученных в непрерывном режиме, предлагаемые способы могут быть более удобны, поскольку такой сценарий позволяет обеспечить более активное взаимодействие с пользователем с помощью вычислительной системы. Например, при получении изображений в непрерывном режиме пользователь может выявить место ошибки в исходных результатах OCR документа и, не отводя камеры от документа, получить дополнительные изображения места ошибки и немедленно выполнить соответствующее дополнительное оптическое распознавшие символов на месте ошибки. Например, если исходные результаты OCR документа содержат ошибку в части документа, напечатанной мелким шрифтом, камеру можно приблизить, или изменить масштаб изображения для места, где находится ошибка, чтобы получить одно или более дополнительных изображений. Дополнительные изображения могут укрупнить или увеличить масштаб части документа, напечатанной мелким шрифтом. Крупный или увеличенный текст может быть проще распознан с помощью технологии OCR. Исправленный вариант текста с мелким шрифтом, полученный на основе результатов OCR укрупненного или увеличенного дополнительного изображения и исходных результатов OCR, может быть вставлен в исходные результаты OCR в нужное место и в нужном масштабе, то есть в то место и с тем масштабом, которые соответствуют части документа с мелким шрифтом, чтобы получить измененные результаты OCR документа.
На Фиг. 1 представлена блок-схема одного иллюстративного примера способа 100 верификации результатов OCR. Способ и (или) каждая из его отдельных функций, процедур, подпрограмм или операций может выполняться одним или более процессорами компьютерной системы, выполняющей этот способ. В некоторых вариантах реализации способ 100 может выполняться в одном потоке обработки. В качестве альтернативы способ 100 может выполняться с использованием двух и более потоков обработки, при этом каждый поток выполняет одну или более отдельных функций, стандартных программ, подпрограмм или операций способа. В качестве иллюстративного примера потоки обработки, реализующие способ 100, могут быть синхронизированы (например, с использованием семафоров, критических секций и (или) других механизмов синхронизации потоков). При альтернативном подходе потоки обработки, в которых реализован способ 100, могут выполняться асинхронно по отношению друг к другу. Таким образом, несмотря на то, что Фиг. 1 и соответствующее описание содержат список операций для метода 100 в определенном порядке, в различных вариантах осуществления способа, как минимум, некоторые из описанных операций могут выполняться параллельно и (или) в произвольно выбранном порядке.
В блоке 102 вычислительная система, которая может быть представлена, например, мобильным устройством, таким как мобильный телефон или планшет, может выполнять OCR одного или более исходных изображений исходного документа для получения исходных результатов OCR. Исходные изображения могут быть получены с помощью камеры. В некоторых вариантах реализации изобретения камера может быть неотъемлемой частью вычислительной системы. В других вариантах реализации изобретения камера может быть отдельным устройством, выполненным с возможностью передачи полученных изображений в вычислительную систему. Каждое из исходных изображений может быть изображением всего документа или изображением части этого документа. В некоторых вариантах реализации изобретения исходные результаты OCR могут быть результатами OCR одного исходного изображения. Также в некоторых вариантах реализации изобретения исходные результаты OCR могут быть комбинированными результатами OCR нескольких изображений, то есть более чем одного изображения. Заявки на патент США №№15/168548 и 15/168525 описывают комбинированные результаты OCR нескольких изображений. Результаты OCR содержат символы распознанного текста, а также информацию о геометрической разметке, такую как координаты каждого символа на изображении, а также, дополнительно, сведения о том, как символы сгруппированы на изображении друг относительно друга: например, как отдельные символы, такие как буквы и цифры, формируют символьные последовательности, такие как слова; как отдельные символьные последовательности, такие как слова, формируют строки текста и т.д.
Исходные результаты OCR могут выводиться для пользователя вычислительной системы с целью верификации на экране/дисплее/мониторе вычислительной системы. В некоторых вариантах реализации изобретения выводимые исходные результаты OCR могут иметь разметку, совпадающую с разметкой исходной физической копии документа. Используя такое представление исходных результатов OCR для верификации, пользователь может получить ясное представление о том, где в исходной физической копии документа расположен выводимый на экран фрагмент документа, который содержит ошибку в исходных результатах OCR. Таким образом, пользователь может легко понять, куда должна быть направлена камера для того, чтобы сделать одно или более дополнительных изображений для исправления этой ошибки.
В блоке 104 вычислительная система может получить отклик от пользователя о наличии ошибки в исходных результатах OCR. Например, пользователь может выявить местоположение ошибки в исходных результатах OCR, это может быть сделано, например, путем указания местоположения ошибки. В отдельных вариантах реализации изобретения пользователь может определить местоположение ошибки, выделив ее. В отдельных вариантах реализации изобретения для указания места ошибки в выводимых результатах OCR пользователь может нажать, прикоснуться или щелкнуть место на сенсорном дисплее вычислительной системы, которое соответствует местоположению ошибки. В отдельных вариантах реализации изобретения для указания всех ошибок, которые могут быть вызваны, например, тем, что в поле обзора камеры не попала часть исходного документа, пользователь может провести пальцем вертикально вниз по сенсорному дисплею. В отдельных вариантах реализации изобретения пользователь может использовать особый жест, например, свайп, чтобы указать место, в котором текст не был обнаружен из-за ошибки.
Для подтверждения того, что место ошибки, определенное пользователем, было принято к обработке, вычислительная система может отобразить выявленные места ошибок, выделив их тем или иным способом. Например, вычислительная система может выделить места выявленных ошибок с помощью фоновой подсветки.
Например, на Фиг. 2А показан дисплей вычислительной системы 200, на котором серым цветом выделено местоположение ошибок 202 (неправильно распознанные слова «СЛОРА», «ЭКВАНЕ» и «НЕВЕРНО»), которая определена пользователем 204 в исходных результатах OCR, выведенных на дисплей 200.
Информация, которая может быть получена на шагах 102 и 104, а именно, исходные результаты OCR, а также информация о местоположении ошибки, полученная от пользователя, может быть использована в качестве шаблона. Дополнительные результаты OCR, которые могут быть получены при обработке одного или более дополнительных изображений, могут сравниваться с этим шаблоном для определения альтернативных вариантов OCR для места ошибки. В этом шаблоне часть текста без обнаруженных ошибок может считаться правильной. Эта часть текста не требует исправлений. С другой стороны, часть текста с ошибкой должна считаться неправильной. Эта часть текста требует исправления ошибки. Такое исправление может быть выявлено среди альтернативных вариантов OCR для этой ошибки, содержащей часть текста, соответствующие варианты могут быть получены путем обработки одного или более дополнительных изображений, которые перекрывают часть текста, содержащую ошибку.
После получения отклика о местоположении ошибки в исходных результатах OCR пользователь может направить камеру на часть исходного документа, которая включает фрагмент текста, соответствующий выявленной ошибке, чтобы получить одно или более дополнительных изображений. Далее на шаге 106 вычислительная система может выполнить OCR дополнительного изображения для получения результатов OCR. На Фиг. 2В схематично показано получение результатов OCR для одного или более дополнительных изображений 206. Дополнительные изображения могут быть получены с помощью той же камеры, которая использовалась для получения исходных изображений, или другой камеры. Камера, которая используется для получения дополнительных изображений, может быть неотъемлемой частью вычислительной системы или отдельным устройством, которое выполнено с возможностью передавать полученные изображения вычислительной системе.
Шаг 108 может включать построение кластера символьных последовательностей, содержащего исходные результаты OCR и дополнительные результаты OCR, то есть результаты OCR одного или более дополнительных изображений. Это может быть выполнено, например, совмещением соответствующих общих фрагментов исходных результатов OCR и дополнительных результатов OCR. Такое совмещение или сравнение может включать определение соответствующих общих особенностей, например, совпадающих символов или последовательностей символов в исходных и дополнительных результатах OCR. Совмещение символьных последовательностей может быть как строгим, так и не строим, в том числе подчиненным нечеткой логике. Например, в одном из вариантов реализации, компьютерная система может выполнить построение графа, вершины которого соответствуют символьным последовательностям, полученным при OCR множества изображений, а ребра графа соединяют те последовательности, которые получены в ходе OCR совпадающих участков изображения (то есть соответствуют одному и тому же фрагменту оригинального текста).
Исходные результаты OCR, в которых пользователь определил местоположение ошибки, могут использоваться в качестве шаблона. Совмещение этого шаблона с дополнительными результатами OCR может позволить определить текстовые фрагменты дополнительных результатов OCR, которые соответствуют местоположению ошибки в исходных результатах OCR. Другими словами, совмещение этого шаблона с дополнительными результатами OCR может позволить определить альтернативные варианты OCR для текстовых фрагментов, которые соответствуют ошибке в исходных результатах OCR. Совмещение исходных результатов OCR и дополнительных результатов OCR может включать определение одного или более общих вариантов, которые могут быть общими текстовыми фрагментами, например, общими символьными последовательностями, такими как общие слова. Для исходных результатов OCR их часть, не содержащая ошибок, может использоваться для определения подобных общих вариантов. С другой стороны, для определения общих вариантов могут использоваться все дополнительные результаты OCR. Общие варианты могут использоваться в качестве опорной точки при вычислении преобразования координат из координат дополнительных результатов OCR в координаты исходных результатов OCR или наоборот. Перевод дополнительных результатов OCR в одинаковые с исходными результатами OCR координаты может позволить определить, как текстовые объекты дополнительных результатов OCR соответствуют текстовым объектам исходных результатов OCR. Совмещение дополнительных результатов OCR и исходных результатов OCR позволяет получить различные альтернативные варианты OCR (символьные последовательности, такие как слова) для того места изображения, где распознавание было выполнено с ошибкой. Варианты OCR для этого места, полученные при обработке одного или более дополнительных изображений, и одно или более дополнительных изображений могут быть объединены в кластер. Кластеры и их обработка рассматриваются, например, в патентных заявках США №№15/168548 и 15/168525, которые полностью включены в этот документ посредством ссылки на них.
Дополнительные результаты OCR, полученные при обработке одного или более дополнительных изображений, могут содержать только часть исходных результатов OCR, например, только часть изображения вокруг того места, где произошла ошибка, указанная пользователем. Причиной этому может быть например то, что пользователь переместил камеру ближе к той части исходного документа, где имела место ошибка, или то, что пользователь увеличил масштаб камеры при съемке данной части документа. Патентные заявки США №№15/168548 и 15/168525, которые полностью включены в этот документ посредством ссылки на них, рассматривают совмещение результатов OCR для изображений, различающихся хотя бы одним из следующих параметров: шум изображения, масштаб изображения, угол съемки, яркость изображения, выдержка, диафрагма, наличие бликов или наличие внешнего документа, который покрывает, как минимум, часть исходного документа.
Шаг 110 может включать повторную сортировку или упорядочение вариантов OCR местоположения ошибки, полученных путем обработки одного или более дополнительных изображений, и одного или более дополнительных изображений. Эта сортировка или упорядочение могут выполняться на основе вычисления заранее определенной метрики для каждого варианта OCR. Например, эта сортировка или упорядочение могут выполняться на основе вычисления вероятности для каждого варианта OCR. В некоторых вариантах реализации изобретения вычисление вероятности может выполняться на основе такой метрики, как расстояние редактирования. Эта метрика отражает, насколько сильно различаются два варианта OCR. Значение этой метрики для отдельного варианта OCR может быть суммой различий с каждым из остальных вариантов OCR в кластере (суммарное расстояние редактирования). Чем меньше значение этой метрики для отдельного варианта OCR в кластере, тем более вероятен этот вариант. Таким образом, исходя из результатов OCR одного или более дополнительных изображений новый вариант OCR может быть добавлен в соответствующий кластер, который уже содержит множество вариантов OCR, основанный на исходных результатах OCR. После этого может быть произведено повторное вычисление значения предварительно определенной метрики для каждого из вариантов OCR в кластере, затем варианты OCR могут быть отсортированы или упорядочены повторно в соответствии с новым вычисленным значением заранее определенной метрики. Например, для рассмотренной ранее метрики расстояния редактирования для каждого варианта OCR в кластере может быть вычислена сумма разностей для каждого из прочих вариантов OCR в кластере (суммарное расстояние редактирования), после чего варианты OCR в кластере могут быть повторно отсортированы или упорядочены на основе соответствующих суммарных расстояний редактирования в порядке возрастания, то есть вариант OCR с минимальным значением суммарного расстояния редактирования (то есть с самой высокой вероятностью) оказывается наверху, а вариант OCR с максимальным значением суммарного расстояния редактирования (то есть с самой низкой вероятностью) - внизу.
Шаг 112 может включать сравнение каждого из отсортированных и вновь упорядоченных вариантов OCR, начиная с наиболее вероятного, то есть с первого сверху в кластере, с исходным вариантом OCR с ошибкой, который выводится в исходных вариантах OCR и указан пользователем как неправильный, для поиска наиболее вероятного варианта OCR, не совпадающего с исходным вариантом OCR. Если другой вариант OCR найден, способ может перейти к шагу 116. Если другие варианты OCR не найдены, способ через шаг 114 (увеличение счетчика) возвращается на шаг 106 для получения новых дополнительных изображений.
Предлагаемые способы не производят поиск альтернативных/отличающихся вариантов OCR для всего текста, выводимого в исходных результатах OCR. Вместо этого поиск альтернативных/отличающихся вариантов OCR может быть ограничен только одной или более ошибками, указанными пользователем.
Шаг 116 может включать вывод на экран измененных результатов OCR, которые содержат наиболее вероятный вариант OCR для места с ошибкой, который отличается от исходного варианта OCR для этого места. Кроме этого исправления в местоположении ошибки измененные результаты OCR могут быть идентичны исходным результатам OCR. Пользователь может переместить камеру, увеличив масштаб, и (или) поднести ее ближе к физической копии документа и перемещать от одного места ошибки к другому. Этот способ может включать выделение исправления в месте ошибки на выводимых измененных результатах OCR. Цвет и способ выделения для исправления может отличаться от цвета и способа, который может использоваться для выделения выявленного пользователем местоположения ошибки. Например, на Фиг. 2С показаны выделенные подчеркиванием исправления 208 (слова «СЛОВА», «ЭКРАНЕ» и «НЕВЕРНО»), соответствующие местоположениям ошибок 202 на Фиг. 2А. Этот способ может также включать генерацию сигнала, например, звука или изменения цвета, при изменении выводимых на экран результатов OCR, то есть при обнаружении и выводе на экран вычислительной системой альтернативного/отличающегося варианта OCR для места ошибки.
На этапе 118 вычислительная система может получать от пользователя дополнительный отклик об ошибке в измененных результатах OCR. В некоторых случаях ошибка в измененных результатах OCR может быть ошибкой в новом месте, которое не было ранее указано пользователем в качестве местоположения ошибки. Также в некоторых случаях ошибка в измененных результатах OCR может быть ошибкой в ранее обнаруженном местоположении ошибки. Этот сценарий соответствует ситуации, когда пользователь не удовлетворен исправлением ошибки, выведенным для измененных результатов поиска. Как и на шаге 104, пользователь предоставляет отклик, отмечая местоположение ошибки в измененных результатах OCR.
Если пользователь предоставляет дополнительный отклик по ошибке (отмечая ее местоположение) в измененных результатах OCR, способ может возвратиться к шагу 106 для получения одного или более дополнительных изображений для поиска альтернативного/другого варианта OCR для выявленного местоположения новой ошибки.
Пользователь может предоставить отклик по ошибкам в выводимых на экран результатах OCR, указав их местоположения в любой момент выполнения раскрываемого способа.
Если через некоторое заранее определенное время после вывода измененных результатов OCR вычислительная система не получает дополнительного отклика от пользователя, вычислительная система может предположить, что ошибок больше нет, то есть, что выводимые на экран измененные результаты OCR могут рассматриваться как верифицированные результаты OCR (шаг 120).
Верификация результатов оптического распознавания символов также может применяться к документам, созданным по образцу, например, к документам, описанным в патентной заявке США №15/195603. Документ, созданный по образцу, имеет не менее одного статического элемента и не менее одного информационного поля. Верификация результатов оптического распознавания символов документов, созданных по образцу, может включать получение одного или более изображений документа. Изображения могут быть получены обрабатывающим устройством вычислительной системы, которая может выполнять оптическое распознавание символов изображений для получения результатов оптического распознавания символов для изображений. Результаты оптического распознавания символов могут совмещаться с шаблоном документа, созданного по образцу. В результате такого совмещения части результата оптического распознавания символов, которые соответствуют статическим элементам документа, созданного по образцу, могут быть отделены, а части результата оптического распознавания символов, которые соответствуют информационным полям документа, созданного по образцу, сохранены для дальнейшей обработки. Таким образом, при обработке нескольких, то есть более одного, изображений документов, созданных по образцу, для каждого информационного поля документов, созданных по образцу, может быть получено несколько символьных последовательностей OCR. С помощью медианной строки можно получить наилучшую (наиболее вероятную) символьную последовательность OCR для каждого информационного поля из соответствующего набора символьных последовательностей OCR. Наилучшая символьная последовательность OCR для определенного информационного поля может быть затем выведена пользователю вычислительной системы. Для документа, созданного по образцу с несколькими информационными полями, наилучшие символьные последовательности OCR для информационных полей документа могут быть, например, выведены пользователю в виде списка. Пользователь может отправить свой отклик компьютерной системе, если он видит, что наилучшая символьная последовательность OCR для определенного информационного поля документа, созданного по образцу, содержит ошибку, то есть когда наилучшая символьная последовательность OCR отличается от соответствующей символьной последовательности в исходном документе, созданном по образцу. Например, пользователь может отправить отклик, нажав или прикоснувшись к наилучшей символьной последовательности OCR на сенсорном дисплее вычислительной системы. После того, как вычислительная система получит от пользователя отклик об ошибке в выводимой наилучшей последовательности OCR, она может вывести пользователю другую символьную последовательность OCR из нескольких символьных последовательностей OCR для этого информационного поля. Другая символьная последовательность OCR может быть, например, второй по качеству (второй по вероятности) символьной последовательностью OCR из нескольких символьных последовательностей OCR для данного информационного поля. Пользователь может оправлять отклики несколько раз. Если система не получает отклик от пользователя в течение некоторого времени, она может предположить, что предлагаемая последовательность OCR для конкретного информационного поля не содержит ошибок. Таким образом, система предполагает, что представленная последовательность OCR является верифицированной символьной последовательностью OCR для данного информационного поля. Система может отправить верифицированную символьную последовательность OCR в базу данных. В определенных вариантах реализации вычислительная система может выводить наилучшую символьную последовательность OCR для каждого из нескольких, то есть более чем одного, информационных полей, например, в виде списка. Затем пользователь может определить среди выведенных символьных последовательностей OCR одну или более символьных последовательностей, содержащих ошибки. Для каждого информационного поля, для которого пользователь определил соответствующую наилучшую текстовую последовательность OCR как содержащую ошибку, вычислительная система может вывести соответствующую вторую наиболее вероятную текстовую последовательность OCR.
Вычислительная система может быть представлена, например, вычислительной системой, показанной на Фиг. 3. Вычислительная система может представлять собой устройство, способное выполнить набор команд (последовательных или иных), которые определяют операции, выполняемые этой вычислительной системой. Например, это может быть персональный компьютер (ПК), планшет, приемник цифрового телевидения (STB), карманный персональный компьютер (КПК) или сотовый телефон. На Фиг. 3 представлена более подробная схема компонентов примера вычислительной системы 300, внутри которой исполняется набор инструкций, которые вызывают выполнение вычислительной системой любого из способов или нескольких способов настоящего изобретения. Вычислительная система 300 может быть соединена с другой вычислительной системой по локальной сети, корпоративной сети, сети экстранет или сети Интернет. Вычислительная система 300 может работать в качестве сервера или клиента в сетевой среде «клиент/сервер», или в качестве однорангового вычислительного устройства в одноранговой (или распределенной) сетевой среде. Вычислительная система 300 может быть представлена персональным компьютером (ПК), планшетным ПК, телевизионной приставкой (STB), карманным ПК (PDA), сотовым телефоном или любой вычислительной системой, способной выполнять набор команд (последовательно или иным образом), определяющих операции, которые должны быть выполнены этой вычислительной системой. Кроме того, хотя показана только одна вычислительная система, термин «вычислительная система» также может включать любую совокупность вычислительных систем, которые отдельно или совместно выполняют набор (или несколько наборов) команд для выполнения одной или более методик, обсуждаемых в настоящем документе.
Пример вычислительной системы 300 включает в себя процессор 302, оперативную память 304 (например, постоянное запоминающее устройство, ПЗУ) или динамическую оперативную память (DRAM)) и устройство хранения данных 318, которые взаимодействуют друг с другом через шину 330.
Процессор 302 может быть представлен одним или более универсальными устройствами обработки данных, например, микропроцессором, центральным процессором и т.д. В частности, процессор 302 может представлять собой микропроцессор с полным набором команд (CISC), микропроцессор с сокращенным набором команд (RISC), микропроцессор с командными словами сверхбольшой длины (VLIW), процессор, реализующий другой набор команд или процессоры, реализующие комбинацию наборов команд. Процессор 302 также может представлять собой одно или более устройств обработки специального назначения, например, заказную интегральную микросхему (ASIC), программируемую вентильную матрицу (FPGA), процессор цифровых сигналов (DSP), сетевой процессор и т.п. Процессор 302 сконфигурирован с возможностью выполнять инструкции 326 для выполнения операций и функций способа по Фиг. 1.
Вычислительная система 300 может дополнительно содержать устройство сетевого интерфейса 322, устройство визуального отображения 310, устройство ввода символов 312 (например, клавиатуру) и устройство ввода в виде сенсорного экрана 314. Устройство хранения данных 318 может включать машиночитаемый носитель данных 324, в котором хранится один или более наборов команд 326, в которых реализован один или более методов или функций, описанных в данном варианте реализации изобретения. Команды 326 также могут находиться полностью или, по меньшей мере, частично в основной памяти 304 и (или) в процессоре 302 во время выполнения их в вычислительной системе 300, при этом оперативная память 304 и процессор 302 также представляют собой машиночитаемый носитель данных. Команды 326 дополнительно могут передаваться или приниматься по сети 316 через устройство сетевого интерфейса 322.
В некоторых вариантах реализации инструкции 326 могут включать инструкции для выполнения одной или более функций способа по Фиг. 1. В то время как машиночитаемый носитель 324, показанный на примере на Фиг. 3, является единым носителем, термин «машиночитаемый носитель» должен включать один носитель или несколько носителей (например, централизованную или распределенную базу данных и (или) соответствующие кэши и серверы), в которых хранятся один или несколько наборов команд. Термин «машиночитаемый носитель данных» также следует рассматривать как термин, включающий любой носитель, который способен хранить, кодировать или переносить набор команд для выполнения машиной, который заставляет эту машину выполнять любую одну или более методик, описанных в настоящем раскрытии изобретения. Соответственно, термин «машиночитаемый носитель данных» также включает, в частности, устройства твердотельной памяти, оптические и магнитные носители.
Иллюстрируемая компьютерная система может включать процессор, основную память (например, только для чтения
Описанные в документе способы, компоненты и функции могут быть реализованы дискретными компонентами оборудования, либо они могут быть интегрированы в функции других аппаратных компонентов, таких как ASICS, FPGA, DSP или подобных устройств. Кроме того, способы, компоненты и функции могут быть реализованы с помощью модулей встроенного программного обеспечения или функциональных схем аппаратного обеспечения. Способы, компоненты и функции также могут быть реализованы с помощью любой комбинации аппаратного обеспечения и программных компонентов, либо исключительно с помощью программного обеспечения.
В приведенном выше описании изложены многочисленные детали. Однако любому специалисту в этой области техники, ознакомившемуся с этим описанием, очевидно, что настоящее изобретение может быть осуществлено на практике без этих конкретных деталей. В некоторых случаях хорошо известные структуры и устройства показаны в виде блок-схем, а не подробно, чтобы не усложнять описание настоящего изобретения.
Некоторые части описания предпочтительных вариантов реализации представлены в виде алгоритмов и символического представления операций с битами данных в памяти компьютера. Такие описания и представления алгоритмов представляют собой средства, используемые специалистами в области обработки данных, чтобы наиболее эффективно передать сущность своей работы другим специалистам в данной области.
Здесь и в целом алгоритмом называется логически непротиворечивая последовательность операций, приводящих к требуемому результату. Операции требуют физических манипуляций с физическими величинами. Обычно, хотя и не обязательно, эти величины принимают форму электрических или магнитных сигналов, которые можно хранить, передавать, комбинировать, сравнивать и выполнять другие манипуляции. Иногда удобно, прежде всего для обычного использования, описывать эти сигналы в виде битов, значений, элементов, символов, терминов, цифр и т.д.
Однако следует иметь в виду, что все эти и подобные термины должны быть связаны с соответствующими физическими величинами и что они являются лишь удобными обозначениями, применяемыми к этим величинам. Если не указано особо, принимается, что в данном описании термины «определение», «вычисление», «расчет», «получение», «установление», «изменение» и т.п.относятся к действиям и процессам вычислительной системы или аналогичной электронной вычислительной системы, которая использует и преобразует данные, представленные в виде физических (например, электронных) величин в реестрах и устройствах памяти вычислительной системы, в другие данные, аналогично представленные в виде физических величин в устройствах памяти или реестрах вычислительной системы или иных устройствах хранения, передачи или отображения такой информации.
Настоящее изобретение также относится к устройству для выполнения операций, описанных в настоящем документе. Такое устройство может быть специально сконструировано для требуемых целей, или оно может содержать универсальный компьютер, который избирательно активируется или перенастраивается с помощью компьютерной программы, хранящейся ч компьютере. Такая компьютерная программа может храниться на машиночитаемом носителе данных, например, в частности, на диске любого типа, включая дискеты, оптические диски, CD-ROM и магнитно-оптические диски, постоянные запоминающие устройства (ПЗУ), оперативные запоминающие устройства (ОЗУ), СППЗУ, ЭППЗУ, магнитные или оптические карты и носитель любого типа, подходящий для хранения электронной информации. Следует понимать, что вышеприведенное описание носит иллюстративный, а не ограничительный характер.
Различные другие варианты реализации станут очевидными специалистам в данной области техники после прочтения и понимания приведенного выше описания. Область применения изобретения поэтому должна определяться с учетом прилагаемой формулы изобретения, а также всех областей применения эквивалентных способов, которые покрывает формула изобретения.
Группа изобретений относится к технологиям оптического распознавания символов (OCR). Техническим результатом является исключение необходимости ручного ввода текста с помощью клавиатуры в процессе верификации результатов OCR. Предложен способ автокоррекции результатов оптического распознавания символов. Способ содержит этап, на котором выполняют оптическое распознавание символов на одном или более исходных изображениях документа с целью получения исходных результатов оптического распознавания символов и демонстрации пользователю исходных результатов оптического распознавания символов документа. Далее согласно способу получают от пользователя отклик, содержащей местоположение ошибки в исходных результатах оптического распознавания символов, при этом местоположение ошибки представляет собой положение последовательности неверно распознанных символов в исходных результатах оптического распознавания символов. 3 н. и 16 з.п. ф-лы, 3 ил.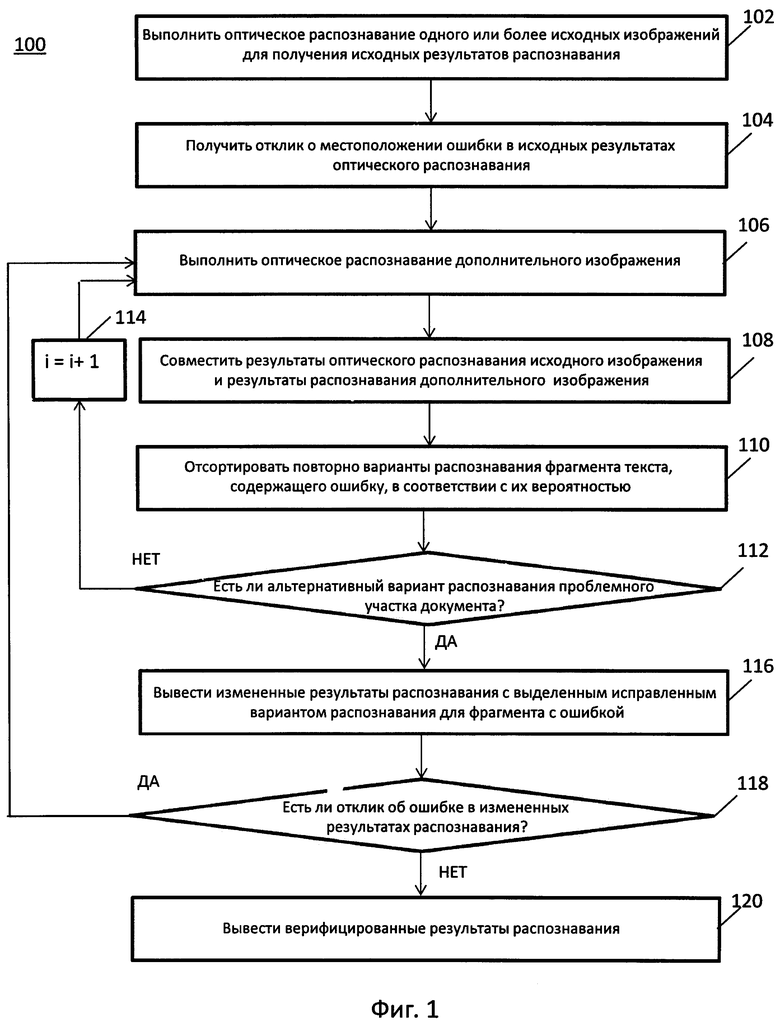
1. Способ автокоррекции результатов оптического распознавания символов, включающий:
выполнение оптического распознавания символов на одном или более исходных изображениях документа с целью получения исходных результатов оптического распознавания символов и демонстрации пользователю исходных результатов оптического распознавания символов документа;
получение от пользователя отклика, содержащего местоположение ошибки в исходных результатах оптического распознавания символов, при этом местоположение ошибки представляет собой положение последовательности неверно распознанных символов в исходных результатах оптического распознавания символов;
получение дополнительного изображения документа, при этом дополнительное изображение содержит часть документа, которая соответствует местоположению ошибки, и выполнение оптического распознавания символов дополнительного изображения для получения дополнительных результатов оптического распознавания символов;
определение кластера символьных последовательностей, которые соответствуют местоположению ошибки с использованием исходных результатов оптического распознавания символов и дополнительных результатов оптического распознавания символов;
определение порядка символьных последовательностей в кластере символьных последовательностей на основе соответствующих им значений вероятности правильного распознавания; и
демонстрацию пользователю измененного результата оптического распознавания символов, который содержит в местоположении ошибки исправленную символьную последовательность, но в остальном идентичен исходному результату оптического распознавания символов, причем исправленная символьная последовательность представляет собой символьную последовательность с максимальным значением вероятности правильного распознавания среди символьных последовательностей кластера, отличающихся от искаженной символьной последовательности.
2. Способ по п. 1, в котором дополнительное изображение отличается от одного или более исходных изображений как минимум одним из параметров: шум изображения, масштаб изображения, угол съемки и яркость изображения.
3. Способ по п. 1, где указанное определение кластера символьных последовательностей, которые соответствуют местоположению ошибки, включает: определение в исходных результатах оптического распознавания символов и дополнительных результатах оптического распознавания символов множества общих признаков для определения опорных точек.
4. Способ по п. 3, также включающий определение с использованием координат опорных точек параметров преобразования координат дополнительных результатов оптического распознавания символов в координаты исходных результатов оптического распознавания символов.
5. Способ по п. 1, где указанное определение порядка символьных последовательностей производится на основе соответствующих значений вероятностей правильного распознавания, включая определение заранее определенной метрики для каждой символьной последовательности кластера и повторную сортировку символьных последовательностей кластера в соответствии со значением заранее определенной метрики.
6. Способ по п. 5, в котором заранее определенная метрика является суммой расстояний редактирования между символьной последовательностью кластера и всеми остальными символьными последовательностями кластера, при этом символьные последовательности повторно сортируются так, что символьная последовательность с наименьшим значением метрики находится наверху кластера, а символьная последовательность с максимальным значением метрики - внизу кластера.
7. Способ по п. 1, где одно или более исходных изображений и дополнительное изображение выбираются из непрерывной последовательности изображений.
8. Способ по п. 1, где указанная демонстрация измененных результатов оптического распознавания символов включает выделение в выводимых измененных результатах оптического распознавания символов исправленной символьной последовательности.
9. Способ по п. 1, также включающий после указанной отправки отклика пользователя выделение местоположения ошибки в выводимых исходных результатах оптического распознавания символов.
10. Способ по п. 1, который выполняется мобильным устройством.
11. Способ по п. 10, где мобильное устройство представляет собой один из вариантов: мобильный телефон, планшет, портативный компьютер, смартфон или карманный персональный компьютер (PDA).
12. Способ по п. 10, где указанное получение отклика от пользователя включает получение отклика о месте на сенсорном дисплее мобильного устройства, которое соответствует местоположению ошибки.
13. Способ по п. 10, где мобильное устройство имеет камеру, и одно или более исходных изображений и дополнительное изображение получены с помощью этой камеры.
14. Система автокоррекции результатов оптического распознавания символов, включающая следующие компоненты:
память;
дисплей;
обрабатывающее устройство, соединенное с памятью и дисплеем, обрабатывающее устройство выполнено с возможностью:
выполнять оптическое распознавание символов на одном или более исходных изображениях документа с целью получения исходных результатов оптического распознавания символов и демонстрации исходных результатов оптического распознавания символов документа пользователю;
получать от пользователя отклик, содержащий местоположение ошибки в исходных результатах оптического распознавания символов, при этом местоположение ошибки представляет собой положение последовательности неверно распознанных символов в исходных результатах оптического распознавания символов;
получать дополнительное изображение документа, при этом дополнительное изображение содержит часть документа, которая соответствует местоположению ошибки, и выполнение оптического распознавания символов дополнительного изображения для получения дополнительных результатов оптического распознавания символов;
определять кластер символьных последовательностей, которые соответствуют местоположению ошибки, используя исходные результаты оптического распознавания символов и дополнительные результаты оптического распознавания символов;
определять порядок символьных последовательностей в кластере символьных последовательностей на основе соответствующих им значений вероятности правильного распознавания; и
демонстрировать пользователю на дисплее измененный результат оптического распознавания символов, который содержит в местоположении ошибки исправленную символьную последовательность, но в остальном идентичен исходному результату оптического распознавания символов, причем исправленная символьная последовательность представляет собой символьную последовательность с максимальным значением вероятности правильного распознавания среди символьных последовательностей кластера, отличающихся от искаженной символьной последовательности.
15. Система по п. 14, которая является мобильным устройством.
16. Система по п. 15, где мобильное устройство представляет собой один из вариантов: мобильный телефон, планшет, портативный компьютер, смартфон или карманный персональный компьютер (PDA).
17. Система по п. 14, где дисплей представлен сенсорным дисплеем и где обрабатывающее устройство получает отклик от пользователя о месте ошибки, принимая сигнал о месте на сенсорном дисплее, на которое нажал пользователь.
18. Система по п. 14, также включающая камеру, которая выполнена с возможностью получения одного или более изображений и следующего изображения и передачи каждого из этих изображений и следующего изображения обрабатывающему устройству.
19. Машиночитаемый постоянный носитель данных, содержащий исполняемые команды, которые направлены на автокоррекцию результатов оптического распознавания символов и при выполнении в вычислительном устройстве заставляют это вычислительное устройство:
выполнять оптическое распознавание символов на одном или более исходных изображениях документа с целью получения исходных результатов оптического распознавания символов и демонстрировать пользователю исходные результаты оптического распознавания символов документа;
получать от пользователя отклик, содержащий местоположение ошибки в исходных результатах оптического распознавания символов, при этом местоположение ошибки представляет собой положение последовательности неверно распознанных символов в исходных результатах оптического распознавания символов;
получать дополнительное изображение документа, при этом дополнительное изображение содержит часть документа, которая соответствует местоположению ошибки, и выполнение оптического распознавания символов дополнительного изображения для получения дополнительных результатов оптического распознавания символов;
определять кластер символьных последовательностей, которые соответствуют местоположению ошибки, с использованием исходных результатов оптического распознавания символов и дополнительных результатов оптического распознавания символов;
определять порядок символьных последовательностей в кластере символьных последовательностей на основе соответствующих им значений вероятности правильного распознавания; и
демонстрировать пользователю измененный результат оптического распознавания символов, который содержит в местоположении ошибки исправленную символьную последовательность, но в остальном идентичен исходному результату оптического распознавания символов, причем исправленная символьная последовательность представляет собой символьную последовательность с максимальным значением вероятности правильного распознования среди символьных последовательностей кластера, отличающихся от искаженной символьной последовательности.
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| US 6047093 A, 04.04.2000 | |||
| US 5933531 A, 03.08.1999 | |||
| Колосоуборка | 1923 |
|
SU2009A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| УСТРОЙСТВО И СПОСОБ ПОИСКА РАЗЛИЧИЙ В ДОКУМЕНТАХ | 2013 |
|
RU2571378C2 |
| СРАВНЕНИЕ ДОКУМЕНТОВ С ИСПОЛЬЗОВАНИЕМ ДОСТОВЕРНОГО ИСТОЧНИКА | 2014 |
|
RU2597163C2 |

