ОБЛАСТЬ ТЕХНИКИ
[0001] Настоящее изобретение в целом относится к вычислительным системам, в частности, - к системам и способам оптического распознавания символов (OCR).
УРОВЕНЬ ТЕХНИКИ
[0002] Оптическое распознавание символов (OCR) представляет собой реализованное вычислительными средствами преобразование изображений, содержащих текст (включая типографский, рукописный или печатный текст), в машиночитаемые электронные документы.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0003] В соответствии с одним или более аспектами настоящего изобретения пример реализации способа выполнения оптического распознавания символов (OCR) изображения с символами может включать: получение обрабатывающим устройством первого изображения документа с множеством пленарных областей, на котором по меньшей мере две планарные области множества планарных областей взаимно не копланарны; выполнение оптического распознавания символов (OCR) первого изображения для определения распознанного текста на первом изображении; получение текста одного или более следующих изображений документа; определение множества опорных точек на первом изображении; определение множества опорных точек в каждом следующем изображении, на которых каждая точка множества опорных точек на соответствующем следующем изображении соответствует одной опорной точке множества опорных точек на первом изображении; определение параметров первого координатного преобразования, конвертирующего координаты первого набора опорных точек множества опорных точек на первом изображении в координаты соответствующих опорных точек множества опорных точек на соответствующем следующем изображении, в котором каждая из опорных точек первого набора опорных точек находится в пределах первой части первого изображения, в котором в первой части первого изображения показана первая планарная область множества планарных областей документа; определение параметров второго координатного преобразования, конвертирующего координаты второго набора опорных точек множества опорных точек на первом изображении в координаты соответствующих опорных точек на соответствующем следующем изображении, на котором каждая опорная точка второго набора опорных точек находится в пределах второй части первого изображения, на котором во второй части первого изображения показана вторая планарная область множества планарных областей документа, и на котором вторая планарная область документа не копланарна по отношению к первой планарной области документа; определение при помощи параметров первого координатного преобразования и параметров второго координатного преобразования кластера последовательностей символов, состоящего из последовательности символов распознанного текста первого изображения и по меньшей мере одной соответствующей последовательности символов на одном или более вторых изображениях; и порождение результирующего распознанного текста OCR, состоящего из медианной последовательности символов кластера последовательностей символов.
[0004] В соответствии с одним или более аспектами настоящего изобретения пример системы для выполнения оптического распознавания символов (OCR) на серии изображений, отображающих символы определенного алфавита, может состоять из памяти, в которой хранятся инструкции, и обрабатывающего устройства, загружающего инструкции из памяти для: получения первого изображения документа с множеством планарных областей, в котором по меньшей мере две планарные области множества планарных областей взаимно не копланарны; выполнения оптического распознавания символов (OCR) первого изображения для определения распознанного текста на первом изображении; получения текста из одного или более вторых изображений документа; определения множества опорных точек на первом изображении; определения множества опорных точек в каждом втором изображении, на котором каждая точка множества опорных точек на соответствующем втором изображении соответствует одной опорной точке множества опорных точек на первом изображении; определения параметров первого координатного преобразования, конвертирующего координаты первого набора опорных точек множества опорных точек на первом изображении в координаты соответствующих опорных точек множества опорных точек на соответствующем втором изображении, на котором каждая из опорных точек первого набора опорных точек находится в пределах первой части первого изображения, на котором на первой части первого изображения показана первая планарная область множества планарных областей документа; определения параметров второго координатного преобразования, конвертирующего координаты второго набора опорных точек множества опорных точек на первом изображении в координаты соответствующих опорных точек на соответствующем втором изображении, на котором каждая опорная точка второго набора опорных точек находится в пределах второй части первого изображения, на котором во второй части первого изображения показана вторая планарная область множества планарных областей документа, и на котором вторая планарная область документа не копланарна в отношении первой планарной области документа; определения при помощи параметров первого координатного преобразования и параметров второго координатного преобразования кластера последовательностей символов, включающего последовательность символов распознанного текста первого изображения и по меньшей мере одну последовательность символов одного или более вторых изображений; и порождение результирующего распознанного текста OCR, состоящего из медианной последовательности символов кластера последовательностей символов.
[0005] В соответствии с одним или более аспектами настоящего изобретения пример машиночитаемого постоянного носителя данных может включать исполнимые команды, которые при их исполнении обрабатывающим (процессорным) устройством заставляют обрабатывающее устройство: получить первое изображение документа, содержащего множество планарных областей, в котором по меньшей мере две планарные области множества планарных областей взаимно не копланарны; выполнить оптическое распознавание символов (OCR) первого изображения для определения распознанного текста на первом изображении; получить текст из одного или более вторых изображений документа; определить множество опорных точек на первом изображении; определить множество опорных точек на каждом втором изображении, на которых каждая точка множества опорных точек соответствующего второго изображения соответствует одной опорной точке множества опорных точек на первом изображении; определить параметры первого координатного преобразования, конвертирующего координаты первого набора опорных точек множества опорных точек на первом изображении в координаты соответствующих опорных точек множества опорных точек на соответствующем втором изображении, на котором каждая из опорных точек из первого набора опорных точек находится в пределах первой части первого изображения, в которой на первой части первого изображения показана первая планарная область множества планарных областей документа; определить параметры второго координатного преобразования, конвертирующего координаты второго набора опорных точек множества опорных точек на первом изображении в координаты соответствующих опорных точек на соответствующем втором изображении, на котором каждая опорная точка второго набора опорных точек находится в пределах второй части первого изображения, на котором на второй части первого изображения показана вторая планарная область множества планарных областей документа, и на котором вторая планарная область документа не копланарна по отношению к первой планарной области документа; определить при помощи параметров первого координатного преобразования и параметров второго координатного преобразования кластер последовательностей символов, включающий в себя последовательность символов распознанного текста первого изображения и по меньшей мере одну соответствующую последовательность символов на одном или более вторых изображениях; и выпонять порождение результирующего распознанного текста OCR, состоящего из медианной последовательности символов кластера последовательностей символов.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0006] Настоящее изобретение иллюстрируется на примерах, без каких бы то ни было ограничений; его сущность становится понятной при рассмотрении приведенного ниже подробного описания изобретения в сочетании с чертежами, при этом:
[0007] На Фиг. 1 показана блок-схема одного иллюстративного примера способа выполнения оптического распознавания символов (OCR) серии изображений, включающей по меньшей мере одно изображение изогнутого документа, в соответствии с одним или более аспектами настоящего изобретения.
[0008] На Фиг. 2 схематически представлен пример первого изображения документа (например, паспорта), который раскрыт не полностью (левая панель), и второе изображение того же документа, который раскрыт полностью (правая панель).
[0009] На Фиг. 3 схематически показан пример реализации процедуры определения граничной линии между двумя планарными областями первого изображения.
[00010] На Фиг. 4 схематически показан пример реализации процедуры определения граничной линии между двумя планарными областями первого изображения, где линия, выбранная для определения граничной линии, практически параллельна граничной линии.
[00011] На Фиг. 5А схематически показана трехмерная иллюстрация примера постоянно сгибаемого документа с двумя планарными областями, соединенными гладкой областью перехода.
[00012] На Фиг. 5В схематически показано изображение примера плавно изогнутого документа из Фиг. 5А с двумя планарными областями, соединенными гладкой областью перехода.
[00013] На Фиг. 6 схематически показан пример диаграммы, состоящей из множества кластеров вершин таким образом, что каждый кластер представляет собой две или более совпадающих последовательностей символов в соответствии с одним или более аспектами настоящего изобретения.
[00014] На Фиг. 7А схематически показан процесс выявления медианной строки из множества последовательностей символов, представляющих собой результаты оптического распознавания символов соответствующих фрагментов изображения в соответствии с одним или более аспектами настоящего изобретения.
[00015] На Фиг. 7В схематически показан процесс выявления медианной строки из множества последовательностей символов, представляющих собой результаты оптического распознавания символов соответствующих фрагментов изображения в соответствии с одним или более аспектами настоящего изобретения.
[00016] На Фиг. 7С схематически показан процесс выявления медианной строки из множества последовательностей символов, представляющих собой результаты оптического распознавания символов соответствующих фрагментов изображения в соответствии с одним или более аспектами настоящего изобретения.
[00017] На Фиг. 8 показана схема иллюстративного примера вычислительной системы, в которой реализованы способы настоящего изобретения.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ РЕАЛИЗАЦИИ
[00018] В данном разделе описаны способы и системы для осуществления оптического распознавания символов (OCR) одного или более изображений, содержащих символы определенного алфавита. Некоторые из изображений могут включать в себя символы, расположенные в разных плоскостях, например, изображения сложенного документа или не полностью открытого документа, изображение улицы с множеством некопланарных знаков, рекламных щитов, витрин, номерных знаков автомобилей, двигающихся в разных направлениях, и тому подобного. Алфавиты, символы которых могут быть обработаны с помощью систем и способов, описанных в настоящем документе, включают в себя алфавиты с отдельными символами или глифами, соответствующими отдельным звукам, а также иероглифические алфавиты с отдельными символами, соответствующими более крупным блокам, таким как слоги или слова.
[00019] В приведенном ниже описании термин «документ» должен толковаться расширительно, как относящийся к широкому спектру носителей текста, включая, помимо прочего, печатные или написанные от руки бумажные документы, баннеры, постеры, знаки, рекламные щиты и (или) другие физические объекты, несущие видимые символы текста на одной или более поверхностях. В приведенном ниже описании термин «изображение документа» относится к изображению по меньшей мере одной части исходного документа (например, страницы бумажного документа).
[00020] Система оптического распознавания символов (OCR) может получать изображение документа и преобразовывать полученное изображение в машиночитаемый формат, допускающий поиск и содержащий текстовую информацию, извлеченную из изображения документа. Процесс OCR может быть затруднен различными дефектами изображения, такими как визуальный шум, расфокусировка или низкая резкость изображения, блики и т.д., которые обычно вызваны дрожанием камеры, недостаточным освещением, неправильно выбранной выдержкой или диафрагмой и (или) другими условиями и осложняющими обстоятельствами. Если обычные способы OCR не всегда могут правильно выполнить распознавание символов при наличии указанных выше и других дефектов изображения, то системы и способы, описанные в настоящем документе, могут значительно повысить качество OCR за счет создания набора изображений и применения к изображению документа различных наборов операций конверсии, как это более подробно описано ниже.
[00021] Кроме того, в результате оптического распознавания символов разных изображений из серии изображений могут получиться не совсем одинаковые последовательности символов. Например, слово «pack» в бумажном документе, таком как страница книги, может быть правильно распознано оптическим распознаванием символов на одном изображении, но неправильно распознано как «puck» оптическим распознаванием символов на другом изображении по причине недостаточного качества этого изображения. В некоторых случаях слово «pack» может быть расположено рядом с серединой книги, где страницы согнуты из-за наличия переплета. В результате этого начало слова может быть расположено в плоскости, значительно отличающейся от плоскости, в которой расположен конец слова, и буква «р», отображенная под острым углом, может быть распознана без округленной части (например, как буква «l»), и все слово будет неправильно распознано как «1асk».
[00022] Наличие нескольких изображений документа может значительно повысить надежность оптического распознавания символов текста этого документа. Например, по результатам оптического распознавания символов первого изображения документа обрабатывающее устройство (например, обрабатывающее устройство системы оптического распознавания символов) может определить последовательность символов (слово, множество слов, предложение, параграф и так далее) в распознанном тексте первой страницы (например, слово «pack»). Обрабатывающее устройство может также определить соответствующую последовательность символов на втором изображении (например, слово «puck»). В некоторых примерах реализации обрабатывающее устройство может также определить соответствующую последовательность символов на третьем изображении (например, слово «lack»). Доступные серии последовательностей символов (например, «pack», «puck» и «1асk») образуют кластер последовательностей символов, соответствующий определенному сегменту текста документа. После определения кластера последовательностей символов обрабатывающее устройство может применить предопределенную систему показателей по отношению к кластеру для определения медианной последовательности символов. Система показателей может быть спроектирована разными способами, которые делают медианную последовательность символов вероятно правильным представлением определенного сегмента текста документа. В одном случае реализации система показателей может рассчитать количество появлений разных символов в разных позициях последовательностей символов. Например, символ «p» может появиться дважды на первой позиции, тогда как символ «l» может появиться всего один раз. Следовательно, обрабатывающее устройство может определить букву «р» как первый символ в медианной последовательности символов. Таким же образом, символ «u» может появиться один раз на второй позиции, тогда как символ «а» может появиться в этом месте дважды. Следовательно, обрабатывающее устройство может определить букву «а» как второй символ в медианной последовательности символов. Во всех трех последовательностях четвертым и третьим символами могут быть буквы «с» и «k» и, таким образом, они могут быть включены в медианную последовательность символов на соответствующих позициях. Вследствие этого обрабатывающее устройство может определить медианную последовательность символов как «pack» и включить ее в распознанный текст документа как возможно истинную последовательность, содержащуюся в определенном сегменте документа. Вышеприведенный пример служит исключительно в качестве иллюстрации. Реальное определение медианной последовательности символов может основываться на другом алгоритме. Другие иллюстративные примеры таких возможных алгоритмов описываются более подробно ниже.
[00023] Качество оптического распознавания символов может зависеть от того, насколько точно различные последовательности символов на разных изображениях совпадают друг с другом. Например, последовательность символов «pack» может быть расположена посередине первого изображения, тогда как последовательность «puck» может быть расположена рядом с левым краем второго изображения. При этом они могут представлять собой результаты оптического распознавания символов одного и того же сегмента документа. Для того чтобы убедиться в правильности сопоставления последовательностей символов на разных изображениях, обрабатывающее устройство может определить параметры координатных преобразований, конвертирующих координаты на одном изображении в координаты на другом изображении. Для N изображений может быть проведено N-1 координатных преобразований для нахождения соответствия между точками, принадлежащими ко всем изображениям. В одном случае реализации N-1 координатных преобразований могут отдельно конвертировать координаты изображения 1 в координаты изображения 2, координаты изображения 1 в изображение 3, … координаты изображения 1 в изображение N. В еще одном случае реализации N-1 координатных преобразований могут последовательно конвертировать координаты изображения 1 в координаты изображения 2, координаты изображения 2 в изображение 3, … координаты изображения N-1 в изображение N. В других случаях реализации может быть любой другой набор из по меньшей мере N-1 координатных преобразований, которые конвертируют координаты любого изображения j в координаты любого другого изображения k напрямую или через одно или несколько промежуточных преобразований (но не более, чем N-1 преобразований в общем).
[00024] В некоторых случаях реализации координатные преобразования могут быть проективными преобразованиями. Под «проективным преобразованием» здесь подразумевается преобразование, которое отображает линии в линии, но не обязательно сохраняет параллельность. Одним примером проективного преобразования является преобразование, конвертирующее координаты, связанные с изображением доски (например, с текстом, написанным на ней), в координаты, связанные с самой доской. Подобным образом, другое проективное преобразование может конвертировать координаты, связанные с первым изображением доски, в координаты, связанные со вторым изображением этой же доски, но полученное камерой с другого места при помощи другой увеличивающей линзы, снятое с другого угла и т.п. Таким же образом, два планарных изображения той же трехмерной местности/места могут быть преобразованы друг в друга при помощи правильно выбранного проективного преобразования.
[00025] Параметры координатных преобразований, конвертирующих координаты одного изображения в координаты другого изображения, могут быть определены на основании известных (например, определенных) опорных точек на обоих изображениях. Например, для того чтобы полностью определить параметры проективного преобразования, могут понадобиться четыре опорные точки. В одном случае реализации четыре точки могут относиться к разметке текста, такой как внешний контур текста на странице (например, четыре угла текста) или углы ограничительной рамки на странице. В других случаях реализации углы рисунка могут выступать в роли опорных точек для определения параметров координатных преобразований. В некоторых случаях реализации с конкретным объектом (например, графическим элементом) может быть связано менее четырех опорных точек, в то время как остальные опорные точки могут быть связаны с другим объектом (например, две опорные точки могут быть концами горизонтальной линии графического элемента заголовка). В еще одном случае реализации, как указано ниже, некоторые или все опорные точки могут быть связаны с одним или несколькими текстовыми артефактами, такими как редкий символ (или последовательность символов), описанными более подробно ниже.
[00026] Тем не менее, во многих случаях единственного координатного преобразования может быть не достаточно, чтобы отобразить всю область документа. Одного преобразования, связывающего координаты, может быть достаточно, если каждое из изображений снято тогда, когда текст и другие компоненты (например, графические материалы, математические уравнения, нотные знакии т.д.) документа расположены в единой плоскости. Это не всегда возможно. В документе, таком как паспорт или книга, может находиться складка, не позволяющая раскрыть документ полностью таким образом, чтобы две открытые страницы документа находились под значительным углом друг к другу, например, 10, 20, 30 или более градусов. Документ может храниться в сложенном (или свернутом) состоянии и (или) может иметь складку, полученную случайно, в результате небрежного обращения. Документ может быть надорван или с оторванной частью, присоединенной к остальному документу или отсоединенной от него, которая может быть расположена на плоскости, не совпадающей с плоскостью остального документа в момент снятия изображения. Во время автоматизированной обработки почты и посылок ярлыки могут оборачиваться вокруг концов двух сопряженных поверхностей или могут быть согнуты во время работы с ними или перевозки.
[00027] В таких случаях координатного преобразования, проведенного на основании множества (например, четырех) опорных точек, определенных без учета некопланарности изображенного документа, может оказаться недостаточно для обеспечения удовлетворительного качества оптического распознавания символов. Например, все случайно выбранные опорные точки могут находиться в пределах первой планарной области документа (например, первой страницы паспорта). В этом случае полученное преобразование координат может достаточно точно конвертировать координаты первой планарной области в координаты второго изображения документа (которое может быть изображением полностью открытого паспорта). Тем не менее, такое преобразование может сработать в отношении второй планарной области документа (например, второй страницы паспорта). После чего обрабатывающее устройство может применить выполненное координатное преобразование ко всему первому изображению документа на основании неверного предположения, что документ является плоским. Это может по-разному сказаться на точности оптического распознавания символов текста документа. Например, обрабатывающее устройство может не определить последовательности символов, расположенные во второй планарной области документа и, вследствие этого, не включить эти последовательности символов в кластер последовательностей символов. Что еще хуже, обрабатывающее устройство может определить и включить неправильные последовательности символов в кластер последовательностей символов, что может значительно снизить общее качество оптического распознавания символов.
[00028] Аспекты настоящего изобретения описывают методы и системы, направленные на исправление этих и других недостатков путем разделения изображения сложенного документа на множество частей, в которых на каждой из частей показана планарная область сложенного документа. Для каждой из частей может быть проведено отдельное, связанное с этой частью изображения (областью документа) координатное преобразование. Параметры множества соответствующих координатных преобразований могут быть определены посредством нахождения опорных точек, расположенных в пределах каждой планарной области документа. Параметры преобразования могут использоваться для нахождения одной или более граничных линий между планарными областями документа. Граничные линии могут использоваться для определения соответствующего координатного преобразования, которое будет использоваться для определенной точки (x, у) изображения в зависимости от планарной области документа, которой соответствует точка (x, у) изображения. Для того чтобы еще больше повысить точность координатных преобразований, обрабатывающее устройство может определить исправления границ, которые могут быть по желанию использованы на участке, в котором пересекаются разные планарные области. Например, между двумя плоскими областями документа на первом изображении может быть не идеально ровная складка. Вместо этого сложенная область может простираться на некоторое расстояние и плавно переходить на планарные области с обеих сторон границы. В таких ситуациях граничная линия может выступать в роли линии начала отсчета для местоположения области складки. Для учета ненулевой пространственной протяженности сложенной области координатные преобразования областей, соседствующих с граничной линией, могут быть улучшены при помощи эвристических исправлений границы, которые могут сократить расстояние от граничной линии.
[00029] Выполнив некоторые или все вышеописанные процедуры, обрабатывающее устройство может определить топологию первого изображения. Подобная топология может включать одну или несколько граничных линий. Они определяют планарные области документа, совокупность преобразований координат, которые соответствуют некоторым или всем планарным областям, а также одну или более поправок границ для областей складок, находящихся вблизи от граничных линий. Установленная топология изображения применима для идентификации последовательностей символов в первом изображении. Кроме того, она применима для идентификации соответствующих им последовательностей символов в других изображениях того же документа. Выявленные совпадающие последовательности символов можно группировать в кластеры для последующего оптического распознавания.
[00030] Различные аспекты упомянутых выше способов и систем подробно описаны ниже в настоящем документе с помощью примеров, без каких бы то ни было ограничений.
[00031] На Рис. 1 показана блок-схема одного иллюстративного примера способа 100 выполнения оптического распознавания символов (OCR) серии изображений, включающей по меньшей мере одно изображение сложенного документа, в соответствии с одним или более аспектами настоящего изобретения. Способ 100 и (или) каждая из его отдельно взятых функций, процедур, подпрограмм или операций могут быть выполнены одним или несколькими процессорами обрабатывающего устройства (например, вычислительной системы 800, которая представлена на Рис. 8), реализующего этот способ. В некоторых реализациях способ 100 может быть осуществлен в одном потоке обработки. В качестве альтернативы способ 100 может быть реализован в ходе двух и более потоков обработки. При этом в каждом потоке выполняется одна или более отдельных функций, стандартных программ, подпрограмм или операций способа. В представленном иллюстративном примере потоки обработки, в которых реализован способ 100, могут быть синхронизированы (например, с использованием семафоров, критических секций и (или) других механизмов синхронизации потоков). Кроме того, потоки обработки, реализующие способ 100, могут выполняться асинхронно друг относительно друга. Таким образом, несмотря на то, что на Рис. 1 и в соответствующем описании представлен список операций способа 100, приведенных в определенном порядке, в различных вариантах реализации этого способа по меньшей мере некоторые из описанных операций могут выполняться параллельно и (или) в произвольно выбранном порядке.
[00032] В некоторых реализациях обработка каждого изображения исходного документа может быть инициирована после получения этого изображения тем обрабатывающим устройством, в котором задействован данный способ. Подобная обработка может быть в основном завершена прежде, чем будет получено следующее изображение. Во множестве различных реализаций обработка последовательных изображений может осуществляться с наложением по времени (например, может выполняться в различных потоках или процессах, которые протекают в одном или нескольких процессорах). Кроме того, два или более изображений могут быть помещены в буфер и обрабатываться асинхронно с учетом получения других изображений из их совокупности, поступающих в вычислительную систему, которая реализует данный способ.
[00033] В блоке 110 обрабатывающее устройство (например, компьютер), реализующее способ 100, может получать первое изображение документа. Первое изображение может быть частью серии изображений одного и того же документа. Термин «первое» попросту обозначает некое изображение в составе подобной серии. Оно необязательно является первым в смысле хронологии съемки по сравнению с прочими в серии. В некоторых случаях первое изображение документа может быть, безусловно, самым ранним. Однако в других случаях в качестве первого может выступать любое изображение из серии, в том числе и самое последнее. В иных случаях первое изображение из серии может быть снято одновременно с еще одним или несколькими. Одна или несколько разных камер могут снять любое количество изображений в составе серии (включая первое). При этом одна и та же камера может делать снимки с одного или нескольких ракурсов. Снимки могут отличаться масштабом, ракурсом, выдержкой, диафрагмой, яркостью, бликами, наличием внешних объектов, которые хотя бы частично закрывают исходный текст, и (или) другими особенностями, визуальными артефактами, а также параметрами процесса обработки изображения.
[00034] Термин «камера» может означать любое устройство, способное выявлять излучаемый или отражаемый объектом свет, а также создавать изображение этого объекта на основе преобразования яркости света. «Камера» может представлять собой аналоговый фотографический аппарат или видеокамеру, любой цифровой фотоаппарат или видеокамеру, а также копировальную машину, сканирующее устройство и тому подобное. В некоторых реализациях произвольное число изображений в составе серии может представлять собой часть одного и того же видеопотока. В некоторых реализациях произвольное число изображений в составе серии может быть снято движущейся камерой, например, смонтированной на двигающемся транспортном средстве, а также портативной, нагрудной и любой иной камерой.
[00035] Первое изображение документа может быть снято, если число планарных областей в нем равно N>1, причем, хотя бы две из них являются взаимно некопланарными. Например, документ может представлять собой книгу, развернутую в форме клина (допустим, эта книга уложена на экран сканера). При этом левая страница представляет собой первую планарную область документа, а правая - вторую. В некоторых реализациях одна страница может быть сложена так, что ее часть будет загнута относительно оставшейся (так могут быть сложены и обе страницы). При этом в документе будет, по крайней мере, три планарных области, из которых по меньшей мере две взаимно не копланарны.
[00036] В блоке 120 обрабатывающее устройство может осуществлять оптическое распознавание символов в первом изображении. Результатом будет распознанный текст и сведения о его компоновке. Сведения о компоновке могут связывать распознанные символы и (или) группы символов с их положением на изображении.
[00037] В блоке 130 обрабатывающее устройство может выявить одно или более вторых изображений документа. Кроме того, оно может получить текст, а также его соответствующую компоновку в каждом из вторых изображений. В некоторых реализациях второе изображение может быть единственным. В других реализациях вторых изображений может быть несколько, например, целая серия. Предполагается, что для ясности и краткости приведенное ниже описание относится к единственному второму изображению. Однако та же самая обработка, в сущности, применима в реализациях с множеством вторых изображений. Соответственно, термин «второе изображение» здесь следует понимать, как «одно или несколько вторых изображений».
[00038] Второе изображение может быть частью той же серии, к которой принадлежит и первое. Второе изображение может быть обработано точно так же, как и первое, либо сходным образом. Например, одно и то же обрабатывающее устройство может проводить оптическое распознавание символов, используя одни и те же способы. Однако в других реализациях второе изображение может быть обработано иным устройством и в другое время (например, ранее). Соответственно, обрабатывающее устройство, использующее способ 100, может получить текст и (или) компоновку второго изображения, извлекая эту информацию из памяти, как локальной, так и удаленной или сетевой (например, облачной), или еще какой-либо.
[00039] В блоке 140 обрабатывающее устройство может определить на первом изображении множество опорных точек. Опорной может быть произвольная точка на первом изображении, связанная с отличительной особенностью документа, которая может использоваться, чтобы установить соответствие между позициями в первом и втором изображении, если в последнем можно определить признак этого соответствия. Некоторые особенности, которые можно использовать в качестве опорных точек, такие как углы, текст, графика, граничные рамки, концы линий и т.п., мы уже обсуждали выше. Кроме того, опорная точка на первом изображении может быть связана с одним или несколькими текстовыми артефактами в результатах оптического распознавания символов. Например, это может быть артефакт, который не повторяется в остальном тексте, полученном после оптического распознавания символов первого изображения. Текстовый артефакт может представлять собой последовательность символов (например, слова), которая редко встречается в оптически распознанном тексте. Например, артефакт может появляться с частотой, которая не превосходит заданное пороговое значение. Это значение можно задать равным 1 и, тем самым, обозначить уникальную последовательность символов, которая появляется только один раз. В иллюстративном примере редкое слово может быть определено путем сортировки слов, полученных в результате OCR в зависимости от частоты и выбора наиболее редко встречающихся слов. В определенных реализациях данный способ позволяет использовать только те последовательности символов, которые обладают соответствующей протяженностью, превосходящей некую пороговую длину. Это объясняется тем, что более короткие последовательности символов могут давать менее надежные опорные точки. В некоторых реализациях для количества последовательностей символов может быть определено число М. Это количество М наиболее редко появляющихся последовательностей. В подобных реализациях, в качестве пороговой частоты появления задают наибольшую из М самых редких последовательностей.
[00040] Обрабатывающее устройство может использовать информацию о компоновке, связанную с определенными текстовыми артефактами. Это позволяет определять хотя бы одну опорную точку, представляющую каждый текстовый артефакт на первом изображении. В иллюстративном примере опорная точка, привязанная к идентифицированной последовательности символов, может быть представлена центром минимального ограничивающего прямоугольника последовательности символов. В другом иллюстративном примере две или более опорных точек, привязанных к идентифицированной последовательности символов, могут быть представлены углами минимального описывающего прямоугольника последовательности символов.
[00041] В некоторых реализациях обрабатывающее устройство может определять на первом изображении заданное количество опорных точек. Например, обрабатывающее устройство может определять по меньшей мере четыре, восемь, десять и т.д. опорных точек. В некоторых реализациях обрабатывающее устройство может определять столько опорных точек, сколько возможно, исходя из заранее заданного критерия точности. Например, новая опорная точка может быть зафиксирована и добавлена к списку, если она отделена от всех прочих подобных расстоянием, равным хотя бы одному размеру знака (его ширине или длине), либо половине этого размера и т.д. Размер знака на первом изображении документа может представлять собой некое характерное значение (например, среднее). И напротив, новая опорная точка может быть исключена из рассмотрения и не добавлена в список выявленных, если она расположена слишком близко к тем, которые уже внесены в него. Список выявленных опорных точек может храниться в памяти обрабатывающего устройства (или любой иной, доступной для него). Список выявленных опорных точек может включать координаты (x, у) каждой из них. В списке может также храниться описание природы опорной точки. Это может быть описание текстового артефакта, с которым связана опорная точка. Например, список может включать опорную точку А, которая связана с текстовым артефактом, представленным словом «unabashedly» (которое могло появиться на первом изображении только единожды). В нем может быть также отношение данной опорной точки к этому текстовому артефакту (например, нижний правый угол граничной рамки, соответствующей слову).
[00042] В блоке 150 обрабатывающее устройство может определять на втором изображении опорные точки, которые соответствуют опорным точкам на первом изображении, выявленным в блоке 140. Блоки 140 и 150 могут исполняться последовательно или параллельно. Например, могут быть сначала определены все опорные точки на первом изображении, а затем выявлены соответствующие им опорные точки на втором. В некоторых случаях на втором изображении не представляется возможным определить кое-какие соответствующие опорные точки. Например, некоторые опорные точки на первом изображении могут соответствовать области на втором. Но эта область может отличаться плохим разрешением, может быть скрыта другим объектом или размещена в той части документа, которая не отражена на втором изображении. Соответственно, подобные опорные точки, ранее выявленные на первом изображении, теперь, возможно, придется исключить из рассмотрения. В некоторых реализациях в способе 100 возможен возврат к блоку 140. Это позволит выявить дополнительные опорные точки, если число оставшихся меньше определенного порогового значения. В некоторых реализациях порядок операций в блоках 140 и 150 является обратным. Таким образом, сначала выявляются опорные точки на втором изображении, а затем соответствующие им опорные точки на первом. В некоторых реализациях операции в блоках 140 и 150 чередуются. Иными словами, если одна опорная точка выявлена на первом (втором) изображении, прежде чем произойдет переход к поиску следующей, определяется соответствующая ей опорная точка на втором (первом) изображении.
[00043] После (или в ходе) определения соответствующих опорных точек на двух изображениях обрабатывающее устройство может проверить выявленные опорные точки и исключить из рассмотрения, по крайней мере, некоторые из них, используя заданный критерий фильтрации. В иллюстративном примере вычислительная система может верифицировать, что произвольно выбранные группы соответствующих опорных точек имеют некоторые геометрические особенности, которые инвариантны для выбранных изображений. Например, (топологически) неизменная геометрическая особенность может представлять собой направление маршрута, охватывающего хотя бы три соответствующие опорные точки. Более конкретно, направление треугольных маршрутов, охватывающих три опорные точки 1, 2 и 3, может быть одинаковым. Т.е. это может быть движение по часовой стрелке на обоих изображениях. Следовательно, опорные точки 1, 2 и 3, вероятно, представляют собой на двух изображениях соответствующие последовательности символов. На них можно полагаться, выполняя последующие операции в рамках способа 100. И наоборот, треугольные маршруты, охватывающие опорные точки 1, 2 и 3, могут быть направлены по часовой стрелке на первом изображении и против часовой стрелки на втором. Отсюда следует, что хотя бы некоторые из опорных точек 1, 2 и 3 на двух изображениях, вероятно, представляют собой различные (несоответствующие) последовательности символов. В результате одну или несколько опорных точек 1, 2 и 3 можно исключить из рассмотрения.
[00044] Дополнительный или альтернативный вариант топологических особенностей, используемых для фильтрации выявленных опорных точек, может включать направление маршрута, охватывающего векторы, которые соединяют произвольно выбранную точку (например, начало плоской системы координат, связанной с изображением) и каждую опорную точку (в порядке их числовых обозначений). Можно также использовать топологию геометрических фигур, выстроенных линиями, которые соединяют произвольно выбранное множество опорных точек. Если число оставшихся после фильтрации опорных точек менее заданного значения, блоки 140 и 150 в рамках способа 100 могут повторяться (а при желании и этапы фильтрации), пока не будет достигнуто предписанное количество выявленных опорных точек.
[00045] В блоках 160 и 170 обрабатывающее устройство может определить, что первым изображением документа является то, в котором есть совокупность (например, N) планарных областей. Обрабатывающее устройство может также определить параметры совокупности (N) преобразований координат, которые следует использовать, чтобы конвертировать координаты (x, у) различных точек первого изображения в координаты второго. Например, если точка (с координатами x, у) находится в первой (второй) части первого изображения, причем эта первая часть представляет собой изображение первой (второй) части планарной области документа, обрабатывающее устройство может использовать первое (второе) преобразование координат, чтобы конвертировать координаты (x, у) на первом изображении в координаты (X, Y) на втором. На Рис. 2 схематически представлен пример 200 первого изображения 210 документа (например, паспорта), который раскрыт не полностью (левая панель), и второе изображение 220 того же документа, который раскрыт полностью (правая панель). Хотя на Рис. 2 показаны декартовы координаты, применимы также любые иные, если они удобны, например, полярные, аффинные, эллиптические и т.д. Ниже блоки 160 и 170 сначала описаны в применении к варианту реализации. При этом вторым изображением документа является то, в котором имеется одна планарная область (например, документ полностью раскрыт). Впоследствии будут обсуждены обобщения, необходимые для реализации оптического распознавания символов в ситуации, где и первое, и второе изображение документа изогнуты (т.е. оба представлены в виде множественных некопланарных областей).
[00046] Вновь обратимся к Рис. 1. В блоке 160 обрабатывающее устройство может построить первое преобразование координат и перевести значения (x, у) первой части первого изображения 210, например, страницы 1 документа, в координаты (X, Y) соответствующей части второго изображения 220 (именно в картинку той же страницы 1). Первое преобразование координат может быть проективным. Его можно описать следующими уравнениями:
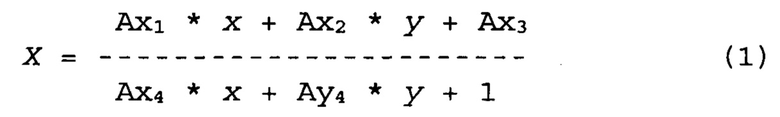
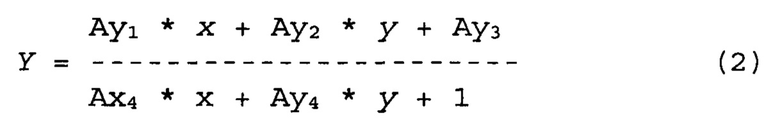
Здесь коэффициенты преобразования {Axj, Ayk} (а именно: Ax1, Ах2, Ах3, Ах4, Ay1, Ау2, Ау3 и Ау4) можно определить, исходя из известных координат, по крайней мере, четырех опорных точек, находящихся в первой части каждого из двух изображений. В результате получим систему из восьми уравнений с восемью же переменными. Чтобы определить коэффициенты преобразования {Axj, Ayk}, обрабатывающее устройство, которое реализует способ 100, может случайным образом выбрать множество опорных точек на первом изображении 210, а также соответствующие им на втором 220. В одной реализации обрабатывающее устройство может выбрать четыре случайные опорные точки и построить первую модель, определяя множество коэффициентов {Axj, Ayk}, исходя из координат (x, у) и (Х, Y) данных опорных точек на двух изображениях 210 и 220. Возможно m=М!/(М-4)!4! различных комбинаций 4 опорных точек. Это справедливо в предположении, что в блоках 140 и 150 выявлено М опорных точек. Обрабатывающее устройство может продолжать случайным образом выбирать дополнительные множества с четырьмя опорными точками из числа m имеющихся множеств. Оно также может строить дополнительные модели путем определения соответствующих коэффициентов {Axj, Ayk} для каждого множества выбранных опорных точек. В некоторых реализациях обрабатывающее устройство может не выстраивать все m возможных моделей. Как разъяснено ниже, оно может остановить дальнейшее построение моделей, если будут получены одна или несколько наиболее подходящих, отличающихся надежностью.
[00047] Обрабатывающее устройство может сопоставлять модели, сравнивая их коэффициенты {Axj, Ayk}. Для этих множеств опорных точек, в которых все четыре точки оказываются внутри одной и той же планарной области документа (например, все точки были случайным образом выбраны на странице 1, или все точки были случайным образом выбраны на странице 2), у различных моделей могут быть коэффициенты {Axj, Ayk}, которые отличаются друг от друга весьма незначительно. Можно полагать, что подобные модели принадлежат к одному и тому же семейству. По сути это позволяет определить проекцию плоскости (X, Y) на плоскость (x, у). Критерием, по которому различные модели в одной реализации следует полагать одинаковыми, может быть то, что разности δХ и δY между координатами, полученными разными моделями, не превышают определенной приемлемой длины. Это может быть размер одного символа или его половина, или любой иной заданный критерий. Символы, которые слишком малы, например, знаки пунктуации, можно игнорировать. В то же время, для тех множеств опорных точек, в которых одна или две точки принадлежат к одной планарной области, а три или две оставшихся - к другой (или к нескольким разным), отклонения δХ и δY могут превышать приемлемую заданную длину. Подобные модели можно считать различными. Модели, которые формируют семейства (например, модели, отличающиеся от всех остальных), могут быть исключены из рассмотрения. В то же время семейства с максимальным количеством моделей можно полагать наиболее подходящими кандидатами для процедуры верификации. В некоторых реализациях можно счесть, вероятно, наиболее подходящей кандидатурой и подвергнуть процедуре верификации некое семейство, включающее хотя бы две модели с близкими коэффициентами {Axj, Ayk}.
[00048] В одной реализации можно рассчитать средние значения коэффициентов {Axj, Ayk} для каждого наиболее подходящего кандидата из числа семейств моделей. Например, средний коэффициент Axj может представлять собой среднее арифметическое (или геометрическое) всех соответствующих коэффициентов Axj в одном и том же семействе моделей. В других реализациях в качестве средних по семейству могут быть приняты случайно выбранные (среди всех моделей семейства) множества коэффициентов {Axj, Ayk}. Есть еще реализации, в которых модель консенсуса случайных выборок (RANSAC) позволяет исключать существенно выпадающие значения и лишь после этого определять среднюю величину.
[00049] В некоторых реализациях все опорные точки можно сверить со средними коэффициентами {Axj, Ayk} каждого семейства моделей. Например, преобразование усредненных координат для первого семейства позволяет конвертировать координаты (x, у)→(X, Y) множества, состоящего из M1 опорных точек, обеспечивая приемлемую точность δХ и δY (допустим, составляющую половину размера типичного символа в первом или втором изображении). Исходя из этого, обрабатывающее устройство способно определить, что множество, состоящее из M1 опорных точек, соответствует первой планарной области документа (например, см. стр. 1 на Рис. 1). Здесь преобразование средних величин позволяет перевести координаты (x, у) первого изображения в координаты (X, Y) второго. Это преобразование описано средними коэффициентами {Axj, Ayk} первого семейства моделей. Обрабатывающее устройство может исключить выявленное множество, имеющее M1 опорных точек, из дальнейших итераций, осуществляемых в соответствии со способом 100.
[00050] Способ 100 допускает продолжение. В блоке 170 обрабатывающее устройство определяет второе преобразование координат, которое позволяет перевести координаты второй части первого изображения 210, например, образ страницы 2 документа, в координаты соответствующей части второго изображения 220. В некоторых реализациях преобразование средних координат для второго семейства, определенное в блоке 160, позволяет превращать координаты множества, состоящего из М2 опорных точек, которые не совпадают ни с одной из M1 точек первого множества. Точность при этом все та же - δХ, δY. Соответственно, обрабатывающее устройство способно определить, что множество, состоящее из М2 опорных точек, соответствует второй планарной области документа (см., например, стр. 2 на Рис. 1), а также то, что средние коэффициенты {Axj, Ayk} второго семейства моделей подлежат использованию для преобразования координат (x, у)→(X, Y) второй планарной области документа. В некоторых реализациях второго семейства моделей хотя бы с двумя множествами коэффициентов {Axj, Ayk} может не быть. В подобных реализациях после того, как первое множество, состоящее из M1 опорных точек, будет исключено из их суммарного количества М, имеющегося на первом изображении (например, после того, как было выявлено, что они соответствуют первой планарной области документа), обрабатывающее устройство может повторить вышеописанные операции, которые относятся к блоку 160. Однако на этот раз с количеством начальных опорных точек, равным М-М1. Подобная итеративная процедура может продолжаться, пока не будут выявлены все опорные точки, принадлежащие к некой планарной области документа. В результате все М опорных точек, выявленных в блоках 140 и 150, могут быть отнесены к N планарным областям документа на первом изображении.
[00051] В некоторых реализациях не представляется возможным определить все опорные точки, как принадлежащие к некой планарной области документа. Например, одна или несколько опорных точек могут находиться вблизи от складки (изгиба), имеющейся в документе. При этом переходы между двумя соседними планарными областями в документе являются плавными (например, в случае, если документ сложен), или складка заострена (например, в случае книги с плотной областью переплета в центре). В подобных реализациях обрабатывающее устройство может остановить дальнейшие итерации, как только будет превышено заданное число опорных точек, например, 60%, 70%, 80% и так далее, распределенное по различным планарным областям. Затем обрабатывающее устройство может определить граничную зону, находящуюся вблизи от пересечения двух плоскостей, которые содержат первую и вторую планарную область документа. Подобное пересечение происходит по линии, которую применительно к данному изобретению называют «граничной». В зависимости от фактической топологии первого изображения, между планарными областями документа может быть несколько граничных линий. Знание мест прохождения граничных линий полезно для определения того, каким преобразованием воспользоваться, конвертируя координаты (x, у)→(X, Y) различных точек (например, не относящихся к опорным) на первом изображении. Кроме того, знание мест прохождения граничных линий позволяет повысить точность преобразований областей первого изображения, которые находятся вблизи от этих граничных линий.
[00052] В некоторых реализациях и на первом, и на втором изображении можно заметить совокупность планарных областей документа. В некоторых реализациях планарные области, представленные в двух документах, могут отличаться. Например, первое изображение может быть снято с раскрытой книги, имеющей две планарные области (страницы). В то же время на втором изображении правая страница книги может быть загнута. Поэтому в книге может быть три планарные области, попавшие на второе изображение. В подобных реализациях применим процесс, в основном сходный с вышеописанным. Он позволяет в большинстве случаев определить N1×N2 преобразования, позволяющие конвертировать координаты N1 планарных областей первого документа в координаты N2 планарных областей второго документа. Максимальное число N1×N2возможных преобразований производится, если каждая планарная область первого документа имеет хотя бы несколько точек, общих с каждой планарной областью второго документа. Например, подобное может случиться, если складки документа на первом изображении расположены горизонтально, а на втором - вертикально. В других реализациях число требуемых преобразований может быть существенно меньше. Например, на приведенной выше иллюстрации раскрытой книги с изгибом на правой странице, который виден на втором изображении, различных преобразований будет всего три (а не 2×3=6). А именно, одно преобразование позволит нанести левую (несложенную) страницу, имеющуюся на первом изображении, в виде левой страницы на втором. Два других преобразования позволят нанести правую страницу, имеющуюся на первом изображении, в виде сложенной правой страницы на втором. Минимальное число необходимых преобразований равно max (N1, N2).
[00053] Чтобы определить преобразования координат, обрабатывающее устройство может случайным образом выбрать множества из четырех опорных точек и для каждого из них выстроить модель (например, набор коэффициентов {Axj, Ayk}), позволяющую конвертировать координаты (x, у) точек множеств, выбранных на первом изображении 210, в координаты (X, Y) соответствующих им точек на втором 220. Обрабатывающее устройство может сопоставить выстроенные модели и выбрать те из них, которые принадлежат к одному семейству (т.е. с теми же коэффициентами {Axj, Ayk} с приемлемой точностью). В некоторых реализациях некое семейство, включающее хотя бы две модели с достаточно близкими коэффициентами {Axj, Ayk}, может быть подвергнуто процедуре верификации. При успешном завершении процедуры верификации первое семейство моделей может быть определено в качестве отображения части первой планарной области первого документа на часть первой планарной области второго. Опорные точки, используемые для выявления этого первого семейства моделей, впоследствии могут быть исключены из дальнейшего итеративного анализа оставшихся опорных точек. Итерационная процедура может продолжаться, пока не будут выявлены все опорные точки, принадлежащие конкретной планарной области на первом изображении документа, а также определенной планарной области на втором. В конце этой итерационной процедуры суммарное количество выявленных преобразований Ntot может быть в диапазоне max(N1, N2)≤Ntot≤N1×N2.
[00054] На Рис. 3 показан пример реализации 300 процедуры определения граничной линии между двумя планарными областями первого изображения. Этот пример отвечает одному или нескольким аспектам настоящего изобретения. Для ясности и краткости предполагается, что настоящее описание относится к единственной граничной линии между двумя планарными областями. Однако практически такая же процедура применима для произвольного количества планарных областей, разделенных соответствующими граничными линиями.
[00055] Координаты (x, у) на стр. 1 (первая планарная область) документа на первом изображении 310 могут быть трансформированы в координаты (X, Y) на втором изображении 320 за счет проективного преобразования (1)-(2) с коэффициентами {Axj, Ayk}, которые могут быть определены в соответствии с приведенными выше пояснениями. Координаты на стр. 2 (вторая планарная область) на первом изображении 310 могут быть трансформированы в соответствующие координаты на втором изображении 320 с помощью другого проективного преобразования
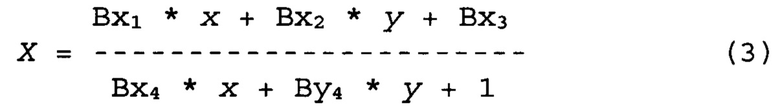
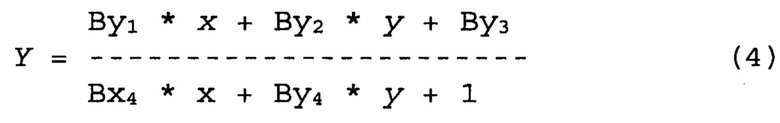
Использованы коэффициенты {Bxj, Byk}, которые можно определить, руководствуясь вышеописанным. Обрабатывающее устройство может выбрать две взаимно перпендикулярные линии, например АВ(Y=Y0) и А'В'(Х=Х0). Линия АВ может пересекать граничную линию в точке О. В то же время линия А'В' может пересекать граничную линию в точке О'. Осуществляя первое проективное преобразование координат (1)-(2), обрабатывающее устройство может получить линии АО и А'О' на первом изображении. Аналогичным образом, осуществляя второе проективное преобразование координат (3)-(4), обрабатывающее устройство может также получить линии АО и А'О' на первом изображении. Точки О и О', в которых пересекаются соответствующие линии, принадлежат граничной линии OO' на первом изображении. Трансформация уравнения Y=Y0 с переходом к координатам x и у первого изображения в соответствии с первым проективным преобразованием (2), а также вторым проективным преобразованием (4), дает следующую систему линейных уравнений для координат точки О:
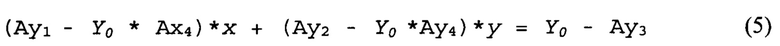
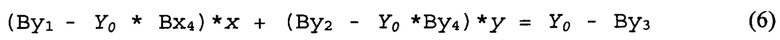
Решение системы уравнений (5)-(6) позволяет определить координаты (хо, уo) точки О. Аналогичным образом, трансформация уравнения Х=Х0 с переходом к координатам x и у первого изображения в соответствии с первым проективным преобразованием (1) и вторым проективным преобразованием (3) дает следующую систему линейных уравнений для координат точки О':
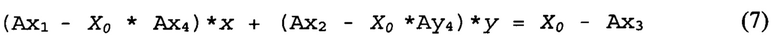
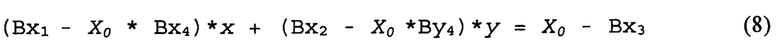
Решение системы уравнений (7)-(8) позволяет определить координаты (хo', уo') точки О'. Исходя из определенных координат точек О' и О, в соответствии со следующим уравнением можно определить граничную линию, разделяющую первую планарную область от второй:
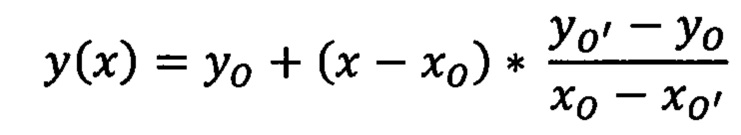
[00056] В некоторых реализациях процесса определения граничной линии одна из пар уравнений (5)-(6) или (7)-(8) может не иметь решения. Например, вторая система (7)-(8) не будет иметь решения, если линия Х=Х0 параллельна граничной линии. В подобных случаях первая система уравнений (5)-(6) обязательно будет иметь решение, поскольку линия Y=Y0 перпендикулярна граничной линии. Как только обрабатывающее устройство определяет, что система (7)-(8) для некоего значения Х0 решения не имеет, оно может задать параметры граничной линии, исходя только из системы (5)-(6). Для этого выбирается другое значение Y0'. Это позволяет получить иную систему уравнений для координат точки, в которой линия Y=Y0' пересекает граничную линию.
[00057] В некоторых реализациях одна из выбранных линий, например, прямая Х=Х0, может не быть в точности параллельной граничной линии, составляя не нулевой, но малый угол по отношению к ней. Это схематически показано на Рис. 4, который служит иллюстрацией для примера реализации 400 процедуры определения граничной линии между двумя планарными областями первого изображения. Здесь линия, выбранная, чтобы определить граничную, оказывается почти параллельной ей.
[00058] В подобных реализациях точка пересечения О' может существовать, но лежать вне контуров документа. Это показано на иллюстрации второго изображения 420. Если точка О', полученная из системы уравнений (7)-(8), лежит слишком далеко от контуров документа, эта точка О' может быть исключена из рассмотрения и не использоваться для определения параметров граничной линии. Например, обрабатывающее устройство может исключить из рассмотрения те точки О', которые отделены от всех опорных точек дистанцией, превышающей максимальное расстояние между двумя опорными точками или его половину, или удвоенное подобное расстояние. Может быть и любой иной заданный критерий. В подобных реализациях обрабатывающее устройство может интерпретировать линии Х=Х0, как практически параллельные граничной. В подобном случае оно определяет параметры граничной линии из двух (или более) уравнений, полученных для прямых Y=Y0. Это было разъяснено выше. В некоторых реализациях может оказаться, что линии Y=Y0 параллельны или почти параллельны граничной. В подобном случае параметры граничных линий можно определить из линий Х=Х0.
[00059] В некоторых реализациях граничную линию можно определить не по двум, а по большему количеству пар уравнений (либо пар (5)-(6), либо пар (7)-(8), либо их комбинации). В этом случае система для параметров граничной линии может быть определена с избыточностью. Подобную систему для параметров граничной линии, которая определена с избыточностью, можно решать средствами регрессионного анализа, такими как метод наименьших квадратов.
[00060] Коэффициенты преобразования для первой трансформации (1)-(2) и второй (3)-(4) применимы к координатам точки, которая была произвольно выбрана на первом изображении, чтобы определить координаты соответствующей ей точки на втором. Определенные таким образом параметры граничной линии применимы, чтобы установить, какой планарной области документа соответствует выбранная точка (x, у) - первой или второй. Соответственно, первая трансформация координат применима для преобразования координат точек первого изображения, которые находятся по одну сторону граничной линии, в то время как вторая трансформация координат применима для преобразования координат точек первого изображения, которые находятся по другую сторону граничной линии. Например, для заданной точки (x, у) можно рассчитать следующий числовой показатель:
С = (х-х0') * (y0'-у0) + (у-y0') * (х0-х0')
Для тех точек, которые находятся по одну сторону граничной линии, С<0. Для тех точек, которые находятся по другую сторону граничной линии, С>0. А для тех точек, которые лежат на граничной линии, С=0.
[00061] В некоторых реализациях, как показано, например, на Рис. 5А, граничная линия, которая была определена согласно описанному выше, как пересечение плоскостей, содержащих смежные планарные области, может не соответствовать острой кромке сгиба документа. На Рис. 5А схематически показана трехмерная иллюстрация примера постоянно сгибаемого документа с двумя планарными областями, соединенными гладкой областью перехода. Как показано на Рис. 5А, в трехмерном пространстве подобное пересечение может даже выходить за двумерную поверхность, в которой лежит документ. Область сгиба документа, например, находящаяся вблизи складки может простираться на некоторое расстояние и плавно переходить в планарные области по обе стороны граничной линии. Это показано на Рис. 5А. В подобных случаях линия границы в виде оси области сгиба может все же служить полезным ориентиром.
[00062] Если снять изображение документа, угол и местоположение камеры могут быть такими, что внутри области сгиба координаты (x, у) на изображении могут не совсем точно соответствовать фактическому размещению точек в документе, если те находятся внутри области сгиба. Это может быть верно, независимо от того, используется ли первое преобразование координат или второе, поскольку ни одно из них внутри области сгиба не может быть точным (например, точность равна половине размера типичного символа в документе). Например, для точки Р, расположенной глубоко внутри второй планарной области, второе преобразование может быть точным. Однако для точки Р', размещенной внутри области сгиба, ни второе, ни первое преобразование координат не могут обеспечить достаточную точность.
[00063] Чтобы повысить точность преобразования различных точек (и, следовательно, символов и последовательностей символов) первого изображения в точки второго (и (или) дополнительных изображений), проективные преобразования (1)-(2) и (или) (3)-(4), установленные для областей, смежных с линией границы, могут быть улучшены при помощи эвристических исправлений границы ΔХ(x, у), ΔY(x, y). В некоторых примерах реализации исправления ΔХ(x, у), ΔY(x, y) могут быть причиной отклонения текущего документа от двух (или более) плоскостей, на которых работают проектные преобразования (вплоть до ошибок, которые могут быть свойственны процессу идентификации опорных точек, используемых в определении параметров двух преобразований). В некоторых примерах реализации исправления ΔХ(x, у), ΔY(x, y) могут зависеть от протяженности (то есть гладкости) области сгиба, угла, на который документ отступает от заостренной складки (изгиба, сгиба), неравномерности деформации документа вдоль направления сгиба и так далее.
[00064] На Рис. 5В схематически показано изображение примера постоянно сгибаемого документа из Рис. 5А с двумя планарными областями, соединенными гладкой областью перехода. В некоторых реализациях исправления границ ΔX(x', y'), ΔY(x', y') могут рассматриваться в рамках локальных координат x' и у', связанных с граничной линией. Например, одна из локальных осей, а именно ось у', может быть выбрана для совмещения с граничной линией, как показано на Рис. 5В. В некоторых реализациях остальные оси x' могут быть выбраны перпендикулярными у' с произвольно выбранным началом координат или с использованием каких-либо средств регрессионного анализа (например, метод наименьших квадратов), как наименее удаленная точка (или все точки на граничной линии) от всех опорных точек, определенных в блоках 140 и 150. Трансформация из координат x и у в локальные координаты x' и у' может быть комбинацией перевода и поворота на угол, который новая ось у' образует со старой осью у.
[00065] В некоторых реализациях исправления границ в локальных координатах x' и у' могут быть приблизительно выражены следующими уравнениями:
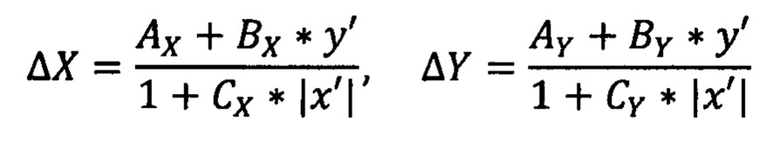
определяющими исправления, которые уменьшают расстояние |x'| от граничной линии x'=0. Коэффициенты АX и AY описывают некоторые средние значения исправлений границ прямо на граничной линии. Коэффициенты ВX и BY описывают неравномерность этих исправлений вдоль граничной линии. Более конкретно, ненулевые значения коэффициентов ВX и BY могут быть задействованы в ситуациях, когда документ имеет сгиб, более острый около одного края линии границы и более широкий около противоположного конца граничной линии. Например, положительные коэффициенты ВX>0 и BY>0 могут указывать на то, что сгиб острее около нижнего края (у'<0) граничной линии и шире около ее верхнего края (у'>0). Коэффициенты СX и CY описывают боковую остроту сгиба. Например, меньшие значения этих коэффициентов могут означать, что зона сгиба занимает широкую область документа, в то время как большие значения этих коэффициентов могут означать, что зона сгиба распространяется на более узкую область.
[00066] Исправления ΔХ(x', у'), ΔY(x', y') могут быть добавлены к одному или нескольким первым координатным преобразованиям или второму координатному преобразованию, или к обоим. Например, при конвертации координат (x, у) первого изображения в координаты второго изображения (X, Y) обрабатывающее устройство может начать с определения отношения координат (x, у) к граничной линии и выбора подходящего (первого или второго) проективного координатного преобразования, в зависимости от определенного отношения. Обрабатывающее устройство может затем, опционально, добавить исправления ΔХ и ΔY к координатам, определенным по результатам проективного координатного преобразования. В некоторых реализациях одни и те же исправления могут добавляться вне зависимости того, был ли определен выбор первого координатного преобразования или второго координатного преобразования. В некоторых реализациях только одно из исправлений ΔХ(x', у'), ΔY(x', y') может быть использовано, в то время как другое исправление не может быть добавлено.
[00067] В некоторых реализациях коэффициенты в исправлениях ΔХ(x', у'), ΔY(x', у') могут быть определены из координат множества опорных точек, расположенных в области сгиба около складки. Например, три пары коэффициентов (AX, AY), (ВX, ВY), (CX,CY) могут быть определены из координат трех опорных точек, расположенных в границах области сгиба. Чтобы обеспечить точность, могут использоваться только опорные точки, достаточно близкие к граничной линии. В некоторых примерах только опорные точки, в которых координаты отличаются от координат, полученных в результате двух преобразований, по меньшей мере некоторыми заранее заданными значениями, могут использоваться для определения коэффициентов (AX, AY), (BX, BY), (СX, Су). Заданное значение может относиться к размеру типичного символа (например, наиболее часто встречающийся размер символа, средний размер символа и так далее) в документе (изображение). В одном из примеров, типичный символ может быть буквой. В некоторых реализациях заданное значение может быть равно высоте (ширине) такого типичного символа или его двойной высоте (ширине), половине его высоты (ширины) или любому другому значению. В некоторых реализациях только эти опорные точки, расположенные в пределах заданного расстояния от граничной линии, могут использоваться для определения коэффициентов (AX, AY), (BX, BY), (CX, CY). Например, заданное расстояние может быть равно десятикратной (или любому другому значению, выраженному целым или дробным числом) высоте (ширине) типичного символа в документе. В некоторых реализациях максимальное расстояние до граничной линии может быть определенной долей размера (ширины, длины) изображения в документе или одной из частей изображения, соответствующей одной из планарных областей документа. В некоторых реализациях исправление границ может быть рассчитано с коэффициентами N, а не с шестью коэффициентами (как в случае выше). В таких реализациях могут быть выбраны опорные точки N/2, чтобы определить коэффициенты N. В некоторых реализациях более трех точек (или более, чем N/2 точек для случаев, когда используются разные формулы для определения исправлений) могут оказаться в пределах граничной зоны. В таких случаях система уравнений для шести (или N) параметров может быть определена с избыточностью. В одной из возможных реализаций эти параметры затем могут быть рассчитаны из такой определенной с избыточностью системы с использованием средств регрессионного анализа, например, методом наименьших квадратов.
[00068] В одном из вариантов реализации после определения параметров первого и второго координатного преобразования, параметров граничной линии и (опционально) граничных исправлений, обрабатывающее устройство, выполняющее метод 100, может продолжить оптическое распознавание символов текста документа следующим образом.
[00069] В соответствии с Рис. 1 в блоке 180 обрабатывающее устройство может определить последовательность символов распознанного текста на первом изображении. Обрабатывающее устройство может определить совпадающие последовательности символов в текстах, созданных при помощи оптического распознавания символов в одном изображении или серии дополнительных изображений документа, которые отличаются от первого изображения. В некоторых реализациях второе изображение, использующееся для определения топологии первого изображения (например, множество планарных областей, отображенных на первом изображении и одна или более граничных линий, разделяющих планарные области), может являться частью последовательности изображений. В других реализациях второе изображение может быть не включено в последовательность изображений для оптического распознавания текста документа.
[00070] Обрабатывающее устройство может связывать точку (x, у) в первом изображении с последовательностью символов (например, нижний левый угол ограничивающего прямоугольника для последовательности символов). Обрабатывающее устройство может установить количество С и определить его знак. Основываясь на знаке С, обрабатывающее устройство может использовать одно из вышеупомянутых координатных преобразований (1)-(2) и (3)-(4) (с добавленными исправлениями границ или без них) для сравнения позиций различных распознанных последовательностей символов на втором изображении и всех дополнительных изображениях, если применимо, и таким образом идентифицировать группы последовательностей символов, которые, возможно, представляют один и тот же фрагмент исходного документа. Например, дополнительные изображения могут включать третье изображение, четвертое изображение и так далее. В некоторых реализациях группы символов на третьем изображении могут быть определены с использованием трансформации из координат второго изображения в координаты третьего изображения (после определения множества трансформаций из первого изображения во второе). В некоторых реализациях координаты третьего (или любого последующего) изображения могут быть определены напрямую из координат первого изображения при помощи использования тех же техник и методов настоящего изобретения относительно преобразований на втором изображении.
[00071] В иллюстративном примере для произвольно выбранной последовательности символов в тексте, созданном при помощи оптического распознавания символов заданного изображения, метод может определить одну или более совпадающих последовательностей символов, созданных оптическим распознаванием символов других изображений данной последовательности изображений. Следует заметить, что «совпадающие последовательности символов» в настоящем документе соответствуют как точно совпадающим, так и нестрого совпадающим последовательностям символов.
[00072] В некоторых вариантах реализации компьютерная система может создавать граф, вершины которого соответствуют последовательностям символов из множеств изображений, а дуги соединяют последовательности символов, определенные как совпадающие (то есть соответствующие одному и тому же фрагменту исходного текста), путем применения указанного выше преобразования координат между изображениями. Как схематически показано на Рис. 6, полученный граф может содержать множество кластеров вершин, таких, что каждый кластер соответствует двум или более совпадающим последовательностям символов. Вершины в каждом кластере соединены соответствующими ребрами, при этом отдельные кластеры могут быть изолированы или слабо связаны друг с другом. На Рис. 6 показаны два кластера (602, 604), представляющие символьные последовательности, создаваемые OCR, для двух исходных строк: «the core» и «method».
[00073] В блоке 190 вычислительная система может выявлять медианную строку одного или более кластеров совпадающих последовательностей символов таким образом, что выявленная медианная строка должна соответствовать результату OCR соответствующего фрагмента изображения. Как схематически показано на Рис. 7А, каждый кластер 702 может содержать множество совпадающих последовательностей символов 704, а результат OCR соответствующего фрагмента изображения может быть представлен медианной строкой 706. В некоторых вариантах реализации медианная строка может быть выявлена как последовательность символов, имеющая минимальную сумму расстояний редактирования до всех символьных последовательностей кластера. Расстояние редактирования, которое в одном из иллюстративных примеров может быть представлено расстоянием Левенштейна, между первой последовательностью символов и второй последовательностью символов может быть равно минимальному количеству редактирований единичных символов (например, вставок, удалений или замен), необходимых для преобразования первой последовательности символов во вторую последовательность символов.
[00074] В некоторых вариантах реализации вычислительная сложность выявления медианной строки может быть уменьшена за счет применения определенных эвристических методов. В одном из иллюстративных примеров вычислительная система может эвристически выявить аппроксимацию нулевого порядка медианной строки. Затем вычислительная система может выровнять последовательности символов, используя строго совпадающие символы внутри каждой последовательности, как схематически показано на Рис. 7В. В другом иллюстративном примере система распознавания может связывать с каждой последовательностью символов кластера весовой коэффициент, отражающий положение последовательности символов в изображении или показатель достоверности OCR. Как схематически показано на Рис. 7С, кластер 712 содержит четыре последовательности символов: TOP, TOP, TORRENT, TORRENT. Первые две последовательности символов соответствуют частям слов, так как расстояние от границы минимального описывающего прямоугольника последовательности символов до края изображения меньше, чем ширина пробела. Поэтому значение показателя достоверности распознавания для первых двух последовательностей символов значительно меньше, чем значение показателя достоверности распознавания для оставшихся двух последовательностей символов, и поэтому последовательность символов TORRENT будет выбрана в качестве медианной строки методом, который принимает во внимание значения достоверности распознавания.
[00075] Обрабатывающее устройство, используя метод 100, может выявлять порядок, в котором указанные выше последовательности символов, представляющие указанный выше кластер, должны располагаться в итоговом тексте. Как было указано выше в этом документе, изображения, соответствующие исходному документу, могут отображать по крайней мере частично перекрывающиеся фрагменты документа и отличаться масштабом изображения, углом съемки, выдержкой, диафрагмой, яркостью изображения, наличием бликов, присутствием внешних объектов, которые по крайней мере частично закрывают оригинальный текст, и (или) другими особенностями изображения, визуальными артефактами и параметрами процесса визуализации. Таким образом, тексты, созданные при OCR каждого отдельного изображения, могут отличаться одним или более имеющимися или отсутствующими словами в каждом результате OCR, вариациями в последовательностях символов, представляющих слова исходного текста, и (или) порядком последовательностей символов.
[00076] В некоторых реализациях изобретения вычислительная система может сравнивать множество перестановок последовательностей символов, которые соответствуют обнаруженным кластерам. Медианное преобразование может быть определено как перестановка, имеющая минимальную сумму тау-расстояний Кендалла по сравнению со всеми другими перестановками. Тау-расстояние Кендалла между первым и вторым преобразованием может быть равно минимальному числу операций обмена в алгоритме «пузырьковой» сортировки для преобразования первой перестановки во вторую перестановку символов.
[00077] В соответствии с Рис. 1 в блоке 195 вычислительная система может использовать полученные последовательности символов, представляющие вышеупомянутые кластеры, для получения итогового текста, соответствующего исходному документу.
[00078] Как отмечено выше, текст, создаваемый системами и способами OCR, описанными в настоящем документе, может подвергаться дальнейшей обработке, например, способами машинного перевода для перевода исходного текста на другой естественный язык. Поскольку описанные в настоящем документе способы позволяют реконструировать исходный текст, а не только отдельные слова, то для повышения качества машинного перевода способы машинного перевода могут использовать синтаксический и (или) семантический анализ.
[00079] На Рис. 8 представлена более подробная схема компонентов примера вычислительной системы 800, внутри которой исполняется набор инструкций, которые инициируют выполнение вычислительной системой любого из одного или более способов данного изобретения. Вычислительная система 800 может быть соединена с другой вычислительной системой по локальной сети, корпоративной сети, сети Экстранет или Интернет. Вычислительная система 800 может работать в качестве сервера или клиента в сетевой среде «клиент/сервер» либо в качестве однорангового вычислительного устройства в одноранговой (или распределенной) сетевой среде. Вычислительная система 800 может быть представлена персональным компьютером (ПК), планшетным ПК, телевизионной приставкой (STB), карманным ПК (PDA), сотовым телефоном или любой вычислительной системой, способной выполнять набор команд (последовательно или иным образом), определяющих операции, которые должны быть выполнены этой вычислительной системой. Кроме того, несмотря на то что показана только одна вычислительная система, термин «вычислительная система» также может включать любую совокупность вычислительных систем, которые отдельно или совместно выполняют набор (или несколько наборов) команд для выполнения одной или более методик, обсуждаемых в настоящем документе.
[00080] Пример вычислительной системы 800 включает процессор 802, основное запоминающее устройство 804 (например, постоянное запоминающее устройство (ROM) или динамическое оперативное запоминающее устройство (DRAM)) и устройство хранения данных 818, которые взаимодействуют друг с другом по шине 830.
[00081] Процессор 802 может быть представлен одним или более универсальными устройствами обработки данных, например, микропроцессором, центральным процессором и т.д. В частности, процессор 802 может представлять собой микропроцессор с полным набором команд (CISC), микропроцессор с сокращенным набором команд (RISC), микропроцессор с командными словами сверхбольшой длины (VLIW), процессор, реализующий другой набор команд, или процессоры, реализующие комбинацию наборов команд. Процессор 802 также может представлять собой одно или более устройств обработки специального назначения, например заказную интегральную микросхему (ASIC), программируемую пользователем вентильную матрицу (FPGA), процессор цифровых сигналов (DSP), сетевой процессор и т.п. Процессор 802 выполнен с возможностью исполнения инструкций 826 для выполнения операций и функций способа 100 оптического распознавания символов серии изображений, содержащих символы текста, как описано выше в этом документе.
[00082] Вычислительная система 800 может дополнительно включать устройство сетевого интерфейса 822, устройство визуального отображения 810, устройство ввода символов 812 (например, клавиатуру) и устройство ввода в виде сенсорного экрана 814.
[00083] Устройство хранения данных 818 может включать машиночитаемый носитель данных 824, в котором хранится один или более наборов инструкций 826, в которых реализован один или более методов или функций, описанных в данном варианте реализации изобретения. Инструкции 826 во время выполнения их в вычислительной системе 800 также могут находиться полностью или по меньшей мере частично в основном запоминающем устройстве 804 и (или) в процессоре 802, при этом основное запоминающее устройство 804 и процессор 802 также представляют собой машиночитаемый носитель данных. Инструкции 826 дополнительно могут передаваться или приниматься по сети 816 через устройство сетевого интерфейса 822.
[00084] В некоторых вариантах реализации инструкции 826 могут включать команды способа 100 для выполнения OCR серии изображений, содержащих символы текста, как описано выше в этом документе. В то время как машиночитаемый носитель 824, показанный на примере на Рис. 8, является единым носителем, термин «машиночитаемый носитель» должен распространяться на один или более носителей (например, централизованную или распределенную базу данных и (или) соответствующие кэш-памяти и серверы), в которых хранятся один или более наборов команд. Термин «машиночитаемый носитель данных» также следует понимать как описывающий любой носитель, который может хранить, кодировать или переносить набор команд для выполнения машиной и который обеспечивает выполнение машиной любой одной или более методик настоящего изобретения. Поэтому термин «машиночитаемый носитель данных» относится, помимо прочего, к твердотельным запоминающим устройствам, а также к оптическим и магнитным носителям.
[00085] Способы, компоненты и функции, описанные в настоящем документе, могут быть реализованы с помощью дискретных компонентов оборудования либо они могут быть встроены в функции других компонентов оборудования, например ASICS (специализированная заказная интегральная схема), FPGA (программируемая логическая интегральная схема), DSP (цифровой сигнальный процессор) или аналогичных устройств. Кроме того, способы, компоненты и функции могут быть реализованы с помощью модулей встроенного программного обеспечения или функциональных схем аппаратного обеспечения. Способы, компоненты и функции также могут быть реализованы с помощью любой комбинации аппаратного обеспечения и программных компонентов либо исключительно с помощью программного обеспечения.
[00086] В приведенном выше описании изложены многочисленные детали. Однако любому специалисту в этой области техники, ознакомившемуся с данным описанием, должно быть очевидно, что настоящее изобретение может быть осуществлено на практике без этих конкретных деталей. В некоторых случаях хорошо известные структуры и устройства показаны в виде блок-схем без детализации, чтобы не усложнять описание настоящего изобретения.
[00087] Некоторые части описания предпочтительных вариантов реализации изобретения представлены в виде алгоритмов и символического представления операций с битами данных в запоминающем устройстве компьютера. Такие описания и представления алгоритмов являются средствами, используемыми специалистами в области обработки данных, что обеспечивает наиболее эффективную передачу сущности работы другим специалистам в данной области. В контексте настоящего описания, как это и принято, алгоритмом называется логически непротиворечивая последовательность операций, приводящих к желаемому результату. Операции подразумевают действия, требующие физических манипуляций с физическими величинами. Обычно, хотя и необязательно, эти величины принимают форму электрических или магнитных сигналов, которые можно хранить, передавать, комбинировать, сравнивать, и выполнять с ними другие манипуляции. Иногда удобно, прежде всего для обычного использования, описывать эти сигналы в виде битов, значений, элементов, символов, терминов, цифр и т.д.
[00088] Однако следует иметь в виду, что все эти и подобные термины должны быть связаны с соответствующими физическими величинами и что они являются лишь удобными обозначениями, применяемыми к этим величинам. Если не указано дополнительно, принимается, что в последующем описании термины «определение», «вычисление», «расчет», «получение», «установление», «изменение» и т.п. относятся к действиям и процессам вычислительной системы или аналогичной электронной вычислительной системы, которая использует и преобразует данные, представленные в виде физических (например, электронных) величин в реестрах и запоминающих устройствах вычислительной системы, в другие данные, аналогично представленные в виде физических величин в запоминающих устройствах или реестрах вычислительной системы или иных устройствах хранения, передачи или отображения такой информации.
[00089] Настоящее изобретение также относится к устройству для выполнения операций, описанных в настоящем документе. Такое устройство может быть специально сконструировано для требуемых целей, либо оно может представлять собой универсальный компьютер, который избирательно приводится в действие или дополнительно настраивается с помощью программы, хранящейся в памяти компьютера. Такая компьютерная программа может храниться на машиночитаемом носителе данных, например, помимо прочего, на диске любого типа, включая дискеты, оптические диски, CD-ROM и магнитно-оптические диски, постоянные запоминающие устройства (ROM), оперативные запоминающие устройства (RAM), EPROM, EEPROM, магнитные или оптические карты и носители любого типа, подходящие для хранения электронной информации.
[00090] Следует понимать, что приведенное выше описание призвано иллюстрировать, а не ограничивать сущность изобретения. Специалистам в данной области техники после прочтения и уяснения приведенного выше описания станут очевидны и различные другие варианты реализации изобретения. Исходя из этого, область применения изобретения должна определяться с учетом прилагаемой формулы изобретения, а также всех областей применения аналогичных способов, на которые в равной степени распространяется формула изобретения.

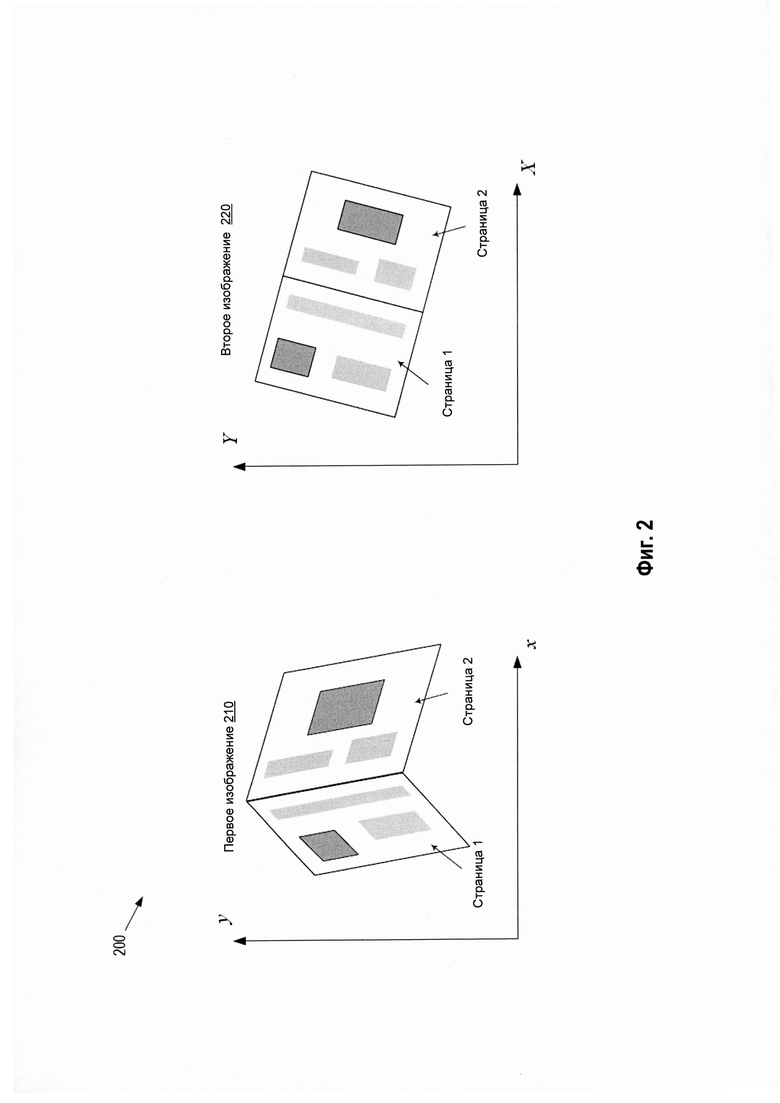
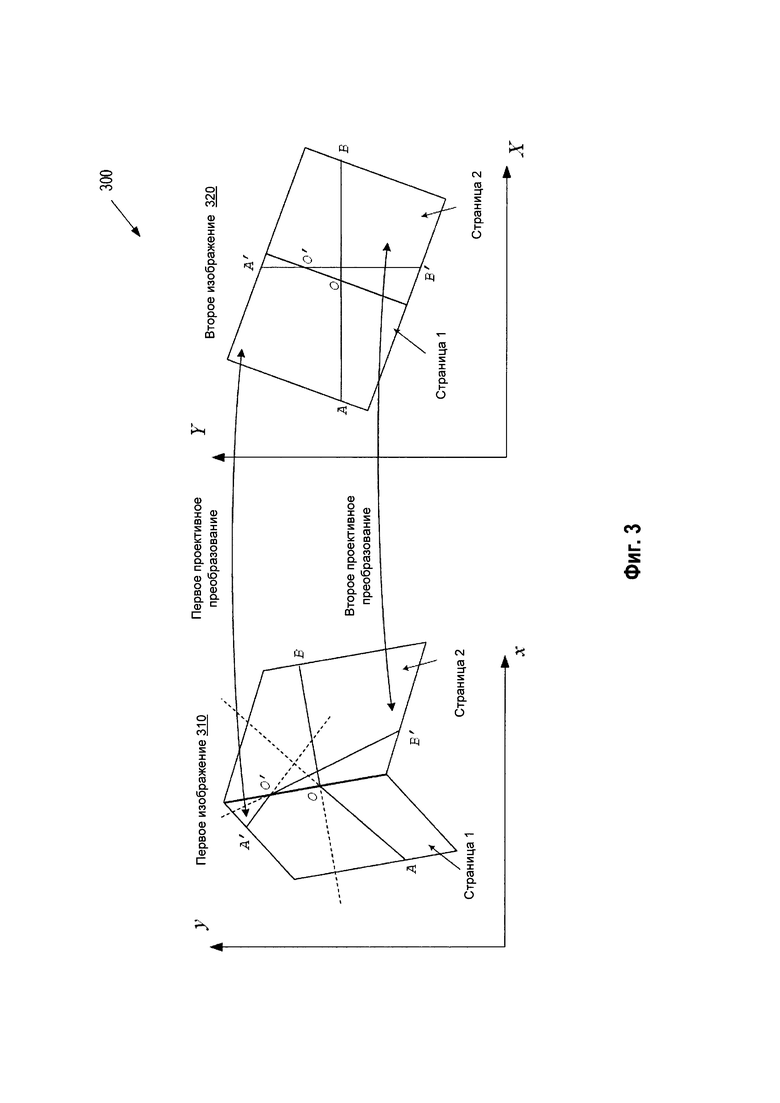
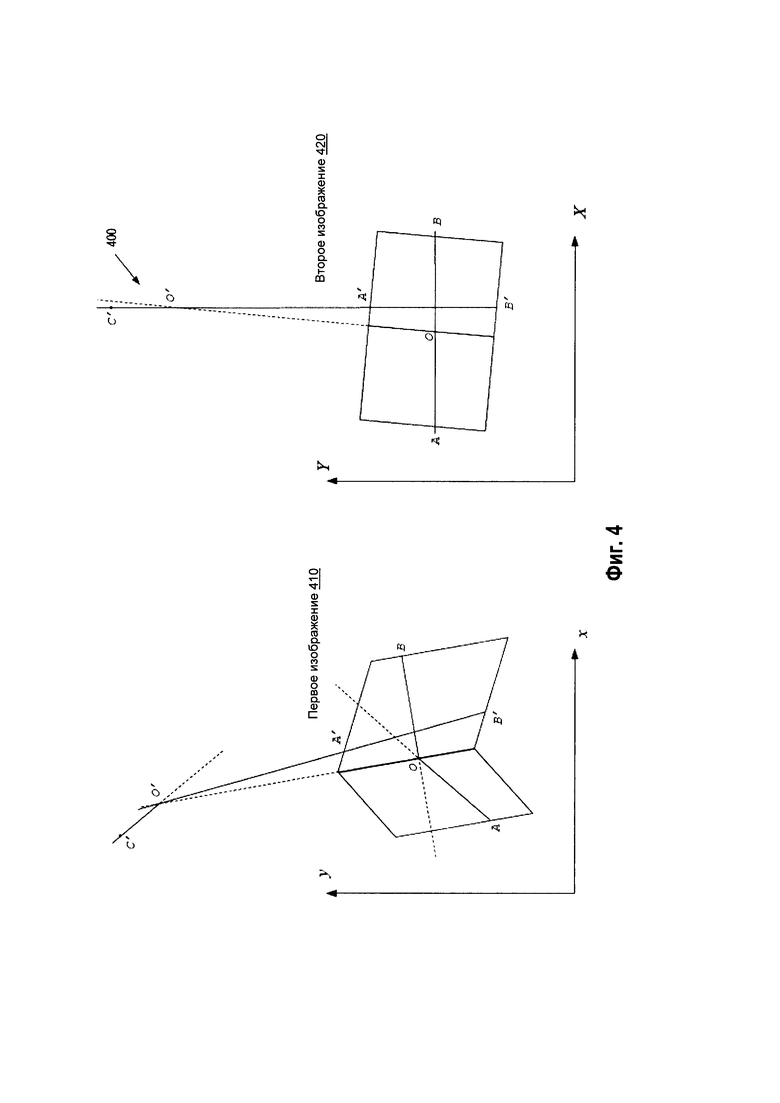
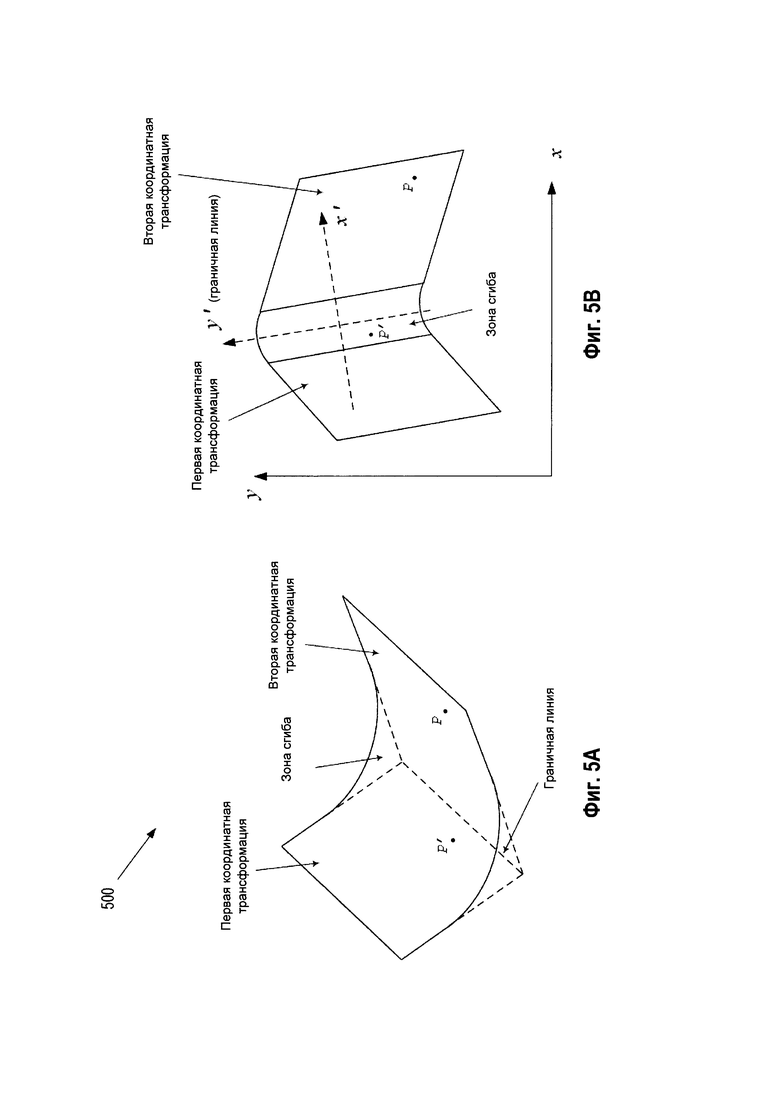
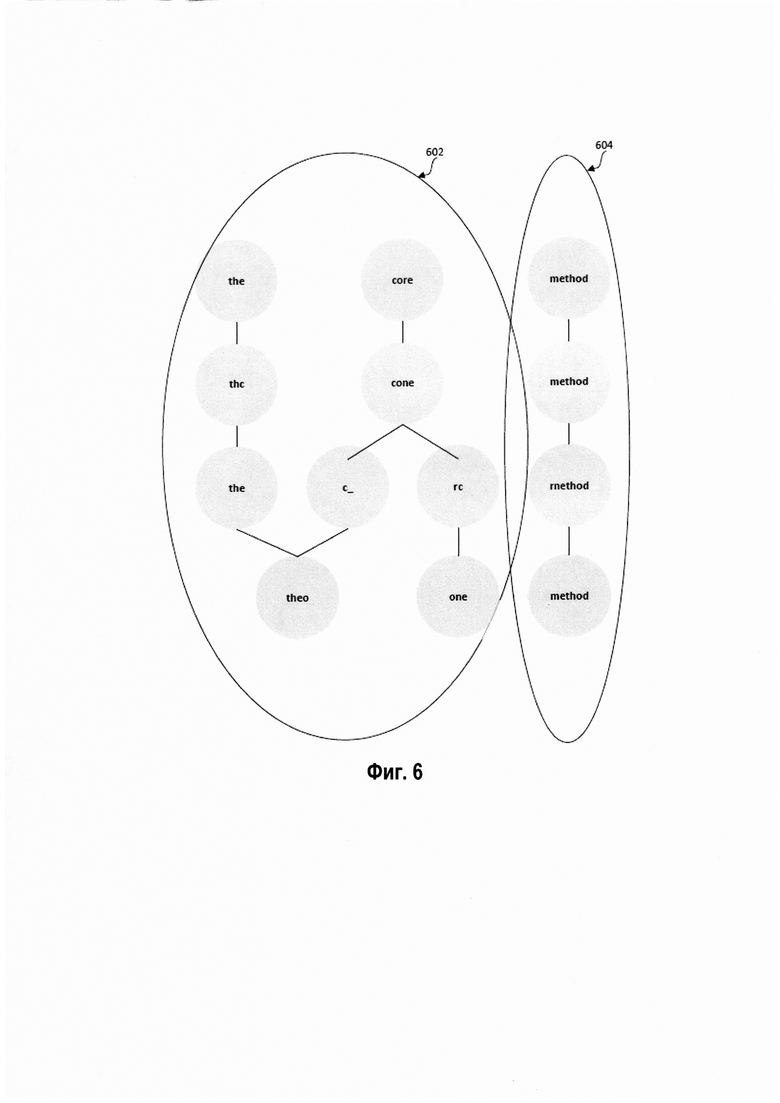
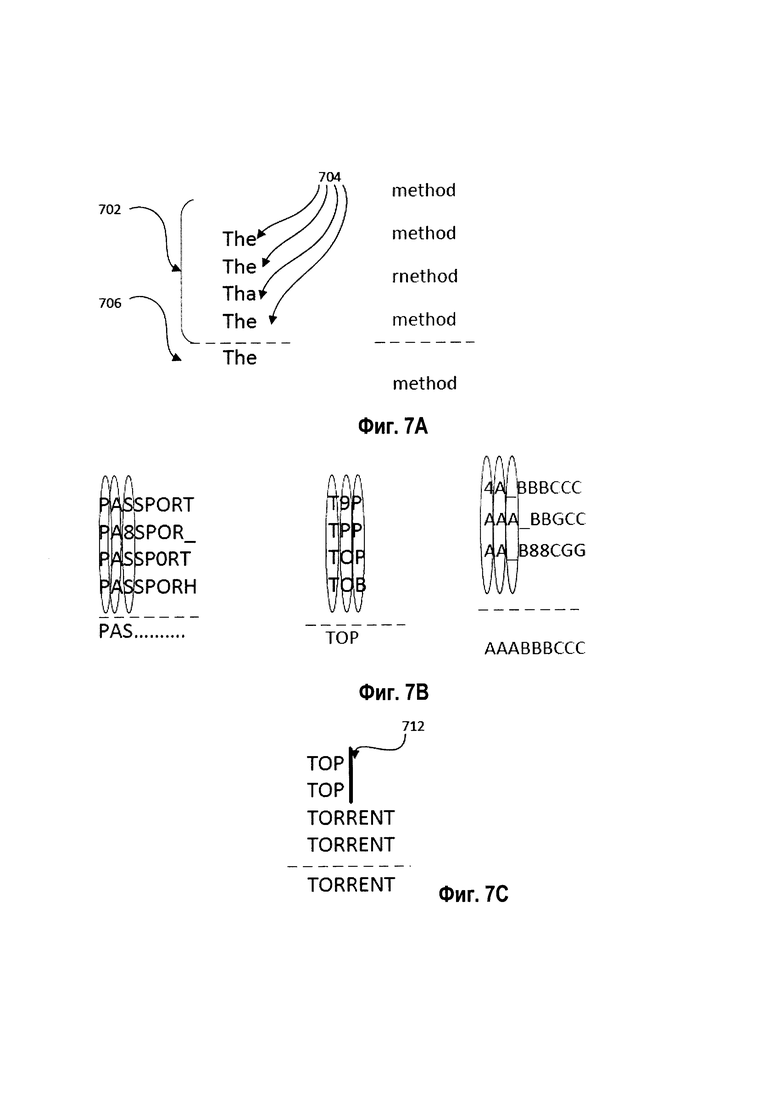
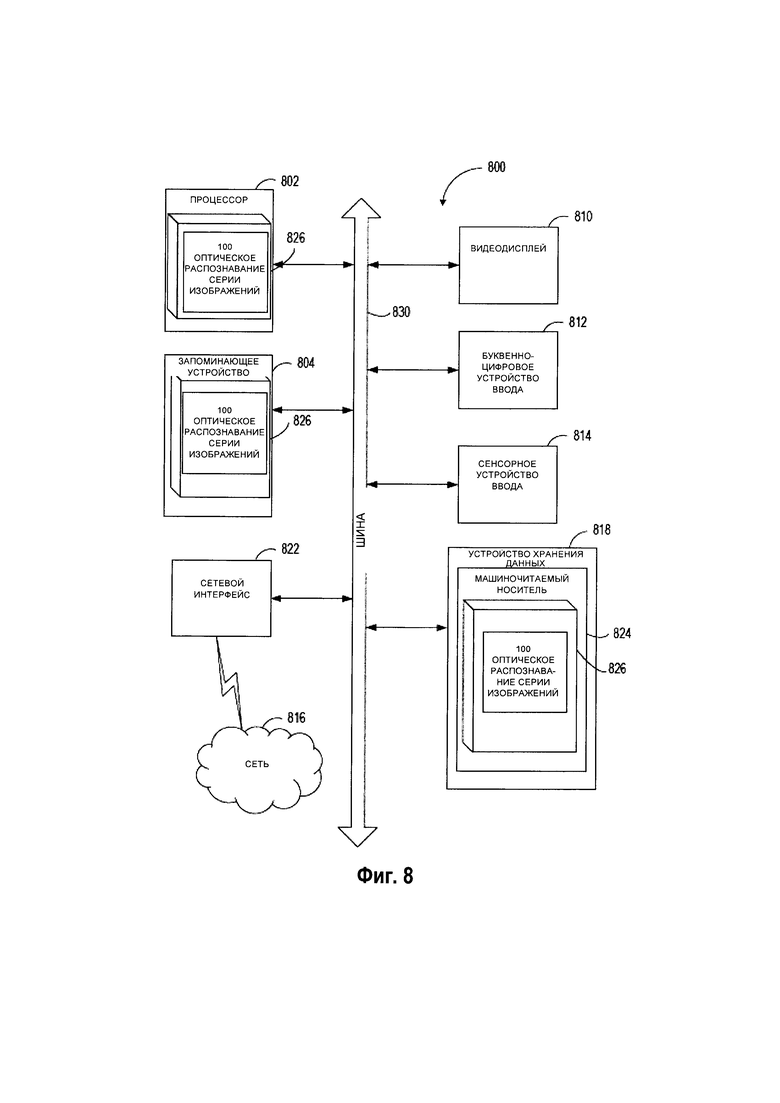
Изобретение относится к области оптического распознавания символов. Технический результат заключается в расширении арсенала средств того же назначения. Способ оптического распознавания последовательности символов, включающий этапы: получение обрабатывающим устройством первого изображения документа с множеством планарных областей, на котором по меньшей мере две планарные области множества планарных областей взаимно не копланарны, выполнение оптического распознавания символов (OCR) первого изображения для определения распознанного текста на первом изображении, получение текста на одном или более вторых изображениях документа, определение множества опорных точек на первом и втором изображениях, определение параметров первого и второго координатных преобразований, определение, используя параметры первого координатного преобразования и параметры второго координатного преобразования, кластера последовательностей символов, содержащего последовательность символов распознанного текста на первом изображении и по меньшей мере одной соответствующей последовательности символов на одном или более вторых изображениях документа и представление результирующего текста оптического распознавания символов (OCR), содержащего медианную последовательность символов для кластера последовательностей символов. 3 н. и 17 з.п. ф-лы, 11 ил.
1. Способ оптического распознавания последовательности символов, содержащий этапы:
получение обрабатывающим устройством первого изображения документа с множеством планарных областей, на котором по меньшей мере две планарные области множества планарных областей взаимно не копланарны;
выполнение оптического распознавания символов (OCR) первого изображения для определения распознанного текста на первом изображении;
получение текста на одном или более вторых изображениях документа;
определение множества опорных точек на первом изображении;
определение множества опорных точек в каждом втором изображении, где каждая точка из множества опорных точек в соответствующем втором изображении соответствует одной опорной точке из множества опорных точек в первом изображении;
определение параметров первого координатного преобразования, конвертирующего координаты первого набора опорных точек множества опорных точек на первом изображении в координаты соответствующих опорных точек множества опорных точек в соответствующем втором изображении, где каждая из опорных точек первого набора опорных точек находится в пределах первой части первого изображения, где первая часть первого изображения отображает первую планарную область множества планарных областей документа;
определение параметров второго координатного преобразования, конвертирующего координаты второго набора опорных точек множества опорных точек на первом изображении в координаты соответствующих опорных точек множества опорных точек на соответствующем втором изображении, где каждая из опорных точек второго набора опорных точек находится в пределах второй части первого изображения, где вторая часть первого изображения отображает вторую планарную область множества планарных областей документа, и где вторая планарная область документа является некопланарной с первой планарной областью документа;
определение, используя параметры первого координатного преобразования и параметры второго координатного преобразования, кластера последовательностей символов, содержащего последовательность символов распознанного текста на первом изображении и по меньшей мере одной соответствующей последовательности символов на одном или более вторых изображениях документа; и
порождение результирующего текста оптического распознавания символов (OCR), содержащего медианную последовательность символов для кластера последовательностей символов.
2. Способ по п. 1, в котором каждая из множества опорных точек на первом изображении связана с по меньшей мере одним текстовым артефактом из множества текстовых артефактов как на первом, так и на втором изображении, где каждый текстовый артефакт представлен последовательностью символов, чья частота встречаемости в пределах текста на первом изображении не превышает пороговую частоту.
3. Способ по п. 1, включающий определение на базе параметров первого координатного преобразования и параметров второго координатного преобразования, параметры граничной линии, которая соответствует границе между первой планарной областью документа и второй планарной областью документа.
4. Способ по п. 3, в котором первое координатное преобразование применимо для преобразования координат точек первого изображения, которые находятся по одну сторону граничной линии, в то время, как второе координатное преобразование применимо для преобразования координат точек первого изображения, которые находятся по другую сторону граничной линии.
5. Способ по п. 4, включающий применение исправления границ по меньшей мере одного из первых координатных преобразований или вторых координатных преобразований, где исправление границ призвано уменьшить расстояние от граничной линии.
6. Способ по п. 1, в котором первое координатное преобразование и второе координатное преобразование являются проективными преобразованиями.
7. Способ по п. 1, в котором медианная последовательность символов для кластера последовательностей символов характеризуется минимальной суммой значений предопределенной системы показателей с учетом кластера последовательностей символов.
8. Способ по п. 7, в котором указанное выше получение медианной строки включает применение весовых коэффициентов к каждой последовательности символов кластера последовательностей символов.
9. Система оптического распознавания последовательности символов, содержащая:
память, которая хранит инструкции; и процессорное устройство для исполнения указанных хранящихся в памяти инструкций, направленных на:
получение первого изображения документа, имеющего множество планарных областей, где по меньшей мере две планарных области множества планарных областей взаимно не копланарны;
выполнение оптического распознавания символов (OCR) первого изображения, чтобы определить распознанный текст на первом изображении;
получение текста на одном или более вторых изображениях документа;
определение множества опорных точек на первом изображении;
определение множества опорных точек на каждом втором изображении, где каждая точка из множества опорных точек в соответствующем втором изображении соответствует одной опорной точке из множества опорных точек в первом изображении;
определение параметров первого координатного преобразования, конвертирующего координаты первого набора опорных точек множества опорных точек на первом изображении в координаты соответствующих опорных точек множества опорных точек в соответствующем втором изображении, где каждая из опорных точек первого набора опорных точек находится в пределах первой части первого изображения, где первая часть первого изображения отображает первую планарную область множества планарных областей документа;
определение параметров второго координатного преобразования, конвертирующего координаты второго набора опорных точек множества опорных точек на первом изображении в координаты соответствующих опорных точек множества опорных точек в соответствующем втором изображении, где каждая из опорных точек второго набора опорных точек находится в пределах второй части первого изображения, где вторая часть первого изображения отображает вторую планарную область множества планарных областей документа, и где вторая планарная область документа является некопланарной с первой планарной областью документа;
определение, с использованием параметров первого координатного преобразования и параметров второго координатного преобразования, кластера последовательностей символов, содержащего последовательность символов распознанного текста на первом изображении и по меньшей мере одной соответствующей последовательности символов на одном или более вторых изображениях документа; и
порождение результирующего текста оптического распознавания символов (OCR), содержащего медианную последовательность символов для кластера последовательностей символов
10. Система по п. 9, в которой каждая из множества опорных точек на первом изображении связана с по меньшей мере одним текстовым артефактом из множества текстовых артефактов как на первом изображении, так и на втором изображении, где каждый текстовый артефакт представлен последовательностью символов, чья частота встречаемости в пределах текста на первом изображении не превышает пороговую частоту.
11. Система по п. 9, в которой процессорное устройство определяет на базе параметров первого координатного преобразования и параметров второго координатного преобразования параметры граничной линии, которая соответствует границе между первой планарной областью документа и второй планарной областью документа.
12. Система по п. 11, в которой первое координатное преобразование применимо для преобразования координат точек первого изображения, которые находятся по одну сторону граничной линии, в то время как второе координатное преобразование применимо для преобразования координат точек первого изображения, которые находятся по другую сторону граничной линии.
13. Система по п. 11, в которой процессорное устройство применяет исправление границ по меньшей мере одного из первых координатных преобразований или вторых координатных преобразований, где исправление границ призвано уменьшить расстояние от граничной линии.
14. Система по п. 9, в которой медианная последовательность символов для кластера последовательностей символов характеризуется минимальной суммой значений предопределенной системы показателей с учетом кластера последовательностей символов.
15. Постоянный машиночитаемый носитель данных, содержащий сохраненные на нем команды, которые при исполнении по меньшей мере одним процессорным устройством вызывают выполнение действий:
получение первого изображения документа, имеющего множество планарных областей, где по меньшей мере две планарных области множества планарных областей взаимно не копланарны;
выполнение оптического распознавания символов (OCR) первого изображения, чтобы определить распознанный текст на первом изображении;
получение текста на одном или более вторых изображениях документа;
определение множества опорных точек на первом изображении;
определение множества опорных точек на каждом втором изображении, где каждая точка из множества опорных точек в соответствующем втором изображении соответствует одной опорной точке из множества опорных точек в первом изображении;
определение параметров первого координатного преобразования, конвертирующего координаты первого набора опорных точек множества опорных точек на первом изображении в координаты соответствующих опорных точек множества опорных точек в соответствующем втором изображении, где каждая из опорных точек первого набора опорных точек находится в пределах первой части первого изображения, где первая часть первого изображения отображает первую планарную область множества планарных областей документа;
определение параметров второго координатного преобразования, конвертирующего координаты второго набора опорных точек множества опорных точек на первом изображении в координаты соответствующих опорных точек множества опорных точек в соответствующем втором изображении, где каждая из опорных точек второго набора опорных точек находится в пределах второй части первого изображения, где вторая часть первого изображения отображает вторую планарную область множества планарных областей документа, и где вторая планарная область документа является некопланарной с первой планарной областью документа;
определение, с использованием параметров первого координатного преобразования и параметров второго координатного преобразования, кластера последовательностей символов, содержащего последовательность символов распознанного текста на первом изображении и по меньшей мере одной соответствующей последовательности символов на одном или более вторых изображениях документа; и
порождение результирующего текста оптического распознавания символов (OCR), содержащего медианную последовательность символов для кластера последовательностей символов
16. Носитель данных по п. 15, в котором при исполнении инструкций каждая из множества опорных точек на первом изображении связана с по меньшей мере одним текстовым артефактом из множества текстовых артефактов как на первом изображении, так и на втором изображении, где каждый текстовый артефакт представлен последовательностью символов, чья встречаемость в пределах текста на первом изображении не превышает пороговую частоту.
17. Носитель данных по п. 15, в котором инструкции побуждают процессорное устройство определять, базируясь на параметрах первого координатного преобразования и параметрах второго координатного преобразования, параметры граничной линии, которая соответствует границе между первой планарной областью документа и второй планарной областью документа.
18. Носитель данных по п. 17, в котором при исполнении инструкций первое координатное преобразование применимо для преобразования координат точек первого изображения, которые находятся по одну сторону граничной линии, в то время как второе координатное преобразование применимо для преобразования координат точек первого изображения, которые находятся по другую сторону граничной линии.
19. Носитель данных по п. 17, где инструкции побуждают процессорное устройство применять исправление границ по меньшей мере одного из первых координатных преобразований или вторых координатных преобразований, где исправление границ призвано уменьшить расстояние от граничной линии.
20. Носитель данных по п. 15, в котором при исполнении инструкций медианная последовательность символов для кластера последовательностей символов характеризуется минимальной суммой значений предопределенной системы показателей с учетом кластера последовательностей символов.
| US 7792363 B2, 07.09.2010 | |||
| US 7743990 B2, 29.06.2010 | |||
| US 7077319 B2, 18.07.2006 | |||
| ВЕРИФИКАЦИЯ РЕЗУЛЬТАТОВ ОПТИЧЕСКОГО РАСПОЗНАВАНИЯ СИМВОЛОВ | 2016 |
|
RU2634194C1 |
| СПОСОБ ОБРАБОТКИ ДАННЫХ ОПТИЧЕСКОГО РАСПОЗНАВАНИЯ СИМВОЛОВ (OCR), ГДЕ ВЫХОДНЫЕ ДАННЫЕ ВКЛЮЧАЮТ В СЕБЯ ИЗОБРАЖЕНИЯ СИМВОЛОВ С НАРУШЕННОЙ ВИДИМОСТЬЮ | 2008 |
|
RU2445699C1 |

