ОБЛАСТЬ ТЕХНИКИ
[1] Настоящее техническое решение, в общем, относится к способам обработки данных для упорядочивания, перестановки или выбора данных согласно заранее установленными правилами, независимо от содержания данных, а более конкретно к автоматизированной генерации и заполнения витрин данных с использованием декларативного описания.
УРОВЕНЬ ТЕХНИКИ
[2] По мере своего развития любая организация накапливает значительное количество информации. Это, например, масса несовместимых таблиц с данными о клиентах, ни одна из которых не содержит полную информацию и не синхронизирована с другими. Данные в этих таблицах имеют разнообразную и сложную структуру. Со временем объемы этой информации уже не позволяют эффективно использовать данные при принятии управленческих решений. Этому мешают различия в способах хранения информации в транзакционных системах, отвечающих за оперативную обработку данных. Кроме того, в транзакционных базах данных достаточно сложно выполнить анализ информации за предыдущие годы. Информация несогласована, рассредоточена, часто избыточна и не всегда достоверна. При поиске решения этих проблем и возникла идея создания хранилищ данных.
Концепция хранилищ информации появилась в 80-х годах XX века в фирме IBM. Считается, что первой публикацией, посвященной хранилищам данных, была статья Барри Девлина и Пола Мэрфи, опубликованная в журнале IBM Systems Journal в 1988 г. Статья называлась «Архитектура деловых и информационных систем» («An Architecture for a Business and Information System»). В 1992 году Уильям Г. Инмон - технический директор компании Prism - в своей монографии «Построение хранилищ данных» («Building the Data Warehouse») дал определение хранилища данных:
[3] Хранилище данных (англ. Data Warehouse) - предметноориентированная, интегрированная, вариантная во времени, неразрушаемая совокупность данных, предназначенная для поддержки принятия управленческих решений.
В настоящее время чаще используют другое определение, практически мало отличающееся от классического: хранилище данных - это предметноориентированная информационная корпоративная база данных, специально разработанная и предназначенная для анализа бизнес-процессов в организации с целью поддержки принятия решений. Основная цель хранилищ - создание единого логического представления данных, содержащихся в разнотипных базах данных или в единой модели корпоративных данных. Хранилищам данных присущи следующие черты:
Предметная ориентированность. Информация в хранилище организована в соответствии с основными аспектами деятельности предприятия (заказчики, продажи, склад и т.п.).
Интегрированность. В разных базах одни и те же данные могут быть выражены в разных единицах измерения. При загрузке в хранилище данные должны быть проверены, очищены и приведены к единому виду. Анализировать такие интегрированные данные намного проще.
Привязка ко времени. Данные, выбранные из оперативных баз данных, накапливаются в хранилище в виде «исторических архивов», каждый из которых относится к конкретному периоду времени. Это позволяет анализировать тенденции в развитии бизнеса.
Неизменяемость. Попав в хранилище, данные уже никогда не меняются. Стабильность данных облегчает их анализ.
[4] Существуют следующие отличия типичных хранилищ данных от обычной реляционной базы данных:
1. Базы данных предназначены для автоматизации бизнес-процессов, тогда как основной задачей хранилищ данных является содержательный анализ информации для качественного функционирования систем поддержки принятия решений. Например, продажа товара и выписка счета производятся с использованием базы данных, предназначенной для обработки транзакций, а анализ динамики продаж за несколько лет, позволяющий спланировать работу с поставщиками, с помощью хранилища данных. Именно поэтому архитектура построения хранилища и принципы проектирования модели данных отличны от тех, что применяются в оперативных системах.
2. Базы данных постоянно изменяются в процессе работы пользователей, а хранилище данных достаточно стабильно - данные в нем обычно обновляются по определенному графику. Эти данные не удаляются и не обновляются непосредственно, а только косвенно - путем приема в загрузочную секцию новых данных. Данные, поступающие в хранилище данных, становятся доступны только для чтения. Можно утверждать, что данные в хранилище точны и корректны в том случае, если они привязаны к некоторому промежутку или моменту времени. Так как данные загружаются в хранилище с определенной периодичностью, актуальность данных несколько отстает от систем, основанных на базах данных.
3. Базы данных чаще всего являются источником данных для хранилищ.
[5] Идея витрин данных (Data Mart) возникла, когда выяснилось, что разработка корпоративного хранилища - длительный и дорогостоящий процесс, требующий значительных усилий по анализу деятельности организации и переориентации ее на новые технологии. Витрины данных возникли с целью избежать трудностей разработки и внедрения хранилищ.
[6] Витрина данных - это специализированное хранилище, обслуживающее, как правило, единственное направление деятельности организации, например учет складских запасов. Достоинствами применения витрин данных является физическое разделение данных между группами аналитиков, а также относительная простота семантики данных в пределах одной витрины (Казакова И.А. «Хранилища и витрины данных в системах поддержки принятия решений», Мир современной науки).
[7] Чаще всего с помощью витрин анализируют данные и строят ML-модели. Также витрины могут использоваться на предприятиях в качестве мастер-данных, например как справочники. Помимо этого, витрина может выступать периферическим узлом в сетях обмена данными между различными участниками. Примером концепции построения таких сетей для обмена данными является Data mesh.
Типовой проект внедрения витрин состоит из технологической и прикладной частей. Если для решения технологических задач брать готовый инструмент, а не писать систему с нуля, то можно заложить больше ресурсов на прикладные задачи, которым зачастую уделяют незаслуженно мало внимания. Для В2В и других проектов, предполагающих внедрение множества витрин у различных заказчиков, готовый инструмент позволит существенно снизить технические риски, уменьшить затраты и сократить сроки внедрения.
[8] Основными требованиями при создании витрин данных являются:
Изоляция данных. Обновление данных, например загрузка справочника, может быть растянуто во времени, при этом до окончания загрузки текущая версия справочника должна быть полностью доступна с исключением «грязного чтения» загружаемой версии.
Гарантии атомарности операций при обновлении данных. В случае сбоев и ошибок загрузки данных витрина остается в состоянии, которое предшествовало сбойному процессу. Другими словами, или данные обновляются полностью, или не обновляются вовсе, не оставляя следов сбойных операций.
Устойчивость к дубликатам изменений. Весьма сложно и дорого реализовывать во всех ИС-источниках данных выгрузку по принципу exactly-once. Наличие дублей одинаковых изменений объектов не должно приводить к нарушению логической целостности состояния витрин.
Системная темпоральность. Мало какая реляционная СУБД имеет функцию системной темпоральности «из коробки». Ведение системного времени и версионирование записей по системному времени позволяет сравнивать состояние данных витрины между двумя разными моментами времени или проводить «расследование», основываясь на данных, которые были в витрине в определенный момент в прошлом. Одним из вариантов обеспечения темпоральности является реализация SCD2 с ведением диапазонов сроков действия для версий записи.
Эффективное выполнение различных видов запросов: сравнительно редких и тяжелых аналитических запросов, затрагивающих большой объем данных (OLAP-нагрузка), и множества одновременных простых запросов (OLTP-нагрузка). Как правило, СУБД заточены на какой-то один вариант нагрузки: OLAP или OLTP.
(Михаил Шамота, «Простор для данных», habr.com)
[9] Как видно из приведенного выше современного уровня техники - создание витрины данных - сложная техническая задача, требующая наличия разнообразного программного инструментария и наличия компетенции в нем. При этом в настоящее время существует потребность возможности создания аналитиком, знающим SQL на уровне написания запросов, промышленных приложений по преобразованию данных в табличном формате - витрин данных, то есть необходимо техническое решение, позволяющее осуществить автоматизацию процесса генерации и заполнения витрин данных.
[10] Из уровня техники известен «СПОСОБ ВВОДА СВЕДЕНИЙ В БАЗУ ДАННЫХ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ» (RU 2569565, Акционерное общество "Ракетно-космический центр "Прогресс" (АО "РКЦ "Прогресс") (RU), 10.12.2014). Изобретение относится к области технической кибернетики и предназначено для ввода сведений в базы данных системы с исключением повторной записи уже имеющихся данных. Технический результат заключается в снижении затраченного времени и количества ошибок при вводе информации в базу данных за счет автоматизации процесса. При занесении данных в базу данных приемник из входного массива записей из базы данных приемника запрашивают записи из независимых таблиц, соответствующих независимым записям входного массива, сравнивают с записями входного массива, при необходимости дополнительно записывают недостающие записи, полученными при этом уникальными ключами и уникальными ключами, уже имевшимися в базе данных до ввода сведений, дополняют подчиненные записи входного массива и после этого записывают данные в соответствующие подчиненные таблицы базы данных.
Из уровня техники известен СПОСОБ И СИСТЕМА ОРГАНИЗАЦИИ И ФУНКЦИОНИРОВАНИЯ БАЗЫ ДАННЫХ НОРМАТИВНОЙ ДОКУМЕНТАЦИИ (RU 2386166, Открытое Акционерное общество Таганрогский Авиационный научно-технический комплекс им. Г.М. Бериева, 10.04.2010), заключающийся в том, что, по меньшей мере, в одном хранилище данных сохраняют объекты нормативной документации, взаимодействуют с хранилищем данных следующим образом: весь объем нормативной документации и содержащейся в ней информации по любой предметной области деятельности помещают в отдельную область базы данных и представляют в виде трехмерного информационного пространства, выбирают три основных характеристических признака и присваивают их названия координатным осям X, Y, Z, определяют составляющие характеристических признаков и откладывают их на координатных осях, образованных ортами (единичными отрезками), которые определяют составляющие характеристических признаков, присваивают кодовые обозначения, исходя из обозначений, применяемых на практике, из орт образуют кластеры - области трехмерного пространства, ограниченные единичными поверхностями единичных отрезков, из кодов соответствующих орт характеристических признаков составляют код каждого кластера, получают трехмерное информационное пространство, состоящее из кластеров с присвоенными им кодами, помещают образованное трехмерное информационное пространство вместе с другими базами данных в общем хранилище информации в виде объектно-ориентированной или реляционной базы данных, каждый документ переводят в формат XML, определяют ключи и атрибуты, ссылки для критериев поиска и анализа и в отформатированном виде располагают в соответствующей области базы данных, а затем анализируют на предмет принадлежности документа, части документа или информации, содержащейся в документе, кластерам трехмерного информационного пространства, формируют по трем осям полный идентификационный номер документа или его части, состоящий из кода ортов в зависимости от принадлежности к одному или нескольким кластерам и идентификационного номера документа, при этом если документ по какой-либо оси принадлежит нескольким кластерам, то код орта по этой оси заменяют нулевым значением, затем полный идентификационный номер документа помещают в кластер или кластеры, к которым принадлежит документ или часть содержащейся в нем информации, через кластер формируют ключи, индексы и атрибуты и присоединяют их к документу в формате XML, по мере анализа документов заполняют таблицы принадлежности документов к характеристическим признакам, хранящиеся в базе данных и позволяющие по полному идентификационному номеру определить составляющие характеристических признаков, к которым принадлежит документ, затем проверяют наличие документов в кластере и анализируют достаточность информации в этих документах по критериям полноты документации, используя надстройки базы данных, результаты анализа помещают в проанализированный кластер и хранят вместе с полными идентификационными номерами документов, для анализа более широкой области, определяющей одну составляющую или весь характеристический признак, делают срез трехмерного информационного пространства в выбранной плоскости, используя надстройки базы данных, анализируют состояние обеспечения нормативной документацией любого направления выбранной области деятельности и принимают решение о необходимости создания нового или дополнения существующего документа, основываясь на том, что в каждом кластере трехмерного информационного пространства в идеальном случае должен содержаться только один документ, полностью описывающий ограниченную этим кластером область деятельности, используя базу шаблонов и критерии полноты документации, выполняют разработку или корректировку нормативных документов, в процессе разработки, и в окончательной редакции новый документ итеративно вновь подвергают проведенному анализу для определения качества и полноты информации и для помещения документа в трехмерное информационное пространство, с помощью средств базы данных выбирают и находят нормативные документы по одному, двум или трем характеристическим признакам, осуществляют доступ к информации по интересующему вопросу, вводят (удаляют) информацию, контролируют полноту и качество получаемой информации, при этом при разработке трехмерного информационного пространства областей деятельности, если часть объема нормативной документации и составляющие характеристических признаков совпадают, аналогичные кластеры новой базы данных получают путем замещения их на существующие.
[11] Общими недостатками существующих решений является отсутствие эффективного и точного инструментария, позволяющего осуществить автоматизацию процесса генерации и заполнения витрин данных.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[12] Данное техническое решение направлено на устранение недостатков, присущих существующим решениям, известным из уровня техники.
[13] Решаемой технической проблемой в данном техническом решении является создание эффективного и точного инструментария, позволяющего осуществить автоматизацию процесса генерации и заполнения витрин данных.
[14] Основным техническим результатом, проявляющимся при решении вышеуказанной проблемы, является повышение скорости и отказоустойчивости генерации и заполнения витрин данных.
[15] Дополнительным техническим результатом, проявляющимся при решении вышеуказанной проблемы, является обеспечение возможности осуществлять процесс генерации и заполнение витрины данных с использованием декларативного описания.
[16] Указанные технические результаты достигаются благодаря осуществлению способа автоматизированной генерации и заполнения витрин данных с использованием декларативного описания, реализуемого с помощью процессора и устройства хранения данных, включающего следующие шаги:
• предварительно на кластере разворачивается ядро фреймворка;
• подготавливают правила генерации витрин данных, содержащие набор параметров преобразования данных, позволяющие автоматически определять типы данных в создаваемых таблицах генерируемой витрины данных;
• подготавливают правила оркестрации данных, содержащие декларативное описание:
 параметры расчета целевых таблиц и выполнения запросов внутри расчетов;
параметры расчета целевых таблиц и выполнения запросов внутри расчетов;
 параметры накопления данных в разрезе истории для каждой таблицы, списки ключевых полей, списки полей для сравнения и хеширования;
параметры накопления данных в разрезе истории для каждой таблицы, списки ключевых полей, списки полей для сравнения и хеширования;
 параметры контекста выполнения;
параметры контекста выполнения;
• подготовленные на предыдущих шагах правила загружают в репозиторий;
• на основе загруженных в репозиторий правил автоматически генерируют и сохраняют в репозиторий дистрибутив витрины данных;
• сгенерированный и сохраненный дистрибутив витрины данных производит на основе декларативного описания:
 преобразование данных;
преобразование данных;
 вызывает процедуры накопления данных в разрезе истории;
вызывает процедуры накопления данных в разрезе истории;
 выполняет резервное копирование;
выполняет резервное копирование;
 выполняет процедуру восстановления процесса трансформации данных после сбоя.
выполняет процедуру восстановления процесса трансформации данных после сбоя.
[17] В одном из частных примеров осуществления способа правила оркестрации данных, содержащие декларативное описание, подготавливают с использованием Data-Product-Language (DPL).
[18] В другом частном примере осуществления способа дистрибутив витрины данных производит накопление статистики о произведенных действиях.
[19] Кроме того, заявленный технический результат достигается за счет системы автоматизированной генерации и заполнения витрин данных с использованием декларативного описания, содержащей:
- по меньшей мере одно устройство обработки данных;
- по меньшей мере одно устройство хранения данных;
- по меньшей мере одну программу, где одна или более программ хранятся на одном или более устройствах хранения данных и исполняются на одном и более устройствах обработки данных, причем одна или более программ обеспечивает выполнение следующих шагов:
• предварительно на кластере разворачивается ядро фреймворка;
• подготавливают правила генерации витрин данных, содержащие набор параметров преобразования данных, позволяющие автоматически определять типы данных в создаваемых таблицах генерируемой витрины данных;
• подготавливают правила оркестрации данных, содержащие декларативное описание:
 параметры расчета целевых таблиц и выполнения запросов внутри расчетов;
параметры расчета целевых таблиц и выполнения запросов внутри расчетов;
 параметры накопления данных в разрезе истории для каждой таблицы, списки ключевых полей, списки полей для сравнения и хеширования;
параметры накопления данных в разрезе истории для каждой таблицы, списки ключевых полей, списки полей для сравнения и хеширования;
 параметры контекста выполнения;
параметры контекста выполнения;
• подготовленные на предыдущих шагах правила загружают в репозиторий;
• на основе загруженных в репозиторий правил автоматически генерируют и сохраняют в репозиторий дистрибутив витрины данных;
• сгенерированный и сохраненный дистрибутив витрины данных производит:
 преобразование данных;
преобразование данных;
 вызывает процедуры накопления данных в разрезе истории;
вызывает процедуры накопления данных в разрезе истории;
 выполняет резервное копирование;
выполняет резервное копирование;
 выполняет процедуру восстановления процесса трансформации данных после сбоя.
выполняет процедуру восстановления процесса трансформации данных после сбоя.
[20] В одном из частных примеров осуществления системы правила оркестрации данных, содержащие декларативное описание, подготавливают с использованием Data-Product-Language (DPL).
[21] В другом частном примере осуществления системы дистрибутив витрины данных производит накопление статистики о произведенных действиях.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[22] Признаки и преимущества настоящего технического решения станут очевидными из приводимого ниже подробного описания и прилагаемых чертежей, на которых:
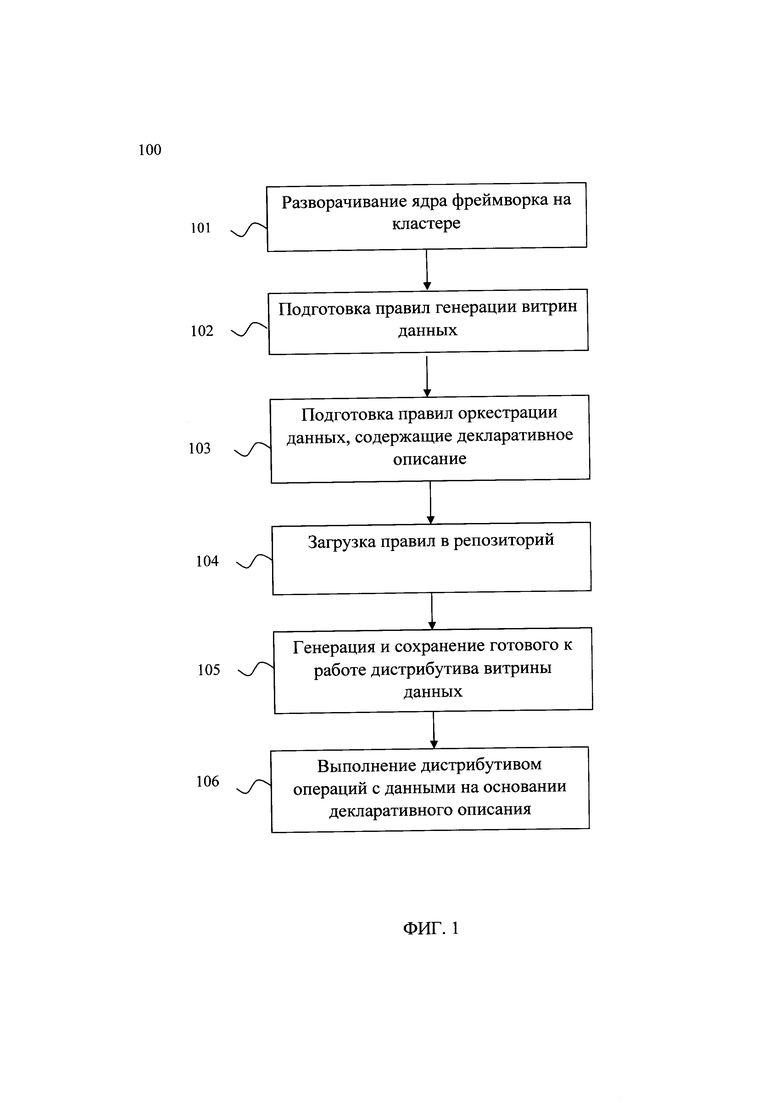
[23] Фиг. 1 иллюстрирует блок-схему выполнения заявленного способа.
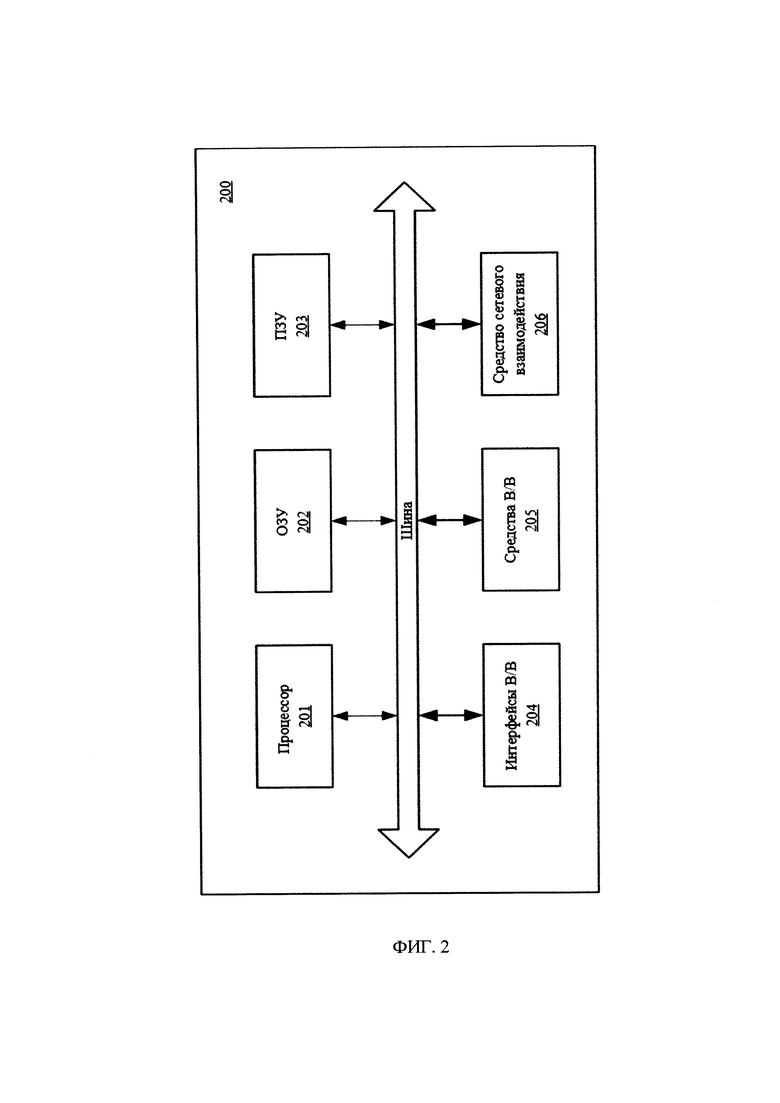
[24] Фиг. 2 иллюстрирует систему для реализации заявленного способа.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[25] Ниже будут описаны термины и понятия, необходимые для реализации настоящего технического решения.
[26] SQL (англ. structured query language - «язык структурированных запросов») - декларативный язык программирования, применяемый для создания, модификации и управления данными в реляционной базе данных, управляемой соответствующей системой управления базами данных. Является информационно-логическим языком, предназначенным для описания, изменения и извлечения данных, хранимых в реляционных базах данных. В общем случае SQL (без ряда современных расширений) считается языком программирования не полным по Тьюрингу, но вместе с тем стандарт языка спецификацией SQL/PSM предусматривает возможность его процедурных расширений. Изначально SQL был основным способом работы пользователя с базой данных и позволял выполнять следующий набор операций: создание в базе данных новой таблицы; добавление в таблицу новых записей; изменение записей; удаление записей; выборка записей из одной или нескольких таблиц (в соответствии с заданным условием); изменение структур таблиц. Со временем SQL усложнился - обогатился новыми конструкциями, обеспечил возможность описания и управления новыми хранимыми объектами (например, индексы, представления, триггеры и хранимые процедуры) - и стал приобретать черты, свойственные языкам программирования.
[27] Фреймворк (от framework - остов, каркас, рама, структура) - программная платформа, определяющая структуру программной системы; программное обеспечение, облегчающее разработку и объединение разных компонентов большого программного проекта.
[28] Заявленное техническое решение может выполняться, например системой, машиночитаемым носителем, сервером и т.д. В данном техническом решении под системой подразумевается, в том числе компьютерная система, ЭВМ (электронно-вычислительная машина), ЧПУ (числовое программное управление), ПЛК (программируемый логический контроллер), компьютеризированные системы управления и любые другие устройства, способные выполнять заданную, четко определенную последовательность операций (действий, инструкций).
[29] Под устройством обработки команд подразумевается электронный блок либо интегральная схема (микропроцессор), исполняющая машинные инструкции (программы).
[30] Устройство обработки команд считывает и выполняет машинные инструкции (программы) с одного или более устройства хранения данных, например таких устройств, как оперативно запоминающие устройства (ОЗУ) и/или постоянные запоминающие устройства (ПЗУ). В качестве ПЗУ могут выступать, но, не ограничиваясь, жесткие диски (HDD), флеш-память, твердотельные накопители (SSD), оптические носители данных (CD, DVD, BD, MD и т.п.) и др.
[31] Программа - последовательность инструкций, предназначенных для исполнения устройством управления вычислительной машины или устройством обработки команд.
[32] Термин «инструкции», используемый в этой заявке, может относиться, в общем, к программным инструкциям или программным командам, которые написаны на заданном языке программирования для осуществления конкретной функции, такой как, например, получение и обработка данных, формирование профиля пользователя, прием и передача сигналов, анализ принятых данных, идентификация пользователя и т.п. Инструкции могут быть осуществлены множеством способов, включающих в себя, например, объектно-ориентированные методы. Например, инструкции могут быть реализованы, посредством языка программирования С++, Java, Python, различных библиотек (например, "MFC"; Microsoft Foundation Classes) и т.д. Инструкции, осуществляющие процессы, описанные в этом решении, могут передаваться как по проводным, так и по беспроводным каналам передачи данных, например, Wi-Fi, Bluetooth, USB, WLAN, LAN и т.п.
[33] Представленный способ автоматизированной генерации и заполнения витрин данных с использованием декларативного описания (на Фиг. 1 представлена схема способа) решает задачу осуществления автоматизации процесса генерации и заполнения витрин данных с использованием декларативного описания, при этом обеспечивая повышение скорости и отказоустойчивости генерации и заполнения витрин данных за счет последовательного выполнения следующих шагов:
• предварительно на кластере разворачивается ядро фреймворка;
• подготавливают правила генерации витрин данных, содержащие набор параметров преобразования данных, позволяющие автоматически определять типы данных в создаваемых таблицах генерируемой витрины данных;
• подготавливают правила оркестрации данных, содержащие декларативное описание:
 параметры расчета целевых таблиц и выполнения запросов внутри расчетов;
параметры расчета целевых таблиц и выполнения запросов внутри расчетов;
 параметры накопления данных в разрезе истории для каждой таблицы, списки ключевых полей, списки полей для сравнения и хеширования;
параметры накопления данных в разрезе истории для каждой таблицы, списки ключевых полей, списки полей для сравнения и хеширования;
 параметры контекста выполнения;
параметры контекста выполнения;
• подготовленные на предыдущих шагах правила загружают в репозиторий;
• на основе загруженных в репозиторий правил автоматически генерируют и сохраняют в репозиторий дистрибутив витрины данных;
• сгенерированный и сохраненный дистрибутив витрины данных производит на основе декларативного описания:
 преобразование данных;
преобразование данных;
 вызывает процедуры накопления данных в разрезе истории;
вызывает процедуры накопления данных в разрезе истории;
 выполняет резервное копирование;
выполняет резервное копирование;
 выполняет процедуру восстановления процесса трансформации данных после сбоя.
выполняет процедуру восстановления процесса трансформации данных после сбоя.
[34] Для приведения подробного примера осуществления данного технического решения выбран следующий технологический стек: Hadoop (hdfs - распределенная файловая система / hive - система организации SQL доступа к структурированным файлам на hdfs / spark - система выполнения расчетов / oozie - планировщик выполнения процессов), для процессов CI/CD (Continuous Integration / Continuous Delivery) использованы инструменты DevOps (git - система контроля версий / maven - система сборки проекта / jenkins - среда выполнения CI/CD процессов), планировщик процессов CTL.
[35] Сервис управления загрузкой - CTL - это программа для управления запуском задач Gob) в оркестраторах.
Сущность, отвечающая и описывающая последовательность и условия запуска задачи именуется потоком загрузки или workflow. Техническая суть реализации потока может быть описана как направленный ациклический граф задач.
Внутри оркестратора задачей (job) может являться:
• приложение YARN (Spark/MapReduce/Tez Job),
• сценарий (sh, cmd, groovy, etc),
• запуск другого приложения,
• запуск другого потока в CTL.
Для реализации потоков загрузки обычно используются специализированные инструменты (оркестраторы или менеджеры потоков). CTL реализует взаимодействие с Apache Oozie, Informatica Workflow Manager, GorskyRS.
Поток загрузки можно понимать, как процедуру с параметрами, которая, в свою очередь запускает другие процедуры в установленном порядке. Каждый шаг такой процедуры (задача) также допускает параметризацию, причем значения параметров задачи может зависеть от результатов выполнения предыдущих задач.
Задачи, которые решает CTL:
• установка расписания выполнения потоков загрузки;
• определение (установка) событий, факт совершения которых является причиной (триггером) для запуска потока;
• автоматическое вычисление значений параметров, с которыми должен быть запущен поток или задача;
• мониторинг (или отслеживание) активности выполнения (только факт - запущено, завершено, ошибка);
• единое хранилище метаданных процессов загрузки:
• история запуска потоков и их параметров;
• события обновления сущностей;
• статистика обновившихся данных (список обработанных файлов из источника, максимальная дата, по которой проводится выборка дельты изменений, набор бизнес-дат в этой дельте и т.п.).
CTL реализуется как как программа, выполняемая в среде JVM.
Пользовательские интерфейсы для работы для работы с функционалом представлены:
• REST API;
• CTL UI - web интерфейс.
В качестве внутреннего хранилища данных используется база PostgreSQL.
[36] Входящие данные и результат обработки - таблицы в hive metastore:
(словарь таблиц, представляющих структурированные файлы на hdfs), которые создаются, или могут быть использованы сторонними приложениями.
[37] Для функционирования описанного способа в предложенном стеке технологии:
• Разработана схема интеграции приложений базовых платформ.
• Разработаны алгоритмы накопления данных в разрезе истории на основании мгновенных снимков данных (предусмотрены варианты с добавлением и замещением данных):
- Создание истории по дням
- Создание истории по периодам (даты начала и окончания действия бизнес значений)
- Поддержание актуального снимка данных с параллельным хранением истории по периодам в отдельной таблице.
• Реализованы Design-time компонент фреймворка - maven-dpl-plugin. Это надстройка над maven, которая на основании набора файлов с sql-запросами и файла описания оркестрации генерирует дистрибутив. Дистрибутив содержит код приложений, исполняемые компонентами платформы:
- ctl потоки - описания в .json-файле
- oozie workflow - описания в .xml-файле
- файлы sql запросов
- настройки для контекста выполнения sql запросов в формате HOCON (Human-Optimized Config Object Notation - подмножество JSON).
Дистрибутив упаковывается в tar-пакет готовый к развертыванию на клайстере Hadoop средствами DevOps
• Реализованы Run-time компоненты фреймворка:
- библиотеки реализации алгоритмов накопления данных в разрезе истории,
- spark приложение-сервис (ядро фреймворка) выполняющее логику:
 создания таблиц;
создания таблиц;
 трансформации данных согласно логике sql запросов, написанных аналитиком;
трансформации данных согласно логике sql запросов, написанных аналитиком;
 накопления данных в разрезе истории;
накопления данных в разрезе истории;
 резервного копирования и восстановление после сбоя.
резервного копирования и восстановление после сбоя.
 Это приложение осуществляет мониторинг и аудит выполняемых операций.
Это приложение осуществляет мониторинг и аудит выполняемых операций.
[38] Реализация требования о пропуске после сбоя расчета для корректно загруженных данных описана далее. При перезапуске после сбоя, данные, корректно рассчитанные предыдущим запуском, не должны пересчитываться заново. Для каждой загружаемой таблицы создается таблица, содержащая статистику (технические метаданные) загрузки. После успешной загрузки в таблице статистики добавляется информация о времени загрузки. Перед загрузкой каждой таблицы анализируется содержимое соответствующей статистической таблицы. Если предыдущая загрузка (например - сегодня) для таблицы была успешна и ранее, чем истек указанный для таблицы период актуальности (например - день), то следующий запуск сочтет данные актуальными и пропустит данный этап загрузки-расчета. Через параметры планировщика процессов CTL можно запустить загрузку в режиме принудительного пересчета (это может быть полезно, если были прислана обновленная версия данных за актуальный период).
[39] Создание аналитиком, знающим SQL на уровне написания запросов, промышленных приложений по преобразованию данных в табличном формате - витрин данных, на стеке Hadoop осуществляется следующим образом (при наличии файлов с sql запросами и настроенном CI/DI процессе дистрибутив может быть получен, развернут и запущен менее чем за час):
• Аналитик создает maven проект, использующий maven-dpl-plugin - design-time компонент фреймворка.
• Аналитик создает набор файлов с sql-запросами, описывающий преобразования данных.
• Аналитик создает файл описания оркестрации с использованием Data-Product-Language (DPL). Данный файл содержит:
- Последовательность расчета целевых таблиц и выполнения sql-запросов внутри расчетов;
- Способы накопления данных в разрезе истории для каждой таблицы - после расчетов для таблиц будут применяться процедуры из runtime библиотек. Настройки алгоритмов: списки ключевых полей, списки полей для сравнения и хеширования;
- Параметры контекста выполнения - в основном параметры выделения ресурсов (например количество spark-executer-ов и памяти для них), определяемые аналитиком на основании демографии данных, их объемов, и, также сложностью расчетов.
• Аналитик загружает созданные файлы в системе управления версиями -git-.
• Аналитик через стандартный jenkuns-job запускает maven с maven-dpl-plugin, который автоматически создает (генерирует) и упаковывает в архив дистрибутив (витрины), содержащий приложения, исполняемые компонентами платформы: ctl потоки, oozie workflow, файлы sql запросов и настроек. Дистрибутив публикуется в nexus репозиторий.
• Предварительно на кластере разворачивается ядро фреймворка.
• Аналитик или администратор (в зависимости от статуса среды) через стандартный jenkuns-job разворачивает на среде дистрибутив.
• созданный на предыдущем шаге, из nexus репозиторий.
• В CTL появляется поток витрины и набор сущностей для регистрации статистик выполнения.
• В HDFS появляются oozie workflow, файлы sql запросов и настроек.
• CTL поток и oozie workflow настроены на запуск ядра фреймворка с параметрами, специфическими для витрины.
• Запускается CTL поток витрины, который запускает oozie workflow.
• В oozie workflow shell action запускают .sh файл из состава ядра фреймворка с параметрами, специфическими для витрины.
• В .sh файле запускается через spark-submit приложение-сервис (ядро фреймворка).
• Ядро фреймворка выполняет следующие операции:
• преобразование данных согласно sql запросам;
• вызывает процедуры накопления данных в разрезе истории;
• если указано - создает Hive-таблицы, для сохранения результата;
• выполняет резервное копирование;
• если требуется - выполняет процедуру восстановления процесса трансформации данных после сбоя.
• После сохранения результата в таблице проставляется соответствующая статистика в CTL.
[40] Скорость выполнения всех указанных операций достигается в данном конкретном варианте осуществления описанного технического решения за счет следующих выполненных технических операций:
• Эффективная схема интеграции базовых платформ Hadoop (hdfs/oozie/hive/spark/kibana - сервис журналирования), приложений (CTL-планировщик) и сервисов автоматизации DevOps (git/maven/Jenkins/nexus) для выполнения требований к эксплуатации и безопасности к бизнес-приложениям, использующим фреймворк.
• Генерация сложного платформенного кода стека Hadoop осуществляется design-time компонентом фреймворка (maven-dpl-plugin). Данный код не нуждается в отладке, а его необходимая параметризация делается в файле DPL, или через автоматически сгенерированные параметры CTL.
• Выполнение sql преобразований бизнес-приложений в контексте runtime компонент фреймворка, которые берут на себя выполнение требований по отказоустойчивости и мониторингу.
• Автоматическое создание таблиц на основании только sql-select выражений - не нужно писать DDL код для создания таблиц. Типы данных в создаваемых таблицах определяются автоматически, соответственно на этапе разработки витрины данных можно не знать точно типы полей. Соответственно для разработки витрины данных не требуется полной и выверенной спецификации данных - такая спецификация может быть получена по результатам работы приложения.
• Разработка алгоритмов накопления данных в разрезе истории на основании мгновенных снимков данных в бизнес-приложении достаточно трудоемка. Фреймворк реализует такие алгоритмы и бизнес-приложению достаточно указать какие алгоритмы к каким таблицам применять. Алгоритмы, реализованные фреймворком, подробно описаны, протестированы на модельных данных - аналитик может просто выбрать нужный на основании соответствия бизнес-данных предлагаемым моделям.
• Создание резервных копий загруженных данных и управление ими, фреймворк берет на себя, освобождая разработчика бизнес-приложений от необходимости реализации данной логики.
[41] Ниже приведен пример создания конкретной витрины на основе вышеописанного стека технологий.
Необходимо создать витрину содержащую историю изменения оборотов по датам. Данные в источнике обновляются ежедневно, но содержат только текущую информацию. Приведены примеры данных в динамике обновления за 2 дня.



План реализации
Для получения результата создаем таблицу-приемник db_tgt.turns2acc. соединяющую (join) данные из источников за текущий день с алгоритмом накопления данных HD_SOFT_INCREMENT.
Для построения витрины на фреймворке нужны:
1. Sql joina склейки таблиц - tgt_turns2acc.sql.
Файл настроек и оркестрации data-product.yml
2. pom.xml - берется из шаблона стандартного для витрин в котором заменяется название артефакта и версия.
Примеры файлов tgt_turns2acc.sql joina
select
current_timestamp() as cbap_validfrom,
a.acc_id,
a.acc_name,
t.sm
from db_src.turns t
join db_src.acc a
on t.acc_id=t.acc_id
data-product.yml
data-product-name: "bdp_demooffline" # Так будет называться главный workflow и поток в CTL (без суффикса).
flume-id: "??????" # У каждого проекта - свой.
parent-ctl-entity-id: "200" # В дистрибутиве автоматически не создается,
job-list:
- job: job_turns2acc
spark-profile-name: default
is-parallel: false # опционально, по умолчанию - false
target-to-run-list:
- target-to-run: job_tgt_turns2acc
query-list:
- tgt_turns2acc.sql
source-list:
- source: "src_acc" # Используется как имя таблицы.
ctl-entity: 201 # Указывается аналитиком, в дистрибутиве НЕ создается.
profile-name: default # Можно убрать - строка для примера: если default не указан, то используется default.
- source: "src_turns" # Используется как имя таблицы.
ctl-entity: 202 # Указывается аналитиком, в дистрибутиве НЕ создается,
source-profile-list:
- source-profile: default
db-name: "db_src"
target-list:
# Соглашение для demo-product: Для target используются четные ctl-entity
- target: turns2acc
ctl-entity: 203 # Указывается аналитиком, в дистрибутиве создается автоматически.
target-profile-name: default # Можно убрать - строка для примера: если default не указан, то используется default.
check-days-diff: 1 # Опционально, приведенные значение может быль проставлено по умолчанию
history: hd_soft_snapshot
key-list: [acc_id]
target-profile-list:
# Наличие default - ОБЯЗАТЕЛЬНО
- target-profile: default
database-pa: "db_tgt"
database-stg: "db_stg"
database-aux: "db_tgt"
database-bkp: "db_bkp"
database-snaphist: "db_tgt"
spark-profile-list:
# Наличие default - ОБЯЗАТЕЛЬНО
- spark-profile: default
executor-memory: 4G
num-executors: 4
executor-cores: 3
driver-memory: 8G
driver-cores: 4
save-query-to: view
[42] В общем виде (см. Фиг. 2) система автоматизированной генерации и заполнения витрин данных с использованием декларативного описания (200) содержит объединенные общей шиной информационного обмена один или несколько процессоров (201), средства памяти, такие как ОЗУ (202) и ПЗУ (203) и интерфейсы ввода/вывода (204).
[43] Процессор (201) (или несколько процессоров, многоядерный процессор и т.п.) может выбираться из ассортимента устройств, широко применяемых в настоящее время, например, таких производителей, как: Intel™, AMD™, Apple™, Samsung Exynos™, MediaTEK™, Qualcomm Snapdragon™ и т.п. Под процессором или одним из используемых процессоров в системе (200) также необходимо учитывать графический процессор, например, GPU NVIDIA с программной моделью, совместимой с CUDA, или Graphcore, тип которых также является пригодным для полного или частичного выполнения способа, а также может применяться для обучения и применения моделей машинного обучения в различных информационных системах.
[44] ОЗУ (202) представляет собой оперативную память и предназначено для хранения исполняемых процессором (201) машиночитаемых инструкций для выполнения необходимых операций по логической обработке данных. ОЗУ (202), как правило, содержит исполняемые инструкции операционной системы и соответствующих программных компонент (приложения, программные модули и т.п.). При этом, в качестве ОЗУ (202) может выступать доступный объем памяти графической карты или графического процессора.
[45] ПЗУ (203) представляет собой одно или более устройств постоянного хранения данных, например, жесткий диск (HDD), твердотельный накопитель данных (SSD), флэш-память (EEPROM, NAND и т.п.), оптические носители информации (CD-R/RW, DVD-R/RW, BlueRay Disc, MD) и др.
[46] Для организации работы компонентов устройства (200) и организации работы внешних подключаемых устройств применяются различные виды интерфейсов В/В (204). Выбор соответствующих интерфейсов зависит от конкретного исполнения вычислительного устройства, которые могут представлять собой, не ограничиваясь: PCI, AGP, PS/2, IrDa, Fire Wire, LPT, COM, SATA, IDE, Lightning, USB (2.0, 3.0, 3.1, micro, mini, type C), TRS/Audio jack (2.5, 3.5, 6.35), HDMI, DVI, VGA, Display Port, RJ45, RS232 и т.п.
[47] Для обеспечения взаимодействия пользователя с устройством (200) применяются различные средства (205) В/В информации, например, клавиатура, дисплей (монитор), сенсорный дисплей, тач-пад, джойстик, манипулятор мышь, световое перо, стилус, сенсорная панель, трекбол, динамики, микрофон, средства дополненной реальности, оптические сенсоры, планшет, световые индикаторы, проектор, камера, средства биометрической идентификации (сканер сетчатки глаза, сканер отпечатков пальцев, модуль распознавания голоса) и т.п.
[48] Средство сетевого взаимодействия (206) обеспечивает передачу данных посредством внутренней или внешней вычислительной сети, например, Интранет, Интернет, ЛВС и т.п. В качестве одного или более средств (206) может использоваться, но не ограничиваться: Ethernet карта, GSM модем, GPRS модем, LTE модем, 5G модем, модуль спутниковой связи, NFC модуль, Bluetooth и/или BLE модуль, Wi-Fi модуль и др.
[49] Конкретный выбор элементов устройства (200) для реализации различных программно-аппаратных архитектурных решений может варьироваться с сохранением обеспечиваемого требуемого функционала. В частности, подобная реализация может быть выполнена с помощью электронных компонент, используемых для создания цифровых интегральных схем. Не ограничиваюсь, могут быть использоваться микросхемы, логика работы которых определяется при изготовлении, или программируемые логические интегральные схемы (ПЛИС), логика работы которых задается посредством программирования. Для программирования используются программаторы и отладочные среды, позволяющие задать желаемую структуру цифрового устройства в виде принципиальной электрической схемы или программы на специальных языках описания аппаратуры: Verilog, VHDL, AHDL и др. Альтернативой ПЛИС являются: программируемые логические контроллеры (ПЛК), базовые матричные кристаллы (БМК), требующие заводского производственного процесса для программирования; ASIC - специализированные заказные большие интегральные схемы (БИС), которые при мелкосерийном и единичном производстве существенно дороже. Таким образом, реализация может быть достигнута стандартными средствами, базирующимися на классических принципах реализации основ вычислительной техники.
[50] Представленные материалы заявки раскрывают предпочтительные примеры реализации технического решения и не должны трактоваться как ограничивающие иные, частные примеры его воплощения, не выходящие за пределы испрашиваемой правовой охраны, которые являются очевидными для специалистов соответствующей области техники.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ СОЗДАНИЯ ВИТРИНЫ ДАННЫХ | 2024 |
|
RU2840319C1 |
| СПОСОБ И СИСТЕМА АВТОМАТИЧЕСКОЙ ГЕНЕРАЦИИ ПРОГРАММНОГО КОДА ДЛЯ КОРПОРАТИВНОГО ХРАНИЛИЩА ДАННЫХ | 2017 |
|
RU2683690C1 |
| РАСПРЕДЕЛЕННАЯ ВСТРОЕННАЯ СИСТЕМА УПРАВЛЕНИЯ ДАННЫМИ И ЗНАНИЯМИ, ИНТЕГРИРОВАННАЯ С АРХИВОМ ДАННЫХ ПЛК | 2015 |
|
RU2701845C1 |
| СПОСОБ И СИСТЕМА ГРАНУЛЯРНОГО ВОССТАНОВЛЕНИЯ РЕЗЕРВНОЙ КОПИИ БАЗЫ ДАННЫХ | 2024 |
|
RU2825077C1 |
| ПЛАТФОРМА СОСТАВНЫХ ПРИЛОЖЕНИЙ НА БАЗЕ МОДЕЛИ | 2008 |
|
RU2502127C2 |
| СИСТЕМА И СПОСОБ УПРАВЛЕНИЯ БАЗАМИ ДАННЫХ (СУБД) | 2018 |
|
RU2704873C1 |
| СУПЕРКОМПЬЮТЕРНЫЙ КОМПЛЕКС ДЛЯ РАЗРАБОТКИ НАНОСИСТЕМ | 2009 |
|
RU2432606C2 |
| АРХИТЕКТУРА ОТОБРАЖЕНИЯ С ПОДДЕРЖАНИЕМ ИНКРЕМЕНТНОГО ПРЕДСТАВЛЕНИЯ | 2007 |
|
RU2441273C2 |
| СПОСОБ ПОСТРОЕНИЯ РАСПРЕДЕЛЕННОЙ ИНФОРМАЦИОННОЙ СИСТЕМЫ | 2018 |
|
RU2699683C1 |
| КОМПИЛЯЦИЯ ПРЕОБРАЗОВАНИЙ В ПОЛЬЗОВАТЕЛЬСКОМ ИНТЕРФЕЙСЕ ПОВТОРНЫХ ВЫЧИСЛЕНИЙ | 2014 |
|
RU2666238C2 |
Изобретение относится к способу и системе автоматизированной генерации и заполнения витрин данных с использованием декларативного описания. Техническим результатом является повышение скорости и отказоустойчивости генерации и заполнения витрин данных. Способ содержит этапы, на которых: предварительно на кластере разворачивается ядро фреймворка; подготавливают правила генерации витрин данных, содержащие набор параметров преобразования данных, позволяющие автоматически определять типы данных в создаваемых таблицах генерируемой витрины данных; подготавливают правила оркестрации данных, содержащие декларативное описание: параметры расчета целевых таблиц и выполнения запросов внутри расчетов; параметры накопления данных в разрезе истории для каждой таблицы, списки ключевых полей, списки полей для сравнения и хеширования; параметры контекста выполнения; подготовленные на предыдущих шагах правила загружают в репозиторий; на основе загруженных в репозиторий правил автоматически генерируют и сохраняют в репозиторий дистрибутив витрины данных; сгенерированный и сохраненный дистрибутив витрины данных производит на основе декларативного описания: преобразование данных; вызывает процедуры накопления данных в разрезе истории; выполняет резервное копирование; выполняет процедуру восстановления процесса трансформации данных после сбоя. 2 н. и 4 з.п. ф-лы, 2 ил.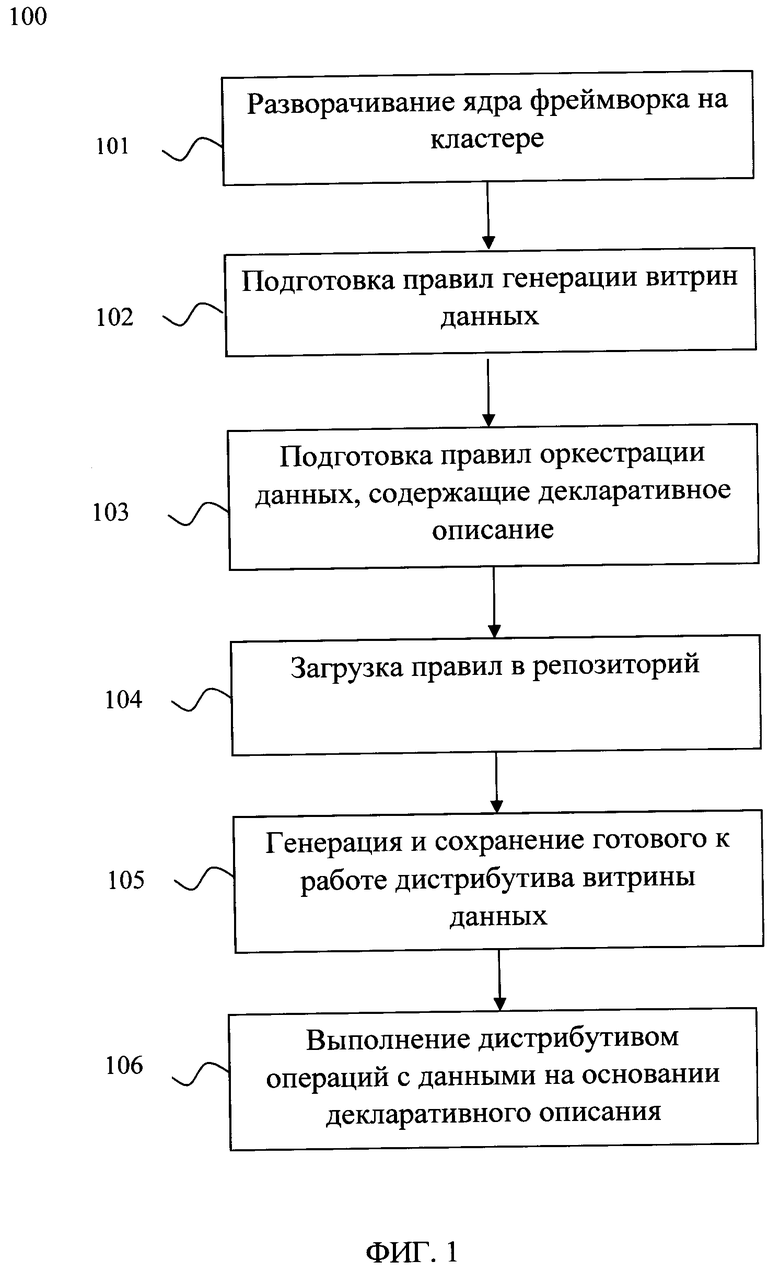
1. Способ автоматизированной генерации и заполнения витрин данных с использованием декларативного описания, реализуемый с помощью процессора и устройства хранения данных, включающий следующие шаги:
• предварительно на кластере разворачивается ядро фреймворка;
• подготавливают правила генерации витрин данных, содержащие набор параметров преобразования данных, позволяющие автоматически определять типы данных в создаваемых таблицах генерируемой витрины данных;
• подготавливают правила оркестрации данных, содержащие декларативное описание:
 параметры расчета целевых таблиц и выполнения запросов внутри расчетов;
параметры расчета целевых таблиц и выполнения запросов внутри расчетов;
 параметры накопления данных в разрезе истории для каждой таблицы, списки ключевых полей, списки полей для сравнения и хеширования;
параметры накопления данных в разрезе истории для каждой таблицы, списки ключевых полей, списки полей для сравнения и хеширования;
 параметры контекста выполнения;
параметры контекста выполнения;
• подготовленные на предыдущих шагах правила загружают в репозиторий;
• на основе загруженных в репозиторий правил автоматически генерируют и сохраняют в репозиторий дистрибутив витрины данных;
• сгенерированный и сохраненный дистрибутив витрины данных производит на основе декларативного описания:
 преобразование данных;
преобразование данных;
 вызывает процедуры накопления данных в разрезе истории;
вызывает процедуры накопления данных в разрезе истории;
 выполняет резервное копирование;
выполняет резервное копирование;
 выполняет процедуру восстановления процесса трансформации данных после сбоя.
выполняет процедуру восстановления процесса трансформации данных после сбоя.
2. Способ по п. 1, характеризующийся тем, что правила оркестрации данных, содержащие декларативное описание, подготавливают с использованием Data-Product-Language (DPL).
3. Способ по п. 1, характеризующийся тем, что дистрибутив витрины данных производит накопление статистики о произведенных действиях.
4. Система автоматизированной генерации и заполнения витрин данных с использованием декларативного описания, содержащая:
- по меньшей мере одно устройство обработки данных;
- по меньшей мере одно устройство хранения данных;
- по меньшей мере одну программу, где одна или более программ хранятся на одном или более устройствах хранения данных и исполняются на одном и более устройствах обработки данных, причем одна или более программ обеспечивает выполнение следующих шагов:
• предварительно на кластере разворачивается ядро фреймворка;
• подготавливают правила генерации витрин данных, содержащие набор параметров преобразования данных, позволяющие автоматически определять типы данных в создаваемых таблицах генерируемой витрины данных;
• подготавливают правила оркестрации данных, содержащие декларативное описание:
 параметры расчета целевых таблиц и выполнения запросов внутри расчетов;
параметры расчета целевых таблиц и выполнения запросов внутри расчетов;
 параметры накопления данных в разрезе истории для каждой таблицы, списки ключевых полей, списки полей для сравнения и хеширования;
параметры накопления данных в разрезе истории для каждой таблицы, списки ключевых полей, списки полей для сравнения и хеширования;
 параметры контекста выполнения;
параметры контекста выполнения;
• подготовленные на предыдущих шагах правила загружают в репозиторий;
• на основе загруженных в репозиторий правил автоматически генерируют и сохраняют в репозиторий дистрибутив витрины данных;
• сгенерированный и сохраненный дистрибутив витрины данных производит:
 преобразование данных;
преобразование данных;
 вызывает процедуры накопления данных в разрезе истории;
вызывает процедуры накопления данных в разрезе истории;
 выполняет резервное копирование;
выполняет резервное копирование;
 выполняет процедуру восстановления процесса трансформации данных после сбоя.
выполняет процедуру восстановления процесса трансформации данных после сбоя.
5. Система по п. 4, характеризующаяся тем, что правила оркестрации данных, содержащие декларативное описание, подготавливают с использованием Data-Product-Language (DPL).
6. Система по п. 4, характеризующаяся тем, что дистрибутив витрины данных производит накопление статистики о произведенных действиях.
| СПОСОБ И СИСТЕМА АВТОМАТИЧЕСКОЙ ГЕНЕРАЦИИ ПРОГРАММНОГО КОДА ДЛЯ КОРПОРАТИВНОГО ХРАНИЛИЩА ДАННЫХ | 2017 |
|
RU2683690C1 |
| СПОСОБ ВВОДА СВЕДЕНИЙ В БАЗУ ДАННЫХ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2013 |
|
RU2569565C2 |
| СПОСОБ И СИСТЕМА ОРГАНИЗАЦИИ И ФУНКЦИОНИРОВАНИЯ БАЗЫ ДАННЫХ НОРМАТИВНОЙ ДОКУМЕНТАЦИИ | 2008 |
|
RU2386166C2 |
| СИСТЕМА УПРАВЛЕНИЯ ЭЛЕКТРОННЫМ ДОКУМЕНТООБОРОТОМ | 2018 |
|
RU2702505C1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Способ регенерирования сульфо-кислот, употребленных при гидролизе жиров | 1924 |
|
SU2021A1 |
| US 6418450 B2, 09.07.2002 | |||
| US 9684703 B2, 20.06.2017 | |||
| US 10885051 B1, 05.01.2021. | |||

