Настоящее изобретение относится к области кодирования/декодирования в телекоммуникации, и более конкретно, к области коррекции потери кадров при декодировании.
"Кадр" - это сегмент аудио, состоящий по меньшей мере из одного отсчета (изобретение применимо к потере одного или нескольких отсчетов при кодировании в соответствии с G.711, а также к потере одного или нескольких пакетов отсчетов при кодировании в соответствии со стандартами G.723, G.729 и т.д.).
Потери аудиокадров возникают, кода осуществление связи с использованием кодера и декодера нарушается из-за условий в сети связи (вследствие радиочастотных проблем, перегрузки сети доступа и т.д.). В этом случае декодер применяет механизмы коррекции потери кадров, чтобы попытаться заменить потерянный сигнал сигналом, реконструированным с использованием доступной декодеру информации (например, аудиосигнала, уже декодированного для одного или нескольких прошлых кадров). Эта технология может поддерживать качество обслуживания, несмотря на уменьшенную пропускную способность сети.
Технологии коррекции потери кадров часто сильно зависят от типа используемого кодирования.
В случае CELP-кодирования обычно повторяют определенные параметры, декодированные в предыдущем кадре (огибающую спектра, основной тон, коэффициенты усиления из кодовых книг), с уточнениями, такими как модификация огибающей спектра так, чтобы она приближалась к средней огибающей, или применение произвольной фиксированной кодовой книги.
В случае кодирования с преобразованием наиболее широко используемая технология коррекции потери кадров состоит в повторении последнего принятого кадра, если кадр потерян, и сброс повторенного кадра в ноль, как только потеряно более одного кадра. Эту технологию применяют во многих стандартах кодирования (G.719, G.722.1, G.722.1C). Также можно упомянуть стандарт кодирования G.711, для которого в примере коррекции потери кадров, описанном в Приложении I к G.711, определен основной период (называемый "периодом основного тона") в уже декодированном сигнале, и его повторяют, перекрывая и добавляя уже декодированный сигнал и повторенный сигнал ("перекрытие-прибавление"). Такое перекрытие-прибавление "стирает" звуковые артефакты, но для его реализации требуется дополнительная задержка в декодере (соответствующая длительности перекрытия).
Более того, в случае стандарта кодирования G.722.1 модулированное преобразование с перекрытием (или MLT) с перекрытием-прибавлением на 50% и синусоидальными окнами гарантирует переход между последним потерянным кадром и повторенным кадром, являющийся достаточно медленным, чтобы стереть артефакты, относящиеся к простому повтору кадра, в случае потери одного кадра. В отличие от коррекции потери кадра, описанной в стандарте G.711 (Приложение I), этот вариант осуществления не требует дополнительной задержки, потому что использует существующую задержку и временное искажение преобразования MLT, чтобы реализовать перекрытие-прибавление с реконструированным сигналом.
Эта технология недорогая, но ее основной недостаток заключается в несовместимости между сигналом, декодированным до потери кадра и повторенным сигналом. Это приводит к фазовой разрывности, которая может дать существенные звуковые артефакты, если продолжительность перекрытия между двумя кадрами мала, как в случае, когда окна, используемые для MLT преобразования, представляют собой "короткую задержку", как описано в документе FR 1350845 со ссылкой на фиг. 1А и 1В этого документа. В таком случае даже решение, сочетающее поиск основного тона, как в случае кодера в соответствии со стандартом G.711 (Приложение I) и перекрытием-прибавление с использованием окна MLT-преобразования, не является достаточным для того, чтобы устранить звуковые артефакты.
В документе FR 1350845 предложен гибридный способ, который сочетает преимущества обоих этих способов для сохранения фазовой непрерывности в преобразованной области. Настоящее изобретение задано в этой общей схеме. Подробное описание решения, предложенного в FR 1350845, приведено ниже со ссылкой на фиг. 1.
Хотя оно является многообещающим, это решение требует усовершенствования, потому что, если кодированный сигнал имеет только один основной период ("один основной тон"), например, в вокализованном сегменте речевого сигнала, то качество звука после коррекции потери кадра может ухудшиться и стать не таким хорошим, как при коррекции потери кадра с применением речевой модели, такой как CELP ("линейное предсказание с кодовым возбуждением").
Настоящее изобретение улучшает эту ситуацию.
Для этого в нем предложен способ обработки цифрового аудиосигнала, содержащего последовательность отсчетов, распределенных в последовательных кадрах, причем способ реализуют при декодировании упомянутого сигнала, чтобы заменить по меньшей мере один потерянный кадр сигнала во время декодирования.
Способ содержит следующие этапы:
a) осуществляют поиск в доступном при декодировании сегменте полезного сигнала по меньшей мере одного периода в сигнале, определяемого на основе упомянутого полезного сигнала,
b) анализируют сигнал в упомянутом периоде, чтобы определить спектральные компоненты этого сигнала в упомянутом периоде,
c) синтезируют по меньшей мере одну замену для потерянного кадра путем построения синтезированного сигнала из:
- сложения компонент, выбранных из упомянутых определенных спектральных компонент, и
- шума, добавленного к сложению компонент.
В частности, величину шума, добавленного к сложению компонент, взвешивают, исходя из голосовой информации полезного сигнала, полученного при декодировании.
Преимущественно, информация о вокализации, используемая при декодировании, передаваемая по меньшей мере с одной скоростью передачи битов кодера, дает больший вес синусоидальным компонентам пройденного сигнала, если сигнал вокализованный, или дает больший вес шуму в противном случае, что приводит к намного более удовлетворительному слышимому результату. Тем не менее, в случае невокализованного сигнала или в случае музыкального сигнала нет необходимости сохранять так много компонентов для синтеза сигнала, замещающего потерянный кадр. В этом случае больший вес можно придать внедряемому для синтеза сигнала шуму. Это преимущественно сокращает сложность обработки, в частности, в случае невокализованного сигнала, не ухудшая при этом качество синтеза.
В варианте осуществления, в котором шумовой сигнал добавляют к компонентам, этот шумовой сигнал взвешивают с меньшим усилением в случае вокализации полезного сигнала. Например, шумовой сигнал может быть получен из ранее принятого кадра путем определения разности между принятым сигналом и сумой выбранных компонент.
В дополнительном или альтернативном варианте осуществления число компонент, выбираемых для сложения, больше в случае вокализации полезного сигнала. Таким образом, если сигнал является вокализованным, то спектру пройденного сигнала придают больше внимания, как указано выше.
Преимущественно, может быть выбрана дополнительная форма варианта осуществления, в которой выбирают больше компонент, если сигнал является вокализованным, минимизируя при этом коэффициент усиления, применяемый к шумовому сигналу. Таким образом, общая величина энергии, затраченной на применение коэффициента усиления, меньшего 1, к шумовому сигналу, частично компенсируется выбором большего числа компонент. Наоборот, коэффициент усиления, который необходимо применить к шумовому сигналу, не уменьшают, а выбирают меньше компонент, если сигнал не является вокализованным или слабо вокализован.
Кроме того, можно дополнительно улучшить компромисс между качеством/сложностью при декодировании, и на этапе а) поиск вышеупомянутого периода может осуществляться в сегменте полезного сигнала большей длительности в случае вокализованного полезного сигнала. В представленном в приведенном ниже подробном описании поиск выполняют путем сопоставления в полезном сигнале периода повторения, обычно соответствующего по меньшей мере одному периоду основного тона, если сигнал вокализованный, и в этом случае, особенно для мужских голосов, поиск основного тона может выполняться, например, на длительности более 30 миллисекунд.
В опциональном варианте осуществления информацию о вокализации передают в кодированном потоке ("битовом потоке"), принимаемым при декодировании и соответствующем упомянутому сигналу, содержащему последовательность отсчетов, распределенных в последовательных кадрах. Тогда, в случае потери кадра при декодировании используют информацию о вокализации в кадре полезного сигнала, предшествующем потерянному кадру.
Таким образом, информация о вокализации поступает из кодера, генерирующего битовый поток и определяющего информацию о вокализации, и в одном отдельном варианте осуществления информацию о вокализации кодируют одним битом в битовом потоке. Тем не менее, в качестве примера осуществления, генерация этих данных о вокализации в кодере может зависеть от того, имеется ли достаточная полоса пропускания в сети связи между кодером и декодером. Например, если ширина полосы пропускания меньше пороговой величины, то данные о вокализации не передаются кодером, чтобы сэкономить полосу пропускания. В этом случае, только для примера, последняя полученная на декодере информация о вокализации может быть использована для синтеза кадра, или как вариант, может быть принято решение применить невокализированный случай для синтеза кадра.
При реализации речевую информацию кодируют одним битом битового потока, значение коэффициента усиления, применяемого к шумовому сигналу, также может быть бинарным, и если сигнал является вокализованным, то значение коэффициента усиления устанавливают равным 0,25, а в противном случае - 1.
Как вариант, речевая информация поступает от кодера, определяющего значение гармоничности или неравномерности спектра (получаемую, например, путем сравнения амплитуд спектральных компонент сигнала с фоновым шумом), затем кодер доставляет это значение в бинарном виде в битовом потоке (используя более одного бита).
При такой альтернативе значение усиления можно определить как функцию упомянутого значения неравномерности (например, непрерывно возрастающую функцию от этого значения).
В общем, упомянутое значение неравномерности можно сравнить с пороговым значением, чтобы определить:
- что сигнал является вокализованным, если значение неравномерности ниже порога, и
- что сигнал не является вокализованным в противном случае, (что бинарным образом характеризует вокализацию).
Таким образом, при реализации с использованием единственного бита, а также в ее варианте, критерий выбора компонент и/или выбора продолжительности сегмента сигнала, в котором происходит поиск основного тона, может быть бинарным.
Например, для выбора компонент:
- если сигнал является вокализованным, то выбирают спектральные компоненты, имеющие амплитуду больше, чем амплитуда первых соседних спектральных компонент, а также первые соседние спектральные компоненты, и
- в противном случае выбирают только спектральные компоненты, имеющие амплитуду больше, чем амплитуда первых соседних спектральных компонент.
Для выбора продолжительности сегмента поиска основного тона, например:
- если сигнал является вокализованным, то осуществляют поиск периода для сегмента полезного сигнала продолжительностью более 30 миллисекунд (например, 33 миллисекунды),
- а если нет, то осуществляют поиск периода для сегмента полезного сигнала продолжительностью менее 30 миллисекунд (например, 28 миллисекунд).
Таким образом, цель изобретения заключается в том, чтобы усовершенствовать имеющийся уровень техники в смысле документа FR 1350845 путем модификации различных этапов обработки, представленной в этом документе (поиск основного тона, выбор компонент, внедрение шума), но основываясь при этом, в частности, на характеристиках исходного сигнала.
Эти характеристики исходного сигнала могут быть закодированы как спектральная информация в потоке данных к декодеру (или в "битовом потоке") в соответствии с разделением на речь и/или музыку, и в соответствующем случае, в частности, на речевой класс.
Эта информация в битовом потоке при декодировании позволяет оптимизировать компромисс между качеством и сложностью и в совокупности:
- изменить коэффициент усиления шума, который следует внедрить в сумму выбранных спектральных компонент, чтобы построить синтезированный сигнал, заменяющий потерянный кадр,
- изменить число компонент, выбранных для синтеза,
- изменить продолжительность сегмента поиска основного тона.
Такой вариант осуществления может быть реализован в кодере для определения информации о вокализации, и конкретнее в декодере, для случая потери кадра. Он может быть реализован в виде программного обеспечения для выполнения кодирования/декодирования для усовершенствованных речевых служб (или "EVS"), заданных группой 3GPP (SA4).
В этом качестве в изобретении также предложена компьютерная программа, содержащая команды для реализации при выполнении процессором этой программы вышеупомянутого способа. В качестве примера ниже в подробном описании представлена блок-схема такой программы, на фиг. 4 для декодирования, а на фиг. 3 для кодирования.
Изобретение также относится к устройству для декодирования цифрового аудиосигнала, содержащего последовательность отсчетов, распределенных в последовательных кадрах. Устройство содержит средство (такое как процессор и память, или специализированная интегральная схема или другая схема) для замены по меньшей мере одного потерянного кадра посредством следующих действий:
a) осуществляют поиск в доступном при декодировании сегменте полезного сигнала по меньшей мере одного периода в сигнале, определяемого на основе упомянутого полезного сигнала,
b) анализируют сигнал в упомянутом периоде, чтобы определить спектральные компоненты этого сигнала в упомянутом периоде,
c) синтезируют по меньшей мере один кадр для замены потерянного кадра путем построения синтезированного сигнала из:
- суммы компонент, выбранных из упомянутых определенных спектральных компонент, и
- шума, добавленного к сумме компонент,
при этом величину шума, добавленного к сумме компонент, взвешивают, исходя из речевой информации полезного сигнала, полученного при декодировании.
Аналогично, изобретение относится к устройству для кодирования цифрового аудиосигнала, содержащему средство (такое как процессор и память, или специализированная интегральная схема или другая схема) для предоставления информации о вокализации в потоке данных, доставляемом кодирующим устройством, различающей речевой сигнал, который вероятно является вокализованным, от музыкального сигнала, и в случае речевого сигнала:
- определяют, что сигнал является вокализованным или типичным, чтобы рассматривать его как в целом вокализованный, или
- определяют, что сигнал является неактивным, переходным или невокализованным, чтобы рассматривать его как в целом невокализованный.
Другие признаки и преимущества изобретения будут очевидными после изучения последующего подробного описания и прилагаемых чертежей, на которых:
- на фиг. 1 собраны основные этапы способ коррекции потери кадров в соответствии с документом FR 1350845;
- на фиг. 2 схематически показаны основные этапы способа в соответствии с изобретением;
- на фиг. 3 приведен пример этапов, реализованных при кодировании в одном варианте осуществления настоящего изобретения;
- на фиг. 4 показан пример этапов, реализованных при декодировании в одном варианте осуществления настоящего изобретения;
- на фиг. 5 показан пример этапов, реализованных при декодировании, для описка основного тона в сегменте Nc полезного сигнала;
- на фиг. 6 схематично показан пример устройств кодера и декодера в соответствии с настоящим изобретением.
Обратимся теперь к фиг. 1, показывающей основные этапы, описанные в документе FR 1350845. Последовательность из N звуковых отсчетов, обозначенную ниже через b(n), сохраняют в буферной памяти декодера. Эти отсчеты соответствуют уже декодированным отсчетам и, поэтому, доступны для коррекции потери кадра в декодере. Если первый отсчет, который надо синтезировать, является отсчетом N, то аудиобуфер соответствует предыдущим отсчетам от 0 до N-1. В случае кодирования с преобразованием аудиобуфер соответствует отсчетам в предыдущем кадре, который не может быть изменен, потому что в этом типе кодирования/декодирования не предусмотрена задержка в реконструкции сигнала; поэтому, не предусмотрена реализация перекрестного затухания достаточной длительности, чтобы охватить потерю кадра.
Затем следует этап S2 частотной фильтрации, на котором аудиобуфер b(n) разделяют на две полосы частот, полосу LB низких частот и полосу НВ высоких частот, при этом частота разделения обозначена через Fc (например, Fc=4 кГц). Эта фильтрация предпочтительно является фильтрацией без задержки. Размер аудиобуфера теперь сокращают до N'=N*Fc/f следом за прореживанием fs до Fc. В вариантах изобретения этот этап фильтрации может быть опциональным, следующие этапы выполняют на полном диапазоне.
Следующий этап S3 состоит в осуществлении поиска в полосе низких частот точки цикла и сегмента p(n), соответствующего основному периоду (или "основному тону") в буфере b(n) прореженном с частотой Fc. Этот вариант осуществления позволяет учесть непрерывность основного тона в потерянном кадре (кадрах), который надо реконструировать.
Этап S4 состоит в разбиении сегмента p(n) на сумму синусоидальных компонент. Например, можно вычислить дискретное преобразование Фурье (DFT) сигнала p(n) на длительности, соответствующей длине сигнала. Таким образом, получают частоту, фазу и амплитуду каждой из синусоидальных компонент (или "пиков") сигнала. Возможны преобразования отличные от DFT. Например, можно применить такие преобразования, как DCT, MDCT или MCLT.
Этап S5 представляет собой этап выбора K синусоидальных компонент, чтобы сохранить только наиболее значимые компоненты. В одном отдельном варианте осуществления выбор компонент прежде всего соответствует выбору амплитуд A(n), для которых A(n)>A(n-1) и A(n)>A(n+1), где 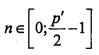 , что гарантирует, что амплитуды соответствуют спектральным пикам.
, что гарантирует, что амплитуды соответствуют спектральным пикам.
Для этого интерполируют отсчеты сегмента p(n) (основного тона), чтобы получить сегмент p'(n), состоящий из P' отсчетов, где  ,
,  - целое число, больше или равное x. Поэтому, анализ с помощью преобразования Фурье FFT выполняют более эффективно на длине, равной степени 2, без модификации действительного периода основного тона (вследствие интерполяции). Вычисляют преобразование FFT сегмента
- целое число, больше или равное x. Поэтому, анализ с помощью преобразования Фурье FFT выполняют более эффективно на длине, равной степени 2, без модификации действительного периода основного тона (вследствие интерполяции). Вычисляют преобразование FFT сегмента 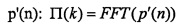 ; и из преобразования FFT непосредственно получают фазы ϕ(k) и амплитуды A(k) синусоидальных компонент, нормализованные частоты от 0 до 1 задаются здесь следующим образом:
; и из преобразования FFT непосредственно получают фазы ϕ(k) и амплитуды A(k) синусоидальных компонент, нормализованные частоты от 0 до 1 задаются здесь следующим образом:
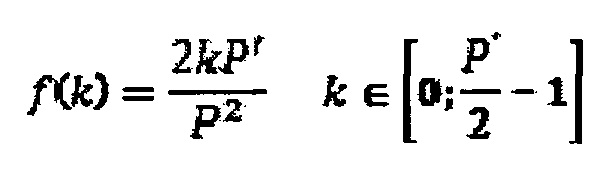
Далее, из амплитуд этого первого выбора выбирают компоненты в порядке уменьшения амплитуд, так что совокупная амплитуда выбранных пиков составляет по меньшей мере x% (например, x=70%) от совокупной амплитуды на, как правило, половине спектра в текущем кадре.
Кроме того, также можно ограничить число компонент (например, 20), чтобы снизить сложность синтеза.
Этап S6 синтеза синусоид состоит в генерации сегмента s(n) длины по меньшей мере равной размеру потерянного кадра (Т). Синтезированный сигнал s(n) вычисляют как сумму выбранных синусоидальных компонент:

где k - индекс K пиков, выбранных на этапе S5.
Этап S7 состоит во "внедрении шума" (заполнение спектральных областей, соответствующих не выбранным линиям), чтобы компенсировать потерю энергии из-за пропуска определенных частотных пиков в полосе низких частот. Одна отдельная реализация состоит в вычислении разности r(n) между сегментом, соответствующим основному тону p(n), и синтезированным сигналом s(n), где, так что:

Эту разность размера P преобразовывают, например, ее обрабатывают методом окна и повторяют с перекрытиями между окнам различных размеров, как описано в патенте FR 1353551:
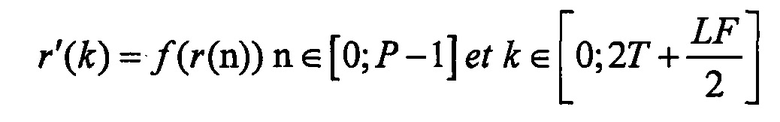
Затем, сигнал s(n) комбинируют с сигналом r'(n):
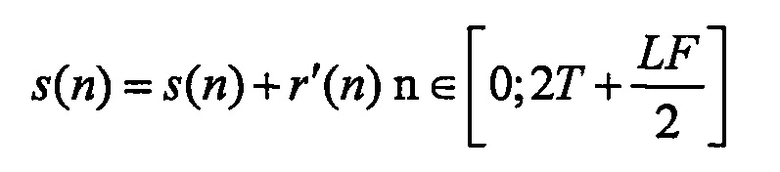
Этап S8, применяемый к полосе высоких частот, может просто состоять в повторе пройденного сигнала.
На этапе S9 синтезируют сигнал путем повторной выборки из полосы низких частот с исходной частотой fc после смешивания на этапе S8 с фильтрованной полосой высоких частот (просто повторенной на этапе S11).
На этапе S10 выполняют перекрытие-сложение, чтобы гарантировать непрерывность между сигналом до потери кадра и синтезированным сигналом.
Теперь опишем элементы, добавленные к способу, показанному на фиг. 1, в одном варианте осуществления настоящего изобретения.
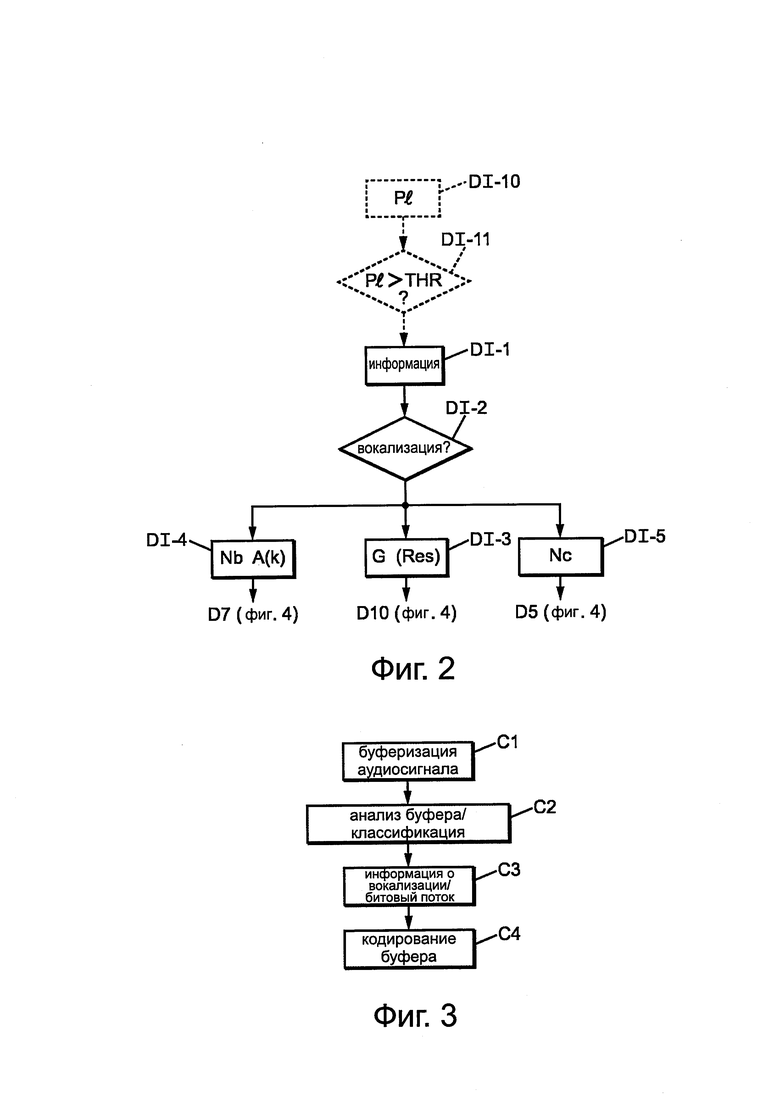
В соответствии с общим подходом, представленным на фиг. 2, информацию о вокализации сигнала до потери кадра, передаваемую по меньшей мере с одной скоростью передачи битов кодера, используют при декодировании (этап DI-1), чтобы количественно определить долю шума, который надо добавить к синтезированному сигналу, заменяющему один или несколько потерянных кадров). Таким образом, декодер использует информацию о вокализации для того, чтобы, исходя из того, является ли сигнал вокализованным или нет, уменьшить общее количество шума, подмешиваемого в синтезированный сигнал (путем задания коэффициента усиления G(res) меньше, чем шумовой сигнал r'(k), получаемый из разности на этапе DI-3, и/или путем выбора большего числа компонент амплитуды A(k) для применения в построении синтезированного сигнала на этапе DI-4).
Кроме того, декодер может регулировать свои параметры, в частности, для поиска основного тона, чтобы оптимизировать компромисс между качеством/сложностью обработки, исходя из информации о вокализации. Например, для поиска основного тона, если сигнал является вокализованным, то окно Nc поиска основного тона может быть больше (на этапе DI-5), как мы увидим на фиг. 5 ниже.
Для определения вокализации кодером может быть предоставлена информация двумя способами по меньшей мере с одной скоростью передачи кодера:
- в виде бита, имеющего значение 1 или 0 в зависимости от степени вокализации, определенной в кодере (полученной от кодера на этапе DI-1 и считанной на этапе DI-2 в случае потери кадра для последующей обработки), или
- в виде значения средней амплитуды пиков, составляющих сигнал при кодировании, по сравнению с фоновым шумом.
Этот спектр "неравномерности" данных 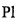 может быть получен декодером в нескольких битах на необязательном этапе DI-10 на фиг. 2, затем сравнен с порогом на этапе DI-11, что является тем же самым, что и определение на этапах DI-1 и DI-2 того, что вокализация выше или ниже порога, и вывод соответствующей обработки, в частности, для выбора пиков и для выбора длины сегмента поиска основного тона.
может быть получен декодером в нескольких битах на необязательном этапе DI-10 на фиг. 2, затем сравнен с порогом на этапе DI-11, что является тем же самым, что и определение на этапах DI-1 и DI-2 того, что вокализация выше или ниже порога, и вывод соответствующей обработки, в частности, для выбора пиков и для выбора длины сегмента поиска основного тона.
В описанном здесь примере эту информацию (либо в виде единственного бита, либо в виде многобитового значения) принимают от кодера (по меньшей мере с одной скоростью передачи битов кодека).
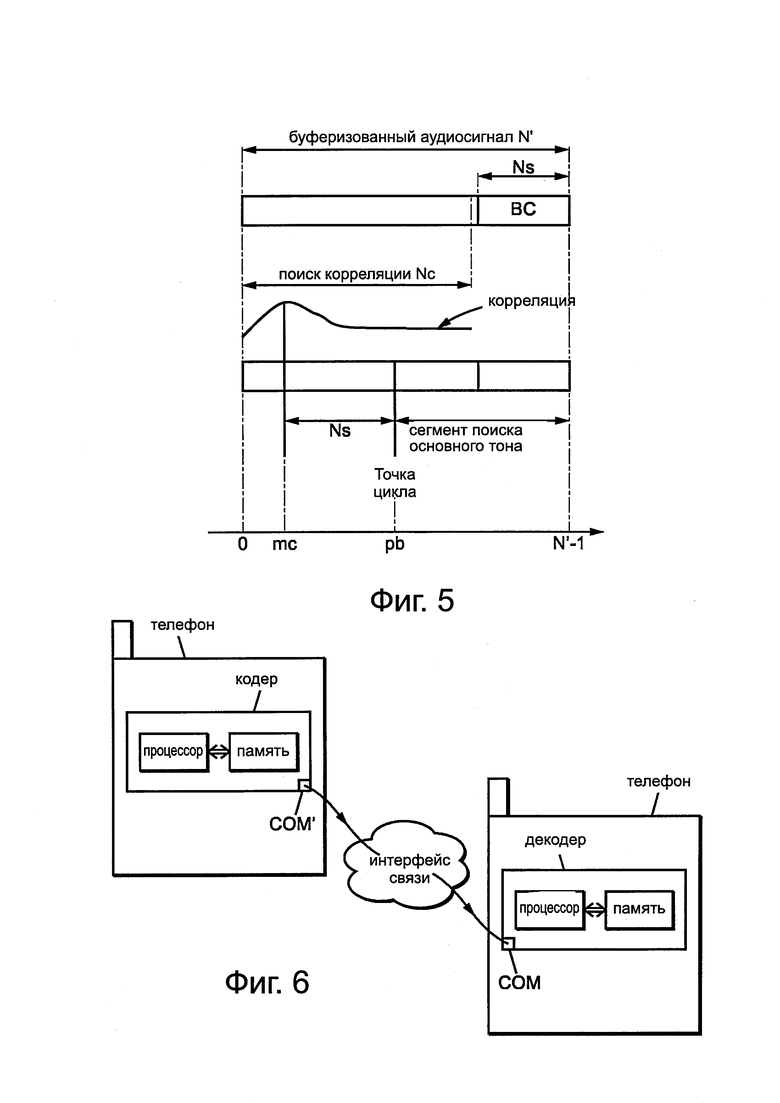
Действительно, со ссылкой на фиг. 3 в кодере входной сигнал, представленный в виде кадров С1, анализируют на этапе С2. Этап анализа состоит в определении, обладает ли аудиосигнал текущего кадра характеристиками, которые требуют специальной обработки в случае потери кадра в декодере, как в случае, например, вокализованных речевых сигналов.
В одном отдельном варианте осуществления для того, чтобы предотвратить увеличение общей сложности обработки, преимущественно используют классификацию (речь/музыка и др.), уже определенную в кодере. Действительно, в случае кодеров, которые могут переключать режимы кодирования между речевым режимом и режимом музыки, классификация в кодере уже позволяет адаптировать используемую технологию кодирования к природе сигнала (речь или музыка). Аналогично, в случае речи предсказывающие кодеры, такие как кодер стандарта G.718, также используют классификацию, чтобы адаптировать параметры кодера к типу сигнала (вокализованные/невокализованные звуки, переходный, типичный, неактивный).
В одном отдельном первом варианте осуществления для "описания потери кадра" зарезервирован только один бит. Его добавляют к кодированному потоку (или "битовому потоку") на этапе С3, чтобы указать, является ли сигнал речевым сигналом (вокализованным или типичным). Этот бит, например, устанавливают равным 1 или 0 в соответствии со следующей таблицей, исходя из:
- решения классификатора речи/музыки,
- а также решения классификатора режима кодирования речи.

Здесь, термин "типичный" относится к обычному речевому сигналу (который не является переходным, относящимся к произношению взрывного звука, не является неактивным, и не обязательно является чисто вокализованным, таким как произношение гласной без согласной).
Во втором альтернативном варианте осуществления информация, передаваемая декодеру в битовом потоке, не является бинарной, но соответствует количественному представлению соотношения между пиками и впадинами в спектре. Это соотношение можно выразить как меру "неравномерности" спектра, обозначенную через :

В этом выражении x(k) - это спектр амплитуды размера N, получаемый из анализа текущего кадра в частотной области (после FFT).
В альтернативе производят синусоидальный анализ, разбивающий сигнал в кодере на синусоидальные компоненты и шум, а меру неравномерности получают из соотношения синусоидальных компонент и общей энергии кадра.
После этапа С3 (включающего в себя один бит информации о вокализации или несколько бит меры неравномерности) аудиобуфер кодера кодируют обычным образом на этапе С4 до последующей передачи на декодер.
Теперь со ссылкой на фиг. 4 опишем этапы, реализуемые в декодере в одном примере осуществления изобретения.
В случае, когда на этапе D1 нет потери кадра (стрелка NOK, отходящая от проверки D1 на фиг. 4), на этапе D2 декодер считывает информацию, содержащуюся в битовом потоке, включая "описание потери кадра" (по меньшей мере с одной скоростью передачи битов кодека). Эту информацию сохраняют в памяти, так что ее можно повторно использовать, если потерян следующий кадр. Затем, декодер продолжает выполнять обычные шаги декодирования D3 и т.д., чтобы получить синтезированный выходной кадр FR SYNTH.
В случае, когда происходит потеря кадра (кадров) (стрелка ОК, отходящая от проверки D1), выполняют этапы D4, D5, D6, D7, D8 и D12, соответствующие этапам S2, S3, S4, S5, S6 и S11 на фиг. 1. Тем не менее, сделано несколько изменений, касающихся этапов S3 и S5 и соответственно этапов D5 (поиска точки цикла для определения основного тона) и D7 (выбора синусоидальных компонент). Более того, внедрение шума на этапе S7 на фиг. 1 выполняют с определением коэффициента усиления за два этапа D9 и D10 на фиг. 4 декодера в соответствии с изобретением.
В случае, когда "описание потери кадра" известно (когда предыдущий кадр был принят), изобретение состоит в модификации обработки на этапах D5, D7 и D9-D10 следующим образом.
В первом варианте осуществления "описание потери кадра" является бинарным и имеет значение:
- равное 0 для невокализованного сигнала такого типа, как музыка или переходной сигнал,
- равное 1 в противном случае (таблица выше).
Этап S5 состоит в осуществлении поиска точки цикла и сегмента p(n), соответствующего основному тону в аудиобуфере, прореженном с частотой Fc. Эта технология, описанная в документе FR 1350845, показана на фиг. 5, на которой:
- аудиобуфер в декодере имеет размер N' отсчетов,
- определяют размер целевого буфера ВС из Ns отсчетов,
- поиск корреляции осуществляют на Nc отсчетах,
- корреляционная кривая "Correl" имеет максимум в точке mc,
- точка цикла обозначена через Loop pt и расположена через Ns отсчетов от максимума корреляции,
- затем определяют основной тон на p(n) оставшихся отсчетах в N'-1.
В частности, вычисляем нормализованную корреляцию corr(n) между сегментом целевого буфера размера Ns, между N'-Ns и N'-1 (например, длительностью 6 мс) и скользящим сегментом размера Ns, который начинается между отсчетом 0 и Nc (где Nc>N'-Ns):

Для музыкальных сигналов вследствие природы этого сигнала не требуется, чтобы значение Nc было очень большим (например, Nc=28 мс). Это ограничение позволяет сэкономить на вычислительной сложности во время поиска основного тона.
Тем не менее, речевая информация, из последнего действительного принятого кадра позволяет определить, является ли сигнал, который надо реконструировать, вокализованным речевым сигналом (один основной тон). Поэтому, в таких случаях и с такой информацией можно увеличить размер сегмента Nc (например, Nc=33 мс), чтобы оптимизировать поиск основного тона (и потенциально найти более высокое значение корреляции).
На этапе D7 на фиг. 4 синусоидальные компоненты выбирают так, что остаются только наиболее значительные компоненты. В одном отдельном варианте осуществления, также представленном в документе FR 1350845, первый выбор компонент эквивалентен выбору амплитуд A(n), где A(n)>A(n-1) и 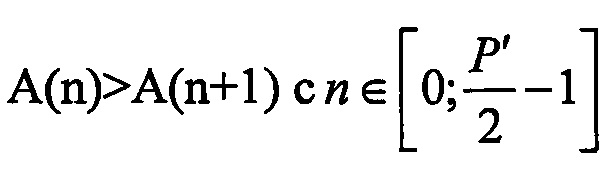 .
.
В случае изобретения преимущественно известно, является ли сигнал, который надо реконструировать, речевым сигналом (вокализованным или типичным), и поэтому в нем имеются произносимые пики и низкий уровень шума. При этих условиях предпочтительно выбирать не только пики A(n), где A(n)>A(n-1) и A(n)>A(n+1), как показано выше, но также расширять выбор до A(n-1) и A(n+1), так что выбранные пики представляют больший участок общей энергии спектра. Эта модификация позволяет понизить уровень шума (и, в частности, уровень шума, внедряемого на этапах D9 и D10, представленных ниже) по сравнению с уровнем сигнала, получаемого посредством синусоидального анализа на этапе D8, при этом сохраняя общий уровень энергии достаточным для того, чтобы не вызывать появление звуковых артефактов, связанных с флуктуациями энергии.
Далее, в случае, когда сигнал не содержит шума (по меньшей мере в низких частотах), как в случае типичного или вокализованного речевого сигнала наблюдаем, что добавление шума, соответствующего преобразованной разнице r'(n) в понимании документа FR 1350845 в действительности ухудшает качество.
Поэтому, речевую информацию преимущественно используют, чтобы снизить шум путем применения коэффициента усиления G на этапе D10. Сигнал s(n), получаемый на этапе D8, смешивают с шумовым сигналом r'(n), получающимся на этапе D9, но применяют коэффициент G усиления, который зависит от "описания потери кадра", получаемого из битового потока предыдущего кадра, то есть:

В отдельном варианте осуществления G может представлять собой константу, равную 1 или 0,25, в зависимости от того, является ли сигнал предыдущего кадра вокализованным или невокализованным, в соответствии с таблицей, приведенной ниже в качестве примера:

В альтернативном варианте осуществления, где "описание потери кадра" имеет несколько дискретных уровней, характеризующих неравномерность спектра, коэффициент усиления G можно выразить непосредственно как функцию значения . Это же верно для границ сегмента Nc для поиска основного тона и/или для числа пиков An, которые надо учесть для синтеза сигнала.
В качестве примера можно задать такую обработку, как приведено ниже.
Коэффициент усиления G уже был непосредственно определен как функция значения  .
.
Кроме того, значение сравнивают со средним значением -3дБ, причем значение 0 соответствует плоскому спектру, а -5дБ соответствует спектру с отчетливыми пиками.
Если значение меньше, чем среднее пороговое значение -3 дБ (соответствуя, таким образом, спектру с отчетливыми пиками, типичными для вокализованного сигнала), то можно задать длительность сегмента для поиска основного тона Nc равной 33 мс, и можно выбрать пики A(n), так что A(n)>A(n-1) и A(n)>A(n+1), а также первые соседние пики A(n-1) и A(n+1).
В противном случае (если значение выше порога, соответствуя менее отчетливым пикам, большему фоновому шуму, как, например, в музыкальном сигнале) продолжительность Nc можно выбрать покороче, например, 25 мс, и выбирают только пики A(n), которые удовлетворяют условию A(n)>A(n-1) и A(n)>A(n+1).
Затем может продолжаться декодирование путем смешивания шума, для которого получен коэффициент усиления, с выбранными таким образом компонентами, чтобы получить синтезированный сигнал в низких частотах на этапе D13, который складывают с синтезированным сигналом в высоких частотах, полученным на этапе D14, чтобы получить общий синтезированный сигнал на этапе D15.
Со ссылкой на фиг. 6, показана одна возможная реализация изобретения, в которой декодер DECOD (содержащий, например, программное и аппаратное обеспечение, такое как соответствующим образом запрограммированная память MEM и процессор PROC, взаимодействующий с этой памятью, или, в качестве альтернативы, такой компонент, как специализированная интегральная схема (ASIC) или другой, а также интерфейс связи СОМ), встроенный, например, в телекоммуникационное устройство, такое как телефон TEL, для реализации способа, показанного на фиг. 4, использует информацию о вокализации, которую принимает от кодера ENCOD. Этот кодер содержит, например, программное и аппаратное обеспечение, такое как соответствующим образом запрограммированная память MEM' для определения информации о вокализации и процессор PROC', взаимодействующий с этой памятью, или, в качестве альтернативы, такой компонент, как ASIC или другой, и интерфейс связи СОМ'. Кодер ENCOD встроен в телекоммуникационное устройство, такое как телефон TEL'.
Конечно, изобретение не ограничено изложенными выше в качестве примера вариантами осуществления; оно распространяется на другие варианты.
Таким образом, например, понятно, что информация о вокализации может принимать различные формы в виде вариантов. В описанном выше примере это может быть бинарное значение из одного бита (вокализованный или невокализованный) или многобитовое значение, которое может касаться такого параметра, как неравномерность спектра сигнала, или любого другого параметра, который позволяет охарактеризовать вокализацию (количественно или качественно). Более того, этот параметр может быть определен путем декодирования, например, на основе степени корреляции, которую можно измерить при идентификации периода основного тона.
Выше в качестве примера был представлен вариант осуществления, который включал в себя разделение на полосу высоких частот и полосу низких частот сигнала из предыдущих действительных кадров, в частности, с выбором спектральных компонент в полосе низких частот. Однако эта реализация является опциональной, хотя предпочтительной, так как снижает сложность обработки. Как вариант, способ замены кадра с помощью информации о вокализации в соответствии с изобретением может быть выполнен при рассмотрении всего спектра полезного сигнала.
Выше был описан вариант осуществления, в котором изобретение реализовано в контексте кодирования с преобразованием с перекрытием-сложением. Тем не менее, этот тип способа можно адаптировать к любому другому типу кодирования (в частности, CELP).
Следует отметить, что в контексте кодирования с преобразованием с перекрытием-сложением (где обычно синтезированный сигнал строят по меньшей мере на продолжительность двух кадров из-за перекрытия), упомянутый шумовой сигнал может быть получен путем нахождения разности (между полезным сигналом и суммой пиков) посредством взвешивания во времени разности. Например, она может быть взвешена посредством перекрывающих окон, как в обычном контексте кодирования/декодирования посредством преобразования с перекрытием.
Понятно, что применение усиления как функции информации о вокализации добавляет другой вес, на этот раз основанный на вокализации.

Изобретение относится к вычислительной технике для обработки цифрового аудиосигнала. Технический результат заключается в повышении качества аудиосигнала после коррекции потери кадра. Технический результат достигается за счет осуществления поиска в доступном при декодировании сегменте полезного сигнала по меньшей мере одного периода в сигнале, определяемого на основе упомянутого полезного сигнала, анализа сигнала в упомянутом периоде, чтобы определить спектральные компоненты сигнала в упомянутом периоде, синтеза по меньшей мере одной замены для потерянного кадра путем построения синтезированного сигнала из: суммы компонент, выбранных из упомянутых определенных спектральных компонент, и шума, добавленного к сумме компонент, при этом величину шума, добавленного к сумме компонент, взвешивают на основании речевой информации полезного сигнала, полученного при декодировании. 3 н. и 12 з.п. ф-лы, 6 ил.
1. Способ обработки цифрового аудиосигнала, содержащего последовательность отсчетов, распределенных в последовательных кадрах, причем способ реализуют при декодировании упомянутого сигнала, чтобы заменить по меньшей мере один потерянный кадр сигнала во время декодирования,
причем способ содержит этапы, на которых:
a) осуществляют поиск в доступном при декодировании сегменте полезного сигнала по меньшей мере одного периода в сигнале, определяемого на основе упомянутого полезного сигнала,
b) анализируют сигнал в упомянутом периоде, чтобы определить спектральные компоненты сигнала в упомянутом периоде,
с) синтезируют по меньшей мере одну замену для потерянного кадра путем построения синтезированного сигнала из:
суммы компонент, выбранных из упомянутых определенных спектральных компонент, и
шума, добавленного к сумме компонент,
при этом величину шума, добавленного к сумме компонент, взвешивают на основании речевой информации полезного сигнала, полученного при декодировании.
2. Способ по п. 1, в котором шумовой сигнал, добавляемый к сумме компонент, взвешивают посредством меньшего коэффициента усиления в случае наличия речевой информации в полезном сигнале.
3. Способ по п. 2, в котором шумовой сигнал получают путем нахождения разности между полезным сигналом и суммой выбранных компонент.
4. Способ по п. 1, в котором число компонент, выбираемых для сложения, больше в случае наличия речевой информации в полезном сигнале.
5. Способ по п. 1, в котором на этапе а) осуществляют поиск периода в сегменте полезного сигнала большей длительности в случае наличия речевой информации в полезном сигнале.
6. Способ по п. 1, в котором речевую информацию передают в битовом потоке, принимаемом при декодировании и соответствующем упомянутому сигналу, содержащему последовательность отсчетов, распределенных в последовательных кадрах,
при этом в случае потери кадра при декодировании используют речевую информацию, содержащуюся в кадре полезного сигнала, предшествующем потерянному кадру.
7. Способ по п. 6, в котором речевая информация поступает из кодера, генерирующего битовый поток и определяющего речевую информацию, при этом речевую информацию кодируют одним битом в битовом потоке.
8. Способ по п. 7, в котором шумовой сигнал, добавленный к сумме компонент, взвешивают с меньшим коэффициентом усиления в случае наличия речевой информации в полезном сигнале, при этом, если сигнал является речевым, то коэффициент усиления равен 0, 25, а в противном случае равен 1.
9. Способ по п. 6, в котором речевая информация поступает от кодера, определяющего значение равномерности спектра, получаемое путем сравнения амплитуд спектральных компонент сигнала с фоновым шумом, причем упомянутый кодер доставляет упомянутое значение в двоичном виде в битовом потоке.
10. Способ по п. 7, в котором шумовой сигнал, добавленный к сумме компонент, взвешивают с меньшим коэффициентом усиления в случае наличия речевой информации в полезном сигнале, при этом значение коэффициента усиления определяют как функцию упомянутого значения равномерности.
11. Способ по п. 9, в котором упомянутое значение равномерности сравнивают с порогом, чтобы определить:
что сигнал является речевым, если значение равномерности ниже порога, и
что сигнал не является речевым в противном случае.
12. Способ по п. 7, в котором количество компонент, выбранных для суммирования, больше в случае наличия речевой информации в полезном сигнале, при этом:
если сигнал является речевым, то выбирают спектральные компоненты, имеющие амплитуду больше, чем амплитуда первых соседних спектральных компонент, а также первые соседние спектральные компоненты, и
в противном случае выбирают только спектральные компоненты, имеющие амплитуду больше, чем амплитуда первых соседних спектральных компонент.
13. Способ по п. 7, в котором на этапе a) осуществляют поиск в упомянутом периоде сегмента полезного сигнала большей длины в случае наличия речевой информации в полезном сигнале, при этом:
если сигнал является речевым, то осуществляют поиск периода в сегменте полезного сигнала длительностью более 30 миллисекунд,
в противном случае осуществляют поиск периода в сегменте полезного сигнала длительностью менее 30 миллисекунд.
14. Считываемый компьютером носитель, содержащий код компьютерной программы, причем компьютерная программа содержит команды для реализации способа по любому из пп. 1-13 при выполнении программы процессором.
15. Устройство для декодирования цифрового аудиосигнала, содержащего последовательность отсчетов, распределенных в последовательных кадрах, при этом устройство содержит компьютерную схему для замены по меньшей мере одного потерянного кадра сигнала посредством:
a) поиска в доступном при декодировании сегменте полезного сигнала по меньшей мере одного периода в сигнале, определяемого на основе упомянутого полезного сигнала,
b) анализа сигнала в упомянутом периоде, чтобы определить спектральные компоненты сигнала в упомянутом периоде,
с) синтеза по меньшей мере одного кадра для замены потерянного кадра путем построения синтезированного сигнала из:
суммы компонент, выбранных из упомянутых определенных спектральных компонент, и
шума, добавленного к сумме компонент,
при этом величина шума, добавленного к сумме компонент, взвешена на основании речевой информации полезного сигнала, полученного при декодировании.
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ, ОСНОВЫВАЮЩЕГОСЯ НА ОБЪЕКТАХ АУДИОСИГНАЛА | 2007 |
|
RU2484543C2 |
| КОДИРОВАНИЕ АУДИОСИГНАЛА | 2008 |
|
RU2428748C2 |

