Область техники, к которой относится изобретение
Данное изобретение относится к области биологической химии, а именно к новому способу синтеза библиотек молекул, содержащих олигонуклеотидную метку. Данные библиотеки могут быть использованы для идентификации соединений, связывающихся с определенной биологической мишенью.
Уровень техники
Поиск более эффективных способов идентификации соединений, характеризующихся ценными биологическими свойствами, привел к развитию методов скриннинга огромного числа различных соединений, собранных в коллекциях, которые называются комбинаторными библиотеками. Такие библиотеки включают 105 или более различных соединений. Существует множество способов создания комбинаторных библиотек, а также описан комбинаторный синтез пептидов, пептидомиметиков и низкомолекулярных органических молекул.
Две основные проблемы при использовании комбинаторного подхода в создании лекарственных средств заключаются в синтезе библиотек достаточной сложности и в идентификации молекул, обладающих активностью, определенной различными методами анализа. Общеизвестно, что чем выше степень сложности библиотеки, т.е. число различных структур, включенных в библиотеку, тем выше вероятность наличия в библиотеке молекул, обладающих требуемой активностью. Следовательно, методы химического синтеза для создания библиотеки должны обеспечивать получение огромного числа соединений в пределах разумного промежутка времени. Однако с учетом данной "формальной" или общей концентрации, при увеличении числа различных членов в библиотеке снижается концентрация конкретного члена в библиотеке, что осложняет идентификацию активных молекул в библиотеках высокой сложности.
Один из подходов к преодолению таких недостатков заключается в создании кодированных библиотек и, прежде всего, библиотек, в которых каждое соединение включает амплифицируемую метку. Такие библиотеки включают ДНК-кодированные библиотеки, в которых меченый фрагмент ДНК, идентифицирующий член библиотеки, можно амплифицировать с использованием методов молекулярной биологии, таких как полимеразная цепная реакция. Однако использование таких способов для получения библиотек, включающих огромное множество соединений, еще находится на стадии разработки, и очевидно, что для реализации такого подхода при создании лекарственных средств существует необходимость в развитии усовершенствованных способов создания таких библиотек.
Раскрытие изобретения
В настоящем изобретении предлагается способ синтеза библиотек молекул, которые включают кодирующую олигонуклеотидную метку. В данном способе используется стратегия "разделения и объединения", которая заключается в том, что раствор, содержащий инициатор, первый структурный фрагмент, связанный с кодирующим олигонуклеотидом, разделяют на множество фракций ("разделение"). В каждой фракции инициатор взаимодействует со вторым, уникальным, структурным фрагментом и вторым уникальным олигонуклеотидом, который идентифицирует второй структурный фрагмент. Эти реакции проводят одновременно или последовательно, и в случае последовательных реакций, каждая реакция предшествует другой реакции. Димерные молекулы, образующиеся в каждой фракции, объединяют ("объединение") и затем снова разделяют на множество фракций. Каждая из таких фракций взаимодействует с третьим уникальным (специфичным для данной фракции) структурным фрагментом и третьим уникальным олигонуклеотидом, который кодирует фрагмент. Число специфичных молекул, присутствующих в полученной библиотеке, зависит (1) от числа различных фрагментов, использованных на каждой стадии синтеза, и (2) от числа стадий разделения и объединения фракций.
В одном варианте осуществления настоящего изобретения предлагается способ синтеза молекулы, содержащей или представляющей собой функциональный компонент, эффективно связанный с кодирующим олигонуклеотидом. Такой способ включает следующие стадии: (1) получение соединения-инициатора, состоящего из функционального компонента, содержащего n структурных фрагментов (где n равно целому числу 1 или более), причем функциональный компонент содержит по меньшей мере одну реакционноспособную группу и эффективно связан с исходным олигонуклеотидом; (2) взаимодействие соединения-инициатора со структурным фрагментом, содержащим по меньшей мере одну комплементарную реакционноспособную группу, которая является комплементарной в отношении реакционноспособной группы, описанной на стадии (1), в условиях, пригодных для взаимодействия реакционноспособной группы и комплементарной реакционноспособной группы с образованием ковалентной связи; (3) взаимодействие исходного олигонуклеотида с новым олигонуклеотидом, который идентифицирует структурный фрагмент, описанным на стадии (b) в присутствии фермента, который катализирует лигирование исходного олигонуклеотида и нового олигонуклеотида в условиях, пригодных для лигирования исходного олигонуклеотида и нового олигонуклеотида, с образованием молекулы, содержащей или представляющей собой функциональный компонент, включающий n+1 структурных фрагментов, которые эффективно связаны с кодирующим олигонуклеотидом. Если функциональная группа, описанная на стадии (3), содержит реакционноспособную группу, то стадии 1-3 при необходимости повторяют один или более раз, при этом проводят циклы 1-i (где i равно целому числу 2 или более) с использованием продукта, полученного на стадии (3) цикла s (где s равно целому числу И или менее), выполняющего функции соединения-инициатора в цикле s+1.
В одном варианте осуществления настоящего изобретения предлагается способ синтеза библиотеки соединений, в которой соединения содержат функциональный компонент, содержащий 2 или более структурных фрагментов, эффективно связанных с олигонуклеотидом, который идентифицирует структуру функционального компонента. Способ включает следующие стадии: (1) получение раствора, включающего m соединений-инициаторов (где m равно целому числу 1 или более), причем соединения-инициаторы состоят из функционального компонента, содержащего n структурных фрагментов (где n равно целому числу 1 или более), которые эффективно связаны с исходным олигонуклеотидом, идентифицирующим n структурных фрагментов; (2) разделение раствора, полученного на стадии (2), на r фракций (где r равно целому числу 2 или более); (3) взаимодействие соединений-инициаторов в составе каждой фракции с одним из r структурных фрагментов с образованием r фракций, содержащих соединения, состоящие из функционального компонента, содержащего n+1 структурных фрагментов, который эффективно связан с исходным олигонуклеотидом; (4) взаимодействие исходного олигонуклеотида в составе каждой фракции с одним из набора r различных новых олигонуклеотидов в присутствии фермента, который катализирует лигирование нового и исходного олигонуклеотидов в условиях, пригодных для ферментативного лигирования нового и исходного олигонуклеотидов, с получением r аликвотных фракций, состоящих из функционального компонента, содержащего n+1 структурных фрагментов, эффективно связанный с удлиненным олигонуклеотидом, который кодирует n+1 структурных фрагментов. Способ необязательно включает стадию (5) рекомбинирования r фракций, полученных на стадии (4), с получением раствора, содержащего соединения, состоящие из функциональной группы, содержащей n+1 структурных фрагментов и эффективно связанной с удлиненным олигонуклеотидом. Стадии (1)-(5) при необходимости повторяют один или более раз, при этом проводят циклы 1-i (где i равно целому числу 2 или более). В цикле s+1 (где s равно целому числу i-1 или менее), раствор, включающий m соединений-инициаторов, описанных на стадии (1), является раствором, описанным на стадии (5) цикла s. Аналогичным образом, соединения-инициаторы, описанные на стадии (1) цикла s+1, являются соединениями-инициаторами, описанными на стадии (5) цикла s.
В предпочтительном варианте для конденсации структурных фрагментов на каждой стадии используют стандартные химические реакции. Фрагменты конденсируют с образованием линейных или разветвленных полимеров или олигомеров, таких как пептиды, пептидомиметики или пептоиды или неолигомерные молекулы, такие как молекулы, включающие структуру-каркас, к которой присоединяют один или более дополнительных химических компонентов. Например, если структурные фрагменты представляют собой аминокислотные остатки, то их конденсируют с использованием стандартных методов пептидного синтеза, таких как синтез в растворе или твердофазный синтез, с использованием известных пригодных способов введения/удаления защитных групп. Предпочтительным способом для конденсирования структурных фрагментов является синтез в растворе. В качестве кодирующих олигонуклеотидов используют одноцепочечные или двухцепочечные олигонуклеотиды, предпочтительно двухцепочечные олигонуклеотиды. Кодирующие олигонуклеотиды предпочтительно включают от 4 до 12 оснований или пар оснований на один структурный фрагмент; кодирующие олигонуклеотиды конденсируют с использованием стандартных методов синтеза олигонуклеотидов в растворе или твердофазного синтеза, но предпочтительно конденсируют с использованием ферментативного синтеза в растворе. Например, олигонуклеотиды конденсируют с использованием топоизомеразы, лигазы или ДНК-полимеразы, если последовательность кодирующих олигонуклеотидов включает инициирующую последовательность для лигирования с одним из таких ферментов. Ферментативная конденсация кодирующих олигонуклеотидов характеризуется следующими преимуществами: (1) высокая точность присоединения по сравнению со стандартной (неферментативной) конденсацией и (2) использование более простого способа введения/удаления защитных групп.
В другом варианте в настоящем изобретении предлагаются соединения формулы I:
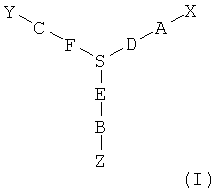
где Х означает функциональный компонент, содержащий один или более структурных фрагментов; Z означает олигонуклеотид, присоединенный через 3'-концевую группу к В; Y означает олигонуклеотид, который присоединен через 5'-концевую группу к С; А означает функциональную группу, ковалентно связанную с X; В означает функциональную группу, связанную с 3'-концевой группой фрагмента Z; С означает функциональную группу, связанную с 5'-концевой группой фрагмента Y; D, F и Е каждый независимо означает бифункциональную связующую группу, a S означает атом или молекулярный каркас. Такие соединения могут быть синтезированы в том числе с использованием способов по настоящему изобретению.
Настоящее изобретение относится также к библиотеке соединений, содержащей соединения, содержащие функциональный компонент, содержащий два или более структурных фрагментов и эффективно связанный с олигонуклеотидом, кодирующим структуру функционального компонента. Такие библиотеки включают от приблизительно 102 до приблизительно 1012 или более различных членов, например 102, 103, 104, 105, 106, 107, 108, 109, 1010, 1011, 1012 или более различных членов, т.е. различных молекулярных структур. В одном варианте осуществления настоящего изобретения библиотека соединений содержит соединения, каждое из которых независимо означает соединение формулы I:
где Х означает функциональный компонент, содержащий один или более структурных фрагментов; Z означает олигонуклеотид, присоединенный через 3'-концевую группу к В; Y означает олигонуклеотид, присоединенный через 5'-концевую группу к С; А означает функциональную группу, ковалентно связанную с X; В означает функциональную группу, связанную с 3'-концевой группой фрагмента Z; С означает функциональную группу, связанную с 5'-концевой группой фрагмента Y; D, F и Е каждый независимо означает бифункциональную связующую группу, a S означает атом или молекулярный каркас. Такие библиотеки могут быть синтезированы в том числе с использованием способов по настоящему изобретению.
В другом аспекте настоящего изобретения предлагается способ идентификации соединения, которое связывается с биологической мишенью, при этом указанный способ включает следующие стадии: (1) контактирование биологической мишени с библиотекой соединений по настоящему изобретению, включающей соединения, которые содержат функциональный компонент, содержащий два или более фрагмента, и эффективно связанную с олигонуклеотидом, кодирующим структуру функционального компонента. Данную стадию проводят в условиях, пригодных для связывания по крайней мере одного члена библиотеки соединений с мишенью; (2) удаление членов библиотеки, которые не связаны с мишенью; (3) амплификация кодирующих олигонуклеотидов по меньшей мере одного члена библиотеки соединений, который связывается с мишенью; (4) секвенирование кодирующих олигонуклеотидов, описанных на стадии (3) и использование последовательностей, определенных на стадии (5), для идентификации структуры функциональных компонентов членов библиотеки соединений, которые связываются с биологической мишенью.
Настоящее изобретение демонстрирует несколько преимуществ идентификации молекул, обладающих требуемыми свойствами. Например, способы по настоящему изобретению обеспечивают использование ряда химических реакций для конструирования молекул в присутствии олигонуклеотидной метки. Способы по настоящему изобретению позволяют вводить с высокой точностью олигонуклеотидные метки в образующиеся таким образом химические структуры. Более того, указанные способы позволяют проводить синтез библиотек, содержащих множество копий каждого члена, что в свою очередь позволяет проводить множество циклов селекции в отношении биологической мишени и при этом остается достаточное число молекул, которые подвергаются конечному циклу амплификации и секвенирования олигонуклеотидной метки.
Краткое описание чертежей
На фиг.1 показана схема лигирования двухцепочечных нуклеотидов, причем исходный нуклеотид содержит выступающий участок, комплементарный выступающему участку нового олигонуклеотида. Исходная цепочка изображена в виде свободной, конъюгированной с аминогексильным линкером или конъюгированной с остатком фенилаланина через аминогексильный линкер.
На фиг.2 показана схема лигирования олигонкулеотидов с использованием фиксирующей цепочки. В данном варианте фиксирующей цепочкой является 12-членный олигонуклеотид с последовательностями, комплементарными одноцепочечному исходному олигонуклеотиду и одноцепочечному новому олигонуклеотиду.
На фиг.3 показана схема лигирования исходного и нового олигонуклеотидов, причем исходный олигонуклеотид содержит две ковалентно связанные цепочки, а новый олигонуклеотид является двухцепочечным.
На фиг.4 показана схема наращивания олигонуклеотидной цепочки с использованием полимеразы. Исходная цепочка изображена в виде свободной, конъюгированной с аминогексильным линкером или конъюгированной с остатком фенилаланина через аминогексильный линкер.
На фиг.5 показана схема синтетического цикла по одному из вариантов осуществления настоящего изобретения.
На фиг.6 показана схема многостадийного процесса идентификации с использованием библиотек по настоящему изобретению.
На фиг.7 показан результат гелевого электрофореза продуктов, полученных в каждом из циклов 1-5, описанных в примере 1, и последующего лигирования замыкающего праймера. Олигонуклеотиды со стандартной молекулярной массой указаны на дорожке 1, и указанные параметры гиперлэддера, для определения количества ДНК, показаны на дорожках 9-12.
На фиг.8 показана схема конденсации структурных фрагментов с использованием азид-алкин-циклоприсоединения.
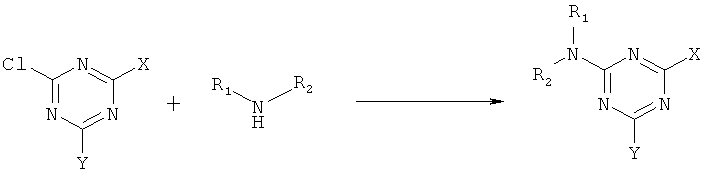
На фиг.9 и 10 показана конденсация структурных фрагментов с использованием нуклеофильного ароматического замещения хлорированного триазина.
На фиг.11 показаны хлорированные гетероароматические структуры, пригодные для синтеза функциональных компонентов.
На фиг.12 показана циклизация линейного пептида с использованием реакции азид-алкин-циклоприсоединения.
На фиг.13A показана хроматограмма библиотеки, полученной, как описано в примере 2, в результате цикла 4.
На фиг.13B показан масс-спектр библиотеки, полученной, как описано в примере 2, в результате цикла 4.
Осуществление изобретения
Настоящее изобретение относится к способам получения соединений комбинаторных библиотек соединений, к соединениям и библиотекам, которые получают с использованием способов по настоящему изобретению, и к способам использования библиотек для идентификации соединений, обладающих требуемыми свойствами, такими как требуемая биологическая активность. Настоящее изобретение относится также к соединениям, которые идентифицируют с использованием таких способов.
Для получения и анализа комбинаторных химических библиотек используют множество подходов. Примеры включают способы, в которых отдельные члены библиотеки физически отделены друг от друга, например, если синтез отдельного соединения проводят в одном из множества отдельных сосудов. Однако обычно в таких библиотеках анализируют единовременно только одно соединение или в лучшем случае несколько эффективным методом скриннинга. Согласно другим способам соединения синтезируют на твердой фазе. Такие твердые носители включают чипы, в которых специфичные соединения занимают особые участки чипа или мембраны ("адресуемое положение"). Согласно другим способам соединения синтезируют на гранулах, при этом каждая гранула несет отдельную химическую структуру.
При анализе больших библиотек возникают две проблемы: (1) множество отдельных соединений, которые подвергаются анализу и (2) идентификация соединений, проявляющих активность при данном методе анализа. Согласно одному способу соединения, проявляющие активность при данном методе анализа, идентифицируют разделением исходной библиотеки на меньшие фракции и подфракции, в каждом случае отбирая фракцию или подфракцию, содержащую активные соединения, и затем снова разделяют на фракции до получения активной подфракции, которая содержит набор соединений, который достаточно мал, чтобы все его компоненты можно было синтезировать каждый в отдельности и получить соединения с требуемой активностью. Такой способ является слишком трудоемким и длительным процессом.
Другой способ обратного анализа комбинаторной библиотеки заключается в использовании библиотек, в которых члены библиотеки содержат индивидуальные метки, т.е. каждая метка, присутствующая в библиотеке, связана с конкретной структурой соединения, присутствующего в библиотеке, таким образом, что идентификация метки определяет структуру меченой молекулы. Один из подходов получения меченых библиотек заключается в использовании олигонуклеотидных меток, как описано, например, в патентах США №№5573905, 5708153, 5723598, 6060596, в опубликованных заявках на выдачу патентов РСТ WO 93/06121, WO 93/20242, WO 94/13623, WO 00/23458, WO 02/074929 и WO 02/103008, а также в работах Brenner and Lenner (Proc. Natl. Acad. Sci. USA, 89, 5381-5383 (1992); Nielsen and Janda (Methods: A Companion to Methods in Enzymology, 6, 361-371 (1994) и Nielesen, Brenner and Janda (J. Amer. Chem. Soc., 115, 9812-9813 (1993)), каждая из которых полностью включена в настоящее описание в качестве ссылки. Такие метки амплифицируют с использованием, например, полимеразной цепной реакции для получения большого числа копий меченого фрагмента и идентификации его при секвенировании. Секвенирование меченого фрагмента позволяет идентифицировать структуру связывающей молекулы, которая может быть синтезирована в чистой форме и протестирована. К настоящему времени данные по использованию методологии, описанной в статье Lerner et al., для получения больших библиотек, отсутствуют. В настоящем изобретении предлагается усовершенствование способов получения ДНК-кодированных библиотек, а также первые примеры больших (105 членов и более) библиотек ДНК-кодированных молекул, в которых функциональный фрагмент получают с использованием синтеза в растворе.
В настоящем изобретении предлагаются способы простого синтеза комбинаторных библиотек, кодированных олигонуклеотидами, причем указанные способы позволяют с высокой точностью вводить олигонуклеотидную метку в каждый член многочисленного набора молекул.
Способы по настоящему изобретению включают способы синтеза бифункциональных молекул, которые включают первый компонент ("функциональный компонент"), которая состоит из структурных фрагментов, и второй компонент, эффективно связанный с первым компонентом, содержащим олигонуклеотидную метку, которая определяет структуру первого компонента, т.е. олигонуклеотидная метка указывает, какие структурные фрагменты были использованы при конструировании первого компонента, и в каком порядке они связаны. В основном, информации, содержащейся в олигонуклеодидной метке, оказывается достаточно для идентификации структурных фрагментов, использованных для конструирования активного компонента. В определенных вариантах последовательность олигонуклеотидной метки является достаточной для определения расположения структурных фрагментов в функциональном компоненте, например для пептидных групп достаточно аминокислотной последовательности.
Термин "функциональный компонент", использованный в данном контексте, означает химический компонент, содержащий один или более структурных фрагментов. Предпочтительно, структурные фрагменты в функциональных компонентах не означают нуклеиновые кислоты. Функциональным компонентом является линейный, разветвленный или циклический полимер или олигомер или низкомолекулярная органическая молекула.
Термин "структурный фрагмент", использованный в данном контексте, означает химическое структурное звено, которое соединено с другими химическими структурными звеньями или присоединено к другим таким звеньям. Если функциональный компонент является полимерным или олигомерным, то фрагменты являются мономерными звеньями полимера или олигомера. Структурные фрагменты включают также структуру-каркас ("каркасный структурный фрагмент"), к которому присоединена или может быть присоединена одна или более дополнительных структур ("периферические структурные фрагменты").
Следует понимать, что термин "структурный фрагмент", использованный в данном контексте, означает химическое структурное звено, которое входит в состав функционального компонента, а также находится в реакционноспособной форме, используемой для синтеза функционального компонента. Структурный фрагмент полностью включен в состав функционального компонента, и ни одна из частей структурного фрагмента не высвобождается при синтезе функционального компонента. Например, если в реакциях, идущих с образованием связи, высвобождается небольшая молекула (см. ниже), то в состав функционального компонента входит "остаток структурного фрагмента", т.е. остаток, который образуется в процессе синтеза при высвобождении из структурного фрагмента атомов, которые присоединяются к высвобожденной молекуле.
В качестве структурных фрагментов используют любые химические соединения, которые являются комплементарными, т.е. эти структурные фрагменты способны взаимодействовать друг с другом с образованием структуры, содержащей два или более таких фрагментов. Обычно все используемые фрагменты содержат по крайней мере 2 реакционноспособные группы, хотя некоторые фрагменты (например, последний структурный фрагмент олигомерного функционального компонента) могут содержать только по одной реакционноспособной группе. Реакционноспособные группы двух различных фрагментов должны быть комплементарными, т.е. способны взаимодействовать друг с другом с образованием ковалентной связи, необязательно с сопутствующим высвобождением небольшой молекулы, такой как вода, HCl, HF и т.п.
Согласно настоящему изобретению две реакционноспособных группы являются комплементарными, если они способны взаимодействовать с образованием ковалентной связи. В предпочтительном варианте реакции с образованием связи протекают быстро в условиях окружающей среды в основном без образования побочных продуктов. Предпочтительно одна реакционноспособная группа взаимодействует с другой комплементарной реакционноспособной группой только один раз. В одном варианте комплементарные реакционносособные группы двух структурных фрагментов взаимодействуют, например, по механизму нуклеофильного замещения с образованием ковалентной связи. В другом варианте один член пары комплементарных реакционноспособных групп является электрофильной группой, а другой член пары - нуклеофильной группой.
Комплементарные электрофильные и нуклеофильные группы включают любые две группы, которые взаимодействуют по механизму нуклеофильного замещения в пригодных условиях с образованием ковалентной связи. В данной области техники известно множество образующих связь реакций. См., например, March, Advanced Organic Chemistry, 4th ed., New York: John Wiley and Sons (1992), гл. 10-16; Carey and Sundberg, Advanced Organic Chemistry, Part B, Plenum (1990), гл. 1-11; Collman et al., Principles and Applications of Organotransition Metal Chemistry, University Science Books, Mill Valley, Calif. (1987), гл. 13-20, каждая из которых полностью включена в настоящее описание в виде ссылки. Примеры пригодных электрофильных групп включают реакционноспособные карбонильные группы, такие как хлорангидридные группы, сложноэфирные группы, включая карбонилпентафторфенильные эфирные группы и сукцинимидные эфирные группы, кето- и альдегидные группы, реакционноспособные сульфонильные группы, такие как сульфонилхлоридные группы и реакционноспособные фосфонильные группы. Другие электрофильные группы включают концевые эпоксидные группы, изоцианатные группы и галогеналкил группы. Пригодные нуклеофильные группы включают первичные и вторичные аминогруппы, гидроксильные группы и карбоксильные группы.
Пригодные комплементарные реакционноспособные группы перечислены ниже. Специалистам в данной области техники известны другие пары реакционноспособных групп, которые можно использовать в настоящем изобретении, а приведенные ниже примеры не ограничивают объем настоящего изобретения.
В первом варианте комплементарные реакционноспособные группы включают активированные карбоксильные группы, реакционоспособные сульфонильные группы или реакционноспособные фосфонильные группы, или комбинацию указанных выше групп, и первичные или вторичные аминогруппы. В данном варианте комплементарные реакционоспособные группы взаимодействуют в пригодных условиях с образованием амидной, сульфонамидной или фосфонамидатной связи.
Во втором варианте осуществления настоящего изобретения, комплементарные реакционноспособные группы включают эпоксидные группы и первичные или вторичные аминогруппы. Эпоксидсодержащий структурный фрагмент взаимодействует с аминосодержащим фрагментом в пригодных условиях с образованием связи углерод-азот, т.е. с образованием β-аминоспирта.
В другом варианте комплементарные реакционноспособные группы включают азиридиновые группы и первичные или вторичные аминогруппы. В пригодных условиях азиридинсодержащий структурный фрагмент взаимодействует с аминосодержащим фрагментом с образованием связи углерод-азот, т.е. с образованием 1,2-диамина.
В третьем варианте комплементарные реакционноспособные группы включают изоцианатные группы и первичные или вторичные аминогруппы. Изоцианатсодержащий структурный фрагмент взаимодействует с аминосодержащим фрагментом в пригодных условиях с образованием связи углерод-азот, т.е. с образованием остатка мочевины.
В четвертом варианте комплементарные реакционноспособные группы включают изоцианатные группы и гидроксильные группы. Изоцианатсодержащий структурный фрагмент взаимодействует с гидроксилсодержащим фрагментом в пригодных условиях с образованием связи углерод-кислород, т.е. с образованием карбаматной группы.
В пятом варианте комплементарные реакционноспособные группы включают аминогруппы и карбонилсодержащие группы, такие как альдегиды или кетогруппы. Амины взаимодействуют с такими группами по реакции восстановительного аминирования с образованием новой связи углерод-азот.
В шестом варианте комплементарные реакционноспособные группы включают фосфор-илидные группы и альдегиды или кетогруппы. Фосфор-илидсодержащий структурный фрагмент взаимодействует с альдегид- или кетосодержащим фрагментом в пригодных условиях с образованием углерод-углеродной двойной связи, т.е. с образованием алкена.
В седьмом варианте комплементарные реакционноспособные группы взаимодействуют по механизму циклоприсоединения с образованием циклической структуры. Один пример таких комплементарных реакционноспособных групп включает алкины и органические азиды, которые в пригодных условиях взаимодействуют с образованием триазольной кольцевой структуры. Пример использования такой реакции для связывания двух фрагментов показан на фиг.8. Пригодные условия для проведения таких реакций известны в данной области техники и включают условия, описанные в заявке WO 03/101972, содержание которой полностью включено в настоящее описание в качестве ссылки.
В восьмом варианте комплементарные реакционноспособные группы включают алкилгалогениды и нуклеофилы, такие как аминогруппа, гидроксигруппа или карбоксильная группа. Такие группы взаимодействуют в пригодных условиях с образованием связи углерод-азот (акилгалогенид + амин) или связи углерод-кислородной (алкилгалогенид + гидроксильная или карбоксильная группа).
В девятом варианте комплементарные реакционноспособные группы включают галогенированную гетероароматическую группу и нуклеофил, и фрагменты связываются в пригодных условиях по реакции ароматического нуклеофильного замещения. Пригодные галогенированные гетероароматические группы включают хлорированные пиримидины, триазины и пурины, которые взаимодействуют с нуклеофилами, такими как амины, в мягких условиях в водном растворе. Примеры реакции олигонуклеотидов, содержащих трихлортриазиновые группы с аминами, показаны на фиг.9 и 10. Примеры пригодных хлорированных гетероароматических групп показаны на фиг.11.
Дополнительные реакции образования связи, которые могут использоваться для соединения структурных фрагментов для получения молекул и библиотек настоящего изобретения, показаны ниже. Эти реакции выделяют реакционноспособные функциональные группы. В реагентах могут присутствовать разнообразные функциональные группы, включая такие, которые обозначены как R1, R2, R3 и R4. Эти заместители могут включать любой подходящий химический фрагмент, но предпочтительно ограничены такими, которые не участвуют или не ингибируют в заметной степени указанные реакции, и, если не указано инначе, могут включать водород, алкил, замещенный алкил, арил, замещенный арил, гетероарил, замещенный гетероарил, алкокси, арилокси, арилалкил, замещенный арилалкил, аминогруппу, замещенную аминогруппу и другие известные из уровня техники заместители. Подходящие заместители у таких групп включают алкил, арил, гетероарил, циано, галоген, гидроксил, нитро, амино, меркапто, карбоксил и карбоксамид. Где указано, подходящие электроноакцепторные группы включают нитро, карбоксил, галогеналкил, такие как трифторметил и другие известные из уровня техники. Примеры подходящих электронодонорных групп включают алкил, алкокси, гидроксил, амино, галоген, ацетамидо и другие известные из уровня техники.
Присоединение первичного амина к алкену:

Нуклеофильное замещение:

Восстановительное алкилирование амина:
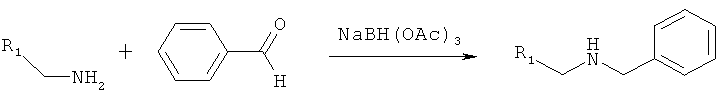

Реакции образования углерод-углеродной связи, катализируемые палладием:

Реакция конденсации Уги:
Реакции электрофильного ароматического замещения:
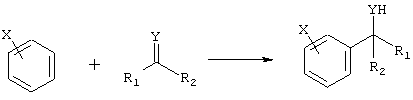
Х представляет собой электронодонорную группу.
Реакции образования имина/иминия/енамина:
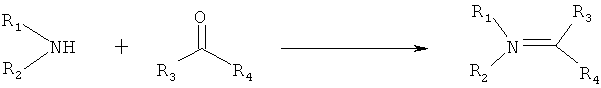

Реакции циклоприсоединения:
Циклоприсоединение Дильса-Альдера:
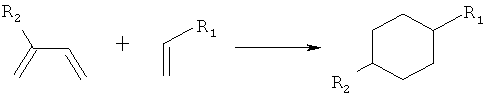
1,3-диполярное циклоприсоединение, X-Y-Z=C-N-O, C-N-S, N3,
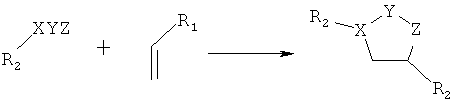
Реакции нуклеофильного ароматического замещения:
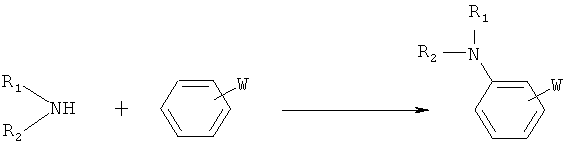
W представляет собой электроноакцепторную группу
Примеры подходящих заместителей Х и Y включают замещенные или незамещенные амино, замещенные или незамещенные алкокси, замещенные или незамещенные тиоалкокси, замещенные или незамещенные арилокси и замещенные или незамещенные тиоарилоксигруппы.
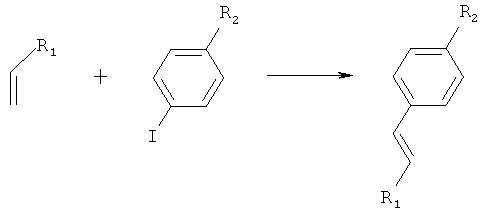
Реакция Хека:
Образование ацеталя:
Примеры подходящих заместителей Х и Y включают замещенные или незамещенные аминогруппу, гидроксил или сульфгидрил; Y является линкером, соединяющим Х и Y и подходит для образования циклической структуры, обнаруживаемой в продукте данной реакции.
Альдольные реакции:

Примеры подходящих заместителей Х включают О, S и NR3.
Каркасные структурные фрагменты, которые могут использоваться для образования молекул и библиотек настоящего изобретения, включают такие, которые имеют две или более функциональных групп, которые могут принимать участие в реакциях образования связи с предшественниками периферических структурных фрагментов, например, с использованием одной или более реакций образования связи, рассмотренных выше. Каркасные фрагменты также могут синтезироваться во время конструирования библиотек и молекул по настоящему изобретению, например, с использованием исходных реагентов для строительных блоков, которые могут реагировать особым образом с образованием молекул, содержащих центральный молекулярный фрагмент, к которому присоединены периферические функциональные группы. В одном варианте осуществления библиотека настоящего изобретения включает молекулы, содержащие константный каркасный фрагмент, но различные периферические фрагменты или различные окружения периферических фрагментов. В определенных библиотеках все члены библиотеки содержат константный каркасный фрагмент; другие библиотеки могут содержать молекулы, имеющие два или более различных каркасных фрагмента. Примеры реаций образования каркасного фрагмента, которые могут использоваться при конструировании молекул и билиотек настоящего изобретения, приведены в Таблице 8. Ссылки, указанные в таблице, приведены в данном контексте во всей своей полноте. Группы R1, R2, R3 и R4 ограничены только тем, что они не должны мешать или значительно ингибировать указанные реакции, и могут быть выбраны из группы, включающей водород, алкил, замещенный алкил, гетероалкил, замещенный гетероалкил, циклоалкил, гетероциклоалкил, замещенный циклоалкил, замещенный гетероциклоалкил, арил, замещенный арил, арилалкил, гетероарилалкил, замещенный арилалкил, замещенный гетероарилалкил, гетероарил, замещенный гетероарил, галоген, алкокси, арилокси, аминогруппа, замещенная аминогруппа и другие известные современной науке. Подходящие заместители включают, но не огранчиваются только ими, алкил, алкокси, тиоалкокси, нитро, гидроксил, сульфгидрил, арилокси, арил-S-, галоген, карбокси, амино, алкиламино, диалкиламино, ариламино, циано, цианат, нитрил, изоцианат, тиоцианат, карбамил и замещенный карбамил.
Следует понимать, что синтез функционального фрагмента можно проводить с использованием одного конкретного типа реакций конденсации, таких как, без ограничения перечисленным, одна из описанных выше реакций, или с использованием комбинации двух или более реакций конденсации, например, двух или более описанных выше реакций. Например, в одном варианте, структурные фрагменты соединеняют путем сочетания образования амидной связи (комплементарные амино- и карбоксильные группы) и восстановительного аминирования (комплементарные амино- и альдегидные или кетогруппы). Можно использовать любые реакции конденсации при условии, что они совместимы с присутствием олигонуклеотида. Двухцепочечные (дуплексные) олигонуклеотидные метки, использованные в определенных вариантах осуществления настоящего изобретения, являются химически более стабильными по сравнению с одноцепочечными метками, и, следовательно, устойчивы в более широком интервале условий реакции и участвуют в реакциях с образованием связи, что невозможно с использованием одноцепочечных меток.
Структурный фрагмент кроме реакционноспособной группы или групп, образующих функциональный компонент, может включать одну или более функциональных групп. Одну или более из таких дополнительных функциональных групп защищают для предотвращения их вступления в нежелательные реакции. Пригодные защитные группы известны в данной области техники для множества функциональных групп (см. книгу Greene and Wuts, Protective Groups in Organic Synthesys, second edition, New York: John Wiley and Sons (1991), включенную в данный контекст в качестве ссылки). Прежде всего используемые защитные группы включают трет-бутиловые простые и сложные эфиры, ацетали, тритильные эфиры и амины, ацетиловые эфиры, триметилсилиловые эфиры, трихлорэтиловые простые и сложные эфиры и карбаматы.
В одном варианте каждый структурный фрагмент включает две реакционноспособные группы, которые могут быть одинаковыми или отличаться друг от друга. Например, каждый структурный фрагмент, добавляемый в цикле s, может включать две одинаковые реакционноспособные группы, но при этом обе группы являются комплементарными с реакционноспособными группами структурных фрагментов, добавляемых на стадиях s-1 и s+1. В другом варианте каждый структурный фрагмент включает две реакционноспособные группы, которые комплементарны друг с другом. Например, библиотеку, содержащую полиамидные молекулы, получают по реакциям между структурными фрагментами, содержащими две первичные аминогруппы, и фрагментами, содержащими две активированные карбоксильные группы. В полученных соединениях отсутствуют N- или С-концевые фрагменты, т.к. альтернативные амидные группы имеют противоположное направление. В другом варианте полиамидную библиотеку получают с использованием структурных фрагментов, каждый из которых включает аминогруппу и активированную карбоксильную группу. В таком варианте структурные фрагменты, добавляемые на стадии n-го цикла, содержат свободную реакционноспособную группу, которая комплементарна с доступной реакционноспособной группой в составе фрагмента n-1, в то время как предпочтительно другая реакционноспособная группа в составе структурного фрагмента n защищена. Например, если члены библиотеки синтезируют в направлении от С-концевого участка к N-концевому участку, то добавляемые структурные фрагменты содержат активированную карбоксильную группу и защищенную аминогруппу.
Функциональные компоненты являются полимерными или олигомерными компонентами, такими как пептиды, пептидомиметики, пептидонуклеиновые кислоты или пептоиды, или они являются низкомолекулярными соединениями, например молекулами со структурой, включающей центральный каркас, и структурами, расположенными по периферии каркаса. Линейные полимерные или олигомерные библиотеки получают с использованием структурных фрагментов с двумя реакционноспособными группами, в то время как разветвленные полимерные или олигомерные библиотеки получают с использованием структурных фрагментов с тремя или более реакционноспособными группами, необязательно в комбинации с фрагментами, содержащими только две реакционноспособные группы. Такие молекулы можно представить общей формулой X1X2…Xn, где каждый Х означает мономерное звено полимера, включающего n мономерных звеньев, где n равно целому числу более 1. В случае олигомерных или полимерных соединений нет необходимости в наличии двух функциональных групп на концевых фрагментах. Например, в случае полиамидной библиотеки С-концевой фрагмент содержит аминогруппу, а присутствие карбоксильной группы необязательно. Аналогичным образом N-концевой фрагмент содержит карбоксильную группу, но не содержит аминогруппу.
Разветвленные олигомерные или полимерные соединения синтезируют также при условии, что по крайней мере один структурный фрагмент включает три функциональные группы, которые взаимодействуют с другими структурными фрагментами. Библиотека по настоящему изобретению включает линейные молекулы, разветвленные молекулы или их комбинацию.
Библиотеки получают также с использованием, например, каркасных фрагментов с одной или двумя реакционноспособными группами, в комбинации с другими структурными фрагментами, содержащими только одну доступную реакционноспособную группу, например, в которых любые другие реакционноспособные группы защищены или нереакционноспособны в отношении других реакционноспособных групп в составе каркасного фрагмента. В одном варианте, например, полученные молекулы могут быть представлены общей формулой X(Y)n, где Х означает каркасный структурный фрагмент, каждый Y означает структурный фрагмент, связанный с X, а n равно целому числу, равному по крайней мере 2, и предпочтительно от 2 до приблизительно 6. В одном предпочтительном варианте исходный фрагмент в цикле 1 означает каркасный фрагмент. В молекулах формулы X(Y)n каждый Y является одинаковым или различным, но в большинстве членов типичной библиотеки каждый Y является различным.
В одном варианте библиотеки по настоящему изобретению содержат полиамидные соединения. Полиамидные соединения состоят из структурных фрагментов, содержащих любые аминокислоты, включая 20 природных α-аминокислот, таких как аланин (Ala, А), глицин (Gly, G), аспарагин (Asn, N), аспартамовая кислота (Asp, D), глутаминовая кислота (Glu, E), гистидин (His, Н), лейцин (Leu, L), лизин (Lys, K), фенилаланин (Phe, F), тирозин (Tyr, Y), треонин (Thr, Т), серин (Ser, S), аргинин (Arg, R), валин (Val, V), глутамин (Gln, Q), изолейцин (Ilе, I), цистеин (Cys, С), метионин (Met, M), пролин (Pro, P) и триптофан (Trp, W), в скобках приведены трехбуквенный и однобуквенный коды обозначения аминокислот. В природной форме все из описанных аминокислот существуют в L-конфигурации, если не указано иное. Однако в настоящем изобретении можно использовать D-конфигурацию указанных аминокислот. Такие D-аминокислоты обозначены в настоящем описании в трех- и однобуквенном коде прописными буквами: ala (a), gly (g), leu (l), gln (g), thr (t), ser (s) и т.п. Фрагменты могут содержать другие α-аминокислоты, включая, без ограничения перечисленным, 3-арилаланины, такие как нафтилаланин, фенилзамещенные фенилаланины, включая 4-фтор-, 4-хлор-, 4-бром- и 4-метилфенилаланин, 3-гетероарилаланины, такие как 3-пиридилаланин, 3-тиенилаланин, 3-хинолилаланин и 3-имидазолилаланин; орнитин, цитрулин, гомоцитрулин, саркозин, гомопролин, гомоцистеин; замещенные пролины, такие как гидроксипролин и фторпролин; дегидропролин, норлейцин, O-метилтирозин, O-метилсерин, O-метилтреонин и 3-циклогексилаланин. Каждую из перечисленных выше аминокислот используют в D- или L-конфигурации.
Фрагменты могут включать также аминокислоты, не являющиеся α-аминокислотами, такие как α-азаминокислоты, β, γ, δ, ∈-аминокислоты, и N-замещенные аминокислоты, такие как N-замещенный глицин, в котором заместитель у атома азота означает, например, замещенный или незамещенный алкил, арил, гетероарил, арилалкил или гетероарилалкил. В одном варианте, заместитель у атома азота означает боковую цепь природных или не природных α-аминокислот.
Структурный фрагмент может также представлять собой структуру пептидомиметика, такого как дипептидный, трипептидный, тетрапептидный или пентапептидный миметик. Такие пептидомиметиковые структурные фрагменты предпочтительно включают производные аминоацильных соединений, например, полученных при добавлении таких структурных фрагментов к наращиваемой поли(аминоацильной) группе по одной и той же или аналогичной реакции, использованной для получения других структурных фрагментов. В качестве структурных фрагментов можно использовать также молекулы, которые образуют связи, изостеричные пептидной связи, с образованием функциональных компонентов пептидомиметиков, включающих модифицированную пептидную цепь, такую как ψ[CH2S], ψ[CH2NH], ψ[CSNH2], ψ[NHCO], ψ[COCH2] и ψ[(Е) или (Z) СН=СН]. В использованной выше номенклатуре ψ означает отсутствие амидной связи. Структура, заменяющая амидную группу, расположена в скобках.
В одном варианте настоящего изобретения предлагается способ синтеза соединения, содержащего или представляющего собой функциональный компонент, который эффективно присоединен к кодирующему олигонуклеотиду. Способ включает следующие стадии: (1) получение соединения-инициатора, состоящего из исходного функционального компонента, содержащего n структурных фрагментов (где n равно целому числу 1 или более), по крайней мере одну реакционноспособную группу, и эффективно связанного с исходным олигонуклеотидом, который кодирует n структурных фрагментов; (2) взаимодействие соединения-инициатора со структурным фрагментом, содержащим по крайней мере одну комплементарную реакционноспособную группу, являющуюся комплементарной с реакционноспособной группой, полученной на стадии (1), в условиях, пригодных для взаимодействия реакционноспособной группы и комплементарной реакционноспособной группы с образованием ковалентной связи; (3) взаимодействие исходного олигонуклеотида с новым олигонуклеотидом в присутствии фермента, который катализирует лигирование исходного олигонуклеотида и нового олигонуклеотида в пригодных для этого условиях, с получением молекулы, содержащей или представляющей собой функциональный компонент, содержащий n+1 структурных фрагментов и эффективно связанный с кодирующим олигонуклеотидом. Если функциональный компонент, полученный на стадии (3), включает реакционноспособную группу, то стадии 1-3 при необходимости повторяют один или более раз, при этом проводят циклы 1-i (i равно целому числу 2 или более), с участием продукта, полученного на стадии (3) в цикле s-1 (где s равно целому числу i или менее), с образованием соединения-инициатора, описанного на стадии (1) в цикле s. В каждом цикле к наращиваемому функциональному компоненту добавляют один структурный фрагмент, а к наращиваемому кодирующему олигонуклеотиду добавляют одну олигонуклеотидную последовательность, которая кодирует новый структурный фрагмент.
В одном варианте осуществления исходное соединение-инициатор(ы) образуется в реакции первого структурного фрагмента с олигонуклеотидом (например, олигонуклеотидом, который включает последовательность PCR праймера или исходный олигонуклеотид) или с линкером, к которому присоединен такой олигонуклеотид. В варианте осуществления, предложенном на фиг.5, линкер содержит реакционноспособную группу для присоединения первого структурного фрагмента и присоединен к исходному олигонуклеотиду. В этом варианте осуществления реакция структурного фрагмента, или в каждой из множества аликвот, одного из коллекции структурных блоков, с реакционноспособной группой линкера и присоединение олигонуклеотида, кодирующего структурный фрагмент к исходному олигонуклеотиду дает одно или более исходных соединений-инициаторов процесса, описанного выше.
В предпочтительном варианте каждый конкретный структурный фрагмент связан с отдельным олигонуклеотидом таким образом, что последовательность нуклеотидов в составе олигонуклеотида, добавленного в данном цикле, идентифицирует функциональный компонент, добавленный в том же цикле.
Конденсация структурных фрагментов и лигирование олигонуклеотидов обычно происходят при одинаковых концентрациях исходных веществ и реагентов. Например, для эффективного связывания структурных фрагментов предпочтительными являются концентрации порядка от микромолярной или миллимолярной, например, от приблизительно 10 мкм до приблизительно 10 Мм.
В некоторых вариантах способ также включает стадию, которая включает удаление всех непрореагировавших исходных функциональных компонентов после проведения стадии (2). Удаление всех непрореагировавших исходных функциональных компонентов в конкретном цикле позволяет исключить взаимодействие исходного функционального компонента в цикле со структурными фрагментами, добавленными в следующем цикле. Такие реакции могут привести к образованию функциональных компонентов, не содержащих один или более структурных фрагментов, и к возможности образования нескольких структур функционального компонента, соответствующих конкретной последовательности олигонуклеотида. Такое удаление проводят при взаимодействии любого остаточного функционального компонента с соединением, которое взаимодействует с реакционноспособной группой, описанной на стадии (2). Предпочтительно соединение, используемое для удаления, быстро взаимодействует с реакционноспособной группой, описанной на стадии (2) и не содержит дополнительных реакционноспособных групп, которые могут взаимодействовать со структурными фрагментами, добавляемыми в следующих циклах. Например, при синтезе соединения, в котором реакционноспособной группой на стадии (2) является аминогруппа, пригодным соединением для удаления является сложный эфир N-гидроксисукцинимида, такой как N-гидроксисукцинимидный эфир уксусной кислоты.
В другом варианте осуществления настоящего изобретения предлагается способ получения библиотек соединений, в которых каждое соединение содержит функциональный компонент, содержащий два или более структурных фрагментов, и который эффективно присоединен к олигонуклеотиду. В предпочтительном варианте олигонуклеотид присутствует в каждой молекуле и позволяет определить структурные фрагменты в составе молекулы и, необязательно, порядок добавления этих фрагментов. В данном варианте, способ по настоящему изобретению включает способ синтеза библиотеки соединений, в которой соединения содержат функциональный компонент, содержащий два или более структурных фрагмента и который эффективно связан с олигонуклеотидом, который определяет структуру функционального компонента. Способ включает следующие стадии: (1) получение раствора, содержащего m соединений-инициаторов (где m равно целому числу 1 или более), состоящих из функционального компонента, содержащего n фрагментов (где n равно целому числу 1 или более), который эффективно связан с исходным олигонуклеотидом, определяющим n структурных компонентов; (2) разделение раствора, полученного на стадии (1), по крайней мере на r фракций (где r равно целому числу 2 или более); (3) взаимодействие каждой фракции с одним из r структурных фрагментов с образованием r фракций, содержащих соединения, состоящие из функционального компонента, содержащего n+1 структурных фрагментов и эффективно связанного с исходным олигонуклеотидом; (4) взаимодействие каждой из r фракций, полученных на стадии (3), с одним из набора r новых различных олигонуклеотидов в условиях, пригодных для ферментативного лигирования нового и исходного олигонуклеотидов, при этом получают r фракций, содержащих молекулы, состоящие из функционального компонента, содержащего n+1 структурных фрагментов и эффективно связанного с удлиненным олигонуклеотидом, который кодирует n+1 структурных фрагментов. Способ необязательно включает стадию (5) объединения r фракций, полученных на стадии (4), при этом получают раствор, содержащий молекулы, состоящие из функционального компонента, содержащего n+1 структурных фрагментов и эффективно связанного с удлиненным олигонуклеотидом, который кодирует n+1 структурных фрагментов. Стадии (1)-(5) повторяют один или более раз, при этом проводят циклы 1-i (где i равно целому числу 2 или более). В цикле s+1, где s равно целому числу i-1 или менее, раствор, содержащий m соединений-инициаторов, полученных на стадии (1), является раствором, полученным на стадии (5) в цикле s. Аналогичным образом соединения-инициаторы, полученные на стадии (1) в цикле s+1, являются продуктами, полученными на стадии (4) в цикле s.
Раствор, полученный на стадии (2), предпочтительно разделяют на r фракций в каждом цикле синтеза библиотеки. В данном варианте, каждая фракция взаимодействует с отдельным структурным фрагментом.
Согласно способу по настоящему изобретению порядок добавления структурных фрагментов и новых олигонуклеотидов не имеет значения, при этом стадии (2) и (3) синтеза молекулы, и стадии (3) и (4) синтеза библиотеки можно проводить в обратном порядке, т.е. новый олигонуклеотид можно лигировать с исходным олигонуклеотидом перед добавлением нового структурного фрагмента. В некоторых вариантах эти две стадии можно проводить одновременно.
В некоторых вариантах способ также включает стадию удаления всех непрореагировавших исходных функциональных компонентов после проведения стадии (2). Удаление всех непрореагировавших исходных функциональных компонентов в каждом цикле позволяет исключить взаимодействие исходного функционального компонента в цикле со структурными фрагментами, добавленными в следующем цикле. Такие реакции могут привести к образованию функциональных компонентов, не содержащих один или более структурных фрагментов, и к возможности образования нескольких структур функционального компонента, которые соответствуют конкретной последовательности олигонуклеотида. Такое удаление проводят при взаимодействии любого остаточного функционального компонента с соединением, которое взаимодействуете реакционноспособной группой, описанной на стадии (2). Предпочтительно соединение, используемое для удаления, быстро взаимодействует с реакционноспособной группой, описанной на стадии (2) и не содержит дополнительных реакционноспособных групп, которые могут взаимодействовать со структурными фрагментами, добавляемыми в следующих циклах. Например, при синтезе соединения, в котором реакционноспособной группой на стадии (2) является аминогруппа, пригодным соединением для удаления является сложный эфир N-гидроксисукцинимида, такой как N-гидроксисукцинимидный эфир уксусной кислоты.
В одном варианте фрагменты, используемые при синтезе библиотеки, выбирают из набора возможных, оценивая способность возможных фрагментов взаимодействовать с соответствующими комплементарными функциональными группами в условиях, используемых для синтеза библиотеки. Фрагменты, которые оказались реакционноспособными в таких условиях, отбирают для включения в библиотеку. Продукты каждого отдельного цикла необязательно очищают. Если цикл является промежуточным циклом, т.е. любым циклом, предшествующим конечному циклу, то продукты, полученные в таких циклах, являются промежуточными соединениями и их очищают перед началом следующего цикла. Если цикл является конечным, то полученные продукты являются конечными продуктами и их очищают перед использованием соединений. На такой стадии очистки, например, удаляют непрореагировавшие реагенты или их избыток, а также фермент, использованный для лигирования олигонуклеотида. Используют любые способы, которые пригодны для отделения продуктов от других соединений, присутствующих в растворе, включая жидкостную хроматографию, такую как высокоэффективную жидкостную хроматографию (ВЭЖХ), и осаждение пригодным сорастворителем, таким как этанол. Выбор пригодных способов очистки зависит от природы продуктов и системы растворителей, используемой для синтеза.
Реакции предпочтительно проводят в водном растворе, таком как буферный водный раствор, но также могут быть проведены в смешанной водно-органической среде, совместимой с растворимостью структурных фрагментов, олигонуклеотидов, промежуточных и конечных продуктов, а также фермента, использованного для катализа лигирования олигонуклеотида.
Следует понимать, что теоретическое число соединений, полученных в данном цикле согласно способу по настоящему изобретению, равно произведению числа различных соединений-инициаторов, m, использованных в данном цикле, на число отдельных фрагментов r, добавленных в цикле. Реальное число отдельных соединений, полученных в цикле, может быть больше произведения r на m (r×m), но может быть и меньше с учетом различий в реакционной способности некоторых структурных фрагментов с некоторыми другими фрагментами. Например, кинетика присоединения определенного структурного фрагмента к определенному соединению-инициатору определяет выход продукта в ходе данного цикла синтеза и в зависимости от указанной кинетики выход продукта составляет незначительную величину или продукт совсем не образуется.
В одном варианте стандартный структурный фрагмент добавляют перед началом цикла 1, после завершения последнего цикла или между двумя любыми циклами. Например, если функциональным фрагментом является полиамид, то стандартный структурный фрагмент с защищенной N-концевой группой добавляют после завершения последнего цикла. Стандартный фрагмент вводят между любыми двумя циклами, например, для включения функциональной группы, такой как алкиновая или азидная группа, которую можно использовать для модификации функциональных компонентов, например, путем циклизации после завершения синтеза библиотеки.
Термин "эффективно связанный", использованный в данном контексте, означает, что две химические структуры связаны вместе таким образом, что связь между ними устойчива в различных условиях, в которых предполагается обрабатывать данную структуру. Обычно функциональный компонент и кодирующий олигонуклеотид связаны ковалентно через соответствующую связующую (мостиковую) группу. Связующая группа означает двухвалентный остаток, содержащий связь для присоединения олигонуклеотида и связь для присоединения функционального компонента. Например, если функциональным компонентом является полиамидное соединение, то полиамид присоединен к связующему звену по N-концевому атому, С-концевому атому или через функциональную группу в одной из боковых цепей. Длина связующей группы, достаточной, чтобы разделить полиамидное соединение и олигонуклеотид, составляет по крайней мере один атом, и предпочтительно, более одного атома, например, по крайней мере два, по крайней мере три, по крайней мере четыре, по крайней мере пять или по крайней мере шесть атомов. Предпочтительно связующая группа является достаточно гибкой для обеспечения связывания полиамидного соединения с молекулами-мишенями независимо от олигонуклеотида.
В одном варианте связующая группа присоединена к N-концевому атому полиамидного соединения и к 5'-фосфатной группе олигонуклеотида. Например, связующую группу можно получить из соответствующего предшественника, содержащего активированную карбоксильную группу на одном концевом участке и активированную сложноэфирную группу на другом концевом участке. Реакция предшественника связующей группы с N-концевым атомом азота приводит к образованию амидной связи, соединяющей связующую группу с полиамидным соединением или N-концевым фрагментом, в то время как реакция предшественника связующей группы с 5'-гидроксильной группой олигонуклеотида приводит к присоединению олигонуклеотида к связующей группе через сложноэфирную связь. Связующая группа включает, например, полиметиленовую цепь, такую как -(СН2)n-, или поли(этиленгликолевую) цепь, такую как -(CH2CH2O)n, где в обоих случаях n равно целому числу от 1 до приблизительно 20. Предпочтительно n равно от 2 до приблизительно 12, более предпочтительно от приблизительно 4 до приблизительно 10. В одном варианте связующая группа включает гексаметиленовую группу (-(CH2)6-).
Если фрагменты означают аминокислотные остатки, то конечный функциональный фрагмент означает полиамид. Аминокислоты конденсируют с использованием любых пригодных методик с образованием амидных связей. Предпочтительно конденсацию аминокислотных фрагментов проводят в условиях, совместимых с ферментативным лигированием олигонуклеотидов, например, при нейтральных или близких к нейтральным pH и в водном растворе. В одном варианте полиамидное соединение синтезируют в направлении от С-концевого атома к N-концевому. В данном варианте первый или С-концевой фрагмент конденсируют по карбоксильной группе с олигонуклеотидом через пригодную связующую группу. Первый функциональный компонент взаимодействует со вторым функциональным компонентом, который предпочтительно содержит активированную карбоксильную группу и защищенную аминогруппу. Используют любые методики активирования/введения защитных групп, пригодные для образования амидной связи в растворе. Например, пригодные активированные карбоксильные соединения включают ацилфториды (патент США №5360928, полностью включенный в данное описание в качестве ссылки), симметричные ангидриды и N-гидроксисукцинимидные сложные эфиры. Ацильные группы также активируют in situ, как известно в данной области техники, по реакции с пригодным активирующим соединением. Пригодные активирующие соединения включают дициклогексилкарбодиимид (DCC), диизопропилкарбодиимид (DIC), 1-этоксикарбонил-2-этокси-1,2-дигидрохинолин (EEDQ), гидрохлорид 1-этил-3-(3-диметиламинопропил)-карбодиимида (EDC), ангидрид н-пропанфосфоновой кислоты (РРА), N,N-бис(2-оксо-3-оксазолидинил)имидофосфорилхлорид (BOP-Cl), гексафторфосфат бром-трис-пирролидинофосфония (PyBrop), дифенилфосфорилазид (DPPA), реагент Кастро (ВОР, PyBOP), соли O-бензотриазолил-N,N,N',N'-тетраметилурония (HBTU), диэтилфосфорилцианид (DEPCN), диоксид 2,5-дифенил-2,3-дигидро-3-оксо-4-гидрокситиофена (HOTDO, реагент Стеглиха), 1,1'-карбонилдиимидазол (CDI) и хлорид 4-(4,6-диметокси-1,3,5-триазин-2-ил)-4-метилморфолиния (DMT-MM). Кондесирующие агенты используют в отдельности или в комбинации с добавками, такими как N,N-диметил-4-аминопиридин (DMAP), N-гидроксибензотриазол (HOBt), N-гидроксибензотриазин (HOOBt), N-гидроксисукцинимид (HOSu), N-гидроксиазабензотриазол (HOAt), соли азабензотриазолилтетраметилурония (HATU, HAPyU) или 2-гидроксипиридин. В некоторых вариантах для синтеза библиотек необходимо использование двух или более методик активации, что необходимо для использования отличающихся в структурном отношении наборов фрагментов. Для каждого фрагмента специалист в данной области техники может определить соответствующую методику активации.
В качестве N-концевой защитной группы используют любые защитные группы, совместимые с условиями проведения процесса, а также защитные группы, пригодные в условиях синтеза в растворе. Предпочтительной защитной группой является флуоренилметоксикарбонильная ("Fmoc") группа. Необходимо также вводить защитные группы во все потенциально реакционноспособные функциональные группы в боковой цепи аминоацильного структурного фрагмента. Предпочтительно защитная группа боковой цепи расположена ортогонально к N-концевой защитной группе, и, таким образом, защитную группу боковой цепи удаляют в условиях, отличающихся от условий, необходимых для удаления N-концевой защитной группы. Пригодные защитные группы боковой цепи включают нитровератрильную группу, которую можно использовать как для защиты карбоксильных групп в составе боковой цепи, так и аминогрупп в составе боковой цепи. Другие пригодные защитные группы аминогрупп в боковой цепи включают N-пент-4-еноильную группу.
Структурные компоненты можно модифицировать после введения их в функциональный компонент, например, путем пригодной реакции, вводящей функциональную группу в один или более структурных фрагментов. Модификация структурных фрагментов может быть проведена после присоединения конечного структурного фрагмента или на любой промежуточной стадии синтеза функционального компонента, например, после любого цикла синтеза. После синтеза библиотеки бифункциональных молекул по настоящему изобретению модификацию структурных фрагментов проводят в составе всей библиотеки или в части библиотеки, при этом возрастает степень сложности библиотеки. Пригодные реакции модификации структурных фрагментов включают такие реакции, которые можно проводить в условиях, совместимых с функциональным компонентом и кодирующим олигонуклеотидом. Примеры таких реакций включают ацилирование и сульфирование аминогрупп или гидроксильных групп, алкилирование аминогрупп, этерификацию или тиоэтерификацию карбоксильных групп, амидирование карбоксильных групп, эпоксидирование алкенов и другие реакции, известные в данной области техники. Если функциональный фрагмент включает фрагмент, содержащий алкиновую или азидную функциональную группу, то реакцию циклоприсоединения азида/алкина используют для модификации структурного фрагмента. Например, структурный фрагмент, включающий алкин, взаимодействует с органическим азидом, или функциональный блок, включающий азид, взаимодействует с алкином, при этом в любом случае образуется триазол. Реакции модификации структурных фрагментов проводят после присоединения конечного фрагмента или на любой промежуточной стадии синтеза и используют для включения в функциональный компонент большого числа химических структур, включая углеводы, металлсвязывающие компоненты и структуры, специфичные к определенным биомишеням или тканям.
В одном варианте функциональный компонент содержит линейную серию структурных фрагментов, которую подвергают циклизации с использованием пригодной реакции. Например, если по крайней мере 2 структурных фрагмента в линейном наборе включают сульфгидрильные группы, то сульфгидрильные группы окисляют с образованием дисульфидной связи, при этом происходит циклизация линейной серии структурных фрагментов. Например, функциональными компонентами являются олигопептиды, которые включают два или более остатков L- или D-цистеина и/или L- или D-гомоцистеина. Структурные фрагменты могут также включать и другие функциональные группы, способные взаимодействовать друг с другом, такие как карбоксильные группы и амино или гидроксильные группы; при этом происходит циклизация линейной серии.
В предпочтительном варианте один из структурных фрагментов в линейном наборе включает алкиновую группу, а другой структурный фрагмент в линейном наборе включает азидную группу. Азидная и алкиновая группа могут взаимодействовать по механизму циклоприсоединения с образованием макроциклической структуры. Как показано на фиг.9, функциональным компонентом является полипептид, содержащий пропаргилглициновый фрагмент в С-концевом участке и азидоацетильную группу в N-концевом участке. Реакция алкиновой и азидной групп в пригодных условиях приводит к образованию циклического соединения, которое включает триазольную структуру в составе макроцикла. В одном варианте каждый член библиотеки включает алкин- и азидсодержащие структурные фрагменты, и, следовательно, их можно циклизовать. Во втором варианте все члены библиотеки включают алкин- и азидсодержащие фрагменты, но только часть библиотеки циклизуется. В третьем варианте только некоторые функциональные компоненты включают алкин- и азидсодержащие фрагменты, и только такие молекулы циклизуются. В описанных выше втором и третьем вариантах, после реакции циклоприсоединения библиотека будет включать как циклические, так и линейные функциональные компоненты.
В некоторых вариантах осуществления настоящего изобретения, в которых одинаковый функциональный фрагмент, например триазин, добавляется к каждой и ко всем фракциям библиотеки во время определенной стадии синтеза, может не являться необходимым добавление олигонуклеотидной метки, кодирующей этот функциональный фрагмент.
Олигонуклеотиды могут сшиваться химическими и ферментативными методами. В одном варианте осуществления, олигонуклеотиды сшиваются химическим образом. Химическое лигирование ДНК и РНК может проводиться с использованием таких реагентов как водорастворимый карбодиимид и цианогенбромид, как показано, например, в Shabarova et al. (1991) Nucleic Acids Research, 19, 4247-4251), Federova, et al. (1996) Nucleosides and Nucleotides, 15, 1137-1147, и Carriero and Damha (2003) Journal of Organic Chemistry, 68, 8328-8338. В одном варианте осуществления химическое лигирование производится с использованием цианогенбромида, 5 М в ацетонитриле, при объемном соотношении 1:10 с 5' фосфорилированным олигонуклеотидом в pH 7,6 буфере (1 М MES + 20 мМ MgCl2) при 0 градусов в течение 1-5 минут. В другом варианте осуществления олигонуклеотиды сшивают с использованием ферментативных методов. В любом варианте осуществления олигонуклеотиды могут быть двуцепочечными, предпочтительно со свисающим концом от примерно 5 до примерно 14 оснований. Олигонуклеотиды могут также быть одноцепочечными, в этом случае участок с перекрыванием в примерно 6 оснований с каждым из сшиваемых олигонуклеотидов используется для позиционирования 5' и 3' фрагментов в непосредственной близости друг к другу.
В одном варианте осуществления, исходный структурный фрагмент эффективно связан с исходным олигонуклеотидом. До или после связывания второго структурного фрагмента с исходным структурным фрагментом вторая олигонуклеотидная последовательность, которая идентифицирует второй структурный фрагмент, сшивается с исходным олигонуклеотидом. Способы сшивания исходной олигонуклеотидной последовательности со входящей олигонуклеотидной последовательностью, показаны на фигурах 1 и 2. На фигуре 1 исходный олигонуклеотид двухцепочечный, и одна цепочка включает свисающую последовательность, которая комплементарна одному из концов второго олигонуклеотида и приводит второй олигонуклеотид в контакт с исходным олигонуклеотидом. Предпочтительно свисающая последовательность исходного олигонуклеотида и комплементарная последовательность второго олигонуклеотида каждые имеют длину по меньшей мере в 4 основания; более предпочтительно обе последовательности имеют одинаковую длину. Исходный олигонуклеотид и входящий олигонуклеотид могут сшиваться с использованием соответствующего фермента. Если исходный олигонуклеотид связан с первым структурным фрагментом по 5'-концу одной из цепочек ("верхняя цепь"), тогда цепь, комплементарная верхней цепи ("нижняя цепь") будет включать свисающую последовательность на 5'-конце, и второй олигонуклеотид будет иметь комплементарную последовательность на своем 5'-конце. После сшивания со вторым олигонуклеотидом, может добавляться цепь, которая комплементарна последовательности второго олигонуклеотида, которая является 3' по отношению к свисающей комплементарной последовательности и которая включает дополнительную свисающую последовательность.
В одном варианте, олигонуклеотид наращивают, как показано на фиг.2. Олигонуклеотид, связанный с наращиваемым функциональным фрагментом, и новый олигонуклеотид предназначены для лигирования с использованием фиксирующей последовательности, которая включает участок, комплементарный 3'-концевому участку в исходном олигонуклеотиде, и участок, комплементарный 5'-концевому участку в новом олигонуклеотиде. Фиксирующая цепь способствует сближению 5'-концевого участка олигонуклеотида с 3'-концевым участком в новом олигонуклеотиде, и лигирование проводят с использованием ферментов. На примере, показанном на фиг.2, исходный олигонуклеотид состоит из 16 оснований, а фиксирующая цепь является комплементарной 6 основаниям, расположенным в 3'-концевом участке. Новый олигонуклеотид включает 12 оснований, а фиксирующая цепь является комплементарной 6 основаниям в 5'-концевом участке. Длина фиксирующей цепи и длина комплементарных участков не являются определяющими. Однако, комплементарные участки должны быть достаточно длинными для образования устойчивого димера в условиях лигирования, и одновременно достаточно короткими, чтобы исключить образование конечных молекул, содержащих слишком длинный кодирующий нуклеотид. Предпочтительно длина комплементарных участков составляет от приблизительно 4 оснований до приблизительно 12 оснований, более предпочтительно от приблизительно 5 оснований до приблизительно 10 оснований и наиболее предпочтительно от приблизительно 5 оснований до приблизительно 8 оснований.
Способы разделения/объединения, используемые в предложенных в данном тексте способах для получения библиотеки, гарантируют, что каждый уникальный функциональный фрагмент эффективно связан с по меньшей мере одной олигонуклеотидной последовательностью, которая идентифицирует функциональный фрагмент. Если 2 или более различных олигонуклеотидных меток используются для по меньшей мере одного структурного фрагмента в по меньшей мере одном из синтетических циклов, каждый различный функциональный фрагмент, содержащий данный структурный фрагмент, будет закодирован несколькими олигонуклеотидами. Например, если 2 олигонуклеотидные метки используются для каждого структурного фрагмента во время синтеза 4-циклической библиотеки, получится 16 ДНК последовательностей (24), которые кодируют каждый уникальный функциональный фрагмент. Есть несколько потенциальных преимуществ кодирования каждого уникального функционального фрагмента несколькими последовательностями. Во-первых, выбор нескольких различных комбинаций последовательностей метки, кодирующих один и тот же функциональный фрагмент, гарантирует, что такие молекулы были выбраны независимо. Во-вторых, выбор различных комбинаций последовательностей метки, кодирующих один и тот же функциональный фрагмент, исключает вероятность того, что выбор был основан на последовательности олигонуклеотида. В-третьих, можно распознать технический артефакт, если анализ последовательности предполагает, что определенный функциональный фрагмент высоко обогащен, но проявляется только одна последовательная комбинация из множества возможных. Многократное мечение может достигаться посредством независимых разделенных реакций с одним и тем же структурным фрагментом, но различными олигонуклеотидными метками. Альтернативно многократное мечение может достигаться смешиванием соответствующих количеств каждой метки в единой реакции мечения с индивидуальным структурным фрагментом.
В одном варианте исходный олигонуклеотид является двухцепочечным и две цепи соединены ковалентной связью. Один из способов ковалентного связывания двух цепей показан на фиг.3, причем для связывания двух цепей и функционального компонента используют связующую группу. В качестве связующей группы используют любую химическую структуру, которая включает первую функциональную группу, способную взаимодействовать со структурным фрагментом, вторую функциональную группу, способную взаимодействовать с 3'-концевым участком олигонуклеотида, и третью функциональную группу, способную взаимодействовать с 5'-концевым участком олигонуклеотида. Предпочтительно вторая и третья функциональные группы расположены таким образом, чтобы две олигонуклеотидные цепи находились в относительной ориентации, обеспечивающей гибридизацию двух цепей. Например, связующая группа характеризуется общей структурой (I):
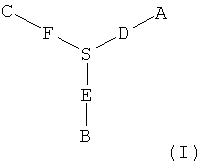
где А означает функциональную группу, которая образует ковалентную связь со структурным фрагментом, В означает функциональную группу, которая образует связь с 5'-концевым участком олигонуклеотида, а С означает функциональную группу, которая образует связь с 3'-концевым участком олигонуклеотида. D, F и Е означают химические группы, которые связывают функциональные группы А, С и В с атомом S, который является центральным атомом или атомами каркаса. Предпочтительно D, Е и F каждый независимо означает цепь, такую как алкиленовая цепь или олиго(этиленгликольная) цепь, и D, Е и F могут быть одинаковыми или различными, и предпочтительно их наличие обеспечивает гибридизацию двух олигонуклеотидов и синтез функционального фрагмента. В одном варианте, трехвалентная связующая группа характеризуется структурой
В этом варианте группа NH доступна для присоединения к структурному фрагменту, в то время как концевые фосфатные группы доступны для присоединения к олигонуклеотиду.
В вариантах, в которых исходных нуклеотид является двухцепочечным, новый олигонуклеотид также является двухцепочечным. Как показано на фиг.3, одна цепь исходного нуклеотида может быть длиннее другой, и таким образом включает дополнительную последовательность. В таком варианте новый олигонуклеотид включает дополнительную последовательность, которая является комплементарной с дополнительной последовательностью исходного олигонуклеотида. Гибридизация двух комплементарных дополнительных последовательностей обеспечивает расположение нового олигонуклеотида, пригодное для лигирования с исходным олигонуклеотидом. Такое лигирование проводят ферментативным методом в присутствии ДНК- или РНК-лигаз. Дополнительная последовательность нового олигонуклеотида и исходного нуклеотида предпочтительно характеризуются одинаковой длиной и состоят из 2 или более нуклеотидов, предпочтительно от 2 до приблизительно 10 нуклеотидов, более предпочтительно от 2 до приблизительно 6 нуклеотидов. В одном предпочтительном варианте новый олигонуклеотид является двухцепочечным, содержащим дополнительную последовательность в каждом концевом участке. Дополнительная последовательность в одном концевом участке является комплементарной дополнительной последовательности исходного олигонуклеотида, в то время как после лигирования нового и исходного олигонуклеотидов, дополнительная последовательность в другом концевом участке превращается в дополнительную последовательность исходного олигонуклеотида в следующем цикле. В одном варианте три дополнительные последовательности все содержат от 2 до 6 нуклеотидов, а кодирующая последовательность нового олигонуклеотида содержит от 3 до 10 нуклеотидов, предпочтительно от 3 до 6 нуклеотидов. В предпочтительном варианте все дополнительные последовательности содержат по 2 нуклеотида, а кодирующие последовательности содержат 5 нуклеотидов.
В варианте, показанном на фиг.4, новая цепь содержит участок в 3'-концевом фрагменте, который является комплементарным с 3'-концевым участком исходного олигонуклеотида, при этом в обеих цепях содержатся дополнительные последовательности в 5'-концевых участках. 5'-концевые последовательности могут быть заполнены путем использования, например, ДНК-полимеразы, такой как vent-полимераза, при этом образуется двухцепочечный олигонуклеотид. Нижнюю цепь такого олигонуклеотида удаляют, а еще одну дополнительную последовательность присоединяют к 3'-концевому участку верхней цепи с использованием аналогичного способа.
Кодирующую олигонуклеотидную метку получают в результате последующего присоединения олигонуклеотидов, которые определяют каждый последующий компонент. В одном варианте способа по настоящему изобретению последующие олигонуклеотидные метки конденсируют методом ферментативного лигирования с образованием кодирующего олигонуклеотида.
Катализируемое ферментом лигирование олигонуклеотидов проводят с использованием любого фермента, который обеспечивает лигирование структурных фрагментов нуклеиновых кислот. Примеры ферментов включают лигазы, полимеразы и топоизомеразы. В предпочтительном варианте осуществления настоящего изобретения для лигирования олигонуклеотидов используют ДНК лигазу (ЕС 6.5.1.1), ДНК полимеразу (ЕС 2.7.7.7), РНК полимеразу (ЕС 2.7.7.6) или топоизомеразу (ЕС 5.99.1.2). Описание ферментов каждого класса ЕС приведено в статье Bairoch, Nucleic Acids Research, 28, 304-4 (2000).
В предпочтительном варианте используемые олигонуклеотиды по настоящему изобретению являются олигодезоксинуклеотидами, а в качестве ферментов для катализа лигирования олигонуклеотидов используют ДНК-лигазу. Чтобы лигирование происходило в присутствии лигазы, т.е. чтобы образовалась фосфодиэфирная связь между двумя олигонуклеотидами, один олигонуклеотид должен содержать свободную 5'-фосфатную группу, и другой олигонуклеотид должен содержать свободную 3'-гидроксильную группу. Примеры ДНК-лигаз по настоящему изобретению включают Т4 ДНК-лигазу, Taq ДНК-лигазу, Т4 РНК-лигазу, ДНК-лигазу (E.coli) (все лигазы выпускаются, например, фирмой New England Biolabs, MA).
Специалистам в данной области техники известно, что каждый фермент для лигирования, характеризуется оптимальной активностью в особых условиях, например при определенных температуре, концентрации буферного раствора, рН и за определенный период времени. С целью обеспечения оптимального лигирования олигонуклеотидных меток все перечисленные выше условия можно изменять, например, согласно инструкциям фирмы-производителя.
Длина нового олигонуклеотида может быть любой, однако предпочтительно она составляет по крайней мере 3 нуклеотида. Более предпочтительно новый олигонуклеотид включает 4 или более нуклеотидов. В одном варианте новый олигонуклеотид включает от 3 до приблизительно 12 нуклеотидов. Олигонуклеотиды в составе молекул в библиотеке по настоящему изобретению предпочтительно включают общую концевую последовательность, которую можно использовать в качестве праймера для ПЦР, как известно в данной области техники. Такую общую концевую последовательность можно включать в виде концевой последовательности в новом олигонуклеотиде, который присоединяют в конечном цикле синтеза библиотеки, или ее включают после завершения синтеза библиотеки, например, с использованием методов ферментативного лигирования. описанных в данном контексте.
Предпочтительный вариант способа по настоящему изобретению показан на фиг.5. Процесс начинают с использования синтетической последовательности ДНК, которая присоединена через 5'-концевой участок к связующей группе, которая содержит концевую аминогруппу. На стадии 1 такую исходную последовательность ДНК лигируют с новой последовательностью ДНК в присутствии фиксирующей цепи ДНК, ДНК-лигазы и дитиотреита в Трис-буферном растворе. При этом получают меченую последовательность ДНК, которую затем непосредственно используют на следующей стадии без дополнительной очистки или очищают перед следующей стадией, например, с использованием ВЭЖХ или осаждения этанолом. На стадии 2 меченая ДНК взаимодействует с защищенной активированной аминокислотой, в данном примере, с фторидом Fmoc-защищенной аминокислоты, при этом получают конъюгат защищенной аминокислоты и ДНК. На стадии 3, в полученном конъюгате аминокислоты и ДНК удаляют защитную группу, например, в присутствии пиперидина, и полученный конъюгат с удаленной защитной группой необязательно очищают, например, ВЭЖХ или осаждением этанолом. Конъюгат с удаленной защитной группой является продуктом первого цикла синтеза, который превращается в исходный материал во втором цикле, в котором присоединеняют второй аминокислотный остаток к свободной аминогруппе конъюгата с удаленной защитной группой.
В вариантах осуществления, в которых ПЦР используют для амплификации и/или установления последовательности кодирующих олигонуклеотидов отдельных молекул, кодирующие олигонуклеотиды могут включать, например, последовательности праймера для ПЦР (например, такие праймеры как 3'-GACTACCGCGCTCCCTCCG-5' и 3'-GACTCGCCCGACCGTTCCG-5'). Последовательность праймера для ПЦР может быть включена, например, в исходный олигонуклеотид до первого синтетического цикла, и/или она может включаться с первым новым олигонуклеотидом, и/или он может сшиваться с кодирующим олигонуклеотидом после заключительного цикла синтеза библиотеки, и/или она может быть включена в состав нового олигонуклеотида в заключительном цикле. Последовательности праймера для ПЦР, присоединяемые после заключительного цикла синтеза библиотеки и/или в составе нового олигонуклеотида в заключительном цикле, обозначаются в данном описании как "закрывающие последовательности".
В одном варианте осуществления последовательность праймера ПЦР включена в состав кодирующей олигонуклеотидной метки. Например, последовательность праймера для ПЦР может быть включена в состав исходной олигонуклеотидной метки и/или она может быть включена в состав целевой олигонуклеотидной метки. В одном варианте осуществления одинаковые последовательности праймера для ПЦР включаются в исходную и целевую олигонуклеотидную метку. В другом варианте осуществления первая последовательность праймера для ПЦР включена в исходную олигонуклеотидную метку, а вторая последовательность праймера для ПЦР включена в целевую олигонуклеотидную метку. Альтернативно вторая последовательность праймера для ПЦР может включаться в состав закрывающей последовательности, как описано в данном контексте. В предпочтительных вариантах осуществления последовательность праймера для ПЦР имеет длину по меньшей мере приблизительно 5, 7, 10, 13, 15, 17, 20, 22 или 25 нуклеотидов.
Пригодные для использования в библиотеках настоящего изобретения последовательности праймера для ПЦР известны из уровня техники; подходящие праймеры и способы предложены, например, в Innis, et al., eds., PCR Protocols: A Guide to Methods and Applications, San Diego: Academic Press (1990), содержание которого включено сюда в виде ссылки во всей своей полноте. Другие подходящие праймеры для использования в построении описанных в данном тексте библиотек это праймеры, описанные в публикациях РСТ WO 2004/069849 и WO 2005/003375, содержание которых включено сюда в виде ссылки во всей своей полноте.
Термин "полинуклеотид", использованный в данном контексте по отношению к праймерам, зондам и фрагментам или сегментам нуклеиновых кислот, которые синтезируются путем наращивания праймера, означает молекулу, включающую два или более дезоксирибонуклеотидов, предпочтительно более трех.
Термин "праймер", использованный в данном контексте, означает полинуклеотид, полученный путем очистки рестрикционного гидролизата нуклеиновой кислоты или путем синтеза, который действует в качестве точки инициации синтеза нуклеиновой кислоты в условиях, в которых индуцируется синтез продукта наращивания праймера, комплементарного цепи нуклеиновой кислоты, т.е. в присутствии нуклеотидов и агента полимеризации, такого как ДНК-полимераза, обратная транскриптаза и т.п., при пригодной температуре и величине pH. Для достижения максимальной эффективности праймер предпочтительно является одноцепочечным, однако в другом варианте является двухцепочечным. В случае двухцепочечного праймера его перед использованием для получения продуктов наращивания сначала обрабатывают для отделения от комплементарной цепи. Предпочтительно праймер предпочтительно является полидезоксирибонуклеотидом. Праймер может быть достаточно длинным, чтобы обеспечивать запуск синтеза продуктов наращивания в присутствии агентов полимеризации. Точная длина праймеров зависит от многих факторов, включая температуру и источник праймера.
Праймеры, используемые в способе по настоящему изобретению, должны быть в "значительной" степени комплементарными другим цепям каждой специфической последовательности, предназначенной для амплификации. Это означает, что праймер должен быть в значительной степени комплементарным, чтобы обеспечивать точную гибридизацию только с соответствующей цепью матрицы. Следовательно, последовательность праймера может отражать или не отражать точную последовательность матрицы.
Полинуклеотидные праймеры получают с использованием любого пригодного способа, такого как, например, фосфотриэфирный или фосфодиэфирный способы, описанные в статье Narang et al., Meth. Enzymol., 68:90 (1979), патентах США №№4356270, 4458066, 4416988 и 4293652, а также в статье Brown et al., Meth. Enzymol., 68:109 (1979). Содержание всех указанных документов полностью включено в объем настоящего изобретения в качестве ссылок.
В случаях, когда последовательности праймера ПЦР включены в состав нового олигонуклеотида, эти новые олигонуклеотиды будут предпочтительно заметно длиннее, чем новые олигонуклеотиды, добавляемые в других циклах, потому что они будут включать как кодирующую последовательность, так и последовательность праймера ПЦР.
В одном варианте осуществления закрывающая последовательность добавляется после присоединения последнего структурного фрагмента и последнего нового олигонуклеотида, и синтез библиотеки, как предложено в данном тексте, включает стадию лигирования закрывающей последовательности с кодирующим олигонуклеотидом, так чтобы олигонуклеотидная часть практически всех членов библиотеки завершалась последовательностью, которая включает последовательность праймера ПЦР. Предпочтительно закрывающая последовательность добавляется путем лигирования с объединенными фракциями, которые являются продуктами заключительного цикла синтеза. Закрывающая последовательность может добавляться посредством ферментативного процесса, используемого в построении библиотеки.
В одном варианте осуществления одинаковая закрывающая последовательность пришивается к каждому члену библиотеки. В другом варианте осуществления используются разнообразные закрывающие последовательности. В этом варианте осуществления олигонуклеотидные закрывающие последовательности, содержащие различные основания, например, пришиваются к членам библиотеки после заключительного цикла синтеза. В одном варианте осуществления после заключительного цикла синтеза фракции объединяются и затем снова разделяются на фракции, при этом к каждой фракции добавляется различная закрывающая последовательность. Альтернативно многочисленные закрывающие последовательности могут добавляться к объединенной библиотеке после заключительного цикла синтеза. В обоих вариантах осуществления члены полученной библиотеки будут включать молекулы, содержащие специфичные функциональные фрагменты, соединенные с идентифицирующими олигонуклеотидами, включающими две или более различные закрывающие последовательности.
В одном варианте осуществления закрывающий праймер включает олигонуклеотидную последовательность, содержащую различные, то есть вырожденные, нуклеотиды. Такие вырожденные основания в составе закрывающих праймеров позволяют идентифицировать интересующие молекулы библиотеки путем определения, является ли комбинация структурных фрагментов следствием ПЦР дупликации (идентичная последовательность) или независимых появлений молекулы (различная последовательность). Например, такие вырожденные основания могут уменьшать потенциальное количество ложноположительных случаев, идентифицированных при биологическом скрининге кодированной библиотеки.
В одном варианте осуществления вырожденный закрывающий праймер содержит или имеет следующую последовательность:
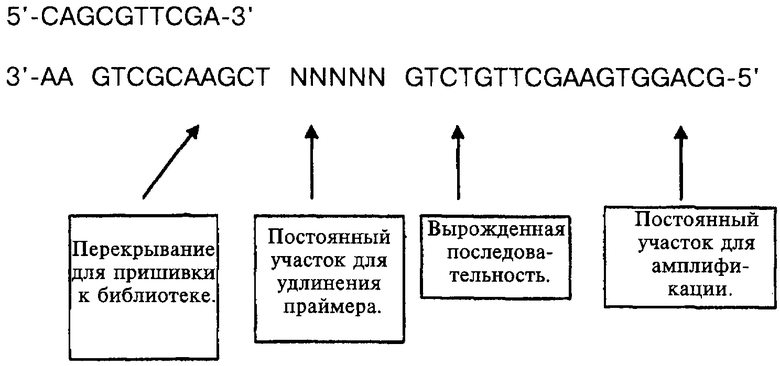
где N может быть любым из 4 оснований, допуская 1024 различных последовательностей (45). Праймер имеет следующую последовательность после его сшивания с библиотекой и удлинения праймера:
5'-CAGCGTTCGA N'N'N'N'N'CAGACAAGCTTCACCTGC-3'
3'-АА GTCGCAAGCT N N N N N GTCTGTTCGAAGTGGACG-5'
В другом варианте осуществления закрывающий праймер содержит или имеет следующую последовательность:
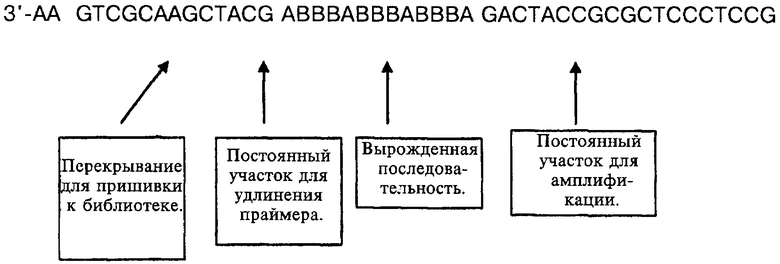
где В может быть любым из С, G или Т, допуская 19,683 различных последовательностей (39). Дизайн вырожденного участка в праймере улучшает анализ последовательности ДНК, так как основание А, которое располагается сбоку и прерывает вырожденные основания В, предотвращает гомополимерные напряжения более чем в 3 основания; и облегчает проверку последовательности.
В одном варианте осуществления вырожденный закрывающий олигонуклеотид лигируется с членами библиотеки с использованием подходящего фермента, и верхняя цепочка вырожденного закрывающего олигонуклеотида впоследствии полимеризуется с помощью подходящего фермента, такого как ДНК-полимераза.
В другом варианте осуществления последовательность праймера ПЦР является "универсальным адаптером" или "универсальным праймером". При использовании в данном контексте, "универсальный адаптер" или "универсальный праймер" представляет собой олигонуклеотид, который содержит уникальный участок праймера ПЦР, т.е., например, приблизительно 5, 7, 10, 13, 15, 17, 20, 22 или 25 нуклеотидов в длину, и расположен рядом с уникальным участком последовательности праймера, который, например, имеет приблизительно 5, 7, 10, 13, 15, 17, 20, 22 или 25 нуклеотидов в длину, и необязательно за ним располагается уникальная дискриминационная ключевая последовательность (или последовательность идентификатора образца), состоящая из по меньшей мере одного из каждых из четырех дезоксирибонуклеотидов (то есть А, С, G, Т).
В данном контексте термин "дискриминационная ключевая последовательность" или "последовательность идентификатора образца" относится к последовательности, которая может использоваться для уникальной метки группы молекул образца. Множество образцов, каждый содержащий уникальную последовательность идентификатора образца, можно смешать, установить последовательность и пересортировать после установления последовательности ДНК для анализа индивидуальных образцов. Одна и та же дискриминационная последовательность может использоваться для целой библиотеки или, альтернативно, могут быть использованы различные дискриминационные ключевые последовательности для отслеживания различных библиотек. В одном варианте осуществления дискриминационная ключевая последовательность находится либо на 5'-праймере ПЦР, 3'-праймере ПЦР или на обоих праймерах. Если оба праймера ПЦР содержат последовательность идентификатора образца, число различных образцов, которые могут быть объединены с уникальными последовательностями идентификатора образца, является произведением числа последовательностей идентификатора образца на каждом праймере. Так, 10 различных 5'-последовательностей идентификатора образца праймеров можно скомбинировать с 10 различными 3'-последовательностями идентификатора образца праймеров с получением 100 различных комбинаций последовательностей идентификатора образца.
Нелимитирующие примеры 5'- и 3'- уникальных праймеров ПЦР, содержащих дискриминационные ключевые последовательности, включают следующие:


В одном варианте осуществления дискриминационная ключевая последовательность имеет приблизительно 4, 5, 6, 7, 8, 9 или 10 нуклеотидов в длину. В другом варианте осуществления дискриминационная ключевая последовательность является комбинацией приблизительно 1-4 нуклеотидов. В другом варианте осуществления каждый универсальный адаптор имеет длину приблизительно в сорок четыре нуклеотида. В одном варианте осуществления адаптеры лигированы с концом кодирующего олигонуклеотида с использованием Т4 ДНК-лигазы. Различные универсальные адаптеры могут создаваться специально для каждого синтеза библиотеки и будут поэтому предоставлять уникальный идентификатор для каждой библиотеки. Размер и последовательность универсальных адапторов могут модифицироваться в случае необходимости, по желанию квалифицированного в данной области специалиста.
Как указано выше, нуклеотидную последовательность меченого олигонуклеотида как часть способа по настоящему изобретению можно определять с использованием полимеразной цепной реакции (ПЦР).
Меченый олигонуклеотид включает полинуклеотиды, которые определяют фрагменты, входящие в состав функционального фрагмента, как описано выше. Последовательность нуклеиновой кислоты меченого олигонуклеотида определяют с помощью реакции ПЦР олигонуклеотидной метки следующим образом. Соответствующий образец смешивают с парой праймеров ПЦР, причем каждый член пары характеризуется предварительно выбранной последовательностью нуклеотидов. Пара праймеров ПЦР инициирует реакцию наращивания цепи праймера при гибридизации с участком связывания праймера в кодирующем меченом олигонуклеотиде. Участок связывания праймера ПЦР предпочтительно включен в кодирующий меченый олигонуклеотид. Например, участок связывания праймера ПЦР включен в исходный меченый олигонуклеотид, а участок связывания второго праймера ПЦР включен в конечный меченый олигонуклеотид. В другом варианте участок связывания второго праймера ПЦР включен в заключительную последовательность, как описано в данном контексте. В предпочтительных вариантах участок связывания праймера ПЦР составляет по крайней мере приблизительно 5, 7, 10, 13, 15, 17, 20, 22 или 25 нуклеотидов.
Реакцию ПЦР проводят при смешении пары праймеров ПЦР, предпочтительно в предварительно определенном количестве, с нуклеиновыми кислотами кодирующего олигонуклеотида, предпочтительно в предварительно определенном количестве, в буферном растворе ПЦР с образованием реакционной смеси ПЦР. Смесь помещают в термический циклизатор и проводят ряд циклов, число которых обычно предварительно определяют, при этом образуется продукт реакции ПЦР. Количество продукта должно быть достаточным, чтобы выделить его в достаточном количестве для определения последовательности ДНК.
ПЦР обычно проводят в термическом циклизаторе, т.е. при повторном увеличении и снижении температуры реакционной смеси ПЦР в пределах температурного интервала, нижняя граница которого составляет от приблизительно 30°С до приблизительно 55°С, а верхняя граница составляет от приблизительно 90°С до приблизительно 100°С. Повышение и снижение температуры можно проводить в непрерывном режиме, но предпочтительно циклы проводят через определенные периоды времени при определенной температуре, при которой обеспечиваются оптимальные условия синтеза полинуклеотидов, денатурации и гибридизации.
Реакцию ПЦР проводят с использованием любого пригодного способа. В основном ее проводят в буферном водном растворе, т.е. в буферном растворе ПЦР, предпочтительно при pH от 7 до 9, предпочтительно в присутствии молярного избытка праймера. Значительный молярный избыток праймера необходим для повышения эффективности процесса.
Буферный раствор ПЦР содержит также термостабильные трифосфаты дезоксирибонуклеотидов (субстраты синтеза полинуклеотидов) dАТФ, dЦТФ, dГТФ и dТТФ и полимеразу, все компоненты в соответствующих количествах, пригодных для реакции наращивания цепи праймера (синтез полинуклеотидов). Полученный раствор (смесь для ПЦР) нагревают при приблизительно 90-100°С в течение от приблизительно от 1 до 10 мин, предпочтительно в течение от 1 до 4 мин. После нагревания раствор охлаждают до 54°С, которая является предпочтительной для гибридизации праймера. Реакцию синтеза проводят при температуре от комнатной температуры до температуры, выше которой снижается эффективность действия полимеразы (индуцирующего агента). Таким образом, например, если используют ДНК-полимеразу, то температура обычно не превышает приблизительно 40°С. Циклы в термическом циклизаторе повторяют до образования требуемого количества продукта ПЦР. Пример буферного раствора ПЦР включает следующие реагенты: 50 Мм KCl, 10 Мм трис-HCl, pH 8,3, 1,5 Мм MgCl2, 0,001 мас./об.% желатины, 20 мкм dАТФ, 200 мкм dТТФ, 200 мкм dЦТФ, 200 мкм dГТФ и 2,5 ед. полимеразы ДНК I (Thermus aquaticus (Taq)) на 100 мкл буферного раствора.
Пригодные ферменты для наращивания последовательностей праймеров включают, например, ДНК полимеразу I E.coli, ДНК полимеразу Taq, фрагмент Кленова ДНК полимеразы I E.coli, T4 ДНК-полимеразу, другие доступные ДНК-полимеразы, обратную транскриптазу и другие ферменты, включая термоустойчивые ферменты, которые способствуют расположению нуклеотидов соответствующим образом с образованием продуктов наращивания цепи праймеров, комплементарных каждой цепи нуклеиновой кислоты. В основном, синтез инициируют в 3'-концевом участке каждого праймера и наращивание цепи происходит в 5'-направлении вдоль цепи матрицы до завершения синтеза с образованием молекул различной длины.
Синтезированная цепь ДНК и комплементарная ей цепь образуют двухцепочечную молекулу, которую используют на следующих стадиях анализа.
Способы амплификации ПЦР подробно описаны в патентах США с номерами 4683192, 4683202, 4800159 и 4965188, а также в книгах PCR Technology: Principles and Applications for DNA Amplifications, H. Erich, ed., Stockton Press, New York (1989) и Innis et al., eds., PCR Protocols: A Guide to Methods and Applications, Academic Press, San Diego, Calif. (1990). Содержание всех документов полностью включено в настоящее описание в качестве ссылок. После амплификации кодирующего меченого олигонуклеотида его последовательность и однозначный состав выбранной молекулы определяют с использованием анализа последовательностей нуклеиновых кислот, известной методики секвенирования последовательностей нуклеотидов. Анализ последовательностей нуклеиновых кислот проводят при комбинации (а) физико-химических методов, основанных на гибридизации или денатурации цепи зонда плюс цепи комплементарной ему мишени, и (б) ферментативных реакций с участием полимеразы.
Настоящее изобретение относится также к соединениям, которые получают согласно способам по настоящему изобретению, и к наборам таких соединений, как в виде отдельных соединений, так и в виде объединения соединений, которые образуют библиотеку химических структур. Соединения по настоящему изобретению включают соединения формулы
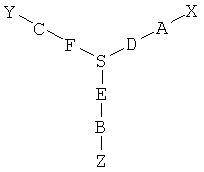
где X означает функциональный компонент, содержащий один или более структурных фрагментов; Z означает олигонуклеотид, присоединенный по 3'-концевому участку к В, a Y означает олигонуклеотид, который присоединен по 5'-концевому участку к С. А означает функциональную группу, образующую ковалентную связь с X; В означает функциональную группу, образующую 3'-связь с Z, а С означает функциональную группу, образующую 5'-связь с Y. D, F и Е означают химические группы, которые связывают функциональные группы А, С и В с S, который означает атом или молекулярный каркас. Предпочтительно D, Е и F каждый независимо означает цепь атомов, таких как алкиленовая цепь или олиго(этиленгликольная) цепь. D, Е и F могут быть одинаковыми или различными, и предпочтительно их наличие обеспечивает гибридизацию двух олигонуклеотидов и синтез функционального фрагмента.
Предпочтительно Y и Z в значительной степени являются комплементарными друг к другу и расположены в соединении таким образом, чтобы способствовать образованию пар Уотсона-Крика и образованию дуплекса в пригодных условиях. Длина Y и Z является одинаковой или различной. Предпочтительно длина Y и Z является одинаковой, или один из Y и Z длиннее другого на 1-10 оснований. В предпочтительном варианте длина каждого Y и Z составляет 10 или более оснований, и эти фрагменты содержат комплементарные участки, включающие от 10 и более оснований. Более предпочтительно Y и Z в значительной степени комплементарны друг другу на протяжении всей длины, т.е. они содержат не более одного ошибочного несовпадения оснований на каждые 10 пар оснований. Более предпочтительно Y и Z комплементарны на протяжении всей длины, т.е. за исключением дополнительного участка в Y или Z, цепи гибридизуются с образованием пар Уотсона-Крика и не содержат ошибочных несовпадений на протяжении всей длины.
S означает отдельный атом или молекулярный каркас. Например, S означает атом углерода, атом бора, атом азота или атом фосфора, или многоатомный каркас, такой как фосфатная группа или циклическая группа, такая как циклоалкил, циклоалкенил, гетероциклоалкил, гетероциклоалкенил, арил или гетероарил. В одном варианте связующая группа означает группу
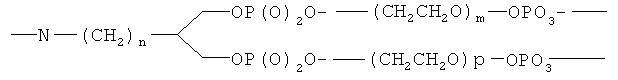 ,
,
где каждый n, m и p независимо равен целому числу от 1 до приблизительно 20, предпочтительно от 2 до 8 и более предпочтительно от 3 до 6. В другом варианте связующая группа означает группу структуры
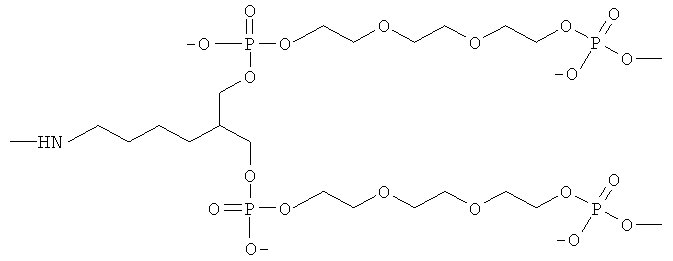
В одном варианте библиотеки по настоящему изобретению включают молекулы, содержащие функциональный компонент, содержащий структурные фрагменты, причем каждый функциональный компонент эффективно связан с кодирующим олигонуклеотидом. Последовательность нуклеотидов в кодирующем олигонуклеотиде определяет структурные фрагменты, присутствующие в функциональном компоненте, а в некоторых вариантах определяет порядок их присоединения или расположение. Способ по настоящему изобретению характеризуется преимуществом, которое заключается в том, что способ конструирования функционального компонента и олигонуклеотида можно проводить в одной и той же реакционной среде, предпочтительно в водной среде, что таким образом упрощает способ получения библиотеки по сравнению со способами, известными из предшествующего уровня техники. В некоторых вариантах, в которых стадии лигирования олигонуклеотида и стадии присоединения структурных фрагментов проводят в водной среде, для каждой реакции существуют различное оптимальное значение pH. В таких вариантах реакцию присоединения структурных фрагментов проводят при пригодных pH и температуре в пригодном водном буферном растворе. Затем буферный раствор можно заменить на водный буферный раствор, характеризующийся подходящим pH для лигирования олигонуклеотида.
В другом варианте осуществления настоящее изобретение представляет соединения и библиотеки, включающие соединения общей Формулы II:
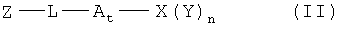
где Х означает молекулярный компонент, каждый Y независимо представляет собой периферический фрагмент, и n означает целое число от 1 до 6. Каждый А независимо представляет собой структурный фрагмент, и n означает целое число от 0 до приблизительно 5. L представляет собой связующий фрагмент и Z это одноцепочечный или двухцепочечный олигонуклеотид, который определяет структуру -At-X(Y)n. Структура X(Y)n может представлять собой одну из каркасных структур, предложенных в Таблице 8 (см. ниже). В одном варианте осуществления настоящее изобретение представляет соединения или библиотеки, содержащие соединения общей Формулы III:
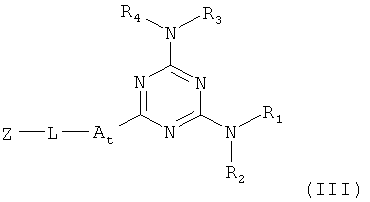
где t означает целое число от 1 до приблизительно 5, предпочтительно от 0 до 3, и каждый А независимо представляет собой структурный фрагмент. L представляет собой связующий фрагмент и Z это одноцепочечный или двухцепочечный олигонуклеотид, который идентифицирует каждый А и R1, R2, R3 и R4. R1, R2, R3 и R4 каждый независимо представляет собой заместитель, выбранный из группы, включающей водород, алкил, замещенный алкил, гетероалкил, замещенный гетероалкил, циклоалкил, гетероциклоалкил, замещенный циклоалкил, замещенный гетероциклоалкил, арил, замещенный арил, арилалкил, гетероарилалкил, замещенный арилалкил, замещенный гетероарилалкил, гетероарил, замещенный гетероарил, алкокси, арилокси, амино и замещенную аминогруппу. В одном варианте осуществления каждый А представляет собой остаток аминокислоты.
Библиотеки, которые включают соединения Формулы II или Формулы III, могут содержать по меньшей мере приблизительно 100; 1000; 10,000; 100,000; 1,000,000 или 10,000,000 соединений Формулы II или Формулы III. В одном варианте осуществления библиотеку получают посредством способа, созданного для получения библиотеки, содержащей по меньшей мере около 100; 1000; 10,000; 100,000; 1,000,000 или 10,000,000 соединений Формулы II или Формулы III.
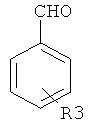
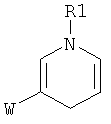
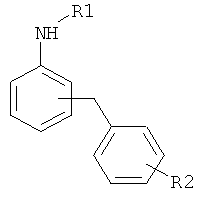
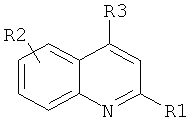
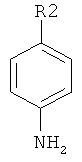
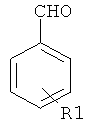
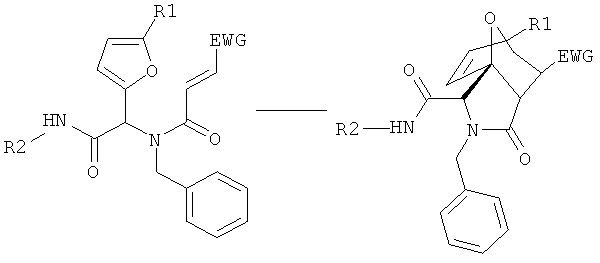
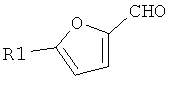
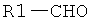
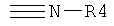
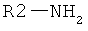
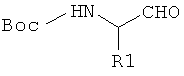
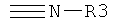
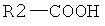
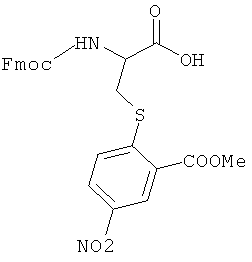
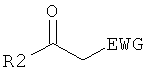
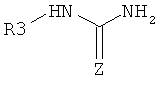
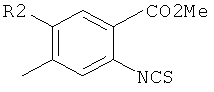
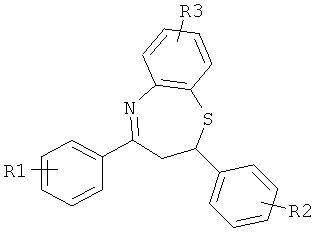

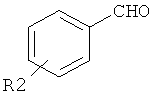
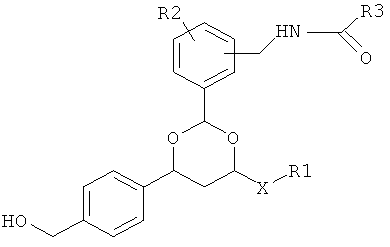

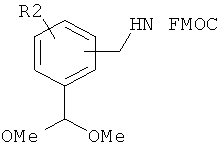
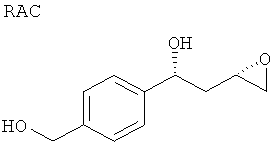
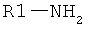
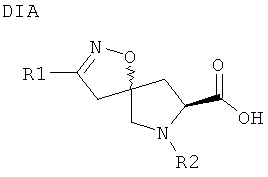
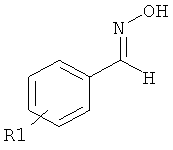
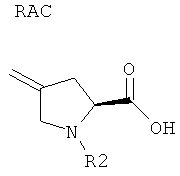
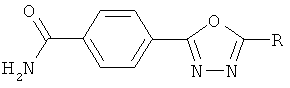
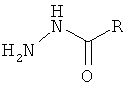
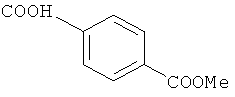
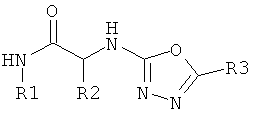
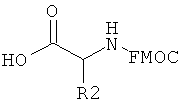
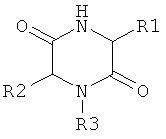
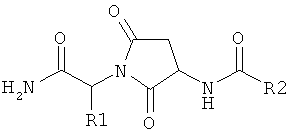
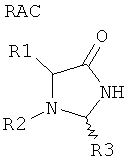
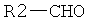
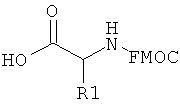
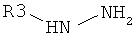
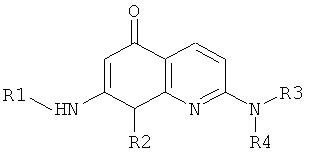
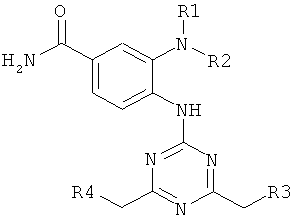
Одно из преимуществ способов по настоящему изобретению заключается в том, что их можно использовать для получения библиотеки, включающей огромное число соединений. Способность амплифицировать последовательности кодирующих олигинуклеотидов с использованием известных способов, таких как полимеразная цепная реакция (ПЦР), означает, что выбранные молекулы можно идентифицировать с использованием лишь относительно малого числа копий. Это позволяет использовать чрезвычайно многочисленные библиотеки, которые вследствие их высокой степени сложности включают либо относительно малое количество копий каждого члена библиотеки, либо требуют использования чрезвычайно больших объемов. Например, библиотека, включающая 108 отдельных структур, в которых каждая структура содержится в виде 1×1012 копий (приблизительно 1 пмоль), требует приблизительно 100 л раствора с эффективной концентрацией 1 мкм. Для той же библиотеки, если каждый член представлен 1000000 копиями, то требуется объем 100 мкл с эффективной концентрацией 1 мкм.
В предпочтительном варианте библиотека включает от приблизительно 103 до приблизительно 1015 копий каждого члена библиотеки. Вследствие различий в эффективности синтеза различных членов библиотеки в любой данной библиотеке члены могут быть представлены различным числом копий. Следовательно, хотя число копий каждого члена, теоретически присутствующего в библиотеке, может быть одинаковым, реальное число копий любого члена данной библиотеки не зависит от числа копий любого другого члена. Более предпочтительно библиотеки соединений по настоящему изобретению включают по крайней мере приблизительно 105, 106 или 107 копий каждого члена библиотеки, или практически всех членов библиотеки. Термин "практически все" члены библиотеки означает по крайней мере приблизительно 85% членов библиотеки, предпочтительно по крайней мере приблизительно 90% или более предпочтительно по крайней мере приблизительно 95% членов библиотеки.
Библиотека предпочтительно включает достаточное число копий каждого члена, чтобы обеспечить выполнение множества экспериментов (т.е. 2 или более) по отбору соединений в отношении биологической мишени, при этом после завершения конечного числа экспериментов по отбору остается достаточное количество связанных молекул после последнего круга выбора для проведения амплификации олигонуклеотидной метки в остальных молекулах и, следовательно, для идентификации функциональных компонентов связывающих молекул. Схема такого процесса отбора показана на фиг.6, где 1 и 2 означают членов библиотеки, В означает молекулу-мишень, а X означает остаток, эффективно связанный с В, что позволяет удалить В из среды для отбора. В данном примере соединение 1 связано с В, в то время как соединение 2 не связано с В. Процесс отбора, как показано в эксперименте 1, включает (I) контактирование библиотеки, включающей соединения 1 и 2, с В-Х в условиях, пригодных для связывания соединения 1 с В, (II) удаление несвязанного соединения 2, (III) диссоциацию соединения 1 от В и удаление ВХ из реакционной среды. Результатом эксперимента 1 является отбор молекул, обогащенных соединением 1 по сравнению с соединением 2. Следующие эксперименты, включающие стадии I-III, приводят к дальнейшему обогащению соединением 1 по сравнению с соединением 2. Хотя на фиг.6 показаны 3 эксперимента, на практике можно выполнить любое число экспериментов, например от 1 до 10 экспериментов, при этом достигается требуемая степень обогащения связывающимися молекулами по сравнению с несвязывающимися.
В варианте, показанном на фиг.6, амплификацию (синтез большего числа копий) соединений, оставшихся после любого из экспериментов отбора, не проводят. Такая амплификация приводит к образованию смеси соединений, не совместимой с относительными количествами соединений, оставшихся после отбора. Такая несовместимость возникает вследствие того, что синтез некоторых соединений проходит с более высоким выходом по сравнению с другими соединениями, и, следовательно, амплификация будет проходить не пропорционально их присутствию после отбора. Например, если соединение 2 синтезируется с большим выходом, чем соединение 2, то амплификация молекул, оставшихся после эксперимента 2, приведет к непропорциональной амплификации соединения 2 по сравнению с соединением 1, и к образованию смеси соединений с значительно меньшим (или с отсутствием) обогащением соединения 1 по сравнению с соединением 2.
В одном варианте мишень иммобилизуют на твердом носителе с использованием любой известной методики иммобилизации. В качестве твердого носителя используют, например, водонерастворимую матрицу, расположенную внутри хроматографической колонки или мембраны. Кодирующую библиотеку наносят на водонерастворимую матрицу, расположенную внутри хроматографической колонки. Затем колонку промывают для удаления неспецифически связанных веществ. Соединения, связанные с мишенью, диссоциируют изменением pH, концентрации соли, концентрации органического растворителя или с использованием других методов, таких как конкурентное связывание известного лиганда с мишенью.
В другом варианте мишень находится в растворе в свободном виде, ее инкубируют в присутствии кодирующей библиотеки. Соединения, связанные с мишенью (называемые в данном контексте "лигандами"), выделяют методом разделения по размерам, таким как гельфильтрация или ультрафильтрация. В одном варианте смесь кодированных соединений и биомолекулу-мишень пропускают через молекулярно-ситовую хроматографическую колонку (гель-фильтрация), на которой происходит отделение любых комплексов лиганд-мишень от несвязанных соединений. Комплексы лиганд-мишень переносят на обращенно-фазовую хроматографическую колонку, на которой происходит диссоциация лигандов от мишени. Затем диссоциированные лиганды анализируют ПЦР амплификацией и секвенированием кодирующего олигонуклеотида. Такой подход является прежде всего преимущественным в случаях, когда иммобилизация мишени приводит к потере ее активности.
В некоторых вариантах осуществления настоящего изобретения способ выбора может включать амплификацию кодирующего олигонуклеотида по меньшей мере одного члена библиотеки соединений, который связывается с мишенью до секвенирования.
В одном варианте осуществления библиотека соединений, содержащих кодирующие олигонуклеотиды, амплифицируется до анализа последовательности в целях минимизации любого потенциального отклонения в групповом распределении молекул ДНК, присутствующих в выбранной библиотечной смеси. Например, только небольшое количество библиотеки возвращается обратно после стадии селекции и обычно амплифицируется с использованием ПЦР перед анализом последовательности. ПЦР потенциально может давать отклонение в групповом распределении молекул ДНК, присутствующих в выбранной библиотечной смеси. Это особенно проблематично, когда число вводимых молекул мало и вводимые молекулы являются плохими темплатами ПЦР. Продукты ПЦР, полученные в ранних циклах, являются более эффективными темплатами, чем библиотека ковалентных дуплексов, и поэтому частота встречаемости этих молекул в конечной амплифицированной группе может быть намного выше, чем в первоначальном вводимом темплате.
Соответственно, для минимизации потенциального ПЦР отклонения, в одном варианте осуществления настоящего изобретения, группу одноцепочечных олигонуклеотидов, соответствующих индивидуальным членам библиотеки, получают, например, с использованием одного праймера в реакции, с последующей амплификацией с использованием двух праймеров. Таким образом, происходит линейная аккумуляция одноцепочечного продукта удлинения праймера перед экспоненциальной амплификацией с помощью ПЦР, и разнообразие и распределение молекул в аккумулированном продукте удлинения праймера более точно отражает разнообразие и распределение молекул в исходном вводимом темплате, поскольку экспоненциальная фаза амплификации проходит только после того, как большая часть первоначального разнообразия молекул представлена в группе молекул, полученных во время реакции удлинения праймера.
Хотя отдельные лиганды идентифицируют по описанным выше методикам, можно использовать различные уровни анализа для исследования взаимосвязи структуры с активностью и для дальнейшей оптимизации аффинности, специфичности и биоактивности лиганда. Для лигандов, полученных из одного каркаса, используют трехмерное молекулярное моделирование для определения важных структурных характеристик, общих для лигандов, получая таким образом семейства низкомолекулярных лигандов, которые предположительно связываются с одним участком биомолекулы-мишени.
Используют ряд подходов к анализу, позволяющих получить лиганды с высоким сродством к одной мишени, но значительно более слабым сродством к другой близкой по строению мишени. Один подход к анализу заключается в идентификации лигандов для обеих биомолекул в параллельных экспериментах и в последовательном удалении общих лигандов при перекрестном сравнении. По данной методике лиганды для каждой биомолекулы идентифицируют отдельно, как описано выше. Такой метод можно использовать как в присутствии иммобилизованных биомолекул-мишеней, так и в присутствии биомолекул-мишеней в растворе.
Для иммобилизованных биомолекул-мишеней другая стратегия заключается во включении дополнительной стадии перед отбором, на которой удаляются из библиотеки все лиганды, которые не связываются с биомолекулой-немишенью из библиотеки. Например, первая биомолекула контактирует с кодирующей библиотекой, как описано выше. Затем соединения, которые не связываются с первой биомолекулой, отделяют от всех образующихся комплексов "первая биомолекула-лиганд". Затем вторая биомолекула контактирует с соединениями, которые не связываются с первой биомолекулой. Соединения, которые связываются со второй биомолекулой, могут быть идентифицированы, как описано выше, и характеризуются более сильным сродством ко второй биомолекуле по сравнению с первой.
Лиганд для биомолекулы с неизвестной функцией, который идентифицируют по методике, описанной выше, можно использовать для определения биологической функции биомолекулы, что является преимуществом, поскольку, хотя все еще существует необходимость в выявлении последовательности новых генов, функции белков, закодированных в этой последовательности, и ценность таких белков в качестве мишеней для поиска и разработки новых лекарственных средств с трудом поддаются определению и, возможно, представляют основной недостаток при применении генетической информации для лечения заболеваний. Мишень-специфичные лиганды, полученные способом по настоящему изобретению, можно эффективно использовать для биологических анализов на основе цельных клеток или на соответствующих моделях животных, т.е. для исследования функции белка-мишени и ценности белка-мишени для применения в медицине. Данный подход подтверждает также тот факт, что мишень прежде всего пригодна для поиска низкомолекулярных лекарственных средств.
В одном варианте одно или более соединений в составе библиотеки по настоящему изобретению являются лигандами для определенной биомолекулы. Способность таких соединений связываться с биомолекулами оценивают методом анализа in vitro. Предпочтительно функциональные фрагменты связывающихся соединений синтезируют без олигонуклеотидной метки или связующей группы, и оценивают способность таких функциональных компонентов связываться с биомолекулой.
Влияние связывания функциональных компонентов с биомолекулой на функцию биомолекулы оценивают также с методом анализа in vitro в отсутствие или в присутствии клеток. В случае биомолекулы с известной функцией анализ включает сравнение активности биомолекулы в присутствии и отсутствие лиганда, например, прямым измерением активности, такой как ферментативная активность, или косвенным анализом, таким как оценка влияния биомолекулы на клеточную функцию. В случае биомолекулы с неизвестной функцией клетку, которая экспрессирует биомолекулу, вводят в контакт с лигандом и оценивают влияние лиганда на жизнеспособность, функцию, фенотип и/или экспрессию гена клеткой. Анализ in vitro включает, например, оценку апоптоза клеток, клеточной пролиферации или репликации вируса. Например, если биомолекулой является белок, экспрессируемый вирусом, то клетку, инфицированную вирусом, вводят в контакт с лигандом для белка. Затем оценивают влияние связывания лиганда с белком на жизнеспособность вируса.
Лиганд, идентифицированный способом по настоящему изобретению, оценивают также на модели in vivo или при испытании на пациентах. Например, действие лиганда оценивают при испытании на животных или в организме, в котором образуется эта биомолекула. При этом определяют любые изменения состояния здоровья (например, развитие болезни) у животного или в организме пациента.
В случае биомолекулы, такой как белок или нуклеиновая кислота, с неизвестной функцией, влияние лиганда, который связывается с биомолекулой, на клетки или организм, в которых образуется биомолекула, позволяет получить информацию о биологической функции биомолекулы. Например, ингибирование конкретного клеточного процесса в присутствии лиганда свидетельствует о том, что процесс зависит, по крайней мере частично, от функции биомолекулы.
Лиганды, идентифицированные с использованием способов по настоящему изобретению, используют также в качестве аффинных реагентов для биомолекулы, с которой они связываются. В одном варианте такие лиганды используют для аффинной очистки биомолекулы, например, при аффинной хроматографии раствора, включающего биомолекулу, с использованием твердой фазы, на которой иммобилизованы один или более таких лигандов.
Настоящее изобретение иллюстрируется следующими примерами, которые не ограничивают его объем. Содержание всех ссылок, патентов и опубликованных заявок на выдачу патента, которые цитируются в описании настоящего изобретения, а также фигуры и перечень последовательностей, включены в объем настоящего изобретения в качестве ссылок.
Примеры
Пример 1. Синтез и характеристика библиотеки, содержащей 105 членов
Синтез библиотеки, включающей порядка 105 отдельных членов, проводят с использованием следующих реагентов:
Соединение 1:
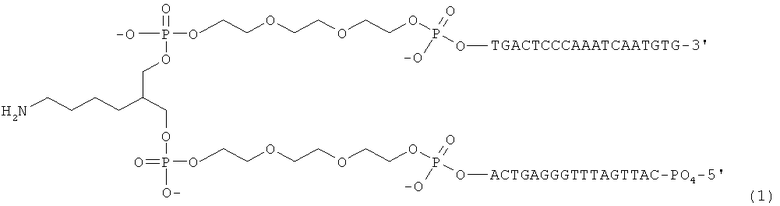
Однобуквенный код структуры дезоксирибонуклеотидов:
А означает аденозин
С означает цитидин
G означает гуанозин
Т означает тимидин
Предшественники структурных фрагментов:
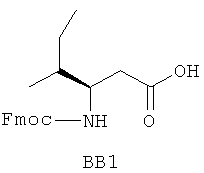
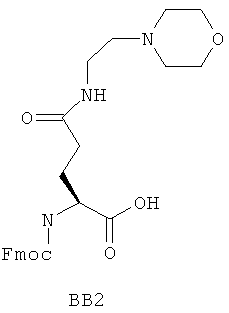
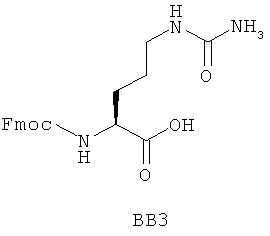
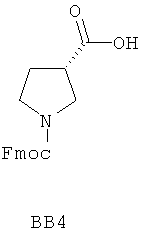
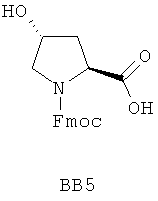
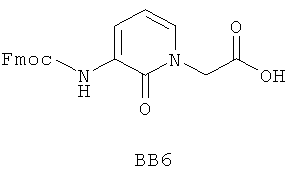
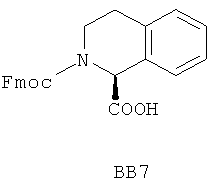
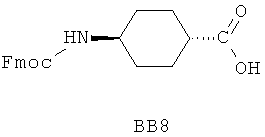
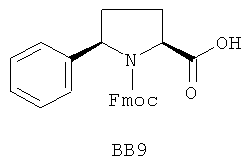
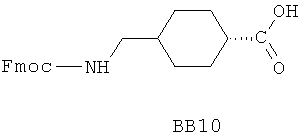
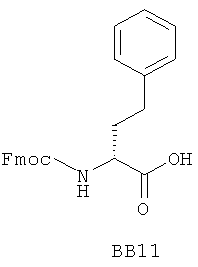
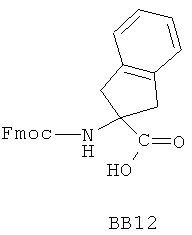
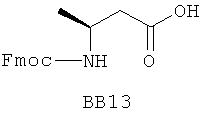
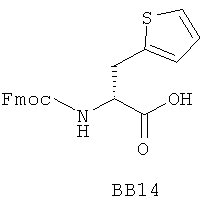
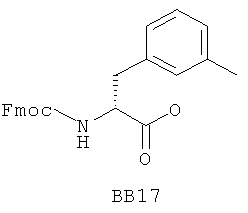
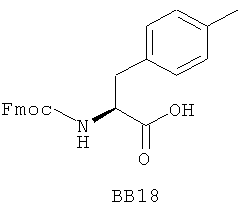
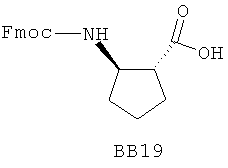
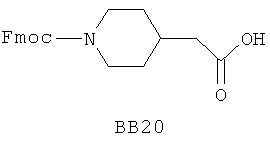
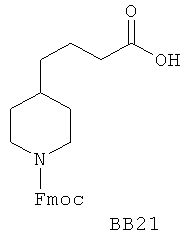
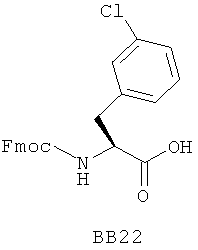
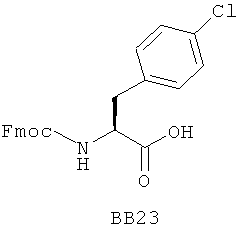
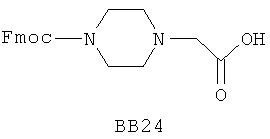
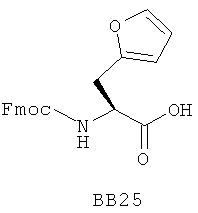
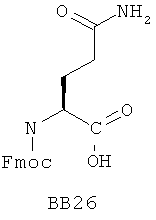
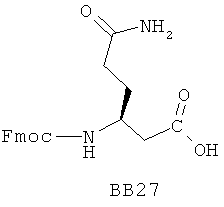
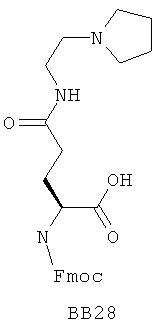
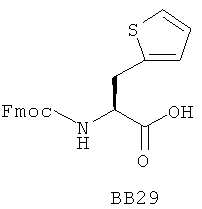
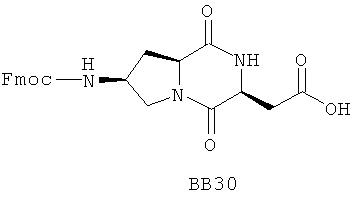
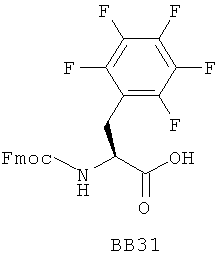
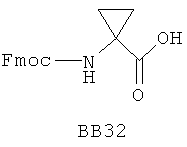
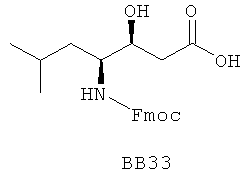
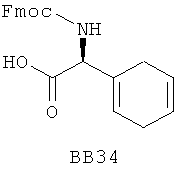
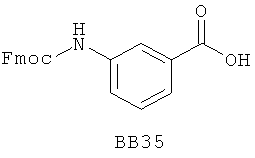
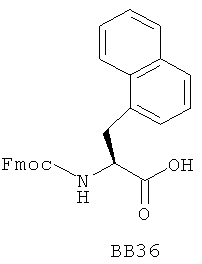
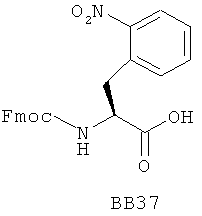
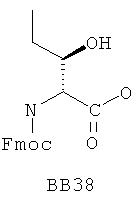
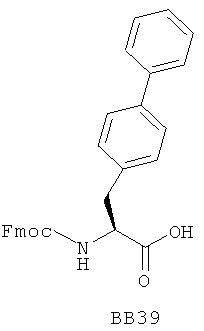
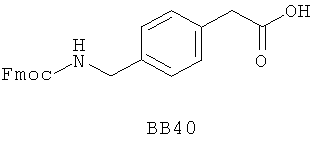
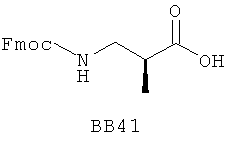
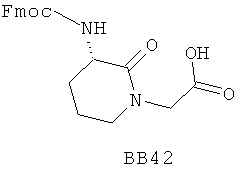
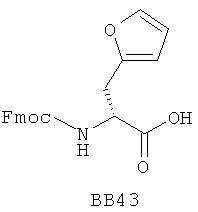
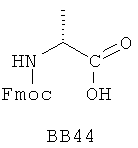
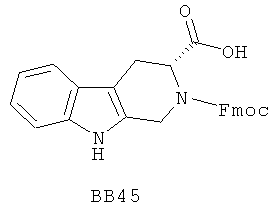
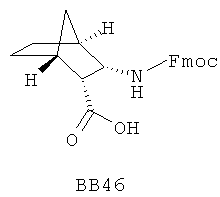
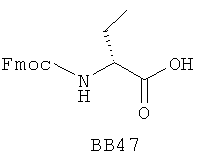
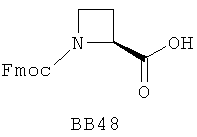
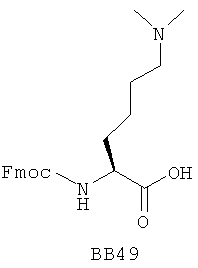
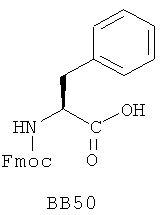
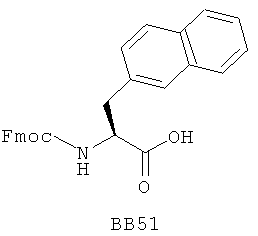
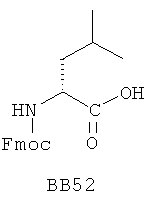

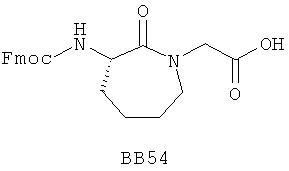
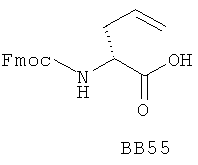
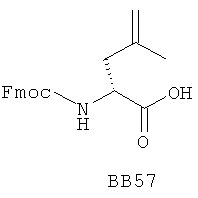
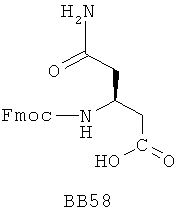
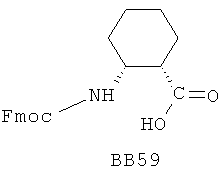
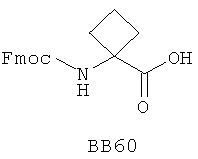
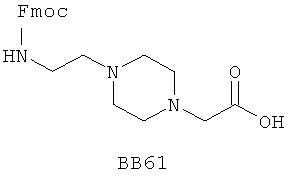
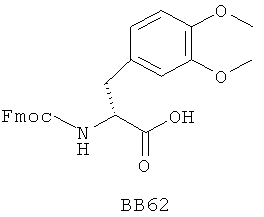
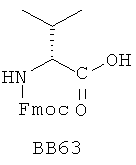
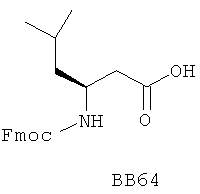
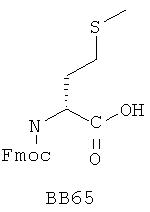
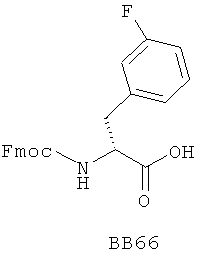
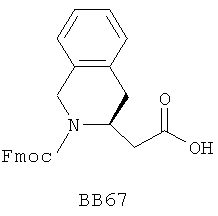
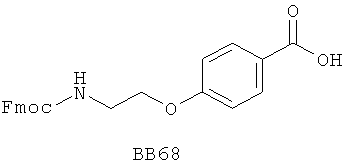
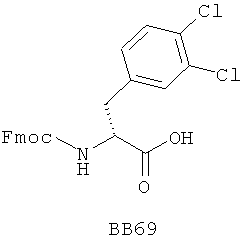
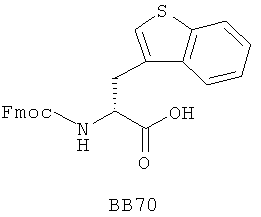
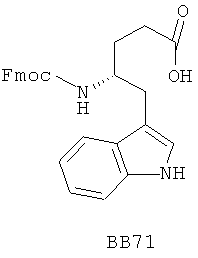
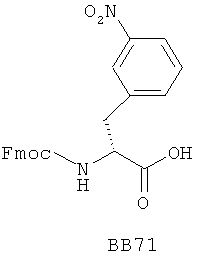
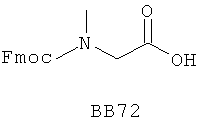
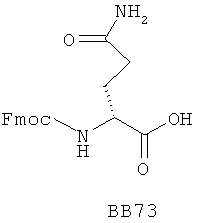

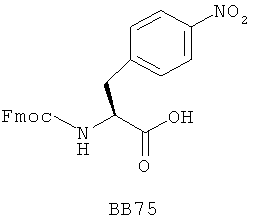
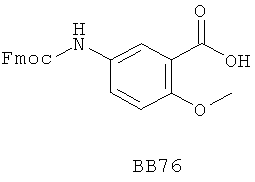
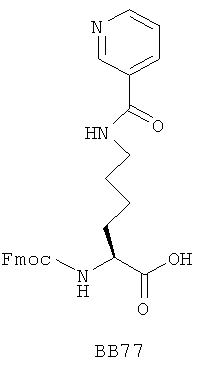
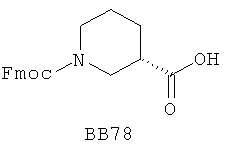
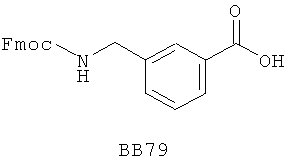
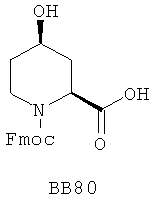
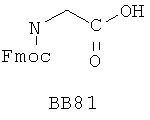
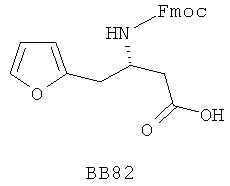
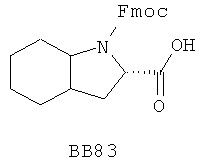
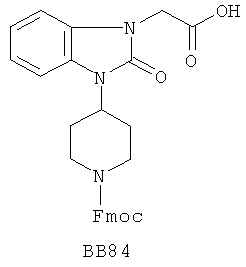
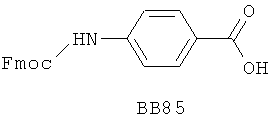
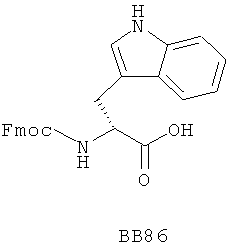
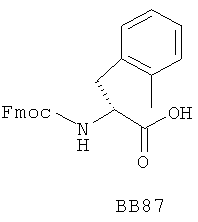
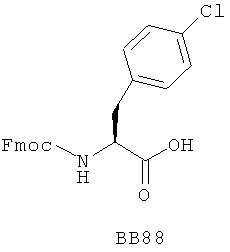
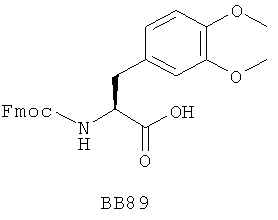
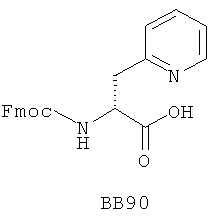
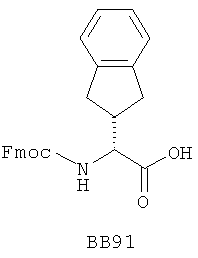
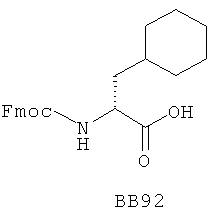
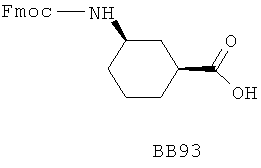
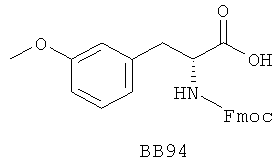
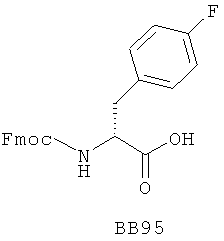
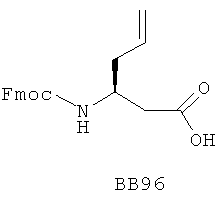




















1Х буферный раствор для лигазы: 50 мМ Трис, pH 7,5, 10 мМ дитиотриит, 10 мМ MgCl2, 50 мМ NaCl.
10Х буферный раствор для лигазы: 500 мМ Трис, pH 7,5, 100 мМ дитиотриит, 100 мМ MgCl2, 20 мМ АТР, 500 мМ NaCl.
Присоединение водорастворимого спейсера к соединению 2
В раствор соединения 2 (60 мл, 1 мМ) в буферном растворе, содержащем борат натрия (150 мМ, pH 9,4), охлажденном до 4°С, добавляют 40 экв. N-Fmoc-15-амино-4,7,10,13-тетраоксаоктадекановой кислоты (S-Ado) в N,N-диметилформамиде (ДМФА, 16 мл, 0,15 М) и 40 экв. гидрата хлорида 4-(4,6-диметокси[1.3.5]триазин-2-ил)-4-метилморфолиния (DMTMM) в воде (9,6 мл, 0,25 М). Смесь осторожно встряхивают в течение 2 ч при 4°С, затем добавляют еще 40 экв. S-Ado и DMTMM, смесь встряхивают в течение 16 ч при 4°С.
После ацилирования добавляют 0,1Х объемов 5 М водного раствора NaCl и 2,5Х объемов охлажденного (-20°С) этанола и смесь выдерживают при -20°С по крайней мере в течение 1 ч. Затем смесь центрифугируют в течение 15 мин при 14000 об/мин при 4°С, при этом получают осадок белого цвета, который промывают охлажденным EtOH и затем подвергают лиофильной сушке при комнатной температуре в течение 30 мин. Твердое вещество растворяют в 40 мл воды и очищают обращенно-фазовой ВЭЖХ на колонке Waters Xterra RP18 (элюент: градиент двухфазной подвижной фазы - 50 мМ водный буферный раствор, содержащий ацетат триэтиламмония, при pH 7,5 и раствор 99% ацетонитрил/1% вода. Очищенный материал концентрируют лиофильно и полученный остаток растворяют в 5 мл воды. К раствору добавляют 0,1X объем пиперидина и смесь осторожно встряхивают в течение 45 мин при комнатной температуре. Продукт очищают осаждением из этанола, как описано выше, и выделяют центрифугированием. Полученный осадок дважды промывают охлажденным EtOH и подвергают лиофильной сушке, и в результате получают очищенное соединение 3.
Цикл 1
В каждую лунку 96-луночного планшета добавляют по 12,5 мкл 4 мМ раствора соединения 3 в воде, 100 мкл 1 мМ раствора одного из олигонуклеотидов 1.1-1.96, как показано в таблице 3 (молярное соотношение соединения 3 к олигонуклеотиду составляет 1:2). Планшеты нагревают при 95°С в течение 1 мин и затем охлаждают до 16°С в течение 10 мин. В каждую лунку добавляют 10 мкл буферного раствора 10Х для лигазы, 30 единиц ДНК Т4 лигазы (1 мкл раствора 30 ед/мкл раствор, фирмы FermentasLife Science, номер по каталогу EL0013), 76,5 мкл воды, и полученный раствор инкубируют в течение 16 ч при 16°С.
После реакции лигирования в каждую лунку добавляют 20 мкл 5М водного раствора NaCl, 500 мкл охлажденного (-20°С) этанола, и выдерживают при -20°С в течение 1 ч. Планшеты центрифугируют в течение 1 ч при 3200g на центрифуге устройства Beckman Coulter Allegra 6R с использованием Beckman Microplus Carriers. Супернатант осторожно удаляют при переворачивании планшета и осадок промывают 70% водным раствором этанола при -20°С. Каждую порцию осадка растворяют в буферном растворе, содержащем борат натрия (50 мкл, 150 мМ, pH 9,4), при этом получают раствор с концентрацией 1 мМ, который охлаждают до 4°С.
В каждый раствор добавляют по 40 экв. одного из 96 предшественников структурных фрагментов в ДМФА (13 мкл, 0,15 мМ), 40 экв. DMTMM в воде (8 мкл, 0,25 М) и раствор осторожно встряхивают при 4°С.Через 2 ч добавляют еще 40 экв. одного из предшественников структурных фрагментов и DMTMM, полученные растворы осторожно встряхивают в течение 16 ч при 4°С. После ацилирования в каждый раствор добавляют 10 экв. N-гидроксисукцинимидного эфира уксусной кислоты в ДМФА (2 мкл, 0,25 М) и смесь осторожно встряхивают в течение 10 мин.
После ацилирования 96 реакционных смесей объединяют и добавляют 0,1 объем 5 М водного раствора NaCl и 2,5 объемов охлажденного абсолютизированного этанола, смесь выдерживают при -20°С в течение по крайней мере 1 ч. Затем смесь центрифугируют. После центрифугирования удаляют максимально возможное количество супернатанта с использованием микродозатора, при этом получают осадок, который промывают охлажденным этанолом и снова центрифугируют. Супернатант удаляют с использованием дозатора объемом 200 мкл. В пробирку добавляют 70% охлажденный этанол и полученную смесь центрифугируют в течение 5 мин при 4°С.
Супернатант удаляют и оставшийся этанол удаляют лиофильно при комнатной температуре в течение 10 мин. Затем осадок растворяют в 2 мл воды и очищают обращенно-фазовой ВЭЖХ на колонке Waters Xterra RP18 (элюент: градиент двухфазной подвижной фазы - 50 мМ водный буферный раствор, содержащий ацетат триэтиламмония, при pH 7,5 и раствор 99% ацетонитрил/1% вода. Фракции, содержащие библиотеку, собирают, объединяют и лиофилизируют. Полученный остаток растворяют в 2,5 мл воды и добавляют 250 мкл пиперидина. Раствор осторожно встряхивают в течение 45 мин и затем осаждают этанолом, как описано выше. Полученный осадок подвергают лиофильной сушке и затем растворяют в буферном растворе, содержащем борат натрия (4,8 мл, 150 мМ, pH 9,4), при этом получают раствор при концентрации 1 мМ.
Раствор охлаждают до 4°С и добавляют по 40 экв. N-Fmoc-пропаргилглицина в ДМФА (1,2 мл, 0,15 М) и DMT-MM в воде (7,7 мл, 0,25 М). Смесь осторожно встряхивают в течение 2 ч при 4°С и затем добавляют еще по 40 экв. N-Fmoc-пропаргилглицина и DMT-MM, раствор встряхивают в течение еще 16 ч. Затем смесь очищают осаждением из EtOH и обращено-фазовой ВЭЖХ, как описано выше, и группу N-Fmoc удаляют обработкой пиперидином, как описано выше. После окончательной очистки осаждением из EtOH полученный осадок подвергают лиофильной сушке и используют на следующей стадии.
Циклы 2-4
Для каждого из таких циклов сухой осадок, полученный в предыдущем цикле, растворяют в воде и концентрацию библиотеки определяют спектрофотометрически с использованием коэффициента экстинкции компонента ДНК, входящего в состав библиотеки, при этом исходный коэффициент экстинкции соединения 2 составляет 131500 л/(моль·см). Концентрацию библиотеки доводят водой таким образом, чтобы конечная концентрация в реакционной среде для лигирования составляла 0,25 мМ. Затем библиотеку делят на 96 равных аликвотных частей в 96-луночном планшете. В каждую лунку добавляют раствор, включающий различные олигонуклеотиды (молярное соотношение компонента библиотеки к олигонуклеотиду составляет 1:2), и проводят лигирование, как описано в цикле 1. Олигонуклеотиды, использованные в циклах 2, 3 и 4, описаны в таблицах 4, 5 и 6, соответственно. Соответствие между олигонуклеотидными метками и предшественниками структурных фрагментов для циклов 1-4 показано в таблице 7. Библиотеку осаждают при добавлении этанола, как описано выше в цикле 1, и растворяют в буферном растворе, содержащем борат натрия (150 мМ, pH 9,4), при этом получают раствор с концентрацией 1 мМ. Последующие ацилирование и очистку проводят, как описано в цикле 1, за исключением очистки ВЭЖХ, исключенной из цикла 3.
Продукты, полученные в цикле 4, лигируют завершающим праймером, показанным ниже, с использованием метода, описанного выше для лигирования олигонуклеотидов.
Результаты
В результате синтеза, описанного выше, получают библиотеку, включающую 964 (приблизительно 108) различных структур. Ход синтеза библиотеки контролируют методами гель-электрофореза и ЖХ/МС продукта, полученного в каждом цикле. После завершения синтеза библиотеку анализируют с использованием различных методов. На фиг.13А показана хроматограмма библиотеки, полученная после цикла 4, но перед лигированием заключительным праймером, на фиг.13B показан масс-спектр библиотеки на той же стадии синтеза. Среднюю молекулярную массу определяют методом ЖХ/МС (отрицательные ионы). Ионные сигналы обрабатывают с использованием программного обеспечения ProMass. Полученный результат соответствует предсказанной величине средней массы библиотеки.
Компонент ДНК в составе библиотеки анализируют методом электрофореза в агарозе, который свидетельствует о том, что основная часть материала библиотеки соответствует лигированому продукту соответствующего размера. Анализ последовательности молекулярных клонов ДНК, продуктов ПЦР, полученных с использованием образцов библиотеки, показывает, что лигирование ДНК проходит с высокой точностью и практически полностью завершено.
Циклизация библиотеки
После завершения цикла 4 в части библиотеки N-концевой остаток блокируют с использованием азидоуксусной кислоты в стандартных условиях ацилирования. После очистки осаждением из EtOH продукт растворяют в буферном растворе, содержащем фосфат натрия (150 мМ, pH 8), при этом получают концентрацию 1 мМ, и в полученный раствор добавляют 4 экв. CuSO4 в воде (200 мМ), аскорбиновой кислоты в воде (200 мМ) и раствор соединения, показанного ниже, в ДМФА (200 мМ). Реакционную смесь осторожно встряхивают в течение 2 ч при комнатной температуре.
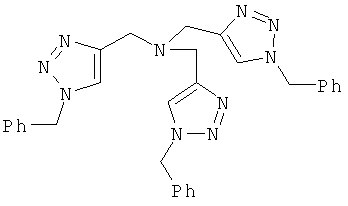
Для оценки степени циклизации 5 мкл аликвотной части реакционной смеси, полученной после циклизации библиотеки, удаляют и обрабатывают флуоресцентно-меченым азидом или алкином (1 мкл 100 мМ раствора в ДМФА), полученного, как описано в примере 4. Через 16 ч поданным ВЭЖХ при 500 нм показано, что ни азидная, ни алкиновая метки не включаются в состав библиотеки, что свидетельствует о том, что библиотека уже не содержит азидных или алкиновых групп, способных к циклоприсоединению, и, следовательно, члены библиотеки будут взаимодействовать друг с другом за счет реакций циклизации или межмолекулярных реакций. Циклизованную библиотеку очищают обращенно-фазовой ВЭЖХ, как описано выше. Контрольные эксперименты с использованием нециклизованной библиотеки показывают полное включение флуоресцентных меток, упомянутых выше.
Пример 4. Получение флуоресцентных меток для анализа методом циклизации
В отдельных пробирках пропаргилглицин или 2-амино-3-фенилпропилазид (по 8 мкмоль каждого) смешивают с FAM-OSu (Molecular Probes Inc., 1,2 экв.) в боратном буферном растворе при pH 9,4 (250 мкл). Реакционную смесь выдерживают при комнатной температуре в течение 3 ч и затем лиофилизируют в течение ночи. После очистки на ВЭЖХ получают требуемый флуоресцентный алкин или азид с количественным выходом.
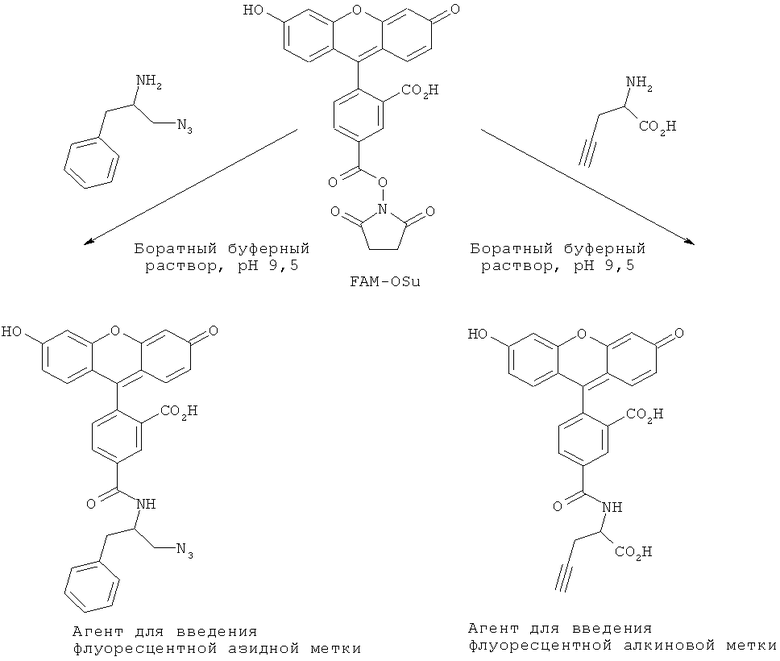
Пример 5. Циклизация индивидуальных соединений с использованием реакции циклоприсоединения азид/алкин
Получение азидоацетил- Gly-Pro-Phe-Pra-NH2:
Указанную последовательность синтезируют с использованием 0,3 ммоль амидной смолы Rink в стандартных условиях твердофазного синтеза с использованием Fmoc-защищенных аминокислот и HATU в качестве активирующего агента (Pra означает С-пропаргилглицин). Азидоуксусную кислоту используют для введения защитной группы в тетрапептид. Пептид отщепляют от смолы при обработке 20% ТФУ/ДХМ в течение 4 ч. После очистки ОФ-ВЭЖХ получают продукт в виде твердого вещества белого цвета (75 мг, 51%). 1H (ДМСО-d6, 400 МГц): 8,4-7,8 (m, 3Н), 7,4-7,1 (m, 7H), 4,6-4,4 (m, 1H), 4,4-4,2 (m, 2H), 4,0-3,9 (m, 2H), 3,74 (dd, 1H, J=6 Гц, 17 Гц), 3,5-3,3 (m, 2H), 3,07 (dt, 1H, J=5 Гц, 14 Гц), 2,92 (dd, 1H, J=5 Гц, 16 Гц), 2,86 (t, 1H, J=2 Гц), 2,85-2,75 (m, 1H), 2,6-2,4 (m, 2H), 2,2-1,6 (m, 4H). ИК (mull) 2900, 2100, 1450, 1300 см-1. MC (ESI): 497,4 ([M+H], 100%), 993,4 ([2M+H], 50%). MC (ESI): (источник ионной фрагментации): 519,3 ([M+Na], 100%), 491,3 (100%), 480,1 ([M-NH2], 90%), 452,2 ([M-NH2-CO], 20%), 424,2 (20%), 385,1 ([M-Pra], 50%), 357,1 ([M-Pra-CO], 40%), 238,0 ([M-Pra-Phe], 100%).
Циклизация азидоацетил-Gly-Pro-Phe-Pra-NH2:
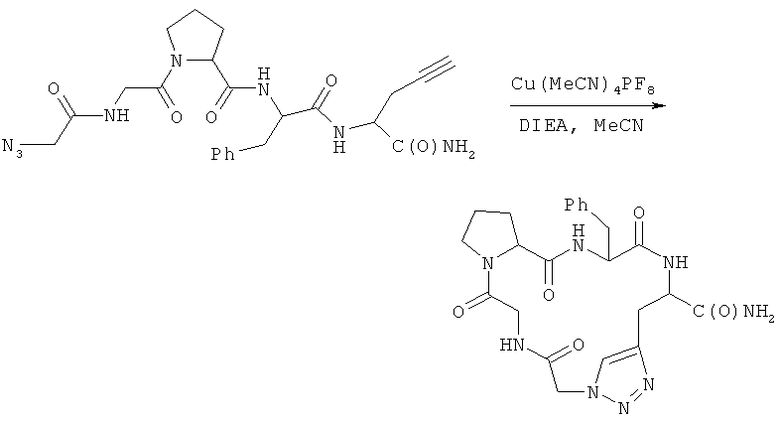
Азидоацилпептид (31 мг, 0,62 ммоль) растворяют в MeCN (30 мл). Затем добавляют диизопропилэтиламин (DIEA, 1 мл) и Cu(MeCN)4PF6 (1 мг). После перемешивания в течение 1,5 ч раствор упаривают и полученный остаток обрабатывают 20% MeCN/H2O. После центрифугирования для удаления нерастворимых солей раствор очищают обращенно-фазовой ВЭЖХ. Требуемый циклический пептид выделяют в виде твердого вещества белого цвета (10 мг, 32%). 1H (ДМСО-d6, 400 МГц): 8,28 (t, 1H, J=5 Гц), 7,77 (s, 1H), 7,2-6,9 (m, 9H), 4,98 (m, 2H), 4,48 (m, 1H), 4,28 (m, 1H), 4,1-3,9 (m, 2H), 3,63 (dd, 1H, J=5 Гц, 16 Гц), 3,33 (m, 2H), 3,0 (m, 3Н), 2,48 (dd, 1H, J=11 Гц, 14 Гц), 1,75 (m, 1H), 1,55 (m, 1H), 1,32 (m, 1H), 1,05 (m, 1H). ИК (mull) 2900, 1475, 1400 см-1. MC (ESI): 497,2 ([M+H], 100%), 993,2 ([2М+Н], 30%), 1015,2 ([2M+Na], 15%). MC (ESI) (источник ионной фрагментации): 535,2 (70%), 519,3 ([M+Na], 100%), 497,2 ([M+H], 80%), 480,1 ([М-NH2], 30%), 452,2 ([M-NH2-CO], 40%), 208,1 (60%).
Получение азидоацетил-Gly-Pro-Phe-Pra-Gly-OH:
С использованием 0,3 ммоль смолы Glycine-Wang указанную последовательность синтезируют в стандартных условиях твердофазного синтеза с использованием Fmoc-защищенных аминокислот и HATU в качестве активирующего агента. Азидоуксусную кислоту используют на последней стадии конденсации в качестве защитной группы для пентапептида. Пептид отщепляют от смолы при обработке 50% ТФУ/ДХМ в течение 2 ч. После очистки ОФ-ВЭЖХ получают продукт в виде твердого вещества белого цвета (83 мг, 50%). 1H ЯМР (ДМСО-d6, 400 МГц): 8,4-7,9 (m, 4H), 7,2 (m, 5H), 4,7-4,2 (m, 3H), 4,0-3,7 (m, 4H), 3,5-3,3 (m, 2H), 3,1 (m, 1H), 2,91 (dd, 1H, J=4 Гц, 16 Гц), 2,84 (t, 1H, J=2,5 Гц), 2,78 (m, 1H), 2,6-2,4 (m, 2H), 2,2-1,6 (m, 4H). ИК (mull) 2900, 2100, 1450, 1300 см-1. МС (ESI): 555,3 ([М+Н], 100%). MC (ESI) (источник ионной фрагментации): 577,1 ([M+Na], 90%), 555,3 (80%), 480,1 ([M-Gly], 100%), 385,1 ([M-Gly-Pra], 70%), 357,1 ([M-Gly-Pra-CO], 40%), 238,0 ([M-Gly-Pra-Phe], 80%).
Циклизация азидоацетил-Gly-Pro-Phe-Pra-Gly-OH:
Пептид (32 мг, 0,058 ммоль) растворяют в MeCN (60 мл). Затем добавляют диизопропилэтиламин (1 мл) и Cu(MeCN)4PF6 (1 мг) и раствор перемешивают в течение 2 ч. Растворитель упаривают и полученный неочищенный продукт очищают ОФ-ВЭЖХ для удаления димеров и тримеров. Циклический мономер выделяют в виде бесцветного стеклообразного вещества (6 мг, 20%). МС (ESI): 555,6 ([М+Н], 100%), 1109,3 ([2М+Н], 20%), 1131,2 ([2M+Na], 15%). МС (ESI) (источник ионной фрагментации) 555,3 ([М+Н], 100%), 480,4 ([M-Gly], 30%), 452,2 ([M-Gly-CO], 25%), 424,5 ([M-Gly-CO], 10%, наблюдается только в циклической структуре).
Конъюгация линейного пептида с ДНК:
Соединение 2 (20 нмоль) растворяют в 45 мкл боратного буферного раствора (pH 9,4, 150 мМ). При 4°С добавляют линейный пептид (18 мкл 100 мМ исходного раствора в ДМФА, 180 нмоль, 40 экв), DMT-MM (3,6 мкл 500 мМ исходного раствора в воде, 180 нмоль, 40 экв.). После встряхивания в течение 2 ч по данным МСЖХ реакция завершена и продукт выделяют осаждением из этанола. МС (ESI); 1823,0 ([М-3H]/3, 20%), 1367,2 ([М-4Н]/4, 20%), 1093,7 ([М-5Н]/5, 40%), 911,4 ([М-6Н)/6, 100%).
Конъюгация циклического пептида с ДНК:
Соединение 2 (20 нмоль) растворяют в 20 мкл боратного буферного раствора (pH 9,4, 150 мМ). При 4°С добавляют линейный пептид (8 мкл 100 мМ исходного раствора в ДМФА, 80 нмоль, 40 экв.), DMT-MM (1,6 мкл 500 мМ исходного раствора в воде, 80 ммоль, 40 экв.). После встряхивания в течение 2 ч по данным МС-ЖХ реакция завершена и продукт выделяют осаждением из этанола. МС (ESI) 1823,0 ([М-3Н]/3, 20%), 1367,2 ([М-4Н]/4, 20%), 1093,7 ([М-5Н]/5, 40%), 911,4 ([М-6Н)/6, 100%).
Циклизация пептида, связанного с ДНК:
Конъюгат линейный пептид-ДНК (10 нмоль) растворяют в натрий-фосфатном буферном растворе, pH 8 (10 мкл, 150 ммоль). При комнатной температуре добавляют по 4 экв. CuSO4, аскорбиновой кислоты и лиганда Sharpless (по 0,2 мкл 200 мМ исходных растворов). Реакционную смесь выдерживают в течение ночи. По данным ОФ-ВЭЖХ линейный пептид-ДНК в смеси отсутствует, и продукт элюируется одновременно с контрольным циклическим пептидом-ДНК. Присутствие следовых количеств димеров или других олигомеров не наблюдается.
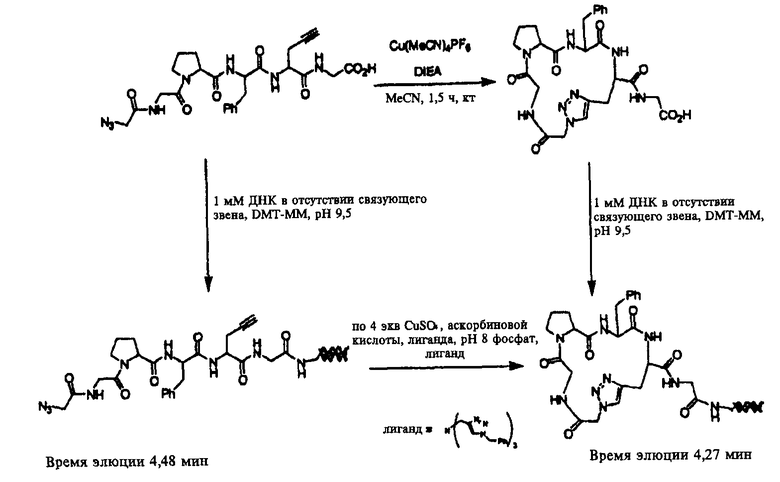
Условия проведения ЖХ: колонка Targa С 18, 2,1†40 мм, 10-40%
MeCN в 40 мМ водном растворе ТЕАА в течение 8 мин.
Пример 6. Применение реакции ароматического нуклеофильного замещения для синтеза функционального компонента
Общая методика арилирования соединения 3 цианурхлоридом:
Соединение 2 растворяют в боратном буферном растворе, pH 9,4, при этом получают раствор при концентрации 1 мМ. Раствор охлаждают до 4°С и затем добавляют 20 экв. цианурхлорида в виде 500 мМ раствора в MeCN. Через 2 ч по данным МС-ЖХ реакция завершена и полученный конъюгат дихлортриазин-ДНК выделяют осаждением этанолом.
Методика аминозамещения конъюгата дихлортриазин-ДНК:
Конъюгат дихлортриазин-ДНК растворяют в боратном буфере, pH 9,5, при этом получают раствор при концентрации 1 мМ. Затем при комнатной температуре добавляют 40 экв. алифатического амина в виде раствора в ДМФА. Ход реакции контролируют методом МС-ЖХ и через 2 ч реакция завершена. Полученный конъюгат алкиламиномонохлортриазин-ДНК выделяют осаждением этанолом.
Методика аминозамещения конъюгата монохлортриазин-ДНК:
Конъюгат алкиламиномонохлортриазин-ДНК растворяют в боратном буферном растворе, pH 9,5, при этом получают раствор при концентрации 1 мМ. Затем при 42°С добавляют 40 экв. второго алифатического амина в виде раствора в ДМФА. Ход реакции контролируют методом МС-ЖХ и через 2 ч реакция завершена. Полученный конъюгат диаминотриазин-ДНК выделяют осаждением этанолом.
Пример 7. Применение реакции восстановительного аминирования для синтеза функционального компонента
Общая методика восстановительного аминирования ДНК-связующее звено, содержащее вторичный амин, с использованием альдегидного структурного фрагмента:
Соединение 2 конденсируют с N-концевым остатком пролина. Полученное соединение растворяют в боратном буферном растворе (50 мкл, 150 мМ, pH 9,5), при этом получают раствор с концентрацией 1 мМ. К полученному раствору добавляют по 40 экв. альдегидного структурного фрагмента в ДМФА (8 мкл, 0,25 М) и цианоборгидрида натрия в ДМФА (8 мкл, 0,25 М), раствор нагревают при 80°С в течение 2 ч. После алкилирования раствор очищают осаждением этанолом.
Общая методика восстановительного аминирования комплекса ДНК-связующее звено, содержащего альдегид, с использованием аминофрагментов:
Соединение 2, конденсированное со структурным фрагментом, содержащим альдегидную группу, растворяют в боратном буферном растворе (50 мкл, 250 мМ, pH 5,5), при этом получают раствор при концентрации 1 мМ. К полученному раствору добавляют по 40 экв. аминофрагмента в ДМФА (8 мкл, 0,25 М) и цианоборгидрида натрия в ДМФА (8 мкл, 0,25 М), раствор нагревают при 80°С в течение 2 ч. После алкилирования раствор очищают осаждением этанолом.
Пример 8. Применение синтеза пептоидных структурных фрагментов для получения функционального компонента
Общая методика синтеза пептоида с использованием комплекса ДНК-связующее звено:

Соединение 2 растворяют в боратном буферном растворе (50 мкл, 150 мМ, pH 9,4), при этом получают раствор при концентрации 1 мМ, который охлаждают до 4°С. К полученному раствору добавляют 40 экв. N-гидроксисукцинимидилбромацетата в ДМФА (13 мкл, 0,15 М) и раствор осторожно встряхивают при 4°С в течение 2 ч. После ацилирования ДНК-связующее звено очищают осаждением этанолом и повторно растворяют в боратном буферном растворе (50 мкл, 150 мМ, pH 9,4), при этом получают раствор при концентрации 1 мМ, который охлаждают до 4°С. К полученному раствору добавляют 40 экв. аминофрагмента в ДМФА (13 мкл, 0,15 М) и раствор осторожно встряхивают при 4°С в течение 16 ч. После алкилирования остаток ДНК-связующее звено очищают осаждением этанолом и повторно растворяют в боратном буферном растворе (50 мкл, 150 мМ, pH 9,4), при этом получают раствор при концентрации 1 мМ, который охлаждают до 4°С. Синтез пептоида продолжают постадийно при добавлении N-гидроксисукцинимидил-бромацетата с последующим добавлением аминофрагмента.
Пример 9. Применение реакции циклоприсоединения азид-алкин для синтеза функционального компонента
Общая методика
Алкинсодержащий конъюгат ДНК растворяют в боратном буферном растворе, pH 8,0, при этом получают раствор при концентрации приблизительно 1 мМ. К полученной смеси добавляют 10 экв. органического азида и по 5 экв. сульфата меди(II), аскорбиновой кислоты и лиганда (трис-((1-бензилтриазол-4-ил)метил)амин) при комнатной температуре. Ход реакции контролируют методом ЖХ-МС и через 1-2 ч реакция завершена. Полученный конъюгат триазол-ДНК выделяют осаждением этанолом.
Пример 10. Идентификация лиганда киназы Abl в составе кодирующей библиотеки
Возможность повышать содержание требуемых молекул в ДНК-кодированной библиотеке по сравнению с нежелательными членами библиотеки является первостепенной при идентификации отдельных соединений с определенными свойствами в отношении исследуемых терапевтических мишеней. Для демонстрации такой возможности обогащения синтезируют известную молекулу (как описано в статье Shah et al., Science 305, 399-401 (2004), включенной в настоящее описание в качестве ссылки), способную связываться с киназой rhAbl (GenBank U07563). Данное соединение присоединяют к двухцепочечному олигонуклеотиду через связующую группу, как описано в предыдущих примерах, с использованием стандартных методик, при этом получают молекулу (функциональный компонент, соединенный с олигонуклеотидом), аналогичную соединениям, которые получают по методике, описанной в примерах 1 и 2. Библиотека, которую в основном получают, как описано в примере 2, и соединенный с ДНК участок связывания с киназой Abl сконструированы из уникальных последовательностей ДНК, которые позволяют провести количественный ПЦР анализ для обоих образцов. Соединенный с ДНК участок связывания с киназой Abl смешивают с библиотекой в соотношении 1:1000. Полученную смесь уравновешивают в присутствии киназы rhAble, и фермент сорбируют на твердой фазе, промывают для удаления несвязанных членов библиотеки и элюируют связывающимися молекулами. Соотношение молекул библиотеки и связанного с ДНК ингибитора киназы Abl в элюате составляет 1:1, что означает обогащение по соединенному с ДНК связывающегося с киназой Abl участка в более 500 раз и в 1000-кратном избытке по отношению к молекулам библиотеки.
Эквиваленты
Специалисты в данной области техники могут выявить с использованием стандартных методик множество эквивалентов специфических вариантов осуществления настоящего изобретения, описанных в данном контексте. Такие эквиваленты определены в следующих пунктах формулы настоящего изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| БИОЛОГИЧЕСКИ АКТИВНОЕ СОЕДИНЕНИЕ, СОДЕРЖАЩЕЕ КОДИРУЮЩИЙ ОЛИГОНУКЛЕОТИД, И БИБЛИОТЕКА СОЕДИНЕНИЙ | 2011 |
|
RU2592673C2 |
| БИОЛОГИЧЕСКИ АКТИВНОЕ СОЕДИНЕНИЕ, СОДЕРЖАЩЕЕ КОДИРУЮЩИЙ ОЛИГОНУКЛЕОТИД (ВАРИАНТЫ), СПОСОБ ЕГО СИНТЕЗА, БИБЛИОТЕКА СОЕДИНЕНИЙ (ВАРИАНТЫ), СПОСОБ ЕЕ СИНТЕЗА И СПОСОБ ПОИСКА СОЕДИНЕНИЯ, СВЯЗЫВАЮЩЕГОСЯ С БИОЛОГИЧЕСКОЙ МИШЕНЬЮ (ВАРИАНТЫ) | 2004 |
|
RU2470077C2 |
| КОНЪЮГАТЫ АФФИННАЯ ЧАСТЬ-ОЛИГОНУКЛЕОТИД И ИХ ПРИМЕНЕНИЯ | 2016 |
|
RU2778754C2 |
| СПОСОБ ИДЕНТИФИКАЦИИ НАТИВНЫХ ПАР ФРАГМЕНТОВ ДНК ИЛИ РНК, ПРИСУТСТВУЮЩИХ В ОДНИХ И ТЕХ ЖЕ ЖИВЫХ КЛЕТКАХ | 2013 |
|
RU2578009C2 |
| НАПРАВЛЯЕМЫЙ ОЛИГОНУКЛЕОТИДАМИ И ОТСЛЕЖИВАЕМЫЙ КОМБИНАТОРНЫЙ СИНТЕЗ КОДИРУЕМЫХ МОЛЕКУЛ-ЗОНДОВ | 2017 |
|
RU2769571C2 |
| АНАЛИЗ МНОЖЕСТВА АНАЛИТОВ С ИСПОЛЬЗОВАНИЕМ ОДНОГО АНАЛИЗА | 2019 |
|
RU2824049C2 |
| СПОСОБ ИДЕНТИФИКАЦИИ НАТИВНЫХ ПАР ФРАГМЕНТОВ ДНК ИЛИ РНК, ПРИСУТСТВУЮЩИХ В ОДНИХ И ТЕХ ЖЕ ЖИВЫХ КЛЕТКАХ | 2015 |
|
RU2600873C1 |
| КРУПНОМАСШТАБНЫЕ МОНОКЛЕТОЧНЫЕ БИБЛИОТЕКИ ТРАНСКРИПТОМОВ И СПОСОБЫ ИХ ПОЛУЧЕНИЯ И ПРИМЕНЕНИЯ | 2019 |
|
RU2773318C2 |
| ВЫСОКОПРОИЗВОДИТЕЛЬНЫЕ БИБЛИОТЕКИ ОДИНОЧНЫХ ЯДЕР И ОДИНОЧНЫХ КЛЕТОК И СПОСОБЫ ИХ ПОЛУЧЕНИЯ И ИСПОЛЬЗОВАНИЯ | 2020 |
|
RU2838545C2 |
| ТРАНСПОЗИЦИЯ С СОХРАНЕНИЕМ СЦЕПЛЕНИЯ ГЕНОВ | 2015 |
|
RU2709655C2 |






























































































































































































































































































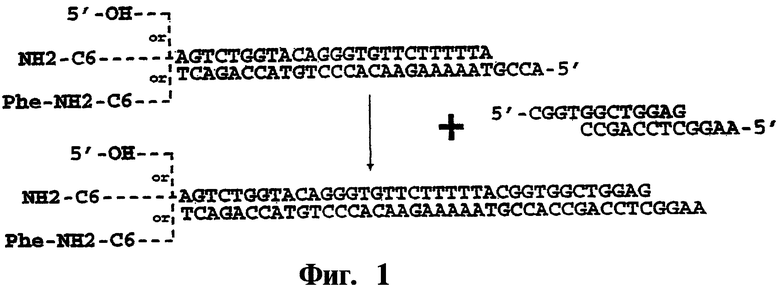
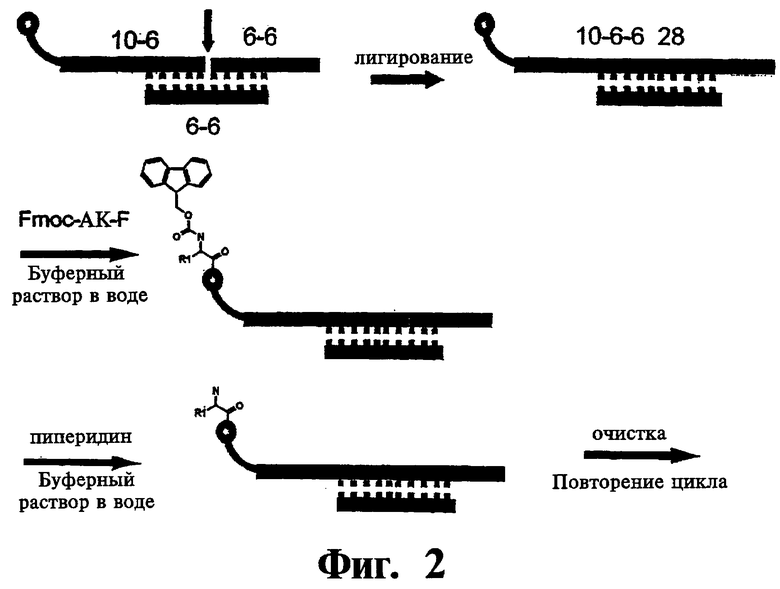
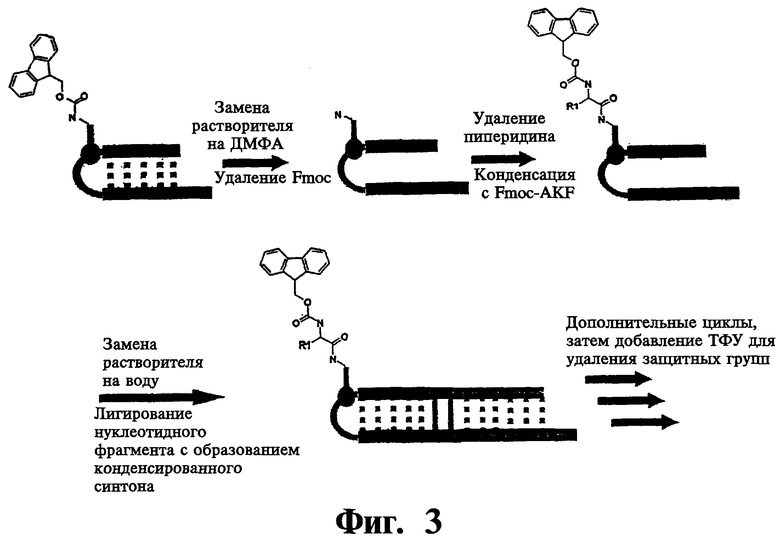
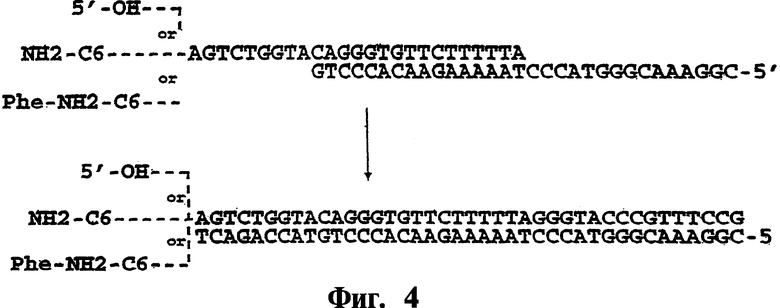
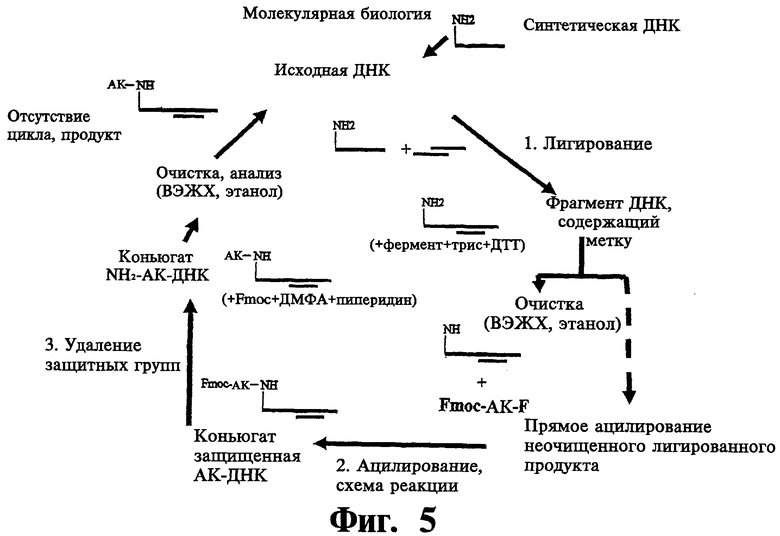
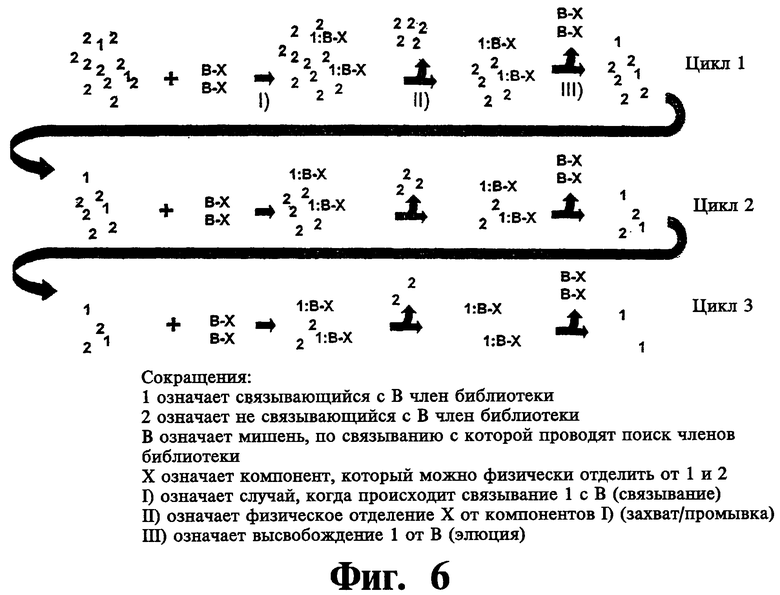
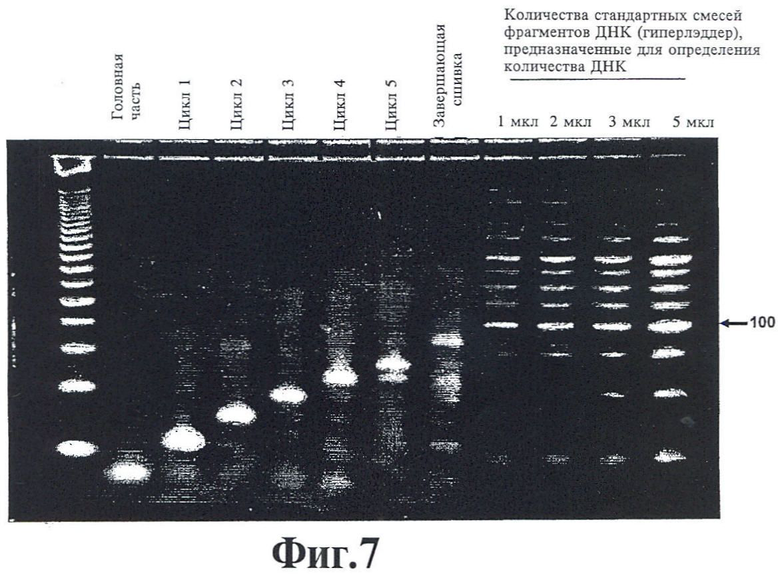
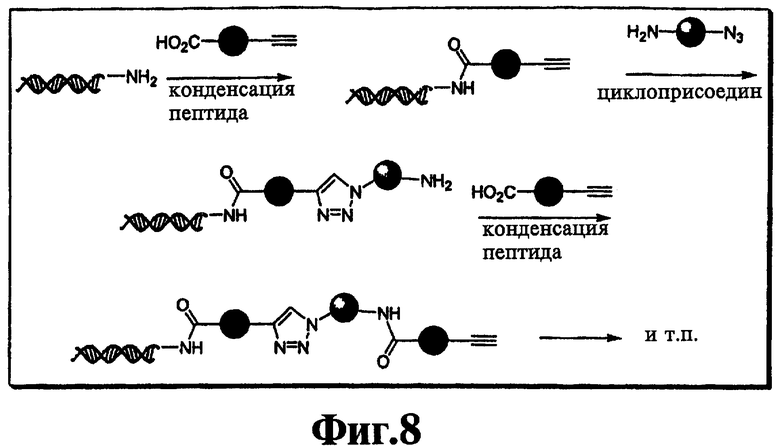
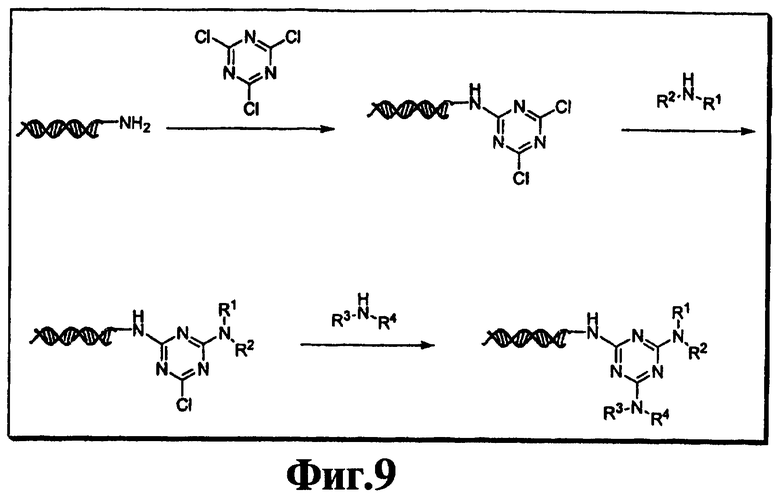
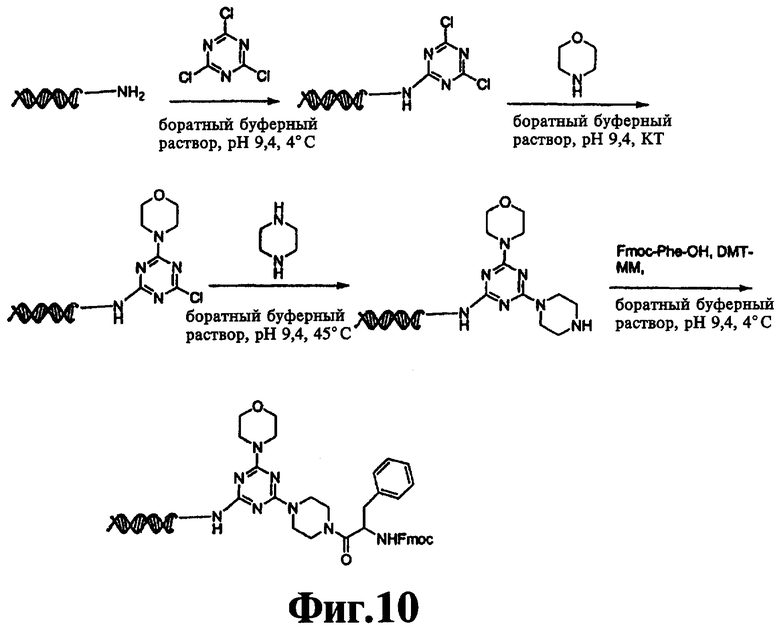
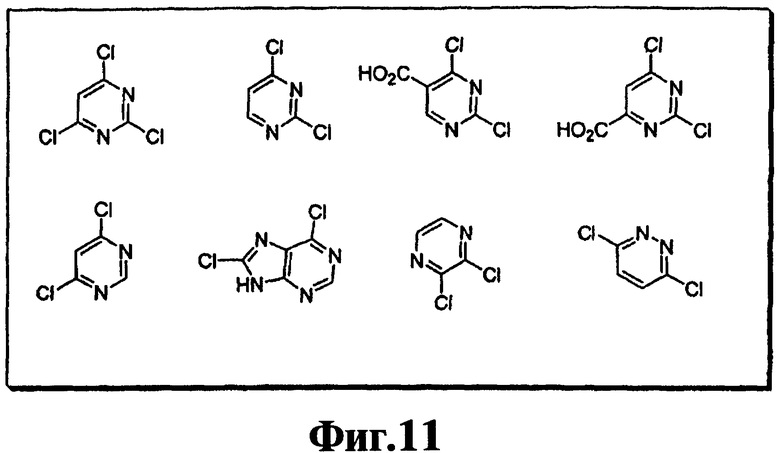
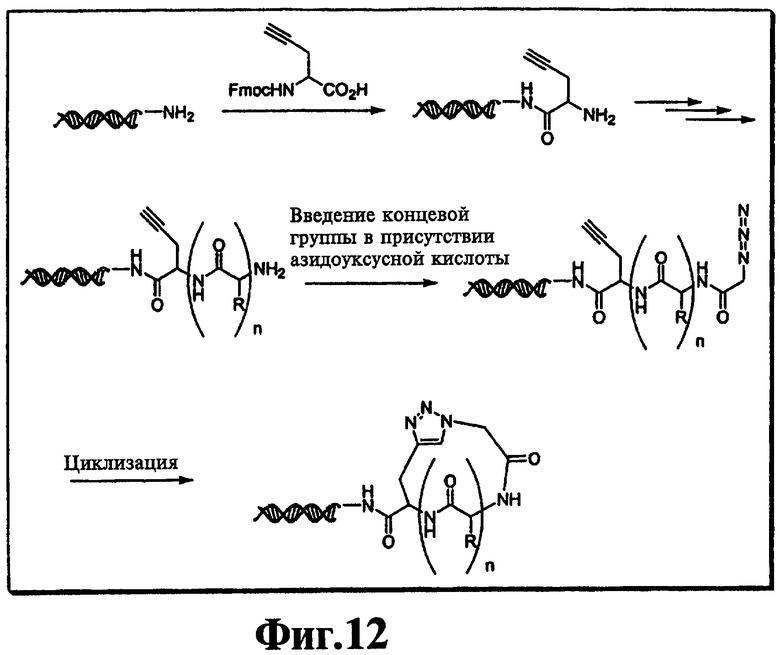
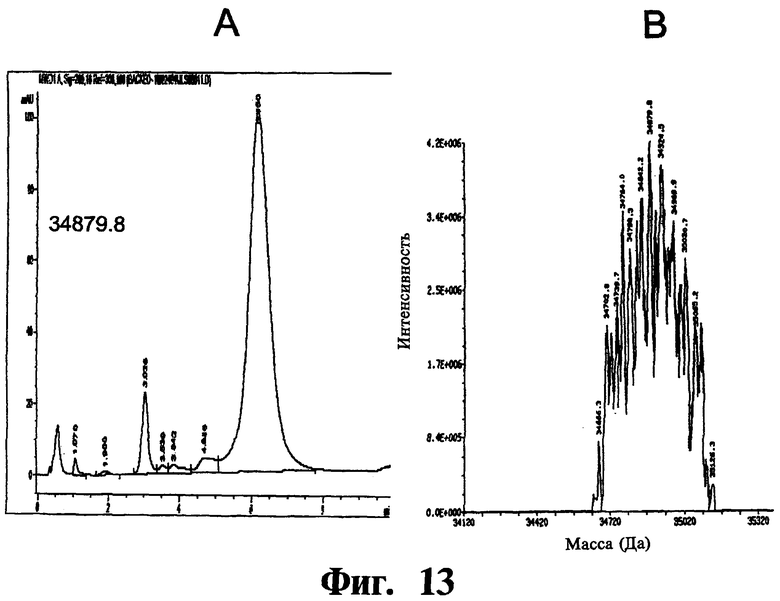
Изобретение относится к области биологической химии. Предложен способ синтеза библиотек молекул, содержащих олигонуклеотидную метку. Полученные библиотеки молекул могут быть использованы для идентификации соединений, связывающихся с определенной биологической мишенью. 6 н. и 126 з.п. ф-лы, 13 ил., 6 табл., 10 пр.
1. Способ получения бифункционального соединения, содержащего функциональный компонент, который эффективно связан с кодирующим олигонуклеотидом, определяющим структуру функционального компонента, отличающийся тем, что он включает следующие стадии:
1) получение соединения-инициатора, состоящего из исходного функционального компонента, содержащего n структурных фрагментов, где n равно целому числу 1 или более, по крайней мере одну реакционноспособную группу и эффективно связанного с исходным двухцепочечным олигонуклеотидом, определяющим структуру указанных n структурных фрагментов, при этом указанные функциональный компонент и исходный олигонуклеотид связаны посредством связующего звена таким образом, что связующее звено образует ковалентную связь с функциональным компонентом и с обеими цепями исходного олигонуклеотида,
2) взаимодействие указанного соединения-инициатора с требуемым структурным фрагментом, содержащим по крайней мере одну реакционноспособную группу, комплементарную реакционноспособной группе соединения-инициатора, в условиях, пригодных для образования ковалентной связи между указанными реакционноспособными группами,
3) взаимодействие исходного олигонуклеотида с вводимым олигонуклеотидом, который определяет структуру требуемого структурного фрагмента, содержащего по крайней мере одну реакционноспособную группу, комплементарную реакционноспособной группе соединения-инициатора, в присутствии фермента, который катализирует лигирование исходного олигонуклеотида и вводимого олигонуклеотида с образованием кодирующего олигонуклеотида, в пригодных для указанного лигирования условиях, при этом последний вводимый олигонуклеотид содержит концевую нуклеотидную последовательность, включающую вырожденные нуклеотиды, или последний вводимый олигонуклеотид лигирован с указанной концевой олигонуклеотидной последовательностью, включающей вырожденные нуклеотиды,
при этом стадия 3) предшествует стадии 2), или стадия 2) предшествует стадии 3),
а в результате вышеперечисленных стадий получают бифункциональное соединение, содержащее функциональный компонент, содержащий n+1 структурных фрагментов и эффективно связанный с кодирующим олигонуклеотидом, который определяет структуру функционального компонента.
2. Способ по п.1, отличающийся тем, что функциональный компонент полученного соединения содержит по меньшей мере одну реакционноспособную группу, а указанное соединение используют в качестве соединения-инициатора для проведения повторного цикла всех стадий способа по п.1, которые повторяют по меньшей мере один раз, причем соединение, полученное в результате каждого цикла, служит соединением-инициатором для последующего цикла реакций.
3. Способ по п.1, отличающийся тем, что по крайней мере один из структурных фрагментов выбран из группы, состоящей из аминокислоты или активированной аминокислоты.
4. Способ по п.1, отличающийся тем, что реакционноспособная группа представляет собой аминогруппу, а комплементарную реакционноспособную группу выбирают из группы, состоящей из карбоксильной группы, сульфонильной группы, фосфонильной группы, эпоксидной группы, азиридиновой группы и изоцианатной группы.
5. Способ по п.1, отличающийся тем, что реакционноспособную группу и комплементарную реакционноспособную группу независимо выбирают из группы, включающей гидроксильную группу, карбоксильную группу, сульфонильную группу, фосфонильную группу, эпоксидную группу, азиридиновую группу и изоцианатную группу.
6. Способ по п.1, отличающийся тем, что реакционноспособная группа представляет собой аминогруппу, а комплементарную реакционноспособную группу выбирают из группы, включающей альдегидную группу и кетогруппу.
7. Способ по п.6, отличающийся тем, что реакцию между реакционноспособной группой и комплементарной реакционноспособной группой проводят в восстанавливающих условиях.
8. Способ по п.1, отличающийся тем, что реакционноспособную группу и комплементарную реакционноспособную группу независимо выбирают из группы, включающей фосфорилидную, альдегидную и кетогруппу.
9. Способ по п.1, отличающийся тем, что реакцию между реакционноспособной группой и комплементарной реакционноспособной группой проводят в условиях циклоприсоединения с образованием циклической структуры.
10. Способ по п.9, отличающийся тем, что реакционноспособную группу и комплементарную реакционноспособную группу независимо выбирают из группы, включающей алкин и азид.
11. Способ по п.9, отличающийся тем, что реакционноспособную группу и комплементарную реакционноспособную группу независимо выбирают из группы, включающей галогенированную гетероароматическую группу и нуклеофил.
12. Способ по п.11, отличающийся тем, что галогенированную гетероароматическую группу выбирают из группы, включающей хлорированные пиримидины, хлорированные триазины и хлорированные пурины.
13. Способ по п.11, отличающийся тем, что нуклеофил представляет собой аминогруппу.
14. Способ по п.1, отличающийся тем, что фермент выбирают из группы, состоящей из ДНК-лигазы, РНК-лигазы, ДНК-полимеразы, РНК-полимеразы и топоизомеразы.
15. Способ по п.1, отличающийся тем, что исходный олигонуклеотид содержит последовательность праймера ПЦР.
16. Способ по п.1, отличающийся тем, что вводимый олигонуклеотид характеризуется длиной от 3 до 10 нуклеотидов.
17. Способ по п.2, отличающийся тем, что вводимый олигонуклеотид в последнем цикле содержит концевой праймер ПЦР.
18. Способ по п.1, отличающийся тем, что лигирование олигонуклеотида, содержащего концевую олигонуклеотидную последовательность с кодирующим нуклеотидом, проводят в присутствии фермента, катализирующего указанное лигирование.
19. Способ по п.2, отличающийся тем, что после завершения последнего цикла дополнительно осуществляют стадию циклизации функционального компонента.
20. Способ по п.19, отличающийся тем, что функциональный компонент содержит алкинильную группу и азидную группу, а соединение обрабатывают в условиях, пригодных для циклоприсоединения алкинильной группы и азидной группы с образованием триазольной группы, и приводящих к циклизации функционального компонента.
21. Способ по п.1, отличающийся тем, что связующее звено содержит первую функциональную группу, которая способна связываться со структурным фрагментом, вторую функциональную группу, способную связываться с 5'-концевым участком олигонуклеотида, и третью функциональную группу, способную связываться с 3"-концевым участком олигонуклеотида.
22. Способ по п.1, отличающийся тем, что связующее звено представляет собой группу формулы
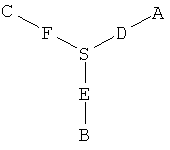
где А означает функциональную группу, ковалентно связанную со структурным фрагментом,
В означает функциональную группу, связанную с 5'-концевым участком олигонуклеотида,
С означает функциональную группу, связанную с 3'-концевым участком олигонуклеотида,
S означает атом или многоатомный каркас,
D означает химическую структуру, соединяющую группу А с группой S,
Е означает химическую структуру, соединяющую группу В с группой S, и
F означает химическую структуру, соединяющую группу С с группой S.
23. Способ по п.22, отличающийся тем, что
А означает аминогруппу,
В означает фосфатную группу и
С означает фосфатную группу.
24. Способ по п.22, отличающийся тем, что D, Е и F каждый независимо выбран из группы, включающей алкиленовую группу или олиго(этиленгликольную) группу.
25. Способ по п.23, отличающийся тем, что S выбран из группы, включающей атом углерода, атом азота, атом фосфора, атом бора, фосфатную группу, циклическую группу или полициклическую группу.
26. Способ по п.22, отличающийся тем, что связующее звено означает группу формулы
где каждый n, m и p независимо равен целому числу от 1 до приблизительно 20.
27. Способ по п.26, отличающийся тем, что каждый n, m и p независимо равен целому числу от 2 до 8.
28. Способ по п.27, отличающийся тем, что каждый n, m и p независимо равен целому числу от 3 до 6.
29. Способ по п.27, отличающийся тем, что связующее звено означает группу формулы
30. Способ по п.1, отличающийся тем, что реакции проводят в растворе.
31. Способ по п.1, отличающийся тем, что полученное соединение является полимерным.
32. Способ по п.1, отличающийся тем, что полученное соединение является неполимерным.
33. Способ по п.1, отличающийся тем, что указанная концевая последовательность содержит последовательность 3'-AAGTCGCAAGCTNNNNNGTCTGTTCGAAGTGGACG-5', где N независимо выбирают из группы, включающей А, Т, G и С.
34. Способ по п.1, отличающийся тем, что указанная концевая последовательность содержит последовательность 3'-AAGTCGCAAGCTACGABBBABBBABBBAGACTACCGCGCTCCCTCCG-5', где В независимо выбирают из группы, включающей Т, G и С.
35. Способ получения библиотеки бифункциональных соединений, содержащих функциональный компонент, эффективно связанный с кодирующим олигонуклеотидом, причем функциональный компонент содержит по меньшей мере два структурных фрагмента, а кодирующий олигонуклеотид определяет структуру функционального компонента, отличающийся тем, что он включает следующие стадии:
1) получают исходный раствор, включающий по меньшей мере одно соединение-инициатор, содержащее функциональный компонент, эффективно связанный с исходным двухцепочечным олигонуклеотидом посредством связующего звена, причем функциональный компонент содержит реакционноспособную группу и n структурных фрагментов, где n равно целому числу 1 или более, исходный олигонуклеотид определяет структуру n структурных фрагментов, а связующее звено образует ковалентную связь с исходным функциональным компонентом и обеими цепями исходного олигонуклеотида,
2) помещают аликвотные части полученного на стадии 1) раствора в по меньшей мере два реакционных сосуда,
3) осуществляют взаимодействие соединений-инициаторов в каждом реакционном сосуде с требуемым структурным фрагментом, который содержит по меньшей мере одну реакционноспособную группу, комплементарную реакционноспособной группе функционального компонента соединения-инициатора, в пригодных для образования ковалентной связи между функциональным компонентом и требуемым структурным фрагментом условиях с образованием соединений, содержащих функциональный компонент, включающий n+1 структурных фрагментов и эффективно связанный с исходным олигонуклеотидом,
4) осуществляют взаимодействие исходного олигонуклеотида в составе каждой аликвотной части с одним вводимым олигонуклеотидом в присутствии фермента, который катализирует лигирование вводимого и исходного олигонуклеотидов с образованием результирующего олигонуклеотида, причем последний вводимый олигонуклеотид содержит концевую нуклеотидную последовательность, включающую вырожденные нуклеотиды, или последний вводимый олигонуклеотид лигирован с указанной концевой олигонуклеотидной последовательностью, включающей вырожденные нуклеотиды,
при этом по крайней мере в одном цикле стадия 4) предшествует стадии 3), и в результате получают по меньшей мере две аликвотные части, содержащие бифункциональные соединения, имеющие в своем составе функциональный компонент, включающий n+1 структурных фрагментов и эффективно связанный с удлиненным кодирующим олигонуклеотидом, который определяет структуру n+1 структурных фрагментов.
36. Способ по п.35, отличающийся тем, что по меньшей мере две полученные аликвотные части дополнительно объединяют с образованием единого раствора.
37. Способ по п.35, отличающийся тем, что все полученные аликвотные части объединяют.
38. Способ по п.35, отличающийся тем, что по меньшей мере две полученные аликвотные части дополнительно объединяют с получением единого раствора, включающего по меньшей мере одно соединение-инициатор, которое используется в качестве исходного раствора для выполнения по меньшей мере одного повторного цикла стадий по п.34.
39. Способ по п.35, отличающийся тем, что по крайней один структурный фрагмент означает аминокислоту.
40. Способ по п.35, отличающийся тем, что фермент выбран из группы, содержащей ДНК-лигазу, РНК-лигазу, ДНК-полимеразу, РНК-полимеразу или топоизомеразу.
41. Способ по п.35, отличающийся тем, что вводимый олигонуклеотид является двухцепочечным.
42. Способ по п.35, отличающийся тем, что связующее звено содержит первую функциональную группу, связанную со структурным фрагментом, вторую функциональную группу, связанную с 5'-концевым участком олигонуклеотида, и третью функциональную группу, связанную с 3'-концевым участком олигонуклеотида.
43. Способ по п.35, отличающийся тем, что связующее звено является структурой формулы
где А означает функциональную группу, которая может образовывать ковалентную связь со структурным фрагментом,
В означает функциональную группу, которая может образовывать связь с 5'-концевым участком олигонуклеотида,
С означает функциональную группу, которая может образовывать связь с 3'-концевым участком олигонуклеотида,
S означает атом или многоатомный каркас,
D означает химическую структуру, соединяющую группу А с группой S,
Е означает химическую структуру, соединяющую группу В с группой S, и
F означает химическую структуру, соединяющую группу С с группой S.
44. Способ по п.43, отличающийся тем, что
А означает аминогруппу,
В означает фосфатную группу и
С означает фосфатную группу.
45. Способ по п.43, отличающийся тем, что D, Е и F каждый независимо выбран из группы, включающей алкиленовую группу или олиго(этиленгликольную) группу.
46. Способ по п.43, отличающийся тем, что S выбран из группы, включающей атом углерода, атом азота, атом фосфора, атом бора, фосфатную группу, циклическую группу или полициклическую группу.
47. Способ по п.46, отличающийся тем, что связующее звено означает группу формулы
где каждый n, m и p независимо равен целому числу от 1 до приблизительно 20.
48. Способ по п.47, отличающийся тем, что каждый n, m и p независимо равен целому числу от 2 до 8.
49. Способ по п.48, отличающийся тем, что каждый n, m и p независимо равен целому числу от 3 до 6.
50. Способ по п.47, отличающийся тем, что связующее звено означает группу формулы
51. Способ по п.35, отличающийся тем, что реакционноспособная группа представляет собой аминогруппу, а комплементарную реакционноспособную группу выбирают из группы, состоящей из карбоксильной группы, сульфонильной группы, фосфонильной группы, эпоксидной группы, азиридиновой группы и изоцианатной группы.
52. Способ по п.35, отличающийся тем, что реакционноспособную группу и комплементарную реакционноспособную группу выбирают из группы, включающей гидроксильную группу, карбоксильную группу, сульфонильную группу, фосфонильную группу, эпоксидную группу, азиридиновую группу и изоцианатную группу.
53. Способ по п.35, отличающийся тем, что реакционноспособная группа представляет собой аминогруппу, а комплементарную реакционноспособную группу выбирают из группы, включающей альдегидную и кетогруппу.
54. Способ по п.35, отличающийся тем, что реакцию между реакционноспособной группой и комплементарной реакционноспособной группой проводят в восстанавливающих условиях.
55. Способ по п.35, отличающийся тем, что реакционноспособную группу и комплементарную реакционноспособную группу независимо выбирают из группы, включающей фосфороилидную группу, альдегидную и кетогруппу.
56. Способ по п.35, отличающийся тем, что реакцию между реакционноспособной группой и комплементарной реакционноспособной группой проводят в условиях циклоприсоединения с образованием циклической структуры.
57. Способ по п.56, отличающийся тем, что реакционноспособную группу и комплементарную реакционноспособную группу независимо выбирают из группы, включающей алкин и азид.
58. Способ по п.35, отличающийся тем, что реакционноспособную группу и комплементарную реакционноспособную группу выбирают из группы, включающей галогенированную гетероароматическую группу и нуклеофил.
59. Способ по п.58, отличающийся тем, что галогенированную гетероароматическую группу выбирают из группы, включающей хлорированные пиримидины, хлорированные триазины и хлорированные пурины.
60. Способ по п.59, отличающийся тем, что нуклеофилом является аминогруппа.
61. Способ по п.35, отличающийся тем, что после завершения последнего цикла дополнительно осуществляют стадию циклизации по меньшей мере одного функционального компонента.
62. Способ по п.61, отличающийся тем, что функциональный компонент на стадии циклизации содержит азидную группу и алкинильную группу.
63. Способ по п.62, отличающийся тем, что функциональный компонент обрабатывают в условиях, пригодных для циклоприсоединения азидной и алкинильной групп с образованием триазольной группы, приводящих к циклизации функционального компонента.
64. Способ по п.63, отличающийся тем, что реакцию циклоприсоединения проводят в присутствии медного катализатора.
65. Способ по п.64, отличающийся тем, что по меньшей мере один функциональный компонент на стадии циклизации содержит по меньшей мере две сульфгидрильные группы, и упомянутый функциональный компонент обрабатывают в условиях, пригодных для взаимодействия двух сульфгидрильных групп с образованием дисульфидной связи, при этом получают циклический функциональный компонент.
66. Способ по п.35, отличающийся тем, что исходный олигонуклеотид содержит последовательность праймера ПЦР.
67. Способ по п.35, отличающийся тем, что проводят лигирование олигонуклеотида, содержащего концевую олигонуклеотидную последовательность, с кодирующим олигонуклеотидом в присутствии фермента, катализирующего указанное лигирование.
68. Способ по п.35, отличающийся тем, что реакции проводят в растворе.
69. Способ по п.35, отличающийся тем, что полученное соединение является полимерным.
70. Способ по п.35, отличающийся тем, что полученное соединение является неполимерным.
71. Способ по п.35, отличающийся тем, что указанная концевая последовательность содержит последовательность 3'-AAGTCGCMGCTNNNNNGTCTGTTCGMGTGGACG-5', где N независимо выбирают из группы, включающей А, Т, G и С.
72. Способ по п.35, отличающийся тем, что указанная концевая последовательность содержит последовательность 3'-AAGTCGCAAGCTACGABBBABBBABBBAGACTACCGCGCTCCCTCCG-5', где В независимо выбирают из группы, включающей Т, G и С.
73. Бифункциональное соединение для идентификации соединений, обладающих искомыми свойствами, содержащее функциональный компонент, который эффективно связан с олигонуклеотидом, определяющим структуру функционального компонента, формулы
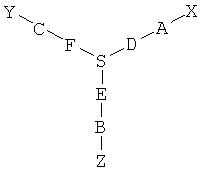
где Х означает функциональный компонент, содержащий по меньшей мере один структурный фрагмент,
Z означает олигонуклеотид, соединенный по 3'-концевому участку с группой В,
Y означает олигонуклеотид, соединенный по 5'-концевому участку с группой С,
А означает функциональную группу, которая образует ковалентную связь с Х,
В означает функциональную группу, которая образует связь с 3'-концевым участком олигонуклеотида Z,
С означает функциональную группу, которая образует связь с 5'-концевым участком олигонуклеотида Y,
D, F и Е каждый независимо означает бифункциональную связующую группу, а
S означает атом или многоатомный каркас, причем А, В, С, D, Е, F и S составляют связующее звено, функциональный компонент и Y и Z соединены ковалентной связью посредством связующего звена и Y и Z содержат концевую последовательность, которая включает вырожденные нуклеотиды.
74. Соединение по п.73, отличающееся тем, что D, F и Е каждый независимо выбраны из группы, состоящей из алкиленовой цепи или олиго(этиленгликольной) цепи.
75. Соединение по п.73, отличающееся тем, что Y и Z являются в основном комплементарными и ориентированы в соединении таким образом, чтобы в пригодных условиях обеспечивать образование пары Уотсона-Крика и дуплекс.
76. Соединение по п.73, отличающееся тем, что Y и Z имеют одинаковую или различную длину.
77. Соединение по п.73, отличающееся тем, что каждый Y и Z характеризуется длиной по меньшей мере 10 оснований, и содержит комплементарные участки длиной по меньшей мере 10 пар оснований.
78. Соединение по п.73, отличающееся тем, что S выбран из группы, состоящей из атома углерода, атома бора, атома азота, атома фосфора и многоатомного каркаса.
79. Соединение по п.73, отличающееся тем, что S выбран из группы, включающей фосфатную группу или циклическую группу.
80. Соединение по п.79, отличающееся тем, что S выбран из группы, включающей циклоалкил, циклоалкенил, гетероциклоалкил, гетероциклоалкенил, арил и гетероарил.
81. Соединение по п.73, отличающееся тем, что связующее звено означает группу формулы
где каждый n, m и p независимо равен целому числу от 1 до приблизительно 20.
82. Соединение по п.81, отличающееся тем, что каждый n, m и р независимо равен целому числу от 2 до 8.
83. Соединение по п.82, отличающееся тем, что каждый n, m и р независимо равен целому числу от 3 до 6.
84. Соединение по п.73, отличающееся тем, что связующее звено означает группу формулы
85. Соединение по п.73, отличающееся тем, что Х и Y содержат последовательность праймера ПЦР.
86. Библиотека бифункциональных соединений для идентификации соединений, обладающих искомыми свойствами, включающая по крайней мере порядка 102 отдельных соединений, содержащих функциональный компонент, который эффективно связан с двуцепочечным олигонуклеотидом, причем функциональный компонент содержит по меньшей мере два структурных фрагмента, а двуцепочечный олигонуклеотид определяет структуру функционального компонента и содержит в по меньшей мере одной цепи концевую нуклеотидную последовательность, включающую вырожденные нуклеотиды.
87. Библиотека соединений по п.86, отличающаяся тем, что она содержит по крайней мере порядка 105 копий каждого из отдельных соединений.
88. Библиотека соединений по п.86, отличающаяся тем, что она содержит по крайней мере порядка 106 копий каждого из отдельных соединений.
89. Библиотека соединений по п.86, отличающаяся тем, что она содержит по крайней мере порядка 104 отдельных соединений.
90. Библиотека соединений по п.86, отличающаяся тем, что она содержит по крайней мере порядка 106 отдельных соединений.
91. Библиотека соединений по п.86, отличающаяся тем, что она содержит по крайней мере порядка 108 отдельных соединений.
92. Библиотека соединений по п.86, отличающаяся тем, что она содержит по крайней мере порядка 1010 отдельных соединений.
93. Библиотека соединений по п.86, отличающаяся тем, что она содержит по крайней мере порядка 1012 отдельных соединений.
94. Библиотека соединений по п.86, отличающаяся тем, что она содержит множество соединений, которые независимо представлены формулой I
где Х означает функциональный компонент, содержащий один или более структурных фрагментов,
Z означает олигонуклеотид, соединенный по 3'-концевому участку с группой В,
Y означает олигонуклеотид, соединенный по 5'-концевому участку с группой С,
А означает функциональную группу, которая образует ковалентную связь с X,
В означает функциональную группу, которая образует связь с 3'-концевым участком олигонуклеотида Z,
С означает функциональную группу, которая образует связь с 5'-концевым участком олигонуклеотида Y,
D, F и Е каждый независимо означает бифункциональную связующую группу, а
S означает атом или многоатомный каркас, причем А, В, С, D, Е, F и S составляют связующее звено, а функциональный компонент и Y и Z соединены ковалентной связью посредством связующего звена.
95. Библиотека соединений по п.86, отличающаяся тем, что каждый из А, В, С, D, Е, F и S имеет одинаковое значение во всех соединениях формулы I.
96. Библиотека соединений по п.86, отличающаяся тем, что она содержит в основном множество соединений формулы I.
97. Библиотека соединений по п.86, отличающаяся тем, что D, F и Е каждый независимо выбраны из группы, состоящей из алкиленовой цепи и олиго(этиленгликольной) цепи.
98. Библиотека соединений по п.86, отличающаяся тем, что Y и Z являются в основном комплементарными и ориентированы в соединении таким образом, чтобы в пригодных условиях обеспечивать образование пары Уотсона-Крика и дуплекс.
99. Библиотека соединений по п.86, отличающаяся тем, что Y и Z имеют одинаковую или различную длину.
100. Библиотека соединений по п.86, отличающаяся тем, что каждый Y и Z характеризуется длиной по меньшей мере 10 оснований и содержит комплементарные участки длиной по меньшей мере 10 пар оснований.
101. Библиотека соединений по п.86, отличающаяся тем, что S выбран из группы, состоящей из атома углерода, атома бора, атома азота, атома фосфора и многоатомного каркаса.
102. Библиотека соединений по п.86, отличающаяся тем, что S выбран из группы, включающей фосфатную группу или циклическую группу.
103. Библиотека соединение по п.102, отличающаяся тем, что S выбран из группы, включающей циклоалкил, циклоалкенил, гетероциклоалкил, гетероциклоалкенил, арил и гетероарил.
104. Библиотека соединений по п.86, отличающаяся тем, что связующее звено означает группу формулы
где каждый n, m и p независимо равен целому числу от 1 до приблизительно 20.
105. Библиотека соединений по п.104, отличающаяся тем, что каждый n, m и p независимо равен целому числу от 2 до 8.
106. Библиотека соединений по п.105, отличающаяся тем, что каждый n, m и p независимо равен целому числу от 3 до 6.
107. Библиотека соединений по п.94, отличающаяся тем, что связующее звено означает группу формулы
108. Библиотека соединений по п.94, отличающаяся тем, что Y и Z содержат последовательность праймера ПЦР.
109. Способ идентификации по меньшей мере одного соединения, связывающегося с биологической мишенью, отличающийся тем, что
1) осуществляют контактирование биологической мишени с соединением библиотеки, полученной способом по п.35, в условиях, пригодных для связывания по крайней мере одного члена библиотеки с мишенью,
2) отделяют те члены библиотеки, которые не связаны с мишенью,
3) амплифицируют кодирующие олигонуклеотиды, которые определяют структуру функционального компонента, по крайней мере одного соединения, связанного с мишенью,
4) секвенируют амплифицированные олигонуклеотиды, и
5) определяют структуры функциональных компонентов, входящих в состав соединений библиотеки, которые связываются с биологической мишенью с использованием последовательностей, определенных при секвенировании амплифицированных олигонуклеотидов.
110. Способ идентификации соединения, связывающегося с биологической мишенью, отличающийся тем, что
1) осуществляют контактирование биологической мишени с соединением библиотеки по п.86 в условиях, пригодных для связывания по крайней мере одного члена библиотеки с мишенью,
2) отделяют те члены библиотеки, которые связаны с мишенью,
3) амплифицируют олигонуклеотиды, которые определяют структуру функционального компонента, по крайней мере одного соединения библиотеки, связанного с мишенью,
4) секвенируют амплифицированные олигонуклеотиды, и
5) определяют структуры функциональных компонентов, входящих в состав соединений библиотеки, которые связываются с биологической мишенью, с использованием последовательностей, определенных при секвенировании амплифицированных олигонуклеотидов.
111. Способ по п.110, отличающийся тем, что библиотека соединений содержит по крайней мере порядка 105 копий каждого из отдельных соединений.
112. Способ по п.110, отличающийся тем, что библиотека соединений содержит по крайней мере порядка 106 копий каждого из отдельных соединений.
113. Способ по п.110, отличающийся тем, что библиотека соединений содержит по крайней мере порядка 104 отдельных соединений.
114. Способ по п.110, отличающийся тем, что библиотека соединений содержит по крайней мере порядка 106 отдельных соединений.
115. Способ по п.110, отличающийся тем, что библиотека соединений содержит по крайней мере порядка 108 отдельных соединений.
116. Способ по п.110, отличающийся тем, что библиотека соединений содержит по крайней мере порядка 1010 отдельных соединений.
117. Способ по п.110, отличающийся тем, что библиотека соединений содержит по крайней мере порядка 1012 отдельных соединений.
118. Способ по п.110, отличающийся тем, что библиотека соединений содержит множество соединений, которые независимо представлены формулой I
где Х означает функциональный компонент, содержащий один или более структурных фрагментов,
Z означает олигонуклеотид, соединенный по 3'-концевому участку с группой В,
Y означает олигонуклеотид, соединенный по 5'-концевому участку с группой С,
А означает функциональную группу, которая образует ковалентную связь с Х,
В означает функциональную группу, которая образует связь с 3'-концевым участком олигонуклеотида Z,
С означает функциональную группу, которая образует связь с 5'-концевым участком олигонуклеотида Y,
D, F и Е каждый независимо означает бифункциональную связующую группу, а
S означает атом или многоатомный каркас, причем А, В, С, D, Е, F и S составляют связующее звено, а функциональный компонент и Y и Z соединены ковалентной связью посредством связующего звена.
119. Способ по п.118, отличающийся тем, что каждый из А, В, С, D, Е, F и S имеет одинаковое значение для каждого соединения формулы I.
120. Способ по п.118, отличающийся тем, что библиотека соединений содержит в основном множество соединений формулы I.
121. Способ по п.118, отличающийся тем, что D, F и Е каждый независимо выбирают из группы, включающей алкиленовую цепь или олиго(этиленгликольную) цепь.
122. Способ по п.118, отличающийся тем, что Y и Z являются в основном комплементарными и ориентированы в соединении таким образом, чтобы обеспечивать образование пары Уотсона-Крика и дуплекс в пригодных условиях.
123. Способ по п.118, отличающийся тем, что Y и Z имеют одинаковую или различную длину.
124. Способ по п.118, отличающийся тем, что каждый Y и Z содержит по меньшей мере 10 оснований и комплементарные участки, содержащие по меньшей мере 10 или более пар оснований.
125. Способ по п.118, отличающийся тем, что S выбран из группы, включающей атом углерода, атом бора, атом азота, атом фосфора и многоатомный каркас.
126. Способ по п.118, отличающийся тем, что S выбран из группы, включающей фосфатную группу или циклическую группу.
127. Способ по п.126, отличающийся тем, что S выбран из группы, включающей циклоалкил, циклоалкенил, гетероциклоалкил, гетероциклоалкенил, арил и гетероарил.
128. Способ по п.118, отличающийся тем, что связующее звено является структурой формулы
где каждый n, m и p независимо равен целому числу от 1 до приблизительно 20.
129. Способ по п.126, отличающийся тем, что каждый n, m и p независимо равен целому числу от 2 до 8.
130. Способ по п.127, отличающийся тем, что каждый n, m и p независимо равен целому числу от 3 до 6.
131. Способ по п.130, отличающийся тем, что связующее звено является структурой формулы
132. Способ п.118, отличающийся тем, что Y и Z включают последовательность праймера ПЦР.
| WO 9320242, 14.10.1994 | |||
| WO 2004039825, 13.05.2004 | |||
| WO 2004083427, 30.09.2004. |

