ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Настоящее изобретение относится, в общем, к компьютерно-реализованным онлайновым поискам и, в частности, к идентификации семантических взаимоотношений в косвенной речи.
ПРЕДШЕСТВУЮЩИЙ УРОВЕНЬ ТЕХНИКИ
Онлайновые механизмы поиска стали в большой мере важным инструментом для ведения исследований или перемещения среди документов, доступных через Интернет. Часто онлайновые механизмы поиска выполняют процесс определения совпадения для обнаружения возможных документов или текста внутри таких документов, для чего используется запрос, даваемый пользователем. Первоначально процесс определения совпадения, предлагаемый обычными онлайновыми механизмами поиска, такими как те, которые поддерживают Google или Yahoo, позволяет пользователю указать в запросе одно или более ключевых слов, чтобы описать информацию, которую он или она ищет. Затем традиционный онлайновый механизм поиска переходит к нахождению всех документов, которые содержат точные совпадения с ключевыми словами, хотя эти документы обычно не обеспечивают релевантные или значимые результаты в ответ на запрос.
Существующие традиционные онлайновые механизмы поиска ограничены тем, что в просмотренных при поиске документах они не распознают слова, соответствующие ключевым словам в запросе, выходящие за рамки точного совпадения, получаемого в процессе определения совпадения. Кроме того, традиционные онлайновые механизмы поиска ограничены, поскольку пользователь ограничен ключевыми словами в запросе, для которых должно быть найдено совпадение, и, таким образом, пользователю не дается возможности точно выразить желаемую информацию, если она неизвестна. Соответственно, реализация механизма поиска на естественном языке, чтобы распознать семантические взаимоотношения между ключевыми словами запроса и словами в просмотренных при поиске документах, могла бы однозначно повысить точность результатов поиска.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Настоящий раздел "Сущность изобретения" предоставлен для введения выборки концепций в упрощенной форме, которые дополнительно описаны ниже в разделе "Подробное описание". Раздел "Сущность изобретения" не предназначен идентифицировать ключевые признаки или существенные признаки заявленного объекта изобретения, а также не предназначен для использования в качестве помощи при определении объема заявленного объекта изобретения.
Варианты осуществления настоящего изобретения относятся к способам, осуществляемым на компьютерной основе, и считываемым компьютером носителям для построения ассоциаций между различными словами, найденными в содержимом документов, извлеченных из Web-сети или некоторого другого репозитория, а также терминами, содержащимися в запросе поиска. Содержимое, которое может быть семантически представлено, может быть косвенной речью и другими сообщениями об отношении, так чтобы семантическое представление содержимого могло быть сравнено с принятыми запросами на естественном языке для предоставления пользователю значимых и высоко релевантных результатов. Семантические взаимоотношения, такие как взаимоотношения "о чем" ("about"), могут идентифицироваться между определенными элементами или поисковыми терминами, чтобы позволить формирование конкретных словесных ассоциаций. Когда семантические взаимоотношения сформированы, может быть создано семантическое представление для содержимого документа и может быть создано высказывание для запроса поиска, каждое из которых позволяет быстрое сравнение высказывания с одним или более семантическими взаимоотношениями для определения наиболее релевантных результатов поиска.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Ниже подробно описаны варианты осуществления настоящего изобретения со ссылкой на прилагаемые чертежи, на которых:
Фиг.1 - блок-схема примера компьютерной среды, пригодной для использования при реализации вариантов осуществления настоящего изобретения;
Фиг.2 - схема примера системной архитектуры, пригодной для использования при реализации вариантов осуществления настоящего изобретения;
Фиг.3 - схема семантического представления, созданного из текстовой части внутри документа, соответствующая варианту осуществления настоящего изобретения;
Фиг.4 - схема семантического представления, созданного из текстовой части внутри документа, соответствующая варианту осуществления настоящего изобретения;
Фиг.5 - схема семантического представления, созданного из текстовой части внутри документа, соответствующая варианту осуществления настоящего изобретения;
Фиг.6 - схема семантического представления, созданного из текстовой части внутри документа, соответствующая варианту осуществления настоящего изобретения;
Фиг.7 - схема высказывания, созданного из запроса поиска в соответствии с вариантом осуществления настоящего изобретения;
Фиг.8 - схема семантического представления, созданного из текстовой части внутри документа, причем текстовая часть содержит два высказывания, соответствующая варианту осуществления настоящего изобретения;
Фиг.9 - блок-схема последовательности выполнения операций способа построения семантических взаимоотношений между элементами, извлеченными из содержимого документа, соответствующая варианту осуществления настоящего изобретения;
Фиг.10 - блок-схема последовательности выполнения операций способа создания, в ответ на получение запроса, ассоциаций между различными терминами, извлеченными из запроса для создания высказывания, соответствующая варианту осуществления настоящего изобретения; и
Фиг.11 - блок-схема последовательности выполнения операций способа построения семантических взаимоотношений между элементами, извлеченными из содержимого документа, соответствующая варианту осуществления настоящего изобретения.
ПОДРОБНОЕ ОПИСАНИЕ
Объект настоящего изобретения описывается здесь конкретно, чтобы выполнить установленные законом требования. Однако само по себе описание не предназначено ограничивать объем настоящего патента. Скорее изобретатели подразумевали, что заявленный объект изобретения мог бы быть также осуществлен другими способами, содержать другие этапы или комбинации этапов, подобных тем, которые описаны в настоящем документе, в сочетании с другими существующими или будущими технологиями. Кроме того, хотя термины "этап" и/или "блок" могут использоваться здесь, чтобы означать различные элементы используемых способов, термины не должны интерпретироваться как подразумевающие какой-либо конкретный порядок различных этапов, раскрытых здесь, если и кроме тех случаев, когда порядок следования индивидуальных этапов описан в явном виде.
Соответственно, в одном аспекте обеспечивается способ, осуществляемый на компьютерной основе, для разработки семантических взаимоотношений между элементами, выделенными из содержимого документа, для создания семантического представления содержимого для индексирования. Первоначально способ содержит идентификацию текстовой части документа, которая должна индексироваться, и определение семантической информации для множества элементов, идентифицированных в текстовой части. Семантическая информация может содержать одно или более значений идентифицированных элементов или грамматические и/или семантические взаимоотношения между идентифицированными элементами. По меньшей мере, один из идентифицированных элементов может быть идентифицирован как действие по сообщению информации, соответствующей косвенной речи или сообщению об отношении. Способ дополнительно содержит ассоциирование идентифицированных элементов так, что каждая ассоциация идентифицированных элементов представляет определенные семантические взаимоотношения, основываясь на определенной семантической информации идентифицированных элементов. Дополнительно, способ содержит создание семантического представления, содержащего ассоциации идентифицированных элементов.
В другом аспекте обеспечивается способ, осуществляемый на компьютерной основе, в котором в ответ на получение запроса на естественном языке, создаются ассоциации между различными терминами, выделенными из запроса, чтобы создать высказывание. Высказывание может использоваться для опроса семантических представлений содержимого из документов, хранящихся в семантическом индексе, чтобы обеспечить релевантные результаты поиска. Способ также содержит определение ассоциированной семантической информации для одного или более поисковых терминов, найденных в пределах запроса. Первое действие по сообщению информации может быть определено в пределах запроса и семантические взаимоотношения могут быть сформированы между первым действием по сообщению информации и, по меньшей мере, одним из поисковых терминов, основываясь на определенной семантической информации для этого поискового термина. Созданная ассоциация между первым действием по сообщению информации и поисковым термином образуется посредством реляционного элемента, описывающего семантические взаимоотношения. Наконец, высказывание, содержащее сформированные ассоциации, может быть создано и может дополнительно сравниваться с семантическими представлениями, чтобы определить высоко релевантные результаты поиска.
Еще в одном аспекте обеспечиваются один или более считываемых компьютером носителей, на которых содержатся команды, исполняемые компьютером для выполнения способа построения семантических взаимоотношений между элементами, выделенными из содержимого документа, чтобы создать семантическое представление содержимого, которое должно индексироваться. Первоначально, способ содержит идентификацию, по меньшей мере, части документа или текстовой части, которые должны быть индексированы. Текстовая часть может затем быть проанализирована, чтобы идентифицировать элементы, которые должны быть семантически представлены. Потенциальные значения и грамматические или семантические взаимоотношения между идентифицированными элементами определяются в дополнение к определению одного или более уровней ассоциации в пределах текстовой части. Способ также содержит идентификацию действия по сообщению информации в пределах текстовой части для каждого одного или более определенных уровней ассоциации, так что первое действие по сообщению информации может ассоциироваться с первым набором идентифицированных элементов. Первое действие по сообщению информации может быть связано с первым уровнем ассоциации. Точно также, второе действие по сообщению информации может быть связано со вторым набором идентифицированных элементов, причем второе действие по сообщению информации ассоциируется со вторым уровнем ассоциации. Дополнительно может создаваться содержащее ассоциации семантическое представление, используя реляционный элемент, описывающий ассоциации между первым набором идентифицированных элементов и первым действием по сообщению информации и между вторым набором идентифицированных элементов и вторым действием по сообщению информации.
Кратко описанный обзор вариантов осуществления настоящего изобретения и некоторые из его признаков являются примером рабочей среды, пригодной для осуществления настоящего изобретения, описанного ниже.
Со ссылкой на чертежи, в целом, и, прежде всего, в частности, на фиг.1, показан пример рабочей среды для реализации вариантов осуществления настоящего изобретения, которая, в целом, определяется как компьютерное устройство 100. Компьютерное устройство 100 является всего лишь одним примером подходящей компьютерной среды и не предназначено предлагать какое-либо ограничение относительно объема использования или функциональных возможностей изобретения. Компьютерное устройство 100 никак не должно интерпретироваться как обладающее какой-либо зависимостью или создающее какое-либо требование, относящееся к любому из показанных компонент или их комбинации.
Изобретение может быть описано в общем контексте машинного кода или машинно-используемых команд, содержащих исполняемые компьютером команды, такие как программные компоненты, выполняемые компьютером или другим устройством, таким как карманный компьютер или другое карманное устройство. В целом, программные компоненты, содержащие подпрограммы, программы, объекты, компоненты, структуры данных и т.п., относятся к коду, который выполняет конкретные задачи или реализует конкретные абстрактные типы данных. Варианты осуществления настоящего изобретения могут быть осуществлены с помощью множества системных конфигураций, в том числе, карманные устройства, бытовая электроника, универсальные компьютеры, специальные компьютерные устройства и т.д. Варианты осуществления изобретения могут также быть реализованы в распределенных компьютерных средах, где задачи выполняются дистанционно обрабатывающими устройствами, которые связаны через сеть связи.
Продолжая обращаться к фиг.1, компьютерное устройство 100 содержит шину 110, которая прямо или косвенно соединяет следующие устройства: запоминающее устройство 112, один или более процессоров 114, один или более компонентов 116 представления, порты 118 ввода-вывода (I/O), компоненты 120 I/O и пример источника 122 электропитания. Шина 110 может быть представлена одной или более шинами (такими как адресная шина, шина данных или их комбинация). Хотя различные блоки на фиг.1 для ясности очерчены линиями, в действительности, очерчивание различных компонентов не столь конкретно и, если быть более точными, линии должны быть серыми и нечеткими. Например, можно рассматривать компонент представления, такой как устройство отображения, как компонент ввода-вывода. Кроме того, процессоры имеют запоминающее устройство. Изобретатели признают, что таков характер техники и снова повторяют, что схема на фиг.1 является просто примером компьютерного устройства, которое может использоваться в связи с одним или более вариантами осуществления настоящего изобретения. Между такими категориями как "рабочая станция", "сервер", "ноутбук", "карманное устройство" и т.д. различия не делается, поскольку все они считаются попадающими в рамки фиг.1 как ссылка на "компьютер" или "компьютерное устройство".
Компьютерное устройство 100 обычно содержит множество считываемых компьютером носителей. Для примера, но не для ограничения, считываемые компьютером носители могут содержать оперативное запоминающее устройство (RAM); постоянное запоминающее устройство (ROM); электрически стираемое программируемое постоянное запоминающее устройство (EEPROM); флэш-память или запоминающие устройства, выполненные по другим технологиям; CD-ROM, цифровые универсальные диски (DVD) или другие оптические или голографические носители; магнитные кассеты, магнитные ленты, запоминающие устройства на магнитных дисках или другие магнитные запоминающие устройства; или любой другой носитель, который может использоваться для кодирования желаемой информации и к которому может получать доступ компьютерное устройство 100.
Запоминающее устройство 112 содержит компьютерный носитель данных в форме энергозависимого и/или энергонезависимого запоминающего устройства. Запоминающее устройство может быть съемным, несъемным или их комбинацией. Примеры аппаратурных устройств содержат твердотельные запоминающие устройства, жесткие диски, оптические дисководы и т.д. Компьютерное устройство 100 содержит один или более процессоров, которые считывают данные от различных объектов, таких как запоминающее устройство 112 или компоненты 120 I/O. Компонент(-ы) 116 представления представляют индикацию данных пользователю или другому устройству. Примеры компоненты представления содержат устройство дисплея, громкоговоритель, печатающий компонент, вибрирующий компонент и т.д. Порты 118 I/O позволяют компьютерному устройству 100 логически соединяться с другими устройствами, в том числе, с компонентами 120 I/O, некоторые из которых могут быть встроенными. Примеры компонент содержат микрофон, джойстик, игровую клавиатуру, спутниковую антенну, сканер, принтер, беспроводное устройство и т.д.
Обратимся теперь к фиг.2, на которой показан пример схемы системной архитектуры 200, пригодной для использования при реализации вариантов осуществления настоящего изобретения в соответствии с вариантом осуществления настоящего изобретения. Специалисты в данной области техники должны понимать и оценить, что пример системной архитектуры 200, показанный на фиг.2, является просто примером одной из пригодных компьютерных сред и не предназначен предлагать какое-либо ограничение в отношении объема использования или функциональных возможностей настоящего изобретения. Пример системной архитектуры 200 никак не должен интерпретироваться как обладающий какой-либо зависимостью или выдвигающим требования, относящиеся к какому-либо одиночному компоненту или комбинации компонент, показанных здесь.
Как показано на чертеже, системная архитектура 200 может содержать распределенную компьютерную среду, где устройство 215 клиента оперативно соединяется с механизмом 290 естественного языка, который, в свою очередь, оперативно соединяется с хранилищем 220 данных. В вариантах осуществления настоящего изобретения, которые реализуются в распределенных компьютерных средах, оперативная связь относится к соединению устройства 215 клиента и хранилища 220 данных с механизмом 290 естественного языка и другим онлайновым компонентам через соответствующие соединения. Эти соединения могут быть проводными или беспроводными. Примеры конкретных вариантов осуществления с проводными средствами в пределах объема настоящего изобретения содержат USB-соединения и кабельные соединения через сеть (не показаны) или шину или другой канал, который связывает компоненты в пределах единого механизма. Примеры конкретных беспроводных вариантов осуществления в пределах объема настоящего изобретения содержат беспроводную сеть ближнего действия и радиочастотную технологию.
Следует понять и оценить, что значение выражения "беспроводная сеть ближнего действия" не означает ограничения и должно интерпретироваться широко, чтобы содержать, по меньшей мере, следующие технологии: закрытые беспроводные периферийные устройства (NWP); беспроводные радиоинтерференционные сети ближнего диапазона (например, беспроводная персональная сеть (wPAN), беспроводная локальная сеть (wLAN), беспроводная глобальная сеть (wWAN), технология Bluetooth™, и т.п.); беспроводная одноранговая связь (например, ультраширокополосная радиосвязь); и любой протокол, который поддерживает беспроводную передачу данных между устройствами. Дополнительно, люди, знакомые с областью техники, к которой относится изобретение, должны понимать, что беспроводная сеть ближнего диапазона может быть осуществлена различными способами передачи данных (например, спутниковая передача, сеть передачи данных и т.д.). Поэтому подчеркивается, что варианты осуществления связи между устройством 215 клиента, хранилищем 220 данных и механизмом 290 естественного языка, например, не ограничиваются описанными примерами, но охватывают большое разнообразие способов связи. В другом варианте осуществления компьютерное устройство может внутренне обладать функциональными возможностями компонента 250 семантической интерпретации, тем самым облегчая зависимость от проводной или беспроводной связи.
Примерная системная архитектура 200 содержит устройство 215 клиента, в частности, для поддержки работы устройства 275 представления. В примере варианта осуществления, где устройство 215 клиента является, например, мобильным устройством, устройство представления (например, дисплей с сенсорным экраном) может быть расположено на устройстве 215 клиента. Кроме того, устройство 215 клиента может принимать форму различных типов компьютерных устройств. Только для примера, устройство 215 клиента может быть персональным вычислительным устройством (например, компьютерным устройством 100, показанным на фиг.1), карманным устройством (например, персональным цифровым помощником), мобильным устройством (например, ноутбуком, сотовым телефоном, медиапроигрывателем), электронным устройством потребителя, различными серверами и т.п. Дополнительно, компьютерное устройство может содержать два или более электронных устройства, выполненных с возможностью совместного использования ими информации.
В вариантах осуществления, как обсуждалось выше, устройство 215 клиента содержит или оперативно подключается к устройству 275 представления, выполненному с возможностью представления дисплея 295 интерфейса пользователя (UI) на устройстве 275 представления. Устройство 275 представления может быть выполнено с возможностью представления в виде любого устройства дисплея, которое способно представлять информацию пользователю, такого как монитор, панель электронного дисплея, сенсорный экран, жидкокристаллический дисплей (LCD), плазменный экран, один или более светоизлучающих диодов (LED), лампы накаливания, лазер, электролюминесцентный источник освещения, химический источник света, гибкий световод и/или источник флуоресцентного света или любой другой тип дисплея или может содержать отражающую поверхность, на которую проектируется визуальная информация. Хотя выше были описаны несколько различных конфигураций устройства 275 представления, специалисты в данной области техники должны понимать, что в качестве устройства 275 представления могут использоваться различные типы устройств представления, которые представляют информацию, и что варианты осуществления настоящего изобретения не ограничиваются теми устройствами 275 представления, которым показаны и описаны.
В одном примере варианта осуществления дисплей 295 UI, представляющий устройство 275 представления, выполнен с возможностью представления Web-страницы (не показана), которая связана с механизмом 290 естественного языка и/или создателем содержимого. В вариантах осуществления Web-страница может показывать область входа в поиск, которая принимает запрос, и результаты поиска, которые обнаруживаются посредством поиска семантического индекса с помощью запроса. Запрос может быть предоставлен пользователем вручную в область входа в поиск или может быть создан автоматически программным обеспечением. Кроме того, как более подробно обсуждается ниже, запрос может содержать одно или более ключевых слов, которые, когда предоставлены, принуждают механизм 290 естественного языка идентифицировать соответствующие результаты поиска, которые наиболее соответствуют ключевым словам в запросе.
Механизм 290 естественного языка, показанный на фиг.2, может принимать форму различных типов компьютерных устройств, таких как, например, компьютерное устройство 100, описанное выше со ссылкой на фиг.1. Только для примера и не для создания ограничения, механизм 290 естественного языка может быть персональным компьютером, настольным компьютером, ноутбуком, электронным устройством потребителя, карманным устройством (например, персональный цифровой секретарь), различными удаленными серверами (например, сетевой канал обслуживания сервера), оборудованием обработки и т.п. Следует отметить, однако, что изобретение не ограничивается реализацией на таких компьютерных устройствах, а может быть реализовано на любом из множества различных типов компьютерных устройств в пределах объема вариантов осуществления настоящего изобретения.
Дополнительно, в одном случае, механизм 290 естественного языка выполнен с возможностью работы в качестве механизма поиска, предназначенного для поиска информации в Интернете и/или в хранилище 220 данных и для получения результатов поиска из информации в рамках объема поиска в ответ на предоставление запроса через устройство 215 клиента. В одном варианте осуществления механизм поиска содержит один или более сетевых поисковых агентов, которые исследуют имеющиеся в наличии данные (например, группы новостей, базы данных, открытые каталоги, хранилище 220 данных и т.п.), доступные через Интернет, и создают семантический индекс 260, содержащий адреса вместе с сущностью Web-страниц или других документов, хранящихся в представительном формате. В другом варианте осуществления механизм поиска способен действовать так, чтобы облегчить идентификацию и извлечение результатов поиска (например, листинг, таблица, ранжированный порядок Web-адресов и т.п.) из семантического индекса, которые релевантны поисковым терминам в пределах поданного запроса. К поисковому механизму могут обращаться интернет-пользователи через приложение Web-браузера, расположенное на устройстве 215 клиента. Соответственно, пользователи могут проводить интернет-поиск, вводя поисковые термины в область ввода для поиска (например, показ на дисплее 295 UI, созданный приложением Web-браузера, связанным с механизмом поиска). В другой конфигурации, поиск может проводиться посредством ввода запроса в один или более системных индексов, чтобы извлечь содержимое из местного хранилища банка информации, такого как жесткий диск пользователя.
Хранилище 220 данных обычно выполняется с возможностью хранения информации, связанной с онлайновыми позициями и/или материалами, которые обладают ассоциированным с ним пригодным для поиска содержимым (например, документы, которые содержат Web-сайт Wikipedia). В различных вариантах осуществления такая информация может содержать, в частности, документы, содержимое Web-страниц/сайта, электронные материалы, доступные через Интернет, местную сеть интранет или запоминающее устройство или жесткий диск компьютера пользователя и другие типичные ресурсы, доступные для механизма поиска. Кроме того, хранилище 220 данных может быть выполнено с возможностью поиска для соответствующего доступа к хранящейся информации. В отдельном случае, разрешение соответствующего доступа содержит выбор или фильтрацию подмножества документов в хранилище данных согласно предоставленным критериям.
Например, хранилище 220 данных может быть доступно для поиска одного или более документов, выбранных для обработки механизмом 290 естественного языка. В вариантах осуществления механизму 290 естественного языка разрешается свободно просматривать хранилище данных для документов, которые были недавно добавлены или исправлены, чтобы обновлять семантический индекс. Процесс просмотра может выполняться непрерывно, с заранее определенными интервалами, или после индикации, что произошло изменение в одном или более документах, собранных в хранилище 220 данных. Специалисты в данной области техники должны понимать, что информация, хранящаяся в хранилище 220 данных, может иметь перестраиваемую конфигурацию и содержать любую информацию в пределах объема онлайнового поиска. Содержание и объем такой информации никоим образом не предназначены ограничивать объем вариантов осуществления настоящего изобретения. Дополнительно, хотя на чертеже оно показано как единый, независимый компонент, хранилище 220 данных может на деле быть множеством баз данных, например, группой баз данных, части которой могут постоянно находиться на устройстве 215 клиента, механизме 290 естественного языка, другом внешнем компьютерном устройстве (не показано) и/или любой их комбинации.
В целом, механизм 290 естественного языка обеспечивает инструмент оказания помощи пользователям, стремящимся искать и находить информацию в онлайновом режиме. В вариантах осуществления этот инструмент работает посредством применения технологии обработки текстов на естественном языке для вычисления значения прохождений в наборах документов, таких как документы, извлеченные из хранилища 220 данных. Эти значения хранятся в семантическом индексе 260, на который делается ссылка при выполнении поиска. Первоначально, когда пользователь вводит запрос в область входа в поиск, конвейер 205 поиска запроса анализирует запрос пользователя (например, строка символов, законченные слова, фразы, буквенно-цифровые выражения, символы или вопросы) и переводит запрос в структурное представление, использующее семантические взаимоотношения. Это представление, упомянутое в дальнейшем как "высказывание", может использоваться для опроса информации, хранящейся в семантическом индексе 260, чтобы прийти к соответствующим результатам поиска.
В отдельном случае, информация, хранящаяся в семантическом индексе 260, содержит представления, извлеченные из документов, хранящихся в хранилище 220 данных, или любых других материалов, попадающих в объем онлайнового поиска. Это представление, упоминаемое в дальнейшем как "семантическое представление", связано с интуитивным значением содержимого, выделенного из общего текста, и может быть сохранено в семантическом индексе 260. В вариантах осуществления семантическое представление получается из семантической структуры, используя упорядоченную последовательность терминов-перезаписываемых правил или любую другую эвристику, известную в соответствующей области. В вариантах осуществления "семантическая структура" создается на промежуточном этапе конвейера анализа в соответствии с документом, анализирующим компонент, который преобразует содержимое документа в семантическую структуру, частично используя лексические семантические правила грамматики.
Архитектура семантического индекса 260 позволяет быстрое сравнение хранящихся семантических представлений с полученными высказываниями, чтобы найти семантические представления, которые совпадают с суждениями, и извлечь документы, отображенные в семантических представлениях, которые релевантны поданному запросу. Соответственно, механизм 290 естественного языка может определить значение требований запроса пользователя из запроса, поданного в интерфейс поиска (например, область ввода для поиска, определенная на дисплее 295 UI), и затем пересмотреть большое количество информации, чтобы найти соответствующие результаты поиска, которые удовлетворят эти нужды.
В вариантах осуществления описанный выше процесс может быть осуществлен различными функциональными элементами, которые выполняют один или более этапов для получения релевантных результатов поиска. Эти функциональные элементы содержат компонент 235, анализирующий запрос, компонент 240, анализирующий документ, компонент 245 семантической интерпретации, компонент 250 семантической интерпретации, компонент 255 спецификации грамматики, семантический индекс 260, компонент 265 определения совпадения, и компонент 270 ранжирования. Эти функциональные компоненты 235, 240, 245, 250, 255, 260, 265 и 270, в целом, обращены к индивидуальным модульным подпрограммам программного обеспечения и их сопутствующим аппаратным средствам, которые динамически связаны и готовы для использования с другими компонентами или устройствами.
Первоначально, хранилище 220 данных, компонент 240 анализа документов и компонент 250 семантической интерпретации содержат конвейер 210 индексации. Во время работы конвейер 210 индексации служит для извлечения семантических представлений из содержимого в пределах документов 230, допущенных в хранилище 220, и создания семантического индекса 260 после сбора семантических представлений. Как обсуждалось выше, после объединения для формирования семантического индекса 260, семантические представления могут сохранять отображение в документах 230 и/или местоположение содержимого внутри документов 230, из которых они были получены. Другими словами, семантический индекс 260 кодирует семантические представления (получаемые из семантических структур, созданных в компоненте 240 анализа документа), созданные и переданные компонентом 250 семантической интерпретации. Однако в других вариантах осуществления компонент 240 анализа документов и компонент 250 семантической интерпретации могут быть выполнены как единый элемент, который не делит обработку текстов на естественном языке на два этапа (то есть, на синтаксический анализ LFG и семантическую интерпретацию), а вместо этого создает семантические представления на едином этапе, не имея отдельного этапа, на котором создаются семантические структуры.
В целом, компонент 240 анализа документов выполнен с возможностью сбора данных, которые доступны механизму 290 естественного языка. В отдельном случае, сбор данных содержит просмотр хранилища 220 данных, чтобы просканировать содержимое документов 230 или другую информацию, хранящуюся там. Поскольку информация внутри хранилища 220 данных может постоянно обновляться, процесс сбора данных может выполняться с регулярными интервалами, непрерывно или по уведомлению, что в одном или более документах 230 сделано обновление.
После сбора содержимого из документов 230 и других доступных источников, компонент 240 анализа документов выполняет различные процедуры, чтобы подготовить содержимое для его семантического анализа. Эти процедуры могут содержать извлечение текста, распознавание объекта и синтаксический анализ. Процедура извлечения текста, по существу, содержит извлечение таблиц, изображений, шаблонов и текстовых разделов данных из содержимого документов 230 и преобразование их из исходного онлайнового формата в формат, пригодный для использования (например, язык гипертекстовой разметки (HTML)), в то же время сохраняя связи с документами 230, из которых они извлечены, чтобы облегчить отображение. Пригодный для использования формат содержимого может затем быть разделен на предложения. В одном случае, разбивка содержимого на предложения содержит ассемблирование строки символов в качестве ввода, применение набора правил, чтобы тестировать строку символов на наличие определенных свойств, и деление содержимого на предложения, основываясь на конкретных свойствах. Только для примера, конкретные свойства тестируемого содержимого могут содержать пунктуацию и преобразование букв в прописные, чтобы определить начало и конец высказывания. Когда последовательность предложений установлена, каждое индивидуальное предложение исследуется, чтобы обнаружить в нем слова и потенциально распознать каждое слово как объект (например, "Гинденбург"), событие (например, "Вторая мировая война"), время (например, "Сентябрь"), глагол или любую другую категорию слова, которая может быть использована для способствования различению между словами или для понимания значения соответствующего высказывания.
Процедура распознавания объекта помогает распознать, какие слова являются названиями, поскольку они обеспечивают конкретные ответы на ключевые слова, связанные с вопросом, из запроса (например, кто, где, когда). В вариантах осуществления распознавание слов содержит идентифицирующие слова, такие как названия, и аннотирование слова с тэгом, чтобы облегчить извлечение при опросе семантического индекса 260. В отдельном случае, идентификация таких слов, как названия, содержит поиск слов в заранее определенном списке названий, чтобы определить, имеется ли совпадение. Если совпадения не существует, то для предположения, является ли слово названием, может использоваться статистическая информация. Например, статистическая информация может помочь при распознавании вариации сложного названия, такого как "USS Enterprise" (военный корабль США "Энтерпрайз"), которое может иметь несколько общих вариацией при проверке правописания.
Процедура синтаксического анализа, когда она осуществляется, обеспечивает возможность проникновения в сущность структуры предложений, идентифицированных выше. В отдельном случае, эта способность проникновения в сущность обеспечивается применением правил, содержащихся в структуре компонента 255 спецификации грамматики. При применении эти правила или грамматика ускоряют анализ предложений для выделения представления взаимоотношений среди слов в предложениях. Как обсуждалось выше, эти представления упоминаются как семантические структуры и позволяют компоненту 250 семантической интерпретации фиксировать критическую информацию о грамматической структуре предложения (например, глагол, подлежащее, дополнение, и т.п.).
Компонент 250 семантической интерпретации обычно выполняется с возможностью диагностики роли каждого слова в семантической структуре(-ах), созданной компонентом 240 анализа документов, распознавая семантические взаимоотношения между словами. Первоначально, диагностирование может содержать анализ грамматической организации семантической структуры и разделение ее на логические утверждения, каждое из которых выражает отдельную идею и конкретные факты. Эти логические утверждения могут быть дополнительно проанализированы, чтобы определить функцию каждого из них в последовательности слов, которая содержит утверждение. В отдельном случае, определение функции последовательности слов содержит использование упорядоченной последовательности правил переписывания терминов или любой другой эвристики, известной в соответствующей области.
При необходимости, основываясь на функции или роли каждого слова, одна или более последовательностей слов может быть расширена, чтобы содержать синонимы (то есть, связи с другими словами, которые соответствуют расширенному конкретному значению слова) или гиперонимы (то есть, связи с другими словами, которые обычно относятся к расширенному общему значению слова). Это расширение слов, функция, которая обслуживает каждое слово в выражении (обсуждалось выше), грамматические взаимоотношения каждой последовательности слов и любая другая информация о семантическом представлении, распознанном компонентом 250 семантической интерпретации, составляют семантическое представление, которое может храниться в семантическом индексе 260 как семантическое представление.
Семантический индекс 260 служит для хранения семантического представления, полученного с помощью одного или более компонент конвейера 210 индексации, и может быть выполнен любым способом, известным в соответствующей области техники. Для примера, семантический индекс может быть выполнен как инвертированный индекс, который структурно подобен обычным индексам механизма поиска. В этом примере варианта осуществления инвертированный индекс является быстродоступным для поиска базой данных, вводы в которую являются словами с указателями на документы 230 и местоположения в ней, в которых появляются эти слова. Соответственно, при записи семантических структур в семантический индекс 260 каждое слово и сопутствующая функция индексируются вместе с указателями на предложения в документах, в которых появлялось семантическое слово. Эта структура семантического индекса 260 позволяет компоненту 265 определения совпадения эффективно получать доступ, перемещаться и определять совпадение с хранящейся информацией, чтобы получать значимые результаты поиска, которые соответствуют поданному запросу.
Устройство 215 клиента, компонент 235 анализа запроса и компонент 245 семантической интерпретации содержат конвейер 205 формирования запроса. Подобно конвейеру 210 индексации, конвейер 205 формирования запроса извлекает значимую информацию из последовательности слов. Однако в отличие от обработки проходов внутри документов 230, конвейер 205 формирования запроса обрабатывает слова, поданные в рамках запроса 225. Например, компонент 235 анализа запроса принимает запрос 225 и выполняет различные процедуры, чтобы подготовить слова для их семантического анализа. Эти процедуры могут быть подобны процедурам, используемым компонентом 240 анализа документов, таким как извлечение текста, распознавание объекта и синтаксический анализ. Кроме того, структура запроса 225 может быть идентифицирована, применяя правила, хранящиеся в структуре компонента 255 спецификации грамматики и в компоненте 245 семантической интерпретации, таким образом, получая значимое представление или высказывание запроса 225.
В вариантах осуществления компонент 245 семантической интерпретации может обрабатывать семантическое представление запроса, по существу, способом, сопоставимым с тем, которым компонент 250 семантической интерпретации интерпретирует семантическую структуру, полученную из прохождения по тексту в документе 230. В других вариантах осуществления компонент 245 семантической интерпретации может идентифицировать грамматические и/или семантические взаимоотношения ключевых слов в пределах строки ключевых слов (например, вопроса или фразы), которая содержит запрос 225. Для примера, идентификация грамматических и/или семантических взаимоотношений содержит идентификацию того, функционирует ли слово или фраза как подлежащее (агент действия), дополнение, сказуемое, косвенное дополнение или временное местоположение высказывания запроса 225. В другом случае высказывание оценивается так, чтобы идентифицировать логическую языковую структуру, связанную с каждым из ключевых слов. Для примера, оценка может содержать один или более следующих этапов: определение функции, по меньшей мере, одного из ключевых слов; основываясь на функции, замена ключевых слов логической переменной, которая охватывает множество значений (например, ассоциируя с функцией множество значений); и запись этих значений в высказывание запроса. Это высказывание запроса 225, ключевые слова и информация, извлеченная из высказывания и/или ключевых слов, затем посылаются к компоненту 265 определения совпадения для сравнения с семантическими представлениями, извлеченными из документов 230, и сохраняются в семантическом индексе 260.
В примере варианта осуществления компонент 265 определения совпадения сравнивает высказывания запросов 225 с семантическими представлениями в семантическом индексе 260, чтобы установить совпадение с семантическими представлениями. Эти совпадающие семантические представления могут отображаться обратно в документы 230, из которых они были извлечены, посредством ассоциирования документов 230 и определения местоположения в них, из которых были получены семантические представления. Эти документы 230, направляемые ассоциированными местоположениями, собираются и сортируются компонентом 270 ранжирования. Сортировка может быть выполнена любым известным способом в соответствующей области техники и может содержать, в частности, ранжирование в соответствии с близостью совпадения, перечисление на основе популярности возвращенных документов 230, или сортировка, основанное на атрибутах пользователя, предоставляющего запрос 225. Эти ранжированные документы 230 содержат результат 285 поиска и передаются в устройство 275 представления для вывода в соответствующем формате на дисплей 295 UI.
Продолжая ссылаться на фиг.2, этот пример системной архитектуры 200 является всего лишь одним примером подходящей среды, которая может быть реализована, чтобы выполнить аспекты настоящего изобретения, и не предназначен предполагать какое-либо ограничение в отношении объема использования или функциональных возможностей изобретения. Ни показанный на чертеже пример системной архитектуры 200, ни механизм 290 естественного языка, не должны интерпретироваться как имеющие какую-либо зависимость или требования, относящиеся к любому компоненту или комбинации компонент 235, 240, 245, 250, 255, 260, 265 и 270, как показано на чертеже. В некоторых вариантах осуществления один или более компонент 235, 240, 245, 250, 255, 260, 265 и 270 могут быть реализованы как автономные устройства. В других вариантах осуществления один или более компонент 235, 240, 245, 250, 255, 260, 265 и 270 могут быть непосредственно интегрированы в устройство 215 клиента. Специалистам в данной области техники должно быть понятно, что компоненты 235, 240, 245, 250, 255, 260, 265 и 270, показанные на фиг.2, являются примерами по своему характеру и количеству и не должны рассматриваться как ограничение.
Соответственно, любое число компонент может использоваться, чтобы достигнуть желательных функциональных возможностей в пределах объема вариантов осуществления настоящего изобретения. Хотя различные компоненты на фиг.2 для ясности показаны четкими линиями, в действительности, деление различных компонентов не настолько четко и, образно говоря, будет более точно, если линии будут полупрозрачными или нечеткими. Дополнительно, хотя некоторые компоненты на фиг.2 изображены как одиночные блоки, описания являются примерами по своему характеру и количеству и не должны рассматриваться как ограничение (например, хотя показано только одно устройство 275 представления, к устройству 215 клиента средствами связи может быть подключено гораздо больше таких устройств).
На фиг.3 показана схема 300 семантического представления, созданного из текстовой части в пределах документа в соответствии с вариантом осуществления настоящего изобретения. Текстовые части могут быть извлечены из содержимого одного или более документов, например, которые могут храниться в хранилище данных для простоты доступа во время индексации. В одном варианте осуществления документ, из которого извлечены текстовые части, является Web-документом, но в других вариантах осуществления документ может быть любого рода документом на основе текста из любого типа сборника документов. Любому специалисту в данной области техники должно стать понятным, что может быть извлечен любой тип документа, такой как документы, извлеченные из любого сборника документа или даже извлеченные для анализа конкретного документа с помощью сборника. Текстовые части могут содержать косвенную речь и другие сообщения о занимаемой позиции, которые могут идентифицироваться множеством слов, найденных в текстовой части, таких как, конечно, не для ограничения, "осудить", "сказать", "полагать", "желать", "отрицать" и т.д. Эти слова идентифицируются в сообщениях об отношении, потому что они описывают отношение человека к определенной теме. Косвенная речь может принимать форму прямых цитирований человека или может быть косвенной речью второго лица. Согласно последующим примерам, показанным и описанным, станут очевидны множество форм косвенной речи и других сообщений об отношении, в том числе, упомянутых выше.
Семантические представления обычно охватывают три основных задачи, в том числе, в частности, значения различных слов, взаимоотношения между словами и контексты. Семантические представления позволяют более полное понимание текста, чем простая зависимость от ключевых слов из запроса, например, совпадающих со словами в документах (например, Web-документах). Здесь взаимоотношения определяются так, чтобы позволить более глубокий анализ текста. Схема 300 содержит текстовую часть 305, первый уровень 310 ассоциации, второй уровень 320 ассоциации и третий уровень 330 ассоциации. Каждый уровень ассоциации 310, 320, и 330 содержит один или более элементов и один или более реляционных элементов. В варианте осуществления, показанном на фиг.3, реляционные элементы представляются позициями 312, 314, 316, 322, 332 и 334. Элементы содержат слова "осудить", "Буш", "Вашингтон", "призывы", "уйти", "США", и "Ирак". Также, для каждого уровня ассоциации показано действие по сообщению информации, которыми здесь являются слова "осудить", "призывы", и "уйти". Также, в некоторых вариантах осуществления могут существовать некоторые слова, являющиеся элементами, но также категоризируются как действия по информации, такие как "осудить", "призывы" и "уйти".
Чтобы ясно продемонстрировать вариант осуществления, показанный на фиг.3, семантическое представление показывается для текстовой части 305, которая является следующей: "В Вашингтоне Джордж Буш осудил призывы к США уйти из Ирака". Следует отметить, что фиг.3 является схемой семантического представления, описанной ниже. Пример предоставлен как в формате схемы, так и семантического представления только в целях демонстрации. В некоторых вариантах осуществления семантические представления создаются и хранятся в семантическом индексе, таком как семантический индекс 260, показанный на фиг.2, но схемы не создаются. В этих вариантах осуществления диаграммы приведены только для иллюстрации и примера.
Контекст (высший): агент DNC: B
Контекст (высший): тема DNC: Контекст (3)
Контекст (3)(высший): местоположение DNC: W
Контекст (3): тема CL: Контекст (5)
Контекст (5): агент WTHD: U
Контекст (5): местоположение WTHD: I
слово: B [Джордж_Буш, человек] Контекст(высший)
слово: DNC [осудить, критиковать, сказать] Контекст(высший)
слово: W [Вашингтон_D", город, местоположение] Контекст(высший)
слово: CL [призыв, сказать] Контекст (3)
слово: WTHD [уход, движение] Контекст (5)
слово: U [Соединенные_Штаты_Америки, страна, местоположение] Контекст (5)
слово: I [Ирак, страна, местоположение] Контекст (5)
Как показано, существуют три уровня ассоциаций, также упомянутых здесь как контексты, которые были идентифицированы в текстовой части (то есть, позиция 305 на фиг.3). Уровнями ассоциации или контекстами являются "Контекст (высший)", "Контекст (3)" и "Контекст (5)". Уровни ассоциации идентифицируются как являющиеся темой действий по сообщению информации, которые обычно являются словами, выражающими действия, и в некоторых вариантах осуществления являются глаголами. Здесь "осудил" является действием по сообщению информации, связанным с первым уровнем 310 ассоциации. Второй уровень 320 ассоциации может рассматриваться как тема действия по сообщению информации, "осудил" идентифицируется на первом уровне 310 ассоциации. Точно также, третий уровень 330 ассоциации может быть темой действия по сообщению информации, "призывы", идентифицированной на втором уровне 320 ассоциации.
Уровни ассоциации формируются так, чтобы собрать вместе пакет взаимоотношений, который полностью сохраняется действительным таким же образом. Верхний уровень ассоциации, такой как "Контекст (высший)", может быть уровнем, который поддерживается действительным согласно каждому вопросу предложения. Например, в варианте осуществления, показанном на фиг.3, может быть действительным, что Буш сделал заявление в Вашингтоне, причем не имеет значения, что он осудил. Это заявление, которое было осуждением со стороны Буша, является вложенным контекстом, и вложенный контекст в этом варианте осуществления состоит в выражении "призывы к США уйти из Ирака." Поскольку уход из Ирака не имел места, согласно этому примеру, это заявление расположено во втором уровне ассоциации, который здесь может быть назван гипотетическим контекстом. Используя контекстную структуру или уровни ассоциации, кратко описанные выше, различные семантические взаимоотношения могут быть идентифицированы как остающиеся действительными при различных обстоятельствах или различными путями.
Действия по сообщению информации могут быть определены, основываясь на ряде факторов, и действие по сообщению информации может быть идентифицировано для каждого уровня ассоциации. Действие по сообщению информации в некоторых случаях является словом, означающим действие, таким, как в варианте осуществления, показанном на фиг.3, "осудил", "призывы", и "уйти". Действия по сообщению информации могут быть, например, глаголами, существительными и т.п. и обычно определяются окружающим текстом или тем, как слово используется в высказывании. Этот тип грамматической информации может быть определен, например, применяя набор правил, которые могут поддерживаться, например, в структуре компонента 255 спецификации грамматики на фиг.2. Применяя набор правил или грамматики, определяются взаимоотношения между словами, которые ведут к идентификации действий по сообщению информации.
Как показано на фиг.3, действие по сообщению информации связано с элементами, такими как слова или фразы, или может быть связано с различными уровнями ассоциации. Действие по сообщению информации идентифицируется как роли в события, которое в случае данного примера может быть названо событием осуждения. Например, "осудил" идентифицируется как действие по сообщению информации для первого уровня ассоциации 310. Слово "осудил" связывается со словом "Буш" и словом "Вашингтон", причем оба появляются в семантически анализируемой текстовой части. "Осудил" связано с "Бушем", поскольку "Буш" является агентом слова "осудил", так как фактически осуждение делает Буш. Поэтому агент 312 является реляционным элементом, соединяющим эти два слова, формируя, таким образом, семантические взаимоотношения. Аналогично, местоположение 314 является реляционным элементом, соединяющим вместе два слова, а именно, "осудил" и "Вашингтон." Чтобы связать реляционный элемент со словом(ами) в пределах другого уровня контекста, может быть найдена тема, которая связывает эти два слова вместе. Например, может быть определено, какое событие осуждается и это может быть темой действия по сообщению информации "осудил". Здесь призывы к чему-либо могут быть темой 316 "осудил", и более того, вывод США из Ирака может быть идентифицировано как тема 322 "призывы" или события призывов, которое является действием по сообщению информации в пределах второго уровня ассоциации. В пределах третьего уровня ассоциации 330 "США" идентифицируются как агент 332 вывода и "Ирак" является местоположением 334 вывода.
Элементы посредством синтаксического анализа извлекаются из необработанного содержимого, и здесь содержатся такие слова, как "осудил", "Буш", "Вашингтон", "призывы", "уйти", "США" и "Ирак". Одно или более этих слов могут иметь схожие значения, которые могут быть представлены в семантическом представлении с помощью логической переменной. Эта логическая переменная может представлять множество синонимов, имеющих значения, схожие с элементом, категориям, в которые вписывается элемент, и может также представлять много значений, которые может иметь элемент. Некоторые элементы проще, чем другие, для определения правильного значения. Значения могут быть определены, в отдельном случае, основываясь на том, как элемент используется внутри контекста текстовой части. Как показано выше, "Буш" идентифицируется как "Джордж Буш", который идентифицируется как человек. "Осудил", действие по сообщению информации, связано как с "критиковать", так и со "сказать", указанные здесь только для примера. Может существовать множество других слов, имеющих значение, схожее с "осудил", и которые также могут быть определены как подлежащие ассоциации с ним. Кроме того, "Вашингтон" ассоциируется с категориями, содержащими город, и с местоположением. "Уход" ассоциируется с "движением" и как "США", так и "Ирак" категоризируются как страна и местоположение.
Семантические представления, такие как те, которые показаны на фиг.3, позволяют получить более точные и более релевантные результаты поиска, которые должны быть возвращены пользователю после того, как запрос пользователя принят и проанализирован. Например, анализируя текст (например, целевое заявление) "В Вашингтоне Джордж Буш осудил призывы к США уйти из Ирака" и разрабатывая семантические взаимоотношения, как описано выше, этот текст может быть возвращен пользователю после получения запроса на естественном языке, такого как "Что сказал Буш об Ираке", но не "Что сказал Буш о Вашингтоне". Обычный поиск по ключевым словам, при предположении, что он мог бы идентифицировать "осудил" как форму "сказал", должен придать терминам "Вашингтон", "США" и "Ирак" равное выдающееся место в целевом заявлении, приводя к его извлечению посредством запроса ключевого слова, такого как "сказал Буш в Вашингтоне." Более передовая схема индексации, которая связала термин "осудил" с его прямым аргументом "призывы", но которая не пошла дальше, будет не в состоянии обнаружить, что в обвинении шла речь об Ираке. Термин "Вашингтон" исключается из связи с "осудил", кроме как с помощью действия по сообщению информации о местоположении 314, поскольку это не идентифицируется как помещенное внутрь текстовой части, которая анализируется.
На фиг.4 показана схема 400 семантического представления, созданного из текстовой части внутри документа, соответствующая варианту осуществления настоящего изобретения. И опять, текстовые части могут содержать косвенную речь и другие сообщения об отношении, которые могут быть идентифицированы множеством слов, найденных в текстовой части, таких как, но, конечно, не ограничиваясь только этим, "осудить", "сказать", "полагать", "желать", "отрицать" и т.д. Хотя вариант осуществления, показанный на фиг.3, обеспечивает семантическое представление как результат анализа семантических взаимоотношений между словами, это представление может быть дополнено информацией о том, какие аргументы к глаголу "осудить" ведут к содержимому осуждения. Дополнительная лексическая информация может быть добавлена, чтобы указать то, о чем осуждение. Ниже приводится семантическое представление того же самого текста, который использовался на фиг.3, который является следующим: "В Вашингтоне Джордж Буш осудил призывы к США уйти из Ирака". Здесь, однако, "приблизительные" взаимоотношения формируются в дополнение к взаимоотношениям, сформированным в варианте осуществления, показанном на фиг.3, чтобы обеспечить еще более релевантные результаты поиска после получения запроса.
Контекст (высший): агент DNC: B
Контекст (высший): тема DNC: Контекст (3)
Контекст (3) (высший): местоположение DNC: W
Контекст (высший): DNC о чем: CL
Контекст (высший): DNC о чем: WTHD
Контекст (высший): DNC о чем: U
Контекст (высший): DNC о чем: I
Контекст (3): тема CL: Контекст (5)
Контекст (5): агент WTHD: U
Контекст (5): местоположение WTHD: I
слово: B [Джордж_Буш, человек] Контекст (высший)
слово: DNC [осудить, критиковать, сказать] Контекст (высший)
слово: W [Вашингтон_DC, город, местоположение] Контекст (высший)
слово: CL [призыв, сказать] Контекст (3)
слово: WTHD [уйти, двигаться] Контекст (5)
слово: U [Соединенные_Штаты_Америки, страна, местоположение] Контекст (5)
слово: I [Ирак, страна, местоположение] Контекст (5)
Есть множество способов, которыми компоновка "близости" может быть вычислена и зарегистрирована. Один из способов состоит в том, чтобы вычислить переходную близость связей контекста и аргумента, начиная с аргумента темы и отмечая любой термин в пределах этой близости, как являющийся близким к сообщению. Этому показывается в приведенном выше семантическом представлении, а также показано на фиг.4.
На фиг.4 показана текстовая часть 405, из которой делается семантическое представление. Как и на фиг.3, на фиг.4 показаны три уровня ассоциации, те, которые являются первым уровнем 410 ассоциации, вторым уровнем 430 ассоциации и третьим уровнем 440 ассоциации.
"Осудил" является действием по сообщению информации первого уровня 410 ассоциации, "призывы" - действием по сообщению информации второго уровня 430 ассоциации, и "уйти" - действием по сообщению информации третьего уровня 440 ассоциации. Как показано на чертеже, "осудил" теперь имеет больше семантических взаимоотношений, чем это было в варианте осуществления, показанном на фиг.3, поскольку взаимоотношения "о чем" теперь показаны в дополнение к предыдущим взаимоотношениям. Семантические взаимоотношения были определены между "осудил" и каждым из "Буш" с помощью агента 412 реляционного элемента, "Вашингтон" - с помощью местоположения 414 реляционного элемента, и второй уровень 430 ассоциации - с помощью темы 416 реляционного элемента события обвинения. Дополнительно, третий уровень 440 ассоциации является темой 432 призывов, "США" является агентом 442 ухода и "Ирак" является местоположением 444 ухода.
В дополнение к этим взаимоотношениям, показаны несколько взаимоотношений "о чем", в том числе, "о чем" 418 связанное с "уйти" на третьем уровне 440 ассоциации, "о чем" 420, связанное с "призывы" на втором уровне 430 ассоциации, "о чем" 422, связанное с "US" на третьем уровне 440 ассоциации, и "о чем" 424, связанное с "Ирак" также на третьем уровне 440 ассоциации. Также, событие осуждения является "о чем" для "уйти", является "о чем" для "призывы", является "о чем" для "США" и является "о чем" для "Ирак". Как показано на чертеже, случай осуждения не является ни "о чем" для "Буш", ни "о чем" для "Вашингтон". Определение этих взаимоотношений "о чем" и избежание взаимоотношений "о чем" с "Буш" и "Вашингтон", например, исключает нерелевантные результаты поиска, возвращаемые пользователю.
На фиг.5 показана схема 500 семантического представления, созданная из текстовой части, взятой в пределах документа в соответствии с вариантом осуществления настоящего изобретения. Семантическое представление этого варианта осуществления показано ниже для следующей текстовой части 505: "В Вашингтоне Джордж Буш осудил призывы к США уйти из Ирака".
Контекст (высший): DNC агент: B
Контекст (высший): DNC тема: Контекст (3)
Контекст (высший): DNC местоположение: W
Контекст (3): CL тема: Контекст(5)
Контекст (3): CL сказано: DNC
Контекст (5): WTHD агент: U
Context (5): WTHD location: I
Контекст (5): WTHD сказано: DNC
слово: B [Джордж_Буш, человек] Контекст (высший)
слово: DNC [осудить, критиковать, сказать] Контекст (высший)
слово: W [Вашингтон_DC, город, местоположение] Контекст (высший)
слово: CL [призыв, сказать] Контекст (3)
слово: WTHD [уйти, движение] Контекст (5)
слово: U [Соединенные_Штаты_Америки, страна, местоположение] Контекст (5)
слово: I [Ирак, страна, местоположение] Контекст (5)
Как показано выше, вместо того, чтобы отмечать каждый элемент, что сообщение - "о чем", как было в случае на фиг.4, индекс отмечает только заголовок каждого сообщаемого факта. Например, на фиг.5 показано, что "осудил" было идентифицировано как действие по сообщению информации первого уровня 510 ассоциации и связывается с различными элементами, такими как "Буш", с помощью агента 512 реляционного элемента и "Вашингтон" с помощью местоположения 514 реляционного элемента. Дополнительно, тема 516 для "осудил" была идентифицирована как выражение "призывы к США уйти из Ирака", которое частично реализуется в пределах второго уровня 530 ассоциации и частично - в пределах третьего уровня 540 ассоциации. "Призывы" связывается с третьим уровнем 540 ассоциации с помощью темы 532 реляционного элемента 532. В пределах третьего уровня 540 ассоциации, "уйти" связывается как с "США", так и с "Ирак" с помощью агента 542 и местоположения 544 реляционных элементов, соответственно.
В дополнение к взаимоотношениям, определенным выше, и вместо взаимоотношений "о чем", существуют два реляционных элемента, названных "сказано" и показанных как "сказано" 518, связанные с "уйти" и "сказано" 520, связанные с "призывы". Эта структура все еще позволяет соединение между "осудил" и "уйти", "США" и даже "Ирак." Различие состоит в том, что эти взаимоотношения в варианте осуществления, показанном на фиг.5, являются косвенными взаимоотношениями, а не прямыми взаимоотношениями. Как описано выше, компромисс при использовании этого варианта осуществления заключается в пониженном использовании запоминающего устройства в пределах индекса, но повышенном времени, требующемся для вычисления после получения запроса.
Продолжая ссылаться на фиг.5, показан альтернативный вариант осуществления относительно варианта осуществления, показанного, например, на фиг.4, который демонстрирует концепцию компромисса между пространством и временем. Как можно заметить, сравнивая схему на фиг.4 и схему на фиг.5, схема на фиг.5, как кажется, более проста, поскольку она явно не содержит никаких взаимоотношений "о чем", используя реляционные элементы "о чем". Поскольку фиг.5 содержит меньше идентифицированных взаимоотношений, они занимают меньшее пространство в пределах индекса и поэтому меньшее пространство хранилища данных, в котором хранится индекс. Хотя меньшее запоминающее устройство и пространство хранения могут использоваться для варианта осуществления, показанного на фиг.5, может потребоваться больше времени, чтобы определить совпадение высказывания запроса с семантическими представлениями в пределах индекса, поскольку взаимоотношения "о чем" не были уже идентифицированы. Другими словами, взаимоотношения "о чем" не были явно закодированы в пределах индекса, чтобы позволить быстрое сравнение. Это требует намного большего объема вычислений на вычислительной машине базы данных, который может привести к увеличенным временам ожидания для пользователей. Альтернативно, вариант осуществления, показанный на фиг.4, явно вычисляет взаимоотношения "о чем" заранее и сохраняет эти взаимоотношения в индексе, который позволяет быстрое сравнение высказываний запроса с семантическими представлениями, приводя в результате к меньшему времени, требующемуся для вычислений после того, как пользователь ввел запрос.
На фиг.6 показана схема 600 семантического представления, созданного из текстовой части, взятой в пределах документа, в соответствии с вариантом осуществления настоящего изобретения. Вариант осуществления, показанный на фиг.6, приводит подобный, все же более простой пример, чем вариант осуществления, показанный на фиг.3 и 4. Текстовая часть 605 заявляет следующее: "Джон полагает, что Мэри поехала в Вашингтон". Ниже приводится семантическое представление текстовой части 605.
Контекст (высший): BEL агент: J
Контекст (высший): BEL тема: Контекст (2)
Контекст (высший): BEL о чем: G
Контекст (высший): BEL о чем: M
Контекст (высший): BEL о чем: W
Контекст (2): G агент: M
Контекст (2): G местоположение: W
слово: J [Джон, человек] Контекст (высший)
слово: BEL [полагает] Контекст (высший)
слово: W [Вашингтон_DC, город, местоположение] Контекст (2)
слово: G [отправилась, движение] Контекст (2)
слово: M [Мэри, человек] Контекст (2)
Анализируемые элементы, взятые из необработанного содержимого, включают "Джон", "полагать", "отправиться", "Мэри" и "Вашингтон." "Полагает" идентифицируется как действие по сообщению информации в пределах первого уровня 610 ассоциации, а "отправилась" является действием по сообщению информации в пределах второго уровня 630 ассоциации. Реляционные элементы, такие, как те, которые определены выше, соединяют элементы и описывают тип ассоциации, содержат "агент" 612, "тема" 614, "о чем" 616, "о чем" 618, "о чем" 620, "агент" 632 и "местоположение" 634. Второй уровень 630 ассоциации является темой "полагает", тогда как три слова, которые являются "о чем" для действия по сообщению информации для "полагает". "Полагает" является "о чем" для "Мэри", где "Мэри" "отправилась" (например, идти) и куда Мэри пошла (например, "Вашингтон"). Опять же, в некоторых вариантах осуществления логическая переменная может быть заменена элементом и логическая переменная может быть связана с множеством синонимов, различными значениями этого элемента или слова или тому подобным.
Обращаясь теперь к фиг.7, на фиг.7 показана схема 700 высказывания, создаваемая из запроса поиска, в соответствии с вариантом осуществления настоящего изобретения. Высказывание создается способом, подобным семантическому представлению (например, представление содержимого, полученного из Web-документа). Здесь запрос 705 является следующим: "Кто сказал что-либо об Ираке?". Высказывание показано ниже.
Контекст(высший): SY-2 агент: P-2
Контекст(высший): SY-2 тема: E-2
Контекст(высший): SY-2 о чем: I-2
слово: P-2 [человек]Контекст(высший)
слово: SY-2 [сказать]Контекст(высший)
слово: E-2 [*] Контекст(высший)
слово: I-2 [Ирак, страна, местоположение]Контекст(высший)
Синтаксический анализ и выполнение семантического анализа для запросов обычно намного проще, чем выполнение того же самого анализа для содержимого документов, поскольку запросы обычно короче по длине и могут содержать только один уровень ассоциации, как показано на фиг.7. Уровень 710 ассоциации содержит несколько элементов, которые были анализированы или идентифицированы, в том числе, "человек", "сказать" и "Ирак". Существует дополнительный элемент, но он подобен универсальному символу, поскольку это может быть много разных вещей, а не только одно слово. Этот дополнительный элемент представляет слово "что-либо" из запроса. В одном варианте осуществления элементы, такие как "что-либо", которые могут в чем-либо совпадать, могут быть извлечены из запроса при анализе запроса, так чтобы не накладывать ограничение, когда для высказывания определяется совпадение с семантическим представлением.
Высказывание, показанное на фиг.7, также содержит действие по сообщению информации, "сказать", в дополнение к нескольким реляционным элементам. Агент 712 связывает "человек" с "сказать". "О чем" 714 связывает "сказать" с "Ирак" и тема 716 связывает "сказать" с универсальным элементом, который, как упомянуто выше, может быть чем угодно. Как показано на чертеже, в высказывании слово "кто" заменяется на "человек".
Семантическое представление, созданное из содержимого документа (например, Web-документа), такого как те, которые показаны выше со ссылкой на фиг.3 и 4, и высказывание, созданное из запроса, такое, как то, которое показано выше со ссылкой на фиг.6, могут быть проверены на совпадение или связано, чтобы определить наиболее релевантные результаты поиска из принятого запроса. Например, показанное ниже семантическое представление демонстрирует совпадение семантического представления и высказывания. Совпадения показываются рядом друг с другом.
Контекст (высший): DNC о чем: CL
Контекст (высший): DNC о чем: WTHD
Контекст (высший): DNC о чем: U
Контекст (5): WTHD агент: U К
Контекст (5): WTHD местоположение: I
Если существует совпадение реляционных элементов, такое как совпадение агента с агентом, то элементы, ассоциированные с реляционными элементами, затем проверяются, чтобы определить, являются ли слова одними и теми же или даже схожими. Выше упоминалось, что "осудить" ассоциировалось с "сказать", чтобы расширить поиск, и "Буш" ассоциировалось с "человек" по той же самой причине. Поэтому, совпадение обнаружено между Контекст(высший): DNC агент: B и Контекст(высший): SY-2 агент: P-2.
На фиг.8 показана схема 800 семантического представления, созданная из текстовой части в пределах документа, текстовая часть, содержащая два предложения, в соответствии с вариантом осуществления настоящего изобретения. Вариант осуществления на фиг.8 показывает, что в одном семантическом представлении может быть представлено больше одного предложения, особенно, если предложения связаны. Здесь, оба предложения созданы одним и тем же человеком, Бушем. Поэтому имеет смысл и уместно поместить оба предложения в единое представление. Следует отметить, что для создания семантического представления может быть сгруппировано любое количество предложений или даже фраз. Процесс синтаксического анализа содержимого, извлеченного из документа (например, Web-документа), может быть выполнен, например, применяя ряд правил для проверки строки символов на конкретные свойства, такие как используемая пунктуация и преобразование букв в прописные. Этот набор правил, подразумевая эти свойства, может быть в состоянии определить различные предложения или фразы, которые связаны вместе, такие как те, которые показаны на фиг.8 как текстовые части 805 и 810. Этот процесс может быть выполнен в соответствии с компонентом анализа документов, такого как компонент 240 на фиг.2.
Для первой текстовой части 805 существуют два показанных уровня ассоциации. Первый уровень 820 ассоциации (например, высший контекст (t) и второй уровень 840 ассоциации (например, Контекст (ctx-7)) непосредственно связаны действием по сообщению информации "сказать", расположенным в пределах первого уровня 820 ассоциации. "Сказать" и второй уровень 840 ассоциации связаны реляционным элементом 824 темы, так что высказывание "призывы уйти - это плохие призывы " является темой того, что сказал Буш. Множество взаимоотношений "о чем" также сформировано и, как упомянуто выше, учитывает более высокую точность результатов поиска. В пределах первого уровня 820 ассоциации, "сказать" связано с "Буш" через реляционный элемент 822 агента, поскольку Буш является человеком или агентом, который произнес или сказал эти слова. Дополнительно, реляционные элементы "о чем" 826, 828 и 830 осуществляют связь от "сказать" к "уйти", "призывы" и "плохие", соответственно. Эти взаимоотношения или ассоциации "о чем" позволяют осуществить действенную и эффективную проверку совпадения этих взаимоотношений с подобными взаимоотношениями, найденными в высказываниях запроса. Дополнительно, в пределах второго уровня ассоциации 840, действие по сообщению информации "призывы" непосредственно связано с "уход" реляционными элементами темы 842 и с "плохой" - модификатором 844 реляционных элементов.
Следует отметить, что существует много способов, которыми можно было бы работать в соответствии со схемой, связанной с первой текстовой частью 805. Например, чтобы дойти до "уйти", один путь состоит в том, чтобы пойти от "сказать" напрямую к "уйти", используя взаимоотношения "о чем" (например, реляционный элемент "о чем" 826). Другой путь косвенно достигает "уйти", сначала используя реляционный элемент "о чем" 828, чтобы достигнуть "призывы", и затем связываясь с "уйти" с помощью реляционного элемента темы 842, поскольку "уйти" является темой "призывы". Дополнительно, используя реляционный элемент темы 824, может быть достигнут второй уровень 840 ассоциации, на котором "уйти" находится внутри этого второго уровня 840 ассоциации.
Если посмотреть на вторую текстовую часть 810 отдельно от первой, то действие по сообщению информации "остаться" идентифицируется для этой текстовой части. Текстовая часть является довольно простой и короткой и поэтому идентифицируется только один уровень 850 ассоциации (например, Контекст (ctx-12)). "Остаться" ассоциируется или связывается с "США" с помощью агента 858 реляционного элемента, и "Ирак" - с помощью местоположения 862 реляционного элемента 862. Кроме того, внутри текстовой части 810 найден термин "должен". В лингвистических целях "должен" может выражать взаимоотношение модальности, которое является выражением, широко ассоциированным с понятиями вероятности и необходимости. Также, модальность (например, "должен") используется как реляционный элемент 860 в этом варианте осуществления и ассоциируется с "остаться". Две текстовых части 805 и 810 могут теперь быть переплетены, чтобы определить взаимоотношения "о чем" между первой текстовой частью 805 и второй текстовой частью 810. На фиг.8 показано, что взаимоотношения "о чем" сформированы между "сказать" и "США", "остаться" и "Ирак" через реляционные элементы "о чем" 852, "о чем" 854 и "о чем" 856, соответственно.
Теперь обратимся к фиг.9, где показана блок-схема 900 последовательности выполнения операций способа построения семантических взаимоотношений между элементами, извлеченными из содержимого документа, чтобы создать семантическое представление содержимого в соответствии с вариантом осуществления настоящего изобретения. Первоначально, текстовая часть идентифицируется на этапе 910, который позволяет индексировать и хранить в семантическом индексе 260, показанном, например, на фиг.2, идентифицированную текстовую часть. Текстовые части могут быть получены из содержимого одного или более документов, таких как Web-страницы, которые могут храниться в хранилище данных, таком как хранилище 220 данных на фиг.2. Когда из документа извлечено содержимое, формат содержимого может быть исходным онлайновым форматом, который требует преобразования. В одном варианте осуществления содержимое преобразуется из исходного онлайнового формата в формат языка разметки гипертекста (HTML), чтобы создать текстовую часть. Содержимое может быть извлечено в форме одного или более предложений или фраз, таблицы, шаблона или множества данных. Текстовые части могут содержать косвенную речь и другие сообщения об отношении, которые могут идентифицироваться множеством слов, найденных в текстовой части, таких как, но, конечно, не ограничиваясь только ими, "осудить", "сказать", "полагать", "желать", "отрицать" и т.д. Эти слова идентифицируются в отчетах об отношении, потому что они описывают отношение человека к определенной теме. Косвенная речь может принимать форму прямых цитирований от человека или может быть речью, о которой сообщает другое лицо.
В одном варианте осуществления текстовая часть может быть проанализирована, чтобы идентифицировать один или более элементов, которые должны быть семантически представлены для дальнейшей индексации. Синтаксический анализ может также содержать текстовое извлечение и распознавание объекта, при котором объект распознается посредством поиска заданного списка слов, хранящихся, например, в хранилище данных 220. Эта процедура помогает в том, что она распознает слова, которые могут быть именем человека или названием вещи. На этапе 920 определяется семантическая информация для каждого из идентифицированных элементов. Семантическая информация может содержать одно или более значений и/или грамматических функций идентифицированных в них элементов. В одном варианте осуществления синонимы или гипонимы могут также быть определены и введены как семантическая информация. Дополнительно, в некоторых вариантах осуществления у одного или более слов могут быть схожие значения и эти слова и значения могут быть представлены в семантическом представлении логической переменной путем замены определенного элемента логической переменной. Эта логическая переменная может представлять множество синонимов, имеющих значения, схожие с элементом, категориям которого элемент соответствует, и может также представлять множество значений, которые может иметь элемент, который позволяет расширенный, но более точный поиск. Логические переменные могут храниться в хранилище данных.
На этапе 930, по меньшей мере, один из идентифицированных элементов идентифицируется как действие по сообщению информации, которая соответствует речевому сообщению или сообщению об отношении. Этап 940 указывает, что идентифицированные элементы ассоциируются друг с другом, чтобы сформировать семантические взаимоотношения, и сформированные ассоциации основываются на семантической информации, определенной выше на этапе 920. В одном варианте осуществления могут быть определены один или более уровней ассоциации или контексты и каждый уровень ассоциации может содержать один или больше идентифицированных элементов. Элементы в пределах различных уровней ассоциации могут ассоциироваться друг с другом и могут быть ассоциированы посредством действия по сообщению информации. Действие по сообщению информации может быть выражено, например, глаголами, существительными или тому подобным образом и обычно определяется окружающим текстом или тем, как слово используется в предложении. Этот тип грамматической информации может быть определен, например, применяя набор правил, которые могут поддерживаться в структуре компонента 255 спецификации грамматики на фиг.2, например. Только для примера, предположим, что в текстовой части говорится: "В Вашингтоне Буш осудил призывы к США уйти из Ирака". Здесь могут быть идентифицированы три уровня ассоциации, причем каждый содержит действие по сообщению информации. Действия по сообщению информации для трех соответствующих уровней ассоциации могут быть идентифицированы как "осудил", "призывы" и "уйти".
В дополнение к уровням ассоциации (например, контексты) и действиям по сообщению информации, могут быть также определены реляционные элементы, которые описывают взаимоотношения между действием по сообщению информации и элементом или уровнем ассоциации. Например, продолжая ссылаться на приведенный выше пример, "Буш" может быть ассоциировано или связано с "осудил" посредством агента реляционного элемента, поскольку Буш является агентом, делающим осуждение. Реляционные элементы могут принимать различные формы взаимоотношений, но могут быть словами, такими как, в частности, агент, местоположение, тема или "о чем", взаимоотношения "о чем" указывают, на какое действие по сообщению информации делается ссылка или о чем идет речь. На этапе 950 создается семантическое представление, которое содержит ассоциации идентифицированных элементов, описанных выше. Семантическое представление может затем быть сохранено в индексе, таком как семантический индекс 260 на фиг.2.
На фиг.10 показана блок-схема 1000 последовательности выполнения операций способа создания, в ответ на получение запроса, ассоциаций между различными терминами, извлеченными из запроса, чтобы создать суждение, причем суждение, используемое для опроса информации, хранящейся в индексе, чтобы обеспечить релевантные результаты поиска в соответствии с вариантом осуществления настоящего изобретения. Суждение является логическим представлением концептуального значения запроса, который используется для опроса семантических взаимоотношений, содержащихся в пределах семантических представлений содержимого из документов. Процесс создания суждения из запроса очень похож на процесс, описанный здесь для создания семантического представления содержимого документа. Первоначально, запрос принимается как ввод от пользователя и в одном варианте осуществления принятый запрос анализируется для определения одного или более поисковых терминов в пределах запроса. Поисковые термины подобны элементам, идентифицированным в текстовой части.
На этапе 1010 определяется семантическая информация для каждого одного или более поисковых терминов и эта семантическая информация может содержать в них одно или более значений и/или грамматических функций поисковых терминов. В дополнение к определению семантической информации, может быть идентифицирована логическая переменная, которая может быть ассоциирована или может даже заменить один или больше терминов для поиска. Логическая переменная может быть числом, буквой или последовательностью или комбинацией того и другого и может представлять множество слов, имеющих подобные значения, в поисковых терминах. Это позволяет получение расширенного, еще более релевантного ответа по результатам поиска пользователем. Первое действие по сообщению информации идентифицируется в пределах запроса на этапе 1020. Действие по сообщению информации может быть глаголом, существительным или любой другой частью речи и может содержать действие, такое как "говорить", "призывать", "осуждать", "полагать" и т.д. В одном варианте осуществления может быть идентифицировано больше одного действия по сообщению информации в пределах запроса, такого как второе действие по сообщению информации.
Семантические взаимоотношения показаны на этапе 1030 и могут определяться между каждым действием по сообщению информации и другим термином для поиска, чтобы создать ассоциацию между словами. Семантические взаимоотношения могут основываться на определенной семантической информации, как описано выше. Ассоциации связываются реляционными элементами, которые описывают ассоциацию, такую как, в частности, агент, местоположение, тема или "о чем". Другие реляционные элементы, конечно, также подразумеваются присутствующими в объеме настоящего изобретения. На этапе 1040 создается суждение, содержащее сформированные ассоциации между каждым действием по сообщению информации и одним или более терминами для поиска, анализированными из запроса. Когда суждение создано, суждение (например, ассоциации внутри суждения) может быть сравнено или проверено на совпадение с одним или более семантическими представлениями, хранящимися в семантическом индексе 260, чтобы, например, определить наиболее релевантные совпадения для суждения. В одном варианте осуществления запрос может содержать больше одного уровня ассоциации, как описано выше, и, таким образом, действие по сообщению информации может быть идентифицировано для каждого уровня ассоциации.
На фиг.11 показана соответствующая варианту осуществления настоящего изобретения блок-схема 1100 последовательности выполнения операций способа для построения семантических взаимоотношений между элементами, извлеченными из содержимого документа, чтобы создать семантическое представление содержимого, дополнительно позволяя индексацию содержимого. На этапе 1110 идентифицируется, по меньшей мере, часть документа (например, Web-документа), который должен индексироваться. Текстовая часть документа анализируется, чтобы идентифицировать элементы, которые должны быть семантически представлены, как показано на этапе 1120. На этапе 1130 обращаются к хранилищу данных, чтобы определить потенциальные значения и грамматические функции идентифицированных элементов.
Продолжая ссылку на фиг.11, на этапе 1140 определяются один или более уровней ассоциации в пределах текстовой части. Действие по сообщению информации в пределах текстовой части идентифицируется для каждого одного или более определенных уровней ассоциации, показанных на этапе 1150. Затем, на этапе 1160, первое действие по сообщению информации ассоциируется с первым набором идентифицированных элементов, которые определяются посредством анализа семантических взаимоотношений между элементами, определенными выше на этапе 1120, и определенным действием предоставления информации. Первое действие по сообщению информации ассоциируется с первым уровнем ассоциации. Второе действие по сообщению информации на этапе 1170 ассоциируется со вторым набором идентифицированных элементов и второе действие по сообщению информации ассоциируется со вторым уровнем ассоциации. Семантическое представление ассоциаций может затем быть создано на этапе 1180, так чтобы оно могло храниться в семантическом индексе 260, например, для дальнейшего анализа, в том числе, для сравнения с суждением запроса, как описано выше.
Настоящее изобретение было описано со ссылкой на конкретные варианты осуществления, которые во всех отношениях предназначены быть примерами, но не ограничениями. Альтернативные варианты осуществления станут очевидны специалистам в области техники, к которой относится настоящее изобретение, не отступая от его объема.
Из вышесказанного должно быть видно, что это изобретение хорошо подходит для достижения всех целей и задач, изложенных выше, вместе с другими преимуществами, которые очевидны и свойственны предложенным способам. Следует понимать, что конкретные признаки и их комбинации обладают полезностью и могут использоваться независимо от других признаков и их комбинаций. Это предусматривается и объемом формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| РАЗРЕШЕНИЕ КОРЕФЕРЕНЦИИ В ЧУВСТВИТЕЛЬНОЙ К НЕОДНОЗНАЧНОСТИ СИСТЕМЕ ОБРАБОТКИ ЕСТЕСТВЕННОГО ЯЗЫКА | 2008 |
|
RU2480822C2 |
| ИСЧЕРПЫВАЮЩАЯ АВТОМАТИЧЕСКАЯ ОБРАБОТКА ТЕКСТОВОЙ ИНФОРМАЦИИ | 2014 |
|
RU2662699C2 |
| МАШИННОЕ ОБУЧЕНИЕ | 2005 |
|
RU2391791C2 |
| СПОСОБ СЕМАНТИЧЕСКОЙ ОБРАБОТКИ ЕСТЕСТВЕННОГО ЯЗЫКА С ИСПОЛЬЗОВАНИЕМ ГРАФИЧЕСКОГО ЯЗЫКА-ПОСРЕДНИКА | 2009 |
|
RU2509350C2 |
| СПОСОБ И СИСТЕМА ОБУЧЕНИЯ СИСТЕМЫ ЧАТ-БОТА | 2023 |
|
RU2820264C1 |
| КОНТЕКСТНЫЕ ДЕЙСТВИЯ В ГОЛОСОВОМ ПОЛЬЗОВАТЕЛЬСКОМ ИНТЕРФЕЙСЕ | 2015 |
|
RU2701129C2 |
| СИСТЕМА И СПОСОБ ДЛЯ ВЫБОРА ЗНАЧИМЫХ ЭЛЕМЕНТОВ СТРАНИЦЫ С НЕЯВНЫМ УКАЗАНИЕМ КООРДИНАТ ДЛЯ ИДЕНТИФИКАЦИИ И ПРОСМОТРА РЕЛЕВАНТНОЙ ИНФОРМАЦИИ | 2015 |
|
RU2708790C2 |
| СИСТЕМА И СПОСОБ ОБНАРУЖЕНИЯ ОРФАННЫХ ВЫСКАЗЫВАНИЙ | 2015 |
|
RU2699399C2 |
| КЛАССИФИКАЦИЯ ТИПА ЭМОЦИИ ДЛЯ ИНТЕРАКТИВНОЙ ДИАЛОГОВОЙ СИСТЕМЫ | 2015 |
|
RU2705465C2 |
| СПОСОБ И УСТРОЙСТВО РАСПОЗНАВАНИЯ КОММУНИКАЦИОННЫХ СООБЩЕНИЙ | 2015 |
|
RU2615632C2 |
Изобретение относится, в общем, к компьютерно-реализованным онлайновым поискам и, в частности, к идентификации семантических взаимоотношений в косвенной речи. Техническим результатом является обеспечение быстрого определения наиболее релевантных результатов. Для достижения технического результата реализован способ построения семантических взаимоотношений между элементами, извлеченными из содержимого документа, чтобы сформировать семантическое представление содержимого. Семантические представления могут содержать элементы, идентифицированные или проанализированные в текстовой части содержания, элементы которого могут ассоциироваться с другими элементами, которые совместно используют семантические взаимоотношения, такие как отношения агента, местоположения или темы. Взаимоотношения могут также строиться посредством ассоциации одного элемента, который находится в связи или около другого элемента, позволяя, таким образом, быстрое и эффективное сравнение ассоциаций, найденных в семантическом представлении, с ассоциациями, полученными из запросов. Семантические взаимоотношения могут определяться, основываясь на семантической информации, такой как потенциальные значения и грамматические функции каждого элемента в пределах текстовой части содержания. 4 н. и 17 з.п. ф-лы, 11 ил.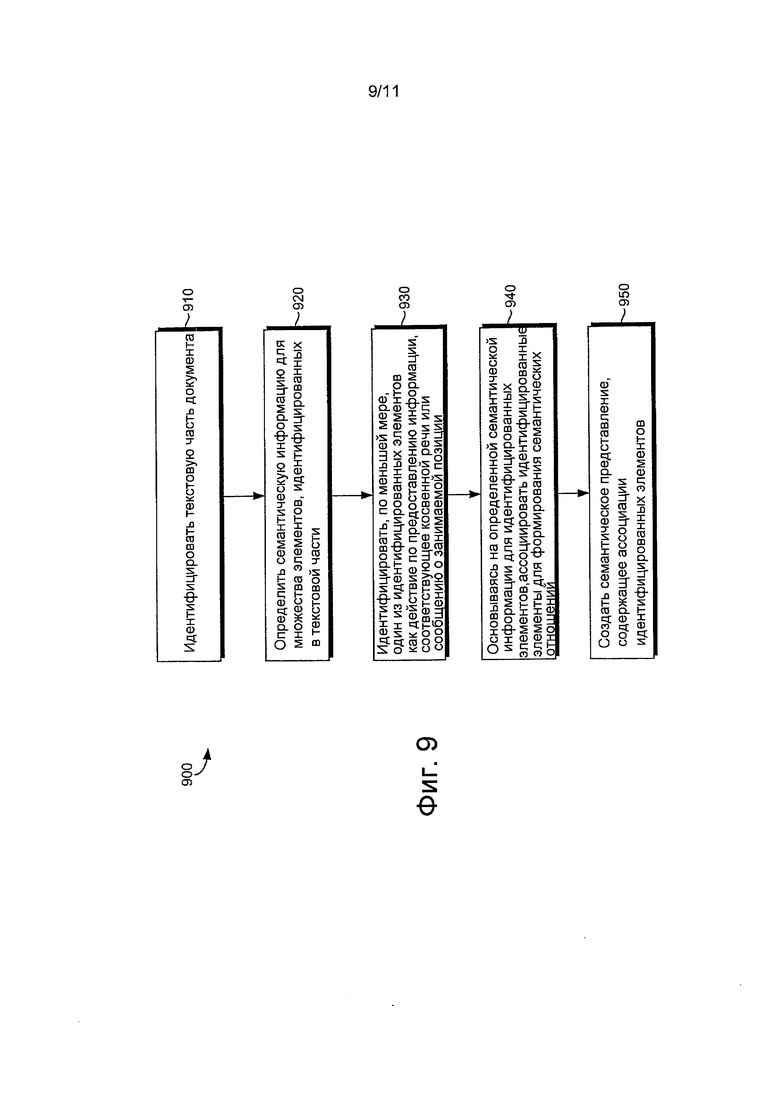
1. Компьютерно-реализуемый способ построения семантических взаимоотношений между элементами, извлеченными из содержимого документа, чтобы сформировать семантическое представление содержимого, содержащий этапы, на которых:
идентифицируют текстовую часть документа;
определяют семантическую информацию для множества элементов, идентифицированных в текстовой части, причем семантическая информация включает в себя одно или более из смысловых значений идентифицированных элементов и грамматических функций идентифицированных элементов;
идентифицируют по меньшей мере один из идентифицированных элементов в качестве субъекта в текстовой части;
идентифицируют по меньшей мере один из идентифицированных элементов в качестве действия по сообщению информации, соответствующей сообщению об отношении, при этом сообщение об отношении описывает отношение субъекта к конкретной теме текстовой части;
основываясь на определенной семантической информации для идентифицированных элементов, ассоциируют идентифицированные элементы так, чтобы каждая ассоциация идентифицированных элементов представляла конкретное семантическое взаимоотношение; и
формируют семантическое представление, которое представляет ассоциации идентифицированных элементов друг с другом.
2. Способ по п.1, в котором текстовая часть содержит по меньшей мере одно из одного или более предложений, таблицы, шаблона и множества данных.
3. Способ по п.1, дополнительно содержащий этап, на котором осуществляют доступ к хранилищу данных для извлечения по меньшей мере части содержимого из документа.
4. Способ по п.1, дополнительно содержащий этап, на котором проводят синтаксический анализ текстовой части документа, чтобы идентифицировать упомянутое множество элементов, которые должны быть включены в семантическое представление.
5. Способ по п.1, дополнительно содержащий этап, на котором распознают один или более объектов в текстовой части, причем эти один или более объектов распознаются посредством поиска по заранее заданному списку слов, хранящемуся в хранилище данных.
6. Способ по п.1, дополнительно содержащий этап, на котором ассоциируют с каждым из идентифицированных элементов множество слов, имеющих схожее смысловое значение.
7. Способ по п.1, в котором при ассоциировании идентифицированных элементов идентифицируют один или более уровней ассоциации в пределах текстовой части, причем каждый из этих одного или более уровней ассоциации включает в себя один или более из идентифицированных элементов.
8. Способ по п.7, дополнительно содержащий этапы, на которых:
идентифицируют действие по сообщению информации для по меньшей мере одного из упомянутых одного или более уровней ассоциации; и
ассоциируют первое действие по сообщению информации с каждым из первого набора идентифицированных элементов, при этом первое действие по сообщению информации ассоциируется с первым уровнем ассоциации.
9. Способ по п.8, дополнительно содержащий этап, на котором ассоциируют второе действие по сообщению информации с каждым из второго набора идентифицированных элементов, при этом второе действие по сообщению информации ассоциируется со вторым уровнем ассоциации.
10. Способ по п.8, в котором первое действие по сообщению информации и каждый из первого набора идентифицированных элементов ассоциируются посредством реляционного элемента, который описывает ассоциацию.
11. Способ по п.10, дополнительно содержащий этап, на котором индексируют семантическое представление, при этом семантическое представление, содержащее идентифицированные элементы и реляционные элементы, хранится в индексе для извлечения, причем индекс доступен для поиска.
12. Способ по п.11, в котором индекс включает в себя указатели из семантического представления на его ассоциированную текстовую часть, которая хранится в хранилище данных.
13. Компьютерно-реализуемый способ создания в ответ на прием запроса ассоциаций между различными терминами, извлеченными из запроса, для генерирования суждения, используемого для опроса семантических представлений содержимого из документов, хранящихся в семантическом индексе, чтобы обеспечить релевантные результаты поиска, при этом способ содержит этапы, на которых:
определяют семантическую информацию для одного или более поисковых терминов;
идентифицируют первое действие по сообщению информации в пределах запроса;
основываясь на упомянутой определенной семантической информации для одного или более поисковых терминов, определяют семантическое взаимоотношение между первым действием по сообщению информации и по меньшей мере одним из упомянутых одного или более поисковых терминов, создавая тем самым ассоциацию с помощью реляционного элемента, который описывает это семантическое взаимоотношение; и
генерируют суждение, причем суждение содержит ассоциацию между первым действием по сообщению информации и упомянутым по меньшей мере одним из одного или более поисковых терминов.
14. Способ по п.13, дополнительно содержащий этап, на котором проводят синтаксический анализ запроса, чтобы определить в нем упомянутые один или более поисковых терминов.
15. Способ по п.13, в котором семантическая информация содержит одно или более из смысловых значений идентифицированных элементов и грамматических функций идентифицированных элементов.
16. Способ по п.13, дополнительно содержащий этап, на котором ассоциируют с каждым из упомянутых одного или более поисковых терминов множество слов, имеющих схожее смысловое значение с упомянутым по меньшей мере одним из одного или более поисковых терминов.
17. Способ по п.13, в котором суждение является логическим представлением смыслового значения запроса, которое используется для опроса семантических взаимоотношений, содержащихся среди семантических представлений содержимого из документов.
18. Способ по п.13, дополнительно содержащий этапы, на которых:
идентифицируют второе действие по сообщению информации в запросе; и
основываясь на упомянутой определенной семантической информации для упомянутых одного или более поисковых терминов, определяют семантическое взаимоотношение между вторым действием по сообщению информации и упомянутым по меньшей мере одним из одного или более поисковых терминов, создавая таким образом ассоциацию посредством реляционного элемента, который описывает семантическое взаимоотношение.
19. Способ по п.13, дополнительно содержащий этап, на котором сравнивают суждение с один или более из семантических представлений, хранящихся в семантическом индексе, чтобы определить одну или более совпадающих пар.
20. Считываемый компьютером носитель, на котором воплощены используемые компьютером команды для выполнения способа построения семантических взаимоотношений между элементами, извлеченными из содержимого документа, чтобы сформировать семантическое представление содержимого, дополнительно обеспечивая возможность индексирования содержимого, при этом способ содержит этапы, на которых:
идентифицируют по меньшей мере часть документа, которая должна быть индексирована, причем эта по меньшей мере часть документа является текстовой частью;
проводят синтаксический анализ текстовой части документа, чтобы идентифицировать элементы, которые должны быть семантически представлены;
осуществляют доступ к хранилищу данных, чтобы определить потенциальные смысловые значения и грамматические функции идентифицированных элементов;
определяют один или более уровней ассоциации в пределах текстовой части, причем эти один или более уровней ассоциации содержат по меньшей мере первый уровень ассоциации и второй уровень ассоциации, так что заявление на первом уровне ассоциации остается действительным независимо от заявления на втором уровне ассоциации, при этом первый уровень ассоциации и второй уровень ассоциации связаны друг с другом посредством действия по сообщению информации, ассоциированного с первым уровнем ассоциации;
идентифицируют действие по сообщению информации в пределах текстовой части для каждого из упомянутых одного или более определенных уровней ассоциации;
ассоциируют первое действие по сообщению информации с первым набором идентифицированных элементов, причем первое действие по сообщению информации ассоциируется с первым уровнем ассоциации;
ассоциируют второе действие по сообщению информации со вторым набором идентифицированных элементов, причем второе действие по сообщению информации ассоциируется со вторым уровнем ассоциации; и
формируют семантическое представление, включающее в себя ассоциации, посредством реляционного элемента, который описывает эти ассоциации, между первым набором идентифицированных элементов с первым действием по сообщению информации и вторым набором идентифицированных элементов со вторым действием по сообщению информации.
21. Считываемый компьютером носитель, на котором воплощены используемые компьютером команды для выполнения способа построения семантических взаимоотношений между элементами, извлеченными из содержимого документа, чтобы сформировать семантическое представление содержимого, дополнительно обеспечивая возможность индексирования содержимого, при этом способ содержит этапы, на которых:
идентифицируют текстовую часть документа для индексирования;
определяют семантическую информацию для множества элементов, идентифицированных в текстовой части, причем семантическая информация включает в себя одно или более из смысловых значений идентифицированных элементов и грамматических функций идентифицированных элементов;
определяют один или более уровней ассоциации в пределах текстовой части;
идентифицируют действие по сообщению информации в пределах текстовой части для каждого из этих одного или более уровней ассоциации;
для идентифицированного действия по сообщению информации в каждом из упомянутых одного или более уровней ассоциации идентифицируют одно или более взаимоотношений "о чем" между действием по сообщению информации и одним или более из идентифицированных в текстовой части;
ассоциируют каждое из идентифицированных действий по сообщению информации с упомянутыми одним или более идентифицированными элементами для формирования взаимоотношений "о чем", причем эти один или более идентифицированных элементов описывают, о чем каждое соответствующее действие по сообщению информации; и
формируют семантическое представление, которое представляет ассоциации действий по сообщению информации и идентифицированных элементов друг с другом.
| СПОСОБ СИНТЕЗА САМООБУЧАЮЩЕЙСЯ СИСТЕМЫ ИЗВЛЕЧЕНИЯ ЗНАНИЙ ИЗ ТЕКСТОВЫХ ДОКУМЕНТОВ ДЛЯ ПОИСКОВЫХ СИСТЕМ | 2002 |
|
RU2273879C2 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| US 7120574 B2, 10.10.2006 | |||
| US 6871199 B1, 22.03.2005. | |||

