Изобретение относится к способу и устройству автоматической диагностики первого приема идентификатора. Изобретение также относится к способу детектирования повторно воспроизводимого сообщения, а также к носителю записи и компьютерной программе, для выполнения этих способов.
Для иллюстрации полезности способа для диагностики первого приема идентификатора описание следует рассматривать в контексте, в котором терминал принимает зашифрованный мультимедийный контент. В таком контексте модуль, обычно называемый агентом DRM (управление цифровыми правами), или CAS (система условного доступа) выполняются в терминале или в карте с микросхемой (или смарт-карте), соединенной с этим терминалом. Такому агенту DRM или CAS доверяют проверку условий доступа к зашифрованному мультимедийному контенту. Если условия доступа соблюдены, он разрешает дешифровку мультимедийного содержания. В противном случае, дешифровка запрещена.
Например, условия доступа содержат наличие действительной лицензии или действительного права доступа. Для простоты здесь предполагается, что условия доступа представляют собой лицензию, содержащую:
- ключ СЕК для дешифровки мультимедийного контента,
- набор прав, определяющих действия, разрешенные над дешифрованным мультимедийным контентом, таких как его просмотр, печать, сохранение и т.д., и
- ограничения, ограничивающие употребление этих прав, такие как максимальная общая продолжительность Тс использования мультимедийного контента или максимальное число Nc пользователей мультимедийного.
В этих условиях недобросовестный пользователь может записать сообщение, содержащее лицензию, и затем время от времени представлять ее снова агенту DRM или CAS, как будто новое сообщение. Это действие многократного представления сообщения называется "повторным воспроизведением сообщения". Попытка повторного воспроизведения сообщения называется "атакой повторного воспроизведения".
Когда терминал имеет возможность связываться в двухстороннем режиме с сервером лицензии, который передает сообщение, содержащее лицензию, существует эффективное решение борьбы против атак повторного воспроизведения. Это решение состоит во вставке случайного числа, определяемого терминалом, в каждый запрос лицензии, передаваемый терминалом на сервер. Сообщение, содержащее запрашиваемую лицензию, которое передается сервером в терминал, содержит это же случайное число, извлеченное из запроса. Это означает, что агент DRM или CAS могут упросить диагностику атаки повторного воспроизведения путем сравнения переданного случайного числа с принятым в ответ. Однако такой подход требует наличия двусторонней передачи данных между терминалом и сервером. В настоящее время такая двусторонняя передача данных не всегда возможна. Например, возникают ситуации, в которых сообщения могут быть переданы только из сервера в терминал, но не в другом направлении.
Если такая двусторонняя передача невозможна, существуют известные способы включения идентификатора UID в каждое сообщение, которое не должно быть повторно воспроизведено. Идентификатор UID обеспечивает уникальную идентификацию данного сообщения среди набора сообщений, которые могут быть сгенерированы. Когда такое сообщение принимают в первый раз, терминал записывает идентификатор UID в запоминающем устройстве для недопущения повторного воспроизведения терминала. Такое запоминающее устройство для недопущения повторного воспроизведения иногда называется "кэшем для недопущения повторного воспроизведения". Однако, если сообщение принимают во второй раз или более, чем два раза, терминал детектирует эту атаку повторного воспроизведения путем поиска идентификатора UID, содержащегося в сообщении, среди содержащихся в запоминающем устройстве недопущения повторного воспроизведения. Если идентификатор UID уже находится в запоминающем устройстве недопущения повторного воспроизведения, это означает, что данное сообщение уже было принято, и поэтому оно представляет собой повторно воспроизведенное сообщение.
Реализуемый способ диагностики, таким образом, содержит:
а) выполняют поиск вновь принятого идентификатора среди содержащихся в запоминающем устройстве недопущения повторного воспроизведения, для проведения диагностики в отношении того, является ли данный прием первым приемом этого вновь принятого идентификатора, причем запоминающее устройство недопущения повторного воспроизведения выполнено с возможностью содержания не менее М идентификаторов.
Эффективность такого способа диагностики первого приема идентификатора UID и, поэтому, детектирования повторно воспроизводимых сообщений ограничена размером запоминающего устройства недопущения повторного воспроизведения. Действительно, запоминающее устройство неизбежно имеет ограниченный размер. Размер запоминающего устройства недопущения повторного воспроизведения зависит от используемого терминала, но он может быть особенно ограниченным, когда агент DRM или CAS представляют собой смарт-карту.
Запоминающее устройство недопущения повторного воспроизведения, поэтому, может содержать только ограниченное количество идентификаторов UID. Максимальное количество идентификаторов UID, которое может быть записано в запоминающем устройстве недопущения повторного воспроизведения, здесь обозначено как М. Следовательно, после того, как М сообщений, и, следовательно М идентификаторов UID, будут приняты в первый раз, необходимо стереть некоторые идентификаторы UID из запоминающего устройства недопущения повторного воспроизведения для того, чтобы иметь возможность записать новые принятые идентификаторы UID. При этом становится возможным повторно воспроизвести сообщения, идентификаторы UID которых были удалены.
В изобретении сделана попытка улучшить эффективность способа диагностики первого приема идентификатора.
Цель изобретения, поэтому, состоит в разработке способа такого рода, содержащего этапы, на которых:
b) строят по меньшей мере один предел как функцию N уже принятых идентификаторов, где N строго больше чем М, причем этот предел строят так, чтобы разграничить диапазон еще не принятых идентификаторов и диапазон идентификаторов, содержащий N уже принятых идентификаторов,
c) сравнивают вновь принятый идентификатор с указанным пределом для определения, принадлежит ли вновь принятый идентификатор диапазону еще не принятых идентификаторов,
d) если вновь принятый идентификатор принадлежит диапазону еще не принятых идентификаторов диагностируют первый прием вновь принятого идентификатора и вновь строят предел как функцию вновь принятого идентификатора, и
e) если вновь принятый идентификатор принадлежит диапазону идентификаторов, содержащему N уже принятых идентификаторов, выполняют этап а).
В описанном выше способе, при условии, что предел рассчитывают как функцию количества уже принятых идентификаторов, большего, чем М идентификаторов, содержащихся в запоминающем устройстве недопущения повторного воспроизведения, этот предел по своей сути сохраняет след количества идентификаторов, строго большего, чем число М. Это означает, что, по меньшей мере, когда вновь принятый идентификатор принадлежит диапазону еще не принятых идентификаторов, степень точности диагностики выше, чем была получена в конце этапа а). Таким образом, эффективность этого способа улучшается.
Варианты осуществления данного способа диагностики могут включать в себя один или более из следующих признаков:
- способ содержит этапы, на которых:
- строят упомянутый предел для разных классов идентификаторов, причем для каждого класса идентификаторов предел, связанный с этим классом, строят как функцию N уже принятых идентификаторов, принадлежащих этому классу идентификаторов,
- идентифицируют класс идентификаторов, которому принадлежит вновь принятый идентификатор, среди существующих классов идентификаторов, и
- на этапе с) сравнивают вновь принятый идентификатор с пределом, связанный с идентифицированным классом, и не сравнивают вновь принятый идентификатор с пределами, связанными с классами, которым он не принадлежит;
- способ содержит этапы, на которых:
- идентифицируют с помощью заданного закона распределения разных идентификаторов, принимаемых в разные участки запоминающего устройства недопущения повторного воспроизведения, участок запоминающего устройства недопущения повторного воспроизведения из нескольких имеющихся участков, записи в которые подлежит вновь принятый идентификатор, и
- на этапе а) выполняют поиск вновь принятого идентификатора только среди идентификаторов, содержащихся в идентифицированном участке запоминающего устройства недопущения повторного воспроизведения, а не среди идентификаторов, содержащихся в участках запоминающего устройства недопущения повторному воспроизведению, записи в которые вновь принятый идентификатор не подлежит;
- способ содержит этапы, на которых:
- выполняют подсчет количества идентификаторов, вновь принятых в течение временного интервала,
- выполняют сравнение этого количества с заданным пороговым значением, и
- если и только если заданное заданный порог превышен, детектируют атаку повторного воспроизведения;
- способ содержит этапы, на которых:
- выполняют подсчет количества идентификаторов в течение временного интервала, диагностированных как принятые не в первый раз,
- выполняют сравнение этого количества с заданным пороговым значением, и
- если и только если этого пороговое значение превышено, детектируют атаку повторного воспроизведения;
- если выполняют этап d), этап а) не выполняют для этого вновь принятого идентификатора;
- построение предела содержит определение миноранты или мажоранты N уже принятых идентификаторов.
Эти варианты осуществления способа диагностики, кроме того, имеют следующие преимущества:
- факт распределения идентификаторов по классам идентификаторов и использования пределов для каждого класса идентификаторов повышает эффективность способа, благодаря увеличению количества случаев, в которых этап а) не выполняется,
- факт поиска вновь принятого идентификатора только среди идентификаторов, содержащихся в определенном участке запоминающего устройства недопущения повторного воспроизведения, позволяет более быстро диагностировать первый прием идентификатора,
- подсчет вновь принятых идентификаторов и сравнение этого количества с пороговым значением обеспечивает возможность детектирования атак повторного воспроизведения,
- подсчет количества идентификаторов, принимаемых в первый раз, и сравнение этого количества с пороговым значением также позволяет детектировать атаки повторного воспроизведения,
- не выполнение этапа а), когда выполняют этап d), обеспечивает уменьшение времени выполнения, поскольку становится возможным диагностировать первый прием идентификатора без необходимости поиска вновь принятого идентификатора среди идентификаторов, содержащихся в запоминающем устройстве недопущения повторного воспроизведения.
Цель изобретения также состоит в способе детектирования повторно воспроизводимого сообщения, причем каждое сообщение содержит идентификатор, используемый для отличия его от других сообщений, этот способ содержит автоматическую диагностику первого приема идентификатора для установления, воспроизводится ли принятое сообщение повторно, в соответствии с описанным выше способом диагностики.
Изобретение также направлено на носитель записи информации и компьютерную программу, содержащую команды для выполнения одного из приведенных выше способов, когда эти команды выполняются с помощью электронного компьютера.
Наконец, целью изобретения также является устройство для автоматической диагностики первого приема идентификатора, содержащее:
- модуль поиска вновь принятого идентификатора среди содержащихся в запоминающем устройстве недопущения повторного воспроизведения,
- причем запоминающее устройство недопущения повторного воспроизведения выполнено с возможностью содержания максимум М идентификаторов, с которыми можно сравнивать вновь принятый идентификатор,
- модуль построения по меньшей мере одного передела как функции N уже принятых идентификаторов, где N строго больше М, выполненный с возможностью построения предела, чтобы разграничить диапазон еще не принятых идентификаторов, и диапазон идентификаторов, содержащих N уже принятых идентификаторов,
- модуль сравнения вновь принятого идентификатора с упомянутым пределом для определения, принадлежит ли вновь принятый идентификатор диапазону еще не принятых идентификаторов, причем компаратор выполнен с возможностью:
- диагностики первого приема вновь принятого идентификатора, если вновь принятый идентификатор принадлежит диапазону еще не принятых идентификаторов, и активации модуля построения для запуска нового построения предела как функции вновь принятого идентификатора, и
- активации модуля поиска для запуска поиска вновь принятого идентификатора среди содержащихся в запоминающем устройстве недопущения повторного воспроизведения, если вновь принятый идентификатор принадлежит диапазону идентификаторов, содержащих N уже принятых идентификаторов.
Изобретение будет более понятно из следующего описания, которое представлено исключительно как не исчерпывающий пример, и со ссылкой на чертежи, на которых:
- на фиг.1 схематично показана иллюстрация архитектуры системы для передачи информации, снабженной устройством диагностики первого приема идентификатора,
- на фиг.2 схематично показана иллюстрация участка сообщения, передаваемого в системе по фиг.1,
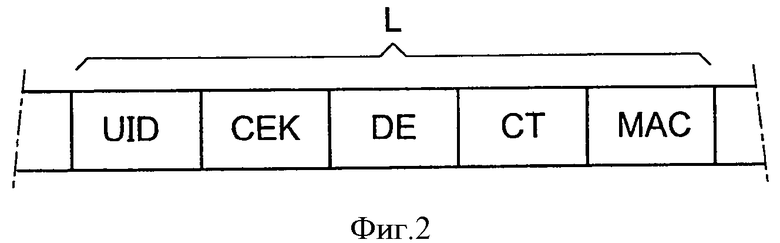
- на фиг.3 показана блок-схема последовательности операций способа детектирования повторно воспроизводимого сообщения, с использованием устройства диагностики системы по фиг.1.
На чертежах одни и те же номера ссылочных позиций используются для обозначения одинаковых элементов.
Здесь, ниже, в данном описании характеристики и функции, хорошо известные специалисту в данной области техники, не будут описаны подробно.
На фиг.1 представлена система 2 передачи информации. В качестве иллюстрации, эта система представляет собой систему передачи зашифрованного мультимедийного контента. Она содержит сервер 4 лицензий, соединенный с множеством терминалов посредством сети 6 передачи информации. Например, сеть 6 представляет собой сеть для передачи информации через спутник.
Для упрощения фиг.1 здесь представлен только один терминал 8.
Сервер 4 передает сообщения в терминалы. Эти сообщения содержат лицензии, позволяющие каждому терминалу дешифровать ранее принятый мультимедийный контент. С этой целью сервер 4 содержит генератор 10 идентификаторов UID. Для каждого сообщения, переданного сервером 4, такой генератор 10 генерирует идентификатор UID, который уникально идентифицирует данное сообщение среди набора переданных сообщений. Например, идентификатор UID получают путем нанесения водяного знака лицензии путем использования таких функций, как функция хеширования. Идентификатор UID также может быть получен путем извлечения случайного числа.
Требуемый размер UID зависит от количества терминалов, в которые должны быть переданы сообщения, а также от количества сообщений передаваемых в каждый терминал. Здесь количество сообщений, передаваемых в каждый терминал, соответствует количеству лицензий, купленных для этого терминала. Как правило, UID кодируют 16 байтами.
Терминал 8 принимает сообщения, передаваемые сервером 4. Например, терминал 8 представляет собой декодер, выполненный с возможностью приема лицензии и зашифрованного мультимедийного контента, и последующего дешифрования мультимедийного содержания с использованием ключа, содержащегося в лицензии, так, чтобы его можно было просматривать в незашифрованной форме на экране 10.
Терминал 8 имеет устройство 12 автоматической диагностики первого приема идентификатора UID. Для упрощения иллюстрации устройство 12 представлено вне терминала 8. Однако на практике устройство 12 интегрировано в терминал 8 или размещено в процессоре безопасности, который соединен с терминалом 8. Например, процессор безопасности представляет собой смарт-карту. Как правило, устройство 12 составляет часть агента DRM или CAS.
Устройство 12 имеет запоминающее устройство 14 недопущения повторного воспроизведения. В данном случае запоминающее устройство 14 разделено на несколько участков SEi. Пересечение любых двух произвольных участков SEi равно нулю.
Устройство 12 также имеет электронный компьютер 16, выполненный с возможностью диагностики первого приема идентификатора UID. С этой целью компьютер 16 содержит:
- модуль 20 поиска идентификаторов UID среди содержащихся в запоминающем устройстве 14,
- модуль 22 сравнения вновь принятого идентификатора с пределами,
- модуль 24 построения пределов, используемых компаратором 22,
- счетчик 26 принятых идентификаторов UID, и
- счетчик 28 повторно воспроизводимых сообщений.
Эти элементы соединены друг с другом, а также с запоминающим устройством 14 и запоминающим устройством 30 с помощью шины передачи данных.
Здесь область значений идентификаторов UID подразделяют на разные классы Cj. Каждый идентификатор UID, поэтому, классифицируют по классу Cj. С этой целью, используют заданную функцию fc классификации. Для каждого идентификатора UID такая функция fc возвращает индекс j класса, которому она принадлежит. Здесь функция fc такова, что объединение множества классов Cj соответствует множеству идентификаторов UID, которые могут быть сгенерированы в системе 2. Предпочтительно, попарное пересечение классов Cj является пустым. Таким образом, заданный идентификатор UID может принадлежать только одному классу Cj. Каждый класс Cj объединяет несколько возможных идентификаторов UID.
Предпочтительно, такая функция fc представляет собой секретную функцию. Например, функция fc представляет собой функцию, которая возвращает результат усложненного деления вновь принятого идентификатора UID на 2m-8, где 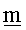
Запоминающее устройство 30 содержит, в частности, ассоциативную таблицу 32. С каждым классом Cj идентификаторов эта таблица 32 ассоциирует предел Sminj и предел Smaxj, построенные модулем 24 построения. Предел Sminj составляет миноранту идентификаторов UID, уже принятых и принадлежащих классу Cj. И, наоборот, предел Smaxj представляет собой мажоранту тех же, уже принятых идентификаторов UID. Таким образом, эти границы разграничивают диапазон [Sminj; Smaxj], содержащий все уже принятые идентификаторы UID и принадлежащие классу Cj. Эти границы также разграничивают два диапазона]-2m-1; Sminj[ и ]Smaxj; +2m-1] еще не принятых идентификаторов UID, где 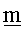
Счетчики 26 и 28 соединены с надежным часами 34.
Компьютер 16 представляет собой, например, программируемый компьютер, выполненный с возможностью выполнения команд, записанных на носителе записи информации. С этой целью, компьютер 16 соединен с запоминающим устройством 36, содержащим программу, образованную командами для выполнения способа по фиг.3.
На фиг.2 представлен участок сообщения, передаваемого из сервера 4 в терминал 8. Это сообщение содержит лицензию L. Лицензия L содержит новый идентификатор UID, криптографический ключ СЕК, права DE не выполнение операций, ограничения СТ и сигнатуру MAC, используемую для проверки целостности лицензии. Сигнатуру MAC рассчитывают на основе набора содержимого лицензии с учетом, в частности, идентификатора UID.
Права на выполнение операций, а также ограничения по этим правам на выполнение операций были определены во вводной части настоящего описания.
Работа системы 2 будет более подробно описана ниже со ссылкой на способ, показанный на фиг.3.
Первоначально, на этапе 50, терминал 8 принимает новое сообщение, переданное сервером 4 через сеть 6.
На этапе 52 терминал выделяет идентификатор UID, содержащийся в сообщении, и передает его в устройство 12. Более конкретно, выделенный идентификатор UID содержится в лицензии L. Идентификатор, переданный таким образом в устройство 12, представляет собой вновь принятый идентификатор UID.
На этапе 54 устройство 12 идентифицирует класс Cj, которому принадлежит вновь принятый идентификатор UID. С этой целью применяют функцию fc к вновь принятому идентификатору UID.
Затем, на этапе 56, устройство 12 выполняет поиск в таблице 32 для того, чтобы определить, каковы пределы Sminj и Smaxj, связанные с классом Cj, идентифицированным на этапе 54. Найденные таким образом пределы затем используют для всех этапов, описанных здесь ниже.
На этапе 58 модуль 22 сравнения выполняет сравнение вновь принятого идентификатора UID с пределами Sminj и Smaxj, найденными на этапе 56. Если вновь принятый идентификатор UID принадлежит диапазону ]-2m-1; Sminj[ или ]Smaxj; +2m-1[ тогда выполняют операцию на этапе 60. В противном случае, выполняют этап 62.
На этапе 60 диагностируют без какого-либо сравнения вновь принятого идентификатора UID с содержащимися в запоминающем устройстве 14, что идентификатор принят в первый раз. Следовательно, принятое сообщение не идентифицируют как повторно воспроизведенное сообщение. Например, эту информацию передают в терминал 8, который принимает принятое сообщение и обрабатывает его. Обработка состоит, например, в выделении ключа СЕК из лицензии и с последующим использованием этого выделенного ключа для дешифровки мультимедийного содержания, так чтобы обеспечить возможность просмотра его на экране 10.
На этапе 60 случай, когда UID строго больше, чем предел Smaxj, отличают от случая, когда UID строго меньше, чем предел Sminj.
Если идентификатор UID строго больше, чем предел Smaxj, тогда на этапе 64 новое значение предела Smaxj строят как функцию вновь принятого идентификатора UID. Действительно, текущее значение предела Smaxj больше не является мажорантой идентификаторов UID, уже принятых и принадлежащих классу Cj. Например, построение нового значения предела Smaxj состоит в замене его текущего значения значением вновь принятого идентификатора UID.
После построения нового значения предела Smaxj на этапе 66, это новое значение записывают в таблице 32 вместо предыдущего значения.
Если вновь принятый идентификатор UID строго меньше, чем предел Sminj, на этапе 68, новое значение предела Sminj строят из вновь принятого значения идентификатора UID. Действительно, в этом случае, текущее значение предела Sminj больше не является минорантой уже принятых идентификаторов UID, принадлежащих классу Cj. Например, построение нового значения предела Sminj состоит в замене его текущего значения значением вновь принятого идентификатора UID.
На этапе 70 новое значение предела Sminj записывают в таблице 32 вместо ее предыдущего значения.
В конце этапа 66 или этапа 70 выполняют этап 71 для идентификации участка SEi, на котором должно быть записано прежнее значение предела Smaxj или Sminj. Действительно, прежнее значение этого предела является значением идентификатора UID, принятого в первый раз, которое еще не было записано в запоминающее устройство 14. Поэтому его обрабатывают как идентификатор UID, принятый в первый раз. Таким образом, как поясняется ниже, такое прежнее значение предела называется "вновь принятым идентификатором UID". С этой целью используется заданная функция fd распределения. Для каждого идентификатора UID функция fd возвращает индекс i участка, на котором он должен быть записан. Здесь функция fd представляет собой сюръективную функцию. Кроме того, с каждым идентификатором UID, который может быть сгенерирован, она связывает только один индекс i. Таким образом, данный идентификатор UID не может быть записан нигде, за исключением только одного участка SEi. Каждый участок SEi обеспечивает возможность записи нескольких идентификаторов UID. Однако, размер каждого участка SEi не может содержать все идентификаторы UID, которые могут быть сгенерированы в системе 2, которые подлежат записи на данном участке.
Например, функция fd идентична функции fc. В этом случае возможно использовать результат этапа 54. Другой пример функции fd представляет собой функцию, которая возвращает остаток идентификатора UID по модулю 1024, который в данном случае может использоваться для группирования идентификаторов вместе на 1024 участка.
Затем, на этапе 72, вновь принятый идентификатор UID записывают на том же участке, что и на этапе 71. Если этот участок не заполнен, вновь принятый идентификатор UID записывают в дополнение к идентификаторам UID, уже содержащимся на этом участке. Однако, если участок SE; запоминающего устройства 14 заполнен, идентификатор UID записывают вместо другого идентификатора UID, содержащегося на том же участке. Этот другой идентификатор UID может быть выбран, например, как случайное число, или в соответствии с принципом "первым прибыл - первым убыл".
В конце этапа 72 процедура возвращается на этап 50.
Этап 62 представляет собой этап определения участка SEi, на котором должен быть записан вновь принятый идентификатор UID. Этот этап идентичен этапу 71.
Затем, на этапе 73, поиск вновь принятого идентификатора UID выполняют исключительно среди идентификаторов, записанных на участке, идентифицированном на этапе 62. Поэтому можно понять, что распределение идентификаторов UID на разных участках запоминающего устройства, используя участок fd, позволяет ускорить сравнение, поскольку только одну часть идентификаторов, записанных в запоминающем устройстве 14, требуется сравнивать с вновь принятым идентификатором UID.
Если вновь принятый идентификатор UID идентичен одному из записанных в запоминающем устройстве 14, тогда на этапе 74 устройство 12 диагностирует тот факт, что происходит не первый прием этого идентификатора. Значит сообщение, содержащее этот идентификатор, повторно воспроизводят. Эту информацию передают в терминал 8.
Такая идентификация повторно воспроизводимого сообщения активирует корректирующие или принудительные меры в терминале 8. Например, повторно воспроизведенное сообщение может быть отброшено, так что ключ СЕК не будет извлечен из лицензии, что делает невозможной дешифровку мультимедийного содержания.
В случае, когда вновь принятый идентификатор UID отсутствует на участке, идентифицированном на этапе 62, то на этапе 76 устройство 12 диагностирует, что данный идентификатор UID принимают в первый раз. Эту часть информации передают в терминал 8, который реагирует соответствующим образом. Например, терминал 8 принимает принятое сообщение, выделяет из него лицензию и, в частности, ключ СЕК, который авторизует дешифровку мультимедийного содержания с использованием выделенного ключа.
Затем, на этапе 78, вновь принятый идентификатор UID записывают на участке, идентифицированном на этапе 62. Этот этап идентичен этапу 72.
В конце этапа 74 или 78 способ возвращается на этап 50.
Здесь значение предела Smaxj строят рекуррентно на основе предыдущего значения предела Smaxj и вновь принятого идентификатора. Вследствие этого, значение предела Smaxj представляет собой функцию N идентификаторов, уже принятых и принадлежащих одному классу Cj. При этом не выполняют сброс значения предела Smaxj. Таким образом довольно быстро число N превышает число М идентификаторов, которые могут быть записаны в запоминающее устройстве 14, с которыми можно сравнивать вновь принимаемый идентификатор. В случае, когда запоминающее устройство 14 будет разделено на несколько участков, число N соответствует максимальному количеству идентификаторов UID, которые могут быть записаны на участке SEi. Действительно, здесь, поиск вновь принятого идентификатора выполняют исключительно среди тех, которые содержатся на участке SEi, в котором он должен быть записан. То же справедливо в отношении построения предела Sminj.
Одновременно с этапами 50-78 устройство 12 переходит к фазе 84 идентификации массивной атаки повторного воспроизведения.
Первоначально, на этапе 86, текущий момент t0, заданный часами 34, записывают с помощью счетчика 26. При этом счетчик Nm-c устанавливают в ноль.
Затем, на этапе 88, для каждого вновь принимаемого идентификатора UID, счетчик Nm-c увеличивает на единицу. Затем, на этапе 90, счетчик Nm-c сравнивают с заданным пороговым значением Nm-s. Такое пороговое значение Nm-s устанавливает, например, оператор. Например, его значение равно 40.
Если счетчик Nm-c не достиг значения порогового значения Nm-s, тогда способ возвращается на этап 88.
Если счетчик Nm-c достиг значения порогового значения Nm-s, то текущее значение момента t1 записывают с помощью счетчика 26.
Затем, на этапе 92, временной интервал Δtc между моментами t0 и t1 сравнивают с заданным пороговым значением Ts времени. Это пороговое значение Ts устанавливает оператор. Например, такой порог равен шести часам.
Если интервал Δtc меньше, чем пороговое значение Ts, тогда, на этапе 94, устройство 12 детектирует массивную атаку повторного воспроизведения. Действительно, массивная атака повторного воспроизведения принимает форму передачи чрезвычайно большого количества идентификаторов UID в течение короткого периода времени. Если это не так, атака повторного воспроизведения не детектируется. Если детектируется атака повторного воспроизведения, эту часть информации передают в терминал 8. В ответ на это терминал 8 инициирует соответствующие корректирующие или принудительные меры.
Фазу 84 повторяют время от времени.
Одновременно с выполнением фазы 84 выполняют другую фазу 100 детектирования массивной атаки повторного воспроизведения.
Первоначально, на этапе 102, счетчик 28 записывает текущий момент t0 и устанавливает в счетчике Nm-r значение, равное нулю.
Затем, на этапе 104, выполняют последовательное приращение счетчика Nm-r на единицу каждый раз, когда выполняют диагностику приема идентификатора UID. Затем, на этапе 106, значение счетчика Nm-r сравнивают с пороговым значением Nm-r-s. Значение этого порогового значения Nm-r-s равно, например, десяти.
До тех пор пока значение счетчика Nm-r меньше, чем пороговое значение Nm-r-s, повторно выполняют этап 104.
В противном случае счетчик 28 записывает текущий момент t1. Затем, на этапе 108, интервал Δtr, полученный в результате расчета разности между моментами t0 и t1, сравнивают с порогом Tr. Значение этого порога Tr, например, равно 5. Если интервал Δtr меньше, чем пороговое значение Tr, тогда это означает, что большое количество идентификаторов UID было принято не в первое время в течение заданного промежутка времени. Такая ситуация представляет массивную атаку повторного воспроизведения. Таким образом, на этапе 110, счетчик 26 детектирует присутствие массивной атаки повторного воспроизведения. Эту информацию передают в терминал 8, который обрабатывает ее аналогично тому, как было описано со ссылкой на этап 94.
После этапа 110 или если интервал Δtr больше, чем пороговое значение Tr, способ возвращается на этап 102.
Таким образом, фазы 84 и 100 используются для детектирования атак повторного воспроизведения, и, следовательно, для принятия соответствующих корректирующих или принудительных мер. Такие корректирующие или принудительные меры могут представлять собой прямую санкцию, такую как запрет любой дешифровки терминалом 8. Эти санкции также могут представлять собой постепенные санкции, которые увеличиваются по мере увеличения количества детектированных атак повторного воспроизведения. В конечном итоге, корректирующая или принудительная мера также может повлечь за собой усиление мониторинга атак повторного воспроизведения для подтверждения реальности таких атак. Мониторинг может быть усилен путем увеличения частоты, с которой выполняют фазы 84 и 100.
Возможно множество других вариантов осуществления. Например, когда сервер должен детектировать, были ли приняты идентификаторы в первый раз, устройство для диагностики первого приема идентификатора, описанное здесь, может быть воплощено на стороне сервера. Например, в этом случае, каждый запрос, передаваемый из терминалов в сервер, будет иметь идентификатор UID.
Терминал 8 не обязательно должен представлять собой декодер. Он может представлять собой мобильный терминал компьютера, карту с микросхемой (или смарт-карту) или любой другой электронный терминал, в котором требуется определить первый прием идентификатора.
Запоминающее устройство 14 может представлять собой файл, такой как, например, файл, записанный на жестком диске.
В запоминающем устройстве 14 идентификаторы UID могут быть связаны с временными метками TS. Такие временные метки обозначают порядок, в котором идентификаторы UID были записаны в запоминающем устройстве 14 или момент записи каждого из этих идентификаторов. Такие временные метки используются для замены самого старого идентификатора UID, содержащегося на участке или во всем запоминающем устройстве 14, вновь принятым идентификатором, когда запоминающее устройство заполнено. Когда используются временные метки, часы 34 также можно исключить. Например, для выполнения фаз 84 и 100 используется временная метка, связанная с каждым идентификатором UID, вместо измерения момента приема такого идентификатора UID с помощью часов 34.
Значения пределов Sminj и Smaxj, связанные с каждым классом, могут сбрасываться время от времени.
Значения пределов Sminj и Smaxj не обязательно должны быть установлены в ноль. Например, пределы Sminj и Smaxj могут быть установлены как ненулевые значения, полученные на основе имеющейся информации об идентификаторах UID, уже используемых в системе 2.
Возможны другие функции fc. Другой пример функции fc представляет собой функцию, которая возвращает остаток по модулю 127 идентификатора UID, и в этом случае это обеспечивает возможность определения 127 классов.
Функция fd может отличаться от функции fc. В этом случае, необходимо применять функцию fd к значению вновь принятого идентификатора UID, принятого на этапе 71, для определения, на каком участке должен быть записан вновь принятый идентификатор UID.
Функции fc и fd делают открытыми или, наоборот, их содержат в секрете.
Функция fc или fd могут, например, быть выбраны из циклических избыточных кодов CRC8 или CRC16 для соответствующего определения 256 участков или 65535 участков.
В одном альтернативном варианте осуществления функция fd может выбираться динамически в соответствии с классом вновь принятого идентификатора UID, причем этот идентификатор определяется по fc. В этом случае применяемая функция fd может быть обозначена как fcd или fd(fc).
Сообщения, содержащие идентификаторы UID, не обязательно должны быть приняты посредством сети передачи данных. Например, такие сообщения могут быть переданы из сервера 4 в терминал 8 посредством носителя записи, такого как CD-ROM или ключ USB (универсальная последовательная шина).
Ассоциативная таблица 32 может быть заменена другими аналогичными механизмами. Например, пределы Sminj и Smaxj могут сохраняться на участке запоминающего устройства 14, который соответствует классу, с которым они связаны.
На этапе 58 также возможно, с использованием монотонной функции g, преобразовать вновь принятый идентификатор UID в идентификатор UID'. Затем этот идентификатор UID' сравнивают с пределами Sminj' и Smaxj'. В таком варианте пределы Sminj' и Smaxj' строят, как описано со ссылкой на этапы 64 и 68, за исключением того, что построение нового значения пределов Sminj' и Smaxj' выполняют, используя идентификатор UID' вместо идентификатора UID. Эти пределы Sminj' и Smaxj', поэтому, строят как функцию N уже принятых идентификаторов UID. Кроме того, функция g представляет собой монотонно возрастающую или монотонно убывающую функцию. Таким образом, сравнение идентификатора UID' с пределами Sminj' и Smaxj' функционально эквивалентно сравнению идентификатора UID с пределами Sminj и Smaxj. Таким образом, сравнение идентификатора UID' с пределами Sminj' или Smaxj' также квалифицируется как и этап "сравнения вновь принятого идентификатора с пределами Sminj или Smaxj".
Предпочтительно, пределы Sminj и Smaxj используются одновременно. Однако, данное описание применимо также в случае использования одного из этих пределов Sminj или Smaxj отдельно.
В одном упрощенном варианте осуществления идентификаторы UID не распределены по разным классам. В этом случае существует только один предел Smin и только один предел Smax, связанные с набором идентификаторов, которые пригодны для генерирования. Аналогично, в упрощенном варианте осуществления, запоминающее устройство 14 не разделяют на несколько участков. Это предотвращает необходимость использования функции распределения.
Пороговое значение, используемое в фазах 84 и 100, может быть фиксировано, как функция хронологии обменов сообщениями между терминалом 8 и сервером 4, или как функция параметра пользователя.
В другом варианте осуществления, период Δtc или Δtr наблюдения являются фиксированными.
В другом упрощенном варианте осуществления исключены счетчики 26 и 28, и фазы 84 и 100 также исключены. Таким образом, в этих вариантах осуществления, атаки повторного воспроизведения не детектируют как функцию количества принятых идентификаторов UID или как функция количества раз диагностики идентификатора UID как принятого не в первый раз.
Изобретение относится к способу и устройству автоматической диагностики первого приема идентификатора. Техническим результатом является повышение точности диагностики за счет определение предела как функции количества уже принятых идентификаторов, большего, чем максимум М идентификаторов. Способ содержит этапы, на которых: а) строят (64, 68) по меньшей мере один предел как функцию N уже принятых идентификаторов, где N строго больше, чем количество максимума М идентификаторов, которые могут содержаться в запоминающем устройстве противодействия повторному воспроизведению, причем предел строят для разграничения диапазона еще не принятых идентификаторов, и диапазона идентификаторов, содержащего N уже принятых идентификаторов; b) сравнивают (58) вновь принятый идентификатор с упомянутым пределом; с) если вновь принятый идентификатор принадлежит диапазону еще не принятых идентификаторов, диагностируют (60) первый прием вновь принятого идентификатора и d) если вновь принятый идентификатор принадлежит диапазону идентификаторов, содержащему N уже принятых идентификаторов, выполняют поиск (73) вновь принятого идентификатора среди содержащихся в запоминающем устройстве недопущения повторного воспроизведения. 4 н. и 6 з.п. ф-лы, 3 ил.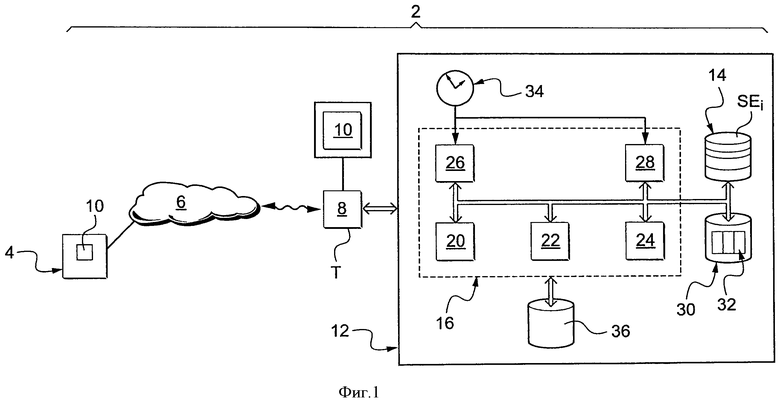
1. Способ автоматической диагностики первого приема идентификатора, содержащий этап, на котором:
a) выполняют поиск (73) вновь принятого идентификатора среди содержащихся в запоминающем устройстве недопущения повторного воспроизведения, причем запоминающее устройство недопущения повторного воспроизведения выполнено с возможностью содержания максимум М идентификаторов для сравнения с вновь принятым идентификатором,
при этом способ содержит этапы, на которых:
b) строят (64, 68) по меньшей мере один предел как функцию N уже принятых идентификаторов, где N строго больше М, причем предел строят для разграничения диапазона еще непринятых идентификаторов и диапазона идентификаторов, содержащего N уже принятых идентификаторов,
c) сравнивают (58) вновь принятый идентификатор с упомянутым пределом для определения, принадлежит ли вновь принятый идентификатор диапазону еще непринятых идентификаторов,
d) если вновь принятый идентификатор принадлежит диапазону еще непринятых идентификаторов, диагностируют (60) первый прием вновь принятого идентификатора и вновь строят (64, 68) упомянутый предел как функцию вновь принятого идентификатора и,
е) если вновь принятый идентификатор принадлежит диапазону идентификаторов, содержащему N уже принятых идентификаторов, выполняют этап а).
2. Способ по п.1, дополнительно содержащий этапы, на которых:
строят (64, 68) упомянутый предел для разных классов идентификаторов, причем для каждого класса идентификаторов предел, ассоциированный с этим классом, является функцией упомянутых по меньшей мере N уже принятых идентификаторов, принадлежащих этому классу идентификаторов,
идентифицируют (54) из имеющихся классов идентификаторов класс идентификаторов, которому принадлежит вновь принятый идентификатор, и
на этапе с) сравнивают (58) вновь принятый идентификатор с пределом, связанным с идентифицированным классом, и не сравнивают вновь принятый идентификатор с пределами, связанными с классами, к которым он не принадлежит.
3. Способ по п.1, дополнительно содержащий этапы, на которых:
идентифицируют (62, 71) с помощью заданного закона распределения разных идентификаторов по разным участкам запоминающего устройства недопущения повторного воспроизведения участок запоминающего устройства недопущения повторного воспроизведения из нескольких имеющихся участков, записи в который подлежит вновь принятый идентификатор, и
на этапе а) выполняют поиск (73) вновь принятого идентификатора только среди идентификаторов, содержащихся в идентифицированном участке запоминающего устройства недопущения повторного воспроизведения, а не среди идентификаторов, содержащихся в участках запоминающего устройства недопущения повторного воспроизведения, записи в которые вновь принятый идентификатор не подлежит.
4. Способ по п.1, дополнительно содержащий этапы, на которых:
выполняют подсчет (88) количества идентификаторов, вновь принятых в течение временного интервала,
сравнивают (90) упомянутое количество с заданным пороговым значением и
детектируют атаку (94) повторного воспроизведения только в случае превышения заданного порога.
5. Способ по п.1, дополнительно содержащий этапы, на которых:
выполняют подсчет (104) количества идентификаторов в течение временного интервала, для которых было диагностировано, что их принимают не в первый раз,
сравнивают (106) упомянутое количество с заданным пороговым значением и
детектируют атаку (110) повторного воспроизведения только в случае превышения упомянутого порогового значения.
6. Способ по п.1, в котором в случае выполнения этапа d) не выполняют этап а) для указанного вновь принятого идентификатора.
7. Способ по любому из пп.1-6, в котором на этапе построения предела определяют миноранту или мажоранту N уже принятых идентификаторов.
8. Способ детектирования повторного воспроизведения сообщения, характеризующийся тем, что каждое сообщение содержит идентификатор, используемый для его различения среди других сообщений, при этом способ содержит этап, на котором:
автоматически диагностируют первый прием идентификатора для установления повторного воспроизведения принятого сообщения,
причем диагностику выполняют в соответствии со способом по любому из пп.1-7.
9. Носитель (36) записи информации, содержащий команды для выполнения способа по любому из пп.1-8 при выполнении команд с помощью электронного компьютера.
10. Устройство автоматической диагностики первого приема идентификатора, содержащее:
модуль (20) поиска вновь принятого идентификатора среди содержащихся в запоминающем устройстве недопущения повторного воспроизведения,
запоминающее устройство (14) недопущения повторного воспроизведения, выполненное с возможностью содержания максимум М идентификаторов для сравнения с вновь принятым идентификатором,
модуль (24) построения по меньшей мере одного предела как функции N уже принятых идентификаторов, где N строго больше М, причем предел предназначен для разграничения диапазона еще непринятых идентификаторов и диапазона идентификаторов, содержащего N уже принятых идентификаторов,
модуль (22) сравнения вновь принятого идентификатора с упомянутым пределом для определения, принадлежит ли вновь принятый идентификатор диапазону еще непринятых идентификаторов, причем модуль сравнения выполнен с возможностью:
диагностики первого приема вновь принятого идентификатора, если упомянутый новый идентификатор принадлежит диапазону еще непринятых идентификаторов, и активации модуля построения для запуска нового построения предела как функции вновь принятого идентификатора, и
активации модуля поиска для запуска поиска вновь принятого идентификатора среди содержащихся в запоминающем устройстве недопущения повторного воспроизведения, если вновь принятый идентификатор принадлежит диапазону идентификаторов, содержащему N уже принятых идентификаторов.
| Машина для склеивания обуви | 1925 |
|
SU9793A1 |
| ЗАЩИТА ОБЪЕКТА ЗАГОЛОВКА ПОТОКА ДАННЫХ | 2003 |
|
RU2332703C2 |
| Приспособление для точного наложения листов бумаги при снятии оттисков | 1922 |
|
SU6A1 |
| Приспособление для точного наложения листов бумаги при снятии оттисков | 1922 |
|
SU6A1 |

