ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Настоящее изобретение в целом относится к области передачи иммерсивного аудио, а более точно, но ни в коем случае не исключительно, к созданию иммерсивной аудиосцены в среде равноправных узлов.
УРОВЕНЬ ТЕХНИКИ ИЗОБРЕТЕНИЯ
В последние годы были значительные достижения в создании визуально иммерсивных виртуальных сред. Эти достижения дали в результате широко распространенное освоение игр с массово многочисленными игроками и ролевым участием, в которых участники могут входить в общую виртуальную среду (такую как поле боя) и представлены в виртуальной среде аватарами, которые типично находятся в форме анимированных персонажей.
Широко распространенное освоение визуально иммерсивных виртуальных сред отчасти обусловлено значительными достижениями как в технологии обработки изображений, дающей высокодетализированной и реалистичной графике возможность формироваться в виртуальной среде, так и развития карт трехмерного звука, применяющих блоки высокоскоростной обработки. Основной недостаток с этими средами, однако, состоит в том, что современные механизмы связи между игроками являются примитивными - обычно, включающими в себя текстовый чат или речевую связь через портативную рацию. Встраивание более естественной среды связи, где голоса кажутся приходящими от аватаров в виртуальном мире, соответствующих игрокам, является сложным для реализации и дорогостоящим для выпуска. Аудио, формируемое каждым игроком, участвующим в виртуальной среде, должно отправляться каждому и всякому другому игроку, который находится в пределах дальности слышимости. Для игр с массово многочисленными игроками, требования к полосе пропускания как потока данных от абонента, так и потока данных к абоненту, для содействия такому обмену аудио могут быть особенно высокими.
Более того, высока стоимость ЦПУ (центрального процессорного устройства, CPU), требуемого для воспроизведения всех из принятых аудиопотоков, требуя, чтобы особенно мощные процессорные блоки применялись для того, чтобы удовлетворять минимальным требованиям к аппаратным средствам для участия в виртуальной среде.
ОПРЕДЕЛЕНИЯ
Последующее предоставляет определения для различных терминов, используемых на всем протяжении этого описания изобретения.
Аудиосцена - аудиоинформация, содержащая комбинированные звуки (например, голоса, принадлежащие другим аватарам, и другие источники звука реального времени в пределах виртуальной среды), которые пространственно размещены и, не обязательно, ослабляются согласно расстоянию между источником и получателем звука. Аудиосцена также может содержать звуковые эффекты, которые представляют акустические характеристики среды.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
В первом аспекте настоящего изобретения предоставляется способ создания аудиосцены для аватара в виртуальной среде, включающей в себя множество аватаров, способ, содержащий этапы создания структуры звеньев между множеством аватаров; и воспроизведение аудиосцены для каждого аватара на основании его связи с другими связанными звеньями аватарами.
Преимущественно, аспекты настоящего изобретения предоставляют не требующую большой производительности технологию для предоставления иммерсивных аудиосцен посредством использования связанной звеньями структуры однорангового типа. Предоставление услуги таким образом устраняет необходимость для отправки потока обмена реального времени через центральный сервер. Это имеет значительную экономию затрат, так как большие серверные фермы и затраты на полосу пропускания обычно требуются для предоставления такой услуги. Взамен, в соответствии с аспектами настоящего изобретения, услуга может предоставляться с использованием ресурсов ЦПУ и полосы пропускания одноранговых узлов сети (или связанных звеньями аватаров), использующих услугу. В дополнение, предоставление услуг может легко масштабироваться по мере того, как растет количество аватаров в виртуальной среде, так как вновь связанный звеньями аватар добавляет ресурсы для поддержки услуги.
В соответствии со вторым аспектом, предоставляется компьютерная программа, содержащая по меньшей мере одну команду для управления компьютером, чтобы реализовывать способ в соответствии с первым аспектом изобретения.
В соответствии с третьим аспектом, предоставляется считываемый компьютером носитель, предоставляющий компьютерную программу в соответствии со вторым аспектом изобретения.
В соответствии с четвертым аспектом, предоставляется пользовательское вычислительное устройство, выполненное с возможностью выполнения этапов способа в соответствии с первым аспектом изобретения.
В соответствии с пятым аспектом, предоставляется система, выполненная с возможностью создания аудиосцены для виртуальной среды, система, содержащая: множество вычислительных устройств, каждое вычислительное устройство является допускающим управление по меньшей мере одним аватаром в виртуальной среде, при этом, каждое вычислительное устройство выполнено с возможностью воспроизведения выходной аудиосцены для по меньшей мере одного аватара и передачи выходной аудиосцены на по меньшей мере одно другое вычислительное устройство.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Несмотря на любые другие формы, которые могут подпадать под объем настоящего изобретения, вариант осуществления настоящего изобретения далее будет описан, только в качестве примера, со ссылкой на прилагаемые чертежи, на которых:
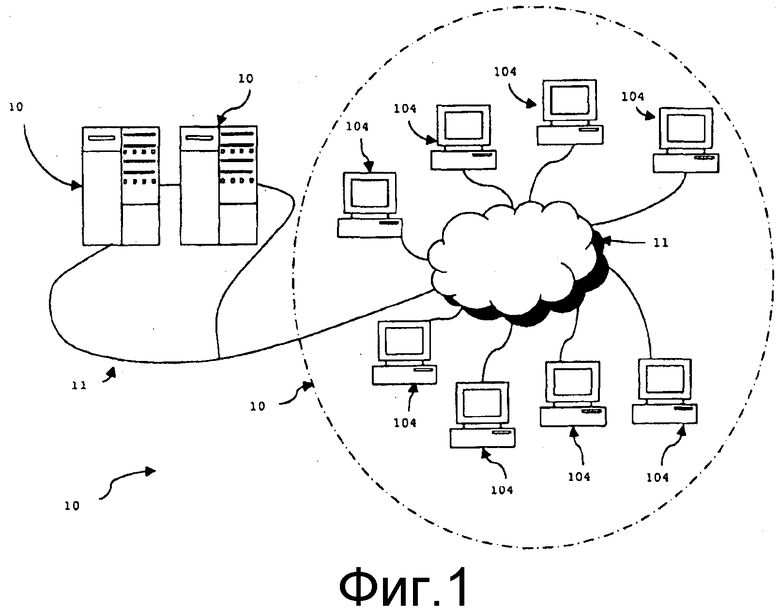
фиг. 1 - блок-схема системы, выполненная с возможностью выполнения варианта осуществления настоящего изобретения;
фиг. 2 показывает пример расположения аватаров в виртуальной среде;
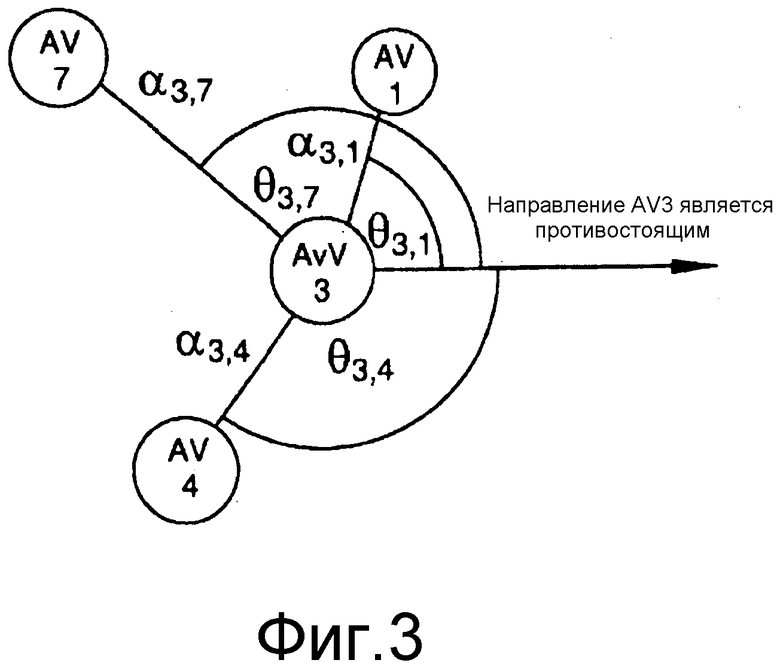
фиг. 3 показывает углы и уровни затухания, требуемые для воспроизведения каждого из аудиопотоков, принимаемых аватаром виртуальной среды по фиг. 2;
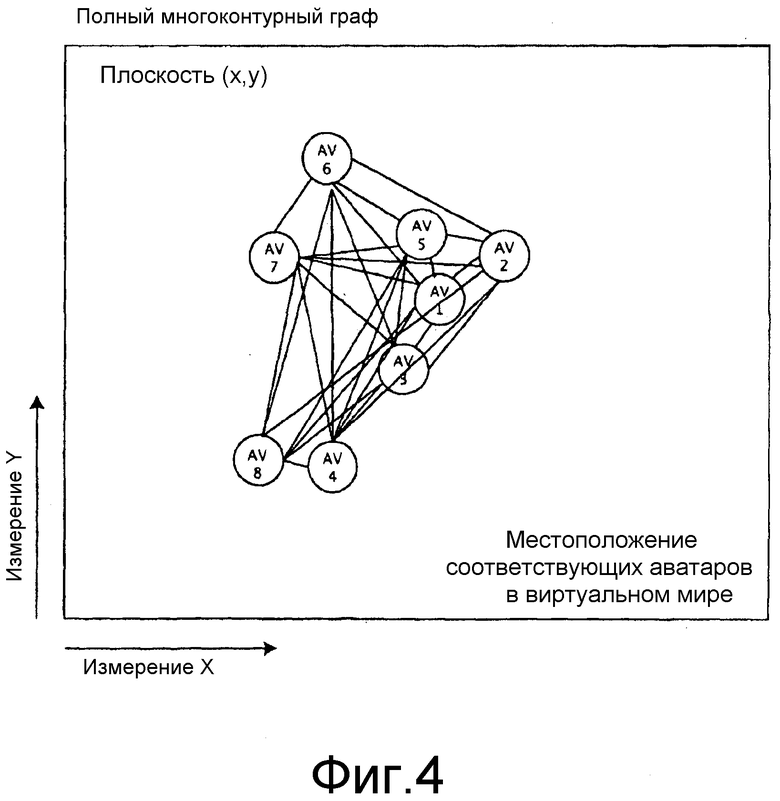
фиг. 4 - пример многоконтурной схемы, связывающей звеньями аватары в виртуальной среде по фиг. 2;
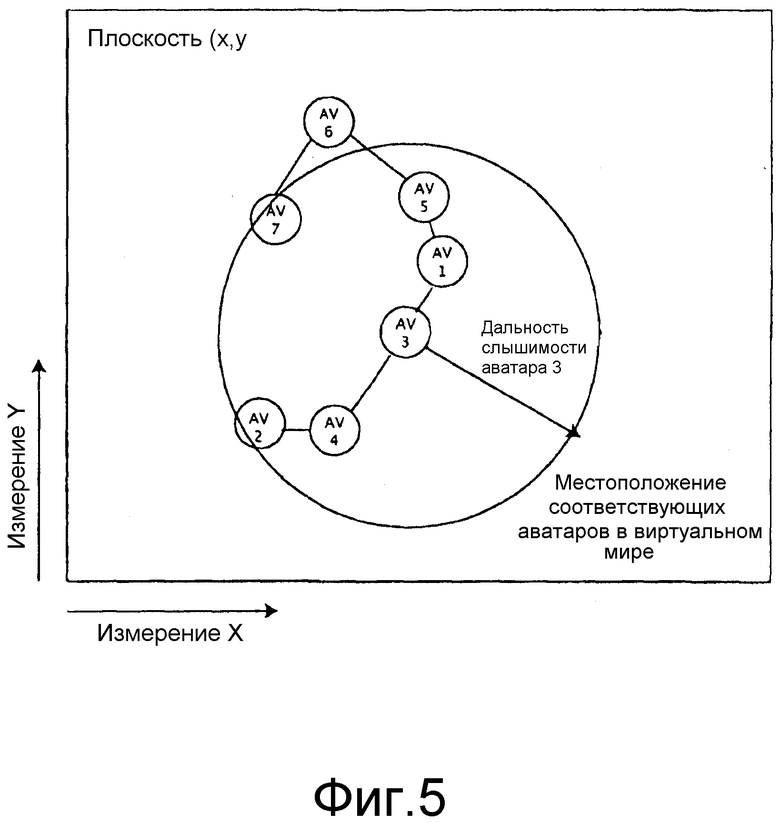
фиг. 5 изображает применение минимального связующего дерева для определения наикратчайших соединений между аватарами по фиг. 2; и
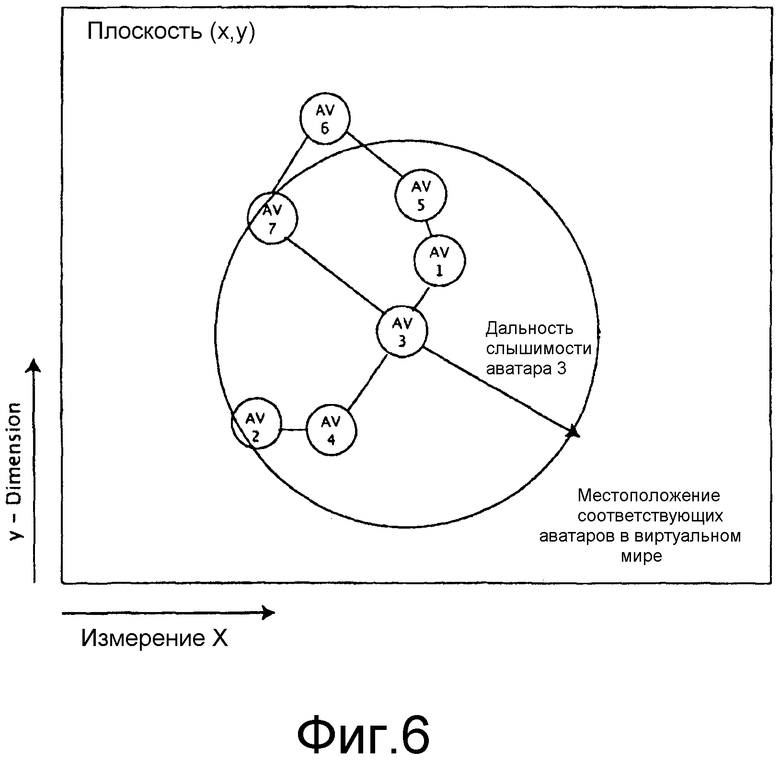
фиг. 6 показывает ребро, добавляемое в минимальное связующее дерево, в соответствии с вариантом осуществления настоящего изобретения.
ПОДРОБНОЕ ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
Со ссылкой на фиг. 1, система 100 включает в себя сервер 102 виртуальной среды; сервер 103 управления, пользовательские вычислительные устройства 104; и систему 106 связи.
Основная функция сервера 102 виртуальной среды состоит в том, чтобы поддерживать информацию о состоянии для виртуальной среды. В настоящем варианте осуществления изобретения, виртуальной средой является поле боя интерактивной игры с многочисленными игроками, а аватары представляют участников (которые являются пользователями пользовательских вычислительных устройств 104) в виртуальной среде и имеют место в виде анимированных солдат. Информация о состоянии, поддерживаемая сервером 102 виртуальной среды, например, содержит положение аватаров в виртуальной среде; то есть, местоположение солдат на поле боя.
Отмечено, что вариант осуществления не ограничен виртуальными средами и аватарами для интерактивных игр с многочисленными игроками. Вариант осуществления имеет применение к диапазону виртуальных сред, в том числе, например, виртуальным средам в деловом контексте (таком как виртуальные собрания персонала) или образовательном контексте (таком как виртуальная лекция).
Для выполнения основных функций поддержания информации о состоянии, сервер 102 виртуальной среды содержит компьютерные аппаратные средства, включающие в себя, материнскую плату, центральные процессорные блоки, оперативное запоминающее устройство, жесткие диски, сетевые аппаратные средства и источник питания. В дополнение к аппаратным средствам, сервер 102 виртуальной среды включает в себя операционную систему (такую как Linux, которая может быть получена из сети Интернет на веб-сайте, расположенном по URL http://www.redhat.com), которая находится на жестком диске и которая действует совместно с аппаратными средствами для предоставления среды, в которой могут выполняться программные приложения. В этом отношении, жесткий диск сервера 102 виртуальной среды загружается приложением сервера виртуальной среды (таким как движок Quake, который может быть получен из сети Интернет на веб-сайте, расположенном по URL http://www.idsoftware.com) для поддержания информации о состоянии.
Сервер 103 управления присоединен к серверу 102 виртуальной среды через высокоскоростную линию 105 связи. Сервер 103 управления заключает в себе такие же аппаратные средства, как сервер виртуальной среды, и загружается приложением сервера управления, которое выполнено с возможностью взаимодействия с сервером 102 виртуальной среды, чтобы получать информацию, которая идентифицирует различные аватары, присутствующие в виртуальной среде, и местоположение аватаров в виртуальной среде. Эта информация также может включать в себя подробности о состоянии аватаров (например, активно или неактивно) и подробности о любых динамических звуковых барьерах. С использованием алгоритмов, встроенных внутри приложения сервера управления, сервер 103 управления формирует информацию о воспроизведении иммерсивного аудио, которое передается в каждое из пользовательских вычислительных устройств. Как изображено на фиг. 1, сервер 103 управления также выполнен с возможностью обмена с пользовательскими вычислительными устройствами через линию 114 связи.
Пользовательские вычислительные устройства 104 имеют место в виде портативных или настольных компьютеров. Однако будет без труда приниматься во внимание, что вариант осуществления не ограничен портативными или настольными устройствами связи. Предусматривается, что в альтернативных вариантах осуществления настоящего изобретения пользовательские вычислительные устройства 104 (например, такие как устройства (04a-h, которые показаны)) могли бы быть переносными устройствами беспроводной связи, такими как Nokia N-Gage и Playstation Portable. Каждое пользовательское вычислительное устройство 104 содержит компьютерные аппаратные средства, включающие в себя материнскую плату, центральный процессорной блок, оперативное запоминающее устройство, жесткий диск или подобное устройство хранения данных, источник питания, монитор и устройство ввода пользовательской информации (например, клавиатуру). В дополнение к аппаратным средствам, жесткий диск каждого пользовательского вычислительного устройства 104 загружен операционной системой, допускающей взаимодействие с аппаратными средствами вычислительного устройства 104 для предоставления среды, в которой могут выполняться программные приложения. В этом отношении, жесткий диск каждого пользовательского вычислительного устройства 104 загружается приложением клиента виртуальной среды и приложением клиента передачи иммерсивного аудио.
Приложение клиента виртуальной среды выполнено с возможностью отправки и приема информации о состоянии для виртуальной среды в и из приложения сервера виртуальной среды, загруженного на сервере 102 виртуальной среды. Приложение клиента передачи иммерсивного аудио выполнено с возможностью отправки и приема аудиоинформации на и от других клиентов передачи иммерсивного аудио. Ранее было описано, что каждое пользовательское вычислительное устройство 104 загружается операционной системой. Вариант осуществления может быть без труда выполнен с возможностью эксплуатации любых разных операционных систем, загруженных на пользовательское вычислительное устройство 104, включая, например, Microsoft Windows XP или Linux (обе из которых типично используются, когда вычислительные устройства 104 представлены в виде настольного компьютера).
Система 106 связи дает приложению клиента виртуальной среды каждого из пользовательских вычислительных устройств 104 и приложению сервера виртуальной среды системы 102 виртуальной среды возможность обмениваться данными (более точно, информацией о состоянии) друг с другом. Система 106 связи также дает приложению клиента передачи иммерсивного аудио каждого из пользовательских вычислительных устройств 104 и серверу 103 управления возможность обмениваться данными (более точно, подробностями о структуре звеньев в виде графа одноранговых узлов) друг с другом.
Для поддержки обмена данными, система 106 связи включает в себя сеть 110 передачи данных в виде сети Интернет для отправки и приема данных с пользовательских вычислительных устройств 104. Настоящее изобретение не ограничивается использованием с сетью Интернет, и альтернативный вариант осуществления настоящего изобретения, например, может применять основанную на протоколе 802.11 беспроводную сеть или тому подобное. Чтобы дать системе 102 виртуальной среды и пользовательским вычислительным устройствам 104 возможность обмениваться данными через систему 106 связи, сервер 102 виртуальной среды присоединяется к сети Интернет 110 через линию 114 связи в виде высокоскоростного канала передачи данных.
Вариант осуществления настоящего изобретения, главным образом, связан с не требующими высокой производительности одноранговыми технологиями для предоставления иммерсивного аудио пользователям пользовательских вычислительных устройств 104, принимающим участие в виртуальной среде. По существу, последующее описание особенно фокусируется на функциональных возможностях приложения сервера управления, загруженного на сервере 103 управления, и приложения клиента передачи иммерсивного аудио, загруженного на пользовательских вычислительных устройствах 104.
Как обсуждено ранее, приложение сервера управления, находящееся на сервере 103 управления, выполнено с возможностью получения информации, относящейся к местоположению аватаров, действующих в виртуальной среде, из приложения сервера виртуальной среды. В соответствии с вариантом осуществления, описанным в материалах настоящей заявки, информация о местоположении представлена в виде пространственных координат (x,y,z). Приложение сервера управления дополнительно сконфигурировано для получения подробностей о любых статических и динамических звуковых барьерах (в дальнейшем, 'информации о барьерах'), которые могут оказывать влияние на распространение звуков в пределах виртуальной среды. Как только была получена информация о местоположении и информация о барьерах, приложение сервера управления выполняет следующие действия.
(1). Рассчитывает дерево или ряд деревьев (если есть некоторое количество несопоставимых группировок аватаров, которые не находятся в пределах дальности слышимости друг друга) на основании координат (x,y,z) аватаров в виртуальной среде. Эти деревья соединяют говорящие аватары со слушающими аватарами. Приложение сервера управления также может учитывать факторы, такие как имеющаяся в распоряжении полоса пропускания и надежность узлов (то есть, соответствующие каждому из пользовательских вычислительных устройств), чтобы определять, каким образом построено дерево. Например, если узел в дереве не имеет высокой имеющейся в распоряжении полосы пропускания, приложение может ограничивать количество других узлов в дереве, к которым он может присоединяться. Если узел ненадежен (например, если узел имеет историю высокой задержки или потери пакетов), то приложению сервера управления может понадобиться удостовериться, что он является листом дерева.
(2). Вводит контуры в дерево для уменьшения длины пути между каждым говорящим и слушателем, чтобы сформировать граф одноранговых узлов. Приложение сервера управления не будет вводить контуры, которые короче, чем заданная длина, чтобы гарантировать, что ни положительная обратная связь, ни заметное эхо не присутствуют в аудиопотоке, в конечном счете выводимом пользовательским вычислительным устройством; и
(3). Передает следующие подробности, ассоциативно связанные с графом одноранговых узлов, на пользовательские вычислительные устройства 104, идентифицированные на графе:
(a) набор аватаров, с которыми пользовательское вычислительное устройство 'A' должно создавать соединения;
(b) значение α коэффициента затухания (α соответствует длине звена графа) для применения к аудиопотокам, которые A будет отправлять по каждому из этих соединений; и
(c) угол θ (θ соответствует углу звена графа), под которым должен воспроизводиться принимаемый аудиопоток.
Что касается функции создания древовидных структур (смотрите п. 1, приведенный выше), могла бы применяться любая пригодная древовидная структура. Однако, в случае настоящего варианта осуществления, применяется минимально связующее дерево (MST). (Оно является минимальным по метрике стоимости, связанной с длиной звеньев в дереве, которая пропорциональна расстоянию между аватарами в виртуальной среде).
Есть две основные функции, выполняемые приложением клиента иммерсивного аудио, находящимся на каждом из пользовательских вычислительных устройств 104. Первая функция состоит в том, чтобы воспроизводить принимаемые аудиопотоки для создания иммерсивной аудиосцены для проигрывания пользователю пользовательского вычислительного устройства 104. Эта последовательность операций, в основном, вовлекает пользовательское вычислительное устройство 104, принимающее аудиопоток по каждому из ребер графа, к которому оно присоединено {E1,E2... En}, и воспроизведение аудиопотока под углом θ, заданным информацией о воспроизведении иммерсивного аудио. Вторая функция вовлекает отправку микшированного аудиопотока пользовательским вычислительным устройством 104, во все другие присоединенные ребрами пользовательские вычислительные устройства/аватары. Микшированный аудиопоток содержит смесь аудиопотока, зафиксированного пользовательским вычислительным устройством (то есть, речи клиента), и аудиопотоков, принимаемых по всем другим ребрам (конечно, исключая ребро, по которому должен отправляться микшированный аудиопоток). Перед отправкой микшированного аудиопотока, он ослабляется с использованием значения α коэффициента затухания для такого конкретного ребра, также заданного информацией о воспроизведении иммерсивного аудио.
Со ссылкой на фиг. с 1 по 6, далее будет описан пример способа для воспроизведения иммерсивных аудиосцен пользовательским вычислительным устройством.
На первом этапе, сервер 102 виртуальной среды пересылает информацию о состоянии виртуальной среды в приложение клиентского сервера у клиентского сервера 103 для последующей обработки. Задан виртуальный мир с N аватарами (A1, A2,... AN), каждое из которых управляется клиентами (C1, C2,.... CN). Аудиоотсчеты (Vi) формируются каждым из этих N клиентов. Граф построен с помощью F ребер (E1, E2,... EF). Каждое из этих ребер имеет ассоциативно связанный угол θ j и коэффициент α j затухания, где 0<j<=F.
(Этап 1) Разместить все аватары на плоскости с их координатами (x, y), соответствующими их координатам (x, y) в виртуальной среде, как показано на фиг. 2.
(Этап 2) Создать многоконтурную схему между всеми узлами графа; если существуют стены, то удалить любые звенья между аватарами, которые находятся на противоположных сторонах стен.
(Этап 3) Рассчитать минимальное связующее дерево (MST) для соединения всех узлов с использованием любого подходящего алгоритма - такого как алгоритм Крускала.
(Этап 4) Удалить все звенья в графе, которые не являются частью минимального связующего дерева.
(Этап 5) В то время как контуры могут добавляться без превышения пределов передачи в узлах, и в то время как возможны контуры, которые превышают пороговое значение (например, удвоенное значение дальности слышимости), затем:
(a) Установить min_edge_length = infinity (длину минимального ребра = бесконечность).
(b) Для каждой пары узлов i, j, которые могут слышать друг друга.
(i) Рассчитать расстояние минимального контура между двумя узлами в качестве: min_loopij = SPij + VDij (минимальный контурij = SPij + VDij). Где SPij - кратчайший путь в дереве между = i,j и VDij = длина прямого звена между i и j, если она существовала,
(ii) Если min_loopij (минимальный контурij) > порогового значения контура (2 × hearing_range (2 × дальность слышимости)), а Dij < min_edge_length (Dij < длины минимального контура)
(1) min_edge_length=VDij (длина минимального ребра =VDij)
(2) min_edge = {i, j} (минимальное ребро = {i, j})
(c) Добавить ребро, указываемое ссылкой посредством min_edge (минимального ребра), в граф. Это является наименьшим ребром, которое вводит приемлемый контур.
Далее, рассмотрим 7 игроков, присоединенных к виртуальной среде. Каждый из игроков использует разный ПК (персональный компьютер, PC), присоединенный к сети Интернет. Каждый из игроков управляет отдельным аватаром - эти аватары названы с A1 по A7. Местоположение x, y (в пространстве) этих аватаров в виртуальном мире являются такими, как показано в таблице 1.
Каждый из аватаров может считаться узлом. Предполагается, что каждый из узлов способен отправлять 4 потока, а дальность слышимости каждого узла равна 115.
Этап 1 размещает аватары на плоскости с такими же координатами x, y, как они занимают в виртуальном мире. Это показано на фиг. 2.
Этап 2 создает многоконтурную схему (то есть, каждый узел присоединен к каждому другому узлу) между узлами. Этот этап предоставляет лежащую в основе топологию узлов для использования алгоритма минимального связующего дерева. Многоконтурная сеть для этого примера показана на фиг. 4.
Расстояние между каждым из аватаров используется позже в алгоритме и рассчитывается в качестве значения (матрицы) VDij, как показано в таблице 2:
На этапе 3, использовался алгоритм Крускала для расчета минимального связующего дерева. Алгоритм Крускала является общим алгоритмом для расчета минимальных связующих деревьев и широко известен инженерам по телекоммуникациям и экспертам теории графов.
На этапе 4, звено, которое не является частью минимального связующего дерева, удаляется из графа. Выходные данные этого этапа показаны на фиг. 5.
Набор узлов, которые могут «слышать» друг друга, рассчитывается на этапе 5:
H = [(3,1), (3,5), (3,7), (3,4), (3,2), (2,4), (1,5), (1,6), (1,7), (5,6), (7,6), (7,5)],
и расстояние каждого звена графа также рассчитывается, как показано в таблице 3:
В заключение рассчитывается кратчайший путь для всех элементов в H.
SP(3,1) = D(3,1)=47
SP(3,5)=D(3,1)+D (1,5)=47+46=93
SP(3,7)=D(3,1)+D(1, 5)+D(5, 6)+D(6,7)=47+46+75+68=236
SP(3,4)=D(3,4)=72
SP(3,2)=D(3,4), D(4,2)=72+45=117
SP(2,4)=D(2,4)=45
SP(1,5)=D(1,5)=46
SP(1,6)=D(1,5)+D(5,6)=46+75=121
SP(1,7)=D(1,5)+D(5,6)+D(6,7)=46+75+68=189
SP(5,6)=D(5,6)=75
SP(7,6)=D(7,6)=68
SP(7,5)=D(7,6)+D(6,5)=68+75=143
min_loopij=SPij+VDij
min_loop(3,l)=47+47=94
min_loop(3,5)=93+86=179
min_loop(3,7)=236+105=341
min_loop(3,4)=72+72=144
min_loop(3,2)=117+105=222
min_loop(2,4)=45+45=90
min_loop(1,5)=46+46=92
min_loop(1,6)=46+115=181
min_loop(1,7)=189+105=194
min_loop(5,6)=75+75=150
min_loop(7,6)=68+68=136
min_loop(7,5)=143+90=233
Затем, с установкой min_edge_length = infinity, обнаруживается, что min_loop (3,7)>2 × hearing_range (230), и VD(3,7)<min_edge_length;
поэтому, min_edge_length=VD(3,7)=105, а Min_edge ={3,7}.
Более того, не существует никакого другого min_loop(i,j)>2 × hearing_range.
Ребро {3,7} затем добавляется в граф, как показано на фиг. 6.
Этап 5 затем повторяется с использованием обновленного графа (звеньев, добавленных предыдущими итерациями этапа 5) до тех пор, пока не остается контуров для добавления.
Следующая итерация этапа 5 обнаруживает, что больше нет приемлемых контуров для добавления, поэтому алгоритм останавливается с добавлением только звена 7,3.
Со ссылкой на фиг. 3, показан граф, обозначающий углы воспроизведения и уровни коэффициента затухания, которые требуются для воспроизведения поступающих аудиопотоков от соответствующего аватара 3. Как показано на предыдущих фигурах, аватар 3 будет принимать аудиопотоки от аватаров 1, 7 и 4. Приложение клиента виртуальной среды, находящееся на пользовательском вычислительном устройстве, управляющем аватаром 3, будет воспроизводить аудиосцену, как изложено ниже: аудио, прибывающее от аватара 1, будет воспроизводиться под углом θ 31 слева от аватара 3. Аудио, принимаемое от аватара 7, будет воспроизводиться на θ 37 градусах слева от слушателя; наряду с тем, что аудио, принимаемое от аватара 4, будет воспроизводиться на θ 34 справа от слушателя, как показано на фиг. 6.
Аудиопотоки, которые принимаются от аватаров 1, 7 и 4, являются ослабленной смесью всех вышерасположенных узлов. Например, аудиопоток, отправленный от аватара 1 на аватар 3, является смесью всех аудио, принимаемых в поступающих потоках (кроме как по звену 3,1), смешанных с речью аватара 1, которая записывается локально пользовательским вычислительным устройством. Эти речевые сигналы ослабляются согласно длине звена, по которому принимается аудио. Поэтому, аудиопоток, который отправляется по звену 3,1, равен: аудиопотоку, отправленному аватаром 2, ослабленному согласно α 12, смешанному с аудио, отправленным аватаром 5, ослабленным согласно α 15, смешанным с локально формируемой речью аватара 1.
Поскольку аудио от каждого аватара смешивается с ослабленным вариантом аудио, принятого по всем входящим звеньям, аватар 3 будет фактически слышать аватары 1 и 5, происходящие с направления аватара 1 с переменными расстояниями, вследствие разных уровней затухания. Речь аватара 6 будет оказывать влияние на аудио, слышимое аватаром 3 с направления обоих аватаров, 1 и 7. Однако, если уровни затухания установлены правильно, то уровень громкости аватара 6 будет незначительным. Также должно быть отмечено, что, в этом примере, если бы не было введено никаких контуров, то аватар 3 не слышал бы аватара 7, так как коэффициент затухания на пути через 5 и 1 был бы слишком большим.
Будет без труда приниматься во внимание, что, хотя вариант осуществления настоящего изобретения был описан в контексте использования для поддержки виртуальной среды, настоящее изобретение не ограничено использованием с виртуальной средой. По существу, настоящее изобретение могло бы использоваться для предоставления системы иммерсивного аудио для использования, например, в качестве системы исключительно аудио-конференц-связи.
Несмотря на то, что изобретение было описано со ссылкой на представленный вариант осуществления, специалистами в данной области техники будет пониматься, что могут быть произведены перестроения, изменения и усовершенствования, и эквиваленты могут использоваться для их элементов и их этапов, не выходя из объема изобретения. В дополнение, могут быть произведены многочисленные модификации, чтобы адаптировать изобретение к конкретной ситуации, или материал к доктринам изобретения, не выходя из его основного объема. Такие перестроения, изменения, модификации и усовершенствования, хотя и не описаны выше явным образом, тем не менее, предполагаются и подразумеваются находящимися в пределах объема и сущности изобретения. Поэтому, предполагается, что изобретение не ограничено конкретным вариантом осуществления, описанным в материалах настоящей заявки, и будет включать в себя все варианты осуществления, подпадающие под объем прилагаемой формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| УСТРОЙСТВА И СПОСОБЫ ДЛЯ ИСПОЛЬЗОВАНИЯ В СОЗДАНИИ АУДИОСЦЕНЫ | 2007 |
|
RU2449496C2 |
| ОПТИМИЗАЦИЯ ДОСТАВКИ ЗВУКА ДЛЯ ПРИЛОЖЕНИЙ ВИРТУАЛЬНОЙ РЕАЛЬНОСТИ | 2018 |
|
RU2750505C1 |
| ОПТИМИЗАЦИЯ ДОСТАВКИ ЗВУКА ДЛЯ ПРИЛОЖЕНИЙ ВИРТУАЛЬНОЙ РЕАЛЬНОСТИ | 2018 |
|
RU2765569C1 |
| ОПТИМИЗАЦИЯ ДОСТАВКИ ЗВУКА ДЛЯ ПРИЛОЖЕНИЙ ВИРТУАЛЬНОЙ РЕАЛЬНОСТИ | 2022 |
|
RU2801698C2 |
| СИСТЕМЫ И СПОСОБЫ УМЕНЬШЕНИЯ ТРАНЗИТНЫХ УЧАСТКОВ, СВЯЗАННЫХ С НАШЛЕМНОЙ СИСТЕМОЙ | 2014 |
|
RU2628665C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ЭФФЕКТИВНОЙ ДОСТАВКИ И ИСПОЛЬЗОВАНИЯ АУДИОСООБЩЕНИЙ ДЛЯ ВЫСОКОГО КАЧЕСТВА ВОСПРИЯТИЯ | 2018 |
|
RU2744969C1 |
| СИСТЕМЫ И СПОСОБЫ ИСПОЛЬЗОВАНИЯ СОКРАЩЕННЫХ ТРАНЗИТНЫХ УЧАСТКОВ ДЛЯ СОЗДАНИЯ СЦЕНЫ ДОПОЛНЕННОЙ ВИРТУАЛЬНОЙ РЕАЛЬНОСТИ С ПОМОЩЬЮ УСТАНАВЛИВАЕМОЙ НА ГОЛОВЕ СИСТЕМЫ | 2014 |
|
RU2639118C2 |
| Аудиоустройство, система распределения аудио и способ их работы | 2019 |
|
RU2816884C2 |
| Аудиоустройство и способ обработки аудио | 2019 |
|
RU2798414C2 |
| Аудиоустройство и способ обработки аудио | 2019 |
|
RU2823573C1 |
Предложенное изобретение относится к области передачи иммерсивного аудиосигнала в среде равноправных узлов. Оно направлено на решение такой задачи, как создание голосов, которые кажутся реально исходящими от аватаров в виртуальном пространстве. Предложенный способ создания аудиосцены для аватара в виртуальной среде включает в себя следующие этапы: создают структуру звеньев в виртуальной среде между множеством аватаров; воспроизводят аудиосцену для каждого аватара на основании его связи с другими связанными звеньями аватарами; при этом созданная структура звеньев выполнена с возможностью действовать для определения угла для воспроизведения аудиосцены и/или коэффициента затухания для применения к аудиопотокам на входящих звеньях, причем угол для воспроизведения аудиосцены соответствует углам звеньев между упомянутым каждым аватаром и другими связанными звеньями аватарами, структура звеньев содержит минимальное связующее дерево, при этом вводят контура в минимальное связующее дерево так, чтобы минимальная длина контуров была меньше, чем предопределенное значение, чтобы предотвратить эхо в аудиосценах воспроизведения. 3 н. и 9 з.п. ф-лы, 3 табл., 6 ил.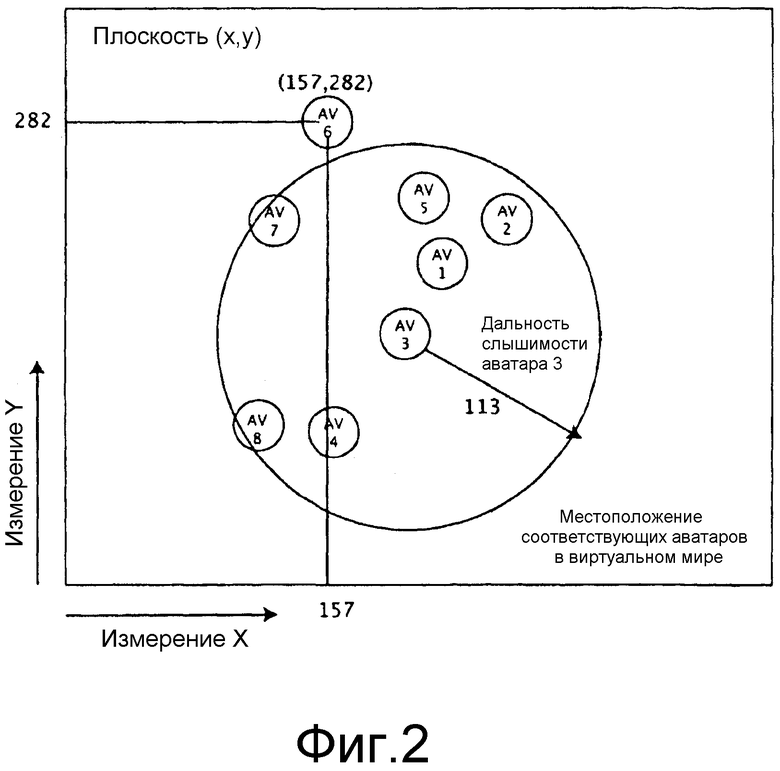
1. Способ создания аудиосцены для аватара в виртуальной среде, включающей в себя множество аватаров, способ, содержащий этапы, на которых:
создают структуру звеньев в виртуальной среде между множеством аватаров и
воспроизводят аудиосцену для каждого аватара на основании его связи с другими связанными звеньями аватарами;
при этом созданная структура звеньев выполнена с возможностью действовать для определения по меньшей мере одного из: угла для воспроизведения аудиосцены или коэффициента затухания для применения к аудиопотокам на входящих звеньях, угол для воспроизведения аудиосцены соответствует углам звеньев между упомянутым каждым аватаром и другими связанными звеньями аватарами, при этом виртуальная среда содержит одно или более из следующего: онлайновая игра с несколькими игроками, виртуальное бизнес-совещание или виртуальная образовательная функция, и при этом каждый из аватаров включает в себя участника в виртуальной среде, при этом структура звеньев содержит минимальное связующее дерево, при этом способ содержит дополнительный этап введения контуров в минимальное связующее дерево так, чтобы минимальная длина контуров была меньше, чем предопределенное значение, чтобы предотвратить эхо в аудиосценах воспроизведения.
2. Способ создания аудиосцены по п.1, в котором структура звеньев с минимальным связующим деревом является минимальной относительно весовой функции, которая связана с длиной звеньев в дереве, и при этом длины звеньев в дереве пропорциональны расстоянию между двумя аватарами в виртуальной среде.
3. Способ создания аудиосцены по п.2, в котором коэффициент затухания содержит значение, которое соответствует длине звена в структуре звеньев.
4. Способ создания аудиосцены по одному из пп.1-3, в котором угол звена между двумя аватарами в структуре звеньев определяет угол воспроизведения.
5. Способ создания аудиосцены по одному из пп.1-3, в котором структура звеньев является древовидной структурой, соединяющей множество аватаров.
6. Способ создания аудиосцены по п.5, в котором древовидная структура является минимальным связующим деревом.
7. Способ создания аудиосцены по п.1, в котором предопределенное значение представляет собой двойную дальность слышимости аватара.
8. Способ создания аудиосцены по одному из пп.1-3, содержащий дополнительный этап микширования воспроизводимой аудиосцены с аудиопотоком, формируемым по меньшей мере одним из множества аватаров.
9. Способ создания аудиосцены по п.8, содержащий дополнительный этап отправки микшированной аудиосцены на другой связанный звеньями аватар.
10. Система для создания аудиосцены для аватара в виртуальной среде, включающей в себя множество аватаров, при этом система содержит:
средство для создания структуры звеньев в виртуальной среде между множеством аватаров и
средство воспроизведения аудиосцены для каждого аватара на основании его связи с другими связанными звеньями аватарами;
при этом созданная структура звеньев выполнена с возможностью действовать для определения по меньшей мере одного из: угла для воспроизведения аудиосцены или коэффициента затухания для применения к аудиопотокам на входящих звеньях, угол для воспроизведения аудиосцены соответствует углам звеньев между упомянутым каждым аватаром и другими связанными звеньями аватарами, при этом виртуальная среда содержит одно или более из следующего: онлайновая игра с несколькими игроками, виртуальное бизнес-совещание или виртуальная образовательная функция, и при этом каждый из аватаров включает в себя участника в виртуальной среде,
при этом структура звеньев содержит минимальное связующее дерево,
при этом система выполнена с возможностью введения контуров в минимальное связующее дерево так, чтобы минимальная длина контуров была меньше, чем предопределенное значение, чтобы предотвратить эхо в аудиосценах воспроизведения.
11. Система, выполненная с возможностью создания аудиосцены для виртуальной среды, включающей в себя множество аватаров, причем имеется структура звеньев в виртуальной среде между множеством аватаров, при этом система содержит: множество вычислительных устройств, каждое вычислительное устройство способно управлять по меньшей мере одним аватаром в виртуальной среде, при этом каждое вычислительное устройство выполнено с возможностью воспроизводить выходную аудиосцену для по меньшей мере одного аватара на основании по меньшей мере одной связи аватара с другими связанными звеньями аватарами и передавать выходную аудиосцену, по меньшей мере, на одно другое вычислительное устройство, при этом созданная структура звеньев выполнена с возможностью действовать для определения по меньшей мере одного из: угла для воспроизведения аудиосцены или коэффициента затухания для применения к аудиопотокам на входящих звеньях, угол для воспроизведения аудиосцены соответствует углам звеньев между упомянутым каждым аватаром и другими связанными звеньями аватарами, при этом виртуальная среда содержит одно или более из следующего: онлайновая игра с несколькими игроками, виртуальное бизнес-совещание или виртуальная образовательная функция, и при этом каждый из аватаров включает в себя участника в виртуальной среде,
при этом структура звеньев содержит минимальное связующее дерево,
при этом система выполнена с возможностью введения контуров в минимальное связующее дерево так, чтобы минимальная длина контуров была меньше, чем предопределенное значение, чтобы предотвратить эхо в аудиосценах воспроизведения.
12. Система, выполненная с возможностью создания аудиосцены, по п.11, в которой каждое вычислительное устройство дополнительно выполнено с возможностью приема входной аудиосцены, по меньшей мере, от одного другого вычислительного устройства и воспроизведения входной аудиосцены с выходной аудиосценой.
| BOUSTEAD P | |||
| and SAFAEI F | |||
| Очаг для массовой варки пищи, выпечки хлеба и кипячения воды | 1921 |
|
SU4A1 |
| BOUSTEAD P | |||
| et al | |||
| "DICE: «Internet delivery of immersive voice communication for crowded virtual spaces», - конференция IEEE Virtual Reality 2005 Proceedings (VR2005) March 12-16, 2005 | |||
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| JP 2004267433 A, 30.09.2004. | |||

