ПЕРЕКРЕСТНАЯ ССЫЛКА НА РОДСТВЕННЫЕ ЗАЯВКИ
[0001] По данной заявке испрашивается приоритет Предварительной Заявки США 61/149,676, поданной 03 Февраля 2009 года, которая во всем своем объеме включена в настоящее описание посредством ссылки.
ПРЕДПОСЫЛКИ СОЗДАНИЯ ИЗОБРЕТЕНИЯ
Область техники, к которой относится изобретение
[0002] Настоящее изобретение в целом относится к распределенному хранению данных на различных узлах в сети.
Описание связанной области техники
[0003] Главной проблемой хранения является то, каким образом хранить данные с избыточностью, чтобы даже при отказе конкретной части хранилища оставалась возможность восстановления данных из других источников. Одной схемой является простое хранение множества копий всего. Несмотря на то что это работает, данный подход требует значительно большего объема хранения для обеспечения конкретного уровня надежности (или, прямо обратно, он обеспечивает значительно меньшую надежность при конкретном объеме хранилища).
[0004] Для достижения лучшей надежности могут использоваться коды стирания. Код стирания берет исходную часть данных и формирует из нее то, что называется «квотами». Квоты выполнены таким образом, что до тех пор, пока существует достаточное количество квот, так что их общий размер такой же, как размер исходных данных, исходные данные могут быть воссозданы из них. В том, что именуется как схема кодирования со стиранием k-из-n, формируется n квот, и любые k из них могут использоваться для воссоздания исходных данных. Каждая квота является размером 1/k от размера исходных данных, так что квоты содержат достаточно информации для воссоздания. n может быть спорадическим. Хранение большего числа квот приведет к большей надежности, но количество квот может измеряться от k до, по сути, бесконечности. Обычная схема простого хранения множества копий исходных данных может рассматриваться как схема 1-из-n для n копий и как очень ненадежная, но при этом простая схема дробления исходных данных на части, а сохранение всех их по отдельности можно рассматривать как схему k-из-k для k частей.
[0005] Метод кодирования со стиранием сначала разбивает исходные данные на k частей, затем обрабатывает данные части как векторы в поле Галуа (Galois) (GF) и формирует квоты посредством умножения частей на произвольные коэффициенты и их сложения. Кодирование со стиранием также может выполняться посредством обработки частей в качестве векторов по модулю простого числа. Для простоты, описанное ниже кодирование со стиранием использует поля Галуа. В итоге квота содержит результат данного вычисления наряду с произвольными коэффициентами. Случайность коэффициентов является причиной того, что существует вероятность того, что исходные данные будут невосстанавливаемыми, которая, по сути, равна обратному количеству используемых элементов поля Галуа. Применительно к хранению, поле Галуа размером 232 или 264 (соответствующее секциям обработки из 4 и 8 байтов соответственно как отдельным элементам) является разумным компромиссом между расходами на вычисления и вероятностью того, что данные будут невосстанавливаемыми, что является крайне маловероятным при 232 и, по сути, невозможным при 264.
[0006] Рассмотренный выше метод сталкивается с ограничениями при использовании применительно к распределенному хранению через Интернет. Применительно к хранению через Интернет недостаточным ресурсом является пропускная способность, а емкость хранения конечных узлов, по сути, бесконечна (или, по меньшей мере, достаточно недорогая, чтобы не быть ограничивающим фактором), приводя к ситуации, где ограничивающим фактором для любого хранения является величина пропускной способности для его отправки. Применительно к исходному хранению это приводит к модели, аналогичной той, при которой ограничивающим фактором является емкость хранения; где существует один к одному замена пропускной способности для хранения. Но после исходного хранения значительные ресурсы пропускной способности могут потребляться для замены отказавших носителей информации (и, в конечном счете, отказывают все носители информации). Как правило, когда избыточное хранение выполнено локально, например в локальной сети, то полное восстановление исходных данных выполняется в отношении квот, которые содержались на отказавших носителях, затем создаются новые квоты и сохраняются на других частях носителей, и затем временная полная копия удаляется. Выполнение такого же действия через Интернет потребует получения k квот из различных оставшихся носителей информации, воссоздания исходных данных, формирования новых k квот и отправки квот на носители информации (включая замещающие носители информации). Это требует использования 2k-кратного размера квот в пропускной способности через Интернет, что становиться быстро неприемлемым по мере роста k.
[0007] Простое хранение нескольких копий данных лучше справляется с задачей, избегая использования пропускной способности, но имеет намного хуже свойства надежности и обладает собственными потерями в масштабе n, так как чем больше копий чего-либо требуется для хранения, тем больше пропускной способности используется по мере того как утрачиваются копии.
КРАТКОЕ ОПИСАНИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
[0008] Система, способ и компьютерный программный продукт заменяют отказавший узел, хранящий данные, относящиеся к части файла данных. В одном варианте осуществления каждым из множества доступных узлов хранения принимается указание на замену отказавшего узла новым узлом хранения. Каждый из доступных узлов хранения содержит множество квот, сформированных из файла данных. Данные квоты могут быть сформированными на основании частей файла данных, используя методики кодирования со стиранием. Заменяющая квота формируется на каждом из множества доступных узлов хранения. Заменяющие квоты формируются посредством создания линейной комбинации квот на каждом узле, используя случайные коэффициенты. Затем, сформированные заменяющие квоты отправляются из множества узлов хранения указанному новому узлу хранения. В дальнейшем эти заменяющие квоты могут использоваться для воссоздания файла данных.
ПЕРЕЧЕНЬ ФИГУР ЧЕРТЕЖЕЙ
[0009] Фиг.1 иллюстрирует среду, включающую в себя узлы хранения для распределенного хранения данных, в одном варианте осуществления.
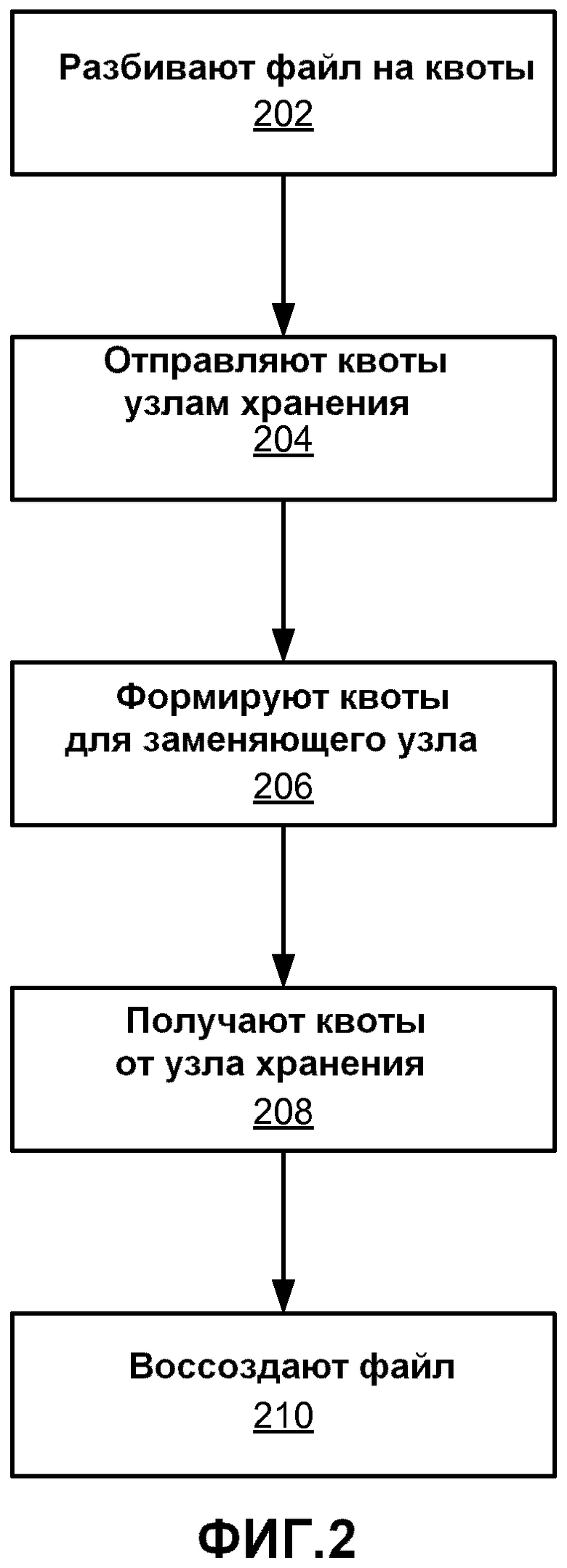
[0010] Фиг.2 является логической блок-схемой, иллюстрирующей способ распределенного хранения данных в одном варианте осуществления.
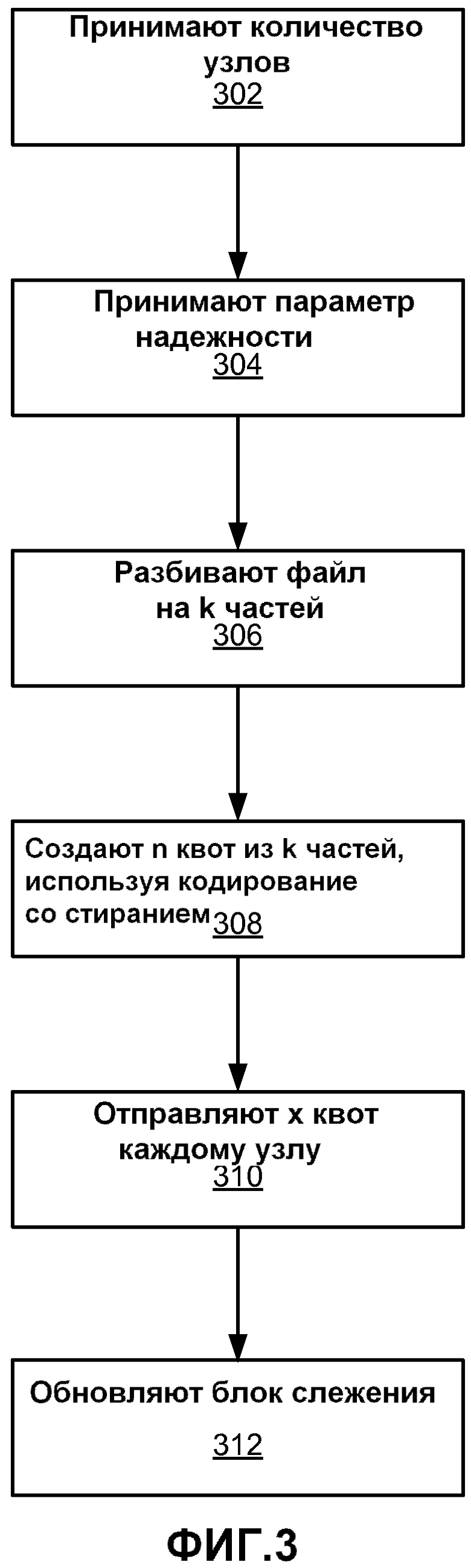
[0011] Фиг.3 является логической блок-схемой, иллюстрирующей способ разбиения файла данных на квоты и отправки квот узлам хранения в одном варианте осуществления.
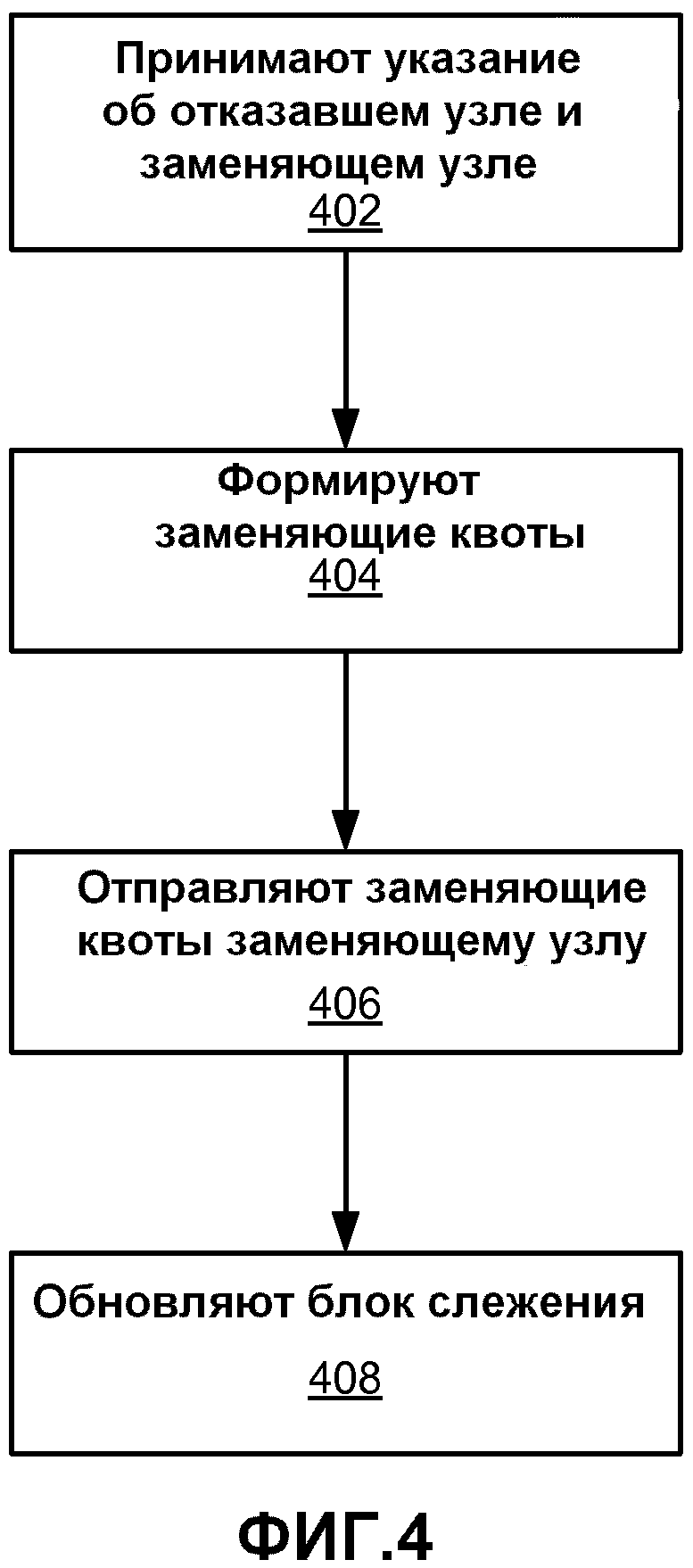
[0012] Фиг.4 является логической блок-схемой, иллюстрирующей способ формирования квот для заменяющего узла хранения в одном варианте осуществления.
[0013] Фиг.5 является принципиальной схемой, иллюстрирующей формирование заменяющих квот для заменяющего узла из оставшихся доступных узлов в одном варианте осуществления.
[0014] Фигуры изображают предпочтительные варианты осуществления настоящего изобретения только в целях иллюстрации. Из нижеследующего рассмотрения специалист легко распознает, что, не отступая от описываемых здесь принципов изобретения, могут быть воплощены альтернативные проиллюстрированным здесь структурам и способам варианты осуществления.
ПОДРОБНОЕ ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
[0015] Фиг.1 иллюстрирует среду 100, включающую в себя узлы 106 хранения для распределенного хранения данных в одном варианте осуществления. Блок 102 выгрузки исходно содержит в себе файл данных, который должен быть сохранен на узлах хранения. Оператор блока выгрузки может пожелать выполнить сохранение файлов на узлах хранения по разным причинам, таким как резервное копирование файла или совместное использование файла. Блок выгрузки разделяет файлы на квоты, дополнительно описываемые ниже, и отправляет квоты различным узлам хранения по сети 104. Узлы 106 хранения принимают квоты и сохраняют квоты. Блок 110 загрузки получает квоты от различных узлов хранения и воссоздает файл данных. В одном варианте осуществления блок 110 загрузки является тем же, что и блок 102 выгрузки. Блок 108 слежения может отслеживать аспекты системы хранения, такие как доступность или недоступность различных узлов хранения и местоположения различных квот. Узлы 106 хранения и блок 102 выгрузки и блок загрузки могут принимать информацию от блока слежения в отношении отправки, приема или создания квот.
[0016] Любой из узлов 106 хранения может в любой момент времени стать недоступным. Например, могут быть потеряны данные, хранящиеся на узле хранения, или может быть потеряна способность узла к соединению с сетью. Квоты, отправленные блоком 102 выгрузки, распределяются по узлам 106 хранения таким образом, чтобы оставалась возможность полного восстановления файла данных даже при отказе одного или более узлов 106 хранения. Существует некоторая избыточность между квотами в разных узлах хранения. Когда конкретный узел 106 хранения становится недоступным, может быть активирован заменяющий узел хранения, а оставшиеся узлы 106 хранения формируют заменяющие квоты и отправляют эти квоты непосредственно заменяющему узлу хранения для хранения на нем. Эти заменяющие (также именуемые как “новые”) квоты могут создаваться посредством повторного объединения существующих квот на оставшихся узлах. Применительно к квотам не является обязательным отправка их в единое местоположение (например, блок выгрузки), воссоздание в исходный файл и затем повторное разделение на новые квоты, которые отправляются текущим узлам. В результате сокращается потребление пропускной способности по сети 104 при хранении квот на заменяющем узле, после того как узел становится недоступным.
[0017] Блок 102 выгрузки, блок 110 загрузки, блок 108 слежения и узлы 106 хранения могут быть компьютерами, содержащими CPU (центральный процессор), память, жесткий диск или другое устройство хранения, сетевой интерфейс, периферийные интерфейсы и прочие широко известные компоненты. Узлы 106 хранения могут включать в себя большие объемы доступного пространства для хранения. В одном варианте осуществления узлы хранения могут быть подключаемыми к сети устройствами хранения. Несмотря на то, что на фиг.1 показано только три узла хранения, их может быть намного больше. В дополнение также может существовать множество блоков 102 выгрузки и блоков 110 загрузки, получающих доступ к узлам хранения. Также может существовать множество блоков 108 слежения (например, могут существовать резервные блоки слежения для случая отказа основного блока слежения).
[0018] Блок 102 выгрузки, блок 110 загрузки, блок 108 слежения и узлы 106 хранения осуществляют связь посредством сети 104. Сеть может быть выполнена в виде Интернет, локальной сети, беспроводной сети и различных других типов сетей. В одном варианте осуществления узлы хранения могут быть географически удалены от блока выгрузки и блока загрузки, и передача по сети больших объемов данных между блоком выгрузки, блоком загрузки и узлами хранения может быть дорогостоящей. В результате в некоторых вариантах осуществления важной может быть минимизация таких передач данных во время операций, таких как предоставление заменяющему узлу квот.
[0019] В одном варианте осуществления блок 108 слежения функционирует в качестве централизованной системы управления и команд, управляемой поставщиком услуг, для координации передачи данных между блоками выгрузки, блоками загрузки и узлами хранения. Так как непосредственно через блок слежения не производятся массовые передачи данных, то его пропускная способность и вычислительные ресурсы могут быть низкими, и он может быть выполнен с использованием обычных методов восстановления после отказа. Блок слежения отвечает за отслеживание местоположений квот и узлов хранения и отслеживания того, какие из операций прошли успешно, а какие отказали. Передача данных квот выполняется непосредственно (например, от блока выгрузки к узлу хранения или от узла хранения к узлу хранения), благодаря координации, обеспечиваемой блоком слежения.
[0020] Фиг.2 является логической блок-схемой, иллюстрирующей способ распределенного хранения данных в одном варианте осуществления. Исходно файл данных, который должен быть сохранен, представлен на блоке 102 выгрузки. Блок выгрузки разбивает 202 файлы на квоты, которые в некоторой степени содержат избыточность. Затем данные квоты отправляются 204 различным узлам 106 хранения и распределяются таким образом, чтобы все же оставалась возможность восстановления исходного файла данных из квот на оставшихся узлах при потере квот на одном или более узлах. В некоторый момент времени один из узлов хранения отказывает, и квоты, хранящиеся на данном узле, теряются. Для сохранения точно такого же уровня надежности хранения в качестве заменяющего узла назначается новый узел 106 хранения. На нескольких из существующих узлов формируются 206 заменяющие квоты, которые будут храниться на заменяющем узле, и эти квоты отправляются заменяющему узлу для хранения на заменяющем узле. Этап 206 может выполняться несколько раз по мере того, как отказывает и заменяется множество узлов. В некоторый момент времени блок 110 загрузки может заинтересоваться в получении файла данных. Блок загрузки получает 208 квоты от доступных в настоящий момент узлов хранения и воссоздает 210 исходный файл данных. Варианты осуществления этапов на фиг.2 более подробно описываются ниже.
[0021] Фиг.3 является логической блок-схемой, иллюстрирующей способ разбиения файла данных на квоты и отправки квот узлам хранения в одном варианте осуществления. Исходно блок 102 выгрузки принимает 302 количество доступных узлов 106 хранения от узла слежения или администратора системы или другого источника. В описании ниже исходное количество доступных узлов представлено как N. Так же принимается 304 параметр x надежности. Параметр x надежности представляет собой количество узлов хранения, содержащих квоты файла данных, доступность которых требуется для восстановления файла данных. Как правило, x выбирается таким, чтобы быть меньше N, и таким образом, чтобы оставалась возможность восстановления файла, если становятся недоступными один или более узлов. В описании ниже x принимается нечетным, тем не менее, с незначительными изменениями могут быть созданы варианты осуществления для четных значений. Параметр надежности может приниматься от блока слежения, или оператора блока выгрузки, или другого источника. Он может быть установлен в соответствии с политикой системы.
[0022] Квоты создаются из файла данных, используя схему кодирования со стиранием k-из-n, описанную выше в разделе “Предпосылки Создания Изобретения”, где k=x*(x+1)/2 в одном варианте осуществления. В одном варианте осуществления k является квадратичной функцией x. Каждая квота имеет размер 1/k файла данных. Создаются квоты общим числом n, где n=xN, и x квот отправляется каждому узлу хранения. В одном варианте осуществления файл данных разбивают 306 на k последовательных частей, которые обрабатываются для формирования 308 n квот, используя кодирование со стиранием. Например, на этапе 306, файл из 10 миллионов байт может быть разбит на последовательные части по 4,000 байт каждая. Обработка на этапе 308 включает в себя умножение частей на произвольные коэффициенты и сложение (масштабированных) частей вместе в различных комбинациях. Например, каждая часть из 4,000 байт может быть умножена на 4-байтный случайный коэффициент посредством умножения каждого 4-байтного сегмента части на случайный коэффициент (по модулю 232) для формирования масштабированных частей. Затем эти масштабированные части могут быть сложены вместе, приводя к квоте, которая является линейной комбинацией частей.
[0023] В одном варианте осуществления случайные коэффициенты, используемые для формирования конкретной квоты, прикрепляются к концу квоты. При использовании квот в качестве векторов в поле Галуа размером 232 это вызывает прикрепление 32-битного (четырехбайтного) значения к концу квоты применительно к каждому коэффициенту. Эти прикрепленные коэффициенты в дальнейшем могут быть обработаны аналогично оставшейся части квоты, упрощая реализацию обработки квот. Например, когда квота умножается на конкретное значение или складывается с другой квотой, случайный коэффициент может аналогичным образом умножаться на значение и складываться с соответствующим коэффициентом в другой квоте. В одном варианте осуществления файл разбивается на единицы оправданного размера и затем вновь разбивается на более мелкие части.
[0024] Затем квоты отправляются 310 узлам 106 хранения и сохраняются в узлах. В частности, x квот отправляется каждому из N узлов хранения, используя описанный выше метод k-из-n. Квоты распределяются по узлам таким образом, чтобы при отказе любых N-x узлов в оставшихся квотах на оставшихся доступных узлах оставалось достаточно информации для воссоздания файла данных. Квоты обеспечивают N узлов хранения некоторым объемом избыточности для того, чтобы противостоять некоторому количеству отказов узлов и предоставлять каждому из узлов информацию, относящуюся ко всем частям файла. Одной оптимизацией применительно к исходному распределению квот является то, что каждая из квот одного узла хранения будет формироваться из разных групп частей (x+1)/2 файла данных. Это дает узлу хранения информацию, относящуюся ко всем частям файла, уменьшая при этом объем вычислений, требуемый для формирования квот. В одном варианте осуществления исходные части файла данных разделяются на сегменты, и каждая квота (для исходного распределения) создается посредством объединения части из каждого из сегментов.
[0025] Блок 108 слежения может обновляться 312, чтобы обладать информацией о текущем статусе квот и узлов хранения. Блок 102 выгрузки может предоставлять блоку слежения информацию, идентифицирующую каждую формируемую квоту и идентифицирующую узел 106 хранения, в котором сохранена квота. Информация идентификации квоты может включать в себя информацию, относящуюся к следующей части файла данных, которой соответствует квота. Блок слежения также может обновляться в отношении статуса каждого узла хранения как являющегося доступным и в отношении содержащихся в нем конкретных квот, связанных с файлом данных. Блок слежения также может обновляться в отношении общего статуса файла данных как находящегося в «сохраненном» состоянии.
[0026] Исходное хранение данных на узлах хранения не может быть реализовано блоком 102 выгрузки в техническим смысле надежным и обладающим способностью к восстановлению после отказа, так как сам по себе блок выгрузки является отдельной точкой отказа. В одном варианте осуществления, когда блок выгрузки запрашивает сохранение файла данных, блок 108 слежения может рассматривать файл данных как находящийся в состоянии “выгрузки”, из которого он может перейти к состоянию “отказавший”, если выявляется, что отказал блок выгрузки. Если достаточное количество узлов хранения приняли требуемые квоты, то затем состояние файла данных обновляется в блоке слежения до состояния “сохранен”. Состояние “сохранен” также может иметь два информационных субсостояния “доступен” и “недоступен”, в зависимости от того, составляет ли количество узлов хранения, которые в настоящий момент имеют квоты, по меньшей мере, x. Исходно, после успешной выгрузки, субсостояние является “доступным”, но может меняться по мере отказа узла, как описывается ниже.
[0027] Фиг.4 является логической блок-схемой, иллюстрирующей способ формирования квот для заменяющего узла 106 хранения в одном варианте осуществления. Как упоминалось выше, узел хранения может в любой момент отказать по различным причинам. Такие причины могут включать в себя, например, отказ оборудования, отказ способности к подключению к сети и отказ по питанию. Узлы хранения также могут умышленно выводиться в автономный режим с или без уведомления заранее. Узел, который отказал или выведен в автономный режим, так же именуется как недоступный узел. Когда узел отказал, зачастую полезным является быстро настроить заменяющий узел, так чтобы в системе узлов хранения сохранялся тот же самый уровень надежности. Если отказало меньше чем N-x узлов, то оставшиеся узлы все еще содержат достаточно информации для восстановления файла данных и, для сохранения надежности системы, в онлайн режим могут быть выведены заменяющие узлы.
[0028] Принимается 402 указание на отказавший узел и заменяющий узел. Также возможно существование нескольких отказавших узлов и заменяющих узлов, но для ясности здесь описывается случай с одним узлом. Это указание может приниматься блоком 108 слежения. В одном варианте осуществления блок слежения периодически проверяет статус узлов (или принимает от узлов обновления статусов) для того, чтобы идентифицировать отказавшие узлы. Блок слежения может идентифицировать конкретный заменяющий узел из совокупности свободных узлов или может принять указание заменяющего узла от некоторого другого источника, такого как администратор системы. Указание на отказавший или заменяющий узел может содержать сетевой адрес или другой идентификатор узла.
[0029] Затем блок 108 слежения уведомляет любые x из оставшихся доступных узлов о заменяющем узле. В одном варианте осуществления эти узлы могут непосредственно принимать уведомление. В одном варианте осуществления блок слежения уведомляет заменяющий узел о доступных узлах, и заменяющий узел инициирует передачи от доступных узлов. Эти x доступных узлов, также именуемые как выгружающие узлы, каждый затем формирует 404 заменяющую квоту и отправляет 406 эту заменяющую квоту заменяющему узлу. Каждый выгружающий узел формирует заменяющую квоту посредством умножения каждой из его квот (включая коэффициенты квот) на случайное масштабирующее значение и затем сложения их вместе. Например, если квота является длиной в 400 байт, а случайное масштабирующее значение является 4-байтным числом, то квота делится на 100 4-байтных секций и каждая секция умножается на случайное масштабирующее значение (по модулю 232). Исходный файл данных, содержащийся в квотах, остается восстановимым, так как коэффициенты квот были изменены при помощи случайных масштабирующих значений таким же образом, как и данные квоты. В результате заменяющая квота, сформированная каждым узлом, представляет собой сочетание данных, содержащихся в настоящий момент в квотах данного узла.
[0030] Фиг.5 является принципиальной схемой, иллюстрирующей формирование заменяющих квот для заменяющего узла из оставшихся доступных узлов в одном варианте осуществления. В примере, показанном на фиг.5, исходное количество узлов, N, равно 5, а параметр надежности x равен 3, так что вплоть до 2 узлов могут отказать, не создавая ситуации потери данных без возможности восстановления. Каждый узел содержит x квот (в данном примере три квоты). Узел N2 отказал, приводя к тому, что доступными остаются четыре узла. N6 был определен как заменяющий (или новый) узел для пополнения количества узлов вновь до пяти. Доступные узлы N1, N4 и N5 были выбраны блоком слежения для формирования заменяющих квот для N6. Каждый из трех выбранных узлов объединяет свои квоты для формирования единой заменяющей квоты для N6. Эти заменяющие квоты отправляются непосредственно от доступных узлов к N6 и сохраняются в N6.
[0031] Блок 108 слежения обновляется 408, чтобы отражать новый доступный узел(ы) и новые квоты на новом узле(ах). Отдельные узлы хранения могут иметь состояние “доступных” или “недоступных”. Новые узлы могут быть обновлены до состояния “доступный”, как только они загрузили все квоты, а отказавший узел может быть обновлен до состояния “недоступный”. В одном варианте осуществления всегда по прошествии некоторого времени предполагается возможность возвращения узла, так что узел не помечается как постоянно “недоступный”. В то время как узел хранения пытается загрузить квоту с других узлов или с блока выгрузки, ему блоком слежения может быть назначено состояние “загружающий”.
[0032] В зависимости от того, имел ли место успех или отказ при попытке узлом хранения сформировать объединенную квоту, узлом хранения производится оценка и результат сообщается блоку 108 слежения. В одном варианте осуществления, во время исходной выгрузки файла данных, блок слежения может начать несколько передач квот узлам 106 хранения, затем добавить еще, в зависимости от того, успешна или нет передача, и произвести остановку, если достаточное количество узлов обладает полным набором квот, или прекратить попытки, если подряд происходит слишком много отказов. Подобным образом, если файл данных был сохранен и достаточное количество узлов хранения отказало, так что объем доступных квот ниже безопасного порогового значения, блок слежения может начать передачу к новому узлу хранения и затем вернуться к устойчивому состоянию, если данная передача успешна, или перейти после отказа к другому узлу, если произошел отказ при передаче, и временно пометить конкретную часть данных как недоступную, если подряд произошли отказы слишком многих передач. В примере на фиг.5 предположим, что в качестве безопасного порогового значения задано пять узлов. Если узел отказывает и количество узлов падает ниже пяти, то блок слежения может связаться с оставшимися узлами на предмет начала формирования заменяющих квот для нового узла. Если происходит отказ при передаче заменяющих квот новому узлу, то блок слежения может пометить данный узел как “отказавший”, идентифицировать второй новый узел и связаться с оставшимися узлами на предмет формирования заменяющих квот для второго нового узла. Если при передаче заменяющих квот второму узлу также происходит отказ, то файл данных квот может быть помечен как временно недоступный для загрузки.
[0033] Передачи могут выполняться посредством формирования выгружающим узлом хранения новой вновь объединенной квоты и простого сохранения ее загружающим узлом хранения. Чтобы сделать систему передачи более универсальной, файл может разбиваться на части исходно (в блоке выгрузки) до того, как будет разбит на квоты, так чтобы x узлы, которые обеспечивают квоты для одной части, не обязательно были теми же самыми, что и x узлы, обеспечивающие квоты для другой части. Передачи могут завершаться группой узлов, отличных от узлов, с которых они начинались, в случае если один из узлов в середине операции выходит из строя. Также передачи могут выполняться одновременно из любого доступного источника квот, что является преимуществом, так как узким местом скоростей передачи данных, как правило, является сторона восходящей линии связи, и таким образом загрузка с нескольких источников приведет к более быстрой передаче, как, впрочем, и более равномерно распределенному использованию пропускной способности. Это, в свою очередь, приводит к более быстрому восстановлению после отказа и, следовательно, к более высокой надежности. В одном варианте осуществления, когда узел хранения начинает передачу, ему дается полный набор доступных источников, которые считаются блоком слежения как находящиеся онлайн, возможно включая и исходный блок выгрузки, и затем он осуществляет передачу на любой скорости, на которую он способен, со всех доступных источников.
[0034] Описанный выше процесс замены отказавшего узла 106 может, при необходимости, повторяться любое количество раз. Следуя данному процессу, узлы хранения могут с течением времени отказывать и заменяться, а квоты для заменяющих узлов могут приходить от узлов, которые сами в прошлой генерации были заменяющими узлами. Любые x узлы с полным набором квот могут использоваться для восстановления исходного файла, независимо от того, как много произошло генераций отказов узлов. В большинстве конкретных случаев количество узлов, требуемых для восстановления, меньше x узлов. Например, при формировании заменяющих квот для первого заменяющего узла после исходного сохранения достаточно квот от любых (x+1)/2 узлов.
[0035] После достаточных генераций узлов, отказавших и замененных, количество узлов, необходимых для полного восстановления, будет монотонно стремиться к x, в особенности в ситуации, когда количество доступных узлов сокращается до x. Несмотря на то, что на практике надежность вероятнее будет выше, строгим минимальным значением обеспечения производительности системы является необходимость в не более чем x узлах. В одном варианте осуществления система хранения может начинать с меньшего количества узлов при исходном сохранении файла данных и со временем может увеличивать количество узлов, по мере того как ожидается, что надежность системы будет падать. Например, по прошествии некоторого времени или после того, как произошло определенное количество отказов и замен узлов, в систему может быть добавлен дополнительный узел. Для данного дополнительного узла квоты могут формироваться таким же образом, как сформированные квоты для заменяющих узлов. Тем не менее, существует возможность того, что надежность системы со временем возрастет, так как узлы, все еще содержащие квоты для файла данных, будут иметь более длительное время работоспособности и, следовательно, откажут с меньшей вероятностью, чем все же непроверенные узлы, которые используются для исходного сохранения. Данное соображение имеет тенденцию сбалансировать упомянутое выше ожидаемое падение надежности.
[0036] Если несколько заменяющих квот предоставляются от одного узла заменяющим узлам через последующие генерации отказа узла, то может произойти потеря данных. Тем не менее, существует возможность использования дополнительной информации для проверки целостности заменяющих квот, принимаемых от доступного узла, для выявления этой потери данных. В случае, когда заменяющая квота не проходит эту проверку, может быть запрошена новая заменяющая квота от узла или другого узла.
[0037] Целостность заменяющей квоты от конкретного доступного узла может проверяться либо посредством приема от конкретного доступного узла дополнительной информации, либо посредством приема информации от другого доступного узла. Данная проверка незначительно увеличивает использование пропускной способности по сети. Для проверки вновь принятой квоты заменяющий (или новый) узел отправляет начальное число генератору псевдослучайных чисел (PRNG) доступного узла. Доступный узел формирует новую повторно объединенную квоту и затем умножает все элементы в ней (за исключением коэффициентов) на соответствующее текущее значение на выходе PRNG и складывает все это вместе. Доступный узел отправляет данную сумму, наряду с коэффициентами, заменяющему узлу в качестве информации проверки, также именуемой как хэш-информация проверки. Затем заменяющий узел может вычислить то, какое значение суммы должно выдаваться всеми его квотами и коэффициентам. Заменяющий узел подтверждает целостность вновь принятой квоты, если вычисленное значение равно принятой сумме. Возможно, что доступные данные не содержат избыточности, и в результате значимость проверки целостности может быть ограничена. Однако, эта возможность очень отдаленна, особенно вскоре после исходного сохранения.
[0038] Эффективность описанного выше подхода по формированию заменяющих квот посредством повторного объединения квот с доступных узлов может быть продемонстрирована эмпирически. Одним способом определения того, какой объем данных возможно восстановить из набора квот после серий повторных объединений, является выполнение симуляции, представляющей каждую квоту случайным вектором. Затем над этими векторами могут быть выполнены серии операций, и может быть вычислен ранг матрицы, формируемой соответствующими векторами. Данный ранг указывает объемы восстановимых данных из векторов (или квот).
[0039] Теперь представляется анализ эффективности описанного выше подхода. Так как х одноранговых узлов требуется для восстановления, то наилучшей возможной производительности, основывающейся на теоретических информационных пределах, будут соответствовать k, или x*(x+1)/2, квот для этих одноранговых узлов. При этой схеме каждый из этих х одноранговых узлов имеет x квот, общим числом их x*x квот. Таким образом, соотношение между двумя параметрами составляет (x*(x+1)/2)/(x*x), что асимптотически приближается к 1/2 по мере роста x, так что x может быть взято произвольно большим при очень небольших дополнительных расходах пропускной способности. Так как большее x соответствует большей надежности, то x желательно выбирать из больших значений (например, чуть меньше общего количества узлов N). На практике ограничивающим фактором для x вероятнее являются расходы на вычисления, несмотря на то, что существуют некоторые другие эффекты второго порядка, которые могут стать заметными. Примерами являются влияния на затраты проводного протокола, затраты на централизованное индексирование данных, становящиеся значительными размеры коэффициентов или приближение x к общему количеству N узлов в системе в целом, что является тяжелым ограничением.
[0040] Посредством формирования заменяющих квот при помощи существующих узлов, как описано выше, могут сохраняться высокие уровни надежности, удерживая при этом низкое использование пропускной способности. Существует возможность просто ожидать до тех пор, пока не останется всего лишь k узлов хранения, и затем выполнить восстановление (и новое формирование квот для восстановления данных в узлах хранения). Данный подход имеет низкие характеристики надежности, так как дополнительный отказ узла хранения может привести к потере данных. Для данного подхода также требуется формирование исходного файла и новых квот (например, на блоке выгрузки). Другим подходом является выполнение полного восстановления и формирования квот (например, на блоке выгрузки) всякий раз, когда теряется узел хранения. Данный подход обладает лучшими характеристиками надежности, но может потребовать больших объемов пропускной способности.
[0041] Возвращаясь к фиг.2, квоты получают 208 от узлов хранения блоком 110 загрузки. Блок загрузки, заинтересованный в файле данных, может получить информацию от блока 108 слежения в отношении того, какие узлы хранения в настоящий момент имеют квоты файла. Затем блок загрузки может непосредственно получить квоты от указанных узлов 106 хранения. Блок загрузки может получить квоты от x или более доступных узлов. Блок загрузки затем воссоздает 210 исходный файл данных из полученных квот. Воссоздание выполняется используя коэффициенты, включенные вместе с каждой квотой наряду с информацией последовательности квот от блока слежения.
[0042] Загрузки в целом не могут быть сделаны надежными в смысле восстановления после отказа, так как сам блок загрузки является отдельной точкой отказа. Информация о загрузке может просматриваться в качестве рекомендательной, и блок слежения может только предоставить предполагаемому блоку загрузки информацию обо всех доступных узлах, обладающих полным набором квот, включая, возможно, и исходный блок выгрузки, а блоки загрузки определяют для себя, будет ли им сопутствовать успех или произойдет отказ (хотя отказ по любой причине, кроме перехода блока загрузки в автономный режим, должен быть редким).
[0043] В противоположность, когда новый узел делается доступным, то приемлемым для узла, выполняющего полное восстановление, является загрузка нескольких квот с одного узла. Предположим, что загружающий узел (например, блок 110 загрузки) уже принял квоту от выгружающего узла 106 хранения. Для того чтобы определить, будет ли полезна дополнительная повторно объединенная квота от выгружающего узла, выгружающий узел может отправить загружающему узлу коэффициенты дополнительной квоты. Загружающий узел может вычислить, является ли данная квота линейно независимой от той, что он уже имеет, используя коэффициенты, и если это так, то загружающий узел может запросить квоту у выгружающего узла. В одном варианте осуществления загружающему узлу не требуется запрашивать ту же квоту, но он может запросить вместо этой другую квоту, потому что, как правило, одна дополнительная квота будет полезна, если и только если полезны все, кроме миниатюрной части других квот. Загружающий узел также может запросить хэш-информацию проверки, используя точно такой же метод, как и тот, что используется новыми узлами для проверки целостности данных, как описано выше. В целом, хэш-информация проверки от узла полезна, если и только если полезны дополнительные квоты от данного узла могут быть.
[0044] В одном варианте осуществления описанные выше методы распределенного хранения применяются на ненадежных, широко распределенных устройствах хранения (возможно прикрепленных к компьютерам). В настоящее время существует много устройств хранения с очень большим объемом неиспользуемой емкости на неизмеренных подключениях к Интернет, которые могут использоваться для распределенного хранения. Эти устройства хранения (т.е. узлы 106 хранения) могут принадлежать и управляться различными предприятиями и индивидами. Устройства хранения могут иметь высокую частоту отказов, но отказы в значительной степени некоррелированные. Так как маловероятно, что одновременно откажет много узлов, то описанный выше подход вероятнее всего будет работать хорошо. В одном варианте осуществления, блок 108 слежения может позволить поставщикам устройств хранения делать свои хранилища доступными для пользователей, нуждающихся в хранении данных. Блок слежения может включать в себя web-сервер для поставщиков устройств хранения для регистрации их устройств хранения на блоке слежения так, что устройства могут начать использоваться в качестве исходных узлов хранения или заменяющих узлов для файлов данных пользователей хранилища. Блок слежения также может отслеживать использование устройств хранения и способствовать организации оплаты от пользователей хранилища поставщикам устройств хранения.
[0045] Ссылка в описании на «один вариант осуществления» или на «вариант осуществления» означает, что конкретный признак, структура или характеристика, описанные в связи с вариантами осуществления, включаются в, по меньшей мере, один вариант осуществления изобретения. Появления фраз “в одном варианте осуществления” или “предпочтительный вариант осуществления” в различных местах описания не обязательно все относятся к одному и тому же варианту осуществления.
[0046] Некоторые части вышеприведенного изложения представлены в виде способов и символических представлений операций над битами данных внутри компьютерной памяти. Эти описания и представления являются средствами, используемыми специалистами для наиболее эффективной передачи сущности их работы другим специалистам. Здесь и в целом, под способом понимается самосогласованная последовательность этапов (инструкций), приводящая к требуемому результату. Этапы - это то, что требует физических манипуляций над физическими величинами. Как правило, хотя не обязательно, эти величины принимают форму электрических, магнитных или оптических сигналов, приспособленных для сохранения, передачи, объединения, сравнения и иного манипулирования. Время от времени удобно, преимущественно по причинам общего использования, именовать эти сигналы как биты, значения, элементы, символы, знаки, понятия, числа или подобное. Кроме того, так же время от времени удобно именовать конкретные совокупности этапов, требующих физических манипуляций над физическими величинами, как модули или кодовые устройства, без потери общности.
[0047] Тем не менее, должно быть принято во внимание, что все эти и аналогичные определения должны быть связаны с соответствующими физическими величинами и являются просто удобными обозначениями, применяемыми к этим величинам. До тех пор, пока конкретно не указано обратное в качестве очевидного из нижеследующего рассмотрения, понимается, что на всем протяжении описания, рассмотрения, использующие понятия, такие как “обработка”, или “вычисление”, или “расчет”, или “определение”, или “отображение”, или “определение”, или подобные, относятся к действиям и процессам компьютерной системы или аналогичного электронного вычислительного устройства, которое манипулирует и преобразует данные, представленные в качестве физических (электронных) величин внутри устройств хранения компьютерной системы или регистрах или другом таком информационном хранилище, устройствах передачи и отображения.
[0048] Некоторые аспекты настоящего изобретения включают в себя этапы процесса и инструкции, описанные здесь в виде способа. Должно быть отмечено, что этапы процесса и инструкции по настоящему изобретению могут быть воплощены в программном обеспечении, встроенном программном обеспечении (firmware) или аппаратном обеспечении, и при воплощении в программном обеспечении могут быть загружены для размещения и функционирования на различных платформах, используемых многообразием операционных систем.
[0049] Настоящее изобретение также относится к устройству для выполнения представленных здесь операций. Данное устройство может быть специально разработанным для требуемых целей или оно может быть выполнено в виде компьютера общего назначения, выборочно активируемого или переконфигурируемого компьютерной программой, хранящейся на компьютере. Такая компьютерная программа может храниться на машиночитаемом носителе данных, таком как, но не в ограничительном смысле, диске любого типа, включая гибкие диски, оптические диски, CD-ROM, магнитооптические диски, постоянных запоминающих устройствах (ROM), запоминающих устройствах с произвольной выборкой (RAM), EPROM, EEPROM, магнитных и оптических картах, специализированных интегральных микросхемах (ASIC), или носителе любого типа, приемлемом для хранения электронных инструкций, и каждый соединен с шиной компьютерной системы. Кроме того, упоминаемые в описании компьютеры могут включать в себя один процессор или могут быть архитектурами, использующими исполнения с несколькими процессорами для увеличения вычислительных возможностей.
[0050] Представленные здесь способы и демонстрации, по сути, не относятся к какому-либо конкретному компьютеру или другому устройству. Также могут использоваться различные системы общего назначения с программами в соответствии с изложенными здесь идеями, или может оказаться удобным создать более специализированное устройство для выполнения требуемых этапов способа. Требуемая структура для разнообразия таких систем станет очевидна из описания ниже. В дополнение, настоящее изобретение не описывается с привязкой к какому-либо конкретному языку программирования. Должно быть принято во внимание, что для реализации идей настоящего изобретения в соответствии с тем, что здесь изложено, может использоваться многообразие языков программирования, и любое упоминание конкретных языков предоставлено для раскрытия реализуемости и наилучшего варианта осуществления настоящего изобретения.
[0051] Несмотря на то, что изобретение было конкретно показано и описано со ссылкой на предпочтительный вариант осуществления и несколько альтернативных вариантов осуществления, специалисту должно быть понятно, что, не отступая от сущности и объема изобретения, могут быть выполнены различные изменения по форме и в деталях.
[0052] В заключении должно быть отмечено, что язык, используемый в описании, был преимущественно выбран для удобочитаемости и в целях обучения, и он не мог быть выбран с целью очертить или ограничить объем изобретения. Соответственно, раскрытие данного изобретения предназначено проиллюстрировать, а не ограничить объем изобретения.

Изобретение относится к вычислительной технике. Технический результат заключается в увеличении надежности хранения данных. Способ замены отказавшего узла, хранящего распределенные данные, содержащий этапы, на которых: посредством первого узла хранения принимают первый набор квот, сгенерированный из файла данных, при этом каждая квота в первом наборе включает в себя линейную комбинацию частей файла данных наряду с набором коэффициентов, использованных для генерирования этой линейной комбинации; посредством первого узла хранения принимают указание нового узла хранения, заменяющего отказавший узел, при этом отказавший узел включает в себя второй набор квот, сгенерированный из файла данных; посредством первого узла хранения генерируют первую заменяющую квоту в качестве реакции на упомянутое указание, при этом первую заменяющую квоту генерируют путем умножения каждой квоты в первом наборе и набора коэффициентов на случайное масштабирующее значение и объединения умноженного первого набора квот и умноженного набора коэффициентов; и посредством первого узла хранения передают сгенерированную первую заменяющую квоту в новый узел хранения, при этом первая заменяющая квота и по меньшей мере одна другая заменяющая квота формируют второй набор квот в новом узле хранения, причем эта другая заменяющая квота генерируется вторым узлом хранения. 3 н. и 20 з.п. ф-лы, 5 ил.
1. Способ замены отказавшего узла, хранящего распределенные данные, содержащий этапы, на которых:
посредством первого узла хранения принимают первый набор квот, сгенерированный из файла данных, при этом каждая квота в первом наборе включает в себя линейную комбинацию частей файла данных наряду с набором коэффициентов, использованных для генерирования этой линейной комбинации;
посредством первого узла хранения принимают указание нового узла хранения, заменяющего отказавший узел, при этом отказавший узел включает в себя второй набор квот, сгенерированный из файла данных;
посредством первого узла хранения генерируют первую заменяющую квоту в качестве реакции на упомянутое указание, при этом первую заменяющую квоту генерируют путем:
умножения каждой квоты в первом наборе и набора коэффициентов на случайное масштабирующее значение и
объединения умноженного первого набора квот и умноженного набора коэффициентов; и
посредством первого узла хранения передают сгенерированную первую заменяющую квоту в новый узел хранения,
при этом первая заменяющая квота и по меньшей мере одна другая заменяющая квота формируют второй набор квот в новом узле хранения, причем эта другая заменяющая квота генерируется вторым узлом хранения.
2. Способ по п.1, в котором общее количество заменяющих квот, сгенерированных для формирования второго набора квот в новом узле хранения, равно параметру надежности, при этом параметр надежности основывается на суммарном количестве узлов хранения, требуемом для того, чтобы файл данных оставался восстановимым.
3. Способ по п.1, дополнительно содержащий этап, на котором проверяют целостность сгенерированных заменяющих квот.
4. Способ по п.1, в котором квоты из первого набора квот генерируются с использованием кодирования со стиранием на основе частей файла данных.
5. Способ по п.1, в котором первая заменяющая квота и по меньшей мере одна другая заменяющая квота используются для воссоздания файла данных.
6. Способ по п.1, в котором первая заменяющая квота и по меньшей мере одна другая заменяющая квота используются для генерирования последующих заменяющих квот для последующего нового узла.
7. Способ по п.1, в котором упомянутое указание принимается от блока слежения, который отслеживает статус узлов хранения и отслеживает местоположения квот.
8. Способ по п.1, дополнительно содержащий этап, на котором отправляют хэш-информацию проверки в новый узел хранения для проверки первой заменяющей квоты.
9. Способ по п.1, в котором целостность первого заменяющего узла проверяют посредством использования новым узлом хранения хэш-информации проверки, предоставляемой дополнительным узлом хранения.
10. Компьютерная система для замены отказавшего узла, хранящего распределенные данные, содержащая:
компьютерный процессор и
невременный машиночитаемый носитель информации, на котором сохранены исполняемые инструкции компьютерной программы, исполняемые компьютерным процессором, причем инструкции компьютерной программы приспособлены для того, чтобы:
принимать первый набор квот, сгенерированный из файла данных, при этом каждая квота в первом наборе включает в себя линейную комбинацию частей файла данных наряду с набором коэффициентов, использованных для генерирования этой линейной комбинации;
принимать указание нового узла хранения, заменяющего отказавший узел, при этом отказавший узел включает в себя второй набор квот, сгенерированный из файла данных;
генерировать первую заменяющую квоту в ответ на это указание, при этом первая заменяющая квота генерируется путем:
умножения каждой квоты в первом наборе и набора коэффициентов на случайное масштабирующее значение и
объединения умноженного первого набора квот и умноженного набора коэффициентов; и
передавать сгенерированную первую заменяющую квоту в новый узел хранения,
при этом первая заменяющая квота и по меньшей мере одна другая заменяющая квота формируют второй набор квот в новом узле хранения, причем эта другая заменяющая квота генерируется вторым узлом хранения.
11. Система по п.10, в которой общее количество заменяющих квот, генерируемых для формирования второго набора квот в новом узле хранения, равно параметру надежности, при этом параметр надежности основывается на суммарном количестве узлов хранения, требуемом для того, чтобы файл данных оставался восстановимым.
12. Система по п.10, в которой инструкции компьютерной программы дополнительно приспособлены для того, чтобы отправлять хэш-информацию проверки в новый узел хранения для проверки первой заменяющей квоты.
13. Система по п.10, в которой первый набор квот генерируется с использованием кодирования со стиранием на основе частей файла данных.
14. Система по п.10, в которой первая заменяющая квота и по меньшей мере одна другая заменяющая квота используются для воссоздания файла данных.
15. Система по п.10, в которой первая заменяющая квота и по меньшей мере одна другая заменяющая квота используются для генерирования последующих заменяющих квот для последующего нового узла.
16. Система по п.10, в которой упомянутое указание принимается от блока слежения, который отслеживает статус узлов хранения и отслеживает местоположения квот.
17. Машиночитаемый носитель данных, на котором записаны исполняемые инструкции компьютерной программы для замены отказавшего узла, хранящего распределенные данные, причем инструкции компьютерной программы приспособлены для:
приема посредством первого узла хранения первого набора квот, сгенерированного из файла данных, при этом каждая квота в первом наборе включает в себя линейную комбинацию частей файла данных наряду с набором коэффициентов, использованных для генерирования этой линейной комбинации;
приема посредством первого узла хранения указания нового узла хранения, заменяющего отказавший узел, при этом отказавший узел включает в себя второй набор квот, сгенерированный из файла данных;
генерирования посредством первого узла хранения первой заменяющей квоты в качестве реакции на упомянутое указание, при этом первая заменяющая квота генерируется путем:
умножения каждой квоты в первом наборе и набора коэффициентов на случайное масштабирующее значение и
объединения умноженного первого набора квот и умноженного набора коэффициентов; и
передачи посредством первого узла хранения сгенерированной первой заменяющей квоты в новый узел хранения,
при этом первая заменяющая квота и по меньшей мере одна другая заменяющая квота формируют второй набор квот в новом узле хранения, причем эта другая заменяющая квота генерируется вторым узлом хранения.
18. Машиночитаемый носитель данных по п.17, при этом инструкции компьютерной программы дополнительно приспособлены для отправки хэш-информации проверки в новый узел хранения для проверки заменяющей квоты.
19. Машиночитаемый носитель данных по п.17, при этом сформированная заменяющая квота используется для воссоздания файла данных.
20. Машиночитаемый носитель данных по п.17, при этом общее количество заменяющих квот, сгенерированных для формирования второго набора квот в новом узле хранения, равно параметру надежности, причем параметр надежности основывается на суммарном количестве узлов хранения, требуемом для того, чтобы файл данных оставался восстановимым.
21. Машиночитаемый носитель данных по п.17, при этом квоты из первого набора квот генерируются с использованием кодирования со стиранием на основе частей файла данных.
22. Машиночитаемый носитель данных по п.17, при этом первая заменяющая квота и по меньшей мере одна другая заменяющая квота используются для генерирования последующих заменяющих квот для последующего нового узла.
23. Машиночитаемый носитель данных по п.17, при этом упомянутое указание принимается от блока слежения, который отслеживает статус узлов хранения и отслеживает местоположения квот.
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Устройство для массажа и электростимуляции рефлекторных точек стопы | 1988 |
|
SU1599013A1 |
| RU 2006125251 A, 27.01.2008. | |||

