Область техники
[01] Настоящая технология относится к технологиям поисковых машин. В частности, настоящая технология направлена на способы и серверы для ранжирования цифровых документов в ответ на запрос.
Уровень техники
[02] Интернет обеспечивает доступ к широкому спектру ресурсов, например, видеофайлам, файлам изображений, аудиофайлам или веб-страницам. Для поиска этих ресурсов используются поисковые машины. Например, цифровые изображения, которые удовлетворяют информационные потребности пользователя, могут быть идентифицированы поисковой машиной в ответ на получение пользовательского запроса, отправленного пользователем. Пользовательские запросы могут состоять из одного или более термов (term, слово) запроса. Поисковая система выбирает и ранжирует результаты поиска на основе их релевантности запросу пользователя и их важности или качества по сравнению с другими результатами поиска, а также предоставляет пользователю наилучшие результаты поиска.
[03] Системы поисковых машин содержат компонент, называемый инвертированным индексом, который включает в себя большое количество списков документов (posting lists), связанных с соответствующими поисковыми термами, и хранит указания документов, которые содержат соответствующие поисковые термы. Такие структуры данных позволяют сократить время, память и ресурсы обработки для выполнения поиска.
[04] Во время поиска система извлекает информацию, относящуюся к термам (из используемого запроса), из инвертированного индекса и конфигурируется для использования этой информации для ранжирования документов в ответ на используемый запрос. Данные, хранящиеся в инвертированном индексе, не зависят от запроса и зависят от терма. Обработка извлеченных данных в реальном времени для ранжирования документов является сложной задачей из-за компромисса между качеством ранжирования и требуемым временем обработки для этого.
[05] Патент США №10,417,687, озаглавленный «Generating modified query to identify similar items in a data store» и опубликованный 17 сентября 2019 года, раскрывает методики идентификации подобных элементов в хранилище данных путем генерирования измененного запроса из пользовательского запроса и из информации о конкретном элементе, хранящейся в хранилище данных. Предварительно определенные описательные термы могут быть обозначены как полезные для идентификации элементов, и эти термы могут быть расположены в данных ключевых слов для конкретного элемента. Корреляции элемента также могут быть идентифицированы относительно обозначения категории элемента. Измененный запрос может быть сгенерирован на основе предварительно определенных описательных термов в данных ключевых слов для элемента и корреляций элементов.
Сущность изобретения
[06] Варианты осуществления настоящей технологии были разработаны на основе выявления разработчиками по меньшей мере одной технической проблемы, связанной с подходами предшествующего уровня техники к классификации объектов.
[07] По меньшей мере в одном широком аспекте настоящей технологии предоставляется сервер, выполняющий множество реализованных на компьютере алгоритмов, называемых здесь «поисковой машиной», которая в широком смысле сконфигурирована для предоставления результатов поиска в ответ на запрос, представленный пользователем электронного устройства.
[08] В широком смысле, сетевая поисковая машина - это программная система, предназначенная для выполнения веб-поиска. Результаты поиска обычно представлены в ранжированном формате, то есть результаты поиска представлены в списке, ранжированном на основе релевантности запросу. Информация обычно отображается пользователю через страницу результатов поисковой машины (SERP). Результатами поиска могут быть цифровые документы, такие как, но не ограничиваясь этим, веб-страницы, изображения, видео, инфографика, статьи, исследовательские работы и другие типы цифровых файлов.
[09] По меньшей мере в одном аспекте настоящей технологии сервер соединен с возможностью осуществления связи с запоминающим устройством, хранящим структурированный набор данных, называемый здесь «инвертированным индексом». В широком смысле, инвертированный индекс - это структура данных, которая используется как компонент алгоритмов индексации поисковой машины. Например, сначала может быть сгенерирован прямой индекс, в котором хранятся списки слов для каждого документа - затем прямой индекс может быть в некотором смысле «инвертирован», так чтобы он хранил списки документов для каждого слова. Запрос к прямому индексу может потребовать последовательных итераций по каждому документу и каждому слову для проверки совпадающего документа. Время, память и ресурсы обработки для выполнения такого запроса не всегда технически реалистичны. Напротив, одно из преимуществ инвертированного индекса состоит в том, что для запроса к такой структуре данных требуется сравнительно меньше времени, памяти и ресурсов обработки.
[10] По меньшей мере в одном широком аспекте настоящей технологии инвертированный индекс хранит данные для соответствующих «пар терм-документ». Предполагается, что данные, хранящиеся в ассоциации с соответствующими парами терм-документ (DT), содержат «запросо-независимые» данные. По меньшей мере в некоторых вариантах осуществления настоящей технологии запросо-независимые данные для данной пары TD могут указывать на зависимое от терма вхождение соответствующего терма в содержимое, связанное с соответствующим документом. Можно сказать, что инвертированный индекс хранит «зависимые от терма» данные для соответствующих термов, в отличие от данных, которые зависят от более чем одного терма из запроса.
[11] По меньшей мере в некоторых аспектах настоящей технологии разработчики настоящей технологии разработали способы и серверы для использования запросо-независимых данных, хранящихся в инвертированном индексе, для генерирования в реальном времени во время заданного поиска, выполняемого в ответ на отправленный запрос, одного или более «запросо-зависимых признаков» на основе извлеченных запросо-независимых данных для одного или более термов из отправленного запроса. По меньшей мере в некоторых вариантах осуществления настоящей технологии можно сказать, что данные, ранее сохраненные в инвертированном индексе, могут быть извлечены во время поиска в реальном времени и обработаны множеством реализованных на компьютере алгоритмов, которые упоминаются здесь как «генератор динамических признаков», который в широком смысле сконфигурирован для генерирования одного или более динамических признаков, где каждый динамический признак зависит от более чем одного терма из запроса.
[12] По меньшей мере в одном варианте осуществления генератор динамических признаков, выполняемый сервером, сконфигурирован для (i) использования запросо-независимых данных, связанных с соответствующими термами, для (ii) генерирования запросо-зависимого признака, указывающего на «групповое вхождение» по меньшей мере пары термов из запроса в содержимое, связанное с соответствующим документом. Предполагается, что сервер сконфигурирован для использования запросо-зависимого признака для ранжирования соответствующего документа среди множества потенциально релевантных документов в ответ на запрос.
[13] В первом широком аспекте настоящей технологии предоставляется способ ранжирования цифровых документов в ответ на запрос. Цифровые документы являются потенциально релевантными запросу, содержащему первый и второй термы. Запрос был отправлен пользователем электронного устройства, соединенного с возможностью осуществления связи с сервером, на котором размещена поисковая машина. Поисковая машина связана с инвертированным индексом, в котором хранится информация, связанная с парами документ-терм (DT). Способ исполняется на сервере. Способ содержит, для данного документа из множества потенциально релевантных документов, осуществление доступа сервером к инвертированному индексу для извлечения запросо-независимых данных для первой пары DT и второй пары DT. Первая пара DT имеет данный документ и первый терм. Вторая пара DT имеет данный документ и второй терм. Запросо-независимые данные указывают на (i) зависимое от терма вхождение первого терма в содержимое, связанное с данным документом, и (ii) зависимое от терма вхождение второго терма в содержимое, связанное с данным документом. Способ содержит для данного документа из множества потенциально релевантных документов генерирование сервером запросо-зависимого признака с использованием запросо-независимых данных, извлеченных для первой пары DT и второй пары DT. Запросо-зависимый признак указывает на групповое вхождение первого терма со вторым термом в содержимое, связанное с данным документом. Способ содержит для данного документа из множества потенциально релевантных документов генерирование сервером ранжирующего признака для данного документа на основе, по меньшей мере, первого терма, второго терма и запросо-зависимого признака. Способ содержит ранжирование сервером данного документа из множества потенциально релевантных документов на основе, по меньшей мере, ранжирующего признака.
[14] В некоторых вариантах осуществления способа генерирование ранжирующего признака для данного документа выполняется нейронной сетью (NN).
[15] В некоторых вариантах осуществления способа способ дополнительно содержит обучение сервером NN для генерирования ранжирующего признака. Обучение NN содержит генерирование сервером обучающего набора для обучающей пары документ-запрос (DQ), которая должна использоваться во время данной итерации обучения NN. Обучающая пара DQ имеет обучающий запрос и обучающий документ. Генерирование содержит генерирование сервером множества вложений обучающих термов на основе соответствующих термов из обучающего запроса. Генерирование содержит осуществление доступа сервером к инвертированному индексу, связанному с поисковой машиной, для извлечения множества запросо-независимых наборов данных, связанных с соответствующими парами из множества обучающих пар DT. Заданная одна из множества обучающих пар DT включает в себя обучающий документ и соответствующий один из множества термов из обучающего запроса. Генерирование содержит генерирование сервером множества векторов обучающих признаков для множества обучающих пар DT с использованием множества запросо-независимых наборов данных. Обучение NN содержит, во время данной итерации обучения NN, ввод сервером в NN упомянутого множества вложений обучающих термов и упомянутого множества векторов обучающих признаков для генерирования предсказанного ранжирующего признака для обучающей пары DQ. Обучение NN содержит, во время данной итерации обучения NN, настройку NN сервером на основе сравнения между меткой и предсказанным ранжирующим признаком, так что NN генерирует для данной используемой пары DQ соответствующий предсказанный ранжирующий признак, который указывает на релевантность соответствующего используемого документа соответствующему используемому запросу.
[16] В некоторых вариантах осуществления способа запросо-независимые данные были сохранены в инвертированном индексе до получения запроса от электронного устройства, и при этом запросо-зависимый признак генерируется после получения запроса от электронного устройства.
[17] В некоторых вариантах осуществления способа запросо-зависимый признак генерируется с использованием запросо-независимых данных в реальном времени во время процедуры ранжирования документов поисковой машины.
[18] В некоторых вариантах осуществления способа ранжирование выполняется с помощью алгоритма машинного обучения (MLA) на основе дерева решений, сконфигурированного для ранжирования множества потенциально релевантных документов на основе их релевантности запросу.
[19] В некоторых вариантах осуществления способа способ дополнительно содержит определение подобного терма для данного одного из множества термов. При осуществлении доступа к инвертированному индексу для извлечения запросо-независимых данных, извлеченные запросо-независимые данные содержат запросо-независимые данные для третьей пары DT, причем третья пара DT имеет данный документ и упомянутый подобный терм.
[20] В некоторых вариантах осуществления способа доступ к инвертированному индексу предназначен для дополнительного извлечения запросо-независимых данных на основе содержимого, связанных с первой парой DT и второй парой DT. Запросо-независимые данные на основе содержимого указывают на текстовый контекст соответствующего терма в содержимом, связанном с данным документом.
[21] В некоторых вариантах осуществления способа зависимое от терма вхождение первого терма содержит по меньшей мере одно из: одной или более позиций первого терма в заголовке, связанном с данным документом; одной или более позиций первого терма в URL, связанном с данным документом; и одной или более позиций первого терма в теле данного документа.
[22] В некоторых вариантах осуществления способа групповое вхождение первого терма со вторым термом в содержимое, связанное с данным документом, содержит по меньшей мере одно из: количества раз, когда второй терм из запроса включен в дополнение к первому терму в заголовок, связанный с данным документом; количества раз, когда второй терм из запроса включен в дополнение к первому терму в URL, связанный с данным документом; и количества раз, когда второй терм из запроса включен в дополнение к первому терму в тело данного документа.
[23] Во втором широком аспекте настоящей технологии предоставляется сервер для ранжирования цифровых документов в ответ на запрос. Цифровые документы являются потенциально релевантными запросу, содержащему первый и второй термы. Запрос был отправлен пользователем электронного устройства, соединенного с возможностью осуществления связи с сервером, на котором размещена поисковая машина. Поисковая машина связана с инвертированным индексом, в котором хранится информация, связанная с парами документ-терм (DT). Сервер сконфигурирован с возможностью, для данного документа из множества потенциально релевантных документов, осуществлять доступ к инвертированному индексу для извлечения запросо-независимых данных для первой пары DT и второй пары DT. Первая пара DT имеет данный документ и первый терм, а вторая пара DT имеет данный документ и второй терм. Запросо-независимые данные указывают на (i) зависимое от терма вхождение первого терма в содержимое, связанное с данным документом, и (ii) зависимое от терма вхождение второго терма в содержимое, связанное с данным документом. Сервер сконфигурирован с возможностью, для данного документа из множества потенциально релевантных документов, генерировать запросо-зависимый признак с использованием запросо-независимых данных, извлеченных для первой пары DT и второй пары DT. Запросо-зависимый признак указывает на групповое вхождение первого терма со вторым термом в содержимое, связанное с данным документом. Сервер сконфигурирован с возможностью, для данного документа из множества потенциально релевантных документов, генерировать ранжирующий признак для данного документа на основе, по меньшей мере, первого терма, второго терма и запросо-зависимого признака. Сервер сконфигурирован для ранжирования данного документа из множества потенциально релевантных документов на основе, по меньшей мере, ранжирующего признака.
[24] В некоторых вариантах реализации сервера сервер использует нейронную сеть для генерирования ранжирующего признака для данного документа.
[25] В некоторых вариантах осуществления сервера сервер дополнительно сконфигурирован для обучения NN генерированию ранжирующего признака. Сервер сконфигурирован для генерирования обучающего набора для обучающей пары документ-запрос (DQ), которая должна использоваться во время данной итерации обучения NN. Обучающая пара DQ имеет обучающий запрос и обучающий документ. Для генерирования обучающего набора сервер сконфигурирован для генерирования множества вложений обучающих термов на основе соответствующих термов из обучающего запроса. Для генерирования обучающего набора сервер сконфигурирован для осуществления доступа к инвертированному индексу, связанному с поисковой машиной, для извлечения множества запросо-независимых наборов данных, связанных с соответствующими парами из множества обучающих пар DT. Заданная одна из множества обучающих пар DT включает в себя обучающий документ и соответствующий один из множества термов из обучающего запроса. Для генерирования обучающего набора сервер сконфигурирован для генерирования множества векторов обучающих признаков для множества обучающих пар DT с использованием множества запросо-независимых наборов данных. Сервер сконфигурирован с возможностью, во время данной итерации обучения NN, вводить сервером в NN упомянутое множество вложений обучающих термов и упомянутое множество векторов обучающих признаков для генерирования предсказанного ранжирующего признака для обучающей пары DQ. Сервер сконфигурирован с возможностью, во время данной итерации обучения NN, настраивать NN на основе сравнения между меткой и предсказанным ранжирующим признаком, так что NN генерирует для данной используемой пары DQ соответствующий предсказанный ранжирующий признак, который указывает на релевантность соответствующего используемого документа соответствующему используемому запросу.
[26] В некоторых вариантах осуществления сервера запросо-независимые данные были сохранены в инвертированном индексе до получения запроса от электронного устройства, и при этом запросо-зависимый признак генерируется после получения запроса от электронного устройства.
[27] В некоторых вариантах осуществления сервера запросо-зависимый признак генерируется с использованием запросо-независимых данных в реальном времени во время процедуры ранжирования документов поисковой машины.
[28] В некоторых вариантах осуществления сервера сервер сконфигурирован для ранжирования с использованием алгоритма машинного обучения (MLA) на основе дерева решений, сконфигурированного для ранжирования множества потенциально релевантных документов на основе их релевантности запросу.
[29] В некоторых вариантах осуществления сервера сервер дополнительно сконфигурирован для определения подобного терма для данного одного из множества термов. При осуществлении доступа к инвертированному индексу для извлечения запросо-независимых данных, извлеченные запросо-независимые данные содержат запросо-независимые данные для третьей пары DT, причем третья пара DT имеет данный документ и упомянутый подобный терм.
[30] В некоторых вариантах осуществления сервера сервер сконфигурирован для осуществления доступа к инвертированному индексу для дополнительного извлечения запросо-независимых данных на основе содержимого, связанных с первой парой DT и второй парой DT. Запросо-независимые данные на основе содержимого указывают на текстовый контекст соответствующего терма в содержимом, связанном с данным документом.
[31] В некоторых вариантах реализации сервера зависимое от терма вхождение первого терма содержит по меньшей мере одно из: одной или более позиций первого терма в заголовке, связанном с данным документом; одной или более позиций первого терма в URL, связанном с данным документом; и одной или более позиций первого терма в теле данного документа.
[32] В некоторых вариантах реализации сервера групповое вхождение первого терма со вторым термом в содержимое, связанное с данным документом, включает в себя по меньшей мере одно из: количества раз, когда второй терм из запроса включен в дополнение к первому терму в заголовок, связанный с данным документом; количества раз, когда второй терм из запроса включен в дополнение к первому терму в URL, связанный с данным документом; и количества раз, когда второй терм из запроса включен в дополнение к первому терму в тело данного документа.
[33] В контексте настоящего описания, если явно не указано иное, «электронное устройство», «электронное устройство», «сервер», «удаленный сервер» и «компьютерная система» представляют собой любое аппаратное обеспечение и/или программное обеспечение, подходящее для соответствующей задачи. Таким образом, некоторые неограничивающие примеры аппаратного обеспечения и/или программного обеспечения включают в себя компьютеры (серверы, настольные компьютеры, ноутбуки, нетбуки и т.д.), смартфоны, планшеты, сетевое оборудование (маршрутизаторы, коммутаторы, шлюзы и т.д.) и/или их комбинации.
[34] В контексте настоящего описания, если специально не указано иное, выражения «компьютерно-читаемый носитель» и «память» предназначены включать в себя носители любого характера и вида, неограничивающие примеры которых включают в себя RAM, ROM, диски (CD-ROM, DVD, гибкие диски, жесткие диски и т.д.), USB-ключи, карты флэш-памяти, твердотельные накопители и ленточные накопители.
[35] В контексте настоящего описания, если прямо не предусмотрено иное, "указание" информационного элемента может быть самим информационным элементом или указателем, ссылкой, гиперссылкой или другим опосредованным механизмом, позволяющим получателю такого указания найти местоположение в сети, памяти, базе данных или другом компьютерно-читаемом носителе, из которого информационный элемент может быть извлечен. Например, указание документа может включать в себя сам документ (т.е. его содержимое), или оно может быть уникальным дескриптором документа, идентифицирующим файл относительно некоторой конкретной файловой системы, или некоторым другим средством направления получателя такого указания в местоположение в сети, таблицу базы данных или иное местоположение, в котором можно осуществить доступ к файлу. Специалист в данной области поймет, что степень точности, требуемая в указании, зависит от степени какого-либо предварительного понимания того, какая интерпретация будет обеспечена информации, обмениваемой во взаимодействии между отправителем и получателем такого указания. Например, если понимается, что до связи между отправителем и получателем указание информационного элемента будет иметь форму ключа базы данных для записи в некоторой конкретной таблице предварительно определенной базы данных, содержащей информационный элемент, то отправка ключа базы данных является всем, что требуется для эффективной передачи информационного элемента получателю, даже если сам информационный элемент не был передан во взаимодействии между отправителем и получателем такого указания.
[36] В контексте настоящего описания, если специально не предусмотрено иное, слова «первый», «второй», «третий» и т.д. Использовались в качестве прилагательных только с целью обеспечения различия между существительными, которые они изменяют, от одного к другому, и не с целью описания каких-либо конкретных отношений между этими существительными. Таким образом, например, следует понимать, что использование понятий "первый сервер" и "третий сервер" не подразумевает какого-либо конкретного порядка, типа, хронологии, иерархии или ранжирования (например) таких/между такими серверами, равно как и их использование (само по себе) не означает, что какой-либо "второй сервер" должен обязательно существовать в любой определенной ситуации. Кроме того, как обсуждается в других контекстах данного документа, ссылка на "первый" элемент и "второй" элемент не исключает того, что эти два элемента фактически являются одним и тем же элементом реального мира. Таким образом, например, в некоторых случаях "первый" сервер и "второй" сервер могут быть одним и тем же программным обеспечением и/или аппаратным обеспечением, в других случаях они могут представлять собой разное программное обеспечение и/или аппаратное обеспечение.
[37] Каждая из реализаций настоящей технологии обладает по меньшей мере одним из вышеупомянутых аспектов и/или целей, но не обязательно имеет их все. Следует понимать, что некоторые аспекты настоящей технологии, которые возникли в попытке достичь вышеупомянутой цели, могут не удовлетворять этой цели и/или удовлетворять другим целям, которые не описаны в данном документе явным образом. Дополнительные и/или альтернативные признаки, аспекты и преимущества реализаций настоящей технологии станут понятными из нижеследующего описания, сопроводительных чертежей и приложенной формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[38] Для лучшего понимания настоящей технологии, а также других аспектов и ее дополнительных признаков, производится обращение к нижеследующему описанию, которое должно использоваться в сочетании с сопроводительными чертежами, на которых:
[39] Фиг. 1 изображает схему системы, реализуемой в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[40] Фиг. 2 изображает представление данных, хранящихся в подсистеме базы данных системы, показанной на Фиг. 1, в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[41] Фиг. 3 изображает представление итерации обучения генератора ранжирующих признаков системы, показанной на Фиг. 1, в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[42] Фиг. 4 изображает представление того, как генератор динамических признаков системы, показанной на Фиг. 1, сконфигурирован для генерирования запросо-зависимых данных на основе запросо-независимых данных, полученных из инвертированного индекса системы на Фиг. 1, в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[43] Фиг. 5 изображает представление фазы использования генератора ранжирующих признаков системы, показанной на Фиг. 1, в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[44] Фиг. 6 изображает представление того, как модель ранжирования системы, показанной на Фиг. 1, сконфигурирована для генерирования ранжированного списка документов в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[45] Фиг. 7 - схематическое представление способа, выполняемого сервером системы, показанной на Фиг. 1, в соответствии с неограничивающими вариантами осуществления настоящей технологии.
Подробное описание
[46] Приведенные в данном документе примеры и условные формулировки призваны главным образом помочь читателю понять принципы настоящей технологии, а не ограничить ее объем такими конкретно приведенными примерами и условиями. Следует понимать, что специалисты в данной области смогут разработать различные механизмы, которые, хоть и не описаны в данном документе явным образом, тем не менее воплощают принципы настоящей технологии и включаются в ее сущность и объем.
[47] Кроме того, нижеследующее описание может описывать реализации настоящей технологии в относительно упрощенном виде для целей упрощения понимания. Специалисты в данной области техники поймут, что различные реализации настоящей технологии могут иметь и большую сложность.
[48] В некоторых случаях также могут быть изложены примеры модификаций настоящей технологии, которые считаются полезными. Это делается лишь для содействия пониманию и, опять же, не для строгого определения объема или очерчивания границ настоящей технологии. Эти модификации не являются исчерпывающим списком, и специалист в данной области может осуществлять другие модификации, все еще оставаясь при этом в рамках объема настоящей технологии. Кроме того, случаи, когда примеры модификаций не приводятся, не следует толковать так, что никакие модификации не могут быть осуществлены и/или что описанное является единственным способом реализации такого элемента настоящей технологии.
[49] Кроме того, все содержащиеся в данном документе утверждения, в которых указываются принципы, аспекты и реализации настоящей технологии, а также их конкретные примеры, призваны охватить как структурные, так и функциональные эквиваленты, вне зависимости от того, известны ли они в настоящее время или будут разработаны в будущем. Таким образом, например, специалисты в данной области должны понимать, что любые блок-схемы в данном документе представляют концептуальные виды иллюстративной схемы, воплощающей принципы настоящей технологии. Аналогичным образом, следует понимать, что любые блок-схемы, схемы последовательности операций, схемы изменения состояний, псевдо-коды и подобное представляют различные процессы, которые могут быть по сути представлены на компьютерно-читаемых носителях и исполнены компьютером или процессором вне зависимости от того, показан такой компьютер или процессор явным образом или нет.
[50] Функции различных элементов, показанных на фигурах, в том числе любого функционального блока, помеченного как "процессор" или "графический процессор", могут быть обеспечены с помощью специализированного аппаратного обеспечения, а также аппаратного обеспечения, способного исполнять программное обеспечение и связанного с надлежащим программным обеспечением. При обеспечении процессором функции могут быть обеспечены одним выделенным процессором, одним совместно используемым процессором или множеством отдельных процессоров, некоторые из которых могут быть совместно используемыми. В некоторых вариантах осуществления настоящей технологии процессор может быть процессором общего назначения, таким как центральный процессор (CPU) или процессор, выделенный для конкретной цели, например графический процессор (GPU). Кроме того, явное использование понятия "процессор" или "контроллер" не должно истолковываться как относящееся исключительно к аппаратному обеспечению, способному исполнять программное обеспечение, и может в неявной форме включать в себя, без ограничений, аппаратное обеспечение цифрового сигнального процессора (DSP), сетевой процессор, интегральную схему специального назначения (ASIC), программируемую пользователем вентильную матрицу (FPGA), постоянную память (ROM) для хранения программного обеспечения, оперативную память (RAM) и энергонезависимое хранилище. Другое аппаратное обеспечение, традиционное и/или специализированное, также может быть включено в состав.
[51] Программные модули, или просто модули, в качестве которых может подразумеваться программное обеспечение, могут быть представлены в настоящем документе как любая комбинация элементов блок-схемы последовательности операций или других элементов, указывающих выполнение этапов процесса и/или текстовое описание. Такие модули могут выполняться аппаратным обеспечением, которое явно или неявно показано.
[52] Учитывая эти основополагающие вещи, рассмотрим некоторые неограничивающие примеры, чтобы проиллюстрировать различные реализации аспектов настоящей технологии.
[53] Со ссылкой на Фиг. 1 проиллюстрировано схематичное представление системы 100, причем система 100 подходит для реализации неограничивающих вариантов осуществления настоящей технологии. Следует четко понимать, что изображенная система 100 является лишь иллюстративной реализацией настоящей технологии. Таким образом, нижеследующее описание предназначено лишь для того, чтобы использоваться в качестве описания иллюстративных примеров настоящей технологии.
[54] В проиллюстрированном примере система 100 может использоваться для предоставления одной или более онлайн-услуг данному пользователю. С этой целью система 100 содержит, среди прочего, электронное устройство 104, связанное с пользователем 101, сервер 112, множество серверов 108 ресурсов и подсистему 150 базы данных.
[55] В контексте настоящей технологии система 100 используется для предоставления услуг поисковой машины. Например, пользователь 101 может отправить данный запрос через электронное устройство 104 на сервер 112, который, в ответ, сконфигурирован для предоставления результатов поиска пользователю 101. Сервер 112 генерирует эти результаты поиска на основе информации, которая была извлечена, например, из множества серверов 108 ресурсов и сохранена в подсистеме 150 базы данных. Эти результаты поиска, предоставленные системой 100, могут быть релевантными отправленному запросу.
[56] Можно сказать, что сервер 112 сконфигурирован для выполнения множества реализованных на компьютере алгоритмов, которые в дальнейшем именуются «поисковой машиной» 160. Как станет очевидно из приведенного ниже описания, поисковая машина 160 в целом сконфигурирована для идентификации потенциально релевантных цифровых документов для запроса и ранжирования их на основе их релевантности запросу.
ЭЛЕКТРОННОЕ УСТРОЙСТВО
[57] Как упомянуто выше, система 100 содержит электронное устройство 104, связанное с пользователем 101. Таким образом, электронное устройство 104 или просто «устройство» 102 иногда может называться «клиентским устройством», «устройством конечного пользователя» или «клиентским электронным устройством». Следует отметить, что тот факт, что электронное устройство 104 связано с пользователем 101, не обязательно предполагает или подразумевает какой-либо режим работы - например, необходимость входа в систему, необходимость регистрации или тому подобное.
[58] В контексте настоящего описания, если прямо не указано иное, «электронное устройство» или «устройство» - это любое компьютерное аппаратное обеспечение, которое способно запускать программное обеспечение, подходящее для соответствующей решаемой задачи. Таким образом, некоторые неограничивающие примеры устройства 104 включают персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.д.), смартфоны, планшеты и т.п. Устройство 104 содержит аппаратное и/или программное обеспечение, и/или микропрограммное обеспечение (или их комбинацию), как известно в данной области техники, для выполнения заданного приложения браузера (не показано).
[59] В широком смысле, назначением определенного приложения браузера является предоставление пользователю 101 возможности доступа к одному или более веб-ресурсам. Реализация определенного приложения браузера не ограничена особым образом. Один из примеров данного приложения браузера, которое выполняется устройством 104, может быть реализован как браузер Яндекс™. Например, пользователь 101 может использовать данное приложение браузера для (i) перехода к заданному веб-сайту поисковой машины и (ii) отправки запроса, в ответ на который ему (ей) должны быть предоставлены релевантные результаты поиска.
[60] Устройство 104 сконфигурировано для генерирования запроса 180 для связи с сервером 112. Запрос 180 может принимать форму одного или более пакетов данных, содержащих информацию, указывающую, в одном примере, запрос, представленный пользователем 101. Устройство 104 также сконфигурировано для приема ответа 190 от сервера 112. Ответ 190 может принимать форму одного или более пакетов данных, содержащих информацию, указывающую, в одном примере, результаты поиска, которые являются релевантными отправленному запросу, и компьютерно-читаемые инструкции для отображения данным приложением браузера пользователю 101 этих результатов поиска.
Сеть связи
[61] Система 100 содержит сеть 110 связи. В одном неограничивающем примере сеть 110 связи может быть реализована как Интернет. В других неограничивающих примерах сеть 110 связи может быть реализована по-другому, например, любая глобальная сеть связи, локальная сеть связи, частная сеть связи и т.п. Фактически, то, как реализована сеть 110 связи, не является ограничением и будет зависеть, среди прочего, от того, как реализованы другие компоненты системы 100.
[62] Назначение сети 110 связи состоит в том, чтобы соединять с возможностью осуществления связи по меньшей мере некоторые компоненты системы 100, такие как устройство 104, множество серверов 108 ресурсов и сервер 112. Например, это означает, что ко множеству серверов 108 ресурсов может осуществляться доступ через сеть 110 связи устройством 104. В другом примере это означает, что ко множеству серверов 108 ресурсов может осуществляться доступ через сеть 110 связи сервером 112. В другом примере это означает, что к серверу 112 может осуществляться доступ через сеть 110 связи устройством 104.
[63] Сеть 110 связи может использоваться для передачи пакетов данных между устройством 104, множеством серверов 108 ресурсов и сервером 112. Например, сеть 110 связи может использоваться для передачи запроса 180 от устройства 104 на сервер 112. В другом примере сеть 110 связи может использоваться для передачи ответа 190 от сервера 112 на устройство 104.
Множество серверов ресурсов
[64] Как упомянуто выше, к множеству серверов 108 ресурсов можно осуществить доступ через сеть 110 связи. Множество серверов 108 ресурсов может быть реализовано как обычные компьютерные серверы. В неограничивающем примере варианта осуществления настоящей технологии данный один из множества серверов 108 ресурсов может быть реализован как сервер Dell™ PowerEdge™, работающий под управлением операционной системы Microsoft™ Windows Server™. Данный один из множества серверов 108 ресурсов также может быть реализован в любом другом подходящем аппаратном и/или программном и/или встроенном программном обеспечении или их комбинации.
[65] Множество серверов 108 ресурсов сконфигурированы для размещения (веб) ресурсов, к которым может осуществить доступ устройство 104 и/или сервер 106. Какой тип ресурсов размещается во множестве серверов 108 ресурсов, не ограничивается. Однако в некоторых вариантах осуществления настоящей технологии ресурсы могут содержать цифровые документы или просто «документы», которые представляют веб-страницы.
[66] Например, множество серверов 108 ресурсов может содержать веб-страницы, что означает, что множество серверов 108 ресурсов может хранить документы, представляющие веб-страницы и доступные устройству 104 и/или серверу 112. Данный документ может быть написан на языке разметки и может содержать среди прочего (i) содержимое (контент) соответствующей веб-страницы и (ii) компьютерно-читаемые инструкции для отображения соответствующей веб-страницы (ее содержимого).
[67] Устройство 104 может осуществить доступ к данному одному из множества серверов 108 ресурсов для извлечения заданного документа, хранящегося на данном одном из множества серверов 108 ресурсов. Например, пользователь 101 может ввести веб-адрес, связанный с данной веб-страницей, в данном приложении браузера устройства 104, и в ответ устройство 104 может осуществить доступ к данному серверу ресурсов, на котором размещена данная веб-страница, для получения документа, представляющего данную веб-страницу, для отображения содержимого веб-страницы через данное приложение браузера.
[68] Сервер 112 может осуществить доступ к данному одному из множества серверов 108 ресурсов, чтобы извлечь данный документ, хранящийся на данном одном из множества серверов 108 ресурсов. Назначение, по которому сервер 112 осуществляет доступ и извлекает документы из множества серверов 108 ресурсов, будет описано более подробно в данном документе ниже.
Подсистема базы данных
[69] Сервер 112 соединен с возможностью осуществления связи с подсистемой 150 базы данных. В широком смысле, подсистема 150 базы данных сконфигурирована для получения данных с сервера 112, хранения данных и/или предоставления данных на сервер 106 для дальнейшего использования.
[70] В некоторых вариантах осуществления подсистема 150 базы данных может быть сконфигурирована для хранения информации, связанной с сервером 112, в данном документе, называемой «данными поисковой машины» 175. Например, подсистема 150 базы данных может хранить информацию о ранее выполненных поисках поисковой машиной 160, информацию о ранее отправленных запросах на сервер 112 и о документах, которые были предоставлены поисковой машиной 160 сервера 112 в качестве результатов поиска.
[71] Предполагается, что в качестве части данных 175 поисковой машины подсистема 150 базы данных может хранить данные запроса, связанные с соответствующими запросами, отправленными в поисковую машину 160. Данные запроса, связанные с данным запросом, могут быть разных типов и не являются ограничивающими. Например, подсистема 150 базы данных может хранить данные запроса для соответствующих запросов, такие как, но не ограничиваясь этим:
популярность данного запроса;
частота отправки данного запроса;
количество кликов (click, нажатий), связанных с данным запросом;
указания других отправленных запросов, связанных с данным запросом;
указания документов, связанных с данным запросом;
другие статистические данные, связанные с данным запросом;
поисковые термы, связанные с данным запросом;
количество символов в данном запросе; и
другие присущие запросу характеристики данного запроса.
[72] Предполагается, что в качестве части данных 175 поисковой машины подсистема 150 базы данных также может хранить данные документа, связанные с соответствующими документами. Данные документа, связанные с данным документом, могут быть разных типов и не являются ограничивающими. Например, подсистема 150 базы данных может хранить данные документов для соответствующих документов, такие как, но не ограничиваясь этим:
популярность данного документа;
соотношение числа кликов к числу показов для данного документа;
время на клик, связанное с данным документом;
указания запросов, связанных с данным документом;
другие статистические данные, связанные с данным документом;
текст, связанный с данным документом;
размер файла данного документа; и
другие присущие документу характеристики данного документа.
[73] Как будет обсуждаться более подробно со ссылкой на Фиг. 2 ниже, подсистема 150 базы данных может быть сконфигурирована для хранения содержимого, связанного с соответствующими цифровыми документами, на основе документ-за-документом. Например, подсистема 150 базы данных может быть сконфигурирована для хранения содержимого, связанного с данным цифровым документом.
[74] Предполагается, что в качестве части данных 175 поисковой машины подсистема 150 базы данных также может хранить пользовательские данные, связанные с соответствующими пользователями. Пользовательские данные, связанные с данным пользователем, могут быть разных типов и не являются ограничивающими. Например, подсистема 150 базы данных может хранить пользовательские данные для соответствующих пользователей, такие как, но не ограничиваясь этим:
данные прошлой веб-сессии, связанные с данным пользователем;
прошлые запросы, отправленные данным пользователем;
данные истории «кликов», связанные с данным пользователем;
другие данные о взаимодействии с данным пользователем и документами; и
предпочтения пользователя.
[75] Как проиллюстрировано на Фиг. 1, подсистема 150 базы данных также сконфигурирована для хранения структурированного набора данных, далее именуемого «инвертированный индекс» 170. В широком смысле, инвертированный индекс 170 - это структура данных, которую можно назвать компонентом поисковой машины 160. Например, сначала может быть сгенерирован прямой индекс, в котором хранятся списки слов (или термов) для каждого документа - затем прямой индекс может быть инвертирован таким образом, чтобы в нем сохранялись списки документов для каждого терма. Для запроса к прямому индексу может потребоваться последовательная итерация по каждому документу и каждому терму для проверки совпадающего документа. Время, память и ресурсы обработки для выполнения такого запроса не всегда технически реалистичны. Напротив, одно из преимуществ инвертированного индекса 170 состоит в том, что для запроса к такой структуре данных в реальном времени требуется сравнительно меньше времени, памяти и ресурсов обработки.
[76] Как будет описано более подробно ниже со ссылкой на Фиг. 2, инвертированный индекс 170 сконфигурирован для хранения множества списков документов, каждый из которых связан с соответствующим термом, и при этом данный список документов содержит множество документов, содержащих соответствующий терм. Кроме того, инвертированный индекс 170 сконфигурирован для хранения данных для соответствующих пар «терм-документ».
Сервер
[77] Система 100 содержит сервер 112, который может быть реализован как обычный компьютерный сервер. В примере варианта осуществления настоящей технологии сервер 112 может быть реализован как сервер Dell™ PowerEdge™, работающий под управлением операционной системы Microsoft™ Windows Server™. Само собой разумеется, что сервер 106 может быть реализован в любом другом подходящем аппаратном и/или программном и/или встроенном программном обеспечении или их комбинации. В изображенном неограничивающем варианте осуществления настоящей технологии сервер 112 является одиночным сервером. В альтернативных неограничивающих вариантах осуществления настоящей технологии функциональные возможности сервера 106 могут быть распределены и могут быть реализованы посредством многочисленных серверов.
[78] Как показано на Фиг. 1, сервер 112 сконфигурирован для размещения поисковой машины 160 для предоставления услуг поисковой машины. В некоторых вариантах осуществления сервер 112 может находиться под управлением и/или администрированием провайдера поисковой машины (не показан), такого как, например, оператор поисковой машины Яндекс™. По существу, сервер 112 может быть сконфигурирован для размещения поисковой машины 160 для выполнения одного или более поисков в ответ на запросы, отправленные пользователями поисковой машины 160.
[79] Например, сервер 112 может получить запрос 180 от устройства 104, указывающий запрос, отправленный пользователем 101. Сервер 112 может выполнять поиск в ответ на отправленный запрос для генерирования результатов поиска, релевантных отправленному запросу. В результате сервер 112 может быть сконфигурирован для генерирования ответа 190, указывающего результаты поиска, и может передавать ответ 190 устройству 104 для отображения результатов поиска пользователю 101, например, через данное приложение браузера.
[80] Результаты поиска, сгенерированные для отправленного запроса, могут принимать разные формы. Однако в одном неограничивающем примере настоящей технологии результаты поиска, сгенерированные сервером 112, могут указывать на документы, которые являются релевантными отправленному запросу. То, как сервер 112 сконфигурирован для определения и извлечения документов, которые являются релевантными отправленному запросу, станет понятным из приведенного здесь описания.
[81] Сервер 106 также может быть сконфигурирован для выполнения приложения 120 поискового робота. В широком смысле, приложение 120 поискового робота может использоваться сервером 112, чтобы «посещать» ресурсы, доступные через сеть 110 связи, и извлекать/загружать их для дальнейшего использования. Например, приложение 120 поискового робота может использоваться сервером 106 для доступа к множеству серверов 108 ресурсов и для извлечения/загрузки документов, представляющих веб-страницы, размещенные на множестве серверов 108 ресурсов.
[82] Предполагается, что приложение 120 поискового робота может периодически выполняться сервером 112 для извлечения/загрузки документов, которые были обновлены и/или стали доступными по сети 110 связи с момента предыдущего выполнения приложения 120 поискового робота.
[83] Сервер 112 также может быть сконфигурирован для выполнения «модели ранжирования» 130, в широком смысле сконфигурированной для использования информации о заданном запросе и множестве потенциально релевантных документов для ранжирования этих документов в ответ на запрос. По меньшей мере в одном варианте осуществления настоящей технологии модель 130 ранжирования может быть реализована как один или более алгоритмов машинного обучения (MLA). Предполагается, что множество потенциально релевантных документов может быть идентифицировано сервером 112 с использованием информации, хранящейся в инвертированном индексе 170.
[84] В широком смысле, данный MLA сначала «строится» (или обучается) с использованием обучающих данных и обучающих целей. Во время данной итерации обучения в MLA вводятся обучающие входные данные, и он генерирует соответствующее предсказание. Затем сервер 112 конфигурируется для того, чтобы в некотором смысле «настраивать» MLA на основе сравнения результата предсказания с соответствующей обучающей целью для обучающих входных данных. Например, настройка может выполняться сервером 112 с использованием одного или более методов машинного обучения, таких как, но не ограничиваясь этим, метод обратного распространения ошибки. Таким образом, после большого количества итераций обучения MLA «настраивается» таким образом, чтобы делать предсказания на основе введенных данных, чтобы эти предсказания были близки к соответствующим обучающим целям.
[85] По меньшей мере в некоторых вариантах осуществления настоящей технологии модель 130 ранжирования может быть реализована как MLA на основе данного дерева решений. В широком смысле, MLA на основе данного дерева решений - это модель машинного обучения, имеющая одно или более «деревьев решений», которые используются (i) для перехода от наблюдений за объектом (представленных в ветвях) к заключениям о целевом значении объекта (представлены в листьях). В одной неограничивающей реализации настоящей технологии MLA на основе дерева решений может быть реализовано в соответствии со структурой CatBoost.
[86] Как MLA, основанный на дереве решений, может быть обучен в соответствии, по меньшей мере, с некоторыми вариантами осуществления настоящей технологии, раскрыто в патентной публикации США №2019/0164084, озаглавленной «METHOD OF AND SYSTEM FOR GENERATING PREDICTION QUALITY PARAMETER FOR A PREDICATION MODEL EXECUTED IN A MAHCINE LEARNING ALGORITHM», опубликованной 30 мая 2019 г., содержание которой полностью включено в настоящий документ посредством ссылки. Дополнительная информация о библиотеке CatBoost, ее реализации и алгоритмах градиентного бустинга доступна на https://catboost.ai.
[87] Какие данные используются моделью 130 ранжирования для генерирования ранжированного списка документов в ответ на запрос, будет более подробно обсуждено в данном документе ниже со ссылкой на Фиг. 6. Однако следует отметить, что модель 130 ранжирования может быть сконфигурирована для использования «ранжирующего признака» для данной «пары документ-запрос» для ранжирования соответствующего документа в ответ на запрос.
[88] Сервер 106 сконфигурирован для выполнения «генератора ранжирующих признаков» 140, который в широком смысле сконфигурирован для использования запросо-зависимых данных, для генерирования одного или более ранжирующих признаков, которые будут использоваться моделью 130 ранжирования. По меньшей мере в одном варианте осуществления настоящей технологии генератор 140 ранжирующих признаков может быть реализован как нейронная сеть (NN).
[89] В широком смысле, NN - это особый класс MLA, состоящий из взаимосвязанных групп искусственных «нейронов», которые обрабатывают информацию, используя коннекционистский подход к вычислениям. NN используются для моделирования сложных взаимосвязей между входными и выходными данными (без фактического знания этих взаимосвязей) или для поиска закономерностей в данных. NN сначала подготавливаются во время фазы обучения, во время которой им предоставляется некоторый известный набор «входных данных» и информация для адаптации NN к генерированию надлежащих выходных данных (для некоторой определенной ситуации, которую пытаются смоделировать). Во время этой фазы обучения эта NN адаптируется к изучаемой ситуации и меняет свою структуру так, чтобы данная NN могла обеспечивать разумные предсказанные выходные данные для определенных входных данных во время некоторой новой ситуации (на основе того, что было изучено). Таким образом, вместо того, чтобы пытаться определить сложные статистические схемы или математические алгоритмы для некоторой определенной ситуации, данная NN пытается дать «интуитивный» ответ, основанный на «восприятии» ситуации. Таким образом, данная NN является своего рода обученным «черным ящиком», который можно использовать в ситуации, когда то, что находится в «ящике», может быть менее важным; и когда более важным является обладание «коробкой», которая дает разумные ответы на имеющиеся входные данные. Например, NN обычно используются для оптимизации распределения веб-трафика между серверами и при обработке данных, включая фильтрацию, кластеризацию, разделение сигналов, сжатие, генерирование векторов и тому подобное.
[90] То, как генератор 140 ранжирующих признаков (например, NN) может быть обучен генерированию данного ранжирующего признака для данной пары документ-запрос, будет более подробно описано в данном документе ниже со ссылкой на Фиг. 3. То, как генератор 140 ранжирующих признаков может затем использоваться в реальном времени во время фазы его использования поисковой машиной 160, будет более подробно описано в данном документе ниже со ссылкой на Фиг. 5. Однако следует упомянуть, что генератор 140 ранжирующих признаков может использовать запросо-зависимые данные, которые динамически генерируются для данной пары документ-запрос.
[91] Сервер 112 также может быть сконфигурирован для выполнения одного или более алгоритмов, реализованных на компьютере, в дальнейшем именуемых «генератором динамических признаков» 150, который в широком смысле сконфигурирован для использования запросо-независимых данных, извлеченных из инвертированного индекса 170, для одного или более термов в следующем порядке: для генерирования в реальном времени (динамически) запросо-зависимых данных. То, как запросо-независимые данные могут использоваться генератором 155 динамических признаков для генерирования запросо-зависимых данных и как генератор динамических признаков может быть реализован сервером 112, будет обсуждаться более подробно здесь ниже со ссылкой на Фиг. 4.
[92] Со ссылкой на Фиг. 2 изображено представление 200 по меньшей мере некоторых данных, хранящихся в подсистеме 150 базы данных. Например, изображено представление 202 по меньшей мере некоторых данных документа, хранящихся в подсистеме 150 базы данных в качестве части данных 175 поисковой машины, как объяснено выше.
[93] Как показано, подсистема 150 базы данных может быть сконфигурирована для хранения множества документов 204, связанных с соответствующими данными содержания. Например, подсистема 150 базы данных может хранить документ 210 вместе с данными 212 содержимого. В этом примере документ 210 может быть данной веб-страницей, которая была просканирована приложением 120 поискового робота и загружена с одного из серверов 108 ресурсов.
[94] Данные 212 содержимого могут содержать множество типов 214 содержимого. Например, один из множества типов 214 содержимого может включать в себя заголовок документа 210. В том же примере другой из множества типов 214 содержимого может включать в себя универсальный указатель ресурса (URL), связанный с документом 210. В том же примере еще один из множества типов 214 содержимого может включать в себя основное содержимое документа 210. Дополнительно или альтернативно, другие типы содержимого, помимо тех, которые неисчерпывающе перечислены выше, могут храниться в качестве части данных содержимого для данного документа, не выходя за рамки настоящей технологии.
[95] Кроме того, изображено представление 222 по меньшей мере некоторых данных, сохраненных в качестве части инвертированного индекса 170. Как объяснено выше, инвертированный индекс 170 может хранить множество списков 224 документов, связанных с соответствующими термами. В широком смысле, данный список документов для данного поискового терма будет содержать ссылки в форме номеров документов, например, на те документы, в которых встречается этот поисковый терм. Ссылки в данном списке документов могут сами быть в числовом порядке, в тоже время между номерами документов будут пробелы, по мере того как поисковый терм не встречается в документах, номера которых пропущены и образуют пробелы. Например, инвертированный индекс 170 сконфигурирован для хранения списка 250 документов, связанного с термом 220 (T1) и множеством документов 230. Как проиллюстрировано, множество документов содержит документ 210 (D1) и другие документы, которые содержат терм 220 (T1) в своем содержимом.
[96] Следует отметить, что данный список документов может содержать данные, указывающие на один или более указателей местоположения касательно позиции соответствующего терма в соответствующих документах.
[97] В некоторых вариантах осуществления предполагается, что множество списков 224 документов может содержать списки документов для «подобных термов». Например, первый терм может быть подобен второму терму, если второй терм является, но не ограничивается этим, синонимом первого терма, нормализованной версией первого терма и т.п. В этом примере первым термом может быть «занятие», а вторым термом может быть «работа». В этом примере первым термом может быть «рабочий», а вторым термом может быть «работа». Как станет очевидно из приведенного ниже описания, сервер 112 может быть сконфигурирован для идентификации одного или более термов, подобных термам из запроса, и их использования в дополнение к термам из запроса для извлечения данных из инвертированного индекса 170.
[98] В контексте настоящей технологии инвертированный индекс 170 сконфигурирован для хранения запросо-независимых данных для соответствующих пар документ-терм (DT). Например, сервер 112 может быть сконфигурирован для хранения запросо-независимых данных 260 для пары D1-T1, то есть запросо-независимые данные 260 связаны с парой, содержащей терм 220 и документ 210.
[99] Можно сказать, что запросо-независимые данные 260 включают в себя набор данных, зависимый от пары DT, сохраненный для соответствующей пары D1-T1. Аналогично, инвертированный индекс 170 может быть сконфигурирован для хранения множества запросо-независимых данных 240 (множество наборов данных, зависимых от пары DT) для соответствующих пар DT.
[100] Следует отметить, что в контексте настоящей технологии «запросо-независимые» данные могут относиться к данным, которые определяются и сохраняются без предварительного знания того, что представляет собой текущий используемый запрос. Предполагается, что запросо-независимые данные 260 указывают на (i) зависимое от терма вхождение терма 220 (T1) в содержимое, связанное с документом 210 (D1).
[101] Предполагается, что зависимое от терма вхождение терма 220 (T1) может включать в себя по меньшей мере одно из: (i) одной или более позиций терма 220 (T1) в заголовке, связанном с документом 210 (D1), (ii) одной или более позиций терма 220 (T1) в URL, связанном с документом 210 (D1), и (iii) одной или более позиций терма 220 (T1) в теле документа 210 (D1).
[102] В некоторых вариантах осуществления настоящей технологии запросо-независимые данные 260 для пары D1-T1 могут дополнительно содержать запросо-независимые данные на основе содержимого, связанные с парой D1-T1. В этих вариантах осуществления запросо-независимые данные на основе содержимого могут указывать на текстовый контекст соответствующего терма в содержимом, связанном с данным документом. В примере пары D1-T1 запросо-независимые данные на основе содержимого в запросо-независимых данных 260 могут указывать на один или более соседних термов с термом 220 (T1) в содержимом документа 210 (D1).
[103] Как станет очевидно из приведенного ниже описания, генератор 155 динамических признаков может использовать запросо-независимые данные, хранящиеся в инвертированном индексе 170, для генерирования в реальном времени запросо-зависимых данных для данной пары документ-запрос (DQ). Генератор 140 ранжирующих признаков затем может использовать запросо-зависимые данные и данные, связанные с различными термами из запроса, для генерирования данного ранжирующего признака для данной пары DQ.
[104] То, как сервер 112 сконфигурирован для использования в реальном времени, в ответ на получение текущего запроса, генератора 155 динамических признаков для генерирования в реальном времени ранжирующего признака с помощью генератора 140 ранжирующих признаков, будет обсуждаться здесь дополнительно ниже со ссылкой на Фиг. 5. Однако то, как сервер 112 сконфигурирован для использования генератора 155 динамических признаков для генерирования обучающих данных для обучения генератора 140 ранжирующих признаков, будет сначала обсуждаться со ссылкой на Фиг. 3 и 4.
[105] На Фиг. 3 изображено представление 300 обучающих данных 310 и представление 350 одной итерации обучения генератора 140 ранжирующих признаков (NN). Сервер 112 может быть сконфигурирован для использования обучающих данных 310, которые могут использоваться для генерирования обучающего набора, который будет использоваться для выполнения одной итерации обучения.
[106] Обучающие данные 310 содержат обучающую пару 302 DQ, имеющую обучающий запрос 304 (Qa) и обучающий документ 306 (Da). Обучающий запрос 304 имеет множество термов 330, содержащих первый терм 332 (Ta), второй терм 334 (Tb) и третий терм 336 (Tc). Обучающие данные 310 связаны с меткой 320. Метка 320 указывает на соответствие обучающего документа 306 (Da) обучающему запросу 304 (Qa).
[107] Например, метка 320 может быть определена оценщиком-человеком, которому было поручено «оценить» релевантность обучающего документа 306 (Da) для обучающего запроса 304 (Qa). Точно так же одному или более оценщикам может быть поручено оценить множество обучающих пар DQ, и множество обучающих пар DQ может быть сохранено в системе 150 базы данных вместе с соответствующими оцененными метками.
[108] Сервер 112 может быть сконфигурирован для использования обучающих данных 310 и метки 320 для генерирования обучающего набора 380 для выполнения одной итерации обучения генератора 140 ранжирующих признаков, показанного на Фиг. 3. Обучающий набор 380 содержит множество вложений 382 обучающих термов, множество векторов 384 обучающих признаков и метку 320.
[109] Сервер 112 может быть сконфигурирован для генерирования множества вложений 382 обучающих термов на основе соответствующих термов из обучающего запроса 304. В широком смысле, вложение (embedding) - это относительно маломерное пространство, в которое можно переводить многомерные векторы. Вложения упрощают машинное обучение для больших входных данных, например, разреженных векторов, представляющих слова. В идеале вложение захватывает некоторую семантику входных данных, помещая семантически похожие входные данные близко друг к другу в пространстве вложения. Также предполагается, что вложения могут быть изучены и повторно использованы в разных моделях. Сервер 112 может быть сконфигурирован для выполнения одного или более реализованных на компьютере алгоритмов вложения, сконфигурированных для приема заданного обучающего терма в качестве ввода и вывода соответствующего вложения обучающего терма. Например, сервер 112 может быть сконфигурирован для генерирования первого вложения 342 обучающего терма на основе первого терма 332 (Ta), второго вложения 344 обучающего терма на основе второго терма 334 (Tb) и третьего вложения 346 обучающего терма на основе третьего терма 336 (Tc).
[110] Как упомянуто выше, обучающий набор 380 содержит множество векторов 384 признаков. Следует отметить, что один или более признаков из множества векторов 384 признаков могут быть сгенерированы генератором 155 динамических признаков. Как теперь будет обсуждаться более подробно со ссылкой на Фиг. 4, один или более признаков из множества векторов 384 признаков могут содержать запросо-зависимые данные, сгенерированные генератором 155 динамических признаков на основе запросо-независимых данных, извлеченных для множества обучающих термов 330 из инвертированного индекса 170.
[111] На Фиг. 4 изображено представление 400 того, как генератор 155 динамических признаков генерирует множество векторов 384 признаков для обучающего набора 380. Сервер 112 сконфигурирован для осуществления доступа к инвертированному индексу 170 для извлечения множества запросо-независимых наборов данных, связанных с соответствующими обучающими парами DT, то есть сервер 112 может извлекать первый запросо-независимый набор 402 данных для обучающей пары Da-Ta, второй запросо-независимый набор 404 данных для обучающей пары Da-Tb и третий запросо-независимый набор 406 данных для обучающей пары Da-Tc. Можно сказать, что первый запросо-независимый набор 402 данных, второй запросо-независимый набор 404 данных и третий запросо-независимый набор 406 данных представляют запросо-независимые данные, извлеченные из инвертированного индекса 170 для множества обучающих пар DT.
[112] Сервер 112 сконфигурирован для ввода извлеченных таким образом запросо-независимых данных в генератор 155 динамических признаков. В широком смысле, генератор 155 динамических признаков выполнен с возможностью генерировать для каждого обучающего терма из обучающего запроса 304 соответствующий вектор признаков. В проиллюстрированном примере генератор 155 динамических признаков использует извлеченные таким образом запросо-независимые данные для генерирования первого вектора 352 признаков для обучающего терма 332 Ta, второго вектора 354 признаков для обучающего терма 334 Tb и третьего вектора 356 признаков для обучающего терма 336 Tc.
[113] Следует отметить, что генератор 155 динамических признаков может содержать множество реализованных на компьютере алгоритмов, которые сконфигурированы для обработки запросо-независимых данных для генерирования множества признаков (для каждого обучающего терма), типы которых предварительно определены. Например, типы признаков, которые должны быть сгенерированы генератором 155 динамических признаков, могут быть определены оператором сервера 112. В этом примере оператор может определить типы признаков, которые он считает полезными для конкретной реализации настоящей технологии.
[114] В некоторых вариантах осуществления типы признаков могут включать в себя запросо-независимые признаки и запросо-зависимые признаки. Разработчики настоящей технологии выявили, что запросо-независимые данные, хранящиеся в инвертированном индексе 170, могут быть извлечены в реальном времени и обработаны для генерирования запросо-зависимых данных. В частности, разработчики настоящей технологии выявили, что запросо-независимые наборы данных, извлеченные для соответствующих пар DT, взятые по отдельности, не включают в себя информацию, которая зависит от более чем одного терма из запроса (следовательно, запросо-независимые). Однако, когда запросо-независимые наборы данных извлекаются для каждой пары DT и анализируются в сочетании друг с другом, сервер 112 может в некотором смысле «извлекать» из него запросо-зависимые данные в форме одного или более запросо-зависимых признаков.
[115] Чтобы лучше проиллюстрировать это, предположим, что запросом 304 является «граница таблицы css» («table border css») и, следовательно, терм 332 (Ta) - это «таблица» («table»), терм 334 (Tb) - это «граница» («border»), а терм 336 (Tc) - это «css». Также предположим, что документ 306 (Da) связан со следующим URL: «https://www.w3schools.com/css/css_table.asp», имеет заголовок «Таблицы стилей CSS» («CSS styling tables»), а тело содержит следующие предложения: «Границы таблицы» («Table Borders»), «Чтобы указать границы таблицы в CSS, используйте свойство границы» («To specify table borders in CSS, use the border property») и «В приведенном ниже примере указана черная граница для элементов <table>, <th> и <td>» («The example below specifies a black border for <table>, <th>, and <td> elements»).
[116] В этом примере первый запросо-независимый набор 402 данных указывает одно или более зависимых от терма вхождений терма 332 (Ta) «таблица» в содержимое, связанное с документом. Например, первый запросо-независимый набор 402 данных может указывать на присутствие терма 332 (Ta) «таблица» в заголовке документа 306. В другом случае первый запросо-независимый набор 402 данных может указывать на присутствие терма 332 (Ta) «таблица» в теле документа 306. В дополнительном случае первый запросо-независимый набор 402 данных может указывать на присутствие терма 332 (Ta) «таблица» в URL документа 306. В еще одном случае первый запросо-независимый набор 402 данных может указывать позицию (или смещение) терма 332 (Ta) «таблица» в содержимом документа 306. В дополнительном случае первый запросо-независимый набор 402 данных может указывать, сколько раз терм 332 (Ta) «таблица» встречается в содержимом документа 306.
[117] Аналогичным образом второй запросо-независимый набор 404 данных указывает одно или более зависимых от терма вхождений терма 334 (Tb) «таблица» в содержимое, связанное с документом 306. Аналогичным образом третий запросо-независимый набор 406 данных указывает одно или более зависимых от терма вхождений терма 336 (Tc) «таблица» в содержимое, связанное с документом 306. Следует отметить, что характер.
[118] Следует отметить, что запросо-независимые данные могут использоваться для генерирования запросо-зависимого признака, который указывает на групповое вхождение данного терма с одним или более другими термами из запроса 304.
[119] Например, оператор может предварительно определить, что один тип запросо-зависимого признака, который генератор 155 должен генерировать на основе запросо-независимых данных - это количество раз, когда данный терм из запроса 304 включен в дополнение ко второму терму в URL, связанный с документом 306. Таким образом, при генерировании первого вектора 352 признаков для пары Da-Ta сервер 112 может определить, что терм 332 (Ta) «таблица» не встречается в дополнение к терму 334 (Tb) «граница» в URL, связанном с документом 306 («https://www.w3schools.com/css/css_table.asp»). В этом случае сервер 112 может определить значение этого признака в первом векторе 352 признаков как «0».
[120] В другом примере оператор может предварительно определить, что еще один тип запросо-зависимого признака, который генератор 155 должен генерировать на основе запросо-независимых данных - это количество раз, когда данный терм из запроса 304 включен в дополнение к третьему терму в URL, связанный с документом 306. Таким образом, при генерировании первого вектора 352 признаков для пары Da-Ta сервер 112 может определить, что терм 332 (Ta) «таблица» встречается один раз в дополнение к присутствию терма 336 (Tc) «css» в URL, связанном с документом 306 («https://www.w3schools.com/css/css_table.asp»). В этом случае сервер 112 может определить значение этого признака в первом векторе 352 признаков как «1».
[121] В дополнительном примере оператор может предварительно определить, что еще один тип запросо-зависимого признака, который генератор 155 должен генерировать на основе запросо-независимых данных - это количество раз, когда данный терм из запроса 304 включен в дополнение к первому терму в URL, связанный с документом 306. Таким образом, при генерировании третьего вектора 356 признаков для пары Da-Tc сервер 112 может определить, что терм 336 (Tc) «css» встречается дважды в дополнение к присутствию терма 332 (Ta) «таблица» в URL, связанном с документом 306 («https://www.w3schools.com/css/css_table.asp»). В этом случае сервер 112 может определить значение этого признака в третьем векторе 356 признаков как «2».
[122] В еще одном примере оператор может предварительно определить, что еще один тип запросо-зависимого признака, который генератор 155 должен генерировать на основе запросо-независимых данных, представляет собой процент термов из запроса 304, которые входят с данным термом в URL, связанный с документом 306. Таким образом, при генерировании первого вектора 352 признаков для пары Da-Ta сервер 112 может определить, что два из трех термов из запроса 304 встречаются с термом 332 (Ta) «таблица» в URL, связанном с документом 306 («https://www.w3schools.com/css/css_table.asp»). В этом случае сервер 112 может определить значение этого признака в первом векторе 352 признаков как «2/3». Однако при генерировании второго вектора 354 признаков для пары Da-Tb сервер 112 может определить, что ни один из термов из запроса 304 не встречается с термом 332 (Tb) «граница» в URL, связанном с документом 306 ( «Https://www.w3schools.com/css/css_table.asp»), потому что терм 332 (Tb) «граница» не встречается в этом URL. В этом случае сервер 112 может определить значение этого признака во втором векторе 354 признаков как «0».
[123] Следует отметить, что при генерировании векторов признаков для соответствующих пар DT генератор 155 может быть сконфигурирован для генерирования векторов признаков предварительно определенного размера. Например, размер может быть определен оператором на основе, например, количества запросо-зависимых признаков, которые он (она) считает полезными для конкретной реализации. Тем не менее, предполагается, что данный вектор признаков может содержать, в дополнение к одному или более запросо-зависимым признакам различных типов, запросо-независимые признаки для соответствующего терма. В одной реализации настоящей технологии размер векторов признаков, генерируемых генератором 155, равен «5».
[124] Возвращаясь к описанию Фиг. 3, сервер 112 генерирует для обучающего набора 380 первый вектор 352 обучающих признаков, второй вектор 354 обучающих признаков и третий вектор 356 обучающих признаков, как описано выше. Сервер 112 вводит вложения 342, 344 и 346 термов и векторы 352, 354 и 356 обучающих признаков в обучаемую NN (генератор 140 ранжирующих признаков). В некоторых вариантах осуществления NN может содержать множество параллельных входных слоев и множество полностью связанных слоев.
[125] Предполагается, что сервер 106 может быть сконфигурирован для конкатенации вложенных термов с соответствующими векторами обучающих признаков. Например, сервер 106 может быть сконфигурирован для конкатенации вложения 342 терма с вектором 352 обучающих признаков для генерирования конкатенированных обучающих входных данных. В том же примере сервер 106 может быть сконфигурирован для конкатенации вложения 344 терма с вектором 354 обучающих признаков для генерирования конкатенированных обучающих входных данных. В том же примере сервер 106 может быть сконфигурирован для конкатенации вложения 346 терма с вектором 356 обучающих признаков для генерирования конкатенированных обучающих входных данных. Сервер 106 может быть сконфигурирован для ввода в NN конкатенированных входных данных, так что NN, в некотором смысле, понимает, какие вложения термов связаны с какими векторами обучающих признаков.
[126] В ответ на входные данные NN выводит предсказанный ранжирующий признак 360. Сервер 112 сконфигурирован для сравнения предсказанного ранжирующего признака 360 с меткой 320. Например, сервер 112 может применить заданную функцию штрафа во время сравнения предсказанного ранжирующего признака 360 с меткой 320. Результат сравнения затем используется сервером 112 для того, чтобы, в некотором смысле, «настроить» NN таким образом, чтобы NN генерировала предсказанные ранжирующие признаки, которые близки к соответствующим меткам. Например, настройка может выполняться с помощью одного или более методов обучения NN (например, обратного распространения ошибки). После большого количества итераций, выполненных аналогичным образом, NN обучается генерировать предсказанные ранжирующие признаки, которые являются предсказаниями релевантности соответствующих документов для соответствующих запросов.
[127] То, как сервер 112 сконфигурирован для использования генератора 140 ранжирующих признаков и генератора 155 динамических признаков в реальном времени для текущего запроса, отправленного пользователем 102, теперь будет описано со ссылкой на Фиг. 5. Здесь изображено представление 500 того, как сервер 112 сконфигурирован для генерирования предсказанного ранжирующего признака 540 для данной пары DQ.
[128] Предположим, что сервер 112 принимает текущий (используемый) запрос 502, отправленный пользователем 102, от электронного устройства 104 через запрос 180. Можно сказать, что как только запрос 502 получен сервером 112, сервер 112 сконфигурирован для использования поисковой машины 160 в реальном времени для генерирования заданной SERP. Запрос 502 (Qw) имеет терм 506 (Tx), терм 507 (Ty) и терм 508 (Tz).
[129] Сервер 112 сконфигурирован для определения множества потенциально релевантных документов 504 для используемого запроса 502. В некоторых вариантах осуществления сервер 112 может использовать одну или более компьютерно-реализуемых процедур для определения множества документов, которые являются потенциально релевантными используемому запросу 502. Предполагается, что сервер 112 может использовать известные в данной области техники способы для идентификации документов, которые должны быть включены во множество потенциально релевантных документов 504.
[130] Сервер 112 сконфигурирован для генерирования предсказанных ранжирующих признаков для соответствующих из множества потенциально релевантных документов 504. В одном примере сервер 112 может быть сконфигурирован для генерирования предсказанного ранжирующего признака 540 для пары, включающей запрос 502 (Qw) и документ 505 (Dw) из множества потенциально релевантных документов 504.
[131] Сервер 112 сконфигурирован для осуществления доступа к инвертированному индексу 170 для извлечения запросо-независимых данных 510. Запросо-независимые данные 510 содержат первый запросо-независимый набор 512 данных для пары Dw-Tx, второй запросо-независимый набор 514 данных для пары Dw-Ty и третий запросо-независимый набор 516 данных для пары Dw-Tz.
[132] В некоторых вариантах осуществления можно сказать, что запросо-независимые данные могут быть «зависимыми от терма» данными. Следует отметить, что первый запросо-независимый набор 512 данных для пары Dw-Tx указывает на зависимое от терма вхождение терма 506 (Tx) в содержимое документа 505 (Dw), второй запросо-независимый набор 514 данных для пары Dw-Ty указывает на зависимое от терма вхождение терма 507 (Tx) в содержимое документа 505 (Dw), а третий запросо-независимый набор 516 данных для пары Dw-Tz указывает на зависимое от терма вхождение терма 508 (Tz) в содержимое документа 505 (Dw).
[133] В некоторых вариантах осуществления запросо-независимые данные 510 могут дополнительно содержать запросо-независимые (зависимые от терма) данные на основе содержимого, указывающие текстовый контекст соответствующего терма в содержимом, связанном с данным документом. Например, текстовый контекст может включать в себя предыдущий терм и следующий терм для соответствующего терма в содержимом, связанном с данным документом.
[134] Сервер 112 сконфигурирован для ввода запросо-независимых данных 510 в генератор 155 динамических признаков для генерирования множества векторов признаков, содержащих первый вектор 532 признаков, второй вектор 534 признаков и третий вектор 536 признаков. Как объяснено выше, первый вектор 532 признаков, второй вектор 534 признаков и третий вектор 536 признаков содержат по меньшей мере один запросо-зависимый признак, указывающий на групповое вхождение соответствующего терма с одним или более другими термами из запроса 502.
[135] По меньшей мере в некоторых вариантах осуществления настоящей технологии можно сказать, что запросо-независимые данные были сохранены в инвертированном индексе 170 до получения запроса 502 от электронного устройства 104, а запросо-зависимый признак генерируется после получения запроса 502 от электронного устройства 104. Можно также сказать, что запросо-зависимый признак генерируется с использованием запросо-независимых данных в реальном времени во время процедуры ранжирования документов поисковой машины 160. Следует отметить, что данные, указывающие на запросо-зависимый признак, не могли быть сохранены в инвертированном индексе 170 для данной пары DT до получения запроса 502, поскольку это зависит от одного или более других термов из запроса 502.
[136] Сервер 112 также сконфигурирован для генерирования вложений 518, 520 и 522 термов для термов 506, 507 и 508 соответственно. Можно сказать, что сервер 112 может быть сконфигурирован для генерирования используемого набора 550 для ввода в генератор 140 ранжирующих признаков (обученная NN), и где используемый набор 550 содержит вложения 518, 520 и 522 термов и векторы 532, 534 и 536 признаков.
[137] Сервер 112 сконфигурирован для ввода используемого набора 550 в генератор 140 ранжирующих признаков, который, в ответ, генерирует предсказанный ранжирующий признак 540 для пары документа 505 и запроса 502. Предполагается, что сервер 106 может быть сконфигурирован для генерирования конкатенированных входных данных путем конкатенации вложения 518 терма с вектором 532 признаков, вложения 520 терма с вектором 534 признаков и вложения 522 терма с вектором 536 признаков и ввода конкатенированных входных данных в генератор 140 ранжирующих признаков.
[138] Как упомянуто выше, сервер 112 может быть сконфигурирован для использования предсказанного ранжирующего признака 540 для ранжирования документа 505 среди множества потенциально релевантных документов 504 в ответ на запрос 502. Со ссылкой на Фиг. 6 изображено представление 600 того, как сервер 112 сконфигурирован для использования модели 130 ранжирования (например, MLA на основе дерева решений) для генерирования ранжированного списка 680 документов для пользователя 102 в ответ на запрос 502. Как видно, сервер 112 может вводить в модель 130 ранжирования данные 602 запроса. Например, сервер 112 может обращаться к подсистеме 150 базы данных и извлекать информацию, связанную с запросом 502, такую как данные прошлого взаимодействия, связанные с запросом 502.
[139] Сервер 112 может также вводить для документа 505 данные 604 документа и предсказанный ранжирующий признак 540. Например, сервер 112 может быть сконфигурирован для осуществления доступа к подсистеме 150 базы данных и извлечения информации, связанной с документом 505. Например, данные 604 документа могут содержать информацию на основе содержимого и/или данные прошлого взаимодействия, связанные с документом 505. Аналогичным образом сервер 112 может также вводить для документа 506 (другого из множества потенциально релевантных документов 504) данные 606 документа и предсказанный ранжирующий признак 620. Сервер 112 может быть сконфигурирован для генерирования предсказанного ранжирующего признака 620 для пары документ 509 - запрос 502 аналогично тому, как сервер 112 сконфигурирован для генерирования предсказанного ранжирующего признака 640 для пары документ 505 - запрос 502. Модель 130 ранжирования сконфигурирована для генерирования в качестве вывода ранжированного списка документов 680, ранжированных на основе их релевантности запросу 502. Сервер 112 может быть сконфигурирован для использования ранжированного списка 680 документов для генерирования SERP и передачи данных, указывающих на это, через ответ 190 на электронное устройство 104 для отображения пользователю 102.
[140] На Фиг. 7 схематично показан способ 700 ранжирования цифровых документов в ответ на запрос. Например, сервер 112 может быть сконфигурирован для выполнения способа 700, этапы которого теперь будут обсуждаться более подробно.
ЭТАП 702: для данного документа, осуществление доступа к инвертированному индексу для извлечения запросо-независимых данных для первой пары документ-терм (DT) и второй пары DT
[141] Способ 700 начинается на этапе 702, на котором сервер 112 сконфигурирован для осуществления доступа к инвертированному индексу 170 для извлечения запросо-независимых данных для первой пары DT и второй пары DT. Например, предположим, что запрос содержит первый терм и второй терм. Первая пара DT имеет данный документ и первый терм, а вторая пара DT имеет данный документ и второй терм.
[142] Как объяснено выше, запросо-независимые данные, полученные сервером 112, указывают на (i) зависимое от терма вхождение первого терма в содержимое, связанное с данным документом, и (ii) зависимое от терма вхождение второго терма в содержимое, связанное с данным документом.
[143] В некоторых вариантах осуществления настоящей технологии сервер 112 может быть сконфигурирован для извлечения запросо-независимых данных для терма, который подобен одному из первого или второго термов. Например, сервер 112 может быть сконфигурирован с возможностью, для данного одного из множества термов из используемого запроса, определять подобный терм, а при осуществлении доступа к инвертированному индексу 170 для извлечения запросо-независимых данных, сервер 112 может быть сконфигурирован для извлечения запросо-независимых данных для третьей пары DT, где третья пара DT имеет данный документ и упомянутый подобный терм.
[144] В дополнительных вариантах осуществления предполагается, что сервер 112 может осуществлять доступ к инвертированному индексу 170, чтобы извлекать запросо-независимые данные на основе содержимого, связанные с первой парой DT и второй парой DT. Запросо-независимые данные на основе содержимого могут указывать на текстовый контекст соответствующего терма в содержимом, связанном с данным документом. Дополнительно или альтернативно, подсистема 150 базы данных может хранить прямой индекс в дополнение к инвертированному индексу 170, который может использоваться сервером 112 для получения таким образом запросо-независимых данных на основе содержимого (текстовый контекст термов в документе).
[145] Предполагается, что зависимое от терма вхождение данного терма может содержать по меньшей мере одно из: (i) одной или более позиций первого терма в заголовке, связанном с данным документом, (ii) одной или более позиций первого терма в URL, связанном с данным документом, и (iii) одной или более позиций первого терма в теле данного документа.
ЭТАП 704: для данного документа, генерирование запросо-зависимого признака с использованием запросо-независимых данных, извлеченных для первой пары DT и второй пары DT
[146] Способ 700 переходит к этапу 704, на котором сервер 112 сконфигурирован для генерирования запросо-зависимого признака с использованием запросо-независимых данных, извлеченных для первой пары DT и второй пары DT, и при этом запросо-зависимый признак указывает на групповое вхождение первого терма со вторым термом в содержимое, связанное с данным документом.
[147] В одном неограничивающем примере, показанном на Фиг. 5, сервер 112 может быть сконфигурирован для осуществления доступа к инвертированному индексу 170 для извлечения запросо-независимых данных 510 (например, этап 702). Запросо-независимые данные 510 содержат первый запросо-независимый набор 512 данных для пары Dw-Tx, второй запросо-независимый набор 514 данных для пары Dw-Ty и третий запросо-независимый набор 516 данных для пары Dw-Tz.
[148] В некоторых вариантах осуществления можно сказать, что запросо-независимые данные могут быть «зависимыми от терма» данными. Следует отметить, что первый запросо-независимый набор 512 данных для пары Dw-Tx указывает на зависимое от терма вхождение терма 506 (Tx) в содержимое документа 505 (Dw), второй запросо-независимый набор 514 данных для пары Dw-Ty указывает на зависимое от терма вхождение терма 507 (Tx) в содержимое документа 505 (Dw), а третий запросо-независимый набор 516 данных для пары Dw-Tz указывает на зависимое от терма вхождение терма 508 (Tz) в содержимое документа 505 (Dw).
[149] В качестве части этапа 704, сервер 112 может быть сконфигурирован для ввода запросо-независимых данных 510 в генератор 155 динамических признаков для генерирования множества векторов признаков, содержащих первый вектор 532 признаков, второй вектор 534 признаков и третий вектор 536 признаков. Как объяснено выше, первый вектор 532 признаков, второй вектор 534 признаков и третий вектор 536 признаков содержат по меньшей мере один запросо-зависимый признак, указывающий на групповое вхождение соответствующего терма с одним или более другими термами из запроса 502.
[150] По меньшей мере в некоторых вариантах осуществления настоящей технологии можно сказать, что запросо-независимые данные были сохранены в инвертированном индексе 170 до получения запроса 502 от электронного устройства 104, а запросо-зависимый признак генерируется после получения запроса 502 от электронного устройства 104. Можно также сказать, что запросо-зависимый признак генерируется с использованием запросо-независимых данных в реальном времени во время процедуры ранжирования документов поисковой машины 160. Следует отметить, что данные, указывающие на запросо-зависимый признак, не могли быть сохранены в инвертированном индексе 170 для данной пары DT до получения запроса 502, поскольку это зависит от одного или более других термов из запроса 502.
[151] По меньшей мере в некоторых вариантах осуществления настоящей технологии групповое вхождение первого терма со вторым термом в содержимое, связанное с данным документом, содержит по меньшей мере одно из: (i) количества раз, когда второй терм из запроса включен в дополнение к первому терму в заголовок, связанный с данным документом, (ii) количества раз, когда второй терм из запроса включен в дополнение к первому терму в URL, связанный с данным документом, (iii) количества раз, когда второй терм из запроса включен в дополнение к первому терму в тело данного документа, и (iv) позиционного смещения между первым термом и вторым термом в теле данного документа.
ЭТАП 706: для данного документа, генерирование ранжирующего признака для данного документа на основе, по меньшей мере, первого терма
[152] Способ 700 переходит к этапу 706, на котором сервер 112 сконфигурирован для генерирования ранжирующего признака для данного документа на основе, по меньшей мере, первого терма, второго терма и запросо-зависимого признака. Например, сервер 112 может быть сконфигурирован для использования генератора 140 ранжирующих признаков для генерирования ранжирующего признака для данного документа.
[153] В некоторых вариантах осуществления настоящей технологии генератор 140 ранжирующих признаков может быть реализован как заданная NN.
ЭТАП 708: ранжирование данного документа из множества потенциально релевантных документов на основе, по меньшей мере, ранжирующего признака
[154] Способ 700 переходит к этапу 708, на котором сервер 112 сконфигурирован для ранжирования данного документа из множества потенциально релевантных документов на основе, по меньшей мере, ранжирующего признака, определенного на этапе 706. Например, сервер 112 может быть сконфигурирован для выполнения модели 130 ранжирования.
[155] По меньшей мере в некоторых вариантах осуществления настоящей технологии модель 130 ранжирования может быть реализована как MLA на основе данного дерева решений. В широком смысле, MLA на основе данного дерева решений - это модель машинного обучения, имеющая одно или более «деревьев решений», которые используются (i) для перехода от наблюдений за объектом (представленных в ветвях) к заключениям о целевом значении объекта (представлены в листьях). В одной неограничивающей реализации настоящей технологии MLA на основе дерева решений может быть реализовано в соответствии со структурой CatBoost.
[156] Предполагается, что сервер 112 может быть сконфигурирован для ранжирования данного документа с использованием MLA на основе дерева решений, сконфигурированного для ранжирования множества потенциально релевантных документов на основе их релевантности запросу.
[157] Следует четко понимать, что не все технические эффекты, упомянутые в данном документе, обязательно будут достигаться в каждом и каждом варианте осуществления настоящей технологии. Например, варианты осуществления настоящей технологии могут быть реализованы без достижения некоторых из этих технических эффектов, в то время как другие варианты осуществления могут быть реализованы с достижением других технических эффектов или вообще без них.
[158] Некоторые из вышеупомянутых этапов, а также отправка/прием сигналов хорошо известны в данной области техники и, как таковые, были опущены в некоторых частях этого описания для его упрощения. Сигналы могут отправляться/приниматься с использованием оптических средств (например, оптоволоконного соединения), электронных средств (например, используя проводное или беспроводное соединение), а также механических средств (например, средств, основанных на давлении, на температуре, или на основе любого другого подходящего физического параметра).
Модификации и улучшения вышеописанных реализаций настоящей технологии могут стать понятными для специалистов в данной области техники. Предшествующее описание предназначено для того, чтобы быть примерным, а не ограничивающим. Поэтому подразумевается, что объем настоящей технологии ограничен только объемом прилагаемой формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ и сервер для ранжирования цифровых документов в ответ на запрос | 2020 |
|
RU2818279C2 |
| СПОСОБ И СИСТЕМА ГЕНЕРИРОВАНИЯ ПРИЗНАКА ДЛЯ РАНЖИРОВАНИЯ ДОКУМЕНТА | 2018 |
|
RU2733481C2 |
| Способ и сервер для формирования расширенного запроса | 2021 |
|
RU2813582C2 |
| СПОСОБ И СЕРВЕР ГЕНЕРИРОВАНИЯ МЕТА-ПРИЗНАКА ДЛЯ РАНЖИРОВАНИЯ ДОКУМЕНТОВ | 2018 |
|
RU2721159C1 |
| СПОСОБ И СИСТЕМА ПОСТРОЕНИЯ ПОИСКОВОГО ИНДЕКСА С ИСПОЛЬЗОВАНИЕМ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2018 |
|
RU2720954C1 |
| СПОСОБ ОБУЧЕНИЯ МОДУЛЯ РАНЖИРОВАНИЯ С ИСПОЛЬЗОВАНИЕМ ОБУЧАЮЩЕЙ ВЫБОРКИ С ЗАШУМЛЕННЫМИ ЯРЛЫКАМИ | 2016 |
|
RU2632143C1 |
| ДЛИНА ДОКУМЕНТА В КАЧЕСТВЕ СТАТИЧЕСКОГО ПРИЗНАКА РЕЛЕВАНТНОСТИ ДЛЯ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2009 |
|
RU2517271C2 |
| ФОРМИРОВАНИЕ ПОИСКОВОГО ЗАПРОСА НА ОСНОВЕ КОНТЕКСТА | 2013 |
|
RU2633115C2 |
| СПОСОБ И СИСТЕМА ДЛЯ РАСШИРЕНИЯ ПОИСКОВЫХ ЗАПРОСОВ С ЦЕЛЬЮ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2018 |
|
RU2720905C2 |
| СПОСОБ И СЕРВЕР ДЛЯ ОБУЧЕНИЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ РАНЖИРОВАНИЮ ОБЪЕКТОВ | 2020 |
|
RU2782502C1 |
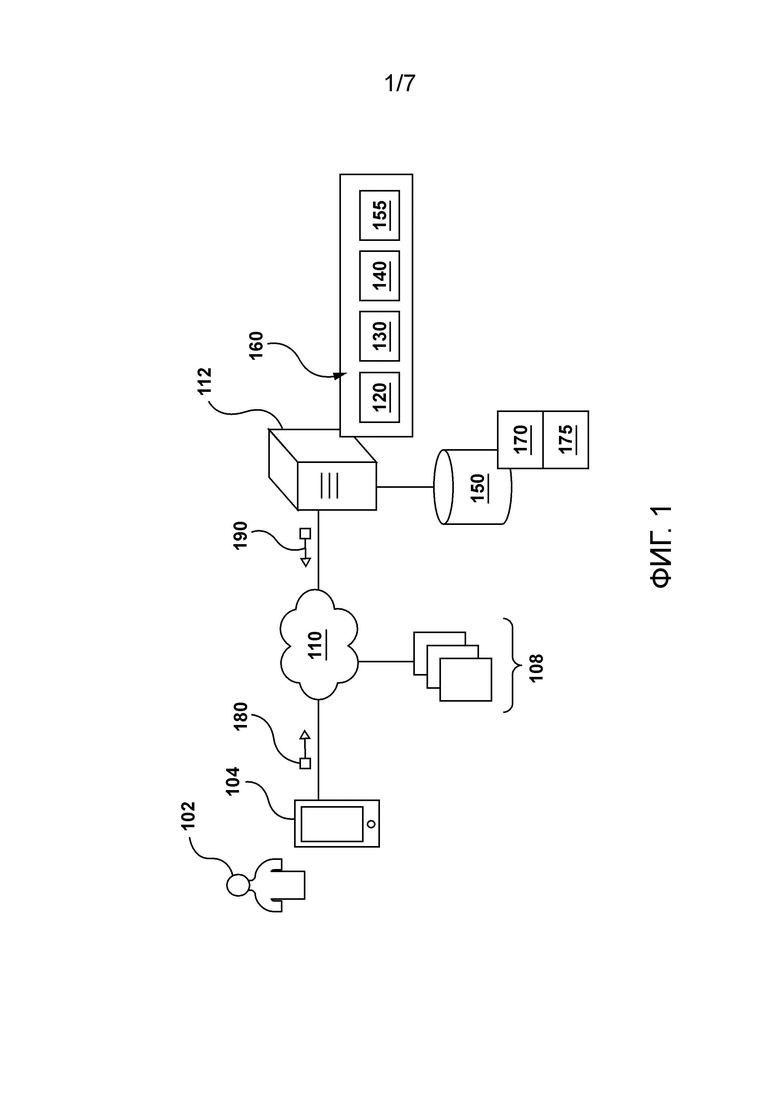
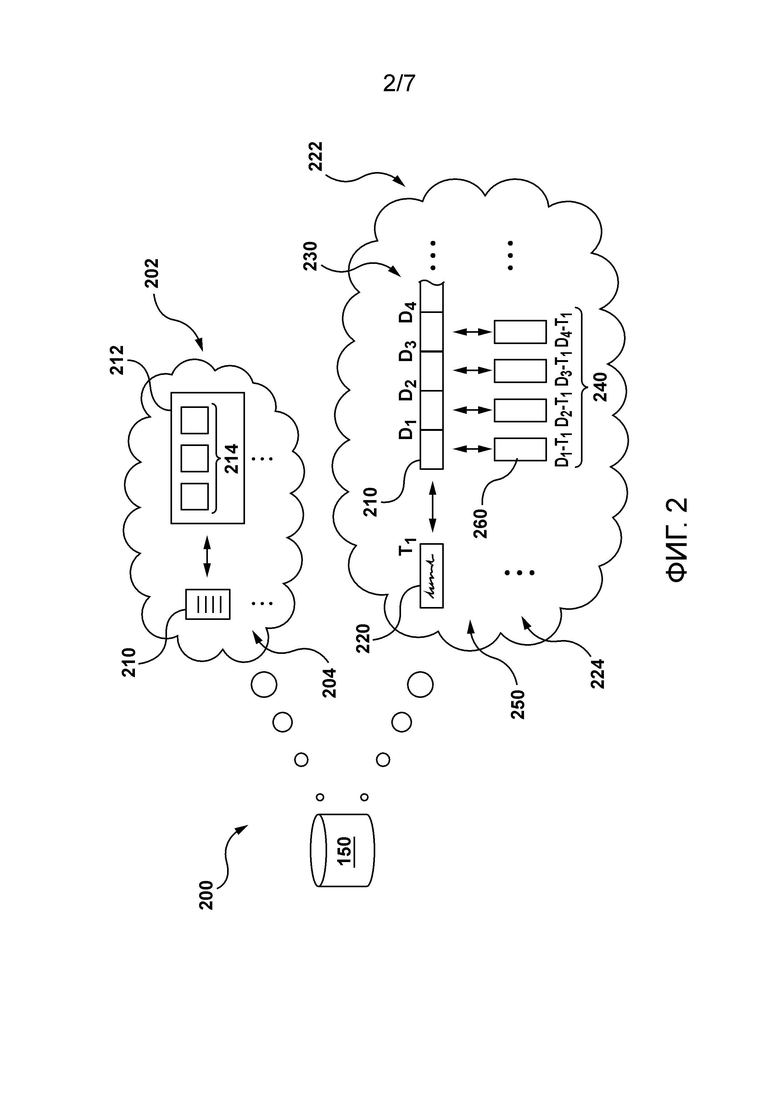

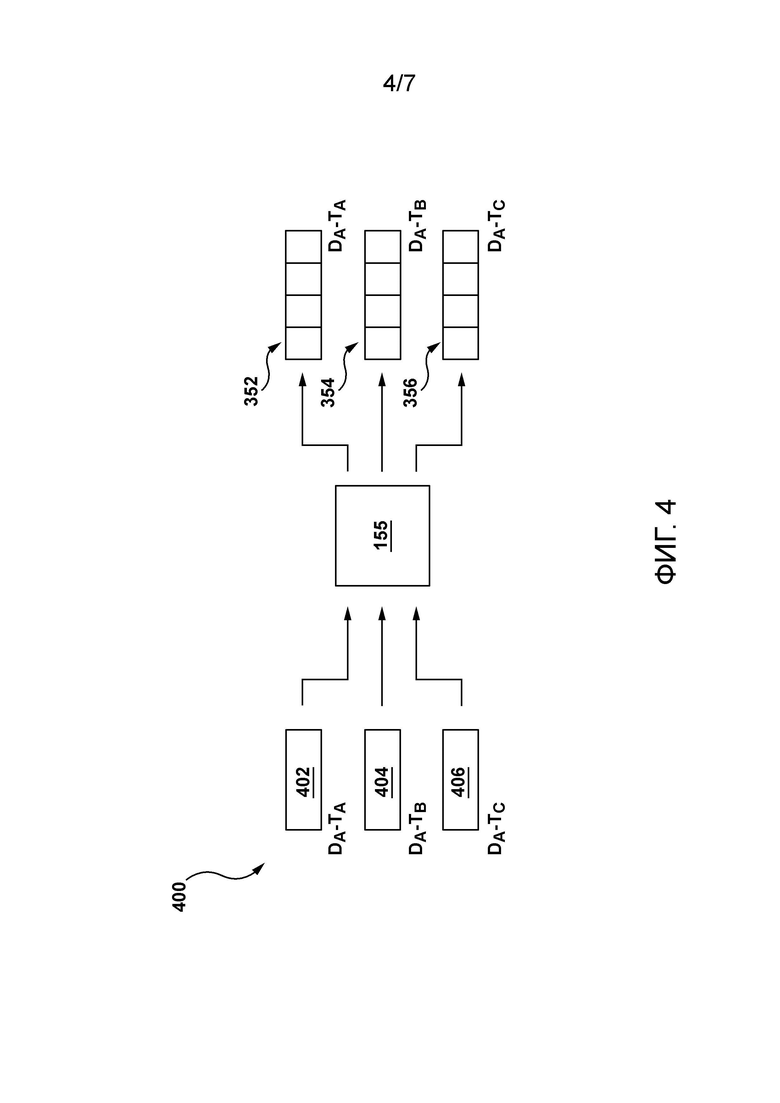
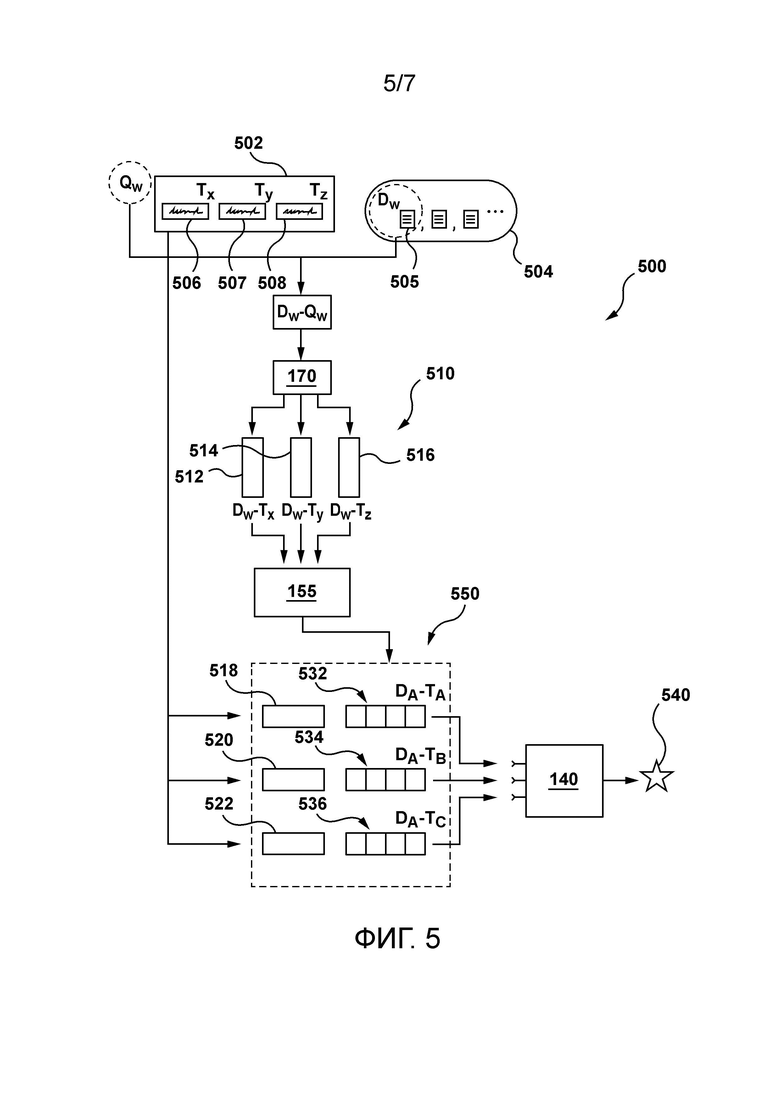
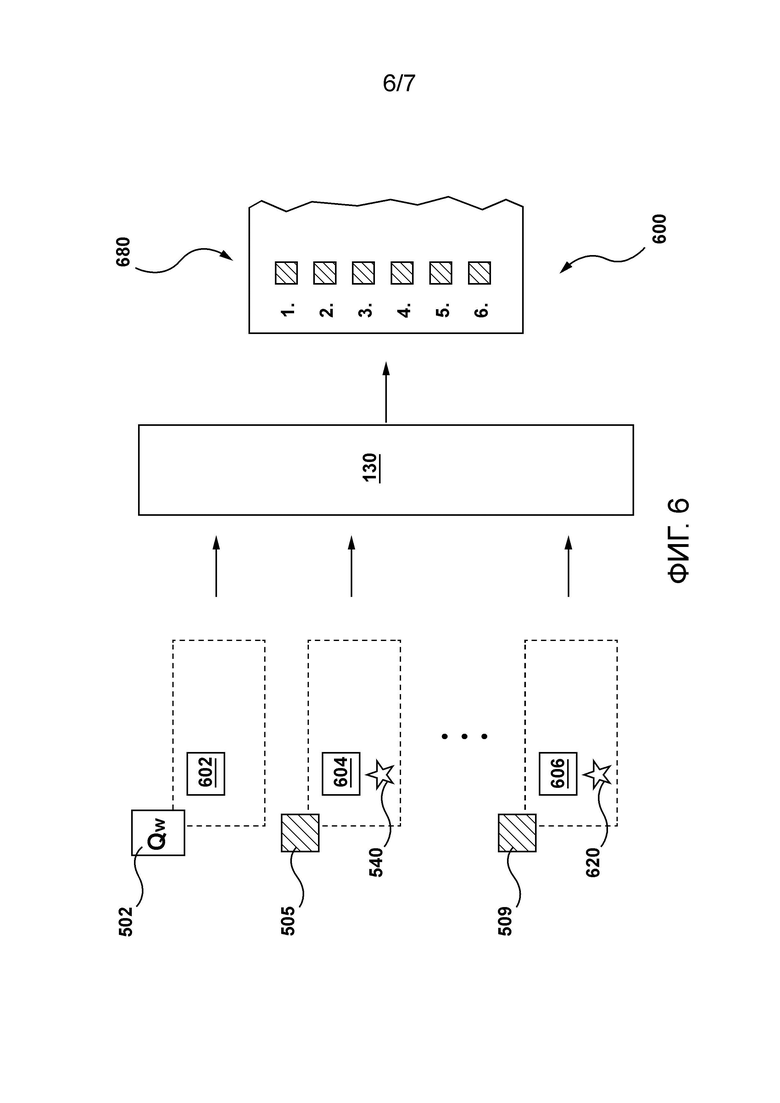
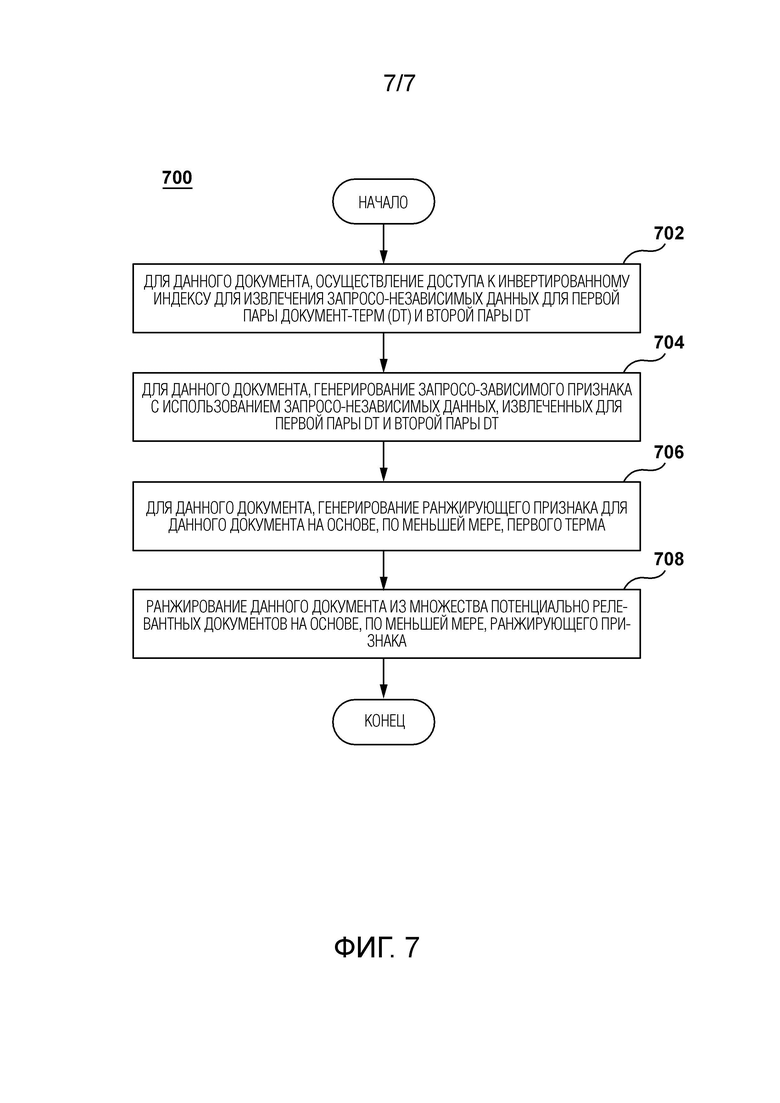
Группа изобретений относится к технологиям поисковых машин и может быть использована для ранжирования цифровых документов для запроса. Техническим результатом является повышение быстродействия. На сервере размещается поисковая машина, связанная с инвертированным индексом. Способ включает в себя осуществление доступа к инвертированному индексу для извлечения запросо-независимых данных для первой пары документ-терм и второй пары документ-терм, причем запросо-независимые данные указывают на (i) зависимое от терма вхождение первого терма в содержимое документа и (ii) зависимое от терма вхождение второго терма в содержимое документа. Способ включает в себя генерирование запросо-зависимого признака с использованием запросо-независимых данных, который указывает на групповое вхождение первого терма со вторым термом в содержимое документа. Способ включает в себя генерирование ранжирующего признака для данного документа на основе, по меньшей мере, первого терма, второго терма и запросо-зависимого признака и ранжирование данного документа на основе, по меньшей мере, ранжирующего признака. 2 н. и 18 з.п. ф-лы, 7 ил.
1. Способ ранжирования цифровых документов в ответ на запрос, причем цифровые документы являются потенциально релевантными запросу, имеющему первый терм и второй терм, причем запрос был отправлен пользователем электронного устройства, соединенного с возможностью осуществления связи с сервером, на котором размещена поисковая машина, причем поисковая машина связана с инвертированным индексом, хранящим информацию, связанную с парами документ-терм (DT), причем способ исполняется сервером, причем способ содержит этапы, на которых:
для данного документа из множества потенциально релевантных документов:
осуществляют доступ сервером к инвертированному индексу для извлечения запросо-независимых данных для первой пары DT и второй пары DT, причем первая пара DT имеет данный документ и первый терм, вторая пара DT имеет данный документ и второй терм,
причем запросо-независимые данные указывают на (i) зависимое от терма вхождение первого терма в содержимое, связанное с данным документом, и (ii) зависимое от терма вхождение второго терма в содержимое, связанное с данным документом;
генерируют сервером запросо-зависимый признак с использованием запросо-независимых данных, извлеченных для первой пары DT и второй пары DT,
при этом запросо-зависимый признак указывает на групповое вхождение первого терма со вторым термом в содержимое, связанное с данным документом;
генерируют сервером ранжирующий признак для данного документа на основе, по меньшей мере, первого терма, второго терма и запросо-зависимого признака; и
ранжируют сервером данный документ из множества потенциально релевантных документов на основе, по меньшей мере, ранжирующего признака.
2. Способ по п. 1, в котором генерирование ранжирующего признака для данного документа выполняется нейронной сетью (NN).
3. Способ по п. 2, в котором способ дополнительно содержит этап, на котором обучают сервером NN для генерирования ранжирующего признака, причем обучение NN содержит этап, на котором:
генерируют сервером обучающий набор для обучающей пары документ-запрос (DQ), которая должна использоваться во время данной итерации обучения NN, причем обучающая пара DQ имеет обучающий запрос и обучающий документ, причем обучающий документ связан с меткой, причем метка указывает на релевантность обучающего документа обучающему запросу, причем генерирование содержит этапы, на которых:
генерируют сервером множество вложений обучающих термов на основе соответствующих термов из обучающего запроса;
осуществляют доступ сервером к инвертированному индексу, связанному с поисковой машиной, для извлечения множества запросо-независимых наборов данных, связанных с соответствующими парами из множества обучающих пар DT,
причем заданная одна из множества обучающих пар DT включает в себя обучающий документ и соответствующий один из множества термов из обучающего запроса;
генерируют сервером множество векторов обучающих признаков для множества обучающих пар DT с использованием множества запросо-независимых наборов данных;
во время данной итерации обучения NN:
вводят сервером в NN упомянутое множество вложений обучающих термов и упомянутое множество векторов обучающих признаков для генерирования предсказанного ранжирующего признака для обучающей пары DQ; и
настраивают сервером NN на основе сравнения между меткой и предсказанным ранжирующим признаком, так что NN генерирует для данной используемой пары DQ соответствующий предсказанный ранжирующий признак, который указывает на релевантность соответствующего используемого документа соответствующему используемому запросу.
4. Способ по п. 1, в котором запросо-независимые данные были сохранены в инвертированном индексе до получения запроса от электронного устройства и в котором запросо-зависимый признак генерируется после получения запроса от электронного устройства.
5. Способ по п. 1, в котором запросо-зависимый признак генерируется с использованием запросо-независимых данных в реальном времени во время процедуры ранжирования документов поисковой машины.
6. Способ по п. 1, в котором ранжирование выполняется с помощью алгоритма машинного обучения (MLA) на основе дерева решений, сконфигурированного для ранжирования множества потенциально релевантных документов на основе их релевантности запросу.
7. Способ по п. 1, при этом способ дополнительно содержит, для данного одного из множества термов, определение подобного терма, и при этом:
при осуществлении доступа к инвертированному индексу для извлечения запросо-независимых данных, извлеченные запросо-независимые данные содержат запросо-независимые данные для третьей пары DT, причем третья пара DT имеет данный документ и упомянутый подобный терм.
8. Способ по п. 1, в котором доступ к инвертированному индексу предназначен для дополнительного извлечения запросо-независимых данных на основе содержимого, связанного с первой парой DT и второй парой DT,
запросо-независимые данные на основе содержимого указывают на текстовый контекст соответствующего терма в содержимом, связанном с данным документом.
9. Способ по п. 1, в котором зависимое от терма вхождение первого терма содержит по меньшей мере одно из:
одной или более позиций первого терма в заголовке, связанном с данным документом;
одной или более позиций первого терма в URL, связанном с данным документом; и
одной или более позиций первого терма в теле данного документа.
10. Способ по п. 1, в котором групповое вхождение первого терма со вторым термом в содержимое, связанное с данным документом, содержит по меньшей мере одно из:
количества раз, когда второй терм из запроса включен в дополнение к первому терму в заголовок, связанный с данным документом;
количества раз, когда второй терм из запроса включен в дополнение к первому терму в URL, связанный с данным документом; и
количества раз, когда второй терм из запроса включен в дополнение к первому терму в тело данного документа.
11. Сервер для ранжирования цифровых документов в ответ на запрос, причем цифровые документы являются потенциально релевантными запросу, имеющему первый терм и второй терм, причем запрос был отправлен пользователем электронного устройства, соединенного с возможностью осуществления связи с сервером, на котором размещена поисковая машина, причем поисковая машина связана с инвертированным индексом, хранящим информацию, связанную с парами документ-терм (DT), причем сервер сконфигурирован с возможностью:
для данного документа из множества потенциально релевантных документов:
осуществлять доступ к инвертированному индексу для извлечения запросо-независимых данных для первой пары DT и второй пары DT, причем первая пара DT имеет данный документ и первый терм, вторая пара DT имеет данный документ и второй терм,
причем запросо-независимые данные указывают на (i) зависимое от терма вхождение первого терма в содержимое, связанное с данным документом, и (ii) зависимое от терма вхождение второго терма в содержимое, связанное с данным документом;
генерировать запросо-зависимый признак с использованием запросо-независимых данных, извлеченных для первой пары DT и второй пары DT,
при этом запросо-зависимый признак указывает на групповое вхождение первого терма со вторым термом в содержимое, связанное с данным документом;
генерировать ранжирующий признак для данного документа на основе, по меньшей мере, первого терма, второго терма и запросо-зависимого признака; и
ранжировать данный документ из множества потенциально релевантных документов на основе, по меньшей мере, ранжирующего признака.
12. Сервер по п. 11, при этом сервер использует нейронную сеть для генерирования ранжирующего признака для данного документа.
13. Сервер по п. 12, при этом сервер дополнительно сконфигурирован для обучения NN генерированию ранжирующего признака, причем сервер сконфигурирован с возможностью:
генерировать обучающий набор для обучающей пары документ-запрос (DQ), которая должна использоваться во время данной итерации обучения NN, причем обучающая пара DQ имеет обучающий запрос и обучающий документ, причем обучающий документ связан с меткой, причем метка указывает на релевантность обучающего документа обучающему запросу, причем для генерирования обучающего набора сервер сконфигурирован с возможностью:
генерировать множество вложений обучающих термов на основе соответствующих термов из обучающего запроса;
осуществлять доступ к инвертированному индексу, связанному с поисковой машиной, для извлечения множества запросо-независимых наборов данных, связанных с соответствующими парами из множества обучающих пар DT,
причем заданная одна из множества обучающих пар DT включает в себя обучающий документ и соответствующий один из множества термов из обучающего запроса;
генерировать множество векторов обучающих признаков для множества обучающих пар DT с использованием множества запросо-независимых наборов данных;
во время данной итерации обучения NN:
вводить сервером в NN упомянутое множество вложений обучающих термов и упомянутое множество векторов обучающих признаков для генерирования предсказанного ранжирующего признака для обучающей пары DQ; и
настраивать NN на основе сравнения между меткой и предсказанным ранжирующим признаком, так что NN генерирует для данной используемой пары DQ соответствующий предсказанный ранжирующий признак, который указывает на релевантность соответствующего используемого документа соответствующему используемому запросу.
14. Сервер по п. 11, в котором запросо-независимые данные были сохранены в инвертированном индексе до получения запроса от электронного устройства и в котором запросо-зависимый признак генерируется после получения запроса от электронного устройства.
15. Сервер по п. 11, в котором запросо-зависимый признак генерируется с использованием запросо-независимых данных в реальном времени во время процедуры ранжирования документов поисковой машины.
16. Сервер по п. 11, при этом сервер сконфигурирован для ранжирования с использованием алгоритма машинного обучения (MLA) на основе дерева решений, сконфигурированного для ранжирования множества потенциально релевантных документов на основе их релевантности запросу.
17. Сервер по п. 11, в котором сервер дополнительно сконфигурирован с возможностью для данного одного из множества термов определять подобный терм, и при этом:
при осуществлении доступа к инвертированному индексу для извлечения запросо-независимых данных извлеченные запросо-независимые данные содержат запросо-независимые данные для третьей пары DT, причем третья пара DT имеет данный документ и упомянутый подобный терм.
18. Сервер по п. 11, в котором сервер сконфигурирован для осуществления доступа к инвертированному индексу для дополнительного извлечения запросо-независимых данных на основе содержимого, связанного с первой парой DT и второй парой DT,
причем запросо-независимые данные на основе содержимого указывают на текстовый контекст соответствующего терма в содержимом, связанном с данным документом.
19. Сервер по п. 11, в котором зависимое от терма вхождение первого терма включает в себя по меньшей мере одно из:
одной или более позиций первого терма в заголовке, связанном с данным документом;
одной или более позиций первого терма в URL, связанном с данным документом; и
одной или более позиций первого терма в теле данного документа.
20. Сервер по п. 11, в котором групповое вхождение первого терма со вторым термом в содержимое, связанное с данным документом, содержит по меньшей мере одно из:
количества раз, когда второй терм из запроса включен в дополнение к первому терму в заголовок, связанный с данным документом;
количества раз, когда второй терм из запроса включен в дополнение к первому терму в URL, связанный с данным документом; и
количества раз, когда второй терм из запроса включен в дополнение к первому терму в тело данного документа.
| US 10417687 B1, 17.09.2019 | |||
| ИСПОЛНЯЕМЫЙ НА КОМПЬЮТЕРЕ СПОСОБ И СИСТЕМА ДЛЯ ПОИСКА В ИНВЕРТИРОВАННОМ ИНДЕКСЕ, ОБЛАДАЮЩЕМ МНОЖЕСТВОМ СПИСКОВ СЛОВОПОЗИЦИЙ | 2014 |
|
RU2718435C2 |
| РАНЖИРОВАНИЕ РЕЗУЛЬТАТОВ ПОИСКА С ИСПОЛЬЗОВАНИЕМ РАССТОЯНИЯ РЕДАКТИРОВАНИЯ И ИНФОРМАЦИИ О ДОКУМЕНТЕ | 2009 |
|
RU2501078C2 |
| WO 2016209975 A2, 29.12.2016 | |||
| US 20200257712 A1, 13.08.2020 | |||
| WO 2019086996 A1, 09.05.2019. | |||

