Область техники, к которой относится изобретение
[001] Настоящая технология в целом относится к поисковым системам, а в частности - к способу и устройству для ранжирования результатов поиска. Описанные здесь системы и способы определяют позиции элементов при ранжировании в системе поискового ранжирования.
Уровень техники
[002] Сеть Интернет предоставляет доступ к самым разным ресурсам, например, к видеофайлам, файлам изображений, аудиофайлам или веб-страницам, включая информационные материалы по тем или иным темам, справочные статьи и новостные статьи. Типичный пользователь имеет возможность выбирать для доступа конкретные веб-ресурсы, используя приложение браузера, запущенное на электронном устройстве, будь то настольный компьютер, портативный компьютер, планшет или смартфон. На рынке представлен целый ряд браузеров, пригодных для выполнения такой задачи: браузер Google Chrome, браузер Internet Explorer, браузер Yandex и т.п. Для получения доступа к необходимому веб-ресурсу пользователь может вводить универсальный указатель ресурса (URL-адрес) или выбирать (щелчком мыши или иным образом) гиперссылку на URL-адрес этого веб-ресурса.
[003] Пользователь может знать лишь вид информации, которую он ищет, но не знать, на каком именно веб-ресурсе она размещена. В этом случае пользователь может воспользоваться так называемой поисковой системой, чтобы найти один или несколько веб-ресурсов, предоставляющих интересующую его информацию. Для этого пользователь отправляет «поисковый запрос», а поисковая система выдает ранжированный список результатов поиска, отвечающих поисковому запросу, в виде страницы результатов поиска (SERP, Search Engine Results Page). В ответ на поисковый запрос пользователю поисковой системы может выдаваться самый разнообразный контент. Например, поисковая система может выдавать пользователю оригинальный контент (созданный авторами контента в рамках рекомендательной системы), веб-контент, видеоконтент, графический контент, новостной контент, аудиоконтент и т.п.
[004] На фиг. 6 представлен снимок 9100 экрана типичной страницы результатов поиска, выдаваемой поисковой системой согласно существующему уровню техники, в данном случае - поисковой системой компании ООО «Яндекс», зарегистрированной по адресу: 119021, Россия, г. Москва, ул. Льва Толстого, д. 16. В качестве примера обращение к поисковой системе, для которой был создан снимок 9100 экрана, производится с настольного компьютера.
[005] В представленном случае пользователь ввел через интерфейс 9102 поискового запроса поисковой системы поисковый запрос «Ecuador» («Эквадор»), предположительно, в поисках информации об Эквадоре. Очевидно, что поисковый запрос «Ecuador» не носит однозначного характера, так как пользователя, вводящего такой запрос, может интересовать информация о стране Эквадор, о песне «Эквадор» группы «Sash!», новости об Эквадоре или фотографии пейзажей Эквадора.
[006] Поисковый запрос, введенный через интерфейс поискового запроса, передается на сервер поисковой системы (не показан), а сервер поисковой системы выполняет поиск и выдает данные для формирования страницы 9104 результатов поиска. Страница 9104 результатов поиска обеспечивает выдачу пользователю одного или нескольких результатов поиска. Результаты поиска, а также их представление варьируются, но в общем случае и исключительно в качестве примера они включают в себя первый результат 9106 поиска, второй 9108 результат поиска, третий 9110 результат поиска и множество дополнительных результатов 9112 поиска. Одну часть этих результатов поиска можно назвать «результатами веб-поиска», а другую - «результатами вертикального поиска». Результаты веб-поиска (например, первый результат 9106 поиска и третий 9110 результат поиска) являются результатами поиска, которые выдаются модулем веб-поиска поисковой системы, и обычно представляют собой ссылки на веб-ресурсы, имеющиеся в сети Интернет (в данном случае это статья об Эквадоре в Википедии на русском языке и статья «Lonely Planet» об Эквадоре, соответственно). Результаты вертикального поиска (например, второй результат 9108 поиска) являются результатами поиска, которые выдаются одним или несколькими модулями вертикального поиска поисковой системы (в данном случае второй результат 9108 поиска представляет собой «виджет» с результатами вертикального поиска видеоматериалов, то есть один или несколько видеоматериалов, отвечающих поисковому запросу «Ecuador»).
[007] Результаты вертикального поиска относятся к определенной категории, области или тематике в рамках более комплексной поисковой системы. В отличие от результатов, отображаемых в общих списках веб-страниц, результаты вертикального поиска относятся к конкретному виду контента или данных. К типичным вертикалям поиска относятся изображения, видео, новостные статьи, местные объявления о продаже, продаваемые товары и т.д. Например, при поиске «лучших смартфонов» поисковая система может выдавать раздел с результатами вертикального поиска, в котором отдельно отображаются объявления о продаже, цены и отзывы для смартфонов.
[008] Виджеты представляют собой небольшие интерактивные или информационные элементы, появляющиеся на странице результатов поисковой системы. Они призваны предоставлять дополнительные возможности или дополнительную информацию, относящуюся к поисковому запросу. Виджеты могут принимать разные формы, такие как блоки знаний (содержащие структурированную информацию об интересующем объекте), расширенные сниппеты (содержащие краткие ответы или описания, наглядно отображаемые в верхней части страницы результатов поиска), эскизы видеоматериалов (содержащие изображения видеоматериалов для предварительного просмотра с их названием, продолжительностью и источником), эскизы изображений (обеспечивающие предварительный просмотр изображений перед переходом по соответствующей ссылке), блок локальной выдачи (содержащий карту и список местных предприятий или мест, связанных с поисковым запросом с учетом местоположения), торговые виджеты (содержащие объявления о продаже, цены и варианты поставки товаров интернет-торговли) и т.д. Виджеты повышают удобство работы пользователей, предоставляя быстрый доступ к нужной информации или к мультимедийному контенту непосредственно на странице результатов поиска, что сокращает необходимость переходов на отдельные веб-страницы.
[009] Страница 9104 результатов поиска также может содержать панель 9120 выбора тематического раздела, которая предоставляет пользователю возможность выбрать (или изменить) раздел поиска. В представленном примере пользователь может перейти с текущего гипертекстового представления результатов поиска на странице 9104 результатов поиска в один из тематических разделов, в частности, в раздел «карты», «картинки», «новости», «видео» и т.п. Тематические разделы позволяют пользователям переключать вид результатов поиска, а количество и виды тематических разделов варьируются в зависимости от типа поисковой системы. Например, если пользователь интересуется изображениями Эквадора, он может перейти в раздел «картинки», что приведет к изменению страницы 9104 результатов поиска и выдаче пользователю результатов поиска из раздела «картинки», а результатом поиска будут изображения, отвечающие поисковому запросу «Ecuador».
[010] Очевидно, что результаты поиска, показанные в составе множества дополнительных результатов 9112 поиска, не охватывают всей совокупности остальных результатов поиска, выдаваемых поисковой системой в ответ на поисковый запрос. Напротив, множество дополнительных результатов 9112 поиска включает в себя большое количество других результатов поиска, которые не видны на снимке 9100 экрана из-за ограниченной площади дисплея электронного устройства. Кроме того, поисковые системы, как правило, разделяют результаты поиска на несколько экранов, а для перехода к следующей части страницы 9104 результатов поиска предусмотрен элемент 9116 прокрутки. Элемент 9116 прокрутки может представлять собой стрелку, указатель номера экрана на странице 9104 результатов поиска и т.п.
[011] Одной из технических задач, стоящих перед сервером поисковой системы, является отбор и ранжирование результатов поиска для формирования страницы 9104 результатов поиска таким образом, чтобы минимизировать затраты времени пользователя. Это выражается в том, что поисковые системы стремятся размещать наиболее релевантные результаты поиска (то есть результаты поиска, которые с большей вероятностью удовлетворяют поисковому намерению пользователя) в начале страницы 9104 результатов поиска. Иными словами, результаты поиска, представленные на верхних позициях страницы 9104 результатов поиска (то есть первые n результатов поиска, отображаемых на первом экране страницы 9104 результатов поиска), должны соответствовать поисковому намерению пользователя. Если пользователю придется «прокручивать» результаты поиска до второго, третьего и т.д. экранов страницы 9104 результатов поиска, «качество» результатов на странице 9104 результатов поиска может быть расценено как несоответствующее ожиданиям.
[012] Поисковые системы используют различные методы и алгоритмы для ранжирования результатов поиска. Как правило, для ранжирования результатов поиска на странице 9104 результатов поиска применяется алгоритм машинного обучения. Существует целый ряд методов ранжирования результатов поиска. Например, в некоторых из известных методов ранжирования результатов поиска по релевантности такое ранжирование осуществляется исходя из (1) степени популярности данного поискового запроса или ответа на него в предыдущих операциях вертикального поиска или веб-поиска, (2) количества результатов, выданных модулями вертикального поиска или веб-поиска, (3) наличия в поисковом запросе каких-либо определяющих слов (таких как «картинки», «фильмы», «погода» и т.п.), (4) частоты использования данного поискового запроса другими пользователями вместе с определяющими словами и/или (5) частоты выбора другими пользователями, выполнявшими аналогичный поиск, того или иного ресурса или тех или иных результатов вертикального поиска после выдачи результатов на странице 9104 результатов поиска.
[013] Некоторые поисковые системы могут выдавать различные виды контента с (1) неконтролируемым соотношением видов контента или (2) заданным соотношением видов контента. При этом, чтобы обеспечивать более релевантные результаты поиска, поисковые системы вынуждены смешивать различные виды контента. Иными словами, поисковым системам приходится ранжировать различные виды контента (результаты веб-поиска, результаты вертикального поиска, виджеты и т.д.), что является трудной задачей. Например, в ответ на поисковый запрос «Rihanna» («Рианна») система смешивает результаты поиска различного вида: видеоматериалы, изображения, документы (например, страницы Википедии), музыкальные записи и т.д.
[014] Из-за разнородности результатов поиска поисковой системе приходится решать, насколько подходят пользователю результаты поиска каждого вида. Для этого может применяться так называемый алгоритм смешивания (алгоритм-блендер), который представляет собой алгоритм машинного обучения. Алгоритму-блендеру требуется определять ранг конкретного элемента результатов поиска, исходя из его содержимого и вида. На вход алгоритма-блендера поступают данные о поисковом запросе, пользователе и веб-документе.
[015] Одной из метрик, максимальное значение которой достигается в процессе обучения алгоритма-блендера, является «прирост». Для каждого результата поиска прирост, как правило, характеризует ситуацию победителя (выигрыш) или проигравшего (проигрыш), при этом выигрыш указывает на то, что результат поиска является «полезным» (признаком полезности конкретного веб-элемента может служить его выбор пользователем или время пребывания в нем). Проигрыш, в свою очередь, связан с взаимодействием пользователя с некоторым веб-элементом, расположенным ниже этого конкретного веб-элемента на странице результатов поиска. Такая логика выигрыша и проигрыша позволяет оценивать вероятность выбора веб-элемента пользователем.
[016] Ранжируя различные виды контента, алгоритм-блендер рассчитывает показатель полезности. По показателю полезности определяется, каким является выбранный элемент - победившим или проигравшим. Победивший элемент может быть отображен в результатах поиска, а проигравший элемент может быть понижен при ранжировании или исключен из результатов поиска на странице результатов поиска. Такой показатель (принимающий значения от 0 до 1) характеризует то, является ли выбранный документ полезным или следует показать другой элемент в сочетании с другими элементами результатов поиска.
[017] Одной из задач при оценке полезности является определение позиционного смещения, связанного с зависимостью релевантности элемента от его позиции на странице результатов поиска. Например, элемент изображения в результатах поиска по запросу «Rihanna», находящийся на позиции ниже 50 и не попадающий на первые экраны страницы результатов поиска, как правило, оказывается бесполезным для пользователя. Скорее всего, пользователь не увидит и не выберет его. Иными словами, полезность снижается в зависимости от положения элемента в результатах поиска.
[018] В патентной публикации US10642905B2 раскрыты способ и система для ранжирования результатов, выдаваемых поисковой системой. Он посвящен способам расчета «параметра интереса» для результатов поиска, который характеризует вероятность выполнения или невыполнения пользователем перехода по ссылке для заданного результата поиска. В этом источнике раскрыта процедура предварительной оценки ранжирования, основанная на применении нескольких алгоритмов машинного обучения для определения элемента выигрыша, элемента проигрыша и параметра полезности на основе разницы между элементами выигрыша и проигрыша. В этом документе раскрыт алгоритм определения (предсказания) каждого из элементов (элемента выигрыша и элемента проигрыша), которые затем используются в функции формирования параметра полезности. Функция полезности позволяет рассчитывать значения параметра полезности на основе значений элементов выигрыша и проигрыша.
[019] В соответствующих алгоритмах патента US10642905 используется метрика выигрыша и проигрыша одного класса. Для ранжирования результатов поиска определяется разница между проигрышем и выигрышем, связанная с выбранным элементом поиска.
[020] В некоторых алгоритмах ранжирования элемент поиска, чей показатель полезности равен нулю, вообще не отображается - он признается «полностью проигравшим» и не включается в результаты поиска в связи с тем, что вероятность выбора пользователем такого элемента полагается незначительной. Остальные элементы ранжируются среди прочих на основе показателя полезности, принимающего значения больше нуля, в диапазоне от 0 до 1. Иными словами, если функция выигрыша-проигрыша, используемая в известных технических решениях, выдает нулевую или отрицательную метрику, результат поиска не ранжируется, вследствие чего результаты поиска могут оказываться абсолютно нерелевантными, хотя при использовании более сложного алгоритма дело может обстоять иначе.
Раскрытие изобретения
[021] Целью настоящего изобретения является устранение по меньшей мере части недостатков известных технических решений. Иными словами, существует потребность в создании алгоритма-блендера для систем и способов ранжирования результатов поиска, способного ранжировать полностью проигрывавшие ранее результаты поиска, чтобы повысить эффективность работы оцениваемой поисковой системы. Кроме того, желательно, чтобы алгоритм в таких системах и способах был способен эффективно обрабатывать больший объем данных и признаков.
[022] В соответствии с первым аспектом реализован способ формирования страницы результатов поиска. Страница результатов поиска подлежит передаче на электронное устройство, связанное с пользователем поисковой системы, размещенной на сервере, соединенном с электронным устройством. Способ выполняется сервером и предусматривает получение от электронного устройства данных о запросе, указывающих на отправленный пользователем запрос, определение на основе данных о запросе набора элементов веб-контента, включающего в себя соответствующие запросу результаты поиска и содержащего заданный элемент веб-контента, формирование контекстных данных на основе набора элементов веб-контента и данных о запросе, а также передачу контекстных данных в модель, представляющую собой мультиклассификационную модель для множества классов, содержащего два класса, назначенные заданной позиции ранжирования на странице результатов поиска. Этими двумя классами являются выигрышный класс, указывающий на прогнозируемую выгоду от размещения заданного элемента веб-контента на заданной позиции ранжирования на странице результатов поиска, и проигрышный класс, указывающий на прогнозируемый ущерб от размещения заданного элемента веб-контента на заданной позиции ранжирования на странице результатов поиска. Способ предусматривает определение значения метрики для заданной пары «элемент веб-контента - позиция», которая включает в себя заданный элемент веб-контента и заданную позицию ранжирования. Значение метрики представляет собой разность между прогнозируемой величиной выгоды выигрышного класса в модели для заданного элемента веб-контента и прогнозируемой величиной ущерба для проигрышного класса в модели в отношении заданного элемента веб-контента. Значение метрики характеризует общую полезность размещения заданного элемента веб-контента на заданной позиции ранжирования. Способ предусматривает формирование страницы результатов поиска с заданным элементом веб-контента, размещенным на заданной позиции ранжирования, на основе значения метрики.
[023] В некоторых вариантах осуществления модель обеспечивает выдачу вероятностей принадлежности к выигрышному классу и к проигрышному классу для каждой позиции ранжирования из набора позиций ранжирования, а также определение значения метрики для каждой позиции ранжирования из набора позиций ранжирования, при этом заданная позиция ранжирования на странице результатов поиска для заданного элемента веб-контента выбирается на основе максимальной разности.
[024] В некоторых вариантах осуществления заданным элементом веб-контента является виджет для размещения среди веб-документов, включенных в соответствующие запросу результаты поиска.
[025] В некоторых вариантах осуществления контекстные данные содержат ранжированные веб-документы из поисковой системы.
[026] В некоторых вариантах осуществления выигрышный класс соответствует вероятности взаимодействия пользователя с заданным элементом веб-контента на заданной позиции ранжирования.
[027] В некоторых вариантах осуществления проигрышный класс соответствует вероятности взаимодействия пользователя с другим элементом веб-контента, находящимся на позиции ниже заданной позиции ранжирования.
[028] В соответствии с другим аспектом реализован способ обучения модели для ранжирования объектов на странице результатов поиска. Страница результатов поиска подлежит передаче на электронное устройство, связанное с пользователем поисковой системы, размещенной на сервере. Сервер соединен с электронным устройством. Способ выполняется сервером и предусматривает получение данных о запросе, связанных с обучающим запросом, представляющим собой запрос, ранее отправленный в поисковую систему, для которого обучающий элемент веб-контента был выдан в качестве результата поиска на заданной позиции ранжирования, получение контекстных данных, связанных с обучающим элементом веб-контента и содержащих данные о запросе, получение данных о взаимодействии пользователя с обучающим элементом веб-контента, которые характеризуют (а) выгоду от размещения обучающего элемента веб-контента на заданной позиции ранжирования в ответ на обучающий запрос и (б) ущерб от размещения обучающего элемента веб-контента на заданной позиции ранжирования в ответ на обучающий запрос, и формирование двух обучающих наборов для пары «обучающий запрос - элемент веб-контента», содержащей обучающий запрос и обучающий элемент веб-контента. Два обучающих набора содержат положительный обучающий набор, содержащий входные данные, в состав которых входят контекстные данные, и первую метку, указывающую на фактическую выгоду от размещения обучающего элемента веб-контента на заданной позиции ранжирования в ответ на запрос. Два обучающих набора также включают в себя отрицательный обучающий набор, содержащий входные данные и вторую метку, указывающую на фактический ущерб от размещения обучающего элемента веб-контента на заданной позиции ранжирования в ответ на запрос. Способ предусматривает обучение модели с использованием положительного и отрицательного обучающих наборов. Модель представляет собой мультиклассификационную модель для множества классов. Множество классов содержит два класса, назначенных заданной позиции ранжирования, а именно - выигрышный класс, указывающий на прогнозируемую выгоду от размещения обучающего элемента веб-контента на заданной позиции ранжирования, и проигрышный класс, указывающий на прогнозируемый ущерб от размещения обучающего элемента веб-контента на заданной позиции ранжирования.
[029] В некоторых вариантах осуществления модель обеспечивает выдачу вероятностей принадлежности к выигрышному классу и к проигрышному классу для каждой позиции ранжирования из набора позиций ранжирования.
[030] В некоторых вариантах осуществления обучающим элементом веб-контента является виджет для размещения среди веб-документов, включенных в соответствующие запросу результаты поиска.
[031] В некоторых вариантах осуществления выигрышный класс соответствует вероятности взаимодействия пользователя с обучающим элементом веб-контента на заданной позиции ранжирования.
[032] В некоторых вариантах осуществления проигрышный класс соответствует вероятности взаимодействия пользователя с другим элементом веб-контента, находящимся на позиции ниже заданной позиции ранжирования.
[033] В некоторых вариантах осуществления модель обеспечивает выдачу вероятностей принадлежности к выигрышному классу и к проигрышному классу для каждой позиции ранжирования из набора позиций ранжирования, а обучение предусматривает настройку модели для минимизации разности между выдаваемыми вероятностями и вероятностями, указанными в положительном и отрицательном обучающих наборах.
[034] В некоторых вариантах осуществления обучение предусматривает сбор случайных данных, при котором заданная позиция ранжирования выбирается случайным образом.
[035] В некоторых вариантах осуществления положительный обучающий набор является примером взаимодействия пользователя с обучающим элементом веб-контента на заданной позиции ранжирования в заданном контексте, а отрицательный обучающий набор - примером взаимодействия пользователя с обучающим элементом веб-контента на позиции ранжирования ниже заданной позиции, при этом обучение обеспечивает настройку модели для расчета вероятностей принадлежности к выигрышному классу и к проигрышному классу.
[036] В соответствии с еще одним аспектом реализована система для формирования страницы результатов поиска. Система содержит сервер, способный передавать страницу результатов поиска на электронное устройство, связанное с пользователем поисковой системы, размещенной на сервере. Сервер соединен с электронным устройством и способен получать от электронного устройства данные о запросе, указывающие на отправленный пользователем запрос, определять набор элементов веб-контента, включающий в себя соответствующие запросу результаты поиска и содержащий заданный элемент веб-контента, на основе данных о запросе, формировать контекстные данные на основе набора элементов веб-контента и данных о запросе, а также передавать контекстные данные в модель, представляющую собой мультиклассификационную модель для множества классов. Множество классов содержит два класса, назначенных заданной позиции ранжирования на странице результатов поиска. Этими двумя классами являются выигрышный класс, указывающий на прогнозируемую выгоду от размещения заданного элемента веб-контента на заданной позиции ранжирования на странице результатов поиска, и проигрышный класс, указывающий на прогнозируемый ущерб от размещения заданного элемента веб-контента на заданной позиции ранжирования на странице результатов поиска. Сервер способен определять значение метрики для заданной пары «элемент веб-контента - позиция», содержащей заданный элемент веб-контента и заданную позицию ранжирования. Значение метрики представляет собой разность между прогнозируемой величиной выгоды выигрышного класса в модели для заданного элемента веб-контента и прогнозируемой величиной ущерба для проигрышного класса в модели в отношении заданного элемента веб-контента. Значение метрики характеризует общую полезность размещения заданного элемента веб-контента на заданной позиции ранжирования. Сервер способен формировать страницу результатов поиска с заданным элементом веб-контента, размещенным на заданной позиции ранжирования, на основе значения метрики.
[037] В некоторых вариантах осуществления модель обеспечивает выдачу вероятностей принадлежности к выигрышному классу и к проигрышному классу для каждой позиции ранжирования из набора позиций ранжирования, а также определение значения метрики для каждой позиции ранжирования из набора позиций ранжирования, при этом заданная позиция ранжирования на странице результатов поиска для заданного элемента веб-контента выбрана на основе максимальной разности.
[038] В некоторых вариантах осуществления заданным элементом веб-контента является виджет для размещения среди веб-документов, включенных в соответствующие запросу результаты поиска.
[039] В некоторых вариантах осуществления контекстные данные содержат ранжированные веб-документы из поисковой системы.
[040] В некоторых вариантах осуществления выигрышный класс соответствует вероятности взаимодействия пользователя с заданным элементом веб-контента на заданной позиции ранжирования.
[041] В некоторых вариантах осуществления проигрышный класс соответствует вероятности взаимодействия пользователя с другим элементом веб-контента, находящимся на позиции ниже заданной позиции ранжирования.
[042] В контексте настоящего описания «сервер» представляет собой компьютерную программу, выполняемую на соответствующих аппаратных средствах и способную принимать по сети запросы (например, от клиентских устройств), а также выполнять эти запросы или инициировать их выполнение. Такие аппаратные средства могут быть реализованы в виде одного физического компьютера или одной физической компьютерной системы, что не имеет существенного значения для настоящей технологии. В данном контексте при употреблении выражения «сервер» не подразумевается, что получение, выполнение или инициирование выполнения какой-либо конкретной задачи или всех задач (например, команд или запросов, вызова архивных сеансов поиска) осуществляются на одном и том же сервере (т.е. одними и теми же программными и/или аппаратными средствами), а имеется в виду, что участвовать в получении, передаче, выполнении или инициировании выполнения каких-либо задач или запросов либо в обработке результатов каких-либо задач или запросов может любое количество программных или аппаратных средств, и что все эти программные и аппаратные средства могут представлять собой один сервер или несколько серверов, при этом выражение «сервер» охватывает оба этих случая.
[043] В контексте настоящего описания «клиентское устройство» представляет собой любые компьютерные аппаратные средства, способные обеспечивать работу программного обеспечения, подходящего для выполнения поставленной задачи. Таким образом, примерами (не имеющими ограничительного характера) клиентских устройств являются персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.п.), смартфоны и планшеты, а также сетевое оборудование, например, маршрутизаторы, коммутаторы и шлюзы. При этом следует отметить, что устройство, выступающее в данном контексте в качестве клиентского, не лишается возможности выступать в качестве сервера для других клиентских устройств. Употребление выражения «клиентское устройство» не исключает использования нескольких клиентских устройств для приема, передачи, выполнения или инициирования выполнения каких-либо задач или запросов, результатов каких-либо задач или запросов либо шагов какого-либо описанного здесь способа.
[044] В контексте настоящего описания термин «база данных» означает любой структурированный набор данных, независимо от его конкретной структуры, программного обеспечения для управления базой данных и компьютерных аппаратных средств для хранения данных, их применения или обеспечения их использования иным способом. База данных может размещаться в тех же аппаратных средствах, в которых реализован процесс, обеспечивающий хранение или использование информации, хранящейся в базе данных, либо в отдельных аппаратных средствах, таких как специализированный сервер или группа серверов.
[045] В контексте настоящего описания выражение «информация» включает в себя информацию любого рода или вида, допускающую хранение в базе данных. Таким образом, информация включает в себя, среди прочего, аудиовизуальные произведения (изображения, фильмы, звукозаписи, презентации и т.д.), данные (данные о местоположении, числовые данные и т.д.), текст (отзывы, комментарии, вопросы, сообщения и т.д.), документы, электронные таблицы и т.д.
[046] В контексте настоящего описания выражение «компонент» означает программное обеспечение (в контексте конкретных аппаратных средств), необходимое и достаточное для выполнения конкретных упоминаемых функций.
[047] В контексте настоящего описания выражение «компьютерный носитель информации» предназначено для обозначения носителей любого рода и вида, включая ОЗУ, ПЗУ, диски (CD-ROM, DVD, дискеты, жесткие диски и т.п.), USB-накопители, твердотельные накопители, ленточные накопители и т.д.
[048] В контексте настоящего описания числительные «первый», «второй», «третий» и т.д. служат лишь для указания на различие между существительными, к которым они относятся, а не для описания каких-либо определенных взаимосвязей между этими существительными. Таким образом, следует понимать, что, например, термины «первый сервер» и «третий сервер» не предполагают существования каких-либо определенных порядка, типов, хронологии, иерархии или ранжирования серверов, а употребление этих терминов (само по себе) не подразумевает обязательного наличия какого-либо «второго сервера» в той или иной ситуации. Кроме того, как встречается в настоящем описании в другом контексте, ссылки на «первый» элемент и «второй» элемент не исключают того, что эти два элемента в действительности могут быть одним и тем же элементом. Так, например, в одних случаях «первый» и «второй» серверы могут представлять собой одни и те же программные и/или аппаратные средства, а в других случаях - разные программные и/или аппаратные средства.
[049] Каждый вариант осуществления настоящей технологии относится по к меньшей мере одной из вышеупомянутых целей и/или к одному из вышеупомянутых аспектов, но не обязательно ко всем ним. Следует понимать, что некоторые аспекты настоящей технологии, связанные с попыткой достижения вышеупомянутой цели, могут не соответствовать этой цели и/или могут соответствовать другим целям, не упомянутым здесь явным образом.
[050] Дополнительные и/или альтернативные признаки, аспекты и преимущества вариантов осуществления настоящей технологии содержатся в дальнейшем описании, на приложенных чертежах и в формуле изобретения.
Краткое описание чертежей
[051] Для более полного понимания настоящего изобретения, а также его аспектов и дополнительных признаков следует обратиться к последующему описанию, которое должно использоваться в сочетании с приложенными чертежами.
[052] На фиг. 1 схематически представлена система, реализованная в соответствии с не имеющими ограничительного характера вариантами осуществления настоящей технологии.
[053] На фиг. 2 схематически представлена работа алгоритма машинного обучения для поисковой системы при ранжировании результатов поиска в соответствии с различными вариантами осуществления настоящей технологии.
[054] На фиг. 3 схематически представлено обучение алгоритма машинного обучения, работа которого показана на фиг. 2, в соответствии с различными вариантами осуществления настоящей технологии.
[055] На фиг. 4 представлена блок-схема способа ранжирования результатов поиска, реализованного в системе, показанной на фиг. 1, в соответствии с не имеющими ограничительного характера вариантами осуществления настоящей технологии.
[056] На фиг. 5 представлена блок-схема способа обучения алгоритма машинного обучения, работа которого показана на фиг. 2, реализованного в системе, показанной на фиг. 1, в соответствии с не имеющими ограничительного характера вариантами осуществления настоящей технологии.
[057] На фиг. 6 представлен снимок экрана типичной страницы результатов поиска, выдаваемой поисковой системой согласно существующему уровню техники.
Осуществление изобретения
[058] На фиг. 1 схематически представлена система 100, пригодная для реализации не имеющих ограничительного характера вариантов осуществления настоящей технологии. Следует понимать, что изображенная система 100 является лишь иллюстративным вариантом реализации настоящей технологии. Соответственно, приведенное ниже описание системы представляет собой описание примеров, иллюстрирующих настоящую технологию. Это описание не предназначено для определения объема или границ настоящей технологии. В некоторых случаях ниже приводятся предположительно полезные примеры модификаций системы 100. Они призваны способствовать пониманию и также не определяют объема или границ настоящей технологии. Представленный перечень модификаций не является исчерпывающим и специалисту в данной области техники должно быть понятно, что возможны и другие модификации. Кроме того, отсутствие конкретных примеров модификаций не означает, что модификации невозможны и/или что описание содержит единственно возможный вариант реализации того или иного элемента настоящей технологии. Специалисту в данной области техники должно быть понятно, что это может быть не так. Также следует понимать, что в некоторых случаях система 100 предусматривает простые варианты реализации настоящей технологии, и что такие варианты представлены для облегчения ее понимания. Специалисты в данной области техники должны понимать, что различные варианты осуществления настоящей технологии могут быть значительно сложнее.
[059] В общем случае, в соответствии с не имеющими ограничительного характера вариантами осуществления настоящей технологии, система 100 способна принимать поисковые запросы, осуществлять поиск (например, общий поиск или вертикальный поиск) в ответ на них, а также формировать аннотированные поисковые индексы. Таким образом, представленные здесь идеи позволяют адаптировать для реализации вариантов осуществления настоящей технологии любой вариант системы, способный обрабатывать поисковые запросы пользователей и формировать аннотированные поисковые индексы.
[060] Система 100 содержит электронное устройство 102. Электронное устройство 102, как правило, связано с пользователем (не показан) и, соответственно, в некоторых случаях может называться «клиентским устройством» или «клиентским электронным устройством». Следует отметить, что для электронного устройства 102, связанного с пользователем, не предлагается и не предусматривается какого-либо конкретного режима работы, например, необходимости входа в систему, необходимости регистрации и т.п.
[061] На реализацию электронного устройства 102 не накладывается особых ограничений и примерами реализации электронного устройства 102 могут служить персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.п.), устройства беспроводной связи (смартфоны, сотовые телефоны, планшеты и т.п.) и сетевое оборудование (например, маршрутизаторы, коммутаторы и шлюзы). Электронное устройство 102 содержит аппаратные средства, программное обеспечение и/или микропрограммное обеспечение (либо их сочетание), которые известны в данной области техники и обеспечивают выполнение поискового приложения 104. В общем случае задачей поискового приложения 104 является предоставление пользователю (не показан) возможности выполнять поиск, например, веб-поиск, с использованием поисковой системы.
[062] При этом на реализацию поискового приложения 104 не накладывается особых ограничений. Одним из примеров реализации поискового приложения 104 является поисковое приложение, доступ к которому осуществляется путем перехода пользователя на веб-сайт, связанный с поисковой системой. Например, доступ к поисковому приложению может осуществляться посредством ввода URL-адреса, связанного с поисковой системой Yandex™ (www.yandex.ru). Очевидно, что для доступа к поисковому приложению 104 может использоваться любая другая коммерческая или проприетарная поисковая система.
[063] В других не имеющих ограничительного характера вариантах осуществления настоящей технологии поисковое приложение 104 может быть реализовано в виде приложения браузера на портативном устройстве (например, на устройстве беспроводной связи). В частности (среди прочего), в тех вариантах реализации, в которых электронное устройство 102 реализовано в виде портативного устройства, например, такого как Samsung™ Galaxy™ SIII, на электронном устройстве 102 может быть запущено браузерное приложение Яндекса. Очевидно, что для реализации не имеющих ограничительного характера вариантов осуществления настоящей технологии может использоваться любое другое коммерческое или проприетарное приложение браузера.
[064] В общем случае поисковое приложение 104 имеет интерфейс 106 поискового запроса и интерфейс 108 результатов поиска. Основной задачей интерфейса 106 поискового запроса является предоставление пользователю (не показан) возможности ввести свой запрос или «строку для поиска». Основной задачей интерфейса 108 результатов поиска является выдача результатов поиска, отвечающих на поисковый запрос пользователя, введенный через интерфейс 106 поискового запроса.
[065] Сервер 116 также соединен с сетью связи. Электронное устройство 102 способно осуществлять доступ к серверу через сеть 110 связи (электронное устройство 102 служит лишь одним из примеров множества других электронных устройств, которые не показаны, но имеют доступ к серверу 116 через сеть 110 связи).
[066] Сервер 116 может быть реализован как обычный компьютерный сервер. В одном из вариантов осуществления настоящей технологии сервер 116 реализован в виде сервера Dell™ PowerEdge™, работающего под управлением операционной системы Microsoft™ Windows Server™. Очевидно, что сервер 116 может быть реализован на базе любых других подходящих видов аппаратных средств, программного обеспечения и/или микропрограммного обеспечения. В показанных не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 116 представляет собой одиночный сервер. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии функции сервера 116 могут быть распределены между несколькими серверами.
[067] Электронное устройство 102 способно обмениваться данными с сервером 116 через сеть 110 связи и канал 112 связи. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сеть 110 связи реализована как сеть Интернет. В других вариантах осуществления настоящей технологии сеть 110 связи может быть реализована иначе, например, как любая глобальная сеть связи, локальная сеть связи, частная сеть связи и т.п.
[068] При этом способ реализации канала 112 связи зависит от способа реализации электронного устройства 102 и на него не накладывается особых ограничений. Для примера можно отметить, что ( среди прочего) в тех вариантах осуществления настоящей технологии, где электронное устройство 102 реализовано в виде устройства беспроводной связи, такого как смартфон, канал 112 связи может быть реализован в виде беспроводного канала связи, такого как (среди прочего) канал сети связи 3G, канал сети связи 4G, канал WiFi® (сокр. от Wireless Fidelity), канал Bluetooth® и т.п. В тех примерах, где электронное устройство 102 реализовано в виде ноутбука, канал связи может быть как беспроводным (например, WiFi®, Bluetooth® и т.п.), так и проводным (например, на основе Ethernet-соединения).
[069] Сервер 116 связан с модулем 118 поиска или имеет доступ к нему иным способом. В соответствии с такими вариантами осуществления настоящей технологии, модуль 118 поиска выполняет общий и/или вертикальный поиск в ответ на поисковые запросы пользователя, вводимые через интерфейс 106 поискового запроса, и выдает результаты поиска для их представления пользователю с использованием интерфейса 108 результатов поиска.
[070] В этих не имеющих ограничительного характера вариантах осуществления настоящей технологии модуль 118 поиска содержит базу 130 данных или имеет доступ к ней иным способом. Специалистам в данной области техники должно быть известно, что в базе 130 данных хранится информация, связанная со множеством ресурсов, к которым возможен доступ через сеть связи (например, ресурсов, размещенных в сети Интернет).
[071] Процесс заполнения и ведения базы 130 данных обычно называется «обходом» (crawling). На реализацию базы 130 данных не накладывается особых ограничений. Следует понимать, что для хранения данных могут применяться любые подходящие аппаратные средства. В некоторых вариантах реализации база 130 данных может быть физически совмещена с модулем 118 поиска в одном элементе аппаратных средств, но это могут быть и отдельные элементы аппаратных средств, как показано на чертежах. В показанных не имеющих ограничительного характера вариантах осуществления настоящей технологии база 130 данных представляет собой единую базу данных. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии база 130 данных может быть разделена на несколько отдельных баз данных (не показаны). Такие отдельные базы данных могут являться частями одной физической базы данных или могут быть реализованы в виде отдельных физических объектов. Например, в одной базе данных из состава базы 130 данных может быть размещен инвертированный индекс, в другой базе данных - доступные ресурсы, а в еще одной базе данных - признаки истории поиска, относящиеся к конкретным поисковым запросам (то есть к архивным сеансам поиска). Очевидно, что приведенный выше пример носит лишь иллюстративный характер и существуют другие возможности для реализации вариантов осуществления настоящей технологии.
[072] В базе 130 данных также хранятся данные, характеризующие прошлые поисковые запросы, в частности, информация о том, что искали пользователи, какие результаты поиска выдавались, какие позиции занимали эти результаты поиска, какие результаты выбирались, выбирался ли заданный результат поиска, сколько времени пользователь проводил на ресурсе, соответствующем заданному прошлому результату, сколько раз пользователь изменял запрос, и т.п. В других вариантах осуществления информация, характеризующая прошлые поисковые запросы, может храниться в отдельной базе данных, не входящей в состав базы 130 данных.
[073] Очевидно, что для облегчения понимания представленного ниже описания конфигурации модуля 118 поиска и базы 130 данных были значительно упрощены. Предполагается, что при этом специалисты в данной области техники в состоянии понять особенности реализации модуля 118 поиска, его элементов и базы 130 данных.
[074] В общем случае поисковый запрос, вводимый пользователем через интерфейс 106 поискового запроса, может рассматриваться как набор из одного или нескольких ключевых слов, а ключевые слова могут быть обозначены как T1, T2, …, Tn. Таким образом, поисковый запрос может трактоваться как запрос для поискового приложения 104 на поиск в совокупности данных всех документов, чьи индексы хранятся в базе 130 данных, содержащих все без исключения ключевые слова T1, T2, …, Tn (логическая операция «и» для ключевых слов, то есть каждый документ, полученный в результате поиска, должен содержать по меньшей мере одно вхождение слова Ti для каждого i от 1 до n). В другом варианте поисковый запрос может трактоваться как запрос для поискового приложения 104 на поиск в совокупности данных всех документов, чьи индексы хранятся в базе 130 данных, содержащих по меньшей мере ключевые слова T1, T2, …, Tn, а также другие условия.
[075] В таких вариантах осуществления настоящей технологии сервер 116 способен обращаться к модулю 118 поиска (для выполнения общего веб-поиска и/или вертикального поиска, например, в ответ на отправленный поисковый запрос). В варианте осуществления, показанном на фиг. 1, сервер 116 в общем случае способен:
[076] (1) принимать от электронного устройства 102 поисковый запрос (например, поисковый запрос, введенный через интерфейс 106 поискового запроса);
[077] (2) осуществлять поиск (за счет обращения к модулю 118 поиска) для формирования списка результатов поиска, содержащего первый результат поиска и второй результат поиска, отвечающие на поисковый запрос (в некоторых вариантах осуществления настоящей технологии первый результат поиска является результатом вертикального поиска, а второй результат поиска - результатом веб-поиска);
[078] (3) проводить анализ результатов поиска и выполнять их ранжирование для формирования ранжированного списка результатов поиска (процесс формирования ранжированного списка результатов поиска более подробно описан ниже);
[079] (4) группировать результаты поиска для формирования страницы результатов поиска, выдаваемой на электронном устройстве 102 в ответ на поисковый запрос.
[080] В частности, сервер 116 соединен с первым модулем 222 поисковой системы, вторым модулем 224 поисковой системы (см. фиг. 2) и, возможно, дополнительными модулями поисковой системы (или имеет доступ к ним иным способом). Каждый из первого модуля 222 поисковой системы и второго модуля 224 поисковой системы способен выполнять соответствующий алгоритм машинного обучения. На конкретную реализацию алгоритма машинного обучения не накладывается особых ограничений и в общем случае таким алгоритмом может быть алгоритм обучения с учителем (алгоритм машинного обучения с учителем). Примерами алгоритмов обучения с учителем, среди прочего, являются искусственная нейронная сеть, обучение на основе байесовской статистики, рассуждения по прецедентам (Case-based Reasoning), регрессия на основе гауссовских процессов, программирование с экспрессией генов (Gene Expression Programming), метод группового учета аргументов (GMDH, Group Method of Data Handling), индуктивное логическое программирование, обучение на примерах, «ленивое» обучение, обучающийся автомат (Learning Automata), квантование обучающего вектора, дерево логистической модели и т.п.
[081] Здесь первый модуль 222 поисковой системы и второй модуль 224 поисковой системы представляют собой отдельные модули поисковой системы, но в поисковой системе может быть реализовано и единое решение. Первый и второй модули 222, 224 поисковой системы передают данные о результатах поиска в алгоритм смешивания, как более подробно описано ниже со ссылкой на фиг. 2. В общем случае данные о результатах поиска, передаваемые первым и вторым модулями 222, 224 поисковой системы, включают в себя различные виды контента, такие как виджеты, элементы результатов вертикального поиска и веб-документы. Различные виды контента результатов поиска, передаваемого первым и вторым модулями 222, 224 поисковой системы, обрабатываются алгоритмом 200 смешивания для ранжирования результатов поиска относительно друг друга на странице результатов поиска в интерфейсе 108 результатов поиска.
[082] В настоящем изобретении алгоритм 200 смешивания определяет ранг результатов поиска с использованием модуля машинного обучения с мультиклассификатором, который выдает для заданного элемента результатов поиска вероятность его принадлежности к выигрышному классу для каждой позиции ранжирования и вероятность его принадлежности к проигрышному классу для каждой позиции ранжирования. Ранжирование элемента результатов поиска (например, виджета) относительно других элементов результатов поиска (например, относительно веб-документа) осуществляется, исходя из разности между вероятностью принадлежности к выигрышному классу и вероятностью принадлежности к проигрышному классу для каждой позиции ранжирования. Иными словами, алгоритм смешивания рассчитывает для каждого элемента результатов поиска первого и второго модулей 222, 224 поисковой системы ранг среди элементов результатов поиска на основе двух классов (или компонентов), которые объединяются для определения показателя полезности. В качестве алгоритма 200 смешивания может использоваться алгоритм «многорукий бандит», получающий контекстные данные, в том числе данные о поисковом запросе, сформированные на основе данных, введенных пользователем через интерфейс 106 поискового запроса, пользовательских параметров, полученных из базы 130 данных, а также данных о результатах поиска и прочих параметров, таких как время выполнения поискового запроса. Алгоритм смешивания оптимизирует показатель полезности, характеризующий степень полезности элемента поиска на выбранной позиции страницы результатов поиска. Показатель полезности зависит от вероятности принадлежности к выигрышному классу и вероятности принадлежности к проигрышному классу. Подробное описание работы алгоритма 200 смешивания приведено ниже, в частности, со ссылкой на фиг. 2.
[083] На фиг. 2 схематически представлена поисковая система 250 для получения данных 214 о поисковом запросе и формирования страницы результатов поиска, содержащей ранжированный список результатов поиска. Поисковая система 250 реализована на сервере 116, как показано на фиг. 1. Сервер 116 содержит один или несколько процессоров (не показаны), исполняющих команды компьютерной программы (не показаны) для выполнения различных функций, описанных со ссылкой на фиг. 2. Сервер 116 содержит модуль 212 формирования контекста, первый модуль 222 поисковой системы, второй модуль 224 поисковой системы, алгоритм 200 смешивания, включающий в себя модель 230 M, и модуль 208 ранжирования. В контексте настоящего документа термин «модуль» относится к любым аппаратным средствам, программному обеспечению, микропрограммному обеспечению, электронному элементу управления, логической схеме обработки данных и/или процессорному устройству, по отдельности или в любом сочетании, включая, среди прочего, специализированную интегральную схему (ASIC), электронную схему, процессор (совместно используемый, выделенный или групповой) и память, хранящую одну или несколько выполняемых программ или микропрограмм, комбинационную логическую схему и/или другие подходящие элементы, обеспечивающие выполнение описанных функций.
[084] Первый модуль 222 поисковой системы формирует первые данные 226 о результатах поиска, которые могут включать в себя веб-контент первого вида, например, список веб-документов. К веб-документам относятся отдельные веб-страницы или интернет-контент, которые могут быть найдены поисковой системой в ответ на запрос пользователя, представленный в виде данных 214 о поисковом запросе, которые вводятся в первый модуль поисковой системы. Такие веб-документы могут содержать URL-адреса (универсальные указатели ресурсов) веб-сайтов. URL-адреса представляют собой веб-адреса, направляющие на определенные веб-сайты или веб-страницы. В контексте поисковых систем они зачастую представляются в виде гиперссылок в результатах поиска. Первый модуль 222 поисковой системы может дополнительно выдавать сниппеты, которые представляют собой краткие текстовые выдержки или описания, извлеченные из веб-документов. На итоговой странице 210 результатов поиска сниппеты, как правило, отображаются в результатах поиска рядом с URL-адресами, чтобы дать пользователям предварительное представление о контенте, размещенном на связанной с этим URL-адресом веб-странице. В другом варианте сниппеты могут извлекаться каким-либо модулем, помимо первого модуля 222 поисковой системы. Веб-документы могут включать в себя широкий спектр интернет-контента, в том числе статьи, сообщения в блогах, страницы товаров, обсуждения на форумах, новостные статьи и т.д. Поисковые системы индексируют и ранжируют эти веб-документы в зависимости от их релевантности запросу пользователя, а результаты поиска, как правило, содержат список URL-адресов и связанных с ними сниппетов. Первые данные 226 о результатах поиска могут выдаваться первым модулем 222 поисковой системы в виде ранжированного списка для смешивания с контентом, включенным во вторые данные 240 о результатах поиска, выданные вторым модулем 224 поисковой системы. Первый модуль 222 поисковой системы во взаимодействии с алгоритмом 200 смешивания выдает пользователю выбранные веб-документы в виде страницы результатов поиска, которая обычно содержит заголовки, сниппеты (краткие описания страниц) и URL-ссылки. Порядок выдачи результатов определяется алгоритмом ранжирования первого модуля 222 поисковой системы, а результаты включают в себя виджеты или другой контент из вторых данных 240 о результатах поиска, размещенные на странице 210 результатов поиска алгоритмом 200 смешивания.
[085] Второй модуль 224 поисковой системы формирует вторые данные 240 о результатах поиска, которые могут включать в себя веб-контент второго вида, например, виджеты. Второй модуль 224 поисковой системы находит релевантные вторые данные 240 о результатах поиска в ответ на данные о поисковом запросе 214, сформированные на основе запроса пользователя, введенного в электронное устройство 102. Алгоритм 200 смешивания осуществляет размещение виджетов на странице результатов поиска на определенной позиции ранжирования относительно контента первых данных 226 о результатах поиска для повышения удобства работы пользователей и для предоставления дополнительной информации или расширения возможностей. Как правило, виджеты служат для представления характерных особенностей или контента, которые связаны с контекстом или с поисковым запросом пользователя. Виджеты могут иметь разное назначение и могут принимать разные формы, например, описанные выше. Виджеты могут включать в себя:
- информационные виджеты. Эти виджеты предоставляют дополнительную информацию непосредственно в результатах поиска. Например, виджет погоды может отображать текущие погодные условия для места, указанного в поисковом запросе;
- интерактивные виджеты. Эти виджеты позволяют пользователям взаимодействовать с контентом или выполнять определенные действия, не покидая страницу результатов поиска. Например, виджет калькулятора дает пользователям возможность производить расчеты прямо на странице результатов поиска;
- мультимедийные виджеты. Эти виджеты отображают мультимедийный контент, например, видео, изображения или аудиофайлы, что упрощает пользователям доступ к мультимедийному контенту, связанному с их запросами, и обеспечивает предварительное ознакомление с ним;
- навигационные виджеты. Некоторые виджеты помогают пользователям быстро переходить к отдельным разделам веб-сайта или получать доступ к определенным возможностям. Например, виджет ссылок на сайт может содержать прямые ссылки на основные страницы веб-сайта;
- динамические виджеты. Эти виджеты могут обновляться в режиме реального времени при взаимодействии с пользователем или при изменении данных. Например, виджет фондового рынка может отображать котировки акций в реальном времени.
[086] Виджеты призваны дополнять страницу 210 результатов поиска полезным и релевантным контентом, сокращая необходимость в переходах пользователей к реальным веб-документам. Они ориентированы на предоставление быстрых ответов, предварительный просмотр или выполнение действий, соответствующих поисковому намерению пользователя. Алгоритм 200 смешивания способен размещать виджеты среди результатов поиска и определять их место и релевантность среди ранжированных результатов. Несмотря на то, что первые данные 226 о результатах поиска описаны здесь преимущественно как содержащие веб-документы, а вторые данные 240 о результатах поиска - преимущественно как содержащие виджеты, первые данные 226 о результатах поиска и вторые данные 240 о результатах поиска могут включать в себя разнообразные виды веб-контента, как прошедшие предварительное ранжирование, так и не прошедшие его, которые подлежат объединению на странице 210 результатов поиска с выполнением оптимального ранжирования, обеспечивающего максимальное удовлетворение потребностей пользователя и в то же время эффективного с точки зрения обработки данных.
[087] Веб-документы (и другие виды веб-контента, включая тематический веб-контент, такой как изображения, видеоматериалы и т.д.) обычно выдаются первым модулем 222 поисковой системы за счет сочетания механизмов обхода веб-контента, индексирования и представления данных. При обходе веб-контента первый модуль 222 поисковой системы применяет поисковые роботы (также называемые пауками или ботами) для навигации по сети Интернет и сбора веб-контента. Такие роботы сначала обращаются к списку начальных URL-адресов, а затем переходят по ссылкам на веб-страницы, чтобы найти новый контент. Они загружают веб-страницы и связанные с ними ресурсы, например, изображения, каскадные таблицы стилей (CSS) и файлы JavaScript. После обхода веб-контента первый модуль 222 поисковой системы выполняет индексирование. В процессе индексирования первый модуль 222 поисковой системы извлекает из веб-документов такую информацию, как текст, метаданные и ссылки. Затем извлеченные данные сохраняются в структурированном формате в индексе поисковой системы. Индекс хранится в базе 130 данных, что позволяет эффективно находить соответствующие документы в ответ на запросы пользователей. Когда пользователь вводит поисковый запрос через электронное устройство 102 для формирования данных 214 о поисковом запросе, первый модуль 222 поисковой системы обрабатывает такой запрос, чтобы определить поисковое намерение и извлечь соответствующие веб-документы из индекса. Этот процесс включает в себя ранжирование веб-документов с учетом таких параметров, как релевантность, достоверность и актуальность.
[088] Виджеты, включенные во вторые данные 240 о результатах поиска, могут выдаваться вторым модулем 224 поисковой системы для размещения алгоритмом 200 смешивания на странице 210 результатов поиска. При этом в других вариантах осуществления алгоритм 200 смешивания может самостоятельно получать и размещать виджеты на основе контекстных данных 202, как описано ниже. В каждом из вариантов реализации первый модуль 222 поисковой системы и/или второй модуль 224 поисковой системы анализируют запрос, представленный в виде данных 214 о поисковом запросе, чтобы оценить намерения и контекст пользователя. Такой анализ включает в себя определение ключевых слов, местоположения пользователя, истории поиска и прочей необходимой информации. По результатам анализа запроса первый модуль 222 поисковой системы извлекает набор релевантных веб-документов (традиционных результатов поиска) из своей индексированной базы 130 данных, как описано выше. Первый модуль 222 поисковой системы и/или второй модуль 224 поисковой системы оценивают соответствие различных виджетов заданному запросу, представленному в виде данных 214 о поисковом запросе. Эти виджеты могут исходить из разных источников, включая собственно поисковую систему, сторонних провайдеров и внешние прикладные программные интерфейсы (API). Первый модуль 222 поисковой системы и/или второй модуль 224 поисковой системы выбирают виджеты, признанные релевантными запросу пользователя. На этот выбор могут оказывать влияние различные факторы, такие как история поиска пользователя, его местоположение, устройство и контекст запроса. Одни виджеты формируются в режиме реального времени на основе поискового запроса и выбранных веб-документов. Другие формируются заранее и сохраняются для быстрого поиска. Выбранные виджеты, которые могут быть включены во вторые данные 240 о результатах поиска, смешиваются с веб-документами из первых данных 226 о результатах поиска с применением алгоритма 200 смешивания и могут быть выданы рядом со сниппетами веб-документов на странице результатов поиска. Алгоритм 200 смешивания ранжирует интегрированные виджеты относительно веб-документов, учитывая релевантность как веб-документов, так и виджетов, согласно модели M алгоритма машинного обучения, которая более подробно описана ниже, чтобы предоставлять пользователю наиболее полезные и содержательные результаты с обеспечением высокой эффективности обработки данных.
[089] Алгоритм 200 смешивания получает контекстные данные 202 (X), которые были сформированы модулем 212 формирования контекста. Контекстные данные 202 (X) включают в себя контекстную информацию, связанную с поисковым запросом или с сеансом поиска пользователя и представленную в виде данных о поисковом запросе. Они собираются и формируются модулем 212 формирования контекста. Конкретный состав контекстных данных 202 (X) варьируется и может включать в себя следующие элементы. Контекстные данные 202 (X) могут включать в себя данные профиля пользователя, содержащие информацию о пользователе, например, его историю поиска, местоположение, языковые настройки, тип устройства и демографические данные. Контекстные данные могут включать в себя данные 214 о поисковом запросе, содержащие фактический запрос, введенный пользователем, в том числе его ключевые слова и фразы, а также намерения пользователя, лежащие в основе запроса. Контекстные данные 202 (X) могут включать в себя временной контекст, который может оказывать влияние на релевантность результатов (таких как последние новости, события или информация, сохраняющая актуальность в течение определенного времени), в частности, время и дату поиска. Контекстные данные 202 (X) включают в себя веб-документы и другой веб-контент, представленные в составе контекстной информации в первых данных 226 о результатах поиска. Эти веб-документы и другой веб-контент представляют собой результаты поиска, которые извлекаются и ранжируются первым модулем 222 поисковой системы на основе запроса пользователя и контекста. Контекстные данные 202 (X) могут включать в себя виджеты и другой веб-контент, которые подлежат размещению на странице результатов поиска в соответствии с результатами ранжирования, произведенного, по меньшей мере частично, алгоритмом 200 смешивания. Контекстные данные 202 (X) могут включать в себя географический контекст, отражающий географический регион или местоположение пользователя, который может оказывать влияние на релевантность результатов (таких как местные предприятия, погодные условия или события). Контекстные данные 202 (X) могут включать в себя контекст сеанса, предоставляющий информацию о текущем сеансе поиска пользователя, включая предыдущие запросы, взаимодействия и продолжительность сеанса. Контекстные данные 202 (X) могут включать в себя контекст устройства, отражающий тип используемого для поиска электронного устройства 102 (например, настольный компьютер, мобильный телефон, планшет) и его возможности. Контекстные данные 202 (X) могут включать в себя поведенческий контекст, куда входят данные, связанные с поведением пользователя, такие как отношения числа переходов к числу показов (CTR, Click-Through Rate), время пребывания на страницах и предыдущие взаимодействия с результатами поиска. Контекстные данные 202 (X) могут включать в себя социальный контекст, содержащий информацию из профилей или связей пользователя в социальных сетях, который может оказывать влияние на отображаемые результаты или виджеты. Контекстные данные 202 (X) могут включать в себя персонализацию, отражающую все предпочтения (настройки) пользователя, такие как предпочтительные источники новостей, избранные веб-сайты и интересы. Контекстные данные 202 (X) могут включать в себя внешние данные, то есть данные из внешних источников, прикладных программных интерфейсов (API) или баз данных, которые предоставляют дополнительный контекст, например, погодные условия, данные фондового рынка или спортивные результаты в реальном времени. Контекстные данные 202 (X) служат для адаптации результатов поиска и виджетов к конкретным потребностям и предпочтениям пользователя. Учитывая такие контекстные элементы, поисковые системы стремятся обеспечивать более персонализированный и релевантный поиск. Возможности внедрения контекста в результаты поиска чрезвычайно широки и могут продолжать расширяться по мере развития технологий и анализа пользовательских данных. Учитывая контекст пользователя, в частности, его профиль, намерения, местоположение и прочие факторы, а также содержимое веб-документов и виджетов, алгоритм 200 смешивания стремится обеспечивать персонализированный и релевантный поиск. Это достигается за счет ранжирования виджетов и веб-документов по степени их релевантности контексту пользователя.
[090] В некоторых вариантах осуществления алгоритм 200 смешивания включает в себя обученную модель 230 M искусственного интеллекта. Алгоритм 200 смешивания, в частности модель 230 M, получает контекстные данные 202 и выдает вероятность 204 принадлежности к выигрышному классу и вероятность 206 принадлежности к проигрышному классу. Иными словами, алгоритм 200 смешивания определяет ранговую оценку конкретного элемента веб-контента (например, виджета из вторых данных 240 о результатах поиска, подлежащего включению в ранжированные веб-документы из первых данных 226 о результатах поиска) на основе модели M, которая, в сочетании с модулем 208 ранжирования представляет собой обученную систему ранжирования на основе машинного обучения для расчета показателя 216 полезности выбранного элемента для каждой позиции на основе двух элементов:
- вероятности 206 принадлежности к проигрышному классу (loss_weight), которая представляет собой вероятность того, что пользователь не будет взаимодействовать с выбранным элементом веб-контента в выбранной позиции (то есть не проявит какой-либо активности в отношении него, например, не выберет его нажатием кнопки мыши или иным способом), при этом вероятность 206 принадлежности к проигрышному классу формируется в результате обучения на основе обучающих данных, которые относятся к случаям, когда пользователь не взаимодействовал с выбранным элементом веб-контента в выбранной позиции (то есть не проявлял какой-либо активности в отношении него, например, не выбирал его нажатием кнопки мыши или иным способом) - эта вероятность является отрицательной целью обучения; и
- вероятности 204 принадлежности к выигрышному классу (win_weight), которая представляет собой вероятность того, что пользователь будет взаимодействовать с выбранным элементом в выбранной позиции (то есть проявит какую-либо активность в отношении него, например, выберет его нажатием кнопки мыши или иным способом), при этом вероятность 204 принадлежности к выигрышному классу формируется в результате обучения на основе обучающих данных, которые относятся к случаям, когда пользователь взаимодействовал с выбранным элементом в выбранной позиции (то есть проявлял какую-либо активность в отношении него, например, выбирал его нажатием кнопки мыши или иным способом) - эта вероятность является положительной целью обучения.
[091] Итоговый показатель 216 полезности определяется модулем 208 ранжирования, исходя из разности между значениями вероятности 204 принадлежности к выигрышному классу и вероятности 206 принадлежности к проигрышному классу.
[092] Алгоритм 200 смешивания и модуль 208 ранжирования на этапе работы системы ранжирования получают рабочий запрос от пользователя в составе контекстных данных 202 (X) и формируют ранжированный список элементов веб-контента для выдачи на странице 210 результатов поиска. Чтобы определить позицию ранжирования для каждого элемента веб-контента в ранжированном списке элементов (подлежащих размещению на итоговой странице 210 результатов поиска), алгоритм 200 смешивания определяет для каждого элемента веб-контента две вероятности (вероятность 204 принадлежности к выигрышному классу и вероятность 206 принадлежности к проигрышному классу) или веса двух гипотез - гипотезы взаимодействия пользователя с конкретным элементом (например, его выбора) и гипотезы отсутствия такого взаимодействия. Итоговая ранговая оценка определяется модулем ранжирования, исходя из показателя 216 полезности, представляющего собой разность между вероятностью 204 принадлежности к выигрышному классу и вероятностью 206 принадлежности к проигрышному классу. Таким образом, алгоритм 200 смешивания представляет собой многоклассовый классификатор, который на основе входного контекста x прогнозирует вероятность размещения виджета или другого элемента веб-контента на каждой позиции ранжирования из набора вероятностей, включающего в себя вероятности принадлежности к выигрышному классу 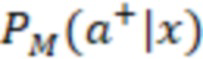 и вероятности принадлежности к проигрышному классу
и вероятности принадлежности к проигрышному классу 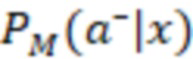 , используя обученную модель M.
, используя обученную модель M.
[093] В некоторых вариантах осуществления модель 230 M служит для прогнозирования и классификации действий на основе предоставленных контекстных данных 202 (X). Входные данные алгоритма 200 смешивания, содержащего модель 230 M, содержат контекстные данные 202 (X), представляющие собой вектор признаков. Этот вектор содержит различные признаки или данные, которые характеризуют текущий контекст поиска, включая намерения пользователя, поисковый запрос, профиль, местоположение и тип устройства пользователя, а также любую другую релевантную информацию, описанную выше. В частности, контекстные данные 202 (X) включают в себя признаки поискового запроса (согласно данным о поисковом запросе), информацию о пользователе и результаты выдачи веб-документов в соответствии с первыми данными 226 результатов поиска. Контекстные данные 202 (X) служат основной для прогнозирования. Основным результатом работы модели 230 M является разделение действий на два класса: a+ (положительный класс) и a- (отрицательный класс). Для каждого действия a и заданного контекста x модель рассчитывает вероятность P(a+|x) того, что действие относится к положительному классу (вероятность 204 принадлежности к выигрышному классу), и вероятность P(a-|x) того, что оно относится к отрицательному классу (вероятность 206 принадлежности к проигрышному классу). Модель 230 M выполнена в виде мультиклассификационной модели. Для каждого действия a и контекста x она рассчитывает вероятности принадлежности к двум классам: a+ и a-. Эти вероятности указывают на то, насколько вероятно, что действие приведет к положительному результату (из класса a+) или отрицательному результату (из класса a-) в заданном контексте. Положительный результат в некоторой степени служит показателем взаимодействия пользователя с элементом веб-контента на заданной позиции, а отрицательный результат - показателем отсутствия такого взаимодействия. Для каждого действия-кандидата a модель 230 M рассчитывает две вероятности: P(a+|x) (вероятность 204 принадлежности к выигрышному классу) и P(a-|x) (вероятность 206 принадлежности к проигрышному классу). Эти вероятности представляют собой вероятность того, что выполнение действия a приведет к положительному или отрицательному результату в текущем контексте. Для составления этих вероятностных прогнозов модель может использовать свои внутренние параметры, определенные в процессе обучения. После расчета вероятностей для всех действий-кандидатов их можно использовать для ранжирования действий на основе разности между P(a+) и P(a-), которая представляет собой показатель 216 полезности. Этот этап ранжирования может выполняться модулем 2081 (1 В переводе исправлено позиционное обозначение.) ранжирования. Действия с большей разностью между вероятностями положительного и отрицательного результатов занимают более высокие позиции при ранжировании, что служит признаком их прогнозируемой желательности. Модуль 208 ранжирования может выбрать действие (позицию ранжирования) с максимальным значением (P(a+|x) - P(a-|x)) в качестве наиболее желательного действия для заданного контекста x. Максимальное значение разности меньше нуля указывает на то, что, согласно прогнозу, ни одно из действий не приведет к положительному результату в заданном контексте, и в этом случае модуль ранжирования может рекомендовать действия «без показа», которые не предполагают отображения элемента веб-контента или виджета пользователю на странице 210 результатов поиска.
[094] На фиг. 3 схематически представлена система 300 обучения, содержащая обучающий модуль 310. Обучающий модуль 310 отвечает за обучение алгоритма машинного обучения, в частности, алгоритма 200 смешивания, включающего в себя модель 230 M. Система 300 обучения, содержащая обучающий модуль 310, реализована на базе одного или нескольких процессоров (совместно используемых, выделенных или групповых) и памяти, хранящей одну или несколько выполняемых программ или микропрограмм, комбинационной логической схемы и/или других подходящих элементов, которые обеспечивают выполнение описанных функций. Один или несколько процессоров могут быть размещены на сервере 116. Система 300 обучения включает в себя базу 302 данных для обучения, которая содержит обучающий набор 304 данных, используемый при обучении модели 220 M. Обучающий модуль 310 использует обучающий набор 304 данных и функцию 314 потерь для формирования данных 316 о потерях, которые позволяют уточнять параметры модели 220 M, выдавая данные прогноза 306 и используя обратную связь 318 и соответствующие уточняющие данные 320.
[095] Прежде чем переходить к подробному описанию работы обучающего модуля, уместно привести некоторое математическое описание лежащей в его основе технологии. В процессе обучения обеспечивается максимальное значение метрики, называемой приростом s. Конкретный способ расчета прироста может варьироваться в зависимости от конкретного виджета или другого элемента веб-контента, но в целом прирост равен разности между выигрышем и проигрышем. Выигрыш представляет собой метрику, указывающую на результативное взаимодействие с виджетом. Например, метрика выигрыша может формироваться на основе показателя перехода по ссылке или другого взаимодействия с заданным временем действия. Метрика проигрыша может быть связана с взаимодействием с веб-документом или другим контентом, расположенным ниже выбранной позиции виджета на странице результатов поиска с ранжированными результатами. Например, метрикой проигрыша может служить произведение показателя перехода по ссылке (или другого взаимодействия) и отношения высоты виджета в пикселях на выбранной позиции к параметру выбранного пользователем веб-контента, расположенного ниже виджета. Метрики выигрыша и проигрыша зависят от конкретного контекста, ранжируемого веб-контента и прочих факторов. Примерами показателей выигрыша, указывающих на взаимодействие с элементом на выбранной позиции, являются отношение числа переходов к числу показов (CTR), коэффициент конверсии, время взаимодействия, глубина прокрутки (для виджетов, содержащих прокручиваемый контент, метрикой выигрыша может быть глубина, на которую пользователи прокручивают виджет), а также метрики, связанные с желанием поделиться информацией (sharing) или социальные метрики. Примерами показателей проигрыша могут служить любые показатели выигрыша, которые указывают на взаимодействие с одним из виджетов или другим веб-контентом, расположенным ниже выбранной позиции.
[096] Для обучения модели 220 M в системе 300 обучения выполняется случайный сбор данных. При случайном сборе данных виджет (или другой веб-контент) размещается в результатах поиска в произвольном месте. Иными словами, обучающий набор 304 данных предоставляет обучающие результаты поиска, аналогичные тем, что выдаются первым модулем 222 поисковой системы, и виджет (или другой элемент веб-контента) для размещения среди них. Позиция выбирается случайным образом согласно схеме обучения со случайным сбором данных. Модель 220 M обучается обучающим модулем 310 с использованием функции 314 потерь, которая может принимать разные формы в рамках следующих математических обозначений:
A - набор действий, выбираемых моделью 220 M. В одном из примеров 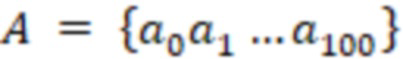 , где
, где 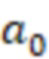 , …,
, …, 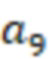 - действия, вызывающие отображение виджета на позициях ранжирования с 0 по 9, а
- действия, вызывающие отображение виджета на позициях ранжирования с 0 по 9, а 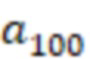 - действие, в результате которого виджет не отображается. Иными словами, набор A действий указывает на позиции элементов веб-контента, подлежащих включению в результаты поиска и отображению на странице 210 результатов поиска. Количество позиций ранжирования на странице 210 результатов поиска, которые можно выбрать, ограничено;
- действие, в результате которого виджет не отображается. Иными словами, набор A действий указывает на позиции элементов веб-контента, подлежащих включению в результаты поиска и отображению на странице 210 результатов поиска. Количество позиций ранжирования на странице 210 результатов поиска, которые можно выбрать, ограничено;
X - разнообразный контекст, в том числе информация о пользователе, поисковый запрос и результаты поиска, среди которых должен быть размещен виджет;
Sa,x - прирост, который рассчитывается при выборе действия a в контексте x и является случайной переменной;
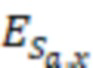 - математическое ожидание прироста, обусловленного действием a в контексте x;
- математическое ожидание прироста, обусловленного действием a в контексте x;
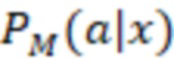 - вероятность, связанная с действием a из модели M в контексте x, то есть с признаками x в соответствии с контекстными данными 202;
- вероятность, связанная с действием a из модели M в контексте x, то есть с признаками x в соответствии с контекстными данными 202;
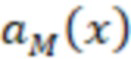 - действие, выбранное моделью 220 M в контексте x;
- действие, выбранное моделью 220 M в контексте x;
arnd(X) - действие, выбранное при случайном сборе данных в контексте x (случайная переменная, принимающая значения из набора A).
[097] Обучающий набор 304 данных, выдаваемый базой данных для обучения, включает в себя N случайно выбранных точек данных. При этом i-й запрос задает обучающий пример вида (wi, xi, ai, si), где:
xi - признаки этого запроса в обучающем наборе 304 данных, который может включать в себя пользовательские данные и веб-контент (например, веб-документы) из поискового запроса и собственно поисковый запрос (или его признаки). Иными словами, xi представляет собой контекстные данные 202 для i-го запроса в обучающем наборе 304 данных;
ai - случайно выбранное для этого запроса действие, которое представляет собой, например, ранжированное размещение виджета или другого веб-контента в результатах поиска;
si - прирост, соответствующий i-му запросу;
wi - вес запроса, 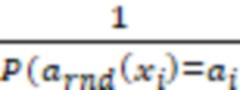 . Вес (wi) каждого запроса определяется, исходя из вероятности (P) того, что случайно выбранное действие (arnd) для этого запроса совпадает с фактически наблюдаемым действием (ai). Величина, обратная этой вероятности, принимается в качестве веса, характеризующего значимость запроса в обучающем наборе данных.
. Вес (wi) каждого запроса определяется, исходя из вероятности (P) того, что случайно выбранное действие (arnd) для этого запроса совпадает с фактически наблюдаемым действием (ai). Величина, обратная этой вероятности, принимается в качестве веса, характеризующего значимость запроса в обучающем наборе данных.
[098] В одной из концепций, представленной для сравнения с настоящей технологией, модель 220 M обучается путем вычисления прироста для модели M по следующей формуле:
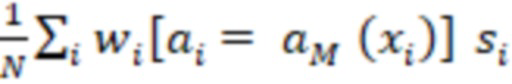 (1)
(1)
[099] Формула (1) позволяет рассчитывать ожидаемое значение с усреднением по N экземплярам данных из обучающего набора 304 данных, где N - общее количество экземпляров. Функция [ai = aM(xi)] представляет собой индикаторную функцию, которая принимает значение 1, когда ai (действие, связанное с i-м экземпляром) совпадает с действием aM(xi), спрогнозированным моделью на основе контекста xi. Если действия не совпадают, функция принимает нулевое значение. Индикаторная функция [ai = aM(xi)] гарантирует внесение вклада в общее ожидаемое значение прироста со стороны лишь тех экземпляров, для которых спрогнозированное моделью действие совпадает с фактическим действием (ai = aM(xi)). Экземпляры, для которых спрогнозированное действие не совпадает с фактическим действием (ai ≠ aM(xi)), вносят вклад, равный нулю. По существу, данная формула определяет ожидаемое значение прироста для тех экземпляров, для которых действие, спрогнозированное моделью, совпадает с фактическим действием.
[100] Авторы настоящей технологии применили более тонкий подход к оценке общего прироста при обучении модели 220 M, обеспечив более выраженное достижение максимального прироста. Формула для обучения модели 220 M не определяет позиции или действия a, а задает некоторое распределение вероятностей для возможных позиций. Иными словами, обучающий модуль оптимизирует метрику, которая оценивает общий прирост при случайном выборе позиции ранжирования или действия в соответствии с заданным распределением. Эту метрику можно назвать сглаженным автономным приростом:
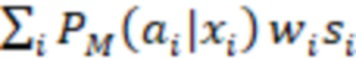 (2)
(2)
Здесь 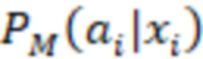 - вероятность, связанная с позицией ai модели M в контексте xi.
- вероятность, связанная с позицией ai модели M в контексте xi.
[101] Новая модель обеспечивает достижение максимума в формуле (3) или, в другом варианте, в формуле (4):
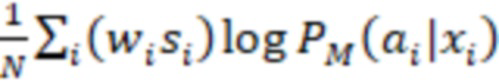 , (3)
, (3)
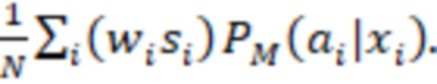 (4)
(4)
[102] Формулы (3) и (4) представляют собой уравнения функции 314 потерь, которая используется обучающим модулем 310 для формирования данных 316 о потерях, чтобы рассчитывать уточненные параметры (веса) по уточняющим данным 320 для модели 220 M с помощью модуля 318 обратной связи. Обучающий модуль 310 выполняет случайный сбор данных из базы 302 данных для обучения, в процессе которого случайным образом выбирается действие a. Обучающий модуль 310 призван расширить мультиклассификационные возможности модели. Процесс обучения начинается с передачи набора из N запросов на случайный сбор данных из обучающего модуля 310 в базу 302 данных для обучения. Для каждого запроса обучающий набор 304 данных включает в себя признаки (xi) поискового запроса пользователя, которые охватывают различные аспекты, связанные с пользователем и с выдачей веб-документов поисковой системой, а также другие аспекты контекста, в котором выполняется запрос. Обучающий набор 304 данных для каждого запроса включает в себя действие (ai), выбранное случайным образом из набора (A) возможных действий, и это действие должно быть спрогнозировано моделью. Обучающий набор 304 данных для каждого запроса включает в себя прирост (si), связанный с конкретным запросом. Прирост характеризует разницу между выгодами и затратами при выполнении действия ai в контексте xi. Обучающий набор 304 данных для каждого запроса включает в себя вес (wi), который служит мерой важности запроса и рассчитывается как величина, обратная вероятности совпадения сделанного моделью прогноза с фактическим действием.
[103] Обучаемая модель M является мультиклассификационной. Она призвана рассчитывать вероятность каждого действия для заданного контекста x. Обучающий модуль 310 обучает модель 220 M, используя градиентную оптимизацию стратегии. Целью является обеспечение максимального ожидаемого прироста. Для этого производится оптимизация стратегии модели, которая присваивает вероятности (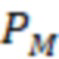 ) действиям в различных контекстах. Модуль 312 расчета потерь использует функцию (
) действиям в различных контекстах. Модуль 312 расчета потерь использует функцию (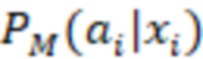 ) потерь из метода градиентной оптимизации стратегии для обучения согласно формуле (3) или (4) или аналогичные функции потерь, которые учитывают вес wi, связанный с каждым запросом, прирост si, полученный для каждого запроса, и рассчитанную вероятность выбора действия ai в контексте xi. Данные 316 о потерях, сформированные с помощью функции 314 потерь, поступают в модуль 318 обратной связи, который использует метод градиентного подъема для стратегии, обеспечивающий изменение вероятностей стратегии () в направлении, увеличивающем ожидаемый прирост. Модуль 318 обратной связи выдает уточняющие данные 320, благодаря которым модель 220 M итеративно уточняется на основе градиентов, вычисляемых с помощью функции 314 методом градиентной оптимизации стратегии. В результате таких уточнений корректируются вероятности действий, что обеспечивает максимальный ожидаемый прирост. Для эффективного нахождения стратегии, обеспечивающей максимальный прирост, модуль 318 обратной связи может использовать алгоритм оптимизации, например, метод стохастического градиентного подъема или метод естественной градиентной оптимизации стратегии. Процесс обучения является итеративным, то есть модель 220 M продолжает обучаться и корректировать свою стратегию до тех пор, пока не будет обеспечена сходимость. Конечной целью этого процесса обучения является получение модели 220 M, способной присваивать максимальную вероятность действиям, приводящим к максимальному приросту, чтобы оптимизировать работу системы в плане выдачи релевантного контента в ответ на запросы пользователей.
) потерь из метода градиентной оптимизации стратегии для обучения согласно формуле (3) или (4) или аналогичные функции потерь, которые учитывают вес wi, связанный с каждым запросом, прирост si, полученный для каждого запроса, и рассчитанную вероятность выбора действия ai в контексте xi. Данные 316 о потерях, сформированные с помощью функции 314 потерь, поступают в модуль 318 обратной связи, который использует метод градиентного подъема для стратегии, обеспечивающий изменение вероятностей стратегии () в направлении, увеличивающем ожидаемый прирост. Модуль 318 обратной связи выдает уточняющие данные 320, благодаря которым модель 220 M итеративно уточняется на основе градиентов, вычисляемых с помощью функции 314 методом градиентной оптимизации стратегии. В результате таких уточнений корректируются вероятности действий, что обеспечивает максимальный ожидаемый прирост. Для эффективного нахождения стратегии, обеспечивающей максимальный прирост, модуль 318 обратной связи может использовать алгоритм оптимизации, например, метод стохастического градиентного подъема или метод естественной градиентной оптимизации стратегии. Процесс обучения является итеративным, то есть модель 220 M продолжает обучаться и корректировать свою стратегию до тех пор, пока не будет обеспечена сходимость. Конечной целью этого процесса обучения является получение модели 220 M, способной присваивать максимальную вероятность действиям, приводящим к максимальному приросту, чтобы оптимизировать работу системы в плане выдачи релевантного контента в ответ на запросы пользователей.
[104] Обучающий модуль 310 выполнен таким образом, чтобы каждый прирост, достигнутый в процессе случайного сбора данных (и включенный в обучающий набор 304 данных), превращался в обучающий пример для алгоритма мультиклассификации. Признаки (контекстные данные 202 (X)) каждого примера в обучающем наборе 304 данных описывают контекст, в котором был достигнут прирост. Целью при обучении модели 220 M является действие, посредством которого был достигнут прирост. Иными словами, обучающий модуль 310 способен определять вероятность для способа достижения прироста в контексте x при случайном сборе данных. В мультиклассификационной модели 220 M функция представляет собой вероятность того, что прирост был достигнут с использованием действия a. Для N примеров данных в обучающем наборе 304 данных вероятности выбираются в процессе обучения для постоянного контекста x согласно схеме обучения с градиентной оптимизацией стратегии, исходя из цели выбранного случайного действия и соответствующих достигнутых приростов.
[105] Для повышения эффективности процесса обучения обучающий модуль 310 осуществляет процесс обучения, как описано выше, но с добавлением в него пары целей обучения - выигрышной и проигрышной. Для каждого действия a задаются два класса a+ и a- и из каждого запроса (с признаками контекста x, позицией a и весом w) в обучающий набор 304 данных включаются два обучающих примера для обучения мультиклассификации. Выигрышный пример содержит признак x, вес Win W (характеризующий взаимодействие пользователя с элементом на заданной позиции ранжирования) и цель a+, а проигрышный пример - признак x, вес Loss W (характеризующий взаимодействие пользователя с элементом на более низкой позиции ранжирования) и цель a-. В некоторых примерах взаимодействие пользователя с элементом на заданной позиции ранжирования и взаимодействие пользователя с элементом ниже заданной позиции ранжирования могут происходить одновременно (например, во время одного веб-сеанса). В таком случае обучающие данные одновременно включают в себя как вес Win W, так и вес Loss W, а выигрышный и проигрышный примеры представляются в виде одного обучающего примера. Иными словами, проигрышный пример соответствует случаю, когда взаимодействие пользователя с элементом приводит к положительному проигрышу (вес loss_weight > 0), а выигрышный пример соответствует случаю, когда взаимодействие пользователя с элементом приводит к положительному выигрышу (вес win_weight > 0). В приведенном выше примере вес win_weight может составлять 0,3, а вес loss_weight может составлять 0,1. Таким образом, модель 220 M обучается определению для заданных контекстных данных x (202) вероятности 204 принадлежности к выигрышному классу (то есть вероятности выполнения пользователем какого-либо действия a из набора A на заданной позиции ранжирования) и вероятности 206 принадлежности к проигрышному классу, используя функцию потерь и методы градиентной оптимизации стратегии, описанные выше.
В некоторых вариантах осуществления, в зависимости от конкретного сценария вовлечения пользователя, обучающий модуль 310 осуществляет процесс обучения, в котором (а) при отсутствии взаимодействия пользователя с заданным элементом веса win_weight и loss_weight приравниваются нулю (0), в связи с чем выбранный обучающий пример исключается из обучающего набора 304 данных (не добавляется в него), (б) при длительном взаимодействии пользователя с выбранным элементом заданному элементу присваиваются вес win_weight и равный нулю (0) вес loss_weight, вследствие чего в обучающий набор 304 данных добавляется выигрышный пример, (в) заданному элементу присваиваются вес loss_weight и равный нулю (0) вес win_weight, вследствие чего в обучающий набор 304 данных добавляется проигрышный пример, и (г) при взаимодействии пользователя как с заданным элементом, так и с другим элементом, находящимся на позиции ниже позиции данного элемента, заданному элементу присваиваются веса win_weight и loss_weight, вследствие чего в обучающий набор 304 данных включается пара обучающих примеров - выигрышный и проигрышный.
[106] Обучающий модуль 310 способен использовать два веса - loss_weight и win_weight, как описано выше. Если выбранный элемент проигрывает (пользователь выполняет действие a с более низким рангом) при заданных контексте x и действии a из обучающего примера, значение прироста для выбранного элемента включается в вес для проигрыша, а если выбранный элемент выигрывает (пользователь выполняет действие a с учетом контекста x), значение прироста для того же элемента включается в вес для выигрыша. Иными словами, для набора признаков x вес win_weight связывается с положительным целевым действием a+, а набор признаков x и вес loss_weight - с отрицательным целевым действием a-. Таким образом, из обучающего набора 304 данных получаются два обучающих примера для задачи мультиклассификации, а именно выигрышный и проигрышный примеры. Вероятности, выдаваемые моделью 220 M для проигрышного и выигрышного классов, итеративно корректируются модулем обратной связи по схеме градиентной оптимизации стратегии, чтобы минимизировать функцию 314 потерь, в результате чего модель 220 M обучается выдавать распределение вероятностей для выигрышного класса 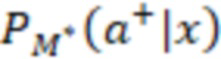 и проигрышного класса
и проигрышного класса 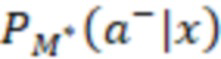 с учетом контекста x. На этапе работы модуль 208 ранжирования определяет действие a с максимальной разностью между вероятностями принадлежности к выигрышному классу и к проигрышному классу (максимальным показателем полезности) и это действие используется для задания позиции ранжирования выбранного виджета на странице 210 результатов поиска.
с учетом контекста x. На этапе работы модуль 208 ранжирования определяет действие a с максимальной разностью между вероятностями принадлежности к выигрышному классу и к проигрышному классу (максимальным показателем полезности) и это действие используется для задания позиции ранжирования выбранного виджета на странице 210 результатов поиска.
[107] Следует отметить, что прирост s и соответствующий вес w могут быть заданы для каждого вида размещаемого контента (будь то виджет или элемент веб-контента другого вида). В некоторых случаях в качестве показателя, указывающего на взаимодействие пользователя с элементом (вовлеченность пользователя) на конкретной позиции ранжирования или на выполнение пользователем действия a, на основе которого определяются значения прироста, может быть задана одна целевая метрика для всех видов контента. В одном из примеров для веб-контента может быть выбрано отношение числа переходов к числу показов (CTR), для видеоконтента - число длительных пребываний на ресурсе после перехода на него (число «длинных кликов»), а для графического контента - другая метрика вовлеченности пользователя. В другом примере для всех видов контента может быть выбрано отношение числа переходов к числу показов (или любая другая общая целевая метрика). В описанную технологию могут быть введены дополнительные показатели (веса), связанные с каждым из элементов результатов веб-поиска.
[108] С учетом описанной выше архитектуры возможна реализация способов формирования страницы 210 результатов поиска. На фиг. 4 представлена блок-схема способа 400, реализованного в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии. Способ 400 может быть реализован на сервере 116.
[109] Пользователь отправляет поисковый запрос в поисковую систему 250, взаимодействуя с ней через интерфейс 106 поискового запроса на электронном устройстве 102 пользователя. Данные, содержащие поисковый запрос, передаются по сети 110 связи на сервер 116. Сервер 116 содержит первый модуль 222 поисковой системы, второй модуль 224 поисковой системы и алгоритм 200 смешивания или связан с ними.
[110] На шаге 410 сервер 116 получает первые и вторые результаты поиска от первого и второго модулей 222, 224 поисковой системы на основе данных 214 о поисковом запросе. Первые и вторые результаты поиска выдаются в виде первых и вторых данных 226, 228 о результатах поиска и могут содержать различные виды веб-контента. Например, первые данные 226 о результатах поиска могут содержать ранжированный список веб-документов, а вторые данные 240 о результатах поиска - один или несколько виджетов, подлежащих включению в первые результаты поиска на позиции, определенной алгоритмом 200 смешивания и модулем 208 ранжирования.
[111] На шаге 420 модуль 212 формирования контекста формирует контекстные данные 202 (X). Контекстные данные 202 (X) включают в себя признаки контекста (X), несущие информацию о пользователе, веб-документах (или других ранжированных элементах веб-контента от первого модуля 222 поисковой системы), данные 214 о поисковом запросе и подлежащий размещению виджет (или другой элемент веб-контента). Признаки контекста могут включать в себя данные пользователя, характеристики документов и атрибуты виджета.
[112] На шаге 430 выполняется смешивание, в процессе которого поисковая система 250 использует модель 230 M, обученную прогнозированию действий (позиций) в результатах поиска на основе контекстных данных 202 (X). Модель 230 M рассчитывает вероятность действия для каждого потенциального действия (каждой позиции) из набора A возможных действий в результатах поиска. Эти вероятности определяются на основе признаков контекста и архивных обучающих данных. Иными словами, на шаге 430 смешивания алгоритм 230 смешивания использует модель M, чтобы определить вероятности, связанные с позицией ранжирования и обусловленные включением виджета в список веб-документов (среди прочего) на этой позиции. Для каждого действия (каждой позиции) моделью 230 M выдаются две вероятности. Выдается вероятность 204 принадлежности к выигрышному классу 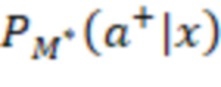 , которая представляет собой вероятность положительного результата (то есть вероятность выигрыша, который выражается во взаимодействии пользователя с элементом веб-контента, расположенным на заданной позиции (действие a)). Выдается вероятность 206 принадлежности к проигрышному классу
, которая представляет собой вероятность положительного результата (то есть вероятность выигрыша, который выражается во взаимодействии пользователя с элементом веб-контента, расположенным на заданной позиции (действие a)). Выдается вероятность 206 принадлежности к проигрышному классу 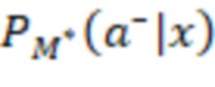 , которая представляет собой вероятность отрицательного результата (то есть вероятность проигрыша, который выражается во взаимодействии пользователя с элементом веб-контента расположенным на позиции ниже выбранной позиции согласно порядку ранжирования).
, которая представляет собой вероятность отрицательного результата (то есть вероятность проигрыша, который выражается во взаимодействии пользователя с элементом веб-контента расположенным на позиции ниже выбранной позиции согласно порядку ранжирования).
[113] На шаге 440 ранжирования результаты поиска из первых данных 226 о результатах поиска и вторых данных 240 о результатах поиска ранжируются, исходя из разности (показателя 216 полезности) между вероятностью 204 принадлежности к выигрышному классу и вероятностью 206 принадлежности к проигрышному классу для каждого действия, определенной модулем 208 ранжирования. Позиция (или действие) с наибольшим показателем полезности выбирается в качестве позиции (или действия) для размещения элемента веб-контента среди первых результатов поиска, например, для размещения виджета среди веб-документов.
[114] На шаге 450 производится формирование страницы 210 результатов поиска на сервере 116, в процессе которого поисковая система 250 компилирует ранжированные веб-документы (или другие элементы веб-контента) и виджеты (или другие элементы веб-контента) для получения итоговой страницы 210 результатов поиска. По сети связи 110 страница 210 результатов поиска передается на электронное устройство 102 для выдачи через интерфейс 106 результатов поиска. На странице 210 результатов поиска, выдаваемой пользователю, отображается наиболее релевантный и полезный контент, основанный на прогнозах, сделанных моделью, и на контексте. Пользователь имеет возможность взаимодействовать с результатами поиска, виджетами и веб-документами на странице 210 результатов поиска, оказывая влияние на формирование будущего контекста и на выдаваемые моделью прогнозы за счет непрерывного обучения и уточнения модели 220 M.
[115] За счет использования признаков контекста, смешивания на основе модели и оценки вероятностей метод 400 обеспечивает выдачу пользователю более персонализированных и релевантных результатов поиска, в которых учитываются как веб-документы, так и виджеты, что в конечном итоге повышает качество поиска.
[116] На фиг. 5 представлена блок-схема способа 500 обучения модели 220 M в алгоритме 200 смешивания, реализованного в соответствии с другими не имеющими ограничительного характера вариантами осуществления настоящей технологии. Способ 500 также может быть реализован на сервере 116 с обучающим модулем 310 или в какой-либо другой вычислительной системе, способной обеспечивать работу обучающего модуля 310.
[117] Модель 220 M инициализируется с использованием начальных параметров. На шаге 510 из базы 302 данных для обучения поступает обучающий набор 304 данных. Обучающий набор 304 данных является результатом сбора данных о фактическом взаимодействии пользователя с поисковой системой. Он содержит различные запросы, выполненные пользователями во время сеансов поиска, связанные с ними результаты поиска, информацию о пользователях, информацию о вовлеченности пользователей и т.д. Для каждого запроса из набора возможных действий (позиций или результатов), представленных на странице результатов поиска, случайным образом выбирается действие (a). Для каждого запроса извлекаются признаки контекста. Эти признаки описывают запрос пользователя, его поведение в прошлом, результаты поиска, тип устройства, местоположение и прочую необходимую информацию. Для каждого запроса определяется прирост (s), который используется в качестве метки данных. Прирост характеризует разницу между положительными результатами (например, переходами по ссылкам, взаимодействием с элементами) и отрицательными результатами (например, отсутствием взаимодействия с элементами) для выбранного действия.
[118] Кроме того, для каждого действия на основе признаков контекста, вероятности принадлежности к выигрышному классу и вероятности принадлежности к проигрышному классу задается начальная вероятность действия.
[119] На шаге 520 по формуле (3) или (4) вычисляется функция потерь, как описано выше. Для этого с использованием модели рассчитываются вероятности 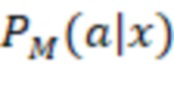 действий в заданном контексте на основе приростов и весов из обучающего набора 304 данных и минимизируется функция потерь для получения данных 316 о потерях.
действий в заданном контексте на основе приростов и весов из обучающего набора 304 данных и минимизируется функция потерь для получения данных 316 о потерях.
[120] На шаге 530 модель 220 M корректируется, исходя из результатов расчета функции потерь, полученных на шаге 520. В некоторых вариантах осуществления вероятности действий корректируются, например, посредством обратной связи по схеме градиентной оптимизации стратегии, чтобы минимизировать потери, рассчитанные с использованием функции 314 потерь. Параметры модели уточняются для оптимизации вероятности действий. Шаг 530 итеративно выполняется до достижения критерия сходимости (например, до тех пор, пока общий сглаженный автономный прирост (формула (2)) не будет отвечать некоторому заданному критерию или не будет выполнено определенное количество итераций).
[121] На шаге 540 формируется обученная модель 220 M, готовая к использованию в процессах ранжирования и смешивания на этапе работы.
[122] Выигрышные и проигрышные обучающие примеры применяются для формирования моделью 220 M двух отдельных классификационных признаков: вероятности принадлежности к выигрышному классу и вероятности принадлежности к проигрышному классу. Иными словами, на выигрышном и проигрышном примерах из обучающего набора данных модель обучается определению вероятностей проигрыша (отсутствия вовлечения пользователя) и выигрыша (вовлечения пользователя), соответствующих определенной позиции (действию). На этапе работы позиция (действие) с максимальной разностью между вероятностями принадлежности к выигрышному классу и к проигрышному классу принимается в качестве выбранной позиции (выбранного действия) на странице 210 результатов поиска.
[123] Следует понимать, что описанная выше процедура является лишь иллюстративным вариантом осуществления настоящей технологии. Она не предназначена для определения объема или границ настоящей технологии.
[124] Очевидно, что не все упомянутые здесь технические эффекты подлежат реализации в каждом конкретном варианте осуществления настоящей технологии. Например, возможны варианты осуществления настоящей технологии, в которых пользователь может получать лишь часть этих технических эффектов, и варианты осуществления, в которых пользователь может получать другие технические эффекты или вовсе не получать их.
[125] Для специалиста в данной области техники могут быть очевидными возможные изменения и усовершенствования описанных выше вариантов осуществления настоящего изобретения. Предшествующее описание приведено лишь в иллюстративных целях, а не для ограничения объема изобретения. Объем охраны настоящего изобретения определяется исключительно объемом приложенной формулы изобретения.
[126] Соответственно, описанные выше варианты осуществления можно обобщить, представив в виде следующего перечня пронумерованных пунктов формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА ДЛЯ ОПРЕДЕЛЕНИЯ РАНЖИРОВАННЫХ ПОЗИЦИЙ ЭЛЕМЕНТОВ СИСТЕМОЙ РАНЖИРОВАНИЯ | 2020 |
|
RU2781621C2 |
| СПОСОБ И СИСТЕМА РАНЖИРОВАНИЯ ЭЛЕМЕНТОВ СЕТЕВОГО РЕСУРСА ДЛЯ ПОЛЬЗОВАТЕЛЯ | 2013 |
|
RU2605039C2 |
| СИСТЕМА И СПОСОБ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2015 |
|
RU2632148C2 |
| СБОР ДАННЫХ О ПОЛЬЗОВАТЕЛЬСКОМ ПОВЕДЕНИИ ПРИ ВЕБ-ПОИСКЕ ДЛЯ ПОВЫШЕНИЯ РЕЛЕВАНТНОСТИ ВЕБ-ПОИСКА | 2007 |
|
RU2435212C2 |
| СПОСОБ И СИСТЕМА ОБРАБОТКИ ПОИСКОВОГО ЗАПРОСА | 2015 |
|
RU2640639C2 |
| ФОРМИРОВАНИЕ ПОИСКОВОГО ЗАПРОСА НА ОСНОВЕ КОНТЕКСТА | 2013 |
|
RU2633115C2 |
| СПОСОБ И СИСТЕМА ПОСТРОЕНИЯ ПОИСКОВОГО ИНДЕКСА С ИСПОЛЬЗОВАНИЕМ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2018 |
|
RU2720954C1 |
| Способ и система для формирования карточки объекта | 2018 |
|
RU2739554C1 |
| СПОСОБ И СЕРВЕР ДЛЯ ПОВТОРНОГО ОБУЧЕНИЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2019 |
|
RU2743932C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ПРОВЕРКИ МЕДИАКОНТЕНТА | 2022 |
|
RU2815896C2 |
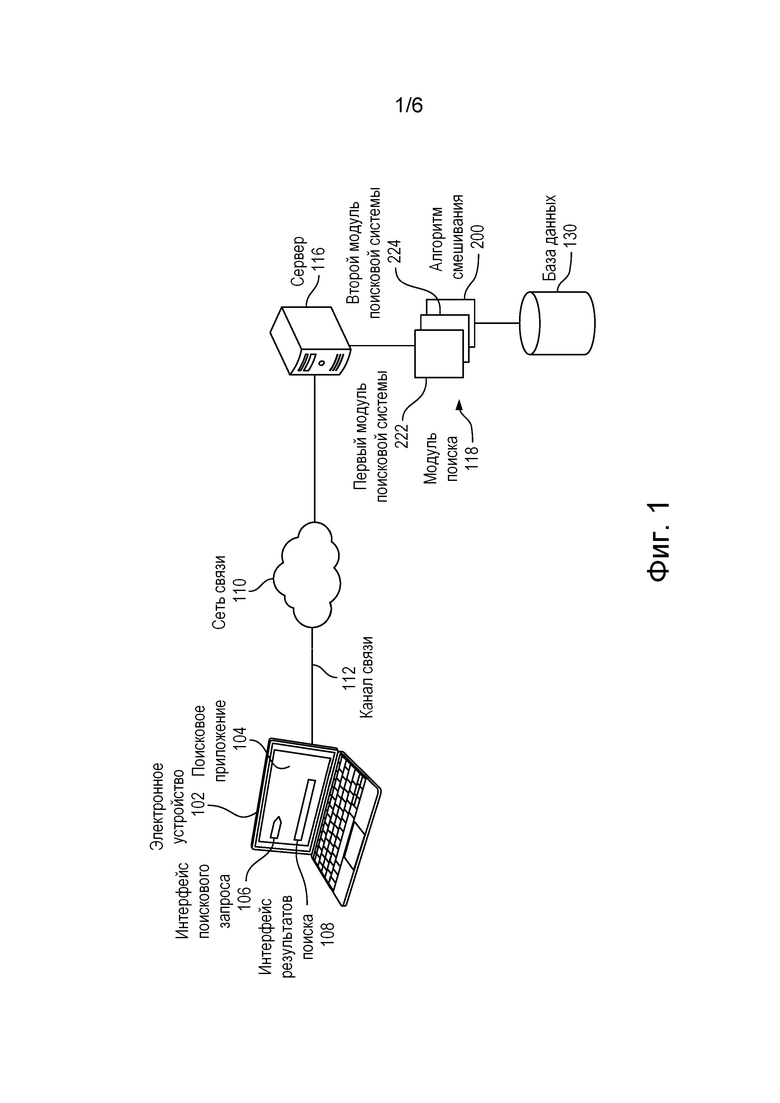
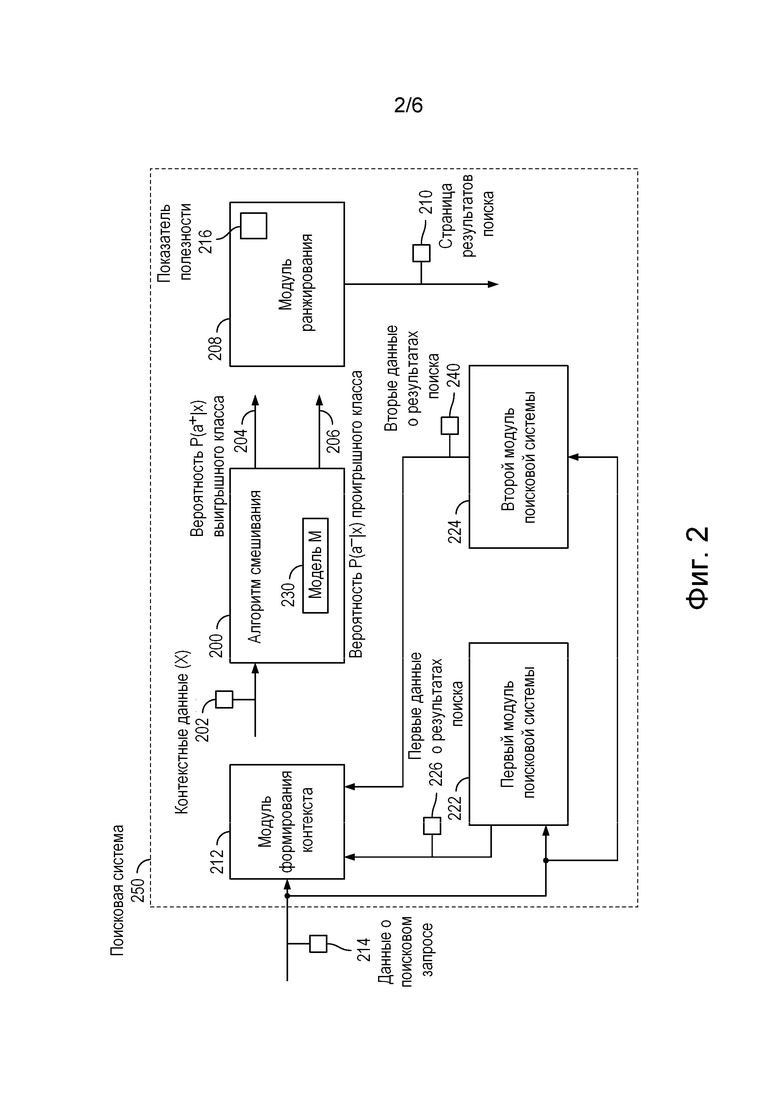
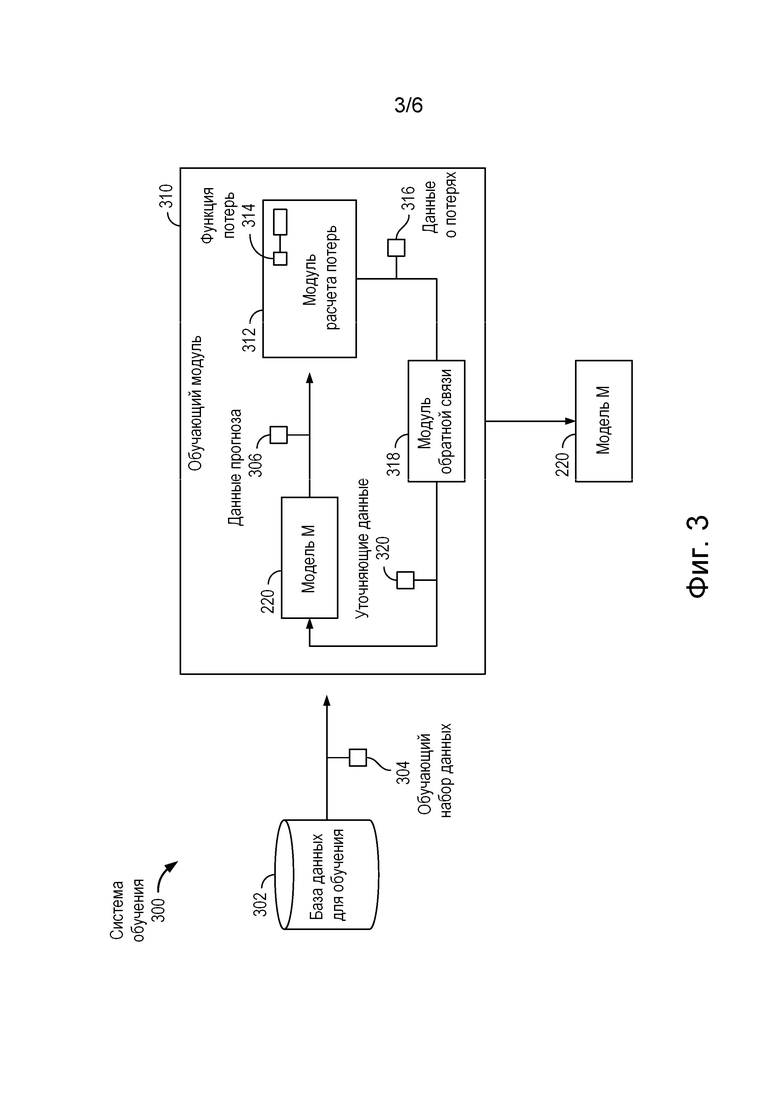
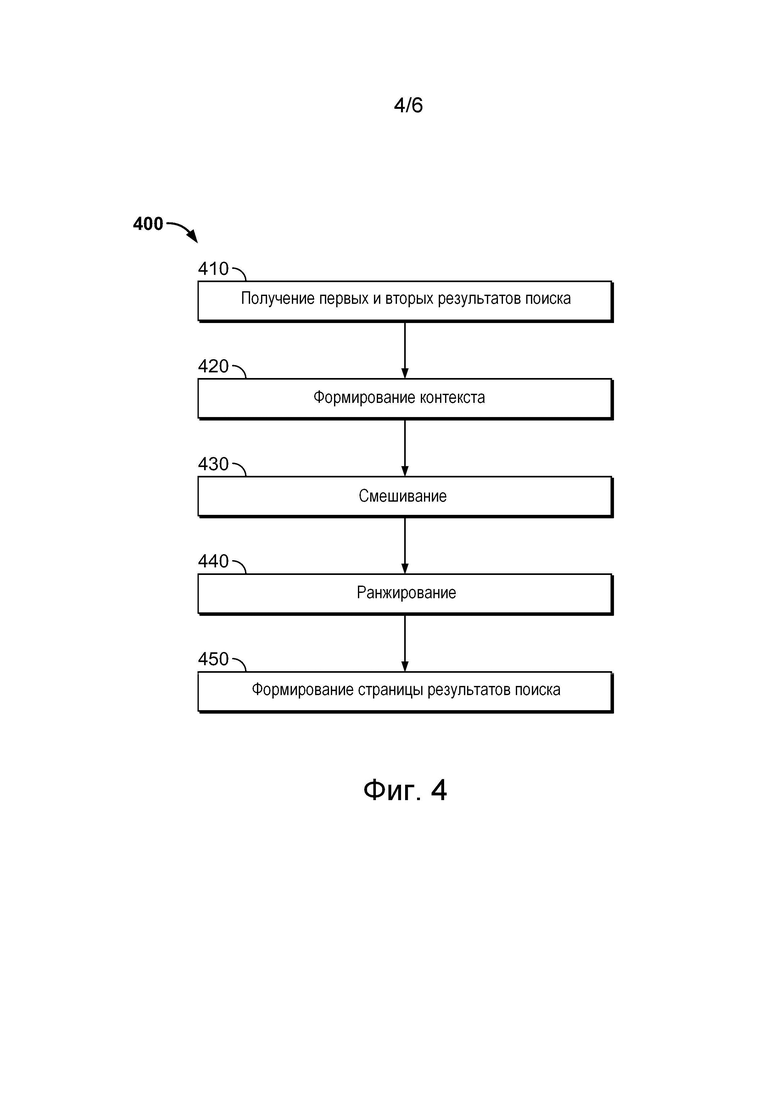
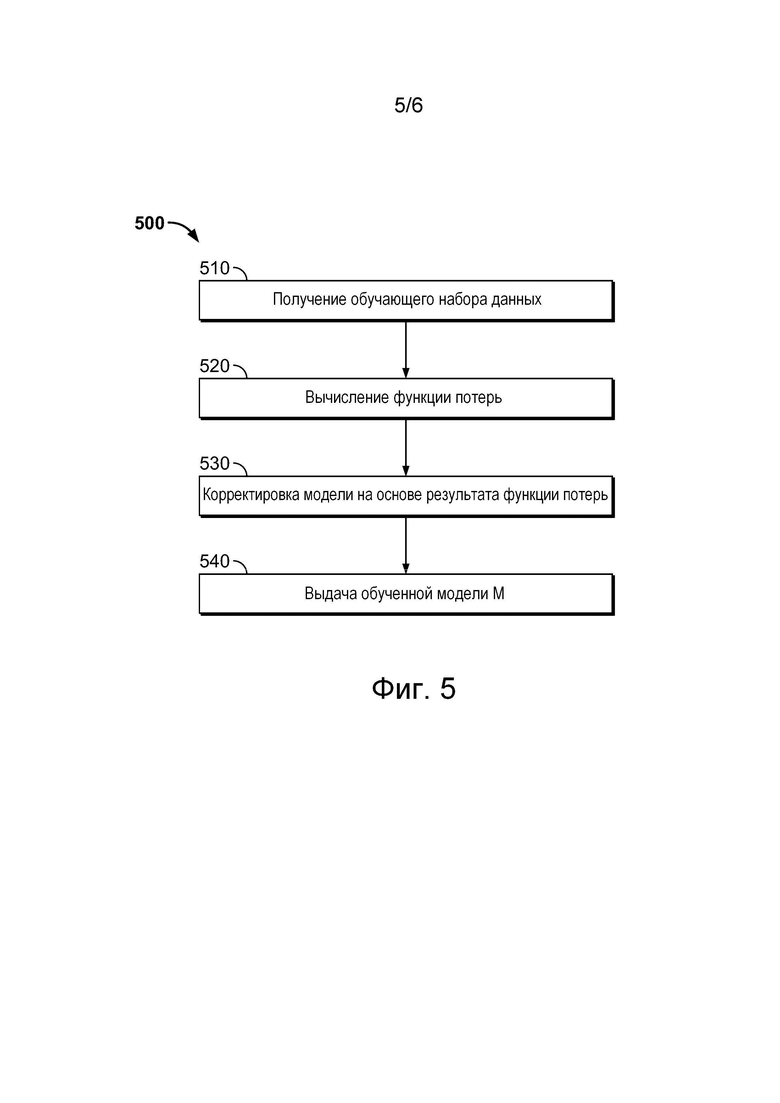
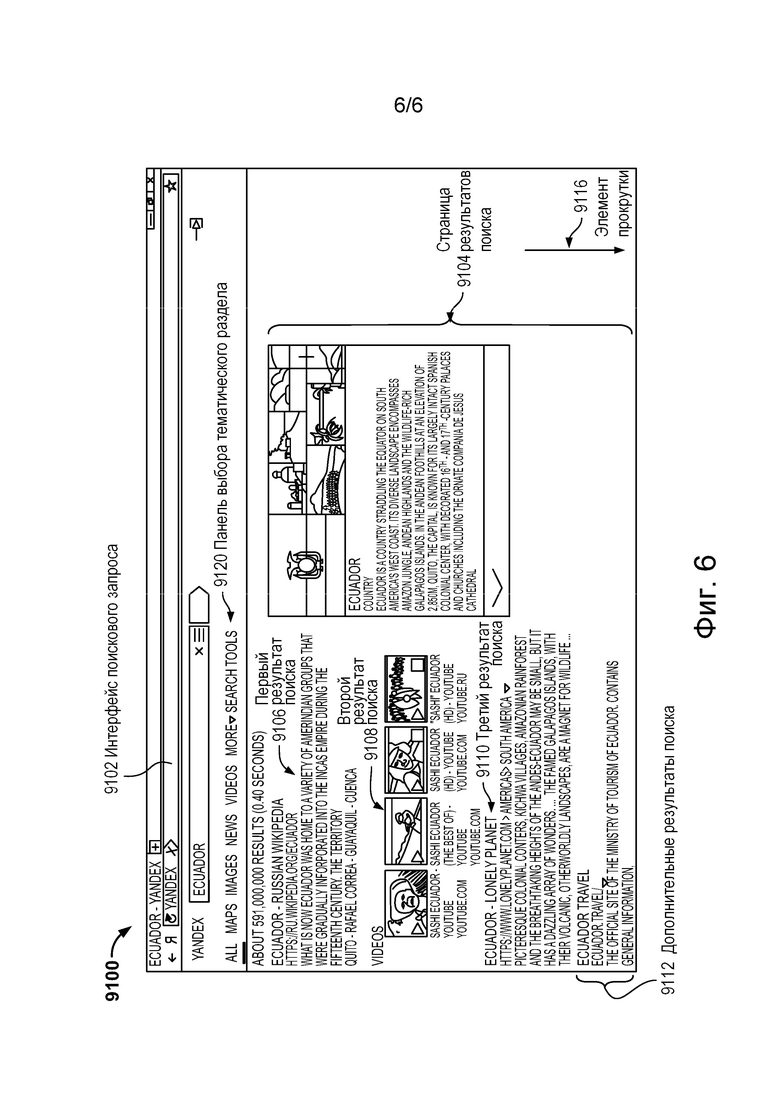
Изобретение относится к области вычислительной техники, а именно к способам и системам ранжирования результатов поиска. Технический результат заключается в повышении точности формирования релевантных результатов поиска. Способ формирования страницы результатов поиска для передачи на электронное устройство, связанное с пользователем поисковой системы, размещенной на сервере, соединенном с электронным устройством, который выполняется сервером и предусматривает: получение от электронного устройства данных о запросе, определение набора элементов веб-контента, включающего в себя соответствующие запросу результаты поиска и содержащего заданный элемент веб-контента, на основе данных о запросе; формирование контекстных данных на основе набора элементов веб-контента и данных о запросе, передачу контекстных данных в модель и определение значения метрики для заданной пары «элемент веб-контента - позиция», формирование страницы результатов поиска с заданным элементом веб-контента, размещенным на заданной позиции ранжирования, на основе значения метрики. 3 н. и 17 з.п. ф-лы, 6 ил.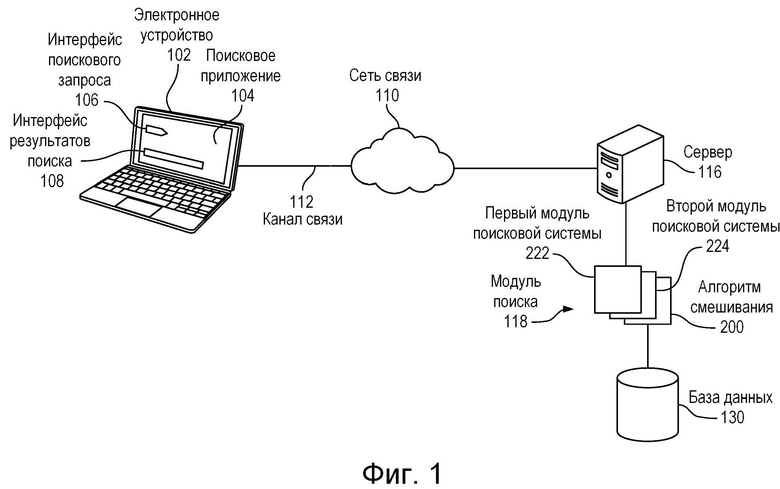
1. Способ формирования страницы результатов поиска для передачи на электронное устройство, связанное с пользователем поисковой системы, размещенной на сервере, соединенном с электронным устройством, который выполняется сервером и предусматривает:
- получение от электронного устройства данных о запросе, указывающих на отправленный пользователем запрос;
- определение набора элементов веб-контента, включающего в себя соответствующие запросу результаты поиска и содержащего заданный элемент веб-контента, на основе данных о запросе;
- формирование контекстных данных на основе набора элементов веб-контента и данных о запросе;
- передачу контекстных данных в модель, представляющую собой мультиклассификационную модель для множества классов, содержащего два класса, назначенных заданной позиции ранжирования на странице результатов поиска, а именно - выигрышный класс, указывающий на прогнозируемую выгоду от размещения заданного элемента веб-контента на заданной позиции ранжирования на странице результатов поиска, и проигрышный класс, указывающий на прогнозируемый ущерб от размещения заданного элемента веб-контента на заданной позиции ранжирования на странице результатов поиска;
- определение значения метрики для заданной пары «элемент веб-контента - позиция», содержащей заданный элемент веб-контента и заданную позицию ранжирования, при этом значение метрики представляет собой разность между прогнозируемой величиной выгоды выигрышного класса в модели для заданного элемента веб-контента и прогнозируемой величиной ущерба проигрышного класса в модели для заданного элемента веб-контента и характеризует общую полезность размещения заданного элемента веб-контента на заданной позиции ранжирования; и
- формирование страницы результатов поиска с заданным элементом веб-контента, размещенным на заданной позиции ранжирования, на основе значения метрики.
2. Способ по п. 1, в котором модель обеспечивает выдачу вероятностей принадлежности к выигрышному классу и к проигрышному классу для каждой позиции ранжирования из набора позиций ранжирования, а также определение значения метрики для каждой позиции ранжирования из набора позиций ранжирования, при этом заданная позиция ранжирования на странице результатов поиска для заданного элемента веб-контента выбирается на основе максимальной разности.
3. Способ по п. 1, в котором заданным элементом веб-контента является виджет для размещения среди веб-документов, включенных в соответствующие запросу результаты поиска.
4. Способ по п. 1, в котором контекстные данные содержат ранжированные веб-документы из поисковой системы.
5. Способ по п. 1, в котором выигрышный класс соответствует вероятности взаимодействия пользователя с заданным элементом веб-контента на заданной позиции ранжирования.
6. Способ по п. 1, в котором проигрышный класс соответствует вероятности взаимодействия пользователя с другим элементом веб-контента, находящимся на позиции ниже заданной позиции ранжирования.
7. Способ обучения модели для ранжирования объектов на странице результатов поиска для передачи на электронное устройство, связанное с пользователем поисковой системы, размещенной на сервере, соединенном с электронным устройством, который выполняется сервером и предусматривает:
- получение данных о запросе, связанных с обучающим запросом, представляющим собой запрос, ранее отправленный в поисковую систему, для которого обучающий элемент веб-контента был выдан в качестве результата поиска на заданной позиции ранжирования;
- получение контекстных данных, связанных с обучающим элементом веб-контента и содержащих данные о запросе;
- получение данных о взаимодействии пользователя с обучающим элементом веб-контента, характеризующих выгоду от размещения обучающего элемента веб-контента на заданной позиции ранжирования в ответ на обучающий запрос и ущерб от размещения обучающего элемента веб-контента на заданной позиции ранжирования в ответ на обучающий запрос;
- формирование двух обучающих наборов для пары «обучающий запрос - элемент веб-контента», содержащей обучающий запрос и обучающий элемент веб-контента, при этом два обучающих набора содержат положительный обучающий набор, содержащий входные данные, в состав которых входят контекстные данные, и первую метку, указывающую на фактическую выгоду от размещения обучающего элемента веб-контента на заданной позиции ранжирования в ответ на запрос, и отрицательный обучающий набор, содержащий входные данные и вторую метку, указывающую на фактический ущерб от размещения обучающего элемента веб-контента на заданной позиции ранжирования в ответ на запрос;
- обучение модели, представляющей собой мультиклассификационную модель для множества классов, с использованием положительного и отрицательного обучающих наборов, при этом множество классов содержит два класса, назначенных заданной позиции ранжирования, а именно - выигрышный класс, указывающий на прогнозируемую выгоду от размещения обучающего элемента веб-контента на заданной позиции ранжирования, и проигрышный класс, указывающий на прогнозируемый ущерб от размещения обучающего элемента веб-контента на заданной позиции ранжирования.
8. Способ по п. 7, в котором модель обеспечивает выдачу вероятностей принадлежности к выигрышному классу и к проигрышному классу для каждой позиции ранжирования из набора позиций ранжирования.
9. Способ по п. 7, в котором обучающим элементом веб-контента является виджет для размещения среди веб-документов, включенных в соответствующие запросу результаты поиска.
10. Способ по п. 7, в котором выигрышный класс соответствует вероятности взаимодействия пользователя с обучающим элементом веб-контента на заданной позиции ранжирования.
11. Способ по п. 7, в котором проигрышный класс соответствует вероятности взаимодействия пользователя с другим элементом веб-контента, находящимся на позиции ниже заданной позиции ранжирования.
12. Способ по п. 7, в котором модель обеспечивает выдачу вероятностей принадлежности к выигрышному классу и к проигрышному классу для каждой позиции ранжирования из набора позиций ранжирования, а обучение предусматривает настройку модели для минимизации разности между выдаваемыми вероятностями и вероятностями, указанными в положительном и отрицательном обучающих наборах.
13. Способ по п. 7, в котором обучение предусматривает сбор случайных данных, при этом заданная позиция ранжирования выбирается случайным образом.
14. Способ по п. 7, в котором положительный обучающий набор является примером взаимодействия пользователя с обучающим элементом веб-контента на заданной позиции ранжирования в заданном контексте, а отрицательный обучающий набор - примером взаимодействия пользователя с обучающим элементом веб-контента на позиции ранжирования ниже заданной позиции, при этом обучение обеспечивает настройку модели для расчета вероятностей принадлежности к выигрышному классу и к проигрышному классу.
15. Система для формирования страницы результатов поиска, содержащая сервер, способный передавать страницу результатов поиска на электронное устройство, связанное с пользователем поисковой системы, размещенной на сервере, соединенном с электронным устройством и способном:
- получать от электронного устройства данные о запросе, указывающие на отправленный пользователем запрос;
- определять набор элементов веб-контента, включающий в себя соответствующие запросу результаты поиска и содержащий заданный элемент веб-контента, на основе данных о запросе,
- формировать контекстные данные на основе набора элементов веб-контента и данных о запросе;
- передавать контекстные данные в модель, представляющую собой мультиклассификационную модель для множества классов, содержащего два класса, назначенных заданной позиции ранжирования на странице результатов поиска, а именно - выигрышный класс, указывающий на прогнозируемую выгоду от размещения заданного элемента веб-контента на заданной позиции ранжирования на странице результатов поиска, и проигрышный класс, указывающий на прогнозируемый ущерб от размещения заданного элемента веб-контента на заданной позиции ранжирования на странице результатов поиска;
- определять для заданной пары «элемент веб-контента - позиция», содержащей заданный элемент веб-контента и заданную позицию ранжирования, значение метрики, представляющее собой разность между прогнозируемой величиной выгоды выигрышного класса в модели для заданного элемента веб-контента и прогнозируемой величиной ущерба проигрышного класса в модели для заданного элемента веб-контента и характеризующее общую полезность размещения заданного элемента веб-контента на заданной позиции ранжирования; и
- формировать страницу результатов поиска с заданным элементом веб-контента, размещенным на заданной позиции ранжирования, на основе значения метрики.
16. Система по п. 15, в которой модель обеспечивает выдачу вероятностей принадлежности к выигрышному классу и к проигрышному классу для каждой позиции ранжирования из набора позиций ранжирования, а также определение значения метрики для каждой позиции ранжирования из набора позиций ранжирования, при этом заданная позиция ранжирования на странице результатов поиска для заданного элемента веб-контента выбрана на основе максимальной разности.
17. Система по п. 15, в которой заданным элементом веб-контента является виджет для размещения среди веб-документов, включенных в соответствующие запросу результаты поиска.
18. Система по п. 15, в которой контекстные данные содержат ранжированные веб-документы из поисковой системы.
19. Система по п. 15, в которой выигрышный класс соответствует вероятности взаимодействия пользователя с заданным элементом веб-контента на заданной позиции ранжирования.
20. Система по п. 15, в которой проигрышный класс соответствует вероятности взаимодействия пользователя с другим элементом веб-контента, находящимся на позиции ниже заданной позиции ранжирования.
| US 9916366 B1, 13.03.2018 | |||
| US 11250074 B2, 15.02.2022 | |||
| СПОСОБ И СИСТЕМА ДЛЯ РАНЖИРОВАНИЯ ЦИФРОВЫХ ОБЪЕКТОВ НА ОСНОВЕ СВЯЗАННОЙ С НИМИ ЦЕЛЕВОЙ ХАРАКТЕРИСТИКИ | 2019 |
|
RU2757174C2 |
| US 9009146 B1, 14.04.2015 | |||
| Способ восстановления спиралей из вольфрамовой проволоки для электрических ламп накаливания, наполненных газом | 1924 |
|
SU2020A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| СПОСОБ ФОРМИРОВАНИЯ ПЕРСОНАЛИЗИРОВАННОЙ МОДЕЛИ РАНЖИРОВАНИЯ, СПОСОБ ФОРМИРОВАНИЯ МОДЕЛИ РАНЖИРОВАНИЯ, ЭЛЕКТРОННОЕ УСТРОЙСТВО И СЕРВЕР | 2014 |
|
RU2580516C2 |
| НАСТРОЙКА ПОИСКА В РЕАЛЬНОМ ВРЕМЕНИ | 2014 |
|
RU2663478C2 |
| СПОСОБЫ И СИСТЕМЫ ДЛЯ УЛУЧШЕНИЯ РАНЖИРОВАНИЯ ПОИСКА С ИСПОЛЬЗОВАНИЕМ ИНФОРМАЦИИ О СТАТЬЕ | 2004 |
|
RU2335013C2 |

