Изобретение относится к вычислительной технике, конкретнее к способам формирования квазиструктурированных моделей фактографического информационного наполнения документов, и может быть использовано при создании баз данных.
Известен способ оценки систем с помощью параметров [Гмошинский, В.Г. Теоретические основы инженерного прогнозирования / В.Г.Гмошинский, Г.И.Флиорент. - М.: Наука, 1973. - 304 с.].
Недостатком данного способа является отсутствие адаптации для формирования квазиструктурированных моделей фактографического информационного наполнения документов, отсутствие рекомендации по сверткам параметров и виду целевой функции для моделей документов.
Наиболее близким к предлагаемому способу является способ формирования технических объектов с помощью параметров эффекта и сформированной целевой функции в виде их свертки [Руднев, В.Е. Формирование технических объектов на основе системного анализа / В.Е.Руднев, В.В.Володин, К.М.Лучанский, В.Б.Петров - М.: Машиностроение, 1991. - 320 с.].
Под параметром эффекта понимают параметр, обладающий физическим смыслом. Важнейшей особенностью параметров эффекта является то, что они устанавливаются через операцию - законченное действие, направленное на решение определенной задачи.
Недостатком известного способа также является отсутствие его адаптации к формированию квазиструктурированных моделей фактографического информационного наполнения документов и отсутствие определения вида целевой функции.
Техническим результатом предлагаемого способа является оптимизация процесса формирования квазиструктурированных моделей фактографического информационного наполнения документов.
Технический результат достигается тем, что в способе формирования квазиструктурированных моделей фактографического информационного наполнения документов, заключающемся в определении параметров эффекта и целевой функции, в качестве параметров эффекта выбирают валидацию модели, степень детализации модели, равномерность распределения структурных единиц модели по документу, насыщенность структурных единиц модели в документе, гибкость модели, а в качестве целевой функции выбирают свертку параметров эффекта, причем валидацию модели определяют из соответствия модели стандарту на содержание и она равна единице, степень детализации модели определяют из отношения количества символов контента структурных единиц модели к общему количеству структурных единиц модели и она минимизирована, равномерность распределения структурных единиц модели по документу определяют из отношения количества символов фрагмента к количеству структурных единиц модели данного фрагмента и она минимизирована, насыщенность структурных единиц модели в документе определяют из отношения количества символов документа к количеству символов контента структурных единиц модели и она минимизирована, гибкость модели определяют из отношения общего количества структурных единиц модели без учета необязательных и повторяющихся структурных единиц модели к общему количеству структурных единиц модели и она стремится к нулю, а целевую функцию определяют из отношения суммы значений всех вышеперечисленных параметров эффекта к значению параметра валидации модели.
Валидацию модели выполняют успешно только при использовании обязательных структурных единиц в порядке следования, определенном его моделью, и при соответствии контента обязательных структурных единиц типам данных и шаблонам, которые заданы в модели в качестве как строковых, целочисленных, вещественных, так и бинарных, темпоральных и пользовательских типов данных.
В качестве шаблонов используют наборы правил, которые накладывают дополнительные ограничения на формат контента структурных единиц в дополнение к типу данных.
В качестве пользовательских типов данных используют набор структурных единиц, правил их использования в документе, а также их шаблоны и типы данных.
Математическая модель информационного наполнения документа с учетом спецификации Xml Schema Definition (XSD) записана следующим образом:

где root - корневой объект, root∈sObj; sObj - конечное множество объектов, каждый из которых содержит фрагмент информационного наполнения документа (текст, рисунок и т.д.) или выполняет роль контейнера для одного или нескольких объектов. Для объектов-контейнеров доступны следующие метасвойства: smetc - определяет объект в качестве контейнера; mixed - разрешает использование объектов-потомков в произвольном порядке; kol_o - количество объектов модели; LObj - отображение, определенное на множестве sObj, такое что 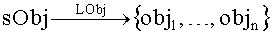
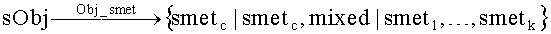
На фиг.1 представлен графический вид электронного документа по предлагаемому способу.
Документ состоит из пяти объектов. Объект А выполняет роль контейнера для объектов В и С, объект В выполняет роль контейнера для объектов D и Е. Объекты А, В, D обязательно должны быть использованы при разработке документа, объект С является необязательным к использованию, объект Е в рассматриваемом примере должен быть использован от трех до пяти раз. Объекту-контейнеру А соответствует метасвойство ограничения smetc, а для объекта-контейнера В определено дополнительно метасвойство mixed. Объект С представлен числовым наполнением, т.е. ему соответствует метасвойство ограничения smet2. Объекты D, Е - имеют символьное информационное наполнение, которому соответствует метасвойство ограничения smet1.
Модель документа имеет вид:
root={A}; sObj=[A,B,C,D,E}; LObj(A)={B,C}, LObj(B)={D,E|E,D], LObj(C)={}, LObj(D)={}, LObj(E}={};
Obj_smet(A)={smetc}, Obj_smet(B)=[smetc,mixed}, Obj_smet(C)={smet2}, Obj_smet(D)={smet1}, Obj_smet(E)={smet1};
minOccurs(A)=1, maxOccurs(A)=1; minOccurs(B)=1, maxOccurs(B)=1;
minOccurs(c)=0, maxOccurs(C)=1; minOccurs(D)=1, maxOccurs(D)=1;
mmOccurs(E)=3, maxOccurs(E)=5.
Для оценки качества квазиструктурированных моделей используют пять параметров эффекта.
Параметр эффекта в виде валидации документа характеризует соответствие модели стандарту на содержание рассматриваемых документов.
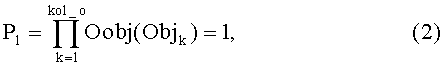
где Oobj - функция, возвращающая единицу для обязательных к использованию объектов в документе, удовлетворяющих условию: minOccurs(Objk)=1, где Objk∈sObj, если они корректно использованы в документе, в противном случае функция возвращает ноль. Данный параметр эффекта должен быть равен единице, так как использование обязательных структурных единиц модели является условием применения модели документа.
Параметр эффекта в виде степени детализации, т.е. размера контента использованных в документе объектов (структурных единиц) модели должен быть минимизирован, так как при работе с объектами всегда проще укрупнять, чем детализировать информационное наполнение документа.

l=1, …, kol_o,
где Len - функция, возвращающая число символов в контенте для указанного объекта; Cobj - функция, возвращающая число объектов множества, удовлетворяющих условию Obj_smet(Objm)∩{smetc}=⌀, m=1, …, kol_o.
Параметр эффекта в виде плотности использования объектов модели, т.е. уровня проработки модели документа, характеризует равномерность распределения объектов (структурных единиц) модели по документу.
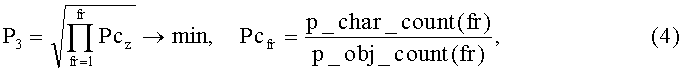
где Pcfr - плотность объектов модели на фрагменте документа (фрагмент равен странице документа или абзацу, т.е. документ состоит mfr (фрагментов);
p_char_count - функция, возвращающая число символов в заданном фрагменте; p_obj_count - функция, возвращающая число объектов Objo таких, что Obj_smet(Objo)∩{smetc}=⌀, O=1, …, kol_o целиком размещенных в заданном фрагменте. Рассматриваемый параметр должен быть минимизирован.
Параметр эффекта в виде насыщенности объектов (структурных единиц) модели в документе, т.е. характеризует качество описания информационного наполнения документа.
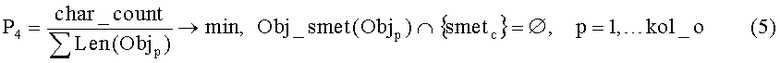
где char_count - функция, возвращающая количество символов в документе. Параметр P4 должен быть минимизирован, так как необходимо сократить неописываемое информационное наполнение в документе.
Параметр эффекта в виде гибкости модели, которая позволяет эффективнее описать квазиструктурированное информационное наполнение документа, следовательно, данный параметр эффекта должен быть минимизирован.

где Aobj - функция, возвращающая число объектов без учета корневого элемента root, Uobj - функция, возвращающая число объектов множества, удовлетворяющих условиям: minOccurs(Objr}=0; maxOccurs{Objr)=>1, r=1, …, kol_o; Robj - функция, возвращающая число объектов множества, удовлетворяющих условиям minOccurs(Objt)=1; maxOccurs(Objt)>1, t=1, …, kol_о.
Для окончательной оценки качества рассматриваемых моделей вводят целевую функцию в виде скалярной критериальной функции:
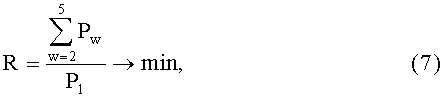
где Pw - значение w-го параметра анализируемой модели. Ее значение для лучшей из рассматриваемых моделей будет минимальным.
Когда модель не соответствует информационному наполнению документа и не выполняется ее валидация, целевая функция (7) будет неопределена, а следовательно, она не может быть использована для описания фактографического информационного наполнения.
Квазиструктурированную модель фактографического информационного наполнения может быть сформирована следующим образом.
Разработку модели для определенного вида документов начинают с поиска ГОСТов и нормативно-технических документов, описывающих требования к контенту документов данного вида.
Если требования к содержимому документов определены в ГОСТах или нормативно-технических документах, то их учитывают при создании модели, в противном случает данные требования формируют на основе анализа содержимого документов данного вида.
Полученные требования организуют в виде модели фактографического информационного наполнения документа, таким образом, чтобы полученная модель была валидной для всех документов данного вида.
Вычисляют значения всех обозначенных выше параметров эффекта и целевой функции для каждого документа, затем вычисляют среднее значение целевой функции.
Проводят анализ контента структурных единиц полученной модели с целью внесения изменений в структуру модели для уменьшения значений параметров эффекта за исключением параметра валидации.
После учета изменений для новой модели выполняют вычисление значений параметров эффекта и целевой функции для каждого документа, затем вычисляют среднее значение целевой функции.
Выполняют сравнение средних значений целевой функции для первоначальной модели и для скорректированной. Если внесение изменений привело к снижению среднего значения целевой функции, то новая скорректированная модель оптимальна с точки зрения эффективности описания фактографического контента информационного наполнения для данного вида документов.
Рассмотренный алгоритм выполняют до тех пор, пока внесение корректировок в модель снижает среднее значение целевой функции для данного вида документов. Алгоритм соответствует методу векторной оптимизации на дискретном множестве.
Использование данного способа для формирования квазиструктурированных моделей фактографического информационного наполнения документов обеспечивает повышение эффективности описания контента на 30% и более в зависимости от вида документов.
Изобретение относится к вычислительной технике и может быть использовано при создании баз данных. Техническим результатом является оптимизация процесса формирования квазиструктурированных моделей фактографического информационного наполнения документов. Способ формирования квазиструктурированных моделей фактографического информационного наполнения документов заключается в определении параметров эффекта и целевой функции. В качестве параметров эффекта выбирают валидацию модели, степень детализации модели, равномерность распределения структурных единиц по документу, насыщенность структурных единиц в документе, гибкость модели. В качестве целевой функции выбирают свертку параметров эффекта. Вычисляют значения всех параметров эффекта и целевой функции для каждого документа, затем вычисляют среднее значение целевой функции. Анализируют контент структурных единиц полученной модели с целью внесения изменений и вычисляют значения параметров эффекта и целевой функции для каждого документа, затем вычисляют среднее значение целевой функции. Сравнивают средние значения целевой функции. Если среднее значение целевой функции снизилось, то новая скорректированная модель оптимальна. 5 з.п. ф-лы, 1 ил.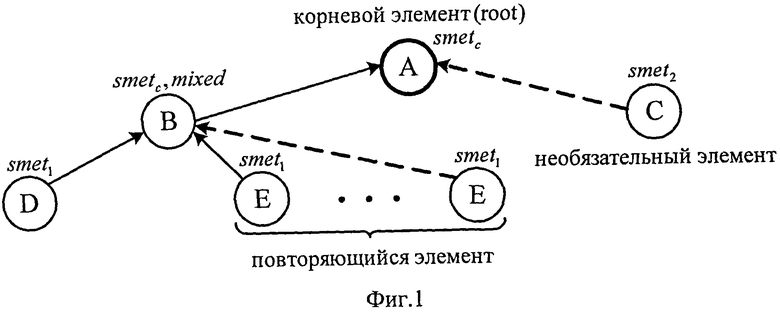
1. Способ формирования квазиструктурированных моделей фактографического информационного наполнения документов, заключающийся в построении первоначальной модели, определении параметров эффекта и целевой функции для каждого документа первоначальной модели, вычислении среднего значения целевой функции первоначальной модели, выполнении анализа контента структурных единиц полученной модели с внесением изменений в структуру первоначальной модели для уменьшения значений параметров эффекта за исключением параметра валидации, определении параметров эффекта и целевой функции для каждого документа скорректированной модели, вычислении среднего значения целевой функции скорректированной модели, сравнении средних значений целевой функции для первоначальной и скорректированной моделей в рамках хотя бы одной итерации, причем в качестве параметров эффекта выбирают валидацию модели, степень детализации модели, равномерность распределения структурных единиц модели по документу, насыщенность структурных единиц модели в документе, гибкость модели, а в качестве целевой функции выбирают свертку параметров эффекта, причем валидацию модели определяют из соответствия модели стандарту на содержание и она равна единице, степень детализации модели определяют из отношения количества символов контента структурных единиц модели к общему количеству структурных единиц модели и она минимизирована, равномерность распределения структурных единиц модели по документу определяют из отношения количества символов фрагмента к количеству структурных единиц модели данного фрагмента и она минимизирована, насыщенность структурных единиц модели в документе определяют из отношения количества символов документа к количеству символов контента структурных единиц модели и она минимизирована, гибкость модели определяют из отношения общего количества структурных единиц модели без учета необязательных и повторяющихся структурных единиц модели к общему количеству структурных единиц модели и она стремится к нулю, а целевую функцию определяют из отношения суммы значений всех вышеперечисленных параметров эффекта к значению параметра валидации модели.
2. Способ по п.1 отличающийся тем, что в первом параметре эффекта валидацию выполняют при использовании обязательных структурных единиц в порядке следования в модели.
3. Способ по п.1 отличающийся тем, что в первом параметре эффекта валидацию выполняют при соответствии контента обязательных структурных единиц типам данных и шаблонам, которые заданы в модели.
4. Способ по п.3 отличающийся тем, что в качестве типов данных используют строковые, целочисленные, вещественные, бинарные, темпоральные и пользовательские.
5. Способ по п.3 отличающийся тем, что в качестве шаблонов используют набор дополнительных ограничений на формат контента структурных единиц.
6. Способ по п.4 отличающийся тем, что в качестве пользовательских типов данных используют набор структурных единиц, правил их использования в документе, а также их шаблоны.
| СИСТЕМЫ И СПОСОБЫ МОДЕЛИРОВАНИЯ ДАННЫХ В ОСНОВАННОЙ НА ПРЕДМЕТАХ ПЛАТФОРМЕ ХРАНЕНИЯ | 2003 |
|
RU2371757C2 |
| СПОСОБ СИНТЕЗА САМООБУЧАЮЩЕЙСЯ СИСТЕМЫ ИЗВЛЕЧЕНИЯ ЗНАНИЙ ИЗ ТЕКСТОВЫХ ДОКУМЕНТОВ ДЛЯ ПОИСКОВЫХ СИСТЕМ | 2002 |
|
RU2273879C2 |
| Химический огнетушитель | 1927 |
|
SU8675A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |

