ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Изобретение относится к кодированию и/или декодированию множества аудиосигналов и в частности, но не исключительно, к кодированию и декодированию множества аудиообъектов.
УРОВЕНЬ ТЕХНИКИ ИЗОБРЕТЕНИЯ
Цифровое кодирование различных сигналов источника становится все более важным в последние десятилетия по мере того как представление и связь на основе цифрового сигнала все более замещает аналоговое представление и связь. Например, аудиоконтент, такой как речь и музыка, все более основан на кодировании цифрового контента.
Форматы аудиокодирования были разработаны для обеспечения более эффективных, разнообразных и гибких аудио услуг и в частности были разработаны форматы аудиокодирования, поддерживающие услуги пространственного аудио.
Общеизвестные технологии кодирования пространственного аудио, подобные DTS и Dolby Digital, создают закодированный многоканальный аудиосигнал, который представляет собой пространственный образ в качестве некоторого количества каналов, которые размещены вокруг слушателя в фиксированных позициях. Для структуры громкоговорителей, которая отличается от структуры, которая соответствует многоканальному сигналу, пространственный образ будет не оптимальным. Также, эти основанные на канале системы аудиокодирования, как правило, не способны справляться с отличным количеством громкоговорителей.
Подход таких обычных подходов иллюстрируется на Фиг. 1 (где буква c относится к аудиоканалу). Входные каналы (например, 5.1 каналы) предоставляются кодеру, который выполняет матрицирование для использования межканальных зависимостей, с последующим кодированием матрицированного сигнала в битовый поток. В дополнение, информация о матрицировании также может быть передана декодеру, как часть битового потока. На стороне декодера этот процесс реверсируется.
Стандарт MPEG Surround предоставляет инструмент кодирования многоканального аудио, который обеспечивает возможность расширения существующих основанных на моно или стерео кодеров для приложений многоканального аудио. Фиг. 2 иллюстрирует пример элементов системы стандарта MPEG Surround. Используя пространственные параметры, получаемые посредством анализа исходного многоканального ввода, декодер стандарта MPEG Surround может воссоздать пространственный образ посредством управляемого разведения моно- или стерео сигнала для получения многоканального выходного сигнала.
Поскольку пространственный образ многоканального входного сигнала является параметризированным, стандарт MPEG Surround обеспечивает возможность декодирования того же многоканального битового потока устройствами рендеринга, которые не используют многоканальную структуру громкоговорителей. Примером является виртуальное окружающее воспроизведение в головных телефонах, которое именуется процессом бинаурального декодирования MPEG Surround. В этом режиме реалистичное окружающее восприятие может быть обеспечено при использовании обыкновенных головных телефонов. Другим примером является преобразование многоканальных выходных данных более высокого порядка, например, 7.1 каналов, в структуры более низкого порядка, например, 5.1 каналы.
Подход стандарта MPEG Surround (и аналогичные подходы параметрического многоканального кодирования, такой как Бинауральное Кодирование с Метками или Параметрическое Стерео) иллюстрируется на Фиг. 3. В противоположность подходу дискретного кодирования или кодирования по форме волны, осуществляется понижающее микширование входных каналов (например, в сигнал стерео микширования). Это понижающее микширование (downmix) затем кодируется, используя традиционные методики кодирования, такие как кодеки семейства AAC. В дополнение к кодированному понижающему микшированию, в битовом потоке также передается представление пространственного образа. Декодер реверсирует процесс.
Для того, чтобы обеспечить более гибкое представление аудио, MPEG стандартизировал формат, известный как ‘Spatial Audio Object Coding’ (MPEG-D SAOC). В противоположность системам кодирования многоканального аудио, таким как DTS, Dolby Digital и MPEG Surround, SAOC обеспечивает эффективное кодирование отдельных аудиообъектов, а не аудиоканалов. Тогда как в стандарте MPEG Surround, каждый канал громкоговорителя может быть рассмотрен, как происходящий из разного рода смеси звуковых объектов, SAOC обеспечивает доступность отдельных звуковых объектов на стороне декодера для интерактивного манипулирования, как иллюстрируется на Фиг. 4. В SAOC, несколько звуковых объектов кодируются в моно или стерео понижающее микширование совместно с параметрическими данными, что позволяет извлекать звуковые объекты на стороне рендеринга, тем самым предоставляя возможность манипулирования отдельными аудиообъектами, например, конечному пользователю.
На самом деле, аналогично стандарту MPEG Surround, SAOC также создает моно или стерео понижающее микширование. В дополнение вычисляются и включаются параметры объекта. На стороне декодера, пользователь может манипулировать этими параметрами для управления различными особенностями отдельных объектов, такими как позиция, уровень, коррекция, или даже применять эффекты, такие как реверберация. Фиг. 5 иллюстрирует интерактивный интерфейс, который предоставляет пользователю возможность управления отдельными объектами в битовом потоке SAOC. Посредством матрицы рендеринга отдельные звуковые объекты отображаются в каналах громкоговорителей.
Фиг. 6 предоставляет высокоуровневую структурную схему параметрического подхода SAOC (или подобных систем кодирования объекта). Осуществляется понижающее микшированием сигналов (o) объекта и кодирование результирующего понижающего микширования. В дополнение, параметрические данные объекта передаются в битовом потоке, связывая отдельные объекты с понижающим микшированием. На стороне декодера, объекты декодируются и выполняется рендеринг по каналам, в соответствии с конфигурацией громкоговорителей. Как правило, в таком подходе, более эффективным является объединение декодирования объектов и рендеринга громкоговорителя.
Вариация и гибкость в конфигурациях рендеринга, используемых для рендеринга пространственного звука, значительно возросли в последние годы, так как основному потребителю становится доступно все больше и больше форматов воспроизведения. Это требует гибкого представления аудио. Важные этапы были предприняты в отношении внедрения кодека MPEG Surround. Все же, аудио все еще создается и передается для конкретной структуры громкоговорителей. Воспроизведение через отличные структуры и через нестандартные структуры (т.е., гибкие или определяемые пользователем) структуры громкоговорителей не определено.
Эта проблема может быть частично решена посредством SAOC, который передает аудиообъекты вместо воспроизведения каналов. Это позволяет стороне декодера размещать аудиообъекты в произвольных позициях в пространстве, при условии, что пространство в достаточной мере охватывается громкоговорителями. Таким образом, отсутствует зависимость между передаваемым аудио и структурой воспроизведения, следовательно, могут быть использованы произвольные структуры громкоговорителей. Это является преимуществом для, например, структур домашнего кинотеатра в типичной гостиной, где громкоговорители почти никогда не находятся в предназначенных позициях из-за планировки гостиной. В SAOC, на стороне декодера принимается решение о том, где размещаются объекты в звуковой сцене. Это часто не желательно с художественной точки зрения, и вследствие этого стандарт SAOC не предоставляет способов для передачи матрицы рендеринга по умолчанию в битовом потоке, исключая ответственность декодера. Эти матрицы рендеринга вновь привязаны к конкретным конфигурациям громкоговорителей.
В SAOC, в результате понижающего микширования, извлечение объекта работает лишь в некоторых границах. Как правило, невозможно извлечь один объект с достаточно высоким отделением от других объектов для воспроизведения без других объектов, например, в случае использования Караоке. Кроме того, из-за параметризации, технология SAOC не очень хорошо масштабируется с битовой скоростью. В частности, подход в виде понижающего микширования и извлечения (повышающего микширования) аудиообъектов приводит к некоторой неотъемлемой потере информации, которая не полностью компенсируется даже при очень высоких битовых скоростях. Таким образом, даже при увеличении битовой скорости, результирующее качество аудио, как правило, снижено и не позволяет обеспечить полную прозрачность операций кодирования/декодирования.
Для решения этой проблемы, SAOC поддерживает так называемое остаточное кодирование, которое может быть применено для ограниченного набора объектов (вплоть до и включая 4, которые были проектным выбором). Остаточное кодирование в основном передает дополнительные компоненты битового потока, которые кодируют сигналы ошибки (включая перекрестные помехи от других объектов на тот объект) так что ограниченное количество объектов может быть извлечено с высокой степенью отделения объекта. Остаточные компоненты формы волны могут доставляться вплоть до конкретной частоты, так что качество может повышаться постепенно. Таким образом, результирующий объект является комбинацией параметрического компонента и компонента формы волны.
Другая спецификация для аудиоформата применительно к 3D аудио разрабатывается Альянсом 3D Аудио (3DAA), который является промышленным альянсом, инициированным SRS (Система Восстановления Звука) Labs. Назначение 3DAA состоит в разработке стандартов для передачи 3D аудио, которые «будет способствовать переходу от настоящей парадигмы подачи на громкоговоритель к гибкому, основанному на объекте, подходу». В 3DAA, должен быть определен формат битового потока, который обеспечивает передачу традиционного многоканального понижающего микширования с отдельными звуковыми объектами. В дополнение, включаются данные позиционирования объекта. Принцип генерирования аудиопотока 3DAA иллюстрируется на Фиг. 7.
В подходе 3DAA, звуковые объекты принимаются по-отдельности в потоке расширения, и они могут быть извлечены из многоканального понижающего микширования. Рендеринг результирующего многоканального понижающего микширования выполняется совместно с доступными по-отдельности объектами.
В 3DAA, многоканальный опорный сигнал микширования (mix) может быть передан вместе с выбором аудиообъектов. 3DAA передает 3D позиционные данные для каждого объекта. Объекты затем могут быть извлечены, используя 3D позиционные данные. В качестве альтернативы, может быть передана обратная матрица микширования, описывающая зависимость между объектами и опорным сигналом микширования. Иллюстрация Фиг. 6 может быть рассмотрена как также соответствующая подходу 3DAA.
Оба подхода SAOC и 3DAA включают в себя передачу отдельных аудиообъектов, которыми можно по-отдельности манипулировать на стороне декодера. Разница между двумя подходами состоит в том, что SAOC предоставляет информацию об аудиообъектах путем предоставления параметров, характеризующих объекты относительно понижающего микширования (т.е. таким образом, что аудиообъекты генерируются из понижающего микширования на стороне декодера), тогда как 3DAA предоставляет аудиообъекты в качестве полных и отдельных аудиообъектов (т.е., которые могут быть сгенерированы независимо от понижающего микширования на стороне декодера).
В MPEG в разработке находится новый рабочий элемент применительно к 3D Аудио. Он именуется MPEG-3D Аудио и предназначен стать частью набора MPEG-H наряду с кодированием видео HEVC и системами DASH. Фиг. 8 иллюстрирует настоящую высокоуровневую структурную схему предназначенной системы MPEG-3D Аудио.
В дополнение к традиционному основанному на канале формату, подход предназначен также поддерживать основанный на объекте и основанный на сцене форматы. Важным аспектом системы является то, что ее качество должно масштабироваться до прозрачности применительно к увеличивающейся битовой скорости, т.е., по мере того как увеличивается скорость передачи данных, ухудшение, вызываемое кодированием и декодированием, должно продолжать уменьшаться до тех пор, пока оно не станет несущественным. Тем не менее, такое требование, как правило, проблематично применительно к методикам параметрического кодирования, которые в достаточно большой степени использовались в прошлом (а именно в HE-AAC v2, MPEG Surround, SAOC, USAC). В частности, компенсация потери информации для отдельных сигналов имеет тенденцию не полностью компенсироваться параметрическими данными даже при очень высоких битовых скоростях. В самом деле, качество будет ограничиваться качеством, которое присуще параметрической модели.
Кроме того, MPEG-3D Аудио стремится предоставить результирующий битовый поток, который является независимым от структуры воспроизведения. Предполагаемые возможности воспроизведения включают в себя гибкие структуры громкоговорителей вплоть до 22.2 каналов, как, впрочем, и виртуальное окружение через головные телефоны и близко расположенные громкоговорители.
Другой подход известен как DirAC - Направленное Кодирование Аудио (DirAC), который подобен MPEG Surround и SAOC в том смысле, что понижающее микширование передается наряду с параметрами, что позволяет воспроизводить пространственный образ на стороне синтеза. В DirAC эти параметры представляют собой результаты анализа направления и диффузности (азимут, высоту и диффузность Ψ(t/f)). Во время синтеза понижающее микширование динамически делится на два потока, один, который соответствует не-диффузному звуку (весовой коэффициент 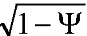 ), а другой, который соответствует диффузному звуку (весовой коэффициент
), а другой, который соответствует диффузному звуку (весовой коэффициент 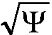 ). Не диффузный звуковой поток воспроизводится с помощью методики направленной на точечные источники звука, а диффузный звуковой поток с помощью методик направленных на восприятие заметного направления с отсутствующим звуком. Подход DirAC иллюстрируется на Фиг. 9.
). Не диффузный звуковой поток воспроизводится с помощью методики направленной на точечные источники звука, а диффузный звуковой поток с помощью методик направленных на восприятие заметного направления с отсутствующим звуком. Подход DirAC иллюстрируется на Фиг. 9.
DirAC может считаться системой кодирования/декодирования основанной на записи в соответствии с подходом на Фиг. 10. В системе, кодируются сигналы (m) микрофона. Это может, например, быть выполнено аналогично параметрическому подходу, используя понижающее микширование и кодирование пространственной информации. На декодере, сигналы микрофона могут быть восстановлены, и на основании предоставленной конфигурации громкоговорителей, может быть выполнен рендеринг сигналов микрофона по каналам. Следует отметить, что по причинам эффективности, процесс декодирования и рендеринг может быть интегрирован в одном этапе.
В документе «The continuity illusion revisited: coding of multiple concurrent sound sources», M. Kelly и др. Proc.MPCA-2002, Левен, Бельгия, 15 ноября 2002 г., предлагается не использовать параметрическое кодирование и понижающее микширование, а вместо этого кодировать отдельные аудиообъекты по-отдельности, используя дискретное кодирование или кодирование по форме волны. Подход иллюстрируется на Фиг. 11. Как иллюстрируется, все объекты кодируются одновременно и передаются на декодер. На стороне декодера, объекты декодируются и выполняется их рендеринг в соответствии с конфигурацией громкоговорителей по каналам. Подход может обеспечить улучшенное качество аудио, и в частности обладает потенциалом масштабирования до прозрачности. Тем не менее, система не обеспечивает значительной эффективности кодирования и требует относительно высоких скоростей передачи данных даже для низкого качества аудио.
Таким образом, существует некоторое количество разных подходов, которые пытаются обеспечить эффективное кодирование аудио.
В наши дни аудиоконтент совместно используется растущим числом разных устройств воспроизведения. Например, аудио может восприниматься через головные телефоны, небольшие громкоговорители, через док-станцию, и/или используя различные многоканальные структуры. Применительно к многоканальным структурам, рекомендуемая ITU 5.1 структура громкоговорителей, которая условно предполагается в качестве номинальной структуры громкоговорителей, часто даже приблизительно не применяется при рендеринге аудиоконтента. Например, точное позиционирование пяти пространственных громкоговорителей в соответствии со структурой часто встречается в типичной гостиной. Громкоговорители размещаются в удобных местоположениях вместо того, чтобы размещаться под рекомендуемыми углами и на рекомендуемых расстояниях. Кроме того, могут быть использованы альтернативные структуры, подобные 4.1, 6.1, 7.1 или даже 22.2 конфигурации. Чтобы обеспечить наилучшее восприятие при всех этих схемах воспроизведения, может наблюдаться тенденция, направленная на кодирование объекта или кодирование сцены. Такие подходы все более внедряются (в настоящее время главным образом для приложений в кинотеатрах, однако ожидается, что более распространенным станет домашнее использование) для замены обычного подхода с аудиоканалами, при котором каждый аудиоканал ассоциируется с номинальной позицией.
Когда количество каналов воспроизведения (т.е., громкоговорителей) и их местоположения не известно, аудиосцена может быть наилучшим образом представлена посредством отдельных аудиообъектов в сцене. На стороне декодера, тогда в отношении каждого из объектов может быть выполнен рендеринг отдельно по каналам воспроизведения так, что пространственное ощущение является наиболее близким к предназначенному ощущению.
Кодирование объектов в качестве отдельных аудиосигналов/потоков требует относительно высокой битовой скорости. Доступные решения (а именно SAOC, DirAC, 3DAA, и т.д.) передают полученные понижающим микшированием сигналы объектов и средства для восстановления сигналов объектов из этого понижающего микширования. Это приводит к значительному сокращению битовой скорости.
SAOC обеспечивает независимое от громкоговорителя аудио посредством эффективного кодирования объекта в понижающее микширование с параметрами извлечения объекта, 3DAA определяет формат, где сцена описывается с точки зрения позиций объекта. DirAC пытается обеспечить эффективное кодирование аудиообъектов посредством использования понижающего микширования B-формата.
Таким образом, эти системы подходят для эффективного и гибкого кодирования и рендеринга аудиоконтента. Может быть достигнуто значительное сокращение скорости передачи данных и соответственно реализации с относительно низкой скоростью передачи данных все же могут обеспечивать разумное или хорошее качество аудио. Тем не менее, проблема таких систем состоит в том, что качество аудио по существу ограничивается параметрическим кодированием и понижающим микшированием. Даже когда доступная скорость передачи данных увеличивается, невозможно достигнуть полной прозрачности, поскольку не может быть выявлено влияние операций кодирования/декодирования. В частности, объект не может быть восстановлен без перекрестных помех от других объектов даже при высоких скоростях передачи данных. Это приводит к уменьшению качества аудио и пространственного ощущения, когда объекты разделаются в пространственном воспроизведении (т.е., выполняется рендеринг в разных позициях). Дополнительный недостаток состоит в том, что в большинстве случаев связность между объектами правильно не восстанавливается, что является важной характеристикой для создания пространственного ощущения. Попытки восстановить связность основаны на использовании декорреляторов и, как правило, приводит к не оптимальному качеству аудио.
Альтернативный подход в виде отдельного кодирования по форме волны аудиообъектов может обеспечить высокое качество при высоких скоростях передачи данных, и может в частности обеспечить полную масштабируемость, включая полностью прозрачное кодирование/декодирование. Тем не менее, такие подходы не подходят для низких скоростей передачи данных, при которых они не обеспечивают эффективного кодирования.
Таким образом, параметрические кодирования, основанные на понижающем микшировании, подходят для низких скоростей передачи данных и масштабируемости в направлении более низких скоростей передачи данных, тогда как кодирования по форме волны объекта подходят для высоких скоростей передачи данных и масштабируемости в направлении высоких скоростей передачи данных.
Масштабируемость очень важный критерий для будущих аудио систем, и вследствие этого весьма желательно иметь эффективную масштабируемость, которая расширяется как в сторону очень низких скоростей передачи данных, так и в сторону очень высоких скоростей передачи данных, и в частности до полной прозрачности. Кроме того, желательно, чтобы такая масштабируемость обладала высокой степенью детализации масштабируемости.
Следовательно, был бы предпочтителен усовершенствованный подход к кодированию/декодированию аудио и, в частности, была бы предпочтительна система, обеспечивающая повышенную гибкость, уменьшенную сложность, усовершенствованную масштабируемость и/или улучшенную производительность.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Соответственно, изобретение предпочтительно стремится подавить, смягчить или исключить один или более из вышеупомянутых недостатков по-отдельности или в любом сочетании.
В соответствии с аспектом изобретения предоставляется декодер, содержащий: приемник для приема закодированного сигнала данных, представляющего собой множество аудиосигналов, причем закодированный сигнал данных содержит закодированные частотно-временные сегменты для множества аудиосигналов, причем закодированные частотно-временные сегменты содержат частотно-временные сегменты без понижающего микширования и частотно-временные сегменты с понижающим микшированием, причем каждый частотно-временной сегмент с понижающим микшированием является понижающим микшированием по меньшей мере двух частотно-временных сегментов из множества аудиосигналов, а каждый частотно-временной сегмент без понижающего микширования представляет собой только один частотно-временной сегмент из множества аудиосигналов, и распределение закодированных частотно-временных сегментов в качестве частотно-временных сегментов с понижающим микшированием или частотно-временных сегментов без понижающего микширования отражает пространственные характеристики частотно-временных сегментов, причем закодированный сигнал данных дополнительно содержит указание понижающего микширования для частотно-временных сегментов из множества аудиосигналов, причем указание понижающего микширования указывает, закодированы ли частотно-временные сегменты из множества аудиосигналов в качестве частотно-временных сегментов с понижающим микшированием или частотно-временных сегментов без понижающего микширования; генератор для генерирования набора выходных сигналов из закодированных частотно-временных сегментов, причем генерирование выходных сигналов содержит повышающее микширование для закодированных частотно-временных сегментов, которые указаны указанием понижающего микширования как являющиеся частотно-временными сегментами с понижающим микшированием; при этом по меньшей мере один аудиосигнал из множества аудиосигналов представляется двумя частотно-временными сегментами с понижающим микшированием, являющимися понижающими микшированиями разных наборов аудиосигналов из множества аудиосигналов; и по меньшей мере один частотно-временной сегмент с понижающим микшированием является понижающим микшированием аудиообъекта, не ассоциированного с номинальной позицией источника звука конфигурации рендеринга источника звука, и аудиоканала, ассоциированного с номинальной позицией источника звука конфигурации рендеринга источника звука.
Изобретение может улучшить декодирование аудио, и, в частности, может во многих вариантах осуществления обеспечить улучшенную масштабируемость. В частности, изобретение может во многих вариантах осуществления обеспечить масштабируемость скорости передачи данных до прозрачности. В частности, во многих сценариях можно избежать или уменьшить искажения кодирования, известные применительно к параметрическому кодированию при более высоких скоростях передачи данных.
Подход может дополнительно обеспечить эффективное кодирование и, в частности, может обеспечить эффективное кодирование при более низких скоростях передачи данных. Может быть достигнута высокая степень масштабируемости и, в частности, масштабируемость для эффективного кодирования при более низких скоростях передачи данных и может быть достигнуто очень высокое качество (и в частности прозрачность) при высоких скоростях передачи данных.
Изобретение может предоставлять очень гибкую систему с высокой возможной степенью адаптации и оптимизации. Операция кодирования и декодирования может быть адаптирована не только к общим характеристикам аудиосигналов, но также к характеристикам отдельных частотно-временных сегментов. Соответственно может быть достигнуто высокоэффективное кодирование.
Повышающее микширование частотно-временного сегмента с понижающим микшированием может быть отдельной операцией или оно может быть объединено с другими операциями. Например, повышающее микширование может быть частью матричной (векторной) операции, которая перемножает значения сигнала для частотно-временного сегмента с матричными (векторными) коэффициентами, при этом матричные (векторные) коэффициенты отражают операцию повышающего микширования, но могут дополнительно отражать прочие операции, такие как отображение в выходные каналы рендеринга. Повышающее микширование не обязательно должно быть повышающим микшированием всех компонентов понижающего микширования. Например, повышающее микширование может быть частичным повышающим микшированием для генерирования только одного из частотно-временных сегментов, содержащихся в понижающем микшировании.
Частотно-временной сегмент является частотно-временным интервалом. Частотно-временной сегмент выходного сигнала может быть сгенерирован из закодированных частотно-временных сегментов, охватывающих некоторый временной интервал и частотный интервал. Аналогичным образом, каждый частотно-временной сегмент с понижающим микшированием может быть понижающим микшированием частотно-временных сегментов аудиосигналов, охватывающих некоторый временной интервал и частотный интервал. Частотно-временные интервалы могут быть взяты по равномерной сетке или могут, например, быть взяты по не равномерной сетке, в частности применительно к частотному измерению. Такая равномерная сетка может, например, применяться для использования и отражения логарифмической чувствительности человеческого слуха.
Для закодированных частотно-временных сегментов, которые не указаны как частотно-временные сегменты с понижающим микшированием, генерирование выходных сигналов не (обязательно) включает в себя повышающее микширование.
Некоторые частотно-временные сегменты из множества аудиосигналов могут быть не представлены в закодированных частотно-временных сегментах. Частотно-временные сегменты из множества аудиосигналов могут быть не представлены либо в закодированном частотно-временном сегменте с понижающим микшированием, либо в частотно-временном сегменте без понижающего микширования.
В некоторых вариантах осуществления, указание того, закодированы ли частотно-временные сегменты из множества аудиосигналов как частотно-временные сегменты с понижающим микшированием или частотно-временные сегменты без понижающего микширования, может быть предоставлено со ссылкой на закодированные частотно-временные сегменты. В некоторых вариантах осуществления, значение указания понижающего микширования может быть предоставлено по-отдельности для частотно-временных сегментов из множества аудиосигналов. Эквивалентно, в некоторых вариантах осуществления значение указания понижающего микширования может быть предоставлено для группы частотно-временных сегментов из множества аудиосигналов.
Частотно-временной сегмент без понижающего микширования представляет собой данные только для одного частотно-временного сегмента аудиосигналов, тогда как частотно-временной сегмент с понижающим микшированием представляет собой два или более частотно-временных сегментов аудиосигналов. Частотно временные сегменты с понижающим микшированием и частотно-временные сегменты без понижающего микширования могут в разных вариантах осуществления быть закодированными разными способами в закодированном сигнале данных, включая, например, варианты, когда: каждый сегмент закодирован отдельно, некоторые или все закодированы вместе и т.д.
В соответствии с опциональным (необязательным) признаком изобретения, закодированный сигнал данных кроме того содержит параметрические данные повышающего микширования, и при этом генератор выполнен с возможностью адаптирования операции повышающего микширования в ответ на параметрические данные.
Это может обеспечить улучшенную производительность, и, в частности, может обеспечить улучшенное качество аудио при более низких скоростях передачи данных. Изобретение может обеспечить гибкую адаптацию и взаимодействие, например, кодирования сигнала по форме и параметрического кодирования для предоставления весьма масштабируемой системы, и, в частности, системы, выполненной с возможностью обеспечения очень высокого качества аудио для высоких скоростей передачи данных, при этом обеспечивая эффективное кодирование при более низких скоростях передачи данных.
Генератор может в частности генерировать выходные сигналы в ответ на параметрические данные повышающего микширования для закодированных частотно-временных сегментов, которые указаны посредством указания понижающего микширования как частотно-временные сегменты с понижающим микшированием (и не для закодированных частотно-временных сегментов, которые указаны указанием понижающего микширования как не являющиеся закодированными частотно-временными сегментами с понижающим микшированием).
В соответствии с опциональным признаком изобретения, генератор содержит блок рендеринга, выполненный с возможностью отображения частотно-временных сегментов для множества аудиосигналов в выходные сигналы, соответствующие конфигурации источника пространственного звука.
Это может обеспечивать эффективное генерирование аудиосигналов, подходящих для рендеринга посредством заданной конфигурации источника пространственного звука (как правило громкоговорителя). Повышающее микширование и отображение рендеринга может в некоторых вариантах осуществления выполняться в качестве единой интегрированной операции, например, в качестве единого матричного умножения.
В некоторых вариантах осуществления, генератор выполнен с возможностью генерирования декодированных аудиосигналов из закодированных частотно-временных сегментов, и генерирования аудиосигналов посредством пространственного отображения декодированных аудиосигналов по наборам выходных сигналов, при этом набор выходных сигналов соответствует структуре источника пространственного звука.
В соответствии с опциональным признаком изобретения, генератор выполнен с возможностью генерирования частотно-временных сегментов для набора выходных сигналов посредством применения матричных операций к закодированным частотно-временным сегментам, коэффициенты матричных операций включают в себя компоненты повышающего микширования для закодированных частотно-временных сегментов, для которых указание понижающего микширования указывает, что закодированный частотно-временной сегмент является частотно-временным сегментом с понижающим микшированием и не для закодированных частотно-временных сегментов, для которых указание понижающего микширования указывает, что закодированный частотно-временной сегмент является частотно-временным сегментом без понижающего микширования.
Это может обеспечивать в частности эффективную работу. Матричные операции могут быть применены к выборкам сигнала закодированных частотно-временных сегментов. Выборки сигналов могут быть сгенерированы посредством операции декодирования.
В соответствии с опциональным признаком изобретения по меньшей мере один аудиосигнал представляется в декодированном сигнале посредством по меньшей мере одного частотно-временного сегмента без понижающего микширования и по меньшей мере одного частотно-временного сегмента с понижающим микшированием.
Отдельные аудиосигналы могут быть представлены как частотно-временными сегментами с понижающим микшированием, так и частотно-временными сегментами без понижающего микширования. Каждый частотно-временной сегмент аудиосигнала может быть представлен посредством частотно-временного сегмента с понижающим микшированием или частотно-временного сегмента без понижающего микширования, не требуя того, чтобы все частотно-временные сегменты были представлены одинаково. Подход может обеспечивать высокую степень гибкости и оптимизации, и может в частности приводить к улучшенному качеству аудио, эффективности кодирования и/или масштабируемости.
В соответствии с опциональным признаком изобретения, указание понижающего микширования для по меньшей мере одного частотно-временного сегмента с понижающим микшированием содержит связь между закодированным частотно-временным сегментом с понижающим микшированием и частотно-временным сегментом из множества аудиосигналов.
Это может во многих вариантах осуществления обеспечить кодирование как гибко оптимизируемое на основе частотно-временного сегмента. Подход может обеспечивать высокую степень гибкости и оптимизации, и может в частности приводить к улучшенному качеству аудио, эффективности кодирования и/или масштабируемости.
По меньшей мере один аудиосигнал из множества аудиосигналов представляется посредством двух частотно-временных сегментов с понижающим микшированием, являющихся понижающими микшированиями разных наборов аудиосигналов множества аудиосигналов.
Это может во многих вариантах осуществления обеспечить кодирование как гибко оптимизируемое на основе частотно-временного сегмента. Подход может обеспечивать высокую степень гибкости и оптимизации, и может в частности приводить к улучшенному качеству аудио, эффективности кодирования и/или масштабируемости.
В соответствии с опциональным признаком изобретения по меньшей мере один аудиосигнал из множества аудиосигналов представляется посредством закодированных частотно-временных сегментов, которые включают в себя по меньшей мере один закодированный частотно-временной сегмент не являющийся частотно-временным сегментом без понижающего микширования или частотно-временным сегментом с понижающим микшированием.
Это может обеспечить улучшенную эффективность кодирования в некоторых вариантах осуществления. Закодированные частотно-временные сегменты, не являющиеся частотно-временными сегментами без понижающего микширования или частотно-временными сегментами с понижающим микшированием, могут, например, быть закодированы в качестве нулевых частотно-временных сегментов (закодированных в качестве пустого частотно-временного сегмента без данных сигнала), или могут, например, быть закодированными при помощи других методик, таких как кодирование методом центральный/боковой (“mid/side”).
По меньшей мере один частотно-временной сегмент с понижающим микшированием является понижающим микшированием аудиообъекта, не ассоциированного с номинальной позицией источника звука конфигурации рендеринга источника звука, и аудиоканала, ассоциированного с номинальной позицией источника звука конфигурации рендеринга источника звука.
Это может обеспечивать улучшенную гибкость и/или более эффективное кодирование. В частности, частотно-временные сегменты с понижающим микшированием могут включать в себя понижающие микширования частотно-временных сегментов аудиообъектов и аудиоканалов.
В соответствии с опциональным признаком изобретения, по меньшей мере, некоторые из частотно-временных сегментов без понижающего микширования являются закодированными по форме волны.
Это может обеспечить эффективное и потенциально высококачественное кодирование/декодирование. Во многих сценариях это может обеспечить улучшенную масштабируемость, и, в частности, масштабируемость до прозрачности.
В соответствии с опциональным признаком изобретения, по меньшей мере, некоторые из частотно-временных сегментов с понижающим микшированием являются закодированными по форме волны.
Это может обеспечить эффективное и потенциально высококачественное кодирование/декодирование.
В соответствии с опциональным признаком изобретения, генератор (1403) выполнен с возможностью повышающего микширования частотных сегментов с понижающим микшированием для генерирования полученных повышающим микшированием частотно-временных сегментов для по меньшей мере одного из множества аудиосигналов частотно-временного сегмента с понижающим микшированием; и генератор выполнен с возможностью генерирования частотно-временных сегментов для набора выходных сигналов, используя полученные повышающим микшированием частотно-временные сегменты для сегментов, для которых указание понижающего микширования указывает, что закодированный частотно-временной сегмент является частотно-временным сегментом с понижающим микшированием.
Это может способствовать реализации и/или обеспечению высокой производительности.
В соответствии с другим аспектом изобретения, способ декодирования содержит этапы, на которых: принимают закодированный сигнал данных, представляющий собой множество аудиосигналов, причем закодированный сигнал данных содержит закодированные частотно-временные сегменты для множества аудиосигналов, причем закодированные частотно-временные сегменты содержат частотно-временные сегменты без понижающего микширования и частотно-временные сегменты с понижающим микшированием, причем каждый частотно-временной сегмент с понижающим микшированием является понижающим микшированием по меньшей мере двух частотно-временных сегментов из множества аудиосигналов и каждый частотно-временной сегмент без понижающего микширования представляет собой только один частотно-временной сегмент из множества аудиосигналов, и распределение закодированных частотно-временных сегментов в качестве частотно-временных сегментов с понижающим микшированием или частотно-временных сегментов без понижающего микширования отражает пространственные характеристики частотно-временных сегментов, причем закодированный сигнал данных дополнительно содержит указание понижающего микширования для частотно-временных сегментов из множества аудиосигналов, причем указание понижающего микширования указывает, закодированы ли частотно-временные сегменты из множества аудиосигналов как частотно-временные сегменты с понижающим микшированием или частотно-временные сегменты без понижающего микширования; и генерируют набор выходных сигналов из закодированных частотно-временных сегментов, причем генерирование выходных сигналов содержит повышающее микширование для закодированных частотно-временных сегментов, которые указаны указанием понижающего микширования как частотно-временные сегменты с понижающим микшированием; при этом по меньшей мере один аудиосигнал из множества аудиосигналов представляется двумя частотно-временными сегментами с понижающим микшированием, являющимися понижающими микшированиями разных наборов аудиосигналов из множества аудиосигналов; и по меньшей мере один частотно-временной сегмент с понижающим микшированием является понижающим микшированием аудиообъекта, не ассоциированного с номинальной позицией источника звука конфигурации рендеринга источника звука, и аудиоканала, ассоциированного с номинальной позицией источника звука конфигурации рендеринга источника звука.
В соответствии с другим аспектом изобретения, обеспечен кодер, содержащий: приемник для приема множества аудиосигналов, каждый аудиосигнал содержит множество частотно-временных сегментов; селектор для выбора первого подмножества из множества частотно-временных сегментов, которые должны быть подвержены понижающему микшированию; блок понижающего микширования для понижающего микширования частотно-временных сегментов из первого подмножества для генерирования полученных понижающим микшированием частотно-временных сегментов; первый кодер для генерирования частотно-временных сегментов, закодированных с понижающим микшированием, посредством кодирования частотно-временных сегментов с понижающим микшированием; второй кодер для генерирования частотно-временных сегментов без понижающего микширования посредством кодирования второго подмножества частотно-временных сегментов аудиосигналов без понижающего микширования частотно-временных сегментов из второго подмножества; блок для генерирования указания понижающего микширования, указывающего, закодированы ли частотно-временные сегменты из первого подмножества и второго подмножества как частотно-временные сегменты, закодированные с понижающим микшированием, или как частотно-временные сегменты без понижающего микширования; и блок вывода для генерирования закодированного аудиосигнала, представляющего собой множество аудиосигналов, причем закодированный аудиосигнал содержит частотно-временные сегменты без понижающего микширования, частотно-временные сегменты, закодированные с понижающим микшированием, и указание понижающего микширования; при этом селектор выполнен с возможностью выбора частотно-временных сегментов для первого подмножества в ответ на пространственную характеристику частотно-временных сегментов; по меньшей мере один аудиосигнал из множества аудиосигналов представляется двумя частотно-временными сегментами с понижающим микшированием, являющимися понижающими микшированиями разных наборов аудиосигналов из множества аудиосигналов; и по меньшей мере один частотно-временной сегмент с понижающим микшированием является понижающим микшированием аудиообъекта, не ассоциированного с номинальной позицией источника звука конфигурации рендеринга источника звука, и аудиоканала, ассоциированного с номинальной позицией источника звука конфигурации рендеринга источника звука.
Изобретение может обеспечить улучшенное кодирование аудио, и, в частности, может во многих вариантах осуществления обеспечить улучшенную масштабируемость. В частности, изобретение может во многих вариантах осуществления обеспечить масштабируемость скорости передачи данных до прозрачности. В частности, во многих сценариях можно избежать или уменьшить искажения кодирования, которые известны применительно к параметрическому кодированию при более высоких скоростях передачи данных.
Подход может дополнительно обеспечить эффективное кодирование и, в частности, может обеспечить эффективное кодирование при более низких скоростях передачи данных. Может быть достигнута высокая степень масштабируемости и, в частности, масштабируемость для эффективного кодирования при более низких скоростях передачи данных и может быть достигнуто очень высокое качество (и в частности прозрачность) при высоких скоростях передачи данных.
Изобретение может предоставлять очень гибкую систему с высокой возможной степенью адаптации и оптимизации. Операция кодирования и декодирования может быть адаптирована не только к общим характеристикам аудиосигналов, но также к характеристикам отдельных частотно-временных сегментов. Соответственно может быть достигнуто высокоэффективное кодирование.
Блок понижающего микширования может быть дополнительно выполнен с возможностью генерирования параметрических данных для восстановления полученных понижающим микшированием частотно-временных сегментов из полученных понижающим микшированием частотно-временных сегментов; и блок вывода может быть выполнен с возможностью включения параметрических данных в закодированный аудиосигнал.
Первый и второй кодеры могут быть реализованы в качестве единого кодера, например, кодирующего понижающие микширования последовательно и возможно используя одинаковый алгоритм кодирования.
Процесс кодирования может учитывать набор частотно-временных сегментов с понижающим микшированием и отдельные частотно-временные сегменты для улучшения эффективности и качества.
В соответствии с опциональным признаком изобретения селектор выполнен с возможностью выбора частотно-временных сегментов для первого подмножества в ответ на целевую скорость передачи данных для закодированного аудиосигнала.
Это может обеспечивать улучшенную производительность, и может в частности обеспечивать эффективное масштабирование закодированного аудиосигнала.
В соответствии с опциональным признаком изобретения, селектор выполнен с возможностью выбора частотно-временных сегментов для первого подмножества в ответ на по меньшей мере одно из: энергии частотно-временных сегментов; пространственной характеристики частотно-временных сегментов; и характеристики когерентности между парами частотно-временных сегментов.
Это может обеспечивать улучшенную производительность во многих вариантах осуществления и для многих сигналов.
В соответствии с другим аспектом изобретения, способ кодирования, содержащий этапы, на которых: принимают множество аудиосигналов, каждый аудиосигнал содержит множество частотно-временных сегментов; выбирают первое подмножество из множества частотно-временных сегментов, которые должны быть подвержены понижающему микшированию; осуществляют понижающее микширование частотно-временных сегментов из первого подмножества для генерирования полученных понижающим микшированием частотно-временных сегментов; генерируют частотно-временные сегменты, закодированные с понижающим микшированием, посредством кодирования полученных понижающим микшированием частотно-временных сегментов; генерируют частотно-временные сегменты без понижающего микширования посредством кодирования второго подмножества частотно-временных сегментов аудиосигналов без понижающего микширования частотно-временных сегментов из второго подмножества; генерируют указание понижающего микширования, указывающее, закодированы ли частотно-временные сегменты из первого подмножества и второго подмножества как полученные понижающим микшированием закодированные частотно-временные сегменты или как частотно-временные сегменты без понижающего микширования; и
генерируют закодированный аудиосигнал, представляющий собой множество аудиосигналов, причем закодированный аудиосигнал содержит частотно-временные сегменты без понижающего микширования, частотно-временные сегменты, закодированные с понижающим микшированием, и указание понижающего микширования; и при этом выбор содержит выбор частотно-временных сегментов для первого подмножества в ответ на пространственную характеристику частотно-временных сегментов; по меньшей мере один аудиосигнал из множества аудиосигналов представляется двумя частотно-временными сегментами с понижающим микшированием, являющимися понижающими микшированиями разных наборов аудиосигналов из множества аудиосигналов; и по меньшей мере один частотно-временной сегмент с понижающим микшированием является понижающим микшированием аудиообъекта, не ассоциированного с номинальной позицией источника звука конфигурации рендеринга источника звука, и аудиоканала, ассоциированного с номинальной позицией источника звука конфигурации рендеринга источника звука.
В соответствии с другим аспектом изобретения система кодирования и декодирования содержит описанный выше кодер и декодер.
Эти и прочие аспекты, признаки и преимущества изобретения станут очевидны из и будут объяснены со ссылкой на вариант(ы) осуществления, описываемый далее.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Варианты осуществления изобретения будут описаны, лишь в качестве примера, со ссылкой на чертежи, на которых
Фиг. 1 иллюстрирует пример принципа кодирования аудио многоканального сигнала в соответствии с известным уровнем техники;
Фиг. 2 иллюстрирует пример элементов системы MPEG Surround в соответствии с известным уровнем техники;
Фиг. 3 иллюстрирует пример элементов системы MPEG Surround в соответствии с известным уровнем техники;
Фиг. 4 иллюстрирует пример элементов системы SAOC в соответствии с известным уровнем техники;
Фиг. 5 иллюстрирует интерфейс взаимодействия, который позволяет пользователю управлять отдельными объектами, содержащимися в битовом потоке SAOC;
Фиг. 6 иллюстрирует пример элементов системы SAOC в соответствии с известным уровнем техники;
Фиг. 7 иллюстрирует пример принципа кодирования аудио стандарта 3DAA в соответствии с известным уровнем техники;
Фиг. 8 иллюстрирует пример элементов системы MPEG 3D Аудио в соответствии с известным уровнем техники;
Фиг. 9 иллюстрирует пример элементов системы DirAC в соответствии с известным уровнем техники;
Фиг. 10 иллюстрирует пример элементов системы DirAC в соответствии с известным уровнем техники;
Фиг. 11 иллюстрирует пример элементов аудиосистемы в соответствии с известным уровнем техники;
Фиг. 12 иллюстрирует пример элементов аудиосистемы в соответствии с некоторыми вариантами осуществления изобретения;
Фиг. 13 иллюстрирует пример элементов кодера в соответствии с некоторыми вариантами осуществления изобретения;
Фиг. 14 иллюстрирует пример элементов декодера в соответствии с некоторыми вариантами осуществления изобретения;
Фиг. 15 иллюстрирует пример элементов декодера аудиосистемы в соответствии с некоторыми вариантами осуществления изобретения;
Фиг. 16 иллюстрирует пример кодирования частотно-временного сегмента аудиосигналов в качестве частотно-временных сегментов с понижающим микшированием или без понижающего микширования в соответствии с некоторыми вариантами осуществления изобретения; и
Фиг. 17 иллюстрирует пример элементов декодера аудиосистемы в соответствии с некоторыми вариантами осуществления изобретения.
ПОДРОБНОЕ ОПИСАНИЕ НЕКОТОРЫХ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
Фиг. 12 иллюстрирует пример системы рендеринга аудио в соответствии с некоторыми вариантами осуществления изобретения. Система содержит кодер 1201, который принимает аудиосигналы, которые должны быть закодированы. Закодированные аудио данные передаются к декодеру 1203 через подходящее средство 1205 связи.
Аудиосигналы, предоставленные кодеру 1201, могут быть предоставлены в разных формах и могут быть сгенерированы разными путями. Например, аудиосигналы могут быть аудио, захваченным с микрофонов, и/или могут быть искусственно сгенерированным аудио таким, как, например, для приложений компьютерных игр. Аудиосигналы могут включать в себя некоторое количество компонентов, которые могут быть закодированы в качестве отдельных аудиообъектов, таких как, например, конкретные искусственно сгенерированные аудиообъекты или микрофоны, размещенные для захвата конкретного аудио источника, такого как, например, один инструмент.
Каждый аудиообъект, как правило, соответствует одному источнику звука. Таким образом, в противоположность аудиоканалам, и в конкретных аудиоканалах обычного пространственного многоканального сигнала, аудиообъекты, как правило, не содержат компонентов от множества источников звука, которые могут обладать, по существу, разными позициями. Аналогичным образом, каждый аудиообъект, как правило, обеспечивает полное представление источника звука. Каждый аудиообъект, следовательно, как правило, связан с данными пространственной позиции для только одного источника звука. Конкретно, каждый аудиообъект может, как правило, быть рассмотрен в качестве одного и полного представления источника звука и может быть связан с одной пространственной позицией.
Аудиообъекты не связаны с какой-либо конкретной конфигурацией рендеринга и, в частности, не связаны с какой-либо пространственной конфигурацией преобразователей звука/громкоговорителей. Таким образом, в противоположность звуковым каналам, которые связаны с конфигурацией рендеринга, как например конкретной пространственной структурой громкоговорителей (например, структурой окружающего звука), аудиообъекты не определены по отношению к какой-либо конкретной пространственной конфигурации рендеринга.
Таким образом, аудиообъект, как правило, является одним или объединенным источником звука, рассматриваемым в качестве отдельного экземпляра, например, певца, инструмента или хора. Как правило, аудиообъект обладает связанной информацией о пространственной позиции, которая определяет конкретную позицию для аудиообъекта, и в частности позицию точечного источника для аудиообъекта. Тем не менее, эта позиция является независимой от конкретной структуры рендеринга. (Аудио) Сигнал объекта является сигналом, представляющим аудиообъект. Сигнал объекта может содержать несколько объектов, например, которые не сходятся во времени.
В противоположность, аудиоканал связан с номинальной позицией аудиоисточника. Таким образом аудиоканала, как правило, не обладает связанными данными позиции, а связан с номинальной позицией громкоговорителя в номинальной связанной конфигурации громкоговорителей. Таким образом, тогда как аудиоканал, как правило, связан с позицией громкоговорителя в связанной конфигурации, аудиообъект не связан с какой-либо конфигурацией громкоговорителей. Таким образом, аудиоканал представляет объединенное аудио, рендеринг которого должен быть выполнен из заданной номинальной позиции, когда рендеринг выполняется при помощи номинальной конфигурации громкоговорителей. Следовательно, аудиоканал представляет все аудиоисточники аудиосцены, в отношении которых требуется, чтобы рендеринг компонента звука был выполнен из номинальной позиции, связанной с каналом для того, чтобы номинальная конфигурация громкоговорителей выполнила пространственный рендеринг аудиоисточника. В противоположность, аудиообъект, как правило, не связан с какой-либо конкретной конфигурацией рендеринга, а вместо этого предоставляет аудио, в отношении которого должен быть выполнен рендеринг из одной позиции источника звука для того, чтобы связанный компонент звука воспринимался, как исходящий из этой позиции.
Устройство 1201 кодирования пространственного аудио выполнено с возможностью генерирования закодированного сигнала, который содержит закодированные данные, которые представляют собой аудиосигналы (в частности аудиообъекты и/или аудиоканалы), предоставляемые устройству 1201 кодирования пространственного аудио.
Закодированный аудиопоток может быть передан посредством любого подходящего средства связи, включая непосредственную связь или вещательные линии связи. Например, связь может осуществляться через Интернет, сети данных, радиовещания, и т.д. Средство связи может в качестве альтернативы или в дополнение быть реализовано через физический носитель данных, такой как CD, Blu-Ray™, карта памяти, и т.д.
Нижеследующее описание сфокусировано на кодировании аудиообъектов, однако следует иметь в виду, что описываемые принципы, по мере необходимости, также могут быть применены, например, к сигналам аудиоканала.
Фиг. 13 иллюстрирует элементы кодера 1201 более подробно. В примере, кодер 1201 принимает множество аудиосигналов, которые в конкретном примере являются аудиообъектами (в конкретном примере показано четыре аудиообъекта с O1 по O4, однако следует иметь в виду, что они представляют собой любое множество аудиообъектов).
Аудиообъекты принимаются приемником 1301 кодирования, который предоставляет частотно-временные сегменты применительно к аудиообъектам оставшимся частям кодера 1201. Как будет известно специалисту в соответствующей области, частотно-временной сегмент для сигнала соответствует сигналу в заданный временной интервал и заданный частотный интервал. Следовательно, представление сигнала в частотно-временных сегментах означает, что сигнал представляется в некотором количестве сегментов, при этом каждый сегмент обладает связанным частотным интервалом и связанным временным интервалом. Каждый частотно-временной сегмент может предоставлять одно (как правило комплексное) значение, отражающее значение сигнала в связанном временном интервале и частотном интервале. Тем не менее, частотно-временные сегменты также могут быть предоставлять множество значений сигнала. Сигнал часто делится на равномерные частотно-временные сегменты, т.е., временной и/или частотный интервал часто имеет один размер для всех частотно-временных сегментов. Тем не менее, в некоторых сценариях или вариантах осуществления, могут быть использованы неравномерные частотно-временные сегменты, например, посредством использования частотно-временных сегментов, для которых размер частотного интервала увеличивается для увеличивающихся частот.
Во многих вариантах осуществления, аудиосигналы могут быть уже предоставлены кодеру в качестве представлений в частотно-временных сегментах. Тем не менее, в некоторых вариантах осуществления, приемник 1301 кодирования может генерировать такие представления. Это, как правило, может выполняться посредством сегментации сигналов на временные отрезки (например, продолжительностью в 20 мс.) и выполнения преобразования времени в частоту, такого как FFT, над каждым отрезком. Каждое из результирующих значений частотной области может непосредственно представлять частотно-временной сегмент, или в некоторых случаях, множество смежных частотных бинов (смежных по времени и/или частоте) может быть объединено в частотно-временной сегмент.
Для краткости, нижеследующее описание будет ссылаться на частотно-временные сегменты, используя сокращенное понятие «сегменты».
Приемник 1301 кодирования соединен с селектором 1303, который принимает сегменты аудиообъектов. Селектор 1303 затем выполнен с возможностью выбора некоторых сегментов, которые будут кодироваться как полученные понижающим микшированием сегменты, и некоторых сегментов, которые будут кодироваться как не полученные понижающим микшированием сегменты. Полученные понижающим микшированием сегменты будут сегментами, которые генерируются посредством понижающего микширования по меньшей мере двух сегментов, как правило, из по меньшей мере двух аудиообъектов, тогда как сегменты без понижающего микширования будут кодироваться без какого-либо понижающего микширования. Таким образом, сегменты без понижающего микширования будут содержать данные только из одного сегмента кодируемого аудиообъекта/сигнала. Таким образом, сегмент без понижающего микширования будет включать в себя вклад только от одного аудиообъекта, тогда как сегменты с понижающим микшированием будут включать в себя компоненты/вклад, от по меньшей мере двух сегментов и, как правило по меньшей мере двух аудиообъектов. Сегмент без понижающего микширования в частности является сегментом, который не является понижающим микшированием двух или более сегментов.
Селектор 1303 соединен с блоком 1305 понижающего микширования, на который подаются сегменты, выбранные селектором 1303. Затем он переходит к генерированию сегментов с понижающим микшированием из этих сегментов. Например, для генерирования одного полученного понижающим микшированием сегмента блоком 1305 понижающего микширования осуществляется понижающее микширование двух соответствующих (с одинаковыми частотным интервалом и временным интервалом) сегментов из разных аудиообъектов, предназначенных для понижающего микширования. Этот подход выполняется для множества сегментов, тем самым генерируя набор полученных понижающим микшированием сегментов, в котором каждый сегмент с понижающим микшированием представляет собой по меньшей мере два сегмента и, как правило, из по меньшей мере двух аудиообъектов.
Во многих вариантах осуществления, блок 1305 понижающего микширования дополнительно генерирует параметрические данные (повышающего микширования), которые могут быть использованы для воссоздания исходных сегментов аудиообъекта посредством выполнения повышающего микширования сегментов с понижающим микшированием. Например, блок 1305 понижающего микширования может генерировать Уровневую Разность Между Объектами (ILD), Временную Разность Между Объектами (ITD), Фазовую Разности Между Объектами (IPD) и/или Коэффициенты Когерентности Между Объектами (ICC), как будет известно специалисту в соответствующей области.
Сегменты с понижающим микшированием подаются на первый кодер 1307, который переходит к кодированию каждого сегмента с понижающим микшированием, чтобы сгенерировать закодированный сегмент с понижающим микшированием. Кодер может, например, быть простым квантованием значений сегментов с понижающим микшированием, и может, в частности быть кодированием, которое сохраняет форму волны, представленную сегментом с понижающим микшированием.
Во многих вариантах осуществления, параметры повышающего микширования также могут быть предоставлены первому кодеру 1307, который может их кодировать, используя подходящий подход кодирования.
Селектор 1303 кроме того связан со вторым кодером 1309, на который подаются сегменты, которые являются сегментами без понижающего микширования. Затем второй кодер переходит к кодированию этих сегментов.
Следует иметь в виду, что, несмотря на то, что Фиг. 13 иллюстрирует первый и второй кодер 1307, 1309 в качестве отдельных функциональных блоков, они могут быть реализованы в качестве единого кодера и одинаковый алгоритм кодирования может быть применен как к сегментам с понижающим микшированием, так и сегментам без понижающего микширования.
Следует иметь в виду, что любое кодирование сегментов с понижающим микшированием и без понижающего микширования может быть использовано для генерирования подходящего закодированного сигнала данных. Например, в некоторых вариантах осуществления все сегменты могут быть закодированы по-отдельности. Например, отдельное кодирование может быть применено для каждого сегмента без учета или влияния любых других сегментов, т.е. закодированные данные для каждого сегмента могут быть сгенерированы независимо от других сегментов. В качестве конкретного примера, квантование и канальное кодирование может быть выполнено по-отдельности для каждого сегмента (с понижающим микшированием или без понижающего микширования) для генерирования данных, которые объединяются для генерирования закодированных данных.
В других вариантах осуществления, может быть использовано некоторое совместное кодирование. В частности, выбор сегментов с понижающим микшированием и/или сегментов без понижающего микширования может быть закодирован совместно для повышения эффективности посредством использования конкретных свойств и/или корреляции сегментов и/или объектов, представленных сегментами.
Селектор 1303 кроме того соединен с процессором 1311 указания, который принимает информацию о том, какие сегменты являются закодированными в качестве сегментов с понижающим микшированием, а какие без понижающего микширования. Процессор 1311 указания затем переходит к генерированию указания понижающего микширования, которое указывает, являются ли сегменты аудиообъектов закодированными в качестве полученных понижающим микшированием сегментов или в качестве сегментов без понижающего микширования. Указание понижающего микширования может, например, содержать данные для каждого сегмента каждого из аудиообъектов, при этом данные для заданного сегмента указывают, является ли он без понижающего микширования или закодированным в качестве понижающего микширования. В последнем случае, данные могут дополнительно указывать, понижающее микширование каких других аудиообъектов осуществлено в одно и то же понижающее микширование. Такие данные могут позволить декодеру идентифицировать, какие данные из закодированного сигнала данных должны быть использованы для декодирования конкретного сегмента.
Первый кодер 1307, второй кодер 1309, и процессор 1311 указания соединены с процессором 1313 вывода, который генерирует закодированный аудиосигнал, который включает в себя сегменты без понижающего микширования, сегменты, закодированные с понижающим микшированием, и указание понижающего микширования. Как правило, также включаются в состав параметры повышающего микширования.
Фиг. 14 иллюстрирует элементы декодера 1203 более подробно.
Декодер 1203 содержит приемник 1401, который принимает закодированный сигнал от кодера 1201. Следовательно, приемник принимает закодированный сигнал данных, который представляет собой множество аудиообъектов, причем закодированный сигнал данных содержит закодированные сегменты, которые либо кодированы в качестве сегментов с понижающим микшированием, либо в качестве сегментов без понижающего микширования. Кроме того, он включает в себя указание понижающего микширования, которое указывает, каким образом было выполнено разделение исходных аудио сегментов на разные типы закодированных сегментов. Как правило, также включены параметры повышающего микширования.
Приемник 1401 связан с генератором 1403, на который подаются сегменты и указатель понижающего микширования, и который в ответ переходит к генерированию набора выходных сигналов. Выходные сигналы могут, например, быть декодированными аудиообъектами, которые могут затем быть обработаны или в отношении них могут быть выполнены другие манипуляции на операции постобработки. В некоторых вариантах осуществления, генератор 1403 может непосредственно генерировать выходные сигналы, которые подходят для рендеринга, используя заданную структуру рендеринга (и в частности конфигурацию громкоговорителей). Таким образом, генератор 1403 может в некоторых сценариях содержать функциональные возможности для отображения аудиообъектов в аудиоканалах конкретной конфигурации рендеринга.
Генератор 1403 выполнен с возможностью обработки закодированных сегментов по-разному в соответствии с тем, являются ли они сегментами с понижающим микшированием или сегментами без понижающего микширования. В частности, применительно к сегментам, которые указаны указанием понижающего микширования как сегменты с понижающим микшированием, генерирование сегментов для выходных сигналов, содержит операцию повышающего микширования. Таким образом, операция повышающего микширования может в частности соответствовать извлечению или воспроизведению сегмента для аудиообъекта из сегмента с понижающим микшированием, в который было осуществлено понижающее микширование сегмента аудиообъекта.
В вариантах осуществления, где сигнал данных включает в себя параметрические данные повышающего микширования, эти данные используются на операции повышающего микширования полученных понижающим микшированием сегментов.
В качестве примера, генератор 1403 может содержать генератор 1405 воспроизведения, который воспроизводит исходные аудиообъекты. Генератор 1405 воспроизведения может, например, обрабатывать каждый аудиообъект по одному за раз, и применительно к каждому обрабатываемому аудиообъекту один сегмент за раз.
Например, генератор 1405 воспроизведения может для заданного (временного) отрезка начинать с сегмента 1 (например, сегмента с самой низкой частотой) аудиообъекта 1. Затем для сегмента 1 применительно к объекту 1 оценивается указание понижающего микширования. Если указание понижающего микширования указывает, что закодированный сегмент применительно к сегменту 1 объекта 1 является без понижающего микширования, закодированный сегмент декодируется с тем, чтобы непосредственно предоставить сегмент 1 объекта 1. Тем не менее, если указание понижающего микширования указывает, что закодированный сегмент применительно к сегменту 1 объекта 1 является закодированным с понижающим микшированием, то закодированный сегмент сначала декодируется для предоставления сегмента с понижающим микшированием и последовательно подвергается повышающему микшированию для воспроизведения исходного сегмента 1 аудиообъекта 1. Это повышающее микширование (закодированного) сегмента с понижающим микшированием таким образом создает (оценку) сегмента 1 аудиообъекта 1 до того, как осуществляется его понижающее микширование в кодере. Повышающее микширование может в частности использовать параметрические данные повышающего микширования, если такие данные доступны. Тем не менее, если такие данные не предоставляются, повышающее микширование может быть слепым повышающим микшированием. Результат операции повышающего микширования, примененной к закодированному сегменту 1 объекта 1, следовательно, является (оценкой) сегментом 1 аудиообъекта 1, который подается на кодер 1201.
Таким образом, результатом операции является сегмент 1 объекта 1, причем генерирование сегмента зависит от того, указывает ли указание понижающего микширования, что сегмент был закодирован как сегмент с понижающим микшированием или как без понижающего микширования.
Генератор 1405 воспроизведения затем переходит к выполнению точно такой же операции для сегмента 2 аудиообъекта 1, тем самым получая результат в виде декодированного сегмента 2 аудиообъекта 1.
Процесс повторяется для всех сегментов аудиообъекта 1 и результирующая совокупность сгенерированных сегментов, таким образом, предоставляет представление в частотно-временных сегментах аудиообъекта 1. Это может быть выведено генератором 1405 воспроизведения (или генератором 1403), или если, например, требуется сигнал временной области, может быть применено преобразование частоты во время (например, iFFT).
Тот же самый подход затем повторяется для аудиообъекта 2, затем аудиообъекта 3 и т.д., до тех пор, пока не сгенерируются все аудиообъекты.
Следует иметь в виду, что в этом примере, несколько операций повышающего микширования применяется к каждому закодированному сегменту с понижающим микшированием. Например, если заданный закодированный сегмент с понижающим микшированием является понижающим микшированием, скажем, сегментов аудиообъекта 1 и 2, то операция повышающего микширования будет выполнена как когда генерируется аудиообъект 1, так и когда генерируется аудиообъект 2. Операции повышающего микширования будут использовать разные параметры повышающего микширования (в частности параметры, которые предоставляются для конкретного объекта).
Следует иметь в виду, что в некоторых вариантах осуществления, повышающее микширование может одновременно предоставлять оба (или все) полученные повышающим микшированием сегменты. Например, матричная операция может быть использована для непосредственного генерирования полученных повышающим микшированием сегментов как для аудиообъекта 1, так и 3. Вся операция повышающего микширования может, например, быть выполнена, когда алгоритм сначала первый раз сталкивается с заданным закодированным сегментом с понижающим микшированием (например, при обработке объекта 1). Результирующие полученные повышающим микшированием сегменты для других объектов могут быть сохранены таким образом, что не требуется отдельной операции повышающего микширования, когда сталкиваются с другими сегментами, подверженными понижающему микшированию в закодированном сегменте с понижающим микшированием (например, при обработке объекта 3 в конкретном примере).
Следует иметь в виду, что в некоторых вариантах осуществления или сценариях, только один полученный повышающим микшированием сегмент может быть сгенерирован из одного закодированного сегмента с понижающим микшированием посредством операций повышающего микширования генератора 1405 воспроизведения. Например, если только объект 1 генерируется генератором 1405 воспроизведения, требуется повышающее микширование заданного сегмента с понижающим микшированием для предоставления полученного повышающим микшированием сегмента для объекта 1.
В некоторых вариантах осуществления, декодированные аудиообъекты могут быть непосредственно выведены из генератора 1403. Тем не менее, в примере на Фиг. 14, декодированные аудиообъекты подаются на процессор 1407 рендеринга, который выполнен с возможностью генерирования выходных сигналов, соответствующих конкретной структуре рендеринга, и в частности конкретной конфигурации громкоговорителей. Процессор 1407 рендеринга таким образом может отображать аудиообъекты в выходные каналы, при этом каждый выходной канал связан с номинальной позицией рендеринга звука. Например, некоторое количество аудиообъектов может быть отображено в аудиоканалы структуры громкоговорителей окружающего звука схемы 5.1.
Специалист в соответствующей области будет в курсе разных алгоритмов для отображения аудиообъектов в аудиоканалы для конкретных пространственных конфигураций громкоговорителей, и следует иметь в виду, что может быть использован любой подходящий подход.
В примере на Фиг. 14, генератор 1403 показан как обладающий отдельной функциональной возможностью для генерирования аудиообъектов и для их рендеринга. Тем не менее, во многих вариантах осуществления, функциональные возможности генератора 1405 воспроизведения и процессора 1407 рендеринга могут быть объединены в единой интегрированной функции или операции. Таким образом, генератор может непосредственно генерировать вывод рендеринга из закодированных данных без генерирования аудиообъектов в качестве явных промежуточных сигналов.
Например, операция повышающего микширования может быть выполнена в качестве матричной операции/умножения (или более сложного умножения, если должно быть сгенерировано только одно значение повышающего микширования). Аналогичным образом, отображение рендеринга может быть выполнено в качестве матричной операции/умножения). Одна или более матричные операции/умножения могут в частности быть векторной операцией/умножением (т.е., используя матрицу только с одним столбцом или строкой). Следует иметь в виду, что два последовательных умножения могут быть объединены в одно матричное умножение, применяемое к значениям сегмента закодированных сегментов. Это может быть достигнуто посредством матричного умножения с матричными коэффициентами, которые отражают как повышающее микширование (если выполняется), так и отображение рендеринга. Такая матрица может, например, быть сгенерирована просто посредством умножения отдельных матриц, связанных с повышающим микшированием и отображением рендеринга. Таким образом, в таком сценарии, повышающее микширование выполняется в качестве входящей в состав части единой матричной операции и не требуя явного генерирования значений полученного повышающим микшированием сегмента или аудиообъектов в качестве промежуточных сигналов. В таких вариантах осуществления, матричные коэффициенты могут, таким образом, отражать/включать в себя повышающее микширование для сегментов, которые указываются как сегменты с понижающим микшированием, но не для сегментов, которые указываются как сегменты без понижающего микширования. В частности, матричные коэффициенты могут зависеть от параметров повышающего микширования принятых в закодированном сигнале данных, когда указание понижающего микширования указывает, что сегмент является сегментом с понижающим микшированием, но не когда оно указывает, что сегмент является сегментом без понижающего микширования.
Подход системы с Фиг. 12 может быть проиллюстрирован Фиг. 15. Как иллюстрируется, подмножество аудиообъектов предоставляется непосредственно для кодирования и кодируется в качестве сегментов без понижающего микширования, т.е., без какого-либо понижающего микширования. Тем не менее, аудиообъекты другого подмножества (отделенные от первого подмножества) не предоставляются непосредственно для кодирования, а сначала объединяются с другими аудиообъектами в понижающее микширование. В примере, четыре аудиообъекта попарно сводятся в два понижающих микширования. Сведение кроме того генерирует параметрические данные повышающего микширования (данные объекта), которые описывают/определяют то, каким образом исходные аудиообъекты могут быть сгенерированы из понижающего микширования. Следует иметь в виду, что такие параметры могут быть предоставлены для более длительных временных интервалов и т.д., и что понижающее микширование и параметрические данные соответственно обеспечивают сокращение данных в сравнении с исходными сигналами. Понижающие микширования затем кодируются вместе с параметрическими данными. На стороне декодера, сначала может быть снято кодирование для генерирования значений сигнала для сигналов без понижающего микширования и для повышающих микширований. Результирующие сигналы затем обрабатываются для генерирования подходящих выходных каналов. Эта обработка включает в себя повышающее микширование применительно к понижающим микшированиям (на основании параметрических данных повышающего микширования) и отображение аудиообъектов в конкретную конфигурацию громкоговорителей.
В системе, сигналы обрабатываются в представлении в частотно-временных сегментах, и в частности посредством обработки в области частотно-временных сегментов. Кроме того, предоставляется указание понижающего микширования, которое может для отдельных сегментов указывать, закодированы ли отдельные сегменты аудиообъекта в качестве сегментов с понижающим микшированием или в качестве сегментов без понижающего микширования. Это указание понижающего микширования сообщается от кодера декодеру и соответственно обеспечивает выполнение распределения сегментов на сегменты с понижающим микшированием и без понижающего микширования на основании очередности сегмент за сегментом. Таким образом, Фиг. 15 может быть рассмотрена как представляющая собой подход для некоторого конкретного сегмента, т.е. применительно к некоторому конкретному временному и частотному интервалу. Тем не менее, для других сегментов, те же самые аудиообъекты могут быть закодированы, используя отличное распределение сегментов на сегменты, закодированные с понижающим микшированием и без понижающего микширования. Таким образом, система может обеспечивать очень гибкое кодирование, а весьма детализированный подход может обеспечить значительную оптимизацию для заданной целевой скорости, при этом оптимизация является специфичной для конкретных характеристик сигнала.
Подход обеспечивает очень эффективный компромисс между сравнительными преимуществами кодирования с понижающим микшированием и кодирования без понижающего микширования (и, следовательно, между сравнительными преимуществами параметрического кодирования и кодирования по форме волны). Например, применительно к более низким скоростям передачи данных, относительно большое количество сегментов может быть параметрически закодировано в качестве сегментов с понижающим микшированием вместе со связанными параметрами. Тем не менее, также существует возможность кодирования критических сегментов без какого-либо понижающего микширования, тем самым сокращая возможное ухудшение качества параметрического кодирования. По мере того как растет целевая/доступная скорость передачи данных, может расти число сегментов, которые являются сегментами без понижающего микширования, тем самым увеличивая качество (в частности аудиообъекты все более являются закодированными по форме волны, а не параметрически закодированными и в частности могут быть сокращены перекрестные помехи аудиообъектов). Этот курс может продолжаться до тех пор, пока все сегменты не станут сегментами без понижающего микширования и весь подход кодирования и декодирования не станет прозрачным. Таким образом, может быть достигнуто высокоэффективное кодирование и масштабируемость до прозрачности.
Систему на Фиг. 12 таким образом можно рассматривать как гибридный по форме волны/параметрический подход, который использует предварительное объединение подмножества доступных сегментов в полученные понижающим микшированием сегменты наряду с сопровождением параметрической информацией. Оставшиеся сегменты совместно с полученными понижающим микшированием сегментами могут быть закодированы, используя обычные сегменты кодирования по форме волны. Параметрическая информация будет устанавливать связь полученных понижающим микшированием сегментов с сегментами аудиообъекта. В дополнение, информация о том, каким образом каждый объект представлен (чисто по форме волны или по форме волны плюс параметрическая информация - т.е. закодирован ли без понижающего микширования или с понижающим микшированием), также переносится в закодированном сигнале данных. Эти особенности в частности обеспечивают улучшенную масштабируемость скорости передачи данных закодированных сигналов.
Одним конкретным примером является кодирование поля диффузного звука. В предположении, что поле диффузного звука в действительности является всенаправленным, это требует виртуально неограниченное количество объектов для представления поля диффузного звука. Как правило, из-за ограничений слуховой системы человека, нет необходимости в представлении поля диффузного звука, используя очень большой объем объектов/каналов. В зависимости от доступной битовой скорости, может быть осуществлено понижающее микширование большого количества объектов/каналов, которые представляют собой поле диффузного звука, в меньшее количество объектов/каналов с сопровождающей параметрической информацией.
В примере на Фиг. 15, кодируется восемь объектов. Кодер определяет, сегменты каких объектов должны быть объединены в полученные понижающим микшированием сегменты. В дополнение к понижающему микшированию, также получают данные объекта, представляющие собой зависимость между полученными понижающим микшированием сегментами и исходными сегментами объекта. Также получают информацию о том, каким образом может быть получен каждый сегмент исходных объектов (непосредственно по форме волны или по форме волны понижающего микширования плюс данные объекта). Результирующая информация, состоящая из сегментов объекта, которые не были подвергнуты понижающему микшированию, сегментов объекта, которые были (частично) подвергнуты понижающему микшированию с их сопроводительными данными объекта, и информация о происхождении (указание понижающего микширования), все вместе кодируется. Сегменты объекта (вне зависимости, получены ли они понижающим микшированием или нет) могут быть закодированы, используя обычные методики кодирования по форме волны.
Декодер принимает один или более сегментов с понижающим микшированием, при этом каждый сегмент с понижающим микшированием представляет собой понижающее микширование одного или более сегментов от одного или более аудиообъектов. В дополнение, декодер принимает параметрические данные, связанные с сегментами объекта в сегментах с понижающим микшированием. Также, декодер принимает один или более сегментов от одного или более сигналов объекта, при этом эти сегменты не представлены в сегментах с понижающим микшированием. Декодер дополнительно принимает указатель понижающего микширования, который предоставляет информацию, которая указывает, закодирован ли заданный объект как сегмент без понижающего микширования или как сегмент с понижающим микшированием с параметрическими данными. На основании этой информации, декодер может генерировать сегменты для выходных сигналов либо используя сегменты с понижающим микшированием плюс параметрическую информацию, либо используя сегменты без понижающего микширования.
В некоторых вариантах осуществления, все операции выполняются над соответствующими сегментами, т.е., обработка выполняется отдельно для каждого частотного интервала и временного интервала сегмента. В частности, выходной сигнал генерируется посредством генерирования сегмента выходного сигнала на основании закодированных сегментов, которые охватывают тот же самый временной и частотный интервал. Тем не менее, в некоторых вариантах осуществления, некоторое частотное или временное преобразование может быть выполнено как часть обработки. Например, множество закодированных сегментов может быть объединено для генерирования выходного сегмента, охватывающего больший частотный интервал.
Также, как правило, будет понижающее микширование сегментов, охватывающих одинаковый частотный интервал или временной интервал. Тем не менее, в некоторых вариантах осуществления, понижающее микширование может быть из сегментов, охватывающих разные интервалы, которые могут быть с перекрытием или непересекающимися. Действительно, в некоторых вариантах осуществления и сценариях, понижающее микширование может быть даже из двух сегментов одного и того же сигнала (например, двух сегментов, являющихся смежными по размерности частоты).
Использование и сообщение указания понижающего микширования обеспечивает очень высокую степень гибкости при кодировании аудиообъектов и, в частности, при выборе того, каким образом объединять (или нет) аудиообъекты как часть процесса кодирования. Подход может обеспечивать возможность гибкого выбора отдельных частей сигнала (отдельных сегментов) для объединения с другими частями сигнала в зависимости от характеристик лишь компонента сигнала. Действительно, вместо выбора лишь того, понижающее микширование каких сигналов или объектов вместе может быть осуществлено, применение указания понижающего микширования на основе сегмента обеспечивает выполнение таких рассмотрений для отдельных частей сигнала и в частности для отдельных сегментов.
В некоторых вариантах осуществления, указание понижающего микширования может включать в себя отдельное указание для каждого сегмента каждого объекта, и кодер может для каждого сегмента определять, подвергается ли понижающему микшированию сегмент, и если так, то он может решать, с каким другим сегментом или сегментами должно быть выполнено понижающее микширование. Таким образом, в таких вариантах осуществления, оптимизация понижающего микширования, основанная на отдельном сегменте, может быть выполнена для всех объектов. Действительно, глобальный процесс оптимизации может быть выполнен для достижения наивысшего качества аудио для заданной целевой скорости.
Подход может в частности обеспечивать возможность понижающего микширования некоторых сегментов заданного объекта с другими сегментами, тогда как другие сегменты объекта кодируются без какого-либо понижающего микширования. Таким образом, кодирование одного объекта может включать в себя как полученные понижающим микшированием сегменты, так и сегменты без понижающего микширования. Это может существенно улучшить эффективность и/или качество кодирования.
Например, два аудиообъекта могут в заданный временной интервал содержать некоторые частотные интервалы, которые в отношении восприятия менее важны (например, из-за низких значений сигнала), тогда как другие частотные интервалы в отношении восприятия являются более важными. В этом случае, сегменты в менее значимых для восприятия интервалах могут быть подвержены понижающему микшированию вместе, тогда как более значимые для восприятия интервалы сохраняются отдельными, чтобы избежать перекрестных помех и повысить качество.
Также, следует иметь в виду, что могут варьироваться объекты, которые включаются в разные понижающие микширования. Например, для заданного объекта, может быть осуществлено понижающее микширование одного сегмента с одним другим объектом, тогда как может быть осуществлено понижающее микширование другого сегмента с другим объектом. В качестве конкретного примера, применительно к низким частотам преимущественным может быть понижающее микширование объектов 1 и 2, тогда как для более высоких частот, преимущественным может быть понижающее микширование объектов 1 и 3 (скажем в примере, когда объект 1 обладает низкой энергией сигнала как на высоких, так и низких частотах, объект 2 обладает низкой энергией сигнала на низких частотах, но высокой энергией сигнала на высоких частотах, а объект 3 обладает низкой энергией сигнала на высоких частотах, но высокой энергией сигнала на низких частотах).
Количество сегментов, подверженных понижающему микшированию в заданный сегмент с понижающим микшированием, кроме того, во многих вариантах осуществления не ограничивается двумя сегментами, и действительно в некоторых вариантах осуществления и сценариях один или более сегментов с понижающим микшированием могут быть сгенерированы посредством понижающего микширования 3, 4 или даже более сегментов.
Гибкость дополнительно расширяется во временном направлении и действительно разнесение сегментов на сегменты с понижающим микшированием и без понижающего микширования может варьироваться по времени. Таким образом разнесение может динамически меняться, и, в частности, новое разнесение/распределение может быть определено для каждого временного интервала.
Также следует иметь в виду, что не обязательно требуется, чтобы все объекты включали в себя один или более сегментов, которые получены понижающим микшированием. Действительно, возможно, что все сегменты одного или более объектов могут быть сегментами без понижающего микширования, тем самым обеспечивая высокое качество аудио этих объектов. Это может быть в частности подходящим, если объекту присуща конкретная воспринимаемая значимость (как например вокалам в музыкальной аудиосцене). Также, возможно, что все сегменты одного или более объектов полностью кодируются в качестве сегментов с понижающим микшированием.
Пример возможной гибкости иллюстрируется на Фиг. 16, которая показывает разнесение сегментов в одном временном интервале. На Фиг. 16, каждый столбец состоит из сегментов заданного аудио входного сигнала, а каждая строка является конкретным частотным интервалом (соответствующим сегментам). Пример иллюстрирует пять аудиообъектов (представленных буквой o) и два сигнала аудиоканала (представленных буквой c). В дополнение, пример основан на кодировании интервала, который для каждого частотного интервала может включать в себя два понижающих микширования (представленных буквой d).
В примере, первый частотный интервал (т.е., первая строка) кодируется, используя только два сегмента с понижающим микшированием. В частности, в этом интервале, сегменты трех крайних левых объектов и двух аудиоканалов могут быть объединены в первое понижающее микширование, а сегменты двух крайних правых объектов могут быть объединены во второй сегмент с понижающим микшированием.
В следующем частотном интервале/строке, все сегменты кодируются в качестве сегментов без понижающего микширования. В следующем частотном интервале/строке, осуществляется понижающее микширование двух сегментов двух аудиоканалов в сегмент с понижающим микшированием, тогда как все сегменты объекта кодируются как сегменты без понижающего микширования. В следующем частотном интервале/строке, осуществляется понижающее микширование двух сегментов двух крайних правых объектов в один сегмент с понижающим микшированием, тогда как все другие сегменты кодируются как сегменты без понижающего микширования. И т.д.
Для эффективного кодирования результирующих сигналов/сегментов, могут быть, например, использованы существующие методики для хранения разряженной матрицы. Дополнительно или в качестве альтернативы, различные методики могут быть использованы для повышения эффективности битовой скорости при кодировании сегментов. Например, уровень квантования для заданного объекта/сегмента может быть увеличен из-за пространственного маскирования посредством других объектов/сегментов в сцене. В крайних случаях, заданный сегмент может, например, совсем не передаваться (т.е., может быть квантован до нуля).
Следует иметь в виду, что разные подходы, алгоритмы или критерии могут быть использованы для выбора того, понижающее микширование каких сегментов осуществляется (и в какие понижающие микширования).
Во многих вариантах осуществления, селектор 1303 может выбирать сегменты для понижающего микширования в ответ на целевую скорость передачи данных для закодированного аудиосигнала. В частности, количество сегментов, понижающее микширование которых осуществляется, и/или количество понижающих микширований, которые включаются в закодированный аудиосигнал, может зависеть от доступной (т.е., целевой) скорости передачи данных. Таким образом, применительно к более низким скоростям передачи данных, генерируется относительно большое количество понижающих микширований. По мере того как целевая скорость передачи данных увеличивается, количество понижающих микширований уменьшается, и действительно, если скорость передачи данных достаточно высока, система может выбирать не создавать каких-либо понижающих микширований. При крайне низких битовых скоростях количество понижающих микширований может быть небольшим, но каждое понижающее микширование может быть понижающим микшированием большого количества сегментов. Таким образом, относительно низкое количество понижающих микширований может представлять большую часть (если не все) частотных сегментов множества аудиосигналов.
Селектор 1303 (также) может выполнять выбор в ответ на энергию сегментов. В частности, может быть осуществлено понижающее микширование сегментов, которые представляют собой более низкую энергию компонента сигнала в сегменте, тогда как сегменты, которые представляют собой более высокую энергию компонента сигнала в сегменте, могут быть закодированы как сегменты без понижающего микширования. Более низкая энергия вероятнее всего менее значима для восприятия и, вследствие этого, последствия (такие как перекрестные помехи) кодирования с понижающим микшированием могут быть соответственно уменьшены. В некоторых сценариях, может быть преимущественным выполнять балансировку энергии сегментов, которые объединяются в заданном понижающем микшировании. Это, например, может уменьшить перекрестные помехи, поскольку сигналы будут более подобными в заданном сегменте.
В некоторых вариантах осуществления, выбор может осуществляться в ответ на пространственные характеристики сегментов. Например, аудиообъект может представлять собой аудиообъекты, которые вероятнее всего будут позиционированы близко друг к другу, и соответственно эти сегменты могут быть выбраны, для понижающего микширования вместе. Во многих вариантах осуществления, будут объединяться объекты, которые являются пространственно соседними. Разумное объяснение этому заключается в том, что чем большее пространственное отделение требуется между объектами, тем большее пространственное разоблачение будет происходить. В частности, менее вероятно восприятие перекрестных помех, когда оно происходит между двумя близкорасположенными аудиоисточниками чем, когда оно происходит между двумя аудиоисточниками, которые пространственно отдалены друг от друга.
В некоторых вариантах осуществления, выбор может осуществляться в ответ на характеристику когерентности между парами сегментов. Действительно, менее вероятно восприятие перекрестных помех между сигналами, которые являются близко коррелирующими, чем между сигналами, которые очень лишь слабо коррелируют.
Следует иметь в виду, что конкретное представление информации указанием понижающего микширования может зависеть от конкретных требований и предпочтений отдельных вариантов осуществления.
В качестве примера, предварительно определенное ограничение может состоять в том, что понижающее микширование аудиообъектов вместе может быть осуществлено в некоторые пары. Например, понижающее микширование сегментов объекта 1 может быть осуществлено только с сегментами (в том же частотном и временном интервале) объекта 2, понижающее микширование сегментов объекта 3 может быть осуществлено только с сегментами объекта 4, и т.д. В таком случае, указание понижающего микширования может просто указывать, понижающее микширование каких сегментов осуществляется, и не требуется явного указания идентификационных данных сегментов, понижающее микширование которых осуществляется в конкретном понижающем микшировании. Например, указание понижающего микширования может включать в себя один бит для каждого частотного интервала объекта 1 и 1, при этом бит просто указывает, осуществляется ли понижающее микширование сегмента. Декодер может интерпретировать этот бит и выполнять повышающее микширование сегмента, чтобы генерировать сегменты для объектов 1 и 2, если бит указывает, что сегмент является понижающим микшированием.
Действительно, не требуется, чтобы указание понижающего микширования было явным, и оно может быть предоставлено посредством других данных. В частности, применительно к вариантам осуществления, где понижающее микширование генерирует параметрические данные, указание того, что сегмент является сегментом с понижающим микшированием, может быть просто обеспечено наличием параметрических данных повышающего микширования. Таким образом, если в аудиосигнале предоставляются параметры, описывающие то, каким образом генерировать сегмент(ы) повышающего микширования из закодированного сегмента, то это обеспечивает указание того, что сегмент действительно является сегментом с понижающим микшированием.
Во многих вариантах осуществления, указание понижающего микширования может указывать, понижающее микширование каких сегментов объекта осуществляется в заданном сегменте с понижающим микшированием. Указание понижающего микширования может для одной или более (возможно всех) сегментов, которые закодированы в качестве сегментов с понижающим микшированием, обеспечивать связь между сегментом с понижающим микшированием и сегментами аудиообъектов. Связь может идентифицировать сегменты, понижающее микширование которых осуществляется в понижающем микшировании. Например, данные связи могут для заданного сегмента с понижающим микшированием указывать, что это понижающее микширование, скажем, объектов 1 и 2, для другого сегмента с понижающим микшированием, что это понижающее микширование, скажем, объектов 2, 4 и 7, и т.д.
Включение идентификации сегментов объекта, которые были получены понижающим микшированием, в сегменты с понижающим микшированием, может обеспечивать увеличенную гибкость и может позволить избежать потребности в предварительно определенном ограничении в отношении того, понижающее микширование каких сегментов может быть осуществлено. Подход может обеспечивать полностью свободную оптимизацию, при которой понижающее микширование сегментов понижающих микширований может быть осуществлено в любом сочетании для обеспечения оптимального (воспринимаемого) качества аудио для заданной скорости передачи данных.
Также следует иметь в виду, что указание понижающего микширования может быть структурировано по-разному в разных вариантах осуществления. В частности, следует иметь в виду, что данные указания понижающего микширования могут быть предоставлены со ссылкой на исходные сегменты объекта (в общем на сегменты кодируемых аудиосигналов). Например, для каждого сегмента каждого объекта, наличие параметрических данных повышающего микширования может указывать, что сегмент является сегментом с понижающим микшированием. Для этого сегмента, предоставляются данные, которые связывают его с конкретным закодированным сегментом с понижающим микшированием. Например, данные могут предоставлять указатель на позицию данных в закодированном сигнале данных, где был закодирован соответствующий сегмент с понижающим микшированием.
Эквивалентно, данные указания понижающего микширования могут быть предоставлены со ссылкой на закодированные сегменты (и в частности на закодированные сегменты с понижающим микшированием аудиосигналов). Например, для закодированного сегмента аудиосигнала, аудиосигнал может включать в себя секцию данных, которая идентифицирует, какие объекты представляет сегмент с понижающим микшированием.
Следует иметь в виду, что эти подходы эквивалентны и что указание понижающего микширования, которое ссылается на закодированные сегменты, по существу, также предоставляет указание понижающего микширования для сегментов объекта. Например, следует отметить, что информация, предоставляемая данными, указывающими, например
Понижающее микширование сегмента N объекта A осуществлено в закодированный сегмент X,
Понижающее микширование сегмента M объекта B осуществлено в закодированный сегмент X,
(т.е., данные которые ссылаются на сегмент объекта) обеспечивают точно такую же информацию, как данные, указывающие:
Закодированный сегмент X является понижающим микшированием сегмента N объекта A и сегмента M объекта B.
(т.е. данные, которые ссылаются на закодированный сегмент).
Расположение данных в закодированном сигнале данных может зависеть от конкретного варианта осуществления. Например, в некоторых вариантах осуществления, данные, представляющие собой указание понижающего микширования, могут быть предоставлены в одной секции данных отдельно от закодированных сегментов данных и параметрического обновления. В других вариантах осуществления, данные могут быть рассеяны, например, при этом каждый сегмент данных, закодированный с понижающим микшированием, сопровождается полем, содержащим параметры повышающего микширования и идентификацию сегментов объекта, включенных в понижающее микширование.
Например, закодированный аудиосигнал может быть структурирован посредством того, что сигналы объекта располагаются последовательно в потоке данных. Таким образом, первые данные могут быть предоставлены для объекта 1. Эти данные могут содержать множество последовательных секций данных, каждая из которых представляет собой один сегмент (например, в очередности возрастающей частоты). Таким образом, первый раздел включает в себя закодированный сегмент для сегмента 1 объекта 1, следующая секция включает в себя закодированный сегмент для сегмента 2 объекта 1, и т.д.
Если секция содержит закодированный сегмент, который является сегментом без понижающего микширования, то в секцию включаются только закодированные данные сегмента. Тем не менее, если сегмент был закодирован в качестве сегмента с понижающим микшированием, секция содержит закодированные данные понижающего микширования, т.е., сегмент с понижающим микшированием. Тем не менее, в дополнение, секция содержит поле, содержащее параметрические параметры повышающего микширования для генерирования сегмента для объекта 1 из сегмента с понижающим микшированием. Это указывает, что секция содержит сегмент с понижающим микшированием. В дополнение, включается поле, которое идентифицирует то, какой другой сегмент(ы) объединен в понижающее микширование (например, оно может содержать данные, указывающие, что соответствующий сегмент объекта 2 также представляется посредством понижающего микширования).
Закодированный аудиосигнал таким образом может содержать последовательные секции для всех сегментов первого аудиообъекта.
Такой же подход затем повторяется для следующего аудиообъекта, т.е. вслед за кодированием данных для объекта 1, закодированные данные для объекта 2 предоставляются во множестве секций, каждая из которых соответствует одному сегменту. Тем не менее, в этом случае, данные кодирования понижающего микширования, которые уже были предоставлены в более ранней секции (например, для предыдущего объекта) не включаются. Например, если понижающее микширование генерируется для сегмента 2 объекта 1 и 2, то эти закодированные данные понижающего микширования уже были предоставлены для сегмента 2 объекта 1, и соответственно секция данных для сегмента 2 объекта 2 не содержит каких-либо закодированных данных. Тем не менее, в некоторых вариантах осуществления она может содержать параметры повышающего микширования для генерирования сегмента 2 объекта 2 из сегмента с понижающим микшированием. В других вариантах осуществления, эти данные могут не предоставляться (т.е., может быть использовано слепое повышающее микширование) или они могут быть предоставлены с помощью закодированных данных сегмента (т.е., в секции данных для сегмента 2 объекта 1). В таких вариантах осуществления, текущая секция может быть пустой или пропущена.
Этот подход может быть продолжен для всех объектов с помощью принципа, что закодированные данные понижающего микширования включаются только первый раз, когда они встречаются в последовательном расположении сегментов закодированного сигнала данных. Закодированные данные для каждого временного интервала могут быть предоставлены как описанные с помощью временных интервалов, последовательно расположенных в закодированном аудиосигнале.
Следует иметь в виду, что возможно много других расположений и что может быть использовано любое подходящее расположение.
Вышеприведенное описание сфокусировано на кодировании аудиообъектов. Тем не менее, следует иметь в виду, что подход также применим к другим аудиосигналам. В частности, он может быть применен для кодирования аудиосигналов/каналов пространственного многоканального сигнала и/или аудиосигналов для каналов, связанных с номинальной позицией в номинальной конфигурации громкоговорителей. В частности, ссылки на аудиообъекты в предыдущем описании могут быть соответствующим образом рассмотрены как ссылки на аудиосигналы.
Действительно, подход может быть использован в гибридной основанной на канале/объекте системе. Пример таковой иллюстрируется на Фиг. 17. В примере, как аудиоканалы, так и объекты рассматриваются образом, который точно такой же, как и тот, что описан ранее для аудиообъектов. Кодер принимает решение о том, какие сегменты объектов и/или каналов должны быть объединены. Этот выбор может в частности объединять сегменты аудиоканалов и объектов в (гибридные) сегменты с понижающим микшированием.
Следует иметь в виду, что вышеприведенное описание для ясности описывало варианты осуществления изобретения со ссылкой на разные функциональные схемы, блоки и процессоры. Тем не менее, должно быть очевидно, что любое подходящее разнесение функциональных возможностей между разными функциональными схемами, блоками или процессорами может быть использовано без приуменьшения изобретения. Например, функциональные возможности, проиллюстрированные как выполняемые отдельными процессорами или контроллерами, могут быть выполнены одним и тем же процессором или контроллером. Следовательно, ссылки на конкретные функциональные блоки или схемы должны рассматриваться лишь как ссылки на подходящие средства для обеспечения описываемых функциональных возможностей, нежели как указывающие жесткую логическую или физическую структуру, или организацию.
Изобретение может быть реализовано в любом подходящем виде, включая аппаратное обеспечение, программное обеспечение, встроенное программное обеспечение или их сочетание. Изобретение может быть опционально реализовано, по меньшей мере, частично в качестве компьютерного программного обеспечения, работающего на одном или более процессорах данных и/или цифровых сигнальных процессорах. Элементы и компоненты варианта осуществления изобретения могут быть физически, функционально и логически реализованы любым подходящим способом. Действительно, функциональные возможности могут быть реализованы в едином блоке, в нескольких блоках или как часть других функциональных блоков. Раз так, то изобретения может быть реализовано в едином блоке или может быть физически и функционально разнесено между разными блоками, схемами и процессорами.
Несмотря на то, что настоящее изобретение было описано в связи с некоторыми вариантами осуществления, оно не предназначено ограничиваться конкретными изложенными в этом документе формами. Наоборот, объем настоящего изобретения ограничивается только сопроводительной формулой изобретения. Дополнительно, несмотря на то, что признак может казаться описанным в связи с конкретными вариантами осуществления, специалист в соответствующей области будет понимать, что различные признаки описанных вариантов осуществления могут быть объединены в соответствии с изобретением. В формуле изобретения, понятие содержащий не исключает наличия других элементов или этапов.
Кроме того, несмотря на то, что проиллюстрированы по-отдельности, множество средств, элементов, схем или этапов способа могут быть реализованы посредством, например, единой схемы, блока или процессора. Дополнительно, несмотря на то, что отдельные признаки могут быть включены в разных пунктах формулы изобретения, они могут быть объединены для получения преимущества, и включение в разные пункты формулы изобретение не предполагает, что сочетание признаков не осуществимо и/или не дает преимуществ. Также, включение признака в одну категорию пунктов формулы изобретения не предполагает ограничение этой категорией, а наоборот указывает, что признак в равной степени применим к другим категориям формулы изобретения по мере необходимости. Кроме того, очередность признаков в формуле изобретения не предполагает какой-либо конкретной очередности, в которой признаки должны работать и, в частности, очередность отдельных этапов в пункте формулы изобретения для способа не предполагает того, что этапы должны выполняться в этой очередности. Наоборот, этапы могут быть выполнены в любой подходящей очередности. В дополнение, упоминание единственного числа не исключает множество. Таким образом упоминание форм единственного числа, а также «первый», «второй» и т.д. не исключает множество. Ссылочные обозначения в формуле изобретения, предусмотренные лишь в качестве поясняющего примера, не должны толковаться как ограничивающие любым образом объем формулы изобретения.
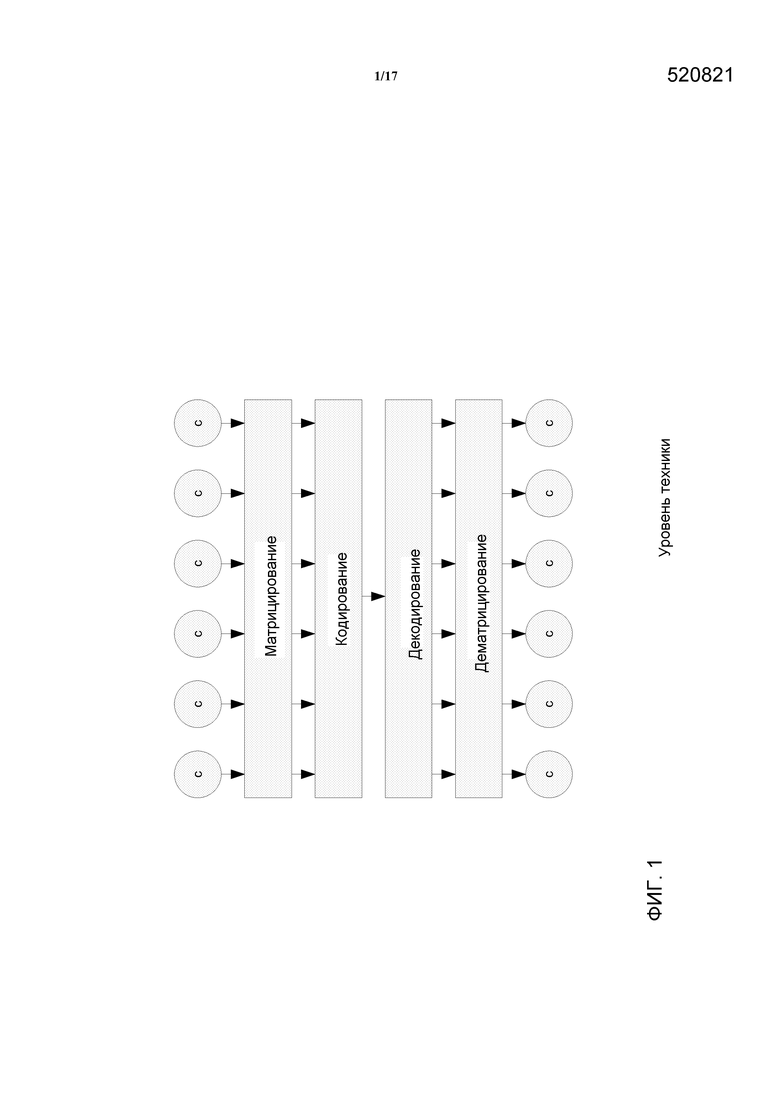
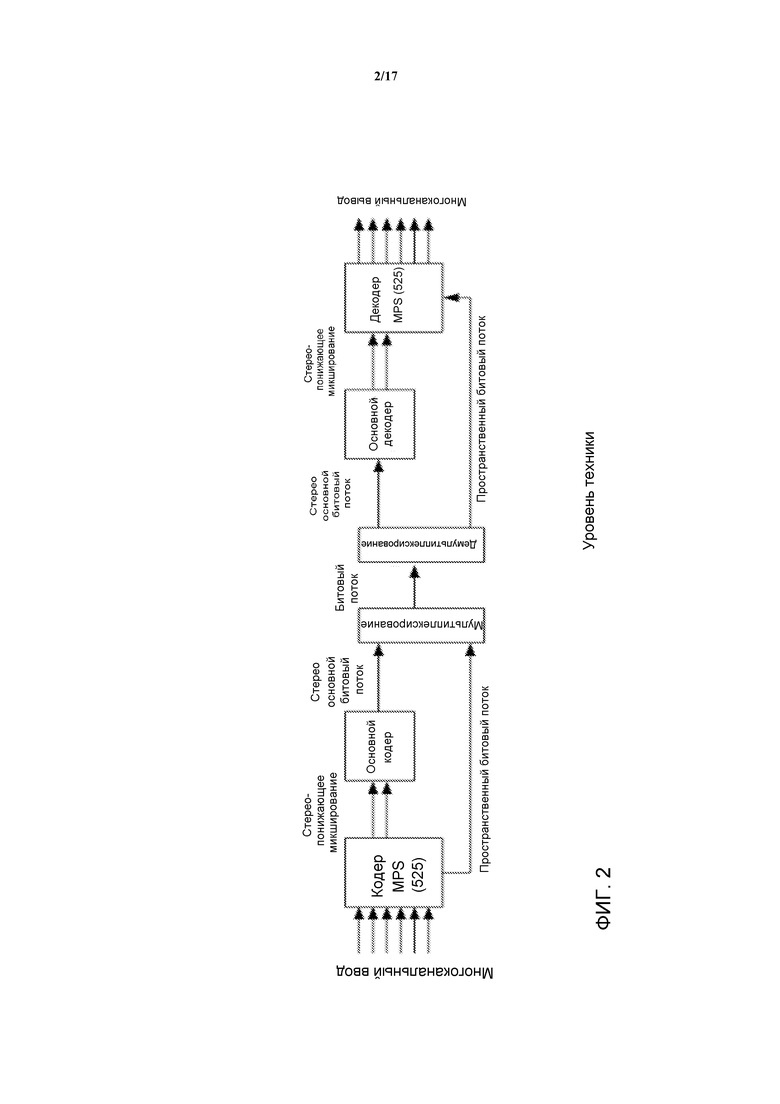
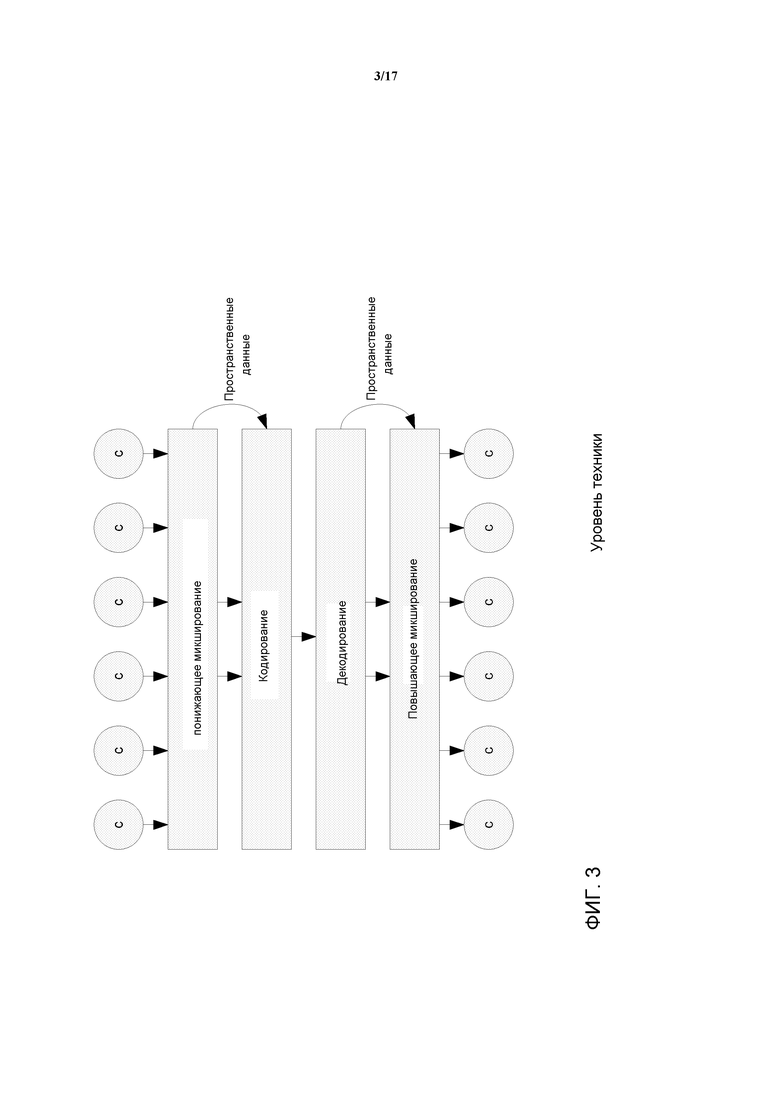
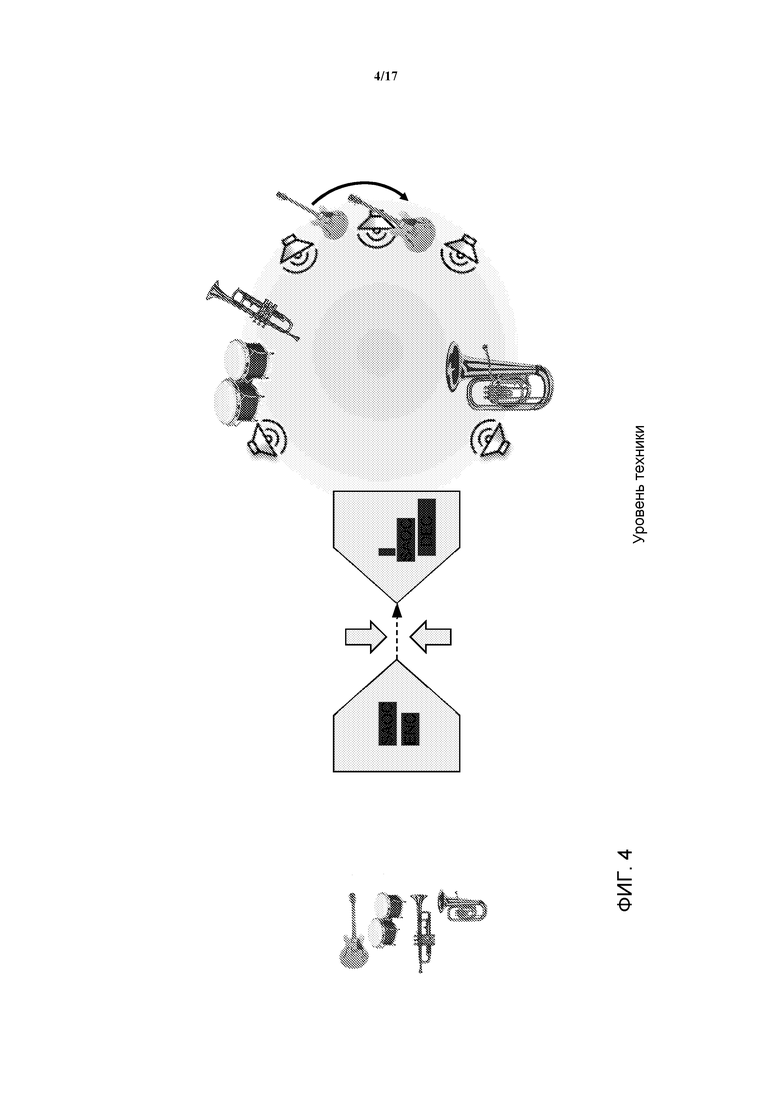

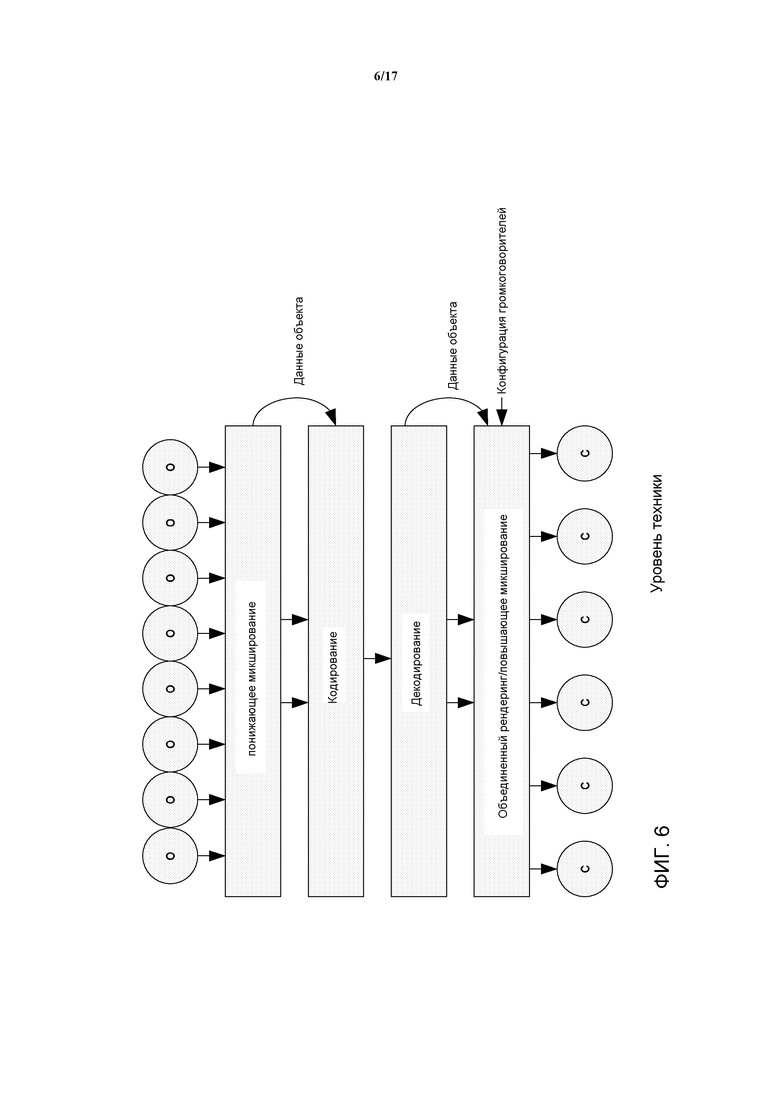
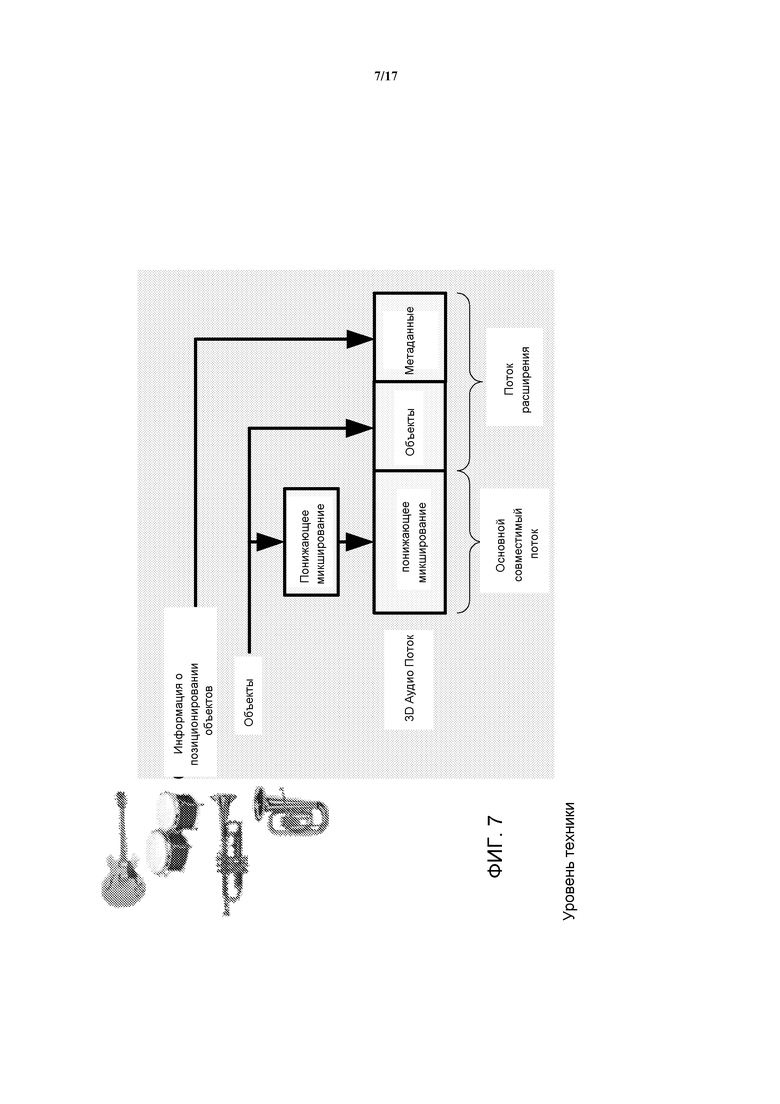
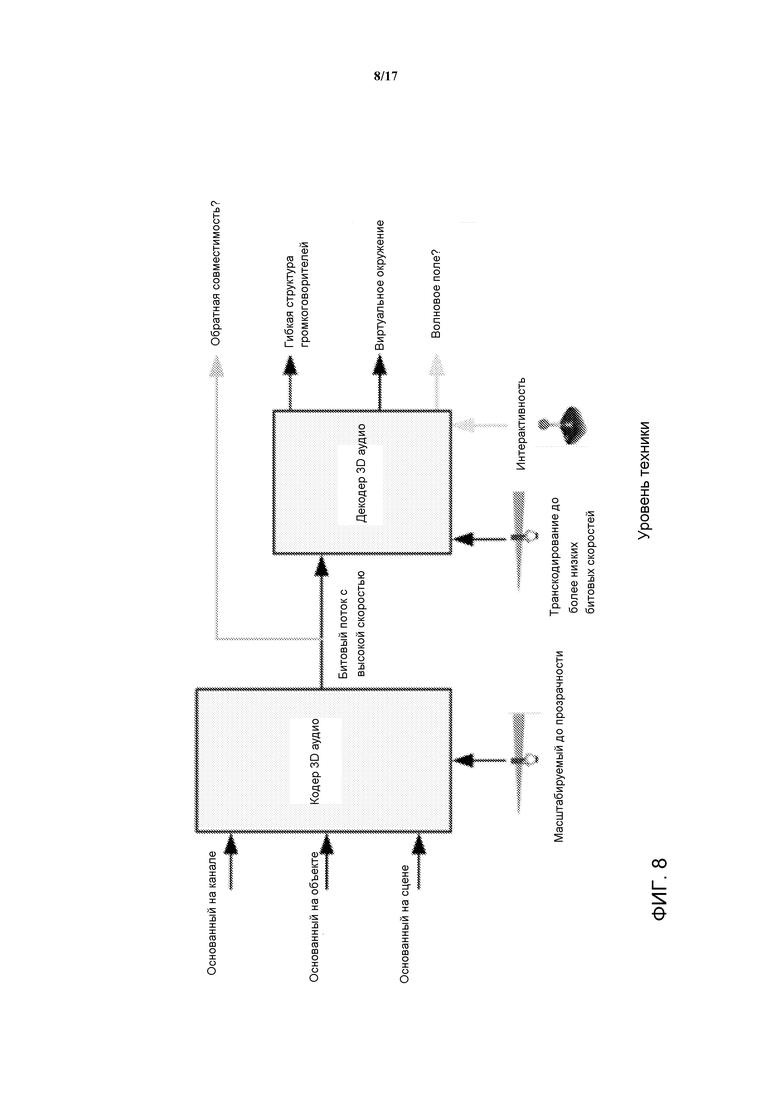
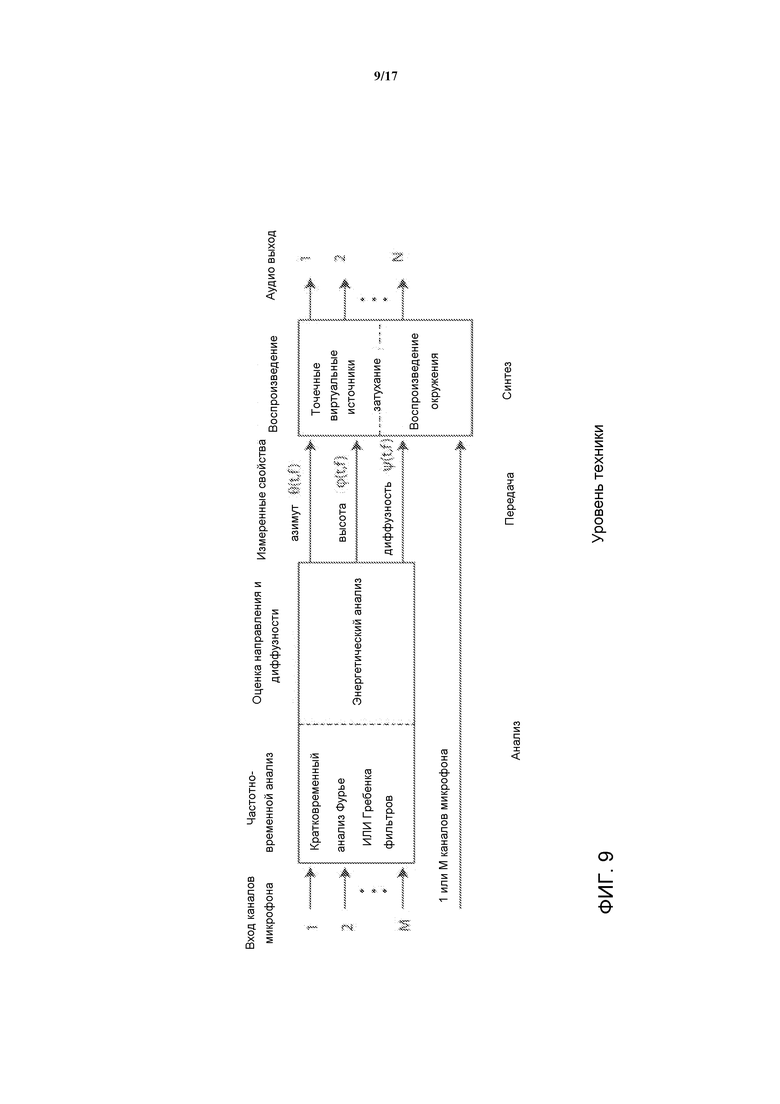
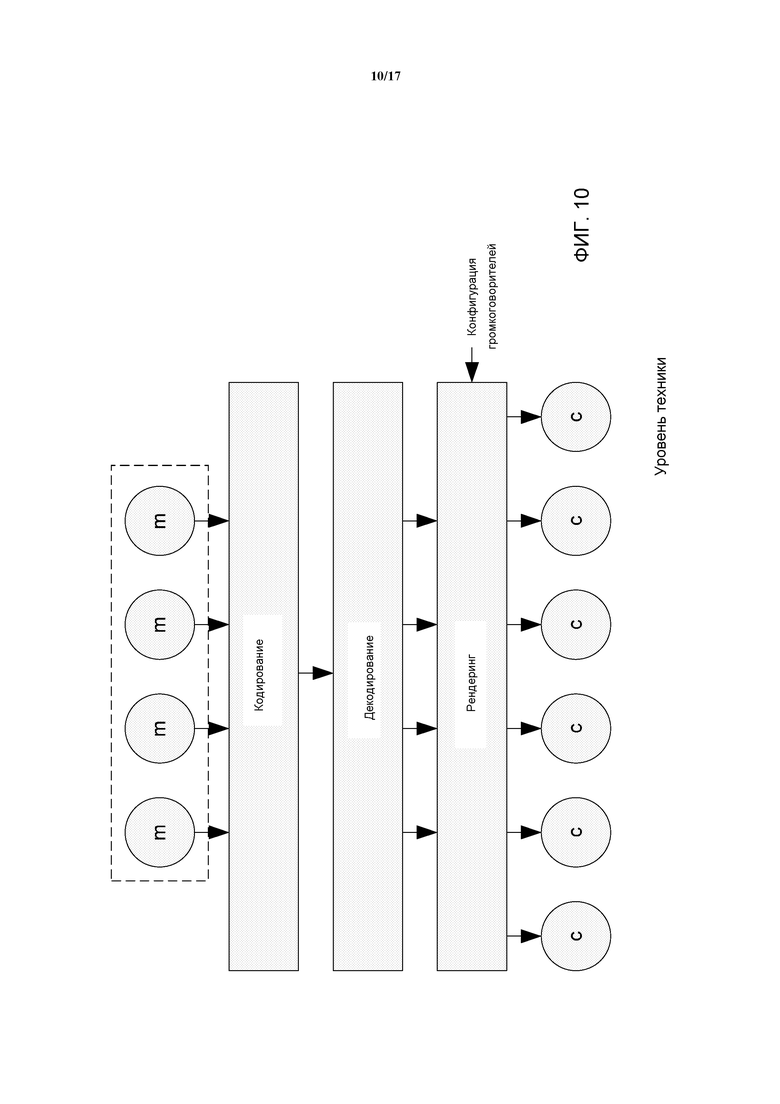
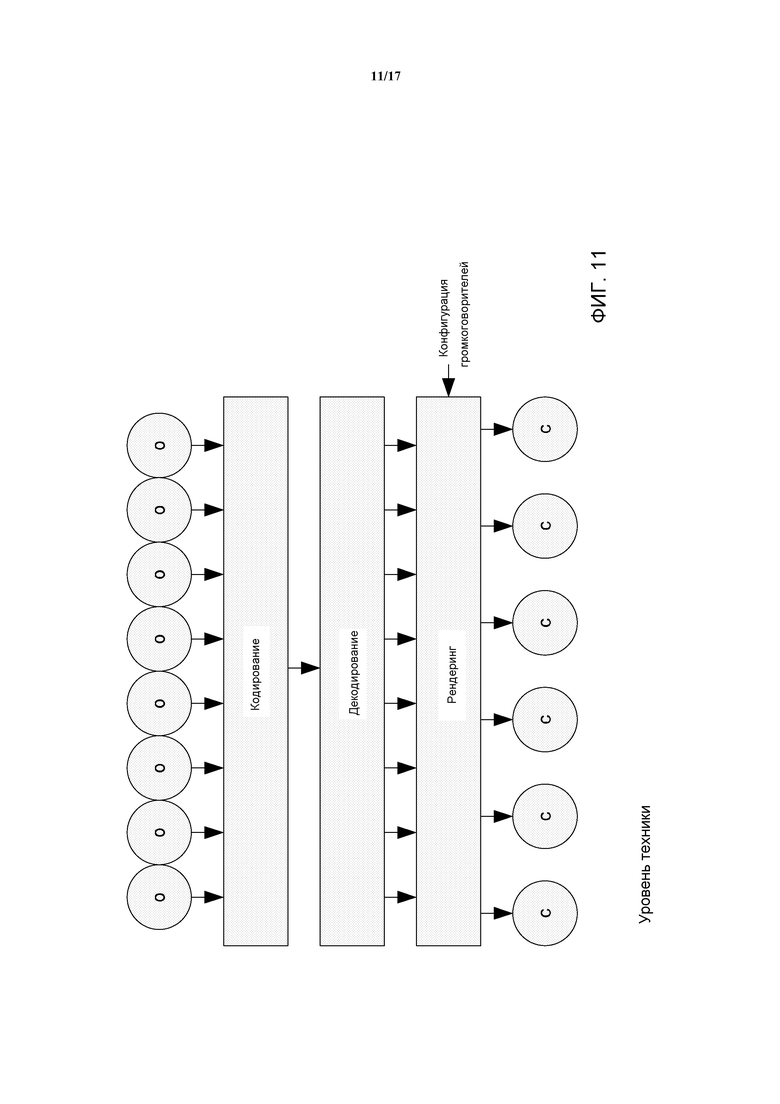
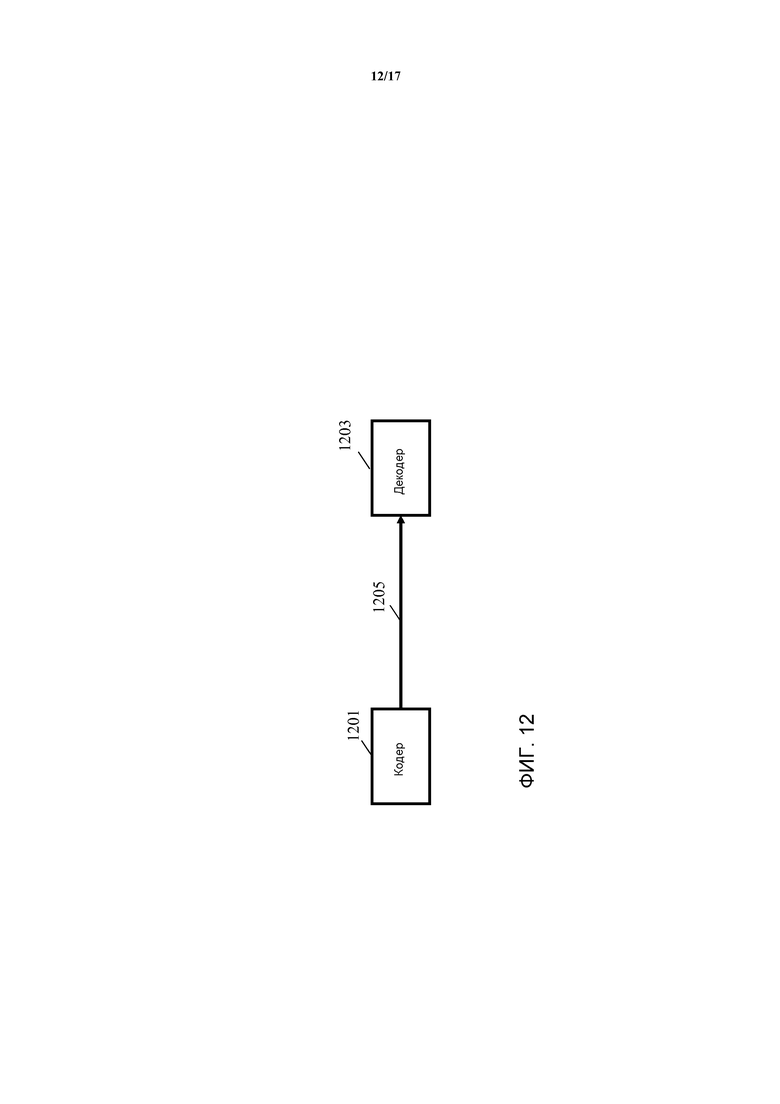
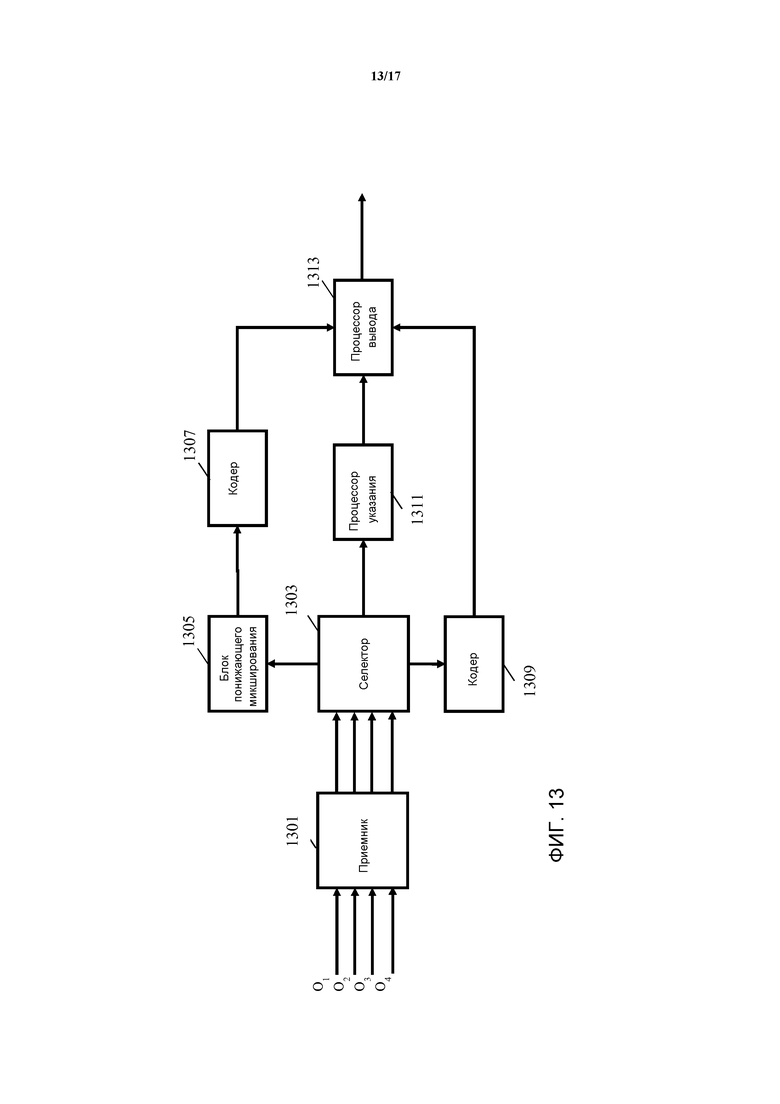
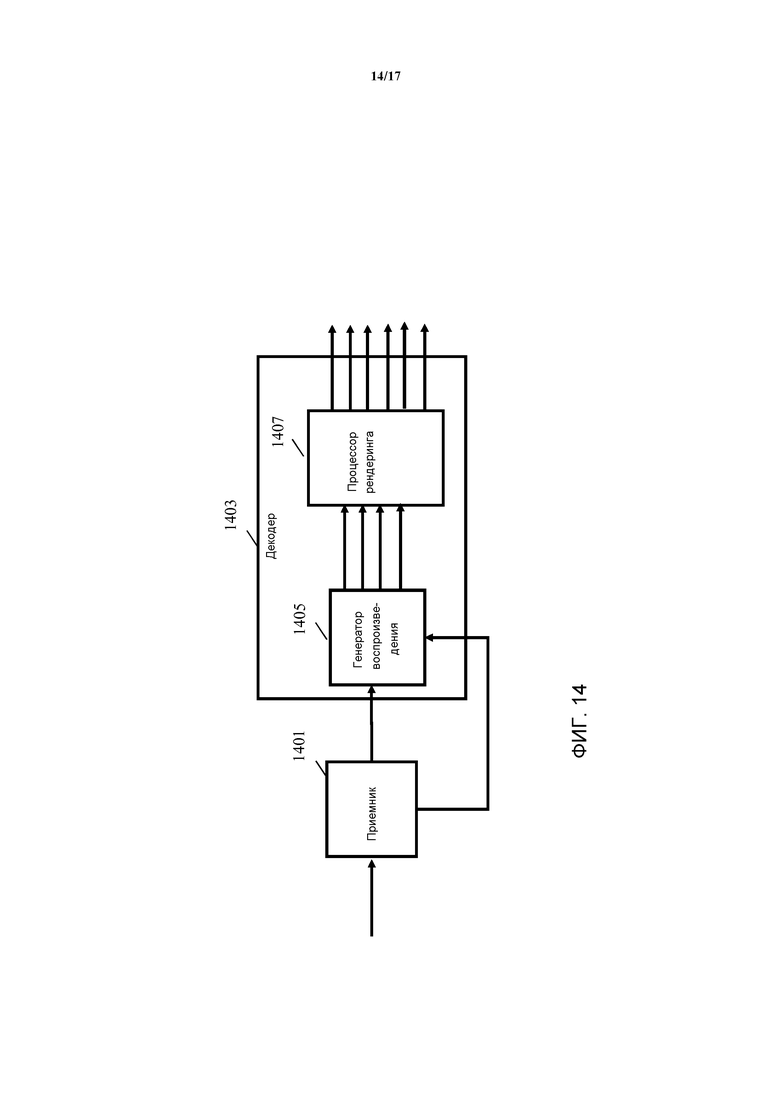
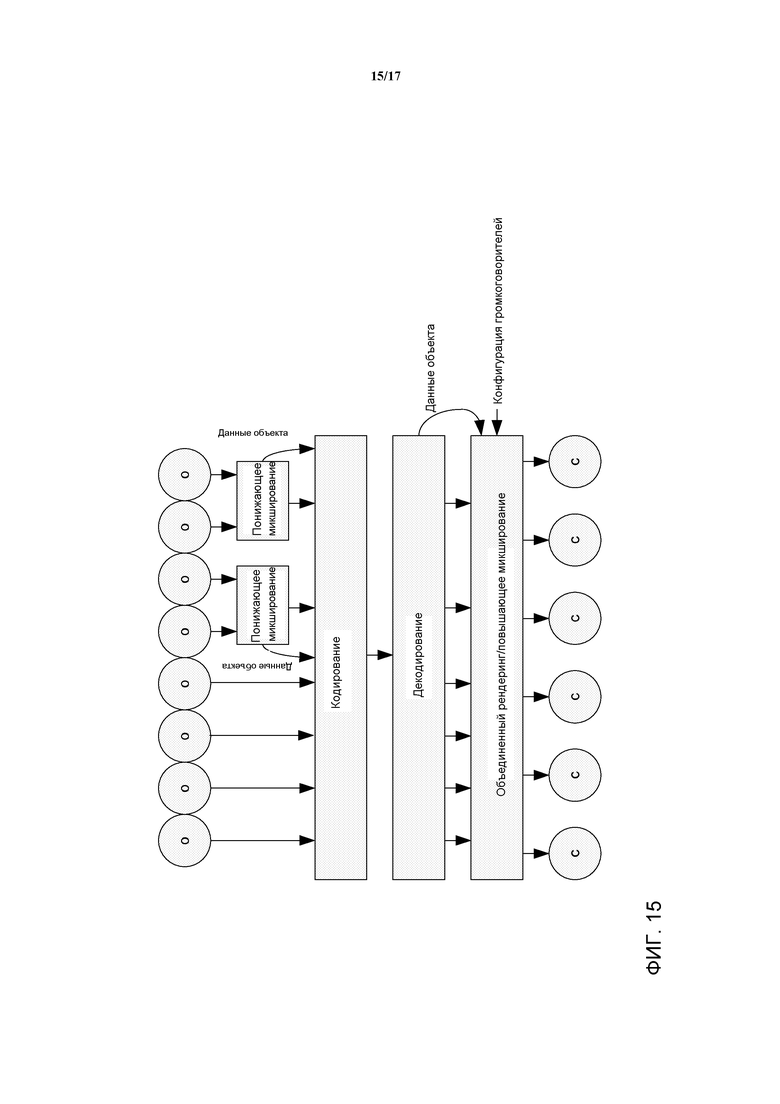

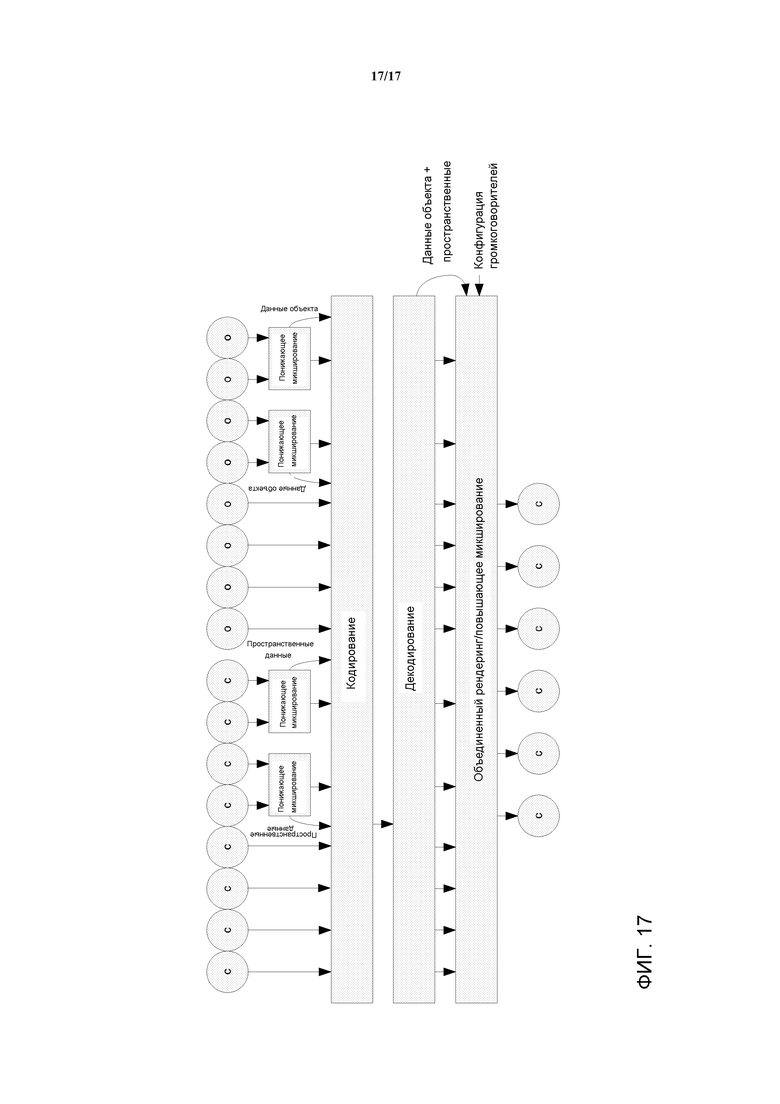
Изобретение относится к кодированию/декодированию множества аудиосигналов. Технический результат изобретения заключается в обеспечении улучшенной масштабируемости, особенно при более высоких скоростях передачи данных. Кодер (1201) содержит селектор (1303), который выбирает подмножество частотно-временных сегментов, которые должны быть подвержены понижающему микшированию, и подмножество сегментов, которые должны быть без понижающего микширования. Генерируется указание понижающего микширования, которое указывает, закодированы ли сегменты как сведенные закодированные сегменты или как сегменты без понижающего микширования. Закодированный сигнал, содержащий закодированные сегменты и указание понижающего микширования, подается на декодер (1203), который включает в себя приемник (1401) для приема сигнала. Генератор (1403) генерирует выходные сигналы из закодированных частотно-временных сегментов, причем генерирование выходных сигналов включает в себя повышающее микширование для сегментов, которые указаны указанием понижающего микширования как закодированные полученные понижающим микшированием сегменты. 5 н. и 11 з.п. ф-лы, 17 ил.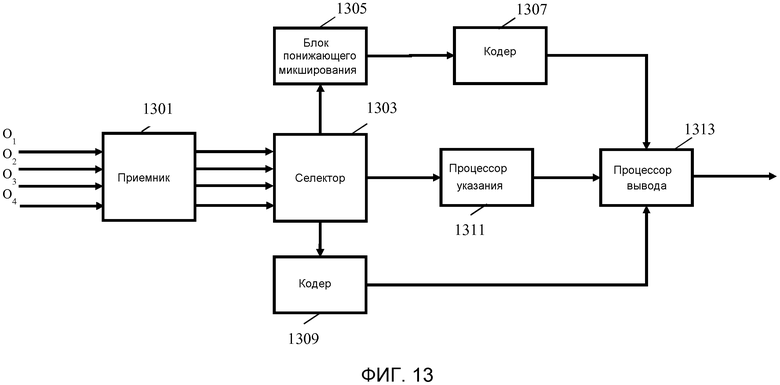
1. Декодер, содержащий:
приемник (1401) для приема закодированного сигнала данных, представляющего собой множество аудиосигналов, причем закодированный сигнал данных содержит закодированные частотно-временные сегменты для множества аудиосигналов, причем закодированные частотно-временные сегменты содержат частотно-временные сегменты без понижающего микширования и частотно-временные сегменты с понижающим микшированием, причем каждый частотно-временной сегмент с понижающим микшированием является понижающим микшированием по меньшей мере двух частотно-временных сегментов из множества аудиосигналов, а каждый частотно-временной сегмент без понижающего микширования представляет собой только один частотно-временной сегмент из множества аудиосигналов, и распределение закодированных частотно-временных сегментов в качестве частотно-временных сегментов с понижающим микшированием или частотно-временных сегментов без понижающего микширования отражает пространственные характеристики частотно-временных сегментов, причем закодированный сигнал данных дополнительно содержит указание понижающего микширования для частотно-временных сегментов из множества аудиосигналов, причем указание понижающего микширования указывает, закодированы ли частотно-временные сегменты из множества аудиосигналов в качестве частотно-временных сегментов с понижающим микшированием или частотно-временных сегментов без понижающего микширования;
генератор (1403) для генерирования набора выходных сигналов из закодированных частотно-временных сегментов, причем генерирование выходных сигналов содержит повышающее микширование для закодированных частотно-временных сегментов, которые указаны указанием понижающего микширования как являющиеся частотно-временными сегментами с понижающим микшированием;
при этом по меньшей мере один аудиосигнал из множества аудиосигналов представляется двумя частотно-временными сегментами с понижающим микшированием, являющимися понижающими микшированиями разных наборов аудиосигналов из множества аудиосигналов; и
по меньшей мере один частотно-временной сегмент с понижающим микшированием является понижающим микшированием аудиообъекта, не ассоциированного с номинальной позицией источника звука конфигурации рендеринга источника звука, и аудиоканала, ассоциированного с номинальной позицией источника звука конфигурации рендеринга источника звука.
2. Декодер по п. 1, в котором закодированный сигнал данных дополнительно содержит параметрические данные повышающего микширования, и при этом генератор (1403) выполнен с возможностью адаптирования операции повышающего микширования в ответ на параметрические данные.
3. Декодер по п. 1, в котором генератор (14 03) содержит блок рендеринга, выполненный с возможностью отображения частотно-временных сегментов для множества аудиосигналов в выходные сигналы, соответствующие конфигурации источника пространственного звука.
4. Декодер по п. 1, в котором генератор (1403) выполнен с возможностью генерирования частотно-временных сегментов для набора выходных сигналов посредством применения матричных операций к закодированным частотно-временным сегментам, коэффициенты матричных операций включают в себя компоненты повышающего микширования для закодированных частотно-временных сегментов, для которых указание понижающего микширования указывает, что закодированный частотно-временной сегмент является частотно-временным сегментом с понижающим микшированием, и не для закодированных частотно-временных сегментов, для которых указание понижающего микширования указывает, что закодированный частотно-временной сегмент является частотно-временным сегментом без понижающего микширования.
5. Декодер по п. 1, в котором по меньшей мере один аудиосигнал представляется в декодированном сигнале посредством по меньшей мере одного частотно-временного сегмента без понижающего микширования и по меньшей мере одного частотно-временного сегмента с понижающим микшированием.
6. Декодер по п. 1, в котором указание понижающего микширования для по меньшей мере одного частотно-временного сегмента с понижающим микшированием содержит связь между закодированным частотно-временным сегментом с понижающим микшированием и частотно-временным сегментом из множества аудиосигналов.
7. Декодер по п. 1, в котором по меньшей мере один аудиосигнал из множества аудиосигналов представляется посредством закодированных частотно-временных сегментов, которые включают в себя по меньшей мере один закодированный частотно-временной сегмент, не являющийся частотно-временным сегментом без понижающего микширования или частотно-временным сегментом с понижающим микшированием.
8. Декодер по п. 1, в котором, по меньшей мере, некоторые из частотно-временных сегментов без понижающего микширования являются закодированными по форме волны.
9. Декодер по п. 1, в котором, по меньшей мере, некоторые из частотно-временных сегментов с понижающим микшированием являются закодированными по форме волны.
10. Декодер по п. 1, в котором генератор (1403) выполнен с возможностью повышающего микширования частотных сегментов с понижающим микшированием для генерирования полученных повышающим микшированием частотно-временных сегментов для по меньшей мере одного из множества аудиосигналов частотно-временного сегмента с понижающим микшированием; и генератор выполнен с возможностью генерирования частотно-временных сегментов для набора выходных сигналов, используя полученные повышающим микшированием частотно-временные сегменты для сегментов, для которых указание понижающего микширования указывает, что закодированный частотно-временной сегмент является частотно-временным сегментом с понижающим микшированием.
11. Способ декодирования, содержащий этапы, на которых:
принимают закодированный сигнал данных, представляющий собой множество аудиосигналов, причем закодированный сигнал данных содержит закодированные частотно-временные сегменты для множества аудиосигналов, причем закодированные частотно-временные сегменты содержат частотно-временные сегменты без понижающего микширования и частотно-временные сегменты с понижающим микшированием, причем каждый частотно-временной сегмент с понижающим микшированием является понижающим микшированием по меньшей мере двух частотно-временных сегментов из множества аудиосигналов и каждый частотно-временной сегмент без понижающего микширования представляет собой только один частотно-временной сегмент из множества аудиосигналов, и распределение закодированных частотно-временных сегментов в качестве частотно-временных сегментов с понижающим микшированием или частотно-временных сегментов без понижающего микширования отражает пространственные характеристики частотно-временных сегментов, причем закодированный сигнал данных дополнительно содержит указание понижающего микширования для частотно-временных сегментов из множества аудиосигналов, причем указание понижающего микширования указывает, закодированы ли частотно-временные сегменты из множества аудиосигналов как частотно-временные сегменты с понижающим микшированием или частотно-временные сегменты без понижающего микширования; и
генерируют набор выходных сигналов из закодированных частотно-временных сегментов, причем генерирование выходных сигналов содержит повышающее микширование для закодированных частотно-временных сегментов, которые указаны указанием понижающего микширования как частотно-временные сегменты с понижающим микшированием; при этом по меньшей мере один аудиосигнал из множества аудиосигналов представляется двумя частотно-временными сегментами с понижающим микшированием, являющимися понижающими микшированиями разных наборов аудиосигналов из множества аудиосигналов; и по меньшей мере один частотно-временной сегмент с понижающим микшированием является понижающим микшированием аудиообъекта, не ассоциированного с номинальной позицией источника звука конфигурации рендеринга источника звука, и аудиоканала, ассоциированного с номинальной позицией источника звука конфигурации рендеринга источника звука.
12. Кодер, содержащий:
приемник (1301) для приема множества аудиосигналов, каждый аудиосигнал содержит множество частотно-временных сегментов;
селектор (1303) для выбора первого подмножества из множества частотно-временных сегментов, которые должны быть подвержены понижающему микшированию;
блок (1305) понижающего микширования для понижающего микширования частотно-временных сегментов из первого подмножества для генерирования полученных понижающим микшированием частотно-временных сегментов;
первый кодер (1307) для генерирования частотно-временных сегментов, закодированных с понижающим микшированием, посредством кодирования частотно-временных сегментов с понижающим микшированием;
второй кодер (1309) для генерирования частотно-временных сегментов без понижающего микширования посредством кодирования второго подмножества частотно-временных сегментов аудиосигналов без понижающего микширования частотно-временных сегментов из второго подмножества;
блок (1311) для генерирования указания понижающего микширования, указывающего, закодированы ли частотно-временные сегменты из первого подмножества и второго подмножества как частотно-временные сегменты, закодированные с понижающим микшированием, или как частотно-временные сегменты без понижающего микширования;
блок (1313) вывода для генерирования закодированного аудиосигнала, представляющего собой множество аудиосигналов, причем закодированный аудиосигнал содержит частотно-временные сегменты без понижающего микширования, частотно-временные сегменты, закодированные с понижающим микшированием, и указание понижающего микширования;
при этом селектор (1303) выполнен с возможностью выбора частотно-временных сегментов для первого подмножества в ответ на пространственную характеристику частотно-временных сегментов; по меньшей мере один аудиосигнал из множества аудиосигналов представляется двумя частотно-временными сегментами с понижающим микшированием, являющимися понижающими микшированиями разных наборов аудиосигналов из множества аудиосигналов; и по меньшей мере один частотно-временной сегмент с понижающим микшированием является понижающим микшированием аудиообъекта, не ассоциированного с номинальной позицией источника звука конфигурации рендеринга источника звука, и аудиоканала, ассоциированного с номинальной позицией источника звука конфигурации рендеринга источника звука.
13. Кодер по п. 12, в котором селектор (1303) выполнен с возможностью выбора частотно-временных сегментов для первого подмножества в ответ на целевую скорость передачи данных для закодированного аудиосигнала.
14. Кодер по п. 12, в котором селектор (1303) выполнен с возможностью выбора частотно-временных сегментов для первого подмножества в ответ на по меньшей мере одно из:
энергии частотно-временных сегментов; и
характеристики когерентности между парами частотно-временных сегментов.
15. Способ кодирования, содержащий этапы, на которых:
принимают множество аудиосигналов, каждый аудиосигнал содержит множество частотно-временных сегментов;
выбирают первое подмножество из множества частотно-временных сегментов, которые должны быть подвержены понижающему микшированию;
осуществляют понижающее микширование частотно-временных сегментов из первого подмножества для генерирования полученных понижающим микшированием частотно-временных сегментов;
генерируют частотно-временные сегменты, закодированные с понижающим микшированием, посредством кодирования полученных понижающим микшированием частотно-временных сегментов;
генерируют частотно-временные сегменты без понижающего микширования посредством кодирования второго подмножества частотно-временных сегментов аудиосигналов без понижающего микширования частотно-временных сегментов из второго подмножества;
генерируют указание понижающего микширования, указывающее, закодированы ли частотно-временные сегменты из первого подмножества и второго подмножества как полученные понижающим микшированием закодированные частотно-временные сегменты или как частотно-временные сегменты без понижающего микширования; и
генерируют закодированный аудиосигнал, представляющий собой множество аудиосигналов, причем закодированный аудиосигнал содержит частотно-временные сегменты без понижающего микширования, частотно-временные сегменты, закодированные с понижающим микшированием, и указание понижающего микширования; и при этом
выбор содержит выбор частотно-временных сегментов для первого подмножества в ответ на пространственную характеристику частотно-временных сегментов; по меньшей мере один аудиосигнал из множества аудиосигналов представляется двумя частотно-временными сегментами с понижающим микшированием, являющимися понижающими микшированиями разных наборов аудиосигналов из множества аудиосигналов; и по меньшей мере один частотно-временной сегмент с понижающим микшированием является понижающим микшированием аудиообъекта, не ассоциированного с номинальной позицией источника звука конфигурации рендеринга источника звука, и аудиоканала, ассоциированного с номинальной позицией источника звука конфигурации рендеринга источника звука.
16. Система кодирования и декодирования, содержащая кодер по п. 12 и декодер по п. 1.
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| СПОСОБ ПОЛУЧЕНИЯ АЦИЛИЗОЦИАНАТОВ | 0 |
|
SU210140A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |

