ОБЛАСТЬ ИЗОБРЕТЕНИЯ
Настоящее изобретение относится к способам распределения заданий вычислительным устройством (сервером), в частности к способам назначения ресурсов посредством операционной системы задачам и подзадачам в системах с множеством вычислительных элементов или устройств.
УРОВЕНЬ ТЕХНИКИ
В настоящее время известно несколько моделей распределения задач операционной системой, отличающихся различными уровнями сложности распределяемых задач. Один из относительно простых способов распределения называется FIFO (First In, First Out - «первым пришел - первым ушел») и предполагает распределение времени CPU в порядке прихода задачи в очередь. Ссылка: http://ru.wikipedia.org/wiki/FIFO. В этом случае каждая задача использует время CPU до тех пор, пока она не будет завершена.
Другой известный способ распределения называется Round robin (обслуживание по кругу - http://ru.wikipedia.org/wiki/Round-robin_(%D0%B0%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC)).
Этот способ предполагает последовательное “круговое” обслуживание заданий, так что каждое задание в очереди получает свой квант времени CPU в соответствии с позицией задания в очереди. Если задание не завершилось в течение отведенного ему кванта времени, задание прерывается и, следующее задание из очереди обрабатывается в течение следующего кванта времени. Прерванное задание вновь получает возможность использовать время CPU для дальнейшей обработки в зависимости от его позиции в очереди, и так до тех пор, пока оно не будет завершено.
Система распределения может разделять сложные задачи на простые подзадачи. Задачи могут быть разбиты на множество подзадач, которые не зависимы друг от друга и которые могут выполняться параллельно без взаимодействия или обмена данными друг с другом и в произвольном порядке. В таком случае подзадачи могут выполняться параллельно и асинхронно, что приводит к тому, что время выполнения основной задачи существенно сокращается. В других случаях некоторые подзадачи могут иметь независимые части, которые могут выполняться параллельно, в то время как сами подзадачи распределяются таким образом, чтобы они могли синхронизироваться и взаимодействовать для выполнения требуемых операций.
Эти способы, однако, имеют ограниченные возможности вследствие того, что не учитывают приоритетность выполняемых задач, наличие заданий с различными приоритетами, не позволяют динамически настраивать систему в соответствии с различными потребностями и стратегиями обработки задач различной сложности и объема.
Заявленная группа изобретений позволяет более эффективно и результативно решить задачу динамического распределения массива заданий с учетом различных приоритетов выполнения и сложности выполняемых заданий, а также позволяет в любой момент запускать на обработку новые задачи.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
Заявленные способ, носитель информации и система служат для распределения задач сервером вычислительной системы.
Так, заявленный способ распределения задач сервером вычислительной системы заключается в том, что:
- определяют совокупное число свободных обработчиков вычислительной системы, доступных для предоставления имеющимся заданиям, включающее множество обработчиков, которые могут быть предоставлены для выполнения обычных задач и множество обработчиков, составляющих неприкосновенный запас;
- однократно выбирают значение коэффициента доступности;
- назначают каждой последующей в очереди задаче число обработчиков из условия наличия свободных обработчиков, которые могут быть предоставлены для выполнения обычных задач, при этом число назначаемых обработчиков не больше, чем число доступных в данный момент времени обработчиков, которые могут быть предоставлены для выполнения обычных задач, умноженное на коэффициент доступности, но не менее одного такого обработчика;
- в случае отсутствия свободных обработчиков, которые могут быть предоставлены для выполнения обычных задач, следующей задаче назначают, по меньшей мере, один обработчик из неприкосновенного запаса.
Предпочтительные, но не обязательные варианты реализации способа предполагают, в частности, дополнительное определение общего числа задач, которым не назначен ни один из обработчиков, при этом такие задачи определяют из условия их приоритетности с последующим назначением свободных обработчиков, которые могут быть предоставлены для выполнения обычных задач, согласно приоритету; множество обработчиков, составляющих неприкосновенный запас, может быть зафиксировано, например, в процентах от общего числа обработчиков; из множества обработчиков, которые могут быть предоставлены для выполнения обычных задач, дополнительно выделяют число обработчиков для распараллеливания (PAT), общее число которых определяют по формуле PAT=Р-Т-ER, где Р - общее число обработчиков, которые могут быть предоставлены для выполнения обычных задач, Т - общее число распределенных задач, ER - число обработчиков, выделенных в неприкосновенный запас, при этом возможность дополнительного назначения каждой последующей в очереди задаче по меньшей мере одного обработчика для распараллеливания определяют из условия сложности такой задачи; при этом число обработчиков (PUT), доступных для выполнения сложной задачи, определяют по формуле max (2, (РТТ+1)*РТР), где РТТ текущее число обработчиков, доступных для распараллеливания, а РТР процент обработчиков, разрешенных использовать для распараллеливания данной задачи; кроме того, итеративное назначение обработчиков задачам в данный момент времени выполняют на основе вычисления нового значения числа обработчиков для задачи, где новое значение числа обработчиков для данной задачи (NPUT) равно max (CPUT, min (PUT, CPUT+FAT, ST)), где CPUT - число обработчиков, используемых данной задачей в данный момент; PUT - число обработчиков, доступных для выделения данной задаче; FAT - максимальное число свободных обработчиков, которое может быть использовано для распараллеливания, где FAT=F-ER; F - общее число свободных обработчиков в данный момент времени; ER - число обработчиков, выделенных в неприкосновенный запас; ST - максимальное число обработчиков, требуемых для обработки данной задачи.
Заявленный машиночитаемый носитель информации, несущий исполняемые компьютером инструкции для обеспечения возможности распределения заданий между множеством вычислительных устройств, содержит инструкцию, сконфигурированную, чтобы обеспечивать возможность:
- определения совокупного числа свободных обработчиков вычислительного системы, доступных для предоставления имеющимся заданиям, включающее множество обработчиков, которые могут быть предоставлены для выполнения обычных задач и множество обработчиков, составляющих неприкосновенный запас;
- однократный выбор значения коэффициента доступности
- назначение каждой последующей в очереди задаче число обработчиков из условия наличия свободных обработчиков, которые могут быть предоставлены для выполнения обычных задач, при этом число назначаемых обработчиков не больше, чем число доступных в данный момент времени обработчиков, которые могут быть предоставлены для выполнения обычных задач, умноженное на коэффициент доступности, но не менее одного такого обработчика;
- в случае отсутствия свободных обработчиков, которые могут быть предоставлены для выполнения обычных задач, назначение следующей задаче по меньшей мере, одного обработчика из неприкосновенного запаса.
Предпочтительные, но не обязательные варианты реализации носителя предполагают, в частности, наличие дополнительной инструкции для определения общего числа задач, которым не назначен ни один из обработчиков, при этом такие задачи определяют из условия их приоритетности с последующим назначением свободных обработчиков, которые могут быть предоставлены для выполнения обычных задач, согласно приоритету; множество обработчиков, составляющих неприкосновенный запас, может быть зафиксировано, например, в процентах от общего числа обработчиков; носитель может содержать дополнительную инструкцию. в которой из множества обработчиков, которые могут быть предоставлены для выполнения обычных задач, дополнительно выделяют число обработчиков для распараллеливания (PAT), общее число которых определяют по формуле PAT=Р-Т-ER, где Р - общее число обработчиков, которые могут быть предоставлены для выполнения обычных задач, Т - общее число распределенных задач, ER - число обработчиков, выделенных в неприкосновенный запас; при этом число обработчиков (PUT), доступных для выполнения сложных задач, определено как max (2, (РТТ+1)*РТР), где РТТ текущее число обработчиков, доступных для распараллеливания, а РТР процент обработчиков, разрешенных использовать для распараллеливания данной задачи; возможно итеративное назначение обработчиков задачам в данный момент времени на основе вычисления нового значения числа обработчиков для задачи, где новое значение числа обработчиков для данной задачи (NPUT) равно max (CPUT, min (PUT, CPUT+FAT, ST)), где CPUT - число обработчиков, используемых данной задачей в данный момент; PUT - число обработчиков, доступных для выделения данной задаче; FAT - максимальное число свободных обработчиков, которое может быть использовано для распараллеливания, где FAT=F-ER; F - общее число свободных обработчиков в данный момент времени; ER - число обработчиков, выделенных в неприкосновенный запас; ST - максимальное число обработчиков, требуемых для обработки данной задачи.
Заявленная система для распределения заданий между множеством вычислительных устройств включает:
один или более процессоров;
одно или более устройств памяти;
программные инструкции для вычислительного устройства, записанные в одно или более устройств памяти, которые при выполнении на одном или более процессорах управляют системой для:
- определения совокупного числа свободных обработчиков вычислительного системы, доступных для предоставления имеющимся заданиям, включающее множество обработчиков, которые могут быть предоставлены для выполнения обычных задач и множество обработчиков, составляющих неприкосновенный запас;
- однократного выбора значения коэффициента доступности
- назначения каждой последующей в очереди задаче число обработчиков из условия наличия свободных обработчиков, которые могут быть предоставлены для выполнения обычных задач, при этом число назначаемых обработчиков не больше, чем число доступных в данный момент времени обработчиков, которые могут быть предоставлены для выполнения обычных задач, умноженное на коэффициент доступности, но не менее одного такого обработчика;
- в случае отсутствия свободных обработчиков, которые могут быть предоставлены для выполнения обычных задач, следующей задаче назначения, по меньшей мере, одного обработчика из неприкосновенного запаса.
Предпочтительные, но не обязательные варианты реализации системы предполагают, в частности, дополнительное определение общего числа задач, которым не назначен ни один из обработчиков, при этом такие задачи определяют из условия их приоритетности с последующим назначением свободных обработчиков, которые могут быть предоставлены для выполнения обычных задач, согласно приоритету; множество обработчиков, составляющих неприкосновенный запас системы может быть зафиксировано, например, в процентах от общего числа обработчиков; возможно из множества обработчиков, которые могут быть предоставлены для выполнения обычных задач, дополнительное выделение некоторого числа обработчиков для распараллеливания (PAT), определяемого по формуле PAT=Р-Т-ER, где Р - общее число обработчиков, которые могут быть предоставлены для выполнения обычных задач, Т - общее число распределенных задач, ER - число обработчиков, выделенных в неприкосновенный запас; при этом число обработчиков (PUT), доступных для выполнения сложных задач, равно max (2, (РТТ+1)*РТР), где РТТ текущее число обработчиков, доступных для распараллеливания, а РТР процент обработчиков, разрешенных использовать для распараллеливания данной задачи; кроме того, итеративное назначение обработчиков задачам в данный момент времени выполняют на основе вычисления нового значения числа обработчиков для задачи, где новое значение числа обработчиков для данной задачи (NPUT) равно max (CPUT, min (PUT, CPUT+FAT, ST)), где CPUT - число обработчиков, используемых данной задачей в данный момент; PUT - число обработчиков, доступных для выделения данной задаче; FAT - максимальное число свободных обработчиков, которое может быть использовано для распараллеливания, где FAT=F-ER; F - общее число свободных обработчиков в данный момент времени; ER - число обработчиков, выделенных в неприкосновенный запас; ST - максимальное число обработчиков, требуемых для обработки данной задачи.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Дополнительные цели, признаки и преимущества настоящего изобретения будут очевидными из прочтения последующего описания осуществления изобретения со ссылкой на прилагаемые чертежи, на которых:
Фиг.1 является блок-схемой алгоритма, иллюстрирующего реализацию способа распределения заданий в вычислительной системе в соответствии с настоящим изобретением.
Фиг.2 иллюстрирует пример реализации компьютерной системы, реализующей распределение задач в соответствии с способом изобретения.
Фиг.3 является блок-схемой алгоритма описываемого метода распределения задач сервером вычислительной системы в соответствии с одним из возможных воплощений изобретения.
Фиг.4 является блок-схемой метода организации параллельной обработки заданий с одинаковым приоритетом в соответствии с одним из возможных воплощений изобретения.
Фиг.5 иллюстрирует пример очереди заданий в системе распределения заданий в соответствии с одним из воплощений метода данного изобретения.
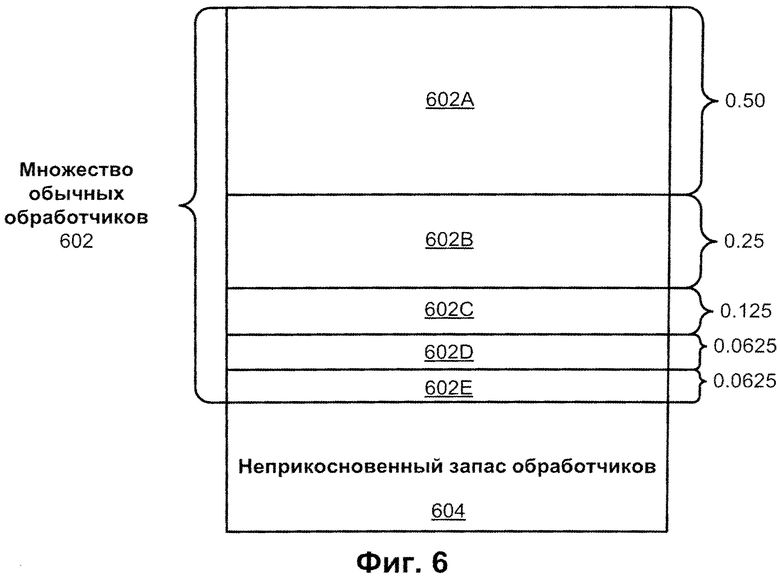
Фиг.6 иллюстрирует картину распределения обработчиков в случае РТР=0.50 в соответствии с некоторым воплощением изобретения.
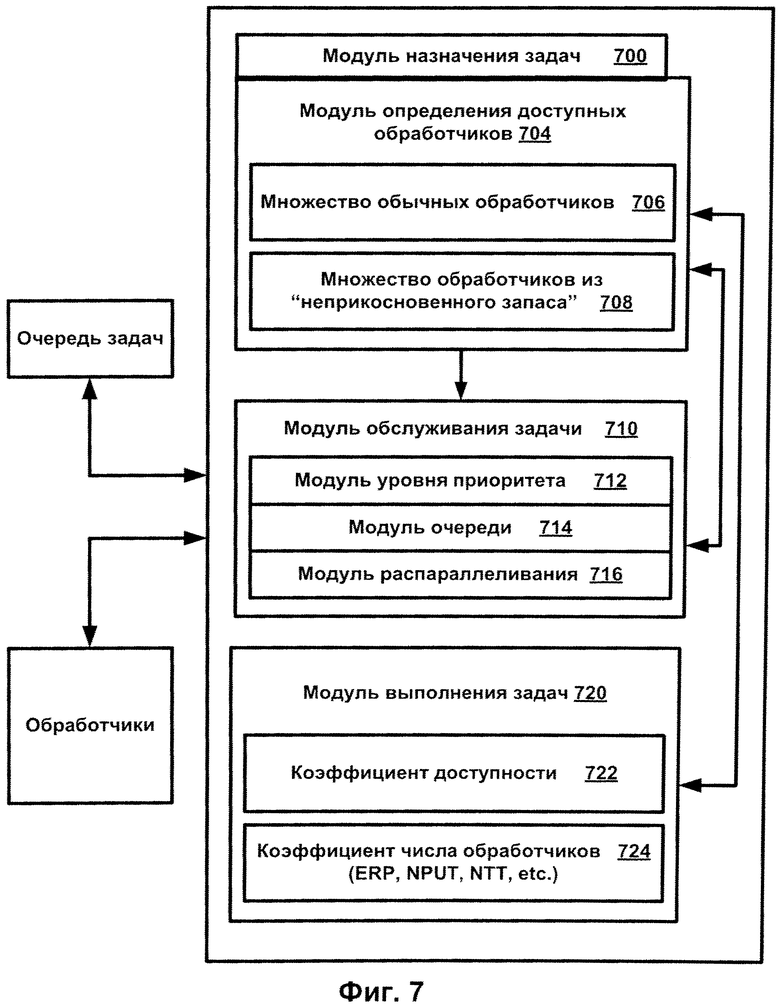
Фиг.7 иллюстрирует схему системы распределения заданий в соответствии с одним из воплощений данного изобретения.
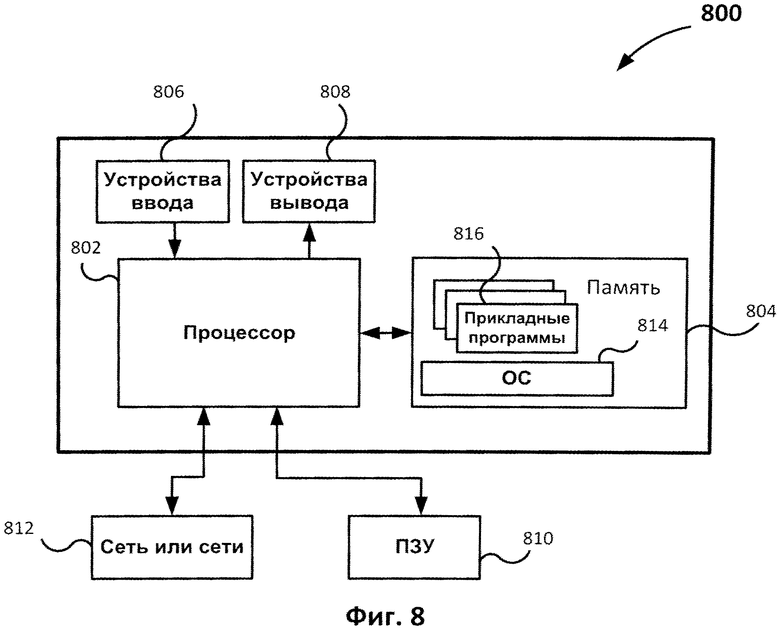
Фиг.8 иллюстрирует возможный пример вычислительного средства, которые могут быть использованы для внедрения настоящего изобретения.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
Объекты и признаки настоящего изобретения, способы для достижения этих объектов и признаков станут очевидными посредством отсылки к примерным вариантам осуществления. Однако настоящее изобретение не ограничивается примерными вариантами осуществления, раскрытыми ниже, оно может воплощаться в различных видах. Сущность, приведенная в описании, является ничем иным, как конкретными деталями, обеспеченными для помощи специалисту в области техники в исчерпывающем понимании изобретения, и настоящее изобретение определяется только в объеме приложенной формулы.
Настоящее изобретение предназначено для использования в любом вычислительном средстве, способном воспринимать и обрабатывать как текстовые данные, так и данные изображений. Это могут быть серверы, персональные компьютеры (ПК), переносные компьютеры (ноутбуки), компактные компьютеры (лаптопы) и любые иные существующие или разрабатываемые, а также будущие вычислительные устройства, подключаемые к компьютерной сети. Предпочтительным вариантом для реализации являются средства, обладающие многопроцессорностью, позволяющие иметь более одного процесса - обработчика на станции обработки, непосредственно выполняющей задание. Только одно задание или одна его подзадача может обрабатываться на каждом обработчике в каждый момент времени.
Варианты осуществления данного изобретения включают систему и способ распределения заданий, выполняемый на компонентах или элементах компьютерной системы. Различные примеры и типы задач, которые могут распределяться и выполняться указанным способом, включают, по меньшей мере, но не ограничиваются ими: анализ и перевод текстов с одного языка на другой, обработка текстовых корпусов - анализ, статистическая обработка и сбор статистических данных, разметка etc., а также извлечение фактов, распознавание речи и т.д. Описанный метод распараллеливания и распределения заданий особенно полезен в случае задач, связанных с обработкой естественного языка, которые могут быть достаточно сложными и требующими значительных вычислительных ресурсов.
Фиг.1 является блок-схемой алгоритма, иллюстрирующего реализацию способа распределения заданий в вычислительной системе в соответствии с настоящим изобретением. Как показано на Фиг.1, описываемый метод включает шаги: определение 110 (также этот шаг описан на Фиг.3) совокупного числа (свободных) обработчиков вычислительного устройства, доступных для предоставления имеющимся заданиям, где совокупное число доступных обработчиков включает множество обработчиков, которые могут быть предоставлены для выполнения обычных задач и множество обработчиков, составляющих неприкосновенный запас. Задачи назначаются обработчикам в соответствии со следующим способом: способ отличается тем, что предполагает назначение (шаг 130) следующей в очереди задаче числа обработчиков не больше, чем число доступных в данный момент обработчиков, умноженного на некоторый, эмпирически выбираемый коэффициент доступности, и итеративное назначение обработчиков задачам в соответствии с описываемым методом пока имеются свободные обработчики, которые могут быть предоставлены для выполнения задач (шаг 120), и в случае отсутствия таковых, следующей задаче назначаются обработчики из неприкосновенного запаса (шаг 140).
Указанный метод распределения задач работает в системах, допускающих многопроцессорную обработку. Распределение выполняется в соответствии с числом доступных для распределения обработчиков, это множество состоит из двух групп - множество обработчиков, которые могут быть использованы для распараллеливания и множества обработчиков, составляющих неприкосновенный запас обработчиков. Обработчики первой группы распределяются в соответствии с описываемым способом, который назначает запрашиваемое число обработчиков вплоть до максимально имеющегося числа обработчиков в этой группе. Это максимальное число обработчиков, которые могут быть использованы для распараллеливания, равно числу свободных обработчиков первой группы, умноженному на коэффициент доступности.
Указанный коэффициент доступности может, например, динамически настраиваться с течением времени, настройка может быть осуществлена вручную или программно. Значение коэффициента доступности может назначаться произвольно или выбираться эмпирически для любой заданной системы. Например, если коэффициент доступности равен 0.5, то 50% от общего числа доступных обработчиков приписывается первой задаче. В случае если выбирается значение коэффициента доступности больше 0.5, ранее пришедшие задачи получают больше обработчиков, и соответственно, степень распараллеливания их будет выше, в то время как пришедшие позже могут дольше дожидаться в очереди. Если же выбирается значение коэффициента доступности меньше 0.5, большее количество задач запускается одновременно, но степень распараллеливания их будет меньше.
Назначение обработчиков задачам продолжается в соответствии с описываемым методом пока имеются свободные обработчики, которые могут быть предоставлены для выполнения задач. Когда исчерпываются обработчики первой группы, назначаются обработчики из неприкосновенного запаса.
В одном случае задачи, назначаемые обработчикам из неприкосновенного запаса, являются простыми и не требующими распараллеливания. В этом случае задачи для обработчиков второй группы распределяются по принципу: одна задача - один обработчик. Наличие подмножества процессоров второй группы позволяет добавить к обработке новые задачи даже тогда, когда все обработчики первой группы заняты. Например, в случае когда система обрабатывает много сложных задач обработки текстов с большим объемом вычислений, занимающих все множество обработчиков первой группы, всего несколько задач занимают все ресурсы, а все остальные пользователи вынуждены ждать, даже если их задачи требуют очень мало ресурсов. Наличие неприкосновенного запаса обработчиков позволяет пользователям поставить свои задачи в очередь в то время, когда все обработчики первой группы заняты, с возможностью получить результат, и получить его достаточно быстро. Для относительно простых задач назначение единственного обработчика может позволить получить результат относительно быстрым образом.
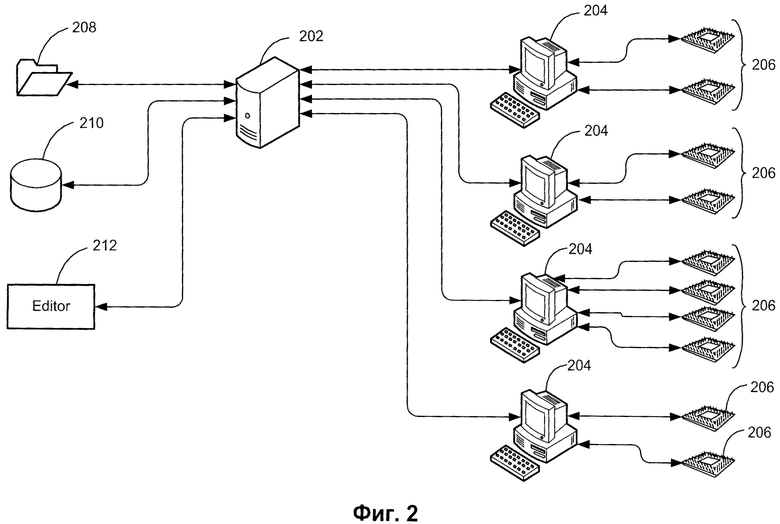
Пример реализации компьютерной системы, реализующей распределение задач в соответствии со способом изобретения, показано на Фиг.2. Система, показанная на Фиг.2, представляет клиент-серверную архитектуру. Сервер 202 соединен с множеством вычислительных устройств 204 (станций обработки). Каждое из вычислительных устройств 204 имеет, по меньшей мере, один обработчик 206. Блоки 208, 210, 212 являются примерами клиентов сервера 202. Клиенты 208, 210, 212 посылают задачи на сервер для обработки, где они могут быть распределены по обработчикам. Например, клиент 208 представляет собой папку заданий, ожидающих обработки (горячую папку), и программное приложение - распределитель файлов, управляющий пересылкой задач из горячей папки на сервер. Метод, связанный с горячей папкой, включает обработку или пересылку каждой новой задачи, поступающей в горячую папку, серверу 202. В другом примере клиент 212 может быть приложением-редактором, работающим на удаленном терминале с пользовательским интерфейсом для перевода текста.
Под задачей здесь и далее понимается простая (неделимая) задача или сложная задача вместе с соответствующими подзадачами. Система распределения (диспетчеризации) может разделить каждую сложную задачу на неделимые подзадачи. Подзадача является единицей обработки для сервера. Например, только одна подзадача может выполняться обработчиком в каждый момент времени. Когда происходит назначение множества обработчиков сложной задаче, подзадачи этой сложной задачи приписываются этому множеству обработчиков. Подзадачи жестко связываются или ассоциируются со своей сложной задачей. Сложные задачи помещаются в очередь для обработки. Все подзадачи одной сложной задачи должны использовать обработчики, назначенные соответствующей сложной задаче.
Число доступных обработчиков для каждой задачи зависит от, например: (1) общего числа задач того же приоритета или выше; (2) числа обработчиков, используемых для выполнения задач с более высоким приоритетом; (3) числа обработчиков, используемых для выполнения задач с тем же приоритетом или выше, которые поступили в очередь раньше. Если число сложных задач выше, чем число обработчиков, каждой сложной задаче может быть назначено не более одного обработчика.
Назначение только одного обработчика единственной сложной задаче может сэкономить процессорное время сервера. Однако эта экономия достигается за счет отсутствия распараллеливания. Если число задач меньше числа обработчиков, задачи, пришедшие раньше, выполняются существенно быстрее, чем в случае, когда число задач больше числа обработчиков.
Преимущество описанного способа распределения для задач обработки естественного языка состоит в возможности разделить обрабатываемый текст, который может быть достаточно объемным, что рассматривается как сложная задача, на несколько частей - подзадач. В одном случае время выполнения для каждой сложной задачи и ее подзадач не определено или может быть измерено только непосредственно перед инициализацией задачи для выполнения. В другом случае число подзадач сложной задачи определяется непосредственно во время ее выполнения.
Описываемый способ распределения задач определяет множество свободных обработчиков из числа предназначенных для назначения задач на выполнение и связывает свободные обработчики с подзадачами. В одном случае число подзадач, образуемых сложной задачей, определяется в самом начале обработки. Например, максимальное число обработчиков, которые могут быть использованы для обработки сложной задачи, есть число ее подзадач - один обработчик на подзадачу, и наоборот - одна подзадача на обработчик. Такой способ распределения является “жадным” в том смысле, что он не отдает все свободные обработчики для выполнения одной сложной задачи.
Описываемый способ распределения может разделять каждую задачу на части, т.е. подзадачи. Время выполнения каждой задачи и ее подзадач не определено до их выполнения. К примеру, способ деления задачи на подзадачи и размер подзадач может быть стандартным или выбираться эвристически.
Цель описываемого способа - так распределить задачи и их подзадачи в вычислительной системе, чтобы любая задача - большая или малая, могла вернуть результат выполнения задачи за ожидаемое время - время, определяемое в зависимости от ситуации. Могут существовать различные типы пользователей, например, работающие в реальном времени, пользователи, отправляющие задания через сайт (портал) и т.п. Могут существовать уровни приоритета, назначаемые каждой задаче, каждой подзадаче или одновременно родительской задаче и одной или более подзадач. Для некоторых пользователей время выполнения несущественно, они могут посылать свои задания в пакете, и время выполнения задач для них не важно.
На Фиг.3 показана блок-схема алгоритма описываемого метода распределения задач сервером вычислительной системы в соответствии с одним из возможных воплощений изобретения. На Фиг.4 показана блок-схема метода организации параллельной обработки заданий с одинаковым приоритетом в соответствии с одним из возможных воплощений изобретения. Способ, составляющий настоящее изобретение, и описываемый здесь, включает шаги, показанные на Фиг.3 и Фиг.4.
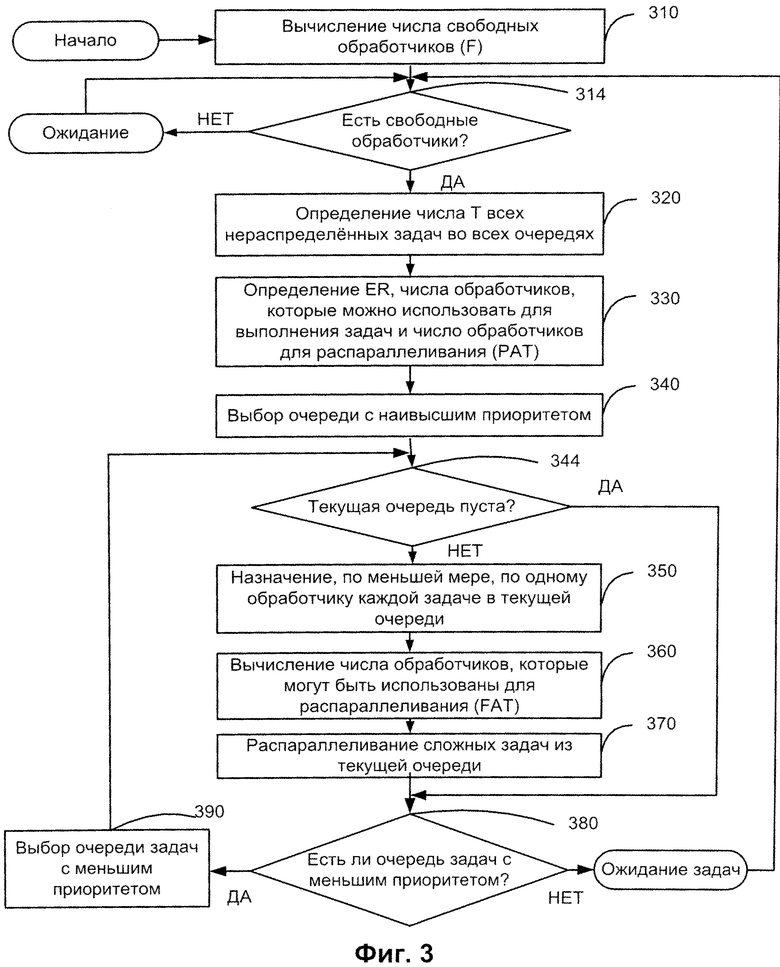
На Фиг.3 показаны следующие этапы метода: вычисление количества свободных обработчиков (310); определение числа всех нераспределенных сложных задач во всех очередях (320); определение актуального числа обработчиков, которые можно использовать для назначения невыполненным задачам, неприкосновенный запас (НЗ) и число обработчиков, которые могут быть использованы для распараллеливания (330); выбор очереди с наивысшим приоритетом (340); проверка, не пуста ли очередь с наивысшим уровнем приоритета (344); в зависимости от этого, назначение, по меньшей мере, по одному обработчику каждой сложной задаче в текущей очереди (350); перевычисление числа свободных обработчиков, которые могут быть использованы для распараллеливания (360), и распараллеливание сложных задач из текущей очереди заданий (370).
Возвращаясь к Фиг.3, число свободных обработчиков (310) в некоторый момент времени может быть обозначено символом F. Если после выполнения шага 310 число свободных обработчиков (F) больше нуля (314), то вычисляется общее число всех задач всех приоритетов (Т) (шаг 320). В противном случае сервер ждет, когда появятся свободные обработчики (F будет больше нуля).
Один из важных шагов - определение числа сложных задач (Т) во всех очередях с различными уровнями приоритетов (шаг 320). После этого вычисляется число обработчиков (Р), доступных для выполнения заданий (шаг 330).
Число обработчиков, которые необходимы системе распределения заданий, чтобы всегда обеспечить возможность начать обработку новой задачи, называется неприкосновенным запасом. В частном случае реализации обработчики, принадлежащие неприкосновенному запасу, не используются для распараллеливания сложных задач. Например, можно иметь один или более обработчиков для создания неприкосновенного запаса. Неприкосновенный запас составляет некоторую фиксированную долю общего числа обработчиков. Для примера, описываемая система распределения задач может требовать, чтобы 10% (ERP=10%) были доступны для начала обработки новой сложной задачи.
Неприкосновенный запас может быть описан как ER=Р*ERP, где ER число обработчиков неприкосновенного запаса, Р - общее число обработчиков в системе, доступных для выполнения обычных задач, ERP - некоторая постоянная фиксированная доля в процентах, необходимая для того, чтобы поддерживать возможность открыть обработку новой задачи. Значение EPR не должно быть слишком большим, в противном случае система не будет в состоянии распараллеливать сложные задачи и выполнять обработку достаточно быстро.
После того как неприкосновенный запас определен, вычисляется число обработчиков, которое разрешено использовать для распараллеливания сложных задач PAT (Processing units Available for Threading). PAT может быть представлено формулой PAT=P-Т-ER, где Р - общее число обработчиков, Т - общее число задач, и ER - число обработчиков, составляющих неприкосновенный запас. Таким образом, каждой задаче передается, по крайней мере, один обработчик плюс некоторое количество обработчиков для распараллеливания.
Обратимся снова к Фиг.3, где выбирается очередь с наивысшим приоритетом (шаг 340). Для примера, очередь может представлять собой упорядоченный по времени поступления список задач с одинаковым приоритетом. Для каждого уровня приоритета создается отдельная очередь. Распределение сложных задач и подзадач между обработчиками в режиме реального времени может быть оптимизировано в соответствии со следующими критериями: (1) настоящий метод распределения сложных задач позволяет запускать новые задачи на выполнение в вычислительной системе по возможности раньше; (2) сложные задачи, имеющие более высокий приоритет, обрабатываются в первую очередь, после чего обрабатываются задачи с меньшим приоритетом; (3) метод может предоставить несколько обработчиков сложным задачам, состоящим из нескольких подзадач, с целью более быстрого выполнения, чем на одном обработчике. Каждая из сложных задач и ее подзадач может иметь некоторый уровень приоритета. Сложные задачи в каждой из очередей обрабатываются по принципу “первый пришел - первым обслужен” для каждого из уровней приоритета по отдельности. Например, могут быть введены три уровня приоритета - низкий, средний и высокий. Для каждого уровня приоритета, сложные задачи обрабатываются одинаковым образом. Приоритет может приписываться задачам, например, априорно, до начала выполнения. Разным сложным задачам может быть присвоен разный приоритет. Например, срочным задачам или задачам, полученным от VIP-клиентов, может быть присвоен высокий приоритет. Все задачи в одной очереди имеют одинаковый приоритет.
Задачи из очереди с наивысшим приоритетом обрабатываются в первую очередь (шаги 350, 370), таким образом, сначала в качестве текущей очереди рассматривается очередь задач с наивысшим приоритетом. Если текущая очередь не пуста, каждой сложной задаче в очереди должен быть назначен, по меньшей мере, один обработчик (шаг 350). После того как задачи из текущей очереди размещаются на предназначенные им обработчики (350), определяется число обработчиков, которые могут быть использованы для распараллеливания (360).
На шаге 310 определяется число свободных обработчиков (F). F - максимальное число обработчиков, которое может быть использовано для назначения задачам и их распараллеливания в данный момент. Исключая неприкосновенный запас ER, число свободных обработчиков, которые могут быть использованы для распараллеливания (FAT=Free processing units Available for Threading), может быть представлено формулой FAT=F-ER. Обработчики из неприкосновенного запаса могут использоваться только для назначения новым задачам, но не для распараллеливания.
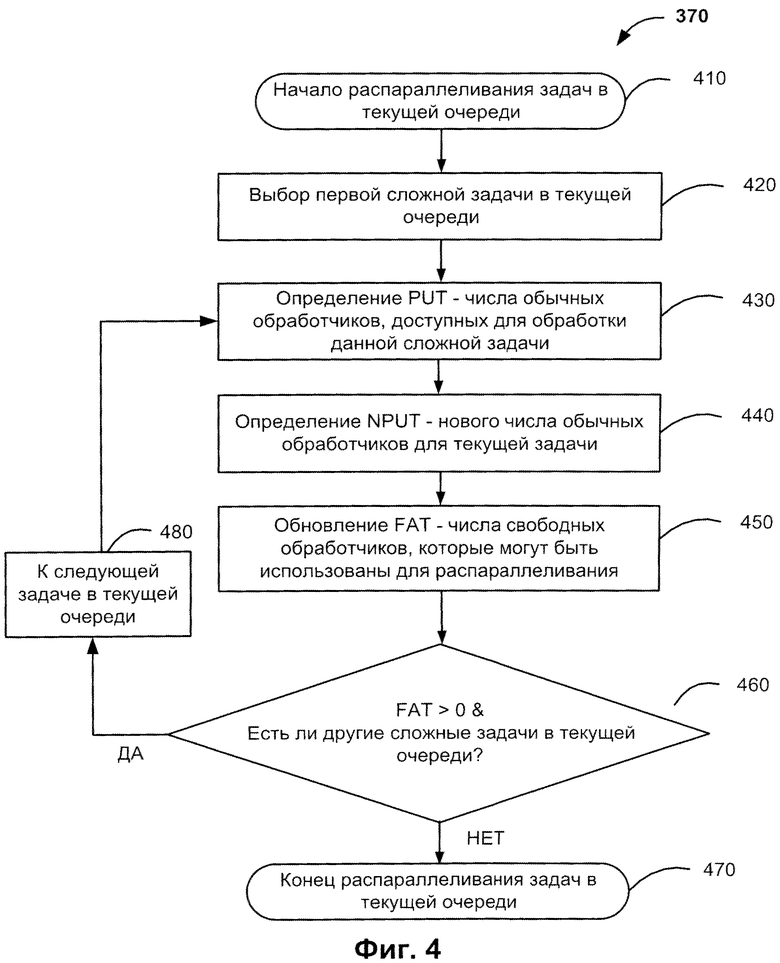
Если число свободных обработчиков, которое может быть использовано для распараллеливания, больше нуля (FAT>0) и общее число обработчиков, которых разрешено использовать для распараллеливания, больше нуля (PAT>0), то выполняются шаги 430, 440, 450, 460, представленные на Фиг.4 для каждой задачи, требующей распараллеливания. РТТ - текущее число обработчиков, доступных для распараллеливания текущей задачи (РТТ=Processing units for Threading Task). Для первой задачи, число обработчиков, которое может быть использовано для ее распараллеливания (РТТ), получает значение PAT - число обработчиков, которое разрешено использовать для распараллеливания сложных задач.
На Фиг.4 показана блок-схема алгоритма метода распараллеливания задач, находящихся в текущей очереди (шаг 370). Например, пусть очередь задач наивысшего приоритета не пуста. На шаге 430 вычисляется число обработчиков, доступных для обработки сложной задачи PUT (Processing units for Use in Task processing). Число обработчиков, доступных для обработки сложной задачи PUT может быть вычислено по формуле PUT=max (2, (РТТ+1)*РТР), где РТТ - текущее число обработчиков, которые могут быть использованы для распараллеливания, а РТР - процент обработчиков, разрешенных для распараллеливания данной задачи. В соответствии с вышеприведенной формулой PUT равно максимальному из значений - (1) целое 2 or (2) округленное значение (РТТ+1), умноженного на РТР, где where РТР - процент обработчиков, разрешенных использовать для распараллеливания. Если (РТТ+1)*РТР меньше 2, то выбирается PUT=2. Поскольку параллельная обработка на одном обработчике невозможно, то значение 2 используется как минимально необходимое число обработчиков для распараллеливания текущей задачи. РТР является константой, обозначающей процент обработчиков, разрешенных к использованию для (распараллеливания) данной задачи. Например, РТР может быть выбрано равным вышеупомянутому коэффициенту доступности. Тогда, предоставление обработчиков задачам осуществляется на основе константы РТР.
Возвращаясь к Фиг.1, обычные обработчики предоставляются для выполнения новых задач таким образом, что максимальное число обычных обработчиков, назначенных для обработки задач равно числу доступных обычных обработчиков, назначаемых для обработки задач, умноженному на РТР.
Например, в системе устанавливается значение константы РТР=50%. Когда новая задача поступает в очередь на распределение, около половины (50%) доступных обработчиков, которые могут быть использованы для распараллеливания, могли бы быть предоставлены этой новой задаче. Когда новая задача появляется в очереди (допустим, ни один обработчик не освободился), то вновь используется константа РТР, и 50% от числа доступных на тот момент обработчиков (50% от оставшихся 50%) будет предоставлено этой следующей новой задаче (около 25% от начального числа доступных обработчиков на момент прихода первой задачи, при условии, что ни один не освободился).
Рассмотрим вычислительную систему с 100 обработчиками и одной очередью задач. Для примера, положим ERP=0 и РТР=50%. Предположим, что первая задача в очереди оказалась очень сложной, и для нее потребовалось 50 обработчиков. Это означает, что после этого 50 обработчиков остались свободными. Далее, вторая пришедшая в очередь задача требует для обработки 25 обработчиков, тогда только 25 обработчиков остаются доступными для распределения следующих задач. Если третья пришедшая в очередь задача потребует 12 обработчиков, останутся свободными 13.
Установленное по умолчанию (default) значение РТР может варьироваться в зависимости от потребностей распределения задач. Например, значение РТР может быть установлено 50%. В другом случае значение РТР может быть, например, 35%. Другое преимущество описываемого метода распределения состоит в том, что в случае, если в некоторый момент есть несколько задач с одинаковым приоритетом, число возможных дополнительных обработчиков для второй задачи всегда меньше, чем число возможных дополнительных обработчиков для первой задачи (около (1-РТР), умноженное на число оставшихся свободных обработчиков после выделения обработчиков предыдущей задаче).
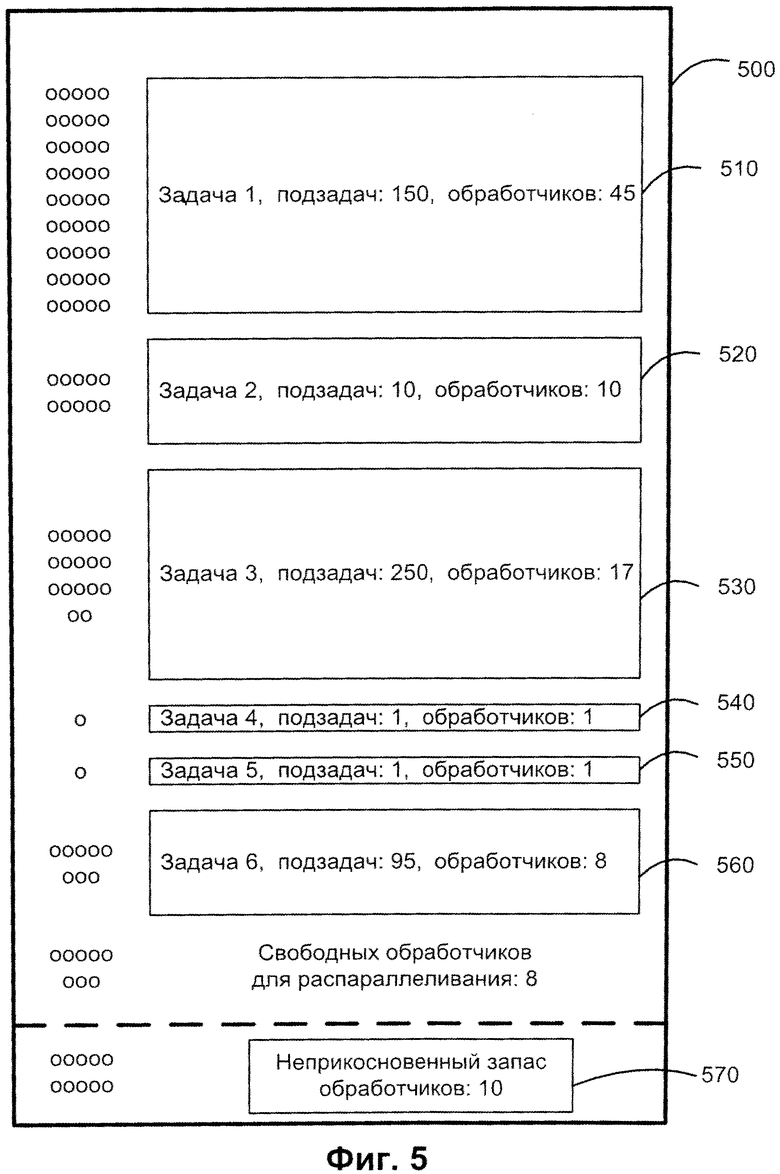
Фиг.5 иллюстрирует пример очереди заданий в системе распределения заданий в соответствии с одним из воплощений метода данного изобретения. На Фиг.5 показан пример очереди 500 задач с одним приоритетом. Задачи были помещены в очередь в следующем порядке: задача 510, задача 520, задача 530, задача 540, задача 550 и задача 560. На Фиг.5 показано, что, например, задача 1, обозначенная 510, разделяется на 150 подзадач, задача 520 делится на 10 подзадач, задача 530 делится на 250 подзадач, задачи 540 и 550 являются простыми неделимыми задачами и задача 560 делится на 95 подзадач.
Предположим, для примера, что клиент - серверная система, поддерживающая очередь заданий, изображенную на Фиг.5, содержит 100 обработчиков и значения ERP=10% и РТР=50%. Обработчики, предоставленные каждой задаче, изображены маленькими кружочками в левой части иллюстрации 500. Пример Фиг.5 показывает, что для значения ERP=10%, 10 обработчиков резервируется как неприкосновенный запас 570, что означает, что 90 обработчиков остаются доступными для обработки заданий. Каждой задаче назначается, по меньшей мере, один обработчик. Описываемый способ распределения заданий предоставляет 45 обработчиков (90*50%) первой задаче. Далее он назначает 10 обработчиков второй задаче и 17 обработчиков ((90-45-10)*50%) третьей задаче. Затем по одному - четвертому и пятому заданиям. Затем 8 обработчиков ((90-45-10-17-1-1)*50%) предоставляются шестой задаче. 8 обработчиков остаются доступными для предоставления новым задачам, которые могут поступать в очередь. 8 обработчиков могут быть использованы как для последовательного выполнения задач, так и для их распараллеливания. Для большей гибкости в достижении целей эффективного распределения, константы ERP и РТР могут быть использованы для настройки конфигурации сервера. Различные режимы работы сервера могут сопровождаться выбором соответствующих ERP и РТР и соответствующих им модулей вычислительной системы. Например, значения ERP=10%, РТР=50% соответствуют обычному (default) режиму в предыдущем примере. В каких-то случаях эти значения (ERP=10%), РТР=50%) соответствуют оптимальному режиму распределения. Значения ERP=0%, РТР=100% позволяют обеспечить режим максимального использования ресурсов для первой пришедшей задачи. Такие значения обеспечивают максимальное распараллеливание (РТР=100% без неприкосновенного запаса (ERP=0)), что эффективно для больших задач. Например, такая конфигурация может использоваться, когда число задач невелико (например, ночью). Значение ERP=100% - это режим, который не поддерживает распараллеливание. Только один обработчик предоставляется каждой задаче. Это приемлемый режим в ситуации, когда есть много малых задач (например, множество онлайн-пользователей).
Фиг.6 иллюстрирует картину распределения обработчиков в случае РТР=0.50 в соответствии с некоторым воплощением изобретения. Как показано выше, обработчики неприкосновенного запаса не назначаются задачам, пока есть свободные обычные обработчики. Обычные обработчики назначаются в соответствии с методом, который дает запрашиваемое число обработчиков вплоть до максимального числа обычных обработчиков. Максимальное число обычных обработчиков равно общему числу доступных обычных обработчиков, умноженному на коэффициент доступности.
Когда коэффициент доступности равен 0.5 (РТР=0.50), то 50% от общего числа доступных обработчиков приписывается первой задаче.
Возвращаясь к предыдущему примеру, показанному на Фиг.5, это множество 0.50 отмечено меткой 602А. Назначение обработчиков продолжается для следующей задачи. Для следующей задачи максимальная доля обработчиков могла бы быть 50% от 50% обычных обработчиков. Это распределение 0.25 (0.5 multiplied by 0.5) показано меткой 602 В. Далее, если есть свободные обработчики, продолжается процесс их распределения, и 50% от 50% от 50% свободных обработчиков предоставляется следующей задаче. Это распределение 0.125 на Фиг.6, следует общей формуле (1-РТР)∧n, где n - целое число.
Процесс распределения продолжается, и 50% от 50% от 50% от 50% свободных обработчиков предоставляется следующей задаче. Это распределение 0.0625 (602С, 602D) на Фиг.6. Предположим для примера, что когда достигается распределение 0.0625, остается свободными только 2 обычных обработчика, что меньше, чем требуется для данной текущей задачи. Тогда задача будет распределена на эти 2 обработчика, а следующей задаче из очереди будут предоставлены обработчики из неприкосновенного запаса 604, поскольку обработчики из неприкосновенного запаса 604 предоставляются только тогда, когда нет свободных обычных обработчиков 602.
На Фиг.4 показана блок-схема метода распараллеливания задач, имеющих одинаковый приоритет. Предположим для примера, что задача требует ST обработчиков (ST - число обработчиков, требуемых для задачи, может равняться, например, числу подзадач), и CPUT - текущее число обработчиков, используемых текущей задачей (CPUT=Current Processing units Used for Task). Если CPUT меньше, чем ST, то желательно дальнейшее распараллеливание.
На Фиг.4 показан этап определения нового числа обработчиков для задачи (440). Новое число обработчиков, которые доступны для выполнения задачи NPUT (New Processing units Used for Task) определяется NPUT=max (CPUT, min (PUT, CPUT+FAT, ST)). Согласно формуле новое число обработчиков, выделяемых задаче, вычисляется как максимальное значение из: (1) CPUT - текущее число обработчиков, используемых текущей задачей в момент времени tc или (2) минимальное из трех значений: PUT (число обработчиков, доступных для выделения данной задаче), CPUT(число обработчиков, используемых задачей в данный момент)+РАТ(максимальное число свободных обработчиков, которое может быть использовано для распараллеливания) и ST(число обработчиков, требуемых данной задаче). Таким образом, определенное новое число обработчиков для задачи NPUT может быть меньше числа обработчиков, доступных для выделения данной задаче - PUT, но не меньше того, что уже выделено данной задаче CPUT.
После определения числа обработчиков, которые доступны для выполнения задачи (440), обновляется F - число свободных обработчиков, FAT - число свободных обработчиков, которые могут быть использованы для распараллеливания (450). Новое значение определяется по формуле FAT:=FAT-(NPUT-CPUT), где FAT - максимальное число свободных обработчиков, которые могут быть использованы для распараллеливания, NPUT - новое число обработчиков, которые используются для выполнения данной задачи, и CPUT - старое число обработчиков, которые использовались для выполнения данной задачи. Кроме того, обновляется также значение РТТ по формуле РТТ:=РТТ-(NPUT-1), где РТТ - текущее число обработчиков, доступных для распараллеливания, а NPUT - новое число обработчиков, которые используются для выполнения задачи.
После обновления числа обработчиков, доступных для распараллеливания, принимается решение: если число свободных обработчиков, которое может быть использовано для распараллеливания, больше нуля (FAT>0) (шаг 460). Если FAT>0, следующая задача подвергается распараллеливанию (переход к шагу 380). Задачи обрабатываются в соответствии с их уровнем приоритета так, что задачи, имеющие более высокий приоритет, выполняются в первую очередь. После того как выполнятся все задачи с высоким приоритетом, выполняются задачи с нормальным приоритетом (шаги 350-370 блок-схемы на Фиг.3). Аналогичным образом, после того как выполнятся все задачи с нормальным приоритетом, выполняются задачи низкого приоритета по той же схеме (шаги 350-370).
Дополнительно увеличения адаптивности метода может учитываться производительность обработчиков. Если новый обработчик добавляется к вычислительной системе, происходит оценка его производительности. Все свободные обработчики упорядочиваются по убыванию производительности. Для каждой порции текста всякий раз выделяется самый мощный обработчик, распределенный для данной задачи.
В качестве примера сложной задачи, подлежащей распараллеливанию, рассмотрим пример перевода текста с одного языка на другой. В случае текста достаточно большого объема он может быть разделен, условно говоря, на страницы, тогда если текст делится на n страниц, то задача - на n подзадач. Размер страницы может быть фиксирован или ограничен, например, 2000 символами. Деление также может предпочтительно выполняться по границам глав, параграфов, абзацев, и непременно с учетом границ предложений.
Принцип деления на подзадачи может быть различным в зависимости от задач обработки. Например, если текст состоит из независимых частей (например, сборник рассказов), то и задачу предпочтительно делить на независимые части в соответствии с границами частей. В других случаях, когда между частями есть существенная тематическая связь, для получения качественного результата могут потребоваться некоторые дополнительные действия.
В отдельных реализациях для того, чтобы получить качественный перевод, могут собираться и учитываться результаты перевода отдельных частей текста и слов, статистика и результаты лексического выбора. Могут собираться и учитываться различные типы статистики как априорные, так и полученные во время выполнения перевода. Собранная статистика может доставляться обработчикам и использоваться ими в процессе обработки для конкретной задачи и ее подзадач. После завершения всех подзадач их результаты объединяются в единое целое. Различные типы статистики могут использоваться и на этом этапе, чтобы оценить качество результата и исправить возможные ошибки.
Например, после обработки сложной задачи и ее обработчик может выполнить дополнительные завершающие операции. В том числе, для описанной выше сложной задачи перевода текста, возможен дополнительный анализ переведенного текста на предмет сопоставления переводных терминов и возможной корректировки. Такие корректирующие операции могут выполняться быстро.
Фиг.7 иллюстрирует схему системы распределения заданий в соответствии с одним из воплощений данного изобретения. На Фиг.7 схематически изображен модуль системы, ответственный за назначение задач из очереди текущим свободным обработчикам. Этот модуль 700 назначения задач включает модуль 704 определения доступных обработчиков, модуль обслуживания задачи 710 и модуль вычисления задач 720.
Схема, показанная на Фиг.7, иллюстрирует пример реализации метода распределения задач, который показан на Фиг.1, Фиг.3 и Фиг.4. Этот метод может быть воплощен в 1) программном обеспечении; 2) аппаратном обеспечении; или 3) комбинации программного и аппаратного обеспечения, который могут быть встроенным или доступным серверу или обработчикам или серверу и обработчикам в комбинации. Так, модуль 700 назначения задач определяет следующую задачу с наивысшим приоритетом в очереди и вычисляет, сколько обработчиков требуется для выполнения этой задачи. Кроме того, модуль 700 назначения задач определяет количество свободных обработчиков и их тип (обычных или из неприкосновенного запаса). Исходя из двух типов доступных обработчиков любая задача может быть назначена 1) не больше, чем имеющемуся в наличии числу доступных обычных обработчиков, умноженному на коэффициент доступности, или 2) по крайней мере одному обработчику из неприкосновенного запаса.
Изображенный на Фиг.7 модуль 700 назначения задач включает модуль 704 определения доступности обработчиков. Модуль определения доступности обработчиков 704 определяет общее число свободных обработчиков, которое может быть использовано для выполнения задач. Например, общее число свободных обработчиков может быть определено на шаге 110. Общее число свободных обработчиков определяется как число свободных обработчиков из множества 706 обычных обработчиков и множества обработчиков из неприкосновенного запаса 708.
Модуль 710 определения текущей задачи аккумулирует информацию о текущей задаче, которая должна быть выполнена. Например, модуль 710 определения задач может включать модуль уровня приоритета 712, модуль очереди 714 и модуль распараллеливания 716. Например, модуль уровня приоритета 712 может определять уровень приоритета текущей задачи, модуль очереди 714 - позицию задачи в очереди, модуль распараллеливания 716 определяет, распараллеливается ли задача или нет и, если распараллеливается, условия ее распараллеливания (например, распараллеливание на 4 подзадачи на 4 обработчика).
Например, модуль 710 обслуживания задач отслеживает число задач и то, как распределяются задачи по обработчикам, хранит информацию о том, какая задача передается какому обработчику. Например, модуль определения задач может определять, на основе информации от модуля 704 определения доступных обработчиков, все ли обычные обработчики распределены (шаг 120). Если не все обычные обработчики распределены, они могут быть назначены в соответствии с методом изобретения. Если все обычные обработчики распределены, распределяются обработчики из неприкосновенного запаса (шаг 140).
Модуль выполнения задач 720 выполняет действия, необходимые для распределения задач. Он хранит значение коэффициента доступности (ERP) 722 и коэффициента числа обработчиков (РТР) 724, которые используются для определения числа обработчиков, необходимых для распределения задач. Например, задачи приписываются некоторому множеству обработчиков, где число назначаемых обработчиков равно числу свободных обычных обработчиков, умноженному на коэффициент доступности.
Настоящее изобретение предназначено для использования в любом вычислительном средстве, способном воспринимать и обрабатывать как текстовые данные, так и данные изображений. Это могут быть серверы, персональные компьютеры (ПК), переносные компьютеры (ноутбуки, нетбуки), компактные компьютеры (лаптопы), а также любые иные существующие или разрабатываемые, а также будущие вычислительные устройства.
На Фиг.8 приведен возможный пример вычислительного средства 800, которое может быть использовано для внедрения настоящего изобретения, осуществленного так, как было описано выше. Вычислительное средство 800 включает в себя, по крайней мере, один процессор 802, соединенный с памятью 804. Процессор 802 может представлять собой один или более процессоров, может содержать одно, два или более вычислительных ядер. Память 804 может представлять собой оперативную память (ОЗУ), а также содержать любые другие типы и виды памяти, в частности устройства энергонезависимой памяти (например, флэш-накопители) и постоянные запоминающие устройства, например жесткие диски и т.д. Кроме того, может считаться, что память 804 включает в себя аппаратные средства хранения информации, физически размещенные где-либо еще в составе вычислительного средства 800, например кэш-память в процессоре 802, память, используемую в качестве виртуальной и хранимую на внешнем либо внутреннем постоянном запоминающем устройстве 810.
Вычислительное средство 800 также обычно имеет некоторое количество входов и выходов для передачи информации вовне и получения информации извне. Для взаимодействия с пользователем вычислительное средство 800 может содержать одно или более устройств ввода (например, клавиатура, мышь, сканер и т.д.) и устройство отображения 808 (например, жидкокристаллический дисплей). Вычислительное средство 800 также может иметь одно или более постоянных запоминающих устройств 810, например привод оптических дисков (CD, DVD или другой), жесткий диск, ленточный накопитель. Кроме того, вычислительное средство 800 может иметь интерфейс с одной или более сетями 812, обеспечивающими соединение с другими сетями и вычислительными устройствами. В частности, это может быть локальная сеть (LAN), беспроводная сеть Wi-Fi, соединенные со всемирной сетью Интернет или нет. Подразумевается, что вычислительное средство 800 включает подходящие аналоговые и/или цифровые интерфейсы между процессором 802 и каждым из компонентов 804, 806, 808, 810 и 812.
Вычислительное средство 800 работает под управлением операционной системы 814 и выполняет различные приложения, компоненты, программы, объекты, модули и т.д., указанные обобщенно цифрой 816.
Вообще программы, исполняемые для реализации способов, соответствующих данному изобретению, могут являться частью операционной системы или представлять собой обособленное приложение, компоненту, программу, динамическую библиотеку, модуль, скрипт либо их комбинацию.
Настоящее описание излагает основной изобретательский замысел авторов, который не может быть ограничен теми аппаратными устройствами, которые упоминались ранее. Следует отметить, что аппаратные устройства, прежде всего, предназначены для решения узкой задачи. С течением времени и с развитием технического прогресса такая задача усложняется или эволюционирует. Появляются новые средства, которые способны выполнить новые требования. В этом смысле следует рассматривать данные аппаратные устройства с точки зрения класса решаемых ими технических задач, а не чисто технической реализации на некой элементной базе.
| название | год | авторы | номер документа |
|---|---|---|---|
| СЕТЕВАЯ ВЫЧИСЛИТЕЛЬНАЯ СИСТЕМА | 2008 |
|
RU2502122C2 |
| СПОСОБ ЗАШИФРОВАННОЙ СВЯЗИ С ИСПОЛЬЗОВАНИЕМ ДЕЦЕНТРАЛИЗОВАННОЙ ВЫЧИСЛИТЕЛЬНОЙ СИСТЕМЫ | 2024 |
|
RU2838643C1 |
| СЕТЕВАЯ ВЫЧИСЛИТЕЛЬНАЯ СИСТЕМА И СПОСОБ ВЫПОЛНЕНИЯ ВЫЧИСЛИТЕЛЬНОЙ ЗАДАЧИ (ВАРИАНТЫ) | 2013 |
|
RU2568289C2 |
| СПОСОБ ОБРАБОТКИ ДЛЯ МНОГОЯДЕРНОГО ПРОЦЕССОРА И МНОГОЯДЕРНЫЙ ПРОЦЕССОР | 2012 |
|
RU2630753C2 |
| СПОСОБ И СИСТЕМА РАСПРЕДЕЛЕНИЯ ВЫЧИСЛИТЕЛЬНЫХ ЗАДАЧ В ОБЛАЧНОЙ СРЕДЕ | 2024 |
|
RU2826431C1 |
| Способ и система графо-ориентированного создания масштабируемых и сопровождаемых программных реализаций сложных вычислительных методов | 2017 |
|
RU2681408C2 |
| Компьютерная система | 2021 |
|
RU2800966C1 |
| Способ планирования задач предобработки данных Интернета Вещей для систем анализа | 2016 |
|
RU2643620C2 |
| СИСТЕМЫ И СПОСОБЫ НАСТРОЙКИ ОПЕРАЦИИ НА КОМПЬЮТЕРНОЙ СИСТЕМЕ, СОЕДИНЕННОЙ СО МНОЖЕСТВОМ КОМПЬЮТЕРНЫХ СИСТЕМ ЧЕРЕЗ КОМПЬЮТЕРНУЮ СЕТЬ, С ИСПОЛЬЗОВАНИЕМ ДВУСТОРОННЕЙ СВЯЗИ ИДЕНТИФИКАТОРА ОПЕРАЦИИ | 2015 |
|
RU2674324C2 |
| КАДРОВЫЙ ПРОТОКОЛ И СИСТЕМА ПЛАНИРОВАНИЯ | 2003 |
|
RU2323429C2 |
Изобретение относится к области распределения задач сервером вычислительной системы. Техническим результатом является повышение эффективности динамического распределения заданий сервером по обработчикам вычислительной системы. Способ распределения задач сервером вычислительной системы заключается в том, что определяют совокупное число свободных обработчиков вычислительной системы, доступных для предоставления имеющимся заданиям, включающее множество обработчиков, которые могут быть предоставлены для выполнения обычных задач, и множество обработчиков, составляющих неприкосновенный запас; однократно выбирают значение коэффициента доступности; назначают каждой последующей в очереди задаче число обработчиков из условия наличия свободных обработчиков, которые могут быть предоставлены для выполнения обычных задач, при этом число назначаемых обработчиков не больше, чем число доступных в данный момент времени обработчиков, которые могут быть предоставлены для выполнения обычных задач, умноженное на коэффициент доступности, но не менее одного такого обработчика; в случае отсутствия свободных обработчиков, которые могут быть предоставлены для выполнения обычных задач, следующей задаче назначают, по меньшей мере, один обработчик из неприкосновенного запаса. 3 н. и 15 з.п. ф-лы, 8 ил.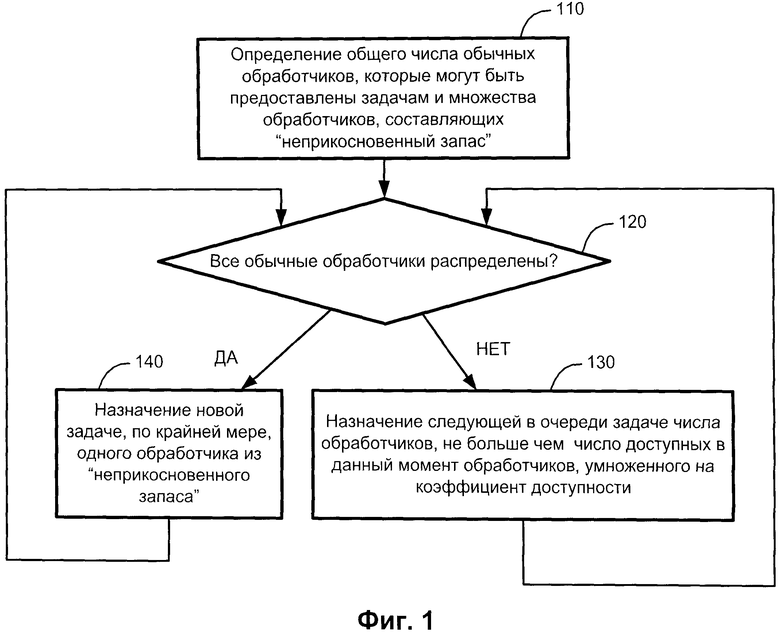
1. Способ распределения задач сервером вычислительной системы, заключающийся в том, что:
- определяют совокупное число свободных обработчиков вычислительной системы, доступных для предоставления имеющимся заданиям, включающее множество обработчиков, которые могут быть предоставлены для выполнения обычных задач, и множество обработчиков, составляющих неприкосновенный запас;
- однократно выбирают значение коэффициента доступности;
- назначают каждой последующей в очереди задаче число обработчиков из условия наличия свободных обработчиков, которые могут быть предоставлены для выполнения обычных задач, при этом число назначаемых обработчиков не больше, чем число доступных в данный момент времени обработчиков, которые могут быть предоставлены для выполнения обычных задач, умноженное на коэффициент доступности, но не менее одного такого обработчика;
- в случае отсутствия свободных обработчиков, которые могут быть предоставлены для выполнения обычных задач, следующей задаче назначают, по меньшей мере, один обработчик из неприкосновенного запаса.
2. Способ по п.1, в котором дополнительно определяют общее число задач, которым не назначен ни один из обработчиков, при этом такие задачи определяют из условия их приоритетности с последующим назначением свободных обработчиков, которые могут быть предоставлены для выполнения обычных задач, согласно приоритету.
3. Способ по п.1, в котором из множества обработчиков, которые могут быть предоставлены для выполнения обычных задач, дополнительно выделяют число обработчиков для распараллеливания (PAT), общее число которых определяют по формуле PAT=Р-Т-ER, где Р - общее число обработчиков, которые могут быть предоставлены для выполнения обычных задач, Т - общее число распределенных задач, ER - число обработчиков, выделенных в неприкосновенный запас.
4. Способ по п.1, в котором множество обработчиков, составляющих неприкосновенный запас зафиксировано, например, в процентах от общего числа обработчиков.
5. Способ по п.3, в котором число обработчиков (PUT), доступных для выполнения сложной задачи, равно max (2, (РТТ+1)*РТР), где РТТ текущее число обработчиков, доступных для распараллеливания, а РТР процент обработчиков, разрешенных использовать для распараллеливания данной задачи.
6. Способ по п.5, где итеративное назначение обработчиков задачам в данный момент времени выполняют на основе вычисления нового значения числа обработчиков для задачи, где новое значение числа обработчиков для данной задачи (NPUT) равно max (CPUT, min (PUT, CPUT+FAT, ST)), где CPUT - число обработчиков, используемых данной задачей в данный момент; PUT - число обработчиков, доступных для выделения данной задаче; FAT - максимальное число свободных обработчиков, которое может быть использовано для распараллеливания, где FAT=F-ER; F - общее число свободных обработчиков в данный момент времени; ER - число обработчиков, выделенных в неприкосновенный запас; ST - максимальное число обработчиков, требуемых для обработки данной задачи.
7. Машиночитаемый носитель информации, несущий исполняемые компьютером инструкции для обеспечения возможности распределения заданий между множеством вычислительных устройств, содержащий инструкции, сконфигурированные, чтобы обеспечивать возможность:
- определения совокупного числа свободных обработчиков вычислительной системы, доступных для предоставления имеющимся заданиям, включающее множество обработчиков, которые могут быть предоставлены для выполнения обычных задач, и множество обработчиков, составляющих неприкосновенный запас;
- однократного выбора значения коэффициента доступности;
- назначения каждой последующей в очереди задаче числа обработчиков из условия наличия свободных обработчиков, которые могут быть предоставлены для выполнения обычных задач, при этом число назначаемых обработчиков не больше, чем число доступных в данный момент времени обработчиков, которые могут быть предоставлены для выполнения обычных задач, умноженное на коэффициент доступности, но не менее одного такого обработчика;
- в случае отсутствия свободных обработчиков, которые могут быть предоставлены для выполнения обычных задач, назначения следующей задаче, по меньшей мере, одного обработчика из неприкосновенного запаса.
8. Носитель по п.7, содержащий дополнительную инструкцию определения общего числа задач, которым не назначен ни один из обработчиков, при этом такие задачи определяют из условия их приоритетности с последующим назначением свободных обработчиков, которые могут быть предоставлены для выполнения обычных задач, согласно приоритету.
9. Носитель по п.7, содержащий дополнительную инструкцию, в которой из множества обработчиков, которые могут быть предоставлены для выполнения обычных задач, дополнительно выделяют число обработчиков для распараллеливания (PAT), общее число которых определяют по формуле PAT=Р-Т-ER, где Р - общее число обработчиков, которые могут быть предоставлены для выполнения обычных задач, Т - общее число распределенных задач, ER - число обработчиков, выделенных в неприкосновенный запас.
10. Носитель по п.7, в котором множество обработчиков, составляющих неприкосновенный запас, зафиксировано, например, в процентах от общего числа обработчиков.
11. Носитель по п.9, в котором число обработчиков (PUT), доступных для выполнения сложных задач, равно max (2, (РТТ+1)*РТР), где РТТ текущее число обработчиков, доступных для распараллеливания, а РТР процент обработчиков, разрешенных использовать для распараллеливания данной задачи.
12. Носитель по п.11, в котором итеративное назначение обработчиков задачам в данный момент времени выполняют на основе вычисления нового значения числа обработчиков для задачи, где новое значение числа обработчиков для данной задачи (NPUT) равно max (CPUT, min (PUT, CPUT+FAT, ST)), где CPUT - число обработчиков, используемых данной задачей в данный момент; PUT - число обработчиков, доступных для выделения данной задаче; FAT - максимальное число свободных обработчиков, которое может быть использовано для распараллеливания, где FAT=F-ER; F - общее число свободных обработчиков в данный момент времени; ER - число обработчиков, выделенных в неприкосновенный запас; ST - максимальное число обработчиков, требуемых для обработки данной задачи.
13. Система для распределения заданий между множеством вычислительных устройств, включающая:
один или более процессоров;
одно или более устройств памяти;
программные инструкции для вычислительного устройства, записанные в одно или более устройств памяти, которые при выполнении на одном или более процессорах управляют системой для:
- определения совокупного числа свободных обработчиков вычислительной системы, доступных для предоставления имеющимся заданиям, включающего множество обработчиков, которые могут быть предоставлены для выполнения обычных задач, и множество обработчиков, составляющих неприкосновенный запас;
- однократного выбора значения коэффициента доступности;
- назначения каждой последующей в очереди задаче числа обработчиков из условия наличия свободных обработчиков, которые могут быть предоставлены для выполнения обычных задач, при этом число назначаемых обработчиков не больше, чем число доступных в данный момент времени обработчиков, которые могут быть предоставлены для выполнения обычных задач, умноженное на коэффициент доступности, но не менее одного такого обработчика;
- в случае отсутствия свободных обработчиков, которые могут быть предоставлены для выполнения обычных задач, следующей задаче назначения, по меньшей мере, одного обработчика из неприкосновенного запаса.
14. Система по п.13, в которой дополнительно определяют общее число задач, которым не назначен ни один из обработчиков, при этом такие задачи определяют из условия их приоритетности с последующим назначением свободных обработчиков, которые могут быть предоставлены для выполнения обычных задач, согласно приоритету.
15. Система по п.13, в которой из множества обработчиков, которые могут быть предоставлены для выполнения обычных задач, дополнительно выделяют число обработчиков для распараллеливания (PAT), общее число которых определяют по формуле PAT=Р-Т-ER, где Р - общее число обработчиков, которые могут быть предоставлены для выполнения обычных задач, Т - общее число распределенных задач, ER - число обработчиков, выделенных в неприкосновенный запас.
16. Система по п.13, в которой множество обработчиков, составляющих неприкосновенный запас, зафиксировано, например, в процентах от общего числа обработчиков.
17. Система по п.15, в которой число обработчиков (PUT), доступных для выполнения сложных задач, равно max (2, (РТТ+1)*РТР), где РТТ текущее число обработчиков, доступных для распараллеливания, а РТР процент обработчиков, разрешенных использовать для распараллеливания данной задачи.
18. Система по п.17, где итеративное назначение обработчиков задачам в данный момент времени выполняют на основе вычисления нового значения числа обработчиков для задачи, где новое значение числа обработчиков для данной задачи (NPUT) равно max (CPUT, min (PUT, CPUT+FAT, ST)), где CPUT - число обработчиков, используемых данной задачей в данный момент; PUT - число обработчиков, доступных для выделения данной задаче; FAT - максимальное число свободных обработчиков, которое может быть использовано для распараллеливания, где FAT=F-ER; F - общее число свободных обработчиков в данный момент времени; ER - число обработчиков, выделенных в неприкосновенный запас; ST -максимальное число обработчиков, требуемых для обработки данной задачи.
| US 8281313 B1, 02.10.2012 | |||
| АВТОКЛАВНЫЙ ЗОЛОПЕНОБЕТОН | 2004 |
|
RU2256632C1 |
| АППАРАТНО-РЕАЛИЗУЕМЫЙ СПОСОБ ВЫПОЛНЕНИЯ ПРОГРАММ | 2007 |
|
RU2450330C2 |
| МУЛЬТИПРОЦЕССОРНАЯ АРХИТЕКТУРА, ОПТИМИЗИРОВАННАЯ ДЛЯ ПОТОКОВ | 2008 |
|
RU2450339C2 |
| МУЛЬТИМЕДИА-ПРОЦЕССОР, МНОГОПОТОЧНЫЙ ПО ТРЕБОВАНИЮ | 2008 |
|
RU2425412C2 |

