Область применения.
Изобретение относится к области медицины, в частности к способам диагностики заболеваний, и может быть использовано в качестве способа автоматизированной диагностики заболеваний по совокупности диагностических признаков состояния организма, полученных в результате обработки измерений, проведенных посредством различных приборов медицинского назначения. Все диагностические признаки (характеристики) должны быть выражены действительными числами.
Уровень техники
В настоящее время в медицинской диагностике широко применяется теория распознавания образов.
Распознавание образов - научное направление, связанное с разработкой принципов и построением систем, предназначенных для определения принадлежности данного объекта к одному из заранее выделенных классов объектов. Под объектами в распознавании образов понимают различные предметы, явления, процессы, ситуации, сигналы. Каждый объект описывается совокупностью основных характеристик (признаков, свойств) Х=(x1,…, х:,…, Хn), где 1-я координата вектора Х определяет значения 1-й характеристики, и дополнительной характеристикой S, которая указывает на принадлежность объекта к некоторому классу. Набор заранее расклассифицированных объектов, т.е. таких, у которых известны характеристики Х и S, используется для обнаружения закономерных связей между значениями этих характеристик и поэтому называется обучающей выборкой. Те объекты, у которых характеристика S неизвестна, образуют контрольную выборку. Обучающая выборка используется для построения решающего механизма, называемого классификатором. Классификатор и используется для принятия решения о принадлежности исследуемого объекта конкретному классу. Проверяются работоспособность и точность классификатора с помощью контрольной выборки. В медицинской диагностике роль классов играют различные заболевания, а объектов - пациенты, представленные результатами измерений различных характеристик состояний организма.
В распознавании образов одной из важных проблем является определение состава вектора характеристик X. Этой задаче уделяется очень большое внимание в литературе, однако до сих пор нет приемлемого решения, которое бы применялось во всех случаях. В каждом конкретном случае исследователь должен решать задачу также конкретно, с учетом особенностей предметной области. Если же использовать для распознавания все характеристики, то точность распознавания будет, скорее всего, низкой из-за наличия большого числа избыточных и нерелевантных характеристик. Все характеристики можно разбить на три группы:
- релевантные (оказывающие влияние на распознавание);
- нерелевантные (могут быть характеристики, не только не влияющие на
распознавание, но и мешающие распознаванию). Среди релевантных размерностей могут быть избыточные.
Известен ближайший аналог - способ автоматизированной диагностики заболеваний и их форм, который также базируется на использовании кластерного анализа (патент РФ 2191429, авторов Базарского О.В., Битюковой В.В., Сидоренко Е.А., опубл. 20.10.2002).
Однако в этом способе не учитывается, что кластеров в пространстве характеристик просто может не быть, а если они есть, то могут перекрываться.
Задача изобретения
Задачей изобретения является создание нового способа автоматизированной диагностики заболеваний при повышении точности, сокращении времени диагностического исследования и повышении информативности при снижении стоимости исследования.
Решение задачи
Поставленная задача решается тем, что создан новый способ автоматизированной диагностики заболеваний на основе распознавания образов, отличающийся тем, что сначала осуществляют выбор характеристик, в пространстве которых для исследуемых объектов существуют различимые кластеры, образованные точками двух типов, первый тип соответствует пациентам с подтвержденным диагнозом диагностируемого заболевания, второй тип соответствует пациентам, не имеющем диагностируемого заболевания, затем в найденном пространстве характеристик определяют обучающие выборки для классификаторов, состоящие из точек - медоидов каждого кластера, и граничных точек, разделяющих кластеры; эти обучающие выборки используются затем при работе двух классификаторов типа «К ближайших соседей», на вход которых подаются данные обследуемого пациента, причем сначала используют классификатор на основе граничных точек в варианте «квалифицированного большинства», затем для точек, не классифицированных первым классификатором, используют классификатор на основе точек - медоидов в варианте «квалифицированного большинства», а для оставшихся точек - классификатор на основе граничных точек в варианте «простого большинства», после постановки диагноза, т.е. определения, к какому из двух классов относится обследуемый пациент, а именно к классу «с диагнозом» или к классу «без диагноза», принимают решение о включении характеристик обследуемого пациента в состав обучающих выборок и, если эти характеристики улучшают точность распознавания, производят включение.
Принципиальным отличием заявляемого способа от ближайшего аналога является предварительный выбор пространства характеристик, в котором кластеры заведомо существуют, причем оценивается и степень их перекрытия. Новизной заявляемого способа автоматизированной диагностики заболеваний является вся заявленная совокупность признаков. Заявляемое изобретение иллюстрируется фиг.1-3. На фиг.1 приведена блок-схема последовательности операций, иллюстрирующая сущность заявленного способа автоматизированной диагностики заболеваний.
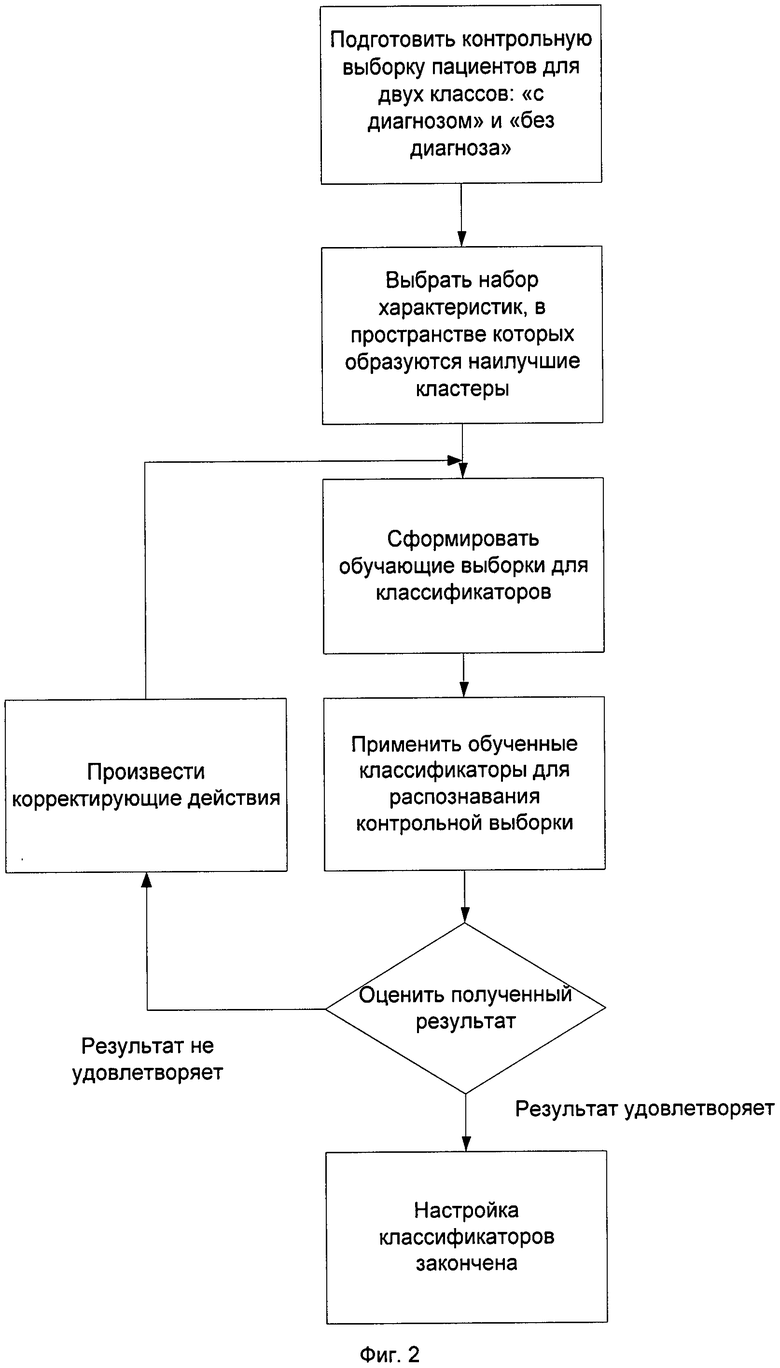
На фиг.2 приведена блок-схема последовательности операций, иллюстрирующая процесс настройки классификаторов в соответствии с заявляемым изобретением.
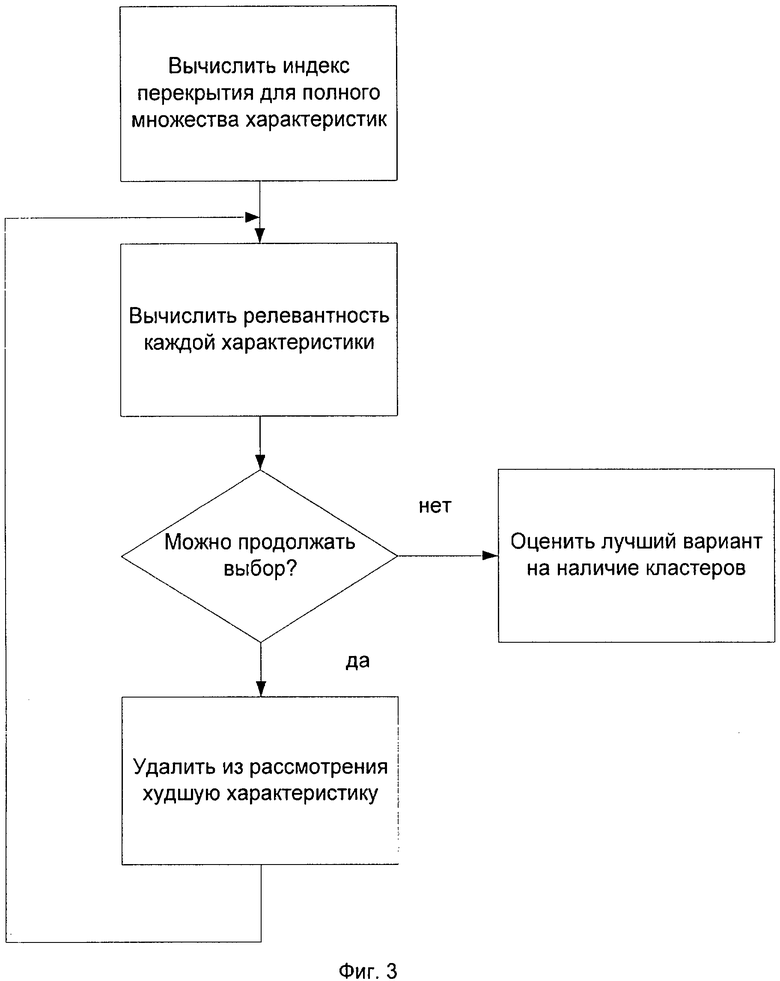
На фиг.3 приведена блок-схема последовательности операций, иллюстрирующая процесс выбора множества характеристик, в пространстве которых образуются наилучшие кластеры в соответствии с заявляемым изобретением.
Предлагаемый способ осуществляют следующим образом (фиг.1).
I. Приготовление выборки, состоящей из объектов двух классов.
Первый класс составляют пациенты с подтвержденным диагнозом заболевания, которое будет диагностироваться в дальнейшем (далее этот класс именуется «с диагнозом»). Второй класс составляют пациенты, не имеющие данного заболевания (далее этот класс именуется «без диагноза»). Оба класса должны содержать не меньше ста пациентов и содержать примерно одинаковое количество пациентов. Затем для всех пациентов производят измерения характеристик с помощью одного или нескольких медицинских приборов. Предполагается, что приборы предназначены для диагностики одного или группы заболеваний. Измеряемых характеристик должно быть больше двух, иначе применение способа не имеет смысла. Эта выборка будет служить эталоном для настройки классификаторов, которые будут использоваться для диагностики остальных пациентов. Способ пригоден и при использовании, например, характеристик, полученных после обработки медицинских изображений.
Предполагается, что все характеристики должны быть выражены количественно действительными числами.
Полученные значения характеристик рассматривают в качестве координат точки в многомерном пространстве. Далее рассчитывают расстояния между точками в этом многомерном пространстве. В качестве метрики предлагается использовать метрику Евклида.
Затем производят настройку классификаторов на основе обработки подготовленной выборки. Настройка заключается в выполнении последовательности операций, показанных на фиг.2.
1. Подготовить контрольную выборку пациентов для двух классов: «с диагнозом» и «без диагноза»
Нужно подготовить контрольную выборку, состоящую из объектов двух
классов. Первый класс составляют пациенты с подтвержденным диагнозом заболевания, которое будет диагностироваться в дальнейшем («с диагнозом»). Второй класс составляют пациенты, не имеющие данного заболевания («без диагноза»).
2. Выбрать набор характеристик, в пространстве которых образуются наилучшие кластеры.
Качество распознавания между двумя классами - «с диагнозом» и «без диагноза» - в решающей степени зависит от выбора пространства характеристик. Предлагают в качестве характеристик выбирать то их подмножество, в котором образуются различимые кластеры двух классов. Выбор характеристик производят согласно последовательности операций, показанной на фиг.3.
В качестве показателя качества кластеризации предлагают использовать индекс перекрытия, вычисляемый следующим образом:
Индекс перекрытия= ΣSj/N, j=1,N
где Sj=БСj/ КБС, БСj - количество соседей того же класса объектов из КБС ближайших для точки j, к которому принадлежит сама точка j, а КБС -количество определяемых ближайших соседей. N - размер исходной выборки. Значение КБС зависит от размера исходной выборки и равняется N/10.
Сначала определяют значение индекса перекрытия для исходного множества характеристик. Затем оценивают релевантность (значимость) каждой характеристики для образования кластеров, а, следовательно, для распознавания класса каждой точки. Для этого по очереди удаляют каждую характеристику и оценить индекс перекрытия для оставшегося подмножества характеристик. Большее значение индекса перекрытия свидетельствует о наличии лучших кластеров. Удаление характеристики может привести как к ухудшению качества кластеров (если значение индекса перекрытия уменьшилось), так и к улучшению. Полученные значения индексов перекрытия сравнивают со значением индекса перекрытия для исходного множества. Если есть большее значение индекса перекрытия, выбор релевантных характеристик можно продолжить. Тогда ту характеристику, при удалении которой достигнуто максимальное значение индекса перекрытия, удаляют из рассмотрения, и выбор продолжают дальше аналогичным образом для оставшихся характеристик. Процесс может быть продолжен, пока не будут рассмотрены пары характеристик или не будет достигнута ситуация, когда удаление любой характеристики только ухудшает качество кластеризации.
Найденный лучший вариант подмножества характеристик должен быть в конце обработки оценен визуально. Для визуального отображения многомерного пространства на плоскость предлагается использовать отображение Сэммона (J.W. Sammon, Jr, "A nonlinear mapping for data structure analysis," IEEE Transactions on Computers, vol. C-18, no. 5, pp.401-409, 1969.).
Можно увидеть как наличие кластеров, так и их отсутствие. Если кластеры отсутствуют, следует увеличить количество характеристик и начать выбор заново. Если присутствуют различимые кластеры, выполняется следующий пункт.
3. Сформировать обучающие выборки для классификаторов
Предлагается сформировать две обучающие выборки. Первая обучающая выборка должна содержать примерно равное (нечетное) количество точек, находящихся на границах каждого из классов. В выборку включают только точки, находящиеся на границе, разделяющей кластеры.
Вторая обучающая выборка должна состоять из точек, являющихся медоидами каждого из классов. Размер обучающей выборки должен быть не менее N/10. Обучающая выборка должна содержать равное (нечетное) количество медоидов обоих классов. Для распознавания предлагают использовать классификаторы типа «К ближайших соседей», настройка таких классификаторов заключается в формировании обучающих выборок.
4. Применить обученные классификаторы для распознавания контрольной выборки
Для распознавания предлагают использовать последовательно два
классификатора типа «К ближайших соседей». На вход подается последовательно каждая точка контрольной выборки. Для нее выбираются значения характеристик, выбранных в п.2.
Сначала применяют классификатор, обученный на граничных точках. Вычисляют расстояние в многомерном пространстве между точкой контрольной выборки и точками первой обучающей выборки. В качестве метрики используется метрика Евклида. Определяют Kb ближайших соседей для искомой точки среди точек обучающей выборки. Подсчитывают Nd -количество среди ближайших соседей точек, принадлежащих классу «с диагнозом» и Nb - количество среди ближайших соседей точек, принадлежащих классу «без диагноза». Решение о принадлежности искомой точки тому или иному классу принимают по правилу «квалифицированного большинства», т.е. когда количество соседей одного класса значительно превышает количество соседей другого, а именно, если | Nd - Nb|<Kb- 2, то если Nd>Nb, точка является точкой класса «с диагнозом», иначе - точкой класса «без диагноза».
Если | Nd - Nb|<Kb - 2, то применяется классификатор, обученный на медоидах.
Определяют Km ближайших соседей для искомой точки среди точек второй обучающей выборки. Подсчитывают N1 - количество среди ближайших соседей точек, принадлежащих классу «с диагнозом» и N2 - количество среди ближайших соседей точек, принадлежащих классу «без диагноза». Решение о принадлежности искомой точки тому или иному классу принимают по правилу «квалифицированного большинства», т.е. когда количество соседей одного класса значительно превышает количество соседей другого, а именно, если | N1 - N2|>=Km - 2, то если N1>N2, точка является точкой класса «с диагнозом», иначе - точкой класса «без диагноза».
Если правило «квалифицированного большинства» и в этом случае не выполняется, тогда применяют правило простого большинства:
если Nd>Nb, то точка является точкой класса «с диагнозом», иначе - точкой класса «без диагноза».
5. Оценить полученный результат
Для контрольной выборки необходимо добиться стопроцентной точности распознавания. Если результат не удовлетворяет, проводят корректирующие действия. Если результат удовлетворяет, то обе обучающие выборки, а также значения Kb и Km используют уже для диагностики других пациентов.
6. Произвести корректирующие действия
Возможно проведение следующих корректирующих действий:
- изменить количество точек - медоидов, которые нужно использовать;
- уточнить границу между классами;
- увеличить количество рассматриваемых точек первичной выборки. После принятия решения о коррекции, повторяют последовательность операций, начиная с п.2.
II. Применение настроенных классификаторов для диагностики пациента.
Классификатор готов и может быть применен для диагностики пациентов уже без предварительно установленной принадлежности к распознаваемым классам. Для его реализации целесообразно разработать специальное программное обеспечение. Данные пациентов из исходной выборки сохраняются в базе данных.
III. Повышение точности распознавания. Точность распознавания может быть увеличена в ходе эксплуатации классификатора.
Для этого проводят визуальную оценку места точки, соответствующей диагностируемому пациенту, среди точек пациентов из текущей базы данных в многомерном пространстве характеристик, отображенном на плоскость с помощью отображения Сэммона. Если новая точка позволит уточнить границу между двумя классами, ее включают в базу данных и включают в состав обучающей выборки граничных точек. Если точка далека от границы двух классов, следует заново определить медоиды соответствующего класса. Если новая точка войдет в состав медоидов класса, ее следует включить в базу данных и включить в состав обучающей выборки медоидов. Заявляемый способ автоматизированной диагностики заболеваний иллюстрируется фигурами 1-3.
Результатом заявляемого изобретения является повышение точности и сокращение времени диагностического исследования, повышение информативности при снижении стоимости исследования.
Указанный технический результат при осуществлении изобретения достигается тем, что используются методы распознавания образов с предварительным определением значимых для данного заболевания характеристик, в пространстве которых существуют хорошо различимые кластеры. Кроме того, обучающая выборка для настройки классификаторов формируется не одномоментно, а уточняется и совершенствуется после каждого сеанса диагностики.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ БИНАРИЗАЦИИ МЕДИЦИНСКИХ ИЗОБРАЖЕНИЙ | 2013 |
|
RU2533876C2 |
| СПОСОБ ОЦЕНКИ СОСТОЯНИЯ ЗДОРОВЬЯ ПАЦИЕНТА, ЭФФЕКТА ПРОВОДИМОГО ЛЕЧЕНИЯ И НАКОПЛЕННОЙ ДОЗЫ ИЗЛУЧЕНИЯ ПО АНАЛИЗУ КРОВИ | 1998 |
|
RU2135997C1 |
| СПОСОБ РАННЕЙ ДИАГНОСТИКИ ХРОНИЧЕСКИХ ЗАБОЛЕВАНИЙ ПАЦИЕНТА, ОСНОВАННЫЙ НА КЛАСТЕРНОМ АНАЛИЗЕ БОЛЬШИХ ДАННЫХ | 2021 |
|
RU2800315C2 |
| Автоматизированная система распределенной когнитивной поддержки принятия диагностических решений в медицине | 2015 |
|
RU2609737C1 |
| СПОСОБ НЕЙРОСЕТЕВОГО АНАЛИЗА СОСТОЯНИЯ СЕРДЦА | 2011 |
|
RU2461877C1 |
| СПОСОБ ДИФФЕРЕНЦИАЛЬНОЙ ДИАГНОСТИКИ МИКРОБОВ И СЛОЖНЫХ АМИНОКИСЛОТ | 2007 |
|
RU2362145C2 |
| Способ формирования математических моделей пациента с использованием технологий искусственного интеллекта | 2017 |
|
RU2720363C2 |
| СПОСОБ АВТОМАТИЗИРОВАННОЙ ДИАГНОСТИКИ ЗАБОЛЕВАНИЙ И ИХ ФОРМ | 2001 |
|
RU2191429C1 |
| Способ диагностики острого коронарного синдрома | 2020 |
|
RU2733077C1 |
| СПОСОБ ДИАГНОСТИКИ ПАТОЛОГИЙ СИСТЕМЫ ГЕМОСТАЗА С ПОМОЩЬЮ НЕЙРОННЫХ СЕТЕЙ | 2011 |
|
RU2449281C1 |
Изобретение относится к области медицины, в частности к способам диагностики заболеваний. Техническим результатом является повышение точности диагностирования заболеваний. В способе осуществляют выбор характеристик, в пространстве которых существуют различимые кластеры, образованные точками двух типов, первый тип соответствует пациентам с подтвержденным диагнозом диагностируемого заболевания, второй тип соответствует пациентам, не имеющем диагностируемого заболевания, определяют обучающие выборки для классификаторов, состоящие из точек - медоидов каждого кластера и граничных точек, разделяющих кластеры. При классификации сначала используют классификатор на основе граничных точек в варианте «квалифицированного большинства», затем для точек, не классифицированных первым классификатором, используют классификатор на основе точек - медоидов в варианте «квалифицированного большинства», а для оставшихся точек - классификатор на основе граничных точек в варианте «простого большинства». После постановки диагноза принимают решение о включении характеристик обследуемого пациента в состав обучающих выборок в случае, если эти характеристики улучшают точность распознавания. 3 ил.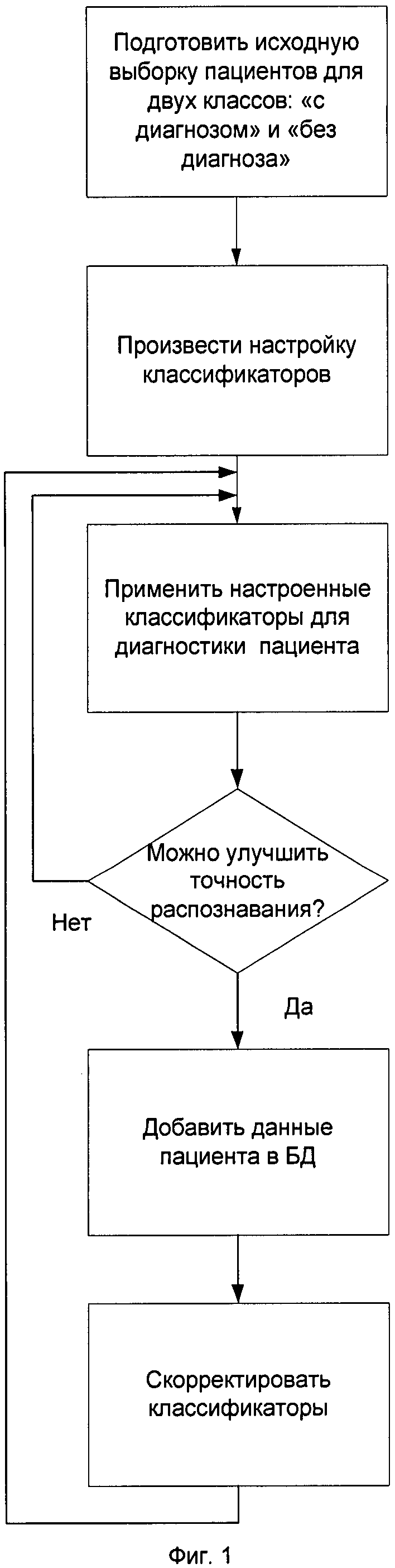
Способ автоматизированной диагностики заболеваний на основе распознавания образов, отличающийся тем, что сначала осуществляют выбор характеристик, в пространстве которых для исследуемых объектов существуют различимые кластеры, образованные точками двух типов, первый тип соответствует пациентам с подтвержденным диагнозом диагностируемого заболевания, второй тип соответствует пациентам, не имеющим диагностируемого заболевания, затем в найденном пространстве характеристик определяют обучающие выборки для классификаторов, состоящие из точек - медоидов каждого кластера, и граничных точек, разделяющих кластеры; эти обучающие выборки используются затем при работе двух классификаторов типа «К ближайших соседей», на вход которых подаются данные обследуемого пациента, причем сначала используют классификатор на основе граничных точек в варианте «квалифицированного большинства», затем для точек, не классифицированных первым классификатором, используют классификатор на основе точек - медоидов в варианте «квалифицированного большинства», а для оставшихся точек классификатор на основе граничных точек в варианте «простого большинства», после постановки диагноза, т.е. определения, к какому из двух классов относится обследуемый пациент, а именно к классу «с диагнозом» или к классу «без диагноза», принимают решение о включении характеристик обследуемого пациента в состав обучающих выборок и, если эти характеристики улучшают точность распознавания, производят включение.
| US20090103794 A1, 23.04.2009 | |||
| СПОСОБ ОБРАБОТКИ КРАЯ ИЗДЕЛИЯ СПИЦАМИ ПРИ ПОМОЩИ ЦЕПОЧКИ, ВЫПОЛНЕННОЙ КРЮЧКОМ | 2003 |
|
RU2239675C1 |
| SHOUMAN M | |||
| et al, "Applying K-Nearest Neigbour in Diagnosing Heart Disease Patients", International Journal of Information and Education Technology, vol | |||
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| СПОСОБ АВТОМАТИЗИРОВАННОЙ ДИАГНОСТИКИ ЗАБОЛЕВАНИЙ И ИХ ФОРМ | 2001 |
|
RU2191429C1 |

